Embed Size (px)
Citation preview

Towards a Semantic Medical Web: HealthCyberMap’s Dublin Core Ontology in Protégé-2000
Kamel Boulos MN, Roudsari AV and Carson ER Centre for Measurement and Information in Medicine, School of Informatics, City University, London, UK
Corresponding Author:
Maged N Kamel Boulos Centre for Measurement and Information in Medicine City University Northampton Square London EC1V 0HB UK E-mail: [email protected]
Abstract
HealthCyberMap (URI: http://healthcybermap.semanticweb.org) aims at mapping health information resources in cyberspace in unique and novel ways, and deliver a semantically superior experience to consumers of these resources. This paper describes the work undertaken in Protégé-2000 to develop a Dublin Core metadata set ontology for HealthCyberMap and a Web resource metadata collection form based on it. The Dublin Core subject field is populated with UMLS terms directly imported from the UMLS Knowledge Source Server using the UMLS tab, a Protégé-2000 plug-in. The ontology and its instances are saved in RDFS/ RDF. The paper also discusses some relevant Semantic Web issues and ways of exploiting Protégé-2000 RDFS/ RDF Output. Although HealthCyberMap’s visualisation components (the different types of hypermaps) contribute significantly to the Semantic Web functionality of the project, these are not discussed in this paper.
Keywords
Semantic Web, Ontologies, RDF, Metadata, Dublin Core, Clinical Codes, Problem-Knowledge Coupling Presented at the Fifth International Protégé Workshop, Sowerby Centre for Health Informatics at Newcastle (SCHIN), University of Newcastle upon Tyne, Newcastle, England (Wednesday 18th July 2001)

HealthCyberMap’s Dublin Core Ontology in Protégé-2000 - ii
TABLE OF CONTENTS
INTRODUCTION ........................................................................................................................................... 1 ONTOLOGIES DEFINED................................................................................................................................ 2 SEMANTIC WEB (ONTOLOGY REPRESENTATION) LANGUAGES................................................................... 2
RDF....................................................................................................................................................... 2 OIL ........................................................................................................................................................ 4 DAML and DAML+OIL ........................................................................................................................ 6
METADATA FOR THE SEMANTIC WEB......................................................................................................... 6 The Dublin Core Metadata Initiative (DCMI) ...................................................................................... 6
Types of Metadata .............................................................................................................................7 DC Qualifiers.....................................................................................................................................9 Extending DC ....................................................................................................................................9
Optimising User Experience ................................................................................................................. 9 Reasoning with Metadata and Generating Topic Maps ...................................................................... 11 Clinical Codes for the DC Subject Field ............................................................................................. 13
Description Logics...........................................................................................................................13 HealthCyberMap Three-Layer Model .............................................................................................14
COMBINING METADATA WITH ONTOLOGIES............................................................................................. 15 Merging Ontologies............................................................................................................................. 16 Medical Terminologies as a Shared Ontology Service........................................................................ 16
SEMANTIC WEB SERVICES........................................................................................................................ 17 HealthCyberMap’s Problem-Knowledge Coupling Service................................................................ 18
HEALTHCYBERMAP'S DC IMPLEMENTATION IN PROTÉGÉ-2000 .............................................................. 18 Protégé-2000 as a Semantic Web Tool ............................................................................................... 18 The UMLS Tab .................................................................................................................................... 19 About UMLS........................................................................................................................................ 21
Using One-to-Many Links to Explore Related Concepts.................................................................22 HealthCyberMap/ DC Project Description......................................................................................... 23 What’s Next? Exploiting Protégé-2000 RDFS Output ........................................................................ 27
CONCLUSION ............................................................................................................................................ 28 REFERENCES............................................................................................................................................. 28

HealthCyberMap’s Dublin Core Ontology in Protégé-2000 - 1
Introduction HealthCyberMap (URI: http://healthcybermap.semanticweb.org) aims at mapping health information resources in cyberspace in unique and novel ways, and deliver a semantically superior experience to consumers of these resources. This is achieved through intelligent categorisation and interactive hypermedia visualisation of the health information cyberspace using metadata, clinical codes and GIS (Geographic Information Systems) technologies. The current Web is primarily designed for (but not optimised for) human consumption. As a result, machines are unaware of the actual context and content meaning of different Web resources. Current Web search engines do not really distinguish officially approved medical guidelines from experts’ opinions on the same topics, and cannot easily tell a personal home page from an academic Web site [1, 2]. Free text word-based (or phrase-based) search engines like AltaVista, Lycos and Excite typically return innumerable completely irrelevant “hits,” requiring much manual weeding by the user [3, 4] and might miss important resources. Free text search is not always efficient and effective for the following reasons [5]: • the sought page might be using a different term (synonym) that points to the same concept; • spelling mistakes and variants are considered as different terms; and • search engines cannot process HTML intelligently, for example, searching for resources on
‘psoriasis’ will retrieve all the documents containing this word, but many of these resources might not be relevant (‘psoriasis’ was just mentioned by the way in these documents and is not their actual topic).
Even when sophisticated statistical techniques are used for information retrieval, e.g., PubMed’s RELATED ARTICLES function, the results are not that good (regarding their relevance) [6]. Liu and Altman [7] developed a program for incremental updates of a bibliography based on PubMed’s RELATED ARTICLES function and could only demonstrate a recall of 75%, a strict retrieval precision of 32% and a partial precision of 42%. Many people have proposed using Natural Language Processing (NLP) to figure out Web pages. Unfortunately, NLP is still immature, and hasn’t yet overcome many tremendous obstacles like the interpretation of Web graphics and diagrams designed for a human reader [3]. On the other hand, human-made Web catalogues or topical directories like Yahoo! and the Open Directory Project (http://dmoz.org/), where resources are classified under different categories, are not much better. The Web is very rapidly growing and changing, with so much information that humans at these directory services cannot possibly keep up [3]. Moreover, there is frequently an inevitable overlap between the categories in a Web catalogue and imprecision regarding the definition of their scope, leading to confusion as to what to expect under a given category [8]. With all current systems, irrespective of the methods they use, there will always be someone who cannot find what they want for semantic reasons. These problems can only be alleviated if search engines no longer search for matching words, but search on the semantic concepts underlying the information in Web pages and their relationships. The Semantic Web initiative aims at creating a Web where information semantics (or meaning) are represented in a form that can be “understood” by machines as well as by humans. This will pave the way to more “intelligent” machine-to-machine communication and information agent interoperability, and should ultimately empower human Web readers and solve many of the information management and

HealthCyberMap’s Dublin Core Ontology in Protégé-2000 - 2
retrieval problems they experience today with the current Web [1, 2]. Ontologies and ontology representation languages are pivotal ingredients of the forthcoming Semantic Web [4].
Ontologies Defined Originally a philosophical discipline, ontologies are now also a hot topic in computer science in such diverse areas as knowledge representation, natural language processing, machine learning, databases, information brokering and retrieval, knowledge discovery and management (transforming document repositories into proper knowledge repositories), multi-agent systems and Semantic Web research [1, 9]. Knowledge Engineers are now called Ontologists [10]. Ontologies can enhance Web searches, relate the information on a page to associated knowledge structures and inference rules, and help us develop agents that can address complicated questions whose answers do not reside on a single Web page [4]. An ontology is a consensual, shared and formal description of the concepts that are important in a given domain and their properties (attributes) and relations between them, i.e., it is a conceptual knowledge model or a specification of a conceptualisation [1, 11]. Property constraints, facts, assertions, axioms and rules are also part of an ontology. Typically, an ontology identifies classes or categories of objects that are important in a domain, and organises these classes in a subclass-hierarchy. Each class is characterised by properties that are shared/ inherited by all elements in that class [1]. This structure might look like a simple taxonomy, but the real power of ontologies depends on the presence of inference and deduction rules, and reasoning and classification services. Ontologies establish a common terminology between members of a community of interest. These members can be human or automated agents [12]. Problems might arise if two ontologies used within the same project refer to the same thing in different ways (e.g., sex and gender, or zip code and postal code). This confusion can be resolved if ontologies (or other Semantic Web services) provide equivalence relations: one or both ontologies may contain the information that, for example, ‘sex’ is equivalent to ‘gender’ [4].
Semantic Web (Ontology Representation) Languages
RDF
In his original 1989 proposal that gave rise to the World Wide Web, Tim Berners-Lee mentioned some ideas very closely related to those formalised nearly a decade later as RDF (Resource Description Framework). In particular, he suggested a directed, labelled graph model with link and node types that encompass metadata applications, in addition to simpler document linking [13]. RDF is a W3C (World Wide Web Consortium) recommendation for metadata. RDF is based on XML (the eXtensible Markup Language), and builds on a well-known branch of mathematics: graph theory, plus the experiences of the knowledge acquisition and representation community. RDF can represent relationships, while raw XML cannot. RDF statements can be viewed in three mathematically equal representations (Figure 1): 1. as a labelled directed graph. This is a good representation for humans; 2. as triples: Object (usually a resource identified by a URI – Universal Resource Identifier),
Attribute (a property of the resource), Value triples (or Subject, Predicate, Object triples). Values can be either atomic or other resources (URIs) or even metadata instances. Triples are accessible to application software; and

HealthCyberMap’s Dublin Core Ontology in Protégé-2000 - 3
3. as an XML-based representation for exchange between computers [5, 14].
Figure 1. SiRPAC rendering of a simple example (Triples of Data Model and Graph). This example states that the Property creator (as defined by Dublin Core Metadata Initiative) of the Object HealthCyberMap (http://healthcybermap.semanticweb.org) is declared at http://healthcybermap.semanticweb.org/proposal.htm (Value given as URI). SiRPAC acronym stands for Simple RDF Parser & Compiler and is available online at: http://www.w3.org/RDF/Implementations/SiRPAC/ RDF is a very simple format for predicate logic, making it possible to use it for modelling ontologies and drawing conclusions by generalising from assertions or from combining several assertions. The difference from traditional predicate logic is that the syntax of RDF is declared in the RDF schema (RDFS), which means it is specific to the application instead of general, like predicate logic. The RDF schema is used to define the set of resources that may be used by a model, including constraints for resource (e.g., range and domain) and literal values (constants or string values). It creates the structure which the user later fills with his/ her description (instances) and which can be used for consistency checks (that the actual RDF triples are following the defined constraints) [14, 15].

