Embed Size (px)
Citation preview

Speech Communication 48 (2006) 1638–1649
www.elsevier.com/locate/specom
Hard C-means clustering for voice activity detection
J.M. Gorriz a,*, J. Ramırez a, E.W. Lang b, C.G. Puntonet c
a Department of Signal Theory, Networking and Communications, University of Granada, 18071 Granada, Spainb Institute of Biophysics, University of Regensburg, 93040 Regensburg, Germany
c Department of Computer Architecture and Technology, University of Granada, 18071 Granada, Spain
Received 27 February 2006; received in revised form 19 July 2006; accepted 20 July 2006
Abstract
An effective voice activity detection (VAD) algorithm is proposed for improving speech recognition performance innoisy environments. The proposed speech/pause discrimination method is based on a hard-decision clustering approachbuilt on a set of subband log-energies and noise prototypes that define a cluster. Detecting the presence of speech (anew cluster) is achieved using a basic sequential algorithm scheme (BSAS) according to a given ‘‘distance’’ (in this case,geometrical distance) and a suitable threshold. The accuracy of the Cluster VAD (ClVAD) algorithm lies in the use ofa decision function defined over a multiple-observation (MO) window of averaged subband log-energies and a suitablenoise subspace model defined in terms of prototypes. In addition, the reduced computational cost of the clusteringapproach makes it adequate for real-time applications, i.e. speech recognition. An exhaustive analysis is conducted onthe Spanish SpeechDat-Car databases in order to assess the performance of the proposed method and to compare it toexisting standard VAD methods. The results show improvements in detection accuracy over standard VADs such asITU-T G.729, ETSI GSM AMR and ETSI AFE and a representative set of recently reported VAD algorithms for noiserobust speech processing.� 2006 Elsevier B.V. All rights reserved.
Keywords: Voice activity detection; Speech recognition; Clustering; C-means; Prototypes; Subband energy
1. Introduction
The emerging wireless communication systemsare demanding increasing levels of performance ofspeech processing systems working in noise adverseenvironments. These systems often benefit from
0167-6393/$ - see front matter � 2006 Elsevier B.V. All rights reserved
doi:10.1016/j.specom.2006.07.006
* Corresponding author. Tel.: +34 95824 3271; fax: +34 958242740.
E-mail address: [email protected] (J.M. Gorriz).
using voice activity detectors (VADs) which are fre-quently used in such application scenarios for differ-ent purposes. Speech/non-speech detection is anunsolved problem in speech processing and affectsnumerous applications including robust speech rec-ognition (Karray and Martin, 2003; Ramırez et al.,2003), discontinuous transmission (ETSI, 1999;ITU, 1996), real-time speech transmission on theInternet (Sangwan et al., 2002) or combined noisereduction and echo cancelation schemes in the con-text of telephony (Basbug et al., 2003). The speech/non-speech classification task is not as trivial as it
.

J.M. Gorriz et al. / Speech Communication 48 (2006) 1638–1649 1639
appears, and most of the VAD algorithms fail whenthe level of background noise increases. During thelast decade, numerous researchers have developeddifferent strategies for detecting speech on a noisysignal (Sohn et al., 1999; Cho and Kondoz, 2001;Gazor and Zhang, 2003; Armani et al., 2003) andhave evaluated the influence of the VAD effective-ness on the performance of speech processingsystems (Bouquin-Jeannes and Faucon, 1995). Mostof them have focussed on the development of robustalgorithms with special attention on the derivationand study of noise robust features and decision rules(Woo et al., 2000; Li et al., 2002; Marzinzik andKollmeier, 2002; Sohn et al., 1999). The differentapproaches include those based on energy thresh-olds (Woo et al., 2000), pitch detection (Chengalv-arayan, 1999), spectrum analysis (Marzinzik andKollmeier, 2002), zero-crossing rate (ITU, 1996),periodicity measures (Tucker, 1992) or combina-tions of different features (Tanyer and Ozer, 2000;ITU, 1996; ETSI, 1999).
The speech/pause discrimination can be describedas a unsupervised learning problem. Clustering is anappropriate solution for this case where the data setis divided into groups which are related ‘‘in somesense’’. Despite the simplicity of clustering algo-rithms, there is an increasing interest in the use ofclustering methods in pattern recognition (Ander-berg, 1973), image processing (Jain and Flynn,1996) and information retrieval (Rasmussen, 1992;Salton, 1991). Clustering has a rich history in otherdisciplines (Jain and Dubes, 1988; Fisher, 1987) suchas machine learning, biology, psychiatry, psychol-ogy, archaeology, geology, geography, and market-ing. Cluster analysis, also called data segmentationhas a variety of goals. All related to grouping orsegmenting a collection of objects into subsets or‘‘clusters’’ such that those within each cluster aremore closely related to one another than objectsassigned to different clusters. Cluster analysis is alsoused to form descriptive statistics to ascertainwhether or not the data consist of a set of distinctsubgroups, each group representing objects withsubstantially different properties.
The essay is organized as follows: in Section 2 wedescribe a suitable signal model to detect the pres-ence of speech in noisy environments. Section 3considers cluster analysis to form ‘‘descriptive statis-tics’’ transforming the noise sample set into a soft-noise model consisting of low-dimensional features.A description of the algorithm is given in Section 4and a complete experimental framework is shown in
Section 5. Finally, we state some conclusions andacknowledgements in the last part of the paper.
2. Segmentation and feature extraction
Let x(n) be a discrete time signal. Consider aframe of signal containing the elements:
xj ¼ fxðiþ j � DÞg; i ¼ 1; . . . ; L; ð1Þ
where D is the window shift (�10 ms), L is the num-ber of samples in each frame and j selects a certaindata window. Consider the set of 2 Æ m + 1 frames{xl�m, . . . ,xl, . . . ,xl+m} centered on frame xl, namelymultiple observation (MO) window, and denote byX(s, j), j = l � m, . . . , l, . . . , l + m its Discrete FourierTransform (DFT) resp.:
X jðxsÞ � X ðs; jÞ
¼XNFFT�1
n¼0
xðnþ j � DÞ � expð�j � n � xsÞ; ð2Þ
where xs ¼ 2p�sNFFT
, 0 6 s 6 NFFT � 1, NFFT is the FFT
resolution (if NFFT > L then the DFT is paddedwith zeros) and j denotes the imaginary unit. Thelog-energies for the jth frame in the MO window,E(k, j), in K subbands (k = 0,1, . . . ,K � 1), are com-puted by means of
Eðk; jÞ ¼ log2K
NFFT
Xskþ1�1
s¼sk
jX ðs; jÞj2 !
;
sk ¼NFFT
2Kk
� �; k ¼ 0; 1; . . . ;K � 1
ð3Þ
where an equally spaced subband assignment is usedand b Æc denotes the ‘‘floor’’ function. Hence, the sig-nal log-energy is averaged over K subbands obtain-ing a suitable representation of the input signal forVAD (Ramırez et al., in press), the observation vec-tor at frame j:
Ej ¼ ðEð0; jÞ; . . . ;EðK � 1; jÞÞT ð4Þ
The VAD decision rule is formulated over a slidingwindow consisting of 2m + 1 observation vectorsaround the frame (l) for which the decision is beingmade, as we will show in the following sections. Thisstrategy, known as ‘‘long term information’’, pro-vides very good results using several approachesfor VAD such as Gorriz et al. (2005).

