Embed Size (px)
Citation preview

Integrating Machine Translation with Translation Memory:A Practical Approach
Panagiotis KanavosFreelance Technical Translator
K. Varnali 20, K. Aharnai, 136 71Athens, Greece
Dimitrios KartsaklisFreelance Software Engineer
M. Mpotsari 46, Petroupolis, 132 31Athens, Greece
Abstract
The purpose of this work is to show howmachine translation can be integrated intoprofessional translation environments usingtwo possible workflows. In the first workflowwe demonstrate the real-time, sentence-by-sentence use of both rule-based and statisticalmachine translation systems with translationmemory programs. In the second workflow wepresent a way of applying machine translationto full translation projects beforehand. We alsocompare and discuss the efficiency of statis-tical and rule-based machine translation sys-tems, and propose some ideas about how thesesystems could be combined with translationmemory technologies into a unified translationapplication.
1 Introduction
Machine Translation (MT) has been evolvingrapidly, drawing attention from other professionalsbesides researchers. However, we cannot claim thatit is generally accepted as a useful and productivetechnology by the professional translation industry.On the one hand this is partly due to unrealistic ex-pectations as to what MT should be able to do andhow it should be able to achieve it. On the otherhand, it is true that the MT community focus mainlyon research, overlooking practical issues. This isreflected in various online surveys and forums re-lated to professional translation, where translatorsand language service providers consider MT an ex-perimental technology suitable for draft translationsof e-mail messages and web pages. To this respect,
Computer-Assisted Translation (CAT) vendors havebeen reluctant or uninterested in investing further inMT technologies, with the exception of Google’sMT service which is offered as a plugin to a fewCAT programs.
We will demonstrate that MT–when com-bined properly with Translation Memory (TM)technologies–is actually a very useful and produc-tive tool for professional translation work, contraryto the common belief that MT is still restricted todraft Web translations of low quality. Furthermore,we will show many possible ways to combine MTsystems with TM workflows, as well as the abilityto use both rule-based and statistical MT systems.
2 Methodology
Our workflows and methodologies are divided intotwo general categories: the on-demand, sentence-by-sentence application of MT, and the one-time ap-plication of MT into the whole translation project.In both cases, we use and combine various tools,MT systems, even operating systems and platforms,to provide a unified translation environment whichmost professional translators are familiar with. TheCAT programs used are Swordfish II (a Java appli-cation) in a Linux operating system, Deja Vu X ina Microsoft Windows environment, and Wordfast, aMicrosoft Word macro template, also used in a Win-dows operating system. The MT systems used arethe Moses statistical system (Koehn et al., 2007),and a rule-based edition of Systran1.
1Although the Systran edition that was available for our lan-guage pair was rule-based, newer editions use a hybrid technol-ogy incorporating both statistical and rule-based elements.
Ventsislav Zhechev (ed.): Proceedings of the Second Joint EM+/CNGL Workshop “Bringing MT to the User:Research on Integrating MT in the Translation Industry” (JEC ’10), pp. 11–20. Denver, CO, 4 November 2010. 11

For the purposes of our research, we chose totranslate two technical books in the field of infor-matics from English to Greek. The first one was aninstructive guide (referred to in this paper as Book 1)to a popular desktop application, which contained alot of steps for accomplishing specific tasks and hada certain amount of repetitive or similar text. Thiskind of text is ideal for work in a TM environmentsince the TM yields a lot of exact and fuzzy matches.The other book was an academic one (referred asBook 2), covering more complex and theoretical top-ics in the field of Computer Science, and containedvery few repetitive sections or step-by-step instruc-tions. Such texts do not benefit particularly fromTM matches, although they do benefit from otherfeatures offered by CAT tools, such as concordancesearches, consistency in style and terminology, auto-matic number and tag checks, etc. The configurationof the CAT programs was almost identical: we usedthe same TM which contained 140,000 translationunits, the same terminology database containing anaverage of 30,000 entries, and the same segmenta-tion rules. All our resources derived from previoustranslations in the Informatics domain. Also, the TMfuzzy threshold was set to 70% for all programs.
We translated both books in our three TM-MTcombinations and obtained measurable results interms of time spent, translation quality, and overallefficiency of our workflows. It should be noted thatthe books translated with our workflows were realassignments from a publishing house and they arenow under publication. We divided each book in sixequal parts (two for each combination) and we cre-ated separate translation projects for each TM-MTcombination. Then, in each combination, we trans-lated one part using only the TM and another partusing both the TM and the MT, keeping track of thetime spent so we could measure the effectiveness ofthe MT. Productivity is expressed in target words perhour.
