Embed Size (px)
Citation preview

Proceedings of the 5th International Workshop on Search-Oriented Conversational AI (SCAI), pages 7–16Online, November 19, 2020. c©2020 Association for Computational Linguistics
ISBN 978-1-952148-67-5
7
A Wrong Answer or a Wrong Question?An Intricate Relationship between Question Reformulation and Answer
Selection in Conversational Question Answering
Svitlana Vakulenko†
University of [email protected]
Shayne Longpre, Zhucheng Tu, Raviteja AnanthaApple Inc.
{slongpre, zhucheng tu,raviteja anantha}@apple.com
Abstract
The dependency between an adequate ques-tion formulation and correct answer selectionis a very intriguing but still underexplored area.In this paper, we show that question rewrit-ing (QR) of the conversational context allowsto shed more light on this phenomenon andalso use it to evaluate robustness of differentanswer selection approaches. We introduce asimple framework that enables an automatedanalysis of the conversational question answer-ing (QA) performance using question rewrites,and present the results of this analysis on theTREC CAsT and QuAC (CANARD) datasets.Our experiments uncover sensitivity to ques-tion formulation of the popular state-of-the-artmodels for reading comprehension and pas-sage ranking. Our results demonstrate that thereading comprehension model is insensitive toquestion formulation, while the passage rank-ing changes dramatically with a little variationin the input question. The benefit of QR isthat it allows us to pinpoint and group suchcases automatically. We show how to use thismethodology to verify whether QA models arereally learning the task or just finding short-cuts in the dataset, and better understand thefrequent types of error they make.
1 Introduction
Conversational question answering (QA) is a newand important task which allows systems to ad-vance from answering stand-alone questions to an-swering a sequence of related questions (Choi et al.,2018; Reddy et al., 2019; Dalton et al., 2019). Suchsequences contain questions that usually revolvearound the same topic and its subtopics, whichis also common for a human conversation. Themost pronounced characteristics of such questionsequences are anaphoric expressions and ellipsis,which make the follow-up questions ambiguous
†Work done as an intern at Apple Inc.
outside of the conversation context. For example,consider a question “When was it discovered?”. Itis not possible to answer the question without re-solving the pronoun it (example of an anaphoricexpression). Ellipsis are even harder to resolvesince they omit information without leaving anyreferences. For example, a question “When?” cannaturally follow an answer to the previous question,such as “Friedrich Miescher discovered DNA.”
Question rewriting (QR) was recently introducedas an independent component for conversationalQA (Elgohary et al., 2019; Vakulenko et al., 2020;Yu et al., 2020). Query rewriting received consider-able attention in the information retrieval commu-nity before but not in a conversational context (Heet al., 2016). Ren et al. (2018) performed similar ex-periments using query reformulations mined fromsearch sessions. However, half of their sampleswere keyword queries rather than natural languagequestions and their dataset was not released to thecommunity. In this paper, we show that QR is notonly operational in extending standard QA modelsto the conversational scenario but can be also usedfor their evaluation.
An input to the QR component is a question andprevious conversation turns. The QR component isdesigned to transform all ambiguous questions, e.g.,“When?”, into their unambiguous equivalents, e.g.,“When was DNA discovered?”. Such unambiguousquestions can be then processed by any standardQA model outside of the conversation history.
Clearly, the quality of question formulation inter-acts with the ability to answer this question. In thispaper, we show that introducing QR componentin the conversational QA architecture, by decou-pling question interpretation in context from thequestion answering task, provides us with a uniqueopportunity to gain an insight on the interaction be-tween the two tasks. Ultimately, we are interestedin whether this interaction can potentially help us

8
to improve the performance on the end-to-end con-versational QA task. To this end we formulate ourmain research question:
How do differences in question formulation ina conversational setting affect question answeringperformance?
The standard approach to QA evaluation isto measure model performance on a benchmarkdataset with respect to the ground-truth answers,such as text span overlap in the reading compre-hension task, or NDCG@3 in the passage retrievaltask. However, such evaluation setups may alsohave their limitations with respect to the biasesin the task formulation and insufficient data diver-sity that allow models to learn shortcuts and over-fit the benchmark dataset (Geirhos et al., 2020).There is already an ample evidence of the pitfalls inthe evaluation setup of the reading comprehensiontask highlighting that the state-of-the-art modelstend to learn answering questions using superficialclues (Jia and Liang, 2017; Ribeiro et al., 2018;Lewis and Fan, 2019).
We aim to further contribute to the research areastudying robustness of QA models by extendingthe evaluation setup to the conversational QA task.To this end, we introduce an error analysis frame-work based on conversational question rewrites.The goal of the framework is to evaluate robust-ness of QA models using the inherent properties ofthe conversational setup itself. More specifically,we contrast the results obtained for ambiguous andrewritten questions outside of the conversation con-text. We show that this data is very well suited foranalysing performance and debugging QA models.In our experiments, we evaluate two popular QAarchitectures proposed in the context of the con-versational reading comprehension (QuAC) (Choiet al., 2018) and conversational passage ranking(TREC CAsT) (Dalton et al., 2019) tasks.
Our results show that the state-of-the-art modelsfor passage retrieval are rather sensitive to differ-ences in question formulation. On the other hand,the models trained on the reading comprehensiontask tend to find correct answers even to incom-plete ambiguous questions. We believe that thesefindings can stimulate more research in this areaand help to inform future evaluation setups for theconversational QA tasks.
2 Experimental Setup
To answer our research question and illustrate theapplication of the proposed evaluation frameworkin practice, we use the same experimental setupintroduced in our earlier work (Vakulenko et al.,2020). This architecture consists of two indepen-dent components: QR and QA. It was previouslyevaluated against competitive approaches and base-lines setting the new state-of-the-art results on theTREC CAsT 2019 dataset. The QR model wasalso shown to improve QA performance on bothpassage retrieval and reading comprehension tasks.
In the following subsection, we describe thedatasets, models, and metrics that were used inour evaluation. Note, however, that our error analy-sis framework can be applied to other models andmetrics as well. The only requirement for apply-ing the framework is the QR-QA architecture thatprovides two separate outputs in terms of ques-tion rewrites and answers. We show that the sameframework can be applied for both reading com-prehension and passage retrieval tasks, althoughthey produce different types of answers and requiredifferent evaluation metrics.
