Embed Size (px)
Citation preview


全国本科计算机应用创新型人才培养规划教材
汇编语言程序设计
主 编 张光长 副主编 朱振玉 李永新 参 编 马甲军

内 容 简 介
本书以 80x86 系列微机为特定对象,从程序员角度介绍 80x86 系统结构和相关资源,以及常用的基本
指令;在此基础上,主要讲述使用汇编指令构造顺序结构、分支结构和循环结构的一些“标准化”方法,
以及模块化程序设计的基本知识、基本原理和相关技术与技巧,如参数传递方法、局部变量分配方法与技
巧、多模块程序汇编连接方法等;此外,还介绍浮点运算的程序设计方法及 SIMD 指令集等内容。
本书可以作为计算机专业本科生的专业教材,也可以作为深入学习计算机科学的读者的自学教材,还
可以作为非计算机专业的研究生、本科生、专科生和从事汇编语言程序设计的技术人员的参考书。
图书在版编目(CIP)数据
汇编语言程序设计/张光长主编. —北京:北京大学出版社,2009.7
(全国本科计算机应用创新型人才培养规划教材)
ISBN 978-7-301-15250-8
Ⅰ. 汇… Ⅱ. 张… Ⅲ. 汇编语言—程序设计—高等学校—教材 Ⅳ. TP313
中国版本图书馆 CIP 数据核字(2009)第 091142 号
书 名:汇编语言程序设计 著作责任者:张光长 主编 策 划 编 辑:乐和琴 责 任 编 辑:刘 丽
标 准 书 号:ISBN 978-7-301-15250-8/TP·1012 出 版 者:北京大学出版社
地 址:北京市海淀区成府路 205 号 100871 网 址:http://www.pup.cn http://www.pup6.com
电 话:邮购部 62752015 发行部 62750672 编辑部 62750667 出版部 62754962 电 子 邮 箱:[email protected]
印 刷 者: 发 行 者:北京大学出版社 经 销 者:新华书店 787mm×1092mm 16 开本 17.25 印张 400 千字 2009 年 7 月第 1 版 2009 年 7 月第 1 次印刷 定 价:28.00 元 未经许可,不得以任何方式复制或抄袭本书之部分或全部内容。
版权所有 侵权必究 举报电话:010-62752024 电子邮箱:fd@pup. pku. edu. cn

序
本套教材经过全国几十所高等学校老师一年多的努力,终于与广大读者见面了。我相信,
它一定会受到全国高等学校计算机界老师和同学们的热烈欢迎。 随着信息技术的飞速发展,单一培养模式已经不能满足社会对计算机专业人才多样化的
需求。应对这一变化的最佳办法,就是采用多种模式的培养方式。当前,高等学校的计算机
教育正处于从过去的单一培养模式向多种培养模式的转变过程中,多种模式的培养方式将是
必然的发展方向。 多种模式的培养方式包括:培养人才的类型不同(研究型,应用型);专业方向不同(计算机软
件,计算机网络,信息安全,信息系统,计算机应用技术等);课程设置的多样性等。 同时,高等教育对科技人才培养的要求是:不但要培养研究型科技人才,还要为国家培
养更多的应用型科技人才(或称工程型科技人才)。也就是说,培养应用型科技人才是百分之九十
以上的普通高等学校的主要任务。 本套教材正是为适应多种模式培养方式的要求,并且着重于培养计算机领域高级应用型
科技人才的需求,而组识编写的。 本套教材具有如下特点。
1.基础理论够用
计算机专业所需的基础理论知识以够用为准,不是盲目扩张。如数字系统的基础知识,
计算机的基本组成原理和体系结构的基础知识,离散数学的基础知识,数据结构和算法的基
础知识,操作系统的基础知识,程序设计的基础知识等,都进行了必要的讲解介绍。
2.强调理论联系实际,学以致用
每本教材的编写都将“理论联系实际,学以致用”的原则贯彻始终。例如,《计算机组
成原理和体系结构》结合现代的计算机讲解,使学生学完之后,确切掌握现代计算机的组成、
结构和工作原理;又如,《程序设计》结合实例讲解,使学生学完之后,真正能够动手编写
程序。
3.强调教材的配套性
根据多年组织教材的经验,只有配套性好的教材才最受教师和学生们的欢迎。我们这套
教材,尽量做到了课堂教材、实训教材和教学课件完全配套,以方便教学使用。 另外,本套教材提供的是一套应用创新型计算机教育系列教材,可供不同类型学校依照
自己的教学计划,根据自身的需要进行选用。 现在把这套教材奉献给全国计算机界的朋友们,真诚希望大家能够喜欢。本套教材难免
会有诸多缺点或不到之处,还希望得到大家的批评和指正。
全国高等学校计算机教育研究会课程与教材建设委员会主任 李大友
2009 年 3 月

前 言
汇编语言是一种符号化的机器语言。一方面由于计算机指令与具体的硬件密切相关,
其所实现的功能是非常基本、具体的,因而其数目繁多,使初学者在初次接触时难以把指
令记准、记全,由此望而却步;另一方面,也正是由于汇编指令的这种功能基本、具体和
密切相关的特点,使它在操纵硬件资源方面显得简单而直接。与高级程序设计语言相比,
用汇编语言编写的程序具有代码短小、执行高效等优点,深得一些程序员喜爱。 汇编语言和 CPU 密切相关。本书以 80x86 系列微型计算机为特定对象,系统地介绍了
汇编语言程序设计的基本知识、基本原理和程序设计技术。从程序员角度简单介绍 80x86系统结构,然后介绍 80x86 的常用基本指令,在此基础上再讲述汇编语言中的结构化程序
设计方法和模块化程序设计方法。全书共分 10 章,内容大致可分成以下几个部分。 第一部分是关于数据表示方面的知识,内容主要集中在第 2 章。在介绍常用数制的基
础上,主要讲述数值类型——整数和浮点数的编码方法;非数值类型——西文字符和汉字
的编码方法,主要目的是使读者清楚,计算机是一个二值处理系统,任何信息都必须用二
进制编码,才能为计算机所识别和处理。此外,本章也介绍了二进制的算术运算和逻辑运
算方面的内容。若读者已具有这方面知识,可直接跳过本章。 第二部分是关于计算机硬件及计算机指令方面相关的知识,内容主要集中在第 3 章和
第 4 章。第 3 章首先介绍 80x86 系统的基本组成结构,主要讲述 CPU 的功能,以便读者能
够更好地理解指令的功能。其次介绍与编程相关的计算机资源:CPU 内部寄存器——用以
临时存放指令执行所产生的中间结果存储单元;内存储器——程序中的指令和处理的数据
主要存放在此存储空间;I/O 地址空间——计算机与外设通过此接口交换数据。第 4 章通过
介绍机器指令的格式方式,引入了指令助记符等概念,然后主要以指令助记符和直接地址
编号来表示内存单元的形式,介绍 80x86 的一些常用指令及相关内容,包括:操作数寻址
方式是指令在执行期间以什么方式取得所需要的数据,如何确定数据存放的位置;数据传
送类指令;算术运算和逻辑运算等运算类指令;串处理类指令;控制转移类指令。如果将
编程比做写作,那么该部分内容相当于写作需要用到的字与词,内容虽然繁多,却是编写
汇编语言程序所必需的基本要素。 第三部分是关于程序设计方面的知识,内容主要集中在第 6 章、第 7 章和第 8 章。
第 6 章主要讲述用汇编语言指令构造顺序结构、分支结构和循环结构的一些“标准化”方
法,以便读者能够使用汇编语言编写结构化程序。第 7 章主要讲述模块化程序的编写方法,
介绍子程序的定义与调用的基本方法、调用子程序时的参数传递方法、局部变量的概念及
在子程序中临时分配局部变量的一般方法、多模块程序的编译(汇编)连接方法等内容,为
读者编写大规模程序提供必要的基础。第 8 章则简要讲述如何用汇编指令实现与外部 I/O设备交换数据,讲述写作中遣词造句和结构安排的方法,这部分内容是汇编语言程序员必
须具备的基础知识和基本技能。

汇编语言程序设计
·IV·
需要说明的是,在第 8 章中特别介绍了计算机中断的基本概念和中断服务程序设计的
一般方法。 第四部分是第 9 章内容,是关于 80x86 指令扩展与延伸方面的,包括讲述浮点运算的
程序设计方法和 SIMD 指令集的简单介绍和程序示例。 余下部分主要是关于 MASM 等方面的,涉及的章节有第 1 章、第 5 章和第 10 章。
第 1 章简单介绍汇编、汇编程序和汇编语言的基本概念;符号编程所涉及的指令助记符和
变量、标号、子程序等地址符号。第 5 章则侧重于介绍汇编语言源程序的一般结构及其用
于编制源程序的各种伪指令。第 10 章则对汇编程序和调试工具的使用方法给予简要说明,
本章内容可以根据需要穿插在前面各章中学习,以便在学习过程中能够编写相应的试验
程序。 本书内容的组织上首先突出汇编语言的本质特点是机器语言的符号化,在此基础上再
介绍其他内容,由浅入深,循序渐进,使读者理解和掌握那些具有普遍意义的指令和关键
概念。本书中所有的例子程序都已经使用 MASM 6.15 调试通过,其源程序尽可能地完整,
以便读者能够上机调试。 本书的另一个特点是将主要精力放在介绍汇编语言程序设计的基本原理和基本方法
上,淡化非程序设计方面的因素。例如,书中尽可能地不过分强调以“段地址:偏移地址”
形式表示的逻辑地址与实际物理地址的对应关系,尽可能地少用系统的功能调用。 作为 80x86 汇编语言程序的编程环境既可以是 16 位地址模式的 DOS 环境,也可以是
32 位地址模式的 Windows 环境,仅仅是将它们用做编程环境平台,并不过多涉及其系统功
能调用和环境细节。为此本书只在附录中列出极少量 DOS 环境下的系统功能调用和 Win32环境的 API,并给予简短的说明,以方便读者编程练习时使用。但是由于 Win32 环境下对
系统资源有很多保护机制,不利于讲解汇编语言的完整性方面内容,尤其是讲解计算机中
断。书中的例子还是以 DOS 环境下的居多。 本书编写分工为:黑龙江科技学院朱振玉编写第 1 章和第 2 章,同济大学张光长编写
第 3 章~第 5 章、第 7 章、第 9 章、第 10 章和附录,黑龙江科技学院李永新编写第 6 章,
黑龙江科技学院马甲军编写第 8 章。全书由张光长负责统稿和定稿。 由于作者学识和见识有限,书中如有疏漏之处,恳请读者不吝指教。

目 录
第 1 章 绪论 ....................................................... 1
1.1 汇编语言概述 ......................................... 1 1.2 学习汇编语言的目的和方法 ................. 2 1.3 汇编语言的移植性问题 ......................... 3 习题 1............................................................... 4
第 2 章 基础知识 .............................................. 5
2.1 常用数制及其相互转换 ......................... 5 2.1.1 十进位计数制 ............................. 5 2.1.2 二进位、八进位及
十六进位计数制 ......................... 5 2.1.3 数制间的转换 ............................. 8
2.2 数与字符的表示方法 ........................... 10 2.2.1 整数的表示 ............................... 10 2.2.2 浮点数的表示 ........................... 15 2.2.3 二进制编码的
十进制(BCD)数 ........................ 16 2.2.4 字符表示 ................................... 17
2.3 二进制码的基本逻辑运算 ................... 19 本章小结........................................................ 20 习题 2............................................................. 21
第 3 章 80x86 微机系统的组成 ................. 23
3.1 基于 80x86 的计算机组织结构 ........... 23 3.2 CPU 资源 .............................................. 24
3.2.1 控制器与运算器 ....................... 25 3.2.2 80x86 寄存器组 ........................ 25
3.3 内存储器............................................... 29 3.3.1 内存单元与数据存放字节顺序29 3.3.2 内存的分段使用 ....................... 30 3.3.3 内存单元寻址 ........................... 32
3.4 I/O 地址空间......................................... 33 本章小结........................................................ 35 习题 3............................................................. 35
第 4 章 80x86 的寻址方式与基本指令 ... 37
4.1 指令系统概述....................................... 37 4.2 数据处理类指令................................... 38
4.2.1 操作数的寻址方式 ................... 38 4.2.2 数据传送指令........................... 42 4.2.3 算术运算指令........................... 49 4.2.4 逻辑指令................................... 55 4.2.5 串处理指令............................... 59
4.3 控制转移类指令................................... 66 4.3.1 无条件转移指令....................... 66 4.3.2 条件转移指令........................... 68 4.3.3 循环指令................................... 71 4.3.4 条件设置字节指令和
条件传送指令........................... 72 4.3.5 子程序调用指令与
子程序返回指令....................... 73 4.3.6 中断调用指令与
中断返回指令........................... 76 4.4 其他类指令........................................... 78
4.4.1 标志位处理指令....................... 78 4.4.2 其他指令................................... 78
本章小结 ....................................................... 79 习题 4 ............................................................ 79
第 5 章 汇编语言程序设计初步 ................ 84
5.1 概述 ...................................................... 84 5.2 汇编语言程序基本框架结构 ............... 86
5.2.1 内存的分段使用....................... 86 5.2.2 源程序的结束与
程序的执行入口....................... 87 5.2.3 汇编语言程序的运行平台 ....... 88
5.3 常数、变量和标号............................... 90 5.3.1 常数........................................... 91 5.3.2 变量........................................... 92

汇编语言程序设计
·IV·
5.3.3 标号........................................... 95 5.3.4 变量名和标号的
其他定义方式 ........................... 97 5.3.5 表达式和运算符 ....................... 97 5.3.6 运算符的优先级 ..................... 101
5.4 MASM 的基本伪指令 ........................ 102 5.4.1 指令集选择伪指令 ................. 102 5.4.2 完整的段定义伪指令 ............. 103 5.4.3 源程序开始与结束伪指令 ..... 105 5.4.4 数据定义伪指令 ..................... 105 5.4.5 符号定义指令 ......................... 106 5.4.6 地址计数器与对准伪指令 ..... 107 5.4.7 子程序定义伪指令 PROC
和 ENDP ................................. 108 5.4.8 其他伪指令 ............................. 108
5.5 MASM 的宏汇编伪指令 .................... 109 5.5.1 宏指令 ..................................... 109 5.5.2 重复汇编 ................................. 114 5.5.3 条件汇编 ................................. 116 5.5.4 结构、联合与记录 ................. 117
5.6 段定义的简化 ..................................... 121 本章小结...................................................... 123 习题 5........................................................... 123
第 6 章 结构化程序设计方法 ................... 128
6.1 概述..................................................... 128 6.2 顺序结构程序设计 ............................. 129 6.3 分支结构程序设计 ............................. 131
6.3.1 二分支结构程序设计 ............. 131 6.3.2 多分支结构程序设计 ............. 138
6.4 循环结构程序设计 ............................. 141 6.5 MASM 的高级控制流伪指令 ............ 146
6.5.1 条件测试 ................................. 146 6.5.2 条件控制伪指令 ..................... 146 6.5.3 循环控制伪指令 ..................... 147
6.6 综合实例............................................. 149 本章小结...................................................... 157 习题 6........................................................... 157
第 7 章 模块化程序设计方法 ................... 161
7.1 子程序的设计方法 ............................. 161
7.1.1 子程序的定义、调用与
返回......................................... 161 7.1.2 寄存器的保护与恢复 ............. 163 7.1.3 子程序的参数传递 ................. 164 7.1.4 静态变量与动态变量 ............. 174 7.1.5 子程序的嵌套与递归调用 ..... 177
7.2 多模块程序设计................................. 179 7.2.1 全局符号与外部符号 ............. 179 7.2.2 多模块程序文件的连接 ......... 181 7.2.3 子程序库................................. 182 7.2.4 汇编语言与高级语言
程序的连接............................. 183 7.3 子程序控制伪指令............................. 185 7.4 综合示例 ............................................ 189 本章小结 ..................................................... 207 习题 7 .......................................................... 207
第 8 章 输入/输出接口程序设计............ 210
8.1 概述 .................................................... 210 8.2 程序直接控制 I/O 方式 ..................... 211
8.2.1 立即传送方式......................... 211 8.2.2 查询传送方式......................... 212
8.3 中断传送方式..................................... 214 8.3.1 中断概述................................. 214 8.3.2 中断处理程序的设计 ............. 217
8.4 直接内存存取(DMA)......................... 220 8.5 乐曲程序 ............................................ 220 本章小结 ..................................................... 223 习题 8 .......................................................... 223
第 9 章 浮点运算与 SIMD 指令集............ 225
9.1 概述 .................................................... 225 9.2 浮点运算指令程序设计..................... 225
9.2.1 浮点单元的结构..................... 225 9.2.2 浮点单元的指令简介 ............. 229 9.2.3 浮点运算的编程示例 ............. 233
9.3 SIMD 指令集...................................... 235 9.3.1 指令集简介............................. 236 9.3.2 SIMD 指令集的
程序设计示例......................... 237

目 录
·V·
本章小结...................................................... 240 习题 9........................................................... 240
第 10 章 汇编语言编程和调试工具 ....... 241
10.1 汇编语言的开发环境 ....................... 241 10.1.1 开发过程 ............................... 241 10.1.2 VC 中汇编集成环境的
设置 ....................................... 244
10.2 调试工具........................................... 246 10.2.1 DEBUG................................. 246 10.2.2 CodeView.............................. 249
附录 ..................................................................... 251
附录 A 常用 80x86 指令速查表 .............. 251 附录 B 编程练习环境说明 ...................... 260
参考文献 ............................................................ 265

第 1 章 绪 论
1.1 汇编语言概述
从本质上讲,汇编语言符号化的机器语言,与具体的处理器等底层硬件密切相关,这给
初学者学习汇编语言带来了相当大的难度。但是使用汇编语言直接利用 CPU 和 I/O 等硬件资
源,用它编写的硬件驱动程序简单而直接,和高级语言相比,汇编语言程序的执行代码简短、
高效,这一特性对程序员来说又具有极大的吸引力。 在程序设计的早期,程序员普遍使用汇编语言编程,但是随着计算机语言编译技术的完
善及硬件性能的提高,目前已经很少有人直接使用汇编语言来开发应用系统了,而代之以高
级语言。但是高级语言程序在执行时必须首先转换成一系列计算机指令,然后 CPU 才能执行
它。例如,下面的 C 语言语句: if(x!=0x1234) y=x-0x1234; z=0x102;
在 8086 系统上可以转换成 5 条机器指令来执行:减法,等于转移,两条数据传送。假设 x, y, z 是 16 位整型变量,对应的内存单元地址为 0x59A0, 0x59A4, 0x59A8,那么这 5 条指令的机
器代码:(以十六进制数表示) B8 A0 59 2D 34 12 74 03 A3 A4 59 C7 06 A8 59 02 01 这种以二进制编码形式表示的计算机指令便是机器指令,可以直接用机器指令编写计算
机程序,这便是机器语言程序。显然机器语言程序不能直观地反映程序员的编程思路,而且
其代码不易阅读、难以维护。 为了改善机器指令的可读性,引入了符号编程,将难以记忆的二进制编码进行符号化:
用一些能反映机器指令功能的单词或单词缩写来代表该机器指令,这便是指令助记符;用变
量名等表示存放数据的内存单元地址,用标号等表示指令在内存中的位置,这便是符号地址;
并且将 CPU 内部的各种资源用专门符号来表示,如寄存器名。 例如,在 MASM 中用 SUB 表示“减法”指令,用 JNE 表示“等于转移”指令,MOV
表示“数据传送”指令;将 16 位内存单元 59A0, 59A4, 59A8 分别用变量名 V1, V2, V3 表示,
将“等于转移”所转向的目标指令在内存中的位置用标号 Loc 表示;用 AX 表示 CPU 中的累
加器,那么上述 5 条指令序列可表示如下: MOV AX, V1 SUB AX, 1234h JZ Loc MOV V2, AX Loc: MOV V3, 0102h … 这种符号化的指令序列在执行时必须将它们翻译成对应的机器指令序列,才能为 CPU 识

汇编语言程序设计
·2·
别并执行。将汇编指令序列转换成机器指令序列的过程称为汇编。汇编工作可以由程序员手
工完成,也可以由软件(程序)处理完成,完成汇编任务的软件叫做汇编程序(assembler),有时
也叫做汇编器。 为便于翻译,汇编程序有自己的一套规则和约定,如规定代码的开始与结束,变量的定
义和存储空间的分配等。这些规则和约定只是汇编程序在翻译过程中使用,故称之为伪指令。
相比较而言,那些用助记符、符号地址等表示的指令,是在程序运行期间由 CPU 来执行的,
所以称之为汇编指令。 汇编程序所能处理的所有汇编指令、伪指令及其表示、使用的规则便构成了汇编语言
(assembly language)。用汇编语言编写的程序称为汇编语言程序,或称为汇编语言源程序,也
简称为源程序。 综上所述,汇编语言本质上是机器语言的符号表示,汇编指令和机器指令有着直接对应
关系。而高级语言程序在执行时 终都转换成机器指令。一般来讲,一条高级语言的执行语
句对应着若干条汇编指令。
1.2 学习汇编语言的目的和方法
目前,高级程序设计语言已经非常成熟,种类也很多,绝大多数计算机应用系统也是使
用高级语言来开发的,已经很少有人直接使用汇编语言来开发大的应用系统。因此,有人认
为已经没有必要再去学那些烦琐的汇编指令了。汇编语言指令烦琐是事实,但由此说没有必
要学习它却不尽然。 一方面,汇编语言是符号化的机器语言,与计算机的 CPU、I/O 等硬件关系密切,所以
我们在学习和使用汇编语言的时候,能够感知计算机的运行过程和原理,从而对计算机硬件
与应用程序之间的联系和交互形成清晰的认识。这使程序员编程思维更符合机器的硬件逻辑,
从而形成一个软、硬兼备的编程知识体系。如果说机器语言是计算机操作的本质,那么汇编
语言就是 接近本质的语言。从这一方面看,其他任何高级语言都是难以达到的。 另一方面,高级语言程序 终都是转换成机器指令而运行的。一般来说,一条高级语言
的执行语句对应着若干条汇编指令,这个转换是由编译程序来完成的。在学习和使用汇编指
令构造高级语言程序结构时,能够加深理解高级语言语句的执行过程,从而使我们能够有意
识地编写高效、健壮的程序代码。而且在理解了高级语言语句和汇编指令的对应关系后,对
我们在学习和理解编译原理等相关课程大有帮助。 再有一点就是,由于汇编语言具有能够直接有效控制硬件的能力,能够编写出运行速度
快、代码量小的高效程序,所以在有些场合是不可替代的。例如,火箭和导弹等发射实时控
制系统,使用汇编语言编写 合适;又如,工业控制、仪器仪表、家用电器等这类小系统中
的控制系统,由于成本和体积等方面原因,使系统使用的程序空间和内存容量受到限制,因
而也常常使用汇编语言编程;再如,现代的操作系统中,某些与硬件有关的功能,如机器的
自检,系统的初始化,实际的输入/输出设备操作,及设备驱动程序等,仍由汇编语言编写的
程序来完成。 目前,硬件设施普遍使用嵌入式方式开发,而很多嵌入式编程使用的是汇编语言。现在
的数码产品很多,而这些数码产品赖以生存的芯片、主板等,都包含了嵌入式程序,这些程
序中,汇编语言的使用是相当多的。

第 1章 绪 论
·3·
汇编语言的另一个典型应用就是现代密码学领域。现代加密算法大都建立在超大数(如1024 二进制位)运算基础上,这些运算在实际运行中非常耗时,为提高程序的执行效率,使算
法具有实用性,其关键部分就需要用汇编语言来实现。 那么,如何学习汇编语言程序设计呢?一般来说从以下几个方面着手。 首先,学习和掌握编程所必要的汇编指令和 CPU 资源等。相对高级语言来说,汇编指令
是非常基本、具体的,因而数目繁多,初学者在学习中往往觉得眼花缭乱,无所适从。在学
习指令的过程中,宜将指令分成几大类,逐一学习。如果其功能一时难以理解,可以先记住
指令的主要功能,以后在使用中用到这个指令,再回过头来理解。当然,时间长了,先前掌
握的指令可能会遗忘,这是正常的,这时只要查一查手册就可以,也就是说,学习汇编语言
必须学会查阅指令手册。 其次,学习和掌握汇编语言的伪指令,先简单,再复杂,循序渐进。MASM 伪指令非常
繁多,掌握所有的伪指令是不可能也是没有必要的。初学者首先掌握汇编语言程序的基本框
架结构,常数、变量和标号定义与分配,以及数据类型等 基本的编程要素,这样就可编写
一些简单的汇编语言程序了。在此基础上,再学习其他一些必要的规则和约定及高级的编程
技巧。 后,用汇编指令构造程序的控制结构,实现结构化程序设计和模块化程序设计。汇编
语言的指令和伪指令相当于英语中的单词和组词规则,但是仅仅记住英语中的单词,而不会
使用它们写作和表达,不能算是掌握了英语。同样,学习汇编语言时,如果只是停留在简单
地记住每条指令的功能,也不能说会使用汇编语言。所以,要学会使用和掌握汇编语言,必
须能够使用汇编指令构造类似高级语言程序中的控制结构,以及模块化结构。 这本教材以 80x86 的指令来讲述汇编语言程序设计,但所讲述的编程方法、控制流结构
和模块化思想是普遍适用的。例如,学习这本教材以后,在实际工作中可能需要使用 C51 汇
编语言,这时只需简单地用相应的 C51 指令代替 80x86 指令即可。
1.3 汇编语言的移植性问题
汇编语言是由汇编指令和伪指令等组成,而汇编指令是直接与机器指令相对应的,所以,
不同 CPU 的电气特性与机器指令集不同,它的汇编语言也不同。通常,大多数人所说的汇编
语言指的是 80x86 指令集的微软宏汇编(MASM)。除此之外,常用的还用 51 系列指令集的汇
编语言,ARM 系列使用的专用 RISC 指令集的汇编语言等。 因为汇编语言只是机器语言的一种符号表示,所以同一类型的机器语言可以有不同的符
号表示,只要有相应的翻译程序(即汇编程序)翻译即可。正因为这样,同一类型 CPU 也可以
使用不同的汇编语言,如 80x86 系列 CPU 的计算机系统,除了微软的宏汇编 MASM,还可
以使用 NASM 或 DP11 等。 基于上述原因,和高级程序设计语言相比,汇编语言程序在代码可移植性方面较差。 需要指出的是,这里所说的代码可移植性指的是源程序,不是它编译成的可执行代码。
实际上,同一个源程序代码在不同类型计算机上运行需要不同的翻译程序。例如,用标准 C语言编写的一段程序,如果要让它在 Pentium 平台上运行,则必须要有相应的翻译程序将它
翻译成 80x86 的机器代码;如果要让它在 51 单片机上运行,则必须用另外一个翻译程序将它

汇编语言程序设计
·4·
翻译成 51 CPU 的执行代码。它们的执行代码是不同的。也就是说,C 语言之所以是可移植的,
是因为 C 语言有一个统一的标准。这样不同类型的计算机系统根据此标准建立各自的翻译程
序,由翻译程序来解决可移植问题。 和高级语言相比,汇编语言没有一个统一标准,因而各类型的计算机系统有各自不同的
汇编指令系统,及相应的汇编程序。即使用同一类型的 CPU,虽然指令系统相同,但由于不
同的汇编程序可以采用不同的指令助记符,以及各自的规则和约定,所以汇编语言程序的源
码一般是不可移植的。
习 题 1
1.1 简述机器语言与汇编语言、高级语言与汇编语言的关系。 1.2 通过例子简要说明什么是指令助记符、变量和标号。 1.3 简要说明汇编程序的用途。 1.4 简要说明汇编指令与伪指令的主要区别。

第 2 章 基 础 知 识
本章主要介绍和汇编语言程序设计密切相关的一些基础知识,包括: • 二进制进位记数制及其与二进制数的相互转换。 • 数值型数据的编码:无符号整数、有符号整数、浮点数和 BCD 码。 • 常用的编码:ASCII 码、汉字国标码等。 • 二进制数的算术运算和逻辑运算。
2.1 常用数制及其相互转换
电子计算机的核心是电子电路,其最基本的逻辑电路是电子开关。一个开关只有两种状
态:不是断开,就是闭合,若将其中的一种状态记做 0(如断开),另一种状态记做 1(如闭合),那么开关电路作为计数器使用。1 路开关可计 2 个数:0, 1;2 路开关可计 4 个数:00, 01,10, 11;依次类推,n 路开关可计 2n 个数。电子计算机本质上是由许许多多这样的开关电路组成的高
速运转的电子装置,所以经常说计算机只认识两种符号:0 和 1,即只能处理二进制代码。 由于计算机只能以二进制方式动作,所以对一切数值数据及非数值数据,也只能由 0 和
1 这两种符号来表示,即必须转换成二进制编码形式,计算机才能识别并处理。 在实际使用中,由于二进制代码位数较长,书写、阅读和计忆都不方便,所以常采用十
六进制数或八进制数形式来表示二进制编码。 但是人类熟悉的是十进制数,并不习惯使用二进制计数,所以在使用中根据需要,计算
机中的编码和数经常用十进制、二进制、十进制和八进制形式表示。 为叙述方便,本书中若没有特别标注或说明,数均为十进制计数形式。
2.1.1 十进位计数制
十进位计数制(简称十进制)使用 10 个数码(0, 1, 2, 3, 4, 5, 6, 7, 8, 9)表示数,低位向高位进
位的规则是“逢 10 进 1”,或高位向低位进位的规则是“借 1 当 10”。 十进制数通常在数值后用下标 10 标识,或加 D(Decimal)或 d 来表示。 例如,十进制数 365,可以写成(365)10,或写成 365D,365d。
2.1.2 二进位、八进位及十六进位计数制
1. 二进制数
二进位计数制(简称二进制)的基数为 2,使用两个数码(0 和 1)表示数。低位向高位进位的
规则是“逢 2 进 1”,或高位向低位进位的规则是“借 1 当 2”。 二进制数通常在数值后用下标 2,或标以字母 B(Binary)或 b 以示区别。例如,二进制数
101101101,可记做(101101101)2,或 101101101B, 101101101b。

汇编语言程序设计
·6·
二进制数所表示的数值可用下列权位展开式计算: 2i
id b= ×∑
其中,bi取 0 或 1,i 在小数点左边(整数部分)自右至左依次取:0, 1, 2, …,小数点右边(小数
部分)自左至右依次是:-1, -2, -3, …。 例如,(1011.01)2 所表示的数为:1×23+0×22+1×21+1×20+0×2-1+1×2-2=(11.25)10。 二进制数的四则运算除了使用 2 进位规则外,其运算法则类似十进制数运算。 1) 加法运算规则 ① 0 + 0=0;② 0 + 1=1;③ 1 + 0=1;④ 1+ 1=0(高位进 1)。 例 2.1 求二进制数 1101 0011 与 1001 0110 的和。 解: 1 1 0 1 0 0 1 1 (被加数) + 1 0 0 1 0 1 1 0 (加数) 1 0 1 1 0 1 0 0 1 (和) 所以,(1101 0011)2 + (1001 0110)2=(1 0110 1000)2。 2) 减法运算规则 ① 0 - 0=0;② 0 - 1=1(高位借 1);③ 1 - 0=1;④ 1 - 1=0。 例 2.2 求二进制数 1101 1010 与 1010 1101 的差。 解: 1 1 0 1 1 0 1 0 (被减数) - 1 0 1 0 1 1 0 1 (减数) 0 0 1 0 1 1 0 1 (差) 所以,(1101 1010)2 + (1010 1101)2=(0010 1101)2。 3) 乘法运算规则 ① 0 × 0=0;② 0 × 1=0;③ 1 × 0=0;④ 1 × 1=1。 例 2.3 求二进制数 1101 与 1011 的积。 解: 1 1 0 1 (乘数) × 1 0 1 1 (乘数) 1 1 0 1 1 1 0 1 0 0 0 0 + 1 1 0 1 1 0 0 0 1 1 1 1 所以,(1101)2 × (1011)2=(1000 1111)2。 4) 除法运算规则 ① 0÷1=0;② 1÷1=1。 例 2.4 求二进制数 11 1110 除以 1011 的商。 解: 1 0 1 (商) (除数) 1 0 1 1 1 1 1 1 1 0 (被除数) - 1 0 1 1 0 1 0 0 1 0 - 1 0 1 1 0 1 1 1 (余数) 所以,(11 1110)2 ÷ (1011)2 的商为(101)2,余数为(0111)2。
第 2 章 基 础 知 识
·7·
2. 八进制数
八进位记数制(简称八进制)的基数为 8,使用 0, 1, 2, 3, 4, 5, 6, 7 共 8 个数码。低位向高位
进位的规则是“逢 8 进 1”,或高位给低位借位的规则是“借 1 当 8”。 八进制数通常在数值后用下标 8,或标以字母 O(Octal)或 o 以示区别。 例如,八进制数 555 可以记作(555)8,或记作 555O,555o。 字母 O 易与数字 0 混淆,应用中多采用在数值后加 Q 或 q 来表示八进制数。 八进制所表示的数值可用下列权位展开式计算:
8iid q= ×∑
式中, iq 取 0~7,I 在小数点左边(整数部分)自右至左依次是:0, 1, 2, …,小数点右边(小数
部分)自左至右依次是:-1, -2, -3, …。 例如,(13.2)8 所表示的数值为 1×81+3×80+2×8-1=(11.25)10。 一个数的二进制表示形式与八进制表示形式有着这样的对应关系:小数点左边(整数部分)
自右至左,每 3 个二进制位对应一个八进制位,最左的数位不够 3 位用 0 补;小数点右边(小数部分)自左至右,每 3 个二进制位对应一个八进制位,最右边的数位不够 3 位用 0 补。反之
亦然。3 位二进制数码与八进制数码间的对应关系见表 2.1。
表 2.1 3 位二进制数码与八进制数码对应关系表
三位二进制数码 000 001 010 011 100 101 110 111
八进制数码 0 1 2 3 4 5 6 7 例如,在将(1011.01)2 转换成八进制数时,应把它理解成(001 011.010)2,为(13.2)8。又如,
在把(15.4)8 转换成二进制数时,直接按顺序将一个八进制位展开成三位二进制位得到
(001 101.100)2,即(1101.1)2。
3. 十六进制数
十六进位记数制(简称十六进制)的基数为 16,使用 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, A, B, C, D, E, F共 16 个数码,其中 A~F 也可用相应的小写字母 a~f,分别与 10, 11, 12, 13, 14, 15 这 6 个数
值对应。低位向高位进位的规则是“逢 16 进 1”,或高位给低位借位的规则是“借 1 当 16”。 通常在十六进制数后用下标 16,或标以字母 H(Hexadecimal)或 h 来标识。 例如,十六进制数 16D 可以写成(16D)16,或写成 16DH,16Dh。 十六进制数所表示的数值可用下列权位展开式计算:
16iid h= ×∑
其中,hi取 0~15,i 在小数点左边(整数部分)自右至左依次是:0, 1, 2, …,在小数点右边(小数部分)自左至右依次是:-1, -2, -3, …。
例如,(B.4)16 所表示的数值为 11×160+4×16-1=(11.25)10。 一个数的二进制表示形式与十六进制表示形式有着这样的对应关系:小数点左边(整数部
分)自右至左,每 4 个二进制位对应一个十六进制位,最左的数位不够 4 位用 0 补;小数点右
边(小数部分)自左至右,每 4 个二进制位对应一个十六进制位,最右边的数位不够 4 位用 0补。反之亦然。4 位二进制数码与十六进制数码之间的对应关系见表 2.2。

汇编语言程序设计
·8·
表 2.2 四位二进制数码与十六进制数码对应关系表
四位二进制数码 0000 0001 0010 0011 0100 0101 0110 0111 1000 1001 1010 1011 1100 1101 1110 1111
十六进制数码 0 1 2 3 4 5 6 7 8 9 A B C D E F 例如,在将(1011.01)2 转换成十六进制数时,应把它看成(1011.0100)2,为(B.4)16。又如,
在把(15.4)6 转换成二进制数时,直接按顺序将一个十六进制位展开成四位二进制位得到
(0001 0101.0100)2,即(10101.01)2。
2.1.3 数制间的转换
对于一个给定的数,可以用不同的进位记数制来表示,例如,可以验算,-(21.25)10、
-(10101.01)2、-(25.2)8、-(15.4)表示同一个数,它们除了外在表现形式不一样,数的本质是一
样的。可以根据需要使用不同的数制来记数。
1. 二(八、十六)进制数转换为十进制数
对于二进制、八进制和十六进制等表示形式的数,直接用权位展开式计算即可得出其对
应的十进制的值。例如: (10101.1011)2=1×24+0×23+1×22+0×21+1×20+1×2-1+0×2-2+1×2-3=21.6875 (1207.3)8=1×83+2×82+0×81+7×80+3×8-1=647.375 (1B2E.D)16=1×163+11×162+2×161+14×160+13×16-1=6958.8125
2. 十进制数转换成二(八、十六)进制数
十进制转换成二进制、八进制和十六进制,通常要区分数的整数部分和小数部分,并按
除基取余数部分和乘基取整数部分两种不同的方法来完成。 1) 十进制整数转换为二进制整数 十进制整数转换为二进制整数采用“除 2 取余,逆序排列”法。具体做法是:用 2 去除
十进制整数,可以得到一个商和余数;再用 2 去除商,又得到一个商和余数,如此反复,直
到商为零时为止,然后把先得到的余数作为二进制数的低位有效位,后得到的余数作为二进
制数的高位有效位,依次排列起来。 例 2.5 将十进制数 105 转换成二进制表示形式。计算过程如下:
2 105 余数为 1,即 b0=1 2 52 余数为 0,即 b1=0
2 26 余数为 0,即 b2=0 2 13 余数为 1,即 b3=1
2 6 余数为 0,即 b4=0 2 3 余数为 1,即 b5=1
2 1 余数为 1,即 b6=1 0 商为 0,终止
即转换后的二进制整数为:(b6b5b4b3b2b1b0)2=(1101001)2。 2) 十进制小数转换为二进制小数 十进制小数转换成二进制小数采用“乘 2 取整,顺序排列”法。具体做法是:用 2 乘十

第 2 章 基 础 知 识
·9·
进制小数,可以得到乘积,将乘积的整数部分取出,再用 2 乘余下的小数部分,又得到一个
乘积,再将乘积的整数部分取出,如此反复进行,直到乘积中的小数部分为零,或者达到所
要求的精度为止。 然后把取出的整数部分按顺序排列起来,先取的整数作为二进制小数的高
位有效位,后取的整数作为低位有效位。 例 2.6 将十进制小数 0.6875 转换成二进制小数。其计算过程如下:
0.6875 × 2 1.3750 整数部分为 1,即 b-1=1 0.3750 × 2 0.7500 整数部分为 0,即 b-2=0 0.7500 × 2 1.5000 整数部分为 1,即 b-3=1 0.5 × 2 1.0000 整数部分为 1,即 b-4=1 0.0000 小数部分为 0,终止
即转换后的二进制小数为(0.b-1b-2b-3b-4)2=(0.1011)2。
并不是所有的十进制小数都能精确地表示成二进制形式,这时要根据要求取有限位二进
制数来近似表示该小数。也就是说,若小数转换不能算尽,那么只算到一定精度的位数为止,
但这样做会产生一定的误差。 例 2.7 将十进制小数 0.32 转换成二进制小数的计算过程如下: 32 24 × 2 × 2 0.64 整数部分为 0,即 b-1=0 0.48 整数部分为 0,即 b-6=0 0.64 0.48 × 2 × 2 1.28 整数部分为 1,即 b-2=1 0.96 整数部分为 0,即 b-7=0 0.28 0.96 × 2 × 2 0.56 整数部分为 0,即 b-3=0 1.92 整数部分为 1,即 b-8=1 0.56 0.92 × 2 × 2 1.12 整数部分为 1,即 b-4=1 1.84 整数部分为 1,即 b-9=1 0.12 … × 2 0.24 整数部分为 0,即 b-5=0
在转换过程中,小数部分始终不为 0,即 0.32= (0.b-1b-2b-3b-4b-5b-6b-7b-8b-9… )2 =
(0.010100011…)2,是一个无限位二进制小数。若精度要求是 8 个二进制位,则可截取前 8 位
作为近似结果:0.32≈(0.b-1b-2b-3b-4b-5b-6b-7b-8)2=(0.01010001)2。 对既有整数部分又有小数部分的十进制数,可以先分别转换,然后将得到的两部分结果
合起来,就得到了转换后的最终结果。例如,105.6875=(1101001.1011)2。

汇编语言程序设计
·10·
参照上述方法,也可以实现十进制到八进制、十进制到十六进制的转换过程。 例 2.8 将十进制数 725.703125 转换成十六进制表示形式的计算过程如下: 整数部分 小数部分
16 725 余数为 5, 即 h0=5 0.703125 16 45 余数为 13,即 h1=D × 16
16 2 余数为 2, 即 h2=2 11.25 整数部分为 11,即 h-1=B 0 商为 0,终止 0.25 × 16 4.00 整数部分为 4,即 h-2=4 0.00 小数部分为 0,终止
将转换后整数部分和小数部分合并得:725.703125=(h2h1.h-1h-2)16=(2D5.B4)16。
2.2 数与字符的表示方法
对于数值、文字、图形、图像、音频和视频等这些数值数据和非数值数据,必须将它们
以二进制编码形式表示出来,才能为计算机识别、存储、处理和传送。本节主要讲述几类基
本的数值数据和非数值数据的二进制编码表示。 需要注意的是,二进制编码与二进制记数是两个有着本质不同的概念,一般来说,二进
制编码所表示的并不是二进制数。
2.2.1 整数的表示
1. 无符号整数的表示
对于 0 和正整数(即非负整数)可直接用二进制编码来表示,即二进制编码就是它所表示数
的二进制记数形式,这便是无符号整数。 例 2.9 二进制编码 1100 0010 所表示的无符号数是:(1100 0010)2=(194)10。 一个 n 位二进制码所表示的无符号整数范围为:0~2n-1。计算机内部常用 1 字节、2 字节、
4 字节和 8 字节等来表示整数,其能表示的无符号整数的范围见表 2.3。
表 2.3 常用数据类型所表示无符号整数的范围
类型/Bytes 二进制位数/bits 范 围 1 8 0~255 2 16 0~65 535(64K-1) 4 32 0~4 294 967 295(4G-1) 8 64 0~18 446 744 073 709 551 615
两个 n 位的无符号数相加减,所得结果若超出它对应的范围,则产生结果溢出,此时,
所得结果不正确,应当选用更大范围的数据类型。例如,采用 8 位无符号编码,65 和 194 分
别为 01000001 和 11000010,但是 65+194=259,65-194=-129,两个结果均不在 8 位无符号
数的范围内(0~255),所以溢出。 无符号数溢出的判断方法较简单:当加法运算结果的最高位产生进位,或减法运算结果
产生最高位借位时,则运算结果溢出。

第 2 章 基 础 知 识
·11·
例如,采用 8 位无符号数,65+194 和 65-194 的运算过程如下: 0100 0001 0100 0001 + 1100 0010 - 1100 0010进位 1←00000011(0000 0011 对应 3) 借位 1←01111111(0111 1111 对应 127)
有进位,产生溢出,结果不正确 有借位,产生溢出,结果不正确
2. 有符号整数的表示
对于有符号数,一般处理的方法是:用 0 表示正数,用 1 表示负数,放在二进制码的最
前面。根据编码规则,有符号整数有多种编码表示,如原码、反码、补码等。不同编码的主
要区别在于二进制编码和数的对应规则不同。 在计算机系统中,目前普遍采用二进制补码来表示有符号整数,所以,这里只介绍二进
制补码的相关内容。长度为 n 位二进制补码编码方案如下。 (1) 最高位(Most Significant Bit, MSB)是符号位,其余 n-1 位是数值位。 (2) 符号位,0 表示正数,1 表示负数。 (3) 数值位,正数的编码是其自身的二进制记数形式,负数的编码是把其正数的二进制编
码各位取反(0 变 1,1 变 0)再加 1,即正数是其数值本身,负数是其正数取反加 1。 例 2.10 求十进制整数+62 和-62 的 8 位补码。 解: +62 的补码 0011 1110 各位取反后 1100 0001 加 1 + 1 得到-62 的补码 1100 0010 按照补码编码规则,当符号位为 0 时,该补码对应的是 0 和正数,其编码就是数的二进
制记数形式;当符号位为 1,该补码对应的是负数,将其编码各位取反再加 1 后所得的二进
制码就是该数绝对值的二进制记数形式。可用这个规则求出补码所表示的整数。 例 2.11 求下列补码所表示的数:(1) 00011000;(2) 11101111;(3) 10000000。 解:(1) 符号位是 0,它所表示的数为+(00011000)2=+(18)16=+(24)10。 (2) 符号位是 1,说明它所表示的是负数。将编码 1110 1111 各位取反再加 1 后得到
0001 0001,所以该补码所表示的数为-(00010001)2=-(11)16=-(17)10。 (3) 符号位是 1,说明它所表示的是负数。将编码 1000 0000 各位取反再加 1 后得到
1000 0000,所以该补码所表示的数为-(10000000)2=-(80)16=-(128)10。 一个 n 位补码所表示数的范围为-(2n-1)~+(2n-1-1)。表 2.4 列出了 8 位、16 位和 32 位补
码所表示的有符号数的范围。
表 2.4 常用数据类型所表示有符号整数的范围
类型/Byte 二进制位数/bit 范 围
1 8 -128~+127
2 16 -32 768~+32 767
4 32 -2 147 483 648~+2 147 483 647
8 64 -9 223 372 036 854 775 808~+9 223 372 036 854 775 807

汇编语言程序设计
·12·
对数 x 的补码(记做[x]补)各位取反后再加 1,即可得到该数负值的补码,即
[x]补 [-x]补 [x]补
例如,+69 和-69 的 8 位补码是(01000101)2 和(10111011)2,分别对它们求反加 1:
[69]补 0100 0101 [-69]补 1011 1011 各位取反后 1011 1010 各位取反后 0100 0100
加 1 + 1 加 1 + 1 1011 1011 0100 0101 10111011 是-69 的补码 01000101 是+69 的补码
即有:[69]补 [-69]补,[-69]补 [69]补。 补码的加法规则:[x + y]补=[x]补+ [y]补。 该规则表明,当有符号的两个数采用补码形式表示时,要完成计算两数之和的补码表示,
只需用两数的补码直接执行加法运算即可,符号位与数值位同等对待,一起参加运算,若运
算的结果不超出对应的补码所表示的范围,则结果的符号位和数值位同时为正确值。
例 2.12 用 8 位二进制补码完成十进制整数运算:62+65,62+(-65),-62+(-65)。 解: 十进制加法 二进制补码加法 62 0011 1110 + 65 + 0100 0001 127 0111 1111 (即 127 的补码) 62 0011 1110 + (–65) + 1011 1111 -3 1111 1101 (即-3 的补码) -62 1100 0010 + (–65) + 1011 1111 -127 1← 1000 0001 (1000 0001 即-127 的补码,丢弃进位,结果正确) 例 2.12 中,符号位和数值一起参加运算,所得结果正确,产生的进位亦可自然丢弃而不
影响结果的正确性。 补码的减法规则:[x - y]补=[x]补-[y]补=[x]补+ [-y]补。 该规则表明,当有符号的两个数采用补码形式表示时,要完成计算两数之差的补码表示,
只需用两数的补码直接执行减法运算即可,同样符号位一起参加运算,若运算的结果不超出
对应的补码所表示的范围,则结果的符号位和数值位同时为正确值。 例 2.13 用 8 位二进制补码完成下列十进制整数运算:62-65,62-(-65),(-62)-65。 解: 十进制减法 二进制补码减法
62 0011 1110 - 65 - 0100 0001 -3 1←1111 1101 (1111 1101即-3的补码,丢弃借位,结果正确) 62 0011 1110 - (-65) - 1011 1111 127 1←0111 1111 (0111 1111即127的补码,丢弃借位,结果正确)
取反加 1 取反加 1
取反加 1 取反加 1

