Embed Size (px)
Citation preview

Task Partitioning and Load Balancing Strategyfor Matrix Applications on Distributed System
Adeela Bashir†, Sajjad A. Madani†, Jawad Haider Kazmi†, Kalim Qureshi§†Department of Computer Science, COMSATS Institute of Information Technology, Abbottabad, Pakistan
§Department of Information Science, Kuwait University, KuwaitEmail: [email protected]
Abstract— In this paper, we present a load-balancingstrategy (Adaptive Load Balancing strategy) for dataparallel applications to balance the work load effec-tively on a distributed system. We study its impact oncomputation-hungry matrix multiplication application.The ALB strategy enhances the performance with fea-tures such as intelligent node selection, pre-task assign-ment, adaptive task sizing and buffer allocation, andload balancing. The ALB strategy exhibits reducednodes idle time and inter process communication time,and improved speed up as compared to Run Time taskScheduling strategy.
Index Terms— task partitioning, load balancing, het-erogeneous distributed systems, matrix multiplication,and performance evaluation
I. INTRODUCTION
Distributed computing system (DS) is a betterchoice for multifarious computations of high pro-cessing demand scientific applications. Nodes in theDS show diverse behaviour in terms of performanceunder variations in workload [1]. Such variationsmandate the effective distribution of tasks which isa major issue in distributed computing environment[2].
Parallel matrix multiplication is one of the moststudied fundamental problems in distributed and highperformance computing. Our focus is to minimizethe total execution time of an application that canbe achieve by reducing inter process communicationand nodes idle time, and incorporating effective loadbalancing components [1]–[3]. Matrix multiplicationis used in many scientific and engineering applica-tions such as robots, remote sensing, and medicalimaging etc. The matrix multiplication is an extensivedata parallel application. We have been evaluatingthe performance of matrix multiplication on networkof workstations [4].
Recently, the matrix multiplication computationalcomplexity has been reduced using Strassens algo-rithm [5]. In [5], author replace the number of matrix
[a11 a12a21 a22
]×[b11 b12b21 b22
]=
[c11 c12c21 c22
]
Q1 = (a11 + a22)(b11 + b22)Q2 = (a21 + a22)b11Q3 = a11(b12 − b22)Q4 = a22(b21 − b11)Q5 = a11 + a12)b22)Q6 = (a21 − a11)(b11 − b12)Q7 = (a12 − a22)(b21 + b22)
C11 = Q1 + Q4 −Q5 + Q7
C12 = Q3 + Q5
C21 = Q2 + Q4
C22 = Q1 + Q3 −Q2 + Q6
Figure 1. Matrix multiplication by Strassen’s algorithm [4]
multiplication by matrix additions that reduced thetime complexity of matrix multiplication from O(n3)to O(n2.8). The proposed model of [4] is shown inFigure 1.
The authors in [5] reduced the mathematicalcomplexity of the application at the cost of supportingfeatures of parallel data applications, for example,independency of sub-tasks and pattern repetition. Themore is the independency and pattern repetitions, theless is the inter process communication time (thisis not the case in [5] as shown in Figure 1). In[6] the authors have provided a new parallel matrixmultiplication algorithm based on the Strassen’salgorithm, which is named CAPS (Communication-Optimal Parallel Algorithm for Strassen’s MatrixMultiplication), in which they have reduced thecommunication overhead of Strassen’s algorithm.The authors also provided a comparison of differentmatrix multiplication algorithms which is shown inTable I. Here ω0 = log2 7 ≈ 2.81 is the exponent ofStrassen; ` is the number of Strassen steps taken.
576 JOURNAL OF COMPUTERS, VOL. 8, NO. 3, MARCH 2013
© 2013 ACADEMY PUBLISHERdoi:10.4304/jcp.8.3.576-584

Classical algorithms must communicate asymptoti-cally more than an optimal Strassen-based algorithm.To compare the lower bounds, it is necessary toconsider three cases for the memory size: whenthe memory-dependent bounds dominate for bothclassical and Strassen, when the memory-dependentbound dominates for classical, but the memory-independent bound dominates for Strassen, and whenthe memory-independent bounds dominate for bothclassical and Strassen. Briefly, the factor by whichthe classical bandwidth cost exceeds the Strassenbandwidth cost is P a where a ranges from 2
ω0− 2
3 ≈0.046 to 3−ω0
2 ≈ 0.10 depending on the relativeproblem size.
Various parallel classical matrix multiplicationalgorithms minimize communication relative to theclassical lower bounds for certain amounts of localmemory M . For example, Cannon’s algorithm [7]minimizes communication for M = O(n2/P ). Sev-eral more practical algorithms exist (such as SUMMA[8]) which use the same amount of local memoryand have the same asymptotic communication costs.We call this class of algorithms “2D” because thecommunication patterns follow a two-dimensionalprocessor grid.
Another class of algorithms, known as “3D” [9],[10] because the communication pattern maps to athree-dimensional processor grid, uses more localmemory and reduces communication relative to2D algorithms. This class of algorithms minimizescommunication relative to the classical lower boundsfor M = Ω(n2/P 2/3). As shown in [11], it is notpossible to use more memory than M = Θ(n2/P 2/3)to reduce communication.
