Embed Size (px)
Citation preview

CURSO LINUX
Módulo Configuração de Redes TCP/IP
por
Celso Kopp Webber


Curso Linux Básico
Módulo Configuração de Redes TCP/IP i
SUMÁRIO
1 INTRODUÇÃO 1
2 INTERFACE DE COMUNICAÇÃO 3
2.1 Reconhecimento das Interfaces de Rede 3
2.2 Configuração as Interfaces 4
2.3 Tabela ARP 6
3 ROTEAMENTO DE DATAGRAMAS IP 8
3.1 Tabela de Roteamento Mínimo 8
3.2 Verificação de Conectividade 10
3.3 Roteamento Dinâmico 11
3.3.1 RIP - Routing Information Protocol 12
4 DOMAIN NAME SERVICE (DNS) 15
4.1 Configuração do Resolver 16
4.2 Configuração do BIND 17
5 NETWORK FILE SYSTEM (NFS) 25
5.1 Exportando Arquivos 25
5.2 Montando Diretórios Remotos 27
6 SESSION MESSAGE BLOCK (SMB) – SAMBA 28
6.1 Resolução de Nomes NetBIOS 28
6.2 Samba – Servidor e Cliente SMB 29
6.2.1 Iniciando o Samba 30
6.2.2 Configuração do arquivo smb.conf 30
7 NETWORK INFORMATION SERVICE (NIS) 35


Curso Linux Básico
Módulo Configuração de Redes TCP/IP 1
1 INTRODUÇÃO
Configurar uma rede TCP/IP envolve conhecer os sistemas operacionais dos computadores
envolvidos, bem como dominar os aspectos teóricos da arquitetura de redes TCP/IP.
Dessa forma, este texto assume que o leitor possui prévio conhecimento de redes TCP/IP,
incluindo:
Conceitos básicos de redes de computadores, incluindo a arquitetura IEEE 802 para
LANs e MANs;
camadas, protocolos, e funcionamento da arquitetura TCP/IP;
endereçamento IP;
roteamento IP, sendo obrigatórios os conceitos de roteamento mínimo e roteamento
estático;
noções sobre os serviços mais comuns sobre TCP/IP, como e-mail, WWW, FTP, e DNS;
conhecimentos sólidos do sistema operacional UNIX, a nível de usuário.
O material descrito a seguir está voltado para o sistema operacional UNIX, tanto a nível de
comandos de configuração, como arquivos de configuração.
Assim, o objetivo final do texto é apresentar ao leitor um resumo dos pontos chave da
configuração de redes TCP/IP utilizando o sistema operacional UNIX, tanto como cliente, como
servidor.
Já que qualquer teoria sem prática tem seu utilidade reduzida, as explicações a seguir tentam,
sempre que possível, apresentar os comandos de forma geral. Quando necessário, diferenças entre
sistemas operacionais UNIX diferentes são mostradas. Porém, o sistema operacional Linux é
tomado como base durante o texto. A razão do Linux ter sido adotado como exemplo principal é a
sua crescente popularidade, o fato de ser gratuito, a grande gama de hardware suportado (desde PCs
até processadors RISC de alto desempenho), e sua fácil instalação em relação a alguns UNIX
comerciais.
Pode-se dizer hoje que é possível que qualquer pessoa com conhecimentos razoáveis de
informática consiga instalar o Linux em sua máquina.
No decorrer do texto, as seguintes notações são utilizadas:
negrito: as palavras em negrito constituem o próprio comando e devem ser digitadas
exatamente como estão escritas;
normal: o texto normal é usado para opções dos comandos, e também deve ser digitado tal
qual está escrito;
sublinhado: o texto em sublinhado representa os parâmetros que o usuário especifica, como
por exemplo uma opção de um comando;
[colchetes]: todo o texto entre colchetes é opcional, e pode ser omitido. Os colchetes não
devem ser digitados;
...: as reticências indicam que o item apresentado pode ser repetido uma ou mais vezes.
opção1 | opção2: quando opções separadas por uma barra vertical são apresentadas, uma
delas deve ser escolhida somente.
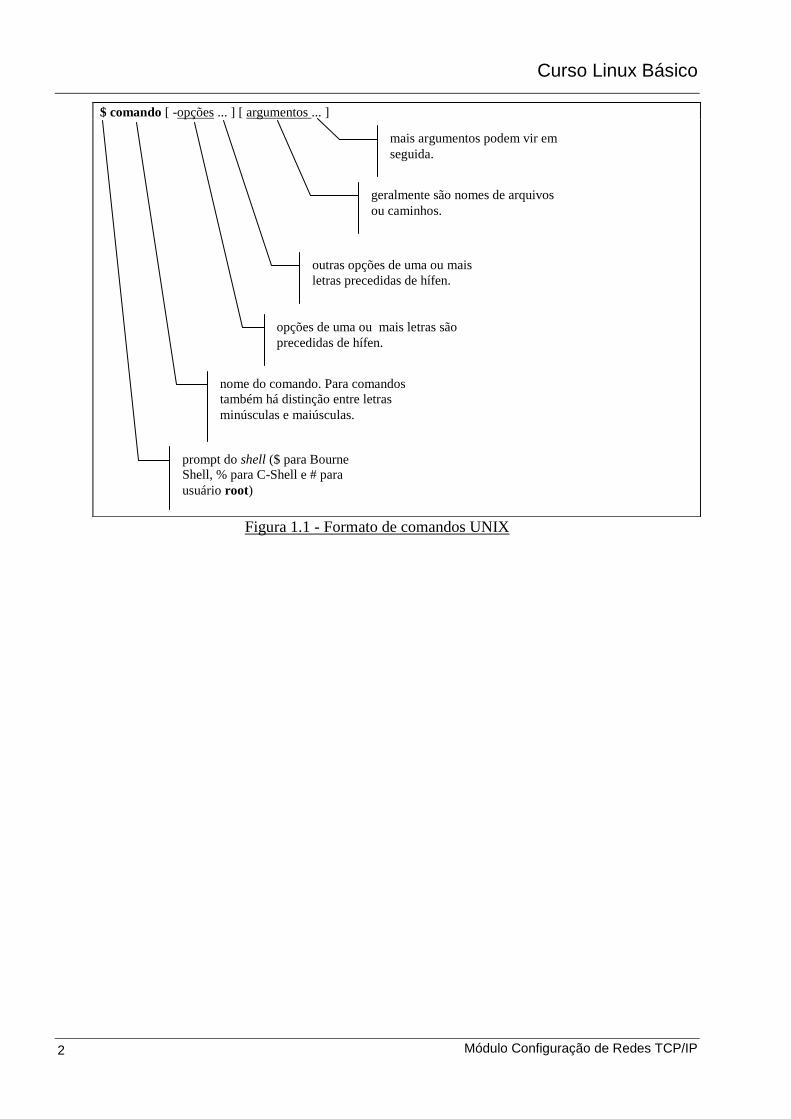
A figura 1.1 ilustra as notações acima, descrevendo o formato geral de um comando UNIX:
Curso Linux Básico
Módulo Configuração de Redes TCP/IP 2
Figura 1.1 - Formato de comandos UNIX
$ comando [ -opções ... ] [ argumentos ... ]
mais argumentos podem vir em
seguida.
geralmente são nomes de arquivos
ou caminhos.
outras opções de uma ou mais
letras precedidas de hífen.
opções de uma ou mais letras são
precedidas de hífen.
nome do comando. Para comandos
também há distinção entre letras
minúsculas e maiúsculas.
prompt do shell ($ para Bourne
Shell, % para C-Shell e # para
usuário root)

Curso Linux Básico
Módulo Configuração de Redes TCP/IP 3
2 INTERFACE DE COMUNICAÇÃO
Configurar máquinas UNIX para operar em uma rede TCP/IP é uma tarefa relativamente
fácil. Entretanto, diferentemente de outros sistemas operacionais voltados para uso individual, o
UNIX precisa ser configurado por um administrador de sistemas para que seus usuários possam
utilizá-los adequadamente.
O primeiro passo que um administrador de sistemas deve realizar ao conectar uma máquina
UNIX a uma rede TCP/IP é configurar suas interfaces de rede. Para isso é necessário primeiro
informar ao sistema operacional as interfaces de rede existentes.
2.1 Reconhecimento das Interfaces de Rede
Este tópico é bastante disperso. Um problema grave com o UNIX atualmente é que existem
diversos fornecedores. Cada um dá seus próprios nomes para placas de rede, terminais, impressoras,
etc. Da mesma forma, cada um implementa um método próprio para operar com o hardware
existente, isto é, a implementação dos drivers para dispositivos, incluindo as placas de rede, não é
padronizada.
Por isso, fazer o sistema operacional (SO) reconhecer todos os dispositivos em uma máquina
muitas vezes não é tarefa simples.
No caso de interfaces de rede, muitas vezes o fabricante da placa fornece o próprio driver em
um disquete que acompanha a placa. Em outros casos, o SO possui suporte nativo para
determinadas marcas e modelos de interfaces de rede.
A recomendação mais sensata é que antes de decidir por qual computador adquirir para
determinada tarefa, conferir qual é o hardware suportado pelo SO. O Linux, apesar de ser de
domínio público, possui grande suporte a hardware de diversos fabricantes. Raramente um
fabricante de hardware fornece drivers para Linux (apesar que isto está começando a mudar), mas
em geral, o sistema suporta as marcas mais comuns de placas diversas.
Fazer o SO reconhecer uma placa de rede envolve basicamente três etapas:
Configurar a placa através de jumpers, dip switches, etc;
instalar fisicamente a placa no computador (e configurá-la via software quando for o caso);
instalar o driver correspondente no sistema operacional, informando os parâmetros
configurados nos passos anteriores.
Em alguns casos, o sistema operacional será capaz de reconhercer automaticamente o
hardware do computador. Infelizmente, tecnologias mais antigas como o barramento ISA em PCs
não ajuda muito nesta tarefa. Placas que utilizam o barramento PCI resolvem este problema fazendo
com que o sistema operacional consiga obter a configuração necessária de todos os dispositivos
instalados no barramento.
Genericamente, o sistema operacional reconhece as placas de rede de duas maneiras:
1. O driver faz parte do kernel do sistema operacional. Esta abordagem é antiga, estando em
desuso pela maioria dos UNIX modernos. Entretanto, pode ser necessário recompilar o
kernel de algum sistema mais antigo para incluir o driver do dispositivo que se deseja
reconhecer;
O driver pode ser carregado separadamente pelo kernel do SO. Assim, o kernel é
especializado nas suas funções, e somente os drivers necessários são carregados em