第 2 章 基 础 知 识
·13·
-62 1100 0010 -65 - 0100 0001 -127 1000 0001 (即-127的补码)
同样,上例中符号位和数值一起参加运算,所得结果正确,并且产生的借位可自然丢弃
而不影响结果的正确性。 式[x]补-[y]补=[x]补+ [-y]补表明,补码的减法运算可转换成补码的加法运算,其中[-y]补只需
对[y]补简单地进行求反加 1 即可得到。这一特性对于简化运算电路的实现非常有用。 两个 n 补码的加、减运算结果若超出它所表示数的范围,则结果产生溢出。
例 2.14 用 8 位补码完成下列十进制整数运算:94+55,-98-59。 解: 十进制运算 二进制补码运算
94 0101 1110 + 55 + 0011 0111 149 1001 0101 (是-107的补码) -98 1001 1110 -59 + 1100 0101 -157 1←0110 0011 (0110 0011是99的补码)
可以看出,例 2.14 中十进制运算结果和其对应的补码运算结果不一致,即补码的运算结
果不正确,为什么呢?主要原因是运算结果 149 和-157 超出了-128~+127 的范围。 只有当同号的补码数相加,或异号补码数相减时,才可能产生溢出,而对于同号数相减,
或异符号数相加,其运算结果不会溢出,为什么呢?且看下列说明。 (1) 若 x,y 同为正数,即 0<x≤2n-1-1,0<y≤2n-1-1,则: 0<x + y≤2×2n-1-2,而 2×2n-1-2>2n-1-1,所以,x + y 可能会溢出。 -(2n-1-1)≤x - y≤2n-1-1,所以,x - y 不会溢出。 若 x,y 同为负整数,即-2n-1≤x<0,-2n-1≤y<0,则: -2×2n-1≤x + y<0,而-2×2n-1<-2n-1,所以,x + y 的结果可能会溢出。 -2n-1<x - y<2n-1≤2n-1-1,所以,x - y 不会溢出。 (2) 若 x 与 y 符号相异,那么 x 与-y 符号相同,所以,x - y 可能会溢出,x + y 不会溢出。 上述特性可作为手工检查运算结果是否溢出的判断方法:当两正数补码相加,或正数补
码减负数补码,所得结果是负数补码,则溢出,是正溢出;当两负数补码相加,或负数补码
减正数补码,所到结果是正数补码,也是溢出,是负溢出。 判断有符号数溢出的常见方法有:①通过参加运算的两个数的符号及运算结果的符号进
行判断。②单符号法。此方法是判断两加数的符号位与结果的符号位是否相异,相异则溢出。
③双进位法。该方法通过符号位和数值部分最高位的进位状态来判断结果是否溢出。④双符
号位法,又称为变形补码法。它是通过运算结果的两个符号位的状态来判断结果是否溢出。4种方法中,第①种方法仅适用于手工运算时对结果是否溢出的判断,其他 3 种方法在计算机
中都可使用。
3. 无符号整数与有符号整数的进一步说明
无符号整数与有符号整数的主要区别在于编码规则不同。如图 2.1 所示,对于无符号整
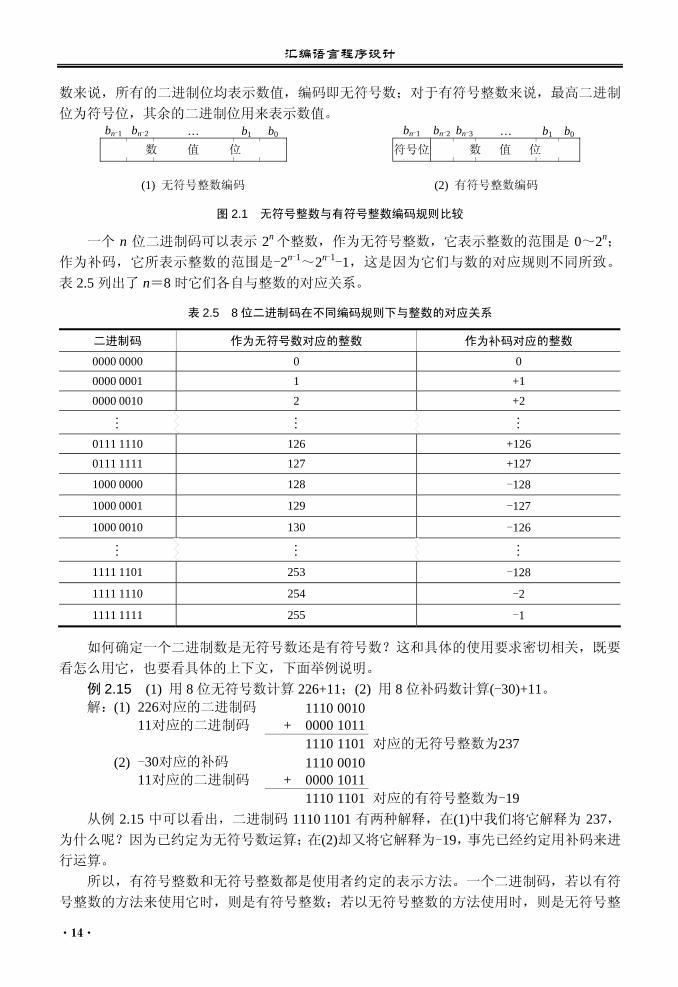
汇编语言程序设计
·14·
数来说,所有的二进制位均表示数值,编码即无符号数;对于有符号整数来说,最高二进制
位为符号位,其余的二进制位用来表示数值。 bn-1 bn-2 … b1 b0 bn-1 bn-2 bn-3 … b1 b0
数 值 位 符号位 数 值 位
(1) 无符号整数编码 (2) 有符号整数编码
图 2.1 无符号整数与有符号整数编码规则比较
一个 n 位二进制码可以表示 2n 个整数,作为无符号整数,它表示整数的范围是 0~2n;
作为补码,它所表示整数的范围是-2n-1~2n-1-1,这是因为它们与数的对应规则不同所致。
表 2.5 列出了 n=8 时它们各自与整数的对应关系。
表 2.5 8 位二进制码在不同编码规则下与整数的对应关系
二进制码 作为无符号数对应的整数 作为补码对应的整数
0000 0000 0 0
0000 0001 1 +1
0000 0010 2 +2
0111 1110 126 +126
0111 1111 127 +127
1000 0000 128 -128
1000 0001 129 -127
1000 0010 130 -126
1111 1101 253 -128
1111 1110 254 -2
1111 1111 255 -1 如何确定一个二进制数是无符号数还是有符号数?这和具体的使用要求密切相关,既要
看怎么用它,也要看具体的上下文,下面举例说明。 例 2.15 (1) 用 8 位无符号数计算 226+11;(2) 用 8 位补码数计算(-30)+11。 解:(1) 226对应的二进制码 1110 0010 11对应的二进制码 + 0000 1011
1110 1101 对应的无符号整数为237 (2) -30对应的补码 1110 0010
11对应的二进制码 + 0000 1011 1110 1101 对应的有符号整数为-19
从例 2.15 中可以看出,二进制码 1110 1101 有两种解释,在(1)中我们将它解释为 237,为什么呢?因为已约定为无符号数运算;在(2)却又将它解释为-19,事先已经约定用补码来进
行运算。 所以,有符号整数和无符号整数都是使用者约定的表示方法。一个二进制码,若以有符
号整数的方法来使用它时,则是有符号整数;若以无符号整数的方法使用时,则是无符号整
第 2 章 基 础 知 识
·15·
数。也就是说,二进制码自身并不能标明是无符号数还是有符号数,能标明它们的是使用者。
若将它作为无符号数使用时,那么就应该用无符号数的方法来处理,若把它作为有符号数使
用时,则应该用有符号数的方法来处理。 例 2.15 还说明一点:无符号整数和补码使用相同的规则来处理加法运算,这一结论对减
法运算也适用。事实上,无符号数和补码数的加法和减法的运算规则完全相同,但是由于约
定的表示规则不一样,所以它们各自采用不同的溢出判断方法。
2.2.2 浮点数的表示
在计算机采用约定小数点位置的方法来表示带小数的数。根据约定规则不同分为:定点
表示法(小数点位置固定不变),又称为定点数;浮点表示法(小数点的位置根据需要而浮动),又称为浮点数。目前,在计算机中多采用浮点数来计算,所以这里只简单介绍浮点数的二进
制编码。 浮点数编码是基于这样的事实:任意一个非 0 数 N,均可写成 N=±(1.m)2×2e。例如,
0.75=(0.11)2=+(1.1)2×2-1,-7.25=-(111.01)2=-(1.1101)2×22。显然,对于 N1=(1.m1)2×2e1 和
N2=(1.m2)2×2e2,若 e1≠e2,那么 N1 和 N2 的小数点位置也不同。 所以,浮点数编码方案的基本思想是:将非 0 数表示成 N=±(1.m)2×2e形式,再分别对小
数部分±(1.m)2 和指数部分 e 进行编码,且约定基数 2 固定不变。其中小数部分给出有效数字
的位数,决定了浮点数的表示精度,指数部分反映了数据中小数点的实际位置,决定了浮点
数的表示范围。当然,小数部分和指数部分都是有符号数,在编码时也要考虑它们的正负号。 按照 IEEE 754 标准(IEEE, 1985),非 0 数 N 表示成(-1)s×(1.m)2×2e,分成三部分:数符(-1)s,
N 为正数时,s=0,N 为负数时,s=1;小数数值 1.m;指数 e。其对应的浮点格式如图 2.2所示,采用的编码规则如下。
(1) 符号位。对应数符,表示数的正负号。正数该位为 0,负数该位为 1。 (2) 尾数(mantissa),是小数数值的编码。由于形如(1.m)2 的小数是规格化数,其整数部分
总是 1,所以在编码时省去最前面的 1,也就是说约定在小数点左部有一位隐含位“1”。 (3) 阶码(exponent),是指数的编码,用移码表示,即指数 e 与一个偏移量之和。
bn-1 bn-2 bn-3 … bk bR-1 … b1 b0
符号位: s 阶码:e+偏移量 尾数:m
图 2.2 IEEE 754 标准的浮点格式
目前,计算机中主要使用三种精度的 IEEE 754 浮点数,见表 2.6。
表 2.6 IEEE 754 标准中的三种浮点数
类型(位数) 数符 阶码 尾数 最小指数 最大指数 指数偏移量 表数范围
短浮点数(32 位) 1 8 23 -126 +127 127(7Fh) 10–38~1038
长浮点数(64 位) 1 11 52 -1022 +1023 1023(3FFh) 10–308~10308
临时浮点数(80 位) 1 15 64 -16382 +16383 16383(3FFFh) 10–4932~104932
表中的短浮点数又叫单精度浮点数,长浮点数又称双精度浮点数,它们都采用隐含尾数
最高数位的方法,这样就增加了一位尾数。临时浮点数又称扩展精度浮点数,无隐含位。

汇编语言程序设计
·16·
下面以 32 位的短浮点数为例,介绍浮点编码与实际值之间的关系。32 位的短浮点数的
最高位为数符位;其后是 8 位阶码,以 2 为底,用移码表示,阶码的偏移量为 127;其余 23位是尾数的数值位。对于规格化的二进制浮点数,约定其最高位总是“1”,故尾数数值实际
上是 24 位,即 1 位隐含位加 23 位小数位。 例 2.16 求 105.6875 的短浮点数的编码。 解:(1) 把十进制数转换成二进制数。 105.6875=(1101001.1011)2
(2) 二进制数进行规格化处理。 (1101001.1011)2=(1.1010011011)2 × 26 (3) 计算出移码(指数的实际值+偏移量)。 6+127=133=(1000 0101)2 (4) 以短浮点数格式存储该数。 该数的符号位是 0,阶码是 1000 0101,尾数是 101 0011 0110 0000 0000 0000。所以,
105.6875 的短浮点编码是 0100 0010 1101 0011 0110 0000 0000 0000。将该二进制编码用十六
进制数表示是(42D36000)16。 例 2.17 求短浮点编码 1100 0010 0000 0110 0100 0000 0000 0000 所表示的数。 解:(1) 从该二进制码中可得: 符号位为 1,阶码为 1000 0100,尾数为 000 0110 0100 0000 0000 0000。 (2) 计算出指数的实际值(即移码-偏移量):(1000 0100)2-127=132-127=5。 (3) 得到此数的规格化二进制数形式:1.000011001×25。
(4) 由于符号位是 1,该浮点编码所表示的数为:-(100001.1001)2=-33.5625。 在 IEEE 754 标准中,阶码的最小数 0 和最大数用来表示特殊数值,0 与最大数之间用来
表示规格化数。以 32 位短浮点编码为例,由表 2.6 可知,其表数范围是-126~+127,加上偏
量 127 后,对应的阶码值的范围是 1~254,用以表示规格化数,而余下两个值 0 和 255 分别
用来表示特殊数值。概括如下: 若 1≤阶码≤254,则指数 e=阶码-127,N=(-1)s × (1.m)2 × 2e,是规格化数。 若阶码=0,且 m=0,则 N 为 0。 若阶码=0,且 m≠0,则 N=(-1)s × (0.m)2 × 2-126,为非规格化数(非常小的数)。 若阶码=255,且 m≠0,则 N=NaN,是一个“非数值”。 若阶码=255,且 m=0,则 N=(-1)s ×∞,是±∞(符号由 s 决定)。
2.2.3 二进制编码的十进制数
用 4 位二进制码表示十进制数码,以此来表示十进制数,这便是二进制编码的十进制
数(Binary Coded Decimal,BCD)。这种编码即具有二进制码的形式(4 位二进制码),又具有十进
制数的特点(每 4 位二进制码表示的是 1 个十进制数码)。 4 位二进制码可以有 16 种组合,而表示十进制数码只需要 10 种组合,因此用 4 位二进
制码来表示十进制数有多种可行的方案。在众多方案中用得最普遍的是 8421,即 4 位二进制
位的位权分别是 8(23), 4(22), 2(21)和 1(20),使用 0000, 0001, …, 1001 这 10 个编码,分别表示
0~9 这 10 个数码,即十进制数码用与其数值相等的 4 位二进制数来表示。 BCD 码可以直接用来编码十进制数。例如,将 294 各个数位分别用 BCD 码(4 位二进制

第 2 章 基 础 知 识
·17·
码)表示,就是它的 BCD 编码 0010 1001 0100。 用 BCD 码表示的数虽然也是二进制形式,但本质上它是十进制数,只不过每位上的数用
二进制编码而已,并没有把十进制数的值转换成真正的二进制值。例如,十进制数 125,用
BCD 码表示为 0001 0010 0101,三组 4 位二进制码,分别对应十进制的个位、十位和百位;
用 8 位补码表示为 0111 1101,其二进制编码就是该数的二进制表示形式。 用 BCD 码表示的十进制数可以按十进制规则运算,但运算过程可能需要进行“十进制调
整”,才能得到正确结果。究其原因,在按二进制数运算时,低 4 位向高 4 位进位或借位相
当于“逢 16 进 1”或“借 1 当 16”,而不是“逢 10 进 1”或“借 1 当 10”。 例如,35+47=82,将它们用 BCD 码表示是:(0011 0101)BCD+(0100 0111)BCD,直接按二进
制数运算所得的结果是“0111 1100”,显然低 4 位的“1100”不是一个 BCD 码,结果错误。
正确的计算过程应该是:先个位数(低 4 位)相加,得 1100,再加 110(即加 6)进行调整,得 0010,同时向十位进 1;再十位数(高 4 位)相加,得 0111,加上个位的进 1,所得结果是 1000。至此
得它们相加结果的 BCD 码:(1000 0010)BCD,结果正确。 十进制调整目的是变 16 进位为 10 进位,其规则如下。 (1) 两个 BCD 码相加,若结果大于(1001)2,亦即大于 9,或者产生了进位,则加 0110(即
加 6)调整,并向十进制数的高位进 1。 (2) 两个 BCD 数码相减,若低 4 位向高 4 位有借位,则低 4 位减 0110(减 6)调整,并向
十进制数高位借 1。 与二进制编码相比,BCD 编码的十进制数缺点比较明显,一方面它存储效率不高,另一
方面由于它的运算规则复杂,因而运算速度较慢。因此,绝大多数现代计算机程序使用二进
制编码来表示所有的数据(包括十进制数据)。尽管如此,BCD 还是具有它的可取之处,用 BCD码表示的十进制数直观而且转换方便,此外,直觉上使用 BCD(或者说十进制)进行计算要比
二进制计算更加准确。所以,BCD 码一般只用于少数商业软件、嵌入式系统及一些专门领域
中,在通用计算机软件中比较少见。
2.2.4 字符表示
计算机除了对数值类型数据处理外,还需处理字符(含各种符号、数字、字母等),因此,
需要为每个字符规定一个特定的编码,以便能够以二进制形式表示。
1. ASCII 字符编码
目前使用最普遍的是ASCII字符编码,即美国标准信息交换码(American Standard Code for Information Interchange, ASCII)。该编码已被国际标准化组织采纳,作为国际通用的信息标准
交换代码。ASCII 码包括标准版和扩展版,通常所说的 ASCII 码指的是标准版。 标准 ASCII 码采用 7 位二进制码表示一个字符,共规定了 128 个字符的编码,见表 2.7。
其中 96 个可打印字符,包括阿拉伯数码、英文字母、标点符号和运算符等,以及 32 个不能
打印出来的控制符号。 表 2.7 中每个字符所在行与列所对应的十六进制码分别是该字符 ASCII 码值的低 4 位和
高 3 位值,例如,‘A’的 ASCII 码值为 41h,‘b’的 ASCII 码值为 62h,ASCII 码值是 30h所对应的字符是‘0’。
为便于记忆,现将 ASCII 码表中的一些规律说明如下。 (1) 表中最前面的 32 个码(00h~1Fh)和最后一个码(7Fh)不对应任何可印刷的字符,主要
汇编语言程序设计
·18·
用于对计算机通信中的通信控制或对计算机设备的控制,称控制码。这些字符中使用比较多
的有:回车符 CR(0Dh)、换行符 LF(0Ah)、退格符 BS(08h)、水平跳格 HT(09h)。 (2) 空格字符 SP 的编码值是 32(20h)。 (3) 数字符‘0’~‘9’的编码值是 48~57(30h~39h);大写英文字母‘A’~‘Z’的
编码值是 65~90(41h~5Ah),小写英文字母‘a’~‘z’的编码值是 97~122(61h~7Ah),大、
小写字母编码值相差 32(20h)。
表 2.7 标准 ASCII 码表
b6b5b4
b3b2b1b0 0 1 2 3 4 5 6 7
0 NUL DLE SP 0 @ P ` p
1 SOH DC1 ! 1 A Q a q
2 STX DC2 " 2 B R b r
3 ETX DC3 # 3 C S c s
4 EOT DC4 $ 4 D T d t
5 ENQ NAK % 5 E U e u
6 ACK SYN & 6 F V f v
7 BEL ETB ' 7 G W g w
8 BS CAN ( 8 H X h x
9 HT EM ) 9 I Y i y
A LF SUB * : J Z j z
B VT ESC + ; K [ k {
C FF FS , < L \ l |
D CR GS - = M ] m }
E SO RS . > N ^ n ~
F SI US / ? O _ o DEL 虽然标准 ASCII 码是 7 位编码,但一般以一个字节来存放一个 ASCII 字符,每一个字节
中多余出来的一位(最高位)通常置 0。 扩展 ASCII 码是在兼容标准 ASCII 码基础上制定的。它是 8 位二进制编码,最高位是 0
的编码 00h~7Fh(0~127)对应的是标准 ASCII 码,最高位为 1 的编码 80h~FFh(128~255)对应的是扩充的 128 个字符。
2. 汉字编码
汉字也是字符,目前使用广泛的汉字编码基准是 GB 2312—1980 或国标码,即中国国家
标准局发布的《信息交换用汉字编码字符集·基本集》。该编码通行于中国,新加坡等地也
采用此编码。 GB 2312—1980 使用双 7 位二进制码表示一个汉字,编码范围是从 2121h(21h 即 33)到
7E7Eh(7Eh 即 126),理论上可规定 8836(94×94)编码,实际上它只选取 6763 个常用汉字和 682个非汉字字符,并为每个字符规定了标准编码,即国标码。
GB 2312—1980 将所有的国标汉字与符号分在 94 个区(按顺序编号为 01~94),每区 94位(按顺序编号为 01~94),组成一个区位码表。汉字和字符就排列在这 94×94 个编码位置所

第 2 章 基 础 知 识
·19·
组成的码位表中,每个汉字字符国标码是: 第一个 7 位编码值=区码+32(20h),第二个 7 位编码值=位码+32(20h)
例如,“啊”位于区位表 16 区 01 位,它国标码是:16+32=48=30h,1+32=33=21h。 尽管国标码是两个 7 位二进制编码,但一般是用两个字节来存放一个汉字字符,为了与
标准的 ASCII 码区分开,通常将每一个字节中多余出来的一位(最高位)置 1。用这种方法表示
的两字节编码就是通常所说的汉字机内码或汉字内码,是用“两个扩展 8 位的 ASCII 码”表
示一个汉字,所以
汉字内码为: 1 国标码第一字节低 7 位 1 国标码第二字节低 7 位
也就是说,汉字内码=国标码+8080h。 所以,国标码和区位码有如下的对应关系:
内码第 1 字节值=区码+160(A0h),内码第 2 字节值=位码+160(A0h) 例如,汉字“啊”的内码为:16+160=176=B0h,1+160=161=A1h。 汉字编码除了 GB 2312 外,还有其他一些编码方案,它们的编码方法与 GB 2312 类似。
其中,兼容 GB 2312 的有 GBK(汉字内码扩展规范)、GB 18030 (信息技术信息交换用汉字编
码字符集基本集的扩充);与 GB 2312 不兼容的有 BIG5(用于台湾、香港地区繁体字编码方案)。需要说明的是,2000 年的 GB 18030 是正式国家标准。
3. Unicode 字符
Unicode 也是一种字符编码方法,不过它是由国际组织设计,可以容纳全世界所有语言文
字的编码方案。Unicode 的学名是“Universal Multiple-Octet Coded Character Set”,简称 UCS。 Unicode 有两套标准,一套叫 UCS-2(Unicode-16),用两个字节为字符编码;另一套叫
UCS-4(Unicode-32),用 4 个字节为字符编码。应用中有 3 种实现的编码标准:UTF-8,UTF-16和 UTF-32。Unicode 码与 UTF 编码的关系类似于汉字的 GB 码与内码的关系。
2.3 二进制码的基本逻辑运算
二进制符号 1 和 0 在逻辑上可以代表“真”与“假”、“是”与“否”、“有”与“无”
等互相对立的两种状态,也就是说它具有逻辑属性,所以,二进制数可以进行逻辑运算。 二进制数的逻辑运算和算术运算处理规则是不同的,逻辑运算是按位进行的,位与位之
间彼此独立,不像加减运算那样,位与位之间存在进位或借位的联系。 常用的基本逻辑运算有 4 种:“与”运算、“或”运算、“非”运算、“异或”运算。
1.“与”运算
“与”运算(AND)即逻辑乘法,通常用符号“∧”或“·”来表示。“与”运算规则如下。 0∧0=0 0∧1=0 1∧0=0 1∧1=1
不难看出,只有当运算各方同时取值为 1 时,其结果才等于 1,否则结果为 0。 例 2.18 求二进制数 1101 0011 与 1001 0110 的逻辑“与”。 解: 1 1 0 1 1 0 1 0 ∧ 1 0 0 1 0 1 1 0 1 0 0 1 0 0 1 0

汇编语言程序设计
·20·
所以,(1101 1010)2∧(1001 0110)2=(1001 0010)2。
2.“或”运算
“或”运算(OR)即逻辑加法,常用符号“∨”或“+”来表示。“或”运算规则如下。 0∨0=0 0∨1=1 1∨0=1 1∨1=1
不难看出,只有当运算各方同时取值为 0 时,其结果才等于 0,否则结果为 1。 例 2.19 求二进制数 1101 1010 与 1001 1001 的逻辑“或”。 解: 1 1 0 1 1 0 1 0 ∨ 1 0 0 1 1 0 0 1 1 1 0 1 1 0 1 1 所以,(1101 1010)2∨(1001 1001)2=(1101 1011)2。
3. “非”运算
“非”运算(NOT)即逻辑否定,通常用符号“¬”或在运算变量上面加一根横线表示。“非”
运算规则如下。 ¬1=0 ¬0=1
不难看出,“非”运算就是“取反”运算。 例 2.20 求二进制数 1101 1010 的逻辑“非”。 解: ¬ 1 1 0 1 1 0 1 0 0 0 1 0 0 1 0 1 所以,¬(1101 1010)2=(0010 0101)2。
4. “异或”运算
“异或”运算(XOR)通常用符号“∀”或“⊕”来表示。“异或”运算规则如下。 0∀0=0 0∀1=01 1∀0=1 1∀1=0
不难看出,只有当运算双方取值为不同时,其结果等于 1,双方取值相同时结果等于 0。 例 2.21 求二进制数 1101 1010 与 1001 1001 的逻辑“异或”。 解: 1 1 0 1 1 0 1 0 ∀ 1 0 0 1 1 0 0 1 0 1 0 0 0 0 1 1 所以,(1101 1010)2∀(1001 1001)2=(0100 0011)2。
本 章 小 结
本章介绍了学习汇编语言所必备的一些基本知识,包括:进位记数制、数与字符表示方
法,以及二进制数的基本运算。 计算机所处理的数据都是使用二进制编码表示的,通常用十六进制数来表示二进制编码,
也就是说,在计算机领域里将十六进制数与二进制编码等同看待。将十进制整数转换成二(八、
十六)进制整数采用“除基取余”法;将十进制小数转换成二(八、十六)进制数小数采用“乘
基取整”法。将二(八、十六)进制数转换成十进制数采用“位权”法。 可以直接将二进制编码看做整数,这便是无符号整数(0 和正数)。有符号整数普遍采用二
进制补码表示,即 0 和正数是其数值本身,负数是其数值的“取反加 1”形式。补码的最高

第 2 章 基 础 知 识
·21·
位(MSB)是 0,则表示的是正数;最高位是 1,则表示的是负数。补码数和无符号数使用相同
的加法、减法运算规则,但使用不同的溢出判断方法。 在计算机中多采用浮点编码格式表示带小数点的数,在 IEEE 754 标准中,浮点数由符号
位、阶码和尾数三部分组成。符号位用于表示正负号;阶码存放的指数值,用移码表示,用
于表示该数的小数点的位置;尾数用于表示数的有效数值。 十进制数另一种表示法是 BCD 码。不同于二进制编码表示,BCD 码是用 4 位二进制码
表示一位十进制数码,因而,本质上它是十进制格式。BCD 码用于少数的商业软件及一些特
殊应用,通用软件基本不使用 BCD 码进行运算。 国际上采用的是 7 位的 ASCII 码,而国内使用广泛的汉字编码基准是 GB 2312—1980,
即国标码。实际使用中,用一个字节来存放一个标准 ASCII 码,且最高位置 0,用两个字节
存放一个汉字内码,且每字节最高位置 1。 二进制编码一方面可以作为二进制数进行算术运算,另一方面它又可具有逻辑属性,可
以进行逻辑运算。基本的逻辑运算有 4 种:“与”运算、“或”运算、“非”运算和“异或”
运算。逻辑运算是按位进行的。
习 题 2
2.1 将下列二进制数转换成八进制数、十六进制数和十进制数。 (1) 1001 1000 (2) 101 1110 (3) 10 0110 0100 1000 (4) 1111 1000 0001 (5) 0.10111 (6) 100.01 (7) 11111.11 (8) 10110.00101 2.2 用十进制记数形式写出下列各数。 (1) (1011011)2 (2) (0.1011)2 (3) (111111.01)2 (4) (1000001.11)2 (5) (377)8 (6) (0.24)8 (7) (3FF)16 (8) (2A.4)16 2.3 将下列十进制数转换成二进制数(无限位时,小数点取后 5 位)、八进制数和十六进制
数形式。 (1) 127 (2) 33 (3) 0.625 (4) 0.3 (5) 126.5 (6) 77 (7) 1/1024 (8) 77/32 2.4 将下列十六进制数转换为二进制数形式。 (1) (3B6)16 (2) (100)16 (3) (80.2)16 (4) (2FF.A)16 2.5 用 8 位和/或 16 位补码表示下列十进制数,再写成十六进制数形式。 (1) +17 (2) -123 (3) -1129 (4) -1 (5) 128 (6) -128 2.6 将下列十六进制数表示的二进制代码。 (1) (6813)16 (2) (EAFA)16 (3) (CD06)16 (4) (1103)16 (5) (3BD6)16 (6) (B758)16 ① 作为无符号数使用,将它们按从小到大的顺序排序。 ② 作为补码使用,将它们按从小到大的顺序排序。 2.7 用 BCD 码表示下列十进制数。 (1) 37 (2) 126 (3) 3790 (4) 3279 2.8 如果用 24 个二进制位表示一个无符号数,这个数的范围是什么?如果表示的是一个
数的补码,那么这个数的范围又是什么?

汇编语言程序设计
·22·
2.9 两个 16 位无符号数相加、相减时,什么情况下结果会溢出?两个 16 位补码数相加、
相减时,什么情况下结果会溢出? 2.10 将下列 8 位二进制数的运算 (1) (15)16+(2B)16 (2) (FB)16+(37)16 (3) (7A)16+(18)16 (4) (86)16+(F4)16
(5) (51)16–(23)16 (6) (27)16–(F5)16 (7) (F7)16–(7A)16 (8) (6F)16–(EB)16 ① 作为无符号数运算,用十进制形式写出运算结果,判断结果是否溢出。 ② 作为补码运算,用十进制形式写出运算结果,判断结果是否溢出。 2.11 用 32 位浮点格式表示下列数。 (1) 3+5/32 (2) -365/1024 (3) -4-15/16 (4) 93 (5) 0 (6) 128 2.12 将下列用十六进制表示的 32 位的浮点数转换成十进制数。 (1) (C04A0000)16 (2) (447FFF80)16 (3) (C77FFF00)16 (4) (3F7FC000)16 2.13 查表,以 ASCII 码形式表示字符串 Masm6.15。 2.14 二进制代码 1001 0111 0101 1000 作为: (1) 无符号数的值是什么? (2) 补码数的值是多少? (3) BCD 码表示的十进制数,它的值是多少? 2.15 将以十六进制数(A8B27050)16 表示的二进制代码作为: (1) 无符号数的值是多少? (2) 补码的值是多少? (3) 32 位浮点数的值是多少? (4) 字符编码所表示的字符是什么?(字节最高位为 0 是 ASCII 码,写出相应字符,字节
最高位为 1 是汉字内码,写出汉字相应的国标码) (5) 怎么确定此编码是无符号数、或补码数、或浮点数、或字符编码呢?(参考例 2.15 的
说明) 2.16 完成下列十六进制数所表示的二进制码的逻辑运算。 (1) (B4)16∧(96)16 (2) (B4)16∨(96)16 (3) ¬(B4)16 (4) (B4)16∀(96)16
第 3 章 80x86 微机系统的组成
本章以 80x86 作为特定对象,重点介绍与汇编语言程序设计密切相关的计算机硬件方面
内容,包括: • CPU 的组织结构及工作原理的简要介绍。 • 80x86 CPU 中寄存器的分类、作用及有关寄存器的特定用法。 • 一般程序中内存的使用方法及 80x86 中内存存储器的分段管理。逻辑地址、物理地址
的概念,以及如何由逻辑地址对应物理地址。 • 80x86 I/O 的组织。
3.1 基于 80x86 的计算机组织结构
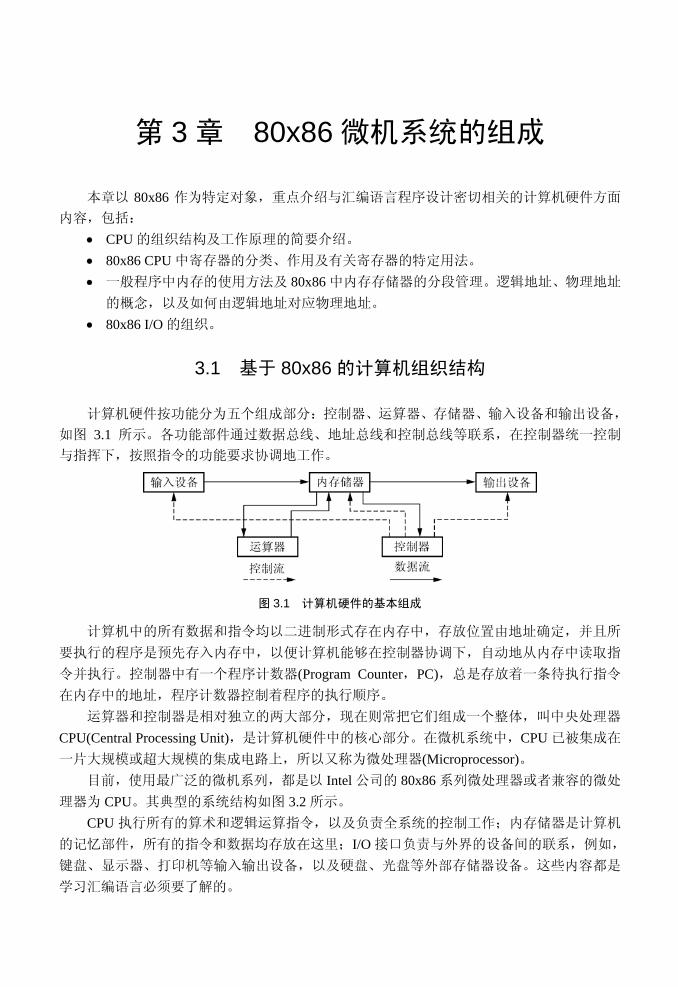
计算机硬件按功能分为五个组成部分:控制器、运算器、存储器、输入设备和输出设备,
如图 3.1 所示。各功能部件通过数据总线、地址总线和控制总线等联系,在控制器统一控制
与指挥下,按照指令的功能要求协调地工作。
图 3.1 计算机硬件的基本组成
计算机中的所有数据和指令均以二进制形式存在内存中,存放位置由地址确定,并且所
要执行的程序是预先存入内存中,以便计算机能够在控制器协调下,自动地从内存中读取指
令并执行。控制器中有一个程序计数器(Program Counter,PC),总是存放着一条待执行指令
在内存中的地址,程序计数器控制着程序的执行顺序。 运算器和控制器是相对独立的两大部分,现在则常把它们组成一个整体,叫中央处理器
CPU(Central Processing Unit),是计算机硬件中的核心部分。在微机系统中,CPU 已被集成在
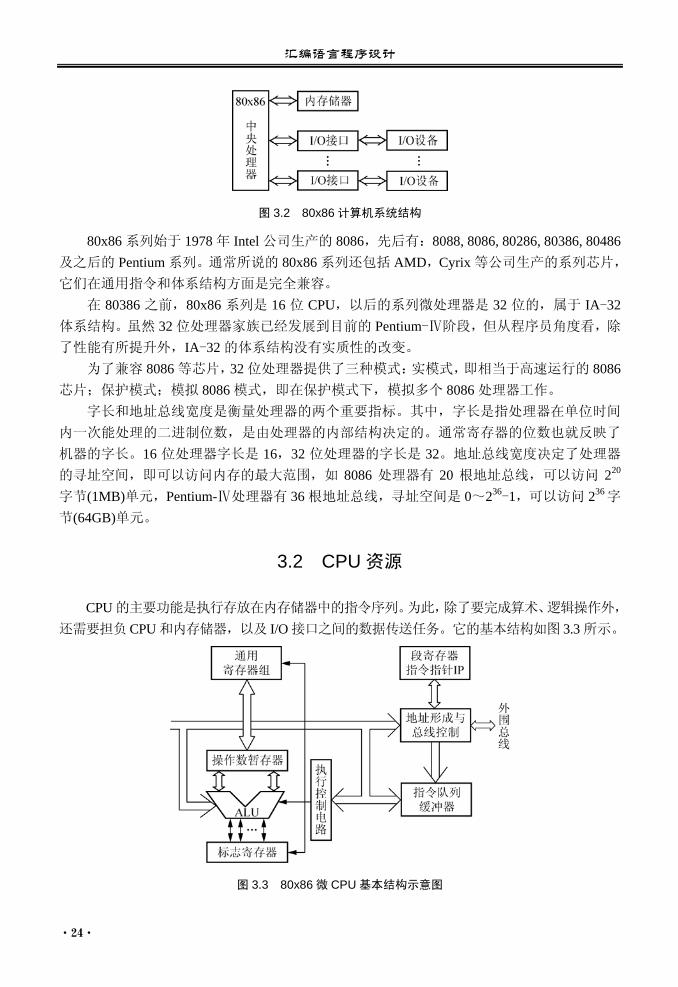
一片大规模或超大规模的集成电路上,所以又称为微处理器(Microprocessor)。 目前,使用最广泛的微机系列,都是以 Intel 公司的 80x86 系列微处理器或者兼容的微处
理器为 CPU。其典型的系统结构如图 3.2 所示。 CPU 执行所有的算术和逻辑运算指令,以及负责全系统的控制工作;内存储器是计算机
的记忆部件,所有的指令和数据均存放在这里;I/O 接口负责与外界的设备间的联系,例如,
键盘、显示器、打印机等输入输出设备,以及硬盘、光盘等外部存储器设备。这些内容都是
学习汇编语言必须要了解的。
汇编语言程序设计
·24·
图 3.2 80x86 计算机系统结构
80x86 系列始于 1978 年 Intel 公司生产的 8086,先后有:8088, 8086, 80286, 80386, 80486及之后的 Pentium 系列。通常所说的 80x86 系列还包括 AMD,Cyrix 等公司生产的系列芯片,
它们在通用指令和体系结构方面是完全兼容。 在 80386 之前,80x86 系列是 16 位 CPU,以后的系列微处理器是 32 位的,属于 IA-32
体系结构。虽然 32 位处理器家族已经发展到目前的 Pentium-Ⅳ阶段,但从程序员角度看,除
了性能有所提升外,IA-32 的体系结构没有实质性的改变。 为了兼容 8086 等芯片,32 位处理器提供了三种模式:实模式,即相当于高速运行的 8086
芯片;保护模式;模拟 8086 模式,即在保护模式下,模拟多个 8086 处理器工作。 字长和地址总线宽度是衡量处理器的两个重要指标。其中,字长是指处理器在单位时间
内一次能处理的二进制位数,是由处理器的内部结构决定的。通常寄存器的位数也就反映了
机器的字长。16 位处理器字长是 16,32 位处理器的字长是 32。地址总线宽度决定了处理器
的寻址空间,即可以访问内存的最大范围,如 8086 处理器有 20 根地址总线,可以访问 220
字节(1MB)单元,Pentium-Ⅳ处理器有 36 根地址总线,寻址空间是 0~236-1,可以访问 236 字
节(64GB)单元。
3.2 CPU 资源
CPU 的主要功能是执行存放在内存储器中的指令序列。为此,除了要完成算术、逻辑操作外,
还需要担负 CPU 和内存储器,以及 I/O 接口之间的数据传送任务。它的基本结构如图 3.3 所示。
图 3.3 80x86 微 CPU 基本结构示意图

第 3 章 80x86 微机系统的组成
·25·
传统的 CPU 由运算器和控制器两大部分组成。但是随着高密度集成电路技术的发展,一
些 CPU 外部的逻辑功能部件纷纷移入 CPU 内部。例如,早期的 80x86 芯片只包括运算器和
控制器两大部分。从 80386 开始,为使内存储器速度能更好地与运算器的速度相匹配,使用
Cache 技术,在芯片内引入高速缓冲存储器。其后生产的 CPU 芯片随着半导体器件集成度的提
高,片内高速缓冲存储器的容量也逐步扩大,但这部分器件就其功能而言还是属于内存储器的。 对于汇编语言程序设计者,CPU 中各寄存器、内存储器和 I/O 端口是他们编程的主要资
源,而且大部分指令是通过寄存器来实现对操作数的预定功能。
3.2.1 控制器与运算器
1. 运算器
运算器是对数据进行加工处理的部件,它主要通过执行算术和逻辑运算操作,来完成对
数据的加工和处理。参与运算的数(称为操作数)由控制器指示,从内存储器或寄存器内取到运
算器,运算结果存放到寄存器或内存储器。 运算器基本都是由算术/逻辑运算单元(ALU)、累加器(ACC)、寄存器组、多路转换器和数
据总线等逻辑部件组成。
2. 控制器
控制器的主要功能是从内存中取出指令,并指出下一条指令在内存中的位置。将取出的
指令经指令寄存器送往指令译码器,经过对指令的分析,发出相应的控制和定时信息,控制
和协调计算机的各个部件的工作,以完成指令所规定的操作。 控制器一般由指令指针寄存器(IP)、指令寄存器(IR)、指令译码器(ID)、标志寄存器、控
制逻辑电路和时钟控制电路等组成。 其中 IP(在 32 位处理器中称为 EIP),其实就是程序计数器 PC。IP 总是指向下一条要取的
指令在内存中的位置,由此实现程序的自动执行。 随着高密度、大规模集成电路技术的发展,新推出的 CPU 不断增加了新的处理和控制功
能。例如,浮点运算单元(Float Point Unit,FPU)是专用于浮点运算的处理器,以前作为一种
单独芯片而存在,但从 80486 开始,Intel 将 FPU 集成在 CPU 芯片中了。如今的 80x86 系列
CPU 中已陆续增加了 MMX, 3DNow, SSE, SSE2, SSE3 等指令集。 尽管 80x86 系列 CPU 的功能日益强大,指令日益丰富,但是在这本书中只介绍 CPU 的
基本功能和常用的基本指令集,以此来讲述汇编语言程序设计的基本内容和基本方法。
3.2.2 80x86 寄存器组
本节介绍与汇编语言程序设计密切相关的寄存器组,这些寄存器有的属于运算器,如累
加器 AX,有的分布在控制器中,如指令指针 IP,总之是包含在 80x86 处理器中的。 8086/8088、80286 这类 16 位 CPU 有 14 个基本寄存器:AX, BX, CX, DX, SP, BP, DI, SI, IP,
FLAGS, CS, DS, ES, SS,这些寄存器都是 16 位的。 32 位 CPU 有 16 个基本的寄存器:EAX, EBX, ECX, EDX, ESP, EBP, EDI, ESI, EIP,
EFLAGS, CS, DS, ES, SS, FS, GS,多出的两个是:FS, GS。在这 16 个寄存器中,以“E”打头
的寄存器都是 32 位寄存器,其余的是 16 位寄存器。所有 32 位寄存器都可用作 16 位寄存器,
例如,EAX 是 32 位寄存器,可以作为 16 位寄存器 AX 来使用,对应 EAX 的低 16 位。若上述

汇编语言程序设计
·26·
所有 32 位寄存器都作为 16 位寄存器使用,则 32 位的 CPU 与 16 位的 8086 没有什么两样。 80x86 的基本寄存器可分为 3 类:通用寄存器、控制寄存器和段寄存器,如图 3.4 所示。
31 16 15 0 EAX AX 累加器(Accumulator) EBX BX 基址寄存器(Base Register) ECX CX 计数寄存器(Count Register) EDX DX 数据寄存器(Data Register) ESP SP 堆栈指针(Stack Pointer) EBP BP 基址指针(Base Pointer) EDI DI 目的变址寄存器(Destination Index Register) ESI SI 源变址寄存器(Source Index Register)
EIP IP 指令指针(Instruction Pointer) EFLAGS FLAGS 标志寄存器(FLAGS Register)
CS 代码段寄存器(Code Segment Register) DS 数据段寄存器(Data Segment Register) ES 附加段寄存器(Extra Segment Register) SS 堆栈段寄存器(Stack Segment Register) FS FS 段寄存器 GS GS 段寄存器
图 3.4 80x86 的基本寄存器
注:① 对于 16 位 CPU,灰色区域寄存器是不存在的。 ② FS 和 GS 段寄存器没有专用名称。
下面介绍 32 位 CPU 中的基本寄存器组,关于 16 位 CPU 的基本寄存器的有关情况,可
以参照此处说明。所说明的内容比较繁杂,初学者可能不好掌握,不过没有关系,在以后章
节中还会进一步讲解。
1. 通用寄存器
这类通用寄存器(General Register)共有 8 个,主要用于算术运算、逻辑运算和数据的传送。
每个寄存器都是 32 位的,但又可作为一个 16 位寄存器来使用。根据使用情况分 3 种:4 个
数据寄存器,两个地址指针寄存器,两个变址寄存器。 8 个 32 位寄存器都可作为内存指针(存放的是内存地址)来使用,但对于 16 位寄存器来说,
BX,BP,SI 和 DI 可用作内存指针,AX,CX,DX 和 SP 不能作为内存指针使用。 这类寄存器虽然是通用寄存器,但各自又有专用用途。 1) 数据寄存器 数据寄存器(Data Register)指的是 EAX, EBX, ECX, EDX,一般用于存放参与运算的操作
数或运算结果。这 4 个 32 位寄存器中的低 16 位又可作为 16 位寄存器来使用,分别记作 AX, BX, CX, DX。4 个 16 位寄存器中的高 8 位、低 8 位又可独立作为两个 8 位寄存器来用。高 8位分别记作 AH, BH, CH, DH,低 8 位分别记作 AL, BL, CL, DL,如图 3.5 所示。
15 8 7 0 AX AH AL (EAX 的低 16 位) BX BH BL (EBX 的低 16 位) CX CH CL (ECX 的低 16 位) DX DH DL (EDX 的低 16 位)
图 3.5 16 位数据寄存器的构成

