Embed Size (px)
Citation preview

Санкт-Петербург 2016
МИНИСТЕРСТВО ОБРАЗОВАНИЯ И НАУКИ РОССИЙСКОЙ ФЕДЕРАЦИИ
САНКТ-ПЕТЕРБУРГСКИЙ НАЦИОНАЛЬНЫЙ ИССЛЕДОВАТЕЛЬСКИЙ УНИВЕРСИТЕТ ИНФОРМАЦИОННЫХ ТЕХНОЛОГИЙ, МЕХАНИКИ И ОПТИКИ
СБОРНИК ТРУДОВ VII НАУЧНО-ПРАКТИЧЕСКОЙ КОНФЕРЕНЦИИ МОЛОДЫХ УЧЕНЫХ «ВЫЧИСЛИТЕЛЬНЫЕ СИСТЕМЫ И СЕТИ (МАЙОРОВСКИЕ ЧТЕНИЯ)»

МИНИСТЕРСТВО ОБРАЗОВАНИЯ И НАУКИ РОССИЙСКОЙ ФЕДЕРАЦИИ
САНКТ-ПЕТЕРБУРГСКИЙ НАЦИОНАЛЬНЫЙ ИССЛЕДОВАТЕЛЬСКИЙ УНИВЕРСИТЕТ ИНФОРМАЦИОННЫХ ТЕХНОЛОГИЙ, МЕХАНИКИ И ОПТИКИ
Сборник трудов
VII научно-практической конференции
молодых ученых «Вычислительные системы и сети (Майоровские чтения)»
Санкт-Петербург
2016

Сборник трудов VII Научно-практической конференции молодых ученых «Вычислительные системы и сети (Майоровские чтения)» / Под ред. д.т.н., проф. Т.И. Алиева. СПб: Университет ИТМО, 2016. – 133 с. Сборник содержит статьи студентов, аспирантов и сотрудников, отобранные по результатам докладов, представленных на 7-й Научно-практической конференции молодых ученых «Вычислительные системы и сети (Майоровские чтения)», состоявшейся в 2015 г. Целью конференции является ознакомление научной общественности с результатами исследований, выполненных студентами, аспирантами и сотрудниками кафедры в рамках научного направления «Организация вычислительных систем и сетей», а также в ходе выполнения научно-исследовательских и опытно-конструкторских работ, проводимых по заказу предприятий и организаций Санкт-Петербурга.
Университет ИТМО – ведущий вуз России в области информационных и фотонных технологий, один из немногих российских вузов, получивших в 2009 году статус национального исследовательского университета. С 2013 года Университет ИТМО – участник программы повышения конкурентоспособности российских университетов среди ведущих мировых научно-образовательных центров, известной как проект «5 в 100». Цель Университета ИТМО – становление исследовательского университета мирового уровня, предпринимательского по типу, ориентированного на интернационализацию всех направлений деятельности.
© Университет ИТМО, Санкт-Петербург,
2016
ISBN: 978-5-7577-0531-6

Сборник трудов VII научно-практической конференции молодых ученых «Вычислительные системы и сети (Майоровские чтения)»
САНКТ-ПЕТЕРБУРГСКИЙ НАЦИОНАЛЬНЫЙ ИССЛЕДОВАТЕЛЬСКИЙ УНИВЕРСИТЕТ ИНФОРМАЦИОННЫХ ТЕХНОЛОГИЙ, МЕХАНИКИ И ОПТИКИ
Сборник трудов VII научно-практической конференции
молодых ученых «Вычислительные системы и сети (Майоровские чтения)»
СОДЕРЖАНИЕ
ПРЕДИСЛОВИЕ ......................................................................................................................... 5
ЭФФЕКТИВНОСТЬ ВЫЧИСЛИТЕЛЬНЫХ СИСТЕМ
Дробышев В. А. Анализ производительности компьютерных сетей в виртуальной и физической инфраструктуре ......................................................................................... 7
Дмитриев А. С. Анализ эффективности протокола MP-TCP для агрегирования пропускной способности каналов связи ...................................................................... 10
Диденко Е. Ю., Кузнецова О. А. Планирование контрольных испытаний надежности вычислительных систем ................................................................................................ 15
Тихомиров А. В. Обеспечение полной воспроизводимости сетевых экспериментов с помощью фреймворка Direct Code Execution ........................................................... 20
Хомоненко А. Д., Новиков П. А., Тухтаходжаев А. Б., Садиков А. Н. Оптимизация размещения Wi-Fi-точек при навигации мобильных устройств внутри помещений ...................................................................................................................... 25
Пахомов И. В. Анализ сценариев использования технологии Wi-Fi в задачах построения беспроводных сенсорных сетей ............................................................... 28
Пушкарева Л. Г. Применение современных информационных технологий при проектировании лесных питомников ........................................................................... 32
ВСТРАИВАЕМЫЕ СИСТЕМЫ И СИСТЕМЫ НА КРИСТАЛЛЕ
Бурнаев Д. В. Методы разработки систем на базе ПЛИС.................................................. 37
Колесниченко Д. М. Учебный RISC-процессор .................................................................. 42
Купсик Н. А. Инструментальные средства для симуляции процессорных ядер ............. 45
Пальцев Е. А. Исследование производительности шинной подсистемы на примере микроконтроллеров семейства STM32L...................................................................... 48
Пичугин Н. С. Обзор виртуальных машин для встраиваемых систем ............................. 56
БЕЗОПАСНОСТЬ ВЫЧИСЛИТЕЛЬНЫХ СИСТЕМ
Малинина А. В. Анализ уязвимостей информационных систем. Защита системы от несанкционированного доступа.................................................................................... 59
Свинолобова Е. Д., Свинолобов С. В. Защита от несанкционированной загрузки ОС и контроль активности КСЗИ........................................................................................... 63
Свинолобов С. В., Свинолобова Е. Д. Методы схемотехнического проектирования аппаратного модуля доверенной загрузки................................................................... 68

4 СОДЕРЖАНИЕ
Сборник трудов VII научно-практической конференции молодых ученых «Вычислительные системы и сети (Майоровские чтения)»
Кушназаров Фар. И., Турдиев О. А., Кушназаров Фир. И. Эффективность цикличес-ких кодов при передаче данных в каналах связи с помехами .................................... 73
Менщиков А. А., Гатчин Ю. А. Методы обнаружения автоматизированного сбора информации с веб-ресурсов........................................................................................... 79
Тауекел Е. Е. Исследование угроз системы «Клиент—банк» ........................................... 84
Симонова О. Н. Сравнение производительности алгоритмов блочного симметричного шифрования..................................................................................................................... 87
ИНТЕЛЛЕКТУАЛЬНЫЕ ИНФОРМАЦИОННЫЕ СИСТЕМЫ
Козин И. О. Персонализация семантического анализа текстов на естественном языке. 90
Нуштаева С. В. Использование машинного обучения в игровых программах .............. 96
Горбачев Я. Г. Использование моделей работы мозга в реконфигурируемом акселераторе .................................................................................................................... 99
Мартыненко М. В. Алгоритмы тонального анализа текстов на естественном языке .... 103
Смирнов П. А. Задача определения математических теорем............................................. 106
Адамчик М. Н. Методы поиска по дереву решений, использование тезауруса предметной области........................................................................................................ 109
Аслами К. З. Организация хранения данных в открытых форматах документов ........... 113
Богданова В. А. Расширяемая грамматика фреймов Филлмора........................................ 117
Широков О. И. Сравнительный анализ C и C++ библиотек для формата JSON............. 120
ТЕХНОЛОГИИ КОМПЬЮТЕРНОЙ ВИЗУАЛИЗАЦИИ
Марьина А. В., Доронина Е. А. Применение технологий захвата движений для управления интерактивными системами в современном искусстве ......................... 123
Кочергина А. М., Короткова Н. Д. Оценка качества распознавания жестов для управления воспроизведением записи видео-360 ....................................................... 127
Погребняк И. В. Анализ эффективности систем оптического распознавания символов .. 130

Сборник трудов VII научно-практической конференции молодых ученых «Вычислительные системы и сети (Майоровские чтения)»
ПРЕДИСЛОВИЕ
Уважаемый читатель!
В сентябре 2015 года на кафедре вычислительной техники (ВТ) Университета ИТМО начаты исследования в рамках НИР «Методы проектирования ключевых систем информа-ционной инфраструктуры», в которой активное участие принимают магистранты и аспи-ранты кафедры. Исследования базируются на результатах работ, выполнявшихся в преды-дущие годы в соответствии с программой научных исследований в рамках научной школы «Организация вычислительных систем и сетей». Научно-исследовательские разработки ве-дутся по нескольким направлениям, включая разработку математических моделей, методов и средств для анализа эффективности и проектирования вычислительных систем различных классов, в том числе встраиваемых систем, удовлетворяющих требованиям производитель-ности, надежности и информационной безопасности; методов и средств для разработки и сопровождения интеллектуальных информационных систем; технологий и алгоритмов компьютерной визуализации.
Выпуск «Сборника трудов VII научно-практической конференции молодых ученых «Вычислительные системы и сети (Майоровские чтения)»» содержит статьи магистрантов, аспирантов и молодых сотрудников нескольких кафедр Университета ИТМО, а также пред-ставителей Петербургского государственного университета путей сообщения Императора Александра I, Санкт-Петербургского государственного лесотехнического университета им. С. М. Кирова, ОКБ «Электроавтоматика». Результаты, представленные в статьях, прошли апробацию на VII научно-практической конференции молодых ученых «Вычислительные системы и сети (Майоровские чтения)» в декабре 2015 года и XLIV научной и учебно-методической конференции Университета ИТМО в феврале 2016 года.
Статьи сборника тематически объединены в пять разделов: «Эффективность вычисли-тельных систем», «Встраиваемые системы и системы на кристалле», «Безопасность вычисли-тельных систем», «Интеллектуальные информационные системы» и «Технологии компью-терной визуализации».
Заведующий кафедрой ВТ Университета ИТМО, Заслуженный работник высшей школы РФ,
д.т.н., профессор Т. И. АЛИЕВ


Сборник трудов VII научно-практической конференции молодых ученых «Вычислительные системы и сети (Майоровские чтения)»
ЭФФЕКТИВНОСТЬ ВЫЧИСЛИТЕЛЬНЫХ СИСТЕМ
УДК 004.7
АНАЛИЗ ПРОИЗВОДИТЕЛЬНОСТИ КОМПЬЮТЕРНЫХ СЕТЕЙ В ВИРТУАЛЬНОЙ И ФИЗИЧЕСКОЙ ИНФРАСТРУКТУРЕ
В. А. Дробышев
Университет ИТМО, 197101, Санкт-Петербург, Россия
Для сравнения производительности виртуализированных компьютер-ных сетей с производительностью аналогичных физических сетей соз-дан лабораторный стенд на базе двух физических серверов и маршрути-затора, а также гипервизора, содержащего две виртуальные машины. В качестве эксперимента была произведена передача трех разновидностей сетевого трафика между двумя физическими серверами, двумя вирту-альными машинами и между компьютером и виртуальной машиной. Ре-зультаты экспериментов показали зависимость фактической скорости передачи данных от структуры трафика в физической инфраструктуре и отсутствие такой зависимости при передаче данных между виртуаль-ными машинами.
Ключевые слова: виртуализация, компьютерная сеть, производительность, виртуализированная сеть, структура трафика.
Существует множество факторов, влияющих на производительность компьютерных се-тей [1]. В случае клиент-серверной модели производительность зависит от:
— конфигурации сети, — структуры и интенсивности сетевого трафика, — доступности вычислительных ресурсов, — аппаратных особенностей сети. Для оценки влияния этих факторов на производительность сети был произведен ряд
экспериментов в физической, виртуальной и смешанной инфраструктуре. Анализ результатов экспериментов производился с помощью утилиты NetPerf, которая позволяет генерировать и передавать пакеты между клиентом и сервером, измеряя при этом производительность сети.
Аналогичные эксперименты уже проводились сотрудниками компании VMware в 2005 году [2]. Однако технологии виртуализации сетей изменились за прошедшие 11 лет, поэтому в ходе проведения настоящей работы были получены иные результаты.
В целях охвата наибольшего количества влияющих на производительность сети факто-ров в экспериментах использовались три типа трафика (см. таблицу): передача файлов мало-го, среднего и большого размера.
Для получения более точных результатов передача файлов каждого типа проводилась 50 раз, фиксировалось пиковое значение скорости передачи данных.
Результаты экспериментов показали, что в физической инфраструктуре (два компьюте-ра, соединенные напрямую) наилучшая производительность достигается при передаче боль-ших файлов, наихудшая — при работе с файлами малого размера. Загрузка ЦП напрямую за-висит от достигнутой скорости передачи данных.

8 ЭФФЕКТИВНОСТЬ ВЫЧИСЛИТЕЛЬНЫХ СИСТЕМ
Сборник трудов VII научно-практической конференции молодых ученых «Вычислительные системы и сети (Майоровские чтения)»
Используемые типы трафика Параметр Маленькие файлы Средние файлы Большие файлы
Размер буфера передачи на локальном компьютере, байт
16384 16384 65536
Размер буфера приема на удаленном компьютере, байт
16384 16384 65536
Размер файла, байт 1024 8192 65536
При проведении эксперимента в смешанной инфраструктуре (виртуальная машина и физический сервер) влияние трафика на производительность сети оказалось идентичным случаю физической инфраструктуры.
Проведение экспериментов в виртуальной среде с использованием виртуализированных сетей (компьютерная сеть, объединяющая только виртуальные машины, без привязки к аппа-ратному сетевому интерфейсу) показало, что производительность в этом случае стремится к пропускной способности сети независимо от передаваемого трафика. Такие результаты обу-словлены тем, что сетевой трафик передается в пределах одного физического хоста и отсут-ствует аппаратное сетевое оборудование, которое могло бы вносить какие-либо задержки. Инженеры компании VMware пришли в своей работе к другим выводам. Очевидно, что про-веденные ими эксперименты утратили свою актуальность [2].
Более подробно результаты проведенных экспериментов показаны на рис. 1: для трех видов трафика слева направо представлены пары значений (отправка и получение трафика) для пары физических хостов, физического сервера и виртуальной машины и двух виртуаль-ных машин (H —эксперименты межу физическими хостами, HV — между физическим и вир-туальным компьютерами, VM — между виртуальными машинами).
Производительность для разных видов сетей, Мбит/с
Рис. 1. Производительность для разных видов сетей
Эксперименты проводились на лабораторном стенде, состоящем из двух физических серверов, сервера под управлением гипервизора VMware ESXi 6.0 с двумя виртуальными машинами и маршрутизатора (рис. 2). Как аппаратная, так и виртуализированная сеть были настроены на передачу данных со скоростью 1 ГБ/с.

ЭФФЕКТИВНОСТЬ ВЫЧИСЛИТЕЛЬНЫХ СИСТЕМ 9
Сборник трудов VII научно-практической конференции молодых ученых «Вычислительные системы и сети (Майоровские чтения)»
Рис. 2. Архитектура лабораторного стенда
В ходе работы были сделаны следующие выводы: — структура передаваемого трафика оказывает существенное влияние на производи-
тельность компьютерных сетей в физической среде, — показатели производительности виртуализированных сетей превосходят показатели
аппаратных сетей при использовании сетевого адаптера с пропускной способностью 1 ГБ/с, — виртуализация сети увеличивает нагрузку на аппаратные ресурсы.
ЛИТЕРАТУРА
1. Алиев Т. И. Сети ЭВМ и телекоммуникации. СПб: СПбГУ ИТМО, 2011. 400 с.
2. Vmware, Inc Network Throughput in a Virtual Infrastructure. 2010. 10 р.
Сведения об авторе Владимир Александрович Дробышев — студент; Университет ИТМО, кафедра вычислительной техники,
E-mail: [email protected]
Ссылка для цитирования: Дробышев В. А. Анализ производительности компьютерных сетей в виртуальной и физической инфраструктуре // Сборник трудов VII научно-практической конференции молодых ученых «Вы-числительные системы и сети (Майоровские чтения)». 2016. С. 7—9.
ANALYSIS OF THE PERFORMANCE OF COMPUTER NETWORKS IN VIRTUAL AND PHYSICAL INFRASTRUCTURE
V. A. Drobyshev
ITMO University, 197101, St. Petersburg, Russia
This article outlines the reasons that affect network performance. Applications deployed on the top of a virtual infrastructure were used in the research. The results of the experiments allows to examine the im-pact of various factors both on physical and virtual networks.
Keywords: virtualization, network, performance, virtual network, traffic patterns.
Data on author Vladimir A. Drobyshev — Student; ITMO University, Department of Computer Science;
E-mail: [email protected]
For citation: Drobyshev V. A. Analysis of the performance of computer networks in virtual and physical in-frastructure // Proceedings of the scientific and practical conference of young scientists «Computing systems and networks (Mayorov’s readings)». 2016. P. 7—9 (in Russian).

10 ЭФФЕКТИВНОСТЬ ВЫЧИСЛИТЕЛЬНЫХ СИСТЕМ
Сборник трудов VII научно-практической конференции молодых ученых «Вычислительные системы и сети (Майоровские чтения)»
УДК 004.057.4
АНАЛИЗ ЭФФЕКТИВНОСТИ ПРОТОКОЛА MP-TCP ДЛЯ АГРЕГИРОВАНИЯ ПРОПУСКНОЙ СПОСОБНОСТИ КАНАЛОВ СВЯЗИ
А. С. Дмитриев
Университет ИТМО, 197101, Санкт-Петербург, Россия
Рассмотрена актуальная проблема, связанная с агрегированием пропуск-ной способности асимметричных каналов связи. Быстрое развитие тех-нологий передачи потокового трафика приводит к задаче поддержания качества сервисов из-за увеличения задержек и нехватки пропускной способности каналов связи. Показаны связанные с этим особенности работы сервисов в сети Интернет и новые возможности увеличения ре-сурсной емкости сетей доступа с помощью протокола MP-TCP. Пред-ставлена имитационная модель компьютерной сети с двумя маршрута-ми, передача данных по которым осуществляется с помощью модели протокола MP-TCP. Рассчитана доля полезной пропускной способности данной компьютерной сети. Выполнено сравнение соответствующей аналитической модели (с дополнительными ограничениями) с имитаци-онной. Описаны преимущества и ограничения использованных в иссле-дованиях моделей по сравнению с натурными экспериментами в реаль-ной сети.
Ключевые слова: MP-TCP, сетевые протоколы, ns-3, имитационное моделирование, аналитическая модель, балансировка нагрузки.
В современных компьютерных сетях существуют десятки независимо управляемых се-тей, через которые требуется передавать данные для предоставления одного сервиса. Но сис-темные администраторы в общем случае не имеют сведений о параметрах не обслуживаемых ими сетей доступа, которые создают нагрузку на их сеть, а также о параметрах соседних се-тей, которые могут снять часть нагрузки с их сетей относительно данного сервиса. Поэтому администраторы не могут оптимально настроить маршрутные таблицы для обеспечения ка-чественного обслуживания и увеличения загрузки своих сетей [1, 2].
Наличие в современных портативных электронных устройствах — таких как ноутбуки, планшеты и смартфоны — нескольких сетевых интерфейсов, беспроводных или проводных, открывает теоретическую возможность совместного их использования для увеличения про-пускной способности и повышения качества сервисов. Для агрегации беспроводных интер-фейсов операторы связи совместно с производителями сетевого оборудования разрабатывают стандарты и спецификации, но это довольно затратный и долгий процесс, и до массового ис-пользования данных технологий еще далеко [3, 4]. Поэтому операторы связи пытаются найти промежуточные решения, которые позволяли бы улучшить качество обслуживания.
Для решения перечисленных задач необходимо использовать межсетевые методы балан-сировки нагрузки. Эти методы находятся на транспортном уровне модели OSI и позволяют в автоматическом режиме распределять нагрузку по нескольким доступным путям в рамках одного сервиса. Одним из таких методов является использование протокола MP-TCP [5], позволяющего выполнить балансировку нагрузки в рамках одного TCP-соединения.
В отличие от других исследований эффективности протокола MP-TCP [6, 7], в настоя-щей работе применяется имитационное моделирование с целью сокращения времени прове-дения необходимых экспериментов вместо использования реальных сетей или имитационных моделей со стеком протоколов, сравнимым с реальной сетью.
Объектом исследования данной работы является протокол транспортного уровня MP-TCP. Предметом исследования является эффективность балансировки трафика при ис-

ЭФФЕКТИВНОСТЬ ВЫЧИСЛИТЕЛЬНЫХ СИСТЕМ 11
Сборник трудов VII научно-практической конференции молодых ученых «Вычислительные системы и сети (Майоровские чтения)»
пользовании многопутевой маршрутизации. Целью исследования является анализ эффектив-ности балансировки трафика с помощью протокола MP-TCP. Для достижения поставленных целей решались следующие задачи:
— выбор инструмента исследования, — реализация протокола МР-ТСР средствами выбранного инструмента, — планирование и постановка экспериментов, — анализ результатов экспериментов. Используемые методы исследования включают имитационное моделирование, методы
матстатистики и теории планирования экспериментов. С помощью средства моделирования ns-3 построена имитационная модель компьютер-
ной сети, состоящая из двух сетей с различной пропускной способностью, между которыми балансируется создаваемая сервисом нагрузка: сети доступа, которая генерирует нагрузку, и сети сервиса, в которой расположен сервер, обслуживающий сервис. В качестве модели про-токола MP-TCP был использован проект с открытым исходным кодом [8], который был в це-лях исследования модифицирован (добавлена возможность использования одного IP-адреса для сервера). Кроме того, в созданной имитационной модели используется расширение «per flow ECMP» и статические маршруты для построения двух путей к серверу через различные сети. Передача данных производилась от клиента к серверу. Топология сети, реализованная в имитационной модели, представлена на рис. 1: C1, ... ,C5 — пропускная способность каналов (C1=1, С2=1..10, С3=С4=С5=100 Мбит/с), на всем пути следования помимо протокола MP-TCP (на клиенте и сервере) используются нижележащие протоколы: IPv4, PPP.
Рис. 1. Топология исследуемой сети
Полученная имитационная модель обладает рядом ограничений по сравнению с реаль-ной сетью и протоколом:
— не учитывается время обработки пакетов в транзитных сетях (Сеть1, Сеть2, Сеть3), — не рассматривается возможное пересечение двух транзитных сетей в узких местах, — используется детерминированное время задержки и поступления пакетов — 10 мс. При использовании настольной ЭВМ средней ценовой категории созданная модель по-
зволяет снизить время эксперимента более чем на 40 % по сравнению с натурным экспе-риментом на реальной сети, однако рассмотренные выше ограничения снижают корректность результатов.
При проведении имитационных экспериментов по передаче 100 МБ трафика получено, что коэффициент эффективности передачи (КЭП, отношение средней скорости передачи данных к суммарной пропускной способности доступных сетей) уменьшается при увеличе-нии суммарной пропускной способности. Связано это с тем, что в протоколе MP-TCP на

12 ЭФФЕКТИВНОСТЬ ВЫЧИСЛИТЕЛЬНЫХ СИСТЕМ
Сборник трудов VII научно-практической конференции молодых ученых «Вычислительные системы и сети (Майоровские чтения)»
старте передачи размер окна равен одному пакету, и нарастание окна происходит постепенно, поэтому для достижения пиковой скорости необходимо время, обратно пропорциональное пропускной способности.
Анализ результатов имитационных экспериментов позволил представить КЭП в виде аналитических зависимостей, которые не учитывают всех особенностей имитационной моде-ли, но дают оценку сверху как для имитационной модели, так и для реальной системы.
В общем случае КЭП уменьшается из-за следующих накладных расходов. 1. Служебные заголовки. Обозначим долю служебных заголовков по отношению к по-
лезному трафику через overheadK .
2. Медленное нарастание окна передачи протокола TCP в начале передачи. Обозначим с помощью slowstartK долю времени, на которую задерживается передача данных.
3. Служебные пакеты создания и завершения соединения. Обозначим через connectionK
долю времени, на которую задерживается передача данных из-за использования служебных пакетов.
Таким образом, получаем следующую формулу расчета КЭП: 1mp tcp overhead slowstart connectionK K K . (1)
Служебные заголовки hL состоят из заголовков канального уровня 2lL , сетевого уровня
3lL , заголовка TCP tcpL и опций MP-TCP в заголовке TCP mp tcpL (все величины указаны в
байтах), т.е. 2 3 .h l l tcp mp tcpL L L L L (2)
Таким образом, доля служебных пакетов, а следовательно и связанное с этим уменьше-ние КЭП, составит:
hoverhead
payload h
LK
L L
, (3)
где payloadL — размер передаваемых данных в одном пакете (байт).
Обозначим сумму значений пропускной способности каналов как 1
n
ii
C C
, где n —
число каналов, iC — пропускная способность i-го канала связи (бит/с), и выразим длину за-
пакованного в заголовки пакета: p payload hL L L .
Для учета фактора нарастания окна передачи необходимо вычислить объем данных, ко-торый мог бы передаваться в i-м канале одновременно при непрерывной передаче: зmin( ,2 )ssi max iL W C t , (4)
где maxW — максимальный размер окна (бит), зt — время задержки передачи пакета по кана-
лу (с). Тогда время простоя канала из-за отсутствия передачи пакетов, размер которых мень-ше оптимального размера окна, равно:
[ ]
1
.
ssi
p
L
Lssi p
ssiij
L jLT
C
(5)
Время передачи без простоя канала:
(1 )ideal
overhead
DT
C K
, (6)
где D — объем передаваемых по сети данных (бит). Получаем долю простоя канала из-за механизма плавающего окна:

ЭФФЕКТИВНОСТЬ ВЫЧИСЛИТЕЛЬНЫХ СИСТЕМ 13
Сборник трудов VII научно-практической конференции молодых ученых «Вычислительные системы и сети (Майоровские чтения)»
1
1
nssii
slowstart nideal ssii
TK
T T
. (7)
Доля служебных пакетов не зависит от их размера и рассчитывается по формуле:
з з з2(2 4 1 ) (8 4)
connectionideal ideal
t n t n tK
T T
, (8)
согласно которой, пока первое соединение не будет установлено/закрыто, остальные потоки не будут инициировать/закрывать свои соединения. Таким образом, служебные пакеты от-крытия/закрытия соединения первого потока передаются за время 2tз, остальных потоков — за 4tз.
Формулы (1)—(8) будут полезны операторам, чтобы рассчитывать теоретически необ-ходимый минимум ресурсоемкости сети, без которого внедрение протокола MP-TCP вызовет ее перегрузку.
Результаты расчетов доли полезной пропускной способности двух методов приведены на рис. 2.
Рис. 2. Зависимость КЭП от пропускной способности каналов
Таким образом, можно сформулировать следующие выводы. 1. Из-за механизма нарастающего окна при старте передачи КЭП уменьшается при уве-
личении пропускной способности каналов связи. 2. Разработанная имитационная модель позволяет сократить время проведения экспе-
римента по сравнению с реальной сетью при получении ограничений, перечисленных выше, что снижает адекватность результатов.
3. Разработанная аналитическая модель позволяет намного сильнее сократить время проведения эксперимента по сравнению с реальной сетью при получении ограничений, пере-численных выше, что еще больше снижает адекватность результатов.
ЛИТЕРАТУРА
1. Ибрагиева Л. О. Анализ проблем обеспечения качества в мультисервисных сетях // Наука и мир. Научное обозрение. 2015. № 6.
2. Гончаров А. А. Исследование условий обеспечения гарантированного качества обслужи-вания в сети Интернет: Автореф. дис. канд. техн. наук. М., 2007. 114 с.
3. Jha S. C., Sivanesan K., Vannithamby R., Koc A. T. Dual Connectivity in LTE small cell networks // Globecom Workshops (GC Wkshps). 2014. P. 1205—1210.

14 ЭФФЕКТИВНОСТЬ ВЫЧИСЛИТЕЛЬНЫХ СИСТЕМ
Сборник трудов VII научно-практической конференции молодых ученых «Вычислительные системы и сети (Майоровские чтения)»
4. Lagrange X. IRISA D2, Telecom Bretagne, Rennes, France Very tight coupling between LTE and Wi-Fi for advanced offloading procedures // Wireless Communications and Networking Conference Workshops (WCNCW), 2014 IEEE. P. 82—86.
5. Ford C., Raiciu M. Handley TCP Extension for Multipath Operation with Multiple Addresses. RFC 6824, 2013.
6. Alheid A., Kaleshi D., Doufexi A. Performance Evaluation of MPTCP in Indoor Heterogeneous Networks // 1st Intern. Conf. on Systems Informatics, Modelling and Simulation. 2014. P. 173—178.
7. Becke M., Adhari H., Rathgeb E. P., Fa Fu, Yang X., Zhou X. Comparison of Multipath TCP and CMT-SCTP based on Intercontinental Measurements // IEEE Global Communications Conf. (GLOBECOM). 2013 P. 1360—1366.
8. Kheirkhah M., Wakeman I., Parisis G. Multipath-TCP in ns-3, arXiv:1510.07721. October 2015.
Сведения об авторе Андрей Сергеевич Дмитриев — студент; Университет ИТМО, кафедра вычислительной техники;
E-mail: [email protected] Ссылка для цитирования: Дмитриев А. С. Анализ эффективности протокола MP-TCP для агрегирования про-пускной способности каналов связи // Сборник трудов VII научно-практической конференции молодых ученых «Вычислительные системы и сети (Майоровские чтения)». 2016. С. 10—14.
EFFECTIVENESS OF MP-TCP PROTOCOL TO AGGREGATE THE BANDWIDTH OF COMMUNICATION CHANNELS
A. S. Dmitriev
ITMO University, 197101, St. Petersburg, Russia
This article is devoted to the current issue of the modern IP networks. A significant development of stream traffic in the Internet has lead to an issue of packet delays and throughput. Degradation of these parameters lead to bad quality. In this paper problems of quality of services in the Internet and new op-portunities that lead to increased network resources are described. The object, subject, problems and methods of this research are provided. Model of two-path computer network transmitting data with model of MP-TCP protocol, results of execution of model and explanations is given. Constraints and advantages of using the ns-3 model given in research instead of real network are taken in account. The calculations of the proportion of the useful bandwidth of the network with its additional restrictions compared to the simulation model and the practical application of these calculations is provided.
Keywords: MP-TCP, network protocols, ns-3, simulation, analytical modeling, load balancing.
Data on author Andrey S. Dmitriev — Student; ITMO University, Department of Computer Science;
E-mail: [email protected]
For citation: Dmitriev A. S. Effectiveness of MP-TCP protocol to aggregate the bandwidth of communication channels // Proceedings of the scientific and practical conference of young scientists «Computing systems and networks (Mayorov’s readings)». 2016. P. 10—14 (in Russian).

ЭФФЕКТИВНОСТЬ ВЫЧИСЛИТЕЛЬНЫХ СИСТЕМ 15
Сборник трудов VII научно-практической конференции молодых ученых «Вычислительные системы и сети (Майоровские чтения)»
УДК 621.396
ПЛАНИРОВАНИЕ КОНТРОЛЬНЫХ ИСПЫТАНИЙ НАДЕЖНОСТИ ВЫЧИСЛИТЕЛЬНЫХ СИСТЕМ
Е. Ю. Диденко, О. А. Кузнецова
ОКБ «Электроавтоматика» им. акад. П. А. Ефимова, 198095, Санкт-Петербург, Россия
Выполнен анализ проблем оценки надежности спроектированного обо-рудования и рассмотрены ее общие принципы. Проведен анализ таких методов оценки надежности, используемых при проектировании, про-изводстве и эксплуатации, как аналитический расчет по справочным данным, анализ статистических данных эксплуатации изделий-аналогов, лабораторные испытания на надежность. Сформулированы критерии выбора метода оценки надежности и выявлены недостатки каждого из методов. Предложена методика планирования испытаний и последующей оценки ожидаемой средней наработки на отказ вычисли-тельных систем, которые предназначены для эксплуатации в тяжелых условиях окружающей среды с динамическими нагрузками и характе-ризуются высокой стоимостью. Основу оценки надежности по предла-гаемой методике составляет обработка немногочисленных статистиче-ских данных об отказах на основе модели эксплуатации и дополнитель-ной априорной информации об изделиях-аналогах, изготавливаемых по единому технологическому процессу. Предлагаемый метод позволяет сократить время испытаний и повысить достоверность оценки показа-телей надежности.
Ключевые слова: надежность, испытания на надежность, безотказность, средняя наработка на отказ, вероятность безотказной работы, вычислительные системы, электроника, приборостроение.
Одной из основных характеристик вычислительных систем являются показатели на-дежности. Учитывая отсутствие у изделий цифровой вычислительной техники отдельных электрических параметров, характеризующих приближение отказа, связанного со старением и износом, определение предельного состояния изделия является актуальной задачей. Одним из параметров предельного состояния цифровой вычислительной техники может быть принят достигнутый уровень надежности. Проектирование вычислительной системы, влияющей в случае отказов на возникновение критических ситуаций, должно выполняться при строгом соблюдении требований по отказобезопасности (отказоустойчивости к видам отказов). Для вычислительных систем, последствия отказов которых могут привести к тяжелым последст-виям, подтверждение заданных уровней безотказности может помимо прогнозирования пока-зателей с помощью аналитических расчетов потребовать проведения дорогостоящих испыта-ний на надежность [1].
Надежность — это свойство системы, которое заключается в выполнении требуемых функций и обеспечении установленных эксплуатационных показателей в заданных пределах по нормативной документации на систему в течение заданного времени.
Оценка ожидаемой наработки на отказ — прогнозирование или исследование надежно-сти системы до ввода ее в эксплуатацию — проводится для обнаружения на ранних этапах жизненного цикла изделия потенциальных проблем, обеспечения уверенности, что система будет отвечать заданным требованиям [2].
Прогнозирование значений показателей безотказности позволяет: — оценить правильность выбранных принципов разработки (структуры резервирова-
ния, выбора элементной базы, конструкции, применяемых методов охлаждения и т.п.), — определить параметры распределения характеристик надежности составных частей
изделий в качестве исходных данных для расчета надежности систем в целом,

16 ЭФФЕКТИВНОСТЬ ВЫЧИСЛИТЕЛЬНЫХ СИСТЕМ
Сборник трудов VII научно-практической конференции молодых ученых «Вычислительные системы и сети (Майоровские чтения)»
— наметить и осуществить конкретные мероприятия по дальнейшему совершенствова-нию конструкций, способов эксплуатации и ремонта,
— обосновать доработку изделий на последующих этапах разработки, — сформировать набор исходных данных для расчета комплекса запасных частей [3].
При оценке надежности учитываются следующие факторы: — функциональное назначение, представленное в техническом задании; — время непрерывной работы изделия; — качество комплектующих радиоэлектронных элементов (вид приемки); — жесткость условий эксплуатации (климатические и механические воздействия, элек-
трические нагрузки). На предприятиях и опытных производствах для получения исходных данных, являю-
щихся входными параметрами, используются разные источники — от справочников, реко-мендованных государственными стандартами, до отчетов об испытаниях и эксплуатации уже разработанных изделий. В работе рассмотрены следующие распространенные методы оценки:
— аналитический расчет показателей надежности; — анализ и оценка по статистическим данным эксплуатации; — лабораторные испытания на надежность. Для аналитического расчета показателей надежности систем используются методы, ос-
нованные на вычислении по справочным и другим данным надежности входящих элементов на уровне электрорадиоизделий, имеющихся к моменту расчета. В последнее время все чаще используются автоматизированные системы, что позволяет заменить испытания вычисли-тельных систем компьютерным моделированием. Моделирование при проектировании дает возможность проанализировать потенциальные механические, тепловые, электромаг-нитные и другие воздействия, что значительно экономит денежные средства [4].
При анализе по статистическим данным эксплуатации с заданной доверительной вероят-ностью используется следующий алгоритм получения данных:
— определение выборки изделий; вычисление точечной оценки средней наработки на отказ вычислительной системы;
— определение границ доверительного интервала (Тниж, Тверх); — сравнение полученных значений показателей надежности с требуемыми (Тα и Тβ) по
графику, пример которого приведен на рис. 1.
Рис. 1. Сравнение результатов оценки соответствия требованиям по надежности
Основная цель лабораторных контрольных испытаний — определение соответствия на-дежности партии вычислительных систем поставленным заказчиком требованиям. В соответ-ствии с предполагаемыми условиями эксплуатации аппаратуры выбираются камеры/обору-

ЭФФЕКТИВНОСТЬ ВЫЧИСЛИТЕЛЬНЫХ СИСТЕМ 17
Сборник трудов VII научно-практической конференции молодых ученых «Вычислительные системы и сети (Майоровские чтения)»
дование для испытаний. В частности, для авионики наибольшее влияние на работоспособ-ность изделий оказывают внешние воздействующие факторы: вибрация, термоциклирование, влажность и давление. Некоторые системы принципиально не могут подвергаться испытаниям, например, из-за жестких ограничений по времени и затратам. В таких случаях могут быть ис-пользованы ускоренные испытания, методы планирования экспериментов и моделирование [5].
Для оценки необходимы следующие исходные данные: — требуемое значение показателя надежности (Ттр), — риски поставщика и заказчика (соответственно α и β), — отношение приемочного и браковочного уровней. Одной из самых спорных задач является определение объема выборки для исследова-
ний, поскольку испытанные изделия не могут быть отправлены в эксплуатацию. Объем вы-борки зависит от критериев, по достижении которых испытания приостанавливаются: сум-марная наработка, обеспечивающая заданный уровень надежности, или получение такого числа отказов, когда график распределения оказывается в области несоответствия.
Лабораторные испытания на надежность могут проводиться на разных уровнях: слож-ные системы могут испытываться не в целом, а на уровне компонентов, устройств, подсис-тем. Например, испытания компонентов на воздействие внешних факторов может выявить проблемы перед тем, как они будут обнаружены на более высоком уровне интеграции. Про-ведение испытаний на каждом уровне интеграции до испытания всей системы с одновремен-ным развитием программы испытаний позволяет снизить риск неудачи. Ограничением явля-ется допустимые габариты камеры испытаний и закладываемый бюджет на проверочные ра-боты [6].
Оценка надежности производится на каждом уровне испытаний. При этом часто ис-пользуются такие методы, как анализ повышения надежности системы отчета и анализ отка-зов и корректирующих действий [7].
Приведенные методы оценки надежности обладают рядом недостатков: — усредненные справочные данные не учитывают технологию отдельно взятого пред-
приятия; — отсутствие достоверных исходных данных для оценки надежности по эксплуатации; — узкий диапазон внешних факторов собираемой из эксплуатации статистики, не соот-
ветствующий требованиям разрабатываемого изделия; — ложная выбраковка продукции по причине эксплуатации с нарушением нормативной
документации; — дороговизна и длительность лабораторных испытаний. Для оценки средней наработки на отказ вычислительных систем предлагается следую-
щая методология, основу которой составляет интеграция результатов наблюдений по экс-плуатации изделий-аналогов и данных, полученных из лабораторных испытаний. Для реали-зации предлагаемой методологии требуется:
1) принять среднее значение коэффициента вариации наработки до отказа аппаратуры; 2) по результатам наблюдений сформировать вариационный числовой ряд по возраста-
нию суммарных наработок до отказа; 3) выбрать требуемые интервалы и граничные значения; 4) определить значения эмпирической функции распределения, соответствующей зако-
ну распределения отказов для данного типа систем, на конец каждого выбранного интервала из п. 3. Наиболее распространен экспоненциальный закон распределения для основного пе-риода эксплуатации, т.е. в однотипных системах преобладают случайные отказы;
5) вычислить точечную оценку параметра масштаба.

18 ЭФФЕКТИВНОСТЬ ВЫЧИСЛИТЕЛЬНЫХ СИСТЕМ
Сборник трудов VII научно-практической конференции молодых ученых «Вычислительные системы и сети (Майоровские чтения)»
Рис. 2. Пример диаграммы результатов совместных испытаний
Расчетно-эквивалентный метод и метод эквивалентно-циклических испытаний не полу-чили широкого применения на практике в связи с недостаточным решением перечисленных проблем основных методов [5]. Важно отметить, что оценка общего уровня надежности при любом выбранном методе необходима для своевременного принятия мер по усовершенство-ванию выпускаемой продукции.
Предложенная выше методика совместных наблюдений также позволит комплексно оценить надежность системы и по отлаженности технологического процесса внутренних из-делий системы, и по устойчивости работы во времени при усложненных внешних воздейст-вующих факторах, а также позволит сократить расходы как и проектирующей, так и эксплуа-тирующей стороны.
ЛИТЕРАТУРА
1. Черкесов Г. Н. Надежность аппаратно-программных комплексов. СПб: Питер, 2005. 480 с.
2. Электронный ресурс: <http://ru.wikipedia.org>.
3. Надежность технических систем: Справочник / Под ред. И. А. Ушакова. М.: Радио и связь, 1985. 608 с.
4. Парамонов П. П., Видин Б. В., Есин Ю. Ф., Жаринов И. О., Колесников Ю. Л., Кофман М. М., Сабо Ю. И., Шек-Иовсепянц Р. А. Теория и практика системного проектирования авионики. Тула: Гриф и К, 2010. 365 с.
5. Парамонов П. П., Бобцов А. А., Видин Б. В., Жаринов И. О., Жаринов О. О., Сабо Ю. И., Шек-Иовсепянц Р. А. Проектирование систем бортового информационного обмена и их функциональных элементов. Тула: Гриф и К, 2010. 208 с.
6. Федоров В. К., Сергеев Н. П., Кондрашин А. А. Контроль и испытания в проектировании и производстве радиоэлектронных средств. М.: Техносфера, 2005. 502 c.
7. Myers R. H., Wong K. L. and Gordy H. M. Reliability Engineering for Electronic Systems. NY: John Wiley, 1964.
Сведения об авторах Екатерина Юрьевна Диденко — ОКБ «Электроавтоматика», кафедра МПБЭВА;
E-mail: [email protected] Ольга Александровна Кузнецова — соискатель; ОКБ «Электроавтоматика», кафедра ПБКС;
E-mail: [email protected]

ЭФФЕКТИВНОСТЬ ВЫЧИСЛИТЕЛЬНЫХ СИСТЕМ 19
Сборник трудов VII научно-практической конференции молодых ученых «Вычислительные системы и сети (Майоровские чтения)»
Ссылка для цитирования: Диденко Е. Ю., Кузнецова О. А. Планирование контрольных испытаний надежности вычислительных систем // Сборник трудов VII научно-практической конференции молодых ученых «Вычисли-тельные системы и сети (Майоровские чтения)». 2016. С. 15—19.
PLANNING CONTROL RELIABILITY TESTS COMPUTING SYSTEMS
E. Yu. Didenko, O. A. Kuznetsova
Joint Stock Company «Design Bureau «Electroavtomatika» named after P. A. Efimov», 198095, St. Petersburg, Russia
The paper discusses the reliability of the test methods the technique of test planning and follow-up evaluation of the expected MTBF systems for severe environments with dynamic loads and are character-ized by high cost. Actual task is to develop the methodology and compilation of test plan, allowing a minimal cost to get the most reliable results. The article is an analysis of reliability assessment methods used in the design, manufacture and operation of equipment for dynamic loads.
Keywords: reliability, reliability testing, operability, mean time between failures, probability of failure on demand, computing, electronics, instrumentation.
Data on authors Ekaterina Yu. Didenko — Design Bureau «Electroavtomatika» named after P. A. Efimov, Depart-
ment of PBKS; E-mail: [email protected] Olga A. Kuznetsova — Design Bureau «Electroavtomatika» named after P. A. Efimov, Depart-
ment of MP BAVE; E-mail: [email protected]
For citation: Didenko E. Yu., Kuznetsova O. A. Planning control reliability tests computing systems // Pro-ceedings of the scientific and practical conference of young scientists «Computing systems and networks (Mayorov’s readings)». 2016. P. 15—19 (in Russian).

