Embed Size (px)
Citation preview

May 6, 2009 17:45 WSPC/115-IJPRAI SPI-J068 00725
International Journal of Pattern Recognitionand Artificial IntelligenceVol. 23, No. 3 (2009) 359–377c© World Scientific Publishing Company
PRECISE EYE AND MOUTH LOCALIZATION
P. CAMPADELLI∗, R. LANZAROTTI† and G. LIPORI‡
Dipartimento di Scienze dell’InformazioneUniversita degli Studi di Milano
Via Comelico, 39/41 - 20135 Milan, Italy∗[email protected]†[email protected]
The literature on the topic has shown a strong correlation between the degree of precisionof face localization and the face recognition performance. Hence, there is a need forprecise facial feature detectors, as well as objective measures for their evaluation andcomparison.
In this paper, we will present significant improvements to a previous method forprecise eye center localization, by integrating a module for mouth localization. Thetechnique is based on Support Vector Machines trained on optimally chosen Haar waveletcoefficients. The method has been tested on several public databases; the results arereported and compared according to a standard error measure. The tests show that thealgorithm achieves high precision of localization.
Keywords: Eye detection; eye localization; face localization; face alignment; supportvector machines; localization error measures.
1. Introduction
Eye localization is a crucial step for applications involving face processing18 suchas eye tracking, face recognition (FR), face expression recognition, etc. Manypapers4, 21, 23, 25, 30, 33, 37, 40 have stressed the strong relation between face recognitionperformance and localization precision.
Although significant efforts have been made in developing precise eye local-ization methods, most of the results are not clearly comparable since they arepresented according to ambiguous criteria (e.g. error expressed in pixels, withoutspecifying the image scale). Therefore, a need arises to evaluate the accuracy ofeye localization objectively. Jesorsky et al.17 proposed a scale independent errormeasure which can be used to compare the performances obtained by differentsystems on different datasets; since then, quite a few researchers in the field haveadopted it. Recently Rodriguez et al.31 proposed a more detailed definition of accu-racy of eye localization, highlighting the need to take into account different errortypes.
359

May 6, 2009 17:45 WSPC/115-IJPRAI SPI-J068 00725
360 P. Campadelli, R. Lanzarotti & G. Lipori
Another important aspect concerns the choice of database: methods shouldbe tested on several databases to prove their capacity of generalization; also,such databases should be public, in order for a direct comparison to bepossible.
The method presented in this paper extends and improves our previous workon eye localization.3, 4 The main novelty is the introduction of a module for mouthdetection that not only enriches the usefulness of the method for initializing otherface processing techniques, but also increases the robustness of eye localization.Higher attention has been devoted to the computational cost of all modules through-out system design, making it affordable for real-world applications. Finally, thenumber and composition of the experimental sets has been augmented to prove therobustness of the method against different acquisition conditions. The tests havebeen carried out on seven public databases.
The discussion is articulated as follows: Sec. 2 will give a brief overview of therelated literature; Sec. 3 will describe the general architecture of the proposed tech-nique for eye and mouth localization; Sec. 4 will specify the details of each moduleby introducing the pattern representation and the procedure of feature selection;Sec. 5 will present the results of localization; Sec. 6 will discuss the computationalaspects; Sec. 7 will draw the conclusions of the work.
2. Related Work
In Ref. 5, we have compiled an overview of methods of eye localization stressingthe importance of precision. This section will give a brief overview of those andother methods which have been presented in subsequent publications. It is possibleto identify some common traits to most techniques: they all proceed in a coarse-to-fine way, increasingly narrowing the search domain and progressively solvingsubproblems which are easier than the original one. The very first step consists ofa rough localization of the face subimage (face detection), it follows the actual eyelocalization that may involve one or more substeps, and sometimes a final validationcriterion based on higher level features is employed to reduce the number of falsepositives and to make localization more robust.
Face detection is a lively research area in itself and many solutions have beenproposed.13, 15, 29, 32, 34 A great number of eye localization techniques6, 9, 20–22, 35, 38
adopt the Viola and Jones detector,36 which is a cascaded AdaBoost classifiertrained on Haar-like wavelet features. Alternatively, the authors of Ref. 37 proposeto apply the AdaBoost classifier to different features, the Recursive NonparametricDiscriminant Features (RNDA). A completely different approach is that in Ref. 10,where the face is assumed to be found in separate patches of the image that havebeen segmented according to a probabilistic inferential model. Finally we noticethat the technique proposed in Ref. 14 does not require any face detector (it workson features extracted from the entire image), while Refs. 8, 19, 27 do not indicatehow they accomplish this fundamental step.

May 6, 2009 17:45 WSPC/115-IJPRAI SPI-J068 00725
Precise Eye and Mouth Localization 361
Some eye localization methods propose to solve the problem directly, with asingle logical step of computation. Examples are those reported in Refs. 9, 20, 27,37, where the search domain is either the whole face subimage,9, 27 its upper half,37
or even an estimate of the eye locations based on the face detection box.20 Inparticular, Ref. 9 compares three approaches: a regression method, an AdaBoostclassifier and a Bayesian approach; the results show that the simple Bayesian modeloutperforms the others. Both Refs. 27 and 37 adopt AdaBoost classifiers; the formerproposes RNDA features for learning, the latter introduces a modified trainingmethod to boost both positive and negative examples. The method in Ref. 20operates on Gabor filters responses.
Other approaches propose to further decompose the eye localization problemand try to solve it in two steps. Reference 38, for instance, employs AdaBoost tolocalize the eye pair, then the position of each eye is refined by using the radialsymmetry of the pupil. In Ref. 10, two boosted classifiers are applied in sequence,one conceived to give a first, rough localization of the eye positions, the second torefine the localization precision.
Many research works devise a validation step to be applied in cascade to thesearch. This is the case of Refs. 19, 21, 35 which adopt eye localization techniquessimilar to those cited above, and resort respectively to an AdaBoost classifier, anSVM and a template matching technique to select the best eye pair among alldetections. Another possible approach is that of Refs. 8, 14, 22 which extract lowlevel features that are fast to compute, lead to a negligible number of false neg-atives, but also introduce a certain amount of false positives which require to bevalidated. In particular, Ref. 22 exploits the peculiarity of eye color by thresholdingthe normalized and equalized R plane in the RGB color space, and validates theregions that are in the upper half of the face box, larger than a certain size andcloser to the center of the face. Reference 8 applies a morphological transformationto extract the “valleys” in the face image, considering that eyes correspond to lowgray level regions, and the correct eye pair is selected by comparing the lacunar-ity of candidates. In Ref. 14, the many candidates obtained with Gabor filteringare grouped into triplets to undergo a first selection via a probabilistic geometricmodel; later, each triplet is used to extract a normalized patch given as input to anSVM trained to recognize well-localized faces.
Finally, Ref. 7 presents the Constrained Local Models (CLM), an evolution ofActive Shape/Appearance Models (ASM/AAM). CLM aim at localizing a wide setof facial features, among which the eye centers; even if — strictly speaking — theyare not an eye localization technique, they can be used for this purpose.
3. Precise Eye and Mouth Localization: The ProposedMethodology
This section describes the search strategy conceived to achieve precise and robusteye and mouth localization. The general outline of the system is sketched in Fig. 1.

