Embed Size (px)
Citation preview

Implementacion del algoritmo de deteccion
facial de Viola-Jones
Autor:Joaquın Planells Lerma
Director:Roberto Paredes Palacios
23 de marzo de 2009

2

Indice general
1. Introduccion 7
1.1. Objetivo . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 71.2. Deteccion de caras . . . . . . . . . . . . . . . . . . . . . . . . 8
1.2.1. Medidas del error de un detector . . . . . . . . . . . . 8
2. Caracterısticas locales 11
2.1. Caracterısticas tipo Haar . . . . . . . . . . . . . . . . . . . . . 112.2. Calculo rapido de caracterısticas con la imagen integral . . . . 132.3. Caracterısticas tipo Haar en la deteccion de caras . . . . . . . 142.4. Implementacion . . . . . . . . . . . . . . . . . . . . . . . . . . 16
2.4.1. Aplicacion de una caracterıstica a una ventana . . . . . 162.5. Referencias . . . . . . . . . . . . . . . . . . . . . . . . . . . . 16
3. Entrenamiento de un detector de caras 19
3.1. Clasificador lineal con caracterısticas tipo Haar . . . . . . . . 193.2. El algoritmo Adaboost . . . . . . . . . . . . . . . . . . . . . . 203.3. La cascada de clasificadores . . . . . . . . . . . . . . . . . . . 223.4. Implementacion . . . . . . . . . . . . . . . . . . . . . . . . . . 243.5. Utilidades para entrenamiento de cascadas . . . . . . . . . . . 25
3.5.1. vjsamples . . . . . . . . . . . . . . . . . . . . . . . . . 253.5.2. vjtest . . . . . . . . . . . . . . . . . . . . . . . . . . . 263.5.3. vjaddstage . . . . . . . . . . . . . . . . . . . . . . . . 263.5.4. train cascade.sh . . . . . . . . . . . . . . . . . . . . 26
3.6. Experimentos . . . . . . . . . . . . . . . . . . . . . . . . . . . 273.6.1. XM2VTS . . . . . . . . . . . . . . . . . . . . . . . . . 27
3.7. Referencias . . . . . . . . . . . . . . . . . . . . . . . . . . . . 29
4. El detector de Viola-Jones 31
4.1. El detector de Viola-Jones . . . . . . . . . . . . . . . . . . . . 314.2. Implementacion del detector . . . . . . . . . . . . . . . . . . . 324.3. Utilidades para la deteccion . . . . . . . . . . . . . . . . . . . 34
3

4 INDICE GENERAL
4.3.1. vjdetector . . . . . . . . . . . . . . . . . . . . . . . . 344.3.2. Demo facedetect de OpenCV . . . . . . . . . . . . . 34
4.4. Experimentos . . . . . . . . . . . . . . . . . . . . . . . . . . . 364.4.1. XM2VTS . . . . . . . . . . . . . . . . . . . . . . . . . 36
4.5. Referencias . . . . . . . . . . . . . . . . . . . . . . . . . . . . 36
A. Estructura del codigo fuente 39
A.1. Software utilizado . . . . . . . . . . . . . . . . . . . . . . . . . 39A.2. Hardware utilizado . . . . . . . . . . . . . . . . . . . . . . . . 40A.3. Ficheros del proyecto . . . . . . . . . . . . . . . . . . . . . . . 40
A.3.1. Estructura para almacenar las imagenes . . . . . . . . 41A.3.2. Estructuras de datos para las caracterısticas . . . . . . 42A.3.3. Estructura de datos para la cascada . . . . . . . . . . . 42A.3.4. Formato para las cascadas . . . . . . . . . . . . . . . . 42
A.4. Compilando el proyecto . . . . . . . . . . . . . . . . . . . . . . 43

Estructura de la memoria
Esta memoria esta dividida en 4 capıtulos. El primer capıtulo es unaintroduccion a la deteccion de caras y a los objetivos de este proyecto defin de carrera. Cada uno de los capıtulos siguientes se dedica a una de las 3aportaciones principales que realizaron Viola y Jones.
Las caracterısticas tipo Haar (capıtulo 2).
La cascada de clasificadores Adaboost (capıtulo 3).
La deteccion en cascada (capıtulo 4).
En cada capıtulo se comenzara con una introduccion general un pocomas teorica y seguidamente se explicaran los detalles mas importantes de laimplementacion y problemas encontrados. Ademas al final de cada capıtulose comentaran los resultados de los experimentos realizados.
Finalmente, en el apendice A se presentaran algunos detalles extra deimplementacion, como las estructuras de datos y formatos de ficheros.
5

6 INDICE GENERAL

Capıtulo 1
Introduccion
1.1. Objetivo
El reconocimiento facial es un campo del reconocimiento de formas conimportantes aplicaciones hoy en dıa como por ejemplo el control de acceso aedificios y laboratorios o la busqueda de imagenes en bases de datos.
Un paso necesario para identificar una cara en una imagen o secuencia devıdeo es poder detectar en que posiciones de la imagen es mas probable quehaya una cara.
El objetivo de este PFC es el estudio e implementacion de un sistemade deteccion de caras en imagenes complejas computacionalmente apto parasu utilizacion en aplicaciones con restricciones de tiempo real. Para ello nosbasaremos en el modelo de detector propuesto por Paul Viola y Michael J.Jones en [9].
La aportacion principal de P. Viola y M.J. Jones fue el uso de una cascadade clasificadores muy sencillos que se ejecutan uno detras de otro. Cadaclasificador de la cascada se entrena con el algoritmo de boosting AdaBoost.Los primeros clasificadores son muy sencillos y permiten rechazar una grancantidad de no caras mientras que aceptan un porcentaje muy alto de caras.La cascada permite desechar gran parte de las regiones de la imagen y soloconcentrarse en las zonas en las que es mas probable que haya una cara porlo que la deteccion es bastante rapida.
Otro factor importante del algoritmo es que cada clasificador de la cascadacomprueba una o mas caracterısticas similares a los wavelets de Haar por loque es posible implementar el algoritmo utilizando unicamente aritmeticaentera lo que redunda tambien en una mayor velocidad de la deteccion.
El trabajo a realizar en el proyecto se podrıa resumir en 3 puntos:
Comprender los fundamentos del algoritmo de deteccion ası como apor-
7

8 CAPITULO 1. INTRODUCCION
taciones de otros autores al trabajo de P. Viola y M.J. Jones.
Implementacion de una plataforma de entrenamiento con la que poderconstruir diferentes detectores de caras en funcion de diversos parame-tros configurables.
Implementacion de un detector de caras que partiendo de los ficherosgeneradores por la plataforma de entrenamiento permita la deteccion decaras en imagenes complejas y devuelva una lista con las coordenadasde las caras encontradas.
1.2. Deteccion de caras
En esta seccion vamos aclarar lo que es la deteccion de caras, que es elobjetivo de este proyecto.
La deteccion de caras consiste en determinar si en una imagen arbitrariahay alguna cara y, en caso se haberla, en que posicion se encuentra. Un de-tector de caras deberıa ser capaz de encontrar todas las caras de una imagen.
Un detector de caras debe devolver para cada cara detectada en la imagenla posicion y tamano de una caja de inclusion en la que se encuentren losojos, la nariz y la boca. Ademas serıa deseable que nos devolviera otros datoscomo el angulo de rotacion de la cara y un score que nos indique la fiabilidadde esa deteccion.
Existen varios algoritmos para la deteccion de caras. Cada uno de estosalgoritmos esta basado alguna tecnica conocida de reconocimiento de for-mas como redes neuronales, vecino mas proximo, etc. Cada detector tienecaracterısticas que lo hacen diferente al resto. Por ejemplo, el detector deViola-Jones que se ha implementado en este proyecto es un detector muyrapido pero no es capaz de calcular la orientacion de la cara ni darnos unaestimacion de lo seguro que esta de la deteccion.
1.2.1. Medidas del error de un detector
A la hora de evaluar un detector de caras debemos fijarnos en 3 medidasfundamentales.
Tasa de deteccion: Es el porcentaje de caras correctamente detectadasrespecto del total de caras de la imagen.
Tasa de falsos positivos : Indica el numero de regiones que se han mar-cada como caras donde realmente no hay una cara.