1 The word cluster is usually assigned to different classes oflabeled data, that is, in this case, the number of clusters (K) isfixed to 2, corresponding to noise and speech frames.
1640 J.M. Gorriz et al. / Speech Communication 48 (2006) 1638–1649
3. Hard partitional C-means clustering applied to
VAD
Hard C-means clustering is a method for findingclusters and cluster centers in a set of unlabeled data
(MacQueen, 1967). The number of cluster centers(prototypes) C is a priori known and the C-meansiteratively moves the centers to minimize the totalcluster variance. Given an initial set of centers theHard C-means algorithm alternates two steps(Hastie et al., 2001):
• for each cluster we identify the subset of trainingpoints (its cluster) that is closer to it than anyother center;
• the means of each feature for the data points ineach cluster are computed, and this mean vectorbecomes the new center for that cluster.
Given a set of input vectors defined in Eq. (4),E = {El�m, . . . ,El, . . . ,El+m}, where Ej ¼ ðEð0; jÞ;. . . ;Eðk; jÞ; . . . ;EðK � 1; jÞÞT 2 RK and each mea-sure E(k, j) is said to be a feature, hard partitionalClustering attempts to seek a C-partition of E,P = {P1, . . . ,PC}, C 6 N, such that:
• Pi 5 ;, i = 1, . . . ,C;• [C
i¼1P i ¼ E;• P i \ P i0 ¼ ;; i, i 0 = 1, . . . ,C and i 5 i 0.
The ‘‘similarity’’ measure is established in termsof a criterion function. The sum of squares errorfunction is one of the most widely used criteriaand is defined as
JðC;MÞ ¼XC
i¼1
Xlþm
j¼l�m
cijkEj �mik2; ð5Þ
where C = cij is a partition matrix, cij ¼1 if Ej 2 P i
0 otherwise
� �with
PCi¼1cij ¼ 1;8j, M = [m1, . . . ,
mC] is the cluster prototype or centroid (means)matrix with mi ¼ 1=Ni
PNj¼1cijEj, the sample mean
for the ith cluster and Ni the number of objects inthe ith cluster. The optimal partition resulting ofthe minimization of the latter criterion can befound by enumerating all possibilities. It is unfeasi-ble due to costly computation and heuristic algo-rithms have been developed for this optimizationinstead. Hard C-means clustering is the best-knownheuristic squared error-based clustering algorithm(MacQueen, 1967).
In the following sections, we show the way weapply this procedure to modelling the noise sub-space and to find a soft decision rule for VAD.
3.1. Noise subspace modelling
The above mentioned procedure is applied to aset of initial pause frames (log-energies) obtaininga set of clusters that characterizes the noise sub-space. We call this set of clusters, individuals or‘‘noise prototypes’’.1 Let reorder indexes of eachobservation vector of the set E by the integerj 2 {1, . . . ,N}, and uniquely assign to a prespecifiednumber of prototypes C < N, labeled by an integeri 2 {1, . . . ,C}. The dissimilarity measure betweenobservation vectors is the squared Euclideandistance:
dðEj;Ej0 Þ ¼XK�1
k¼0
ðEðk; jÞ � Eðk; j0ÞÞ2
¼ kEj � Ej0 k2; j; j0 2 f1; . . . ;Ng ð6Þ
and the loss function to be minimized is defined asin Eq. (5). The loss function is minimized by assign-ing N observations to C prototypes, in such a waythat within each prototype the average dissimilarityof the observations is minimized. Once convergenceis reached, N K-dimensional pause feature vectorsare efficiently modelled by C K-dimensional noiseprototype centers (mi) denoted by
M ¼ ½m1; . . . ;mC�: ð7ÞIn Fig. 1 we observed how the complex nature ofnoise can be simplified (smoothed) using a cluster-ing approach.
In order to adapt the noise model to a non-sta-tionary environment we propose a competitive rulewhich adjusts noise prototypes centers to the cur-rent detected pause frame, that is, only the closestnoise prototype mc is moved towards the currentfeature vector:
mc ¼ arg minikmi � Elk2� �
) mnewc
¼ a �moldc þ ð1� aÞ � El; ð8Þ
where a is a normalized constant. Its value is closeto one for a soft decision function (i.e. we selectedin simulation a = 0.99), that is, uncorrected
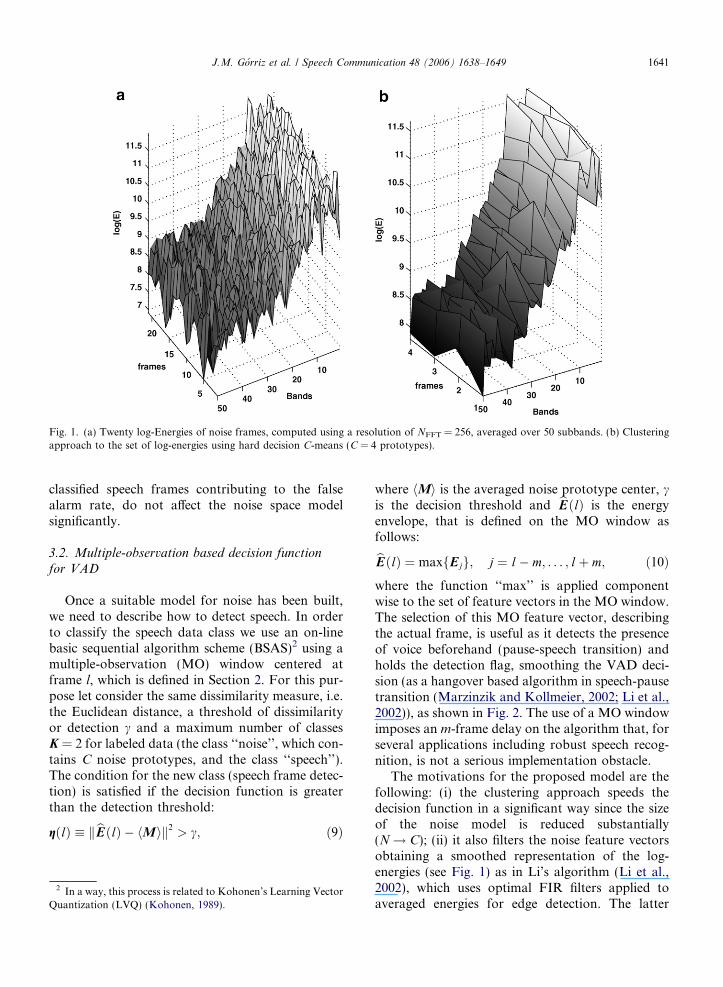
Fig. 1. (a) Twenty log-Energies of noise frames, computed using a resolution of NFFT = 256, averaged over 50 subbands. (b) Clusteringapproach to the set of log-energies using hard decision C-means (C = 4 prototypes).
J.M. Gorriz et al. / Speech Communication 48 (2006) 1638–1649 1641
classified speech frames contributing to the falsealarm rate, do not affect the noise space modelsignificantly.
