Embed Size (px)
Citation preview

52 IEEE TRANSACTIONS ON SYSTEMS, MAN, AND CYBERNETICS—PART C: APPLICATIONS AND REVIEWS, VOL. 37, NO. 1, JANUARY 2007
A Performance Study on a MultiagentE-Scheduling and Coordination Framework
for Maintenance NetworksFeng Zhang, Eugene Santos, Jr., Senior Member, IEEE, and Peter B. Luh, Fellow, IEEE
Abstract—Many maintenance networks as well as supply net-works and virtual enterprises consist of multiple organizations. Acommon problem arising in these different domains is multiorga-nization scheduling and coordination. The traditional centralizedmethods are not appropriate because of the existence of privateinformation and decision-making authorities at different organiza-tions. Although many distributed mechanisms have been presentedfor supply networks and virtual enterprises, they may not be effec-tive for maintenance networks because of the difficulties of schedul-ing the tightly related maintenance operations and handling themassive uncertainties involved. These difficulties as well as the het-erogeneity of the distributed environment make it challenging todevelop an efficient framework for maintenance networks that canobtain a high-quality solution under different conditions, sched-ule in a timely manner, solve large-scale problems, and so on. Inthis paper, a price-based multiagent scheduling and coordinationframework for maintenance networks is explored, and a systematicexperimental study is carried out to evaluate the effects of differentfactors on its performance. The results show that the framework isable to overcome these difficulties and could be a step toward thenext generation of e-scheduling for maintenance networks.
Index Terms—Lagrangian relaxation, maintenance networks,multiagent, multiorganization scheduling and coordination.
I. INTRODUCTION
A SSET MAINTENANCE is needed almost everywhere,from everyday life to production and service industries.
The reason is that the assets, such as automobiles, jet enginesof airlines, and generators of electric utilities, become worn outover time. The role of maintenance networks is to conduct a re-manufacturing process in which the worn-out assets are restoredto a like-new condition through a series of disassembly, cleaning,repair, and assembly operations with the infusion of new partsas necessary. Similar to supply networks and virtual enterprises,many maintenance networks consist of multiple organizations,including overhaul centers (disassembling the worn-out assetsinto parts for repair and reassembling the parts after repair),repair shops (repairing the parts), warehouses of rotable inven-tory (storing the parts usable by multiple assets), spare part
Manuscript received March 28, 2005; revised August 9, 2005. This workwas supported in part by the National Science Foundation under Grant DMI-0223443. This paper was recommended by Associate Editor R. Brennan.
F. Zhang is with the Department of Computer Science and Engineering, Uni-versity of Connecticut, Storrs, CT 06269 USA (e-mail: [email protected]).
E. Santos is with the Thayer School of Engineering, Dartmouth College,Hanover, NH 03755 USA (e-mail: [email protected]).
P. B. Luh is with the Department of Electrical and Computer Engineering,University of Connecticut, Storrs, CT 06269 USA, and also with the Centerfor Intelligent and Networked Systems, Department of Automation, TsinghuaUniversity, Beijing 100084, China (e-mail: [email protected]).
Digital Object Identifier 10.1109/TSMCC.2006.876057
Fig. 1. Maintenance process illustration.
distributors, and manufacturers. In this paper, the focus is onmaintenance of jet engines, but the work can also be appliedto other asset maintenance networks. A simplified asset main-tenance process is shown in Fig. 1. The worn-out assets withvarious priorities arrive at the overhaul center and are disassem-bled into serial-number-specific parts (required to be assembledinto the original assets they belong to) and rotable parts (sat-isfying certain qualification for general use). After inspection,good parts are ready for reassembly, while the repairable partsare delivered to the repair shop and the remaining parts arescrapped. For simplicity, scrapping a part is supposed to triggerthe ordering of a new part with an uncertain lead time. Hence,the warehouse of rotable inventory, which stores good as wellas repaired rotable parts, has more or less a constant number ofrotable parts over time. Since repair of rotable parts may take along time, it is important to have some extra rotable parts ini-tially (i.e., a small nonzero initial inventory level) for reducingasset turnaround times without incurring a high inventory cost.In the view that ordering a new part can be modeled similarlyas a repair operation, it is assumed here that all the parts canbe repaired. Assembly can start when the required parts areready. The multiorganization maintenance scheduling problemis to find a scheduling policy to arrange the asset overhaul andpart repair operations with the objective of minimizing meanasset turnaround time and mean inventory cost (INVC), sub-ject to intraorganization constraints such as resource capacityconstraints and interorganization constraints such as disassem-bly/repair precedence constraints [1].
The multiorganization maintenance scheduling andcoordination problem can hardly be solved optimally sincescheduling in general is NP-hard. The goal, therefore, is toidentify an approach that can obtain a nearly optimal solutionefficiently. The following difficulties, however, make themaintenance scheduling problem more difficult to solve. First,the maintenance processes are generally characterized bymassive uncertainties, including the uncertain asset arrivalsand operation processing times. These uncertainties can leadto unpredictable asset turnaround times. Furthermore, the large
1094-6977/$25.00 © 2007 IEEE

ZHANG et al.: PERFORMANCE STUDY ON A MULTIAGENT E-SCHEDULING AND COORDINATION FRAMEWORK 53
number of maintenance operations are tightly related becausemost of the repaired parts (excluding parts in the warehouses ofrotable inventory) have to be assembled back into assets. Suchtight relations make it difficult for the organizations with theirown sensitive information and decision-making authorities tocoordinate with each other for finding a high-quality solution.Finally, the computing resources of the organizations aregenerally connected through the Internet. The Internet, withvarious processor speeds and communication delays, imposesrestrictions on implementing multiorganization scheduling andcoordination. For example, a synchronous coordination schemewill be either slow or hardly scalable because of its potentiallyhigh-synchronization overhead.
To overcome the difficulties, a price-based schedulingmethod, which considers the massive uncertainties involved,was presented in [1]. Its key idea is decomposition and coordi-nation in that it employs Lagrangian relaxation to decompose theoriginal problem into a set of subproblems, which are solved byusing stochastic dynamic programming given the current prices(i.e., the Lagrange multipliers). With the current subproblemsolutions available, the prices are updated at the upper levelby using a surrogate subgradient method: increase prices if thecorresponding constraints are violated, and reduce prices other-wise. Under the new prices, the previous solutions may not becost effective, and new solutions need to be computed. Throughiterative updating of both the prices and subproblem solutions,the original problem can be solved. The method was shown tobe nearly optimal using a centralized setting. A challenge of ap-plying the method is how to efficiently deploy it in a distributedenvironment while facilitating organization autonomy. Efficientdeployment means that the performance of the distributed ap-proach should be close to that of the centralized implementation.Since many factors may affect its performance, it is essential tosystematically show how it works in a distributed environmentunder different conditions, such as with sufficient or insuffi-cient resources, nonzero or zero initial inventory level, certainor uncertain information, etc.
In this paper, a multiagent scheduling and coordination frame-work built on the price-based scheduling method is developedto solve the multiorganization maintenance scheduling problem.The use of agents makes it possible to protect private informa-tion and respect the decision-making authorities of the organi-zations. Our first step is to decompose the problem into sev-eral organization-level problems. Because of complexity, eachorganization-level problem is further decomposed into smallerasset-level/part-level subproblems. Next, an agent is associatedwith each individual organization, asset, and part to solve thecorresponding subproblem. Each agent will communicate withthe relevant agents for exchanging nonprivate information, in-cluding subproblem solution and new prices. While the frame-work facilitates organization autonomy, is it efficient? Specif-ically, can the framework find a high-quality solution underdifferent conditions? Can it schedule in a timely manner? Is theframework scalable?
To answer the above-mentioned questions, a systematic ex-perimental study is carried out by evaluating the impact of se-lected factors on the performance of the agent framework.
1) A solution framework factor is selected to examinewhether the performance of the agent scheduling frame-work can approach that of the centralized implementationor not. Moreover, the following four factors that reflect thedifferent conditions arising in maintenance scheduling arechosen.
a) Initial inventory relative level and holding cost arethe two factors related to rotable inventory manage-ment. Initial inventory relative level, a ratio of initialinventory level to the total number of worn-out as-sets, is used to reflect the conditions with nonemptyor empty initial inventory and holding cost used toreflect the conditions with high or low inventorymanagement cost.
b) Targeted utilization of resources of a maintenanceresource type, an estimated ratio of their busy timeto their total available time, is used to reflect theconditions with sufficient or insufficient resources.
c) Uncertainty level is used to capture the uncertainasset arrivals and operation processing times.
2) To determine the timeliness of scheduling in a distributedenvironment, two factors, processor speed and communi-cation delay, are selected.
3) To examine whether the framework is scalable, the numberof assets is varied to reflect different problem scales.
