Embed Size (px)
DESCRIPTION
第 2 章 线性表. 主要内容: 线性表的概念和逻辑结构 线性表的顺序表示和实现 线性表的链式表示和实现 一元多项式的表示和相加. 线性表 (Linear List) : 由 n ( n ≥ 0 ) 个数据元素 ( 结点 ) a 1 , a 2 , … , a n 组成的有限序列。. §2.1 线性表的概念和逻辑结构. 1. 线性表的定义. 数据元素的个数 n 为表的长度。当 n=0 时为空表,非空的线性表 ( n>0 ) 记为: ( a 1 , a 2 , … , a n ) - PowerPoint PPT Presentation
Citation preview

1
第 2 章 线性表
主要内容: 线性表的概念和逻辑结构 线性表的顺序表示和实现 线性表的链式表示和实现 一元多项式的表示和相加

2
§2.1 线性表的概念和逻辑结构 1. 线性表的定义 线性表 (Linear List):由 n(n≥0) 个数据元
素 ( 结点 )a1 , a2 ,…, an 组成的有限序列。 数据元素的个数 n 为表的长度。当 n=0 时为空表,
非空的线性表 (n>0) 记为: (a1 , a2 ,…, an)
ai(1≤i≤n) 只是一个抽象的符号,在同一表中特性相同,且相邻数据元素之间具有序偶关系。
例 1 :英文字母表: (A, B, C, …, Z) 例 2 :一周的组成: ( 周日 , 周 1, 周 2, …, 周六 ) 例 3 :扑克的点数: (2, 3, 4, …, J, Q, K, A)

3
2. 形式定义形式定义: Linear—List = (D , R)
D = { a1 , a2 ,……, an }
R = {<ai-1 , ai>│i = 2…..n} n 称为线性表长度, n = 0 称空表; ai 为数据元素; 当线性表非空时, i 为数据元素 ai 在表中的
位序。 a1 是第 1 个数据元素, a2 是第 2 个数据元素, an
是第 n 个数据元素, ai 是第 i 个数据元素。

4
非空线性表的逻辑特征
有且仅有一个被称为“第 1 个”的首元素a1 ,它没有直接前趋,至多有一个直接后继
有且仅有一个被称为“最后 1 个”的尾元素an ,它没有直接后继,至多有一个直接前趋
除首元素外,任何元素有且仅有一个前驱 除尾元素外,任何元素有且仅有一个后继 每个元素有一个位序

5
3. 抽象数据类型定义ADT List{ 数据对象: D 数据关系: R 基本操作: Initlist(&L) ; Destroylist(&L) ; Clearlist(&L) ; Listempty(L) ; Listlength(L) ; Getelem(L, i, &e) ; Locatelem(L,e) ; Priorelem(L,e,&pe) ; Nextelem(L,e,&ne) ; Listinset(&L,i,e) ; Listdelete(&L,i,&e) ; Listtraverse(L) ;} ADT List

6
§2.2 线性表的顺序表示和实现 1. 顺序表 顺序表:把线性表的结点按逻辑顺序依次存放在
一组地址连续的存储单元里。用这种方法存储的线性表简称顺序表。 特点:逻辑上相邻←→物理地址相邻
顺序表存储结构的描述 存储空间的起始地址 顺序表的容量 ( 最大长度 ) 顺序表的当前长度
顺序表的内存分配:一维数组

7
顺序表存储示意图 设:
b 为存储空间的首地址 l 为数据元素长度
第 i+1 个数据元素的存储位置和第 i 个数据元素的存储位置之间满足下列关系:
LOC(ai+1)=LOC(ai) + l
线性表的第 i 个数据元素 ai
的存储位置为: LOC(ai)=LOC(a1)+(i-1)*l
b
b+l
…
b+(i-1)l
b+(n-1)l…
b+nl
…
b+(maxlen-1)l
存储地址1
2
…
i
n
…
空闲
元素位序a1
a2
……
ai
……
an
内存状态
任何数据元素均可在 O(1)时间内存取任何数据元素均可在 O(1)时间内存取

8
2. 顺序结构的实现 组成
一组连续存储空间 当前长度 空间大小 ( 当前分配的存储容量 )
elem[ ] length listsize
#define List-Init-Size 100#define Listincrement 10typedef struct { Elemtype *elem ; //基地址 int length ; //数据个数 int listsize ; //总容量} Sqlist;
存储结构定义的 C 语言实现

