Embed Size (px)
Citation preview

94 IEEE TRANSACTIONS ON MEDICAL IMAGING, VOL. 28, NO. 1, JANUARY 2009
User-Agent Cooperation in MultiagentIVUS Image Segmentation
E. G. P. Bovenkamp*, J. Dijkstra, J. G. Bosch, and J. H. C. Reiber, Fellow, IEEE
Abstract—Automated interpretation of complex images requireselaborate knowledge and model-based image analysis, but oftenneeds interaction with an expert as well. This research describesexpert interaction with a multiagent image interpretation systemusing only a restricted vocabulary of high-level user interactions.The aim is to minimize inter- and intra-observer variability bykeeping the total number of interactions as low and simple as pos-sible. The multiagent image interpretation system has elaboratehigh-level knowledge-based control over low-level image segmen-tation algorithms. Agents use contextual knowledge to keep thenumber of interactions low but, when in doubt, present the userwith the most likely interpretation of the situation. The user, inturn, can correct, supplement, and/or confirm the results of image-processing agents. This is done at a very high level of abstractionsuch that no knowledge of the underlying segmentation methods,parameters or agent functioning is needed. High-level interactionthereby replaces more traditional contour correction methods likeinserting points and/or (re)drawing contours. This makes it easierfor the user to obtain good results, while inter- and intra-observervariability are kept minimal, since the image segmentation itselfremains under control of image-processing agents. The system hasbeen applied to intravascular ultrasound (IVUS) images. Experi-ments show that with an average of 2-3 high-level user interactionsper correction, segmentation results substantially improve whilethe variation is greatly reduced. The achieved level of accuracy andrepeatability is equivalent to that of manual drawing by an expert.
Index Terms—Cooperative systems, image segmentation, knowl-edge based systems.
I. INTRODUCTION
A. Knowledge-Based (Medical) Image Interpretation
M EDICAL image datasets are often very large and dif-ficult to interpret. This makes manual segmentation
highly sensitive to intra- and inter-observer variability and verytime consuming [1]. Therefore, an automatic segmentationmethod is needed.
Unfortunately, the complex and variable structures, whichmay be observed in such images, are not easily modeled.
Manuscript received February 06, 2008; revised May 26, 2008. First pub-lished July 02, 2008; current version published December 24, 2008. This workwas supported by the Dutch Innovative Research Program (IOP) under GrantIBV97008 and Grant IBV00304. Asterisk indicates corresponding author.
*E. G. P. Bovenkamp is with the Division of Image Processing (LKEB), De-partment of Radiology, Leiden University Medical Center, 2300RC Leiden, TheNetherlands (e-mail: [email protected]).
J. Dijkstra, J. G. Bosch, and J. H. C. Reiber are with the Division of Image Pro-cessing (LKEB), Department of Radiology, Leiden University Medical Center,2300RC Leiden, The Netherlands.
Color versions of one or more of the figures in this paper are available onlineat http://ieeexplore.ieee.org.
Digital Object Identifier 10.1109/TMI.2008.927351
Therefore standalone image segmentation algorithms haveoften proved insufficient and more elaborate knowledge- andmodel-based methods have to be devised to interpret theseimages. Good overview articles on knowledge-based imageunderstanding have been published [2]–[4]. Basically, threeimage interpretation strategies can be distinguished, which area bottom-up, a top-down, and a hybrid approach.
Bottom-up, or input driven, image processing aims to get asmuch structure as possible from the image without invoking ob-ject-specific knowledge and then to match the resulting struc-tures with available object knowledge [3].
Top-down, or model-driven, image processing starts withknowledge about (the shape and appearance of) objects, whichis then used to search for that object in a particular image.Examples of such models are snakes [5] and active shape/ap-pearance models [6].
Both approaches have problems that limit the applicability toreal world domains, such as intractability, object assumptionsthat are not met, and object dependency related problems likeocclusion.
Knowledge-based methods offer a third line of approach,which combines both bottom-up and top-down processes. Tohandle intractability of the bottom-up process, object knowl-edge is used to constrain it by posing object hypotheses aboutthe image content [7]. Examples of systems which combinebottom-up and top-down image interpretation processes areblackboard systems like the Schema system by Draper et al. [8],the Condor system by Strat and Fischler [9] (natural outdoorscene interpretation), and the Sigma system by Matsuyama[10] (remote sensing image interpretation). Knowledge-basedhybrid approaches lack the restrictions of bottom-up andtop-down approaches and can, for instance, interpret the resultsof a model-driven approach, or deal with multiple models andseveral interrelated objects. Such behavior is beyond the scopeof more classical approaches.
However, hybrid approaches introduce new problems thatconcern controlling the image interpretation process as a whole[2]. A partial answer to the problems facing hybrid knowl-edge-based image interpretation systems have been multiagentsystems, which offer the possibility of distributed knowledgeand control. For an overview on agents, agent theories, andagent architectures the reader is referred to [11]–[13]. Advan-tages of multiagent image interpretation are [3].
• Possibility of separate representation of knowledge of dif-ferent domains (problem solving, image processing, appli-cation domain).
• Possibility of separation of image processing algorithmsfrom control strategies. Accommodates a large variety
0278-0062/$25.00 © 2008 IEEE

BOVENKAMP et al.: USER-AGENT COOPERATION IN MULTIAGENT IVUS IMAGE SEGMENTATION 95
of control heuristics and can select the best processingmethods for different data situations.
• Ease of construction and maintenance.• Ability to benefit from parallel architectures.• Focusing ability: not all knowledge is needed for all tasks.
Both spatial and interpretive focus possible.• Heterogeneous problem solving, for example use symbolic
AI for spatial reasoning and active appearance models forimage segmentation.
• Reliability: an agent may be corrected by other agents.Several multiagent image interpretation systems have been
reported in the literature, like [14]–[20], but none of these sys-tems implements higher order reasoning and control capabilitieslike problem solving, elaboration and reflection. Furthermore,conflicting views are usually solved in very basic ways. All sys-tems do, however, implement local adaptive behavior and onesystem [15] does distinguish between control and image pro-cessing operators, but only on a single-agent basis and within amuch more limited scope.
Therefore, we developed a novel multiagent image interpreta-tion system [21], which is markedly different from previous ap-proaches in especially its elaborate high-level knowledge-basedcontrol over low-level image segmentation algorithms. Agentsin this system dynamically adapt their segmentation algorithms;this adaptation is based on knowledge about global constraints,contextual knowledge, local image information, and personalbeliefs like confidence in their own image processing results. Inthis current research, the lumen-agent, for example, encodes andcontrols an image processing pipeline which includes binarymorphological operations, an ellipse-fitter and a dynamic pro-gramming module and sets all relevant parameters. Generally,agent control allows the underlying segmentation algorithms tobe simpler and to be applied to a wider range of problems witha higher reliability [21].
The agent knowledge model is further general and modular tosupport easy construction and addition of agents for any image-processing task. Each agent in the system is responsible for onetype of high-level object and cooperates with other agents tocome to a consistent overall image interpretation. Cooperationinvolves communicating hypotheses and results, and resolvingconflicts between the interpretations of individual agents.
B. Intravascular Ultrasound (IVUS)
IVUS provides real-time high resolution tomographic imagesof the coronary vessels wall, and is able to show the presenceor absence of compensatory artery enlargement. IVUS allowsprecise tomographic measurement of the lumen area and plaquesize, distribution and, to some extent, composition of the plaque.Some examples of IVUS images are shown in Fig. 8.
To obtain insight into the status of an arterial segment, aso-called catheter pullback is carried out: an ultrasound probe ispositioned distally (downstream) in the segment of interest andthen mechanically pulled back (typically at a speed of 0.5 mm/s)during continuous image acquisition to the proximal (upstream)part of the segment of interest.
Experienced users may then conceptualize the complex 3-Dstructure of the morphology and pathology of the arterial seg-ment from this stack of images by reviewing such a sequence
repeatedly. Typically, one such pullback sequence consists of500–1000 images ( MB), which represents about 50 mmof vessel length.