第 3 章 80x86 微机系统的组成
·27·
(1) EAX。作为累加器使用,是算术运算所使用的主要寄存器。8 位、16 位和 32 位累加
器分别对应 AL, AX 和 EAX。在乘除等指令中指定用累加器存放操作数。此外,所有的 I/O指令都使用累加器与外设端口交换信息。
(2) EBX。可用作基址寄存器,或作为内存储器指针来使用。 (3) ECX。作为计数器使用。8 位、16 位和 32 位计数器分别对应 CL,CX 和 ECX。在循
环(LOOP)、串处理及某些移位指令中用作隐含的计数器。 (4) EDX。数据寄存器。在做 16 位乘法运算时,乘法运算结果(32 位)存放在 DX:AX 中,
其中 DX 存放高 16 位;在做 32 位乘法运算时,乘法运算结果(64 位)存放在 EDX:EAX 中,
其中 EDX 存放高 32 位;在做 32 位除法运算时,被除操作数(32 位)存放在 DX:AX 中,其中
DX 存放高 16 位,除法运算结果的余数存放在 DX 中;在做 64 位除法运算时,被除操作数(64位)存放在 EDX:EAX 中,其中 EDX 存放高 32 位,除法运算结果的余数存放在 EDX 中。在
寄存器间接寻址的 I/O 指令中,DX 存放 I/O 端口地址。 2) 指针寄存器 指针寄存器(Pointer Register)包括 ESP 和 EBP,其对应的 SP 和 BP 寄存器可作为 16 位内
存指针使用。 (1) ESP。堆栈指针。专门用以访问堆栈上数据的寄存器,一般不应该在算术运算和数据
传送中使用。32 位模式下使用 ESP,16 位模式下使用 SP,其内容始终指向堆栈栈顶。从这
一点上看,ESP/SP 是专用的。 (2) EBP。基址指针。可以用来存放数据,但更经常、更重要的用途是作为堆栈区的一个
基地址,以便访问堆栈中的数据。EBP 或 BP 一般不应该在算术运算和数据传送中使用。 3) 变址寄存器 变址寄存器(Index Register)包括 ESI 和 EDI,其对应的 SI 和 DI 寄存器可作为 16 位内存
指针使用。 (1) ESI。源变址寄存器。作为串处理指令中隐含的源变址寄存器,32 位模式下使用 ESI,
16 位模式下使用 SI,指向源串在内存中的起始地址。 (2) EDI。目的变址寄存器。作为串处理指令中隐含的目的变址寄存器,32 位模式下使用
EDI,16 位模式下使用 DI,指向目的串在内存中的起始地址。
2. 控制寄存器
控制寄存器(Control Register)包括 EIP 和 EFLAGS。 EIP。用于存放下一条要执行的指令的内存地址。32 位模式下使用的是 EIP,16 位模式
下使用的是 IP。在程序运行期间,CPU 会自动修改(E)IP 的内容,以使它始终指向下一条要
执行指令的内存偏移地址,从而实现程序的自动执行。用户程序不能直接修改(E)IP,但是随
着指令的执行,(E)IP 的内容会相应地变动。 EFLAGS。用以保存一条指令执行后,CPU 所处的状态信息及运算结果的特征。主要有:
运算结果标志、状态控制标志和系统状态标志等寄存器。16 位模式下是 FLAGS。 EFLAGS 有较多的信息位,如图 3.6 所示。但作为基本编程只使用其中的 9 个标志位:6
位运算结果标志和 3 位状态控制标志。
31 30 29 28 27 26 25 24 23 22 21 20 19 18 17 16 15 14 13 12 11 10 9 8 7 6 5 4 3 2 1 0 ID VIPVIFACVMRF NT IOPLOFDF IF TFSFZF AF PF CF
图 3.6 Pentium 处理器的标志寄存器

汇编语言程序设计
·28·
1) 运算结果标志 运算结果标志用来保存算术运算指令、逻辑运算指令及各类测试指令的结果状态,为后
续指令的执行提供执行依据。 (1) 进位标志 CF(Carry Flag)。当进行加或减运算时,若最高位发生进位或借位,则 CF
为 1,否则为 0。该标志可用于判断无符号数运算结果是否溢出。80x86 用于设置 CF 位的指
令有:STC(CF 置 1)、CLC(CF 清 0)及 CMC(CF 取反)。 (2) 奇偶标志 PF(Parity Flag)。反映运算结果中 1 的个数的奇偶性。含有偶数个 1,PF 为
1,否则为 0。 (3) 辅助进位标志 AF(Auxiliary Flag)。执行一条加法或减法运算指令时,最低 4 位向高位
有进位或借位时,AF 为 1,否则为 0。 (4) 零标志 ZF(Zero Flag)。当前的运算结果为 0,则 ZF 为 1,否则为 0。 (5) 符号标志 SF(Sign Flag)。运算结果的最高位为 1,SF=1,否则为 0。也就是说该标志
反映的是补码数正负性。 (6) 溢出标志 OF(Overflow Flag)。当运算结果超出了补码所能表示的范围,即溢出时,
OF=1,否则为 0。用来判断有符号数运算结果是否溢出。 在应用程序中,以上介绍的 6 个标志位中,ZF, OF, CF 和 SF 经常使用,而 PF 和 AF 较
少使用。 CPU 每执行一条算术运算指令或逻辑运算指令,都要根据运算的结果状态来设置各标志
位。例如,执行 8 位操作:1Bh-8Dh,运算结果为 18Eh,根据此结果将各标志位设置为: CF=1, PF=1, AF=1, ZF=0, SF=1, OF=1;7Fh∧95h,运算结果为 15h,据此设置的各标志
位为:CF=0, PF=0, AF=0, ZF=0, SF=0, OF=0。 2) 状态控制标志 状态控制标志用来控制 CPU 的操作,可通过专门的指令设置或清除。 (1) 陷阱标志 TF(Trap Flag)。若 TF 置 1,则 CPU 每执行完一条指令,便产生一个单步中
断。这主要用于程序的调试。 (2) 中断允许标志 IF(Interrupt–enable Flag)。若 IF 置 1,则表示允许 CPU 响应外部从 INTR
引脚上发来的 I/O 中断请求;若 IF 清 0,则禁止 CPU 响应 I/O 中断请求。80x86 中专门用于
将 IF 置 1 的指令是 STI,专门用于将 IF 清 0 的指令是 CLI。 (3) 方向标志 DF(Direction Flag)。若 DF 清 0,串操作指令按加方式改变相关的(E)SI 和
(E)DI 的值;若将 DF 置 1,串操作指令按减方式改变相关的(E)SI 和(E)DI 的值。80x86 中专
门用于将 DF 清 0 的指令是 CLD,专门用于将 DF 置 1 的指令是 STD。
3. 段寄存器
在 80x86 系统中,将一个连续字节单元的内存区域称为一个段,而段寄存器是专门用于
存放指示该段首地址的相关内容。 16 位 CPU 有 4 个段寄存器:CS, DS, SS 和 ES,32 位 CPU 又增加了两个:FS 和 GS。 在应用程序中,一般以分段方式来使用内存空间,通常内存是分为 3 个段(区):代码段(区)、
数据段(区)和堆栈段(区),它们的基地址分别通过 CS, DS 和 SS 来确定,即 CS, DS 和 SS 中存
放的内容分别是代码段、数据段及堆栈段的起始地址(16 位地址模式)或段选择器(32 位地址
模式)。

第 3 章 80x86 微机系统的组成
·29·
3.3 内 存 储 器
内存储器(简称内存)主要用于存放 CPU 要执行的指令和所处理的数据,它的存取基本单
位是字节(Byte)。内存中的每个字节单元都有一个唯一编号(从 0 开始顺序递增),称为地址,
CPU 等通过地址来访问内存单元。 CPU 能够访问最大的内存单元的地址范围称为寻址空间,它是由地址总线宽度决定的。
8086/8088 地址总线是 20 位,可访问字节单元地址范围是 00000h~FFFFFh,共 220字节(1MB)。80386、80486 和 Pentium 的地址总线宽度为 32 位,相应的地址范围是 00000000h~FFFFFFFFh,共 232 字节(4GB)。而目前主流的 Pentium-Ⅳ的地址总线宽度为 36 位,相应的地址范围是
000000000h~FFFFFFFFFh,共 236 字节(64GB)。
3.3.1 内存单元与数据存放字节顺序
内存的存取的基本单位是字节。连续若干个字节可以作为一个整体来使用,这样便有:1字节、2 字节、4 字节、8 字节等不同类型的内存单元。2, 4, 8 字节单元又叫做字(Word)、双
字(DWord)、四字(QWord)单元。 内存单元是以它所占用内存块的起始地址来标识,正因为如此,同一个地址可以用来存
取不同类型的内存单元。如图 3.7 所示,通过 100 号地址可以访问:字节单元、2 字节单元与
4 字节单元等。虽然它们都是有 100 号地址表示,但是 100 号字节单元只占用 1 个字节空间,
100 号 2 字节(字)单元表示的是首地址为 100 的 2 字节空间,4 字节(双字)单元所表示的是首
地址为 100 的 4 字节空间。 单字节类型数据以字节单元为单位存放,如 ASCII 字符;多字节型数据以多字节单元作
为单位存放,如 16 位有符号整数,是以 2 字节内存单元为单位存放的,32 位浮点数,则以 4字节内存单元为单位存放。
在 80x86 系统中多字节类型数据是按“小端字节序”存放:低位数据存放在低地址单元,
高位数据存放在高地址单元,所以多字节型数据的位编号是按地址从低到高的顺序进行排列
的,如图 3.7 所示。
7 6 5 4 3 2 1 0 位编号
←字节型 100
151413121110 9 8 7 6 5 4 3 2 1 0 位编号
←2 字节型 101 100
313029282726252423 22212019181716151413121110 9 8 7 6 5 4 3 2 1 0 位编号
←4 字节型 103 102 101 100
图 3.7 用同一个地址标识不同类型的内存单元示意图
例如,将 32 位 12345678H 存放到 10 号 4 字节单元中,则存放的字节顺序如图 3.8 所示。
… 10 11 12 13 14 … 91 92 93 94 95 96 …
… 78 56 34 12 CD … 1B 50 70 B2 A8 00 …
图 3.8 内存数据存放格式示意图
地址
内容

汇编语言程序设计
·30·
此处,10 号地址是 4 字节(双字)单元地址。实际上 10 号地址还可以表示字节单元、2 字
节(字)单元、8 字节(四字)单元。如图 3.8 中,10 号地址的字节单元内容是 78h;10 号地址的
字单元内容是 5678h。 连续若干字节中的二进制代码,可以是无符号数、补码、浮点数编码、字符编码等。例
如在图 3.8 中,从 92~95 号字节中的二进制代码分别是:50H,70H,B2H,A8H;若将它们看做
是 16 位无符号数,则表示的是两个数:(7050)16、(A8B2)16;若将它们看做是 32 位无符号数,
则表示的是一个数:(A8B27050)16;若将它们看做是 16 位补码数,则表示的是两个数:(7050)16、
-(574E)16;若将它们看做是 32 位补码数,则表示的是一个数:-(574D8FB0)16;若将它们看
做是 32 位浮点数,则表示的是一个数:-(1.64E0A)16×2-46;若将它们看做是字符编码,则表
示的是两个 ASCII 字符:‘P’,‘p’,即一个汉字:“波”。到底是哪一种编码,这要看
使用时的约定。若对这一点还比较困惑,可以参阅例 2.15 的有关说明。 这里所列的例子是通过地址编号(如 10 号地址)来存取内存单元,但是在汇编源程序中,
很少这样直接使用地址编号,而代之以变量名或标号等,用符号地址来访问内存单元。有关
变量和标号等内容在 5.2 节中有专门说明,在此只是让读者对符号地址有一个初步印象。
3.3.2 内存的分段使用
80x86 系统采用内存分段(区)的方法来访问内存。 若干连续字节的内存区域称为内存段。如图 3.9 所示,内存段一般用基地址(base)和长度
(length)确定,段内单元地址用偏移地址(offset,相对于 base 的偏移量)来表示。这样内存中单
元的地址由两部分组成,即 base 和 offset。在 80x86 中经常用 EA(Effective Address)表示偏移
地址。
图 3.9 内存段示意图
在 80x86 系统中,内存段基地址由专门的寄存器——段寄存器来确定,所以指令访问内
存单元的地址形式为 段寄存器:偏移地址
段寄存器可以是 CS, DS, SS, ES, FS, GS 之一;偏移地址可以直接是地址编号,也可以是
存有偏移地址的寄存器。段寄存器与偏移地址有如下的默认组合关系。 (1) 偏移地址存放在 EIP/IP 中,默认使用 CS 段寄存器。 (2) 偏移地址存放在 ESP/SP, EBP/BP 中,默认使用 SS 段寄存器。 (3) 在串处理指令中,存放在 EDI/DI 的偏移地址默认与 ES 段寄存器组合。 (4) 其他形式的偏移地址,默认使用 DS 段寄存器。 在没有明确指定段寄存器的情况下,则使用默认段寄存器。例如,地址 DS:[10]可以直接
写成[10],而地址[EBP]的默认组合是 SS:[EBP]。

第 3 章 80x86 微机系统的组成
·31·
一般应用程序将内存分成三种类型区域:代码段(区)、数据段(区)、堆栈段(区)。如图 3.10所示,代码内存区用来存放程序的指令代码,其起始地址由 CS 段寄存器确定;数据内存区用
来存放程序中静态数据,其起始地址由 DS 段寄存器确定;堆栈内存区为程序中的堆栈提供
存储区域,主要用来暂存中断和子程序调用时的返回地址、现场数据保护、传递的参数及其
他需要临时保存的数据等,它的起始地址由 SS 段寄存器确定。
CS→
代 DS→数 SS→
堆 码 据 栈 内 内
(E)SP→内 ←栈顶
存 存 存 区 区 区 ←栈底
图 3.10 一般应用程序的内存分区示意图
堆栈对实现子程序的调用非常重要,下面对堆栈区作一些简要说明。 堆栈(Stack)是由若干个连续内存单元组成的、按先进后出(First In Last Out, FILO)或后进
先出(Last In First Out, LIFO)原则进行存取的数据结构。在堆栈结构中,最先存入数据的单元
称为栈底,最后存入数据的堆栈单元称为栈顶。通常栈底是固定不变的,而栈顶却是随着数
据的进栈和出栈不断变化的。在堆栈操作中,数据按顺序存入堆栈称为数据进栈(PUSH)或压
入;从堆栈中按与进栈相反的顺序取出数据称为出栈(POP)或弹出。 堆栈栈顶是浮动的,为此专门设有一个指针——堆栈指针(Stack Pointer, SP),使之始终指
向栈顶。这样,进栈和出栈限定在栈顶进行,由 SP 确定存取位置。 在一般程序中专门划出一块内存区供堆栈使用,这便是堆栈区。堆栈区大小设置应该满
足应用程序中堆栈使用要求,不能出现堆栈超出堆栈区的现象,否则堆栈“溢出”。 在 80x86 中,寄存器 SS 专用于确定堆栈区的起始地址,(E)SP 专门用于指示栈顶的位置,
即总是指向最近进栈的数据位置。栈底固定为栈区的最高地址单元,所以,执行 PUSH 操作,
(E)SP 要向低地址方向移动,执行 POP 操作,(E)SP 要向高地址方向移动。 80x86 的栈单元基本单位是 2 字节。在 16 位 CPU 中,只能以 2 字节为单位进行进栈和出
栈操作,在 32 位 CPU 中,栈存取单位一般是 4 字节,但也可以按 2 字节操作。 例如,设堆栈区为从 1000h 号地址开始、连续 800h 字节的内存区,那么第一个 2 字节单
元地址是 1000h,最后一个 2 字节单元(即栈底)地址是 17FEh,如图 3.11 所示。图 3.11(a)是初
始状态,ESP 所指向栈单元的数据是 7050h;图 3.11(b)是在初始状态下 16 位数据 1234h 进栈
后的状态,容易看出,ESP 已经向低地址方向移动 2 字节;图 3.11(c)是在初始状态下,32 位
数据 12345678h 进栈后的状态,容易看出,ESP 已经向低地址方向移动了 4 字节;图 3.11(d)是在初始状态下,从堆栈中弹出一个 16 位数据后的状态,容易看出,ESP 向高地址方向移动
2 字节,弹出的数据是 7050h;图 3.11(e)是在初始状态下,从堆栈中弹出一个 32 位数据后的
状态,容易看出,ESP 向高地址方向移动 4 字节,弹出的数据是 A8B27050h。(弹出数据时,
原数据并没有被破坏) 在程序中,堆栈有以下几种重要的用途。 (1) 堆栈可用于临时保存寄存器内容,在寄存器使用完毕之后,可恢复其原始值。 (2) 在调用子程序时,CPU 用堆栈保存当前过程的返回地址。

汇编语言程序设计
·32·
(3) 在调用子程序时,可以通过堆栈传递参数。 (4) 过程内的局部变量在堆栈上创建,过程结束时,这些变量被丢弃。
SS SS
SS SS SS
1000 1000 1000 1000 1000 ESP→ 1234 2008 ESP→ 1234 5678 2008 2008
ESP→ 7050 7050 7050 7050 7050 A8B2 A8B2 A8B2 ESP→ A8B2 A8B2 ESP→ 17FE 17FE 17FE 17FE 17FE
(a) 初始状态 (b) 2 字节进栈 (c) 4 字节进栈 (d) 2 字节出栈 (e) 4 字节出栈
图 3.11 堆栈示意图
在 80x86 指令中,进栈指令有:PUSH, PUSHF, PUSHA, PUSHFD, PUSHAD 等,出栈指
令有:POP, POPF, POPA, POPFD, POPAD 等。此外,还有一些指令也要使用堆栈,如 CALL, RET, INT, IRET 等。这些指令的功能将在以后章节陆续介绍。
3.3.3 内存单元寻址
前面说过,指令以“段:偏移”这样的形式访问内存单元,这种形式的地址称为逻辑地址,
那么逻辑地址是如何对应到内存单元的物理地址的呢?在 16 位地址模式下和 32 位保护模式
下,CPU 采用不同的对应规则将逻辑地址转换成物理地址。下面分别说明。
1. 16 位地址模式内存寻址
在实地址模式和虚 8086 模式下,偏移地址都是 16 位,合称为 16 位地址模式。 16 位地址模式的地址宽度是 20 位,可以表示字节单元地址的范围是 00000~FFFFFh,
即寻址空间是 220 字节(1MB)。而在 16 位模式下,偏移地址是 16 位的,可表示字节单元的地
址范围是 0000~FFFFh,即最大长度是 216 字节(64KB)。也就是说,16 位地址模式的最大特
征是:程序的寻址空间是 1MB,每个段的最大长度是 64KB。 在 16 位地址模式下,段寄存器里存放的是 20 位地址的高 16 位,逻辑地址“段:偏移”
与 20 位物理地址间的对应关系是: 20 位地址=段地址×16+偏移地址
例 3.1 设 CS=1000h,DS=1200h,SS=2000h,BP=2000h,求下列单元的 20 位地址:
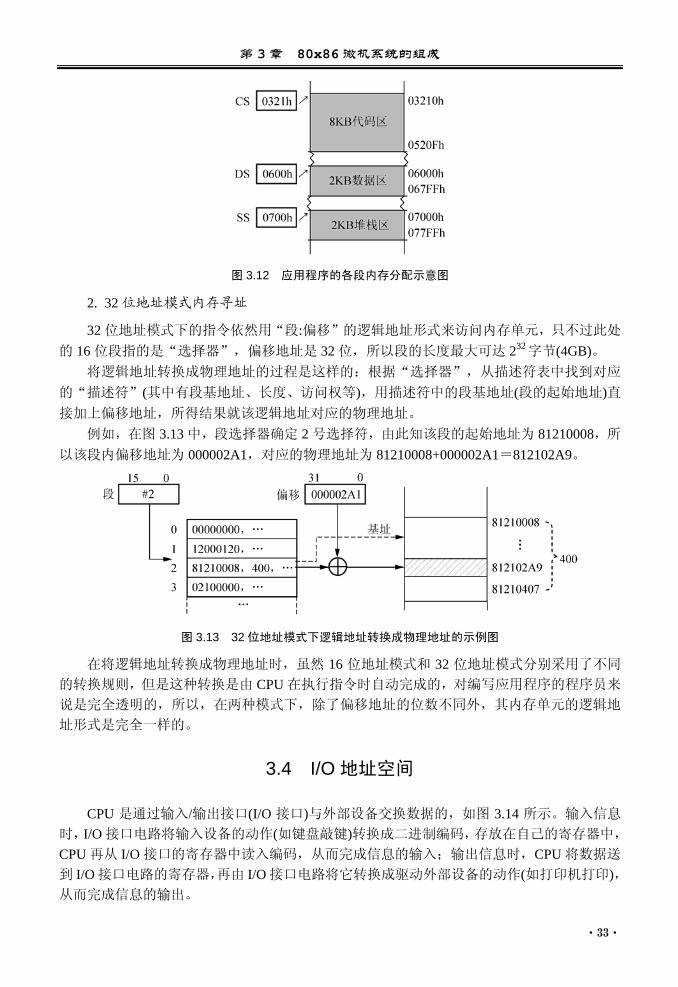
(1)CS:[1234h];(2)[1234h];(3)[BP];(4)DS:[BP]。 解:(1) 20 位地址=1000h×16+1234h=10000h+1234h=11234h (2) 默认的段是 DS,所以 20 位地址=1200h×16+1234=13234h (3) 默认的段是 SS,所以 20 位地址=2000h×16+2000h=22000h (4) 20 位地址=1200h×16+2000h=14000h 例 3.2 某应用程序中的代码区、数据区和堆栈区的大小分别为:8KB(2000h), 2KB(800h),
2KB(800h)。此时可按如图 3.12 所示来为各段分配内存区。注意:虽然可说为各段分配了各
自的长度,但是在 16 位地址模式下,CPU 并不检查每个段是否越界,所以当以某一个段寄存
器访问内存单元时,有可能会超出本段。例如,字节单元 CS:[3000h],就是落在代码段之外,
实际上对应的是数据段中的一个字节单元(DS:[0210h])。
第 3 章 80x86 微机系统的组成
·33·
图 3.12 应用程序的各段内存分配示意图
2. 32 位地址模式内存寻址
32 位地址模式下的指令依然用“段:偏移”的逻辑地址形式来访问内存单元,只不过此处
的 16 位段指的是“选择器”,偏移地址是 32 位,所以段的长度最大可达 232 字节(4GB)。 将逻辑地址转换成物理地址的过程是这样的:根据“选择器”,从描述符表中找到对应
的“描述符”(其中有段基地址、长度、访问权等),用描述符中的段基地址(段的起始地址)直接加上偏移地址,所得结果就该逻辑地址对应的物理地址。
例如,在图 3.13 中,段选择器确定 2 号选择符,由此知该段的起始地址为 81210008,所
以该段内偏移地址为 000002A1,对应的物理地址为 81210008+000002A1=812102A9。
图 3.13 32 位地址模式下逻辑地址转换成物理地址的示例图
在将逻辑地址转换成物理地址时,虽然 16 位地址模式和 32 位地址模式分别采用了不同
的转换规则,但是这种转换是由 CPU 在执行指令时自动完成的,对编写应用程序的程序员来
说是完全透明的,所以,在两种模式下,除了偏移地址的位数不同外,其内存单元的逻辑地
址形式是完全一样的。
3.4 I/O 地址空间
CPU 是通过输入/输出接口(I/O 接口)与外部设备交换数据的,如图 3.14 所示。输入信息
时,I/O 接口电路将输入设备的动作(如键盘敲键)转换成二进制编码,存放在自己的寄存器中,
CPU 再从 I/O 接口的寄存器中读入编码,从而完成信息的输入;输出信息时,CPU 将数据送
到 I/O 接口电路的寄存器,再由 I/O 接口电路将它转换成驱动外部设备的动作(如打印机打印),从而完成信息的输出。
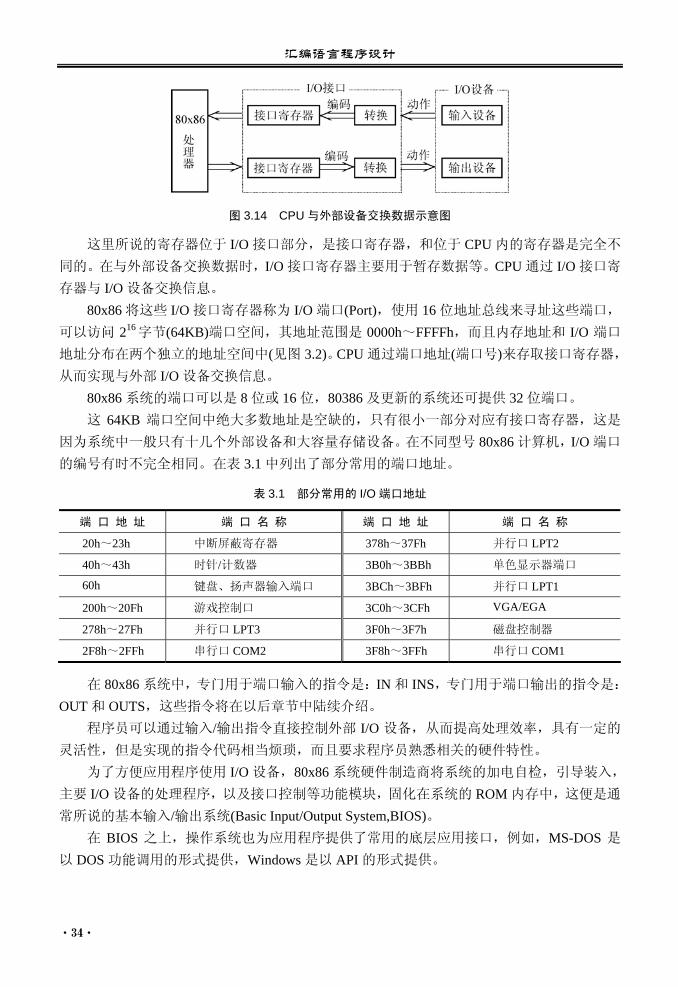
汇编语言程序设计
·34·
图 3.14 CPU 与外部设备交换数据示意图
这里所说的寄存器位于 I/O 接口部分,是接口寄存器,和位于 CPU 内的寄存器是完全不
同的。在与外部设备交换数据时,I/O 接口寄存器主要用于暂存数据等。CPU 通过 I/O 接口寄
存器与 I/O 设备交换信息。 80x86 将这些 I/O 接口寄存器称为 I/O 端口(Port),使用 16 位地址总线来寻址这些端口,
可以访问 216字节(64KB)端口空间,其地址范围是 0000h~FFFFh,而且内存地址和 I/O 端口
地址分布在两个独立的地址空间中(见图 3.2)。CPU 通过端口地址(端口号)来存取接口寄存器,
从而实现与外部 I/O 设备交换信息。 80x86 系统的端口可以是 8 位或 16 位,80386 及更新的系统还可提供 32 位端口。 这 64KB 端口空间中绝大多数地址是空缺的,只有很小一部分对应有接口寄存器,这是
因为系统中一般只有十几个外部设备和大容量存储设备。在不同型号 80x86 计算机,I/O 端口
的编号有时不完全相同。在表 3.1 中列出了部分常用的端口地址。
表 3.1 部分常用的 I/O 端口地址
端 口 地 址 端 口 名 称 端 口 地 址 端 口 名 称
20h~23h 中断屏蔽寄存器 378h~37Fh 并行口 LPT2
40h~43h 时针/计数器 3B0h~3BBh 单色显示器端口
60h 键盘、扬声器输入端口 3BCh~3BFh 并行口 LPT1
200h~20Fh 游戏控制口 3C0h~3CFh VGA/EGA
278h~27Fh 并行口 LPT3 3F0h~3F7h 磁盘控制器
2F8h~2FFh 串行口 COM2 3F8h~3FFh 串行口 COM1 在 80x86 系统中,专门用于端口输入的指令是:IN 和 INS,专门用于端口输出的指令是:
OUT 和 OUTS,这些指令将在以后章节中陆续介绍。 程序员可以通过输入/输出指令直接控制外部 I/O 设备,从而提高处理效率,具有一定的
灵活性,但是实现的指令代码相当烦琐,而且要求程序员熟悉相关的硬件特性。 为了方便应用程序使用 I/O 设备,80x86 系统硬件制造商将系统的加电自检,引导装入,
主要 I/O 设备的处理程序,以及接口控制等功能模块,固化在系统的 ROM 内存中,这便是通
常所说的基本输入/输出系统(Basic Input/Output System,BIOS)。 在 BIOS 之上,操作系统也为应用程序提供了常用的底层应用接口,例如,MS-DOS 是
以 DOS 功能调用的形式提供,Windows 是以 API 的形式提供。

第 3 章 80x86 微机系统的组成
·35·
本 章 小 结
本章主要介绍 80x86 寄存器组、内存及 I/O 地址空间等。 80x86 包括 16 位 CPU 和 32 位 CPU 两大类。16 位 CPU 有 14 个基本寄存器:AX, BX, CX,
DX, SP, BP, DI, SI, IP, FLAGS, CS, DS, ES, SS,这些寄存器都是 16 位的;32 位 CPU 有 16 个
基本的寄存器:EAX, EBX, ECX, EDX, ESP, EBP, EDI, ESI, EIP, EFLAGS, CS, DS, ES, SS, FS, GS,其中以“E”打头的寄存器都是 32 位寄存器,它们又都可作为 16 位寄存器来使用。
80x86 的最大寻址空间由地址总线宽度决定。在 80x86 系统中,内存的基本访问单位是
字节,此外,还有 2 字节(字)单元、4 字节(双字)单元、8 字节(四字)单元等;内存单元以它的
最低字节单元地址来标识,这样,同一个地址可以用来存取不同类型的内存单元;多字节类
数值型数据按“小端字节序”存放:低位存放在低地址内存处,高位存放在高地址内存处,
对应的位编号是按地址从低到高的顺序进行的。 80x86 系统将内存分段(区)使用。指令使用“段寄存器:偏移地址”的形式来存取内存单元;
段寄存器与偏移地址间的默认组合关系是:(E)SP,(E)BP默认与SS组合,串处理指令中的(E)DI默认与 ES 组合,其他形式则默认使用 DS。
在一般应用程序中,应该将内存至少分成三块区域:由 CS 指示的代码段、由 DS 指示的
数据段、由 SS 指示的堆栈段,其中堆栈段主要为堆栈提供内存区域。 堆栈是一种 FILO 的数据结构,主要有进栈和出栈两种操作。堆栈对计算机系统实现与应
用程序的运行都是不可或缺的。 在将“段:偏移”形式的逻辑地址转换为物理地址时,虽然 16 位地址模式(实地址和虚 8086
模式)和 32 位地址模式使用的方法是不一样的,但对应用程序员来说,这种转换是透明的,
所以两种模式下除了偏移地址位数不同外,所用的编程指令的形式是一样的。 80x86 通过 I/O 端口来访问外部 I/O 设备。端口地址范围是 0000h~FFFFh,而且 I/O 端口
与内存是在两个独立的地址空间中。
习 题 3
3.1 什么是微处理器?它包含哪几部分? 3.2 80x86 微处理器从功能上讲由哪几部分组成?它们各自的功能是什么? 3.3 简述 80x86 CPU 的寄存器组成。 3.4 试述汇编语言编程中常用的 80x86 CPU 标志寄存器各位的含义与作用。 3.5 写出 80x86 处理器完成下列 8 位或 16 位二进制数的运算后各标志位的状态。 (1) 49h + 5Dh (2) 41h - ABh (3) A95Bh + 8C82h (4) 6531h + B52Dh 3.6 在 80x86 中,16 位地址模式与 32 位地址模式的内存寻址方式有何不同? 3.7 在 80x86 的输入/输出指令中,I/O 端地址通常是由 DX 寄存器提供的,有时也可以在
指令中直接指定 00H~0FFH 的端口地址。试问可直接由指令指定的 I/O 端口数是多少? 3.8 有两个 16 位无符号数 1EE5h 和 2A3Ch,分别存放在内存的[B0h]和[B3h]单元中。请
用图表示出它们的存放情况。

汇编语言程序设计
·36·
3.9 哪些寄存器可以作为指针来使用? 3.10 在 80x86 系统中多字节类型数据存放顺序是什么?将 4 字节整型数 11223344h 存放
在 1000h 号 Dword 单元中,那么字节单元 1000h,10001h,10002h 和 10003h 中内容各是
什么? 3.11 各段寄存器所指示段区的前 32 字节内容如下所示,且 EIP=7h,EAX=0Eh,
EBX=12h,ESP=18h,ESI=4h,EDI=10h。
CS→ 0E 1F BA 0E 00 B4 09 CD 21 B8 01 4C CD 21 54 68 69 73 20 70 72 6F 67 72 61 6D 20 63 61 6E 6E 6F …
DS→ 1C 8B F2 50 F0 FF 08 20 40 00 8D 4C 24 0C 8D 54 24 1C 51 52 6A 01 6A 02 6A 03 6A 04 6A 05 6A 06 …
SS→ 53 6A 00 66 89 74 24 74 FF 15 04 20 40 00 8B 35 00 20 40 00 8B 44 24 10 50 FF D6 8B 4C 24 0C 51 …
ES→ FF D6 B8 01 41 61 7A 5A 5E 5B 83 C4 54 C3 90 90 55 8B EC 6A FF 68 98 20 40 00 68 80 15 40 00 64 …
(1) CPU 要执行的下一条指令存放在什么地方? (2) 查表写出 CS:[EAX]~[19h]字节单元所对应的 ASCII 字符。 (3) 字节单元[4]中的补码表示的是什么数?2 字节单元[4]中的补码表示的是什么数?
4 字节单元[4]中的补码表示的是什么数? (4) 将 8 位数 1Fh 存入[16h]单元中,标出它存放的位置;将 16 位数 1F2Eh 存入[16h]单元
中,标出它存放的位置及格式;将 32 位数 1F2E3D4Ch 存入[16h]单元中,标出它存放的位置
及格式。 (5) 16 位数 1234h 进栈后,堆栈的状态有什么改变?32 位数进栈后,堆栈的状态又有什
么变化? (6) 从堆栈中弹出一个 16 位数后,堆栈的状态有什么变化?这个数是多少?从堆栈中弹
出一个 32 位数后,堆栈的状态又有什么变化?这个数是多少? (7) 从下列各内存单元中取出 16 位无符号数,它的值是多少?[EAX];[BX];ES:[BX];
CS:[3h];CS:[SI];[ESP];DS:[ESP]。 (8) 在 16 位模式下,设 CS=1000h,DS=1200h,SS=2000h,求下列单元的 20 位形式
的地址:CS:[SI];[DI];[SP];DS:[SP]。 3.12 各段寄存器所指示段区的前 32 字节内容如习题 3.10 所示。若将 ES:[4h]~[7h]字节
单元中的内容看做: (1) 无符号数,那么它所表示的是什么数? (2) 补码数,那么它所表示的是什么数? (3) 32 位浮点数,那么它所表示的是什么数? (4) 字符编码,那么它所表示的是什么字符? (5) 怎么确定此 4 字节内容是无符号数、补码、浮点数,还是字符编码呢?

第 4 章 80x86 的寻址方式与基本指令
本章主要介绍在应用程序中常用的 80x86 基本指令内容。包括: • 操作数的寻址方式和转移目标位置的寻址方式。 • 数据处理类指令:数据传送指令、算术指令、逻辑指令、串处理指令。 • 控制转移类指令。 • 处理器控制类指令。 全面而准确地理解每条指令的功能和应用,是编写汇编语言程序的关键,所以,在学习
指令时要注意以下几个方面。 • 指令的功能——该指令能够实现何种操作。通常指令助记符就是指令功能的英文单词
或其缩写形式。 • 指令中操作数的寻址方式——该指令中的操作数可以采用何种寻址方式。 • 指令对标志的影响——该指令执行后是否对各个标志位有影响,以及如何影响。 • 其他方面——该指令其他需要特别注意的地方,如指令执行时的约定设置,必须预置
的参数,隐含使用的寄存器等。 • 在叙述指令时,使用符号约定如下: src 源操作数(Source)。 dst 目的操作数(Destination) imm 立即数。8/16/32 位立即数记作:imm8/imm16/imm32。 reg 通用寄存器。8/16/32 位寄存器记作:reg8/reg16/reg32。 seg 段寄存器,代表的是 CS, DS, SS, ES, FS, GS。 mem 内存单元。8/16/32 位等内存单元记作:mem8/mem16/mem32。 acc 累加器。8/16/32 位累加器对应 AL/AX/EAX。 cnt 计数器。8/16/32 位计数器对应 CL/CX/ECX。
4.1 指令系统概述
CPU 是计算机系统中的控制和执行部件,它的所有功能 终都可分解为若干个基本的操
作,如数据传送、加法、减法、转移等基本操作。这些 CPU 可以执行的基本操作便是计算机
指令,所有这些的基本操作构成了计算机的指令系统,它反映了计算机所具有的 基本的硬
件功能。 和数据表示一样,在计算机内部,指令也必须用二进制编码来表示,才能为 CPU 所识别,
并执行指令所指示的操作。 用二进制编码表示的指令叫做机器指令,它通常是若干个字节,由操作码和操作数两部
分组成。操作码确定计算机要执行的具体操作,如传送、运算、移位、转移等,是指令中不
可缺少的组成部分;操作数指出指令执行时所需要的操作数据,它可以是数的本身,也可以
是存放数的存储单元(寄存器或内存)。

汇编语言程序设计
·38·
例如,如图 4.1(a)所示的一条 8086 机器指令。其中操作码是“C7 06”,表示执行的是“16位数据传送”操作;操作数是“A8 59 2B 1A”,指出了两个操作数据:16 位数 1A2Bh 和 2字节内存单元[59A8h]。该指令功能是:将 1A2Bh 传送到 2 字节单元[1000h]。
当使用“助记符”来表示操作码(称为指令助记符),如用“MOV”来表示上述操作码;
用符号来表示内存单元地址(称为符号地址),如用“Variable”表示上述字单元的地址,机器
指令就被“符号化”了,如图 4.1(b)所示。经过符号化的机器指令就是汇编指令,它与机器指
令有着直接对应关系。
C7 06 A8 59 2B 1A
操作码 操作数
MOV Variable, 1A2Bh
操作数指令助记符 符号地址
(a) 机器指令 (b) 汇编指令
图 4.1 机器指令与汇编指令示例
计算机中的指令有些不需要操作数,大多数指令采用一个或两个操作数,还有少数指令
需要更多的操作数。大多数运算型指令需要两个操作数,例如:MOV Variable, 1A2Bh。这条
指令将 16 位数 1A2Bh 存入 Variable,其中 1A2Bh 是指令处理数据的来源,称为源操作数,
Variable 供指令存放处理的结果,称为目的操作数。在 80x86 汇编指令中,目的操作数一般在
左边,源操作数在目的操作数的右边。 操作数可以放在操作码之后,称为立即数;也可以存放在 CPU 内部的寄存器中,称为寄
存器操作数;大多数情况下操作数是存放在内存中,称为内存操作数。指令指定了操作数的
位置,在执行时根据指定的位置找到所需的数据。这种寻找操作数的过程称为寻址,而寻找
操作数的方法称为寻址方式。操作数有多种寻址方式,详见 4.2.1 节。 通常所说的计算机指令都是指汇编格式的指令,一台计算机所支持的全部指令,就是该
计算机的指令系统。根据指令的功能,可将指令分类为:数据传送、算术逻辑运算类、移位
操作类、转移类、堆栈操作类、输入输出类等。不同类型的计算机具有不同的指令系统,有
的计算机指令系统很简单,只有二三十条指令,有的计算机指令系统复杂,支持的指令多达
几百条,但是无论繁简,其所支持的指令都可分成这几类。 80x86 系列在不断发展,相应指令也在不断丰富。 初的 8086 指令系统有 117 条指令,
如今的 Pentium 4 除了 初的 8086 指令集外,还具有浮点运算、MMX、3DNow、SSE、SSE2、SSE3 等多个扩展指令集。这本教材只是讲述汇编语言程序设计,所以只介绍 80x86 指令系统
中常用的基本指令,其他指令的介绍,参见相应的资料手册。
4.2 数据处理类指令
计算机程序对数据的处理主要由数据处理类指令来完成,主要包括:数据传送指令、算
术指令、逻辑指令、串处理指令等。
4.2.1 操作数的寻址方式
数据处理指令所处理的数据从何处取,处理的结果放到何处去?这些便是操作数寻址的
问题。一般来说,存在多种方法获取操作数据及操作结果的存放位置,这些方法统称为操作
数寻址方式。

第 4 章 80x86 的寻址方式与基本指令
·39·
例如,需要完成的操作是:将 1A2BH 传送到 DX 中去。那么从何处能取到 1A2B 呢?如
果 1A2B 放在操作码后面,那么可直接从指令中取到,这便是立即寻址方式;如果 1A2B 放
在寄存器中,如放在 AX 中,那么指令执行时可从 AX 中取到,也就是说源操作数是寄存器
寻址方式;如果 1A2B 是存于[0200h]单元中,那么执行时可以从字单元[0200h]中取到,此处
的源操作数是内存操作数寻址方式。同样,该操作处理的结果是放到寄存器 DX 中去,所以
此处的目的操作数也寄存器寻址方式。 为了方便,我们以“MOV dst, src”形式的指令来说明操作数的寻址方式。这是一条数据
传送指令,其功能是:将源操作数 src 传送到目的操作数 dst 中。 一般来说,操作数据及操作结果主要有三种存放形式:放在指令的操作数中,存放在寄
存器中,存放在内存单元中。与之对应的有三种操作数:立即操作数、寄存器操作数和内存
操作数。因而有三种基本寻址方式:立即寻址方式、寄存器寻址方式和内存操作数寻址方式(又包括多种寻址方式)。除此之外,80x86 还有少数隐含操作指令、端口输入输出指令等,这些
将在后续章节中陆续介绍。
1. 立即寻址
操作数作为指令的一部分直接放在指令操作码之后,这种操作数称为立即数。在实地址
模式中,立即数可以是 8 位或 16 位;在保护模式中,立即数可以是 8 位或 32 位。 在指令手册中,立即数一般用 imm 表示,8/16/32 位立即数记作:imm8/imm16/imm32。 例 4.1 下列汇编指令中的源操作数均为立即寻址方式。 (1) MOV DX, 1A2BH (2) MOV Variable, 1A2BH 指令(2)经汇编后的机器指令代码如图 4.2 所示,1A2B 放在操作码之后。
CS→ … F8 C7 06 A8 59 2B 1A 50 …
立即数机器指令代码
图 4.2 指令(2)经汇编后的机器指令代码示意图
立即数对应的是一个数,不对应任何寄存器或内存单元,它只能用作源操作数。
2. 寄存器寻址
操作数存放在寄存器中。在机器格式指令中,寄存器以编号形式出现在指令代码中,在
汇编指令中,则直接用寄存器名来表示操作数。 在指令手册中,寄存器寻址一般用 reg 符号表示,可以是 reg8:AL, AH, BL, BH, CL, CH,
DL, DH,也可以是 reg16:AX, BX, CX, DX, SP, BP, SI, DI,还可以是 reg32:EAX, EBX, ECX, EDX, ESP, EBP, ESI, EDI。此外,段寄存器 CS, DS, SS, ES, FS, GS 也可作为寄存器操作数使用。
例 4.2 下列指令中的操作数使用了寄存器寻址。 (1) MOV Variable,AX ; 源操作数是寄存器寻址方式 (2) MOV EDX, 12345678H ; 目的操作数是寄存器寻址方式 由于指令所需的操作数据已存于寄存器中,或操作的结果数据存入目的地是寄存器,这
样在执行过程中,会减少存取内存单元的次数。所以,寄存器寻址方式要比内存操作数寻址
方式的执行速度快。

汇编语言程序设计
·40·
3. 内存操作数寻址
实际上,大多数情况下操作数是存放在内存单元中,此时在指令中需要给出存放操作数
的内存单元地址等信息。 在 80x86 汇编格式指令手册中,一般用符号 mem 表示内存操作数,8/16/32 位等内存操作
数记作:mem8/mem16/mem32。 特别注意,一条 80x86 指令 多只能有一个操作数使用内存操作数寻址。 例 4.3 下列指令中的操作数使用了内存操作数寻址。 (1) MOV [59A8h], AX ; 目的操作数是内存操作数寻址方式 (2) MOV EDX, [1000h] ; 源操作数是内存操作数寻址方式 这里直接用地址编号来表示内存单元,但在汇编源程序中,一般很少直接使用地址编号,
而是用符号来表示内存单元地址,例如,用 Variable 来表示地址编号 59A8h,那么指令:MOV [59A8h], AX,就可改写为:MOV Variable, AX。虽然它们形式有所不同,但本质上是一回事,
都是使用内存操作数寻址。 内存操作数的单元地址可以直接用地址编号给出,也可全部或部分放在寄存器中。在
例 4.3(1)中,直接用地址编号表示 59A8h 号字单元,即[59A8h];如果将 59A8h 存放到 BX,
那么该字单元也可表示为[BX];如果 BX 中存放的是 59A0h,那么[BX+8]对应的也是 59A8h号字单元。也就是说同一个内存单元可以有多种寻址方式。
在 80x86 中,内存单元的地址(偏移地址)EA=基址+变址+位移量。3 个分量可有不同组
合,从而使用内存单元有以下 5 种不同的寻址方式。 1) 直接寻址 指令所需要的操作数据存放在内存单元中,指令码中直接包括了操作数的地址,放在指
令操作码之后。即 EA=位置量。 直接寻址的汇编格式为:[地址编号] 或 符号地址 或 符号地址表达式 例 4.4 下列指令使用了直接寻址方式的操作数。 (1) MOV [100h],2B1Ah ; 目的操作数是直接寻址方式(直接地址) (2) MOV Variable, 2B1Ah ; 目的操作数是直接寻址方式(符号地址) (3) MOV ES: Variable, 2B1Ah ; 目的操作数是直接寻址方式(符号地址) (4) MOV AX, Variable+4 ; 源操作数是直接寻址方式(地址表达式) (5) MOV EAX, [100Ah] ; 源操作数是直接寻址方式(直接地址) (6) MOV EAX, SS: [100Ah] ; 源操作数是直接寻址方式(直接地址) 如果执行前数据段区和堆栈段区内容如图 4.3 所示,那么指令(5)执行后,EAX 内容为
44434241h;指令(6)执行后,EAX 内容为 038B9A04h(因为使用了不同的段寄存器)。
1000h DS→ … 30 31 32 33 34 35 36 37 38 39 41 42 43 44 45 46 …
1004h SS→ … 00 AB F4 97 45 00 04 9A 8B 03 89 83 D2 96 13 99 …
1008h ES→ … 2A 4C CD 20 80 90 44 5A 70 6D C9 63 40 0E 20 B8 …
图 4.3 例 4.4~例 4.8 所用的各段内存区内容

