Embed Size (px)
Citation preview

WORKING PAPER
Estimasi Joint Probability Of Default
Menggunakan Pendekatan Copula : Studi Kasus
Sistem Keuangan Indonesia
Departemen Kebijakan Makroprudensial
Bekerjasama dengan
Fakultas Ekonomi dan Bisnis, Universitas
Indonesia
WP/3/2019
2019
Kesimpulan, pendapat, dan pandangan yang disampaikan oleh penulis dalam paper
ini merupakan kesimpulan, pendapat, dan pandangan penulis dan bukan
merupakan kesimpulan, pendapat, dan pandangan resmi Bank Indonesia.

ESTIMASI JOINT PROBABILITY OF DEFAULT
MENGGUNAKAN PENDEKATAN COPULA : STUDI
KASIS SISTEM KEUANGAN INDONESIA
Zaafri A. Husodo, Sigit S. Wibowo, M. Budi Prasetyo, Usman
Arief, Maulana Harris Muhajir
Abstrak
Penelitian ini mengkaji potensi sistemik risk dari sistem keuangan di
Indonesia terutama pada sektor bank dan pembiayaan. Kami menggunakan pendekatan pair copula construction (PCC) untuk mengestimasi probability
of default (PD) dari setiap individu sample. Kami menggunakan data bulanan
dari seluruh populasi bank sejak September 2000 sampai dengan Desember 2018 serta sample 31 perusahaan pembiayaan yang memiliki market share
lebih dari 80%. Selanjutnya, kami membuat indeks probability of default
sebagai benchmark dynamic PD secara industri. Untuk mengidentifikasi potensi SIFI kami menggunakan pendekatan korelasi parsial. Hasil empiris
kami menunjukkan bahwa peningkatan PoD untuk bank pemerintah, bank
swasta, dan foreign bank di Indonesia dimulai setelah tahun 2008 (global financial crysis). Pengujian kami menunjukkan bahwa bank yang masuk ke
dalam SIFI merupakan trigger utama dari financial de-stability di Indonesia.
Key word: Copula, Pair copula construction, Systemic risk, Sistem keuangan
JEL Classification: G12, G14, G18, E31, E32, D5

2
1. Pendahuluan
1.1. Latar Belakang
Setelah krisis keuangan global 2008, keterkaitan makro-keuangan telah menjadi
masalah penting bagi stabilitas sistem keuangan yang ditunjukkan oleh fluktuasi siklus bisnis.
Claessens dan Kose (2018) menunjukkan bahwa variabel keuangan dan makroekonomi
memainkan peran penting dalam menjelaskan siklus tersebut. Lebih penting lagi kedua variabel
tersebut terkait erat dan memiliki dampak besar pada posisi keuangan rumah tangga dan
perusahaan. Masalah lain yang terkait dengan stabilitas keuangan adalah amplifikasi risiko.
Brunnermeier dan Sannikov (2014) berpendapat bahwa kontraksi keuangan berdampak pada
penguatan goncangan dari dua saluran: leverage dan harga. Mereka juga menunjukkan bahwa
guncangan kecil mungkin memiliki dampak potensial pada perekonomian. Ini termasuk risiko
istimewa yang dapat menyebabkan risiko sistemik yang lebih tinggi. Leverage yang dapat
menekan kekayaan bersih agen terkait yang memiliki aset dengan leverage dapat memicu risiko
sistemik yang lebih tinggi jika aset tersebut sangat terkonsentrasi. Brunnermeier dan Sannikov
(2014) juga menunjukkan beberapa karakteristik penting ketika sistem keuangan gagal. Reaksi
sistem terhadap guncangan bersifat nonlinear dan asimetris. Ada juga risiko endogen yang
berarti bahwa risiko itu dihasilkan sendiri oleh sistem itu sendiri. Itu juga mendominasi
dinamika volatilitas dalam perekonomian.
Mengingat karakteristik ini, kita memerlukan beberapa model non-linear untuk
menangkap risiko yang tertanam dalam sistem keuangan dan pada saat yang sama juga
membangun hubungan antara agen dalam perekonomian. Model ekonometrik linier standar
mungkin tidak dapat menangkap risiko tersebut (lihat misalnya Dalla Valle et al., 2016;
Pourkhanali et al., 2016). Pendekatan lain untuk menangkap risiko ini menggunakan
probabilitas default berdasarkan model struktural berdasarkan Merton (1974). Pendekatan ini,
yang didasarkan pada nilai-nilai pasar dan memiliki beberapa kelemahan. Nilai aset yang
menjadi aset dasar untuk klaim kontinjensi bersifat eksogen. Merton (1974) juga
mengasumsikan non-negatif untuk nilai aset dan ekuitas di pasar aset. Namun, nilai-nilai ini
bisa negatif dalam akuntansi. Volatilitas tidak didasarkan pada struktur modal perusahaan,
tetapi ditentukan oleh volatilitas nilai pasar aset.
Pendekatan ini, yang didasarkan pada nilai-nilai pasar, memiliki beberapa kelemahan.
Nilai aset yang menjadi aset dasar untuk klaim kontinjensi adalah eksogen. Volatilitas tidak
didasarkan pada struktur modal perusahaan, tetapi ditentukan oleh volatilitas nilai pasar aset.
Sehubungan dengan pengamatan ini, kami berpendapat bahwa multivariat dependensi
harus dipertimbangkan untuk memperkirakan probabilitas default pada tingkat perusahaan
berdasarkan nilai buku ekuitas. Pendekatan semacam itu mampu meminimalkan potensi noise
yang timbul dari nilai pasar aset. Makalah ini mengambil pendekatan empiris dalam
memperkirakan risiko sistemik dalam sistem keuangan yang muncul yang didominasi oleh
sektor perbankan. Kami menggunakan pendekatan pair copula construction (PCC) untuk
memperkirakan joint probabilitas default (PD) dalam sistem keuangan Indonesia. Tujuan dari
penelitian ini juga untuk mengidentifikasi struktur ketergantungan PD bersama antara lembaga
keuangan. Oleh karena itu, kami dapat memperkirakan potensi risiko sistemik dalam
perusahaan-perusahaan ini.
Makalah ini disusun sebagai berikut. Pada bagian 2 kami memeriksa literatur yang ada
terkait dengan risiko sistemik dan pendekatan copula. Pada bagian 3 kami menggambarkan
konstruksi pasangan copula untuk memperkirakan probabilitas gabungan default di sektor
keuangan Indonesia. Bagian 4 menyajikan analisis dan diskusi empiris. Bagian 5 merupakan
kesimpulan dari berbagai temuan dan analisis yang didapatkan dari kajian ini.

3
1.2. Tujuan Penelitian
Tujuan penelitian ini adalah sebagai berikut:
1. Mengukur probability of default dengan menggunakan metode copula.
2. Mengukur joint probability of default atau correlated default antara entitas lembaga
keuangan.
3. Mengidentifikasi potensi risiko sistemik antara lembaga keuangan.
1.3. Batasan Penelitian
Penelitian ini menempatkan temuan empiris berdasarkan behavioral data laporan
keuangan bank dan lembaga keuangan. Ukuran nilai probability of default dihasilkan dari
dependensi antara variable di laporan keuangan menggunakan metode pair-copula construction
sehingga mampu menangkap idiosyncratic behavior dari masing-masing lembaga keuangan
bank dan non-bank. Untuk mengukur potensi risiko sistemik, penelitian ini menggunakan
pendekatan partial correlation.
1.4. Sistematika Penulisan
Sistemika penulisan penelitian ini pada Bab 1 menjelaskan latar belakang, tujuan dan
batasan penelitian disertai dengan studi literatur terkait, Bab 2 menjelaskan data dan konstrukti
variabel, Bab 3 membahas hasil-hasil estimasi empiris dan Bab 4 merupakan simpulan hasil
riset disertai dengan rekomendasi.
2. Telaah Literatur
Kami melihat beberapa literatur untuk menjelaskan bagaimana risiko idiosyncratik
memiliki dampak besar pada risiko sistemik. Salah satu literatur adalah pendekatan ekonomi
untuk risiko sistemik misalnya: Bernanke dan Gertler (1989), Kiyotaki dan Moore (1997), dan
Brunnermeier dan Sannikov (2014). Mereka mempelajari ekonomi dalam dinamika
kesetimbangan penuh dengan gesekan keuangan, di mana gesekan ini menciptakan risiko
sistemik dan risiko endogen. Studi-studi ini penting untuk melihat hubungan antara agen dan
bagaimana risiko muncul dalam agen ini. Selain itu, penelitian ini juga menunjukkan betapa
pentingnya kebijakan makro-prudential dalam menghadapi risiko sistemik. Namun, studi-studi
ini meninggalkan investigasi yang lebih empiris tentang bagaimana risiko endogen dapat
diperkirakan.
Salah satu pendekatan untuk memperkirakan risiko sistemik adalah menggunakan
ukuran risiko pada tingkat perusahaan seperti probabilitas default untuk suatu perusahaan.
Probabilitas default terjadi ketika perusahaan tidak dapat memenuhi komitmen mereka dalam
kontrak keuangan. Dalam literatur keuangan, probabilitas seperti itu juga dikenal sebagai risiko
kredit. Merton (1974) mengusulkan model untuk menilai risiko kredit suatu perusahaan dengan
menggunakan struktur keuangan perusahaan. Model ini mengasumsikan bahwa nilai pasar aset
dianggap eksogen dan mengikuti gerakan Brownian, dan koefisien volatilitas tidak tergantung
pada struktur modal lembaga. Selain itu, nilai aset juga diperlakukan sebagai aset dasar dalam
kerangka klaim kontinjensi. Karena model menggunakan nilai pasar aset, model ini dianggap
sebagai model risiko kredit berbasis pasar.
Pendekatan lain disebut sebagai model fundamental yang mempekerjakan data laporan
keuangan untuk memperkirakan nilai perusahaan dan untuk menentukan probabilitas default
perusahaan. Beaver (1968) dan Altman (1968) mengembangkan model berdasarkan analisis
diskriminan linier untuk memprediksi default perusahaan menggunakan rasio keuangan.

4
Ohlson (1980) menggunakan informasi serupa untuk memperkirakan kemungkinan
kebangkrutan finansial menggunakan model logit. Studi-studi ini bergantung pada ketersediaan
informasi keuangan.
Kelemahan utama dari kedua pendekatan ini adalah ketidakmampuan mereka untuk
sepenuhnya memahami struktur dependensi dalam peristiwa-peristiwa ekstrem. Pourkhanali et
al. (2016), Zhang (2014), dan Brechmann et al. (2013) menggunakan pendekatan copula untuk
memperkirakan struktur ketergantungan dalam perusahaan. Ini adalah masalah yang sangat
penting karena peristiwa dalam isolasi, risiko ekor, telah menjadi sangat dahsyat dalam krisis
keuangan baru-baru ini. Berdasarkan Sklar (1959), pendekatan ini dapat memperoleh distribusi
multivariat bersama dengan menanamkan struktur ketergantungan variabel. Dalam perspektif
tail risiko dan sistemik, copula sangat menarik karena fungsinya memungkinkan kita untuk
menguraikan distribusi marjinal (yang terkait dengan risiko ekor) dari struktur ketergantungan
(terkait dengan risiko sistemik) dan masing-masing model secara terpisah dengan tingkat
presisi yang lebih besar. Kedua, copula menyediakan kerangka kerja yang nyaman untuk
mengukur ketergantungan ekstrim antara dua variabel acak. Keuntungan lain menggunakan
copula adalah kemampuan untuk menangkap struktur ketergantungan non-linear dalam
kompleksitas data finansial yang sangat tinggi.
3. Metodologi Penelitian
Untuk mengatasi kekurangan seperti yang dinyatakan dalam literatur yang ada,
penelitian ini menggunakan pendekatan copula karena keuntungan dari copula adalah untuk
menghilangkan hubungan spurious (palsu) baik selama kondisi normal maupun selama
peristiwa ekstrim. Dalam kondisi krisis, fungsi copula dapat digunakan untuk memperkirakan
struktur dependensi antara variabel dengan presisi tinggi. Keuntungan dari kedua fungsi copula
dapat dengan mudah menangkap struktur ketergantungan antara dua variabel acak yang
asimetris (negatif atas, atau positif atas). Dalam studi keuangan, beberapa variabel acak yang
memiliki struktur dependensi negatif atas akan mengalami amplifikasi guncangan negatif
daripada variabel lain yang memiliki struktur dependensi negatif non-atas, sehingga beberapa
studi keuangan menggunakan basis ketergantungan negatif atas untuk memodelkan crash dari
hasil guncangan negatif Patton (2006). Keuntungan ketiga dengan menggunakan pendekatan
copula adalah kemampuan untuk menangkap hubungan non-linear antara variabel dengan
struktur data yang kompleks. Patton (2006) menyatakan bahwa kekurangan dari model utama
dalam keuangan adalah mengasumsikan semua hubungan bergerak secara linier, sehingga
kondisi ini disebut kutukan linearitas yang menyebabkan model-model menghitung risiko
ketidakakuratan dan kondisi peristiwa ekstrem yang kurang mampu ditangkap.
3.1 Copula
Pendekatan Copula diperkenalkan oleh Sklar (1959). Copula adalah fungsi
ketergantungan bentuk marginal yang memungkinkan menggabungkan dua marginal menjadi
satu fungsi (distribusi bersama). Singkatnya, distribusi bersama terdiri dari distribusi copula
dan marginal. Dengan menggunakan copula, kita dapat mengisolasi struktur ketergantungan
dalam distribusi multivariat. Copula berguna dalam memahami berbagai kesalahan yang
berhubungan dengan korelasi. Di bidang keuangan, copula dapat digunakan untuk menentukan
harga aset keuangan. Yang lain menggunakan copula untuk memahami sifat aset berisiko.
Dalam kasus kami, copula memainkan peran penting dalam memeriksa hubungan antara
perusahaan, terutama ketika peristiwa ekstrim terjadi memberikan teorema mendasar dalam
pendekatan copula.

