Embed Size (px)
Citation preview

Second Language Research29(2) 145 –164
© The Author(s) 2013Reprints and permissions:
sagepub.co.uk/journalsPermissions.navDOI: 10.1177/0267658313479359
slr.sagepub.com
secondlanguageresearch
Input processing of Chinese by ab initio learners
ZhaoHong Han and Zehua LiuColumbia University, New York, USA
AbstractWe report on a study of first-exposure learners with different first languages (L1s: English, Japanese) to examine their ability to process input for form and meaning. We used a rich set of tasks to tap respectively into processing, comprehension, imitation, and working memory. We show that there are advantages to having a first language (L1) that brings familiarity with the target language. We also show that when presented with natural auditory input, learners are able to process form only minimally. These findings are inconsistent with other studies that suggest that segmentation is easy and rapid. Additionally, we show that such learners comprehend meaning by relying on ‘top-down’ strategies. These findings challenge some of the claims on Input Processing theory.
KeywordsChinese as a second language, form and meaning, input processing
I Introduction
Input processing at the second language (L2) initial state has recently emerged as a topic of interest to second language acquisition (SLA) researchers. Driving this interest are chiefly two factors: Most of the existing research on input processing has focused only on learners en route (e.g. VanPatten, 2004), and most of the research to date on the initial state has focused only on representation (e.g. Schwartz and Sprouse, 1996). As a result of the ‘skewed’ approach, the general understanding of input processing is limited, as is the understanding of the L2 initial state. As Perdue (1996) noted, ‘Far too little empirical attention has been paid to the very beginnings of the acquisition process’ (p. 138).
Recently, attention in the realm of input processing has begun to shift to ab initio learn-ers, who, by definition, are genuine beginners, and who, therefore, have had zero to little experience with the target language (TL). Theoretically, pursuing this line of inquiry may potentially fill two conceptual voids in L2 research on input processing and initial state.
Corresponding author:ZhaoHong Han, Teachers College, Columbia University, Box 66, 525 West 120th Street, New York, NY 10027, USA. Email: [email protected]
479359 SLR29210.1177/0267658313479359Second Language ResearchHan and Liu2013
Article

146 Second Language Research 29(2)
A handful of such studies have already appeared in the L2 literature, involving an array of target languages, including, but not limited to, Chinese, French, German, Korean, Norwegian, and Polish. A noteworthy fact is, however, that, by virtue of their experimen-tal nature, these studies have mostly used contrived input as stimuli; little, therefore, is as yet understood of learners’ strategies for processing natural input (see, however, Han and Peverly, 2007; Park, 2011; Park and Han, 2008). The study reported in this article is an attempt to fill that gap.
In the sections that follow, there first will be a brief review of the relevant literature. After that, the study will be presented, followed in order by a discussion of the results and a conclusion providing a sketch of methodological suggestions for future research.
II Literature review
1 L2 initial state
Research on L2 initial state began in the mid-1990s, almost exclusively in a generativist tradition. Notable works included Epstein et al. (1996), Eubank (1996), Platzack (1996), Schwartz and Sprouse (1996), Vainikka and Young-Scholten (1996), and White (1986) where the initial state of L2 learning is defined as ‘the starting point of non-native gram-matical knowledge’ (Schwartz and Sprouse, 1996: 1). Researchers differed in their views of the L2 initial state, the focal point of contention being whether Universal Grammar (UG) or first language (L1) constitutes the lion’s share of the initial state. The latter view appears to have prevailed. The widely cited Full Transfer/Full Access Hypothesis (Schwartz and Sprouse, 1996) claims that the initial state of L2 acquisition is the final state of L1 acquisition, except for the phonetic matrices of lexical and morphological items, though UG is fully available. Thus, when formulating interlanguage (IL), learners first will rely on L1 grammar, but when and where their L1-based processing of L2 input fails, UG will guide their restructuring of the IL grammar. This hypothesis has received considerable empirical support (e.g. Leung, 2005; Slabakova, 2000; White, 1986; Yuan, 1998). By way of illustration, Leung (2005) examined the L2 and L3 (third language) initial state in a comparative study of Vietnamese monolinguals and Cantonese–English bilinguals acquiring French, focusing on the determiner phrase, a feature shared by all four relevant languages (French, English, Vietnamese, and Cantonese), albeit with dif-ferent instantiations thereof: [±definite] feature in English and French; [±specific] fea-ture in Vietnamese and Cantonese. Results showed full transfer of L1 in the L2 initial state but partial transfer of L1 and L2 in the L3 initial state.
Another hypothesis in the same camp is the Valueless Feature Hypothesis (Eubank, 1996), which holds that L1 grammar is transferred in almost its entirety to IL except for the ‘strength’ values of features under functional heads. According to this hypothesis, overt inflectional morphology (or the strength value of the features, for that matter), which putatively instantiates the parametric values such as the strength of agreement, is not transferred. Similarly, the Minimal Trees Hypothesis (Vainikka and Young-Scholten, 1996) argues that only lexical categories and their linear orientation in L1 grammar are transferred in L2 acquisition, while the functional projections are not, and, therefore, need to be developed during acquisition of lexical items.

Han and Liu 147
While the generative perspective, overall, predicts that L1 transfer plays into the L2 initial state, and this prediction has ostensibly garnered substantial empirical support, it seems that detailed studies have yet to be conducted to show how transfer occurs at the L2 initial state. As early as 1989, White – speculating on the possible implications of the distinction between competence and processing – raised the following questions:
Do L2 learners use the same mechanisms for processing the L2 as they do for the L1, or must new mechanisms be constructed? How can one tell? It is only with relatively sophisticated processing theories that one will be able to translate these speculations into specific claims. (White, 1989: 180)
Indeed, specific claims do exist in the present day. For instance, the Developmentally Moderated Transfer Hypothesis (Pienemann, 1998) states that transfer is constrained by the processability of the structure to be learned. From a processing perspective, Pienemann argues that the prerequisite of L1 transfer is that the target structure could be processed in the L1. In this light, the initial state of L2 does not necessarily equal the final state of L1, because there is no guarantee that a given L2 structure can be processed in the L1 or a given L1 structure can be processed by the under-developed L2 parser (Håkansson et al., 2002).
Taking processability into consideration, early works on L2 initial state learning are largely confined to languages that have certain shared or similar structures, such as the negation in German and English (Eubank, 1996). This leaves open the questions of how beginning learners process an L2 structure that is not present or processable in the L1, and how, in general, these learners process input of an L2 that is typologically distant from their L1. In the next section we briefly review first-exposure studies focusing on input processing in ab initio learners, including both typologically close and distant scenarios.
2 Input processing at the initial state
Several first-exposure studies have appeared in recent years, and they mostly come in two distinct strands, as judged by their conceptual framework. One strand is framed within what Klein (1986) has delineated as the learner’s ‘problem of analysis’, which encompasses essentially three facets:
• the segmentation of the continuous speech stream to identify words;• the identification of relevant meaning in the environment that can be mapped onto
the sound strings identified; and• the generalization beyond the input stimuli.
Rast (2008) provides a noteworthy instantiation of this conception. The study compared first-exposure learners to beginning-level learners vis-à-vis Polish as the target language. Participants (n = 127) constituted two experimental groups and one control group. One of the experimental groups was made up of 19 French speakers attending a Polish course at the time of the study (hereafter ‘learner group’), and the other, 96 French speakers with no prior exposure to Polish (hereafter ‘first-exposure group’). The control group had 12

