Embed Size (px)
Citation preview

Övervakningssystem för tåg
Insamling och presentation av data via ett grafiskt gränssnitt
Monitoring system for trains
Gathering and presentation of data via a graphical interface
Karl Hansson
Ivan Toma
Fakulteten för hälsa, natur- och teknikvetenskap
Datavetenskap
C-uppsats 15 hp
Handledare: Lothar Fritsch
Examinerande lärare: Johan Eklund
Datum: 2019-01-16


iii
Sammanfattning
I dagsläget finns en del problem vid beslutsprocesser som trafikledningen inom tågtrafiken
dagligen får handskas med. Dessa beslutsprocesser kan effektiviseras genom ett förbättrat stöd
och underlag och tanken med projektet var att skapa detta stöd.
Detta projekt har resulterat i ett enkelt system som samlar in och presenterar data över tåg i ett
grafiskt gränssnitt i form av en karta. Systemet är utvecklat för att enkelt kunna få fler
funktioner applicerade i framtiden och var från början tänkt att bestå av högre utbud funktioner
än vad det har i dagsläget. Projektet har tagit form med hjälp av tågbolaget SJ med information
om de hinder de stöter på, och riktlinjer satta från vår handledare under projektet.
Vi kommer i denna rapporten att beskriva mer detaljerat hur projektet tagit form, vilka problem
vi fått handskas med och hur systemet är utvecklat.

iv

v
Abstract
Currently there exists several problems with the decision-making processes that the traffic
management within train traffic daily must put up with. The decision processes can be made
more efficient by having a good support and structure, and the goal of this project was to create
this support.
This project has resulted in a simple system that collects and presents train data on a graphical
interface in the form of a map. The system is designed to be expandable with new features and
functionalities with relative ease and was initially supposed to include some of these extra
features. The project has taken shape with help from the train company SJ with information
about problems they’ve encountered, and guidelines set by our supervisor during the project
In this report we will describe how the project has taken shape, what problems we have dealt
with and how the system is developed.

vi

vii
Tack
Vi vill tacka alla inblandade på Softcode som bidragit med stöd, expertis och även en mycket
trevlig arbetsplats. Vi vill även tacka Anders Åslund som genom Softcode har bidragit med
råd på vägen. Ett tack vill vi även ge till Christoffer Andersson som tog emot oss på SJ och
visade oss runt.
Vi vill även tacka vår handledare Lothar Fritsch för rådgivning, och Katarina Asplund för
tiden hon tog för att bidra med extra stöd.

viii

ix
Innehållsförteckning
1 Inledning ............................................................................................................................ 1
1.1 Syfte ........................................................................................................................... 1
1.2 Mål ............................................................................................................................. 2
1.3 Uppdragsbeskrivning ................................................................................................. 2
1.4 Disposition ................................................................................................................. 4 Kapitel 2 – Bakgrund ............................................................................................................... 4 Kapitel 3 – Projektdesign ......................................................................................................... 4 Kapitel 4 – Implementation ...................................................................................................... 4 Kapitel 5 – Utvärdering ............................................................................................................ 4 Kapitel 6 – Slutsats .................................................................................................................. 4
2 Bakgrund ........................................................................................................................... 5
2.1 Språk .......................................................................................................................... 5 SQL .......................................................................................................................................... 5 C ............................................................................................................................................. 5 C++ .......................................................................................................................................... 5 Java .......................................................................................................................................... 6 C# ............................................................................................................................................. 6 PHP .......................................................................................................................................... 6 HTML ...................................................................................................................................... 7 JavaScript ................................................................................................................................. 7
2.2 Verktyg ...................................................................................................................... 8 Microsoft Azure ....................................................................................................................... 8 Apache Kafka ........................................................................................................................... 8 Kubernetes ............................................................................................................................... 9 Docker .................................................................................................................................... 10 Git .......................................................................................................................................... 10 MySQL Workbench ............................................................................................................... 11 Open Street Map .................................................................................................................... 11 Mapbox .................................................................................................................................. 11 Leaflet .................................................................................................................................... 11 Google Maps .......................................................................................................................... 12 Pubnub ................................................................................................................................... 12 XAMPP .................................................................................................................................. 13 NMEA GPRMC ..................................................................................................................... 13 AJAX ..................................................................................................................................... 14 JSON ...................................................................................................................................... 15
2.3 Reguljära uttryck ..................................................................................................... 17
2.4 Existerande lösningar ............................................................................................... 17 Utplacerade avläsningspunkter .............................................................................................. 18 Kommunikation via ombord personalens mobiler ................................................................. 19 GPS-enheter på tåg ................................................................................................................. 19
3 Projektdesign ................................................................................................................... 20
3.1 Projektets grundidé .................................................................................................. 20
3.2 Planering .................................................................................................................. 20 Möten med olika trafikledningar ............................................................................................ 20 Möten med handledare ........................................................................................................... 21

x
Vägledning på Softcode ......................................................................................................... 22
3.3 Motivering och mål kring projektändringarna ......................................................... 22
3.4 Användarfall ............................................................................................................ 23
3.5 Generell design ........................................................................................................ 23 Databas ................................................................................................................................... 24 Dataomvandlare ..................................................................................................................... 25 Grafiskt gränssnitt .................................................................................................................. 25
3.6 Val av språk ............................................................................................................. 25
3.7 Testning och validering av verktyg ......................................................................... 25
3.8 Design av databasen ................................................................................................ 26
3.9 Design av dataomvandlarna ..................................................................................... 27
3.10 Design av det grafiska gränssnittet .......................................................................... 28
4 Implementation ............................................................................................................... 29
4.1 Introduktion ............................................................................................................. 29 Mjukvara och programspråk som använts under implementationen ...................................... 29
4.2 Lokalisering av tågstationer och mötespunkter på järnvägen .................................. 30 Inhämtning av data och felhantering ...................................................................................... 30 Formatering av inhämtade data .............................................................................................. 32 Stationstabellens SQL-struktur och inmatning av data .......................................................... 33
4.3 Lokalisering av aktiva och inaktiva fordon ............................................................. 33 Inhämtning av data och felhantering ...................................................................................... 33 Formatering av inhämtade data .............................................................................................. 35 Tågtabellens SQL-struktur och inmatning av data ................................................................. 37
4.4 Databas och versionshantering ................................................................................ 38 Utvecklingsmiljö .................................................................................................................... 38 Produktionsmiljö .................................................................................................................... 38
4.5 Visualisering av data ................................................................................................ 39
5 Utvärdering ...................................................................................................................... 43
5.1 Resultat .................................................................................................................... 43
5.2 Problem .................................................................................................................... 44 GDPR-skyddade data och tillgång till API:er ........................................................................ 44 API:er som inte ville fungera ................................................................................................. 45
6 Slutsats ............................................................................................................................. 48
6.1 Helhetsbild av projektet ........................................................................................... 48
6.2 Vidareutveckling av systemet .................................................................................. 48
Referenser ............................................................................................................................... 50
Informationskällor ............................................................................................................. 50
Bildkällor ........................................................................................................................... 53
A Bilagor .............................................................................................................................. 54
A.1 Stationsdataomvandlaren ......................................................................................... 54

xi
A.2 Tågdataomvandlaren ................................................................................................ 59
A.3 Webbgränsnittet ....................................................................................................... 65 A.3.1 Index ...................................................................................................................................... 65 A.3.2 Trains ..................................................................................................................................... 72 A.3.3 Stations ................................................................................................................................... 73

xii
Figurförteckning
Figur 1.1 Översikt av projektet ........................................................................................... 3
Figur 2.1 SQL-exempel ....................................................................................................... 5
Figur 2.2 Exempel på PHP och HTML ............................................................................... 7
Figur 2.3 JSON-objekt ...................................................................................................... 15
Figur 2.4 JSON-array ........................................................................................................ 16
Figur 2.5 JSON-värde ....................................................................................................... 16
Figur 2.6 JSON-sträng ...................................................................................................... 16
Figur 2.7 JSON-nummer ................................................................................................... 17
Figur 2.8 RFID-tekniken ................................................................................................... 18
Figur 3.1 Visualisering av systemet .................................................................................. 22
Figur 3.2 Generell design av systemet .............................................................................. 24
Figur 3.3 Databasens tabeller ............................................................................................ 27
Figur 3.4 Första gränssnittsdesignen ................................................................................. 28
Figur 4.1 Frågan som skickas till Trafikverkets API ........................................................ 31
Figur 4.2 Utdrag ur svaret Trafikverkets API ................................................................... 31
Figur 4.3 Reguljärt uttryck för tolkning av Trafikverkets JSON-data .............................. 32
Figur 4.4 Utdrag ur stationstabellen .................................................................................. 33
Figur 4.5 Exempel på inhämtad data från Oxyfi ............................................................... 34
Figur 4.6 Reguljärt uttryck för tolkning av Oxyfi:s data .................................................. 34
Figur 4.7 Utdrag ur det reguljära uttrycket för tolkning av Oxyfi:s data .......................... 36
Figur 4.8 Utdrag ur tågtabellen ......................................................................................... 38
Figur 4.9 Utdrag ur JSON-strängen som kartan hämtar för att rita ut tågen ..................... 39
Figur 4.10 Utdrag ur JSON-strängen som kartan hämtar för att se tåg vid trafikplatser .. 39
Figur 4.11 Sveriges alla trafikplatser ................................................................................ 40
Figur 4.12 Värmlands (med omnejd) alla trafikplatser ..................................................... 41
Figur 5.1 Översikt över de aktiva tågen i Värmland ......................................................... 43

xiii
Tabellförteckning
Tabell 2.1 NMEA GPRMC ............................................................................................... 14


1
1 Inledning
I en allt mer digitaliserad värld förväntar sig konsumenter som leverantörer större, bättre och
smidigare systemlösningar. Någonting som dock inte hängt med ordentligt är Sveriges
järnvägar och kringliggande system. I dagsläget finns inte en komplett vy över var Sveriges alla
järnvägsoperatörer har sina fordon, både parkerade och resande, samt annan nyttig information
som kringliggande terräng. Detta projekt syftade till att bygga upp ett grundläggande system
som knyter ihop relevant (och tillgänglig) data för att sedan kunna användas till en lämplig
systemlösning, för att i sin tur kunna användas för att övertyga operatörer att se fördelarna och
användbarheten med ett sådant system.
1.1 Syfte
SJ, som idag är en marknadsledande tågoperatör, knyter samman Sverige och likaså
Skandinaviens huvudstäder Stockholm, Köpenhamn och Oslo. [1] Detta skapar idag
möjligheter för människor att kunna bo, arbeta och studera på platser och även kunna resa på
ett enkelt sätt. Med 1200 dagliga avgångar, 284 trafikerade stationer, cirka 4500 anställda och
en summa på ca 47,5 miljoner resenärer varje år, placeras en stor vikt på säkerhet och
framkomligheten för att resenärerna ska känna trygghet i att välja SJ som tågoperatör.
För att kunna garantera denna trygghet behöver trafikledningen på SJ diverse stöd för att
försäkra sig om att de hela tiden värnar om säkerheten för resenärer och även personal som
finns på tågen och även att framkomligheten är god så att resenärerna kommer fram enkelt och
i tid. Ett exempel på detta är att ha god vetskap om terrängen runt om ett tåg för att vid
evakuering kunna flytta resenärer och personal från ett tåg, på ett säkert och smidigt sätt. Ett
annat exempel är att kunna se när ett tåg står stilla på ett spår där det inte borde. I nuläget så tar
den beslutprocess och det arbetet för att lösa uppkomna problem inom de två exempel som
precis har givits, betydligt längre tid än vad som önskas. Det krävs att man letar inom flera olika
system och även förlitar sig på kommunikation mellan personalen på tåget och trafikledningen.
Inom vissa områden har man till och med inget underlag alls för att tackla problemen.

2
Att inte ha all data samlat på ett ställe och samtidigt inte ha en översikt över tågen i realtid är
det som tar tid och markant påverkar beslutsprocesserna. Syftet med detta projekt var att
underlätta och effektivisera dessa beslutsprocesser genom att skapa ett underlag i form av ett
system som kan knyta ihop den utspridda datan och ge en visuell överblick över tågens position.
Systemet kommer att fungera som ett demo för framtida implementationer.
1.2 Mål
Målet med detta projektet var att skapa ett system som kan fungera som underlag och upplysa
om de behov och möjligheter som finns för att utforma ett liknande system storskaligt. Tanken
var att samla in data i en databas, anpassat för att kunna användas till att bygga flertalet lager
med funktionalitet på en karta som kan användas till att underlätta beslutskrävande processer.
1.3 Uppdragsbeskrivning
Arbetet var tänkt att agera som underlag för framtida implementationer av ett liknande system.
Systemet skulle kunna använda sig av den insamlade datan för att presentera detta i ett grafiskt
gränssnitt. Datainsamling skulle ske från ett antal olika API:er. Datan som hämtas kunde
innehålla sådant som anses vara onödigt och även data som är trasigt. På lämpligt sätt skulle
den data som är nödvändig för det uttänkta systemet filtreras från resterande data och sedan
läggas in i en databas. Därefter skulle funktionalitet byggas för att kunna presentera ett antal
användarfall i ett grafiskt gränssnitt.
Figur 1.1 visar ett exempel på hur detta systemet var tänkt att se ut och användas. Användaren
var i detta fall tänkt att vara en trafiksamordnare eller annan ledningspersonal på trafikverket.
Data samlas in från ett antal API:er in i en omvandlare. Omvandlaren filtrerar och gör om datan
så den är i rätt format, och därefter lägger in datan i en databas. Från databasen hämtas data ut
till ett antal användarfall. Dessa användarfall skulle fungera som tilläggsprogram till ett grafiskt
gränssnitt, i detta fall fungera som lager på en karta med olika funktionaliteter.
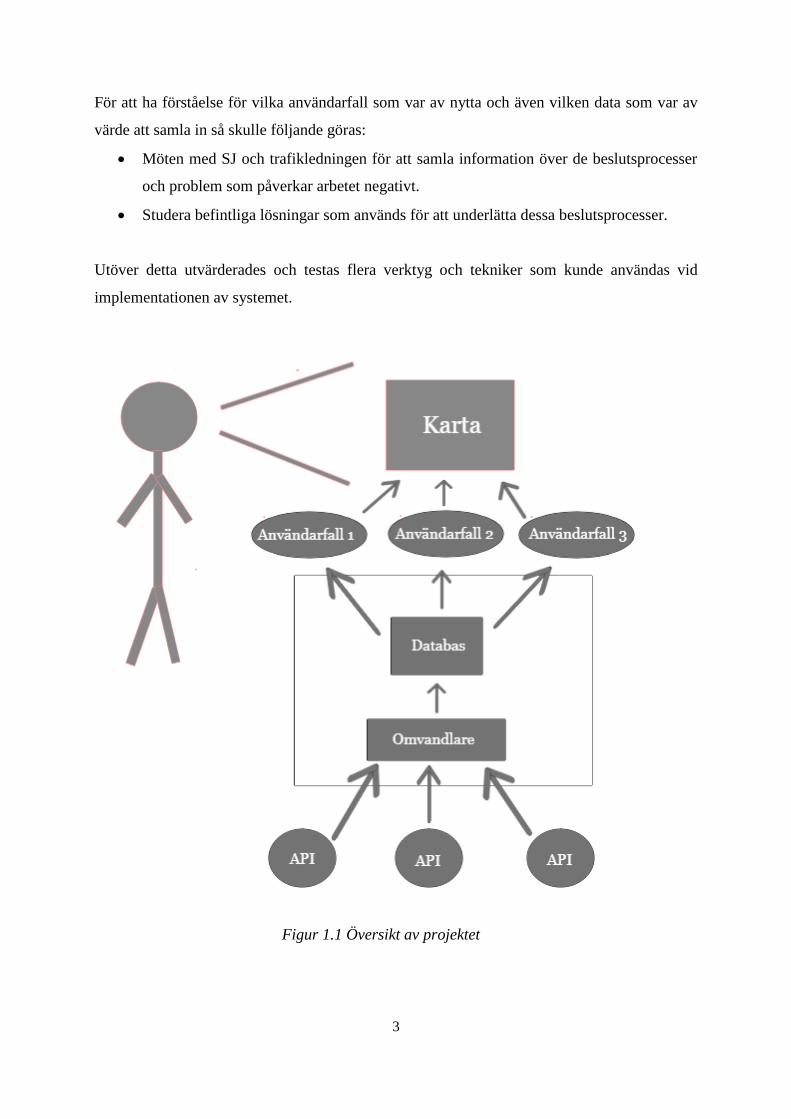
3
För att ha förståelse för vilka användarfall som var av nytta och även vilken data som var av
värde att samla in så skulle följande göras:
• Möten med SJ och trafikledningen för att samla information över de beslutsprocesser
och problem som påverkar arbetet negativt.
• Studera befintliga lösningar som används för att underlätta dessa beslutsprocesser.
Utöver detta utvärderades och testas flera verktyg och tekniker som kunde användas vid
implementationen av systemet.
Figur 1.1 Översikt av projektet

4
1.4 Disposition
Kapitel 2 – Bakgrund
Kapitel 2 avser att introducera olika programmeringsspråk och verktyg som kommer att nämnas
i andra kapitel. De existerande lösningar som finns hos trafikledningen idag presenteras också.
Kapitel 3 – Projektdesign
I kapitel 3 ges en tydligare introduktion till projektet, hur projektet utformats och även de mål
som sattes för projektet. Här presenteras även test och utvärdering av olika verktyg och språk
för att ge en klar bild av varför projektet tog den form det gjorde.
Kapitel 4 – Implementation
Kapitel 4 presenterar systemet och dess komponenter. Här presenteras både systemets
inhämtning av data, filtrering av onödiga och nödvändiga data och det grafiska användar-
gränssnittet i detalj.
Kapitel 5 – Utvärdering
I kapitel 5 utvärderas projektet och systemet analyseras. Utvärderingen ska styrka de mål som
satts för projektet och ett helhetsresultat ges. I kapitlet presenteras även de problem och hinder
som uppstod under projektets gång och som påverkat slutprodukten.
Kapitel 6 – Slutsats
Kapitel 6 knyter samman projektet och ger en summering av hur arbetet har gått. Vidare ges
även förslag på hur systemet kan vidareutvecklas.