Recently, a more general algorithm has beendeveloped which minimizes communication in allcases. Because it reduces to a 2D and 3D for theextreme values of M but interpolates for the valuesbetween, it is known as the “2.5D” algorithm [12].
It is therefore evident that, in such applications,the distribution of tasks become very complex andeffectively increases the network usage and nodesidle time [13]. Due to wide range usage of matrixmultiplication in many scientific and engineeringapplications, there is a need to develop an efficienttask partitioning, scheduling, and load balancingstrategy for such resource hungry computations.
The static and dynamic (RTS) task distributionstrategies are used to balance the loads amongthe WSs/PCs. Since WSs/PCs have a performancevariation characteristic [2], [18], therefore, the statictask distribution is not effective for HCC system
[19]. RTS strategy can achieve nearly perfect loadbalancing [20], because the machines performancevariations and non-homogeneous nature of the ap-plication (image) is adjusted at runtime [5]. TheRTS strategy’s performance depends upon the sizeof the sub-task. If sub-task size is too small thenit generates a serious inter-process communicationoverhead. In other case, if the sub-task size is toolarge then it may create a longer master (client)machine waiting time due to the inappropriate sub-tasks size of slow performance machine [5]. Manyresearchers suggested enhancement in dynamic taskscheduling strategies for homogeneous HCC system[21] [6-7]. However, these strategies do not workwell for heterogeneous HCC system without furthermodifications. The crucial point is that they are basedon fixed parameters that are tuned for the specifiedhardware. In heterogeneous systems, this tuning isoften not possible because both the computationalpower and the network bandwidth are not knownin advance, which may change unpredictably duringruntime.
The strategies based on task distribution and thentask migration from heavy loaded to light-loadednodes are expressed [22], [23]. The task migrationhas two serious drawbacks [23]:• All nodes should continuously monitor the status
of other nodes.• During the computations, a node has to search
its load and float the information on the network,hence, produces a large amount of communica-tion overhead.
In DS, static and dynamic task partitioning strate-gies are common. Static strategy is effective onlyin cases where there is no change in the nature ofapplication and system during the dispensation ofapplication [24]. To deal with nodes performancevariation problem, Runtime Task Scheduling (RTS)strategy was proposed which provides effective loadbalancing, but fixed task size in RTS has raisedmany problems, i.e., appropriate determination of tasksize for each node is very difficult [4]. It increasesthe number of requests and replies and effectivelyincreases the nodes idle time. Optimal task sizingis a complex problems small task size increasescommunication cost while large task size increasesnodes idle time [4].
Dynamic scheduling for the purpose of loadbalancing scientific computations on homogeneousas well as heterogeneous systems has been exten-sively researched [25], [26]. In general, scientificapplications adapt to variable work loads from one
JOURNAL OF COMPUTERS, VOL. 8, NO. 3, MARCH 2013 577
© 2013 ACADEMY PUBLISHER
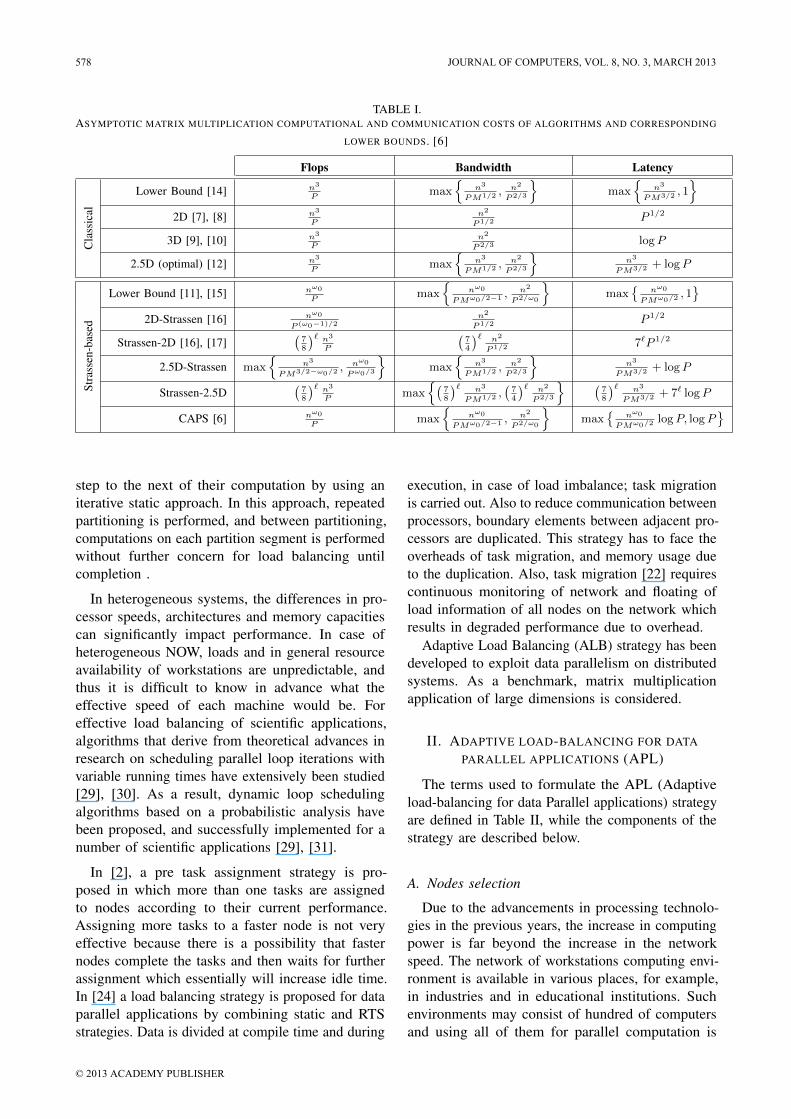
TABLE I.ASYMPTOTIC MATRIX MULTIPLICATION COMPUTATIONAL AND COMMUNICATION COSTS OF ALGORITHMS AND CORRESPONDING
LOWER BOUNDS. [6]
Flops Bandwidth Latency
Cla
ssic
al
Lower Bound [14] n3
Pmax
n3
PM1/2 ,n2
P2/3
max
n3
PM3/2 , 1
2D [7], [8] n3
Pn2
P1/2 P 1/2
3D [9], [10] n3
Pn2
P2/3 logP
2.5D (optimal) [12] n3
Pmax
n3
PM1/2 ,n2
P2/3
n3
PM3/2 + logP
Stra
ssen
-bas
ed
Lower Bound [11], [15] nω0
Pmax
nω0
PMω0/2−1 ,n2
P2/ω0
max
nω0
PMω0/2 , 1
2D-Strassen [16] nω0
P (ω0−1)/2n2
P1/2 P 1/2
Strassen-2D [16], [17](78
)` n3
P
(74
)` n2
P1/2 7`P 1/2
2.5D-Strassen max