HealthCyberMap’s Dublin Core Ontology in Protégé-2000 - 4
RDF schema enables us to express relations like rdfs:subClassOf and rdfs:subPropertyOf that standard relational database management systems (RDBMS) cannot easily cope with (though storing the base RDF Object-Attribute-Value triples in an RDBMS is not a problem). XML namespaces are used in RDF to unambiguously define the context of statements, e.g., that we specifically mean the Dublin Core creator element (as defined at http://purl.org/dc/elemenets/1.1/creator) when using the Property (or Predicate) creator in the example shown in Figure 1 above, and not any other definition of creator [14]. RDF offers only the most basic ontology-modelling primitives; it only knows binary relations (properties), and so cannot model ontological axioms, which correspond to n-ary relations between class expressions, where n is two or greater. On the other hand, OIL and DAML+OIL, which build on RDFS (see below), offer full support for axioms. Axioms are factual statements that assert some additional facts about ontology classes. For example, an axiom might state that the classes male and female are disjoint (i.e, have no instances in common); a reasoner can then infer given a statement like “Rami is type male” that the statement “Rami is type female” must be false and is not possible. Axioms are considered one of the key ingredients in ontology definitions and are one of the major benefits of ontology applications [15, 16, 17]. RDF also forms the basis of other emerging W3C standards, e.g., the Composite Capability/ Preference Profile (CC/PP) uses RDF to communicate profiles of mobile device properties to servers in order to deliver better tailored content for these often restricted Web clients [1, 14, 18].
OIL
The Ontology Inference Layer (OIL) is a proposal for a Web-based representation and inference layer for ontologies. It is layered on top of RDF schema. The layering is done by adding reification features (statements about statements) to RDF schema. This is known as Core OIL. The next level, Standard OIL, contains modelling primitives that are necessary to provide adequate power of expression and clarity (derived from frame-based systems and description logics, based on the notions of classes, concepts or frames having properties, roles or slots). Slots can have their own properties, e.g., domain and range, and can be arranged in a hierarchy. Standard OIL allows semantics to be very precisely specified and complete inferences to be viable. The third level, Instance OIL, allows for database capabilities. The fourth layer, Heavy OIL, has not been yet defined (as of June 2001) and may include additional representational and reasoning capabilities. Simple RDF schema parsers can still process OIL ontologies, but will not capture all meanings as OIL-aware programs (backward compatibility) [1, 14, 19, 20]. The development of OIL was sponsored by the European Community via two Information Society Technologies (IST) projects with participants from the Free University of Amsterdam, University of Karlsruhe (Germany) and the University of Manchester (UK), in addition to prominent industrial partners like BT Labs (UK). OIL’s steering committee also includes prominent scientists from Stanford University (US) and Massachusetts Institute of Technology (US) [20]. Many OIL tools are already available (Figures 2 and 3).

HealthCyberMap’s Dublin Core Ontology in Protégé-2000 - 5
Figure 2. Screenshot of OILEd, the free OIL editor developed at the University of Manchester, UK (URI: http://img.cs.man.ac.uk/oil/). FaCT (Fast Classification of Terminologies), also developed at the University of Manchester, is a Description Logic (DL) classifier that can also be used for modal logic satisfiability testing (URI: http://www.cs.man.ac.uk/~horrocks/FaCT/). It exists in CORBA and Lisp flavours. It can be invoked from within OILEd (Reasoner Menu). In the screenshot above, FaCT detected that “tasty_plant” (highlighted in red near the bottom of the screenshot) has a problem [having “carnivore” as value for the slot “is_eaten_by” since this conflicts with the class “carnivore” (only eats animals, but “tasty_plant” is a subclass of “plant”)]. N.B.: An important feature of DL expressions is that they can be described in a mathematically precise way, enabling reasoning with concept descriptions and the automatic derivation of classification taxonomies.

HealthCyberMap’s Dublin Core Ontology in Protégé-2000 - 6
Figure 3. The same result is obtained in Protégé-2000 (URI: http://protege.stanford.edu) with the OIL classifier tab which allows the classification of OIL ontologies by calling the same FaCT descriptions logic classifier.
DAML and DAML+OIL
DARPA Agent Markup Language (DAML) program of the Defense Advanced Research Projects Agency, US, aims at enabling software agents to dynamically identify and understand the semantics of information resources, and to provide semantic interoperability between machines. Web site authors will have to add DAML mark-up to their pages to describe their contents for DAML-enabled search engines and other programs to be able to function properly [21, 22]. OIL is said to achieve greater backward compatibility with RDF schema than DAML and to offer better reasoning services, in addition to few other differences described briefly in [1]. A merger language, DAML+OIL, has been also proposed [23].
Metadata for the Semantic Web Metadata are documentation about documents and objects, or structured information about information. When properly implemented, metadata can crisply and unambiguously describe information resources, enhancing information retrieval and enabling accurate matches to be done, while being totally transparent and invisible to the user. Search specificity is increased (noise reduction/only good matches) and search sensitivity is boosted (i.e., silence or missed matches are decreased and signal-to-noise ratio increased/all good matches) [5].
The Dublin Core Metadata Initiative (DCMI)
The Dublin Core (DC), conceived at a workshop convened by OCLC (Online Computer Library Centre, Inc.) and the National Centre for Supercomputing Applications in 1995 in Dublin, Ohio, is a 15-element metadata set intended to aid discovery of electronic resources. The current DC

HealthCyberMap’s Dublin Core Ontology in Protégé-2000 - 7
version (URI: http://dublincore.org/documents/dces/ – accessed 7 June 2001) describes the following elements covering resource content, intellectual property and instantiation: title, creator, subject (using a controlled vocabulary for this element is recommended), description, publisher, contributor, date, type, format, identifier, source, language, relation, coverage and rights. Most of the elements have commonly understood semantics of roughly the complexity of a library catalogue card [24, 25].
Types of Metadata
DCMI defines two interrelated types of metadata [25]: 1. metadata embedded within the resource (peripheral metadata; this type helps automating the
acquisition of the second type); and 2. stand-alone metadata (central catalogue or index metadata). Metadata of the first type can be inserted in the header of HTML documents (resources) using meta and link tags [5] as in the following example: <html>
<head><link rel="schema.DC"href="http://dublincore.org/documents/1999/07/02/dces/#"><meta name="DC.Title" content="HealthCyberMap"><meta name="DC.Creator" content="Maged Nabih Kamel Boulos"><meta name="DC.Subject" content="Health Cyberspace; Hypermedia GIS; ClinicalCodes; Semantic Web; Visualisation"><meta name="DC.Description" content="Mapping the Health Cyberspace UsingHypermedia GIS and Clinical Codes; Visualisation of Health Cyberspace; MedicalSemantic Web"><meta name="DC.Publisher" content="MIM Centre, School of Informatics, CityUniversity, London, UK"><meta name="DC.Contributor" content="Abdul V Roudsari and Ewart R Carson"><meta name="DC.Date" scheme="W3CDTF" content="2001-06-08"><meta name="DC.Type" scheme="DCMIType" content="Service"><meta name="DC.Format" content="text/html"><meta name="DC.Format" content="4434 bytes"><meta name="DC.Language" scheme="RFC1766" content="en"><meta name="DC.Identifier"content="http://healthcybermap.semanticweb.org/default.htm"><meta http-equiv="Content-Type" content="text/html; charset=windows-1252"><meta name="GENERATOR" content="Microsoft FrontPage 4.0"><meta name="ProgId" content="FrontPage.Editor.Document"><title>HealthCyberMap</title><link rel="stylesheet" type="text/css" href="style.css" /></head>
<body>… (the rest of the HTML source of the page follows here)
Some offline and online tools already exist that will assist the creators of Web resources in compiling and inserting DC metadata mark-up into their HTML documents, e.g., ReadTag (offline – [5]), and Reggie and UKOLN (online – [26, 27]). Stand-alone metadata can exist in any kind of database (including RDF), and provides a link to the described peripheral (external) resource. HealthCyberMap relies on stand-alone (central) metadata, coupled with a medical terminology or classification, e.g., ICD (International Classification of Diseases) or SNOMED-CT (Systematised Nomenclature of Medicine - Clinical Terms), for crisp subject descriptions and to allow semantic reasoning about the indexed resources and their relations with each other.

