Embed Size (px)
Citation preview

1
Algorithms for Large Data Sets
Ziv Bar-YossefLecture 11
June 11, 2006
http://www.ee.technion.ac.il/courses/049011

2
Random Samplingfrom
a Search Engine’s Index
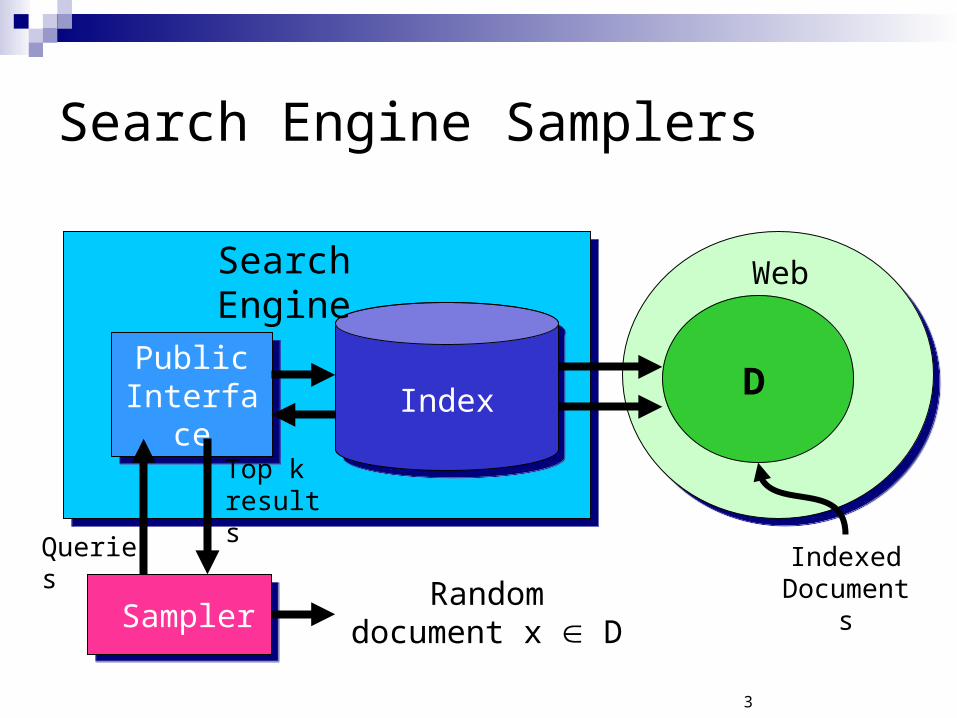
3
Search Engine Samplers
IndexPublicInterface
PublicInterface
Search Engine
Sampler
Web
D
Queries
Top k results
Random document x D
Indexed Documents

4
Motivation Useful tool for search engine evaluation:
Freshness Fraction of up-to-date pages in the index
Topical bias Identification of overrepresented/underrepresented topics
Spam Fraction of spam pages in the index
Security Fraction of pages in index infected by viruses/worms/trojans
Relative Size Number of documents indexed compared with other search
engines

5
Size Wars
August 2005
: We index 20 billion documents.
So, who’s right?
September 2005
: We index 8 billion documents, but our index is 3 times larger than our competition’s.

6
The Bharat-Broder Sampler: Preprocessing Step
C
Large corpusL
t1, freq(t1,C)t2, freq(t2,C)……
Lexicon

7
The Bharat-Broder Sampler
Search Engine
BB Sampler
t1 AND t2Top k results
Random document from top k results
LTwo random terms t1, t2
Only if:• all queries return the same number of results ≤ k • all documents are of the same lengthThen, samples are uniform.
Only if:• all queries return the same number of results ≤ k • all documents are of the same lengthThen, samples are uniform.

