Embed Size (px)
Citation preview

ARTICLE IN PRESS
0098-3004/$ - se
doi:10.1016/j.ca
E-mail addr
Computers & Geosciences 33 (2007) 94–103
www.elsevier.com/locate/cageo
Historical seismometry database project: A comprehensiverelational database for historical seismic records
Andrea Bono
Istituto Nazionale di Geofisica e Vulcanologia, Rome, Italy
Received 24 January 2006; received in revised form 27 May 2006; accepted 29 May 2006
Abstract
The recovery and preservation of the patrimony made of the instrumental registrations regarding the historical
earthquakes is with no doubt a subject of great interest. This attention, besides being purely historical, must necessarily be
also scientific. In fact, the availability of a great amount of parametric information on the seismic activity in a given area is
a doubtless help to the seismologic researcher’s activities. In this article the project of the Sismos group of the National
Institute of Geophysics and Volcanology of Rome new database is presented. In the structure of the new scheme the
matured experience of five years of activity is summarized.
We consider it useful for those who are approaching to ‘‘recovery and reprocess’’ computer based facilities. In the
past years several attempts on Italian seismicity have followed each other. It has almost never been real databases.
Some of them have had positive success because they were well considered and organized. In others it was limited
in supplying lists of events with their relative hypocentral standards. What makes this project more interesting compared
to the previous work is the completeness and the generality of the managed information. For example, it will be possible
to view the hypocentral information regarding a given historical earthquake; it will be possible to research the seismo-
grams in raster, digital or digitalized format, the information on times of arrival of the phases in the various stations,
the instrumental standards and so on. The relational modern logic on which the archive is based, allows the carrying
out of all these operations with little effort. The database described below will completely substitute Sismos’ current
data bank.
Some of the organizational principles of this work are similar to those that inspire the database for the real-time
monitoring of the seismicity in use in the principal offices of international research. A modern planning logic in a distinctly
historical context is introduced.
Following are the descriptions of the various planning phases, from the conceptual level to the physical implementation
of the scheme. Each time principle instructions, rules, considerations of technical–scientific nature are highlighted that take
to the final result: a vanguard relational scheme for historical data.
r 2006 Elsevier Ltd. All rights reserved.
Keywords: Relational database project; Historical seismometry; Oracle; MySQL
1. Introduction
The digital preservation of the unique seismolo-gical heritage consisting of historical seismograms
e front matter r 2006 Elsevier Ltd. All rights reserved
geo.2006.05.007
ess: [email protected].
and earthquake bulletins, and of related docu-mentation (e.g. observatory logbooks, stationbooks, etc.), is critically important in order toavoid deterioration and loss over time (Kanamori,1988).
.

ARTICLE IN PRESS
Fig. 1. A concise data-flow of present SISMOS Group activities.
A. Bono / Computers & Geosciences 33 (2007) 94–103 95
Sismos Group1 is the italian team in charge of thedigital archive of paper record seismograms and ofhistorical seismic bulletins for the period late ‘800 toearly 1980s.
The Project became effective in the late 1990swhen funding was granted through a joint effort ofthe Italian Ministries of the Environment and ofPublic Labor. Thus, activities started at the end ofthe 1990s as a historical seismology preservationprogramme aimed toward the preservation of themainly on paper Italian seismological patrimonyarchived by the different observatories.
In the last years an EuroSeismos Project2 startedin order to spread this venture in all Europeanpartners. This took Sismos Group to become theleading firm in the recovering and reprocessing ofhistorical seismological data.
As of March 2006, more than 94,000 seismogramrecords have been scanned and made available.
The original idea behind Sismos was conceived inthe late 1980s when it became clear that the Italianpaper seismogram patrimony was at risk. Becauseof paper deterioration, which sometimes worsenedby storage in high humidity precarious places, inaddition to the moving of the Istituto Nazionale di
Geofisica e Vulcanologia (Italian Institute forGeophysics and Volcanology) headquarters to adifferent location, it was thought that high-resolu-tion digital scanning of the paper material wouldhave been a feasible solution to the purpose ofpreservation (Michelini et al., 2005). A computerbased scansion-and-storage facility was necessary.The attention focused at once on a Relational
Database based System.In Fig. 1 we show a flow-diagram identifying the
different work stages leading to scanning and
1SISMOS Web Site: http://sismos.ingv.it2EUROSEISMOS Web Site: http://storing.ingv.it/es_web
archiving historical material processed by SismosGroup. As you can see, the database is at the core ofthe storage management.