HealthCyberMap’s Dublin Core Ontology in Protégé-2000 - 8
Unlike other approaches like SHOE (Simple HTML Ontology Extension), HealthCyberMap does not impose any structural changes, e.g., embedded metadata or ontology instance mark-up, on the peripheral resources, or their hosting servers. However, HealthCyberMap should ideally make use of any available peripheral metadata (DC tags) to automate as much as possible the process of building and updating its own central database of metadata. N.B.: SHOE requires ontology instance mark-up to be embedded in Web pages (ontology instances based on template ontologies that define ontological relations, with references to the URIs of these template ontologies). This enables a robot (Exposé) to find Web pages with SHOE mark-up, read the knowledge from them, and load it into PARKA, a frame-based, property/ class system that uses database management systems technology. This knowledge can then be queried using the PARKA Interface for Queries (PIQ) or SHOE Search [28, 29]. A related type of stand-alone metadata (annotations) has been proposed by the W3C Annotea Project and implemented in their Amaya editor/ browser [30, 31]. Annotations are external comments, notes, remarks that can be attached to any Web document or a selected part of the document. They are classified as metadata, as they give additional information about an existing piece of data (the annotated resource). Amaya’s annotations are based on W3C RDF, XLink, and XPointer recommendations. Annotations can be stored locally (on the user’s machine) or in one or more annotation servers for wider accessibility. When a document is browsed, Amaya queries each of these user-defined servers, requesting the annotations related to that document. Amaya uses XPointer to describe where an annotation should be attached to a document. With this technique, it is possible to annotate any Web document independently, without the need to edit that document (so you don’t need write access to the annotated document). Metadata about metadata (metadata about the annotations, like author name) are also captured and stored. Filtering options exist to show or hide annotations based on the author of the annotation, type of annotation, server hosting the annotation, or any combination of the aforementioned selection criteria. Finally, Amaya presents annotations with yellow pencil annotation icons and attaches XLink attributes to these icons. If the user single-clicks on an annotation icon, the text that was annotated is highlighted. If the user double-clicks on this icon, the annotation text and other metadata are presented in a separate window (Figure 4).
Figure 4. Annotations can be the basis of multiple resource ratings (quality benchmarking) by different individuals and groups at the same time. You always know who the rater is (DC creator element attached to the annotation).

HealthCyberMap’s Dublin Core Ontology in Protégé-2000 - 9
DC Qualifiers
DCMI describes two broad classes of DC qualifiers [25, 32]: • Element Refinement Qualifiers. These qualifiers make the meaning of an element
narrower or more specific, e.g., the table of contents and abstract element refinements for the DC description element. A refined element shares the meaning of the unqualified element, but with a more restricted (specialised) scope.
• Encoding Scheme. These qualifiers identify schemes that aid in the interpretation of an element value. These schemes include controlled vocabularies and formal notations or parsing rules. A value expressed using an encoding scheme will thus be an instance selected from a controlled vocabulary, e.g., a term from a medical terminology or a classification, or a string formatted in accordance with a formal notation (e.g., “2001-07-01” using ISO 8601-based W3C date encoding rules [33]). This helps preventing any ambiguities and making the string machine-understandable (in the last example, the machine can be sure that we only mean 1st of July 2001).
DCMI is supporting the use of RDF and RDFS to express DC [32, 34, 35].
Extending DC
DC is not a complete solution. For example, although an event type is defined (for DC type element), DC is not good enough for describing events (e.g., a conference). Hjelm [14] suggests adopting iCalendar, the standard proposed by the Structured Knowledge Initiative [36], as an alternative. Besides, DC cannot be used to describe the quality [37] or location of a resource (location is different than coverage, although both are geographic elements). There are no DC elements covering these important aspects of a resource. HealthCyberMap attempts to fill these gaps using its own elements to extend the standard DC elements. This approach of patching DC is not completely new. The W3C RDFPic project for describing and retrieving digitised photos with RDF metadata extends the DC schema by adding its own technical schema to define important elements not covered by DC, e.g., camera, film, lens and film development date [38]. The W3C RDFPic idea can be used to tag clinical images, e.g., in an online digital dermatology atlas, with relevant metadata and thus enhance the retrieval of these images.
Optimising User Experience
Metadata is not limited to describing information resources. Two other groups of metadata are equally important, namely user profiles (including user’s location profile which directly affects user’s health) and device descriptions. An ideal system should be able to reason with all three types of metadata to personalise and optimise a Web user’s experience (Figure 5).

HealthCyberMap’s Dublin Core Ontology in Protégé-2000 - 10
Figure 5. Three interrelated categories of metadata are required to optimise a user’s experience. Metadata is important for customisation as it helps selecting suitable online resources for a particular user and his/ her particular needs at a given time, and also present them in a form that is appropriate for this user and the device he/ she is using to access the resources. For example, one can think about setting HealthCyberMap’s Web interface language to match user’s preference/ location language (if a multilingual version of HealthCyberMap is developed) and retrieving/ giving more importance to Web resources in user’s location language. The latter can be achieved using the DC language field in HealthCyberMap’s database, which makes possible the selection of resources based on their language to match a user’s preferred language [39]. Hjelm [14] lists the following parameters upon which content customisation may depend: • device type, e.g., phone, PDA, or PC and device processing power, screen resolution, colour
depth, and other display parameters; • user agent (browser), supported scripting languages, supported tag sets and datatypes, and
installed plug-ins and versions; • input modalities and output modalities, e.g., keyboard vs. mouse/ pen vs. voice, and text vs.
images/ video vs. audio only; • network capabilities such as bandwidth; • security needs; and • user preferences, e.g., acceptable language/ character encoding, cost of content and payment
mechanisms. For HealthCyberMap, the following parameters can be added to the above list: • other user’s needs including any special accessibility features (e.g., large type) and his/ her
demographic and health profiles; and • the user’s location and its known health and healthcare makeup that could directly affect the
user’s health. HealthCyberMap features a DC coverage field that is used to store the spatial extent or scope of the content of a given resource; this should help selecting those resources that are appropriate for a user’s location. A user’s location can be collected through a Web form that the user fills, or automatically detected based on the user’s IP address (though this is not always successful) [24]. In wireless Internet, mobile devices will be able to send their location, e.g., via assisted global positioning
Resources Device/ agent
User (and his/ her location)
Optimised user
experience

HealthCyberMap’s Dublin Core Ontology in Protégé-2000 - 11
services (AGPS) [40, 41]. It is expected that personalised, location-based services will be a vital application for the success of the wireless Internet. However, privacy issues must be observed (e.g., when a user does not want to reveal his/ her location, this should be respected) [40].
Reasoning with Metadata and Generating Topic Maps
Bechhofer and colleagues [42] describe two generations of hypertext systems. The first generation, e.g., the current World Wide Web, is inspired by Memex (“memory extender”) machine proposed by Vannevar Bush in 1945 [43]. It is defined as a network of static, manually authored, point to point links that are prescriptive and determined by the system designer. It suffers from maintenance problems, e.g., dangling links. Second-generation hypertext is characterised by the separation of links and navigation from resources. It relies on metadata to reason about the content and structure of the resources and to dynamically generate associations (links) between documents. If a resource URI changes, only its metadata record needs to be updated (no other documents need updating). The next time this resource is referenced, the reference will point to the correct link. This can improve authoring and browsing. HealthCyberMap belongs to this second-generation hypertext. Topic Maps (ISO/IEC 13250 [44]) are closely related to the concepts behind second-generation hypertext systems. We already appreciate the advantages of using cascading style sheets to control the formatting and layout of Web pages. Topic Maps introduce the concept of creating style sheets (hypertext navigation layer) to control the access and navigation of knowledge resources. Different Topic Maps can be applied to the same underlying set of information resources to match the requirements of different users having different profiles. One can think of Topic Maps as structured views or themes, e.g., a view for consultant dermatologists and another one for general practitioners treating skin diseases [45]. A topic is the building block of Topic Maps. It is a multi-headed (one to many) link that points to all its occurrences. Among all occurrences of a given topic, a distinction can be made among subgroups. Each subgroup is defined by a common role. Occurrence roles are user-definable and can be used to distinguish main occurrences and definitions from ordinary occurrences, graphic from text (e.g., a photo of ‘guttate psoriasis’ vs. a textual account on the same condition), etc. They correspond to Dublin Core type element. Topics can be grouped into user-defined classes known as “topic types”. A topic type is a category to which one given topic instance belongs. Topic types can be used to build specialised indexes and improve search facilities. A topic may have zero, one, or several names (for synonyms and multilingual support). By using a medical terminology and/ or classification to describe resource subjects, HealthCyberMap can automatically support all synonyms of medical concepts and even multiple languages. A topic without a name is usually a link between occurrences covering the same subject (cross-references). Topic display names can be something else than characters; they can be graphics (cf. BodyViewer maps of HealthCyberMap – Figure 6) [46].