Curso Linux Básico
Módulo Configuração de Redes TCP/IP 4
memória. Isto reduz seu tamanho e aumenta sua eficiência. A maioria dos UNIX atuais
utiliza esta abordagem.
Como exemplos, no Linux os comandos:
insmod nome-do-driver [ parâmetros ] e
modprobe nome-do-driver
são usados para inserir um driver (chamado de módulo no Linux) em memória. Os parâmetros
podem ser especificados com o comando insmod, ou podem ser “adivinhados” com o comando
modprobe. No Solaris da Sun, o comando equivalente é o modload. As páginas de manual on-line
(comando man) devem ser consultadas para maiores detalhes.
Uma vez que o SO tenha reconhecido as interfaces de rede, sejam elas Ethernet, Token Ring,
FDDI, etc., resta-nos saber que nome o SO utiliza para fazer referência a elas sob o diretório /dev.
A tabela a seguir mostra como algumas versões de UNIX chamam as interfaces Ethernet (as mais
usadas):
Sistema Operacional Nome adotado para a primeira interface Ethernet
SCO UNIX depende do fabricante (ex: e3B0)
Linux eth0
Digital UNIX ln0, tu0
Solaris le0
SunOS le0, ie0, ec0
AIX en0 (Ethernet), et0 (802.3)
HP-UX lan0
Outros tipos de interfaces possuem outros nomes sob o diretório /dev, como por exemplo fi0
para interfaces FDDI. A interface loopback, implementada em software, é chamada de lo0 em todos
os UNIX, exceto no Linux, que simplesmente a denomina lo.
2.2 Configuração as Interfaces
O comando ifconfig é usado para informar ao sistema operacional o endereço IP, a máscara
de subrede (netmask), e o endereço de broadcast para cada interface de comunicação.
SINOPSE:
ifconfig [ interface ]
ifconfig interface [ addr_family ] [ address ] [ netmask mask ] [ broadcast address ] [ up | down ] [ [-]arp ] [ metric n ] [ mtu n ]
ARGUMENTOS:
interface: nome da interface de rede a ser configurada (eth0, lo, etc);
addr_family: parâmetro opcional que informa o tipo de endereço sendo configurado. Para endereços IP, este parâmetro deve ser inet;
address: especifica address como o endereço IP associado à interface;
netmask mask: associa a máscara de rede mask à interface;
broadcast address: informa o endereço de broadcast da interface para address.

Curso Linux Básico
Módulo Configuração de Redes TCP/IP 5
EXPLICAÇÃO:
Na primeira forma, o comando apenas mostra a situação da interface especificada, ou de todas as interfaces, caso este parâmetro seja omitido.
Na segunda forma, especifica uma interface e seus parâmetros a serem configurados.
EXEMPLO:
Na terceira linha aparece uma lista de opções:
up: a interface está habilitada para o uso;
down: a interface está desabilitada para o uso;
broadcast: a interface suporta broadcast;
notrailers: a interface não suporta trailers;
running: a interface está operacional.
Pode-se usar um hostname em vez do endereço IP. Neste caso, o arquivo /etc/hosts deve
conter a entrada correspondente ao nome utilizado.
Usando um hostname, então, o comando poderia ser:
O ifconfig é normalmente executado na hora de inicialização da máquina por um arquivo de
boot. Nos sistemas BSD, os comandos do ifconfig geralmente estão localizados nos arquivos
/etc/rc.boot e /etc/rc.local. Nos sistemas System V, os comandos do ifconfig geralmente estão
localizados em arquivos como /etc/tcp e /etc/init.d/tcp.
Os parâmetros adicionais do ifconfig mais utilizados são descritos abaixo:
root@frajola# ifconfig eth0
eth0 Link encap:Ethernet HWaddr 00:60:52:00:EF:F5
inet addr:10.0.0.254 Bcast:10.0.0.255 Mask:255.255.255.0
UP BROADCAST RUNNING MULTICAST MTU:1500 Metric:1
RX packets:307 errors:0 dropped:0 overruns:0
TX packets:260 errors:0 dropped:0 overruns:0
Interrupt:10 Base address:0x320
venus# cat /etc/hosts
127.0.0.1 localhost loghost
#
# inf.ufsc.br Subnet
#
150.162.60.1 venus loghost
150.162.60.2 apolo
150.162.60.3 vesta
150.162.60.4 atlas
150.162.60.5 ceres
150.162.60.6 baco
venus# ifconfig le0 venus

Curso Linux Básico
Módulo Configuração de Redes TCP/IP 6
down: desabilita a interface;
up: habilita a interface;
metric n: define a métrica como sendo n;
arp: habilita o uso do protocolo ARP no mapeamento entre os endereços do nível de rede e os endereços do nível de interface de rede;
-arp: desabilita o uso do protocolo ARP;
mtu n: define o MTU como sendo n.
As páginas de manual sobre o comando ifconfig dão maiores detalhes das opções de
configuração.
2.3 Tabela ARP
A tabela ARP (Address Resolution Protocol) descreve, para cada interface de uma máquina
que roda a protocolo IP, a relação entre endereços lógicos (endereços IP) e endereços físicos
(endereços da placa de rede, por exemplo, um endereço MAC Ethernet).
Toda vez que uma máquina precisa comunicar-se via protocolo IP com outra, ela precisa
descobrir o endereço físico da placa de rede da máquina destino. O protocolo ARP cuida desta
função. Como cada tecnologia de rede (Ethernet, FDDI, Token Ring, ATM) possui seu próprio
formato de endereço, bem como diferentes métodos de acesso ao meio, o ARP é diferente para cada
tipo de placa de rede.
No ambiente UNIX, é possível manipular diretamente a tabela ARP, através do comando arp.
Em apenas casos muito específicos é necessário adicionar manualmente entradas na tabela ARP,
pois durante o funcionamento normal da rede, o próprio protocolo se encarrega da descoberta
dinâmica dos endereços físicos associados com os endereços lógicos que a máquina está tentando
acessar.
arp [ -v ] [ -n ] [ -i interface ] -a [ máquina ]
arp [ -v ] [ -i interface ] -s máquina endereço físico [ temp ]
arp [ -v ] [ -i interface ] -d máquina
ARGUMENTOS:
-v fornece mensagens detalhadas (verbose)
-n modo numérico, mostra apenas endereços, isto é, não tenta converter um endereço para o nome de uma máquina
root@frajola# ifconfig eth0 10.3.2.1 netmask 255.255.0.0 broadcast
10.3.255.255 up
root@frajola# ifconfig eth0
eth0 Link encap:Ethernet HWaddr 00:60:52:00:EF:F5
inet addr:10.3.2.1 Bcast:10.3.255.255 Mask:255.255.0.0
UP BROADCAST RUNNING MULTICAST MTU:1500 Metric:1
RX packets:307 errors:0 dropped:0 overruns:0
TX packets:260 errors:0 dropped:0 overruns:0
Interrupt:10 Base address:0x320

Curso Linux Básico
Módulo Configuração de Redes TCP/IP 7
-i interface especifica o nome da interface de rede cuja table ARP será manipulada;
-a máquina a opção “-a” mostra a tabela ARP. Se um nome ou endereço de máquina é especificado, mostra somente as entradas daquela máquina
-s máquina end.fís. adiciona uma entrada manualmente à tabela, associando o endereço lógico de uma máquina ao seu endereço físico. Se a opção “temp” é especificada, a entrada é temporária, sendo eliminada após um tempo padrão, caso contrário a entrada é estática (permanente)
-d máquina remove a entrada correspondente ao nome ou endereço de uma máquina

Curso Linux Básico
Módulo Configuração de Redes TCP/IP 8
3 ROTEAMENTO DE DATAGRAMAS IP
Existem 3 tipos básicos de configurações de roteamento:
Roteamento mínimo: uma rede completamente isolada de todas as demais redes TCP/IP
necessita somente de um roteamento mínimo;
Roteamento estático: uma rede com um número limitado de gateways para outras redes
TCP/IP pode ser configurada com roteamento estático;
Roteamento dinâmico: uma rede com mais de uma possível rota para o mesmo destino
deve usar o roteamento dinâmico.
Rotas são construídas pelo próprio processo de boot do sistema, baseando-se nas informações
usadas para o comando ifconfig, manualmente pelo administrador (através do comando route) ou
dinamicamente pelos protocolos de roteamento.
As rotas estão sempre organizadas numa tabela própria.
3.1 Tabela de Roteamento Mínimo
Uma tabela de roteamento mínimo é construída pelos scripts de boot do sistema operacional
após a configuração da interface com o comando ifconfig. O roteamento mínimo é composto de
uma rota para cada rede a que pertence cada interface (incluindo a interface loopback), e uma rota
default.
Com exceção do Linux, todos os UNIX constroem a tabela de roteamento mínimo
automaticamente a partir do comando ifconfig. Entretanto, é ainda necessário estabelecer uma rota
default. Cada versão de UNIX obtém o roteador default a partir de localizações diferentes. Por
exemplo, o Solaris da Sun obtém esta informação do arquivo /etc/defaulroute, enquanto o RedHat
Linux obtém do arquivo /etc/sysconfig/network.
O comando netstat pode ser usado para mostrar informações sobre conexões da máquina, e
também para mostrar a tabela de rotas.
SINOPSE:
netstat [ -n ] [ -r ] [ -i interface ]
ARGUMENTOS:
interface: nome da interface de rede da qual se deseja obter informações sobre conexões;
-n: mostra endereços e portas em modo numérico, isto é, não faz tradução para nomes;
-r: mostra a tabela de rotas corrente;
-i interface: mostra somente informações relacionadas à interface especificada;
EXPLICAÇÃO:
Em geral, o comando netstat é utilizado com as opções –rn para mostrar a tabela de rotas. Adicionalmente, pode ser usado para verificar quais conexões estão atualmente abertas com a máquina.

Curso Linux Básico
Módulo Configuração de Redes TCP/IP 9
EXEMPLO:
No campo Flags da saída do comando netstat, temos os significados:
U: A rota está no ar (Up);
H: A rota é para um host (máquina);
G: A rota é estabelecida passando por um gateway;
D: Rota aprendida dinamicamente, ou por um daemon de roteamento
dinâmico, ou pelo recebimento de um ICMP Redirect.
O comando route é usado para a criação de uma tabela estática, adicionando ou removendo
rotas manualmente. Rotas adicionadas com o comando route só podem ser removidas com outro
comando route. Quando uma máquina não está atuando como um gateway, o roteamento mínimo
provido com o comando route é suficiente. Quando um determinado gateway está configurado para
um esquema de roteamento simples, também é suficiente estabelecer algumas rotas estáticas com o
comando route. Os rotadores principais de uma rede maior são em geral candidatos a utilizar
roteamento dinâmico.
SINOPSE:
route add [ -host | -net ] destination [ netmask mask ] [ gateway router ] [ metric M ] [ mss M ] [ window W ] [ device ]
route del [ -host | -net ] destination [ netmask mask ] [ gateway router ] [ device ]
ARGUMENTOS:
-host ou –net: determina se a rota é para um máquina ou para uma rede. Se este parâmetro for omitido, é assumido o valor “-host”;
destination: informa destino da rota;
netmask mask: utiliza mask como máscara de subrede para esta rota;
gateway router: utiliza router como o gateway para esta rota. Se for utilizado como gateway um endereço de uma das interfaces da máquina, a rota será estabelecida enviando diretamente por aquela interface;
device: nome da interface de rede que esta rota utilizará como saída;
metric M: estabelece a métrica para a rota sendo estabelecida;
mss M: estabelece o MSS – Maximum Segment Size (tamanho máximo do segmento) TCP a usar com esta rota;
window W: informa o tamanho da janela TCP a ser usada nessa rota.
EXPLICAÇÃO:
Algumas versões do comando route entendem que se destination for uma rede à qual uma das interfaces da máquina pertence, uma rota do roteamento mínimo está
apolo# netstat -rn
Kernel IP routing table
Destination Gateway Genmask Flags MSS Window irtt Iface
255.255.255.255 0.0.0.0 255.255.255.255 UH 1500 0 0 eth0
10.0.0.0 0.0.0.0 255.255.255.0 U 1500 0 0 eth0
127.0.0.0 0.0.0.0 255.0.0.0 U 3584 0 0 lo
0.0.0.0 192.1.2.3 0.0.0.0 UG 1500 0 0 ppp0