2.1 Applying MT on demand during thetranslation process
The ability to use MT engines from within CAT pro-grams is largely dependent on the CAT program it-self. Thus, there has to be a way to connect the MTengine to the TM application and invoke it at willfor selected segments. For this reason, we chose the
Swordfish II CAT program, which offers a flexibleplugin architecture allowing the user to connect toexternal applications or scripts, and Wordfast Clas-sic, which provides a feature for connecting to MTsystems. Although both programs are used under thesame method, their combination with MT systemsvaries significantly because of the operating systemsinvolved and the MT systems they can be connectedto. Swordfish was used with Moses, while Wordfastwas used with the Systran engine. These particu-lar combinations were chosen based on the tools wehad available and some practical factors (explainedin the following sections) concerning the integrationof each CAT tool with the corresponding MT sys-tem.
2.1.1 Swordfish’s translation environmentSwordfish’s translation environment offers all theusual features met in CAT tools, such as thetranslation grid where the segmented text is pre-sented for translation, the TM database resultspane, the terminology database results pane, andan Auto-Translation pane, which shows the resultsof the program’s attempt to assemble translationsusing matches from the TM and the terminologydatabases. This is of special interest for the purposesof our work since it is the closest native feature theapplication offers to MT. Another feature we willuse for comparison is the application’s GTranslateplugin which can be invoked by the user on-demandfor automatic translation using Google’s MT engine.
The workflow presented by Swordfish is typicalof CAT programs:
• Import, conversion, and segmentation of thesource files into Swordfish’s native format(XLIFF)
• Connection of TM and terminology databasesinto the project
• Pretranslation of the entire project using theconnected TMs (optional)
• Translation of the project, segment by segment
• Export the project into the original file format
Swordfish integrates seamlessly with any externalapplication or script due to its plugin architecture.
JEC 2010 “Bringing MT to the User” Denver, CO
12

This is a key feature that let us customize our work-flow to a great extent. We created a custom Pythonplugin that manipulated the current segment. Theexchange file created by Swordfish is in the XLIFFformat (XML-based), so the translatable text can beeasily extracted using Python’s XML modules.
The XLIFF project format used by Swordfish isvery flexible for applying MT since it does not re-quire any special conversions or additional prepa-ration steps. Furthermore, integrating the MT re-sults into Swordfish’s environment was seamless,since we could automatically create an appropriateXML element for each machine-translated segmentand make the translation appear into the TM matchespane.
2.1.2 The Moses Statistical MT SystemMoses is a statistical MT system developed by theEuroMatrix2 and EuroMatrixPlus3 projects and var-ious institutions and universities and is licensed un-der the LGPL (Lesser General Public License). Suchsystems require large corpora of text for training andcreating phrase tables and language models whichare used during the automatic translation (decoding).Translators can benefit from such systems since theyalready have available considerable amounts of textsin the form of TMs. All CAT programs offer an op-tion for extracting the entries of the TMs into theindustry-standard TMX format which can be easilymanipulated for preparing the text corpus.
Moses, along with the required utilities andscripts, requires a Unix environment and a fairly ca-pable computing system. These requirements canimpose practical restrictions for wider adoption ofthis workflow, since most translators use PCs andlaptops with limited computing power while few ofthem work in a Unix environment. This issue is alsodiscussed in Section 4.1.2. We installed and config-ured Moses on a Linux Server machine with a dual-core processor and 8 GB RAM, in a LAN environ-ment.
The steps we followed for preparing an MT sys-tem with Moses are outlined in Figure 1. The paral-lel corpora extracted from our TM contained about140,000 sentences, an amount not particularly largefor statistical MT training. However, the efficiency
2See www.euromatrix.net3See www.euromatrixplus.eu
Figure 1. Steps for preparing a Moses MT system
of our MT system was not hindered by the limita-tion in the amount of sentences because the train-ing corpus was very domain-specific to our transla-tion project. This issue is extremely important whencombining MT and TM technologies and it is ana-lyzed in greater depth in Section 4.
2.1.3 Integrating Moses into SwordfishThe connection of the two systems was achievedwith the custom Python plugin that extracted thetranslatable text from the temporary XLIFF file gen-erated by Swordfish for the current segment and sentit to Moses for decoding using the XMLRPC API.The translated text was then copied to the XLIFFfile which, in turn, was inserted back to our currentsegment in Swordfish’s translation grid.