20 ЭФФЕКТИВНОСТЬ ВЫЧИСЛИТЕЛЬНЫХ СИСТЕМ
Сборник трудов VII научно-практической конференции молодых ученых «Вычислительные системы и сети (Майоровские чтения)»
УДК 004.414.23
ОБЕСПЕЧЕНИЕ ПОЛНОЙ ВОСПРОИЗВОДИМОСТИ СЕТЕВЫХ ЭКСПЕРИМЕНТОВ
С ПОМОЩЬЮ ФРЕЙМВОРКА DIRECT CODE EXECUTION
А. В. Тихомиров
Университет ИТМО, 197101, Санкт-Петербург, Россия
Рассмотрены возможности и преимущества фреймворка Direct Code Execution. Данное программное обеспечение является первым в своем роде и решает главную задачу последних десятилетий — обеспечение возможности тестирования и воспроизведения сценариев работы с ре-альными сетями, используя дискретность времени. Определены причи-ны сложности исследования компьютерных сетей и рассмотрены неко-торые возможности фреймворка на практике.
Ключевые слова: прямое выполнение кода, сетевой симулятор, моделирование, дискретность, фреймворк.
Введение
Direct Code Execution (DCE) является фреймворком с открытым исходным кодом, кото-рый базируется на использовании сетевого симулятора NS3, обеспечивает увеличение числа доступных для моделирования сетевых протоколов и большую реалистичность симуляции.
Помимо воспроизведения функционирования реальных сетей DCE преследует дости-жение следующих целей:
1) поддержка модели дискретного времени; 2) масштабируемость, обеспечиваемая гибкостью модельного времени; 3) улучшенная возможность отладки путем исполнения в едином адресном пространстве. О необходимости воспроизведения исследований в вычислительных науках говорилось
не раз в течение последних десятилетий [1]. Несмотря на это, ученым, изучающим компью-терные сети, не всегда предоставлялось возможным повторить исследования, описанные в литературе, по ряду причин:
— нехватка деталей в документации по сценариям, — сложность воспроизведения идентичных сценариев, — отсутствие доступа к исходному коду и скриптам, — сложность воспроизведения сценариев в реальных условиях. Только недавно исследователи компьютерных сетей начали облегчать решение этой за-
дачи, подробно описывая детали экспериментальных сценариев, делая свой код и скрипты доступными сетевому сообществу и иногда используя средства, улучшающие воспроизводи-мость экспериментов.
В идеале каждый ученый должен иметь возможность повторить эксперимент своего коллеги, оценить и отладить его на других сценариях в различных масштабах, сравнить его с другими подходами и, возможно, предложить улучшения, а не только посмотреть опублико-ванные в журналах результаты.
В настоящей статье полная воспроизводимость определяется как способность обеспе-чить все требования. Следующие требования являются наиболее сложными при обеспечении воспроизводимости.
1. Реализм эксперимента. Это требование удовлетворяется, когда обеспечиваются: — функциональный реализм, т.е. программная реализация тестируемой системы явля-
ется аналогом реальной системы,

ЭФФЕКТИВНОСТЬ ВЫЧИСЛИТЕЛЬНЫХ СИСТЕМ 21
Сборник трудов VII научно-практической конференции молодых ученых «Вычислительные системы и сети (Майоровские чтения)»
— временной реализм, т.е. временное поведение тестируемой системы схоже с поведе-нием реальной,
— реализм маршрутизации, т.е. источники трафика повторяют поведение аналогов в ре-альных системах.
2. Гибкость топологии. Экспериментальное окружение и входные параметры должны быть настраиваемыми вплоть до мелочей, благодаря чему обеспечивается возможность ис-следования любых топологий.
3. Простой интерфейс и низкая стоимость. Должна обеспечиваться возможность повто-рения эксперимента с малыми затратами.
4. Масштабируемость экспериментов. Возможность расширения сценариев не должна быть ограничена ресурсами вычислительного комплекса, запускающего эксперименты.
5. Легкость отладки. Это свойство обеспечивает поиск возможных проблем тестируе-мой системы, в частности, при наличии распределенной системы, функционирующей на не-скольких узлах.
Цель этой статьи — описать способы обеспечения пяти вышеизложенных требований с помощью DCE, который позволяет сделать эксперименты полностью воспроизводимыми. DCE использует библиотеку операционной системы LibOS и ядро как основу своей архитек-туры с целью возможности запуска и оценки реализаций протоколов реальных сетей. Так как DCE использует единственный процесс в модели, необходимо обеспечить избыточность ко-да для поддержания совместимости. Тем не менее, тесная интеграция c симулятором на осно-ве дискретных событий NS3 позволяет полностью воспроизводить опыты.
Архитектура фреймворка представлена на рис 1.
Рис. 1. Архитектура фреймворка Direct Code Execution
Ядро ресурсов. DCE выполняет каждый моделируемый процесс как часть процесса хоста. Эта модель поведения, базирующаяся на использовании единственного процесса, позволяет синхронизировать процессы и планировать их выполнение без использования механизмов межпроцессного взаимодействия. Более того, она позволяет пользователям проследить за несколькими процессами в течение эксперимента без необходимости распределения, а также использовать общий отладчик.
Недостатком такого подхода является то, что операционная система хоста должна осво-бождать ресурсы для каждого моделируемого процесса. Необходимо отслеживать конфликт-ные ситуации в каждом случае.
Программное ядро поддерживает реализацию сетевых протоколов, взятую из ядра Линукс. Этот уровень контактирует с NS3 посредством определенного интерфейса. На ниж-нем уровне сетевого стека Линукс пакеты MAC-уровня проходят через ядро, используя

22 ЭФФЕКТИВНОСТЬ ВЫЧИСЛИТЕЛЬНЫХ СИСТЕМ
Сборник трудов VII научно-практической конференции молодых ученых «Вычислительные системы и сети (Майоровские чтения)»
программно реализованную структуру net_device, которая контактирует непосредственно с C++ эквивалентом в NS3- ns3::NetDevice [2]. На верхнем уровне стека взаимодействие с при-ложением осуществляется через структуры данных сокетов на уровне ядра.
Пользователь может использовать стандартные утилиты командной строки Линукс для настройки конфигурации уровня маршрутизации (IP), такие как ip, iptables, устанавливая нужные параметры ip-адресов, таблиц маршрутизации и сетевых экранов.
POSIX-уровень. Поскольку спецификация POSIX достаточно обширна, реализация функций стандартной библиотеки во фреймворке представлена подмножеством, используе-мым приложениями, тестируемыми с помощью DCE. И хотя предоставлены не все возмож-ности, фреймворк позволяет запускать большинство Си-приложений, представляющих инте-рес для изучения.
Системные вызовы и функции, используемые тестируемыми приложениями, связанные со временем, возвращают модельное время вместо реального. Также осуществляется под-держка системных вызовов fork() и vfork() с помощью контроля доступа к ресурсам памяти и сохранения/восстановления доступных адресов при переключении контекста.
Эксперимент
Для проведения эксперимента на языке C++ (используется фреймворком) была создана модель сети, состоящая из пяти узлов (рис. 2), и замерено время выполнения утилиты ping с различными параметрами числа пакетов. Следует отметить, что указание ключей для запуска приложения обеспечивается с помощью единственной строки в скрипте [3], которая легко может быть изменена, тем самым обеспечив моделирование совершенно другого экспери-мента. По результатам проведенного эксперимента (рис. 3), при моделировании отправки 100 000 пакетов модельное время составило около 64 с, а реальное — 100 000 с. Очевидно, что разница колоссальная. Получившиеся значения модельного и реального времени, с ука-занием доверительного интервала при доверительной вероятности 95 %, отображены в таб-лице.
Рис. 2. Визуализация эксперимента с утилитой ping

ЭФФЕКТИВНОСТЬ ВЫЧИСЛИТЕЛЬНЫХ СИСТЕМ 23
Сборник трудов VII научно-практической конференции молодых ученых «Вычислительные системы и сети (Майоровские чтения)»
Рис. 3. Сравнение модельного и реального времени
Сравнение модельного и реального времени Граница доверительного интервала реального вре-
мени при доверительной вероятности 95 %, с
Число пакетов
Модельное время, с
Среднее значение реального времени, с
нижняя верхняя 0 0 0,934 0,893 0,975
500 500 1,203 1,143 1,263 5000 5000 3,864 3,824 3,904
10000 10000 7,08 7,035 7,125 50000 50000 32,562 32,365 32,759
100000 100000 64,213 64,057 64,369
Выводы
Подводя итоги, можно отметить, что Direct Code Execution: — обеспечивает полную воспроизводимость экспериментов; — предоставляет простой интерфейс для изменения входных параметров и эксперимен-
тального окружения; — не требует наличия дополнительных ресурсов при расширении модели, за счет чего
обеспечивается низкая стоимость проведения экспериментов; — сокращает время тестирования сетевых приложений.
ЛИТЕРАТУРА
1. Tazaki H., Urbani F., Mancini E., Lacage M., Câmara D., Turletti Th., Dabbous W. Direct Code Execution: Revisiting Library OS Architecture for Reproducible Network Experiments. University of Tokyo, Japan ALCMEON, France INRIA, France, 2013. 13 р.
2. NS-3 Tutorial [Электронный ресурс]: <https://www.nsnam.org>.
3. Lacage M., Tazaki H., Urbani F. Ns-3 Direct Code Execution (DCE) Manual Release 1.7. 2015. 67 р.
Сведения об авторе Анатолий Владимирович Тихомиров — студент; Университет ИТМО, кафедра вычислительной техники;
E-mail: [email protected]

24 ЭФФЕКТИВНОСТЬ ВЫЧИСЛИТЕЛЬНЫХ СИСТЕМ
Сборник трудов VII научно-практической конференции молодых ученых «Вычислительные системы и сети (Майоровские чтения)»
Ссылка для цитирования: Тихомиров А. В. Обеспечение полной воспроизводимости сетевых экспериментов с помощью фреймворка Direct Code Execution // Сборник трудов VII научно-практической конференции моло-дых ученых «Вычислительные системы и сети (Майоровские чтения)». 2016. С. 20—24.
ENSURE COMPLETE REPRODUCIBILITY NETWORK OF EXPERIMENTS WITH FRAMEWORK DIRECT CODE EXECUTION
A. V. Tikhomirov
ITMO University, 197101, St. Petersburg, Russia
During Direct Code Execution framework studying, its capabilities and advantages were examined. This software solution is the first of its kind and it solves the main problem of recent decades - the opportunity to test and execute scenarios with real networks using discrete time. There were also identified the rea-sons for the complexity of the studying of computer networks and discussed some features of the frame-work in practice.
Keywords: Direct Code Execution, network simulator, simulation, discreteness, framework.
Data on author Anatoly V. Tikhomirov — Student; ITMO University, Department of Computer Science;
E-mail: [email protected]
For citation: Tikhomirov A. V. Ensure complete reproducibility network of experiments with framework Direct Code Execution // Proceedings of the scientific and practical conference of young scientists «Computing systems and networks (Mayorov’s readings)». 2016. P. 20—24 (in Russian).

ЭФФЕКТИВНОСТЬ ВЫЧИСЛИТЕЛЬНЫХ СИСТЕМ 25
Сборник трудов VII научно-практической конференции молодых ученых «Вычислительные системы и сети (Майоровские чтения)»
УДК 004.89+004.94
ОПТИМИЗАЦИЯ РАЗМЕЩЕНИЯ WI-FI-ТОЧЕК ПРИ НАВИГАЦИИ МОБИЛЬНЫХ УСТРОЙСТВ ВНУТРИ ПОМЕЩЕНИЙ
А. Д. Хомоненко, П. А. Новиков, А. Б. Тухтаходжаев, А. Н. Садиков
Петербургский государственный университет путей сообщения Императора Александра I, 190031, Санкт-Петербург, Россия
Рассмотрена концепция построения системы навигации внутри поме-щений с использованием нейронных сетей и данных беспроводной сети Wi-Fi. В качестве механизма для хранения и обработки радиоотпечат-ков файла часто рассматривается модель искусственных нейронных се-тей.
Ключевые слова: нейронные сети; навигация внутри помещений; навигационные системы; алгоритм обучения; мобильные устройства.
Введение
Задачи навигации мобильных устройств внутри помещений в настоящее время приоб-ретают все большую актуальность, в том числе применительно к транспортным логистиче-ским системам. В качестве мобильных устройств могут рассматриваться роботы, используе-мые для перемещения грузов в складских помещениях. Это могут быть также мобильные устройства сотрудников или клиентов логистических центров транспортных систем. Разра-ботка и совершенствование подходов к навигации внутри помещений позволяет строить карты помещений, прокладывать маршруты перемещения, находить нужные товары и оборудова-ние, решать другие прикладные задачи для логистических центров транспортных систем.
Модели распространения
Механизм распространения электромагнитной волны можно охарактеризовать с помо-щью явлений отражения, дифракции и рассеивания. Модели распространения обычно обес-печивают прогноз средней мощности принимаемого сигнала на заданном расстоянии от передатчика, а также изменчивость уровня сигнала в непосредственной близости от конкрет-ного местоположения пользователя. Вывести эти модели можно путем расчета параметра «пространственное затухание», представляющего собой затухание сигнала, измеряемое в де-цибелах [1]: разницы между передаваемой и принимаемой мощностями.
Метод, рассматриваемый в этой статье, основывается на коммуникационной технологии Wi-Fi [2, 3]. Для работы такого сервиса требуется развернутая сеть беспроводного доступа Wi-Fi и поддерживающее ее клиентское мобильное устройство на платформе Android или IOS [4—6]. Точность позиционирования устройства на карте полностью зависит от плотности и расположения Wi-Fi-источников.
Работа навигационной системы на основе радиоотпечатков от Wi-Fi-точек доступа предполагает:
1) создание «карты» помещений на основе радиоотпечатков с сопоставленными им за-ранее известными координатами;
2) определение координат помещения по новым радиоотпечаткам. Для реализации системы навигации был создан комплекс программного обеспечения,
обеспечивающий выполнение следующих функций. 1. Сбор данных о радиоотпечатках в исследуемых помещениях. На выходе получается
набор файлов, каждый из которых содержит набор векторов (матрицу) измерений сигналов Wi-Fi-точек.

26 ЭФФЕКТИВНОСТЬ ВЫЧИСЛИТЕЛЬНЫХ СИСТЕМ
Сборник трудов VII научно-практической конференции молодых ученых «Вычислительные системы и сети (Майоровские чтения)»
2. Объединение всех исходных файлов в один. В результате получается один общий файл с измерениями во всех исследуемых помещениях. Кроме того, создается файл “names.txt”, в котором перечислены mac-адреса всех сетей в том порядке, в котором они рас-полагаются в файле обучения.
3. Составляется карта сопоставления названий помещений с их формальным числовым представлением.
4. На основе содержимого файлов предыдущих шагов создается файл с данными для обучения сети: в первой строке указываются параметры создаваемой нейросети; далее указа-ны пары строк, представляющие соответственно входной и выходной векторы.
5. Полученный вектор передается в нейронную сеть, которая возвращает результирую-щий вектор. Так как нейронная сеть обучена на основе одномерных данных, то представляет интерес только первый элемент результирующего вектора [7].
6. Полученное значение сравнивается с данными из карты помещений. В используемой версии программного комплекса на карте ищется наиболее близкое значение к текущему по-лученному из сети значению. После нахождения его на экран выводится название текущего помещения, которому соответствует измеренный радиоотпечаток.
В помещениях, где установлено большое количество Wi-Fi-точек доступа, некоторые точки малодоступны. Подобная ситуация может возникнуть, например, если составление кар-ты помещений производилось не на всей исследуемой территории, а только в некоторых ее частях, и в измерения попали дальние Wi-Fi-точки доступа со слабым сигналом. Специфика комплекса состоит в том, что размерность вектора данных искусственных нейронных сетей равна количеству всех участвующих в измерениях Wi-Fi-точек доступа [7]. Так как от раз-мерности вектора данных зависит скорость и качество обучения искусственных нейронных сетей, целесообразно уменьшить его размерность.
Задачу уменьшения размерности вектора данных можно решить несколькими путями: — установить порог мощности сигнала. Данным способом будут отфильтрованы сети,
которые имеют нестабильный слабый сигнал; — установить минимальное количество радиоотпечатков; — использовать комбинацию из обоих подходов, описанных выше.
Заключение
Общим преимуществом подхода является то, что пакет программ может быть развернут на существующей инфраструктуре сетей Wi-Fi, которые работают на множестве объектов, таких как жилые здания и торговые центры, вокзалы и аэропорты.
Недостаток подхода заключается в том, что для его полноценной работы необходимо заранее составить карту помещений, где будет осуществляться навигация.
ЛИТЕРАТУРА
1. Соловьев Ю. А. Системы спутниковой навигации. М.: ЭКО ТРЕНДЗ, 2000. 267 с.
2. Evennou F., Marx F. Advanced Integration of WiFi and Inertial Navigation Systems for Indoor Mobile Positioning // EURASIP J. on Applied Signal Processing. 2006. Article ID 86706. P. 1—11.
3. Шахиди Акобир. Алгоритм обучения RProp — математический аппарат. Электронный ресурс: <http://basegroup.ru/community/articles/rprop>.
4. Навигация в помещениях с iBeacon и ИНС. Электронный ресурс: <http://habrahabr.ru/post/245325>.

ЭФФЕКТИВНОСТЬ ВЫЧИСЛИТЕЛЬНЫХ СИСТЕМ 27
Сборник трудов VII научно-практической конференции молодых ученых «Вычислительные системы и сети (Майоровские чтения)»
5. Дворкина Н. Б., Намиот Д. Е., Дворкин Б. А. Мобильные навигационные сервисы и применение технологии OpenCellID для определения местоположения // ГЕОМАТИКА. 2010. № 2. С. 80—87. Электронный ресурс: <http://sovzond.ru/upload/ iblock/fbf/2010_02_014.pdf>.
6. Shu Wang, Jungwon Min, Byung K. Yi. Location Based Services for Mobiles: Technologies and Standards. LG Electronics Mobile Research, USA. 2008.
7. Хомоненко А. Д., Яковлев Е. Л. Нейросетевая аппроксимация характеристик многоканальных немарковских систем массового обслуживания // Труды СПИИРАН. 2015. № 4(41) С. 81—93.
Сведения об авторах Анатолий Дмитриевич Хомоненко — д-р. техн. наук, профессор; ПГУПС, кафедра информационных и
вычислительных систем; заведующий кафедрой; E-mail:[email protected]
Павел Андреевич Новиков — аспирант; ПГУПС, кафедра информационных и вычислительных систем; E-mail: [email protected]
Адхам Баходирович Тухтаходжаев — магистрант; ПГУПС, кафедра информационных и вычислитель-ных систем; E-mail: [email protected]
Азамат Нематуллаевич Садиков — магистрант; ПГУПС, кафедра информационных и вычислитель-ных систем; E-mail: [email protected]
Ссылка для цитирования: Хомоненко А. Д., Новиков П. А., Тухтаходжаев А. Б., Садиков А. Н. Оптимизация размещения Wi-Fi точек при навигации мобильных устройств внутри помещений // Сборник трудов VII научно-практической конференции молодых ученых «Вычислительные системы и сети (Майоровские чтения)». 2016. С. 25—27.
OPTIMIZATION OF WI-FI ACCESS POINTS FOR INDOOR MOBILE NAVIGATION
A. D. Khomonenko, P. A. Novikov, A. B. Tuxtaxodjayev, A. N. Sadikov
St. Petersburg State University of Railways of Emperor Alexander I, 190031, St. Petersburg, Russia
Mobile navigation systems indoors are becoming more widespread in many areas (transport, public insti-tutions, logistics and others.). The article discusses the concept of building indoor navigation using neural network data wireless network Wi-Fi. As a mechanism for storing and processing the radio fingerprint is often considered a model of artificial neural networks (ANN).
Keywords: neural network; mobile navigation indoor; navigation systems; learning algorithms; mobile devices.
Data on authors Anatoliy D. Khomonenko — Dr. Sci., Professor; St. Petersburg State University of Railways of
Emperor Alexander I, Department of information and computing sys-tems; Head of the Department; E-mail:[email protected]
Pavel A. Novikov — Post-Graduate Student; St. Petersburg State University of Railways of Emperor Alexander I, Department of information and computing sys-tems; E-mail: [email protected]
Adham B. Tuhtaxodjayev — Student; St. Petersburg State University of Railways of Emperor Alexander I, Department of information and computing systems; E-mail: [email protected]
Azamat N. Sadikov — Student; St. Petersburg State University of Railways of Emperor Alexander I, Department of information and computing systems; E-mail: [email protected]
For citation: Khomonenko A. D., Novikov P. A., Tuxtaxodjayev A. B., Sadikov A. N. Optimization of Wi-Fi access points for indoor mobile navigation // Proceedings of the scientific and practical conference of young scientists «Computing systems and networks (Mayorov’s readings)». 2016. P. 25—27 (in Russian).

28 ЭФФЕКТИВНОСТЬ ВЫЧИСЛИТЕЛЬНЫХ СИСТЕМ
Сборник трудов VII научно-практической конференции молодых ученых «Вычислительные системы и сети (Майоровские чтения)»
УДК 004.716
АНАЛИЗ СЦЕНАРИЕВ ИСПОЛЬЗОВАНИЯ ТЕХНОЛОГИИ WI-FI В ЗАДАЧАХ ПОСТРОЕНИЯ БЕСПРОВОДНЫХ СЕНСОРНЫХ СЕТЕЙ
И. В. Пахомов
Университет ИТМО, 197101, Санкт-Петербург, Россия
Проанализированы сценарии использования технологии Wi-Fi в задачах построения беспроводных сенсорных сетей. Приводятся результаты сравнительного анализа характеристик существующих приемопередат-чиков Wi-Fi, которые можно использовать для организации взаимодей-ствия между узлами в беспроводной сенсорной сети. Предложено два варианта организации сети Wi-Fi, оптимизированных по стоимости, энергопотреблению, скорости передачи данных и производительности узлов сети.
Ключевые слова: Wi-Fi, сенсорные сети, интернет вещей, умный дом, модем, точка доступа.
Введение
В настоящее время наблюдается стремительное развитие технологий беспроводных сенсорных сетей, во многом обусловленное растущим потребительским спросом на высоко-технологичные решения в приложениях «Интернет вещей» и «Умный дом» [1, 2].
Сегодня сфера беспроводных сетей малой (1—10 м) и средней (10—100 м) дальности «занята» четырьмя технологиями: Bluetooth, UWB, ZigBee и Wi-Fi [3—5].
Bluetooth стала первой технологией, добившейся успеха на рынке персональных мо-бильных устройств. Однако маленький радиус действия (до 10 м) и низкая пропускная спо-собность (1 Мбит/с) сделали ее менее привлекательной в условиях роста номенклатуры и объема данных, которые требуется передавать через сеть [5]. Технология UWB позволяет до-биться лучших скоростных характеристик (53—480 Мбит/с [6]), но также обладает малым радиусом действия (до 10 м). Ключевой особенностью технологии ZigBee является низкое энергопотребление используемого оборудования. В качестве недостатка можно отметить низкую скорость передачи данных (20—250 Кбит/с) [5].
Технология Wi-Fi позволяет строить сети с радиусом действия до 100 м и скоростью пере-дачи данных до 100 Мбит/с — это лучшие показатели среди всех технологий. Недостатком Wi-Fi является высокое энергопотребление используемых радиомодулей. Однако в последнее время обнаруживается тенденция к снижению энергопотребления Wi-Fi-оборудования. Уже выпущен ряд модулей со сравнительно низкими требованиями к энергоресурсам (200—300 мА/ч). Таким образом, технология Wi-Fi становится конкурентоспособной в задачах построения беспровод-ных сенсорных сетей. Наличие развитой инфраструктуры сетей Wi-Fi и постоянное снижение стоимости приемопередатчиков делает актуальным вопрос применимости Wi-Fi в данных при-ложениях [7].
В литературе обычно используют модули Wi-Fi одного вида для построения сенсорных сетей, не приводя анализа множества существующих на рынке модулей и выбора оптималь-ного среди них [7—9].
Варианты построения сенсорных сетей с использованием технологии Wi-Fi
Проанализируем характеристики существующих на рынке приемопередатчиков Wi-Fi, пригодных для построения сенсорных сетей. С целью ограничения пространства поиска были сформулированы следующие требования, сравнимые с требованиями к типовому радиоузлу в рассматриваемых приложениях: а) диапазон цен от 2 до 48 долларов; б) энергопотребление < 400 мА/ч; в) поддерживаемые стандарты 802.11 b/g/n, передача пакетов TCP и UDP.

ЭФФЕКТИВНОСТЬ ВЫЧИСЛИТЕЛЬНЫХ СИСТЕМ 29
Сборник трудов VII научно-практической конференции молодых ученых «Вычислительные системы и сети (Майоровские чтения)»
Требованиям удовлетворяют 16 Wi-Fi-модулей семи производителей: 1) Espressif: ESP8266; 2) High-Flying: HF-LPB100, HF-LPB200, HF-LPT100; 3) Texas Instruments: CC3100, CC3200; 4) Atmel: ATSAMW25, ATWILC1000A, ATWILC3000, ATWINC1500-MR210PA, ATWINC3400; 5) GainSpan: GS2100M, GS1011M; 6) STMicroelectronics: SPWF01SA; 7) BlueGiga: WF111, WF121.
Выделим четыре критерия построения беспроводной сенсорной сети: энергопотребле-ние, скорость передачи данных, вычислительные возможности и цена. При этом многокрите-риальная задача примет следующий вид:
1 1max, 10 Мбит/сZ f X g X ,
где Z — целевая функция, X — множество выбранных Wi-Fi-модулей, f1 — функция отноше-ния «цена/энергопотребление» модуля, g1 — функция максимальной скорости передачи мо-дуля Wi-Fi.
В результате сравнительного анализа характеристик выбранного множества модулей Wi-Fi предложены два варианта построения сенсорной сети.
Первый вариант (рис. 1, а) оптимален по цене и энергопотреблению. Данная сеть состо-ит из пяти модулей ESP8266 в роли клиентов (Station) и HF-LPB100 в роли точки доступа (Access Point). ESP8266 является одним из самых дешевых модулей Wi-Fi на рынке (око-ло 2—8 долларов), его энергопотребление достаточно мало (215 мА/ч в режиме передачи, около 60 мкА/ч в режиме глубокого сна). Скорость передачи и приема данных в такой сети достигает 54 Мбит/с, что подходит для большинства сенсорных сетей с несложными сенсо-рами. Также ядро модулей ESP8266 обладает относительно неплохими вычислительными ха-рактеристиками.
Второй вариант (рис. 1, б) является оптимальным по скорости передачи данных и коли-честву устройств в сети, работающих одновременно. Данная сеть состоит из пяти ATWINC3000 в роли клиентов и CC3200 в роли точки доступа. Модули могут передавать и принимать данные со скоростью до 72 Мбит/с, что необходимо для сетей с большим количе-ством сенсоров и соответственно с большим трафиком. Также модуль CC3200 гарантирован-но поддерживает одновременный обмен данными с восемью модулями в роли клиентов. Вы-числительные возможности модулей сети превосходят возможности модулей первого вари-анта, что позволяет использовать их для управления более сложными периферийными уст-ройствами, например, видеокамерами.
Рис. 1 наглядно демонстрирует физическую топологию предложенных сетей.
а) б)
Рис. 1. Варианты построения сетей Wi-Fi
Сводная таблица характеристик предложенных вариантов построения сенсорных сетей представлена в таблице.

30 ЭФФЕКТИВНОСТЬ ВЫЧИСЛИТЕЛЬНЫХ СИСТЕМ
Сборник трудов VII научно-практической конференции молодых ученых «Вычислительные системы и сети (Майоровские чтения)»
Сравнительная таблица характеристик предложенных сетей
Характеристика № 1 № 2
Энергопотребление, мА/ч 1275 1854
Скорость передачи/приема данных, Мбит/с до 54 до 72
Вычислительные возможности Клиенты: Tensilica l106 MCU (1.22 DMIPS/MHz)
Точка доступа: MC101 MCU
Клиенты: Cortus APS3 (1.67 DMIPS/MHz)
Точка доступа: ARM Cortex-M4 (210 DMIPS/ 1.25 DMIPS/MHz)
Цена, долларов 44,3 120,68
Заключение
Рассмотрены варианты построения беспроводных сенсорных сетей с использованием технологии Wi-Fi. Были выбраны 16 Wi-Fi-модулей различных производителей, которые подходят по своим характеристикам для решения этой задачи.
На основании анализа характеристик выбранных модулей предложены два варианта по-строения беспроводной сети с наименьшей ценой, максимальной скоростью передачи/приема данных, наибольшим числом подключаемых одновременно клиентов и высокой производи-тельностью узлов сети.
ЛИТЕРАТУРА
1. Doherty L., Simon J., Watteyne T. Wireless Sensor Network Challenges and Solutions. White Paper. Linear Technology Corporation, 2012.
2. Bandyopadhyay S., Coyle E. J. An Energy Efficient Hierarchical Clustering Algorithm for Wireless Sensor Networks // School of Electrical and Computer Engineering. Purdue University, West Lafayette, IN, USA, 2003.
3. Chakkor S., Baghouri M., El Ahmadi C., Hajraoui A. Comparative Performance Analysis of Wireless Communication Protocols for Intelligent Sensors and Their Applications // Intern. J. of Advanced Computer Science and Applications. 2014. Vol. 5, N 4.
4. Shahzad K., Oelmann B. A comparative study of in-sensor processing vs. raw data transmission using ZigBee, BLE and Wi-Fi for data intensive monitoring applications // 11th Intern. Symp. on Wireless Communications Systems. Barcelona, 2014.
5. Ibrahim A. U., Shanono I. H. ICT for Smart Appliances: Current Technology and Identification of Future ICT Trend // Intern. Scholarly and Scientific Research & Innovation. 2016. Vol. 2, N 10.
6. Liu W., Yan Y. Application of ZigBee Wireless Sensor Network in Smart Home System // Intern. J. of Advancements in Computing Technology. 2011. Vol. 3, N 5.
7. Tozlu S., Senel M., Mao W. Wi-Fi Enabled Sensors for Internet of Things: A practical Approach // IEEE Communication Magazine. 2012. P. 134—143.
8. Mendez G. R., Yunus M. A., Mukhopadhyay S. Ch. A Wi-Fi Based Smart Wireless Sensor Network for an Agricultural Environment // 5th Intern. Conf. on Sensing Technology. November 2011
9. Samotaev N., Ivanova A., Oblov K., Soloviev S., Vasiliev A. Wi-Fi Wireless Digital Sensor Matrix for Environmental Gas Monitoring // EUROSENSORS 2014, the XXVIII edition of the conf. ser. National Research Nuclear University MEPhI (Moscow Engineering Physics Institute), Moscow, Russia. 2014.

ЭФФЕКТИВНОСТЬ ВЫЧИСЛИТЕЛЬНЫХ СИСТЕМ 31
Сборник трудов VII научно-практической конференции молодых ученых «Вычислительные системы и сети (Майоровские чтения)»
Сведения об авторе Илья Владимирович Пахомов — студент; Университет ИТМО, кафедра вычислительной техники;
E-mail: [email protected] Ссылка для цитирования: Пахомов И. В. Анализ сценариев использования технологии Wi-Fi в задачах по-строения беспроводных сенсорных сетей // Сборник трудов VII научно-практической конференции молодых ученых «Вычислительные системы и сети (Майоровские чтения)». 2016. С. 28—31.
ANALYSIS OF USING WI-FI TECHNOLOGY IN TASKS OF CONSTRUCTION OF WIRELESS SENSOR NETWORKS
I. V. Pakhomov
ITMO University, 197101, St. Petersburg, Russia
This article is dedicated to analysis of the scenarios of Wi-Fi technology usage in tasks of construction of wireless sensor networks. The results of the comparative analysis of the characteristics of existing Wi-Fi transceivers, which can be used for the organization of interaction between nodes in a wireless sensor network, are given in this article. Proposed two options for the organization of Wi-Fi networks that are optimized by cost, power consumption, data rate and performance of the network nodes.
Keywords: Wi-Fi, sensor networks, Internet of Things, smart home, modem, access point.
Data on author Ilya V. Pakhomov — Student; ITMO University, Department of Computer Science;
E-mail: [email protected]
For citation: Pakhomov I. V. Analysis of using Wi-Fi technology in tasks of construction of wireless sensor networks // Proceedings of the scientific and practical conference of young scientists «Computing systems and networks (Mayorov’s readings)». 2016. P. 28—31 (in Russian).

32 ЭФФЕКТИВНОСТЬ ВЫЧИСЛИТЕЛЬНЫХ СИСТЕМ
Сборник трудов VII научно-практической конференции молодых ученых «Вычислительные системы и сети (Майоровские чтения)»
УДК 004.422.8
ПРИМЕНЕНИЕ СОВРЕМЕННЫХ ИНФОРМАЦИОННЫХ ТЕХНОЛОГИЙ ПРИ ПРОЕКТИРОВАНИИ ЛЕСНЫХ ПИТОМНИКОВ
Л. Г. Пушкарева
Санкт-Петербургский государственный лесотехнический университет имени С. М. Кирова, 194021, Санкт-Петербург, Россия
Обоснована необходимость применения современных информационных технологий при проектировании лесных питомников. Предложен и реа-лизован программный комплекс, включающий в себя систему управле-ния базами данных и web-приложение, обеспечивающее проектирова-ние лесного питомника. Пользователям также предоставляется возмож-ность расчета общей площади лесного питомника и поиска информации по различным категориям, получения данных о каждом отделении лес-ного питомника. Процедура ввода данных для расчетов осуществляется посредством специально разработанных форм. Структура разработан-ной базы данных учитывает специфику предметной области.
Ключевые слова: лесной питомник, информационные технологии, web-приложение, клиент-сервер, лесовосстановление.
Решение одной из главных в воспроизводстве лесов задачи — своевременного и качест-венного лесовосстановления — осуществляется в основном за счет искусственного выращи-вания посадочного материала в лесных питомниках (ЛП). Снижение объемов лесовосстанов-ления и особенно его качества несет реальную угрозу продукционному потенциалу лесов, восстановлению и сохранению экологической обстановки в регионах с интенсивными лесоза-готовками прошлых лет [1].
Совершенствование деятельности питомников, применение инновационных техноло-гий в выращивании посадочного материала является важнейшей задачей с природоохран-ной точки зрения. Однако этому направлению не уделяется должного внимания: нет дос-таточной информации о деятельности и современных методах работы питомников, а также о положении на рынке предлагаемых продуктов и услуг. Если информация о применении передовых технологий, относящихся к предметной области — лесоразведению, имеется, то данные по использованию современных информационных технологий в проектирова-нии и деятельности лесных питомников отсутствует [2, 3]. Современные методы проекти-рования разных объектов, основанные на широком использовании средств автоматизации и программных продуктов информатизации, отсутствуют в рассматриваемой предметной области.
Проектирование ЛП связано с решением большого количества разнообразных задач как вычислительного, так и экспертно-аналитического характера. Для их эффективного решения разработан программный комплекс, включающий в себя систему управления базой данных и web-приложение, обеспечивающее проектирование лесного питомника [4].
На основе проведенного анализа выбрана клиент-серверная web-среда разработки [5], позволившая использовать для создания web-приложения совокупность следующих про-граммных компонентов.
Пользовательский интерфейс
1. Язык разметки HTML использовался для создания структуры web-страниц. 2. Таблицы каскадных стилей CSS применялись для оформления внешнего вида web-
страниц (например, выпадающие списки).

ЭФФЕКТИВНОСТЬ ВЫЧИСЛИТЕЛЬНЫХ СИСТЕМ 33
Сборник трудов VII научно-практической конференции молодых ученых «Вычислительные системы и сети (Майоровские чтения)»
3. Язык сценариев JavaScript использовался для придания интерактивности страницам. В приложении использовалась технология AJAX для формирования «живого» поиска.
Реализация функций Web-приложения
Для создания клиент-серверной среды web-приложения использовалась технология AMP (Apache + MySQL + PHP): web-сервер Apache, СУБД MySQL и интерпретатор PHP. Все данные, вводимые пользователем, хранятся в СУБД и в любой момент будут доступны через пользовательский интерфейс [6].
Приложение имеет дружественный и интуитивно понятный интерфейс, освоение кото-рого не вызовет затруднений даже у сотрудников ЛП, не имеющих большого опыта работы с компьютером (рис. 1).
Рис. 1. Главная страница приложения
Для навигации по разделам приложения разработано главное меню, обеспечивающее доступ к следующим функциям: ввод и редактирование данных различных отделений ЛП, расчет общей площади питомника, поиск информации по различным категориям (рис. 2).
Рис. 2. Главное меню приложения
В структуре базы данных (рис. 3) определены связи между ключевыми элементами ее таблиц, реализующие логическую модель БД и функционал приложения и обеспечивающие как правильное взаимодействие элементов, так и достаточно простое масштабирование при-ложения в зависимости от потребностей пользователей в процессе эксплуатации. Добавление новых функций, решающих растущие потребности проектирования ЛП, осуществляется за счет создания необходимых таблиц и генерации связей между ними.

34 ЭФФЕКТИВНОСТЬ ВЫЧИСЛИТЕЛЬНЫХ СИСТЕМ
Сборник трудов VII научно-практической конференции молодых ученых «Вычислительные системы и сети (Майоровские чтения)»
Рис. 3. Структура базы данных
Использование систем управления базами данных позволяет централизованно хранить большой объем информации и извлекать ее в удобном для пользователя виде. Также на осно-вании накопленных данных можно проводить анализ процесса проектирования ЛП. Пользо-ватели могут моделировать различные ситуации, производить сравнение и выбирать наилуч-шие варианты размещения ЛП.
Рассматриваемое web-приложение предоставляет пользователям выполнять: — ввод и редактирование информации о лесничестве — пользователь имеет возмож-
ность просматривать, добавлять, вносить необходимые изменения в информацию; — ввод и редактирование данных различных отделений лесного питомника — пользо-
ватель может выполнять указанные выше операции для каждого из отделений ЛП (рис. 4);
Рис. 4. Формы просмотра, добавления и редактирования данных
— поиск по данным различных отделений ЛП (рис. 5) — пользователю предоставляется возможность поиска информации по двум категориям: по лесничеству и по породе [7];

ЭФФЕКТИВНОСТЬ ВЫЧИСЛИТЕЛЬНЫХ СИСТЕМ 35
Сборник трудов VII научно-практической конференции молодых ученых «Вычислительные системы и сети (Майоровские чтения)»
Рис. 5. Формы поиска данных
— расчет общей площади ЛП осуществляется на основании ранее введенных данных, то есть заранее рассчитанных значениях площадей каждого из отделений лесного питомника.
Разработанное web-приложение позволяет повысить эффективность процесса разработ-ки ЛП за счет автоматизации процессов ввода, анализа, обработки, хранения и вывода информации, сократить сроки проектирования ЛП и, в конечном итоге, повысить качество посадочного материала.
ЛИТЕРАТУРА
1. Распоряжение Правительства России от 28 декабря 2012 г. № 2593Р. Об утверждении государственной программы Российской Федерации «Развитие лесного хозяйства» на 2013—2020 годы.
2. Петровский В. С. Автоматизация технологических процессов и производств лесопро-мышленного комплекса. М.: Изд. центр «Академия», 2013.
3. Алексеев А. С., Селиховкин А. В. Особенности воспроизводства лесных ресурсов и проблема интеграции лесного хозяйства в рыночную экономику. СПб, 2012.
4. Krasowski M. J. Forests and forest plants. Vol. III. Producing Planting Stock in Forest. University of New Brunswick, Canada. Электронный ресурс: <http://www.eolss.net/sample-chapters/c10/e5-03-05-07.pdf>.
5. Свид-во о гос. рег. программ для ЭВМ №2015660492. Информационно-аналитическое Web-приложение для решения задач проектирования лесных питомников / Л. Г. Пушка-рева, А. М. Заяц, М. Е. Гузюк.
6. Никсон Р. Создаем веб-сайты с помощью PHP, MySQL и JS. O’Reilly, 2011.
7. Auto complete text box with PHP, jQuery and MySQL / Wai Linn Oo. 2012. Электронный ресурс: <http://tutsforweb.blogspot.in/2012/05/auto-complete-text-box-with-php-jquery.html>.