5
Misalkan fungsi distribusi kumulatif bersama dengan d-dimensi F (x1, ..., xd) dan distribusi
kumulatif marginal F1, ..., Fd, maka fungsi copulanya adalah :
𝐹(𝑥1, … , 𝑥𝑑) = 𝐶(𝐹1(𝑥1), … , 𝐹𝑑(𝑥𝑑); 𝚯) (1)
Untuk setiap nilai 𝑥𝑖 ∈ [−∞, ∞], 𝑖 = 1, … , 𝑑. 𝚯 adalah paramater dari copula tersebut.
Jika nilai 𝐹𝑖 adalah continuous untuk setiap 𝑖 = 1, … , 𝑑 maka 𝑑 − adalah dimensi dari copula
yang dibentuk tersebut. Melalui pendekatan yang sebaliknya, kita bisa melihat fungsi copula
adalah sebagai berikut:
𝐶(𝑢1, … , 𝑢𝑑) = 𝐹(𝐹1−1(𝑢1), … 𝐹𝑑
−1(𝑢𝑑)) (2)
dimana 𝐹1−1(𝑢1), … 𝐹𝑑
−1(𝑢𝑑) adalah fungsi general dari marginal inversion. Nilai fungsi joint
densitasnya adalah sebagai berikut.
𝑓(𝑥1, … , 𝑥𝑑) = 𝑐(𝐹1(𝑥1), … , 𝐹𝑑(𝑥𝑑)) ⋅ 𝑓1(𝑥1) ⋯ 𝑓𝑑(𝑥𝑑) (3)
dimana 𝑐(𝐹1(𝑥1), … , 𝐹𝑑(𝑥𝑑)) adalah d−variate copula densitas berdasarkan nilai
konstruksinya.
3.2 Vine copula
Namun, ada beberapa masalah terkait penggunaan copula. Estimasi parameter dari
distribusi multivariat bersama mungkin tidak akurat ketika setiap variabel tidak memiliki
marginal distribusi yang sama. Selain itu, ini menjadi lebih sulit ketika distribusi bersama
dibangun dengan menentukan marginal dan copula. Namun, penggunaan copula lebih
menantang ketika dalam dimensi yang lebih tinggi, di mana copula multivariat standar tidak
cukup fleksibel dan dibatasi parameter.
Untuk mengatasi keterbatasan tersebut dan mampu memodelkan pola ketergantungan
yang kompleks dari sejumlah besar bivariat copula, kami menggunakan pendekatan pair copula
construction (PCC) untuk memeriksa struktur ketergantungan sektor keuangan Indonesia.
Kami mengikuti Joe (1993), Bedford dan Cooke (2001); Bedford dan Cooke (2002),
Kurowicka and Cooke (2006), dan Aas et al. (2009) untuk mengembangkan strategi empiris
kami. Vine copula diusulkan oleh Joe (1996) dan dikembangkan lebih lanjut oleh Bedford dan
Cooke (2001) dengan mengalirkan kaskade bivariat copula, yang dikenal sebagai konstruksi
pasangan-copula (PCC), untuk memperkirakan copula multivariat dari fungsi copula bivariat.
Karena PCC dipilih secara independen, PCC menyediakan kerangka kerja yang fleksibel secara
signifikan untuk pemodelan ketergantungan dalam memperkirakan PD.
Vine copula mampu menguraikan distribusi multivariat menjadi distribusi bivariat
dengan ketergantungan (Joe, 1994). Tanaman merambat adalah struktur grafis yang
menggambarkan distribusi probabilitas gabungan (lihat Bedford dan Cooke, 2001; Cooke,
1997; Kurowicka dan Cooke, 2006). Vine adalah metode grafis untuk memberi label batasan
dalam distribusi dengan dimensi tinggi.
Untuk mendapatkan vine copula, pertama-tama kita men-faktorkan joint distribusi dari
𝑓(𝑥1, … , 𝑥𝑑) yang merupakan random vector 𝑿 = 𝑋1, … , 𝑋𝑑 sebagai sebuah produk dari
conditional densitas dari ;

6
𝑓(𝑥1, … , 𝑥𝑑) = 𝑓𝑑(𝑥𝑑) × 𝑓𝑑−1|𝑑(𝑥𝑑−1|𝑥𝑑) × … × 𝑓1|2−𝑑(𝑥1|𝑥2, … , 𝑥𝑑). (4)
Menggunakan Sklar theorema joint distribusi dari subvector (𝑋𝑑 , 𝑋𝑑−1) dapat ditulis
berdasarkan definisi densitas dari copula sebagai berikut;
𝑓(𝑥𝑑−1, 𝑥𝑑) = 𝑐𝑑−1.𝑑(𝐹𝑑−1(𝑥𝑑−1), 𝐹𝑑(𝑥𝑑)) × 𝑓𝑑−1(𝑥𝑑−1) × 𝑓𝑑(𝑥𝑑)
dimana 𝑐𝑑−1.𝑑 adalah arbitrary dari bivariate copula. Maka, conditional densitas dari 𝑋𝑑 , 𝑋𝑑−1
dapat ditulis sebagai berikut:
𝑓𝑑−1|𝑑(𝑥𝑑−1|𝑥𝑑) = 𝑐𝑑−1,𝑑(𝐹𝑑−1(𝑥𝑑−1), 𝐹𝑑(𝑥𝑑)) × 𝑓𝑑−1(𝑥𝑑−1) (5)
Menggunakan rumus ke (5), untuk setiap (4) dapat di dekomposisi menjadi copula dengan
sebuah densitas conditional marginal. Untuk setiap elemen dari 𝑋𝐽 di dalam vector 𝑿, kita dapat
memperoleh;
𝑓𝑋𝐽|𝒗(𝑋𝐽|𝒗) = 𝑐𝑋𝐽|𝒗−𝓵(𝐹𝑋𝐽|𝒗−𝓵
(𝑋𝐽|𝒗−𝓵), 𝐹𝑣ℓ|𝑣ℓ(𝑣ℓ|𝑣ℓ)) × 𝑓𝑥𝐽|𝑣−ℓ
(𝑥𝐽|𝑣−ℓ) (6)
dimana 𝒗 adalah conditioning vector, 𝑣ℓ yang merupakan generic component dari 𝒗, 𝑣−ℓ dan
merupakan vector v tanpa komponen 𝑣ℓ, 𝐹𝑋𝐽|𝒗−𝓵(⋅ | ⋅) dimana the conditional distribution dari
𝑥𝐽 berdasarkan 𝑣−ℓ, dan 𝑐𝑋𝐽|𝒗−𝓵(⋅,⋅) yang merupakan conditional densitas pair copula.
PCC dibangun dengan mendekomposisi fungsi distribusi multivariat bersama d-
dimensi menjadi produk dari kopula bivariat dan distribusi marjinal dengan cara memasukkan
Persamaan (6) secara rekursif (6) dalam (4). Karena PCC tergantung pada urutan, pilihan
urutan variable menjadi sangat penting. Pilihan akan menentukan PCC dan faktorisasi
distribusi multivariat bersama. Karena alasan ini, penting untuk menentukan representasi
distribusi tinggi yang sesuai dalam PCC. Bedford dan Cooke (2001); Bedford dan Cooke
(2002) mengusulkan Regular vines (R-vines) sebagai representasi PCC. Karena vine V pada
n variabel dapat digambarkan sebagai kumpulan tree terhubung yang nested V = {T1, ..., T (n-
1)} di mana edge tree j adalah tree node j + 1, j = 1, ..., n-2, vine biasa dapat didefinisikan
sebagai kasus khusus yang semua batasannya dua dimensi atau dua dimensi bersyarat. Dalam
hal ini, vine reguler pada variabel n adalah vine di mana dua edge adalah tree j bergabung
dengan edge di tree j + 1 hanya jika edge ini berbagi node umum j = 1,…, n-2. Tree vine biasa
disebut kanonik atau C − vine jika setiap tree T_i memiliki node unik derajat n-i, dan karenanya
memiliki derajat maksimum. C − vine adalah vine reguler yang memiliki pusat ketergantungan.
Vine biasa disebut vine D atau vine yang dapat ditarik jika semua node di T1 memiliki derajat
tidak lebih tinggi dari 2 (lihat Kurowicka dan Joe, 2010).
Konstruksi R-vine dapat diilustrasikan seperti pada Gambar 1. Setiap titik disebut node.
Setiap node dihubungkan oleh sebuah edge. Node dan edge dapat diplot di tree atas. Di tree
kedua (T_2), ujung {4,5 | 1} adalah ketergantungan antara dimensi (variabel) 4 dan 5 dengan
menghilangkan efek 1. Pada tree ke-4 (T4), hanya ada satu sisi yaitu {2.5 | 134}.
3.3 Empirical strategy
Penelitian ini bertujuan untuk menguji struktur ketergantungan dalam sistem keuangan
Indonesia. Metodologi dalam makalah ini dapat dibagi menjadi:
1. Memperkirakan probabilitas default individu (PD) dari masing-masing perusahaan
dengan pendekatan kopula untuk menangkap dependensi multivariat,

7
2. Memperkirakan estimasi standar berkorelasi dari masing-masing PD di masing-masing
perusahaan,
3. Mengidentifikasi dan menganalisis potensi risiko sistemik dari estimasi PD bersama
dari masing-masing perusahaan.
Dengan menggunakan vine copula, kami secara tidak langsung memperkirakan amplifikasi
risiko dengan sistem keuangan.
3.4 Data
Kami menggunakan data neraca dari masing-masing bank yang terdiri dari aset lancar
(CA), aset jangka panjang (LA), kewajiban lancar (CL), dan kewajiban jangka panjang (LL)
yang akan digunakan untuk memperkirakan probabilitas default (PD). Dalam tulisan ini, kami
mendefinisikan nama akun neraca bank sebagai berikut:
1. aset lancar (CA) adalah aset bank yang memiliki jatuh tempo kurang dari satu tahun (aset
likuid)
2. aset jangka panjang (LA) adalah aset bank yang memiliki jatuh tempo lebih dari satu tahun
3. liabilitas lancar (CL) adalah liabilitas bank yang memiliki jatuh tempo kurang dari satu
tahun
4. liabilitas jangka panjang (LL) adalah liabilitas bank yang memiliki jatuh tempo lebih dari
satu tahun
Semua CA dan LA masing-masing memiliki nilai bersih yang berarti bahwa nilai aset
dikurangkan dengan provisi dan depresiasi kerugian pinjaman. Selain itu, kami mengeluarkan
pos tagihan dan kewajiban antar kantor cabang dari neraca bank. Semua data keuangan bank
Indonesia diambil dari basis data Bank Indonesia. Kami juga menggunakan perusahaan
pembiayaan untuk melengkapi analisis kami untuk sektor non-perbankan. Di Indonesia,
perusahaan pembiayaan menyediakan layanan leasing, anjak piutang, dan pembiayaan
konsumen. Di Indonesia, perusahaan pembiayaan meliputi: (1) Perusahaan pembiayaan
(perusahaan pembiayaan) adalah badan usaha yang didirikan khusus untuk melakukan leasing,
anjak piutang, pembiayaan konsumen, dan / atau bisnis kartu kredit; (2) Modal Ventura
(perusahaan modal ventura) adalah badan usaha yang melakukan pembiayaan usaha /
penyertaan modal dalam perusahaan yang menerima bantuan pembiayaan (perusahaan
investee) untuk periode tertentu dalam bentuk penyertaan modal, penyertaan melalui
pembelian barang konversi obligasi, dan atau pembiayaan berdasarkan distribusi hasil operasi,
dan (3) Perusahaan pembiayaan infrastruktur adalah perusahaan yang didirikan khusus untuk
melakukan pendanaan dalam bentuk penyediaan dana untuk proyek-proyek infrastruktur.
Karena perusahaan pembiayaan memiliki periode pelaporan yang berbeda kepada
regulator, kami menetapkan nama akun neraca sebagai berikut:
1. aset lancar (CA) adalah aset perusahaan yang memiliki jatuh tempo kurang dari tiga tahun
(aset likuid)
2. aset jangka panjang (LA) adalah aset perusahaan yang memiliki jatuh tempo lebih dari tiga
tahun
3. liabilitas lancar (CL) adalah liabilitas perusahaan yang memiliki jatuh tempo kurang dari
tiga tahun
4. liabilitas jangka panjang (LL) adalah liabilitas perusahaan yang lebih dari tiga tahun.

8
3.5 Individual Probability of Default
Pada tahap ini, kami menguji probabilitas default untuk setiap perusahaan berdasarkan
karakteristik neraca. Langkah-langkahnya adalah:
1. menentukan distribusi marginal
2. memilih struktur ketergantungan (pohon) dan memilih keluarga kopula yang tepat
3. melakukan simulasi untuk mendapatkan estimasi nilai ekuitas
4. Fungsi terbalik dari pengamatan semu ke pengamatan asli
5. probabilitas estimasi default di mana probabilitas diambil dari nilai ekuitas negatif.
Untuk memperkirakan dinamika nilai perusahaan, kami menggunakan PCC seperti
yang dijelaskan dalam Dalla Valle et al. (2016). Model dasar adalah model klaim kontinjensi
di mana efek yang mendasarinya adalah ekuitas dan hutang perusahaan. Data neraca dapat
digunakan sebagai proksi untuk nilai pasar perusahaan. Nilai "laten" dari perusahaan
berdasarkan pada:
𝐴𝑇 = 𝐺(𝐸𝑇 , 𝐵𝑇; 𝑇) (7)
dimana 𝐺(⋅) adalah fungsi pay-off yang merupakan, 𝐴𝑇 , 𝐸𝑇 , 𝐵𝑇 asset, equity and debt untuk
periode T. Secara intuitif turunan dari persamaan (7) adalah sebagai berikut :
𝐸𝑇 = 𝐺1(𝐴𝑇, 𝐵𝑇: 𝑇) = (𝐴𝑇 − 𝐵𝑇)
𝐸𝑇 = 𝐺1(𝐴𝑡, 𝐵𝑡; 𝑡) = 𝑃(𝑡, 𝑇) ∫ ∫ 𝐺1(𝐴𝑇 , 𝐵𝑇; 𝑇)𝑔1(𝐴𝑇 , 𝐵𝑇)𝑑𝐴𝑇𝑑𝐵𝑇
∞
0
∞
0
Laten variable di dalam bentuk volatilitas dan nilai asset dipecah menjadi beberapa komponan
berdasarkan akun yang ada di laporan keuangan (neraca):
𝐸𝑡 = 𝐺2(𝐴𝐶𝑡, 𝐴𝐿𝑡
, 𝐵𝐶𝑡, 𝐵𝐿𝑡
; 𝑡)
= 𝑃(𝑡, 𝑇) ∫ ∫ ∫ ∫ 𝐺2(𝐴𝐶𝑇, 𝐴𝐿𝑇
, 𝐵𝐶𝑇, 𝐵𝐿𝑇
; 𝑇)∞
0
∞
0
∞
0
∞
0
× 𝑔2(𝐴𝐶𝑇, 𝐴𝐿𝑇
, 𝐵𝐶𝑇, 𝐵𝐿𝑇
)𝑑𝐴𝐶𝑇𝑑𝐴𝐿𝑇
𝑑𝐵𝐶𝑇𝑑𝐵𝐿𝑇
Menggunakan Sklar’s theorema, realisasi dari data berdasarkna neraca dapat dikonstruksi
menjadi copula dengan fungsi dibawah ini:
𝐸𝑡 = 𝑃(𝑡, 𝑇) ∫ ∫ ∫ ∫ 𝐺2(𝐴𝐶𝑇, 𝐴𝐿𝑇
, 𝐵𝐶𝑇, 𝐵𝐿𝑇
; 𝑇)∞
0
∞
0
∞
0
∞
0
× 𝑐(𝐹𝐴𝐶, 𝐹𝐴𝐿
, 𝐹𝐵𝐶, 𝐹𝐵𝐿
)𝑓𝐴𝐶𝑓𝐴𝐿
𝑓𝐵𝐶𝑓𝐵𝐿
𝑑𝐴𝐶𝑇𝑑𝐴𝐿𝑇
𝑑𝐵𝐶𝑇𝑑𝐵𝐿𝑇
(8)
dimana 𝑐(⋅) adalah four-dimensional densitas copula, 𝐹(⋅) adalah marginal cumulative
distribution function, and 𝑓(⋅) adalah marginal probability density function.
Menggunakan Monte-Carlo simulation, nilai ekuitas dapat dibentuk dengan rumus sebagai
berikut:
�̃�𝑡 = 𝑃(𝑡, 𝑇)1
𝑁∑ 𝐺2(�̃�𝐶𝑇𝑘
, �̃�𝐿𝑇𝑘, �̃�𝐶𝑇𝑘
, �̃�𝐿𝑇𝑘; 𝑇)
𝑁
𝑘=1
(9)

9
Inverse function dari uniform distribution menjadi real distribution dapat diestimasi dengan
fungsi sebagai berikut:
𝐶(𝑢1, … , 𝑢𝑑) = 𝐹(𝐹1−1(𝑢1), … , 𝐹𝑑
−1(𝑢𝑑)). (10)
3.6 Time series probability of default
Pada tahap berikutnya, kami menganalisis probabilitas default di seluruh periode
pengamatan dengan menggunakan estimasi bergulir dengan window 36 bulan. Alasan
menggunakan window 36 bulan adalah untuk mendapatkan nilai optimal. Jika kami
menggunakan window kurang dari 36 bulan, hasilnya kurang stabil. Jika kami menggunakan
window lebih dari 36 bulan, maka pengamatan kita lebih sedikit.
Gambar 1. Rolling estimation
Proses estimasi untuk mendapatkan nilai PD dari masing-masing bank melalui proses
PCC hanya mendapat nilai statis. Sementara itu, untuk mendapatkan hasil estimasi PD secara
dinamis selama periode tertentu proses estimasi bergulir dilakukan untuk mendapatkan nilai
ekuitas dinamis dengan rolling window 3 tahun.
3.7 Systemic Risk Measurement
Korelasi default yang terkait adalah kondisi di mana default dari satu bank memiliki
hubungan yang kuat atau ketergantungan pada bank lain. Hubungan ini menunjukkan bahwa
peningkatan probabilitas default dari satu bank akan direspon secara positif oleh peningkatan
probabilitas default oleh bank dan lembaga keuangan lainnya. Namun, dari perspektif
makroprudensial, pemantauan korelasi default antara bank dalam sistem keuangan kurang
efektif karena akan melibatkan matriks korelasi yang besar. Selain itu, pengawasan kelompok
bank yang berkontribusi terhadap default berkorelasi tinggi dianggap lebih efektif dan tepat
karena kelompok bank ini memiliki potensi untuk berkontribusi pada peningkatan korelasi
default untuk bank lain. Karena itu, Pourkhanali et al. (2016) menyarankan pendekatan untuk
mengamati bank yang berpotensi sistemik menggunakan konsep korelasi parsial.
Alih-alih melihat korelasi default antara bank dan lembaga keuangan, konsep korelasi
parsial memeriksa bank mana yang memiliki kontribusi signifikan dalam meningkatkan nilai
korelasi default. Gambar 2 adalah contoh dari hasil estimasi menggunakan copula anggur
kanonik dari empat bank. Gambar 2 mengilustrasikan bahwa keempat bank memiliki hubungan
yang saling tergantung di mana Bank 3 adalah pusat ketergantungan. Sebagai contoh, korelasi
default antara Bank 1 dan Bank 2 memiliki nilai besar 90%, dan setelah hubungan dikontrol
(melalui korelasi parsial) oleh Bank 3 nilai ketergantungan menjadi -10%. Jadi berdasarkan
contoh ini Bank 3 berpotensi menjadi sistemik karena menyebabkan korelasi default yang
tinggi pada Bank 1 dan Bank 2. Dalam analisis grafis, tampaknya Bank 3 memiliki dependensi
terbanyak dibandingkan dengan bank lain, sehingga secara konseptual bank ini memiliki
kontribusi dalam meningkatkan korelasi default di bank lain.