Our workflow with this configuration can be sum-marized as follows:
• We translated our project segment by segment(pretranslation with the TM was not applied)
• TM matches above 80% were always acceptedand the proposed translations were edited asnecessary
November 4th, 2010 Panagiotis Kanavos and Dimitrios Kartsaklis
13
• When the TM offered matches below 80%, thequality of the match was evaluated and theproposed translation was either accepted andedited or rejected
• When a TM match was rejected, MT was ap-plied to the segment and the result was editedaccordingly
• For segments with no TM matches, we alwaysapplied MT and the result was either acceptedand edited or rejected (in that case we had totranslate ourselves the whole segment)
Our decision point of 80% for the fuzzy thresh-old was selected based on our previous experiencewith similar setups. Up to this fuzzy threshold,Moses proposed translation is usually quite accu-rate and comparable with the TM match. This hap-pens because the TM used in the current project–and thus the matching translation unit–was also usedfor training our MT system. Furthermore, the trans-lation unit is also contained in our MT’s languagemodel. Above this fuzzy threshold, the TM match isusually very close to the desired translation, so edit-ing the proposed translation is more time-efficient.The 80% threshold was also suggested in a similarstudy by Carl and Hansen (1999).
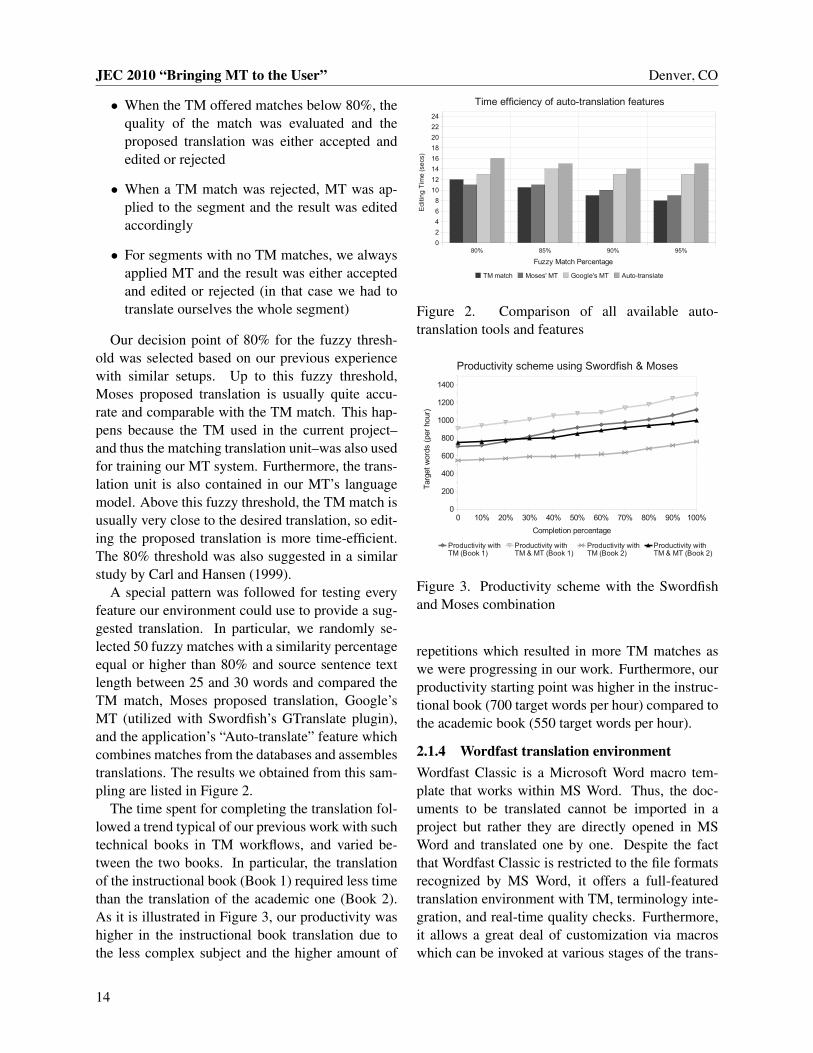
A special pattern was followed for testing everyfeature our environment could use to provide a sug-gested translation. In particular, we randomly se-lected 50 fuzzy matches with a similarity percentageequal or higher than 80% and source sentence textlength between 25 and 30 words and compared theTM match, Moses proposed translation, Google’sMT (utilized with Swordfish’s GTranslate plugin),and the application’s “Auto-translate” feature whichcombines matches from the databases and assemblestranslations. The results we obtained from this sam-pling are listed in Figure 2.
The time spent for completing the translation fol-lowed a trend typical of our previous work with suchtechnical books in TM workflows, and varied be-tween the two books. In particular, the translationof the instructional book (Book 1) required less timethan the translation of the academic one (Book 2).As it is illustrated in Figure 3, our productivity washigher in the instructional book translation due tothe less complex subject and the higher amount of
Figure 2. Comparison of all available auto-translation tools and features
Figure 3. Productivity scheme with the Swordfishand Moses combination
repetitions which resulted in more TM matches aswe were progressing in our work. Furthermore, ourproductivity starting point was higher in the instruc-tional book (700 target words per hour) compared tothe academic book (550 target words per hour).