HealthCyberMap’s Dublin Core Ontology in Protégé-2000 - 12
Figure 6. Three BodyViewer hypermaps from HealthCyberMap (URI: http://healthcybermap.semanticweb.org). Clicking the Heart (Cardiovascular) on the main Human Body Map brings another detailed map of the Cardiovascular System. Clicking the Heart again on the latter map, calls a third map with a detailed view of the Heart. Topics can be related together based on user-defined semantics that describe the relationships between topics. For example, one topic can be a container for other topics, and it becomes possible to describe topic trees [46]. Again, this is can be found in HealthCyberMap (Figure 6). Topic associations are independent of the source documents in which the actual topic occurrences are present. Topic Maps are as important as the actual information resources they point to, as they optimise and maximise the exploitation of the latter. There are more sophisticated features of Topic Maps, like scopes, facets and the ability to merge two or more Topic Maps [46], the discussion of which is beyond the scope of this document. Although the current HealthCyberMap implementation does not comply with the published Topic Maps ISO standard [44], HealthCyberMap is clearly sharing most of Topic Maps’ pivotal concepts. Thanks to its comprehensive database of resource metadata, HealthCyberMap can automatically and dynamically generate different sets of visual and textual “Topic Maps” and categorise the resources in its index in many different ways to match the many different profiles

HealthCyberMap’s Dublin Core Ontology in Protégé-2000 - 13
of user requirements. Although the acquisition of metadata in HealthCyberMap still depends on a human cataloguer, the automated categorisation of these resources (into visual and textual maps, directories and topic trees) based on clinical codes and other metadata fields should save the cataloguer a lot of effort and time.
Clinical Codes for the DC Subject Field
Metadata can greatly enhance information retrieval, but this depends on the quality of the metadata we are using. Using keywords in the DC subject field to describe the content of a resource is not the optimal solution. The user might not know which keywords or terms were used to index the resource and can thus miss a relevant resource when performing a search [13, 47]. A further improvement would be to use a thesaurus to care for more synonyms or force the user to select keywords from a predefined collection of terms we are using in our metadata. But, thesauri also have their own limitations [47]. They do not allow users to ask questions like “Get pages describing the complications of diabetes mellitus” and retrieve relevant pages, say on peripheral neuropathy, because the thesaurus does not know the relationship between diabetes mellitus and peripheral neuropathy (peripheral neuropathy is not a synonym or variant of diabetes mellitus). A coding scheme would take this one step further by offering a collection of terms along with a hierarchy that tells us which terms are kinds of one another. We can use the hierarchy to ask more general questions. Queries for endocrine disorders can now pick up diabetes mellitus and Grave’s disease. Unfortunately, coding schemes still have their drawbacks. A term has to be introduced for anything that we want to represent. This can lead to an unmanageable number of terms (and many concepts will still be missing at the end, irrespective of how hard we try). Adding compositional and multiple parentage capabilities to coding schemes can solve this [47]. This is the approach adopted in Read Codes (Clinical Terms Version 3) for example. Having multiple parentage in a terminology allows a resource to appear under all relevant categories (when browsing resources by categories) and greatly enhances search results (Figure 7). Figure 7. “Surgical Operation” acts as parent for “Transplant Operation” and “Kidney Operation,” which are both in turn parents of “Kidney transplant” (multiple parentage). Search for either “Transplant Operation” or “Kidney Operation” would find “Kidney Transplant.”
Description Logics
A description logic (DL) lies at the heart of any clinical terminology, e.g., SNOMED. A DL is a language that allows reasoning about information, in particular supporting the classification of descriptions. It can infer knowledge implied by an ontology. A DL models a domain in terms of individuals (modelled objects), concepts (descriptions of groups of objects sharing common
Surgical Operation
Transplant Operation Kidney Operation
Kidney Transplant

HealthCyberMap’s Dublin Core Ontology in Protégé-2000 - 14
characteristics) and roles (the relationships between concepts or individuals). Individuals are instances of the concepts that represent them [47, 48]. DLs allow us to reason about the concepts and work out how they relate to one another. The subsumption or kind-of relationship is the most important, e.g., “Surgical Operation” subsumes “Kidney Transplant” as every “Kidney Transplant” is a “Surgical Operation.” A collection of descriptions can be organised into a classification using the subsumption relationship, forming a hierarchy of descriptions, ranging from general to specific. Classification is dynamic as new descriptions can get their position in an existing hierarchy determined by a classifier. We can make assertions about individuals (objects) which tell us facts about them and we can relate two individuals (objects) using a role. This may change the classification of concerned individuals. Given a concept definition or description, we can ask for or retrieve all the individuals that are instances of that concept. The hierarchy can be used during retrieval to allow different types of queries with very crisp results. Given an individual, we can also determine the most specific concepts that the individual is an instance of, taking into account any assertions that have been made about the individual. This is known as realisation. DL is often described as being split into two parts: T-box and A-Box. The T-box is concerned with reasoning about the concept definitions, providing subsumption and classification services. The A-box reasons about relationships between individuals (instances), providing retrieval and realisation services [47, 48].
HealthCyberMap Three-Layer Model
Appleyard and Malet [49] were probably the first to mention that “the incorporation of nomenclatures, such as UMLS (Unified Medical Language System) and SNOMED, into meta-tags will allow the linking of Web-based knowledge sources into electronic medical record systems.” Rector [50] mentions the following tasks relevant to digital libraries and management of knowledge resources among other tasks that a clinical terminology can fulfil: • navigating and browsing through information – either locally or on the Web; • authoring knowledge – either static knowledge for browsing or dynamic decision support;
and • indexing knowledge – both general medical knowledge and information about individual
patients (this can be the basis of problem-knowledge coupling). HealthCyberMap has been designed to use clinical codes like SNOMED-CT (a terminology or nomenclature) or ICD (a classification) as basic (template) medical ontologies for mapping the health cyberspace (the codes are used to populate the DC subject field in HealthCyberMap’s database – Figure 8). A terminology (or classification) is a kind of ontology by definition as it preserves (and “understands”) the relationships between the 1,000s of terms in it or else it would become a mere dictionary (or at best a thesaurus). By labelling or tagging a resource with clinical codes, we are automatically establishing the relationships (as defined by the coding scheme used to tag the resource) between this resource and related (tagged) resources in the medical Web and also the (similarly coded) Electronic Patient Record (for problem-knowledge coupling). The current HealthCyberMap Web implementation uses ICD-9-CM (International Classification of Diseases, ninth revision, Clinical Modification), a hierarchical classification with no support for multiple parentage, as we rely on a GIS extension that currently only understands ICD-9 to generate the BodyViewer maps. However, there is no reason (at least from a theoretical point of view) why the system shouldn’t be expanded to include other more comprehensive clinical coding systems like UMLS (the Unified Medical Language System which we have used in our DC implementation in Protégé-2000 – see below).

HealthCyberMap’s Dublin Core Ontology in Protégé-2000 - 15
Figure 8. Clinical Codes Ontology/ DC Vocabulary/ RDF Interrelation. HealthCyberMap DC RDF instances use clinical codes to populate the DC subject field.
Combining Metadata with Ontologies
Semantic Web resources must be marked-up with metadata or indexed in a central database using metadata. Explicit concepts in the metadata would then map onto an ontology, e.g., a clinical terminology or classification, or a collection of merged ontologies allowing a Semantic Web agent/ search engine to infer implicit meanings not directly mentioned in either the resource or its metadata (Figure 9) [51].
Figure 9 (Modified from [51]). Metadata alone is not enough for successful retrieval of this resource. In this example, even though the resource and its metadata do not mention ‘exposure risk to Borrelia Burgdorferi in north-eastern United States,’ an assisted search for ‘exposure risk to Borrelia Burgdorferi in north-eastern United States’ would find http://geo.arc.nasa.gov/sge/health/projects/lymeny/study1.html.

HealthCyberMap’s Dublin Core Ontology in Protégé-2000 - 16
Merging Ontologies
Merging multiple ontologies (knowledge domains) is usually necessary to solve real world problems. Sharing and re-using ontologies can save time, make systems more flexible and facilitate many maintenance tasks. The Medical Guidelines Technology (MGT) project at the Open University in Milton Keynes, UK, is a good example. It uses a guideline ontology, e.g., covering hypertension, that is separate from, yet builds upon, a general medical knowledge ontology and another general problem-solving ontology [52]. Another example is MELISA (MEdical Literature Search Agent), an ontology based information retrieval agent that merges a custom-built medical ontology with MeSH (Medical Subject Headings) ontology. MELISA demonstrates how ontologies can be very useful in enhancing Web searches [53]. Similarly, it is possible to use and merge together several ontologies, including a clinical terminology/ classification in HealthCyberMap (Figure 10). Figure 10. This diagram illustrates some of the possible ontologies that can be used and merged together in HealthCyberMap, and their intersections with each other and with HealthCyberMap’s main DC ontology of metadata and its instances.
Medical Terminologies as a Shared Ontology Service
According to Bechhofer and colleagues [54], terminologies, or controlled vocabularies, are a rich means of representing the metadata in applications having partially structured and incomplete dynamic data to describe, and exploratory and inexact queries to express. Clearly, a wide range of clinical applications (including Electronic Patient Records) share the same settings and needs. They concluded that such terminologies represent ontologies that should not be embedded in
dc:creatordc:titledc:publisherdc:datedc:typedc:languagehcm:quality
dc:coveragehcm:location(city, country)
HealthCyberMap (bibliographic ontology)
Geographic ontology (general and health geography)
dc:subjectdc:description
Medical ontology (clinical terminology/ classification and other medical knowledge)
User profile: location, language, information needs/ questions, user’s Web client (device) characteristics, etc.