5
2 Bakgrund
Syftet med detta kapitel är att ge en kort introduktion till de olika språk som under projektets
gång har använts eller övervägts att användas. Vidare presenteras de verktyg som testades och
även en kort presentation av de lösningar som trafikledningen använder sig av idag. Även
reguljära uttryck presenteras kort, då det kan vara av användning för att förstå delar av
implementationen. I kapitel 3.6 står det om vilka av språken som valdes för projektet och i
kapitel 3.7 så står det om vilka verktygen som valdes.
2.1 Språk
SQL
SQL är ett programspråk som används för att hantera data i relationsdatabaser, och började
utvecklades av IBM på 1970-talet [2]. Exempel på SQL-kommando (Figur 2.1):
Hämta ut värdena namn och nummer från tabellen Kontakter där värdet favoriter är lika med
ja, sorterat efter värdet namn i bokstavsordning.
C
C är ett ALGOL-baserat (ALGOL, programspråk från 1958) imperativt programspråk [3].
Programspråket B, som C är baserat på, var inte plattformsoberoende, utan skrevs på PDP-7,
och hade endast en datatyp (word). C skapades därefter med kravet på att kunna fungera på
mainframe-, mini- och mikrodatorer. C släpptes för första gången 1970 och var skrivet i
assembler. C är idag ett av de mest populära programspråken och näst intill varje plattform har
C-kompilatorer.
C++
C++ är ett programspråk som stödjer objektorienterad programmering, generisk
programmering, dataabstraktion samt lågnivå hårdvarunära programmering [4]. Språket är
Figur 2.1 SQL-exempel

6
baserat på C, och omfattar stora delar av språket, men har också många semantiska skillnader.
C++ används mer och mer idag på områden där C traditionellt använts. C++ är idag, likt C, ett
av de mest populära språken och hittas ofta i produkter som datorspel, konsumentelektronik
och allt däremellan.
Java
Java är ett objektorienterat programspråk [5]. Språket skapades som ett alternativ till C och
C++, och dess syntax kommer därifrån. Javakod kompileras till Java-bytekod som senare kan
exekveras på alla enheter som stödjer Java, då bytekoden körs på virtuella Java-maskiner. Java
är, likt de två föregående språken, även det ett av de mest använda språken på marknaden.
C#
C# är ett objektorienterat programspråk [6]. Språket är i grunden baserat på C++, men har stora
liknelser med Java. C# är dock inte plattformsoberoende, då fria implementationer av språket
är ofullständiga och saknar vissa komponenter ur .NET-ramverket som C# är en del av. C#
använder, likt Java, bytekod som körs i en virtuell maskin. De olika bytekoderna är dock inte
kompatibla med varandra.
PHP
PHP är en förkortning för ”PHP: Hypertext Preprocessor” och är ett öppet generellt skriptspråk
som huvudsakligen är lämpat för webbutveckling och kan mycket smidigt integreras med
HTML [7]. PHP är väldigt enkelt för nybörjare samtidigt som det erbjuder avancerade
funktioner för utvecklare med mer erfarenhet. Fördelarna med PHP är att istället för att ha flera
rader med HTML kommandon så kan de ersättas med PHP. I Figur 2.2 ges exempel av kod
skriven i PHP. Koden är omsluten av instruktioner som avser start och slut av PHP. ’<?php’
anger starten av PHP-blocket och ’?>’ slutet. I exemplet så kommer ”Exempel på PHP” att
skrivas ut på skärmen.

7
HTML
HTML står för ”Hypertext Markup Language” och är ett sidbeskrivningsspråk för att skapa
webbsidor och webbapplikationer [8]. Ett sidbeskrivningsspråk är ett slags format för
dokument. Webbläsare får dessa HTML-dokument från en webbserver eller en lokal lagring.
Dessa dokument översätts till multimediasidor.
Grunden och byggstenarna i HTML-sidor är HTML-element. Dessa element är representerade
av taggar. Varje tagg beskriver olika delar av innehållet på en webbsida som tillexempel
”Header”, ”Paragraph” och ”Table”. Webbläsarna visar i sin tur inte dessa taggar utan använder
de för att rendera innehållet av webbsidorna. Taggarna är element som är omslutna av
vinkelparenteser och kommer i par med en start och en sluttagg.
JavaScript
JavaScript är ett skriptspråk som gör det möjligt att implementera mer komplexa funktioner på
en webbsida än HTML [9]. Med JavaScript kan man dynamiskt uppdatera innehållet på en
webbsida, kontrollera media, animera bilder, kontrollera fält innan data skickas vidare och en
mängd andra funktioner. Utöver detta så används JavaScript även i andra användningsområden
som till exempel: Tillämpningar på serversidan för att arbeta med olika databasanslutningar,
skicka data över nätet och liknande tillämpningar.
Figur 2.2 Exempel på PHP och HTML

8
2.2 Verktyg
Microsoft Azure
Microsoft Azure är en uppsättning med molntjänster från Microsoft skapta för att bygga och
hosta webbapplikationer [10]. Dessa görs via Microsofts egna datacenter. Bland dessa
molntjänster finns ”Azure SQL Database” som är en relationsdatabastjänst. ”Azure SQL
Database” har stöd för strukturer som JSON och XML och ska enligt Microsoft vara
högpresterande, tillförlitlig och en mycket säker databas [11]. Microsoft Azure utlovar även en
tillgänglighet på 99,99%. Tillgängligheten är väldigt viktig när man bygger ett realtidssystem
då man inte vill att det sker någon förlust av data. Bland alla funktioner finns alternativ som
kolumnlagringsindex för en enklare och effektiv analytisk analys, minnesintern OLTP för bättre
transaktionell bearbetning och elastiska pooler för att lösa problem som kan uppkomma för
företag med oförutsägbara användningsmönster. En elastisk pool innebär att prestandaresurser
allokeras till en enda pool istället för en databas. Detta gör att användarna inte behöver reglera
databasprestanda upp och ner efter behov.
Apache Kafka
Apache Kafka är en open-source-strömningsplattform [12]. Kafka är vanligtvis användbart
inom två väldigt breda användningsområden. Det ena är utveckling av datapipelines i realtid
som på ett säkert sätt hanterar och får data mellan olika system eller applikationer. Det andra är
utveckling av realtidsströmmande applikationer som omvandlar eller reagerar på olika
dataflöden.
För att förstå Kafka så behöver man ha vetskapen om att:
• Kafka körs på en eller flera servrar, som ett kluster, och kan ha ett span över multipla
datahallar.
• Kafka klustret lagrar flöden av poster i olika ämnen / kategorier.
• Varje post har en nyckel, ett värde och en angiven tidpunkt.
Därefter är det även viktigt att veta att Kafka består av fyra API:er:
• Producer API som tillåter en applikation att publicera en ström av olika register till en
eller flera antal Kafka kategorier,
• Consumer API som tillåter en applikation att prenumerera på en eller flera antal ämnen
och därefter bearbeta strömmen av poster som applikationen mottager.

9
• Streams API som tillåter en applikation att fungera likt en strömprocessor och
omvandlar en ingångström av poster från en eller flera ämnen till en utgångström för en
eller flera utgångsämnen.
• Connector API som gör det möjligt att bygga och köra återanvändbara producenter eller
prenumeranter som ansluter en eller flera Kafka ämnen till befintliga applikationer.
I kärnan av Kafka finns ämnen. Ett ämne är en kategori som poster publiceras till [13]. Ett ämne
kan ha inga, en eller flera prenumeranter på den data som skrivs till ämnet. Varje ämne blir
tilldelat en partitionerad logg. De partitionerade loggarna distribueras över Kafka-klustrets
olika servrar, där varje server hanterar data och förfrågningar för att läsa från loggarna. Sedan
kopieras partionerna till ett antal konfigurerbara servrar för felhantering.
Varje partion har en server som agerar som huvudserver och därefter noll, en eller flera servrar
som kan tänkas agera som ”följare”. Huvudservern hanterar partionernas alla läs och
skrivförfrågningar medan ”följarna” har i uppgift att hela tiden replikera huvudservern. Skulle
huvudservern misslyckas så kommer en av följarna att bli den nya huvudservern. Belastningen
är välbalanserad inom klustret just för att varje server fungerar som en huvudserver för några
av dess partitioner samtidigt som den är en ”följare” för andra servrar.
Kubernetes
Kubernetes är en portabel open-source-plattform som är till för hantering av tjänster och
arbetsbelastningar i containrar [14]. Kubernetes kan kortfattat ses som en mikroservice-
plattform eller en container-plattform och den tillhandahåller en container-centrerad
förvaltningsmiljö där den anpassar data, nätverk och lagring baserat på användarens
arbetsbelastningar. Målet med Kubernetes är att automatisera skalning, implementering, drift
och resurstilldelning av containrar över kluster. Kubernetes används främst tillsammans med
Docker (se delkapitel 2.2.4 för beskrivning av Docker).
Kubernetes centrala schemaläggningsenhet kallas för pod [15]. En pod består av en eller flera
containrar som kan dela resurser. Varje pod har en unik IP-adress inom klustret för att göra det
möjligt för applikationer att använda portar utan risk för att problem ska uppstå. Inom en pod
kan alla olika containrar referera till varandra på localhost men ingen av dessa containrar kan
direkt referera till en container inom en annan pod. Detta görs istället genom IP-adressen alla
podar blivit tilldelade.

10
Docker
Det Docker gör är att sätta upp containrar [16]. Detta görs baserat på virtualisering på
operativsystemnivå snarare än på hårdvarunivå. Detta innebär att containrarna är isolerade ifrån
varandra. De har sina egna filsystem och deras användning av datorresurser kan begränsas.
Samtidigt som de är enklare att sätta upp än virtuella maskiner så är de även bärbara över molnet
och operativsystemsfördelningar, då de inte är kopplade till det underliggande filsystemet och
infrastrukturen. Containrar gör det möjligt för en utvecklare att packa ner en applikation
tillsammans med alla de delar som den behöver [17]. Exempelvis så kan de bibliotek och
inställningar applikationen behöver, skickas med i en container. Detta gör att det går att leverera
allting som ett enda paket och försäkra sig om att applikationen kan köras på vilken annan
maskin som helst oavsett den nya maskinens inställningar.
Git
Git är ett versionshanteringssystem som är utformat för att hantera allt från små till stora projekt
[18]. Versionshantering har en rad med fördelar. En av de största fördelarna är att alla ändringar
av en kod lagras i en databas och hålls koll på. Detta gör det möjligt för utvecklare att jämföra
olika versioner med varandra och vid fel kunna gå tillbaka till en tidigare version av koden.
Det som även möjliggörs är att utvecklarna kan arbeta på samma kod utan att påverka
varandra [19]. För att ge en enkel överblick kan Git beskrivas med följande: En utvecklare
skriver kod, en annan ändrar på kod och den tredje tar bort kod och detta kan de göra samtidigt
utan att påverka varandra genom att befinna sig på olika brancher. En branch är en kopia av
koden där den enskilde utvecklaren kan arbeta med koden och därefter göra en merge, det vill
säga, slå ihop sina ändringar med huvudkoden och samtidigt kontrollera att inga konflikter
uppstår med ändringarna.
Ett annat exempel är att en utvecklare skapar en branch från version 1.5 av exempelprogrammet
”X” [20]. Syftet här är att förbereda publiceringen av version 1.6. Utvecklaren gör sina
ändringar och bestämmer sig för att göra en commit på dessa ändringar. En commit innebär att
ändringarna sparas till repositoryt och ett repository är ett förråd som lagrar metadata för bland
annat ändringar i koden. Utvecklaren bestämmer sig sedan för att hoppa till branchen för
version 1.3 av ”exempelprogrammet ”X. Här skapas en branch för att hantera en bugg som bara

11
påverkar version 1.3 av programmet. Buggen löses och branchen mergas tillbaka in i branchen
för version 1.3, detta utan att påverka ändringarna som skett i branchen för version 1.6.
MySQL Workbench
MySQL Workbench är ett verktyg som visuellt tillhandahåller datamodellering, SQL-
utveckling och annan databashantering [21]. MySQL Workbench underlättar databashantering
markant genom att möjliggöra hantering, generering modellering och design av databaser
visuellt. Här finns det även möjlighet för att kunna skapa, exekvera och optimera SQL-
kommandon samtidigt som färgmarkering av syntax, automatiskt slutförande, kortkommandon
och historik över tidigare SQL-kommandon förenklar arbetet med databaserna. Här kan
utvecklaren även visuellt strukturera sina databaser, sätta upp nya tabeller, redigera kolumner
och primärnycklar.
Open Street Map
Open Street Map är ett projekt framtaget och byggt av kartografer för att distribuera geografiska
data gratis [22]. Denna data kan i sin tur sedan användas för att skapa allt från vägkartor till
kartor för att presentera GPS-data till kartor över sevärdheter och en mängd andra
användningsområden. Open Street Maps data uppdateras och underhålls tack vare kartografer
men även bidragsgivare så som GIS-proffs, ingenjörer och frivilliga med hjälp av flygbilder,
GPS-enheter och lågteknologiska fältkartor.
Mapbox
Maxbox är en stor och växande leverantör av anpassningsbara kartor online för webbsidor och
mobilapplikationer [23]. Bland dessa finns giganter som Facebook och Snapchat. Mapbox
startades upp 2010 som en del av projektet Development Seed, där målet var att kunna erbjuda
anpassningsbara kartor till ej vinstgivande kunder. Mapbox använder sig av data hämtat från en
rad öppna datakällor, bland dessa finns Open Street Map. Det Mapbox också gör är att använda
data som kommer från användare på applikationer som använder sig av Mapbox för att med
hjälp av automatiserade funktioner upptäcka data som troligtvis saknas i Open Street Map.
Därefter rapporterar Mapbox-utvecklarna in detta till underhållarna av Open Street Map eller
själva hjälper till med att gå in och fixa problemen.
Leaflet
Leaflet är ett stort öppet JavaScript-bibliotek som används för att bygga applikationer för
webbkartläggning [24]. Leaflet stödjer de flesta mobilapplikationer och datorprogram med

12
HTML5 och CSS (se kapitel 4.1.1 för beskrivning av CSS). Leaflet är en av de mest populära
JavaScript-biblioteken för kartläggning och används av stora sidor som bland annat Pinterest.
Leaflet gör det möjligt för utvecklare med en bakgrund inom geografiska informationssystem
att enkelt och snabbt anpassa och visa ”tile maps” på publika servrar. ”Tile maps”-kartor som
presenteras i webbläsaren är byggda genom att limma ihop flera individuella bilder som bildar
en karta och är det mest populära sättet att visa och navigera i kartor på nätet. En bonus här är
möjligheterna att ladda in data från GeoJSON-filer för att kunna anpassa och skapa interaktiva
lager på kartan så som markörer, punkter som rör sig i realtid och klickbara områden med
popup-fönster.
Google Maps
Google Maps är en öppen webbkartläggningstjänst från Google som har allt från satellitbilder
till 360 graders panoramavy av gator till realtidsinformation av trafiksituationer [25]. Det
började som ett datorprogram utvecklat av ”Where 2 Technologies”, skrivet i C++. Programmet
köptes sedan upp av Google som vidareutvecklade programmet till en webbapplikation som är
byggt med en front av XML, JavaScript och Ajax. De kartor och satellitbilder som Google
Maps använder sig av täcker nästintill hela världen och det finns möjligheter för att zooma in
och ut utan problem. Flertalet av kartorna kommer ifrån olika leverantörer, bland annat Tele
Atlas och Transnavicom. Upptäcks fel i kartan av användarna kan det rapporteras in och i vissa
fall till och med rättas till direkt. Detta gör att kartorna håller sig uppdaterade och uppehåller
god kvalitet. Google Maps API som lanserades i juni 2005 gjorde det möjligt för utvecklare att
integrera Google Maps med sina webbsidor.
Pubnub
Pubnub är ett stort dataströmningsnätverk framtaget för utvecklare för att underlätta och ge stöd
för utveckling av realtidsapplikationer [26]. Med hjälp av PubNub kan man tillämpa en rad med
funktioner till sitt program så som till exempel:
• Strömma geografiska platsdata från valfri mängd av källor och anpassa denna efter
behov innan det presenteras på en karta.
• Lägga till dynamiska kartfunktioner.
• Skicka notifikationer till mobil- och dataplattformar.
• Aktivera SMS-baserade händelser baserat på olika event eller larm.
• Presentera aktioner, börs, poängställningar och liknande i realtid.