2.1.4 Wordfast translation environmentWordfast Classic is a Microsoft Word macro tem-plate that works within MS Word. Thus, the doc-uments to be translated cannot be imported in aproject but rather they are directly opened in MSWord and translated one by one. Despite the factthat Wordfast Classic is restricted to the file formatsrecognized by MS Word, it offers a full-featuredtranslation environment with TM, terminology inte-gration, and real-time quality checks. Furthermore,it allows a great deal of customization via macroswhich can be invoked at various stages of the trans-
JEC 2010 “Bringing MT to the User” Denver, CO
14

lation process and provides integration with MT sys-tems.
2.1.5 The Systran MT systemSystran is a widely known MT application that isavailable in various editions and language pairs. Thelatest editions of Systran include a much improvedhybrid MT engine with many customization options,and the ability to create custom user dictionaries.The version we used for this work, however, wasusing only rule-based MT technology. The entriesin the user dictionaries are not merely used as word-to-word translations, but rather they are subject tothe MT engine’s rules and thus they can generateinflected forms. This provides a great means for im-proving the MT engine but also imposes a restric-tion: building the user dictionary before actuallyworking on a specific translation project is rather te-dious and time-inefficient for the following reasons:
• The translator can’t possibly know how a par-ticular term or phrase will be translated in aspecific context by the MT engine
• The custom dictionary entries should be testedin a sample sentence
• Inflected forms of some entries cannot be trans-lated correctly by the MT engine so othermeans of improving the engine should be ap-plied (for example, post-editing macros–see thefollowing section)
It should be noted, however, that after building acustom user dictionary for a specific domain it canbe used and tweaked for future projects in the samedomain.
2.1.6 Integrating Systran with WordfastThe integration of the two systems was achieved viaa special Wordfast’s feature that works as follows: ifthere is no TM exact or fuzzy match for the segmentcurrently translated, then the segment is transferredto the MT engine and the translation is copied intothe target segment.
Our system was also improved by using two setsof custom Word macros. The first set includedmacros that accomplished various pre-translationtasks which were executed to the source segment
Figure 4. Productivity chart using the Systran andWordfast combination
before submission to the MT engine. Such tasks in-volved the temporary substitution of source wordsor phrases that couldn’t be translated properly bySystran’s engine with other similar that didn’t al-ter the sentence’s meaning. For example, the en-gine could not translate correctly the auxiliary verb“might”, even though the word was properly codedin our user dictionary. Our macro was simply substi-tuting “might” with “may”, and after the translationwas returned to our segment the original word wasrestored. The second set of macros executed post-translation actions to the translated segment returnedby Systran. These actions improved the style of thetranslated text by various ways, very specific to ourtarget language.
Our productivity is presented in Figure 4. As it isillustrated in the chart, our productivity was lower atthe beginning of our work. This was due to the timewe had to spend to build the custom Systran dic-tionary. When we had completed about 20% of thetranslation and had added 80 entries in our customdictionary, our productivity increased to our usualstandards. Beyond this point our productivity in-creased drastically while the number of entries wehad to put in our dictionary was constantly decreas-ing. By the end of the translation our dictionary con-tained only 240 entries.
2.2 Applying MT to the full project
The implementation of this approach does not nec-essarily require a plugin or some other means of con-necting the CAT program to MT systems, although
November 4th, 2010 Panagiotis Kanavos and Dimitrios Kartsaklis
15

such a feature would be more convenient and restrictthe number of steps required to prepare the projectfile. The number of steps is also greatly reduced ifthe application’s project file has a standard or openformat such as XLIFF or other XML-based format.For the implementation of this approach we usedDeja Vu X, a Microsoft Windows application basedon the Jet Database engine.
2.2.1 Deja Vu X’s translation environmentDeja Vu X is based on a concept similar to Sword-fish’s. It offers a two-column translation grid withthe source segments in the first column and emptycells in the second column where the user can typetheir translations or insert matches from the TM, aswell as TM and terminology match panes. The ap-plication also includes a special feature called “As-semble” which applies EBMT (Example-Based Ma-chine Translation) algorithms for converting fuzzymatches to exact by combining TM and terminologyentries.