148 Second Language Research 29(2)
native speakers of Polish. The participants had miscellaneous L2 or L3 backgrounds, such as Dutch, German, Italian, Russian, and Spanish.
Both experimental groups carried out a series of tasks. The tasks for the first-exposure group were sentence repetition, which involves repeating sentences upon first listening, and oral and written word translation from Polish to French. The learner group, on the other hand, undertook a word order test, a grammaticality judgment test, a written trans-lation of the grammaticality judgment test task, an oral translation test, and a sentence repetition task – similar to that for the first-exposure group.
Results for the first-exposure group indicated that as far as sentence repetition is con-cerned, the accuracy of word recognition depended largely on the degree of resemblance between Polish and the participants’ L1 or L2. Similarly, on the translation task, partici-pants appeared to rely heavily on their previously acquired languages to map meaning onto form. The influence of the previous language seemed so strong that speakers of L2 German and Russian, which are typologically close to Polish, were consistently advan-taged over others in word segmentation, especially concerning words harder to recog-nize. Just as the positive influence of a previously learned language was visible (see Leung, 2005), so was its negative influence, as seen in the higher number of errors com-mitted. Moreover, word length, word stress, phonemic distance, and transparency all seemed to have played a role, as well, in the accuracy of speech perception, when the first-exposure group was compared with the learner group on the sentence repetition task. Interestingly, the effects of these factors gradually picked up in strength as the length of exposure – mediated by instruction – increased.
While the Rast study employed contrived input as the stimulus, other studies endeav-ored to use input that is more natural or authentic. Zwitserlood et al. (2000), adopting the same conceptual framework as Rast (2008), exposed native speakers of Dutch for the first time to a 15-minute story narration in Chinese. Four input conditions were created to which participants were assigned as follows: the film group, the film plus speech group, the speech only group, and the no input group. The film group watched a film of the story; the film plus speech group watched the film first and then listened only to the narration; the speech only group listened only to the narration; and the control group received no input of any nature. As part of its design, the study manipulated the fre-quency and salience (through highlighting) of key words that were presented along with pictures. Upon the first exposure, participants performed four tasks: word discrimina-tion, picture–word matching, lexical decision, and phonemic minimal pair judgment. Results showed, amongst other things, that on the word discrimination task, the film group and the film plus speech group significantly outperformed the speech only group. It appears that participants were able to discriminate words only in the presence of visual information. On the lexical decision task, which required participants to determine if an auditory segment is a word of Chinese, all three input groups did better than the control group, suggesting that with as little as 15 minutes of exposure, participants were able to pick out certain sound regulations and patterns from the sound stream of the unknown language. On the phonemic minimal pair judgment task, there was no significant differ-ence between the groups, including the control group; all four groups were able to decide whether the two sounds were identical or not, with a 99% overall accuracy. This finding may be an artifact of the monosyllabic nature of Chinese whose canonical CVC syllabic

Han and Liu 149
structure requires processing sound differences at the word level. On the picture–word matching task, all groups except the speech only group, which did not participate due to the difficulty they had had with the word discrimination task, showed superior perfor-mance with highlighted and high-frequency words.
Gulberg et al. (2010) investigated the effects of first exposure to Chinese on native speakers of Dutch. The input used was a 7-minute long weather report, ‘controlled but naturalistic’ with the target words manipulated for frequency and salience (again via highlighting), and accompanied by gestures. The input was presented both orally and visually. Four tasks were used to measure the contents of input processing, three of which were similar to those used in Zwitserlood et al. (2000): word discrimination, picture–word matching, and lexical decision. The results were also similar, in that participants were able to recognize words, map sound to weather icon pictures, and detect regularities of Chinese sound combinations. In addition, the researchers examined the neural corre-lates of word discrimination, measuring the functional connectivity of the regions that were involved in word learning at three time periods: 5 minutes before the presentations, between and after the two presentations of the weather report. The results consistently pointed to the supramarginal gyri area – the insula, the left posterior temporal cortex, and the hippocampus – as involved in word learning (see McNealy et al., 2006).
A notable departure from the above studies that focused on identifying the general con-tents of processing, Carroll (2005) honed in on ab initio learners’ sensitivity to phonologi-cal, morphosyntactic, or semantic cues to gender attribution in French. Auditory sequences of [Det+N] in French paired with English translation equivalents were presented, in list form, to 88 native speakers of English. The highly patterned data thereby served as a vehi-cle of phonological, morphosyntactic, and semantic cues to input processing. Participants were subsequently tested on the number of items correct on the first trial of each of the learning phase, the number of trials needed to reach criterion, and the number of items cor-rect on item-guessing lists. Results showed, amongst other things, that ab initio learners were particularly sensitive to semantic and morphological patterns and that such sensitivity appeared to be generalizable to novel exemplars. L1-based processing procedures were speculated to have played a role in leading to the observed ability.
A second major strand of first-exposure studies are situated in the framework of VanPatten’s (1996, 2004) input processing principles. According to VanPatten, second language learners have natural tendencies in processing input, or appear to follow a set of principles (2004):
• Principle 1. The Primacy of Meaning Principle: Learners process input for mean-ing before they process it for form.
• Principle 1a. The Primacy of Content Words Principle: Learners process content words in the input before anything else.
• Principle 1b. The Lexical Preference Principle: Learners will tend to reply on lexi-cal items as opposed to grammatical form to get meaning when both encode the same semantic information.
• Principle 1c. The Preference for Non-redundancy Principle: Learners are more likely to process non-redundant meaningful forms before they process redundant meaningful forms.

