Embed Size (px)
Citation preview

1
Memory Management Challenges in
the Power-Aware Computing Era
Dr. Avi Mendelson,Dr. Avi Mendelson, Intel Intel - - Mobile Processors Architecture groupMobile Processors Architecture [email protected]@intel.com
and adjunct Professor in the CS and EE departments, and adjunct Professor in the CS and EE departments, Technion HaifaTechnion Haifamendlson@{cs,ee}.technion.ac.ilmendlson@{cs,ee}.technion.ac.il
Dr. Avi Mendelson,Dr. Avi Mendelson, Intel Intel - - Mobile Processors Architecture groupMobile Processors Architecture [email protected]@intel.com
and adjunct Professor in the CS and EE departments, and adjunct Professor in the CS and EE departments, Technion HaifaTechnion Haifamendlson@{cs,ee}.technion.ac.ilmendlson@{cs,ee}.technion.ac.il

© Dr. Avi Mendelson - ISMM'2006 2June 10th 2006
Disclaimer
No Intel proprietary information is disclosed. Every future estimate or projection is only a speculation Responsibility for all opinions and conclusions falls on the author
only. It does not mean you cannot trust them…

© Dr. Avi Mendelson - ISMM'2006 3June 10th 2006
Before we start
• Personal observation: focusing on low-power
resembles Alice through the Looking-Glass: We are looking at the same old problems, but from the other side of the looking glass, and the landscape appears much different...
Out of the box thinking is needed

© Dr. Avi Mendelson - ISMM'2006 4June 10th 2006
Agenda
What are power aware architectures and why they are needed Background of the problem Implications and architectural directions
Memory related issues Static power implications Dynamic power implications
Implications on software and memory management Summary

© Dr. Avi Mendelson - ISMM'2006 5June 10th 2006
The “power aware era”
Introduction Implications on computer architectures

© Dr. Avi Mendelson - ISMM'2006 6June 10th 2006
Moore’s law “Doubling the number of transistors on a manufactured
die every year” - Gordon Moore, Intel Corporation
Sou
rce:
Inte
l S
ourc
e: In
tel
Tra
nsi
sto
rs P
er D
ieT
ran
sist
ors
Per
Die
’’7070 ’’7373 ’’7676 ’’7979 ’’8282 ’’8585 ’’8888 ’’9191 ’’9494 '97'97 20002000
101088
101077
101066
101055
101044
101033
101022
4M4M
MemoryMemory
MicroprocessorMicroprocessor
101099
64K64K
1M1M
1K1K
256K256K
4K4K16K16K
16M16M64M64M
4004400480808080
80868086
8028680286i386™i386™
i486™i486™PentiumPentium®®
256M256M
PentiumPentium®®
ProPro
PentiumPentium®®IIIIII
PentiumPentium®®44
PentiumPentium® ® IIII

© Dr. Avi Mendelson - ISMM'2006 7June 10th 2006
In the last 25 years life was easy(*)
Idle process technology allowed us to Double transistor density every 30 months Improve their speed by 50% every 15-18 month Keep the same power density Reduce the power of an old architecture or introduce a new
architecture with significant performance improvement at the same power
In reality Process usually is not ideal and more performance than
process scaling is needed, so: Die size and power and power densities increased over time
Tech Old Arch mm (linear) New Arch mm (linear) Ratio Ratio i386C 6.5 i486 11.5 3.1
i486C 9.5 Pentium® 17 3.2
Pentium® 12.2 Pentium® Pro 17.3 2.1
Pentium® III 10.3 Next Gen ? 2--3
(*) source source Fred Pollack, Fred Pollack, Micro-32Micro-32

© Dr. Avi Mendelson - ISMM'2006 8June 10th 2006
Processor power evolution
Traditionally: a new generation always increase powerTraditionally: a new generation always increase power Compactions: higher performance at lower powerCompactions: higher performance at lower power Used to be “one size fits all”: start with high power and shrink for mobileUsed to be “one size fits all”: start with high power and shrink for mobile
Ma
x P
ow
er
(Wa
tts
)
i386 i386
i486 i486
Pentium® Pentium®
Pentium® w/MMX tech.
Pentium® w/MMX tech.
1
10
100
Pentium® Pro Pentium® Pro
Pentium® II Pentium® II Pentium® 4Pentium® 4Pentium® 4Pentium® 4
??
Pentium® III Pentium® III