36 ЭФФЕКТИВНОСТЬ ВЫЧИСЛИТЕЛЬНЫХ СИСТЕМ
Сборник трудов VII научно-практической конференции молодых ученых «Вычислительные системы и сети (Майоровские чтения)»
Сведения об авторе Любовь Геннадьевна Пушкарева — магистрант; Санкт-Петербургский государственный лесотехнический
университет имени С. М. Кирова, кафедра информационных систем и технологий; E-mail: [email protected]
Ссылка для цитирования: Пушкарева Л. Г. Применение современных информационных технологий при про-ектировании лесных питомников // Сборник трудов VII научно-практической конференции молодых ученых «Вычислительные системы и сети (Майоровские чтения)». 2016. С. 32—36.
THE USE OF MODERN INFORMATION TECHNOLOGY IN THE DESIGN OF FOREST NURSERIES
L. G. Pushkareva
St. Petersburg State Forestry University named after S. M. Kirov, 194021, St. Petersburg, Russia
In the article we reviewed necessity of using modern information technologies in the design of forest nurseries. In the thesis proposed and implemented a software complex, including database management system and web-based application that provides design of forest nursery. Also, users have the opportunity to calculate the total area of forest nursery and find information by the various categories, obtaining data about each forest nursery department. Data for the calculations entry is carried out by means of specially designed forms. Structure of the developed database takes into account the specificity of the subject area.
Keywords: forest nursery, information technology, Web-application, client-server, reforestation.
Data on author Lubov G. Pushkareva — Student; St. Petersburg State Forestry University named after S. M. Kirov,
Department of Information Systems and Technology; E-mail: [email protected]
For citation: Pushkareva L. G. The use of modern information technology in the design of forest nurseries // Proceedings of the scientific and practical conference of young scientists «Computing systems and networks (Mayorov’s readings)». 2016. P. 32—36 (in Russian).

Сборник трудов VII научно-практической конференции молодых ученых «Вычислительные системы и сети (Майоровские чтения)»
ВСТРАИВАЕМЫЕ СИСТЕМЫ И СИСТЕМЫ НА КРИСТАЛЛЕ
УДК 004.41
МЕТОДЫ РАЗРАБОТКИ СИСТЕМ НА БАЗЕ ПЛИС
Д. В. Бурнаев
Университет ИТМО, 197101, Санкт-Петербург, Россия
Рассмотрен процесс реализации интерфейса DVI на базе ПЛИС. Выде-лены основные этапы разработки, связи между ними, определены про-блемные места. Предложены альтернативные подходы к процессу соз-дания продукта, проанализированы сильные и слабые стороны каждого из них.
Ключевые слова: ПЛИС, методы разработки, DVI, использование IP-ядер, этапы разработки.
Введение
В современном мире созданием систем на основе ПЛИС занимается все большее число специалистов. В условиях повышающейся конкуренции каждый производитель пытается как можно быстрее вывести свой продукт на рынок. Такой дефицит времени может привести к значительному ухудшению качества систем. Одним из способов преодоления данной про-блемы является использование эффективных методов проектирования и разработки. Для ана-лиза различных методов приходится решать задачи оценки их эффективности, универсально-сти и возможности автоматизации процесса.
Целью настоящей статьи является анализ различных методов разработки на примере реализации интерфейса цифровой передачи данных DVI на ПЛИС фирмы Altera, выявление преимуществ и недостатков каждого из них.
DVI — стандарт на интерфейс, предназначенный для передачи видеоизображения на жид-кокристаллические мониторы, телевизоры и проекторы. На вход данного интерфейса подаются: данные изображения (Pixel Data, 24 бита), управляющие сигналы (Control Data, 6 бит), синхрони-зирующий импульс (clk, 1 бит) и сигнал наличия данных (data enable, 1 бит). Каждая составляю-щая цвета (синий, красный, зеленый) и два управляющих сигнала попадают в блок, где происхо-дит кодирование 8/10 бит, после чего выполняется преобразование данных из параллельного ко-да в последовательный, и данные отправляются передатчиком (рис. 1).
Рис. 1. Схема получения выходных сигналов интерфейса DVI

38 ВСТРАИВАЕМЫЕ СИСТЕМЫ И СИСТЕМЫ НА КРИСТАЛЛЕ
Сборник трудов VII научно-практической конференции молодых ученых «Вычислительные системы и сети (Майоровские чтения)»
Методы разработки
Изначально было решено попробовать представить логику работы интерфейса в виде конечного автомата (рис. 2). На этапе проектирования была получена необходимая информа-ции из спецификаций как на сам интерфейс [1], так и на ПЛИС [2], после чего составлялся конечный автомат. Далее происходило описание логики автомата на языке Verilog [3]. С по-мощью моделирования в среде ModelSim выявлялись ошибки, после чего выполнялась код исправлялся. Такой процесс отладки затрагивал только уровни «написания кода» и «тестиро-вания». Повторный анализ модели на концептуальном уровне не проводился, что даже в та-ком небольшом проекте привело к значительным временным затратам на выявление ошибок в коде (позднее было выявлено, что автомат был составлен некорректно). Это потребовало добавления обратной связи между тестированием в среде ModelSim и концептуальном уров-нем, что должно было ускорить процесс нахождения ошибок (рис. 3). Но из-за низкого уров-ня детализации было крайне сложно найти локализацию ошибки. Кроме того, приходилось перекомпилировать весь проект целиком при каждом изменении [4, 5].
Рис. 2. Метод конечных автоматов Рис. 3. Расширенный метод конечных автоматов
В связи с указанными особенностями было решено разработать и опробовать иные под-ходы к реализации интерфейса.
Появилась идея описать модель с помощью языка программирования Си, а уже пра-вильно работающий, протестированный код перевести на язык описания аппаратуры — ме-тод System to RTL (рис. 4). Такой подход облегчил сам процесс написания кода, но следовало создавать тесты на обоих уровнях. Сам процесс перевода на уровень регистровых передач

ВСТРАИВАЕМЫЕ СИСТЕМЫ И СИСТЕМЫ НА КРИСТАЛЛЕ 39
Сборник трудов VII научно-практической конференции молодых ученых «Вычислительные системы и сети (Майоровские чтения)»
проходил с использованием специального программного обеспечения (фреймворк PandA). Причем этот фреймворк не всегда предоставлял оптимальное решение, а некоторый код на языке Си приходилось переписывать несколько раз, чтобы программа верно его сконвертиро-вала на язык Verilog.
Рис. 4. System to RTL
Поскольку перевод атомарных сущностей дает лучший результат, был разработан метод независимых блоков (рис. 5), его главная особенность в том, что на концептуальном уровне проект разбивается на небольшие независимо разрабатываемые блоки. Такой подход упро-стил процедуру выявления ошибок, но также увеличил число необходимых тестов, помимо того, необходимо выбрать оптимальную стратегию интегрирования всех блоков в единое це-лое [6].
При использовании метода IP-ядер (рис. 6) во время разработки главная задача — на концептуальном уровне произвести такое разбиение проекта, чтобы вместо большего количе-ства частей можно было использовать готовые IP-блоки, зачастую имеющие хорошую произ-водительность и занимающие малую площадь на кристалле. Очевидно, что использование таких IP-ядер позволило уменьшить объем написанного кода, что ускорило сам процесс раз-работки системы в целом.

40 ВСТРАИВАЕМЫЕ СИСТЕМЫ И СИСТЕМЫ НА КРИСТАЛЛЕ
Сборник трудов VII научно-практической конференции молодых ученых «Вычислительные системы и сети (Майоровские чтения)»
Рис. 5. Метод независимых блоков Рис. 6. Метод IP-ядер
В таблице приведен сравнительный анализ методов по следующим критериям: 1) сложность отладки (зависит от объема кода, в котором приходилось искать ошибку,
также учитывается, на каком языке этот код составлен); 2) необходимость дополнительного программного обеспечения (использование какого-
то дополнительного программного обеспечения помимо IDE и среды моделирования); 3) использование IP-ядер; 4) степень детализации при разработке (показывает, как на концептуальном уровне
произошло разделение проекта на независимые части); 5) сложность разработки (как много строк кода получилось в результате, сколько тестов
пришлось написать, с помощью какого языка проходила разработка.
Параметр Метод конечных автоматов
System To RTL
Метод незави-симых блоков
Метод IP-ядер
Сложность отладки 1,0 0,7 0,5 0,4 Необходимость допол-нительного программ-
ного обеспечения
– + – –
Использование IP-ядер – – – +
Степень детализации при разработке
Низкая Низкая Высокая Высокая
Сложность разработки 1,0 0,5 0,75 0,5
Заключение
Из таблицы видно, что с лучшей стороны себя показал метод IP-ядер, он не требует до-полнительного программного обеспечения, у него ниже сложность отладки и разработки. Но стоит отметить, что при выборе методов и подходов к разработке продукта стоит уделять внимание таким факторам, как сложность системы, время, выделенное на создание, а также ресурсы и опыт разработчика.

ВСТРАИВАЕМЫЕ СИСТЕМЫ И СИСТЕМЫ НА КРИСТАЛЛЕ 41
Сборник трудов VII научно-практической конференции молодых ученых «Вычислительные системы и сети (Майоровские чтения)»
ЛИТЕРАТУРА
1. Digital Visual Interface Specification. Revision 1.0. 1999. 76 р.
2. Stratix II GX Device Handbook. 2007. Vol. 1. 1486 р.
3. Sutherland S. The Verilog PLI Handbook: A User's Guide and Comprehensive Reference on the Verilog Programming Language Interface. 1999.
4. Рабаи Ж. М., Чандракасан А., Николич Б. Цифровые интегральные схемы. Методология проектирования. М.: Вильямс, 2007. 912 с.
5. Паттерсон Д., Хеннеси Дж. Архитектура компьютера и проектирование компьютерных систем. СПб: Питер, 2012. 784 с.
6. Sass R., Schmidt A. G. Embedded Systems Design with Platform FPGAs: Principles and Practices. 2010. 381 р.
Сведения об авторе Дмитрий Владимирович Бурнаев — студент; Университет ИТМО, кафедра вычислительной техники;
E-mail: [email protected]
Ссылка для цитирования: Бурнаев Д. В. Методы разработки систем на базе ПЛИС // Сборник трудов VII на-учно-практической конференции молодых ученых «Вычислительные системы и сети (Майоровские чтения)». 2016. С. 37—41.
METHODS FOR THE DEVELOPMENT OF SYSTEMS BASED ON FPGA
D. V. Burnaev
ITMO University, 197101, St. Petersburg, Russia
This paper considers the implementation process of the protocol DVI to FPGA. Highlighted the main stages of development, the relationship between them, and the problem areas. The author proposes the al-ternative approaches to the process of creating a product, represents its strengths and weaknesses, makes a comparative analysis.
Keywords: FPGA, methods, development, design, verification.
Data on author Dmitrii V. Burnaev — Student; ITMO University, Department of Computer Science;
E-mail: [email protected]
For citation: Burnaev D. V. Methods for the development of systems based on FPGA // Proceedings of the scientific and practical conference of young scientists «Computing systems and networks (Mayorov’s readings)». 2016. P. 37—41 (in Russian).

42 ВСТРАИВАЕМЫЕ СИСТЕМЫ И СИСТЕМЫ НА КРИСТАЛЛЕ
Сборник трудов VII научно-практической конференции молодых ученых «Вычислительные системы и сети (Майоровские чтения)»
УДК 004.41
УЧЕБНЫЙ RISC-ПРОЦЕССОР
Д. М. Колесниченко
Университет ИТМО, 197101, Санкт-Петербург, Россия
Описывается архитектура учебного RISC-процессора, включая исполь-зуемые блоки, их интерфейс, объясняются причины выбора именно этой архитектуры. Рассмотрены возможности доработки процессора.
Ключевые слова: процессор, RISC, обучение, архитектура, команда.
Введение
Для исключения зависимости всей сферы вычислительной техники в России от импорт-ных комплектующих необходимо создавать собственную элементную базу, которая могла бы способствовать обучению молодых специалистов. Именно поэтому было решено создать учебный RISC-процессор. Такая архитектура приобрела большую популярность благодаря простоте, быстродействию и удобству написания компиляторов.
Разработка архитектуры
При разработке учитывалось, что процессор должен быть несложным, но в то же время охватывать основные инженерные решения, характерные для RISC-архитектуры [1]. Именно поэтому он содержит такие блоки, как счетчик команд, 32-разрядные память и регистр ко-манд, 16-разрядный регистровый файл, АЛУ [2], статусный регистр, 16-разрядная память данных, аппаратный стек и устройство управления (рис. 1).
Рис. 1. Структурная схема
Адрес текущей инструкции хранится в счетчике команд. Инструкция, находящаяся по этому адресу в памяти команд, считывается и записывается в регистр команд. Далее ее опе-рационная часть поступает в устройство управления, которое в зависимости от кода операции посылает определенные сигналы на соответствующие блоки. Дальнейшая часть цикла ма-шинной команды зависит от кода операции.
Статусный регистр был выделен специально, чтобы его функции и отличие от осталь-ных регистров были сразу понятны даже людям, находящимся на начальной стадии изучения

ВСТРАИВАЕМЫЕ СИСТЕМЫ И СИСТЕМЫ НА КРИСТАЛЛЕ 43
Сборник трудов VII научно-практической конференции молодых ученых «Вычислительные системы и сети (Майоровские чтения)»
вычислительной техники. Регистр содержит биты, отвечающие за перенос, нулевой резуль-тат, знак результата, переполнение и половинный перенос.
Для того чтобы показать принципы работы стека и его функции, было решено сделать его аппаратным.
Разработка системы команд
В данной системе команд существуют следующие типы операций: 1) арифметические операции с
— одним операндом, — двумя операндами, — константой;
2) операции работы со стеком; 3) операции работы с памятью; 4) операции перехода; 5) операции работы со статусным регистром; 6) операции работы с подпрограммой; 7) операции организации циклов. Разработанная система команд является достаточно полной для учебного процессора,
имеющего такую архитектуру [3]. При использовании всех этих команд задействуются все блоки текущего процессора, что важно для понимания необходимости различных связей ме-жду его частями и принципов его функционирования. Соответственно когда будут разраба-тываться новые блоки этого процессора, должны появиться и новые команды (например, при реализации системы прерываний должны будут появиться команды разрешения и запреще-ния прерываний, возврата из прерывания).
Сравнение с существующими аналогами
Сравнительный анализ разработанного процессора с существующими аналогами [4, 5] приведен в таблице.
Процессор Простота архитектуры
Язык написания
Понятность кода
Наличие конвейера
Полнота документации
Наличие компилятора
1 ± VHDL ± + ± – 2 ± Verilog – + + +
Разрабатываемый + SystemVerilog + – – +
Сравнение ведется по следующим критериям, которые выбирались в соответствии с це-лью разработки данного процессора.
1. Простота архитектуры – оцениваются понятность алгоритма работы процессора ис-ходя из его схемы и число используемых в устройстве блоков. Первые два процессора оказа-лись сложнее за счет использования дополнительных регистров и блоков обработки прерыва-ний.
2. Язык написания и понятность кода. Для описания архитектуры был выбран язык Sys-temVerilog [6], так как он достаточно прост для понимания.
3. Наличие конвейера. Первые два процессора имеют 4-ступенчатый конвейер, в то вре-мя как в разрабатываемом процессоре конвейер отсутствует
4. Полнота документации. Для процессора 1 существует лишь краткое описание систе-мы команд. Для процессора 2 составлено полноценное учебное пособие с описанием всех блоков, их функций и системы команд. Для разрабатываемого процессора документация на-ходится в стадии подготовки.
5. Наличие компилятора. Для процессора 1 компилятор не прилагался. Для процессора 2 имеется компилятор ассемблера на языке Python. Для разрабатываемого процессора напи-сан компилятор языка C на Python.

44 ВСТРАИВАЕМЫЕ СИСТЕМЫ И СИСТЕМЫ НА КРИСТАЛЛЕ
Сборник трудов VII научно-практической конференции молодых ученых «Вычислительные системы и сети (Майоровские чтения)»
Заключение
Разработанный процессор предоставляет возможности для изучения устройства техни-ки, построенной на основе RISC-архитектуры, понимания основных принципов функциони-рования процессора и различных его частей, этапов выполнения машинных команд.
ЛИТЕРАТУРА
1. Паттерсон Д., Хеннеси Дж. Архитектура компьютера и проектирование компьютерных систем. СПб: Питер, 2012. 784 с.
2. Угрюмов Е. П. Цифровая схемотехника. 2010.
3. Харрис Д. М., Харрис С. Л. Цифровая схемотехника и архитектура компьютера. 2013.
4. Процессор 1 [Электронный ресурс]: <http://kanyevsky.kpi.ua/useful_core/risc_strus.html>.
5. Процессор 2 [Электронный ресурс]: <https://github.com/tugrulyatagan/RISC-processor>.
6. Sutherland S., Davidmann S., Flake P. System Verilog for Design. 2006.
Сведения об авторе Дмитрий Михайлович Колесниченко — студент; Университет ИТМО, кафедра вычислительной техники;
E-mail: [email protected] Ссылка для цитирования: Колесниченко Д. М. Учебный RISC-процессор // Сборник трудов VII научно-практической конференции молодых ученых «Вычислительные системы и сети (Майоровские чтения)». 2016. С. 42—44.
EDUCATIONAL RISC CPU
D. M. Kolesnichenko
ITMO University, 197101, St. Petersburg, Russia
This article describes the architecture of the educational RISC CPU, used blocks, their interface and communication between them. It explains the reasons why this architecture was selected. The author tells about the possibilities of processor improvements to best suit their requirements and functions.
Keywords: CPU, RISC, education, architecture, instruction.
Data on author Dmitrii M. Kolesnichenko — Student; ITMO University, Department of Computer Science;
E-mail: [email protected]
For citation: Kolesnichenko D. M. Educational RISC CPU // Proceedings of the scientific and practical con-ference of young scientists «Computing systems and networks (Mayorov’s readings)». 2016. P. 42—44 (in Russian).

ВСТРАИВАЕМЫЕ СИСТЕМЫ И СИСТЕМЫ НА КРИСТАЛЛЕ 45
Сборник трудов VII научно-практической конференции молодых ученых «Вычислительные системы и сети (Майоровские чтения)»
УДК 004.4
ИНСТРУМЕНТАЛЬНЫЕ СРЕДСТВА ДЛЯ СИМУЛЯЦИИ ПРОЦЕССОРНЫХ ЯДЕР
Н. А. Купсик
Университет ИТМО, 197101, Санкт-Петербург, Россия
Проанализированы способы организации симуляторов процессоров, их особенности, основные задачи, решаемые данным инструментарием. Рассмотрены основные недостатки инструментов симуляции на приме-ре gpsim, gem5, Keil uVision. Критерием для сравнения служила одна из задач симуляторов — изучение микроархитектуры процессора. Иссле-дование проводилось с целью выбора способа организации и средств разработки симулятора, характеризующегося простотой организации, разнообразием поддерживаемых процессоров, простотой реконфигура-ции симулятора под выбранный процессор, достаточным уровнем дета-лизации для изучения микроархитектуры процессора. Гибкость симуля-тора обеспечит использование Domain Specific Language, разработанно-го в MPS JetBrains, удобство конфигурации — создание независимой от архитектуры процессора базовой части симулятора в IntelliJ IDEA JetBrains на языке Java.
Ключевые слова: инструменты симуляции, микроархитектура, Domain Specific Language, моделиро-вание, конфигурация, MPS JetBrains, встроенные системы.
Симулятор встраиваемых систем — это инструмент, позволяющий производить отладку и создание программного обеспечения на ранних этапах разработки (например, параллельно с проектированием аппаратного обеспечения). Также симулятор позволяет решать следую-щие задачи: прототипирование целевой аппаратуры, изучение микроархитектуры, оценка производительности.
Инструментальные средства для симуляции можно классифицировать по [1]: 1) способу организации (симуляторы вычислительной архитектуры, языки описания и
моделирования аппаратного обеспечения), 2) широте охвата (полносистемные, микроархитектурные), 3) виду работы (потактовые, симуляторы набора инструкций). Кроме того, симулятор может иметь гибридную организацию: поддерживать как моде-
лирование аппаратного обеспечения, так и его конфигурацию с помощью специализирован-ных языков. Примером такого инструментального средства является симулятор для микро-контроллеров семейства PIC — gpsim, который поддерживает собственный язык VIC для описания аппаратного обеспечения [2].
Преимуществом таких инструментов симуляции является возможность конфигурации архитектуры в зависимости от поставленной задачи, основным недостатком — поддержка ограниченного числа семейств процессоров.
Эту особенность демонстрирует программный продукт Keil: для семейства mcs-51 дос-тупно моделирование работы с поддержкой не только просмотра содержимого регистров, но и отладки различной периферии — например, UART [3]. Однако в рамках данного пакета для другого семейства таких возможностей не предусмотрено. Это ограничивает возможность отладки и изучения архитектуры различных семейств на равноценном уровне.
Также к числу симуляторов с большим количеством поддерживаемых процессоров от-носится gem5 [4], который характеризуется большим объемом исходного кода, сложным процессом симуляции и конфигурации. За счет таких особенностей gem5 удобнее применять при углубленном изучении архитектуры и особенностей процессоров.

46 ВСТРАИВАЕМЫЕ СИСТЕМЫ И СИСТЕМЫ НА КРИСТАЛЛЕ
Сборник трудов VII научно-практической конференции молодых ученых «Вычислительные системы и сети (Майоровские чтения)»
Основные ограничения, накладываемые на инструменты симуляции: время и число уча-стников его разработки, простота организации и структуры. Таким образом, для решения за-дачи изучения различных типов микроархитектуры процессора инструмент разработки и мо-делирования должен быть гибким (программируемым) и являться компромиссным решением между количеством поддерживаемой периферии и сложностью организации такого инстру-мента.
Гибкое средство моделирования процессорных ядер позволяет при помощи специфич-ного языка конфигурировать настройки симуляции для каждого типа ядра.
Основные составляющие симулятора: Domain Specific Language (DSL), IDE для разра-ботки симулятора, поддерживающая DSL.
Разработка и использование DSL подразумевает: синтаксическое дерево, редактор, ком-пилятор.
Простота разработки и изучения симулятора обеспечивается за счет применения про-граммных продуктов MPS и IntelliJ IDEA от JetBrains. Их совместное использование обу-словливается возможностью интеграции MPS в IntelliJ IDEA [5]. Первый продукт позволяет с помощью определенных правил описывать синтаксис и возможности DSL, который затем возможно транслировать в Java. IntelliJ IDEA поддерживает разработанный DSL как расши-рение над языком Java [6]. Это позволит задавать особенности каждого языка при помощи DSL, при этом основная структура будет оставаться неизменной. Несмотря на отличительные достоинства такого симулятора и метода его разработки возникает проблема создания DSL, который позволит одинаково описывать разные процессорные ядра. Одним из способов решения может являться выделение общих черт архитектуры различных процессоров, и на основе такого анализа — разработка соответствующего DSL. Сложность такого языка опре-деляется как пересечение множеств вариантов реализаций систем команд. Для изучения мик-роархитектуры в рамках разработки такого симулятора будут задействованы основные (са-мые распространенные) типы процессоров, что позволит обеспечить одинаковый уровень си-муляции и простоту организации.
ЛИТЕРАТУРА
1. Bertels K., Dimopoulos N., Silvano C., Wong S. Embedded Computer Systems: Architectures, Modeling, and Simulation. SAMOS, 2005.
2. Gpsim Users Guide. 2015.
3. Keil µVision Getting Started. 2015.
4. Binkert N., Beckmann B., Black G. The gem5 simulator // Computer Architecture News. ACM New York, NY, USA. 2011. № 39. р. 1—7.
5. Fowler M. A Language Workbench in Action — MPS. 2015.
6. Давыдов С., Ефимов А. IntelliJ IDEA. Профессиональное программирование на Java. М.: БХВ-Петербург, 2005. 800 с.
Сведения об авторе Наталия Александровна Купсик — студент; Университет ИТМО, кафедра вычислительной техники;
E-mail: [email protected]
Ссылка для цитирования: Купсик Н. А. Инструментальные средства для симуляции процессорных ядер // Сборник трудов VII научно-практической конференции молодых ученых «Вычислительные системы и сети (Майоровские чтения)». 2016. С. 45—47.

ВСТРАИВАЕМЫЕ СИСТЕМЫ И СИСТЕМЫ НА КРИСТАЛЛЕ 47
Сборник трудов VII научно-практической конференции молодых ученых «Вычислительные системы и сети (Майоровские чтения)»
WORKBENCH FOR THE SIMULATION OF PROCESSOR CORES
N. A. Kupsik
ITMO University, 197101, St. Petersburg, Russia
This article discusses the main ways of organizing simulation processors and their features, the basic tasks to be solved by the tools, is shown the corresponding classification. It describes the basic shortcom-ings of simulation tools as an example gpsim, gem5, Keil uVision. The criterion for comparison is one of the tasks of simulation - the study of the processor microarchitecture. The research was conducted in or-der to select the method of organization and resources to develop a tool for the simulation, which allows to solve the problem mentioned earlier in sufficient amounts. The main criteria for this simulator are: ease of organization, a variety of supported processors, easy configuration of the simulator for the selected processor, an adequate level of detail to study the architecture of microprocessor. According to a survey for the flexibility of the simulator will be used by Domain Specific Language, developed at MPS Jet-Brains. For easy configuration, independent of the processor core architecture base part of the simulator will be created in IntelliJ IDEA JetBrains in Java. Individual features of the processor will be described in the relevant DSL, which will be used to describe the core of the simulator in the same project. This is achieved through the integration of MPS software and IntelliJ IDEA.
Keywords: tools for simulation, microarchitecture, Domain Specific Language, modeling, configuration, MPS JetBrains, embedded systems.
Data on author Natalia A. Kupsik — Student; ITMO University, Department of Computer Science;
E-mail: [email protected]
For citation: Kupsik N. A. Workbench for the simulation of processor cores // Proceedings of the scientific and practical conference of young scientists «Computing systems and networks (Mayorov’s readings)». 2016. P. 45—47 (in Russian).

48 ВСТРАИВАЕМЫЕ СИСТЕМЫ И СИСТЕМЫ НА КРИСТАЛЛЕ
Сборник трудов VII научно-практической конференции молодых ученых «Вычислительные системы и сети (Майоровские чтения)»
УДК 004.324
ИССЛЕДОВАНИЕ ПРОИЗВОДИТЕЛЬНОСТИ ШИННОЙ ПОДСИСТЕМЫ НА ПРИМЕРЕ МИКРОКОНТРОЛЛЕРОВ СЕМЕЙСТВА STM32L
Е. А. Пальцев
Университет ИТМО, 197101, Санкт-Петербург, Россия
Рассмотрена шинная подсистема микроконтроллеров семейства STM32L, предложен метод тестирования ее производительности. Вы-двинуто предположение о том, что шинная подсистема может являться узким местом при одновременном обмене информацией между ядром и контроллером прямого доступа к памяти. Измерено контрольное значе-ние производительности шинной подсистемы микроконтроллера в слу-чае обмена данными посредством ядра при отключенном контроллере прямого доступа к памяти, а также в случае одновременного обмена данными посредством ядра и контроллера прямого доступа к памяти между периферийными устройствами в различных комбинациях. Даны рекомендации по разработке программного обеспечения микрокон-троллеров семейства STM32L, позволяющие снизить влияние обнару-женных узких мест на общую производительность системы.
Ключевые слова: шинная подсистема, шинная матрица, микроконтроллер, узкое место, прямой дос-туп к памяти, память, внешние устройства.
Введение
При проектировании высоконагруженных встраиваемых систем разработчики сталки-ваются с тем, что производительность, или пропускная способность, системы ограничена одним или несколькими компонентами или ресурсами (эффект узкого места). Таким узким местом может оказаться шинная подсистема микроконтроллера. Это наиболее вероятно, если микроконтроллер активно использует обмен не только с помощью ядра, но и с помощью кон-троллера прямого доступа к памяти. В таком случае выгода от использования контроллера прямого доступа к памяти может оказаться значительно ниже ожидаемой.
Целью настоящей работы является изучение производительности шинной подсистемы микроконтроллеров семейства STM32L на примере того, насколько замедляется параллель-ная работа ядра и контроллера прямого доступа к памяти при обращении к общим устройст-вам и устройствам, которые задействуют общую шинную подсистему.
Объектом тестирования выступают микроконтроллеры семейства STM32L (в частности, STM32L151C8T6).
Данное семейство микроконтроллеров обладает следующими особенностями: — 32-разрядное ядро ARM Cortex-M3 с трехступенчатым конвейером [1, 2], — единое адресное пространство [3, 4], — встроенная память flash, sram и eeprom, работающая на частоте ядра [3, 4], — контроллер прямого доступа к памяти, имеющий доступ как к памяти, так и к реги-
страм периферии [3, 4], — набор инструкций Thumb и Thumb-2 [1, 2]. На рис. 1 приведены основные блоки микроконтроллера (ядро, память, контроллер пря-
мого доступа к памяти), внешние устройства, а также связи между ними. Эти блоки подклю-чены друг к другу посредством шин, а коммутация шин осуществляется шинной матрицей. Ведущими устройствами могут выступать ядро и контроллер прямого доступа к памяти, ве-домыми — внешние устройства и память.

ВСТРАИВАЕМЫЕ СИСТЕМЫ И СИСТЕМЫ НА КРИСТАЛЛЕ 49
Сборник трудов VII научно-практической конференции молодых ученых «Вычислительные системы и сети (Майоровские чтения)»
Рис. 1. Основные блоки микроконтроллера
Для определения степени влияния обмена данными с помощью контроллера прямого доступа к памяти на работу ядра требуется получить контрольное значение производительно-сти шинной подсистемы при отключенном контроллере прямого доступа к памяти. В качест-ве контрольного значения было выбрано число тактов, необходимое для пересылки из одного порта ввода-вывода в другой.
Для измерения значений была собрана установка для тестирования, в которой тактиро-вание, выставление и считывание значений на портах тестируемого микроконтроллера про-изводится с помощью дополнительного ведущего микроконтроллера. Для удобства считыва-ния показаний все линии заведены на логический анализатор. Схема подключения изображе-на на рис. 2.
Рис. 2. Схема подключения
Для измерения контрольного значения был составлен следующий программный код (см. листинг). В нем производится пересылка значений из порта ввода-вывода B в порт А. Пересылка осуществляется с помощью команд LDRH (загрузка полуслова из адреса) и STRH

50 ВСТРАИВАЕМЫЕ СИСТЕМЫ И СИСТЕМЫ НА КРИСТАЛЛЕ
Сборник трудов VII научно-практической конференции молодых ученых «Вычислительные системы и сети (Майоровские чтения)»
(сохранение полуслова по адресу) [5]. Для уменьшения влияния выполнения команды пере-хода на результат измерения в программу внесен большой блок из повторяющихся команд LDRH и STRH (в листинге не указан).
Листинг. Примеры исходного текста программы void main (void) { GpioInit(); HseClockEnable(); asm volatile ("\n" "MOV r1, #0 \n" "MOVT r1, #0x4002 \n" "_l1: \n" "LDRH r0, [r1, #0x410] \n" //load IDR of B PORT "STRH r0, [r1, #0x14] \n" //store to ODR of A PORT //~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~ "LDRH r0, [r1, #0x410] \n" //load IDR of B PORT "STRH r0, [r1, #0x14] \n" //store to ODR of A PORT "B _l1 \n" "\n"); }
В результате измерений было установлено, что прохождение сигнала занимает 3—4 такта (рис. 3). Этот результат хорошо согласуется с теорией.
Рис. 3. Результаты измерений
Рассмотрим первый вариант. На рис. 4 представлено состояние конвейера команд в мо-мент появления фронта сигнала на порте B контроллера. На рис. 5 представлено состояние наиболее важных линий шины AHB в момент появления фронта сигнала на порте B контрол-лера. Сигналы HCLK, HADDR, HWRITE, HRDATA, HWDATA относятся к сигналам шины AHB [6—12].

ВСТРАИВАЕМЫЕ СИСТЕМЫ И СИСТЕМЫ НА КРИСТАЛЛЕ 51
Сборник трудов VII научно-практической конференции молодых ученых «Вычислительные системы и сети (Майоровские чтения)»
Рис. 4. Состояние конвейера команд (1-й вариант)
Рис. 5. Состояние наиболее важных линий шины (1-й вариант)
Разберем прохождение сигнала по тактам. Такт 1: Сигнал поступает, когда на стадии DECODE находится команда загрузки
(LDRH), выставляющая на шину AHB адрес (в данном случае адрес регистра IDR порта GPIOB, (ADR B)). Порты ввода-вывода подключены к шине AHB, время прохождения дан-ных по шине AHB занимает один такт [4].
Такт 2: Команда LDRH находится на стадии выполнения, данные (B data) заносятся в регистр. В то же время команда STRH, которая находится на стадии DECODE, выставляет на шину адрес регистра ODR порта GPIOA (ADR A)
Такт 3: Команда STRH выдает данные на шину (A data), данные поступают в регистр ODR порта GPIOA, соответственно на выходе порта А появляется сигнал.
Рассмотрим второй вариант. На рис. 6 представлено состояние конвейера команд в мо-мент появления фронта сигнала на порте B контроллера. На рис. 7 представлено состояние наиболее важных линий шины AHB в момент появления фронта сигнала на порте B контрол-лера.

52 ВСТРАИВАЕМЫЕ СИСТЕМЫ И СИСТЕМЫ НА КРИСТАЛЛЕ
Сборник трудов VII научно-практической конференции молодых ученых «Вычислительные системы и сети (Майоровские чтения)»
Рис. 6. Состояние конвейера команд (2-й вариант)
Рис. 7. Состояние наиболее важных линий шины (2-й вариант)
Разберем прохождение сигнала по тактам. Такт 1: Фронт сигнала приходит, когда на стадии DECODE находится команда выгруз-
ки (STRH) Такт 2: На стадии DECODE находится команда загрузки (LDRH), выставляющая на ши-
ну адрес (в данном случае адрес регистра IDR порта GPIOB). Порты ввода-вывода подключе-ны к шине AHB, время прохождения данных по шине AHB занимает один такт.
Такт 3: Команда LDRH находится на стадии выполнения, данные заносятся в регистр. В то же время команда STRH, которая находится на стадии DECODE, выставляет на шину ад-рес регистра ODR порта GPIOA.

ВСТРАИВАЕМЫЕ СИСТЕМЫ И СИСТЕМЫ НА КРИСТАЛЛЕ 53
Сборник трудов VII научно-практической конференции молодых ученых «Вычислительные системы и сети (Майоровские чтения)»
Такт 4: Команда STRH выдает данные на шину, данные поступают в регистр ODR порта GPIOA, и следовательно, на выходе порта А появляется сигнал.
Таким образом, можно установить, что сигнал появляется на выходах порта спустя три такта от начала выполнения команды STRH, а пересылка значения из входного регистра в выходной регистр порта может занимать три или четыре такта, в зависимости от того, какая команда выполняется в момент поступления фронта сигнала на входах.
Тест 1 Ядро и контроллер прямого доступа к памяти обращаются к общему ресурсу — портам
ввода-вывода. Ядро пересылает данные из порта B в порт A, контроллер прямого доступа к памяти пересылает данные из оперативной памяти в порт C. Так как порты ввода-вывода подключены к одной общей шине (AHB) [3, 4], то ожидается увеличение задержки доступа к портам по сравнению с тем случаем, когда запросы к шине AHB будет отдавать только одно ведущее устройство — ядро или контроллер прямого доступа к памяти.
Тест 2 Ядро и контроллер прямого доступа к памяти не используют общие ресурсы. Ядро пе-
ресылает данные из порта B в порт A, контроллер прямого доступа к памяти пересылает дан-ные участками оперативной памяти. При пересылке данных межу портами ядро не обращает-ся к оперативной памяти, поскольку все данные хранятся в регистрах ядра, а команды выби-раются непосредственно из flash-памяти [4]. По этой причине задержка доступа к портам должна остаться неизменной.
Тест 3 Ядро и контроллер прямого доступа к памяти обращаются к общему ресурсу — flash-
памяти. Поскольку из flash-памяти выбираются команды, выполняемые ядром, то ожидается увеличение задержки доступа к портам по сравнению с тем случаем, когда контроллер пря-мого доступа к памяти не обращается к flash-памяти.
Тест 4 Контроллер прямого доступа к памяти пересылает данные из eeprom-памяти в опера-
тивную память. Ядро пересылает данные из порта B в порт A. В данной программе ядро не обращается к eeprom-памяти. Однако eeprom и flash имеют общий контроллер [4], а flash-память используется ядром. По этой причине вероятны конфликты доступа между ядром и контроллером прямого доступа к памяти, из-за чего возможно увеличение задержки доступа к портам.
Результаты тестов представлены в таблице.
Номер теста
Вид обмена Измеренный результат, такты
Производительность по сравнению с контрольной
1 Ядро: обмен между ВУ ПДП: обмен между ВУ и SRAM
3—6 Снизилась
2 Ядро: обмен между ВУ ПДП: обмен между SRAM и SRAM
3—4 Не изменилась
3 Ядро: обмен между ВУ ПДП: обмен между FLASH и SRAM
3—6 Снизилась
4 Ядро: обмен между ВУ ПДП: обмен между EEPROM и SRAM
3—6 Снизилась
Заключение
Полученные результаты замеров показывают, что периферийные устройства и шины данного семейства микроконтроллеров, задействованные при тестах, не предназначены для одновременного управления несколькими ведущими устройствами, такими как контроллер прямого доступа к памяти и ядро микроконтроллера. Обладая этой информацией при разра-ботке устройств, можно минимизировать влияние данного недостатка путем разделения во времени периодов использования общих шин ядром и контроллером прямого доступа к памя-

54 ВСТРАИВАЕМЫЕ СИСТЕМЫ И СИСТЕМЫ НА КРИСТАЛЛЕ
Сборник трудов VII научно-практической конференции молодых ученых «Вычислительные системы и сети (Майоровские чтения)»
ти. Это позволит использовать возможности этого семейства микроконтроллеров более пол-ноценно.
ЛИТЕРАТУРА
1. Cortex m3 Technical Reference Manual, ARM Inc [Электронный ресурс]: <http://infocenter.arm.com/help/topic/com.arm.doc.ddi0337h/DDI0337H_cortex_m3_r2p0_trm.pdf>.
2. ARM®v7-M Architecture Reference Manual. ARM Inc. 2010.
3. Ultra-low-power 32-bit MCU ARM®-based Cortex®-M3, STMicroelectronics [Электронный ресурс]: <http://www.st.com/web/en/resource/technical/document/datasheet/CD00277537.pdf>.
4. Reference Manual STM32L100xx, STM32L151xx, STM32L152xx and STM32L162xx advanced ARM®-based 32-bit MCUs, STMicroelectronics, [Электронный ресурс]: <http://www.st.com/web/en/resource/technical/document/reference_manual/CD00240193.pdf>.
5. Thumb® 16-bit Instruction Set Quick Reference Card, ARM Inc [Электронный ресурс]: <http://infocenter.arm.com/help/topic/com.arm.doc.qrc0006e/QRC0006_UAL16.pdf>.
6. AMBA specification Rev2.0. ARM Inc. 2008.
7. ARM AMBA-3 AHB-Lite Protocol Specification, ARM Inc. 2008.
8. Hu Yueli, Yang Ben. Building an AMBA AHB compliant Memory Controller. 2011.
9. PrimeCell AHB SRAM/NOR Memory Controller, Technical Reference Manual, ARM Inc. 2006.
10. Vani R. M. and Roopa M. Design of AHB2APB Bridge for different phase and Frequency, International Journal of Computer and Electrical Engineering. 2011. Vol. 3, N 2.
11. Gandhani P., Patel Ch. Moving from AMBA AHB to AXI Bus in SoC Designs: A Comparative Study, Int. J Comp Sci. Emerging Tech. 2011. Vol. 2, N 4. P. 476—479.
12. Koti R., Meshram D. An Overview of Advance Microcontroller Bus Architecture Relate on APB Bridge // Intern. J. of Scientific and Research Publications. 2013. Vol. 3, Is. 4.
Сведения об авторе Евгений Алексеевич Пальцев — студент; Университет ИТМО, кафедра вычислительной техники;
E-mail: [email protected] Ссылка для цитирования: Пальцев Е. А. Исследование производительности шинной подсистемы на примере микроконтроллеров семейства STM32L // Сборник трудов VII научно-практической конференции молодых уче-ных «Вычислительные системы и сети (Майоровские чтения)». 2016. С. 48—55.
STUDYING OF BUS SUBSYSTEM PERFORMANCE USING STM32L MICROCONTROLLER FAMILY AS AN EXAMPLE
E. A. Paltsev
ITMO University, 197101, St. Petersburg, Russia
The article describes bus subsystem of STM32L microcontroller family. The possibility of bus subsystem becoming bottleneck was considered. Bus subsystem performance testing method was suggested. Refer-ence performance value was measured when programmed input/output method was used and direct mem-ory access controller was disabled. Bus performance was measured in several tests based on simultaneous programmed input/output and direct memory access methods of transferring data between peripherals. A general conclusion was made concerning the bottleneck. Recommendation on reducing the impact of bus subsystem bottleneck on the overall performance was suggested.