n3
PM3/2−ω0/2 ,nω0
Pω0/3
max
n3
PM1/2 ,n2
P2/3
n3
PM3/2 + logP
Strassen-2.5D(78
)` n3
Pmax
(78
)` n3
PM1/2 ,(74
)` n2
P2/3
(78
)` n3
PM3/2 + 7` logP
CAPS [6] nω0
Pmax
nω0
PMω0/2−1 ,n2
P2/ω0
max
nω0
PMω0/2 logP, logP
step to the next of their computation by using aniterative static approach. In this approach, repeatedpartitioning is performed, and between partitioning,computations on each partition segment is performedwithout further concern for load balancing untilcompletion .
In heterogeneous systems, the differences in pro-cessor speeds, architectures and memory capacitiescan significantly impact performance. In case ofheterogeneous NOW, loads and in general resourceavailability of workstations are unpredictable, andthus it is difficult to know in advance what theeffective speed of each machine would be. Foreffective load balancing of scientific applications,algorithms that derive from theoretical advances inresearch on scheduling parallel loop iterations withvariable running times have extensively been studied[29], [30]. As a result, dynamic loop schedulingalgorithms based on a probabilistic analysis havebeen proposed, and successfully implemented for anumber of scientific applications [29], [31].
In [2], a pre task assignment strategy is pro-posed in which more than one tasks are assignedto nodes according to their current performance.Assigning more tasks to a faster node is not veryeffective because there is a possibility that fasternodes complete the tasks and then waits for furtherassignment which essentially will increase idle time.In [24] a load balancing strategy is proposed for dataparallel applications by combining static and RTSstrategies. Data is divided at compile time and during
execution, in case of load imbalance; task migrationis carried out. Also to reduce communication betweenprocessors, boundary elements between adjacent pro-cessors are duplicated. This strategy has to face theoverheads of task migration, and memory usage dueto the duplication. Also, task migration [22] requirescontinuous monitoring of network and floating ofload information of all nodes on the network whichresults in degraded performance due to overhead.
Adaptive Load Balancing (ALB) strategy has beendeveloped to exploit data parallelism on distributedsystems. As a benchmark, matrix multiplicationapplication of large dimensions is considered.
II. ADAPTIVE LOAD-BALANCING FOR DATA
PARALLEL APPLICATIONS (APL)
The terms used to formulate the APL (Adaptiveload-balancing for data Parallel applications) strategyare defined in Table II, while the components of thestrategy are described below.
A. Nodes selection
Due to the advancements in processing technolo-gies in the previous years, the increase in computingpower is far beyond the increase in the networkspeed. The network of workstations computing envi-ronment is available in various places, for example,in industries and in educational institutions. Suchenvironments may consist of hundred of computersand using all of them for parallel computation is
578 JOURNAL OF COMPUTERS, VOL. 8, NO. 3, MARCH 2013
© 2013 ACADEMY PUBLISHER

TABLE II.SYMBOLS USED AND THEIR DEFINITIONS
Term DefinitionT Total number of tasks (size of matrix)i Node numberti Node’s assigned task or computed sub-task sizeTb Total number of unprocessed tasks (Tb = Tti)
Np(i) Node’s estimated current performancepi Node time taken to process |1x1| matrixBi Node’s buffer size
Npslow Slowest node’s estimated current performanceFi Number of pre-tasks assign to nodes bufferWi Power weight factor of nodeNT Total number of nodes used in DSOi Client waiting timeTpf The time taken by the fastest machine to process
the application independentlyTDS Time take by the distributed system to process
the applicationtci Node’s completion time for the tasktsi Node’s start time for the task
not scalable due to the instability of nodes perfor-mance [32], limited network performance, and overutilization of network.