C. Adding User Interaction
In previous experiments, using our multiagent approach,IVUS images from seven patients were segmented fully au-tomatically (without any user interaction) by five agents,specialized in lumen, vessel, calcified-plaque, shadow, andsidebranch detection. Contours were compared to those man-ually drawn by an expert. Results showed good correlationsbetween agents and expert with for the lumen and
for the vessel cross-sectional areas, respectively [21].However, these results can still be improved upon by adding
user interaction. The multi-agent platform allows to employ userinteraction in much more sophisticated ways than in a classicalapproach.
User interaction in the classical sense involves mainly initial-ization (placing a start point, indicating a region of interest, etc.)and hard corrections (manually correcting contours, placing ad-ditional control points, etc.) This is meant to overcome limita-tions of the detection system, but this is achieved at the cost ofextra efforts from the user, additional variability and reductionof repeatability. Mostly, the correction work is cumbersome,since the system does not use the corrections effectively, anddoes not learn from previous corrections.
In recent literature on user interaction in medical image anal-ysis the following criteria are given which should be satisfied inorder to obtain reproducible results in an efficient manner [22].
• Capability to generate the delineation as commanded bythe user.
• Simple efficient interaction, best obtained with pictorialinput or at a higher abstract level than the underlying com-putational method.
• Minimum interaction, kept when the user only has tochoose among options or when the system can learn frominteraction in the long term.
• User input should not be taken directly as part of the result,but should be used instead to configure parameters for thecomputational method or to select the best solution amongcomputed results.
The multiagent concept offers excellent opportunities for userinteraction that exploit the high-level knowledge of the user inan efficient way. Our goals for including user interaction wereas follows.
• Improve system accuracy. Combine the strength of the user(global image understanding of) with the strengths of theimage processing agents (repeatability).
• Keep the number of interactions minimal, both for effi-ciency and to limit observer variability.
• Use only high-level interactions to reduce observer vari-ability, to increase reproducibility, to support data abstrac-tion for future learning, and to avoid the necessity of tuningthe underlying image processing by the user.
We have implemented user interaction within the multiagentframework by including the user as an additional agent in themultiagent system using only a restricted vocabulary of high-

96 IEEE TRANSACTIONS ON MEDICAL IMAGING, VOL. 28, NO. 1, JANUARY 2009
level user interactions. This approach satisfies the above consid-erations and constraints and naturally fits in with the multiagentsystem as agents in the system already interact with one anotherat a high-level of abstraction (the image object level, or problemdomain level) and are able to translate high-level commands/constraints into low-level image processing pipelines with ap-propriate parameter settings. The user is represented by an ad-ditional (user-)agent and allowed to interact with the system inthe following ways (terminology taken from [22]).
• Initialize: roughly suggest a possible location where (addi-tional) objects may be found/detected.
• Judge: approve/disapprove a result.• Steer: suggest a strategy to improve the current result. For
example, suggest to make an object “larger” or “smaller.”The full interaction vocabulary is described in the next section
as well as the reasoning that is initiated by it.The aim of this research is to see whether it is possible to
get more accurate, reproducible results in an efficient mannerwith only a restricted set of high-level user interactions. Even-tually we also want agents to gradually adjust their behavior bylearning from these interactions such that less user interventionmay be necessary. It is expected that this will lead to even lessobserver variability and increased repeatability and efficiency.This future goal is not pursued in this paper. Also, the ergonomicaspects of optimal human–machine dialogs (although undoubt-edly important for practical deployment) are beyond the scopeof this paper.
II. THEORY/METHODS
Basically there are two types of interactions possible:• user-initiated interaction, when the user is not satisfied
with image interpretation by the multi-agent system;• agent-initiated interaction, when an agent seeks directions
or confirmation from the user (see Fig. 2).User-initiated interaction can happen at any time and anywherein the process. The user-agent represents the user in the multia-gent system and the user directly communicates with this agentthrough a user-agent interface as sketched in Fig. 1 and as shownin more detail in Figs. 6 and 7. The task of the user-agent isto channel user-requests to the appropriate image-processingagent(s) and to keep information in the user-interface up-to-date. Examples of user-initiated interaction are given below.
Agent-initiated interaction can happen in two specific cases:1) when two agents cannot resolve a mutual conflict, or 2) whileevaluating the results of an image processing action as shown inFig. 2. Situation 1) arises when any two agents are both 100%sure about there mutually conflicting results which causes astalemate. Situation 2) arises when the result of an image in-terpretation action does not match an agent’s expectations. Forexample, the agent expects a lumen of at least 20 mm , but is re-turned a result of 15 mm . When user interaction is required, theagent creates a general agent–user interface with context spe-cific choices and dependencies and preselects the settings thatseem most appropriate. The interface thus reflects an agent’sassessment of the situation and ideally just requires the user toconfirm this (“ok”) as shown in Fig. 5.
Both types of interaction allow the user to initialize, judge, orsteer the image segmentation by the multiagent system, but the
Fig. 1. Global view of the multiagent system architecture. The figure showsIVUS image processing agents that can interact with other agents through com-munication, act on the world by performing image processing operations andperceive that same world by accessing image processing results. User interac-tion components are shown in gray.
Fig. 2. Possible agent-initiated interaction in the image-processing loop.
image segmentation itself remains under control of image-pro-cessing agents. The user is not allowed to use more traditional“hard” contour correction methods like inserting control pointsand/or (re)drawing contours, because such methods potentiallylead to nonuniform properties of the segmentation result and arelikely to be less reproducible [22].