ВСТРАИВАЕМЫЕ СИСТЕМЫ И СИСТЕМЫ НА КРИСТАЛЛЕ 55
Сборник трудов VII научно-практической конференции молодых ученых «Вычислительные системы и сети (Майоровские чтения)»
Keywords: bus subsystem, bus matrix, microcontroller, bottleneck, direct memory access, memory, pe-ripheral.
Data on author Evgeniy A. Paltsev — Student; ITMO University, Department of Computer Science;
E-mail: [email protected]
For citation: Paltsev E. A. Studying of bus subsystem performance using STM32L microcontroller fam-ily as an example // Proceedings of the scientific and practical conference of young scientists «Computing systems and networks (Mayorov’s readings)». 2016. P. 48—55 (in Russian).

56 ВСТРАИВАЕМЫЕ СИСТЕМЫ И СИСТЕМЫ НА КРИСТАЛЛЕ
Сборник трудов VII научно-практической конференции молодых ученых «Вычислительные системы и сети (Майоровские чтения)»
УДК 004.031.6
ОБЗОР ВИРТУАЛЬНЫХ МАШИН ДЛЯ ВСТРАИВАЕМЫХ СИСТЕМ
Н. С. Пичугин
Университет ИТМО, 197101, Санкт-Петербург, Россия
Рассматривается ряд виртуальных машин, разработанных для использо-вания во встраиваемых системах. Обоснована целесообразность исполь-зования виртуальных машин при разработке встраиваемых систем, рас-сматриваются особенности конкретных виртуальных машин, произво-дится их сравнительный анализ.
Ключевые слова: встраиваемые системы, виртуальные машины, реальное время. Цель настоящей работы — выяснить, какие виртуальные машины используются при
разработке встраиваемых систем, сравнить их и выявить некие общие тенденции. Виртуальная вычислительная машина в широком смысле реализует семантику заданной
модели вычислений [1]. Использование виртуальных машин при разработке встраиваемых систем реального времени обеспечивает [1, 2]:
— абстрагирование от аппаратной платформы. Виртуальные машины позволяют при-кладному программисту не заботиться об особенностях и различиях аппаратных платформ, предоставляя универсальную платформу;
— избегание часто встречающихся ошибок программирования. Системное программи-рование зачастую сопряжено с рисками, связанными с человеческим фактором: это не только логические ошибки, но и неэффективное расходование ресурсов системы, а также проблемы безопасности. Виртуальные машины позволяют адресовать и максимально нивелировать эти риски;
— упрощение поддержки программного обеспечения встраиваемой системы (ВсС). За-траты на поддержку ПО ВсС можно существенно сократить за счет перекладывания части работ (как правило, связанных с низкоуровневыми аспектами системы) на виртуальную ма-шину;
— возможность перейти к другой, более удобной для конкретной задачи модели вычис-лений.
Выделим пять критериев сравнения виртуальных машин. 1. Поддержка жесткого времени. Этот критерий наиболее важен, поскольку встраивае-
мые системы зачастую проектируются для решения задач, требующих ограничений реально-го времени.
2. Самодостаточность, или возможность работы без привлечения операционных систем реального времени (ОСРВ). Встраиваемые системы чаще всего разрабатываются при ограни-чении аппаратных ресурсов, поэтому желательно, чтобы программная часть ВсС была наи-менее требовательна к аппаратной.
3. Основной язык высокого уровня для прикладного программирования. Этот критерий субъективен, поскольку любой язык обладает своими уникальными особенностями, плюсами и минусами.
4. Поддерживаемые процессоры. Очевидно, что поддержка более широкого ряда цен-тральных вычислительных процессоров предоставит прикладному программисту больше сво-боды при проектировании аппаратной платформы.
5. Открытый исходный код. Доступность исходных текстов виртуальной машины и воз-можность их модификации может позволить доработать машину для конкретной задачи или использовать ее в образовательных целях.

ВСТРАИВАЕМЫЕ СИСТЕМЫ И СИСТЕМЫ НА КРИСТАЛЛЕ 57
Сборник трудов VII научно-практической конференции молодых ученых «Вычислительные системы и сети (Майоровские чтения)»
Сравним несколько виртуальных машин по приведенным критериям. AERO-VM [3]. Закрытый научно-исследовательский проект, предназначенный для ис-
пользования в аэрокосмических аппаратах под управлением специализированных процессо-ров ERC32 и Leon. Это модифицированный вариант виртуальной машины Java с поддержкой реального времени. Требует работы ОСРВ.
Jamaica VM [4]. Коммерческая версия виртуальной машины Java, ориентированная на использование в бытовой технике, IoT и ВсС общего назначения. Оптимизирована для рабо-ты на многоядерных системах. Работает на широком спектре процессоров, но требует ОСРВ.
PTC Perc [5]. Коммерческая версия виртуальной машины Java реального времени, ориентированная на использование в автомобильных системах, на промышленных производ-ственных линиях и т.п. Отличается относительно высокими требованиями к аппаратному обеспечению. Поддерживает процессоры архитектур x86, ARM и PPC, также требует работы ОСРВ.
Fiji VM [6]. Проект R&D, целью которого является разработка виртуальной машины Java с поддержкой реального времени, а также специализированного компилятора языка Java с агрессивными оптимизациями. Исходный код закрыт, но есть возможность связаться с раз-работчиками, чтобы получить копию в образовательных целях. Поддерживает широкий спектр процессоров, но требует ОСРВ.
MicroEJ [7]. Еще одна коммерческая реализация виртуальной машины Java с поддерж-кой реального времени. В отличие от предыдущих виртуальных машин, эта может работать как на ОСРВ, так и без нее. Авторы предлагают несколько демонстрационных проектов для отладочных плат на базе микроконтроллеров STM32, однако спектр поддерживаемых про-цессоров ими далеко не ограничивается.
NanoVM [8]. Открытый проект по портированию самодостаточной виртуальной машины Java на микроконтроллеры семейства AVR. Поддержкой реального времени не обладает.
EmbedVM [9]. Открытый проект по созданию учебной виртуальной машины для микро-контроллеров AVR и компилятора C-подобного языка высокого уровня для нее. Поддержкой реального времени не обладает.
Составим сравнительную таблицу.
Критерий AERO VM Jamaica VM PTC Perc Fiji VM MicroEJ Nano VM Embed VMРеальное время + + + + + — — Работа без ОС — — — — + + + Основной ЯВУ Java Java Java Java Java Java C Поддерживаемые процессоры
ERC32, Leon
* x86, ARM,
PPC * * AVR AVR
Открытый исходный код
— — — — — + +
П р и м е ч а н и е : * означает поддержку широкого спектра процессоров.
Вывод
В результате исследования было установлено, что большинство виртуальных машин для встраиваемых систем представляют собой закрытые коммерческие версии JVM с поддержкой жесткого реального времени для широкого спектра процессоров, однако такие машины не мо-гут работать самостоятельно.
ЛИТЕРАТУРА
1. Платунов А. Е., Постников Н. П. Высокоуровневое проектирование встраиваемых систем (часть 1). СПб: Университет ИТМО, 2011.
2. Douglas B. P. Real-Time Design Patterns: Robust Scalable Architecture for Real-Time Systems. Addison-Wesley, 2002.

58 ВСТРАИВАЕМЫЕ СИСТЕМЫ И СИСТЕМЫ НА КРИСТАЛЛЕ
Сборник трудов VII научно-практической конференции молодых ученых «Вычислительные системы и сети (Майоровские чтения)»
3. AERO Project. Электронный ресурс: <http://www.aero-project.org/index.html>.
4. aicas GmbH. Электронный ресурс: <https://www.aicas.com/cms/en/JamaicaVM>.
5. PTC Inc. Электронный ресурс: <http://ru.ptc.com/developer-tools/perc>.
6. Ziarek L., Blanton E. Электронный ресурс: <http://fiji-systems.com>.
7. Industrial Smart Software Technology S.A. Электронный ресурс: <http://www.is2t.com/products>.
8. Harbaum T. Электронный ресурс: <http://www.harbaum.org/till/nanovm/index.shtml>.
9. Wolf C. EmbedVM: a small embeddable virtual machine for microcontrollers. Электронный ресурс: <http://www.clifford.at/embedvm>.
Сведения об авторах Никита Сергеевич Пичугин — студент; Университет ИТМО, кафедра вычислительной техники;
E-mail: [email protected] Ссылка для цитирования: Пичугин Н. С. Обзор виртуальных машин для встраиваемых систем // Сборник тру-дов VII научно-практической конференции молодых ученых «Вычислительные системы и сети (Майоровские чтения)». 2016. С. 56—58.
REVIEW OF VIRTUAL MACHINES FOR EMBEDDED SYSTEMS
N. S. Pichugin
ITMO University, 197101, St. Petersburg, Russia
In this report, a brief review of embedded virtual machines is given. Arguments for a possible adopting of virtual machines in an embedded system design are given. Some of the specific virtual machine examples are compared and analyzed.
Keywords: embedded systems, virtual machines, real-time.
Data on author Nikita S. Pichugin — Student; ITMO University, Department of Computer Science;
E-mail: [email protected]
For citation: Pichugin N. S. Review of virtual machines for embedded systems // Proceedings of the sci-entific and practical conference of young scientists «Computing systems and networks (Mayorov’s read-ings)». 2016. P. 56—58 (in Russian).

Сборник трудов VII научно-практической конференции молодых ученых «Вычислительные системы и сети (Майоровские чтения)»
БЕЗОПАСНОСТЬ ВЫЧИСЛИТЕЛЬНЫХ СИСТЕМ
УДК 004.056.53
АНАЛИЗ УЯЗВИМОСТЕЙ ИНФОРМАЦИОННЫХ СИСТЕМ. ЗАЩИТА СИСТЕМЫ ОТ НЕСАНКЦИОНИРОВАННОГО ДОСТУПА
А. В. Малинина
Университет ИТМО, 197101, Санкт-Петербург, Россия
Проанализированы уязвимости информационных систем и исследованы особенности поведения атак при защите системы от несанкционирован-ного доступа. Предметом исследования служат уязвимости, создающие предпосылки для проведения атак на компьютерные системы, методы противодействия атакам на компьютерные системы. Построена модель поведения злоумышленника, позволяющая выявить уязвимые места системы и вовремя исправить ошибки, тем самым не позволив зло-умышленникам эксплуатировать систему в своих целях. Рассмотрены подходы к анализу защищенности ОС и выявлены их особенности и существенные недостатки. Представлены результаты исследования наиболее распространенных уязвимостей разработки за последние годы.
Ключевые слова: анализ защищенности, уязвимость, информационная безопасность, информацион-ная система, несанкционированный доступ, злоумышленник, атака, риск, конфиденциальность.
Использование информационных систем непосредственно связано с определенной со-вокупностью рисков, основной причиной которых являются уязвимости информационных технологий и систем. Развитие технологий требует постоянного повышения эффективности функционирования информационных систем и ставит задачи, для решения которых требуется научный подход, а именно:
— анализ уязвимостей ПО и оценка их уровня рисков; — разработка критериев и модели оценки защищенности ОС от различных видов не-
санкционированного доступа (НСД); — исследование «реакции» уязвимостей на защиту от НСД и построение соответст-
вующих схем атак. Одним из распространенных методов НСД является «взлом» компьютерных систем.
НСД могут быть подвержены серверы, на которых хранятся и обрабатываются информаци-онные ресурсы, маршрутизаторы, через которые ведется обмен информацией между различ-ными сегментами сетей, а также персональные компьютеры [1—6].
В исследованиях по веб-приложениям представлено 1200 видов уязвимости (рис. 1). При этом 68 % систем содержат уязвимости высокой степени риска. Кроме того, в 2013 г. в среднем на каждое веб-приложение приходилось 15 уязвимостей, а в 2014 г. это число воз-росло почти в два раза — до 29,9. Необходимо отметить, что большинство новых методов защиты, вводимых в современные ОС, строится на принципе исправления ошибок и недос-татков, свойственных базовым средствам защиты ОС, что не позволяет комплексно решать задачу защиты ОС.
Для решения проблем, связанных с защитой ОС от возможных последствий ошибок в программном коде или конфигурации системы, необходима разработка критериев и методов комплексной оценки защищенности ОС от различных вариантов НСД. Были рассмотрены:
— методы оценки рисков (ГРИФ, RiskWatch),
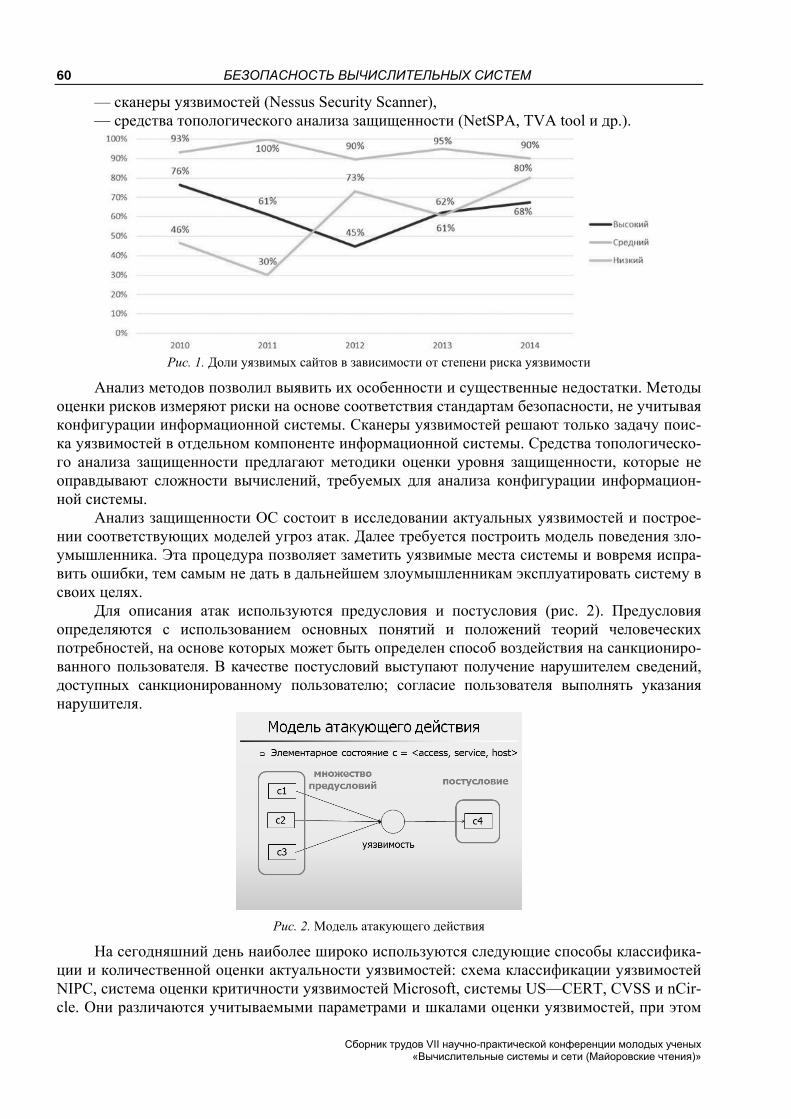
60 БЕЗОПАСНОСТЬ ВЫЧИСЛИТЕЛЬНЫХ СИСТЕМ
Сборник трудов VII научно-практической конференции молодых ученых «Вычислительные системы и сети (Майоровские чтения)»
— сканеры уязвимостей (Nessus Security Scanner), — средства топологического анализа защищенности (NetSPA, TVA tool и др.).
Рис. 1. Доли уязвимых сайтов в зависимости от степени риска уязвимости
Анализ методов позволил выявить их особенности и существенные недостатки. Методы оценки рисков измеряют риски на основе соответствия стандартам безопасности, не учитывая конфигурации информационной системы. Сканеры уязвимостей решают только задачу поис-ка уязвимостей в отдельном компоненте информационной системы. Средства топологическо-го анализа защищенности предлагают методики оценки уровня защищенности, которые не оправдывают сложности вычислений, требуемых для анализа конфигурации информацион-ной системы.
Анализ защищенности ОС состоит в исследовании актуальных уязвимостей и построе-нии соответствующих моделей угроз атак. Далее требуется построить модель поведения зло-умышленника. Эта процедура позволяет заметить уязвимые места системы и вовремя испра-вить ошибки, тем самым не дать в дальнейшем злоумышленникам эксплуатировать систему в своих целях.
Для описания атак используются предусловия и постусловия (рис. 2). Предусловия определяются с использованием основных понятий и положений теорий человеческих потребностей, на основе которых может быть определен способ воздействия на санкциониро-ванного пользователя. В качестве постусловий выступают получение нарушителем сведений, доступных санкционированному пользователю; согласие пользователя выполнять указания нарушителя.
Рис. 2. Модель атакующего действия
На сегодняшний день наиболее широко используются следующие способы классифика-ции и количественной оценки актуальности уязвимостей: схема классификации уязвимостей NIPC, система оценки критичности уязвимостей Microsoft, системы US—CERT, CVSS и nCir-cle. Они различаются учитываемыми параметрами и шкалами оценки уязвимостей, при этом
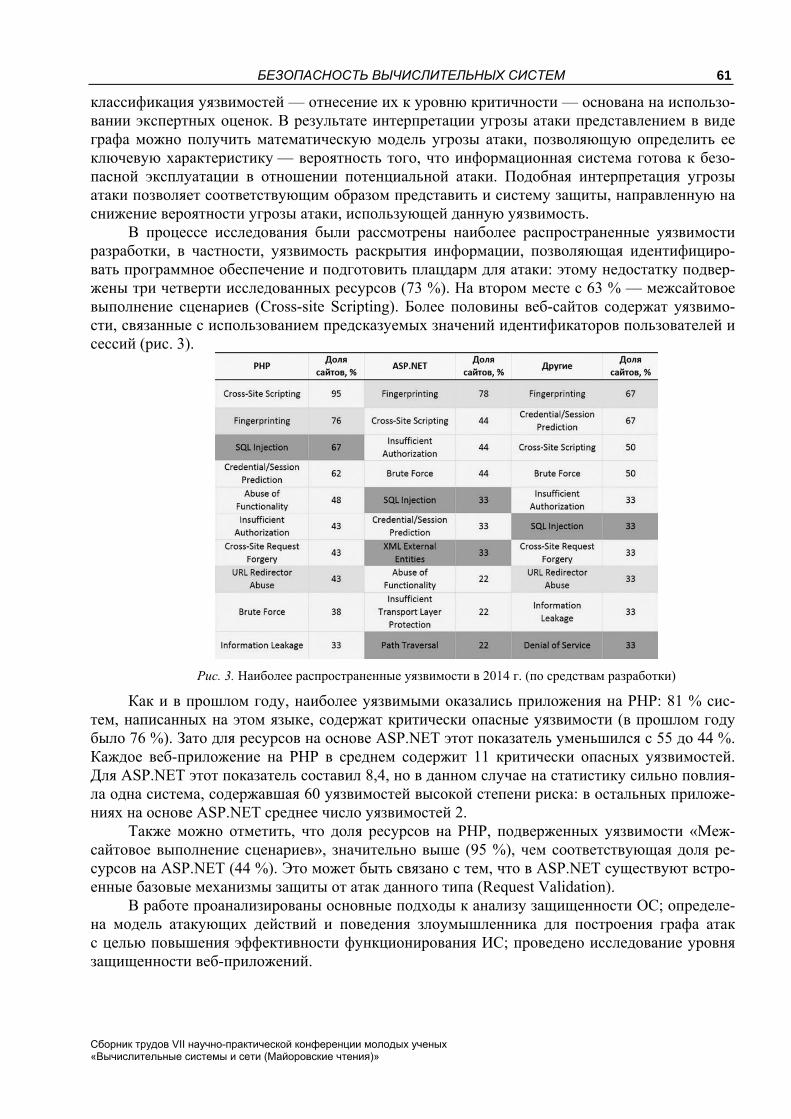
БЕЗОПАСНОСТЬ ВЫЧИСЛИТЕЛЬНЫХ СИСТЕМ 61
Сборник трудов VII научно-практической конференции молодых ученых «Вычислительные системы и сети (Майоровские чтения)»
классификация уязвимостей — отнесение их к уровню критичности — основана на использо-вании экспертных оценок. В результате интерпретации угрозы атаки представлением в виде графа можно получить математическую модель угрозы атаки, позволяющую определить ее ключевую характеристику — вероятность того, что информационная система готова к безо-пасной эксплуатации в отношении потенциальной атаки. Подобная интерпретация угрозы атаки позволяет соответствующим образом представить и систему защиты, направленную на снижение вероятности угрозы атаки, использующей данную уязвимость.
В процессе исследования были рассмотрены наиболее распространенные уязвимости разработки, в частности, уязвимость раскрытия информации, позволяющая идентифициро-вать программное обеспечение и подготовить плацдарм для атаки: этому недостатку подвер-жены три четверти исследованных ресурсов (73 %). На втором месте с 63 % — межсайтовое выполнение сценариев (Cross-site Scripting). Более половины веб-сайтов содержат уязвимо-сти, связанные с использованием предсказуемых значений идентификаторов пользователей и сессий (рис. 3).
Рис. 3. Наиболее распространенные уязвимости в 2014 г. (по средствам разработки)
Как и в прошлом году, наиболее уязвимыми оказались приложения на PHP: 81 % сис-тем, написанных на этом языке, содержат критически опасные уязвимости (в прошлом году было 76 %). Зато для ресурсов на основе ASP.NET этот показатель уменьшился с 55 до 44 %. Каждое веб-приложение на PHP в среднем содержит 11 критически опасных уязвимостей. Для ASP.NET этот показатель составил 8,4, но в данном случае на статистику сильно повлия-ла одна система, содержавшая 60 уязвимостей высокой степени риска: в остальных приложе-ниях на основе ASP.NET среднее число уязвимостей 2.
Также можно отметить, что доля ресурсов на PHP, подверженных уязвимости «Меж-сайтовое выполнение сценариев», значительно выше (95 %), чем соответствующая доля ре-сурсов на ASP.NET (44 %). Это может быть связано с тем, что в ASP.NET существуют встро-енные базовые механизмы защиты от атак данного типа (Request Validation).
В работе проанализированы основные подходы к анализу защищенности ОС; определе-на модель атакующих действий и поведения злоумышленника для построения графа атак с целью повышения эффективности функционирования ИС; проведено исследование уровня защищенности веб-приложений.

62 БЕЗОПАСНОСТЬ ВЫЧИСЛИТЕЛЬНЫХ СИСТЕМ
Сборник трудов VII научно-практической конференции молодых ученых «Вычислительные системы и сети (Майоровские чтения)»
ЛИТЕРАТУРА
1. [Электронный ресурс]: <http://www.cve.mitre.org/cgi-bin/cvename.cgi?name=CVE-2015-2534>.
2. [Электронный ресурс]: <https://technet.microsoft.com/ru-ru/forefront/ee175814>.
3. Благодаренко А. В. Разработка метода, алгоритмов и программ для автоматического поис-ка уязвимостей программного обеспечения в условиях отсутствия исходного кода. Таган-рог, 2011. 129 с.
4. Девянин П. Н. Модели безопасности компьютерных систем. М.: Академия, 2005. 143 с.
5. Симонов C. B. Анализ рисков в информационных системах. М.: ФОРУМ, 2007. 239 с.
6. Шаньгин В. Ф. Защита компьютерной информации. Эффективные методы и средства. М.: ДМК Пресс, 2007. 544 с.
Сведения об авторе Анна Валерьевна Малинина — студент; Университет ИТМО, кафедра вычислительной техники;
E-mail: [email protected]
Ссылка для цитирования: Малинина А. В. Анализ уязвимостей информационных систем. Защита системы от несанкционированного доступа // Сборник трудов VII научно-практической конференции молодых ученых «Вычислительные системы и сети (Майоровские чтения)». 2016. С. 59—62.
ANALYSIS OF VULNERABILITIES OF INFORMATION SYSTEMS. PROTECTING THE SYSTEM FROM UNAUTHORIZED ACCESS
A. V. Malinina
ITMO University, 197101, St. Petersburg, Russia
This article is devoted to the analysis of information systems and vulnerability analysis of the behavior attack while protecting the system from unauthorized access. Use of information systems directly linked to a particular set of risks, which are a major cause of vulnerability of information technology and sys-tems. Technology development requires continuous improvement of information systems and poses prob-lems for solutions that require a scientific approach. One of the types of problems will be dealt with in the work, namely research and analysis of the behavior of the actual attack software vulnerabilities. The sub-ject of research are the vulnerabilities that create preconditions for attacks on computer systems, methods of countering attacks on computer systems. In the definition of the operating system security analysis model of behavior the attacker was built, allowing the system to notice the vulnerability of space and time to correct errors, thereby to prevent further malicious users to exploit the system for their own pur-poses. The article reviewed the existing approaches to the analysis of OS security and identified their fea-tures and significant shortcomings. Also in the work it was presented results of a study of the most com-mon vulnerabilities development in recent years.
Keywords: security analysis, vulnerability, information security, information systems, illegal access, at-tacker, attack, risk, confidentiality.
Data on author Anna V. Malinina — Student; ITMO University, Department of Computer Science; E-mail:
For citation: Malinina A. V. Analysis of vulnerabilities of information systems. Protecting the system from unauthorized access // Proceedings of the scientific and practical conference of young scientists «Computing systems and networks (Mayorov’s readings)». 2016. P. 59—62 (in Russian).

БЕЗОПАСНОСТЬ ВЫЧИСЛИТЕЛЬНЫХ СИСТЕМ 63
Сборник трудов VII научно-практической конференции молодых ученых «Вычислительные системы и сети (Майоровские чтения)»
УДК 004.056
ЗАЩИТА ОТ НЕСАНКЦИОНИРОВАННОЙ ЗАГРУЗКИ ОС И КОНТРОЛЬ АКТИВНОСТИ КСЗИ
Е. Д. Свинолобова, С. В. Свинолобов
Университет ИТМО, 197101, Санкт-Петербург, Россия
Рассматриваются задачи защиты от несанкционированной загрузки ОС и корректного функционирования комплексных систем защиты инфор-мации. Приведены базовые защитные функции разрабатываемых про-граммного и аппаратного модулей. Описаны подходы к реализации до-веренной загрузки и контроля активности. Выявлены их преимущества и недостатки.
Ключевые слова: операционная система, несанкционированная загрузка, КСЗИ, контроль активно-сти, доверенная загрузка.
Введение
Современные комплексные системы защиты информации (КСЗИ) применяются по-всеместно с целью защиты конфиденциальных данных. Одной из возможностей таких КСЗИ является обеспечение доверенной загрузки операционной системы, препятствующее несанкционированному запуску персонального компьютера, несанкционированной загруз-ке ОС и, как следствие, хищению конфиденциальной информации [1—3]. Но при этом сле-дует учитывать, что КСЗИ является программным средством защиты и имеет свои собст-венные ключевые файлы. Эти файлы нуждаются в защите от несанкционированных воздей-ствий (атак) [4], которые могут привести к тому, что механизмы защиты будут отключены наряду с системными файлами в процессе загрузки ОС и на протяжении всей работы пер-сонального компьютера.
Целью работы является описание метода защиты, в основу которого положен про-граммно-аппаратный комплекс (ПАК), решающий следующие базовые задачи защиты:
— осуществление доверенной загрузки ОС и КСЗИ; — обеспечение активного и корректного функционирования КСЗИ уже после доверен-
ной загрузки, т.к. компьютер с установленной на нем КСЗИ защищен до тех пор, пока на-стройки корректны и компоненты КСЗИ активны.
Общий принцип работы ПАК
В общем виде рассматриваемый ПАК включает следующие компоненты (рис. 1): — КСЗИ, которая защищает персональный компьютер; — аппаратный компонент защиты, реализованный в виде платы, которая в обязатель-
ном порядке является пассивной (может получать сигналы, но не может их посылать) и рас-полагается в корпусе компьютера (при этом доступ к плате должен быть невозможен как фи-зически, так и программно);
— программный компонент защиты, осуществляющий взаимодействие между КСЗИ и аппаратным компонентом и обеспечивающий контроль всех этапов загрузки ОС и КСЗИ, ак-тивности и корректности функционирования ключевых исполняемых файлов КСЗИ, в ре-зультате которого платой вырабатывается реакция, не позволяющая незащищенному компь-ютеру работать [5].

64 БЕЗОПАСНОСТЬ ВЫЧИСЛИТЕЛЬНЫХ СИСТЕМ
Сборник трудов VII научно-практической конференции молодых ученых «Вычислительные системы и сети (Майоровские чтения)»
Рис. 1. Обобщенная схема ПАК
Доверенная загрузка ОС и КСЗИ
В рамках доверенной загрузки обеспечивается синхронность трех этапов загрузки ОС и КСЗИ относительно включения питания компьютера, продолжительность которых должна быть заранее однозначно определена:
1) контроль, с какого места загружается система; 2) контроль факта загрузки КСЗИ и ОС и продолжительности загрузки; 3) контроль корректности загрузки ОС и КСЗИ и их настроек. ПАК доверенной загрузки ОС и КСЗИ (рис. 2) включает в себя аппаратный и про-
граммный компоненты. В состав последнего входят два модуля, обеспечивающих контроль начала загрузки ОС и контроль завершения и корректности загрузки ОС и КСЗИ [5].
Рис. 2. ПАК доверенной загрузки ОС и КСЗИ
Модули посылают аппаратному компоненту некий сигнал в виде зашифрованного па-рольного слова, который означает, что соответствующий этап загрузки выполнен корректно. В случае неполучения такого сигнала компонент вырабатывает реакцию в виде сигнала на аппаратном уровне, который отключает компьютер.
Рассмотрим на временной диаграмме работу доверенной загрузки ОС и КСЗИ (рис. 3).
Рис. 3. Временная диаграмма работы ПАК доверенной загрузки ОС и КСЗИ

БЕЗОПАСНОСТЬ ВЫЧИСЛИТЕЛЬНЫХ СИСТЕМ 65
Сборник трудов VII научно-практической конференции молодых ученых «Вычислительные системы и сети (Майоровские чтения)»
Модуль, контролирующий начало загрузки ОС, размещен в BUUT-секторе жесткого диска. Он обеспечивает контроль факта загрузки ОС именно с жесткого диска. В случае кор-ректной загрузки модуль посылает сигнал на плату. В течение определенного времени T1 плата ожидает сигнал. Не получив сигнал, плата отключает компьютер, иначе загрузка ОС и КСЗИ продолжается. В течение интервала T2 плата также ожидает сигнал от модуля контро-ля завершения и корректности загрузки ОС и КСЗИ. Последний этап контроля корректности загрузки ОС и КСЗИ в рамках доверенной загрузки осуществляется аналогично первым двум.
Контроль активности КСЗИ
После завершения доверенной загрузки ОС и КСЗИ наступает время контролировать активность и корректность функционирования КСЗИ. Здесь осуществляется взаимодействие модуля контроля активности и корректности функционирования КСЗИ с аппаратным компо-нентом (рис. 4) [5].
Рассмотрим временную диаграмму работы контроля активности КСЗИ (рис. 5). Модуль контроля активности и корректности функционирования КСЗИ организует регулярный пе-риодический мониторинг состояния компонентов КСЗИ, в случае факта активности и кор-ректности механизмов и их настроек выдает сигнал на плату аналогично схеме, описываю-щей доверенную загрузку. Но в отличие от доверенной загрузки, периоды T, в течение кото-рых аппаратный компонент ожидает сигнал, одинаковы. И как только плата получила сигнал, отсчет интервала начинается заново. В случае неполучения платой сигнала аппаратный ком-понент отключает питание компьютера.
Рис. 4. ПАК контроля активности и корректности функционирования КСЗИ
Рис. 5. Временная диаграмма работы ПАК контроля активности и корректности функционирования КСЗИ
Заключение
В заключение хотелось бы отметить, что рассмотренный ПАК требует доработки, он имеет ряд преимуществ и недостатков. К первым относится то, что:
1) система загружается исключительно с жесткого диска (таким образом предотвраща-ется несанкционированная загрузка ОС, любой другой способ загрузки невозможен);

66 БЕЗОПАСНОСТЬ ВЫЧИСЛИТЕЛЬНЫХ СИСТЕМ
Сборник трудов VII научно-практической конференции молодых ученых «Вычислительные системы и сети (Майоровские чтения)»
2) на всех этапах обеспечивается контроль загрузки ОС и КСЗИ; 3) защищаемый компьютер работает только, если КСЗИ и ОС загружены корректно; 4) пассивность аппаратного компонента исключает возможность осуществления атаки
на нее с целью программного отключения (невозможно атаковать сигналы, т.к. предполагает-ся, что они зашифрованы и сгенерированы случайным образом [6]; нельзя атаковать периоды, в течение которых аппаратный компонент ожидает сигнал от программного, так как они за-даются на самой плате;
5) нельзя атаковать реакцию аппаратного компонента (т.к. она осуществляется на аппа-ратном уровне);
6) работа защищаемого компьютера после загрузки ОС возможна, только если КСЗИ активна и функционирует корректно (при любой атаке аппаратный компонент выключает компьютер).
Недостатком служит то, что регулярные периоды тестирования и передачи сигналов за-медляют работу компьютера.
В дальнейшем планируется развить подход к реализации рассмотренного ПАК, выявить прочие недостатки его работы и наделить компоненты дополнительными защитными функ-циями.
ЛИТЕРАТУРА
1. Правовые и организационные основы комплексных систем защиты информации [Элек-тронный ресурс]: <http://www.comizdat.com/index_.php?in=ksks_articles_id&id=676>.
2. [Электронный ресурс]: <http://www.ru-ib.ru/cat/285>.
3. Щеглов А. Ю. Защита компьютерной информации от несанкционированного доступа. СПб: Наука и техника, 2004.
4. Грибунин В. Г., Чудовский В. В. Комплексная система защиты информации на предпри-ятии. М.: Академия, 2009.
5. Щеглов А. Ю. Компьютерная безопасность: доверенная нагрузка или контроль защи-щенности? [Электронный ресурс]: <http://www.itsec.ru/articles2/Inf_security/dov-ili-control>.
6. Петров А. А. Компьютерная безопасность. Криптографические методы защиты. M.: ДМК, 2000.
Сведения об авторах Евгения Дмитриевна Свинолобова — студент; Университет ИТМО, кафедра вычислительной техники;
E-mail: [email protected] Сергей Владимирович Свинолобов — студент; Университет ИТМО, кафедра вычислительной техники;
E-mail: [email protected] Ссылка для цитирования: Свинолобова Е. Д., Свинолобов С. В. Защита от несанкционированной загрузки ОС и контроль активности КСЗИ // Сборник трудов VII научно-практической конференции молодых ученых «Вы-числительные системы и сети (Майоровские чтения)». 2016. С. 63—67.
PROTECTION AGAINST UNAUTHORIZED LOADING OF AN OPERATING SYSTEM AND CONTROL ACTIVITY OF CSIP
E. D. Svinolobova, S. V. Svinolobov
ITMO University, 197101, St. Petersburg, Russia
The thesis discusses the problem of protection against unauthorized loading of the OS and the correct functioning of the CSIP. The basic protective functions of the developing software and hardware modules

БЕЗОПАСНОСТЬ ВЫЧИСЛИТЕЛЬНЫХ СИСТЕМ 67
Сборник трудов VII научно-практической конференции молодых ученых «Вычислительные системы и сети (Майоровские чтения)»
are listed. The approaches to implementation of trusted boot and control activity are described. The ad-vantages and disadvantages of described software and hardware modules are detected.
Keywords: operating system, unauthorized loading, CSIP, control activity, trusted boot.
Data on authors Evgeniia D. Svinolobova — Student; ITMO University, Department of Computer Science;
E-mail: [email protected] Sergei V. Svinolobov — Student; ITMO University, Department of Computer Science;
E-mail: [email protected]
For citation: Svinolobova E. D., Svinolobov S. V. Protection against unauthorized loading of an operating system and control activity of CSIP // Proceedings of the scientific and practical conference of young scien-tists «Computing systems and networks (Mayorov’s readings)». 2016. P. 63—67 (in Russian).

68 БЕЗОПАСНОСТЬ ВЫЧИСЛИТЕЛЬНЫХ СИСТЕМ
Сборник трудов VII научно-практической конференции молодых ученых «Вычислительные системы и сети (Майоровские чтения)»
УДК 004.056
МЕТОДЫ СХЕМОТЕХНИЧЕСКОГО ПРОЕКТИРОВАНИЯ АППАРАТНОГО МОДУЛЯ ДОВЕРЕННОЙ ЗАГРУЗКИ
С. В. Свинолобов, Е. Д. Свинолобова
Университет ИТМО, 197101, Санкт-Петербург, Россия
Рассматривается задача обеспечения доверенной загрузки операцион-ной системы и контроля активности с помощью аппаратного модуля. Приведены возможные схемотехнические решения, рассмотрены их преимущества и недостатки. Выбрана оптимальная схема реализации аппаратного модуля на основе сравнительного анализа характеристик рассмотренных микросхем.
Ключевые слова: аппаратный модуль, доверенная загрузка, контроль активности, контроль целост-ности, coreABC, CORTEXM3, IGLOO2, SmartFusion2, Actel.
Введение
В настоящие время для защиты операционной системы от несанкционированной за-грузки обычно применяются комплексные системы защиты информации (КСЗИ). Но, как правило, их механизмы защиты являются программными, и в процессе загрузки операцион-ной системы, когда многие компоненты еще не загружены, злоумышленник может получить доступ к системным файлам и нарушить санкционированную загрузку операционной систе-мы; в процессе штатной работы операционной системы злоумышленник может отключить программный компонент и произойдет утечка информации. Во избежание этого необходимо применить внешний независимый аппаратный блок, благодаря которому можно надежно за-щитить файлы операционной системы и КСЗИ на протяжении всей работы компьютера и предотвратить несанкционированную загрузку [1].
Постановка задачи
Необходимо разработать оптимальную схему аппаратного модуля, который, взаимодей-ствуя с программными модулями и КСЗИ, будет эффективно реагировать на противоправные действия в системе. Аппаратный компонент должен выполнять ряд защитных функций, таких как:
— обеспечение загрузки только с заранее определенного места; — «логирование» и ведение собственного журнала событий; — выключение компьютера в случае возникновения нештатной ситуации (несанкцио-
нированной загрузки, нарушения целостности файлов и драйверов ОС и КСЗИ в процессе за-грузки и работы компьютера и т.д.).
На протяжении всей работы операционной системы аппаратный модуль должен регу-лярно или в строго определенное время получать сигнал «нормальной работы» от программ-ных модулей, гарантирующих корректную загрузки ОС и КСЗИ и дальнейшую корректность работы КСЗИ уже после санкционированной загрузки. В нештатной ситуации (если сигнал «нормальной работы» не поступил на микроконтроллер) аппаратный модуль должен мгно-венно сформировать ответную реакцию: отключить питание компьютера [2]. Чтобы реакция была оперативной, необходимо выполнение следующих условий:
1) все микросхемы платы в любой момент времени должны находиться в исправном со-стоянии, в противном случае плата не сможет сформировать сигнал и произойдет утечка ин-формации;

БЕЗОПАСНОСТЬ ВЫЧИСЛИТЕЛЬНЫХ СИСТЕМ 69
Сборник трудов VII научно-практической конференции молодых ученых «Вычислительные системы и сети (Майоровские чтения)»
2) схема, реализованная на аппаратном модуле, должна иметь минимальное количество соединений и минимально возможный набор используемых микросхем, чтобы ответная реак-ция платы произошла без каких-либо задержек;
3) логика работы аппаратного модуля должна быть жестко определена: каждая микро-схема должна соответствовать своему назначению; написанная программа микроконтроллера должна быть максимально проста и эффективна в реализации, чтобы сформировать мгновен-ную ответную реакцию.
Выбор элементной базы
С целью эффективной реализации аппаратного модуля необходимо сформировать ми-нимально возможный набор микросхем [3], который должен включать в себя:
— кварцевый резонатор; — батарейку; — энергонезависимую память; — микроконтроллер; — преобразователь PCIe в PCI. При построении схемы и выборе элементной базы необходимо использовать современ-
ные микросхемы. Особое внимание уделяется стоимостной составляющей микросхем — об-щая стоимость программно-аппаратного модуля комплексной системы защиты информации должна быть сопоставимой с ценой реализованных аналогичных КСЗИ.
Благодаря анализу элементной базы микросхем по оптимальному сочетанию це-на/качество были выбраны семейства CORTEX, Texas Instrument, IGLOO. На основе выбран-ной элементной базы можно построить три схемы и сравнить их характеристики.
Способы реализации схем
Первый вариант реализации схемы аппаратного модуля доверенной загрузки приведен на рис. 1.
Рис. 1. Структурная схема аппаратного модуля на базе микроконтроллера CORTEX M3
За логику работы и скорость ответной реакции отвечает микроконтроллер CORTEX M3 [4]. Поскольку CORTEX M3 не включает в себя модуль PCI express (PCIe), необходимо ис-пользовать преобразователь «PCIe в PCI». Кварцевый резонатор необходим для задания час-тоты работы микроконтроллера. Батарейка на схеме предназначена для поддержки работы энергонезависимой памяти в момент отключения питания компьютера.
Основным недостатком этой схемы является отсутствие в микроконтроллере CORTEX M3 преобразователя «PCIe в PCI». В процессе работы аппаратного модуля может выйти из строя преобразователь «PCIe в PCI», и плата прекратит функционирование, поскольку из-за

70 БЕЗОПАСНОСТЬ ВЫЧИСЛИТЕЛЬНЫХ СИСТЕМ
Сборник трудов VII научно-практической конференции молодых ученых «Вычислительные системы и сети (Майоровские чтения)»
преобразователя CORTEX M3 не будет получать необходимые данные. Из-за выявленного существенного недостатка необходимо реализовать схему на базе других элементов.
Второй вариант реализации схемы аппаратного модуля приведен на рис. 2.
Рис. 2. Структурная схема аппаратного модуля на базе микросхемы IGLOO2
Микроконтроллер IGLOO2 включает в себя модуль PCIe, поэтому нет необходимости в использовании преобразователя «PCIe в PCI», это позволяет не только упростить схему, но и уменьшить общую стоимость аппаратного модуля [5]. Основным недостатком в построенной схеме является отсутствие готового микроконтроллера в микросхеме, поэтому его необходи-мо реализовывать на языке VHDL, таким образом, процессор будет работать гораздо медлен-нее, чем процессор, используемый в микроконтроллере CORTEX M3. Такого типа микропро-цессор не подойдет для реализации поставленной задачи, поскольку аппаратный модуль доверенной загрузки должен формировать максимально быструю ответную реакцию на про-тивоправное действие в системе, в противном случае возможна утечка информации. Необхо-димо подобрать схему, в которой будет использован микроконтроллер, включающий в себя модуль PCIe, а также быстродействующий микропроцессор.
На рис. 3 приведен третий вариант реализации схемы с использованием микроконтрол-лера Smart Fusion 2.
Рис. 3. Структурная схема аппаратного модуля на базе микроконтроллера SmartFusion2
В этом микроконтроллере используется быстродействующий процессор STM 32 [6], также микроконтроллер включает в себя модуль PCIe, это и есть необходимый минимум для реализации поставленной задачи.