Curso Linux Básico
Módulo Configuração de Redes TCP/IP 10
sendo feita, e por isso os outros parâmetros não precisam ser especificados. É recomendável sempre o uso do parâmetro netmask, caso contrário geralmente o comando assume a máscara padrão (conforme a classe) do endereço destino especificado.
EXEMPLO:
Se a palavra chave default for utilizada como destination, route cria uma rota default. Esta
rota default é utilizada quando não há uma rota específica para o destino desejado. É possível
especificar a rota default estabelecendo uma rota para a rede 0.0.0.0.
Para se colocar as informações de roteamento estático nos arquivos de boot duas modificações
são necessárias:
Adicionar a rota desejada ao arquivo de boot;
Remover (ou comentar) do arquivo de boot comandos que chamem algum protocolo de
roteamento.
Os arquivos a serem modificados variam conforme a plataforma. Nos UNIX baseados em
BSD, geralmente os comandos de adição de rotas estáticas e/ou de execução de protocolo de
roteamento estão nos arquivos /etc/rc.*. No System V, geralmente estão sob o diretório /etc/init.d,
no arquivo boot, tcp ou inet.
3.2 Verificação de Conectividade
Freqüentemente em uma rede é necessário saber se uma máquina “enxerga” outra. A
ferramenta de diagnóstico mais popular entre os usuários e administradores de rede é o “ping”. ping
é um utilitário onde a máquina origem envia uma mensagem ICMP “echo request” (solicitação de
eco) para a máquina destino. Se esta estiver no ar, ao receber o “echo request” ela responde com
outra mensagem ICMP “echo reply” (resposta de eco).
root@frajola# route add -net 10.3.0.0 netmask 255.255.0.0
root@frajola# route add –net 10.2.1.0 netmask 255.255.255.0 gateway
10.3.0.254 eth0
root@frajola# netstat –rn
Kernel IP routing table
Destination Gateway Genmask Flags MSS Window irtt Iface
10.3.0.0 0.0.0.0 255.255.0.0 U 1500 0 0 eth0
10.2.1.0 10.3.0.254 255.255.255.0 UG 1500 0 0 eth0
127.0.0.0 0.0.0.0 255.0.0.0 U 3584 0 0 lo
root@frajola# route add default gateway 10.3.0.252
root@frajola# route add –net 0.0.0.0 gateway 10.3.0.252
root@frajola# netstat -rn
Kernel IP routing table
Destination Gateway Genmask Flags MSS Window irtt Iface
10.3.0.0 0.0.0.0 255.255.0.0 U 1500 0 0 eth0
10.2.1.0 10.3.0.254 255.255.255.0 UG 1500 0 0 eth0
127.0.0.0 0.0.0.0 255.0.0.0 U 3584 0 0 lo
0.0.0.0 10.3.0.252 0.0.0.0 UG 1500 0 0 eth0

Curso Linux Básico
Módulo Configuração de Redes TCP/IP 11
SINOPSE:
ping [ -f ] [ -i tempo espera ] [ -count quantidade ] destino
ARGUMENTOS:
-f envia um novo “ping” assim que receber a resposta do anteriormente enviado. A comportamento default é enviar uma requisição a cada segundo;
-i tempo espera informa o tempo entre cada envio de um novo “ping”;
-count quantidade informa quantos “pings” devem ser enviados. O comportamento default é enviar “pings” eternamente, até o comando ser cancelado;
destino: informa o endereço ou nome da máquina destino.
`
3.3 Roteamento Dinâmico
Todos os protocolos de roteamento possuem a mesma função básica: determinar a melhor rota
para cada destino e distribuir informações de roteamento entre os sistemas em uma rede.
Protocolos de roteamento são divididos em dois grupos principais:
Internos: São protocolos utilizados internamente em uma rede independente. Na
terminologia TCP/IP, estes sistemas de redes são chamados de “sistemas autônomos”
(AS). Dentro de um AS, as informações de roteamento são trocadas utilizando um
protocolo interno escolhido pelo administrador local. Exemplos de protocolos de
roteamento internos incluem o RIP (Routing Information Protocol), o IGRP (Internet
Gateway Routing Protocol) e o EIGRP (Enhanced IGRP), e o OSPF (Open Shortest Path
First);
Externos: São protocolos utilizados para trocar informações de roteamento entre
sistemas autônomos. As informações de roteamento trocadas entre os AS são chamadas
de informações de alcançabilidade. Informação de alcançabilidade é simplesmente a
informação sobre quais redes podem ser alcançadas através de um AS. Exemplos destes
protocolos são o antigo EGP (Exterior Gateway Protocol), que está em desuso, e o mais
recente BGP (Border Gateway Protocol).

Curso Linux Básico
Módulo Configuração de Redes TCP/IP 12
O figura a seguir mostra um exemplo de vários AS interconectados pelo protocolo BGP. Note
que as empresas conectadas aos provedores não utilizam nenhum protocolo de roteamento dinâmico
entre elas e os provedores. Isto é bastante fácil de compreender, afinal a empresa possui apenas um
canal de saída, que é o provedor, bastando portanto configurar seu roteador para apontar a rota
default para o roteador do provedor. Internamente, as empresas utilizam seus próprios protocolos de
roteamento.
A definição de um AS, de acordo com a RFC 1930, é a seguinte:
“Um AS é um grupo conectado de um ou mais prefixos de endereços IP,
administrados por um ou mais operadores de rede que possuem uma
ÚNICA e CLARAMENTE DEFINIDA política de roteamento.”
Assim, um AS é visto como um conjunto de redes cujos endereços IP “começam” com o
mesmo prefixo, por exemplo, todas as redes classe C que começam com “200.135”.
O protocolo IP, ao decidir por onde enviar um datagrama, consulta uma tabela de roteamento.
Com os protocolos de roteamento dinâmicos, esta tabela é constantemente atualizada, de forma
automática. Caso mais de uma rota exista para um determinado destino, o campo métrica das rotas
é comparado. A rota com a menor métrica é então escolhida.
O significado da métrica depende de cada protocolo de roteamento em uso. O protocolo IP
simplesmente escolhe a rota com menor métrica.
Vejamos a seguir um exemplo de protocolo de roteamento dinâmico, incluindo seu
funcionamento básico e suas considerações sobre métricas.
3.3.1 RIP - Routing Information Protocol
É o protocolo interno mais utilizado, pois é disponibilizado como parte da maioria dos
sistemas UNIX. RIP seleciona a rota com o menor hop count como sendo a melhor. O hop count
ABC Ltda
RIP
Provedor
Baía Norte
EIGRP
Cia. das
Índias
IGRP
Provedor
Bananal Sul
EIGRP
Serralheria
Metal Sul
EIGRP
Provedor
Manezinho
OnLine
OSPF
Provedor
Bananal Sul
EIGRP
BGP
BGP
BGP
BGP

Curso Linux Básico
Módulo Configuração de Redes TCP/IP 13
representa o número de gateways que o pacote passa até chegar ao seu destino final. A melhor rota
é aquela que usa o menor número de gateways. Assim, a métrica utilizada pelo RIP é “o número de
roteadores” até o destino final. No UNIX, o protocolo RIP é executado através do servidor de
roteamento routed.
Quando um sistema configurado para prover informação RIP escuta uma requisição, ele
responde com um pacote de atualização baseado na sua tabela de roteamento. Este pacote de
atualização contém o endereço destino retirado da tabela de roteamento e a métrica associada a cada
destino.
Pacotes de atualização não são apenas enviados em resposta a solicitações, mas são também
enviados periodicamente para manter as informações de roteamento atualizadas. O routed envia
periodicamente, a cada 30 segundos, todas as rotas que possui para todas as interfaces configuradas.
Quando um pacote de atualização é recebido pelo routed, ele obtém estas informações e atualiza
suas tabelas de roteamento. Se a rota recebida não consta da tabela ela é adicionada. Se a rota
recebida descreve uma rota para um endereço que já existe, ela somente é usada se possuir um custo
(métrica) menor.
O protocolo RIP também remove rotas da tabela de roteamento. Existem duas razões para isto
acontecer:
1. O gateway para o destino diz que o custo da rota é maior que 15 hops;
2. gateways por onde passam certas rotas não enviaram pacotes de atualização por um dado
período, portanto foram considerados fora de serviço. As rotas que passam por eles são
consideradas inválidas.
O routed vem geralmente incluído nos arquivos de boot. A maioria dos sistemas usa
/etc/routed para rodar o servidor, mas os sistemas SunOS usam /usr/etc/in.routed. No Linux,
normalmente é encontrado em /usr/sbin/in.routed.
Nos UNIX que seguem a linha BSD, o routed é geralmente executado a partir do script de
inicialização /etc/rc.local. No System V, normalmente existe um script próprio chamado
/etc/init.d/routed para executar este daemon.
O routed pode construir uma tabela de roteamento só com as informações recebidas dos
pacotes de atualização, mas algumas vezes é necessário alguma forma de complemento, como uma
rota default inicial. O arquivo /etc/gateways contém estas informações adicionais de roteamento.
routed lê o arquivo /etc/gateways quando é inicializado. O uso mais comum do arquivo
/etc/gateways é definir uma rota default ativa, como no exemplo a seguir:
Todas as entradas do arquivo /etc/gateways começam com a palavra net ou host para indicar
quando o endereço que segue é de uma rede ou de um host. No comando route o parâmetro default
é utilizado para indicar a rota default, mas no arquivo /etc/gateways a rota default é indicada pelo
endereço 0.0.0.0. O parâmetro gateway vem seguido do seu endereço IP e a métrica pelo seu valor.
Todas as entradas do arquivo /etc/gateways terminam com o parâmetro passive ou active.
SINOPSE:
routed [ -q ] [ -g ] [ -s ]
ARGUMENTOS:
# net 0.0.0.0 gateway 150.162.1.1 metric 1 active

Curso Linux Básico
Módulo Configuração de Redes TCP/IP 14
-q: Instrui o routed a apenas “escutar” rotas, sem anunciar as suas próprias rotas (quiet);
-g: Anuncia aos demais roteadores uma rota default apontando para si. Geralmente isto é usado em um gateway padrão de uma rede, para que os outros roteadores apontem suas rotas default para ele;
-s: Força o routed a anunciar suas rotas. Normalmente, routed apenas anuncia suas rotas a cada 30 segundos se a máquina possuir mais de uma interface de rede configurada (excetuando-se a interface loopback).
EXPLICAÇÃO:
Normalmente, o backbone de uma rede conterá vários roteadores para redes menores. Um dos roteadores no backbone será o roteador padrão, que fará o roteamento para o mundo externo. Assim, o roteador padrão deveria executar routed com as opções –s e –g, enquanto os demais apenas com a opção –s.
EXEMPLOS:
NO GATEWAY PADRÃO
root@frajola# routed –s –g
NOS DEMAIS GATEWAYS
root@frajola# routed –s
EM GATEWAYS PARA UMA ÚNICA REDE
root@frajola# routed -q