2.2.2 Using Moses with Deja Vu XDeja Vu X does not offer a way to connect to exter-nal applications or scripts, so using MT segment bysegment is not possible. Instead, the only efficientway to use Moses with this CAT program was to ex-tract the whole project file and pretranslate it withMoses. The application offers an option to exportthe whole project file into a table in RTF format.Each table row consists of three fields and corre-sponds to a segment. The first field (cell) is a uniquerow ID number which must not be altered in anyway because then the application cannot re-importthe file back to the project. The second field is thesource segment, which includes the source text andthe internal formatting tags, and must not be alteredtoo. The third field is the target segment where atranslation can be typed in. Before we exported theproject, however, we applied pretranslation againstour translation memory with a fuzzy threshold equalto 80% and then we locked the pretranslated seg-ments to avoid exporting them with the rest of theproject. With this approach the number of segmentswas reduced to some extent so Moses had to trans-late fewer sentences. The workflow is outlined inFigure 5.
An alternative workflow that may seem more rea-
sonable at first glance would be to export all thesegments without applying pretranslation; translatethe whole project with Moses; import the translationback to the project file; and then compare Mose’stranslations with the TM matches and keep the besttranslations. However, the benefits with this ap-proach would be minimal because above the 80%fuzzy threshold it is more time-efficient to accept theTM matches and edit them as necessary.
When the file was translated, we reversed the or-der of the preparation steps in order to re-createthe RTF table and place the machine-translated seg-ments to their corresponding cells. Then we im-ported the file back to our project and started work-ing segment by segment. It should be noted thatthe fuzzy match threshold was lowered to our stan-dard 70%. This resulted in some segments whichwere filled with MT translations and also had fuzzymatches between 70% and 79%. Now our work-flow was quite different than the one followed inthe Swordfish-Moses combination because all of ourproject’s target segments were filled with transla-tions and our work essentially involved editing. Thisworkflow consisted of the following steps:
• Segments contained TM matches were editedas required
• Segments contained MT translations werequickly evaluated for accuracy and were eithererased or edited
• When an MT translation was rejected, therewere two possible options: if a fuzzy matchwas available from the TM, it was inserted in
Figure 5. Steps for translating a Deja Vu X projectwith Moses
JEC 2010 “Bringing MT to the User” Denver, CO
16
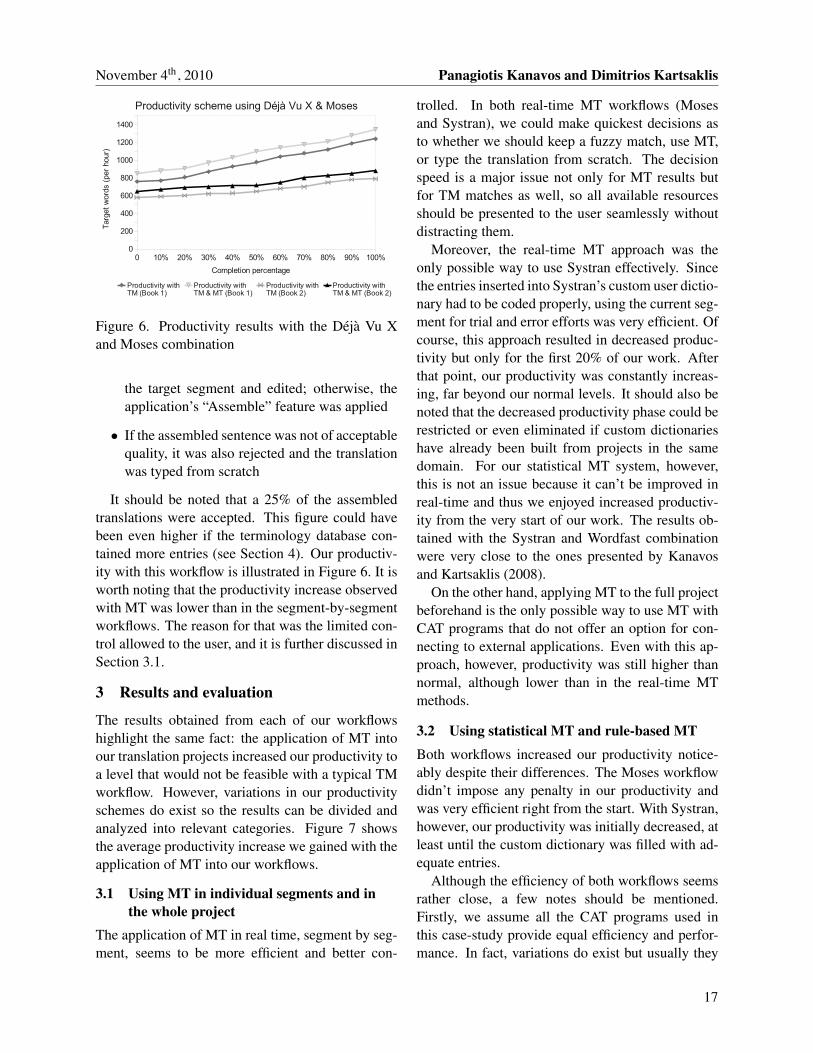
Figure 6. Productivity results with the Deja Vu Xand Moses combination
the target segment and edited; otherwise, theapplication’s “Assemble” feature was applied
• If the assembled sentence was not of acceptablequality, it was also rejected and the translationwas typed from scratch
It should be noted that a 25% of the assembledtranslations were accepted. This figure could havebeen even higher if the terminology database con-tained more entries (see Section 4). Our productiv-ity with this workflow is illustrated in Figure 6. It isworth noting that the productivity increase observedwith MT was lower than in the segment-by-segmentworkflows. The reason for that was the limited con-trol allowed to the user, and it is further discussed inSection 3.1.