БЕЗОПАСНОСТЬ ВЫЧИСЛИТЕЛЬНЫХ СИСТЕМ 71
Сборник трудов VII научно-практической конференции молодых ученых «Вычислительные системы и сети (Майоровские чтения)»
В таблице приведены основные преимущества микроконтроллеров.
Заключение
Проведя сравнительный анализ, можно сделать вывод, что вариант схемы, приведенный на рис. 3, максимально подходит для реализации аппаратного модуля доверенной загрузки. Он соответствует набору требований, необходимых для реализации поставленной задачи. Благодаря минимальному числу микросхем на плате и соединений между ними аппаратный модуль доверенной загрузки сможет максимально быстрого сформировать ответный сигнал выключения питания компьютера и работать без сбоев на протяжении длительного времени. Выбранная схема будет взята за основу при построении электрической принципиальной схе-мы аппаратного модуля доверенной загрузки.
ЛИТЕРАТУРА
1. Щеглов А. Ю. Защита компьютерной информации от несанкционированного доступа. СПб: Наука и Техника, 2004.
2. Безбогов А. А., Яковлев А. В., Мартемьянов Ю. Ф. Безопасность операционных систем. М.: Машиностроение-1, 2007.
3. Кияев В., Граничин О. Безопасность информационных систем. Национальный Открытый Университет «ИНТУИТ», 2016.
4. Cortex-M3. information about Processor [Электронный ресурс]: <http://www.arm.com/ prod-ucts/processors/cortex-m/cortex-m3.php>.
5. Information about Processor IGLOO2 [Электронный ресурс]: < http://www.microsemi.com/ products/fpga-soc/fpga/igloo2-fpga>.
6. Actel SmartFusion2 MSS user guide [Электронный ресурс]: <http://www.eecs.umich.edu/ courses/eecs373/readings/Actel_SmartFusion_MSS_UserGuide.pdf>.
Сведения об авторах Сергей Владимирович Свинолобов — студент; Университет ИТМО, кафедра вычислительной техники;
E-mail: [email protected] Евгения Дмитриевна Свинолобова — студент; Университет ИТМО, кафедра вычислительной техники;
E-mail: [email protected]
Ссылка для цитирования: Свинолобова Е. Д., Свинолобов С. В. Методы схемотехнического проектирования аппаратного модуля доверенной загрузки // Сборник трудов VII научно-практической конференции молодых ученых «Вычислительные системы и сети (Майоровские чтения)». 2016. С. 68—72.
CIRCUIT DESIGN TECHNIQUES OF TRUSTED DOWNLOAD HARDWARE MODULE
S. V. Svinolobov, E. D. Svinolobova
ITMO University, 197101, St. Petersburg, Russia
The article describes the problem of ensuring the trusted operating system is loaded and control activity using a hardware module. The possible circuit solutions, and also their advantages and disadvantages are

72 БЕЗОПАСНОСТЬ ВЫЧИСЛИТЕЛЬНЫХ СИСТЕМ
Сборник трудов VII научно-практической конференции молодых ученых «Вычислительные системы и сети (Майоровские чтения)»
listed. The optimal scheme of realization of hardware module based on a comparative analysis of the characteristics of the considered circuits is purposed.
Keywords: hardware module, trusted boot, control activity, integrity control, trusted boot. coreABC, CORTEXM3, IGLOO2, SmartFusion2, Actel.
Data on authors Sergei V. Svinolobov — Student; ITMO University, Department of Computer Science;
E-mail: [email protected] Evgeniia D. Svinolobova — Student; ITMO University, Department of Computer Science;
E-mail: [email protected]
For citation: Svinolobov S. V., Svinolobova E. D. Circuit design techniques of trusted download hard-ware module // Proceedings of the scientific and practical conference of young scientists «Computing systems and networks (Mayorov’s readings)». 2016. P. 68—72 (in Russian).

БЕЗОПАСНОСТЬ ВЫЧИСЛИТЕЛЬНЫХ СИСТЕМ 73
Сборник трудов VII научно-практической конференции молодых ученых «Вычислительные системы и сети (Майоровские чтения)»
УДК 004.4
ЭФФЕКТИВНОСТЬ ЦИКЛИЧЕСКИХ КОДОВ ПРИ ПЕРЕДАЧЕ ДАННЫХ В КАНАЛАХ СВЯЗИ С ПОМЕХАМИ
Фар. И. Кушназаров, О. А. Турдиев, Фир. И. Кушназаров
Петербургский государственный университет путей сообщения Императора Александра I, 190031, Санкт-Петербург, Россия
Одним из методов борьбы с помехами, которые отрицательно влияют на достоверность передаваемых данных, является добавление кон-трольной суммы в конец кадра с целью проверки целостности получен-ных данных. Для расчета контрольной суммы частично используются циклические коды. Во избежание катастрофических последствий, осо-бенно в системах реального времени, например пропуска искажения управляющих сигналов в транспортных системах, необходимо опреде-лить вероятность пропуска в циклических кодах кадров с ошибками. Предложена имитационная модель, обеспечивающая определение оди-наковых остатков деления для разных данных, при этом учитывающая различие этих данных (расстояние Хемминга для сравниваемых дан-ных). Приведенная математическая модель определяет вероятность пропуска ошибок для разных типов полиномов. Результаты математи-ческой модели и имитационной модели совпадают на 96,8 %, что ука-зывает на достоверность результатов. Модели могут быть использованы разработчиками протоколов для превращения пропуска в некоторый массив запрещенных данных путем добавления выявленных одинако-вых остатков.
Ключевые слова: циклические коды, каналы связи, физическая среда, передача данных.
В настоящее время основным способом обеспечения достоверности сообщений при их передаче по каналам связи в случае воздействия непреднамеренных помех является помехо-устойчивое кодирование. Эффективность такого кодирования достигается за счет введения искусственной избыточности в передаваемое сообщение, что приводит к расширению ис-пользуемой полосы частот и уменьшению скорости передачи.
Применение циклических кодов в каналах связи
На канальном уровне передаются данные с сетевого уровня от источника сообщения к его получателю. Кроме того, он реализует следующие основные функции:
— разбиение потока битов на кадры; — управление потоком кадров; — обработка ошибок передачи. Под разбиением на кадры обычно подразумевается добавление набора служебных дан-
ных до и после поля пользовательских данных. В большинстве протоколов кадры выглядят так, как показано на рис. 1.
Рис. 1. Общий вид формата кадра
Под управлением потоком кадров понимается выбор метода передачи данных, размера кадра (размера окна) и других параметров, при которых можно увеличить производитель-ность протоколов канального уровня.
На канальном уровне большинство протоколов добавляют поле после пользовательских данных для проверки их целостности (например, HDLC, рис. 2) — так называемые поля FCS
Начало кадра Служебные данные Пользовательские данные Конец кадра

74 БЕЗОПАСНОСТЬ ВЫЧИСЛИТЕЛЬНЫХ СИСТЕМ
Сборник трудов VII научно-практической конференции молодых ученых «Вычислительные системы и сети (Майоровские чтения)»
(FrameCheckSequence). Поля для проверки целостности используют помехозащищенные, а именно циклические избыточные коды.
Флаг, Адрес 011111101, z
Управление 1 или 2
Информация kкод (символов)
FCSФлаг 2 или 4
01111110
Рис. 2. Формат кадра HDLC
Циклические коды нашли наибольшее практическое применение в протоколах каналь-ного уровня. Основные оценочные характеристики помехоустойчивых кодов [1]:
— длина кода nкод — число битов, составляющих помехозащищенную кодовую комби-нацию;
— число пользовательских символов kкод — число битов кодируемых данных; — число проверочных символов — rкод;
— избыточность кода кодкод
код
rR
n ;
— вес кода код — число единичных символов;
— расстояние Хэмминга d — число отличных битов на соответствующих позициях в кодах одинаковой длины. Например, для 11010 и 10011 d = 2, так как они различаются во втором и пятом разрядах. Минимальное расстояние Хэмминга dmin — минимальное расстоя-ние для всех возможных кодовых комбинаций;
— вероятность необнаружения ошибки Pвер.ош — вероятность события, при котором принятые пользовательские данные будут отличны от исходных данных, а помехоустойчивые коды не определят наличия ошибки;
— корректирующая способность кода — способность обнаруживать или исправлять возникающие в результате воздействия помех ошибки в принятых данных.
По dmin можно определить корректирующую способность кода [2]: min обнр 1d t , (1)
где tобнр — число обнаруживаемых ошибок; min исп2 1d t , (2)
где tисп — количество исправляемых ошибок. Из формул (1) и (2) видно, что способность кода обнаруживать ошибки намного выше,
чем способность их исправлять. Идея кодов Хэмминга состоит в том, что результат декодирования указывает на поло-
жение ошибки: например, при кодах nкод= 7, rкод= 4 или (7,4) если 0, то ошибок нет; если 1, то ошибка в первом разряде; если 10, то ошибка в втором разряде и т.д. При этом dmin=3, а код Хэмминга (7,4) может исправлять только одиночные ошибки (2).
CRC-коды. Влияние вида порождающего полинома на качество обнаружения ошибок в кадрах
Циклические избыточные коды (Cyclic Redundancy Check, CRC) являются подклассом блочных кодов и применяются в протоколах HDLC, Token Ring, Token Bus, в семействах протоколов Ethernet и других протоколах канального уровня. Популярность CRC-кодов обу-словлена тем, что процедура кодирования и декодирования достаточно проста и не требует больших вычислительных ресурсов и сложных аппаратных средств (строятся на основе реги-стровых схем) [2]. Под вычислительными ресурсами понимается память, мощность процес-сора, а также число регистров сдвига. Циклический код представляется в виде порождающего полинома — множества всех полиномов степени (rкод–1), содержащих в качестве общего множителя некоторый фиксированный полином G(x), который называется порождающим полиномом кода. Например, x4+x+1, здесь rкод=5, поскольку двоичная последовательность выглядит как 10011.

БЕЗОПАСНОСТЬ ВЫЧИСЛИТЕЛЬНЫХ СИСТЕМ 75
Сборник трудов VII научно-практической конференции молодых ученых «Вычислительные системы и сети (Майоровские чтения)»
Для циклических кодов характерны следующие свойства [3]: 1) обнаруживать все одиночные ошибки, если порождающий полином содержит более
одного члена. Если G(x)=x+1, то код обнаруживает все одиночные и все нечетные ошибки; 2) код с G(x)=(x+1)G(x) обнаруживает все одиночные, двойные и тройные ошибки; 3) код с порождающим полиномом G(x) степени rкод=nкод–kкод обнаруживает все группо-
вые ошибки длительностью rкод символов;
4) код может не выявить ошибки с вероятностью 1
2r, где r — степень порождающего
полинома. Вероятность необнаружения ошибки в кадре для CRC-кодов рассчитывается по формуле
1*(1 1 )
2
Nd r
P BER , (3)
где N — размер кадра. В табл. 1 представлены результаты парного сравнения данных при кодировании с по-
мощью порождающего полинома CRC-8-CCITT. Целью модели было найти данные, у кото-рых остаток от деления (CRC-код) будет совпадать, а также расстояние Хэмминга между этими данными, чтобы определить, для какого числа битов возможна подмена CRC. В ре-зультате моделирования обнаружено 31 парное совпадение (в табл. 1 приведено пять парных
совпадений), что примерно совпадает с 8
1 1 310,125 0,121
2562 2r . В таблице приведены
максимальное, минимальное и несколько средних значений расстояния Хэмминга. Среднее значение расстояния Хэмминга для данных 21 — свидетельство того, что при замене 21 бита (если известны их позиции) из 32 битов данных возможна интерпретация искаженных дан-ных как принятых корректно. При этом размер кодируемых данных, kкод= 4 байта (псевдо-случайные числа); количество кодируемых данных, M = 256; порождающий полином, G(x) = =x8+x2+x+ 1.
Ниже приведен один из результатов моделирования как пример совпадения CRC-остатков для разных данных (цветом выделены несовпадающие биты):
— CRC-остаток — 1101011; — данные:
0010 0100 0101 1110 0000 1101 0001 1100, 0110 1101 00000001111000110110 1100,
— расстояние Хэмминга 14.
Таблица 1
Результаты парного сравнения данных при кодировании с помощью порождающего полинома CRC-8-CCITT
№ Номера отправляемых данных
Номера отправляемых данных
CRC-остаток Расстояние Хэмминга
1 1 233 10100000 28 2 13 22 01010011 26 3 17 171 01101100 21 4 59 151 01000010 14 (минимальное) 5 186 193 11011100 31 (максимальное)
Для порождающего полинома по стандарту CRC-8-ETSIEN 302 307 был выполнен подобный эксперимент по обнаружению одинаковых CRC-остатков. В качестве входных использовались данные из предыдущего эксперимента, порождающий полином взят по стандарту G(x) = x8+x7+x6+x4+x2+1. В результате поиска одинаковые CRC-остатки были

76 БЕЗОПАСНОСТЬ ВЫЧИСЛИТЕЛЬНЫХ СИСТЕМ
Сборник трудов VII научно-практической конференции молодых ученых «Вычислительные системы и сети (Майоровские чтения)»
обнаружены в 36 случаях. В табл. 2 представлено пять парных совпадений (максимальное, минимальное и несколько средних значений расстояния Хэмминга). Среднее значение расстоя-ния Хэмминга для порождающего полинома по стандарту CRC-8-ETSIEN 302 307 равно 23.
Сравнив результаты кодирования двух порождающих полиномов, можно сказать, что CRC-8-CCITT имеет лучшие характеристики, нежели CRC-8-ETSIEN 302 307, так как у него меньше случаев совпадения CRC-остатков. Результаты этих двух экспериментов показывают значимость выбора порождающего полинома, так как изменив вид порождающего полинома (не меняя его разрядности), возможно достичь уменьшения случаев совпадения CRC-остатков, тем самым уменьшив вероятность необнаружения ошибочного кадра.
Таблица 2 Результаты парного сравнения данных при кодировании
с помощью порождающего полинома CRC-8-ETSIEN 302 307 № Номера отправляемых
данных Номера отправляемых
данных Остаток
от деления Расстояние Хэмминга
1 26 218 00110000 17 (минимальное) 2 27 48 00010101 24 3 28 179 10110100 21 4 33 88 11101001 25 5 109 236 10001100 30 (максимальное)
Логическим продолжением предыдущих экспериментов было увеличение разрядности порождающих полиномов, при котором уменьшается вероятность необнаружения ошибки в кадре, и соответственно должно уменьшиться число совпадений CRC-остатков.
Для эксперимента выбраны следующие входные данные: — размер кодируемых данных — 64 байта, заполненные псевдослучайными числами; — количество попыток — 1 000 000; — порождающий полином по стандарту CRC-32-IEEE 802.3 — x32+x26+x23+x22+x16+
+x12+x11+x10+x8+x7+ x5+x4+x2+ x + 1. Результаты эксперимента приведены в табл. 3. При моделировании было получено три
парных совпадения CRC-остатков. Среднее значение расстояние Хэмминга для трех парных данных равно 188. Эти результаты подтверждают, что разрядность порождающего полинома обратно пропорциональна вероятности необнаружения ошибки в кодируемом кадре.
Таблица 3 Результаты парного сравнения данных при кодировании с помощью порождающего полинома CRC-32-IEEE 802.3
№ Номера отправляемых
данных
Номера отправляемых
данных Остаток от деления
Расстояние Хэмминга
1 7229 88243 01111010011001100100011101000101 251 2 9007 37241 11001001000100010101000000010111 110 3 19940 86166 00000001011100010010010001011011 204
Определим способность обнаружения ошибки в информационных данных для разных порождающих полиномов с разрядностью 32. Для порождающего полинома по стандарту CRC-32-IEEE 802.3 экспериментальным путем были найдены случаи совпадения CRC-остатков. Тот же эксперимент проведем для порождающего полинома по стандарту CRC-32K (Koopman), в качестве входных возьмем данные предыдущего эксперимента. В качестве по-рождающего был выбран полином CRC-32K (Koopman) как эффективный, согласно работам [4, 5]. В табл. 4 показаны случаи совпадения CRC-остатков для CRC-32K. Количество совпа-дений — в три раза меньше, чем у порождающего полинома по стандарту CRC-32-IEEE 802.3, и этот результат совпадает с работами Купмана.

БЕЗОПАСНОСТЬ ВЫЧИСЛИТЕЛЬНЫХ СИСТЕМ 77
Сборник трудов VII научно-практической конференции молодых ученых «Вычислительные системы и сети (Майоровские чтения)»
Таблица 4 Случаи совпадения CRC-остатков для CRC-32K
№ Номера отправляемых
данных
Номера отправляемых
данных Остаток от деления
Расстояние Хэмминга
1 6582 78952 11101010011001100100000101011101 253
Представляет интерес влияние формата кадров (размеров кадров) на частоту совпадения CRC-остатков, для чего были проведены эксперименты при следующих условиях:
— размер кодируемых данных — 1200 байт, заполненные псевдослучайными числами; — число попыток — 10 000 000; — для двух полиномов — CRC-32-IEEE 802.3 и CRC-32K (Koopman). Результаты, приведенные в табл. 5, показывают, что при больших размерах кодируемых
данных вероятность необнаружения ошибки в кадре уменьшается в связи с большими числа-ми расстояния Хэмминга. Количество парных одинаковых остатков для обоих порождающих полиномов равно единице. Естественно, при больших размерах данных нахождение данных с одинаковыми CRC-остатками затрудняется в связи с требованием большего объема памяти для хранения кодируемых данных и CRC-остатков, также необходимо больше вычислитель-ных ресурсов. Таблица 5
Влияние формата кадров на частоту совпадения CRC-остатков
Номера отправляемых
данных
Номера отправляемых
данных Остаток от деления
Расстояние Хэмминга
Полином
128527 6845684 1110101001100110 0100000101011101
6603 CRC-32K
32179 4548974 0000000101110001 0010010001011011
4387 CRC-32-IEEE 802.3
Заключение
Проведено имитационное моделирование передачи данных с использованием CRC-кодов, выполнен анализ результатов при различных значениях отношения сигнал/помеха. Рассмотрено влияние видов стандартизированных полиномов на вероятность необнаружения ошибок в кадрах. На основе результатов моделирования даны рекомендации по выбору по-рождающего полинома.
По экспериментальным данным при порождении полиномов по стандарту CRC-32K (Koopman) было выявлено, что количество совпадений в три раза меньше, чем у CRC-32-IEEE 802.3.
На основе имитационного моделирования предложен способ использования кодов для увеличения производительности протоколов канального уровня. Рассчитана вероятность не-обнаружения ошибки в кадрах. Результаты моделирования позволяют говорить о возможно-сти нахождения одинаковых остатков для разных данных.
ЛИТЕРАТУРА
1. Хэмминг Р. В. Теория кодирования и теория информации. М.: Радио и связь, 1983. 176 с.
2. Березюк Н. Т., Андрущенко А. Г., Мощицкий С. С. и др. Кодирование информации (двоич-ные коды). Харьков: Вища школа, 1978. 252 с.
3. [Электронный ресурс]: <https://ru.wikipedia.org/wiki/Циклический_избыточный_код>.
4. Koopman P., Theresa C. The Effectiveness of Checksums for Embedded Control Networks // IEEE Transactions on Dependable and Secure Computing. 2009. Vol. 6, N 1.

78 БЕЗОПАСНОСТЬ ВЫЧИСЛИТЕЛЬНЫХ СИСТЕМ
Сборник трудов VII научно-практической конференции молодых ученых «Вычислительные системы и сети (Майоровские чтения)»
5. Koopman P. 32-Bit Cyclic Redundancy Codes for Internet Applications // Intern. Conf. on De-pendable Systems and Networks. 2002. р. 459. DOI:10.1109/DSN.2002.102893.
Сведения об авторах Фаррух Исакулович Кушназаров — аспирант; ПГУПС, кафедра информационных и вычислительных
систем; E-mail: [email protected] Одилжан Акрамович Турдиев — ПГУПС, кафедра информационных и вычислительных систем; ин-
женер программист; E-mail: [email protected] Фирдавс Исакулович Кушназаров — ПГУПС, кафедра информационных и вычислительных систем; асси-
стен; ассистент; E-mail: [email protected] Ссылка для цитирования: Кушназаров Фар. И., Турдиев О. А., Кушназаров Фир. И. Эффективность цикличес-ких кодов при передаче данных в каналах связи с помехами // Сборник трудов VII научно-практической конфе-ренции молодых ученых «Вычислительные системы и сети (Майоровские чтения)». 2016. С. 73—78.
EFFICIENCY CYCLIC CODES WHEN TRANSMITTING DATA TO THE COMMUNICATION MEDIUM NOISE
Far. I Kushnazarov, O. A. Turdiev, Fir. I. Kushnazarov St. Petersburg State University of Railways of Emperor Alexander I,
190031, St. Petersburg, Russia
Purpose: when transmitting data in communication channels messages are sent by batches are divided into frames, each frame to lead round the beginning and end, is inserted between user data. Almost all the communication channels have different kinds of interference that adversely impact the reliability of the transmitted data. One common method of combating interference is to add a checksum to the end of the frame, to verify the integrity of received data. As checksum calculation, cyclic codes are partly used. A relevant issue determining the efficiency of cyclic codes, the bitness of the characteristic polynomials. But there are also generating polynomials of equal width with different polynomial. Results: the problems are formulated defining the probability of missing codes in cyclic frames with errors. No error detection in the cyclic frame codes can lead to catastrophic consequences, especially in real-time systems, for ex-ample, the skipping distortion of the control signals in transport systems. The proposed simulation model determines the efficiency of cyclic codes by determining the residues of the same division for different data, also takes into account the difference between these data (the Hamming distance to compare data). The mathematical model determines the likelihood of missing errors for different types of polynomials, a certain size of data with a given level of noise transmitted in the transmission medium. The results of the mathematical model and the simulation model are the same of 96.8%, indicating the reliability of the re-sults. Practical value: the results of the model can be used by developers of protocols for the conversion pass in some array of prohibited data by adding identified the same residues.
Keywords: cyclic codes, communication channels, physical environment, data transfer.
Data on authors Far. I Kushnazarov — Post-Graduate Student; St. Petersburg State University of Railways of
Emperor Alexander I, Department of Information and Computing Sys-tems; E-mail: [email protected]
O. A. Turdiev — St. Petersburg State University of Railways of Emperor Alexander I, Department of Information and Computing Systems; Programmer Engi-neer; E-mail: [email protected]
Fir. I. Kushnazarov — St. Petersburg State University of Railways of Emperor Alexander I, Department of Information and Computing Systems; Assistant Profes-sor; E-mail: [email protected]
For citation: Kushnazarov Far. I, Turdiev O. A., Kushnazarov Fir. I. Efficiency cyclic codes when transmit-ting data to the communication medium noise // Proceedings of the scientific and practical conference of young scientists «Computing systems and networks (Mayorov’s readings)». 2016. P. 73—78 (in Russian).

БЕЗОПАСНОСТЬ ВЫЧИСЛИТЕЛЬНЫХ СИСТЕМ 79
Сборник трудов VII научно-практической конференции молодых ученых «Вычислительные системы и сети (Майоровские чтения)»
УДК 004.056.5
МЕТОДЫ ОБНАРУЖЕНИЯ АВТОМАТИЗИРОВАННОГО СБОРА ИНФОРМАЦИИ С ВЕБ-РЕСУРСОВ
А. А. Менщиков, Ю. А. Гатчин
Университет ИТМО, 197101, Санкт-Петербург, Россия
На сегодняшний день существует проблема несанкционированного ав-томатизированного сбора информации в Интернете. Изучены методы обнаружения автоматизированного сбора информации с веб-ресурсов. Предложена структурная схема комплексной системы обнаружения ав-томатизированного сбора информации с веб-ресурсов, учитывающая возможность синтеза различных методов обнаружения. Прототип сис-темы протестирован на наборе данных крупного веб-ресурса, исследо-ваны логи поведения веб-робота и обычных пользователей. На основе полученной информации сравнивается поведение веб-робота и пользо-вателя, выявлены наиболее отличающиеся параметры. Рассмотрены ме-ханизмы идентификации пользовательских сессий. Параметры поведе-ния рассчитаны в рамках сессий. Приведены результаты обнаружения автоматизированных сессий на основе сравнения наиболее значимых параметров поведения на веб-ресурсе. Ручная проверка результатов об-наружения подтвердила высокое качество и работоспособность систе-мы. Полученные результаты послужат базой для разработки комплекс-ной системы обнаружения и противодействия автоматизированному сбору информации с веб-ресурсов.
Ключевые слова: веб-роботы, парсинг, сбор информации, обнаружение веб-роботов, информацион-ная безопасность, защита информации.
Введение
Сегодня все более остро встает проблема защиты информации, содержащейся на веб-ресурсе. В сети зачастую содержится ценная и уникальная информация, являющаяся основой бизнес-процессов [1, 2]. Содержащаяся на веб-ресурсе информация подвергается автоматизи-рованному сбору и обработке специальными средствами — веб-роботами [3]. Известны при-меры поисковых роботов, соблюдающих соглашения и учитывающих пожелания владельцев ресурса [4]. Однако существуют роботы, которые используются злоумышленниками для сбо-ра информации с целью последующей рассылки спама, фишинга, таргетированных атак [3, 5]. Такие роботы увеличивают частоту запросов и число потоков, что приводит к нагрузке на веб-ресурс и проблемам с его доступностью [6]. Зачастую данные системы выполняют не только пассивный сбор информации, но и активно используют функционал самого ресурса для поиска информации и таких активных действий, как покупка билетов или написание комментариев.
Классификация веб-роботов
Выделим три основных вида веб-роботов [3, 7]: 1) любительские, осуществляющие простейшие операции; 2) профессиональные, выполняющие сложные алгоритмы поведения; 3) «продвинутые», содержащие механизмы имитации поведения обычных пользова-
телей. Существует множество методов обнаружения таких систем, каждый из которых имеет
свои ограничения по использованию, требует разное количество вычислительных мощностей и эффективен только для обнаружения определенных категорий веб-роботов.

80 БЕЗОПАСНОСТЬ ВЫЧИСЛИТЕЛЬНЫХ СИСТЕМ
Сборник трудов VII научно-практической конференции молодых ученых «Вычислительные системы и сети (Майоровские чтения)»
Методы обнаружения разделяют на [3, 7]: 1) синтаксический анализ логов веб-сервера; 2) сигнатурный анализ трафика; 3) анализ трафика на основе машинного обучения; 4) программные методы обнаружения и противодействия веб-роботам.
Проблема сбора информации
При создании систем автоматизированного сбора информации приходится учитывать множество различных факторов, что ограничивает создание универсальных систем [7, 8]. Ос-новные проблемы, которые стоят перед разработчиками таких систем, можно сгруппировать следующим образом.
— В процедуре настройки и отладки системы сбора информации с каждого конкретного веб-ресурса требуется участие человека.
— Системы сбора информации должны уметь обрабатывать большие объемы данных за относительно короткое время.
— Веб-ресурсы часто подвергаются изменениям структуры и формы подачи контента, поэтому требуется постоянно обновлять систему сбора информации, подстраивая ее под из-менения.
При разработке системы противодействия автоматизированному сбору информации с веб-ресурсов очень важно понимать, какие сложности стоят перед разработчиками парсеров, и использовать их в процессе защиты веб-ресурса [8].
Идентификация пользовательских сессий
Определим проблему обнаружения трафика, принадлежащего веб-роботу, а не человеку [9—11]. Обозначим набор всех HTTP-запросов через R. Для каждого запроса r R будем оп-ределять, принадлежит r множеству запросов H, сгенерированных пользователями, или же он послан автоматизированной системой. Запросы одного и того же пользователя в рамках не-прерывного визита связаны между собой и представляют собой сессию S, r S . Таким обра-зом, если идентифицировать сессию как принадлежащую человеку или роботу, автоматиче-ски можно получить информацию о каждом запросе в рамках сессии. А значит, сначала тре-буется решить проблему разбиения множества запросов на сессии, по имеющемуся набору HTTP-запросов R найти множество сессий { }a a AS S такое, что 0 ,i jS S i ,j A i j .
Задача идентификации сессий решается, как правило, на основе соотношения IP-адреса и не-изменных параметров HTTP-запроса, например, версии браузера пользователя. Можно пред-ставить следующий алгоритм:
for request in Requests: for session in ActiveSessions: if (request.time — session.lastTime > delta): session.close() else: if (session.containsIP(request.ip) and \\ session.containsUserAgent(request.userAgent)): session.add(request) else: newSession = new Session() newSession.add(request)
Схема работы
Для решения проблемы парсинга веб-ресурсов требуется целый комплекс инструментов [12—14]. Во-первых, необходимы методы, позволяющие выявлять веб-роботов на основе оп-ределенных параметров запросов и информации об их активности. Во-вторых, требуется раз-

БЕЗОПАСНОСТЬ ВЫЧИСЛИТЕЛЬНЫХ СИСТЕМ 81
Сборник трудов VII научно-практической конференции молодых ученых «Вычислительные системы и сети (Майоровские чтения)»
работать систему, позволяющую эти методы применять, собрать всю необходимую информа-цию, осуществить ее препроцессинг, обработку и принять решение. В-третьих, требуется соз-дать подсистему, встраиваемую в веб-сервер для поддержания работоспособности всех ос-тальных систем и получения доступа к логам веб-сервера и системам фильтрации трафика. В-четвертых, необходим фреймворк для настройки работы систем обнаружения и противо-действия, а также мониторинга их работы и эффективности [15].
Результаты исследования
Для изучения характеристик поведения обычных пользователей и веб-роботов исполь-зовался набор запросов к крупному веб-ресурсу, содержащий сто тысяч записей.
— Число запросов за сессию. Веб-роботы, целью которых является сбор максимального количества информации, имеют довольно высокий показатель количества запросов. Десятка лидеров по данному показателю — это поисковые роботы и средства проверки веб-ресурса, принадлежащие хостерам.
— Число ошибок. Данный показатель не имеет большого значения для обнаружения ав-томатизированного трафика. Ошибки 404 практически не встречаются в наборе данных, ошибки 304 не являются показательными.
— Незаполненный реферрер. Данный показатель у обычных пользователей очень низок. Десятка лидеров по запросам с незаполненным полем referrer состоит из адресов, принадле-жащих компаниям Amazon, Yandex, Microsoft и некоторым анонимным парсерам. При этом поисковики компании Amazon скрывают свой User-agent.
— Запросы HTTP HEAD, характерные для браузеров с плагинами, ускоряющими за-грузку веб-страниц и для любительских веб-роботов.
— Запросы к robots.txt. Позволяет выявлять только легитимных роботов, которые со-блюдают пожелания администраторов ресурса.
— Доля запросов к статичным файлам. Очень значимый показатель, величина которого является низкой для веб-роботов, получающих контент, экономя на подгрузке картинок, скриптов и стилей. Почти все веб-роботы, присутствующие в наборе данных, оказались вы-явлены благодаря этому показателю.
— Среднеквадратическая глубина просмотров веб-страниц. Данный параметр очень вы-сок для веб-роботов, которые обходят веб-ресурс в глубину.
Были изучены методы обнаружения автоматизированного сбора информации с веб-ресурсов, разработан программный продукт автоматизации анализа веб-логов, а также прове-дены эксперименты на наборе логов веб-сервера. Теоретическая и практическая значимость полученных результатов заключается в получении новых вычислительных результатов, кото-рые послужат базой для разработки комплексной системы обнаружения и противодействия автоматизированному сбору информации с веб-ресурсов.
ЛИТЕРАТУРА
1. Отчет компании distil networks [Электронный ресурс]: <http://resources.distilnetworks.com/ h/i/81324486-2015-bad-bot-landscape-report/185088>.
2. Отчет компании scrapesentry [Электронный ресурс]: <https://www.scrapesentry.com/ scrape-sentry-scraping-threat-report-2015>.
3. Менщиков А. А., Гатчин Ю. А. Методы обнаружения автоматизированного сбора инфор-мации с веб-ресурсов // Кибернетика и программирование. 2015. № 5. С. 136—157.
4. Robots Exclusion Protocol Guide [Электронный ресурс]: <http://www.bruceclay.com/ seo/robots-exclusion-guide.pdf>.

82 БЕЗОПАСНОСТЬ ВЫЧИСЛИТЕЛЬНЫХ СИСТЕМ
Сборник трудов VII научно-практической конференции молодых ученых «Вычислительные системы и сети (Майоровские чтения)»
5. Гатчин Ю. А., Сухостат В. В. Теория информационной безопасности и методология за-щиты информации. СПб: СПбГУ ИТМО, 2010. 98 с.
6. Almeida V., Menasce D. A., Riedi R., Ribeiro F. P., Fonseca R., Meira W., Jr. Analyzing Web robots and their impact on caching // Proc. 6th Workshop on Web Caching and Content Distribu-tion. 2001. P. 299—310.
7. Derek D., Gokhale S. A Classification Framework for Web Robots // J. of American Society of Information Science and Technology. 2012. Vol. 63. P. 2549—2554.
8. Jacob G., Kirda E., Kruegel C., Vigna G. PUB CRAWL: Protecting Users and Businesses from CRAWLers // Security'12: Proc. of the 21st USENIX Conf. on Security symp. 2012. P. 25—36.
9. Pang-Ning T., Vipin K. Discovery of web robot sessions based on their navigational patterns // Data Mining and Knowledge Discovery. 2002. Vol. 6(1). P. 9—35.
10. Derek D., Gokhale S. Discovering new trends in web robot traffic through functional classifica-tion // Proc. IEEE Intern. Symp. on Network Computing and Applications. 2008. p. 275—278.
11. Quan B., Gang X., Yong Z., Longtao H. Analysis and detection of bogus behavior in web crawler measurement // Procedia Computer Science. 2014. Vol. 31. P. 1084—1091.
12. Derek D., Gokhale S. Detecting web robots using resource request patterns // Proc. 11th Intern. Conf. on Machine Learning and Applications. 2012. Vol. 1. P. 7—12.
13. Lee J., Cha S., Lee D., Lee H. Classification of web robots: An empirical study based on over one billion requests // Computers and security. 2009. Vol. 28. P. 795—802.
14. Sardar T., Ansari Z. Detection and confirmation of web robot requests for cleaning the volumi-nous web log data // Proc. Intern. Conf. on the IMpact of E-Technology on US. 2014. Vol. 28. P. 795—802.
15. Sisodia D., Verma S., Vyas O. Agglomerative approach for identification and elimination of web robots from web server logs to extract knowledge about actual visitors // J. of Data Analysis and Information Processing. 2015. Vol. 3. P. 1—10.
Сведения об авторах Александр Алексеевич Менщиков — аспирант; Университет ИТМО, кафедра проектирования и безопас-
ности компьютерных систем; E-mail: [email protected] Юрий Арменакович Гатчин — д-р техн. наук, профессор; Университет ИТМО, кафедра проектиро-
вания и безопасности компьютерных систем; E-mail: [email protected]
Ссылка для цитирования: Менщиков А. А., Гатчин Ю. А. Методы обнаружения автоматизированного сбора информации с веб-ресурсов // Сборник трудов VII научно-практической конференции молодых ученых «Вы-числительные системы и сети (Майоровские чтения)». 2016. С. 79—83.
WEB-CRAWLING DETECTION METHODS
A. A. Menshchikov, Yu. A. Gatchin
ITMO University, 197101, St. Petersburg, Russia
Today there is a problem of unauthorized massive and automated information crawling on the internet. Studying the ways of automated information gathering attempts detection and crawling prevention is ur-gent. We analyze web-crawling detection methods and provide classification of these methods. We de-fine the concept of web-robot and study its behavior on a large web resource. A block diagram of an in-tegrated system of web-crawling detection has been proposed, taking into account the possibility of the synthesis of various detection methods. A prototype of the system was tested on a data set of a large web resource. We compare behavior of web-robot and website users on the basis of the received information

БЕЗОПАСНОСТЬ ВЫЧИСЛИТЕЛЬНЫХ СИСТЕМ 83
Сборник трудов VII научно-практической конференции молодых ученых «Вычислительные системы и сети (Майоровские чтения)»
by various indicators and determine different parameters. We provide session identification problem so-lution and calculate parameters for users in sessions. The web-crawling sessions detection results based on a comparison of the most significant behavior parameters has been provided. Manual inspection of the detection results confirmed the high quality and efficiency of the system. Theoretical and practical sig-nificance of the results is in obtaining new computational results that will serve as a basis for the devel-opment of complex web-crawling detection and prevention system.
Keywords: web-robots, parsing, information gathering, web-crawling detection, information security, in-formation protection.
Data on authors Alexander A. Menshchikov — Post-Graduate student; ITMO University, Department of Computer
Systems Design and Security; E-mail: [email protected] Yury A. Gatchin — Dr. Sci., professor; ITMO University, Department of Computer Sys-
tems Design and Security; E-mail: [email protected]
For citation: Menshchikov A. A., Gatchin Yu. A. Web-crawling detection methods // Proceedings of the sci-entific and practical conference of young scientists «Computing systems and networks (Mayorov’s read-ings)». 2016. P. 79—83 (in Russian).

84 БЕЗОПАСНОСТЬ ВЫЧИСЛИТЕЛЬНЫХ СИСТЕМ
Сборник трудов VII научно-практической конференции молодых ученых «Вычислительные системы и сети (Майоровские чтения)»
УДК 004.056
ИССЛЕДОВАНИЕ УГРОЗ СИСТЕМЫ «КЛИЕНТ—БАНК»
Е. Е. Тауекел
Университет ИТМО, 197101, Санкт-Петербург, Россия
Система «Клиент—Банк» представляет собой программный комплекс, позволяющий клиентам оперативно управлять личными финансовыми средствами, производить операции по счету, получать электронные до-кументы. На фоне таких операций система может подвергаться угрозам и обеспечение ее безопасности является актуальной задачей.
Ключевые слова: безопасность систем «Клиент—Банк», безопасность ДБО, информационная безо-пасность, угрозы систем, актуальные угрозы, архитектура систем, безопасность приложений.
Обеспечение безопасности систем «Клиент—Банк», содержащих большое количество секретной информации, позволяющих производить операции с финансовыми активами, явля-ется одной из актуальнейших задач.
Для дальнейшего исследования необходимо ознакомиться с основными понятиями. Уязвимость может пониматься как слабая сторона или изъян в программе, что позволя-
ет злоумышленнику выполнять нежелательные операции или получать несанкционирован-ный доступ. Наличие уязвимости создает угрозу для пользователя приложения, к примеру, может привести к компрометации данных.
Угроза — событие или действие, которое может нанести ущерб безопасности. Угроза может быть также описана как потенциальное нарушение безопасности. Пример: вирус.
Атака — любое действие по нарушению безопасности системы. Пример: Man in the middle («человек посередине»).
Эксплойт — последовательность команд или фрагмент данных, применяемые для того, чтобы воспользоваться преимуществами изъяна или уязвимости приложения. Пример: MS 12-020 RDP.
Наиболее популярны атаки на компьютер клиента банка с целью хищения и использо-вания ключа его электронно-цифровой подписи и перехвата логина и пароля учетной записи в системе «Клиент—Банк». Причиной тому является плохая защищенность клиента, ситуа-цию усугубляет использование однотипного программного обеспечения для доступа к дис-танционному — банковскому — обслуживанию [1].
Одним из объектов атаки служит социальная инженерия, с помощью которой можно уз-нать личные данные клиента, отправив на электронную почту ссылку на сайт банка, минимально отличающуюся от официальной, либо отправить pdf-файл с просьбой ознакомиться с новыми уведомлениями. Данные файлы и сайты содержат эксплойты с кодом, позволяющие захватить контроль над компьютером [2].
По результатам независимого исследования компании Digital Security в России в основ-ном используют боксовые решения для системы «Клиент—Банк», это связано с тем, что соз-дание новой системы затруднено финансовыми вопросами [3]. Результаты анализа показали актуальные угрозы для данных систем.
1) Cross-Site Scripting (XSS), man-in-the-browser — межсайтовое выполнение сценариев. Является методом нападения, который вынуждает веб-сайт выводить подготовленный зло-умышленником программный код, который загружается в браузере пользователя. Злоумыш-ленник может инициировать скрипты в браузере, управлять сессией клиента, перенаправить пользователя и захватить контроль над учетной записью.
2) Man-in-the-browser — атака «человек в браузере», через уязвимость межсайтовго скриптинга подгружается фрейм со страницей системы «Клиент—Банк», скрипт атакующего

БЕЗОПАСНОСТЬ ВЫЧИСЛИТЕЛЬНЫХ СИСТЕМ 85
Сборник трудов VII научно-практической конференции молодых ученых «Вычислительные системы и сети (Майоровские чтения)»
контролирует все содержимое во фрейме, при этом пользователь видит фрейм с интерфейсом ПО. Как только пользователь начинает операции со счетом, создает платежное поручение, скрипт атакующего подменяет реквизиты получателя на реквизиты злоумышленника. При этом в интерфейсе отображаются данные, которые ввел пользователь.
3) SQL-инъекция позволяет атакующему общаться с базой данных системы «Клиент—Банк» в обход правил системы, что может привести к утечке или изменению базы клиентов, их счетов, номеров пластиковых карт, платежных поручений, паролей от системы и т.п. Это возможно, так как обеспечение безопасности и разделения доступа часто лежит на web-приложении, имеющем единственную учетную запись в базе данных. Когда злоумышленник выполняет SQL-инъекцию, он обходит все уровни защиты web-приложения и работает с ба-зой данных под учетной записью этого приложения, вследствие чего у него появляется дос-туп ко всем таблицам системы. Кроме того, критичная информация в базе данных шифруется не всегда [4].
4) Heartbleed является серьезной уязвимостью в популярной библиотеке OpenSSL крип-тографического программного обеспечения. Она позволяет красть информацию даже при ис-пользовании шифрования SSL/TLS, обеспечивающего безопасность и конфиденциальность связи для таких приложений, как электронная почта, мгновенный обмен сообщениями и дис-танционное обслуживание. Heartbleed позволяет всем пользователям в сети «прочитать» па-мять (секретные ключи, используемые для выявления поставщиков услуг и для шифрования трафика, имена и пароли пользователей с фактическим содержимым) систем, защищенных программным обеспечением OpenSSL [5]. Это позволяет злоумышленникам перехватывать коммуникации и выдавать себя либо в роли сервера, либо клиента.
Для обеспечения безопасности необходимо (см. таблицу) использовать сертифициро-ванное и новейшее ПО, защитные интернет-механизмы, флаги защиты cookie: HTTPOnly, Secure, поддержку SSL при аутентификации и доступе к системе, контроль загрузки во фрей-ме (Frame Busting), белый список проверки данных, защитную метку от переполнения буфера в стеке; устранять ошибки при разработке; проводить тесты на уязвимости и ошибки, при об-наружении их должны выпустить обновления для предотвращения угроз [6].
Угроза Решение Cross-Site Scripting (XSS) Использовать белый список проверки данных Man-in-the-Browser ПО ZEUS, ПО Trusteer Rapport, блокировка APIS SQL-injection Placeholder, идентификаторы — белые списки Heartbleed Использовать CVE-2014-0160
Для полной защиты от угроз в системе «Клиент—Банк» банки должны использовать свои разработанные системы, регулярно производить IT-аудит, тестирование на проникнове-ние, повышать качество информационной безопасности. Клиентам следует использовать только лицензированное ПО, SSL протокол, е-токены, защитить ПК от НСД посторонних лиц, не заходить на подозрительные ссылки, тем более вводить там свои данные. Таким обра-зом, в целом можно обезопасить себя от угроз и не понести финансовый ущерб.
ЛИТЕРАТУРА
1. Безопасность банк-клиентов [Электронный ресурс]: <http://www.dsec.ru/ipm-research-center/article/bezopasnost_bank_klientov>.
2. Эффект дежавю: безопасность систем ДБО банк — клиентов находится на уровне 1990х [Электронный ресурс]: <http://www.dsec.ru/ipm-research-center/article/ the_effect_of_deja_ vu_security_systems_rbs_bank_customers_is_at_the_level_of_the_1990s>.
3. Атаки на банковские системы [Электронный ресурс]: <http://habrahabr.ru/company/ dsec/blog/214351>.