HealthCyberMap’s Dublin Core Ontology in Protégé-2000 - 17
client applications, but should be shared and reused as a distributed resource by implementing it as a service through a terminology server. A terminology server is a special type of ontology servers that allows retrieval of related concepts and synonyms, and querying and cross-mapping multiple terminologies/ classifications at the same time. Ideally, it should also support concept mapping, which involves processing free text queries to identify corresponding terms from a controlled vocabulary; this relieves users from any restrictions while ensuring accurate results (contextual relevancy) and can also support multiple languages. Chute et al [55] mention the following desiderata for a clinical terminology server: word normalisation, word completion, target terminology specification, spelling correction, lexical matching, term completion, semantic locality, term composition and decomposition. Using a terminology server can help formulating and optimising DC subject queries passed to HealthCyberMap (Figure 11). It can also assist in relating the resource pointers stored in HealthCyberMap to each other and classifying them based on their subject and clinical context as determined by their DC subject field. Figure 11. Using a terminology server to enhance DC subject queries in HealthCyberMap. Examples of terminology servers include Saphire International (http://www.ohsu.edu/cliniweb/saphint/) and jTerm (http://www.jterm.org), a Java-based open source terminology server.
Semantic Web Services
McIlraith et al [56] and Hendler [57] provide an extensive discussion of Semantic Web Services. Hendler mentions a service advertise/ discover mechanism and Microsoft has already implemented closely related ideas in its .NET framework and Web Services [58]. An SDL (Service Description Language) contract in XML is automatically published by the Internet Information Server (IIS) of Web Service provider and is used to prepare the necessary Proxy Class DLL on the remote client. A Proxy Class allows us to code locally against a remote Web Service by proxy. The philosophy behind Microsoft’s implementation is that systems should be able to talk to each other instantly and reliably without the “headache” of developing ad hoc information exchange protocols. It’s about developing “an information architecture that is oriented around people and their data, instead of around specific devices, applications, or locations.”
Raw user query: partially structured, incomplete, exploratory and inexact
Terminology server
HealthCyberMap with clinical codes in DC subject field
Concept and synonym(s) codes; related concepts
codes passed to HealthCyberMap
Relevant resources
Points to

HealthCyberMap’s Dublin Core Ontology in Protégé-2000 - 18
HealthCyberMap’s Problem-Knowledge Coupling Service
In the case of HealthCyberMap, one can think of a very useful Semantic Web Service, namely a Problem-Knowledge Coupling Service to be consumed by Electronic Patient Records (EPR) clients. Coupling is possible because both the EPR and HealthCyberMap will be using the same clinical coding system (or two different systems with reliable cross-mapping facilities). In the Web Demo (available at: http://healthcybermap.semanticweb.org/pk.htm), we assumed an EPR that codes diagnoses in ICD-9-CM, and since HealthCyberMap crisply describes the subjects of the Web resources stored in its database using the same ICD-9-CM codes, a link between the two systems in the form of: http://www.healthcybermap.org/icd.asp?SearchText=PUT_SINGLE_ICD-9-CM_CODE_HERE will be all what is needed to perform the coupling query and dynamically link the EPR to contextually relevant medical knowledge and guidelines. Problem-specific knowledge (the right, contextually relevant knowledge) coupled with real patient data is the key to informed clinical decision making and better healthcare outcomes. Of course a different/ additional clinical coding system can be used, and, if necessary, the service can be implemented as a .NET Web Service, or according to any other Semantic Web Service standard when such standard becomes available. Unlike other problem-knowledge coupling solutions (like Dr. Lawrence L. Weed’s Problem Knowledge Couplers or PKCs [59]), HealthCyberMap’s solution is flexible and dynamic. You can keep adding (or deleting) new resources to HealthCyberMap and have all new changes reflected on your output without modifying HealthCyberMap’s architecture or code (or the client’s calling code). You can choose to call certain resource categories you need most, e.g., guidelines, instead of all resource types (based on DC type field). Dr Weed’s PKCs are somewhat inflexible and the knowledge in them is hard-coded and cannot be easily and dynamically changed or updated.
HealthCyberMap's DC Implementation in Protégé-2000
Ontology modelling languages and tools like Protégé-2000 (http://protege.stanford.edu/) and OILEd (http://img.cs.man.ac.uk/oil/) supply the modelling primitives necessary to provide adequate power of expression and clarity and to support the function of inference and reasoning services. These primitives are derived from first-order logic, description logics and frame-based systems, based on the notions of classes (concepts or frames) having properties (roles or slots). Slots can have their own properties (constraints), e.g., domain and range, and can be arranged in a hierarchy (i.e., subslots).
Protégé-2000 as a Semantic Web Tool
Protégé-2000 is a tool that allows users to construct a domain ontology, customise knowledge-acquisition forms for it and enter domain knowledge structure and instances. It can be extended with many useful plug-ins like the OntoViz tab that permits the visualisation of Protégé-2000 ontologies, and the UMLS tab (see below) [60]. Stoffel and colleagues [61] distinguish between two types of ontologies: • Traditional ontologies consisting of only the definitions (correspond to RDF schema). • Hybrid ontologies combining both ontological relations and the instances defined thereon
(correspond to RDF schema + RDF instances). Protégé-2000 supports hybrid ontologies and saves class definitions and instances in two separate files (under the same project). A Protégé JDBC database back-end permits the storage of Protégé-2000 knowledge bases in a relational database. Users can access the database outside Protégé-2000 environment, and will

HealthCyberMap’s Dublin Core Ontology in Protégé-2000 - 19
benefit from the faster access and search facilities that a relational database offers. An RDF Schema backend plug-in is also available that allows saving and opening projects in RDFS and OIL formats (Figure 12) [60, 62].
Figure 12. Protégé-2000 JDBC and RDFS back-ends allow storing ontologies and their instances in a relational database or as RDFS/ RDF documents. Noy and colleagues [63] propose using Protégé-2000 as an editor for Semantic Web languages like RDFS and OIL, as well as an interchange/ translation module between these languages. Their paper describes how they managed to reconcile the differences between Protégé’s native knowledge model and RDFS knowledge model, and have Protégé-2000 generate the right output through the RDFS back-end plug-in. For example, instances in native Protégé-2000 are of a single class, while in RDFS they can be direct instances of several classes at the same time; this is cared for automatically by the RDFS back-end when importing RDFS instance data into Protégé-2000. Noy et al [63] also suggest that developers should create their own Protégé-2000 tab plug-ins to include custom Semantic Web applications that can benefit from the live connection to the knowledge base in Protégé-2000. Such plug-ins can: • connect to, query, reason with and update the current Protégé-2000 knowledge base; • support annotation of HTML documents with semantic elements and maybe also the
automatic extraction of semantic data from these documents; and • graphical visualisation of a set of interrelated resources.
The UMLS Tab
The UMLS tab is a handy Protégé-2000 plug-in that connects from within Protégé-2000 to the UMLS Knowledge Source Server (KSS) of the US National Library of Medicine (the user must first register his/ her IP address with the UMLS KSS). It allows browsing and searching UMLS, and directly annotating an ontology in Protégé-2000 with elements imported from UMLS (Figure 13) [62].

HealthCyberMap’s Dublin Core Ontology in Protégé-2000 - 20
Figure 13. Screenshot of Protégé-2000 showing UMLS search results/ narrow tree for ‘psoriasis’ in the UMLS tab. HealthCyberMap’s Dublin Core implementation in Protégé-2000 uses UMLS terms (other clinical coding systems are also allowed, each belonging to different DC SubjectScheme) as slot values for the DC subject field (Figures 14a and 14b). Thanks to the UMLS tab, any imported element instance from the remote UMLS knowledge base becomes a permanent part of HealthCyberMap’s Dublin Core ontology, available for annotating (populating the DC subject field of) any number of current or future HealthCyberMap Resource instances, even when there is no more connection to the UMLS KSS. This virtually eliminates any need to manually copy, paste and/ or type terms from the remote knowledge source [62].