Two orthogonal arrays are applied to systematically conduct theexperiments based on the selected factors and reduce the total ex-perimental cost. In the following, a literature review is first given.A brief presentation of the problem formulation and the price-based scheduling method follows. A multiagent e-schedulingand coordination framework is described in Section IV. In Sec-tion V, the experimental design is presented in detail. The ex-perimental results in Section VI show that our framework isable to overcome the major difficulties. Built on the price-basedscheduling method, it can obtain a high-quality solution quicklyin most cases, even for large-scale problems. More importantly,relations between the selected factors and the performance mea-sures are drawn from the results. These results can provideorganizations with guidance on setting up a suitable amountof resources and initial inventory level. From these results, itis concluded that the framework performs well under the dif-ferent conditions in a distributed environment and could be astep toward the next generation of e-scheduling for maintenancenetworks.
II. RELATED WORK
Remanufacturing and the associated repairable inventory the-ory have been summarized in [2] and [3]. It was concluded thata specifically designed framework and the corresponding mod-els were lacking for the production planning and control ofremanufacturing systems. In addition, a critical feature of re-manufacturing, i.e., the presence of rotable inventory, has notbeen well addressed, although the value of rotable inventoryto coordinate material flows has been identified [4]. In the past,excessive preventive maintenance has been mainly used to max-imize asset availability by industries such as the power indus-try. The downside of excessive maintenance is unnecessary and

54 IEEE TRANSACTIONS ON SYSTEMS, MAN, AND CYBERNETICS—PART C: APPLICATIONS AND REVIEWS, VOL. 37, NO. 1, JANUARY 2007
increased maintenance cost. To reduce the cost while maximiz-ing asset availability, condition-based maintenance and repairhas emerged [5], [6], which can often detect the potential prob-lems early based on the historic asset condition information sothat the necessary maintenance can be done less expensively.While the issues of collecting and using condition informationhave been addressed by the current generation of e-schedulingframeworks, organization autonomy and performance optimiza-tion have not received enough attention. Although the work insupply networks [7], [8] and virtual enterprises [9] generallyconsider organization autonomy, they may not be effective formaintenance networks because of the tightly related mainte-nance operations and the massive uncertainties involved. In ourview, the next generation of e-scheduling frameworks will notonly seek the needed information actively, but also optimizeperformance actively while facilitating autonomy.
Multiagent systems (MASs) have been studied intensively totackle many complex and distributed application domains, suchas e-commerce [10], logistics management [11], weather fore-casting [12], and network management [13]. Generally, a MASconsists of a set of software agents that operate continuously andautonomously with their own threads of control in a distributedenvironment. These agents try to achieve their goals in an intel-ligent fashion by planning and targeting the best action in a dy-namic environment. They can either work on their own or coop-erate with each other. By employing multiple agents, MASs canachieve distributed decision-making and site autonomy, supportcomplicated cooperation among the different entities, provideplatforms for deploying the distributed scheduling methods, andefficiently utilize the available distributed computing resources.Of course, there are still several concerns currently on usingMASs, such as malicious agents, interoperability between twodifferent agent platforms, and lacking of inherent methodolo-gies for designing and developing MASs. But, with more andmore work focusing on these concerns, it is expected that MASswill be widely used.
A variety of agent-based coordination models have been pre-sented in the past [10], [14]. Some models are based on thecontract net protocol [9], [15], [16], which is simple but notgood for iterative optimization in the view that it is very diffi-cult to change the commitments made previously, while severalother models, such as generalized partial global planning [17],distribute planning capabilities to all the agents and employ anextendable set of coordination mechanisms for more genericapplicability. In the case of unreliable and low-bandwidth com-munication, a coordination protocol was presented in [18] toallow the agents to choose actions locally based on the predeter-mined strategies, which can be decided offline or formed duringperiods of full communication. This protocol may not be feasi-ble for maintenance networks because it is often hard to identifythe effective strategies beforehand in maintenance scheduling.A rule-based coordination infrastructure was presented in [9]for virtual enterprise systems, and information resource hetero-geneity was addressed while impact of heterogeneous processorspeeds and communication delays on system performance wasnot. Several approaches investigated optimal scheduling andcoordination in different domains [7].
MASs have also been applied in solving maintenance prob-lems [6], [19], [20]. A multiagent framework was developedin [19] based on the RETSINA agent architecture. In this frame-work, the role of the agents is to search for information that canassist the mechanics and engineers to identify the problems andselect appropriate repair methods in a short time. A multiagentscheduling model based on mixed-integer programming waspresented in [20] to solve a deterministic power equipment main-tenance scheduling problem with the objective of minimizingmaintenance cost and revenue loss.
In view of the major difficulties encountered in developingthe next generation of e-scheduling for maintenance networks,few of the past work are feasible. Therefore, new models needto be developed to overcome the difficulties. In Section III, theproblem formulation and the price-based scheduling method arebriefly described. After that, a price-based multiagent schedul-ing and coordination framework, which could be a step towardthe next generation of e-scheduling for maintenance networks,is presented.
III. PROBLEM FORMULATION AND PRICE-BASED
SCHEDULING METHOD
This section briefly summarizes the problem formulation andsolution methodology presented in [1]. For the simplicity ofthe discussions in Sections III-A and B, assume one overhaulcenter, one repair shop, and one warehouse of rotable inventory.It is straightforward to extend the formulation to the case withmultiple overhaul centers, repair shops, and/or warehouses ofrotable inventory.
A. Problem Formulation
The multiorganization maintenance scheduling problem issubject to two categories of constraints.
1) Intraorganization constraints: The major constraints forthe overhaul center or the repair shop include thefollowing.
a) Operation processing constraints: Each mainte-nance operation has to be processed by some re-sources for some amount of time.
b) Precedence constraints between adjacent opera-tions: Each succeeding operation cannot be starteduntil the current operation is completed plus a re-quired timeout (e.g., transportation time).
c) Arrival time constraints: Disassembly of each assetcan be started no earlier than its arrival plus a re-quired wait time. These constraints are consideredfor the overhaul center.
d) Expected resource capacity constraints: The ex-pected number of active maintenance operations us-ing the same type of resources cannot exceed theavailable resources at any time. Since these con-straints are relaxed in the solution methodologydescribed in Section III-B, their formulations areshown here. Let (a; j) denote the jth overhaul op-eration of asset a. For simplicity, let (a; 1) representthe aggregate disassembly operation and (a; 2) the

ZHANG et al.: PERFORMANCE STUDY ON A MULTIAGENT E-SCHEDULING AND COORDINATION FRAMEWORK 55
aggregate assembly operation. The time horizon andthe number of type h resources available at time kare denoted by K and Mkh. Let δajkh be a binaryvariable defined to be one if the operation (a, j) isactive at time k on the resource type h and zero oth-erwise. Similarly, let (a, i), Jai, and (a, i; j) denotepart i of asset a, the total number of repair opera-tions, and the jth operation of (a, i)(j ∈ [1, Jai]). Abinary variable δaijkh is defined for the operation(a, i; j). Using the notation, the resource capacityconstraints for the overhaul center (1) and for therepair shop (2) are
E[∑aj
δajkh] ≤ Mkh, ∀k, and h (1)
E[∑aij
δaijkh] ≤ Mkh, ∀k, and h. (2)
The major constraints for the warehouse of rotable in-ventory are inventory dynamics. The inventory dynamicsconstraints describe that the number of parts of a rotabletype r in the warehouse at the current time slot k, denotedby Ir(k), is equal to the available parts at the previousslot plus the parts repaired in the previous slot and minusthe parts used for assembly starting at the current slot.Let βr
aiJai kbe one if (a, i) is a rotable part of type r and
its last operation (a, i;Jai) completes at time k − 1 andzero otherwise. Similarly, αr
a2k indicates the beginning ofthe assembly operation (a; 2) if a rotable part of type r isused in assembly, and is set to one if the operation (a; 2)starts at time k and zero otherwise. The initial inventorylevel of type r at the time slot 0 is given, denoted byIr0[= Ir(0)]. The inventory dynamics constraints for typer can be formulated as follows (k ≥ 1):
Ir(k) = Ir(k − 1) +∑ai
βraiJai k
−∑
a
αra2k
= Ir0 +∑ai
[k∑
K=1
βraiJaiK
]−
∑a
[k∑
K=1
αra2K
].
Since the increase and decrease of inventory level are af-fected by rotable part repair and asset assembly that areconducted by two different organizations, the nonnegativeinventory-level constraints are classified into interorgani-zation constraints.