86 БЕЗОПАСНОСТЬ ВЫЧИСЛИТЕЛЬНЫХ СИСТЕМ
Сборник трудов VII научно-практической конференции молодых ученых «Вычислительные системы и сети (Майоровские чтения)»
4. [Электронный ресурс]: <http://iso27000.ru/chitalnyi-zai/bezopasnost-elektronnyh-platezhei/ bank-klient-protiv-hakerov-chya-vozmet>.
5. [Электронный ресурс]: <http://heartbleed.com>.
6. [Электронный ресурс]: <https://xakep.ru/2001/04/03/12274>.
Сведения об авторе Еркинбек Ермекулы Тауекел — магистрант; Университет ИТМО, кафедра вычислительной техники;
E-mail: [email protected] Ссылка для цитирования: Тауекел Е. Е. Исследование угроз системы «Клиент—банк»// Сборник трудов VII научно-практической конференции молодых ученых «Вычислительные системы и сети (Майоровские чтения)». 2016. С. 84—86.
RESEARCH OF THREATS OF «CLIENT—BANK» SYSTEMS
Ye. Ye. Tauyekel
ITMO University, 197101, St. Petersburg, Russia
«Client — Bank» system is a program, which gives an opportunity to the clients quickly manage personal finances, carry out operations on the account, get e-documents. Due to these operations given system can be exposed to the threats and security of this system is an urgent task.
Keywords: security of «Client — Bank» systems, security of RBS, information security, threats of the systems, urgent threats, systems architecture, security of the applications.
Data on author Yerkinbek Ye. Tauyekel — Student; ITMO University, Department of Computer Science;
E-mail: [email protected]
For citation: Tauyekel Ye. Ye. Research of threats of «Client—Bank» systems // Proceedings of the sci-entific and practical conference of young scientists «Computing systems and networks (Mayorov’s read-ings)». 2016. P. 84—86 (in Russian).

БЕЗОПАСНОСТЬ ВЫЧИСЛИТЕЛЬНЫХ СИСТЕМ 87
Сборник трудов VII научно-практической конференции молодых ученых «Вычислительные системы и сети (Майоровские чтения)»
УДК 004.056.55
СРАВНЕНИЕ ПРОИЗВОДИТЕЛЬНОСТИ АЛГОРИТМОВ БЛОЧНОГО СИММЕТРИЧНОГО ШИФРОВАНИЯ
О. Н. Симонова
Университет ИТМО, 197101, Санкт-Петербург, Россия
Рассматриваются особенности оценки качества работы алгоритмов блочного симметричного шифрования. Приводятся результаты сравне-ния производительности распространенных алгоритмов.
Ключевые слова: алгоритм блочного симметричного шифрования, криптостойкость, эффективность, производительность.
В настоящее время особое значение имеет защита данных при их обработке, хранении и передаче. При решении задач защиты информации центральное место занимает шифрование, обеспечивающее конфиденциальность, целостность и доступность данных. Но существует проблема выбора между необходимым уровнем защиты и эффективностью работы алгоритма шифрования [1]. Поэтому все большее значение приобретает задача выбора и оценки алго-ритмов шифрования с учетом различных показателей качества и эффективности их работы.
Важнейшими показателями качества алгоритмов шифрования являются параметры их криптостойкости:
— время, необходимое для вскрытия ключа; — вероятность вскрытия ключа; — стоимость взлома. Они характеризуют способность криптографических алгоритмов противостоять различ-
ным видам криптоанализа [2, 3]. В реальных приложениях необходимо дополнительно учи-тывать показатели эффективности алгоритмов:
— скорость инициализации; — производительность (скорость работы); — требовательность к ресурсам. Наиболее значимым показателем является производительность алгоритма шифрования.
Она зависит от вычислительной сложности выполняемых при шифровании операций, а также от конкретного способа реализации алгоритма.
На рисунке приведены результаты практического измерения производительности рас-пространенных блочных алгоритмов шифрования, реализованных в криптографической биб-лиотеке LibreSSL [4], а также в библиотеке алгоритмов ГОСТ [5, 6]. Измерения проводились путем выполнения множества операций шифрования массива данных с последующим усред-нением результатов. Наибольшую производительность показали алгоритмы AES. При этом скорость шифрования увеличивается с уменьшением длины ключа. Наименьшую производи-тельность показали алгоритмы ГОСТ 28147-89 и ГОСТ 34.12-2015. Причем скорость шифро-вания по алгоритму ГОСТ 28147-89 существенно зависит от его реализации в конкретной криптографической библиотеке. Реализация в библиотеке LibreSSL по сравнению с библио-текой алгоритмов ГОСТ является более оптимизированной и показывает в четыре раза боль-шую производительность.

88 БЕЗОПАСНОСТЬ ВЫЧИСЛИТЕЛЬНЫХ СИСТЕМ
Сборник трудов VII научно-практической конференции молодых ученых «Вычислительные системы и сети (Майоровские чтения)»
Результаты измерения производительности алгоритмов шифрования
Практическое применение алгоритмов шифрования требует соблюдения баланса между необходимым уровнем защиты и эффективностью работы системы. При этом следует учиты-вать особенности реализации криптографических алгоритмов, а также правильно оценивать эффективность их работы.
ЛИТЕРАТУРА
1. Шнайер Б. Прикладная криптография. Протоколы, алгоритмы и исходные тексты на язы-ке C. М., 2002.
2. Гатченко Н. А., Исаев А. С., Яковлев А. Д. Криптографическая защита информации. СПб: НИУ ИТМО, 2012.
3. Груздева Л. М., Монахов М. Ю. Повышение производительности корпоративной сети в условиях воздействия угроз информационной безопасности // Изв. вузов. Приборо-строение. 2012. № 8.
4. LibreSSL [Электронный ресурс]: <https://www.libressl.org>.
5. ГОСТ Р 34.12–2015. Информационная технология. Криптографическая защита информации. Блочные шифры. Введ. 2015-07-19. М.: Стандартинформ, 2015.
6. Технический комитет по стандартизации «Криптографическая защита информации» (TK 26) [Электронный ресурс]: <http://tc26.ru>.
7. Efficient Software Implementation of AES on 32-Bit Platforms [Электронный ресурс]: <http://www.springerlink.com/index/UVX5NQGNN55VK199.pdf>.
Сведения об авторе Ольга Николаевна Симонова — студент; Университет ИТМО, кафедра вычислительной техники;
E-mail: [email protected]
Ссылка для цитирования: Симонова О. Н. Сравнение производительности алгоритмов блочного симметричного шифрования // Сборник трудов VII научно-практической конференции молодых ученых «Вычислительные сис-темы и сети (Майоровские чтения)». 2016. С. 87—89.

БЕЗОПАСНОСТЬ ВЫЧИСЛИТЕЛЬНЫХ СИСТЕМ 89
Сборник трудов VII научно-практической конференции молодых ученых «Вычислительные системы и сети (Майоровские чтения)»
COMPARISON OF PERFORMANCE OF SYMMETRIC BLOCK CIPHER ALGORITHMS
O. N. Simonova
ITMO University, 197101, St. Petersburg, Russia
The article discusses the peculiarities of estimating the quality of operation of symmetric block cipher al-gorithms. The results of comparison of widespread algorithms are presented.
Keywords: symmetric block cipher algorithm, cryptographic strength, efficiency, performance.
Data on author Olga N. Simonova — Student; ITMO University, Department of Computer Science;
E-mail: [email protected]
For citation: Simonova O. N. Comparison of performance of symmetric block cipher algorithms // Proceed-ings of the scientific and practical conference of young scientists «Computing systems and networks (Mayo-rov’s readings)». 2016. P. 87—89 (in Russian).

Сборник трудов VII научно-практической конференции молодых ученых «Вычислительные системы и сети (Майоровские чтения)»
ИНТЕЛЛЕКТУАЛЬНЫЕ ИНФОРМАЦИОННЫЕ СИСТЕМЫ
УДК 004.048
ПЕРСОНАЛИЗАЦИЯ СЕМАНТИЧЕСКОГО АНАЛИЗА ТЕКСТОВ НА ЕСТЕСТВЕННОМ ЯЗЫКЕ
И. О. Козин
Университет ИТМО, 197101, Санкт-Петербург, Россия
Исследована проблема повышения качества семантического анализа текстов на естественном языке за счет принятия во внимание индивиду-альности автора и иной информации о нем как о личности. Для персо-нализации предлагается составить профиль автора, учитывающий идео-логические, культурные и психологические особенности, а также вклю-чающий в себя такую информацию об активности в информационном пространстве индивида, как число друзей и идеологическая направлен-ность групп социальных сетей. Полученный профиль следует в даль-нейшем использовать при классификации текста. Показан простой ме-ханизм персонализации анализа текстов в социальной сети: за счет пер-воначальной классификации текстов без учета личности определяется направленность текстов авторов и текстов, размещенных в группах, за счет чего формируются начальные классы данных пользователей и групп. После этого классы корректируются за счет добавления сведений об активности пользователей и таких особенностях групп, как число и начальные классы пользователей, состоящих в группе. Параллельно оценивается эмоциональная тональность текстов пользователей и отно-сительное число их друзей. За счет этих действий формируется профиль пользователя, готовый к использованию для повторной классификации текстов с учетом индивидуальных особенностей.
Ключевые слова: персонализация, обработка естественных языков, классификация, контекст, семан-тический анализ.
Введение
В настоящее время практически востребован семантический (смысловой) анализ тек-стов на естественном языке (NLP). В эту область входит задача классификации и класте-ризации больших массивов текстов, например, для выявления фрагментов экстремистско-го содержания или для дальнейшего анализа, например, тонального (сентимент-анализ).
Цель исследования состоит в повышении качества автоматизированного анализа текстов.
Проблема учета автора при анализе текста
Один лишь семантический анализ не может полностью выявить смысл текста. В лин-гвистической модели «смысл—текст», как отмечено в [1], «семантический анализ текста вы-полняется в отрыве от реальной действительности и потому лишен контекста. Альтернатив-ным подходом к определению и нахождению смысла является онтологический подход».
C точки зрения составления онтологической модели для анализа текста важен учет смысла того или иного понятия для говорящего. В свою очередь, для правильной классифи-кации текста необходимо его правильное понимание анализатором, т.е. чтобы и автор, и чи-татель обладали одинаковым запасом слов, и этим словам в их сознаниях соответствовали

ИНТЕЛЛЕКТУАЛЬНЫЕ ИНФОРМАЦИОННЫЕ СИСТЕМЫ 91
Сборник трудов VII научно-практической конференции молодых ученых «Вычислительные системы и сети (Майоровские чтения)»
адекватные понятия [2]. Применительно к системам NLP это означает, что такая система по-зволяет учитывать различия в смысле, который вкладывают в текст люди из разных культур и групп. В тексте автора, широко использующего метафоры, их не следует понимать букваль-но. Содержание сатирических текстов без учета контекста можно классифицировать как экс-тремистское. Тексты автора, известного своими провокационными речами и поступками, не воспринимаются всерьез как содержащие достойные внимания угрозы.
Из этого можно прийти к заключению, что именно автор текста является звеном между текстом и соответствующей ему предметной областью. Игнорирование личности автора при-водит к потере или искажению смысла передаваемой информации. Поэтому для классифика-ции текстов по их смыслу и содержанию путем семантического и прагматического анализа необходимо произвести классификацию и их авторов. В информационном пространстве та-кой системы каждому известному автору соответствует структура-профиль, содержащая ин-формацию о принадлежности его к одной или нескольким контекстно-смысловым группам.
Работа системы персонализации происходит по следующей схеме: 1) производится семантический и тональный анализ предыдущих текстов автора (если
есть) на основе текущей базы знаний; 2) анализируется активность автора в рамках информационного пространства; 3) на основе двух предыдущих пунктов составляется профиль автора; 4) производится корректировка результатов анализа текста на основе профиля автора. Такой алгоритм позволит выделить пользователей, интересующихся той или иной тема-
тикой или обладающих теми или иными психологическими особенностями. Следует отме-тить, что важным аспектом персонализации является изучение динамики профиля на предмет выявления общего развития взглядов и интересов автора и нахождения аномальных для него текстов.
Пример простой модели учета личности автора при классификации
Допустим, есть два взаимоисключающих класса: «красные» и «синие» (r, b), cK — ко-
эффициент, характеризующий степень принадлежности к тому или иному классу пользовате-лей и сообществ по их «идеологии». Пусть есть начальный тезаурус, в котором каждое слово отнесено к тому или иному классу (r, b), и методы классификации, полученные с помощью методов, описанных в [3—5]. В каждом сообществе g есть определенное число записей в
них ( gP ) и число пользователей ( gU ). Аналогично для пользователя и uF — число друзей,
uG — число групп, в которых состоит пользователь, uP — число записей пользователя. Ве-
личины, принадлежащие r или b, обозначены как cuN для пользователей и cgN — для групп
(например, ruG — число групп, в которых состоит пользователь, принадлежащих классу r
(«красные»), или, на поздних этапах, сумма коэффициентов 0 1rgK этих групп). Сумма
всех коэффициентов принадлежности пользователя или группы равна 1 (так, 1)ru buK K .
Если величина gU , uF , uG , gP или uP нулевая, то слагаемое с ней пропускается:
2
cg cg
g gcg
U P
U PK
, (1)
3
cu cu cu
u u ucu
F P G
F P GK
. (2)

92 ИНТЕЛЛЕКТУАЛЬНЫЕ ИНФОРМАЦИОННЫЕ СИСТЕМЫ
Сборник трудов VII научно-практической конференции молодых ученых «Вычислительные системы и сети (Майоровские чтения)»
Общая принадлежность того или иного сообщества ( cgK ) или пользователя ( cuK ) к од-
ному из классов определяется на начальном уровне по формулам (1) и (2). 1. Вначале система анализирует все имеющиеся тексты пользователей и тексты в сооб-
ществах классическим образом и относит их (однозначно) к одному из классов. 2. Коэффициенты определяются по формулам для начальной классификации, учиты-
вающим лишь сумму всех текстов автора или группы, что, согласно [6], соответствует обоб-щенному понятию «языковая личность».
cucu
u
PK
P , (3)
cg
cgg
PK
P . (4)
3. На основе этого поочередно корректируются коэффициенты сначала групп, а затем пользователей с использованием в параметрах суммы коэффициентов для класса X вместо 1 и 0. Например, пусть в сообщество входят два пользователя, 1u и 2u , и опубликованы записи
1p , 2p , 3p и 4p с коэффициентами, приведенными в таблице. Отсюда получаем 2gU ,
4gP , 0,53 0,75 1, 28bgU , 1 1 1 3bgP , тогда по формуле (1):
1, 28 30,64 0,752 4 0,695
2 2 2
bg bg
g gbg
U P
U PK
.
Процесс корректировки продолжается до некоего числа итераций или достижения дос-таточно малого изменения коэффициентов, как показано на рис. 1.

ИНТЕЛЛЕКТУАЛЬНЫЕ ИНФОРМАЦИОННЫЕ СИСТЕМЫ 93
Сборник трудов VII научно-практической конференции молодых ученых «Вычислительные системы и сети (Майоровские чтения)»
Рис. 1. Подготовительная классификация групп и пользователей
4. После прохождения подготовительной фазы получен список коэффициентов принад-лежности пользователей к тому или иному классу из взаимоисключающего набора (здесь на-бор «red-blue»). Существуют параметры, определяющие активность пользователя, не связан-ную с его идеологией или подобными предпочтениями, такие как эмоциональность текстов пользователя и относительное число его друзей, оцениваемые от 1 до 9. Третьей группой па-раметров в профиле являются однозначно определяемые, такие как язык и зарегистрирован-ная страна проживания пользователя. Условиями начала персонализированного анализа тек-стов являются стабильность всех коэффициентов и достаточное (превышающее заранее оп-ределенную отметку) число пользователей, групп и текстов. Дальнейшая модель работы с текстом производится в соответствии с рис. 2.
Рис. 2. Усовершенствованная классификация текстов на основе профиля пользователя
5. Шаги 3 и 4 повторяются всякий раз при появлении нового текста, пользователя, груп-пы и других изменений, влияющих на классификацию. К таким изменениям относится также

94 ИНТЕЛЛЕКТУАЛЬНЫЕ ИНФОРМАЦИОННЫЕ СИСТЕМЫ
Сборник трудов VII научно-практической конференции молодых ученых «Вычислительные системы и сети (Майоровские чтения)»
изменение класса текста при корректировке. Каждое изменение профиля пользователя фик-сируется при каждом замере данных для изучения его динамики.
Заключение
В статье рассмотрен вопрос учета личности автора при классификации текстов и разра-ботана модель составления его профиля на основе поведения. Направлением дальнейшей ра-боты является разработка математических формул и логических правил, позволяющих непо-средственно использовать переменные профиля в классификации текстов автора.
ЛИТЕРАТУРА
1. Святогор Л. А., Гладун В. П. Определение понятия «смысл» через онтологию. Семантический анализ текстов естественного языка // XVth Intern. Conf. "Knowledge-Dialogue-Solution". KDS 2009, Varna, Bulgaria, June-July 2009. Р. 53—61.
2. Иванова Е. Г. Условия понимания текстов на естественных языках // Изв. ЮФУ. Технические науки. 2005. № 6. С. 134—138.
3. Nugumanova A., Baiburin Y., Bessmertny I. Enhancement of binary text classification using automatic relation extraction // Communications in Computer and Information Science. 2015. Vol. 535. p. 686—693.
4. Nugumanova A., Bessmertny I. Applying the latent semantic analysis to the issue of automatic extraction of collocations from the domain texts // Communications in Computer and Information Science. 2013. Vol. 394. p. 92—101.
5. Nugumanova A., Novosselov A., Baiburin Y., Karimov A. Automatic keywords extraction from the domain texts: Implementation of the algorithm based on the MapReduce model // Proc. of the 2013 Intern. Conf. on Current Trends in Information Technology. 2013. art. no. 6749500. p. 186—189.
6. Осокина С. А. Индивидуальный тезаурус как система знаний: соотношение понятий «индивидуальный тезаурус» и «языковая личность» // Знание. Понимание. Умение. 2011. № 4. С. 178—183.
Сведения об авторах Илья Олегович Козин — магистрант; Университет ИТМО, кафедра вычислительной техники;
E-mail: [email protected]
Ссылка для цитирования: Козин И. О. Персонализация семантического анализа текстов на естественном язы-ке // Сборник трудов VII научно-практической конференции молодых ученых «Вычислительные системы и сети (Майоровские чтения)». 2016. С. 90—95.
PERSONALIZATION OF SEMANTIC ANALYSIS OF NATURAL LANGUAGE TEXTS
I. O. Kozin
ITMO University, 197101, St. Petersburg, Russia
The article deals with the problem of improving the quality of semantic analysis of natural language texts by taking into account the individual characteristics of behavior of the authors and other information about them as persons. The properties of texts are shown which are not covered without taking into ac-count the personality and context of the author. Creation of an author's profile is proposed as a personal-ization method. Said profile contains ideological, cultural, and psychological traits of the author, and also includes information about the author's activity in an observed information space, such as the number of his friends and the ideology of the groups the author had joined. The complete profile is to be used to af-fect the result of text classification. An example is given of a simple personalization model for a social

ИНТЕЛЛЕКТУАЛЬНЫЕ ИНФОРМАЦИОННЫЕ СИСТЕМЫ 95
Сборник трудов VII научно-практической конференции молодых ученых «Вычислительные системы и сети (Майоровские чтения)»
network. In this model, at first, with the help of non-personalized classification, a general class direction of posts by users and in groups is determined, defining the initial classes of these users and groups. After that, these classes are corrected by adding information about the activity of the users and the traits of the groups, such as the number of the users in a group and their initial classes. Information about emotional tonality of users' texts and relative number of their friends is gathered in parallel to the previous process. As a result of these steps, a profile of an author is composed and is ready to be used for a second classifi-cation of texts, influenced by the individual traits of users.
Keywords: personalization, natural language processing, classification, context, semantic analysis.
Data on author Ilya O. Kozin — Student; ITMO University, Department of Computer Science;
E-mail: [email protected]
For citation: Kozin I. O. Personalization of semantic analysis of natural language texts // Proceedings of the scientific and practical conference of young scientists «Computing systems and networks (Mayorov’s readings)». 2016. P. 90—95 (in Russian).

96 ИНТЕЛЛЕКТУАЛЬНЫЕ ИНФОРМАЦИОННЫЕ СИСТЕМЫ
Сборник трудов VII научно-практической конференции молодых ученых «Вычислительные системы и сети (Майоровские чтения)»
УДК 004.855.5
ИСПОЛЬЗОВАНИЕ МАШИННОГО ОБУЧЕНИЯ В ИГРОВЫХ ПРОГРАММАХ
С. В. Нуштаева
Университет ИТМО, 197101, Санкт-Петербург, Россия
Рассматриваются особенности применения антропоморфного преце-дентного подхода к построению игровых программ, в которых на осно-ве машинного обучения накапливаются интеллектуальные навыки, по-зволяющие быстро находить выигрышные ходы, не углубляясь в поиск на дереве решений. С одной стороны, это позволяет существенно уско-рить поиск решений, с другой — строить игровые программы без раз-работки алгоритмов, реализующих выигрышные стратегии. Экспери-ментальным путем определен наиболее эффективный способ обучения машины в программной среде SWI-Prolog.
Ключевые слова: прецедентный подход, искусственный интеллект, игровая программа, машинное обучение, дерево решений.
Многие игровые программы реализуют задачи поиска на дереве решений и вследствие этого имеют экспоненциальную сложность [1, 2]. Для сокращения размерности дерева реше-ний используют либо эвристики [3], либо алгоритмы, реализующие массовую обработку фак-тов методами реляционной алгебры [4]. В работе [5] на задаче поиска путей на графе был ап-робирован метод случайных блужданий, который продемонстрировал, что с его помощью можно найти все пути быстрее, нежели путем поиска в ширину находится одно решение.
В рамках настоящего исследования было предложено использовать антропоморфный прецедентный подход [6]. Основной идеей является использование результатов предыдущих игр для выбора очередного хода. Такой подход универсален, он не зависит от специфики кон-кретных задач и достаточно широко используется.
Для достижения поставленной цели были проведены эксперименты с использованием игры «Крестики-нолики» с размерностью поля 3×3. Эксперименты проводились в программ-ной среде SWI-Prolog. Основная идея заключалась в том, что использование запомненных выигрышных комбинаций для выбора хода позволит вообще отказаться от спуска по дереву решений, за счет чего обеспечит радикальное сокращение сложности задачи. Эксперимент заключался в том, чтобы обучить машину исключительно на основе статистики предыдущих игр, не прибегая к созданию алгоритмов. Всего было проведено четыре эксперимента, ре-зультаты которых демонстрируются на рисунке.
Результативность машинного обучения

ИНТЕЛЛЕКТУАЛЬНЫЕ ИНФОРМАЦИОННЫЕ СИСТЕМЫ 97
Сборник трудов VII научно-практической конференции молодых ученых «Вычислительные системы и сети (Майоровские чтения)»
Результативность машины R в каждой серии игр вычислялась по следующей формуле:
R = (w – l) / n,
где w — число выигрышей машины в серии, l — число проигрышей машины, n — число игр в серии. Ничейные результаты не учитывались.
В первом эксперименте обучение машины происходило следующим образом: чередова-лись 10 обучающих игр с запоминанием выигрышных комбинаций, проведенных случайным образом, и 10 игр без запоминания выигрышных позиций, где человек выбирал ход осознан-но. В представленном графике можно увидеть, что этот способ обучения оказался непродук-тивным, так машина игнорировала более быструю возможность выигрыша, используя в каче-стве хода запомненный неэффективный сценарий. Результат в конце эксперимента достиг 0,2: число выигрышей больше числа проигрышей на 20 %.
При проведении второго эксперимента машина обучалась человеком, пытающимся выиграть на протяжении 20 игр с запоминанием выигрышных комбинаций. Далее произво-дился контроль проведенного обучения в течение 10 игр, где человек ходил случайным обра-зом. Машина, используя накопившиеся в процессе своего обучения знания, играет гораздо эффективнее. К концу эксперимента превышение числа выигрышей составляет 80 %.
В третьем эксперименте также создавалась база прецедентов на основе выигрыша че-ловека, однако обучение происходило на протяжении 50 игр. Для чистоты эксперимента при проведении 50 контрольных игр запоминание выигрышей не производилось. Максимальное превышение выигрышей над проигрышами составило 70 %.
Четвертый эксперимент производился аналогичным образом, что и второй, но машину обучали самым эффективным, с точки зрения стратегии игры, ходам: то есть начинать игру с ходов 2:2, 1:1, 3:3, 1:3, 3:1, которые чаще других могут привести к выигрышу. Такой способ обучения оказался самым эффективным, так как показал наилучшие результаты на более ран-них этапах.
Таким образом, предложенный подход продемонстрировал работоспособность и доста-точно быстрый выход на превышение выигрышей над проигрышами. Использование машин-ного обучения с помощью прецедентного подхода является универсальным и может исполь-зоваться в других задачах без разработки алгоритмов, реализующих выигрышные стратегии.
ЛИТЕРАТУРА
1. Рассел С., Норвиг П. Искусственный интеллект: современный подход. М.: Вильямс, 2007. 1424 с.
2. Бессмертный И. А. Искусственный интеллект. СПб: СПбГУИТМО, 2010. 132 с.
3. Бессмертный И. А. Методы поиска информации в продукционных системах // Изв. вузов Приборостроение. 2011. № 6.
4. Бессмертный И. А., Катериненко Р. С. Метод ускорения логического вывода в продукционной модели знаний // Программирование. 2011. Т. 42. № 4. С. 76—80.
5. Бессмертный И. А., Булыгин К. А. Многоагентный подход к решению задач неинформированного поиска // Научно-технический вестник информационных технологий, механики и оптики 2011. № 4(74). С. 98—102.
6. Бессмертный И. А., Королева Ю. А. Способ организации фактов в базах знаний, ориентированный на создание и использование прецедентов // Труды межд. конгресса по интеллектуальным системам и информационным технологиям IS&IT'14. М.: Физматлит, 2014. С. 245—250.

98 ИНТЕЛЛЕКТУАЛЬНЫЕ ИНФОРМАЦИОННЫЕ СИСТЕМЫ
Сборник трудов VII научно-практической конференции молодых ученых «Вычислительные системы и сети (Майоровские чтения)»
Сведения об авторе Светлана Владиславовна Нуштаева — магистрант; Университет ИТМО, кафедра вычислительной техни-
ки; E-mail: [email protected] Ссылка для цитирования: Нуштаева С. В. Использование машинного обучения в игровых программах // Сборник трудов VII научно-практической конференции молодых ученых «Вычислительные системы и сети (Майоровские чтения)». 2016. С. 96—98.
USING THE MACHINE LEARNING IN GAME PROGRAMS
S. V. Nushtaeva
ITMO University, 197101, St. Petersburg, Russia
The paper considers using anthropomorphic case based approach to game programs where computer col-lects intelligent skills during the machine learning. It allows find beneficial moves quick without a search in the decision tree. On one hand, it allows significantly accelerate search, on other hand, to build game programs without a development algorithms implementing winning strategies. With experiments we de-fined the most effective way to learn machine on the program environment SWI-Prolog.
Keywords: case based approach, artificial intelligence, game program, machine learning, decision tree.
Data on author Svetlana V. Nushtaeva — Student; ITMO University, Department of Computer Science;
E-mail: [email protected]
For citation: Nushtaeva S. V. Using the machine learning in game programs // Proceedings of the scientific and practical conference of young scientists «Computing systems and networks (Mayorov’s readings)». 2016. P. 96—98 (in Russian).

ИНТЕЛЛЕКТУАЛЬНЫЕ ИНФОРМАЦИОННЫЕ СИСТЕМЫ 99
Сборник трудов VII научно-практической конференции молодых ученых «Вычислительные системы и сети (Майоровские чтения)»
УДК 004.2
ИСПОЛЬЗОВАНИЕ МОДЕЛЕЙ РАБОТЫ МОЗГА В РЕКОНФИГУРИРУЕМОМ АКСЕЛЕРАТОРЕ
Я. Г. Горбачев
Университет ИТМО, 197101, Санкт-Петербург, Россия
Проанализирована возможность создания реконфигурируемых акселе-раторов при помощи использования знаний о человеческом мозге. Мозг выбран за эталон, поскольку является естественной высокоэффективной реконфигурируемой системой, созданной в результате многовековой эволюции и естественного отбора. Проанализированы алгоритмические и функциональные свойства мозга, которые могут быть использованы в вычислительной аппаратуре, выполнен обзор существующих решений, осуществляющих в той или иной мере нейроморфные вычисления, кратко описан предлагаемый подход к созданию реконфигурируемых акселераторов. Подход позволяет оптимизировать последовательные вычисления их естественным распараллеливанием.
Ключевые слова: акселератор, реконфигурируемая система, ассоциативный процессор, модели вы-числений, распараллеливание программ, нейроморфные вычисления, функциональные и алгоритмические мо-дели головного мозга.
Двумя актуальными задачами в современной вычислительной технике являются орга-низация реконфигурируемых систем и тесно связанный с нею поиск методов автоматическо-го преобразования последовательных алгоритмов в параллельные. Примером биологической высокоэффективной параллельной реконфигурируемой системы является головной мозг че-ловека и проявления мыслительной деятельности.
1. Мозг естественно сочетает в себе параллельную и последовательную модели вычисле-ний. Имеются сознание, осуществляющее логическое осмысление и решение сложных много-шаговых задач, а также подпороговое восприятие и машинальные реакции — отдельные про-стейшие функции, которые выполняются одновременно и постоянно, обычно без необходимо-сти обращений к сознанию. Аналогичным образом организуется управление в человеческих коллективах — подчиненные решают элементарные задачи и обращаются к вышестоящим по служебной лестнице только при невозможности разрешать проблемы самостоятельно.
2. Отдельные зоны коры головного мозга устроены одинаково, мозг продолжает функ-ционировать при утрате частей коры, их функциональность может изменяться (явление ней-ропластичности), т.е. реализована естественная реконфигурация.
3. В мозге естественным образом происходят архивация и сжатие информации об окру-жающем мире, выделение необходимой для каждой конкретной задачи сути, создание моде-лей окружающей действительности, оперирование абстракциями и инвариантными представ-лениями.
4. Мозг является энергетически эффективной системой. 5. Структура коры головного мозга масштабируема. 6. Мозг обладает свойствами обучаемости, адаптивности, самоорганизации. На данный момент не существует полного понимания организации и функционирова-
ния мозга, но существует некоторое количество гипотез и теорий. Изучение ведется как сни-зу вверх, от низкоуровневой организации и рассмотрения связей и функций отдельных ней-ронов (Human Brain Project, BRAIN), так и сверху вниз: от внешних проявлений высшей нерв-ной деятельности, данных, известных из психологии и изучения поведения людей и живот-ных (например, модель память-предсказание). Известно, что отдельные нейроны реагируют на конкретные раздражители, посылая электрические сигналы, и не реагируют на другие.

100 ИНТЕЛЛЕКТУАЛЬНЫЕ ИНФОРМАЦИОННЫЕ СИСТЕМЫ
Сборник трудов VII научно-практической конференции молодых ученых «Вычислительные системы и сети (Майоровские чтения)»
Кора организована иерархически, на нижние уровни поступают сигналы напрямую с рецеп-торов, верхние уровни принимают сигналы от нижних — каждый сигнал соответствует ка-кой-то распознанной входной последовательности, является ее «именем». Благодаря этому автоматически происходят архивация и классификация — последовательность сигналов за-меняется их «именами», единичными сигналами. Также учитывается и временной аспект — предыдущие состояния «входов», и состояние остальных участков коры. В моторные зоны сигналы передаются сверху вниз: от более абстрактных представлений, «разворачиваясь» в конкретные последовательности. Связи между конкретными нейронами крепнут при одно-временном возбуждении последних, за счет этого происходит так называемое «обучение». И на базовом уровне все вычисления в мозгу заменяются выборками уже существующих вари-антов из памяти.
Выполнено множество попыток повторить работу мозга или отдельные принципы в ис-кусственных системах, в основном на основе нейронных сетей, используемых обычно в зада-чах распознавания сигналов (пример успешного применения — deep learning). Как правило, эти реализации громоздки и требуют больших вычислительных мощностей. Для ускорения вычислений создаются различные нейроморфные вычислители (SyNAPSE, CogniMem, kt-RAM).
В решении некоторых задач настолько подробные повторения мозговой деятельно-сти — излишняя, необязательная сложность, и некоторые отдельные аспекты могут модели-роваться гораздо более простым образом. Так, ассоциативная память точного совпадения грубо моделирует способность нейронов к запоминанию и развертыванию последовательно-стей. Таблицы поиска (lookup tables, LUT), табличные процессоры, табличные оптимизации в программах представляют собой простейшую эмуляцию деятельности мозга — реакции на известную последовательность известными решениями. В каком-то смысле функции коры повторяются в ПЛИС, свойства которых напрямую меняются в зависимости от записанных значений. Сжатие при помощи словарей достаточно эффективно повторяет принцип передачи информации между зонами коры. Но все описанные механизмы применяют только часть функциональных возможностей мозга.
Исходя из сказанного предлагается опробовать решение, относительно простое и при-менимое на платформах с ограниченными ресурсами, дающее возможность оптимизации и распараллеливания последовательного алгоритма. Суть его в следующем. При наличии пол-ной исходной спецификации вычислительного процесса на последовательном языке и неко-торого последовательного процессора или его модели возможно реализовать прослушивание значащих входов и выходов этого процессора, с помощью чего будут запоминаться входная активность и ответы на нее неким дополнительным устройством — акселератором. После «обучения» такой акселератор может перехватывать входящие сигналы и автоматически от-вечать на них, если в его память уже заложены соответствующие последовательности, а если нет — передавать эти сигналы на уровень выше, т.е. изначальному универсальному вычисли-телю. Благодаря этому можно выделять из основного вычислительного процесса подзадачи и распределять их между вспомогательными блоками, разгружая и ускоряя основной вычисли-тель верхнего уровня. Значения можно получать как в ходе симуляции, так и на лету, в по-следнем случае система получается адаптивной. Перехватываться значения могут как между вычислителем и внешними входами и выходами, так и между вычислителем, внутренними регистрами и памятью.
При реализации данного подхода возникают следующие проблемы. — Необходимо находить и выделять в исходной последовательной спецификации вы-
числительного процесса значения, которые можно эффективно оптимизировать. Поиск может производиться вручную, на основании имеющегося опыта, а может быть автоматизирован при помощи статистических методов и моделирования.
— Возможно возникновение необходимости изменять исходный код оптимизируемой

ИНТЕЛЛЕКТУАЛЬНЫЕ ИНФОРМАЦИОННЫЕ СИСТЕМЫ 101
Сборник трудов VII научно-практической конференции молодых ученых «Вычислительные системы и сети (Майоровские чтения)»
программы или явно указывать предназначенные для оптимизации места, добавляя в про-грамму проверку решения задачи акселератором.
— Определение емкости и глубины блоков памяти акселератора. В зависимости от внутренней структуры оптимизируемого процесса могут быть эффективны различные вари-анты — либо достаточно глубокие, способные содержать сложные последовательности, либо простые, но содержащие множество простейших последовательностей. Размерность блоков может определяться в зависимости от контекста либо задаваться для всех ситуаций.
— Принципиальная организация базовых блоков. Акселератор, в зависимости от огра-ничений и задачи, может организовываться как в виде простейшего табличного вычислителя, так и в виде вычислителя, распознающего пространственно-временные последовательности, в виде нейронной сети, простейшего процессора с памятью или сетевого кластера.
— Необходимость передавать большие объемы данных между блоками, проблема реа-лизации между ними соединений. В идеале данные должны передаваться параллельно, но объемы слишком велики, и следует использовать некие последовательные интерфейсы. Со-единения между блоками могут задаваться жестко, а могут в виде сетей и относительно сложных протоколов, при этом в первом случае теряется гибкость, во втором — производи-тельность.
— Согласование частот входных сигналов, универсального верхнего уровня процессора и акселератора, определение, по какому событию начинать преобразование, возможные рас-согласования. Если входной сигнал слишком быстро меняется, более инерционный акселера-тор не успеет отрабатывать изменения. Также проблемы могут возникнуть при согласовании с изначальным, универсальным, вычислителем.
— Определение, как заводить данные о контексте задачи, о состоянии универсального вычислителя — «сверху» или «снизу». При выборке решения акселератором должны исполь-зоваться как внешние сигналы, так и понятие «контекста», передаваемое из универсального вычислителя, что необходимо для принятия верного решения. Значение контекста можно за-водить снизу, как и обычные сигналы, и сверху — через иерархию.
— Нахождение простого способа внедрения и реализации. Получившаяся система ви-дится довольно сложной, сложность представляет и ее внедрение. Однако изначально ее суть должна быть направлена на упрощение задачи разработчиков. Упрощение подхода возможно за счет автоматизации некоторых шагов.
Описанный выше подход позволяет распараллеливать изначально последовательный про-цесс, в идеале — автоматически, используя только начальную спецификацию вычислительного процесса, некоторый изначальный, оптимизируемый, вычислитель и информацию о вероятных входных данных. В теории подобные акселераторы могут масштабироваться, позволяя запоми-нать либо больше вариантов значений, либо более сложные последовательности.
При этом имеется ряд ограничений: — необходимы исходная спецификация вычислительного процесса и некоторый вычис-
литель с возможностью прослушивания его входов и выходов, возможно — модель; — спектр возможных значений должен быть ограничен, иначе объем памяти сильно
разрастается; — входные сигналы должны обладать некоторой повторяемостью, иначе эффектив-
ность сильно снизится; — при «непопадании» входных данных в известные последовательности возникают
большие задержки, требующие обращения к универсальному процессору; — замедляется доступ напрямую к универсальному вычислителю из-за наличия акселе-
ратора; — между базовыми блоками должны передаваться большие объемы данных; — вероятна большая стоимость низкоуровневой аппаратной реализации решения.