In a DS, the dynamic nature of operating systemsand variation in computing power compel to dis-tribute workload as per nodes capacity. But thereis a possibility that faster nodes becomes idle aftercompleting all assigned tasks while a slower nodeis still processing it. A better idea will be to choosewell performing and more stable nodes [32].
The stability of a node is the ratio by which thenode changes its performance in the presence ofheavy work load [9]. To calculate the stability of anode, we measured the variance in performance ofnodes by using unit of the task (one row multiplyby one column) and measured the time taken by thenode. Nodes average performance is measured byaverage the results after 5 runs of pi. Equation 1 isused to compute the nodes variance in performance.
V ariance =n∑
i=1
(pi − pavg)2
n(1)
If a node shows more variance in performance,it means the node is not stable, i.e., in loadedcondition its performance will degrade. Variancesof all nodes are sent to a master which calculatesvariance percentage by using the Equation 2.
V ariance percentage =V ariance
n× 100 (2)
The nodes with less than 33 percentages inperformance-variation are considered stable nodes
and can be use in the distributed system while theothers are discarded. This reduction in number ofnodes is not more than 20 percent of the total numberof available nodes. Using the stable nodes in DSguarantee the DS will give a better scalability andspeedup by reducing the overhead of task-migration[32].
B. Dynamic task sizing
After selecting the stable nodes for DS, the tasksize for each node is calculated (by using Equation3). As the node start processing her share of work,its runtime performance is estimated (by usingEquation 4). The runtime performance is than used tocalculated the dynamic task size for each subsequentassignments the the respective node. which will beused to calculate each node runtime task size.
Np(i) =1
pi(3)
Each node computes its task size whenever thenode performance varies in 25 percent as compareto current nodes performance. We consider that ma-chine’s performance have dynamic in nature and 25%variation is toleratable. The updated performance ofslowest node is multicast to all nodes whenever it isneed to update.
ti =Np(i)
Npslow(4)
C. Adaptive semi de-centralized approach of re-sources management
Since centralized resource management strategydegrades the performance of master node, therefore,the master node cannot make new assignments orreceive reports from slave nodes on immediate basis[5]. This results in increased idle time of the nodesand subsequently in degraded DS performance. InAPL strategy, we use a semi-decentralized approachof resources management. Initially, the master nodecomputes the initial task size for each node and theneach node is responsible to compute its performanceand current task size accordingly. Therefore, in ourproposed strategy, the master node can make newassignments as well as receive reports from slavenodes thus enhancing DS performance by decreasingidle time.
JOURNAL OF COMPUTERS, VOL. 8, NO. 3, MARCH 2013 579
© 2013 ACADEMY PUBLISHER

D. Dynamic buffering
To completely eliminate the nodes idle time, weintroduce a buffer for each node that contains thenumber of tasks to be execute by the node. Thenumber of tasks is dependent on nodes performance..In APL strategy we classified the number node intothree categories:• Category A – Highest performance Pi ≤ 25%Pi nodes
• Category B – Pi of 25% ≤ 50% Pi nodes• Category C – All Remaining nodesThe size of the buffer to hold the number of task
in advance is dependent upon the node performanceand is determine by Equation 5.
Bi = ti × Fi (5)
Where Fi forCategory A node is 4Category B node is 3Category C node is 2
Therefore, when a node completes task processingand result reporting; another thread starts processinganother task available in the buffer, thus minimizesthe waiting time to start new task. In maximum, 4tasks can be held by the buffer of the node. Increasein the number of tasks in buffer will result in loadbalancing and task migration overhead [2].
E. Availability of tasks at the end of application
As discussed previously, the master node is respon-sible for assigning tasks and collecting results. Theavailability of unprocessed tasks in main task bufferis the key to guarantee that none of the nodes is idle.For this purpose, the master node assigns tasks to thenodes on the basis of their performance as describedabove. The master follows this mechanism till 70%of the application is completed. After that, masternode reduces the sub task size by 30%, i.e., the nodesgetting 4 tasks previously starts getting 3 tasks. Themechanism makes sure that the buffer is not emptyand requests made by nodes are entertained until theapplication cycle is complete. We implemented thesame idea in [2].
F. Sub-task duplication
Once all the tasks are assigned and the bufferis empty, the faster nodes finish the tasks earliercompared to the slower ones; whereas, the slow nodesvery often create a master / manager waiting time.
