Embed Size (px)
Citation preview

Proceedings of the 10th International Conference of
Students of Systematic Musicology (SysMus17)
London, UK, September 13–15, 2017 Peter M. C. Harrison (Ed.).

© 2018 SysMus17. Permission is granted to redistribute part or all of this document
on the condition that the original source be properly cited.
Print version: March 2018

i
Preface
SysMus17, the 10th International Conference of Students of Systematic Musicology, took place on September 13–15, 2017 at Queen Mary, University of London. The SysMus conference series is run by students for students, and provides the opportunity to gain experience in conference attending, presenting, networking, and organising. SysMus17 received 76 submissions in the form of extended abstracts1. Each abstract was reviewed by two reviewers and one meta-reviewer from the SysMus17 scientific committee. On the basis of these reviews, 47 abstracts (62%) were accepted for the conference. Each of these accepted submissions is represented in this proceedings book, either by an extended abstract or by a longer paper. The SysMus17 papers represent a variety of perspectives on systematic musicology. Most describe empirical studies, but also included are theory, analysis, and history papers. The ‘word cloud’ on the cover of this proceedings book plots the 100 most common words found in the SysMus17 proceedings, with the size of each word proportional to its frequency of occurrence2. The word cloud clearly indicates that music is at the centre of SysMus17; within music, particular focuses include performance, emotion, rhythm, analysis, listening, perception, teaching, and creativity. It was a pleasure to receive so many submissions for SysMus17, and to work with the authors to finalise their proceedings contributions. I’m excited to imagine how our new generation of systematic musicologists will contribute to the field in the coming years. Peter Harrison Scientific Chair, SysMus17 January 2018
1 These figures exclude submissions subsequently withdrawn by the authors. 2 The word list was curated to remove uninformative words, such as stop words and paper metadata. Counts for words with similar stems (e.g. ‘music’ and ‘musical’) were combined. The word cloud was created using the software environment R and the R packages tm and wordcloud.

ii

iii
Committees
Core SysMus17 Hosting Committee SysMus17 Chair Sarah Sauvé1 IT Manager Pedro Douglass-Kirk2
Scientific Committee Chair Peter Harrison1 Social Secretary Katie Rose Sanfilippo2
SysMus17 Supervisor Marcus Pearce1
1Music Cognition Lab, Queen Mary, University of London http://music-cognition.eecs.qmul.ac.uk/ 2Music, Mind & Brain, Goldsmiths, University of London http://www.musicmindbrain.com/ Volunteers Canishk Naik Ioanna Zioga Jiajie Dai Manuel Anglada-Tort Ozge Alakus Rebeka Bodak Sarah Toorani Shirley Wu Scientific Committee Agata Zelechowska Angel Faraldo Anja-Xiaoxing Cui Anthony Chmiel Brooke Okada Cárthach Ó Nuanáin Cory Meals Daniel Fiedler David Baker Fabian Moss Georgios Diapoulis Gesine Wermke Hayley Trower Helena Dukic Jason Noble Jessica Crich Juan Ignacio Mendoza Garay Jun Jiang Katie Rose Sanfilippo Keith Phillips
Kelly Whiteford Landon Peck Manuel Anglada-Tort Marco Susino Michaela Korte Moe Touizrar Montserrat Pàmies-Vilà Mylène Gioffredo Nerdinga Letule Noah Little Olivia Podolak Raluca Matei Riza Veloso Savvas Kazazis Scott Bannister Steffen Herff Suzanne Ross Tejaswinee Kelkar Ulf Holbrook

iv
Table of Contents
Paper Page
Aydin Anic, William Forde Thompson, Kirk N. Olsen. Stimulation of the Primary Motor Cortex Enhances Creativity and Technical Fluency of Piano Improvisations.
1–7
Jay Appaji, Zachary Wallmark, Jay Dowling. Cognition of South Indian Percussion.
8
Lotte Armbrüster, Werner Mende, Hanna Ehlert, Gesine Wermke, Kathleen Wermke. Musical Intervals in Baby Sounds.
9–10
Joshua S. Bamford. Chance Music is Best Not Left to Chance.
11
Scott Bannister. A Survey of Musically-Induced Chills: Emotional Characteristics and ‘Chills Moments’ in Music.
12
Stefanie Bräuml. Neuroaesthetics and Music: Difficulties of a Young Field of Research.
13
Sarah Campbell, Paul Sowden. ‘Feeling the Gap’: Does Interoceptive Ability Mediate the Disparity Between Physiological and Subjective Emotional Response to Music Listening?
14
Francisco Cardoso. Towards a New Model for Effective Musical Teaching in Performance-Oriented Settings.
15–19
Álvaro M. Chang-Arana. Spanish Version of the Kenny-Music Performance Anxiety Inventory (K-MPAI): Factorial Structure and First Statistical Analyses of a Peruvian Sample.
20–23
Anthea Cottee, Sean O’Connor. Adaptation of the Mindfulness-Acceptance-Commitment Approach for Groups of Adolescent Musicians: An Assessment of Music Performance Anxiety, Performance Boost, and Flow.
24
Pablo Cuevas. Sounds of Native Cultures in Electroacoustic Music: Latin American Study Cases.
25–28

v
Anna Czepiel, Emma Allingham, Kendra Oudyk, Adrianna Zamudio, Pasi Saari. Musicians’ Timbral Adjustments in Response to Emotional Cues in Musical Accompaniments.
29
Georgios Diapoulis, Marc Thompson. Kinematics Feature Selection of Expressive Intentions in Dyadic Violin Performance.
30–33
Katerina Drakoulaki, Robin Lickley. Grammaticality Judgments in Linguistic and Musical Structures.
34
Daniel Fiedler, Daniel Müllensiefen. Musical Trajectories and Creative Music Teaching Interventions Affect the Development of Interest in ‘Music’ of German Secondary Schools’ Students.
35–36
Konstantinos Giannos, Emilios Cambouropoulos. Chord Encoding and Root-finding in Tonal and Non-Tonal Contexts: Theoretical, Computational and Cognitive Perspectives.
37–42
Luciana F. Hamond. Visual Feedback in Higher Education Piano Learning and Teaching.
43–48
Marvin Heimerich, Kimberly Severijns, Sabrina Kierdorf, Kevin Kaiser, Philippe Janes, Rie Asano. Investigating the Development of Joint Attentional Skills in Early Ontogeny Through Musical Joint Action.
49
Dasaem Jeong, Juhan Nam. How the Rhythm is Actually Performed in the First Movement of the Beethoven’s Seventh Symphony.
50–55
Elizabeth Kunde, Kate Leonard, Jim Borling. The Effect of Socio-Cultural Identity on Musical Distaste.
56
John Lam Chun-fai. Modes of Listening to Chinese Pentatonicism in Parisian Musical Modernity.
57–59
Rebecca Lancashire. An Experience-Sampling Study to Investigate the Role of Familiarity in Involuntary Musical Imagery Induction.
60–66
Chloe Stacey MacGregor, Daniel Müllensiefen. Factors Influencing Discrimination of Emotional Expression Conveyed Through Music Performance.
67–73

vi
Raluca Matei, Jane Ginsborg, Stephen Broad, Juliet Goldbart. A Health Course for Music Students: Design, Implementation and Evaluation.
74
Pablo Mendoza-Halliday. A Theory of the Musical Genre: The Three-Phase Cycle.
75–77
Jaco Meyer. Musical Forces Can Save Analysts from Cumbersome Explanations.
78
Robyn Moran, Richard Race, Arielle Boneville-Roussy. Measuring Rhythmic Abilities: The Development of a Computer-Based Test to Assess Individual Differences in Beat Keeping.
79
Ekaterina Pavlova. Selling Madness: How Mental Illness Has Been Commercialised in the Music Business.
80–83
Landon S. L. Peck. Experiences and Appraisals of Musical Awe.
84
Keith Phillips. Investigating the Improvisers’ Perspective Using Video-Stimulated Recall.
85
Sinead Rocha, Victoria Southgate, Denis Mareschal. Infant Spontaneous Motor Tempo.
86
D. C. Rose, L. E. Annett, P. J. Lovatt. Investigating Beat Perception and Sensorimotor Synchronisation in People With and Without Parkinson’s Disease.
87
Suzanne Ross, Elvira Brattico, Maria Herrojo-Ruiz, Lauren Stewart. The Effect of Auditory Feedback on Motor Sequence Learning in Novices.
88
Pathmanesan Sanmugeswaran. Performing Auspiciousness and Inauspiciousness in Parai Mēlam Music Culture in Jaffna, Sri Lanka.
89
Katharina Schäfer, Tuomas Eerola. Social Surrogacy: How Music Provides a Sense of Belonging.
90
Theresa Schallmoser, Siavash Moazzami Vahid, Richard Parncutt. Estimation of Time in Music: Effects of Tempo and Familiarity on the Subjective Duration of Music.
91

vii
Eva Schurig. Urban Traffic Safety While Listening to Music – Views of Listeners and Non-Listeners.
92–95
Jan Stupacher, Guilherme Wood, Matthias Witte. Infectious Grooves: High-Groove Music Drives Auditory-Motor Interactions.
96
Jasmine Tan, Joydeep Bhattacharya. Interoception in Musicians’ Flow.
97
M. S. Tenderini, T. M. Eilola, E. de Leeuw, M. T. Pearce. Affective Priming Effects Between Music and Language in Bilinguals’ First and Second Language.
98
Hayley Trower, Adam Ockelford, Arielle Bonneville-Roussy. Using Zygonic Theory to Model Expectations in Repeated Melodic Stimuli.
99
Michelle Ulor, Freya Bailes, Daryl O’Connor. Can Individuals be Trained to Imagine Musical Imagery? A Preliminary Study.
100
Joy Vamvakari. “Let the Music Flow in You”: Music Listening, Health and Wellbeing in Everyday Life.
101
Makarand Velankar, Parag Kulkarni. Study of Emotion Perception for Indian Classical Raga Music.
102–105
Gesine Wermke, Andreas C. Lehmann, Phillip Klinger, Bettina Lamm. Reproduction of Western Music Rhythms by Cameroonian School Children.
106–107
Johanna N. Wilson. Analysing the Implications of Music Videos on Youths’ Listening Experience.
108
Adrien Ycart, Emmanouil Benetos. Neural Music Language Models: Investigating the Training Process.
109

Proceedings of the 10th International Conference of Students of Systematic Musicology (SysMus17), London, UK, September 13-15, 2017. Peter M. C. Harrison (Ed.).
Stimulation of the Primary Motor Cortex Enhances Creativity and Technical Fluency of Piano Improvisations
Aydin Anic*#†1, William Forde Thompson*#†2, Kirk N. Olsen#†3 *ARC Centre of Excellence in Cognition and its Disorders, Macquarie University, Australia
#Centre for Elite Performance, Expertise, and Training, Macquarie University, Australia †Department of Psychology, Macquarie University, Australia
[email protected], [email protected], [email protected]
ABSTRACT Musical improvisation is an ecologically valid and contextually appropriate medium to investigate the neuroscience of creativity. Previous research has identified several brain regions that are involved in musical creativity: the dorsolateral prefrontal cortex (DLPFC), the ventral medial prefrontal cortex (vMPFC), the pre-supplementary motor area (pre-SMA), and the ventral and dorsal premotor cortex (vPMC and dPMC, respectively). These brain regions underpin high-level processing and motor functions. The present study asked whether the primary motor cortex (M1 region) plays a role in creativity and technical fluency. The M1 region underpins the acquisition and consolidation of novel motor skills and hand movement. Here, we used transcranial direct current stimulation (tDCS) to investigate the overarching research question. tDCS is a non-invasive mode of brain stimulation that is delivered via two saline-soaked electrodes diametric in charge: the anodal electrode stimulates neural activation; the cathodal electrodes inhibits neural activation. A bi-hemispheric, online tDCS montage was used in this study. Eight proficient pianists were recruited and separated into two tDCS groups: Anodal-Left M1/Cathodal-Right M1 (n = 4) and Cathodal-Left M1/Anodal-Right M1 (n = 4). tDCS was administered whilst participants performed musical improvisations. The level of creativity and technical fluency was judged independently by an expert musician adjudicator. We hypothesised that the Anodal-Left M1/Cathodal-Right M1 (excitatory) tDCS group will demonstrate an enhancement of creativity and technical fluency compared to the Cathodal-Left M1/Anodal-Right M1 (inhibitory) tDCS group. The preliminary results show that during musical improvisation, creativity (p = .07) and technical fluency (p = .05) increased when excitatory tDCS was applied to the left M1 region of proficient pianists. Furthermore, there was no apparent decrease in creativity and technical fluency for the inhibitory tDCS group. In light of these preliminary findings, we conclude that there is some evidence that the M1 region does contribute to musical creativity. Future work with a larger sample size will shed further light on this contribution.
I. INTRODUCTION
Investigating the neural underpinnings of creative cognition is important to understand how novel ideas and behaviour manifest. The two key constituents of creativity include: originality and congruency (Boccia, Piccardi, Palermo, Nori & Palmiero, 2015). Originality involves the generation of novel responses to a stimulus; congruency
relates to the appropriateness of the responses given in a specific context (Dietrich, 2004). Musical improvisation is a quintessential creative behaviour that can be investigated using neuroscientific methods to identify specific brain regions that contribute to creativity (McPherson & Limb, 2013). A prominent method used to investigate musical creativity is functional magnetic resonance imaging (fMRI) (e.g., Limb & Braun, 2008). fMRI measures the blood-oxygenated level dependent (BOLD) signal that indicates the activation and deactivation patterns of brain regions in response to a stimulus (Sawyer, 2011). We now review the core brain regions involved in musical improvisation – a form of musical performance that requires, by definition, creativity (Bengtsson, Csıkszentmihalyi & Ullén, 2007). A. Brain Regions Involved in Musical Improvisation and
Creativity
Previous literature has shown that several brain regions are involved in creative music improvisations: the dorsolateral prefrontal cortex (DLPFC), which is part of the Executive Control Network (ECN) and regulates attention, working memory and monitoring (Limb & Braun, 2008; Bengtsson, Csıkszentmihalyi & Ullén, 2007); and the ventral medial prefrontal cortex (vMPFC), which is part of the Default Mode Network (DMN) and regulates mental simulation and mind wandering (Bashwiner, Wertz, Flores & Jung, 2016). Importantly, these brain regions are diametrically opposed; the activation of one (e.g., ECN) results in the deactivation of the other (e.g., DMN) (Limb & Braun, 2008; Bengtsson, Csıkszentmihalyi & Ullén, 2007; de Manzano & Ullén, 2012a).
However, recent studies have also shown that these two brain regions operate concurrently in musical improvisations (Pinho, Ullén, Castelo-Branco, Fransson & de Manzano, 2016). Further research has investigated high-level motor areas and their role in musical creativity, including the pre-supplementary motor area (pre-SMA) and the premotor cortex (PMC). The PMC can be further separated into the ventral premotor cortex and dorsal premotor cortex (vPMC & dPMC, respectively) (Berkowitz & Ansari, 2008; de Manzano & Ullén, 2012a). These premotor areas are interconnected and involved in cognition (Bashwiner et al. 2016). Specifically, the pre-SMA is involved in timing aspects of performance; the PMC is involved in performance of original motor tasks (Berkowitz & Ansari, 2008; de Manzano & Ullén, 2012a).
1

The focus of the present study is on the primary motor cortex (M1 region) and its possible role in mediating creativity and also technical fluency in the context of improvised jazz performance. B. The Primary Motor Cortex
The M1 region is involved in the consolidation and acquisition of new motor skills (Sosnik, Flash, Sterkin, Hauptmann & Karni, 2014; Karok & Witney, 2013). Furthermore, the M1 underpins movement properties of the hand that include: dexterity, finger individuation, velocity, and direction (Sosnik et al. 2014). The M1 region covers both hemispheres of the brain (Vines, Nair & Schlaug, 2008). The connection between the two hemispheres is inhibitory in nature, and this is known as the inter-hemispheric inhibition connection (IHIC) (Vines, Nair & Schlaug, 2008). In other words, when the M1 region of a specific hemisphere is activated (e.g., the left M1), the right M1 is inhibited through the IHIC system to further concentrate activation to the left M1 region (Vines, Nair & Schlaug, 2008). Moreover, the left M1 mediates control of the right hand, whereas the right M1 mediates control of the left hand (Vines, Nair & Schlaug, 2008). Studies have confirmed that the M1 region operates asymmetrically. For instance, Vines, Nair and Schlaug (2008) found in right handers that stimulating the left (dominant) M1 region with transcranial direct stimulation (tDCS) had effects for both hands; whereas, stimulating the right (non-dominant) M1 region had effects for the contralateral (opposite) hand. For the purpose of experimental control in the present study, pianists were instructed to only use their right hand when performing jazz improvisations. C. Technical Fluency in Musical Improvisations
In a musical context, technical fluency refers to the technical ability of the performer to express musical ideas with their musical instrument. Together with creativity, technical fluency of musical improvisations in the present study are measured. It is, however, yet to be determined if these components are related. Thus, another aim of the study is to assess whether technical fluency and creativity are related in an improvised jazz context. D. Transcranial Direct Current Stimulation
In this study, tDCS was applied to modulate the activation of the M1 region of proficient musicians. tDCS is a neuro-modulatory brain stimulation technique that alters the activation patterns of neurons over a desired area (Karok & Witney, 2013; Vines, Nair & Schlaug, 2008). tDCS is comprised of two saline-soaked electrodes that deliver two different charges: the anode (positive) electrode stimulates neural activity; whereas the cathode (negative) electrode inhibits neural activity (Nitsche, Schauenburg, Lang, Liebetanz, Exner, Paulus & Tergau, 2003). There are disparate tDCS methodologies that have been used in previous studies (e.g., Furuya, Klaus, Nitsche, Paulus & Altenmuller, 2014). There are two forms of tDCS that are used for
experimentation: Online vs. offline tDCS. Online tDCS involves the simultaneous application of tDCS and measurement of task performance; whereas, offline tDCS involves a separation of stimulation and task performance (Karok & Witney, 2013).
Furthermore, there are two tDCS configurations (placement) of electrodes: unihemispheric and bihemispheric. Unihemispheric tDCS involves one electrode (either the anodal or cathodal) over a specific area and hemisphere of the brain (e.g., the left DLPFC) and the remaining electrode is placed on the contralateral (opposite) hemisphere’s mastoid (behind the ear) and serves as a reference and concentrates stimulation (Karok & Witney, 2013). Bihemispheric tDCS is comprised of both electrodes placed on both hemispheres of the brain (e.g., left and right M1 region) stimulating one hemisphere and inhibiting the other (Waters-Metenier, Husain, Wiestler & Diedrichsen, 2014). A study conducted by Karok & Witney (2013) investigated the optimal tDCS configuration and found bihemispheric, online tDCS is a superior method compared to unihemispheric tDCS (Karok & Witney, 2013). Therefore, the present study incorporated a bihemispheric, online tDCS montage. E. Aims, Design & Hypothesis
The aims of the study were to: (1) investigate the M1 region as a possible brain region that contributes to musical creativity and technical fluency; and (2) assess the possible relationship between technical fluency and creativity in the context of a musical improvisation. There were two tDCS conditions: Anodal-Left M1/Cathodal-Right M1 (n = 4) and Cathodal-Left M1/Anodal-Right M1 (n = 4). We predicted that the application of Anodal-Left M1/Cathodal-Right M1 tDCS would improve creativity and technical fluency relative to the application of Cathodal-Left M1/Anodal-Right M1 tDCS.
II. METHOD
A. Participants
Eight proficient jazz pianists (4 female; mean age = 20.25, SD = 2.25) and one independent expert musician adjudicator participated in the study. Six of the eight participants were right-handed; one participant was left-handed and one was mixed-handed. All participants gave informed consent to participate in the study. A TMS screener was administered prior to tDCS application to ensure that participants did not have any neurological disorders, metal implants, or any other brain-related conditions that may cause risk or harm. All participants satisfied the TMS screener. Participants were reimbursed $50 or course credit for their participation. This study was approved by the Macquarie University Human Research Ethics Committee (HREC Medical Sciences) Reference number: 5201600392.
2

B. Stimuli
Ten original musical pieces were written specifically for this study to ensure novelty. All pieces incorporated an electronic drum kit, electronic piano, grand piano and live electric bass guitar. The electronic drum kit, electronic piano, and grand piano were programmed using Notion music generation software; the live electric bass was recorded using GarageBand and was performed by the first author. Each musical piece contained a total of ten bars. As shown in Figure 1, the first bar involved a four-beat count-in using the high-hat of the drum kit to indicate that the piece is about to begin. The next four bars, indicated with the rehearsal mark ‘A’, involved all instruments and a novel melody which was presented on the treble clef only. Participants played along to the melody while sight-reading a musical score. The next section, indicated with the rehearsal mark ‘B’, consisted of five measures representing the section when participants performed their improvisations. All the pieces were written to conform to the jazz genre in terms of harmonic and rhythmic qualities. Six of the ten pieces were written in varying major key signatures; the remaining four pieces were written in varying minor key signatures. All ten pieces were programmed at 90 beats per minute.
Figure 1. A sample of the stimuli used in the experiment. The stimuli was divided into two sections: Section ‘A’ required sight-reading a novel melody to ensure ecological validity and a context on which to base their improvisations. Section ‘B’ was the improvisation section that was designated for improvisations. Participants played with their right-hand only.
C. Equipment
A bihemispheric, online tDCS montage was used in the study. tDCS consisted of two saline-soaked electrodes (anode and cathode). The electrodes were placed on C3 and C4 sites that correspond to stimulation of the M1 region. These sites are derived from the 10-20 electroencephalogram system that specifically targets the M1 region. tDCS was programmed to deliver 1.4mA constantly during the session. The participants
were subjected to tDCS stimulation lasting between fifteen and twenty-one minutes (including ramp-up and ramp-down). This duration of tDCS is considered safe (Bikson, Datta and Elwassif, 2009). The ramp-up period lasted 30 seconds when the session began; the ramp-down period lasted 30 seconds at the session. All participants were stimulated for two and a half minutes (including the ramp-up period) before the task commenced to ensure a controlled and adequate degree of stimulation was administered before the performance began.
tDCS was administered using the Neuro-Electrics Instrument Controller (NIC) on a 15-inch MacBook Pro. The NIC software controlled the configuration of tDCS and allowed the impedances of the electrodes to be monitored. An 11-inch MacBook Air was connected via a ThunderBolt cable to a 27-inch iMac to present the musical stimuli to the participants. The 11-inch MacBook Air was used by the experimenter to organise and record the performances. All performances were conducted on a Musical Instrument Digital Interface (MIDI) keyboard.
D. Experimental Paradigm
The participants were pseudo-randomised into the two tDCS stimulation groups: Anodal-Left M1/Cathodal-Right M1 (n = 4) and Cathodal-Left M1/Anodal-Right M1 (n = 4). The ten novel musical stimuli were initially randomised into two melodic sequences to organise the presentation of the stimuli; each melodic sequence consisted of five of the ten musical stimuli and corresponded to the two blocks of the experiment. For each participant, the trials within the respective melodic sequence were randomised to mitigate any presentation bias due to order effects. The experimental paradigm consisted of two blocks: block one served as the control in which no tDCS was administered; block two consisted of one of the two types of tDCS stimulation. See Table 1 and Figure 2 for a detailed description of the experimental paradigm and design. The duration of the experiment lasted for approximately 90 minutes.
Table 1. Experimental conditions used in the study.
Group Block one Block two Melodic sequence
1A No treatment Anodal-Left M1/Cathodal-
Right M1
Melodic sequence 1 – Melodic sequence
2
1B No treatment Anodal-Left M1/Cathodal-
Right M1
Melodic sequence 2 – Melodic sequence
1
2A No treatment Cathodal-Left
M1/Anodal-Right M1
Melodic sequence 1 – Melodic sequence
2
2B No treatment Cathodal-Left
M1/Anodal-Right M1
Melodic sequence 2 – Melodic sequence
1
3

Figure 2. The experimental procedure. The first block consisted of five trials with no stimulation. The second block consisted of five trials with tDCS stimulation set at 1.4mA.
E. Procedure
Upon entering the laboratory, participants were presented with the TMS screener to determine if the application of tDCS was safe to administer. Participants then provided informed consent and completed a demographic questionnaire. To familiarize the participants with the experiment, two practice trials were administered. Both the practice trials and experiment trials consisted of two stages: familiarisation and performance.
The familiarisation stage consisted of two playings of each stimulus. In the first playing, the participant was instructed to listen and follow the melody presented in section ‘A’ without playing the piano. The entire duration of the stimuli was presented. In the second playing, the participants were instructed to play the melody presented in section ‘A’ with their right hand only. Section ‘B’ in the second playing was not played. In the familiarisation stage, the piano accompaniment playing the melody in the section was played through the speakers. The purpose of the familiarisation stage was to ensure that the participants were familiar with the procedure of the trial. A sub-set of participants required more playing’s to be familiar with the piece before the performance.
In the performance stage, two opportunities to play the entire trial was afforded. The participants were instructed to play the melody presented in section ‘A’ and then improvise in section ‘B’. Importantly, the piano accompaniment was removed during their improvisation. Participants were informed of this instruction prior to the commencement of the performance stage. The audio from all the trials were randomised across participants, conditions, and blocks, and collected onto a USB and sent to the independent expert musician adjudicator for evaluation.
F. Expert Adjudication
In order to adjudicate the performances, the independent expert musician adjudicator was presented with the audio files of all trials and the musical stimuli used in the study. The adjudicator was blind to each participant’s allocated condition. In the adjudicator’s instructions, the definitions of technical fluency and creativity were outlined to create a well-defined focus for adjudication of these constituents of performance. Both technical fluency and creativity were judged using two separate Likert scales ranging from one to ten. A score of one represented a low level of creativity/technical fluency; a score of ten represented a high level of creativity/technical fluency.
III. RESULTS
A. Creativity in Musical Improvisation
An independent samples t-test was computed to compare the mean difference in creativity scores between block one (control) and block two (stimulation) for the two tDCS groups: Anodal-Left M1/Cathodal-Right M1 (excitatory tDCS) and Cathodal-Left M1/Anodal-Right M1 (inhibitory tDCS). The analysis revealed that creativity increased for the excitatory tDCS group (M = 1.20, SD = 0.82) compared to the inhibitory tDCS group (M = .15, SD = .50) and this difference approached statistical significance; t(6) = 2.19, p = .07. A Cohen’s d effect size calculation revealed a large effect size, d = 1.55. The present results demonstrate that there is a trend that stimulation of the left M1 region in musical improvisation enhances creativity. See Figure 3 for the mean creativity scores for both tDCS groups.
Figure 3. Mean creativity scores for both tDCS groups and the difference between baseline and tDCS stimulation blocks.
B. Technical Fluency in Musical Improvisations
An independent samples t-test was computed to compare the mean difference in technical fluency scores between block one (control) and block two (stimulation) for the two tDCS groups: Anodal-Left M1/Cathodal-Right M1
Block Two 5
Trials Anodal-Left/Cathodal-
Right n = 4
Block one
5 Trials N = 8
No Stimulation
1.4mA tDCS
Block Two 5
Trials Cathodal-Left/Anodal-
Right n = 4
1.4mA tDCS
4

(excitatory tDCS) and Cathodal-Left M1/Anodal-Right M1 (inhibitory tDCS) between block one (control) and block two (stimulation). The analysis revealed that technical fluency increased for the excitatory tDCS group (M = 1.05, SD = 0.41) compared to the inhibitory tDCS group (M = .20, SD = .57). This difference was statistically significant; t(6) = 2.42, p = .05. A Cohen’s d effect size calculation revealed a large effect size, d = 1.72. See Figure 4 for the mean technical fluency scores for both tDCS groups. Interestingly, there was no apparent decrease in creativity and technical fluency for the inhibitory tDCS group.
Figure 4. Mean technical fluency scores for both tDCS groups and difference between baseline and tDCS stimulation blocks.
C. Correlation Between Technical Fluency and Creativity
A Pearson’s r correlation coefficient was computed to determine if there is a significant relationship between technical fluency and creativity. Firstly, all eighty trials from both stimulation groups across all blocks and participants were used in the analysis. There was a statistically significant positive correlation between technical fluency and creativity, irrespective of tDCS group, r(78) = .765, p < .001. Further analyses was conducted by separating the trials to the respective stimulation groups (excitatory tDCS = 40 trials; inhibitory = 40 trials). There was a statistically significant difference between technical fluency and creativity scores for the excitatory tDCS group, r(38) = .820, p < .001 and the inhibitory tDCS group, r(38) = .732, p < .001.
D. Follow-Up Analysis: Melodic Features
In a follow-up analysis, three melodic features were analysed to determine if tDCS had an effect on the above findings. The three melodic features analysed were: number of notes, pitch range, and number of different notes. These features were analysed for performances in the improvisation section only (section ‘B’ of each stimulus). An independent samples t-test was computed to investigate the difference in each performed melodic feature in each stimulation group:
1) Number of notes.
A difference score was calculated for each tDCS group between block one (control) and block two (stimulation). The
number of notes increased in the excitatory tDCS group (M = 3.25 SD = 4.08) relative to the inhibitory tDCS group (M = 1.00 SD = 2.35), but this difference was not statistically significant; t(6) = .955, p > .05. See Figure 5 for the mean number of notes used for both tDCS groups.
Figure 5. Mean number of notes used for both tDCS groups and difference between baseline and tDCS stimulation blocks.
2) Pitch range.
A difference score was calculated for each tDCS group between block one (control) and block two (stimulation). Although pitch range did increase for the excitatory tDCS group (M = 1.90 SD = 1.50) relative to the inhibitory tDCS group (M = .20 SD = .37), this difference was not statistically significant; t(3.35) = 2.201, p > .05. See Figure 6 for the mean pitch range used for both tDCS groups.
Figure 6. Mean pitch range for both tDCS groups and difference between baseline and tDCS stimulation blocks.
3) Number of different notes.
A difference score was calculated for each tDCS group between block one (control) and block two (stimulation). The number of different notes used was higher for the excitatory tDCS group (M = 1.20 SD = .43) relative to the inhibitory tDCS group (M = .60 SD = .71), but this difference was not statistically significant; t(6) = 1.441, p > .05. See Figure 7 for the mean number of different notes used for both tDCS groups.
5

Figure 7. Mean number of different notes used for both tDCS groups and difference between baseline and tDCS stimulation blocks.
E. Multiple Regression: Melodic Features
A multiple regression was computed to determine if the three melodic features (number of notes, pitch range, and number of different notes) significantly predicted creativity scores. The multiple regression showed no statistical significance for the three predictors on creativity, F(3,4) = .899, p > .05, adjusted R2 = -.045. Furthermore, a multiple regression was computed to investigate whether results on the three melodic features significantly predicted technical fluency score. The multiple regression demonstrated no statistical significance for the three predictors on technical fluency, F(3,4) = .463, p > .05, adjusted R2 = -.299.
IV. DISCUSSION
The aims of the study were to (1) assess the M1 region and its influence on creativity and technical fluency in an improvised jazz context using tDCS; and (2) examine whether creativity and technical fluency as interrelated concepts in jazz improvisations. The hypothesis for the study was that participants who receive excitatory tDCS will show an increase in creativity and technical fluency when compared to participants who receive inhibitory tDCS. The results provide preliminary support for both hypotheses.
A. Creativity and Technical Fluency
This preliminary study has shown that when excitatory tDCS was applied to the M1 region, creativity and technical fluency both increased when compared to inhibitory tDCS application. These increases were significant for technical fluency and approached significance for creativity (p = .07). Furthermore, there was evidence to suggest that creativity and technical fluency are interrelated concepts in the context of musical improvisations. Specifically, there was a strong positive correlation between creativity and technical fluency, irrespective of tDCS application (r = .765). Subsequent analysis revealed a stronger positive correlation for improvisations following excitatory tDCS (r = .820, p < .001) than for improvisations following inhibitory tDCS (r = .732, p < .001). In other words, excitatory tDCS elicited higher
performance scores on creativity and technical fluency and a stronger relationship between ratings of creativity and technical fluency. Although the correlations for both tDCS group elicited statistical significance, a tentative interpretation suggests that excitatory tDCS benefits creativity through an enhancement of technical fluency, whereas inhibitory tDCS does not. Overall, the excitatory tDCS findings suggest that the M1 region does influence technical fluency and creativity in the context of musical improvisations.
B. Melodic Feature Analysis
Specific melodic features in the performances were analysed to determine whether they were also influenced by tDCS. These features include the number of performed notes, pitch range, and number of different notes used in the improvisation section of each trial. Although statistical significance was not reached for the aforementioned features, a positive numerical trend suggested that improvisers in the excitatory tDCS group employed a greater number of performed notes, a larger pitch range, and a greater number of different notes, relative to improvisers in the inhibitory tDCS group.
C. Implications
The primary implication from this study is preliminary evidence that the M1 region contributes to creative cognition in a musical context, perhaps to some extent via an increase in technically fluent performances. In light of the previous literature focusing on creativity in musical improvisations (e.g., Bengtsson, Csıkszentmihalyi & Ullén, 2007; Bashwiner et al. 2016; de Manzano & Ullén, 2012a), this study has provided preliminary evidence that creativity does involve low-level motor areas such as the M1 region (Sosnik et al. 2014).
D. Limitations and Future Directions
The small sample size of this study (N = 8) has resulted in low statistical power. Thus, a replication of this study using a greater sample size is needed for strong conclusions to be drawn. Furthermore, the implementation of a control group with no tDCS stimulation will provide a control in which to illustrate any change in creativity and technical fluency scores when compared to the two types of tDCS stimulation. Indeed, with the use of a control group, stronger conclusions can be made about the M1 region and its effects on creativity and technical fluency in the context of a musical improvisation. Finally, the recruitment of multiple expert adjudicators in future work will significantly enhance reliability of the results, as inter-rater reliability measures can then be calculated.
V. CONCLUSION
This preliminary tDCS study is the first to utilise bihemispheric online tDCS over the M1 region to determine
6

its influence on creativity and technical fluency in the context of improvised jazz performance. The preliminary evidence suggests that excitatory tDCS applied over the M1 region of proficient pianists enhances both creativity and technical fluency, relative to inhibitory tDCS. We conclude that creative cognition in a musical context encapsulates technical fluency and involves the M1 region. Future research with a greater sample size will shed further light on these findings.
ACKNOWLEDGMENTS
The authors would like to thank Associate Professor Paul Sowman for assistance in the tDCS component of the study, Jordan Wehrman for assistance with participant testing, and the Macquarie University Music, Sound, and Performance Lab for helpful comments throughout the process of experimental design and analysis.
REFERENCES
Bashwiner, D.M., Wertz, C.J., Flores, R.A., & Jung, R.E. (2016). Musical creativity “revealed” in brain structure: interplay between motor, default mode, and limbic networks. Scientific Reports, 6, 1-8.
Bengtsson, S.L., Csıkszentmihalyi, M., & Ullén, F. (2007). Cortical regions involved in the generation of musical structures during improvisation in pianists. Journal of Cognitive Neuroscience, 19, 830–842.
Berkowitz, A.L., & Ansari, D. (2008). Generation of novel motor sequences: The neural correlates of musical improvisation. NeuroImage, 41, 535-543.
Bikson, M., Datta, A. & Elwassif, M. (2009). Establishing safety limits for transcranial direct current stimulation. Clinical Neurophysiology, 120, 1033–1034.
Boccia, M., Piccardi, L., Palermo, L., Nori, R., & Palmiero, M. (2015). Where do bright ideas occur in our brain? Meta-analytic evidence from neuroimaging studies of domain-specific creativity. Frontiers in Psychology, 6, 1-12.
de Manzano, O., & Ullén, F. (2012a). Activation and connectivity patterns of the presupplementary and dorsal premotor areas during free improvisation of melodies and rhythms. NeuroImage, 63, 72–280.
Dietrich, A. (2004). The cognitive neuroscience of creativity. Psychonomic Bulletin & Review, 11, 1011-1026.
Furuya, S., Klaus, M., Nitsche, M.A., Paulus, W., & Altenmuller, E. (2014). Ceiling effects prevent further improvement of transcranial stimulation in skilled musicians. The Journal of Neuroscience, 34, 13834-13839.
Karok, S. & Witney, A.G. (2013). Enhanced motor learning following task-concurrent dual transcranial direct current stimulation. PLoS ONE, 8, e85693.
Kim, Y.K. & Shin, S.H. (2014). Comparison of effects of transcranial magnetic stimulation on primary motor cortex and supplementary motor area in motor skill learning (randomized, cross over study). Frontiers in Human Neuroscience, 8, 937.
Limb, C.J, & Braun, A.R. (2008). Neural substrates of spontaneous musical performance: an fMRI study of jazz
improvisation. PLoS ONE, 3, e1679. McPherson, M. & Limb, C.J. (2013). Difficulties in the
neuroscience of creativity: jazz improvisation and the scientific method. Annals of the New York Academy of Sciences, 1303, 80–83.
Nitsche, M.A., Schauenburg, A., Lang, N., Liebetanz, D., Exner, C., Paulus, W. & Tergau, F. (2003). Facilitation of implicit motor learning by weak transcranial direct current stimulation of the primary motor cortex in the human. Journal of Cognitive Neuroscience, 15, 619–626.
Pinho, A.L., de Manzano, O., Fransson, P., Eriksson, H., & Ullén, F. (2014). Connecting to create: Expertise in musical improvisation is associated with increased functional connectivity between premotor and prefrontal areas. The Journal of Neuroscience, 34, 6156 – 6163.
Pinho, A.L., Ullén, F., Castelo-Branco, M., Fransson, P., & de Manzano, O. (2016). Addressing a paradox: Dual strategies for creative performance in introspective and extrospective networks. Cerebral Cortex, 26, 3052–3063.
Sawyer, K. (2011). The cognitive neuroscience of creativity: A critical review. Creativity Research Journal, 23, 137-154.
Sosnik, R., Flash, T., Sterkin, A., Hauptmann, B., & Karni, A. (2014). The activity in the contralateral primary motor cortex, dorsal premotor and supplementary motor area is modulated by performance gains. Frontiers in Human Neuroscience, 8, 1-18.
Vines, B.W., Nair, D., & Schlaug, G. (2008). Modulating activity in the motor cortex affects performance for the two hands differently depending upon which hemisphere is stimulated. European Journal of Neuroscience, 28, 1667–1673.
Waters-Metenier, S., Husain, M., Wiestler, T., & Diedrichsen, J. (2014). Bihemispheric transcranial direct current stimulation enhances effector-independent representations of motor synergy and sequence learning. The Journal of Neuroscience, 34, 1037–1050.
7

Proceedings of the 10th International Conference of Students of Systematic Musicology (SysMus17), London, UK, September 13-15, 2017. Peter M. C. Harrison (Ed.).
Cognition of South Indian Percussion
Jay Appaji*1, Zachary Wallmark*2, Jay Dowling#3
*Southern Methodist University, Dallas, Texas USA; #University of Texas at Dallas, Richardson, Texas, USA
[email protected], [email protected], [email protected]
ABSTRACT
Background The mridangam is a double-headed pitched drum
prominently featured in South Indian (Carnatic) music. Carnatic music utilizes a series of looped percussive patterns that often feature rhythmic accents between pulses. While previous studies in rhythmic memory have dealt with Western rhythms (Iversen, Repp, & Patel, 2009), few have focused on Indian rhythms (Srinivasamurthy, Tronel, Subramanian, & Chordia, 2012) . Studies on the cognitive representation of rhythm suggest that listeners’ attention is directed toward the downbeat of a rhythm, then organizes other parts of the rhythm in reference to the downbeat in a “hierarchical” sequence (Fitch, 2013).
Aims We aim to explore what inherent qualities of Carnatic
rhythm aid and impede rhythmic memory, understand how ordering affects rhythmic recognition accuracy, and determine to what extend memory for isolated Carnatic rhythms is modulated by delay between stimuli.
Method In Experiment 1, we evaluated naïve participants’ (N = 36)
memory for 27 natural and mechanical (computer generated) versions of mridangam rhythmic patterns, with a “target” rhythm memorized in contrast to two lure patterns, designated as “similar” and “different”, separated by three delay times (3s, 6s, and 12s).
In Experiment 2 (N = 24), listeners heard a series of 20 rhythmic trials. Each trial began with a “target” rhythm, followed by a pool of three answer choices comprised of a random order of the “target,” a similar lure, and a different lure. Participants were instructed to determine which of the three was the “target,” and to rate their confidence in their answer using a 6-point Likert scale.
Results Results of Experiment 1 suggested that there was not a
significant difference in listeners’ ability to distinguish between natural and mechanical versions, F(1, 35) = .52, ns. Difference between “similar” and “different” lures was significant, F(1, 35) = 16.85, p < .001; delay time between samples also appeared to have an effect on identification, F(2, 70) = 5.06, p < .01.
Mean accuracy rate in Exp. 2 was high (91%), though accuracy decreased with ordering of the target (i.e., position 3 targets had lower accuracy than position 1). We used general estimations equation modeling (GEE) and receiver operating
characteristic (ROC) to test the significance of position, trial type, and confidence level on recognition accuracy. Conclusion
From Experiment 1, we can conclude that trial type was significant in affecting listeners’ ability to identify rhythmic samples. Delay time between samples also played a role in the identification task. The results of Experiment 2 indicate that recognition accuracy was highest when the correct answer was in position one, while the lowest accuracy rate occurred when the correct answer was in position three. We conclude with a discussion of implications of our findings for our understanding of culturally unfamiliar rhythms.
Keywords rhythm; cross-cultural music cognition; South Indian music;
n-back; memory
REFERENCES Iversen, J. R., Repp, B. H., & Patel, A. D. (2009). Top-Down
Control of Rhythm Perception Modulates Early Auditory Responses. Annals of the New York Academy of Sciences, 1169(1), 58–73.
Fitch, W. T. (2013). Rhythmic cognition in humans and animals: distinguishing meter and pulse perception. Frontiers in Systems Neuroscience, 7.
Srinivasamurthy, A., Subramanian, S., Tronel, G., & Chordia, P. (2012). A beat tracking approach to complete description of rhythm in Indian classical music. In Proc. of the 2nd CompMusic Workshop (pp. 72–78).
8
Proceedings of the 10th International Conference of Students of Systematic Musicology (SysMus17), London, UK, September 13-15, 2017. Peter M. C. Harrison (Ed.).
Musical Intervals in Baby Sounds
Lotte Armbrüster*1, Werner Mende#, Hanna Ehlert*, Gesine Wermke†, Kathleen Wermke*
*Center for Pre-Speech Development & Developmental Disorders, University Hospital, Würzburg, Germany
#Berlin-Brandenburg Academy of Sciences & Humanities, Berlin, Germany †Institute of Music Research, University Würzburg, Germany
ABSTRACT
Background Perception and memorizing of salient, regularly occurring
sounds start in the womb at about the third trimester of gestation. Fetuses are particularly sensitive to ‘musical’ elements of their mother’s voice and speech sounds, based on prosodic elements such as melody, rhythm, tempo and pitch. The auditory stimulation experienced in the womb was found to imprint and shape postnatal auditory development and musical preferences (Ullal-Gupta, 2013). Young babies are able to communicate by vocal sounds long before vocabulary and grammar is established, and they do so by making extensive use of melody (f0 contour) (Wermke & Mende, 2011). They are also well-equipped with surprising musical perceptual capabilities (Trehub, 2003). In two previous pilot studies, we identified and analyzed f0 ratios in infant cry melody and observed a stable pattern of several musical intervals (Wermke & Mende, 2009; Dobnig et al., 2017).
Aims The aim of this study was to quantitatively characterize
musical interval-like substructures of the melody (f0 contour) of pre-speech sounds of babies during their first three months of life.
Method Spontaneously uttered sounds of 12 healthy German babies
were recorded in weekly intervals over the first three months. Frequency spectrograms and melodies of 6,059 vocalizations were analyzed by using the open-source software Praat 6.0.26. After low-pass filtering (40 Hz Gaussian Filter), intervals were identified and quantitatively analysed. The applied interval model was defined as plateau-transition-plateau structure in the melody, with each plateau lasting ≥ 50 ms, containing a f0 variation smaller than ± a quarter tone (according to perceptual entities) and creating a relative reference tone. Here, each measured interval was auditory re-evaluated by the first author using a special Praat routine. Results are reported for (1) frequency of occurrence of melodies containing intervals and (2) distribution of all identified frequency ratios displayed in a cent scale (organized around musical intervals from the prime to the octave and above).
Results Over the three months, a number of 3,587 (59%)
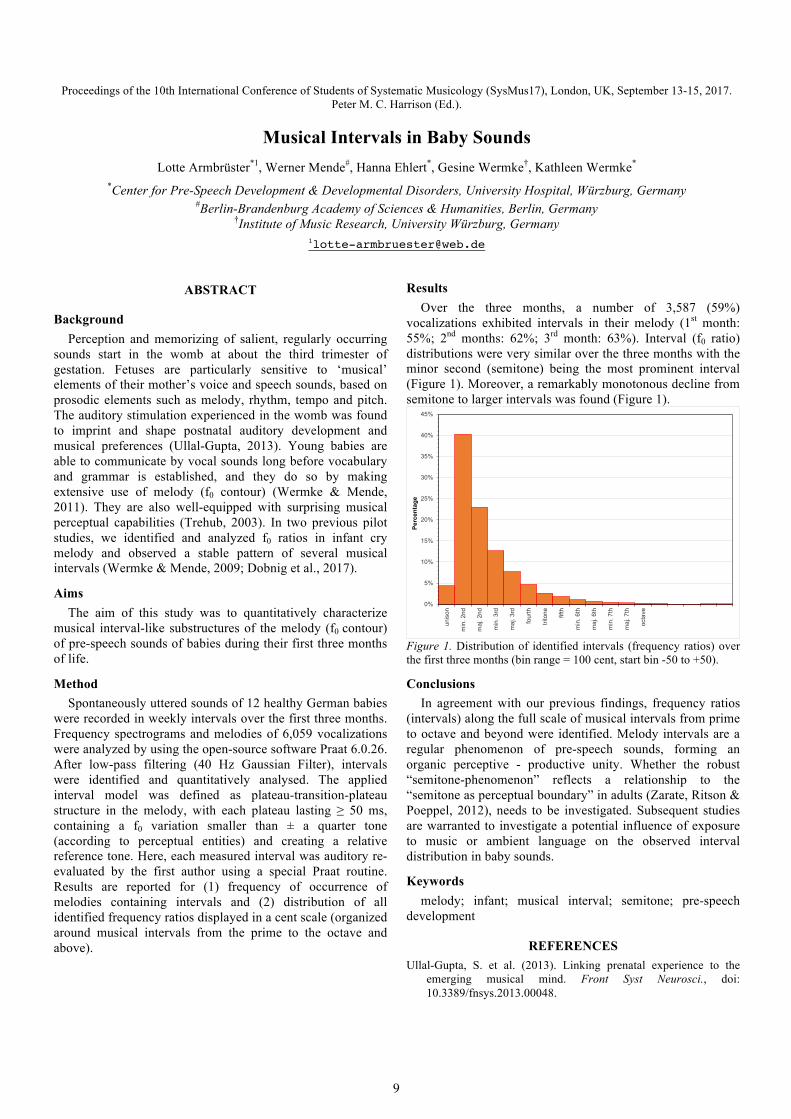
vocalizations exhibited intervals in their melody (1st month: 55%; 2nd months: 62%; 3rd month: 63%). Interval (f0 ratio) distributions were very similar over the three months with the minor second (semitone) being the most prominent interval (Figure 1). Moreover, a remarkably monotonous decline from semitone to larger intervals was found (Figure 1).
0%
5%
10%
15%
20%
25%
30%
35%
40%
45%
unis
on
min
. 2nd
maj
. 2nd
min
. 3rd
maj
. 3rd
four
th
trito
ne fifth
min
. 6th
maj
. 6th
min
. 7th
maj
. 7th
octa
ve
Percentage
Figure 1. Distribution of identified intervals (frequency ratios) over the first three months (bin range = 100 cent, start bin -50 to +50).
Conclusions In agreement with our previous findings, frequency ratios
(intervals) along the full scale of musical intervals from prime to octave and beyond were identified. Melody intervals are a regular phenomenon of pre-speech sounds, forming an organic perceptive - productive unity. Whether the robust “semitone-phenomenon” reflects a relationship to the “semitone as perceptual boundary” in adults (Zarate, Ritson & Poeppel, 2012), needs to be investigated. Subsequent studies are warranted to investigate a potential influence of exposure to music or ambient language on the observed interval distribution in baby sounds.
Keywords melody; infant; musical interval; semitone; pre-speech
development
REFERENCES
Ullal-Gupta, S. et al. (2013). Linking prenatal experience to the emerging musical mind. Front Syst Neurosci., doi: 10.3389/fnsys.2013.00048.
9

Wermke, M.; Mende, W. (2011). From Emotion to Notion: The Importance of Melody. The Oxford Handbook of Social Neuroscience, pp. 624–648.
Trehub SE. (2003). The developmental origins of musicality. Nat Neurosci., Review 6, 669–673.
Wermke, K; Mende, W. (2009). Musical elements in human infants’ cries. In the beginning is the melody. Musicae Scientiae 13 (2 Suppl), 152-175.
Dobnig, D. et al. (2017). It all starts with music – Musical intervals in neonatal crying. Paper presented at the 25th Simposio Internacional de Comunication Social, Santiago de Cuba, Cuba.
Zarate, J.M., Ritson, C. R., & Poeppel, D. (2012). Pitch-interval discrimination and musical expertise: Is the semitone a perceptual boundary? J Acoust Soc Am., 132(2), 984–993.
10

Proceedings of the 10th International Conference of Students of Systematic Musicology (SysMus17), London, UK, September 13-15, 2017. Peter M. C. Harrison (Ed.).
Chance Music is Best Not Left to Chance Joshua S. Bamford
Finnish Centre for Interdisciplinary Music Research, University of Jyväskylä, Finland
ABSTRACT
Background Understanding random events is an ability which eludes
humanity. Truly random events may be misinterpreted as conforming to a pattern, while events with a pattern may seem to have none. In most cases, people will assume that a “random” distribution should be more evenly distributed than it really is (Ladouceur et al., 1996). Meanwhile, highly complex patterns may be perceived as random if they’re not understood (Falk & Konold, 1997). It is important to distinguish between random processes and seemingly random outcomes, however these are easily confused in perception. This has been demonstrated across many domains, but never when perceiving stimuli through sound, even though chance and serial composers of the mid-20th Century provided perfect study material for us.
Aims This study aimed to test perception of randomness through
sound, using the principles of chance and serial composition. It was hypothesised that participants would be unable to distinguish 12-tone rows from random sequences of 12 notes, thus scoring no better than chance on a forced-choice task.
Method A battery of 16 chance composed melodies and 16 12-tone
rows were composed, and presented to participants in a forced-choice paradigm. Chance melodies were composed using a random number generator in MATLAB, which picked 12 numbers as independent events, from a possible range of 1 to 12, corresponding to the 12 notes of the chromatic scale. Tone rows were composed by the experimenter, using principles of 12-tone music in which no note may be repeated. All notes of both melodies were of equal length at a constant tempo with no rhythmic variation.
Participants were presented with one chance melody and one 12-tone row in random order. They were then asked which of the two pieces sounded more “random”. This was repeated over 16 trials, and participants were given a point every time they correctly identified the chance melody as being the more “random” of the two stimuli.
Results Testing is ongoing, but the initial sample (N = 16) already
suggests significant results on a Wilcoxon test, z = 2.82, p < .01, with nearly all participants performing worse than chance and worse than expected in the hypothesis (Mdn = 6, compared to expected 8 correct out of possible 16).
Conclusions It was expected that participants would be unable to
distinguish 12-tone from chance melodies as neither would form any recognisable pattern. If this were true, participants should have performed at chance level. This turned out not to be the case as participants seemed to consistently misidentify 12-tone serialism as being more “random”.
This is possibly because no notes are repeated in a 12-tone row, thus achieving a perfectly even distribution, while chance music often results in repetitions or clusters of notes. This is similar in nature to the Birthday Problem, in which the probability of two people at a party sharing a birthday is remarkably higher than expected (Ball, 1960:45). Using the Birthday Problem equation, we can calculate the probability of having a repeated note in a random sequence of 12 notes drawn from the Chromatic scale. It is, in fact, highly probable that a random melody of 12 notes would contain at least one repetition; there is a probability 99.9% that at least one note will be repeated. Human ears may use the lack of tonal centre created through an even distribution of notes as a heuristic for gauging randomness, demonstrating an intuitive misunderstanding of probability.
These findings are consistent with the findings of Ladouceur and colleagues (1996), who suggest that an even distribution is often perceived as being more random. This expands upon our understanding of general principles in the perception of random events across sensory modalities. It also highlights the importance of establishing a tonal centre for the perception of structure in music. Although this study exclusively used 12-tone rows out of the context of a larger musical structure; it supports previous research that suggests the tone row structures in dodecaphonic music are imperceptible to listeners (Raffman, 2003). Thus, it is suggested that human perception should be considered when analysing chance and serial works, or assessing their historical success.
Keywords chance music; serial music; music perception; probability
REFERENCES
Ball, W. W. (1960). Other questions on probability, in Mathematical recreations and essays. Macmillan: New York.
Falk, R. and Konold, C. (1997). Making sense of randomness: implicit encoding as a basis for judgment. Psychological Review, 104(2), 301-318.
Raffman, D. (2003). Is twelve-tone music artistically defective? Midwest Studies in Philosophy, 27(1), 69-87.
Ladouceur, R., Paquet, C. and Dube, D. (1996). Erroneous Perceptions in generating sequences of random events. Journal of Applied Social Psychology, 26(24), 2157-2166.
11

Proceedings of the 10th International Conference of Students of Systematic Musicology (SysMus17), London, UK, September 13-15, 2017. Peter M. C. Harrison (Ed.).
A Survey of Musically-Induced Chills: Emotional Characteristics and ‘Chills Moments’ in Music
Scott Bannister
Department of Music, Durham University, United Kingdom [email protected]
ABSTRACT
Background Musically-induced chills have received some attention in
music and emotion research (Grewe et al., 2007; Panksepp, 1995); however, little is known about the emotional characteristics of chills, although theories have linked the experience to social separation (Panksepp and Bernatzky, 2002), and the mixed emotional concept of ‘being moved’ (Wassiliwizky, Wagner, and Jacobsen, 2015). In addition, the links between chills and various musical features or moments are still unclear.
Aims This study aims to develop a preliminary understanding of
the emotional characteristics of chills, and to collect a variety of musical excerpts and features that elicit chills in different listeners.
Method A survey was administered to participants (N = 375),
collecting open ended responses regarding an experience of musical chills (subjective feelings, musical features, situation). Additionally, two extra chills pieces were requested to be described by participants (sound, notable features, specific chills moments).
Results The open-ended responses were analyzed through the
process of thematic analysis, coding raw data and developing broader themes. Results suggest that the experience of chills is pleasurable but often involves mixed emotions of happiness and sadness; accordingly, participants often used language such as ‘being moved by the music’ or ‘being touched’, terms previously associated with mixed emotional states (Kuehnast et al., 2014). Responses often contained references to tears or crying, alongside reports of gooseflesh, tingling sensations and feelings in the chest, suggesting that chills reflect strong emotional experiences. In terms of specific chills moments across musical excerpts, five main themes emerged, namely ‘entrances of instruments’, ‘peaks and build up’, ‘social concepts’, ‘transitions and change’, and ‘voice and words’. These themes represent aspects of music such as dynamic and structural changes, the effects of the human singing voice, and more abstract social concepts, such as the presence of many voices, or the musical unity of a large orchestra.
Conclusions The data indicate that chills are pleasurable, but often reflect
mixed emotions, possibly like being moved (Wassiliwizky,
Wagner, and Jacobsen, 2015). Additionally, new evidence regarding specific chills moments in music suggest that although dynamic and musical change may elicit chills, there is a need to consider the role of perception and experience of social relationships with regards to musical chills; this could be within a piece of music (perception of unity and togetherness), or between the music and listener (comfort and reducing loneliness; empathizing with the human voice). Further empirical work is required to test existing theories of musical chills. The current study provides one of the first investigations into the various emotional qualities of chills, beyond feelings of peak pleasure. Additionally, the study presents the first extensive dataset regarding musical excerpts that elicit chills, and specific moments in the pieces that are linked to the experience.
Keywords music; emotion, chills; induction mechanisms; open-ended
responses
REFERENCES Grewe, O., Nagel, F., Kopiez, R., and Altenmüller, E. (2007).
Listening to music as a re-creative process: Physiological, psychological, and psychoacoustical correlates of chills and strong emotions. Music Perception, 24(3), 297-314.
Juslin, P. N. (2013). From everyday emotions to aesthetic emotions: Towards a unified theory of musical emotions. Physics of Life Reviews, 10(3), 235-266.
Kuehnast, M., Wagner, V., Wassiliwizky, E., Jacobsen, T., Menninghaus, W. (2014). Being moved: Linguistic representation and conceptual structure. Frontiers in Psychology, 5, 1242.
Panksepp, J. (1995). The emotional sources of “chills” induced by music. Music Perception: An Interdisciplinary Journal, 13(2), 171-207.
Panksepp, J., and Bernatzky, G. (2002). Emotional sounds and the brain: The neuro-affective foundations of musical appreciation. Behavioural Processes, 60(2), 133-155.
Wassiliwizky, E., Wagner, V., and Jacobsen, T. (2015). Art-elicited chills indicate states of being moved. Psychology of Aesthetics, Creativity, and the Arts, 9(4), 405-416.
12