2) Interorganization constraints: The interorganizationprecedence constraints, including disassembly/repairprecedence constraints and repair/assembly precedenceconstraints, exist between the overhaul center and the re-pair shop. Let baj , paj , caj , and saj represent the begin-ning times, processing times, completion times, and thetimeout values of the disassembly/assembly operations.Similarly, define baij , paij , caij , and saij for the repairoperations. The disassembly/repair constraints (3) reflectthat part repair cannot start until disassembly is done plus
a required timeout (i.e., sa1), while the repair/assemblyconstraints (4) depict that assembly has to wait till serial-number-specific (SNS) part repair is finished plus a re-quired timeout. The nonnegative inventory-level con-straints (5), existing between the warehouse of rotableinventory and the overhaul center/repair shop, state thatthe expected number of rotable parts in the inventory can-not be below zero. If the initial inventory level of rotablepart type r is high, the corresponding constraints tend tobe violated less frequently during scheduling than the casewith low or zero initial inventory level
E[ba1 + pa1 + sa1 − bai1] ≤ 0, ∀(a, i) (3)
E[baiJai+ paiJai
+ saiJai− ba2] ≤ 0, ∀SNS(a, i) (4)
E[Ir(k)] ≥ 0, ∀r, k ∈ [1,K]. (5)
The objectives of the overall maintenance scheduling in-clude minimizing the asset turnaround times, reducing thework-in-process inventory, and keeping a low inventorycost. These objectives are weighted together and modeledby the following objective function:
J = E
[∑a
(waT 2
a + βaEa
)+
∑r
(K∑
k=1
γrIr(k)
)]. (6)
In the function, wa, βa, and γr represent the nonnegativepenalty weight for tardiness Ta, the nonnegative penaltyweight for earliness Ea, and the inventory holding costof rotable part type r, respectively. The scheduling prob-lem is to select the best beginning times of disassem-bly/assembly and repair operations to minimize the aboveobjective function (6) subject to intraorganization andinterorganization constraints.
B. Price-Based Scheduling Method
The price-based scheduling method [1] decomposes themaintenance scheduling problem into a set of subprob-lems and coordinates the subproblem solutions iteratively.Since the expected resource capacity constraints (1), (2),the interorganization precedence constraints (3), (4), and thenonnegative inventory-level constraints (5) couple different as-sets, parts, or organizations and are difficult to deal with, theprice-based scheduling method first employs a set of nonnega-tive Lagrange multipliers (called “shadow prices”), specifically,π (resource prices), η (precedence prices), and µ (inventoryprices) to relax these hard coupling constraints into soft penaltyterms such that the relaxed problem becomes unconstrained.Given the current values of π, η, and µ, the relaxed problem isto select the best beginning times of disassembly/assembly andrepair operations to minimize the summation of the original ob-jective function and the penalty terms, as the following function

56 IEEE TRANSACTIONS ON SYSTEMS, MAN, AND CYBERNETICS—PART C: APPLICATIONS AND REVIEWS, VOL. 37, NO. 1, JANUARY 2007
shows:
L̃ = J +∑kh
πkh
∑
aj
E(δajkh) − Mkh
+∑kh
πkh
∑
aij
E(δaijkh) − Mkh
−∑kr
µkrE(Ir(k)) +∑ai
ηai1E[ba1 + pa1 + sa1 − bai1]
+∑ai
ηaiJaiE[baiJai
+ paiJai+ saiJai
− ba2].
The dual problem is to select the optimal set of prices to maxi-mize the minimum of L̃. To solve the dual problem, an iterativeprocess is used. In each iteration, the relaxed problem is solvedgiven the current prices and the prices are then updated. In par-ticular, since the relaxed problem L̃ is separable, it is classifiedinto asset-level/part-level subproblems, which can be solved inpolynomial time by using stochastic dynamic programming. Thesubproblem solutions are coordinated through iterative updatingof the prices. As discussed in [1] and [21], because of the poten-tially large number of coupling constraints of different natures,the above solution methodology may not be effective to reducethe constraint violation level, and a satisfactory solution maynot be obtained in a short time. To improve algorithm conver-gence and solution quality, an augmented surrogate subgradientsolution methodology was presented in [1], which basically in-corporates extra terms for penalizing violation of the couplingconstraints. Since the changes to the subproblems in the aug-mented methodology are straightforward, they are omitted here.
IV. PRICE-BASED MULTIAGENT SCHEDULING
AND COORDINATION FRAMEWORK
In the view that the original implementation is central-ized and the presented surrogate solution methodology doesnot facilitate organization autonomy, the problem is decom-posed into multiple organization-level scheduling problems(i.e., overhaul/repair/warehouse-level) first. Because of com-plexity, each organization-level problem is further decomposedinto smaller asset-level (corresponding to asset overhaul) andpart-level (corresponding to part repair) subproblems. The sub-problem corresponding to asset a (7) is to select the best be-ginning times of disassembly and assembly given the pricesto minimize La(π, η, µ), which measures the costs of disas-sembling/assembling asset a, including the earliness and tar-diness penalties, the resource usage cost, and other costs dueto relaxation of the corresponding precedence constraints andinventory-level constraints
La(π, η, µ) = E
[βaEa +
ca1∑k=ba1
πkh +
(∑i
ηai1
)ba1
]
+∑
i
[ηai1E(pa1 + sa1)]
+ E
[waT 2
a +ca2∑
k=ba2
πkh −(∑
i
ηaiJai
)ba2
+∑
r
[K∑
k=1
(µkr − γr)k∑
K=1
αra2K
]]. (7)
The subproblem corresponding to part (a, i) is to selectthe best beginning times of the part repair operations giventhe prices to minimize Lai(π, η, µ), including the resource us-age cost of repairing the part and other costs due to relaxationof the precedence constraints (and inventory-level constraints ifthe part is rotable). Equations (8) and (9) are for the SNS partsand rotable parts, respectively
Lai(π, η, µ)=E
∑
j
caij∑
k=baij
πkh
−ηai1bai1+ηaiJai
baiJai
+ ηaiJaiE(paiJai
+ saiJai) (8)
Lai(π, η, µ) = E
∑
j
caij∑
k=baij
πkh
− ηai1bai1
+K∑
k=1
(γr − µkr)k∑
K=1
βraiJaiK
. (9)
Let L∗a and L∗
ai be the minimal costs of (7) and of (8) and (9).The organization-level problems (overhaul-level, repair-level,and warehouse-level) are defined as
max qo(π, η, µ) = max
[∑a
L∗a(π, η, µ)−
∑kh
πkhMkh
](10)
max qr(π, η, µ) = max
[∑ai
L∗ai(π, η, µ)−
∑kh
πkhMkh
]
(11)
max qw(µ) = max
[∑kr
Ir0(γr − µkr)
]. (12)
On the basis of the above decomposition and autonomy of theorganizations, each organization is associated with a coordina-tor agent, and each asset or part is represented by an agent.Each agent has a behavior module, which basically solves itscorresponding subproblem. Specifically, the overhaul coordina-tor, the repair coordinator, and the warehouse coordinator solvethe overhaul-level problem (10), the repair-level problem (11),and the warehouse-level problem (12), respectively, while eachasset agent or part agent solves an asset-level subproblem (7)or a part-level subproblem (8), (9). These scheduling agents donot work in isolation, but need to coordinate with each other.To provide support for possible interactions among the agents,each agent contains the other three modules: a message receiv-ing channel, a message sending channel, and an informationmodule. The receiving channel stores the incoming messages,while the sending channel stores the outgoing messages. Theinformation module manages the local knowledge of the agentas well as the information collected from the outside.

ZHANG et al.: PERFORMANCE STUDY ON A MULTIAGENT E-SCHEDULING AND COORDINATION FRAMEWORK 57
Before the above agents can be applied to solve the mainte-nance scheduling problem in a distributed environment, severalcoordination-related issues need to be addressed, specifically:What information is managed by each agent and transmitted be-tween the agents? How is asynchronous coordination achieved?and What does the coordination language among the agents,consist of? The basic idea is to let the individual agents managethe related prices. For example, an overhaul (or a repair) coor-dinator agent is in charge of updating the resource prices basedon the solutions obtained by the asset (or part) agents, whilea warehouse coordinator agent manages the inventory prices.Given the new price information, each asset agent or part agentwill apply stochastic dynamic programming to solve the cor-responding subproblem in polynomial time and return the bestbeginning times to the coordinator agents. Since a coordinatoragent does not need to wait for the information from all therelevant agents (based on the surrogate solution methodology),price updating as well as subproblem solving can be overlapped.This also explains why the agents can coordinate with each otherasynchronously most of the time. A challenging issue is whowill manage the precedence prices, which are accessed and up-dated in both overhaul scheduling and repair scheduling. Oneway is to let the overhaul coordinator and the repair coordinatormanage the prices. To avoid simultaneous updating of the pricesby them, a token-based heuristic can be used as in [7]. A draw-back of this strategy is that the two coordinator agents may needto exchange a lot of token messages during scheduling. Anotheroption is to let each asset agent as well as the associated partagents use the token-based heuristic to manage the correspond-ing precedence prices. This alternative is used in our frameworksince it does not have the drawback.
Our agent negotiation and communication language is de-fined to facilitate transmission of solution and price informa-tion as well as coordination among the agents. It currentlyconsists of a set of message types, including resource multi-plier message, inventory multiplier message, precedence multi-plier message, subproblem solution message, and agent registra-tion/deregistration message. The resource multiplier message,containing the latest resource price information, is sent fromthe overhaul/repair coordinator to an asset/part agent while theinventory multiplier message, containing the latest rotable partprice information, is sent from a warehouse coordinator to an as-set/part agent. The precedence multiplier message is exchangedbetween an asset agent and a part agent. The agent registrationmessage is sent by an asset/part agent to register itself with acoordinator agent, while the deregistration message is sent toa coordinator agent when an asset/part agent notices that theasset/part has been maintained.