Curso Linux Básico
Módulo Configuração de Redes TCP/IP 15
4 DOMAIN NAME SERVICE (DNS)
Freqüentemente os usuários de uma rede sabem o nome da máquina à qual desejam se
conectar na Internet, mas raramente conhecem o endereço IP correspondente. Entretanto, o
protocolo IP trabalha com endereços.
Assim, uma forma de traduzir nomes em endereços faz-se necessária. No início da utilização
do TCP/IP na ARPANET, uma tabela estática com todos os nomes de máquinas e seus endereços
era mantida de forma centralizada pelo DOD NIC (Departmento Of Defense Network Information
Center). Quando uma máquina era adicionada à rede, as atualizações eram enviadas por e-mail ao
DOD NIC, que regularmente atualizava a tabela de hosts.
Regularmente, as demais máquinas da ARPANET copiavam através da rede esta tabela, o que
com o passar do tempo passou a ser uma tarefa dispendiosa e demorada.
A solução rapidamente adotada foi a concepção de um sistema de resolução de nomes com as
seguintes características principais:
provê um serviço de tradução de nomes para endereços (e endereços para nomes)
automatizado;
utiliza uma base de dados distribuída hierarquicamente, evitando centralizar informações
em um único ponto;
cada organização que registra um nome no sistema é responsável pelo gerenciamento dos
nomes abaixo de seu domínio;
é mantido um cache atualizável das informações obtidas, desta forma eliminando-se a
necessidade de se obter a mesma informação repetidamente.
Este sistema foi batizado de DNS (Domain Name Services) e divide o espaço de nomes em
domínios. Cada domínio deve possuir um servidor primário, e no mínimo um servidor secundário
para fins de redundância. A implementação do DNS usada na maioria dos sistemas UNIX é a
Berkeley Internet Name Domain (BIND).
O software do DNS é conceitualmente dividido em duas partes: um resolver e um servidor de
nomes. O resolver formula a consulta e solicita uma resposta. O servidor de nomes é o processo
que responde às consultas.
O servidor de nomes do BIND executa como um processo distinto chamado named.
Servidores de nomes são classificados conforme a sua configuração:
primary: servidores de onde todos os dados sobre o domínio são derivados. São ditos
authoritatives, por terem autoridade para responder a solicitações envolvendo máquinas
do seu domínio com informações próprias;
secondary: servidores que guardam consigo uma cópia das informações mantidas pelo
servidor primary. Também são authoritatives para o domínio;
caching-only: servidores caching-only recebem as respostas de todas as consultas de
outros servidores de nomes, e guardam em cache para usarem em futuras respostas a
solicitações. São chamados de servidores non-authoritatives. Servidores primários e
secundários também fazem caching para melhoria de desempenho.
Um servidor pode ser enquadrado em mais de uma categoria. Ele pode ser primary para um
domínio e secondary para outro, por exemplo.

Curso Linux Básico
Módulo Configuração de Redes TCP/IP 16
Os nomes do DNS têm uma organização hierárquica, constituindo de domínios aninhados
dentro de domínios. Os nomes são escritos da base para o topo, com pontos separando os níveis.
Os nós imediatamente abaixo da raiz da árvore (br, edu, com, …) são chamados de domínios
top-level. Um desses domínios, chamado arpa possui significado especial. Para que seja possível
fazer a tradução reversa de nomes, isto é, traduzir endereços para nomes, o nó arpa contém o nó
in-addr, que contém todos os endereços Internet (endereços IP). Na verdade, não existem outros
tipos de endereços alocados na árvore, mas o sistema inicialmente previu esta possibilidade.
Da mesma forma que um nome como www.cade.com.br é organizado na árvore no sentido
inverso, do mais geral (br), até o mais específico (www), os endereços IP também são organizados
no sentido inverso, como por exemplo, 1.250.135.200.in-addr.arpa, que representará o nome
correspondente ao endereço IP 200.135.250.1.
4.1 Configuração do Resolver
Toda máquina que utiliza o sistema DNS, independente de ser servidor DNS ou não, precisa
utilizar um resolver para traduzir consultas de nomes em endereços e endereços em nomes. O
resolver normalmente é uma biblioteca de funções ligada aos programas executáveis, como telnet,
ftp, etc.
No UNIX, a configuração do resolver é feita no arquivo /etc/resolv.conf .As cláusulas
permitidas no arquivo resolv.conf são:
www.cade.com.br
www.mit.edu
mail.hp.com
raiz “.”
br
com
cade
www
edu com
mit hp
www mail
arpa
in-addr
200
135
250
1 2

Curso Linux Básico
Módulo Configuração de Redes TCP/IP 17
nameserver address: identifica o servidor do qual o resolver pode solicitar informações sobre domínios. Mais de uma linha (normalmente até 3) podem aparecer com a cláusula nameserver. Os servidores são consultados na ordem em que eles aparecem no arquivo. Se nenhuma reposta é obtida do primeiro, o próximo é tentado e assim por diante;
domain domínio: define o nome do domínio default. O resolver adiciona o domínio default a todo nome de host que não contenha um ponto no final. Após isto, ele usa este nome de host expandido para fazer a consulta ao servidor de nomes;
search lista: especifica uma lista de domínios que o resolver deve tentar adicionar a nomes que não contenham um ponto no final. Cada entrada da lista é tentada até que uma delas seja encontrada, ou até que tenha sido esgotada.
O exemplo a seguir define o domínio minha.rede.com.br, com dois servidores de nomes, e
configura o resolver para tentar adicionar os domínios minha.rede.com.br e rede.com.br caso o
nome especificado nao termine com um ponto.
4.2 Configuração do BIND
Um servidor DNS pode servir vários domínios. Quando necessário, um domínio pode ser
subdividido em subdomínios. A parte de um domínio pela qual um servidor é responsável é
chamada de zona. Considere o domínio a seguir, subdividido em três zonas:
# cat /etc/resolv.conf
domain minha.rede.com.br
nameserver 200.135.250.1
nameserver 200.135.250.2
search minha.rede.com.br rede.com.br
raiz “.”
br
com
rede
jurere
minha sua
mole joaca
www
fusca bmw
zona “minha”
zona “rede”
zona “sua”
domínio “rede”
Curso Linux Básico
Módulo Configuração de Redes TCP/IP 18
Neste exemplo, toda a Internet enxerga que o servidor responsável pelo domínio rede.com.br
é também responsável pelos subdomínios, pois terminam em rede.com.br. Entretanto, o servidor
deste domínio pode “delegar” um ramo da árvore de rede.com.br, como por exemplo,
minha.com.br a um outro servidor.
Assim, um servidor é na verdade responsável por uma ou mais zonas de um domínio. Às
vezes um servidor é responsável por todo o domínio, mas ainda assim é importante diferenciar o
conceito de domínio de zona.
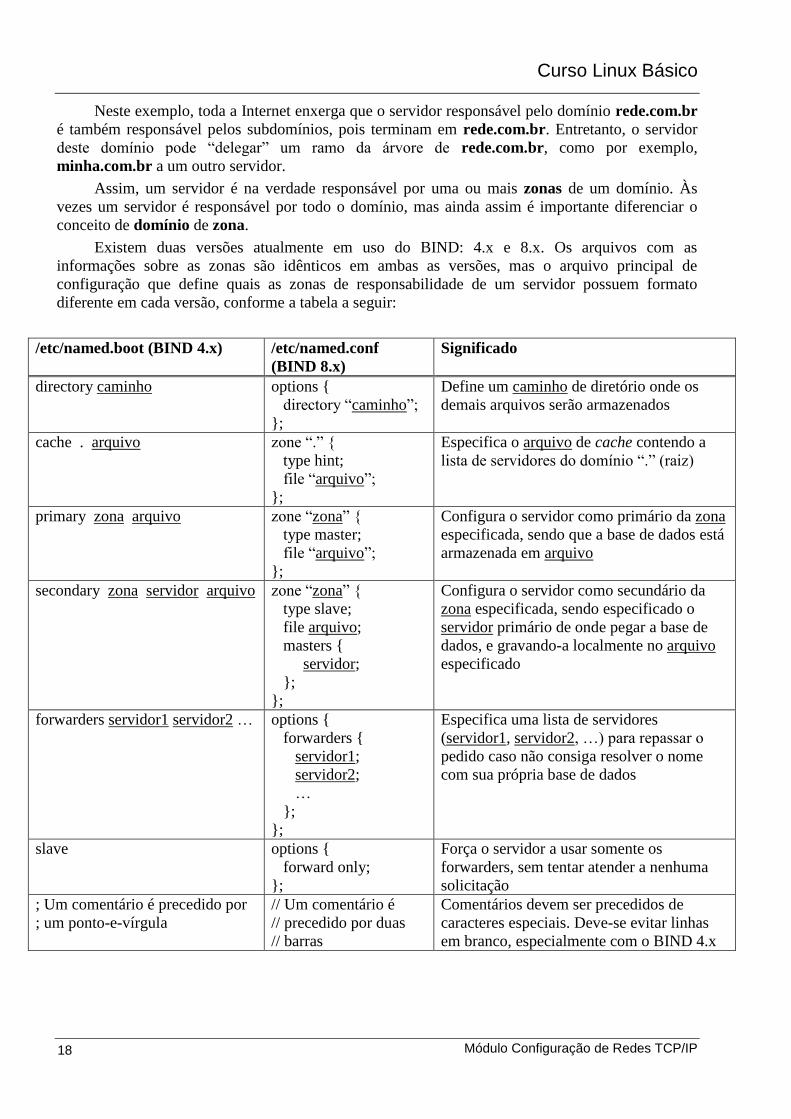
Existem duas versões atualmente em uso do BIND: 4.x e 8.x. Os arquivos com as
informações sobre as zonas são idênticos em ambas as versões, mas o arquivo principal de
configuração que define quais as zonas de responsabilidade de um servidor possuem formato
diferente em cada versão, conforme a tabela a seguir:
/etc/named.boot (BIND 4.x) /etc/named.conf
(BIND 8.x)
Significado
directory caminho options {
directory “caminho”;
};
Define um caminho de diretório onde os
demais arquivos serão armazenados
cache . arquivo zone “.” {
type hint;
file “arquivo”;
};
Especifica o arquivo de cache contendo a
lista de servidores do domínio “.” (raiz)
primary zona arquivo zone “zona” {
type master;
file “arquivo”;
};
Configura o servidor como primário da zona
especificada, sendo que a base de dados está
armazenada em arquivo
secondary zona servidor arquivo zone “zona” {
type slave;
file arquivo;
masters {
servidor;
};
};
Configura o servidor como secundário da
zona especificada, sendo especificado o
servidor primário de onde pegar a base de
dados, e gravando-a localmente no arquivo
especificado
forwarders servidor1 servidor2 … options {
forwarders {
servidor1;
servidor2;
…
};
};
Especifica uma lista de servidores
(servidor1, servidor2, …) para repassar o
pedido caso não consiga resolver o nome
com sua própria base de dados
slave options {
forward only;
};
Força o servidor a usar somente os
forwarders, sem tentar atender a nenhuma
solicitação
; Um comentário é precedido por
; um ponto-e-vírgula
// Um comentário é
// precedido por duas
// barras
Comentários devem ser precedidos de
caracteres especiais. Deve-se evitar linhas
em branco, especialmente com o BIND 4.x

