Embed Size (px)
Citation preview

Probabilistic Models in Information Retrieval
NORBERT FUHR
University of Dortmund, Informatik VI, P.O. Box 500500, W-4600 Dortmund, Germany
In this paper, an introduction and survey over probabilistic information retrieval (IR) is given. First, the basic conceptsof this approach are described: the probability-ranking principle shows that optimum retrieval quality can be achievedunder certain assumptions; a conceptual model for IR along with the corresponding event space clarify theinterpretation of the probabilistic parameters involved. For the estimation of these parameters, three different learningstrategies are distinguished, namely query-related, document-related and description-related learning. As arepresentative for each of these strategies, a specific model is described. A new approach regards IR as uncertaininference; here, imaging is used as a new technique for estimating the probabilistic parameters, and probabilisticinference networks support more complex forms of inference. Finally, the more general problems of parameterestimations, query expansion and the development of models for advanced document representations are discussed.
Received December 1991
1. INTRODUCTIONA major difference between information retrieval (IR)systems and other kinds of information system is theintrinsic uncertainty of IR. Whereas for database systemsan information need can always (at least for standardapplications) be mapped precisely on to a queryformulation, and there is a precise definition of whichelements of the database constitute the answer, thesituation is much more difficult in IR; here neither aquery formulation can be assumed to represent uniquelyan information need, nor is there a clear procedure thatdecides whether a DB object is an answer or not.(Boolean IR systems are not an exception to thisstatement; they only shift all problems associated withuncertainty to the user.) As the most successful approachfor coping with uncertainty in IR, probabilistic modelshave been developed.
According to the definition of the desired set of answersto a query in an IR system, two major approaches inprobabilistic IR can be distinguished. The classicalapproach is based on the concept of relevance, that is, auser assigns relevance judgements to documents w.r.t. hisquery, and the task of the IR system is to yield anapproximation of the set of relevant documents. The newapproach formulated by van Rijsbergern overcomes thissubjective definition of an answer in an IR system bygeneralising the proof-theoretic model of databasesystems towards uncertain inference.
In this paper, an introduction into past and currentresearch in probabilistic IR is given. The major goal hereis to present important concepts of this field of research,while no attempt is made to give a complete survey overwork in this area. In the following, the classical approachin probabilistic IR is presented in Sections 2 and 3, whileSection 4 describes the new direction. In Section 5, somegeneral problems of both approaches are discussed. Anoutlook to future research areas finishes the paper.
2. BASIC CONCEPTS OF RELEVANCEMODELS
2.1 The binary independence retrieval model
In order to introduce some basic concepts of the classicalapproach to probabilistic IR, we first present a fairly
simple model, the so-called binary independence retrieval(BIR) model. This model will be introduced moreinformally, whereas the precise assumptions underlyingthis model will be developed throughout the followingsections.
In the BIR model, as in most other probabilistic IRmodels, we seek to estimate the probability that a specificdocument dm will be judged relevant w.r.t. a specificquery qk. In order to estimate this probability (denotedas P(R\qk,dm)) in the following, we regard the dis-tribution of terms within the documents of the collection.(In general, a term is any non-trivial word reduced to itsword stem, but see also Section 5.3 for other kinds ofterm.) The basic assumption is that terms are distributeddifferently within relevant and non-relevant documents.This assumption, known as the 'cluster hypothesis', hasbeen verified experimentally already in Ref. 1. Let T ={tu ...,tn} denote the set of terms in the collection. Thenwe can represent the set of terms d^ occurring indocument dm as a binary vector x = (xu ... ,xn) with xt= 1, if tted^ and xt = 0 otherwise.
Now we distinguish only between documents con-taining different sets of terms, so instead of estimatingP{R\qk,dm) for a specific document dm, we actuallyestimate the probability P(R\qk,x), where differentdocuments containing the same set of terms will yield thesame estimate of probability of relevance. In addition,the BIR model assumes a query qk to be just a set ofterms q[ a T. In Section 4.2 we shall also discuss the caseof other forms of query.
In order to derive a formula for this probability, weshall apply two kinds of transformation that arefrequently used for the derivation of probabilistic IRmodels:
(1) application of Bayes' theorem (in the form P{a\b)= P(b\a)P(a)/P(b));
(2) usage of odds instead of probabilities, where 0{y)
This way, we can compute the odds of a documentrepresented by a binary vector x being relevant to aquery qk as
THE COMPUTER JOURNAL, VOL. 35, NO. 3, 1992 24316-2
by guest on August 11, 2016
http://comjnl.oxfordjournals.org/
Dow
nloaded from

N. FUHR
Now additional independence assumptions are neededin order to arrive at a formula that is applicable forretrieval of documents. As has been pointed out in arecent paper by Cooper,2 the assumption underlying theBIR is in fact not a set of independence assumptions(from which the name of the model is derived), but ratherthe assumption of linked dependence of the form
P(x\R,qk)=»P(x(\R,qk)P{x\Rq) i\P(x\RqY
(2)
This assumption implies that the ratio between theprobabilities of x occurring in the relevant and the non-relevant documents is equal to the product of thecorresponding ratios of the single terms. Of course, thelinked dependence assumption does not hold in reality.However, it should be regarded as a first-order ap-proximation. In Section 2.6, we shall discuss betterapproximations.
With assumption (2) we can transform (1) into
O(R\qk,x) = O(R\qk)U_\P(xt\R,qkY
The product of this equation can be split according to theoccurrence of terms in the current document:
O(R\qkix) =P{xt=\\R,qk)
n = 0|
Now let ptk = P(xt = 11R, qk) and qik = P{xt = 11R,qk). In addition, we assume that/?jfc = qik for all terms notoccurring in the set qk of query terms. This assumptionis also subject to change, as discussed in Section 5.2.With these notations and simplifications, we arrive at theformula
n ^ n
n
(3)
(4)
In the application of this formula, one is mostlyinterested only in a ranking of the documents withrespect to a query, and not in the actual value of theprobability (or odds) of relevance. From this point ofview, since the second product of Equation (4) as well asthe value of O(R | qk) are constant for a specific query, weonly have to consider the value of the first product for aranking of the documents. If we take the logarithm ofthis product, the retrieval status value (RSV) of documentdm for query qk is computed by the sum
£ clk with cfk = log
The documents are ranked according to descendingRSVs.
In order to apply the BIR model, we have to estimatethe parameters ptk and qik for the terms t(eql. This can bedone by means of relevance feedback. For that, let usassume that the IR system has already retrieved somedocuments for query qk (in Section 5.1, we show how theparameters of the BIR model can be estimated withoutrelevance information). Now the user is asked to giverelevance judgements for these documents. From thisrelevance feedback data, we can estimate the parametersof the BIR model as follows. Let/denote the number ofdocuments presented to the user, of which r have beenjudged relevant. For a term ti,fl is the number among the/documents in which tt occurs, and rt is the number ofrelevant documents containing /,. Then we can use theestimates ptk x rjr and q(k x. (/, — r()/(f— r). (Better est-imation methods are discussed in Section 5.1.)
We illustrate this model by giving an example. Assumea query q containing two terms, that is qT = {tv t2}. Table1 gives the relevance judgements from 20 documentstogether with the distribution of the terms within thesedocuments.
For the parameters of the BIR model, we get pl =8/12 = 2/3, q1 = 3/8, p? = 7/12 and q2 = 4/8. So weget the query term weights c1 = log 10/3 x, 1.20 andc2 = log 7/5 x 0.33. Based on these weights, documentsare ranked according to their corresponding binaryvector x in the order (1,1) —(1,0) —(0,1) —(0,0). Ob-viously this ranking is correct for our example.
Table 2. Estimates for the probability of relevance for ourexample.
P(R\q,x)
BIR actual
0,1)(1,0)(0,1)(0,0)
0.760.690.480.4
0.80.670.50.33
In addition, we can also compute the estimates for theprobability of relevance according to Equation (3). WithO(R\q) = 12/8, we get the estimates shown in Table 2for the different x vectors, where they are compared withthe actual values. Here the estimates computed by thetwo methods are different. This difference is due to thelinked dependence assumption underlying the BIRmodel.
We have described this model in detail because itillustrates a number of concepts and problems inprobabilistic IR. In the following, we shall first describethe major concepts.
Table 1.
d,
x i
x2
r(q,d()
Example
1
11R
2
11R
for
3
11R
the BIR
4
11R
model.