HealthCyberMap’s Dublin Core Ontology in Protégé-2000 - 21
Figure 14a. Screenshot of a Resource Instance Form from HealthCyberMap/ Dublin Core project in Protégé-2000. The DC subject value is a UMLS term instance; double-clicking it displays all properties and relationships among other terms for this term (‘psoriasis’ in this example). To improve the quality of metadata, one should select the most specific term(s) that best describe a resource, avoiding whenever possible broader/ more general terms.
Figure 14b. UMLS terms can be also imported as classes, preserving their tree hierarchy and allowing easier navigation of the imported terms when selecting a value for the DC subject slot (Figure 14b). Note that in Figure 14a ‘psoriasis’ has been imported as a UMLS instance. (The DC subject slot can be set to take instances or subclasses of UMLS_ROOT depending on how we have opted to import UMLS terms.)
About UMLS
The 2001 edition of the Unified Medical Language System (UMLS) Metathesaurus includes about 800,000 concepts and 1.9 million concept names in over 60 different biomedical source vocabularies, some in multiple languages, all available through the UMLS tab in Protégé-2000. The UMLS Semantic Network is indeed a huge

HealthCyberMap’s Dublin Core Ontology in Protégé-2000 - 22
ontology on its own merits [64]. A system using UMLS can (if properly implemented) support concept synonyms, multilingual concepts, concept qualifiers, and semantic relationships (related concepts) like ancestors, descendants, parents, children, siblings, narrower, broader and other related concepts (Figure 15).
Figure 15. Online UMLS Metathesaurus Concept Search page at UMLS Knowledge Source Server showing the different possible types of UMLS Related Concepts. One interesting point in UMLS Semantic Network (not shown in this figure) is that the Semantic Type “Spatial Concept” has the following subtypes: “Body Location or Region,” “Body Space or Junction,” “Geographic Area,” and “Molecular Sequence;” this emphasises the notion that locations are not limited to geographic positions.
Using One-to-Many Links to Explore Related Concepts
Starting with a single concept and exploring its semantic relationships/ related concepts can prove very useful in navigating Web resources. One-to-many links are needed to implement this functionality (going from one concept/ resource to a list of related concepts/ resources). This idea is already adopted in Topic Maps [46]. Microsoft Smart Tags are one example of a one-to-many link implementation [65], though they are not really smart as they will underline all instances of recognised words irrespective of their context (Figure 16).

HealthCyberMap’s Dublin Core Ontology in Protégé-2000 - 23
Figure 16. Screenshot of Microsoft Internet Explorer 6 showing Microsoft Smart Tags in action (related links for the “University of California, Los Angeles”).
HealthCyberMap/ DC Project Description
We found the frame-based approach of Protégé-2000 v1.6 to be very convenient. Knowledge is represented into a hierarchical tree, with classes, subclasses and instances of these classes. If needed, a class can be defined as subclass of two (or more) classes (superclasses). Each object has some slots or properties that we can define their data type (e.g., string or integer) and set their cardinality (required or optional/ multiple values or single). Classes and instances of classes can also act as slot values for instances of other classes. Slots can have subslots. The descendants of a class inherit its slots and values (white S slot icons vs. cyan S slot icons in parent class). We have implemented the Qualified Dublin Core Metadata Set based on three currently approved DCMI metadata packages with the following namespaces (Figure 17): • http://purl.org/dc/elements/1.1/ • http://dublincore.org/2000/03/13/dcq# • http://dublincore.org/2000/03/13/dctype#

HealthCyberMap’s Dublin Core Ontology in Protégé-2000 - 24
Figure 17. Screenshot of HealthCyberMap/ Dublin Core project namespaces in Protégé-2000. We have also added our own HealthCyberMap extensions: quality and location. The slot value for location stores the resource publisher or author(s)’ main geographical location, whichever is more relevant, and takes the form of an ISO3166 country code, plus a city value from the Getty Thesaurus of Geographic Names (TGN – URI: http://www.getty.edu/research/tools/vocabulary/tgn/). The quality element should store a resource’s level of evidence (whether it is an official guideline, systematic review, randomised controlled trial (RCT), other peer-reviewed study, official critically appraised topic (CAT), or expert opinion), and any other relevant information regarding its compliance to a recognised code of ethics (e.g., Health On the Net – URI: http://www.hon.ch/) or quality seal, and whether it has been published by a trusted publisher or listed in trusted directory, e.g., OMNI (URI: http://omni.ac.uk).

HealthCyberMap’s Dublin Core Ontology in Protégé-2000 - 25
Figure 18. Screenshot of HealthCyberMap/ Dublin Core project classes in Protégé-2000. A Resource class (template Bibliographic card) has been defined (Figure 18). Instances of this class collectively form HealthCyberMap’s database of resource metadata. Each instance describes a single resource using the DC and HealthCyberMap elements that we have defined. More than half of the slots in class Resource take instances of other classes as their values. For example, we have defined language codes once as instances of ISO639-2 Language Scheme, and then used them to populate the dc:language slot of all instances of class Resource (Figure 19).
Figure 19. Language codes were defined once as instances of ISO639-2 Language Scheme, and then used to populate the dc:language slot of all instances of class Resource.
HealthCyberMap’s Dublin Core Ontology in Protégé-2000 - 26
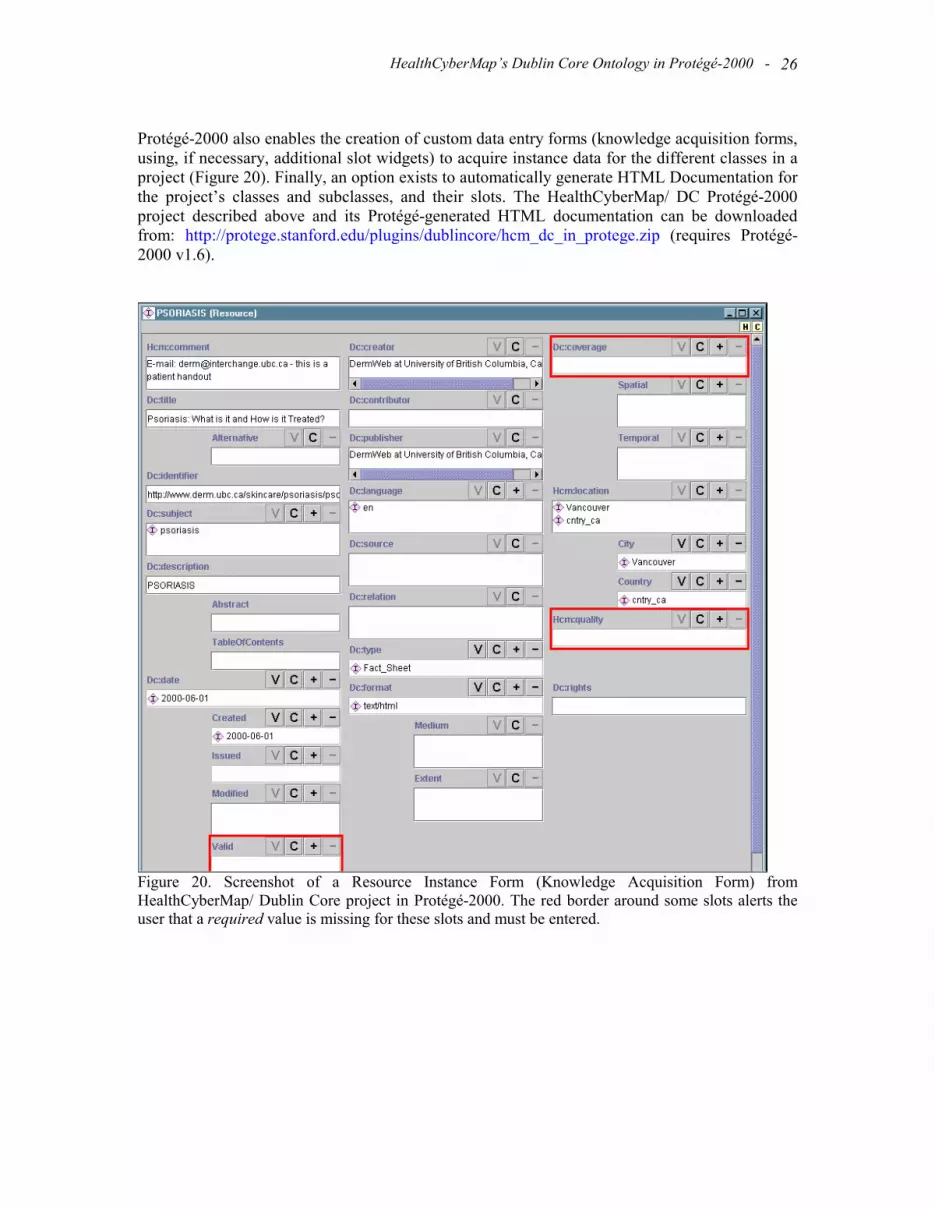
Protégé-2000 also enables the creation of custom data entry forms (knowledge acquisition forms, using, if necessary, additional slot widgets) to acquire instance data for the different classes in a project (Figure 20). Finally, an option exists to automatically generate HTML Documentation for the project’s classes and subclasses, and their slots. The HealthCyberMap/ DC Protégé-2000 project described above and its Protégé-generated HTML documentation can be downloaded from: http://protege.stanford.edu/plugins/dublincore/hcm_dc_in_protege.zip (requires Protégé-2000 v1.6).
Figure 20. Screenshot of a Resource Instance Form (Knowledge Acquisition Form) from HealthCyberMap/ Dublin Core project in Protégé-2000. The red border around some slots alerts the user that a required value is missing for these slots and must be entered.