150 Second Language Research 29(2)
• Principle 1d. The Meaning-before-non-meaning Principle: Learners are more likely to process meaningful grammatical forms before non-meaningful forms irrespective of redundancy.
• Principle 1e. The Availability of Resources Principle: For learners to process either redundant meaningful grammatical forms or non-meaningful forms, the processing of overall sentential meaning must not drain available processing resources.
• Principle 1f. The Sentence Location Principle: Learners tend to process items in sentence initial position before those in final position and those in medial position.
• Principle 2. The First Noun Principle: Learners tend to process the first noun or pronoun they encounter in a sentence as subject or agent.
• Principle 2a. The Lexical Semantics Principle: Learners may rely on lexical semantics, where possible, instead of word order to interpret sentences.
• Principle 2b. The Event Probability Principle: Learners may rely on event proba-bilities, where possible, instead of word order to interpret sentences.
• Principle 2c. The Context Constraint Principle: Learners may rely less on the First Noun Principle if preceding context constrains the possible interpretation of a clause or sentence.
Of these principles, Principle 1 has served as a framework for research on input process-ing by ab initio learners (see, for example, Han and Peverly, 2007; Park, 2011; Park and Han, 2008). This principle essentially argues that learners process input for meaning before they process it for form, implicating meaning-based processing as the default processing approach. The principle has a number of corollaries (see above, 1a–1f), speaking to the multi-manifestation of meaning orientation, such as processing content words in the input before anything else (1a) and processing meaningful grammatical forms before non-meaningful grammatical forms (1d).
Han and Peverly (2007) were the first to set out to test this principle among first-exposure learners from a variety of L1 backgrounds, using Norwegian as the target lan-guage. The participants (n = 12) had zero knowledge of the TL at the onset of the study. The input stimulus used was extracted from a beginning level Norwegian textbook, a partner-seeking letter by a college student (125 words). Participants were divided into two groups: a simultaneous processing (SM) group, which read the input text twice con-secutively and subsequently completed two tasks, and a sequential processing group (SQ), which read the text twice, but with each reading followed by one task. The two measurement tasks were written-recall and gap-filling, respectively targeting meaning and form. Data, therefore, comprised students’ recalls and answers provided on the gap-filling task. In addition, an exit questionnaire was administered to probe participants’ experience with the tasks but, more importantly, their processing strategies. Results showed that both groups scored low on the recall task but higher on the gap-filling task, suggesting difficulty of comprehension but relative ease of recognition of form. This, coupled with the questionnaire data, suggests that the learners were using primarily a form-oriented rather than a meaning-based approach to processing input, even when they had been oriented to processing the input for meaning. Participants were found primarily engaged in ‘cracking the code’ (Cook, 1997): processing the input for form, a finding

Han and Liu 151
that runs counter to VanPatten’s claim on meaning primacy. Han and Peverly explicated the results by pointing to two sets of constraints, linguistic and functional:
First, the learners had no prior knowledge of the target language, and hence they had little to resort to in order to aid their comprehension. Using Krashen’s term, they did not even have i, to begin with. Second, the stimuli (i.e. the reading passages) were devoid of any extralinguistic cues, such as pictures and background information, which would have given the learners some contextual information to make sense of the input. These two – one posing a linguistic constraint and the other functional – collectively made the input outright incomprehensible. Under such circumstances, the learners had no recourse but to perform bottom-up processing, primarily at the word level. (Han and Peverly, 2007: 32)
Importantly, the study led to a two-fold hypothesis, which posits that learners with some proficiency in the TL adopt a meaning-based approach to input processing, but that learners with little proficiency adopt a form-oriented approach to input processing. The latter hypothesis has indeed been confirmed in subsequent studies (see, Han and Sun, 2009; Park, 2011; Park and Han, 2008).
The Park and Han (2008) study is, in particular, worthy of note, not only because it confirmed the two-part hypothesis but also because it addressed an issue raised in Han and Peverly (2007), namely how much knowledge of the TL is necessary for learners to switch from a form-based approach to a meaning-based approach. The study also sought to isolate the relative influence of the L1 in input processing. Native speakers of Japanese and English were subjected to two experimental conditions: processing input with or without prior knowledge. Japanese is putatively typologically close to, and English typo-logically distant from, Korean, the target language. The study had both a between-group and within-group design to allow for inter-group (Japanese versus English) and intra-group comparisons. With contrived texts (mean = 64 words), participants were asked to perform a while-reading task – underlining anything that stood out in the passage – and a post-reading task: writing down any questions about the passage. The resultant data shed light on the features of the input the learners noticed upon their first versus subse-quent exposure to the TL input. Specifically, upon the first exposure, both the Japanese group and the English group displayed an overall tendency to notice items that were frequent and salient by virtue of their sentential positions (i.e. initial and final). Both groups, therefore, exhibited what appears to be a form-oriented, rather than a meaning-oriented, approach to input processing. In other words, their processing was substantially guided by the physical attributes of the input text. However, on the subsequent exposure, by which time the participants had been equipped, through limited instruction, with some lexical knowledge (i.e. six Korean words), the two groups showed distinct trends in their processing of the input. For instance, the English group asked, predominantly, form-related questions such as word order, tense, and gender, but the Japanese group demon-strated a strong interest in the content of the text. In other words, once there was some prior knowledge in place, the two groups exhibited distinct predilections while process-ing the same input, with English speakers oriented towards formal properties of the input and Japanese speakers oriented towards meaning. The most-asked questions from the Japanese group were related to the meaning of recurrent words and the overall meaning of the input text. These results were meaningful on at least two levels: First, they showed

152 Second Language Research 29(2)
that contra VanPatten’s (1996) meaning primacy principle (see above), ab initio learners do not, by default, adopt a meaning-based approach to input processing. Second, L1-influence on input processing becomes tangible only after learners have developed some knowledge of the TL. This latter finding seems in keeping with Pienemann’s notion of processability as well as Andersen’s (1983) ‘transfer to somewhere’ principle, both positing, albeit in their own terms, that L1 transfer presupposes learners having some L2 knowledge.
III The study
This study is yet another attempt to investigate, within the VanPatten framework, input processing by ab initio learners. The study was motivated, this time around, by an interest in how learners process naturalistic oral input, how cross-linguistic influ-ence may temper the process, and whether or not working memory is implicated in the extent of processing. As with most studies of its kind, the study focused on perceptual learning and, in particular, ‘the initial analytical capabilities of absolute learners’ (Carroll, 2005: 70).
The study was conceptually driven by an overarching question: To what extent are first-exposure learners able to process naturalistic input? The study sought specifically to address the following questions:
• To what extent are ab initio learners able to process form? • To what extent are they able to process meaning? • To what extent does the L1 influence processing? • To what extent does working memory relate to processing?
Following Carroll’s (2005) conception of input processing, in this study ‘processing’ encompasses perception, operationalized as ‘morphemic segmentation’, and representa-tion, operationalized as ‘morphemic storage’.
1 Participants
Twenty ab initio learners of Chinese participated in the study: 10 native speakers of Japanese and 10 native speakers of American English (AE). All except one were female, with a mean age of 38 for the Japanese group and 31 for the AE group. All had a high motivation to learn Chinese. The Japanese group was bilingual with English uniformly as their second language, while the AE group, on average, spoke three languages (range: 1–4), the second and third languages varying a great deal from Arabic to German, Korean, and Spanish. The average age of onset of foreign language learning was 13 for the Japanese group, and 11 for the AE group.
2 Input
The input comprised 10 video episodes, grouped into two sets respectively on the themes of ordering food in a restaurant and bargaining in a shop. Each episode lasting 2–3