A database system consists of physical and logicalstructures in which system, user and controlinformation is stored.
Relational database systems exploit relationsamong data entities such as, for example, Seismic
Stations and Seismograms. They have becomeincreasingly popular since the late 1970s becausethey offer very powerful methods for storing data inan application-independent manner. For manymodern scientists the database is at the core of theresearch strategy. We think that advances in aspecific research field can progress around arelatively stable database structure which is secure,reliable, efficient, and transparent.
A first Sismos database structure was available in1998. An intensive use of this archive and therelated data manipulation software draw the en-gineers attention to many lacks in the originaldesign.
Some of these are to bring back to a project phasethat is too short and approximate. Particularly theexcessive narrowness deriving from some ‘‘integrityconstraints’’ that induce inefficiency and a remark-able redundancy are denoted. Other bonds thatshould have been imposed have been unheard; thishas often made necessary extraordinary mainte-nance interventions of the archive occur. Over theyears many modifications have been made to theoriginal scheme, up to the complete re-design thattakes to the system in object, called Historical
Seismometry DataBase (HSDB).
2. Conceptual design
The contents of a historical seismology databasecan hold a variety of different entities. To make our

ARTICLE IN PRESSA. Bono / Computers & Geosciences 33 (2007) 94–10396
archive design more straightforward, its contentsare divided up into two concepts: the Schema andthe Data.
The Schema is the structure of data, whereas theData are the ‘‘facts’’.
The best way to start analising HSDB data-base is considering the Data Dictionary: it listsin a single table all data entities with a detaileddescription. HSDB Data Dictionary is shown inTable 1.
As you can see, all meaningful information abouthistorical seismic records are collected.
The basic data set for observational seismologicalresearch is an archive of analogue and digitalseismograms and the related parametric informa-tion. The information content of these records isviewed as a convolution of a source wavelet with theinstrument response. Only if the instrument re-sponse is known accurately and can be correctedfor, inferences on the structure of the earth and themechanism of earthquakes can be made (Dost andHaak, 2002).
So it is very important that our archive containsinformation relative to siesmetric stations andinstruments, and also to seismograms and bulletins.
Table 1
HSDB Data Dictionary is a list of Entities
Entity name Description
ARRIVAL Identifies phase a
BULLETIN Is an historical se
CHANNEL List of channel c
COMPONENT Component code
DIGITALWAVE Entity of digital
DISTRICT Is a station distri
DOCUMENT Identifies all gene
EVENT Is the Seismic Ev
INSTR_PARAMS Instrument techn
INSTR_PROTOTYPE Is the entity that
INSTR_SUPPORT Each record iden
INSTR_TYPE An instrument ca
INSTRUM_INSTALL An instrument is
LOCATION Earthquake Hyp
MAGNITUDE Earthquake mag
MOMENT_TENSOR Earthquake mom
NETWORK Seismic network
OWNER Identifies the own
PHASE Is a seismic phas
SEISMOGRAM Is the entity of se
STATION Contains alia dat
STATION_LOCATION A station can be
USER Identifies the use
Please note that it does not portray actual Tables in DataBase.
Unfortunately, it is not possible to summarize ina few lines the heterogeneity of the source informa-tion and the formats of the information cataloguedin HSDB. For example, for what the informationregarding the seismic events (phases and hypocenterparameters) are concerned, one can consult theBulletins of the National Institute of Geophysicsand various other parametric catalogues (Boschiet al., 2000; CPTI Working Group, 2004). For theinstrumental data and the information on seismo-grams, besides the aforesaid documents, station log-books are collected, summary documents on theactivities of some observers and even autographednotes of antique seismologists.
To reprocess historical seismograms with moderninstruments, it has been decided to develop aspecific digitalization software called Teseo (Pintoreet al., 2005). Naturally HSDB is capable ofpreserving information on the digitalized seismo-grams, as also on the process of digitalization.
Database schema can be complex to understandto begin with, but really indicates the rules whichthe Data must obey.
The Entity-Relationship Diagram (E-R, see Fig. 2)is a design tool that gives a graphical representation
rrivals of an earthquake
ismic bulletin
odes (example, SH for short period, EH for Enlarged band, etc.)
s: Z, N, E, EW, NS, etc.
wave files: collects information about digitized seismograms
ct
ral data about a stored document (seismogram, bulletin, etc.)
ent entity. Each record identifies an earthquake.
ical settings: they can vary every day!!
collects info about a certain instrument: Galitzin, Wiechert, etc.
tifies a writing method: smoked paper, smoked glass, red ink
n be a mechanic system, an electronic one, or other
installed in a certain seismic station
ocentral location as Latitude, Longitude, Depth, etc.
nitude
ent tensor parameters
codes
er of a document; can be an Agency or Institution, or other
e name (P, PG, S, SG, etc.)
ismograms. A seismogram is a document subclass.
a about a seismic station history
moved in Latitude/Longitude along time
r name and profile in the system

ARTICLE IN PRESS
Fig. 2. HSDB Entity-Relationship Schema showing conceptual entities and relations.