102 ИНТЕЛЛЕКТУАЛЬНЫЕ ИНФОРМАЦИОННЫЕ СИСТЕМЫ
Сборник трудов VII научно-практической конференции молодых ученых «Вычислительные системы и сети (Майоровские чтения)»
ЛИТЕРАТУРА
1. Hawkins J., George D. Hierarchical Temporal Memory Concepts, Theory, and Terminology, Numenta Inc., 2007.
2. Hubel D. H., Wiesel T. N. Receptive Fields, Binocular Interaction and Functional Architecture in the Cat's Visual Cortex // Journal of Physiology. 1962. Vol. 160. P. 106—154.
3. Hubel D. H., Wiesel T. N. Receptive Fields of Single Neurones in the Cat's Striate Cortex // Journal of Physiology. 1959. Vol. 148. P. 574—591.
4. The Mystery of the Mind: A Critical Study of Consciousness and the Human Brain. Penfield, Wilder. Princeton University Press, 1975.
5. Zimmermann R. Datapath Synthesis for Standard-Cell Design // 19th IEEE Intern. Symposium on Computer Arithmetic. 2009.
6. Platunov A., Kluchev A., Penskoi A. HLD Methodology: The Role of Architectural Abstractions in Embedded Systems Design // 14th GeoConf. on Informatics, Geoinformatics and Remote Sensing. 2014. P. 209—218.
7. Platunov A., Kluchev A., Penskoi A. Expanding Design Space for Complex Embedded Systems with HLD-methodology // Proc. of the 6th Intern. Congress on Ultra Modern Telecommunications and Control Systems and Workshops (ICUMT). 2015. P. 157—164.
Сведения об авторе Ярослав Георгиевич Горбачев — Университет ИТМО, кафедра вычислительной техники; инженер-
исследователь; E-mail: [email protected]
Ссылка для цитирования: Горбачев Я. Г. Использование моделей работы мозга в реконфигурируемом акселе-раторе // Сборник трудов VII научно-практической конференции молодых ученых «Вычислительные системы и сети (Майоровские чтения)». 2016. С. 99—102.
USING MODELS OF THE BRAIN IN THE RECONFIGURABLE ACCELERATOR
Ya. G. Gorbachev
ITMO University, 197101, St. Petersburg, Russia
The sequential calculations optimizing approach which implies adding of the reconfigurable accelerator is described. The accelerator operation principles are based on simplified models of the brain, which is nature's high-performance reconfigurable system.
Keywords: accelerator, reconfigurable computing, associative processor, model of computation, paral-lelization, function and algorithmic brain models.
Data on author Yaroslav G. Gorbachev — ITMO University, Department of Computer Science; Research En-
geneer; E-mail: [email protected]
For citation: Gorbachev Ya. G. Using models of the brain in the reconfigurable accelerator // Proceed-ings of the scientific and practical conference of young scientists «Computing systems and networks (Mayorov’s readings)». 2016. P. 99—102 (in Russian).

ИНТЕЛЛЕКТУАЛЬНЫЕ ИНФОРМАЦИОННЫЕ СИСТЕМЫ 103
Сборник трудов VII научно-практической конференции молодых ученых «Вычислительные системы и сети (Майоровские чтения)»
УДК 004.823
АЛГОРИТМЫ ТОНАЛЬНОГО АНАЛИЗА ТЕКСТОВ НА ЕСТЕСТВЕННОМ ЯЗЫКЕ
М. В. Мартыненко
Университет ИТМО, 197101, Санкт-Петербург, Россия
Изучены основные задачи тонального анализа текстов на естественном языке. Описаны и классифицированы основные подходы, используемые в системах тонального анализа. Рассмотрены возможности использова-ния семантических фреймов в решении задач тонального анализа. По-ставлена задача расширения возможностей тонального анализа с помо-щью фреймов путем создания новых фреймов, выражающих тональный окрас текста.
Ключевые слова: тональный анализ, семантические фреймы, обработка естественного языка, мнение, репутация.
Введение
Задача оценки чужого мнения или отношения к какой-либо теме является фундамен-тальной в проблеме обработки естественного языка [1]. Действительно, люди всегда стремят-ся узнать чужое мнение по интересующей их теме, чтобы сформировать собственное отно-шение. Все это привело к возникновению необходимости в системах, способных найти и оценить тон автора текста.
В настоящей работе проанализированы существующие методы и алгоритмы тонального анализа текстов на естественном языке и выполнена их классификация с целью сравнения различных подходов и поиска новых.
Классификация подходов к тональному анализу текста
Существует несколько подходов к тональному анализу текста, но в общем случае их ал-горитм сводится к тому, что текст необходимо разбить на синтаксические единицы для опре-деления частей, несущих тональный окрас; это мнение необходимо выбрать и оценить, после чего на основе собранных оценок производить общий анализ.
Существующие решения по тональному анализу можно классифицировать по несколь-ким признакам: методу, уровню детализации анализа текста и уровню оценки [2].
— Метод машинного обучения использует алгоритмы обучения для определения тона текста путем тренировки на известном наборе данных.
— Лексиконный подход подразумевает вычисление полярности с использованием се-мантической ориентации слов или предложений в тексте. Под «семантической ориентацией» подразумевается мера субъективности и мнения в тексте.
— Подход с использованием правил ищет слова-мнения в тексте и классифицирует их, основываясь на количестве «позитивных» и «негативных» слов. Такой подход использует различные правила классификации, например, полярность словаря, слова-отрицания.
— Статистические модели представляют каждый текст как смесь латентных аспектов и рейтингов. Считается, что аспекты и их рейтинги могут быть представлены распределениями и главные термины можно группировать в аспекты, а мнения — в рейтинги.
Другая классификация разделяет методы по уровню детализации текста: на уровне до-кумента, предложения или слова. Большинство методов используют оценку на уровне доку-мента.
Также методы можно разделять по оценке отдельных аспектов или глобальной оценке. Большинство глобальных методов оценивают только полярность текста и используют методы

104 ИНТЕЛЛЕКТУАЛЬНЫЕ ИНФОРМАЦИОННЫЕ СИСТЕМЫ
Сборник трудов VII научно-практической конференции молодых ученых «Вычислительные системы и сети (Майоровские чтения)»
машинного обучения. Более детальные оценки используют больше различных лингвистиче-ских признаков, включая усиление, отрицание, модальность, и структуру текста.
Использование семантических фреймов для тонального анализа текста
Перспективным подходом к решению проблем тонального анализа может быть исполь-зование семантических фреймов для анализа семантической структуры текста. Теория семан-тических фреймов основывается на работе Чарльза Филлмора [3]. Согласно его исследовани-ям, слова и их значения в сознании человека организуются в некие смысловые рамки, исполь-зующиеся для понимания концепций и ассоциаций, связанных с этими словами.
Практической реализацией теории фреймов является лексическая база данных FrameNet [4], содержащая в себе фреймы английского языка. В ходе работы была изучена структура фреймов из этой базы данных. Фрейм состоит из лексической единицы (обычно глагола); элемента фрейма, его специфичной семантической роли; и определения фрейма, то есть опи-сания ситуации и участвующих в ней концептуальных ролей [5]. С помощью фреймов можно определить контекст слов, несущих мнение автора, а также распознать больше их лингвисти-ческих признаков.
Некоторые из фреймов FrameNet содержат в своем определении элементы тональности текста, применимые для оценки текста в целом или отдельных его аспектов. К примеру, фрейм «популярность» (popularity) [6] описывает меру использования или принятия оцени-ваемого субъекта (человека или предмета). Однако для получения наилучшего результата при использовании фреймов можно расширить модель FrameNet путем создания новых фреймов или модификации существующих [7]. Такие фреймы будут называться фреймами мнения (opinion frames) и будут состоять из элементов, описывающих эмоциональный окрас и его контекст (цель, источник, полярность, интенсивность и т.п.). Применение такого фрей-ма к предложению «Иван думает, что я скупой» позволяет сразу определить, кому принадле-жит мнение, к кому оно относится, и «каким мнением» является. Главным достоинством та-кого подхода является глубина анализа текста [8]: с помощью расширенной модели фреймов приложение сможет выбирать ресурсы, необходимые для поиска в тексте элементов, выра-жающих более комплексные мнения (например, неуверенность).
Заключение
Поскольку фреймы представляют возможность улучшения результатов существующих подходов к тональному анализу текста, целесообразно расширить возможности их примене-ния, а с этой целью создать набор фреймов для обнаружения и анализа тонального окраса текста. Такой набор может быть создан на основе нового корпуса текстов, составленного из предложений, выражающих мнение или эмоции автора.
ЛИТЕРАТУРА
1. Pang B., Lee L. Opinion Mining and Sentiment Analysis // Yahoo! Research. Computer Science Department, Cornell University, 2008.
2. Collomb A., Costea C., Joyeux D., Hasan O., Brunie L. A Study and Comparison of Sentiment Analysis Methods for Reputation Evaluation. University of Lyon, 2014.
3. Fillmore Ch. J., Baker C. F. Frame Semantics for Text Understanding. North American Chapter of the Association for Computational Linguistics. 2001.
4. FrameNet Berkeley Project [Электронный ресурс]: <https://framenet.icsi.berkeley.edu>.
5. Ruppenhofer J., Ellsworth M., Petruck M. R. L., Johnson Ch. R., Scheffczyk J. FrameNet II: Extended Theory and Practice. International Computer Science Institute, 2006.

ИНТЕЛЛЕКТУАЛЬНЫЕ ИНФОРМАЦИОННЫЕ СИСТЕМЫ 105
Сборник трудов VII научно-практической конференции молодых ученых «Вычислительные системы и сети (Майоровские чтения)»
6. FrameNet Data [Электронный ресурс]: <https://framenet.icsi.berkeley.edu/ fndrupal/ index.php?q=frameIndex>.
7. Baccianella S., Esuli A., Sebastiani F. SENTIWORDNET 3.0: An enhanced lexical resource for sentiment analysis and opinion mining. European Language Resources Association (ELRA), 2008.
8. Ruppenhofer J., Rehbein I. Semantic frames as an anchor representation for sentiment analysis. Association for Computational Linguistics, 2012.
Сведения об авторе Марк Владимирович Мартыненко — магистрант; Университет ИТМО, кафедра вычислительной техники;
E-mail: [email protected] Ссылка для цитирования: Мартыненко М. В. Алгоритмы тонального анализа текстов на естественном языке // Сборник трудов VII научно-практической конференции молодых ученых «Вычислительные системы и сети (Майоровские чтения)». 2016. С. 103—105.
SENTIMENT ANALYSIS ALGORITHMS FOR NATURAL LANGUAGE TEXTS
M. V. Martynenko
ITMO University, 197101, St. Petersburg, Russia
The fundamental goals of sentiment analysis of natural language texts have been studied. The common ap-proaches used in sentiment analysis systems have been described and classified. The possibility of using frame semantics to solve sentiment analysis problems has been considered, along with its potential benefits.
Keywords: sentiment analysis, frame semantics, natural language processing, opinion, reputation.
Data on author Mark V. Martynenko — Student; ITMO University, Department of Computer Science;
E-mail: [email protected]
For citation: Martynenko M. V. Sentiment analysis algorithms for natural language texts // Proceedings of the scientific and practical conference of young scientists «Computing systems and networks (Mayorov’s read-ings)». 2016. P. 103—105 (in Russian).

106 ИНТЕЛЛЕКТУАЛЬНЫЕ ИНФОРМАЦИОННЫЕ СИСТЕМЫ
Сборник трудов VII научно-практической конференции молодых ученых «Вычислительные системы и сети (Майоровские чтения)»
УДК 004.832
ЗАДАЧА ОПРЕДЕЛЕНИЯ МАТЕМАТИЧЕСКИХ ТЕОРЕМ
П. А. Смирнов
Университет ИТМО, 197101, Санкт-Петербург, Россия
Рассмотрена задача автоматического доказательства теорем путем по-иска доказательства в дереве решений. Подобная задача характеризует-ся классической экспоненциальной пространственной и/или временной сложностью поиска. Основная часть методов редуцирования этой слож-ности подобных методов либо недостаточно эффективны, либо специ-фичны для решения каждой отдельной задачи, что требует дополни-тельных ресурсов на формирование подобного решения. В результате исследования в качестве наиболее общего и эффективного выбран пре-цедентный подход. Предложен метод выявления наиболее полезных прецедентов, апробированный на примере доказательства эквивалент-ности выражений.
Ключевые слова: автоматическое доказательство теорем, деревья решений, поиск в дереве решений, неинформированный поиск, прецеденты.
Решение задачи автоматического доказательства теорем сводится к поиску пути в дере-
ве состояний для удовлетворения условия определенной задачи [1]. Методы поиска решений определяют порядок обхода состояний в дереве решений.
В основном методы поиска решений разделяются на информированные и неинформи-рованные [1]. В качестве обобщенных методов поиска доказательства могут использоваться только неинформированные методы, вследствие того что информированные специфициру-ются на решении определенного круга задач. К основным неинформированным методам от-носят поиск в глубину, в ширину, двусторонний, эвристический [1].
Поскольку полный перебор всех вершин в дереве решений требует слишком большого времени [2], в качестве единственно удовлетворительного могут использоваться эвристиче-ские. Вследствие того, что эвристические методы поиска, как правило, являются также узко-специализированными, необходим другой подход к решению этой задачи.
Прецедентный подход используется для внедрения эффекта памяти вычислений в поиске в дереве решений [2, 3]. Он позволяет редуцировать повторяющиеся части дерева решений, что потенциально может сильно снизить время вычислений [2]. Однако главным минусом является сильная зависимость прецедентного подхода от количества и качества прецедентов в каждом отдельном случае. Для описания эффективности подхода используем следующую функцию, определяющую временную сложность.
,k kO l l P (1)
где l — степень ветвления, k — глубина поиска, P — количество прецедентов. Из формулы (1) можно сделать вывод, что уменьшение глубины поиска с использованием
прецедентов эффективно, только при:
1
21,
k
kp l
(2) где k1, k2 — глубина поиска с использованием и без использования прецедентов соответст-венно.
Согласно (1), минимизация числа прецедентов приведет к уменьшению пространствен-ной и временной сложности. Концептуально необходимость в минимизации определяется различием в смыслах термина «теорема» для науки и для машин вывода. Термин «теорема» в

ИНТЕЛЛЕКТУАЛЬНЫЕ ИНФОРМАЦИОННЫЕ СИСТЕМЫ 107
Сборник трудов VII научно-практической конференции молодых ученых «Вычислительные системы и сети (Майоровские чтения)»
общепринятом смысле означает логически выводимое утверждение из определенного набора аксиом, в то время как в математическом (научном) — универсальное, обобщенное и дока-занное утверждение, позволяющее выводить новые утверждения.
Так, в соответствии с (2) для машины вывода соотношение не будет выполняться:
kO p l . (3)
Зная, что математических теорем на текущий момент конечное число, а глубина поиска может быть бесконечной, можно догадаться, что если все прецеденты являются математиче-скими, то условие выполняется:
kp l . (4) На примере задачи доказательства эквивалентности выражений были предложены два
свойства для множества сохраненных прецедентов: 1) уникальность — каждый прецедент множества должен быть уникален, т.е. не выво-
дим из любого другого менее чем за N шагов, 2) простота — каждый прецедент является наиболее абстрактным и имеет наиболее об-
щую форму. Уникальность и простота каждого прецедента позволяют наиболее общим образом опи-
сать условие сохранения подобных прецедентов. Так, простота позволяет кодировать только обобщенную форму прецедента, а уникальность — экспоненциально уменьшить пространст-во прецедентов. На примере задачи доказательства эквивалентности выражений свойство простоты позволяет убрать зависимость от констант и названий неизвестных; свойство уни-кальности позволяет убрать «мусор», с точки зрения остальных правил и прецедентов.
Для удовлетворения этим двум свойствам в рамках решения задачи был предложен ме-тод, состоящий из следующих шагов:
— появление прецедента, — абстрагирование и его упрощение, — проверка на его уникальность путем последовательного применения n правил для
каждого из существующих прецедентов, — сохранение прецедента
1 2Nk k . (5)
Тогда согласно (5) соотношение (2) выполняется, что означает эффективность метода:
11
2 1nkp l . (6)
Автоматическое доказательство теорем при помощи алгоритмов поиска решений путем полного перебора, как правило, требует слишком большого количества ресурсов. Использо-вание методов эвристического поиска позволяет снизить их только в определенных ситуаци-ях при определенных условиях.
Представленный метод уникальных прецедентов позволил снизить теоретическую про-странственную и временную сложность автоматического доказательства теорем в общем ви-де. На примере задачи эквивалентности выражений была показана его эффективность. Таким образом, снизились минимальные вычислительные ресурсы, упростилась разработка про-грамм автоматического доказательства теорем.
ЛИТЕРАТУРА
1. Berliner H. J. The B* tree search algorithm: a best-first proof procedure. Carnegie-Mellon University, 1978.
2. Berliner H. J., McConnell C. B* Probability Based Search. Artificial Intelligence. 1996. Vol. 86 (1). P. 97—156.

108 ИНТЕЛЛЕКТУАЛЬНЫЕ ИНФОРМАЦИОННЫЕ СИСТЕМЫ
Сборник трудов VII научно-практической конференции молодых ученых «Вычислительные системы и сети (Майоровские чтения)»
3. Nosrati M., Karimi R., Hasanvand H. A. Investigation of the *(Star) Search Algorithms: Characteristics, Methods and Approaches // World Applied Programming. 2012. Vol. 2(4). P. 251—256.
Сведения об авторе Павел Андреевич Смирнов — магистрант; Университет ИТМО, кафедра вычислительной техники;
E-mail: [email protected] Ссылка для цитирования: Смирнов П. А. Задача определения математических теорем // Сборник трудов VII научно-практической конференции молодых ученых «Вычислительные системы и сети (Майоровские чтения)». 2016. С. 106—108.
PROBLEM OF MATHEMATICAL THEOREMS DETERMINATION
P. A. Smirnov
ITMO University, 197101, St. Petersburg, Russia
Existing methods in space complexity reduction do not allow to freely use logical programming in the task of automated theorem proving. In this study were suggested and tested modified case-based ap-proach for efficient decision trees reduction.
Keywords: theorem reasoning, decision tree search, decision tree, uninformative search, precedents, case-based reasoning.
Data on author Pavel A. Smirnov — Student; ITMO University, Department of Computer Science;
E-mail: [email protected]
For citation: Smirnov P. A. Problem of mathematical theorems determination // Proceedings of the scien-tific and practical conference of young scientists «Computing systems and networks (Mayorov’s read-ings)». 2016. P. 106—108 (in Russian).

ИНТЕЛЛЕКТУАЛЬНЫЕ ИНФОРМАЦИОННЫЕ СИСТЕМЫ 109
Сборник трудов VII научно-практической конференции молодых ученых «Вычислительные системы и сети (Майоровские чтения)»
УДК 004.832
МЕТОДЫ ПОИСКА ПО ДЕРЕВУ РЕШЕНИЙ, ИСПОЛЬЗОВАНИЕ ТЕЗАУРУСА ПРЕДМЕТНОЙ ОБЛАСТИ
М. Н. Адамчик
Университет ИТМО, 197101, Санкт-Петербург, Россия
При поиске решений в пространствах с множеством состояний одной из проблем является временная и ресурсная сложность алгоритмов. Пред-ложен способ преодоления проблемы временной сложности путем ис-пользования данных тезауруса предметной области при решении задач поиска с применением логического вывода. Приведен краткий обзор существующих стратегий и методов поиска по деревьям решений, опи-сывается назначение и применение тезаурусов в информационных сис-темах и задачах интеллектуального анализа данных. Рассмотрен пример поиска решений с использованием логических выводов в области хими-ческого неорганического синтеза — решается задача поиска исходных простых веществ для получения сложного вещества с заданными свой-ствами. При решении этой задачи составляется онтология предметной области, выявляются сложности, возникающие при применении мето-дов полного перебора или эвристического поиска, формируются логи-ческие выводы, позволяющие найти решение, строится дерево решений. Сделан вывод о том, что поиск с использованием логических выводов и сведений предметной области позволяет решать более абстрактные за-дачи, чем поиск с использованием других методов.
Ключевые слова: поиск решений в пространстве состояний, деревья решений, логический вывод, неинформированный поиск, информированный поиск, тезаурус.
Существуют две стратегии поиска решений: поиск от начального состояния к целевому
(поиск по данным) и поиск от цели к исходному состоянию. Поиск от цели позволяет отсечь заведомо ложные ветви, но он применим, только если цель в задаче известна. Поиск по дан-ным лучше применять, если известны все исходные данные [1].
Использование слепого поиска в широкой предметной области может потребовать слишком высоких затрат времени и ресурсов.
Эвристические методы повышения эффективности поиска учитывают сведения о ре-шаемых задачах. Информация представляется в виде эвристической функции, выражающей стоимость пути от текущего узла до цели [2].
Известны следующие алгоритмы информированного поиска: жадный поиск по первому наилучшему совпадению, алгоритмы A* [2—5], рекурсивный поиск по первому наилучшему совпадению (RBFS), поиск B* [3, 6, 7], алгоритм минимакса и альфа-бета-отсечение [1, 8].
Сократить пространство поиска можно также с помощью алгебры логики, например, путем поиска на основе исчисления предикатов [1, 8, 9]. Поиск в данном случае заключается в формировании логических выводов из информации об истинности высказываний.
Тезаурус используется для описания сведений о предметной области и представляет со-бой словарь терминов и связей между ними. В информационных системах тезаурусы чаще используются для классификации или индексации понятий, а также для навигации по тезау-русу: поиск понятия в тезаурусе, а затем поиск ресурсов, относящихся к этому понятию [10]. В таких тезаурусах связи описывают логику предметной области. Тезаурусы активно исполь-зуются при решении лингвистических задач, например, информационного поиска [11].

110 ИНТЕЛЛЕКТУАЛЬНЫЕ ИНФОРМАЦИОННЫЕ СИСТЕМЫ
Сборник трудов VII научно-практической конференции молодых ученых «Вычислительные системы и сети (Майоровские чтения)»
При поиске по дереву решений применение тезауруса позволяет исключить ветви, ко-торые не соответствуют искомому решению, за счет ограничения множества понятий, ис-пользуемых в данной предметной области.
Пусть необходимо выявить требуемые реагенты для получения соединения с заданны-ми свойствами из простых веществ. Пусть также сложное вещество относится к классу гид-роксидов, проявляет основные свойства, является сильным и растворимым в воде.
При поиске методами полного перебора коэффициент ветвления будет слишком боль-шим. Для применения эвристических алгоритмов необходимо определить функцию оценки. Свойства получаемых промежуточных соединений не отображают приближение к решению, поскольку они меняются при каждом взаимодействии. Функция оценки, основанная на набо-ре химических элементов в соединении, не может использоваться в данном случае — хими-ческая формула искомых и целевых веществ неизвестна. Для решения поставленной задачи возможно использование логических выводов на основе информации о предметной области.
Тезаурус, включающий в себя понятия атомов, простых и сложных веществ, их свойств и связи между понятиями, представленный в виде онтологии, созданной в редакторе Protégé, по-казан на рис. 1. Свойства неорганических веществ, релевантные для программной реализации поиска решений в данной предметной области, были установлены в работе [12].
Рис. 1. Тезаурус, представленный в виде онтологии
Онтология предметной области позволяет получить правила, основанные на свойствах веществ. Эти правила используются при логическом выводе. Для категоризации целевого сложного соединения анализируются правила, связанные с заданными свойствами. В частно-сти, из логического вывода видно, что искомое вещество — щелочь:
ЦВ Г РВВ СИЛ ОСНГ ОСН ОГ
Г РВВ СИЛ ОСН ОГ РВВ СИЛ щелочьОГ РВВ СИЛ
щелочь
(1)
где ЦВ — целевое вещество, Г — гидроксид, ОГ — основный гидроксид, РВВ — растворим в воде, СИЛ — сильный, ОСН — основный.
Получение типа искомого вещества позволяет осуществить поиск по дереву с использо-ванием терминов предметной области, обобщая узлы, представляющие конкретные вещества, в узлы-классы. Это позволит быстрее установить путь между группой исходных простых ве-ществ и целевой группой сложных веществ.

ИНТЕЛЛЕКТУАЛЬНЫЕ ИНФОРМАЦИОННЫЕ СИСТЕМЫ 111
Сборник трудов VII научно-практической конференции молодых ученых «Вычислительные системы и сети (Майоровские чтения)»
С помощью правил протекания химических реакций, задающих переходы в дереве ре-шений, устанавливается класс исходных простых веществ. Зная класс и необходимые свойст-ва исходных веществ, можно установить действительные решения, основываясь на сведениях о свойствах простых веществ в тезаурусе.
Путь по дереву решений, где узлы — понятия тезауруса, представлен на рис. 2.
Рис. 2. Путь по дереву решений
Таким образом, данные тезауруса использовались для навигации по дереву решений. Задача поиска была решена при использовании известных свойств веществ для установления соответствия с определенным понятием тезауруса и дальнейшим применением логических выводов из правил.
Поиск решений с помощью алгоритмов полного перебора затруднителен в широких предметных областях. При использовании алгоритмов эвристического поиска не всегда воз-можно установление подходящих функций оценки для решения задач.
Использование данных онтологии предметной области в качестве источника сведений для формирования правил и фактов в методах поиска решений, основанных на логике, позво-ляет значительно уменьшить количество исследуемых узлов и ветвей дерева.
ЛИТЕРАТУРА
1. Люгер Дж. Ф. Искусственный интеллект. Стратегии и методы решения сложных проблем. М.: Вильямс, 2003.
2. Рассел С., Норвиг П. Искусственный интеллект: Современный подход. М.: Вильямс, 2006.
3. Nosrati M., Karimi R., Hasanvand H. A. Investigation of the *(Star) Search Algorithms: Characteristics, Methods and Approaches // World Applied Programming. TI Journals. 2012. Vol. 2(4). P. 251—256.
4. Russell S. Efficient memory-bounded search methods // Proc. of the 10th European Conf. on Artificial intelligence (ECAI 92). 1992. P. 1—5.
5. Zhou R., Hansen E. A. Memory-Bounded A* Graph Search // 15th Intern. FLAIRS Conf. Pensecola, Florida, 2002.
6. Berliner H. J. The B* tree search algorithm: a best-first proof procedure. Carnegie-Mellon University, Dept. of Computer Science, 1978.
7. Berliner H. J., McConnell Ch. B* Probability Based Search // Artificial Intelligence. 1996. Vol. 86(1). P. 97—156.
8. Нильсон Н. Искусственный интеллект. Методы поиска решений. М.: Мир, 1973.

112 ИНТЕЛЛЕКТУАЛЬНЫЕ ИНФОРМАЦИОННЫЕ СИСТЕМЫ
Сборник трудов VII научно-практической конференции молодых ученых «Вычислительные системы и сети (Майоровские чтения)»
9. Нугуманова А. Б., Бессмертный И. А., Денисова Н. Ф. Интеллектуальные системы. Усть-Каменогорск: ВКГТУ, 2013.
10. Нгуен Х. М., Аджиев А. С. Описание и использование тезаурусов в информационных системах, подходы и реализация // Электронные библиотеки. 2004. Т. 7, № 1.
11. Лукашевич Н. В. Тезаурусы в задачах информационного поиска. М., 2010.
12. Адамчик М. Н. Поиск на дереве решений в задачах неорганического синтеза // Сборник трудов молодых ученых и сотрудников кафедры ВТ. 2015. C. 16—18.
Сведения об авторе Марина Николаевна Адамчик — магистрант; Университет ИТМО, кафедра вычислительной техники;
E-mail: [email protected] Ссылка для цитирования: Адамчик М. Н. Методы поиска по дереву решений, использование тезауруса пред-метной области // Сборник трудов VII научно-практической конференции молодых ученых «Вычислительные системы и сети (Майоровские чтения)». 2016. С. 109—112.
METHODS OF DECISION TREE SEARCH, USAGE OF A SUBJECT DOMAIN THESAURUS
M. N. Adamchik
ITMO University, 197101, St. Petersburg, Russia
When performing a decision search in spaces will a lot of states one of the problems are time and re-source complexity of the algorithms. The solution of time complexity problem by usage of subject do-main thesaurus data in cases of solving decision search issues by inference is offered in the article. Short overview of existing strategies and methods of search on a decision tree is given, usage of thesauruses in information systems and data mining tasks is described. A decision search with inference is shown on ex-ample in chemistry inorganic synthesis subject domain — a task of searching simple compounds needed to get complex compound with exact properties is being solved. While solving the task an ontology of the subject domain is being created, difficulties of using exhaustive search methods or heuristics search methods are being identified, inferences for getting a solution are being formed, a decision tree that dem-onstrates the solution is being created. By results of the work the conclusion is that search with usage of inferences and data of a subject domain manages to solve more abstract tasks than search with another methods.
Keywords: state space search, decision tree, inference, exhaustive search, heuristic search, thesaurus.
Data on author Marina N. Adamchik — Student; ITMO University, Department of Computer Science;
E-mail: [email protected]
For citation: Adamchik M. N. Methods of decision tree search, usage of a subject domain thesaurus // Proceedings of the scientific and practical conference of young scientists «Computing systems and net-works (Mayorov’s readings)». 2016. P. 109—112 (in Russian).

ИНТЕЛЛЕКТУАЛЬНЫЕ ИНФОРМАЦИОННЫЕ СИСТЕМЫ 113
Сборник трудов VII научно-практической конференции молодых ученых «Вычислительные системы и сети (Майоровские чтения)»
УДК 004.912
ОРГАНИЗАЦИЯ ХРАНЕНИЯ ДАННЫХ В ОТКРЫТЫХ ФОРМАТАХ ДОКУМЕНТОВ
К. З. Аслами
Университет ИТМО, 197101, Санкт-Петербург, Россия
Рассматривается организация хранения данных в открытых форматах документов. Описывается модуль, используемый в текстовом процессо-ре LibreOffice Writer для представления документов в памяти. Изучен исходный код офисного пакета LibreOffice с целью выделить основные структуры, необходимые для корректной работы с текстовыми файлами различного формата. В результате исследования определена стратегия использования такого подхода для разработки модуля предварительной обработки документов в системе семантического анализа.
Ключевые слова: SwDoc, открытые форматы документов, LibreOffice Writer, текстовый процессор, неструктурированные данные, семантический анализ.
Введение
В связи с экспоненциальным увеличением объема неструктурированной текстовой ин-формации трудоемкость процесса анализа данных человеком возрастает. Автоматизировать решение такой задачи позволяют системы извлечения и анализа данных, осуществляющие лингвистическую обработку текста [1—6].
Интеллектуальный анализ текста может быть осуществлен путем извлечения семанти-ческой информации — смыслового содержания контекста. Создание инструмента, автомати-зирующего этот процесс, позволит анализировать большие массивы информации в сравни-тельно короткие сроки.
Одним из этапов разработки системы семантического анализа является организация из-влечения текстовой информации из документов различных форматов. При этом возникает проблема неоднородности структур данных, использующихся различными текстовыми про-цессорами для представления документа. Каждый текстовый формат имеет собственный язык разметки, поэтому для преодоления этой проблемы необходимо унифицировать способ хра-нения документов. Такой подход позволяет осуществлять интеллектуальный анализ текста независимо от исходного формата файла.
Возможность обработки текстовых документов различных форматов реализована в большинстве современных текстовых процессоров, и в настоящей работе рассматривается решение, используемое офисным пакетом LibreOffice.
Представление документов
LibreOffice — свободно распространяемый кроссплатформенный пакет офисных про-грамм с открытым исходным кодом. Текстовый процессор LibreOffice Writer позволяет обра-батывать наиболее распространенные форматы документов, в том числе RTF, XHTML, DOC и DOCX, а по умолчанию используется расширение ODT, являющееся частью международ-ного стандарта Open Document Format. LibreOffice распространяется по свободной лицензии GNU Lesser General Public License v3. Это позволяет использовать пакет как для персональ-ных, так и для коммерческих целей, копировать и распространять его, а также модифициро-вать для создания производных работ.
Исходный код проекта LibreOffice был создан как код проприетарной программы StarWriter, выпущенной 1985 г. компанией StarDivision. По этой причине модуль текстового процессора, который отвечает за преобразование документов и организацию взаимодействия

114 ИНТЕЛЛЕКТУАЛЬНЫЕ ИНФОРМАЦИОННЫЕ СИСТЕМЫ
Сборник трудов VII научно-практической конференции молодых ученых «Вычислительные системы и сети (Майоровские чтения)»
между моделью данных и их представлением, носит название SW. Модуль содержит логику работы LibreOffice Writer и описывает структуру представления документов в памяти. Имен-но эта структура является результатом унификации текстовых файлов различных форматов. Она отделяет представление документа от его модели.
Представление документа задается так называемыми фреймами (Frame) — областями, определяющими внешний вид основной части документа, верхнего и нижнего колонтитулов, секций и других разделов. Все фреймы наследуются от базового класса SwFrm, который яв-ляется производным от SwClient. Несколько фреймов одного уровня иерархии связаны друг с другом указателями на предыдущий (pPrev) и последующий (pNext). Фреймовые объекты разных уровней и типов связаны указателями на объект, который владеет текущим (pUpper), и объект, который содержится в текущем (pLower), при условии, что такие имеются. Некото-рые объекты могут отображаться на нескольких страницах, в таком случае указывается их продолжение (pFollow). Пример представления документа показан на рис. 1. Для решения поставленной задачи визуальное отображение документа не играет определяющей роли, по-этому более детальное описание фреймов выходит за рамки работы.
Рис. 1. Представление документа
Модель документа представлена классом SwDoc. В нем содержится объект SwNodes, который представляет собой массив указателей на начальные и конечные области каждого узла (Node, SwNode) — логического объединения различных разделов документа. Модель документа имеет иерархическую структуру, поэтому каждый раздел содержит указатель (pStartOfSection) на начало узла, в котором находится текущий. При создании раздела проис-ходит вызов метода (MakeFrms), который создает соответствующий фрейм, описывающий внешнее представление текущей области. Также он подписывается на так называемые собы-тия узла и в случае изменений обновляет отображение.

ИНТЕЛЛЕКТУАЛЬНЫЕ ИНФОРМАЦИОННЫЕ СИСТЕМЫ 115
Сборник трудов VII научно-практической конференции молодых ученых «Вычислительные системы и сети (Майоровские чтения)»
В целом документ разбивается: первый раздел всегда пустой и не используется, далее следует раздел сносок и примечаний, затем — раздел верхнего и нижнего колонтитулов. Чет-вертый раздел, как правило, скрыт от пользователя и содержит удаленный контент текущего файла, что позволяет осуществить повтор или отмену какого-либо совершенного действия, пятый объединяет основное содержимое документа.
На рис. 2 представлен пример структур модели и представления документа. Данный до-кумент содержит верхний колонтитул с двумя параграфами, условно обозначенными как X и Y. Основное содержимое состоит из параграфа A, секции S, в которой содержится абзац B, и еще двух параграфов C и D вне секции. При этом параграф C не поместился на одну страни-цу, поэтому часть его содержимого находится на второй странице.
Рис. 2. Структура модели и представления документа
Работа с различными текстовыми форматами в LibreOffice Writer реализована при по-мощи так называемых фильтров. Они определяют тип документа, создают необходимые структуры (потоки) для чтения и записи данных, а затем считывают (или записывают) ин-формацию. На рис. 3 представлена иерархия классов, осуществляющих чтение данных из файлов различных форматов.
Рис. 3. Иерархия классов
Из схемы видно, что для каждого типа документа необходим отдельный компонент, а именно: структура AsciiReader для работы с потоком ASCII-символов, HTMLReader и SWRTFReader для чтения файлов HTML и RTF соответственно, WW8Reader для старой вер-сии формата Microsoft Word (.doc), а также XMLReader для XML-структур. Необходимо от-метить, что на диаграмме отсутствуют компоненты, осуществляющие чтение файлов Open-Documet Format и нового стандарта Microsoft Word (.docx). Дело в том, что эти форматы представляют собой архив, содержащий текст в виде XML, следовательно, они не требуют дополнительных классов.

116 ИНТЕЛЛЕКТУАЛЬНЫЕ ИНФОРМАЦИОННЫЕ СИСТЕМЫ
Сборник трудов VII научно-практической конференции молодых ученых «Вычислительные системы и сети (Майоровские чтения)»
Заключение
В работе рассмотрена организация представления документов в памяти, используемая в текстовом процессоре LibreOffice Writer. Исследование показало, что такой подход может быть использован для создания модуля предварительной обработки документов в системе семантического анализа. На следующем этапе разработки необходимо выделить рассмотрен-ные компоненты, избавившись от внешних зависимостей, оставив лишь те файлы исходного кода, которые требуются для чтения и представления документов в памяти.
ЛИТЕРАТУРА
1. OOoAuthors Team Staff. OpenOffice.org 3 Impress Guide/OOoAuthors, Friends of OpenDocument. Lulu.com, 2010. 291 р.
2. Заботкина В. И. Методы когнитивного анализа семантики слова: компьютерно-корпусный подход. М.: Языки славянской культуры, 2015. 344 с.
3. Ахутина Т. В. Нейролингвистический анализ лексики, семантики и прагматики. М.: Языки славянской культуры, 2014. 424 с.
4. Writer application code source and explanation [Электронный ресурс]: <http:// opengrok.libreoffice.org/xref/core/sw/>.
5. Writer/Core And Layout explanation [Электронный ресурс]: <https://wiki.openoffice.org/wiki/ Writer/Core_And_Layout>.
6. LibreOffice Module sw (master) Documentation [Электронный ресурс]: <https:// docs.libreoffice.org/sw/html/index.html>.
Сведения об авторе Камилла Зарифовна Аслами — студент; Университет ИТМО, кафедра вычислительной техники;
E-mail: [email protected] Ссылка для цитирования: Аслами К. З. Организация хранения данных в открытых форматах документов // Сборник трудов VII научно-практической конференции молодых ученых «Вычислительные системы и сети (Майоровские чтения)». 2016. С. 113—116.
STORING DATA IN OPEN DOCUMENT FORMATS
K. Z. Aslami
ITMO University, 197101, St. Petersburg, Russia
The paper describes the organization of storing data in open document formats. It describes the module used in LibreOffice Writer word processor for the representation of documents in memory. The research was conducted by investigating the source code of LibreOffice project in order to identify the main struc-tures needed for correct work with text files of various formats. The results helped to determine the strat-egy of using the regarded implementation for developing the module for pre-processing documents in the semantic analysis system.
Keywords: LibreOffice Writer, word processor, SwDoc, Open Document Format, semantic analysis.
Data on author Kamilla Z. Aslami — Student; ITMO University, Department of Computer Science;
E-mail: [email protected]
For citation: Aslami K. Z. Storing data in open document formats // Proceedings of the scientific and practical conference of young scientists «Computing systems and networks (Mayorov’s readings)». 2016. P. 113—116 (in Russian).

ИНТЕЛЛЕКТУАЛЬНЫЕ ИНФОРМАЦИОННЫЕ СИСТЕМЫ 117
Сборник трудов VII научно-практической конференции молодых ученых «Вычислительные системы и сети (Майоровские чтения)»
УДК 004.823
РАСШИРЯЕМАЯ ГРАММАТИКА ФРЕЙМОВ ФИЛЛМОРА
В. А. Богданова
Университет ИТМО, 197101, Санкт-Петербург, Россия
Изучены основные положения теории фреймов Филлмора, позволяю-щей решать задачи обработки текста на естественном языке. Проанали-зированы и описаны основные особенности фреймов, входящих в базу данных FrameNet. Обоснована необходимость разработки языка, позво-ляющего динамически расширять грамматику фреймов с целью упро-стить задачу обработки и добавления новых данных для FrameNet. Перечислены основные требования, предъявляемые к языку.
Ключевые слова: семантический анализ, фрейм, лексическая единица, FrameNet, обработка естест-венного языка, семантика фреймов, SEMAFOR, автоматическая разметка семантических ролей.
Семантический анализ текста — один из элементов теории создания искусственного интеллекта в области обработки естественного языка и компьютерной лингвистики. Резуль-таты семантического анализа могут применяться в поисковых системах, системах автомати-ческого перевода и т.д. Задача семантического анализа является одной из сложнейших в ма-тематике. Вся сложность заключается в том, чтобы «научить» компьютер правильно тракто-вать образы, которые автор текста пытается передать своим читателям/слушателям. Основ-ные проблемы могут заключаться в равнозначности слов, различных формах предложений в разных языках, обучении системы предметной области.
Для решения задач обработки естественного языка может быть использована теория фреймов, основные идеи которой были выдвинуты в 1960—1970 гг. Чарльзом Филлмором [1], она стала развитием его идеи о семантических ролях.
Во время исследований Филлмор пришел к выводу, что значения слов в сознании орга-низованы в некие структуры — фреймы, т.е. смысловые рамки, которые используются чело-веком для понимания чего-либо, набор ассоциаций, связанный с этой смысловой рамкой. Например, чтобы описать значение глагола «продавать», необходимы знания о том, что су-ществуют продавец, покупатель, деньги, товар и что все эти объекты определенным образом связаны между собой.
То, что в 1960—1980-х гг. развивалось как фреймовая семантика [2], в 1990-х преврати-лось во фреймовые сети, описание семантики языка при помощи сети взаимосвязанных фреймов, где каждое слово связано с набором примеров. Практическое воплощение этой идеи — проект FrameNet [3], начавшийся в 1997 году. Он представляет собой лексическую базу дан-ных английского языка, организованную по фреймам, в которые входят слова. База данных позволяет исследователю искать нужные фреймы, элементы, слова. Для каждого значения каждого слова доступны примеры его употребления.
В ходе работы была изучена структура фреймов, составляющих базу данных FrameNet. Фреймы состоят из нескольких элементов [4]:
— лексический блок, лексическая единица (Lexical unit, LU) — «слово» в одном из сво-их возможных значений (обычно глагол). Лексический блок вызывает фрейм;
— элемент фрейма (Frame Element, FE) — семантическая роль как базовая единица фрейма, которая специфична именно для данного фрейма, имеет к нему отношение;
— определение фрейма — словесное описание ситуации, включающей в себя различ-ных участников и другие концептуальные роли, каждая из которых образует, представляет собой элемент фрейма.