13
Utöver detta så har man tagit fram EON [27]. EON är ett projekt framställt för att stärka
utvecklingen av kartor med realtidsdata. EON är ett JavaScript-ramverk för grafer och
realtidskartor och fungerar på flera enheter. EON kopplar C3 diagram och Mapbox
kartfunktioner till Pubnubs dataströmningsnätverk och skapar tack vare detta ett enkelt sätt att
visualisera realtidsdata på grafer, diagram eller kartor.
XAMPP
XAMPP kan ses som en webbserverlösning som kommer i ett packet med flera
undersystem [28]. XAMPP består huvudsakligen av Apache HTTP-server, MariaDB-databas
och ett antal programtolkar för att exekvera instruktioner skrivna i PHP eller Perl. Då
majoriteten av faktiska webbservrar använder sig av samma komponenter som XAMPP
tillhandahåller så möjliggörs en enkel övergång av att sätta upp en lokal testserver till att vara
en live-server. Målet med XAMPP är att göra det enkelt för utvecklare att sätta upp en Apache
HTTP-webbserver och installeras med alla de funktioner som behövs där varje funktion är
konfigurerat för att kunna startas upp och köras direkt.
NMEA GPRMC
NMEA kan vara förvirrande då det är en förkortning för ”National Marine Electronics
Association” och är från början en förening som bildades 1957 av en grupp elektroniska
återförsäljare, vars syfte var att skapa en bättre kommunikation mellan dem och tillverkare [29].
Idag är NMEA ett standardiserat dataformat inom GPS-världen som stöds av alla GPS
tillverkare.
NMEA:s syfte är att ge användare möjlighet att själva blanda hårdvara och mjukvara. Ett
standardiserat dataformat gör det också möjligt för utvecklare att enklare skriva mjukvara för
en stort mängd av olika sorters GPS-mottagare.
Det man måste förstå om NMEA är att det inte bara finns ett enda NMEA-meddelande. Olika
NMEA meddelanden har olika funktioner och förmågor precis som GPS-mottagare har olika
kapaciteter. NMEA-data kan skickas över en stor mängd av olika kommunikationssätt, allt från
USB till WIFI.
$GPGGA är det grundläggande GPS NMEA meddelandet som innehåller GPS-koordinater.
Utöver detta finns det NMEA-meddelanden som innehåller ytterligare information som till
exempel $GPVTG som även inkluderar hastigheten över marken.
$GPRMC är ett alternativ till $GPGGA, och avser att täcka position, hastighet och tid.
14
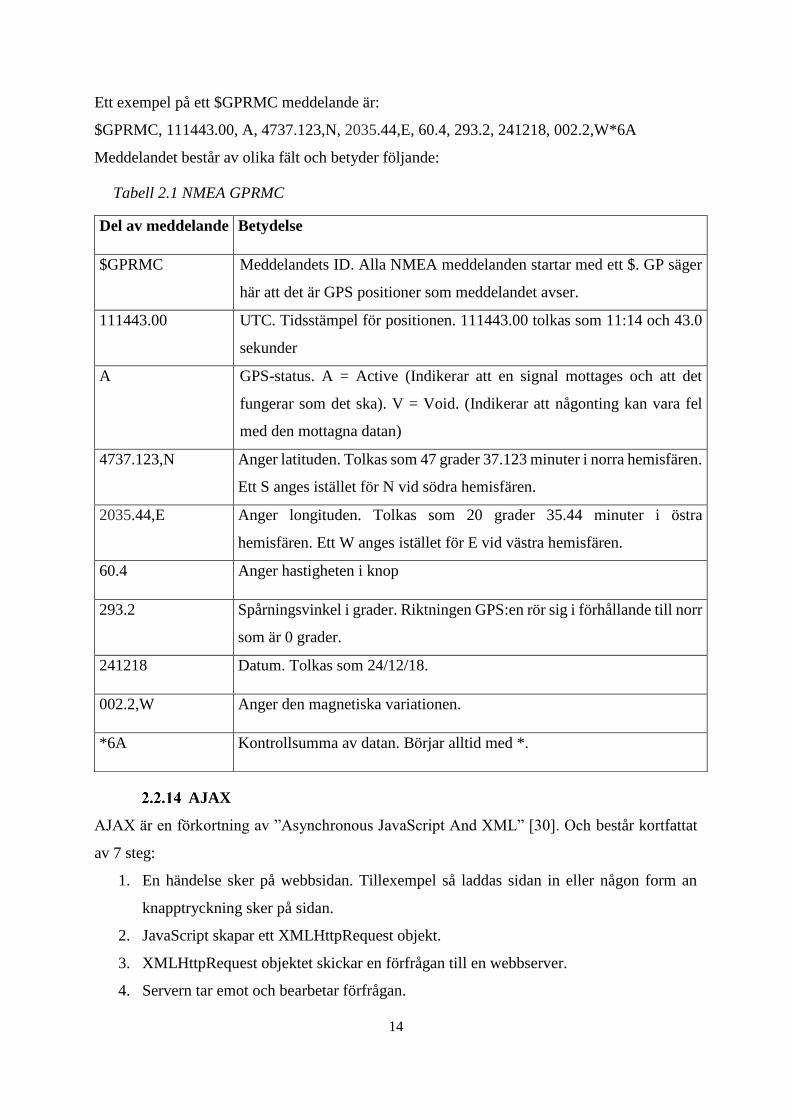
Ett exempel på ett $GPRMC meddelande är:
$GPRMC, 111443.00, A, 4737.123,N, 2035.44,E, 60.4, 293.2, 241218, 002.2,W*6A
Meddelandet består av olika fält och betyder följande:
Tabell 2.1 NMEA GPRMC
AJAX
AJAX är en förkortning av ”Asynchronous JavaScript And XML” [30]. Och består kortfattat
av 7 steg:
1. En händelse sker på webbsidan. Tillexempel så laddas sidan in eller någon form an
knapptryckning sker på sidan.
2. JavaScript skapar ett XMLHttpRequest objekt.
3. XMLHttpRequest objektet skickar en förfrågan till en webbserver.
4. Servern tar emot och bearbetar förfrågan.
Del av meddelande Betydelse
$GPRMC Meddelandets ID. Alla NMEA meddelanden startar med ett $. GP säger
här att det är GPS positioner som meddelandet avser.
111443.00 UTC. Tidsstämpel för positionen. 111443.00 tolkas som 11:14 och 43.0
sekunder
A GPS-status. A = Active (Indikerar att en signal mottages och att det
fungerar som det ska). V = Void. (Indikerar att någonting kan vara fel
med den mottagna datan)
4737.123,N Anger latituden. Tolkas som 47 grader 37.123 minuter i norra hemisfären.
Ett S anges istället för N vid södra hemisfären.
2035.44,E Anger longituden. Tolkas som 20 grader 35.44 minuter i östra
hemisfären. Ett W anges istället för E vid västra hemisfären.
60.4 Anger hastigheten i knop
293.2 Spårningsvinkel i grader. Riktningen GPS:en rör sig i förhållande till norr
som är 0 grader.
241218 Datum. Tolkas som 24/12/18.
002.2,W Anger den magnetiska variationen.
*6A Kontrollsumma av datan. Börjar alltid med *.

15
5. Servern skickar därefter ett svar tillbaka till webbsidan.
6. Svaret hanteras och tolkas av JavaScript.
7. JavaScript utför rätt funktion. Till exempel sidan uppdateras eller en punkt på
webbsidan förflyttas.
AJAX använder sig alltså av ett XMLHttpRequest-objekt inbyggt i webbläsaren för att begära
data från en webbserver och JavaScript och HTML för att presentera eller använda sig av datan.
Att tänka på är att AJAX kan vara väldigt missledande. Namnet avser användning av XML för
överföring av data medan det samtidigt är vanligt att används sig av JSON eller vanlig text
istället för XML.
Fördelarna med AJAX är att utvecklare kan läsa data från en webbserver även efter att
webbsidan har laddats in, webbsidan kan uppdateras utan att en omladdning av webbsidan krävs
och data kan skickas till webbservern. Detta är stora fördelar vid implementering av webbsidor
som ska presentera realtidsdata.
JSON
JSON (JavaScript Object Notation) är ett datautbytesformat [31]. Lätt att läsa för användare,
och lätt att läsa och generera för datorer. JSON är ett textformat som är helt programspråks-
oberoende men använder konventioner från C-familjen (så som C, C++, C#, Java, JavaScript
etc).
JSON består av två strukturer: En samling av namn/värde-par (objekt), och en ordnad lista
(array). En JSON-sträng kan börja med både ett objekt eller en array. Ett objekt är, som redan
nämnt, en oordnad uppsättning av namn/värde-par och omsluts av ett klammerparentespar
”{ }”, namnet är en sträng som följs av ett kolon ”:” och sedan av värdet. Varje par separeras
med ett kommatecken ”,” ifall det finns fler än ett par i objektet (se Figur 2.3).
Figur 2.3 JSON-objekt [37]
16
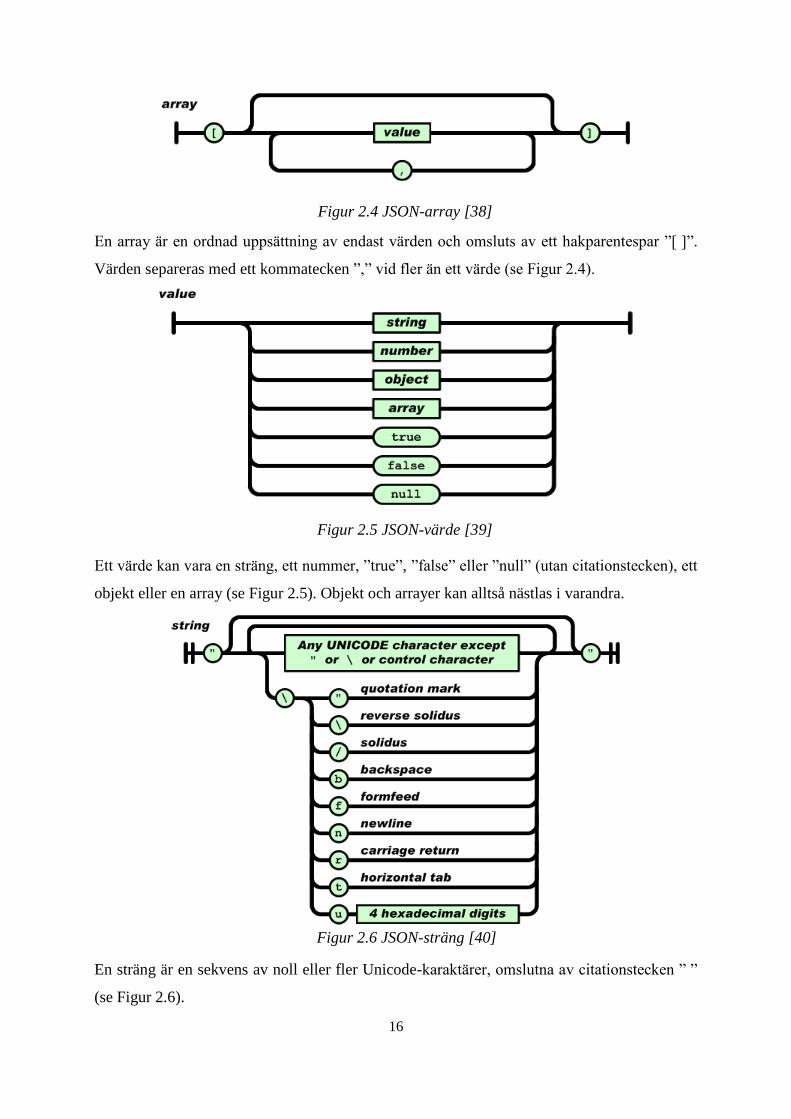
En array är en ordnad uppsättning av endast värden och omsluts av ett hakparentespar ”[ ]”.
Värden separeras med ett kommatecken ”,” vid fler än ett värde (se Figur 2.4).
Ett värde kan vara en sträng, ett nummer, ”true”, ”false” eller ”null” (utan citationstecken), ett
objekt eller en array (se Figur 2.5). Objekt och arrayer kan alltså nästlas i varandra.
En sträng är en sekvens av noll eller fler Unicode-karaktärer, omslutna av citationstecken ” ”
(se Figur 2.6).
Figur 2.4 JSON-array [38]
Figur 2.6 JSON-sträng [40]
Figur 2.5 JSON-värde [39]

17
Ett nummer är uppbyggd som ett vanligt nummer, där en punkt ”.” används som decimaltecken
(se Figur 2.7).
2.3 Reguljära uttryck
Reguljära uttryck är en notation till att beskriva mängder av strängar [32], och ett uttryck består
av en sträng med särskilda syntaxregler. Ett reguljärt uttryck med endast ett tecken ”t” matchar
tecknet ”t” i order ”tryck”. Man kan bygga ihop uttryck med operatorer för att matcha
komplicerade mönster där strängar med olika innehåll kan matchas av samma uttryck.
Exempelvis så kan ”[0-9]” matcha en godtycklig siffra, medan ”[0-9]*” matchar allt från inga
till oändligt många godtyckliga nummer. ”Regulj(a|ä)r” matchar antingen ”Reguljar” eller
”Reguljär”, ”G(äv|ef)le” matchar antingen ”Gävle” eller ”Gefle”. En punkt ”.” används som
jokertecken och matchar alla typer av tecken. ”a{0-5}” matchar ”a”, ”aa”, ända till ”aaaaa”.
”.*” matchar inga till oändligt antal godtyckliga tecken. För att matcha en punkt måste ett
omvänt snedstreck placeras framför ”\.”.
Exempel: ”(Hej|Hallå), jag är 2[0-9] år gammal” matchar en sträng som börjar antingen med
”Hej” eller ”Hallå” och fortsätter med ”, jag är 2” följt av godtycklig siffra mellan 0 och 9, och
sedan ” år gammal”. ”2[0-9]” matchar alltså tal mellan 20 och 29.
2.4 Existerande lösningar
I nuläget har trafikledningen tillgång till en rad olika verktyg för att kunna följa tågen på ett
eller annat sätt. Vissa av verktygen är mer pålitliga än andra medan flertalet av lösningarna inte
täcker de behov eller tillför det stöd som trafikledningen behöver. Under ett studiebesök som
Figur 2.7 JSON-nummer [41]

18
gjordes hos SJ under projektets gång så presenterades tre sätt som används mest för att följa
tågen.
Utplacerade avläsningspunkter
Tack vare trafikverket kan man idag veta tågens position på järnvägen med hjälp av RFID-
teknik [33]. RFID som är en förkortning av ”Radio Frequency Identification”, är en teknik som
använder sig av trådlös informationsöverföring mellan en RFID-tagg och en RFID-läsare. RFID
har många användningsområden i dagens samhälle bland dessa går det att hitta busskort,
passering genom tullar, stöldskydd i butiker och passagesystem i byggnader. Inom tågtrafiken
finns ett stort nät av RFID-läsare där möjligheten att spåra och följa enskilda fordon ges. I
början på 2018 fanns det cirka 300 RFID-läsare runt om i landet och utbyggnad av dessa har
och pågår än idag.
Med RFID-tekniken så finns även möjligheten att koppla detektormätvärden och larm ihop med
fordonen (se Figur 2.8). Detta möjliggör att man får aktuell status och aktuella mätvärden för
varje individuellt fordon för att snabbt upptäcka fel och behov av service. Utöver RFID-läsarna
finns cirka 180 detektorer utplacerade. Data hämtas genom att RFID-taggar finns placerade på
varsin sida av ett fordon. När tågen passerar en RFID-läsare så registreras taggen och data
sparas i trafikverkets databas. Exempel på data är fordonets ID, vilken plats fordonet passerat,
fordonets hastighet, tidpunkt, skador på hjulen och inbromsningar. Denna information finns
tillgänglig som prenumerationsunderlag och används bland annat av SJ. För att få en bättre bild
av tågens position använder man sig av ett par algoritmer som räknar ut var tåget borde befinna
sig med tanke på hastighet och tidpunkt som tåget hade vid passering av en specifik RFID-
läsare. De problem som kan uppstå här är att man inte vet exakt var tågen befinner sig. Då varje
Figur 2.8 RFID-tekniken [42]

19
RFID-läsare kan befinna sig flera kilometer från varandra så går det inte att avgöra var på spåret
tåget är, hur terrängen runtom tåget ser ut och hur den faktiska tågsituationen är vilket i vissa
fall kan orsaka flera problem.
Kommunikation via ombord personalens mobiler
Personalen ombord på tågen har idag möjlighet att logga in genom en applikation på deras
mobiltelefoner och på så sätt dela med sig av GPS-data via den mobila enheten. Till skillnad
från tekniken att beräkna tågets position med hjälp av avläsningspunkter så är denna variant
mer tillförlitlig och täcker de områden som idag saknar avläsningspunkter. När personalen för
en specifik tågresa först befinner sig på tåget så ska de logga in via deras mobila enheter. När
de gör detta så börjar den mobila enheten att skicka GPS-data till de uppsatta databaserna.
Samtidigt som de loggar in så anger personalen även vilket tåg de befinner sig på, detta för att
kunna identifiera vilket tåg GPS-informationen avser. Därefter finns ett visuellt gränssnitt
uppsatt hos trafikledningen där personalen kan följa tågen. Ett problem som blir mycket tydligt
vid användningen av denna teknik är när tågen plötsligt inte befinner sig på tågrälsen utan
förflyttar sig åt annat håll. Orsaken till detta är att personalen kan glömma att stänga av
applikationen som skickar GPS-data och tar med sig mobilen hem, vilket även gör att tåget
följer med hem enligt det grafiska gränssnittet.
GPS-enheter på tåg
GPS-enheter finns på de modernare tågen idag som till exempel X40-tågen. Dessa skickar GPS-
data om det fordon de sitter på och datan lagras och presenteras i ett visuellt kartgränssnitt.
Detta är den absolut bästa lösningen och den lösning som man gärna ser appliceras på alla
fordon.