2.1 Datasets
We chose two conversational QA datasets for theevaluation of our approach: (1) TREC CAsTfor conversational passage ranking (Dalton et al.,2019), and (2) CANARD, derived from QuestionAnswering in Context (QuAC) for conversationalreading comprehension (Choi et al., 2018). SinceTREC CAsT is a relatively small dataset, we usedonly CANARD for training our QR model. Thesame QR model trained on CANARD was thenevaluated on both CANARD and TREC CAsT in-dependently.
Following the setup of the TREC CAsT 2019,we use the MS MARCO passage retrieval (Nguyenet al., 2016) and the TREC CAR (Dietz et al.,2018) paragraph collections. After de-duplication,the MS MARCO collection contains 8.6M docu-ments and the TREC CAR – 29.8M documents.The model for passage retrieval is tuned on asample from the MS MARCO passage retrievaldataset, which includes relevance judgements for12.8M query-passage pairs with 399k uniquequeries (Nogueira and Cho, 2019). We evaluatedon the test set with relevance judgements for 173questions across 20 dialogues (topics).
We use CANARD (Elgohary et al., 2019) and

9
QuAC (Choi et al., 2018) datasets jointly to anal-yse performance on the reading comprehensiontask. CANARD is built upon the QuAC datasetby employing human annotators to rewrite origi-nal questions from QuAC dialogues into explicitquestions. CANARD contains 40.5k pairs of ques-tion rewrites that can be matched to the originalanswers in QuAC. We use CANARD splits fortraining and evaluation. Each answer in QuAC isannotated with a Wikipedia passage from which itwas extracted alongside the correct answer spanswithin this passage. We use the question rewritesprovided in CANARD and passages with answerspans from QuAC. In our experiments, we referto this joint dataset as CANARD for brevity. Ourmodel for reading comprehension was also pre-trained using MultiQA dataset (Fisch et al., 2019)to further boost its performance. MultiQA contains75k QA pairs from six standard QA benchmarks.
2.2 Conversational QA Architecture
Our architecture for conversational QA is designedto be modular by separating the original task intotwo subtasks. The subtasks are (1) QR, responsiblefor the conversational context understanding andquestion formulation, and (2) QA that exactly cor-responds to the standard non-conversational task ofanswer selection (reading comprehension or pas-sage retrieval). Therefore, the output of the QRcomponent is an unambiguous question that is sub-sequently used as input to the QA component toproduce the answer.
Question Rewriting The task of question rewrit-ing is to reformulate every follow-up question in aconversation, such that the question can be unam-biguously interpreted without accessing the conver-sation history. The input to the QR model is thequestion with previous conversation turns separatedwith a [SEP ] token (in our experiments, we useup to maximum of 5 previous conversation turns).Using our running example, the input would be:Friedrich Miescher discovered DNA [SEP ] When?and the expected output from the QR model is:When was DNA discovered?.
Our QR model is based on a unidirectional Trans-former (decoder) designed for the sequence gener-ation task. It was initialised with the weights of thepre-trained GPT2 (Radford et al., 2019) and furtherfine-tuned on the QR task. The training objectivein QR is to predict the output sequence as in theground truth question rewrites produced by human
annotators. The model is trained via the teacherforcing approach. The loss is calculated with thenegative log-likelihood (cross-entropy) function.At inference time, the question rewrites are gen-erated recursively turn by turn for each of the dia-logues using the previously generated rewrites asinput corresponding to the dialogue history, i.e.,previous turns.
For our experiments, we adopt the same QRmodel architecture proposed in the previous work(Transformer++) (Anantha et al., 2020; Vakulenkoet al., 2020). It was shown to outperform a co-reference baseline and other Transformer-basedmodels on CANARD, TREC CAsT and QReCC.
Question Answering We experiment with twodifferent QA models that reflect the state-of-the-art in reading comprehension and passageretrieval (Nogueira and Cho, 2019). All ourQA models are initialised with a pre-trainedBERTLARGE (Devlin et al., 2019) and then fine-tuned on each of the target tasks.
Our model for reading comprehension followsthe standard architecture design for this task. Werestrict our implementation to the simplest but avery competitive model architecture that more com-plex approaches usually build upon (Liu et al.,2019; Lan et al., 2019). This model consists ofa Transformer-based bidirectional encoder and anoutput layer that predicts the answer span. The in-put to the model is the sequence of tokens formedby concatenating a question and a passage, the twoare separated with a [SEP ] token.
Our passage retrieval approach is implementedfollowing Nogueira and Cho (2019). It usesAnserini for the candidate selection phase withBM25 (top-1000 passages) and BERTLARGE forthe passage re-ranking phase.1 The re-rankingmodel was tuned on a sample from MS MARCOwith 12.8M query-passage pairs and 399k uniquequeries.