3.2. Multiple-observation based decision function
for VAD
Once a suitable model for noise has been built,we need to describe how to detect speech. In orderto classify the speech data class we use an on-linebasic sequential algorithm scheme (BSAS)2 using amultiple-observation (MO) window centered atframe l, which is defined in Section 2. For this pur-pose let consider the same dissimilarity measure, i.e.the Euclidean distance, a threshold of dissimilarityor detection c and a maximum number of classesK = 2 for labeled data (the class ‘‘noise’’, which con-tains C noise prototypes, and the class ‘‘speech’’).The condition for the new class (speech frame detec-tion) is satisfied if the decision function is greaterthan the detection threshold:
gðlÞ � kbEðlÞ � hMik2> c; ð9Þ
2 In a way, this process is related to Kohonen’s Learning VectorQuantization (LVQ) (Kohonen, 1989).
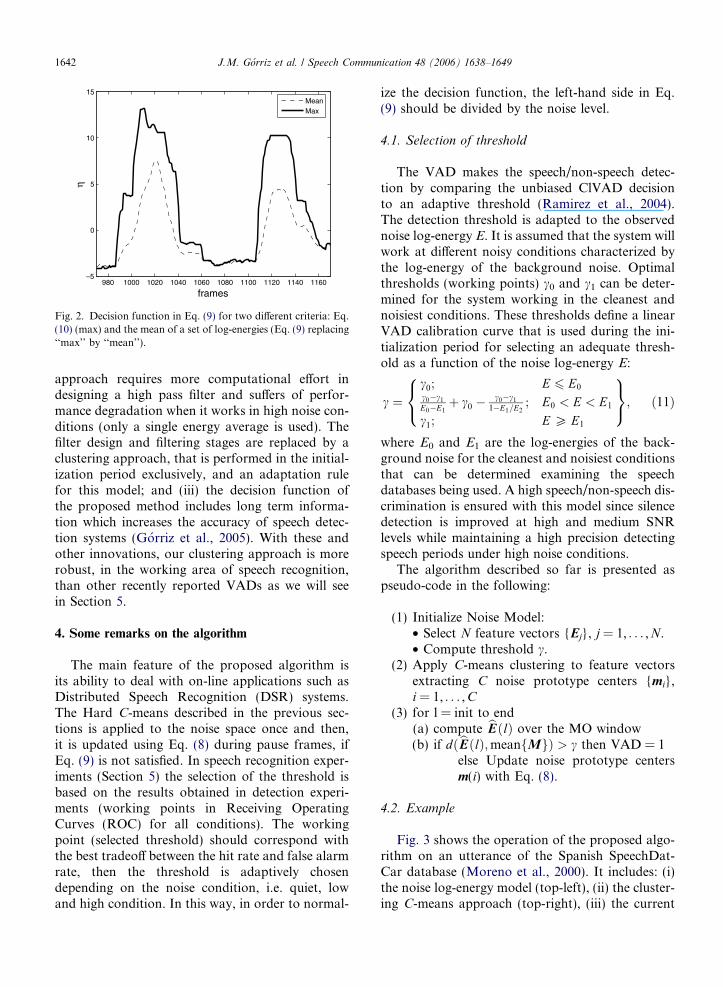
where hMi is the averaged noise prototype center, cis the decision threshold and bEðlÞ is the energyenvelope, that is defined on the MO window asfollows:bEðlÞ ¼ maxfEjg; j ¼ l� m; . . . ; lþ m; ð10Þwhere the function ‘‘max’’ is applied componentwise to the set of feature vectors in the MO window.The selection of this MO feature vector, describingthe actual frame, is useful as it detects the presenceof voice beforehand (pause-speech transition) andholds the detection flag, smoothing the VAD deci-sion (as a hangover based algorithm in speech-pausetransition (Marzinzik and Kollmeier, 2002; Li et al.,2002)), as shown in Fig. 2. The use of a MO windowimposes an m-frame delay on the algorithm that, forseveral applications including robust speech recog-nition, is not a serious implementation obstacle.
The motivations for the proposed model are thefollowing: (i) the clustering approach speeds thedecision function in a significant way since the sizeof the noise model is reduced substantially(N! C); (ii) it also filters the noise feature vectorsobtaining a smoothed representation of the log-energies (see Fig. 1) as in Li’s algorithm (Li et al.,2002), which uses optimal FIR filters applied toaveraged energies for edge detection. The latter
980 1000 1020 1040 1060 1080 1100 1120 1140 1160–5
0
5
10
15
frames
η
MeanMax
Fig. 2. Decision function in Eq. (9) for two different criteria: Eq.(10) (max) and the mean of a set of log-energies (Eq. (9) replacing‘‘max’’ by ‘‘mean’’).
1642 J.M. Gorriz et al. / Speech Communication 48 (2006) 1638–1649
approach requires more computational effort indesigning a high pass filter and suffers of perfor-mance degradation when it works in high noise con-ditions (only a single energy average is used). Thefilter design and filtering stages are replaced by aclustering approach, that is performed in the initial-ization period exclusively, and an adaptation rulefor this model; and (iii) the decision function ofthe proposed method includes long term informa-tion which increases the accuracy of speech detec-tion systems (Gorriz et al., 2005). With these andother innovations, our clustering approach is morerobust, in the working area of speech recognition,than other recently reported VADs as we will seein Section 5.
4. Some remarks on the algorithm
The main feature of the proposed algorithm isits ability to deal with on-line applications such asDistributed Speech Recognition (DSR) systems.The Hard C-means described in the previous sec-tions is applied to the noise space once and then,it is updated using Eq. (8) during pause frames, ifEq. (9) is not satisfied. In speech recognition exper-iments (Section 5) the selection of the threshold isbased on the results obtained in detection experi-ments (working points in Receiving OperatingCurves (ROC) for all conditions). The workingpoint (selected threshold) should correspond withthe best tradeoff between the hit rate and false alarmrate, then the threshold is adaptively chosendepending on the noise condition, i.e. quiet, lowand high condition. In this way, in order to normal-
ize the decision function, the left-hand side in Eq.(9) should be divided by the noise level.
4.1. Selection of threshold
The VAD makes the speech/non-speech detec-tion by comparing the unbiased ClVAD decisionto an adaptive threshold (Ramirez et al., 2004).The detection threshold is adapted to the observednoise log-energy E. It is assumed that the system willwork at different noisy conditions characterized bythe log-energy of the background noise. Optimalthresholds (working points) c0 and c1 can be deter-mined for the system working in the cleanest andnoisiest conditions. These thresholds define a linearVAD calibration curve that is used during the ini-tialization period for selecting an adequate thresh-old as a function of the noise log-energy E:
c ¼c0; E 6 E0c0�c1
E0�E1þ c0 � c0�c1
1�E1=E2; E0 < E < E1
c1; E P E1
8<:9=;; ð11Þ
where E0 and E1 are the log-energies of the back-ground noise for the cleanest and noisiest conditionsthat can be determined examining the speechdatabases being used. A high speech/non-speech dis-crimination is ensured with this model since silencedetection is improved at high and medium SNRlevels while maintaining a high precision detectingspeech periods under high noise conditions.
The algorithm described so far is presented aspseudo-code in the following:
(1) Initialize Noise Model:• Select N feature vectors {Ej}, j = 1, . . . ,N.• Compute threshold c.
(2) Apply C-means clustering to feature vectorsextracting C noise prototype centers {mi},i = 1, . . . ,C
(3) for l = init to end(a) compute bEðlÞ over the MO window(b) if dðbEðlÞ;meanfMgÞ > c then VAD = 1
else Update noise prototype centersm(i) with Eq. (8).
