Embed Size (px)
Citation preview

1
The World Wide Web
HAIT
Summer 2005

2
History• The World Wide Web is an architectural framework
for accessing linked documents spread out over millions of machines all over the Internet.
• The Web began in 1989 at CERN, the European center for nuclear research. CERN has several teams of scientists that have members from half a dozen or more countries.
• The Web grew out of the need to have these large teams collaborate.
• The initial proposal for a web of linked documents came from CERN in March 1989.

3
History – Cont.
• In 1994, CERN and M.I.T. signed an agreement setting up the World Wide Web Consortium, an organization devoted to further developing the Web, standardizing protocols, and encouraging interoperability between sites.
• The best place to get up-to-date information about the Web is (naturally) on the Web itself. The consortium's home page is at www.w3.org.

4
Architectural Overview
• The Web consists of a vast, worldwide collection of documents or Web pages, often just called pages for short.
• Each page may contain links to other pages anywhere in the world.
• The idea of having one page point to another, now called hypertext, was invented by a visionary M.I.T. professor of electrical engineering, in 1945, long before the Internet was invented.

5
A Web Page
• Pages are viewed with a browser, Internet Explorer and Netscape Navigator are two popular ones.
• The browser fetches the page requested, interprets the text and formatting commands on it, and displays the page, properly formatted, on the screen.
• Many Web pages start with a title, contains some information, and ends with the e-mail address of the page's maintainer.
• Hyperlinks are often highlighted, by underlining, displaying them in a special color, or both.

6
The Web Model
• The browser is displaying a Web page on the client machine.
• When the user clicks on a line of text that is linked to a page on the abcd.com server, the browser follows the hyperlink by sending a message to the abcd.com server asking it for the page.
• When the page arrives, it is displayed. • If this page contains a hyperlink to a page on the
xyz.com server that is clicked on, the browser then sends a request to that machine for the page, and so on indefinitely.
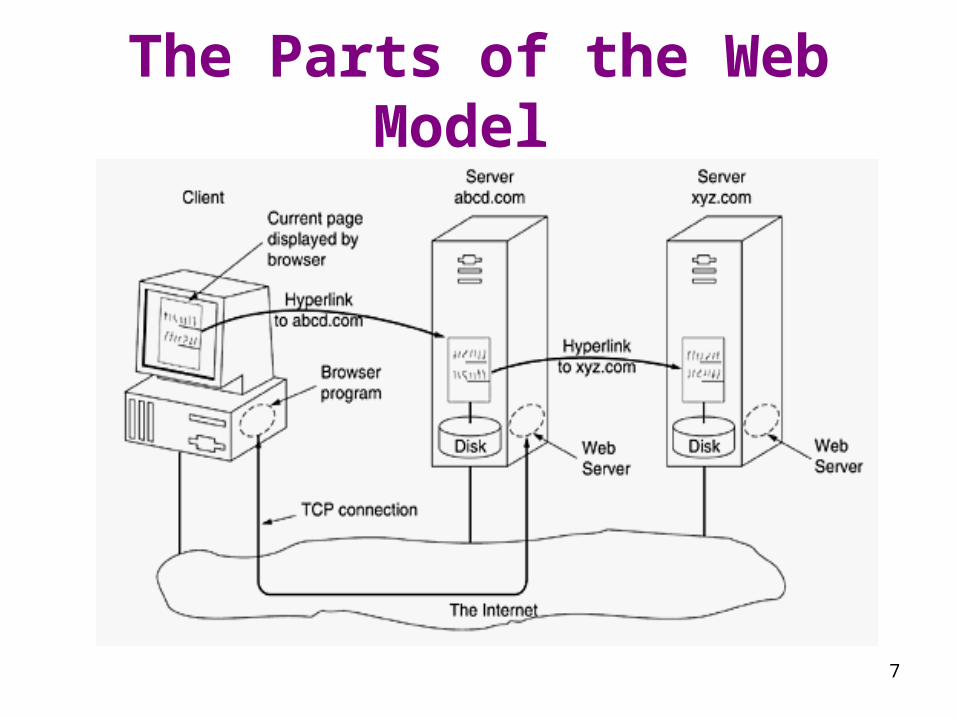
7
The Parts of the Web Model

8
The Client Side
• A browser is a program that can display a Web page and catch mouse clicks to items on the displayed page.
• When an item is selected, the browser follows the hyperlink and fetches the page selected.
• The embedded hyperlink needs a way to name any other page on the Web.
• Pages are named using URLs (Uniform Resource Locators). A typical URL is:http://www.abcd.com/products.html

9
URL
• URL has three parts: – the name of the protocol (http)– the DNS name of the machine where the page is located (
www.abcd.com)– (usually) the name of the file containing the page (products.html).
• When a user clicks on a hyperlink, the browser carries out a series of steps in order to fetch the page pointed to.
• Suppose that a user is browsing the Web and finds a link on Internet telephony that points to ITU's home page, which is http://www.itu.org/home/index.html.
• There are few steps that occur when this link is selected.