2.3 Metrics
We use the standard performance metrics for eachof the QA subtasks. We use normalized discountedcumulative gain (NDCG@3) and precision on thetop-passage (P@1) to evaluate quality of passageretrieval (with a relevance threshold of 2 in accor-dance with the official evaluation guidelines forCAsT). We use F1 metric for reading comprehen-
1https://github.com/nyu-dl/dl4marco-bert
10
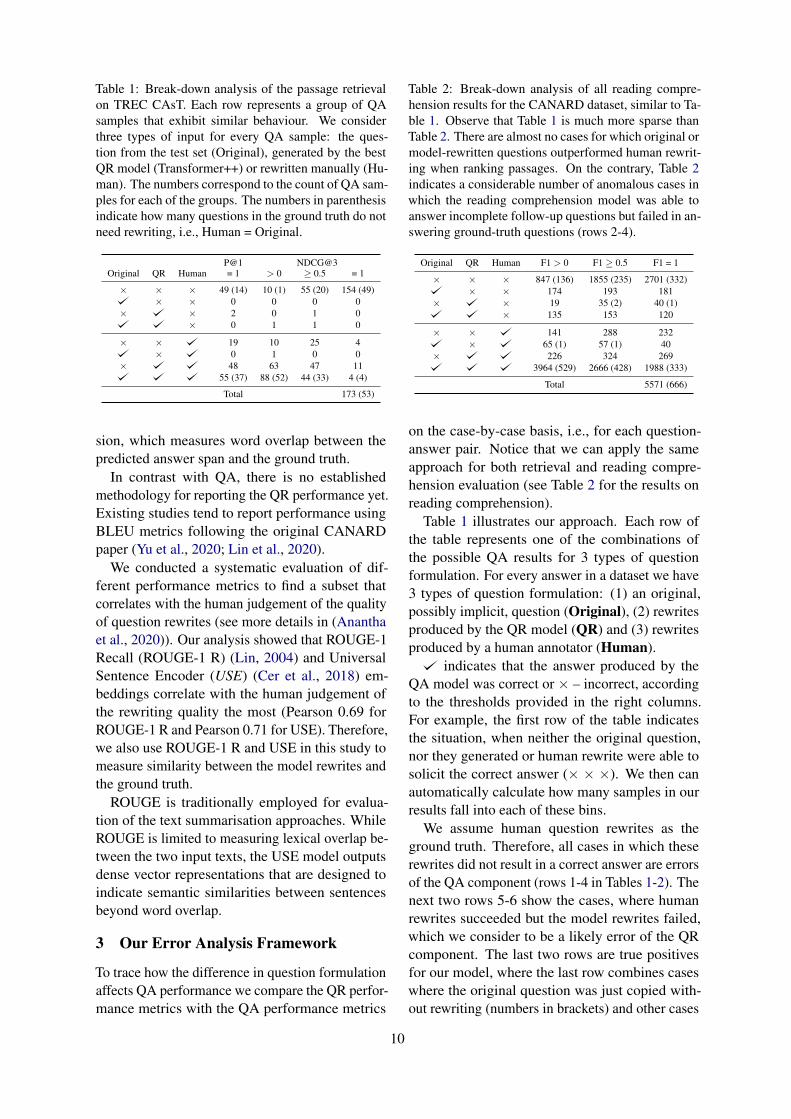
Table 1: Break-down analysis of the passage retrievalon TREC CAsT. Each row represents a group of QAsamples that exhibit similar behaviour. We considerthree types of input for every QA sample: the ques-tion from the test set (Original), generated by the bestQR model (Transformer++) or rewritten manually (Hu-man). The numbers correspond to the count of QA sam-ples for each of the groups. The numbers in parenthesisindicate how many questions in the ground truth do notneed rewriting, i.e., Human = Original.
P@1 NDCG@3Original QR Human = 1 > 0 ≥ 0.5 = 1
× × × 49 (14) 10 (1) 55 (20) 154 (49)× × 0 0 0 0
× × 2 0 1 0× 0 1 1 0
× × 19 10 25 4× 0 1 0 0
× 48 63 47 1155 (37) 88 (52) 44 (33) 4 (4)
Total 173 (53)
sion, which measures word overlap between thepredicted answer span and the ground truth.
In contrast with QA, there is no establishedmethodology for reporting the QR performance yet.Existing studies tend to report performance usingBLEU metrics following the original CANARDpaper (Yu et al., 2020; Lin et al., 2020).
We conducted a systematic evaluation of dif-ferent performance metrics to find a subset thatcorrelates with the human judgement of the qualityof question rewrites (see more details in (Ananthaet al., 2020)). Our analysis showed that ROUGE-1Recall (ROUGE-1 R) (Lin, 2004) and UniversalSentence Encoder (USE) (Cer et al., 2018) em-beddings correlate with the human judgement ofthe rewriting quality the most (Pearson 0.69 forROUGE-1 R and Pearson 0.71 for USE). Therefore,we also use ROUGE-1 R and USE in this study tomeasure similarity between the model rewrites andthe ground truth.
ROUGE is traditionally employed for evalua-tion of the text summarisation approaches. WhileROUGE is limited to measuring lexical overlap be-tween the two input texts, the USE model outputsdense vector representations that are designed toindicate semantic similarities between sentencesbeyond word overlap.
3 Our Error Analysis Framework
To trace how the difference in question formulationaffects QA performance we compare the QR perfor-mance metrics with the QA performance metrics
Table 2: Break-down analysis of all reading compre-hension results for the CANARD dataset, similar to Ta-ble 1. Observe that Table 1 is much more sparse thanTable 2. There are almost no cases for which original ormodel-rewritten questions outperformed human rewrit-ing when ranking passages. On the contrary, Table 2indicates a considerable number of anomalous cases inwhich the reading comprehension model was able toanswer incomplete follow-up questions but failed in an-swering ground-truth questions (rows 2-4).
Original QR Human F1 > 0 F1 ≥ 0.5 F1 = 1
× × × 847 (136) 1855 (235) 2701 (332)× × 174 193 181
× × 19 35 (2) 40 (1)× 135 153 120
× × 141 288 232× 65 (1) 57 (1) 40
× 226 324 2693964 (529) 2666 (428) 1988 (333)
Total 5571 (666)
on the case-by-case basis, i.e., for each question-answer pair. Notice that we can apply the sameapproach for both retrieval and reading compre-hension evaluation (see Table 2 for the results onreading comprehension).
Table 1 illustrates our approach. Each row ofthe table represents one of the combinations ofthe possible QA results for 3 types of questionformulation. For every answer in a dataset we have3 types of question formulation: (1) an original,possibly implicit, question (Original), (2) rewritesproduced by the QR model (QR) and (3) rewritesproduced by a human annotator (Human).
indicates that the answer produced by theQA model was correct or × – incorrect, accordingto the thresholds provided in the right columns.For example, the first row of the table indicatesthe situation, when neither the original question,nor they generated or human rewrite were able tosolicit the correct answer (× × ×). We then canautomatically calculate how many samples in ourresults fall into each of these bins.