5
11R
6
10R
1
10R
8
10R
9
10R
10
10R
11
10R
12
01R
13
01R
14
01R
15
01R
16
01R
17
01R
18
00R
19
00R
20
00R
244 THE COMPUTER JOURNAL, VOL. 35, NO. 3, 1992
by guest on August 11, 2016
http://comjnl.oxfordjournals.org/
Dow
nloaded from

PROBABILISTIC MODELS IN INFORMATION RETRIEVAL
2.2 A conceptual model for IR
In our example, it may be argued that the approachchosen in the BIR model for representing documentsmay be rather crude, and that a more detailed rep-resentation of documents may be desirable, especiallysince documents in an IR system may be rather complex.The relationship between documents and their represen-tations (and similarly for queries) can be illustratedbest by regarding the conceptual IR model depicted infigure 1.
D *• D
Figure 1. Conceptual model.
Here dm and qk denote the original document andquery, respectively. In our terminology, a query is unique(i.e. a specific information need of a specific user), so twoqueries from different users (or issued from the same userat different times) can never be identical. This concept ofa query has been introduced first in Ref. 3, where it wastermed a 'use'. Between a document and a query, thereexists a relevance relationship as specified by the user.Let 2̂ = {R, R} denote the set of possible relevancejudgements, then the relevance relationship can beregarded as a mapping r: QxD^-ffl. Since an IR systemcan only have a limited understanding of documents andqueries, it is based on representations of these objects,here denoted as dm and qk. These representations arederived from the original documents and queries byapplication of the mappings <xD and aQ, respectively. Inthe case of the BIR model the representation of adocument dm is a set of terms, namely the set d^. Forqueries, the representation contains, in addition to theset of query terms q\", a set of relevance judgements qJ
k— {(dm, r(dm, qk))}. So in our conceptual model therepresentatToiTof an object comprises the data relating tothis object that is actually used in the model. Different IRmodels may be based on quite different representations.For example, in Boolean systems with free text search,the document representation is a list of strings (words),and the query representation is a Boolean expression,where the operands may be either single words oradjacency patterns (comprised of words and specialadjacency operators).
For the models regarded here, there is an additionallevel of representation, which we call description. As canbe seen from the BIR model, the retrieval function doesnot relate explicitly to the query representation, it usesthe query-term weights derived from the relevancejudgements instead. We call the arguments of the retrievalfunction the description of documents and queries. In theBIR model the document representation and the de-scription are identical. The query description, however,is a set of query terms with the associated query-termweights, that is, qD
k = {(/„ cik)}.Representations are mapped on to descriptions by
means of the functions flD and y?Q, respectively. Based onthe descriptions, the retrieval function p(qk, d%) computes
the retrieval status value, which is a real number ingeneral. This conceptual model can be applied toprobabilistic IR models as well as to other models.Especially when comparing the quality of differentmodels, it is important to consider the representationsused within these models. With respect to representations,two directions in the development of probabilistic IRmodels can be distinguished.
(1) Optimisation of retrieval quality for a fixedrepresentation. For example, there have been a numer ofattempts to overcome the limitations of the BIR modelby revising the linked dependence assumption andconsidering certain other forms of term dependencies(see Section 2.6). In these approaches, documents are stillrepresented as sets of terms.
(2) Development of models for more detailedrepresentations of queries and documents. Since thedocument representation used within the BIR model israther poor, it is desirable to derive models that canconsider more detailed information about a term in adocument, e.g. its within-document frequency, or theoutput of advanced text analysis methods (e.g. forphrases in addition to words). We shall discuss this issuein Section 5.3.
2.3 Parameter learning in IR
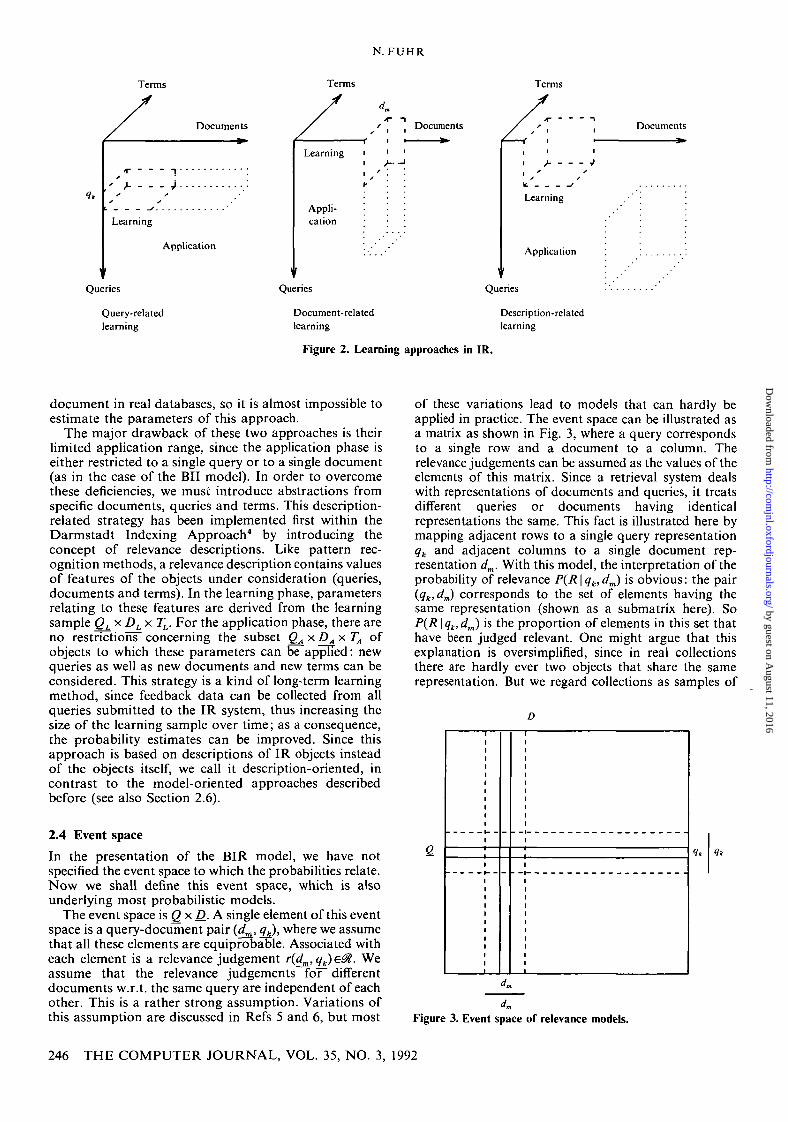
We can make another observation with the BIR model:this model makes very poor use of the relevance feedbackinformation given by the user, since this information isonly considered in the ranking process for the currentquery. For a new query, none of this data can be used atall. If we regard probabilistic IR models as (parameter)learning methods, then three different approaches asshown in Fig. 2 can be distinguished. The three axesindicate to what kinds of objects probabilisticparameters may relate: documents, queries and terms(that is, elements of the representation). In each of thethree approaches, we can distinguish a learning phaseand an application phase. In the learning phase, we haverelevance feedback data for a certain subset QL x D^ x TLof Q x D x T (where T denotes the set of fefVns in thecollection) from which we can derive probabilisticparameters. These parameters can be used in theapplication phase for the improvement of the descriptionsof documents and queries.
In query-related learning, relevance feedback data isused for weighting of search terms (e.g. in the BIRmodel) with respect to a single query (representation) qk.Here we have relevance information from a set ofdocuments DL, and we can estimate parameters for theset of termi~7^ occurring in these documents. In theapplication phase, we are restricted to the same query qkand the set of terms TL, but we can apply our model toall documents in D.
Document-related learning is orthogonal to the query-related strategy: probabilistic indexing models (seeSection 3.1) collect relevance feedback data for a specificdocument dm from a set of queries QL, with the set ofterms TL occurring in these queried The parametersderived from this data can be used for the same documentand the same set of terms TL (occurring in queries) only,but for all queries submitted to the system. The majorproblem with this approach, however, is the fact thatthere are not enough relevance judgements for a single
THE COMPUTER JOURNAL, VOL. 35, NO. 3, 1992 245
by guest on August 11, 2016
http://comjnl.oxfordjournals.org/
Dow
nloaded from
N. FUHR
Terms Terms Terms
/
T ~ "
.' y - -
Learning
Documents
. j ;
••
Application
Documents
Learning ii A-1 ,y
Appli-cation
Queries
11
Queries
Documents
>
Application
11
Queries
Query-relatedlearning
Document-related Description-relatedlearning learning
Figure 2. Learning approaches in IR.
document in real databases, so it is almost impossible toestimate the parameters of this approach.