Overall, our agent scheduling framework is distributed by de-composing the original problem into organization-level schedul-ing problems, which are further decomposed into smaller asset-level and part-level subproblems, and implementing distributedand asynchronous scheduling and coordination as describedabove (and illustrated in Fig. 2). Each coordinator agent willinteract with the relevant asset and part agents to perform intraor-ganization scheduling. The asset agents also interact with thepart agents for reducing the violation of precedence constraints
Fig. 2. Schematic of the price-based method. The role of the over-haul/repair/warehouse coordinator is to solve the overhaul-level/repair-level/warehouse-level scheduling problem, while the role of each asset/partagent is to solve the corresponding asset-level/part-level problem.
gradually. All these agents together perform the optimization,and they can be run on different computing resources. In theexperimental study, the timeliness and scalability of the agentscheduling framework will be demonstrated by varying hetero-geneity of the distributed environment and number of worn-outassets processed over time.
In addition to the above-mentioned scheduling agents, othertypes of agents can be important from a futuristic point of view.In the future, assets and parts will have computing, communica-tion, and sensing capabilities. It is envisioned that the associatedagents can directly run in the onboard processing units of assetsand parts to collect asset and part condition information in realtime, help improve scheduling, and monitor the execution ofmaintenance operations. In particular, the onboard agents willenable assets and parts to actively participate in the schedulingprocess by suggesting what maintenance operations are neededand exploring where and when to perform the operations. Allthese agents can be in different status as time passes by. Thecondition-information-collecting agents will be generally ac-tive if possible. The maintenance monitoring agents may beinactive before assets and parts are sent for maintenance, whilethe scheduling agents may be inactive if no potential prob-lem is identified and become active otherwise. Moreover, thecollecting and monitoring agents generally stay in the onboardprocessing units of assets and parts, while the scheduling agentsmay migrate from the assets and parts to the overhaul centersand repair shops to explore where and when to perform the oper-ations. After scheduling is done, they then migrate back to theircorresponding assets and parts. The agents with the ability ofmigrating from one computing resource (e.g., the onboard pro-cessing unit of an asset) to another resource (e.g., a computerof an overhaul center) are called mobile agents. These func-tionalities of agents are expected to be a key characteristic ofnext-generation e-scheduling. To support such functionalities,other message types such as inquiry need to be defined to extendour agent communication language.

58 IEEE TRANSACTIONS ON SYSTEMS, MAN, AND CYBERNETICS—PART C: APPLICATIONS AND REVIEWS, VOL. 37, NO. 1, JANUARY 2007
In the view that a large number of agents in a maintenancenetwork interact with each other for scheduling overhaul andrepair operations, the multiagent architecture should be robustand scalable. Carolina [22], a Java-based distributed agent ex-ecution environment, was chosen among several because oftwo reasons. First, Carolina was developed with the goal ofrobustness and scalability, and its performance has been sys-tematically studied. In particular, a distributed directory ser-vice was employed to avoid the risk of single-point failure anddeal with a large number of agents. In addition, an ANTS-style approach for message forwarding and routing optimizationwas used to ensure successful communications among mobileagents. Second, we have been using Carolina for some time andfeel comfortable to implement the agent-scheduling frameworkin Carolina. Like Jade (http://jade.tilab.com) as well as otherJava-based agent systems, Carolina employs the threading sup-port of Java to achieve the autonomy of agents, provides a setof services to be used by agents for accessing distributed re-sources and interacting with other agents, and relies on Java’sserialization/deserialization support for transmitting messagesand migrating objects (agents) through the network. A differ-ence is that the message format in Jade conforms to the agentcommunication language (ACL) of FIPA, while the format inCarolina does not. To deploy our scheduling framework in adistributed environment with multiple agent infrastructures, itis necessary to implement the framework in an infrastructuresuch as Jade or extend Carolina with some interoperable proto-cols (e.g., ACL of FIPA). However, this issue is not addressedhere.
V. EXPERIMENTAL DESIGN
The goal of the experimental study is to answer the questionsposed earlier regarding the performance of the agent schedulingframework in a distributed environment. Two hypotheses areexamined. Our first hypothesis is that the framework, built onthe price-based method, can obtain a high-quality solution ina timely manner. The second hypothesis is that the frameworkwould be able to solve large-scale problems by schedulingin a distributed and asynchronous fashion. In this section,the experimental design is described in detail with the focuson selecting factors that are key to answering our questionsand to validating the hypotheses. Other related issues are alsoaddressed, including performance measures, specification ofexperiments, and testbed setup.
A. Performance Measures
For the ease of validating the hypotheses, the following per-formance measures are considered. To reflect the different re-quirements of high-priority assets and those of low-priority as-sets (as described in Section V-B), the quality of a solutionis defined by three measures: mean turnaround time of high-priority assets (HTAT), mean turnaround time of low-priorityassets (LTAT), and mean INVC. In addition to these three mea-sures, another two measures of interest are the total schedulingtime (SCHT) for a given test case and the total number of prece-dence messages that are transmitted between the asset agents
and the part agents in the case of using our agent schedul-ing framework. The number of precedence messages reflectsthe amount of interorganization coordination traffic betweenoverhaul scheduling and repair scheduling. Another reason forcounting the number of precedence messages only is that thenumber of other types of messages is a constant, given the sameiterations (as the stopping criterion of scheduling) and the same-scale test cases.
B. Factor Selection
To help answer the questions and validate the hypotheses, atotal of eight factors were selected.
1) Solution framework type (SolFrm): SolFrm is definedfor the purpose of checking whether the performance ofthe agent scheduling framework can approach that of acentralized implementation of the price-based schedulingmethod.
2) Communication delay (CommuDelay) and ProcessorSpeed (ProcSpd): These two factors reflect heterogene-ity in a distributed environment and may prevent the agentscheduling framework from finding a high-quality solu-tion in a short time interval (e.g., 5 min). To see how muchthe framework is influenced under different communica-tion delay and processor speed patterns, three levels aredefined for each factor to reflect three cases, specifically, ahomogeneous case, a less heterogeneous case, and a veryheterogeneous case.
a) Levels for communication delay: Since our experi-ments are carried out in a local area network, whichgenerally has a small communication delay due tosmall latency and large bandwidth, artificial delayfunctions are applied to simulate the three cases ofcommunication delays. One is a small uniform delaypattern (for homogeneous communication delay),under which all the messages are delayed between0 and 30 ms before being sent. The reason of usinga small uniform delay pattern is that, even in thehomogeneous case, the actual delay for a messagetransmission varies in a small range. The second is alarge uniform delay pattern from 0.5 to 3 s (for veryheterogeneous communication delay). The last oneis a combination of the previous two, with 90% of themessages being delayed slightly and 10% delayedsignificantly.
b) Levels for processor speed: Two heterogeneous sys-tems are considered. In one very heterogeneoussystem, all the repair shops use different types ofworkstations from those for the overhaul centers.In the less-heterogeneous system, half of the repairshops use different types of workstations while theother half uses the same types of workstations asthe overhaul centers. As a comparison, a homoge-neous system is also considered. In the study, threetypes of workstations are used. Pentium IV 2-GHz1-GRAM workstations form the homogeneous sys-tem, and they are also utilized to schedule overhaul
ZHANG et al.: PERFORMANCE STUDY ON A MULTIAGENT E-SCHEDULING AND COORDINATION FRAMEWORK 59
operations in the heterogeneous systems (and oneof them is used to test centralized scheduling).Pentium IV 2.6-GHz 512-MRAM and Pentium III1-GHz 128-MRAM workstations are used togetherto schedule repair operations in the heterogeneoussystems.
3) Number of assets: This factor reflects the problem scale,and the agent scheduling framework scalability can beshown by examining the results of scheduling different-scale problems. This factor specifies the total number ofworn-out assets considered in a test case. While the exactnumber of assets arriving over time may not be knownbeforehand in practice, it can often be estimated. So, inthe experiments, it is assumed to be known. In addition, inpractice, some worn-out assets are considered to be moreimportant than others. As such, in the experiments, theassets are classified into two categories, specifically, 30%high-priority assets and 70% low-priority assets. Thosehigh-priority assets should be maintained as soon as pos-sible without being delayed by maintenance of the low-priority ones.
4) Initial inventory relative level (InitInv), holding cost (γr),targeted resource utilization (ResUtil), and uncertaintylevel (UncertL): These factors reflect the different condi-tions arising in maintenance scheduling.
a) InitInv: This is defined to be a ratio of the initialinventory level to the number of assets. The initialinventory level Ir0 is proportional to the number ofassets, being equal to InitInv∗# of assets. A highinitial inventory relative level may improve meanHTAT and LTAT as well as lead to a high inventorycost. So it needs to be chosen suitably. For simplicity,only one rotable part type is assumed here (note that,in the case of multiple rotable part types, a differentinitial inventory relative level may be specified foreach type).
b) γr: At each time slot t, the current inventory levelmultiplied by γr is the inventory cost at t. The totalinventory cost is the summation of the inventory costat each time slot, and mean INVC is the total cost di-vided by the total time. While a high initial inventoryrelative level may shorten mean HTAT and LTAT, itmay increase mean INVC because the current in-ventory level at any time slot t is more likely to behigh.
c) ResUtil: This factor is defined to be a ratio of thetotal busy time to the total available time of the re-sources of a maintenance resource type. A resourceis busy at time slot t if it is conducting a main-tenance operation at that time. This factor is usedto simulate the cases with sufficient or insufficientmaintenance resources. Specifically, given a targetedlevel of resource utilization, the estimated process-ing requirements of maintenance operations, and theavailable time per resource, the numbers of availableresources in the overhaul centers and repair shopscan be decided.