第 4 章 80x86 的寻址方式与基本指令
·41·
2) 寄存器间接寻址 指令所需要的操作数据存放在内存中,其地址存放在寄存器中。即 EA=寄存器。 寄存器间接寻址的格式为:[寄存器]。 可用于间接寻址的寄存器有:BX, SI, DI 和 BP,以及所有的 32 位通用寄存器。(E)BP, ESP
用作间接寻址寄存器时,则默认的段寄存器是 SS。 例 4.5 指出在下列指令中使用寄存器间接寻址方式的操作数。 (1) MOV [BX], AX ; 目的操作数是寄存器间接寻址方式 (2) MOV [EBP], CX ; 目的操作数是寄存器间接寻址方式 (3) MOV EAX, [BP] ; 源操作数是寄存器间接寻址方式 (4) MOV EAX, ES: [BP] ; 源操作数是寄存器间接寻址方式 (5) MOV EAX, [EBX] ; 源操作数是寄存器间接寻址方式 如果执行前,EBP 内容为 8001000Ch,EBX 内容为 00001006h,数据段区、堆栈段区和
附加段区内容如图 4.3 所示,那么指令(3)执行后,EAX 内容为 8389038Bh;指令(4)执行后,
EAX 内容为 5A449080h;指令(5)执行后,EAX 内容为 39383736h。 3) 寄存器相对寻址 这种寻址也叫直接变址寻址。指令所需要的操作数据存放在内存中,内存单元地址是寄
存器内容与指令中指定的位移量之和,即 EA=[寄存器]+位移量。 寄存器相对寻址的格式为:disp[寄存器]或[寄存器+disp]。 其中,disp 是位移量,是指令指定的一个 8 位或 16/32 位的补码数。 可用于相对寻址的寄存器有:BX, SI, DI 和 BP,以及所有的 32 位通用寄存器。(E)BP、
ESP 用作相对寻址寄存器时,则默认的段寄存器是 SS。 例 4.6 下列指令中使用了寄存器相对寻址方式的操作数。 (1) MOV 4[BX], AX ; 目的操作数是寄存器相对寻址方式 (2) MOV -4[EBP], CX ; 目的操作数是寄存器相对寻址方式 (3) MOV AX, [BP-2] ; 源操作数是寄存器相对寻址方式 (4) MOV AX, ES: -2[BP] ; 源操作数是寄存器相对寻址方式 (5) MOV AX, 8[EBX] ; 源操作数是寄存器相对寻址方式 如果执行前,EBP 内容为 8001000Ch,EBX 内容为 00001006h,数据段区、堆栈段区和
附加段区内容如图 4.3 所示,那么指令(3)执行后,AX 内容为 9A04h,取自堆栈段区字单元
[100Ah];指令(4)执行后,AX 内容为 20CDh,取自附加段区字单元[100Ah];指令(5)执行后,
AX 内容为 46455h,取自数据段内存区字单元[100Eh]。 4) 基址变址寻址 指令所需要的操作数据存放在内存中,内存单元地址是基址寄存器内容与变址寄存器内
容之和,即 EA=基址寄存器+变址寄存器。 基址变址寻址的格式为: (1) [基址寄存器][变址寄存器] (2) [基址寄存器+变址寄存器] 可用作基址寄存器的有:BX 和 BP,以及所有的 32 位通用寄存器;可用作变址寄存器的
有:SI 和 DI,以及除 ESP 之外的所有 32 位通用寄存器。(E)BP, ESP 用作基址变址寻址寄存
器时,则默认的段寄存器是 SS。

汇编语言程序设计
·42·
例 4.7 下列指令中使用了基址变址寻址方式的操作数。 (1) MOV [BX][SI], AX ; 目的操作数是基址变址寻址方式 (2) MOV [BP+SI], CX ; 目的操作数是基址变址寻址方式 (3) MOV AX, [BP][DI] ; 源操作数是基址变址寻址方式 (4) MOV AX, DS: [BP][DI] ; 源操作数是基址变址寻址方式 (5) MOV AX, [EAX+EDX] ; 源操作数是基址变址寻址方式 如果执行前,BP 内容为 100Ch,DI 内容为 0002h,数据段区、堆栈段区如图 4.4 所示,
那么,指令(3)执行后,AX 内容为 8389h,取自堆栈段内存区的单元[100Eh];指令(4)执行后,
AX 内容为 4645h,取自数据段内存区的单元[100Eh]。 5) 相对基址变址寻址 指令所需要的操作数据存放在内存中,内存单元地址是基址寄存器内容、变址寄存器内
容以及位移量之和,即 EA=基址寄存器+变址寄存器+位移量。 基址变址寻址的格式为: (1) disp[基址寄存器][变址寄存器] (2) [基址寄存器+变址寄存器+disp] 其中,disp 是位移量,是指令指定的一个 8 位或 16/32 位的补码数。 可用作基址寄存器的有:BX 和 BP,以及所有的 32 位通用寄存器;可用作变址寄存器的
有:SI 和 DI,以及除 ESP 之外的所有 32 位通用寄存器。(E)BP, ESP 用作基址变址寻址寄存
器时,则默认的段寄存器是 SS。 例 4.8 下列指令中使用了相对基址变址寻址方式的操作数。 (1) MOV 100[BX][DI], AX ; 目的操作数是基址变址寻址方式 (2) MOV 100[BP+DI], CX ; 目的操作数是基址变址寻址方式 (3) MOV AL, 2[BP][SI] ; 源操作数是基址变址寻址方式 (4) MOV AL, DS: 2[BP][SI] ; 源操作数是基址变址寻址方式 (5) MOV AL, 20[EAX+EDX] ; 源操作数是基址变址寻址方式 如果执行前,BP 内容为 100Ch,SI 内容为 0001h,数据段区、堆栈段区如图 4.3 所示,
那么,指令(3)执行后,AL 内容为 83h,取自堆栈段区的单元[100Fh];指令(4)执行后,AL 内
容为 46h,取自数据段区的单元[100Fh]。 6) 比例因子寻址 对于 32 位 CPU 来说,内存操作数还可使用比例因子的寻址方式。即
EA=32 位基址寄存器+32 位变址寄存器×比例因子+位移量 其中,disp 是位移量,是指令指定的一个 8 位或 32 位的补码数,比例因子是:1, 2, 4 或 8。
比例因子寻址的格式为: (1) disp[32 位基址][32 位变址×因子] (2) [32 位基址+32 位变址×因子+disp] 例 4.9 下列指令中使用了比例因子寻址方式。 MOV EAX, count[ESI×2] ; 源:比例变址寻址,目的:寄存器寻址 MOV GS: [EAX][EBX×4], Byte Ptr 10 ; 源:立即寻址;目的:基址比例变址寻址 MOV EAX, [EBP+EBX×8+10] ; 源:相对基址比例变址寻址;目的:寄存器寻址
4.2.2 数据传送指令
高级语言中的赋值语言一般由数据传送类指令来实现。数据传送指令的主要功能是将数
据传送到寄存器或内存单元中,又可分为 4 类:通用数据传送指令——MOV, PUSH, POP,
第 4 章 80x86 的寻址方式与基本指令
·43·
XCHG 等;地址传送指令——LEA, LDS, LES 等;标志位传送指令——LAHF, SAHF, PUSHF, POPF 等;输入输出指令——IN, OUT 等。为了方便,将类型转换指令也放在这一节。这些指
令除了和标志位有关的传送指令外,均不影响标志位。
1. 通用数据传送指令
数据传送类指令是使用 频繁的一类指令,主要包括以下指令: 基本传送 MOV 传送 XCHG 交换 MOVZX 符号扩展传送 MOVSX 零扩展传送 堆栈类 PUSH 压栈 POP 出栈 PUSHA/PUSHAD 所有 16/32位通用寄存器进栈 POPA/POPAD 所有 16/32位通用寄存器出栈 其他 XLAT, 查表换码 1) MOV 指令(MOVe) 格式:MOV 目的操作数,源操作数。 功能:数据传送,将源操作数传送到目的储存单元中,源地址单元内容不变。 操作数的寻址方式: MOV reg/mem, imm ; 立即数⇒寄存器/内存
MOV reg/mem/seg, reg ; 寄存器⇒寄存器/内存/段寄存器 MOV reg/seg, mem ; 内存⇒寄存器/段寄存器 MOV reg/mem, seg ; 段寄存器⇒寄存器/内存 关于操作数的寻址方式可参照 80x86 的指令手册。在编写程序时,若操作数不符合寻址
要求,则汇编时不通过。此外需要注意:一般情况下,源目的操作数类型长度要一致;立即
数要在目的操作数类型值范围内;当两个操作数类型均不明确时,必须至少指定一个操作数
类型。为方便以后叙述,将指定类型的伪操作符罗列如下(伪操作符有关概念在以后章节中
叙述) Byte Ptr 指定数据类型为字节类型(8 位数据) Word Ptr 指定数据类型为 2 字节(字)类型(16 位数据) DWord Ptr 指定数据类型为 4 字节(双字)类型(32 位数据) FWord Ptr 指定数据类型为 6 字节类型(48 位数据) QWord Ptr 指定数据类型为 8 字节(四字)类型(64 位数据) TByte Ptr 指定数据类型为 10 字节类型(80 位数据) 例 4.10 指出在下列汇编指令是否正确。 MOV CS, DX ; 错误, CS不能用作目的操作数 MOV DX, CS ; 正确 MOV DS, DX ; 正确 MOV AL, 0A0Dh ; 错误, 0A0Dh超过 8位数范围 MOV Variable, [SI] ; 错误, 不支持 MOV mem, mem,即内存⇒内存 MOV EAX, DX ; 错误, 两操作数类型不一致 MOV [EAX], 41h ; 类型不明确。可改为 MOV [EAX], DWord Ptr 41h MOV DS, 1000h ; 错误, 不支持 MOV seg, imm,即立即数⇒段寄存器 MOV GS, CS ; 错误, 不支持 MOV seg, seg,即段寄存器⇒段寄存器

汇编语言程序设计
·44·
例 4.11 将双字单元[1000h]的内容传送到双字单元[2000h]中。 解:80x86 不支持 MOV mem, mem 指令格式,故用两条 MOV 指令来实现。 MOV EAX, DWord Ptr [1000h] ; [1000h] ⇒EAX MOV DWord Ptr [2000h], EAX ; EAX⇒ [2000h] 2) XCHG 指令(eXCHanGe) 格式:XCHG 操作数 1,操作数 2。 功能:数据交换,操作数 1 与操作数 2 单元的内容互相交换。 由于两操作数即是源操作数,又是目的操作数,故它们的位置顺序无关紧要。 操作数的寻址方式为: XCHG reg/mem, reg ; 寄存器⇔寄存器 例 4.12 指出在下列汇编指令是否正确。 XCHG EAX, EBX ; 正确 XCHG AX, 0A0Dh ; 错误, 不支持 XCHG reg, imm XCHG Variable, [EAX] ; 错误, 不支持 XCHG mem, mem XCHG DS, Word Ptr[BX] ; 错误, 不支持 XCHG mem, seg XCHG DS, BX ; 错误, 不支持 XCHG reg, seg XCHG AX, BL ; 错误, 类型长度不一致 例 4.13 将双字单元[1000h]中内容与双字单元[2000h]中内容互换。 解:80x86 不支持 XCHG mem, mem 寻址方式指令,故用如下指令实现。 MOV EAX, [100h] ; [100h] ⇒EAX XCHG [200h], EAX ; EAX⇔ [200h] 3) MOVSX 指令(MOVe with Sign-eXtend) 格式:MOVSX 寄存器,源操作数。 功能:带符号扩展传送指令。源操作数符号扩展后,传送到目的寄存器中,源操作数内
容不变。由于源操作数要进行扩展,所以源操作数类型长度必须小于目的操作数。 操作数的寻址方式: MOVSX reg, reg/mem ; 符号扩展(寄存器)⇒寄存器 例 4.14 指出在下列汇编格式指令是否正确。 MOVSX EAX, EBX ; 错误, 源类型必须小于目的类型 MOVSX AX, 8Dh ; 错误, 不支持 MOVSX reg, imm MOVSX Word Ptr[BX], AL ; 错误, 不支持 MOVSX mem, reg MOVSX DS, BL ; 错误, 不支持 MOVSX seg, reg 例 4.15 将字节(8 位)单元[1000h]中补码存入双字(32 位)单元[2000h]中。 解:将 8 位补码扩展成 32 位补码,再传送到[2000h]单元。 MOVSX EAX, Byte Ptr [1000h] ; 符号扩展([1000h]) ⇒EAX MOV [2000h], EAX ; EAX⇒ [2000h] 假设[1000h]中的补码为 FEh(即-2 的 8 位补码),指令执行后,[2000h]单元中的内容为
FFFFFFFEh(即-2 的 32 位补码);若[1000h]中的补码为 02h,则[2000h]单元内容为 00000002h。 由此可见,对负数扩展,则所有的扩展位均置 1;若对正数扩展,则扩展位均清 0。 4) MOVZX 指令(MOVe with Zero-eXtend) 格式:MOVZX 寄存器,源操作数。

第 4 章 80x86 的寻址方式与基本指令
·45·
功能:带零扩展传送指令。源操作数零扩展后,传送到目的寄存器中,源操作数内容不
变。由于源操作数要进行扩展,所以源操作数类型长度必须小于目的操作数。 操作数的寻址方式: MOVZX reg, reg/mem ; 零扩展(寄存器)⇒寄存器 例 4.16 指出下列汇编指令是否正确。 MOVZX EAX, EBX ; 错误, 源类型必须小于目的类型 MOVZX AX, 8Dh ; 错误, 不支持 MOVZX reg, imm MOVZX Word Ptr[BX], AL ; 错误, 不支持 MOVZX mem, reg MOVZX DS, BL ; 错误, 不支持 MOVZX seg, reg 例 4.17 将 2 字节(16 位)单元[1000h]中无符号数存入双字(32 位)单元[2000h]中。 解:将 16 位补码扩展成 32 位无符号数,再传送到[2000h]单元。 MOVSX EAX, Word Ptr[1000h] ; 零扩展([1000h]) ⇒EAX MOV [2000h], EAX ; EAX⇒ [2000h] 假设[1000h]中的无符号数为 FEh,指令执行后,[2000h]单元中的内容为 000000FEh;若
[1000h]中的无符号数为 02h,则[2000h]单元内容为 00000002h。 由此可见,执行零扩展传送指令时,则所有的扩展位均清 0。 5) PUSH 指令(PUSH onto the stack) 格式:PUSH 源操作数。 功能:数据进栈。当源操作数为 16 位时,(E)SP 内容减 2,即向低地址端调整 2 字节;
当源操作数为 32 位时,(E)SP 中内容减 4,即向低地址端调整 4 字节。 注意,进栈数据只能是 16/32 位数据。8086CPU 只能是 16 位。 操作数的寻址方式:PUSH reg/mem/seg/imm (8086 不支持 PUSH imm)。 例 4.18 指出下列汇编指令是否正确。 PUSH AX ; 正确 PUSH CS ; 正确 PUSH AL ; 错误, 进栈数据必须是 16位或 32位 PUSH Word Ptr 41h ; 在 32位 CPU中正确,在 8086中是错误的 PUSH 125h ; 类型不明确,可指定为 PUSH DWord Ptr 125h 6) POP 指令(POP from the stack) 格式:POP 目的操作数。 功能:数据出栈。从堆栈中弹出数据到目的操作数所确定的单元中。若操作数为 16 位,
(E)SP 向高地址端调整 2 字节;若操作数为 32 位时,(E)SP 向高地址端调整 4 字节。 注意,出栈数据只能是 16/32 位数据。8086CPU 只能是 16 位。 操作数寻址方式:POP reg/mem/seg。 例 4.19 指出下列汇编指令是否正确。 POP AX ; 正确 POP CS ; 错误, CS不能用作目的操作数 POP AL ; 错误, 出栈数据必须是 16位或 32位 POP 41h ; 错误, 不支持 POP imm 堆栈操作的主要指令是 PUSH 和 POP 指令。另外,由于堆栈操作与(E)SP 密切相关,所
以,一般在程序中不要将(E)SP 作为数据寄存器等使用。

汇编语言程序设计
·46·
例 4.20 使用 PUSH 和 POP 指令,将字(16 位)单元[1000h]内容和字单元[2000h]内容分
别放入 EAX 低 16 位和高 16 位。 解:先将两个 16 位数按存放顺序要求进栈,再从堆栈弹出一个 32 位数到 EAX。 PUSH Word Ptr[2000h] ; EAX高 16位数进栈 PUSH Word Ptr[1000h] ; EAX低 16位数进栈 POP EAX ; 弹出 32位数⇒EAX 假设字单元[1000h]内容为 1A2B,字单元[2000h]内容为 3C4Dh,执行该指令序列时,堆
栈状态及 EAX 内容变化如图 4.4 所示。
SS SS SS SS ESP→ 2B 1A ESP→ 4D 4D 3C 3C
ESP→ ESP→ EAX=? EAX=? EAX=? EAX= 3C4D1A2Bh
(a) 初始状态 (b) PUSH Word Ptr[200h]后 (c) PUSH Word Ptr[100h]后 (d) POP EAX 后
图 4.4 堆栈状态及 EAX 内容变化示意图
7) PUSHA/PUSHAD 指令(PUSH All registers onto the stack) 格式:PUSHA/PUSHAD。 功能:所有通用寄存器进栈。 PUSHA,8 个 16 位通用寄存器内容进栈,顺序:AX, CX, DX, BX, SP, BP, SI, DI,之后
(E)SP 内容减 16,SP 进栈的内容是指令执行前的内容。 PUSHAD,8 个 32 位通用寄存器内容进栈,顺序:EAX, ECX, EDX, EBX, ESP, EBP, ESI,
EDI,之后(E)SP 内容减 32,ESP 进栈的内容是指令执行前的内容。 8) POPA/POPAD 指令(POP All registers from the stack) 格式:POPA/POPAD。 功能:所有通用寄存器出栈。 POPA,从堆栈栈顶弹出 8 个数据到 16 位通用寄存器,顺序:DI,SI, BP, SP, BX, DX, CX,
AX,但 ESP 内容仍是指向出栈操作后的栈顶。 PUSHAD,从堆栈栈顶弹出 8 个数据到 32 位通用寄存器,顺序:EDI,ESI, EBP, ESP, EBX,
EDX, ECX, EAX,但 ESP 内容仍是指向出栈操作后的栈顶。 9) XLAT 指令(transLATe) 格式:XLAT。 功能:查表换码。将以(E)BX 基址,以 AL 内容为位移量的字节单元内容传送给 AL。 这条指令使用隐含操作数。在指令执行前约定:必须已经建立一个字节表,表首地址已
经放入基址寄存器 EBX;查找项的位移量已经放入 AL。 例 4.21 AL 存放的是一个 0~15 的数,用 XLAT 指令将它转换成十六进制数。 解:设数据区内从偏移地址 1000h 开始,连续 16 个字节单元中存放的是十六进制数(ASCII
码),如图 4.3 所示,那么转换的指令如下: MOV EBX, 1000h ; 字节表首地址⇒EBX XLAT ; 查找数码⇒AL

第 4 章 80x86 的寻址方式与基本指令
·47·
若指令执行前 AL 内容为 0Bh,那么指令执行后 AL 内容为 42h('B'的 ASCII 码)。
2. 地址传送指令
1) LEA 指令(Load Effective Address) 格式:LEA 寄存器,源内存操作数。 功能:有效地址送寄存器。将内存操作数的偏移地址(EA)传送至目的寄存器中。 操作数的寻址方式为:LEA reg16/reg32, mem。 注意,目的操作数必须是 16/32 位通用寄存器。若是 16 位寄存器,那么只装入 EA 的低
16 位。 例 4.22 说明下列两条指令的区别。 (1) LEA AX, [EBX][ESI] (2) MOV AX, [EBX][ESI] 解:指令(1)取源内存操作数的偏移地址 EA,并存入 AX,而指令(2)取 EA 所对应的内存
2 字单元内容,并存入 AX。前者取的是地址,而后者取的是单元中的内容。若 EBX=1000h,ESI=8h,假设数据区内容如图 4.3 所示,那么指令(1)执行后,AX 内容为 1008h,是内存单
元的偏移地址;指令(2)执行后,AX 内容为 3938h,即内存单元[1008h]的内容。 2) LDS/LSS/LES/LFS/LGS 指令(Load DS/SS/ES/FS/GS with pointer) 这一组指令的格式和操作数寻址方式完全一样。 格式:LDS/LSS/LES/LFS/LGS 目的寄存器,源内存操作数。 功能:内存指针送寄存器和段寄存器指令。将源内存操作数中的低 2/4 字节内容传送到
目的寄存器,及高 2 字节内容传送至段寄存器 DS/SS/ES/FS/GS。 操作数的寻址方式: LDS/LSS/LES/LFS/LGS reg16, mem32 (16 位地址模式); LDS/LSS/LES/LFS/LGS reg32, mem48 (32 位地址模式)。 假设数据段区内容如图 4.3 所示,执行 LES AX, DWord Ptr[1000h]指令后(16 位模式),ES
内容为 3433h,AX 内容为 3231h;执行 LES EAX, FWord Ptr[1000h]指令后(32 位模式),ES内容为 3635h,EAX 内容为 34333231h(仅作为示例,不考虑内容合法性)。
3. 标志位传送指令
1) LAHF 指令(Load AH with Flags) 格式:LAHF。 功能:标志送 AH。将 FLAGS 的低 8 位送至 AH,包括了 SF, ZF, AF, PF, CF。 2) SAHF 指令(Store AH into Flags) 格式:SAHF。 功能:AH 送标志寄存器指令。将 AH 内容送至标志寄存器低 8 位。 3) PUSHF/PUSHFD 指令(PUSH Flags onto the stack by word/Double word) 格式:PUSHF/PUSHFD。 功能:标志寄存器进栈指令。16/32 位标志寄存器 FLAGS/EFLAGS 内容进栈。 4) POPF/POPFD 指令(POP Flags from the stack by word/Double word) 格式:POPF/POPFD。 功能:标志寄存器出栈。从堆栈弹出 16/32 位数据到标志寄存器 FLAGS/EFLAGS。

汇编语言程序设计
·48·
4. 输入输出指令
80x86 有一组专门的输入输出指令来读写 I/O 端口,从而实现与外部设备交换数据。而且
只能使用累加器来接收、发送数据。 1) IN 指令(INput) 格式:IN 累加器,端口地址。 累加器可以是 AL, AX, EAX;端口地址可以是 imm8,或存放在 DX 中。 功能:从端口输入。把 1/2/4 字节端口中的数据传送给 AL/AX/EAX。 80x86 系统的端口地址范围是 0000h~FFFFh。使用 imm8 形式端口,则指令中的端口地
址范围只能是 00h~FFh;使用 DX 来存放端口地址,则指令中的端口地址范围是 0000h~FFFFh。此外,和内存操作数不同的是,IN 指令的源操作数据是来自 I/O 端口。
2) OUT 指令(OUTput) 格式:OUT 端口地址,累加器。 累加器可以是 AL, AX, EAX;端口地址可以是 imm8,或存放在 DX 中。 功能:端口输出指令。把 AL/AX/EAX 中的内容输送到 1/2/4 字节端口。 使用 imm8 形式端口,则指令中的端口地址范围只能是 00h~FFh;使用 DX 来存放端口
地址,则指令中的端口地址范围是 0000h~FFFFh。此外,和内存操作数不同的是,OUT 指
令的目的操作数据将传送到 I/O 端口中去。 例 4.23 说明下列 IN/OUT 指令执行功能。通过这个例子体会 IN/OUT 指令的用法。 IN AL, 20h ; 20h端口的 1字节内容⇒AL(imm8直接) IN AX, 20h ; 20h端口、21h端口中的 2字节内容⇒AX(imm8直接) IN AL 378h ; 378h超出 imm8范围,此指令不正确 MOV DX, 378h IN EAX, DX ; 4字节端口 378h的内容⇒EAX,即依次取 378h~37Bh端口数据(DX间接) OUT DX AL ; 将 AL内容⇒378h端口 OUT DX, AX ; 将 AX内容⇒378h和 379h端口 OUT DX, EAX ; 将 EAX内容⇒378h~37Ch端口
5. 类型转换指令
1) CBW 指令(Convert Byte to Word) 格式:CBW。 功能:将字节类型数据转换成字类型指令。将 AL 内容符号扩展到 AH,形成 AX 中的 16
位数据。即若 AL 高位为 0,则将 AH 置为 0;若 AL 高位为 1,则将 AH 置为 FFh。 2) CWD 指令(Convert Word to Double-word) 格式:CWD。 功能:字类型转换为双字类型指令。将 AX 内容符号扩展到 DX,形成 DX:AX 中的 32
位数据。即若 AX 高位为 0,则将 DX 置为 0;若 AX 高位为 1,则将 DX 置为 FFFFh。 3) CWDE 指令(Convert Word to Extended Double-word) 格式:CWDE。 功能:扩展的字类型转换为双字类型指令。将 AX 内容符号扩展为 EAX,形成 EAX 中
的 32 位数据。

第 4 章 80x86 的寻址方式与基本指令
·49·
4) CDQ 指令(Convert Double-word to Quad-word) 格式:CDQ。 功能:双字类型转换为四字类型指令。将 EAX 内容符号扩展到 EDX,形成 EDX:EAX
中的 64 位数据。即若 EAX 高位为 0,则将 EDX 置为 0;若 EAX 高位为 1,则将 EDX置为 FFFFFFFFh。
5) BSWAP 指令(Byte SWAP) 格式:BSWAP reg32。 功能:字节交换指令。将 reg32 中内容按字节次序变反。例如,EAX 内容为 12345678h,
执行 BSWAP EAX 指令后,EAX 内容为 78563412h。
4.2.3 算术运算指令
算术运算指令用来执行加、减、乘和除四则运算。80x86 提供二进制数的运算指令和十
进制数(BCD 码表示)的运算指令。 由于 80x86 采用补码表示有符号数,所以对于加法、减法运算采用相同的运算规则,但
是,对于乘法、除法运算,则需要使用不同的运算规则。 算术运算指令的执行结果一般会影响标志位 CF, ZF, SF, OF, AF, PF。所以,在学习中,
一方面要掌握各指令的功能,另一方面要清楚指令对各标志位的影响。
1. 加法指令
基本的加法指令包括 3 条指令:ADD 加法、ADC 带进位加法和 INC 加 1。 80x86 采用补码表示有符号数,所以对于有符号数和无符号数采用相同的加法运算规则,
也就是说,下面介绍的加法指令,既可用于无符号数运算,也可用于补码数运算。但要注意
的是,对于无符号数加法,其运算结果溢出与否是通过 CF 指示出来的;对于补码数加法,其
运算结果溢出与否是通过 OF 指示出来的。 1) ADD 指令(ADDition) 格式:ADD 目的操作数,源操作数。 功能:加法指令。将源操作数与目的操作数相加所得的结果存入目的操作数。 操作数的寻址方式: ADD reg, reg/mem/imm; ADD mem, reg/imm。 注意,该指令根据执行的结果设置 CF, AF, PF, ZF, SF, OF 的状态。 2) ADC 指令(ADd with Carry) 格式:ADC 目的操作数,源操作数。 功能:带进位加法指令。即将源操作数、目的操作数和 CF 相加,所得的结果存入目的操
作数。 操作数的寻址方式: ADC reg, reg/mem/imm; ADC mem, reg/imm。 该指令根据执行的结果设置 CF, AF, PF, ZF, SF, OF 的状态。 3) INC 指令(INCrement) 格式:INC 操作数。 功能:加 1 指令。操作数自身加 1,即将操作数加 1,所得的结果存入操作数。

汇编语言程序设计
·50·
操作数的寻址方式:INC reg/mem。 与前两条指令不同的是,该指令影响 AF, PF, ZF, SF 和 OF,但不影响 CF。 4) XADD 指令(eXchange and ADD) 格式:XADD 目的操作数,源操作数。 功能:交换并相加指令。源操作数, 目的操作数内容互换,再执行加法操作,运算结果
放入目的操作数确定的单元中。 操作数的寻址方式: XADD reg/mem, reg。 该指令影响 CF, AF, PF, ZF, SF, OF。 例 4.24 完成两个 64 位数相加,被加数存放在[1000h]单元中,加数放在[2000h]单元中,
结果放到[3000h]单元中。 解:用两次 32 位加指令来完成,在作高 32 位加法时,须考虑从低 32 位传来的进位,所
以采用 ADC 指令。指令序列如下: MOV ESI, 0 ; 0⇒EAX MOV EAX, 1000h[ESI×4] ; 取被加数的低 32位 ADD EAX, 2000h[ESI×4] ; 低 32位相加 MOV 3000h[ESI×4], EAX ; 保存结果的低 32位 INC ESI ; 指向下一个 32位 MOV EAX, 1000h[ESI×4] ; 取被加数的高 32位 ADC EAX, 2000h[ESI×4] ; 高 32位相加 MOV 3000h[ESI×4], EAX ; 保存结果的高 32位
2. 减法指令
基本的减法指令包括 5 条指令:SUB 减法、SBB 带借位减法、DEC 减 1、NEG 求补、
CMP 比较。 减法指令既可用于无符号数运算,也可用于补码数运算。对于无符号数减法,其运算结果溢
出与否是通过 CF 指示出来的;对于补码数减法,其运算结果溢出与否是通过 OF 指示出来的。 1) SUB 指令(SUBtraction) 格式:SUB 目的操作数,源操作数。 功能:减法指令。即目的操作数减去源操作数,所得的结果存入目的操作数。 操作数的寻址方式: SUB reg, reg/mem/imm; SUB mem, reg/imm。 该指令根据执行的结果设置 CF, AF, PF, ZF, SF, OF 的状态。 2) SBB 指令(SuBtract with Borrow) 格式:SBB 目的操作数,源操作数。 功能:带借位减法指令。即目的操作数减去源操作数,再减去 CF,所得的结果存入目的
操作数。 操作数的寻址方式: SBB reg, reg/mem/imm; SBB mem, reg/imm。 该指令根据执行的结果设置 CF, AF, PF, ZF, SF, OF 的状态。 3) DEC 指令(DECrement) 格式:DEC 操作数。

第 4 章 80x86 的寻址方式与基本指令
·51·
功能:减 1 指令。操作数自身减 1,即操作数减去 1,所得的结果存入操作数。 操作数的寻址方式:DEC reg/mem。 与前两条指令不同的是,该指令影响 AF, PF, ZF, SF 和 OF,但不影响 CF。 4) NEG 指令(NEGate) 格式:NEG 操作数。 功能:求补指令。操作数各位取反再加 1(求补),即将 0 减去操作数,所得的结果存入操
作数。 操作数的寻址方式:NEG reg/mem。 该指令影响 CF, AF, PF, ZF, SF, OF。只有当操作数为 0 时,求补运算的结果才使 CF=0,
其他情况则均为 1;只有当操作数为-128(8 位运算)或-32 768(16 位运算)或-231(32 位运算)时,
求补运算的结果才使 OF=1,其他情况则均为 0。 5) CMP 指令(CoMPare tow Operand) 格式:CMP 目的操作数,源操作数。 功能:比较指令。两操作数比较大小,根据目的操作数减去源操作数的运算结果,从而
影响标志位。 操作数的寻址方式: CMP reg, reg/mem/imm; CMP mem, reg/imm。 该指令影响 CF, AF, PF, ZF, SF, OF。 这条指令除了相减结果不保存外,其他情况与 SUB 指令完全相同。 例 4.25 完成 64 位数相减,被减数存放在[1000h]单元中,减数放在[2000h]单元中,结
果放到[3000h]单元中。 解:通过两次 32 位减操作来完成,其中进行高 32 位减法时,须考虑从低 32 位传来的借
位,所以采用 SBB 指令。编制的指令如下: SUB ESI, ESI ; 0⇒EAX MOV EAX, 1000h[ESI×4] ; 取被减数的低 32位 SUB EAX, 2000h[ESI×4] ; 低 32位相减 MOV 3000h[ESI×4], EAX ; 保存结果的低 32位 MOV EAX, 1000h[ESI×4+4] ; 取被减数的高 32位 SBB EAX, 2000h[ESI×4+4] ; 高 32位相减 MOV 3000h[ESI×4+4], EAX ; 保存结果的高 32位
3. 乘法指令
和加法、减法指令不一样,对于无符号数和补码数,80x86 使用不同的处理规则,所以
有两类乘法指令:MUL 无符号数乘法和 IMUL 有符号数乘法。 1) MUL/IMUL 指令(unsigned/signed MULtiple) 格式:MUL/IMUL 源操作数。 功能: 无/有符号数乘指令。 若为 8 位(字节)操作,AL×源操作数⇒AX; 若为 16 位(字)操作,AX×源操作数⇒DX,AX; 若为 32 位(双字)操作,EAX×源操作数⇒EDX,EAX。 操作数寻址方式:MUL/IMUL reg/mem。

汇编语言程序设计
·52·
两者的区别在于:MUL 的操作数内容看做无符号数,IMUL 操作数内容看做补码。 在乘法指令中,被乘数隐含在 AL(8 位运算)或 AX(16 位运算)或 EAX(32 位运算)中;乘
数也就是源操作数,决定了乘法是 8 位运算,还是 16 位运算或者 32 位运算。两个 8 位数相
乘所得结果为 16 位,存放在 AX 中,如图 4.5(a)所示;两个 16 位数相乘所得结果是 32 位,
存放在 DX,AX 中,如图 4.5(b)所示,其中,DX 存放高 16 位,AX 存放低 16 位;两个 32 位
数相乘所得结果是 64 位,存放在 EDX,EAX 中,如图 4.5(c)所示,其中,EDX 存放高 32 位,
EAX 存放低 32 位。
AL AX EAX × 8 位数 × 16 位数 × 32 位数
AH AL DX AX EDX EAX (a) 8 位乘法运算 (b) 16 位乘法运算 (c) 32 位乘法运算
图 4.5 乘法指令运算示意图
乘法指令不影响除 CF 和 OF 以外的标志位状态。 对于 MUL 来说,如果乘积的高半部分为 0,则 CF 和 OF 均为 0,否则 CF 和 OF 均为 1;
对 IMUL 来说,如果乘积的高半部分是低半部分的符号扩展,则 CF 和 OF 均为 0,否则均为
1。通过测试这两个标志位,就能够知道乘积的高半部分是否有效数字。 例 4.26 分别将字节单元[1000h]和[2000h]中内容作为:① 8 位无符号数;② 8 位有符
号数。求这两个数的乘积,所得 16 位数结果放到 2 字节单元[3000h]中去。 解:对于加法和减法,无符号数与有符号数用相同指令。但对于乘法,则要用不同的指
令。无符号乘法用 MUL 指令,有符号数用 IMUL 指令。实现的指令如下: ① 作为 8位无符号数的指令 ② 作为 8位有符号数的指令 MOV AL, [1000h] MOV AL, [1000h] MUL Byte Ptr[2000h] IMUL Byte Ptr[200h] MOV [3000h], AX MOV [3000h], AX 设字节单元[1000h]中内容为 FEh、字节单元[2000h]中内容为 05h,则:指令①执行后,
字单元[3000h]中的内容是 04F6h,CF=OF=1;指令②执行后,字单元[3000h]中的内容是
FFF6h,CF=OF=0。尽管两操作数内容相同,但由于编码约定不同而选择不同的乘法指令,
因而所得结果也不一样。 2) 双操作数 IMUL 指令 这是 80286 及后续处理器增加的指令。 格式:IMUL 目的操作数,源操作数。 功能:双操作数有符号乘法指令。即将目的操作数与源操作数相乘的结果存入目的操
作数。 操作数的寻址方式为 IMUL reg16, reg16/mem16 或 IMUL reg32, reg32/mem32 若结果正常,则 CF=OF=0;若结果超出范围,则 CF=OF=1。其他位未定义。 3) 三操作数 IMUL 指令 这是 80286 及后续处理器增加的指令。 格式:IMUL 目的操作数,源操作数,立即数。 功能:三操作数有符号乘法指令。即将源操作数与立即数相乘的结果存入目的操作数。

第 4 章 80x86 的寻址方式与基本指令
·53·
操作数的寻址方式为:IMUL reg16,reg16/mem16,imm 或 IMUL reg32,reg32/mem32,imm。 若结果正常,则 CF=OF=0;若结果超出范围,则 CF=OF=1。其他位未定义。
4. 除法指令
对应无符号数和补码数,分别有 DIV 无符号数除法和 IDIV 有符号数除法。要求被除数
的位数必须是除数的两倍。DIV/IDIV 指令(unsigned/sIgned DIVision)说明如下。 格式:DIV 源操作数。 功能:无/有符号数除法指令。 8 位(字节)操作时,AX 除以源操作数,所得的商存入 AL,余数存入 AH; 16 位(字)操作时,DX,AX 除以源操作数,所得的商存入 AX,余数存入 DX; 32 位(双字)操作时,EDX,EAX 除以源操作数,所得的商存入 EAX,余数存入 EDX。 操作数的寻址方式为:DIV/IDIV reg/mem。 两者的区别在于:DIV 的操作数约定是无符号数,商和余数均为无符号数;IDIV 操作数
约定是补码,商和余数均为有符号数,余数符号与被除数符号相同。 在除法中,被除数隐含在 AX(8 位运算)或 DX:AX(16 位运算)或 EDX:EAX(32 位运算)中,
除数即源操作数,决定了除法是 8 位运算,还是 16 位运算或者 32 位运算。16 位数除以 8 位
数,商是 8 位,存放在 AL 中,余数是 8 位,存放在 AH 中,如图 4.6(a)所示;32 位数除以
16 位数,商是 16 位,存放在 AX 中,余数是 16 位,存放在 DX 中,如图 4.6(b)所示;64 位数
除以 32 位数,商是 32 位,存放在 EAX 中,余数是 32 位,存放在 EDX 中,如图 4.6(c)所示。
商→ AL 商→ AX 商→ EAX
8 位数 AH AL 16 位数 DX AX 32 位数 EDX EAX 余数→ AH 余数→ DX 余数→ EDX
(a) 8 位除法运算 (b) 16 位除法运算 (c) 32 位除法运算
图 4.6 除法指令运算示意图
一条除法指令可能导致两类错误:一类是除数为零,另一类是商溢出。当除法运算所得
的商超过表示范围时,就产生商溢出。例如,2000h 除以 20h,所得商为 100h,超出 AL 所能
表示的范围,导致除法溢出。当产生这两类除法错误时,处理器就会产生一次中断处理。 除法指令对所有标志位无定义。 例 4.27 分别按:① 无符号数;② 符号数,用 2 字节单元[1000h]中的数除以字节单元
[2000h]中的数,所得商和余数分别存放到单元[3000h]和[4000h]中去。 解:无符号数除法用 DIV 指令计算,有符号数用 IDIV 指令计算。指令序列如下: ① 作为 8位无符号数指令序列 ② 作为 8位有符号数指令序列 MOV AX, [1000h] MOV AX, [1000h] DIV Byte Ptr[2000h] IDIV Byte Ptr[2000h] MOV [3000h], AL MOV [3000h], AL MOV [4000h], AH MOV [4000h], AH 设字单元[1000h]中内容为 0105h,字节单元[2000h]中内容为 81h。指令序列①执行后,
字节单元[3000h]和[4000h]的内容分别是 02h 和 03h,即有:105h=02h×81h+03h。由于 16 位
补码 0105h 表示的数是 261,8 位补码 81h 表示的数是-127,且有 261=-127×(-2)+7,所以指

汇编语言程序设计
·54·
令序列②执行后,字节单元[3000h]和[4000h]的内容分别是 FEh 和 07h。
5. 十进制调整指令
用 BCD 码表示的数具有十进制数格式,但在计算机内部仍然使用二进制方法运算。为方
便十进制数运算,80x86 提供了一组十进制调整指令,用于将二进制数调整为 BCD 码。 BCD 码有两种存储格式:压缩和非压缩。压缩 BCD 码指每个字节存储两个 BCD 码;非
压缩 BCD 码指每个字节存储一个 BCD 码,其中低 4 位存储数字的 BCD 码,高 4 位为 0。 1) DAA 指令(Decimal Ajust for Addition) 格式:DAA。 功能:压缩 BCD 码加法的十进制调整指令。调整 AL 中的二进制数和,规则:若 AF=1
或低 4 位大于 9,则 AL 加 6;若 CF=1 或高 4 位大于 9,则 AL 加 60h。本指令对 OF 无定义,
但影响其他所有标志位。 2) DAS 指令(Decimal Ajust for Subtraction) 格式:DAS。 功能:压缩 BCD 码减法的十进制调整指令。调整 AL 中的二进制数差,规则:若 AF=1,
则 AL 减 6;若 CF=1,则 AL 减 60h。本指令对 OF 无定义,影响其他所有标志位。 3) AAA 指令(ASCII Ajust for Addition) 格式:AAA。 功能:加法的非压缩调整指令。调整 AL 中的和,规则:① 若 AF=1 或者低 4 位大于 9,
则 AL+6,AH+1,置 AF=1;② 高 4 位置 0;③ AF⇒CF。影响 AF 和 CF,其余无定义。 4) AAS 指令(ASCII Ajust for Subtration) 格式:AAS。 功能:减法的非压缩调整指令。调整 AL 中的差,规则:① 若 AF=1,则 AL-6,AH-1;
② AL 高 4 位置 0;③ AF⇒CF。影响 AF 和 CF,其余无定义。 5) AAM 指令(ASCII Ajust for Multiplication) 格式:AAM。 功能:乘法的非压缩调整指令。调整 AL 中的积,规则:AL÷10,商⇒AH,余数⇒AL。
本指令影响 SF, ZF 和 PF,其余无定义。 6) AAD 指令(ASCII Ajust for Division) 格式:AAD。 功能:除法的非压缩调整指令。调整 AX 中的非压缩 BCD 码为二进制数,存入 AL,规
则:AH×10+AL⇒AL,0⇒AH。影响 SF, ZF 和 PF。其余无定义。 例 4.28 十进制数 153.8, 417.9 按压缩 BCD 码已分别存于[1000h]2 字节和[2000h]2 字节
中。用二进制运算求它们的和,并存于[3000h]中。 MOV AL, [1000h] ; 38h⇒AL ADD AL, [2000h] ; 38h+79h⇒AL,AL内容为 B1h DAA ; 压缩 BCD加法的十进制调整后,AL内容为 17h,CF=1 MOV [3000h], AL ; 存结果 MOV AL, [1001h] ; 15h⇒AL ADC AL, [2001h] ; 15h+41h+CF⇒AL,AL内容为 57h DAA ; 调整后,AL内容为 57h MOV [3001h], AL ; 存结果

第 4 章 80x86 的寻址方式与基本指令
·55·
约定保留 1 位小数。执行后,[3000h]内容为 5717h,即:153.8+417.9=571.7。
4.2.4 逻辑指令
逻辑指令包括逻辑运算指令和移位指令。
1. 逻辑运算指令
逻辑运算是按位操作的,包括:AND, OR, NOT, XOR 和 TEST 指令。其中 AND, OR, XOR和 TEST 都是双操作数指令,形式相似,操作数的寻址方式与算术运算指令相同,对标志位
的影响也相同,即 CF=0,OF=0,AF 无定义,SF, ZF 和 PF 根据结果设置。 1) AND 指令 格式:AND 目的操作数,源操作数。 功能:逻辑与。执行按位“逻辑与”操作,目的操作数∧源操作数⇒目的操作数。 操作数的寻址方式: AND reg, reg/mem/imm; AND mem, reg/mem。 根据结果设置 SF, ZF 和 PF,CF=0,OF=0,AF 无定义。 2) OR 指令 格式:OR 目的操作数,源操作数。 功能:逻辑或。执行按位“逻辑或”操作,目的操作数∨源操作数⇒目的操作数。 操作数的寻址方式: OR reg, reg/mem/imm; OR mem, reg/mem。 根据结果设置 SF, ZF 和 PF,CF=0,OF=0,AF 无定义。 3) NOT 指令 格式:NOT 目的操作数。 功能:逻辑非指令。执行按位取反操作,即:¬目的操作数⇒目的操作数。 操作数的寻址方式:NOT reg/mem。 不影响标志位。 4) XOR 指令(eXclusive OR) 格式:XOR 目的操作数,源操作数。 功能:逻辑异或。执行按位“逻辑异或”操作,目的操作数∀源操作数⇒目的操作数。 操作数的寻址方式: XOR reg, reg/mem/imm; XOR mem, reg/mem。 根据结果设置,SF、ZF 和 PF,CF=0,OF=0,AF 无定义。 5) TEST 指令 格式:TEST 目的操作数,源操作数。 功能:测试指令。按位逻辑与进行测试,根据目的操作数与源操作数的逻辑与运算结果
设置标志位。 操作数的寻址方式为:TEST reg, reg/mem/imm; TEST mem, reg/mem。 根据结果设置 SF, ZF 和 PF,CF=0,OF=0,AF 无定义。 TEST 与 AND 都是两操作数按位“逻辑与”,但 TEST 的结果不保存。