Curso Linux Básico
Módulo Configuração de Redes TCP/IP 19
Configuração exemplo de um servidor (named.boot):
Configuração exemplo de um servidor (named.conf):
# cat /etc/named.boot
; named.boot – BIND 4.x
directory /var/named
cache . named.ca
primary 0.0.127.in-addr.arpa named.local
;
primary rede.com.br rede.zone
primary 250.135.200.in-addr.arpa rede.revzone
secondary minha.rede.com.br 200.135.251.1 minha.zone
secondary 251.135.200.in-addr.arpa 200.135.251.1 minha.revzone
;
forwarders 200.135.15.3 150.162.1.3
# cat /etc/named.conf
// named.conf – BIND 8.x
options {
directory “/var/named”;
forwarders {
200.135.15.3;
150.162.1.3;
};
};
zone “.” {
type hint;
file “named.ca”;
};
zone “0.0.127.in-addr.arpa” {
type master;
file “named.local”;
};
zone “rede.com.br” {
type master;
file “rede.zone”;
};
zone “250.135.200.in-addr.arpa” {
type master;
file “rede.revzone”;
};
zone “minha.rede.com.br” {
type slave;
file “minha.zone”;
masters {
200.135.251.1;
};
};
zone “251.135.200.in-addr.arpa” {
type slave;
file “minha.revzone”;
masters {
200.135.251.1;
};
};
Curso Linux Básico
Módulo Configuração de Redes TCP/IP 20
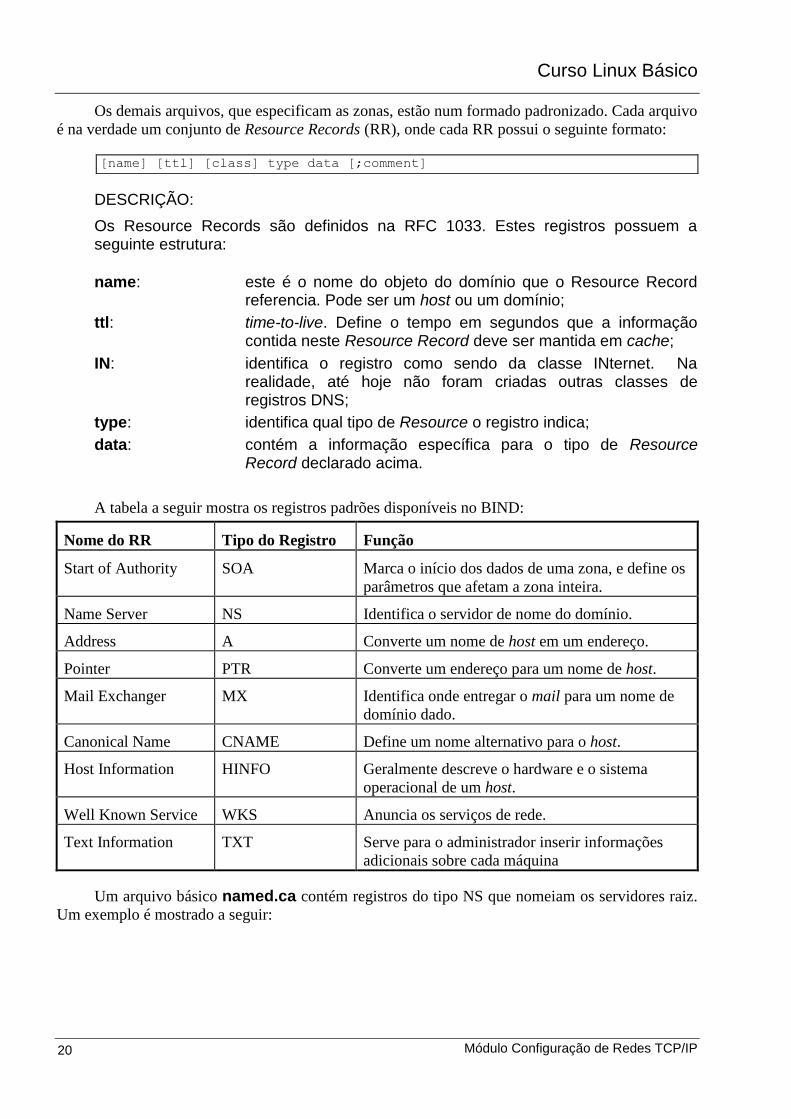
Os demais arquivos, que especificam as zonas, estão num formado padronizado. Cada arquivo
é na verdade um conjunto de Resource Records (RR), onde cada RR possui o seguinte formato:
DESCRIÇÃO:
Os Resource Records são definidos na RFC 1033. Estes registros possuem a seguinte estrutura:
name: este é o nome do objeto do domínio que o Resource Record referencia. Pode ser um host ou um domínio;
ttl: time-to-live. Define o tempo em segundos que a informação contida neste Resource Record deve ser mantida em cache;
IN: identifica o registro como sendo da classe INternet. Na realidade, até hoje não foram criadas outras classes de registros DNS;
type: identifica qual tipo de Resource o registro indica;
data: contém a informação específica para o tipo de Resource Record declarado acima.
A tabela a seguir mostra os registros padrões disponíveis no BIND:
Nome do RR Tipo do Registro Função
Start of Authority SOA Marca o início dos dados de uma zona, e define os
parâmetros que afetam a zona inteira.
Name Server NS Identifica o servidor de nome do domínio.
Address A Converte um nome de host em um endereço.
Pointer PTR Converte um endereço para um nome de host.
Mail Exchanger MX Identifica onde entregar o mail para um nome de
domínio dado.
Canonical Name CNAME Define um nome alternativo para o host.
Host Information HINFO Geralmente descreve o hardware e o sistema
operacional de um host.
Well Known Service WKS Anuncia os serviços de rede.
Text Information TXT Serve para o administrador inserir informações
adicionais sobre cada máquina
Um arquivo básico named.ca contém registros do tipo NS que nomeiam os servidores raiz.
Um exemplo é mostrado a seguir:
[name] [ttl] [class] type data [;comment]

Curso Linux Básico
Módulo Configuração de Redes TCP/IP 21
O arquivo named.local é utilizado para converter o endereço 127.0.0.1 (loopback) no nome
do localhost. Basicamente, o arquivo named.local é sempre o mesmo em qualquer servidor DNS,
apesar de ser possível expressar a mesma coisa de formas diferentes:
Observe o caractere “@” no início do arquivo. Se olharmos para o formato de um RR, o
primeiro item define um nome de domínio ou host sobre o qual queremos definir um RR. O
caractere “@” especifica para utilizar o próprio domínio definido como “zona” no arquivo
/etc/named.boot ou /etc/named.conf. Quando o item “name” do RR não é definido em uma linha,
é assumido o valor definido no registro SOA.
O registro SOA define um conjunto de valores da zona sendo especificada:
Na primeira linha temos o domínio específico desta zona, seguido do endereço de e-mail
# cat /var/named/named.ca
; This file is made available by InterNIC registration services
; under anonymous FTP as
; file /domain/named.root
; on server FTP.RS.INTERNIC.NET
. 3600000 IN NS A.ROOT-SERVERS.NET.
A.ROOT-SERVERS.NET. 3600000 A 198.41.0.4
. 3600000 NS B.ROOT-SERVERS.NET.
B.ROOT-SERVERS.NET. 3600000 A 128.9.0.107
. 3600000 NS C.ROOT-SERVERS.NET.
C.ROOT-SERVERS.NET. 3600000 A 192.33.4.12
. 3600000 NS D.ROOT-SERVERS.NET.
D.ROOT-SERVERS.NET. 3600000 A 128.8.10.90
. 3600000 NS E.ROOT-SERVERS.NET.
E.ROOT-SERVERS.NET. 3600000 A 192.203.230.10
. 3600000 NS F.ROOT-SERVERS.NET.
F.ROOT-SERVERS.NET. 3600000 A 192.5.5.241
. 3600000 NS G.ROOT-SERVERS.NET.
G.ROOT-SERVERS.NET. 3600000 A 192.112.36.4
. 3600000 NS H.ROOT-SERVERS.NET.
H.ROOT-SERVERS.NET. 3600000 A 128.63.2.53
. 3600000 NS I.ROOT-SERVERS.NET.
I.ROOT-SERVERS.NET. 3600000 A 192.36.148.17
. 3600000 NS J.ROOT-SERVERS.NET.
J.ROOT-SERVERS.NET. 3600000 A 198.41.0.10
. 3600000 NS K.ROOT-SERVERS.NET.
K.ROOT-SERVERS.NET. 3600000 A 193.0.14.129
. 3600000 NS L.ROOT-SERVERS.NET.
L.ROOT-SERVERS.NET. 3600000 A 198.32.64.12
. 3600000 NS M.ROOT-SERVERS.NET.
M.ROOT-SERVERS.NET. 3600000 A 202.12.27.33
@ IN SOA localhost. root.localhost. (
1997022700 ; Serial
86400 ; Refresh after 24 hours
7200 ; Retry after 2 hours
2592000 ; Expire after 30 days
345600 ) ; Minimum ttl of 4 days
IN NS localhost.
;
1 IN PTR localhost.

Curso Linux Básico
Módulo Configuração de Redes TCP/IP 22
da pessoa responsável, apenas trocando o caractere especial “@” por um ponto “.”;
Serial: número de série do arquivo de zona. É importante incrementar este número
sempre que o arquivo for modificado, pois dessa forma os servidores secundários da zona
saberão que o arquivo foi alterado. A convenção AAAAMMDDNN, onde AAAA=ano,
MM=mês, DD=dia, e NN=número da alteração no dia, garante que o número de série
sempre será maior do que o anterior quando for modificado;
Refresh: intervalo em segundos que os servidores secundários devem verificar por
modificações no servidor primário;
Retry: intervalo em segundos que os servidores secundários devem esperar para tentar
novamente caso não tenham conseguida conexão para um Refresh;
Expire: tempo máximo de validade dos registros no servidor secundário, após não ter
conseguido atualizar sua cópia. Após este tempo decorrido sem atualização, o servidor
secundário deve parar de responder requisições para a zona;
Minimum: tempo default de ttl para os demais registros, quando especificado.
O arquivo de inicialização rede.revzone é similar ao arquivo named.local. Ambos os
arquivos traduzem endereços IP em nomes de hosts através de registros PTR, como pode-se ver no
exemplo:
O arquivo de inicialização rede.zone contém a maioria das informações de domínio. Este
arquivo converte nomes de hosts em endereços IP, mas também contém registros dos tipos MX,
CNAME e outros.
@ IN SOA 250.135.200.in-addr.arpa. root.250.135.200.in-addr.arpa. (
1998072400 ; Serial
86400 ; Refresh after 24 hours
7200 ; Retry after 2 hours
2592000 ; Expire after 30 days
345600 ) ; Minimum ttl of 4 days
IN NS ns.rede.com.br.
;
1 IN PTR ns.rede.com.br.
2 IN PTR www.rede.com.br.
3 IN PTR ftp.rede.com.br.
4 IN PTR mail.rede.com.br.