4.2. Example
Fig. 3 shows the operation of the proposed algo-rithm on an utterance of the Spanish SpeechDat-Car database (Moreno et al., 2000). It includes: (i)the noise log-energy model (top-left), (ii) the cluster-ing C-means approach (top-right), (iii) the current
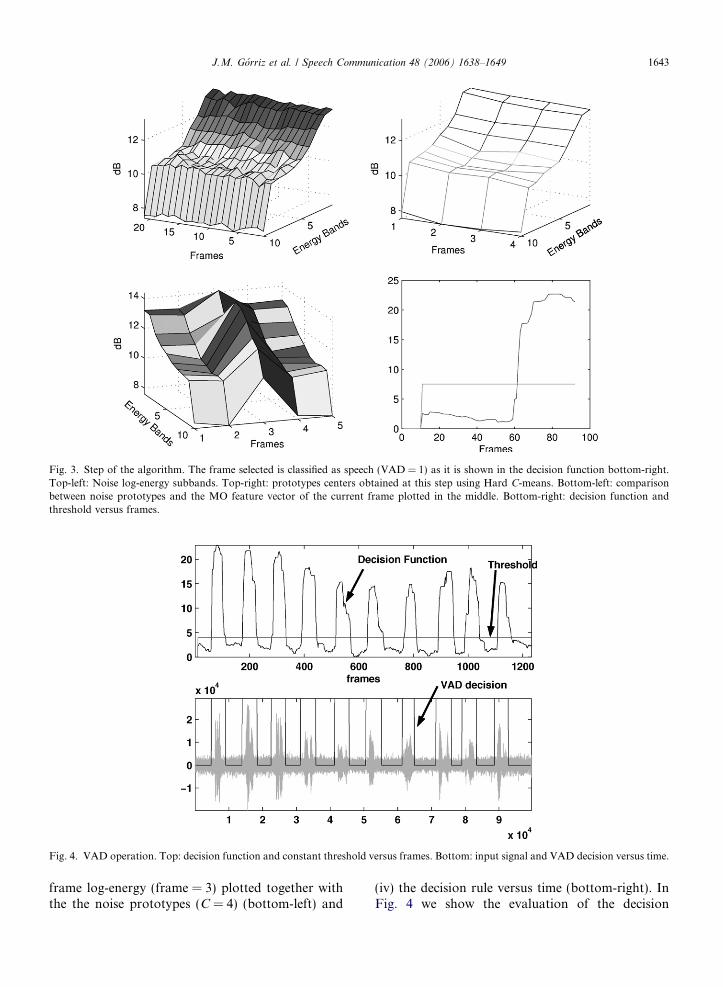
Fig. 3. Step of the algorithm. The frame selected is classified as speech (VAD = 1) as it is shown in the decision function bottom-right.Top-left: Noise log-energy subbands. Top-right: prototypes centers obtained at this step using Hard C-means. Bottom-left: comparisonbetween noise prototypes and the MO feature vector of the current frame plotted in the middle. Bottom-right: decision function andthreshold versus frames.
Fig. 4. VAD operation. Top: decision function and constant threshold versus frames. Bottom: input signal and VAD decision versus time.
J.M. Gorriz et al. / Speech Communication 48 (2006) 1638–1649 1643
frame log-energy (frame = 3) plotted together withthe the noise prototypes (C = 4) (bottom-left) and
(iv) the decision rule versus time (bottom-right). InFig. 4 we show the evaluation of the decision
1644 J.M. Gorriz et al. / Speech Communication 48 (2006) 1638–1649
function of the proposed VAD on the same utter-ance of the Spanish SpeechDat-Car (SDC) database(Moreno et al., 2000). The phonetic transcription is:0tres, 0nwebe, 0hero, 0sjete, 0hiNko, 0dos, 0uno, 0obtSo,0sejs, 0kwatro. We also show the binary VADdecision and the selected threshold in the ClVADoperation for the same phrase.
5. Experimental framework
Several experiments are commonly conducted toevaluate the performance of ClVAD algorithm. Theanalysis is normally focused on the determination ofmisclassification errors at different SNR levels(Marzinzik and Kollmeier, 2002), and the influenceof the VAD decision on speech processing systems(Bouquin-Jeannes and Faucon, 1995; Karray andMartin, 2003). The experimental framework andthe objective performance tests conducted to evalu-ate the proposed algorithm are described in thissection.
5.1. Speech/non-speech discrimination analysis
In this section, the ROC curves are used for theevaluation of the proposed VAD. These plotsdescribe completely the VAD error rate and showthe trade-off between the speech and non-speecherror probabilities as the threshold c varies. TheSpanish SpeechDat-Car database was used in theanalysis. This database contains recordings in acar environment from close-talking and hands-free
ROC High Noise
0
20
40
60
80
100
0False Alarm
Pau
se H
it R
ate
(HR
0)
4
Fig. 5. ROC curves in high noisy conditions for different number of nolog-energy subbands were used to build features vectors and the MO-w
microphones. Utterances from the close-talkingdevice with an average SNR of about 25 dB werelabeled as speech or non-speech for reference whilethe VAD was evaluated on the hands-free micro-phone. As in the whole SDC database, the filesare categorized into three noisy conditions: quiet,low and highly noisy conditions, which representdifferent driving conditions and average SNR valuesof 12 dB, 9 dB and 5 dB. The speech and non-speechhit rates (HR1,HR0) were determined in each noisecondition as a function of the decision threshold cfor each of the VAD tested. They are defined asthe fraction of all actual pause or speech frames thatare correctly detected as pause or speech frames,respectively:
HR1 ¼ N 1j1
N ref :1
; HR0 ¼ N 0j0
N ref :0
; ð12Þ
where N ref :1 and N ref :
0 are the number of real non-speech and speech frames in the whole databaseand N1j1 and N0j0 are the number of real speechand non-speech frames correctly classified, respec-tively. The false alarm rate (FAR) in each state isdefined as FAR{0,1} = 1 � HR{1, 0}.