We assume human question rewrites as theground truth. Therefore, all cases in which theserewrites did not result in a correct answer are errorsof the QA component (rows 1-4 in Tables 1-2). Thenext two rows 5-6 show the cases, where humanrewrites succeeded but the model rewrites failed,which we consider to be a likely error of the QRcomponent. The last two rows are true positivesfor our model, where the last row combines caseswhere the original question was just copied with-out rewriting (numbers in brackets) and other cases
11
0.0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1.0NDCG@3 Threshold
0.0
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1.0
Perc
enta
ge o
f Tes
t Set
0.0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1.0F1 Threshold
0.0
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1.0
Perc
enta
ge o
f Tes
t Set
Original (✕) | QR (✕) | Human (✕)Original (✕) | QR (✕) | Human (✓)Original (✕) | QR (✓) | Human (✕)Original (✕) | QR (✓) | Human (✓)Original (✓) | QR (✕) | Human (✕)Original (✓) | QR (✕) | Human (✓)Original (✓) | QR (✓) | Human (✕)Original (✓) | QR (✓) | Human (✓)
Score Card
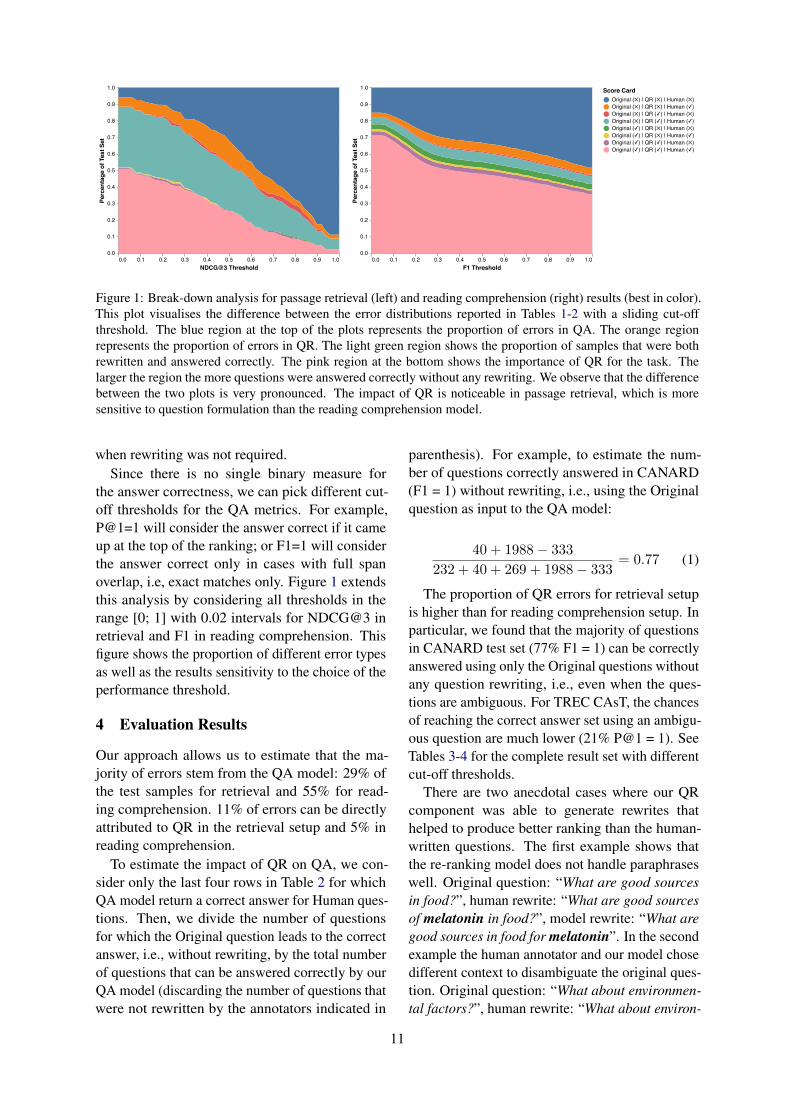
Figure 1: Break-down analysis for passage retrieval (left) and reading comprehension (right) results (best in color).This plot visualises the difference between the error distributions reported in Tables 1-2 with a sliding cut-offthreshold. The blue region at the top of the plots represents the proportion of errors in QA. The orange regionrepresents the proportion of errors in QR. The light green region shows the proportion of samples that were bothrewritten and answered correctly. The pink region at the bottom shows the importance of QR for the task. Thelarger the region the more questions were answered correctly without any rewriting. We observe that the differencebetween the two plots is very pronounced. The impact of QR is noticeable in passage retrieval, which is moresensitive to question formulation than the reading comprehension model.
when rewriting was not required.Since there is no single binary measure for
the answer correctness, we can pick different cut-off thresholds for the QA metrics. For example,P@1=1 will consider the answer correct if it cameup at the top of the ranking; or F1=1 will considerthe answer correct only in cases with full spanoverlap, i.e, exact matches only. Figure 1 extendsthis analysis by considering all thresholds in therange [0; 1] with 0.02 intervals for NDCG@3 inretrieval and F1 in reading comprehension. Thisfigure shows the proportion of different error typesas well as the results sensitivity to the choice of theperformance threshold.
4 Evaluation Results
Our approach allows us to estimate that the ma-jority of errors stem from the QA model: 29% ofthe test samples for retrieval and 55% for read-ing comprehension. 11% of errors can be directlyattributed to QR in the retrieval setup and 5% inreading comprehension.
To estimate the impact of QR on QA, we con-sider only the last four rows in Table 2 for whichQA model return a correct answer for Human ques-tions. Then, we divide the number of questionsfor which the Original question leads to the correctanswer, i.e., without rewriting, by the total numberof questions that can be answered correctly by ourQA model (discarding the number of questions thatwere not rewritten by the annotators indicated in
parenthesis). For example, to estimate the num-ber of questions correctly answered in CANARD(F1 = 1) without rewriting, i.e., using the Originalquestion as input to the QA model:
40 + 1988− 333
232 + 40 + 269 + 1988− 333= 0.77 (1)
The proportion of QR errors for retrieval setupis higher than for reading comprehension setup. Inparticular, we found that the majority of questionsin CANARD test set (77% F1 = 1) can be correctlyanswered using only the Original questions withoutany question rewriting, i.e., even when the ques-tions are ambiguous. For TREC CAsT, the chancesof reaching the correct answer set using an ambigu-ous question are much lower (21% P@1 = 1). SeeTables 3-4 for the complete result set with differentcut-off thresholds.