HealthCyberMap’s Dublin Core Ontology in Protégé-2000 - 27
Figure 21. The Queries tab in Protégé-2000.
What’s Next? Exploiting Protégé-2000 RDFS Output
Protégé-2000 RDFS output for HealthCyberMap’s Dublin Core project comprises an .rdfs file for the RDF schema (definitions of classes and slots) and an .rdf file for the RDF instances (where the actual resources are described; this is the equivalent of database records), plus Protégé’s own .pprj project file, which contains information about the project’s Forms and the slot widgets they are using. Two main approaches have been proposed for querying RDF metadata [66]: 1. the SQL/XQL style approach, viewing RDF metadata as a relational or XML database
(HealthCyberMap currently stores resource records in an Access database and queries them using SQL); and
2. viewing the Web described by RDF metadata as a knowledge base and, thus, applying knowledge representation and reasoning techniques on RDF metadata.
The first approach builds on the fact that the basic RDF model maps very directly to the relational database model, as Tim Berners-Lee explains [67]: • a record is an RDF node; • the field (column) name is RDF propertyType; and • the record field (table cell) is a value. The second approach is the one currently supported by the W3C RDF founders and working group, as well as other Semantic Web researchers. An RDF query language should provide facilities for simple property-value queries, path traversal based on the RDF graph model and more complex logical queries, in addition to supporting the following deductions and inferences [66]: • subsumptions between classes and/or properties not explicitly declared in an RDF schema; • classification of resources: given that the domain of a property is of a specific class, the
system should be able to infer that a resource appearing in a metadata instance and having this property is actually an instance of this class;
• inverse references fulfilling: if Researcher1 has Publication Paper1, then the system should be able to infer that Paper1 has author Researcher1; and
• automatic query expansion to explore generalisation/ specialisation (broader term, narrower term and synonym) relations between property values.

HealthCyberMap’s Dublin Core Ontology in Protégé-2000 - 28
A new W3C querying language, Metalog, has been proposed that attempts to fulfil these criteria [68]. Another attempt is SiLRI (Simple Logic-based RDF Interpreter), an inference engine that implements a major part of Frame-Logic functionality [69]. SiLRI has got some limitations, for example, no inference can be performed based on property hierarchies (it doesn’t consider properties as first-class objects, as suggested by the RDF model) and inference is based on manually added rules (there are no generic inference facilities based on RDFS semantics) [66]. Similar deductions and inferences are also expected in terminology servers (see ‘Medical Terminologies as a Shared Ontology Service’ above).
Conclusion By making medical Web resources more meaningful to computers, i.e., making their context and meaning (semantics), not merely their raw text and formatting, amenable to computer “understanding” and “intelligent” processing, we can hopefully end up with an “intelligent” medical Web. The latter in turn will be more meaningful and useful to humans, and capable of providing the public, patients and their caregivers with more relevant answers to the medical questions they ask, and the specific clinical problems they face. However, we still need to agree on standards and develop user-friendly and reliable tools if we are to realise the full potential of the Semantic Web on a wide scale. In the medical domain, we are fortunate to have many ready-to-use, mature domain ontologies (the clinical terminologies and classifications), and these should be used in any Semantic Medical Web implementation whenever possible to avoid wasting precious time and resources on reinventing the wheel. We also need to adopt solutions that do not require any modification of existing resources and servers hosting them (like HealthCyberMap’s own approach). This is very important if we want to quickly realise a Semantic Medical Web during the next five to ten years (interim period), and until everyone has started to mark-up their Web resources with ontology instances according to some future standard.
References 1. Fensel D (Editor). The semantic Web and its languages. IEEE Intelligent Systems.
2000;15(6):67-73. URI: http://www.cs.man.ac.uk/~horrocks/Publications/download/2000/faqs-on-oil.pdf (accessed 12 June 2001)
2. Berners-Lee T and Hendler J. Nature Debates Scientific publishing on the ‘semantic web.’ Nature. 26 April 2001. URI: http://www.nature.com/nature/debates/e-access/Articles/bernerslee.htm (accessed 16 June 2001)
3. The SHOE FAQ. Parallel Understanding Systems Group, University of Maryland, US. URI: http://www.cs.umd.edu/projects/plus/SHOE/faq.html (accessed 23 June 2001)
4. Berners-Lee T, Hendler J and Lassila O. Feature Article: The Semantic Web. Scientific American. May 2001. URI: http://www.sciam.com/2001/0501issue/0501berners-lee.html (accessed 14 April 2001)
5. Kamel Boulos MN. A Preparatory Study on the Dermatology Virtual Branch Library of the NeLH (MSc Thesis in Medical Informatic). GKT School of Medicine, KCL, University of London. 2000
6. PubMed. Computation of Related Articles. URI: http://www.ncbi.nlm.nih.gov/PubMed/computation.html (accessed 11 June 2001)
7. Liu X and Altman RB. Updating a bibliography using the related articles function within PubMed. Proc AMIA Symp. 1998;750-4 (URI: http://www-smi.stanford.edu/pubs/SMI_Reports/SMI-98-0725.pdf – accessed 11 June 2001)

HealthCyberMap’s Dublin Core Ontology in Protégé-2000 - 29
8. Risden K. Toward usable browse hierarchies for the Web. In Bullinger H and Ziegler J (Editors). Human Computer Interaction: Ergonomics and User Interfaces. 1999;1:1098-1102. URI: http://www.microsoft.com/usability/UEPostings/HCI-kirstenrisden.doc (accessed 25 June 2001)
9. ECML-PKDD 2001 Tutorial: Development and Applications of Ontologies. URI: http://www.afia.polytechnique.fr/CAFE/ECML01/ontology.html (accessed 24 June 2001)
10. Musen M. Protégé-2000: Advanced Tools for Building Intelligent Systems. SMI Symposium and Affiliates’ Day, 4 May 1999. URI: http://protege.stanford.edu/publications/KMG-Presentation-for-Affiliates/KMG%20Presentation%20for%20Affiliates.PPT (accessed 10 May 2001)
11. Gruber T. What is an Ontology? URI: http://www-ksl.stanford.edu/kst/what-is-an-ontology.html (accessed 24 June 2001)
12. SemanticWeb.org. Markup Languages and Ontologies. URI: http://semanticweb.org/knowmarkup.html (accessed 23 June 2001)
13. Berners-Lee T. Information Management: A Proposal (The Original Proposal of the WWW; March 1989, May 1990). URI: http://www.w3.org/History/1989/proposal.rtf (accessed 7 June 2001)
14. Hjelm J. Creating the Semantic Web with RDF. New York: John Wiley & Sons, 2001 15. Staab S, Erdmann M, Maedche A and Decker S. An Extensible Approach for Modeling
Ontologies in RDF(S). ECDL 2000 Workshop on the Semantic Web Lisbon, Portugal (Session 2; 21 September 2000). URI: http://www.ics.forth.gr/proj/isst/SemWeb/proceedings/session2-1/html_version/index.html (accessed 7 June 2001)
16. Broekstra J, Klein M, Decker S, Fensel D, van Harmelen F and Horrocks I. Enabling knowledge representation on the Web by extending RDF Schema (10 November 2000). URI: http://www.ontoknowledge.org/oil/extending2.pdf (accessed 14 June 2001)
17. Fikes R and McGuinness DL. An Axiomatic Semantics for RDF, RDF-S, and DAML+OIL. Knowledge Systems Laboratory, Stanford University (11 January 2001). URI: http://www.daml.org/2000/12/axiomatic-semantics.html (accessed 14 June 2001)
18. World Wide Web Consortium (W3C). Composite Capabilities-Preferences Profile Working Group Public Home Page. URI: http://www.w3.org/Mobile/CCPP/ (accessed 14 June 2001)
19. Bechhofer S et al. An informal description of Standard OIL and Instance OIL. URI: http://networkinference.semanticweb.org/downloads/OIL.pdf (accessed 1 June 2001)
20. Ontology Inference Layer (OIL) Home Page. URI: http://www.ontoknowledge.org/oil (accessed 8 June 2001)
21. DARPA Agent Mark Up Language (DAML). 01 January 2000. URI: http://dtsn.darpa.mil/iso/programtemp.asp?mode=347 (accessed 8 June 2001)
22. Rapoza J. DAML could take search to a new level. PC Week Labs. 7 February 2000. URI: http://www.zdnet.com/eweek/stories/general/0,11011,2432538,00.html (accessed 8 June 2001)
23. Horrocks I et al. DAML+OIL (March 2001). URI: http://www.daml.org/2001/03/daml+oil-index (accessed 8 June 2001)
24. The Dublin Core Metadata Initiative. URI: http://www.dublincore.org/ (accessed 7 June 2001)
25. Hillmann D. Using Dublin Core (12 April 2001). URI: http://www.dublincore.org/documents/2001/04/12/usageguide/ (accessed 11 June 2001)
26. Reggie - The Metadata Editor. URI: http://metadata.net/dstc/ (accessed 13 June 2001) 27. The UK Office for Library and Information Networking (UKOLN). DC-dot Dublin Core
metadata editor. URI: http://www.ukoln.ac.uk/cgi-bin/dcdot.pl (accessed 13 June 2001)