“Hard” corrections in this respect are corrections which areby definition elements of the final segmentation result. Notethat adding control points in an interactive segmentation methoddoes not necessarily mean these corrections are “hard.” In thededicated semi-automatic IVUS segmentation system used asa benchmark system in this paper, for example, corrections areusually less “hard” because user-inserted control points merelyindicate a region of interest through which the final segmenta-tion result should go. In this case the hardness of the correctiondepends on the area and associated cost function defined for thecontrol point. If an added control point does not yield the desiredresult, the user may further manipulate the associated area andcost function variables (make the correction “harder”), as wellas certain other variables related to the segmentation method it-self. However, this requires interacting in the image processingdomain which may be less intuitive to the user, may potentiallylead to slower operation and, of course, to possible nonuniformresults which are difficult to reproduce. Thus, adding control
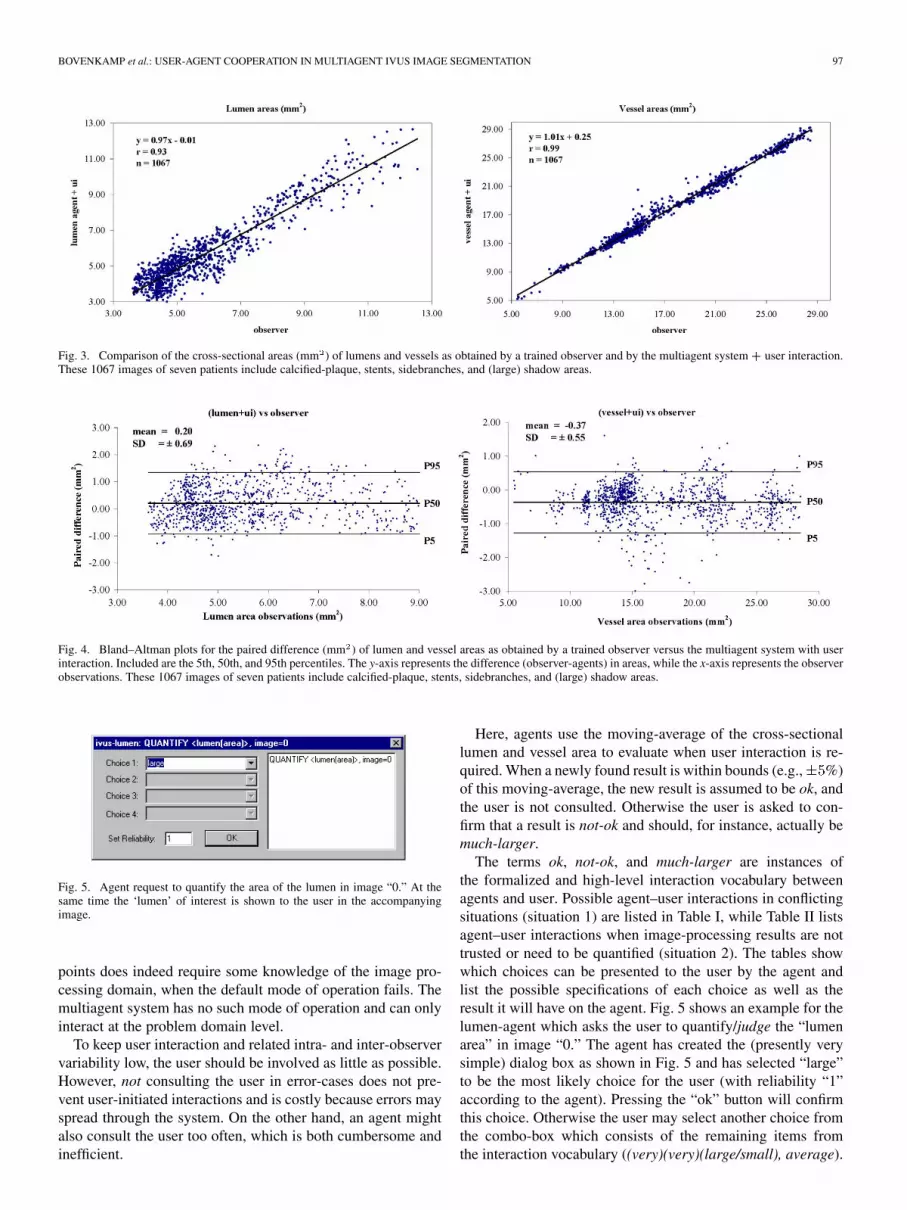
BOVENKAMP et al.: USER-AGENT COOPERATION IN MULTIAGENT IVUS IMAGE SEGMENTATION 97
Fig. 3. Comparison of the cross-sectional areas (mm ) of lumens and vessels as obtained by a trained observer and by the multiagent system � user interaction.These 1067 images of seven patients include calcified-plaque, stents, sidebranches, and (large) shadow areas.
Fig. 4. Bland–Altman plots for the paired difference (mm ) of lumen and vessel areas as obtained by a trained observer versus the multiagent system with userinteraction. Included are the 5th, 50th, and 95th percentiles. The y-axis represents the difference (observer-agents) in areas, while the x-axis represents the observerobservations. These 1067 images of seven patients include calcified-plaque, stents, sidebranches, and (large) shadow areas.
Fig. 5. Agent request to quantify the area of the lumen in image “0.” At thesame time the ‘lumen’ of interest is shown to the user in the accompanyingimage.
points does indeed require some knowledge of the image pro-cessing domain, when the default mode of operation fails. Themultiagent system has no such mode of operation and can onlyinteract at the problem domain level.
To keep user interaction and related intra- and inter-observervariability low, the user should be involved as little as possible.However, not consulting the user in error-cases does not pre-vent user-initiated interactions and is costly because errors mayspread through the system. On the other hand, an agent mightalso consult the user too often, which is both cumbersome andinefficient.
Here, agents use the moving-average of the cross-sectionallumen and vessel area to evaluate when user interaction is re-quired. When a newly found result is within bounds (e.g., %)of this moving-average, the new result is assumed to be ok, andthe user is not consulted. Otherwise the user is asked to con-firm that a result is not-ok and should, for instance, actually bemuch-larger.
The terms ok, not-ok, and much-larger are instances ofthe formalized and high-level interaction vocabulary betweenagents and user. Possible agent–user interactions in conflictingsituations (situation 1) are listed in Table I, while Table II listsagent–user interactions when image-processing results are nottrusted or need to be quantified (situation 2). The tables showwhich choices can be presented to the user by the agent andlist the possible specifications of each choice as well as theresult it will have on the agent. Fig. 5 shows an example for thelumen-agent which asks the user to quantify/judge the “lumenarea” in image “0.” The agent has created the (presently verysimple) dialog box as shown in Fig. 5 and has selected “large”to be the most likely choice for the user (with reliability “1”according to the agent). Pressing the “ok” button will confirmthis choice. Otherwise the user may select another choice fromthe combo-box which consists of the remaining items fromthe interaction vocabulary ((very)(very)(large/small), average).

98 IEEE TRANSACTIONS ON MEDICAL IMAGING, VOL. 28, NO. 1, JANUARY 2009
TABLE IAGENT–USER INTERACTION, INITIATED WHEN A MUTUAL CONFLICT CANNOT BE RESOLVED
TABLE IIAGENT–USER INTERACTION, INITIATED WHEN AN AGENT NEEDS USER INPUT DURING EVALUATION OF AN IMAGE-PROCESSING RESULT
Fig. 6. User request to make the vessel in image “0” “a-little smaller.” At thesame time the “vessel” of interest is shown to the user in the accompanyingimage.
The lumen-agent will store this knowledge with the lumen andcontinue with the segmentation of the next slice in the imagevolume.
Possible user interactions which can be initiated by the userat any time during the process are listed in Table III. Interactionsneed up to three specifications as listed in the table. The title barof the user-agent interface shows the total interaction and pos-sible missing specifications as shown in Fig. 6. An interactionwill only be executed when it is fully specified. The user-agentnotifies all involved agents of the user interaction. Agents try tosatisfy the user request and will enter an agent–user interactioncycle until the user is fully satisfied. An example which demon-strates how the user can steer the system is shown in Fig. 6. Theuser requests the agents to make the detected vessel in image “0”“a-little smaller”. Other possible choices for the user are alsolisted in this figure [(a-little/much/very-much)(larger/smaller)].The user cannot change the interaction vocabulary. The userrequest initiates the following reasoning action: the user-agentidentifies which agent was responsible for the object (the vessel-agent). It transfers the request to that agent, who will conse-quently translate the request into an image segmentation action.For the appropriate segmentation method and parameters, theagent reflects on its previous segmentation attempt(s) of whichit keeps a record. Based on this knowledge it adjusts the seg-mentation algorithm and parameters such that it will most likelyyield the result requested by the user.
Since the request was issued by the user, the responsible agentwill then construct a dialog box similar to the one shown inFig. 5 in which it will ask the user if he/she is satisfied with theresult. Effectively the agent has now entered the user interactionloop as shown in Fig. 2 and will continue to adjust its imageprocessing until the user is satisfied with the result.
A third example demonstrates initialization and is given inFig. 7, where the user requests that “deep-calcified-plaque”should be detected in image “0” around the location indicatedby the user with a “point.” The figure also shows other possi-bilities for the user to select the region of interest which are acontour, pie-slice, global. Reasoning initiated by this commandis that the user-agent searches for an agent that can detect“deep-calcified-plaque” and then sends the request to detectthat object at the specified location. The capable agent willthen execute the command similar to the vessel-agent in theprevious example and similarly enter the user interaction loopas shown in Fig. 2.
If the user requests the agent-system to adjust to an objectwhile no agent has the capability to detect it, the user is askedto roughly draw that object.
Agents use lookup tables to translate low-level imageprocessing commands, parameter settings, and object-fea-ture values into the formalized interaction vocabulary, andvice-versa. These lookup tables provide absolute and relativeclassification and adaptation values that are derived from dataand experience. Currently these values are preset by the systemdesigner, but will be made adaptive in the future to supportagent learning from user interaction. User-accepted quantifi-cations of cross-sectional lumen areas (large, small, etc.), forexample, provide the system with labeled data which can beused to (re)train probabilistic classifiers when the number ofuser corrections exceeds a certain threshold.