9
3. 顺序表的基本操作 (1) 初始化status Initlist_Sq(Sqlist &L){ L.elem=(ElemType*)malloc(LIST_INIT_SIZE* sizeof(ElemType)); if(!L.elem) exit(OVERFLOW); //存储分配失败 L.length=0; //空表长度为 0 ,满为 List-Init-Size L.listsize= List-Init-Size; //初始存储容量 return OK;}

10
(2) 查找
int LocateElem_Sq(SqList L,ElemType e){ int i=0; while(i < L.length && L.elem[i] != e) i++; if(i<L.length) return(i+1); else return(0);}
按位序 void GetElem_Sq(L,i,&e) { e=L.elem[i-1]; }
按数据元素值
平均比较次数为:( 1+2+3+…+n)/n=(n+1)/2算法时间复杂度为 O(n)
平均比较次数为:( 1+2+3+…+n)/n=(n+1)/2算法时间复杂度为 O(n)

11
(3) 插入 插入是指在表的第 i (1≤i≤n+1) 个位置上,插入一个
新结点 x ,使长度为 n 的线性表: (a1 ,…, ai-
1 , ai ,…, an) ,变成长度为 n+1 的线性表: (a1
,…, ai-1 , x , ai ,…, an) 。1213212428304277
数据元素序号12345678
插入 25
下移一格
注意边界条件,即什么时候不能插入①表空间已满②插入位置 i 的值非法
注意边界条件,即什么时候不能插入①表空间已满②插入位置 i 的值非法
12132124
28304277
25
数据元素
9
序号12345678

12
status Listinsert_Sq(Sqlist &L,int i, Elemtype e){ if (i<1‖i >L.length+1) return ERROR; if (L.length>=L.listsize) //判断是否有空闲的存储空间 { newbase=(ElemType *)realloc(L.elem, (L.listsize+Listincrement)*sizeof(ElemType)); if(!newbase) exit(OVERFLOW); L.elem=newbase; L.listsize+=Listincrement; } q=&(L.elem[i-1]); //q 为插入位置 for (p=&(L.elem[L.length-1]); p>=q; --p) *(p+1)=*p; //插入位置及之后的元素后移 *q=e; //插入 ++L.length; return OK; }
for(j = L.length; j >= i; j --) L.elem[j] = L.elem[j-1];L.elem[j] = e;
for(j = L.length; j >= i; j --) L.elem[j] = L.elem[j-1];L.elem[j] = e;
13
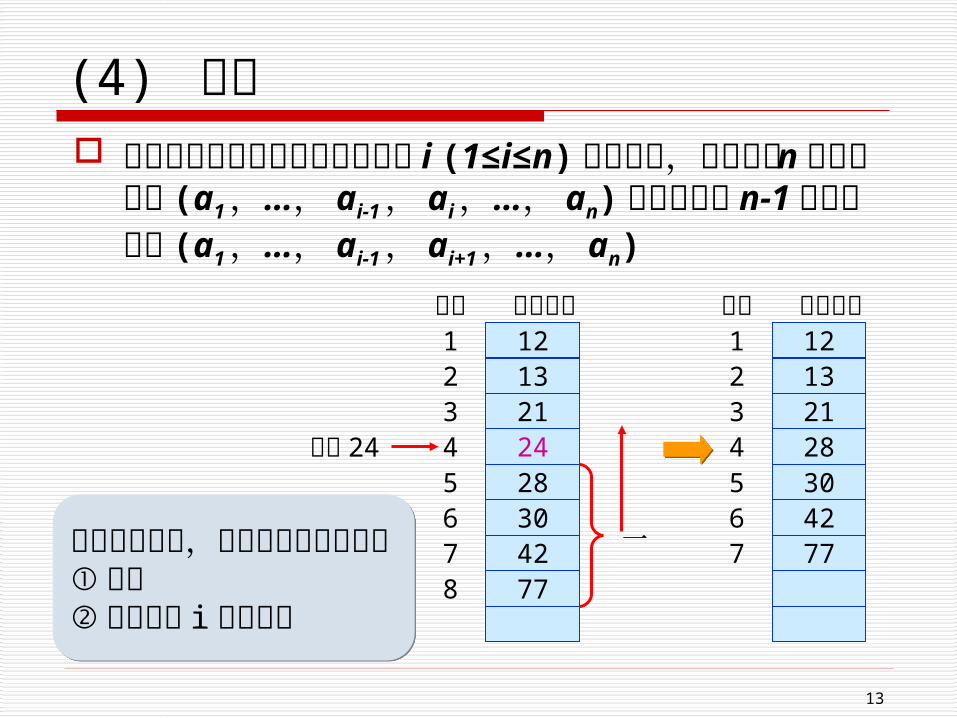
(4) 删除 线性表的删除运算是指将表的第 i (1≤i≤n) 结点删除
,使长度为 n 的线性表: (a1 ,…, ai-1 , ai ,…, an) 变成长度为 n-1 的线性表: (a1 ,…, ai-1
, ai+1 ,…, an)
1213212428304277
数据元素序号12345678
删除 24 上移一格
12132128304277
数据元素序号1234567
注意边界条件,即什么时候不能删除①表空②删除位置 i 的值非法
注意边界条件,即什么时候不能删除①表空②删除位置 i 的值非法