8
The Bharat-Broder Sampler:Drawbacks Documents have varying lengths
Bias towards long documents
Some queries have more than k matchesBias towards documents with high static rank

9
Search Engines as Hypergraphs
results(q) = { documents returned on query q } queries(x) = { queries that return x as a result } P = query pool = a set of queries Query pool hypergraph:
Vertices: Indexed documents Hyperedges: { result(q) | q P }
www.cnn.com
www.foxnews.com
news.google.com
news.bbc.co.ukwww.google.com
maps.google.com
www.bbc.co.uk
www.mapquest.com
maps.yahoot.com
“news”
“bbc”
“google”
“maps”
en.wikipedia.org/wiki/BBC

10
Query Cardinalities and Document Degrees
Query cardinality: card(q) = |results(q)| card(“news”) = 4, card(“bbc”) = 3
Document degree: deg(x) = |queries(x)| deg(www.cnn.com) = 1, deg(news.bbc.co.uk) = 2
Cardinality and degree are easily computable
www.cnn.com
www.foxnews.com
news.google.com
news.bbc.co.ukwww.google.com
maps.google.com
www.bbc.co.uk
www.mapquest.com
maps.yahoot.com
“news”
“bbc”
“google”
“maps”
en.wikipedia.org/wiki/BBC

11
Sampling documents uniformly
Sampling documents from D uniformly Hard Sampling documents from D non-uniformly: Easier
Will show later: can sample documents proportionally to their degrees:

12
Sampling documents by degree
p(news.bbc.co.uk) = 2/13 p(www.cnn.com) = 1/13
www.cnn.com
www.foxnews.com
news.google.com
news.bbc.co.ukwww.google.com
maps.google.com
www.bbc.co.uk
www.mapquest.com
maps.yahoot.com
“news”
“bbc”
“google”
“maps”
en.wikipedia.org/wiki/BBC

13
Monte Carlo Simulation
We need: Samples from the uniform distribution We have: Samples from the degree distribution Can we somehow use the samples from the degree
distribution to generate samples from the uniform distribution?
Yes!
Monte Carlo Simulation Methods
Rejection Sampling
Rejection Sampling
Importance Sampling
Importance Sampling
Metropolis-Hastings
Metropolis-Hastings
Maximum-Degree
Maximum-Degree

14
Monte Carlo Simulation : Target distribution
In our case: = uniform on D p: Trial distribution
In our case: p = degree distribution
Bias weight of p(x) relative to (x): In our case:
Monte Carlo Simulator
Monte Carlo Simulator
Samples from p
Sample from
x
Sampler
(x1,w(x)), (x2,w(x)),… p-Samplerp-Sampler

15
Bias Weights Unnormalized forms of and p:
: (unknown) normalization constants
Examples: = uniform: p = degree distribution:
Bias weight:

16
C: envelope constant C ≥ w(x) for all x
The algorithm: accept := false while (not accept)
generate a sample x from p toss a coin whose heads probability is if coin comes up heads,
accept := true
return x
In our case: C = 1 and acceptance prob = 1/deg(x)
Rejection Sampling [von Neumann]

17
Pool-Based Sampler
Degree distribution sampler
Degree distribution sampler
Search EngineSearch Engine
Rejection Sampling
Rejection Sampling
q1,q2,…results(q1), results(q2),…
x
Pool-Based Sampler
(x(x11,1/deg(x,1/deg(x11)),)),
(x(x22,1/deg(x,1/deg(x22)),…)),…
Uniform sample
Documents sampled from degree distribution with corresponding weights
Degree distribution: p(x) = deg(x) / x’deg(x’)

18
Sampling documents by degree
Select a random query q Select a random x results(q) Documents with high degree are more likely to be sampled If we sample q uniformly “oversample” documents that
belong to narrow queries We need to sample q proportionally to its cardinality
www.cnn.com
www.foxnews.com
news.google.com
news.bbc.co.ukwww.google.com
maps.google.com
www.bbc.co.uk
www.mapquest.com
maps.yahoot.com
“news”
“bbc”
“google”
“maps”
en.wikipedia.org/wiki/BBC