汇编语言程序设计
·56·
例 4.29 指出下列指令执行逻辑指令时的状态变化。 MOV AX, 43E9h ; 43E9h⇒AX AND AX, AX ; AX无变化,但 CF=OF=0,SF=0,ZF=0,PF=0 AND AL, 6Eh ; b0,b4,b7清 0,AL:68h,CF=OF=0,SF=0,ZF=0,PF=0 OR AH, AH ; AH无变化,CF=OF=0,SF=0,ZF=0,PF=0 OR AH,80h ; b7置 1,AH:C3h,CF=OF=0,SF=1,ZF=0,PF=1 XOR AX, 304h b2,b8,b9变反,AX:C06Ch,CF=OF=0,SF=1,ZF=0,PF=1 NOR AX ; AX各位取反,AX:3F93h,标志位无变化 例 4.30 80x86 标志寄存器中,DF, TF, IF 和 SF 分别对应位 8, 10, 9 和 7。若将 DF, TF
清 0,IF 置 1,SF 变反,其余保持不变,则可用如下的指令序列: PUSHF ; 标志寄存器低 16位进栈 POP AX ; 标志寄存器低 16位⇒AX AND AX, 0FAFFh ; b8,b10清 0,即 DF和 TF清 0 OR AX, 0200h ; b9置 1,即 IF置 1 XOR AX, 0080h ; b7变反,即 SF变反 PUSH AX POPF ; 从堆栈中弹出 16位数据⇒标志寄存器低 16位
2. 移位指令
移位指令包括:逻辑移位指令、算术移位指令和循环移位指令。这些指令都是按指令规
定的方式,对目的操作数执行向左或向右移动若干个二进制位数的操作。 双操作数移位指令格式是:
指令助记符 reg/mem, imm8/CL (对于 8086,imm8 只能取 1) 三操作数的双精度移位指令格式是:(80386 及后续 CPU 提供)
指令助记符 reg/mem, reg, imm8/CL 1) SHL 指令(SHift logical Left) 格式:SHL 目的操作数,移动位数。 功能:逻辑左移指令。目的操作数逻辑左移, 后移出的位进入 CF, 低位用 0 填充,
如图 4.7(a)所示。 操作数的寻址方式为:SHL reg/mem, imm8/CL。 本指令影响 CF, OF, SF, ZF, PF,而 AF 不确定。其中 OF 在左移 1 位时有效,否则不确定。
左移 1 位后,若符号位改变,则 OF=1,否则 OF=0。 2) SHR 指令(SHift logical Right) 格式:SHR 目的操作数,移动位数。 功能:逻辑右移指令。目的操作数逻辑右移, 后移出的位进入 CF, 高位用 0 填充,
如图 4.7(b)所示。 操作数的寻址方式为:SHR reg/mem, imm8/CL。 本指令影响 CF, OF, SF, ZF, PF,而 AF 不确定。其中 OF 在右移 1 位时有效,否则不确定。
右移 1 位后符号位改变,则 OF=1,否则 OF=0。 3) SAL 指令(Shift Arithmetic Left) 格式:SAL 目的操作数,移动位数。 功能:算术左移指令。SAL 与 SHL 是同一条指令,即一个操作码对应的两个助记符。
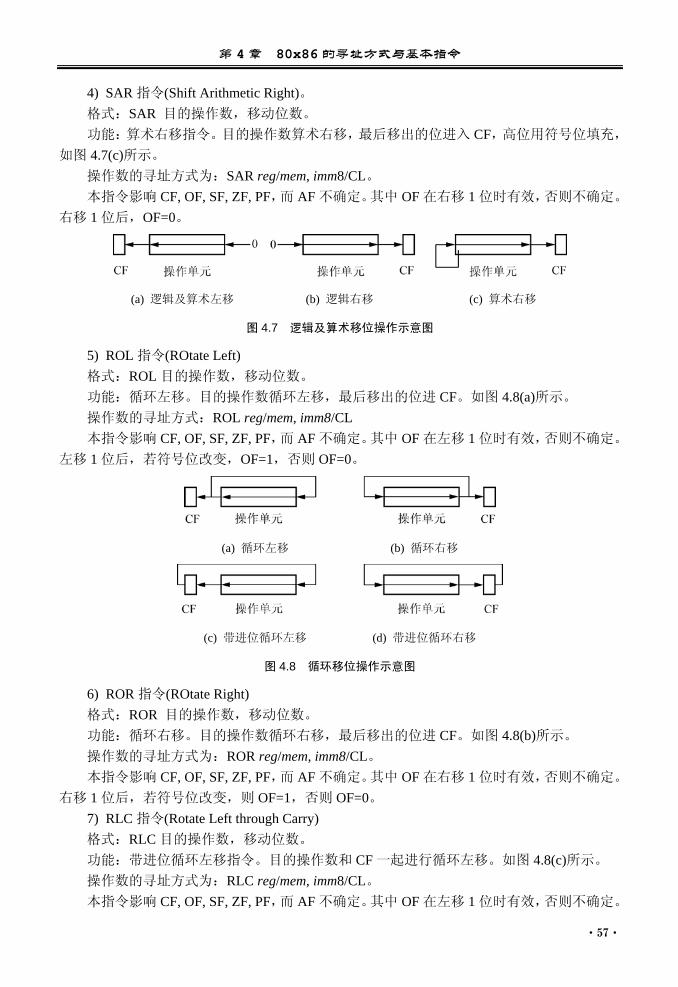
第 4 章 80x86 的寻址方式与基本指令
·57·
4) SAR 指令(Shift Arithmetic Right)。 格式:SAR 目的操作数,移动位数。 功能:算术右移指令。目的操作数算术右移, 后移出的位进入 CF,高位用符号位填充,
如图 4.7(c)所示。 操作数的寻址方式为:SAR reg/mem, imm8/CL。 本指令影响 CF, OF, SF, ZF, PF,而 AF 不确定。其中 OF 在右移 1 位时有效,否则不确定。
右移 1 位后,OF=0。
(a) 逻辑及算术左移 (b) 逻辑右移 (c) 算术右移
图 4.7 逻辑及算术移位操作示意图
5) ROL 指令(ROtate Left) 格式:ROL 目的操作数,移动位数。 功能:循环左移。目的操作数循环左移, 后移出的位进 CF。如图 4.8(a)所示。 操作数的寻址方式:ROL reg/mem, imm8/CL 本指令影响 CF, OF, SF, ZF, PF,而 AF 不确定。其中 OF 在左移 1 位时有效,否则不确定。
左移 1 位后,若符号位改变,OF=1,否则 OF=0。
(a) 循环左移 (b) 循环右移
(c) 带进位循环左移 (d) 带进位循环右移
图 4.8 循环移位操作示意图
6) ROR 指令(ROtate Right) 格式:ROR 目的操作数,移动位数。 功能:循环右移。目的操作数循环右移, 后移出的位进 CF。如图 4.8(b)所示。 操作数的寻址方式为:ROR reg/mem, imm8/CL。 本指令影响 CF, OF, SF, ZF, PF,而 AF 不确定。其中 OF 在右移 1 位时有效,否则不确定。
右移 1 位后,若符号位改变,则 OF=1,否则 OF=0。 7) RLC 指令(Rotate Left through Carry) 格式:RLC 目的操作数,移动位数。 功能:带进位循环左移指令。目的操作数和 CF 一起进行循环左移。如图 4.8(c)所示。 操作数的寻址方式为:RLC reg/mem, imm8/CL。 本指令影响 CF, OF, SF, ZF, PF,而 AF 不确定。其中 OF 在左移 1 位时有效,否则不确定。

汇编语言程序设计
·58·
左移 1 位后,若符号位改变,则 OF=1,否则 OF=0。 8) RRC 指令(Rotate Right through Carry) 格式:RRC 目的操作数,移动位数。 功能:带进位循环右移指令。目的操作数和 CF 一起进行循环右移。如图 4.8(d)所示。 操作数的寻址方式为:RCR reg/mem, imm8/CL。 本指令影响 CF, OF, SF, ZF, PF,而 AF 不确定。其中 OF 在右移 1 位时有效,否则不确定。
右移 1 位后,若符号位改变,则 OF=1,否则 OF=0。 9) SHLD 指令(SHift Left Double) 格式:SHLD reg/mem, reg, imm8/CL。 功能:双精度左移指令。第一操作数左移 n 位,其“空出”的低位由第二操作数的高 n
位来填补,第二操作数内容不变。如图 4.9(a)所示.。操作数只能是 16 位、32 位。 本指令影响 CF, SF, ZF, PF,而 AF, OF 不确定。 10) SHRD 指令(SHift Right Double) 格式:SHRD reg/mem, reg, imm8/CL。 功能:双精度右移指令。第一操作数右移 n 位,其“空出”的高位由第二操作数的低 n
位来填补,第二操作数内容不变。如图 4.9(b)所示。操作数只能是 16 位、32 位。 本指令影响 CF, SF, ZF, PF,而 AF, OF 不确定。
图 4.9 双精度移位操作示意图
例 4.31 ECX=9F801E05h,ESI=1000h,字单元[1000h]内容是 8064h,双字单元[2000h]和[4000h]内容为 4B383709h 和 51476162h。写出执行下列每条指令的内容变化。
SAR BytePtr[ESI], CL ;算术右移 5位,相当于除以 25,100(64h)÷25的商为 3 ;此指令执行后,字单元[1000h]内容为:8003h SHL ESI, 2 ;左移 2位,相当于乘以 4,执行后,ESI内容为:4000h SHLD [ESI], ECX, 12 ;执行后,双字单元[4000h]内容为: 761629F8h,ECX内容不变 SHRD SI, CX, 4 ;ESI内容:5400h 左移 n 位相当于乘以 2n,右移 n 位相当于除以 2n,也就是说,用移位指令可以完成乘、
除 2n 运算。由于移位指令的执行速度大大快于乘、除运算指令,所以,对于乘、除 2n的运算,
宜用移位指令实现。
3. 位扫描指令
1) BSF 指令(Bit Scan Forward) 格式:BSF reg, reg/mem。 功能:正向位扫描指令。按由低位向高位扫描,在第二个操作数中找“1”的位置。若找
到,则首个 1 的位置存入目的寄存器,置 ZF 为 1,否则置 ZF 为 0,且目的寄存器内容不确
定。操作数是 16 位、32 位。影响 ZF,其余不确定。 2) BSR 指令(Bit Scan Reverse) 格式:BSF reg, reg/mem。 功能:反向位扫描指令。按由高位向低位扫描,在第二个操作数中找“1”的位置。若找

第 4 章 80x86 的寻址方式与基本指令
·59·
到,则首个 1 的位置存入目的寄存器,置 ZF 为 1,否则置 ZF 为 0,且目的寄存器内容不确
定。操作数是 16 位、32 位。影响 ZF,其余不确定。 例如,若 EAX 内容为 1A2B1234h,分别执行下列指令。 BSF ECX, EAX ; 指令执行后,ECX=00000002h BSR ECX, EAX ; 指令执行后,ECX=0000001Ch(28)
4. 位测试指令
1) BT 指令(Bit Test) 格式:BT reg/mem, imm/reg。 功能:将 reg/mem 中由 imm/reg 指定的位存入 CF。 2) BTR 指令(Bit Test and Reset) 格式:BTR reg/mem, imm/reg。 功能:将 reg/mem 中由 imm/reg 指定的位存入 CF,目的操作数的该位置 0。 3) BTS 指令(Bit Test and Set) 格式:BTS reg/mem, imm/reg。 功能:将 reg/mem 中由 imm/reg 指定的位存入 CF,目的操作数的该位置 1。 4) BTC 指令(Bit Test and Complement) 格式:BTC reg/mem, imm/reg。 功能:将 reg/mem 中由 imm/reg 指定的值存入 CF,目的操作数的该位变反。 说明:① 本组指令中操作数为 16 位、32 位。② 影响 CF,其余不确定。③ 目的操作数
是寄存器,位置范围:0~31;若是内存操作数,其范围可以大于 31。 例如,若 EAX 内容为 1A2B1234h,分别执行下列指令。 BT EAX, 2 ; 指令执行后, CF=1,EAX=1A2B1234h BTR EAX, 10 ; 指令执行后, CF=0,EAX=1A2B1234h BTS EAX, 14 ; 指令执行后, CF=0,EAX=1A2B5234h BTC EAX, 2 ; 指令执行后, CF=0,EAX=1A2B1230h
4.2.5 串处理指令
串处理指令的实质是对内存块中的数据进行处理。在处理过程中,使用隐含方式指示内
存块起始地址:源内存块的开始地址隐含由指针 DS:(E)SI 指示;目的内存块的开始地址隐含
由指针 ES:(E)DI 来指示。 处理的数据单位可以是:1 字节、2 字节(字)或 4 字节(双字),处理的方向由 DF 决定。当
DF=0 时,正向处理:每执行一次串操作后,(E)SI 及(E)DI 内容增∆(1, 2, 4);当 DF=1 时,反
向处理:每执行一次串操作后,(E)SI 及(E)DI 内容减∆(1, 2, 4)。 在 80x86 中,专门用于将 DF 清 0 的指令是 CLD(CLear Direction Flag);专门用于将 DF
置 1 的指令是 STD(SeT Direction flag)。 串处理指令经常与串重复前缀指令配合使用,此时,(E)CX 存放的是待处理的单元数(字
节数/字数/双字数),即重复次数由(E)CX 决定。 串处理指令有:MOVS 串传送、STOS 存串、LODS 取串、CMPS 串比较、SCAS 串扫描、
INS 串端口输入、OUTS 串端口输出。串重复前缀有:REP 重复、REPE/REPZ 相等/为零时重
复、REPNE/REPNZ 不等/不为零时重复。下面将这些内容分两组来介绍。

汇编语言程序设计
·60·
1. 能与 REP 配合使用的 MOVS, STOS, LODS, INS 和 OUTS 指令
REP 的功能是:重复执行其后的串处理指令 n 次,重复次数 n 预先存于(E)CX。注意,
当 n 为 0 时,不执行其后的串指令。 格式:REP MOVS/STOS/LODS/INS/OUTS。 1) MOVS 指令(MOVe String by Byte / Word / Double word) 格式:MOVSB/MOVSW/MOVSD。 功能:串传送指令。把由 DS:(E)SI 指向的 1/2/4 字节内存单元内容,传送到由 ES:(E)DI
指向的 1/2/4 字节内存单元,再根据 DF 所确定的方向来调整(E)SI 和(E)DI 指针,使之指向下
一个传送单元,即:若 DF=0,正向传送,(E)SI+1/2/4⇒(E)SI,(E)DI+1/2/4⇒(E)DI;若 DF=1,反向传送,(E)SI-1/2/4⇒(E)SI,(E)DI-1/2/4⇒(E)DI。
本组指令的操作数采用隐含寻址方式,所以,在使用串传送指令前,必须已经设置好
DS:(E)SI 和 ES:(E)DI,以及 DF 状态。但(E)SI 可以与其他寄存器组合使用,如在例 4.32 的指
令序列②中,使用 ES:SI 指向源内存块中的单元。 在源程序中,也出现“MOVS 目的操作数,源操作数”这样格式的指令。此处的源、目
的操作数仅仅是个形式,汇编程序根据操作数类型,决定将 MOVS 翻译成 MOVSB,还是
MOVSW 或者 MOVSD。 本组指令不影响标志位。 与 REP 配合使用的指令格式为:REP MOVSB/MOVSW/MOVSD。 功能:重复执行串传送指令,重复次数由计数器((E)CX)的内容决定。执行的效果是:将
源内存块内容传送到目的内存块。 例 4.32 附加段内存区中有一个首地址为 1000h 的、连续 400h 个字节单元的内存块。编
写指令序列,将这 400 字节数据传送到首地址为 2000h 的内存块中。 解:400h 字节单元,用字节串传送指令(MOVSB),须重复传送 400h 次;用 2 字节串传
送指令(MOVSW),须重复传送 200h;用 4 字节串传送指令(MOVSD),必须重复传送 100h。下面使用串重复前缀 REP,按正向和反向传送方式,实现内存块数据的传送。读者从中可以
学习 MOVS 指令的使用方法,也可复习其他指令的使用方法。 ① 使用 REP MOVSB,正向方式传送。在 16 的地址模式下,编制的指令如下。 PUSH DS ; 由于要修改 DS的内容,故先保存 DS,以便以后恢复 CLD ; 置 DF为 0,即设置为正向传送方式 MOV AX, ES ; ES⇒AX MOV DS, AX ; AX⇒DS MOV SI, 1000h ; DS:SI指向源内存块开始传送的字节单元地址 MOV DI, 2000h ; ES:DI指向目的内存块开始接收的字节单元地址(ES不须重置) MOV CX, 400h ; 传送的字节单元的个数,即重复次数 REP MOVSB ; 重复执行字节串传送,正向传送内存块,即 DS:[SI]⇒ES:[DI] POP DS ; 处理完毕,恢复 DS以前的内容 REP MOVSB 前若干指令主要是准备 DS:SI,ES:DI,CX 等内容。REP MOVSB 是重复执
行 MOVSB 指令 400h 次,每执行 1 次,SI 和 DI 自动增 1,以便指向下一个处理单元。执行
1 次 MOVSB 后,状态如图 4.10(b)所示,执行 400h 次 MOVSB 后,即 REP MOVSB 执行完毕
后,它的状态如图 4.10(c)所示。

第 4 章 80x86 的寻址方式与基本指令
·61·
SI→ ## 1000h DI→ 2000h ## 1000h ## 2000h ## 1000h ## 2000h ## 1001h 2001h SI→ ## 1001h DI→ 2001h ## 1001h ## 2001h … … … … ## 13FFh 23FFh ## 13FFh 23FFh ## 13FFh ## 23FFh 1400h 2400h 1400h 2400h SI→ 1400h DI→ 2400h (a) 初始状态 (b) 执行 1 次 MOVSB (c) REP MOVSB 执行后
图 4.10 正向 REP MOVSB 指令的执行示意图
② 使用 REP MOVSW,正向方式传送。在 16 的地址模式下,编制的指令如下。 CLD ; 置 DF为 0,即设置为正向传送方式 MOV SI, 1000h ; ES:SI指向源内存块开始传送的字单元地址 MOV DI, 2000h ; ES:DI指向目的内存块开始接收的字单元地址(ES不需设置) MOV CX, 200h ; 传送的字单元的个数, 即重复次数 REP MOVS Word Ptr[DI],ES:[SI] ; 重复执行字串传送指令,即 ES:[SI]⇒ES:[DI] REP ES:MOVSW 是重复执行 MOVSW 指令 200h 次,每执行 1 次,SI 和 DI 自动增 2,
以便指向下一个处理单元。执行 1 次 ES:MOVSW 后,状态如图 4.11(b)所示,执行 200h 次
MOVSW 后,即 REP ES:MOVSW 执行完毕后,它的状态如图 4.11(c)所示。
SI→ ## 1000h DI→ 2000h ## 1000h ## 2000h ## 1000h ## 2000h ## 1001h 2001h ## 1001h ## 2001h ## 1001h ## 2001h ## 1002h 2002h SI→ ## 1002h DI→ 2002h ## 1002h ## 2002h ## 1003h 2003h ## 1003h 2003h ## 1003h ## 2003h … … … … ## 13FEh 23FEh ## 13FEh 23FEh ## 13FEh ## 23FEh ## 13FFh 23FFh ## 13FFh 23FFh ## 13FFh ## 23FFh 1400h 2400h 1400h 2400h SI→ 1400h DI→ 2400h (a) 初始状态 (b) 执行 1 次 ES:MOVSW (c) REP ES:MOVSB 执行后
图 4.11 正向 REP MOVSW 指令的执行示意图
③ 使用 REP MOVSW,反向方式传送。在 32 的地址模式下,编制的指令如下。 STD ; 置 DF为 1, 即设置为反向传送方式 MOV ESI, 13FEh ; ES:ESI指向源内存块开始传送的字单元地址 MOV EDI, 23FEh ; ES:EDI指向目的内存块开始接收的字单元地址(ES不须重置) MOV CX, 200h ; 传送的字单元的个数,即重复次数 REP MOVS Word Ptr[EDI],ES:[ESI] ;重复执行字串传送,即 ES:[ESI]⇒ES:[EDI] 与②类似但方向相反,每执行 1 次,ESI 和 EDI 自动减 2,以便指向下一个处理单元。执
行 1 次 ES:MOVSW 后,状态如图 4.12(b)所示,执行 200h 次 MOVSW 后,即 REP ES:MOVSW执行完毕后,它的状态如图 4.12(c)所示。
④ 使用 REP MOVSD,正向方式传送。在 32 的地址模式下,编制的指令如下。 CLD ; 置 DF为 0,即设置为正向传送方式 MOV SI, 1000h ; DS:SI指向源内存块开始传送的字节单元地址 MOV DI, 2000h ; ES:DI指向目的内存块开始接收的字节单元地址(ES不须设置) MOV CX, 100h ; 传送的 4字节单元的个数,即重复次数 REP MOVS DWord Ptr[EDI],ES:[ESI] ;重复执行双字串传送,即 ES:[ESI]⇒ES:[EDI] 与③类似但处理的是 4 字节单元。每执行 1 次,ESI 和 EDI 自动加 4,以便指向下一个 4
字节(双字)单元。
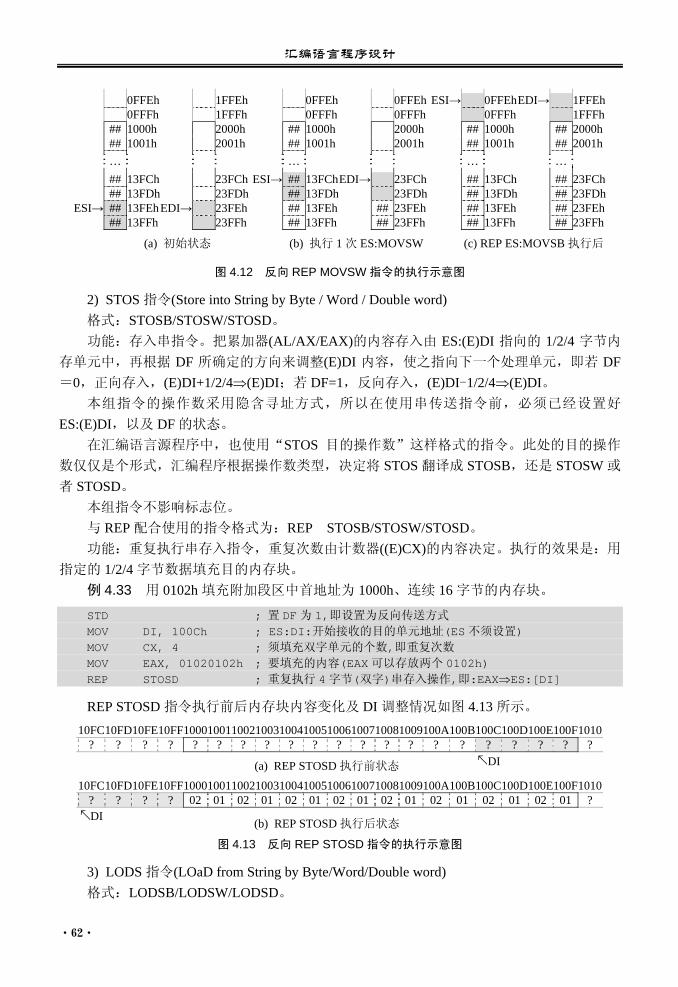
汇编语言程序设计
·62·
0FFEh 1FFEh 0FFEh 0FFEh ESI→ 0FFEh EDI→ 1FFEh 0FFFh 1FFFh 0FFFh 0FFFh 0FFFh 1FFFh
## 1000h 2000h ## 1000h 2000h ## 1000h ## 2000h ## 1001h 2001h ## 1001h 2001h ## 1001h ## 2001h … … … … ## 13FCh 23FCh ESI→ ## 13FChEDI→ 23FCh ## 13FCh ## 23FCh ## 13FDh 23FDh ## 13FDh 23FDh ## 13FDh ## 23FDhESI→ ## 13FEh EDI→ 23FEh ## 13FEh ## 23FEh ## 13FEh ## 23FEh ## 13FFh 23FFh ## 13FFh ## 23FFh ## 13FFh ## 23FFh
(a) 初始状态 (b) 执行 1 次 ES:MOVSW (c) REP ES:MOVSB 执行后
图 4.12 反向 REP MOVSW 指令的执行示意图
2) STOS 指令(Store into String by Byte / Word / Double word) 格式:STOSB/STOSW/STOSD。 功能:存入串指令。把累加器(AL/AX/EAX)的内容存入由 ES:(E)DI 指向的 1/2/4 字节内
存单元中,再根据 DF 所确定的方向来调整(E)DI 内容,使之指向下一个处理单元,即若 DF=0,正向存入,(E)DI+1/2/4⇒(E)DI;若 DF=1,反向存入,(E)DI-1/2/4⇒(E)DI。
本组指令的操作数采用隐含寻址方式,所以在使用串传送指令前,必须已经设置好
ES:(E)DI,以及 DF 的状态。 在汇编语言源程序中,也使用“STOS 目的操作数”这样格式的指令。此处的目的操作
数仅仅是个形式,汇编程序根据操作数类型,决定将 STOS 翻译成 STOSB,还是 STOSW 或
者 STOSD。 本组指令不影响标志位。 与 REP 配合使用的指令格式为:REP STOSB/STOSW/STOSD。 功能:重复执行串存入指令,重复次数由计数器((E)CX)的内容决定。执行的效果是:用
指定的 1/2/4 字节数据填充目的内存块。 例 4.33 用 0102h 填充附加段区中首地址为 1000h、连续 16 字节的内存块。 STD ; 置 DF为 1,即设置为反向传送方式 MOV DI, 100Ch ; ES:DI:开始接收的目的单元地址(ES不须设置) MOV CX, 4 ; 须填充双字单元的个数,即重复次数 MOV EAX, 01020102h ; 要填充的内容(EAX可以存放两个 0102h) REP STOSD ; 重复执行 4字节(双字)串存入操作,即:EAX⇒ES:[DI] REP STOSD 指令执行前后内存块内容变化及 DI 调整情况如图 4.13 所示。
10FC 10FD10FE 10FF1000100110021003100410051006100710081009100A100B100C100D 100E100F 1010 ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? (a) REP STOSD 执行前状态 DI
10FC 10FD10FE 10FF1000100110021003100410051006100710081009100A100B100C100D 100E100F 1010 ? ? ? ? 02 01 02 01 02 01 02 01 02 01 02 01 02 01 02 01 ? DI
(b) REP STOSD 执行后状态
图 4.13 反向 REP STOSD 指令的执行示意图
3) LODS 指令(LOaD from String by Byte/Word/Double word) 格式:LODSB/LODSW/LODSD。

第 4 章 80x86 的寻址方式与基本指令
·63·
功能:从串取指令。把由 DS:(E)SI 指向的 1/2/4 字节内存单元中的内容传送到累加器
(AL/AX/EAX),再根据 DF 所确定的方向来调整(E)SI 内容,使之指向下一个处理单元,即若
DF=0,正向读取,(E)SI+1/2/4⇒(E)SI;若 DF=1,反向读取,(E)SI-1/2/4⇒(E)SI。 本组指令的操作数采用隐含寻址方式,所以在使用串传送指令前,必须已经设置好
DS:(E)SI,以及 DF 的状态。但指令也可使用非默认的寄存器(使用方法参考例 4.32)。 在汇编语言源程序中,有时也用“LODS 源操作数”这样格式的指令。此处的源操作数
仅仅是个形式,汇编程序根据操作数类型,决定将 LODS 翻译成 LODSB,还是 LODSW 或者
LODSD。 本组指令不影响标志位。 与 REP 配合使用的指令格式为:REP LODSB/LODSW/LODSD。 但是,REP LODS 没有实际意义,所以一般不使用这种形式。 例 4.34 数据段区首地址为 1000h 的 8 字节内存块中存放的是 ASCII 码,将它们转换成
小写形式,再存于附加段区首地址为 2000h 的 8 字节内存块中。指令如下: CLD ; 置 DF为 0,即设置为正向传送方式 MOV SI, 1000h ; DS:SI:源内存块首地址(DS不须设置) MOV DI, 2000h ; ES:DI:目的内存块首地址(ES不须设置) LODSD ; DS:[SI]⇒EAX,SI+4⇒SI,EAX中有 4个 ASCII码 OR EAX, 20202020h ; 设置为小写(小写 ASCII码 b5=1,大写 b5=0),一次转换 4个 STOSD ; EAX⇒ES:[DI],DI+4⇒DI,即保存 4个 ASCII码 LODSD ; DS:[SI]⇒EAX,SI+4⇒SI,EAX中有 4个 ASCII码 OR EAX, 20202020h ; 设置为小写字母(小写 ASCII码 b5=1,大写 b5=0) STOSD ; EAX⇒ES:[DI],DI+4⇒DI,即保存 4个 ASCII码 4) INS 指令(INput from port to String by Byte / Word / Double word) 格式:INSB/INSW/INSD。 功能:端口输入串指令。把由 DX 指定的 1/2/4 字节宽度的端口中数据传送到 ES:(E)DI
所指向的 1/2/4 字节内存单元中,再根据 DF 所确定的方向来调整(E)DI 内容,使之指向下一
个处理单元,即若 DF=0,正向读取, (E)DI+1/2/4⇒(E)DI;若 DF=1,反向读取,
(E)DI-1/2/4⇒(E)DI。 本组指令的操作数采用隐含寻址方式,所以在使用串传送指令前必须已经设置好
ES:(E)DI,以及 DF 的状态。 在汇编语言源程序中,有时也使用“INS 目的操作数,DX”这样格式的指令。此时,目
的操作数仅仅是个形式,汇编程序根据操作数类型,决定将 INS 翻译成 INSB,还是 INSW 或
者 INSD。 本组指令不影响标志位。 与 REP 配合使用的指令格式为:REP INSB/INSW/INSD。 功能:重复执行 INS 指令,重复次数由计数器((E)CX)的内容决定。执行的效果是:连续
从端口输入数据,传送到目的内存块中。 注意,使用串重复前缀 REP 前,重复次数必须已经存于计数器中。 需要注意的是,I/O 端口处理速度必须能与 REP INS 执行速度相匹配,否则不能保证输
入数据串的正确性。一般情况下,I/O 处理速度远远慢于 CPU 指令的速度,所以在应用中,
很少使用 REP INS。

汇编语言程序设计
·64·
5) OUTS 指令(OUTput String to port by Byte/Word/Double word) 格式:OUTSB/OUTSW/OUTSD。 功能:串端口输出指令。把由 DS:(E)SI 所指向的 1/2/4 字节内存单元中的内容传送到由
DX 指定的 1/2/4 字节宽度端口中去,再根据 DF 所确定的方向来调整(E)SI 内容,使之指向下
一个处理单元,即若 DF=0,正向读取, (E)SI+1/2/4⇒(E)SI;若 DF=1,反向读取,
(E)SI-1/2/4⇒(E)SI。 本组指令的操作数采用隐含寻址方式,所以在使用串传送指令前,必须已经设置好
DS:(E)SI,以及 DF 的状态。但指令也可使用非默认的寄存器(使用方法参考例 4.32)。 在汇编语言源程序中,有时也使用“OUTS DX,源操作数”这样格式的指令。此处的源
操作数仅仅是个形式,汇编程序根据操作数类型,决定将 OUTS 翻译成 OUTSB,还是 OUTSW或者 OUTSD。
本组指令不影响标志位。 与 REP 配合使用的指令格式为:REP OUTSB/OUTSW/OUTSD。 功能:重复执行 OUTS 指令,重复次数由计数器((E)CX)的内容决定。执行的效果是:连
续把源内存块的数据传送到 I/O 端口中去。 需要注意的是,I/O 端口处理速度必须能与 REP OUTS 执行速度相匹配,否则 I/O 接口不
能正确处理输出数据。一般情况下,I/O 处理速度远远慢于 CPU 指令的速度,所以在应用中,
很少使用 REP OUTS。
2. 能与 REPE/REPZ 和 REPNE/REPNZ 配合使用的 CMPS 和 SCAS
REPE 与 REPZ 是一个操作码对应的两个助记符,它们的功能完全相同:重复执行其后的
串处理指令 n 次,重复执行期间,若 ZF=0,即退出,重复次数 n 要预先存于(E)CX。显然当
n=0 时,不执行其后的串指令;当 n≠0 时,其后的串指令 多被执行 n 次。 格式:REPE/REPZ CMPS/SCAS。 REPNE 与 REPNZ 也是一个操作码对应的两个助记符,它们的功能完全相同:重复执行
其后的串处理指令 n 次,期间若 ZF=1,即退出,重复次数 n 要预先存于(E)CX。显然, 当 n=0 时,不执行其后的串指令;当 n≠0 时,其后的串指令 多被执行 n 次。
格式:REPNE/REPNZ CMPS/SCAS。 1) CMPS 指令(CoMP String by Byte/Word/Double word) 格式:CMPSB/CMPSW/CMPSD。 功能:串比较指令。把由 DS:(E)SI 指向的一个 1/2/4 字节内存单元的内容与由 ES:(E)DI
指向的同类型单元的内容相减,据此设置各标志位,然后根据 DF 所确定的方向来调整(E)SI和(E)DI 的内容,使之指向下一个处理单元,即若 DF=0,正向比较,(E)SI+1/2/4⇒(E)SI,(E)DI+1/2/4⇒(E)DI;若 DF=1,反向比较,(E)SI-1/2/4⇒(E)SI,(E)DI-1/2/4⇒(E)DI。
本组指令的操作数采用隐含寻址方式,所以在使用串传送指令前,必须已经设置好
DS:(E)SI 和 ES:(E)DI,以及 DF 的状态。 在汇编源程序中,有时用“CMPS 目的操作数,源操作数”这样格式的指令。此处的源、
目的操作数仅仅是个形式,汇编程序根据操作数类型,将 CMPS 翻译成 CMPSB,还是 CMPSW或者 CMPSD。
本组指令影响 CF, PF, AF, ZF, SF 和 OF,其中 ZF 有实际意义。

第 4 章 80x86 的寻址方式与基本指令
·65·
与 REPE/REPZ 配合使用的指令格式为:REPE/REPZ CMPSB/CMPSW/CMPSD。 功能:重复执行串比较指令,重复次数由(E)CX 决定,直到 ZF=0 时退出执行。执行的
效果是:源内存块和目的内存块逐个单元内容相比较,直到不同为止。 与 REPNE/REPNZ 配合使用的指令格式为:REPNE/REPNZ CMPSB/CMPSW/CMPSD。 功能:重复执行串比较指令,重复次数由(E)CX 决定,直到 ZF≠0 时退出执行。执行的
效果是:源内存块和目的内存块逐个单元内容相比较,直到相同为止。 2) SCAS 指令(SCAn String by Byte/Word/Double word) 格式:SCASB/SCASW/SCASD。 功能:串扫描指令。把累加器(AL/AX/EAX)内容与由 ES:(E)DI 指向的同类型的 1/2/4 字
节内存单元内容相减,据此设置标志位,然后根据 DF 所确定的方向来调整(E)DI 的内容,使
之指向下一个内存单元,即:若 DF=0,正向扫描,(E)DI+1/2/4⇒(E)DI;若 DF=1,反向扫
描,(E)DI-1/2/4⇒(E)DI。 本组指令的操作数采用隐含寻址方式,所以在使用串传送指令前,必须已经设置好
ES:(E)DI,以及 DF 的状态。 在汇编语言源程序中,使用“SCAS 目的操作数”这样格式的指令。此时,目的操作数
仅仅是个形式,汇编程序根据操作数类型,决定将 SCAS 翻译成 SCASB,还是 SCASW 或者
SCASD。 本组指令影响 CF, PF, AF, ZF, SF 和 OF,其中 ZF 有实际意义。 与 REPE/REPZ 配合使用的指令格式为:REPE/REPZ SCASB/SCASW/SCASD。 功能:重复执行串扫描指令,重复次数由(E)CX 决定,直到 ZF=0 时退出执行。执行的
效果是:累加器和目的内存块逐个单元的内容相比较,直到不同为止。 与 REPNE/REPNZ 配合使用的指令格式为:REPNE/REPNZ SCASB/SCASW/SCASD。 功能:重复执行串扫描指令,重复次数由(E)CX 决定,直到 ZF≠0 时退出执行。执行的
效果是:累加器和目的内存块逐个单元的内容相比较,直到相同为止。 例 4.35 若数据段区部分内容如下,指出各指令序列的功能及执行后的相应状态。
… 1000
1001
1002
1003
1004
1005
1006
1007
1008
1009
100A
100B
100C
100D
100E
100F
1010
1011
1012
1013
1014
1015
1016
1017
1018
…
… 31 20 72 65 70 65 61 74 20 75 6E 74 69 6C 20 65 71 75 61 6C 00 00 00 00 00 …
… 3000
3001
3002
3003
3004
3005
3006
3007
3008
3009
300A
300B
300C
300D
300E
300F
3010
3011
3012
3013
3014
3015
3016
3017
3018
…
… 32 20 72 65 70 65 61 74 20 75 6E 74 69 6C 20 6E 6F 74 20 65 71 75 61 6C 00 …
;指令序列① ;指令序列② ;指令序列③ ;指令序列④ CLD CLD STD CLD MOV SI, 1000h MOV SI, 1002h MOV AX, 0 MOV AL, 20h MOV DI, 3000h MOV DI, 3002h MOV DI, 1017h MOV DI, 1000h MOV CX, 0Ch MOV CX, 16h MOV CX, 0Ch MOV CX, 16h REPNE CMPSW REPE CMPSB REPE SCASW REPNE SCASB
指令序列①:以字单位正向比较两个内存块,直到找出匹配的位置止。指令序列执行后,
SI=1004h,DI=3004h,CX=0Ah(剩下还未比较的字单元个数),ZF=1。如果行结束后,CX=0且 ZF=0,则说明所有位置上内容都不匹配。
指令序列②:以字节单位正向比较两个内存块,直到找出不匹配的位置止。指令序列执
行后 SI=1010h,DI=3010h,CX=08h(剩下还未比较的字节单元个数),ZF=0。如果执行结束后,
CX=0 且 ZF=1,则说明两个数据块内容相同。

汇编语言程序设计
·66·
指令序列③:以字单位反向扫描内存块,直到找出和 AX 内容不同的单元位置止。指令
序列执行后 DI=1011h,CX=9h(剩下还未比较的字单元个数),ZF=0。如果执行结束后,CX=0且 ZF=1,则说明内存块所有单元的内容与 AX 相同。
指令序列④:以字节单位正向扫描内存块,直到找出和 AL 内容相同的单元位置止。指
令序列执行后,DI=1011h,CX=14h(剩下还未比较的单元个数),ZF=1。如果执行结束后,CX=0且 ZF=0,则说明 AL 中内容在内存块中未出现。
4.3 控制转移类指令
在 80x86 系统中,处理器的 CS:(E)IP(32 位地址模式用 EIP,16 位地址模式用 IP)总是指
向下一条要执行的指令在内存中的地址,因而,控制转移指令实际上通过改变 CS:(E)IP 来达
到控制程序的执行流程。这类指令包括:无条件转移指令、条件转移指令、循环指令、子程
序调用和返回指令,以及中断调用和中断返回指令。 如果控制转移指令仅能改变(E)IP,则是近转移或段内转移;如果既可改变(E)IP,又可改
变 CS,则是远转移或段间转移。
4.3.1 无条件转移指令
80x86 指令系统中,JMP(JUMP)类指令是无条件转移指令。 格式:JMP 目标地址。 功能:无条件转移指令。无条件转移到目标地址,执行从该地址开始的指令序列。 目标地址有两种寻址方式,一种是直接寻址方式:目标地址作为指令的一部分,直接存
放在操作码后面,如图 4.14 中的虚线方框标注的 JMP 指令;另一种是间接寻址方式:目标地
址存放在寄存器或内存单元中,如图 4.14 中的实线方框标注的 JMP 指令。 图 4.14 仅仅为了说明 JMP 指令格式,在实际程序中不会出现如此“糟糕”的转移代码。
示例中有两个代码段:由 CS 指示的段(左边部分,正在执行的代码段)和由段地址 0011 指示
的段(右边部分)。注意,这段代码并不是汇编语言源代码,而是机器指令的“反汇编”(仅用
指令助记符表示的机器指令,没有符号地址)。下面在此示例代码基础上,说明 JMP 指令格式
及其汇编指令的用法。
地址 机器指令 汇编指令 地址 机器指令 汇编指令 CS:0100 2B C0 SUB AX, AX 0011:0168 C3 RET CS:0102 05 34 12 ADD AX, 1234 0011:0169 90 NOP CS:0105 78 03 JS 010A 0011:016A 8B 1E 13 99 MOV BX,[9913]CS:0107 E9 F8 FF JMP Near Ptr 0102 0011:016E 83 FB 00 CMP BX,0 CS:010A 3D 00 A0 CMP AX, A000 0011:0171 7E 13 JLE 0186 CS:010D 77 02 JA 0111 0011:0173 8B 0E E1 99 MOV CX,[99E1]CS:010F EB 10 JMP Short 0121 0011:0177 8B 16 DF 99 MOV DX,[99DF]CS:0111 7B 09 JPO 011C 0011:017B 8B C1 MOV AX,CX CS:0113 2E CS: 0011:017D 0B C2 OR AX,DX CS:0114 FF 2E 18 01 JMP DWord Ptr[0118] 0011:017F 74 05 JZ 0186 CS:0118 87 01 11 00 DB 87,01,11,00 0011:0181 B8 00 42 MOV AX,4200 CS:011C EA 6A 01 11 00 JMP 001A:016A 0011:0184 CD 21 INT 21 CS:0121 BE 00 01 MOV SI, 0100 0011:0186 CC INT 3 CS:0124 FF E6 JMP SI 0011:0187 B4 40 MOV AH,40 CS:0126 CC INT 3 0011:0189 CC INT 3

第 4 章 80x86 的寻址方式与基本指令
·67·
图 4.14 JMP 指令格式的代码示例
1. 直接寻址方式的转移指令
转移的目标地址直接用标号标识出来,其格式为: JMP 标号 此处标号直接标识指令的存放位置。 1) 段内直接近转移 当标号和转移指令同属于一个代码段,就是直接近转移,其格式为: JMP Near Ptr标号 在实际程序中,可直接写成“JMP 标号”形式,这样,只要标号和转移指令是在相同的
代码段,汇编程序就会将它翻译成直接近转移指令。 在直接近转移指令对应的机器指令中,操作码后面是目标的偏移地址的相对位移量,即
目标地址和 JMP 指令的下一条指令的地址的相对位移。目标地址在当前位置之前用负数表示,
在当前位置之后用正数表示,所以操作码后面的位移量用补码表示。 在 16 位地址模式下,操作码后面是一个 8 位或者 16 位补码,对应的转移范围是:-128~
+127 或者-32768~+32767(-32K~+32K-1)个字节;在 32 位地址模式下,操作码后面是一个
8 位或者 32 位补码,对应的转移范围是:-128~+127 或者-2147483648~+2147483647(-2G~
+2G-1)个字节。 例如,图 4.14 中 CS:0107 处的指令“E9 F8 FF”,E9 是操作码,F8 FF 是位移量。补码
FFF8 表示的数是-8,由此算出目标地址为 010Ah-8=0102h。所以机器指令 EB F8 FF 对应汇
编指令为 JMP 0102。 在示例中直接使用地址编号表示转向的目标地址,但是在源程序中则应该用标号来表示,
例如,CS:102~10A 的指令,在汇编源程序中可编写成如下形式: Loc1: ADD AX, 1234h JS Loc2 JMP Near Ptr Loc1 Loc2: CMP AX, 0A000h 特别地,当位移量用 8 位补码表示,这样形式的转移指令称为直接短转移,它的转移目
标范围是:-128~+127 个字节。如图 4.14 中 CS:010F 处的指令“EB 10”,EB 是操作码,10是位移量,由此可以计算出转移的目标地址:0111h+10h=0121h。所以机器指令 EB 10 对应
的汇编指令是 JMP 0121。 短转移指令的格式为:JMP Short 标号。 2) 段间直接远转移 当标号和转移指令不在同一个代码段,就是直接远转移,其格式为: JMP Far Ptr标号 在实际程序中,可直接写成“JMP 标号”的形式,只要标号和转移指令是在不同的代码
段,汇编程序就会将它翻译成直接远转移指令。 在直接远转移指令所对应的机器指令中,操作码后直接存放目标的偏移地址和段地址。
如图 4.14 中 CS:011C 处的指令“EA 6A 01 11 00”,EA 是操作码,6A 01 和 11 00 分别是目