Han and Liu 153
minutes presented somewhat different content. For example, among the episodes in Set 2, Bargaining in a Shop, some ended with the customers purchasing the desired items and some with a disagreement over the price. One half of the episodes involved two interlocutors, and the other half three interlocutors. The mean number of turns for Set 1, Ordering Food in a Restaurant, was 8.5, and for Set 2, Bargaining in a Shop, 8.7. The mean length of utterance was 6.23 words for Set 1 and 9.72 words for Set 2.
3 Measures
Five tasks, which translated into 8 measures (see Coding and Analysis), were developed to jointly assess the scope and depth of processing:
• Task 1, ‘free recall’, measures form segmentation and storage following the viewing of an episode.
• Task 2, ‘comprehension’, measures meaning processing of the episode.• Task 3, ‘note-taking’, seeks to capture ‘on-line’ segmentation while viewing the
episode.• Task 4, ‘elicited imitation’, focuses on segmentation and prosodic features.• Task 5 is a working memory test adapted from Daneman and Carpenter (1980),
intended to measure the participants’ default capacity for processing and representation.
4 Procedures
Data collection proceeded on a one-on-one basis. Participants first were given a bio-graphic questionnaire to fill out. They were then played the entire footage of the two sets of episodes. After that, they watched each episode twice. Upon the first viewing, they completed a free recall task (Task 1), lasting about five minutes, oriented by the instruc-tions ‘What did you hear? Write down anything you heard.’ This was then followed by a comprehension task (Task 2) for about five minutes, guided by the question ‘What is this episode about?’ During the second viewing, participants completed a note-taking task (Task 3), which lasted about 8 minutes, guided by the instructions ‘What are you hear-ing? Write down what you are hearing.’ After that, participants were subjected to elicited imitation (Task 4) lasting about five minutes on which the following instructions were given: ‘You are now going to listen to a number of sentences and there will be a brief pause after each one for you to orally imitate the sentence.’ The sentence stimuli were each selected from a video episode on two criteria: length and frequency. Accordingly, each stimulus sentence needed to comprise 5 or 6 words, and to have appeared more than once in a given episode.
The series of procedures noted above was repeated for each episode. Finally, a work-ing memory test (Task 5) culminated the data collection cycle. The working memory test exposed participants to a total of 15 sets of sentences of increasing length. After reading each set, participants had to (a) decide whether each sentence in the set is logical or not, and (b) write down the last word of each sentence. Table 1 summarizes the data collec-tion procedures matched by their underlying intentions.

154 Second Language Research 29(2)
Table 2. Coding scheme.
Tasks Coding
Task 1_FR Morphemes accurately recalled: 1 point for a correct morpheme and 0 points for an incorrect morpheme
Task 2_Comp A five-point Likert scale for scope and degree of comprehension: 5 points are given for 100% comprehension, 4 for 80%, 3 for 60%, 2 for 40%, and 1 for 20% or less
Task 3_NT Morphemes accurately noted: 1 point for a correct morpheme and 0 points for an incorrect morpheme
Task 4_EI Morphemes accurately imitated: 1 point for a correct morpheme and 0 points for an incorrect morpheme
Task 4_EI_Tone Tones accurately imitated: 1 point for a correct tone and 0 points for an incorrect tone
Task 5_WM Combined accuracy of comprehension and of words recalledTask 5_WM_P Accuracy of comprehension: 1 point for accurate comprehension and
0 points for inaccurate comprehensionTask 5_WM_S Accuracy of words recalled: 1 point for an accurately recalled word
and 0 points for an inaccurately recalled word
Notes: Task 1_FR = free recall; Task 2_Comp = comprehension; Task 3_NT = note-taking; Task 4_EI = elic-ited imitation; Task 5_WM = working memory; Task 5_WM_P = work memory/processing; Task 5_WM_S = working memory/storage.
Table 1. Data collection procedures.
Task Duration Instruction Intention
Free recall 5 minutes What did you hear? Write down anything you heard.
Segmentation; storage
Comprehension 5 minutes What is this episode about? Global and local comprehension
Note-taking 8 minutes What are you hearing? Write down what you are hearing.
Segmentation
Elicited imitation 5 minutes You are now going to listen to a number of sentences, and there will be a brief pause after each one for you to orally imitate what you hear.
Segmentation; prosodic features
Working memory test 25 minutes Standard Default capacity
5 Coding and analysis
Table 2 displays the coding scheme employed. Notice that for Task 1, Task 3, and Task 4, a morpheme rather than a word constituted the basic unit of analysis. This is because Chinese is monosyllabic and mono-morphemic. A word in Chinese may, therefore, com-prise more than one morpheme or character. For example, kan4jian (看见) consists of two morphemes and characters, kan4 (看) ‘look’ and jian4 (见) ‘see’. For Tasks 1 and 3,
Han and Liu 155
participants received a point for each accurately recorded morpheme and 0 points for an incorrectly recorded morpheme. For the comprehension task (Task 2), participants’ responses were rated on a five-point Likert-scale, reflecting an increasing scope and degree of comprehension. Task 4, elicited imitation, was coded in two ways: segmenta-tion accuracy and tonal accuracy. Thus, for each imitated sentence, both accurately imi-tated morphemes (T4-EI) and accurately imitated tones (T4_EI_Tone) were counted. Task 5, the working memory test, was coded into processing, based on the accuracy of comprehension (Task 5_WM_P), and storage, based on the accuracy of words recalled (Task 5_WM_S). The two sets of scores were also combined to yield a total score for working memory (Task 5_WM).
The data were subsequently analysed, using SPSS 19 (IBM, 2010). First, descriptive statistics were computed to obtain an overview of the means and standard deviations, among other things, for both groups across the tasks. Repeated measures ANOVA was then conducted to ascertain within-group and between-group differences, if any, across the tasks. This was followed by one-way ANOVAs to assess differences between the two groups on each measure. Lastly, correlation analyses were carried out to see if partici-pants’ performances correlated on any of the tasks.
IV Results
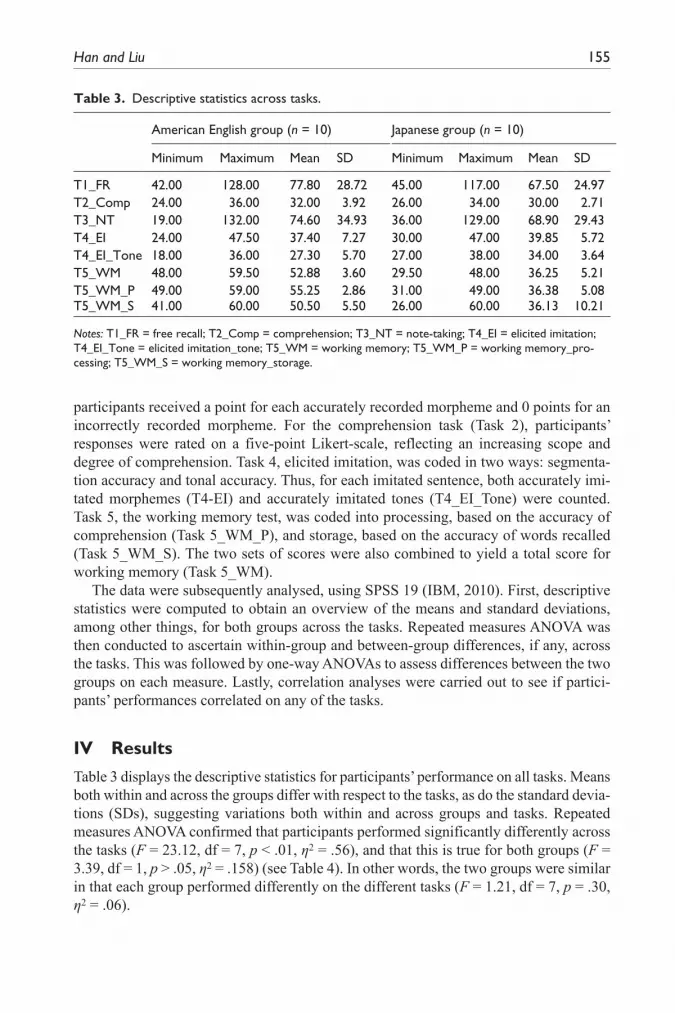
Table 3 displays the descriptive statistics for participants’ performance on all tasks. Means both within and across the groups differ with respect to the tasks, as do the standard devia-tions (SDs), suggesting variations both within and across groups and tasks. Repeated measures ANOVA confirmed that participants performed significantly differently across the tasks (F = 23.12, df = 7, p < .01, η2 = .56), and that this is true for both groups (F = 3.39, df = 1, p > .05, η2 = .158) (see Table 4). In other words, the two groups were similar in that each group performed differently on the different tasks (F = 1.21, df = 7, p = .30, η2 = .06).
Table 3. Descriptive statistics across tasks.
American English group (n = 10) Japanese group (n = 10)
Minimum Maximum Mean SD Minimum Maximum Mean SD
T1_FR 42.00 128.00 77.80 28.72 45.00 117.00 67.50 24.97T2_Comp 24.00 36.00 32.00 3.92 26.00 34.00 30.00 2.71T3_NT 19.00 132.00 74.60 34.93 36.00 129.00 68.90 29.43T4_EI 24.00 47.50 37.40 7.27 30.00 47.00 39.85 5.72T4_EI_Tone 18.00 36.00 27.30 5.70 27.00 38.00 34.00 3.64T5_WM 48.00 59.50 52.88 3.60 29.50 48.00 36.25 5.21T5_WM_P 49.00 59.00 55.25 2.86 31.00 49.00 36.38 5.08T5_WM_S 41.00 60.00 50.50 5.50 26.00 60.00 36.13 10.21
Notes: T1_FR = free recall; T2_Comp = comprehension; T3_NT = note-taking; T4_EI = elicited imitation; T4_EI_Tone = elicited imitation_tone; T5_WM = working memory; T5_WM_P = working memory_pro-cessing; T5_WM_S = working memory_storage.