19
Sampling documents by degree (2)
Select a query q proportionally to its cardinality Select a random x results(q) Analysis:
www.cnn.com
www.foxnews.com
news.google.com
news.bbc.co.ukwww.google.com
maps.google.com
www.bbc.co.uk
www.mapquest.com
maps.yahoot.com
“news”
“bbc”
“google”
“maps”
en.wikipedia.org/wiki/BBC

20
Degree Distribution Sampler
Search EngineSearch Engine
results(q)
xCardinality Distribution Sampler
Cardinality Distribution Sampler
Sample x uniformly from results(q)
Sample x uniformly from results(q)
q
Degree Distribution Sampler
Query sampled from cardinality
distribution
Document sampled from
degree distribution

21
Sampling queries by cardinality
Sampling queries from pool uniformly:Easy
Sampling queries from pool by cardinality: Hard Requires knowing cardinalities of all queries in the
search engine
Use Monte Carlo methods to simulate biased sampling via uniform sampling: Target distribution: the cardinality distribution Trial distribution: uniform distribution on the query pool

22
Sampling queries by cardinality
Bias weight of cardinality distribution relative to the uniform distribution:
Can be computed using a single search engine query
Use rejection sampling: Envelope constant for rejection sampling:
Queries are sampled uniformly from the pool Each query q is accepted with probability

23
Degree Distribution Sampler
Degree Distribution Sampler
Complete Pool-Based Sampler
Search EngineSearch Engine
Rejection Sampling
Rejection Sampling
x(x,1/deg(x)),…
Uniform document
sample
Documents sampled from degree distribution with corresponding weights
Uniform Query Sampler
Uniform Query Sampler
Rejection Sampling
Rejection Sampling
(q,card(q)),…
Uniform query
sampleQuery
sampled from cardinality distribution
(q,results(q)),…

24
Dealing with Overflowing Queries
Problem: Some queries may overflow (card(q) > k) Bias towards highly ranked documents
Solutions: Select a pool P in which overflowing queries are rare
(e.g., phrase queries) Skip overflowing queries Adapt rejection sampling to deal with approximate weights
Theorem:
Samples of PB sampler are at most -away from uniform. ( = overflow probability of P)

25
Creating the query pool
C
Large corpusPq1
……
Query Pool
Example: P = all 3-word phrases that occur in C If “to be or not to be” occurs in C, P contains:
“to be or”, “be or not”, “or not to”, “not to be”
Choose P that “covers” most documents in D
q2

26
A random walk sampler Define a graph G over the indexed documents
(x,y) E iff queries(x) ∩ queries(y) ≠
Run a random walk on G Limit distribution = degree distribution Use MCMC methods to make limit distribution uniform.
Metropolis-Hastings Maximum-Degree
Does not need a preprocessing step Less efficient than the pool-based sampler

27
Bias towards Long Documents
0%
10%
20%
30%
40%
50%
60%
1 2 3 4 5 6 7 8 9 10
Deciles of documents ordered by size
Perc
ent
of
docu
ments
fro
m s
am
ple
.
Pool Based
Random Walk
Bharat-Broder

28
Relative Sizes of Google, MSN and Yahoo!
Google = 1
Yahoo! = 1.28
MSN Search = 0.73

29
Random Sampling

30
Outline
The random sampling model Mean estimation Median estimation O(n) time median algorithm (Floyd-Rivest) MST weight estimation (Chazelle-
Rubinfeld-Trevisan)

31
The Random Sampling Model
f: An B A,B arbitrary sets n: positive integer (think of n as large)
Goal: given x An, compute f(x) Sometimes, approximation of f(x) suffices
Oracle access to input: Algorithm does not have direct access to x In order to probe x, algorithm sends queries to an “oracle” Query: an index i {1,…,n} Answer: xi
Objective: compute f with minimum number of queries

32
Motivation
The most basic model for dealing with large data sets Statistics Machine learning Signal processing Approximation algorithms …
Algorithm’s resources are a function of # of queries rather than of the input length
Sometimes, constant # of queries suffices