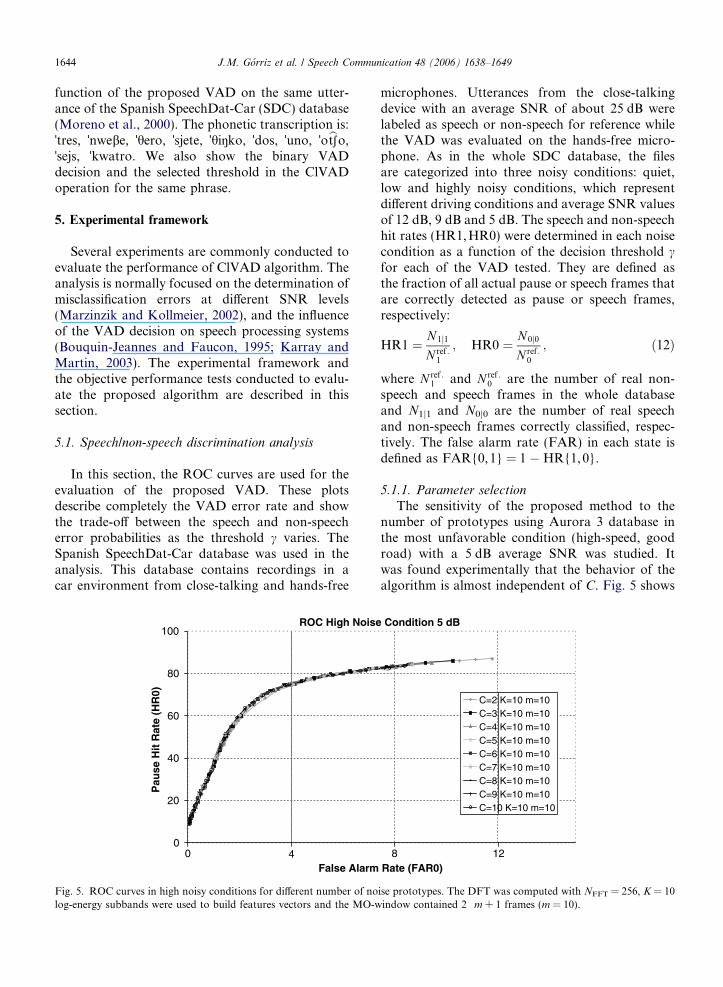
5.1.1. Parameter selection
The sensitivity of the proposed method to thenumber of prototypes using Aurora 3 database inthe most unfavorable condition (high-speed, goodroad) with a 5 dB average SNR was studied. Itwas found experimentally that the behavior of thealgorithm is almost independent of C. Fig. 5 shows
Condition 5 dB
8 12 Rate (FAR0)
C=2 K=10 m=10C=3 K=10 m=10C=4 K=10 m=10C=5 K=10 m=10C=6 K=10 m=10C=7 K=10 m=10C=8 K=10 m=10C=9 K=10 m=10C=10 K=10 m=10
ise prototypes. The DFT was computed with NFFT = 256, K = 10indow contained 2 Æ m + 1 frames (m = 10).
ROC High Noise Condition 5 dB
0
20
40
60
80
100
0 10 15 20
False alarm Rate (FAR0)
Pau
se H
it R
ate
(HR
0)
C=8 K=10 m=1C=8 K=10 m=2C=8 K=10 m=4C=8 K=10 m=5C=8 K=10 m=7C=8 K=10 m=8C=8 K=10 m=10C=8 K=10 m=11
5
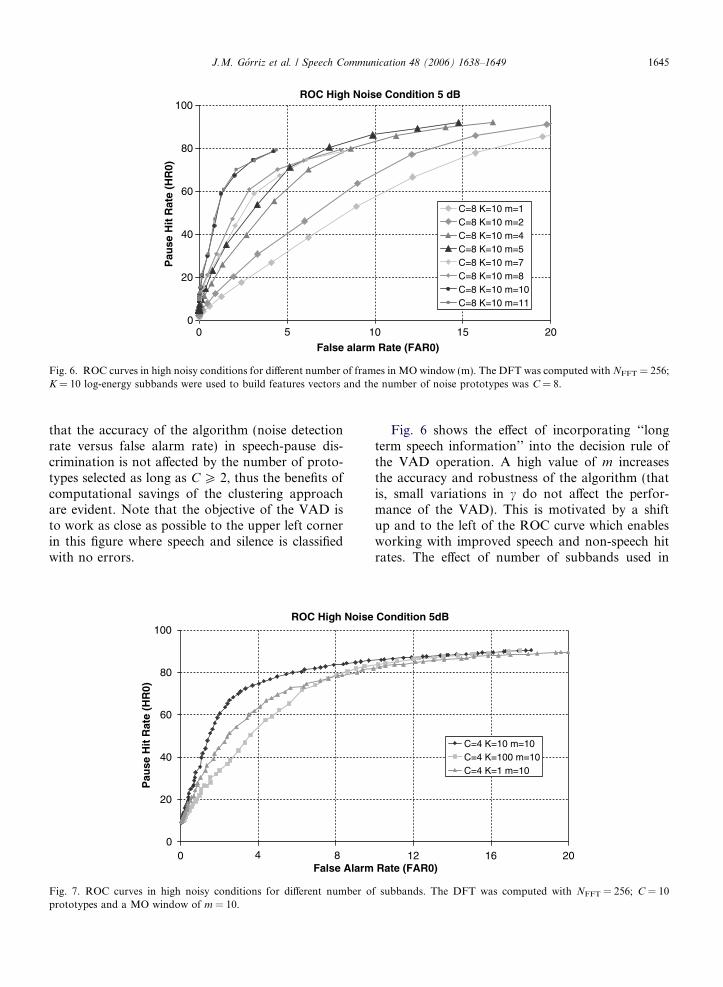
Fig. 6. ROC curves in high noisy conditions for different number of frames in MO window (m). The DFT was computed with NFFT = 256;K = 10 log-energy subbands were used to build features vectors and the number of noise prototypes was C = 8.
J.M. Gorriz et al. / Speech Communication 48 (2006) 1638–1649 1645
that the accuracy of the algorithm (noise detectionrate versus false alarm rate) in speech-pause dis-crimination is not affected by the number of proto-types selected as long as C P 2, thus the benefits ofcomputational savings of the clustering approachare evident. Note that the objective of the VAD isto work as close as possible to the upper left cornerin this figure where speech and silence is classifiedwith no errors.
ROC High Noise
0
20
40
60
80
100
0False Alarm
Pau
se H
it R
ate
(HR
0)
4 8
Fig. 7. ROC curves in high noisy conditions for different number oprototypes and a MO window of m = 10.
Fig. 6 shows the effect of incorporating ‘‘longterm speech information’’ into the decision rule ofthe VAD operation. A high value of m increasesthe accuracy and robustness of the algorithm (thatis, small variations in c do not affect the perfor-mance of the VAD). This is motivated by a shiftup and to the left of the ROC curve which enablesworking with improved speech and non-speech hitrates. The effect of number of subbands used in
Condition 5dB
12 16 20 Rate (FAR0)
C=4 K=10 m=10C=4 K=100 m=10C=4 K=1 m=10
f subbands. The DFT was computed with NFFT = 256; C = 10
1646 J.M. Gorriz et al. / Speech Communication 48 (2006) 1638–1649
the algorithm is plotted in Fig. 7. The use of the fullband energy average (K = 1) or raw data (K = 100)reduces the effectiveness of the clustering proceduremaking its accuracy equivalently to other recentlyproposed VADs, i.e. (Sohn et al., 1999).