14
status Listdelete_Sq(Sqlist &L,int i, Elemtype &e){ if (i<1‖i >L.length) return ERROR; p=&(L.elem[i-1]); //被删除元素的位置 e=*p; //取出被删结点元素 q=L.elem+L.length-1; //表尾位置 for (++p;p<=q;++p) *(p-1)=*p; //被删除元素之后的元素左移 --L.length; return OK;}
删除程序
for(j=i;j<L.length;j++) L.lem[j-1]=L.lem[j];for(j=i;j<L.length;j++) L.lem[j-1]=L.lem[j];

15
算法复杂度分析 问题规模为表的长度,设为 n
移动结点的次数由表长 n 和插入位置 i 决定 当 i=n+1( 插入 ),或 i=n( 删
除 ) 时,由于操作都在尾部,将不移动语句。这是最好情况,其时间复杂度 O(1) 。
当 i=1 时,移动语句将循环执行 n 次 ( 插入 ) 或 n-1 次 ( 删除 ) ,需移动表中所有结点,这是最坏情况,其时间复杂度为 O(n) 。
上移一格下
移一格
121321…28304228…
数据元素序号123
i-1i
4277n
n+1
i+1
n-(i-1)
n-i

16
算法复杂度分析 (. 续 ) 平均时间复杂度:
插入:在长度为 n 的线性表中第 i 个位置之前插入一个结点,则在第 i 个位置之前插入一个结点的移动次数为 n-i+1 。令 Eis(n) 表示移动结点的期望值 (即移动的平均次数 ) ,故:
1
1
( ) ( 1)n
is ii
E n p n i
删除:在长度为 n 的线性表中删除第 i 个元素所需
移动的元素次数为 为 n-i ,则其数学期望值为:
1
( ) ( )n
dl ii
E n q n i

17
1
1
1( ) ( 1)
1 2
n
isi
nE n n i
n
1
1 1( ) ( )
2
n
dli
nE n n i
n
在等概率插入的情况下 O(n) 。
假设在表中任何位置 (1≤i≤n+1) 上插入或删除结点的机会是均等的,则:
pi+1=1/(n+1) , qi = 1/n
算法复杂度分析 (.. 续 )

18
(5) 其它操作
void DestroyList_Sq(&L){ free(L.elem); L.elem=NULL; }
void ClearList_Sq(&L){ L.length=0; }
int ListLength_Sq(L){ return(L.length); }
status ListEmpty_Sq(SqList L){ if(L.length==0) return(TRUE); else return(FALSE); }

19
顺序表总结
优点 存储空间使用紧凑 可随机存取任一元素
缺点 预先分配空间需按最大空间分配,利用不充分 表容量扩充麻烦 插入、删除操作需要移动大量元素

20
§2.3 线性表的链式表示和实现 1. 线性链表 ( 单链表 ) 链式存储结构特点
用一组任意的存储单元存储线性表的数据元素 利用指针实现用物理上不相邻的存储单元存放逻
辑上相邻的元素 每个数据元素 ai ,除存储本身信息外,还需存储
包含其相邻数据元素的位置信息的指针 线性链表 ( 单链表 ) 特点
每个数据元素结点只包括一个指针域,存放直接后继的地址信息

21
线性链表的表示
数据域 指针域结点
data next
数据元素 / 结点
线性链表 每个结点的存储地址都由前一结点的指针域指示 设头指针 head ,指出第 1 个结点的地址 最后一个结点无后继结点,其指针域为空
a1 a2 …head
an ^元素结点 尾结点
data 域是数据域存放元素本身信息
next 是指针域 ( 链域 ) ,存放直接后续的存储位置