Proceedings of the 10th International Conference of Students of Systematic Musicology (SysMus17), London, UK, September 13-15, 2017. Peter M. C. Harrison (Ed.).
Neuroaesthetics and Music: Difficulties of a Young Field of Research
Stefanie Bräuml
University of Vienna [email protected]
ABSTRACT
Background Neuroaesthetics is a young and controversially discussed
field of research. In the beginnings of the 21st century, British neurobiologist Semir Zeki brought the term “neuroaesthetics” as a subdiscipline between humanities and natural science in the discourse. Neuroaesthetics tries to investigate aesthetic problems empirically. Depending on the self-conception of the discipline, the methodological spectrum moves in a wider or narrower framework and bases only on magnetic resonance imaging or includes additionally psychological as well as evolutionary biological research methods.
Aims In my poster presentation, I would like to delineate a series
of difficulties of neuroaesthetics in music research: (1) challenges concerning the identity and aims of the field of research; (2) methodological difficulties which require substantial improvement; (3) external and internal coherence; (4) criticism on reductionism; (5) demands on a modified purpose; (6) integration of the physical dimension of aesthetic experience; call for an observance of the existence of mirror cells; (7) questions on the relevance of neuroaesthetics as an autonomous field of research; (8) criticism on the dominance of neuroimaging; and (9) ecological validity of neuroaesthetic studies.
Method Literature review.
Results (1) There’s still no agreement concerning the key fields,
research questions and objects of neuroaesthetics. The question if neuroaesthetics should focus only on aesthetic experiences or not is still not answered sufficiently. (2) We should gain a deeper understanding of the possibilities and limits of neuroimaging methods in neuroaesthetic research projects (there’s a strong tendency to over-interpretate data gained from functional magnetic resonance imaging surveys). (3) Neuroaesthetics is a genuine interdisciplinary field of research and needs an embedment in all disciplines taking part. Conclusion
As a young and promising field of research, neuroaesthetics has to face its difficulties and has to find appropriate solutions to them in order to stabilize and strengthen its potential as a discipline anchored between humanities and natural sciences.
Keywords neuroaesthetics and Music; methodology of neuroaesthetics;
theory of Neuroaesthetics; criticism of neuroaesthetics
REFERENCES Zeki, S. (2001). Artistic Creativity and the Brain. Science, 293, 51-52.
13

Proceedings of the 10th International Conference of Students of Systematic Musicology (SysMus17), London, UK, September 13-15, 2017. Peter M. C. Harrison (Ed.).
‘Feeling the Gap’: Does Interoceptive Ability Mediate the Disparity Between
Physiological and Subjective Emotional Response to Music Listening? Sarah Campbell1, Paul Sowden
School of Psychology, University of Surrey, Guildford, UK
ABSTRACT
Background Emotion involves an interplay between bodily reactions
(objective physiology) and cognitive processing (subjective perception).The circumplex model of emotion (Russell, 1980) characterizes emotions into four quadrants of a 2D emotion space, comprised of a valence dimension and an arousal dimension.
In music-evoked emotion research, a disparity between physiological and subjective responses has been noted. In the present study we investigate the hypothesis that the size of this disparity is a function of an individual’s ability to perceive internal bodily signals (interoceptive ability; Craig, 2002). Specifically, we expect that individuals with high awareness of their internal bodily sensations will display a subjective experience of emotion that is more strongly predicted by their physiological response.
In addition, we hypothesized that the disparity will vary as a function of emotion quadrant. This is because high arousal emotions provide a stronger physiological signal and therefore require less interoceptive awareness. Consequently, the discrepancy will be less dependent on interoception for high arousal than for low arousal emotions where the physiological signal is weaker.
AimsThe current study aimed to ascertain whether disparity
between physiological and subjective responses of music-evoked emotion results from individual differences in interoceptive ability. A further aim was to examine the relationship between subjective and objective music-evoked emotional responses in each of the four emotion quadrants of a 2D emotion space.
Method Seventy-seven participants listened to four self-selected
pieces of emotional music, one for each quadrant of the emotion space: one happy, one sad, one tender, and one tense. During music listening, participants continuously reported their subjective emotional response, then completed a static emotion measure. Physiological measures shown to differentiate arousal and valence were recorded, namely facial EMG, EDA and ECG. Participants then completed subjective and objective measures of interoceptive ability.
Results Moderation analyses showed subjective musical emotion
was characterized by differentiated physiological profiles
dependent upon emotion quadrant. The disparity between objective and subjective music-evoked emotional response was moderated by interoceptive ability.
Conclusions Different types of subjective music-evoked emotion are
characterized by different physiological profiles and an individual’s ability to subjectively experience and report their emotional state is moderated by their interoceptive ability. Thus, we argue that peoples’ emotional experience of music is related to the integration between their body awareness and subjective processing. Training interoceptive ability may therefore be a useful approach to maximize the effectiveness of using music as an emotion regulation tool.
Keywords music; emotion; psychophysiology.
REFERENCES Russell, J.A.. (1980). A Circumplex Model of Affect. Journal of
Personality and Social Psychology, 39, 1161-1178. Craig, A.D.. (2002). How do you feel? Interoception: the sense of the
physiological condition of the body. Nature Reviews Neuroscience, 3, 655-666.
14

Proceedings of the 10th International Conference of Students of Systematic Musicology (SysMus17), London, UK, September 13-15, 2017. Peter M. C. Harrison (Ed.).
Towards a New Model for Effective Musical Teaching in Performance-Oriented
Settings Francisco Cardoso
Centro de Estudos de Sociologia e Estética Musical, Escola Superior de Música de Lisboa, Portugal
ABSTRACT There is a discernable growing concern about teaching effectiveness in music education. Current effective teaching models fail to fully describe the phenomenon of effective teaching, and fail to fully serve teacher education. The goal was to find a model that could: (1) help instrumental teachers to measure their own levels of teaching efficacy within a short period of time and in a specific setting, (2) respond to specific needs teachers have, helping them managing and improve their levels of teaching efficacy during their daily practice, and (3) allow teachers to improve themselves through time, even many years after finishing their degree. A model that had the potential to fulfill such goals consisted of a self-analysis tool with 19 effective teaching descriptors to be used along with video-recorded lessons. In this study 45 different instrumental teachers analyzed a total of 180 different instrumental lessons. Results suggest that 98% of teachers were to use this tool to measure their teaching effectiveness, being able to identify areas of their teaching that needed improvement. Results suggest that this model allows teachers to identify clearly what aspects of effective teaching are missing in their practice, and allows them to reinforce good teaching practices. These results indicate that it is possible to improve the quality of teaching in an educational setting where the main goal keeps being to raise the future generation of performers, and where the didactical options taken by teachers are still strongly influenced by tradition.
I. INTRODUCTION The growing concerns about teaching effectiveness in
music education may be explained by factors like: (1) the growing body of research in music education suggesting that the existing teaching and learning models are limited in terms of their contribution to improving pupils’ learning outcomes (Muijs, 2006). New research has also brought to light “progressive teaching strategies and styles” (Beheshti, 2009, p. 107; Zhukov, 1999, p. 6) and has defined the “so-called best [teaching] practices” (Westerlund, 2008, p. 91). (2) the fact that each year, only a small percentage of the total number of students attending instrumental lessons in specialist Music Schools and Conservatoires, become expert performers (Sloboda, 1991). Most of the schools report a large number of drop-outs among students within the first two to three years of instrumental tuition (Costa-Giomi, Flowers, & Sasaki, 2005; Mills, 2007). (3) The traditional model of instrumental teaching, one-to-one tuition, tends to be seen as “very expensive” (Bolliger & Reed, 2008, p. 1).
Research has shown that differences in the quality, depth and speed of instrumental learning are commonly attributed to teachers’ ability to convey appropriate guidance and to provide the necessary conditions for learning to occur (Duke, 2009; Hallam, 1998, 2006; Lehmann, Sloboda, & Woody,
2007; Manturzewska, 1986; Mills, 2007; Sosniak, 1990). For example, research outlines the considerable qualitative changes which occur in learning when teachers adapt their teaching to students’ individual characteristics and needs (Beheshti, 2009; Hultberg, 2002; North & Hargreaves, 2008; Sloboda, 1986); or that successful learning occurs when the teacher can provide the ‘scaffold’ for the development of skills in the early stages, and then, remove it progressively according to the student’s increasingly individual autonomy (Burwell, 2005; Hallam, 2006; Jorgensen, 2000; Lehmann et al., 2007; McPhail, 2010). Therefore, teachers’ effectiveness can be said to be at the centre of the learning process and as the main parameter influencing successful learning.
II. EFFECTIVE TEACHING MODELS Effective teaching can be, to a large extent, identified,
observed and measured (Collinson, 1999, p. 10; Gunderson, 2009, p. 16; Kohut, 1985, p. 74). Two well-known effective teaching models are the End Products Model and the Teachers Characteristics Model.
According to the first one - End Products Model - effective teaching can be identified in the form of observable end products (i.e. what students’ learn, which skills they acquire) (Muijs, 2006; Tuckman & Tuckrnan, 1995). These ‘end products’ are in themselves learning goals and vary according to the fundamentals and principles that guide the learning process. Therefore, within this model, teacher efficacy is measured according to the ability displayed in helping their students to reach the established goals (Hallam, 2006; Regelski, 2006; Ryans, 1963).
However, a detailed analysis of the two allow us to see that they fail to fully describe the phenomenon of effective teaching (Cardoso, 2012), and fail to fully serve teacher education, because they are somewhat detached from practice (Madsen, 2003). The key problems of these two models may be summarized in two main aspects: first, the time-scale used, and second, the singular perspective adopted.
Scale Issue - The identification of effective teaching and effective teachers tends to occur as the result of a generalization process. However, the scale involved in these two effective teaching models is considerable.
Perspective Issue - In addition to the adoption of a smaller measurement unit, an adequate perspective on effective teaching should pay attention to approaches other than external ones. Discussion of effective teaching has tended to adopt an almost exclusively external perspective, i.e. those that observe, describe and measure effective teaching are outside the learning process (Coles, 2009; Lehmann et al., 2007; Madsen, 2003; Mills, 2007; Mills & Smith, 2003; Reid, 2001; Wood & Wood, 1996; Zhukov, 1999).
15
Therefore, the goal was to find a model that could, ultimately, help instrumental teachers to measure their own levels of teaching efficacy within a short period of time and on a specific setting, one that could respond to certain needs teachers have (e.g. challenging learning problems, students that fail in acquire certain skills), and that allowed teachers to improve themselves through time, even many years after finishing their degree. This is especially important considering that musicians become conservatoire teachers usually "without any rigorous preparation for the work" (Kemp, 1996, p. 230).
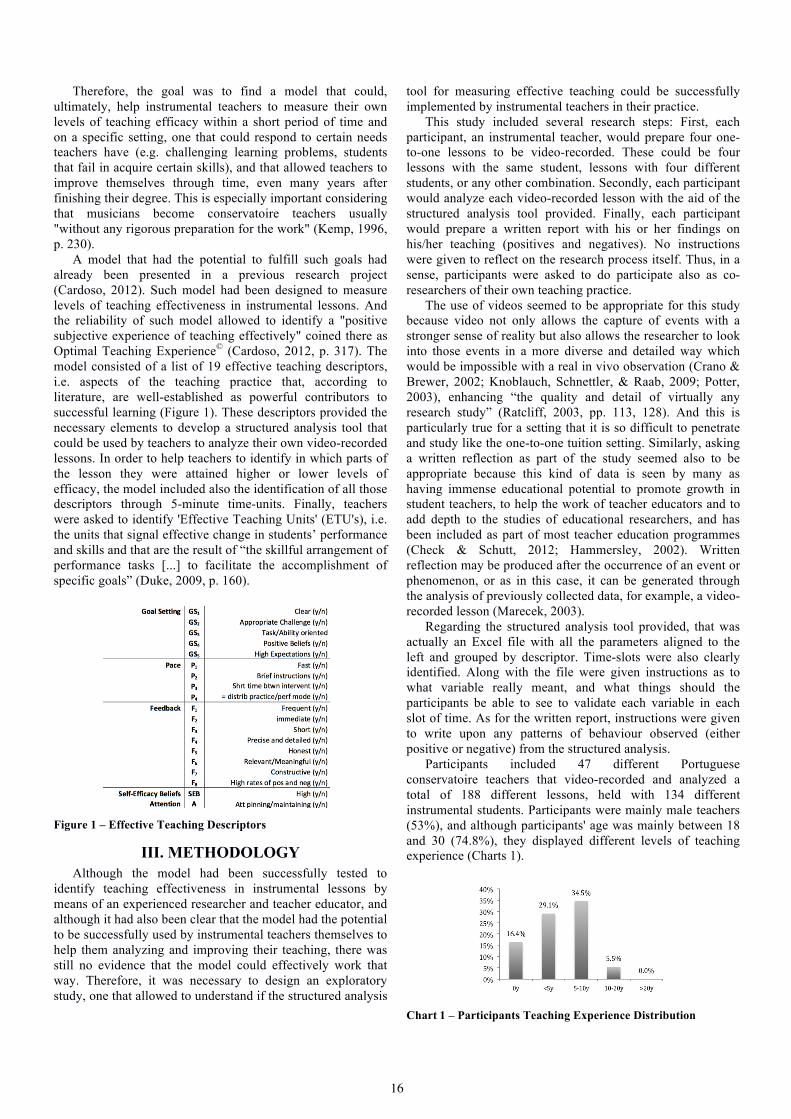
A model that had the potential to fulfill such goals had already been presented in a previous research project (Cardoso, 2012). Such model had been designed to measure levels of teaching effectiveness in instrumental lessons. And the reliability of such model allowed to identify a "positive subjective experience of teaching effectively" coined there as Optimal Teaching Experience© (Cardoso, 2012, p. 317). The model consisted of a list of 19 effective teaching descriptors, i.e. aspects of the teaching practice that, according to literature, are well-established as powerful contributors to successful learning (Figure 1). These descriptors provided the necessary elements to develop a structured analysis tool that could be used by teachers to analyze their own video-recorded lessons. In order to help teachers to identify in which parts of the lesson they were attained higher or lower levels of efficacy, the model included also the identification of all those descriptors through 5-minute time-units. Finally, teachers were asked to identify 'Effective Teaching Units' (ETU's), i.e. the units that signal effective change in students’ performance and skills and that are the result of “the skillful arrangement of performance tasks [...] to facilitate the accomplishment of specific goals” (Duke, 2009, p. 160).
Figure 1 – Effective Teaching Descriptors
III. METHODOLOGY Although the model had been successfully tested to
identify teaching effectiveness in instrumental lessons by means of an experienced researcher and teacher educator, and although it had also been clear that the model had the potential to be successfully used by instrumental teachers themselves to help them analyzing and improving their teaching, there was still no evidence that the model could effectively work that way. Therefore, it was necessary to design an exploratory study, one that allowed to understand if the structured analysis
tool for measuring effective teaching could be successfully implemented by instrumental teachers in their practice.
This study included several research steps: First, each participant, an instrumental teacher, would prepare four one-to-one lessons to be video-recorded. These could be four lessons with the same student, lessons with four different students, or any other combination. Secondly, each participant would analyze each video-recorded lesson with the aid of the structured analysis tool provided. Finally, each participant would prepare a written report with his or her findings on his/her teaching (positives and negatives). No instructions were given to reflect on the research process itself. Thus, in a sense, participants were asked to do participate also as co-researchers of their own teaching practice.
The use of videos seemed to be appropriate for this study because video not only allows the capture of events with a stronger sense of reality but also allows the researcher to look into those events in a more diverse and detailed way which would be impossible with a real in vivo observation (Crano & Brewer, 2002; Knoblauch, Schnettler, & Raab, 2009; Potter, 2003), enhancing “the quality and detail of virtually any research study” (Ratcliff, 2003, pp. 113, 128). And this is particularly true for a setting that it is so difficult to penetrate and study like the one-to-one tuition setting. Similarly, asking a written reflection as part of the study seemed also to be appropriate because this kind of data is seen by many as having immense educational potential to promote growth in student teachers, to help the work of teacher educators and to add depth to the studies of educational researchers, and has been included as part of most teacher education programmes (Check & Schutt, 2012; Hammersley, 2002). Written reflection may be produced after the occurrence of an event or phenomenon, or as in this case, it can be generated through the analysis of previously collected data, for example, a video-recorded lesson (Marecek, 2003).
Regarding the structured analysis tool provided, that was actually an Excel file with all the parameters aligned to the left and grouped by descriptor. Time-slots were also clearly identified. Along with the file were given instructions as to what variable really meant, and what things should the participants be able to see to validate each variable in each slot of time. As for the written report, instructions were given to write upon any patterns of behaviour observed (either positive or negative) from the structured analysis.
Participants included 47 different Portuguese conservatoire teachers that video-recorded and analyzed a total of 188 different lessons, held with 134 different instrumental students. Participants were mainly male teachers (53%), and although participants' age was mainly between 18 and 30 (74.8%), they displayed different levels of teaching experience (Charts 1).
Chart 1 – Participants Teaching Experience Distribution
16
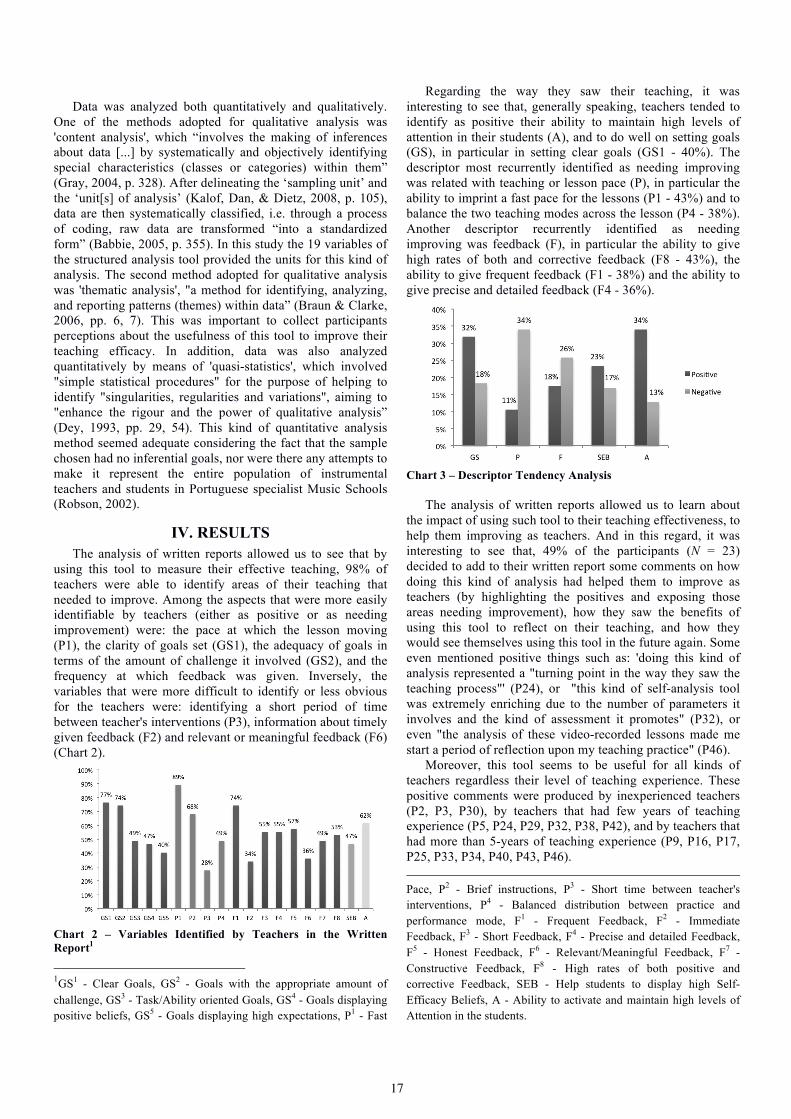
Data was analyzed both quantitatively and qualitatively.
One of the methods adopted for qualitative analysis was 'content analysis', which “involves the making of inferences about data [...] by systematically and objectively identifying special characteristics (classes or categories) within them” (Gray, 2004, p. 328). After delineating the ‘sampling unit’ and the ‘unit[s] of analysis’ (Kalof, Dan, & Dietz, 2008, p. 105), data are then systematically classified, i.e. through a process of coding, raw data are transformed “into a standardized form” (Babbie, 2005, p. 355). In this study the 19 variables of the structured analysis tool provided the units for this kind of analysis. The second method adopted for qualitative analysis was 'thematic analysis', "a method for identifying, analyzing, and reporting patterns (themes) within data” (Braun & Clarke, 2006, pp. 6, 7). This was important to collect participants perceptions about the usefulness of this tool to improve their teaching efficacy. In addition, data was also analyzed quantitatively by means of 'quasi-statistics', which involved "simple statistical procedures" for the purpose of helping to identify "singularities, regularities and variations", aiming to "enhance the rigour and the power of qualitative analysis” (Dey, 1993, pp. 29, 54). This kind of quantitative analysis method seemed adequate considering the fact that the sample chosen had no inferential goals, nor were there any attempts to make it represent the entire population of instrumental teachers and students in Portuguese specialist Music Schools (Robson, 2002).
IV. RESULTS The analysis of written reports allowed us to see that by
using this tool to measure their effective teaching, 98% of teachers were able to identify areas of their teaching that needed to improve. Among the aspects that were more easily identifiable by teachers (either as positive or as needing improvement) were: the pace at which the lesson moving (P1), the clarity of goals set (GS1), the adequacy of goals in terms of the amount of challenge it involved (GS2), and the frequency at which feedback was given. Inversely, the variables that were more difficult to identify or less obvious for the teachers were: identifying a short period of time between teacher's interventions (P3), information about timely given feedback (F2) and relevant or meaningful feedback (F6) (Chart 2).
Chart 2 – Variables Identified by Teachers in the Written Report1
1GS1 - Clear Goals, GS2 - Goals with the appropriate amount of challenge, GS3 - Task/Ability oriented Goals, GS4 - Goals displaying positive beliefs, GS5 - Goals displaying high expectations, P1 - Fast
Regarding the way they saw their teaching, it was interesting to see that, generally speaking, teachers tended to identify as positive their ability to maintain high levels of attention in their students (A), and to do well on setting goals (GS), in particular in setting clear goals (GS1 - 40%). The descriptor most recurrently identified as needing improving was related with teaching or lesson pace (P), in particular the ability to imprint a fast pace for the lessons (P1 - 43%) and to balance the two teaching modes across the lesson (P4 - 38%). Another descriptor recurrently identified as needing improving was feedback (F), in particular the ability to give high rates of both and corrective feedback (F8 - 43%), the ability to give frequent feedback (F1 - 38%) and the ability to give precise and detailed feedback (F4 - 36%).
Chart 3 – Descriptor Tendency Analysis
The analysis of written reports allowed us to learn about
the impact of using such tool to their teaching effectiveness, to help them improving as teachers. And in this regard, it was interesting to see that, 49% of the participants (N = 23) decided to add to their written report some comments on how doing this kind of analysis had helped them to improve as teachers (by highlighting the positives and exposing those areas needing improvement), how they saw the benefits of using this tool to reflect on their teaching, and how they would see themselves using this tool in the future again. Some even mentioned positive things such as: 'doing this kind of analysis represented a "turning point in the way they saw the teaching process"' (P24), or "this kind of self-analysis tool was extremely enriching due to the number of parameters it involves and the kind of assessment it promotes" (P32), or even "the analysis of these video-recorded lessons made me start a period of reflection upon my teaching practice" (P46).
Moreover, this tool seems to be useful for all kinds of teachers regardless their level of teaching experience. These positive comments were produced by inexperienced teachers (P2, P3, P30), by teachers that had few years of teaching experience (P5, P24, P29, P32, P38, P42), and by teachers that had more than 5-years of teaching experience (P9, P16, P17, P25, P33, P34, P40, P43, P46). Pace, P2 - Brief instructions, P3 - Short time between teacher's interventions, P4 - Balanced distribution between practice and performance mode, F1 - Frequent Feedback, F2 - Immediate Feedback, F3 - Short Feedback, F4 - Precise and detailed Feedback, F5 - Honest Feedback, F6 - Relevant/Meaningful Feedback, F7 - Constructive Feedback, F8 - High rates of both positive and corrective Feedback, SEB - Help students to display high Self-Efficacy Beliefs, A - Ability to activate and maintain high levels of Attention in the students.
17

V. DISCUSSION Results indicate resulting benefits of using this structured
tool to identify effective teaching by teachers themselves. It not only allows teachers to identify clearly what aspects of effective teaching are missing, but allows them also to reinforce good teaching practices. Teachers were able to use the tool themselves and, more importantly, they were able to draw conclusions from what they saw.
Therefore, it can be said that this model of effective teaching that consists of identifying and measuring effective teaching descriptors through the systematic analysis of 5-minute slots in video-recorded lessons represents a powerful tool for instrumental teachers to measure their own levels of teaching efficacy within a short period of time and on a specific setting, to respond to specific pedagogical and didactical needs, and to allow teachers to improve themselves through time, even after many years of teaching experience.
In order to be able to generalize these findings and to prove this model even more useful, this study should be replicated to a larger number of conservatoire teachers. Additionally, it would be interesting to measure the level of accuracy that teachers display in the identification of effective teaching descriptors through video-analysis. Adding this extra element to the findings may result into an additional layer of perception about this model.
REFERENCES Babbie, E. (2005). The Basics of Social Research. Belmont, USA:
Thomson Wadsworth. Beheshti, S. (2009). Improving studio music teaching through
understanding learning styles. International Journal of Music Education, 27(2), 107–115. https://doi.org/10.1177/0255761409102319
Bogunović, B., Stanković, I., & Stanišić, J. (2009). Coping styles of music teachers, (Escom), 615–618.
Bolliger, T., & Reed, G. (2008). Context: One-to-one tuition. INVITE Conference. Helsinki, Finland.
Braun, V., & Clarke, V. (2006). Using thematic analysis in psychology. Qualitative Research in Psychology, 3(2), 77–101.
Burwell, K. (2005). A degree of independence: teachers’ approaches to instrumental tuition in a university college. British Journal of Music Education, 22(3), 199. https://doi.org/10.1017/S0265051705006601
Cardoso, F. (2012). Optimal Teaching Experiences: Phenomenological Route for Effective Instrumental Teaching. Institute of Education. University of London, London.
Check, J., & Schutt, R. K. (2012). Research Methods in Education. London: SAGE Publications.
Coles, A. (2009). An Investigation into Effective Instrumental Teaching and Learning. Institute of Education. University of London, London.
Collinson, V. (1999). Redefining teacher excellence. Theory Into Practice, 38(1), 4–11.
Costa-Giomi, E., Flowers, P. J., & Sasaki, W. (2005). Piano Lessons of Beginning Students Who Persist or Drop out: Teacher Behavior, Student Behavior, and Lesson Progress. Journal of Research in Music Education, 53(3), 234–247.
Crano, W. D., & Brewer, M. B. (2002). Principles and Methods of Social Research. Mahwah, New Jersey: Lawrence Erlbaum Associates.
Dey, I. (1993). Qualitative data analysis: A user-friendly guide for social scientists. London: Routledge. Retrieved from http://scholar.google.com/scholar?hl=en&btnG=Search&q=intitle:Qualitative+data+analysis:+A+User-
Friendly+Guide+for+Social+Scientists#0 Duke, R. A. (2009). Intelligent Music Teaching. Austin: Learning
and Behavior Resources. Gray, D. E. (2004). Doing Research in the Real World. London:
SAGE Publications. Gunderson, J. (2009). Flow and Effective Teaching: A Study.
Saarbrüchen, Germany: VDM Verlag Dr. Müller. Haddon, E. (2009). Instrumental and vocal teaching: how do music
students learn to teach? British Journal of Music Education, 26(1), 57–70.
Hallam, S. (1998). Instrumental Teaching: A practical Guide to Better Teaching and Learning. Oxford: Heinemann International.
Hallam, S. (2006). Music Psychology in Education. London: Institute of Education - University of London.
Hammersley, M. (2002). Action Research: A Contradiction in Terms? Annual Conference of the British Educational Research Association. University of Exeter, England: British Educational Research Association.
Hultberg, C. (2002). Approaches to Music Notation: the printed score as a mediator of meaning in Western tonal tradition. Music Education Research, 4(2), 185–197.
Jorgensen, H. (2000). Student learning in higher instrumental education: who is responsible? British Journal of Music Education, 17(1), 67–77.
Kalof, L., Dan, A., & Dietz, T. (2008). Essentials of Social Research. Maidenhead, Berkshire: Open University Press.
Kemp, A. E. (1996). The Musical Temperament - Psychology and Personality of Musicians. New York: Oxford University Press.
Knoblauch, H., Schnettler, B., & Raab, J. (2009). Video-Analysis: Methodological Aspects of Interpretive Audiovisual Analysis in Social Research. In H. Knoblauch, B. Schnettler, J. Raab, & H.-G. Soeffner (Eds.), Video Analysis: Methodology and Methods: Qualitative Audiovisual Data Analysis in Sociology. New York: Peter Lang GmbH.
Kohut, D. L. (1985). Musical Performance: Learning Theory and Pedagogy. New Jersey: Prentice-Hall.
Lehmann, A. C., Sloboda, J. A., & Woody, R. H. (2007). Psychology for Musicians: Understanding and Acquiring the Skills. New York: Oxford University Press.
Madsen, C. K. (2003). The magic of motivation: practical implications from research. American Music Teacher, 7.
Manturzewska, M. (1986). Musical talent in the light of biographical research. In Musikalische Begabung finden und förden. Munchen: Bosse Verlag.
Marecek, J. (2003). Dancing Through Minefields: Toward a Qualitative Stance in Psychology. In P. M. Camic, J. E. Rhodes, & L. Yardley (Eds.), Qualitative Research in Psychology: Expanding Perspectives in Methodology and Design. Washington: American Psychological Association.
McPhail, G. J. (2010). Crossing boundaries: sharing concepts of music teaching from classroom to studio. Music Education Research, 12(1), 33–45. https://doi.org/10.1080/14613800903568296
Mills, J. (2007). Instrumental Teaching. Oxford: Oxford University Press.
Mills, J., & Smith, J. (2003). Teachers’ beliefs about effective instrumental teaching in schools and higher education. British Journal of Music Education, 20(1), 5–27. https://doi.org/10.1017/S0265051702005260
Muijs, D. (2006). Measuring teacher effectiveness: Some methodological reflections. Educational Research and Evaluation, 12(1), 53–74.
North, A., & Hargreaves, D. (2008). The Social and Applied Psychology of Music. Oxford: Oxford University Press.
Potter, J. (2003). Discourse Analysis and Discursive Psychology. In P. M. Camic, J. E. Rhodes, & L. Yardley (Eds.), Qualitative Research in Psychology: Expanding Perspectives in Methodology and Design. Washington: American Psychological
18

Association. Ratcliff, D. (2003). Video Methods in Qualitative Research. In P. M.
Camic, J. E. Rhodes, & L. Yardley (Eds.), Qualitative Research in Psychology: Expanding Perspectives in Methodology and Design. Washington: American Psychological Association.
Regelski, T. A. (2006). “Music appreciation” as praxis. Music Education Research, 8(2), 281–310.
Reid, A. (2001). Variation in the Ways that Instrumental and Vocal Students Experience Learning Music. Music Education Research, 3(1), 25–40.
Robson, C. (2002). Real World Research. New York: Blackwell Publishing.
Ryans, D. G. (1963). Teacher Behavior Theory and Research: Implications for Teacher Education. Journal of Teacher Education, 14(3), 274–293. https://doi.org/10.1177/002248716301400308
Sloboda, J. A. (1986). The Musical Mind: The Cognitive Psychology of Music. New York: Oxford University Press.
Sloboda, J. A. (1991). Musical Expertise. In K. A. Ericsson & J. Smith (Eds.), Toward a General Theory of Expertise: Prospects and Limits. New York: Cambridge University Press.
Sosniak, L. A. (1990). The tortoise, the hare, and the development of talent. In M. J. A. Howe (Ed.), Encouraging the development of exceptional abilities and talents (pp. 149–164). Leicester: British Psychological Society.
Tuckman, B. W., & Tuckrnan, B. W. (1995). Assessing Effective Teaching, 70(2), 127–138.
Westerlund, H. (2008). Justifying Music Education: A View From Here-and-Now Value Experience. Philosophy of Music Education Review, 16(1), 79–95.
Wood, D., & Wood, H. (1996). Tutoring and Learning. Oxford Review of Education, 22(1), 5–16.
Zhukov, K. (1999). Problems of Research into Instrumental Music Teaching. (N. Jeanneret & K. Marsh, Eds.), Opening the Umbrella; an Encompassing View of Music Education. University of Sydney, NSW, Australia: Australian Society for Music Education.
19

Proceedings of the 10th International Conference of Students of Systematic Musicology (SysMus17), London, UK, September 13-15, 2017. Peter M. C. Harrison (Ed.).
Spanish Version of the Kenny-Music Performance Anxiety Inventory (K-MPAI): Factorial Structure and First Statistical Analyses of a Peruvian Sample
Álvaro M. Chang-Arana
University of Jyväskylä, Finland [email protected], [email protected]
ABSTRACT This study estimated validity evidence based on internal structure, and reliability evidence for scores derived from the intended uses of the Spanish Kenny-Music Performance Anxiety Inventory (K-MPAI). It also provided the first statistical analyses of a Peruvian sample of 455 music students (mean-age = 21.19, SD = 3.13). A high-order exploratory factor analysis with Schmid-Leiman solution was performed on the K-MPAI items. One high-order factor (ordinal alpha α = .97) and two first order factors (ordinal alpha α = .93; α = .92) were obtained, explaining 58.65% of shared variance. A significant effect was found for gender differences, but not for musical institutions or genre. A high-order factor called “negative affectivity in relation to music performance anxiety” and two first-order factors labelled “music performance anxiety” and “depressive components” were proposed. Gender-related score differences for MPA and the lack of significant differences in MPA scores between musical genre or musical institution were partially consistent with previous literature.
I. INTRODUCTION According to Kenny (2011), music performance anxiety
(MPA) is characterized by an apprehensive and persistent anxiety towards musical performance, especially in situations where one is being scrutinized by others and where there is a fear of failing (Kenny, 2011). It originates in the confluence of “underlying biological and/or psychological vulnerabilities and/or specific anxiety-conditioning experience” (p. 61). MPA can be experienced by musicians at any point in their professional life, and it is partially independent of their age, accomplishment level, amount of practice, etc. (Chang-Arana, 2016; Kenny, 2011; Ortiz, 2011a, 2011b; Yoshie, Kudo, & Ohtsuki, 2008). However, although widely experienced by musicians (Fishbein & Middlestadt, 1988), adequate levels of MPA can result in a facilitated performance, caused by an increase in concentration and attention (Martínez & Paterna, 2010; Papageorgi, Creech, & Welch, 2011).
Nevertheless, increased levels of MPA which surpass the individuals’ adaptive coping levels can have potentially detrimental effects on the professional life and health of musicians. For instance, threats include drugs consumption (legal, illegal and non-prescribed), impaired performances, and even abandonment of the profession (Kenny, 2011; Ortiz, 2011a; Taylor & Wasley, 2004; West, 2004). Recently, Peru has experienced an increase in higher music education programs and youth professional orchestras, raising the chances for people to become musicians and experience MPA. Nevertheless, its systematic study was until recently in its infancy in Peru due to a lack of solid psychological measurement tools. Therefore, one of the main priorities was to explore the underlying structure of the Kenny Music Performance Anxiety Inventory (K-MPAI, Kenny, 2009) for
two reasons: to identify the specific behavior of MPA in a Peruvian sample; and to assess whether the theorized structure by Kenny (2009; 2011) resembled the Peruvian sample.
Chang-Arana (2015a, 2015b) adapted the K-MPAI to the Peruvian context and estimated its psychometric properties in a large sample of tertiary music students from three major music institutions. Later, the same author (Chang-Arana, 2016) reported the first statistical analysis of the Peruvian sample. Nevertheless, the results of those research experiences are partially unpublished and available only in Spanish, raising the need to communicate these findings to wider audiences. Consequently, this paper is based upon sections from previous Chang-Arana’s works (2015a, 2015b, 2016).
II. AIMS Estimate validity evidence based on internal structure and
reliability evidences for scores derived from the intended uses of the Spanish K-MPAI (Chang-Arana, 2015b; Kenny, 2009).
Provide the first statistical analyses of a Peruvian sample (Chang-Arana, 2016).
III. METHOD After translating the K-MPAI to Spanish through a back-
translation process (Brislin, 1986), the author of the inventory recognized it as the official Spanish version (D. T. Kenny, personal communication, October 16, 2013). Through a convenience sample, 455 tertiary Peruvian music students (mean-age = 21.19, SD = 3.13) were group-surveyed with the Spanish version of the K-MPAI. Consent forms and response instructions were read aloud, clarifying any possible doubt from participants.
A high-order exploratory factor analysis (HOEFA) with Schmid-Leiman-solution (SLS, Schmid & Leiman, 1957) was performed on the scored items of 455 tertiary Peruvian music students from three music faculties. Reliability was estimated through ordinal alpha, due to the polychoric nature (i.e. Likert scale) of the items (Bonanomi, Ruscone, & Osmetti, 2013; Gadermann, Guhn, & Zumbo, 2012; Zumbo, Gadermann, & Zeisser, 2007).
Differences in MPA scores for gender, musical genres and musical institutions were tested with t-test and one-way-ANOVA, respectively.
HOEFA and reliability values were calculated using Factor 9.3.1 (Lorenzo-Seva & Ferrando, 2015). Additional data analyses were calculated in SPSS 21. Effect sizes were interpreted according to Ellis (2010) and statistical power was interpreted according to Cohen (1992).
20

IV. RESULTS A. High-Order Exploratory Factor Analysis
The extraction method selected for the HOEFA was Minimum Rank Factor Analysis (MRFA). After this step, an oblique promin rotation was selected given the theoretical dependence of first order factors towards the high order factor. When deciding about what kind of correlation matrix to factorize, a polychoric correlation matrix was chosen since a Likert scale (polychoric scale) was used to collect the answers from ordinal variables (Burga, 2006). In order to ease the interpretation of the factorial matrix, an orthogonal correction was performed through SLS, thus allowing an easier interpretation of factorial loadings from every item towards the first and second order factors. Minimum Average Partial (MAP) method was selected to determine the amount of factors to retain. Finally, items with factorial loadings equal or higher than .30 were retained (Wolff & Preising, 2005).
The initial conditions for performing the HOEFA were adequate, Kaiser-Meyer-Olkin (KMO) = .91, χ²(780) = 6390.8, p < .001. Factor extraction was repeated until a stable structure was obtained still presenting adequate values for the KMO and Bartlett’s sphericity tests, KMO = .93, χ²(435) = 4948.9, p < .001. One high-order factor (G) and two first order factors (F1, F2) were obtained, explaining 58.65% of shared variance (see Table 1). Large effect correlations were obtained between G and F1, r = .73; and G and F2, r = .91. Ordinal alpha levels and standard error measurement were subsequently calculated and are presented in Table 2. Table 2. Ordinal alpha and SEM for K-MPAI high and low level factors.
Factors Ordinal α SEM
G (30 items) .97 4.87
F1 (21 items) .93 6.11
F2 (10 items) .92 3.01 Note: G = high-order factor; F1 = first first-order factor; F2 = second first-order factor. Item 14 loaded for both F1 and F2.
B. MPA differences According to Gender, Musical Genre and Musical Institution Descriptive statistics and Shapiro-Wilk normality tests were
calculated for MPA scores according to gender, musical genre and musical institution (see Table 3). Evidences of proceeding from a normally distributed population were obtained. Even though musical institution A violated the normality assumption, it was assumed as normally distributed, basing this claim on the central limit theorem (Field, 2009).
A medium effect was found for gender, t(448) = -4.83, p < .001, d = .50, 1 – β = .81; but not for musical genre, t(442) = 0.03, p = .98, d = .003, 1 – β = .05; or musical institution, F(2, 452) = 1.42, p = .24, η2 = .006, 1 – β = .30.
Table 3. Descriptive statistics and Shapiro-Wilk normality test for MPA scores according to gender, musical genre and institution.
Variables M SD n S-W df p Gender
Male 67.57 27.52 337 0.99 337 .11 Female 82.53 31.14 113 0.99 113 .76
Musical Genre
Classical 71.68 29.71 161 0.99 161 .43 Modern 71.60 29.19 283 0.99 283 .22
Musical Institution
A 71.34 29.31 230 0.99 230 .03* B 75.93 26.54 84 0.98 84 .37 C 69.19 30.18 141 0.99 141 .57
Note: Adapted from “Music Performance Anxiety in Peruvian Music Students: Differences According to Gender, Educational Institution and Musical Genre,” by A. M. Chang-Arana, Persona, 19. *p < .05.
V. CONCLUSION The aim of this paper was two-fold. First, to estimate validity
evidence based on internal structure and reliability evidences for scores derived from the intended uses of the Spanish K-MPAI (Chang-Arana, 2015b; Kenny, 2009). A high-order factor called “negative affectivity in relation to music performance anxiety” and two first-order factors named “music performance anxiety” and “depressive components” were proposed, resembling the tripartite model of anxiety and depression (Anderson & Hope, 2008; Clark & Watson, 1991) and Kenny’s typology of MPA (2011).
Second, the first statistical analyses of a Peruvian sample were provided (Chang-Arana, 2016). On the one hand, higher levels of MPA detected in female participants may coincide with previous biological and cultural explanations, particularly with gender-based raising patterns (Branney & White, 2008; Olatunji & Wolitzky-Taylor, 2009; Robson & Kenny, 2017; Winkler, Pjrek & Kasper, 2006). On the other hand, no significant differences were found in MPA scores according to the musical genre of specialty (Kenny, 2011). However, alternative results can be found in the literature. For instance, Papageorgi et al. (2011) reported significantly higher MPA levels in Western classical musicians when compared to Scottish traditional or jazz musicians. These differences were found when surveyed right before a solo performance context. Future research could use the K-MPAI to study how musicians from different genres experience MPA, according to performance context (e.g. solo or group) and proximity of performance (e.g. before or after a performance).
Lastly, despite the existence of differences in MPA levels according to gender or musical genre, the importance of this research field still stands. MPA can have detrimental effects on the life of musicians at several levels, and interventions should be planned in order to protect them. Nevertheless, one of the requirements to achieve this goal is to count with solid psychological measurement instruments. This research has been an empirical effort in that direction.
21

Table 1. HOEFA of the K-MPAI items in a Peruvian sample.
Items Music
Performance Anxiety (F1)
Depressive Components (F2)
Negative Affectivity in Relation to Music
Performance Anxiety (G) 10. Prior to, or during a performance, I get feelings akin to panic .479 .527
11. I never know before a concert whether I will perform well .264 .644
12. Prior to, or during a performance, I experience dry mouth .335 .456
15. Thinking about the evaluation I may get interferes with my performance .385 .463
16. Prior to, or during a performance, I feel sick or faint or have a churning in my stomach .286 .544
17. Even in the most stressful performance situations, I am confident that I will perform well .165 .427
18. I am often concerned about a negative reaction from the instructor or listener/audience .396 .342
19. Sometimes I feel anxious for no particular reason .274 .457
20. From early in my music studies, I remember being anxious about performing .566 .363
21.I worry that one bad performance may ruin my career .405 .381
24. I give up worthwhile performance opportunities .193 .476
26. My worry and nervousness about my performance interferes with my focus and concentration .496 .516
28. I often prepare for a concert with a sense of dread and impending disaster .269 .676
29. One or both of my parents were overly anxious .227 .407
30. Prior to, or during a performance, I have increased muscle tension .423 .507
32. After the performance, I replay it in my mind over and over .331 .350
34. I worry so much before a performance, I cannot sleep .463 .473
36. Prior to, or during a performance, I experience shaking or trembling or tremor .516 .483
38. I am concerned about being scrutinized by others .535 .483 39. I am concerned about my own judgement of how I will perform .406 .329
14. During a performance I find myself thinking about whether I'll even get through it .185 .185 .618
1. I generally feel in control of my life .233 .494
3. Sometimes I feel depressed without knowing why .251 .569
4. I often find it difficult to work up the energy to do things .216 .490
5. Excessive worrying is a characteristic of my family .203 .456
6. I often feel that life has not much to offer me .403 .613
7. Even if I work hard in preparation for a performance, I am likely to make mistakes .171 .494
13. I often feel that I am not worth much as a person .413 .714
27. As a child, I often felt sad .257 .493
31. I often feel that I have nothing to look forward to .308 .646
Note: N = 455. Extraction method: Minimum Rank Factor Analysis (MRFA).Method used for estimating advised number of dimensions to retain: Minimum Average Partial (MAP).
22

ACKNOWLEDGMENT This study was possible thanks to a group of professors and
colleague classmates who supported me through the whole process. Particularly, I would like to express my gratitude to two people. First, to Professor Andrés Burga-León, my thesis supervisor who walked me through my psychometric learning; and, second, to Professor Dianna T. Kenny for trusting me with her inventory and being an active supporter of my research. Finally, I would like to thank the anonymous SysMus17 reviewers for their valuable commentaries and suggestions.
REFERENCES Anderson, E. R., & Hope, D. A. (2008). A review of the tripartite model
for understanding the link between anxiety and depression in youth. Clinical Psychological Review, 28, 275-287. doi: 10.1016/j.epr.2007.05.004
Barlow, D. (2000). Unravelling the mysteries of anxiety and its disorders from the perspective of emotion theory. American Psychologist, 55(11), 1247-1263. doi: 10.1037/0003-066X.55.11.1247
Bonanomi, A., Ruscone, M. N., & Osmetti, S. A. (2013). The Polychoric Ordinal Alpha, measuring the reliability of a set of polytomous ordinal items. In Advances in Latent Variables-Methods, Models and Applications. Retrieved from http://meetings.sis-statistica.org/index.php/sis2013/ALV/paper/viewFile/2651/424
Branney, P., & White, A. (2008). Big boys don’t cry: Depression and men. Advances in Psychiatric Treatment, 14(4), 256-262. doi: 10.1192/apt.bp.106.003467
Brislin, R. W. (1986). The wording and translation of research instruments. In W. J. Lonner & J. W. Berry (Eds.), Field methods in cross-cultural research (pp. 137-164). USA: Sage Publications.
Burga, A. (2006). La unidimensionalidad de un instrumento de medición: Perspectiva factorial [The unidimensionality of a measurement instrument: A factorial perspective]. Revista de Psicología de la PUCP, 24(1), 54–80. Retrieved from http://revistas.pucp.edu.pe/index.php/psicologia/article/view/642/629
Chang-Arana, A. M. (August, 2015a). Adaptation and psychometric properties of the Kenny-Music Performance Anxiety Inventory (K-MPAI). Paper presented at the X Latin- American Regional Conference and III Pan American Regional Conference of Music Education, Lima, Peru. Retrieved from http://congreso.pucp.edu.pe/isme/wp-content/uploads/sites/8/2013/07/Actas-ISME-Per%C3%BA-2015.pdf
Chang-Arana, A. M. (2015b). Adaptation and psychometric properties of the Kenny-Music Performance Anxiety Inventory (K-MPAI) (unpublished bachelor thesis). University of Lima: Peru.
Chang-Arana, A. M. (2016). Music performance anxiety in Peruvian music students: differences according to gender, educational institution and musical genre. Persona, 19, 167-177.
Clark, L. A., & Watson, D. (1991). Tripartite model of anxiety and depression: Psychometric evidence and taxonomic implications. Journal of Abnormal Psychology, 100(3), 316-336. doi: 10.1037/0021-843X.100.3.316
Cohen, J. (1992). A power primer. Psychological Bulletin, 112(1), 155-159. doi: 10.1037/0033-2909.112.1.155
Ellis, P. D. (2010). The essential guide to effect sizes: Statistical power, meta-analysis, and the interpretation of research results. UK: Cambridge University Press.
Field, A. (2009). Discovering statistics using SPSS (and sex and drugs and rock ‘n’ roll) (3a ed.). Dubay: Sage.
Fishbein, M., & Middlestadt, S. (1988). Medical problems among ICSOM: Overview of a national survey. Medical Problems of Performing Arts, 3(1), 1-8.
Gadermann, A. M., Guhn, M., & Zumbo, B. D. (2012). Estimating ordinal reliability for Likert-type and ordinal item response data: A conceptual, empirical, and practical guide. Practical Assessment, Research & Evaluation, 17(3), 1-13. Retrieved from http://www.pareonline.net/getvn.asp?v=17&n=3
Kenny, D. T. (2011). The psychology of music performance anxiety. New York: Oxford University Press.
Kenny, D. T. (December, 2009). The factor structure of the revised Kenny Music Performance Anxiety Inventory. Research presented at the International Symposium on Performance Science, Auckland, New Zealand. Retrieved from http://www.legacyweb.rcm.ac.uk/cache/fl0019647.pdf
Martínez, M. C., & Paterna, C. (2010). Manual de psicología de los grupos [Group psychology manual]. Madrid: Síntesis.
Papageorgi, I., Creech, A., & Welch, G. (2011). Perceived performance anxiety in advanced musicians specializing in different musical genres. Psychology of Music, 41(1), 18-41. doi: 10.1177/0305735611408995
Lorenzo-Seva, U., & Ferrando, P. J. (2006). FACTOR: A computer program to fit the exploratory factor analysis model. Behavior Research Methods, 38(1), 88–91. doi:10.3758/BF03192753
Olatunji, B. O., & Wolitzky-Taylor, K. B. (2009). Anxiety sensitivity and the anxiety disorders: A meta-analytic review and synthesis. Psychological Bulletin, 135(6), 974-999. doi: 10.1037/a0017428
Ortiz, A. (2011a). Music performance anxiety-Part 1: A review of its epidemiology. Medical Problems of Performing Artists, 26(2), 102-105.
Ortiz, A. (2011b). Music performance anxiety-part 2: A review of treatment options. Medical Problems of Performing Artists, 26(3), 164-171.
Robson, K. E., & Kenny, D. T. (2017). Music performance anxiety in ensemble rehearsals and concerts: A comparison of music and non-music major undergraduate musicians. Psychology of Music, 1-18. Doi: 10.1177/0305735617693472
Schmid, J., & Leiman, J. M. (1957). The development of hierarchical factor solutions. Psychometrika, 22(1), 53-61.
Taylor, A., & Wasley, D. (2004). Physical fitness. In A. Williamon (Ed.), Musical excellence: Strategies and techniques to enhance performance (pp. 163-178). New York: Oxford University Press.
West, R. (2004). Drugs and Musical Performance. In A. Williamon (Ed.). Musical Excellence: Strategies and Techniques to Enhance Performance (pp. 271-290). New York: Oxford University Press.
Winkler, D., Pjrek, E., & Kasper, S. (2006). Gender specific symptoms of depression and anger attacks. The Journal of Men’s Health and Gender, 3(1), 19-24. doi: 10.1016/j.jmhg.2005.05.004
Wolff, H. G., & Preising, K. (2005). Exploring item and high order factor structure with the Schmid-Leiman solution: Syntax codes for SPSS and SAS. Behavior Research Methods, 37(1), 48–58. doi:10.3758/BF03206397
Yoshie, M., Kudo, K., & Ohtsuki, T. (2008). Effects of psychological stress on state anxiety, electromyographic activity, and arpeggio performance in pianists. Medical Problems of Performing Artists, 23, 120-132.
Zumbo, B. D., Gadermann, A. M., & Zeisser, C. (2007). Ordinal versions of coefficients alpha and theta for Likert Rating Scales. Journal of Modern Applied Statistical Methods, 6(1), 21-29. Retrieved from http://digitalcommons.wayne.edu/jmasm/vol6/iss1/4
23

Proceedings of the 10th International Conference of Students of Systematic Musicology (SysMus17), London, UK, September 13-15, 2017. Peter M. C. Harrison (Ed.).
Adaptation of the Mindfulness-Acceptance-Commitment Approach for Groups of Adolescent Musicians: An Assessment of Music Performance Anxiety, Performance
Boost, and Flow Anthea Cottee1, Sean O’Connor2
University of Sydney, Australia [email protected], [email protected]
ABSTRACT
Background Many musicians experience Music Performance Anxiety
(MPA; Kenny, 2011) which may develop early, peak in adolescence (Osborne & Kenny, 2005) and continue into professional life, impacting on general well-being (Kenny, Driscoll, & Ackermann, 2014). Adrenaline in performance can have a positive effect, known as performance boost (Simoens, Puttonen, & Tervaniemi, 2015). Strategies assisting a state of flow (Csikszentmihalyi, Abuhamdeh, & Nakamura, 2005) have been suggested to assist managing MPA (Lamont, 2012). Rather than challenging difficult thoughts, the Mindfulness, Acceptance and Commitment (MAC) Approach (Gardner & Moore, 2004) uses mindfulness and acceptance strategies that have been shown to decrease anxiety and increase flow in sport (Gardner & Moore, 2012).
Aims Exploration of MPA, performance boost, and flow may
enhance psychological understanding of performance. The adaptation of the MAC Approach for musicians aims to develop an early intervention approach for MPA.
Method 36 musicians (13-22yr) participated in seven focused and
interactive group sessions of the MAC Approach, or a no-intervention control group, and completed questionnaires of demographics, MPA, boost, flow, and qualitative feedback.
Results Relationships between measures were all significant: MPA
and boost (r = -.554, p < .001), MPA and flow (r = -.476, p = .003), and boost and flow (r = .485, p = .003). Post MAC sessions the intervention group had a non-significant reduction in MPA compared to control (p = .097, η2
p = .08, two-tailed), and a significant reduction in performance context factor (p = .048, η2
p = .11). No significant differences were found for boost or flow. Follow up results demonstrated a non-significant trend of reduced MPA for the intervention group, and also non-significant improvement in the control group. Analysis of qualitative feedback was 71% positive.
Conclusions Analysis of the relationships between MPA, performance
boost, and flow presents an addition to current literature. Development of the MAC approach for adolescent musicians aims to address the need for early intervention for MPA.
While reduction in overall MPA was not significant, results are noteworthy for a small and variable population. Timing of the improvement of the control group MPA at follow-up raises the possibility of a ‘coaching ripple effect’ (O’Connor & Cavanagh, 2013) occurring as a result of shared experiential interactions that warrants further exploration. Factor analysis and qualitative feedback assist in understanding mechanisms of MPA. This study makes a valuable contribution to addressing a potentially debilitating problem for musicians.
Keywords performance anxiety; flow; performance boost;
mindfulness; acceptance
REFERENCES Csikszentmihalyi, M., Abuhamdeh, S., & Nakamura, J. (2005). Flow
Handbook of competence and motivation (pp. 598-608). New York, NY: Guilford Publications; US.
Gardner, F. L., & Moore, Z. E. (2004). A Mindfulness-Acceptance-Commitment-Based Approach to Athletic Performance Enhancement: Theoretical Considerations. Behavior Therapy, 35(4), 707-723. doi:10.1016/S0005-7894%2804%2980016-9
Gardner, F. L., & Moore, Z. E. (2012). Mindfulness and Acceptance Models in Sport Psychology: A Decade of Basic and Applied Scientific Advancements. Canadian Psychology, 53(4), 309-318.
Kenny, D. (2011). The psychology of music performance anxiety. Oxford: Oxford University Press.
Kenny, D., Driscoll, T., & Ackermann, B. (2014). Psychological well-being in professional orchestral musicians in Australia: A descriptive population study. Psychology of Music, 42(2), 210-232. doi:10.1177/0305735612463950
Lamont, A. (2012). Emotion, engagement and meaning in strong experiences of music performance. Psychology of Music, 40(5), 574-594. doi:10.1177/0305735612448510
O’Connor, S., & Cavanagh, M. (2013). The coaching ripple effect: The effects of developmental coaching on wellbeing across organisational networks. Psychology of Well-Being: Theory, Research and Practice, 3(1), 2. doi:10.1186/2211-1522-3-2
Osborne, M., & Kenny, D. (2005). Development and validation of a music performance anxiety inventory for gifted adolescent musicians. Journal of Anxiety Disorders, 19(7), 725-751. doi:10.1016/j.janxdis.2004.09.002
Simoens, V. L., Puttonen, S., & Tervaniemi, M. (2015). Are music performance anxiety and performance boost perceived as extremes of the same continuum? Psychology of Music, 43(2), 171-187. doi:10.1177/0305735613499200
24