There are two anecdotal cases where our QRcomponent was able to generate rewrites thathelped to produce better ranking than the human-written questions. The first example shows thatthe re-ranking model does not handle paraphraseswell. Original question: “What are good sourcesin food?”, human rewrite: “What are good sourcesof melatonin in food?”, model rewrite: “What aregood sources in food for melatonin”. In the secondexample the human annotator and our model chosedifferent context to disambiguate the original ques-tion. Original question: “What about environmen-tal factors?”, human rewrite: “What about environ-
12
Table 3: The fraction of questions in TREC CAsT thatwere answered correctly without rewriting.
P@1 NDCG@3Questions = 1 > 0 ≥ 0.5 = 1
All 0.45 0.55 0.38 0.21Human != Original 0.21 0.34 0.13 0
Table 4: The fraction of questions in CANARD thatwere answered correctly without rewriting.
Questions F1 > 0 F1 ≥ 0.5 F1 = 1
All 0.92 0.82 0.80Human != Original 0.91 0.79 0.77
mental factors during the Bronze Age collapse?”,model rewrite: “What about environmental factorsthat lead to led to a breakdown of trade”. Eventhough both model rewrites are not grammaticallycorrect they solicited correct top-answers, whilethe human rewrites failed, which indicate flaws inthe QA model performance.
5 QA-QR Correlation
In this section, we check whether the QR metricscan predict the QA performance for the individualquestions by measuring the correlation betweenthe QR and QA metrics. This analysis shows howthe change in question formulation affects the an-swer selection. In other words, we are interestedwhether similar questions also produce similar an-swers, and whether distinct questions result in dis-tinct answers.
To discover the correlation between question andanswer similarity, we discarded all samples, wherethe human rewrites do not lead to the correct an-swers (top 4 rows in Tables 1-2). The remainingsubset contains only the samples in which the QAmodel was able to find the correct answer. We thencompute ROUGE for the pairs of human and gener-ated rewrites, and measure its correlation with P@1to check if rewrites similar to the correct questionwill also produce correct answers, and vice versa.
There is a strong correlation for ROUGE = 1,i.e., when the generated rewrite is very close to thehuman one. However, when ROUGE < 1 the an-swer is less predictable. Even for rewrites that havea relatively small lexical overlap with the ground-truth (ROUGE ≤ 0.4) it is possible to retrieve acorrect answer, and vice versa.
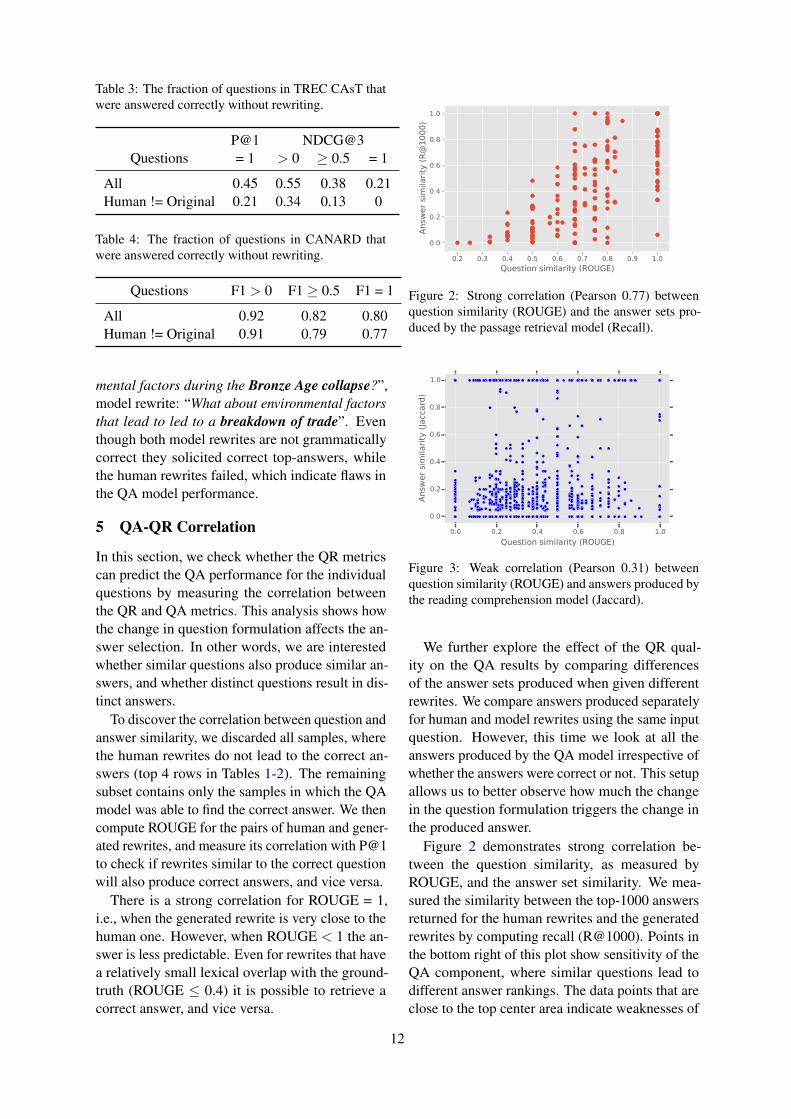
Figure 2: Strong correlation (Pearson 0.77) betweenquestion similarity (ROUGE) and the answer sets pro-duced by the passage retrieval model (Recall).
0.0 0.2 0.4 0.6 0.8 1.0
Question similarity (ROUGE)
0.0
0.2
0.4
0.6
0.8
1.0
Answ
er
sim
ilari
ty (
Jacc
ard
)
Figure 3: Weak correlation (Pearson 0.31) betweenquestion similarity (ROUGE) and answers produced bythe reading comprehension model (Jaccard).
We further explore the effect of the QR qual-ity on the QA results by comparing differencesof the answer sets produced when given differentrewrites. We compare answers produced separatelyfor human and model rewrites using the same inputquestion. However, this time we look at all theanswers produced by the QA model irrespective ofwhether the answers were correct or not. This setupallows us to better observe how much the changein the question formulation triggers the change inthe produced answer.