May 6, 2009 17:45 WSPC/115-IJPRAI SPI-J068 00725
362 P. Campadelli, R. Lanzarotti & G. Lipori
Fig. 1. An outline of the eye and mouth localization system.
The method consists of three modules: a face detector, an eye detector, anda mouth detector, plus the (optional) module for refining the eye localizationprecision, thus called the eye localization module. The employed face detector isa custom reimplementation of the Viola–Jones detector, so it will not be furtherdiscussed. The other modules are all initialized with an estimate of the pattern sizeinferred on the basis of the face region size, and each of them is built around abinary SVM classifier trained on optimally selected wavelet features; the patternrepresentation, the feature selection and the training parameters will be analyzedin the next section.
The eye detector serves two distinct purposes: not only does it produce a coarselocalization of the eye positions, it also validates the output of the face detector. Aprospective face region is validated as such if and only if there has been at least aneye detection within it.
The main novelty of the method, with respect to our previous work, is the intro-duction of the mouth detector. This also serves two aims: it enriches the numberof detected facial features and, above all, diminishes the ambiguity of the search,in this way reducing the number of false positives. These goals are obtained byemploying a simple geometric model of eyes-mouth configuration that is used tovalidate the correct triplets, and also to infer the position of missing detections.A bivariate Gaussian is sufficient to model all possible triplet configurations: letl1 be the segment connecting the two eye centers, let l2 be the segment connect-ing the midpoint of l1 to the mouth center, then the model (R, A) ∼ N (µ, Σ) isdefined in terms of the ratio R = l2/l1 and the angle A = ∠(l1, l2). The distribu-tion is entirely specified by the means (µR, µA) and by the covariance matrix, the

May 6, 2009 17:45 WSPC/115-IJPRAI SPI-J068 00725
Precise Eye and Mouth Localization 363
values of which have been estimated on a sample of about one thousand nearly-frontal face images: µ = (1.22, 1.57), var[R] = 8.16 × 10−3, var[A] = 2.01 × 10−3
and cov[R, A] = 1.41× 10−4. The geometric model is used in conjunction with thediscriminative power of SVMs in order to detect the facial features and select themost favorable triplet for each face region. The in-plane rotation of the whole faceis intendedly not included in the model, allowing to relax the verticality assump-tion that was made in previous works to select among eye couples. It should benoticed that, in absence of a correct mouth detection, the method works exactly asin previous publications.
Before introducing the actual search strategy, let us formalize the output ofeach detection module. Let Sf be the search domain (a set of candidate points)for facial feature f , let ρf (x) be the margin of the corresponding SVM classi-fier when evaluated on an image patch centered in x, then the output mf (Sf )of the detection module for f is the set Df of detected positions obtained asfollows:
1. Discard negatives by thresholding the margin of the classifier: S+f = {x ∈ Sf |ρf (x) > 0}.
2. Group multiple detections of the same pattern by partitioning S+f on the basis of pixel
distance:
Gf = {G ⊆ S+f |∀xi, xj ∈ G, i �= j, ‖xi − xj‖ ≤ 5s},
XG∈Gf
|G| = |S+f |,
where s is a fixed fraction of the face region size set to 115
of the estimated inter-oculardistance.∗
3. Output the weighted centroid of each group:
Df =
8<:x
˛˛˛ ∀G ∈ Gf ,x =
1
|G|X
xi∈G
xi × ·ρf (xi)
9=; , |Df | = |Gf |,
and assign
ρf (x) =1
|G|X
xi∈G
ρf (xi), ∀x ∈ Df .
∗In general Gf is not necessarily unique, as partitioning depends on the order of visit.However, as multiple detections are usually tightly clustered, the results of our experimentsare always consistent and the distance threshold is not a critical parameter.
We know that, in the absence of occlusions, in a face region it should be|Deye| = 2 and |Dmouth| = 1. If x,y ∈ Deye, z ∈ Dmouth, and c = (x + y)/2,let us call P (x,y, z) = P (R = zc/xy, A = ∠(xy, zc)), i.e. the probability assignedto the configuration of three detections according to the geometric model. Thefollowing instructions show how this can be used to reduce the ambiguity of eye

May 6, 2009 17:45 WSPC/115-IJPRAI SPI-J068 00725
364 P. Campadelli, R. Lanzarotti & G. Lipori
detection (to discard false positives), and to recover missed detections:
For each face region:
1. Extract the set E of candidate eye centers by sampling the edges of the upper part ofthe face region with step s.
2. Detect positives Deye = meye(E).3. Extract the set M of (s-spaced) candidate mouth centers by sampling
(a) the set {x | ∀xi, xj ∈ Deye, i �= j, P (xi,xj , x) > θ} if |Deye| > 1,(b) the edges of the lower part of the face region if |Deye| ≤ 1.
4. Detect positives Dmouth = mmouth(M).5. If |Deye| > 1
(a) if |Dmouth| > 0, then among all (xi,xj , xl) ∈ Deye × Deye × Dmouth select the besttriplet
(x, y, z) = arg maxxi,xj ,xl
ρeye(xi) × ρeye(xj) × ρmouth(xl) × P (xi,xj , xl).
(b) if |Dmouth| = 0, then select the best eye couple (x, y) = arg maxxi,xj
ρeye(xi) · ρeye(xj)
1 + v(xi, xj),
where v is proportional to horizontal misalignment (to favor face verticality).
Else if |Deye| = 1, try to recover the lost eye by extracting a second set E′ of candidate eyecenters by sampling {x | ∀xj ∈ Deye, ∀xl ∈ Dmouth, P (x,xj ,xl) > θ}, update Deye =Deye ∪ meye(E′) and if now |Deye| > 1 go back to the beginning of step 3, otherwisefail.
The threshold θ on probability is set to a value small enough to account for moderatepose variability (out-of-plane rotations).
Finally, the module for eye localization is conceived to be applied in cascade tothe previous method in order to increase the localization precision of the detectedeye positions. Differently from the detection modules operating on sampled loca-tions, it is applied densely in the neighborhood of detections in order to main-tain maximum search resolution, therefore it is more computationally expensive.The system does not provide any mouth localization module for two reasons: first,because the emphasis is put on eye localization precision, and the mouth searchis introduced mainly to assist eye detection as explained above; second, since themouth search domain is very much narrowed by utilizing the geometric model,mouth detection is somewhat easier than eye detectiona and it is possible to “tune”the detail of the mouth pattern representation so as to place its performance at alevel in between that achieved by eye detection and localization. How this is donewill be discussed in the next section.
4. Pattern Representation and Feature Selection
The intrinsic difficulty of the task of object recognition requires an accurate choiceof a suitable representation of the visual pattern of interest. In our case, we are
aHowever, mouth detection turns out to be more difficult if both modules are applied on samplededges without the assistance of the geometric model.