5.1.2. Comparison with referenced VADs
Fig. 8 shows the ROC curves in the most unfa-vorable condition (high-speed, good road) with a5 dB average SNR. It was shown that increasingthe number of observation vectors m improves theperformance of the proposed ClVAD. The bestresults are obtained for m = 10 while increasingthe number of observations over this value reportsno additional improvements. In the working area,the proposed VAD outperforms the Sohn’s VAD(Sohn et al., 1999), which assumes a single observa-tion likelihood ratio test (LRT) in the decision ruletogether with an Hidden Markov Model (HMM)-based hangover mechanism, as well as standardizedVADs such as G.729 and AMR (ITU, 1996; ETSI,1999). It also improves recently reported methods(Sohn et al., 1999; Li et al., 2002; Woo et al., 2000Marzinzik and Kollmeier, 2002). It is interestingmentioning the connection of the proposed methodwith Li’s algorithm which uses FIR filters for edgedetection. The latter method uses a pre-filteringstage to the decision function which is based on asingle averaged energy. In our method we replacethis single feature by a set of noise prototypeswhich tracks the noise non-stationarity, makingpre-filtering or hangover mechanisms unnecessary
0
20
40
60
80
100
0 10 20
False Alarm R
Pau
se H
it R
ate
(HR
0)
Working Area
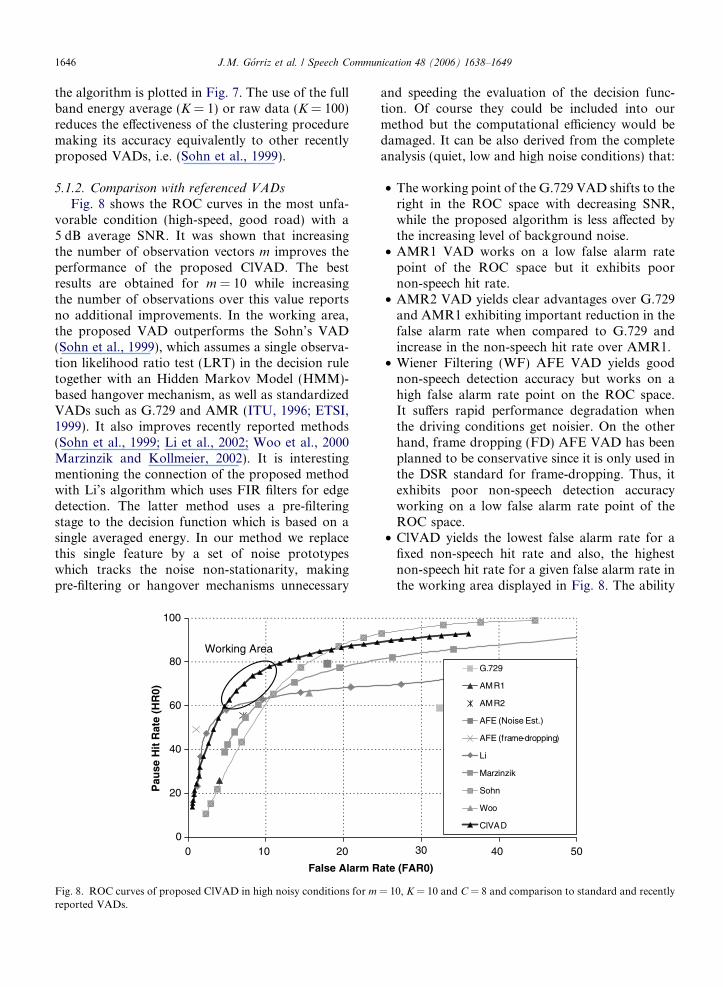
Fig. 8. ROC curves of proposed ClVAD in high noisy conditions for m
reported VADs.
and speeding the evaluation of the decision func-tion. Of course they could be included into ourmethod but the computational efficiency would bedamaged. It can be also derived from the completeanalysis (quiet, low and high noise conditions) that:
• The working point of the G.729 VAD shifts to theright in the ROC space with decreasing SNR,while the proposed algorithm is less affected bythe increasing level of background noise.
• AMR1 VAD works on a low false alarm ratepoint of the ROC space but it exhibits poornon-speech hit rate.
• AMR2 VAD yields clear advantages over G.729and AMR1 exhibiting important reduction in thefalse alarm rate when compared to G.729 andincrease in the non-speech hit rate over AMR1.
• Wiener Filtering (WF) AFE VAD yields goodnon-speech detection accuracy but works on ahigh false alarm rate point on the ROC space.It suffers rapid performance degradation whenthe driving conditions get noisier. On the otherhand, frame dropping (FD) AFE VAD has beenplanned to be conservative since it is only used inthe DSR standard for frame-dropping. Thus, itexhibits poor non-speech detection accuracyworking on a low false alarm rate point of theROC space.
• ClVAD yields the lowest false alarm rate for afixed non-speech hit rate and also, the highestnon-speech hit rate for a given false alarm rate inthe working area displayed in Fig. 8. The ability
30 40 50
ate (FAR0)
G.729
AMR1
AMR2
AFE (Noise Est.)
AFE (frame-dropping)
Li
Marzinzik
Sohn
Woo
ClVAD
= 10, K = 10 and C = 8 and comparison to standard and recently

Table 1Average word accuracy (%) for the Spanish SDC database
Base G.729 AMR1 AMR2 AFE
WM 92.94 88.62 94.65 95.67 95.28MM 83.31 72.84 80.59 90.91 90.23HM 51.55 65.50 62.41 85.77 77.53
Average 75.93 75.65 74.33 90.78 87.68
Woo Li Marzinzik Sohn ClVAD
WM 95.35 91.82 94.29 96.07 97.53
MM 89.30 77.45 89.81 91.64 92.94
HM 83.64 78.52 79.43 84.03 85.19
Average 89.43 82.60 87.84 90.58 91.89
J.M. Gorriz et al. / Speech Communication 48 (2006) 1638–1649 1647
of the adaptive ClVAD to tune the detectionthreshold by means the algorithm described inSection 4 enables working on the optimal pointof the ROC curve for different noisy conditions.Thus, the algorithm automatically selects theappropriate decision value for a given noisy con-dition in a similar way as it is carried out in theAMR (option 1) standard.
Thus, the proposed VAD works with improvedspeech/non-speech hit rates when compared to themost relevant algorithms to date. Although the dis-crimination analysis or the ROC curves are effectiveto evaluate a given algorithm, the influence of theVAD in a speech recognition system was alsostudied.
5.2. Influence of the VAD on a speech recognition
system
The reference framework considered for theseexperiments was the ETSI AURORA project forDSR (ETSI, 2000). The recognizer is based on theHTK (Hidden Markov Model Toolkit) softwarepackage (Young et al., 1997). The task consists ofrecognizing connected digits which are modelled aswhole word HMMs (Hidden Markov Models) withthe following parameters: 16 states per word, simpleleft-to-right models, mixture of three Gaussians perstate (diagonal covariance matrix) while speechpause models consist of three states with a mixtureof six Gaussians per state. The 39-parameter featurevector consists of 12 cepstral coefficients (withoutthe zero-order coefficient), the logarithmic frameenergy plus the corresponding delta and accelera-tion coefficients. For the AURORA-3 SpeechDat-Car databases, the so called well-matched (WM),medium-mismatch (MM) and high-mismatch(HM) conditions are used. These databases containrecordings from the close-talking and distant micro-phones. In WM condition, both close-talking andhands-free microphones are used for training andtesting. In MM condition, both training and testingare performed using the hands-free microphonerecordings. In HM condition, training is done usingclose-talking microphone material from all drivingconditions while testing is done using hands-freemicrophone material taken for low noise and highnoise driving conditions. Finally, recognition per-formance is assessed in terms of the word accuracy(WAcc) that considers deletion, substitution andinsertion errors.
An enhanced feature extraction scheme incorpo-rating a noise reduction algorithm and non-speechFD was built on the base system (ETSI, 2000).The noise reduction algorithm has been imple-mented as a single Wiener filtering stage asdescribed in the AFE standard (ETSI, 2002) butwithout Mel-scale warping. No other mismatchreduction techniques already present in the AFEstandard have been considered since they are notaffected by the VAD decision and can mask theimpact of the VAD precision on the overall systemperformance.