156 Second Language Research 29(2)
Table 4. Repeated measures of within- and between-participant task effects.
Source df F Significance Partial eta squared
Task 7 23.12 .00 .562Task * group 7 1.21 .30 .060Group 1 3.39 .08 .158
When the two groups were compared, however, significant differences were found for some tasks but not for others. Specifically, the AE and Japanese groups performed simi-larly on Task 1(free recall), Task 2 (comprehension), Task 3 (note-taking), and Task 4 (elicited imitation), but significantly differently on Task 4 (elicitation imitation – tone) when tonal accuracy was separately analysed (F = 7.59, df = 1, p < .05), and on Task 5 (working memory; F = 23.58, df = 1, p < .01), including processing (F = 19.88, df = 1, p < .01) and storage (F = 10.00, df = 1, p < .01).
Figure 1 provides a visual display of the differences between the two groups per each measure. It is clear that the AE group performed better than the Japanese group. The superiority, albeit to varying extent, was seen on six of the eight measures: Task 1 (free recall), Task 2 (comprehension), Task 3 (note-taking), Task 5 (working memory), Task 5 (working memory – processing), and Task 5 (working memory – storage). The Japanese group, nevertheless, did slightly better on Task 4 (elicited imitation), and noticeably bet-ter on Task 4 (elicited imitation – tone).
Table 5 summarizes the results from Pearson correlation analyses. The correlation coefficients displayed therein showed a significant positive relationship between partici-pants’ performance on Task 1 (free recall) and Task 3 (note-taking), r = .723, p < .001. A significant correlation was also found for Task 4 (elicited imitation) between segmenta-tion and tonal accuracy, r = .519, p < .05. Moreover, there was a significant negative correlation between Task 4 (elicited imitation – tone) and Task 5 (working memory), r =
Figure 1. Task performance by American English (AE) versus Japanese groups.Notes: T1_FR = free recall; T2_Comp = comprehension; T3_NT = note-taking; T4_EI = elicited imitation; T4_EI_Tone = elicited imitation_tone; T5_WM = working memory; T5_WM_P = working memory_pro-cessing; T5_WM_S = working memory_storage.

Han and Liu 157
Table 5. Correlation analysis by task.
T1_FR T2_Comp T3_NT T4_EI T4_EI_tone T5_WM T5_WM_P T5_WM_S
T1_FR 1.000 −.186 .723** .411 .252 .114 .011 .178T2_Comp −.186 1.00 −.163 .000 −.169 .300 .399 .141T3_NT .723** −.163 1.00 .290 .321 −.006 −.080 .060T4_EI .411 .000 .290 1.00 .519* −.075 −.118 −.019T4_EI_Tone .252 −.169 .321 .519* 1.00 −.485* −.594** −.272T5_WM .114 .300 −.006 −.075 −.485* 1.000 .853** .889**T5_WM_P .011 .399 −.080 −.118 −.594** .853** 1.000 .520*T5_WM_S .178 .141 .060 −.019 −.272 .889** .520* 1.000
Notes: T1_FR = free recall; T2_Comp = comprehension; T3_NT = note-taking; T4_EI = elicited imitation; T4_EI_Tone = elicited imitation_tone; T5_WM = working memory; T5_WM_P = working memory_processing; T5_WM_S = working memory_storage. * p < .05, ** p < .001.
Table 6. Task correlations for AE group.
T1_FR T2_Comp T3_NT T4_EI T4_EI_Tone T5_WM T5_WM_P T5_WM_S
T1_FR 1.000 −.285 .637* .508 .474 .180 .352 .053T2_Comp −.285 1.000 −.296 .133 −.085 .716* .759* .543T3_NT .637* −.296 1.000 .195 .470 −.220 .040 −.308T4_EI .508 .133 .195 1.000 .611 .055 .179 −.021T4_EI_Tone .474 −.085 .470 .611 1.000 −.243 −.142 −.244T5_WM .180 .716* −.220 .055 −.243 1.000 .722* .933**T5_WM_P .352 .759* .040 .179 −.142 .722* 1.000 .424T5_WM_S .053 .543 −.308 −.021 −.244 .933** .424 1.000
Notes: T1_FR = free recall; T2_Comp = comprehension; T3_NT = note-taking; T4_EI = elicited imitation; T4_EI_Tone = elicited imitation_tone; T5_WM = working memory; T5_WM_P = working memory_pro cessing; T5_WM_S = working memory_storage. * p < .05, ** p < .001
–.485, p < .05, and, similarly, between Task 4 (elicited imitation – tone) and Task 5 (working memory–processing), r = –.594, p < .001.
Furthermore, when the two groups were analysed separately for correlation, a more nuanced picture emerged. Table 6 displays the Pearson correlation coefficients for the AE group. Significant correlations existed (a) between Task 1 (free recall) and Task 3 (note-taking), r = .637, p < .05; (b) between Task 2 (comprehension) and Task 5 (working memory), r = .716, p < .05; and (c) between Task 2 (comprehension) and Task 5 (work-ing memory – processing), r = .759, p < .05. Interestingly, a lack of correlation was found between Task 5 (working memory – processing) and Task 5 (working memory – stor-age), r = .424, p = .295.
Similar results were obtained for the Japanese group, as Table 7 shows. First, a strong and significant correlation was found between Task 1 (free recall) and Task 3 (note-tak-ing), r = .803, p < .001. Second, a significant negative correlation was found between Task 2 (comprehension) and Task 5 (working memory), r = –.674, p < .05. Third, inter-estingly, while there was a strong and significant correlation between Task 5 (working