20
3 Projektdesign
I detta kapitel presenteras hur projektet har tagit form. En kort beskrivning av projektets
grundidé presenteras och därefter hur projektet formades och motivering till den nya
projektspecifikationen ges. Här presenteras också de val som gjorts kring de verktyg och språk
som använts för projektet och även hur systemets design var tänkt att se ut.
3.1 Projektets grundidé
Projektet påbörjades med en väldigt bristande förståelse om vad för sorts system som skulle
utvecklas och vad för möjligheter som fanns. Grundtanken var att det skulle utvecklas ett
system som skulle agera som underlag och stöd för att effektivisera beslutsprocesser av
operativa problem inom tågtrafiken. Systemet som skulle utvecklas var även tänkt att
effektivisera beslutsprocesserna genom att med hjälp av machine learning automatisera flödet
och påskynda besluten.
Under projektets första vecka hade följande tre frågeställningar utformats:
• Kan man med hjälp av en eller flera systemlösningar effektivisera och förenkla
beslutsprocessen för trafikledning inom tågtrafik?
• Kan man med denna lösning samla in data och statistik som på sikt kan vara användbart
för att effektivisera andra processer?
• Kan man med hjälp av denna/dessa lösningar, i framtiden, fatta beslut per automatik
genom att göra systemet självgående, t.ex. med hjälp av machine learning?
Dessvärre föll dessa bort rätt fort och nedan presenteras hur och varför projektet formades om.
3.2 Planering
Möten med olika trafikledningar
För att förstå vilka operativa problem som trafikledningen fick handskas med dagligen så
gjordes ett besök hos trafikledningen på SJ och Nobina redan första veckan. Målet med detta
var att lokalisera resurskrävande problem som skulle kunna automatiseras och lösas genom
någon typ av applikation. Besöken visade sig inte vara lika givande som önskat, då ingen tydlig
bild gavs av vad som kunde lösas som inte var internt inom trafikledningen. SJ:s personal

21
fokuserade på problem med existerande programvara, och besöket på Nobina resulterade inte i
något givande för det arbete som skulle genomföras. Resultatet var i grund och botten en rundtur
genom Nobina:s kontor, och en genomgång av vad de arbetar med.
Således fick ett nytt besök på SJ:s trafikledning göras i tredje veckan, där taktiken i
problemsökandet ändrades. En diskussion och genomgång av de problem som hade upptäckts
under första besöket som trafikledningen inte tänkte på genomfördes. Strategin var nu att istället
komma med förslag på funktionalitet som ansågs kunna hjälpa personalen och göra deras jobb
enklare. Detta i sin tur gjorde att personalen själva började komma med idéer och förslag på
vad de skulle vilja få stöd till. Det andra mötet gav mycket att arbeta med och funktionalitet
som till sist kunde anses som bra att ha var följande:
1. Realtidspositionering av tåg på karta, deras planerade körväg, samt planerade
passeringar av trafikplatser (där användaren kunde markera en trafikplats och få ut rätt
information).
2. Varningar för tåg som inte håller sitt planerade körschema och vid stillastående fordon
på plats där låga hastigheter inte ska uppstå.
3. Information om varje sträcka såsom hur många och vilka tåg som kör på vald plats.
4. Beräkning av sparad resetid vid ersättningstrafik.
Dessa funktioner fick senare omformuleras och begränsas på grund av de problem som
presenteras längre fram i kapitel 5.
Möten med handledare
I början av projektet hölls regelbunden kontakt med universitetets handledare, med möten
varannan vecka. Efter det andra mötet hos trafikledningen kunde en klarare bild av projektets
mål presenteras för handledaren som i sin tur informerade om vad för något han ville se i
projektet. Under veckan informerade handledaren om följande:
1. Ett datahanteringssystem som hämtar in data från olika källor och klistrar ihop det.
2. Användarfall i form av tilläggsprogram som använder sig av datan och presenterar den
i någon form för användaren.
22
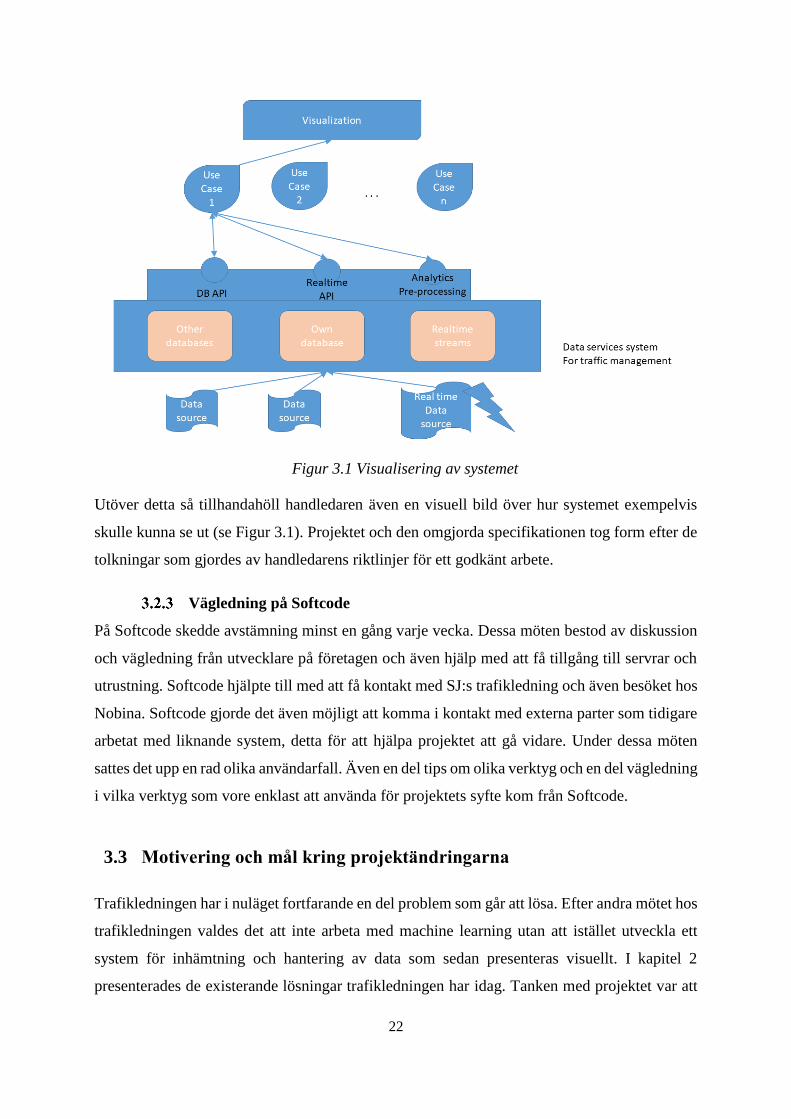
Utöver detta så tillhandahöll handledaren även en visuell bild över hur systemet exempelvis
skulle kunna se ut (se Figur 3.1). Projektet och den omgjorda specifikationen tog form efter de
tolkningar som gjordes av handledarens riktlinjer för ett godkänt arbete.
Vägledning på Softcode
På Softcode skedde avstämning minst en gång varje vecka. Dessa möten bestod av diskussion
och vägledning från utvecklare på företagen och även hjälp med att få tillgång till servrar och
utrustning. Softcode hjälpte till med att få kontakt med SJ:s trafikledning och även besöket hos
Nobina. Softcode gjorde det även möjligt att komma i kontakt med externa parter som tidigare
arbetat med liknande system, detta för att hjälpa projektet att gå vidare. Under dessa möten
sattes det upp en rad olika användarfall. Även en del tips om olika verktyg och en del vägledning
i vilka verktyg som vore enklast att använda för projektets syfte kom från Softcode.
3.3 Motivering och mål kring projektändringarna
Trafikledningen har i nuläget fortfarande en del problem som går att lösa. Efter andra mötet hos
trafikledningen valdes det att inte arbeta med machine learning utan att istället utveckla ett
system för inhämtning och hantering av data som sedan presenteras visuellt. I kapitel 2
presenterades de existerande lösningar trafikledningen har idag. Tanken med projektet var att
Figur 3.1 Visualisering av systemet

23
utveckla ett program som tar emot tågdata från externa parter och sedan presenterar datan på
en karta i realtid. Tanken var att motivera trafikledningen till att införskaffa GPS-enheter på
alla fordon och att ge dem ett underlag till de problem de har idag. Systemet var tänkt att även
lösa följande problem som trafikledningen stöter på idag:
• Sätta prioritering på sena tåg, tåg som är ute och kör och tåg ska börja köra.
o Lösningsförslag: En visuell översikt över tågen i realtid skulle göra det möjligt
att enklare sätta prioriteringar på tågen då man kan se hur tågen förhåller sig till
varandra.
• Evakuering av personal och resenärer.
o Lösningsförslag: En visuell översikt över tågen i realtid skulle göra det möjligt
att se miljön runtom tågen och på så sätt enklare och snabbare planera in
evakuering och ersättningstrafik.
• Se mötesplatser och tågens förhållande till dessa.
o Lösningsförslag: En visuell översikt över tågen i realtid skulle göra det möjligt
att snabbare planera in ett nytt möte längs en sträcka.
3.4 Användarfall
De användarfall som sattes för projektet är:
• Följa tåg i realtid på en karta
• På lämpligt sätt se om ett tåg står stilla.
• Se tåg som ankommer, avgår eller har varit på en specifik trafikplats.
Dessa användarfall var även de mål som satts upp för att bedöma resultatet av systemet i slutet
av projektet. Projektet skulle komma använda sig av dessa användarfall som riktlinjer vid
utveckling av systemet och datainhämtningen.
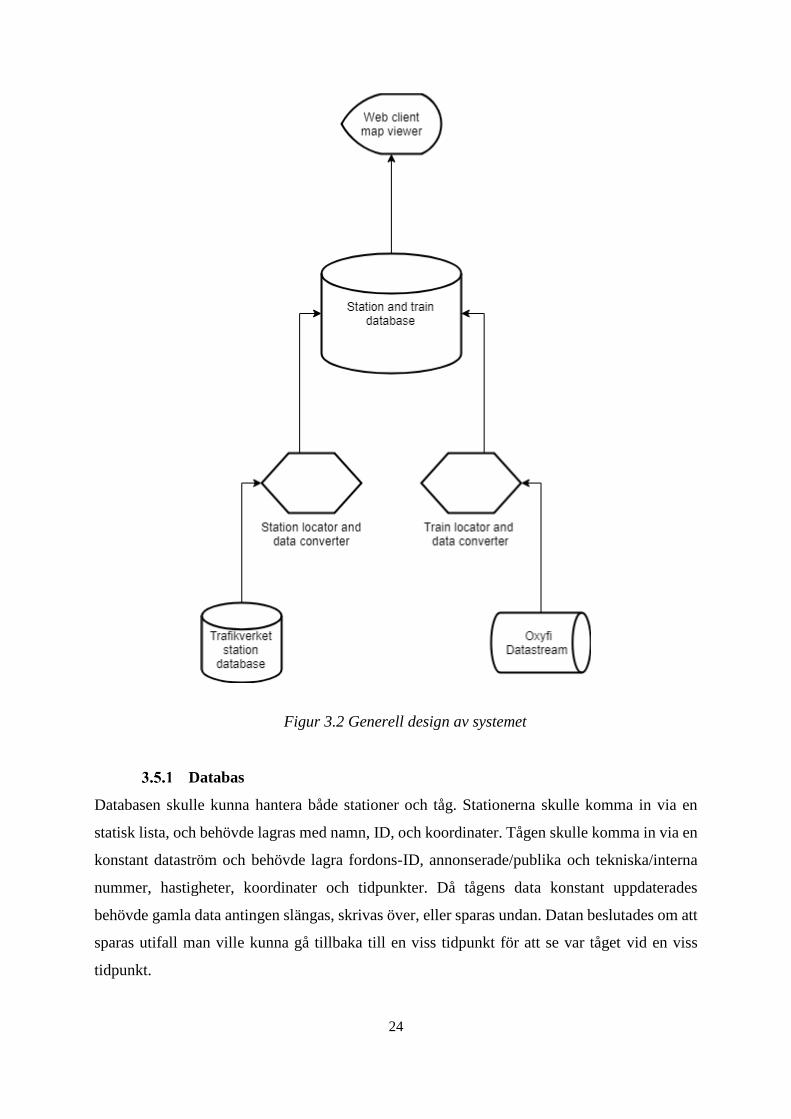
3.5 Generell design
Huvudkomponenten i programmet skulle vara ett databassystem med kringliggande data-
omvandlare som förbereder inkommande data för att lagras i databasen. Ett grafiskt gränssnitt
som refererar till databasen för att få ut nödvändig information skulle också vara en del av
programmet (se Figur 3.2).
24
Databas
Databasen skulle kunna hantera både stationer och tåg. Stationerna skulle komma in via en
statisk lista, och behövde lagras med namn, ID, och koordinater. Tågen skulle komma in via en
konstant dataström och behövde lagra fordons-ID, annonserade/publika och tekniska/interna
nummer, hastigheter, koordinater och tidpunkter. Då tågens data konstant uppdaterades
behövde gamla data antingen slängas, skrivas över, eller sparas undan. Datan beslutades om att
sparas utifall man ville kunna gå tillbaka till en viss tidpunkt för att se var tåget vid en viss
tidpunkt.
Figur 3.2 Generell design av systemet

25
Dataomvandlare
För att stations- och tågdatan skulle kunna läggas in i databasen behövdes en omvandlare för
att kunna ta ut rätt och relevant information från den inkommande datan, då de olika källorna
som användes matade ut sin data på olika format. Dessutom behövdes en datauppladdare för
att faktiskt få in datan i databasen. Dessa två skulle kombineras så att omvandlaren även laddade
upp datan till databasen.
Då datan från stationerna inte kom från samma källa som datan från tågen (då de hade olika
attribut, och då stationsdatan inte behövde uppdateras lika frekvent som tågdatan) bestämdes
det att två olika omvandlare skulle köras separat.
Grafiskt gränssnitt
Förutom databassystemet skulle även ett grafiskt gränssnitt implementeras. Anledningen var
att ha någonting som använde sig av det underliggande systemet och kunde påvisa dess
funktionalitet, och samtidigt något att testa systemet med för att se så att den inkommande datan
inte hade bristande frekvens eller dåliga mätvärden som skulle kunna visa tåg på platser där de
inte skulle vara.
3.6 Val av språk
Språk som valdes för den grundläggande arkitekturen var C#, med tillägg för stöd av SQL. C#
valdes då det bedömdes vara det som var bäst lämpat för projektet och det systemet som var
tänkt att utvecklas. Webbgränssnittet skulle skrivas i PHP och HTML då kunskaperna inom
språken var goda. JavaScript skulle även användas för att rita ut kartan och dess innehåll.
Utöver detta testades och övervägdes C, C++ och Java. Dessa valdes dock bort väldigt fort. C
valdes bort på grund av språkets komplicerade kompilerings-, och felhanteringsprocess. I C++
saknades essentiella kunskaper om språkets syntax och funktioner. Java som är likt C# valdes
bort då kunskaperna ansågs vara bredare inom C#.
3.7 Testning och validering av verktyg
De verktyg som testades för kartbygget var Open Street Map, MapBox, Leaflet, Google Maps
och PubNub. Leaflet är i grund och botten byggt med delar från MapBox, och när MapBox

26
testades uppstod stora bekymmer som länge troddes kunde lösas. Då Leaflet dock skiljer sig en
del från MapBox på vissa håll men liknar på många andra så gjordes antaganden att samma
problem skulle uppstå även i Leaflet vilket gjorde att det valdes att inte lägga mer tid på det.
Valet stod sedan länge mellan MapBox och Google Maps. MapBox hade en rad användbara
funktioner som Google Maps inte hade, vilket gjorde att sökandet efter en lösning pågick
väldigt länge. PubNub upptäcktes sent in i projektet, i början på december, med stöd för både
MapBox och Google Maps. Efter att PubNub testats med MapBox, som kunde ha löst
problemet, visade det sig att PubNub:s kod för MapBox var utdaterad och kvar återstod
alternativet att använda Google Maps, trots att Google Maps inte erbjöd samma funktionalitet
som önskades (se kapitel 5.2.3 för mer djupgående beskrivning på problemet). Open Street Map
testades i början men eftersom att MapBox är byggt med hjälp av Open Street Map och
dessutom tillhandahöll mer funktionalitet så gjordes ingen djupgående testning med Open
Street Map.
Git valdes för versionshantering av koden och Docker och XAMPP för databashantering och
servrar. MySQL Workbench valdes för att visuellt presentera innehållet i databasen. Microsoft
Azure, Apache Kafka och Kubernetes valdes bort och detta på grund av verktygens komplexitet
och brist på kunskap om verktygen. Efter testning valdes det att fortsätta med Docker och
XAMPP då dessa var smidigare och snabbare att sätta upp, samt på grund av den tidspress som
projektet redan hade på sig i detta stadiet.
3.8 Design av databasen
Efter en undersökning på indatan från Trafikverket och Oxyfi (som är ett företag som bland
annat tillhandahåller realtidspositioneringsdata över tåg [34]), bestämdes databasens design, de
tabeller som skulle användas och hur tabellerna skulle vara uppbyggda. Databasen skulle bestå
av två tabeller. En för trafikplatserna, och en för tågen och deras positioner.
Trafikplatstabellen ”trainstations” skulle innehålla fem attribut, varav en primärnyckel. De
fem attributen skulle vara trafikplatsens namn ”AdvertisedLocationName”, trafikplatsens
ID/signatur ”LocationSignature” (som även var primärnyckel), trafikplatsens typ
”Prognosticated” (sant om station, falskt om mötespunkt), samt latitud ”Y” och longitud ”X”
(se Figur 3.3).