10
Gambar 2. An example of Vine copula
Dalam penelitian ini korelasi default menggunakan model Vine Copula untuk menguji
struktur ketergantungan antara perusahaan. Kami memperkirakan default korelasi di seluruh
perusahaan dan melakukan analisis risiko sistemik dengan menggunakan korelasi parsial.
Untuk memperkirakan risiko sistemik, kami mengikuti Pourkhanali et al. (2016) sebagai
berikut:
𝜌𝑌𝑋|𝑍1,𝑍2…,𝑍𝑛=
𝜌𝑌𝑋|𝑍1,𝑍2…,𝑍𝑛−1− (𝜌𝑌𝑍𝑛|𝑍1,𝑍2…,𝑍𝑛−1
)(𝜌𝑋𝑍𝑛|𝑍1,𝑍2…,𝑍𝑛−1)
√(1 − 𝜌𝑌𝑍𝑛|𝑍1,𝑍2…,𝑍𝑛−1
2 )(1 − 𝜌𝑋𝑍𝑛|𝑍1,𝑍2…,𝑍𝑛−1
2 )
3.8 Systemic Risk Index
Pendekatan serupa juga digunakan oleh Acharya et al. (2014), dan Rosenberg dan
Schuermann (2006). Indeks probabilitas default (PD) untuk sektor perbankan adalah agregasi
probabilitas default dari 4 kelompok bank, yaitu bank milik negara (GOV), bank swasta
(BUSN), bank asing (KCBA), dan bank pembangunan daerah (BPD). PD agregat dari masing-
masing kelompok disusun menggunakan pendekatan nilai tertimbang berdasarkan total aset
perusahaan. Indeks PD disusun menggunakan pendekatan Bayesian di mana bobot masing-
masing kelompok bank ditentukan berdasarkan standar deviasi:
𝐼𝑛𝑑𝑒𝑥𝑃𝐷𝑡= ∑ 𝑤𝑖,𝑡𝑃𝐷𝑖,𝑡
𝑁
𝑖=1
(12)
dimana 𝑤𝑖,𝑡 =𝐼𝑃,𝑡
𝐼𝐺𝑂𝑉,𝑡+𝐼𝐵𝑈𝑆𝑁,𝑡+𝐼𝐾𝐶𝐵𝐴,𝑡+𝐼𝐵𝑃𝐷,𝑡 and 𝐼𝑃,𝑡 =
1
𝜎𝑃,𝑡.
4. Hasil dan Analisis
Kami menggunakan data seluruh bank dan perusahaan pembiayaan yang ada di
Indonesia dengan periode September 2000 hingga Desember 2018 (217 bulan). Data tersebut
didapatkan dari database Bank Indonesia. Jumlah bank yang digunakan sebagai sampel dalam
penelitian ini adalah sebanyak 104 bank. Dengan demikian, kami memiliki 22,880 observasi.

11
Namun untuk perusahaan pembiayaan, kami melakukan beberapa proses seleksi sampel
lebih lanjut. Hal tersebut disebabkan karena adanya permasalahan pada kualitas data laporan
keuangan perusahaan pembiayaan. Jumlah total perusahaan pembiayaan yang ada di Indonesia
adalah sebanyak 253 perusahaan. Dari jumlah tersebut, kami melakukan beberapa penyaringan
lebih lanjut, yaitu:
1. Pada tahap pertama, sebanyak 153 dari 253 perusahaan pembiayaan harus dieliminasi
dari sampel karena perusahaan tersebut memiliki observasi dengan nilai 0 dengan
proporsi lebih dari 50% dari total observasi. Pada tahap ini, jumlah perusahaan PP
yang diproses lebih lanjut adalah sebanyak 100 perusahaan.
2. Pada tahap kedua, sebanyak 69 dari 100 perusahaan pembiayaan harus dieliminasi
karena masih memiliki permasalahan banyaknya observasi pada keempat variable
(CA, LA, CL, dan LL) yang memiliki nilai 0. Meskipun jumlahnya kurang dari 50%
dari total observasi, observasi dengan nilai 0 tersebut terjadi secara berurutan selama
periode waktu tertentu sehingga membuat estimasi PoD dengan Copula menjadi
bermasalah.
3. Total sampel perusahaan pembiayaan yang digunakan setelah melalui dua tahap
seleksi di atas adalah sebanyak 31 perusahaan. Untuk memastikan keterwakilan
sampel terhadap industry perusahaan pembiayaan, kami menghitung market share dari
31 perusahaan tersebut terhadap total asset industry perusahaan pembiayaan. Hasilnya
adalah, 31 perusahaan pembiayaan yang kami gunakan dalam penelitian ini memiliki
market share dalam hal total asset sebesar 82.77% (posisi Desember 2018) terhadap
total asset industry perusahaan pembiayaan di Indonesia.
4. Kami melakukan intervensi pada data karena data seluruh perusahaan pembiayaan
pada periode September – Desember 2017 tidak tersedia. Kami menggunakan
interpolasi dengan random number pada interval nilai minimum dan maksimum setiap
variable sejak awal periode hingga periode Agustus 2017.
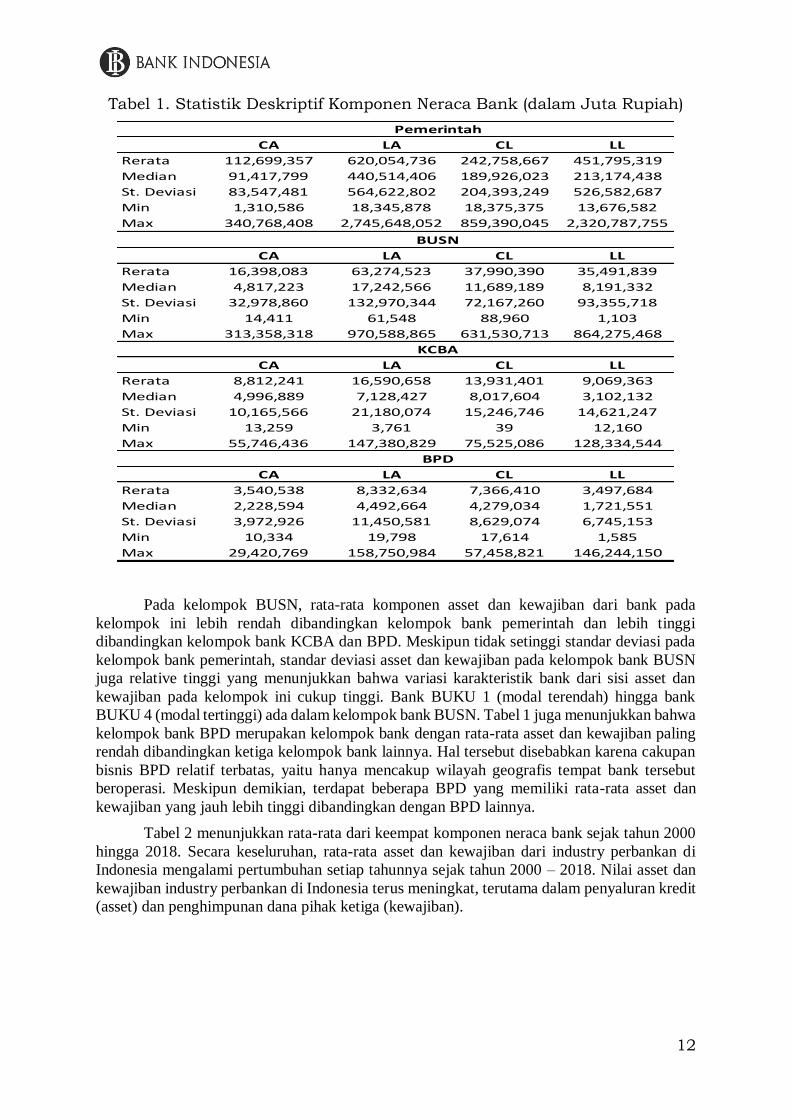
Statistik deskriptif empat komponen neraca bank di Indonesia dapat dilihat pada tabel
1 dan 2. Tabel 1 menunjukkan statistic deskriptif dari empat komponen neraca bank yang
dikelompokkan berdasarkan jenis bank berdasarkan kepemilikan, yaitu pemerintah, Bank
Umum Swasta Nasional (BUSN), Kantor Cabang Bank Asing (KCBA), dan Bank Pemerintah
Daerah (BPD). Dari keempat kelompok bank tersebut, kelompok bank pemerintah memiliki
rata-rata nilai CA, LA, CL, dan LL yang paling tinggi dibandingkan kelompok bank lainnya.
Meskipun hanya terdiri dari 4 bank, bank yang masuk dalam kelompok bank pemerintah
memiliki posisi penting dan dominan dalam industry perbankan di Indonesia. Namun, standar
deviasi dari keempat komponen pada statistic deskriptif komponen neraca kelompok bank
pemerintah juga paling tinggi dibandingkan dengan kelompok bank lainnya. Hal tersebut
menunjukkan adanya variabilitas yang tinggi antar bank dalam kelompok bank pemerintah.
Terdapat 1 bank pemerintah yang memiliki nilai asset dan kewajiban yang jauh lebih rendah
dibandingkan ketiga bank pemerintah lainnya.
12
Tabel 1. Statistik Deskriptif Komponen Neraca Bank (dalam Juta Rupiah)
Pada kelompok BUSN, rata-rata komponen asset dan kewajiban dari bank pada
kelompok ini lebih rendah dibandingkan kelompok bank pemerintah dan lebih tinggi
dibandingkan kelompok bank KCBA dan BPD. Meskipun tidak setinggi standar deviasi pada
kelompok bank pemerintah, standar deviasi asset dan kewajiban pada kelompok bank BUSN
juga relative tinggi yang menunjukkan bahwa variasi karakteristik bank dari sisi asset dan
kewajiban pada kelompok ini cukup tinggi. Bank BUKU 1 (modal terendah) hingga bank
BUKU 4 (modal tertinggi) ada dalam kelompok bank BUSN. Tabel 1 juga menunjukkan bahwa
kelompok bank BPD merupakan kelompok bank dengan rata-rata asset dan kewajiban paling
rendah dibandingkan ketiga kelompok bank lainnya. Hal tersebut disebabkan karena cakupan
bisnis BPD relatif terbatas, yaitu hanya mencakup wilayah geografis tempat bank tersebut
beroperasi. Meskipun demikian, terdapat beberapa BPD yang memiliki rata-rata asset dan
kewajiban yang jauh lebih tinggi dibandingkan dengan BPD lainnya.
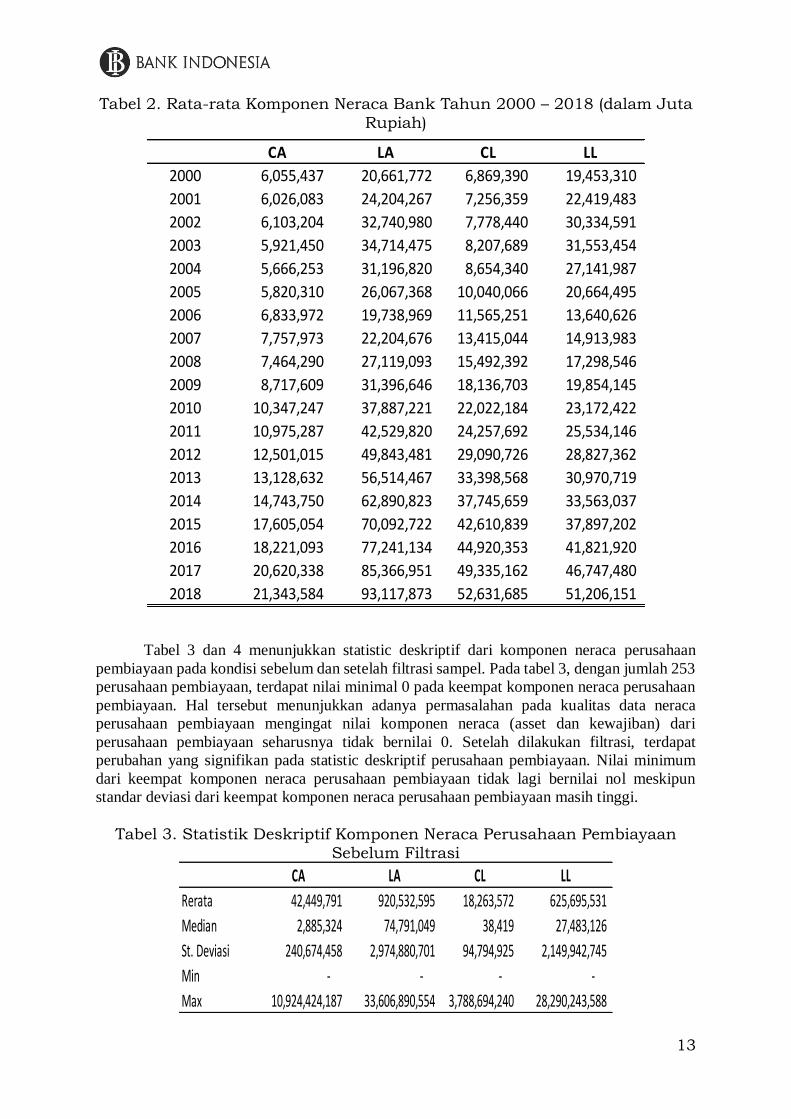
Tabel 2 menunjukkan rata-rata dari keempat komponen neraca bank sejak tahun 2000
hingga 2018. Secara keseluruhan, rata-rata asset dan kewajiban dari industry perbankan di
Indonesia mengalami pertumbuhan setiap tahunnya sejak tahun 2000 – 2018. Nilai asset dan
kewajiban industry perbankan di Indonesia terus meningkat, terutama dalam penyaluran kredit
(asset) dan penghimpunan dana pihak ketiga (kewajiban).
CA LA CL LL
Rerata 112,699,357 620,054,736 242,758,667 451,795,319
Median 91,417,799 440,514,406 189,926,023 213,174,438
St. Deviasi 83,547,481 564,622,802 204,393,249 526,582,687
Min 1,310,586 18,345,878 18,375,375 13,676,582
Max 340,768,408 2,745,648,052 859,390,045 2,320,787,755
CA LA CL LL
Rerata 16,398,083 63,274,523 37,990,390 35,491,839
Median 4,817,223 17,242,566 11,689,189 8,191,332
St. Deviasi 32,978,860 132,970,344 72,167,260 93,355,718
Min 14,411 61,548 88,960 1,103
Max 313,358,318 970,588,865 631,530,713 864,275,468
CA LA CL LL
Rerata 8,812,241 16,590,658 13,931,401 9,069,363
Median 4,996,889 7,128,427 8,017,604 3,102,132
St. Deviasi 10,165,566 21,180,074 15,246,746 14,621,247
Min 13,259 3,761 39 12,160
Max 55,746,436 147,380,829 75,525,086 128,334,544
CA LA CL LL
Rerata 3,540,538 8,332,634 7,366,410 3,497,684
Median 2,228,594 4,492,664 4,279,034 1,721,551
St. Deviasi 3,972,926 11,450,581 8,629,074 6,745,153
Min 10,334 19,798 17,614 1,585
Max 29,420,769 158,750,984 57,458,821 146,244,150
Pemerintah
BUSN
KCBA
BPD
13
Tabel 2. Rata-rata Komponen Neraca Bank Tahun 2000 – 2018 (dalam Juta
Rupiah)
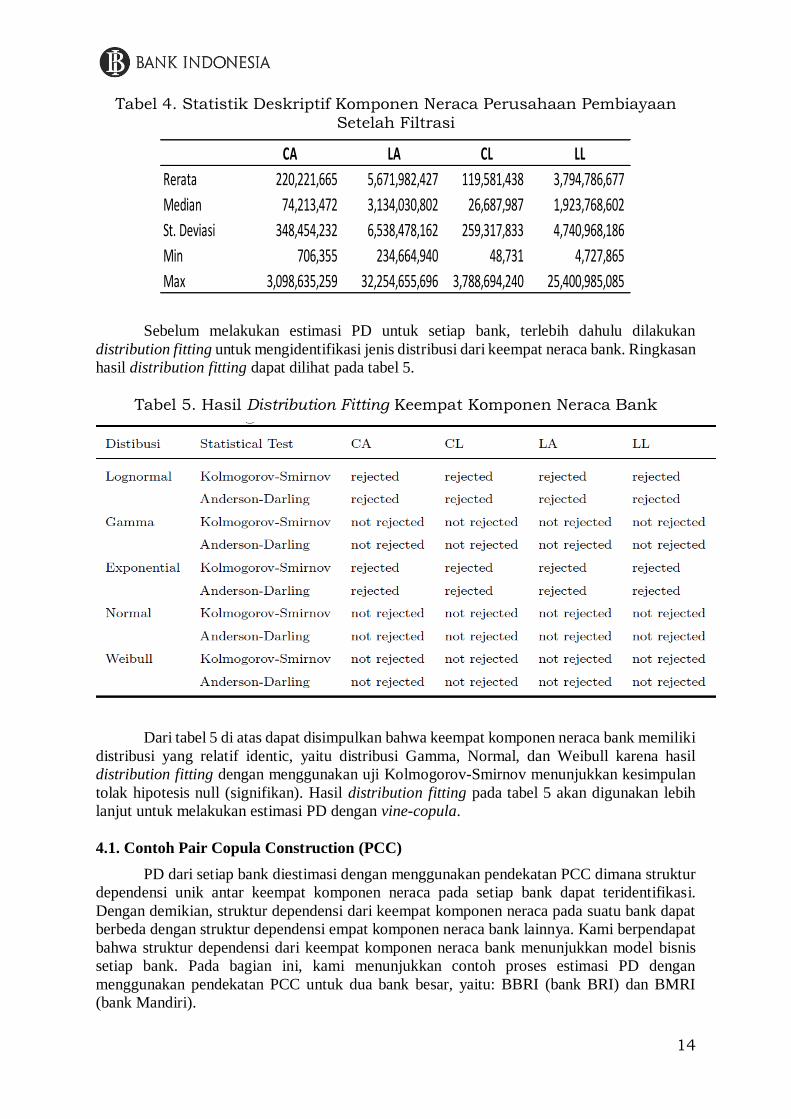
Tabel 3 dan 4 menunjukkan statistic deskriptif dari komponen neraca perusahaan
pembiayaan pada kondisi sebelum dan setelah filtrasi sampel. Pada tabel 3, dengan jumlah 253
perusahaan pembiayaan, terdapat nilai minimal 0 pada keempat komponen neraca perusahaan
pembiayaan. Hal tersebut menunjukkan adanya permasalahan pada kualitas data neraca
perusahaan pembiayaan mengingat nilai komponen neraca (asset dan kewajiban) dari
perusahaan pembiayaan seharusnya tidak bernilai 0. Setelah dilakukan filtrasi, terdapat
perubahan yang signifikan pada statistic deskriptif perusahaan pembiayaan. Nilai minimum
dari keempat komponen neraca perusahaan pembiayaan tidak lagi bernilai nol meskipun
standar deviasi dari keempat komponen neraca perusahaan pembiayaan masih tinggi.
Tabel 3. Statistik Deskriptif Komponen Neraca Perusahaan Pembiayaan
Sebelum Filtrasi
CA LA CL LL
2000 6,055,437 20,661,772 6,869,390 19,453,310
2001 6,026,083 24,204,267 7,256,359 22,419,483
2002 6,103,204 32,740,980 7,778,440 30,334,591
2003 5,921,450 34,714,475 8,207,689 31,553,454
2004 5,666,253 31,196,820 8,654,340 27,141,987
2005 5,820,310 26,067,368 10,040,066 20,664,495
2006 6,833,972 19,738,969 11,565,251 13,640,626
2007 7,757,973 22,204,676 13,415,044 14,913,983
2008 7,464,290 27,119,093 15,492,392 17,298,546
2009 8,717,609 31,396,646 18,136,703 19,854,145
2010 10,347,247 37,887,221 22,022,184 23,172,422
2011 10,975,287 42,529,820 24,257,692 25,534,146
2012 12,501,015 49,843,481 29,090,726 28,827,362
2013 13,128,632 56,514,467 33,398,568 30,970,719
2014 14,743,750 62,890,823 37,745,659 33,563,037
2015 17,605,054 70,092,722 42,610,839 37,897,202
2016 18,221,093 77,241,134 44,920,353 41,821,920
2017 20,620,338 85,366,951 49,335,162 46,747,480
2018 21,343,584 93,117,873 52,631,685 51,206,151
CA LA CL LL
Rerata 42,449,791 920,532,595 18,263,572 625,695,531
Median 2,885,324 74,791,049 38,419 27,483,126
St. Deviasi 240,674,458 2,974,880,701 94,794,925 2,149,942,745
Min - - - -
Max 10,924,424,187 33,606,890,554 3,788,694,240 28,290,243,588
14
Tabel 4. Statistik Deskriptif Komponen Neraca Perusahaan Pembiayaan
Setelah Filtrasi
Sebelum melakukan estimasi PD untuk setiap bank, terlebih dahulu dilakukan
distribution fitting untuk mengidentifikasi jenis distribusi dari keempat neraca bank. Ringkasan
hasil distribution fitting dapat dilihat pada tabel 5.
Tabel 5. Hasil Distribution Fitting Keempat Komponen Neraca Bank
Dari tabel 5 di atas dapat disimpulkan bahwa keempat komponen neraca bank memiliki
distribusi yang relatif identic, yaitu distribusi Gamma, Normal, dan Weibull karena hasil
distribution fitting dengan menggunakan uji Kolmogorov-Smirnov menunjukkan kesimpulan
tolak hipotesis null (signifikan). Hasil distribution fitting pada tabel 5 akan digunakan lebih
lanjut untuk melakukan estimasi PD dengan vine-copula.
4.1. Contoh Pair Copula Construction (PCC)
PD dari setiap bank diestimasi dengan menggunakan pendekatan PCC dimana struktur
dependensi unik antar keempat komponen neraca pada setiap bank dapat teridentifikasi.
Dengan demikian, struktur dependensi dari keempat komponen neraca pada suatu bank dapat
berbeda dengan struktur dependensi empat komponen neraca bank lainnya. Kami berpendapat
bahwa struktur dependensi dari keempat komponen neraca bank menunjukkan model bisnis
setiap bank. Pada bagian ini, kami menunjukkan contoh proses estimasi PD dengan
menggunakan pendekatan PCC untuk dua bank besar, yaitu: BBRI (bank BRI) dan BMRI
(bank Mandiri).
CA LA CL LL
Rerata 220,221,665 5,671,982,427 119,581,438 3,794,786,677
Median 74,213,472 3,134,030,802 26,687,987 1,923,768,602
St. Deviasi 348,454,232 6,538,478,162 259,317,833 4,740,968,186
Min 706,355 234,664,940 48,731 4,727,865
Max 3,098,635,259 32,254,655,696 3,788,694,240 25,400,985,085