The major drawback of these two approaches is theirlimited application range, since the application phase iseither restricted to a single query or to a single document(as in the case of the BII model). In order to overcomethese deficiencies, we must introduce abstractions fromspecific documents, queries and terms. This description-related strategy has been implemented first within theDarmstadt Indexing Approach4 by introducing theconcept of relevance descriptions. Like pattern rec-ognition methods, a relevance description contains valuesof features of the objects under consideration (queries,documents and terms). In the learning phase, parametersrelating to these features are derived from the learningsample QLxDLx TL. For the application phase, there areno restrictions" concerning the subset Q^ x D^ x TA ofobjects to which these parameters can be applied: newqueries as well as new documents and new terms can beconsidered. This strategy is a kind of long-term learningmethod, since feedback data can be collected from allqueries submitted to the IR system, thus increasing thesize of the learning sample over time; as a consequence,the probability estimates can be improved. Since thisapproach is based on descriptions of IR objects insteadof the objects itself, we call it description-oriented, incontrast to the model-oriented approaches describedbefore (see also Section 2.6).
2.4 Event spaceIn the presentation of the BIR model, we have notspecified the event space to which the probabilities relate.Now we shall define this event space, which is alsounderlying most probabilistic models.
The event space is Q x D. A single element of this eventspace is a query-document pair (d^, q^), where we assumethat all these elements are equiprobable. Associated witheach element is a relevance judgement ^d^q^e^. Weassume that the relevance judgements for" differentdocuments w.r.t. the same query are independent of eachother. This is a rather strong assumption. Variations ofthis assumption are discussed in Refs 5 and 6, but most
of these variations lead to models that can hardly beapplied in practice. The event space can be illustrated asa matrix as shown in Fig. 3, where a query correspondsto a single row and a document to a column. Therelevance judgements can be assumed as the values of theelements of this matrix. Since a retrieval system dealswith representations of documents and queries, it treatsdifferent queries or documents having identicalrepresentations the same. This fact is illustrated here bymapping adjacent rows to a single query representationqk and adjacent columns to a single document rep-resentation dm. With this model, the interpretation of theprobability of relevance P(R \ qk, dm) is obvious: the pair(qk, dm) corresponds to the set of elements having thesame representation (shown as a submatrix here). SoP(R | qk, dm) is the proportion of elements in this set thathave been judged relevant. One might argue that thisexplanation is oversimplified, since in real collectionsthere are hardly ever two objects that share the samerepresentation. But we regard collections as samples of
D
Figure 3. Event space of relevance models.
246 THE COMPUTER JOURNAL, VOL. 35, NO. 3, 1992
by guest on August 11, 2016
http://comjnl.oxfordjournals.org/
Dow
nloaded from

PROBABILISTIC MODELS IN INFORMATION RETRIEVAL
possibly infinite sets of documents and queries, wherethere might be several (up to infinity) objects with thesame representation. Especially with regard to the poorrepresentation of retrieval objects that is actually in use(in comparison to the human understanding ofdocuments and queries), it is obvious that a singlerepresentation may stand for a number of differentobjects.
2.5 The Probability Ranking Principle
The Probability Ranking Principle (PRP) represents thetheoretical justification of probabilistic IR models. Itshows how optimum retrieval quality can be achieved.Optimum retrieval is defined w.r.t. representations. Incontrast, perfect retrieval relates to the objects itself,saying that all relevant documents should be rankedahead of any nonrelevant one. But as an IR system isbased on representations, perfect retrieval is not asuitable goal. Optimum retrieval has only been definedprecisely for probabilistic IR, where the optimality canbe proved theoretically. The 'Probability RankingPrinciple' described in Ref. 5 says that optimum retrievalis achieved when documents are ranked according todecreasing values of the probability of relevance (withrespect to the current query). The decision-theoreticjustification of the PRP is as follows (in Ref. 5,justifications w.r.t. retrieval measures are also given). LetC denote the costs for the retrieval of a nonrelevantdocument, and C the costs for the retrieval of a relevantdocument. Now the decision-theoretic rule says thatdocument dm should be retrieved next from the collectionif
CP(R|qk,dj + C(\-P(R\qk, J ) < CP[R|qk,d>)+ C(\-P(R\qk,dj))
for any other document d, in the collection (that has notbeen retrieved yet). In other terms: retrieve that documentfor which the expected costs of retrieval are a minimum.Because of C < C, the above condition is equivalent to
P{R\qk,dm)>P{R\qk,d}.
So we have the rule that documents should be rankedaccording to their decreasing probability of beingrelevant. The PRP can be extended to cope withmultivalued (ordinal) relevance scales instead of binaryones, as shown in Ref. 7. Assume that for n relevancevalues with Rx< R2< ... < Rn the correponding costsfor the retrieval of a document with that retrievaljudgement are Cv C2,..., Cn. Then documents should beranked according to their expected costs
EC(qt,dJ=iciP(Rl\qk,dm).i-i
In contrast to the binary case where only the probabilityP(R\qk,dm) has to be estimated for a query documentpair, here n— 1 estimates P(Rt \ qk, dm) are needed in orderto rank the documents w.r.t. a query. Furthermore, theactual values of the cost factors C, are required in orderto produce a ranking, since they cannot be eliminated asin the binary case. Using multivalued relevance scalesinstead of binary ones seems to be more appropriate;however, the only experimental results comparing binaryvs. multivalued relevance scales published so far did
not show any differences in terms of retrieval quality.8 Soit might be feasible to offer a multivalued relevance scalefor the users of a probabilistic IR system, but this scalecan be mapped on to a binary one for the calculationsperformed by the system.
With multivalued relevance scales, we can also draw aconnection to fuzzy retrieval approaches (see Ref. 9 fora survey on this subject), where the relevance scale isassumed to be continuous, that is, a relevance judgementnow is a real number re[0, 1]. In this case, the probabilitydistribution PiR^q^d^ from above is replaced by adensity function p{r \ qk, dm) as well as the cost factors C,by a cost function c{r). This way, fuzzy and probabilisticretrieval can be combined. In contrast, pure fuzzyretrieval approaches seem to be inappropriate from thepoint of view of probabilistic IR, since the intrinsicaspect of uncertainty in IR is ignored in these approaches.
2.6 Model-oriented vs. description-oriented approaches
The formulation of the PRP acts as a goal for anyprobabilistic IR model. In general, the optimum retrievalquality as specified by the PRP cannot be achieved by areal system. For example, in the BIR model, we wouldhave to know the exact probabilities P{R\qk,x) for allbinary vectors x occurring in the document collection.Except for rather trivial cases, these probabilities canhardly be estimated directly, because the number ofdifferent representations is too large in comparison to theamount of feedback data available (so there would noteven be any observation for most representations). Inorder to overcome this difficulty, additional simplifyingassumptions are needed. With regard to the nature ofthese assumptions, two kinds of approaches have beendeveloped, as follows.
Model-oriented approaches (like the BIR model, forexample) are based on certain probabilistic independenceassumptions concerning the elements of the represent-ations (e.g. single terms or pairs, triplets of terms). Inthese approaches, first probability estimates relating tothe representation elements are computed. Then, byapplying the independence assumptions, the estimatesfor the different representations can be derived.
Description-oriented approaches are similar to feature-based pattern-recognition methods. Given therepresentations of queries and documents, first a set offeatures for query-document pairs is defined, and eachpair is mapped on to a feature vector x(qk, dm). (A specificfeature vector could be for example the binary vector x= x(dm) as defined in the BIR model; however, since thisdefinition does not consider the query, the resultingretrieval function would be query-specific.) With the helpof a learning sample containing query-document pairswith their corresponding relevance judgements, aprobabilistic classification function e(x) that yieldsestimates of the probability P(R | x(qk, dm)) is developed(see Section 3.4).
Because of the problem of specifying the featurevector, description-oriented approaches are moreheuristical in comparison to model-oriented ones. On theother hand, the assumptions underlying the description-oriented approach do not have to be made as explicit asin the model-oriented case. The most important ad-vantage of description-oriented approaches is theiradaptability to rather complex representations, where it
THE COMPUTER JOURNAL, VOL. 35, NO. 3, 1992 247
by guest on August 11, 2016
http://comjnl.oxfordjournals.org/
Dow
nloaded from

N. FUHR
is hard to find appropriate independence assumptions.Especially with regard to advanced text analysis methods,this feature seems to be rather important.
