Embed Size (px)
DESCRIPTION
제 5 부 정보 검색 제 20 장 문서 클러스터링. NLP Lab. 세미나 발표자 : 이주호 2007 년 7 월 18 일 수요일. 목차. 1. 문서 클러스터링의 개요 Jaccard’s coefficient Dice’s coefficient The cosine measure The inclusion measure The overlap coefficient 2. 문서 클러스터링 알고리즘 계층적 클러스터링 할당식 클러스터링 클러스터링 결과 판단. 문서 클러스터링. 클러스터링 - PowerPoint PPT Presentation
Citation preview
제 5 부 정보 검색제 20 장 문서 클러스터링
NLP Lab. 세미나 발표자 : 이주호
2007 년 7 월 18 일 수요일

목차 1. 문서 클러스터링의 개요
Jaccard’s coefficient Dice’s coefficient The cosine measure The inclusion measure The overlap coefficient
2. 문서 클러스터링 알고리즘 계층적 클러스터링 할당식 클러스터링
클러스터링 결과 판단
문서 클러스터링 클러스터링
주어진 데이터를 의미 있는 그룹으로 분류 하는 방법 문서 클러스터링
대용량의 문서를 주제에 따라 분류하는 것 문서 클러스터링의 이점
검색효율 향상 탐색 시간 절약
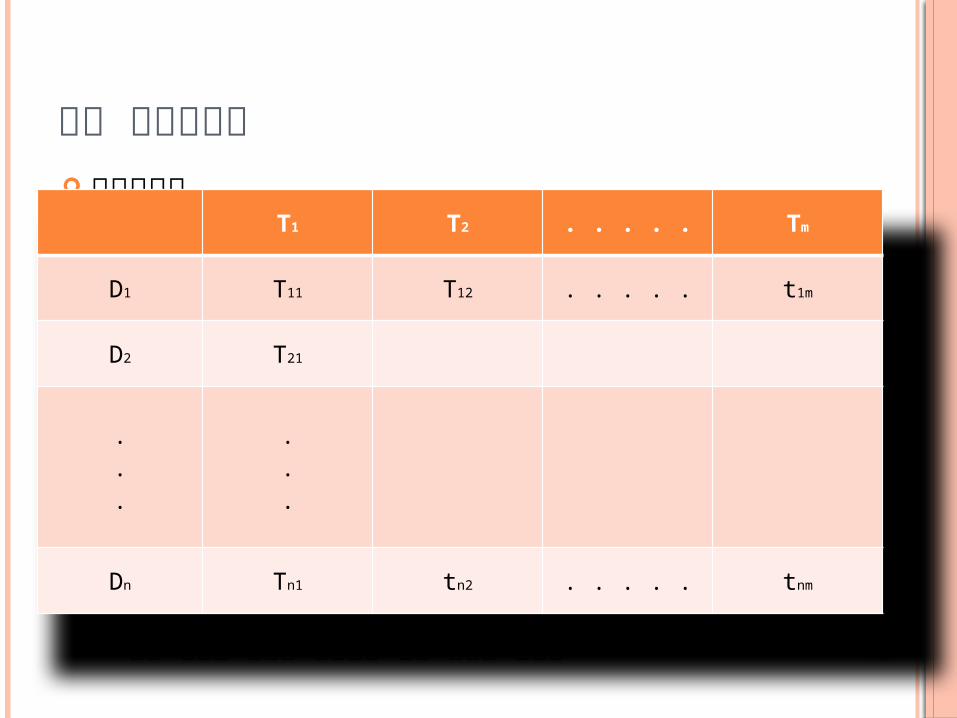
색인 , 불용어 제거 등의 과정을 거쳐 대상 문서들을 문서 - 색인어 행렬 만들어서 클러스터링을 진행
bag-of-word 접근법 단어의 의미 , 순서 등을 고려하지 않음 같은 주제는 비슷한 단어들의 출현 패턴을 보인다
T1 T2 . . . . . Tm
D1 T11 T12 . . . . . t1m
D2 T21
.
.
.
.
.
.
Dn Tn1 tn2 . . . . . tnm