1.2. DETECCION DE CARAS 9
Tasa de falsos negativos : Indica el numero de caras que no han sidocorrectamente detectadas. Es decir, que han sido clasificadas negativa-mente.
Es importante utilizar los 2 ultimos conjuntamente para no inducir aerror. Por ejemplo un detector que encontrara caras en todos los pixels de laimagen tendrıa una tasa de falsos negativos de 0,0 pero en cambio su tasa defalsos positivos serıa cercana a 1,0.
En una misma imagen solo puede unas pocas caras, en cambio puedehaber miles de regiones. Esta muy desequilibrado el numero de caras y nocaras por tanto necesitamos que la tasa de falsos positivos sea varios ordenesde magnitud en comparacion con la tasa de falsos negativos. En la figura 1.1podemos ver una imagen con la cara correctamente detectada (arriba), unaimagen con 2 falsos positivos (en medio) y otra en la que se ha detectadouna sola cara y hay 5 falsos negativos.

10 CAPITULO 1. INTRODUCCION
Figura 1.1: Ejemplo de una deteccion correcta, de una imagen con falsospositivos y una con falsos negativos.

Capıtulo 2
Caracterısticas locales
En este capıtulo vamos a hablar de la primera aportacion importante quehicieron Viola y Jones en [9]: las caracterısticas tipo Haar. Se mostrara pri-mero en que consisten las caracterısticas tipo Haar y como pueden ser uti-lizadas para distinguir entre imagenes de caras y no caras, posteriormentese vera como calcular eficientemente los valores de estas caracterısticas yfinalmente como se han implementado en el proyecto.
La idea es utilizar caracterısticas locales en vez que la informacion directade los pixels ya que las caracterısticas locales permiten modelar mejor lainformacion del dominio (en este caso las caras humanas) y son sencillas deaprender a partir de conjuntos de muestras.
2.1. Caracterısticas tipo Haar
Una de las ideas fundamentales del detector de caras propuesto por Violay Jones eran las caracterısticas tipo Haar. Segun los autores estan basadasen las funciones base de Haar presentadas por Papageorgiou et al. en [8].
Estas caracterısticas tipo Haar se definen sobre regiones rectangularesde una imagen en escala de grises. Una caracterıstica esta formado por unnumero finito de rectangulos y su valor escalar consistira la sumar de lospixels de cada rectangulo sumados aplicando un cierto factor de peso.
La formula para calcular el valor de una caracterıstica es
caracterısticaj =∑
1≤i≤N
wi · Suma rectangulo(ri)
donde {r1, . . . , rN} son los rectangulos que forman la caracterıstica y wi
el peso de cada uno.
11

12 CAPITULO 2. CARACTERISTICAS LOCALES
Figura 2.1: Las caracterısticas tipo Haar de 2, 3 y 4 rectangulos tal y comofueron definidas por Viola y Jones. Debajo se muestran las caracterısticasrotadas
Los autores limitaron el espacio de caracterısticas permitiendo solo 2, 3o 4 rectangulos. Ademas, estos rectangulos deben ser adyacentes y todos delmismo tamano. Con estas limitaciones, las caracterısticas se dividen en 3tipos: las de bordes (2 rectangulos), la de lineas (3 rect.) y las de forma deX (4 rect.). Los pesos tambien se limitan a los valores 1 y −1.
En la figura 2.1 vemos un ejemplo de cada uno de los 3 tipos de carac-terısticas. El valor de una caracterıstica se obtiene sumando todos los pixelsdel rectangulo blanco y restandole todos los pixels del rectangulo negro. Porejemplo, la caracterıstica central de 3 rectangulos tratarıa de representar queen general la region de los ojos es mas oscura que las regiones de alrededor.Cada caracterıstica (excepto la de 4 rectangulos) se puede rotar 90 gradospara obtener nuevas caracterısticas, tambien se puede invertir el peso de cadauno rectangulos.
El numero de caracterısticas diferentes que se pueden generar para unaimagen de 21x21 pixels es de mas de 90000. En su artıculo, Viola y Jonessolo emplean caracterısticas cuadradas por lo que en una ventana de 24x24consideran un total de 45396 caracterısticas distintas.En este proyecto se hapreferido no limitar la proporcion de las caracterısticas y permitir que elancho y alto de las caracterısticas sean independientes.

2.2. CALCULO RAPIDO DE CARACTERISTICAS CON LA IMAGEN INTEGRAL13
2.2. Calculo rapido de caracterısticas con la
imagen integral
Como hemos visto, se pueden definir mas de 90000 caracterısticas diferen-tes en una ventana de 21x21 pixels modificando el tamano de las caracterısti-cas tipo Haar y su polaridad. Sumar uno a uno los pixels de cada uno de losdiferentes rectangulos tiene un coste computacional proporcional al area delrectangulo pero los autores propusieron un metodo para calcular los valoresen tiempo constante a partir de lo que ellos llamaron la imagen integral1.
La imagen integral es una representacion alternativa para la imagen quese puede calcular de manera muy rapida. Un valor de la imagen integralii(x, y) sera igual al valor del pixel i(x, y) de la imagen sumado a todos lospixels de la imagen que esten a la izquierda y arriba de la posicion (x, y).
ii(x, y) =∑
x′≤x,y′≤y
i(x′, y′)
La imagen integral se puede calcular iterativamente comenzando por laposicion (0, 0). En la figura 2.3 podemos ver una representacion de la imagenintegral de una fotografıa. El pixel de abajo a la derecha contiene la suma detodas las intensidades de los pixels de la imagen.
s(x, y) = s(x, y − 1) + i(x, y)
ii(x, y) = ii(x− 1, y) + s(x, y)
Gracias a esta representacion podemos calcular la suma de los pixels de unrectangulo de cualquier tamano utilizando unicamente 4 accesos a memoria.Para calcular el valor de un rectangulo A cuya esquina superior izquierdaesta en (x, y) y cuyo tamano es (sx, sy) unicamente necesitamos acceder alvalor de la imagen integral de 4 esquinas. En la figura 2.2 se puede ver elesquema de la siguiente formula.
v(x, y, sx, sy) = ii(x+sx, y+sy)−ii(x−1, y+sy)−ii(x+sx, y−1)+ii(x−1, y−1)
Ademas, como las caracterısticas tipo Haar consisten en 2, 3 o 4 rectangu-los contiguos se pueden evitar accesos a memoria calculando el valor de todoslos rectangulos conjuntamente.
La unica desventaja de la imagen integral es que ocupa hasta 4 vecesmas memoria que la imagen original. Al ser una suma de los pixels de la
1En sus artıculos, Lienhart utiliza el nombre Summed Area Table (SAT) para referirsea la imagen integral.

14 CAPITULO 2. CARACTERISTICAS LOCALES
Figura 2.2: Calculo de un rectangulo a partir de la imagen integral. Paracalcular el valor del rectangulo A se debe realizar la operacion A−B−C+D.
imagen, no puede se definida como matriz de bytes tal y como se hace conlas imagenes ası que debemos utilizar una matriz de enteros que en la mayorpartes de sistemas ocupan 4 bytes.
2.3. Caracterısticas tipo Haar en la deteccion
de caras
Una vez definidas las caracterısticas de tipo Haar y ver que tenemosun mecanismo eficiente para calcular su valor pasamos a comprobar comose pueden aplicar a la deteccion de caras. Si comparamos las figuras 2.1 y2.4 vemos como las caracterısticas adquieren un cierto significado. Podemosutilizarlas para modelar las diferencias de intensidad de los pixels de lasdistintas zonas de la cara. Viola y Jones comprobaron que no hace faltacalcular el valor de todas las caracterısticas para una misma imagen si noque con una pequena parte ya podemos discernir con poco error si una regiones o no una cara.
En la figura 2.4 vemos los 3 tipos de caracterısticas aplicadas sobre unacaras. La primera caracterıstica trata de representar que la region de los ojosy cejas es mas oscura que la region de debajo.