Proceedings of the 10th International Conference of Students of Systematic Musicology (SysMus17), London, UK, September 13-15, 2017. Peter M. C. Harrison (Ed.).
Sounds of Native Cultures in Electroacoustic Music: Latin American Study Cases Pablo Cuevas
Musikwissenschaftliches Institut, Universität zu Köln, Germany [email protected]
ABSTRACT The electroacoustic music for tape of Latin American origin shows a rich history and a large, relative unexplored repertoire since its beginnings in the middle of the 20th century. In this paper, I study the inclusion of sounds of native cultures in a group of selected electroacoustic works between 1961-1989. A musical analytical inductive process divided in three stages was used to recognize and interpret this recurring topic. I formulate the notion of distance to embrace three types of references to the sounds of native cultures that can be found in this music. These references operate as indexes of a cultural identity that the composers were trying to portrait.
I. BACKGROUND In an article published in 1992 the composer and
musicologist Graciela Paraskevaídis (1940-2017) transcribed and analysed the electroacoustic work Tramos (1975, 16´53´´, 1-ch., Buenos Aires) by Argentinean composer Eduardo Bértola (1939-1996). She saw this work as a dialectical counterpart to some previous electroacoustic music of European origin that should have worked as an early model for the creation of electroacoustic music in Latin America (Paraskevaídis 1992, p. 4). Her postulate implies the recognition and a critical examination of the historical, performative and compositional practices of European academic music that were imported in the Americas since the beginnings of the colonial processes in the 16th century. Bértolas´ Tramos – a work consisting of a montage of radio cuts that produce meaning through their semantical interpretation – is a part of a group of 10 electroacoustic works composed in Latin America between 1970-1980 that Paraskevaídis selected as the basis for her approach and out of which she draws 7 common features that would characterize these musics. The root of her inductive venture was her encyclopaedic knowledge of the history of academic music in Latin America, which indeed prevent her from generalizing as she pointed out the need of a methodological differentiation among works and their individual character in order to compare them one another rightly (Paraskevaídis 1992, p. 4). A similar approach can be found in an article by composer and musicologist Coriún Aharonián, where he uses the same idea of cultural countermodel (Aharonián 2000, p. 3) as a selection criterium to conform a group of (not exclusively electroacoustic) musical works out of which he draws 13 possible trends that would be distinctive for these musics. In this case he focuses on 30 works between 1971-1992.
Although the personal bond among the above-mentioned authors is not to be underestimated if the coincidences in their thinking and methodology are to be mentioned, I will consider nonetheless two common epistemic aspects which are
irrefutable because of their sufficient general nature. First, the necessity of caution while trying to operate inductively with musics of Latin American origin must be observed, since one considers a space with a rich, complex, and regional highly differentiated history, comprising a territory two times bigger than Europe. Any hasty, simplifying approach to its cultural products should therefore be avoided.
Second, I concentrate on a broad question that is partially shared by both authors: How did composers express their origins and culture in their electroacoustic works for tape? To answer it, I incorporated subsequent bibliography concerning individual composers and national approaches to this subject (For reasons of space this entire bibliography cannot be cited within this paper). I also broadened the study subject to include electroacoustic works produced by composers of Latin American origin (but not necessarily in Latin America) according to their historical weight. I built a corpus of 47 musical works from 16 composers in the time-lapse between 1961 to 1989. The selection criteria for the data collection process have their roots on the following methodological aspects.
A. Historical Relevance 1) First level. I took the broad notion of Mediamorphose to
conceptualize the sociohistorical role of technology as a key aspect of electroacoustic music. Mediamorphosen are the transformations in the production of culture under the influence of historical new communicational technologies (Smudits 2002, p. 16). Cultural products are then defined by both the intrinsic, autonomous dynamics of the implicated communicational technology and by external, political, economic, and ideological conditions (Smudits 2002, p. 43), in other words, the dialectical interaction between technology and society conditions the electroacoustic music that emerges from it. Although this sociohistorical role of technology could be criticized as a technological determinism that obscures the social fundaments that had opened the way for technological innovations (Sterne 2003, p. 8), it is also true that electroacoustic music is a cultural product of a technological moment that was initiated with the invention of electronic analogue signal recording and broadcasting technology, in other words, this music results from the electronic Mediamorphose. Composers did face creative challenges while working with this new medium and these challenges reveal the presence of electronic analogue technology in all dimensions of music (composition, storage, and reproduction) for the first time in history.
2) Second level. I focused on a regional level and applied the above-mentioned notion of electronic Mediamorphose to select exclusively analogue electroacoustic music for tape
25

produced by composers of Latin American origin. In order to deal with the vast geocultural region called Latin America I studied primarily composers that were active at the Latin American Center for Higher Musical Studies (CLAEM, 1962–1970) of the Instituto Torcuato Di Tella in Buenos Aires, because of its relevance in the institutional history of academic music in Latin America (e.g., Castañeira de Dios, 2011), and contained an electroacoustic studio that was among the best equipped of its time. Besides, the great majority of composers that were active there had shown remarkable professional paths after their residency in Argentina (Novoa 2011, pp. 28-29).
B. References to the Region The presence references to the region of origin and to the
culture of the composers was the last criterium for the selection of electroacoustic works to be studied. These references allude a spatial location in its geocultural dimension (Said 1994, p. 52). In the case of electroacoustic music, they can be recognized in the work title, dedication, literary or poetic source, musical and style quotations, use of speech, environmental recordings, and in the creative information provided by composers. From the 133 works I had collected following the second socio-historical level, I choose 47 pieces, from which 8 are early examples of electroacoustic music from some composers which do not show any references to the region.
II. AIMS In this paper, I discuss one type of reference that is common
to 10 electroacoustic works within the musical corpus of 47 pieces that I studied: The presence sounds of native cultures. I explore the ways in which these sounds were incorporated, how they were approached and what meaning can be extracted from the music.
III. METHOD For the analysis of electroacoustic music, I followed and
applied the semiological tripartite model of music as symbolic form according to Nattiez (1975). The musical corpus was analysed in three stages. First, an analysis of each work based on pre-established criteria. The segmentation and comparison of the compounding sounds of a piece follows an interpretation of the Gestalt principles applied to the auditory experience as postulated by Roy (2003). Second, I added compositional information to define a poietic level for each work (Nattiez 1975, p. 52)
As a result of the analytical data evaluation many recurring features were recognized among these works; the presence of sounds of native cultures was one of them. The interpretative analysis of this recurring aspect was the last stage. Here I combine the two-level analytical data that I previously obtained with information about the context of creation of this electroacoustic music as a horizon of expectation (Jauß 1970, pp. 173-174) that opens a way for the interpretation of the music.
IV. RESULTS I postulate the notion of distance to conceptualize the ways
in which composers operated with the sounds of native cultures. There are three types of distance that correspond to different,
increasing proximity grades: silent references, sounding references, and aesthetical references.
A. Silent Reference The sounds of native cultures are integrated in some works
that paradoxically do not contain them. The title of the electroacoustic piece huauqui (1975, 11´03´´, 1-ch., Montevideo) by Uruguayan composer Graciela Paraskevaídis is a word in Quechua (the language of the Inca), which has a double meaning for her. First as a statuette that was sculpted by an Inca according to his own image and likeness, second, as a word representing the idea of fraternity and community. She conceived this piece as the starting point of a personal search for a new, concise composing style, as she began to concentrate herself on the use of few sound materials out of which she constructs her music (Paraskevaídis, 1996), as can be exemplified in the electronic (e.g., 0´´-2´09´´), vocal (3´35´´ -4´40´´) and instrumental (2´10´´-3´34´´) sounds in huauqui and their static developments. That would partly explain why she refers to this self-portrait character of the huauqui. This reference to the Inca world was the first reference to the Latin American region in the titles of her musical works, which date back to 1967 and had shown the presence of Spanish, Italian, and German words mostly deriving from the literary sources she used.
In another context, but operating with the same reference enclosed in the title one finds the electroacoustic work Canto selvagem (1967, 2´55´´, 2-ch., Rio de Janeiro) by Brazilian composer Jorge Antunes (1942). This short “wild song” consist of two sound layers that build a two-part form and show the character of an accompanied melody: Percussion instruments that are intended to represent primitive cultures (Lintz-Maués 2002, pp. 72-73) and a melody composed with synthetic sounds that should evoke wild screams. The composer does not engage deeply with the native cultures he alludes and remains therefore in the experimental, improvisatorial terrain that characterizes his early electroacoustic music, as exemplified by his previous work Valsa sideral (1962, 3´10´´, 2-ch., Rio de Janeiro), the first electroacoustic work composed exclusively with synthetic sounds in Brazil, whose melodic features reminds those from Canto selvagem.
Although these two composers share a strong social committed thinking that can be found in their music -with more or less intensity according to biographical circumstances-, they show very different starting points for their compositions. One shared aspect of their approaches is nonetheless the reference to the sounds of native cultures, which is silent since no engagement with these cultures can be acoustically proved.
B. Sounding Reference In another level, one finds electroacoustic works that
present sounds of native cultures that were electronically processed and mounted. The composers tried to enrich personal, mostly already defined personal styles with the addition of these sounds.
The work Guararia Repano (1968, 14´20´´, 2-ch., Caracas) by Chilean composer and CLAEM invited teacher José Vicente Asuar (1933-2017) resulted from the materials he collected for a previous multimedia work in which he co-worked. He used two “instrumental songs from the Guajiro Indian” (Asuar 1975, p. 15) and integrated them in key moments in the highly
26

differentiated form of Guararia Repano, the native name for a mountain nearby Caracas (Venezuela). Both sound materials show a melodic character that reveals the composer’s creative intention as he constructs an imitative polyphony between the second material and an electronic variation of it at 4´00´´. Asuar had no interest in dealing with the geocultural origins of these native sounds since he explored their sound qualities abstractly, alluding partially to traditional techniques while building the form of this musical work, where synthetic sounds and recordings seem to coexist intermingled together.
A recording from a cosmogonic ritual-song of the U'wa natives is the basic material for the work Creación de la tierra (1972, 18´19´´, 1-ch., Buenos Aires) by Colombian composer Jacqueline Nova (1935-1975). She approached to this native sounds in an abstract way too, showing a strictly musical interest in the sound of this native language and its compounding elements, an interest that dates back to some of her previous music like Uerjayas (1967) for voices and traditional instruments, which displays “Birth Songs” of the U'wa. In Creación de la tierra one hears an original recording of a song for the “Creation of the Earth” at 16´28´´. Before this happens, she processed these vocal sounds to create long reverberant layers and opposed rhythmic structures that derive from the rhythmic and repetitive character of the original recording. She creates a contrast between both types of material, as occurs at the beginning of the work at 2´16´´, or symmetrically near the end of it between 14´46´´-15´04´´. The way she worked with the native sounds reminds the abstract musical principles that rule the sound world of her previous electroacoustic work Oposición-Fusión (1968, 10´50´´, 2-ch., Buenos Aires), particularly in the tensions between continual and discontinuous sounds.
Uruguayan composer Coriún Aharonián (1940) used exclusively sounds of native and mestizo flutes in his Homenaje a la flecha clavada en el pecho de Don Juan Díaz de Solís (1974, 13´25´´, 2-ch., Bourges). The approach of Aharonián can be summarized as the use of technology to potentiate native sounds, since he does not modify the instrumental sounds electronically, but isolate them at first, superposing them later creating dense sound layers from 7´17´´ onwards. Whilst the title of the work recalls the murder of the Spanish conquistador Juan Díaz de Solís (1470-1516) by an Indian arrow as he was sailing upstream nearby today´s Uruguay, the wind instruments used by Aharonián belong indeed to the Altiplano region in west-central South America. The composer denies that there was any programmatic link between the sound world of the piece and its title (Aharonián 1995, pp. 8-9), and that partly explains the abstract character of his approach as he concentrates exclusively on the native sounds as they emanate out of these flutes which he played and recorded himself.
C. Aesthetical references The use of sounds of native cultures as the basis for the
construction of personal aesthetics finds an example in the electroacoustic music of Guatemalan composer Joaquín Orellana (1930) and Argentinean composer Oscar Bazán (1936-2005).
Orellana´s electroacoustic work Humanofonía (1971, 11' 13”, 1-ch., Guatemala City) can be considered as a speech-composition because of the musical and aesthetical relevance
of the human voices it contains, which operate both as sounding and aesthetical references. I will focus on the latter. A Mayan language spoken by a male voice can be heard at 1´01´´ -1´14´´ and 10´07´´ -11´13´´. These two extracts are inserted symmetrically at begin and at the end of the work, while in the middle of it one hears a poem in Spanish recited by the composer at 4´58´´ -6´15´´. All this, combined with a solid control of the durations of the formal units, speaks of the relevance the composer gives to this voice. He coined the term humanofonal (humanphonal) to describe the human presence within a sound landscape, which he discovered while experimenting with environmental recordings in Guatemala since 1968. This human presence in the native languages contains for him a historical and anthropological dimension that he tries to portrait in his música ideológica [ideological music]. He hears in these languages an old suffering that dates back to the colonial processes in the Americas and the annihilation of native cultures (Vázquez 2015, p. 203.) The composer´s approach to the language focus on its musical character and not on its meaning (Gamazo 2016) and that can be related to the work of Jacqueline Nova, although the ideological concerns and an implicit social critique are stronger in the case of Orellana. He used a Mayan language again in his work Rupestre en el Futuro (1979, 22' 41”, 1-ch., Guatemala City), which has its precedent in a short piece called Iterotzul (1973, 3' 13”, 1-ch., Guatemala City) where the presence of Mayan language is predominant. This same language and voice are a recurring element in Rupestre, whose title portrays ironically the difficulties of composing electroacoustic music without appropriate equipment. It is no coincidence that at 22´01´´ and until the end of the piece one hears the Mayan language in the same symmetrical position and with the same relevance as in the previous Humanofonía.
Oscar Bazán composed an electroacoustic trilogy that was based in his experiences with the music of the Selk’nam natives. These three works are Episodios (1973, 4´47´´), Austera (1973, 12´28´´), and Parca (1974, 8´43´´), all of them stereophonic pieces composed in Buenos Aires. The native sounds were the starting point for a personal search that led him to the notion of música austera [austere music], a music where repetitions and an overall simplicity prevails (it cannot be considered minimal music because of the geocultural sources out of which Bazán conceived the idea.) The three above-mentioned works are connected through shared features, for instance, the use of major seconds in Austera (2´01´´ -4´27´´) and Parca (2´35´´ -5´01´´), the stereophonic spacialization of the sounds in Parca (0´´ -2´34´´) and Episodios (0´´ -30´´), or the presence of intentional out-of-tune minor-scale intervals in Austera (4´28´´ -6´´18´´) and Parca (2´35´´ -5´01´´). In Episodios (0´´-30´´) and Austera (2´01´´ -4´27´´) the composer emulates a native drum and a flute with the synthesizer, although these are exceptional moments that reveal the origins of his conception of austere music. The overall sound world of the pieces remains of electronic nature.
V. CONCLUSIONS The composition of academic music with references to
native cultures shows classical, extensively studied examples in the vocal-instrumental repertoire of Latin American origin, for instance the Sinfonía india (1936) by Mexican composer Carlos Chávez (1899-1978.) I concentrate my study on the
27

specificities of the electroacoustic music repertoire, which is a relatively unexplored musicological subject. The notion of distance that I postulate and its three subcategories seems appropriate to systematically describe the varying ways in which composers approach these sound worlds.
This distance can be found in other references to the region that are found within this musical corpus I study. For instance, some silent political references to the region can be found in the title of some pure electronic pieces like ¡Volveremos a las montañas! (1968, 12´20´´, 2-ch., Buenos Aires) by Chilean composer Gabriel Brnčić (1942), or as sounding references in works were the voice of politicians can actually be heard, as in Trópicos (1973, 19´44´´, 2-ch., New York) by Venezuelan composer Alfredo del Mónaco (1938-2015.) This is nonetheless a subject for future research.
I must finally remark that although the composers I mentioned shown different approaches to the sounds of native cultures, one can recognize nonetheless a common feature: All of them were trying to represent their region using sound materials that worked as indexes of a cultural identity. They were trying to differentiate his electroacoustic music from other electroacoustic musics. While doing so they approached to their cultures of origin in various ways, under which the use of recorded sounds related to the region appears to be the specific aspect of their electroacoustic music.
REFERENCES Aharonián, C. (1995). Gran Tiempo - Composiciones Electroacústicas
[CD]. Montevideo: Tacuabé. Aharonián, C. (2000). An Approach to Compositional Trends in Latin
America. Leonardo Music Journal, 10, 3-5. Asuar, J. V. (1975). Recuerdos. Revista Musical Chilena, 132, 5-22. Castañeira de Dios, J. (Ed.) (2011). La música en el Di Tella:
resonancias de la modernidad. Buenos Aires: Secretaria de Cultura de la Presidencia de la Nación.
Gamazo, C. (2016). Joaquín Orellana o una plaza triste y el silencio de siempre. Retrieved March 4, 2017, from https://www.plazapublica.com.gt/content/joaquin-orellana-o-una-plaza-triste-y-el-silencio-de-siempre
Jauß, H. R. (1970). Literaturgeschichte als Provokation. Frankfurt a. M.: Suhrkamp.
Nattiez, J. J. (1975). Fondements d'une sémiologie de la musique. Paris: Union Générale d´Éditions.
Novoa, L. (2011). Cuando el futuro sonaba eléctrico. In J. Castañeira de Dios (Ed.), La música en el Di Tella: resonancias de la modernidad (22-29). Buenos Aires: Secretaria de Cultura de la Presidencia de la Nación.
Paraskevaídis, G. (1992). Tramos. Lulú. Revista de teorías y técnicas musicales, 3, 47-52.
Paraskevaídis, G.(1996). Magma. 9 Compositions [CD]. Montevideo: Tacuabé.
Roy, S. (2003). L'analyse des musiques électroacoustiques. Paris: L´Harmattan.
Said, E. (1994). Culture and Imperialism. New York: Vintage. Smudits, A. (2002). Mediamorphosen des Kulturschaffens. Kunst und
Kommunikationstechnologien im Wandel. Vienna: Braumüller. Sterne, J. (2003). The audible past. Cultural origins of sound
reproduction. Durham: Duke University Press. Vázquez, H. G. (2015). Conversaciones en torno al CLAEM. Buenos
Aires: Instituto Nacional de Musicología Carlos Vega.
28

Proceedings of the 10th International Conference of Students of Systematic Musicology (SysMus17), London, UK, September 13-15, 2017. Peter M. C. Harrison (Ed.).
Musicians' Timbral Adjustments in Response to Emotional Cues in Musical
Accompaniments Anna Czepiel1, Emma Allingham2, Kendra Oudyk3, Adrianna Zamudio4, Pasi Saari5
Department of Music, Art and Culture Studies, University of Jyväskylä, Finland [email protected], [email protected], [email protected],
[email protected], [email protected]
ABSTRACT
Background Previous research has linked the musical communication of
emotion to changes in timbre (e.g. Hailstone et al., 2009). Furthermore, timbral changes in musical performances have been observed when musicians are given verbal instructions to convey a certain emotion in their playing. (Gabrielsson & Juslin, 1996).
Aims The present study aimed to evoke changes in timbre in a
cellist’s performance using musical cues, as opposed to verbal cues, and to explore whether these changes could be successfully perceived by listeners.
Method Three melodies were composed that were intended to be
neither specifically major nor minor. Both major (happy) and minor (sad) accompaniments were composed for each melody, and each accompaniment was recorded on both MIDI and real piano. The intention was that the minor accompaniment would prompt the cellist to create a “sad” timbre in the melody and the major accompaniment would prompt a “happy” timbre. Further, a bass line only accompaniment was used, intended as an emotionally “neutral” comparison. The MIDI/real piano comparisons were included to allow exploration of the effects of these modes on the cellist’s playing. The cellist was asked to write down his performance intentions and what informed them.
Firstly, acoustic features of the cello recordings alone were extracted and analysed using the MIRtoolbox in MATLAB (Lartillot & Toiviainen, 2007). Secondly, the cello recordings were perceptually rated by 47 listeners in terms of how happy and sad they were perceived to be on a scale of 1 to 7, in comparison to the “neutral” version. Listeners could not hear the accompaniment and were asked to describe how they made their decisions.
A two-way ANCOVA was used to analyse the data obtained from the feature extraction and a factorial repeated-measures ANOVA was used to analyse the perceptual data. Content analysis was used on the qualitative data.
Results The “mode” (major or minor) of the accompaniments had a
significant effect on mean “attack time”, F(1,7) = 6.86, p = .03, η2 = .50 and mean “RMS” F(1,7) = 8.87, p = .02, η2 = .56. The
effects were not significant when “melody” was entered as a covariate. There were no significant main effects of “mode” on “spectral centroid”, “inharmonicity”, or “spectral flux”.
There was a significant main effect of mode on perceptual ratings F(1,44) = 16.29, p < .001, η2 = .27. The direction of the effect was as expected; happier ratings for major keys and sadder ratings for minor keys.
Content analysis of the cellist’s comments confirmed that the major accompaniments were considered “happy” and the minor accompaniments were considered “sad”. Content analysis of the participants’ comments showed that the ratings were influenced by musical features such as dynamics and technical aspects of playing such as vibrato, articulation and bowing. Surprisingly, some listeners perceived changes in the tonality and “speed” of the melodies.
Conclusions Attack time was the only timbral feature analysed that was
significantly affected by mode of accompaniment. Variations in mean attack time and mean RMS may be related to differences in mode (major-minor) of accompaniment, although they may have been caused by aspects of the melodies themselves. It cannot be concluded, from this study, that timbre was significantly affected by mode of accompaniment.
However, the perceptual results suggest that the musician did encode emotions in his playing, prompted by major and minor accompaniments that were successfully decoded by listeners. Investigating the acoustic features related to these emotions could be the topic of future research.
Keywords music perception; timbre; emotion; music performance;
expressivity; MIR
REFERENCES Gabrielsson, A., & Juslin, P. N. (1996). Emotional expression in music
performance: Between the performer’s intention and the listener’s experience. Psychology of Music, 24, 68–91.
Hailstone, J. C., Omar, R., Henley, S. M., Frost, C., Kenward, M. G., & Warren, J. D. (2009). It's not what you play, it's how you play it: Timbre affects perception of emotion in music. The Quarterly Journal of Experimental Psychology, 62(11), 2141-2155.
Lartillot, O., & Toiviainen, P. (2007). A Matlab toolbox for musical feature extraction from audio. In International Conference on Digital Audio Effects (pp. 237-244)
29

Proceedings of the 10th International Conference of Students of Systematic Musicology (SysMus17), London, UK, September 13-15, 2017. Peter M. C. Harrison (Ed.).
Kinematics Feature Selection of Expressive Intentions in Dyadic Violin Performance Georgios Diapoulis1, Marc Thompson2
University of Jyväskylä Dept., Music, Arts, and Culture Studies, Finland [email protected], [email protected]
ABSTRACT There is evidence that bodily movement plays a crucial role in regulating expressivity in music performance. Advances in technologies related to human movement research (e.g. motion capture using infrared cameras) give us the opportunity to study bodily motion with millimeter precision. Consequently, we can extract fine-grained kinematic characteristics and perform statistical learning techniques in order to identify similarities and differences in spatial accuracy of intended expressive movements. In this study, we applied feature extraction and feature generation algorithms to identify the kinematic characteristics that better predict expressive intentions. The results suggest that musical expressivity is not physically rendered in similar movement patterns during perception and during production of dyadic musical performance. We propose that future studies should focus on the interaction between motor experience and visual perception of expressivity.
I. INTRODUCTION Expressive bodily motion is a fundamental property of
music performance, and highly important aspect to deepen our understanding of human interaction (Palmer, 1997). Advances in motion capture technologies make possible to record bodily motion with high spatial and temporal accuracy. Thus, there is growing interest to explain behavioural and affective phenomena based on objective measures of motion capture data. The research program of embodied music cognition suggest that bodily motion has major importance in musical activities (Leman, 2008). Investigating motion is a continuing concern within natural sciences, and the study of physical motion in the 17th century established what is known today as Newtonian physics or classical mechanics. As an analogy, the study of human motion might be the appropriate focal point for sound and reproducible studies within behavioural and cognitive sciences.
Full-body human movement recordings may produce high-dimensional spaces which make the analysis of the data a challenging endeavour. Dimension reduction techniques are based on feature extraction and feature generation. Feature selection is a feature extraction technique which selects the appropriate subset of features that optimize the learning performance. Feature selection is a family of different techniques that may vary from a simplistic exhaustive search of all possible combinations of a set of features, to highly sophisticated techniques. On the other hand, principal component analysis (PCA) is a technique that is used to perform feature generation. PCA generates a new synthetic data set which produces a new transformed coordinate system based on the percent of explained variance. The fundamental difference between PCA and feature selection is that PCA is
an unsupervised machine learning technique whereas feature selection is supervised technique.
Computational approaches such as feature selection and feature transformation (e.g. PCA) can provide us with useful insights about the embodiment of expressive performance. More specifically, PCA has been used to detect the dominant modes in movement data (Daffertshofer, Lamoth, Meijer & Beek, 2004, Toiviainen et al., 2010). For example, in a previous study using the same data set (Diapoulis, 2016) we applied joint-PCA on the violin dyads; the first principal component (PC) consisted of movement on the mediolateral axis, the second PC consisted of movement on the anteroposterior axis, and the third PC consisted of movement on the vertical axis. On the other hand, feature selection does not transform the original data, instead it is the process of selecting the appropriate subset of features. Whereas PCA transforms the original dimensions of the movement data and generates a new synthetic data set, feature selection algorithms are used to identify which feature subset can better perform predictions.
Broughton & Davidson (2016) described the expressive moments in marimba performance using Laban movement analysis, and they reported that head nod, head shake, upper body wiggle, and anteroposterior surge, along with a regular sway (anteroposterior movement) are all factors of expressive performance. Bodily sway has been shown in many studies to be a significant factor of communication and interpersonal coordination of leader-follower dynamics (Chang, Livingstone, Bosnyak & Trainor, 2017; Keller & Appel, 2010).
The perception of expressive performance is associated with a wide variety of movement patterns, but there is consensus in literature that bodily sway is a dominant component of expressive gestures (Broughton & Davidson, 2016; Dahl & Friberg, 2007; Diapoulis, 2016). On the other hand, there are no studies that attempt to identify which bodily parts can better discriminate different expressive manners. The present study fills a gap in the literature by shifting the focus on the kinematic features that discriminate the different expressive manners. Thus, we make use of third-person objective movement measures to classify intersubjective experience of expressive intentions. An important point that we have to clarify is that the focus is on intended and not on perceived expressivity in music performance. That is, our aim is to identify which kinematic features account for the embodiment of intended expressivity in dyadic music performance.
30

II. METHODS A. Participants and Procedure
Three violin dyads participated in this study (6 musicians total; 4 females; age: M = 24.1, SD = 1.7). The violinists were recruited from student populations at the University of Jyväskylä and the Jyväskylä University of Applied Science. Musicians had received on average 15.8 (SD = 2.3) years of instrumental training on the violin.
The violin dyads performed while standing and looking at each other as shown in Figure 1. The dyads performed a short piece arranged for two violins: "De Kleinste", composed by J. Beltjens (16 bars, 6/8 time signature), and the score is available in Diapoulis (2016). After a short rehearsal period, each dyad performed the piece nine times in a 3 × 3 task design: three expressive intentions (deadpan, normal, exaggerated) performed using three timing conditions (60-BPM, 90-BPM, free tempo). In the current study, we ignored the effect of tempo, as a factor that might have an effect on the classification of different expressive conditions.
Figure 1. Snapshot from a dyadic performance.
B. Apparatus Optical motion capture data was produced using 8 Qualisys
Oqus infrared cameras at 120 Hz sampling rate. Twenty-six markers were placed on the joints of each musician, and five markers were placed on the violin (2 on the bow, and 3 on the violin itself). The data was labeled within Qualisys' Track Manager software and analyzed in MATLAB using functions within the MoCap Toolbox (Toiviainen & Burger, 2010), and the MATLAB statistics and machine learning toolbox.
C. Experimental Design This study is based on the experimental design that was
reported in Diapoulis (2016). The aforementioned study had two experiments; a motion capture experiment of dyadic violin performance, and a perceptual experiment of evaluating expressivity in performance. Figure 1 shows a screenshot from a perceptual stimulus. In the current study, we have used the motion capture segments that we used as stimuli for perceptual evaluation of expressivity. No perceptual data are used in the current study. As noted in Diapoulis (2016) the total number of perceptual stimuli was 72 segments (3×2×3×4); three dyads, two expressive conditions (deadpan and exaggerated), three modalities (audiovisual, audio-only and visual-only), and four melodic segments. The decision to eliminate the normal expressive manner, was done based on
Thompson and Luck (2012). In this study, the authors reported that there is no consistency in the embodiment of normal and exaggerated piano performance. The decision to take the two extreme expressive conditions (deadpan and exaggerated) was done with a view to reduce the average duration of the perceptual experiment, due to the fact that the perceptual experiment was web-based (online) and we didn't provide any incentives to the participants (for details see Diapoulis, 2016).
D. Movement Analysis All the analysis is based only on motion captured data. In
the pre-processing stage of the movement analysis we reduce the 26 markers to 20 joint markers for each violinist, ignoring the markers on the violin. Then we connected the 20 joint markers in order to create stick figures as shown in Figure 2. This was done to facilitate presentation view and had no effect on the movement analysis. Preliminary movement analysis showed that the musicians embodied the different levels of expressivity by moving with more kinetic energy in the more exaggerated expressive conditions. This preliminary result was interpreted as evidence that the assigned linguistic descriptions (i.e. normal, deadpan, exaggerated) had causal effect on the embodiment of the musicians' expressive intentions.
Figure 2. Stick figure of violinist, this is the back view of the
performer.
For the movement analysis, we assigned to the stick figures frontal view in respect to the two markers on the hips. This step was done in order to standardize the motion capture data. Then we segmented each motion capture recording in four parts based on the score, and we computed the velocities for every marker (120 timeseries = 20 markers x 3 dimensions x 2 performers). The next step was to concatenate the two timeseries for each segment, in order to treat the dyad as a whole. First, we computed the velocities and then we applied concatenation of co-performers in order to eliminate the
31

possibility of applying derivation on non-continuous timeseries, which implements noise in variance. This error was done by the first author in Diapoulis (2016), and the result was that the joint-PCA produced five dimensions for explained variance of 95%.
E. Kinematic Features and Statistical Learning The statistical analysis was based on the global descriptor
of standard deviation for each segment. We applied forward sequential feature selection (FSFS) using cross-validation, in order to identify which markers can better predict the different expressive intentions. For that purpose, we evaluate the performance of both linear and quadratic classifiers of discriminant analysis.
Moreover, we also applied FSFS and backward sequential feature selection (BSFS) on transformed kinematics that we generated by applying joint-PCA on a small subset of ancillary markers (head, root, left and right shoulder). For this purpose, we followed the feature extraction process that we already described, but we focused on the subset of ancillary markers and we applied joint-PCA in advance of calculating the statistical moment of standard deviation. The decision to focus on the subset of ancillary markers, was done due to the fact that the first three principal components generated new synthetic dimensions that describe movement on the mediolateral, anteroposterior and vertical axis (see Introduction). The computational procedure is shown in Figure 3.
Figure 3. Computational process for generating features based on joint principal component analysis.
III. RESULTS We remind the reader that the motion capture segments
were identical to the perceptual stimuli that we used in
Diapoulis (2016). The mean duration of each perceptual stimulus was 8.89 seconds, whereas the mean duration for the exaggerated condition was 9.20 seconds and the mean duration for the deadpan condition was 8.58 seconds.
A. Kinetic Energy For each dyadic performance, we extracted the
instantaneous kinetic energy for each performer using the method used by Toiviainen, Luck & Thompson (2010). The total kinetic energy was estimated as the sum of both performers' translational and rotational energy of each marker. We trimmed each performance from five to twenty-five seconds, and we estimated the kinetic energy within this time span. The total mean instantaneous kinetic energy across all segments for all dyads per expressive condition was .31, .80, 1.20 Joules for deadpan, normal and exaggerated expressive intentions respectively. This measure provides an estimation of the overall physical activity, and provide us the initial evidence to continue to further analysis.
B. Principal component analysis We applied joint-PCA on the ancillary markers, of head,
root, left and right shoulder of the timeseries data. We selected this small subset of ancillary markers, because ancillary gestures have been proposed that play a crucial role in the perception of expressivity (Thompson and Luck, 2012; Wanderley 2002). Furthermore, joint-PCA produced four synthetic dimensions that explained more than 95% of variance (see Table 1), and the first three principal component consist of movements on different axes, which makes the interpretation of the components trivial (see Introduction). Figure 4 shows the principal component loadings matrix based on varimax rotation. The latter is a linear transformation which rotates the coordinate system in order to maximize the explained variance.
Table 1. Explained variance of the first four principal components.
Figure 4. Principal component loadings matrix based on varimax rotation.
Principal Components PC1 PC2 PC3 PC4
Percent of explained variance 72.0 12.7 6.3 4.5
32

C. Feature Selection We applied feature selection on two sets of kinematic
features; the extracted and the generated kinematics. The extracted kinematics described a 60-dimensional space. The global descriptor of standard deviation was extracted for every marker for each segment. The set of the generated features, described a four-dimensional space, based on the global descriptors of standard deviation that was calculated from the joint-PCA for each segment.
1) FSFS on the extracted kinematics. We applied forward sequential feature selection on the global descriptors of all the markers. Our analysis, showed that FSFS using 6-fold cross-validation on a quadratic discriminant classifier predict the expressive intentions of deadpan and exaggerated with 100.0% accuracy based on the confusion matrix. This prediction performed using the kinematic features of standard deviation of the left knee and the head on the vertical axis. We also performed FSFS based on linear discriminant classifier. This approach predicted the expressive intentions with 98.6% accuracy, based on the kinematics of the right ankle and head on the vertical axis.
2) FSFS and BSFS on the generated kinematics. We applied FSFS and BSFS based on the kinematics that were generated from joint-PCA. This analysis showed that the third principal component (PC3) was the best predictor of expressive intentions for both FSFS and BSFS. Using quadratic discriminant analysis (QDA) the accuracy was 97.2% and using linear discriminant analysis (LDA) the accuracy was 93.0%.
IV. DISCUSSION The aim of the study was to identify which kinematics
features can better discriminate performances of deadpan and exaggerated expressive intentions. Three violin dyads participated and they performed a short composition. The instruction given to the violists was to perform the piece under three expressive manners (for details see in Methods, subsection Experimental Design). We segmented the song in four melodic segments based on the score (for detailed information see Diapoulis, 2016), and for each segment we both extracted and generated global descriptors based on velocity timeseries data. The statistical moment of standard deviation was the most appropriate descriptor of expressivity.
Our goal was to identify which kinematic features can better predict intended expressivity in musical dyads. Thus, our focus was to use a variety of machine learning techniques in order to predict the qualities of deadpan and exaggerated expressive intentions. For that purpose, we used both supervised and unsupervised algorithms. Forward sequential feature selection using QDA showed that the velocities of the left knee and the head across the vertical axis are the most important kinematic features. Using LDA the kinematic feature of the left knee was replaced by vertical motion of the right ankle. Furthermore, we applied both FSFS and BSFS on the transformed kinematics (i.e. PCA). Once again, movement on the vertical axis showed to be the most important predictor of expressive intention.
The aforementioned evidence raises questions whether or not the intended expressivity shares the same movement patterns as perceived expressivity. The perception of expressive bodily motion seems to had major influences from
body sway. Our analysis shows that the production of deadpan and exaggerated expressive performance can better discriminated based on movement on the vertical axis. Thus, the results suggest that bodily movement based on motoric experience might not align with visual perception of expressive music performance.
V. CONCLUSION We presented evidence that intended expressive
performance might not share the same movement patterns with visual perception of expressivity. Future studies should focus on the comparison of expert musicians and non-musicians populations in order to study the interaction between motor experience and visual perception of expressive music performance. Ultimately, the focus should be placed on kinematic correlates of intended and perceived expressivity in music performance. Data collection is ongoing and future reports will include more violin dyads.
REFERENCES Broughton, M. C., & Davidson, J. W. (2016). An Expressive Bodily
Movement Repertoire for Marimba Performance, Revealed through Observers' Laban Effort-Shape Analyses, and Allied Musical Features: Two Case Studies. Frontiers in Psychology, 7.
Daffertshofer, A., Lamoth, C. J., Meijer, O. G., & Beek, P. J. (2004). PCA in studying coordination and variability: a tutorial. Clinical biomechanics, 19(4), 415-428.
Dahl, S., & Friberg, A. (2007). Visual Perception of Expressiveness in Musicians9 Body Movements. Music Perception: An Interdisciplinary Journal, 24(5), 433-454.
Diapoulis, G. (2016). Exploring the perception of expressivity and interaction within musical dyads. (Master’s thesis, University of Jyväskylä, Jyväskylä, Finland). Retrieved from http://r.jyu.fi/jXo
Keller, P. E., & Appel, M. (2010). Individual differences, auditory imagery, and the coordination of body movements and sounds in musical ensembles. Music Perception: An Interdisciplinary Journal, 28(1), 27-46.
Leman, M. (2008). Embodied music cognition and mediation technology. Mit Press.
Palmer, C. (1997). Music performance. Annual review of psychology, 48(1), 115-138.
Thompson, M. R., & Luck, G. (2012). Exploring relationships between pianists’ body movements, their expressive intentions, and structural elements of the music. Musicae Scientiae, 16(1), 19-40.
Toiviainen, P., & Burger, B. (2010). Mocap toolbox manual. Online at:http://www.jyu.fi/music/coe/materials/mocaptoolbox/MCTmanual.
Toiviainen, P., Luck, G., & Thompson, M. R. (2010). Embodied meter: hierarchical eigenmodes in music-induced movement. Music Perception: An Interdisciplinary Journal, 28(1), 59-70.
Wanderley, M. M. (2002). Quantitative analysis of non-obvious performer gestures. Lecture notes in computer science, 241-253.
33

Proceedings of the 10th International Conference of Students of Systematic Musicology (SysMus17), London, UK, September 13-15, 2017. Peter M. C. Harrison (Ed.).
Grammaticality Judgments in Linguistic and Musical Structures
Katerina Drakoulaki*1, Robin Lickley#
*Department of Linguistics, Faculty of Philology, School of Philosophy, National and Kapodistrian University of Athens
#Speech and Hearing Sciences Division, School of Health Sciences, Queen Margaret University, Edinburgh
ABSTRACT
Background A common hierarchical organization in language and music
has been speculated with accounts that posit shared syntactic rules (Katz & Pesetsky 2011) or gradient structural constraints (Optimality Theory, Katz 2006). There is evidence that processing of syntactic hierarchical organization is localized in the same cortical areas (BA 44, 45). A shared processing resources network has been suggested (SSIRH, Patel 2008).
Aims It is not clear whether the same syntactic rules are shared or
whether syntactic constraints are organized differently in language and music. It was hypothesized that participants would find stimuli containing syntactic linguistic and musical deviances less acceptable than stimuli containing a linguistic semantic deviance.
Method An online, graded acceptability judgment task was
administered to adults. Stimuli were either read or heard depending on their type. For linguistic syntax, deviant stimuli with adjective-noun mismatch were read; for musical syntax, deviant stimuli with cadence violation were heard (Jentschke et al. 2008). For linguistic semantics, deviant sentences containing reversed thematic roles of non-reversible verbs were read.
Results Judgments were successful altogether; regular stimuli were
given high scoring and irregular stimuli low scoring. Linguistic stimuli caused a binary judgment, with syntactic and semantic regular stimuli receiving the highest possible scoring, while syntactic and semantic irregular stimuli received the lowest possible scoring. Scoring for irregular music stimuli was more evenly distributed. The results were not predicted in the hypothesis.
Conclusions Optimality Theory suggests that constraint rules are
hierarchically organized for each language, resulting in hard and soft constraints. Similarly, Generative Theory of Tonal Music (Lerdahl & Jackendoff 1983) suggests constraint rules. There have been efforts to align these theories for some levels of analysis, although not for syntax. It is suggested that the constraints for linguistic stimuli are hard, whereas the constraint for music stimuli is soft but further research is needed.
Keywords music psychology; psycholinguistics
REFERENCES Jentschke, S., Koelsch, S., Sallat, S., Friederici, A., D. 2008. Children
with Specific Language Impairment also show impairment of music-syntactic processing. Journal of Cognitive Neuroscience. Vol. 20, pp. 1940-1951. doi: 10.1162/jocn.2008.20135
Katz, J. 2006. Language, music and mind: an optimality-theoretic approach. Massachusetts: IT. Retrieved from: www.web.mit.edu/.
Katz, J., Pesetsky, D. 2011. The identity thesis for language and music. Retrieved from: http://ling.auf.net/lingbuzz/000959
Lerdahl, F., Jackendoff, R. 1983. A generative theory of tonal music. Cambridge, Massachusetts: MIT Press
Patel, A. 2008. Music, language, and the brain. New York: Oxford University press.
34

Proceedings of the 10th International Conference of Students of Systematic Musicology (SysMus17), London, UK, September 13-15, 2017. Peter M. C. Harrison (Ed.).
Musical Trajectories and Creative Music Teaching Interventions Affect the Development of Interest in ‘Music’ of German Secondary Schools’ Students
Daniel Fiedler*1, Daniel Müllensiefen#2
*Department of Music, University of Education Freiburg, Germany
#Goldsmiths, University of London, United Kingdom
[email protected], [email protected]
ABSTRACT
Background Trajectories of musical development can be very different
across adolescence and the causes and mechanisms leading to these differences are often the focus of research in music education (e.g., Müllensiefen et al., 2015). To measure the aspects of musical development, the psychometric constructs ‘musical self-concept’ (Spychiger, 2017) and ‘musical sophistication’ (Müllensiefen et al., 2014) as well as ‘interest in music as a school subject’ (Rakoczy et al., 2008) can be used. However, there is no study, which shows that there are different developmental trajectory groups of the constructs ‘musical self-concept’ and ‘musical sophistication’, which differ from the absolute level as well as them continually changing over time. Moreover, there are also only very few studies, which analyses the effects of specific music lessons–especially of creative music teaching interventions (about 10 double-lessons)–on the development of the target variable of this research study ‘interest in music as a school subject’. To analyse these effects, the specific music lessons or the creative music teaching interventions include a higher amount of creative, i.e. productive and transformative, forms of activities as well as methods (e.g., composing, improvising, arranging, dancing or drawing to music etc.).
Aims The aims of this repeated-measurement study with four
different time-points in the school years 2014/2015 and 2015/2016 were: (1) to identify different typical developmental trajectories (regarding the constructs ‘musical self-concept’ and ‘musical sophistication’) within a sample of secondary school students, and (2) to analyse how ‘musical self-concept’ and ‘musical sophistication’ as well as time-shifted creative music teaching interventions contribute to the development of ‘interest in music as a school subject’.
Method Data of 167 students (f = 94, m = 73) from two Grammar
Schools and two Middle Schools are presented. The data comprised the self-assessed psychometric constructs as well as music-specific and demographic background variables (e.g., age, sex, etc.) at four time points across nearly two school years. The data were analyzed using sequence pattern analyses (Aisenbrey & Fasang, 2010; Gabadinho, 2011) and multilevel linear models.
Results The sequence pattern analyses identified three
developmental trajectories of ‘musical self-concept’ and ‘musical sophistication’, which differ from the absolute level as well as them continually changing over time. From these, two typical trajectories of musical development were identified and associations with the variables sex (phi = .299, p ≤ .001), musical status (phi = .229, p ≤ .001), type of school (n. s.), and the overall self-assessed marks in ‘music’ (n. s.) as well as the self-closeness to the school subject ‘music’ (r = .250, p ≤ .001), were found. The multilevel analysis shows that the two typical developmental trajectories affect students’ ‘interest in music as a school subject’ over the four time points. Additional, the multilevel analysis shows that the interest in ‘music’ is decreasing (p ≤ .001), but students in the typical high developmental trajectory demonstrate a significant higher interest in ‘music’ over time (p ≤ .001)–compared to the students in the typical low developmental trajectory. Moreover, a further analysis shows that creative music teaching interventions (p ≤ .05) as well as the typical high developmental trajectory of students (p ≤ .001) affect the development of interest in ‘music’, while ‘interest in music as a school subject’ is generally decreasing over time (p ≤ .001).
Conclusions In summary, the identified two typical developmental
trajectories as well as the creative music teaching interventions (about 10 double-lessons) contribute the development of ‘interest in music as a school subject’ over time. Hence, this study makes an important contribution to the understanding of the mechanisms of musical development during adolescence, and of the effects of of a creative orientation of music lessons.
Keywords Music education, musical developmental trajectories,
musical sophistication, musical self-concept, creative music teaching interventions
REFERENCES Aisenbrey, S. & Fasang, A. E. (2010). New Life for Old Ideas: The
“Second Wave” of Sequence Analysis. Bringing the “Course” Back Into the Life Course. Sociological Methods & Research, 38(3), 420-462.
Gabadinho, A., Ritschard, G., Struder, M. & Müller, N. S. (2011). Minning sequence data in R with the TraMineR package. A user’s guide. University of Geneva. Retrieved from:
35

http://mephisto.unige.ch/pub/TraMineR/doc/TraMineR-Users-Guide.pdf [06/30/2017].
Müllensiefen, D., Gingras, B., Musil, J. & Stewart, L. (2014). The Musicality of Non-Musicians: An Index for Assessing Musical Sophistication in the General Publication. PLoS ONE, 9(2): e89642. doi:10.1371/journal.pone.0089642.
Müllensiefen, D., Harrison, P., Caprini, F., & Fancourt, A. (2015). Investigating the importance of self-theories of intelligence and musicality for students’ academic and musical achievement. Frontiers in Psychology, 6:1702. doi: 10.3389/fpsyg.2015 .01702
Rakoczy, K., Klieme, E., & Pauli, C. (2008). Die Bedeutung der wahrgenommenen Unterstützung motivationsrelevanter Bedürfnisse und des Alltagsbezugs im Mathematikunterricht für die selbstbestimmte Motivation. [The Impact of the Perceived Support of Basic Psychological Needs and of the Perceived Relevance of Contents on Students’ Self-Determined Motivation in Mathematics Instruction]. Zeitschrift für Pädagogische Psychologie, 22, 25-35.
Spychiger, M. (2017). Musical self-concept as a mediating psychological structure. From musical experience to musical identity. In R. MacDonald, D. J. Hargreaves, & D. Miell (Eds.): Handbook of Musical Identity (pp. 267-287). Oxford, UK: Oxford University Press.
36

Proceedings of the 10th International Conference of Students of Systematic Musicology (SysMus17), London, UK, September 13-15, 2017. Peter M. C. Harrison (Ed.).
Chord Encoding and Root-finding in Tonal and Non-Tonal Contexts: Theoretical, Computational and Cognitive Perspectives
Konstantinos Giannos1, Emilios Cambouropoulos2 School of Music Studies, Aristotle University of Thessaloniki, Greece
[email protected], [email protected]
ABSTRACT The concept of root is of great significance in chord encoding in tonal music. Is this notion useful in non-tonal idioms or should it be extended, changed or abandoned in different musical contexts? A series of harmonic excerpts from diverse idioms are examined through the application of different root-finding and chord encoding models, such as Parncutt’s perceptual virtual pitch root-finding model, the harmonic system of Paul Hindemith, and the General Chord Type (GCT) representation. This way, the models are tested in various contexts, such as tonal, neo-tonal, whole-tone or atonal harmonies. In this process, the abstract encoding of chords in diverse tonal or non-tonal contexts is explored, employing a utilitarian notion of ‘reference tone’ in cases where root ambiguity is strong and cannot be resolved.
I. INTRODUCTION In the early 20th century, the concept of tonality has been
brought to its limits. New scales along with new chords have been introduced in the spectrum of composers’ tools. Music theory had to catch up to such innovations, attempting to describe new scales, how new chords are formed and how they fit in the context of a musical piece. The task of describing chords and providing a rather general theory that encodes them has proven to be a difficult task.
In tonal music labelling notations include: a) figured bass (basso continuo, intervals above a given bass note), b) roman numerals (chord functions within a certain key), c) popular music or jazz notation. In atonal and non-tonal music, the concepts of pitch class sets and interval vectors are commonly employed.
In the current paper, an encoding scheme is examined, which aims to be applicable in various idioms in a universal manner. Furthermore, the encoding of chord types is reviewed focusing on the principle of root and on the intervals involved in the simultaneity. Is root useful in every case? Would it be better if it were abandoned or is there a need to be extended or changed? On which principles can one base such a chord labelling system?
II. CHORD ENCODING A. Historical approach on the Concept of Root
Following the seminal reference to the concept of chord in Gioseffo Zarlino’s (1517-90) Le institutioni harmoniche (1558), music theorists attempted to discover the rules that govern chords. Jean-Philippe Rameau (1683-1764), a couple centuries later, discusses major and minor triads. Some important topics include the suggestion that the origin of all
harmonies via various processes are the consonant root-position triad and the dissonant chord of a triad with an added 7th; the notion of the root (son fondamental) as the basis to create a chord is also introduced (Lester, 2007). Rameau realised himself that the system he proposed, regardless its great strengths, had some inadequacies and ambiguities. To illustrate this better he explains that the sixte ajouté, subdominant chord with added 6th, can have double meaning, either as such a subdominant or as a supertonic with added 7th.
A further revolutionary approach on the theory on chords was the functional theory of Hugo Riemann (1849-1919). He tries to solve problems, like the above, by establishing the relation of chords to the three main chord functions in a scale, namely, Tonic (T), Dominant (D) and Subdominant (S).
As music got more complex, no theory was sufficient to deal with the ambiguities that emerged. A work that attempted to fulfil this role, was that of Paul Hindemith (1895-1963) in The Craft of Musical Composition (1937/1945). There, based on principles like the harmonic series and combination tones he proposes two series in which intervals are ordered and become important factors in finding a chord’s root and categorising them in one of the six groups.
B. Chord Grouping as a Result of Categorical Perception Auditory scene analysis suggests that grouping as well as
segregating sound information, are processes of music perception (Bregman, 1990). According to Gestalt psychology, as listeners, we perceive rather complex entities as wholes instead of their constituent parts, as in the case of complex tones or even chords (Vernon, 1934).
To name such musical entities one could mention pitches, intervals, chords, durational relationships, rhythmic patterns, or even phrases and phrase groups (Deutsch, 2013). Of course such entities are not all perceived at the same perceptual level; for instance, chords and any pitch simultaneity may be seen as being significant perceptual ‘primitives’ already at the level of the musical surface (Cambouropoulos, 2010).
Chord labelling means abstracting from a multitude of actual pitch renderings to a sufficiently concise encoding. In order to abstract any chord type, it is necessary to take into account some general characteristics, like perceptual equivalences and similarities. The first characteristic is octave equivalence and the other is the interval equivalence. Octave equivalence refers to the strong perceptual similarity between two tones related by octaves and relates to terms such as pitch classes or tone chroma. As far as the interval equivalence is concerned, it is derived directly from octave equivalence. Pairs of inversion related intervals, also known as interval classes, have a perceptual relationship, a fact noticed by both
37

music theorists (Piston, 1948/1987) as well as by music perception researchers (Plomp, Wagenaar, and Mimpen, 1973; Deutsch and Roll, 1974). However, an interval class may not be perceived directly, but rather as a result of a pitch class and an interval (Deutsch, 2013).
With regards to triads, major and minor chords fall into two distinct perceptual categories (Locke and Kellar, 1973); their inversions aren’t considered as different chords (Hubbard and Datteri, 2001). To compare these two types, they both have a fifth, a minor and a major third, with the thirds being ordered differently within the fifth. Therefore, factors like order of intervals and a tone of reference, or root in this case, seem to play an important role in categorising chord types.
“The roots of non-tertian chords are not defined by any generally accepted theory or by the common agreement of listeners” (Kostka, 2006, p.100-101). It is straightforward to determine the intervals involved in a certain chord, but looking for a root based upon theoretical principles can be a much harder task. The most complete work on the subject comes from Paul Hindemith (1937/1945), which, however, has received criticisms from more recent researchers (Thomson, 1965, 1993; Kostka, 2006; O’Connell, 2011).
There exists an enormous number of possible pitch simultaneities that include different numbers and combinations of notes in various transpositions and inversions. Allen Forte’s (1977) theory reduces chord types to up to 11 sets with cardinality 3, 29 sets with cardinality 4, 35 with 5 and so on. Such a drastic reduction is problematic for tonal music as, for instance, major and minor chords are represented by the same pc-set. On the other hand, the traditional encoding of triad-based chords is insufficient for non-tonal music.
It seems to be interesting and useful to find a method to encode all these pitch combinations that takes into account perceptual factors (e.g. octave and interval equivalence, consonance/dissonance), and at the same time adapts to many different idioms, if not all Western music idioms, in a manner that is appropriate to them. Such a encoding scheme may be used both as an analytical tool and in compositional processes. The General Chord Type (GCT) representation, explained below, aims to cover these goals.
III. THE GENERAL CHORD TYPE REPRESENTATION
It is nearly impossible to use the same tools of music analysis in different music idioms and draw significant results. A special theory has been developed for the atonal, 12-tone or serialism, with regards to 20th century music analysis, that is the set theory, including representations like pitch class sets and interval vectors (Forte, 1977). However, it is debatable if such representations work efficiently in tonal and the non-tonal idioms in between.
In order to deal with the problem of labelling any collection of pitches within a given hierarchy (e.g. key) and also functioning properly in different harmonic contexts, the General Chord Type (GCT) representation has been proposed, which will be described below (Cambouropoulos, Kaliakatsos-Papakostas, Tsougras, 2014).
A. Description of the GCT Algorithm
The GCT algorithm aims to encode any given pitch collection based on two main parameters: a binary classification of consonance and dissonance, and a scale hierarchy. For the first, a 12-value consonance/dissonance vector is introduced, where 0 means dissonance and 1 means consonance. As for the scale, it is necessary for the definitions of a tonic (or reference note) and also to know which chord notes belong to the respective scale.
For example, the regular consonance / dissonance vector for a tonal context is [1,0,0,1,1,1,0,1,1,1,0,0]; this means that the unison, minor and major third, perfect fourth, perfect fifth, minor and major sixth are considered consonant, whereas the rest dissonant, i.e. minor and major second, tritone, minor and major seventh.
Pitch hierarchy (assuming there is one) is given as a ‘tonic’ and its scale tones, e.g. 0 [0,2,4,5,7,9,11] for C major or 3 [0,2,3,5,6,8,9,11] for Eb octatonic (whole-step-half-step scale).
An input chord to the GCT algorithm is given as a list of MIDI numbers which is converted to pitch classes (i.e., MIDI numbers modulo 12) before being fed into the algorithm.
The basics of how this algorithm works on a given input chord is explained here:
GCT Algorithm
find all subsets of pairwise consonant tones select maximal subsets of maximum length for all selected maximal subsets do
order the pitch classes of each maximal subset in the most compact form (chord ‘base’) add the remaining pitch classes (chord ‘extensions’) above the highest pitch of the chosen maximal subset (if necessary, add octave - pitches may exceed the octave range) the lowest tone of the chord is the ‘root’ transpose the tones of chord so that the lowest becomes 0 find position of the ‘root’ in regards to the given tonal centre (pitch scale)
endfor
To illustrate this better, let’s assume the chord consisting of
MIDI pitch numbers 54. 62, 69 and 72 and try to convert them into a GCT representation. Let the key be C major: 0 [0,2,4,5,7,9,11] and consonance / dissonance vector as above. The pitches mod12 equal to [6,2,9,0] and are ordered from lower to higher [0,2,6,9].
We observe that the maximal consonant subset appears to be [2,6,9] (the rest with only two elements are [2,6], [2,9], [0,9] and [6,9]), and is considered the ‘base’ of the representation. Tone 0 is added to the right as an extension and is written as [2,6,9,12]. Comparing it with the given scale, 2 becomes the ‘root’ of the chord and it is rewritten as [2,[0,4,7,10]]. The specific chord is a major 7th chord on the 2nd degree, note D, i.e., the secondary dominant in C major.
B. Evaluating the GCT Representation The GCT algorithm has been tested in a tonal context
against the Kostka-Payne harmonic analysis dataset created by
38