22
举例:单链表存储示意 例如:线性表 [BAT, CAT, HAT, KAT, VAT,
WAT] 的顺序存储结构和链式存储结构
L0+6l
地址 数据
顺序分配
L0+lL0
L0+2lL0+3lL0+4lL0+5l
BATCATHATKATVATWATNIL
指针表示头指针head
KAT VAT WAT ^HATCATBAT
链接分配
初始地址L0+4l
地址
L0+lL0
L0+2lL0+3lL0+4lL0+5l
数据 指针KATWATCATHATBATVAT
NIL
L0+2l
L0+3lL0
L0+5l
L0+l

23
头结点 空表和非空表
头结点:为链表设置一相同类型的表头结点,一般无数据信息,只含首元素的地址信息
空表: head=Null
a1 a2 …head
an ^
非空表:
a1 a2head an ^
头结点
^head 空表: 非空表:

24
2. 线性链表的实现
存储结构:非顺序映象或链式映象 存储结构的 C 语言定义
typedef struct LNode{ ElemType data; /*定义链表中数据类型 */ struct LNode *next; /*定义链表中下一个数据地址 */} Lnode, *LinkList; /*该链表的名称 */

25
3. 线性链表的基本操作 (1) 查找 按序号查找 / 按值查找 例如:访问以 L为头结点的链表中第 i个结点,且
将此结点的地址存在 p中。
a1 a2L an ^a3
p p p p
核心操作:遍历 从头结点出发,通过工作指针的反复后移而将整个单链
表“审视”一遍的方法称为扫描或遍历
如何让工作指针后移?如何让工作指针后移?p=p->next;

26
查找程序
status Get_Elem(LinkList L, int i, ElemType &e){ p=L->next; /*将 p 指向链表的第一个结点 */ j=1; /*结点计数器 j 置 1*/ while(p && j<i) /*查找第 i 个元素 */ { p=p->next; /* p 指针后移,同时计数器加 1*/ j++; } if(!p || j>i) return ERROR; //表空和 i>表长 ||i<1非法 e=p->data; return OK; }

27
(2) 插入 在第 i个元素前插入一个新结点
找到插入位置,一般是第 i个结点的前驱结点 构造新结点 插入
插入过程
a b
p
x ^s
a b
p
x ^s
s->next=p->next; p->next=s;

28
算法程序
时间复杂度: O(n)
status Listinsert_L(Linklist &L,int i,Elemtype e){ p=L; j=0; //插入位置可为 1 ,因此其前一位置 j 从 0 开始 while (p && j<i-1) //查找第 i-1个结点 { p=p->next; ++j; } if ( !p || j>i-1) return ERROR; //表空和 i>表长 ||i<1操作非法 s=(Linklist)malloc(sizeof(LNodes)); // 或 new(s); s->data=e; s->next=p->next; //插入 p->next=s; return OK; }

29
(3) 删除 删除第 i个元素
找到删除位置 删除 释放结点 ai空间
删除过程
a b c
q=p->next;p->next=q->next;
q=p->next;p->next=p->next->next;
p q

30
算法程序
时间复杂度: O(n)
status Listdelete_L(Linklist &L,int i,Elemtype &e){ p=L; j=0; while (p->next && j<i-1) //查找第 i-1个结点 { p=p->next; ++j; } if ( !(p->next) || j>i-1) return ERROR; //删除位置非法 q= p->next ; p->next=q ->next; //删除结点 e=q ->data; free(q); return OK; }
注意:当 i=n+1(被删结点不存在 ) ,其前趋结点存在,为尾结点,此时 p 不为空。因此仅当 *p 存在,且 *p 不是尾结点时 (p->next!=NULL),才能确定被删结点存在。
注意:当 i=n+1(被删结点不存在 ) ,其前趋结点存在,为尾结点,此时 p 不为空。因此仅当 *p 存在,且 *p 不是尾结点时 (p->next!=NULL),才能确定被删结点存在。

31
(4) 建立单链表 尾插法建表
构造结点,将输入数据以正序依次插入表尾 头插法建表
构造结点,将输入数据以逆序依次插入表头
^head
an ^s
head
an ^s
s->next=head->next;head->next=s;
head an ^
head
an-1s
an ^
an-1 ^s