Figure 2 demonstrates strong correlation be-tween the question similarity, as measured byROUGE, and the answer set similarity. We mea-sured the similarity between the top-1000 answersreturned for the human rewrites and the generatedrewrites by computing recall (R@1000). Points inthe bottom right of this plot show sensitivity of theQA component, where similar questions lead todifferent answer rankings. The data points that areclose to the top center area indicate weaknesses of

13
the QR metric as a proxy for the QA results: oftenquestions do not have to be the same as the groundtruth questions to solicit the same answers. Theblank area in the top-left of the diagonal shows thata lexical overlap is required to produce the sameanswer set, which is likely due to the candidatefiltering phase based on the bag-of-word represen-tation matching.
We also compared ROUGE and Jaccard similar-ity for the tokens in reading comprehension resultsbut they showed only a weak correlation (Pearson0.31). This result confirms our observation that theextractive model tends to be rather sensitive to aslight input perturbation but will also often providethe same answer to very distinct questions.
Thus, our results show that the existing QR met-rics have a limited capacity in predicting the perfor-mance on the end-to-end QA task. ROUGE corre-lates with the answer recall for the retrieval model,but cannot be used to reliably predict answer cor-rectness for the individual question rewrites. SinceROUGE treats all the tokens equally (except for thestop-word list) it is unable to capture importance ofthe individual tokens that modify question seman-tics. The correlation of the QA performance withthe embedding-based USE metric is even lowerthan with ROUGE for the both QA models.
6 Discussion
We showed that QA results can identify questionparaphrases. However, this property directly de-pends on the ability of the QA model to matchequivalent questions to the same answer set.
Wrong answer or wrong question? Our pas-sage retrieval model is using BM25 as a filteringstep, which relies on the lexical match between theterms in the question and the terms in the passage.Hence, synonyms, like “large” and “big”, cannot bematched with this model. This effect explains thatdissimilar questions are never matched to the sameanswers in Figure 2. The drawback of this modelis that it suffers from the “vocabulary mismatch”problem (Van Gysel, 2017).
A one-word difference between a pair of ques-tions may have a very little as well as a very dra-matic effect on the question interpretation. Thisclass of errors corresponds to the variance evidentfrom Figure 2.
Our error analysis indicates that small pertur-bations of the input question, such as anaphoraresolution, often cause a considerable change in
the answer ranking. For example, the pair of theoriginal question: “Who are the Hamilton Electorsand what were they trying to do?”, and the humanrewrite: “Who are the Hamilton Electors and whatwere the Hamilton Electors trying to do?” produceROUGE = 1 but R@1000 = 0.33. We also identi-fied many cases in which inability of the QR com-ponent to generate apostrophes resulted in incorrectanswers (original question: “Describe Netflixs sub-scriber growth over time”, and the human rewrite:“Describe Netflix’s subscriber growth over time”).
In contrast, our reading comprehension modelsis based solely on the dense vector representations,which should be able to deal with paraphrases. Inpractice, we see from Figure 3 that this feature mayalso introduce an important drawback, when themodel produces a correct answer even when givenan incorrectly formulated question. This stabilityand undersensitivity of the reading comprehensionmodel may indicate biases in the dataset and evalu-ation setup. When the answers no longer dependson the question being asked, but can be also pre-dicted independently from the question, the QAmodel evidently fails to learn the mechanisms un-derlying QA. Instead, it may learn a shortcut inthe benchmark dataset that allows to guess correctquestions, such as likely answer positioning withinan article.
Our experiments show that the retrieval-basedsetup is more adequate in judging model robust-ness. The size of the answer space is sufficientlylarge so as to exclude spurious cues that the modelcan exploit for shortcut learning. The role of QRis, therefore, much more evident in this task, sinceto be able to find the correct answer the questionhas to be formulated well by disambiguating con-versational context. While it may be redundant tooverspecify the question when given several pas-sages to choose the answer from, it becomes of avital importance when given several million pas-sages. This argument holds, however, only whenassuming a uniform answer distribution, which isoften not the case unless for sufficiently large webcollections. This particular observation brings usto the next question that we would like to discussin more detail.
Rewrite or not to rewrite? Our experimentsdemonstrated the challenges in the quality controlof the QR task itself. Human rewrites are not per-fect themselves since it is not always clear whetherand what should be rewritten. Considering the

14
human judgment of the QR quality independentfrom the QA results, little deviations may not seemimportant. However, from the pragmatic point ofview, they may have a major impact on the overallperformance of the end-to-end system.
The level of detail required to answer a particu-lar question is often not apparent and depends onthe dataset. However, we can argue that inconsis-tencies, such as typos and paraphrases, should behandled by the QA component, since they do notoriginate from the context interpretation errors.
Further on, we evaluated our assumption abouthuman rewrites as the reliable ground truth. Ourevaluation results indeed showed that human rewrit-ing was redundant in certain cases. There are casesin which original questions without rewriting werealready sufficient to retrieve the correct answersfrom the passage collection (see last row of theTable 1). In particular, we found that 10% of thequestions in TREC CAsT were rewritten by humanannotators that did not need rewriting to retrievethe correct answer. For example, original ques-tion: “What is the functionalist theory?”, humanrewrite: “What is the functionalist theory in soci-ology?”. However, in another question from thesame dialogue, omitting the same word from therewrite leads to retrieval of an irrelevant passage,since there are multiple alternative answers.
The need for QR essentially interacts with thesize and diversity of the possible answer space,e.g., collection content, with respect to the question.Some of the questions were correctly answeredeven with underspecified questions, e.g., originalquestion: “What are some ways to avoid injury?”,human rewrite: “What are some ways to avoidsports injuries?”, because of the collection bias.
The goal of QR is to learn patterns that correctquestion formulation independent from the collec-tion content. This approach is similar to how hu-mans handle this task when formulating searchqueries, i.e., based on their knowledge of languageand the world. Humans can spot ambiguity regard-less of the information source by modeling the ex-pected content of the information source even with-out the need to have direct access to it. Clearly, thisexpectation may not be optimal or even sufficientto be able to formulate a single precise question,which is exactly the point at which the need for aninformation-seeking dialogue naturally arises.