May 6, 2009 17:45 WSPC/115-IJPRAI SPI-J068 00725
Precise Eye and Mouth Localization 365
interested in either eyes or mouth pattern instances (image patches); let us firstintroduce a unified framework for pattern representation and feature selection,afterwards we will clearly state the choices specific to each pattern.
It has been observed that wavelet representation is more favorable than directrepresentation (the pixel luminance values) as it leads to a smaller generalizationerror.16 Haar-like wavelets permit to describe a pattern in terms of luminancechanges at different frequencies, positions and orientations. Moreover, an over-complete analysis of patterns is desirable as one wants to increase the cardinalityof the feature “vocabulary” before going through the selection procedure.28
All image patches undergo an illumination normalization (a contrast stretchingoperation), are reduced to the target size of 16 × 16 pixels,b and are subsequentlyprocessed via a variant of the bi-dimensional Fast Wavelet Transform (FWT) thatproduces almost four times as many wavelet coefficients with respect to the stan-dard FWT, thus bringing about new details that are not caught by the standardtransform (Fig. 2 visualizes the decomposition of the over-complete 2D FWT). Inparticular, the variant is obtained by simply skipping the subsampling step on thewavelet coefficients, hence the over-complete FWT enjoys the same computationalproperties as the original definition, i.e. its time complexity is linear in the size ofthe patches, though four times slower.
Fig. 2. The first row (from left to right) depicts the mean pattern used for eye detection, mouthdetection and eye localization respectively. The second row illustrates the corresponding waveletdecomposition. The third row shows the selected features; the contours are meant to highlight thedim coefficients.
bSuch a dimension has been experimentally chosen as a trade off between the necessity to maintainlow the computational cost and the need for sufficient details to learn the pattern shape.

May 6, 2009 17:45 WSPC/115-IJPRAI SPI-J068 00725
366 P. Campadelli, R. Lanzarotti & G. Lipori
In order to prepare the wavelet coefficients pool for feature selection, a bigsample of pattern instances is gathered, all patches are decomposed via the over-complete 2D FWT, the wavelet coefficients are averaged over the sample and theresulting means are normalized with respect to the frequency band they belongto. In Ref. 3, we detail the normalization step and consider a feature selectionprocedure based on a reconstructive criterion to find the optimal compromisebetween the retained “quantity of information” and the error of reconstruction.However, as the selected features are to be input to SVM classifiers, it is interest-ing to consider also an alternative principle to drive the selection process whichis based on the “classification power” of coefficients. In particular, we trainedas many SVM classifiers as the possible combinations of features in the searchdomain, and defined a minimization problem with objective function equal to|support vectors |×(1− precision ×recall ) to trade off between classifier complexityand generalization ability.
Quite interestingly, experiments show that feature selection produces similarresults whichever criterion is chosen (classifiers based on either one perform equallywell in the detection task), thus suggesting that the over-complete wavelet represen-tation, together with the normalization step, induces a natural separation betweendiscriminative and nondiscriminative features. As the criterion based on classifica-tion is computationally much more expensive (it requires a large number of trainingexperiments), the criterion based on reconstruction is preferred.
Let us now detail choices made to represent each pattern for learning, bearing inmind the search strategy discussed in the previous section. All SVMs are regulatedby the error-penalization parameter C, and are defined in terms of the RBF kernelc
parameterized by γ = 1/2σ2. Parameter tuning was carried out on a proper valida-tion set maximizing the precision × recall . All samples have been extracted from1416 images: 600 belonging to the FERET database (controlled images of frontalfaces), 416 to the BANCA database (to model closed eyes and open mouth), and600 taken from a custom database containing many heterogenous and uncontrolledpictures of various people (taken in various occasions like holidays, family reunions,friends’ meetings, etc. useful to model pose and illumination variations, non-neutralface expressions and random background examples).
The pattern learned by the SVM of the eye detection module has been extractedfrom square eye patches with receptive field width equal to the inter-ocular distance.The wavelet coefficients belonging to the highest frequency have been removed fromthe feature pool prior to selection, as this pattern definition intends to capture thegeneral structure of the entire eye region, not the finest details. This intuition hasbeen confirmed by experimentation: high frequencies do not make the resultingSVM more discriminative, they just increase its complexity. Feature selection has
cIn the experiments, the Gaussian kernel outperformed the linear kernel and performed slightlybetter than polynomial kernels (being the third degree the best).