문서 클러스터링 m = 6 , n = 5 T={computer,retrieval,archiving,hypertext,hypermedia,inde
xing} D1={computer,retrieval,archiving,hypertext,hypermedia}
={1,1,1,1,1,0} q1={archiving,hypermedia}
={0,0,1,0,1,0} q2={retrieval, indexing}
={0,1,0,0,0,1}

문서 클러스터링JACCARD’S COEFFICIENT
167.06/1),(
4.05/2),(
)(
)(
),(
2
1
1'
1'
1
1'
'
iJacc
iJacc
m
jjiij
m
jji
m
jij
m
jjiij
iiJacc
DqSIM
DqSIM
TTTT
TT
DDSIM

문서 클러스터링DICE’S COEFFICIENT
286.05.3/1),(
5714.05.3/2),(
])([2
),(
2
1
1'
1
1'
'
iDice
iDice
m
jji
m
jij
m
jjiij
iiDice
DqSIM
DqSIM
TT
TT
DDSIM

문서 클러스터링THE COSINE MEASURE
316.010/1),(
632.010/2),(
])()([
)(
),(
2cos
1cos
21
1
2'
1
2
1'
'cos
i
i
m
jji
m
jij
m
jjiij
ii
DqSIM
DqSIM
TT
TT
DDSIM
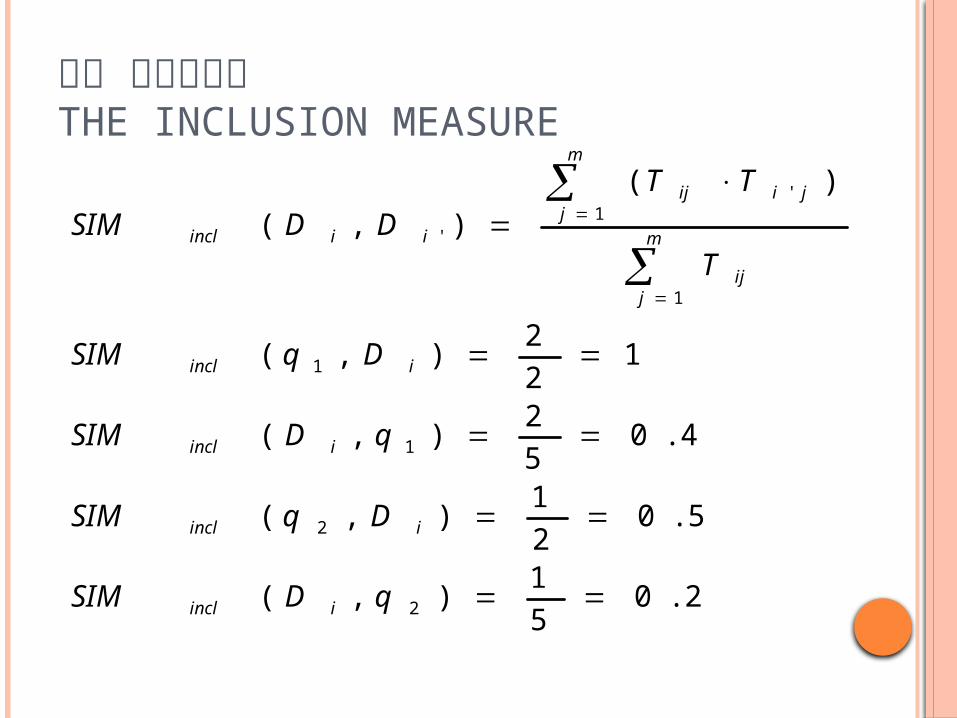
문서 클러스터링THE INCLUSION MEASURE
2.05
1),(
5.02
1),(
4.05
2),(