To avoid such type of waiting times, the followingslow nodes task duplication mechanism from [2] isimplemented:
“...master / manager searches the leastperformance node in the current HDCconfiguration and duplicates its assignedtask to the next idle node. It creates acompetition between two nodes, the resultof the node who completes the task firstis considered and that of the other isignored. Each least nodes task is duplicatedonly once. So all computing resources areutilized at the end of application. This alsoeliminates the excessive manager waitingtime that would have occurred at the endof application..”
G. ALP strategy in steps
The breakdown of the ALP into steps is shown inthe Table III.
TABLE III.MAJOR STEPS IN ALP
Step Description1 Assign task of size pi five times to each
node i to calculate the performance variation.Reduce NT upto 10% by dropping nodes withhigher performance-variation (to reduce thetask-migration overhead).
2 Multicast Npslow to all connected nodes.3 Each node i computes ti, categorises itself on
the basis of Np(i) and calculates Fi.4 Each node i informs master about ti. The
master then assign task according to Fi.5 When a node i experiences a performance
variation higher than 25% it repeats Step 3& 4.
6 When 70% of T is completed, ti is reduce by30% for all i.
7 Sub-task duplication mechanism (Section II-F)remains in effect.
III. COMPARISON AND IMPLEMENTATION
Runtime task scheduling strategy (RTS): TheRTS strategy uses a unit of task that is distributedat runtime. As the node completes the previouslyassigned sub-task, new task is assigned for processing.The performance of ALB strategy is compared withRTS in terms of number of requests made by nodesto the master, client waiting time, and speedup ofthe system.
Client waiting time: It is the amount of idletime that nodes have to wait between completion
580 JOURNAL OF COMPUTERS, VOL. 8, NO. 3, MARCH 2013
© 2013 ACADEMY PUBLISHER

of previous task and assignment of next task. It isdirectly proportional to the number of requests madeby the nodes to master / manager [2], [4]. It can becalculated as
Oi = tsi − tci−1 (6)
Where Oi is the overhead time during which all thecommunication and data access delays are performed[33]. Thus the total client waiting time is as follows:
Client′s waiting time cost =Wt∑i=1
Oi (7)
The theoretical speedup and measured speedupof ALB strategy is also compared. The theoreticalspeedup can be calculated as follows.
Power weight: The power weight of a node is thenodes computing speed relative to the fastest node inthe distributed system [33]. It can be calculated as:
Power weight(Wi) =Tpf
Tpi(8)
Power weight is then used to compute the theoret-ical speedup of distributed system [32] as:
NT∑i=1
Wi (9)
Measured speedup: Speedup is used to measurethe performance gain from parallel computation ofan application over its execution independently onthe fastest node in the system. It can be defined as:
Tpf
TDS(10)
All measurements are carried out on homogeneousdistributed computing environment. The system iscomposed of 30 nodes with speed of 1 GHz andLinux Operating System. Dimensions 512 x 512 and1024 x 1024 of matrices multiplication applicationhas been selected for the performance evaluation ofthe proposed strategy. Measurements are taken inboth un-loaded and loaded environments, i.e., withand without users using the network.
IV. RESULTS AND DISCUSSIONS
The measured number of returns and replies madeby the master node are listed in Table 2 for RTSand ALB strategies. From Table IV, we can observethat for each DS configuration, the total number ofreturns and replies occurs in ALB strategy is quiteless as compared to RTS strategy. The less number of
Figure 2. Measured client waiting time of five distributed systemconfigurations in RTS strategy for matrix dimension 1024x1024.
returns and replies means lesser utilization of networkresources and lower overhead. Therefore, ALB haspriority on RTS strategy.
TABLE IV.COMPARISON OF RTS AND ALB STRATEGIES IN TERM OF
NUMBER OF REQUESTS MADE BY THE MASTER TO
DISTRIBUTE THE TOTAL TASK AMONG THE NODES
NodesRTS Strategy ALB Strategy
Matrix Dimensions Matrix Dimensions512x512 1024x1024 512x512 1024x1024
5 512 1024 52 9810 512 1024 84 15215 512 1024 103 21020 512 1024 167 33025 512 1024 210 450
The measured results of non-optimal (using all theavailable nodes) DS and optimal nodes (omit the highperformance variation nodes from the available nodesof DS) DS is shown in Table V. The measurement iscarried out by five DS configuration. From Table Vit show that not using the high performance variationnodes in DS give a better speed up.
The measured client waiting time occur in RTSstrategy is shown in Figure IV. Due to the pre-taskassignment and dynamic buffer sizing features ofALB strategy the client waiting time is not occur inALB strategy.
The theoretical and measured speedup comparisonis shown in figure. From Figure IV, we can concludethat measure speedup achieved by ALB strategy isclosed to theoretical speedup.
The measured speedup for RTS and ALB strategyfor five DS configuration is listed in Table VI. Foreach DS configuration the ALB strategy has betterspeedup as compared to RTS strategy as shown inTable VI.