2.3. CARACTERISTICAS TIPO HAAR EN LA DETECCION DE CARAS15
Figura 2.3: Representacion en pixels de la imagen integral de una fotografıa.
Figura 2.4: Ejemplos de caracterısticas locales de 2, 3 y 4 rectangulos apli-cadas a una cara.

16 CAPITULO 2. CARACTERISTICAS LOCALES
2.4. Implementacion
La implementacion de las caracterısticas se ha realizado de manera analo-ga a la de OpenCV. Para realizar menos accesos a memoria las caracterısticasde 3 rectangulos que hemos explicado en 2.1 se almacenan como dos rectangu-los, uno del tamano de toda la caracterıstica y otro para representar el centrode la misma. Este ultimo rectangulo tendra el doble de peso (2 o −2) paracontrarrestar el falso peso que ha anadido el rectangulo grande. Analoga-mente, la caracterıstica de 4 rectangulos se almacena internamente como 3rectangulos.
No se han utilizado la idea de los autores de aprovechar que son rectangu-los contiguos para realizar menos accesos a memoria ya que eso complicadamas el codigo. Con la implementacion actual es sencillo definir cualquier tipode caracterıstica rectangular solo modificando una funcion.
2.4.1. Aplicacion de una caracterıstica a una ventana
Las caracterısticas tipo Haar se definen a partir de un tamano de ventana(por ejemplo, 21x21). Es muy facil aplicar la caracterıstica a una subventanadel mismo tamano que la ventana original. No tiene sentido utilizar subven-tanas de tamano menor que la ventana original pero sı podemos aplicar unacaracterıstica en subventanas de mayor tamano. Para ello hemos de reescalarlos rectangulos de la caracterıstica.
La imagen integral es un espacio discreto y por tanto el reescalado se debelimitar a los numeros con lo que perderemos precision. El principal problemadel reescalado es el umbral que, en caso de escalar mucho los rectangulos,puede modificar mucho el valor de la caracterıstica. Para evitar este proble-ma debemos de modificar el peso de cada rectangulo teniendo en cuenta ladiferencia de areas entre el rectangulo original y el escalado.
w′ =area original
area escalada
Durante el entrenamiento nos podemos cenir a las caracterısticas sin es-calar, pero durante la deteccion es imprescindible aumentar de tamano lascaracterısticas para poder abarcar toda la imagen.
2.5. Referencias
Este capıtulo se ha basado casi exclusivamente en el artıculo original deViola y Jones[9]. Las caracterıstica tipo Haar adquirieron gran importancia

2.5. REFERENCIAS 17
Figura 2.5: Escalado de caracterısticas
en la deteccion de caras despues de la publicacion del artıculo y otros au-tores propusieron nuevos conjuntos de caracterısticas. Por ejemplo Lienhart,Kuranow y Pisarevsky en [5] definieron un conjunto de caracterısticas comolas de Viola y Jones pero rotadas 45o. Su idea era que un conjunto de carac-terısticas rotadas permitıa modelar mejor algunos rasgos de la cara que noes posible modelar solo con lıneas rectas horizontales y verticales.
Para poder calcular eficientemente este tipo de caracterısticas rotadas senecesita un nuevo tipo de imagen integral, la imagen integral rotada. En[5], los autores logran una pequena mejora respecto al algoritmo originalutilizando este nuevo conjunto de caracterısticas y realizando un postprocesode la cascada. En la literatura parece que pocos autores se inclinan por estenuevo conjunto. La implementacion del detector de caras de OpenCV, creadapor el propio Lienhart, no utiliza por defecto las caracterıstica rotadas.

18 CAPITULO 2. CARACTERISTICAS LOCALES

Capıtulo 3
Entrenamiento de un detector
de caras
En este capıtulo se explicara el proceso de entrenamiento del detector decaras y los detalles de la implementacion. Viola y Jones propusieron entrenarsu detector de caras con un algoritmo de boosting que se encargara de selec-cionar de entre las miles de posibles caracterısticas las que mejor separabanel espacio entre las caras y no caras.
Un algoritmo de boosting es aquel que se basa en la union de varios clasifi-cadores sencillos (en nuestro caso basados las caracterısticas tipo Haar) paracrear un clasificador que tiene una menor tasa de error que los clasificadoresindividuales que lo forman. El algoritmo de boosting utilizado por Viola yJones es el Adaboost que pasamos a explicar a continuacion.
3.1. Clasificador lineal con caracterısticas ti-
po Haar
A partir de una caracterıstica tipo Haar podemos definir un clasificadorque diga si una imagen es o no una cara. Para ello calculamos el valor de lacaracterıstica y si el valor es menor que un cierto umbral, asumimos que laimagen es una cara y si el valor supera el umbral consideramos que no lo es.
Formalmente un clasificador basado en una caracterıstica j se expresacomo
hj(x) =
{
1 si pjfj(x) < pjθj
0 en otro caso
donde fj(x) es el valor que se obtiene al aplicar la caracterıstica j sobre laimagen x, θj es el umbral de la caracterıstica y pj es la polaridad. Este ultimo
19

20 CAPITULO 3. ENTRENAMIENTO DE UN DETECTOR DE CARAS
Figura 3.1: Ejemplo de una caracterıstica seleccionada por Adaboost.
valor puede ser 1 o −1 y nos permite invertir una caracterıstica convirtiendolos rectangulos positivos en negativos y viceversa. Una de las utilidades dela polaridad es que en caso de que el clasificador obtuviera un error ǫj mayorque 0,5, podrıamos utilizar la caracterıstica inversa y obtener un error de1− ǫj que sera menor que 0,5.
3.2. El algoritmo Adaboost
En la seccion anterior hemos definido un clasificador lineal basado en unasola caracterıstica como sigue:
hj(x) =
{
1 si pjfj(x) < pjθj
0 en otro caso
Donde fj(x) es el valor de la caracterıstica f en la imagen, pj la polaridady θj es el umbral de la caracterıstica. En nuestra implementacion tomaremosuna caracterıstica y su inversa como distintas ası que podemos prescindir delparametro pj quedandonos:
hj(x) =
{
1 si fj(x) < θj
0 en otro caso
Con un clasificador tan sencillo no se puede crear un detector de carasrobusto. En la figura 3.1 podemos ver una de las primeras caracterısticas queselecciono Adaboost en una de las pruebas.
Viola y Jones propusieron combinar diversas caracterısticas sencillas enun solo clasificador entrenado con el algoritmo de boosting Adaboost. Enen el cuadro 3.1 podemos ver un resumen del algoritmo de boosting que seencargara de seleccionar las mejores caracterısticas para la deteccion.
Adaboost asigna unos pesos a cada muestra de entrenamiento y seleccionala caracterıstica que mejor clasifica las muestras en funcion de los pesos. La

3.2. EL ALGORITMO ADABOOST 21
La entrada consiste en un conjunto de n imagenes (x1, y1), . . . , (xn, yn)donde yi ∈ {0, 1}. El valor 1 representa que la imagen es una cara y 0que no lo es.
Sean m y l el numero caras y no caras respectivamente, inicializar lospesos de cada imagen w1,i con los valores 1
2mpara las muestras positivas
y 1
2lpara las muestras negativas.
Para t = 1, . . . , T :
1. Normalizar los pesos de las muestras, wt,i ←wt,i
∑
nj=1
wt,jpara que wt
sea una distribucion de probabilidad.
2. Para cada caracterıstica j entrenar un clasificador hj. El errorpara ese clasificador respecto a wt es el valor de la expresion:ǫj =
∑
i wi|hj(xi)− yi|.
3. Seleccionar el clasificador ht con menor error ǫj.
4. Actualizar los pesos de las muestras: wt+1,i = wt,iβ1−ei
t . Con ei = 0si xi se clasifica correctamente con ht o e1 = 1 en caso contrario ycon βt = ǫt
1−ǫt
El clasificador final es:
h(x) =
{
1∑T
t=1 αtht ≥1
2
∑Tt=1 αt
0 en otro caso
con αt = log 1
βt.
Cuadro 3.1: Algoritmo Adaboost para entrenar detectores de caras.