As a general property of both kinds of approaches, wecan see that the additional assumptions are onlyapproximations to reality. For example, we can hardlyexpect that terms are distributed independently indocuments (as suggested by the BIR model). A similarstatement holds for the description-oriented approaches.This fact makes the main difference between optimumretrieval quality and the actual performance of a model.The other reason is the problem of parameter estimation.Without going into the details of parameter estimationhere (but see Section 5.1), we can describe the generalproblem by using the example of the BIR model. Thedirect estimation of the probabilities P(R | qk, x) vs. thecomputation of this parameter by means of the BIRmodel are two extreme possibilities where either theprobabilities cannot be estimated in a real application orthe independence assumptions seem to be too strong. Itis possible to develop variants of the BIR model whereonly pairs or triplets of terms are assumed to beindependent of each other (see e.g. Refs 10 and 11 forsuch models and 12, chapter 8 for a general survey onprobabilistic dependence models). With these models,however, more parameters have to be estimated from lessobservations for each parameter. For example, in thetree dependence model developed by van Rijsbergenwhich considers pairwise dependencies,13 the parametersto be estimated for a dependent pair (/,., t}) are P{xt = 1,x, = \\R), P(x( = \,Xj = 0|.R) P(x( = 0,Xj =\\R) andp(x( = 0, X] = 01R) (plus the corresponding estimatesfor nonrelevant documents). In contrast, the BIRmodel only requires the parameters P(xt = 11R) andP(x, = 01R) for the relevant documents, so the treedependence model splits the learning data required forestimating these parameters according to the value of x}.As a consequence, experimental evaluations showed thatthe gain from improved independence assumptions doesnot outweigh the loss from increased estimation errors.
3. SURVEY OVER RELEVANCE MODELSIn this section we shall first present two probabilisticmodels that are representative of second and thirddifferent learning strategies as described above. Then weshall discuss models that aim to overcome the simplerepresentation of the BIR model.
3.1 The binary independence indexing model
The binary independence indexing (BII) model14 is avariant of the very first probabilistic IR model, namelythe indexing model of Maron and Kuhns.15 Whereas theBIR model regards a single query w.r.t. a number ofdocuments, the BII model observes one document inrelation to a number of queries submitted to the system.In this model, the representation qk of a query qk is a setof terms qi c T. As a consequence, the BII mcfdel willyield the same ranking for two different queriesformulated with the same set of terms. In the followingwe shall also use a binary vector zk = (zk, ...,zk ) insteadof qk, where zk = 1, if /, eqk, and zk = 0 otherwise. Thedocument representation is not further specified in the
BII model, and below we shall show that this is a majoradvantage of this model. In the following, we shallassume that there exists a set d^ <= T of terms which areto be given weights w.r.t. the document. For brevity, weshall call (Fm ' the set of terms occurring in the document'in the following, although the model can also be appliedin situations where the elements of cFm are derived fromthe document text with the help of a thesaurus (see e.g.Ref. 16). The BII model now seeks for an estimate of theprobability P(R | qk, dm) = P(R | zk, dm) that a documentwith the representation dm will be judged relevant w.r.t.a query with the representation qk = qk. Applying Bayes'theorem, we first get
P{R\zk,dn) = P{R\d, P{zk\R,dm)(5)
Here P{R \ dm) is the probability that document dm willbe judged relevant to an arbitrary request. P(zk \ R, dm) isthe probability that dm will be relevant to a query withrepresentation zk, and P(zk\dm) is the probability thatsuch a query will be submitte to the system.
Assuming that the distribution of terms in all queriesto which a document with representation dm is in-dependent :
P(zk\R,dJ=TlP(zkt\R,dJf-i
and the additional simplifying assumption that therelevance of a document with representation dm withrespect to a query qk depends only on the terms from ql,and not on other terms, we get the ranking formula
nit P(zk) P{R\zk = 1,
(6)
The value of the first fraction in this formula is aconstant ck for a given query qk, so there is no need toestimate this parameter for a ranking of documents w.r.t.
P(R | zkf = 1, dm) = P(R 11(, dm) is the probabilisticindex term weight of tt w.r.t. dm, the probability thatdocument dm will be judged relevant to an arbitaryquery, given that it contains /(. From our model, itfollows that d^ should contain at least those terms fromT for which P(R \ tt, dm) 4= P(R \ dm). Assuming thatP(R\ti,dm) = P(R\dJ for all ttidl, the final BIIformula yields
(7)P(R\dJ
However, in this form the BII model can hardly beapplied, because in general there will not be enoughrelevance information available for estimating theprobabilities P(R \ tt, dm) for specific term-documentpairs. In order to overcome this difficulty, one canassume a document to consist of independentcomponents (e.g. sentences or words) to which theindexing weights relate, but experimental evaluations
248 THE COMPUTER JOURNAL, VOL. 35, NO. 3, 1992
by guest on August 11, 2016
http://comjnl.oxfordjournals.org/
Dow
nloaded from

PROBABILISTIC MODELS IN INFORMATION RETRIEVAL
showed only moderate retrieval results for this ap-proach.17
3.2 A description-oriented indexing approach
As a more successful method, the application of the thirdlearning strategy as outlined above has been devised.This learning strategy leads to a description-orientedapproach, where features of terms in documents areregarded instead of the document-term pairs themselves.The basic ideas of this approach have been developedwithin the framework of the Darmstadt IndexingApproach (DIA).1618 Within the DIA, the indexing taskis subdivided into a description step and a decision step.In the description step, relevance descriptions for term-document pairs (t,,dm) are formed, where a relevancedescription x(tt, dm) contains values of attributes of theterm /„ the document dm and their relationship. Sincethis approach makes no additional assumptions aboutthe choice of the attributes and the structure of x, theactual definition of relevance descriptions can be adaptedto the specific application context, namely the rep-resentation of documents and the amount of learningdata available. For example, in the work described inRef. 14, the following elements were defined: Xj = tfmi,the within-document frequency (wdf) of tf in dm;x2 = theinverse of the maximum wdf of a term in dm; x3 = inversedocument frequency of tt in the collection; xt = log | dFm \(numbers of terms in dm); xb = 1, if /( occurs in the titleof dm, and 0 otherwise.
In the decision step, a probabilistic index term weightbased on this data is assigned. This means that we esti-mate instead of/>(/? \ tf, dm) the probability P(R \ x(tt, dm)).In the former case, we would have to regard a singledocument dm with respect to all queries containing tt inorder to estimate P(R | /„ dm). Now we regard the set ofall query-document pairs in which the same relevancedescription x occurs. The probabilistic index term weightsP(R | x(tt, dm)) are derived from a learning example L <=QxDx& of query-document pairs for which we haverelevance judgements, so L = {{qk,dm, rkm)}. By formingrelevance descriptions for the terms common to queryand document for every query-document pair in L, weget a multi-set (bag) of relevance descriptions withrelevance judgements Lx = [(x{tt,dm),rkm)\t(eq^ n dl A(qk,dm,rkm)eL\. From this set with multiple occurrencesof elements, the parameters P(R \ x(t(, dm)) could beestimated directly by computing the correspondingrelative frequencies. However, better estimates can beachieved by applying probabilistic classificationprocedures as developed in pattern recognition ormachine learning. Within the DIA, this classificationprocedure yielding approximations of P{R\x{ti,dm)) istermed an indexing function e(x(t,,dm)). Severalprobabilistic classification algorithms have been used forthis purpose (see e.g. Ref. 14). Here we want to describebriefly the application of least-square polynomials(LSP)1916 as indexing functions, where we furthermorerestrict to the case of linear functions. So our indexingfunction yields e(x) = aTx, where a is the coefficientvector to be estimated.
Let y{gk, dm) = ykm denote a class variable for eachelement of L with ykm = 1 if rkm = R and ykm = 0otherwise. Then the coefficient vector a is estimated suchthat it minimises the squared error E({y — aTx)2), where
£(•) denotes the expectation. The coefficient vector a canbe computed by solving the linear equation system (seeRef. 8)
(8)
As an approximation for the expectations, the cor-responding arithmetic means from the learning sampleare taken. The major advantage of this indexing approachis its flexibility w.r.t. the representation of documents,which becomes important when advanced text analysismethods are used (e.g. noun phrases in addition towords, see for example Ref. 8).
3.3 The 2-Poisson model
On the other hand, one might prefer to have a moreexplicit model relating to the elements of therepresentation. One such approach is the 2-Poissonmodel. This model has been proposed first by Booksteinand Swanson.20 Similar to the indexing model describedabove, the Bookstein/Swanson model seeks for thedecision whether an index term should be assigned to adocument or not. So there are two classes of documentswith respect to a specific term. Now the number ofoccurrences tfim of the term /, within the document dm isregarded, and it is assumed that the distribution of thisfeature is different in the two document classes. As asimple probabilistic model, Bookstein and Swansonassumed a Poisson distribution in each of these classes.For a specific document class Kt], let )Hi denote theexpectation of the wdf of t(. Then the probability that adocument contains / occurrences of /(, given that itbelongs to class K(j is
For a document chosen randomly from the collection,we assume that ntj is the probability that it belongs toclass Kir Then the probability of observing / occurrenceswithin such a document is
In the 2-Poisson model, there are two document classesK(1 and Kl2 for each term, so ntl + n{2= 1. From theseequations, the probabilistic index term weighs P(dmeKtjI tfim = 0 c a n be derived. The parameters nt] and ltj canbe estimated without feedback information from thedocument collection.