Curso Linux Básico
Módulo Configuração de Redes TCP/IP 23
O comando nslookup é uma ótima ferramenta para localização de erros no servidor, pois
permite que qualquer um realize consultas diretamente ao servidor de nomes e recupere qualquer
uma das informações conhecidas pelo DNS. Ele pode ser usado diretamente na linha de comando
ou através do modo interativo. No modo direto, procede-se como no exemplo:
E no modo interativo:
Comandos úteis no modo interativo:
server server name muda o servidor DNS a ser questionado;
set type = type muda o tipo (A, PTR, MX, NS, Any, etc) do registro pesquisado;
set domain=domain muda o nome do domínio pesquisado;
ls domain recupera o arquivo de zonas do domínio;
exit sai do modo interativo.
@ IN SOA rede.com.br. root.rede.com.br. (
1998072400 ; Serial
86400 ; Refresh after 24 hours
7200 ; Retry after 2 hours
2592000 ; Expire after 30 days
345600 ) ; Minimum ttl of 4 days
IN NS ns.rede.com.br.
IN MX 1 mail.rede.com.br.
;
ns IN A 200.135.250.1
MX 1 mail.rede.com.br.
; Subdominios - delegation
minha IN NS ns.minha.rede.com.br.
ns.minha IN A 200.135.251.1
;
www IN A 200.135.250.2
MX 1 mail.rede.com.br.
ftp IN A 200.135.250.3
MX 1 mail.rede.com.br.
mail IN A 200.135.250.4
MX 1 mail.rede.com.br.
$ nslookup www.rede.com.br
Server: ns.rede.com.br
Address: 200.135.250.1
Non-authoritative answer:
Name: www.rede.com.br
Address: 200.135.250.2

Curso Linux Básico
Módulo Configuração de Redes TCP/IP 24
$ nslookup
Default Server: ns.rede.com.br
Address: 200.135.250.1
> www.rede.com.br
Server: ns.rede.com.br
Address: 200.135.250.1
Non-authoritative answer:
Name: www.rede.com.br
Address: 200.135.250.2
> set type=mx
> rede.com.br
Server: ns.rede.com.br
Address: 200.135.250.1
rede.com.br preference = 1, mail exchanger = mail.rede.com.br
rede.com.br nameserver = ns.rede.com.br
mail.rede.com.br internet address = 200.135.250.4
ns.rede.com.br internet address = 200.135.250.1

Curso Linux Básico
Módulo Configuração de Redes TCP/IP 25
5 NETWORK FILE SYSTEM (NFS)
O Network File System (NFS) permite o compartilhamento de arquivos através de uma rede.
Ele foi desenvolvido pela Sun Microsystems e hoje se encontra disponível em muitas plataformas,
sendo o padrão para compartilhamento de arquivos no ambiente UNIX. Existem soluções NFS para
ambientes como o MS-DOS e o MS-Windows, o que permite uma integração destes ambientes com
o UNIX.
Através do NFS, usuários e aplicações podem acessar arquivos remotos como se fossem
locais, de forma transparente.
As principais vantagens de se usar o NFS são:
A possibilidade de se ter estações sem disco;
Racionalização do uso dos discos, pois muitos softwares passam a residir exclusivamente
em um servidor;
Manutenção centralizada dos arquivos do domínio;
Transparência perante os usuários.
O NFS é constituído de processos servidores e clientes. Um host executando os processos
clientes do NFS acessa arquivos remotos como se fizessem parte do sistema de arquivos local. Um
host executando os processos servidores do NFS disponibiliza seus arquivos para uso pelos clientes.
Um cliente acessa arquivos remotos fazendo um “mount”, da mesma forma que acessa um
filesystem local em um disco, por exemplo. Um servidor disponibiliza seus arquivos através de um
“export”. Freqüentemente um host executa tanto os processos servidores quanto os clientes.
Os principais daemons envolvidos com o NFS são:
nfsd: executado pelos servidores para atender às requisições de acesso aos arquivos feitas
pelos clientes;
biod: executado pelos clientes (Block I/O Daemon);
rpc.lockd: executado por clientes e servidores a fim de negociar o fornecimento de locks
para arquivos;
rpc.statd: executado por clientes e servidores para monitorar o NFS; é utilizado para
reestabelecer a comunicação entre clientes e servidores após uma falha de rede;
rpc.mountd: executado pelos servidores para atender as requisições de mount feitas
pelos clientes;
rpc.rquotad: executado pelos servidores para fornecer informações sobre quotas de
usuários aos clientes que montam o filesystem exportado.
5.1 Exportando Arquivos
O primeiro passo na configuração de um servidor NFS é decidir quais arquivos serão
exportados. Exporte apenas os arquivos que realmente serão utilizados pelos clientes.
O controle de acesso remoto aos arquivos locais está associado aos diretórios e não aos
arquivos em particular. Portanto, não podemos exportar um arquivo de um diretório sem exportar os
demais.
O arquivo /etc/exports especifica quais diretórios são exportados pelo servidor, quais
clientes poderão acessá-los o que poderão fazer com os arquivos.
Cada entrada no arquivo /etc/exports segue o formato:

Curso Linux Básico
Módulo Configuração de Redes TCP/IP 26
diretório [-opção] [,opção]
As principais opções são:
ro os clientes não podem escrever nos arquivos (read-only);
rw = host [:host]: permite que os usuários do(s) host(s) citado(s) escrevam no arquivo;
root = host [: host]: dá acesso de root aos usuários root de determinado(s) host(s);
access = host [:host]: permite acesso somente a partir do(s) host(s) listado(s).
|No Linux, um novo formato de arquivo é utilizado, que permite mais flexibilidade. Cada
entrada do arquivo /etc/exports no Linux segue o formato:
diretório [host][(opção, [opção])] …
host: um host pode ser especificado por seu endereço IP, pelo seu nome DNS, por uma faixa de IPs (ex: 200.30.40.0/255.255.255.0), ou por uma faixa de domínio (ex: *.rede.com.br). Quando o campo host é vazio, o diretório é exportado para qualquer host;
As principais opções são:
ro: o diretório é exportado como read-only;
rw: o diretório é exportado como read-write (isto é default);
noaccess: informa que o diretório não deve ser exportado (útil para exportar um diretório e não permitir acesso a um subdiretório deste diretório);
no_root_squash: permite que o usuário root da máquina cliente acesse o diretório montado remotamente com permissão de root.
O comando exportfs lê o arquivo /etc/exports a fim de exportar um diretório:
# cat /etc/exports
/usr -access=servidor1:servidor2
/usr/local -access=servidor1:servidor2
/usr/local/tmp -access=servidor1:servidor2
/usr/local/www -access=servidor1:servidor2
/var/spool/mail -access=servidor1:servidor2
/home/venus -access=servidor1:servidor2
/projects proj*.rede.com.br(rw)
/usr *.rede.com.br(ro) 10.1.2.0/255.255.255.0(rw)
/home/server2 server1(rw,no_root_squash)
/pub (ro)
/pub/private (noaccess)
venus# exportfs /usr
venus# exportfs -a

Curso Linux Básico
Módulo Configuração de Redes TCP/IP 27
5.2 Montando Diretórios Remotos
Um cliente NFS pode acessar apenas os diretórios que lhe foram exportados. O comando
showmount verifica quais diretórios estão disponíveis ao cliente em um determinado servidor.
O comando mount é utilizado pelos clientes para montar um diretório remoto:
mount - monta um sistema de arquivos.
SINOPSE:
mount [ -o options ] hostname:filesystem mount-point
ARGUMENTOS:
hostname: nome do host servidor;
filesystem: nome do diretório ou sub-diretório exportado pelo servidor;
mount-point: nome do diretório local onde o diretório remoto será montado.
DESCRIÇÃO:
O comando mount permite que diretórios exportados por um servidor NFS sejam montados
localmente. Subdiretórios dos diretórios exportados também podem ser montados. Por exemplo, se
um servidor exporta o diretório /usr, um cliente pode decidir montar apenas o diretório /usr/man.
Quando se monta um diretório sobre um diretório não vazio, o conteúdo deste, apesar de não
ser visível, continua inalterado. Assim que o mount for desfeito o conteúdo original do diretório
volta a ser visível. O comando umount desmonta um diretório.
O arquivo /etc/fstab provê informações sobre os sistemas de arquivos a serem montados na
inicialização do sistema.
apolo$ showmount -e venus
export list for venus:
/pub/private (everyone)
/pub <anon clnt>
/home/server2 server1
/usr 10.1.2.3/255.255.255.0,*.rede.com.br
/projects proj*.rede.com.br
venus# mount apolo:/home/apolo /home/apolo
venus# umount /home/apolo

Curso Linux Básico
Módulo Configuração de Redes TCP/IP 28
6 SESSION MESSAGE BLOCK (SMB) – SAMBA
O protocolo SMB é um dos protocolos mais “populares” de compartilhamento de arquivos e
impressoras atualmente, principalmente no ambiente de microcomputadores. Com o sucesso do
sistema operacional Microsoft Windows, o uso do protocolo se tornou praticamente obrigatório nos
ambientes onde máquinas com este sistema operacional estão interligadas em rede.
O SMB é na verdade o protocolo utilizada pelo NetBIOS, um conjunto de serviços sobre o
protocolo SMB que foi padronizada por ocasião das primeiras experiências de ligar PCs em rede.
Assim, quanto o termo NetBIOS é usado, na verdade o protocolo que transporta os serviços de
compartilhamento de arquivos e impressoras é o SMB. Por isso os dois termos podem ser usados de
forma intercambiável.
O NetBIOS é um protocolo da camada de aplicação, e define que cada nó da rede possui um
nome de até 15 caracteres. Os dois serviços do NetBIOS, serviço de datagrama e serviço de nomes,
estão padronizados no RFC 1001 e RFC 1002, respectivamente.
O NetBIOS pode operar sobre os seguintes protocolos de transporte (de nível inferior à
aplicação): TCP/IP, NetBEUI, e SPX/IPX (da Novell). Enquanto o NetBEUI é apenas uma
implementação de NetBIOS direta sobre a subcamada LLC (padrão IEEE), os outros dois (TCP/IP e
SPX/IPX) são realmente protocolos de transporte/rede, em relação ao modelo OSI. A desvantagem
de utilizar NetBEUI é o que o protocolo exige que todas as máquinas estejam na mesma rede física
(porque não utiliza como transporte um protocolo que permita roteamento, como o IP).
Dessa forma, quando uma máquina utiliza NetBIOS sobre TCP/IP (NBT) ou NetBIOS sobre
IPX, é preciso uma forma de traduzir os nomes NetBIOS para os endereços IP ou IPX, conforme o
protocolo utilizado.
Os nomes NetBIOS podem ser de dois tipos: UNIQUE e GROUP. Toda máquina rodando
NetBIOS em uma rede deve possuir um nome único (UNIQUE), que não pertença a outra máquina
na rede. Se necessário, a máquina pode solicitar na rede um nome GROUP, ao qual várias máquinas
podem pertencer.
6.1 Resolução de Nomes NetBIOS
Como o NetBIOS utiliza nomes para identificar as máquinas, e os protocolos inferiores
utilizam endereços numéricos, uma forma de resolução de nomes é necessária. No caso de
NetBEUI, a tradução de nomes será diretamente para endereços físicos 802.3 (Ethernet). No caso de
IP, a tradução será de nomes para endereços IP (semelhante ao DNS), assim como no caso de IPX a
tradução será de nomes para endereços IPX (que são constituídos do endereço 802.3 mais um
prefixo que identifica a rede a que pertence a máquina).
A resolução de nomes NetBIOS pode ser feita de duas formas: por difusão (broadcast) ou por
requisição direta a um servidor de nomes (point-to-point).
Na resolução por broadcast, uma máquina simplesmente envia por difusão na rede um
anúncio do nome que deseja utilizar. Se não houver objeção por parte de outra máquina que já
esteja utilizando o nome, ela então o adota como sendo seu.
Quando a máquina deseja transmitir para outra, ela também envia por difusão uma pergunta
pelo nome destino. A máquina destino, escutando a requisição, responde com seu endereço, de
maneira muito semelhante ao protocolo ARP usado na camada de acesso à rede da arquitetura
TCP/IP.