33
Adaptive vs. Non-adaptive Sampling Non-adaptive sampling
Algorithm decides which indices to query a priori. Queries are performed in batch at a pre-processing step Number of queries performed is the same for all inputs.
Adaptive sampling Queries are performed sequentially:
Query i1 Get answer xi1 Query i2 Get answer xi2 … Algorithm stops whenever has enough information to compute f(x)
In order to decide which index to query, the algorithm can use answers to previous queries.
Number of queries performed may vary for different inputs. Example: OR of n bits

34
Randomization vs. Determinism
Deterministic algorithms Non-adaptive: always queries the same set of indices Adaptive: choice of it deterministically depends on
answers to first t-1 queries
Randomized algorithms Non-adaptive: indices are chosen randomly according
to some distribution (e.g., uniform) Adaptive: it is chosen randomly according to a
distribution, which depends on the answers to previous queries
Our focus: randomized algorithms

35
(,)-approximation
M: a randomized sampling algorithm M(x): output of M on input x
M(x) is a random variable > 0: approximation error parameter 0 < < 1: confidence parameter
Definition: M is said to -approximate f with confidence 1 - , if for all inputs x An,
Ex: With probability ≥ 0.9,

36
Query Complexity
Definition: qcost(M) = the maximum number of queries M performs on: worst choice of input x worst choice of random bits
Definition: eqcost(M) = the expected number of queries M performs on: worst choice of input x expectation over random bits
Definition: The query complexity of f isqc,(f) = min { qcost(M) | M -approximates f
with confidence 1- } eqc, similarly defined

37
dd dd
Want relative approximation:
Naïve algorithm: Choose: i1,…,ik (uniformly and independently) Query: i1,…,ik Output: (sample mean)
How large should k be?
Estimating the Mean

38
Chernoff-Hoeffding Bound
X1,…,Xn i.i.d. random variables have a bounded domain [0,1] E[xi] = for all i
By linearity of expectation:
Theorem [Chernoff-Hoeffding Bound]:For all 0 < < 1,

39
Analysis of Naïve Algorithm
Lemma: queries suffice. Proof:
For i = 1,…,k, let Xi = answer to i-th query Then, output of algorithm: By Chernoff-Hoeffding bound:

40
dd dd
Want rank approximation:
Sampling algorithm: Choose: i1,…,ik (uniformly and independently) Query: i1,…,ik Output: (sample median)
How large should k be?
Estimating the Median

41
Analysis of Median Algorithm
Lemma: queries suffice. Proof:
For j = 1,…,k, let

42
The Selection Problem
Input: n real numbers x1,…,xn
Integer k {1,…,n} Output:
xi whose rank is k/n Ex:
k = 1: minimum k = n: maximum k = n/2: median
Can be easily solved by sorting (O(n log n) time) Can we do it in O(n) time?

43
The Floyd-Rivest Algorithm Note: Our approximate median algorithm can be
generalized to any quantile 0 < q < 1.
Floyd-Rivest algorithm
1. Set = 1/n1/3, = 1/n2. Use approximate quantile algorithm for
Let xL be the element returned
3. Use approximate qunatile algorithm for Let xR be the element returned
4. Let kL = rank(xL)5. Keep only elements in the interval [xL,xR]6. Sort these elements and output the element whose rank
is k – kL + 1

44
Analysis of Floyd-Rivest
Theorem: With probability 1 – O(1/n), the Floyd-Rivest algorithm finds the k-th largest number from the input at O(n) time.
Proof: Let x* = element of rank k/nLemma 1: With probability ≥ 1-2/n, x* [xL,xR]
Proof:

45
Analysis of Floyd-Rivest Let S = input elements that belong to [xL,xR] Lemma 2: With probability ≥ 1-2/n, |S| ≤ O(n2/3) Proof:
Therefore, with probability ≥ 1-2/n, at most 4n = O(n2/3)
elements are between xL and xR
Running time analysis: O(n2/3 log n): approximate quantile computations O(n): calculation of rank(xL) O(n): filtering elements outside [xL,xR] O(n2/3 log n): sorting S

46
End of Lecture 11





