David Temperley, where the automatic chord labelling was correct by 92.16%, compared to the Kostka-Payne ground truth (Kaliakatsos-Papakostas, Zacharakis, Tsougras, Cambouropoulos, 2015).
Even though the aim of GCT is to be applied in many other non-tonal music idioms, it has not been tested systematically on them yet. The difficulty of this task resides on the lack of a systematic approach to label symbolically the chords used in non-tonal music. Therefore, it is difficult to find similar ground truth for 20th century harmonic styles.
It is important to note that, the application of the GCT both as an analytical and compositional tool depends on the user’s settings. The algorithm labels given simultaneities (taken from a harmonic reduction that has been manually constructed); it does not produce harmonic reduction and analyses automatically. However, the fact that one can ‘learn’ from data which chords comprise a specific idiom, and thus occur more often, can lead the algorithm a step further in doing a harmonic reduction itself.
IV. ROOT-FINDING IN NON-TONAL CONTEXTS
In this part, the effectiveness of GCT on finding a tone upon on which a chord is built will be evaluated, compared with Parncutt’s tonal root-finding model (1997) based on Terhardt’s theory of virtual pitch and the ‘universal’ theory of chord roots proposed by Hindemith (1937/1945). Apart from that, it will be paralleled with the abstract encodings of Forte’s pc-sets and their efficiency on different contexts.
Note that in the current paper, the step of voicing in Parncutt’s model is omitted, because in non-tonal contexts all the resulting values are really close to each other. If it is taken into account the weighted bass note tends to become the respective perceptual pitch. Also, the application of Krumhansl/Kessler profiles (1982) is being the same as the one in Parncutt (2007), where he examines the profiles of Tn-Types. It is agreed that since the concept of tonality doesn’t fit on the examined excerpts, Krumhansl/Kessler profiles would bias mistakenly the results.
The application of the three models in a tonal context is tested on Beethoven’s Sonata op.27 no.2 (Figure 1). All three models agree on the same roots. Here the standard concept of root can be observed. Note that Parncutt’s model suggests two possible roots, because it isn’t used in its full version. As far as set theory is concerned, it is less efficient to provide information on the chord degrees, thus their function in the key, and the different types of chords, since major and minor chords group together.
In Table 1 below, which corresponds to Figure 1, the pitch classes of the chords, their respective prime forms and GCTs are presented. GCTs appear in two forms: one with the ‘standard’ tonal consonance vector and one with a vector where all intervals are ‘consonant’, all vector entries are 1 (abbr. GCT-all1). With regards to tonal consonance GCTs, both the degrees and the chord types are described. The first part explains the position of the chord in the scale, while the latter the intervals comprising the chord.
Figure 1 Reduction of m.1-5 of Beethoven’s Piano Sonata op.27 no.2.
Obviously, it is ineffective to analyse tonal music harmonically with set theory. It is claimed that octave equivalence and inversional equivalence are shared features of all – at least Western music – idioms’ analysis. However, inversion is used slightly differently in the two contexts. For instance, in atonal music it refers to setting the order of intervals of a pitch-class set in reverse (Kostka, 2006). Whereas in tonal idioms, or idioms that have a tonal component, it seems that the order of intervals in a pitch simultaneity is important.
Table 1 List of representations for Beethoven op.27 no.2.
PCs Forte sets GCT GCT_all1
1 4 8 0 3 7 0 0 3 7 0 0 3 7 1 4 8 11 0 3 5 8 0 0 3 7 10 7 0 3 5 8 1 4 9 0 3 7 8 0 4 7 8 0 4 7 2 6 9 0 3 7 1 0 4 7 1 0 4 7 0 6 8 0 2 6 7 0 4 10 5 0 2 6 1 4 8 0 3 7 0 0 3 7 0 0 3 7 0 3 6 8 0 2 5 8 7 0 4 7 10 11 0 3 6 8* 1 4 8 0 3 7 0 0 3 7 0 0 3 7
Apart from atonal music, where tonality is non-existent, one can discover tonal centres in other non-tonal idioms. Kostka (2006) calls the method to establish a tonal centre in such works, tonic by assertion, and is achieved by “the use of reiteration, return, pedal point, ostinato, accent, formal placement, register, and similar techniques” (p.102).
The next two examples, figure a tonal centre, so it can be used as a reference in a pitch hierarchy. In the Hindemith excerpt (Fig. 2), a B appears as a drone tone in the soprano, while there is a melodic movement around E in the bass. E is picked between the two as the main pitch reference, and the pitch hierarchy suggested is E mixolydian, or in GCT notation 4 [0,2,4,5,7,9,10].
The excerpt from Scriabin’s etude (Fig. 3) is a bit more complex. There are two whole tone scales in m. 1,3-4 and m. 2 respectively. It is very hard to say which are the bases of those two scales. The chromatic scale can be a common reference point for the whole excerpt, also because it deals with the interchange between two scales in such a short period.
39
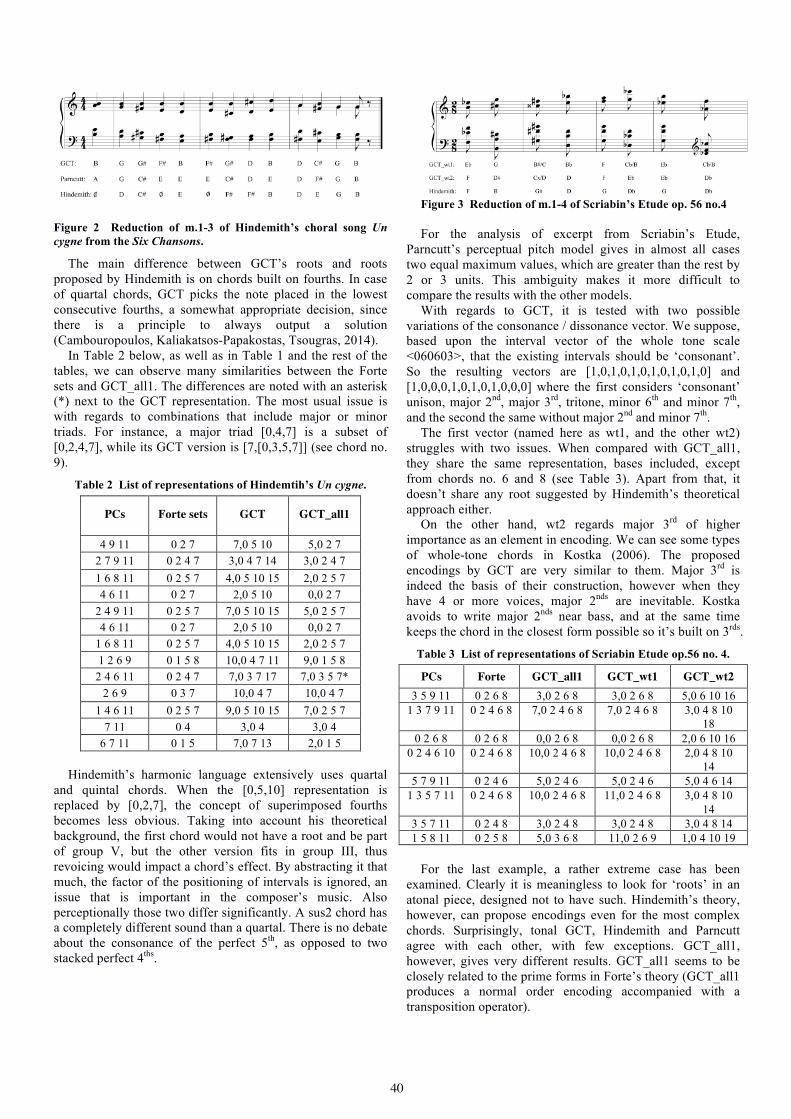
Figure 2 Reduction of m.1-3 of Hindemith’s choral song Un cygne from the Six Chansons.
The main difference between GCT’s roots and roots proposed by Hindemith is on chords built on fourths. In case of quartal chords, GCT picks the note placed in the lowest consecutive fourths, a somewhat appropriate decision, since there is a principle to always output a solution (Cambouropoulos, Kaliakatsos-Papakostas, Tsougras, 2014).
In Table 2 below, as well as in Table 1 and the rest of the tables, we can observe many similarities between the Forte sets and GCT_all1. The differences are noted with an asterisk (*) next to the GCT representation. The most usual issue is with regards to combinations that include major or minor triads. For instance, a major triad [0,4,7] is a subset of [0,2,4,7], while its GCT version is [7,[0,3,5,7]] (see chord no. 9).
Table 2 List of representations of Hindemtih’s Un cygne.
PCs Forte sets GCT GCT_all1
4 9 11 0 2 7 7,0 5 10 5,0 2 7 2 7 9 11 0 2 4 7 3,0 4 7 14 3,0 2 4 7 1 6 8 11 0 2 5 7 4,0 5 10 15 2,0 2 5 7 4 6 11 0 2 7 2,0 5 10 0,0 2 7
2 4 9 11 0 2 5 7 7,0 5 10 15 5,0 2 5 7 4 6 11 0 2 7 2,0 5 10 0,0 2 7
1 6 8 11 0 2 5 7 4,0 5 10 15 2,0 2 5 7 1 2 6 9 0 1 5 8 10,0 4 7 11 9,0 1 5 8
2 4 6 11 0 2 4 7 7,0 3 7 17 7,0 3 5 7* 2 6 9 0 3 7 10,0 4 7 10,0 4 7
1 4 6 11 0 2 5 7 9,0 5 10 15 7,0 2 5 7 7 11 0 4 3,0 4 3,0 4
6 7 11 0 1 5 7,0 7 13 2,0 1 5 Hindemith’s harmonic language extensively uses quartal
and quintal chords. When the [0,5,10] representation is replaced by [0,2,7], the concept of superimposed fourths becomes less obvious. Taking into account his theoretical background, the first chord would not have a root and be part of group V, but the other version fits in group III, thus revoicing would impact a chord’s effect. By abstracting it that much, the factor of the positioning of intervals is ignored, an issue that is important in the composer’s music. Also perceptionally those two differ significantly. A sus2 chord has a completely different sound than a quartal. There is no debate about the consonance of the perfect 5th, as opposed to two stacked perfect 4ths.
Figure 3 Reduction of m.1-4 of Scriabin’s Etude op. 56 no.4 For the analysis of excerpt from Scriabin’s Etude,
Parncutt’s perceptual pitch model gives in almost all cases two equal maximum values, which are greater than the rest by 2 or 3 units. This ambiguity makes it more difficult to compare the results with the other models.
With regards to GCT, it is tested with two possible variations of the consonance / dissonance vector. We suppose, based upon the interval vector of the whole tone scale <060603>, that the existing intervals should be ‘consonant’. So the resulting vectors are [1,0,1,0,1,0,1,0,1,0,1,0] and [1,0,0,0,1,0,1,0,1,0,0,0] where the first considers ‘consonant’ unison, major 2nd, major 3rd, tritone, minor 6th and minor 7th, and the second the same without major 2nd and minor 7th.
The first vector (named here as wt1, and the other wt2) struggles with two issues. When compared with GCT_all1, they share the same representation, bases included, except from chords no. 6 and 8 (see Table 3). Apart from that, it doesn’t share any root suggested by Hindemith’s theoretical approach either.
On the other hand, wt2 regards major 3rd of higher importance as an element in encoding. We can see some types of whole-tone chords in Kostka (2006). The proposed encodings by GCT are very similar to them. Major 3rd is indeed the basis of their construction, however when they have 4 or more voices, major 2nds are inevitable. Kostka avoids to write major 2nds near bass, and at the same time keeps the chord in the closest form possible so it’s built on 3rds.
Table 3 List of representations of Scriabin Etude op.56 no. 4.
PCs Forte GCT_all1 GCT_wt1 GCT_wt2 3 5 9 11 0 2 6 8 3,0 2 6 8 3,0 2 6 8 5,0 6 10 16
1 3 7 9 11 0 2 4 6 8 7,0 2 4 6 8 7,0 2 4 6 8 3,0 4 8 10 18
0 2 6 8 0 2 6 8 0,0 2 6 8 0,0 2 6 8 2,0 6 10 16 0 2 4 6 10 0 2 4 6 8 10,0 2 4 6 8 10,0 2 4 6 8 2,0 4 8 10
14 5 7 9 11 0 2 4 6 5,0 2 4 6 5,0 2 4 6 5,0 4 6 14
1 3 5 7 11 0 2 4 6 8 10,0 2 4 6 8 11,0 2 4 6 8 3,0 4 8 10 14
3 5 7 11 0 2 4 8 3,0 2 4 8 3,0 2 4 8 3,0 4 8 14 1 5 8 11 0 2 5 8 5,0 3 6 8 11,0 2 6 9 1,0 4 10 19
For the last example, a rather extreme case has been examined. Clearly it is meaningless to look for ‘roots’ in an atonal piece, designed not to have such. Hindemith’s theory, however, can propose encodings even for the most complex chords. Surprisingly, tonal GCT, Hindemith and Parncutt agree with each other, with few exceptions. GCT_all1, however, gives very different results. GCT_all1 seems to be closely related to the prime forms in Forte’s theory (GCT_all1 produces a normal order encoding accompanied with a transposition operator).
40

Figure 4 m.1-4 of Webern’s choral song Entflieht auf leichten Kähnen op.2.
Table 4 List of representations of Webern’s Entflieht auf leichten Kähnen op.2.
PCs Forte sets GCT GCT-all_1
2 5 9 11 0 2 5 8 2,0 3 7 9 9,0 2 5 8 0 4 6 10 0 2 6 8 0,0 4 6 10 4,0 2 6 8 2 7 11 0 3 7 7,0 4 7 7,0 4 7* 0 4 8 0 4 8 0,0 4 8 0,0 4 8
1 5 9 10 0 1 4 8 10,0 3 7 11 9,0 1 4 8 4 5 9 0 1 5 5,0 4 11 4,0 1 5
4 6 7 10 0 2 3 6 4,0 3 6 14 4,0 2 3 6 2 6 7 11 0 1 5 8 7,0 4 7 11 6,0 1 5 8 1 2 8 10 0 1 4 6 10,0 3 4 10 8,0 2 5 6*
0 4 9 0 3 7 9,0 3 7 9,0 3 7 1 8 10 0 2 5 10,0 3 10 8,0 2 5 4 7 10 0 3 6 4,0 3 6 4,0 3 6
2 6 8 11 0 2 5 8 11,0 3 7 9 6,0 2 5 8 1 5 8 9 0 1 4 8 1,0 4 7 8 5,0 3 4 8* 0 5 9 0 3 7 5,0 4 7 5,0 4 7*
1 5 7 10 0 2 5 8 10,0 3 7 9 5,0 2 5 8 3 7 10 11 0 1 4 8 3,0 4 7 8 7,0 3 4 8* 2 8 10 11 0 2 3 6 8,0 3 6 14 8.0 2 3 6 2 5 9 10 0 1 5 8 10,0 4 7 11 9.0 1 5 8
V. CONCLUSION Tonal ambiguity in non-tonal – even in some tonal –
contexts has been a hard issue to resolve, since the conception of ‘chord’ and ‘root’. For sure, naming roots considering the general existing hierarchies might lead to fallacies, like in atonal music. Nevertheless, when we decide to encode a symmetrical or a complex non-tertian chord it is necessary to reach a ‘reasonable’ solution. Topics in categorical perception make the whole enterprise of encoding chords an interesting problem.
GCT representation works effectively in tonal idioms, when tested against standard harmonic ground truth data or compared with other models, such as Parncutt’s perceptual root model. As far as Hindemith’s neo-tonal music, the representation of quartals was sufficient also with regards to maintaining the order of intervals in a chord. For different pitch hierarchies, like the whole-tone idiom, it is not trivial to encode chords effectively. Interval vectors can be a useful tool to deal with them. Seconds, when considered ‘consonant’ in the above examples, had the tendency to preoccupy the representations in comparison to other intervals. This can be seen between GCT_all1 and GCT_wt1.
Apart from those idioms, GCT works well in atonal music. The flexibility of the consonance/dissonance vector, makes GCT_all1 similar to Forte’s prime forms (literally identical to Tn-transposition-related normal orders). With regards to
Hindemith’s theory, it isn’t accepted by many theorists and can only be loosely applied in atonal settings. Parncutt’s perceptual root-finding model was primarily designed for tonal music, but it might be extended if empirical results come up from research similar to that of Krumhansl and Kessler (1982).
Forte’s prime forms are based on the structure of intervals in a pitch class set, omitting the need to a referential point. However, it seems necessary, when the existing tonality, whichever its use, is taken into account. Although, it is uncertain whether the strict mathematical abstraction of Forte’s prime forms or the more generic one of GCT fits better at the concepts of categorical perception suggested in the beginning.
ACKNOWLEDGMENT I would like to thank Maximos Kaliakatsos-Papakostas for
his help about the algorithmic applications and Costas Tsougras for his theoretical insights.
REFERENCES Bernstein, D. W. (2007). Nineteenth-century harmonic theory. In
Christensen, T. (Ed.) The Cambridge History of Western Music Theory (pp. 778-811). Cambridge University Press.
Bregman, A. S. (1990). Auditory Scene Analysis: The Perceptual Organization of Sound. Cambridge, MA: MIT Press.
Cambouropoulos, E. (2010). The Musical Surface: Challenging Basic Assumptions. Musicae Scientiae, 131-147.
Cambouropoulos, E., Kaliakatsos-Papakostas, M., & Tsougras, C. (2014). An Idiom-independent Representation of Chords for Computational Music Analysis and Generation. Proceedings of the Joint 11th Sound and Music Computing Conference (SMC) and 40th International Computer Music Conference (ICMC). Athens.
Cambouropoulos E. (2015) The Harmonic Musical Surface and Two Novel Chord Representation Schemes. In Meredith. D. (Ed.), Computational Music Analysis, (pp.31-56), Springer.
Deutsch, D. (2013). Grouping Mechanisms in Music. In D. Deutsch (Ed.), Psychology of Music (pp. 183-248). San Diego: Elvesier Academic Press.
Deutsch, D. (2013). The Processing of Pitch Combinations. In D. Deutsch (Ed.), Psychology of Music (pp. 249-325). San Diego: Elvesier Academic Press.
Deutsch, D., & Roll, P. L. (1974). Error patterns in delayed pitch comparison as a function of relational context. Journal of Experimental Psychology, 103, 1027-1034.
Forte, A. (1977). The Structure of Atonal Music. New Haven, CT: Yale University Press.
Hindemith, P. (1945). The Craft of Musical Composition. (A. Mendel, Trans.). New York: Associated Music Publishers, Inc. (Original work published 1937)
Hubbard, T. L., & Datteri, D. L. (2001). Recognizing the component tones of a major chord. American Journal of Psychology, 114(4), 569-589.
Kaliakatsos-Papakostas M., Zacharakis A., Tsougras C., Campouropoulos E. (2015). Evaluating the General Chord Type Representation in Tonal Music and Organising GCT Chord Labels in Functional Chord Categories. Proceedings of the 16th International Society for Music Information Retrieval Conference (ISMIR). Malaga.
Kostka, S. (2006). Materials and Techniques of Twentieth-Century Music. New Jersey: Pearson Prentice Hall.
Krumhansl, C. L. (2001). Cognitive Foundations of Musical Pitch. New York, NY: Oxford University Press.
41

Krumhansl, C. L., & Kessler, E. J. (1982). Tracing the Dynamic Changes in Perceived Tonal Organization in a Spatial Representation of Musical Keys. Psychological Review, 89, 334-368.
Lester, J. (2007). Rameau and eighteenth-century harmonic theory. In Christensen, T. (Ed.) The Cambridge History of Western Music Theory (pp. 753-777), Cambridge University Press.
Locke, S. & Kellar, L. (1973). Categorical Perception in a non-Linguistic Mode. Cortex, 9, 355-369.
O’Connell, K. (2011). Hindemith’s voices. The Musical Times, 152(1915), 3-18. Retrived January 23, 2017, from http://www.jstor.org/stable/23039710
Parncutt, R. (1997). A Model of the Perceptual Root(s) of a Chord Accounting for Voicing and Prevailing Tonality. In Music, Gestalt, and Computing (Vol. 1317, Lecture Notes in Computer Science, pp. 181-199). Berlin: Springer.
Parncutt, R. (2009). Tonal implications of harmonic and melodic Tn-Types. In T. Klouche & T. Noll (Eds.), Mathematics and Computation in Music (pp. 124-139). Berlin Heidelberg: Springer.
Persichetti, V. (1961). Twentieth-Century Harmony: Creative Aspects and Practice. New York: W. W. Norton & Company
Piston, W. (1987). Harmony (2nd ed.). London, England: Norton. (Original work published 1948)
Plomp, R., Wagenaar, W. A., & Mimpen, A. M. (1973). Musical Interval Recognition with Simultaneous Tones. Acustica, 29, 101-109.
Thomson, W. (1965). Hindemith's Contribution to Music Theory. Journal of Music Theory, 9(1), 52-71. Retrieved January 23, 2017, from http://www.jstor.org/stable/843149
Thomson, W. (1993). The Harmonic Root: A Fragile Marriage of Concept and Percept. Music Perception 10(4), 385-415.
Vernon, P. E. (1934). Auditory perception. I. The Gestalt approach. II. The evolutionary approach. British Journal of Psychology, 25, 123-139; 265-283.
42

Proceedings of the 10th International Conference of Students of Systematic Musicology (SysMus17), London, UK, September 13-15, 2017. Peter M. C. Harrison (Ed.).
Visual Feedback in Higher Education Piano Learning and Teaching Luciana F. Hamond
Baden Powell Music School – FAETEC-RJ, Brazil [email protected]
ABSTRACT Feedback is crucial for learning; in piano learning, feedback is both intra- and inter-personal. Evidence indicates that the application of visual feedback can enhance instrumental and singing learning. However, what is not yet clear is exactly how visual feedback might be used in higher education piano studios. An exploratory study (Hamond, 2017) was conducted to investigate the pedagogical uses of additional visual feedback generated by technology in higher education piano studios. Three teacher-student pairs in higher education in Brazil and the researcher, as technology-mediator, participated in this study. Each pair chose a movement of a classical sonata of their current repertoire to work on in two piano lessons. The technology system involved a digital piano, connected with a laptop running Digital Audio Workstation (DAW) software (Cockos’ Reaper) via MIDI interface, and an additional PC screen. Data collection encompassed the video observation of two lessons, interviews with participants, and MIDI data. A multi-methods Qualitative Data Analysis (QDA) was used: thematic analysis for videos and interviews, microstructure analysis of musical behavior in videoed lessons, and MIDI QDA. Real-time and post-hoc visual feedback was generated by the technology system, combined or not with auditory feedback. Results indicated that additional visual feedback can augment intrapersonal feedback, enhance conscious-awareness of students’ performances and subsequently enhance learning and performance. Teacher-student pairs differed in preferences when using either auditory or visual feedback.
I. INTRODUCTION Feedback makes learning possible. The impact of feedback
on learning has been indicated in the literature of cybernetics (Schwartz & Andrasik, 2003; Annett, 1969; Wiener, 1961), motor control and learning (Gibson, 1968; Magill, 1989; Schmidt & Lee, 2011), music learning (e.g. Welch, 1983, 1985a, 1985b) and one-to-one instrumental and vocal learning (Creech & Gaunt, 2012, for an overview). A master-apprenticeship model has been noted in one-to-one instrumental and vocal learning in several studies (e.g. Hallam, 1998; Jørgensen, 2000) ‘where the dominating mode of student learning is imitation’ (Jørgensen, 2000, p. 68). Some research has highlighted the supportive use of technology in one-to-one instrumental learning ‘as a medium of transformative change’ (Creech & Gaunt, 2012, p.701) towards ‘student reflection, autonomy [and] motivated, self-directed learning’ (Creech & Gaunt, 2012, p. 703).
The provision of feedback is a crucial aspect of ensuring learning in educational environments. Feedback can be defined as the “information provided by an agent (e.g., teacher, peer, book, parent, self, experience) regarding aspects of one’s performance or understanding” (Hattie & Timperley, 2007, p.81). In instrumental and vocal learning, the nature of
feedback is both intra- and interpersonal (Hamond, 2017; Welch et al., 2005). Intrapersonal feedback occurs within the individual (i.e. the student) and primarily involves the sensory system. In piano learning and playing, intrapersonal feedback is mainly auditory (Banton, 1995; Finney, 1997), visual (Banton, 1995; Bishop & Goebl, 2015) and proprioceptive (Brown & Palmer, 2012; Wöllner & Williamon, 2007). Intra-personal feedback in piano learning also encompasses other internal processes such as the conscious-awareness state of the individual (Acitores, 2011), metacognitive knowledge (Hallam, 2001), self-regulatory skills (Nielsen, 2001), and a sense of self (Damasio, 2000) which also play their roles in learning.
In piano learning and teaching, there are two types of inter-personal feedback: (a) between the teacher and the student; and (b) between individuals and a technology system. Interpersonal feedback involves information which is delivered by the teacher in order to improve a student’s performance. Inter-personal feedback in piano learning is both verbal and non-verbal. Types of verbal and non-verbal feedback in piano learning were observed in several studies (Benson & Fung 2005; Burwell 2010; Hamond 2013; Siebenaler 1997). Types of verbal feedback involve: giving directions or instructions, providing information, asking questions, offering general feedback – positive, negative or ambiguous, and also off-task comments. Types of non-verbal feedback encompass: teacher’s playing or singing, teacher’s modelling, teacher’s imitating student’s playing, making hand gestures, body movements, conducting, tapping the pulse, and also smiling, laughing, nodding, shaking, as well as using other facial expressions.
Interpersonal feedback can also occur between individuals and technology. The perspectives of teachers, expert pianists and students on the use of technology in instrumental learning have been investigated in several studies (Benson, 1998; Daniel, 2001; Riley, 2005; Tomita & Barber, 2008). Various types of technology have been investigated in these studies: video recording (Daniel, 2001), MIDI protocols and piano roll visualization (Riley, 2005; Tomita & Barber, 2008), and instructional media (Benson, 1998). However, these studies investigated the application of technology based on student self-reports and self-assessment (Benson, 1998; Daniel, 2001; Riley, 2005; Tomita & Barber, 2008).
The application of real-time visual feedback, as a new technology system, has been investigated by several studies in instrumental and vocal learning (Brandmeyer, 2006; Sadakata et al., 2008; Welch, 1983, 1985b; Welch et al., 2005). Real-time visual feedback was researched in tapping and percussion learning when imitating rhythms (Brandmeyer, 2006; Sadakata et al., 2008). The benefits and limitations of
43

using real-time visual feedback were investigated in higher education singing studios (Welch, 1983, 1985b; Welch et al., 2005).
Different types of technology have been used in piano-related studies (François, Chew, & Thurmond, 2007; Himonides, 2012; McPherson, 2013). Measurements and assessments of piano performance practices and /or improvisations have been conducted when using different types of technologies with visual feedback (François et al., 2007; McPherson, 2013). However, the use of technology in higher education piano studios, especially for the use of additional visual feedback, seems to be under-researched.
II. METHOD For this research I used an action-case study (Braa &
Vidgen, 1999), a hybrid methodology where aspects of case study and action research can be combined. Data collection involved three sources: video recording of two piano lessons (n = 6), audio recorded interviews with teachers and students separately (n = 12) after each piano lesson, and technology-generated MIDI data. A multi-method qualitative data analysis approach was adopted in this study: thematic analysis (Braun & Clarke, 2008) was adopted for video and interview data, microstructure analysis of the musical behaviour such as playing and listening back (Demos & Chaffin, 2009), as well as MIDI technology-generated data qualitative data analysis.
A. Ethical Review This study used British Educational Research Association
(BERA, 2011) guidelines and obtained ethical approval by the advisory committee of the UCL Institute of Education, University College London. All the participants received an information leaflet describing the nature of this research and the confidentiality of this study. Although participation in this study was voluntary, participants had their travel expenses reimbursed. Participants had the opportunity to ask the researcher questions about the study in advance. They also signed a consent form before taking part in the study.
B. Participants The participants (n = 6) in the study were three piano
teachers and one of their piano students (principal or second instrument) in higher education in Brazil. At the time the data was collected (between November 2013 and February 2014) the piano teachers had an average age of 49, while the average age of the piano students was 26. Teachers had an average of 25 years’ teaching experience. Participants had to fall into the following criteria to be part of thes study: (a) be teacher-student pairs in higher education; (b) have worked on a regular weekly one-to-one basis for at least one term; and (c) have chosen a memorized piece from their current repertoire to work on in two piano lessons with the technology system. The three pairs chose to work on one movement of a classical sonata. The researcher also participated in this study by playing the facilitator role with the technology system in two piano lessons. The three pairs are called case studies A, B and C. Students in case study B and C were principal instrument piano students whilst the student in case study A was a second instrument piano student.
C. Materials The technology system encompassed: a digital piano, two
MIDI cables, a laptop computer running Cockos’ Reaper DAW software with piano roll screen option via a MIDI interface, one additional PC computer screen to be placed in front of the piano student, and one VGA cable to connect the laptop computer and the additional PC screen. The technology system allowed the collection of MIDI data on the DAW software. The equipment used to collect the video and interview data involved: two digital cameras, two tripods for the digital cameras, and one voice recorder.
D. Procedure Each teacher-student pair had two piano lessons videoed
alongside the application of the technology system which was facilitated by the researcher (the author). During the two piano lessons, a large amount of MIDI technology-generated data was recorded at the DAW software Cockos’ Reaper whilst participants played the piano; this data could be played back alongside visualizations of participants’ performances as a piano-roll form. The main data collection and analyses were video and MIDI. Interviews were conducted in order to complement the findings from the video and MIDI QDA. Semi-structured interviews were conducted after each piano lesson with each participant separately. The interviews focused on participant perspectives on the application of this technology system, particularly visual feedback, in a higher education piano studio. Participants’ reports on their background, piano learning and teaching experiences, were also examined. In the piano lessons, teacher-student pairs were asked to choose a memorized piece from their current repertoire. The chosen piano pieces were one movement of a classical sonata: (a) Mozart Piano Sonata No.16 in C major, K.545, 2nd movement, in case study A; (b) Beethoven Piano Sonata No.9 in E major, Op.14 No.1, 1st movement, in case study B; and (c) Mozart Piano Sonata No.2 in F major, K.280, 1st movement, in case study C. All students also brought the respective scores to the lessons so that their teachers could check the musical notation whilst they were playing. The average duration of each lesson was 55 minutes. The interval between the first and second lessons was 4 days in case study A, 9 days in case study B, and 7 days in case study C. These lesson interval differences do not appear to have interfered with the results of this study. Each piano lesson was video recorded using two digital cameras: one camera captured the interaction between the participants and the other camera focused on what was happening on the additional PC screen.
E. Analysis A multi-method qualitative analysis was adopted in this
study. Video QDA involved the thematic analysis of the videoed lessons for: (1) the nature of feedback; (2) the pedagogical uses of technology-mediated feedback; and (3) additional auditory feedback accordingly with the musical behaviour. MIDI QDA encompassed the qualitative analysis of the performance-related data which was available on the computer screen after being recorded on the DAW software. Interview QDA involved the thematic analysis of the interview data by complementing the findings of the two main sources: video and MIDI. A triangulation of data collection and analysis was conducted in order to ensure trustworthiness
44

and assure quality criteria in this qualitative research study (Guba, 1981; Shenton, 2004).
III. RESULTS Findings of the video QDA suggested that the nature of
interpersonal feedback (between teacher and student) is verbal and non-verbal feedback. Types of verbal feedback were related to the following behaviours: providing information, giving direction, and asking questions. Types of non-verbal feedback were linked with the following behaviours: head and body movements, hand gestures, pointing (to the music score or computer screen), playing and singing. Types of verbal and non-verbal feedback were related with three main areas: music, performance and technology. Music regarded the aspects of musical notation, and musical structure of the piece. Performance was linked to aspects of the musical performance such as dynamics, articulation, melodic and rhythmic accuracy, phrasing and pedalling. Technology was related to the MIDI parameters, i.e. MIDI note colours, sizes, asynchrony, key velocity number, MIDI recording version, and digital piano use.
Video QDA focused on the pedagogical technology-mediated feedback uses which were facilitated by the researcher in the piano lessons. Results of this video QDA suggest that pedagogical uses of this technology system can be: (1) in real-time; (2) post-hoc in the original tempo; (3) post-hoc at a slower tempo; and (4) silent post-hoc (without auditory feedback). Real-time feedback use was available to participants when participants played the digital piano whilst the researcher recorded the performance-related data. Post-hoc feedback use was available to participants when the researcher played the previously recorded performance-related data back to participants. Post-hoc feedback use involved listening back to the performance-related data or/and seeing the piano-roll visualization of the performances for enhancing piano learning and performance. Post-hoc feedback could be: (a) in the original tempo when the performance-related data was played back exactly the same as it was played/recorded; and at a slower tempo when the performance-related data was played back at half speed of the original tempo. Post-hoc feedback could also be: (a) normal when auditory feedback was available; and (b) silent when auditory feedback was not available (visual feedback only). The three case studies used post-hoc feedback in the original tempo. However, some pedagogical uses of technology-mediated feedback were particular to each case study. Real-time feedback use for individual experience and silent post-hoc feedback use was a characteristic of case study A. Real-time feedback for shared experience featured in case study B. Post-hoc feedback use at a slower tempo was an observed characteristic of case study C.
Video QDA for musical behaviours examined pedagogical uses of additional auditory feedback across case studies. Auditory feedback which was available in lessons was systematically analysed through the use of the Study Your Musical Practice (SYMP) software developed by Demos & Chaffin (2009) for individual musical practice. In this study, the SYMP software template was customized for musical behaviours (playing and listening back) in piano lessons with the application of technology-mediated feedback. Findings of this video QDA suggested that additional auditory feedback could be: (1) in real-time for the moments where the
participants were playing the piano; (2) and post-hoc for the moments where participants listened back to their recorded performance-related data. Additional auditory feedback involved auditory feedback which was not commonly found in one-to-one piano lessons: this was post-hoc feedback which was combined with visual feedback. Additional auditory feedback varied in three aspects: (a) performer (the student, the teacher, or both); (b) the musical excerpt (the bar group of the musical structure of the piano piece); and (c) the version of the recorded performance data (1st version, 2nd version, etc.).
MIDI QDA focused on the pedagogical uses of additional visual feedback in piano lessons with the application of technology-mediated feedback. Findings of MIDI QDA suggested that visual feedback could be: in real-time (Figure 1) and post-hoc (Figure 2). Real-time or post-hoc visual feedback use involved seeing the piano-roll visualization of the performances for enhancing piano learning and performance whilst playing/recording or seeing/playing back the performance-related data. Real-time feedback use happened for two purposes: (a) individual experience: when the student used it for their own learning needs; and (b) shared experience: when both teacher and student used it for a particular lesson focus. Post-hoc feedback use was available to participants when the researcher played the previously recorded performance-related data back to participants. Post-hoc feedback use happened in three categories: (a) shared experience purpose when the teacher was working alongside student with visual feedback combined with auditory feedback; (b) silent mode purpose (visual feedback only); and (c) attentive listening purpose. Findings of the MIDI QDA suggest that additional visual feedback can make the lesson focus clearer for the following parameters: articulation, dynamics, melodic and rhythmic accuracy, as well as pedal use. An example of a musical excerpt and the respective additional visual feedback in real-time and post-hoc of the performance-related data generated by the technology system is given below.
Figure 1. Musical excerpt of Mozart Piano Sonata No. 16 in C major, K. 545, second movement, bars 1-4
45
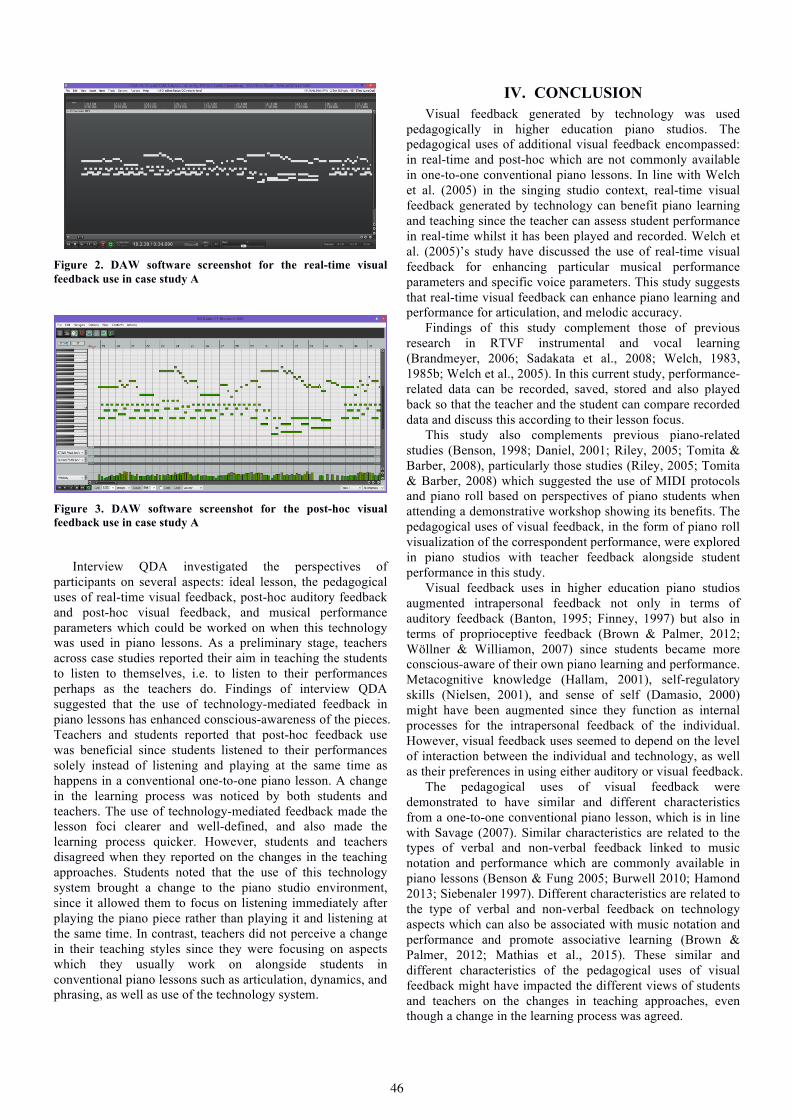
Figure 2. DAW software screenshot for the real-time visual feedback use in case study A
Figure 3. DAW software screenshot for the post-hoc visual feedback use in case study A
Interview QDA investigated the perspectives of participants on several aspects: ideal lesson, the pedagogical uses of real-time visual feedback, post-hoc auditory feedback and post-hoc visual feedback, and musical performance parameters which could be worked on when this technology was used in piano lessons. As a preliminary stage, teachers across case studies reported their aim in teaching the students to listen to themselves, i.e. to listen to their performances perhaps as the teachers do. Findings of interview QDA suggested that the use of technology-mediated feedback in piano lessons has enhanced conscious-awareness of the pieces. Teachers and students reported that post-hoc feedback use was beneficial since students listened to their performances solely instead of listening and playing at the same time as happens in a conventional one-to-one piano lesson. A change in the learning process was noticed by both students and teachers. The use of technology-mediated feedback made the lesson foci clearer and well-defined, and also made the learning process quicker. However, students and teachers disagreed when they reported on the changes in the teaching approaches. Students noted that the use of this technology system brought a change to the piano studio environment, since it allowed them to focus on listening immediately after playing the piano piece rather than playing it and listening at the same time. In contrast, teachers did not perceive a change in their teaching styles since they were focusing on aspects which they usually work on alongside students in conventional piano lessons such as articulation, dynamics, and phrasing, as well as use of the technology system.
IV. CONCLUSION Visual feedback generated by technology was used
pedagogically in higher education piano studios. The pedagogical uses of additional visual feedback encompassed: in real-time and post-hoc which are not commonly available in one-to-one conventional piano lessons. In line with Welch et al. (2005) in the singing studio context, real-time visual feedback generated by technology can benefit piano learning and teaching since the teacher can assess student performance in real-time whilst it has been played and recorded. Welch et al. (2005)’s study have discussed the use of real-time visual feedback for enhancing particular musical performance parameters and specific voice parameters. This study suggests that real-time visual feedback can enhance piano learning and performance for articulation, and melodic accuracy.
Findings of this study complement those of previous research in RTVF instrumental and vocal learning (Brandmeyer, 2006; Sadakata et al., 2008; Welch, 1983, 1985b; Welch et al., 2005). In this current study, performance-related data can be recorded, saved, stored and also played back so that the teacher and the student can compare recorded data and discuss this according to their lesson focus.
This study also complements previous piano-related studies (Benson, 1998; Daniel, 2001; Riley, 2005; Tomita & Barber, 2008), particularly those studies (Riley, 2005; Tomita & Barber, 2008) which suggested the use of MIDI protocols and piano roll based on perspectives of piano students when attending a demonstrative workshop showing its benefits. The pedagogical uses of visual feedback, in the form of piano roll visualization of the correspondent performance, were explored in piano studios with teacher feedback alongside student performance in this study.
Visual feedback uses in higher education piano studios augmented intrapersonal feedback not only in terms of auditory feedback (Banton, 1995; Finney, 1997) but also in terms of proprioceptive feedback (Brown & Palmer, 2012; Wöllner & Williamon, 2007) since students became more conscious-aware of their own piano learning and performance. Metacognitive knowledge (Hallam, 2001), self-regulatory skills (Nielsen, 2001), and sense of self (Damasio, 2000) might have been augmented since they function as internal processes for the intrapersonal feedback of the individual. However, visual feedback uses seemed to depend on the level of interaction between the individual and technology, as well as their preferences in using either auditory or visual feedback.
The pedagogical uses of visual feedback were demonstrated to have similar and different characteristics from a one-to-one conventional piano lesson, which is in line with Savage (2007). Similar characteristics are related to the types of verbal and non-verbal feedback linked to music notation and performance which are commonly available in piano lessons (Benson & Fung 2005; Burwell 2010; Hamond 2013; Siebenaler 1997). Different characteristics are related to the type of verbal and non-verbal feedback on technology aspects which can also be associated with music notation and performance and promote associative learning (Brown & Palmer, 2012; Mathias et al., 2015). These similar and different characteristics of the pedagogical uses of visual feedback might have impacted the different views of students and teachers on the changes in teaching approaches, even though a change in the learning process was agreed.
46

Future research is needed in order to explore the application of this new pedagogical tool in a longitudinal study. Other aspects which can also be investigated are: the frequency of use of the technology system, the appropriateness of repertoire, the level of expertise of the student, and the stage of the learning process (i.e. sight-reading, memorisation, etc.).
In conclusion, visual feedback generated by technology can optimize traditional one-to-one piano pedagogical approaches. Outcomes of this research might benefit and impact a student’s self-study and performance monitoring prior to a live performance, digital piano instrument learning and performance, and evaluation of teacher’s feedback effectiveness.
ACKNOWLEDGMENT I am very grateful to the participants of this study. I thank
very much Professor Graham F. Welch and Dr. Evangelos Himonides of the UCL Institute of Education, University College London for the knowledge and experience shared as my supervisors during my PhD journey. I also acknowledge the scholarship I received from the Brazilian government CAPES (Coordenação de Aperfeiçoamento de Pessoal de Nível Superior) which funded four years of full-time international tuition and maintenance fees as a PhD student in the UK.
REFERENCES Acitores, A. P. (2011). Towards a theory of proprioception as a
bodily basis for consciousness in music. In D. Clarke & E. Clarke (Eds.), Music and consciousness: Philosophical, psychological, and cultural perspectives (pp. 215-231). Oxford: Oxford University Press.
Annett, J. (1969). Feedback and human behaviour: the effects of knowledge of results, incentives and reinforcement on learning and performance. Harmondsworth: Penguin.
Banton, L. J. (1995). The role of visual and auditory feedback during the sight-reading of music. Psychology of Music, 23(1), 3-16. doi: 10.1177/0305735695231001
Benson, C. (1998). The effects of instructional media on group piano student performance achievement and attitude. (D.M.A.), University of Texas, Austin.
Benson, C., & Fung, C. V. (2005). Comparisons of teacher and student behaviors in private piano lessons in China and the United States. International Journal of Music Education, 23(1), 63-72. doi: 10.1177/0255761405050931
BERA (2011). Ethical Guidelines for Educational Research 2011. Retrieved from https://www.bera.ac.uk/researchers-resources/publications/ethical-guidelines-for-educational-research-2011 [Last accessed 23/08/2016]
Bishop, L., & Goebl, W. (2015). When they listen and when they watch: Pianists’ use of nonverbal audio and visual cues during duet performance. Musicae Scientiae, 19(1), 84–110. doi: 10.1177/1029864915570355
Braa, K., & Vidgen, R. (1999). Interpretation, intervention, and reduction in the organizational laboratory: a framework for in-context information system research. Accounting, Management and Information Technologies, 9(1), 25-47.
Brandmeyer, A. (2006). Real-time visual feedback in music pedagogy: Do different visual representations have different effects on learning? (MSc). Radboud University, Nijmegen.
Braun, V., & Clarke, V. (2008). Using thematic analysis in psychology. Qualitative Research in Psychology, 3(2), 77-101. doi: http://dx.doi.org/10.1191/1478088706qp063oa
Brown, R. M., & Palmer, C. (2012). Auditory-motor learning influences auditory memory for music. Memory & Cognition, 40(4), 567-578. doi: 10.3758/s13421-011-0177-x
Burwell, K. (2010). Instrumental teaching and learning in Higher Education. (PhD). University of Kent, Canterbury.
Creech, A., & Gaunt, H. (2012). The changing face of individual instrumental tuition: Value, purpose and potential. In G. McPherson & G. Welch (Eds.), The Oxford Handbook of Music Education (Vol.1, pp. 694-711). Oxford: Oxford University Press.
Damasio, A. (2000). The feeling of what happens : body and emotion in the making of consciousness. London: Heinemann.
Daniel, R. (2001). Self-assessment in performance. British Journal of Music Education, 18(3), 215-226.
Demos, A. P., & Chaffin, R. (2009). A software tool for studying music practice: SYMP (Study Your Music Practice). Poster presented at the European Society for the Cognitive Sciences of Music (ESCOM), Jyväskylä, Finland. Retrieved from http://musiclab.uconn.edu/wp-content/uploads/sites/290/2013/10/DemosESCOM-Poster.pdf [Last accessed 23/08/2016]
Finney, S. A. (1997). Auditory feedback and musical keyboard performance. Music Perception, 15(2), 153-174.
François, A. R. J., Chew, E., & Thurmond, D. (2007). Visual feedback in performer-machine interaction for musical improvisation. Paper presented at the NIME07, New York, NY. Retrieved from http://www.nime.org/proceedings/2007/nime2007_277.pdf [Last acessed 23/08/2016]
Gibson, J. J. (1968). The Senses Considered as Perceptual Systems. London: Allen & Unwin.
Guba, E. G. (1981). Criteria for assessing the trustworthiness of naturalistic inquiries. Educational Communication and Technology, 29(2), 75-91.
Hallam, S. (1998). Instrumental teaching: a practical guide to better teaching and learning. Oxford: Heinemann.
Hallam, S. (2001). The development of metacognition in musicians: implications for education. British Journal of Music Education, 18(1), 27-39. doi: 10.1017/S0265051701000122
Hamond, L. (2013). Feedback on elements of piano performance: Two case studies in higher education studio. In A. Williamon & W. Goebl (Eds.), Proceedings of the International Symposium on Performance Science 2013 (pp. 33-38). Brussels: European Association of Conservatoires.
Hamond, L. (2017). The pedagogical use of technology-mediated feedback in a higher education piano studio: an exploratory action-case study. (PhD), University College London, Institute of Education, London.
Hattie, J., & Timperley, H. (2007). The power of feedback. Review of Educational Research, 77(1), 81-112. doi: 10.3102/003465430298487
Himonides, E. (2012). The misunderstanding of music-technology-education: A Meta Perspective. In G. McPherson & G. Welch (Eds.), The Oxford Handbook of Music Education (Vol. 2, pp. 433-456). Oxford: Oxford University Press.
Jørgensen, H. (2000). Student learning in higher instrumental education: who is responsible? British Journal of Music Education, 17(1), 67-77.
Magill, R. A. (1989). Motor learning: concepts and applications. (3rd ed.). Dubuque, IA: Wm. C. Brown.
Mathias, B., Palmer, C., Perrin, F., & Tillmann, B. (2015). Sensorimotor learning enhances expectations during auditory perception. Cerebral Cortex, 25(8), 2238-2254. doi:10.1093/cercor/bhu030
McPherson, A. (2013). Portable measurement and mapping of continuous piano gesture. Paper presented at the Proceedings of the International Conference on New Interfaces for Musical Expression (NIME 2013), Seoul, Korea. Retrieved from
47

http://nime.org/proceedings/2013/nime2013_240.pdf [Last accessed 23/08/2016]
Mozart, W. A. (1938). Sonaten für Klavier zu zwei Händen [Piano Sonatas], K. 545 [Piano score]. Leipzig: Peters (Original work published 1788). Retrieved from http://imslp.org/ on 21/12/2015.
Riley, K. (2005). Understanding piano playing through students’ perspectives on performance analysis and learning. American Music Teacher, 54(6), 33-37.
Sadakata, M., Hoppe, D., Brandmeyer, A., Timmers, R., & Desain, P. (2008). Real-time visual feedback for learning to perform short rhythms with expressive variations in timing and loudness. Journal of New Music Research, 37(3), 207-220. doi: 10.1080/09298210802322401
Savage, J. (2007). Reconstructing music education through ICT. Research in Education, 78(1), 65-77.
Schmidt, R. A., & Lee, T. D. (2011). Motor control and learning : a behavioral emphasis. (5th ed.). Champaign, IL: Human Kinetics.
Schwartz, M. S., & Andrasik, F. (2003). Biofeedback: A practitioner's guide. New York, NY: Guilford Press.
Shenton, A. K. (2004). Strategies for ensuring trustworthiness in qualitative research projects. Education for Information, 22(2), 63-75.
Siebenaler, D. J. (1997). Analysis of teacher-student interactions in the piano lessons of adults and children. Journal of Research in Music Education, 45(1), pp. 6-20.
Tomita, Y., & Barber, G. (2008). New technology and piano study in higher education: Getting the most out of computer-controlled player pianos. British Journal of Music Education, 13(2), 135-141. doi: 10.1017/S0265051700003107
Welch, G. F. (1983). Improvability of poor pitch singing: experiments in feedback. (PhD). Institute of Education, University of London, London.
Welch, G. F. (1985a). A schema theory of how children learn to sing in tune. Psychology of Music, 13(1), 3-18.
Welch, G. F. (1985b). Variability of practice and knowledge of results as factors in learning to sing in tune. Bulletin of the Council for Research in Music Education, 85, 238-247.
Welch, G. F., Howard, D. M., Himonides, E., & Brereton, J. (2005). Real-time feedback in the singing studio: an innovatory action-research project using new voice technology. Music Education Research, 7(2), 225-249. doi: 10.1080/14613800500169779
Wiener, N. (1961). Cybernetics: or, control and communication in the animal and the machine. Cambridge, MA: The MIT Press.
Wöllner, C., & Williamon, A. (2007). An exploratory study of the role of performance feedback and musical imagery in piano playing. Research Studies in Music Education, 29(1), 39-54. doi: 10.1177/1321103X07087567
48

Proceedings of the 10th International Conference of Students of Systematic Musicology (SysMus17), London, UK, September 13-15, 2017. Peter M. C. Harrison (Ed.).
Investigating the Development of Joint Attentional Skills in Early Ontogeny Through
Musical Joint Action Marvin Heimerich1, Kimberly Severijns2, Sabrina Kierdorf, Kevin Kaiser, Philippe Janes, Rie Asano
Department of Systematic Musicology, University of Cologne, Germany [email protected], [email protected]
ABSTRACT
Background Joint attention is a set of non-verbal, communicative
behaviors (“joint attentional skills”), which are proposed to emerge in early ontogeny during the period of 9 to 15 months (Carpenter et al., 1998). It is an important basis for joint action, i.e. coordinating attention and intention to act mutually to bring about a change in the environment (Knoblich & Sebanz, 2008). Although the emergence of joint attention has been extensively studied through examining joint attentional skills in early ontogeny, research on their possible enhancement alongside the children’s social cognitive development is rare. Especially, research on a possible enhancement exceeding the period of the development of social cognitive mechanisms like empathy and Theory of Mind is still missing. We hypothesize that joint attention, scaffolding social interaction as well as higher level social cognitive mechanisms, enhances alongside further social cognitive development.
Aims The goal of our current study is to investigate whether joint
attentional skills show enhancement in the later course of development, namely after 15 months of age. Additionally, our study aims at investigating if this enhancement potentially corresponds to increasingly more complex social interactions such as making music together.
Method An observational study was conducted with children of
different age-groups (1.5–2.5 y; 3–4 y; 5–6 y) in a musical joint action setting (music education for young children) in which children were free to move, sing and clap together under the guidance of a tutor. Structured observation in a musical joint action setting allows us to examine children’s nonverbal interactive behavior in an ecologically valid group interaction environment independently of their language skill.
Results Joint attentional skills and non-verbal interactive behavior
are coded in terms of two categories: social gaze (gaze targeting and gaze following) and musical gestures (rocking, clapping, and singing). “Gaze following” was chosen as a code because it is a key component of joint attention (Falck-Ytter et al., 2015) and easily observable in a natural interactive setting. A possible quantitative increase in coding “gaze following” (Social gaze) would portend an
enhancement of joint attention. “Gaze targeting” (social gaze) was chosen as it allows us to control for other types of social gaze that are not part of joint attention. In contrast, “Rocking”, “clapping” and “singing” (musical gestures) indicate musical interactive behavior. By examining the relation between the two categories social gaze and musical gestures, it is possible to investigate whether children’s interactive behaviors are linked to an enhancement of joint attentional skills. In addition to presenting and discussing the design of our coding scheme, we report results from our first application of this coding scheme.
Conclusions To the best of our knowledge, our study is the first
empirical study investigating the developmental trajectory of joint attention by examining a possible enhancement of joint attention through gaze following in a natural musical joint action setting. Furthermore, if there is an enhancement of joint attention, we are able to report on a possible correlation between enhanced joint attention and increasing social interaction through musical gestures. Although joint attention forms the basis for musical joint action, the nature of a possible relationship between enhanced joint attention and social interactive behavior is still unclear.
Keywords social interaction; development; joint attention; gaze;
musical joint action; structured observation
REFERENCES Carpenter, M., Nagell, K., Tomasello, M., Butterworth, M., Moore,
C. (1998). Social Cogntion, Joint Attention, and Communicative Competence from 9 to 15 Months of Age. Monographs of the Society for Research in Child Development, 63(4), 1-174.
Falck-Ytter, T., Thorup, E., & Bolte, S. (2015). Brief report: Lack of processing bias for the objects other people attend to in 3-year-olds with autism. J Autism Dev Disord, 45(6), 1897-1904.
Knoblich, G., Sebanz, N. (2008). Evolving intentions for social interaction: from entrainment to joint action. Philosophical Transactions of Royal Society B, 12(36), 2021-2031.
49