© Dr. Avi Mendelson - ISMM'2006 9June 10th 2006
Suddenly, the power monster appears in all market segments

© Dr. Avi Mendelson - ISMM'2006 10June 10th 2006
Power & energyPowerPower Dynamic power: consumed by all transistor that Dynamic power: consumed by all transistor that
switchswitchP = P = CVCV22ff - - WorkWork done per time unit ( done per time unit (Watts)Watts)
((: activity, C: capacitance, V: voltage, f: frequency): activity, C: capacitance, V: voltage, f: frequency) Static power (leakage): consumed by all “inactive Static power (leakage): consumed by all “inactive
transistors” - depends on transistors” - depends on temperaturetemperature and and voltagevoltage..
EnergyEnergy Power consumed during a time period.Power consumed during a time period.
Energy efficiency Energy efficiency Energy * Delay (or Energy * Delay2)

© Dr. Avi Mendelson - ISMM'2006 11June 10th 2006
Why high power maters Power Limitations
Higher power higher current– Cannot exceed platform power delivery constraints
Higher power higher temperature– Cannot exceed the thermal constraints (e.g., Tj < 100oC)– Increases leakage.
The heat must be controlled in order to avoid electric migration and other “chemical” reactions of the silicon
Avoid the “skin effect”
Energy Affects battery life.
Consumer devices – the processor may consume most of the energy Mobile computers (laptops) - the system (display, disk, cooling, energy supplier,
etc) consumes most of the energy Affects the cost of electricity

© Dr. Avi Mendelson - ISMM'2006 12June 10th 2006
The power crisis – power consumption
Sourse: cool-
chips, Micro
32
© Dr. Avi Mendelson - ISMM'2006 13June 10th 2006
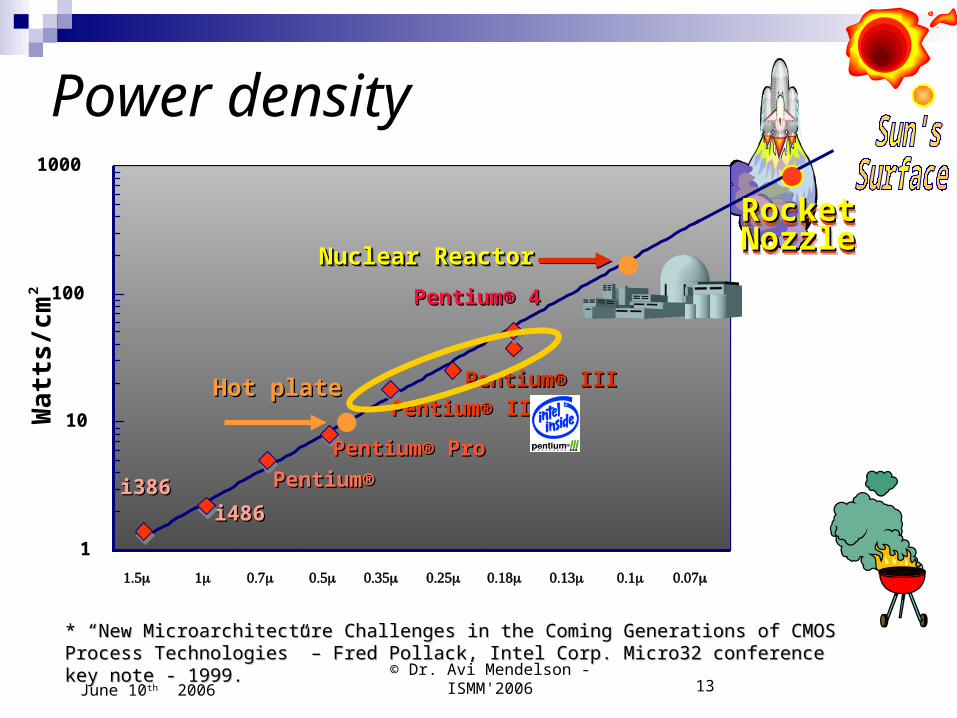
Power densityW
att
s/c
m2
1
10
100
1000
i386i386i486i486
Pentium® Pentium®
Pentium® ProPentium® Pro
Pentium® IIPentium® IIPentium® IIIPentium® IIIHot plateHot plate
Nuclear ReactorNuclear ReactorNuclear ReactorNuclear Reactor
RocketRocketNozzleNozzleRocketRocketNozzleNozzle
* “New Microarchitecture Challenges in the Coming Generations of CMOS Process Technologies” – * “New Microarchitecture Challenges in the Coming Generations of CMOS Process Technologies” – Fred Pollack, Intel Corp. Micro32 conference key note - 1999.Fred Pollack, Intel Corp. Micro32 conference key note - 1999.
Pentium® 4Pentium® 4