III. EXPERIMENTS
The IVUS images pullback series considered in this paperwere acquired with a 20-MHz Endosonics Five64 catheterusing a motorized pullback device (1 mm/s). Image size was384 384 pixels and the acquired pullback series consistedgenerally of about 600 images each. One experienced observer

BOVENKAMP et al.: USER-AGENT COOPERATION IN MULTIAGENT IVUS IMAGE SEGMENTATION 99
TABLE IIIPOSSIBLE USER INTERACTIONS WHICH CAN BE INITIATED BY THE USER AT ANY TIME DURING THE PROCESS. INTERACTIONS NEED
UP TO THREE SPECIFICATIONS AS LISTED BELOW
Fig. 7. User request to detect “deep-calcified-plaque” at the location indicatedwith a “point” by the user. At the same time the “point” is shown to the user inthe accompanying image (“0”).
analyzed images of seven patients. The observer used a dedi-cated semi-automatic segmentation method (QCU-CMS, see[1]) to obtain lumen and vessel contours, which were thenmanually corrected where necessary. These final segmentationsserved as an independent standard.
Experiments with lumen, vessel, sidebranch, shadow, calci-fied-plaque, and status agents were performed on 1067 images.Processing speed of the multiagent system + user-interactionwas 10–20 frames/minute depending on image difficulty (QCU-CMS: 20 frames/minute maximum). The starting point of agentimage analysis was always at the 200th image in a run. Thispoint was chosen since the most interesting images in a pullbackrun are usually not situated near the start or end. Then a max-imum of 200 consecutive images per patient were analyzed, oras many as were available. Due to initial practical limitations ofmemory and processing time (now resolved), these image se-ries were further cut into 40 smaller parts/experiments, but no
images from these series were excluded and different configura-tions with calcified plaque, shadows, sidebranches, and dropoutregions were present.
For these series fully automatic multiagent image segmenta-tions were compared with the results obtained with the extendedsystem with user interaction. Eleven subseries (seven patients,283 images, 11 experiments) were selected to test the inter- andintra-observer error using the extended system with user inter-action. Selection was based on the high degree of error and/orhigh amount of effort by the original automatic agent systemon those images, because this is where high-level user direc-tions/interactions are expected to be most helpful. This was con-firmed by closer inspection of the selected image series which,for example, revealed the presence of objects unknown to theagents, like stents and deep calcified plaque, or large (shadow)regions without any image information. Since automatic seg-mentation of these images proved very difficult, it was also agood test to see whether acceptable segmentations could be ob-tained with only high-level user interactions.
For comparison, segmentations of all image series were alsoperformed with a dedicated semi-automatic IVUS segmentationsystem (QCU-CMS, [1]) system which is being used in clinicalpractice. This system uses segmentation methods which workon both the original (transversal) images and longitudinal cross-cuts of those images [1]. The user generally starts by addingcontrol points to the longitudinal images until he/she is satisfiedwith the longitudinal contour detection. The resulting contoursare then translated into a set of control points for the detectionin the transversal images. The resulting segmentations may thenneed additional correction which can be done by adding controlpoints to the transversal images. This process may iterate a fewtimes. Both the number of user interactions and the inter-ob-server variability were determined.

100 IEEE TRANSACTIONS ON MEDICAL IMAGING, VOL. 28, NO. 1, JANUARY 2009
TABLE IVPAIRED DIFFERENCE BETWEEN MULTIAGENT SYSTEM (MA) WITH/WITHOUT USER INTERACTION (UI) AND SEMI-AUTOMATIC SEGMENTATION WITH QCU-CMS[1]. DIFFERENCES ARE GIVEN AS MEAN � 1 SD. FROM THE ORIGINAL IMAGE SERIES (“ALL,” SEVEN PATIENTS, 1067 IMAGES) 11 DIFFICULT IMAGE SUBSERIES
WERE SELECTED (“SELECTION,” SEVEN PATIENTS, 283 IMAGES) TO ASSESS INTER- AND INTRA-OBSERVER VARIABILITY. FOR REFERENCE, COMPARISONS
BETWEEN MANUALLY DRAWN EXPERT CONTOURS (OBSERVER AND QCU-CMS AS REPORTED BY KONING ET AL IN [1] ARE ALSO LISTED
IV. RESULTS
A. Accuracy
Lumen and vessel detection by the agent system without userinteraction were compared with expert corrected contours in[21]. Those results showed good correlation between agents andobserver for the lumen and very good correlationfor the vessel cross-sectional areas. Paired differ-ence between agents (without user interaction) and observer was
mm for the vessel, and mm for thelumen cross-sectional areas. The student t-test showed no sta-tistically significant difference for the vessel areas ,but significance for the lumen cross-sectional areas(see also Table IV).
Based on those earlier experiments it was concluded that thefully automatic IVUS image interpretation by the agent systemwas very good. This is especially true when one takes into ac-count that, contrary to our experiments, image acquisition andselection in referenced studies [23]–[25] were such that only“optimal” images were considered with little missing informa-tion and clearly visible objects in order to minimize inter- andintraobserver variability. Further, lumen and vessel border con-tours in those studies were either fully hand drawn or manuallycorrected.
The earlier multiagent experiments are repeated here with thesystem plus user interaction to see how much results might im-prove (accuracy) if the user was allowed to interact with theagent-system (in a high-level fashion only) and at what costs,in terms of the number of user interactions required (efficiency)and inter- and intra-observer variability (repeatability). For ref-erence these results were also compared with the segmenta-tion by a dedicated semi-automatic IVUS segmentation system(QCU-CMS).
The new experiments resulted in a paired difference betweenagents and observer of mm for the vessel, and
mm for the lumen cross-sectional areas as pre-sented in Table IV and in Figs. 3 and 4. Results show that vari-ance was reduced and correlations between user interacted agentsystem and expert-drawn contours were much better with
for the lumen (versus 0.84) and for the vessel(versus 0.92) cross-sectional areas. However, user interactionsintroduced a somewhat larger bias than was originally the case
and the student t-test further showed that these differences werestatistically significant . The cause of these differ-ences is further investigated in Section IV-D.
When compared with the semi-automatic detection method(QCU-CMS) (see [1] and Table IV) the experiments show thatour system can obtain very comparable results using only high-level user interaction. The table shows that QCU-CMS had lessvariance on the lumen detection ( versus ), whereasthe multiagent system had less variance on the vessel detection( versus ).
Results on the very-hard-to-segment subseries improvedeven more dramatically with much lower variabilities and muchbetter correlations as also shown in Table IV. Obviously, theoverview of the user is of much help here. This is especially truefor the vessel detection, which is hampered most by missingimage information due to large shadows and/or sidebranches.Table IV also shows that performance of the QCU-CMS systemon these subsets is almost equal to performance on the fullimage sets. This is due to the fact that (the overview of) the useris always included by default and because this system actuallyworks on a larger range of images including user-inserted con-trol points to help it guide through the more difficult sections.
B. Repeatability: Inter- and Intra-Observer Variability
The same very-hard-to-segment image series were used to as-sess inter- and intra-observer variability, where one observer didthe experiment with user interaction twice with time betweenexperiments of more than six months to negate learning effects.These segmentation results were compared with the results byanother observer and with values found in literature and are pre-sented in Table V.
Intra-observer results show that allowing only high-level userinteraction to segment these very difficult images leads to resultsthat are comparable to values found in literature.
Inter-observer variability shows comparable results, althoughthe difference between observers for the lumen segmentation issomewhat large. Upon investigation it showed that, in certaincases, the user is presented with either of two choices, whichare neither entirely correct. Due to the high-level mode of in-teraction there is also no option for the user to enforce the cor-rect solution and differences in preference may then lead to dif-ferent choices for different users. This is further explained inSection IV-D.