TABLE IFACTORS AND THEIR LEVELS
TABLE IIORTHOGONAL ARRAY L9, CONSISTING OF FOUR
COLUMNS AND NINE ROWS
d) UncertL: This factor captures the uncertaintiesinvolved in scheduling, including uncertain assetarrivals and operation processing times. Here, itdenotes the standard deviation of each uncertainvariable. Each variable is assumed to take three val-ues with equal probability if UncertL is nonzero.
For each of the factors, since the framework may behave dif-ferently under its different levels, its impact is studied. Further-more, these factors together may have different effects on sys-tem performance from the impact of each individual one. In thisstudy, the interactions between CommuDelay and ProcSpd areexamined to determine the timeliness of agent-based schedul-ing. In addition, the interactions between InitInv and ResUtil arestudied because both factors are important for reducing meanasset turnaround time.
Except for the solution framework type, which has only twolevels, every factor has three levels because any interestingtrends can be seen only by using more than two levels (as shownin Table I).
C. Specification of Experiments and Testbed Setup
Even with the above eight factors selected, it is still too costlyto measure the impact of all level combinations of these fac-tors (2 × 37 combinations). So, a subset of level combinationshas to be considered, which can be decided by employing or-thogonal arrays [23]. An orthogonal array is a two-dimensionalmatrix with orthogonality satisfied. The rows are called cells,representing experiments to be performed, while the columnscorrespond to the different factors whose effects will be stud-ied. An orthogonal array of strength g(g ≥ 2) means that, forany g columns, all level combinations of factors represented bythe g columns occur an equal number of times. This balancingproperty is called orthogonality. As an example, the standard or-thogonal array L9 [23, p. 287] has nine cells and four columns

60 IEEE TRANSACTIONS ON SYSTEMS, MAN, AND CYBERNETICS—PART C: APPLICATIONS AND REVIEWS, VOL. 37, NO. 1, JANUARY 2007
(representing four three-level factors at most), as shown inTable II.
To measure the main effect of each of the eight factorson system performance, the standard orthogonal array L18
[23, p. 291] is applied. Orthogonal array L18 can handle seventhree-level factors and one two-level factor. Furthermore, toidentify the possible interactions between CommuDelay andProcSpd as well as between InitInv and ResUtil in using theagent scheduling framework, another orthogonal array L9 is ap-plied. In this case, the middle levels of the rest five factors arealways used. Overall, one set of test cases is generated based onL18 and two other sets of test cases based on L9.
In addition to the above eight factors, other factors, suchas the number of operations per part repair and the operationprocessing times, need to be specified as well. Our rule for set-ting these factors is based on simplicity and consistency so thattheir effects can be minimized. Specifically, the high-priorityassets are assigned a tardiness weight of 10.0, and the low-priority ones are assigned a weight of 1.0. Each asset containsone SNS part and one rotable part. Asset overhaul has one dis-assembly operation and one assembly operation, and part repairconsists of two operations. Each type of the operations (e.g.,disassembly, first operation of rotable repair, etc.) is conductedby a different maintenance resource type. The expected process-ing time is set to 4 for rotable part repair operations and 3 forall the other operations. Using these settings, it is clear that themaintenance of an asset (i.e., disassembly plus assembly plustwo repair operations on the SNS part) can be done in 12 timeslots on average if there are sufficient maintenance resourcesand rotable parts. However, it is often the case that insufficientmaintenance resources are available. So the due date should notbe set too tight. Here, it is set to the expected asset arrival timeplus 17 (22) for a high-priority (low-priority) asset. The main-tenance network consists of one overhaul center and two repairshops, one in charge of the SNS parts and the other responsiblefor the rotable parts. All these values are kept the same in thetest cases to minimize the effects of the associated factors.
To conduct the experiment, a simulation control module isimplemented at the top of the agent scheduling framework.It loads the test cases into the system one at a time and callsagent-based scheduling or centralized scheduling on the sce-nario captured by each test case. Before agent-based schedulingis called, all the needed scheduling agents are created first onthe agent servers running in the homogeneous or heterogeneoussystem, as described in Section V-B. Since two single-processorcomputers are used to perform scheduling of the overhaul centeras well as each repair shop, the corresponding coordinator agentruns on one computer, while the related asset agents or partagents are evenly dispatched to the two assigned computers.To handle dynamic asset arrivals, the control module callsrescheduling at a specified interval. Specifically, the simulationhorizon is set long enough for maintaining all the assets, whilefor (re)scheduling, a shorter horizon is used to restrict theattention to the assets that will arrive in the near future aswell as those that have arrived but not finished maintenance.Upon the completion of (re)scheduling, the scheduling policyobtained is recorded and used to guide the arrangement of
TABLE IIIRESULTING p-VALUES OF ONE-WAY ANOVA ANALYSIS
TABLE IVRESULTING p-VALUES OF TWO-WAY ANOVA ANALYSIS
maintenance operations. To make measures meaningful, thebehavior of the system in the initial warm-up phase and finalphase is intentionally ignored. In particular, only the assetscompleted during a chosen interval are counted, and the intervalstarts right after the first 20% of assets finish maintenance andterminates when 70% of assets are maintained.
To facilitate the study, all the test cases are generated of-fline, each of which contains complete information of whatmaintenance resources are there in each organization, when theworn-out assets arrive, what operations need to be carried out,and so on. Such complete information, however, is not usedall at once during (re)scheduling. As mentioned above, onlythe information that is considered currently available is usedin each scheduling period. Hence, our scheduling framework isdynamic.
VI. EXPERIMENTAL RESULTS
Analysis of variance (ANOVA) [24] is a statistical techniquethat measures the relative effects of the different factors on sys-tem performance. In this study, one-way and two-way ANOVAsare applied to analyze the main effects of the individual factors(see Table III) and the possible interactions between commu-nication delays and processor speeds as well as between in-ventory levels and resource utilizations (see Table IV), respec-tively. From the results and analyses, it is concluded that theagent scheduling framework can approach similar performanceas a centralized implementation of the price-based schedulingmethod in terms of the solution-quality-related measures. Fur-thermore, the framework can schedule in a timely manner inthat its SCHT is within 5 min (from about 60 to 270 s) formost test cases. Only for the 400-asset test cases is the timeover 5 min, about 330 s, under large uniform communicationdelays. As a comparison, the SCHT of the centralized schedul-ing is less than 1 min. This is because Java is slow in messagetransmission. When new techniques become available, messagetransmission time may be reduced greatly. Overall, the agent
ZHANG et al.: PERFORMANCE STUDY ON A MULTIAGENT E-SCHEDULING AND COORDINATION FRAMEWORK 61
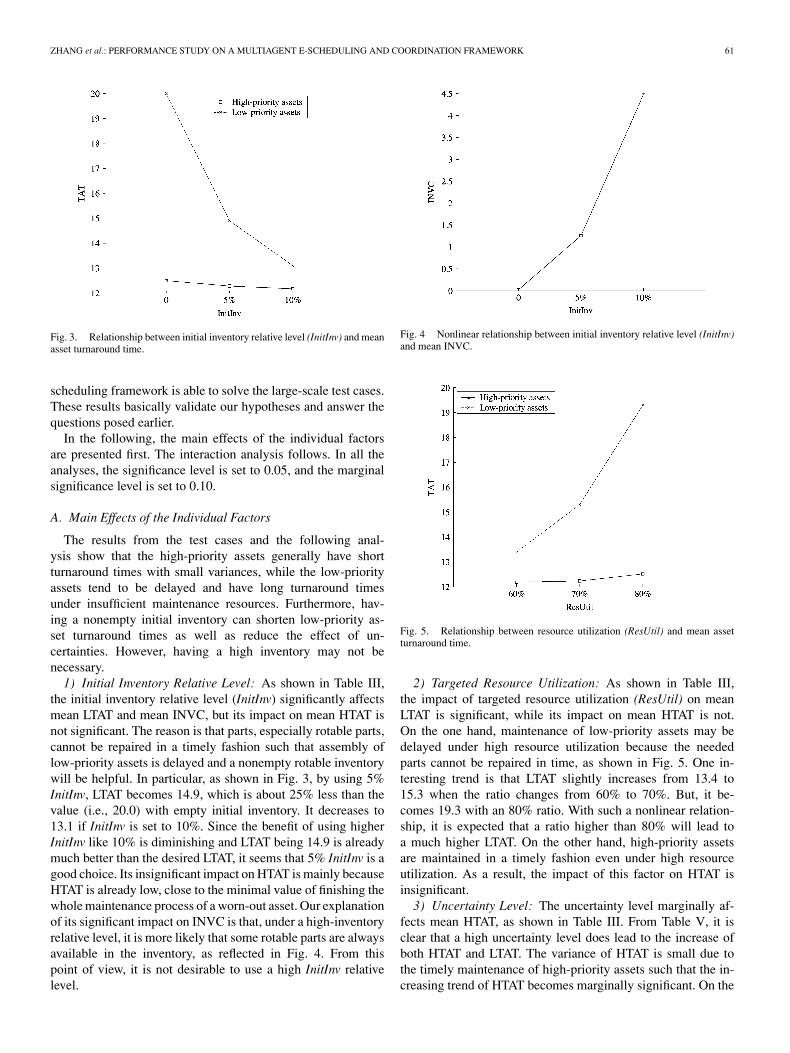
Fig. 3. Relationship between initial inventory relative level (InitInv) and meanasset turnaround time.
scheduling framework is able to solve the large-scale test cases.These results basically validate our hypotheses and answer thequestions posed earlier.