27
Tågtabellen ”trainlocations” skulle innehålla nio attribut, varav ett primärnyckelpar som
omfattade två av attributen. Tågets/fordonets ID-nummer ”Vehicle” och tidsstämpel för
avläsningen ”Time” (som tillsammans utgör primärnyckeln), annonserat/publikt nummer
”PublicNumber”, tekniskt/internt nummer ”InternalNumber”, status på tågets GPS-signal
”Active”, tågets latitud ”Y” och longitud ”X”, hastigheten ”Speed” samt riktningen tåget åker
i ”Angle” (som dock inte användes till något i denna lösning) (se Figur 3.3).
3.9 Design av dataomvandlarna
Dataomvandlarna skulle ha kontakt med varsin tabell i databasen samt varsin källa där indatan
kom från. Databasuppkopplingen skulle ske genom en MySQL-uppkoppling, och stations-
dataomvandlaren skulle skicka en förfrågan till Trafikverket om hämtning av stationsdata.
Detta skulle sedan tolkas och konverteras till SQL-vänlig kod som skrev till databasen. I
händelse av att kontakten bröts med databasen skulle omvandlaren stoppa uppladdningen och
upprepa uppkopplingsförsöket tills en återanslutning hittats och kommunikationen med
databasen kunde fortsätta. Tågdataomvandlaren skulle istället lyssna på Oxyfi:s dataström för
att kunna hämta tågdatan. För varje meddelande skulle detta tolkas och konverteras till SQL-
vänlig kod som sedan skrev till databasen. I händelse av att kontakten bröts skulle omvandlaren
kasta det uppladdade meddelandet och göra ett återuppkopplingsförsök. Detta skulle göras en
gång per meddelande då det handlar om realtidsdata och inte statiska data som för stationerna.
Figur 3.3 Databasens tabeller

28
3.10 Design av det grafiska gränssnittet
Det grafiska gränssnittet var ett komplement till databassystemet (databasen och omvandlarna)
och skulle presentera datan på ett snyggt men smidigt sätt. De första redan existerande kartor
som övervägdes att användas var MapBox eller Google Maps. MapBox valdes då dess
redigeringsmöjligheter för olika kartdesigner var mycket bättre än vad Google erbjöd.
Dessvärre gjordes ändringar i slutskedet av projektet och MapBox bytes bort mot Google Maps
på grund av problem med MapBox (se Kapitel 5.2.2).
Båda API:erna (MapBox och Google Maps), var gratis att använda. MapBox hade en
begränsning på hur ofta man kunde ladda in kartan, men begränsningen låg högt nog för att inte
skapa en oro för att behöva betala för överflödet av användning. Google Maps var gratis i ett år
för utvecklare.
För denna prototypversion valdes det att endast ha kartan på webbsidan utan någonting annat
(se Figur 3.4). Framtida möjligheter skulle kunna vara tabeller med tågens/valda tågs
information, så som hastighet, och förseningar.
Se även Figur 1.1 för hur systemet är tänkt att se ut och användas.
Figur 3.4 Första gränssnittsdesignen

29
4 Implementation
Hur implementationen genomfördes beskrivs utförligt i detta kapitel. Då flera olika mindre
program är delaktiga i hela processen, och då flera tidigare implementationer tvingats skrotas,
så delas dessa beskrivningar in i mindre delkapitel, där var och en genomgående beskriver en
huvudsaklig del i implementationen. Alla de problem som stöttes på under projektets gång tas
upp i kapitel 5.
4.1 Introduktion
Grundfunktionaliteten hos programmet var att lättvindigt kunna hämta in data från flera olika
källor och spara dem i en enda gemensam databas. Andra program skulle därefter kunna hämta
denna data för att enkelt kunna göra beräkningar på de tåg som datan avser och kunna skapa
grafiska lösningar för att förenkla lokalisering och informationshämtning för operatörer och
eventuellt resenärer. En sådan grafisk lösning är även inkluderad i detta program.
Källkod för stationsdataomvandlaren hittas i Bilagor A.1, tågdataomvandlaren hittas i Bilagor
A.2 och webbgränssnittet hittas i Bilagor A.3.
Mjukvara och programspråk som använts under implementationen
Då hela projektet bestod av mindre program som utförde olika typer av operationer har flertalet
olika språk använts.
1. De två programmen som kommunicerade med Trafikverket och Oxyfi skrevs båda i
C#.NET för att hämta in nödvändiga data, och använder SQL-kommandon för att
kommunicera med projektets databas.
2. Den grafiska klienten skrevs i HTML, PHP, SQL, JavaScript. Även lite CSS användes,
vilket kan ses som stilmallar för att beskriva hur HTML-element ska presenteras [35].
3. XAMPP Control Panel 3.2.2 användes för att kunna köra en lokal Apache server
tillsammans med en MariaDB-modul, där den inhämtade datan förvarades, när den
dedikerade databasen inte var tillgänglig.
4. Visual Studio Community 2017 användes som IDE (Integrated Development
Environment).
5. Git användes för versionshantering.

30
4.2 Lokalisering av tågstationer och mötespunkter på järnvägen
Inhämtning av data och felhantering
Namn, koordinater, signaturer och urskiljning av stationer och mötespunkter hämtades från
Trafikverket med deras egna API (se Figur 4.1), och lades in i en egen tabell i databasen. Denna
funktion kördes en gång då värdena den får in var statiska platser och behöver inte automatiskt
uppdateras. Skulle det dock hända att förändringar skedde genom exempelvis att en ny järnväg
lades till kunde man manuellt köra operationen igen.
När operationen sätts igång kan flera olika saker hända vid dataöverföringen då databasen kan
vara både tillgänglig eller otillgänglig
1. Operationen startas, men databasen är otillgänglig.
När operationen startas så etableras en anslutning till databasen. Skulle en sådan inte
hittas repeteras anslutningsförsöket utan automatiskt stopp tills att en anslutning hittats.
Skulle en anslutning aldrig hittas måste programmet stängas av manuellt, skulle beslutet
tvingas att fattas.
2. Operationen startas, och databasen är tillgänglig.
När operationen startas så etableras en anslutning till databasen. Operationen genomförs
och en eventuellt äldre variant av tabellen tas bort och ersätts med en ny version (skulle
tabellens struktur ha behövt ändras). Värdena laddas sedan upp i tabellen.
3. Operationen kör, men anslutningen till databasen avbryts mitt i dataöverföringen.
Skulle databasen plötsligt bli otillgänglig (till exempel vid strömavbrott, nätverksfel,
systemkrasch m.fl.) försöker programmet återansluta till databasen och dataöverföringen
pausas tills att en återanslutning kunnat genomföras. Dataöverföringen fortsätter sedan
som normalt från där den slutat fungera utan att hoppa över missade överföringar.

31
Figur 4.2 Utdrag ur svaret Trafikverkets API
Figur 4.1 Frågan som skickas till Trafikverkets API

32
Formatering av inhämtade data
Datan som hämtades från Trafikverket (se Figur 4.1) var i ett JSON-format (se Figur 4.2) och
behövde först tolkas för att kunna extrahera värdena så de kunde skickas in till databasen. För
att tolka JSON-datan användes ett reguljärt uttryck (se Figur 4.3). Parenteserna i uttrycket är
grupper som sedan går att anropa för att få in just den data som finns mellan parenteserna.
Första gruppen som hämtas in är ”AdvertisedLocationName” och matchar bara om JSON-datan
innehåller just den textsträngen, följt av ”.{0,40}” vilket betyder att upp till och med 40
godtyckliga tecken grupperas in till ett ord eller mening. Detta är själva namnet på trafikplatsen
och kan innehålla mer än ett ord.
Grupp tre matchar ”Geometry” och visar att trafikplatsens koordinater kommer.
Matchningen måste även här vara exakt. Grupp fyra och fem är båda ”[0-9.]*” vilket matchar
godtyckligt antal tecken som är antingen siffror eller punkter. Detta motsvarar trafikplatsens
koordinater i longitud och latitud.
Grupp sex matchar ”LocationSignature” och måste vara en exakt matchning. Följt kommer
då trafikplatsens signatur. Exempelvis så har Stockholm Central signaturen ”Cst”, Karlstad C
har signaturen ”Ks”, och Göteborg C har signaturen ”G”. Detta är då matchningen i grupp sju
där signaturen kan vara ett till och med tjugo godtyckliga tecken, men vanligtvis är det inte mer
än fyra till fem tecken som mest. Signaturen är unik för varje trafikplats.
Grupp åtta matchar ”Prognosticated” och måste vara en exakt matchning. Grupp nio matchar
antingen ”true” eller ”false”. En prognostiserad trafikplats är en tågstation eller mötespunkt där
av- och påstigning antas vara tillåten. En ej prognostiserad trafikplats är en mötespunkt där på-
och avstigning vanligtvis inte tillåts enligt föregående antagande. Detta antagande har gjorts då,
vid kontroll av markörplacering på kartan, prognostiserade trafikplatser hamnat på tågstationer,
och ej prognostiserade trafikplatser hamnat på enbart mötespunkter.
Den skarpsynte kan se att det reguljära uttrycket använder apostrofer (’) medan JSON-strängen
som hämtas från Trafikverket använder citationstecken (”). Stationslokaliseraren formaterar om
JSON-strängen då det reguljära uttrycket blir lättare att hantera i koden.
Figur 4.3 Reguljärt uttryck för tolkning av Trafikverkets JSON-data

33
Stationstabellens SQL-struktur och inmatning av data
Stationstabellen är den tabell som har hand om alla trafikplatser, där deras namn, koordinater,
signaturer och trafikplatstyp sparas. Signaturen är alltid unik och används därför som
primärnyckel (flera rader kan inte ha samma värde i sin primärnyckel) i databasen.
Koordinaterna är av WGS84-format [36], där heltalen representeras av grader och decimaler.
Trafikplatstyperna är i det här fallet antingen är prognostiserade eller inte. Se Figur 4.4 för
utdrag från stationstabellen.
Stationslokaliserarens enda uppgift är att formatera den inhämtade JSON-datan, så att den
kan laddas upp till databasen. Uppladdningen sker med SQL-kommandon, där den eventuellt
äldre versionen av tabellen tas bort. Anledningen är att tabellens struktur kan ha uppdaterats.
Exempel på anledningar kan vara att Trafikverket helt byggt om sin egen struktur på sin data,
vilket eventuellt kan innebära att tabellens struktur också måste uppdateras.
4.3 Lokalisering av aktiva och inaktiva fordon
Inhämtning av data och felhantering
Fordonsnummer (statiskt nummer knutet till just det fordonet), annonserat nummer (det
nummer som resenärer ser), tekniskt nummer (internt nummer som trafikledningen ser, då ett
tåg kan ha olika tekniska nummer om det kör på fler än en sträcka), koordinater, tidpunkter och
hastighet hämtades genom Oxyfi och deras realtidspositionerings-API. Den inhämtade datan
lades in i en egen tabell i databasen. Denna funktion var byggd för att köras oavbrutet och
stannar vid manuell avstängning.
Figur 4.4 Utdrag ur stationstabellen

34
När operationen sätts igång kan flera olika saker hända vid dataöverföringen då databasen kan
vara både tillgänglig och otillgänglig.
1. Operationen startas, men databasen är otillgänglig.
När operationen startas så etableras en anslutning till databasen. Skulle en sådan inte
hittas repeteras anslutningsförsöket utan automagiskt stopp tills att en anslutning hittats.
Skulle en anslutning aldrig hittas måste programmet stängas av manuellt.
2. Operationen startas, och databasen är tillgänglig.
När operationens startas så etableras en anslutning till databasen. Operationen genomförs
och en eventuellt äldre variant av tabellen tas bort och ersätts med en ny version (skulle
tabellens struktur ha behövt andras). Värdena laddas sedan upp i tabellen.
3. Operationen körs, men anslutningen till databasen avbryts mitt i dataöverföringen.
Skulle databasen plötsligt bli otillgänglig (till exempel vid strömavbrott, nätverksfel,
systemkrasch m.fl.) försöker programmet återansluta till databasen och dataöverföringen
pausas tills att en återanslutning kunnat genomföras. Dataöverföringen fortsätter sedan
som normalt från där den slutat fungera utan att hoppa över missade överföringar.
Figur 4.5 Exempel på inhämtad data från Oxyfi
Figur 4.6 Reguljärt uttryck för tolkning av Oxyfi:s data

35
Formatering av inhämtade data
Datan som hämtades in är i ett NMEA GPRMC-format (se Figur 4.5) och behövde tolkas och
konverteras så att värdena kunde skickas till databasen. För att tolka NMEA GPRMC-datan
användes ett reguljärt uttryck (se Figur 4.6).
På första raden: de tre första grupperna som matchar ”[0-9]{2}” vilket är ett godtyckligt
nummer mellan 10 och 99. Dessa tillsammans bildar en tidstämpel, där den första matchningen
är timmar, andra är minuter, och tredje är sekunder. Den fjärde matchningen är ”[.0-9]*” och
matchar eventuella millisekunder, skulle sådana finnas.
På andra raden: först matchas antingen ett ”A”, som betyder ”OK”, eller ett ”V” för att
indikera en varning då något kan vara fel med positionssändningen. Sedan matchas ”[0-9.]*”
där värdet kommer vara tågets longitud, följt av en matchning av antingen ”N”, för nord, eller
”S” för syd. ”[0-9.]*” matchas återigen för tågets latitud och ”E” eller ”W” matchas för öst eller
väst.
På tredje raden: först matchas ”[0-9.]*” vilket blir tågets hastighet i knop, sedan matchas
”[0-9.]*” för tågets riktning i grader (0-360). Nästkommande tre matchningar, ”[0-9]{2}”,
matchar datumet där den första är året ”ÅÅ”, andra är månaden ”MM” och tredje är dagen
”DD”.
På fjärde raden: först matchas ”[0-9.]*” och antingen ”E” eller ”W”. Detta är den magnetiska
variationen, i vilken riktning, och hur gravt. Detta värde skickas dock inte in till databasen.
Detta följs av en matchning av ett till sex godtyckliga tecken, där checksumman finns. Denna
används dock inte.
Sedan fortsätter matchningen på fjärde raden men resterande matchning är nästlad. I Figur 4.7
har det reguljära uttrycket gjorts mer läsbart. Varje parentes indikerar en ny grupp, och varje
slutparentes indikerar slutet på en grupp. Enligt radnumreringen i Figur 4.7 matchas först ”[0-
9]+” mellan rad 1 och 3, vilket är tågets unika ID-nummer. Detta är unikt för varje tåg och
ändras inte mellan olika resor. Nästa grupp är mellan rad 3 och 30 och kan exempelvis kallas
för ”3-30”, där slutparentesen på rad 30 följs av ett frågetecken. I den här gruppen matchas först
en intern grupp ”[0-9]+”, tågets annonserade eller tekniska nummer, följt av ”public” eller
”internal”, vilket indikerar om det föregående numret är annonserat/publikt eller
tekniskt/internt, följt av en upprepning av gruppen ”3-30”. Denna gruppen ”8-29” fungerar

36
likadant som ”3-30” och har en egen nästlad grupp ”14-28”, som fungerar likadant som ”8-29”,
som i sig har en egen nästlad grupp ”20-27”. Denna sista nästlade grupp har dock ingen egen
nästlad grupp.
Det som händer i ”3-30” är att den matchar ett tågs annonserade/publika eller tekniska/interna
nummer. Anledningen till att den matchar flera grupper nästlade är att ett tåg kan ha olika
annonserade/publika och tekniska/interna nummer, och dessutom ha flera annonserade/publika
och tekniska/interna nummer då ett tåg kan köra på fler än en sträcka (därav flera
tekniska/interna nummer) eller vara försenat till sin nästa resa (därav flera annonserade/publika
nummer). Anledningen till att alla dessa nästlade grupper följs av ett frågetecken är att
grupperna inte behöver existera, detta skulle medföra att tåget inte alltid har ett
Figur 4.7 Utdrag ur det reguljära uttrycket för
tolkning av Oxyfi:s data

37
annonserat/publikt eller tekniskt/internt nummer i databasen, så inte alla fordon alltid har det.
De som inte har ett annonserat/publikt eller tekniskt/internt nummer får värdet 0 i databasen.
De flesta värdena som hämtades vid alla matchningar behövede inte konverteras, utan kunde
direkt läggas in i databasen. Däremot så behövde värdena för longitud, latitud och hastigheten
konverteras till rätt format och värden. Hastigheten var enklast att konvertera, vilket var angett
i knop och konverteras då till km/h. Longitud och latitud var däremot lite krångligare att
konvertera. Koordinaterna var angivna i ett format som liknar WGS84, men satte
decimaltecknet på ett annat ställe. Formatet använde grader, minuter och decimaler istället för
endast grader och decimaler. Graderna konkatenerades med minuterna och decimalerna, vilket
resulterade i en longitud som såg ut såhär: ”GGGMM.DDDD” där GGG är grader 000-180,
MM är minuter 00-59 och DDDD är decimaler 0000-9999, och en latitud med
”GGMM.DDDD”, där GG är grader 00-90. Koordinaterna är således stora tal på upp till 18 000,
med decimaler på upp till 9999.
För att det skulle matcha med koordinatsystemet som stationerna och Google Maps använde
behövde de konverteras till ett tal med värdena ”GG.DDDDDD” (eller ”GGG.DDDDDD”).
Detta gjordes med följande matematisk formel:
𝑎 = ⌊𝑏
100⌋ +
(𝑏
100 − ⌊𝑏
100⌋)
0,6
Värdet ”a” är den konverterade koordinaten på formen ”GG.DDDDD” och ”b” är den
inhämtade koordinaten på formen ”GGMM.DDDD”.
Tågtabellens SQL-struktur och inmatning av data
Tågtabellen (se Figur 4.8) är den tabell som har hand om alla aktiva och inaktiva fordon, där
deras annonserade/publika och tekniska/interna nummer, koordinater, tidpunkter och
hastigheter sparas. Fordonets unika nummer används som identifierare och är ett fyra till fem
tecken långt nummer som tillsammans med tidpunkten är primärnyckel i tabellen. Detta för att
kunna spara undan äldre data, utifall man vill kunna gå tillbaka och se var ett tåg varit vid en
viss tidpunkt.
Tåglokaliserarens enda uppgift är att formatera om NMEA GPRMC-datan så att den kan
laddas upp till databasen. Uppladdningen sker med SQL-kommandon, där den eventuellt äldre
versionen av tabellen tas bort vid uppstart. Detta då tabellens struktur kan ha uppdaterats, då
mer data kan behöva läggas in i tabellen vid nyare versioner.