BOVENKAMP et al.: USER-AGENT COOPERATION IN MULTIAGENT IVUS IMAGE SEGMENTATION 101
TABLE VINTRA- AND INTER-OBSERVER VARIABILITY
TABLE VINUMBER OF USER INTERACTIONS WITH THE AGENT SYSTEM (SEVEN
PATIENTS, 1067 IMAGES). A DIFFERENCE IS MADE BETWEEN USER- AND
AGENT INITIATED INTERACTIONS. FURTHER THE AVERAGE NUMBER OF
INTERACTIONS PER CORRECTION AND CORRECTION RATE ARE GIVEN
TABLE VIISAME AS TABLE VI, WHEN INTERACTIONS RECORDED IN THE
FIRST IMAGE OF EACH EXPERIMENT ARE DISCARDED
Generally, however, both in absolute terms and in terms ofintra- and inter-observer variability, results demonstrate thatwith only high-level user interaction it is possible to obtain asegmentation quality for very difficult images which is similarto the quality of manually drawn contours in “optimal” im-ages as reported in literature. Even when compared with theinter-observer results obtained with QCU-CMS the repeata-bility of user-guided multiagent image segmentation was good,knowing that the ground-truth contours were also obtained withQCU-CMS.
C. Efficiency of User-Guided Multiagent Segmentation
High-level user interaction does significantly improve thesegmentation results of the standalone system. However, thequestion is at what cost. To quantify this, the number of requestsfor feedback (and resulting user-actions) by the lumen- andvessel-agent were recorded. Similarly user-initiated interac-tions were recorded. Results of these experiments are presentedin Tables VI and VII. For reference these results were alsocompared with user interaction in a dedicated semi-automaticIVUS segmentation system (QCU-CMS) which is being usedin medical practice. These results are presented in Table VIII.
TABLE VIIINUMBER OF USER INTERACTIONS RECORDED WITH A DEDICATED
SEMI-AUTOMATIC SYSTEM (QCU-CMS) ON THE SAME
IMAGES AS IN TABLE VI
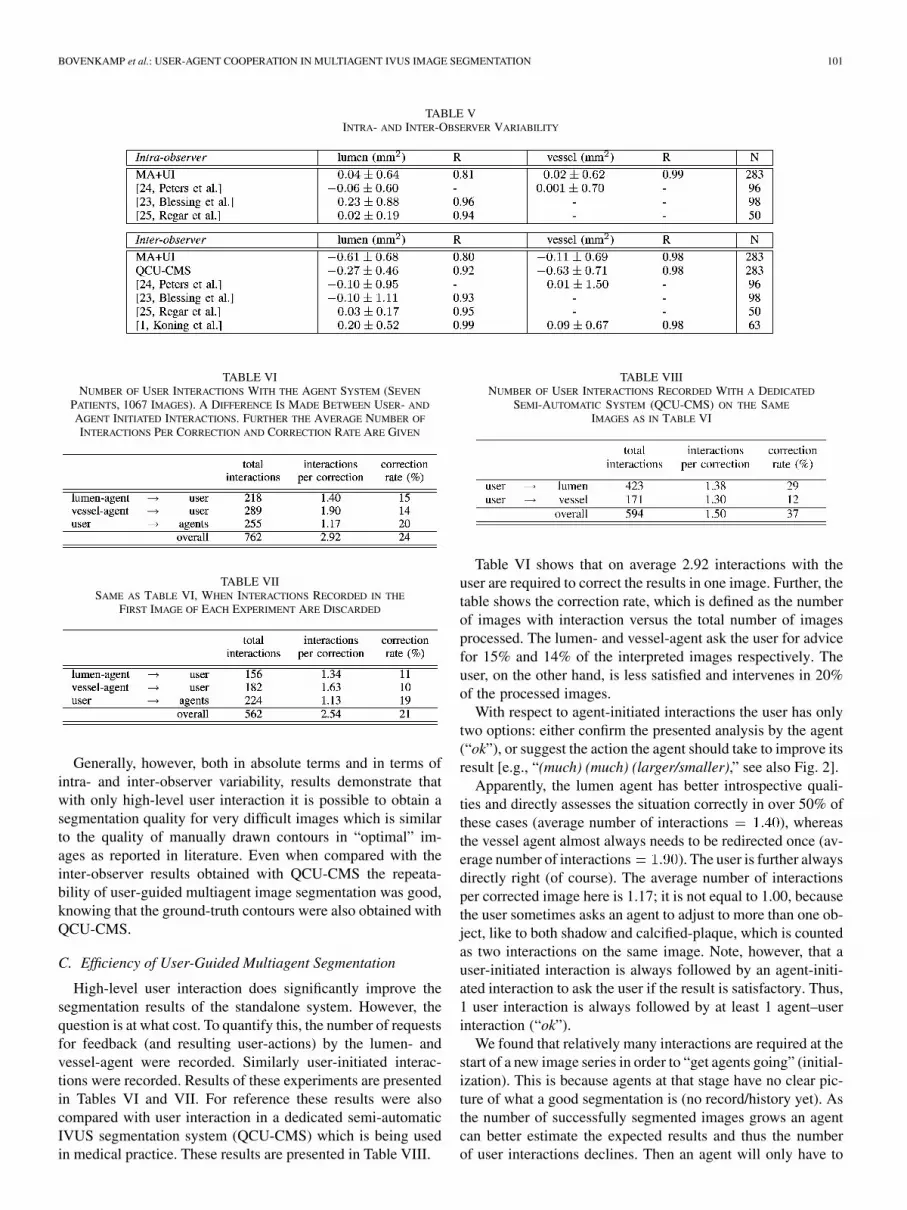
Table VI shows that on average 2.92 interactions with theuser are required to correct the results in one image. Further, thetable shows the correction rate, which is defined as the numberof images with interaction versus the total number of imagesprocessed. The lumen- and vessel-agent ask the user for advicefor 15% and 14% of the interpreted images respectively. Theuser, on the other hand, is less satisfied and intervenes in 20%of the processed images.
With respect to agent-initiated interactions the user has onlytwo options: either confirm the presented analysis by the agent(“ok”), or suggest the action the agent should take to improve itsresult [e.g., “(much) (much) (larger/smaller),” see also Fig. 2].
Apparently, the lumen agent has better introspective quali-ties and directly assesses the situation correctly in over 50% ofthese cases (average number of interactions ), whereasthe vessel agent almost always needs to be redirected once (av-erage number of interactions ). The user is further alwaysdirectly right (of course). The average number of interactionsper corrected image here is 1.17; it is not equal to 1.00, becausethe user sometimes asks an agent to adjust to more than one ob-ject, like to both shadow and calcified-plaque, which is countedas two interactions on the same image. Note, however, that auser-initiated interaction is always followed by an agent-initi-ated interaction to ask the user if the result is satisfactory. Thus,1 user interaction is always followed by at least 1 agent–userinteraction (“ok”).
We found that relatively many interactions are required at thestart of a new image series in order to “get agents going” (initial-ization). This is because agents at that stage have no clear pic-ture of what a good segmentation is (no record/history yet). Asthe number of successfully segmented images grows an agentcan better estimate the expected results and thus the numberof user interactions declines. Then an agent will only have to

102 IEEE TRANSACTIONS ON MEDICAL IMAGING, VOL. 28, NO. 1, JANUARY 2009
TABLE IXAGENT–USER INTERACTIONS SPECIFIED ACCORDING TO TYPE
ask the user for feedback in case a result is outside the rangeof expected values. This initial uncertainty of agents can be de-rived from Tables VI and VII: 28%, 37%, and 12% of the totalnumber of interactions occurred in the first image of a new ex-periment for lumen-agent, vessel-agent, and user, respectively.Omitting the interactions in those first images results in the fig-ures as shown in Table VII. So, after having established a goodstart in the first image, the user is then only consulted by thelumen (vessel) agent for 11% (10%) of the images versus 15%(14%) earlier as can be read from Tables VI and VII. For theuser, with global overview, this issue does not matter very much:20% versus 19%.