May 6, 2009 17:45 WSPC/115-IJPRAI SPI-J068 00725
Precise Eye and Mouth Localization 367
been carried out on a sample of 3364 eye examples, leading to only 95 wavelet coeffi-cients. After training with parameters C = 6 and γ = 4.0×10−4, the correspondingSVM consists of 1698 support vectors out of 13,591 examples. The test experimentproduced 3.0% of misclassifications on a set of 6969 examples.
The module for mouth detection is built analogously, with the only differencethat it turns out to be more effective by letting all frequencies into the featureselection pool. This has to do with the way the module is employed in the searchstrategy; in fact its search domain is conditioned on the output of eye detection, soin a certain sense its learning can fit more to data as there is less need for a greatgeneralization ability. The sample of 1682 mouth positives leads to a selection of 402features. The training was carried out with parameters C = 1.5 and γ = 4.2×10−4
on 9052 examples, giving rise to a machine of 771 support vectors that exhibitsa very low error rate of 0.5% on 8832 test patches suggesting a slight over-fit, asalready discussed.
The eye localization modules is applied to patches with receptive field equalto half that of eye detection, and the feature selection is carried out on the entirewavelet pool, leading to a representation of 334 coefficients. Negative examplesare no more instances of other facial features, but are extracted as small randomdisplacements of positive examples. These choices are motivated by the necessityto learn the fine structure of the eye center. The training set of 22,647 examplesproduced an SVM of 3209 support vectors (C = 1.35, γ = 3.6× 10−4) that exhibita misclassification rate of 2.5% on the a test set of 11,487 examples.
Figure 2 visualizes the selected features for each module.
5. Experimental Results
In order to assess the precision of eye detection and localization, we refer to therelative error measure introduced by Jesorsky et al.,17 defined as
deye =max(‖Cl − Cl‖, ‖Cr − Cr‖)
‖Cl − Cr‖where the values Cr/l stand for the detected eye positions, while the values Cr/l
are the ground truth annotations. This measure, which normalizes the localizationerror over the inter-ocular distance, is scale-independent and therefore permits acomparison among results obtained on face regions with different resolution. Weanalogously define the dmouth measure as the mouth detection error normalizedover the inter-ocular distance.d There is another measure31 aiming to decompose theeye localization error in terms of the translational, rotational and scale components,since not all errors are the same and usually the last two types are more disruptivethan the first for the purpose of face alignment. We will not report the results interms of this measure because, to our knowledge, it has not been adopted by other
ddeye is somehow more severe than dmouth because it is a worst-case measure.