Experimental evaluations of this model were onlypartially successful. In Refs 21 and 22 the/2-test rejectedthe hypothesis of a 2-Poisson distribution for 62% of theterms tested. Experiments with a higher number ofclasses (termed «-Poisson model) as described in Ref. 23,also did not give clear improvements. In the study,24 animproved parameter estimation method is applied incombination with longer documents than in previousevaluations, thus leading to the result that the assumptionof an w-Poisson distribution holds for about 70 % of allterms.
3.4 Retrieval models for improved documentrepresentations
As a consequence of the poor performance of the 2-Poisson model, a so-called non-binary Retrieval model
THE COMPUTER JOURNAL, VOL. 35, NO. 3, 1992 249
by guest on August 11, 2016
http://comjnl.oxfordjournals.org/
Dow
nloaded from

N. FUHR
has been proposed as a variant of the BIR model in Refs25. Instead of indicating only the presence or absence ofa term tt, the elements xt of the vector representing adocument now give the wdf of tv As a consequence,parameters P(x( = \\R) and P{x( = l\R) for / = 0,1,2,... have to be estimated in this model. The results givenin Ref. 26 for predictive retrieval did not show anyimprovements over the BIR model, obviously due toparameter estimation problems. This problem seems tobe intrinsic to all approaches that aim to improve theBIR model by using a more detailed document rep-resentation. Although the document representation ofthe BIR model is rather poor, the amount of feedbackdata available in predictive retrieval prohibits anyrefinement of the document representation.
A different approach has been taken in the formulationof the retrieval-with-probabilistic-indexing (RPI) modelpresented in Ref. 16. This model assumes that a moredetailed document representation than in the case of theBIR model has been used for estimating probabilisticindex term weights of the form P(C | /„ dm), where Cdenotes the event of correctness. The decision whetherthe assignment of t( to dm is correct or not can bespecified in various ways, e.g. by comparison withmanual indexing or by regarding retrieval results as inthe case of the BII model. Like the non-binary modelmentioned before, the RPI model also is a generalisationof the BIR model. However, since weighted documentindexing is regarded as document description in the RPImodel, the number of parameters remains the same as inthe BIR model, only the definition of these parameters ischanged appropriately. For this reason, there are noadditional parameter estimation problems in comparisonto the BIR model, but a more detailed documentrepresentation can be considered. This goal is achievedby shifting the task of mapping document representationson to indexing weights over to an appropriate indexingmodel.
A similar model that integrates probabilistic indexingwith the BIR model has been proposed as the 'unifiedmodel' in Ref. 3; however, this model suffered fromincompatible independence assumptions. In Ref. 27, ageneralisation of this model with modified independenceassumptions is presented.
As mentioned before, description-oriented approachesalso can be applied for developing retrieval functionsthat are able to consider more detailed documentrepresentations. Here query-document pairs are mappedon to a feature vector x(qk, dm). In principle, there is norestriction on the structure of the representations ofqueries and documents, only the feature vector has to bedenned appropriately. In order to develop the retrievalfunction p(x) that yields estimates of the probabilityP(R | x{qk, dm)), a learning sample of query-documentpairs (according to the third learning strategy) is used(see Ref. 8 for a detailed description of this approach).For most applications, it may be more appropriate toconsider improved document representations already inthe indexing process, so the RPI model can be used forretrieval instead of a description-oriented function.However, when more complex query structures are to beused, retrieval functions derived with the description-oriented approach may be feasible. In addition, a majoradvantage of retrieval functions of this kind is that theyyield estimates of the probability of relevances, whereas
the estimation of this probability is rather difficult withmost other models.
4. IR AS UNCERTAIN INFERENCE
Although the relevance models described in the previoussections have been rather successful in the past, there arethree major shortcomings of this approach, as follows.# The concept of relevance can be interpreted in
different ways. One can either regard relevance of adocument w.r.t. a query or information need, inwhich cases the user who submitted the query givesthe relevance judgement; this approach has beentaken so far in this paper. Alternatively, relevancecan be defined w.r.t. the query formulation, assumingthat an objective judgement (e.g. given by specialistsof the subject field) can be made. Of course, the latterapproach would be more desirable in order to collect'objective' knowledge within an IR system.
# The relevance models are strongly collection-de-pendent, that is, all the parameters of a model areonly valid for the current collection. When a newcollection is set up, the 'knowledge' from othercollections cannot be transferred.
# Relevance models are restricted to rather simpleforms of inference. In the models presented here, onlythe relationships between terms and queries areconsidered. It would be desirable to include in-formation from other knowledge sources (e.g. from athesaurus) in an IR model. With description-orientedapproaches, this problem can be partly solved (seee.g. Ref. 8), but there is a need for a general modeldealing with this issue.
4.1 Rijsbergen's model
In Ref. 28 a new paradigm for probabilistic IR isintroduced: IR is interpreted as uncertain inference. Thisapproach can be regarded as a generalisation of deductivedatabases, where queries and database contents aretreated as logical formulas. Then, for answering a query,the query has to be proved from the formulas stored inthe database.29 For document retrieval, this means that adocument dm is an answer to a query qk if the query canbe proved from the document, that is, if the logicalformula qk*-dm can be shown to be true. In order toprove this formula, additional knowledge not explicitlycontained in the document can be used. For example, ifdr is about 'squares', and ql asks for documents about'rectangles', the inference process can use the formula' rectangle' <-' squares' in order to prove q1<-d1. ForIR, however, the approach from deductive databases isnot sufficient, for two reasons: (1) whereas in databasesall statements are assumed to be true at the same time, adocument collection may contain documents that con-tradict each other; (2) in order to cope with the intrinsicuncertainty of IR, first-order predicate logic must bereplaced by a logic that incorporates uncertainty. For thefirst problem, Rijsbergen identifies each document with apossible world W, that is, a set of propositions withassociated truth values. Let T denote a truth function,then x{W,x) denotes the truth of the proposition x in theworld W, where T(W, X) = 1 if A: is true at Wand x{W,x)= 0 if x is false at W.
In order to cope with uncertainty, a logic for
250 THE COMPUTER JOURNAL, VOL. 35, NO. 3, 1992
by guest on August 11, 2016
http://comjnl.oxfordjournals.org/
Dow
nloaded from

PROBABILISTIC MODELS IN INFORMATION RETRIEVAL
probabilistic inference is introduced. In this logic,conditionals of the form y^-x can be uncertain. Forquantifying the uncertainty, the probability P(y -> x) hasto be estimated in some way. As described in Ref. 30, thisprobability can be computed via imaging. Let a(W,y)denote the world most similar to W where y is true. Theny->x is true at W if and only if JC is true at a(W,y).
For estimating P(y->x) (independent of a specificworld), all possible worlds must be regarded. Each worldPFhas a probability P(fV), so that they sum to unity overall possible worlds. Then P{y^-x) can be computed inthe following way:
(9)= ZP(W)T(a(W,y),x).
So we have to sum over all possible worlds, look for theclosest world where y is true, and add the truth of x forthis world. This formula can be illustrated by an exampleshown in Table 3. If we assume that P{W^) = 0.1 for i =1,... , 10, then we get P(y->x) = 0.6.
Table 3. Imaging example.
Wt x{y) a{Wt,y) Wt, y) x)
123456789
10
0100010101
1001010100
2 02 06 16 16 16 18 18 1
10 010 0
In this framework, the concept of relevance does notfeature. The most obvious way for mapping the outcomeof the uncertain inference process on to the probabilityof relevance is via another conditional probability:
P(R) = P(R | qk +- dm) P{qk «- dm) + P(R | -<(qk <- dj)Piria^dJ). (10)
This leaves us with the problem of estimating theprobabilities P(R\qk*-dm) and P(R\->(qk<~dm)). So far,there is no obvious method for deriving the values ofthese parameters. On the other hand, according toformula (10), P(R) is a monotonous function of P(qk <-dm), thus only the value of the latter probability isrequired for a ranking of documents w.r.t. a query.
4.2 Inference networks
When IR is regarded as uncertain inference as describedabove, the structure of inference from documents toqueries become more complex, as in the case of therelevance models. In general, one gets an inferencenetwork. As a probabilistic formalism for inferencenetworks with uncertainty, Bayesian inference networkshave been described in Ref. 12. Turtle and Croft31
applied this formalism to document retrieval. An example
Figure 4. Example inference network.
inference network is shown in Fig. 4. Here each noderepresenting either a document, a query or a concept cantake on the value true or false. In contrast to the modelsdiscussed so far in this paper, we assume that there aretwo kinds of concepts, namely document concepts tt andquery concepts r(. The directed arcs of this networkindicate probabilistic dependence of nodes. The prob-ability of a node being true depends only on the values ofits parents. This relationship must be specified as afunction within the node. In order to estimate theprobability of P(d-+q), the document node is set to' true' and then the probabilities of the depending nodesare computed until the value of P(q = true) is derived.