15
Tabel 6 dan 7 menunjukkan hasil output estimasi PCC dengan menggunakan model R-
Vine. Tabel tersebut menunjukkan informasi mengenai tree, edge (struktur dependensi), famili
dari copula, parameter copula, dan korelasi kendall-tau. Pada tabel 6, nilai dependensi bivariate
copula untuk BBRI paling tinggi pada tree pertama. Pada tree tersebut, struktur dependensi
tertinggi terjadi pada komponen asset jangka panjang (LA) dan kewajiban jangka pendek (CL)
dengan nilai korelasi Kendal-tau adalah sebesar 0.96 dan famili Copula distribusi Frank.
Tabel 6. Ringkasan Hasil Estimasi PCC R-Vine untuk BBRI
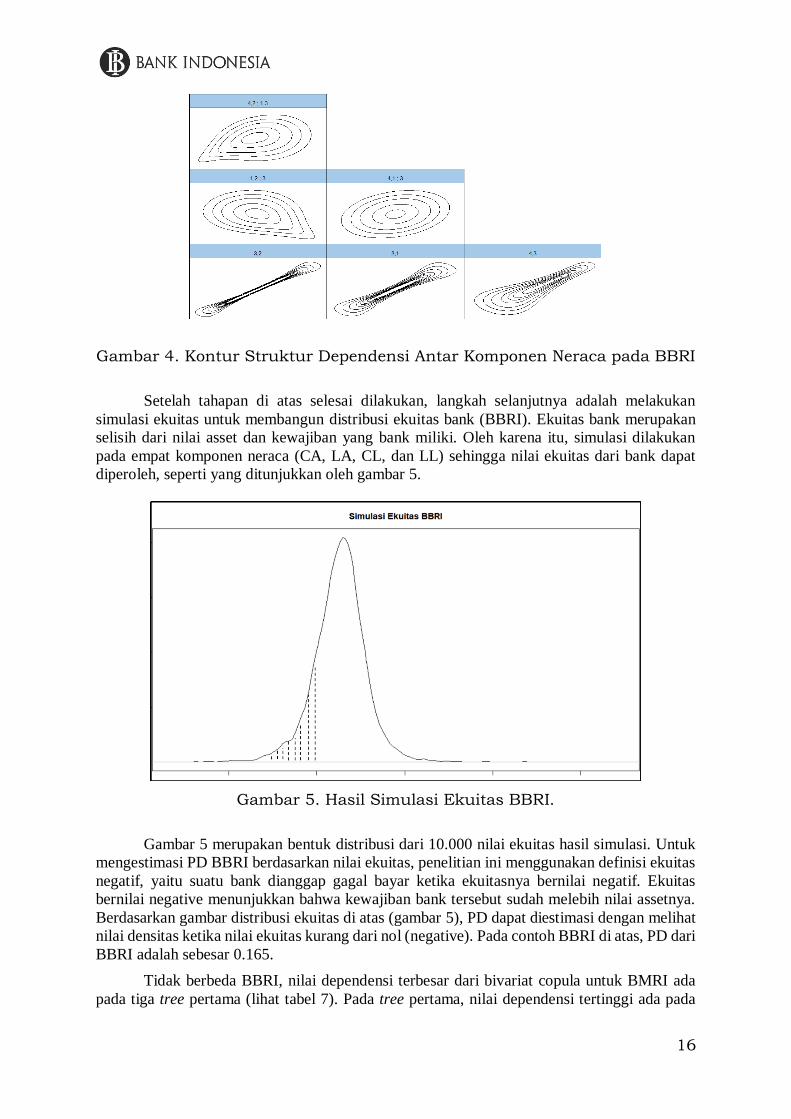
Struktur tree dari BBRI dapat dilihat pada gambar 3. Model vine-copula yang dipilih
adalah model C-Vine (Canonical Vine), yaitu model vine-copula yang memiliki center
dependence. Selain itu, kontur dari setiap hubungan berpasangan dapat dilihat pada gambar 4.
Gambar 3. Konstruksi Tree C-Vine pada BBRI
16
Gambar 4. Kontur Struktur Dependensi Antar Komponen Neraca pada BBRI
Setelah tahapan di atas selesai dilakukan, langkah selanjutnya adalah melakukan
simulasi ekuitas untuk membangun distribusi ekuitas bank (BBRI). Ekuitas bank merupakan
selisih dari nilai asset dan kewajiban yang bank miliki. Oleh karena itu, simulasi dilakukan
pada empat komponen neraca (CA, LA, CL, dan LL) sehingga nilai ekuitas dari bank dapat
diperoleh, seperti yang ditunjukkan oleh gambar 5.
Gambar 5. Hasil Simulasi Ekuitas BBRI.
Gambar 5 merupakan bentuk distribusi dari 10.000 nilai ekuitas hasil simulasi. Untuk
mengestimasi PD BBRI berdasarkan nilai ekuitas, penelitian ini menggunakan definisi ekuitas
negatif, yaitu suatu bank dianggap gagal bayar ketika ekuitasnya bernilai negatif. Ekuitas
bernilai negative menunjukkan bahwa kewajiban bank tersebut sudah melebih nilai assetnya.
Berdasarkan gambar distribusi ekuitas di atas (gambar 5), PD dapat diestimasi dengan melihat
nilai densitas ketika nilai ekuitas kurang dari nol (negative). Pada contoh BBRI di atas, PD dari
BBRI adalah sebesar 0.165.
Tidak berbeda BBRI, nilai dependensi terbesar dari bivariat copula untuk BMRI ada
pada tiga tree pertama (lihat tabel 7). Pada tree pertama, nilai dependensi tertinggi ada pada
17
LA dan CL dengan famili copula adalah Frank dan nilai korelasi Kendall-tau adalah sebesar
0.82. Struktur tree dari BMRI dapat dilihat pada gambar 6 dimana model vine-copula yang
digunakan adalah D-Vine (Drawable vine).
Tabel 7. Ringkasan Hasil Estimasi PCC R-Vine untuk BMRI
Gambar 6. Konstruksi Tree D-Vine Copula untuk BMRI
18
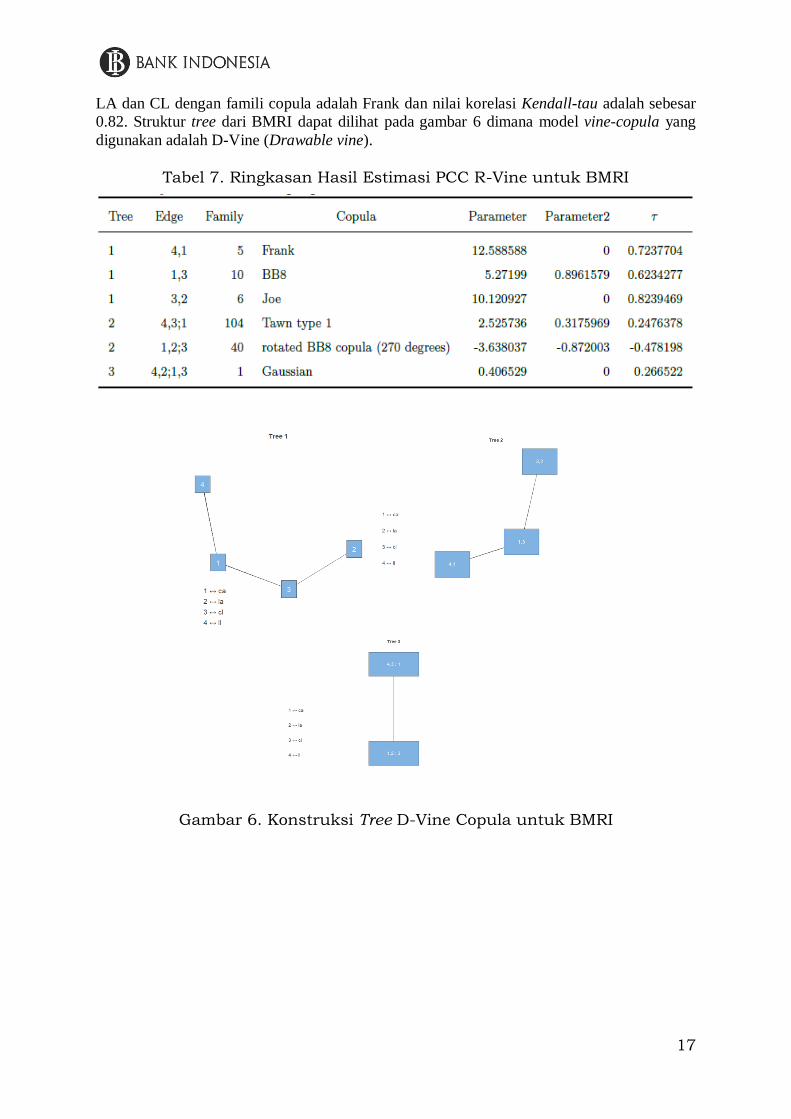
Gambar 7. Kontur Struktur Dependensi Antar Komponen Neraca BMRI
Seperti halnya BBRI, simulasi monte carlo sebanyak 10,000 kali pada keempat
komponen neraca untuk mendapatkan distribusi ekuitas BMRI. Hasil simulasi ekuitas untuk
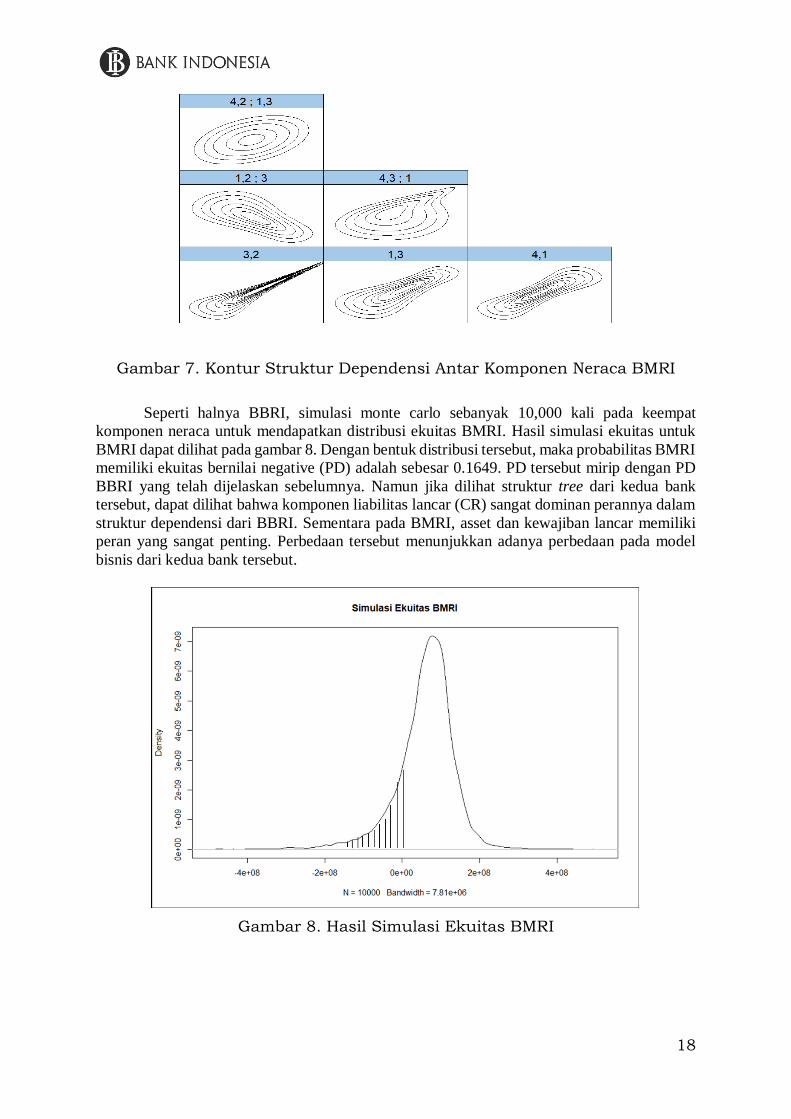
BMRI dapat dilihat pada gambar 8. Dengan bentuk distribusi tersebut, maka probabilitas BMRI
memiliki ekuitas bernilai negative (PD) adalah sebesar 0.1649. PD tersebut mirip dengan PD
BBRI yang telah dijelaskan sebelumnya. Namun jika dilihat struktur tree dari kedua bank
tersebut, dapat dilihat bahwa komponen liabilitas lancar (CR) sangat dominan perannya dalam
struktur dependensi dari BBRI. Sementara pada BMRI, asset dan kewajiban lancar memiliki
peran yang sangat penting. Perbedaan tersebut menunjukkan adanya perbedaan pada model
bisnis dari kedua bank tersebut.
Gambar 8. Hasil Simulasi Ekuitas BMRI
19
4.2. Validasi Estimasi PD
Salah satu isu terbesar dalam estimasi PD dengan menggunakan pendekatan copula
adalah validitas dari hasil estimasi PD. Jika PD yang diestimasi dengan copula gagal
menangkap even default, maka dapat dikatakan metode perhitungan PD dengan menggunakan
copula tidak valid atau harus disempurnakan lebih lanjut. Oleh karena itu, idealnya uji validasi
PD dengan copula dilakukan pada kasus bank gagal seperti yang dilakukan oleh Valle et al.,
(2016) ketika menggunakan copula dalam melakukan estimasi PD dari perusahaan Enron.
Namun, hal tersebut sulit dilakukan di Indonesia karena tidak ada bank yang gagal bayar pada
periode tahun 2000 – 2018. Oleh karena itu, kami melakukan estimasi PD untuk beberapa bank
di Amerika yang masuk dalam kelompok TARP (Trouble Asset Relief Program), yaitu Bank
of New York Mellon (BONY), JP Morgan Chase & Co (JPM), Morgan Stanley (MS), Goldman
Sachs (GS), dan Citigroup Inc (CITI). Estimasi PD untuk kelima bank Amerika tersebut
dilakukan secara rolling agar PD runtun waktu dari kelima bank tersebut dapat diperoleh dan
dilakukan event analysis untuk mengetahui apakah PD pada periode tertentu sesuai dengan
kondisi yang terjadi pada periode tersebut. Hasil estimasi PD untuk 5 bank Amerika yang
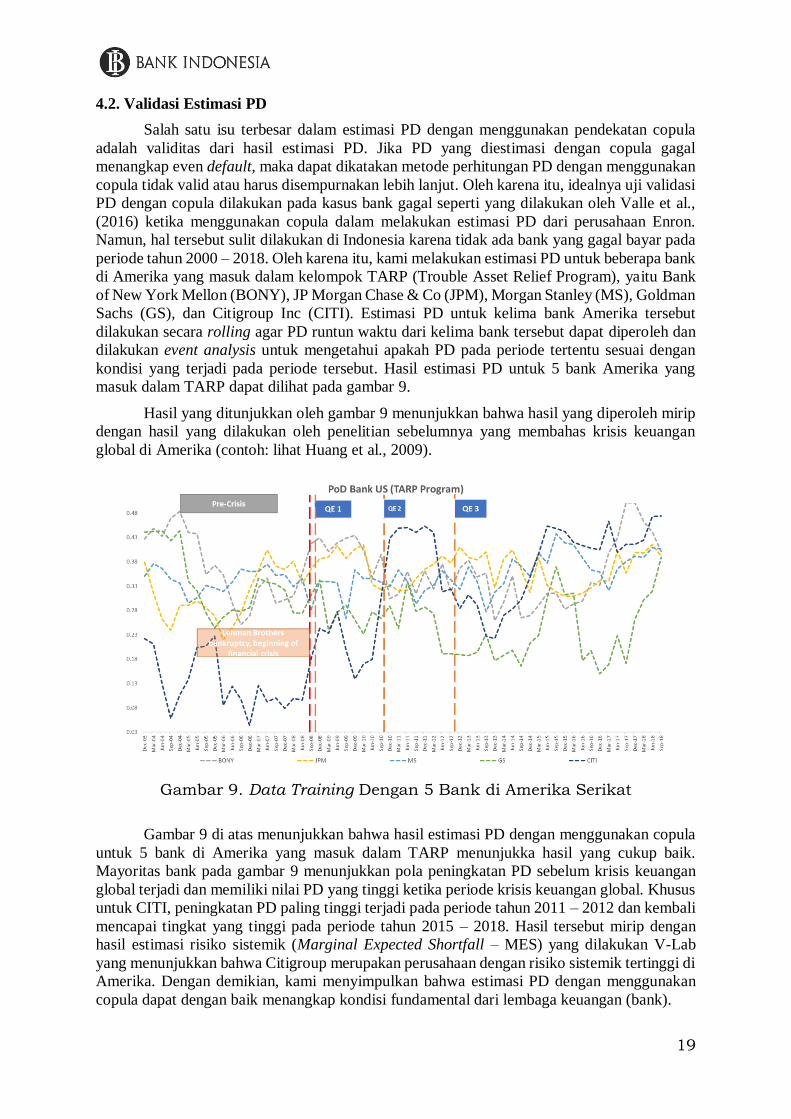
masuk dalam TARP dapat dilihat pada gambar 9.
Hasil yang ditunjukkan oleh gambar 9 menunjukkan bahwa hasil yang diperoleh mirip
dengan hasil yang dilakukan oleh penelitian sebelumnya yang membahas krisis keuangan
global di Amerika (contoh: lihat Huang et al., 2009).
Gambar 9. Data Training Dengan 5 Bank di Amerika Serikat
Gambar 9 di atas menunjukkan bahwa hasil estimasi PD dengan menggunakan copula
untuk 5 bank di Amerika yang masuk dalam TARP menunjukka hasil yang cukup baik.
Mayoritas bank pada gambar 9 menunjukkan pola peningkatan PD sebelum krisis keuangan
global terjadi dan memiliki nilai PD yang tinggi ketika periode krisis keuangan global. Khusus
untuk CITI, peningkatan PD paling tinggi terjadi pada periode tahun 2011 – 2012 dan kembali
mencapai tingkat yang tinggi pada periode tahun 2015 – 2018. Hasil tersebut mirip dengan
hasil estimasi risiko sistemik (Marginal Expected Shortfall – MES) yang dilakukan V-Lab
yang menunjukkan bahwa Citigroup merupakan perusahaan dengan risiko sistemik tertinggi di
Amerika. Dengan demikian, kami menyimpulkan bahwa estimasi PD dengan menggunakan
copula dapat dengan baik menangkap kondisi fundamental dari lembaga keuangan (bank).
20
4.3. Penyusunan Indeks PD per Kelompok Bank
Setelah estimasi PD untuk setiap bank dapat dilakukan, kami melakukan estimasi PD
secara dinamis untuk mendapatkan PD runtun waktu selama periode penelitian. Untuk
melakukan hal tersebut, kami melakukan estimasi PD secara rolling dengan rolling window 36
bulan (3 tahun). Setelah PD dinamis untuk setiap individu bank dapat diperoleh, kami
menyusun indeks PD berdasarkan kelompok bank, yaitu kelompok bank pemerintah, kelompok
BUSN, kelompok KCBA, dan kelompok bank BPD. Statistik deskriptif PD pada setiap
kelompok bank dapat dilihat pada tabel 8. Pada tabel tersebut, jika dilihat selama 10 tahun
terakhir (2008 – 2018), PD dari kelompok BPD paling tinggi dibandingkan dengan kelompok
bank lainnya. Sementara PD kelompok bank pemerintah paling rendah dibandingkan PD
kelompok bank lainnya.
Tabel 8. Statistik Deskriptif PD Per Kelompok Bank
Dari sisi variabilitas yang diukur dengan standar deviasi, statistik deskriptif PD pada
tabel 8 menunjukkan bahwa standar deviasi PD pada kelompok bank pemerintah paling rendah
dibanding ketiga kelompok bank lainnya. Hal tersebut menunjukkan bahwa kondisi antar bank
dalam kelompok bank pemerintah relatif homogen, berbeda dengan kelompok bank lainnya
yang memiliki kondisi PD yang lebih heterogen. Hal tersebut dapat disebabkan oleh
karakteristik dari individu bank yang ada di setiap kelompok. Bank pemerintah memiliki skala
bisnis yang relative sama. Sementara bank BUSN memiliki skala bisnis yang berbeda-beda.
Demikian halnya dengan kelompok KCBA dan BPD.
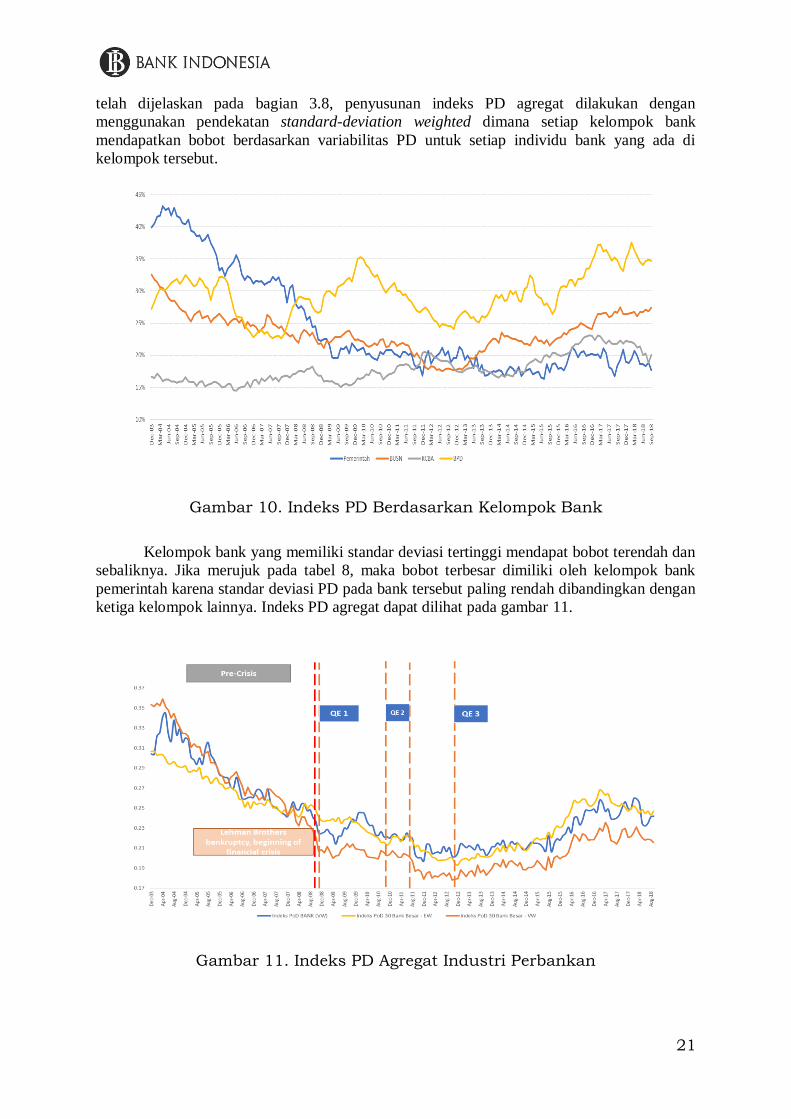
Gambar 10 menunjukkan Indeks PD untuk setiap kelompok bank dimana PD per
kelompok bank diestimasi dengan menggunakan pendekatan value weighted berdasarkan asset
bank. Dari gambar tersebut, terdapat beberapa temuan menarik. Sebelum periode krisis
keuangan global tahun 2007 – 2008, kelompok bank pemerintah memiliki indeks PD tertinggi
dibandingkan kelompok bank lainnya. Namun setelah krisis, kelompok bank BPD memiliki
indeks PD tertinggi dibandingkan dengan kelompok bank lainnya dan memiliki trend yang
cenderung meningkat. Selain itu, gap antara PD kelompok BPD dan kelompok bank lainnya
juga meningkat. Gambar 10 juga menunjukkan bahwa PD dari kelompok bank pemerintah
relatif stabil setelah tahun 2013.
4.4. Indeks PD Agregat
Langkah selanjutnya setelah melakukan estimasi indeks PD berdasarkan kelompok
bank adalah membentuk indeks PD untuk industri perbankan secara keseluruhan. Indeks
tersebut dapat menjadi indikator tingkat risiko yang ada di industry perbankan. Seperti yang
N Rerata St. Deviasi Min Max N Rerata St. Deviasi Min Max N Rerata St. Deviasi Min Max N Rerata St. Deviasi Min Max
2004 4 0.419 0.049 0.302 0.490 58 0.286 0.103 0.014 0.533 18 0.226 0.112 0.010 0.506 24 0.313 0.060 0.175 0.476
2005 4 0.386 0.061 0.250 0.492 58 0.283 0.107 0.014 0.558 18 0.226 0.115 0.021 0.490 24 0.319 0.062 0.211 0.470
2006 4 0.345 0.058 0.253 0.494 58 0.280 0.101 0.028 0.547 18 0.219 0.114 0.028 0.443 24 0.277 0.056 0.151 0.462
2007 4 0.301 0.048 0.203 0.388 58 0.286 0.104 0.058 0.567 18 0.221 0.111 0.011 0.443 24 0.245 0.045 0.149 0.376
2008 4 0.264 0.053 0.180 0.369 58 0.284 0.099 0.019 0.558 18 0.224 0.099 0.054 0.442 24 0.288 0.062 0.159 0.469
2009 4 0.231 0.053 0.144 0.318 58 0.279 0.100 0.012 0.460 18 0.198 0.079 0.031 0.398 24 0.323 0.066 0.162 0.525
2010 4 0.218 0.050 0.138 0.299 58 0.267 0.103 0.007 0.481 18 0.195 0.083 0.032 0.417 24 0.341 0.070 0.160 0.482