May 6, 2009 17:45 WSPC/115-IJPRAI SPI-J068 00725
368 P. Campadelli, R. Lanzarotti & G. Lipori
research works on eye localization. Moreover, for small values of deye such as theones we are looking at, the different error components are equally limited and sodeye is still informative enough.
Before going into the details of the experimentation, it is worth making a briefobservation on what level of error should be considered as “acceptable”. The answerreally depends on the requirements of the face processing task that is initialized onthe detected feature positions. For instance, some experiments4, 31 have shown thatcertain FR methods prove to be more susceptible to misalignments than others,and they suffer a dramatic performance drop even for small localization errors. Inthe following, the choice to consider deye errors below 0.1 for precise localization,and deye ≤ 0.25 to flag correct detection, has been made in accordance with otherworks in the literature17, 19–22, 35, 41 to favor comparison. However, there is no reasonto prefer one value to another and, where possible, results should be given for allprecision values in the form of cumulative curves. As clearly stated in Ref. 31, itwould be ideal to couple face recognition methods with feature localization methodsthat exhibit an error within their tolerance.
Experiments have been carried out on samples from many publicly availabledatasets (see Fig. 4 for some examples), so composed: 1518 images from the ARdatabase24 (one image for each of the 139 subjects from Secs. 1–3, 5–7, the same forthe 120 subjects from Secs. 14–16, 18–20); 832 pictures from the BANCA databaseof English people1 (52 subjects, 4 sessions from sections adverse and controlled, bytaking the first and last picture of each session for each subject); the whole BioIDdataset2 (1521 pictures); 1175 pictures from the FERET dataset11 (200 of type“ba”, 400 “fa”, 575 “fb”); 1157 images from the FRGC v1.0 database12 (of which748 in controlled conditions, obtained taking for each subject the first image of thefirst two sections, plus 409 uncontrolled images, collected according to the samecriterion); 2860 images from the FRGC v2.012 (two smiling and two neutral, halfcontrolled, half uncontrolled, from the first session of all the 370 subjects from Fall2003 section, the same for all the 345 subjects from Spring 2004 section); all 1180images from the XM2VTS39 (295 subjects in four sessions). Controlled images inthese sets depict each a single face with nearly vertical, frontal pose, moderate orno face expression, eyes closed or open, presence or absence of spectacles, beard,mustache, makeup; the uncontrolled sections add some more variability with respectto resolution, degradation (especially the BANCA adverse section), illumination(especially the AR Secs. 5–7, 18–20, the FRGC v1.0/2.0 uncontrolled images), poseand scale, face expression (especially the AR Secs. 2, 3, 15, 16 that depict peoplesmiling or in anger). None of these images has been used to train the SVM classifiers.With respect to previous works, both the range and composition of the datasetshave been increased in order to augment the reliability of the results.
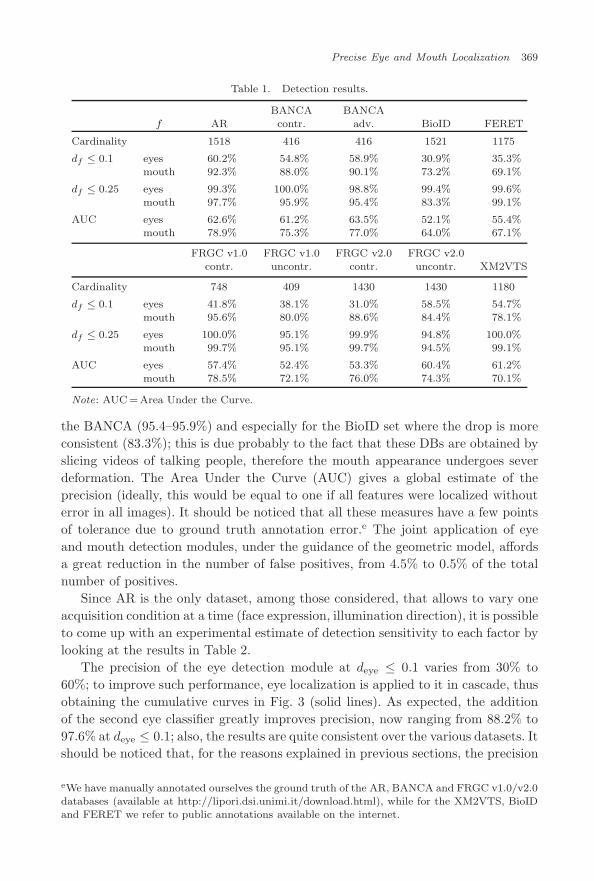
Table 1 summarizes the results of the detection modules, given in terms of theaforementioned bounds on deye and dmouth. The measured detection rate is about99–100% on all datasets, except for uncontrolled sections where it achieves 95%.Mouth detection pays only a few decimals with respect to eye detection, except for
May 6, 2009 17:45 WSPC/115-IJPRAI SPI-J068 00725
Precise Eye and Mouth Localization 369
Table 1. Detection results.
BANCA BANCAf AR contr. adv. BioID FERET
Cardinality 1518 416 416 1521 1175
df ≤ 0.1 eyes 60.2% 54.8% 58.9% 30.9% 35.3%mouth 92.3% 88.0% 90.1% 73.2% 69.1%
df ≤ 0.25 eyes 99.3% 100.0% 98.8% 99.4% 99.6%mouth 97.7% 95.9% 95.4% 83.3% 99.1%
AUC eyes 62.6% 61.2% 63.5% 52.1% 55.4%mouth 78.9% 75.3% 77.0% 64.0% 67.1%
FRGC v1.0 FRGC v1.0 FRGC v2.0 FRGC v2.0contr. uncontr. contr. uncontr. XM2VTS
Cardinality 748 409 1430 1430 1180
df ≤ 0.1 eyes 41.8% 38.1% 31.0% 58.5% 54.7%mouth 95.6% 80.0% 88.6% 84.4% 78.1%
df ≤ 0.25 eyes 100.0% 95.1% 99.9% 94.8% 100.0%mouth 99.7% 95.1% 99.7% 94.5% 99.1%
AUC eyes 57.4% 52.4% 53.3% 60.4% 61.2%mouth 78.5% 72.1% 76.0% 74.3% 70.1%
Note: AUC = Area Under the Curve.
the BANCA (95.4–95.9%) and especially for the BioID set where the drop is moreconsistent (83.3%); this is due probably to the fact that these DBs are obtained byslicing videos of talking people, therefore the mouth appearance undergoes severdeformation. The Area Under the Curve (AUC) gives a global estimate of theprecision (ideally, this would be equal to one if all features were localized withouterror in all images). It should be noticed that all these measures have a few pointsof tolerance due to ground truth annotation error.e The joint application of eyeand mouth detection modules, under the guidance of the geometric model, affordsa great reduction in the number of false positives, from 4.5% to 0.5% of the totalnumber of positives.
Since AR is the only dataset, among those considered, that allows to vary oneacquisition condition at a time (face expression, illumination direction), it is possibleto come up with an experimental estimate of detection sensitivity to each factor bylooking at the results in Table 2.
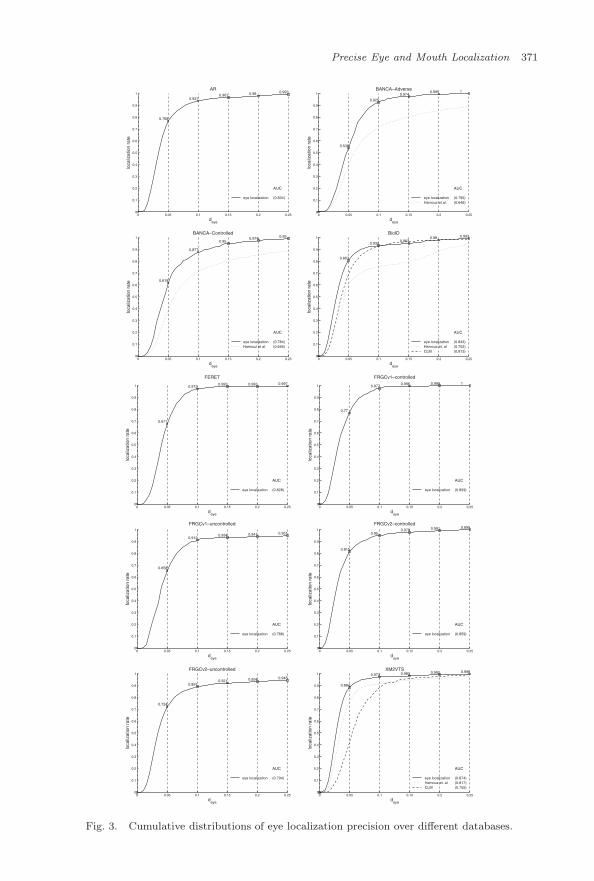
The precision of the eye detection module at deye ≤ 0.1 varies from 30% to60%; to improve such performance, eye localization is applied to it in cascade, thusobtaining the cumulative curves in Fig. 3 (solid lines). As expected, the additionof the second eye classifier greatly improves precision, now ranging from 88.2% to97.6% at deye ≤ 0.1; also, the results are quite consistent over the various datasets. Itshould be noticed that, for the reasons explained in previous sections, the precision
eWe have manually annotated ourselves the ground truth of the AR, BANCA and FRGC v1.0/v2.0databases (available at http://lipori.dsi.unimi.it/download.html), while for the XM2VTS, BioIDand FERET we refer to public annotations available on the internet.