22 CAPITULO 3. ENTRENAMIENTO DE UN DETECTOR DE CARAS
caracterıstica se anade al clasficador final y se reducen los pesos de las mues-tras clasificadas correctamente (para restarles importancia) y se seleccionauna nueva caracterısticas. El algoritmo continua hasta que se han selecciona-do T caracterısticas. A cada clasificador debil se le asignara un valor α quesera mas grande cuanto mejor sea la caracterıstica.
Una vez termina Adaboost, clasificar una muestra es un proceso sencillo:Se aplican las caracterısticas del clasificador a la muestra y se suman losvalores α de aquellas que consideren que la muestra es una cara. Si la sumaes mayor que la mitad del total los valores α se etiqueta la muestra comocara.
Es posible utilizar la constante 1
2como potenciador. Si utilizamos un valor
menor clasificaremos mas muestras como caras, mientras que si aumentamosel factor el clasificador sera mas exigente con las muestras y como resultadohabra un menor numero de caras”.
Uno de los problemas que tiene Adaboost es que no minimiza directa-mente los falsos negativos si no que minimiza el error total (falsos negativos+ falsos positivos). Esto hace que al entrenar un clasificador con Adaboosten el que queremos una tasa de falsos negativos mucho menos que la defalsos positivos, obtengamos un clasificador con mas caracterısticas de lasnecesarias.
3.3. La cascada de clasificadores
A pesar de que se pueden construir detectores de caras basados en Ada-boost con resultados bastante buenos, tenemos el problema de la distribucionde las caras y no caras en una fotografıa. Mientras que subventanas de caraspuede haber unas pocas en una imagen, podemos encontrar miles o millonesde subventanas de no caras. Este desequilibrio hace que necesitemos una tasade error muchısimo mas baja en las no caras. Por ejemplo en una imagen fic-ticia que con 106 subventanas de las cuales solo 10 son caras. Si entrenamosun clasificador con una tasa de falsos negativos del 0,1 detectarıamos 9 de las10 caras. Si ese mismo clasificador tiene una tasa de falsos positivos del 0,01,el numero de falsas detecciones en esta imagen serıa de 10000. Como vemos,la tasa de falsos positivos ha de ser mucho menor que la de falsos negativospara tener un detector util.
La idea presentada por Viola y Jones para solventar este problema fuela de una cascada de clasificadores. La idea es no utilizar un clasificadorque tenga que distinguir entre las caras y todas las no caras, si no uno quesea capaz de clasificar correctamente un alto porcentaje de caras y al me-nos la mitad de las no caras. A la salida de este clasificador parcial se le

3.3. LA CASCADA DE CLASIFICADORES 23
Figura 3.2: Cascada de clasificadores. Todas las subventanas de la imagencomienzan en la etapa 1 y van siendo procesadas por todas las etapas mientrassean aceptadas.
anadira otro clasificador que tambien sera capaz de detectar casi todas lascaras, eliminando parte de las no caras.
El detector consistira en una serie de clasificadores (etapas) puestas encascada. Una subventana se clasificara con la primera etapa, si la etapa con-sidera que es una cara continuara con la siguiente etapa. En cambio, si laetapa lo clasifica como no cara, la subventana se desecha. Las subventanasiran atravesando uno tras otro clasificadores cada vez mas complicados y sololas que lleguen al final de todos se consideraran caras.
Cada clasificador de la cascada se entrena con un conjunto de caras ycon otro de no caras que hayan sido mal clasificados por el clasificador ante-rior. En la practica quiere decir que se entrenara un primer clasificador quesera capaz de eliminar las no caras faciles, luego otro que eliminara no ca-ras mas difıciles y ası hasta el numero de etapas que queramos. Cada nuevaetapa anadida tendra no caras mas difıciles (mas parecidas a caras) lo quehara que esa etapa tenga mas clasificadores que la anterior.
Si entrenamos por ejemplo una cascada con 10 etapas y en cada una ellasconseguimos rechazar un 50 % de las no caras. Obtendremos una tasa de falsospositivos de ǫ = 0,510. Los falsos positivos se reducen geometricamente conla cascada.
Lo mismo ocurre con los falsos negativos, si obligamos a que cada etapaclasifique correctamente el 99 % de las caras obtendremos una tasa de acierto

24 CAPITULO 3. ENTRENAMIENTO DE UN DETECTOR DE CARAS
final del 90 % ya que cada etapa eliminara algunas de las caras.
3.4. Implementacion
En esta seccion vamos a hablar de la implementacion realizada del algo-ritmo Adaboost (funcion boosting del fichero adaboost.c). Para el boostingnecesitamos 4 parametros:
Array de muestras de entrenamiento img samples.
Array de caracterısticas feats.
Tasa de falsos negativos que deseamos expected pos error.
Tasa de falsos positivos expected neg error.
El algoritmo seleccionara caracterısticas de la lista hasta que consiga al-canzar las tasas de error requeridas. Se ha asumido que no puede aparecerla misma caracterıstica mas de una vez en el clasificador. En caso de permi-tir repeticion de caracterısticas se podrıa eliminar una de ellas y sumar susfactores α.
La seleccion de las caracterısticas es el proceso mas costoso computacio-nalmente del algoritmo. Es necesario aplicar la caracterıstica a todas lasmuestras almacenandose el resultado obtenido. Una vez se han obtenido to-dos los valores se procede a ordenar la lista de menor a mayor. Al igual queViola y Jones, hemos asumido que dado un umbral, las muestras con valoresmenores que el han de ser caras y las mayores no caras. Por tanto, calcula-mos en cada posicion del array ordenado cuantas caras hay por encima delumbral y cuantas no caras por debajo. Con esto podemos calcular el umbralque miniza el error para la caracterıstica actual.
Una vez seleccionada la mejor caracterıstica con el mejor umbral, se aplicasobre las muestras el clasificador completo para obtener las tasas de errorpositiva y negativa. En caso de no cumplir los objetivos se continua anadiendocaracterısticas.
El clasificador resultante se almacena en una estructura CascadeStage
que almacena todas las caracterısticas seleccionadas con su umbrales y valoresde α.
El entrenamiento de una cascada de clasificadores se consigue con suce-sivas llamadas a la funcion de boosting, concatenando los clasificadores enuna estructura Cascade.

3.5. UTILIDADES PARA ENTRENAMIENTO DE CASCADAS 25
3.5. Utilidades para entrenamiento de casca-
das
Se han desarrollado varias utilidades para facilitar el entrenamiento decascadas. A continuacion explicamos brevemente cada una de ellas:
3.5.1. vjsamples
La utilidad vjsamples nos permite generar un conjunto de muestrasde entrenamiento. Para entrenar un clasificador necesitaremos una serie deimagenes del tamano de la ventana (por ejemplo 24x24) y ademas, estasmuestras deben de ser muestras mal clasificadas por las etapas anteriores.
Esta utilidad recibe 3 parametros. El primero es un fichero de cascada,de este fichero se tomara el tamano de las muestras. El segunda parametroes un fichero de texto con un listado de imagenes que no contengan caras. Seescanearan estas imagenes en posiciones aleatorias para encontrar ventanasque no se clasifiquen correctamente con las cascada. El tercer parametro esel numero de muestras que queremos generar.
Por ejemplo, si quisieramos generar 1000 muestras que fallaran en la cas-cada cascade.txt utilizarıamos la siguiente llamada:
vjsamples cascade.txt not_faces.txt 1000
En esta llamada el fichero not faces.txt contiene un listado de imagenesque no contienen ninguna cara.
vjsamples generara en el directorio actual tantas muestras como necesi-temos con los nombres samplesXXX.pgm. Se garantiza que todas las muestrasgeneradas en una misma ejecucion son distintas porque la utilidad cuandoobtiene una nueva muestra compara con las anteriores para evitar mues-tras duplicadas. Esta informacion no ser conserva en sucesivas llamadas avjsamples, si ejecutamos 2 veces la llamada del ejemplo anterior y juntamoslas muestras podrıa haber muestras repetidas.
Para obtener muestras aleatorias para la primera etapa del clasificadorpodemos pasarle un fichero de cascada que contenga una cascada vacıa (con0 etapas). Esta cascada clasificara como cara cualquier muestra que reciba.
A continuacion se muestra un fichero para una cascada de 24x24 vacıa.
vjc 1
min_mean: 40
max_mean: 200
min_sd: 20