In the following, the main effects of the individual factorsare presented first. The interaction analysis follows. In all theanalyses, the significance level is set to 0.05, and the marginalsignificance level is set to 0.10.
A. Main Effects of the Individual Factors
The results from the test cases and the following anal-ysis show that the high-priority assets generally have shortturnaround times with small variances, while the low-priorityassets tend to be delayed and have long turnaround timesunder insufficient maintenance resources. Furthermore, hav-ing a nonempty initial inventory can shorten low-priority as-set turnaround times as well as reduce the effect of un-certainties. However, having a high inventory may not benecessary.
1) Initial Inventory Relative Level: As shown in Table III,the initial inventory relative level (InitInv) significantly affectsmean LTAT and mean INVC, but its impact on mean HTAT isnot significant. The reason is that parts, especially rotable parts,cannot be repaired in a timely fashion such that assembly oflow-priority assets is delayed and a nonempty rotable inventorywill be helpful. In particular, as shown in Fig. 3, by using 5%InitInv, LTAT becomes 14.9, which is about 25% less than thevalue (i.e., 20.0) with empty initial inventory. It decreases to13.1 if InitInv is set to 10%. Since the benefit of using higherInitInv like 10% is diminishing and LTAT being 14.9 is alreadymuch better than the desired LTAT, it seems that 5% InitInv is agood choice. Its insignificant impact on HTAT is mainly becauseHTAT is already low, close to the minimal value of finishing thewhole maintenance process of a worn-out asset. Our explanationof its significant impact on INVC is that, under a high-inventoryrelative level, it is more likely that some rotable parts are alwaysavailable in the inventory, as reflected in Fig. 4. From thispoint of view, it is not desirable to use a high InitInv relativelevel.
Fig. 4 Nonlinear relationship between initial inventory relative level (InitInv)and mean INVC.
Fig. 5. Relationship between resource utilization (ResUtil) and mean assetturnaround time.
2) Targeted Resource Utilization: As shown in Table III,the impact of targeted resource utilization (ResUtil) on meanLTAT is significant, while its impact on mean HTAT is not.On the one hand, maintenance of low-priority assets may bedelayed under high resource utilization because the neededparts cannot be repaired in time, as shown in Fig. 5. One in-teresting trend is that LTAT slightly increases from 13.4 to15.3 when the ratio changes from 60% to 70%. But, it be-comes 19.3 with an 80% ratio. With such a nonlinear relation-ship, it is expected that a ratio higher than 80% will lead toa much higher LTAT. On the other hand, high-priority assetsare maintained in a timely fashion even under high resourceutilization. As a result, the impact of this factor on HTAT isinsignificant.
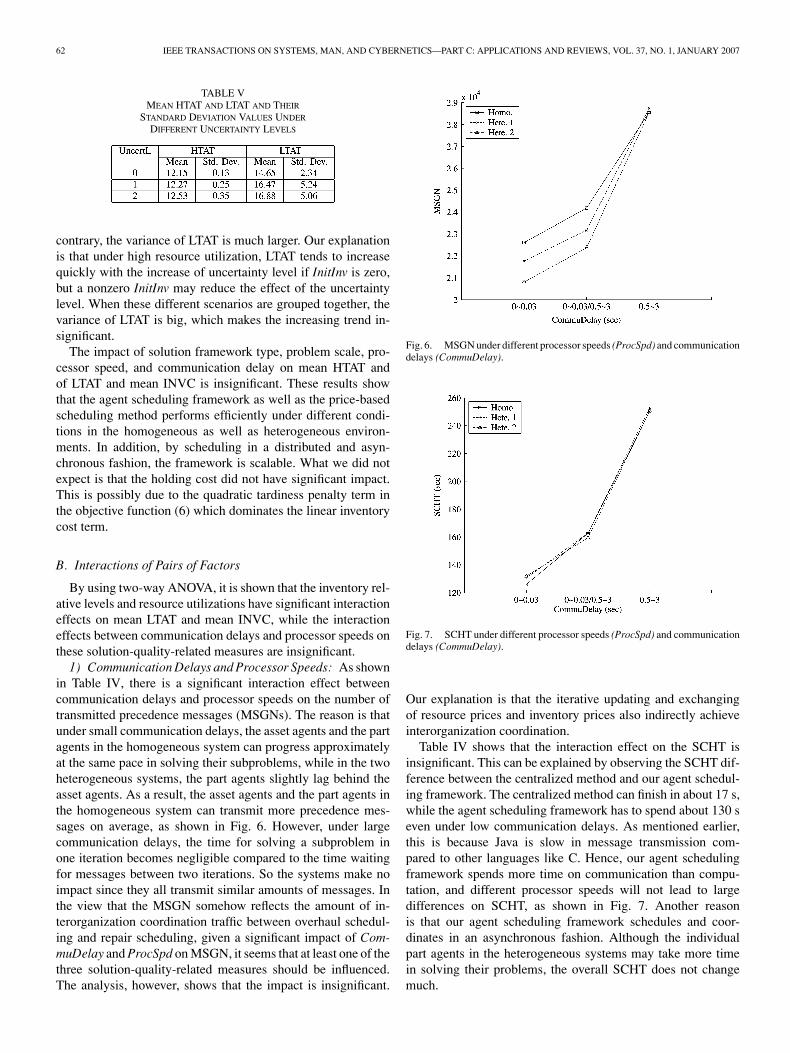
3) Uncertainty Level: The uncertainty level marginally af-fects mean HTAT, as shown in Table III. From Table V, it isclear that a high uncertainty level does lead to the increase ofboth HTAT and LTAT. The variance of HTAT is small due tothe timely maintenance of high-priority assets such that the in-creasing trend of HTAT becomes marginally significant. On the
62 IEEE TRANSACTIONS ON SYSTEMS, MAN, AND CYBERNETICS—PART C: APPLICATIONS AND REVIEWS, VOL. 37, NO. 1, JANUARY 2007
TABLE VMEAN HTAT AND LTAT AND THEIR
STANDARD DEVIATION VALUES UNDER
DIFFERENT UNCERTAINTY LEVELS
contrary, the variance of LTAT is much larger. Our explanationis that under high resource utilization, LTAT tends to increasequickly with the increase of uncertainty level if InitInv is zero,but a nonzero InitInv may reduce the effect of the uncertaintylevel. When these different scenarios are grouped together, thevariance of LTAT is big, which makes the increasing trend in-significant.
The impact of solution framework type, problem scale, pro-cessor speed, and communication delay on mean HTAT andof LTAT and mean INVC is insignificant. These results showthat the agent scheduling framework as well as the price-basedscheduling method performs efficiently under different condi-tions in the homogeneous as well as heterogeneous environ-ments. In addition, by scheduling in a distributed and asyn-chronous fashion, the framework is scalable. What we did notexpect is that the holding cost did not have significant impact.This is possibly due to the quadratic tardiness penalty term inthe objective function (6) which dominates the linear inventorycost term.
B. Interactions of Pairs of Factors
By using two-way ANOVA, it is shown that the inventory rel-ative levels and resource utilizations have significant interactioneffects on mean LTAT and mean INVC, while the interactioneffects between communication delays and processor speeds onthese solution-quality-related measures are insignificant.
1) Communication Delays and Processor Speeds: As shownin Table IV, there is a significant interaction effect betweencommunication delays and processor speeds on the number oftransmitted precedence messages (MSGNs). The reason is thatunder small communication delays, the asset agents and the partagents in the homogeneous system can progress approximatelyat the same pace in solving their subproblems, while in the twoheterogeneous systems, the part agents slightly lag behind theasset agents. As a result, the asset agents and the part agents inthe homogeneous system can transmit more precedence mes-sages on average, as shown in Fig. 6. However, under largecommunication delays, the time for solving a subproblem inone iteration becomes negligible compared to the time waitingfor messages between two iterations. So the systems make noimpact since they all transmit similar amounts of messages. Inthe view that the MSGN somehow reflects the amount of in-terorganization coordination traffic between overhaul schedul-ing and repair scheduling, given a significant impact of Com-muDelay and ProcSpd on MSGN, it seems that at least one of thethree solution-quality-related measures should be influenced.The analysis, however, shows that the impact is insignificant.