Proceedings of the 10th International Conference of Students of Systematic Musicology (SysMus17), London, UK, September 13-15, 2017. Peter M. C. Harrison (Ed.).
How the Rhythm is Actually Performed in the First Movement of the Beethoven’s Seventh Symphony
Dasaem Jeong1, Juhan Nam2
Graduate School of Culture Technology, KAIST, Republic of Korea [email protected], [email protected]
ABSTRACT The first movement of Beethoven’s Seventh Symphony uses a characteristic rhythm pattern throughout its main section. We analyzed 62 recordings of this movement by semi-manual method aided by audio signal processing to examine how accurately this rhythm pattern was performed in selected excerpts. The result showed that only few recordings performed this rhythm accurately as it is notated. In most of the cases, the rhythm was not accurate and its characteristic as a compound meter was diluted. We found that the rhythmic accuracy was mainly varied by musical texture of excerpts. Some conductors like Karajan, C. Kleiber, and Gardiner performed the rhythm more accurately than the others in most of the excerpts. The analysis result says that the recordings of American orchestras showed lower rhythmic accuracy than Austro-German orchestras or early music orchestras.
I. INTRODUCTION Despite that few scholars like Nicolas Cook (Cook, 1999)
and José Antonio Bowen (Bowen, 1996) argued the importance of music performance analysis, there was not enough research on music performance analysis in the musicology area. One of the reason is that there is no quantitative representation of the performance. In case of music analysis, scholars analyze and debate about the music using the score, which consists of quantitative and objective information. But there is no proper standard way to measure the characteristic of each performance. The question of measuring still lies on the performance analysis.
Unlike other musical characteristics, the rhythm is a relatively easy feature to measure from an audio recording. By detecting note onsets from a recording, one can analyze the rhythmic characteristic of the performance. Recent research applied an onset detection algorithm for estimating swing ratios in jazz recordings (Dittmar, 2015). The research analyzed the swing ratio of professional jazz drummers based on the onset timing of ride cymbal. This approach can be also applied to classical music, if rhythmic ratio is an important factor of performance.
Beethoven’s Seventh symphony is well known for its constant use of characteristic rhythmic pattern. Each of the movements, especially the first, second, and fourth movement, repeats the characteristic rhythmic patterns obsessively. The main vivace section of the first movement is in six-eight time, and starts with the specific rhythm pattern as below, also known as an “Amsterdam rhythm”. This rhythm is a variation of a crotchet followed by a quaver, which is a typical rhythm pattern in six-eight time.
Figure 1. “Amsterdam” rhythm
Though this rhythm seems relatively easy to play, some conductors pointed out that the rhythm can be easily distorted if the musicians do not pay enough attention in this symphony. Gunther Schuller introduced his own classification of various recordings according to rhythmic accuracy. He insisted that only Carlos Kleiber and Jeffrey Tate’s recording achieved the rhythmic precision constantly through the whole movement (Schuller, 1997). This analysis is a surprise considering that the Seventh symphony is frequently performed all around the world and has been recorded for numerous times. Normal del Mar also mentioned that there is a danger of “degeneration” of the Amsterdam rhythm especially in the measure 195 to 200, where the strings play this rhythm repeatedly (Norman, 2002).
The difficulty of playing the Amsterdam rhythm causes a characteristic difference in the performances and thus provides interesting examples for studying rhythm performance in orchestra music. Also, this movement contains a lot of homorhythmic texture, which make the onset detection much easier and more correct. Furthermore, the Amsterdam rhythm appears in different instrumentation and articulation throughout the movement. Therefore, we can survey several factors that effect on rhythm performance by analyzing recordings of this piece.
Please note that the goal of this research is not evaluating the artistic value of performances. We do not want to argue that the rhythm should be always performed strictly as it is notated. In this research, we use the term “rhythmic accuracy” only in a mathematical context, not in an aesthetic context.
II. METHODS Our first approach was applying automatic onset detection
algorithms that was introduced by Duxbury, Sandler, and Davies (2002), and Dittmar, Pfleiderer, and Müller (2015). The first one suggested an onset function based on subband decomposition of spectral energy. The research also proposed a smoothing scheme for calculating the transient difference of spectral energy. The second research employed spectral energy difference for detecting onsets. The goal of this research was estimating swing ratios of jazz drummers, and the authors proposed two methods to calculate a swing ratio:
50

calculating based on onset detection, and employing log-lag auto-correlation function.
We have applied these algorithms to recordings of the Beethoven’s symphony, but the results were not enough reliable because of two reasons. First, the onsets of orchestral sound are not sharp enough to determine exact onset time. The orchestral instruments have softer attacks compare to a piano or a drum set. Also, though orchestra musicians are trained to play the music in synchronous way, it is physically impossible for all players to play notes at the exactly same moment. During the analysis, we found some cases that show a separation of an onset played in tutti. Second, because of the fast tempo, an onset interval is too short to be detected separately. Dull onset peaks and short onset intervals make the log-lag autocorrelation function impossible to distinguish an onset of semiquaver and quaver. Above all, detecting every onset with perfect precision and accuracy in fully-automatic way is unachievable even with the state-of-art algorithm.
Therefore, based on the onset detection functions, we found every onset in semi-manual way. We used temporal difference of spectral energy within certain frequency range, as same with the research of Dittmar (2015) for the onset detection function. First, we calculate the short-time Fourier transform (STFT) of selected audio clip, which can be represented as !(#, %), where # and % denotes index of time window and frequency bin respectively. Then, we derive log-STFT like ' #, % ≔ log(1 + . ∙ ! #, % ), with a proper constant . ≥ 1 . The transient sound in onset part can be estimated from the difference between time frames in this log-STFT. Instead of using the difference between only adjacent frames, we also consider the difference be following the previous research (Duxbury, Sandler & Davies, 2002). The onset detection function 123 # can be represented as below:
123 # = ' #, % −' # − 7, %
7
8
9:; .
=
>:;
We plot this onset detection function of the audio clip, then estimate the onset positions on the graph. After marking the onsets, we listen to the audio-clip with tick sounds at the marker positions in slow playback speed so that we can refine the onset position. This procedure is repeated until we consider that the onset positions are well synchronized with the actual audio clip. Then we measure the length of each note, and calculated rhythm ratio ? ≔ (@AB + @CD)/@D from each set of three notes that form the Amsterdam rhythm (Figure 1). If the music is performed exactly as notated in the score, the rhythm ratio ? becomes 2.
III. EXPERIMENT Among the first movement of the Seventh Symphony, we
selected eleven different excerpts that contain the Amsterdam rhythm, so that we can examine the difference in rhythm performance according to the instrumentation and rhythm pattern. There are three different types of rhythm, which can be represent as Figure 2.
Figure 2. Three different types of Amsterdam Rhythm in the first movement of Beethoven's Seventh Symphony
The selected excerpts are explained in below. The score reduction was done by the first author based on Bärenreiter edition of the score.
Figure 3. Excerpt (i)
The excerpt (i) is the beginning of Vivace, which is from measure 63 to 66, and the very first part that plays this rhythmic pattern. In this excerpt, only the flute and oboe solo plays the rhythm at the beginning and other woodwind instruments join later. We omitted last three notes because many recordings include tempo rubato in this section.
Figure 4. Excerpt (ii)
The excerpt (ii) is from measure 195 to 200, which is the beginning development section. Only the strings play the Amsterdam rhythm with the repeated pitch.
Figure 5. Excerpt (iii) and (iv)
The excerpt (iii) is from measure 205 to 206. In this excerpt, the entire woodwind instruments and horns play the Amsterdam rhythm, while the second violin plays another accompaniment rhythm.
The excerpt (iv) is from measure 211 to 212, which is almost same with the third excerpt except that there is no accompaniment by the second violins and the wind instruments play the different pitch.
Figure 6. Excerpt (v)
51

The excerpt (v) is from measure 217 to 219. Here, the strings and woodwinds play the rhythm (a) alternately.
Figure 7. Excerpt (vi)
The excerpt (vi) is from measure 250 to 253. In this excerpt, the strings and the woodwinds with horns play the rhythm B alternately.
Figure 8. Excerpt (vii)
The excerpt (vii) is from 254 to 255, in which the whole orchestra plays the rhythm (b) simultaneously.
Figure 9. Excerpt (viii)
The excerpt (viii) is from 268 to 271, where the whole strings play the rhythm B in different pitch.
Figure 10. Excerpt (ix)
The excerpt (ix) is from measure 423 to 426, where the entire orchestra plays rhythm A simultaneously.
Figure 11, Excerpt (x)
The excerpt (x) is from 432 to 437. Here, strings and woodwinds with horns play the rhythm (c) alternatively.
Figure 12. Excerpt (xi)
The last one, excerpt (xi) is from 445 to 447, which is the ending part of the movement and also the very last part that plays the Amsterdam rhythm.
We have selected 62 recordings, which include 44 conductors and 34 orchestras. To examine the influence of a conductor or an orchestra on the rhythm performance, we included multiple recordings by the same conductor or orchestras. The selected recordings are listed at the end of the paper. We have implemented an audio-to-audio alignment algorithm by Ewert, Müller and Grosche (2009) to auto-matically find the playing position of each excerpt in each recording.
IV. RESULT AND DISCUSSION A. Influence of musical characteristics on the rhythm ratio
We calculated the rhythm ratio and compared them according to the excerpts. The box plot on the Figure 13 shows the average rhythm ratio ? of selected recordings for each excerpt. The performed rhythm ratio was lower than ideal value 2 for most of the recording in every excerpt. As we expected, the rhythm ratios were clearly different according to the musical characteristics of the excerpts.
Figure 13. Box plot of measured rhythm ratio of 62 recordings according to the excerpts. Most of the recordings showed lower rhythm ratio than it is notated. Also, there are clear differences of rhythm ratios between each excerpt.
The most accurately performed excerpt was the excerpt (v), in which the strings and woodwinds play the rhythm (a) alternately, so that none of the orchestra plays the rhythm continuously. Compare to the other excerpts that contains repetitive rhythm (a) played by strings or woodwinds (e.g. excerpt (ii), (iii), (iv)), the excerpt (v) was performed more accurately. The similar results with the rhythm (b) can be examined by comparing the result of excerpt (vi) and (vii). This result suggests that orchestra musicians may play this
52
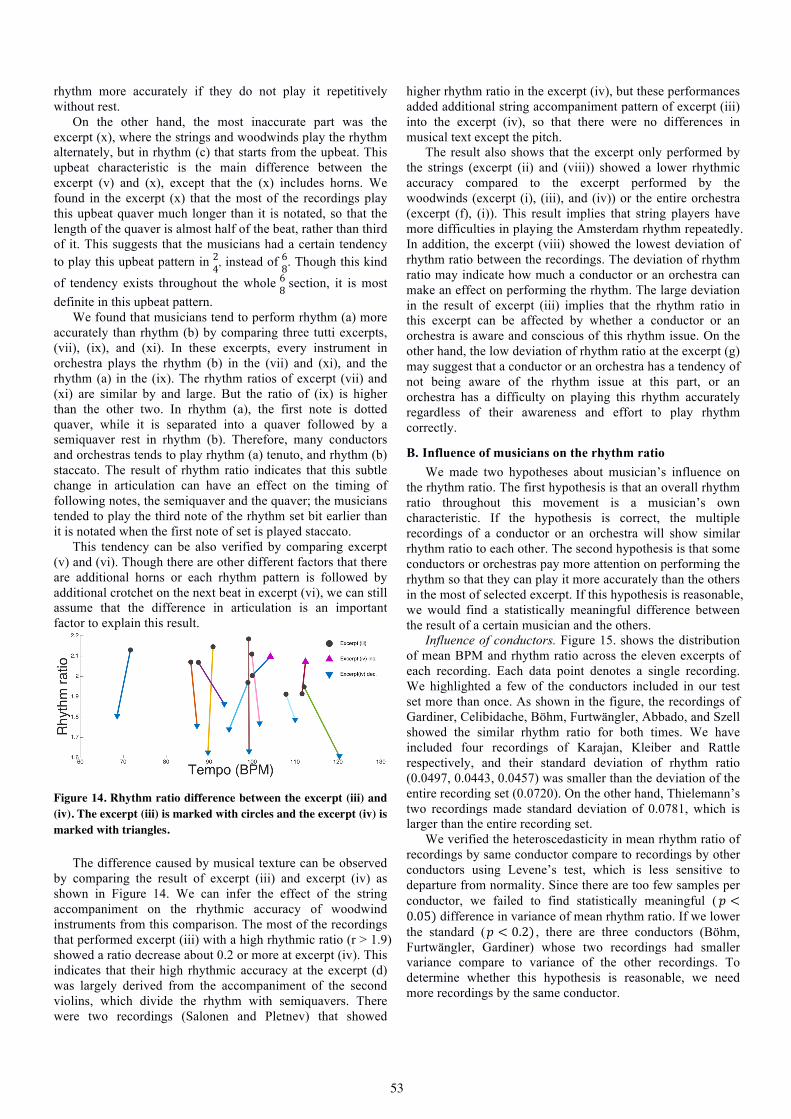
rhythm more accurately if they do not play it repetitively without rest.
On the other hand, the most inaccurate part was the excerpt (x), where the strings and woodwinds play the rhythm alternately, but in rhythm (c) that starts from the upbeat. This upbeat characteristic is the main difference between the excerpt (v) and (x), except that the (x) includes horns. We found in the excerpt (x) that the most of the recordings play this upbeat quaver much longer than it is notated, so that the length of the quaver is almost half of the beat, rather than third of it. This suggests that the musicians had a certain tendency to play this upbeat pattern in 24, instead of 68. Though this kind of tendency exists throughout the whole 68 section, it is most definite in this upbeat pattern.
We found that musicians tend to perform rhythm (a) more accurately than rhythm (b) by comparing three tutti excerpts, (vii), (ix), and (xi). In these excerpts, every instrument in orchestra plays the rhythm (b) in the (vii) and (xi), and the rhythm (a) in the (ix). The rhythm ratios of excerpt (vii) and (xi) are similar by and large. But the ratio of (ix) is higher than the other two. In rhythm (a), the first note is dotted quaver, while it is separated into a quaver followed by a semiquaver rest in rhythm (b). Therefore, many conductors and orchestras tends to play rhythm (a) tenuto, and rhythm (b) staccato. The result of rhythm ratio indicates that this subtle change in articulation can have an effect on the timing of following notes, the semiquaver and the quaver; the musicians tended to play the third note of the rhythm set bit earlier than it is notated when the first note of set is played staccato.
This tendency can be also verified by comparing excerpt (v) and (vi). Though there are other different factors that there are additional horns or each rhythm pattern is followed by additional crotchet on the next beat in excerpt (vi), we can still assume that the difference in articulation is an important factor to explain this result.
Figure 14. Rhythm ratio difference between the excerpt (iii) and (iv). The excerpt (iii) is marked with circles and the excerpt (iv) is marked with triangles.
The difference caused by musical texture can be observed by comparing the result of excerpt (iii) and excerpt (iv) as shown in Figure 14. We can infer the effect of the string accompaniment on the rhythmic accuracy of woodwind instruments from this comparison. The most of the recordings that performed excerpt (iii) with a high rhythmic ratio (r > 1.9) showed a ratio decrease about 0.2 or more at excerpt (iv). This indicates that their high rhythmic accuracy at the excerpt (d) was largely derived from the accompaniment of the second violins, which divide the rhythm with semiquavers. There were two recordings (Salonen and Pletnev) that showed
higher rhythm ratio in the excerpt (iv), but these performances added additional string accompaniment pattern of excerpt (iii) into the excerpt (iv), so that there were no differences in musical text except the pitch.
The result also shows that the excerpt only performed by the strings (excerpt (ii) and (viii)) showed a lower rhythmic accuracy compared to the excerpt performed by the woodwinds (excerpt (i), (iii), and (iv)) or the entire orchestra (excerpt (f), (i)). This result implies that string players have more difficulties in playing the Amsterdam rhythm repeatedly. In addition, the excerpt (viii) showed the lowest deviation of rhythm ratio between the recordings. The deviation of rhythm ratio may indicate how much a conductor or an orchestra can make an effect on performing the rhythm. The large deviation in the result of excerpt (iii) implies that the rhythm ratio in this excerpt can be affected by whether a conductor or an orchestra is aware and conscious of this rhythm issue. On the other hand, the low deviation of rhythm ratio at the excerpt (g) may suggest that a conductor or an orchestra has a tendency of not being aware of the rhythm issue at this part, or an orchestra has a difficulty on playing this rhythm accurately regardless of their awareness and effort to play rhythm correctly.
B. Influence of musicians on the rhythm ratio We made two hypotheses about musician’s influence on
the rhythm ratio. The first hypothesis is that an overall rhythm ratio throughout this movement is a musician’s own characteristic. If the hypothesis is correct, the multiple recordings of a conductor or an orchestra will show similar rhythm ratio to each other. The second hypothesis is that some conductors or orchestras pay more attention on performing the rhythm so that they can play it more accurately than the others in the most of selected excerpt. If this hypothesis is reasonable, we would find a statistically meaningful difference between the result of a certain musician and the others.
Influence of conductors. Figure 15. shows the distribution of mean BPM and rhythm ratio across the eleven excerpts of each recording. Each data point denotes a single recording. We highlighted a few of the conductors included in our test set more than once. As shown in the figure, the recordings of Gardiner, Celibidache, Böhm, Furtwängler, Abbado, and Szell showed the similar rhythm ratio for both times. We have included four recordings of Karajan, Kleiber and Rattle respectively, and their standard deviation of rhythm ratio (0.0497, 0.0443, 0.0457) was smaller than the deviation of the entire recording set (0.0720). On the other hand, Thielemann’s two recordings made standard deviation of 0.0781, which is larger than the entire recording set.
We verified the heteroscedasticity in mean rhythm ratio of recordings by same conductor compare to recordings by other conductors using Levene’s test, which is less sensitive to departure from normality. Since there are too few samples per conductor, we failed to find statistically meaningful (J <0.05) difference in variance of mean rhythm ratio. If we lower the standard (J < 0.2) , there are three conductors (Böhm, Furtwängler, Gardiner) whose two recordings had smaller variance compare to variance of the other recordings. To determine whether this hypothesis is reasonable, we need more recordings by the same conductor.
53
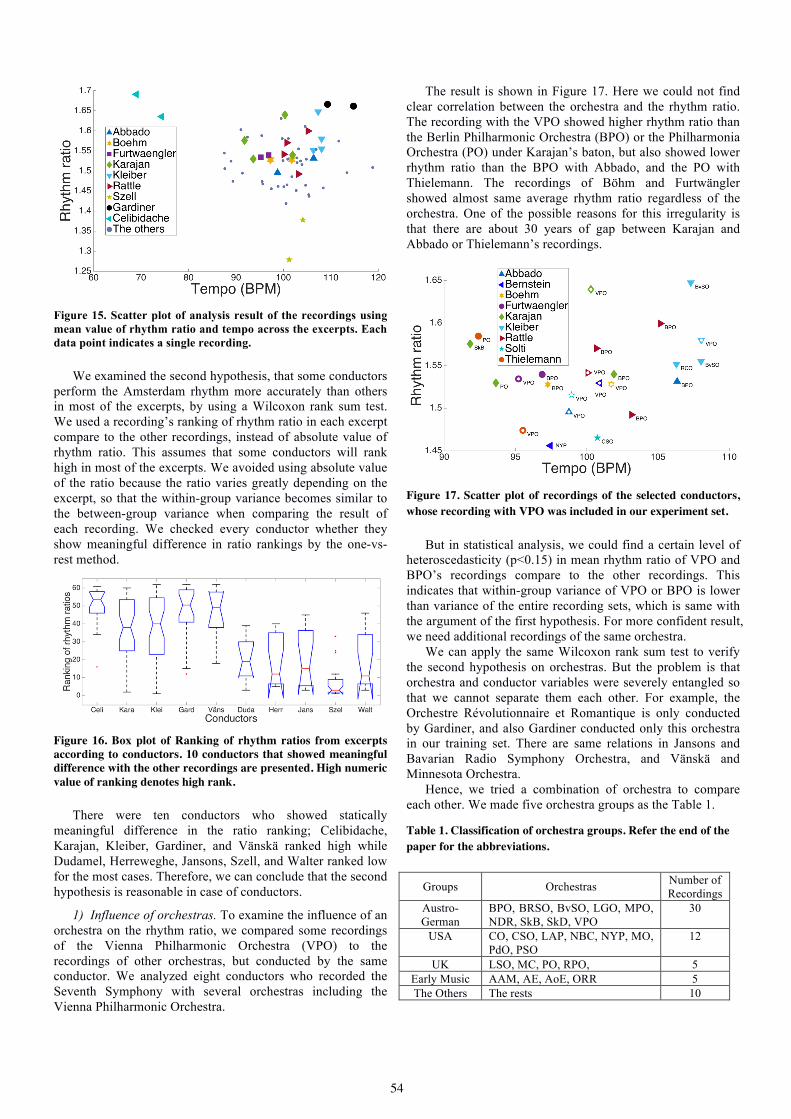
Figure 15. Scatter plot of analysis result of the recordings using mean value of rhythm ratio and tempo across the excerpts. Each data point indicates a single recording.
We examined the second hypothesis, that some conductors perform the Amsterdam rhythm more accurately than others in most of the excerpts, by using a Wilcoxon rank sum test. We used a recording’s ranking of rhythm ratio in each excerpt compare to the other recordings, instead of absolute value of rhythm ratio. This assumes that some conductors will rank high in most of the excerpts. We avoided using absolute value of the ratio because the ratio varies greatly depending on the excerpt, so that the within-group variance becomes similar to the between-group variance when comparing the result of each recording. We checked every conductor whether they show meaningful difference in ratio rankings by the one-vs-rest method.
Figure 16. Box plot of Ranking of rhythm ratios from excerpts according to conductors. 10 conductors that showed meaningful difference with the other recordings are presented. High numeric value of ranking denotes high rank.
There were ten conductors who showed statically meaningful difference in the ratio ranking; Celibidache, Karajan, Kleiber, Gardiner, and Vänskä ranked high while Dudamel, Herreweghe, Jansons, Szell, and Walter ranked low for the most cases. Therefore, we can conclude that the second hypothesis is reasonable in case of conductors.
1) Influence of orchestras. To examine the influence of an orchestra on the rhythm ratio, we compared some recordings of the Vienna Philharmonic Orchestra (VPO) to the recordings of other orchestras, but conducted by the same conductor. We analyzed eight conductors who recorded the Seventh Symphony with several orchestras including the Vienna Philharmonic Orchestra.
The result is shown in Figure 17. Here we could not find clear correlation between the orchestra and the rhythm ratio. The recording with the VPO showed higher rhythm ratio than the Berlin Philharmonic Orchestra (BPO) or the Philharmonia Orchestra (PO) under Karajan’s baton, but also showed lower rhythm ratio than the BPO with Abbado, and the PO with Thielemann. The recordings of Böhm and Furtwängler showed almost same average rhythm ratio regardless of the orchestra. One of the possible reasons for this irregularity is that there are about 30 years of gap between Karajan and Abbado or Thielemann’s recordings.
Figure 17. Scatter plot of recordings of the selected conductors, whose recording with VPO was included in our experiment set.
But in statistical analysis, we could find a certain level of heteroscedasticity (p<0.15) in mean rhythm ratio of VPO and BPO’s recordings compare to the other recordings. This indicates that within-group variance of VPO or BPO is lower than variance of the entire recording sets, which is same with the argument of the first hypothesis. For more confident result, we need additional recordings of the same orchestra.
We can apply the same Wilcoxon rank sum test to verify the second hypothesis on orchestras. But the problem is that orchestra and conductor variables were severely entangled so that we cannot separate them each other. For example, the Orchestre Révolutionnaire et Romantique is only conducted by Gardiner, and also Gardiner conducted only this orchestra in our training set. There are same relations in Jansons and Bavarian Radio Symphony Orchestra, and Vänskä and Minnesota Orchestra.
Hence, we tried a combination of orchestra to compare each other. We made five orchestra groups as the Table 1.
Table 1. Classification of orchestra groups. Refer the end of the paper for the abbreviations.
Groups Orchestras Number of Recordings
Austro-German
BPO, BRSO, BvSO, LGO, MPO, NDR, SkB, SkD, VPO
30
USA CO, CSO, LAP, NBC, NYP, MO, PdO, PSO
12
UK LSO, MC, PO, RPO, 5 Early Music AAM, AE, AoE, ORR 5 The Others The rests 10
54

Figure 18. Box plot of ranking of rhythm ratio according to the orchestra group. There was statically meaningful difference between the Austro-German group and USA group or Early Music group and USA group.
We compared the distribution of ratio rankings in each excerpt by the orchestra groups. The box plot of the result is presented in Figure 18.
The result of Wilcoxon rank sum test showed that there are statistically meaningful (J < 0.05) differences between the orchestras in the USA and Austro-German orchestras, the early music orchestras orchestras, or the Others group. The J-value of difference between the Austro-German groups and the Others was 0.0548. The early music orchestra group also showed certain level of difference with the Others group (J =0.0654).
The entanglement of conductors and orchestras on recordings still existed in this group classification. The conductors of Austro-German orchestras and orchestras from the USA were clearly separated. There were only two conductors, Bernstein and Solti, who made recordings with both Austro-German orchestra and American orchestra. But if we consider the orchestra’s selection of conductor as a characteristic of the orchestra, this analysis gives a meaningful result. American orchestras tended to play the Amsterdam rhythm less accurately than the other orchestras, especially the Austro-German orchestras, whether it comes from natural characteristic of musicians in American orchestras, or their tendency to perform with the conductors who usually perform this rhythm less accurately. To establish a exact reason for this difference, we need more recordings of different orchestra group conducted by a same conductor.
V. CONCLUSION We analyzed 69 recordings of the first movement of
Beethoven’s Seventh Symphony, and analyzed how the specific rhythm pattern called “Amsterdam” rhythm was actually performed in the eleven selected excerpts. The result showed that the rhythm was performed quite differently from as it is notated so that its characteristic as a compound meter is diluted. The performance of the Amsterdam rhythm varied largely depending on the musical texture of the excerpt. Musicians tended to play this rhythm less accurately when they repeat this rhythm continuously. Playing the first note of the rhythm pattern tenuto instead of staccato made the rhythm more accurately. Also, the result showed that the strings are less probable to play the rhythm accurately. By analyzing the result according to conductors and orchestras, we founded that some conductors performed this rhythm more accurately than others. Another interesting analysis was that recordings by
orchestras in America showed low accuracy compared to Austro-German orchestras or early music orchestras.
However, there were clear limitations caused by limited recording set. We need to analyze more recordings to clearly verify the influence of a conductor or an orchestra on performing the Amsterdam rhythm. Another limitation was that our research was only focused on numerical length ratio of notes, and did not consider other factors that might affect human perception of the rhythm, like an articulation or dynamics of each note of the performance. We hope our research can be further improved with future research.
REFERENCES Beethoven, L. (2000). Symphony No. 7 in A major op. 92, Kassel,
Germany: Bärenreiter Cook, N. (1999). Analysing performance and performing analysis. In
N. Cook and M. Everist (Eds.), Rethinking music (pp. 239-61), Oxford: Oxford University Press.
Dittmar, C., Pfleiderer, M., & Müller, M. (2015). Automated Estimation of Ride Cymbal Swing Ratios in Jazz Recordings. In Proceeding of International Society of Music Information Retrieval (ISMIR) (pp. 271-277).
Del Mar, N. (2002). Conducting Beethoven Volume 1 The Symphonies. New York: Oxford University Press Inc.
Duxbury, C., Sandler, M., & Davies, M. (2002, September). A hybrid approach to musical note onset detection. In Proceding of Digital Audio Effects Conference (DAFX,’02) (pp. 33-38).
Ewert, S., Müller, M., & Grosche, P. (2009). High resolution audio synchronization using chroma onset features. In Proceeding of IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) (pp. 1869-1872). IEEE.
Schuller, G. (1997). The Compleat Conductor. New York: Oxford University Press Inc.
Bowen, J. A. (1996). Tempo, duration, and flexibility: Techniques in the analysis of performance. Journal of Musicological Research, 16(2), 111-156.
List of Recordings used in the experiments Conductor, Orchestra (Abbreviation) [Label Recording_year] (Kleiber denotes Carlos Kleiber, not Erich Kleiber)
Abbado, Berlin Philharmonic Orchestra (BPO) [DG 1999] / Abbado, Vienna Philharmonic Orchestra (VPO) [DG 1987] / Barenboim, Berlin Staatskapelle (SkB) [Warner 1999] / Bernstein, New York Philharmonic (NYP) [DG 1990] / Bernstein, VPO [DG 1978] / Blomstedt, Dresden Staatskapelle (SkD) [Brilliant Classics 1975] / Böhm, VPO [DG 1972] / Böhm, BPO [DG 1958] / Boulez, NYP [1975] / Boyd, Manchester Camerata (MC) [Avie 2007] / Brugge, Orchestra of the 18th Century (OoE) [Philips 1988] / Celibidache, Stockholm Philharmonia Orchestra [Arkadia 1969] / Celibidache, Munich Philharmonic Orchestra (MPO) [EMI] / Chailly, Leipzig Gewandhaus Orchestra (LGO) [Decca 2008] / Clutens, BPO [EMI 1960] / Dohnanyi, Cleveland Orchestra [Telarc 1987] / Dudamel, Simon Bolivar Youth Orchestra [DG 2006] / Furtwängler, BPO [DG 1943] / Furtwängler, VPO [EMI 1950] / Gardiner, Orchestré Révolutionnaire et Romantique (ORR) [DG 1992] / Gardiner, ORR [SDG 2011] / Haitink, London Symphony Orchestra (LSO) [LSO 2005] / Harnoncourt, Chamber Orchestra of Europe [Teldec 1990] / Herreweghe, Royal Flemish Philharmonic [Pentatone 2004] / Hogwood, Academy of Ancient Music (AAM) [L’oiseau-Lyre 1989] / Honeck, Pittsburgh Symphony Orchestra (PSO) [Reference Recordings 2014] / Immerseel, Anima Eterna (AE) [Zig Zag 2006] / Jansons, Bavarian Radio Symphony Orchestra (BRSO) [BR Classic 2008] / Jochum, BPO [DG 1952] / Karajan, SkB [DG 1941] / Karajan, Philharmonia Orchestra (PO) [EMI 1951] / Karajan, VPO [Decca 1959] / Karajan BPO [DG 1962] / Kleiber, VPO [DG 1975] / Kleiber, Bavaria State Orchestra (BvSO) [Orfeo 1982] / Kleiber, Amsterdam Concertgebouw Orchestra [Philips, 1983] / Kleiber, BvSO [Memories Excellence 1986] / Klemperer, PO [Documents 1966] / Krivine, Le Chamber Philharmonique [Naïve 2010] / Leibowitz, Royal Philharmonic Orchestra (RPO) [1961] / Masur, LGO [Philips 1972] / Monteux, French National Orchestra [Music & Arts 1952] / Ormandy, Philadelphia Orchestra (PdO) [1964] / Pletnev, Russian National Orchestra [DG 2006] / Rattle, VPO [EMI 2002] / Rattle, BPO [Digital Concert Hall 2008] / Rattle, BPO [Digital Concert Hall 2012] / Rattle, BPO [Digital Concert Hall 2015] / Salonen, Los Angeles Philharmonic (LAP) [DG 2006] / Scherchen, VPO [Tahra 1954] / Solti, VPO [Decca 1958] / Solti, Chicago Symphony Orchestra (CSO) [Decca 1972] / Szell, NYP [West Hill Radio Archive 1943] / Szell, CO [Sony 1959] / Tate SkD [EMI 1986] / Thielemann, PO [DG 1996] / Thilemeann, VPO [C Major 2009] / Toscanini, NBC Symphony Orchestra (NBC) [RCA] / Vänskä, Minnesota Orchestra (MO) [BIS 2008] / Walter, NYP [Music & Arts 1951] / Wand, NDR Symphony Orchestra (NDR) [RCA 1987] / Zinman, Tonhalle Orchestra Zürich [Arte Nova 1997]
55

Proceedings of the 10th International Conference of Students of Systematic Musicology (SysMus17), London, UK, September 13-15, 2017. Peter M. C. Harrison (Ed.).
The Effect of Socio-Cultural Identity on Musical Distaste
Elizabeth Kunde1, Kate Leonard, Jim Borling
Radford University, Virginia, USA [email protected]
ABSTRACT
Background Many researchers strive to know what music people enjoy.
While that aspect of music is clearly important, this one-sided view excludes characteristic musical taste that is just as pertinent: musical distaste. Ackermann (2016) examined musical dislike in a series of 21 interviews. The results of these interviews suggested that musical distaste is an important aspect in the affirmation of personal identity. The following research will expand on Ackermann’s work by looking directly at socio-cultural identity and musical distaste.
Aims The researchers attempted to determine if socio-cultural
identities are partially defined by music that the individual dislikes.
Method The participants, who were recruited from two universities
and the surrounding area in southwestern Virginia, USA, completed surveys detailing their socio-cultural identity and background, and his/her musical taste. Then five excerpts from the American genres of country (Gammond, n.d.) (Neal, 2012), rap (Wilton, n.d.) (Toop, Cheney, & Kajikawa, 2012), pop (Middleton & Manuel, 2015), classic rock (Moore, 2002) (Vallee, 2013), and heavy metal (Walser, n.d.) (Wilton, n.d.) were played and participants completed six surveys to determine any positive or negative responses to the music as well as levels of dislike for each excerpt.
Results It appears there is a correlation between personal identity
and musical distaste in some individuals; the trend appears to be strongest in participants between ages 18 and 27. This age group, when they responded negatively to a song, seemed to be more likely to write that the reason was because of negative familial ties, negative socio-political views on the song’s associated culture, or an inability to relate to or align with the culture of the music. Other age groups when responding to disliked music, wrote more about the music itself as opposed to the associated cultures.
Conclusions There appears to be a correlation between musical distaste
and personal identity especially in the generation that was born in the 90s. However, research that implements different recordings, different music, better quality delivery systems, and more in-depth forms of data collection such as both a survey and interview are essential to further establish the
boundaries and depth of the relationship between musical distaste and personal identity.
Keywords musical distaste, music therapy, socio-cultural identity
REFERENCES Ackermann, T. (2016). "I don't like that!" - Why and what for we dislike music [poster presentation]. International Conference of Students of Systematic Musicology SysMus16, Jyväskylä. Gammond, P. (n.d.). Country music. Oxford Companion to
Music. Hevner, K. (1936). Experimental studies of the elements of
expression in music. American Journal of Psychology, 48, 246-268. Middleton, R. and Manuel, P. (2015). Popular music. Grove
Music Online. Moore, A.F. (2002). Classic rock (ii). Grove Music Online. Neal, J.R. (2012). Country music. Grove Music Online. Tellegen, A., D. Watson, and L. A. Clark (1999). On the
dimensional and hierarchical structure of affect. Psychological Science, 10, 297-303. Toop, D., Cheney, C., & Kajikawa, L. (2012) Rap. Grove
Music Online. Vallee, M. (2013). Classic rock. Grove Music Online. Walser, R. (n.d.). Heavy metal. Grove Music Online. Wilton, P. (n.d.). Heavy metal. Oxford Music Online. Wilton, P. (n.d.). Rap. Oxford Music Online.
56

Proceedings of the 10th International Conference of Students of Systematic Musicology (SysMus17), London, UK, September 13-15, 2017. Peter M. C. Harrison (Ed.).
Modes of Listening to Chinese Pentatonicism in Parisian Musical Modernity John Lam Chun-fai
Department of Music, The Chinese University of Hong Kong, China [email protected]
ABSTRACT How can we listen to modernist manipulations of the anhemitonic pentatonic scale, which was referred to as ‘gamme chinoise’ (Chinese scale) in early twentieth-century Paris? This study proposes multiple listening pathways by revealing creative approaches to the scale at different levels of a musical structure. Drawing on music-theoretical underpinnings and cross-cultural capacities of the scale, this paper scrutinises three representative Parisian pieces bearing extra-musical associations with China and devises modes of listening based on analytical readings. It is found that creative approaches range from alteration of dominant ninth chord as pentatonic harmony (Ravel) and exploitation of pentatonicised octatonic space (Schmitt) to formulation of pentatonic network (Stravinsky). Historically-informed analyses and listening pathways based on the two pentatonic scale-steps – minor third and whole tone – impact on our aural perception of culturally encoded techniques, shed light on cross-cultural dynamics between China and France, and contribute toward a theory of Chinese pentatonicism in Parisian musical modernity. Keywords: Music theory and analysis; pentatonicism; China; Paris; modernity
I. INTRODUCTION
In view of an expanding scholarship on music-theoretical underpinnings and cross-cultural capacities of the anhemitonic pentatonic scale, this paper integrates perspectives from both directions in the quest of advancing our understanding of what early twentieth-century Parisian musicians characterised as ‘gamme chinoise’ (Chinese scale). Not only does my investigation share the spirit of important Anglophone and French studies (Kopp 1996; Picard 2001; Day O’Connell 2009) by proposing modes of listening to pentatonic practices, but it also advances the efforts of existing Sino-French cultural studies (Tchen 1974; Tao 2001) by placing a special focus on Parisian musical modernity.
Taking a cue from what Marcel Proust (1913) referred to as ‘emploi exclusive de la gamme chinoise’ (exclusive employment of the Chinese scale), this paper probes into the little-understood reception of Chinese pentatonic scale in early twentieth-century Paris and places at its focal point novel manipulations of the scale. The key questions are: what analytical evidences can be drawn from different levels of a musical structure? How can these findings guide our understanding of and listening to Chinese sounds?
II. METHOD Taking into consideration sketch materials housed at the
Bibliothèque national de France and Paul Sacher Stiftung, I scrutinised pentatonicism in selected passages from three representative pieces bearing extra-musical associations with China and devised listening models based on analytical readings. Set-theoretical approaches were adopted where appropriate.
The selected passages were as follows:
A. Maurice Ravel: ‘Asie’ from Shéhérazade (1903), bars 83–
87;
B. Florent Schmitt: ‘Le parapluie chinois’ from Une semaine du petit elfe Ferme-l’œil (1912), bars 27–34;
C. Igor Stravinsky: Introduction to Act I of Le rossignol
(1908–14), bars 36–43.
III. RESULTS A range of creative approaches to the Chinese scale were
unravelled as follows:
A. Alteration of dominant ninth chord as pentatonic harmony (Ravel)
B. Exploitation of pentatonicised octatonic space (Schmitt)
C. Formulation of pentatonic network (Stravinsky)
IV. DISCUSSION A. Alteration of dominant ninth chord as pentatonic
harmony (Ravel) The key to understanding the pentatonicism of the passage
under scrutiny (Figure 1) lies in a chord mediating the transition from triadic to pentatonic harmonies. The chord in point is placed at the word ‘Chine’ and stands out in a bar framed by double bar-lines (bar 85). The mediating role of the ‘Chine’ chord is, I suggest, attributed by its double identity – triadic and pentatonic – which stems from the preceding ninth chord and the ensuing pentatonic harmonies.
57

In the two bars before the ‘Chine’ chord, the three-note figure, C#-D#-F#, is featured in the vocal melody (‘Je voudrais voir la Perse, et l’Inde’) and the harmony (right hand of the piano). In the two bars after the ‘Chine’ chord, another three-note figure, D-F-G, is featured in the vocal melody (‘sous les ombrelles’) and the top line of the accompaniment.
Figure 1. ‘Asie’, bars 84–87.
The two figures – C#-D#-F# and D-F-G – are both (025) sets, but they are contextualised differently: the former set is heard in a ninth chord (B-D#-F#-(A)-C#) while the latter set in harmonies derivable from the pentatonic scale (Bb-C-D-F-G). In this light, the ‘Chine’ chord can be viewed as a chromatically heightened ninth chord (C-E-G-Bb-D) which is slightly altered (C-F-G-Bb-D) in order to accommodate all the five notes of the Bb pentatonic scale. The set-class (025), highlighted in the ‘Chine’ chord (right hand of the piano), forms the basis of the chord’s triadic-pentatonic nature and contributes to its mediating role.
B. Exploitation of pentatonicised octatonic space (Schmitt) A cultivation of an octatonic sound world with pentatonic
sets is at work in the passage under scrutiny (Figure 2). The passage is mainly built around two pentatonic set-classes – (0358) and its subset (025) – retrievable from the Chinese-inspired theme, yet not a single note involved falls outside the octatonic scale starting with F# and G, or what Pieter van den Toorn (1983) designated as ‘octatonic collection III’.
At the start of this passage (bars 27–28), the theme based
on the tetrachord, A#-C#-D#-F#, is heard with two other layers of the same tetrachord. It is restated literally at a minor third above as C#-E-F#-A (bars 29–30), and accompanied by (025) in the form of ornamented percussive chords. The theme is then transposed yet a minor third higher as E-G-A-C (bars 31–33) and fragmented to produce (025). Up to this point, the music has been organised at three of the four minor-third related octatonic nodes – F#, A and C – which are inferable from the changes of key signature. Further T3 operations in quick succession (bar 34) bring (025) to the last node Eb and finally back to the starting node F#. The circulation of (0358)
and (025) through the four octatonic nodes facilitates an extensive exploitation of the octatonic-III space. In a sense, the octatonic space is pentatonicised.
Figure 2. ‘Le parapluie chinois’, bars 26–34.
C. Formulation of pentatonic network (Stravinsky)
Embedded in the orchestral fabric of the passage under
scrutiny (Figure 3) are two ascending lines of strings marked flautando. Stravinsky’s sketch for these eight bars shows that the string lines were conceived as a cascade of thirds (Taruskin 1996), which, I propose, can be viewed as an intricate pentatonic network.
In the sketch, eight thirds are drafted at a perfect fourth
higher and with halved values. Beamed four by four, the thirds present a two-by-two harmonic pattern of minor third and major third. If the upper and lower notes of each harmonic thirds are considered separately, it can be observed that each of the two layers is made up of a linear pattern of minor third and major second, or (025) in set-theoretical terms. A reading of the first two consecutive sets of the upper layer – Bb-C#-Eb-F#-Ab – reveals the orthographically veiled presence of the black-key pentatonic scale. If the characteristic intervallic pattern is extended until the first harmonic third is reached again, a series of twelve pentatonic scales would be formed along the circle of fifths. The orderly yet out-of-phase transitions of pentatonic spaces in the two layers interact with each other and transform their respective pentatonic sonorities. In this light, an underlying pentatonic network lurks behind the cascade of thirds.
58

Figure 3. Introduction to Act I of Le rossignol, bars 36–43.
V. CONCLUSIONS Preliminary research shows that creative approaches to the
Chinese scale under discussion drew on the pentatonic set-class (025). The two pentatonic scale-steps integral to this set-class – minor third and whole tone – are fundamental to our understanding of and listening to Chinese pentatonicism in Parisian musical modernity.
REFERENCES
Day-O’Connell, Jeremy. (2009). Debussy, Pentatonicism, and the
Tonal Tradition. Music Theory Spectrum 31(2), 225–61. Kopp, David. (1997). Pentatonic Organization in Two Piano Pieces
of Debussy. Journal of Music Theory 41(2), 261–87. Lorent, Catherine. (2012). Florent Schmitt. Paris, Bleu nuit éditeur. Orenstein, Arbie. (1975). Ravel: Man and Musician. New York:
Columbia University Press. Orledge, Robert. (1982). Debussy and the Theatre. Cambridge:
Cambridge University Press. Picard, François. (2001). Modalité et pentatonisme: deux univers
musicaux à ne pas confondre. Analyse Musicale 38, 37–46. Proust, Marcel. (1913). Du côté de chez Swann. Paris: Grasset. Tao, Ya-bing. (2001). Mingqingjian de zhongxi yinyue jiaoliu.
(Musical Exchanges between the East and the West in the Ming and the Qing Dynasties). Beijing, Dongfang chubanshe.
Taruskin, Richard. (1996). Stravinsky and the Russian Tradition: A Biography of the Works through Mavra. Oxford: Oxford University Press.
Tchen, Ysia. (1974). La musique chinoise en France au XVIIIe siècle. Paris: Publications orientalistes de France.
Van den Toorn, Pieter. (1983). The Music of Igor Stravinsky. New Haven: Yale University Press.
59

Proceedings of the 10th International Conference of Students of Systematic Musicology (SysMus17), London, UK, September 13-15, 2017. Peter M. C. Harrison (Ed.).
An Experience-Sampling Study to Investigate the Role of Familiarity in Involuntary Musical Imagery Induction
Rebecca Lancashire
Department of Music, University of Hull, United Kingdom [email protected], [email protected]
ABSTRACT Despite its prevalence in Western society, little is known about why certain songs get stuck in our heads or the intrinsic musical features which contribute to their potential as involuntary musical imagery (INMI). This paper considers the use of Experience-Sampling Methods to explore the role of familiarity in inducing INMI. Eighteen participants of varying musical expertise were provided with four prescribed musical stimuli, three of which had been selected for their low INMI potential according to the melodic analysis software FANTASTIC (Müllensiefen, 2009), and requested to listen to each piece a minimum of once per day for a seven-day period. Over the following week, participants continued with their listening but were also signaled randomly three times per day to fill out an experience-sampling form (ESF), which contained open-ended questions and scaled items relating to both listening and imagery experiences. Participants reported imagining the prescribed stimuli for 11% of all recorded episodes. A significant link was also found between musical experience and INMI occurrence and focus. The results indicate that musical training can make a listener more susceptible to INMI induction, even when the intrinsic features of the piece are not conducive to leading to INMI. This paper will contribute to existing research on the extra-musical factors which may lead to or trigger INMI episodes, and through a more detailed analysis of the intra-musical features which evoked INMI episodes in these participants it may be possible to develop a more comprehensive method of assessing the INMI potential of a piece analytically.
I. INTRODUCTION Music is a ubiquitous experience that prevails even in
silence. Musical experiences can persist introspectively, without the need for an external stimulus. The ‘inner hearing’ of a mental representation of music is known as musical imagery (Bailes, 2002). Musicians may use voluntary musical imagery (VMI) to aid with performance preparation or composition. However, musical imagery may also occur spontaneously, which is often referred to as an “earworm” (a direct translation of the German word Ohrwurm), in which we involuntarily revive the auditory image of a piece in the absence of an external source (Bailes, 2007; Brown, 2006; Sacks, 2007), which may then go on to repeat outside of conscious control (Beaman and Williams, 2010). Involuntary musical imagery (INMI), which is sometimes referred to as “stuck song syndrome” (Levitin, 2006), is especially prevalent within Western society, with 33.2% of a recent survey indicating that they experienced INMI daily, whilst 89% reported experiencing the phenomenon at least once a week (Liikkanen, 2012b).
Recent scientific literature has refrained from the use of the term “earworm”, considering it an insufficient description of the phenomenon, and potentially even ‘misleading’ (Liikkanen, 2012b). Accordingly, for the purpose of this report I shall refer to the phenomenon only as INMI. Despite being considered an integral part of our musical mind, there is a dearth of empirical knowledge on the subject. As Bailes (2002) suggests, this may be due to the private and internal nature of the phenomenon, which has led to significant methodological problems, and as such, psychological methods of examining the phenomenon are necessarily restricted to indirect research techniques making INMI experiences onerous to substantiate.
An expanding body of literature has begun to examine the traits that predispose an individual toward experiencing INMI (Beaman and Williams, 2013; Beaty et al., 2013; Floridou, Williamson and Müllensiefen, 2012; Müllensiefen, Jones, Jilka, Stewart and Williamson, 2014), and the circumstances under which INMI is most likely to occur (Floridou and Müllensiefen, 2015; Hemming, 2009; Liikkanen, 2012a; Williamson et al., 2012). Through grounded theory analysis, Williamson et al. (2012) composed a list of eight dominant themes that describe the circumstances of INMI episodes: Recent, Repeated, Association, Recollection, Anticipation, Affective state, Dreams and Mind wandering. These eight themes were then further grouped into four abstract categories, with musical exposure (“recent” and “repeated”) being considered the most prevalent trigger for INMI.
It has been shown that the brain has a tendency to loop the latest tune processed, and therefore it is the most recently acquired or activated memory of music that is most likely to be experienced as INMI (Bailes, 2007; Kvavilashvili and Mandler. 2004). This implies a strong recency effect for INMI. Incidentally, self-report studies have revealed that recent exposure to a tune is generally the most regularly reported cause of INMI experiences in diary and questionnaire studies (Bailes, 2015; Floridou and Müllensiefen, 2015; Hemming, 2009; Jakubowski, Farrugia, Halpern, Sankarpandi and Stewart, 2015; Williamson et al., 2012). However, researchers do state that other factors are also likely to be of significance.
Repeated exposure is also a significant factor in influencing INMI, with Bailes (2002) going as far as to say that ‘familiarity with the music is key to imagery definition’. Beaman and Williams (2010) found that all reported earworms came from music that had been previously familiar to the participants, and it is generally understood that the greater the individual’s familiarity with the music, the greater the likelihood of it stabilizing in the mind as a mental representation. The more we are exposed to a stimulus, the stronger our memory for it will be, and as such, musical imagery is thought to reflect high
60

familiarity with the music (Clynes and Walker, 1986). It is also unusual to experience entirely novel music as INMI, denoting the important link between INMI and familiarity.
Despite the commonality of INMI, the question of which certain songs get stuck in our heads is still not well understood. This is due in part to the fact that there are an array of both extra- and intra-musical factors which contribute to a song’s INMI potential, and very few studies have explored the latter. Anecdotal evidence indicates that musical works differ in their intrinsic ability to induce INMI, yet we are still lacking a comprehensive method to assess the INMI potential of a piece analytically. Recent research has however begun to identify the musical features which tend to be recurrent in the majority of INMI pieces (Jakubowski et al., 2016). The most commonly found characteristics were simple, repetitive patterns, small melodic intervals and longer note durations. These characteristics are also fundamental in creating melodies that are easy to sing, even for non-musicians. Subsequently, these findings led Williamson and Müllensiefen (2012) to propose that ‘INMI episodes are essentially your brain singing’.
Margulis (2013) suggests that when music is familiar to you, it encapsulates expectations of how the piece will progress and develop. This may explain why INMI candidates also tend to contain a certain amount of predictability. However, not all music we are exposed to conforms to conventional and familiar patterns of style, form and harmonic structure. It remains to be seen whether music that should not be considered conducive to emerging as INMI due to its unpredictable and unfamiliar nature could potentially by induced in listeners if they were exposed to such music regularly.
The primary aim of the present study was to explore the role that familiarity plays in the potential of a piece to emerge as INMI, and whether familiarity and regular exposure can negate the intrinsic features of the music to produce INMI. A preliminary investigation was used to determine the features of pieces with high INMI potential, through use of the melodic analysis software FANTASTIC (Feature ANalysis Technology Accessing STatistics [in a Corpus]; Müllensiefen, 2009). Based on the findings from this preliminary analysis, four pieces were selected as musical stimuli for this study. Three of these pieces scored very low on their INMI potential when analysed computationally, and the current model is said to have an 80% success rate on predicting whether a tune has the latent potential to be INMI. Through exposing participants to these three unfamiliar musical stimuli, along with an additionally unfamiliar baseline piece, over a period of seven days, we can begin to examine through use of experience-sampling methods whether it is possible to induce INMI episodes of these pieces despite their apparently incongruous intra-musical characteristics.
II. METHOD
A. Design To investigate these research questions, a mixed methods design was employed. Experience-sampling methods (ESM) combined the approaches of observational field study with self-report diary. The method allows individuals to record thoughts and feelings extemporaneously in a real naturalistic environment, through self-report forms with open-ended and scaled items. The method is direct, allowing respondents to
provide an immediate response, rather than a retrospective report, without parting them from their current location and activity. The contiguity of sampling experience in real time prevents the distortions involved when asking people to report retrospectively.
B. Participants Eighteen participants were recruited through response to an email advertisement for the study which was sent out to several British universities. The study consisted of five men and thirteen women, aged from 18 to 72 (M = 29.06 years; SD = 13.55). It is likely that the gender imbalance observed may be attributed to general trends which reflect significant differences between men and women in their willingness to participate in ESM studies. Previous research indicates that women are more likely to volunteer, and also display greater response rates to signals, than men (Hektner, Schmidt and Csikszentmihalyi, 2007). Two-thirds of the sample also reported prior exposure to musical training to some extent, which may reflect their willingness to participate, as the study was advertised as ideal for music enthusiasts who engage in daily listening. Participants were grouped according to their responses to a selection of questions taken from the Goldsmith’s Musical Sophistication Index (GMSI; 2014). The group of ‘musicians’ were primarily experts in the field (n = 6; five females, one male; mean age = 28; SD = 8.29), those with some ‘musical experience’ were either hobbyists or had a history of musical training earlier in life (n = 6; four females, two males; mean age = 32.67; SD = 20.51), and the ‘non-musicians’ had no experience of formal musical training (n = 6; four females, two males; mean age = 26.5; SD = 10.46).
C. Materials Participation in the study required the use of a mobile telephone, which participants were instructed to carry with them at all times. Ideally the telephone was set to silent-vibrate mode, or a single-tone notification. The message read ‘Please complete form’ and also included an identification stamp to facilitate easier tracking of contact times. Experiencing sampling forms were sent to participants along with a consent form, demographic questionnaire and listening diary, which they were asked to complete and return. Participants were also provided with an information sheet about the study. This sheet also contained the definition of INMI: ‘The experience whereby a (usually) short section of music comes into the mind, unintentionally, without effort, and then tends to repeat without conscious control (i.e. “tune on the brain”)’ so as to help participants identify this phenomenon when it occurred. 1) The stimuli. Four short pieces of piano music were used in this study, all of which were composed in the twentieth century: Philip Glass’s Etude No. 3; Scriabin’s Poeme-Nocturne, Op. 61; the first of Arnold Schoenberg’s Three Piano Pieces, Op. 11; and Luciano Berio’s Rounds, for piano solo. All four pieces were unfamiliar to the participants at the onset of the study. The Glass was chosen as a baseline with which to compare participants’ responses to the other three stimuli, due to its sense of stasis and repetitive nature. The Scriabin is less conventional, and despite relying on traditional sonata principles, draws heavily on chromaticism and the mystic chord.
61

The Schoenberg marks an important milestone in the evolution of the composer’s compositional style as one of his first free atonal works, however, conventional features of form, melody, rhythm and texture are maintained. The Berio also adheres to a typical ternary form structure, but the textural and rhythmic features are much more complex. Although the piece is atonal, there is a discernible pitch centre in the work. 2) The Experience Sampling Form (ESF). The ESF consisted of three primary sections and is closely based on that used by Bailes (2002), comprising both open-ended and closed questions, as well as Likert rating scales, which were designed to be analysed in conjunction with each other. The form was designed to take no more than a few minutes to complete to minimise disruption to daily activities. Respondents were requested to note both the time they were contacted and the time they completed the form in order to monitor any discrepancies and so that data could be discounted if the response was delayed. Part A of the form gathered information about the participant’s location and current activities. Part B concerned the hearing of real music, whilst Part C inquired about any imagery experienced. In both Part B and Part C respondents were asked to rate, on a scale of 1–7, their levels of concentration on the music, the importance of the music to the moment and whether they would have preferred to hear alternative music or no music. Free descriptive responses were also invited to highlight any other important or noticeable features of the music. Participants were also questioned as to whether they had recently heard the music they were imagining, and invited to provide a potential reason for the episode. Likert scales were also used to assess the vividness (scale of 1–7) of various musical dimensions.
D. Procedure The study was conducted in two stages over a two-week period, with each stage lasting seven days. Prior to the start of the study, participants were provided with a WAV file of each of the musical stimuli, along with a listening diary and a demographic questionnaire. On day one, participants were requested to listen to each of the musical stimuli whilst completing their demographic questionnaire, which had a section for participants to record their preference and liking for the pieces, as well as comment on whether any of the music was familiar to them. Over the rest of stage one participants were instructed to listen to each of the pieces a minimum of once per day. Listening did not have to be focused and did not need to occur all in one session, or in the order the tracks were presented. The listening diary allowed participants to track how many times they listened to each piece on each day. In preparation for stage two of the study, which commenced immediately following stage one, participants were provided with an electronic copy of the ESF, allowing them to print as needed or fill it out electronically from a mobile device. The information sheet presented to all interested participants had outlined the procedure of the study, including the potential contact hours of the study, during which time phones should be switched on and set to silent-vibrate mode. Call times were between 9am and 9pm each day, for seven consecutive days. One call would be made within every four-hour block. Calls were made in quick succession to each participant (starting with a different participant each time). Participants were called within 90 seconds of each other to allow for an examination of
a cross-section of data at any particular time episode. Participants were requested to complete a form as soon as they received the signal, or at the next convenient moment if this was not possible.
III. RESULTS AND DATA ANALYSIS Compliance rate for the study was high (99%), with a total of 374 completed ESFs, called “episodes”, being recorded. For analysis of general trends and emerging patterns, all completed forms were used with any unanswered questions being discounted in the analyses. For more detailed analyses, any ESFs completed more than 30 minutes later than the time of the signal (13%) were discounted, leaving a collection of 325 responses (86% of all possible returns). Of these 325 responses, imagery episodes were isolated, and a particular focus assigned to those relating to the prescribed stimuli. As experience was semi-randomly sampled throughout the week, it was possible to calculate the amount of time spent in each musical state. These results are a general measure of the overall prevalence of INMI experiences in general, and for the prescribed stimuli, during a seven-day period. Participants reported hearing music in 33% of episodes, and imagining music in 26% of episodes, which leaves 41% of episodes in which music was neither heard nor imagined. Results are shown in Figure 1, where a distinction has been indicated between INMI relating to the prescribed stimuli (11%), and those episodes in which participants experienced INMI of other, unrelated music (15%).
Within this global measure of the prevalence of INMI, there was great individual variation. The participant who experienced the least INMI did so for 11% of the time, while another participant reported imagining music as much as 44% of the time. Previous studies have provided evidence to support an association between musical imagery and musical experience, and therefore it was to be expected that those participants categorized as ‘musicians’ reported more imagery episodes (M = 38%) than those with little (M = 27%) or no musical experience (M = 24%) (Fig. 2).
Hearing
ImaginingNon-prescribed
ImaginingPrescribed
None
Figure 1. Distribution of musical episodes (N = 374)
62
A repeated measures ANOVA was carried out on the number of INMI episodes with a within-subjects factor of ‘piece’ and a between-subjects factor of ‘musical experience’ which showed a significant main effect of musical experience (F(2,15) = 10.931, p < .001) on the piece imagined. Post-hoc tests using Games-Howell comparisons revealed significant differences between musicians and those with some musical experience (mean difference = 0.3667, p <.05) and also between musicians and non-musicians (mean difference = 0.5667, p <.01). However, the difference between non-musicians and those with some musical experience was not found to be significant. Musical experience was further shown to be related to not only the prevalence of INMI episodes, but also to the type of music imagined (Fig. 3). Musicians generally displayed more episodes of the prescribed stimuli than the other two groups, and INMI induction of certain pieces only seemed to be possible in those with musical experience, which is likely to be due to the intrinsic characteristics of the work.
For the purpose of exploring the relationship between familiarity and occurrence of INMI episodes relating to the
prescribed piece, all participants have been considered as one group. Table 1 shows the results of a Spearman’s rank correlation test, and it can be seen that only the piece by Philip Glass produced a significant correlation (.440, p < .05), which shall be explored in more depth later in this paper. The correlation with the occurrence of non-prescribed stimuli was also significant (.684, p < .001) which may be due to a response bias. General trends between prescribed stimuli and familiarity (indicated by the data point in the study) can be seen in Figure 4, which also highlights certain anomalies in the data set, which may have caused skew in the correlational analysis.
For each prescribed imagery episode, vividness ratings were recorded for the musical dimensions of melody, timbre, harmony, expression, dynamics, and texture. Ratings were collated and a mean value for each dimension per prescribed stimuli was calculated. These data were analysed with a one-way ANOVA and the result was significant (p < 0.001). Melody and expression are rated as being the most vivid dimensions of musical imagery overall, with timbre being rated as the least vivid. Figure 5 illustrates the resultant hierarchy of vivid features (1 = absent, 7 = very vivid), averaged across all participants. Despite having a clear melodic line, dynamics and texture were the most prominent features of the Schoenberg, which may be due to the atonal nature of the piece. The complexity of the Berio is evident here, as participants struggled to develop a vivid image of any of the dimensions, with the exception of dynamics. Further discussion of how intrinsic characteristics relate to the likelihood of the piece to emerge as INMI will be discussed subsequently.
0
0.2
0.4
0.6
0.8
1
1.2
1.4
Musician Some Non-Musician
Est
imat
ed M
argi
nal M
eans
Experience
0
0.5
1
1.5
2
2.5
3
3.5
4
Est
imat
ed M
argi
nal M
eans
Piece imagined
MusicianSomeNon-musician
0
1
2
3
4
5
6
7
0 3 6 9 12 15 18 21
No.
of I
NM
I epi
sode
s
Contact Point
Other musicPrescribed stimuli
0
1
2
3
4
5
6
7
Mea
n V
ivid
ness
Rat
ing
Musical Dimension
GlassSchoenbergScriabinBerio
Figure 2. Estimated Marginal Means for imagery based on musical experience
Figure 3. Estimated Marginal Means for each piece based on musical experience
Figure 4. Correlation between familiarity and all INMI episodes for prescribed pieces
Figure 5. Vividness of Imagery for Musical Dimensions within the Prescribed Stimuli (Scale 1–7)
63