158 Second Language Research 29(2)
memory) and Task 5 (working memory – storage), r = .879, p < .001, there was only a moderate positive correlation between Task 5 (working memory) and Task 5 (working memory – processing), r = .285, p = .426, and even a moderate negative correlation between Task 5 (working memory – processing) and Task 5 (working memory – stor-age), r = –.207, p = .567.
When the task raw accuracy scores were converted into ratios, and then averaged for each group, an order of task difficulty surfaced. Figure 2 displays the mean percentages of task accuracy for both groups, from which an ascending order of difficulty can be inferred: Task 4 (elicited imitation) > Task 5 (working memory) > Task 5 (working mem-ory–storage) > Task5 (working memory – processing) > Task 2 (comprehension) > Task 4 (elicited imitation – tone) > Task 1 (free recall) > Task 3 (note-taking). When similar analyses were performed for the two groups separately, slightly different orders were obtained, as shown in Figure 3:
For the AE group: Task 5 (working memory) > Task 5 (working memory – storage) > Task 5 (working memory – processing) > Task 4 (elicited imitation) > Task 2 (comprehension) > Task 4 (elicited imitation – tone) > Task 1 (free recall) > Task 3 (note-taking)
For the Japanese group: Task 4 (elicited imitation) > Task 4 (elicited imitation – tone) > Task 5 (working memory – processing) > Task 5 (working memory) > Task 5 (working memory – storage) > Task 2 (comprehension) > Task 3 (note-taking) > Task 1 (free recall)
What stood out from comparing the group-particular orders was that, for both groups, Task 1 (free recall) and Task 3 (note-taking) appear to have been the most challenging. Equally notable was that Task 4 (elicited imitation) and Task 4 (elicited imitation – tone) were easy for the Japanese group but quite difficult for the AE group.
V Discussion
This study sought to address four questions. The first question was to what extent ab initio learners were able to process input for form. Results from Task 1 (free recall), Task
Table 7. Task correlation for Japanese group.
T1_FR T2_Comp T3_NT T4_EI T4_EI_Tone T5_WM T5_WM_P T5_WM_S
T1_FR 1.000 −.394 .803** .223 .321 −.140 −.332 .022T2_Comp −.394 1.000 −.210 −.208 −.071 −.455 .423 −.674*T3_NT .803** −.210 1.000 .367 .340 −.037 −.276 .099T4_EI .223 −.208 .367 1.000 .146 .263 .023 .257T4_EI_Tone .321 −.071 .340 .146 1.000 .292 .134 .232T5_WM −.140 −.455 −.037 .263 .292 1.000 .285 .879**T5_WM_P −.332 .423 −.276 .023 .134 .285 1.000 −.207T5_WM_S .022 −.674* .099 .257 .232 .879** −.207 1.000
Notes: T1_FR = free recall; T2_Comp = comprehension; T3_NT = note-taking; T4_EI = elicited imitation; T4_EI_Tone = elicited imitation_tone; T5_WM = working memory; T5_WM_P = working memory_processing; T5_WM_S = working memory_storage. * p < .05, ** p < .001.

Han and Liu 159
3 (note-taking), Task 4 (elicited imitation), and Task 4 (elicited imitation – tone) all shone a light on this question. Taken together, the results showed that participants were able to process form to some extent: They were able to accurately segment syllables, but appear to have, overall, done substantively better on tasks that required less effort than on tasks requiring more. On the two tasks that required participants to rely on themselves to segment and store streams of sounds, i.e. Task 1 (free recall) and Task 3 (note-taking), participants performed only minimally albeit accurately, but significantly worse than they did on tasks where segmentation was more or less provided externally, e.g. Task 4 (elicited imitation): the mean difference between Task 1 and Task 4 is –.733, p < .001,
Figure 2. Task difficulty for both American English and Japanese groups.Notes: T1_FR = free recall; T2_Comp = comprehension; T3_NT = note-taking; T4_EI = elicited imitation; T4_EI_Tone = elicited imitation_tone; T5_WM = working memory; T5_WM_P = working memory_pro-cessing; T5_WM_S = working memory_storage.
Figure 3. Task difficulty for American English (AE) versus Japanese group.Notes: T1_FR = free recall; T2_Comp = comprehension; T3_NT = note-taking; T4_EI = elicited imitation; T4_EI_Tone = elicited imitation_tone; T5_WM = working memory; T5_WM_P = working memory_pro-cessing; T5_WM_S = working memory_storage.

160 Second Language Research 29(2)
and, with striking similarity, the mean difference between Task 3 and Task 4 is –.735, p < .001. Pearson correlation analyses confirmed that the processing incurred by Task 1 and Task 3 was similar, r = .723, p < .001, as was that incurred by Task 4 (elicited imita-tion) and Task 4 (elicited imitation – tone), r = .519, p < .05. The low processing scores from Tasks 1 and 3 may be indicative of a pre-parsing phase of processing, featuring sporadic picking up of acoustic properties of the sound stream. The accurate albeit low rate of segmentation attested in both groups can be accounted for by the syllabic salience of the target language. In other words, the monosyllabic nature of Chinese appears to have provided strong cues to morpheme boundaries.
The participants’ minimal processing of input as shown in Task 1 and Task 2 is con-sistent with the results reported in Han and Peverly (2007), Han and Sun (2009), and Park and Han (2008). It thus appears categorically that ab initio learners – no matter what the target language and what the modality of the input – are only able to minimally scratch the surface of the input. The content of the processing indicates a form-oriented approach to input processing, not a meaning-oriented approach, as VanPatten (1996, 2004) has hypothesized for L2 learners, in general.
A second research question addressed in the present study was to what extent ab initio learners are able to process naturalistic input for meaning. Results from Task 2 (comprehension) directly shed light on this question, indicating, amongst other things, that learners from both the AE and the Japanese group were able to achieve above 60% comprehension of the input (see Figure 2). However, this high level of processing of meaning is attributable to use of a top-down processing strategy. The answers provided by the participants showed ample evidence of their use of prior experience and knowl-edge of the world, cued by visual images; in stark contrast, little evidence was available of bottom-up processing, that is, comprehension through ‘code-breaking’ (Cook, 1997). Therefore, in spite of the impressive level of global comprehension, little form–mean-ing mapping occurred for the participants. According to Sharwood Smith (1986), who talks about a dual route to input processing, bottom-up processing engaging the lan-guage processor, rather than top-down processing, is what leads to development of lin-guistic competence. Similarly, the Shallow Processing Hypothesis (Clahsen and Felser, 2006) underscores that adult second language learners have a generic tendency to per-form top-down processing and not to perform bottom-up processing of input. This hypothesis contributes to an explanation of the dramatic difference in first versus sec-ond language ultimate attainment. The lack of productive bottom-up processing or form–meaning mapping among the ab initio learners observed in the present study was further seen in the drastic difference between their performance on Tasks 1 (free recall) and 3 (note-taking) versus Task 2 (comprehension): the mean differences were respec-tively –.580, p < .001; –.582, p < .001. It must be pointed out, however, that the minimal bottom-up processing, as has been reported elsewhere (e.g. Han and Peverly, 2007; Park and Han, 2008), was not a matter of choice or preference on the part of the ab initio learners, but rather it was due to a lack of ability to crack the code, as is further dis-cussed below.
Turning now to our third research question – to what extent the L1 influences process-ing – as reported earlier (see Figure 2), the two groups, although similarly performing poorly on Task 1 (free recall) and Task 3 (note-taking), exhibited notable differences on