10
Sequence of Events
1. The browser determines the URL.2. The browser asks DNS for the IP address of www.itu.org.3. DNS replies with 156.106.192.32.4. The browser makes a TCP connection to port 80 on
156.106.192.32.5. It then sends over a request asking for file /home/index.html.6. The www.itu.org server sends the file /home/index.html.7. The TCP connection is released.8. The browser displays all the text in /home/index.html.9. The browser fetches and displays all images in this file.

11
Browser Features
• The browser has to understand the format of the presented page. • To allow all browsers to understand all Web pages, Web pages
are written in a standardized language called HTML. • A browser is basically an HTML interpreter, but most browsers
have numerous buttons and features to make it easier to navigate the Web.
• back button - going back to the previous page • Forward button - going forward to the next page• Home button - going straight to the user's own start page. • Bookmark - button or menu item to set a bookmark on a given
page and another one to display the list of bookmarks.

12
Web Page
• Web pages can also contain icons, line drawings, maps, and photographs.
• Each of these can (optionally) be linked to another page.
• A page may consist of a formatted document in PDF format, an icon in GIF format, a photograph in JPEG format, a song in MP3 format, a video in MPEG format, or any one of hundreds of other file types.
• Since standard HTML pages may link to any of these, the browser might have a problem when it encounters a page it cannot interpret.

13
Web Page – Cont.
• When a server returns a page, it also returns some additional information about the page.
• This information includes the MIME type of the page. • Pages of type text/html are just displayed directly. • If the MIME type is not one of the built-in ones, the
browser consults its table of MIME types to tell it how to display the page.
• This table associates a MIME type with a viewer.

14
The Server Side
• When the user types in a URL or clicks on a line of hypertext, the browser parses the URL and interprets the part between http:// and the next slash as a DNS name to look up.
• Armed with the IP address of the server, the browser establishes a TCP connection to port 80 on that server.
• Then it sends over a command containing the rest of the URL, which is the name of a file on that server.
• The server then returns the file for the browser to display.

15
Sequence of Events
1. Accept a TCP connection from a client (a browser).
2. Get the name of the file requested.
3. Get the file (from disk).
4. Return the file to the client.
5. Release the TCP connection.

16
Server Caching
• Every request requires making a disk access to get the file. • The Web server cannot serve more requests per second than it
can make disk accesses. • One obvious improvement is to maintain a cache in memory
of the n most recently used files. • Before going to disk to get a file, the server checks the cache.• If the file is there, it can be served directly from memory.• Although effective caching requires a large amount of main
memory and some extra processing time to check the cache and manage its contents, the savings in time are nearly always worth the overhead and expense.

17
Multithreaded Server
• The server consists of a front-end module that accepts all incoming requests and k processing modules.
• The k + 1 threads all belong to the same process so the processing modules all have access to the cache within the process' address space.
• When a request comes in, the front end accepts it and builds a short record describing it. It then hands the record to one of the processing modules.

18
Multithreaded Server – Cont.
• The processing module first checks the cache. • If the file is not there, the processing module starts a disk
operation to read it into the cache. • When the file comes in from the disk, it is put in the cache and
also sent back to the client.• While one or more processing modules are blocked waiting
for a disk operation to complete, other modules can be actively working on other requests.
• Another improvement - having multiple disks, so more than one disk can be busy at the same time.
• With k processing modules and k disks, the throughput can be as much as k times higher than with a single-threaded server and one disk.

19
One More Improvement
• If too many requests come in each second, the CPU will not be able to handle the processing load, no matter how many disks are used in parallel.
• The solution is to add more nodes (computers).• A front end still accepts incoming requests but sprays
them over multiple CPUs rather than multiple threads to reduce the load on each computer.
• The individual machines may themselves be multithreaded as before.
• What about the cache?