Depending on the combining function of a node, aninference network may contain different types of nodes,e.g. for Boolean connectors as well as for probabilisticcorrelation as in the relevance models described before.As a simple example, assume that the representationconcept rx is ' IR' which is defined as an OR-combinationof the two document concepts (terms) tl = 'informationretrieval' an t2 = 'document retrieval'. Then the prob-ability of rx being true can be computed by the function
P(rx = true) = 1 - (1 -P^ = true))(l -P(?2 = true)).
This approach has several advantages in comparison tothe relevance models, as follows.# As most probabilistic IR models can be mapped on
to an inference network, this formalism gives aunifying representation for the different models (seee.g. Ref 31). In contrast to these models, the networkapproach does not require the derivation of a closedprobabilistic formula, so more complex inter-dependences can be incorporated.
# The network approach allows for the combination ofmultiple sources of evidence. For example, infor-mation about the similarity of documents can beconsidered, as well as knowledge from externalsources like a thesaurus.
# Different query formulations and types of queryformulation can be combined in order to answer asingle query. For example, a Boolean and aprobabilistic formulation can be used in parallel,
THE COMPUTER JOURNAL, VOL. 35, NO. 3, 1992 251
by guest on August 11, 2016
http://comjnl.oxfordjournals.org/
Dow
nloaded from

N. FUHR
where the network combinesformulations.
the results of both terms of retrieval quality, whereas maximum likelihoodestimates gave significantly worse results.
5. GENERAL PROBLEMSIn this section we discuss some problems that are generalto any probabilistic IR model, namely parameterestimation, query expansion and the representation ofdocuments and queries.
5.1 Parameter estimation
Any probabilistic IR model requires the estimation ofcertain parameters before it can be applied. A surveyover estimation schemes in IR is given in Ref. 32. Herewe want to describe briefly the two major solutions tothis problem.
The general situation is as follows: in a collection ofdocuments, each document may have several features et.For a fixed set of n feature pairs, we are seeking forestimates of P(e<|e,), the probability that a randomdocument has feature et, given that it has feature eP In arandom sample of g objects, we observe / objects withfeature e} of which h objects also have the feature e{. Inthe case of the BIR model, the features et are eitherrelevance or non-relevance w.r.t. the current query, andthe features et denote the presence of the terms t,.
Now the problem is to derive an estimate p(ef | ep (h,f,g)) for P(e(\e}), given the parameter triple (h,f,g). Themost simple estimation method uses the maximumlikelihood estimate, which yields p{et \ ep(h,f, g)) = h/f.Besides the problem with the quotient 0/0, this estimatealso bears a bias (see the experimental results in Ref.32).
Bayesian estimates in combination with a beta priorhave been used by most researchers in probabilistic IR.For the parameters a and b of the beta distribution anda quadratic loss function, one gets the estimate
h + a™eta f+a + b
For the choice of the parameters a and b, a = b = 0.5 hasbeen used in most experiments (see also Ref. 33 forexperiments with different values for these parameters).This kind of estimate also can be applied when norelevance feedback data is available, that is , /= h = 0. Inthe case of the BIR model, experiments without feedbackdata as described in Ref. 34 gave good results.
However, experimental results described in Ref. 32have shown that the assumption of a beta prior may betheoretically inadequate. Instead, an optimum estimatebased on empirical distributions is derived. Assume thatE(h,f, g) denotes the expectation of the number of thoseof the n feature pairs for which the parameters (h,f,g)were observed. These expectations can be taken from thefrequency statistics of a large number of feature pairs (e(,et). Then the optimum estimate is computed according tothe formula
(h+l)E(h + !,g)
\)E(h+\,f+l-h)E(h,f+ \,gY
Experimental comparisons of this optimum estimatewith Bayesian estimates showed almost no difference in
5.2 Query expansionClosely related to the problem of parameter estimation isthe question: which terms should be included in thequery formulation? In derivation of the BIR model, wehave assumed that pik = qik for all terms not occurring inthe query. Of course, there will be a number of additionalterms for which this assumption does not hold, so theyshould be included in the query, too. If the queryformulation is to be expanded by additional terms, thereare two problems that are to be solved, namely (1) howare these terms selected, and (2) how are the parameterscik estimated for these terms?For the selection task three different strategies have beenproposed, as follows.• Dependent terms: here terms that are dependent on
the query terms are selected. For this purpose, thesimilarity between all terms of the document col-lection has to be computed first.35
• Feedback terms: from the documents that have beenjudged by the user, the most significant terms(according to a measure that considers the dis-tribution of a term within relevant and nonrelevantdocuments) are added to the query formulation.36
• Interactive selection: by means of one of the methodsmentioned before, a list of candidate terms iscomputed and presented to the user, who makes thefinal decision on which terms are to be included in thequery.37
With respect to the parameter estimation task,experimental results have indicated that the probabilisticparameters for the additional query terms should beestimated in a slightly different way than for the initialquery terms, e.g. by choosing different parameters a andb in the beta estimate (that is, a different prior distributionis assumed for the new terms).3638
The experimental results available so far indicate thatthe dependent-terms method does not lead to betterretrieval results,35 whereas clear improvements arereported in Refs 36 and 39 for the feedback-termsmethod.
5.3 Representation of documents and queries
So far in this paper we have assumed that a query is a setof terms, which in turn are words (with the exception ofthe Bayesian network approach, where a query also maycontain Boolean connectors). But as more advanced textanalysis methods are available, there is a growing needfor models that can be combined with refined rep-resentation formalisms. Several authors have investigatedthe additional use of phrases as query terms.40"42 Theresults from this experimental work do not give a clearindication whether retrieval quality can be improvedwith phrases as query terms. However, three problemsshould be considered when interpreting these results.
(1) Phrases are a different kind of terms in comparisonto words. For this reason, the application of the standardweighting schemes developed for words may not beappropriate.
(2) When phrases as well as their components are usedas query terms, these terms are highly dependent, so a
252 THE COMPUTER JOURNAL, VOL. 35, NO. 3, 1992
by guest on August 11, 2016
http://comjnl.oxfordjournals.org/
Dow
nloaded from

PROBABILISTIC MODELS IN INFORMATION RETRIEVAL
dependence model should be used, as for example in Ref.43.
(3) The document collections used for experimentsmay be too small to show any benefit from phrases.Other experiments with larger collections have suc-cessfully used phrases in addition to words.1844
A dependence model for phrases is not sufficient, sincethis approach only regards the occurrence of the phrasecomponents in a document, without considering thesyntactical structure of the phrase as it occurs in thedocument. So the certainty of identification also shouldbe considered (e.g. whether the components occuradjacent or only within the same paragraph). This can beachieved via application of probabilistic indexingmethods (e.g. with the BII model in combination with adescription-oriented approach); furthermore, with re-gard to the first point above, indexing methods computecorrect weights for different kinds of terms.
In contrast to the approaches discussed so far that arebased on free text search, there is also work on automaticindexing with a controlled vocabulary (descriptors). Inthis case an indexing dictionary is required that containspairs (with associated weights) of text terms anddescriptors. For the problem of computing an indexingweight for a descriptor with indications from differentterms within a document, either model-oriented45 ordescription-oriented approaches1844 can be applied.Although many researchers are convinced that a con-trolled vocabulary offers no advantage over a freevocabulary, there is in fact little substantial experimentalevidence supporting this position.46
As an example for an advanced text representationmethod, in Ref. 47 a semantic network representation isused for medical documents and queries (in conjunctionwith a fuzzy retrieval function). For probabilistic IR, thiskind of representation is a challenge. Theoretically, theuncertain inference approach as developed by vanRijsbergen could be applied here - although the problemof parameter estimation has not been finally solved.Another possibility is the description-oriented approachdescribed in Ref. 8, which, however, requires fairly largelearning samples for application.
6. CONCLUSION AND OUTLOOKIn this paper the major concepts of probabilistic IR havebeen described. Following this goal, we have onlyoccasionally referred to experimental results; of course,experiments are necessary in order to evaluate and
compare different models. For future research it seems tobe important to use test collections that are morerepresentative for the intended applications, e.g.collections with 10s—106 documents with regard to largeonline databases.
As new possible applications for IR methods arise, thescope of the field also has to be revised. In the past,collections with short documents (i.e. abstracts) havebeen investigated almost exclusively. Nowadays, fulltextdocument databases are set up for many applications; sofar, no experimental results are available for theapplicability of probabilistic methods (for example, theBIR model seems to be inappropriate in this case since itdoes not distinguish between terms that occur only oncein a text and others that represent important concepts ofa document). With multimedia documents there is theproblem of representation for the non-textual parts:should they be represented by a set of keywords, or arestructured descriptions required (as in Ref. 48)?