May 6, 2009 17:45 WSPC/115-IJPRAI SPI-J068 00725
370 P. Campadelli, R. Lanzarotti & G. Lipori
Table 2. Detection sensitivity to acquisition conditions in the AR database.
1, 14 2, 15 3, 16 5–6, 18–19 7, 20Sections f Neutral Smile Anger Side Light All Sides Light
Cardinality 253 253 253 506 253
df ≤ 0.1 eyes 58.2% 63.2% 60.5% 65.4% 48.2%mouth 98.4% 88.5% 95.3% 92.7% 86.2%
df ≤ 0.25 eyes 99.2% 99.2% 99.6% 99.2% 99.6%mouth 99.2% 98.8% 98% 96.6% 96.8%
AUC eyes 62.5% 64.1% 62.5% 63.9% 58.6%mouth 84.2% 76.1% 83.0% 77.3% 75.5%
of mouth detection is much closer to that of eye localization w.r.t. that of eyedetection. When available, we report in figuref also the performance of ConstrainedLocal Models (CLM)7 and of the method presented by Hamouz et al.14 Figure 4visualizes the results obtained on some images taken from the datasets.
Other works8, 20–22, 27, 35, 38 use deye to assess the quality of eye localization,but results are reported only in correspondence to some specific values; in thefollowing, we will concentrate on the level of precision obtained on the datasets ofour experiments. Reference 35 refers to the BioID database, achieving rates of 91.8%and 98.1% at deye ≤ 0.1 and deye ≤ 0.25 respectively. Reference 27 shows hits in98.1% of images from XM2VTS and 93% from BioID, both at deye ≤ 0.1 (the paperalso reports cumulative curves, but values are not tabulated and image resolutionprevents from reading them). In Ref. 20, tests are carried out on several databases;on BioID, the method attains success in 93.8%, 96.4% and 98.8% of cases for deye
smaller than or equal to 0.07, 0.1 and 0.25 respectively. Table 3 reports the meanlocalization error of our technique and summarizes the results of other techniquesthat are directly comparable.
In other works, the reported tests make a direct comparison difficult for one ofthe following reasons: the datasets are proprietary or unspecified, they are built bymixing subsets of public databases, or simply there is no intersection with the oneswe run our tests on. Reference 21 shows poor results on a mix of AeroInfo, PoliceFace and Yale databases. In Ref. 38, tests are carried out on a set of 600 FERETimages plus 4532 of the CAS-PEAL, obtaining a rate of 98.1% at deye ≤ 0.2. InRef. 8, tests are carried out on the Yale database, reporting the percentage atdeye ≤ 0.25 and showing that variations in perspective and illumination cause themost significant loss of performance (75% and 87.5%), while upright and tilted facesobtain the best results (94.4% and 96.4%). In Ref. 22, tests are carried out on aprivate database achieving in 92.6% of cases deye ≤ 0.1.
Finally, some works use different metrics: e.g. in Refs. 9, 19, 37, a normalizedmean error is adopted. Notice that this measure is more indulgent as it will always
fThe results of CLM plotted on the graphs have been kindly provided by the authors of thatmethod.
May 6, 2009 17:45 WSPC/115-IJPRAI SPI-J068 00725
Precise Eye and Mouth Localization 371
0 0.05 0.1 0.15 0.2 0.250
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1AR
deye
loca
lizat
ion
rate
0.768
0.9370.967 0.98 0.993
AUC
eye localization (0.834)
0 0.05 0.1 0.15 0.2 0.250
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1BANCA–Adverse
deye
loca
lizat
ion
rate
0.538
0.925
0.9740.995 1
AUC
eye localization (0.795)Hamouz et al. (0.646)
0 0.05 0.1 0.15 0.2 0.250
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1BANCA–Controlled
deye
loca
lizat
ion
rate 0.618
0.877
0.950.974 0.99
AUC
eye localization (0.784)Hamouz et al. (0.646)
0 0.05 0.1 0.15 0.2 0.250
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1BioID
deye
loca
lizat
ion
rate
0.807
0.9320.953
0.98 0.993
AUC
eye localization (0.843)
CLM (0.813)Hamouz et. al (0.702)
0 0.05 0.1 0.15 0.2 0.250
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1
FERET
deye
loca
lizat
ion
rate
0.677
0.9730.993 0.993 0.997
AUC
eye localization (0.828)
0 0.05 0.1 0.15 0.2 0.250
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1
FRGCv1–controlled
deye
loca
lizat
ion
rate
0.77
0.9770.996 0.999 1
AUC
eye localization (0.859)
0 0.05 0.1 0.15 0.2 0.250
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1
FRGCv1–uncontrolled
deye
loca
lizat
ion
rate
0.658
0.9120.934 0.941 0.951
AUC
eye localization (0.788)
0 0.05 0.1 0.15 0.2 0.250
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1
FRGCv2–controlled
deye
loca
lizat
ion
rate
0.815
0.950.978 0.991 0.999
AUC
eye localization (0.859)
0 0.05 0.1 0.15 0.2 0.250
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1FRGCv2–uncontrolled
deye
loca
lizat
ion
rate
0.724
0.8910.921 0.934 0.945
AUC
eye localization (0.794)
0 0.05 0.1 0.15 0.2 0.250
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1XM2VTS
deye
loca
lizat
ion
rate
0.884
0.973 0.982 0.992 0.998
AUC
eye localization (0.874)
CLM (0.755)Hamouz et. al (0.817)
Fig. 3. Cumulative distributions of eye localization precision over different databases.

May 6, 2009 17:45 WSPC/115-IJPRAI SPI-J068 00725
372 P. Campadelli, R. Lanzarotti & G. Lipori
Fig. 4. Some examples (two for each database section) of mouth and eye localizations of variousprecision levels (some localization errors are also reported). Blue and red crosses indicate eye andmouth localizations respectively, white circles are drawn around the manually annotated centerof features in correspondence to the precision level deye ≤ 0.25.
give smaller error results w.r.t to deye. In the first work,37 an error of 2.67% on theentire FRGC v1.0 is obtained. By adopting this measure on the FRGC v1.0 subsetsof our experiments, we observe an error of 2.73% and 3.92% on the controlled anduncontrolled images (respectively). In the second work,19 the test set consists of

May 6, 2009 17:45 WSPC/115-IJPRAI SPI-J068 00725
Precise Eye and Mouth Localization 373
Table 3. Localization results.
This Work Ref. 7 Ref. 14 Ref. 27Ref. 35 Ref. 20
Measure All DBs I II I II I II I I II I
deye ≤ 0.1 92.1% 92.2% 95.6% 94.9% 95.1% 71.4% 91.5% 91.8% 93% 98.1% 96.4%deye ≤ 0.25 98.7% 98.9% 100% 98.5% 99.7% 88.8% 97.5% 98.1% — — 98.8%
Note: I= BioID; II =XM2VTS.
5902 images taken from the FERET, the BioID, the Yale and the ORL databases.In 93.71% of images the normalized error is lower than 0.1. In the third work,9
experiments are carried out on the FERET database: in 90% of images the meanrelative error is reported to be smaller or equal to 0.047 (for the same level ofprecision, on FERET we count 81.6% of images).
6. Computational Issues
The focus of our research is on localization precision; real-time computation was nota strict requirement when designing our system, as nowadays dedicated architec-tures exist that can boost execution time by orders of magnitude. Nonetheless, weare concerned with the computational load of the proposed method, which is directlyproportional to three factors: face resolution; the number of SVM evaluations; thenumber of support vectors defining each SVM. In particular, approximately 80% oftime is spent computing SVM predictions, so their efficiency deserves the greatestattention. We have put some effort in reducing the computational burden of allthree variables, trying not to affect the level of localization precision. Notice thatthe results declared in the previous section are obtained after application of thefollowing optimization.
Regarding face resolution, by experimentation it turns out that the precisionof the method only suffers a small decrease (0.6% of AUC) if large face regionsare subsampled to a target size in which the inter-ocular distance is expected tobe 75 pixels (smaller regions are untouched). This operation tends to normalizethe computational cost on different images (the inter-ocular distance in the publicdatasets described above varies greatly, ranging from about 50 to 250 pixels).
For what concerns the number of SVM evaluations within each face region, onaverage both the eye and mouth detection modules are applied in the order of 100times, while the eye localization module would be applied more than 1000 times ifit were done densely in the detections’ neighborhood. This number can be greatlyreduced, altogether preserving the degree of precision, by starting the refinementprocess from a sample of positions that are placed along a retinotopic grid centeredin the detections, so as to progressively decrease the search resolution when movingaway from the center. All the positions responding positively to the classifier aretaken as seeds of the flood fill algorithm that outputs regions connected on the basisof positiveness. The result of refinement is the centroid of the connected region thatminimizes a simple function proportional to the distance from the grid center, and