12
2),(
)(
),(
2
2
1
1
1
'1
'
qDSIM
DqSIM
qDSIM
DqSIM
T
TT
DDSIM
iincl
iincl
iincl
iincl
m
jij
ji
m
jij
iiincl
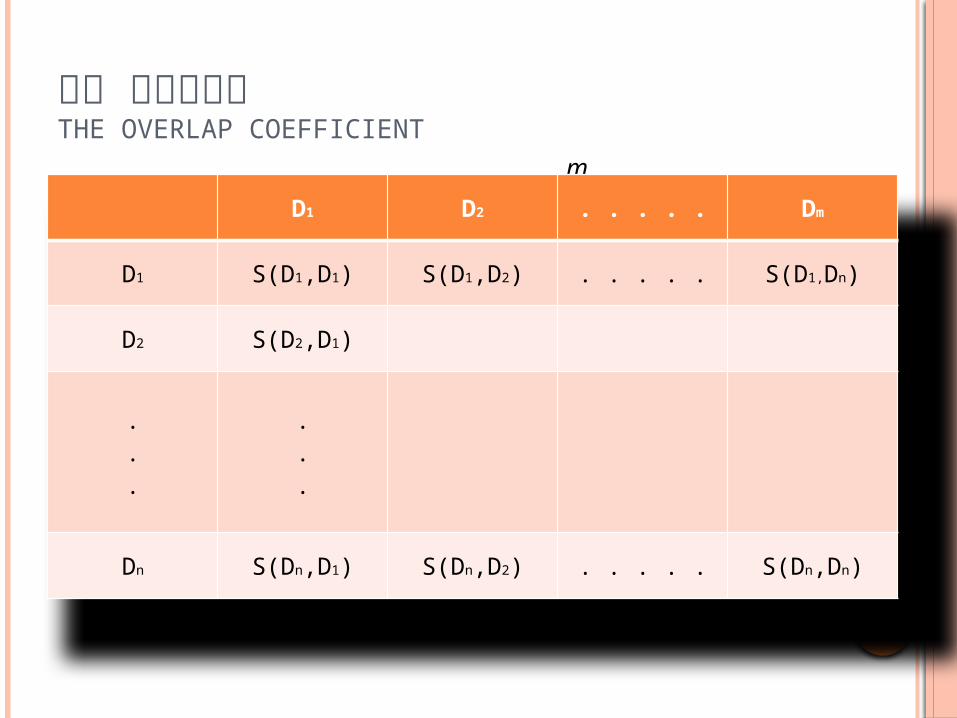
문서 클러스터링THE OVERLAP COEFFICIENT
5.0)2,5min(
1),(
1)2,5min(
2),(
),min(
)(
),(
1
1
1 1'
1'
'
iOVL
iOVL
m
j
m
jjiij
m
jjiij
iiOVL
DqSIM
DqSIM
TT
TT
DDSIM
D1 D2 . . . . . Dm
D1 S(D1,D1) S(D1,D2) . . . . . S(D1,Dn)
D2 S(D2,D1)
.
.
.
.
.
.
Dn S(Dn,D1) S(Dn,D2) . . . . . S(Dn,Dn)
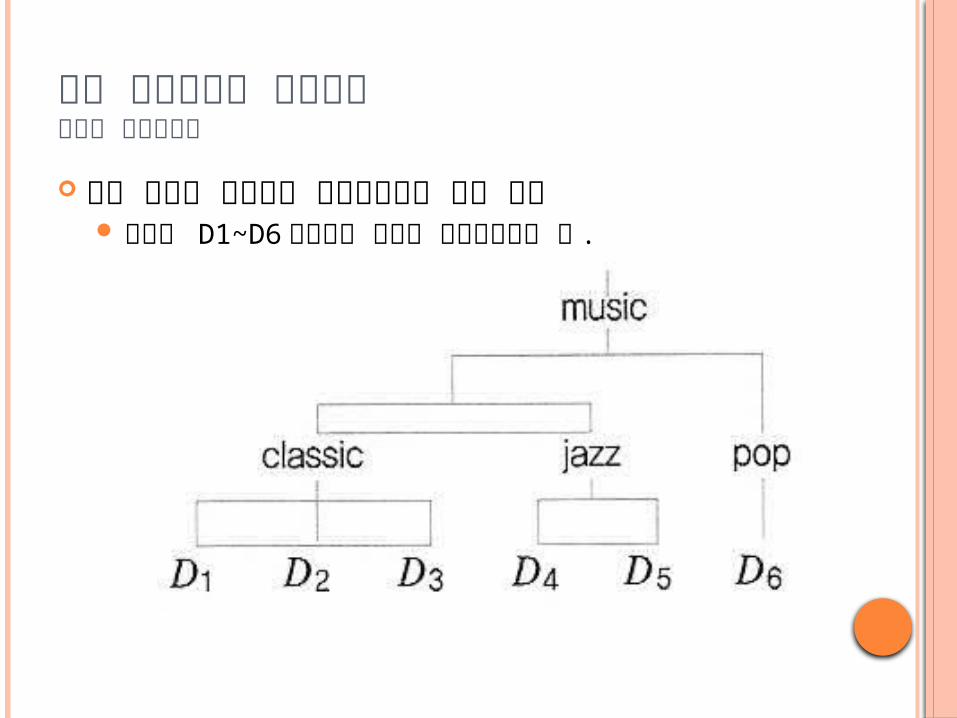
문서 클러스터링 알고리즘계층적 클러스터링
트리 구조를 형성하여 클러스터링을 하는 모델 그림은 D1~D6 문서들을 계층적 클러스터링한 예 .
문서 클러스터링 알고리즘계층적 클러스터링
장단점 장점 : 문서 간의 계층 제공 단점 : 클러스터링 시간이 할당식 클러스터링에 비해 오래
걸림 병합식과 분할식
병합식 클러스터링 첫 단계에서 각 문서가 각각의 클러스터를 형성한다고
가정 알고리즘이 진행 될수록 가장 가까운 문서끼리 병합 새로운
클러스터를 형성 분할식
모든 문서가 하나의 클러스터에 속한다고 가정 알고리즘 진행 매 단계별 유사도가 작은 문서의 집합끼리 분할