汇编语言程序设计
·68·
标的偏移地址 016A 和 0011。该机器指令对应的汇编格式指令为 JMP 0011:016A。(在汇编源
程序中应该用标号代替目标地址)
2. 间接寻址方式的转移指令
目标地址不直接用标号标识,而是间接地放在寄存器或内存单元中,其格式为: JMP reg/mem 1) 段内间接近转移 寄存器或者内存单元存放的是转移目标的偏移地址。其格式为: JMP reg16/mem16 (16位地址模式) JMP reg32/mem32 (32位地址模式) 如图 4.14 中 CS:0124 处的指令“JMP SI”,此处 SI 中存放的是目标的偏移地址。 2) 段间间接远转移 转移目标的偏移地址和段地址都存放在内存单元中。其格式为: JMP mem32 (16位地址模式,低字是偏移地址,高字是段地址) JMP mem48 (32位地址模式,低 4字节是偏移地址,高字是段选择器) 如图 4.14 中 CS:0113 处的指令“CS:JMP DWord ptr [0118]”,此处双字单元 CS:[0118]
中前两字节存放的是偏移地址,后两字节存放的是段地址。 再如,JMP FWord Ptr 100h[EBX],6 字节单元[EBX+100h]中低 4 字节是转移目标的偏移
地址,高字则是转移目标的段选择器。 说明:所有的直接近转移(包括稍后介绍的条件转移、直接子程序调用等)采用的是相对地
址转移,所以直接近转移指令符合程序的重定位要求;所有的间接转移及直接远转移所用的
是绝对地址转移,所以使用了这些指令的程序是不能够进行重定位的。 在 16 位地址模式下,段内直接转移的目标仅有-32K~+32K-1,所以经常使用远转移指
令;在 32 位地址模式下,段内直接转移的目标范围较大,可确定-2G~+2G-1,所以应用程
序极少使用远转移指令。
4.3.2 条件转移指令
条件转移指令是依据某种特定条件而转移的指令。条件满足时则转移,条件不满足时,
则顺序执行后面的指令。 80x86 条件转移类指令主要是根据一个或多个运算结果标志位的状态来控制程序转移的
一类指令,影响的标志位有:CF, PF, AF, ZF, SF, OF 等,因而条件转移指令有 16 条之多。此
外,还有测试计数器为 0 的转移指令:JCXZ, JECX。 在汇编语言中,虽然各条件转移指令助记符不同,但它的汇编指令格式相似。为简化和
方便说明起见,常用 Jcc 来代表这类指令的助记符。其格式如下: Jcc 标号
其中,Jcc 代表所有条件指令助记符;标号用以标识要转移的目标位置,必须与转移指令同处
于一个代码段(所以是直接近转移)。 所有的条件转移指令都是段内直接近转移,是相对地址转移。在机器指令格式中,目标
地址的相对位移量直接放在指令操作码之后,如图 4.14 中的指令 JS 010A,其转移目标地址
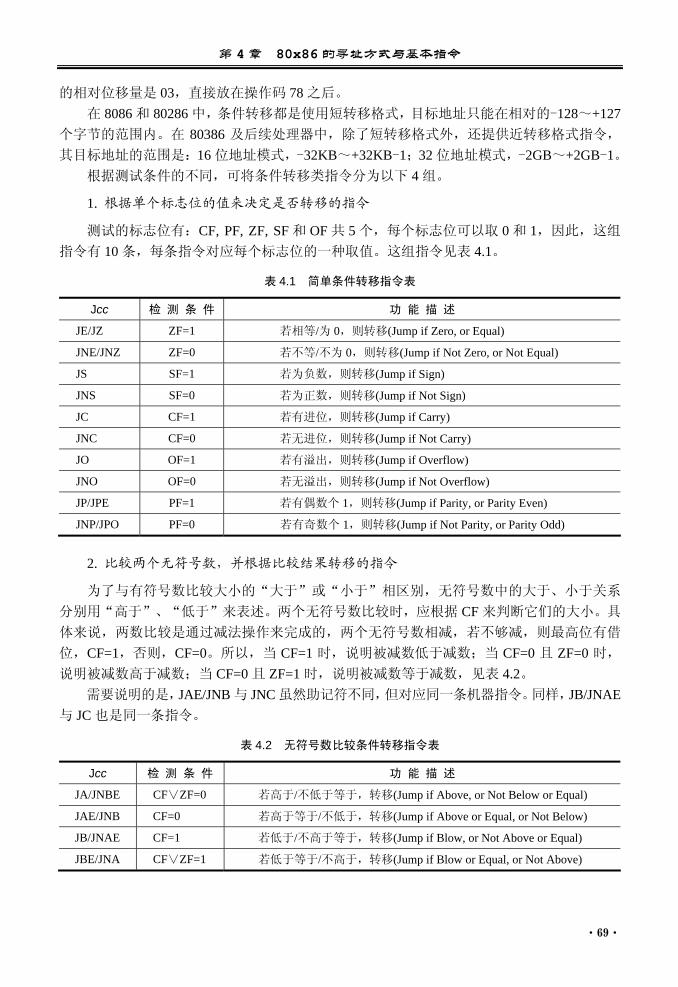
第 4 章 80x86 的寻址方式与基本指令
·69·
的相对位移量是 03,直接放在操作码 78 之后。 在 8086 和 80286 中,条件转移都是使用短转移格式,目标地址只能在相对的-128~+127
个字节的范围内。在 80386 及后续处理器中,除了短转移格式外,还提供近转移格式指令,
其目标地址的范围是:16 位地址模式,-32KB~+32KB-1;32 位地址模式,-2GB~+2GB-1。 根据测试条件的不同,可将条件转移类指令分为以下 4 组。
1. 根据单个标志位的值来决定是否转移的指令
测试的标志位有:CF, PF, ZF, SF 和 OF 共 5 个,每个标志位可以取 0 和 1,因此,这组
指令有 10 条,每条指令对应每个标志位的一种取值。这组指令见表 4.1。
表 4.1 简单条件转移指令表
Jcc 检 测 条 件 功 能 描 述
JE/JZ ZF=1 若相等/为 0,则转移(Jump if Zero, or Equal)
JNE/JNZ ZF=0 若不等/不为 0,则转移(Jump if Not Zero, or Not Equal)
JS SF=1 若为负数,则转移(Jump if Sign)
JNS SF=0 若为正数,则转移(Jump if Not Sign)
JC CF=1 若有进位,则转移(Jump if Carry)
JNC CF=0 若无进位,则转移(Jump if Not Carry)
JO OF=1 若有溢出,则转移(Jump if Overflow)
JNO OF=0 若无溢出,则转移(Jump if Not Overflow)
JP/JPE PF=1 若有偶数个 1,则转移(Jump if Parity, or Parity Even)
JNP/JPO PF=0 若有奇数个 1,则转移(Jump if Not Parity, or Parity Odd)
2. 比较两个无符号数,并根据比较结果转移的指令
为了与有符号数比较大小的“大于”或“小于”相区别,无符号数中的大于、小于关系
分别用“高于”、“低于”来表述。两个无符号数比较时,应根据 CF 来判断它们的大小。具
体来说,两数比较是通过减法操作来完成的,两个无符号数相减,若不够减,则 高位有借
位,CF=1,否则,CF=0。所以,当 CF=1 时,说明被减数低于减数;当 CF=0 且 ZF=0 时,
说明被减数高于减数;当 CF=0 且 ZF=1 时,说明被减数等于减数,见表 4.2。 需要说明的是,JAE/JNB 与 JNC 虽然助记符不同,但对应同一条机器指令。同样,JB/JNAE
与 JC 也是同一条指令。
表 4.2 无符号数比较条件转移指令表
Jcc 检 测 条 件 功 能 描 述
JA/JNBE CF ZF=0∨ 若高于/不低于等于,转移(Jump if Above, or Not Below or Equal)
JAE/JNB CF=0 若高于等于/不低于,转移(Jump if Above or Equal, or Not Below)
JB/JNAE CF=1 若低于/不高于等于,转移(Jump if Blow, or Not Above or Equal)
JBE/JNA CF ZF∨ =1 若低于等于/不高于,转移(Jump if Blow or Equal, or Not Above)
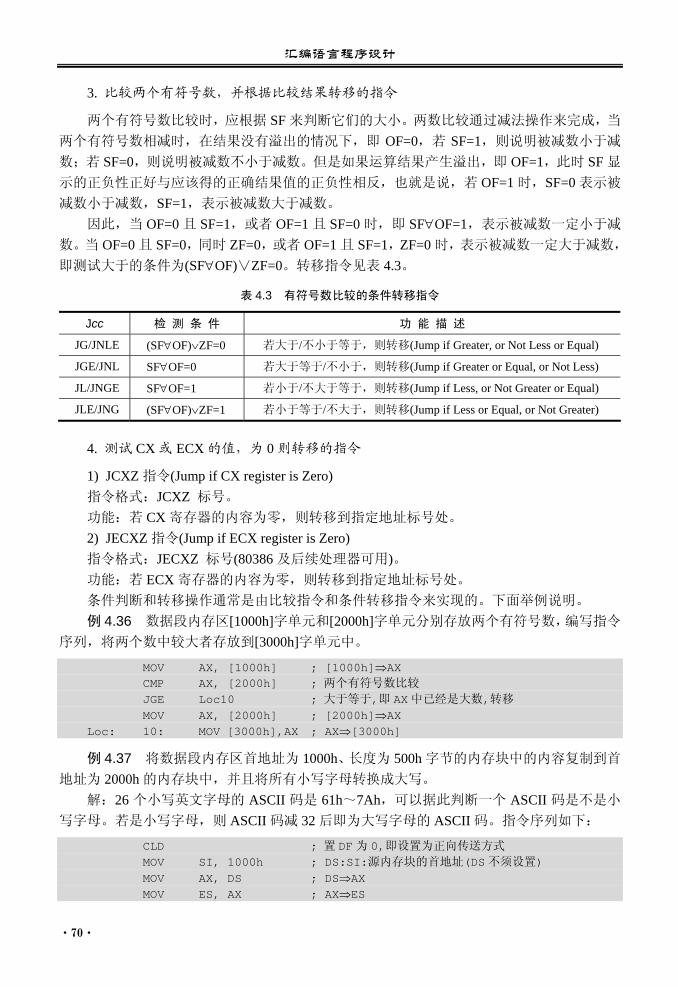
汇编语言程序设计
·70·
3. 比较两个有符号数,并根据比较结果转移的指令
两个有符号数比较时,应根据 SF 来判断它们的大小。两数比较通过减法操作来完成,当
两个有符号数相减时,在结果没有溢出的情况下,即 OF=0,若 SF=1,则说明被减数小于减
数;若 SF=0,则说明被减数不小于减数。但是如果运算结果产生溢出,即 OF=1,此时 SF 显
示的正负性正好与应该得的正确结果值的正负性相反,也就是说,若 OF=1 时,SF=0 表示被
减数小于减数,SF=1,表示被减数大于减数。 因此,当 OF=0 且 SF=1,或者 OF=1 且 SF=0 时,即 SF∀OF=1,表示被减数一定小于减
数。当 OF=0 且 SF=0,同时 ZF=0,或者 OF=1 且 SF=1,ZF=0 时,表示被减数一定大于减数,
即测试大于的条件为(SF∀OF)∨ZF=0。转移指令见表 4.3。
表 4.3 有符号数比较的条件转移指令
Jcc 检 测 条 件 功 能 描 述
JG/JNLE (SF∀OF)∨ZF=0 若大于/不小于等于,则转移(Jump if Greater, or Not Less or Equal)
JGE/JNL SF∀OF=0 若大于等于/不小于,则转移(Jump if Greater or Equal, or Not Less)
JL/JNGE SF∀OF=1 若小于/不大于等于,则转移(Jump if Less, or Not Greater or Equal)
JLE/JNG (SF∀OF)∨ZF=1 若小于等于/不大于,则转移(Jump if Less or Equal, or Not Greater)
4. 测试 CX 或 ECX 的值,为 0 则转移的指令
1) JCXZ 指令(Jump if CX register is Zero) 指令格式:JCXZ 标号。 功能:若 CX 寄存器的内容为零,则转移到指定地址标号处。 2) JECXZ 指令(Jump if ECX register is Zero) 指令格式:JECXZ 标号(80386 及后续处理器可用)。 功能:若 ECX 寄存器的内容为零,则转移到指定地址标号处。 条件判断和转移操作通常是由比较指令和条件转移指令来实现的。下面举例说明。 例 4.36 数据段内存区[1000h]字单元和[2000h]字单元分别存放两个有符号数,编写指令
序列,将两个数中较大者存放到[3000h]字单元中。 MOV AX, [1000h] ; [1000h]⇒AX CMP AX, [2000h] ; 两个有符号数比较 JGE Loc10 ; 大于等于,即 AX中已经是大数,转移 MOV AX, [2000h] ; [2000h]⇒AX Loc: 10: MOV [3000h],AX ; AX⇒[3000h] 例 4.37 将数据段内存区首地址为 1000h、长度为 500h 字节的内存块中的内容复制到首
地址为 2000h 的内存块中,并且将所有小写字母转换成大写。 解:26 个小写英文字母的 ASCII 码是 61h~7Ah,可以据此判断一个 ASCII 码是不是小
写字母。若是小写字母,则 ASCII 码减 32 后即为大写字母的 ASCII 码。指令序列如下: CLD ; 置 DF为 0,即设置为正向传送方式 MOV SI, 1000h ; DS:SI:源内存块的首地址(DS不须设置) MOV AX, DS ; DS⇒AX MOV ES, AX ; AX⇒ES
第 4 章 80x86 的寻址方式与基本指令
·71·
MOV DI, 2000h ; ES:DI:目的内存块的首地址 MOV CX, 500h ; 内存块中的字符个数 Loc: 10: ; Loc是标号 LODSB ; DS:[SI]⇒AL,SI+1⇒SI,取 1个 ASCII码到 AL CMP AL, 61h ; 与'a'比较 JB Loc20 ; 低于'a'则转移 CMP AL, 'z' ; 'z'就是 ASCII码 7Ah,与'z'比较 JA Loc20 ; 高于'z'则转移 SUB AL, 20h ; 转换成大写字母 Loc20: STOSB ; AL⇒ES:[DI],DI+1⇒DI,即保存 1个 ASCII码 DEC CX ; CX-1⇒CX JNZ Loc10 ; 运算结果不为 0,转移
4.3.3 循环指令
80x86 专门针对(E)CX 提供了设计一组循环指令。 1) LOOP 指令(LOOP) 格式:LOOP 地址标号。 功能:先执行(E)CX-1⇒(E)CX,之后若(E)CX≠0,则转移。 2) LOOPZ/LOOPE 指令(LOOP while Zero, or Equal) 格式:LOOPZ/LOOPE 地址标号。 功能:先执行(E)CX-1⇒(E)CX,之后若 ZF=1 且(E)CX≠0,则转移。 3) LOOPNZ/LOOPNE 指令(LOOP while NonZero, or Not Equal) 格式:LOOPNZ/LOOPNE 地址标号。 功能:先执行(E)CX-1⇒(E)CX,之后若 ZF=0 且(E)CX≠0,则转移。 例 4.38 用 LOOP 指令改写例 4.37 中的指令序列。 CLD ; 置 DF为 0,即设置为正向传送方式 MOV SI, 1000h ; DS:SI:源内存块的首地址(DS不须设置) MOV AX, DS ; DS⇒AX MOV ES, AX ; AX⇒ES MOV DI, 2000h ; ES:DI:目的内存块的首地址 MOV CX, 500h ; 内存块中的字符个数 Loc :10: ; Loc是标号 LODSB ; DS:[SI]⇒AL,SI+1⇒SI,取 1个 ASCII码到 AL CMP AL, 61h ; 与'a'比较 JB Loc20 ; 低于'a'则转移 CMP AL, 'z' ; 'z'就是 ASCII码 7Ah,与'z'比较 JA Loc20 ; 高于'z'则转移 SUB AL, 20h ; 转换成大写字母 Loc20: STOSB ; AL⇒ES:[DI],DI+1⇒DI,即保存 1个 ASCII码 LOOP Loc10 ; CX-1⇒CX, 则 CX≠转移 例 4.39 下列指令序列实现的是例 4.35 指令序列④的功能。 CLD MOV AL, 20h MOV DI, 100h MOV CX, 16h

汇编语言程序设计
·72·
Loc :10: INC DI CMP AL [DI-1] LOOPNE Loc10
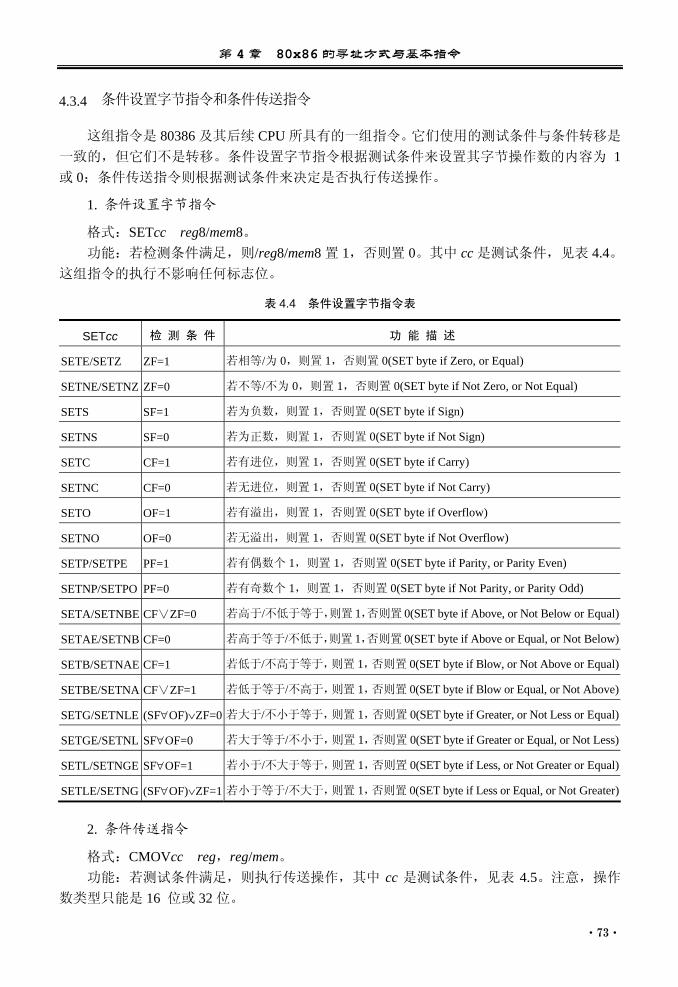
第 4 章 80x86 的寻址方式与基本指令
·73·
4.3.4 条件设置字节指令和条件传送指令
这组指令是 80386 及其后续 CPU 所具有的一组指令。它们使用的测试条件与条件转移是
一致的,但它们不是转移。条件设置字节指令根据测试条件来设置其字节操作数的内容为 1或 0;条件传送指令则根据测试条件来决定是否执行传送操作。
1. 条件设置字节指令
格式:SETcc reg8/mem8。 功能:若检测条件满足,则/reg8/mem8 置 1,否则置 0。其中 cc 是测试条件,见表 4.4。
这组指令的执行不影响任何标志位。
表 4.4 条件设置字节指令表
SETcc 检 测 条 件 功 能 描 述
SETE/SETZ ZF=1 若相等/为 0,则置 1,否则置 0(SET byte if Zero, or Equal)
SETNE/SETNZ ZF=0 若不等/不为 0,则置 1,否则置 0(SET byte if Not Zero, or Not Equal)
SETS SF=1 若为负数,则置 1,否则置 0(SET byte if Sign)
SETNS SF=0 若为正数,则置 1,否则置 0(SET byte if Not Sign)
SETC CF=1 若有进位,则置 1,否则置 0(SET byte if Carry)
SETNC CF=0 若无进位,则置 1,否则置 0(SET byte if Not Carry)
SETO OF=1 若有溢出,则置 1,否则置 0(SET byte if Overflow)
SETNO OF=0 若无溢出,则置 1,否则置 0(SET byte if Not Overflow)
SETP/SETPE PF=1 若有偶数个 1,则置 1,否则置 0(SET byte if Parity, or Parity Even)
SETNP/SETPO PF=0 若有奇数个 1,则置 1,否则置 0(SET byte if Not Parity, or Parity Odd)
SETA/SETNBE CF ZF=0∨ 若高于/不低于等于,则置 1,否则置 0(SET byte if Above, or Not Below or Equal)
SETAE/SETNB CF=0 若高于等于/不低于,则置 1,否则置 0(SET byte if Above or Equal, or Not Below)
SETB/SETNAE CF=1 若低于/不高于等于,则置 1,否则置 0(SET byte if Blow, or Not Above or Equal)
SETBE/SETNA CF ZF=1∨ 若低于等于/不高于,则置 1,否则置 0(SET byte if Blow or Equal, or Not Above)
SETG/SETNLE (SF∀OF)∨ZF=0 若大于/不小于等于,则置 1,否则置 0(SET byte if Greater, or Not Less or Equal)
SETGE/SETNL SF∀OF=0 若大于等于/不小于,则置 1,否则置 0(SET byte if Greater or Equal, or Not Less)
SETL/SETNGE SF∀OF=1 若小于/不大于等于,则置 1,否则置 0(SET byte if Less, or Not Greater or Equal)
SETLE/SETNG (SF∀OF)∨ZF=1 若小于等于/不大于,则置 1,否则置 0(SET byte if Less or Equal, or Not Greater)
2. 条件传送指令
格式:CMOVcc reg,reg/mem。 功能:若测试条件满足,则执行传送操作,其中 cc 是测试条件,见表 4.5。注意,操作
数类型只能是 16 位或 32 位。
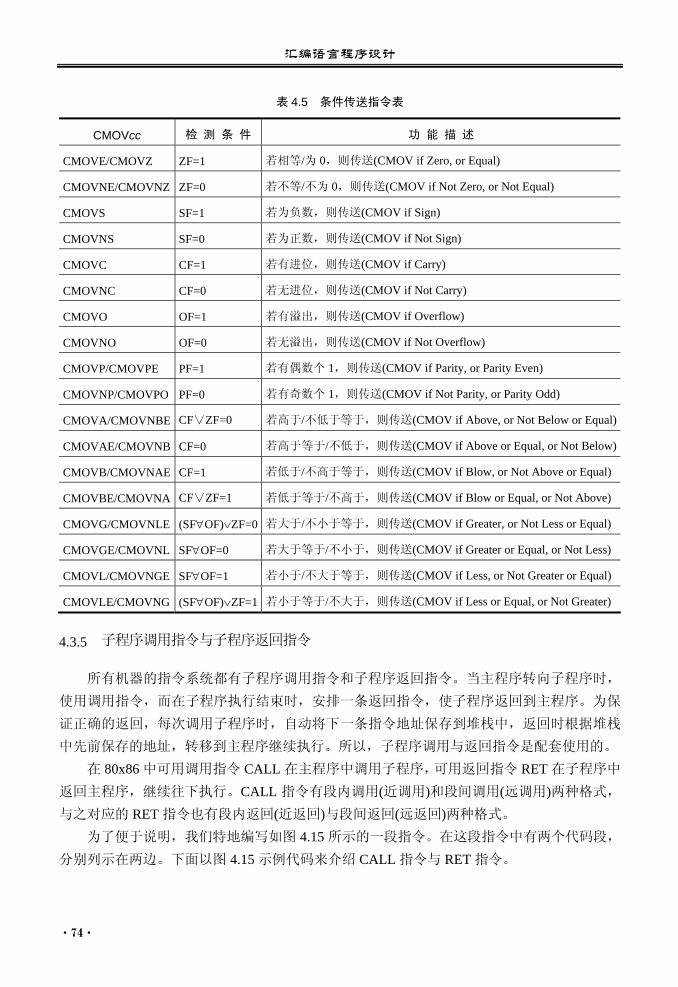
汇编语言程序设计
·74·
表 4.5 条件传送指令表
CMOVcc 检 测 条 件 功 能 描 述
CMOVE/CMOVZ ZF=1 若相等/为 0,则传送(CMOV if Zero, or Equal)
CMOVNE/CMOVNZ ZF=0 若不等/不为 0,则传送(CMOV if Not Zero, or Not Equal)
CMOVS SF=1 若为负数,则传送(CMOV if Sign)
CMOVNS SF=0 若为正数,则传送(CMOV if Not Sign)
CMOVC CF=1 若有进位,则传送(CMOV if Carry)
CMOVNC CF=0 若无进位,则传送(CMOV if Not Carry)
CMOVO OF=1 若有溢出,则传送(CMOV if Overflow)
CMOVNO OF=0 若无溢出,则传送(CMOV if Not Overflow)
CMOVP/CMOVPE PF=1 若有偶数个 1,则传送(CMOV if Parity, or Parity Even)
CMOVNP/CMOVPO PF=0 若有奇数个 1,则传送(CMOV if Not Parity, or Parity Odd)
CMOVA/CMOVNBE CF∨ZF=0 若高于/不低于等于,则传送(CMOV if Above, or Not Below or Equal)
CMOVAE/CMOVNB CF=0 若高于等于/不低于,则传送(CMOV if Above or Equal, or Not Below)
CMOVB/CMOVNAE CF=1 若低于/不高于等于,则传送(CMOV if Blow, or Not Above or Equal)
CMOVBE/CMOVNA CF∨ZF=1 若低于等于/不高于,则传送(CMOV if Blow or Equal, or Not Above)
CMOVG/CMOVNLE (SF∀OF)∨ZF=0 若大于/不小于等于,则传送(CMOV if Greater, or Not Less or Equal)
CMOVGE/CMOVNL SF∀OF=0 若大于等于/不小于,则传送(CMOV if Greater or Equal, or Not Less)
CMOVL/CMOVNGE SF∀OF=1 若小于/不大于等于,则传送(CMOV if Less, or Not Greater or Equal)
CMOVLE/CMOVNG (SF∀OF)∨ZF=1 若小于等于/不大于,则传送(CMOV if Less or Equal, or Not Greater)
4.3.5 子程序调用指令与子程序返回指令
所有机器的指令系统都有子程序调用指令和子程序返回指令。当主程序转向子程序时,
使用调用指令,而在子程序执行结束时,安排一条返回指令,使子程序返回到主程序。为保
证正确的返回,每次调用子程序时,自动将下一条指令地址保存到堆栈中,返回时根据堆栈
中先前保存的地址,转移到主程序继续执行。所以,子程序调用与返回指令是配套使用的。 在 80x86 中可用调用指令 CALL 在主程序中调用子程序,可用返回指令 RET 在子程序中
返回主程序,继续往下执行。CALL 指令有段内调用(近调用)和段间调用(远调用)两种格式,
与之对应的 RET 指令也有段内返回(近返回)与段间返回(远返回)两种格式。 为了便于说明,我们特地编写如图 4.15 所示的一段指令。在这段指令中有两个代码段,
分别列示在两边。下面以图 4.15 示例代码来介绍 CALL 指令与 RET 指令。

第 4 章 80x86 的寻址方式与基本指令
·75·
地址 机器指令 汇编指令 地址 机器指令 汇编指令 1012:0100 B9 02 10 MOV CX,1002 0111:0160 51 PUSH CX 1012:0103 E8 1B 00 CALL 0121 0111:0161 E8 15 00 CALL 0179 1012:0106 9A 60 01 CALL 0111:0160 0111:0164 83 C4 02 ADD SP,02 11 01 0111:0167 CB RETF 1012:010B BA 21 01 MOV DX,0121 0111:0168 55 PUSH BP 1012:010E FF D2 CALL DX 0111:0169 89 E5 MOV BP,SP 1012:0110 C7 06 00 MOV Word Ptr[1000],0174 0111:016B 8B 46 04 MOV AX,[BP+04] 10 74 01 0111:016E 01 C0 ADD AX,AX 1012:0116 C7 06 02 MOV Word Ptr[1002],0111 0111:0170 5D POP BP 10 11 01 0111:0171 C2 02 00 RETN 0002 1012:011C FF 1E 00 CALL DWord Ptr[1000] 0111:0174 51 PUSH CX 10 0111:0175 E8 F0 FF CALL 0168 1012:0120 CC INT 3 0111:0178 CB RETF 0111:0179 55 PUSH BP 1012:0121 89 C8 MOV AX,CX 0111:017A 89 E5 MOV BP,SP 1012:0123 01 C0 ADD AX,AX 0111:017C 8B 46 04 MOV AX,[BP+04] 1012:0125 C3 RETN 0111:017F 01 C0 ADD AX,AX 0111:0181 5D POP BP 0111:0182 C3 RETN
图 4.15 CALL 与 RET 指令示例
1. CALL 指令(CALL a procedure)
格式:CALL 目标地址。 功能:子程序调用指令。首先把该指令之后的地址进栈,然后转移到目标地址,去执行
从该地址开始的指令。 与 JMP 指令类似,CALL 指令中的目标地址有直接寻址和间接寻址两种方式。 从功能方面看,CALL 指令与 JMP 指令很相似,都是无条件地转移到目的地址处,并执
行该处指令,但是,它们是不同类型的指令:通过 CALL 指令实现的转移,可以用 RET 指令
返回,而 JMP 却不能。 1) 段内直接近调用 目标地址直接以子程序名、标号等给出,且目标与 CALL 指令同处一个段。 格式:CALL Near Ptr 子程序名。 功能:首先把该指令之后的地址(返回地址)的偏移地址(16/32 位)进栈,再转向子程序入
口地址,执行子程序的第一条指令。转移后 CS 内容没有变化。 注意,与此格式的调用指令相配套的是段内近返回指令。 在段内直接近调用指令所对应的机器指令中,目标地址以相对位移量的形式直接存放在
操作码之后。在 16 位地址模式下,这样格式的指令是一条 3 字节指令:1 个字节的操作码,
以及其后的 2 个字节的 16 位的位移量,如图 4.15 中 1012:0103 处的指令“E8 1B 00”,E8是操作码,1B 00 是位移量,由此计算出子程序开始地址(目标地址)是:0106h+001Bh=0121h;在 32 位地址模式下,这样格式的指令是一条 5 字节指令:1 个字节的操作码,以及其后的4
个字节的 32 位的位移量。 2) 段间直接远调用 目标地址直接以子程序名、标号等给出,且目标与 CALL 指令不在同一个段。 格式:CALL Far Ptr 子程序名。 功能:首先把该指令之后的地址(返回地址),按段、偏移(16/32 位)的次序进栈,再转向

汇编语言程序设计
·76·
子程序入口地址,执行子程序的第一条指令。转移后,CS 内容一般会发生变化。 注意,与此格式的调用指令相配套的是段间远返回指令。 在段间直接远调用所对应的机器指令中,转移的目标地址以段、偏移的次序直接存放在
操作码之后。在 16 位地址模式下,这样格式的指令是一条 5 字节指令:1 个字节的操作码,
以及其后的 2 个字节偏移地址和 2 字节的段地址,例如,图 4.15 中 1012:0106 处的指令“9A 60 01 11 01”,其中 9A 是操作码,60 01 是偏移地址 0160h,11 01 是段地址 0111;在 32 位
地址模式下,这样格式的指令是一条 7 字节指令:1 个字节的操作码,以及其后的4个字节
的 32 位的偏移地址和 2 字节的段选择器。 在汇编源程序中,很少直接用具体地址来指明子程序的入口,而代之以子程序名、标号
等。而且也可直接用“CALL 子程序名”的形式来调用子程序,汇编程序在处理这条指令时,
将根据子程序的定义情况确定是生成 Near Ptr 格式的调用指令,还是生成 Far Ptr 格式的调用
指令。关于子程序定义等内容将在以后章节中详细介绍。 3) 段内间接调用 目标的偏移地址不直接给出,而是存放在寄存器或内存单元中。 格式:CALL reg/mem。 功能:首先把该指令之后的地址(返回地址)的偏移地址(16/32 位)进栈,再转向由 reg/mem
所确定的子程序入口,执行子程序的第一条指令。转移后,CS 内容没有变化。 注意,与此格式的调用指令相配套的是段内近返回指令。 例如,图 4.15 中 1012:010E 处的指令“CALL DX”,其转向的偏移地址存放在 DX 中。 4) 段间间接远调用 目标的偏移地址和段地址不直接给出,而是存放在内存单元中。 格式:CALL mem (16 位地址模式是 mem32,32 位地址模式是 mem48)。 功能:首先把该指令之后的地址(返回地址),按段、偏移(16/32 位)的次序进栈,然后转
向由 mem 所确定的子程序入口地址,执行子程序的第一条指令。 注意,与此格式的调用指令相配套的是段间远返回指令。 例如,图 4.15 中 1012:011C 处的指令“CALL DWord Ptr[1000]”,其转向的子程序入口
的偏移地址存放在[1000h]单元中,段地址存放在[1002h]单元中。
2. RET 指令(RETurn from procedure)
格式:RET/RET [imm16]。 功能:子程序返回指令。首先从堆栈栈顶弹出返回的目标地址,然后转移到该地址处执
行。若其后有 imm16,则还要执行(E)SP+imm16⇒(E)SP。 从功能方面看,RET 也属于转移类指令,只不过它须与 CALL 指令配套使用,实现从子
程序中返回,继续主程序的执行。 1) 段内近返回 格式:RETN/RETN imm16。 功能:子程序执行结束,返回主程序继续执行。即首先从堆栈栈顶弹出返回的偏移地址
(16/32 位),再转移到该地址处执行。转移后的 CS 内容没有变化。当其后带有 imm16,则(E)SP还会向高地址端调整 imm16 个字节单位,即(E)SP+imm16⇒(E)SP。

第 4 章 80x86 的寻址方式与基本指令
·77·
2) 段间远返回 格式:RETF/RETF imm16。 功能:子程序执行结束,返回主程序继续执行。即:首先从堆栈栈顶,以偏移(16/32 位)、
段的次序弹出返回的目标地址,再转移到该目标地址处执行。当其后带有 imm16,则(E)SP 还
会向高地址端调整 imm16 个字节单位,即(E)SP+imm16⇒(E)SP。 在汇编源程序中,常用“RET”或“RET imm16”形式,汇编程序在汇编这条指令时,
根据子程序的定义情况来确定生成近返回指令(RETN),还是远返回指令(RETF)。 为进一步说明 CALL 和 RET 的配套使用,从 1012:0100 开始执行图 4.15 中的指令序列,
到1012:0120处终止。先后执行的指令有:(以指令所在的地址表示)1012:0100, 0103, 0121, 0123, 0125, 0106, 0111:0160, 0161, 0179, 017A, 017C, 017F, 0181, 0182, 0164, 0167, 1012:010B, 010E, 0121, 0123, 0125, 0110, 0116, 011C, 0111:0174, 0175, 0168, 0169, 016B, 016E, 0170, 0171, 0178, 1012:0120。期间堆栈变化如图 4.16 所示。
SP→ 1002 SP→ 010B 010B SP→ 0106 0106 1012 1012
SP→ SP→ (1) 初始状态 (2) CALL 0121 后 (3) RETN 后 (4) CALL 0111:0160 后 (5) PUSH CX 后
SP→ BP 原内容 BP 原内容 BP 原内容 BP 原内容
SP→ 0164 0164 SP→ 0164 0164 0164 1002 1002 1002 SP→ 1002 1002 010B 010B 010B 010B SP→ 010B 1012 1012 1012 1012 1012
(6) CALL 0179 后 (7) PUSH BP 后 (8) POP BP 后 (9) RETN 后 (10) ADD SP,02 后
BP 原内容 BP 原内容 BP 原内容 BP 原内容 BP 原内容 0164 0164 0164 0164 0164 1002 1002 1002 1002 SP→ 1002 010B 010B 010B SP→ 0120 0120 1012 SP→ 0110 0110 1012 1012
SP→ SP→ (11) RETF 后 (12) CALL DX 后 (13) RETN 后 (14) ALL Far[1000]后 (15) PUSH CX 后
SP→ BP 原内容 BP 原内容 BP 原内容 BP 原内容
SP→ 0178 0178 SP→ 0178 0178 0178 1002 1002 1002 1002 1002 0120 0120 0120 SP→ 0120 0120 1012 1012 1012 1012 1012
SP→ (16) CALL 0168 后 (17) PUSH BP 后 (18) POP BP 后 (19) RETN 0002 后 (20) RETF 后
图 4.16 执行图 4.15 中指令序列的堆栈状态变化示意图
4.3.6 中断调用指令与中断返回指令
中断调用和中断返回类似于子程序间接远调用和返回,只不过中断服务子程序的入口地

汇编语言程序设计
·78·
址保存在专门的内存区域,此外,在转移到中断服务子程序前,还需要把标志寄存器的内容
保存入栈,以便当从中断服务子程序返回时,再将标志寄存器恢复到调用前的状态。 80x86 的中断分为外中断和内中断。两种类型中断的处理机制一样,不同的是外中断的
中断源来自 CPU 外部,如 I/O 设备的中断请求,而内中断的中断源来自 CPU 内部,如执行
INT 指令,执行除法指令产生溢出。有关外中断处理的问题将在以后章节专门介绍,这里只
介绍和中断相关的中断调用指令和中断返回指令。 由于在保护模式下,80x86 的中断处理机制比较复杂,为了简化起见,以下仅在实地址
模式下介绍中断调用指令与中断返回指令。 在 80x86 系统中,中断服务子程序的入口地址称为中断向量。当 80x86 在实地址模式下
工作时,内存中的 低 1KB 区域专门用来保存中断向量,称为中断向量表。每 4 字节保存一
个中断向量:16 位偏移地址和 16 位段地址,并按顺序编号为:00h, 01h, …, FFh(0, 1, …, 255),这样中断向量表保存有 256 个中断服务子程序的入口地址,相应的编号称为中断类型号。其
对应关系是:中断类型号为 n,则该类型号中断服务子程序入口地址保存在地址为 0000h:4×n的 4 字节单元中,其中低 2 字节存放的是偏移地址,高 2 字节存放的是段地址。80x86 实地
址模式下的中断向量表如图 4.17 所示。
图 4.17 80x86 实地址模式下的中断向量表
从汇编指令的形式上看,与中断相关的指令主要有 INT, INTO 和 IRET。 1) INT 指令(Interrupt) 格式:INT imm8。 功能:中断调用指令。产生一次类型号为 imm8 的中断:首先 FLAGS 进栈,再将 IF 和
TF 清 0;然后该指令之后的地址(返回地址),按段、偏移的次序进栈; 后转向类型号为 imm8的中断向量,即双字单元 0000h:[4×imm8]所确定的中断服务子程序入口地址处执行。
由于一条 INT 指令相当于产生一次中断,其处理过程与外部中断处理过程一样,所以,
INT 指令又称为软中断指令。 2) INTO 指令(Interrupt Overflow) 格式:INTO。 功能:若 OF=1,产生一次类型号为 4 的中断,相当于 INT 4;否则顺序执行。 3) IRET 指令(Return from Interrup)

第 4 章 80x86 的寻址方式与基本指令
·79·
格式:IRET。 功能:中断处理结束,返回中断发生处继续执行。即首先从堆栈中以“偏移地址、段地
址、16 位标志”这样的次序弹出转向的目标地址和 FLAGS,再转移到该目标地址去执行。
4.4 其他类指令
4.4.1 标志位处理指令
80x86 提供有 7 条无操作数指令,专门用于设置或清除标志位。 CLC 指令(CLear Carry) 进位标志位清 0,即:0⇒CF; CMC 指令(CoMplement Carry) 进位标志位取反,即:¬CF⇒CF; STC 指令(SeT Carry) 进位标志位置 1,即:1⇒CF; CLD 指令(CLear Direction) 方向标志位清 0,即:0⇒DF; STD 指令(SeT Direction) 方向标志位置 1,即:1⇒DF; CLI 指令(CLear Interrupt) 中断标志位清 0,即:0⇒IF; STI 指令(SeT Interrupt) 中断标志位置 1,即:1⇒IF。
4.4.2 其他指令
1) NOP 指令(No OPeration) 格式:NOP。 功能:空操作指令。不执行任何操作。 说明:该指令的机器码(90h)占 1 个字节的内存单元,在调试程序时用它占有一定的存储
单元,以便在正式运行时用其他指令取代。 2) HLT 指令(HaLT) 格式:HLT。 功能:停机指令。使 CPU 处于“什么也不干”的暂停状态,等待 I/O 中断发生。 说明:退出暂停状态有 3 种方法:中断、复位或 DMA 操作。实际使用时,该条指令往
往出现在程序等待硬中断的地方,一旦中断返回,就可使 CPU 脱离暂停状态,继续 HLT 指
令的下一条指令,实现了软件与外部硬件同步的目的。 3) WAIT 指令(WAIT white test pit not asserted) 格式:WAIT。 功能:等待指令。不断测试 WAIT 引脚。 说明:若测试到 WAIT 引脚状态为 0,则 CPU 处于暂停状态;若一旦测试到引脚状态为 1,
则 CPU 脱离暂停状态,继续往下执行。 4) LOCK 指令(LOCK bus) 格式:LOCK XXXX 指令。 功能:总线封锁指令。使 LOCK 引脚输出低电平信号。 说明:实际使用中,CPU 的引脚与总线控制器 8289 的引脚相连。执行 LOCK 指令后,
CPU 通过引脚送出一个低电平信号,总线控制器封锁总线,使其他处理器得不到总线控制权。
这种状态一直延续到指令之后的指令执行完为止。

汇编语言程序设计
·80·
LOCK 总线封锁指令也叫前缀指令,可放在任何一条指令的前面。 5) ESC 指令(ESCape) 格式:ESC mem。 功能:换码指令。指定内存单元中内容为由协处理器执行的指令。自 80486 起,这条指
令码已成为未定义指令。
本 章 小 结
计算机指令系统是汇编语言程序设计的基本要素,本章集中介绍 80x86 应用程序中使用
较多的基本指令及其操作数寻址方式。 80x86 指令的操作数有三类寻址方式:立即寻址,操作数是指令的一部分,直接存放在
操作码之后;寄存器寻址,操作数存放于 CPU 内的寄存器中;内存操作数寻址,操作数存放
在内存单元中。其中,内存操作数的 EA=基址+变址+位移量,由此形成内存操作数的 5 种寻
址方式:直接寻址、寄存器间接寻址、寄存器相对寻址、基址变址寻址、相对基址变址寻址。
此外,32 位的 80x86 还提供了一组比例因子寻址方式:EA=32 位基址寄存器+32 位变址寄存
器×比例因子+位移量。 本章介绍的指令较多,归纳起来主要有与数据处理类相关的指令、与转移类相关的指令
两大类,以及标志位处理指令。在学习指令时,首先要理解指令的功能,其次要清楚指令中
操作数的寻址方式,再次还要注意指令中的特别约定等。 基本的数据处理类指令:(1)数据传送指令包括 MOV, XCHG, PUSH, POP, XLAT;LEA,
LDS, LES;LAHF, SAHF, PUSHF, POPF;IN, OUT;CBW, CWD/CWDE, CDQ。(2)算术运算
指令包括 ADD, ADC, INC;SUB, SBB, DEC, NEG, CMP;MUL, IMUL;DIV, IDIV。(3)逻辑
指令包括 AND, OR, NOT, XOR, TEST;SHL, SHR, SAL, SAR, ROL, ROR, RCL, RCR。(4)串处
理指令包括 MOVS, LODS, STOS, CMPS, SCAS;REP, REPZ/REPE, REPNZ/REPNE。 基本的转移类指令:JMP, Jcc, LOOP/LOOPZ/LOOPNZ, CALL/RET, INT/IRET。
标志位处理指令:CLC, CMC, STC, CLD, STD, CLI, STI。
习 题 4
4.1 机器指令分成几部分?每部分的作用是什么? 4.2 分别指出下列各指令的源操作数和目的操作数的寻址方式。 (1) MOV AX, 255Ah (2) ADD [1000h], DI (3) MOV AH, 100h[SI] (4) SUB ES:[BX+200h], DX (5) MOV DX,300h[BX][DI] (6) MOV Word Ptr [BP], 127 (7) MOV [EDX*8], EAX (8) ADC AX, [EDX+EBX*4+10] (9) SUB [ECX*2+100h], AL (10) AND ESI, 7FFFFFFFh 4.3 指出下列指令中操作数寻址是否正确,若不正确,说出错误原因。 (1) MOV [DI], 255Ah (2) MOV CS, AX (3) MOV [BP+SI], AX (4) MOV ES:[200h], 41h (5) MOV DS, 1000h (6) MOV AX, [SI][DI]

第 4 章 80x86 的寻址方式与基本指令
·81·
(7) MOV 3000h, DX (8) MOV SI, [ECX+EAX*4] (9) MOV [ESP*8+100h], AX (10) MOV BX, AH 4.4 指出下列指令是否正确,若不正确,说出错误原因。 (1) MOV [DI], [255Ah] (2) XCHG AX, 1234h (3) PUSH AL (4) POP CS (5) MOVSZ EDX, EBX (6) PUSH DWord Ptr [EAX] (7) IN AL, 100h (8) OUT EAX, DX (9) LEA EAX. [ESP*8+100h] (10) LES [100h], DWord Ptr[BX] (11) ADD [1000h], 38h (12) SUB [DX], AX (13) INC [BX] (14) CMP 100h, AX (15) MUL AX, BX (16) IDIV Word Ptr 100h (17) AND AX, DS (18) TEST 7Fh, AL (19) SAR EAX, 3 (20) RCL AX, CH 4.5 指出下列指令使用的隐含操作数,以及执行的操作。 (1) XLAT (2) CBW (3) PUSHA (4) LDS SI, DWord Ptr [BX] (5) LAHF (6) IMUL Byte Ptr [100h] (7) DIV ECX (8) MOVSB (9) REP STOS Word Ptr[DI] (10) REPE CMPSD (11) LOOP 010Ah (12) JCXZ 0110h (13) CMC (14) CLD (15) STI (16) INT 10h (17) RET (18) IRET 4.6 已知 BX=2000h,BP=2000h,SI=000Ah,内存中部分单元内容如图 4.18 所示,说
明下列各条指令执行完后,AX 寄存器的内容是什么? (1) MOV AX, 6162h (2) MOV AX, [BP] (3) MOV AX, [BP][SI] (4) MOV AX, [BX] (5) MOV AX, [BX][SI] (6) MOV AX, ES:[BP]
2000h DS→ … 03 20 32 33 34 35 36 37 38 39 41 42 43 44 45 46 …
2000h SS→ … 00 AB F4 97 45 00 04 9A 8B 03 89 83 D2 96 13 99 …
2000h ES→ … 2A 4C CD 20 80 90 44 5A 70 6D C9 63 40 0E 20 B8 …
图 4.18 供习题使用的各段内存区内容
4.7 已知 SP=1FFEh,BX=1565h,CX=7FFFh,那么: (1) 执行 PUSH BX 指令后,SP 内容是什么? (2) 执行 PUSH CX 及 POP AX 指令后,SP 和 AX 内容各是什么? 4.8 已知 AX=1357h,BX=1008h,CX=7FFFh,BP=10F0h,SI=00EAh,DI=0F160h,
内存的部分单元内容如图 4.18 所示,那么下列各指令或指令序列执行后的结果如何?