When the question formulation procedure is de-signed to be independent of the collection content,
it also allows for querying several sources with thesame question. This property is especially help-ful when the content of the collection is unknown,which also allows to work with 3rd party APIs toaccess information in a distributed fashion. We maysee a similar effect as in human-human communi-cation here as well, when the need for an automatedinformation-seeking dialogue between distributedsystems may arise to better negotiate the informa-tion need and disambiguate the question furtherwith respect to the content of each remote informa-tion source.
7 Related Work
Several recent research studies reported that state-of-the-art machine learning models lack in robust-ness across several NLP tasks (Li and Specia, 2019;Zeng et al., 2019). In particular, these models werefound to be sensitive to input perturbations.
Jia and Liang (2017) analysed this problem in thecontext of the reading comprehension task. Theyshowed in the experimental evaluation that QAmodels suffer from overstability, i.e., they tendto provide the same answer to a different question,when it is sufficiently similar to the correct question.Lewis and Fan (2019) also showed this deficiencyof the state-of-the-art models for reading compre-hension that learn to attend to just a few words inthe question.
Our evaluation results support these findings us-ing the conversational settings. We showed thatmany ambiguous questions in QuAC can be an-swered correctly without the conversation history(see Table 2). In contrast, this effect is absent in thepassage retrieval setup (see Table 1 or Figure 1).These results suggest that the passage retrieval eval-uation setup is more adequate for training robustQA models.
Previous work that focused on analysing and ex-plaining performance of Transformer-based modelson the ranking task used word attention visualisa-tion and random removals of non-stop words (Daiand Callan, 2019; Qiao et al., 2019). The analysisframework proposed here provides a more system-atic approach to model evaluation using ambiguousand rewritten question pairs, which is a by-productof applying QR in conversational QA.
Our approach is most similar to the one proposedby Ribeiro et al. (2018), who used semanticallyequivalent adversaries to analyse performance inseveral NLP tasks, including reading comprehen-

15
sion, visual QA and sentiment analysis. Similarly,in our approach, question rewrites, as paraphraseswith different levels of ambiguity, are a naturalchoice for evaluation of the conversational QA per-formance. The difference is that we do not needto generate semantically equivalent questions butcan reuse question rewrites as a by-product of in-troducing the QR model as a component of theconversational QA architecture.
8 Conclusion
QR is a challenging but a very insightful task de-signed to capture linguistic patterns that identifyand resolve ambiguity in question formulation. Ourresults demonstrate the utility of QR as not onlyenabler for conversational QA but also as a toolthat helps to understand when QA models fail.
We introduced an effective error analysis frame-work for conversational QA using QR and used itto evaluate sensitivity of two state-of-the-art QAmodel architectures (for reading comprehensionand passage retrieval tasks). Moreover, the frame-work we introduced is agnostic to the model ar-chitecture and can be reused for performance eval-uation of different models using other evaluationmetrics as well.
QR helps to analyse model performance and dis-cover their weaknesses, such as oversensitivity andundersensitivity to differences in question formula-tion. In particular, the reading comprehension tasksetup is inadequate to reflect the real performanceof a question interpretation component since am-biguous or even incorrect question formulations arelikely to result in a correct answer span. In passageretrieval, we observe an opposite effect. Since thespace of possible answers is very large it is im-possible to hit the correct answer by chance. Wediscover, however, that these models tend to sufferfrom oversensitivity instead, i.e., when even a sin-gle character will trigger a considerable change inanswer ranking.
In future work, we should extend our evalua-tion to dense passage retrieval models and exam-ine their performance using the conversational QAsetup with the QR model. We should also lookinto training approaches that could allow QA mod-els to further benefit from the QR component. Aswe showed in our experiments QR provides use-ful intermediate outputs that can be interpreted byhumans and used for evaluation. We believe thatQR models can be also useful for training more ro-
bust QA models. Both components can be trainedjointly, which is inline with Lewis and Fan (2019),who showed that the joint objective of questionand answer generation further improves QA perfor-mance.
Acknowledgements
We would like to thank our colleagues SrinivasChappidi, Bjorn Hoffmeister, Stephan Peitz, RussWebb, Drew Frank, and Chris DuBois for theirinsightful comments.
ReferencesRaviteja Anantha, Svitlana Vakulenko, Zhucheng Tu,
Shayne Longpre, Stephen Pulman, and SrinivasChappidi. 2020. Open-Domain Question Answer-ing Goes Conversational via Question Rewriting.arXiv preprint.
Daniel Cer, Yinfei Yang, Sheng-yi Kong, Nan Hua,Nicole Limtiaco, Rhomni St. John, Noah Constant,Mario Guajardo-Cespedes, Steve Yuan, Chris Tar,Brian Strope, and Ray Kurzweil. 2018. UniversalSentence Encoder for English. In Proceedings of the2018 Conference on Empirical Methods in NaturalLanguage Processing. 169–174.
Eunsol Choi, He He, Mohit Iyyer, Mark Yatskar, Wen-tau Yih, Yejin Choi, Percy Liang, and Luke Zettle-moyer. 2018. QuAC: Question Answering in Con-text. In Proceedings of the 2018 Conference on Em-pirical Methods in Natural Language Processing.2174–2184.
Zhuyun Dai and Jamie Callan. 2019. Deeper text un-derstanding for IR with contextual neural languagemodeling. In Proceedings of the 42nd InternationalACM SIGIR Conference on Research and Develop-ment in Information Retrieval. 985–988.
Jeffrey Dalton, Chenyan Xiong, and Jamie Callan.2019. CAsT 2019: The Conversational AssistanceTrack Overview. In Proceedings of the 28th Text RE-trieval Conference. 13–15.
Jacob Devlin, Ming-Wei Chang, Kenton Lee, andKristina Toutanova. 2019. BERT: Pre-training ofDeep Bidirectional Transformers for Language Un-derstanding. In Proceedings of the 2019 Conferenceof the North American Chapter of the Associationfor Computational Linguistics: Human LanguageTechnologies. 4171–4186.
Laura Dietz, Ben Gamari, Jeff Dalton, and NickCraswell. 2018. TREC Complex Answer RetrievalOverview. TREC.