In the field of database research, there is also growinginterest in methods for coping with imprecision indatabases.49-50 As new databases for technical, scientificand office applications are set up, this issue becomes ofincreasing importance. A first probabilistic model thatcan handle both vague queries and imprecise data hasbeen presented in Ref. 51. Furthermore, the integrationof text and fact retrieval will be a major issue.52
Finally, it should be mentioned that the modelsdiscussed here scarcely take into account the specialrequirements of interactive retrieval. Even the feedbackmethods are more or less related to batch retrieval, wherefeedback from the first retrieval run is used in order toimprove the quality of the second run (an exception mustbe made for Bookstein's paper,53 where iterative feedbackmethods are discussed). Since an interactive systemallows a larger variety of interactions than just queryformulation and relevance feedback (see e.g. Ref. 54),these interactions should be incorporated in a model forinteractive probabilistic retrieval. Especially, the role ofprobabilistic parameters in the interaction process shouldbe investigated: how should probabilistic weights (if atall) be presented to the user, and should there be apossibility for a user to specify probabilistic weights? Inorder to answer these questions, more experimentalresearch is necessary. A major impediment for this kindof research is the fact that experiments with interactivesystems and real users require a much bigger effort thantesting ranking procedures in a batch environment.
REFERENCES
1. C. van Rijsbergen and K. Sparck Jones, A test for theseparation of relevant and non-relevant documents inexperimental retrieval colletions. Journal of Documentation29, 251-257 (1973).
2. W. Cooper, Some inconsistencies and misnomers inprobabilistic IR. In Proceedings of the Fourteenth AnnualInternational ACM/SIGIR Conference on Research andDevelopment in Information Retrieval, edited A. Bookstein,Y. Chiaramella.G. Salton.V. Raghavan,pp. 57-61. ACM,New York (1991).
3. S. Robertson, M. Maron and W. Cooper, Probability ofrelevance: a unification of two competing models fordocument retrieval. Information Technology: Research andDevelopment 1, 1-21 (1982).
4. N. Fuhr and G. Knorz, Retrieval test evaluation of a rulebased automatic indexing (AIR/PHYS). In Research andDevelopment in Information Retrieval, edited C. VanRijsbergen, pp. 391—408. Cambridge University Press,Cambridge (1984).
5. S. Robertson, The probability ranking principle in IR.Journal of Documentation 33, 294-304 (1977).
6. K. Stirling. The effect of document ranking on retrievalsystem performance: a search for an optimal ranking rule.In Proceedings of the American Society for InformationScience 12, 105-106 (1975).
7. A. Bookstein, Outline of a general probabilistic retrievalmodel. Journal of Documentation 39 (2), 63-72 (1983).
8. N. Fuhr, Optimum polynomial retrieval functions based
THE COMPUTER JOURNAL, VOL. 35, NO. 3, 1992 253
by guest on August 11, 2016
http://comjnl.oxfordjournals.org/
Dow
nloaded from

N. FUHR
on the probability ranking principle. ACM Transactions onInformation Systems 7 (3), 183-204 (1989).
9. A. Bookstein, Probability and fuzzy-set applications toinformation retrieval. Annual Review of Information Scienceand Technology 20, 117-151 (1985).
10. C. van Rijsbergen, Information Retrieval, 2nd edn, chapter6, pp. 111-143. Butterworths, London (1979).
11. C. Yu, C. Buckley, K. Lam and G. Salton, A generalizedterm dependence model in information retrieval. Infor-mation Technology: Research and Development 2, 129-154(1983).
12. J. Pearl, Probabilistic Reasoning in Intelligent Systems:Networks of Plausible Inference. Morgan Kaufman, SanMateo, CAL (1988).
13. C. van Rijsbergen, A theoretical basis for the use of co-occurrence data in information retrieval. Journal ofDocumentation 33, 106-119 (1977).
14. N. Fuhr and C. Buckley, A probabilistic learning approachfor document indexing. ACM Transactions on InformationSystems 9(3), 223-248 (1991).
15. M. Maron and J. Kuhns, On relevance, probabilisticindexing, and information retrieval. Journal of the ACM 7,216-244 (1960).
16. N. Fuhr, Models for retrieval with probabilistic indexing.Information Processing and Management 25 (1), 55-72(1989).
17. K. Kwok, Experiments with a component theory ofprobabilistic information retrieval based on single terms asdocument components. ACM Transactions on InformationSystems 8, 363-386 (1990).
18. P. Biebricher, N. Fuhr, G. Knorz, G. Lustig and M.Schwantner, The automatic indexing system AIR/PHYS -from research to application. In 11th International Con-ference on Research and Development in InformationRetrieval, edited Y. Chiaramella, pp. 333-342. PressesUniversitaires de Grenoble, Grenoble, France (1988).
19. G. Knorz, Automatisches Indexierne als Erkennenabstrakter Objekte. Niemeyer, Tubingen (1983).
20. A. Bookstein and D. Swanson, Probabilistic models forautomatic indexing. Journal of the American Society forInformation Science 25, 312-318 (1974).
21. S. Harter, A probabilistic approach to automatic keywordindexing, part I. On the distribution of speciality words ina technical literature. Journal of the American Society forInformation Science 26, 197-206 (1975).
22. S. Harter, A probabilistic approach to automatic keywordindexing. Part II. An algorithm for probabilistic indexing.Journal of the American Society for Information Science 26,280-289 (1975).
23. P. Srinivasan, A comparison of two-poisson, inversedocument frequency and discrimination value models ofdocument representation. Information Processing andManagement 26 (2), 269-278 (1990).
24. E. Margulis, N-Poisson Document Modelling Revisited.Technical Report 166, ETH Zurich, DepartmentInformatique, Institut fur Informationssysteme (1991).
25. C. Yu, W. Meng and S. Park, A framework for effectiveretrieval. ACM Transactions on Database Systems 14 (2),147-167 (1989).
26. C. Yu and H. Mizuno, Two learning schemes in infor-mation retrieval. In 11th International Conference onResearch & Development in Information Retrieval, edited Y.Chiaramella, pp. 201-218. Presses Universitaires deGrenoble, Grenoble, France (1988).
27. S. Wong and Y. Yao, A generalized binary probabilisticindependence model. Journal of the American Society forInformation Science 41 (5), 324-329 (1990).
28. C. J. van Rijsbergen, A non-classical logic for informationretrieval. The Computer Journal 29 (6) (1986).
29. R. Reiter, Towards a logical reconstruction of relationaldatabase theory. In On Conceptual Modelling, edited M.
Brodie, J. Mylopoulos and J. Schmidt, pp. 191-233.Springer, New York (1984).
30. C. van Rijsbergen, Towards an information logic. InProceedings of the Twelfth Annual InternationalACMSIGIR Conference on Research and Development inInformation Retrieval, edited N. Belkin and C. vanRijsbergen, pp. 77-86. ACM, New York (1989).
31. H. Turtle and W. B. Croft, Inference networks for docu-ment retrieval. In Proceedings of the 13th InternationalConference on Research and Development in InformationRetrieval, edited J.-L. Vidick, pp. 1-24. ACM, New York(1990).
32. N. Fuhr, H. Hiither, Optimum probability estimation fromempirical distributions. Information Processing and Man-agement 25 (5), 493-507 (1989).
33. R. Losee, Parameter estimation for probabilisticdocument-retrieval models. Journal of the American Societyfor Information Science 39 (1), 8-16 (1988).
34. W. Croft and D. Harper, Using probabilistic models ofdocument retrieval without relevance information. Journalof Documentation 35, 285-295 (1979).
35. C. van Rijsbergen, D. Harper and M. F. Porter, Theselection of good search terms. Information Processing andManagement 17, 77-91 (1981).
36. G. Salton and C. Buckley, Improving retrieval perfor-mance by relevance feedback. Journal of the AmericanSociety for Information Science 41 (4), 288-297 (1990).
37. D. Harman, Towards interactive query expansion. In 11thInternational Conference on Research & Development inInformation Retrieval, edited Y. Chiaramella, pp. 321-331.Presses Universitaires de Grenoble, Grenoble, France(1988).
38. S. Robertson, On relevance weight estimation and queryexpansion. Journal of Documentation 42, 182-188 (1986).
39. K. Kwok, Query modification and expansion in a networkwith adaptive architecture. In Proceedings of the FourteenthAnnual International ACM/SIGIR Conference on Researchand Development in Information Retrieval, edited A.Bookstein, Y. Chiaramella, G. Salton and V. Raghavan,pp. 192-201. ACM, New York (1991).