26 CAPITULO 3. ENTRENAMIENTO DE UN DETECTOR DE CARAS
window_width: 24
window_height: 24
nstages: 0
3.5.2. vjtest
Esta utilidad aplica un cascada sobre una lista de imagenes y muestrapor pantalla el valor 1 o 0 dependiendo si lo ha clasificado como cara o no.
vjtest solo recibe dos parametros, el primero es el fichero con las cascadaa aplicar y el otro un fichero de texto con una lista de imagenes de muestra.
vjtest cascade.txt samples_list.txt
Esta utilidad solo permite utilizar imagenes del mismo tamano con elque se ha entrenado la cascada. En el capıtulo 4 veremos las utilidades paradetectar caras en imagenes complejas de cualquier tamano.
3.5.3. vjaddstage
Esta es la utilidad principal para el entrenamiento de cascadas. Toma unfichero de cascada y a partir de conjuntos de entrenamiento y test anade unanueva etapa a la cascada. Tal y como vimos en vjtest para crear la primeraetapa de una cascada debemos comenzar con una cascada con 0 etapas yutilizar vjaddstage.
Los parametros que recibe la llamada son el fichero de cascada, ficheroscon listas de muestras de entrenamientos de caras y no caras y por ultimo lastasas de error positiva y negativa que deseamos obtener con el clasificador.A continuacion vemos un ejemplo de una llamada tıpica a vjaddstage:
vjaddstage cascade.txt faces.txt notfaces.txt 0.05 0.5
El programa comenzara a seleccionar caracterısticas utilizando el algorim-to Adaboost hasta que consiga una tasas de error menores a las introducidas.
Para un correcto entrenamiento, las muestras negativas deben haber sidoseleccionadas con vjsamples y ser clasificadas como caras por la cascada.
3.5.4. train cascade.sh
Para el entrenamiento hemos utilizado un script que ejecuta sucesivas lla-madas vjsamples, vjtest y vjaddstage. En las primeras lıneas del script sehan de especificar donde estan las imagenes, el numero de etapas y muestrasque queremos utilizar y las tasas de error deseadas.

3.6. EXPERIMENTOS 27
El algoritmo implementado en el script en basicamente el propuesto porViola y Jones para entrenar con Adaboost.
Generar cascada vacıa (con 0 etapas).
Para cada etapa
• Generar n muestras de no caras que no se clasifiquen bien con lacascada actual
• Comprobar las muestras de la etapa anterior y guardar las quefallen
• Fusionar las muestras generadas y las que fallaban de la etapaanterior
• Entrenar una etapa con el nuevo conjunto generado
3.6. Experimentos
3.6.1. XM2VTS
Se ha entrenado una cascada de clasificadores con la base de datos de carasXM2VTS [7]. Esta base de datos consta de 2360 fotografıas de 295 individuos.Hay 8 fotografıas de cada individuo tomadas en 4 sesiones separadas en eltiempo.
Se han han recortado a tamano 21x21 las caras de las 2360 fotografıas y sehan generado 2 imagenes: una original y otra invertida horizontalmente paraobtener 2 muestras. Las 4720 muestra obtenidas se han barajado y obtenidoaleatoriamente un conjunto de entrenamiento de 3776 muestras. El resto, un20 % de las muestras, se ha reservado para test.
Para las muestras de no caras utilizamos un conjunto de unos 800MBde imagenes de todo tipo que no contenıan personas. Para cada etapa delclasificador utilizamos las 3776 caras y 4000 no caras extraıdas del conjuntosde fotografıas.
Ponemos como objetivo que cada etapa sea capaz de clasificar correcta-mente mas del 98 % de las caras (0.02 de tasa de falsos negativos) y rechaceal menos un 50 % de las no caras. Como hemos seleccionado un tamano deventana de 21x21 pixels, el numero de posibles caracterısticas distintas es90234.
Vamos a ver a continuacion los resultados obtenidos en el entrenamiento.Cada iteracion de adaboost requiere unos 5 minutos de calculo.

28 CAPITULO 3. ENTRENAMIENTO DE UN DETECTOR DE CARAS
Figura 3.3: Caracterısticas seleccionadas por la primera etapa del clasificador.
Etapa Iteraciones Falsos negativos Falsos positivos1 3 0.007680 (29) 0.035000 (140)2 4 0.017479 (66) 0.028750 (115)3 9 0.019862 (75) 0.047250 (189)4 20 0.019333 (73) 0.056500 (226)5 24 0.013242 (50) 0.053500 (214)
Cuadro 3.2: Resultado del entrenamiento de una cascada con la base de datosXM2VTS.
La primera etapa solo ha necesitado 3 caracterısticas para cumplir con latasa de error exigida. Solo la primera caracterıstica ha obtenido una tasa defalsos negativos de 0.029 y un 0.084 de falsos positivos.
Las 4 etapas siguientes han necesitado 4, 9, 20 y 24 iteraciones paracumplir los objetivos marcados. No se ha podido entrenar una sexta etapaporque en el conjunto de fotografıas apenas se han encontrado 2000 muestraspara el conjunto de no caras a pesar de escanear exhaustivamente todas lasfotografıas en diferentes escalas.
En el cuadro 3.2 podemos ver un resumen de los resultados del entre-namiento con las tasas de error de las distintas etapas. Entre parentesisse muestra el error absoluto. Al ser XM2VTS una base de datos de fotos”posadas.es un ambiente controlado, es mas sencillo encontrar caracterısticasque obtienen altas tasas de aciertos.
La figura 3.3 muestra las caracterısticas seleccionadas en la primera eta-pa. Las caracterısticas son relativamente pequenas comparadas con las quemuestran Viola y Jones en su artıculo, seguramente porque las muestras po-sitivas de entrenamiento son muy regulares. Con un conjunto mas variablees de esperar que las primeras caracterısticas tengan un area superior.
Hablaremos de los resultados de deteccion de esta cascada en 4.4.

3.7. REFERENCIAS 29
3.7. Referencias
La mayor parte de este capıtulo esta basado en el artıculo original de Violay Jones [9]. En [2] se puede encontrar una breve introduccion de Freund ySchapire al boosting en la que se pueden encontrar detalles sobre el algoritmoAdaboost que se suponen conocidos en el artıculo de Viola y Jones.
Posteriormente se ha tratado de evitar el problema de la minimizacionglobal del error y se han propuesto otros algoritmos de boosting como Asym-metric Adaboost [10] en el que se dan mas importante a los falsos negativosque a los falsos positivos. En [6] se comparan cascadas entrenadas con di-ferentes versiones de Adaboost (Discrete, Real y Gentle Adaboost) ademasde Adaboost con arboles de decision. Este trabajo es uno de los orıgenes delalgoritmo implementado en la librerıa OpenCV.

30 CAPITULO 3. ENTRENAMIENTO DE UN DETECTOR DE CARAS

Capıtulo 4
El detector de Viola-Jones
En este capıtulo vamos a hablar del detector propuesto por Viola y Jones,posteriormente comentaremos algunos algunos detalles de la implementacion.
4.1. El detector de Viola-Jones
Una vez tenemos la cascada entrenada, podemos utilizarla para detectarcaras en imagenes de tamano arbitrario. La cascada se ha entrenado con untamano pequeno comparado con el tamano tıpico de las fotos o las imagenesde webcam. En el capıtulo anterior entrenamos con un tamano de ventanade 21x21. Para poder detectar caras en imagenes mas grandes hemos deir desplazando una subventana a lo largo de toda la imagen aplicando lacascada. Ademas hemos de escalar el clasificador para que pueda detectarcaras de distintos tamanos.
En otros sistemas de deteccion era muy difıcil escalar el clasificador ası quese debıa de escalar la imagen cada vez a tamanos mas pequenos para poderrealizar la deteccion en todas las escalas. Las caracterısticas tipo Haar per-miten escalarse a cualquier tamano y por tanto nos permite realizar unadeteccion multiescala sobre la misma imagen.
Como ya hemos visto en capıtulos anteriores una caracterıstica es unconjunto de rectangulos adyacentes. Por lo tanto solo necesitamos reescalarcada rectangulo al tamano deseado para obtener la caracterıstica reescalada.
Las imagenes son un espacio discreto ası que no podemos esperar unreescalado perfecto de los rectangulos ya que nos deberemos cenir a las coor-denadas enteras. Como base para el escalado tomamos la proporcion entre laventana que estamos usando en este momento y la original. Con esta propor-cion ya podemos aproximar el escalado de los lados del rectangulo. Dado quehemos modificado el area del rectangulo debemos modificar tambien el peso
31