JOURNAL OF COMPUTERS, VOL. 8, NO. 3, MARCH 2013 581
© 2013 ACADEMY PUBLISHER
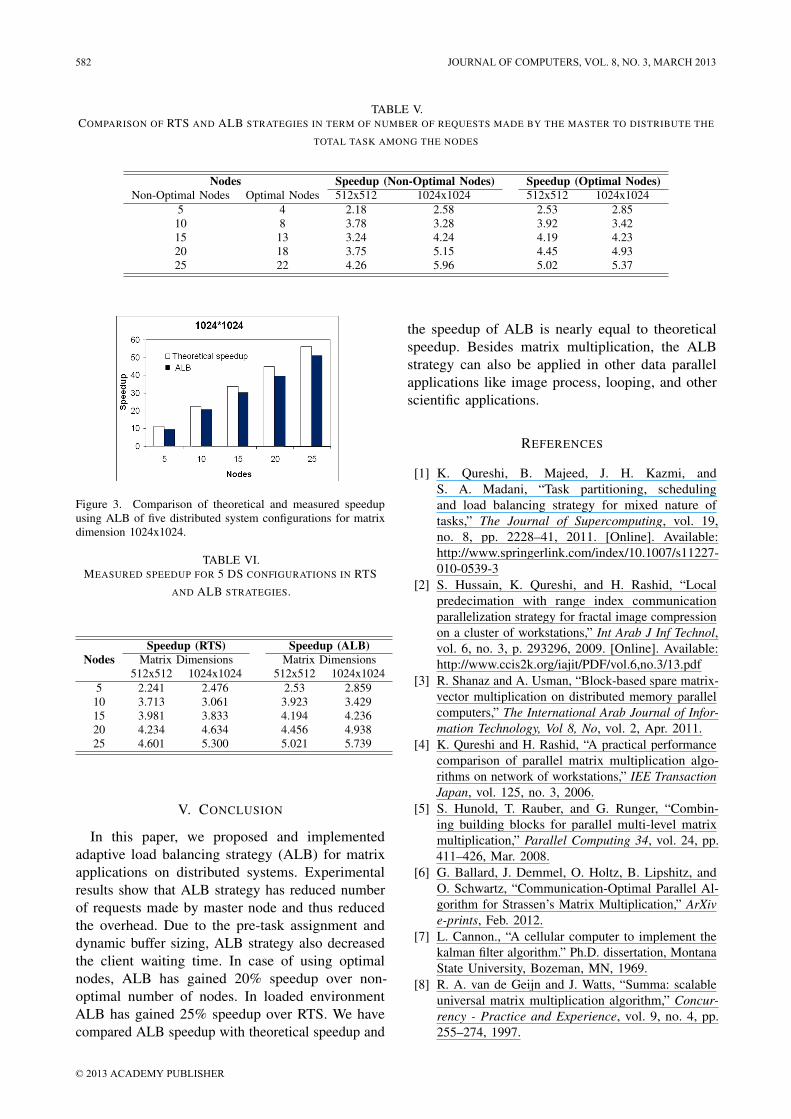
TABLE V.COMPARISON OF RTS AND ALB STRATEGIES IN TERM OF NUMBER OF REQUESTS MADE BY THE MASTER TO DISTRIBUTE THE
TOTAL TASK AMONG THE NODES
Nodes Speedup (Non-Optimal Nodes) Speedup (Optimal Nodes)Non-Optimal Nodes Optimal Nodes 512x512 1024x1024 512x512 1024x1024
5 4 2.18 2.58 2.53 2.8510 8 3.78 3.28 3.92 3.4215 13 3.24 4.24 4.19 4.2320 18 3.75 5.15 4.45 4.9325 22 4.26 5.96 5.02 5.37
Figure 3. Comparison of theoretical and measured speedupusing ALB of five distributed system configurations for matrixdimension 1024x1024.
TABLE VI.MEASURED SPEEDUP FOR 5 DS CONFIGURATIONS IN RTS
AND ALB STRATEGIES.
NodesSpeedup (RTS) Speedup (ALB)
Matrix Dimensions Matrix Dimensions512x512 1024x1024 512x512 1024x1024
5 2.241 2.476 2.53 2.85910 3.713 3.061 3.923 3.42915 3.981 3.833 4.194 4.23620 4.234 4.634 4.456 4.93825 4.601 5.300 5.021 5.739
V. CONCLUSION
In this paper, we proposed and implementedadaptive load balancing strategy (ALB) for matrixapplications on distributed systems. Experimentalresults show that ALB strategy has reduced numberof requests made by master node and thus reducedthe overhead. Due to the pre-task assignment anddynamic buffer sizing, ALB strategy also decreasedthe client waiting time. In case of using optimalnodes, ALB has gained 20% speedup over non-optimal number of nodes. In loaded environmentALB has gained 25% speedup over RTS. We havecompared ALB speedup with theoretical speedup and
the speedup of ALB is nearly equal to theoreticalspeedup. Besides matrix multiplication, the ALBstrategy can also be applied in other data parallelapplications like image process, looping, and otherscientific applications.