38
4.4 Databas och versionshantering
Utvecklingsmiljö
Under utvecklingen och testning av systemen sattes en testmiljö upp på en av utvecklings-
datorerna. Detta gjordes med hjälp av XAMPP som gav tillgång till en Apache server och en
MariaDB-databas färdigkonfigurerad och redo att köras. Anledningen till att XAMPP valdes
att användas var för att hålla testdatan separerad ifrån den faktiska datan. Detta för att inte
riskera att lägga in trasiga data i databasen och för säkrare hantering av datan som användes
under utvecklingen. Dessutom underlättade detta utvecklingen då det möjliggjorde att alltid
kunna ha datan tillgängligt lokalt och därav blev frekvent testning av programmet smidigare
och enklare. En konfigurering som gjordes var att lägga till ett användarkonto med ett lösenord
för att kunna hämta och ladda upp data till MariaDB-databasen. Därefter skapades en ny databas
manuellt där stationslokaliseraren och tåglokaliseraren sedan skickade data till sina separerade
tabeller.
Produktionsmiljö
Produktionsmiljön bestod av Git för versionshanteringen av systemen. Detta gjorde det möjligt
att arbeta på samma kod samtidigt på olika brancher och testa dessa utan att påverka de delar
av systemet som var fullt fungerande. Med hjälp av Docker sattes det upp en MariaDB container
som stationslokaliseraren och tåglokaliseraren kunde skicka data till. Denna fanns på Softcode:s
server. En VPN tilldelades av Softcode för att kunna nå servern när utvecklingen skedde utanför
Figur 4.8 Utdrag ur tågtabellen

39
kontoret där nätverket inte var tillgänglig. För att visualisera innehållet i databasen så användes
MySQL Workbench.
4.5 Visualisering av data
Tågens unika ID-nummer, tidstämpel, koordinater, annonserat/publikt nummer och hastighet
hämtades in från databasen med SQL-kod och lades upp på en separat PHP-sida från den sida
där kartan visades (se Figur 4.9). Tågens unika identifieringsnummer, annonserat/publikt
nummer och hastighet för de tåg som var i närheten av en trafikplats lades även upp på en annan
Figur 4.9 Utdrag ur JSON-strängen som
kartan hämtar för att rita ut tågen Figur 4.10 Utdrag ur JSON-strängen
som kartan hämtar för att se tåg vid
trafikplatser
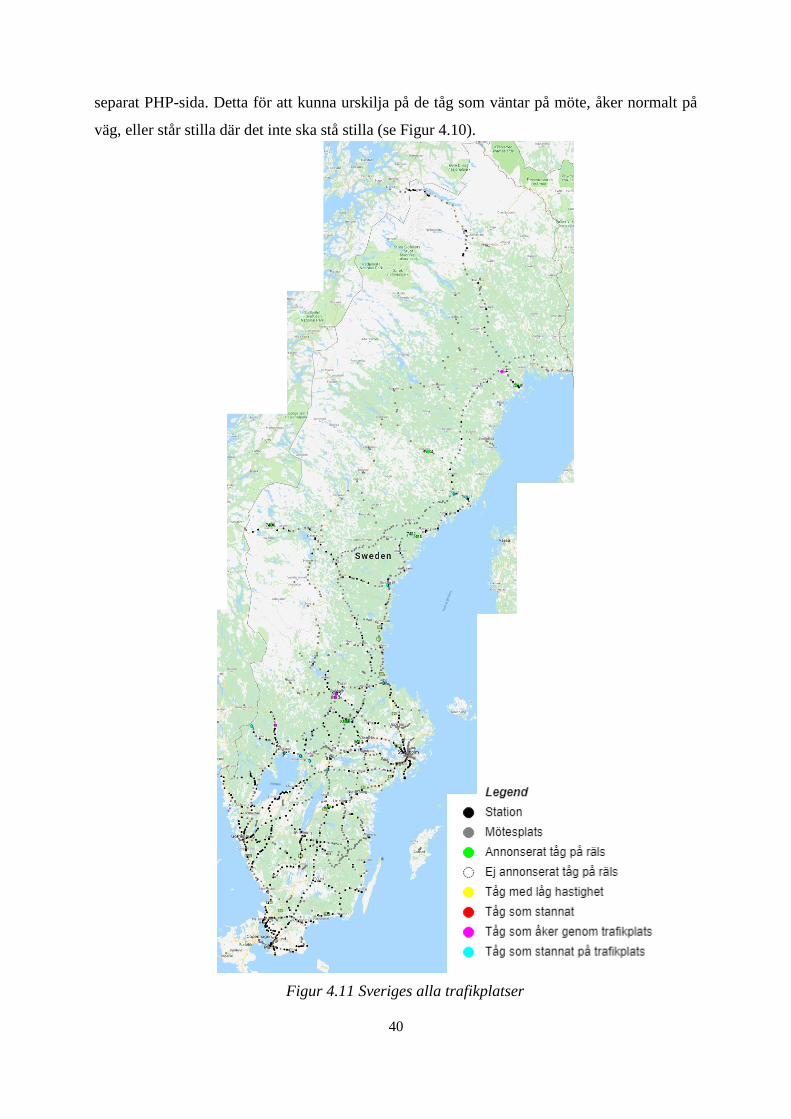
40
separat PHP-sida. Detta för att kunna urskilja på de tåg som väntar på möte, åker normalt på
väg, eller står stilla där det inte ska stå stilla (se Figur 4.10).
Figur 4.11 Sveriges alla trafikplatser

41
Gränssnittet för kartan ligger på en PHP-sida, där genereringen av kartan görs i JavaScript. För
att rita ut själva kartan användes Google Maps API, där trafikplatser och tåg sedan ritas ut. De
trafikpunkter som visas på kartan är begränsade till Värmland och ett fåtal tilliggande
trafikplatser (se Figur 4.12), så som till exempel Åmål. Begränsningen är gjord med hjälp av
koordinater och bildar en rektangel där trafikplatser inom begränsningarna visas. Detta på grund
av att de för nuvarande över 1 600 i Sverige existerande trafikplatser är väldigt prestanda-
krävande att rita ut (se Figur 4.11), då de datorer som använts inte klarat av att hantera så många
punkter på en gång utan att bli långsamma och oresponsiva. Stationer ritas ut som svarta prickar,
mötespunkter ritas ut som mörkgråa prickar.
Till skillnad från trafikplatserna så ritas alla i databasen existerande tåg dock ut. Detta på grund
av att det är få tåg som kör i enbart Värmland vid godtyckligt angiven tidpunkt, och att få in
fler tåg som kan påvisa programmets funktionalitet tycktes vara bra. Tågen, likt trafikplatserna,
ritas ut med JavaScript, men datan hämtas inte direkt från databasen, utan från de två separata
PHP-sidorna. En JavaScript-funktion körs kontinuerligt med ett intervall på 1 000
Figur 4.12 Värmlands (med omnejd) alla trafikplatser

42
millisekunder, där den exekverar de två PHP-sidorna, genom ett Ajax-anrop, för att kunna läsa
in den data som ligger där, och för att kunna se till att den data som hämtas från databasen är
den senaste. Datan som hämtas är två olika textsträngar, som sedan konverteras till mer läsbart
JSON-format (se Figur 4.9 och 4.10). Med hjälp av reguljära uttryck läses varje JSON-objekt
av för att kunna få ut tågens information (som beskrivet i början på detta delkapitel).
Skulle ett avläst tåg inte redan finnas på kartan, eller vid uppstart av programmet, ritas tågen ut
på kartan med en gul färg. Tågets annonserade/publika nummer skrivs ut på markören. Om
tågen dock redan finns så uppdateras istället deras koordinater och eventuellt färg.
1. Ett tåg med en hastighet över 30 km/h utanför trafikplats markeras med grön färg (vit för
tåg som inte har ett annonserat/publikt nummer).
2. Tåg som kör mellan 10 och 30 km/h markeras med gul färg. Detta för att kunna se om
ett tåg åker ovanligt långsamt.
3. Ett tåg som kör över 10 km/h och är i närheten av en trafikplats markeras istället med en
lila färg. Dessa tåg accelererar eller bromsar vanligtvis in inför en station, eller kör
igenom en mötespunkt. Detta för att en operatör ska kunna se när ett tåg passerar en
trafikplats.
4. Ett tåg som har en hastighet på mindre än 10 km/h i närheten av en trafikplats markeras
med ljusblå färg. Detta för att urskilja på de tåg som står stilla på mötespunkter eller
stationer mot de tåg som står stilla ute på räls där de inte ska stå stilla.
5. Ett tåg som har en hastighet på mindre än 10 km/h utanför trafikplats markeras med röd
färg. Detta för att en operatör snabbt ska kunna se att det eventuellt kan ha skett en
olycka, så som urspårning, krock med till exempel personbil vid vägkorsning, krock med
vilt djur m.fl.

43
5 Utvärdering
I detta kapitlet ges ett resultat på hur projektet har gått och även en utvärdering av systemet och
de mål som sattes för projektet. Vidare kommer dessutom de problem som uppstått under
projektet att presenteras och även en mer detaljerad förklaring till problemen.
5.1 Resultat
Projektet resulterade i ett enkelt datainsamlingssystem med en grafisk visualisering av den
inhämtade datan (se Figur 5.1). I kapitel 3 presenterades ett antal användarfall som sattes som
mål för projektet.
• Det första målet var att kunna följa tåg i realtid på en karta. Detta mål fullföljdes, även
om det inte är de tåg som var önskat att presenteras så är det fortfarande tåg i realtid
som man kan se förflytta sig på kartan.
Figur 5.1 Översikt över de aktiva tågen i Värmland

44
• Det andra målet var att kunna se om tågen står stilla vilket fullföljes under projektet. Då
alla tåg markeras med olika färger beroende på deras hastighet och placering. Tåg som
står stilla på plats där de inte ska göra det markeras som röda.
• Det tredje målet var att kunna se tåg som ankommer, avgår eller har varit på en specifik
trafikplats. På grund av den lilla tiden som fanns kvar och avsaknad av rätt data så kunde
inte detta mål fullföljas. Detta främst på grund av svårigheter i att få tillgång till data
över tågens planerade körväg eller störningsinformation, vilket gjorde att det inte gick
att göra några beräkningar på hur tågen skulle köra. Då implementeringen startade
mycket senare än vad som faktiskt var planerat så fanns det inte tillräckligt med tid för
att komma på en lämplig lösning för att få in den datan som behövdes.
Emellertid går det dock att se tåg som avgår och ankommer till en trafikplats, i och med
den visuella delen av kartan, dock inte genom att välja en trafikplats och se planerade
ankomster och avgångar.
Systemet kan idag användas till att följa tåg som körs av Värmlandstrafik, Norrtåg och TÅGAB
och kan enkelt konfigureras om för att istället presentera andra tågkompaniers tåg om deras
data blir tillgänglig.
5.2 Problem
Detta projekt har haft flera problem som under hösten har fördröjt utvecklingen med flera
veckor. I detta delkapitel ges en mer detaljerad förklaring av de problem och motgångar som
stöttes på under projektets gång, och vilka konsekvenser dessa har haft på projektet.
GDPR-skyddade data och tillgång till API:er
Ett problem som stöttes på från SJ var inhämtningen av data över tågens positioner mm. Tanken
från början var att använda SJ:s data över de tåg som idag på något sätt samlade in GPS-
information. Dessvärre blev väntan på att få tillgång till API:erna lång (enda fram till december)
och under tiden hade ett byte skett till att hämta data från andra källor (Tidigare omnämnda
Oxyfi). Det som försvårade mycket var att data som hämtades in kunde innehålla information
om personal och detta minskade möjligheterna att få tillgång till den då den var GDPR-skyddad.
Annat som försvårade tillgång till datan var att vi ständigt skickades runt till flertalet olika
personer. När frågan om tillgång till API:erna ställdes så skickades frågan vidare till näste
person i ledet. Inom kort så hade det blivit till en ond cirkel med många samtal och mail fram

45
och tillbaka mellan oss och trafikledningen, där resultatet var många veckors väntan och till
slut ingen tillgång till någon data alls.
API:er som inte ville fungera
Redan de första veckorna i september hittades ett till synes väl fungerande API för ett
webbgränssnitt som kunde rita ut punkter på en karta. Detta API tillhandahölls av MapBox, och
kartan som användes hämtade MapBox från Open Street Map. Efter att ha först läst på om
API:ets funktionalitet under en vecka påbörjades testning av API:et för att se huruvida det
fungerade som det skulle. Under några veckor experimenterades det med realtidsuppdaterande
exempeldata som MapBox refererade till i sina manualer. Först så testades själva kartan i sig,
för att se om den överhuvudtaget gick att rendera i webbläsaren. Detta verkade fungera mycket
bra, så testningarna fortsatte med att försöka få en punkt att röra sig på kartan. Detta fungerade
även det, så tester med den existerande exempeldata som tillhandahölls började genomföras.
Samtidigt som dessa tester gjordes börjades det även experimenteras med olika kartdesigner för
att kunna ta bort så mycket onödig information som möjligt för att kunna få ett enkelt och
prestandavänligt gränssnitt som användaren sedan kan jobba med. Prestandan är i det här fallet
mycket viktig då flera animerade punkter kan komma att göra programmet långsamt och till
synes oresponsivt. MapBox erbjuder sina användare att kunna redigera de färger som
kartobjekten har, samt att till och med ta bort objekt från kartan helt och hållet. Detta var något
som önskades att användas till åtminstone en av de flera vyer som var planerade att
implementeras, där prioriteringen enbart skulle ligga på att visa räls, tåg, trafikplatser, samt att
kunna urskilja mellan land och vatten.
Med hjälp av tilesets och datasets kan punkter i GeoJSON-format på förhand ritas ut på kartan
och därmed öka prestandan på kartan och på så sätt kunna rita ut så många trafikplatser som
möjligt utan att prestandan tar för mycket stryk. Ett godtyckligt antal punkter fick därför ritas
ut först för att testa funktionaliteten och prestandan av kartan. Detta gjordes innan inhämtningen
av alla trafikplatsers koordinater, namn och annan information från trafikverkets sida och deras
API:er.
När såväl detta sedan testades i samband med testningen av realtidsdatan och de manuellt
angivna trafikplatserna verkade inga konkreta problem uppstå. Däremot gick allt snett när
testningen av egen realtidsdata började. Denna så kallade realtidsdata var i själva verket en

46
GeoJSON-sträng, kopierad från den exempeldata som redan använts vid tidigare tester, inlagd
i en GeoJSON-fil som låg i en lokal mapp på datorn. När bytet skedde till den lokala filen
istället för exempeldatan ville punkten inte längre ritas ut. Flertaliga försök med olika filtyper
så som JSON och HTML testades med till ingen nytta. Filerna testades även att läggas upp på
en webbserver som vi hade temporär tillgång till men inte heller det verkade fungera. Länge
undersöktes det om det möjligtvis kan ha varit en websocket av något slag som pushade upp
datan, men exempeldatan visade sig ligga på ett HTTPS-server vilket gjorde att vi fick börja
leta efter andra lösningar på problemet.
Vid det här laget hade redan halva oktober passerat och fram till början på november försökte
en lösning hittas på detta problem men förgäves hittades inga lösningar vare sig på MapBox
egna webbsida, dokumentation eller tutorials. Inte heller fanns det någon lösning på flertalet
programmeringsinriktade webbforum. Vid det här laget hade implementationen av inhämtning
av data från trafikverket påbörjats. Dessutom hittades ett API för inhämtning av tågpositioner
på www.trafiklab.se genom Oxyfi och deras verktyg (som nämndes i förra delkapitlet) så att
kunna hämta hem faktiska data gavs en högre fokus än innan. Sökandet efter lösningar till
MapBox-problemet fortsatte bredvid.
Så sent som i början på december hittades till sist PubNub, ett API specialiserat på att kunna
rita ut flertalet olika punkter på en karta från realtidsdata. PubNub skulle fungera på både
MapBox och Google Maps. Med tanke på de kartfunktionaliteter som MapBox hade valdes det
att försöka få det att fungera med MapBox. Problem uppstod dock ganska fort då det
uppdagades att PubNub var gjord för en äldre, numera otillgänglig, version av MapBox. Det
resulterade i att kartan fick till slut istället göras i Google Maps. Kort därefter fanns till slut en
fungerande karta med statiska tåg- och stationsmarkörer. Koden för realtidsuppdateraren hade
inte skrivits ännu.
Så till sist i mitten på december lyckades tågen till slut att röra på sig på kartan. Ett annat
problem uppstod istället då det upptäcktes att tågens koordinater på kartan inte stämde överens
med vad de egentligen borde ha. Efter en lång dag med att samla in koordinater från olika tåg
landet över, genom att hämta deras koordinater när de stannat vid stationer och sedan jämfört
dessa koordinater mot varandra så insågs ganska fort att problemet låg i att Google Maps
koordinater och Oxyfi:s koordinater var på olika format. Google Maps använde sig av grader

47
och decimaler, medan Oxyfi använde sig av grader, minuter och decimaler. Efter att Oxyfi:s
koordinater konverterats om i tåglokaliseraren lyckades kartan till sist att fungera som den
skulle.