3 Results and evaluation
The results obtained from each of our workflowshighlight the same fact: the application of MT intoour translation projects increased our productivity toa level that would not be feasible with a typical TMworkflow. However, variations in our productivityschemes do exist so the results can be divided andanalyzed into relevant categories. Figure 7 showsthe average productivity increase we gained with theapplication of MT into our workflows.
3.1 Using MT in individual segments and inthe whole project
The application of MT in real time, segment by seg-ment, seems to be more efficient and better con-
trolled. In both real-time MT workflows (Mosesand Systran), we could make quickest decisions asto whether we should keep a fuzzy match, use MT,or type the translation from scratch. The decisionspeed is a major issue not only for MT results butfor TM matches as well, so all available resourcesshould be presented to the user seamlessly withoutdistracting them.
Moreover, the real-time MT approach was theonly possible way to use Systran effectively. Sincethe entries inserted into Systran’s custom user dictio-nary had to be coded properly, using the current seg-ment for trial and error efforts was very efficient. Ofcourse, this approach resulted in decreased produc-tivity but only for the first 20% of our work. Afterthat point, our productivity was constantly increas-ing, far beyond our normal levels. It should also benoted that the decreased productivity phase could berestricted or even eliminated if custom dictionarieshave already been built from projects in the samedomain. For our statistical MT system, however,this is not an issue because it can’t be improved inreal-time and thus we enjoyed increased productiv-ity from the very start of our work. The results ob-tained with the Systran and Wordfast combinationwere very close to the ones presented by Kanavosand Kartsaklis (2008).
On the other hand, applying MT to the full projectbeforehand is the only possible way to use MT withCAT programs that do not offer an option for con-necting to external applications. Even with this ap-proach, however, productivity was still higher thannormal, although lower than in the real-time MTmethods.
3.2 Using statistical MT and rule-based MTBoth workflows increased our productivity notice-ably despite their differences. The Moses workflowdidn’t impose any penalty in our productivity andwas very efficient right from the start. With Systran,however, our productivity was initially decreased, atleast until the custom dictionary was filled with ad-equate entries.
Although the efficiency of both workflows seemsrather close, a few notes should be mentioned.Firstly, we assume all the CAT programs used inthis case-study provide equal efficiency and perfor-mance. In fact, variations do exist but usually they
November 4th, 2010 Panagiotis Kanavos and Dimitrios Kartsaklis
17

Figure 7. MT overall efficiency measurement inboth real-time and non-real-time settings
are negligible for measurements in this scale, assum-ing the user is equally skilled in all the CAT pro-grams. Secondly, the Systran version that was avail-able for our target language was rather limited com-pared to other versions, thus the results could be bet-ter with an improved version. We should also men-tion that most recent Systran versions offer hybridMT capabilities that could have yielded much betterresults if we had the opportunity to use them. Onthe other hand, the Moses workflow could have alsobeen more efficient had we used a factored model(Koehn and Hoang, 2007). Moses is a very flexiblesystem that can be enriched with morphological andsyntactical information for more accurate decoding.
4 Discussion and assessment
The results obtained with each workflow can varyin some degree depending on a number of language,text context and style, and application-specific fac-tors. For instance, the quantity and quality of the TMentries affect directly the performance of the MosesMT system. The more entries a TM contains, themore efficient the MT system will be since the train-ing corpus will also be larger. Furthermore, the qual-ity of the TM affects both the matches obtained fromit and the efficiency of the MT system, for obviousreasons. Equally important is the number and thequality of the terminology entries for yielding betterresults from the “assemble” feature offered by theCAT programs.