Han and Liu 161
Task 4 (elicited imitation), and especially on Task 4 (elicited imitation – tone), with the latter reaching significance: F = 7.59, df = 1, p < .05. While, as noted earlier, the AE group outperformed the Japanese group on most of the measures, the Japanese group outshined their counterpart on the elicited imitation measures (see Figure 3). This dis-tinctive edge is indisputably due to the Japanese participants’ familiarity with the phono-logical features of Chinese. Japanese and Chinese, though quite distinct from each other morphosyntactically, share a historical affinity in the lexicon and phonology. Kanji, one of the three scripts used in the Japanese language, came from the Chinese script Hanzi. Many of the Kanji characters have more or less carried their original Chinese pronuncia-tion to date, known as On-reading (Shih, 2008). Systematic comparisons of Japanese and Chinese phonology have largely confirmed a phonological and phonetic correspondence between Kanji and Hanzi (see, for example, Cheng, 1996; Hu, 1999; Wan, 1999; Wang, 1998, 2004). English and Chinese, on the other hand, are known to be typologically apart on all levels, from the morphosyntactic to the phonological.
That being the case, the question remains: In the present study, why was the L1-based advantage not attested in Task 1 (free recall) and Task 3 (note-taking)? It may be, as reported in Park and Han (2008), that L1 transfer presupposes some knowledge of the TL, which functions to induce perception of similarities and differences between the L1 and the TL (see Andersen, 1983; Pienemann, 1998). As mentioned earlier, Task 1 and Task 3 both tapped learners’ own processing capability more than Task 4 (elicited imitation). In the cases of Tasks 1 and 3, both the AE group and the Japanese group started out on the same footing; neither group had any knowledge of the TL to assist transfer, so to speak. But in the case of Task 4, transfer was aided by virtue of the fact that the TL stimuli given were in the form of isolated sentences rather than continuous strings of utterances, which cut back on the processing load, thereby allowing the participants to tune in to the seg-mentation and prosodic features. And such processing conditions clearly favored the Japanese group due to the above noted phonological familiarity with the TL, Chinese.
Our fourth research question concerned the relationship between working memory and processing. The motivation for this question was two-fold: (a) to investigate the role of working memory in processing; and (b) to do so among ab initio learners. The latter motive serves as an antidote to extant practice in SLA research of testing working memory among learners who have already had at least some proficiency in the TL, a practice potentially confounding working memory capacity with proficiency. Such conflation was, in part, attested in the present study as well, in that, overall, the AE group did better than the Japanese group on the working memory test, the medium of which was English, the AE group’s L1. A study by Service et al. (2002) shows that ‘working memory span and decision accuracy were better for native-language than foreign-language sentences’ (p. 383). This, thus, raises a red flag about the test used in the present study: whether or not it accurately and adequately measured working memory. Indeed, the Pearson correla-tion analyses turned up a number of intriguing, if not random, results. Among them, first, when the data were pooled for both groups, working memory correlated significantly only with Task 4 (elicited imitation – tone) (see Table 5); second, when the data were analysed separately by group, working memory seems to have held a different relationship with processing for the AE group versus the Japanese group. For the AE group (see Table 6), Task 2 (comprehension) had a significant correlation with Task 5 (working memory) and

162 Second Language Research 29(2)
Task 5 (working memory – processing), but not with Task 5 (working memory – storage); for the Japanese group (see Table 7), Task 2 (comprehension) had a significant correlation with Task 5 (working memory – storage), but neither with Task 5 (working memory) nor with Task 5 (working memory – processing). Yet, the most intriguing finding was that working memory (two separate measures included) only had a weak or even negative cor-relation with Tasks 1 and 3, the two tasks that truly tapped learners’ processing capacity. The disparate results do not lend themselves to a coherent – let alone reliable – under-standing of whether working memory played a role in the input processing by the ab initio learners. It appears that future research examining this issue must first set out to validate the working memory test, and/or even the construct itself, before delving into the relation-ship between working memory and input processing in a second language. Related issues that are worth investigating include, but are not limited to, the relationship (or lack thereof) between working memory and unit of processing.
VI Conclusions
SLA research has increasingly highlighted the importance of input. Yet, as Carroll (2005) has aptly pointed out, ‘most research dealing with ‘input’ provided descriptions of what people say to learners, not what learners can perceive and represent’ (p. 81). While the number of studies on input processing is clearly on the rise, most of these studies have focused on learners who have already developed some knowledge of the target language, for one, and on processing of isolated sentences, for another. There are, therefore, notable gaps in the general understanding regarding how learners break into the input, extrapolate an understanding of form–meaning connection, and build an underlying linguistic compe-tence. Thus, first-exposure studies assume a particular importance, both theoretically and empirically. Theoretically, such research may directly contribute to the general under-standing of the L2 initial state, complementing the existing generative line of inquiry focusing on representation; empirically, it helps to build a tangible understanding of what and how adult learners, with all their cognitive baggage, do with novel language input.
First-exposure studies are still few and far between, and they have mostly continued the tradition of sentence processing research, namely, focusing on isolated and contrived input. Although the present study sought to provide an alternative to the latter by using natural input, it suffers another major weakness, as do most of its counterparts, in that it was only a one-shot study. As such, it tells us little about how ab initio learners’ processing ability develops over time. Longitudinal research is, clearly, desirable, because it is only through longitudinal studies that we are likely to discover the developmental trajectory.
The present study, for all its limitations, allowed us, nevertheless, to experiment with using natural input as stimuli, thereby putting us a step closer to understanding how beginning learners process real language input as it is heard in the real world. In addition to the ecological consideration, the study employed multiple tasks to measure process-ing, and it was found that the different tasks revealed different aspects of processing, thereby yielding more nuanced results than studies employing fewer tasks (e.g. Han and Peverly, 2007). In hindsight, the present study could have employed an additional task, perhaps more restricted than Task 2 (comprehension), to allow for an assessment of form–meaning mapping at the individual morpheme level.