20
The Cache Problem
• There is no longer a shared cache because each processing node has its own memory.
• The front end keeps track of where it sends each request and send subsequent requests for the same page to the same node.
• Each node is a specialist in certain pages.
• Cache space is not wasted by having every file in every cache.

21
URLs—Uniform Resource Locators
• Three questions had to be answered before a selected page could be displayed:– What is the page called?– Where is the page located?– How can the page be accessed?

22
URL Components
• Each page is assigned a URL that serves as the page's worldwide name.
• URLs have three parts: – the protocol– the DNS name of the machine on which the page is
located– a local name uniquely indicating the specific page
• http://www.cs.vu.nl/video/index-en.html

23
Default URLs
• At many sites, a null file name defaults to the organization's main home page.
• Typically, when the file named is a directory, this implies a file named index.html.
• ~user/ might be mapped onto user's WWW directory, and then onto the file index.html in that directory.

24
Statelessness and Cookies • The Web is stateless - there is no concept of a login
session. • The browser sends a request to a server and gets back a
file. Then the server forgets that it has ever seen that particular client.
• Consider the following: – Some Web sites require clients to register to use them. This
raises the question of how servers can distinguish between requests from registered users and everyone else.
– e-commerce - a user wanders around an electronic store, tossing items into his shopping cart, how does the server keep track of the contents of the cart?
– Yahoo - Users can set up a detailed initial page with only the information they want, but how can the server display the correct page if it does not know who the user is?

25
Solution
• What about tracking users by observing their IP addresses?– IP address identifies the computer not the user.– many ISPs use NAT - all outgoing packets from all
users bear the same IP address
• The working solution called cookies.

26
Cookies
• When a client requests a Web page, the server supply additional information along with the requested page.
• This information may include a cookie, which is a small (at most 4 KB) file.
• Browsers store offered cookies in a cookie directory on the client's hard disk unless the user has disabled cookies.
• Cookies are just files, not executable programs. • A cookie may contain up to five fields.

27
Cookie Example
• Domain - where the cookie came from.• Path - a path in the server's directory structure that identifies
which parts of the server's file tree may use the cookie. It is often /, which means the whole tree.
• Content - takes the form name = value. Both name and value can be anything the server wants.
• Expires - specifies when the cookie expires. • Secure - indicate that the browser may only return the cookie to a
secure server.

28
How it’s used?
• Just before a browser sends a request for a page to some Web site, it checks its cookie directory to see if any cookies there were placed by the domain the request is going to.
• If so, all the cookies placed by that domain are included in the request.
• The server interprets them any way it wants to.
• In the previous example, when the client logs in, the browser sends over the cookie so the server knows who it is.
• The server can look up the customer's record in a database and use this information to build an appropriate Web page to display.

29
Another Use
• Cookies can also be used for the server's own benefit. • For example, suppose a server wants to keep track of
how many unique visitors it has had and how many pages each one looked at before leaving the site.
• When the first request comes in, there will be no accompanying cookie, so the server sends back a cookie containing Counter = 1.
• Subsequent clicks on that site will send the cookie back to the server. Each time the counter is incremented and sent back to the client.

30
Misused Cookie
• One can secretly collect information about users' Web browsing habits.
• An advertising agency contacts major Web sites and places banner ads on their pages.
• Instead of giving the site a GIF or JPEG file to place on each page, it gives them a URL to add to each page.
• Each URL it hands out contains a unique number in the file part, such as http://www.sneaky.com/382674902342.gif

31
Misused Cookie – Cont.
• When a user first visits a page P, containing such an ad, the browser fetches the HTML file and sends a request to www.sneaky.com for the image.
• A GIF file containing an ad is returned, along with a cookie containing a unique user ID, 3627239101.
• Sneaky records the fact that the user with this ID visited page P. This is easy to do since the file requested (382674902342.gif) is referenced only on page P.
• The actual ad may appear on thousands of pages, but each time with a different file name.
• Sneaky probably collects a couple of pennies from the product manufacturer each time it ships out the ad.

32
Misused Cookie – Cont.
• Later, when the user visits another Web page containing any of Sneaky's ads, it sees the link to, say, http://www.sneaky.com/493654919923.gif and requests that file.
• Since it already has a cookie from the domain sneaky.com, the browser includes Sneaky's cookie containing the user ID. Sneaky now knows a second page the user has visited.
• Sneaky can build up a complete profile of the user's browsing habits.
• To maintain some semblance of privacy, some users configure their browsers to reject all cookies. However, this can give problems with legitimate Web sites that use cookies.



