Fig. 6. MSGN under different processor speeds (ProcSpd) and communicationdelays (CommuDelay).
Fig. 7. SCHT under different processor speeds (ProcSpd) and communicationdelays (CommuDelay).
Our explanation is that the iterative updating and exchangingof resource prices and inventory prices also indirectly achieveinterorganization coordination.
Table IV shows that the interaction effect on the SCHT isinsignificant. This can be explained by observing the SCHT dif-ference between the centralized method and our agent schedul-ing framework. The centralized method can finish in about 17 s,while the agent scheduling framework has to spend about 130 seven under low communication delays. As mentioned earlier,this is because Java is slow in message transmission com-pared to other languages like C. Hence, our agent schedulingframework spends more time on communication than compu-tation, and different processor speeds will not lead to largedifferences on SCHT, as shown in Fig. 7. Another reasonis that our agent scheduling framework schedules and coor-dinates in an asynchronous fashion. Although the individualpart agents in the heterogeneous systems may take more timein solving their problems, the overall SCHT does not changemuch.
ZHANG et al.: PERFORMANCE STUDY ON A MULTIAGENT E-SCHEDULING AND COORDINATION FRAMEWORK 63
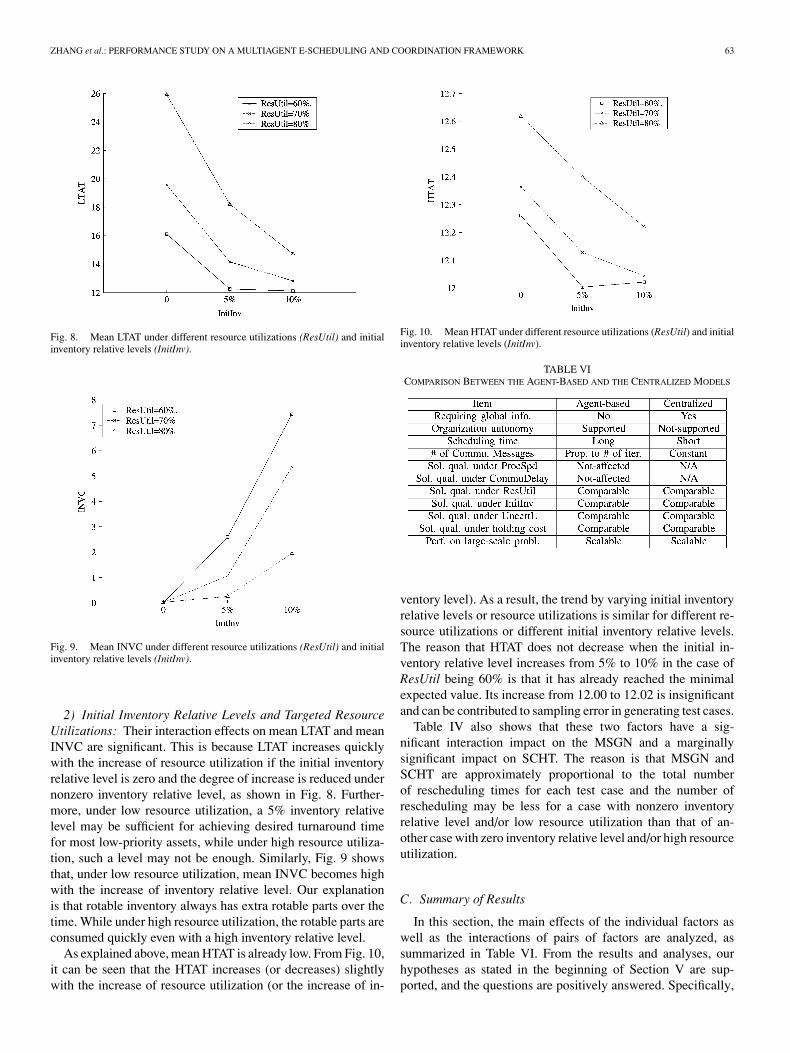
Fig. 8. Mean LTAT under different resource utilizations (ResUtil) and initialinventory relative levels (InitInv).
Fig. 9. Mean INVC under different resource utilizations (ResUtil) and initialinventory relative levels (InitInv).
2) Initial Inventory Relative Levels and Targeted ResourceUtilizations: Their interaction effects on mean LTAT and meanINVC are significant. This is because LTAT increases quicklywith the increase of resource utilization if the initial inventoryrelative level is zero and the degree of increase is reduced undernonzero inventory relative level, as shown in Fig. 8. Further-more, under low resource utilization, a 5% inventory relativelevel may be sufficient for achieving desired turnaround timefor most low-priority assets, while under high resource utiliza-tion, such a level may not be enough. Similarly, Fig. 9 showsthat, under low resource utilization, mean INVC becomes highwith the increase of inventory relative level. Our explanationis that rotable inventory always has extra rotable parts over thetime. While under high resource utilization, the rotable parts areconsumed quickly even with a high inventory relative level.
As explained above, mean HTAT is already low. From Fig. 10,it can be seen that the HTAT increases (or decreases) slightlywith the increase of resource utilization (or the increase of in-
Fig. 10. Mean HTAT under different resource utilizations (ResUtil) and initialinventory relative levels (InitInv).
TABLE VICOMPARISON BETWEEN THE AGENT-BASED AND THE CENTRALIZED MODELS
ventory level). As a result, the trend by varying initial inventoryrelative levels or resource utilizations is similar for different re-source utilizations or different initial inventory relative levels.The reason that HTAT does not decrease when the initial in-ventory relative level increases from 5% to 10% in the case ofResUtil being 60% is that it has already reached the minimalexpected value. Its increase from 12.00 to 12.02 is insignificantand can be contributed to sampling error in generating test cases.
Table IV also shows that these two factors have a sig-nificant interaction impact on the MSGN and a marginallysignificant impact on SCHT. The reason is that MSGN andSCHT are approximately proportional to the total numberof rescheduling times for each test case and the number ofrescheduling may be less for a case with nonzero inventoryrelative level and/or low resource utilization than that of an-other case with zero inventory relative level and/or high resourceutilization.
C. Summary of Results
In this section, the main effects of the individual factors aswell as the interactions of pairs of factors are analyzed, assummarized in Table VI. From the results and analyses, ourhypotheses as stated in the beginning of Section V are sup-ported, and the questions are positively answered. Specifically,

64 IEEE TRANSACTIONS ON SYSTEMS, MAN, AND CYBERNETICS—PART C: APPLICATIONS AND REVIEWS, VOL. 37, NO. 1, JANUARY 2007
the price-based agent scheduling and coordination frameworkcan obtain a high-quality solution under different conditionsin a timely manner. On the one hand, the framework achievesthe same level of performance as a centralized implementationof the price-based scheduling method in terms of the solution-quality-related measures. On the other hand, heterogeneity in adistributed environment does not prevent the framework fromperforming effectively. In addition, the results and analyses re-flect that high-priority assets are maintained in time while manylow-priority assets are delayed under high resource utilizationbecause of the delay of repairing parts, especially rotable parts.That is why a nonzero initial inventory relative level may leadto shorter turnaround times for low-priority assets. These rela-tions can provide organizations with guidance on setting up asuitable amount of resources and initial inventory relative level.Since these factors, such as resource utilization and heterogene-ity, are not restricted to the maintenance scheduling problemonly, the results may provide insights for other multiorganiza-tion scheduling problems.
VII. CONCLUSION
In this paper, a price-based multiagent scheduling and coor-dination framework for maintenance networks is explored, andseveral key factors that may affect the performance of the frame-work are identified and their effects experimentally studied.Two orthogonal arrays are applied to systematically conduct theexperiments and reduce the total experimental effort. The resultsvalidate our hypotheses and demonstrate that our frameworkovercomes the major difficulties and could be a first step towardthe next generation of e-scheduling for maintenance networks.
The current model incorporates a number of simplifying as-sumptions. To deploy it, the activities of other service providers,such as ordering and production planning of part distributorsand spare part manufacturers, need to be modeled. In addition,rather than giving the information to the agents, it is better forthe agents to retrieve the information automatically and up-date their knowledge over time. To obtain faster convergence,intraorganization scheduling as well as interorganization coor-dination needs to be further improved. With the advancement ofcomputing, communication, and sensing capabilities of assetsand parts, it is important to explore how to monitor asset/partconditions in real time and improve scheduling by using mobilesoftware agents. Finally, the issues related with security andfault tolerance should be addressed.
ACKNOWLEDGMENT
The authors would like to thank D. Yu for her helpful dis-cussions and the anonymous reviewers who helped to signifi-cantly improve this paper. Earlier preliminary work was reportedin [25] and [26].