Table 1. Spearman’s rho correlation for familiarity and prescribed INMI occurrence
Day Glass Schoenberg Scriabin Berio Other Sum of prescribed pieces Spearman’s rho Day Correlation
Coefficient 1.000 .440 -.133 .396 -.429 .684 .376
Sig. (2-tailed) . .046 .564 .076 .053 .001 .093 N 21 21 21 21 21 21 21
An aim of the study was to determine the relationship of
imagined to heard experiences of music. Two questions on the ESF addressed this question directly: ‘Had you actually heard the music since the last time you were contacted?’ and ‘If possible, please explain why you might have been imagining that particular music’. In response to the first of these, 53% said ‘yes’ and 47% said ‘no’. This question only related back in time to the last call received and it is possible that hearings of music less recently, such as within the last week, might also have an important influence on the music imagined. The second question allowed for a more open-ended explanation for the possible occurrence of particular music to account for this. Results in Figure 6 have been categorized according to the eight dominant themes that form the illustrative model of themes proposed by Williamson et al. (2012).
Having heard the piece of music recently was the most
common reason provided for subsequently imagining it. Across all episodes, respondents were able to name the majority of their INMI episodes (95%). This suggests a high level of familiarity with the original music, which also suggests an association between hearing and subsequently imagining a particular piece of music. Repeated exposure to a piece was the second most reported trigger for INMI episodes, and was particularly valid with relation to the prescribed stimuli. Participants also reported ‘association’ as being a common trigger for imagining one of the prescribed stimuli, and free descriptive responses revealed that for several participants they likened the prescribed stimuli to other familiar pieces in an attempt to familiarize themselves with them and gauge a better understanding of the works. Only 10% of responses overall reported ‘anticipation’ as a trigger for INMI. However, four out
of five of these responses stated that imagery was experienced as a reaction to the experiment.
IV. DISCUSSION A summary of the finding from the completed ESFs implies
a strong association for familiarity and INMI more generally, as participants were able to name the majority of their imagery, and also regularly reported having heard the piece recently prior to experiencing it as a form of musical imagery. In this study, over half of all INMI episodes (53%) resulted from having heard the music since last being contacted, which provides strong support for what is known as the most recent activation hypothesis. Cognitive psychologists use the concept of serial position to explain this phenomenon, and lab-based studies provide support for the recency effect, showing that a piece which has been heard aloud more recently is more likely to become INMI than a piece heard less recently (Hyman et al., 2013; Liikkanen, 2012b). Although recent exposure is the dominant trigger for INMI, other research has also supported the importance of repeated exposure. Beaman and Williams (2010) suggest that only ‘overlearned’ pieces are likely to appear as INMI. However, the researchers do not define the point at which a piece of music is considered overlearned, although it is possible that this may differ from person to person, which may explain the individual differences evident between participants in this study, and the rate at which they began to experience INMI episodes of the prescribed pieces. Margulis (2005) suggests that expectations begin to arise after the ‘fourth or fifth time’ of listening, whilst Byron and Fowles (2015) found that participants who were exposed to a previously unfamiliar song six times were more likely to experience the song as INMI. Experience-sampling commenced after seven consecutive days of listening to the prescribed stimuli, with the assumption that all participants would have heard each piece a minimum of seven times at this point, and subsequently could be considered “familiar” with them. However, the results from this study evidently indicate that the relationship between familiarity and INMI is much more complex, given that participants varied greatly in both the frequency of their INMI episodes, and the pieces that they experienced.
A large portion of the research on INMI suggests that memory is a significant factor in its emergence. Shouse (2001) suggested that INMI results from the memory process of ‘chunking’ and that the mental repetition we experience is a means of retaining the information. INMI can be constructed from long-tern memory, but also relies on the phonological loop – a short-term memory system in the auditory cortex. However, Kellaris (2008) proposed that only certain pieces of music are capable of arousing the brain’s attention and forcing the song to repeat in the phonological loop, and it is this repetition which is essential for INMI, or what Kellaris has labelled, the “cognitive itch”. The most significant predisposing factors identified were: accessibility, diatonicism
0
5
10
15
20
25
30
35
40
45
50
Perc
enta
ge (%
)
Named trigger for INMI episode
Prescribed music
Non-prescribed music
Figure 6. Frequency of reported triggers for INMI episodes for both prescribed and non-prescribed music
64

and melodic contour (Francès, 1988). Based on these features it is possible to see why the pieces by Scriabin, Schoenberg and Berio did not produce a significant correlation between familiarity and INMI occurrence. Generally, works by these composers are not easily accessible, especially for those with little or no musical training. Atonality makes it difficult for listeners to develop expectations about how a piece will progress, due to a lack of tonal hierarchy or harmonic progression. Furthermore, the complex rhythms and disjunct motion in Berio makes both pulse and melody hard to discern. Although a lyrical melody is evident in Schoenberg, a tonal hearing is hard to sustain. Those who did experience INMI of these works tended to have a reasonable level of musical experience, allowing them to experience more complete episodes, which became more musically embellished as familiarity also increased. For those who could not access the intrinsic working of the pieces, priming of the memory networks in listening to music was unlikely to occur, and therefore the original stimuli was unlikely to be encoded or recalled.
This study found a significant association between musical experience and INMI, both with regards to the prevalence and also which pieces were likely to be imagined. Musicians generally tended to experience more INMI episodes than the other two groups, and they were also the only group to report episodes relating to all four prescribed stimuli. The Berio, which was considered the most complex of the pieces, was only experienced as INMI by musicians. However, musicians and those with some musical experience did not differ with regards to the Glass, which may suggest that the complexity of the music is a significant factor in INMI occurrence. More simplistic and repetitive works tend to be accessible to all, whereas the intrinsic features of both the Berio and Schoenberg proved too complex for any form of schema to develop in the minds of those with no musical experience. It is important to note however that musical training is also likely to have enabled descriptions of musical dimensions and experiences that may prove more challenging for a non-musician.
Although there is still no definitive evidence explanation of why INMI occurs, this research has provided a new insight into what may now be considered a tripartite system, consisting of situational, extra-musical and intra-musical factors that contribute to creating INMI episodes. Thus far, pitch-based features tend to be the most veridical and have been reported to influence INMI more than other musical dimensions, which demonstrates the appropriateness of the expression “tune on the brain”. Francès (1988) specifically highlighted the importance of melodic contour, and previous research has shown that adult listeners remember familiar music in terms of their intervallic structure, focusing on the interval between adjacent notes, rather than the specific pitches themselves (Hannon and Trainor, 2007). The two features used in analysis of the prescribed pieces were pitch range and pitch entropy. However, as the pieces lack a distinct melody, this analysis may not be thorough enough to support a conclusion as to whether the piece has INMI potential or not. Timbre was reported as the least vivid dimension in imagery. This constraint may be attributed to the vocal system’s lack of capacity to stimulate different timbres. Furthermore, research has shown that imagined music for an instrument which the listener plays may retain timbral vibrancy in a way that it may not for others
(Crowder, 1989), and thus we may conclude that people can only veridically imagine sounds which they can physically produce. Data from the Likert scales in Part C of the ESF revealed that those who reported experience of piano training did in fact report stronger vividness for timbre, and also texture, than those who played other instruments. Vocalists, or those with choral experience, also tended to display a greater awareness of the melodic content of the Schoenberg, as indicated in their free descriptive responses to the open-ended question about noticeable features of the imagery episode. However, it is worth noting that the overall sample size was relatively small and therefore some of these findings lack generalizability as they are based only on a small number of episodes.
Previous experience-sampling studies have used varying ranges of signals per day, and therefore it could also be argued that more cues were needed in order to gauge an accurate impression of the week. However, results from this study do correspond with previous research which suggest there is approximately 35-45% chance of hearing music when signalled. Unusually, this study also saw a significant increase in imagery episodes relating to non-prescribed pieces over the duration of the week which may relate to general trends of increased listening as a consequence of the study. This data may reflect demand characteristics, as awareness of the investigator’s interest in INMI experiences might have encouraged participants to exaggerate their real imagery experiences or the process of introspection may have resulted in a more conscious awareness of imagery experiences than usual. Nonetheless, experiencing-sampling is advantageous due to the breadth and depth of data it produces, and it being the closest possible method to observing real-time experiences.
The melodic analysis software used in this study (FANTASTIC; Müllensiefen, 2009) relied on pitch range and pitch entropy, but did not examine any other features in order to assess INMI potential. However, ratings for vividness of musical dimensions reveal that for certain works, other features were more veridical. The pieces used in this study do not represent music as a whole, and the atonal nature of the works mean that a more comprehensive analytical method of assessing INMI potential needs to consider other significant compositional features not represented within the single-line melodic analysis implemented in FANTASTIC, such as harmonic content or chord structure of the music, articulation, and expressive timing, which could contribute to the INMI nature of a piece.
One of the main reasons that INMI is such a difficult concept to explain resides with the fact that the likelihood of a piece becoming INMI is influenced by a wide array of factors, and having heard it recently is just one of these. Based on the results, it would appear that regular exposure to music and familiarity can too induce INMI, however, this may differ dependent on individual differences, such as musical experience. Future research may look at extending this study to include a larger sample size and more regular signals, whilst also reworking the ESF in a way that it may gauge a more in-depth exploration of the situational, extra-musical and intra-musical factors influencing an INMI episode at any one time.
65

REFERENCES Bailes, F. (2002). Musical imagery: hearing and imagining music.
PhD thesis, University of Sheffield. Bailes, F. (2007). The prevalence and nature of imagined music in the
everyday life of music students. Music Psychology, 35(4), 555–570.
Bailes, F. (2015). Music in Mind? An Experience Sampling Study of What and When, Towards an Understanding of Why. Psychomusicology: Music, Mind, and Brain, 25(1), 3–4.
Beaman, C. & Williams, T. (2010). Earworms (‘stuck song syndrome’): Towards a natural history of intrusive thoughts. British Journal of Psychology, 101, 637–653.
Beaman, C. & Williams, T. (2013). Individual differences in mental control predict involuntary musical imagery. Musicae Scientae, 17(4), 398–409.
Beaty, R., Burgin, C., Nusbaum, E., Kwapil, T., Hodges, D. & Silvia, P. (2013). Music to the inner ears: Exploring individual differences in musical imagery. Consciousness and Cognition, 22(4), 1163–1173.
Brown, S. (2006). The Perceptual Music Track: The Phenomenon of Constant Musical Imagery. Journal of Consciousness Studies, 13, 43–62.
Byron, T. & Fowles, L. (2015). Repetition and recency increases involuntary musical imagery of previously unfamiliar songs. Psychology of Music, 43(3), 375–389.
Clynes, M. & Walker, J. (1986). Music as Time’s Measure. Music Perception: An Interdisciplinary Journal, 4(1), 85–119.
Crowder, R. (1989). Imagery for musical timbre. Journal Of Experimental Psychology: Human Perception And Performance, 15(3), 472–478.
Finkel, S., Jilka, S., Williamson, V., Stewart, L. & Müllensiefen, D. (2010). Involuntary musical imagery: Investigating musical features that predict earworms. Paper presented at the Third International Conference of Students of Systematic Musicology (SysMus10). University of Cambridge, UK.
Floridou, G. & Müllensiefen, D. (2015). Environmental and mental conditions predicting the experience of involuntary musical imagery: An experience sampling method study. Consciousness and Cognition, 33, 472–486.
Floridou, G., Williamson, V., & Müllensiefen, D. (2012). Contracting Earworms: The Roles of Personality and Musicality. Paper presented at the 12th International Conference on Music Perception and Cognition. Thessaloniki, Greece.
Francès, R. (1988). The perception of music. Hillsdale, NJ: Lawrence Erlbaum Associates. (Original work published 1958).
Hannon, E. & Trainor, L. (2007). Music acquisition: effects of enculturation and formal training on development. Trends In Cognitive Sciences, 11(11), 466–472.
Hektner, J., Schmidt, J. & Csikszentmihalyi, M. (2007). Experience sampling method: Measuring the Quality of Everyday Life. Thousand Oaks, Calif.: Sage Publications.
Hemming, J. (2009). Zur Phänomenologie des Ohrwurms. Musikpsychologie, 20, 184–207.
Hyman, I., Burland, K., Duskin, H., Cook, M., Roy, C., McGrath, J. & Roundhill, R. (2013). Going Gaga: Investigating, Creating, and Manipulating the Song Stuck in My Head. Applied Cognitive Psychology, 27(2), 204–215.
Jakubowski, K., Farrugia, N., Halpern, A., Sankarpandi, S. & Stewart, L. (2015). The speed of our mental soundtracks: Tracking the tempo of involuntary musical imagery in everyday life. Memory and Cognition, 43, 1229–1242.
Jakubowski, K., Finkel, S., Stewart, L., & Müllensiefen, D. (2017). Dissecting an earworm: Melodic features and song popularity predict involuntary musical imagery. Psychology Of Aesthetics, Creativity, And The Arts, 11(2), 122–135.
Kellaris, J. J. (2008). Music and consumers. In C. P. Haugtvedt, P. Herr & F. R. Kardes (Eds.), Handbook of consumer psychology (pp. 837–856). New York: Taylor and Francis.
Kvavilashvili, L. & Mandler, G. (2004). Out of one’s mind: A study of involuntary semantic memories. Cognitive Psychology, 48(1), 47–94.
Levitin, D. (2006). This is your brain on music: The science of a human obsession. New York: Penguin.
Liikkanen, L. (2012a). Musical activities predispose to involuntary musical imagery. Psychology Of Music, 40(2), 236–256.
Liikkanen, L. (2012b). Inducing involuntary musical imagery: An experimental study. Musicae Scientiae, 16(2), 217–234.
Margulis, E. (2013). On Repeat: How Music Plays the Mind. New York: Oxford University Press.
Müllensiefen. D. (2009). FANTASTIC: Feature ANalysis Technology Accessing STatistics (In a Corpus): Technical Report. Retrieved from http://www.doc.gold.ac.uk/isms/m4s/FANTASTIC_docs.pdf
Müllensiefen, D., Jones, R., Jilka, S., Stewart, L. & Williamson, V. (2014). Individual Differences Predict Patterns in Spontaneous Involuntary Musical Imagery. Music Perception: An Interdisciplinary Journal, 31(4), 323–338.
Sacks, O. (2007). Musicophilia. New York: Alfred A. Knopf. Shouse, B. (2001). ‘Oops! I did it again!’ New Scientist, 2301, 44–45. Williamson, V., Jilka, S., Fry, J., Finkel, S., Müllensiefen, D. &
Stewart, L. (2012). How do "earworms" start? Classifying the everyday circumstances of Involuntary Musical Imagery. Psychology Of Music, 40(3), 259–284.
Williamson, V. & Müllensiefen, D. (2012). Earworms from three angles. In E. Cambouropoulos, C. Tsougras, K. Mavromatis, K. Pastiadis (Eds.) Proceedings of ICMPC-ESCOM 12. Thessaloniki, Greece.
66

Proceedings of the 10th International Conference of Students of Systematic Musicology (SysMus17), London, UK, September 13-15, 2017. Peter M. C. Harrison (Ed.).
Factors Influencing Discrimination of Emotional Expression Conveyed Through Music Performance
Chloe Stacey MacGregor1, Daniel Müllensiefen2 Department of Psychology, Goldsmiths, University of London, England
[email protected], [email protected]
ABSTRACT Previous research has shown that levels of musical training and emotional engagement with music are associated with an individual’s ability to decode the intended emotional expression from a music performance (Akkermans & Schapiro, 2016). The present study aims to go further and investigate the contribution of auditory perceptual abilities to decoding performance as measured by a new effective emotion discrimination task (EDT). The first experiment investigated features that influenced the difficulty of the stimulus items (length, melody, instrument, target-/comparison emotion) in order to produce a short calibrated version of the EDT and ensure an optimal level of difficulty. The second experiment then assessed the contribution of individual differences measures of emotional intelligence as well as pitch and duration discrimination abilities. Findings displayed performance on the EDT was correlated with level of emotional intelligence. This research therefore contributes to the understanding of the origins of individual differences in musical emotional abilities.
I. INTRODUCTION The emotional experience associated with music is widely
acknowledged to be one of the main reasons why so many people regularly engage in musical activities (Juslin & Laukka, 2004). Music is often used in a constructive manner, to express emotion through composition and performance, or to evoke or regulate an emotional state through listening; this has proven to be extremely beneficial in the field of therapy and has also been influential in other areas such as film and marketing (Juslin & Sloboda, 2011). Due to the vast range of practical applications, the amount of research contributing to an understanding of emotional processes in relation to music has increased considerably over the last few decades, most of which has focused especially on the expression and induction of musical emotions (Thompson, 2009). Despite this, questions still remain as to how individual differences in emotional, musical and perceptual skills may affect the ability to perceive emotion in music (Taruffi, Allen, Downing & Heaton, 2017).
It been suggested that the perception of musical emotions may vary between individuals, just as recognition of facial and vocal expressions has been found to vary according to individual differences (Taruffi et al., 2017; Palermo, O’Connor, Davis, Irons & McKone, 2013). The current study therefore aims to investigate whether differences in emotional, musical and perceptual abilities may account for variation in perceived musical emotion.
One potential factor that may influence emotion recognition is emotional intelligence (EI): the ability to categorize, express and regulate one’s emotions, as well as
those of others (Salovey & Mayer, 1990). EI is typically separated into two constructs for the purpose of measurement; ability EI, measured using cognitive ability tests, and trait EI, assessed via self-report methods (Petrides, Frederickson & Furnham, 2004). In keeping with a recent study of emotion decoding in music (Akkermans & Schapiro, 2016), a self-report measure of trait EI was used within the current research. Differences in recognition of emotion within speech prosody have previously been linked to EI (Trimmer & Cuddy, 2008), suggesting its potential importance in terms of musical emotion decoding ability. Furthermore, Resnicow, Salovey and Repp (2004) found a positive correlation between EI and a test of emotion recognition, in which participants’ rated basic emotions conveyed through piano pieces. This evidence therefore indicates that differences in EI may explain variation in music-perceived emotion.
Another element of emotional ability that should be taken into account is emotional contagion (EC), which refers to ones’ tendency to be influenced by, or unconsciously mimic, others’ emotional states (Doherty, 1997). EC has mostly been investigated in relation to facial expressions (Juslin & Västfjäll, 2008), though contagion from vocal expression has also been found to occur (Neumann & Strack, 2000). On the basis of such evidence, as well as the aforementioned notion that music’s emotional quality may be derived from its similarities to vocal expression (Juslin & Laukka, 2003), it has been speculated that EC may occur in music listening through the internal mimicking of a perceived expression (Juslin, Liljeström, Västfjäll, & Lundquist, 2009). This is backed up by neuroimaging research conducted by Koelsch, Fritz, Müller & Friederici (2006); activation was found within mirror-neuron systems believed to be involved in vocal production when participants listened to music. It is thought that this could suggest the mimicking of emotions expressed by music (Juslin & Västfjäll, 2008). This implies that EC may play a role in the ability to categorize emotions in music.
Though a high level of emotional ability is likely to result in a consistent level of emotion processing throughout different modalities, it is arguable that emotional ability may vary specifically in relation to music. Therefore, it is necessary to consider an individuals’ typical level of emotional engagement with music, alongside more general measures of emotional ability, when investigating factors influencing emotion recognition. Emotional engagement with music can be measured using the Goldsmiths Musical Sophistication Index (GOLD-MSI) (Müllensiefen, Gingras, Musil, & Stewart, 2013), a self-report tool that allows for the assessment of a wide range of musical skills and behaviours.
67

This subscale was used in a recent study, which found that level of emotional engagement with music predicted level of accuracy when decoding emotions in music (Akkermans & Schapiro, 2016). Level of emotional engagement with music, as measured using the emotions subscale of the GOLD-MSI, may therefore influence recognition of a conveyed expression in music.
Musical ability has also been explored in relation to emotional ability. The idea that musical expertise may enhance emotional skills seems plausible, when taking into account other cognitive advantages found to result from training (Schellenberg, 2005). In accordance with this, it has been suggested that enhanced musical and acoustic processing, acquired through musical training (Kraus & Chandrasekaran, 2010), may lead to superior performance in emotion recognition tasks (Taruffi et al., 2017). Research has provided supportive evidence for this claim; accurate categorisation of musical emotions was found to be associated with the amount of musical training an individual had received (Lima & Castro, 2011). On the other hand, some studies have demonstrated little difference between the emotion decoding abilities of musicians and non-musicians (Trimmer & Cuddy, 2008). Therefore, further investigation is required to establish whether a relationship exists between musical training and recognition of emotion in music (Taruffi et al., 2017).
If we are to assume that superior emotion recognition ability may result from enhanced perceptual processing, it follows that fundamental differences in auditory perception may also influence recognition ability. The pitch and duration of musical events are important cues for interpreting emotional expression in speech and music (Juslin & Laukka, 2003; Lima et al., 2016), meaning that differences in perceptual sensitivity may be predictive of differences in emotion perceived in music.
The current research is based upon a recent replication (Akkermans & Schapiro, 2016) of a study carried out by Gabrielsson and Juslin (1996). The original study investigated expressive cues involved in communication of emotion in music. A production-recognition paradigm was used to accomplish this; firstly, a flutist, violinist and vocalist were recorded performing three melodies in order to convey a certain emotional expression (happy, sad, angry, fearful, tender solemn or without expression). These performances were analysed in terms of musical characteristics that contributed towards the overall expression. Listening experiments were then carried out in which participants were asked to identify the emotions expressed within each performance. Results indicated that expressive intentions were usually identified correctly, and a higher decoding accuracy was displayed for basic emotions, in accordance with Juslin’s (1995) hypothesis that basic emotions would be easiest to communicate. In the replication study, emotional and musical skills were assessed in regard to their influence on decoding accuracy (Akkermans & Schapiro, 2016); accuracy was found to be associated with participants’ level of musical training and emotional engagement.
The present investigation aimed to further explore what might make one individual better at decoding emotions conveyed through music than another. Thus, the main objectives for the current study were: firstly, to develop a short and effective Emotion Discrimination Task (EDT),
which tests an individuals’ ability to perceive emotions in music using a simple response format. Secondly, to further examine individual differences in EI, EC, musical training and emotional engagement, in relation to their influence on perceived emotion in music, and finally, to extend previous research by investigating the contribution of low-level auditory ability to emotion decoding performance. In pursuit of achieving these aims, two experiments were carried out. Experiment 1 consisted of a preliminary EDT, in which two excerpts of the same melody were presented that differed only in terms of emotional expression. Excerpts differed between trials in terms of features such as: length, instrument, melody, target emotion and comparison emotion. The effect of these features on the item difficulty was assessed, not only to gain a better understanding of the cognitive processes underlying task performance but also to optimally calibrate overall test difficulty and thus being able to form a shorter test of emotion discrimination. The refined EDT was formed of excerpts that were shortest in length, and featured only one of the two melodies from the preliminary task. This task was then utilized within experiment 2, along with measures of individual differences and perceptual ability.
II. EXPERIMENT 1
METHOD A. Participants
33 participants were recruited through advertisement on social network platforms and the Goldsmith’s research participation scheme. Participants ranged from 18-80 years of age, (M = 37.06, SD = 22.65), and included 21 females, 10 males and 2 individuals who preferred to withhold gender information. The current study was granted ethical approval by Goldsmith’s Research Ethics Committee.
B. Materials & Stimuli 1) Melody recordings. For the EDT, melodies B and C
from Gabrielsson and Juslin’s (1996) study were employed. Melody B is a Swedish folk melody, while Melody C was composed specifically for use within their research (see Figure 1).
Hereafter, Melody B will be referred to as melody 1, and melody C as melody 2. The musical extracts utilized in the current study were re-recordings of the stimuli used by Gabrielsson and Juslin (1996) and were validated through their comprehensive study. In addition, the replication study carried out by Akkermans and Schapiro (2016) validated the re-recorded versions of the stimuli. In this study, only recordings that conveyed angry, happy, sad and tender expressions on piano, violin or voice were used, as findings indicated these were the most accurately perceived by listeners (Akkermans & Schapiro, 2016).
2) Editing. Recordings were edited in order to establish a greater variation of difficulty between items in the EDT. This was achieved by splitting audio files into musically meaningful phrases using Adobe audition CC. Melody 1 was split into 4, 4 bar phrases, while melody 2 was split into 6, 2 bar phrases; all possible combinations of consecutive sequences of phrases were produced. These excerpts were then paired in terms of their main musical features, but not in terms of emotional expression. Pairs of clips were then
68

merged to create one mp3 file using SoundeXchange software, with a buzzer inserted in-between. Thus, 1116 items were produced that featured two clips with the same melody, instrument and phrases, but differing emotional expressions.
Figure 1. Notation, melodies B & C (1 & 2)
3) Emotion discrimination task. The EDT consisted of 112
items, of which 36 were randomly presented to participants. Responses were collected using a two-alternative forced choice format (2-AFC).
4) Depression screening. The Patient Health Questionnaire
(PHQ-9), a short, self-administered survey, was used to assess current depression severity (Kroenke & Spitzer, 2002). This measure consists of 9 items, directly related to the diagnostic criteria within the DSM-IV.
C. Procedure This experiment was conducted online, thus participants
gained access to Qualtrics via a URL; this allowed for automatic administration of the information sheet, consent form, depression screening, EDT, demographics form and debrief. For the EDT, participants were told that they would hear two versions of a melody at a time, which would differ in terms of emotional expression and that they should indicate which version they felt was most representative of the emotion in each question. Participants were exposed to 21 audio clips, and instructed as follows: ‘Please listen to the following clips and select which one sounds happier to you. Select 1 for the clip heard before the buzzer, or 2 for the clip heard after the buzzer.’ This task took around 15-20 minutes to complete.
RESULTS
From the initial sample of 78 participants, 35 participants were excluded from analysis, as they had not fully completed the experiment. Additionally, 10 participants were excluded as their scores were above the typical cut off point (≥10) in the depression screening (Manea, Gilbody & McMillan, 2012).
A. Musical Features
Correct responses were scored with a value of 1 and incorrect with 0. The total correct response rate was 83.4%.
1) Target emotion. A chi-square test of independence was used to investigate the relationship between target emotion (happy, angry, sad, tender) and performance in the EDT (correct, incorrect response). The relationship between these variables was found to be statistically significant, χ2(3, 693) = 15.12, p = .002, with an effect size of φc=.15. Findings indicated that questions featuring sad as the target emotion were most likely to be answered correctly, while those with tender as the target emotion were the least likely to elicit a correct response, as shown in Table 1.
Table 1. Cross-Tabulation of Target Emotion and Task Performance.
Target Emotion
Response Correct Incorrect χ2
φc
Angry 183 (88.4%)
24 (11.6%)
15.12** .15
Happy 150 (78.1%)
42 (21.9%)
Sad 147 (88.6%)
19 (11.4%)
Tender 98 (76.6%)
30 (23.4%)
Note. ** = p ≤ .01. χ2 represents chi-square statistic. φc represents phi coefficient. Percentages appear in parentheses below frequencies.
2) Length. A chi-square test of independence was
performed to examine the association between length of melody (one phrase, two phrase, three phrase) and EDT performance (correct/incorrect response). The relationship between these variables was significant, χ2(2, 693) = 9.43, p = .009, while the effect size was small, φc = .12. Results displayed that extracts of only one phrase in length were least likely to elicit a correct response, as can be seen in Table 2.
Table 2. Cross-Tabulation of Item Length and Task Performance. Length Response
Correct Incorrect χ2
φc
One Phrase
154 (76.6%)
47 (23.4%)
9.43** .12
Two Phrase
251 (86.3%)
40 (13.7%)
Three phrase
173 (86.1%)
28 (13.9%)
Note. ** = p ≤ .01. χ2 represents chi-square statistic. φc represents phi coefficient. Percentages appear in parentheses below frequencies.
Three further chi-square tests of independence were conducted to assess the relationship between task performance (correct, incorrect response), and comparison emotion (angry, happy, sad, tender), instrument (piano, violin, voice) or melody (1,2); none of the findings were statistically significant. Additionally, a logistic regression was performed; musical feature variables were assessed as independent variables with regard to their ability to predict EDT performance. This analysis confirmed the findings of the chi-square tests.
B
C
69

III. EXPERIMENT 2
METHOD A. Participants
45 participants (26 female) were recruited, partly through advertisement on social media, and partly in exchange for participation in other studies. The majority of participants were students from Goldsmiths, University of London, ranging from 20-50 years of age (M = 24.71, SD = 5.86). This study gained ethical approval from Goldsmiths Research Ethics Committee.
B. Materials & Stimuli 1) Individual difference measures. The Goldsmiths Musical
Sophistication Index (GOLD-MSI), was used to assess musical behaviours and skills using a self-report questionnaire (Müllensiefen et al., 2013). This inventory consists of 5 sub-scales, of which 3 were used; these measured musical training, emotional engagement with music and active engagement with music.
The Trait Emotional Intelligence Questionnaire Short Form (TEIQue-SF) was administered, in order to measure EI via self-report (Petrides, 2009).
Emotional contagion was measured using the Emotional Contagion Scale (Doherty, 1997), which consists of 15 self-report items, including hypothetical scenarios such as ‘When someone smiles warmly at me, I smile back and feel warm inside.’
2) Emotion discrimination task. The refined EDT was comprised of 28 items, 8-23 seconds in length, which contained only one phrase and featured only melody 1. Responses were collected using a 2-AFC format.
3) Auditory perception tasks. Psychoacoustic tests were also employed to establish participants’ ability to discriminate duration and pitch. These were run using two experiments from the Maximum Likelihood Procedure (MLP) toolbox on MATLAB 2013b (Grassi & Soranzo, 2009): namely, pitch discrimination complex tone and duration discrimination complex tone. Experiments were set up so that 2 blocks of 20 trials were completed per test, and responses were collected using a 3-AFC format. Default settings, as specified by the MLP toolbox, were otherwise maintained. Participants carried out both the new EDT and psychoacoustic tests using AKG-K451 headphones and responses were collected using a computer keyboard and mouse.
C. Procedure For this experiment, both the short EDT and
psychoacoustic tests were completed separately to the individual difference measures, in a silent, controlled setting. If participants had not taken part in Experiment 1, they were asked to complete the individual difference measures, either before or after the in-lab tests took place. At the beginning of each part of this study, participants were provided with an information sheet and consent form.
For the short EDT, participants received the same instructions as were provided in the first experiment; this task took approximately 8-10 minutes. Following this, participants took part in two psychoacoustic tests; for each test, they were told that they would hear three tones per trial. For the first, they were asked to distinguish which tone was longer in
duration, while for the second they were asked to identify which was higher in pitch. Each test took around 3 minutes to complete. After the online individual differences measures and the in-lab auditory experiments had been completed, participants were thanked and debriefed.
RESULTS From the initial 60 responses, data from three participant’s
was excluded from analysis as they had not completed the individual difference test battery, while 12 participants were excluded as a consequence of high scores in the depression screening (≥10).
A. Individual differences Total correct responses were calculated as a measure of
EDT performance, which ranged from 17-25 out of 28 (M = 21.38, SD = 1.81). Active engagement was excluded from analysis, due to the high correlation with emotional engagement found in Experiment 1. For the psychoacoustic measures, an auditory threshold estimate was produced for each block of trials. Out of the two blocks completed within each test, the lower threshold was retained for analysis. For duration tests, thresholds ranged from 258.36 - 330.03 ms (M = 282.28, SD = 14.9), while for pitch discrimination, thresholds ranged from 330.76 - 349.07 Hz (M = 334.34, SD = 4). For a complete outline of the descriptive statistics obtained for each measure, see Table 3.
Correlational analyses were carried out to distinguish whether the individual difference and perceptual measures were associated with EDT scores. Emotional intelligence (M = 4.99, SD = .61) and EDT performance were positively correlated, r(45) = .27, p = .04, one-tailed (as shown in Figure 2). None of the other personality traits or perceptual ability differences were significantly correlated with performance.
Figure 2. Graph to display correlation between EDT score and emotional intelligence. r denotes Pearson’s correlation coefficient.
In addition, a multiple regression was performed to establish whether EI, EC, musical training, emotional engagement with music, pitch threshold and duration threshold predicted EDT performance. Backwards elimination was used to discard variables that were not significantly contributing to the model (p < .05). The sixth model arrived at through this process indicated that emotional intelligence displayed a trend in the prediction of EDT performance, R² = .07, adjusted R² = .05, F(1, 43) = 3.24, p = .08, as outlined in Table 4.
70

Table 4. Regression Model of Total EDT Score. B SE β p Constant 21.14 .3 <.001 EI .48 .3 .27 .08
Note. B represents unstandardized regression coefficient. SE represents standard error of B. β represents standardized regression coefficient. EI=Emotional Intelligence.
IV. DISCUSSION Primarily, the focus of Experiment 1 was to identify
features that contributed to the difficulty of task items; item difficulty was influenced by how many phrases were featured in the musical extract, and which emotion participants were required to identify. Extracts featuring ‘tender’ as a target emotion or only one phrase of the melody appeared to be the most difficult, when looking at the percentage of correct responses per item (refer to Tables 1 & 2). Therefore, results provide support for the hypothesis that features of musical excerpts may contribute to the overall difficulty of individual task items.
The main aim of Experiment 2 was to determine factors that might influence the ability to discriminate performer-intended expressions of emotion in music. It was expected that those with a high level of emotional, musical and perceptual skills would display superior discrimination ability. While skills such as emotional intelligence were found to be positively associated with discrimination ability, there was no evidence to suggest that musical or perceptual abilities had a significant impact on performance; therefore the original hypothesis was not fully supported.
Nevertheless, the present study presents a first step towards the creation of a short and effective EDT and secondly, has aided the investigation of individual differences in emotional, musical and perceptual abilities that may have contributed to variation in task performance. Experiment 1 results were used to establish a shorter test, which was found to be an effective measure of emotion discrimination ability, on the basis that mean level of task performance in Experiment 2 was at 76% and therefore half way between chance level (50%) and perfect discrimination. The refined EDT was further validated by Experiment 2 results, displaying that discrimination ability was associated with, and to some extent predicted by, level of EI. These findings are also of importance, as they contribute to an understanding of the factors that might influence the ability to recognize emotions conveyed through music performance.
Emotional intelligence typically refers to a capacity to recognize one’s own emotions and those of others; thus, it is possible that the ability to perceive emotions in music relies on similar emotional processes. This backs up previous findings that individual differences in EI relate to individual
differences in emotion recognition ability in the music domain (Resnicow et al., 2004). Additionally, this experiment extends previous findings, by demonstrating that EI is associated with perception of emotional expression in musical extracts featuring instruments other than piano. Therefore, the results from experiment 2 support and extend previous findings, indicating that the ability to recognize emotional expressions conveyed through music may be an important aspect of EI.
Based on this evidence the claim that emotional ability impacts upon the perception and identification of emotions in music seems to be reasonably justified. Although, in contrast to this conclusion, results indicate that the emotions subscale of the GOLD-MSI and the emotional contagion scale were not associated with EDT performance. The findings from the present experiment appear to be inconsistent with this rationale as well as the findings from previous studies (Akkermans & Schapiro, 2016). This either indicates that typical emotional engagement with music does not impact upon emotion recognition ability or that a larger sample size may be required to establish an effect. The latter would appear the most plausible explanation meaning that further testing is necessary in order to establish the concurrent validity of the EDT.
It was suggested by Juslin & Västfjäll (2008) that emotional responses to music might occur through internal mimicking of emotions expressed in music. The current results do not appear to support this claim, as emotional contagion was not associated with emotion recognition ability, though this could be due to the study of perceived emotional expression as opposed to ‘felt’ emotions (Gabrielsson, 2001). Conceptually, it is arguable that EC is more involved with emotions evoked by music, than emotions perceived in music, which could account for the discrepancy in results. It may, therefore, be more appropriate to study EC with regard to individual differences in emotions evoked during music listening.
The hypothesis that musical expertise may have a positive influence on the ability to perceive intended expressions in music was not supported by the current experiment; there was no evidence to suggest that musical training influenced EDT performance. These findings are a result of a low level of musical training within the current sample, according to normative data from the GOLD-MSI (Müllensiefen, Gingras, Musil, & Stewart, 2014). Further investigation with a larger proportion of musically trained participants is required to clarify the effect of musical training on the ability to discriminate emotions conveyed by music.
In accordance with findings relating to musical ability, no significant relationship was established between pitch or duration discrimination ability and the recognition of a musically conveyed expression. It could be argued that this is an unexpected result, as pitch and duration are both expressive cues used within the interpretation of musical and vocal
M SD Range EDT score Emotional intelligence
21.38 4.99
1.81 .61
17-25 3.7-6.2
Emotional contagion 50.24 8.63 33-65 Musical training 22.11 5.26 13-39 Emotional engagement 29.09 4.34 16-36 Pitch discrimination 334.38 4.1 330.76-349.07Hz Duration discrimination 280.53 14.19 258.36-330.03ms
Table 3. Descriptive statistics. Experiment 2.
71

emotional expression (Juslin & Laukka, 2003). Although, Filipic, Tillmann and Bigand, (2010) found that emotion judgments were not affected by basic acoustic features; they suggest that perception of musical emotion is based on the interpretation of a complex combination of features, as has also been found in studies of facial expression. This would account for the finding that psychoacoustic abilities did not influence performance on the EDT.
From a broader perspective, the finding that emotional abilities such as EI, previously found to be related to recognition of both facial (Petrides & Furnham, 2003) and vocal (Trimmer & Cuddy, 2008) expression, are involved in musical emotion recognition is of significance. While this is not a novel discovery, results from this study provide further evidence to suggest that recognition of emotion within music is supported by an innate mechanism for emotional processing. Furthermore, this finding is consistent with the predictions put forward in functionalist perspective of music and emotion (Juslin, 1997), suggesting a link between processes involved in recognition of emotions in speech and music (Juslin & Laukka, 2003).
In addition, the fact that listeners were able to distinguish between basic emotions conveyed through music supports the theoretical assumption that basic emotions can be portrayed through music performance (Juslin, 1995), and the applicability of discrete emotional constructs within the study of music and emotion. However, it must be considered that the stimuli used within the current experiment were specifically manipulated in order to portray these particular emotions, and this procedure is distinct from that which is likely to occur within a natural music performance. In a realistic setting, intrinsic structural aspects of the score would typically determine the intended emotional expression, and these emotive intentions would then be reflected by the musicians’ performance (Resnicow et al., 2004). Another issue with validity that the current investigation poses is the fact that only three performers were featured. Performers may differ in terms of their technical skill (Gabrielsson & Juslin, 1996) as well as their interpretation of emotional expression (Akkermans & Schapiro, 2016). This could impact upon the ease with which listeners are able to recognize intended expressions. Future studies should, therefore, aim towards including a wider range of stimuli that are more representative of music that one would typically encounter in everyday life, and feature a larger sample of performers.
V. CONCLUSION While music’s appeal lies within the emotive character it
conveys, it appears that individuals differ in the extent to which they are able to perceive music-portrayed emotions. This research represents a step towards a short and effective measure of an individuals’ capacity to perceive performer-intended emotional expressions using musical stimuli. Furthermore, it contributes to an understanding of the origins of individual differences in music-perceived emotions, backing up previous findings that suggest the ability to identify intended emotional expressions is dependent on emotional intelligence. Further investigation into factors influencing perception of emotions in music is necessary, in order to determine whether music may truly be considered a universal ‘language of emotion’ (Cooke, 1959).
ACKNOWLEDGMENT This research was conducted in collaboration with Jessica
Akkermans and Renee Schapiro, MSc graduates (provided stimuli) from Goldsmiths, University of London and Peter Harrison, PhD student (edited sound clips) from Queen Mary University of London.
REFERENCES Akkermans, J., Schapiro, R. (2016). Expressive performance and
listeners’ decoding of performed emotions: A multi-lab extension. Unpublished MSc dissertation. Goldsmiths, University of London.
Bigand, E., & Poulin-Charronnat, B. (2006). Are we “experienced listeners”? A review of the musical capacities that do not depend on formal musical training. Cognition, 100(1), 100-130.
Cooke, D. (1959) The language of music. Oxford University Press. Doherty, R. W. (1997). The emotional contagion scale: A measure of
individual differences. Journal of nonverbal Behavior, 21(2), 131-154.
Filipic, S., Tillmann, B., & Bigand, E. (2010). Judging familiarity and emotion from very brief musical excerpts. Psychonomic Bulletin & Review, 17(3), 335-341.
Gabrielsson, A. (2001). Emotion perceived and emotion felt: Same or different?. Musicae Scientiae, 5, 123-147.
Gabrielsson, A., & Juslin, P. N. (1996). Emotional expression in music performance: Between the performer's intention and the listener's experience. Psychology of music, 24(1), 68-91.
Grassi, M., & Soranzo, A. (2009). MLP: a MATLAB toolbox for rapid and reliable auditory threshold estimation. Behavior research methods, 41(1), 20-28.
Juslin, P. N. (1995). A functionalistic perspective on emotional communication in music. European Society for the Cognitive Sciences of Music, 8, 11-16.
Juslin, P. N. (1997). Emotional communication in music performance: A functionalist perspective and some data. Music Perception: An Interdisciplinary Journal, 14(4), 383-418.
Juslin, P. N., & Laukka, P. (2003). Communication of emotions in vocal expression and music performance: Different channels, same code?.Psychological bulletin, 129(5), 770.
Juslin, P. N., & Laukka, P. (2003). Emotional expression in speech and music. Annals of the New York Academy of Sciences, 1000(1), 279-282.
Juslin, P. N., & Laukka, P. (2004). Expression, perception, and induction of musical emotions: A review and a questionnaire study of everyday listening. Journal of New Music Research, 33(3), 217-238.
Juslin, P., Liljeström, S., Västfjäll, D., & Lundquist, L. O. (2009). How does music evoke emotions? Exploring the underlying mechanisms. Handbook of Music and Emotion: Theory, research, applications (pp. 605-642). Oxford University Press.
Juslin, P. N., & Sloboda, J. (2011). Introduction: aims organization and terminology. In Handbook of music and emotion: Theory, research, applications (pp. 3-12). Oxford University Press.
Juslin, P. N., & Västfjäll, D. (2008). Emotional responses to music: The need to consider underlying mechanisms. Behavioral and brain sciences, 31(05), 559-575.
Koelsch, S., Fritz, T., Müller, K., & Friederici, A. D. (2006). Investigating emotion with music: an fMRI study. Human brain mapping, 27(3), 239-250.
Kraus, N., & Chandrasekaran, B. (2010). Music training for the development of auditory skills. Nature Reviews Neuroscience, 11(8), 599-605.
Kroenke, K., & Spitzer, R. L. (2002). The PHQ-9: a new depression diagnostic and severity measure. Psychiatric annals, 32(9), 509-515.
72

Lima, C. F., Brancatisano, O., Fancourt, A., Müllensiefen, D., Scott, S. K., Warren, J. D., & Stewart, L. (2016). Impaired socio-emotional processing in a developmental music disorder. Scientific reports, 6.
Lima, C. F., & Castro, S. L. (2011). Speaking to the trained ear: musical expertise enhances the recognition of emotions in speech prosody. Emotion, 11(5), 1021.
Manea, L., Gilbody, S., & McMillan, D. (2012). Optimal cut-off score for diagnosing depression with the Patient Health Questionnaire (PHQ-9): a meta-analysis. Canadian Medical Association Journal, 184(3), E191-E196.
Müllensiefen, D., Gingras, B., Musil, J., & Stewart, L. (2014). The musicality of non-musicians: an index for assessing musical sophistication in the general population. PloS one, 9(2), e89642.
Müllensiefen, D., Gingras, B., Stewart, L., & Musil, J. J. (2013). Goldsmiths Musical Sophistication Index (Gold-MSI) v1. 0: Technical Report and Documentation Revision 0.3. London: Goldsmiths, University of London.
Neumann, R., & Strack, F. (2000). " Mood contagion": the automatic transfer of mood between persons. Journal of personality and social psychology, 79(2), 211.
Palermo, R., O’Connor, K. B., Davis, J. M., Irons, J., & McKone, E. (2013). New tests to measure individual differences in matching and labelling facial expressions of emotion, and their association with ability to recognise vocal emotions and facial identity. PloS one, 8(6).
Palermo, R., O’Connor, K. B., Davis, J. M., Irons, J., & McKone, E. (2013). New tests to measure individual differences in matching and labelling facial expressions of emotion, and their association with ability to recognise vocal emotions and facial identity. PloS one, 8(6).
Petrides, K. V. (2009). Technical manual for the Trait Emotional Intelligence Questionnaires (TEIQue) (1st edition, 4th printing). London: London Psychometric Laboratory.
Petrides, K. V., Frederickson, N., & Furnham, A. (2004). Emotional intelligence. Psychologist, 17(10), 574.
Petrides, K. V., & Furnham, A. (2003). Trait emotional intelligence: Behavioural validation in two studies of emotion recognition and reactivity to mood induction. European journal of personality, 17(1), 39-57.
Punkanen, M., Eerola, T., & Erkkilä, J. (2011). Biased emotional recognition in depression: perception of emotions in music by depressed patients. Journal of affective disorders, 130(1), 118-126.
Resnicow, J. E., Salovey, P., & Repp, B. H. (2004). Is recognition of emotion in music performance an aspect of emotional intelligence?. Music Perception: An Interdisciplinary Journal, 22(1), 145-158.
Salovey, P., & Mayer, J. D. (1990). Emotional intelligence. Imagination, cognition and personality, 9(3), 185-211.
Schellenberg, E. G. (2005). Music and cognitive abilities. Current Directions in Psychological Science, 14(6), 317-320.
Taruffi, L., Allen, R., Downing, J., & Heaton, P. (2017). Individual Differences in Music-Perceived Emotions. Music Perception: An Interdisciplinary Journal, 34(3), 253-266.
Thompson, W. F. (2009). Music, thought, and feeling. Understanding the psychology of music. Oxford: Oxford University Press.
Trimmer, C. G., & Cuddy, L. L. (2008). Emotional intelligence, not music training, predicts recognition of emotional speech prosody. Emotion, 8(6), 838.
73

Proceedings of the 10th International Conference of Students of Systematic Musicology (SysMus17), London, UK, September 13-15, 2017. Peter M. C. Harrison (Ed.).
A Health Course for Music Students: Design, Implementation and Evaluation Raluca Matei*1, Jane Ginsborg*2, Stephen Broad#3, Juliet Goldbart†4
*Centre for Music Performance Research, Royal Northern College of Music, UK #Research and Knowledge Exchange, Royal Conservatoire of Scotland, UK
†Faculty of Health, Psychology and Social Care, Manchester Metropolitan University, UK [email protected],
[email protected], [email protected], [email protected]
ABSTRACT
Background The Health Promotion in Schools of Music (HPSM) project
has recommended the implementation of undergraduate health courses for music majors (Chesky, Dawson, & Manchester, 2006). Few such courses have been evaluated to date. On this basis, a health promotion module was designed and implemented at the Royal Northern College of Music, in Manchester.
Aims To design, run and evaluate a health and wellbeing module
for first-year students, as part of their core curriculum, lasting six months, starting from October 2016.
Method A health and wellbeing module was designed based on a
critical appraisal of the literature, consideration of HPSM recommendations and the availability of staff members and preparation. Lectures and seminars covered a range of topics, including tools for better practice and time management, information on musicians’ health and wellbeing, anatomy, hearing loss and music performance anxiety (MPA). Self-report data on a variety of health-related issues, behaviours and attitudes were gathered, both before (T1) and after the module was delivered (T2). Quantitative data were analysed using the Wilcoxon Signed-Rank Test. Semi-structured interviews were conducted at T2.
Results Although positive affect was lower at T2 than T1 (Z = -
3.434, p < 0.001), causal inferences cannot be made. Improved scores were found for perceived knowledge of effective practising strategies (Z = -4.325, p < .001); effective rehearsal strategies (Z = -3.842, p < .001); learning and memorizing strategies (Z = -2.649, p < .01); ergonomics and posture (Z = -2.450, p = .014); MPA (Z = -4.972, p < .001); behaviour change techniques (Z = -3.671, p < .001); resources for healthy music-making (Z = -4.520, p < .001); sound intensity levels associated with hearing loss (Z = -2.090, p < .01); and awareness of risk factors for performance-related musculoskeletal disorders (PRMDs) (Z = -3.091, p < .01). Thematic analysis of interview data is underway.
Conclusions Increases in perceived knowledge and awareness of some
relevant health-related topics were noted at T2. However, a
control group or another comparable intervention is needed to infer causality.
Keywords health promotion course, behaviour change, music students
REFERENCES Chesky, K.S., Dawson, W.J., & Manchester, R. (2006). Health
promotion in schools of music: Initial recommendations for schools of music. Medical Problems of Performing Artists, 21, 142-144.
74

Proceedings of the 10th International Conference of Students of Systematic Musicology (SysMus17), London, UK, September 13-15, 2017. Peter M. C. Harrison (Ed.).
A Theory of the Musical Genre: The Three-Phase Cycle Pablo Mendoza-Halliday
Programa de Doctorado en Música UNAM, Mexico [email protected]
ABSTRACT Musical genre is a form of categorization that groups musical entities, such as musical works, which share affinity criteria. However, the way we use the category and theorize about it depends on how we define the concept of musical genre. Current musicological theories propose genres to be sets, with properties defining their boundaries; or cognitive categories profiled through cognitive processes involving perception, memory, imagination and intuition; or cultural units that emerge through intersubjective negotiations among semiotic codes. The theory here explained claims that musical genre can simultaneously be a cognitive category, a cultural unit, and a taxonomical class; they work as phases of a cyclic dynamic that covers the entire concept of genre. Set theory can explain the properties of sets while cognitive categories need to be explained with cognitive theories such as prototypes and family resemblances. This study aims for a broader definition of genre that solves some of the inconsistencies of current genre theories.
I. INTRODUCTION To talk about music is to talk of categories. Our way to
communicate concepts about music makes use of categories that describe music or represent its features. Moreover, music itself becomes categories when we refer to what we hear. One of the most common categories used to represent music is the musical genre.
Genre theorists have defined genre in multiple ways. A classic definition by Swales (1990) says that: “a genre comprises a class of communicative events, the members of which share some set of communicative purposes”. The musical genre is thus a category that groups musical entities or events, such as “musical works”, which share one or several criteria of social compatibility, contextual affinity and symbolic truth of aesthetic nature. Genre creates meaning in communication: it guides toward attitudes, conjectures and expectations around the cultural artefact or the musical fact as social phenomena.
However, there are different ways to look at categories. Cognitive scientists, such as Rosch (1978) and Lakoff (1987), distinguish between what they call “classical categories”, defined by the properties shared by all their members, and “prototype-based categories”, defined by cognitive models. The discussion on this topic has tend to focus on which model seems to be the right one. Applied to the musical genre, the question would be: Is the genre a classical category or a cognitive category? I claim that this discussion is misleading the real subject, because both types of categories operate at different levels. What we need to do, if we want to understand the full complexity of musical genre, is to investigate how musical categories operate within these levels.
II. COGNITIVE CATEGORY, TAXONOMIC CLASS, OR CULTUAL UNIT?
In scientific literature concerning categorization, there has been a tendency to treat the terms “category” and “class” as equal. Nevertheless, it is precisely these concepts that make the difference. Classes are groups that have close definitions. They work as sets and follow the logic of set theory. Within this logic, sets have necessary and sufficient conditions of membership; hence, it is either absolute or null: an element “is” o “is not” part of a set. However, Lofti Zadeh (1965) extended the set logic theory to include fuzzy sets: sets with degrees of membership. If musical categories are open concepts, they have no clear definitions. Their boundaries are fuzzy due to their nature as symbolic forms.
Classes are organized by means of taxonomies. Taxonomies are structured through a stable conceptual system that sets the rules for classification. For example, if an element has certain properties of membership, it is part of a set X; if another element has different properties of membership, then it is not part of set X, but of set Y. There can even be a vertical organization of levels of inclusiveness; this implies that an element of set X can also be part of a bigger set with a broader definition.
With the definition of classes and rules that govern the taxonomy, neither the classes nor the taxonomy are tied to a particular context. Classification, under this logic, can be pursued in any time, place, culture or any particular state. It is a question of pure logic, not of cognition (although the relationship between pure logic and cognition is a major topic in my doctoral dissertation). This is what differentiates classification from cognitive categorization.
By means of cognition, categorization does not work with closed definitions because grouping depend of the cognitive capacities, such as perception, memory, imagination and intuition. These groups do not work as sets and are not bound within set logic. Instead, they work through family resemblances, as Wittgenstein (1953) claims. Something is part of a category because it resembles another thing in some way, and it does not matter if other things are part of the category because they resemble in another way. Although these categories have fuzzy limits, these boundaries cannot be fully explained by fuzzy logic since the categories are achieved by means of cognition, with all the limitations implied by cognitive capacities and context. The best way to understand these categories is through prototype-effects, as explained by Rosch (1978).
According to Rosch’s theory, cognitive categories tend to become defined in terms of prototypical instances that contain
75

the most representative attributes of the category. Category membership is therefore a judgement according to the degree of typicality with respect to the prototype.
Now, which one of the category models suits the best for the concept of musical genre? The answer is both of them. A genre can be conceived as a taxonomic class or as a cognitive category. As classes, genres have close definitions according to the conceptual systems that structure the musical taxonomy under which they operate. Being sets, the “membership” of a musical event in a genre depends on the conceptual model that establishes definitions. As open concepts, genres have fuzzy boundaries that can be analyzed through fuzzy set theory. Moreover, genres can be modelled using artificial intelligence to create automatic classification systems, such as those achieved for Music Information Retrieval.
On the other hand, genres can also stand for cognitive categories. When someone categorizes a piece of music, neither the category nor the musical properties that lead the categorization process are taken for granted. The properties of the musical event depend on cognitive capacities, context (whether social, historical, or emotional) and signification. These variables can produce diverse categorizations on a same event, even contradictory among them.
The conceptual models we use to deal with musical experiences determine the categorization process using both musical competences and knowledge mediated through culture. Genre, as a cognitive category, is projected mainly in the music identification cognitive processes, which deal with perception, memory, imagination and intuition. These categories have graded membership and fuzzy borders. We can analyze the family resemblances that structure genres as prototype effects. The spectrum of possible categories include those that are part of musical taxonomies (the ones we could call “official” genres), and categories that are not part of shared taxonomies among musical communities, which originate from a subjective relationship with music. Genre theorists such as Miller (1984) call these categories de facto genres.
The decisions by which one categorizes something into some genre rely, firstly, on one’s experience and knowledge. Nevertheless, to work as a category they need to be socialized so people within a musical community can find agreements for the use of the genres. According to Fabbri (2006), musical genres are cultural units, which are types of musical events, regulated by semiotic codes that associate a plane of expression to a plane of content. Semiotic codes can be interpreted as socially accepted norms, although mostly tacit. These norms can only be relevant if they are conventionalized.
Lopez Cano (2006) follows this assertion by saying that the musical genre is the result of signification operations and both intersubjective and contextual negotiations. For a genre to be a social category, it needs to pass through this process of assimilation of conventions within a musical community.
The difference of cultural units with cognitive categories is that the former are formed as cognitive types while the later involve semiotic types that deal with intersubjective negotiations. Still they are context dependant and that is what differentiates them from taxonomic classes. However, accepting that genres can work as cultural units is not evidence that deny the category models of genres as cognitive categories and taxonomic classes.
III. CONCLUSION: THE THREE-PHASE CYCLE
Social conventions aim to create the conceptual stability that is necessary for taxonomy formations. Hence, social conventions are a necessary step to convert the intersubjective categorization process into a classification, relying then on an established taxonomy and not on volatile contexts or experiences. Furthermore, these taxonomic classes, into which genres are converted, are as well part of the knowledge used to keep categorizing music.
So finally it completes a cycle: when someone ‘thinks’ music, or uses a musical genre he starts a categorization process that involves his cognitive capacities and experiences. Within these are his knowledge and experiences with musical taxonomies, that is, genres as classes. When these resulting categories have been socialised, there is a negotiation process to accept the ones that work fine for most people (within the community) and reject the ones that do not get into agreement. The agreements are achieved by semantic codes that can furtherly be translated into conventions that define the genres. With definitions, genres become part of musical taxonomies that are used for further categorization processes and therefore the cycle continues.
Figure 1. The three-phase cycle of genre This cycle can also lead to transformation and
reconfiguration of genres. As social conventions, genres “are born” and “die”, as Fabbri (2006) says; but as taxonomic classes, they are immanent, and changes over time are just attachments to their historical definitions.
REFERENCES
Aucouturier, J.J. & Pachet, F. (2003). Representing Musical Genre: A State of the Art. Journal of New Music Research, 32 (1), 83-93.
Barsalou, L.W. (1992). Frames, concepts, and conceptual Fields. In Lehrer, A. & Kittay, E.F. (Eds.). Frames, Fields, and Contrasts: New essays in semantic and lexical organization (pp. 21-74). Hillsdale, NJ: Lawrence Erlbaum Associates Publishers.
Fabbri, F. (2006). Tipos, categorías, géneros musicales. ¿Hace Falta una teoría? Conference at the VII Congress of the International Association for the Study of Popular Music, Latin American branch, IASPM-AL, “Música popular: cuerpo y escena en la América Latina”. La Habana: Casa de las Americas.
Goehr, L. (1992). The Imaginary Museum of Musical Works. An Essay in the Philosophy of Music. Oxford: Oxford University Press.
Jakob, E.K. (2004). Classification and Categorization: A Difference that Makes a Difference. Library Trends, 52 (3), 515-540.
Lakoff, G. (1987). Women, Fire, and Dangerous Things, What Categories Reveal about the Mind. Chicago: University of Chicago Press.
López-Cano, R. (2006). ‘Asómate por debajo de la pista’: timba cubana, estrategias músico-sociales y construcción de géneros en
Cultural Unit
Taxonomic Class
Cognitive Category
76

la música popular. Lecture at the VII Congress of the International Association for the Study of Popular Music, Latin American branch, IASPM-AL, “Música popular: cuerpo y escena en la América Latina”. La Habana: Casa de las Americas.
Miller, C.R. (1984). Genre as Social Action. Quarterly Journal of Speech 70, 151-167.
Nattiez, J.J. (1990). Music and Discourse: Towards a Semiology of Music. Princeton: Princeton University Press.
Rosch, E. (1978). Principles of Categorization. In E. Rosch & B.B. Lloyds (Eds.), Cognition and Categorization (pp.27-48). Hilsdale, N.J.: Lawrence Erlbaum Associates.
Swales, J.M. (1990). Genre Analysis. Cambridge: Cambridge University Press.
Wittgenstein, L. (1953). Philosophical Investigations. New York: Macmillan.
Zadeh, L. (1965). Fuzzy Sets. Information and Control, 8, 338-53. Zbikowski, L. (2002). Conceptualizing music: cognitive structure,
theory, and analysis, AMS studies in music. Oxford: Oxford University Press.
77