2011 4 0.203 0.040 0.137 0.292 58 0.255 0.096 0.025 0.489 18 0.210 0.093 0.034 0.383 24 0.300 0.078 0.138 0.500
2012 4 0.205 0.034 0.134 0.252 58 0.229 0.087 0.022 0.499 18 0.213 0.096 0.039 0.428 24 0.262 0.065 0.151 0.518
2013 4 0.199 0.053 0.116 0.287 58 0.225 0.091 0.010 0.554 18 0.188 0.077 0.030 0.422 24 0.265 0.051 0.161 0.406
2014 4 0.189 0.057 0.104 0.286 58 0.235 0.099 0.004 0.499 18 0.181 0.075 0.024 0.356 24 0.300 0.070 0.172 0.462
2015 4 0.191 0.046 0.099 0.268 58 0.236 0.093 0.032 0.494 18 0.192 0.071 0.051 0.387 24 0.304 0.075 0.132 0.500
2016 4 0.206 0.033 0.133 0.279 58 0.250 0.095 0.008 0.526 18 0.211 0.088 0.064 0.432 24 0.325 0.055 0.174 0.486
2017 4 0.203 0.039 0.141 0.283 58 0.269 0.088 0.010 0.502 18 0.219 0.089 0.030 0.410 24 0.356 0.066 0.212 0.536
2018 4 0.195 0.038 0.134 0.271 58 0.278 0.082 0.005 0.452 18 0.212 0.093 0.028 0.415 24 0.360 0.064 0.182 0.519
Pemerintah BUSN KCBA BPDTahun
21
telah dijelaskan pada bagian 3.8, penyusunan indeks PD agregat dilakukan dengan
menggunakan pendekatan standard-deviation weighted dimana setiap kelompok bank
mendapatkan bobot berdasarkan variabilitas PD untuk setiap individu bank yang ada di
kelompok tersebut.
Gambar 10. Indeks PD Berdasarkan Kelompok Bank
Kelompok bank yang memiliki standar deviasi tertinggi mendapat bobot terendah dan
sebaliknya. Jika merujuk pada tabel 8, maka bobot terbesar dimiliki oleh kelompok bank
pemerintah karena standar deviasi PD pada bank tersebut paling rendah dibandingkan dengan
ketiga kelompok lainnya. Indeks PD agregat dapat dilihat pada gambar 11.
Gambar 11. Indeks PD Agregat Industri Perbankan
22
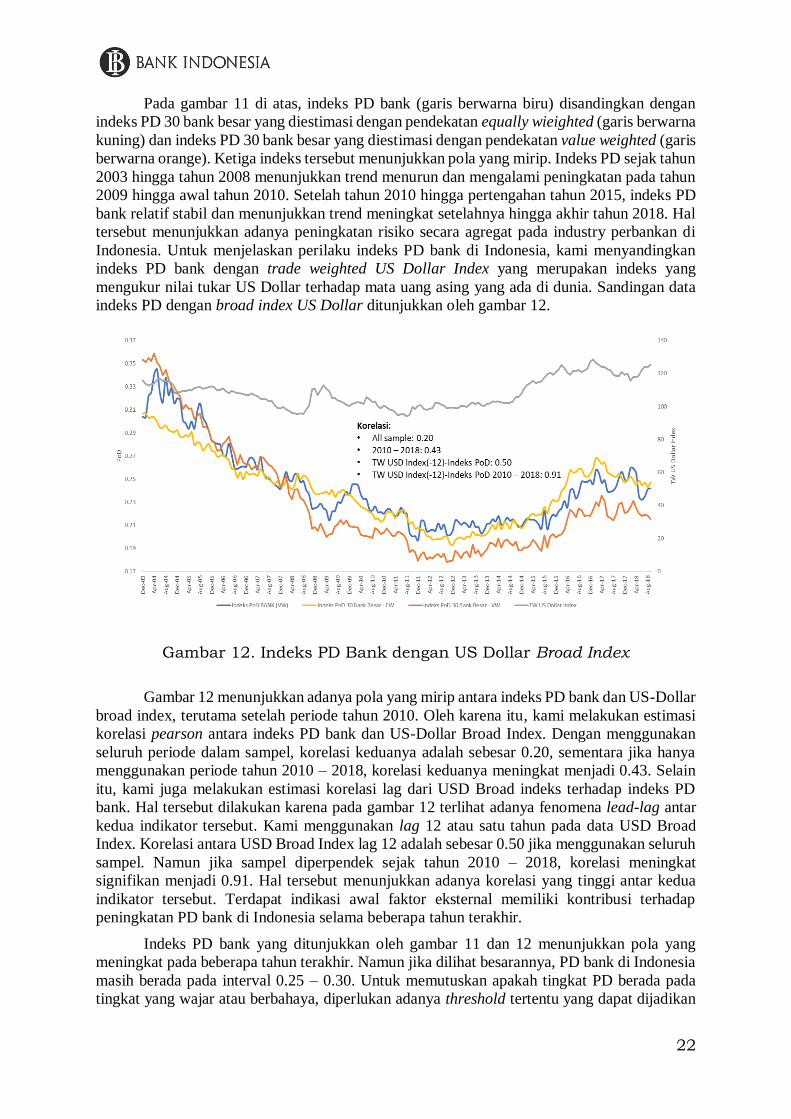
Pada gambar 11 di atas, indeks PD bank (garis berwarna biru) disandingkan dengan
indeks PD 30 bank besar yang diestimasi dengan pendekatan equally wieighted (garis berwarna
kuning) dan indeks PD 30 bank besar yang diestimasi dengan pendekatan value weighted (garis
berwarna orange). Ketiga indeks tersebut menunjukkan pola yang mirip. Indeks PD sejak tahun
2003 hingga tahun 2008 menunjukkan trend menurun dan mengalami peningkatan pada tahun
2009 hingga awal tahun 2010. Setelah tahun 2010 hingga pertengahan tahun 2015, indeks PD
bank relatif stabil dan menunjukkan trend meningkat setelahnya hingga akhir tahun 2018. Hal
tersebut menunjukkan adanya peningkatan risiko secara agregat pada industry perbankan di
Indonesia. Untuk menjelaskan perilaku indeks PD bank di Indonesia, kami menyandingkan
indeks PD bank dengan trade weighted US Dollar Index yang merupakan indeks yang
mengukur nilai tukar US Dollar terhadap mata uang asing yang ada di dunia. Sandingan data
indeks PD dengan broad index US Dollar ditunjukkan oleh gambar 12.
Gambar 12. Indeks PD Bank dengan US Dollar Broad Index
Gambar 12 menunjukkan adanya pola yang mirip antara indeks PD bank dan US-Dollar
broad index, terutama setelah periode tahun 2010. Oleh karena itu, kami melakukan estimasi
korelasi pearson antara indeks PD bank dan US-Dollar Broad Index. Dengan menggunakan
seluruh periode dalam sampel, korelasi keduanya adalah sebesar 0.20, sementara jika hanya
menggunakan periode tahun 2010 – 2018, korelasi keduanya meningkat menjadi 0.43. Selain
itu, kami juga melakukan estimasi korelasi lag dari USD Broad indeks terhadap indeks PD
bank. Hal tersebut dilakukan karena pada gambar 12 terlihat adanya fenomena lead-lag antar
kedua indikator tersebut. Kami menggunakan lag 12 atau satu tahun pada data USD Broad
Index. Korelasi antara USD Broad Index lag 12 adalah sebesar 0.50 jika menggunakan seluruh
sampel. Namun jika sampel diperpendek sejak tahun 2010 – 2018, korelasi meningkat
signifikan menjadi 0.91. Hal tersebut menunjukkan adanya korelasi yang tinggi antar kedua
indikator tersebut. Terdapat indikasi awal faktor eksternal memiliki kontribusi terhadap
peningkatan PD bank di Indonesia selama beberapa tahun terakhir.
Indeks PD bank yang ditunjukkan oleh gambar 11 dan 12 menunjukkan pola yang
meningkat pada beberapa tahun terakhir. Namun jika dilihat besarannya, PD bank di Indonesia
masih berada pada interval 0.25 – 0.30. Untuk memutuskan apakah tingkat PD berada pada
tingkat yang wajar atau berbahaya, diperlukan adanya threshold tertentu yang dapat dijadikan
23
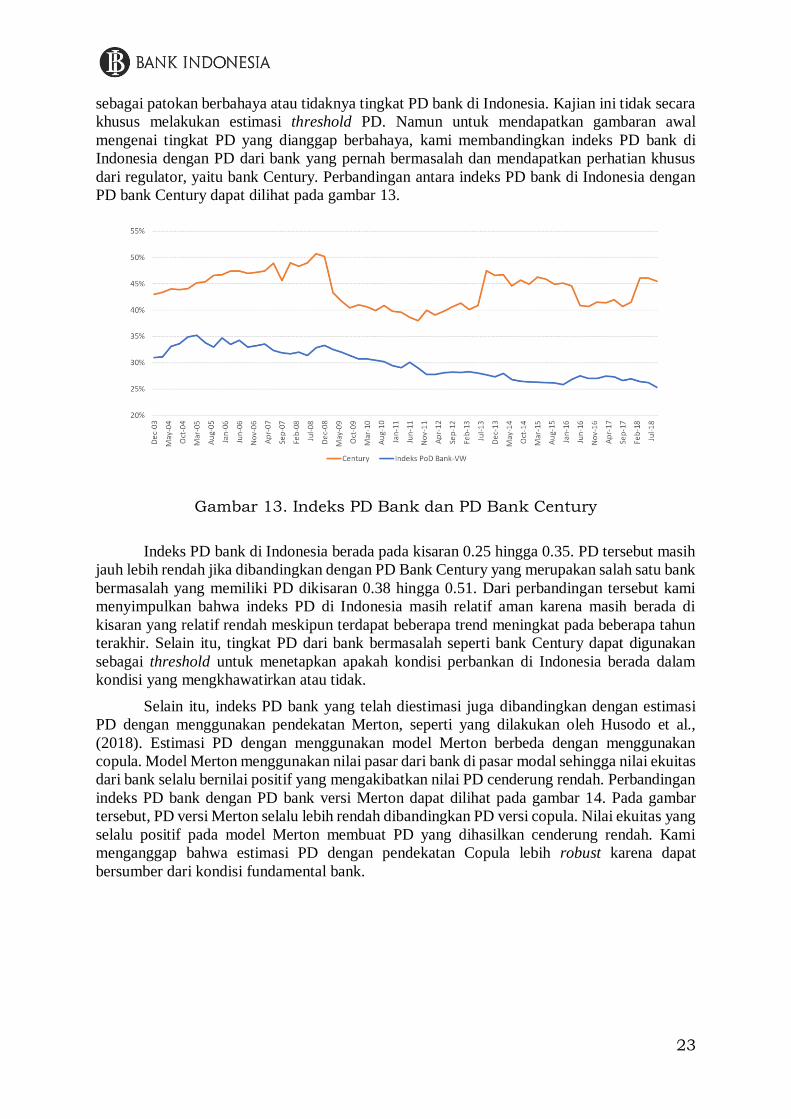
sebagai patokan berbahaya atau tidaknya tingkat PD bank di Indonesia. Kajian ini tidak secara
khusus melakukan estimasi threshold PD. Namun untuk mendapatkan gambaran awal
mengenai tingkat PD yang dianggap berbahaya, kami membandingkan indeks PD bank di
Indonesia dengan PD dari bank yang pernah bermasalah dan mendapatkan perhatian khusus
dari regulator, yaitu bank Century. Perbandingan antara indeks PD bank di Indonesia dengan
PD bank Century dapat dilihat pada gambar 13.
Gambar 13. Indeks PD Bank dan PD Bank Century
Indeks PD bank di Indonesia berada pada kisaran 0.25 hingga 0.35. PD tersebut masih
jauh lebih rendah jika dibandingkan dengan PD Bank Century yang merupakan salah satu bank
bermasalah yang memiliki PD dikisaran 0.38 hingga 0.51. Dari perbandingan tersebut kami
menyimpulkan bahwa indeks PD di Indonesia masih relatif aman karena masih berada di
kisaran yang relatif rendah meskipun terdapat beberapa trend meningkat pada beberapa tahun
terakhir. Selain itu, tingkat PD dari bank bermasalah seperti bank Century dapat digunakan
sebagai threshold untuk menetapkan apakah kondisi perbankan di Indonesia berada dalam
kondisi yang mengkhawatirkan atau tidak.
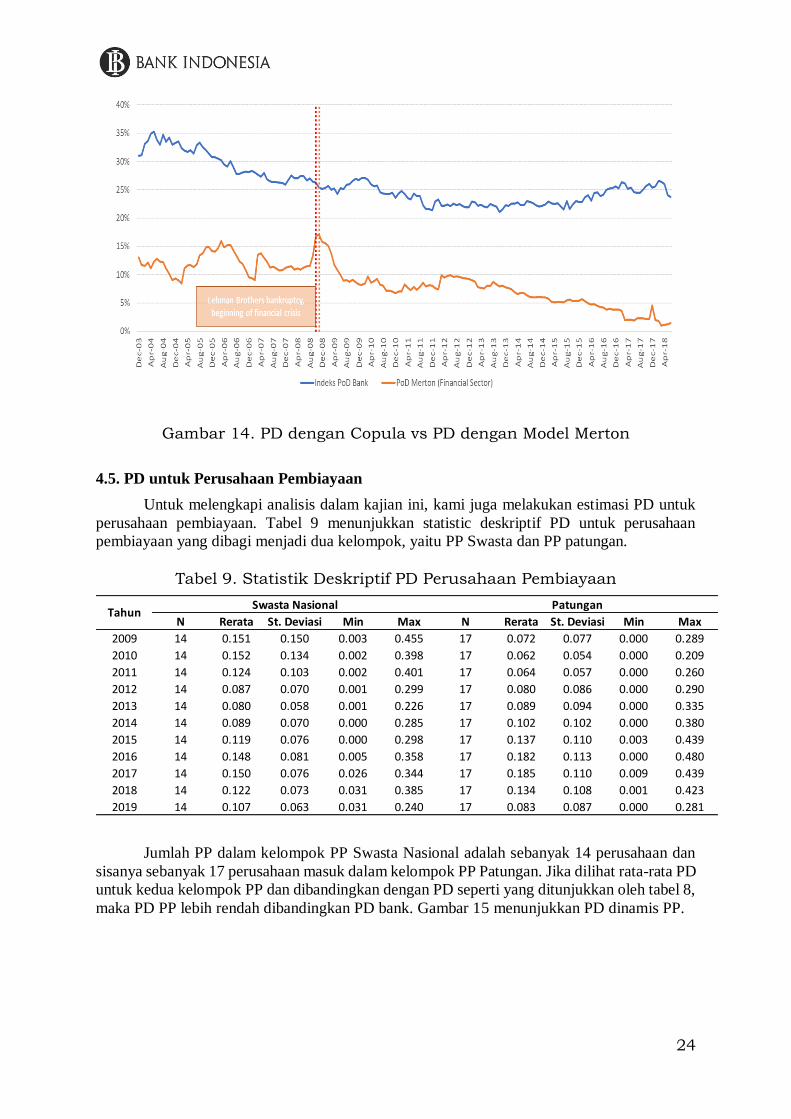
Selain itu, indeks PD bank yang telah diestimasi juga dibandingkan dengan estimasi
PD dengan menggunakan pendekatan Merton, seperti yang dilakukan oleh Husodo et al.,
(2018). Estimasi PD dengan menggunakan model Merton berbeda dengan menggunakan
copula. Model Merton menggunakan nilai pasar dari bank di pasar modal sehingga nilai ekuitas
dari bank selalu bernilai positif yang mengakibatkan nilai PD cenderung rendah. Perbandingan
indeks PD bank dengan PD bank versi Merton dapat dilihat pada gambar 14. Pada gambar
tersebut, PD versi Merton selalu lebih rendah dibandingkan PD versi copula. Nilai ekuitas yang
selalu positif pada model Merton membuat PD yang dihasilkan cenderung rendah. Kami
menganggap bahwa estimasi PD dengan pendekatan Copula lebih robust karena dapat
bersumber dari kondisi fundamental bank.
24
Gambar 14. PD dengan Copula vs PD dengan Model Merton
4.5. PD untuk Perusahaan Pembiayaan
Untuk melengkapi analisis dalam kajian ini, kami juga melakukan estimasi PD untuk
perusahaan pembiayaan. Tabel 9 menunjukkan statistic deskriptif PD untuk perusahaan
pembiayaan yang dibagi menjadi dua kelompok, yaitu PP Swasta dan PP patungan.
Tabel 9. Statistik Deskriptif PD Perusahaan Pembiayaan
Jumlah PP dalam kelompok PP Swasta Nasional adalah sebanyak 14 perusahaan dan
sisanya sebanyak 17 perusahaan masuk dalam kelompok PP Patungan. Jika dilihat rata-rata PD
untuk kedua kelompok PP dan dibandingkan dengan PD seperti yang ditunjukkan oleh tabel 8,
maka PD PP lebih rendah dibandingkan PD bank. Gambar 15 menunjukkan PD dinamis PP.
N Rerata St. Deviasi Min Max N Rerata St. Deviasi Min Max
2009 14 0.151 0.150 0.003 0.455 17 0.072 0.077 0.000 0.289
2010 14 0.152 0.134 0.002 0.398 17 0.062 0.054 0.000 0.209
2011 14 0.124 0.103 0.002 0.401 17 0.064 0.057 0.000 0.260
2012 14 0.087 0.070 0.001 0.299 17 0.080 0.086 0.000 0.290
2013 14 0.080 0.058 0.001 0.226 17 0.089 0.094 0.000 0.335
2014 14 0.089 0.070 0.000 0.285 17 0.102 0.102 0.000 0.380
2015 14 0.119 0.076 0.000 0.298 17 0.137 0.110 0.003 0.439
2016 14 0.148 0.081 0.005 0.358 17 0.182 0.113 0.000 0.480
2017 14 0.150 0.076 0.026 0.344 17 0.185 0.110 0.009 0.439
2018 14 0.122 0.073 0.031 0.385 17 0.134 0.108 0.001 0.423
2019 14 0.107 0.063 0.031 0.240 17 0.083 0.087 0.000 0.281
Swasta Nasional PatunganTahun
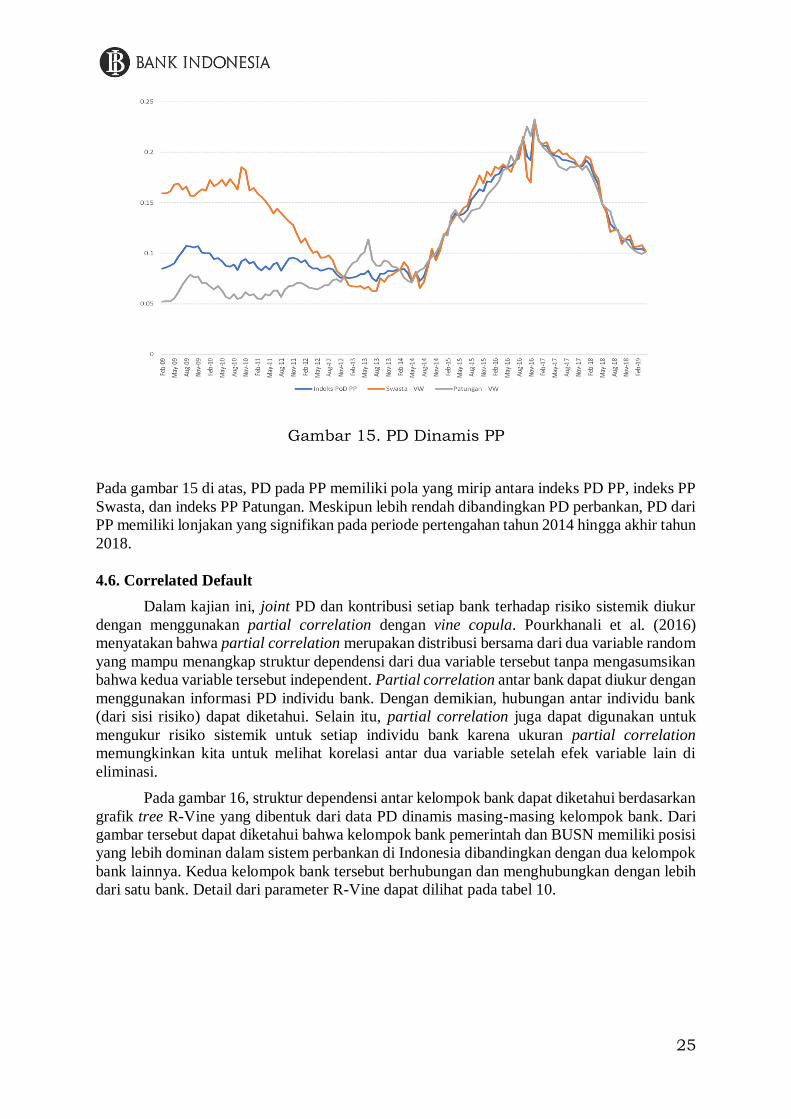
25
Gambar 15. PD Dinamis PP
Pada gambar 15 di atas, PD pada PP memiliki pola yang mirip antara indeks PD PP, indeks PP
Swasta, dan indeks PP Patungan. Meskipun lebih rendah dibandingkan PD perbankan, PD dari
PP memiliki lonjakan yang signifikan pada periode pertengahan tahun 2014 hingga akhir tahun
2018.
4.6. Correlated Default
Dalam kajian ini, joint PD dan kontribusi setiap bank terhadap risiko sistemik diukur
dengan menggunakan partial correlation dengan vine copula. Pourkhanali et al. (2016)
menyatakan bahwa partial correlation merupakan distribusi bersama dari dua variable random
yang mampu menangkap struktur dependensi dari dua variable tersebut tanpa mengasumsikan
bahwa kedua variable tersebut independent. Partial correlation antar bank dapat diukur dengan
menggunakan informasi PD individu bank. Dengan demikian, hubungan antar individu bank
(dari sisi risiko) dapat diketahui. Selain itu, partial correlation juga dapat digunakan untuk
mengukur risiko sistemik untuk setiap individu bank karena ukuran partial correlation
memungkinkan kita untuk melihat korelasi antar dua variable setelah efek variable lain di
eliminasi.
Pada gambar 16, struktur dependensi antar kelompok bank dapat diketahui berdasarkan
grafik tree R-Vine yang dibentuk dari data PD dinamis masing-masing kelompok bank. Dari
gambar tersebut dapat diketahui bahwa kelompok bank pemerintah dan BUSN memiliki posisi
yang lebih dominan dalam sistem perbankan di Indonesia dibandingkan dengan dua kelompok
bank lainnya. Kedua kelompok bank tersebut berhubungan dan menghubungkan dengan lebih
dari satu bank. Detail dari parameter R-Vine dapat dilihat pada tabel 10.