For reference we compared these results with user interactionin the dedicated semi-automatic QCU-CMS system using theset of final control points that were added by the user. Eachcontrol point was counted as 1 user interaction, although theuser may have changed such a control point several times beforefinally accepting it. The results of applying this system to thesame images as before are given in Table VIII. Precision andaccuracy of this experiment were also assessed and are given inTables IV and V.
Table VIII shows that fewer interactions were necessary withthe semi-automatic system (594 versus 762), but at a higher cor-rection rate (37% versus 24%). So the agent system was moreoften correct, but correction of an agent took more effort, atleast, when looking at it in absolute numbers. This is therebymostly true for the vessel detection which needed only an av-erage of 1.30 interactions per correction versus 1.90 interactionsfor the agent system. The lumen detection required on averagean equal number of corrections (1.38 versus 1.40).
On the other hand the user intervened with the agent system inonly 255 cases versus 594 times for the semi-automatic system(in which only user-initiated interventions exist). Agent-initi-ated interaction was further investigated as shown in Table IX.The table lists the total number of interaction requests by thelumen- and vessel-agent sorted with respect to the interactionwhich resulted. As the table shows this amounted for a very largepart (66%) to simply affirm the judgment of the situation by theagent (pressing the “ok” button). So the nature of these inter-actions was mostly very simple, while every interaction in thesemi-automatic system required the user to set a control pointwith a pointing device in the image. Something which must bedone with considerable attention and precision.
Finally, from a user point of view, the total number of inter-actions does not seem to be excessive knowing that the semi-au-
tomatic system is being used in medical practice and is reportedto be acceptable to its users.
D. Sources of Difference
Statistically significant differences were found both betweenmultiagent system and expert-drawn contours and between theresults of observers in the user interaction experiments as shownin Table IV. Four possible causes for these differences wereidentified.
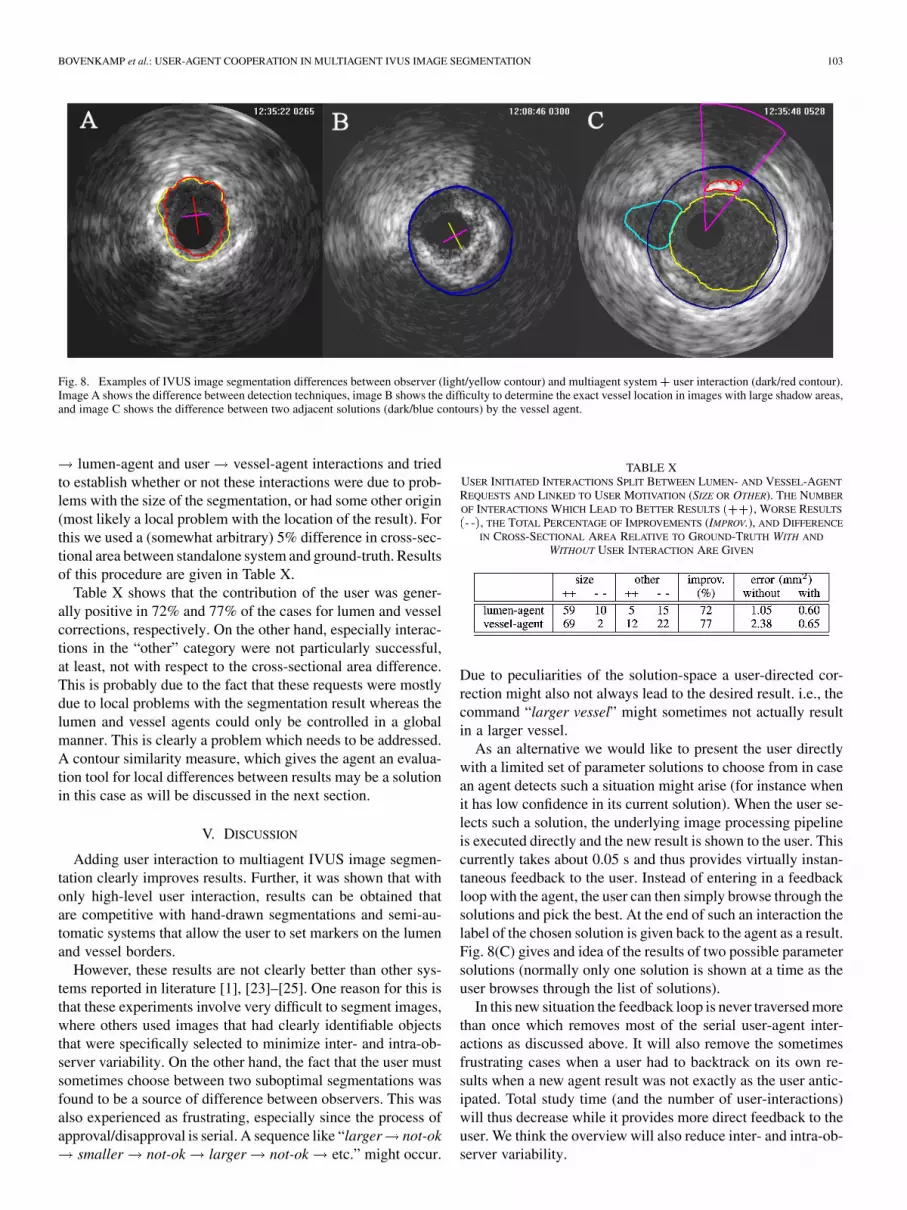
A first and fundamental source of difference is betweenany results obtained with the multiagent system with/withoutuser interaction and the manually corrected segmentationsthat served as ground-truth. These ground-truth segmentationswere obtained with a (semi-automatic) segmentation method(QCU-CMS), which differs from the multiagent system in bothmethod and resolution. As a consequence the solution space forthe multiagent system is not equal to that of QCU-CMS. Sincethe user can further only interact with the multiagent systemat a high level of abstraction, the user can direct the agent toa particular solution in this solution space, but cannot createnew (intermediate) solutions. This contrasts with systems likeQCU-CMS where the user can force a segmentation to gothrough a set of user-defined points. This may result in differentoutcomes such as can be seen in Fig. 8(A). Two adjacent seg-mentations in the solution space of the vessel agent are shownin Fig. 8(C).
A second source of difference between any two observers re-sults from images with very little information regarding the truelumen and vessel border locations. This occurs in images withlarge sidebranches and/or shadow regions like in Fig. 8(B). Acertain difference between any two observers will almost al-ways exist in such ultrasound images. The difference shown inFig. 8(B) is both a difference between systems and a differencebetween observers.
A third source of difference between observers that interactwith the multiagent system occurs when no solution provided bythe multiagent system is entirely correct. Having only high-levelcontrol over agents can be frustrating in such cases, since theuser has to choose between two suboptimal results. Choosingan option is then just a matter of preference and thus a source ofintra- and inter-observer error. In practice, an additional “hard”correction would be required/desired, but for the sake of theevaluation of our current approach this was not allowed. It isa subject for further study, however. Fig. 8(C) shows two so-lutions for the vessel segmentation, where one option is clearlythe best. In images with very little information, like in Fig. 8(B),the best choice between such competing solutions is not so clear,however.
User interaction by itself can also be a (fourth) source oferror. Therefore we retrospectively investigated whether addinguser interaction might possibly deteriorate results as previouslyfound by the standalone system. To this end we compared thefinal results by the standalone multiagent system with those bythe same system with high-level user interaction. We looked atthe difference in cross-sectional areas of lumen and vessel forexactly those images where user initiated user interaction couldunequivocally be established. We split these interactions in user
BOVENKAMP et al.: USER-AGENT COOPERATION IN MULTIAGENT IVUS IMAGE SEGMENTATION 103
Fig. 8. Examples of IVUS image segmentation differences between observer (light/yellow contour) and multiagent system� user interaction (dark/red contour).Image A shows the difference between detection techniques, image B shows the difficulty to determine the exact vessel location in images with large shadow areas,and image C shows the difference between two adjacent solutions (dark/blue contours) by the vessel agent.
lumen-agent and user vessel-agent interactions and triedto establish whether or not these interactions were due to prob-lems with the size of the segmentation, or had some other origin(most likely a local problem with the location of the result). Forthis we used a (somewhat arbitrary) 5% difference in cross-sec-tional area between standalone system and ground-truth. Resultsof this procedure are given in Table X.