Han and Liu 163
In conclusion, two methodological directions seem imperative to elevate the status of first-exposure research. One is to conduct longitudinal studies with a view to uncovering a developmental trajectory. The other is to continue the search for tasks that are not just relevant but more sensitive to incipient input processing.
Acknowledgements
The authors gratefully acknowledge the insightful comments and useful suggestions from Susanne Carroll, two anonymous reviewers, and Honggang Jin. The authors also gratefully acknowledge the technical assistance of Yuan-Yuan Meng and Hiromi Noguchi. Any errors that remain are exclusively our own.
Funding
This research received no specific grant from any funding agency in the public, commercial, or not-for-profit sectors.
References
Andersen RW (1983) Transfer to somewhere. In: Gass S and Selinker L (eds) Language transfer in language learning. Rowley, MA: Newbury House, 177–201.
Carroll S (2005) Input and SLA: Adults’ sensitivity to different sorts of cues to French. Language Learning 55: 79–138.
Cheng C-Y (1996) Hanyu yunmu yu riyu yindu changyin de duiyin guanxi [The correspondences between Chinese vowels and long vowels of On-reading in Japanese]. Riyu Xuexi Yu Yanjiu 2: 8–15.
Clahsen H and Felser C (2006) Continuity and shallow structures in language processing. Applied Psycholinguistics 27: 107–26.
Cook VJ (1997) Second language learning and language teaching. London: Arnold.Daneman M and Carpenter H (1980) Individual differences in working memory and reading.
Journal of Verbal Learning and Verbal Behavior 19: 450–66.Epstein SD, Flynn S and Martohardjono G (1996) Second language acquisition: Theoretical
and experimental issues in contemporary research. Behavioral and Brain Sciences 19: 677–758.
Eubank L (1996) Negation in early German-English interlanguage: More value-less features in the L2 initial state. Second Language Research 12: 73–106.
Gulberg M, Roberts L, Dimroth C, Veroude K and Indefrey P (2010) Adult language learning after minimal exposure to an unknown natural language. Language Learning 60: 5–24.
Han Z-H and Peverly S (2007) Input processing: A study of ab initio learners with multilingual backgrounds. The International Journal of Multilingualism 4: 17–37.
Han Z-H and Sun YY (2009) Input processing: A replication of Han and Peverly (2007). Unpublished paper presented at the GURT 2009 colloquium on learner spontaneous process-ing of input, Washington, DC, USA.
Håkansson G, Pienemann M and Sayehli S (2002) Transfer and typological proximity in the con-text of second language processing. Second Language Research 18: 250–73.
Hu C-N (1999) Riben de guozi [A study on Japanese ‘Kokuji’]. Riyu Xuexi Yu Yanjiu 2, 75–78.IBM Corp. (released 2010). IBM SPSS Statistics for Windows, Version 19.0. Armonk, NY: IBM
Corp.Klein W (1986) The problem of analysis: Second language acquisition. Cambridge: Cambridge
University Press.

164 Second Language Research 29(2)
Leung YI (2005) L2 vs. L3 initial state: A comparative study of the acquisition of French DPs by Vietnamese monolinguals and Cantonese–English bilinguals. Bilingualism: Language and Cognition 8: 39–61.
McNealy K, Mazziotta JC and Dapretto M (2006) Cracking the language code: Neural mecha-nisms underlying speech parsing. Journal of Neuroscience 26: 7629–39.
Park ES (2011) Learner-generated noticing of written L2 input: What do learners notice and why? Language Learning 61: 146–86.
Park ES and Han Z-H (2008) Learner spontaneous attention in L2 input processing: An explora-tory study. In: Han Z-H (ed.) Understanding second language process. Clevedon: Multilingual Matters, 106–32.
Perdue C (1996) Pre-basic varieties: The first stages of second language acquisition. Toegepaste Taalwetenschap in Artikelen 55: 135–50.
Pienemann M (1998) Language processing and second language acquisition: Processability the-ory. Amsterdam: John Benjamins.
Platzack C (1996) The initial hypothesis of syntax. In: Clahsen H (ed.) Generative perspectives on language acquisition. Amsterdam: John Benjamins, 369–414.
Rast R (2008) Foreign language input: Initial processing. Clevedon: Multilingual Matters.Schwartz BD and Sprouse R (1996) L2 cognitive states and the Full Transfer/Full Access model.
Second Language Research 12: 40–72.Service E, Simola M, Metsaenheimo O and Maury S (2002) Bilingual working memory span is
affected by language skill. European Journal of Cognitive Psychology 13: 383–407.Sharwood Smith M (1986) Comprehension versus acquisition: Two ways of processing input.
Applied Linguistics 7: 239–56.Shih L (2008) Enhancing the effectiveness of Kanji learning for the L1 Chinese-background stu-
dents through a Sino-Japanese phonological correspondence-based strategy. Unpublished doc-toral dissertation, Purdue University, IN, USA.
Slabakova R (2000) L1 transfer revisited: The L2 acquisition of telicity in English by Spanish and Slavic native speakers. Linguistics 38: 739–70.
Vainikka A and Young-Scholten M (1996) Gradual development of L2 phrase structure. Second Language Research 12: 7–39.
VanPatten B (1996) Input processing and grammar instruction in second language acquisition. Norwood, NJ: Ablex.
VanPatten B (2004) Processing instruction: Theory, research, and commentary. Mahwah, NJ: Lawrence Erlbaum.
Wan JF (1999) Zhongri hanzi de duyin bijiao [A comparison of Chinese and Japanese characters]. Riyu xuexi yu yanjiu 1: 35–38.
Wang JY (1998) Xiandai hanri hanzi duyin duizhao yanjiu [A comparative study on modern Sino-Japanese Kanji reading]. Riyu Xuexi Yu Yanjiu 4: 35–43.
Wang BT (2004) Guanyu hanyu de yunmu yu riyu hanzi yindu [A study on the vowels of Chinese and Japanese Kanji On-reading]. Riyu Xuexi Yu Yanjiu 3: 34–38.
White L (1986) Implications of parametric variation for adult second language acquisition: An investigation of the pro-drop parameter. In: Cook V (ed.) Experimental approaches to second language acquisition. Oxford: Pergamon Press, 55–72.
White L (1989) Universal Grammar and second language acquisition. Amsterdam: John Benjamins.Yuan B (1998) The interpretation of binding and orientation of the Chinese reflexive ziji by
English and Japanese speakers. Second Language Research 14: 325–40.Zwitserlood P, Klein W, Liang J, Perdue C and Kellerman E (2000) The first minutes of foreign-
language exposure. Unpublished manuscript, Max-Planck Institute for Psycholinguistics, Nijmegen, The Netherlands.





