REFERENCES
[1] K. Qureshi, B. Majeed, J. H. Kazmi, andS. A. Madani, “Task partitioning, schedulingand load balancing strategy for mixed nature oftasks,” The Journal of Supercomputing, vol. 19,no. 8, pp. 2228–41, 2011. [Online]. Available:http://www.springerlink.com/index/10.1007/s11227-010-0539-3
[2] S. Hussain, K. Qureshi, and H. Rashid, “Localpredecimation with range index communicationparallelization strategy for fractal image compressionon a cluster of workstations,” Int Arab J Inf Technol,vol. 6, no. 3, p. 293296, 2009. [Online]. Available:http://www.ccis2k.org/iajit/PDF/vol.6,no.3/13.pdf
[3] R. Shanaz and A. Usman, “Block-based spare matrix-vector multiplication on distributed memory parallelcomputers,” The International Arab Journal of Infor-mation Technology, Vol 8, No, vol. 2, Apr. 2011.
[4] K. Qureshi and H. Rashid, “A practical performancecomparison of parallel matrix multiplication algo-rithms on network of workstations,” IEE TransactionJapan, vol. 125, no. 3, 2006.
[5] S. Hunold, T. Rauber, and G. Runger, “Combin-ing building blocks for parallel multi-level matrixmultiplication,” Parallel Computing 34, vol. 24, pp.411–426, Mar. 2008.
[6] G. Ballard, J. Demmel, O. Holtz, B. Lipshitz, andO. Schwartz, “Communication-Optimal Parallel Al-gorithm for Strassen’s Matrix Multiplication,” ArXive-prints, Feb. 2012.
[7] L. Cannon., “A cellular computer to implement thekalman filter algorithm.” Ph.D. dissertation, MontanaState University, Bozeman, MN, 1969.
[8] R. A. van de Geijn and J. Watts, “Summa: scalableuniversal matrix multiplication algorithm,” Concur-rency - Practice and Experience, vol. 9, no. 4, pp.255–274, 1997.
582 JOURNAL OF COMPUTERS, VOL. 8, NO. 3, MARCH 2013
© 2013 ACADEMY PUBLISHER

[9] J. Berntsen, “Communication efficient matrix mul-tiplication on hypercubes,” Parallel Computing,vol. 12, no. 3, pp. 335–342, 1989.
[10] R. C. Agarwal, S. M. Balle, F. G. Gustavson,M. Joshi, and P. Palkar, “A three-dimensional ap-proach to parallel matrix multiplication,” IBM Jour-nal of Research and Development, vol. 39, pp. 39–5,1995.
[11] G. Ballard, J. Demmel, O. Holtz, B. Lipshitz, andO. Schwartz., “Strong scaling of matrix multiplica-tion algorithms and memory-independent communi-cation lower bounds,” 2012., submitted to SPAA.
[12] E. Solomonik and J. Demmel., “Communication-optimal parallel 2.5d matrix multiplication and lufactorization algorithms.” in Euro-Par11: Proceed-ings of the 17th International European Conferenceon Parallel and Distributed Computing. Springer,2011.
[13] K. Qureshi and M. Hatanaka, “A Practical Approachof Task Scheduling and Load Balancing on Heteroge-neous Distributed Raytracing System,” InformationProcessing Letter (IPL), Elsevier press, vol. 79,no. 30, pp. 65–71, June 2001.
[14] D. Irony, S. Toledo, and A. Tiskin, “Communicationlower bounds for distributed-memory matrix multi-plication,” J. Parallel Distrib. Comput., vol. 64, no. 9,pp. 1017–1026, 2004.
[15] G. Ballard, J. Demmel, O. Holtz, and O. Schwartz,“Graph expansion and communication costs of fastmatrix multiplication,” in SPAA 11: Proceedingsof the 23rd annual symposium on parallelism inalgorithms and architectures, 2011, pp. 1–12.
[16] Q. Luo and J. Drake, “A scalable parallel Strassensmatrix multiplication algorithm for distributed-memory computers,” in Proceedings of the 1995ACM symposium on Applied computing, SAC 95,1995, pp. 221–226.
[17] B. Grayson, A. Shah, and R. van de Geijn, “A highperformance parallel Strassen implementation,” inParallel Processing Letters, 1995, vol. 6, pp. 3–12.
[18] M. Hamid and C. Le, “Dynamic load-balancing ofimage processing applications on cluster of worksta-tions,” Parallel Computing, vol. 22, pp. 1477–1492,1997.
[19] Y. Zhang, H. Kameda, and S. L. Hung, “Comparisonof dynamic and static load-balancing strategies inheterogeneous distributed systems,” IEE ProceedingComput. Digit. Tech., vol. 144, no. 2, pp. 100–107,1997.
[20] J. Bloomer, Power programming with RPC. OReilly& Associates, 1991.
[21] C. Lee and M. Hamid, Parallel image processingapplications on a network of workstations. ParallelComputing, 1995.
[22] P. Liu and C.-H. Yang, “Locality-preserving dynamicload balancing for data-parallel applications ondistributed-memory multiprocessors,” 2000.
[23] R. L. Cariiio, I. Banicescu, R. K. Vadapalli, C. A.
Weatherford, and J. Zhu, “Parallel adaptive quantumtrajectory method for wavepacket simulations,” inProceedings of the IEEE International Parallel andDistributed Processing Symposium (IPDPS 2003) -PDSECA Workshop, IEEE Computer Society Press,2003, pp. 202–211.