32 CAPITULO 4. EL DETECTOR DE VIOLA-JONES
del mismo ya que en caso de no hacerlo nuestros umbrales del clasificadordejarıan de tener sentido. Para el escalado del peso se utiliza la proporcionentre el area del rectangulo original original y el escalado.
4.2. Implementacion del detector
En este proyecto el detector implementado necesita un fichero con unacascada entrenada y 3 parametros:
scale step: Es el factor por el que se multiplicara la subventana debusqueda cada iteracion, por defecto utilizamos 1.5.
win step: Numero de pixels que se desplazara la subventana, por defectoutilizamos 2.
alpha factor : Potenciador para la deteccion. Por defecto es 0.5, el mismoque utilizan Viola y Jones.
La escala inicial se utiliza el doble que el tamano de la cascada entrenaday como escala maxima se ha elegido 500x500 pixels. Para imagenes masgrandes es preferible realizar una reduccion previa del tamano y luego aplicarel detector sobre la imagen reducida.
El algoritmo de deteccion de caras es sencillo de implementar. Se reco-rre completamente la imagen dando saltos de win step pixels aplicando lacascada completa cada vez. Despues de escala la ventana de busqueda multi-plicando sus lados por scale step hasta que se ha llegado a la escala maxima.
Al realizar la deteccion multiescala en una imagen arbitraria se observaque detecta caras en multitud de posiciones de la imagen. Es necesario fu-sionar las detecciones que esten muy cercanas, a ser posible que todas lasdetecciones de la misma cara se colapsen en una sola. Ademas la fusion nosproporciona una medida de confianza de la deteccion que no se puede obtenerde la cascada directamente. Podemos suponer que despues de realizar la fu-sion de detecciones, las que tengan mayor numero de detecciones colapsadases mas probable que sean caras. Ademas en caso de ser una sola deteccionaislada se puede suponer que es un falso positivo.
En la figura 4.4 vemos el resultado de la deteccion. Se obtienen 182 detec-ciones en una imagen con una sola cara, pero si fusionamos las deteccionesutilizando los algoritmos de dilatado y erosionado se agrupan en 4. Las 4 de-tecciones resultantes estan alrededor de la cara pero una de ellas en la fusionde 151 de las 182 detecciones originales, esta claro que esta es la que masprobablemente sera una cara. En efecto, tomando la region que acumula masdetecciones obtenemos una muy buena deteccion de la cara.
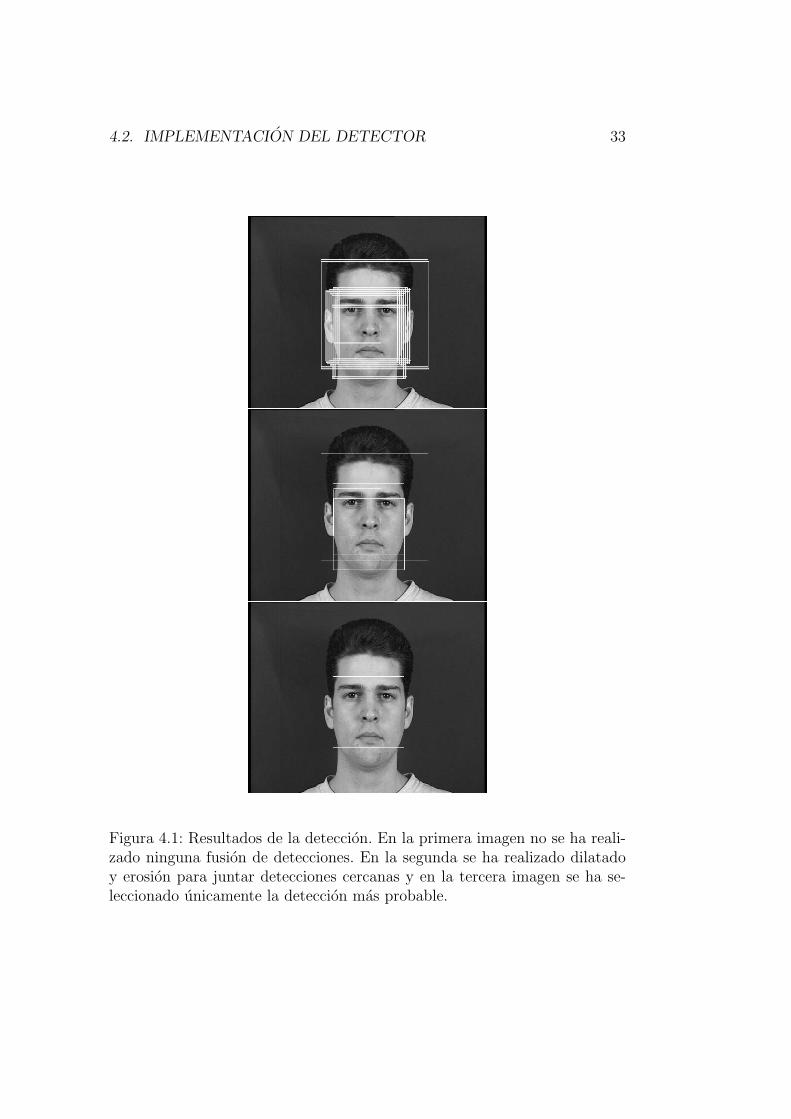
4.2. IMPLEMENTACION DEL DETECTOR 33
Figura 4.1: Resultados de la deteccion. En la primera imagen no se ha reali-zado ninguna fusion de detecciones. En la segunda se ha realizado dilatadoy erosion para juntar detecciones cercanas y en la tercera imagen se ha se-leccionado unicamente la deteccion mas probable.