40. W. B. Croft, Boolean queries and term dependencies inprobabilistic retrieval models. Journal of the AmericanSociety for Information Science 37 (2), 71-77 (1986).
41. J. Fagan, The effectiveness of a nonsyntactic approach toautomatic phrase indexing for document retrieval. Journalof the American Society for Information Sciences 40 (2),115-132(1989).
42. T. Sembok, and C. van Rijsbergen, SILOL: A simplelogical-linguistic document retrieval system. InformationProcessing and Management 26 (1), 111-134 (1990).
43. W. Croft, H. Turtle, D. Lewis, The use of phrases andstructured queries in information retrieval. In Proceedingsof the Fourteenth Annual International ACM/SIGIR Con-ference on Research and Development in InformationRetrieval, edited A. Bookstein, Y. Chiaramella, G. Salton,A. Raghavan, pp. 32-45. ACM, New York (1991).
44. N. Fuhr, S. Hartmann, G. Knorz, G. Lustig, M.Schwantner and K. Tzeras, AIR/X - a rule-basedmultistage indexing system for large subject fields.Proceedings of the RIAO'91, Barcelona, Spain, 2-5 April,1991, pp. 606-623 (1991).
45. S. Robertson and P. Harding, Probabilistic automaticindexing by learning from human indexers. Journal ofDocumentation 40, 264-270 (1984).
46. G. Salton, Another look at automatic text-retrievalsystems. Communications of the ACM 29 (7), 648-656(1986).
47. Y. Chiaramella and J. Nie, A retrieval model based on anextended modal logic and its application to the rimeexperimental approach. In: Proceedings of the 13th In-ternational Conference on Research and Development in
254 THE COMPUTER JOURNAL, VOL. 35, NO. 3, 1992
by guest on August 11, 2016
http://comjnl.oxfordjournals.org/
Dow
nloaded from

PROBABILISTIC MODELS IN INFORMATION RETRIEVAL
Information Retrieval, edited J.-L. Vidick, pp. 25-44.ACM, New York (1990).
48. F. Rabitti and P. Savino, Image query processing based onmulti-level signatures. In: Proceedings of the FourteenthAnnual International ACM/SIGIR Conference on Researchand Development in Information Retrieval, edited A.Bookstein, Y. Chairamella, G. Salton and V. Raghavan,pp. 305-314. ACM, New York (1991).
49. IEEE. IEEE Data Engineering 12(2). Special Issue onImprecision in Databases (1989).
50. A. Motro, Accommodating imprecision in databasesystems: issues and solutions. IEEE Data EngineeringBulletin 13 (4), 29-42 (1990).
51. N. Fuhr, A probabilistic framework for vague queries andimprecise information in databases. In Proceedings of the
16th International Conference on Very Large Databases,edited D. McLeod, R. Sacks-Davis and H. Schek, pp.696-707. Morgan Kaufman, Los Altos, CA (1990).
52. F. Rabitti and P. Savino, Retrieval of multimediadocuments by imprecise query specification. In Advances inDatabase Technology - EDBT '90, edited F. Bancilhon,C. Thanos and D. Tsichritzis, pp. 203-218. Springer, Berlinet al. (1990).
53. A. Bookstein, Information retrieval: a sequential learningprocess. Journal of the American Society for InformationScience 34, 331-342(1983).
54. W. B. Croft and R. H. Thompson, I3R: A new approachto the design of document retrieval systems. Journal of theAmerican Society for Information Science 38 (6), 389—404(1987).
Book Review
NELL DALE and CHIP WEEMSIntroduction to Pascal and Structured Design,3rd editionD. C. Heath and Co., Lexington, 1991925 pp. 0-669-20238-X.NELL DALE and SUSAN C. LILLYPascal plus Data Structures, Algorithms andAdvanced Programming, 3rd editionD. C. Heath and Co., Lexington, 1991850 pp. 0-669-24830-4.
Any book that comes out in a third edition inthe cut-throat world of first-year Pascal textsdeserves close scrutiny. These two books are asample from a suite of six books, twolaboratory courses and a video course thatNell Dale and colleagues have publishedthrough D. C. Heath since 1983. They haveevidently refined their winning formula to thepoint where it is a 'success at over 1250schools' (quoted from the publisher's ad-vertising). So what is it that the customerslike? Why are these books so successful?
There seem to be two factors involved:pedagogy and quality. Both books cover theirtopics absolutely thoroughly, explaining eachnew feature as it arises, using interestingexamples, both classic (binary search) andnovel (absenteeism pattern). Some of theexamples progress through the book, becom-ing more sophisticated as the student's ex-pertise increases, and there are several largercase studies. The order of topics has beencarefully chosen, and the authors have adaptedthe material through each revision so as toreflect changing trends. The teaching andlearning aids are impressive: the introductorybook concludes each chapter with case studies,advice on testing and debugging, and thenfour levels of exercises for the students, from aquick check quiz to genuine programmingproblems. Beginners will find these veryreassuring. The advanced book ends eachchapter with an extensive set of exercises, andhas a separate section at the end of the bookwith nearly 30 programming assignments.These have obviously been class tested and theattention to detail makes it possible for thelecturer to set them for a class as-is.
Through the editions, the authors have hadthe time to add in additional material whichmay be regarded as peripheral, but which, inmy opinion, greatly enhances the value ofthese books. The introductory text is par-ticularly good in this regard, and includes pensketches of famous computer scientists, snip-pets of related theory, advice on style andguidelines for program design. The programsare all of a consistently high standard, usingplentiful comments, good type definitions,and procedures with parameters to the full.The advanced book includes a diskette con-taining all the programs, which is a very goodsign that the programs have been well tested.Both books are produced in two colours, withcartoons and many graphic illustrations.Quality indeed!
The introductory book has 17 chapters,which take a genuine beginner through theprogramming process, design methodologyand problem solving, to simple Pascal withcontrol structures, procedures and parameters,on to functions, data types and recursion.Purists can note that looping is taught withwhile statements and that repeat and for onlyappear later on in the data types section.Subranges are emphasised from chapter 10onwards, and I was glad to see that they comebefore arrays. Unlike many books that diveinto array handling at the start, Nell andWeems take this conceptually difficult hurdleslowly. Chapters 11,12 and 13 introduce arrayprocessing, patterns of array access, lists,strings tables. Chapter 15 covers files andpointers and chapter 16 provides a gentleintroduction to the advanced book on datastructures.
The only problem with this book is that itcovers standard Pascal and only standardPascal. Thus many common operations (read-ing in a string) are long-winded, some (e.g.assigning a file name) have to be side-stepped,and the important programming issues ofscreen and graphics handling, separate com-pilation and objects, are simply ignored. Thereis a companion volume which is a TurboPascal version, and one hopes that theseaspects are fully addressed there.
Because the advanced book follows thesame easily accessible style and high-qualitylayout of the introductory text (complete withjokes), I was tempted to regard it as not aserious contender in the Data Structures andAlgorithms text stakes. Closer scrutiny provedme wrong. Dale and Lilly have managed toretain a high level of rigour in the presentationof abstract data types while still making eachof them truly usable in practice. Stacks,queues, lists and binary trees are covered indetail, and the efficiency of each of thealgorithms applied to them is formally dis-cussed. Sorting and searching (includinghashing) receive similar treatment. However,the book stops short of the next level of ADTs- bags, sets, B-Trees, directed graphs. TurboPascal is made use of in places where theauthors were really desperate, and there is alsoa Turbo Pascal version of the book (but how'Turbo' it is, I do not know).
So, how would these books fit into firstcourses outside the US? The introductorybook is too basic and too slow for a typicalfirst-semester course, where the majority ofstudents will have programmed at school andmay even know Pascal. The insight intoprogramming is fine, but is dispersed through-out the text, and overall the book is just toobig for the subject it covers. On the otherhand, the pedagogical aids are first class, andI would certainly advise any student who ishaving difficulty with a Pascal course to getthis book as back-up. The advanced book isalso hefty, and although thorough, does notgo as far into the exciting aspects of algorithmsas the more formal and classic texts do. On theother hand, the examples and assignments arefirst rate, and I am very glad to have this bookon my shelf.
These are both excellent books in all respectsexcept coverage, and I would certainly rec-ommend that any teachers of first or secondyear should inspect copies and judge whetherthe coverage is sufficient for the courses underconsideration. If it is, then both class andlecturer will be joining the other 1250 satisfiedschools, and are on to a winner.
JUDY BISHOPPretoria
THE COMPUTER JOURNAL, VOL. 35, NO. 3, 1992 255
by guest on August 11, 2016
http://comjnl.oxfordjournals.org/
Dow
nloaded from





