HealthCyberMap’s Dublin Core Ontology in Protégé-2000 - 30
28. Hendler JA. SHOE (Simple HTML Ontology Extension) Description. URIs: http://www.cs.umd.edu/users/hendler/shoe.html and http://www.cs.umd.edu/projects/plus/SHOE/ (accessed 12 June 2001)
29. Heflin J and Hendler J. Dynamic Ontologies on the Web. In Proceedings of 17th National Conference on Artificial Intelligence (AAAI-2000). 2000. URI: http://www.cs.umd.edu/projects/plus/SHOE/pubs/aaai2000.pdf (accessed 13 June 2001)
30. World Wide Web Consortium (W3C). Annotea Project. 31 May 2001. URI: http://www.w3.org/2001/Annotea/ (accessed 5 June 2001)
31. World Wide Web Consortium (W3C). Amaya Home Page - W3C’s Editor/Browser. 23 April 2001. URI: http://www.w3.org/Amaya/ (accessed 5 June 2001)
32. Dublin Core Metadata Initiative (DCMI) Architecture Working Group: Expressing Qualified Dublin Core in RDF. URI: http://www.mathematik.uni-osnabrueck.de/projects/dcqual/qual21.3.1/ (accessed 7 June 2001)
33. World Wide Web Consortium (W3C) Date and Time Formats. URI: http://www.w3.org/TR/NOTE-datetime (accessed 7 June 2001)
34. Dublin Core Metadata Initiative (DCMI). An XML Encoding of Simple Dublin Core Metadata. URI: http://dublincore.org/documents/2000/11/dcmes-xml/ (accessed 23 February 2001)
35. Dublin Core Metadata Initiative (DCMI). DC type element schema. URI: http://dublincore.org/2000/03/13/dctype# (accessed 5 June 2001)
36. The Structured Knowledge Initiative – SKICal. URI: http://www.skical.org/ (accessed 5 June 2001)
37. Kamel Boulos MN, Roudsari AV, Gordon C and Muir Gray JA. The Use of Quality Benchmarking in Assessing Web Resources for the Dermatology Virtual Branch Library of the National electronic Library for Health (NeLH). Journal of Medical Internet Research. 2001;3(1):e5 <URI: http://www.jmir.org/2001/1/e5/>
38. World Wide Web Consortium (W3C). Describing and retrieving photos using RDF and HTTP. 28 September 2000. URI: http://www.w3.org/TR/photo-rdf/
39. Kamel Boulos MN. HealthCyberMap Pilot Web Site: Customisation - Detecting User’s Location. URI: http://healthcybermap.semanticweb.org/ip.htm (accessed 13 June 2001)
40. Moore C. Location-based services called key to unplugged Internet. InfoWorld. 12 February 2001. URI: http://www.itworld.com/Tech/2424/IW010212hnmobilecomm/ (accessed 8 June 2001)
41. Prasad M. Location Based Services. URI: http://www.gisdevelopment.net/application/lbs/lbs002pf.htm (accessed 8 June 2001)
42. Bechhofer S, Drummond N and Goble CA. Supporting Public Browsing of an Art Gallery Collections Database. Proceeedings of the 11th International Conference and Workshop on Database and Expert Systems Applications DEXA 2000. September 4-8, 2000 London - Greenwich, United Kingdom. Springer Verlag LNCS Vol. 1873. URI (of slides/ video): http://potato.cs.man.ac.uk/slides/dexa.zip (accessed 12 June 2001)
43. Bush V. As We May Think. The Atlantic Monthly. 1945;176(1): 101-108. URI: http://www.theatlantic.com/unbound/flashbks/computer/bushf.htm (accessed 13 June 2001)
44. ISO/IEC 13250 Topic Maps (3 December 1999). URI: http://www.y12.doe.gov/sgml/sc34/document/0129.pdf (accessed 21 May 2001)
45. Understanding Topic Maps. Infoloom. URI: http://www.infoloom.com/whitepaper.htm (accessed 27 March 2001)
46. Biezunski M. Topic Maps at a glance. Infoloom. URI: http://www.infoloom.com/tmsample/bie0.htm (accessed 27 March 2001)
47. Bechhofer S and Goble C. STARCH Project (Structured Terminologies for ARCHives - Managing Semi-Structured Information). The Information Management Group (IMG) at the

HealthCyberMap’s Dublin Core Ontology in Protégé-2000 - 31
University of Manchester, UK. URI: http://potato.cs.man.ac.uk/starch/starch.ppt (accessed 2 May 2001)
48. Network Inference Web site – Technology: Description Logics and Inference. URI: http://networkinference.semanticweb.org/technology.asp?id=44&menu=2 (accessed 23 June 2001)
49. Appleyard RJ and Malet G. A Proposal for using Metadata Encoding Techniques for Health Care Information Indexing on the WWW. AMIA Proceedings. 1997
50. Rector AL. Clinical Terminology: Why Is it so Hard? Methods Inf Med. 1999;38(4-5):239-52 51. Network Inference Web site – Technology: The Semantic Web. URI:
http://networkinference.semanticweb.org/technology.asp?id=46&menu=2 (accessed 5 June 2001)
52. The Medical Guidelines Technology (MGT) project (The Open University, Milton Keynes, UK). URI: http://frost.open.ac.uk/mgt/ (accessed 15 June 2001)
53. Abasolo JM and Gómez M. MELISA: An ontology-based agent for information retrieval in medicine. ECDL 2000 Workshop on the Semantic Web Lisbon, Portugal (Session 3; 21 September 2000). URI: http://www.ics.forth.gr/proj/isst/SemWeb/proceedings/session3-1/html_version/index.html (accessed 7 June 2001)
54. Bechhofer SK, Goble CA, Rector AL, Solomon WD, and Nowlan WA. Terminologies and Terminology Servers for Information Environments. In: Proceedings of STEP '97 Software Technology and Engineering Practice, 1997. URI: http://citeseer.nj.nec.com/354766.html (accessed 9 May 2001)
55. Chute CG, Elkin PL, Sheretz DD and Tuttle MS. Desiderata for a Clinical Terminology Server. In: Proceedings of AMIA'99 Annual Symposium, 1999. URI: http://www.amia.org/pubs/symposia/D005782.PDF (accessed 24 June 2001)
56. McIlraith SA, Son TC and Zeng H. Semantic Web Services. IEEE Intelligent Systems. 2001;16(2):46-53. (March/April 2001). URI: http://www.computer.org/intelligent/ex2001/pdf/x2046.pdf (accessed 14 June 2001)
57. Hendler J. Agents and the Semantic Web. IEEE Intelligent Systems. 2001;16(2 - March/April 2001). URI: http://www.cs.umd.edu/~hendler/AgentWeb.html (accessed 14 June 2001)
58. Microsoft Corporation. The .NET Show: Your First .NET Application. URI: http://msdn.microsoft.com/theshow/Episode013/ (accessed 29 May 2001)
59. PKC Corporation. Problem Knowledge Couplers. URI: http://www.pkc.com/ (accessed 2 May 2001)
60. What is Protégé-2000? URI: http://protege.stanford.edu/whatis.html (accessed 25 June 2001) 61. Stoffel K, Taylor M and Hendler J. Efficient Management of Very Large Ontologies.
Proceedings of American Association for Artificial Intelligence Conference (AAAI-97). AAAI/MIT Press. 1997. URI: http://www.cs.umd.edu/projects/plus/Parka/aaai97.ps (accessed 23 June 2001)
62. Li Q, Shilane P, Noy NF and Musen MA. Ontology Acquisition from On-line Knowledge Sources. AMIA Symposium 2000. URI: http://www.amia.org/pubs/symposia/D200524.PDF (accessed 11 June 2001)
63. Noy NF, Sintek M, Decker S, Crubézy M, Fergerson RW and Musen MA. Creating Semantic Web Contents with Protégé-2000. IEEE Intelligent Systems (computer.org/intelligent). 2001;16(2):60-71 (March/April 2001). URI: http://protege.stanford.edu/publications/ProtegeForSemanticWeb.pdf (accessed 11 June 2001)
64. US National Library of Medicine. Unified Medical Language System Fact Sheet. URI: http://www.nlm.nih.gov/pubs/factsheets/umls.html (accessed 23 June 2001)
65. Cornell P. Adding Smart Tags to Web Pages. Microsoft Corporation (May 2001). URI: http://www.microsoft.com/officedev/xp_06_2001/odc_stwebpages.htm (accessed 23 June 2001)

HealthCyberMap’s Dublin Core Ontology in Protégé-2000 - 32
66. Karvounarakis G. RDF Query Languages: A state-of-the-art. URI: http://139.91.183.30:9090/RDF/publications/state.html (accessed 7 June 2001)
67. Berners-Lee T. What the Semantic Web can represent (The Semantic Web and Relational Databases). 17 September 1998. URI: http://www.w3.org/DesignIssues/RDFnot.html (accessed 26 June 2001)
68. Marchiori M and Saarela J. Query + Metadata + Logic = Metalog. In: QL'98 - The Query Languages Workshop, W3C, 1998. URI: http://www.w3.org/TandS/QL/QL98/pp/metalog (accessed 24 June 2001)
69. Stefan Decker S, Brickley D, Saarela J and Angele J. A Query and Inference Service for RDF. In: QL'98 - The Query Languages Workshop, W3C, 1998. URI: http://www.w3.org/TandS/QL/QL98/pp/queryservice.html (accessed 25 June 2001)





