34 CAPITULO 4. EL DETECTOR DE VIOLA-JONES
4.3. Utilidades para la deteccion
4.3.1. vjdetector
Para detectar caras en imagenes se utiliza la utilidad vjdetector. Acontinuacion vemos una llamada tıpica a esta utilidad.
vjdetector cascade.txt lena.jpg 1.5 0.5 1
El primero y segundo parametro son el fichero de cascada y la imagen adetectar. Los siguiente parametros son todos opcionales e indican los valoresscale step, el factor α y el numero de detecciones que queremos obtener.
vjdetector imprimira en la salida estandar las posiciones de las deteccio-nes que ha obtenido, ası como el contador de fusiones realizadas. El siguienteresultado pertenece a la salida obtenida por la segunda imagen de la figura4.4.
image: 720 x 576
256 224 215 215 151
257 269 215 215 22
220 134 323 323 7
258 239 143 143 2
Detected faces: 4
En caso de haber utilizar como quinto argumento el valor 1, solo ob-tendrıamos la mejor deteccion, la que ha fusionado 151 rectangulos. Ademas,se genera un fichero result.pgm en el que se pueden ver recuadros alrededorde las caras detectadas.
4.3.2. Demo facedetect de OpenCV
OpenCV incluye un directorio con programas de ejemplo de los distintosalgoritmos implementados en la librerıa. Uno de estos programas es la uti-lidad facedetect que tiene una funcionalidad similar a la de vjdetector.facedetect muestra por pantalla la imagen que recibe como argumento mar-cando con un cırculo las caras detectadas y, en caso de no recibir imagen,realiza la deteccion en tiempo real s tomando la senal de la webcam.
facedetect --cascade=cascade.txt --scale=2
En la figura 4.2 se puede ver una captura de pantalla de facedetect
detectando caras a partir de la webcam. En un ordenador comun es capazde detectar caras a unos 5 frames por segundo.
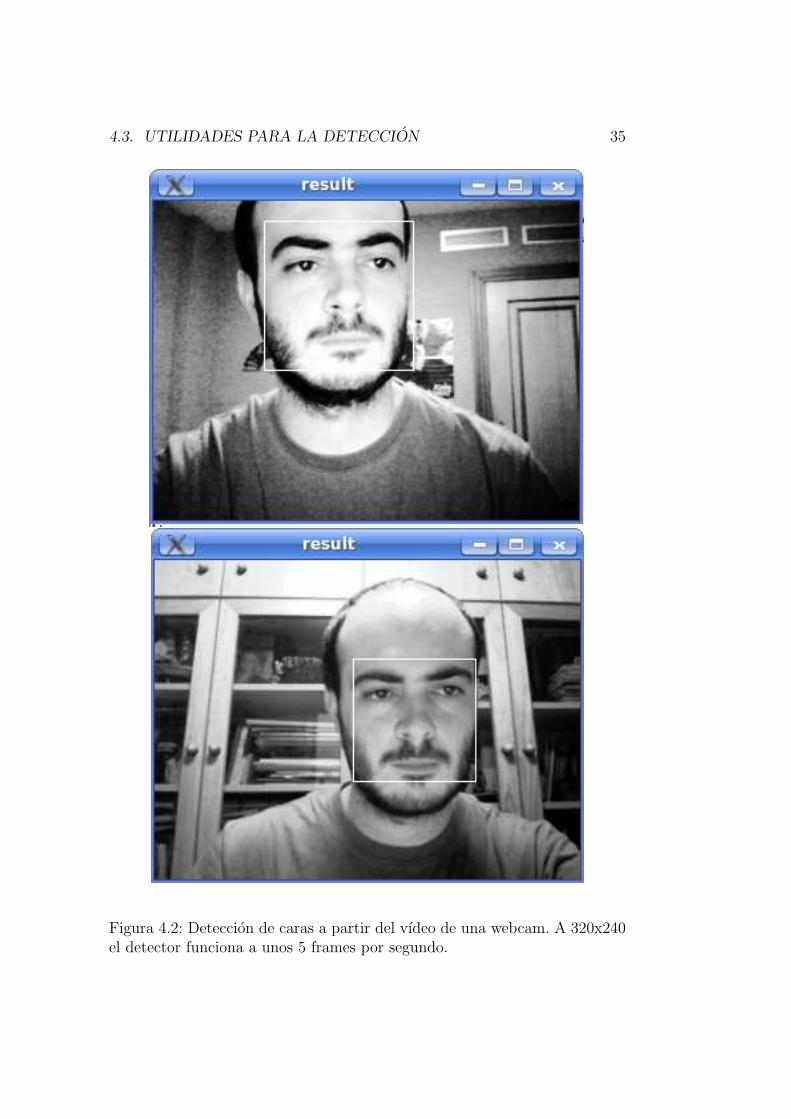
4.3. UTILIDADES PARA LA DETECCION 35
Figura 4.2: Deteccion de caras a partir del vıdeo de una webcam. A 320x240el detector funciona a unos 5 frames por segundo.

36 CAPITULO 4. EL DETECTOR DE VIOLA-JONES
4.4. Experimentos
4.4.1. XM2VTS
En la seccion 3.6.1 hemos visto como se entreno un cascada de clasifica-dores utilizando las base de datos XM2VTS [7]. Se utilizaron para entrena-miento 3776 caras de esta base de datos. En esta seccion vamos a utilizar las944 restantes para probar la calidad de la deteccion.
Para este experimento se ha realizado una deteccion multiescala comen-zando con una ventana de tamano 42x42 (el doble de la ventana original)hasta 500. Las imagenes en las que se detectaran caras tienen un tamano de720x576 pixels y hay una sola cara en cada una de ellas. Ademas, las carasen las fotos no estan totalmente rectas por lo que este conjunto de test esmas difıcil que las muestras de entrenamiento, que habıan sido escaladas yrotadas para crear caras rectas.
Detectaremos caras en cada imagen y nos quedaremos con la mas probabledespues de fusionar las detecciones cercanas.
Una vez explicado el experimento, procedemos a ver los resultados. Trasaplicar el detector en las 944 imagenes y comprobar las detecciones se hanobtenido los siguientes resultados:
Detecciones correctas: 801 (84,8 %)
Detecciones incorrectas: 24 (2,5 %)
Sin deteccion: 119 (12,6 %)
Se ha considerado como deteccion correcta si el rectangulo de la deteccionincluye los ojos y la boca y no es mucho mas grande que la cabeza. 24detecciones incorrectas senalaban regiones de la cara pero dejando fuera laboca o alguno de los ojos. Las imagenes en las que no se ha detectado ningunacara en su mayorıa tenıan la cabeza inclinada.
En resumen, con un detector entrenado solo con caras rectas de 21x21pixels se ha conseguido una tasa de acierto del 85 % en un conjunto de carasde tamano e inclinacion variable. Es de esperar que si se entrena el detectorcon mas muestras y anadiendo cierta variabilidad en el angulo y posicion delas caras se consigan resultados mejores.
4.5. Referencias
Una referencia sobre una implementacion del detector de Viola-Jones enlenguaje C la encontramos en [3] en el que se explican ciertos detalles deimplementacion del detector de caras para el sistema de vision CMUcam3.

4.5. REFERENCIAS 37
En su artıculo original, Viola y Jones [9] comentan que su detector escapaz de procesar imagenes de 384x288 pixels a 15 frames por segundo. Uti-lizaban un escalado de ventanas de 1.5 pero no indican en que lenguajeprogramaron el detector.
Lienhart et al. consiguieron en [5] con su implementacion en C++ unatasa de 5 fps. Segun el artıculo utilizaban un escalado de 1.2.

38 CAPITULO 4. EL DETECTOR DE VIOLA-JONES

Apendice A
Estructura del codigo fuente
A.1. Software utilizado
La mayor parte de este proyecto se ha realizado empleando software opensource. Toda la programacion de las utilidades, los experimentos y esta me-moria se han llevado a cabo con codigo libre.
Aparte de los editores de texto, compiladores y demas herramientas, ca-be destacar una librerıa que es parte fundamental del proyecto: OpenCV[1].OpenCV es una librerıa multiplataforma de vision artificial desarrollada porIntel. Esta orientada al procesamiento de imagenes en tiempo real e incluyemultitud de algoritmos para esta tarea como detector de bordes o segmenta-cion.
Entre estos algoritmos figura un detector de caras basado en el propues-to por Lienhart, Kuranov y Pisarevsky en [4] que es una modificacion deldetector de Viola-Jones.
En el proyecto nos limitamos a utilizar la OpenCV para leer y escribirimagenes en disco y para la obtencion de video de la webcam. La imagenesse leen mediante las funciones de OpenCV que trabajan con estructuras detipo IplImage, inmediatamente se convierte a una estructura Image que es conla que trabajaremos. Para escribir una imagen a disco se realiza el procesoinverso: se convierta la imagen a IplImage y se utilizan las funciones de lalibrerıa para almacenar la imagen en un fichero. Con esto nos evitamos tenerque trabajar con los distintos tipos de imagen ya que OpenCV tiene soportepara muchısimos formatos.
39

40 APENDICE A. ESTRUCTURA DEL CODIGO FUENTE
A.2. Hardware utilizado
Los experimentos y pruebas se han realizado en un ordenador portatilcon las siguientes caracterısticas:
CPU Intel Core 2 Duo T7500 a 2.20GHz
Memoria cache de 4 MB
2 GB de memoria RAM
Disco duro de 160 GB
Sistema operativo Ubuntu Linux
Webcam de 2.0 mpx integrada
A.3. Ficheros del proyecto
Los ficheros que forman el codigo fuente del proyecto se pueden dividiren dos grupos: los que definen funciones y los que son utilidades.
A continuacion se resena brevemente el contenido de cada fichero:
types.h: Define todas las estructuras de datos utilizadas en el proyecto.
adaboost.c: Contiene el algoritmo de entrenamiento.
cascade.c: Aquı estan todas las funciones para crear, eliminar y aplicarcascada a imagenes.
detection.c: Algoritmo de deteccion.
feature.c: Funciones para la creacion de las caracterısticas.
image.c: Diversas funciones para trabajar con imagenes.
integral image.c: Calculo de la imagen integral.
io.c: Encapsula la lectura y escritura de imagenes que se realiza a travesde la librerıa OpenCV.
memory.c: Funciones comunes para crear y liberar matrices.
morph.c: Diversas funciones que se utilizan durante la deteccion comoel dilatado/erosionado.