REFERENCES
[1] P. B. Luh, D. Yu, S. Soorapanth, A. I. Khibnik, and R. Rajamani, “ALagrangian relaxation based approach to schedule asset overhaul andrepair services,” IEEE Trans. Autom. Sci. Eng., vol. 2, no. 2, pp. 145–157,Apr. 2005.
[2] V. Guide, Jr., M. Kraus, and R. Srivastava, “Scheduling policies for re-manufacturing,” Int. J. Prod. Econ., vol. 48, pp. 187–204, 1997.
[3] V. Guide, Jr., V. Jayaraman, and R. Srivastava, “Production planning andcontrol for remanufacturing: A state-of-the-art survey,” Robot. Comput.Integr. Manuf., vol. 15, pp. 221–230, 1999.
[4] V. Guide, Jr. and R. Srivastava, “Inventory buffers in recoverable manu-facturing,” J. Oper. Manage., vol. 16, pp. 551–568, 1998.
[5] R. Pool, “If it ain’t broke, fix it,” Technol. Rev., vol. 104, no. 7, p. 64, Sep.2001.
[6] M. Koc and J. Lee, “System framework for next-generation e-maintenancesystems,” Trans. Chin. Mech. Eng., vol. 12, no. 5, 2001.
[7] P. B. Luh, M. Ni, H. Chen, and L. S. Thakur, “Price-based approach foractivity coordination in a supply network,” IEEE Trans. Robot. Autom.,vol. 19, no. 2, pp. 335–346, Apr. 2003.
[8] N. M. Sadeh, D. W. Hildum, D. Kjenstad, and A. Tseng, “MASCOT: Anagent-based architecture for dynamic supply chain creation and coordi-nation in the internet economy,” Prod. Planning Control, vol. 12, no. 3,2001.
[9] N. Zarour, M. Boufaida, L. Seinturier, and P. Estraillier, “Supportingvirtual enterprise systems using agent coordination,” Knowl. Inf. Syst.,vol. 8, no. 3, pp. 330–349, Sep. 2005.
[10] H. Pham, “Software agents for internet-based systems and their design,” inIntelligent Agents and Their Applications, L. Jain, Z. Chen, and N. Ichalka-ranje, Eds. Heidelberg, Germany: Physica-Verlag, 2002, pp. 109–154.
[11] E. Santos, Jr., F. Zhang, and P. B. Luh, “Intra-organizational logisticsmanagement through multi-agent systems,” Electron. Commerce Res.,vol. 3, no. 3–4, pp. 337–364, 2003.
[12] R. Lee and J. Liu, “iJADE WeatherMAN: A weather forecasting systemusing intelligent multiagent-based fuzzy neuro network,” IEEE Trans.Syst., Man, Cybern. C, Appl. Rev., vol. 34, no. 3, pp. 369–377, May2004.
[13] I. Satoh, “Building reusable mobile agents for network management,”IEEE Trans. Syst., Man, Cybern. C, Appl. Rev., vol. 33, no. 3, pp. 350–357, May 2003.
[14] E. Oliveira, K. Fischer, and O. Stepankova, “Multi-agent systems: Whichresearch for which applications,” Robot. Autonom. Syst., vol. 27, pp. 91–106, 1999.
[15] R. G. Smith, “The contract net protocol: High-level communication andcontrol in a distributed problem solver,” IEEE Trans. Comput., vol. 29,no. 12, pp. 1104–1113, Dec. 1980.
[16] N. M. Sadeh, D. W. Hildum, and D. Kjenstad, “Agent-based e-supplychain decision support,” J. Org. Comput. Electron. Commerce, vol. 13,no. 3, pp. 225–241, 2003.
[17] K. Decker and V. Lesser, “Designing a family of coordination algorithms,”in Proc. 1st Int. Conf. Multi-Agent Systems (ICMAS’95), San Francisco,CA, 1995, pp. 73–80.
[18] P. Stone and M. Veloso, “Task decomposition, dynamic role assignment,and low-bandwidth communication for real-time strategic teamwork,”Artif. Intell., vol. 110, no. 2, pp. 241–273, 1999.
[19] O. Shehory, G. Sukthankar, and K. Sycara, “Agent aided aircraft main-tenance,” presented at the Conf. Autonomous Agents, Seattle, WA,1999.
[20] X. Xu and M. Kezunovic, “Mobile agent software applied in maintenancescheduling,” presented at the 2001 North American Power Symp., CollegeStation, TX, 2001.
[21] D. Yu, P. B. Luh, and S. Soorapanth, “A new Lagrangian relaxation basedmethod to improve schedule quality,” presented at the 2003 IEEE/RSJ Int.Conf. Intell. Robots Syst., Las Vegas, NV, 2003.
[22] M. G. Saba and E. Santos, Jr., “The multi-agent distributed goal satisfac-tion system,” in Proc. Int. ICSC Symp. Multi-Agents and Mobile Agentsin Virtual Org. and E-Commerce, 2000, pp. 389–394.
[23] M. S. Phadke, Quality Engineering Using Robust Design. EnglewoodCliffs, NJ: Prentice-Hall, 1989.
[24] D. G. Kleinbaum, L. L. Kupper, K. E. Muller, and A. Nizam, Ap-plied Regression Analysis and Other Multivariable Methods. Duxbury,1997.
[25] F. Zhang, E. Santos, Jr., and P. B. Luh, “Mobile multi-agent-based schedul-ing and coordination of maintenance networks,” in Proc. Int. Conf. Paralleland Distributed Processing Techniques and Applications, Las Vegas, NV,2003, pp. 279–285.
[26] F. Zhang, P. B. Luh, and E. Santos, Jr., “Performance study of multi-agentscheduling and coordination framework for maintenance networks,” inProc. 2004 IEEE/RSJ Int. Conf. Intelligent Robots and Systems (IROS2004), Sendai, Japan, 2004, pp. 2390–2395.

ZHANG et al.: PERFORMANCE STUDY ON A MULTIAGENT E-SCHEDULING AND COORDINATION FRAMEWORK 65
Feng Zhang received the B.S. degree in computerscience and technology and the M.S. degree in com-puter applications from Tsinghua University, Beijing,China, in 1993 and 1995, respectively. He is cur-rently pursuing the Ph.D. degree at the University ofConnecticut, Storrs.
From 1995 to 1999, he was a Software Engi-neer with the Tsinghua Unispendour Group, Beijing,working on research and development of computer-aided-design software. His research interests includemultiagent scheduling and coordination, load balanc-
ing, cooperative algorithm portfolios, and modeling of restricted processorsharing.
Eugene Santos, Jr. (M’93–SM’04) received the B.S.degree in mathematics and computer science andthe M.S. degree in mathematics (specializing in nu-merical analysis) from Youngstown State University,Youngstown, OH, in 1985 and 1986, respectively,and the Sc.M. and Ph.D. degrees in computer sciencefrom Brown University, Providence, RI, in 1988 and1992, respectively.
He is currently a Professor of engineering at theThayer School of Engineering, Dartmouth College,Hanover, NH, and Director of the Distributed Infor-
mation and Intelligence Analysis Group (DI2AG). Previously, he was a facultymember at the Air Force Institute of Technology, Wright-Patterson AFB, andthe University of Connecticut, Storrs. He has over 130 refereed technical pub-lications and specializes in modern statistical and probabilistic methods withapplications to intelligent systems, uncertain reasoning, and decision science.Most recently, he has pioneered new research on user and adversarial behavioralmodeling. He is an Associate Editor for the International Journal of Image andGraphics.
Dr. Santos is an Associate Editor of the IEEE TRANSACTIONS ON SYSTEMS,MAN, AND CYBERNETICS. He has chaired or served on numerous major IEEEconferences and professional society meetings.
Peter B. Luh (S’76–M’80–SM’91–F’95) receivedthe B.S. degree in electrical engineering from theNational Taiwan University, Taipei, Taiwan, R.O.C.,in 1973, the M.S. degree in aeronautics and astro-nautics engineering from the Massachusetts Instituteof Technology, Cambridge, in 1977, and the Ph.D.degree in applied mathematics from Harvard Univer-sity, Cambridge, in 1980.
Since 1980, he has been with the University ofConnecticut, Storrs, and currently is the SNET Pro-fessor of communications and information technolo-
gies in the Department of Electrical and Computer Engineering. He is also aVisiting Professor at the Center for Intelligent and Networked Systems, Depart-ment of Automation, Tsinghua University, Beijing, China. He is interested inplanning, scheduling, and coordination of design, manufacturing, supply chain,and other activities; configuration and operation of building elevator and HVACsystems for normal and emergency conditions; schedule, auction, portfolio op-timization, and load/price forecasting for power systems; and decision makingunder uncertain, fuzzy, or distributed environments. He is an Associate Editor ofthe IIE Transactions on Design and Manufacturing and Discrete Event DynamicSystems.
Dr. Luh is the founding Editor-in-Chief of the IEEE TRANSACTIONS ON
AUTOMATION SCIENCE AND ENGINEERING. From 1999 to 2003, he was theEditor-in-Chief of the IEEE TRANSACTIONS ON ROBOTICS AND AUTOMATION.





