汇编语言程序设计
·82·
(1) MOV [BP][DI], AX (2) XCHG CX, 1000h[BX] (3) LEA BX, [BX+SI] (4) MOV [2002h], ES MOV AX, [BX][DI] LDS SI, DWord Ptr[2000h] MOV [SI], BX 4.9 执行下列指令序列,写出每条指令执行后 AL 的值,以及 CF, AF, PF, ZF, SF 和 OF
的状态。 MOV AL, 45h ADD AL, AL ADC AL, 9Fh CMP AL, 0ACH SBB AL, 34h DEC AL NEG AL 4.10 已知 AX=4A50h,CX=5402h,CF=1,执行下列指令序列后,AX=?,CF=? RCL AX, CL AND AH, CH RCR AX, CL 4.11 已知 AX=CF49h,CX=0504h,CF=1,执行下列指令序列后,AX=?,CF=? SAR AX, CL XCHG CH, CL SHL AX, CL 4.12 已知 AX=1A49h,执行下列指令序列后,AX=?,为什么有这样的结果? NOT AX INC AX NOT AX INC AX 4.13 已知 DX=AF43h,字变量 Variable 值为 004Fh,分别指出下列指令执行后的结果。 (1) AND DX, Variable (2) OR DX, Variable (3) XOR DX, Variable (4) SHL DX, 1 (5) NOT Variable (6) TEST DX, 80h 4.14 用一条指令实现把 BX 和 SI 之和传送给 CX。 4.15 简述指令 AND 和 TEST、NOT 和 NEG 之间的区别。 4.16 写出实现下列要求的单条指令。 (1) 把 1234h 传送给 AX (2) 从 AX 中减去 1234h (3) 把变量 Variable 的偏移地址送入 SI (4) 把字变量 Variable 内容送入 SI (5) 将 AX 的高 4 位清 0 (6) 将 AX 的高 4 位置 1 4.17 在 16/32 位 CPU 中,标志位寄存器的内容进栈和出栈的指令是什么? 4.18 编写指令序列,实现将 80x86 标志寄存器中的标志位 IF 置 1,DF 变反,CF, PF, AF,
ZF, SF, OF 和 TF 清 0,其他位保持不变。

第 4 章 80x86 的寻址方式与基本指令
·83·
4.19 选择适当的指令实现下列功能。 (1) 右移 DI 三位,并把 0 移入 高位。 (2) 把 AL 左移一位,使 0 移入 低一位。 (3) AL 循环左移三位。 (4) EDX 带进位位循环右移四位。 (5) DX 右移六位,且移位前后的正负性质不变。 4.20 a, b, c, d, r 均为存放 16 位数内存单元的符号地址,分两种情况:① 将它们看做是
符号数;② 将它们看做是有符号数,编写出实现下列各算式的指令序列。 (1) a+(b-c)⇒r (2) d-a×c⇒r (3) (d+b)×a÷c ⇒r (4) (a×a+b)÷(c×c-d),商⇒a,余数⇒r
4.21 方向标志 DF 的作用是什么?用于设置或清除该标志位的指令是什么? 4.22 按下列要求编写指令序列,实现将堆栈段中的起始地址是 6000h、长度为 1000 字节
的内存块内容,复制到数据段中的起始地址为 1000h 的内存块中。并指出指令序列执行完毕
后,SI 及 DI(或 ESI 及 EDI)的内容是什么? (1) 使用字节串处理指令,按正向方式复制内存块内容。 (2) 使用字节串处理指令,按反向方式复制内存块内容。 (3) 使用 2 字节串处理指令,按正向方式复制内存块内容。 (4) 使用 2 字节串处理指令,按反向方式复制内存块内容。 (5) 使用 4 字节串处理指令,按正向方式复制内存块内容。 (6) 使用 4 字节串处理指令,按反向方式复制内存块内容。 4.23 编写指令序列,实现将堆栈段内存区首地址为 2000h、长度为 500 字节的内存块中
内容,复制到数据段首地址为 1000h 的内存块中,并且将所有大写字母转换成小写字母。 4.24 数据段首地址为 1000h、长度为 1000 字节的内存块内,存放的是一段英文文字,按
下列要求编写指令序列。 (1) 将 前面的空格字符所在位置⇒SI,若没有空格,则 FFFFh⇒SI。 (2) 将 后面的空格字符所在位置⇒SI,若没有空格,则 FFFFh⇒SI。 (3) 将 前面的非空格字符所在位置⇒SI,若全部是空格,则 FFFFh⇒SI。 (4) 将 后面的非空格字符所在位置⇒SI,若全部是空格,则 FFFFh⇒SI。 4.25 数据段内存区中的 2 字节单元[100h]、[200h]和[300h]分别存放 3 个 16 位数,按下
列要求编写指令序列,找出 3 个数中的 大数,并存放到[400h]单元中。 (1) 3 个数都是 16 位无符号数。 (2) 3 个数都是 16 位有符号数。 4.26 段间远转移和段内近转移之间的区别是什么? 4.27 指出下列转移类指令的格式是否正确,若不正确,说出错误原因。 (1) JMP 010Ah (2) JMP AX (3) JNA AX (4) JMP DWord Ptr [AX] (5) JMP DWord Ptr SI (6) JMP Word Ptr [SI] (7) CALL SI (8) CALL Word Ptr [SI] (9) RET CX (10) RET 10h

汇编语言程序设计
·84·
4.28 若 BP=16A0h,内存中部分单元内容如图 4.18 所示,指出下列转移类指令的目标地
址是什么?(16 位地址模式) (1) JMP BP (2) JMP Word Ptr 096Ah[BP] (3) JMP DWord Ptr 096Ah[BP] (4) JMP DWord Ptr DS:096Ah[BP] 4.29 在图 4.14 中,如果指令 JS 的操作码 78 之后的二进制编码是 F8h,则该指令转向的
目标地址是什么?如果转向的目标地址是 00A0,即 JS 00A0,则其操作码 78 之后的二进制编
码又是什么?。 4.30 子程序调用指令、子程序返回指令与堆栈有什么关系? 4.31 计算机内存中有如下一段指令序列(16 位地址模式),若从 0AE8:0108 处开始执行此
指令序列,至 0AE8:0112 处终止,请说明在执行期间堆栈的变化情况,以及指令序列执行完
毕后 AX 内容是什么? 0AE8:0100 5B POP BX 0AE8:0101 8D 47 01 LEA AX, [BX+01] 0AE8:0104 87 C3 XCHG AX, BX 0AE8:0106 53 PUSH BX 0AE8:0107 C3 RETN 0AE8:0108 E8 F5 FF CALL 100 0AE8:010B 90 NOP 0AE8:010C 50 PUSH AX 0AE8:010D 9A 21 13 05 32 CALL 3205:1321 0AE8:0112 CC INT 3
3205:1321 55 PUSH BP 3205:1322 89 E5 MOV BP, SP 3205:1324 8B 46 02 MOV AX, [BP+02] 3205:1327 2B 46 06 SUB AX, [BP+06] 3205:132A 5D POP BP 3205:132B CA 02 00 RETF 0002

第 5 章 汇编语言程序设计初步
本章介绍如何使用符号:指令助记符、变量和标号,来编写汇编代码,包括: • 汇编语言程序的编辑、汇编、连接和调试的过程。 • 汇编语言源程序的框架结构。 • 常量的使用,变量定义及使用,标号的定义与使用。 • 常用的基本伪指令和操作符。 • 一些高级汇编伪指令。
5.1 概 述
汇编语言是一种符号化的机器语言,用助记符表示机器指令中的操作码,例如,加法指
令就用 ADD 表示,数据传送用 MOV 表示等。用符号地址来代替直接地址:将内存操作数中
的地址编号用变量名表示,将直接转移指令中的目标地址用标号表示。例如,指令 MOV [1000h], AX,用变量名可写成:MOV Variable, AX;又如,指令 ADD DL, 100[SI],用变量名
可表示为:ADD DL, Array[SI];再如,指令 JS 010A,用标号则可写成:JS Loc。 汇编语言程序的核心内容是,用指令助记符和符号地址来编写程序,再由汇编程序将源
代码翻译成二进制编码:助记符转换成指令操作码;为程序中的变量安排存储空间,并由此
计算出各变量对应的内存单元地址编号;根据标号所在位置确定标号所对应的内存地址。 除了与机器语言有直接对应关系的助记符、变量、标号外,源程序中还应该包含有一些
告诉汇编程序如何进行翻译操作的说明性信息,例如,程序代码何处开始、何处结束,变量
需要占据多少字节的空间,标号如何定义,开始运行的第一条指令在什么位置等说明信息。
与汇编指令相比,这类说明在翻译结果中并没有对应的机器代码,所以称为“伪指令”。 所以说,汇编语言包括:指令助记符、数据和存放数据的变量、标号、伪指令,以及相
应的使用规则等内容。一方面,不同类型处理器它们的汇编语言不同,另一方面,同一类型
处理器上的汇编语言还和具体实现的汇编程序相关。 用汇编指令助记符与伪指令助记符,以及相应的规则编写的程序是汇编语言源程序。在
源程序中每一条汇编指令或伪指令均占一行,称为一条汇编语言语句,其中 汇编指令语句格式: [标号:] 指令助记符 [操作数 1][,操作数 2,…][;注释] 伪指令语句格式: [符号] 伪指令助记符 [操作数 1][,操作数 2,…][;注释] 通常所说的 80x86 汇编指的是 Microsoft 公司的宏汇编程序 MASM(Macro Assembler)。除
此之外,常用的还有 51 系列的汇编语言、ARM 系列专用 RISC 指令集的汇编语言等。 MASM 是运行于 DOS 平台的汇编程序,作为单独版本发行的 后版本是 MASM 6.15,
用它既可生成 DOS 格式的目标代码,也可生成 Win32 格式的目标代码。与 MASM 兼容的还
有 Borland 公司推出的 TASM(Turbo Assembler),它们只是在某些细微之处有差别,而在大多
数情况下是兼容的。本书采用的是 MASM 6.15 所提供的指令助记符和伪操作符,以及相应的
编程规则。

第 5章 汇编语言程序设计初步
·85·
汇编语言程序的开发过程与高级语言一样,即输入源程序、编译(汇编)、连接等过程。整
个过程如图 5.1 所示。
图 5.1 汇编语言程序的开发过程示意图
1. 汇编源程序的编辑
任何一个纯文本处理软件均可编辑汇编源程序,例如,DOS 下的 EDIT,Windows 下的
记事本(NotePad)。编辑完毕之后,源程序以.ASM 类型保存,如保存为 Exam.ASM。
2. 汇编源程序的汇编
我们以 MASM 作为 80x86 汇编语言的汇编程序,其目的是将汇编语言源程序汇编成目标
代码(.OBJ 文件)。在 DOS 环境下,汇编源程序的一般操作如下: MASM Exam.ASM ↵ Exam.ASM 经 MASM 汇编后可生成 Exam.OBJ。 一般来讲,程序汇编的主要功能是:首先检查源程序是否符合汇编语言的规则,即进行
语法检查。语法检查通过后,再将源程序中的指令助记符、符号地址等转换成二进制编码,
形成目标代码。否则 MASM 将给出相应的错误信息,这时应根据错误信息,重新编辑源程序
后,再进行汇编。 MASM 6.15 中的 MASM.EXE 实际上是调用 ML.EXE,所以,汇编操作实际上是: ML /c Exam.ASM ↵
3. 目标代码的连接
连接程序主要作用将目标代码转换成可重定位的执行文件(.EXE 等类型文件)。在 DOS 环
境下,简单的连接操作如下: LINK Exam.OBJ ↵ 如果连接通过,LINK 将生成一个可执行文件 Exam.EXE。否则将提示相应的错误信息,
这时需要根据错误信息修改源程序后再汇编、连接,直到生成可执行文件。 上面所说的汇编、连接这两个操作过程,可由 ML 直接完成,即: ML Exam.ASM ↵
4. 可执行程序的运行与调试
经汇编、连接生成的运行程序 Exam.EXE,在 DOS 系统下输入文件名即可运行。 Exam ↵ DOS 将 Exam.EXE 调入内存,并开始运行。Exam.EXE 运行结束后返回 DOS。 程序的调试是程序开发的一个重要环节,但是汇编语言在程序调试时所关注的内容更细、
更具体,在每一条指令执行后,需要观察:相关变量(即内存单元)、寄存器等内容的变化、标
志寄存器各标志状态的改变、堆栈状态的变化等。 汇编语言程序的调试工具有:Debug、Codeview,以及其他一些可视的化界面调试工具。

汇编语言程序设计
·86·
这里建议大家使用 Debug 一类的调试工具,因为使用 Debug 时所积累的经验和技巧等具有普
遍适用性,毕竟在实际开发中,很多时候使用的不是 80x86 汇编语言。
5.2 汇编语言程序基本框架结构
在应用程序中,内存是分段使用的,一般情况下,内存被分为 3 种类型区:堆栈段存储
区、数据段存储区和代码段存储区。80x86 汇编语言程序也是如此,而且 80x86 程序运行时
还有专门的段寄存器指向这些段:CS 指向正处于运行的代码段,DS 指向当前的数据段,SS指向当前的堆栈段。
下面先给出一个简单的程序例子,以此来介绍汇编语言程序的基本框架结构。 例 5.1 在屏幕上显示“Hello, World!”的 16 位模式下的源程序如下: _STACK SEGMENT STACK 'STACK' ; 定义堆栈段 DB 32766 DUP(0) ; 堆栈区长度:32 766+2=32KB TOS DW 0 ; 初始堆栈栈顶 _STACK ENDS ; 堆栈段定义结束 _DATA SEGMENT ; 定义数据段 Msg DB 'Hello, World!', 13,10,'$' _DATA ENDS ; 数据段定义结束 _TEXT SEGMENT 'CODE' ; 定义代码段 ASSUME CS: _TEXT, DS:_DATA, SS:_STACK Start: MOV AX, _DATA ; 取数据内存区段地址 MOV DS, AX ; 设置数据段寄存器 CLI ; 设置堆栈期间,禁止响应中断 MOV AX, _STACK ; 取堆栈内存区段地址 MOV SS, AX ; 设置堆栈段寄存器 MOV SP, Offset TOS ; 设置初始状态时的堆栈指针 STI ; 堆栈设置完毕,允许中断 MOV DX, Offset Msg MOV AH, 9 INT 21h ; 中断 21h的 9号功能,显示 DS:DX指向的字符串 MOV AX, 4C00h INT 21h ; 运行结束,返回 DOS _TEXT ENDS ; 代码段定义结束 END Start ; 源程序到此为止 源程序中每行中“;”(分号)后的所有内容是注释。 这是一个 DOS 系统下运行的汇编语言程序,源程序中有许多与 DOS 系统相关的指令代
码,这里暂且不去理会这些细节,只是从总体上来掌握汇编源程序的基本框架结构。
5.2.1 内存的分段使用
一个完整的汇编语言源程序应包括 3 种类型段:堆栈段、数据段和代码段。
1. 堆栈段
该段主要内容是:定义并分配程序在运行期间供堆栈使用的内存区,并且用一个符号表
示栈内存区 高栈单元,用来指示初始堆栈栈顶单元位置,从而方便对 SP 的初始赋值。

第 5章 汇编语言程序设计初步
·87·
在例 5.1 中,从“_STACK SEGMENT STACK”开始,到“_STACK ENDS”结束,这一
段代码为堆栈段。此段共分配了 32 766+2=32 768(字节)的堆栈内存区,即堆栈区长度为 32KB,用 TOS 指示栈内存区 高栈单元。注意,“_STACK”只是堆栈段的名字,程序员可以根据
实际情况,或自己的喜好选用其他的名字,比如,MyStack,Stack1 等。 在源程序中,须用如下指令序列,将程序的堆栈设置到_STACK 堆栈内存区。
CLI ; 设置堆栈期间,禁止响应中断 MOV AX, _STACK ; 取堆栈内存区段地址 MOV SS, AX ; 设置堆栈段寄存器 MOV SP, Offset TOS ; 设置初始状态时的堆栈指针 STI ; 堆栈设置完毕,允许中断
2. 数据段
主要为存储程序中的数据提供内存区。一般情况下,程序中的变量都应放在数据段中。 在例 5.1 中,从“_DATA SEGMENT”开始,到“_DATA ENDS”结束,这一段代码为
数据段。此段中只定义了一个变量 Msg。注意,“_DATA”只是该数据段的名字,程序员可
以根据实际情况,或自己的喜好,选用其他的名字,比如,MyData,Data1 等。 在源程序中,须用如下指令序列,使 DS 指向程序员所定义的数据段存储区,以便指令
执行时能正确存取到变量中的内容。 MOV AX, _DATA ; 取数据内存区段地址 MOV DS, AX ; 设置数据段寄存器
3. 代码段
为存储程序中的指令代码提供内存区。一般情况下,程序中指令代码都应放在代码段内。 在例 5.1 中,从“_TEXT SEGMENT”开始,到“_TEXT ENDS”结束,这一段代码为代
码段。注意,此处的“_TEXT”只是该代码段的名字,程序员可以根据实际情况,或自己的
喜好,选用其他的名字,比如,Code,Code1 等。
5.2.2 源程序的结束与程序的执行入源
汇编语言源程序总是以 END 作为结束标志,所有的代码必须在 END 之前。 END 后面可附带一个在程序中已定义的标号,用以说明程序的在调入时开始执行的第一
条指令所在位置。例如,例 5.1 中的源程序 后一行的“END Start”,其中 Start 是标号,定
义在指令“MOV AX, _DATA”前面,表示该指令是程序开始执行的第一条指令。说明一下,
此处的 Start 仅是个标号,程序员可以根据实际情况,或自己的喜好,选用其他的标识符来表
示此标号,如 Begin,main 等。 如果源程序是一个独立的程序或主模块,那么伪指令 END 后面必须附带一个标号;如果
源程序仅是一个普通模块,那么其 END 后面就不能附带标号。 那么程序什么时候执行结束?初学者可能很自然地认为程序执行到 END 处就结束了,其
实不然,END 是一个伪指令(它不对应任何机器指令),仅仅用来说明源程序代码到此结束,
汇编程序对 END 之后的任何内容都不作处理,所以,通常情况下 END 总是位于源程序的
后位置,是源程序结束的标志,而不是程序的运行终止。

汇编语言程序设计
·88·
一般来讲,运行于操作系统下的汇编语言程序,须在程序中通过操作系统的相关功能调
用来结束其运行,例如,在 DOS 系统下,可通过 4Ch 号 DOS 功能调用来结束程序运行,返
回操作系统;在 Windows 系统下,可调用 API 中的 ExitProcess 过程,使应用程序结束运行,
返回操作系统。 在例 5.1 的汇编语言源程序中,指令: MOV AX, 4C00h INT 21h
的作用就是结束程序运行,返回 DOS 系统。这也是以后编写的 DOS 程序结束运行所采用的
方法。只要在用户程序需要结束处,安排这两条指令即可。
5.2.3 汇编语言程序的运行平台
用汇编语言可开发运行在不同的系统平台上的应用程序,虽然它们基本框架结构相似,
但是在具体的系统功能调用是完全不同的。例如,16 位地址模式的 DOS 系统下的汇编语言
程序,其系统功能调用是通过中断调用方式实现的,而 32 位地址模式的 Windows 系统的汇
编语言程序,其系统功能调用是通过系统的 API 调用来实现的。甚至有的应用程序自身就是
一个监控程序,没有任何系统功能可供调用。 一方面 DOS 环境下的汇编语言程序结构和大多数应用中的汇编语言程序结构相似,具有
代表性,另一方面 16 位地址模式下的指令(主要是转移、子程序调用、中断调用等)处理较为
简单,便于讲述汇编语言程序设计的基本思想,所以本教材主要以 DOS 环境来介绍汇编语言
程序设计中的基本方法。 为便于学习和编写程序,下面首先介绍 DOS 环境下的汇编源程序的框架结构,然后以示
例的方式介绍 Win32 的程序结构、监控程序的组织结构。建议初学者此时只掌握 DOS 程序的
框架结构,跳过后面的内容。 之所以安排 Win32、监控程序的程序结构等内容,是因为一方面让读者在具备了汇编语
言编程经验之后,可通过示例学习编写其他环境下的程序,另一方面用来说明,使用汇编语
言不仅能开发 DOS 平台上的应用程序,也能在非 DOS 平台上开发应用程序。
1. DOS 环境下的源程序框架结构
一般来说可用如图 5.2 所示的框架结构来编写 DOS 环境下的程序。在编写具体的程序时,
根据实际问题,将实际堆栈空间大小、程序用的数据和变量、解决问题所需要的指令代码直
接填写到相应的阴影处即可。(对照例 5.1 阅读源程序的框架结构) 在 DOS 环境下编写程序时,应注意以下几点。 (1) 在 16 位地址模式下使用汇编指令,即使用 16 位偏移地址。 (2) 用 INT 指令调用系统功能(DOS, BIOS)。为避免讲解程序时过多地涉及系统繁杂的功
能调用,书中示例程序仅使用 1, 2, 9, A, 4C 号 DOS 功能调用(INT 21h)。关于 DOS 系统下汇
编语言程序的编程练习环境说明参见附录 B。

第 5章 汇编语言程序设计初步
·89·
_STACK SEGMENT STACK 'STACK' … ; 根据实际需要分配堆栈内存区空间 TOS DW 0 ; 初始堆栈栈顶 _STACK ENDS _DATA SEGMENT … ; 定义所有的内存数据 _DATA ENDS _TEXT SEGMENT 'CODE' ASSUME CS:_TEXT,DS:_DATA, SS:_STACK Start: MOV AX, _DATA MOV DS, AX };设置数据段
CLI MOV AX, _STACK MOV SS, AX MOV SP, Offset TOS STI
};将堆栈设置到堆栈内存区
… ; 完成问题要求的指令代码 MOV AX, 4C00h INT 21h _TEXT ENDS END Start
图 5.2 汇编语言源程序的框架结构
2. Win32 示例程序
当读者具有一定的编程经验后,可仿照例 5.2 编写 Windows 环境下的汇编语言程序。 例 5.2 在屏幕上显示“Hello, World!”的 Win32 环境下的源程序如下: .386 INCLUDELIB KERNEL32.LIB EXTRN _ExitProcess@4: Near, _WriteConsoleA@20: Near, _GetStdHandle@4: Near _DATA SEGMENT USE32 'DATA' Num DD 0 Msg DB 'Hello, World!', 13, 10, 0 MsgBytes = $-Msg -1 _DATA ENDS _TEXT SEGMENT DWORD PUBLIC USE32 'CODE' ASSUME CS: _TEXT, DS: _DATA _main: PUSH Dword Ptr -11 CALL _GetStdHandle@4 PUSH DWord Ptr 0 PUSH DWord Ptr Offset Num PUSH DWord Ptr MsgBytes PUSH DWord Ptr Offset Msg PUSH EAX CALL _WriteConsoleA@20 ; 调用 API,显示字符若干个字符 PUSH DWord Ptr 0 CALL _ExitProcess@4 ; 调用 API,退出应用程序,返回系统 _TEXT ENDS END _main

汇编语言程序设计
·90·
在 Win32 环境下编写程序时,应注意以下几点。 (1) 在 32 位地址模式下使用汇编指令,用的是 32 位偏移地址。 (2) 使用 Win32 的 API 调用系统功能。Win32 的 API 数目繁多,在练习编程时可尽量少
调用 API,以免消耗过多精力。附录 B 列出的一些 API 已足够编程练习使用。 (3) Windows 是多任务系统,对应用程序有很多限制,程序中的堆栈段和数据段由系统
的调入程序自动完成,所以源程序不能设置它们。
3. 监控程序的示例
没有任何操作系统支持的应用程序,其实是一个监控程序。
例 5.3 编写简单的烟雾报警主控程序模块,假定,F0h 号字节端源反映的是检测烟雾的
探头的状态信息:00 正常,FFh 探测到有烟雾。F1h 号字节端源用来驱动报警器,01 是拉响
报警装置。主控程序如下:
_STACK SEGMENT STACK 'STACK’ DB 254 DUP(0) ; 堆栈区长度:254+2=256 B TOS DW 0 _STACK ENDS _DATA SEGMENT 'DATA' Sta DB 0 _DATA ENDS _TEXT SEGMENT 'CODE' ASSUME CS: _TEXT, DS: _DATA, SS:_STACK Begin: MOV AX, _DATA MOV DS, AX CLI MOV AX, _STACK MOV SS, AX MOV SP, Offset TOS STI again: IN AL, 0F0h CMP AL, 0FFh JNE loc1 MOV Sta, AL MOV AL, 1 OUT 0F1h,AL HLT loc1: JMP Again _TEXT ENDS END Begin 但需要注意的是,由于没有操作系统支持, 后运行的代码由程序员放到内存区的合适
位置,一般放在 ROM中,只要电源开启,CPU 就能执行它。
5.3 常数、变量和标号
在说明了汇编源程序的框架结构之后,接下来讲述汇编语言程序其他两方面内容:与数
据相关的常量与变量;与转移地址相关的标号与过程。在此主要介绍常量、变量和标号,以

第 5章 汇编语言程序设计初步
·91·
及与它们相关的内容,有关过程定义及调用等内容在以后章节介绍。 标号名、变量名、过程名、段名等符号名统称为标识符,其组成规则如下。
(1) 组成标识符的字符是:字母(A~Z, a~z)、数字(0~9)及?、.、@、$和_(下划线)。 (2) 数字不用作标识符的首字符,只能作为标识符的首字符。 (3) 标识符的长度没有严格限制,但一般不应超过 31 个字符。 (4) 保留字不能作为标识符使用。 总之,其规则可简单地认为是:标识符是以字母开头、字母与数字的组合。
5.3.1 常数
常量是数的本身,不对应任何存储单元(寄存器或内存单元),其数值在汇编期间已能够完
全确定,且在程序运行期间也不会发生变化。常量一般可分为:数值常数和字符串常数。
1. 数值常数
数值常量分为整数常量和实数(带小数点的数)常数。 (1) 整数常数。在汇编语言程序中,整数常数可以有以下几种进制的形式表示。 十进制常数:由 0~9 数字组成,以 D 或 d 结尾,一般情况下,其后 D 或 d 可以省略,
例如:100, 255D。 十六进制常数:由 0~9, A~F 或 a~f 组成,以 H 或 h 结尾,例如:64h, 0B8h。为区别
于其他符号,以 A~F 或 a~f 开头的十六进制数前面必须加 0。 二进制常数:由 0, 1 数字组成,以字母 B 或 b 结尾,例如:01101100B。 八进制常数:由 0~7 数字组成,以字母 Q 或 q 结尾(或 O, o),如 144Q。 一般情况下,源程序中的常数默认为十进制形式,此时后面的 D 或 d 可省略。可以用伪
指令 RADIX 改变默认的数制,其格式为: .RADIX 用十进制形式表示的基数 例如,在使用“.RADIX 16”之后,则默认的常数为十六进制形式,那么 123 表示的是
123h,而不是 123D。 (2) 实数常数。实数其实就是带小数点的数。在汇编语言程序中,实数常数有两种形式表
示:带小数点的十进制数形式和指数形式。例如,-1.414, 4.56E-2, -1.732E+10 都是正确的实
数形式。
2. 字符串常数
字符串常数是用“'”(单撇号)或“"”(双撇号)括起来的单个字符或多个字符,对于 ASCII字符来说,其数值是每个字符对应的 ASCII 码的值,例如,'d'对应的是 64h,'AB'对应的是 41h, 42h,"Hello, World!"对应的是 48h, 65h, 6Ch, 6Ch, 6Fh, 2Ch, 20h, 57h, 6Fh, 72h, 6Ch, 64h, 21h。对于汉字来说,其数值是每个汉字的内码,例如,字符串:'你好!',在基于 GB 2312 汉字内
码系统中,其对应的数值是 0C4h, 0E3h 0Bah, 0C3h, 21h。
3. 常数在程序中的应用
在汇编语言程序中,常数主要用于以下几个方面。 (1) 作为立即数出现在汇编指令的源操作数位置上,注意,此时常数应符合目的操作数类
型要求。例如:

汇编语言程序设计
·92·
MOV AX, 1234h SUB AL, '0' AND EAX, 7FFFFFFFh (2) 在汇编指令中,作为内存操作数寻址方式中的位移量(地址编号)。例如: MOV AX, [1000h] ADD 100h[BX], AL TEST EAX, [1000h+EBX+EDX*4] (3) 在数据定义伪指令中(下面即将介绍),对分配的存储单元预置初始值。例如: Variable DW 1234h Str DB "Hello, World!", 13, 10, '$' x DQ 4.756E3
5.3.2 变量
在汇编语言程序中,变量是存放数据的内存单元名称。在 80x86 系统中,内存单元是以
其 低字节单元地址表示的,因而从本质上讲变量名是符号地址,另一方面,内存单元有 1字节、2 字节、4 字节等类型,与之对应的变量也具有这些类型。简而言之,变量具有两方面
属性:既是符号地址,也具有类型属性。
1. 变量的定义
通常,变量是在数据内存区中,使用数据定义伪指令来定义的,如例 5.1 中,用 DB 伪指
令定义了一个字符串变量 Msg,即 Msg DB 'Hello, World!', 13, 10, '$'。数据定义究其实质是为
存放数据而分配内存空间的,即告诉汇编程序,在汇编时从某个地址开始预留一定数量的内
存单元。有时为已分配的内存单元赋予一个名称,这便是变量名。在分配内存空间的同时,
也可为内存单元预置初始内容。 数据定义伪指令的格式是: [变量名] 数据定义伪指令 初值表 [;注释] 功能:分配一个或多个指定类型的内存单元,并可用变量表示该内存单元。 变量名是可选项,如果有变量名,那么它仅代表所定义的数据存储区的第一个单元地址。 常用的数据定义伪指令有以下几种。 DB 定义并分配一个或多个字节类型的存储单元及初始化。初值表中每项必须是字节类
型(Byte),即 8 位数据,可以用来存放:8 位无符号数/补码、字符串常量。 DW 定义并分配一个或多个 2 字节类型的存储单元及初始化。初值表中每项必须是 2 字
节类型(Word),即 16 位数据,可以用来存放:16 位无符号数/补码、段地址、偏移地址(16 位
地址模式)。 DD 定义并分配一个或多个 4 字节类型的存储单元及初始化。初值表中每项必须是 4 字
节类型(DWord),即 32 位数据,可以用来存放:32 位无符号数/补码、16 位地址模式的远指
针(高 16 位段地址和低 16 位偏移地址)、单精度浮点数、32 位地址模式的偏移地址。 DF 定义并分配一个或多个 6 字节类型的存储单元及初始化。初值表中每项必须是 6 字
节类型(FWord),即 48 位数据。可以用来存放:32 位地址模式下的远指针(高 16 位段选择器
和低 32 位偏移地址)。

第 5章 汇编语言程序设计初步
·93·
DQ 定义并分配一个或多个 8 字节类型的存储单元及初始化。初值表中每项必须是 8 字
节类型(QWord),即 64 位数据,可以用来存放:双精度浮点数。 DT 定义并分配一个或多个 10 字节类型的存储单元及初始化。初值表中每项必须是 10
字节类型(TByte)即 80 位数据,可以用来存放:80 位的临时浮点数。 这些伪指令可以把其后跟着的数据存入指定的存储单元,形成初始化了的存储空间,也
可以只分配存储空间而并不存入确定的数值,形成未初始化的存储空间。 初值表,用逗号分隔开的若干个数据项,每个数据项是定义并分配的存储单元的一个初
始内容。数据项有以下几种形式。 (1) 常数或常数表达式。为一个或多个数据分配存储单元,并设置初始内容。例如, Msg DB "Hello" DB 13, 10, "$" Cnt DW 5*20, -2 L DD 1234A1B2h, 87654321h F DQ 1.5 上述伪指令定义并分配的数据存储单元及初始化情况如图 5.3 所示。
48 65 6C 6C 6F 0D 0A 24 64 00 FE FF B2 A1 34 12 21 43 65 87 00 00 00 00 00 00 F8 3F
Msg↖ Cnt↖ L↖ F↖
图 5.3 数据及变量的存储单元分配、初始内容示意图
(2)“?”形式。分配一个或多个数据存储单元,但其内容不确定。一般情况下,程序在汇
编时以 0 填充。 (3) 符号地址及地址表达式。由于符号地址(如变量名)在程序运行前就已经能完全确定下
来,所以这种形式的数据项其实就是常数数据形式。在 16 位地址模式下,只适用于 DW 和
DD,对于 DW 伪指令,存储单元中的内容是符号地址的 16 位偏移地址,对于 DD 伪指令,
存储单元中的内容是符号地址的 16 位偏移地址和 16 位段地址;在 32 位地址模式下,只适用
于 DD 和 DF,对于 DD 伪指令,存储单元中的内容是符号地址的 32 位偏移地址,对于 DF伪指令,存储单元中的内容是符号地址的 32 位偏移地址和 16 位段地址。例如,
Msg DB "Hello" 13, 10, "$" p1 DW Msg, Msg+5 p2 DD Msg, Msg+5 假设程序运行前 Msg 表示的地址是 1AB0:0110,那么上述伪指令定义并分配的数据存储
单元及初始化情况如图 5.4 所示。
48 65 6C 6C 6F 0D 0A 24 10 01 15 01 10 01 B0 1A 15 01 B0 1A
Msg↖ p1↖ p2↖
图 5.4 以符号地址为初始内容的数据及变量定义的存储单元示意图
(4) 若初值表中有 n 个项相同,则可以用 DUP 把该项重复 n 次。其格式为: n DUP(数据项) 例如,s1 DB "你好", 2 DUP('!'), 2 DUP ('A', 'B'), 3 DUP(1, 2, 2 DUP('$'))

汇编语言程序设计
·94·
定义了以 s1 为首地址的 22 个字节单元,其初始内容是 0C4h, 0E3h, 0BAh, 0C3h, 21h, 21h, 41h, 42h, 41h, 42h, 01h, 02h, 24h, 24h, 01h, 02h, 24h, 24h, 01h, 02h, 24h, 24h。
2. 变量的属性
变量表示的是内存单元,由于其存放的内容可以随时改变,故称变量。变量具有两方面
属性,一方面变量名是符号地址,具有地址属性,另一方面,变量对应的是内存单元,具有
类型属性。 1) 地址属性 变量名表示的是它所对应的存储单元的 低字节单元地址编号,这个地址编号在程序运
行前就已经完全能确定下来,而且在运行过程中,变量名和地址编号间的对应关系不会改变,
所以说,本质上讲符号地址是一个常数项。 在 80x86 汇编语言中,变量所对应的地址有两方面内容:段地址和偏移地址。其中,段
地址可由 SEG 运算符返回,偏移地址可由运算符 OFFSET 返回。例如,对于例 5.1 中的变量
Msg,可以通过下述指令取出其对应的段地址和偏移地址。 MOV AX, SEG Msg ; 将 Msg的段地址送到 AX MOV BX, OFFSET Msg ; 将 Msg的偏移地址送到 BX 注意,上面的 SEG Msg 和 OFFSET Msg 是常数,虽然在编程时程序员可能不知道它所对
应的具体值,但是在程序运行前,它们是完全能确定下来的,且在运行期间不会再改变。 在汇编语言程序中,通常将程序中所有的变量集中放在数据段存储区,汇编程序在为数
据及变量安排内存空间时,遵照以下的规则。 (1) 同一段内的变量具有相同的段地址。 (2) 按照数据定义的先后次序,依次对各变量分配偏移地址。 (3) 除非有其他伪指令说明,段内的第一个变量被分在偏移地址为 0 处。 (4) 一条数据定义伪指令所分配的存储空间的大小由其类型和初值表决定。 (5) 除非有特别说明,在分配完前一个数据项后,紧接着分配下一个。 对于 80x86 系统而言,当需要存取某一数据段存储区中的变量时,必须首先将该段的段
地址放到相应的段寄存器(如 DS、ES 等)。例如,在例 5.1 示例程序中,通过指令: MOV AX, _DATA MOV DS, AX
将数据段存储区的段地址送到 DS 中,以便能正确存取该段内的变量。 2) 类型属性 变量的类型属性是变量所占存储单元的字节数,由数据定义伪指令(DB, DW, DD, DF, DQ,
DT)在定义变量时确定,可以是 1, 2, 4, 6, 8, 10 字节类型。 在汇编语言程序中,指令中的操作数必须符合类型要求。例如,MOV 指令要求两操作数
类型必须一致,否则,程序在汇编时就认为是语法错。所以,对于字节类型变量 Msg,指令
MOV AL, Msg 符合语法要求,而 MOV AX, Msg 不符合语法要求。如果要将 Msg 中前两字节
内容送到 AX,须用类型运算符 Word Ptr 来指定操作数类型,即 MOV AX, Word Ptr Msg。其
他情况以此类推。 MASM 中指定数据类型运算符有以下几个。 Byte Ptr 指定数据或变量为字节类型(8 位)。

第 5章 汇编语言程序设计初步
·95·
Word Ptr 指定数据或变量为 2 字节(字)类型(16 位)。 DWord Ptr 指定数据或变量为 4 字节(双字)类型(32 位)。 FWord Ptr 指定数据或变量为 6 字节类型(48 位)。 QWord Ptr 指定数据或变量为 8 字节(四字)类型(64 位)。 TByte Ptr 指定数据或变量为 10 字节类型(80 位)。 因为变量名对应的是一个内存单元地址,本质上讲它是整数常数,所以变量名加、减一
个整数其实就是地址编号加、减一个整数,仍然是一个整数常数,也对应一个内存单元地址,
其类型属性与原变量属性相同。例如,变量 L 的定义形式为: L DD 1234A1B2h, 87654321h
那么,L 是 4 字节类型的内存单元,其内容是 1234A1B2h,L+1 对应的也是 4 字节类型存储
单元,其内容是 211234A1h。 在汇编语言中,L+1 可以写成 L[1],注意,L[1]是 L 的偏移地址加 1 而不是加 1×4,所以
对应存储单元的内容是 211234A1h,而不是 87654321h,这一点和高级语言是不相同的。 每种数据类型用其占用的存储单元字节数作为它的类型值,可以用运算符 TYPE 将它分
离出来。例如,在例 5.1 中,数据段内的变量 Msg 和堆栈段中的变量 TOS 分别是字节类型和
2 字节(字)类型,TYPE Msg 和 TYPE TOS 返回的类型值分别是 1 和 2。
3. 变量的使用
在汇编指令中,对于内存操作数,除寄存器间接寻址方式不使用变量名外,其余各种寻
址方式均可使用变量名表示。例如,变量 Variable 的定义形式为: Variable DW 100 DUP(0) 几种用变量名表示的内存操作数寻址方式为: 直接寻址: MOV AX, Variable 寄存器相对寻址: MOV AX, Variable [SI] 相对基址变址寻址: MOV AX, Variable [BX][DI] 比例因子寻址: MOV EAX, DWord Ptr Variable [EBX][4*ECX] 注意,这些寻址方式的操作数的类型属性和变量的类型属性相同。
5.3.3 标号
1. 标号的定义
标号表示的是指令在内存中存放的位置。当在程序中使用一条转移指令的时候,可以用
标号来表示转移的目标地址,汇编程序在汇编时会把它替换成地址。 标号既可以定义在目的指令同一行的 前面,也可以在目的指令前一行单独用一行定义,
标号定义的格式是: 标号名: 其功能是表示标号后首条汇编指令在内存中的存放位置(地址)。 例如,在例 5.3 中定义了 3 个标号:“Begin”,表示的是指令 MOV AX, _DATA 在内存
中的存放位置;“again”,表示指令 IN AL, 0F0h 的存放位置;“loc1”表示指令 JMP Again

汇编语言程序设计
·96·
的存放位置。
2. 标号的属性
标号代表的是指令存放的符号地址,所以它也具有地址属性和类型属性。 1) 地址属性 标号代表的是其后首条指令在内存中的存放地址。 可用 SEG 来返回标号所在段的段地址,可用 OFFSET 来返回标号所在段的偏移地址。例
如,可用如下指令返回例 5.3 中标号 loc1 的段地址和偏移量: MOV AX, SEG loc1 ; 将 loc1的段地址送到 AX MOV BX, OFFSET loc1 ; 将 loc1的偏移地址送到 BX 2) 类型属性 标号具有 NEAR 和 FAR 两种属性,其类型值分别为-1 和-2,可用运算符 TYPE 返回其
类型值,例如,MOV AX, TYPE loc1,如果 loc1 是 NEAR 类型,则传送到 AX 中的是-1;如
果 loc1 是 FAR 类型,则送到 AX 中去的是-2。 到此为止,我们已经介绍完汇编语言程序中的 基本要素:指令助记符、寄存器助记符、
符号地址和常数等,有了这些符号,就可以编写汇编语言程序了。 由于 MASM 的伪指令规则非常繁多,建议读者先掌握汇编语言程序的 基本要素,在此
基础上编写程序。至于其他内容,根据需要以后反复练习,逐步地掌握。 例 5.4 编写程序从键盘输入两个字符,并输出其中 ASCII 码较大的字符。参照图 5.2 所
示的程序框架结构,将堆栈区大小、数据定义、实现题目要求的指令序列分别填写在相应处(用阴影和黑体标出)。读者可参照此例编写汇编语言程序。
_STACK SEGMENT STACK 'STACK' DB 2046 DUP(0) ;分配堆栈区空间:2046+2=2KB TOS DW 0 _STACK ENDS _DATA SEGMENT S DB 13, 10, ?," is greater$" ;定义字符串变量 s _DATA ENDS _TEXT SEGMENT 'CODE' ASSUME CS: _TEXT, DS: _DATA, SS: _STACK Start: MOV AX, _DATA MOV DS, AX CLI MOV AX, _STACK MOV SS, AX MOV SP, Offset TOS STI MOV AH, 1 INT 21h MOV s+2, AL MOV AH, 1 INT 21h CMP AL, s+2 ;解决问题的指令 JB loc1 MOV s+2, AL loc1: MOV DX, Offset s

第 5章 汇编语言程序设计初步
·97·
MOV AH, 9 INT 21h MOV AX, 4C00h INT 21h _TEXT ENDS END Start
5.3.4 变量名和标号的其他定义方式
在 MASM 中,可以通过伪指令 LABEL 和 EQU 来定义变量名或标号。 格式: 标识符 LABEL 类型 标识符 EQU THIS 类型 功能:定义一个指定类型的变量名或标号。 如果类型为 BYTE, WORD, DWORD, FWORD, QWORD 和 TBYTE 等,则定义的是一个
变量名;如果类型是 NEAR 和 FAR,则定义的是一个标号,注意,用这种方式定义的标号,
标识符后不要加“:”。用这两个伪指令只是将当前地址定义为一个变量名或标号,并不为它
们分配内存空间,这一点与数据定义伪指令有着本质的不同。 例如,在下列伪指令中: bVariable LABEL BYTE wVariable DW 100 第一条伪指令仅仅定义了一个具有字节类型的变量名,但并没有为它分配存储空间;第
二条伪指令定义了一个字类型的变量,而且为它分配了 2 字节的存储空间。因此,符号地址
bVariable 与 wVariable 代表的是同一个地址,但具有不同的数据类型属性。 又如,伪指令:Loc LABEL FAR 定义了一个具有远转移类型的标号,该标号指向其后第一条汇编指令的存放地址。 同样,在下列伪指令中: wVariable EQU THIS DWORD dwVariable DB 100 第一条伪指令仅仅定义了一个具有 2 字节类型的变量名,但并没有为它分配存储空间;
第二条伪指令定义了一个 4 字节类型的变量,而且为它分配了 4 字节的存储空间。因此,符
号地址 dwVariable 与 wVariable 代表的是同一个地址,但具有不同的数据类型属性。 伪指令:Loc EQU THIS NEAR 定义了一个具有近转移类型的标号,该标号指向其后第一条汇编指令的存放地址。
5.3.5 表达式和运算符
表达式是将常数、符号地址及其符号常量用运算符连接起来的有意义的式子。在汇编语
言中,表达式是操作数项的常见形式,其值的计算是在源程序汇编过程中完成的,而不是在
程序运行过程中进行的,所以表达式的结果是一个常数,这一点初学者要特别注意,它表示
的是一个纯数值或者地址编号。 在 80x86 汇编语言中,操作数的运算符分为:算术运算符、逻辑运算符、关系运算符、
数值返回运算符、属性运算符和字节分离运算符。下面分别介绍它们。

汇编语言程序设计
·98·
1. 算术运算符
表 5.1 列出了算术运算符,其中+, -, *, /这 4 个运算符是 常用的算术运算符。参加运算
的各数据项和运算的结果均为整数常数。注意,当符号地址出现在表达式中时,指的是符号
所代表的地址编号参加运算。
表 5.1 算术运算符
运 算 符 格 式 功 能 描 述
+ +<表达式> 表达式值取正 - -<表达式> 表达式值取负 * <表达式 1>*<表达式 2> 两式相乘 / <表达式 1>/<表达式 2> 两式相除
MOD <表达式 1>MOD<表达式 2> 两式整除取余 + <表达式 1>+<表达式 2> 两式相加 - <表达式 1>-<表达式 2> 两式相减
SHR <表达式 1>SHR<N> 将表达式的值右移 N 位 SHL <表达式 1>SHL<N> 将表达式的值左移 N 位 [ ] <表达式 1>[表达式 2] 等同<表达式 1>+<表达式 2>
当算术运行符用于地址表达式时,只有当运算结果具有明确的物理意义时,才能算有效
的结果。例如,两个符号地址相乘或相除,其结果无实际意义。 在地址表达式中,经常使用的形式是:符号地址±n,它是有实际意义的,例如,s+1 是
指 s 字节单元的后一个字节单元地址(注意,不是 s 单元内容加 1),而 s-1 则是指 s 字节单元
的前一个字节单元的地址。例如,将首地址为 Array 的 16 位数组的第 6 项传送到 DX 寄存器,
可用如下指令: MOV DX, Array+(6-1)*2 在地址表达式中,经常使用的还有两个符号地址相减,它也是有实际意义的。两个符号
地址相减,其结果是一个整数常数,表示的是这两个符号地址间的相距字节数。例如,有如
下的变量定义: Array DD 1, 2, 3, 4, 5, 6, 7 ,8 Cnt DW (Cnt-Array)/4 则变量 Cnt 中存入的是数组 Array 的元素个数(数组长度),在源程序汇编期间,可计算出
它的值是 8。
2. 逻辑运算符
表 5.2 列出了逻辑运算符。逻辑运算是按位操作的,参加运算的各数据项必须是常数。
由于逻辑运算是在源程序汇编期间完成的,因而所得的结果仍然是常数。
表 5.2 逻辑运算符
运 算 符 格 式 功 能 描 述
NOT NOT<表达式> 表达式值按位取“反”
AND <表达式 1>AND<表达式 2> 两表达式值按位“与”

第 5章 汇编语言程序设计初步
·99·
OR <表达式 1>OR<表达式 2> 两表达式值按位“或”
XOR <表达式 1>XOR<表达式 2> 两表达式值按位“异或”
注意,出现在表达式中的逻辑运算符不是汇编指令,运算符指定的运算是在源程序汇编
期间执行的,所得结果是常数,而逻辑指令是在程序运行期间所执行的逻辑运算。例如: AND AX, NOT 0FEh MOV AL, 77h AND 0F0h 上述两条指令经汇编后,其结果如下: AND AX, 0FF01h MOV AL, 70h
3. 关系运算符
表 5.3 列出了关系运算符。它们用于两个常数的比较,若关系成立,其结果为全-1(所有
位均为 1);若关系不成立,则结果为 0。例如: MOV AX, 0Ah EQ 1110b MOV BX, 56h GT 55h 上述两条指令经汇编后,其结果如下: MOV AX, 0FFFFh MOV BX, 0000h
表 5.3 关系运算符
运 算 符 格 式 功 能
EQ <表达式 1>EQ<表达式 2> 两个表达式值相等为真,否则为假
NE <表达式 1>NE<表达式 2> 两个表达式值不相等为真,否则为假
LT <表达式 1>LT<表达式 2> 表达式 1<表达式 2 为真,否则为假
LE <表达式 1>LE<表达式 2> 表达式 1≤表达式 2 为真,否则为假
GT <表达式 1>GT<表达式 2> 表达式 1>表达式 2 为真,否则为假
GE <表达式 1>GE<表达式 2> 表达式 1≥表达式 2 为真,否则为假
4. 数值返回运算符
数值返回运算符对符号地址进行分析,回送其地址属性值(符号地址对应的段基址、偏移
量),或类型属性值(如数据类型值、变量长度、变量元素个数等),其运算结果也是一个常数。
见表 5.4。
表 5.4 数值返回运算符
运 算 符 格 式 功 能 描 述
SEG SEG<符号地址> 返回符号地址的段地址
OFFSET OFFSET<符号地址> 返回符号地址的偏移地址
LENGTH LENGTH<变量> 返回变量元素个数
汇编语言程序设计
·100·
SIZE SIZE<变量> 返回变量所占字节数
TYPE TYPE<符号地址> 返回变量或标号的类型值
1) SEG 运算符 格式:SEG 符号地址。 功能:返回符号地址所在段的段地址。 例如,将变量 s 所在段的段地址送到 ES 段寄存器中,可用如下指令: MOV AX, Seg s MOV ES, AX 2) OFFSET 运算符 格式:OFFSET 符号地址。 功能:返回符号地址所在段的偏移地址。 例如,将变量 s 的偏移地址传送到 BX 中,可用下列指令: MOV BX, Offset s 3) TYPE 运算符 格式:TYPE 符号地址。 功能:返回符号地址类型值。MASM 定义的类型值见表 5.5。
表 5.5 类型属性数值表
数 据 类 型 类 型 值 标 号 类 型 类 型 值
1 字节 1 NEAR -1
2 字节 2 FAR -2
4 字节 4
6 字节 6
8 字节 8
10 字节 10 4) LENGTH 运算符 格式:LENGTH 变量。 功能:返回变量所含的数据存储单元个数。 该运算符只针对内存变量而设,它返回重复操作符 DUP 中的重复数。如果第一个表达式
为“n DUP(数据项)”形式,则返回值是 前面的重复次数 n;如果没有操作符 DUP,则返
回 1。 5) SIZE 运算符 格式:SIZE 变量。 功能:返回内存变量所含存储区的总字节数,其值等于 LENGTH 和 TYPE 两个运算符返
回值的乘积。
5. 属性运算符
用于设定或说明符号地址的属性,以及对运算对象的操作数的类型属性的设定,使运算
第 5章 汇编语言程序设计初步
·101·
过程具有相同属性。 1) 类型运算符 PTR 格式:类型 PTR 符号地址/数值。 功能:用于指定变量、标号、内存操作数或立即操作数的类型。 在 MASM 中,对于数据类的操作对象,类型可以是 BYTE, WORD, DWORD, FWORD,
QWORD 和 TBYTE 等;对于转换类的目标地址,类型可以是 NEAR 和 FAR,见表 5.6。
表 5.6 类型属性数值表
类型运算符 功 能 描 述
Byte Ptr 指定数据或变量为字节类型(8 位)
Word Ptr 指定数据或变量为 2 字节(字)类型(16 位)
DWord Ptr 指定数据或变量为 4 字节(双字)类型(32 位)
FWord Ptr 指定数据或变量为 6 字节类型(48 位)
QWord Ptr 指定数据或变量为 8 字节(四字)类型(64 位)
TByte Ptr 指定数据或变量为 10 字节类型(80 位)
Near Ptr 指定标号为近转移目标地址
Far Ptr 指定标号为远转移目标地址 例如, MOV AX, Byte Ptr s SUB [BX], Word Ptr 100 INC Word Ptr [SI] JMP Near Ptr Loc1 CALL Far Ptr Sub 2) 定义类型运算符 THIS 格式:标识符 EQU THIS 类型。 功能:定义一个指定类型的变量名或标号。 如果类型为 BYTE, WORD, DWORD, FWORD, QWORD 和 TBYTE 等,则定义的是一个
变量名;如果类型是 NEAR 和 FAR,则定义的是一个标号。详见 5.3.4 节相关内容。
6. 分离运算符
1) HIGH 与 LOW 格式:HIGH/LOW 常数/符号地址。 功能:对常数或符号地址进行字节分离,其中,HIGH 返回的是高 8 位,LOW 返回的是
低 8 位。 2) HIGHWORD 与 LOWWORD 格式:HIGHWORD/LOWWORD 常数/符号地址。 功能:对常数或符号地址进行字分离,其中,HIGHWORD 返回的是高 16 位,LOWWORD
返回的是低 16 位。
5.3.6 运算符的运先级