Table X shows that the contribution of the user was gener-ally positive in 72% and 77% of the cases for lumen and vesselcorrections, respectively. On the other hand, especially interac-tions in the “other” category were not particularly successful,at least, not with respect to the cross-sectional area difference.This is probably due to the fact that these requests were mostlydue to local problems with the segmentation result whereas thelumen and vessel agents could only be controlled in a globalmanner. This is clearly a problem which needs to be addressed.A contour similarity measure, which gives the agent an evalua-tion tool for local differences between results may be a solutionin this case as will be discussed in the next section.
V. DISCUSSION
Adding user interaction to multiagent IVUS image segmen-tation clearly improves results. Further, it was shown that withonly high-level user interaction, results can be obtained thatare competitive with hand-drawn segmentations and semi-au-tomatic systems that allow the user to set markers on the lumenand vessel borders.
However, these results are not clearly better than other sys-tems reported in literature [1], [23]–[25]. One reason for this isthat these experiments involve very difficult to segment images,where others used images that had clearly identifiable objectsthat were specifically selected to minimize inter- and intra-ob-server variability. On the other hand, the fact that the user mustsometimes choose between two suboptimal segmentations wasfound to be a source of difference between observers. This wasalso experienced as frustrating, especially since the process ofapproval/disapproval is serial. A sequence like “larger not-ok
smaller not-ok larger not-ok etc.” might occur.
TABLE XUSER INITIATED INTERACTIONS SPLIT BETWEEN LUMEN- AND VESSEL-AGENT
REQUESTS AND LINKED TO USER MOTIVATION (SIZE OR OTHER). THE NUMBER
OF INTERACTIONS WHICH LEAD TO BETTER RESULTS ����, WORSE RESULTS
�- -�, THE TOTAL PERCENTAGE OF IMPROVEMENTS (IMPROV.), AND DIFFERENCE
IN CROSS-SECTIONAL AREA RELATIVE TO GROUND-TRUTH WITH AND
WITHOUT USER INTERACTION ARE GIVEN
Due to peculiarities of the solution-space a user-directed cor-rection might also not always lead to the desired result. i.e., thecommand “larger vessel” might sometimes not actually resultin a larger vessel.
As an alternative we would like to present the user directlywith a limited set of parameter solutions to choose from in casean agent detects such a situation might arise (for instance whenit has low confidence in its current solution). When the user se-lects such a solution, the underlying image processing pipelineis executed directly and the new result is shown to the user. Thiscurrently takes about 0.05 s and thus provides virtually instan-taneous feedback to the user. Instead of entering in a feedbackloop with the agent, the user can then simply browse through thesolutions and pick the best. At the end of such an interaction thelabel of the chosen solution is given back to the agent as a result.Fig. 8(C) gives and idea of the results of two possible parametersolutions (normally only one solution is shown at a time as theuser browses through the list of solutions).
In this new situation the feedback loop is never traversed morethan once which removes most of the serial user-agent inter-actions as discussed above. It will also remove the sometimesfrustrating cases when a user had to backtrack on its own re-sults when a new agent result was not exactly as the user antic-ipated. Total study time (and the number of user-interactions)will thus decrease while it provides more direct feedback to theuser. We think the overview will also reduce inter- and intra-ob-server variability.

104 IEEE TRANSACTIONS ON MEDICAL IMAGING, VOL. 28, NO. 1, JANUARY 2009
We plan to use evolutionary strategies to find these parametersolutions, which should be linked to user requests like “larger”while taking into consideration the interpretation context, e.g.,“small lumen” with “large vessel.” Cases where user interac-tions are not directly successful are stored and when enough datafor a request in a particular context has been collected, a new setof parameters will be learned for these cases. These parametersolutions will replace the parameter values in the lookup tables,that are currently preset by the system designer. The numberof solutions will thereby be dynamic such that refinements canbe added when needed. First positive results with this approachwere published in [26], [27] for IVUS and for computed tomo-graphic angiography (CTA) images in [28].
In addition we will use reinforcement learning to train agentsto pick the best prelearned optimal parameter solutions for a par-ticular situation. After initial training the exploration/exploita-tion rate of the reinforcement learning algorithm will be usedto adapt to the user: if unsatisfied (derived from the number ofcorrections), exploration will be used to find better default solu-tions, otherwise an agent will simply exploit its current knowl-edge.
Another goal is to gradually reduce the number of user in-teractions by learning from the user. Ultimately agents shouldgradually anticipate on possible user interactions such that thesecan already proactively be incorporated in their behavior. As aresult less real user interactions will be required which will leadto less observer variability and increased repeatability. To thisend, user interactions (that are currently already recorded) willbe used by agents to learn and adapt to the user. This will berealized in future projects, where agents will start from basicrules and learn from presegmented images and user interactionsto improve their results.
A third improvement may be achieved by letting the user pro-vide an initial segmentation of the first image in a sequence afterall. This will give agents information about good/bad segmen-tations from the beginning and remove a considerable numberof user interactions at the start of an image sequence.
A last improvement is to give agents an evaluation tool forlocal differences between results. Agents should therefore beextended with an additional contour similarity measure whichcan calculate differences in location between consecutive re-sults. In this way an agent can also directly ask the user for direc-tions in case of a dissimilar result, even when the cross-sectionalarea seems fine. This would allow for a more direct and efficientinteraction as the error cannot spread through the system beforethe user approves. It would also remove consequent user initi-ated interactions with agent initiated actions. This has the addi-tional advantage that the agent (rather than the user) will set theparameters for most chance on success. Generally, it then onlyrequires the user to accept the suggestion by the agent whichwill result in less and faster interactions. A possible candidatefor such a measure is given in [27] where it was successfullyused as the fitness value in a mixed-integer evolution strategy tofind optimal parameters for the lumen segmentation pipeline.
Generally, users found the present system a bit too global innature, especially when it was obvious for the user that a localadaptation should be made while the agents tried to get a good
result with only global control. This was experienced as frus-trating, because it was time-consuming while the user had nomeans to correct it. Therefore it would also definitely be animprovement if the approximate location of the problem couldbe indicated with(in) the agent–user interface. Providing agentswith local control in combination with the aforementioned simi-larity measure should reduce the number of agent errors consid-erably. At the same time it provides a handle for user interaction.Next to the global interactions already present, users would begiven the opportunity to issue localized commands like “(much)(much) (larger/smaller) here,” where “here” is indicated witha mouse click and is only used in a very approximate way tolargely prevent inter- and intra-observer variance.
Finally, we would also like to apply the presented system toother image modalities like computed tomography angiography(CTA). Most of the agent knowledge is already domain inde-pendent (450 out of 464 rules). To create a similar approach forCTA requires changing the domain specific rules which statean agent’s capability and how this capability is implemented.Further these rules tell the agent how to interpret the results itobtains with this capability and how to react on this. In additionsome very general domain rules are needed which describe theapplication domain objects and how these are related in general(lumen inside vessel, etc.).
VI. CONCLUSION
It has been shown that with only high-level user interactionin a multiagent IVUS image segmentation system it is possibleto obtain results which are at the least competitive with a ded-icated semi-automatic system with low-level user interaction.With relatively few (2–3) high-level user interactions per cor-rection, multiagent IVUS image segmentation can substantiallybe improved, while the user is initiating corrective actions inonly about 43% (255 versus 594) of the cases when comparedwith the dedicated semi-automatic system. No image processingor agent knowledge is required of the user to correct image seg-mentation results. Experiments show that even when images arevery difficult to segment, competitive results can be obtained inthis fashion. However, although sufficient for most cases, lim-ited control by the user over the segmentation process (only veryhigh level) was sometimes too restrictive to get to the desired re-sult and is a source of observer errors.