Proceedings of the 10th International Conference of Students of Systematic Musicology (SysMus17), London, UK, September 13-15, 2017. Peter M. C. Harrison (Ed.).
Musical Forces Can Save Analysts from Cumbersome Explanations Jaco Meyer
School of Music and Conservatory, North-West University, South Africa
ABSTRACT
Background The solo flute composition Syrinx, or La Flûte de Pan as it
was originally titled, by Claude Debussy (1862-1918) is regarded as one of the most important solo compositions in flute literature. Comprehensive and contradictory literature on this composition, the original manuscript, analyses, and interpretations of the composition exist. Analyses of Syrinx in literature were done using a wide variety of analytical approaches, including less conventional approaches like Gestalt perception and spectral analysis of flute tone quality. Most of the authors provide cumbersome explanations in their analyses and a popular topic of discussion in these analyses is hierarchies and interactions of musical tones in Syrinx.
Aims The aim of this paper will be to show how existing analyses
of Syrinx can be reinterpreted in terms of Larson's theory of musical forces. It is important to mention that it is not the aim or in the scope of this article to evaluate or criticise these analyses, but rather to show how these analyses can be understood differently and provide new insights when it is reinterpreted in terms of Larson's theory of musical forces.
Method The vast majority of these cumbersome explanations can be
explained simpler in terms of Steve Larson's (2012) theory of musical forces. I will use this theory as a method of analysis in this paper. Larson's theory of musical forces states that there are stable and unstable tones in tonal music. Unstable tones are then attracted toward more stable tones due to the interaction of musical forces. These musical forces are: musical gravity: the tendency of an unstable tone to descend to a more stable tone; musical magnetism: the tendency of an unstable tone to ascend or descend to the closest stable tone; and musical inertia: the tendency of a musical pattern to continue in the same fashion it started. I will present instances from existing analyses of Debussy's Syrinx as a case and an analysis of Syrinx in terms of musical forces as another case. The two cases will then be compared to show how the cumbersome explanations and arguments of the one case can be explained simpler by using the other case as an exemplar.
Results In my analysis of Debussy's Syrinx I found that the theory
of musical forces is a useful music analytical tool that can be employed in order to avoid cumbersome explanations in written music analyses. This analytical tool can also be employed in many other compositions or employed to simplify existing written analyses. Analyses in which the theory of musical forces were employed also open up alternative ways to interpret compositions and create opportunities for new topics of discussion.
Conclusions The presentation of a musical analysis of Debussy's Syrinx
can be simplified when musical forces are employed as an analytical tool to describe music phenomena.
Keywords musical forces; analysis; Syrinx
78

Proceedings of the 10th International Conference of Students of Systematic Musicology (SysMus17), London, UK, September 13-15, 2017. Peter M. C. Harrison (Ed.).
Measuring Rhythmic Abilities: The Development of a Computer-Based Test to Assess
Individual Differences in Beat Keeping Robyn Moran1, Richard Race2, Arielle Boneville-Roussy3
School of Education, University of Roehampton
[email protected], [email protected], [email protected]
ABSTRACT
Background Although psychological investigations of rhythm have
increased in recent years, few studies have addressed the matter of rhythmic ability. There is no universally accepted definition of what it entails and, despite the existence of a number of tools for measuring a variety of different aspects of rhythm perception and performance, a standardised instrument for measuring rhythmic ability across a comprehensive range of dimensions has yet to be developed.
Aims This study investigates individual differences in beat
keeping and developed a prototypical computer-based instrument to administer experimental tasks and capture performance data. The research set out to address the questions of how widely individuals differ in terms of their beat-keeping abilities and how successfully the tasks and measures used in the test identify individual differences in beat keeping.
Method The test was based on the Beat Alignment Test (BAT)
(Iversen and Patel, 2008), which was implemented in its original form, using the software authoring environment Max/MSP (Cycling74, 2017), and to which was added a novel offbeat-tapping task and a feedback section. The overall test consisted of a ten item questionnaire, three metronome-tapping tasks, four offbeat tapping tasks, twelve music tapping tasks, thirty-six beat perception tasks, and an eight item feedback section. The software recorded participants' tap times, which were made by pressing the spacebar on the keyboard. It was administered to 70 college students with and without musical training (66% female, mean age 18.5) and the tapping data were analysed for accuracy and variability.
Results Results showed that, whilst the majority of people
performed with high degrees of accuracy when tapping to a metronome, there was a greater range of performance in terms of variability. Similarly, the majority of people were successful in tapping the offbeat and this task produced a much wider range of performance. The tasks involving tapping and listening to musical excerpts produced the widest range of individual differences. Significant differences were found between the performance of individuals with and without musical training for all the tasks, with musically trained participants tapping more accurately and less variably
than untrained, and achieving significantly higher scores on the beat-perception test. No gender or age differences were found.
Conclusions The results demonstrate that the BAT is an effective tool
for discriminating between different levels of beat keeping ability and the subject is worthy of further investigation. In addition the software prototype proved to be a viable platform, which could be extended in future to assess rhythmic ability on a much broader range of dimensions.
Keywords rhythm; rhythmic ability; individual differences; beat
keeping; computer-based test
REFERENCES
Iversen, J. R., & Patel, A. (2008). The Beat Alignment Test (BAT): Surveying beat processing abilities in the general population. In K. Miyazaki, Y. Hiraga, M. Adachi, Y. Nakajima, & M. Tsuzaki (Eds.), Proceedings of the 10th international conference on music perception ad cognition (ICMPC 10). Sapporo, Japan (pp. 465-468). Adelaide, Australia: Causal Productions
Cycling74, (2016). [online] Available at: https://cycling74.com/products/max/
79

Proceedings of the 10th International Conference of Students of Systematic Musicology (SysMus17), London, UK, September 13-15, 2017. Peter M. C. Harrison (Ed.).
Selling Madness: How Mental Illness Has Been Commercialised in the Music Business
Ekaterina Pavlova Department of Music, King’s College London, England
ABSTRACT As history shows, madness has fascinated human minds for centuries. I reveal how this fascination has led to the establishment and, at times, dangerous exploitation of the ‘mad musician’ gimmick - a profitable commonplace in the music industry. After a historical outline of social definitions of madness, I determine the trope’s contemporary relevance and profitability through an analysis of contrasting 20-21st-century case studies. I build a multidimensional narrative addressing not only how these case studies were marketed, but also ethical and sociological issues arising from evocations of mental illness and suicide, gender and genre attributions, and the role of music journalism in systematic, occasionally post-mortem exploitation of mentally ill musicians. By undertaking this research, I intend to demonstrate that in music studies 'madness' should be placed alongside other more obvious tropes, such as sexuality, and studied in conjunction with its infinite commercial potential granted by its socially constructed, fluid definition.
I. INTRODUCTION The concept of madness is socially constructed and,
therefore, fluid. As Walser quotes Roy Porter, mental illness challenges the discourse of the normal (Walser, 1993, p. 122), which is dependent upon the status quo. As a result, any behaviour can be labelled as ‘abnormal’ if it does not conform to the society’s expectations and does not fit within the prescribed framework of societal norms of the times. A commonplace in the music business, such behaviour can be easily regarded as theatrical, as it draws attention to itself through its irrationality and inexplicability and showcases the individual’s uniqueness and ‘otherness’.
In this research paper, I aim to show how mental illness has been commercialised in the music industry. First, my narrative will focus on the key stages in the history of our fascination with mental health issues in order to outline various social definitions of madness. This will allow me to analyse the formation of the audiences’ relationship with madness and explain how and why mentally ill musicians came to be seen as a fascinating spectacle and, consequently, a profitable commonplace in the music industry. Then, these definitions will serve as a springboard for the analysis of two case studies which have successfully commercialised mental illness: Nirvana’s ‘Lithium’, eventually followed by Kurt Cobain’s suicide, and Evanescence’s ‘Lithium’. To assist the analysis, other case studies, ethical issues, genre attributions, the nature of the established artist-audience relationship and the response of music journalists will also be addressed. By doing so, I 1By this observation, I also refer to the fact that people seek to identify themselves with songs’ protagonists.
intend to provide evidence of the high level of profitability of the ‘mad musician’ gimmick'. Furthermore, I will consider the prominence of gendered madness in the contemporary music business. All in all, my analysis will allow me to demonstrate that in the music business studies madness should be placed alongside more obvious and widely discussed tropes such as gender and sexuality.
II. FROM ASYLUMS TO CHARTS: A BRIEF HISTORY
Diverse factors, such as advances in medicine and sociocultural changes, have contributed to the fluidity of the definition of mental illness. In music, varied attitudes towards madness came to occupy the whole vast equilibrium between fascination and condemnation. As this section will show, each of the presented definitions has strong selling points and commercial potential gained through the audience’s deep interest in transgressions of societal standards.
Amongst the most popular and earliest mentions of madness is Plato’s ‘divine madness’, which portrays inspiration as an uncontrollable product of the genius (Hyland, 2008, p. 70). A good example of this concept’s application to music is the 19-century German Lied. Its ideology connected one’s subjectivity, the nature, and the sublime, linking a creative human being to the forces unattainable by ‘ordinary’ individuals. An artist, in this case, is separated from the rest of the society through a set of extraordinary qualities - extraordinary and, therefore, fascinating. In the music business, this model has been widely used to establish the gimmick of the true artist: lonely, gifted and cursed by inspiration and talent, separated from the society through their ‘otherness’ but still an appropriate candidate to speak for the society.1 This very ‘otherness’ also justifies the artist’s transgression of social norms: if they are not like us, how can we expect them to be?
Madness as a medical condition has also come to be seen as a fascinating spectacle praised for its theatricality. Bethlem, England’s first hospital for the mentally ill, remained open for public visitors for five centuries (Andrew et al., 1997, p. 152). Later, in 19th-century Germany, after the emergence of psychiatry, fascination was accompanied by fear, as musicians, such as Robert Schumann, evoke madness in their works (Rosen, 1995, pp. 646-648). Developments in psychiatry were not unnoticed by the 20th-century artists either, when many artists, such as Pink Floyd, Alice Cooper, and David Bowie supported the anti-psychiatry movement. The movement criticised inhumane methods of medicinal treatment and questioned biological causes of mental illness. Instead, mental
80

illness was perceived as ‘the product of social circumstances’ or even as a mere failure of an individual to conform to the social norms (Spelman, 2012, pp. 1-3).
At first, sociocultural factors were ignored by psychiatry. A men-run discipline in a patriarchal society, it gave rise to another artistic trope – female hysteria. In The Female Malady, Showalter describes how femininity, female sexuality and nonconformity were equated to insanity. This way, what was a normal behaviour for men was seen as pathology in women, resulting in an unequal female-to-male patient ratio. Soon, the artistic potential was acknowledged: Charcot, one of the greatest theorists in the realm of neurology, turned his female patients’ hysteria into a public spectacle so theatrical that many contemporaries believed that it was staged, while his female patients established a kind of a performing career within the asylum (Showalter, 1987, pp. 145-154).
The mad musician gimmick proves to be more promising for some genres than others. Rock and heavy metal employ ‘otherness’ as an ideology, often taking it to extremes. This has led to accusations by music scholars (e.g. Stuessy’s The Heavy Metal User’s Manual)2 and even trials (e.g. Judas Priest, 1990, Walser, 1993, pp. 139-147) 3. In America, in 1985, the Parents’ Music Resource Center (PMRC) was established with the aim to launch a music censorship campaign protecting young people from dangerous or adult content, chiefly targeting rap and heavy metal (Walser, 1993, pp. 137-138). Such reception may lead to a conclusion that rock and metal are often understood as ‘madness’ on their own. After all, depression and suicide – two rather prominent metal discourses – immediately encourage medical treatment. Here an ethical issue arises: performed by youth idols, such hits as ‘A Tout le Monde’ (Megadeth, 1994), ‘Last Resort’ (Papa Roach, 2000) and ‘Suicide Solution’ (Ozzy Osbourne, 1980) may become dangerous and even manipulative when heard by someone already considering such a ‘last resort’. While it is easy to object to this assumption (for example, see Walser, 1993, p. 147), it is much harder to disconnect a mere mention of suicide and self-harming from the notion of mental illness. Consequently, a parallel can be drawn between rock and metal subcultures (e.g. famously prone to self-harming goths or antisocial punks) and mental illness. In this case, mental illness is an ideology, a genre’s ‘religion’, which forms not only the audience’s musical taste but also their lifestyle. Rock and metal underline the importance of madness as a trope - so successful in the music industry that an entire genre and its numerous subgenres’ ideology can be based on it. This also allows one to suggest that ‘otherness’ – any type of it – is the key prerequisite of the success of the mad musician gimmick, while ‘divine madness’, ‘medical madness’ and ‘female hysteria’ are mere examples of numerous possibilities of the trope’s realisation.
III. LITHIUM: TWO CASE STUDIES In Lithium: What You Should Know, Eshom starts his strictly
scientific prose with a reference to the song ‘Lithium’ - one of the singles released by Nirvana (1992) from their second studio 2Joe Stuessy’s “The Heavy Metal User’s Manual”, which accused heavy metal lyrics of being violent. 3According to the suit, Stained Glass (1978) contained ‘subliminal messages’ which inspired fans to commit suicide.
album Nevermind (1991). Eshom’s description of lithium sets the scene for Nirvana's song: ‘a “miracle” drug that supposedly erases all negative and sad feelings’, used to treat mood disorders and ADD (Attention Deficit Disorder) (Eshom, 1999, p. 13). Cobain’s protagonist indeed seems to experience all of the above-mentioned. Despite rather cheerful exclamations (‘hey, hey, hey’, ‘I’m not sad’), he expresses rather disturbing ideas (‘I killed you, I’m not gonna crack’) and resorts to inadequate and unsound solutions to his emotional crisis (‘I’m so lonely but that’s okay I shaved my head’). The sections with repeated ‘I’m gonna crack’ could either symbolise a relationship struggle or a bipolar disorder – a struggle between the two sides of his personality.
It is not surprising to find a reference to Nirvana in such an ‘unmusical’ book. Nevermind, sometimes described as ‘the album of a generation’, has brought Geffen Records alone $80 million dollars (Frith et al., 2001, p. 204). One of the causes of such success is the album’s vivid depiction of adolescent frustration (Frith et al., 2001, p. 204) - the discourse with which, in one way or another, any young person can identify. At that point, depression and frustration with life had been approaching one of its historical peaks in the USA: 13.6 suicides per 100,000 people aged 15-24 (1994), with a particular rise in the 15-19 group (from 5.9 per 100,000 in 1970 to 11.1 in 1990) (Evans et al., 2012, p. 434). Although it is hard to estimate the exact number of people who suffered from various types of mental illness, both diagnosed and undiagnosed, it is clear that at the time when ‘Lithium’ was released it openly addressed a growing trend – and an enormous audience. With Kurt Cobain’s suicide in 1994, young people all over the world saw their idol jumping to the ultimate solution, which by that time had spread like a disease amongst the American youth. The story, however, did not educate the corporations and the press on the dangers of selling mental illness. On the contrary, it allowed for even more systematic exploitation (Frith et al., 2001, p. 204), giving a real-life feel to Cobain’s lyrics and stage persona.
It is important that in the 1994 media reports surrounding Cobain’s suicide we see neither an individual who gradually lost his struggle with depression nor a typical rock star death. Instead, journalists presented the news as a story of a noble death of the true artist who could not take the pressure of corrupting ‘mainstream’ (Leonard, 2007, pp. 70-71). This way, the fluidity of the definition of mental illness was exploited at its best: from a medical diagnosis further complicated by Cobain’s substance abuse, his suicide was elevated to the status of ‘divine madness’.
Without any doubt, such transformation may increase sales, but it victimises the artist and attaches a romantic image4 to the extremely problematic discourse of drug and alcohol addiction, and mental illness. Furthermore, the publicity surrounding such case studies renders them representative of the current status quo and inspires a dangerous identification of the entire generation with the fate of their idols. As much as it raises concern, it could possibly contribute to an increase of suicide and depression rates. With the death of Cobain, his self-
4It is an old perception that gifted musicianship – or artistry in general – always somehow leads to the ultimate sacrifice.
81

branding strategy was altered and applied posthumously as a commercial master plan. As Jones points out in his ‘Better off Dead’, after Cobain’s death Billboard noticed a significant rise in sales of Nirvana albums, while one author in Entertainment Weekly described Cobain as ‘a licenser’s nirvana’ (Jones, 2005, p. 8). All in all, it leads to two conclusions: first one is that in terms of commercial success being ‘better off dead’ is not a purely classical music phenomenon, and second that an artist’s mental illness has become a selling point and a profitable commonplace in the music business, in particular, when it culminates with a suicide.
Later, the title ‘Lithium’ was adopted in 2006 by the American alternative metal band Evanescence. Destroying old gendered madness stereotypes, the female protagonist faces a similar struggle, although despite her illness causing her lover’s drinking problem, she refuses to take lithium.
It seems unlikely that the band’s focus on lithium was not affected by Nirvana’s song. Despite the gothic image and frequent references to death in Evanescence’s lyrics, their ‘Lithium’ is not a definite ideological counterpart to Nirvana’s. Rolling Stone, in fact, insisted that Evanescence’s ‘Lithium’ is an ode to Kurt Cobain (Sheffield, 2006), so is it an attempt to evoke sympathy or even ‘save’ Cobain in retrospect? Or simply to adopt Cobain’s commercial success by applying a similar, dangerously romantic gimmick? However, unlike Cobain’s protagonist, Amy Lee’s protagonist rejects lithium treatment, which in real life still could be followed by deterioration and suicide. The band does not suggest a possibility of a magical cure, as the minor mode ending seems to imply the tragic outcome. Whatever was their goal, the gimmick of a mentally ill individual facing side effects of lithium has made its return in 2006, becoming US Billboard 200’s no. 1 and selling 447,000 copies in the first week (Billboard, 2006).
IV. IS COMMERCIALISED MADNESS GENDERED?
It seems that the historically crucial trope of female hysteria has lost its social pertinence, and gendered madness is no longer relevant enough to be widely employed. A lot of rumours surround the stage persona of Lady Gaga, who, through explicit self-branding, shocks her audience with a provocative style and music. In an interview to Daily Mail, she has confessed that her costumes are inspired by her suffering from a mental illness earlier in life (Cogan, 2013). A rather familiar story of depression and drug abuse, it allows to suggest that the rise of feminism and gender equality has laid the groundwork for the annihilation of gendered attributions of madness. One could also argue that Nirvana’s ‘Lithium’ presents a kind of male hysteria, and so do many other world-famous hits depicting abnormal or antisocial behavior amongst males (one the most explicit ones is Rammstein’s ‘Mein Teil’, which presents a true cannibalism story of two men meeting for the purpose of one eating the other) (Wiederhorn, 2004). At the same time, the music business has made female madness more masculine: the life of Courtney Love, as an example, is not particularly different from the life of her husband (Leonard, 2007, pp. 77-82). Female hysteria as a gender defining trope was also rendered irrelevant though the rise of ‘agender’ artists (e.g feminine males), while the perception that musicians are already outside social norms has made irrelevant the whole reason why female hysteria came to being. Such historical
changes, once again, demonstrate that madness, unlike female sexuality, is an extremely flexible commercial trope which has remarkably easily adapted to changes in gender politics. However, the ethical issue remains the same: like sexuality, madness is rather vulnerable in the eyes of parental censorship, should campaigns like PMRC target it.
V. CONCLUSION In this research paper, I have outlined how and why mental
illness has become a profitable commonplace in the music business. I have demonstrated the application and the commercial success of the mad musician gimmick by looking at a number of case studies. I have also considered gender and genre attributions, as well as social and ethical aspects of the trope’s application.
All conclusions drawn in this research suggest that madness can indeed be awarded the title of a music business trope. There are many other numerous examples of its commercial success, and whether they evoke sympathy for the mentally ill, present the world through the eyes of the mentally ill, or both, the findings I have presented suggest that this trope is not prone to ‘running out of steam’. First of all, it is largely defined by the social order, which in its turn is in a state of constant flux. Secondly, it demonstrates the society’s reaction to the social order. Finally, as the history has shown, its commercial success has been granted by the actual existence of mental illness which has challenged the human mind for centuries.
ACKNOWLEDGMENTS I wish to thank Ruard Absaroka who taught me for my
intercollegiate Music Business module at SOAS and provided the advice I needed to write this paper and take the first steps in my research into music and madness.
I also wish to thank Katerina Koutsantoni (King’s College London) whose interdisciplinary module ‘A Beautiful Mind: Art, Science and Mental Health’ helped me to discover my passion.
REFERENCES Andrews, Jonathan, Briggs, Asa, Porter, Roy, Tucker, Penny,
Waddington, Keir (1997). The History of Bethlem. London and New York: Routledge.
Billboard (2006, November 10). Retrieved February 20, 2017, from http://www.billboard.com/articles/news/56996/evanescence-zooms-by-killers-to-take-no-1.
Cogan, Judy (2013, November 5). ‘I Heard Voices in My Head: Lady Gaga Says She Uses Outrageous Costumes to Deal with Her ‘Insanity’ as a Youngster’. Retrieved February 20, 2017, from http://www.dailymail.co.uk/tvshowbiz/article-2487854/Lady-Gaga-used-costumes-deal-insanity-youngster.html.
Eshom, Daniel (1999). Lithium: What You Should Know. New York: The Rosen Publishing Group, Inc.
Evans, Dwight L., Foa, Edna B., Gur, Raquel E., Hendin, Herbert, O’Brien, Charles P., Seligman, Martin E. P., Walsh, Timothy, eds. (2012). Treating and Preventing Adolescent Mental Health Disorders: What We Know and What We Don’t Know. Oxford: Oxford University Press.
Frith, Simon, Straw, Will, Street, John, eds. (2001). The Cambridge Companion to Pop and Rock. Cambridge: Cambridge University Press.
Hyland, Drew A. (2008). Plato and the Question of Beauty. Indiana: Indiana University Press, 2008.
82

Jones, Steve (2005). ‘Better off Dead’. In Steve Jones and Joli Jensen (Eds.), Afterlife as Afterimage: Understanding Posthumous Fame (pp. 3-16). New York: Peter Lang Publishing, Inc.
Leonard, Marion (2007). Gender in the Music Industry. Ashgate Publishing, 2007.
Rosen, Charles (1995). The Romantic Generation. Cambridge, MA: Harvard University Press.
Sheffield, Rob (2006, October 5). ‘Evanescence: The Open Door’. Rolling Stone. Retrieved February 20, 2017, from http://www.rollingstone.com/music/albumreviews/the-open-door-20061005.
Showalter, Elaine (1987). The Female Malady: Women, Madness and English Culture, 1830-1980. Virago Press.
Spelman, Nicola (2012). Popular Music and the Myths of Madness. Ashgate Publishing.
Walser, Robert (1993). Running with the Devil: Power, Gender, and Madness in Heavy Metal Music. Middletown, CT: Wesleyan University Press.
Wiederhorn, Jon (2004, December 28). ‘German Cannibal Helps Rammstein Write New Single’, MTV. Retrieved February 20, 2017, from http://www.mtv.com/news/1495200/german-cannibal-helps-rammstein-write-new-single/.
83

Proceedings of the 10th International Conference of Students of Systematic Musicology (SysMus17), London, UK, September 13-15, 2017. Peter M. C. Harrison (Ed.).
Experiences and Appraisals of Musical Awe Landon S. L. Peck
Faculty of Music, University of Oxford, United Kingdom
ABSTRACT
Background A proposed model for the emotion of awe created by
Keltner and Haidt (2003) suggests that one may perceive awe when encountered with a stimulus that is both vast and requires change in existing schemas. Additional hedonic appraisals of threat, beauty, ability, virtue, and supernatural causation are thought to shape this experience. Alternatively, awe has been proposed as an aesthetic reaction to the sublime, comprised of joy and fear, and only when experienced with thrills/chills and being moved does the emotion emerge (Konečni, 2005).
Aims The aims of this study were to gather experiences of
musical awe to empirically test proposed appraisal models, evaluate commonalities in experiences, and derive a better characterization and understanding of musically-induced awe.
Method Questionnaires based on the Geneva Appraisal
Questionnaire (Scherer, 2001) were collected from the general public. Participants were asked if they have felt awe (defined as ‘a combination of appreciation of beauty surprise and possibly fear’) in response to music and to describe their experience. Finally, based on their own experiences of musical awe, participants rated theoretical appraisal factors by way of psychometric scales.
Results Results showed an overwhelming association with the term
‘awe’ when classifying powerful emotional moments experienced from music. Participants’ vivid recollections described highly intense yet pleasurable chill-inducing experiences with beautiful and often virtuosic. Increased enjoyment and engagement with the music was also found while few participants related their experience to that of fear.
Conclusions Musical awe was found to be an uncommonly occurring
complex emotional experience that is not perceived as terrible or fearsome but has retained its sense of grandeur and power. These positive associations suggest that musically-induced awe may be a particular illustration of the sublime that emphasizes vastness, beauty and virtuosity that is closely related to states of being moved. Future studies building on the analysis of this questionnaire will continue to investigate the causes and effects of awe-inducing music.
Keywords awe; music psychology; emotions
REFERENCES Keltner, D., & Haidt, J. (2003). Approaching awe, a moral, spiritual,
and aesthetic emotion. Cognition & Emotion, 17(2), 297-314. doi:10.1080/02699930302297
Konečni, V.J. (2005). The aesthetic trinity: Awe, being moved, thrills. Bulletin of Psychology and the Arts, 5(2), 27-44.
Scherer, K. R. (2001). Appraisal considered as a process of multi-level sequential checking. In K. R. Scherer, A. Schorr, & T. Johnstone (Eds.), Appraisal processes in emotion: Theory, methods, research (pp. 92-120). New York and Oxford: Oxford University Press.
84

Proceedings of the 10th International Conference of Students of Systematic Musicology (SysMus17), London, UK, September 13-15, 2017. Peter M. C. Harrison (Ed.).
Investigating the Improvisers’ Perspective Using Video-Stimulated Recall
Keith Phillips
Royal Northern College of Music, UK
ABSTRACT
Background There have been a number of studies and ethnographies
investigating the complex creative activity of improvisation. Two important recurring themes are the use of multiple strategies (Norgaard, 2011) and the importance of prospective auditory imagery. Comparatively few studies have focused on the privileged role of auditory imagery strategies in validating improvisation as a creative practice, however.
Aims The aim of the study is to obtain accounts of musicians’
experience of idea generation in improvisation, with a focus on strategy use and the role of auditory imagery. Participants are also invited to talk about why they improvise and what they value in the practice.
Method Six participants who self-identified as improvisers (1
female, mean age = 29 years, range = 30 years) were each video recorded whilst improvising to a backing track. Immediately after the improvisation, participants were asked to offer a commentary on their video during semi-structured interviews. These were then transcribed and a thematic analysis carried out (Braun & Clarke, 2006).
Results Thematic analysis of the data is in progress, but preliminary
results indicate the use of multiple strategies, including music-theoretic, motor and imagery-driven approaches. There is also evidence of sketch planning (Norgaard, 2011), and the importance of auditory imagery.
Conclusions Although any conclusions must be tentative until the
analysis is complete, the use of auditory imagery was important to these improvisers and motivations for improvising were bound up with concepts of freedom and creativity. It is possible that the privileged status of auditory imagery in improvisation is related to these ideas.
Keywords improvisation; auditory imagery; video-stimulated recall
REFERENCES Braun, V., & Clarke, V. (2006). Using thematic analysis in
psychology. Qualitative research in psychology, 3(2), 77-101. Norgaard, M. (2011). Descriptions of Improvisational Thinking by
Artist-Level Jazz Musicians. Journal of Research in Music Education, 59(2), 109-127. doi:10.1177/0022429411405669
85

Proceedings of the 10th International Conference of Students of Systematic Musicology (SysMus17), London, UK, September 13-15, 2017. Peter M. C. Harrison (Ed.).
Infant Spontaneous Motor Tempo Sinead Rocha1, Victoria Southgate, Denis Mareschal
Centre for Brain and Cognitive Development, Birkbeck, University of London
ABSTRACT
Background Spontaneous Motor Tempo (SMT), or the interval between
self-paced repetitive movements, is known to slow with age (McAuley, 2006), and preferred tempo correlates with body size, with larger bodies preferring slower rhythms (Mishima, 1965; Todd, Cousins & Lee, 2007; Dahl, Huron, Brod & Altenmüller, 2014). Rate of locomotion is a hypothesised factor underlying these links. Studying the development of SMT in infants, whose primary experience of locomotion is of being carried by their caregiver, may help us to parse the contribution of experience of locomotion from one’s own biomechanical features, to better understand what may ‘set’ our SMT.
Aims The current study therefore aimed to i) be the first to create
a measure of infant SMT, ii) elucidate the relationship between SMT and age over the first two years of life, iii) measure the relationship between infant SMT and own body size, and iv) measure the relationship between infant SMT and parental body size.
In line with existing literature, we predicted that infant SMT would slow with age, and would correlate with anthropometric features, such that larger babies would show a slower SMT. However, as infants are often carried by their caregiver, we also predicted that SMT may be linked to passive experience of the parent’s rate of locomotion, such that infants with larger parents would exhibit slower SMT.
Method 170 infants (M = 12.3 months, SD = 6.5 months) took part
in a spontaneous drumming task for up to five minutes. We recorded the sound wave of their drumming and computed the mean inter-onset-interval to give the SMT for each infant, and obtained demographic and anthropometric information. Infants had to perform at least four sequential hits to be included for analyses, leaving 115 infants with useable data.
Results Contrary to our hypothesis, we found that infant SMT
negatively correlated with age, such that older infants were faster (r(114) = -.279, p = .003). Older infants were also more consistent drummers, with a negative correlation between age and the Relative Standard Deviation (RSD) of drumming (r(114) = -.217, p = .021). Infants who did not show a consistent SMT (RSD more than one SD above the mean) were excluded from further analyses. On the remaining 94 infants, a linear regression assessing the contribution of infant age, infant arm length, infant leg length, parent height, parent
arm length and parent leg length to infant SMT, revealed that infant age (β = -.459, p = .012) and parental height (β = .413, p = .013) were the only significant predictors. The overall model fit was R2= .266.
Conclusions We find that infant SMT becomes faster with age. This can
be explained by the fact that younger infants are still learning how to control their limbs to make continuous and targeted movements. Indeed, infants also get more regular with age. Our results are the first to suggest a U-shaped, rather than linear, relationship between age and SMT.
Whilst tempo does not seem influenced by own body size, we see a relationship between infant SMT and parental height, such that infants with taller parents drum more slowly than infants with shorter parents. We suggest that infants’ self-produced rhythm may be influenced by their parents’ walking tempo, and particularly by the vestibular information they receive when being carried on the caregiver’s body.
Keywords development; rhythm; Spontaneous Motor Tempo;
locomotion
REFERENCES Dahl, S., Huron, D., Brod, G., & Altenmüller, E. (2014). Preferred
dance tempo: does sex or body morphology influence how we groove?. Journal of New Music Research, 43(2), 214-223.
McAuley, J. D., Jones, M. R., Holub, S., Johnston, H. M., & Miller, N. S. (2006). The time of our lives: life span development of timing and event tracking. Journal of Experimental Psychology: General, 135(3), 348.
Mishima, J. (1965). Introduction to the Morphology of Human Behaviour: The Experimental Study of Mental Tempo. Tokyo: Tokyo Publishing.
Todd, N. P. M., Cousins, R., & Lee, C. S. (2007). The contribution of anthropometric factors to individual differences in the perception of rhythm.
86

Proceedings of the 10th International Conference of Students of Systematic Musicology (SysMus17), London, UK, September 13-15, 2017. Peter M. C. Harrison (Ed.).
Investigating Beat Perception and Sensorimotor Synchronisation in People With and
Without Parkinson’s Disease D. C. Rose1, L. E. Annett, P. J. Lovatt
Department of Psychology and Sport Sciences, University of Hertfordshire, United Kingdom. [email protected]
ABSTRACT
Background Studies have shown that beat perception is impaired in
people with Parkinson’s disease (PD), demonstrating the role of the basal ganglia in temporal processing and movement automation (Grahn & Brett, 2007; 2009). Certain types of external auditory cues may provide a compensatory mechanism for people with PD enabling entrainment, perhaps dependent on perceptual ability for rhythm, potentially mediated by previous music and dance experience (Cameron et al., 2016). This may explain why some, but not all, people with PD benefit from music and dance-based therapeutic interventions (Nombela et al., 2012).
Aims The aims of this study are threefold:
1. To establish whether there is a link between perception and production abilities in people with PD.
2. To explore how the modality of entrainment might affect measures of sensorimotor synchronisation.
3. To explore how naturalistic instrumental music excerpts compare to basic auditory entrainment stimuli (metronome) at different tempi.
Method This is a three-way mixed design study. The between-
subjects factor is Group (PD and Age Matched Controls). There are two within-subjects factors: Stimuli (Music/Metronome) and Modality (of physical entrainment). Tempi (range 779 ms – 417 ms) is an independent variable nested within Stimuli. Modality includes finger tapping, toe tapping and marching up and down ‘on the spot’ as a proxy for dancing. The finger tapping condition enables comparison with other studies. The toe tapping and ‘marching’ are included as naturalistic movements associated with music and dancing. The Beat Alignment Test, a measure of beat perception, from the Gold Musical Sophistication Index (Müllensiefen et al., 2014) has also been included. Instrumental naturalistic musical stimuli with an easily identifiable tactus has been developed though pilot testing. An estimate of preferred beat period will also be collected for all three modalities.
Results Data collection is currently underway and preliminary
results will be presented.
Keywords Parkinson’s; sensorimotor synchronisation; music; beat
perception, spontaneous motor tempo
REFERENCES Cameron, D. J., Pickett, K. A., Earhart, G. M., & Grahn, J. A. (2016).
The effect of dopaminergic medication on beat-based auditory timing in Parkinson’s disease. Frontiers in neurology, 7.
Grahn, J. A., & Brett, M. (2007). Rhythm and beat perception in motor areas of the brain. Journal of cognitive neuroscience, 19(5), 893-906.
Grahn, J. A., & Brett, M. (2009). Impairment of beat-based rhythm discrimination in Parkinson’s disease. Cortex, 45(1), 54–61. http://doi.org/10.1016/j.cortex.2008.01.005
Müllensiefen, D., Gingras, B., Musil, J., & Stewart, L. (2014). The musicality of non-musicians: an index for assessing musical sophistication in the general population. PloS one, 9(2), e89642.
Nombela, C., Hughes, L. E., Owen, A. M., & Grahn, J. A. (2013). Into the groove: Can rhythm influence Parkinson’s disease? Neuroscience & Biobehavioral Reviews, 37(10), 2564–2570. http://doi.org/10.1016/j.neubiorev.2013.08.003
87

Proceedings of the 10th International Conference of Students of Systematic Musicology (SysMus17), London, UK, September 13-15, 2017. Peter M. C. Harrison (Ed.).
The Effect of Auditory Feedback on Motor Sequence Learning in Novices
Suzanne Ross*1, Elvira Brattico*, Maria Herrojo-Ruiz#, Lauren Stewart*
*Center for Music in the Brain, Aarhus University and the Royal Academy of Music Aarhus/Aalborg, Denmark #Goldsmiths, University of London, UK
ABSTRACT
Background Is learning to play music a purely motoric process, or does
the auditory feedback contribute to learning and memory of motor sequences? In musicians, absence of auditory feedback has no effect on performance of well-learned music. It does, however, affect learning, with musicians making fewer errors after learning new music with sound compared to learning without sound (Finney & Palmer, 2003). Pfordesher (2005) previously found no effect of auditory feedback absence on learning in novices; however, this study allowed participants in the no-sound condition to hear feedback for three trials before removing it. We therefore address this confound by fully withholding auditory feedback in one condition.
Aims We aim to explore the effect of presence or absence of
auditory feedback on motor sequence learning in musical novices. We hypothesise that learning with or without auditory feedback will have a differential effect on immediate recall and recall after a 24-hour consolidation period.
Method Data collection is currently ongoing, and we plan to recruit
50 novices with less than 3 years of musical training, none of which occurred in the past 10 years. In this task, participants learn to play a simple 4-bar melody on a MIDI piano. Half of participants learn with sound and half learn without sound. Participants repeat the melody from beginning to end for 10 minutes, and are then tested on recall after 5 minutes (immediate) and 24 hours, with test conditions congruent to the learning condition (i.e. with or without sound).
Results Preliminary results are presented for N = 16 participants (8
per condition). Model comparison showed that the model with an interaction between test (test/retest), condition (sound/no-sound) and bar (1-4) was the best-fitting model: X2(10) = 69.43, p < .001, R2 = .87. Tukey-corrected post-hoc tests showed a significant difference between conditions at bar 3, t(48) = 3.67, p = .013 and bar 4, t(48) = 4.37, p = .002 in the immediate test, and between conditions at bar 3, t(48) = 7, p < .001 and bar 4, t(48) = 6.3, p < .001 in the 24-hour test, with the auditory feedback condition having lower accuracy scores overall.
Conclusions Whereas previous research showed that auditory feedback
may enhance learning in musicians (Finney & Palmer, 2003),
our preliminary results demonstrate that this effect is reversed for novices. Recall was less accurate in the latter half of the 4-bar sequence for participants who learned with auditory feedback compared to participants who learned without feedback. Specifically, the recency effect is diminished in the auditory feedback group. This might mean that auditory feedback interferes with motor sequence learning in novices. Further analysis will elucidate whether this result persists in the full sample.
Keywords learning; memory; serial position; recall; recency effect
REFERENCES Finney, S. A., & Palmer, C. (2003). Auditory feedback and memory
for music performance: sound evidence for an encoding effect. Memory & Cognition, 31(1), 51–64.
Pfordresher, P. Q. (2005). Auditory feedback in music performance: the role of melodic structure and musical skill. Journal of Experimental Psychology. Human Perception and Performance, 31(6), 1331–1345.
88

1
Proceedings of the 10th International Conference of Students of Systematic Musicology (SysMus17), London, UK, September 13-15, 2017. Peter M. C. Harrison (Ed.).
Performing Auspiciousness and Inauspiciousness in Parai Mēlam Music Culture in
Jaffna, Sri Lanka Pathmanesan Sanmugeswaran
Department of Anthropology, University of Kentucky [email protected]
ABSTRACT
Background Parai mēlam1 music occupies a significant position in
Jaffna Tamil culture, and has not been discussed much ethnomusicologically and anthropologically in terms of caste purity – pollution and religiosity (Valarmathi 2009; Jeyakantha 2005; Dumont 1980). For two reasons, parai mēlam music is identified as an inauspicious type as follows: (1) funeral is an inauspicious ritual in Jaffna Saiva ritual tradition. As parai mēlam music takes place in a funeral ritual, this music is recognized as an inauspicious; (2) people consider this music as an inauspicious because performers (paraiyar) are from the so-called low caste category and knows as untouchable. Although the performers argue that this music is a part of the Tamil music culture, the dominant caste people in Jaffna always recognize this instrument and its music as inauspicious because the performers belong to a low-caste category in the Jaffna caste system. Also, this drum is seen as a funeral drum. In the Hindu ritual context, funeral ritual is an inauspicious ritual. Even though parai mēlam performance contributes to the funeral and religious rituals, it is often called inauspicious. However, there is no intensive ethnomusicological study on Jaffna parai mēlam music culture, questioning why it is so? As an ethnomusicological study of Jaffna parai mēlam music is a broad area of study, this paper focuses on performing auspiciousness and inauspiciousness in parai mēlam music.
Aims This study aims to study the position and placement of
parai mēlam music in Tamil culture in the context of changing modern Jaffna Tamil Hindu society. How do members of the Jaffna Tamil community decide what is auspicious and inauspicious? How are the music rhythms created, performed, taught, and continued?
Method This study uses ethnographic research methods such as
participant observation, semi-structured interviews, and key-informant interviews in addition to ethnomusicological perspectives and methods. I gathered qualitative data from the fieldwork conducted among the paraiyar community at different villages in Jaffna.
1A double headed cylindrical drum played with two sticks.
Results Parai mēlam music is often identified as an inauspicious as
it is, in particular, commonly performed for funeral rituals of high castes in Jaffna. Parai mēlam performers are from a low caste, namely the paraiyar community. “Structural replication” and “downward displacement” (McGilvray 1983) in addition to “pollution” and “purity” (Dumont 1980) have characterized the nature of inauspiciousness of parai mēlam music and performers. Due to the low caste identity, ritual pollution and superior consciousness of pēriya mēlam music and karnatic music (South Indian classical music) (Terada 2005; Dumont 1980), this music and its performers are seen as untouchables, despite performance being mandatory for high-caste funeral rites. Unlike wedding or puberty rituals, Jaffna Tamil Hindus identify the funeral as an inauspicious ritual. Thus, Jaffna Tamil Hindu rituals are seen in two folds: auspicious rituals and inauspicious rituals. This categorization influences Jaffna Tamil Hindus to perceive the music with this dichotomy. Uniqueness of this musical tradition acquaints duality of auspiciousness and inauspiciousness in composing rhythms. It is the only musical tradition that holds dual positions in religious related and non-religious related fields.
Conclusions People are sometimes not practicing with this drum because
it is inauspicious due to the performers being of low caste and its association with the funeral ritual. Symbolic and cultural expression of parai mēlam is most significant in caste and religious contexts in Jaffna. In world drum tradition, the parai mēlam music has a long history, but unfortunately this performing art is diminishing due to various factors. Different dialogues and perspectives are built on this tradition and some argue the need to discourage learning and performing parai mēlam while others wish to encourage it. Reputed temples still maintain this music because it is always mandatory for high-caste funeral rituals.
Keywords auspiciousness; inauspiciousness; parai mēlam music;
Jaffna Tamil culture; ethnomusicology References Dumont, L. (1998). Homo Hierarchius. New Delhi: Oxford Jeyakanthan, R. (2005). Performing Tradition of Parai. Unpublished
dissertation, Department of Music, University of Jaffna. Jaffna: University of Jaffna
McGilvray, D.B. (1983). Paraiyar Drummers of Sri Lanka: Consensus and Constraint in an Untouchable Caste. American Ethnologist, 10 (1), 97-115. USA: Blackwell
Valarmathi, M. (2009). Parai. Chennai: Amrudha Publishers.
89

Proceedings of the 10th International Conference of Students of Systematic Musicology (SysMus17), London, UK, September 13-15, 2017. Peter M. C. Harrison (Ed.).
Social Surrogacy: How Music Provides a Sense of Belonging Katharina Schäfer*1, Tuomas Eerola#
* University of Jyväskylä, Finland # Durham University, United Kingdom
ABSTRACT
Background As social animals, we have a need to form and maintain
strong interpersonal relationships. If direct social interaction is not possible, we resort to social surrogates which provide temporary substitutes for direct interaction (Gardner, Pickett, & Knowles, 2005). Those surrogates can have different forms: Some people like to immerse themselves into narratives (Gabriel & Young, 2011) while others prefer the virtual company of TV characters (Derrick, Gabriel, & Hugenberg, 2009). Previous research suggests that also music could be used as social surrogate (e.g. Lee, Andrade, & Palmer, 2013), but there is no consensus about the ways through which music listening might provide company.
Aims The aim of this study was twofold. First, we wanted to
know, if music is used as temporary substitute for social interaction at all. Second, it was tested, if music listening conveys company in similar ways like literary fiction (Gabriel et al., 2011) or TV programs (Derrick et al., 2009).
Method In order to explore the ways through which media provide
company, 30 statements about possible ways music, TV, and fiction could provide social surrogacy were compiled. The statements were inspired by a comprehensive analysis about the psychological functions of music listening (Schäfer, Sedlmeier, Städtler & Huron, 2013). The dominant part of the statements was derived from typical manifestations of social surrogates suggested by previous investigations in the domains of literature (Gabriel et al., 2011) and TV (Derrick et al., 2009). Additionally, statements about media as reminders of real relationship partners were added (Gardner et al., 2005). The statements were adjusted to fit the domains of music, TV, and, literature. Over 300 participants, mostly from Skandinavia, rated their agreement to the statements across the three domains in an online survey. To identify separate facets of social surrogacy, a factor analysis was conducted for each domain separately.
Results The results suggest that music is used as temporary
substitute for social interaction. Regarding the ways through which music listening might provide company, music’s ability to remind us of meaningful life events and significant others plays a key role in this process. The aspect of reminiscence
did not seem as important in the other two domains. In all three domains, identification with and feeling understood by the performer (music) or character(s) (TV, movies, and literary fiction) were identified as relevant ways, how media may provide company and comfort.
Conclusions Music is used as temporary substitute for social interaction,
but it acts differently from TV, films, or literary fiction.
Keywords social surrogacy; music; TV; literature; interpersonal
relationships
REFERENCES Derrick, J. L., Gabriel, S., & Hugenberg, K. (2009). Social
surrogacy: How favored television programs provide the experience of belonging. Journal of Experimental Social Psychology, 45(2), 352–362.
Gabriel, S., & Young, A. F. (2011). Becoming a Vampire Without Being Bitten. Psychological Science, 22(8), 990–994.
Gardner, W. L., Pickett, C. C., & Knowles, M. L. (2005). Social Snacking and Shielding: Using Social Symbols, Selves, and Surrogates in the Service of Belonging Needs. In The social outcast: Ostracism, social exclusion, rejection, and bullying (pp. 227–242).
Lee, C. J., Andrade, E. B., & Palmer, S. E. (2013). Interpersonal Relationships and Preferences for Mood-Congruency in Aesthetic Experiences. Journal of Consumer Research, 40(2), 382–391.
Schäfer, T., Sedlmeier, P., Städtler, C., & Huron, D. (2013). The psychological functions of music listening. Frontiers in Psychology, 4, 1–33.
90

Proceedings of the 10th International Conference of Students of Systematic Musicology (SysMus17), London, UK, September 13-15, 2017. Peter M. C. Harrison (Ed.).
Estimation of Time in Music: Effects of Tempo and Familiarity on the Subjective
Duration of Music Theresa Schallmoser1, Siavash Moazzami Vahid, Richard Parncutt
University of Graz, Austria [email protected]
ABSTRACT
Background Our perception of time is open to manipulation in different
ways. Two similar events with the same duration can be judged to have different lengths based on their properties. According to Ornstein (1969) and Boltz (1991) this difference comes from different factors such as the complexity of the events or our familiarity with them. In the case of musical stimuli, Jones and Boltz (1989) considered equally long tunes with more tones as getting perceived as longer, which led us to our hypothesis regarding tempo.
Aims The current study investigates the manipulation of
perceived durations of musical pieces through changing the inner-musical parameters tempo and familiarity. Additionally, musical expertise of listeners was observed in two groups, on suspicion that musically trained individuals may be more used to estimate durations in music than non-musicians.
Method Both groups of respectively 10 subjects rated the duration
of musical pieces of different categories of familiarity and tempo on a rating scale after listening. We chose short passages (10 seconds) of various styles of music and divided into slow, medium and fast but also into familiar and non-familiar musical stimuli by ourselves. We did not concentrate on the styles of music, but tried to vary as much as possible. Familiar music was considered as familiar to a western culture listener. Unfamiliar music was unfamiliar in musical culture, instrumentation or sound. Our tempo categories were not chosen by bpm, but rather based on our impression of pace and speed of the rhythm. Regarding the groups, musicians were students of musical instruments and non-musicians did not play an instrument for less than two years in their lives.
Results Statistical analysis by 3-way ANOVA showed an effect of
the different tempo categories, namely that faster music is perceived as longer than slower music (p < .001). Significant effects of the familiarity and the expertise variables were not found. In general, both groups of participants tended to underestimate the length of the stimuli.
Conclusions The amount of information perceived in a certain period of
time seems to have an influence on time perception also in music. Possible effects of familiarity cannot be ruled out yet,
but will be considered in further investigation, for example at a post-study to validate our choice of stimuli categories. Other considerable influences, like complexity and arrangement of stimulus items – how the interval is filled – (Jones, 1990) still create further questions on which role the music itself plays at estimating durations while listening.
Keywords music perception; time perception; estimation of duration;
information processing; tempo; familiarity
REFERENCES Boltz, M. (1991). Time estimation and attentional perspective.
Perception & Psychophysics, 49(5), 422-433. Jones, M. (1990). Musical events and models of musical time. In
R.A. Block (Ed.), Cognitive models of psychological time (207-240). East Sussex: Psychology Press.
Jones, M. & Boltz, M. (1989). Dynamic Attending and Responses to Time. Psychological Review, 96/3, 459-491.
Ornstein, R. (1969) On the experience of time. Baltimore, MD: Penguin.
91

Proceedings of the 10th International Conference of Students of Systematic Musicology (SysMus17), London, UK, September 13-15, 2017. Peter M. C. Harrison (Ed.).
Urban Traffic Safety While Listening to Music – Views of Listeners and Non-Listeners Eva Schurig
Department of Sociology, Philosophy and Anthropology, University of Exeter, UK [email protected]
ABSTRACT The health and safety of the population is an important topic which requires adapting measures to the development of new technologies and their use. One aim of this doctoral research was to investigate mobile music listening in relation to health and safety. Using interviews and shadowing, the opinions and behaviours of mobile-music listeners have been studied, while a second study asked non-users of portable listening devices about their views. Results show that mobile music listeners are aware of the negative effect music listening over headphones in public could have on them, namely the danger of missing signals from their environment. All interviewees have strategies to deal with this issue in different ways. Non-listeners are conscious of risks, too, since one of their main concerns is the inability of listeners to notice auditory stimuli and react appropriately and quickly in traffic.
I. INTRODUCTION Most people choose to listen to music using portable
listening devices (Krause & North, 2014), which is not very surprising, considering how many people can be seen in the streets wearing headphones. However, opinions differ on whether this behaviour is safe for the user and the surrounding people.
Ever since the dawn of the Walkman in 1979, there have been worries about the detrimental effects it could have on the listener and others, especially regarding sociability (e.g., Bull, 2000; Flynn, 2014; Prior, 2013). With the spread of a growing variety of portable listening devices, those worries are increasingly expanding to include the safety of listening to music over headphones in urban traffic (Neider et al., 2010; Lichenstein et al., 2012). While it is not an offence in some countries to use portable listening devices while cycling as long as the listener is not "deemed not to have proper control of their vehicle or to be driving without reasonable consideration for others" (PNLD, n.d.), other countries have forbidden cyclists to listen to music over headphones (Bergal, 2015). The state of Utah went a step further and is fining pedestrians $50 for “distracted walking” near the railways (Henderson, 2014). This includes talking and texting on the phone as well as listening to music over headphones (Davidson, 2012).
A study carried out in the Netherlands (Goldenbeld et al., 2012) discovered that the proclivity to listen to music while cycling reduces with age, starting at 76% for teenagers and decreasing to 14% for over 50-year-olds. When taking into consideration how often the different age groups had bicycle crashes, analysis showed that using portable electronic devices (phones and music listening devices) increased the risk of having an accident by 1,6 to 1,8 for teenagers and
young adults, which is very low compared to the risk that texting harbours for car drivers (ca. 23, 24% increased risk of being involved in an accident) (Olson et al., 2009).
While it is more obvious why cyclists who listen to mobile music might be risking more accidents (they have a higher travel speed, and more and closer interactions with vehicles on the road than pedestrians), studies concerning distracted behaviour of pedestrians who listen to music over headphones come to a variety of conclusions. Neider et al. (2010), Nasar et al. (2008) and Walker et al. (2012) agree that music listening devices are prone to be less dangerous in traffic than using a mobile phone. In different experimental and observational conditions, they each come to the separate conclusion that listening to music is as unsafe as not using a device at all, or even increases cautionary behaviour (see Walker et al., 2012). Therefore, they suggest treating mobile listening devices differently than mobile phones when thinking of strategies to increase pedestrian safety.
As opposed to this, Lichenstein et al. (2012) analysed media reports of accidents in relation to the use of headphones (although a causal relationship could not be proven with this method) in a retrospective study. They found that 70% of these accidents were fatal, and that most victims involved were under 30 years old (67%). Their conclusion is that headphone use can be potentially dangerous in traffic, especially when auditory cues are necessary to stay safe. The danger, the researchers say, is the “environmental isolation” and “inattentional blindness” (ibid., p. 290), i.e. the inability to perceive auditory stimuli, and distraction.
In their study of street-crossing behaviour in a virtual environment, Schwebel et al. (2012) came to a similar conclusion. When comparing music listening, texting, and talking on a phone in a condition where pedestrians had to cross a virtual street, listening to music turned out to be the most dangerous, even more dangerous than texting. Participants talking on the phone had the least accidents in this experiment. Schwebel et al. also explain this through the necessity of auditory cues to stay safe in certain situations.
While an increasing amount of studies show the dangers involved with mobile music listening in public, the application of this information and the everyday behaviour of mobile music listeners has not been considered in most of these quantitative studies. There are many anecdotes in newspapers and online forums about the behaviour of mobile music listeners in traffic (over 11m results in a Google search), but most of them are just that – anecdotes. Hardly any of them have any scientific foundation and are based on own experiences and speculation. To change this and gain more insight into the views of different parties involved, i.e. listeners and non-listeners, preliminary research was carried
92

out as part of more extensive studies about mobile music listening. The aim was to discover how much the music listeners are aware of potential danger in traffic, and what their strategies are to circumvent harm. To understand if and how these strategies are perceived by passers-by, non-listeners were asked about their opinions, too.
II. METHODS Two separate studies were carried out in the context of this
doctoral research. In the first study, eleven mobile music listeners (4 female, 7 male, aged 20-42, of 9 different nationalities) were recruited through word of mouth, advertisement at the author's workplace outside of university, and snowballing. The second study was advertised on university and church noticeboards, Facebook, the author's workplace and word of mouth. Eleven non-users of mobile listening devices responded (10 female, 1 male, aged 28-76, of 4 different nationalities).
The first study consisted of three separate stages. At the beginning, an interview was carried out with the listeners to get to know them and their music listening behaviours. After completing a short demographic questionnaire, questions regarding their musical preferences, the use of their portable listening devices (e.g., how is it organised, when and why is it used) and their reactions to certain situations (e.g., traffic, social situations) were asked. Interviews lasted between 20 minutes and an hour.
Several days later the participant and the researcher met again. The aim was for the researcher to follow the participant around (i.e. shadow them) while they displayed their usual music listening behaviour in a normal, everyday environment, i.e. the streets and shops of a small city in England. The method for this was adapted from DeNora (2003), who had shadowed her participants while they went shopping. Both the researcher and the participant in her study were equipped with an audio recorder which recorded their thoughts that were spoken out loud. Since speaking out loud would disrupt the music listening experience, and focussing on the environment would take the attention from the music, this approach was modified for this study. Here, only the researcher carried an audio recorder, which was used to take down impressions of the environment and to occasionally approach the participant and ask them about the music they were listening to and the reasons for that. This way the disruptions were kept to a minimum and an as natural as possible experience was ensured. Pictures of the environment were taken to have a point of reference for the analysis.
Because interruptions were limited, another interview was carried out immediately after the shadowing to talk about the experience and about behaviour that was noticed and that needed clarification.
Interviews were also carried out with the participants of the second study. They were asked about their general music listening behaviour, the reasons why they do not use mobile listening devices, and their impressions of and experiences with people who do.
All the interviews were transcribed and coded according to Interpretative Phenomenological Analysis using NVivo. Ethical approval for these studies was obtained by the Ethics Committee of the University of Exeter. All the names mentioned here are pseudonyms.
III. RESULTS AND DISCUSSION When talking about moving around the city wearing
headphones, many of the music listening participants seemed to be aware of the fact that it could be quite dangerous to be in traffic and not be able to hear much. However, the interviewees always appeared to have an opinion or a specific strategy to deal with this. Thomas (20 years old), for example, does not rely on his hearing, but trusts a different sense altogether:
I don't hear the traffic. I look. I use my eyes rather than ears, because I think ears can mess you up a bit? You know, you can hear something that's not there, but you can't not see something that's not there. Do you know what I mean?
This behaviour agrees with the observations of Walker et
al. (2012) who found that especially men tended to display a more cautionary behaviour when crossing streets while listening to music compared to no music. Whether this increases safety remains to be seen, because, as Goldenbeld et al. (2012) discovered, young cyclists in the Netherlands have the highest risk of being involved in an accident due to use of portable electronic devices, even though they reported that they pay more attention to traffic when using these devices. The researchers conclude from this, that this compensatory behaviour is not enough to increase safety.
Anne (21 years old), on the other hand, says that she is very sensitive to noise and listening to music actually helps her move through traffic. Additionally, she prefers cycling on the pavement, which makes it a bit less dangerous:
'Cause I don't like to cycle on the roads. I think, as long as I can hear the noise around me and, to be honest, I find most other noises so loud even when I have my music playing at a level that I find pleasant, I can still hear everything else.
Anne is very sensitive to stimuli from her environment,
which makes it difficult for her to manage sound and the information she perceives. For this reason, she uses her portable listening device like an “audio-visual pair of sunglasses” (Bull, 2007, p. 32), which keep the incoming stimuli to a minimum and help her concentrate on what is important, therefore keeping her safer than she would be without her headphones.
An altogether different way to cycle while listening to music is chosen by Max (42 years old). He is very much aware of the danger he is facing while listening to music in traffic, but he decides to do it anyway. His reasoning for that, however, does not lie within himself, but is part of a bigger way of living, a kind of lifestyle that comes with riding his bike, the BMX. Max believes that when he uses his BMX, he is freed of certain rules and can show behaviour that would not be accepted otherwise, like cycling on the pavement. According to Max, listening to music in traffic is very dangerous, but it seems that, since he sees himself as exempt from particular rules in traffic because of his bike, he can cycle somewhere where listening to music is not as dangerous, and can therefore “afford” to listen to music over headphones while cycling.
E: Ok. And how do you work out if there's a car?
93