Curso Linux Básico
Módulo Configuração de Redes TCP/IP 29
A implementação de um servidor de nomes, de acordo com a RFC 1001, é apenas possível
quando se utiliza NetBIOS sobre TCP/IP. A implementação de um servidor de nomes point-to-point
da Microsoft foi denominada WINS (Windows Internet Name Service).
A resolução de nomes NetBIOS através de um servidor WINS resolve o problema de excesso
de broadcasts na rede em decorrência da resolução de nomes. Quando uma máquina deseja registrar
seu nome, ela contacta o servidor WINS para isso. Desta forma, as máquinas da rede que não se
registrarem ao servidor WINS ficarão “invisíveis” pelas demais, quando consultarem o servidor
WINS.
O processo de registro de nomes das máquinas é feito assim que o protocolo entra no ar.
Quando a máquina é desligada, a máquina solicita a retirada do nome do servidor. Caso a máquina
seja desligada abruptamente, sem ter a oportunidade de retirar seu nome do registro, o servidor
WINS não terá como saber que o nome não está mais associado a uma máquina ativa.
Como o protocolo de transporte para o servidor WINS é o TCP/IP, máquinas espalhadas por
várias redes, inclusive interconectadas por uma WAN, conseguem se registrar e consultar o servidor
de nomes. É possível assim ter um único servidor de nomes na rede, onde todos podem obter
informações sobre os endereços das máquinas que rodam NetBIOS, de forma muito semelhante ao
DNS.
É possível existir mais de um servidor WINS na rede, de forma que a base de dados fique
replicada, e caso o servidor principal saia do ar, o servidor secundário assume a responsabilidade.
Além disso, o administrador da rede pode incluir entradas estáticas no servidor WINS, por exmeplo,
para máquinas servidoras da rede, já que estas normalmente não mudam de endereço IP e de nome.
6.2 Samba – Servidor e Cliente SMB
Atualmente, o protocolo nativo de compartilhamento de arquivos e impressoras na família de
sistemas operacionais Windows, da Microsoft, é o SMB. Isto abriu várias oportunidade de mercado
para desenvolvedores de soluções de conectividade entre plataformas. Por exemplo, vários
fornecedores comercializam implementações de NFS para Windows, de forma que os clientes
Windows de uma rede enxerguem os diretórios exportados via NFS em servidores UNIX.
Para integrar sistemas Windows e UNIX, uma outra abordagem é implementar o protocolo
SMB no lado UNIX. Diversos fornecedores independentes, bem como os próprios fornecedores de
UNIX possuem suas próprias soluções SMB para integração com máquinas Windows, sem
necessidade de adicionar software a elas. Esta solução talvez seja a melhor para integrar sistemas
UNIX e sistemas Windows, pois em geral as máquinas Windows existem em maior quantidade do
que as máquinas UNIX, e o fato de não ser necessária a instalação de software adicional no lado
Windows é uma grande vantagem.
Boa parte das implementações dos fornecedores de UNIX é simplesmente um acordo com a
Microsoft para licenciarem o código nativo do LanManager, que era antigamente a implementação
SMB da Microsoft para UNIX (por ocasião da Microsoft comercializar seu próprio UNIX, o
Xenix).
Entretanto, existe uma solução de domínio público (freeware), chamada Samba, que foi
desenvolvida incialmente por Andrew Tridgell em 1992 quando era um estudante de PhD na
Universidade Nacional Australiana, em Canberra, Austrália.
Apesar dos primeiros testes e início do desenvolvimento do Samba terem sido no SunOS, da
Sun Microsystems, o início de seu desenvolvimento mais sério foi sobre a plataforma Linux, sendo
que atualmente já existem versões para diversas plataformas, inclusive não-UNIX, como: Linux,

Curso Linux Básico
Módulo Configuração de Redes TCP/IP 30
SunOS, Solaris, SVR4, Ultrix, OSF1, AIX, BSDI, NetBSD, Sequent, HP-UX, SGI, FreeBSD,
NeXT, ISC, A/UX, SCO, Intergraph, Domain/OS, DGUX, QNX, NetWare, VMS, OS/2, Amiga, e
outros que eventualmente são incluídos na lista.
Todas as informações sobre o produto, downloads, FAQs, entre outros, está disponível no site
http://www.samba.org, além dos mirrors espalhados pelo globo. O primeiro passo é obter o
software, preferencialmente pré-compilado para o sistema operacional do servidor a ser utilizado.
Após instalado, sua configuração é limitada a apenas um arquivo de configuração, chamado
smb.conf, e geralmente encontrado sob o diretório /etc ou sob o diretório /usr/local/samba/lib.
Conforme a utilização dada ao servidor Samba, configurações adicionais incluirão criação de
diretórios de arquivos compartilhados, ajustes de permissões, etc.
6.2.1 Iniciando o Samba
O samba é composto de dois processos: smbd e nmbd. O primeiro é o servidor propriamente
dito, enquanto o segundo é responsável pela resolução de nomes (ou via broadcast ou via protocolo
WINS).
Preferencialmente, o samba deve ser inciado durante o boot do sistema, ficando disponível
para conexões assim que a máquina servidora estiver no ar. Este modo coloca os dois processos
para rodar como daemons. Entretanto, pode ser que em algumas situações não seja adequado o
samba estar todo o tempo rodando, pois é usado raramente, e a máquina possui pouca memória e
CPU disponível. Neste caso pode-se iniciar o samba via inetd, que escuta as requisições na rede
para vários serviços (telnet, ftp, talk) e dispara o servidor adequado assim que uma requisição
chegar pela rede.
SINOPSE:
smbd [ -D ] [ -d nível ]
nmbd [ -D ] [ -d nível ]
ARGUMENTOS:
-D: inicia o processo como daemon. Caso esta opção não seja especificada, o processo somente inicia se tiver sido chamado pelo inetd;
-d nível: especifica o nível de detalhes a ser armazenado no arquivo de logs do sistema. O valor default é 3, a não ser que outro seja especificado no arquivo de configuração smb.conf.
6.2.2 Configuração do arquivo smb.conf
A único arquivo de configuração necessário para o Samba é o smb.conf. A localização padrão
do arquivo depende dos parâmetros especificados no momento da compilação do programa.
O arquivo de configuração é orientado a linhas, sendo composto de seções, e dentro de cada
seção, parâmetros. Cada seção especifica um item compartilhado, normalmente chamado de
compartilhamento (share). Os parâmetros para cada share podem ser então especificados
individualmente. Caso seja necessário que uma linha de configuração continue na linha seguinte,
deve-se colocar o caractere “\” (barra invertida) no final da linha a ser continuada. Além disso, toda
linha que começa com o caractere “#” ou “;” é considerada um comentário.
Dentro do arquivo, as seções são especificados por um nome entre colchetes. Não existe

Curso Linux Básico
Módulo Configuração de Redes TCP/IP 31
limite no tamanho do nome do compartilhamento, que pode inclusive conter espaços, mas a
recomendação é que sejam utilizados no máximo 8 caracteres, sem espaços, para evitar problemas
futuros com alguns clientes de rede mais antigos (DOS, Windows for Workgroups, e até mesmo
Windows 95).
Existem também três seções especiais:
[global]: parâmetros nesta seção aplicam-se ao servidor em si, ou definem valores default
para os outros compartilhamentos;
[homes]: esta seção permite que usuários conectem-se diretamente a seus diretórios
home. O Samba automaticamente mapeia o compartilhamento [homes] para o login do
usuário que está conectando ao servidor;
[printers]: a seção [printers] é um serviço automático, que lê o arquivo /etc/printcap (se
impressão estilo BSD estiver em uso), e apresenta todas as impressoras encontradas
automaticamente.
Os parâmetros são normalmente compostos de uma ou mais palavras, e são especificados no
formato:
nome-do-parâmetro = valor
O valor de cada parâmetro pode ser de um dos seguintes tipos:
string: uma seqüência qualquer de caracteres, como por exemplo o parâmetro que
especifica o nome do servidor: netbios name = Server1
numérico: um número qualquer decimal, como por exemplo o parâmetro que especifica o
tamanho máximo do arquivo de logs, em Kbytes: max log size = 250
booleano: um opção que especifica os valores verdadeiro ou falso. Estes valores podem
ser especificados como yes/no, true/false, ou 1/0. Como exemplo, a opção que informa se
o nmbd atuará com servidor WINS ou não: wins support = yes
Os principais parâmetros são especificados a seguir. À frente de cada nome de parâmetro
listado, é mostrado entre parênteses se o parâmetro se aplica à seção global (G), a
compartilhamentos (C) específicos. Quando um parâmetro que se aplica a compartilhamentos (C)
for encontrado na seção global, ele será interpretado como o valor default para este parâmetro
quando ele não for especificado em um determinado compartilhamento.
PARÂMETROS:
workgroup (G): parâmetro do tipo string que informa ao servidor a qual workgroup / domínio pertence;
server string (G): string que será mostrada como “comentário” ao lado do nome do servidor em um cliente SMB;
status (G): parâmetro booleano que configura o servidor para fornecer informações sobre seu status ou não;
wins support (G): parâmetro booleano que instrui o nmbd para atuar ou não como um servidor WINS;
security (G): string que especifica o modelo de autenticação a ser utilizado pelo servidor. No modo “share” a autenticação é como no Windows 3.x/9x, ou seja, um compartilhamento possui uma senha simples para leitura e/ou escrita. No modo “user” a autenticação é feita localmente no arquivo de usuários do UNIX

Curso Linux Básico
Módulo Configuração de Redes TCP/IP 32
(passwd). No modo “server” a autenticação é feita repassada para um servidor de autenticação Windows NT ou Samba;
password server (G): nome da máquina responsável por autenticação. Este parâmetro só é válido se “security = server”;
share modes (G): parâmetro booleano que habilita ou não locking em arquivos;
comment string (C): string de comentário para um compartilhamento;
path (C): string que especifica o diretório que está sendo compartilhado;
browseable (C): parâmetro booleano que especifica se o compartilhamento será visível para o cliente (por exemplo, no Ambiente de Rede do Win95);
public (C): especifica se o compartilhamento requer que o usuário se identifique e autentique;
writable (C): se este parâmetro é true, compartilha em modo read-write;
read only (C): se este parâmetro é true, compartilha em modo read-only. Este parâmetro é um sinônimo para “writable”, apenas com o significado invertido;
create mode (C): modo numérico (usado pelo comando chmod) com o qual novos arquivos serão criados;
valid users (C): lista de usuários separados por vírgula que possuem direito de conexão ao compartilhamento. Grupos podem ser especificados colocando-se um caractere “@” em frente ao nome do grupo na lista;
invalid users (C): lista de usuários separados por vírgula que NÃO possuem direito de conexão ao compartilhamento. Grupos podem ser especificados colocando-se um caractere “@” em frente ao nome do grupo na lista;
write list (C): lista de usuários separados por vírgula que possuem direto de escrita no compartilhamento. Grupos podem ser especificados colocando-se um caractere “@” em frente ao nome do grupo na lista.