26
Gambar 16. Struktur Tree R-Vine Dari Kelompok Bank.
Keterangan: 1 adalah bank pemerintah, 2 adalah BUSN, 3 adalah KCBA, dan 4 adalah BPD
Tabel 10. Parameter R-Vine Pada Kelompok Antar Bank
Karena yang ingin diukur secara langsung adalah partial correlation, maka proses PCC
saja tidak cukup untuk mengetahui korelasi antar bank. Oleh karena itu, kami melengkapi
analisis dengan menggunakan ukuran korelasi dan kemudian melakukan partial correlation
dengan melakukan conditioning setiap kelompok bank yang ada. Matriks korelasi antar bank
dapat dilihat pada tabel 11.
Tabel 11. Matriks Korelasi Antar Kelompok Bank
Pada tabel 11, pemerintah dan BUSN memiliki korelasi yang relative tinggi, yaitu
sebesar 0.4955. Sementara kelompok bank pemerintah dan KCBA juga memiliki korelasi yang
tinggi namun memiliki arah berkebalikan, yaitu sebesar -0.555. Untuk mengetahui lanjut
kelompok bank manakah yang memiliki pengaruh paling dominan dalam sistem perbankan,
tabel 12 menunjukkan partial correlation dengan melakukan conditioning pada setiap
kelompok bank.
No tree edge family cop par par2 tau utd ltd
1 1 4,2 1 N 0.426908 0 0.280794 0 0
2 1 2,1 1 N 0.495494 0 0.330026 0 0
3 1 1,3 1 N -0.55549 0 -0.37494 0 0
4 2 4,1;2 1 N -0.34627 0 -0.22511 0 0
5 2 2,3;1 1 N 0.168336 0 0.107679 0 0
6 3 4,3;2,1 1 N 0.319249 0 0.206861 0 0
pemerintah busn kbca bpd
pemerintah 1.0000 0.4955 -0.5555 -0.0605
busn 0.4955 1.0000 -0.1537 0.4269
kbca -0.5555 -0.1537 1.0000 0.3292
bpd -0.0605 0.4269 0.3292 1.0000
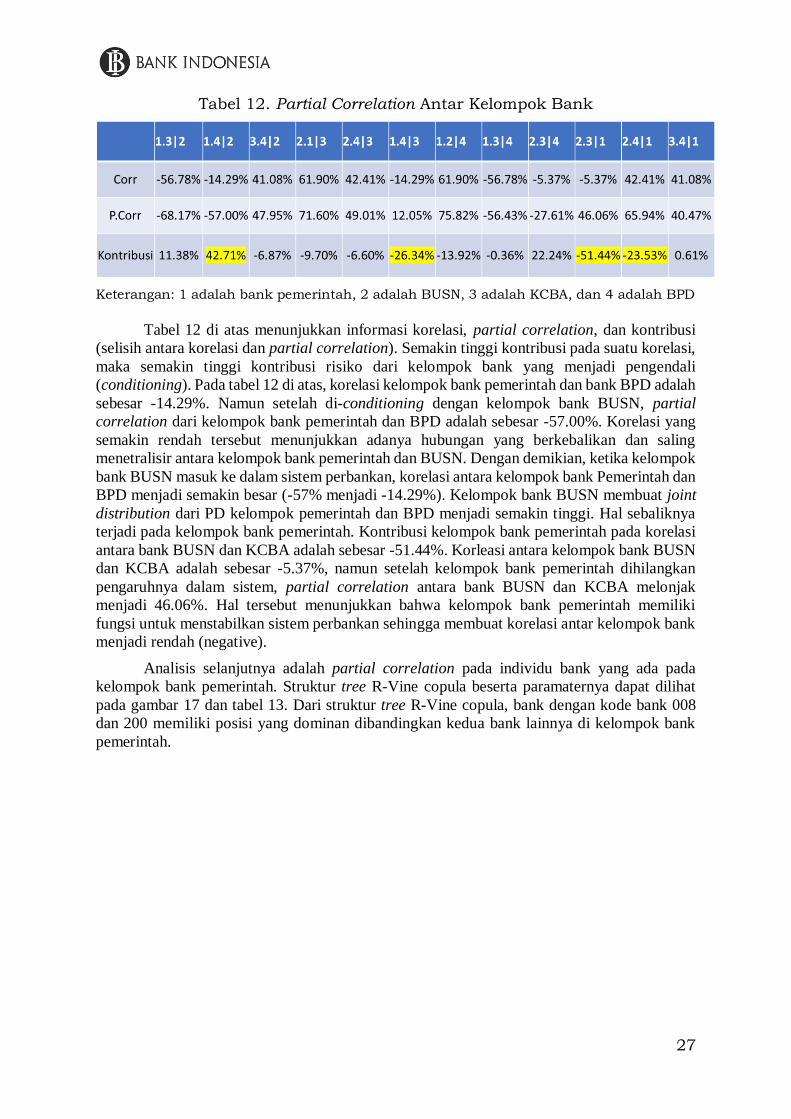
27
Tabel 12. Partial Correlation Antar Kelompok Bank
Keterangan: 1 adalah bank pemerintah, 2 adalah BUSN, 3 adalah KCBA, dan 4 adalah BPD
Tabel 12 di atas menunjukkan informasi korelasi, partial correlation, dan kontribusi
(selisih antara korelasi dan partial correlation). Semakin tinggi kontribusi pada suatu korelasi,
maka semakin tinggi kontribusi risiko dari kelompok bank yang menjadi pengendali
(conditioning). Pada tabel 12 di atas, korelasi kelompok bank pemerintah dan bank BPD adalah
sebesar -14.29%. Namun setelah di-conditioning dengan kelompok bank BUSN, partial
correlation dari kelompok bank pemerintah dan BPD adalah sebesar -57.00%. Korelasi yang
semakin rendah tersebut menunjukkan adanya hubungan yang berkebalikan dan saling
menetralisir antara kelompok bank pemerintah dan BUSN. Dengan demikian, ketika kelompok
bank BUSN masuk ke dalam sistem perbankan, korelasi antara kelompok bank Pemerintah dan
BPD menjadi semakin besar (-57% menjadi -14.29%). Kelompok bank BUSN membuat joint
distribution dari PD kelompok pemerintah dan BPD menjadi semakin tinggi. Hal sebaliknya
terjadi pada kelompok bank pemerintah. Kontribusi kelompok bank pemerintah pada korelasi
antara bank BUSN dan KCBA adalah sebesar -51.44%. Korleasi antara kelompok bank BUSN
dan KCBA adalah sebesar -5.37%, namun setelah kelompok bank pemerintah dihilangkan
pengaruhnya dalam sistem, partial correlation antara bank BUSN dan KCBA melonjak
menjadi 46.06%. Hal tersebut menunjukkan bahwa kelompok bank pemerintah memiliki
fungsi untuk menstabilkan sistem perbankan sehingga membuat korelasi antar kelompok bank
menjadi rendah (negative).
Analisis selanjutnya adalah partial correlation pada individu bank yang ada pada
kelompok bank pemerintah. Struktur tree R-Vine copula beserta paramaternya dapat dilihat
pada gambar 17 dan tabel 13. Dari struktur tree R-Vine copula, bank dengan kode bank 008
dan 200 memiliki posisi yang dominan dibandingkan kedua bank lainnya di kelompok bank
pemerintah.
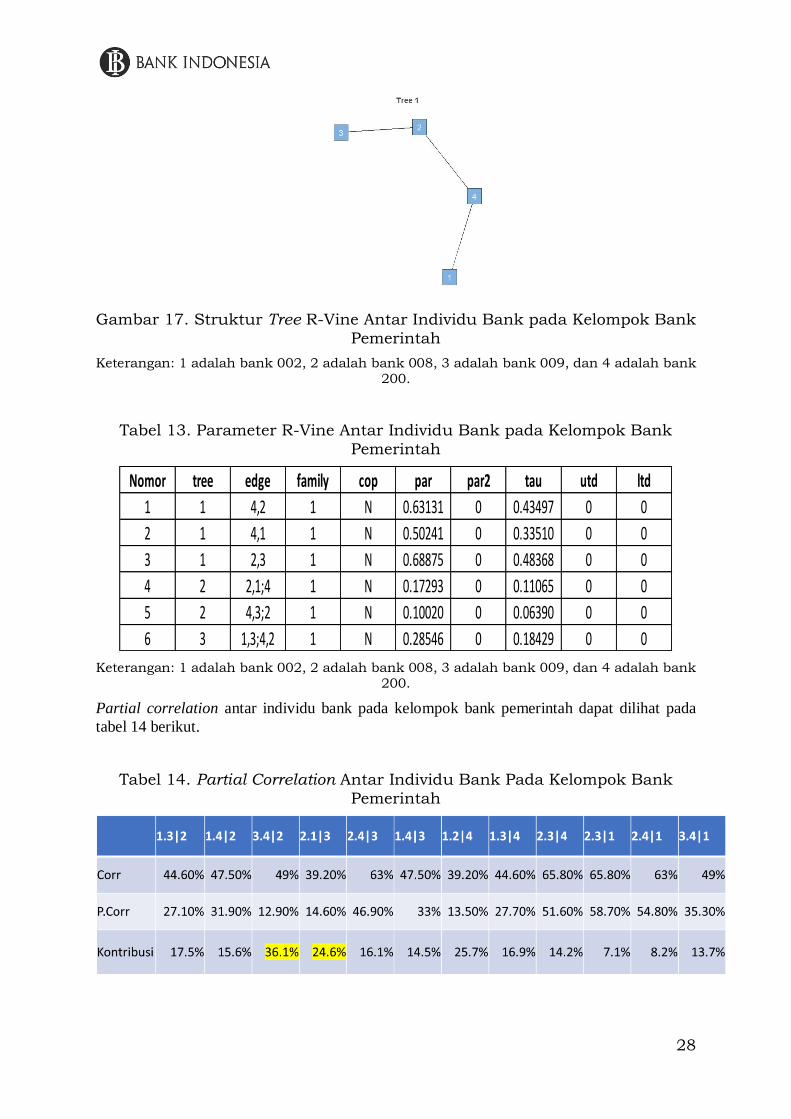
28
Gambar 17. Struktur Tree R-Vine Antar Individu Bank pada Kelompok Bank
Pemerintah
Keterangan: 1 adalah bank 002, 2 adalah bank 008, 3 adalah bank 009, dan 4 adalah bank 200.
Tabel 13. Parameter R-Vine Antar Individu Bank pada Kelompok Bank
Pemerintah
Keterangan: 1 adalah bank 002, 2 adalah bank 008, 3 adalah bank 009, dan 4 adalah bank 200.
Partial correlation antar individu bank pada kelompok bank pemerintah dapat dilihat pada
tabel 14 berikut.
Tabel 14. Partial Correlation Antar Individu Bank Pada Kelompok Bank
Pemerintah
Nomor tree edge family cop par par2 tau utd ltd
1 1 4,2 1 N 0.63131 0 0.43497 0 0
2 1 4,1 1 N 0.50241 0 0.33510 0 0
3 1 2,3 1 N 0.68875 0 0.48368 0 0
4 2 2,1;4 1 N 0.17293 0 0.11065 0 0
5 2 4,3;2 1 N 0.10020 0 0.06390 0 0
6 3 1,3;4,2 1 N 0.28546 0 0.18429 0 0
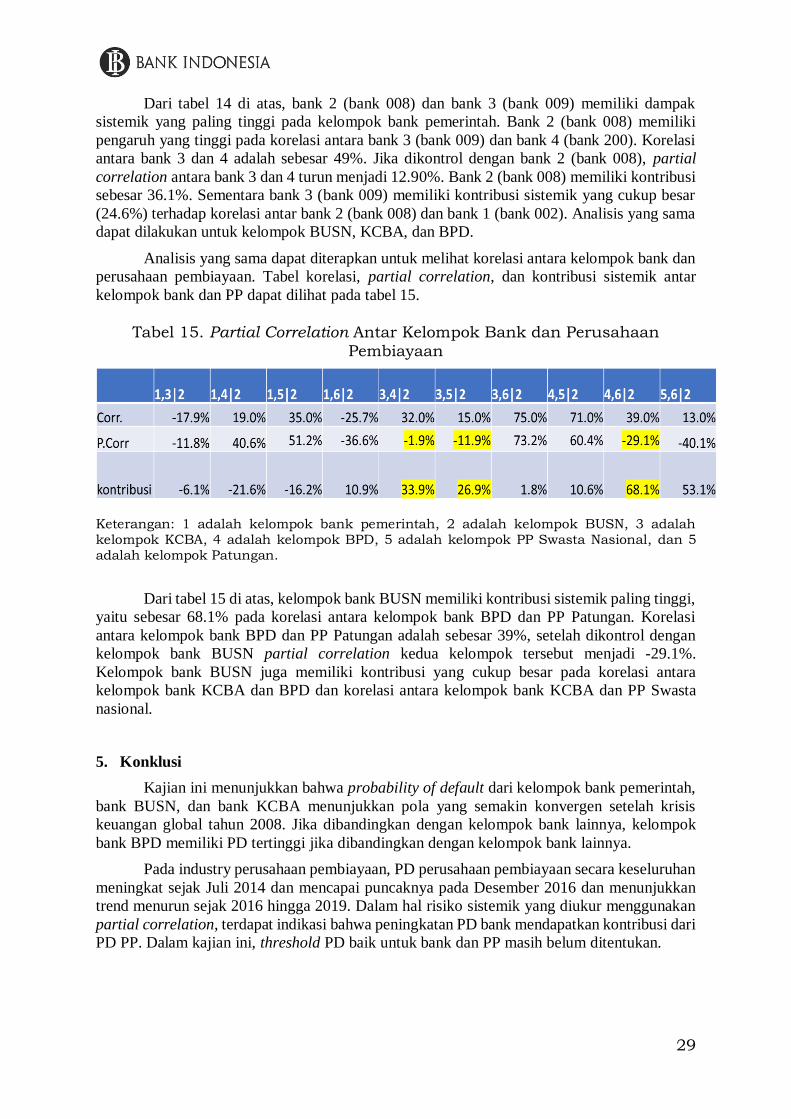
29
Dari tabel 14 di atas, bank 2 (bank 008) dan bank 3 (bank 009) memiliki dampak
sistemik yang paling tinggi pada kelompok bank pemerintah. Bank 2 (bank 008) memiliki
pengaruh yang tinggi pada korelasi antara bank 3 (bank 009) dan bank 4 (bank 200). Korelasi
antara bank 3 dan 4 adalah sebesar 49%. Jika dikontrol dengan bank 2 (bank 008), partial
correlation antara bank 3 dan 4 turun menjadi 12.90%. Bank 2 (bank 008) memiliki kontribusi
sebesar 36.1%. Sementara bank 3 (bank 009) memiliki kontribusi sistemik yang cukup besar
(24.6%) terhadap korelasi antar bank 2 (bank 008) dan bank 1 (bank 002). Analisis yang sama
dapat dilakukan untuk kelompok BUSN, KCBA, dan BPD.
Analisis yang sama dapat diterapkan untuk melihat korelasi antara kelompok bank dan
perusahaan pembiayaan. Tabel korelasi, partial correlation, dan kontribusi sistemik antar
kelompok bank dan PP dapat dilihat pada tabel 15.
Tabel 15. Partial Correlation Antar Kelompok Bank dan Perusahaan
Pembiayaan
Keterangan: 1 adalah kelompok bank pemerintah, 2 adalah kelompok BUSN, 3 adalah kelompok KCBA, 4 adalah kelompok BPD, 5 adalah kelompok PP Swasta Nasional, dan 5 adalah kelompok Patungan.
Dari tabel 15 di atas, kelompok bank BUSN memiliki kontribusi sistemik paling tinggi,
yaitu sebesar 68.1% pada korelasi antara kelompok bank BPD dan PP Patungan. Korelasi
antara kelompok bank BPD dan PP Patungan adalah sebesar 39%, setelah dikontrol dengan
kelompok bank BUSN partial correlation kedua kelompok tersebut menjadi -29.1%.
Kelompok bank BUSN juga memiliki kontribusi yang cukup besar pada korelasi antara
kelompok bank KCBA dan BPD dan korelasi antara kelompok bank KCBA dan PP Swasta
nasional.
5. Konklusi
Kajian ini menunjukkan bahwa probability of default dari kelompok bank pemerintah,
bank BUSN, dan bank KCBA menunjukkan pola yang semakin konvergen setelah krisis
keuangan global tahun 2008. Jika dibandingkan dengan kelompok bank lainnya, kelompok
bank BPD memiliki PD tertinggi jika dibandingkan dengan kelompok bank lainnya.
Pada industry perusahaan pembiayaan, PD perusahaan pembiayaan secara keseluruhan
meningkat sejak Juli 2014 dan mencapai puncaknya pada Desember 2016 dan menunjukkan
trend menurun sejak 2016 hingga 2019. Dalam hal risiko sistemik yang diukur menggunakan
partial correlation, terdapat indikasi bahwa peningkatan PD bank mendapatkan kontribusi dari
PD PP. Dalam kajian ini, threshold PD baik untuk bank dan PP masih belum ditentukan.