Another very important factor is the domain ofthe translation material used to train a statistical MT
system. Our workflow with Moses was success-ful because the TM entries with which we createdthe MT system had been derived from informaticsbooks translations. This can be a serious restric-tion for translators who work frequently with smalltexts covering several different domains. In suchcases, there probably won’t be enough entries fromeach domain to build different MT systems. On theother hand, translation agencies that translate veryhigh volumes of texts in different domains can eas-ily build separate MT models and use the appropri-ate one for each specific project. Systran, however,does not have these restrictions. What matters mostin a workflow with Systran is the efficiency of therules inherent to the MT engine, which admittedly ishigh, and the availability of custom user dictionariesfor different domains. The Systran English-Greekedition we used did not have the ability to use multi-ple user dictionaries, although this feature is offeredin other editions and language pairs. Thus, while fora successful Moses system huge amounts of domain-specific corpora are required, Systran’s custom dic-tionaries require a few hundred carefully coded en-tries.
The language pair is also a very important fac-tor when building statistical models for Moses andcoding efficient Systran user dictionaries. Greek is amorphologically and syntactically rich language thatcan challenge any MT system. Furthermore, it is notan ideal language for accurate “assembled” transla-tions that some CAT programs can generate becausethe terminology entries used in such operations donot make use of morphological or syntactical infor-mation.
Productivity gains may also vary depending onthe style of the translation work. For instance, us-ing these workflows for translating texts with repet-itive and step-by-step sections is more productivethan translating texts with a more natural or aca-demic style. However, in either case there are stillbenefits in productivity. It is worth noting that inall relevant measurements and comparisons the MTsystems (even the mainstream Google Translate ser-vice which cannot be customized) outperformed theCAT programs’ native “assemble” features.
Some other important but non-measurable fac-tors that should be taken into consideration whenevaluating productivity with these workflows are the
JEC 2010 “Bringing MT to the User” Denver, CO
18

so-called “human factors”, such as familiarity withall involved technologies, experience in the sub-ject of the translation, volume of the translationproject, ability to identify text patterns and predictMT results, usability issues, etc (Lagoudaki, 2008).For general acceptance and use, these technologiesshould be integrated into an intuitive end-user appli-cation. In the following section we attempt to pro-vide some suggestions and outlines as to how suchan application should be designed and what func-tions it should be able to perform.
4.1 A proposal for a unified application
An application that would incorporate both tech-nologies (MT and TM) should mainly be a TM ap-plication. No matter how efficient an MT systemis, professional translators will always rely on theirTMs and terminology databases. Besides, our in-creased productivity resulted from the MT systemsin our workflows was possible only because we usedthem on top of TM environments. What is actuallyneeded is a user-friendly “wrapper” application thatwill be able to perform the steps in our methodolo-gies automatically for the user.
4.1.1 Basic features and designThe basic components of the application should bethe translation editor, where the actual translationwork will be performed; the TM databases and theterminology databases; an editor for examining andrevising the TM and terminology databases; anda document aligner for creating translation memo-ries from existing translations. The translation ed-itor should offer rich text editing features and theability to filter and sort segments based on certaincriteria. The editor’s environment should also pro-vide panes for displaying TM matches, terminologymatches and, for our purpose, MT results. Selectiveapplication of MT and presenting MT suggestionsas another source of reference is a key for success-ful integration, as it is also mentioned by Lagoudaki(2008).
Other useful features that could be implementedinclude concordance searches against the TM andterminology databases; ability to assemble trans-lations from all available databases; interoperabil-ity with other CAT applications via open standards(TMX, XLIFF, TBX); automatic quality assurance
control (spell-checking, number and tag checking);and robust filters for importing and exporting vari-ous file formats. These features are particularly fa-vored by TM users (Lagoudaki, 2006).
4.1.2 MT integrationA statistical MT system (such as Moses) integratedinto a CAT program can be trained with existingTMs. TM databases are usually organized into sub-jects so our proposed application could monitor thenumber of entries in domain-specific TM databasesand provide the user with an option to train anMT system when this number reaches a satisfactorylevel (for example, 50,000 translation units). How-ever, there are some critical restrictions with thisapproach, such as the computing resources and thetime required for training. A solution to this prob-lem could be the deployment of the MT componentinto a separate server machine, either on the user-side or in a third party’s premises. This third-partycould act as a service provider, so in that case theMT feature could be offered as Software as a Service(SaaS). Also, the application may offer an option touse Moses when there are no TM matches, similarto the feature offered by Wordfast Classic, and ondemand by the user.
Another statistical MT-related feature that couldbe implemented is the ability to build factored mod-els using the terminology databases. Most modernCAT tools allow the user to enter linguistic informa-tion to terminology entries, although this informa-tion is only used for reference purposes. Our appli-cation, however, could possibly use it in conjunctionwith a POS (Part-of-Speech) tagger to create fac-tored models for better MT performance.