© Dr. Avi Mendelson - ISMM'2006 14June 10th 2006
Conclusions so far Currently and in the near future, new processes keep
providing more transistors, but the improvement in power reduction and speed is much lower than in the past
Due to power consumption and power density constrains, we are limited in the amount of logic that can be devoted to improve single thread performance
We can use the transistors to add more “low power density” and “low power consumption” such as memory, assuming we can control the static power.
BUT, we still need to double the performance of new computer generations every two years (in average).

© Dr. Avi Mendelson - ISMM'2006 15June 10th 2006
We must go parallel In theory, power increases in the order of the
frequency cube. Assuming that frequency approximates
performance Doubling performance by increasing its frequency
increases the power exponentially Doubling performance by adding another core,
increases the power linearly. Conclusion: as long as enough parallelism
exists, it is more efficient to achieve the same performance by doubling the number of cores rather than doubling the frequency.

© Dr. Avi Mendelson - ISMM'2006 16June 10th 2006
CPU architecture - multicores
Power
Performance
Uniprocessors
CMP
Uniprocessors have lower power efficiency due to higher speculation and complexity
Power Wall
MP Overhead
Source: Tomer Morad, Ph.D student, Technion

© Dr. Avi Mendelson - ISMM'2006 17June 10th 2006
The new trend – parallel systems on die There are at least three camps in the computer
architects community Multi-cores - Systems will continue to contain a small
number of “big cores” – Intel, AMD, IBM Many-cores – Systems will contain a large number of
“small cores” – Sun T1 (Niagara) Asymmetric-cores – combination of a small number of
big cores and a large number of small cores – IBM Cell
architecture.

© Dr. Avi Mendelson - ISMM'2006 18June 10th 2006
I remember, in the late 80’s it was clear that we cannot improve the performance of single threaded programs any longer, so we went parallel as well
But this is totally different!!!!, now Alewife is called Niagra, DASH
is called NOC and shared bus architecture
is called CMP!!!
Hammm, you are right - it is all of a new world.
Let’s hope this time we will have an
“happy end ”
We deserve it.!!!We deserve
it.!!!
New era in computer architectures

© Dr. Avi Mendelson - ISMM'2006 19June 10th 2006
From the opposite side of the mirror
There are many similarities between the motivation and the solutions we are building today and what was developed in the late 80’s
But the root-cause is different, the software environment is different and so new approach is needed to come with right solutions
Power and power density are real physical limitations so changing them requires a new direction (biological computing?????)

© Dr. Avi Mendelson - ISMM'2006 20June 10th 2006
Agenda
What is power aware architectures and why they are needed Background on the problem Implications and architectural directions
Memory related issues Static power implications Dynamic power implications
Implications on software and memory management Summary

© Dr. Avi Mendelson - ISMM'2006 21June 10th 2006
Memory related implications
The portion of the memory out of the overall die area increases over time (cache memories)
Most of memory has very little contribution to the active power consumption Most of the active power that on-die memory consumes is spent
at the L1 cache (which remains at the same or smaller size) Most of the active power that off-die memory consumes is spent
on the busses, interconnect and coherency related activities. Snoop traffic may have significant impact on active power
But larger memory may consume significant static power (leakage) if not handled very carefully Will be discussed in the next few slides