32
头插法算法程序
void CreateList_L(LinkList &L, int n){ L=(LinkList)malloc(sizeof(Lnode) ); L->next=NULL; //先建立带头结点的空链表 for(i=n; i>0; --i) { s=(LinkList)malloc(sizeof(Lnode)); scanf(s->data); s->next=L->next; //插入表头 L->next=s; } }
时间复杂度 O(n)

33
(5) 有序表的合并
合并方法:将两个有序表以遍历的方式依次插入到第 3 个表中。
b1 b2
pbbm ^
Lb
a1 a2
paan ^
La
^pc
Lc
pc

34
算法程序void Mergelist_L(Linklist &La, Linklist &Lb, Linklist &Lc){ pa=La->next; pb=Lb->next; Lc=pc=La; // 用 La的头结点作为 Lc的头结点 while (pa && pb) { if ( pa->data<=pb->data)
{ pc->next=pa;pc=pa;pa=pa->next;} else { pc->next=pb;pc=pb;pb=pb->next;} } pc->next =pa? pa:pb; //插入剩余段 free(Lb); //释放 Lb的头结点}
时间复杂度 O(m+n)

35
(6) 其它操作初始化LinkList InitList_L(void){ head=(ListNode *)malloc(sizeof(ListNode)); head->next=NULL; return(head); }
撤销void DestroyList_L(LinkList *L){ p=*L; *L=NULL; while(p) { q=p->next; free(p); p=q; } }
清空void ClearList_L(LinkList *L){ p=L->next; L->next=NULL; while(p) { q=p->next; free(p); p=q; } }

36
单链表总结 优点
它是一种动态结构,整个存储空间为多个链表共用,不需要预先分配空间
插入删除不需要移动数据元素 缺点
指针占用额外存储空间 不能随机存取,查找速度慢

37
4. 循环链表 循环链表:一种头尾相接的链表。即表中最后一个
结点的指针域指向头结点,整个链表形成一个环。 特点:从任一结点出发,可以访问表中所有其它结点,提高了查找效率,且无须增加存储量
单循环链表:在单链表中,将终端结点的指针域NULL改为指向表头结点的或开始结点,就构成了单循环链表。一般设置: 头结点:使空表和非空表的运算统一 尾指针:表的实际操作多是在尾部进行,可以减小时间
复杂度。 O(n) → O(1)
a1 an
H…
H

38
操作算法特点 其操作算法与单链表基本一致。但由于循环链表的
尾结点中没有 NULL 指针,其循环终止条件是判断是否等于头结点。
void GetElem_L(LinkList L, int i, ElemType &e){ p=L->next; … while (p != L && j < i) /*查找第 i 个元素 */ { p = p -> next; ++ j; } if ( p == L) return ERROR; … } while(p && j<i)
{ p=p->next; j++; }if(!p || j>i) return ERROR;
while(p && j<i){ p=p->next; j++; }if(!p || j>i) return ERROR;

39
5. 双向链表 双向链表:每个结点设置两个指针域,一个指向直
接前驱,一个指向直接后继。 双向循环链表:将头结点和尾结点链接起来,即第
一个结点 ( 或头结点 ) 的前向指针指向最后一个结点,最后一个结点的后向指针指向第一个结点 ( 或头结点 ) ,就构成双向循环链表
data next
结点结构prior
H a1 a2
Han

40
存储结构定义
typedef struct DuLNode{ ElemType data; /*定义数据 */ struct DuLNode *prior; /*定义指向直接前驱的指针 */ struct DuLNode *next; /*定义指向直接后继的指针 */}DuLNode, *DuLinkList; /*定义该双向链表 */

41
插入
算法如下: 取第 i个结点的指针 p;若该元素不存在,则返回 建立新的结点 s,并赋值 将 s的前驱指向p的前驱 , p 前驱结点的后继指向 s 将 s的后继指向p, p的前驱指向 s
第 i个结点p
es
^ ^……L
s->prior = p->prior ; p->prior->next = s ;s->next = p ; p->prior = s ;
① ③④②

42
算法程序
void ListInsert_DuL(DuLinkList L,int i, ElemType e){ if(!(p=GetElem_DuL(L,i))) /*取第 i 个元素的地址 p*/ return ERROR; if(!(s=(DuLinkList)malloc(sizeof(DuLNode)))) return ERROR; s->data=e; /*新结点赋值 */ s->prior=p->prior; /*s 的前驱指向 p 的前驱 */ p->prior->next=s; /*p 的前驱的后继指向 s*/ s->next=p; /*s 的后继指向 p*/ p->prior=s; /*p 的前驱指向 s*/ return OK;}