M: Em by using my gut feeling (laughs). I must admit that I might be a bit dangerous there. (Max)
Even though Max wears a helmet to increase his safety, it is
understandable why non-listeners worry about the risk cyclists who listen to mobile music are facing. Steven (29 years old, non-listener) concludes, that if cyclists wear helmets to stay safe, they are compromising this gained safety if they were to listen to music, too:
I don't have a helmet, but lots of people have a helmet and they also have headphones. I'm like - come on, you're kind of losing the .. if you're wearing a helmet to be safe, then maybe the headphones aren't a good idea.
While non-listeners especially worry about cyclists who
use mobile listening devices, they observe that the danger is closely connected to the volume the music is listened at:
Sometimes I wonder about safety. Like, especially when you cycle. But I guess it depends on if you're used to and if you keep the music like super loud or at a normal volume. (Agatha, 28 years old)
However, not only cycling, but walking while listening to
music over headphones can be dangerous, too. Annabel (28 years old, listener) is aware that listening to music can take your attention from what is important, especially in environments where other people are present:
So sometimes I think you zone out and it's kind of sometimes it can be dangerous, because you have to make sure that when you get to roads and stuff, you're looking left and right or you bump into someone or you'd probably be less aware of your environment by having the headphones in. Most of the time.
While using portable listening device does require
monitoring a screen constantly, the concern about being involved in serious accidents through inattentiveness is still very valid. Even in the short time it takes to look for a new song to listen to, an accident could happen:
If they're changing the music on their iPhone or something they're actually not aware of what they're walking into. You know, could have an accident, it's quite dangerous. (Julia, 61 years old, non-listener)
As opposed to this, an argument, that Neider et al. (2010)
would subscribe to, might be that listening to music leaves you free to partake in your environment, and is therefore less dangerous than looking at the screen of a smartphone:
I think you are more distracted if you just keep looking on your mobile phone, like what people do. Because when you have the headphones you still look around, there's nothing you have to look at. (Maria, 53 years old, non-listener)
Although none of the interviewees deny the danger that is
associated with mobile music listening in urban traffic, there are different strategies that help listeners navigate the streets as safely as possible even while listening to music. However, the interviewed non-listeners were barely aware of these strategies, because they were hardly ever mentioned, and the general consensus was that listening to music over
headphones in public can be unsafe, especially in regard to being able to hear signals from the environment. Comparing these two positions, it seems that more studies are necessary to verify the effectiveness of the safety measures that mobile music listeners use. A variety of questions arise from these studies, e.g., how safe are cyclists who listen to music while wearing a helmet compared to cyclists without either? Is listening to music while cycling on the pavement, albeit illegal in many countries, less dangerous than cycling on the road? How much can visual cues compensate for auditory cues from the environment when trying to stay safe? These and many other queries should be considered in future studies.
IV. CONCLUSION In summary, this research offered an insight into the
opinions and behaviours of mobile music device users and non-users. All the interviewees are conscious of risks involved with listening to music in an urban environment and especially cycling is seen as particularly dangerous. Strategies are employed to lower potential risks when cycling while listening to music, but these are scarcely noticed by non-listeners, although it is observed that there are different factors, e.g., volume of the music, that could influence how much a music listener perceives from their environment.
An approach for the future would be to ask music listeners and non-listeners alike, where their opinion on the danger of mobile music listening derived from. This could lead to an analysis of the effectiveness of media communication. Additionally, it would be interesting to include more participants across several cultures in a similar study to discover whether the present results are only the opinions and behaviours of these particular interviewees, and whether there are any correlations with different traffic situations, i.e. more or less cycling routes, urban versus rural traffic, or less regulated traffic in different countries.
What this study shows, however, is that it is not enough to investigate the danger of mobile music listening in traffic per se, but that it should be considered what the users actually do and what measures they employ to increase their safety, because there are different nuances in behaviour that make certain situations more or less dangerous. This has not been reflected in studies so far.
REFERENCES
Bergal, J. (2015, November). Cities and States Try to Crack Down on Distracted Bicycling. The Pew Charitable Trusts. Retrieved 17.06.2017, from http://www.pewtrusts.org/en/research-and-analysis/blogs/stateline/
2015/11/17/cities-and-states-try-to-crack-down-on-distracted-bicycling
Bull, M. (2000). Sounding Out the City. Personal Stereos and the Management of Everyday Life. Oxford: Berg.
Bull, M. (2007). Sound moves. iPod culture and urban experience. Routledge: London.
Davidson, L. (2012, March). 'Distracted walking' by rails may now bring fines. The Salt Lake Tribune. Retrieved 29.05.2017, from http://archive.sltrib.com/story.php?ref=/sltrib/politics/53811747-90/board-distracted-fines-ordinance.html.csp
DeNora, T. (2003). After Adorno. Rethinking music sociology. Cambridge: Cambridge University Press.
Flynn, K. (2014, November). How To Listen To Loud Music On Headphones Without Hurting Your Ears. The Huffington Post.
94

Retrieved 21.06.2016, from http://www.huffingtonpost.com/2014/11/24/loud-music-headphones_n_6174340.html
Goldenbeld, C., Houtenbos, M., Ehlers, E., and Waard, D. de (2012). The use and risk of portable electronic devices while cycling among different age groups, Journal of Safety Research, 43 (1), 1–8.
Henderson, T. (2014, December). Too Many Pedestrians Injured by Looking at Their Phones. Governing. Retrieved 29.05.2017, from http://www.governing.com/topics/transportation-infrastructure/too-many-pedestrians-injured-by-looking-at-their-phones.html
Krause, A. E., and North, A. C. (2014). Music listening in everyday life: Devices, selection methods, and digital technology, Psychology of Music, 44 (1), 129-147.
Lichenstein, R., Smith, D. C., Ambrose, J. L., and Moody, L. A. (2012). Headphone use and pedestrian injury and death in the United States: 2004–2011, Injury Prevention, (18), 287–290.
Nasar, J., Hecht, P., and Wener, R. (2008). Mobile telephones, distracted attention, and pedestrian safety, Accident Analysis & Prevention, 40 (1), 69–75.
Neider, M. B., McCarley, J. S., Crowell, J. A., Kaczmarski, H., and Kramer, A. F. (2010). Pedestrians, vehicles, and cell phones, Accident Analysis & Prevention, 42 (2), 589–594.
Olson, R. L., Hanowski, R. J., Hickman, J. S., & Bocanegra, J. (2009). Driver distraction in commercial vehicle operations (No. FMCSA-RRR-09-042). Washington, DC: U.S. Department of Transportation DOT, Federal Motor Carrier Safety Administration
PNLD (n.d.). Q724: Can I listen to my MP3 or iPod player whilst driving a car or riding a bicycle? Retrieved 18.02.2017, from https://www.askthe.police.uk/Content/Q724.htm
Prior, N. (2013, December). The iPod zombies are more switched on than you think. The Conversation. Retrieved 11.10.2016, from http://theconversation.com/the-ipod-zombies-are-more-switched-on-than-you-think-21262
Schwebel, D. C., Stavrinos, D., Byington, K. W., Davis, T., O'Neal, E. E., and de Jong, D. (2012). Distraction and pedestrian safety. How talking on the phone, texting, and listening to music impact crossing the street, Accident Analysis & Prevention, 45, 266–271.
Walker, E. J., Lanthier, S. N., Risko, E. F., and Kingstone, A. (2012). The effects of personal music devices on pedestrian behaviour, Safety Science, 50, (1), 123–128.
95
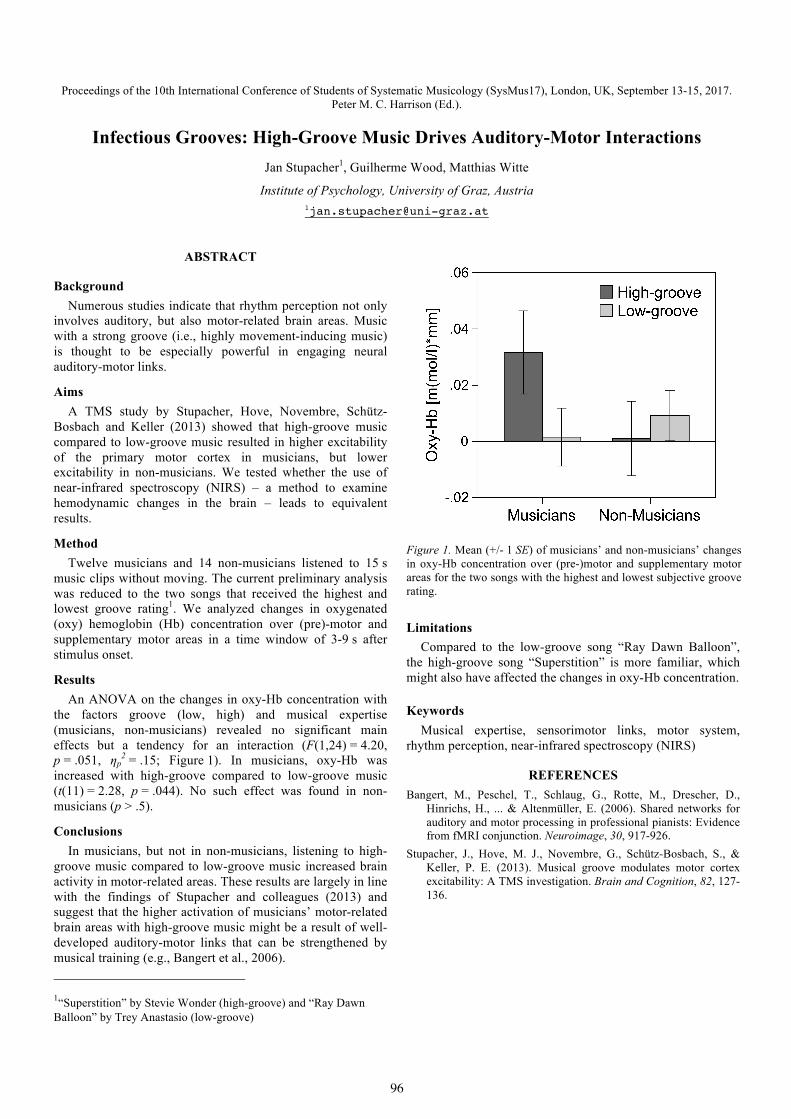
Proceedings of the 10th International Conference of Students of Systematic Musicology (SysMus17), London, UK, September 13-15, 2017. Peter M. C. Harrison (Ed.).
Infectious Grooves: High-Groove Music Drives Auditory-Motor Interactions
Jan Stupacher1, Guilherme Wood, Matthias Witte
Institute of Psychology, University of Graz, Austria
ABSTRACT
Background Numerous studies indicate that rhythm perception not only
involves auditory, but also motor-related brain areas. Music with a strong groove (i.e., highly movement-inducing music) is thought to be especially powerful in engaging neural auditory-motor links.
Aims A TMS study by Stupacher, Hove, Novembre, Schütz-
Bosbach and Keller (2013) showed that high-groove music compared to low-groove music resulted in higher excitability of the primary motor cortex in musicians, but lower excitability in non-musicians. We tested whether the use of near-infrared spectroscopy (NIRS) – a method to examine hemodynamic changes in the brain – leads to equivalent results.
Method Twelve musicians and 14 non-musicians listened to 15 s
music clips without moving. The current preliminary analysis was reduced to the two songs that received the highest and lowest groove rating1. We analyzed changes in oxygenated (oxy) hemoglobin (Hb) concentration over (pre)-motor and supplementary motor areas in a time window of 3-9 s after stimulus onset.
Results An ANOVA on the changes in oxy-Hb concentration with
the factors groove (low, high) and musical expertise (musicians, non-musicians) revealed no significant main effects but a tendency for an interaction (F(1,24) = 4.20, p = .051, ηp
2 = .15; Figure 1). In musicians, oxy-Hb was increased with high-groove compared to low-groove music (t(11) = 2.28, p = .044). No such effect was found in non-musicians (p > .5).
Conclusions In musicians, but not in non-musicians, listening to high-
groove music compared to low-groove music increased brain activity in motor-related areas. These results are largely in line with the findings of Stupacher and colleagues (2013) and suggest that the higher activation of musicians’ motor-related brain areas with high-groove music might be a result of well-developed auditory-motor links that can be strengthened by musical training (e.g., Bangert et al., 2006). 1“Superstition” by Stevie Wonder (high-groove) and “Ray Dawn Balloon” by Trey Anastasio (low-groove)
Figure 1. Mean (+/- 1 SE) of musicians’ and non-musicians’ changes in oxy-Hb concentration over (pre-)motor and supplementary motor areas for the two songs with the highest and lowest subjective groove rating.
Limitations Compared to the low-groove song “Ray Dawn Balloon”,
the high-groove song “Superstition” is more familiar, which might also have affected the changes in oxy-Hb concentration.
Keywords Musical expertise, sensorimotor links, motor system,
rhythm perception, near-infrared spectroscopy (NIRS)
REFERENCES Bangert, M., Peschel, T., Schlaug, G., Rotte, M., Drescher, D.,
Hinrichs, H., ... & Altenmüller, E. (2006). Shared networks for auditory and motor processing in professional pianists: Evidence from fMRI conjunction. Neuroimage, 30, 917-926.
Stupacher, J., Hove, M. J., Novembre, G., Schütz-Bosbach, S., & Keller, P. E. (2013). Musical groove modulates motor cortex excitability: A TMS investigation. Brain and Cognition, 82, 127-136.
96

Proceedings of the 10th International Conference of Students of Systematic Musicology (SysMus17), London, UK, September 13-15, 2017. Peter M. C. Harrison (Ed.).
Interoception in Musicians’ Flow
Jasmine Tan1, Joydeep Bhattacharya2
Goldsmiths, University of London
[email protected], [email protected]
ABSTRACT
Background Flow is a state in which an individual is intensely engaged
with a skill-matched challenging activity and the experience is intrinsically rewarding. People often report a different bodily sensation during flow, most commonly a sense of effortless movement and a merging of action and awareness. However, the nature of interoception, i.e. the brain perceiving the bodily sensations, during flow is not yet characterized.
Aims We investigated the degree of interoception in musicians’
flow experience by the heartbeat-evoked potential (HEP), an event-related potential (ERP) reflecting cortical processing of the heartbeat.
Methods 40 musicians were instructed to play a self-selected musical
piece that did induce flow. Further, they also played two other self-selected musical pieces that did not induce flow but were matched with the flow-inducing piece either in challenge (non-flow equal challenge) or in liking (non-flow equal liking). These non-flow inducing pieces were selected to differentiate the contributions of two different aspects of flow, namely that it involves a challenging task matched to the player’s ability and it is also an experience that is intrinsically rewarding. EEG and ECG signals were continuously measured. The HEP was extracted in the period immediately after musicians stopped playing, and subsequently compared across the three conditions.
Results The HEP differed notably between the three conditions.
Compared to the two non-flow states, flow state was associated with a stronger lateralisation effect: the HEP was more negative specifically over the left frontal electrodes for the flow condition. Comparing the two non-flow states, the HEP was more negative for non-flow equal challenge at the earlier latency but equal liking became more negative at the later latency (i.e. after 280 ms). As more negative HEPs are usually associated with better interoception, these results suggest that flow is linked with stronger interoception.
Conclusions We demonstrate that the cortical processing of heartbeat is
significantly modulated by the flow experience in musicians, providing a novel insight into the brain-body interaction during flow.
Keywords Musicians, music performance, flow experience,
interoception, HEP
97

Proceedings of the 10th International Conference of Students of Systematic Musicology (SysMus17), London, UK, September 13-15, 2017. Peter M. C. Harrison (Ed.).
Affective Priming Effects Between Music and Language in Bilinguals’ First and
Second Language M. S. Tenderini *1, T. M. Eilola*2, E. de Leeuw#3, M. T. Pearce†4
*School of Biological and Chemical Sciences, Queen Mary University of London, England #School of Language, Linguistics and Film, Queen Mary University of London, England
†School of Electric Engineering and Computer Science, Queen Mary University of London, England [email protected], [email protected], [email protected], [email protected]
ABSTRACT
Background This project investigated connections between the
perception and processing of emotion in music and language. Previous research has shown interactions in emotional processing of music and language by means of the affective priming paradigm (Goerlich et al., 2012). Here this research is extended to examine differences in priming between bilinguals’ first (L1) and second, later acquired (L2) language.
Aims The main question was whether emotional responses to
music, primed by affective words, differs between the L1 and the L2. In accordance with literature showing that late bilinguals often report their L2 to be perceived as less emotional (Dewaele, 2008) we hypothesised that L2 words would have weaker priming strength than L1 words on affective judgements of musical stimuli. Music on the other hand is hypothesised to prime affective responses equally in both languages.
Method Single words (L1/L2) with a positive (e.g. ‘friend’) or
negative (e.g. ‘war’) valence were presented together with musical excerpts with positive or negative valence (see Figure 1). Fifty German-English late bilinguals evaluated the second stimulus (target) as positive or negative while the prime
preceding the target could either have congruent or incongruent valence. The first experiment examined responses to word-targets primed by music, while the second examined responses to music-targets primed by words. Reaction times (RT) and the electrophysiological neural response (N400 component) were analysed with respect to the congruence of the stimulus pair and language (L1, L2).
Results The RT results supported our hypothesis: While music
primed words of both languages, there was a difference between the L1 and L2 when priming the musical stimuli. The L1 words primed the musical excerpts; the L2 words however did not. EEG-data will be presented at the conference.
Conclusions The behavioural results suggest decreased integration of
emotional information communicated by L2 compared to L1 words. Conversely, music has a consistent priming effect across L1 and L2.
Keywords affective priming; bilinguals; N400
REFERENCES Dewaele, J. (2008). The emotional weight of I love you in
multilinguals’ languages. Journal of Pragmatics, 40, 1753–1780. Goerlich, K. S., Witteman, J., Schiller, N. O., Heuven, V. J. Van,
Aleman, A., & Martens, S. (2012). The Nature of Affective Priming in Music and Speech. Journal of Cognitive Neuroscience, 24 (8), 1725–1741.
Vieillard, S., Peretz, I., Gosselin, N., Khalfa, S., Gagnon, L., & Bouchard, B. (2008). Happy, sad, scary and peaceful musical excerpts for research on emotions. Cognition & Emotion, 22(4), 720–752.
Figure 1. Affective priming paradigm with a music prime and a written word target. The presentation of the target stimulus is terminated by the evaluation of the participant; SOA = stimulus onset asynchrony, musical excerpt from Vieillard et al. (2008).
Evaluation of target Prime Target
RT
SOA
Incongruent
Congruent vs.
short RT
long RT
98

Proceedings of the 10th International Conference of Students of Systematic Musicology (SysMus17), London, UK, September 13-15, 2017. Peter M. C. Harrison (Ed.).
Using Zygonic Theory to Model Expectations in Repeated Melodic Stimuli
Hayley Trower1, Adam Ockelford2, Arielle Bonneville-Roussy3
University of Roehampton, London, UK
[email protected], [email protected], [email protected]
ABSTRACT
Background The disruption of melodic expectations can generate
emotional pleasure even when the listener is familiar with a musical piece and knows what is coming next. The zygonic model of musical understanding (Ockelford, 2012) proposes that this is a result of the interplay between different forms of expectation that arise from a) previously heard musical structures encoded schematically that provide a general indication about the future, b) current musical structures that offer a secondary source of general implication, and c) previously heard musical structures encoded veridically, providing specific knowledge about upcoming events, however more empirical evidence is required to support this idea within the context of musical repetition.
Aims The first aim was to determine the degree of interaction
between a), b), and c) during listening to familiar music by measuring expectations in response to a repeating melody. The second aim was to incorporate those measurements into a model of musical understanding that considers ‘rehearing’ musical pieces, by extending the theoretical underpinnings set out by Thorpe et al. (2012), and introducing a revised version of the zygonic model.
Method Forty-three adult listeners were presented with a twenty-six
note diatonic piano melody four times during each of two sessions. Repetitions of the (initially novel) stimulus were separated by a distractor. Participants made note-by-note expectancy ratings for each stimulus presentation by using a touch sensitive apparatus known as a CReMA (Himonides, 2011) which transmits MIDI data to a connected laptop.
Results Analysis is ongoing. Initial results show that although
schematic expectations are consistent with each stimulus repetition, veridical expectations are affected incrementally, representing an increase in perceived familiarity with each stimulus repetition. Furthermore, the relationship between schematic and veridical expectations appears to be ‘reset’ during the period of rest.
Conclusions A discussion will be couched in relation to the revised
zygonic model of expectation, providing insight into the way that familiar music retains moments of expressivity. Results will contribute towards a comprehensive model of expectation
that uniquely incorporates the common behaviour of repeated listening to the same pieces of music.
Keywords melodic expectation; zygonic; perception; cognition;
repetition
REFERENCES Ockelford, A. (2012). Applied musicology: using zygonic theory to
inform music education, therapy, and psychology research. Oxford University Press.
Thorpe, M.., Ockelford, A., Aksentijevic, A. (2012). An empirical exploration of the zygonic model in music. Psychology of Music, 40(4), 429-470.
Himonides, E. (2011). Mapping a beautiful voice. Journal of Music, Technology and Education, 4(1), 5-25.
99

Proceedings of the 10th International Conference of Students of Systematic Musicology (SysMus17), London, UK, September 13-15, 2017. Peter M. C. Harrison (Ed.).
Can Individuals be Trained to Imagine Musical Imagery? A Preliminary Study
Michelle Ulor1, Freya Bailes2, Daryl O’Connor3
School of Music, University of Leeds, United Kingdom
[email protected], [email protected], 3d.b.o’[email protected]
ABSTRACT
Background Psychologists have studied imagery-based therapy for
anxiety, but with a strong emphasis on visual imagery rather than imagery for other modalities (e.g. auditory imagery). Based on the evidence that anxiety is influenced by negative thoughts (Rood, Roelofs, Bögels & Alloy, 2010), voluntary musical imagery could be offered as an alternative. To test this idea, it is important to look at which methods would be best at training people to imagine music and assessing their abilities at doing so. Thus this study seeks to investigate these methods.
Aims To examine the feasibility of training individuals to
imagine music.
Method Three stages of the study take place over five days;
training, practising and testing. During training, the participants learn to imagine music (self-selected pieces) using a volume fader task. Participants listen to their pieces, then lower the fader as soon as they are able to continue the music in their minds, raising it as necessary to check their mental image. Next, the participants practice imagining music in response to six text message prompts from the experimenter (sent periodically throughout the day), and additionally complete experience sampling method diary entries after each attempt. Finally, the participants’ ability to imagine music is assessed using a spot task, involving exposure to their self-selected pieces interpolated with silent gaps. During the silent gaps, the participants imagine what they believe would be heard, then decide whether the piece was reintroduced at the correct position.
Results Indices of success in imagining music will be analysed,
including beat tapping accuracy and spot task scores.
Conclusions This study will determine the possibility of training people
to imagine music. If positive significant results are produced, this method can be tested as therapy for anxiety.
Keywords voluntary musical imagery; anxiety
REFERENCES Rood, L., Roelofs, J., Bögels, S. M., & Alloy, L. B. (2010).
Dimensions of Negative Thinking and the Relations with Symptoms of Depression and Anxiety in Children and Adolescents. Cognitive Therapy and Research, 34(4), 333-342.
100

Proceedings of the 10th International Conference of Students of Systematic Musicology (SysMus17), London, UK, September 13-15, 2017. Peter M. C. Harrison (Ed.).
“Let the Music Flow in You”: Music Listening, Health and Wellbeing in Everyday
Life Joy Vamvakari
University of Edinburgh, UK [email protected]
ABSTRACT
Background This paper discusses music listening behaviours in relation
to wellbeing in everyday life. Music listening is pervasive (MacDonald, 2013) and can address diverse aims (DeNora, 2013). While the field of music, health and wellbeing has attracted increasing interest (MacDonald et al., 2012), there is need for further research, in order to understand the outcomes and motivations of music listening for wellbeing purposes, within contemporary contexts.
Aims This study focuses on the associations between music
listening behaviours and wellbeing measures in the international general population. As a secondary aim, it explores the potential of online crowdsourcing for music psychology research.
Method This study uses an online survey distributed through the
crowdsourcing platform CrowdFlower to a diverse sample of the international, general population. The survey focuses on two themes: music listening behaviours and subjective health and wellbeing, using Likert scale self-report measures. Furthermore, the survey includes open-ended questions exploring the individual experience of music listening in relation to wellbeing and self-care practices.
Results The participant sample (N = 215) comprises of 69% male,
30% female and 1% non-binary participants, from a wide age range (18-42) and 46 nationalities, while 33% of the participants reported facing physical/mental health difficulties.
The statistical analysis highlights the association between demographic factors, music listening behaviours and wellbeing measures. For example, the positive influence of music listening on wellbeing is associated with music listening frequency; participants who reported strong positive influence engage in music listening more frequently (chi-squared test, χ2 = 62.75, df = 6, p < .001), as a cause or result of their awareness of this positive influence.
Furthermore, themes and individual experiences emerging from the qualitative data, coded through thematic analysis, are discussed, regarding particular ways that music listening helps, and why and when it is ineffective.
Conclusions These findings highlight the association between music
listening behaviours and aspects of wellbeing in everyday life, as an intricate, complex form of self-care.
Keywords music listening; subjective health; wellbeing;
crowdsourcing; survey research; international
REFERENCES DeNora, T. (2013). Music Asylums: Wellbeing through music in
everyday life (Music and Change: Ecological Perspectives series). Surrey: Ashgate Publishing Ltd.
MacDonald, R.A.R. (2013). Music, health and well-being: A review. International Journal of Qualitative Studies on Health and Well-being, 8, pp. 206-235.
MacDonald, R.A.R., Kreutz, G. & Mitchell, L. (eds.) (2012). Music, Health and Wellbeing. Oxford: Oxford University Press.
101

Proceedings of the 10th International Conference of Students of Systematic Musicology (SysMus17), London, UK, September 13-15, 2017. Peter M. C. Harrison (Ed.).
Study of Emotion Perception for Indian Classical Raga Music
Makarand Velankar*1, Parag Kulkarni#2 *PhD Student, PICT and Assistant Professor Cummins College, Savitribai Phule Pune University, India
#Iknowletion Research labs pvt ltd., Pune, India [email protected], [email protected]
ABSTRACT Indian Classical Music (ICM) has a long tradition and people from various cultural backgrounds are fascinated by it. Each performance of a given raga in ICM is supposed to create a common mood among the listeners. We have selected all clips of instrument flute in order to eliminate the effect of timbre and lyrics on perceived emotions. For our initial experiments, we have selected 2 ragas. The 3 clips selected in each raga were one with fast rhythm, one with medium rhythm and one with alap which is arrhythmic. We have obtained total 240 responses with 40 responses per clip during 6 different sessions. Each session was planned with 2 clips per session with same tempo of different raga. The sessions were planned to eliminate the effect of possible ordering of music clips. Listeners provided rating for 13 different emotions on a numeric scale of 0 to 100 for musical clip. The results are presented using different statistical data charts along with the analysis of data. The critical findings about the expression creation are presented with support of data. These initial experiments revealed strong evidence of raga association with the specific emotion for novice listeners.
I. INTRODUCTION ICM has a long history. It has evolved to its present form
over at least 600 years. The khyal form of vocal music and instrumental presentation mimicking vocal styles are relatively recent developments in ICM. In vocal music, the lyrics in the song are associated with possible meaning. In case of instrumental music one can eliminate possible effect of lyrics on emotion perception.
Instrumental classical music has numerous variants considering different instruments. ICM instruments are traditionally classified into different types based on sound production method such as wind instruments, string instruments, vitata instruments etc. Popular string instruments are Sitar, Sarod, Santoor, Sarangi etc. Popular wind instruments are bamboo flute or Basuri, Shahanai, Harmonium etc. Vitata instruments like Tabla, Pakhwaj etc generally used for taal or rhythm in ICM.
We have selected one wind instrument Bansuri or Bamboo Flute for our experiments. Bansuri has also long history and is also associated with lord Krishna in Hindu religion. In recent years, artists like Pandit Pannalal Ghosh, Pandit Hariprasad Chaurasiya etc. are the main contributors for popularizing Basuri among ICM listeners.
Raga in ICM is a framework with certain rules about notes to be played, their sequence, their prominence etc. In a framework of raga, we have many bandishes or melodies composed by different composers. These different compositions in the same raga along with enormous possibilities for improvisation during presentation are the
main features of ICM. Raga music in ICM is covered by many books in detail with noticeable contribution in the context of computational musicology.
The ICM performance in Khyal form usually has music rendition in 3 parts: first alap, followed by vilambit or Madhya laya and finally drut laya. In alap, raga notes are played or sung with slow tempo to build the atmosphere at the beginning. During alap, there is no rhythm accompaniment. Vilambit laya means slow tempo, Madhya laya means medium tempo and drut laya means fast tempo.
We have discussed the emotion and raga correlation with performers and some seasoned listeners. Most of them were agreeing to specific emotional feel associated with the raga. Some of them expressed an opinion that they can reach at the highest level of happiness with a meditative feeling after listening to their favorite artist/ raga in ICM.
Like every human being raga has its own name and individual characteristics. Raga can be classified according to time of playing or moods created from them. Raga- bhava or mood is the expected atmosphere created or experience of listeners to a raga rendition. It is very difficult to express it in words and is matter of personal experience according to many seasoned listeners and the performers.
We have chosen 2 ragas - Marubihag and Marwa for our initial experiments. They are perceived to create different emotional atmospheres. Marubihag is supposed to create happy and excited emotion whereas Marwa is supposed to create sad and depressed emotion. The work presented here is the extension of our own work done before.
Ethnomusicologists around the world are also exploring association between music and felt emotions. Martin Clayton made the following points in his article “Musical experience depends on our attention primarily on auditory information and perhaps in the extent to which sound information is understood in a non-linguistic mode. Each individual perceives and decodes the information differently. Thus the meaning or experience is always experience to someone.” He further states that “We need to recognize that musical experience is meaningful in a variety of ways, that these ways are interconnected and that the relationships between different dimensions of meaning are important”.
The feeling or expression or emotion created by music in different listeners, or even the same listener at different times, may vary. The response of a listener depends on many factors such as cultural background, upbringing, current emotional state of the listener and individual likes and dislikes as factors related to individuals. The response is also dependent on the attention of the listener towards timbre of voice or instrument, notes played, tempo and rhythm in the clip. Meaning or expression from music can be entirely different depending on
102

the focus of the listener. Our aim was to catch possible common expression for the specific raga for different perceived emotions.
II. AIM Although it is difficult to catch the common expressions
from any music form, we have attempted to find, as far as it is possible, the common expression created by ICM on Indian listeners with almost similar cultural background. All the listeners in the experiments were young Indians with age group of 18-20 years studying in the college.
Considering the viewpoints and findings by researchers, the emotional experience is generally subjective and different for individuals. We have attempted to validate the hypothesis as “Each raga is associated with specific mood” by listening experiments for novice Indian listeners with no or little background of ICM.
Our main aims in this pilot study for 2 selected ragas are, • Identify Raga association with distinct emotional
musical appeal. • Study of effect of tempo variations on different
emotion perceptions.
III. LITERATURE SURVEY Emotional modeling and conceptualization has been
attempted by many researchers to capture emotional response of music from the listeners. Emotions were clustered in 8 categories by Hevner for representing perceived music by listeners. Different approaches proposed in the literature mostly refer to either emotion categorization or using valence-arousal dimensional approach.
In emotion categorization approach, subjects or listeners report emotions in specific category such as happy or sad etc. Listeners can express emotions in their own words or they are asked to rate given emotions on the scale from low to high. This approach has advantage as it is easy for listeners to report ratings and specific emotions experienced in their own words. It is likely that sometimes listeners unable to express their emotions in proper words and can lead to false emotional interpretations.
In dimensional approach, listeners select some position on emotion dimension axis. This position is associated with some number to identify intended emotion. Valance arousal circumflex model proposed by Russell is a dimensional model used widely. Two dimensional model with X axis as Valance to represent emotion as positive or negative and arousal to represent intensity on Y axis as high or low for specific emotion. It divides the plan in 4 different quadrants. Three dimensional models are also proposed but they lag in visualization aspects and issues related to annotations from subjects. Two dimensional models are better compare to three dimensional models considering the simplicity aspect.
Musical piece may have changing emotions over a timeline as listeners may perceive different emotions corresponding to different musical sections or segments of same musical clip. Annotation by listener over a timeline by selecting musical segment and stating experienced emotion is another approach used by researchers. This approach is also termed as expert approach.
Annotation methods used to record emotions are time consuming and do have certain flaws. No design is perfect
considering the goal to catch emotions. Since perceived emotions are subjective, complete agreement among listeners is unlikely. Ground truth is generally obtained by averaging the opinions of the subjects.
IV. METHODOLOGY We decided to use novice listeners as subjects in our
experiments to understand the expression created from a raga. Seasoned listeners have their predefined mindsets built through listening to raga music for years and knowledge of convention. We have selected all clips of bansuri in order to eliminate possible impact of timbre variation. We have discussed with Pandit Keshav Ginde, a renowned bansuri player, about the emotions associated with ragas and his own experience while presenting specific ragas. We discussed about features of bansuri performances and perceived feedback from the listeners. He advised us about suitable duration and experiment conduction considering the listener’s age and background.
We selected 3 clips of each raga with naming convention as A, M and D corresponding to alap (no rhythm accompaniment), Madhya laya(medium tempo) and drut laya(fast tempo) respectively. For 2 different ragas 6 clips are named as A1and A2 for alap clips, M1 and M2 for Madhya laya clips and D1and D2 for drut or fast tempo clips.
Generally duration of alap and fast tempo is small as compared to Madhya or Vilambit laya in the raga performance. We selected all clips of duration around 2 to 3 minutes regardless of the duration of the corresponding section of the performance. We selected the clip durations of 2 to 3 minutes considering the attention span of novice listeners and an estimate of the minimum time required to embark the emotion.
Before the actual sessions, we did experimental sessions with one clip per session without any feedbacks to understand the patience and get feedback to design the actual experiments. After getting initial feedback about possible patience of novice listeners to listen ICM, we decided to play 2 melodies per session with a gap of about 5 minutes for the 6 sessions done. We decided to observe effect of same tempo and different raga notes on same set of listeners. We conducted total 6 listening sessions with 20 listeners in each session and playing 2 clips per session.
Sessions planned with clips combination and sequence as shown below. As one can notice sessions 1 and 2 used same clips but the order of playing of clips was changed to eliminate possible effect of order in the perceived emotions. Similar logic is reflected in sessions 3, 4 and 5, 6.
Session 1: A1 followed by A2 Session 2: A2 followed by A1 Session 3: M1 followed by M2 Session 4: M2 followed by M1 Session 5: D1 followed by D2 Session 6: D2 followed by D1 Since most of the listeners were in the age group of 18-20
with almost no exposure to ICM, we kept an open mind about the outcome of the sessions. We gave them a brief introduction before the session, explaining the objective of session and how to fill the feedback forms. This exercise helped us to bring the mind sets of all listeners into a common
103

mode of listening and to experience the emotion created from the clip.
The feedback consisted of 2 parts. First part contained questions about personal musical background and information about the listeners. In the second part, we asked them to rate 13 different emotions on the scale of 0 to 100. For example extremely happy can be 100 and very sad can be 0 for the emotion “happy”. After rating about individual emotions, listeners expressed their listening experience with rating their enjoyment association with parameters timbre, melody and rhythm in the rank 1 to 3. This gives us possible attention or influencing features of music for emotions perceived. We also held personal discussions with some of the listeners to understand the effectiveness of the session and understand their view points about listening music. The exercise of discussion after session has given us insight into thought processes of youth and their perceived emotions and expectations from ICM.
V. RESULTS We have presented comparative data for 2 ragas
Marubihag and Marwa [referred as MB and M respectively in figures and tables. Figures 1 to 3 shows comparative average responses for Alap, Madhya laya and Drut for different emotions on the numeric scale of 0 to 100. We have shown data in the range 30 to 85 as all average responses were in this range. Each figure represents average rating response related to each emotion to both ragas. We can analyze different emotional parameters at different tempos for 2 ragas. Table 1 represents responses of user counts in percentage about the comparative perception of specific emotions to each raga. Table 2 represents enjoyment rating matrix to understand liking and possible attention parameters.
Figure 1. Comparison of alap clips A1 and A2
Comparative average rating of 40 responses per clip recorded in session 1 and 2 are shown in figure 1. This session had alap musical clips of 2 ragas without any rhythm association. We can observe that meditative and peaceful are most prominent emotions related to alap music for both ragas.
Request is more prominent feeling in Marwa compare to Marubihag and Happy is protuberant in Marubihag compare to Marwa. Poor rating for exciting feeling indicates that alap form does not excite the listeners.
Figure 2. Comparison of Madhya laya clips M1 and M2
Comparative average rating of 40 responses per clip recorded in session 3 and 4 are shown in figure 2. This session had Madhya laya or medium tempo musical clips with rhythm accompaniment. We can observe that peaceful is most prominent emotion for both ragas. Marubihag is perceived as more pure, gentle, graceful and happy compare to Marwa. Marwa perceived to have more surrender, love and satisfaction feel compare to Marubihag.
Figure 3. Comparison of drut clips D1 and D2 Comparative average rating of 40 responses per clip
recorded in session 5 and 6 are shown in figure 3. This session had drut laya or fast tempo musical clips with rhythm accompaniment. We can observe that peaceful is most appealing emotion for Marwa compare to Marubihag.
30 35 40 45 50 55 60 65 70 75 80 85
HappyExciting
SatisfactionPeacefulGracefulGentleHuge
SurrenderLove
RequestTouching
PureMeditative
MB M
30 35 40 45 50 55 60 65 70 75 80 85
HappyExciting
SatisfactionPeacefulGracefulGentleHuge
SurrenderLove
RequestTouching
PureMeditative
MB M
30 35 40 45 50 55 60 65 70 75 80 85
HappyExciting
SatisfactionPeacefulGracefulGentleHuge
SurrenderLove
RequestTouching
PureMeditative
MB M
104

Marubihag is perceived as more exciting, huge and graceful compare to mawa. Marwa perceived to have more surrender, love and satisfaction feel compare to Marubihag.
This average response for each emotion perceived can be misleading as it only represents the average ratings by user. Thus we have decided to observe relative response of each user for different emotions. Table 1 shows the percentage of 240 relative responses for each emotion reported as same perception in both ragas, perceived more in Marubihag and Marwa respectively. Figures in bold indicates percentage of listeners with majority perceptions. Pure, love, surrender, huge and exciting feeling is observed at same level by majority of listeners. Marwa is perceived as more touching, request and peaceful feel compare to Marubihag. Marubihag is perceived as graceful and happy compare to Marwa.
Emotions Perceived same in
both Raga
Perceived more in
Marubihag
Perceived more in Marwa
Meditative 33.33 17.5 49.17 Pure 54.17 25.83 20 Touching 22.5 24.17 53.33 Request 22.5 12.5 65 Love 62.5 27.5 10 Surrender 52.5 22.5 25 Huge 65 15 20 Gentle 35 37.5 27.5 Graceful 27.5 52.5 20 Peaceful 15 30 55 Satisfaction 35 35 30 Exciting 57.5 22.5 20 Happy 30 55 15
Table 1: Raga wise comparison in percentage response
Listeners also provided information about the enjoyable parameters as what they like more on the rating scale of 1 to 3. We have provided parameters as Timbre and melody for first 2 sessions with 80 responses. 58% rated timbre at rating 1 and remaining 42% rated melody at rating 1. Enjoyment rating matrix for sessions 3 to 6 is shown in table 2 for 160 responses as it had additional component as rhythm. This information is useful to understand possible attention and liking of listeners.
Parameter Timbre Melody Rhythm Rating 1 38.75 36.25 25 Rating 2 30 47.5 22.5
Table 2: Enjoyment rating Matrix
Table 1 represents better comparative perceptions for each
emotion in selected 2 ragas. Table 2 corresponds to rating matrix representing percentage of listeners with attention rating to musical parameters as timbre, melody and rhythm.
VI. CONCLUSION Raga association with specific emotion is a non-trivial task.
Many musical dimensions such as timbre, tempo, rhythm etc. influence the listener perception. Isolating effect of melody of raga to associate emotions to raga is difficult. Subjects with same Indian cultural background were participated for the
experiments. It would be interesting to extend the experiments for different cultural backgrounds to see the effect of culture in the emotion perception of raga.
Marubihag is perceived as more happier and graceful than Marwa. Marwa is perceived as creating a stronger feeling of request, touching and peacefulness than Marubihag. Other emotions as Pure, Huge, Gentle and meditative for which we have strong support in both ragas can be perceived as effect of quality of sound or can be a reaction of genre or both. Fast tempo seems to be the most important factor in creating “excitement”. Marwa is perceived as sadder and more pleading as compared to Marubihag. This is most prominent in their responses to alap and Madhya laya clips. Rhythm adds more excitement and faster tempo perceiving towards the happier mood whereas slow temp with the reflection of sad mood. However, experiments reveal strong evidence of raga association with the specific mood.
Another interesting observation is statistical data can be misleading at times. The average absolute mean values for each emotion related to each raga shown in charts does not reflect raga-wise comparative data. Table 1 with subject-wise comparative information can be more useful to compare raga emotions. Due care needs to be taken for representation of data and drawing conclusions in such multivariate data analysis. It would be interesting to further explore data in Table 2 about enjoyment rating matrix to classify and analyze possible effect of attention of listener on emotions.
We have plans to conduct similar sessions with clips of different ragas, and other sessions with clips in the same raga with wider range of instruments to verify our observations about raga and observe inter-instrumental differences. We are of the view to conduct sessions with clips of different duration to verify our assumption about the minimum time span required to affect the emotion of the listener. All these exercises will help us to verify our assumptions and observations. Our exercise can be useful for musicologist or researchers working in the area of music emotion recognition.
ACKNOWLEDGMENT We wish to convey our sincere thanks to Dr. H.V.
Sahasrabuddhe and Pandit Ginde for valuable guidance and to all students who participated and provided feedback about the perceived emotions during the listening ICM sessions.
REFERENCES S. Rao & P.Rao (2014). An overview of Hindustani classical music
in the context of computational musicology. In Journal of new music research volume 43, Issue 1 March 2014.
M. Velankar & H. Sahasrabuddhe(2012). A pilot study of Hindustani music sentiments in 2nd Workshop on Sentiment Analysis where AI meets Psychology (SAAIP 2012)
Dr. Martin Clayton (2001). Towards a theory of musical meaning in British Journal of ethnomusicology vol-10/I.
Pandit Vishnunarayan Bhatkhande (1957). Kramik pustak malika-part 1 to 6 Hathras: Sangeet Karyalaya 1st edition.
Y. Yang & H. Chen (2012). Machine Recognition of music emotion: A review in ACM Transactions on Intelligent system and Technology, Vol 3, No 3. May 2012
Mathieu Barthet, David Marston, Chris Baume, Gy¨orgy Fazekas, Mark Sandler (2013). Design and Evaluation of semantic mood models for music recommendation, ISMIR 2013
105

Proceedings of the 10th International Conference of Students of Systematic Musicology (SysMus17), London, UK, September 13-15, 2017. Peter M. C. Harrison (Ed.).
Reproduction of Western Music Rhythms by Cameroonian School Children
Gesine Wermke*1, Andreas C. Lehmann#2, Phillip Klinger#3, Bettina Lamm†4
*Institute of Music Research, Julius-Maximilian University of Würzburg, Germany
#University of Music Würzburg, Germany †Faculty of Human Sciences, Learning and Development, University of Osnabrück, Germany
[email protected], [email protected], [email protected], [email protected]
ABSTRACT
Background Rhythm is present in all musical cultures, though its
distinctive characteristics might be culture-specific, and even tapping to a beat might reveal the participants culture-specific biases or perception. Yet the design of experiments regarding rhythm perception and production are generally Eurocentric. Hence, participants from non-Western music cultures might be at an advantage for some tasks and at disadvantage for others. Developing a culture-neutral approach would be desirable.
Aims This study was designed to identify patterns of rhythmic
reproduction based on sensori-motor synchronization (SMS); we investigated strategies of Cameroonian (Nso) children to synchronize a rhythmic motor pattern (finger tapping) with externally perceived typical Western music stimuli. Cameroonian Nso parents typically establish rhythmic vocal and motor patterns characterized by crossmodal and interpersonal synchronicity with their infants (Demuth, Keller, & Yovsi, 2012; Keller, Otto, Lamm, Yovsi, & Kärtner, 2008). While some primitive forms of SMS appear to exist at birth (Provasi, Anderson, & Barbu-Roth, 2014), children of 11 years and above are recognized to exhibit stable SMS skills (Schlaug, 2001).
Method Fifty-five (26 female) Nso children aged 11-15 years
participated in this study, which was undertaken in the city of Kumbo (North Cameroon). An age-matched sample of German children is currently under investigation for comparison.
Following extant research by Hasselhorn and Lehmann (2015) and Kopiez, Langner, & Steinhagen (1999), rhythms with different meter (3/4, 4/4, 6/8) and different speeds (72 bpm, 80 bpm, 90 bpm, 110 bpm) were generated using Ableton (V. Live 8.0.9). Every sample was looped six times. In the experiment at least five stimuli were randomly selected from the item pool for each participant.
The stimuli were presented to each child via headphones, which were connected to a mp3-player with speakers. The children were instructed to reproduce the rhythm with their preferred hand (finger) or a pencil. The stimulus was first presented (participants might or might not tap along), then the children continued tapping after the presentation terminated.
Information about the children’s musical behaviour (musical experience, musical background) was also collected.
The audio-visually recorded data were auditory analysed by two musically trained judges according to meter, speed and rhythm patterns.
Results Different reproduction patterns of the 4/4- and 6/8-stimuli
were observed and categorized: 1. At least one sample of the original rhythmic stimuli
was reproduced. 2. Small variations in meter, speed or rhythm pattern
were produced. 3. After reproducing the first bar, different variants of
the subsequent rhythms followed. 4. Rhythm variations that occurred in at least two
children. 5. Individual children’s variations.
The reproductions of the ¾ triplet (Bolero; see Figure 1) showed four different results:
1. No reproduction of at least one original sample was observed.
2. Several variations of individual children of all ages deviated from the original stimuli (Figure 1, red colour).
3. Furthermore, the Bolero rhythm was grouped according to different gestalt perceptions by 84% of all subjects (Figure 1, all colours but red and orange).
4. A variation of the presented rhythm, which was reoccurring in the reproduction of several children (Figure 1, orange colour)
Figure 1. Variants of rhythm reproduction and grouping in the ¾ triplet rhythm of every child. Key: Gender: 1 = female; 2 = male; Age in years Red: The reproduction patterns of individual children deviated from the original stimuli; Orange: A variation of the presented rhythm, which was reoccurring in the reproduction of several children; Green: Grouping: Reproduction started with a Group of two; Blue: Reproduction of the second bar of the original rhythmic stimuli; Violet: Grouping: Reproduction of two different parts of the original stimuli: group of two and group of long-short-short-short/ group of shorts; Pink: Grouping: Reproduction of three different elements of the original stimuli: group of two, group of long-short-short-short and group of several shorts
Conclusions Trying to apply a culture-neutral analysis, several versions
of the original stimuli were observed independent of age
106

and/or musical experience. For the 4/4- and 6/8-stimuli a smaller inter-individual variability was observed compared to the ¾-triplet (Bolero) stimulus. Whether the observed patterns were caused by culture-specific experience can be ascertained once the comparison data of German pupils is collected (cf. poster presentation at conference). A quantitative temporal analysis of the performances is warranted to validate the judges’ findings.
Keywords Rhythm, finger tapping, children, cross-culture, gestalt
grouping
REFERENCES
Demuth, C., Keller, H., & Yovsi, R. (2012). Cultural models in communication with infants – lessons from Kikaikelaki, Cameroon and Muenster, Germany. Journal of Early Childhood Research, 10(1), 70–87. doi:10.1177/1476718x11403993
Hasselhorn, J., Lehmann, A. (2015). Leistungsheterogenität im Musikunterricht. Eine empirische Untersuchung zu Leistungsunterschieden im Bereich der Musikpraxis in Jahrgangsstufe 9. In J. Knigge & A. Niessen (eds.), Theoretische Rahmung und Theoriebildung in der musikpädagogischen Forschung, 163-176. Münster: Waxmann.
Keller, H., Otto, H., Lamm, B., Yovsi, R., & Kärtner, J. (2008). The timing of verbal/vocal communications between mothers and their infants: a longitudinal cross-cultural comparison. Infant Behavior & Development, 31(2), 217–226. doi: 10.1016/j.infbeh.2007.10.001
Kopiez, R., Langner, J., & Steinhagen, P. (1999). Afrikanische Trommler (Ghana) bewerten und spielen europäische Rhythmen. Musicae Scientiae, 3, 139-160. doi: 10.1177/102986499900300201
Provasi, J., Anderson, D., & Barbu-Roth, M. (2014). Rhythm perception, production, and synchronization during the perinatal period. Frontiers in Psychology, 5. doi: 10.3389/fpsyg.2014.01048
Schlaug, G. (2001). The Brain of Musicians. A Model for Functional and Structural Adaptation. Annals of the New York Academy of Sciences, 930, 281–299. doi: 10.1111/j.1749-6632.2001.tb05739.x
107

Proceedings of the 10th International Conference of Students of Systematic Musicology (SysMus17), London, UK, September 13-15, 2017. Peter M. C. Harrison (Ed.).
Analysing the Implications of Music Videos on Youths’ Listening Experience
Johanna N. Wilson
University of Jyväskylä, Finland [email protected]
ABSTRACT
Introduction Previous research has analysed the psychological functions
of music listening during adolescence and young adulthood, particularly in respect to its use for affect regulation (Laiho, 2004; Saarikallio & Erkkilä, 2007). However, little research exists that analyses the effect of music videos (MVs) in re-spect to these functions of listening. MVs require the subject to pay attention to both audio and visual materials, and as a result, some emotional responses may arise from MV watch-ing that do not occur in music listening alone.
Aims This is an exploratory study which aims to provide new
insights into youths’ experiences with MVs. The study will examine how they divide their attention between the music and the video. To what extent this affects their emotional engagement with the music when no video is present is considered, as well as whether individual differences such as personality type and music listening habits effect these outcomes.
Method The study consists of open-ended questions and survey
measures. The questionnaire asks participants about their experience with MVs, the contexts they watch them in, and whether or how the video affects their perception or interpretation of the music. Whether the video enhances or weakens their emotional outcomes in subsequent listenings is also of interest. Individual differences concerning personality and music listening habits are explored using three surveys: B-MMR, HUMS and a ten-item Big Five personality scale. Participants are Canadian high school students, university students, and young adults between the ages of 14 to 24.
Results Data are currently being collected.
Conclusions It is expected that MVs may affect the listener’s emotional
engagement and perception of the music in subsequent listens, however this will depend on whether the video is in line with their subjective interpretation of the music’s meaning. Furthermore, individual differences such as personality type, age, and reasons for listening may determine whether these outcomes have positive or negative implications on the individual.
Keywords Music video, youth, perception, interpretation, emotion
REFERENCES Laiho, S. (2004). The psychological functions of music in adoles-
cence. Nordic Journal of Music Therapy, 13(1), 47-63. Saarikallio, S., & Erkkilä, J. (2007). The role of music in adolescents'
mood regulation. Psychology of Music, 35(1), 88-109.
108

Proceedings of the 10th International Conference of Students of Systematic Musicology (SysMus17), London, UK, September 13-15, 2017. Peter M. C. Harrison (Ed.).
Neural Music Language Models: Investigating the Training Process
Adrien Ycart1, Emmanouil Benetos2
Centre for Digital Music, Queen Mary University of London
[email protected], [email protected]
ABSTRACT
Background Automatic music transcription (AMT) is the problem of
converting an audio signal into some form of music notation. It remains a challenging task, in particular with polyphonic music (Benetos et al., 2013)
In most AMT systems, an acoustic model estimates the pitches present in each time frame, and a language model links those estimations using high-level musical knowledge to build a binary piano-roll representation. While the former task has been widely discussed in the literature, the latter has received little attention until quite recently (Raczyński et al., 2013; Sigtia et al., 2015).
Aims We aim to investigate the use of recurrent neural networks
(RNN) as language models for AMT to estimate the probability of pitches present in the next frame, given the previously observed. Most of the existing literature focuses on the architecture; here we will investigate the training process. More precisely we will consider how the choice of the time steps, the choice of the training set, and various data augmentation techniques can influence their predictive power.
Method We will train a simple Long Short-Term Memory (LSTM)
architecture (Hochreiter & Schmidhuber, 1997) with polyphonic MIDI data, taken from a classical piano music dataset1. The performance of the resulting RNN will be compared in terms of prediction accuracy and cross-entropy. We will compare time steps in physical time and in fractions of a beat, similarly to a study by Korzeniowski and Widmer (2017). We will investigate the influence of various types of training data (different genres, composers, artificial data). We will also assess how data pre-processing (cutting the training sequences into smaller chunks) and data augmentation (transposition, time-stretching) can improve the results.
Results This research is ongoing; most results have yet to be
obtained. The first results suggest that time-steps in milliseconds perform better in terms of prediction because self-transitions are more frequent, but do nothing more than a simple smoothing. On the other hand, time-steps of a sixteenth note perform worse on prediction, but they allow to better model tonality and meter.
1www.piano-midi.de
Conclusions This study will be a first step towards implementing a
neural music language model (MLM). It will later be integrated with state-of-the-art acoustic models to make a full AMT system; experiments will be carried out in future work on how MLMs can improve AMT performance.
Keywords Automatic music transcription, neural networks, music
language models, polyphonic music prediction
REFERENCES Benetos, E., Dixon, S., Giannoulis, D., Kirchhoff, H., & Klapuri, A.
(2013). Automatic music transcription: challenges and future directions. Journal of Intelligent Information Systems, 41(3), 407-434.
Raczyński, S. A., Vincent, E., & Sagayama, S. (2013). Dynamic Bayesian networks for symbolic polyphonic pitch modeling. IEEE Transactions on Audio, Speech, and Language Processing, 21(9), 1830-1840.
Sigtia, S., Benetos, E., & Dixon, S. (2015). An end-to-end neural network for polyphonic music transcription. IEEE Transactions on Audio, Speech, and Language Processing, 24(5), 927–939.
Hochreiter, S., & Schmidhuber, J. (1997). Long short-term memory. Neural computation, 9(8), 1735-1780.
Korzeniowski, F., & Widmer, G. (2017). On the Futility of Learning Complex Frame-Level Language Models for Chord Recognition. arXiv preprint arXiv:1702.00178.
ACKNOWLEDGEMENTS AY is supported by a QMUL EECS Research Studentship. EB is supported by a RAEng Research Fellowship (RF/128).
109





