A. Bono / Computers & Geosciences 33 (2007) 94–103 97
of the database system. It provides a high-levelconceptual data model showing entities and rela-
tionships between entities.
This conceptual view is an abstract representationof the entire information content of the database, a‘‘model’’ of the ‘‘realworld’’.

ARTICLE IN PRESSA. Bono / Computers & Geosciences 33 (2007) 94–10398
At this stage of project all storage structure anddata access strategies are ignored.
3. LOGICAL DESIGN: Let us normalize
The logical database design process lets the usercreate efficient databases so that the applicationswill perform smoothly and will be easy to maintainand support. This process consists of several distinctsteps, but the most important one is the Data
Normalization. This is the process of taking datafrom a problem and reducing it to a set of relationswhile ensuring data integrity and eliminating alldata redundancy.
A relation is in First Normal Form (1NF) if allrecords can be uniquely indetified by one (or more)field, called Primary Key.
A relation is in Second Normal Form (2NF) if it isin 1NF and every non-key attribute is fullydependent on the whole key. This means that allpart-key dependencies have to be removed.
Third Normal Form (3NF) is an even stricternormal form and removes virtually all the redun-dant data: all non-key attributes are not dependenton other non-key attributes. We make all datadependent on nothing but the key.
The database schema presented for HSDB isconsidered to be in 3rd normal form.
For example, if the architecture of an informationtable is on a siesmetric station. We could think of astructure like the one in Fig. 3(a). But if we considerthe fact that a given station can change geographiccollocation over the years we then face a problem:we would be obligated to repeat the general data ofthe station (Code and Name for example) in a newrecord to memorize the new coordinates. So wehave introduced redundancy and waste in thememory space. Fortunately the normalization helps
Fig. 3. An example of Normalization: Stations Table is split into
two (or more) stations in order to avoid redundancy and space
loss.
us. We can proceed as shown in Fig. 3(b), breakingthe old STATION table into three tables: STA-TION, STATION LOCATION and DISTRICT.The first will be prepared to take in generalinformation on the station, the second and thethird will count all of its position variations over theyears.
3.1. Integrity constraints
An integrity constraint is a rule that restricts thevalues that may be present in the database. Therelational data model includes constraints that areused to verify the validity of the data as well asadding meaningful structure to it:
�
Entity integrity: The rows (or tuples) in a relationrepresent entities, and each one must be uniquelyidentified. Hence we have the primary key thatmust have a unique non-null value for each row. � Referential integrity: This constraint involves theforeign keys. Foreign keys tie the relationstogether, so it is vitally important that the linksare correct. Every foreign key must either be nullor its value must be the actual value of a key inanother relation.
Many constraints are implemented in HSDBcreation scripts in order to guarantee data integrity.
3.2. Final logical schema
The schema we present in Figs. 4 and 5 is theresult of a global normalisation and review process.We discover the Tables representing the entities atlast. As you can see, some ‘‘conceptual’’ relationsbecome tables in the logical view. All foreign-key
constraints produce a link between tables.Schema was divided into two portions to make it
more readable. In Fig. 4 we show a parametricschema regarding seismic stations, instruments,seismic events, hypocentral locations and para-meters. In Fig. 5 we show tables regardingseismograms, bulletins and other records. Relationsbetween tables crossing the two portions have beenomitted. A whole digital picture of the schema willbe provided on request.
Refer to Table 2 for a complete list of HSDBtables.
As you can see, a wide variety of data manipula-tion operations are possible. A quite plain feature isthat users can set up different ‘‘versions’’ of the

ARTICLE IN PRESS
Fig. 4. HSDB Logical Schema showing Tables related to seismic observatories and other parametric information. Here are stored, for
example, stations coordinates, instrumental parameters and hypocenters.
A. Bono / Computers & Geosciences 33 (2007) 94–103 99
same earthquake (see ASSOC_EVENT descriptionin Table 2), linking them with potentially differentphase arrivals and seismograms. This allows in-dependent researchers to examine an event withvirtually no restrictions on customization.