43
删除
算法: 判断p是否为头结点,若是,则退出。 将 p的前驱的后继指向p的后继 将 p的后继的前驱指向p的前驱 释放该结点所占用的存储空间
L^ ^……
p1
2
p->prior->next=p->next;p->next->prior=p->prior;

44
算法程序
void delete(DuLinkList L, DuLinkList P){ if (p==L) return; else{ p->prior->next=p->next; //p 的前驱的后继指向 p 的后继 p->next->prior=p->prior; //p 的后继的前驱指向 p 的前驱 } free(p); return; }

45
总结:顺序表和单链表比较 时间性能比较
按位查找: 顺序表的时间为 O(1) ,是随机存取 单链表的时间为 O(n) ,是顺序存取
插入和删除: 顺序表需移动元素,时间为 O(n) ; 单链表不需要移动元素,在 给出某个合适
位置的指针后,插入和删除操作所需的时间仅为 O(1) 。

46
顺序表和单链表比较 (. 续 ) 空间性能比较
结点的存储密度: 顺序表中每个结点的存储密度为 1 ,没有浪费空间 单链表的每个结点的存储密度 <1 ,有指针的结构
性开销。 整体结构:
顺序表需要预分配存储空间,如果预分配过大,造成浪费,若估计过小,又将发生上溢;
单链表不需要预分配空间,元素个数没有限制。
数据域占用的存储量整个结点占用的存储量存储密度=

47
顺序表和单链表比较 (.. 续 )
若线性表需频繁查找却很少进行插入和删除操作,或其操作和元素在表中的位置密切相关时,宜采用顺序表作为存储结构;若线性表需频繁插入和删除时,则宜采用单链表做存储结构。
当线性表中元素个数变化较大或者未知时,最好使用单链表实现;而如果用户事先知道线性表的大致长度,使用顺序表的空间效率会更高。

48
§2.4 一元多项式表示及运算 一元多项式可以表示为:
20 1 2( ) n
n nP x p p x p x p x ……
计算机中,可以用线性表 P来表示:
0 1 2( , , , , )nP p p p p ……
每一项的指数 i隐藏在系数 pi的序号里 存储结构
顺序表: n+1 个单元。当 n 很大、 0 系数较多时,浪费空间和时间。
线性链表:具有灵活性,该线性链表结点应有三个域:系数域 coef ,指数域 exp ,指针域 next 。

49
链式存储结构定义
typedef struct Node{ float coef; int expn; struct Node *next }PolyNode,*polynomial;
expn next
结点结构coef
3 cP
d ^ b 10 20
3 10 2020 ( )P x bx cx dx

50
一元多项式相加 运算规则:
指数相等,则系数相加,若为 0 ,该项取消。 指数不同,则两项系数照抄。
例如: A=1+3X5+6X10+2X30
B=5X5-8X12+5X25
A01 53 106 ^302
B55 12-8 ^255
C

51
算法 设 p、 q分别指向两个多项式中当前被检测的结点 若 p->exp<q->exp ,则插入结点 p 若 p->exp=q->exp ,则求 p->coef=p->coef+q->coef
结果不为 0 ,插入结点 p,并删除结点 q 结果为 0 ,删除结点 p, q
若 p->exp>q->exp ,则插入结点 q 若第 2 个多项式结点未取完,则把剩余结点链到后面
注意:第 2步里两种情况均要删除q,因此可以在第 2步后统一删除注意:第 2步里两种情况均要删除q,因此可以在第 2步后统一删除

52
void AddPoly(polynomial &pa, polynomial &pb) { p=pa->next; q=pb->next; pc=pa; while(p && q ) if(p->expn < q->expn) { pc=p; p=p->next; } //插入 p ,后移 else if(p->expn==q->expn) { p->coef=p->coef+q->coef; //新系数放入 p if(p->coef!=0) pc=p; //新系数不为 0 ,插入 p else { pc->next=p->next; free(p); } //删除 p p=pc->next; // p 指针后移 e=q; q=q->next; free(e); } //删除 q else { e=q; q=q->next; // q 后移, e 为待插入结点 e->next=p; pc->next=e; //插入 q,前驱结点 pc, 后一结点 p pc=e; } // pc指针后移 if(q!=NULL) pc->next=q; //如果第 2 个链不空,接续 free(pb); pb=NULL; }