Ahmed Elgohary, Denis Peskov, and Jordan Boyd-Graber. 2019. Can You Unpack That? Learning toRewrite Questions-in-Context. In Proceedings of the

16
2019 Conference on Empirical Methods in NaturalLanguage Processing and the 9th International JointConference on Natural Language Processing. 5920–5926.
Adam Fisch, Alon Talmor, Robin Jia, Minjoon Seo, Eu-nsol Choi, and Danqi Chen. 2019. MRQA 2019Shared Task: Evaluating Generalization in ReadingComprehension. arXiv preprint arXiv:1910.09753(2019).
Robert Geirhos, Jorn-Henrik Jacobsen, ClaudioMichaelis, Richard S. Zemel, Wieland Brendel,Matthias Bethge, and Felix A. Wichmann. 2020.Shortcut Learning in Deep Neural Networks. CoRRabs/2004.07780 (2020).
Yunlong He, Jiliang Tang, Hua Ouyang, ChangsungKang, Dawei Yin, and Yi Chang. 2016. Learn-ing to rewrite queries. In Proceedings of the 25thACM International on Conference on Informationand Knowledge Management. 1443–1452.
Robin Jia and Percy Liang. 2017. Adversarial Ex-amples for Evaluating Reading Comprehension Sys-tems. In Proceedings of the 2017 Conference onEmpirical Methods in Natural Language Processing,EMNLP 2017, Copenhagen, Denmark, September 9-11, 2017. 2021–2031.
Zhenzhong Lan, Mingda Chen, Sebastian Goodman,Kevin Gimpel, Piyush Sharma, and Radu Soricut.2019. Albert: A lite BERT for self-supervisedlearning of language representations. arXiv preprintarXiv:1909.11942 (2019).
Mike Lewis and Angela Fan. 2019. Generative Ques-tion Answering: Learning to Answer the WholeQuestion. In 7th International Conference on Learn-ing Representations, ICLR 2019, New Orleans, LA,USA, May 6-9, 2019.
Zhenhao Li and Lucia Specia. 2019. Improving NeuralMachine Translation Robustness via Data Augmen-tation: Beyond Back-Translation. In Proceedings ofthe 5th Workshop on Noisy User-generated Text, W-NUT@EMNLP 2019, Hong Kong, China, November4, 2019. 328–336.
Chin-Yew Lin. 2004. Rouge: A package for auto-matic evaluation of summaries. In Text summariza-tion branches out. 74–81.
Sheng-Chieh Lin, Jheng-Hong Yang, RodrigoNogueira, Ming-Feng Tsai, Chuan-Ju Wang, andJimmy Lin. 2020. Query Reformulation usingQuery History for Passage Retrieval in Conversa-tional Search. arXiv preprint arXiv:2005.02230(2020).
Yinhan Liu, Myle Ott, Naman Goyal, Jingfei Du, Man-dar Joshi, Danqi Chen, Omer Levy, Mike Lewis,Luke Zettlemoyer, and Veselin Stoyanov. 2019.Roberta: A robustly optimized bert pretraining ap-proach. arXiv preprint arXiv:1907.11692 (2019).
Tri Nguyen, Mir Rosenberg, Xia Song, Jianfeng Gao,Saurabh Tiwary, Rangan Majumder, and Li Deng.2016. MS MARCO: A Human Generated MAchineReading COmprehension Dataset. In Proceedings ofthe Workshop on Cognitive Computation: Integrat-ing neural and symbolic approaches.
Rodrigo Nogueira and Kyunghyun Cho. 2019. Pas-sage Re-ranking with BERT. arXiv preprintarXiv:1901.04085 (2019).
Yifan Qiao, Chenyan Xiong, Zhenghao Liu, andZhiyuan Liu. 2019. Understanding the Behaviors ofBERT in Ranking. arXiv preprint arXiv:1904.07531(2019).
Alec Radford, Jeffrey Wu, Rewon Child, David Luan,Dario Amodei, and Ilya Sutskever. 2019. Languagemodels are unsupervised multitask learners. OpenAIBlog 1, 8 (2019).
Siva Reddy, Danqi Chen, and Christopher D Manning.2019. CoQA: A Conversational Question Answer-ing Challenge. Transactions of the Association forComputational Linguistics 7 (2019), 249–266.
Gary Ren, Xiaochuan Ni, Manish Malik, and Qifa Ke.2018. Conversational query understanding using se-quence to sequence modeling. In Proceedings of the2018 World Wide Web Conference. 1715–1724.
Marco Tulio Ribeiro, Sameer Singh, and CarlosGuestrin. 2018. Semantically Equivalent Adversar-ial Rules for Debugging NLP models. In Proceed-ings of the 56th Annual Meeting of the Associa-tion for Computational Linguistics, ACL 2018, Mel-bourne, Australia, July 15-20, 2018, Volume 1: LongPapers. 856–865.
Svitlana Vakulenko, Shayne Longpre, Zhucheng Tu,and Raviteja Anantha. 2020. Question Rewriting forConversational Question Answering. arXiv preprintarXiv:2004.14652.
Christophe Van Gysel. 2017. Remedies against the vo-cabulary gap in information retrieval. Ph.D. Disser-tation. University of Amsterdam.
Shi Yu, Jiahua Liu, Jingqin Yang, Chenyan Xiong, PaulBennett, Jianfeng Gao, and Zhiyuan Liu. 2020. Few-Shot Generative Conversational Query Rewriting. InProceedings of the 43rd International ACM SIGIRconference on research and development in Infor-mation Retrieval, SIGIR 2020, Virtual Event, China,July 25-30, 2020. 1933–1936.
Xiaohui Zeng, Chenxi Liu, Yu-Siang Wang, WeichaoQiu, Lingxi Xie, Yu-Wing Tai, Chi-Keung Tang, andAlan L. Yuille. 2019. Adversarial Attacks Beyondthe Image Space. In IEEE Conference on ComputerVision and Pattern Recognition, CVPR 2019, LongBeach, CA, USA, June 16-20, 2019. 4302–4311.





