30
Referensi
Aas, K., Czado, C., Frigessi, A., and Bakken, H. (2009). Pair-copula constructions of multiple
dependence. Insurance: Mathematics and Economics, 44(2):182–198.
Acharya, V., Engle, R., and Pierret, D. (2014). Testing macroprudential stress tests: The risk
of regulatory risk weights. Journal of Monetary Economics, 65:36–53.
Altman, E. I. (1968). Financial ratios, discriminant analysis and the prediction of corporate
bankruptcy. The Journal of Finance, 23(4):589–609.
Beaver, W. H. (1968). Market prices, financial ratios, and the prediction of failure. Journal of
Accounting Research, 6(2):179–192.
Bedford, T. and Cooke, R. M. (2001). Probability density decomposition for conditionally
dependent random variables modeled by vines. Annals of Mathematics and Artificial
Intelligence, 32(1):245–268.
Bedford, T. and Cooke, R. M. (2002). Vines-a new graphical model for dependent random
variables. The Annals of Statistics, 30(4):1031–1068.
Bernanke, B. and Gertler, M. (1989). Agency costs, net worth, and business fluctuations. The
American Economic Review, 79(1):14–31.
Brechmann, E. C., Hendrich, K., and Czado, C. (2013). Conditional copula simulation for
systemic risk stress testing. Insurance: Mathematics and Economics, 53(3):722–732.
Brunnermeier, M. K. and Sannikov, Y. (2014). A macroeconomic model with a financial
sector. American Economic Review, 104(2):379–421.
Claessens, S. and Kose, M. A. (2018). Frontiers of Macrofinancial Linkages. BIS Paper
Number 95. Bank for International Settlements.
Cooke, R. M. (1997). Markov and entropy properties of tree- and vine-dependent variables. In
Proceedings of the Section on Bayesian Statistical Science. American Statistical
Association.
Dalla Valle, L., De Giuli, M. E., Tarantola, C., and Manelli, C. (2016). Default probability
estimation via pair copula constructions. European Journal of Operational Research,
249(1):298–311.
Dißmann, J., Brechmann, E., Czado, C., and Kurowicka, D. (2013). Selecting and estimating
regular vine copulae and application to financial returns. Computational Statistics &
Data Analysis, 59:52–69.
Huang, X., Zhou, H., and Zhu, H. (2009). A framework for assessing the systemic risk of major
financial institutions. Journal of Banking & Finance, 33(11):2036– 2049.
Joe, H. (1993). Parametric families of multivariate distributions with given margins. Journal
of Multivariate Analysis, 46(2):262–282.
Joe, H. (1994). Multivariate extreme-value distributions with applications to environmental
data. The Canadian Journal of Statistics / La Revue Canadienne de Statistique,
22(1):47–64.
Joe, H. (1996). Families of m-variate distributions with given margins and m(m-1)/2 bivariate
dependence parameters. Institute of Mathematical Statistics Lecture Notes-Monograph
Series, 28:120–141.