Table 1 shows the recognition performance forthe Spanish SDC database for the different train-ing/test mismatch conditions (HM, high mismatch,MM: medium mismatch and WM: well matched)when WF and FD are performed on the base system(ETSI, 2000). The VAD outperforms all the algo-rithms used for reference, yielding relevant improve-ments in speech recognition. Note that the SDCdatabases used in the AURORA 3 experiments havelonger non-speech periods than the AURORA 2database and then, the effectiveness of the VADresults more important for the speech recognitionsystem. This fact can be clearly shown when compar-ing the performance of the proposed VAD to Marzi-nzik’s VAD (Marzinzik and Kollmeier, 2002). Theword accuracy of both VADs should be quite similarfor the AURORA 2 task. However, the proposedVAD yields a significant performance improvementover Marzinzik’s VAD for the SDC databases.Together with Aurora3’s real recordings, this factmakes Aurora 3 a suitable database.
Using Aurora 2 database two training modes aredefined for the experiments: (i) training on cleandata only (Clean Training, CT), and (ii) trainingon clean and noisy data (Multi-Condition Training,
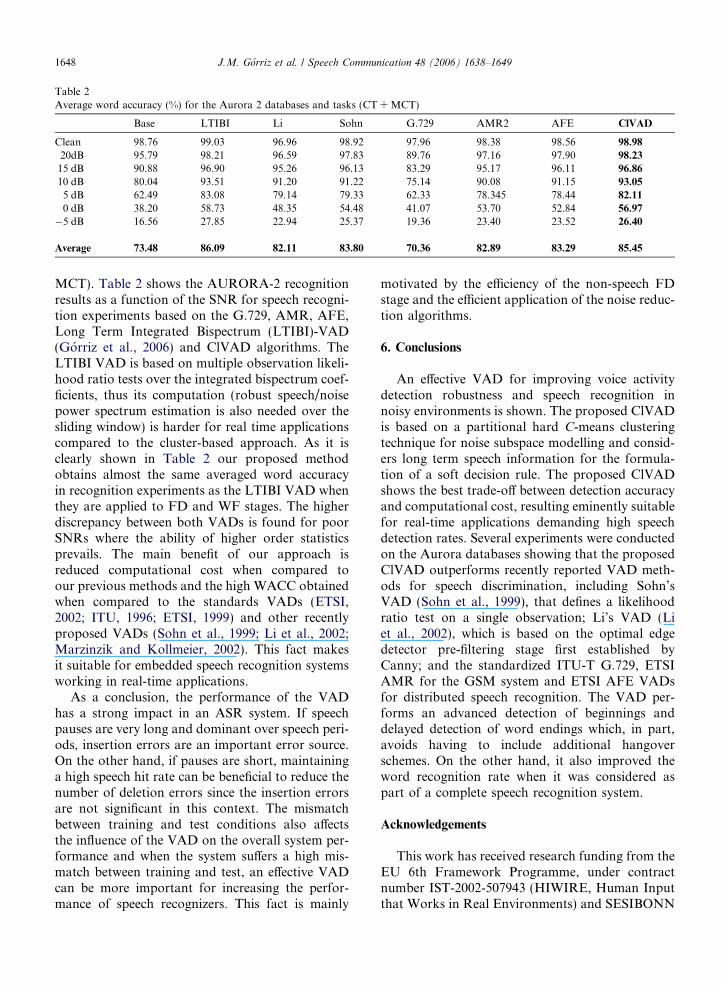
Table 2Average word accuracy (%) for the Aurora 2 databases and tasks (CT + MCT)
Base LTIBI Li Sohn G.729 AMR2 AFE ClVAD
Clean 98.76 99.03 96.96 98.92 97.96 98.38 98.56 98.98
20dB 95.79 98.21 96.59 97.83 89.76 97.16 97.90 98.23
15 dB 90.88 96.90 95.26 96.13 83.29 95.17 96.11 96.86
10 dB 80.04 93.51 91.20 91.22 75.14 90.08 91.15 93.05
5 dB 62.49 83.08 79.14 79.33 62.33 78.345 78.44 82.11
0 dB 38.20 58.73 48.35 54.48 41.07 53.70 52.84 56.97
�5 dB 16.56 27.85 22.94 25.37 19.36 23.40 23.52 26.40
Average 73.48 86.09 82.11 83.80 70.36 82.89 83.29 85.45
1648 J.M. Gorriz et al. / Speech Communication 48 (2006) 1638–1649
MCT). Table 2 shows the AURORA-2 recognitionresults as a function of the SNR for speech recogni-tion experiments based on the G.729, AMR, AFE,Long Term Integrated Bispectrum (LTIBI)-VAD(Gorriz et al., 2006) and ClVAD algorithms. TheLTIBI VAD is based on multiple observation likeli-hood ratio tests over the integrated bispectrum coef-ficients, thus its computation (robust speech/noisepower spectrum estimation is also needed over thesliding window) is harder for real time applicationscompared to the cluster-based approach. As it isclearly shown in Table 2 our proposed methodobtains almost the same averaged word accuracyin recognition experiments as the LTIBI VAD whenthey are applied to FD and WF stages. The higherdiscrepancy between both VADs is found for poorSNRs where the ability of higher order statisticsprevails. The main benefit of our approach isreduced computational cost when compared toour previous methods and the high WACC obtainedwhen compared to the standards VADs (ETSI,2002; ITU, 1996; ETSI, 1999) and other recentlyproposed VADs (Sohn et al., 1999; Li et al., 2002;Marzinzik and Kollmeier, 2002). This fact makesit suitable for embedded speech recognition systemsworking in real-time applications.
As a conclusion, the performance of the VADhas a strong impact in an ASR system. If speechpauses are very long and dominant over speech peri-ods, insertion errors are an important error source.On the other hand, if pauses are short, maintaininga high speech hit rate can be beneficial to reduce thenumber of deletion errors since the insertion errorsare not significant in this context. The mismatchbetween training and test conditions also affectsthe influence of the VAD on the overall system per-formance and when the system suffers a high mis-match between training and test, an effective VADcan be more important for increasing the perfor-mance of speech recognizers. This fact is mainly
motivated by the efficiency of the non-speech FDstage and the efficient application of the noise reduc-tion algorithms.
6. Conclusions
An effective VAD for improving voice activitydetection robustness and speech recognition innoisy environments is shown. The proposed ClVADis based on a partitional hard C-means clusteringtechnique for noise subspace modelling and consid-ers long term speech information for the formula-tion of a soft decision rule. The proposed ClVADshows the best trade-off between detection accuracyand computational cost, resulting eminently suitablefor real-time applications demanding high speechdetection rates. Several experiments were conductedon the Aurora databases showing that the proposedClVAD outperforms recently reported VAD meth-ods for speech discrimination, including Sohn’sVAD (Sohn et al., 1999), that defines a likelihoodratio test on a single observation; Li’s VAD (Liet al., 2002), which is based on the optimal edgedetector pre-filtering stage first established byCanny; and the standardized ITU-T G.729, ETSIAMR for the GSM system and ETSI AFE VADsfor distributed speech recognition. The VAD per-forms an advanced detection of beginnings anddelayed detection of word endings which, in part,avoids having to include additional hangoverschemes. On the other hand, it also improved theword recognition rate when it was considered aspart of a complete speech recognition system.