Besides, it is possible to trace seismometers’configuration parameters and position during theirwhole lifetime. In fact, Seismic Instruments (seetables INSTR_*) are classified in a mixed gerarch-
ical-relational way going down from prototype toparameters. Each record in the INSTR_PARAMS
table represents changes in the configuration. Note
that some observatories scheduled daily configura-tion changes and this is the only architecture thatenables an accurate tracing.
The fact that historical type of information ismanaged, then, must make one think of the greatdifficulty of retrieval and validation of these. Forexample, often there are seismograms for which theinstrument is not known or, if it is known, itscharacteristic standards like amplification, dead-ening, mass, etc. are not known. So, the archive andthe management software must be prepared to takein all the available information, but they must also
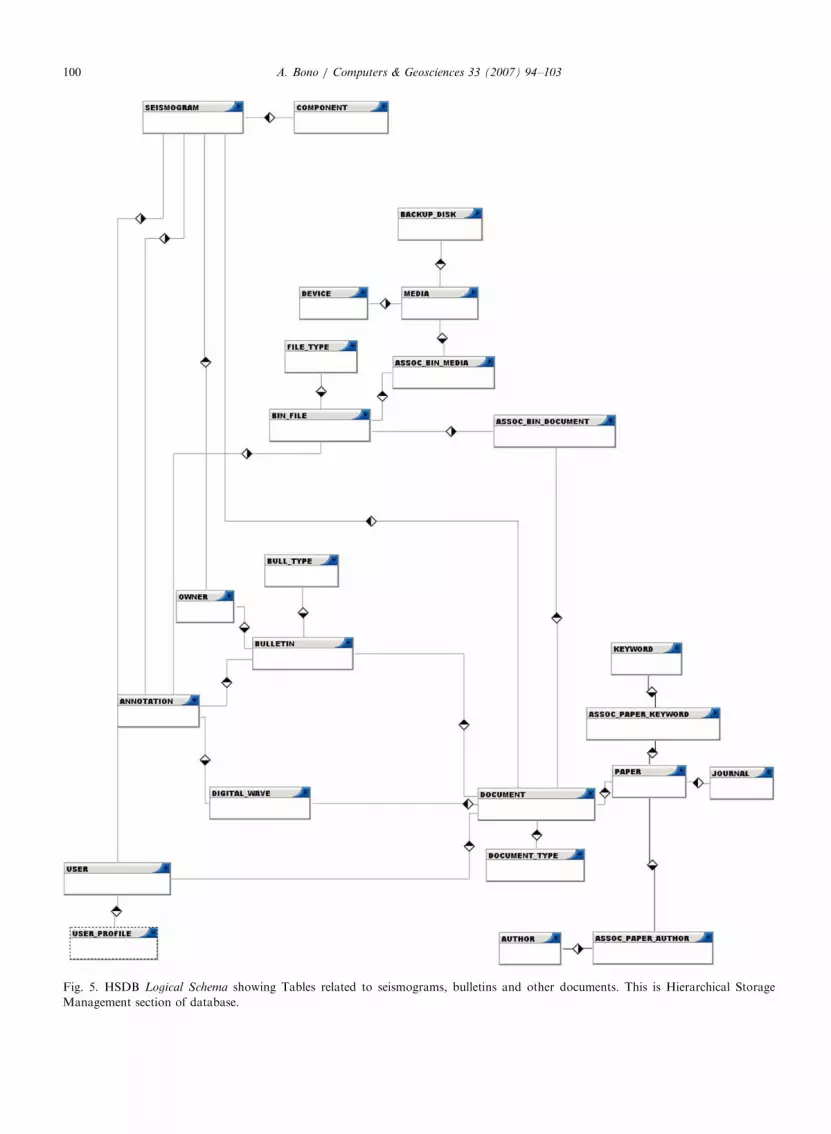
ARTICLE IN PRESS
Fig. 5. HSDB Logical Schema showing Tables related to seismograms, bulletins and other documents. This is Hierarchical Storage
Management section of database.
A. Bono / Computers & Geosciences 33 (2007) 94–103100

ARTICLE IN PRESS
Table 2
Catalogue of current HSDB Tables
Table Description
AGENCY It’s used to trace information and data sources
ANNOTATION Contains all annotations and is linked to many other tables
ARRIVAL Identifies Seismic Phase arrivals of an earthquake
AUTHOR Contains information about the author of a certain Document
ASSOC_BIN_DOCUMENT Combines Documents with Binary files
ASSOC_BIN_MEDIA Combines Binary files with Medias
ASSOC_EVENT Creates Arrivals collections to organize Seismic Events
ASSOC_PAPER_AUTHOR Combines Papers with their Authors
ASSOC_PAPER_KEYWORD Combines Papers with specific Keywords
BACKUP_DISK Lists all DVDs used for data backup
BIN_FILE Identifies information about all binary files (seismograms, digital signals, etc.)