May 6, 2009 17:45 WSPC/115-IJPRAI SPI-J068 00725
374 P. Campadelli, R. Lanzarotti & G. Lipori
inversely proportional to the region margin integral. By doing so, the average num-ber of visits drops to about 300 without any significant loss in performance.
Regarding the SVM evaluation complexity, we used the support vector reductiontechnique described in Ref. 26; due to space constraints we refer to Ref. 4 for detailson the reduction experiment.
In previous works, we declared a computational time of 12 s (Pentium 4,3.2GHz, Java code) on face regions with inter-ocular distance of 70 pixels;all together, these improvements lead to reducing execution time to 3 s and,what is more, the computational load becomes almost insensitive to face res-olution. If there is no need for high precision, by inactivating the localiza-tion module the overall execution time would be reduced to approximately onesecond.
7. Summary and Conclusions
In this paper we have presented a method for precise eye and mouth localization,under the assumption that no severe occlusions hide their appearance: both theeye and mouth regions are visible, even through transparent spectacles, fringe hair,mustache or beard. The approach does not explicitly model variations in illumina-tion, pose and expression; all the variability is implicitly encoded in the trainingsamples relying on the generalization ability of the classifiers to achieve robustdetection even in the presence of moderate alterations to the ideal case (frontalpose, uniform ambient illumination, neutral expression).
Regarding face orientation, although the geometric model is estimated on asample of nearly frontal faces (with rotation angles alike those found in the datasetsof the experiments), the value used to threshold it is so low that, once eye positionsare fixed, the region of interest for the mouth is quite wide (in fact an ellipsis withaxes that are about half to two-thirds the inter-ocular distance), so in practicethe model suits also moderately rotated poses. For what concerns variations inillumination and face expression, from Table 2, we can observe that the formerseem to cause a larger degradation of performance, while the latter appear to havea smaller impact. In order to increase the robustness of the application, a pre-processing step for illumination compensation should be added.
One advantage of the architecture of the system is its modularity: all modulesare built according to a common framework for feature selection and SVM training,and their operation is coordinated by a simple geometric model of eyes-mouthconfiguration. The flexibility of the chosen wavelet representation and the coarse-to-fine search strategy afford a nearly optimal detection rate and a high level oflocalization precision. The results in Table 3 and Fig. 3 show the competitivenessof the proposed system, and the generality of the method is supported by thenumber and variety of datasets employed in our experimental tests. Finally, a greateffort has been put into identifying the computational bottlenecks of the systemand in reducing its cost.

May 6, 2009 17:45 WSPC/115-IJPRAI SPI-J068 00725
Precise Eye and Mouth Localization 375
References
1. D. B. Banca, Web address: http://www.ee.surrey.ac.uk/Research/VSSP/banca/.2. D. B. BioID, Web address: http://www.humanscan.de/support/downloads/facedb.
php.3. P. Campadelli, R. Lanzarotti and G. Lipori, Precise eye localization through a general-
to-specific model definition, Proc. British Machine Vision Conference (BMVC2006),Edinburgh, UK, 1 (2006) 187–196.
4. P. Campadelli, R. Lanzarotti and G. Lipori, Automatic facial feature extraction forface recognition, Face Recognition, eds. K. Delac and M. Grgic (I-Tech Education andPublishing, Vienna, July 2007), pp. 31–58.
5. P. Campadelli, R. Lanzarotti and G. Lipori, Eye localization: a survey, The Funda-mentals of Verbal and Non Verbal Communication and the Biometrical Issues, eds.A. Esposito, E. Keller, M. Marinaro and M. Bratanic NATO Science Series (Septem-ber 2006).
6. D. Cristinacce and T. F. Cootes, Facial feature detection and tracking with automatictemplate selection, Proc. Int. Conf. Automatic Face and Gesture Recognition (2006),pp. 429–434.
7. D. Cristinacce and T. F. Cootes, Feature detection and tracking with constrainedlocal models, Proc. British Machine Vision Conf. 3 (2006) 929–938.
8. G. Du, Eye localization method based on symmetry analysis and high-order fractalfeature, IEE Proc. Vis. Image Sign. Process 153(1) (2006) 11–16.
9. M. R. Everingham and A. Zisserman, Regression and classification approaches toeye localization in face images, Proc. 7th Int. Conf. Automatic Face and GestureRecognition (FG2006) (2006), pp. 441–446.
10. I. Fasel, B. Fortenberry and J. Movellan, A generative framework for real time objectdetection and classification, Comput. Vis. Imag. Underst. 98 (2005) 182–210.
11. FERET DB, Web address: http://www.itl.nist.gov/iad/humanid/feret/.12. FRGC DB, Web address: http://www.frvt.org/FRGC/.13. C. Garcia and M. Delakis, Convolutional face finder: a neural architecture for fast and
robust face detection, IEEE Trans. Patt. Anal. Mach. Intell. 26(11) (2004) 1408–1423.14. M. Hamouz, J. Kittler, J. K. Kamarainen, P. Paalanen, H. Kalviainen and J. Matas,
Feature-based affine invariant localization of faces, IEEE Trans. Patt. Anal. Mach.Intell. 27(9) (2005) 1490–1495.
15. E. Hjelmas and B. Kee Low, Face detection: a survey, Comput. Vis. Imag. Underst.83(3) (2001) 236–274.
16. J. Huang and H. Wechsler, Eye detection using optimal wavelet packets and radialbasis functions (RBFs), Int. J. Patt. Recogn. Artif. Intell. 13(7) (1999) 1009–1026.
17. O. Jesorsky, K. J. Kirchberg and R. W. Frischholz, Robust face detection using theHausdorff distance, Lecture Notes in Computer Science, Vol. 2091 (2001), pp. 212–227.
18. Q. Ji, H. Wechsler, A Duchowski and M. Flickner, Special issue: eye detection andtracking, Comput. Vis. Imag. Underst. 98(1) (2005) 1–3.
19. L. Jin, X. Yuan, S. Satoh, J. Li and L. Xia, A hybrid classifier for precise and robusteye detection, Proc. Int. Conf. Pattern Recognition (ICPR) 4 (2006) 731–735.
20. S. Kim, S. Chung, S. Jung, D. Oh, J. Kim and S. Cho, Multi-scale gabor featurebased eye localization, Proc. World Academy of Science, Engineering and Technology21 (2007) 483–487.
21. Y. Ma, X. Ding, Z. Wang and N. Wang, Robust precise eye location under probabilisticframework, Proc. IEEE Int. Conf. Automatic Face and Gesture Recognition (2004),pp. 339–344.