© Dr. Avi Mendelson - ISMM'2006 22June 10th 2006
Accessing the cache can be power hungry if designed for speed
If access time is very important: Memory cells are tuned for speed,
not for power parallel access to all ways in the
tag and data arrays of the cache TLB is accessed in parallel (need
to make sure that the width of the cache is less than a memory page)
Power is mainly spent in the sense amplifiers.
High associativity increases the power of external snoops as well.
Way
Sets
Tag Data
AddressTLB
To CPU
Set select
V-address
P-address

© Dr. Avi Mendelson - ISMM'2006 23June 10th 2006
There are many techniques to control the power consumption of the cache (and memory) if designed for power
Active power Sequential access (tag first and only then data) Optimized cells (can help both active and leakage
power) Passive (Leakage) power
Will be discuss later on
BUT if the cache is large, the accumulative static power can be very significant.

© Dr. Avi Mendelson - ISMM'2006 24June 10th 2006
How to control static power - General Process optimizations are out of the scope of this talk Design techniques
Sleep transistors Power gating Forward and backward biasing (out of our scope)
Micro-architecture level Hot spot control Allowing advanced design techniques
Architectural level Program behavior dependent techniques Compiler and program’s hint based techniques ACPI

© Dr. Avi Mendelson - ISMM'2006 25June 10th 2006
Design techniques – few examplesDescription GranularityImpact
Sleep transistor – data preserved
Allow to lower the voltage on the gate to the level where data is preserved but can not be accessed
Small- medium
~10x leakage reduction. Longer access time to retrieve data
Sleep transistor – data not preserved
Lower the power on gate to a level that data may be corrupted
Small - medium
20-100x Leakage reduction. Need to bring data from higher memory (costs time and power)
Power gate“Cut the power” from the gate
LargeNo leakage. Longer access time than sleep transistor

© Dr. Avi Mendelson - ISMM'2006 26June 10th 2006
K=10 Tetha = 3
0
5
10
15
20
25
30
35
40
Time
Uni
que
Line
s
BDL
B L D
Architectural level – program behavior related techniques
We knows for long time that most of the lines in the cache are “dead”
But dead lines are not free since they are consuming leakage power
So, if we can predict what lines are dead we could put them under sleep transistor that keeps the data (in the case that the prediction was
not perfect) – Drowsy cache save more leakage power and use sleep transistors that loose the data
and pay higher penalty for miss-predicting a dead line -- cache decay

© Dr. Avi Mendelson - ISMM'2006 27June 10th 2006
Architectural level – ACPI Operating system mechanism to
control power consumption at the system level. (we will focus on CPU only)
Control three aspects of the system C-State, when the system has nothing
to do, how deep it can go to sleep. Deeper more power is saved, but more time is needed to wake it.
P-State, when run, what is the minimum frequency (and voltage) the processor can run at without causing a notable slow down to the system
T-State, prevents the system from becoming too hot.
Implementation: Periodically check the activity
of the system and decide if to change the operational point.

© Dr. Avi Mendelson - ISMM'2006 28June 10th 2006
Combining sleep transistors and ACPI – Intel Core Duo example Intel Core Duo was designed to be dual core
for low-power computer. L2 cache size in Core Duo is 2MB and in
Core Duo-2, 4M
When the system runs (C0 states) all the caches are active
It has a sophisticated DVS algorithm to control the T and P states When starting to “nap” (C3), it cleans the L1 caches and close the power to
them (to save leakage) When in sleep (C4), it gradually shrink the size of the L2 till it is totally
empty. How much performance you pay for this? some time you gain
performance, most of the time it is in order of 1%.
More details: Intel Journal of Technology, May, 2006

© Dr. Avi Mendelson - ISMM'2006 29June 10th 2006
Agenda
What is power aware architectures and why they are needed Background on the problem Implications and architectural directions
Memory related issues Static power implications Dynamic power implications
Implications on software and memory management Summary