48
6 Slutsats
Här summeras projektet genom att presentera en helhetsbild av hur det har gått och även förslag
på hur systemet kan vidareutvecklas.
6.1 Helhetsbild av projektet
Projektet i det stora hela kunde gått mycket bättre till, under de förutsättningar att projektets
uppgift hade varit bättre definierad från början. Det vi inte tänkte på vid kursens start var
riskerna för att påbörja arbetet utan att få tillräckligt med information från trafikledningen. Vi
startade första veckan med att försöka definiera projektet bättre men upptäckte mycket tidigt
att det skulle uppkomma stora problem och att grundidén behövde omformas samt nya riktlinjer
behövde sättas. På grund av faktorer som avsaknad av material från SJ gjorde att projektet under
lång tid spenderades på att definiera specifikationen.
Trots dessa förutsättningar så tog projektet fart och resulterade i ett simpelt men fullt fungerande
verktyg för att följa ett antal tåg. Två av de mål som sattes vid framtagandet av den nya
specifikationen avklarades helt.
Vi hoppades hinna bygga ut systemet med ytterligare funktionalitet men är i grund och botten
nöjda med vår insats och tror att vi gjort allt som varit möjligt utifrån förutsättningarna. Vidare
presenteras exempel på hur vi skulle vidareutvecklat systemet.
6.2 Vidareutveckling av systemet
Vid en vidareutveckling av systemet kan man lägga till flera olika funktionaliteter. Hade vi haft
tid hade vi försökt implementera några av dessa. Exempel på funktionaliteter är möjligheten att
välja ett specifikt tåg och få fram dess planerade körväg, och hur den håller sig till sin tidtabell.
Med tanke på att kartan blev långsam att ladda när många trafikplatser renderades kan endast
det valda tågets planerade passeringar tänkas visas. Annat exempel på funktionalitet är att välja
en trafikplats och kunna se vilka tåg som passerat, alternativt välja en sträcka och se vilka tåg
som kör på sträckan, detta. Ytterligare exempel kan vara möjligheten att se planerade möten,
som eventuellt skulle kunna planeras om vid förseningar. Slutligen vore det fördelaktigt om

49
MapBox hade fungerat från start. Sannolikt hade vi kunnat haft fler funktioner, men också en
bättre design på kartan.

50
Referenser
Informationskällor
[1] SJ, “OM SJ,” [Online]. Tillgänglig: https://www.sj.se/sv/om/om-sj [Hämtad: 2018-10-
05].
[2] Techopedia, ”Structured Query Language” [Online] Tillgänglig:
https://www.techopedia.com/definition/1245/structured-query-language-sql
[Hämtad: 2019-01-16].
[3] Tutoralspoint, ”C - programspråk” [Online] Tillgänglig:
https://www.tutorialspoint.com/cprogramming/c_overview.htm [Hämtad: 2019-01-16].
[4] Techopedia, ”C++ - programspråk” [Online] Tillgänglig:
https://www.techopedia.com/definition/26184/c-programming-language
[Hämtad: 2019-01-16].
[5] Techopedia, ”Java” [Online] Tillgänglig:
https://www.techopedia.com/definition/3927/java [Hämtad: 2019-01-16].
[6] Techopedia, ”C-sharp” [Online] Tillgänglig:
https://www.techopedia.com/definition/26272/c-sharp [Hämtad: 2019-01-16].
[7] W3SCHOOLS, ”PHP” [Online] Tillgänglig:
http://php.net/manual/en/intro-whatis.php [Hämtad: 2018-12-05].
[8] W3SCHOOLS, ”HTML” [Online] Tillgänglig:
https://www.w3schools.com/html/html_intro.asp [Hämtad: 2018-12-05].
[9] Techopedia, ”JavaScript” [Online] Tillgänglig:
https://www.techopedia.com/definition/3929/javascript-js [Hämtad: 2019-01-16].
[10] Microsoft, ”Azure” [Online] Tillgänglig:
https://azure.microsoft.com/sv-se/overview/what-is-azure/ [Hämtad: 2018-12-21].
[11] Microsoft, ”Azure Database” [Online] Tillgänglig:
https://docs.microsoft.com/sv-se/azure/sql-database/ [Hämtad: 2018-12-21].

51
[12] Apache, ”Kafka” [Online] Tillgänglig:
https://kafka.apache.org/intro [Hämtad: 2018-12-21].
[13] Apache, ”Kafka documentation” [Online] Tillgänglig:
https://kafka.apache.org/documentation/ [Hämtad: 2019-01-16].
[14] Kubernetes, ”What is Kubernetes” [Online] Tillgänglig:
https://kubernetes.io/docs/concepts/overview/what-is-kubernetes [Hämtad: 2018-12-21].
[15] Kubernetes, ”Pods” [Online] Tillgänglig:
https://kubernetes.io/docs/concepts/workloads/pods/pod/ [Hämtad: 2019-01-16].
[16] OpenSource, ”Docker” [Online] Tillgänglig: [Hämtad: 2019-01-16].
https://opensource.com/resources/what-docker [Hämtad: 2018-12-23].
[17] Docker, ”Containers” [Online] Tillgänglig:
https://www.docker.com/resources/what-container [Hämtad: 2018-12-23].
[18] Microsoft, ”Git” [Online] Tillgänglig:
https://docs.microsoft.com/en-us/azure/devops/learn/git/what-is-git
[Hämtad: 2019-01-16].
[19] Atlassian, ”Version control” [Online] Tillgänglig:
https://www.atlassian.com/git/tutorials/what-is-version-control [Hämtad: 2019-01-04].
[20] Atlassian, ”What is git” [Online] Tillgänglig:
https://www.atlassian.com/git/tutorials/what-is-git [Hämtad: 2019-01-04].
[21] MySQL, ”Workbench” [Online] Tillgänglig:
https://www.mysql.com/products/workbench/ [Hämtad: 2019-01-04].
[22] OpenStreetMap, ”About Openstreetmap” [Online] Tillgänglig:
https://www.openstreetmap.org/about [Hämtad: 2019-01-04].
[23] Wikipedia, ”MapBox” [Online] Tillgänglig:
https://en.wikipedia.org/wiki/Mapbox [Hämtad: 2019-01-04].
[24] Wikipedia, ”Leaflet” [Online] Tillgänglig:

52
https://en.wikipedia.org/wiki/Leaflet_(software) [Hämtad: 2019-01-04].
[25] Wikipedia, ”Google Maps” [Online] Tillgänglig:
https://en.wikipedia.org/wiki/Google_Maps [Hämtad: 2019-01-05].
[26] PubNub, ”PubNub” [Online] Tillgänglig:
https://www.pubnub.com/solutions/realtime-updates/ [Hämtad: 2019-01-05].
[27] PubNub, ”EON” [Online] Tillgänglig:
https://www.pubnub.com/developers/eon/ [Hämtad: 2019-01-05].
[28] Apachefriends, ”XAMPP” [Online] Tillgänglig:
https://www.apachefriends.org/about.html [Hämtad: 2019-01-16].
[29] GPSworld, ”NMEA” [Online] Tillgänglig:
https://www.gpsworld.com/what-exactly-is-gps-nmea-data/ [Hämtad: 2019-01-05].
[30] W3SCHOOLS, ”Ajax” [Online] Tillgänglig:
https://www.w3schools.com/js/js_ajax_intro.asp [Hämtad: 2019-01-05].
[31] JSON, ”JSON” [Online] Tillgänglig:
https://www.json.org/ [Hämtad: 2019-01-05].
[32] Fitzgerald. Introducing Regular Expressions (Första upplagan). Sebastopol: O’Reilley
Media Inc; 2012. Kapitel 1, What Is a Regular Expression?; s 1-11
[33] Trafikverket, ”RFID” [Online] Tillgänglig:
https://www.trafikverket.se/tjanster/system-och-verktyg/trafik/identifiering-och-
positionering-av-jarnvagsfordon-rfid/ [Hämtad: 2019-01-03].
[34] Trafiklab, ”Oxyfi” [Online] Tillgänglig:
https://www.trafiklab.se/api/oxyfi-realtidspositionering [Hämtad: 2019-01-20].
[35] W3SCHOOLS, ”CSS” [Online] Tillgänglig:
https://www.w3schools.com/css/css_intro.asp [Hämtad: 2019-01-16].
[36] GisGeography, ”World Geodetic System” [Online] Tillgänglig:
https://gisgeography.com/wgs84-world-geodetic-system/ [Hämtad: 2019-01-16].

53
Bildkällor
[37] JSON, ”JSON object” [Online] Tillgänglig:
https://www.json.org/object.gif [Hämtad: 2019-01-05].
[38] JSON, ”JSON array” [Online] Tillgänglig:
https://www.json.org/array.gif [Hämtad: 2019-01-05].
[39] JSON, ”JSON value” [Online] Tillgänglig:
https://www.json.org/value.gif [Hämtad: 2019-01-05].
[40] JSON, ”JSON string” [Online] Tillgänglig:
https://www.json.org/string.gif [Hämtad: 2019-01-05].
[41] JSON, ”JSON number” [Online] Tillgänglig:
https://www.json.org/number.gif [Hämtad: 2019-01-05].
[42] Trafikverket, ”RFID” [Online] Tillgänglig:
https://www.trafikverket.se/contentassets/1cdf41b979b24b8eafe1b2f2d421c72e/identifi
ering_och_positionering_brodtext.png [Hämtad: 2019-01-05].

54
A Bilagor
A.1 Stationsdataomvandlaren
using System; using System.Collections.Generic; using System.IO; using System.Linq; using System.Net; using System.Text; using System.Text.RegularExpressions; using System.Xml; using System.Xml.Linq; using MySql.Data; using MySql.Data.MySqlClient; namespace StationLocator { class Program { static void Main(string[] args) { string Server = "SERVER_LOCATION", UserID = "USER", Password = "PASSWORD", Database = "DATABASE"; string Credentials = @"server=" + Server + ";userid=" + UserID + ";password=" + Password + ";database=" + Database; string StationTable = "TrainStations"; bool ConnectionSuccess = false; MySqlConnection conn = null; WebClient webclient = new WebClient(); do { try { conn = new MySqlConnection(Credentials); conn.Open(); Console.WriteLine("MySQL version: {0}", conn.ServerVersion); Console.WriteLine("--- Download data sample ---"); webclient.UploadStringCompleted += (obj, arguments) => { if (arguments.Cancelled == true)

55
{ Console.Write("User Cancelled Request"); } else if (arguments.Error != null) { Console.WriteLine(arguments.Error.Message); Console.Write("Request Failed"); } else { string Result = arguments.Result.Replace("\"", "'"); Regex RGX = new Regex(@"\{\'(AdvertisedLocationName)':'" + @"(.{0,40})',.?'"(Geometry)':{'WGS84':'POINT.{0,2}" + @"\(([0-9.]*) ([0-9.]*)\)'},'(LocationSignature)': " + @"'(.{1,20})','(Prognosticated)':(true|false)}"); MySqlCommand RMVT = new MySqlCommand(); RMVT.Connection = conn; RMVT.CommandText = "DROP TABLE IF EXISTS " + StationTable + ";"; bool RemoveSuccess = true;
do { try { RMVT.ExecuteNonQuery(); Console.WriteLine("Removed previous instance of table"); RemoveSuccess = true; } catch (MySql.Data.MySqlClient.MySqlException error) { Console.WriteLine("Could not execute query!"); RemoveSuccess = false; } catch (System.InvalidOperationException error) { RemoveSuccess = false; try { conn.Open(); } catch (MySqlException e) { Console.WriteLine("Connection to the server was lost! " + "Reconnecting."); } } }

56
while (!RemoveSuccess); MySqlCommand CT = new MySqlCommand(); CT.Connection = conn; MySqlCommand AddStation = new MySqlCommand(); AddStation.Connection = conn; bool first = true, QuerySuccess = false; string LogText = "", geojson = ""; foreach (Match Set in RGX.Matches(Result)) { do { try { if (first) { first = false; CT.CommandText = "CREATE TABLE IF NOT EXISTS " + StationTable + " (" + Set.Groups[1].Value + " TEXT, " + Set.Groups[6].Value + " VARCHAR(11), " + Set.Groups[8].Value + " TEXT, Y DOUBLE, X DOUBLE, " + "PRIMARY KEY (" + Set.Groups[6].Value + "));"; Console.WriteLine(CT.CommandText); LogText += CT.CommandText + "\n\n"; geojson += "{\n\t\"features\": [\n"; CT.ExecuteNonQuery(); Console.WriteLine("Added new instance of table"); QuerySuccess = true; } AddStation.CommandText = "INSERT INTO " + StationTable + " (" + Set.Groups[1].Value + ", " + Set.Groups[6].Value + ", " + Set.Groups[8].Value + ", X, Y) " + "VALUES ('" + Set.Groups[2].Value + "', '" + Set.Groups[7].Value + "', '" + Set.Groups[9].Value + "', '" + Set.Groups[4].Value + "', '" + Set.Groups[5].Value + "');"; AddStation.ExecuteNonQuery(); QuerySuccess = true; Console.WriteLine("'" + Set.Groups[2].Value + "', '" + Set.Groups[7].Value + "', '" + Set.Groups[9].Value + "', '" + Set.Groups[4].Value + "', '" + Set.Groups[5].Value + "'"); LogText += AddStation.CommandText + "\n";

57
geojson += "\t\t{\n" + "\t\t\t\"type\": \"Feature\",\n" + "\t\t\t\"properties\": {\n" + "\t\t\t\t\"title\": \"" + Set.Groups[2].Value + "\"\n" + "\t\t\t},\n" + "\t\t\t\"geometry\": {\n" + "\t\t\t\t\"coordinates\": [\n" + "\t\t\t\t\t" + Set.Groups[4].Value + ",\n" + "\t\t\t\t\t" + Set.Groups[5].Value + "\n" + "\t\t\t\t],\n" + "\t\t\t\t\"type\": \"Point\"\n" + "\t\t\t}\n" + "\t\t},\n"; } catch (MySql.Data.MySqlClient.MySqlException error) { Console.WriteLine("Could not execute query!"); QuerySuccess = true; } catch (System.InvalidOperationException error) { QuerySuccess = false; try { conn.Open(); } catch (MySqlException e) { Console.WriteLine("Connection to the server was lost! " + "Reconnecting."); } } } while (!QuerySuccess); } DirectoryInfo OutputDir = Directory.CreateDirectory("C:\\__TSLT"); File.Create("C:\\__TSLT\\output.log").Dispose(); File.WriteAllText("C:\\__TSLT\\output.log", geojson); Console.Write("Data downloaded"); } Console.WriteLine(", press 'X' to exit."); }; ConnectionSuccess = true; }
catch (MySqlException e)

58
{ Console.WriteLine("Connection error, trying to reconnect!"); ConnectionSuccess = false; } finally { if (conn != null) { //conn.Close(); } } if (ConnectionSuccess) { try { // API server url Uri address = new Uri("http://api.trafikinfo." + "trafikverket.se/v1/data.json"); string requestBody = "<REQUEST>" + "<LOGIN authenticationkey='SECRET_API_KEY'/>" + "<QUERY objecttype='TrainStation' >" + "<INCLUDE>AdvertisedLocationName</INCLUDE>" + "<INCLUDE>LocationSignature</INCLUDE>" + "<INCLUDE>Geometry.WGS84</INCLUDE>" + "<INCLUDE>Prognosticated</INCLUDE>" + "</QUERY>" + "</REQUEST>"; Console.WriteLine("Fetching data ... (press 'C' to cancel)"); webclient.UploadStringAsync(address, "POST", requestBody); } catch (UriFormatException) { Console.WriteLine("Malformed url, press 'X' to exit."); } catch (Exception ex) { Console.WriteLine(ex.Message); Console.WriteLine("An error occured, press 'X' to exit."); } char keychar = ' '; while (keychar != 'X') { keychar = Char.ToUpper(Console.ReadKey().KeyChar); if (keychar == 'C') { webclient.CancelAsync(); } } }

59
} while (!ConnectionSuccess); } } }
A.2 Tågdataomvandlaren
using System; using System.Collections.Generic; using System.IO; using System.Linq; using System.Net; using System.Text; using System.Text.RegularExpressions; using System.Xml; using System.Xml.Linq; using WebSocketSharp; using MySql.Data; using MySql.Data.MySqlClient; namespace TrainLocator { class Program { static void Main(string[] args) { //Connect to database string Server = "SERVER_LOCATION", UserID = "USER", Password = "PASSWORD", Database = "DATABASE"; string Credentials = @"server=" + Server + ";userid=" + UserID + ";password=" + Password + ";database=" + Database; string TrainTable = "TrainLocations"; bool ConnectionSuccess = false; double SpeedMultiplier = 1.852; MySqlConnection conn = null; const string TrainPositionRGX = @"\$GPRMC,([0-9]{2})([0-9]{2})" + @"([0-9]{2})([.0-9]*){0,},(A|V),([0-9.]*),(N|S),([0-9.]*)," + @"(E|W),([0-9.]*),([0-9.]*),([0-9]{2})([0-9]{2})([0-9]{2})," + @"([0-9.]*|),(E|W|)(.{1,6}),([0-9]+)\.trains.se,,(;?([0-9]+)" + @"\.(public|internal)\.trains.se@[0-9-]*(;?([0-9]+)\." + @"(public|internal)\.trains.se@[0-9-]*(;?([0-9]+)" + @"\.(public|internal)\.trains.se@[0-9-]*(;?([0-9]+)" + @"\.(public|internal)\.trains.se@[0-9-]*)?)?)?)?,oxyfi";