Acknowledgements
This work has received research funding from theEU 6th Framework Programme, under contractnumber IST-2002-507943 (HIWIRE, Human Inputthat Works in Real Environments) and SESIBONN

J.M. Gorriz et al. / Speech Communication 48 (2006) 1638–1649 1649
and SR3-VoIP projects (TEC2004-06096-C03-00,TEC2004-03829/TCM) from the Spanish govern-ment. The views expressed here are those of theauthors only. The Community is not liable for anyuse that may be made of the information containedtherein.
References
Anderberg, M.R., 1973. Cluster Analysis for Applications.Academic Press, Inc., New York, NY.
Armani, L., Matassoni, M., Omologo, M., Svaizer, P., 2003. Useof a CSP-based voice activity detector for distant-talkingASR. In: Proc. EUROSPEECH 2003, Geneva, Switzerland,September, pp. 501–504.
Basbug, F., Swaminathan, K., Nandkumar, S., 2003. Noisereduction and echo cancellation front-end for speech codecs.IEEE Trans. Speech Audio Process. 11 (1), 1–13.
Bouquin-Jeannes, R.L., Faucon, G., 1995. Study of a voiceactivity detector and its influence on a noise reduction system.Speech Comm. 16, 245–254.
Chengalvarayan, R., 1999. Robust energy normalization usingspeech/non-speech discriminator for German connected digitrecognition. In: Proc. EUROSPEECH 1999, Budapest,Hungary, September, pp. 61–64.
Cho, Y.D., Kondoz, A., 2001. Analysis and improvement of astatistical model-based voice activity detector. IEEE SignalProcess. Lett. 8 (10), 276–278.
ETSI, 1999. Voice Activity Detector (VAD) for Adaptive Multi-Rate (AMR) Speech Traffic Channels, ETSI EN 301 708Recommendation.
ETSI, 2000. Speech Processing, Transmission and Quality aspects(STQ); Distributed speech recognition; Front-end featureextraction algorithm; Compression algorithms, ETSI ES 201108 Recommendation.
ETSI, 2002. Speech Processing, Transmission and Quality aspects(STQ); Distributed speech recognition; Advanced front-endfeature extraction algorithm; Compression algorithms, ETSIES 201 108 Recommendation.
Fisher, D., 1987. Knowledge acquisition via incremental concep-tual clustering. Machine Learning 2, 139–172.
Gazor, S., Zhang, W., 2003. A soft voice activity detector basedon a Laplacian–Gaussian model. IEEE Trans. Speech AudioProcess. 11 (5), 498–505.
Gorriz, J.M., Ramırez, J., Segura, J.C., Puntonet, C.G., 2005.Improved MO-LRT VAD based on bispectra Gaussianmodel. Electron. Lett. 41 (15), 877–879.
Gorriz, J.M., Ramırez, J., Segura, J.C., Puntonet, C.G., Garcıa,L., 2006. Effective speech/pause discrimination using anintegrated bispectrum likelihood ratio test. In: Proc. IEEEInternat. Conf. on Acoustics, Speech and Signal Processing,Toulousse, France May 2006.
Hastie, T., Tibshirani, R., Friedman, J., 2001. The Elements ofStatistical Learning Data Mining, Inference, and PredictionSeries: Springer Series in Statistics, first ed. ISBN: 0-387-95284-5.
ITU, 1996. A silence compression scheme for G.729 optimizedfor terminals conforming to recommendation V.70, ITU-TRecommendation G.729-Annex B.
Jain, A.K., Dubes, R.C., 1988. Algorithms for Clustering Data.Prentice-Hall Advanced Reference Series. Prentice-Hall, Inc.,Upper Saddle River, NJ.
Jain, A.K., Flynn, P.J., 1996. Image segmentation using cluster-ing. In: Ahuja, N., Bowyer, K. (Eds.), Advances in ImageUnderstanding. A Festschrift for Azriel Rosenfeld. IEEEPress, Piscataway, NJ, pp. 65–83.
Karray, L., Martin, A., 2003. Towards improving speechdetection robustness for speech recognition in adverse envi-ronments. Speech Comm. (3), 261–276.
Kohonen, T., 1989. Self Organizing and Associative Memory,third ed. Springer-Verlag, Berlin.
Li, Q., Zheng, J., Tsai, A., Zhou, Q., 2002. Robust endpointdetection and energy normalization for real-time speech andspeaker recognition. IEEE Trans. Speech Audio Process. 10(3), 146–157.
MacQueen, J.B., 1967. Some methods for classification andanalysis of multivariate observations. Proc. 5th BerkeleySympos. on Mathematical Statistics and Probability, Vol. 1.University of California Press, Berkeley, 281–297.
Marzinzik, M., Kollmeier, B., 2002. Speech pause detection fornoise spectrum estimation by tracking power envelopedynamics. IEEE Trans. Speech Audio Process. 10 (6), 341–351.
Moreno, A., Borge, L., Christoph, D., Gael, R., Khalid, C.,Stephan, E., Jeffrey, A., 2000. SpeechDat-Car: A large speechdatabase for automotive environments. In: Proc. II LRECConf.
Ramırez, J., Segura, J.C., Benıtez, M.C., de la Torre, A., Rubio,A., 2003. A new adaptive long-term spectral estimation voiceactivity detector. In: Proc. EUROSPEECH 2003, Geneva,Switzerland, September, pp. 3041–3044.
Ramirez, J., Segura, J.C., Benıtez, C., de la Torre, A., Rubio, A.,2004. Efficient voice activity detection algorithms using long-term speech information. Speech Comm. 42 (3–4), 271–287.
Ramırez, J., Segura, Jose C., Benıtez, C., de la Torre, A., Rubio,A., in press. An effective subband OSF-based VAD with noisereduction for robust speech recognition. IEEE Trans. SpeechAudio Process.
Rasmussen, E., 1992. Clustering algorithms. In: Frakes, W.B.,Baeza-Yates, R. (Eds.), Information Retrieval: Data Struc-tures and Algorithms. Prentice-Hall, Inc., Upper SaddleRiver, NJ, pp. 419–442.
Salton, G., 1991. Developments in automatic text retrieval.Science 253, 974–980.
Sangwan, A., Chiranth, M.C., Jamadagni, H.S., Sah, R., Prasad,R.V., Gaurav, V., 2002. VAD techniques for real-time speechtransmission on the Internet. IEEE Internat. Conf. High-Speed Networks Multimedia Comm., 46–50.
Sohn, J., Kim, N.S., Sung, W., 1999. A statistical model-basedvoice activity detection. IEEE Signal Proc. Lett. 7 (1), 1–3.
Tanyer, S.G., Ozer, H., 2000. Voice activity detection innonstationary noise. IEEE Trans. Speech Audio Process. 8(4), 478–482.
Tucker, R., 1992. Voice activity detection using a periodicitymeasure. IEE Proc. Comm. Speech Vision 139 (4), 377–380.
Woo, K., Yang, T., Park, K., Lee, C., 2000. Robust voice activitydetection algorithm for estimating noise spectrum. Electron.Lett. 36 (2), 180–181.
Young, S., Odell, J., Ollason, D., Valtchev, V., Woodland, P.,1997. The HTK Book. Cambridge University.





