문서 클러스터링 알고리즘계층적 클러스터링
단순한 병합식 클러스터링 알고리즘 문서의 개수만큼 클러스터를 생성하여 각 문서가 각
클러스터로 각각 할당되도록 한다 . 각 클러스터의 중심은 자신이 포함하고 있는 문서가 된다 .
모든 문서가 하나의 클러스터로 할당될 때까지 다음을 계속한다 모든 클러스터 간의 유사도를 계산 한다 가장 가까운 두 클러스터를 하나로 병합 병합된 두 클러스터를 유사도 행렬에서 제외하고 새로 만들어진
클러스터와 다른 클러스터와의 유사도를 계산하여 유사도 행렬을 갱신한다 .
클러스터의 중심 벡터의 클러스터에 포함된 문서의 평균 벡터이다

문서 클러스터링 알고리즘할당식 클러스터링
클러스터의 계층을 고려하지 않고 각 문서를 평면적으로 클러스터링 하는 방법 미리 나누어질 클러스터의 개수를 예상하고 클러스터를 재공 문서 클러스터링에는 K-means 알고리즘을 많이 사용
기본적인 K-means 알고리즘 K 개의 문서를 임으로 선택하여 초기 클러스터의 중심으로
할당 . K 개의 클러스터의 중심이 바뀌지 않을 때까지 다음과정
반복 나머지 모든 문서들을 가장 유사도가 높은 중심에 해당하는
클러스터로 할당 각 클러스터의 중심을 다시 계산

클러스터링 결과 판단 엔트로피 방법
Pij 는 클러스터 j 에 포함된다고 판단된 문서들이 실제로 클래스 i 에 포함될 확률
클러스터 j 에 대한 엔트로피
Ej 가 양수이고 이값이 0 에 가까울수록 정확하게 클러스터링이 된것
전체적인 클러스터링 평가 각 클러스터의 엔트로피에 클러스터의 크기를 곱하여 평균을 낸
값으로 평가
i ijj pE log
K
j
jjCS N
EnE
1

클러스터링 결과 판단 F- measure
정보 검색에서는 이 방법을 더 많이 사용 nij = 클래스 i 에 속한 문서가 클러스터 j 에 속한다고
판단된 문서 정확률 : 어떤 클러스터에 속한다고 판정된 문서 중 제대로
클러스터링이 된 문서의 비율 재현률 : 어떤 클래스에 속한 다고 판정된 문서 중 제대로
클러스터링이된 문서의 비율 클러스터 j 와 클래스 i 에 대한 F-measure
iij nnjiecision /),(Pr jij nnjicall /),(Re
)),(Re),((Pr
)),(Pr*),(Re*2(),(
jicalljiecision
jiecisionjicalljiF

Q&A
수고 하셨습니다 .
























![[인천] 지니어스팩토리 서비스 홍보자료(문서)](https://img.dokumen.tips/doc/110x75/58a515591a28ab8e1c8b67df/-58a515591a28ab8e1c8b67df.jpg)