60
do { try { conn = new MySqlConnection(Credentials); conn.Open(); Console.WriteLine("MySQL version: {0}", conn.ServerVersion); MySqlCommand RMVT = new MySqlCommand(); RMVT.Connection = conn; RMVT.CommandText = "DROP TABLE IF EXISTS " + TrainTable; bool RemoveSuccess = true; do { try { RMVT.ExecuteNonQuery(); Console.WriteLine("Removed previous instance of table"); RemoveSuccess = true; } catch (MySql.Data.MySqlClient.MySqlException error) { Console.WriteLine("Could not execute query!"); RemoveSuccess = false; } catch (System.InvalidOperationException error) { RemoveSuccess = false; try { conn.Open(); } catch (MySqlException e) { Console.WriteLine("Connection to the server was lost! " + "Reconnecting."); } } } while (!RemoveSuccess); MySqlCommand CT = new MySqlCommand(); CT.Connection = conn; CT.CommandText = "CREATE TABLE IF NOT EXISTS " + TrainTable + "(Vehicle INT, PublicNumber INT, InternalNumber INT, " + "Time DATETIME, Active TEXT, Y DOUBLE, X DOUBLE, " + "Speed DOUBLE, Angle DOUBLE, PRIMARY KEY (Vehicle, Time))"; bool QuerySuccess = true;

61
do { try { CT.ExecuteNonQuery(); Console.WriteLine("Added new instance of table"); QuerySuccess = true; } catch (MySql.Data.MySqlClient.MySqlException error) { Console.WriteLine("Could not execute query!"); QuerySuccess = false; } catch (System.InvalidOperationException error) { QuerySuccess = false; try { conn.Open(); } catch (MySqlException e) { Console.WriteLine("Connection to the server was lost! " + "Reconnecting."); } } } while (!QuerySuccess); MySqlCommand SQL = new MySqlCommand(); SQL.Connection = conn; using (var ws = new WebSocket("wss://api.oxyfi.com/trainpos" + "/listen?v=1&key=SECRET_API_KEY")) { ws.OnMessage += (sender, e) => { Match Train = Regex.Match(e.Data, TrainPositionRGX); if (Train.Success) { double Vehicle = 0, PublicNumber = 0, InternalNumber = 0, TrainX = 0, TrainY = 0, TrainSpeed = 0, TrainAngle = 0;

62
if (Train.Groups[18].Value != null && Train.Groups[18].Value != "") Vehicle = Convert.ToDouble(Train.Groups[18].Value); if (Train.Groups[20].Value != null && Train.Groups[20].Value != "" && Train.Groups[21].Value == "public") { PublicNumber = Convert.ToDouble(Train.Groups[20].Value); } else if (Train.Groups[23].Value != null && Train.Groups[23].Value != "" && Train.Groups[24].Value == "public") { PublicNumber = Convert.ToDouble(Train.Groups[23].Value); } else if(Train.Groups[26].Value != null && Train.Groups[26].Value != "" && Train.Groups[27].Value == "public") { PublicNumber = Convert.ToDouble(Train.Groups[26].Value); } else if (Train.Groups[29].Value != null && Train.Groups[29].Value != "" && Train.Groups[30].Value == "public") { PublicNumber = Convert.ToDouble(Train.Groups[29].Value); } if (Train.Groups[20].Value != null && Train.Groups[20].Value != "" && Train.Groups[21].Value == "internal") { InternalNumber = Convert.ToDouble(Train.Groups[20].Value); } else if (Train.Groups[23].Value != null && Train.Groups[23].Value != "" && Train.Groups[24].Value == "internal") { InternalNumber = Convert.ToDouble(Train.Groups[23].Value); } else if (Train.Groups[26].Value != null && Train.Groups[26].Value != "" && Train.Groups[27].Value == "internal") { InternalNumber = Convert.ToDouble(Train.Groups[26].Value); }

63
else if (Train.Groups[29].Value != null && Train.Groups[29].Value != "" && Train.Groups[30].Value == "internal") { InternalNumber = Convert.ToDouble(Train.Groups[29].Value); } if (Train.Groups[8].Value != null && Train.Groups[8].Value != "") { TrainX = (int)(Convert.ToDouble(Train.Groups[8].Value) / 100) + ((Convert.ToDouble(Train.Groups[8].Value) / 100) - (int)(Convert.ToDouble(Train.Groups[8].Value) / 100)) / 0.6; } if (Train.Groups[6].Value != null && Train.Groups[6].Value != "") { TrainY = (int)(Convert.ToDouble(Train.Groups[6].Value) / 100) + ((Convert.ToDouble(Train.Groups[6].Value) / 100) - (int)(Convert.ToDouble(Train.Groups[6].Value) / 100)) / 0.6; } if (Train.Groups[10].Value != null && Train.Groups[10].Value != "") TrainSpeed = Convert.ToDouble(Train.Groups[10].Value) * SpeedMultiplier; if (Train.Groups[11].Value != null && Train.Groups[11].Value != "") TrainAngle = Convert.ToDouble(Train.Groups[11].Value); try { SQL.CommandText = "INSERT INTO " + TrainTable + " (Vehicle, PublicNumber, InternalNumber, Time, " + "Active, Y, X, Speed, Angle)" + " VALUES ('" + Vehicle + "', '" + PublicNumber + "', '" + InternalNumber + "', '20" + Train.Groups[14].Value + "-" + Train.Groups[13].Value + "-" + Train.Groups[12].Value + " " + Train.Groups[1].Value + ":" + Train.Groups[2].Value + ":" + Train.Groups[3].Value + "', '" + Train.Groups[5].Value + "', '" + TrainY + "', '" + TrainX + "', '" + TrainSpeed + "', '" + TrainAngle + "');"; SQL.ExecuteNonQuery();

64
Console.WriteLine("INSERT INTO " + TrainTable + " (Vehicle, PublicNumber, InternalNumber, " + "Time, Active, X, Y, Speed, Angle)" + " VALUES ('" + Vehicle + "', '" + PublicNumber + "', '" + InternalNumber + "', '20" + Train.Groups[14].Value + "-" + Train.Groups[13].Value + "-" + Train.Groups[12].Value + " " + Train.Groups[1].Value + ":" + Train.Groups[2].Value + ":" + Train.Groups[3].Value + "', '" + Train.Groups[5].Value + "', '" + TrainX + "', '" + TrainY + "', '" + TrainSpeed + "', '" + TrainAngle + "');"); } catch (MySql.Data.MySqlClient.MySqlException) { } catch (System.InvalidOperationException exception) { try { conn.Open(); } catch (MySqlException ex) { Console.WriteLine("Connection to the server was lost! " + "Reconnecting."); } } } else { Console.WriteLine("Something went wrong"); } }; ws.WaitTime = TimeSpan.FromMilliseconds(10000); ws.Connect(); ws.Send("TEST"); Console.ReadKey(true); } } catch (MySqlException e) { Console.WriteLine("Connection error, trying to reconnect!"); ConnectionSuccess = false; } finally { if (conn != null) { //conn.Close();

65
} } } while (!ConnectionSuccess); } } }
A.3 Webbgränsnittet
A.3.1 Index
<!DOCTYPE html> <?php //include "trains.php"; $servername = "SERVER_LOCATION"; $username = "USER"; $password = "PASSWORD"; $database = "DATABASE"; $conn = new mysqli($servername, $username, $password, $database); if ($conn->connect_error) die("Connection failed: " . $conn->connect_error); $stationQuery = "SELECT Y, X FROM trainstations WHERE " . "Prognosticated = 'true' AND Y >= '59.03609 ' AND " . "Y <= '60.216595 ' AND X >= '12.093117' AND X <= '14.55';"; $meetingQuery = "SELECT Y, X FROM trainstations WHERE " . "Prognosticated = 'false' AND Y >= '59.03609 ' AND " . "Y <= '60.216595 ' AND X >= '12.093117' AND X <= '14.55';"; $trainQuery = "SELECT t1.Vehicle, t1.PublicNumber, t1.Time, " . "t1.Y, t1.X FROM trainlocations t1 INNER JOIN ( SELECT Vehicle, " . "max(Time) as MaxTime FROM trainlocations GROUP BY Vehicle ) t2 " . "ON t1.Vehicle = t2.Vehicle AND t1.Time = t2.MaxTime;"; $stationResult = $conn->query($stationQuery); $meetingResult = $conn->query($meetingQuery); $trainResult = $conn->query($trainQuery); ?> <html> <head> <title>Simple Map</title> <meta name="viewport" content="initial-scale=1.0"> <meta charset="utf-8">

66
<style> </style> <link rel="stylesheet" href="https://maxcdn.bootstrapcdn.com/bootstrap/3.3.7/css/bootstrap.min.css" /> <link rel="stylesheet" href="https://maxcdn.bootstrapcdn.com/bootstrap/3.3.7/css/bootstrap-theme.min.css" /> <script src="https://ajax.googleapis.com/ajax/libs/jquery/3.3.1/jquery.min.js"> </script> <script src="https://cdn.pubnub.com/sdk/javascript/pubnub.4.19.0.min.js"> </script> </head> <body> <div id="map-canvas" style="width:100%;height:700px;"></div> <script> window.lat = 59.6; window.lng = 13.5; var iconBase = "icons/"; var icons = { station: { icon: iconBase + 'station.png' }, meeting: { icon: iconBase + 'meeting.png' }, trainMoving: { icon: iconBase + 'trainMoving.png' }, trainParked: { icon: iconBase + 'trainParked.png' }, trainSlow: { icon: iconBase + 'trainSlow.png' }, trainStopped: { icon: iconBase + 'trainStopped.png' }, } var map; var stations = []; var trains = new Object(); var initialize = function() { map =

67
new google.maps.Map(document.getElementById('map-canvas'), { center:{ lat:lat, lng:lng }, zoom:8 }); <?php if ($stationResult->num_rows > 0) { while($row = $stationResult->fetch_assoc()){ ?>stations.push(new google.maps.Marker({ position:{ <?php echo "lat:" . $row["Y"] . ",\n\t\t\t\t\tlng:" . $row["X"] . "\n"; ?> }, icon: { path: google.maps.SymbolPath.CIRCLE, scale: 2, fillColor: 'black', fillOpacity: 1.0, strokeColor: 'black', zIndex: 2 }, map:map })); <?php } } if ($meetingResult->num_rows > 0) { while($row = $meetingResult->fetch_assoc()){ ?>stations.push(new google.maps.Marker({ position:{ <?php echo "lat:" . $row["Y"] . ",\n\t\t\t\t\tlng:" . $row["X"] . "\n"; ?> }, icon: { path: google.maps.SymbolPath.CIRCLE, scale: 2, fillColor: 'gray', fillOpacity: 1.0, strokeColor: 'gray', zIndex: 1 }, map:map })); <?php } }

68
?> }; window.initialize = initialize; setInterval(function() { var rowRegex = /\{"Vehicle":"(\d+).{30,35}"Y":"(\d+(\.(\d+)?)?)","X":"(\d+(\.(\d+)?)?)","PublicNumber":"(\d+)","Speed":"(\d+(\.(\d+)?)?)"}/g; var dataRegex = /\{"Vehicle":"(\d+).{30,35}"Y":"(\d+(\.(\d+)?)?)","X":"(\d+(\.(\d+)?)?)","PublicNumber":"(\d+)","Speed":"(\d+(\.(\d+)?)?)"}/; var json_station = JSON.parse("[]"); $.ajax({ type: 'POST', url: 'stations.php', success: function(stationData){ json_station = JSON.parse(JSON.stringify(stationData)); }, async: false }); $.ajax({ type: 'POST', url: 'trains.php', async: false, success: function(trainData){ var json_obj = JSON.parse(JSON.stringify(trainData)); var match = json_obj.match(rowRegex); for (var i in match){ var matchTrain = match[i].match(dataRegex); try { trains[matchTrain[1]].setPosition({ lng:Number(matchTrain[5]), lat:Number(matchTrain[2]), alt:0 }); } catch(err){ console.log("Train : " + matchTrain[1] + " - lat: " + matchTrain[2] + " - lng: " + matchTrain[5]); trains[matchTrain[1]] = new google.maps.Marker({ position:{ lng:Number(matchTrain[5]), lat:Number(matchTrain[2]) }, icon: { path: google.maps.SymbolPath.CIRCLE, scale: 4, fillColor: 'yellow', fillOpacity: 1.0,

69
strokeColor: 'yellow', zIndex: 3 }, label: matchTrain[8], labelOrigin: new google.maps.Point(200,0), map:map }); } var StationRegex = new RegExp('\\{"Vehicle":"(' + Number(matchTrain[1]) + ')","PublicNumber":"(\\d+)"'); var matchStation = json_station.match(StationRegex); if (matchStation != null){ if (matchTrain[1] == matchStation[1]) { if (Number(matchTrain[9]) > 10){ try { trains[matchStation[1]].setIcon({ path: google.maps.SymbolPath.CIRCLE, scale: 4, fillColor: 'fuchsia', fillOpacity: 1.0, strokeColor: 'fuchsia', zIndex: 3 }); } catch (err){ console.log(err); } } else { try { trains[matchStation[1]].setIcon({ path: google.maps.SymbolPath.CIRCLE, scale: 4, fillColor: 'aqua', fillOpacity: 1.0, strokeColor: 'aqua', zIndex: 3 }); } catch (err){ console.log(err); } } } else { if (Number(matchTrain[9]) < 10){ try { trains[matchTrain[1]].setIcon({ path: google.maps.SymbolPath.CIRCLE,

70
scale: 4, fillColor: 'red', fillOpacity: 1.0, strokeColor: 'red', zIndex: 3 }); } catch (err){ console.log(err); } } else if (Number(matchTrain[9]) < 30){ try { trains[matchTrain[1]].setIcon({ path: google.maps.SymbolPath.CIRCLE, scale: 4, fillColor: 'yellow', fillOpacity: 1.0, strokeColor: 'yellow', zIndex: 3 }); } catch (err){ console.log(err); } } else if (Number(matchTrain[8]) == 0){ try { trains[matchTrain[1]].setIcon({ path: google.maps.SymbolPath.CIRCLE, scale: 4, fillColor: 'white', fillOpacity: 1.0, strokeColor: 'white', zIndex: 3 }); } catch (err){ console.log(err); } } else { try { trains[matchTrain[1]].setIcon({ path: google.maps.SymbolPath.CIRCLE, scale: 4, fillColor: 'lime', fillOpacity: 1.0, strokeColor: 'lime',

71
zIndex: 3 }); } catch (err){ console.log(err); } } } } else { if (Number(matchTrain[9]) < 10){ try { trains[matchTrain[1]].setIcon({ path: google.maps.SymbolPath.CIRCLE, scale: 4, fillColor: 'red', fillOpacity: 1.0, strokeColor: 'red', zIndex: 3 }); } catch (err){ console.log(err); } } else if (Number(matchTrain[9]) < 30){ try { trains[matchTrain[1]].setIcon({ path: google.maps.SymbolPath.CIRCLE, scale: 4, fillColor: 'yellow', fillOpacity: 1.0, strokeColor: 'yellow', zIndex: 3 }); } catch (err){ console.log(err); } } else if (Number(matchTrain[8]) == 0){ try { trains[matchTrain[1]].setIcon({ path: google.maps.SymbolPath.CIRCLE, scale: 4, fillColor: 'white', fillOpacity: 1.0, strokeColor: 'white', zIndex: 3

72
}); } catch (err){ console.log(err); } } else { try { trains[matchTrain[1]].setIcon({ path: google.maps.SymbolPath.CIRCLE, scale: 4, fillColor: 'lime', fillOpacity: 1.0, strokeColor: 'lime', zIndex: 3 }); } catch (err){ console.log(err); } } } } } }); }, 1000); </script> <script src="https://maps.googleapis.com/maps/api/js?v=3.exp&key=SECRET_API_KEY&callback=initialize" async defer> </script> </body> </html>
A.3.2 Trains
<?php $trainData = array(); $servername = "SERVER_LOCATION"; $username = "USER"; $password = "PASSWORD"; $database = "DATABASE"; $conn = new mysqli($servername, $username, $password, $database); if ($conn->connect_error) die("Connection failed: " . $conn->connect_error); $trainQuery = "SELECT t1.Vehicle, t1.Time, t1.Y, t1.X, t1.PublicNumber, " .

73
"t1.Speed FROM trainlocations t1 INNER JOIN ( SELECT Vehicle, max(Time) " . "as MaxTime FROM trainlocations GROUP BY Vehicle ) t2 " . "ON t1.Vehicle = t2.Vehicle AND t1.Time = t2.MaxTime;"; $trainResult = $conn->query($trainQuery); if ($trainResult->num_rows > 0) { while($row = $trainResult->fetch_assoc()){ array_push($trainData, $row); } } echo json_encode($trainData); ?>
A.3.3 Stations
<?php $stationData = array(); $servername = "SERVER_LOCATION"; $username = "USER"; $password = "PASSWORD"; $database = "DATABASE"; $conn = new mysqli($servername, $username, $password, $database); if ($conn->connect_error) die("Connection failed: " . $conn->connect_error); $stationQuery = "SELECT DISTINCT trainlocations.Vehicle, " . "trainlocations.PublicNumber, trainlocations.Speed FROM " . "trainlocations INNER JOIN trainstations ON trainlocations.Y " . "< (trainstations.Y + 0.02) AND trainlocations.Y > " . "(trainstations.Y - 0.02) AND trainlocations.X < " . "(trainstations.X + 0.02) AND trainlocations.X > " . "(trainstations.X - 0.02) INNER JOIN (SELECT DISTINCT " . "Vehicle, Max(Time) as MaxTime FROM trainlocations " . "GROUP BY Vehicle) t2 ON trainlocations.Vehicle" . " = t2.Vehicle AND trainlocations.Time = t2.MaxTime ORDER BY " . "trainlocations.PublicNumber DESC, trainlocations.Vehicle " . "ASC, trainlocations.Speed DESC"; $stationResult = $conn->query($stationQuery); if ($stationResult->num_rows > 0) { while($row = $stationResult->fetch_assoc()){ array_push($stationData, $row); } } echo json_encode($stationData); ?>























![[citation needed] - DiVA](https://img.dokumen.tips/doc/110x75/63247dbbf021b67e740890a0/citation-needed-diva.jpg)