118 ИНТЕЛЛЕКТУАЛЬНЫЕ ИНФОРМАЦИОННЫЕ СИСТЕМЫ
Сборник трудов VII научно-практической конференции молодых ученых «Вычислительные системы и сети (Майоровские чтения)»
Рассмотрим пример фрейма «тепловая обработка пищи» (см. таблицу). В целом понятие тепловой обработки включает в себя личность, которая выполняет приготовления (Повар, тот, кто готовит) и применяет тепло к пище, сама еда, которая готовится (Еда), Настрой-ка_температуры разогрева, кроме того, могут быть также указаны длительность воздействия и источник тепла, т.е. инструмент, с помощью которого разогревается пища. В базе данных FrameNet эта концепция представлена как фрейм Apply_heat [5] (тепловая обработка), и слова Повар, пища, инструмент приготовления и Настройка_температуры называются элементами фрейма (т.е. роли, которые относятся к фрейму). Слова, которые вызывают фрейм (лексиче-ские единицы) — кипятить, жарить, варить, печь и др. (как правило, это глаголы, но могут быть и существительные — Тушение, Жарка и др.).
Элементы фрейма «Тепловая обработка пищи» Определение Элементы фрейма Лексические единицы
Повар обрабатывает еду под воздействием
температуры. Могут быть указаны
Значение_температуры, Длительность обработки,
Инструмент
Повар Еда (пища)
Значение_температуры Длительность Инструмент
Кипятить Жарить Печь Варить Тушение Жарка и др.
Основная задача FrameNet — обнаружить фрейм и проаннотировать предложения, что-бы показать, как элементы фрейма (роли) соответствуют словам, которые вызывают фрейм.
FrameNet использует лексикографическую аннотацию примеров. В каждом предложе-нии-примере помечается одна цель — составляющая, которая помогает иллюстрировать при-мерами элементы фреймов (роли). Аннотация необходима, чтобы показать слово-цель (лек-сический блок), используемый в языке; также она позволяет учесть элементы фрейма, кото-рые не проиллюстрированы примером.
FrameNet содержит множество аннотированных примеров. Благодаря этим примерам FrameNet используют разработчики в системах, которые обучаются на аннотированных дан-ных и автоматически производят похожие аннотации для новых, ранее неизвестных, текстов. Этот процесс назвали автоматической разметкой семантических ролей. Существует несколько систем для такого анализа, одна из них — SEMAFOR [6], находящаяся в свободном доступе.
Однако FrameNet не лишен недостатков, один из главных — необходимость обрабаты-вать фреймы, лексические единицы и различную информацию о них вручную. Были проана-лизированы исходные данные для FrameNet [7], представляющие собой набор файлов xml, каждый из которых хранит информацию об отдельном фрейме или лексической единице, в частности, идентификатор фрейма. Отдельными тегами помечаются элементы фрейма (роли), тип роли (может быть главной и второстепенной), проаннотированные примеры и отношения между фреймами.
Таким образом, поскольку для хранения фреймов используется единый формат, суще-ствует возможность реализовать автоматическую или полуавтоматическую обработку дан-ных, поэтому необходимо создать единый язык для описания фреймов. Язык должен добав-лять новые фреймы, сохраняя их в определенном формате, изменять уже существующие и использовать некоторые внешние источники информации, позволяющие упростить и уско-рить обработку фреймов.
ЛИТЕРАТУРА
1. Fillmore Ch. J., Baker C. F. Frame Semantics for Text Understanding. North American Chapter of the Association for Computational Linguistics, 2001.

ИНТЕЛЛЕКТУАЛЬНЫЕ ИНФОРМАЦИОННЫЕ СИСТЕМЫ 119
Сборник трудов VII научно-практической конференции молодых ученых «Вычислительные системы и сети (Майоровские чтения)»
2. Dipanjan D., Chen D., Martins A. F. T., Schneider N., Smith N. A. Frame-Semantic Parsing. Association for Computational Linguistics, 2014.
3. FrameNet Berkeley Project [Электронный ресурс]: <https://framenet.icsi.berkeley.edu>.
4. Ruppenhofer J., Ellsworth M., M. Petruck R. L., Johnson Ch. R., Scheffczyk J. FrameNet II: Extended Theory and Practice. International Computer Science Institute, 2006.
5. FrameNet Data [Электронный ресурс]: <https://framenet.icsi.berkeley.edu/fndrupal/ index.php?q=frameIndex>.
6. SEMAFOR – frame-semantic parser [Электронный ресурс]: <http://www.cs.cmu.edu/ ~ark/SEMAFOR/>.
7. Baker C. F., Sato H. The FrameNet Data and Software // The Companion Volume to the Proc. of 41st Annual Meeting of the Association for Computational Linguistics. 2003.
Сведения об авторе Валентина Алексеевна Богданова — студент; Университет ИТМО, кафедра вычислительной техники;
E-mail: [email protected]
Ссылка для цитирования: Богданова В. А. Расширяемая грамматика фреймов Филлмора // Сборник трудов VII научно-практической конференции молодых ученых «Вычислительные системы и сети (Майоровские чтения)». 2016. С. 117—119.
EXTENSIBLE GRAMMAR OF FILLMORE’S FRAMES
V. A. Bogdanova
ITMO University, 197101, St. Petersburg, Russia
The fundamentals of the theory of Fillmore’s frames that allows to solve the problem of text processing in natural language were studied. The main features of the frames included in the database FrameNet were analyzed and described. It posed the problem of developing of language that allows to dynamically expand the grammar of frames to simplify the task of processing and adding new data to FrameNet. It was listed the basic requirements for language.
Keywords: semantic analysis, frame, lexical unit, FrameNet, natural language processing, frame seman-tics, SEMAFOR, automatic semantic role labeling.
Data on author Valentina A. Bogdanova — Student; ITMO University, Department of Computer Science;
E-mail: [email protected]
For citation: Bogdanova V. A. Extensible grammar of fillmore’s frames // Proceedings of the scientific and practical conference of young scientists «Computing systems and networks (Mayorov’s readings)». 2016. P. 117—119 (in Russian).

120 ИНТЕЛЛЕКТУАЛЬНЫЕ ИНФОРМАЦИОННЫЕ СИСТЕМЫ
Сборник трудов VII научно-практической конференции молодых ученых «Вычислительные системы и сети (Майоровские чтения)»
УДК 004
СРАВНИТЕЛЬНЫЙ АНАЛИЗ C И C++ БИБЛИОТЕК ДЛЯ ФОРМАТА JSON
О. И. Широков
Университет ИТМО, 197101, Санкт-Петербург, Россия
Выполнен сравнительный анализ ряда библиотек для работы с форма-том JSON в приложениях на C/C++. Разработаны набор критериев, а также методика сравнения производительности различных библиотек. К сравнению были предложены библиотеки, имевшие программный ин-терфейс для использования в языке C++, а именно: RapidJSON, Jannson, JsonSpirit, JsonCpp, cJSON, JSMN. По результатам сравнения был обос-нован выбор библиотеки RapidJSON, наилучшим образом подходящей для разработки модуля внешнего сетевого интерфейса системы семан-тического анализа.
Ключевые слова: C, C++, JSON, оценка производительности, API. В последнее время в связи с огромным ростом текстовой информации в электронном
виде большое развитие получили системы семантического анализа текстовых документов, которые могут использоваться в автоматическом режиме для извлечения и обработки инфор-мации, представленной на естественных языках [1—6]. Как правило, такие системы предъяв-ляют повышенные требования к вычислительным ресурсам и объемам дисковых хранилищ, поэтому рациональным является использование клиент-серверной архитектуры и размещение у конечных пользователей лишь относительно небольших приложений, использующих сеть для взаимодействия с удаленной системой. Такое решение требует разработки специальных компонентов для сетевого взаимодействия. Были определены: транспортный протокол и формат передачи данных от клиента серверу — HTTP и JSON соответственно. Был выбран язык программирования, на котором должна вестись разработка — C++.
JavaScript Object Notation (JSON) — популярный текстовый формат передачи данных, несмотря на простоту, он хорошо подходит для сериализации сложных структур, а также мо-жет быть легко прочитан человеком. Ввиду его популярности существует множество готовых библиотек для различных языков программирования, что ставит задачу выбора подходящей библиотеки для работы с JSON. Самостоятельная разработка JSON-парсера требует выполне-ния достаточно большого объема работ и является достаточно трудоемкой, поэтому ввиду существования большого числа готовых решений представляется нерациональной.
После анализа существующих решений, в ходе которого выбирались библиотеки с C/C++-совместимым интерфейсом, а также с лицензионными требованиями, позволяющими использовать их в проекте, были выбраны: RapidJSON, JsonSpirit, JsonCpp, cJSON, Janson, JSMN.
Для определения наиболее подходящей библиотеки были определены следующие кри-терии сравнения:
— скорость разбора JSON, — скорость доступа к значениям полученного после разбора представления в памяти, — уровень абстракции интерфейса от данных. Для сравнения скорости разбора был разработан набор тестов. В каждом тесте измеря-
лось время, затраченное на разбор переданного файла и конкатенацию всех значений (с при-ведением к строковому типу) с использованием определенной библиотеки. Для исключения влияния системы кэширования на результаты измерений исключались первые несколько ре-зультатов, кроме того, каждый тест выполнялся несколько раз.

ИНТЕЛЛЕКТУАЛЬНЫЕ ИНФОРМАЦИОННЫЕ СИСТЕМЫ 121
Сборник трудов VII научно-практической конференции молодых ученых «Вычислительные системы и сети (Майоровские чтения)»
Тест запускался для файлов размером в 500, 2500, 5000 и 15000 элементов. Для запуска тестов использовался стенд со следующей конфигурацией:
— CPU: Intel i5-2410m 2.30 GHz, — OS: Linux 4.2.0-19-generic x86_64, — GCC v. 5.2.1, — опции сборки: "-O3 -std=c++11". Данные, полученные после выполнения тестов, отражены на рисунке.
Сравнение по уровню абстракции позволяет оценить затраты на использование самой
библиотеки в коде. Очевидно, что программные средства, обладающие высокоуровневым программным интерфейсом, упрощают доступ к полученным данным, а следовательно, более предпочтительны для использования в рамках разрабатываемой программы.
Для наглядности результаты сравнения представленных решений сведены в таблицу.
Библиотека Производительность Уровень абстракции
RapidJSON 1 Управление памятью реализовано в коде библиотеки. Доступ к данным через классы, реализованные в библиотеке
JsonSpirit 6 Управление памятью реализовано в коде библиотеки. Доступ к данным через классы, реализованные в библиотеке
JsonCpp 3 Управление памятью реализовано в коде библиотеки. Доступ к данным через классы, реализованные в библиотеке
cJSON 2 Необходимо вручную вызывать методы для инициализации и освобожде-ния памяти под необходимые для внутренних структур библиотеки
Jansson 4 Необходимо вручную вызывать методы для инициализации и освобожде-ния памяти под необходимые для внутренних структур библиотеки
JSMN 5 Необходимо вручную освобождать память. Библиотека возвращает индек-сы конца и начала подстроки в переданной библиотеке JSON-строке, со-держащей запрошенное значение
Из данных таблицы можно сделать вывод, что библиотека RapidJSON наиболее подхо-дит для использования в проекте, поскольку показывает наилучшие результаты в тестах про-изводительности, а также предоставляет высокоуровневый интерфейс работы с данными, что

122 ИНТЕЛЛЕКТУАЛЬНЫЕ ИНФОРМАЦИОННЫЕ СИСТЕМЫ
Сборник трудов VII научно-практической конференции молодых ученых «Вычислительные системы и сети (Майоровские чтения)»
избавляет разработчика от необходимости прямой работы с памятью и влечет за собой уменьшение количества ошибок в программном коде.
В итоге был проведен анализ существующих решений, выделены критерии сравнения, разработан набор тестов, и определена наилучшим образом подходящая библиотека для раз-работки модуля сетевого интерфейса семантической системы.
ЛИТЕРАТУРА
1. The JavaScript Object Notation (JSON) Data Interchange Format [Электронный ресурс]: <https://tools.ietf.org/html/rfc7159>.
2. RapidJSON [Электронный ресурс]: <http://rapidjson.org>.
3. JSMN [Электронный ресурс]: <http://zserge.com/jsmn.html>.
4. Wilkinson J. W. JSON Spirit: A C++ JSON Parser/Generator Implemented with Boost Spirit [Электронный ресурс]: <http://www.codeproject.com/Articles/20027/JSON-Spirit-A-C-JSON-Parser-Generator-Implemented>.
5. Jsoncpp [Электронный ресурс]: <https://github.com/open-source-parsers/jsoncpp>.
6. Jansson [Электронный ресурс]: <http://www.digip.org/jansson>.
Сведения об авторе Олег Игоревич Широков — студент; Университет ИТМО, кафедра вычислительной техники;
E-mail: [email protected] Ссылка для цитирования: Широков О. И. Сравнительный анализ C и C++ библиотек для формата JSON // Сборник трудов VII научно-практической конференции молодых ученых «Вычислительные системы и сети (Майоровские чтения)». 2016. С. 120—122.
COMPARISION ANALYSIS OF JSON PARSERS
O. I. Shirokov
ITMO University, 197101, St. Petersburg, Russia
The article describes a comparative analysis of a number of libraries for working with JSON format in C / C++ programs, caused by the necessity of providing a certain level of performance. JavaScript Object Notation (JSON) is a popular and simple text data format suitable for the serialization of complex struc-tures. Despite the wide use of JSON format, many libraries for various programming languages are ex-ists. That was the cause of the problem of choosing a suitable library to parse this format. For the task so-lution a set of comparison criteria was developed as well as a method of comparing the performance of different libraries. The comparison list included libraries: RapidJSON, Jannson, JsonSpirit, JsonCpp, cJSON, JSMN. As a result RapidJSON had the best performance and user-friendly API to work with.
Keywords: C, C++, JSON, Perfomance testing, API
Data on author Oleg I. Shirokov — Student; ITMO University, Department of Computer Science;
E-mail: [email protected]
For citation: Shirokov O. I. Comparision analysis of JSON parsers // Proceedings of the scientific and practical conference of young scientists «Computing systems and networks (Mayorov’s readings)». 2016. P. 120—122 (in Russian).

Сборник трудов VII научно-практической конференции молодых ученых «Вычислительные системы и сети (Майоровские чтения)»
ТЕХНОЛОГИИ КОМПЬЮТЕРНОЙ ВИЗУАЛИЗАЦИИ
УДК 004.4'27
ПРИМЕНЕНИЕ ТЕХНОЛОГИЙ ЗАХВАТА ДВИЖЕНИЙ ДЛЯ УПРАВЛЕНИЯ ИНТЕРАКТИВНЫМИ СИСТЕМАМИ
В СОВРЕМЕННОМ ИСКУССТВЕ
А. В. Марьина, Е. А. Доронина
Университет ИТМО, 197101, Санкт-Петербург, Россия
Проведена обработка данных устройства Kinect и определены опти-мальные параметры помещений для использования интерактивных сис-тем. Примером такой системы служит интерактивная инсталляция, на-писанная в среде программирования Processing с использованием ряда библиотек для Kinect и визуализации данных.
Ключевые слова: обработка данных, программирование, natural interfaces, визуализация, медиаискусство, Kinect, язык программирования Processing.
Современное искусство, особенно некоторые его формы, например, инсталляции, под-
разумевают интерактивность, т.е. способность зрителя влиять на произведение искусства. Чаще всего это обеспечивается использованием устройств захвата движения и визуализаци-ей/сонификацией получаемых данных, а также взаимодействием этих данных со сгенериро-ванными на компьютере в режиме реального времени объектами [1]. В ходе создания подоб-ной интерактивной системы — инсталляции — возникла необходимость решения некоторых задач, связанных как с разработкой системы, так и с организацией пространства для инстал-ляции.
Так как устройства захвата движения имеют некоторые ограничения, важно обеспечить подходящее пространство взаимодействия человека с интерактивной системой, однако четко сформулированных требований к помещениям для взаимодействия с объектами искусства нет, в то время как это необходимо для корректного отображения данных и организации про-странства [2].
Для решения этой задачи были проведены следующие эксперименты: с помощью кон-троллера Kinect и компьютерной программы Kinect2BVH были получены 9 захватов движе-ния рабочего пространства Kinect. Для каждого из 9 захватов с помощью вычислительного пакета MATLAB по методике построения карт рабочего пространства [3] были составлены диаграммы зон захвата движений, показывающие отношение числа ошибок к числу кадров в разных зонах пространства по логарифмической шкале с условными обозначениями от 1 до 10. После этого для каждого участка пространства было вычислено среднее арифметическое этого показателя и составлена усредненная рабочая карта пространства (рис. 1):
2
ср1( ( , ) ( , ))
( , )
nii
R X Z R X ZX Z
n
, (1)
где X, Z — координаты участка пространства; n — число имеющихся проходов; Ri — отно-шение ошибок к кадрам в текущем проходе; Rср — усредненное по проходам отношение ошибок к кадрам. Среднеквадратическое отклонение, оцененное для каждого участка про-странства по формуле (1), не превышает 1 для большинства точек пространства (рис. 2). Это

124 ТЕХНОЛОГИИ КОМПЬЮТЕРНОЙ ВИЗУАЛИЗАЦИИ
Сборник трудов VII научно-практической конференции молодых ученых «Вычислительные системы и сети (Майоровские чтения)»
означает, что, согласно правилу нормального распределения, погрешность десятибалльной оценки в этих зонах не превышает ±2 с доверительной вероятностью 86,4 %.
Рис. 1. Общая карта пространства
Рис. 2. Среднеквадратические отклонения для карты отношений ошибок к кадрам
Анализ усредненной карты пространства позволил сформулировать следующие пара-метры пространства, где устройство Kinect работает с минимальным количеством ошибок: минимальное расстояние от устройства до корректно распознаваемого объекта — 125 см; максимальное расстояние — 350 см; максимальная ширина области захвата — 260 см. Таким образом, при организации пространства для любой интерактивной системы, где необходимо корректное распознавание человека и захват движения, следует ориентироваться на эти дан-ные.
В качестве среды разработки инсталляции была выбрана Processing, а проблемы, свя-занные с визуализацией данных и взаимодействием графических объектов, были решены с помощью ряда библиотек.
Для получения данных с устройства Kinect была выбрана библиотека SimpleOpenNI, ко-торая является оберткой для Processing библиотек OpenNI и NITE и поддерживается плат-формами Windows, Mac OS X, Linux [4].
Основная библиотека, используемая для работы с графикой, — jBox2D, она содержит различные методы для обеспечения взаимодействия между графическими элементами в про-

ТЕХНОЛОГИИ КОМПЬЮТЕРНОЙ ВИЗУАЛИЗАЦИИ 125
Сборник трудов VII научно-практической конференции молодых ученых «Вычислительные системы и сети (Майоровские чтения)»
грамме [4]. В данном случае jBox2D использовалась для реалистического характера движе-ний частиц, а обработку столкновений обеспечила библиотека toxiclibs. Также в разработке использовалась библиотека BlobDetection, которая помогает создать силуэт, превращая его в последовательность точек, которые, образуют полигон, обеспечивают возможность взаимо-действия человека с виртуальными объектами (рис. 3).
Рис. 3. Скриншот работы программы
Таким образом, при создании инсталляции были изучены основные средства разработки, а в результате проведенных экспериментов, анализа данных и построения карт пространства определены параметры зоны безошибочного захвата Kinect, что решает проблему организа-ции рабочего пространства для интерактивных инсталляций.
ЛИТЕРАТУРА
1. Ribas L. Audiovisual Dynamics: An approach to Sound and Image Relations in Digital Interactive Systems, xCoAx 2013 // Proc. of the 1st Conf. on Computation, Communication, Aesthetics and X, 2013.
2. Zhang Z., Seah H., Quah C., Sun J. A markerless motion capture system with automatic subject-specific body model acquisition and robust pose tracking from 3D data // Image Processing (ICIP): 18th IEEE Intern. Conf. 2011. P. 525—528.
3. Egorova L., Lavrov A. Determination of workspace for motion capture using Kinect // 56th Intern. Scientific Conf. of Power and Electrical Engineering of Riga Technical University (RTUCON). Riga, Latvia, 2015. P. 121—124.
4. Shiffman D. The Nature of Code: Simulating Natural Systems with Processing. The Nature of Code, 2012.
Сведения об авторах Анна Викторовна Марьина — магистрант; Университет ИТМО, кафедра графических технологий;
E-mail: [email protected] Екатерина Андреевна Доронина — магистрант; Университет ИТМО, кафедра графических технологий;
E-mail: [email protected] Ссылка для цитирования: Марьина А. В., Доронина Е. А. Применение технологий захвата движений для управления интерактивными системами в современном искусстве // Сборник трудов VII научно-практической конференции молодых ученых «Вычислительные системы и сети (Майоровские чтения)». 2016. С. 123—126.

126 ТЕХНОЛОГИИ КОМПЬЮТЕРНОЙ ВИЗУАЛИЗАЦИИ
Сборник трудов VII научно-практической конференции молодых ученых «Вычислительные системы и сети (Майоровские чтения)»
THE USE OF MOTION CAPTURE TECHNOLOGIES
FOR CONTROLLING THE INTERACTIVE SYSTEMS IN CONTEMPORARY ART
A. V. Maryina, E. A. Doronina
ITMO University, 197101, St. Petersburg, Russia
This shows the results of processing data from the Kinect controller, so there were determined the opti-mal parameters for spaces intended to be used for interactive systems. The example of such system is the interactive installation made in the Processing programming environment using some special libraries for Kinect and data visualization.
Keywords: Data processing, programming, natural interfaces, visualization, new media art, Kinect, Proc-essing programming language.
Data on authors Anna V. Maryina — Student; ITMO University, Department of Chair of Graphic Technolo-
gies; E-mail: [email protected] Ekaterina A. Doronina — Student; ITMO University, Department of Chair of Graphic Technolo-
gies; E-mail: [email protected]
For citation: Maryina A. V., Doronina E. A. The use of motion capture technologies for controlling the interactive systems in contemporary art // Proceedings of the scientific and practical conference of young scientists «Computing systems and networks (Mayorov’s readings)». 2016. P. 123—126 (in Russian).

ТЕХНОЛОГИИ КОМПЬЮТЕРНОЙ ВИЗУАЛИЗАЦИИ 127
Сборник трудов VII научно-практической конференции молодых ученых «Вычислительные системы и сети (Майоровские чтения)»
УДК 004.93'12
ОЦЕНКА КАЧЕСТВА РАСПОЗНАВАНИЯ ЖЕСТОВ ДЛЯ УПРАВЛЕНИЯ ВОСПРОИЗВЕДЕНИЕМ ЗАПИСИ ВИДЕО-360
А. М. Кочергина, Н. Д. Короткова
Университет ИТМО, 197101, Санкт-Петербург, Россия
Определены наиболее удобные для пользователей жесты для управле-ния записью видео-360 при его просмотре в очках виртуальной реаль-ности с учетом технологий, доступных пользователям. Выявлены наи-более распознаваемые жесты, составлены возможные наборы жестов для заявленных действий, сформулированы обобщенные рекомендации к выбору жестов.
Ключевые слова: система распознавания жестов, Microsoft Kinect, Leap Motion Controller, запись видео-360.
Видео-360 — это интерактивная видеозапись, при которой зритель может управлять ра-курсом, т.е. направлять камеру в любую сторону, наблюдая за всем, что происходит вокруг него. Для ощущения полного погружения в видеосюжет используются очки виртуальной ре-альности, такие как Oculus Rift или Samsung Gear VR. При таком методе воспроизведения встает вопрос об удобном управлении записью: необходимо иметь возможность начать, оста-новить, приостановить, перемотать воспроизведение, не используя стандартные средства управления — клавиатуру и мышь. В данном случае решением задачи может быть использо-вание получивших в последние годы распространение недорогих технологий захвата движе-ний, таких как Microsoft Kinect и Leap Motion.
Leap Motion Controller — это технология, основанная на захвате движения, для челове-ко-компьютерного взаимодействия. Устройство размещается на передней поверхности шле-ма, чтобы создать ощущение, будто объектами на экране управляют с помощью рук. После подключения устройства над ним образуется виртуальная перевернутая пирамида с цен-тральной вершиной в устройстве. Наиболее эффективный диапазон распространяется от 25 до 600 мм над контроллером с областью видимости 150° [1].
Microsoft Kinect — бесконтактный сенсорный игровой контроллер. Датчик Kinect по-зволяет непосредственно различать третье измерение (глубина), распознает речь, интерпре-тирует движения, также может быть использован для получения цветного изображения [2]. Для Kinect v2 рабочий диапазон depth-камеры составляет от 0,8 до 4,5 м [3].
На сегодняшний день проводится много исследований особенностей управления муль-тимедийными системами с помощью жестов, в частности, управления презентациями [4], приложениями для просмотра фильмов или другого содержимого [5], различного рода инте-рактивными аудио- и видеоинсталляциями. Но проблема управления видео-360 в очках вир-туальной реальности недостаточно изучена.
Цель эксперимента — выбрать наиболее удобные с точки зрения пользователей жесты для управления записью видео-360, оценить качество их распознавания и выбрать наиболее хорошо распознаваемые. Данный эксперимент проводился для технологий Microsoft Kinect и Leap Motion Controller. Жесты и методы исследования и анализа различаются для каждой из технологий, но, тем не менее, можно составить общий план эксперимента.
На первом этапе был составлен список основных действий для управления записью и выбраны наиболее удачные жесты пользователя для управления.
Список действий: Play, Stop, Pause, Rewind, Selection.

128 ТЕХНОЛОГИИ КОМПЬЮТЕРНОЙ ВИЗУАЛИЗАЦИИ
Сборник трудов VII научно-практической конференции молодых ученых «Вычислительные системы и сети (Майоровские чтения)»
Второй этап — запись выбранных жестов. С помощью программы Brekel Pro и пакета средств разработки Microsoft Kinect для Windows были записаны и проанализированы жесты для наилучшей работы с Leap Motion Controller и Microsoft Kinect.
Каждый жест был записан многократно, нопоскольку эксперимент был очень ограничен по времени, для более тщательного анализа требуется больше данных.
Третий этап — тестирование записанных жестов, формирование выводов. Каждый жест тестировался с разного расстояния, разных углов, с разной скоростью выполнения, для того чтобы приблизиться к его возможному воспроизведению в реальности пользователем. В ре-зультате были выявлены наиболее распознаваемые жесты, составлены возможные наборы жестов для заявленных действий, сформулированы обобщенные рекомендации к выбору жестов.
На основе проведенного тестирования для Microsoft Kinect были соотнесены действия с жестами и составлен возможный набор для управления воспроизведением видео-360 в очках виртуальной реальности.
1. Play — хлопок перед собой. 2. Stop — руки в положении «крест» перед собой. 3. Pause — удар кулаком о другой кулак. 4. Rewind — вращение кистью руки. 5. Select — ладонь перпендикулярна полу, движение вперед. Общие рекомендации к выбору жестов для Microsoft Kinect: — не использовать похожие жесты в одном наборе действий; — предпочтительны «однозначные» действия (действия, которые большинство пользо-
вателей сделает одинаковым образом); — исключить все жесты, связанные с движением головы; — целесообразно использовать жесты, имитирующие нажатие кнопки (например, рукой
к плечу). Общие рекомендации к выбору жестов для Leap Motion Controller: — радиус действия Leap — в пределах 20—40 сантиметров от сенсора; — контроллер распознает отдельные пальцы, но иногда не распознает соединенные
друг с другом пальцы; — при положении ладони ребром — Leap воспримет такой жест как один палец или же
вовсе не распознает ладонь. — если используются две руки, то они не должны перекрывать друг друга.
ЛИТЕРАТУРА
1. Coelho J. C., Verbeek F. J. The leap motion controller in a 3D virtual environment. Explorations and evaluations of poiting tasks // Proc. of the 8th Intern. Conf. on Interfaces and Human Computer Interaction (IHCI). 2014.
2. Zeng W. Microsoft Kinect Sensor and Its Effect. University of Missouri, 2012.
3. Human Interface Guidelines for Kinect 2.0, Microsoft Corporation, 2014.
4. Martinovikj D., Ackovska N. Gesture recognition solution for presentation control // 10th Conf. for Informatics and Information Technology. 2013.
5. Khoa Thi-Minh Tran, Seung-Hyun Oh. A hand gesture recognition library for a 3D viewer supported by kinect’s depth sensor // Intern. Journal of Multimedia and Ubiquitous Engineering. 2014. Vol. 9, N 4. P. 297—308.

ТЕХНОЛОГИИ КОМПЬЮТЕРНОЙ ВИЗУАЛИЗАЦИИ 129
Сборник трудов VII научно-практической конференции молодых ученых «Вычислительные системы и сети (Майоровские чтения)»
Сведения об авторах Александра Михайловна Кочергина — магистрант; Университет ИТМО, кафедра графических техноло-
гий, Санкт-Петербург; E-mail: [email protected] Наталья Дмитриевна Короткова — магистрант; Университет ИТМО, кафедра графических техноло-
гий, Санкт-Петербург; E-mail: [email protected]
Ссылка для цитирования: Кочергина А. М., Короткова Н. Д. Оценка качества распознавания жестов для управления воспроизведением записью видео-360// Сборник трудов VII научно-практической конференции мо-лодых ученых «Вычислительные системы и сети (Майоровские чтения)». 2016. С. 127—129.
ASSESSMENT OF QUALITY OF GESTURE RECOGNITION TO CONTROL
THE PLAYBACK OF 360-VIDEO RECORDING
A. M. Kochergina, N. D. Korotkova
ITMO University, 197101, St. Petersburg, Russia
The purpose of this article has been selected to determine the most convenient gestures to control video recording 360 when you view it in virtual reality glasses. As a result, the most well recognized gestures was identified, the sets of possible gestures for alleged actions was composed. The article concludes made general recommendations to the choice of gestures.
Keywords: gesture recognition system, Microsoft Kinect, Leap Motion Controller, video-360 recording.
Data on authors Alexandra M. Kochergina — Student; ITMO University, Department of Chair of Graphic Tech-
nologies; E-mail: [email protected] Natalia D. Korotkova — Student; ITMO University, Department of Chair of Graphic Tech-
nologies; E-mail: [email protected]
For citation: Kochergina A. M., Korotkova N. D. Assessment of quality of gesture recognition to control the playback of 360-video recording // Proceedings of the scientific and practical conference of young scientists «Computing systems and networks (Mayorov’s readings)». 2016. P. 127—129 (in Russian).

130 ТЕХНОЛОГИИ КОМПЬЮТЕРНОЙ ВИЗУАЛИЗАЦИИ
Сборник трудов VII научно-практической конференции молодых ученых «Вычислительные системы и сети (Майоровские чтения)»
УДК 004.42
АНАЛИЗ ЭФФЕКТИВНОСТИ СИСТЕМ ОПТИЧЕСКОГО РАСПОЗНАВАНИЯ СИМВОЛОВ
И. В. Погребняк
Университет ИТМО, 197101, Санкт-Петербург, Россия
Рассмотрены системы оптического распознавания символов. По трем критериям (наличие открытого программного обеспечения, востребо-ванность системы, тип — приложение для персонального использова-ния) выбраны системы оптического распознавания символов (использо-ваны рукописный, печатный, машинописный тексты). Для анализа и сравнения систем используются следующие характеристики: наличие возможности работы с определенным видом исходных данных, наличие возможности работы с определенным языком, зависимость точности распознавания от качества исходных данных. Оценка точности распо-знавания проводится с помощью критериев оценки качества: коэффи-циента корректно распознанных символов, коэффициента корректно распознанных слов, точности в символах, точности в словах, точности в словах без учета порядка. Результатом проведенного анализа является выбор для каждого вида текста системы с лучшими показателями точ-ности распознавания. Для печатных и машинописных текстов такой системой является Tesseract OCR, для рукописных — SimpleOCR.
Ключевые слова: оптическое распознавание символов, компьютерное зрение, CuneiForm, SimpleOCR, Tesseract OCR, OCR ImageToText.
Введение
Перенос информации вручную с бумажных носителей на электронные занимает много времени. Существует способ решения указанной проблемы, который заключается в переводе изображения печатного, машинописного или рукописного текста в текстовые данные, пред-ставленные в электронном виде — оптическое распознавание символов [1].
Существует большое количество систем, реализующих различные алгоритмы оптиче-ского распознавания символов (СОРС), работающих с разными видами текста.
Сравнение систем
Отбор систем, участвующих в анализе и сравнении, производился с учетом следующих характеристик:
— наличие свободного и открытого программного обеспечения; — тип системы — приложение для персонального использования; — воcтребованность системы. Востребованность системы учитывалась на основании опроса пользователей [2]. Вы-
браны четыре работающие в Windows системы, соответствующие всем указанным выше ха-рактеристикам: CuneiForm, версия 2008 года, от компании Cognitive Technologies [3], Sim-pleOCR, версия 2013 года, от компании Simple Software [4], Tesseract OCR, версия 2012 года, от Google [5] и OCR ImageToText, версия 2015 год,а от компании OCR tools Division [6].
Определены критерии, на основании которых произведены анализ и сравнение СОРС: — возможность работы с определенным видом исходных данных; — возможность работы с определенным языком; — точность распознавания в зависимости от различного качества исходных данных. Оценка точности распознавания произведена при помощи критериев оценки качества [7],
а именно:

ТЕХНОЛОГИИ КОМПЬЮТЕРНОЙ ВИЗУАЛИЗАЦИИ 131
Сборник трудов VII научно-практической конференции молодых ученых «Вычислительные системы и сети (Майоровские чтения)»
а) коэффициента корректно распознанных символов: cc
crT
n , где c — число символов
эталона, nc — число корректно распознанных символов;
b) коэффициента корректно распознанных слов: ww
wrT
n , где w — число слов эталона,
nw — число корректно распознанных слов;
c) точности в символах: 1 c c cc
i s dA
c
, где ic, sc, dc — число ошибочно вставлен-
ных, замещенных и удаленных символов соответственно, c — число символов эталона;
d) точности в словах: 1 w w ww
i s dA
w
, где iw, sw, dw — число ошибочно вставлен-
ных, замещенных и удаленных слов соответственно, w — число слов эталона;
e) точности в словах без учета порядка: 1b
missed wrongw
n nA
w
, где nmissed — число
пропущенных слов, nwrong — число ошибочно распознанных слов, w — число слов эталона.
Результаты измерений
В табл. 1 представлены результаты оценки двух первых критериев выбора системы — возможности работы с определенным видом исходных данных и возможности работы с опре-деленным языком. Так как не все участвующие в сравнении системы содержат функциональ-ность, заключающуюся в работе с русским языком, и поскольку распознавание символов русского языка не является ключевым параметром для достижения поставленной цели, в ходе оценки критерия точности распознавания использован текст на английском языке.
Таблица 1 Функциональность анализируемых СОРС
Текст Язык Система
ПечатныйМашинописный Рукописный Английский Русский CuneiForm + + — + + SimpleOCR + + + + —
Tesseract OCR + + + + + OCR
ImageToText + + + + —
Оценка точности распознавания заключается в определении критериев оценки качества [7]. Значения критериев рассчитаны на основании результатов эксперимента, в ходе проведе-ния которого на вход каждой системы подаются наборы изображений с различными видами текста, а именно: рукописный текст со слитным написанием букв, рукописный текст с раз-дельным написанием букв, печатный текст хорошего качества, печатный текст плохого каче-ства, машинописный текст хорошего качества, машинописный текст плохого качества. Каж-дая система производит преобразование информации изображения в текстовые данные. Затем на основании анализа полученных текстовых данных определены входные значения (число корректно распознанных символов, слов и т.д.) и рассчитаны критерии оценки качества для каждого изображения. На последнем шаге для каждого набора изображений определены средние значения критериев оценки качества (табл. 2—4, под эталоном подразумевается кор-ректное распознавание всех символов на изображении).
Сравнение систем по третьему критерию (точности распознавания) произведено на ос-новании отклонения их значений от эталонного: чем меньше отклонение от эталона, тем вы-ше точность распознавания.

132 ТЕХНОЛОГИИ КОМПЬЮТЕРНОЙ ВИЗУАЛИЗАЦИИ
Сборник трудов VII научно-практической конференции молодых ученых «Вычислительные системы и сети (Майоровские чтения)»
Таблица 2 Оценка качества распознавания печатного текста
Критерий Эталон Tesseract OCR CuneiForm SimpleOCR OCR ImageToText Плохое качество изображения
rTc 1 1,04 1,11 1,15 1,18 rTw 1 1,11 1,53 1,22 1,91 Ac 1 0,96 0,88 0,86 0,85 Aw 1 0,90 0,79 0,82 0,52 Awb 1 0,90 0,67 0,82 0,52
Хорошее качество изображения rTc 1 1,00 1,09 1,03 1,08 rTw 1 1,00 1,43 1,09 1,67 Ac 1 0,99 0,89 0,97 0,90 Aw 1 0,98 0,70 0,92 0,58 Awb 1 1,00 0,72 0,90 0,60
Таблица 3 Оценка качества распознавания машинописного текста
Критерий Эталон Tesseract OCR CuneiForm SimpleOCR OCR ImageToText Плохое качество изображения
rTc 1 1,08 1,65 1,19 1,48 rTw 1 1,33 1,60 2,18 8,00 Ac 1 0,91 0,59 0,84 0,67 Aw 1 0,75 0,33 0,46 0,13 Awb 1 0,75 0,63 0,46 0,13
Хорошее качество изображения rTc 1 1,01 1,05 1,15 1,26 rTw 1 1,05 1,13 1,24 2,86 Ac 1 0,99 0,95 0,85 0,78 Aw 1 0,95 0,89 0,78 0,35 Awb 1 0,95 0,89 0,78 0,35
Таблица 4 Оценка качества распознавания рукописного текста
Критерий Эталон Tesseract OCR SimpleOCR OCR ImageToText Слитные буквы
rTc 1 4,00 1,75 5,00 rTw 1 16,00 12,00 17,20 Ac 1 0,09 0,56 0,03 Aw 1 0,02 0,08 0,02 Awb 1 0,02 0,08 0,02
Раздельные буквы rTc 1 3,00 1,33 3,70 rTw 1 5,50 1,85 6,00 Ac 1 0,12 0,73 0,08 Aw 1 0,10 0,42 0,06 Awb 1 0,10 0,54 0,06
Выводы
По результатам проведенных экспериментов системами с лучшими показателями точ-ности распознавания являются: Tesseract OCR для печатных и машинописных текстов, SimpleOCR — для рукописных текстов. Отклонение показателей точности распознавания

ТЕХНОЛОГИИ КОМПЬЮТЕРНОЙ ВИЗУАЛИЗАЦИИ 133
Сборник трудов VII научно-практической конференции молодых ученых «Вычислительные системы и сети (Майоровские чтения)»
рукописного текста от эталона в рассмотренных системах в среднем менее 50 % , что не по-зволяет рекомендовать их для профессионального использования.
ЛИТЕРАТУРА
1. Cheriet M. Character recognition systems: a guide for students and practioners. John Wiley & Sons, Inc. 2007.
2. Опрос по СОРС [Электронный ресурс]: <http://www.makeuseof.com>.
3. CuneiForm [Электронный ресурс]: <http://cognitiveforms.com/ru/products_and_services/ cuneiform>.
4. SimpleOCR [Электронный ресурс]: <http://www.simpleocr.com/>.
5. Tesseract OCR [Электронный ресурс]: <https://code.google.com/p/tesseract-ocr/ https:// directory.fsf.org/wiki/Clara_OCR>.
6. OCR ImageToText [Электронный ресурс]: <https://www.ocrtools.com/fi/ prdOCRFree.aspxhttps://directory.fsf.org/wiki/Clara_OCR>.
7. Смирнов С. В. Критерии оценки качества результатов оптического распознавания // XVI Междунар. науч.-практ. конф. «Перспективы развития информационных технологий». Новосибирск, 2013. С. 33—38.
Сведения об авторе Ирина Викторовна Погребняк — магистрант; Университет ИТМО, кафедра вычислительной техники;
E-mail: [email protected]
Ссылка для цитирования: Погребняк И. В. Анализ эффективности систем оптического распознавания симво-лов // Сборник трудов VII научно-практической конференции молодых ученых «Вычислительные системы и сети (Майоровские чтения)». 2016. С. 130—133.
EFFICIENCY ANALYSIS OF OPTICAL CHARACTER RECOGNITION SYSTEMS
I. V. Pogrebnyak
ITMO University, 197101, St. Petersburg, Russia
Optical character recognition systems are considered. The purpose of the analysis is choice of optical character recognition system. The choice of systems is made by three criterions: the use of open source software, the demand for system, type — application for personal use. List of the selected systems include: CuneiForm, SimpleOCR, Tesseract OCR, OCR ImageToText. The initial data are images from different kinds of text: handwritten, printed, typewritten. The following characteristics are used for analysis and comparison of sys-tems: the ability to work with a certain type of data, the ability to work with a specific language, recognition accuracy depending on the different input data quality. Evaluation of the recognition accuracy is performed using the quality estimation criterion: factor of correctly recognized characters, factor of correctly recognized words, accuracy in characters, accuracy in words, accuracy in words without considering the order. The result of the analysis is to select for each type of text system with better accuracy of recognition. For printed and typewritten texts such a system is Tesseract OCR, for handwritten texts such a system is SimpleOCR.
Keywords: optical character recognition, machine vision, CuneiForm, SimpleOCR, Tesseract OCR, OCR ImageToText.
Data on author Irina V. Pogrebnyak — Student; ITMO University, Department of Computer Science;
E-mail: [email protected]
For citation: Pogrebnyak I. V. Efficiency analysis of optical character recognition systems // Proceedings of the scientific and practical conference of young scientists «Computing systems and networks (Mayo-rov’s readings)». 2016. P. 130—133 (in Russian).

Сборник трудов VII Научно-практической конференции молодых ученых
«Вычислительные системы и сети (Майоровские чтения)»
В авторской редакции Редакционно-издательский отдел Университета ИТМО Зав. РИО Н.Ф. Гусарова Лицензия ИД № 00408 от 05.11.99 Подписано к печати Заказ № Тираж 100 экз.

Редакционно-издательский отдел Университета ИТМО, Санкт-Петербург 197101, Санкт-Петербург, Кронверкский пр., 49





