May 6, 2009 17:45 WSPC/115-IJPRAI SPI-J068 00725
376 P. Campadelli, R. Lanzarotti & G. Lipori
22. J. Maia, F. Gomes and O. Souza, Automatic eye localization in color images, Proc.XX Brazilian Symp. Computer Graphics and Image Processing (SIBGRAPI) (2007),pp. 195–204.
23. A. M. Martinez, Recognizing imprecisely localized, partially occluded, and expressionvariant faces from a single sample per class, IEEE Trans. Patt. Anal. Mach. Intell.24(6) (2002) 748–763.
24. A. M. Martinez and R. Benavente, The AR face database, CVC Technical Report 24(June 1998).
25. J. Min, K. W. Bowyer and P. J. Flynn, Eye perturbation approach for robust recog-nition of inaccurately aligned faces, Proc. Int. Conf. Audio and Video Based Biomet-ric Person Authentication (AVBPA), Lecture Notes in Computer Science, Vol. 3546(2005), pp. 41–50.
26. D. Nguyen and T. Ho, An efficient method for simplifying support vector machines,Proc. Int. Conf. Machine Learning (2005), pp. 617–624.
27. Z. Niu, S. Shan, S. Yan, X. Chen and W. Gao, 2D Cascaded AdaBoost for eye Local-ization, Proc. 18th Int. Conf. Patt. Recogn. 2 (2006) 1216–1219.
28. M. Oren, C. Papageorgiou, P. Sinha, E. Osuna and T. Poggio, Pedestrian detec-tion using wavelet templates, Proc. Computer Vision and Pattern Recognition (1997),pp. 193–199.
29. M. Osadchy, M. L. Miller and Y. LeCun, Synergistic face detection and pose estima-tion with energy-based models, Advances in Neural Information Processing Systems,eds. L. K. Saul, Y. Weiss and L. Bottou, Vol. 17 (MIT Press, 2005), pp. 1017–1024.
30. T. Riopka and T. Boult, The eyes have it, Proc. ACM SIGMM Workshop on Biomet-rics Methods and Applications (WBMA) (2003), pp. 9–16.
31. Y. Rodriguez, F. Cardinaux, S. Bengio and J. Mariethoz, Measuring the performanceof face localization systems, Imag. Vis. Comput. 24 (2006) 882–893.
32. Schneiderman and T. Kanade, Object detection using the statistics of parts, Int. J.Comput. Vis. 56(1) (2004) 151–177.
33. S. Shan, Y. Chang, W. Gao and B. Cao, Curse of mis-alignment in face recognition:problem and a novel mis-alignment learning solution, Int. Conf. Autom. Face andGesture Recognition (2004), pp. 314–320.
34. P. Shih and C. Liu, Face detection using discriminating feature analysis and supportvector machine, Patt. Recogn. 39 (2006) 260–276.
35. X. Tang, Z. Ou, T. Su, H. Sun and P. Zhao, Robust precise eye location by AdaBoostand SVM techniques, Proc. Int. Symp. Neural Networks (2005), pp. 93–98.
36. P. Viola and M. Jones, Robust real time object detection, Int. J. Comput. Vis. 57(2)(2004) 137–154.
37. P. Wang and Q. Ji, Multi-view face and eye detection using discriminant features,Comput. Vis. Imag. Underst. 105(2) (2007) 55–62.
38. Z. Wencong, C. Hong, Y. Peng, L. Bin and Z. Zhenquan, Precise eye localization withAdaboost and fast radial symmetry, Proc. Int. Conf. Computational Intelligence andSecurity 1 (2006) 725–730.
39. XM2VTS DB, Web address: http://www.ee.surrey.ac.uk/Research/VSSP/xm2vtsdb/.
40. W. Zhao, R. Chellappa, P. J. Phillips and A. Rosenfeld, Face recognition: a literaturesurvey, ACM Comput. Surv. 35(4) (2003) 399–458.
41. Z. H. Zhou and X. Geng, Projection functions for eye detection, Patt. Recogn. J. 37(2004) 1049–1056.

May 6, 2009 17:45 WSPC/115-IJPRAI SPI-J068 00725
Precise Eye and Mouth Localization 377
Paola Campadelli re-ceived the Laurea degreein biological sciencesfrom the Universita deg-li Studi di Modena(Italy) in 1975 andthe Ph.D in computerscience from the Uni-versita degli Studi diMilano (Italy) in 1988.
She has been a researcher at the ItalianNational Scientific Council (CNR) from 1976to 1992, thereafter she joined the Universitadegli Studi di Milano as Associate Professorin Cybernetics and, since 2000, as Full Pro-fessor in Computer Science. She is currentlyleading the Laboratory for the Analysis ofImages and Vision (LAIV) of the ComputerScience Department at the same University.
Giuseppe Lipori re-ceived the Laurea degreein computer science, aswell as the Ph.D inmathematics and statis-tics for computationalsciences, from the Uni-versita degli Studi diMilano (Italy) in 2003and 2006 respectively.
Currently, he is a Post-doc researcher at thesame University.
Raffaella Lanzarottireceived her Laurea deg-ree and Ph.D in com-puter science from theUniversity of Milan in1999 and 2003 respec-tively. Currently she isAssistant Professor atthe Department of Com-puter Science at thesame University.




