The statistical MT technology can also find otheruses beyond its main purpose of translating text au-tomatically, as introduced by the TransType project(Langlais et al., 2000; Esteban et al., 2004). A typ-ical example of such use is Caitra (Koehn and Had-dow, 2009), a CAT tool developed by the Univer-sity of Edinburgh and based on the Moses decoder.Caitra uses Interactive Machine Translation, a tech-nology that offers suggestions of short phrases asthe translator is typing. The suggestions are offeredin an intuitive way without distracting the transla-tor who has the option to accept the suggestions orignore them and continue typing. While the trans-
November 4th, 2010 Panagiotis Kanavos and Dimitrios Kartsaklis
19

lator continues to type, the suggestions offered bythe system change dynamically so the user has al-ways the option to accept or ignore them. Trados isa well-known CAT program that implements a sim-ilar feature called “AutoSuggest”.
Integrating rule-based MT features into a CATprogram seems easier and more flexible. Forinstance, Systran requires average computing re-sources and does not involve any special preparationsteps. However, the efficiency of Systran is greatlydependent on the quality of the custom dictionaries.Thus, our unified application should provide a wayto build Systran’s user dictionaries from within theapplication. This can be achieved via the terminol-ogy databases which may include additional fieldsfor coding Systran’s user dictionaries.
5 Conclusions
All workflows presented in this work lead to theconclusion that machine translation, either statisti-cal or rule-based, has already matured and can in-crease substantially the productivity of professionaltranslators. Although a comparison with other rel-evant work would have been of particular interest,to the best of our knowledge this is the first large-scale work testing multiple TM-MT configurationsin real-world scenarios. Furthermore, the fact thatour approach is successful with a target language ashighly inflective as Greek means that we can safelyexpect productivity increase in many other settingsinvolving Western language pairs. A crucial factoris the availability of in-domain corpora, as well asthe domain itself. The benefits of integrating TMand MT technologies would be even greater for lan-guage service providers who work with high vol-umes of technical texts. However, restrictions doexist, particularly in the implementation of MT inprofessional workflows. Currently, there is not astraightforward way for using MT in TM environ-ments or a translation software that integrates tightlyboth technologies, but work towards this purpose isin progress by the authors.
The results presented in this work show that trans-lation workflows are likely to change in the near fu-ture and machine translation will certainly has itsrole in it.
ReferencesCarl, Mark and Silvia Hansen. 1999. Linking Transla-
tion Memories with Example-Based Machine Transla-tion. In Machine Translation Summit VII, pages 617–624, Singapore.
Esteban, Jose, Jose Lorenzo, Antonio S. Valderrabanos,and Guy Lapalme. 2004. Transtype2–An In-novative Computer-Assisted Translation System.In Proceedings of the ACL-2004 InteractivePosters/Demonstrations Session, pages 94–97,Morristown, NJ, USA.
Kanavos, Panagiotis and Dimitrios Kartsaklis. 2008.Translation and Computers (in Greek). ScientificAmerican, Greek edition, 6(2):24–31.
Koehn, Philipp and Barry Haddow. 2009. Interactive As-sistance to Human Translators Using Statistical Ma-chine Translation Methods. In Machine TranslationSummit XII, pages 73–80, Ottawa, Canada.
Koehn, Philipp and Hieu Hoang. 2007. Factored Trans-lation Models. In Proceedings of the 2007 JointConference on Empirical Methods in Natural Lan-guage Processing and Computational Natural Lan-guage Learning (EMNLP-CoNLL ’07), pages 868–876, Prague, Czech Republic.
Koehn, Philipp, Hieu Hoang, Alexandra Birch, ChrisCallison-Burch, Marcello Federico, Nicola Bertoldi,Brooke Cowan, Wade Shen, Christine Moran, RichardZens, Chris Dyer, Ondrej Bojar, Alexandra Con-stantin, and Evan Herbst. 2007. Moses: Open SourceToolkit for Statistical Machine Translation. In Pro-ceedings of the Demo and Poster Sessions of the 45thAnnual Meeting of the Association for ComputationalLinguistics (ACL ’07), pages 177–180, Prague, CzechRepublic.
Lagoudaki, Elina. 2006. Translation Memory Systems:Enlightening Users Perspective. Key Findings of theTM Survey 2006 Carried out During July and August2006. Imperial College London.
Lagoudaki, Elina. 2008. The Value of Machine Trans-lation for the Professional Translator. In Proceedingsof the 8th Conference of the Association for MachineTranslation in the Americas, pages 262–269, Waikiki,Hawaii.
Langlais, Philippe, George Foster, and Guy Lapalme.2000. Transtype: A Computer-Aided Translation Typ-ing System. In EmbedMT ’00: ANLP-NAACL 2000Workshop: Embedded Machine Translation Systems,pages 46–51, Morristown, NJ, USA.
JEC 2010 “Bringing MT to the User” Denver, CO
20





