ACKNOWLEDGMENT
The authors would like to thank the reviewers for their valu-able comments and suggestions.
REFERENCES
[1] G. Koning, J. Dijkstra, C. von Birgelen, J. Tuinenburg, J. Brunette,J.-C. Tardif, P. Oemrawsingh, C. Sieling, and S. Melsa, “Advancedcontour detection for three-dimensional intracoronary ultrasound: Val-idation—In vitro and in vivo,” Int. J. Cardiovascular Imag., no. 18, pp.235–248, 2002.
[2] B. Draper, A. Hanson, and E. Riseman, “Knowledge-directed vision:Control, learning, and integration,” Proc. IEEE, vol. 84, no. 11, pp.1625–1637, Nov. 1996.
[3] D. Crevier and R. Lepage, “Knowledge-based image understandingsystems: A survey,” Comput. Vis. Image Understand., vol. 67, no. 2,pp. 161–185, Aug. 1997.

BOVENKAMP et al.: USER-AGENT COOPERATION IN MULTIAGENT IVUS IMAGE SEGMENTATION 105
[4] J. Duncan and N. Ayache, “Medical image analysis: Progress over twodecades and the challenges ahead,” IEEE Trans. Pattern Anal. Mach.Intell., vol. 22, no. 1, pp. 85–105, Jan. 2000.
[5] M. Kass, A. Witkin, and D. Terzopoulos, “Snakes: Active contourmodels,” Int. J. Comput. Vis., vol. 1, no. 4, pp. 321–331, 1987.
[6] T. Cootes and C. Taylor, “Statistical models of appearance for medicalimage analysis and computer vision,” in SPIE Medical Imaging, M.Sonka and K. Hanson, Eds. Bellingham, WA: SPIE, 2001, vol. 4322,pp. 236–248.
[7] B. Draper, A. Hanson, and E. Riseman, “Learning blackboard-basedscheduling algorithms for computer vision,” Int. J. Pattern Recognit.Artif. Intell., vol. 7, no. 2, pp. 309–328, 1993.
[8] B. Draper, R. Collins, J. Brolio, A. Hanson, and E. Riseman, “Theschema system,” Int. J. Comput. Vis., vol. 2, no. 3, pp. 209–250, Jan.1989.
[9] T. Strat and M. Fischler, “Context-based vision: Recognizing objectsusing information from both 2-D and 3-D imagery,” IEEE Trans. Pat-tern Anal. Mach. Intell., vol. 13, no. 10, pp. 1050–1065, Oct. 1991.
[10] T. Matsuyama, “Expert systems for image processing: Knowl-edge-based composition of image analysis processes,” Comput. Vis.,Graphics, Image Process., no. 48, pp. 22–49, 1989.
[11] S. Franklin and A. Graesser, “Is it an agent, or just a program?: A tax-onomy for autonomous agents,” in Intelligent Agents III. Agent Theo-ries, Architectures and Languages (ATAL’96), ser. Lecture Notes in Ar-tificial Intelligence. Berlin, Germany: Springer-Verlag, Aug. 1996,vol. 1193, pp. 21–35, ECAI’96.
[12] H. Nwana, “Software agents: An overview,” Knowledge Eng. Rev., vol.11, no. 3, pp. 205–244, Oct.–Nov. 1996.
[13] M. Wooldridge and N. Jennings, “Intelligent agents: Theory and prac-tice,” Knowledge Eng. Rev., vol. 10, no. 2, pp. 115–152, 1995.
[14] A. Boucher, A. Doisy, X. Ronot, and C. Garbay, “A society of goal-oriented agents for the analysis of living cells,” Artif. Intell. Med., no.14, pp. 183–199, 1998.
[15] R. Clouard, A. Elmoataz, C. Porquet, and M. Revenu, “Borg: A knowl-edge-based system for automatic generation of image processing pro-grams,” IEEE Trans. Pattern Anal. Mach. Intell., vol. 21, no. 2, pp.128–144, Feb. 1999.
[16] L. Germond, M. Dojat, C. Taylor, and C. Garbay, “A cooperativeframework for segmentation of MRI brain scans,” Artif. Intell. Med.,vol. 20, no. 1, pp. 77–93, 2000.
[17] G. Hamarneh, T. McInerney, and D. Terzopoulos, “Intelligent agentsfor medical image processing,” in Medical Image Computing andComputer-Assisted Intervention, W. Niessen and M. Viergever,Eds. Utrecht, The Netherlands: Springer-Verlag, 2001, pp. 66–76.
[18] J. Liu and Y. Tang, “Adaptive image segmentation with distributed be-havior-based agents,” IEEE Trans. Pattern Anal. Mach. Intell., vol. 21,no. 6, pp. 544–551, Jun. 1999.
[19] V. Rodin, F. Harrouet, P. Ballet, and J. Tisseau, “oRis: Multiagentsapproach for image processing,” in SPIE Conference on Parallel andDistributed Methods for Image Processing II, H. Shi and P. Coffield,Eds., San Diego, CA., Jul. 1998, vol. 3452, pp. 57–68.
[20] C. Spinu, C. Garbay, and J. Chassery, “A cooperative and adaptiveapproach to medical image segmentation,” in Lecture Notes in Arti-ficial Intelligence, M. S. P. Barahona and J. Wyatt, Eds. New York:Springer-Verlag, 1995, pp. 379–390.
[21] E. Bovenkamp, J. Dijkstra, J. Bosch, and J. Reiber, “Multi-agentsegmentation of IVUS images,” Pattern Recognit., vol. 37, no. 4, pp.647–663, Apr. 2004.
[22] S. Olabarriaga and A. Smeulders, “Interaction in the segmentation ofmedical images: A survey,” Med. Image Anal., no. 5, pp. 127–142,2001.
[23] E. Blessing, D. Hausmann, M. Sturm, H.-G. Wolpers, I. Amende, andA. Mügge, “Intravascular ultrasound and stent implantation: Intraob-server and interobserver variability,” Amer. Heart J., vol. 137, no. 2,pp. 368–371, Feb. 1999.
[24] R. Peters, W. Kok, H. Rijsterborgh, M. van Dijk, K. Koch, J. Piek, G.David, and C. Visser, “Reproducibility of quantitative measurementsfrom intracoronary ultrasound images,” Eur. Heart J., no. 17, pp.1593–1599, 1996.
[25] E. Regar, F. Werner, U. Siebert, J. Rieber, K. Theisen, H. Mudra, andV. Klauss, “Reproducibility of neointima quantification with motorizedintravascular ultrasound pullback in stented coronary arteries,” Amer.Heart J., vol. 139, no. 4, pp. 632–637, Apr. 2000.
[26] R. Li, M. Emmerich, E. Bovenkamp, J. Eggermont, T. Bäck, J. Dijkstra,and J. Reiber, “Mixed-integer evolution strategies and their applica-tion to intravascular ultrasound image analysis,” in Appl. EvolutionaryComput.: Evoworkshops (EvoIASP), 2006, pp. 415–426.
[27] E. Bovenkamp, J. Eggermont, R. Li, M. Emmerich, T. Bäck, J. Dijk-stra, and J. Reiber, “Optimizing IVUS lumen segmentations using evo-lutionary algorithms,” in 1st Int. Workshop Comput. Vis. IntravascularIntracardiac Imag., Copenhagen, Denmark, Oct. 1–5, 2006, pp. 74–81.
[28] J. Eggermont, R. Li, E. Bovenkamp, H. Marquering, M. Emmerich,A. van der Lugt, T. Bäck, J. Dijkstra, and J. C. Reiber, “Optimizingcomputed tomographic angiography image segmentation using fitnessbased partitioning,” in Applications of Evolutionary Computing, ser.Lecture Notes in Computer Science. Berlin, Germany: Springer,2008, pp. 275–284.





