Curso Linux Básico
Módulo Configuração de Redes TCP/IP 33
EXEMPLO:
#==== Opcoes Globais ====
#
# Ultima alteracao: 24/07/98, Celso
[global]
# Opcoes gerais
workgroup = CURSO
server string = Samba Server
# Opcoes de impressao
printcap name = /etc/printcap
print command = lpr -h -r -P %p %s
lprm command = lprm -P %p %j; /usr/local/bin/lpreset /dev/lp1
load printers = yes
printing = bsd
# Opcoes de log
log file = /var/log/samba/log.%m
max log size = 50
# Opcoes de seguranca
hosts allow = 127. 10.0.0.
security = user
encrypt passwords = yes
smb passwd file = /etc/smbpasswd
guest ok = no
# Opcoes de rede / desempenho
socket options = TCP_NODELAY
; interfaces = 192.168.12.2/24 192.168.13.2/24
# Controle de listas. Este servidor possuira’ a lista de maquinas da rede
os level = 33
domain master = yes
preferred master = yes
# Opcoes de controle de dominio. Este servidor atuara’ como um PDC
domain logons = yes
domain admin group = @celso
logon drive = x:
logon script = local.bat
logon path = \\%L\profiles\%U
# Suporte a WINS
wins support = yes
dns proxy = no

Curso Linux Básico
Módulo Configuração de Redes TCP/IP 34
# Convencoes de nomes de arquivos
preserve case = yes
short preserve case = yes
veto files = /lost+found/quota.user/quota.group/
#==== Definicoes de Compartilhamentos ====
[homes]
comment = Directorios dos Usuarios
browseable = no
writable = yes
[printers]
comment = Todas as impressoras
path = /var/spool/samba
browseable = no
guest ok = yes
writable = no
printable = yes
[FloppyA]
comment = Unidade de disquete
path = /misc/fd
browseable = yes
public = yes
writable = yes
guest ok = yes
[Temp]
comment = Espaco temporario
path = /tmp
browseable = yes
public = yes
writable = yes
guest ok = yes
Neste exemplo, os parâmetros em negrito são os parâmetros usuais em um arquivo de
configuração, que devem ser adaptados para cada caso específico (por ex,: parâmetro workgroup).

Curso Linux Básico
Módulo Configuração de Redes TCP/IP 35
7 NETWORK INFORMATION SERVICE (NIS)
Freqüentemente, em uma rede de computadores, é desejável que a autenticação de usuários
seja centralizada em servidores centrais de autenticação. Este modelo de segurança em redes é
adotado por vários produtos, por exemplo, a família Mirosoft Windows. Em UNIX, normalmente a
autenticação é feita localmente, consultando o arquivo /etc/passwd.
Entretanto, a Sun Microsystems definiu um padrão que serve, entre outras coisas, para este
propósito. Inicialmente o produto foi chamado de YP – Yellow Pages (Páginas Amarelas), pois
tratava-se de um mecanismo de distribuição centralizada de informações pelas estações da rede.
Entretanto YP era já uma marca registrada na Inglaterra, e a Sun rebatizou o produto de NIS –
Network Information Service (Serviço de Informações de Rede).
O NIS é um banco de dados administrativo utilizado para disseminar informações por todo o
domínio (note-se que o conceito de domínio aqui é diferente daquele do DNS. Um domínio NIS
está restrito a um conjunto de máquinas sob a mesma administração, e não se enquadra em uma
estrutura hierárquica, nem aceita subdivisões). O NIS converte uma série de arquivos
administrativos do UNIX em mapas disponíveis pela rede.
Os principais arquivos convertidos em mapas pelo NIS são:
/etc/passwd: contém informações sobre usuários;
/etc/group: contém informações sobre grupos de usuários;
/etct/ethers: associa endereços IP a endereços físicos (usado pelo RARP);
/etc/hosts: associa nomes de hosts a endereços IP;
/etc/networks: associa nomes de redes a endereços IP;
/etc/netmasks: associa netmasks às redes;
/etc/protocols: contém protocolos suportados pelo host;
/etc/services: contém serviços suportados pelo host;
/etc/aliases: contém mail aliases;
/etc/netgroup: define grupos de hosts e de usuários.
O principal motivo para se utilizar NIS é a facilidade administrativa. Com NIS, os arquivos de
configuração podem ser mantidos de forma centralizada em um servidor e disponibilizados
automaticamente pelo domínio.
Um conjunto de máquinas que compartilham os mesmos mapas do NIS formam um domínio
NIS. É recomendável que o nome de um domínio NIS coincida com o nome do domínio Internet. O
servidor NIS cria um sub-diretório para cada domínio que ele serve no diretório /var/yp.
O comando domainname define ou mostra o nome do domínio NIS corrente.
O nome do domínio NIS é normalmente configurado na inicialização do sistema a partir do
arquivo /etc/defaultdomain. Este é o arquivo utilizado no SunOS e no Solaris durante o boot do
sistema para descobrir qual o domínio NIS em uso. Outros UNIX provavelmente irão armazenar o
nome do domínio NIS em outros locais.
venus% domainname inf.ufsc.br
venus% domainname
inf.ufsc.br

Curso Linux Básico
Módulo Configuração de Redes TCP/IP 36
Os principais programas envolvidos com o NIS são:
ypserv: daemon servidor do NIS, responsável pelo atendimento às requisições dos
clientes;
ypbind: daemon cliente do NIS, responsável por encaminhar as requisições ao servidor;
ypinit: programa de inicialização do NIS; lê os arquivos de /etc e cria os mapas
correspondentes. Este programa normalmente está no diretório /usr/lib/yp;
ypxfrd: daemon responsável por transferir os mapas do servidor mestre para os
servidores escravos;
yppasswdd: daemon responsável por receber notificações de alteração de senha de um
usuário em uma máquina cliente.
O NIS cria um mapa equivalente ao arquivo /etc/hosts. Logo, ele pode dispensar o uso do
DNS para domínios pequenos e isolados da Internet. Entretanto, alguns resolvers, quando
configurados para utilizar NIS, ignoram completamente a configuração DNS (/etc/resolv.conf) e
passam somente a consultar nomes no mapa hosts do domínio NIS. A solução é fazer com que o
servidor NIS, quando receba a consulta por um nome que não está em seu mapa hosts, consulte um
servidor DNS. Isto pode ser feito incluindo a cláusula “B=-b” no arquivo de construção dos mapas
NIS, localizado em /var/yp/Makefile.
Para garantir o funcionamento do serviço, o NIS define duas classes de servidores: master e
slave. Um domínio NIS deve possuir pelo menos um servidor master (mestre), e opcionamente
vários servidores slave (escravos), que obterão cópias dos mapas NIS a partir do servidor master.
Para inicializar o servidor mestre do domínio e criar os mapas iniciais, os seguintes passos
devem ser feitos:
Configurar o domínio NIS com o comando domainname;
Executar o comando ypinit –m. Este comando lerá os arquivos do diretório /etc e criará
os mapas correspondentes no diretório /var/yp/domainname, onde domainname é o
nome do domínio ajustado no passo anterior;
Dispare os daemons necessários. O daemon ypserv é o servidor em si, portanto deve
sempre estar rodando no servidor. Se existem servidores slave que irão se conectar ao
servidor master, ele deve rodar também o daemon ypxfrd. Se os clientes precisarem
alterar senhas de usuários no servidor NIS, então o daemon yppasswdd também deve
ser executado. Por fim, a máquina servidora precisa também ser configurada como cliente
NIS, executando o ypbind.
Para disparar um servidor slave os seguintes passos devem ser seguidos:
Configurar o domínio NIS com o comando domainname;
venus# vi /var/yp/Makefile
# Set the following variable to "-b" to have NIS servers use the domain
# name resolver for hosts not in the current domain.
B=-b
babbage# domainname servers
babbage# /usr/lib/yp/ypinit –m
babbage# ypserv
babbage# ypxfrd
babbage# yppasswdd
babbage# ypbind

Curso Linux Básico
Módulo Configuração de Redes TCP/IP 37
Executar o comando ypinit –s master. Este comando fará com que o servidor master seja contactado, e seus mapas copiados;
Dispare os daemons necessários. O daemon ypserv é o servidor em si, portanto deve
sempre estar rodando no servidor. Por fim, a máquina servidora precisa também ser
configurada como cliente NIS, executando o ypbind.
Para disparar um cliente NIS, basta configurar o domínio NIS e disparar o daemon cliente:
No servidor NIS mestre, toda vez que um dos arquivos exportados for alterado, é necessário
reconstruir o mapa correspondente. Para isso, é necessário executar o comando make dentro do
diretório /var/yp. O comando make irá reconstruir os mapas de acordo com as regras do arquivo
/var/yp/Makefile existente, deixando-os sincronizados com os arquivos originais. O exemplo a
seguir ilustra a situação.
pascal# domainname servers
pascal# /usr/lib/yp/ypinit –s babbage
pascal# ypserv
pascal# ypbind
hollerith# domainname servers
hollerith# ypbind
babbage# cd /var/yp
babbage# make
gmake[1]: Entering directory `/var/yp/servers'
Updating passwd.byname...
Updating passwd.byuid...
Updating group.byname...
Updating group.bygid...
Updating hosts.byname...
Updating hosts.byaddr...
gmake[1]: Leaving directory `/var/yp/servers'
babbage#

Curso Linux Básico
Módulo Configuração de Redes TCP/IP 38
BIBLIOGRAFIA
1. ALBITZ, Paul; LIU, Cricket. DNS and BIND. O’Reilly & Associates, 1992.
2. FEIT, Sidnie. TCP/IP – Architecture, Protocols, and Implementation with IP v6 and IP
Security. 2nd
. ed. McGraw-Hill, 1996.
3. FRISCH, Ællen. Essential System Administration. 2nd
. ed. O’Reilly & Associates, 1996.
4. HUNT, Craig. TCP/IP Network Administration. 2nd
. ed. O’Reilly & Associates, 1997.
5. STERN, Hal. Managing NFS and NIS. O’Reilly & Associates, 1991.
Dúvidas, críticas e sugestões sobre esta apostila: mailto:[email protected]





