BULLETIN Contains information about historical seismic bulletins
BULL_TYPE Used to collect log-books as well as general bulletins
CHANNEL List of channel codes (example, SH for short period, EH for Enlarged band, etc.)
COMPONENT Component codes: Z, N, E, EW, NS, etc.
DEVICE Is a specific device on a storage hardware
DIGITAL_WAVE Entity of digital wave files: collects information about digitized seismograms
DISTRICT Is a station’s district
DOCUMENT Is the table of collected document typologies (seismograms, bulletins, binary files)
DOCUMENT_TYPE Identifies all general data about stored documents (seismogram, bulletin, etc.)
EVENT Is the Seismic Event entity. Each record identifies an earthquake.
FILE_TYPE Identifies a binary file extension
INSTR_PARAMS Instrument technical settings: they can vary every day!!
INSTR_PROTOTYPE Is the entity that collects info about a certain instrument: Galitzin, Wiechert, etc.
INSTR_SUPPORT Each record identifies a writing method: stain paper, stain glass, red ink on paper...
INSTR_TYPE An instrument can be a mechanic system, an electronic one, or other
INSTRUM_INSTALL An instrument is installed in a certain seismic station
JOURNAL Journal that contains a certain paper
KEYWORD List of keywords for & paper
LOCATION Earthquake Hypocentral location as Latitude, Longitude, Depth, etc.
MAGNITUDE Earthquake magnitude
MAGTYPE Magnitude type: Ml, Mb, etc.
MEASURE_UNIT Measure unit for moment tensor parameters set
MEDIA Lists all medias used for data storage
MOMENT_TENSOR Earthquake moment tensor parameters
NETWORK Seismic network codes
OWNER Identifies the owner of a document; can be an Agency or Institution, or other
PAPER Is used to collect scientific papers
PHASE Is a seismic phase name (P, PG, S, SG, etc.)
REFERENCE_SYSTEM Is the reference system used to calculate a moment tensor
SEISMOGRAM Is the entity of seismograms. A seismogram is a document subclass.
SOURCE Identifies the source of a moment tensor. Can be an agency, istitution or person.
STATION Contains alia data about a seismic station history
STATION_LOCATION A station can be moved in Latitude/Longitude along time
USER Identifies the user name in the system
USER_PROFILE Is used to grant different privileges to users
A. Bono / Computers & Geosciences 33 (2007) 94–103 101
make some basic elaborations possible when theinformation is incomplete.
4. Conclusive technical considerations
The DataBase Management System (DBMS)is the software that handles all access to the
database. It is also responsible for applyingthe authorization checks and validation proce-dures. When a user issues an access request, usingsome particular Data Manipulation Language,the DBMS intercepts the request and interpretsit. So it is critical how the DBMS works in thosecases.

ARTICLE IN PRESSA. Bono / Computers & Geosciences 33 (2007) 94–103102
The facilities offered by DBMS vary a great deal,depending on their level of sophistication. In general,however, a good DBMS should provide the follow-ing advantages over a conventional system:
�
3
com4
Independence of data and program: This is aprime advantage of a database. Both the databaseand the user program can be altered indepen-dently of each other thus saving time and moneywhich would be required to retain consistency.
� Data shareability and non-redundance of data:The ideal situation is to enable applications toshare an integrated database containing all thedata needed by the applications and thuseliminate as much as possible the need to storedata redundantly.
� Integrity: With many different users sharingvarious portions of the database, it is impossiblefor each user to be responsible for the consistencyof the values in the database and for maintainingthe relationships of the user data items to allother data item, some of which may be unknownor even prohibited for the user to access.
� Centralized control: With central control of thedatabase, the DBA can ensure that standards arefollowed in the representation of data.
� Security: Having control over the database theDBA can ensure that access to the database isthrough proper channels and can define theaccess rights of any user to any data items ordefined subset of the database. The securitysystem must prevent corruption of the existingdata either accidently or maliciously.
� Performance and Efficiency: In view of the size ofdatabases and of demanding database accessingrequirements, good performance and efficiencyare major requirements. Knowing the overallrequirements of the organization, as opposed tothe requirements of any individual user, the DBAcan structure the database system to provide anoverall service that is ‘‘best for the enterprise’’.