31
Kiyotaki, N. and Moore, J. (1997). Credit cycles. Journal of Political Economy, 105(2):211–
248.
Kurowicka, D. and Cooke, R. (2006). Uncertainty Analysis with High Dimensional
Dependence Modelling. John Wiley & Sons, Ltd, West Sussex.
Kurowicka, D. and Joe, H. (2010). Dependence Modeling: Vine Copula Handbook. World
Scientific Publishing Co Pte Ltd, Singapore.
Merton, R. C. (1974). On the pricing of corporate debt: The risk structure of interest rates. The
Journal of Finance, 29(2):449–470.
Morales-Nápoles, O. (2010). Counting vines. In Kurowicka, D. and Joe, H., editors,
Dependence Modeling: Vine Copula Handbook, pages 189–218. World Scientific
Publishing Co Pte Ltd, Singapore.
Ohlson, J. A. (1980). Financial ratios and the probabilistic prediction of bankruptcy. Journal
of Accounting Research, 18(1):109–131.
Patton, A. J. (2006). Modelling asymmetric exchange rate dependence. International Economic
Review, 47(2):527–556.
Pourkhanali, A., Kim, J.-M., Tafakori, L., and Fard, F. A. (2016). Measuring systemic risk
using vine-copula. Economic Modelling, 53:63–74.
Rosenberg, J. V. and Schuermann, T. (2006). A general approach to integrated risk
management with skewed, fat-tailed risks. Journal of Financial Economics, 79(3):569–
614.
Sklar, A. (1959). Fonctions de r´ epartition à n dimensions et leurs marges. Publications de
l’Institut Statistique de l’Universit´ e de Paris, 8:229–231.
Zhang, D. (2014). Vine copulas and applications to the European Union sovereign debt
analysis. International Review of Financial Analysis, 36:46–56.




















![CIVIL CASES] [DEFAULT / OTHER MATTERS] - Supreme](https://img.dokumen.tips/doc/110x75/63199bb91e5d335f8d0b3a5a/civil-cases-default-other-matters-supreme-.jpg)