[24] K. Schloegel, G. Karypis, and V. Kumar, “Dynamicrepartitioning of adaptively refined meshes,” inProceedings of the 1998 ACM/IEEE conferenceon Supercomputing (CDROM), ser. Supercomputing’98. Washington, DC, USA: IEEE ComputerSociety, 1998, pp. 1–8. [Online]. Available:http://dl.acm.org/citation.cfm?id=509058.509087
[25] A. Sarje and G. Sagar, “heuristic model for taskallocation in distributed computing systems,” IEEProceedings -E, vol. 5, pp. 313–318, 1991.
[26] S. P. Dandamudi, “Sensitivity evaluation of dynamicload sharing in distributed systems,” IEEE Concur-rency, vol. 6, no. 3, pp. 62–72, July 1998. [Online].Available: http://dx.doi.org/10.1109/4434.708257
[27] R.-Z. Khan, “Empirical study of task partitioningscheduling and load balancing for distributed im-age computing system,” Ph.D. dissertation, JamiaHamdard, Dheli, India, 2005.
[28] H. Rashid, “Parallel scientific applications schedulingon distributed computing system,” Ph.D. dissertation,Preston University, Pakistan, 2006.
[29] S. F. Hummel, E. Schonberg, and L. E.Flynn, “Factoring: a method for schedulingparallel loops,” Commun. ACM, vol. 35, no. 8,pp. 90–101, Aug. 1992. [Online]. Available:http://doi.acm.org/10.1145/135226.135232
[30] R. Biswas and L. Oliker, “Load balancing unstruc-tured adaptive grids for cfd problems,” in 8th IEEESymposium on Parallel and Distributed Processing,1997, pp. 26–33.
[31] I. Banicescu and S. Flynn Hummel, “Balancingprocessor loads and exploiting data localityin n-body simulations,” in Proceedings of the1995 ACM/IEEE conference on Supercomputing(CDROM), ser. Supercomputing ’95. New York,NY, USA: ACM, 1995. [Online]. Available:http://doi.acm.org/10.1145/224170.224306
[32] S. Fu, “Failure-aware construction and reconfig-uration of distributed virtual machines for highavailability computing,” in Proceedings of the2009 9th IEEE/ACM International Symposium onCluster Computing and the Grid, ser. CCGRID’09. Washington, DC, USA: IEEE ComputerSociety, 2009, pp. 372–379. [Online]. Available:http://dx.doi.org/10.1109/CCGRID.2009.21
[33] X. Zhang and Y. Yan, “Modeling andcharacterizing parallel computing performanceon heterogeneous networks of workstations,” inProceedings of the 7th IEEE Symposium onParallel and Distributeed Processing, ser. SPDP’95. Washington, DC, USA: IEEE ComputerSociety, 1995, pp. 25–. [Online]. Available:
JOURNAL OF COMPUTERS, VOL. 8, NO. 3, MARCH 2013 583
© 2013 ACADEMY PUBLISHER

http://dl.acm.org/citation.cfm?id=829516.830568
Adeela Bashir did her MS (Computer Science)from COMSATS Institute of Information Technology,Abbottabad, Pakistan, in 2010. Currently she is a facultymember of Abah University college, Saudi Arabia.
Dr. Sajjad Ahmad Madani, currently AssociateProfessor at COMSATS Institute of InformationTechnology (CIIT) Abbottabad Campus, hasjoined CIIT in August 2008 as Assistant Profes-
sor. Previous to that, he was with the institute of computertechnology, Austria, from 2005 to 2008 as guest researcherwhere he did his PhD research. Prior to joining ICT, hetaught at COMSATS institute of Information Technologyfor a period of 2 years. He has done MS in ComputerSciences from Lahore University of Management Sciences(LUMS), Pakistan with excellent academic standing. Hehas already done BSc Civil Engineering from UET Pe-shawar and was awarded a gold medal for his outstandingperformance in academics. His areas of interest includelow power wireless sensor network and application ofindustrial informatics to electrical energy networks. He haspublished more than 35 papers in international conferencesand journals.
Jawad Haider Kazmi is currently workingas Assistant Professor at the department ofcomputer science, CIIT Abbottabad, Pakistan
since 2008. He took MIT in 2003 and his MS in ComputerScience in 2007, after many years of industry experience.His research interest includes medical imaging, distributedsystems and computer networks.
Dr. Kalim Qureshi, currently Associate Pro-fessor at the Information Science Departmentof the Kuwait University, Kuwait. His research
interests include network parallel distributed computing,thread programming, concurrent algorithms designing, taskscheduling, and performance measurement. Dr. Qureshireceive his Ph.D and MS degrees from Muroran Instituteof Technology, Hokkaido, Japan in (2000, 1997).
584 JOURNAL OF COMPUTERS, VOL. 8, NO. 3, MARCH 2013
© 2013 ACADEMY PUBLISHER





