The relational DBMSs we choose to implementthe HSDB schema are Oracle 10g3 and MySQL 5.4
Complete database creation scripts for bothDBMSs are available on request. We decided toprovide different scripts that enable a user to createHSDB in a free open source environment and alsoin a consolidated commercial one.
ORACLE Web Site: ORACLE Web Site: http://www.oracle.
MYSQL Web Site: http://dev.mysql.com
Oracle offers excellent concurrency, high perfor-mance, and powerful language support for storedprocedures and triggers. Besides, it has specificinstruments to prevent disk space fragmenta-tion and improve performance (Himatsingka andLoaiza, 2002). It has been used in productionsystems, under a variety of forms since the begin-ning of 1980s.
MySQL is quite new and it’s available for freedownload on a dedicated web site. Its new imple-mentations are supplying very interesting features.
Some differences become effective when analyz-ing the creation scripts. In fact, Oracle does notimplement CASCADE ON UPDATE features andAUTOINCREMENT fields.
Even though such features should not be con-sidered essential for a correct database project, wemust point out that in some cases they speed up aDB Administrator’s activities. Sequences and trig-
gers are used to implement such features in theOracle script. Furthermore, many indexes wereimplemented in the physical layout of the HSDBSchema in order to improve global performances.
Observing the MEDIA, USER, USER_PRO-FILE, ASSOC_BIN_MEDIA, BACKUP_DISKand DEVICE tables, the tendency of the projectto implement a real system of Hierarchical StorageManagement (HSM) is noted.
That is policy-based management of file backup
and archiving in a way that uses storage deviceseconomically and without the user needing to beaware of when files are being retrieved from backupstorage media. Although HSM can be implementedon a standalone system, it is more frequently used inthe distributed network of an enterprise. Thehierarchy represents different types of storage media,such as redundant array of independent diskssystems, optical storage, or tape, each type repre-senting a different level of cost and speed of retrievalwhen access is needed. For example, as a file ages inan archive, it can be automatically moved to aslower but less expensive form of storage. Using anHSM product, an administrator can establish andstate guidelines for how often different kinds of filesare to be copied to a backup storage device. Oncethe guideline has been set up, the HSM softwaremanages everything automatically.
HSM automation level in Sismos is still in itsinitial phase, though the strategy is to automate thefile management as much as possible, making thearchive as enjoyable as possible to the scientificcommunity. By the way, Sismos engineers designed

ARTICLE IN PRESSA. Bono / Computers & Geosciences 33 (2007) 94–103 103
and implemented a registered user web portal to theSISMOS archive and a few interesting features arealready available at http://sismos.ingv.it.
References
Boschi, E., Guidoboni, E., Ferrari, G., Mariotti, D., Valensise,
G., Gasperini, P., 2000. Catalogue of strong Italian earth-
quakes from 461 B.C. to 1997. Annals of Geophysics 43 (4),
609–868.
CPTI Working Group (Catalogo Parametrico dei Terremoti
Italiani), 2004. Parametric Catalogue of Italian earthquakes,
Istituto Nazionale di Geofisica e Vulcanologia (edited by
Compositori), Bologna, Italy, 88pp.
Dost, B., Haak, H., 2002. A comprehensive description of the
KNMI seismological instrumentation, Koninklijk Nederlands
Meteorologisch Instituut (Royal Netherlands Meteorological
Institute) Technical Report, TR-245, De Bilt, Netherlands.
Himatsingka, B., Loaiza, J., 2002. How to stop defragmenting
and start living: the definitive word on fragmentation. Oracle
White Papers 711. Oracle Corporation, Redwood Shores, CA,
9pp.
Kanamori, H., 1988. Importance of historical seismograms for
geophysical research. In: Lee, W.H.K., Meyers, H., Shima-
zaki, K. (Eds.), Historical Seismograms and Earthquakes of
the World. Academic Press, Pasadena, CA, pp. 16–33.
Michelini, A., Amato, A., De Simoni, B., Boschi, E., 2005.
Collecting, digitizing and distributing historical seismological
data. EOS. Transactions of the American Geophysical Union
86 (28), 261, 266.
Pintore, S., Quintiliani, M., Franceschi, D., 2005. TESEO: a
vectoriser of historical seismograms. Computers & Geos-
ciences 31 (10), 1277–1285.





