A.3. FICHEROS DEL PROYECTO 41
Finalmente, las utilidades son las siguientes:
vjaddstage.c: Se utiliza para crear la cascada.
vjdetector.c: El detector de Viola-Jones.
vjsamples.c: Genera muestras para el entrenamiento.
vjtest.c: Clasifica un conjunto de muestras en caras y no caras.
facedetect.c: Utilidad para la deteccion. Es uno de los ejemplo que seincluyen en la OpenCV que ha sido modificado para que utilice el de-tector de este proyecto.
A.3.1. Estructura para almacenar las imagenes
Como hemos visto, las caracterısticas locales tipo Haar se basan en ladiferencia de intensidad entre 2 regiones de la imagen, por tanto todas lasimagenes que utilizaremos en el proyecto deben estar en escala de grises. Seha definido la estructura Image que contiene una matriz de bytes y toda lainformacion asociada con la imagen: ancho, alto y etiqueta. Asumimos queuna etiqueta 1 indica que la muestra es una cara y 0 indica no cara. Ademasla estructura Image incorpora una matriz de enteros para la imagen integral(Ver 2.2).
typedef unsigned char gray ;typedef unsigned int I I ;
typedef struct {int w;int h ;gray ∗∗ p i x e l s ;I I ∗∗ i i 1 ;unsigned char l a b e l ;
} Image ;
Segun el uso que se vaya a hacer de la imagen, puede ser que la matriz ii1no este reservada o que label no tenga sentido. En estos casos ii1 tendra valornulo y label normalmente sera 0. Dependera de que cada funcion utilizar estoscampos o no.

42 APENDICE A. ESTRUCTURA DEL CODIGO FUENTE
typedef struct {int x , y ;int sx , sy ; // s i z e x , s i z e yint w; // weigh t
} Rect ;
typedef struct {int nr e c t s ;Rect r e c t s [ 3 ] ;int th r e sho ld ;
} HaarFeature ;
Cuadro A.1: Definicion de una caracterıstica en el proyecto.
A.3.2. Estructuras de datos para las caracterısticas
En el proyecto cada una de las caracterısticas ha sido representada conuna estructura HaarFeature (ver cuadro A.1). La estructura consta de unarray de Rect que representan los rectangulos y de un umbral.
A.3.3. Estructura de datos para la cascada
typedef struct {int n f e a t s ;HaarFeature ∗ f e a t s ;f loat ∗alpha ;f loat t o t a l t h r e s h o l d ;
} CascadeStage ;
A.3.4. Formato para las cascadas
Los scripts de entrenamiento generan un fichero de texto con la especifica-cion completa de la cascada (normalmente llamado cascade.txt). Este ficheroposteriormente se utiliza en el detector y o en otras etapas del entrenamiento,por ejemplo al generar muestras.
Un fichero de cascada es un fichero de texto ASCII que consta de unacabecera donde estan los datos principales de la cascada y seguidamente laespecificacion de las distintas etapas de la cascada una por una.
En el cuadro A.2 podemos ver un fragmento de cascada. La primera linease utiliza para distinguir un fichero de cabecera de cualquier otro fichero de

A.4. COMPILANDO EL PROYECTO 43
texto y debe contener el codigo vjc 1. Las siguientes lineas son los parame-tros con los que ha sido entrenada la cascada. min_mean y max_mean definenun rango, solo se procesaran con la cascada las ventanas cuya intensidadmedia este dentro de ese rango rechazandose el resto. min_sd nos sirve pa-ra rechazar rapidamente las ventanas demasiado uniformes. window_width ywindow_height indican el tamano de ventana que se ha usado en el entre-namiento y nstages el numero de etapas que tiene la cascada.
El formato para las etapas es muy sencillo. Una linea indica el numero deetapa y seguidamente se definen dos valores para esa etapa: la suma de todoslos valores α (total_threshold) de la etapa y el numero de caracterısticas(nfeats). A continuacion se especifican una a una las caracterısticas. Comohemos visto anteriormente, una caracterıstica esta definida por un umbral(threshold), el valor α (alpha) asociado que define la calidad de esa carac-terıstica y el numero de rectangulos (nrects). A su vez un rectangulo quedadefinido por 5 valores x y sx sy w. Los dos primeros indican la posicion(x, y) de la esquina superior izquierda del rectangulo mientras que (sx, sy)indican el tamano del mismo. w es el peso que tiene el rectangulo.
A.4. Compilando el proyecto
Todo el codigo del proyecto esta escrito en C por lo que deberıa ser posiblecompilar las utilidades en cualquier plataforma con un compilador de C. Launica dependencia es la librerıa OpenCV que tambien es multiplataforma.
En Ubuntu podemos instalar todo lo necesario con un solo comando:
sudo apt-get install build-essential libcv-dev
build-essential es el paquete que incluye los compiladores de C y C++ yotras utilidades como make, libcv-dev es la librerıa OpenCV.
Una vez ya tengamos las dependencias instaladas, ejecutando make enel directorio del proyecto ya deberıa compilar todo correctamente. En el di-rectorio bin se crearan las utilidades para entrenamiento y deteccion queveremos en los proximos capıtulos.

44 APENDICE A. ESTRUCTURA DEL CODIGO FUENTE
vjc 1
min_mean: 40
max_mean: 200
min_sd: 20
window_width: 21
window_height: 21
nstages: 12
stage 0
total_threshold: 7.249029
nfeats: 3
feature 0
threshold: -186
alpha: 2.809804
nrects: 2
rect 3 5 5 2 1
rect 3 7 5 2 -1
feature 1
threshold: -358
alpha: 2.463207
nrects: 2
rect 10 1 3 6 -1
rect 13 1 3 6 1
feature 2
threshold: -1778
alpha: 1.976018
nrects: 2
rect 10 8 6 6 -1
rect 12 8 2 6 2
Cuadro A.2: Cabecera y primera etapa de una cascada.

Bibliografıa
[1] Open computer vision library. http://sourceforge.net/projects/opencvlibrary.
[2] Y. Freund and R. Schapire. A short introduction to boosting, 1999.
[3] Dhiraj Goel. Viola-jones face detector report. Technical report, Docu-mentation of CMUcam3.
[4] R. Lienhart, L. Liang, and A. Kuranov. A detector tree of boostedclassifiers for real-time object detection and tracking. Multimedia andExpo, 2003. ICME’03. Proceedings. 2003 International Conference on,2, 2003.
[5] R. Lienhart and J. Maydt. An extended set of haar-like features forrapid object detection. volume 1, pages I–900–I–903 vol.1, 2002.
[6] Rainer Lienhart, Alexander Kuranov, and Vadim Pisarevsky. Empiri-cal analysis of detection cascades of boosted classifiers for rapid objectdetection. 2003.
[7] K. Messer, J. Matas, J. Kittler, J. Luettin, and G. Maitre. XM2VTSDB:The extended M2VTS database. In R. Chellapa, editor, Second Inter-national Conference on Audio and Video-based Biometric Person Aut-hentication, pages 72–77, Washington, USA, March 1999. University ofMaryland.
[8] C.P. Papageorgiou, M. Oren, and T. Poggio. A general framework forobject detection. Computer Vision, 1998. Sixth International Conferen-ce on, pages 555–562, Jan 1998.
[9] Paul Viola and Michael Jones. Robust real-time object detection. InInternational Journal of Computer Vision, 2001.
[10] Paul Viola and Michael Jones. Fast and robust classification using asym-metric adaboost and a detector cascade. In Advances in Neural Infor-mation Processing System 14, pages 1311–1318. MIT Press, 2002.
45









![Deteccion de viremia en la infeccion experimental por Rubulavirus porcino [sindrome del ojo azul]](https://img.dokumen.tips/doc/110x75/63272ab7507eb8f462038126/deteccion-de-viremia-en-la-infeccion-experimental-por-rubulavirus-porcino-sindrome.jpg)



