© Dr. Avi Mendelson - ISMM'2006 30June 10th 2006
Memory management
Adding larger shared memory arrays on die may not make sense any more Access time to the LLC (last level cache) start to be very slow
But it is too fast for handling it with SW or OS May cause a contention on resources (shared memory and
buses). Solving these problems may cost a significant power
What are the alternatives (WIP) COMA within the chip Use of buffers instead of caches – change of the programming
model May require different approach for memory allocation
Separate the memory protection mechanisms from the VM mechanism

© Dr. Avi Mendelson - ISMM'2006 31June 10th 2006
Compiler and applications Currently most of the cache related optimization are based on
performance Many of them are helping energy since they improve the efficiency of
the CPU. But may worsen the max power and power density
Increasing parallelism is THE key for future systems. Speculation may hurt if not done with a high degree of confidence. Do we need a new programming models such as transactional memory
for that? Reducing working sets can help reducing leakage power if the
system supports Drowsy or Decay caches The program may give the HW and the OS “hints” that can help
improving the efficiency of power consumption Response time requirements If new HW/SW interfaces defined, we can control the power of the
machine at a very fine granularity; e.g., when Floating-Point is not used, close it to save leakage power

© Dr. Avi Mendelson - ISMM'2006 32June 10th 2006
Garbage collection In many situations, not all the cores in the system will be
active. An idle processor can be used to perform GC In this case we may want to do the CG at a very fine granularity.
Most of CMP architectures shares many of the memory hierarchies. GC done by one processor may replace the cache content and slow down the execution of the entire system. Thus we may like to do the GC at a very coarse granularity in
order to limit the overhead. New interface between HW and SW may be needed in
order to allow new algorithms for GC or optimize the execution of the system when using the current ones

© Dr. Avi Mendelson - ISMM'2006 33June 10th 2006
Summary and future directions Power aware era impacts all aspects of computer architecture It forces the market to “go parallel” and may cause the memory portion of
the die to increase over time To take advantage of “cold transistors” To reduce memory and IO bandwidth
We may need to start looking at new paradigms for memory usage and HW/SW interfaces At all levels of the machine; e.g., programming models, OS etc. New programming models such as Transactional Memory may become very
important in order to allow better parallelism. Do we need to develop a new memory paradigm to support it?
Software will determine if the new (old) trend will become a major success or not. Increase parallelism (but use speculative execution only with high confidence) Control power New SW/HW interfaces may be needed.

© Dr. Avi Mendelson - ISMM'2006 34June 10th 2006
Question?

© Dr. Avi Mendelson - ISMM'2006 35June 10th 2006
Multi-cores – Intel AMD and IBM
Both companies have dual core processors Intel uses shared cache architecture and AMD introduces split cache architecture AMD announces that in their next generation processors they will use shared LLC (last level
cache) as well Intel announced that they are working on a four-core processors. Analysts think that
AMD are doing the same. Intel said that they will consider going to 8 way processors only after SW will catch
up. AMD had a similar announcement. For servers, analysts claims that Intel is building a 16 way Itanium based processor
for 2009 time frame. Power4 has 2 cores and power5 has 2 cores+SMT. They are considering to move in
the near future to 2 cores+SMT for each of them. Xbox has 3 Power4 cores.
All the three companies promise to increase the number of cores in a pace that fits the market’s needs.
back

© Dr. Avi Mendelson - ISMM'2006 36June 10th 2006
Sun – Sparc-T1: Niagara
Looking at in-order machine, each thread has computational time followed by LONG memory access time (a)
If you put 4 of them on die, you can overlap between I/O, memory and computation (b)
You can use this approach to extend your system (c) Alewife project did it in the 80’s
)a(
)b( )c(
back

© Dr. Avi Mendelson - ISMM'2006 37June 10th 2006
Cell Architecture - IBM
BIG core
Small core
Ring base bus
unit
back



















![ɷ[elliott mendelson] schaum's outline](https://img.dokumen.tips/doc/110x75/568cac071a28ab186da7e9f3/elliott-mendelson-schaums-outline.jpg)





![[Elliott mendelson] schaum's_3,000_solved_problems](https://img.dokumen.tips/doc/110x75/5550ca32b4c905f2318b480d/elliott-mendelson-schaums3000solvedproblems.jpg)