汇编语言程序设计
·102·
在 80x86 汇编语言中规定了运算的运先等级,参见表 5.7。
第 5章 汇编语言程序设计初步
·103·
表 5.7 常用运算符的优先级
优 先 级 别 运 算 符
0 括号中的表达式
1 LENGTH,SIZE,WIDTH,MASK
2 PTR,OFFSET,SEG,TYPE,THIS,段前缀(段寄存器名):
3 HIGH,LOW
4 *,/,MOD,SHL,SHR
5 +,-
6 EQ,NE,LT,LE,GT,GE
7 NOT
8 AND
9 OR,XOR
10 SHORT
5.4 MASM 的基本伪指令
伪指令又称为伪操作,前面已经简单介绍了伪指令的作用,以及使用了一些伪指令。伪
指令不像机器指令那样是在程序运行期间由计算机来执行的,而是在汇编程序对源程序汇编
期间由汇编程序处理的操作,它们可以完成诸如定义程序段、定义数据、分配存储区和指示
程序结束等功能。伪指令在形式上与一般指令相似,但伪指令只是为汇编程序提供有关信息,
不产生相应的机器代码。 MASM 提供有几十种伪指令,根据伪指令的功能,大致可以分为以下几类:数据定义、
符号定义、段定义、过程定义、宏处理、模块定义与连接、处理器方式、条件、列表、其他
伪指令等。在这些数目繁多的伪指令中,有的伪指令非常重要,在编程中必须经常使用,而
大多数伪指令却不那么重要,编程中也很少使用。 为了便于学习,前面已经介绍了一些使用频率较高的、编程中必须使用的伪指令。在此,
再介绍 MASM 的基本伪指令,为了完整起见,也包括前面已经介绍了的伪指令。
5.4.1 指令集选择伪指令
MASM 在默认情况下只接受 8086 指令集。如果程序员需要使用 8086 以后微处理器新增
加的指令,必须使用指令集选择伪指令,见表 5.8。
表 5.8 指令集选择伪指令
伪 指 令 功 能 描 述
.8086 仅接受 8086 指令(默认状态)
.186 接受 80186 指令
.286 接受除特权指令外的 80286 指令
.286P 接受全部 80286 指令,包括特权指令

汇编语言程序设计
·104·
续表 伪 指 令 功 能 描 述
.386 接受除特权指令外的 80386 指令
.386P 接受全部 80386 指令,包括特权指令
.486 接受除特权指令外的 80486 指令,包括浮点指令
.486P 接受全部 80486 指令,包括特权指令和浮点指令
.8087 接受 8087 数学协处理器指令
.287 接受 80287 数学协处理器指令
.387 接受 80387 数学协处理器指令
.No87 取消使用协处理器指令
.586 接受除特权以外的 Pentium 指令
.586P 接受全部的 Pentium 指令
.686 接受除特权以外的 Pentium Pro 指令
.686P 接受全部的 Pentium Pro 指令
.MMX 接受 MMX 指令
.K3D 接受 AMD 处理器的 3DNow!指令
.XMM 接受 SEE 指令和 SSE2 指令 指令集选择伪指令一般放在源程序的 前面。若不给出,则默认使用 8086 指令集。从使
用指令集伪指令之处起,以后汇编程序就可以识别并汇编指定指令集的指令。
5.4.2 完整的段定义伪指令
使用完整的段定义伪指令来定义一个段,可具体控制汇编程序 MASM 和连接程序 LINK在内存中组织代码和数据的方式。
1. 段定义伪指令 SEGMENT 和 ENDS
格式: 段名 SEGMENT [定位类型] [组合方式] [地址模式] ['分类名']
段名 ENDS 功能:在程序中定义一个逻辑段,指定段的名字和范围,段在内存中的起始位置,以及
段与段之间的连接关系。 段定义格式中各项说明如下。 (1) 段名是由程序员指定的一个标识符。在段定义格式中,段开始与结束的段名必须一致。
一个程序模块中可以定义若干个段,段名可以各不相同,也可以重复,汇编程序将一个程序
中的同名段处理成一个段。 (2) 每个逻辑段都以 SEGMENT 伪指令为开始标记,以 ENDS 伪指令为结束标记。段开
始和结束标记之间部分是段的内容:对数据段和堆栈段而言,一般由存储单元定义、分配等
伪指令所组成,对代码段,则主要是由可执行指令及某些伪指令组成。 (3) 在程序运行时,必须将 DS 和 SS 指向当前正在使用的数据段和堆栈段,才能正确使
用数据段内变量和正确设置程序堆栈。

第 5章 汇编语言程序设计初步
·105·
(4) 定位类型、组合方式、地址模式、'分类名',这 4 个段的属性项是可选项,视情况可
以选用或省略。若对本逻辑段在内存中的定位加以限定,或需与其他段相连接,则须按规定
选择这些项。 定位类型(align-type)规定该段在内存中起始位置的对齐方式。有以下几种方式可以选择。 • BYTE 段可以从任何地址开始,这样起始的偏移地址可能不为 0。 • WORD 段必须从字的边界开始,即段起始地址必须为偶数。 • DWORD 段必须从双字的边界开始,即段起始地址必须为 4 的整数倍。 • PARA 段必须从节边界开始,即段起始地址必须是 16 的整数倍。 • PAGE 段必须从页边界开始,即段起始地址必须是 256 的整数倍。 定位类型默认项是 PARA,即未指定定位类型,则汇编程序选择 PARA 方式。 组合方式(combine-type)说明程序连接时的段合并方法,它们可以是: • PRIVATE 本段为私有段,在连接时不与其他模块中的同名段合并。 • PUBLIC 在满足定位类型的条件下,在连接时本段将与其他具有 PUBLIC 属性的同
名段连接形成一个连续的大逻辑段,连接次序由连接命令指定。 • COMMON 在连接时,本段和其他具有 COMMON 属性的同名段重叠,对各段指定
相同的起始地址,因而产生覆盖。COMMON 连接后段的长度是各连接段中 大段的
长度。 • STACK 把不同模块中具有 STACK 属性的同名段连接成一个连续的堆栈段,连接后
的堆栈段长度是各个堆栈段长度之和。定义堆栈段时没有将其说明为 STACK 类型,
连接程序 LINK 在连接时会给出一个警告信息。 • MEMORY 与 PUBLIC 同义。 • AT 表达式 指定由表达式给出的本段段地址。AT 方式不能用在代码段中。 组合方式的默认项是 PRIVATE。 地址模式(use-type)说明本段使用 16 位地址模式,还是 32 位地址模式。 • USE16 使用 16 位地址模式,对于 16 位处理器不使用 USE 选项。 • USE32 使用 32 位地址模式,这是 32 位处理器的默认项。 使用 USE16 时,则该段 大长度是 64KB,地址形式是 16 位段地址和 16 位偏移地址;
使用 USE32 时,则该段 大长度为 4GB,地址形式是 16 位段地址和 32 位偏移地址。 '分类名'(class)是用单撇号括起来的长度不超过 40 个字符的字符串。连接程序把不同模块
中分类名相同的段组织成一类,存放在连续的存储区域。习惯上数据段、代码段、堆栈段的
分类名分别用'DATA', 'CODE', 'STACK'表示。
2. 段指定伪指令 ASSUME
格式:ASSUME 段寄存器名:段名 [段寄存器名:段名, …] 其中,段名是用 SEGMENT/ENDS 伪指令定义的段名,可以是“SEG 符号地址”返回的
段地址,或者关键字 NOTHING。段寄存器名必须是 CS, DS, SS, ES, FS, GS。 功能:此伪指令用来设定段寄存器和段之间的关联关系。以便汇编程序在汇编源程序期
间能正确确定指令要访问的是哪个段,如何访问。可用伪指令: ASSUME 段寄存器:NOTHING 或 ASSUME NOTHING

汇编语言程序设计
·106·
取消段寄存器与段的关联关系,或取消所有段寄存器与段的关系。 ASSUME 伪指令只是建立段名和段寄存器之间的关联,并未把各个段的段地址装入相应
的段寄存器中。段地址的装入通常要在程序中通过指令来完成。如在例 5.1 示例程序中,我
们通过指令设置了 DS 和 SS 及 SP。 对于 CS 和 IP,如果汇编语言程序是运行在操作系统(如 DOS、Windows)下,在程序运行
前由装入(Loader)程序根据当时情况自动填入;如果不是运行在操作系统下,则需要程序员手
工设置。 在 DOS 环境下,如果源程序中没有设置堆栈段,那么系统会设置一个默认的堆栈段。
3. 段组定义伪指令 GROUP
格式:段组名 GROUP 段名 1[, 段名 2, …] 功能:GROUP 把程序模块中若干个不同名字的段组合成一个组,并赋予一个段组名称,
组内各段都装在一个物理段中。
5.4.3 源程序开始与结束伪指令
1. 源程序开始伪指令
源程序开始处可用 NAME 或 TITLE 表示源程序的开始,并为模块取名字。 1) NAME 伪指令 格式:NAME 模块名。 功能:汇编程序将以给定的“模块名”作为模块的名字。 2) TITLE 伪指令 格式:TITLE 标题。 功能:指定在列表文件中每一页上打印的标题, 多为 60 个字符。如果程序中没有使用
NAME 伪指令,则汇编程序 MASM 将用 TITLE 语句中标题的前 6 个字符作为模块名。 如果一个汇编语言程序中既没有 NAME 伪指令,又没有 TITLE 伪指令,则用源文件名作
为模块名。一般常使用 TITLE,以便在列表文件中能打印出标题来。
2. 源程序结束伪指令 END
格式:END [标号/过程名]。 功能:该伪指令一般放在源程序 后一行,表示源程序到此结束。 END 后有一个可选项:标号/过程名。若选用此选项,则表明标号或过程名所指向的指令
是程序执行的第一条指令,所以,此处的标号或过程名,实际上是程序运行的入源地址。 只有主模块才可有此选项,其他模块则不能有此选项。
5.4.4 数据定义伪指令
用变量表示内存中的数据,是汇编语言中普遍采用的方法。变量名是存放数据的存储单
元符号地址,变量值是对应存储单元的内容。常用的数据定义伪指令有:DB, DW, DD, DF, DQ, DT。
格式:[变量名] 数据定义伪指令 初值表 [;注释]。 功能:定义并分配数据存储区,类型由数据定义伪指令确定,初始内容由其后的初值表

第 5章 汇编语言程序设计初步
·107·
给出。详细内容参见 5.3.2 节有关变量的定义与使用等内容。 在 MASM 汇编语言中,可用 LABEL 和 EQU 伪指令来定义一个符号地址(变量名或标号)。
注意,仅仅是定义一个符号地址,并不分配存储空间。 格式: 标号名 LABEL 类型。 标号名 EQU THIS 类型。 功能:如果类型为 BYTE, WORD, DWORD, FWORD, QWORD 和 TBYTE,则定义的是
一个变量名;如果类型是 NEAR 和 FAR,则定义的是一个标号。详细说明见 5.3.4 节相关内容。
5.4.5 符号定义指令
使用符号定义伪指令为程序中多次出现的同一个常数、符号串或表达式定义一个标识符,
以便在源程序中用此标识符来代替对应的常数、符号串或表达式。有以下两种。
1. 等值伪指令 EQU
格式:名字 EQU 符号串。 功能:为常量、表达式及其他符号定义一个符号名,供以后引用。 注意,其后的符号串可以是常数或数值表达式,地址表达式,变量、标号或者指令助记
符等。例如,有如下的等值定义: CONST EQU 50 ; 定义常数符号 VAR EQU Word Ptr X ; 定义变量属性 LAB EQU Strat ; 定义符号 M EQU MOV ; 定义指令助计符 C EQU CONST+300 ; 定义常数表达式 ADI EQU [SI+4] ; 定义地址表达式
那么下列的指令: M AX, VAR ADD AX, CONST SUB AX, ADI
经汇编后与下列指令等同: MOV AX, Word Ptr X ADD AX, 50 SUB AX, [SI+4]
2. 等号伪指令=
格式:名字=表达式。 功能:与 EQU 功能类似,不同的是等号伪指令可以对所定义的符号多次重复定义,且以
后一次定义的内容为准。例如: FH=SUB NUM=10 FH=ADD NUM=NUM+1

汇编语言程序设计
·108·
5.4.6 地址计数器与对准伪指令
1. 地址计数器
在汇编程序对源程序汇编的过程中,使用地址计数器(Location Counter)来指示当前正在处
理的汇编指令或伪指令所在处的偏移地址。当开始汇编或在每一段开始时,把地址计数器初
始化为 0,以后在汇编过程中,每处理一条汇编指令或数据定义等伪指令,地址计数器就增
加一个值,此值为该指令所需要的字节数。地址计数器的内容用“$”来表示,汇编语言允许
程序员直接用$来引用地址计数器的值。 当$用在指令中时,它表示该指令的第一个字节的地址。例如, JNE $+6
的转向地址是 JNE 指令的首地址加上 6。 当$用在数据定义等伪指令的参数字段时,则和它用在汇编指令中的情况不同,它所表示
的是地址计数器的当前值。例如: ARRAY DW 1, 2, $, 3, 4, $
假设汇编时 ARRAY 分配的偏移地址为 0074,则汇编后的存储区内容如下:
ARRAY→ 01 00 02 00 78 00 03 00 04 00 7E 00 ARRAY 变量中的两个$得到的结果是不同的,这是由于$的值是在不断变化的缘故。
2. 定位伪指令 ORG
格式:ORG 常数。 功能:将地址计数器设置到由常数指定的地址位置。如常数的值为 n,则指示汇编程序
在处理下一条汇编指令或数据定义等伪指令所用的存储地址为 n。其结果是留下 n-$个字节未
初始化的存储空间。注意,常数所指定的地址必须不能在当前$之前。 ORG 伪指令可以用在数据段中,例如: DEMO SEGMENT ORG 10 V1 DW 47A5h ORG $+3 V2 DW 5C96h DEMO ENDS 则 V1 的偏移地址值为 10,而 V2 的偏移地址值为 15,存储空间分配情况如图 5.5 所示。
00 00 00 00 00 00 00 00 00 00 A5 47 00 00 00 96 5C ↖V1 ↖V2
图 5.5 使用 ORG 伪指令定义数据的存储空间示意图
ORG 伪指令也可以用在代码段中,例如: ORG 100h JMP Loc ORG 200h

第 5章 汇编语言程序设计初步
·109·
Loc: MOV AX, 1200h …
则指令 JMP 存放的地址为 100h,而指令 MOV AX, 1200h 存放的地址,即 JMP 的转移目标标
号 Loc 所对应的地址为 200h,100h~200h 的存储空间中,除了 JMP 指令外,其余内容均为
未初始化内容。
3. EVEN 伪指令
格式:EVEN。 功能:使下一个变量或指令开始于偶数地址处。其结果可能留下 1 字节未初始化的空间。
4. ALIGN 伪指令
格式:ALIGN 2n形式的常数。 功能:使下一个变量或指令开始于 2n整数倍地址处。其结果可能留下若干字节未初始化
的空间。
5.4.7 子程序定义伪指令 PROC 和 ENDP
如果某程序段在源程序内反复出现,那么,就可把该程序段定义为子程序(也叫过程)。MASM 用于定义子程序的伪指令格式如下:
子程序名 PROC [NEAR/FAR] … ;子程序体
子程序名 ENDP 其中子程序名是子程序的入源地址的符号表示,是符号地址,也具有地址属性和类型属
性。具体使用说明在以后章节介绍。
5.4.8 其他伪指令
1. 注释伪指令 COMMENT
格式:COMMENT 分隔符 注释内容 分隔符。 功能:分隔符之间的任何内容均作为注释内容,但分隔符本身不能出现在注释内容中。
此伪指令非常适合放置大段注释内容,例如: COMMENT *This is a example for demo comment directive 这是用来演示注释伪指令的示例*
MOV AX, _DATA … 在这个示例中,'*'便是分隔符。任何字符都可以作为分隔符,只要注释内容中没有出现
分隔符,比如在上例中,'/'、'z'可作为分隔符,但'a'不可以,因为注释中包括了字符'a'。
2. 文件包含伪指令 INCLUDE
格式:INCLUDE 文件名。 功能:在源程序中,将一个外部文件插入到此伪指令所在处。

汇编语言程序设计
·110·
3. 全局符号名说明伪指令 PUBLIC
格式:PUBLIC 符号名 1[, 符号名 2, …]。 功能:将本模块中定义的一个或多个符号名说明为全局符号,这样在其他模块中可以引
用该符号。符号名可以是变量、符号常量、标号或过程名。
4. 外部符号名说明伪指令 EXTRN
格式:EXTRN 符号名 1:类型[, 符号名 2:类型, …]。 功能:说明本模块中将要引用的外部模块中的符号名,它们应在外部某个模块中已用
PUBLIC 伪指令进行了说明,类型应与原模块中定义的类型一致,对于符号地址,其类型可
以是:Byte, Word, DWord, FWord, QWord, TByte, Near, Far;对于常数则是 ABS。
5.5 MASM 的宏汇编伪指令
前面介绍的伪指令为汇编程序提供了简单的控制功能,本节所介绍的伪指令可为汇编程
序提供复杂的控制功能,包括:宏汇编、重复汇编、条件汇编,以及结构、联合和记录的
定义。
5.5.1 宏指令
在程序设计中,为了简化程序的设计,将多次重复使用的程序段用宏指令代替。宏指令
是指程序员事先定义的特定的“指令”,这种“指令”是一组重复出现的程序指令块的缩写
和替代。宏指令定义后,凡在宏指令出现的地方,汇编程序总是自动地把它们替换成对应的
程序指令块。宏指令有时也称为宏,包含宏定义和宏调用。
1. 宏指令的定义、调用和展开
1) 宏指令的定义 宏是源程序中的一段具有独立功能的程序代码。它只要在源程序中定义一次,就可以多
次调用,调用时只要使用一个宏指令语句就可以了。宏指令定义由开始伪指令 MACRO、宏
指令体、宏指令定义结束伪指令 ENDM 组成。格式如下: 宏指令名 MACRO [形式参数 1,形式参数 2,…,形式参数 n] … ; 宏指令体(宏体) ENDM 其中,宏指令名是宏定义为宏体程序块规定的名称,可以是任意合法的名字,甚至可以
是系统保留字(如指令助记符、伪指令操作符等),当宏指令名是某个系统保留字时,则该系统
保留字就被赋予新的含义,从而失去原有的意义。MACRO 语句到 ENDM 语句之间的所有汇
编语句构成宏指令体,简称宏体,宏体中使用的形式参数必须在 MACRO 语句中列出。 形式参数是出现在宏体内某些位置上可以变化的符号。在定义宏指令时,可以没有形式
参数,也可以有一个或多个形式参数。当形式参数多于一个时,形式参数之间用逗号隔开。
注意,形式参数仅仅是个形式,在宏调用(引用)时用相应的实际参数替代。 宏指令必须先定义后调用(引用)。宏指令可以重新定义,也可以嵌套定义。嵌套定义是指
在宏指令体内还可以再定义宏指令或调用另一宏指令。

第 5章 汇编语言程序设计初步
·111·
2) 宏指令的调用 宏指令一旦定义后,就可以用宏指令名字(宏名)来调用(引用),其调用格式为 宏指令名 实际参数 1,实际参数 2,…,实际参数 n 其中,“实际参数”的类型和顺序要与形式参数的类型和顺序保持一致,宏调用时将一
一对应地替换宏指令体中的形式参数。宏指令调用时,实际参数的数目并不一定要和形式参
数的数目一致。当实参个数多于形参的个数时,忽略多余的实参;当实参个数少于形参个数
时,其余的形参用空串代替。 宏调用实质是要求汇编程序把宏指令定义的程序段复制到调用点。如果此宏定义是带参
数的,则用宏调用时的实际参数对应地替代形式参数的位置。 3) 宏指令的展开 宏汇编程序遇到宏指令定义时,并不对它进行汇编,只有在程序中引用的时候,汇编程
序才把对应的宏体的代码替代宏指令调用,并进行汇编处理(语法检查和代码块的插入),这个
过程称为宏展开。 例 5.5 下列源程序中定义了宏指令 ExitToDos 和 InOutStr,在代码段中调用它们。 ; 将返回 DOS代码定义成宏指令 ExitToDOS MACRO MOV AX, 4C00h INT 21h ENDM ; 定义宏指令,用于显示(fun=09h)/输入(fun=0Ah)字符串。 InOutStr MACRO Fun, str MOV AH, Fun LEA DX, str INT 21h ENDM _STACK SEGMENT STACK DB 32766 DUP (?) TOS DW ? _STACK ENDS _DATA SEGMENT Msg DB 'Hello, World!', 13, 10, '$' _DATA ENDS _TEXT SEGMENT 'CODE' ASSUME CS:_TEXT, DS:_DATA, SS:_STACK Start: MOV AX, _DATA MOV DS, AX CLI MOV AX, _STACK MOV SS, AX MOV SP, Offset TOS STI InOutStr 9, Msg ExitToDOS _TEXT ENDS END Start 经 MASM 汇编生成列表文件中的部分内容显示如下,此清单展示了宏指令的展开代码,

汇编语言程序设计
·112·
即列表中二进制编码与汇编指令之间标记为 1 的代码为宏指令展开代码。 ; 将返回 DOS代码定义成宏指令 ExitToDOS MACRO MOV AX, 4C00h INT 21h ENDM ; 定义宏指令,用于显示(fun=09h)/输入(fun=0Ah)字符串 InOutStr MACRO Fun, str MOV AH, Fun LEA DX, str INT 21h ENDM 0000 _STACK SEGMENT STACK 0000 7FFE [ DB 32766 DUP (?) 00 ] 7FFE 0000 TOS DW ? 8000 _STACK ENDS 0000 _DATA SEGMENT 0000 48 65 6C 6C 6F 2C Msg DB 'Hello, World!',13,10,'$' 20 57 6F 72 6C 64 21 0D 0A 24 0010 _DATA ENDS 0000 _TEXT SEGMENT 'CODE' ASSUME CS:_TEXT,DS:_DATA,SS:_STACK 0000 B8 ---- R Start: MOV AX, _DATA 0003 8E D8 MOV DS, AX 0005 FA CLI 0006 B8 ---- R MOV AX, _STACK 0009 8E D0 MOV SS, AX 000B BC 7FFE R MOV SP, Offset TOS 000E FB STI InOutStr 9,Msg 000F B4 09 1 MOV AH, 9 0011 8D 16 0000 R 1 LEA DX, Msg 0015 CD 21 1 INT 21h ExitToDOS 0017 B8 4C00 1 MOV AX, 4C00h 001A CD 21 1 INT 21h 001C _TEXT ENDS END Start 4) 宏指令的嵌套 宏指令定义中还可以含有宏定义,或者宏指令定义中含有宏调用,这两种形式都属于宏
指令的嵌套。
2. 宏操作符
宏汇编程序提供了一些特殊宏处理运算符,增加了定义和引用宏指令的灵活性。 1) 连接运算符& 操作符&用来连接字符串或符号。汇编程序在宏展开时并不识别符号与字符串中的形式

第 5章 汇编语言程序设计初步
·113·
参数,但是在其前面加上一个&记号后,MASM 程序就能用实际参数代替这种形式参数。 例如,宏指令定义为: SHIFT MACRO REG, DIRECT, COUNT MOV CL, COUNT S&DIRECT REG, CL ENDM
那么宏调用 SHIFT AX, HR, 3 的展开形式为: 1 MOV CL, 3 1 SHR AX, CL 再如,有如下宏定义: ALLOC MACRO NUM, PLACE, INITVAL PLACE DB NUM DUP ('&INITVAL') ENDM
那么宏调用:ALLOC 100, ARRAY, 0 的宏展形式为: 1 ARRAY DB 100DUP ('0') 2) 文本操作符<> 文本操作符是一对尖括号<>,在宏调用过程中,视一对尖括号括起来的内容为一个实际
参数。例如,有如下宏定义: NUMBER MACRO THEDATA DB THEDATA ENDM
那么宏调用:NUMBER <1, 2, 3>的宏展开形式为: 1 DB 1, 2, 3 3) 表达式操作符% 在宏调用时,先计算出操作符%后的实际参数(常数表达式)的数值,宏展开时用该实际数
值替代其相应的形式参数,而不是实参本身的符号。 例如,有如下的符号常数和宏指令的定义: NUMBER MACRO X, Y, Z DB X, Y, Z ENDM I EQU 30 J EQU 10
则宏调用 NUMBER 10, %I+J, %I-J 的展开形式为: 1 DB 10, 40, 20 4) 字符操作符! 用此操作符标明其后是普通字符,不作为特殊字符使用。例如,宏指令定义为: DEF_MSG MACRO STRING DB '&STRING&$' ENDM

汇编语言程序设计
·114·
则宏调用指令 DEF_MSG <Input a number(!>0):>的展开形式为: 1 DB 'Input a number(>0):$'
3. 宏汇编中的伪指令
1) MACRO 和 ENDM 在前面的宏指令的定义中已经介绍过,这两个伪指令必须配套使用。 2) PURGE PURGE 的功能是取消其后一个或多个宏定义,即一个宏指令定义可通过伪指令 PURGE
来取消,然后重新定义。其格式如下: PURGE 宏指令名 1[, 宏指令名 2, …] 取消宏定义就是使该宏定义成为空。程序中如果出现已取消的宏定义的宏调用,汇编过
程中不会报错,此宏调用展开形式为空。 3) LOCAL 宏指令体内定义和使用符号名(标号或变量)后,如果多次调用这样的宏指令,汇编程序就
会多次进行宏扩展,从而造成同一符号名引起重复定义的错误。使用 LOCAL 伪指令可以避
免此类错误。其格式为: LOCAL 符号 1[, 符号 2, …] 伪指令 LOCAL 只能在宏指令定义体中使用,且只能是紧跟 MACRO 语句之后的第一条
语句。在宏扩展时,汇编程序为 LOCAL 所指定的符号按顺序依次产生唯一的特殊符号(符号
的范围从??0000~??FFFF),并替换宏指令体中 LOCAL 伪指令所指定的对应符号。 例如,将“两个无符号数据 X,Y 中 大数送到 Z”定义成宏指令: MAX MACRO Z, X, Y LOCAL LOC MOV AX, X CMP AX, Y JA LOC MOV AX, Y LOC: MOV Z, AX ENDM
若在程序中对此宏指令进行两次调用: MAX A, B, C NOP MAX V1, V2, V3
则相应的宏展开是: 1 MOV AX, [SI] 1 CMP AX, [DI] 1 JA ??0000 1 MOV AX, [DI] 1 ??0000: MOV [BX], AX NOP 1 MOV AX, [BP+4]

第 5章 汇编语言程序设计初步
·115·
1 CMP AX, [BP+100] 1 JA ??0001 1 MOV AX, [BP+100] 1 ??0001: MOV DX,AX 4) EXITM 宏调用扩展时,若只需部分展开或者因某种条件的需要而退出宏扩展,则可用 EXITM 伪
指令。通常,EXITM 和条件汇编伪指令一起使用。如果含有 EXITM 的宏指令体嵌套在另一
宏指令体中,仅退出内层的宏指令而继续扩展外层的宏指令。
4. 宏指令库
将经常使用的、具有通用性的宏定义放在一个文件中,形成了宏指令库,简称宏库。 例如,IO.MAC 文件中包括下列 3 个宏定义: INPUTC MACRO MOV AH, 1 INT 21h ENDM OUTPUTS MACRO ADDR LEA DX, ADDR MOV AH, 9 INT 21h ENDM RetrunToDOS MACRO MOV AX, 4C00h INT 21h ENDM 当源程序中要使用 MACROIO.LIB 中定义的宏指令时,可在源程序中使用包含伪指令
INCLUDE,即 INCLUDE IO.MAC
就可以指示汇编程序将 IO.MAC 读入 INCLUDE 所在处,相当于在此处定义了三个宏指令。
5.5.2 重复汇编
宏功能的另一种特殊形式是重复汇编操作,它与宏指令的不同之处在于不必预先进行定
义,因此重复汇编伪指令可以不在宏体内,也可以在宏体内。当宏汇编程序遇到一个重复汇
编伪指令时,立即按规定的重复次数展开重复汇编指令体的代码序列。 重复汇编语句有 3 种形式:固定重复伪指令 REPT,不定重复伪指令 IRP 和单字符参数
的不定重复伪指令 IRPC,均以 ENDM 作为结束标志。
1. 固定重复伪指令 REPT REPT 常数表达式 …; 重复代码块 ENDM 重复 REPT 和 ENDM 之间的指令序列(重复块)n 次,n 为常数表达式的值。例如,定义数

汇编语言程序设计
·116·
字 1~3 的字节数据。 X=10 REPT 3 DB X X=X+10 ENDM 经汇编后结果如下: DB 10 DB 20 DB 30
2. 不定重复伪指令 IRP
IRP形参, <实参 1[, 实参 2, …]> …; 重复代码块 ENDM 将 IRP 和 ENDM 之间的代码块重复 n 次(n 为实参的个数)。每次重复代码块时,就用一
个实参替代形参。第 1 次重复将用第 1 个实参替换形参,第 2 次重复用第 2 个实参,以此类
推,直到所有实参用完为止。各实参之间用逗号分隔开。 例如,用 IRP 伪指令产生将 AX, BX, CX 和 DX 压入堆栈的指令。 IRP REG, <AX, BX, CX, DX> PUSH REG ENDM 经汇编处理展开的代码序列为 PUSH AX PUSH BX PUSH CX PUSH DX
3. 单字符不定重复伪指令 IRPC IRPC 形参, 字符串 …; 重复代码块 ENDM 将 IRPC 和 ENDM 之间的代码块重复 n 次,n 等于字符串中字符的个数。第 1 次重复用
字符串的第 1 个字符去替换形参,第 2 次用第 2 个字符替换形参,依次类推。IRPC 和 IRP 操
作类似,不过 IRPC 的实参只能是单个字符,而且实参之间不用任何分隔符。 例如,用 IRPC 伪指令生成将 AX, BX 和 CX 顺序压入堆栈的指令。 IRPC CHR, ABC PUSH CHR&X ENDM 经汇编后产生下列指令序列:
第 5章 汇编语言程序设计初步
·117·
PUSH AX PUSH BX PUSH CX 在 MASM 6.x 中,可用 REPEAT, FOR 和 FORC 取代 REPT, IRP 和 IRPC。
5.5.3 条件汇编
条件汇编允许用户在编制汇编语言程序时根据某些条件是否成立(为真)来决定是否汇编
某一段代码。条件汇编指令有 10 个,分为互补的五对,分别用来测试表达式扫描遍数、符号
定义、参数和两个字符串是否相同等。条件汇编伪指令的一般格式是: IFxx表达式或参数 …; 代码块 1 [ELSE] …; 代码块 2 ENDIF IFxx 与 ENDIF 必须有,且成对出现,ELSE 是可选项。其中,IFxx 可以是 IF, IF1, IF2, IFE,
IFDEF, IFNDEF, IFB, IFNB, IFIDN 和 IFDIF 等。当被测试的表达式或参数符合条件(成立)时,
汇编程序将汇编代码块 1,否则汇编代码块 2(如果没有 ELSE,就直接忽略 IFxx 与 ENDIF 间
代码),见表 5.9。
表 5.9 条件汇编伪指令简表
伪 指 令 汇 编 条 件
IF 表达式 如果表达式的值不为零,则为真
IFE 表达式 表达式的值为零时,则为真
IF1 第一遍扫描
IF2 第二遍扫描时为真
IFB 参数 如果参数为空,则为真
IFNB 参数 如果参数不为空,则为真
IFDEF 符号 如果符号已定义,则为真
IFNDEF 符号 如果符号没有定义,则为真
IFIDN 参数 1,参数 2 如果参数 1 与参数 2 相同,则为真
IFIDN 参数 1,参数 2 如果参数 1 与参数 2 不同,则为真 条件汇编根据条件把一段代码包括在源程序中或排除在外,也可以根据不同条件选择不
同的代码段进入源程序,这就为汇编语言编程提供了很大的便利。 例 5.6 用条件伪指令在源程序中插入调试代码,以便在调试时用来显示一些信息,即当
汇编成调试版时(DEBUG=1),包括调试代码,但生成正式版时(DEBUG=0),将调试代码排除
在外。注意,此源程序仅用于演示条件伪指令的使用。读者可分别在 DEBUG=1 和 DEBUG=0两种情况下生成汇编,观察汇编后生成的代码和运行的显示。
DEBUG=1 ?debug MACRO str LOCAL Loc, Msg

汇编语言程序设计
·118·
IF DEBUG PUSH DS PUSH DX PUSH AX PUSH CS POP DS LEA DX, Msg MOV AH, 9 INT 21h JMP Loc Msg DB '&str', 13, 10, '$' Loc: POP AX POP DX POP DS ENDIF ENDM _STACK SEGMENT USE16 STACK DB 32766 DUP(0) TOS DW 0 _STACK ENDS _DATA SEGMENT USE16 Msg DB 'Hello, World!', 13,10,'$' _DATA ENDS _TEXT SEGMENT USE16 'CODE' ASSUME CS:_TEXT, DS:_DATA, SS:_STACK Start: MOV AX, _DATA MOV DS, AX CLI MOV AX, _STACK MOV SS, AX MOV SP, Offset TOS STI IF DEBUG NOP ; 填写调试时替换代码 ELSE MOV AX, AX ; 填写不需要调试的代码 ENDIF MOV DX, Offset Msg ?debug <MOV DX, Offset Msg> ; 显示调试信息 MOV AH, 9 ?debug <MOV AH, 9> ; 显示调试信息 INT 21h ?debug <INT 21h> ; 显示调试信息 MOV AX, 4C00h INT 21h _TEXT ENDS END Start
5.5.4 结构、联合与记录
MASM 也有类似 C 语言的结构体、共用体复合数据类型的定义,只是在汇编语言中存取

第 5章 汇编语言程序设计初步
·119·
这些数据是在汇编指令级基础上进行的。下面分别介绍它们。
1. 结构类型
在数据定义伪指令中所说的重复说明符 DUP 只能用于重复同一数据类型的变量说明,它
不可以重复不同数据类型的变量说明。为了把一组不同类型的变量说明组合在一起,汇编语
言提供了另一种复合数据类型说明符——结构类型说明符 STRUC。 1) 结构类型的定义 用 STRUC 和 ENDS 可以把一系列数据定义伪指令括起来,作为一种新的、用户定义的
结构类型。其一般格式如下: 结构名 STRUC [Alignment][, NONUNIQUE] 定义字段伪指令序列 结构名 ENDS 其中,结构名是一个合法的标识符,且具有唯一性。结构名代表整个结构类型,前后两
个结构名必须一致。结构体内所定义的变量为结构字段,变量名即为字段名。一个结构中允
许含有任意多个字段,各字段的类型和所占字节数也都可任意。如果字段有字段名,则字段
名必须唯一。每个字段可独立存取。 Alignment:对齐方式,可用 1, 2 或 4 来指定结构中字段的对齐方式,其默认值为 1,即
以字节对齐。见 5.4.6 节中的有关叙述。 NONUNIQUE:要求结构中的字段必须用全名访问。 注意,结构类型定义只是定义了结构类型的“模板”,并没有分配存储空间。 例如,定义如下的结构类型: STU STRUC No DD ? cName DB 20 dup(?) Score DW 60 STU ENDS 其中,STU 是结构名,它含有三个字段:No, cName 和 Score,这些字段的类型分别是
DD, DB 和 DW。结构类型 STU 的“模板”如下所示:
?? ?? ?? ?? ?? ?? ?? ?? ?? ?? ?? ?? ?? ?? ?? ?? ?? ?? ?? ?? ?? ?? ?? ?? 3C 00 ↖No ↖cName ↖Score
从中不难看出,结构类型 STU 共占 26 个字节,其字段 No, cName 和 Score 在“模板”中
的偏移量分别为:0, 4 和 24(18h)。 2) 结构类型变量的定义 在定义某个结构类型后,就可以用它来定义数据及变量。其格式如下: [变量名] 结构名 <[字段值表]> 汇编程序按定义的结构类型“模板”分配存储空间,并置相应的初始内容。其中: 变量名:即为该结构类型的变量名,它可以没有。如果没有,则不能用符号名来访问该
内存单元。 字段值表:给变量各字段赋初值,中间用逗号“,”分开,字段值的排列顺序及类型应与
该结构说明时各字段相一致。如果结构变量中某字段用其说明时的默认值,那么,可用逗号

汇编语言程序设计
·120·
来表示;如果所有字段都默认,则可省去字段值表,但必须保留一对尖括号“<”、“>”。 例如, Stu1 STU <> Stu2 STU <123, 'Zhang San', 80> Stu3 STU <234, "Li Si",> 3) 结构类型字段的引用 结构类型变量中的字段的引用方法有好几种,以上面的定义为例,如果要使用 Stu1 中的
Score 字段, 直接的办法是: MOV AX, Stu1.Score 它表示把 Score 字段的内容放入 AX 中去。假设 Stu1 在内存中的偏移地址是 3000h,这
条指令对应的是 MOV AX, [3018h]。 常常有使用指针存取结构类型变量的情况,如用 SI 为指针寻址,下列指令完成同样的
功能: LEA SI, Offset Stu1 MOV AX, [SI + STU.Score] 注意,第二条指令使用的是[SI + STU.Score]而不是[SI + Stu1.Score],因为前者对应的是
MOV AX, [SI+18h],而后者则是 MOV AX,[SI+3018h],后者的代码显然是错误的。 如果要对一个结构类型变量中的大量字段进行操作,这种写法显然比较烦琐,此时可用
ASSUME 伪指令把寄存器预先定义为结构类型指针,再进行操作。例如: LEA SI, Offset Stu1 ASSUME SI: Ptr STU MOV AX, [SI].Score ; … ASSUME SI: NOTHING 这样,使用寄存器也可以用点号引用字段名,程序的可读性比较好。注意:在不再使用
SI 寄存器作指针的时候,要用 ASSUME SI:NOTHING 取消定义。 4) 结构类型的嵌套定义 结构类型的定义也可以嵌套,如果要定义一个新的 BASEINFO 结构类型,里面包含一个
STU 结构类型字段和一个新的 Addr 字段,那么可以如下定义: BASEINFO STRUCT ADDR DB 20 DUP(?) _STU STU <> BASEINFO ENDS 假设现在 SI 是指向一个 BASEINF 变量的指针,那么引用里面嵌套的_STU 中的 Score 字
段时,就可以用下面的指令: MOV AX, [SI]._STU.Score
2. 联合类型
联合数据类型是一种特殊的数据类型。它可以实现:多种类型数据公用一块存储空间。 1) 联合类型的定义

第 5章 汇编语言程序设计初步
·121·
联合数据类型的定义格式如下: 联合类型名 UNION [Alignment] [, NONUNIQUE] 字段定义伪指令序列 联合类型名 ENDS 联合类型中的各字段相互重叠,即同样的存储单元被多个不同的字段所对应,并且其每
个字段的偏移量都为 0。联合类型所占的字节数是其所有字段所占字节数的 大者。 Alignment:对齐方式,可用 1, 2 或 4 来指定结构字节的对齐方式,其默认值为 1,即字
节对齐。它还用可伪指令 ALIGN 或 EVEN 来重新定界。 NONUNIQUE:要求联合类型中的字段必须用全名访问。 注意,联合类型定义只是定义了联合类型的“模板”,并没有分配存储空间。 例如,有如下的联合类型的定义: UD UNION bV DB ? ; 定义一个字节类型的字段 wV DW ? ; 定义一个字类型的字段 dwV DD ? ; 定义一个双字类型的字段 UD ENDS 联合类型 UD 的“模板”分布如下所示:
bV wV
dwV 2) 联合类型变量的定义与引用 定义联合类型变量及引用其字段的方法与前面结构类型变量相似,但在定义变量时,只
能用第一个字段的数据类型来进行初始化。 例如,Ud1 UD <'J'> 定义了联合类型的变量后,就可根据需要,以不同的数据类型或字段名来存取该联合类
型中的数据。例如, MOV Ud1.wV, 1234h ; 给联合类型变量赋字数据 MOV AL, Ud1.bV ; AL=34h MOV Ud1.bV, 'A' ; Ud1.wV的内容是 1241h,41h是'A'的 ASCII码
3. 记录类型
在 MASM 中,记录提供了直接按名访问字或字节中的若干位的方法,记录中的基本存取
单位是二进制位。 1) 记录类型的定义 记录类型使用伪指令 RECORD 来定义,其格式如下: 记录名 RECORD 字段 1 [, 字段 2] … 其中,“字段”的形式是:字段名:宽度[=初值表达式],字段中的“宽度”表示该字段所
占的二进制位数,它必须是一个常数,并且所有字段的宽度之和不能大于 32,根据其总长度
相应地分配 1 字节或 2 字节或 4 字节。

汇编语言程序设计
·122·
记录中的字段依次按“从右向左”由低向高分配对应内存单元的二进制位,内存单元中
没有用完的位补 0。 注意,记录类型定义只是定义一个“模板”,并没有分配实际存储空间。 例如,短浮点数格式定义为如下的记录类型: FLOAT RECORD Sign:1, Exp:8, Dat:23 它有 3 个字段:Sign(尾数的符号位)、Exp(阶码)和 Data(尾数)。总长度 32 位。 2) 记录类型变量的定义 记录类型变量的定义格式与其他类型变量类似,以前面的定义记录类型 FLOAT 为例,下
面的操作是分配两个短浮点数据存储空间,并置初始值为-3.0 和 0.875。 f1 FLOAT <1, 80h, 400000h>, <0, 7Eh, 600000h> 3) 记录类型变量的引用 和记录类型变量相关的操作符有:WIDTH,返回记录或记录字段的二进制位数,即宽度;
MASK,返回指定记录字段使用的对应位的值为 1 的整数常数。它们的一般书写格式如下: WIDTH 记录名/记录字段名 MASK 记录名/记录字段名 假设有前面定义的记录类型 FLOAT,那么,WIDTH FLOAT 的值为 32,WIDTH
FLOAT.Sign 的值为 1,WIDTH FLOAT.Exp 的值为 8,WIDTH FLOAT.Dat 的值为 23;MASK FLOAT.Sign 的值为 80000000h,MASK FLOAT.Exp 的值为 7F800000h,WIDTH FLOAT.Dat的值为 007FFFFFh。
可直接引用记录中的字段名,但它表示的该字段 低位在记录中的位置。例如: MOV CL, Sign ; 等同于 MOV CL, 31 MOV CL, Dat ; 等同于 MOV CL, 0 用以上介绍的操作符等可以取出记录变量中对应字段的内容,例如: MOV EAX, f1 AND EAX, MASK FLOAT.Exp SHR EAX, Exp
执行后,EAX 存放的是单精度浮点数的阶码。 用记录类型可以构造常数。例如,通过 FLOAT<1,10+127,2C0000h>构造常数 C4AC0000h,
再传送到 f1 单元中,实现-(1.01011)2×210⇒f1,指令如下: MOV f1, FLOAT<1, 10+127, 2C0000h>
5.6 段定义的简化
在 MASM5.0 及后续版本中,段的定义可以非常简单,以简化程序设计中的代码输入。 例 5.7 用简化段定义模式重新编写例 5.1 的程序。 .MODEL Small .STACK 32768 .DATA

第 5章 汇编语言程序设计初步
·123·
Msg DB 'Hello, World!', 13, 10, '$' .CODE Start: .STARTUP MOV DX, Offset Msg MOV AH, 9 INT 21h .EXIT 0 END Start 用于简化段定义的常用伪指令有以下几类。
1. 模式定义伪指令
使用简化段定义伪指令前,必须先说明程序使用的内存模式。其格式如下: .MODEL <存储模式>[,语言类型][,操作系统类型][,堆栈类型] 存储模式:Tiny/Small/Medium/Compact/Large/Huge/Flat。 语言类型:C/Syscall/Stdcall/Basic/Fortran/Pascal。 系统类型:OS_DOS。 堆栈类型:NEARSTACK/FARSTACK。
2. 简化段定义伪指令
每个简化段伪指令都表示一个段的开始,同时也说明前一个段结束。说明如下: .STACK [长度] 定义堆栈段,长度默认值为 1KB .CODE [名字] 定义代码段 .DATA 定义数据段 .DATA? 定义数据段,初值不确定 .FARDATA [名字] 定义远调用数据段 .FARDATA? [名字] 定义远调用数据段,初值不确定 .CONST 定义只读常数数据段
3. 生成启动和返回代码的指令
应该说这一组不是伪指令,它确实生成了汇编代码。说明如下: .STARTUP 程序入源,生成一些初始化 DS, SS和 SP等指令代码 .EXIT [n] 程序运行结束点。默认时为.exit 0相当于 MOV AX,4c00h和 INT 21h
4. 定义段序伪指令
MASM 可以规定汇编结果的目标文件中各段的位置顺序。有 3 种: .SEG 按在程序中出现的先后顺序安排各段。这是默认方式 .ALPHA 按照字母顺序安排各段 .DOSSEG 按照 DOS定义的标准安排各段顺序 使用简化的段定义伪指令,每个段都有一个默认的段名,如下所示。 MASM 允许用@代替简化段定义伪指令前的点号,如@CODE 代表.CODE 定义的段名,
@DATA 代表.DATA、.DATA?、.CONST 和.STACK 共享的组名,@FARDATA 代表.FARDATA定义的段名。

汇编语言程序设计
·124·
本 章 小 结
本章主要介绍一般汇编语言源程序的基本结构,其基本内容是: 理解汇编语言程序中对存储区分段使用用途,在此基础上掌握基于完整段定义的 80x86
汇编语言源程序的基本框架结构,以及 DOS 下的程序结构(便于学习中调试程序)。 掌握在汇编语言中经常使用的常数表示方式,数据和变量定义及应用,表示转移的目标
地址的标号定义与使用,以及符号地址的地址属性和类型属性。 掌握汇编语言源程序的编辑、汇编、连接和调试的方法。 这些内容为以后学习其他汇编或开发其汇编语言程序打下坚实基础。 其他内容还有:MASM 的基本伪指令;MASM 的宏汇编伪指令,包括宏指令、重复汇编、
条件汇编;以及复杂的数据类型定义与使用,包括结构类型、联合类型与记录类型。 由于 MASM 的伪指令及其规则非常繁多,建议读者先掌握基本内容,并编写练习程序。
在此基础上,根据需要再逐步地掌握其他内容。
习 题 5
5.1 汇编语言程序的开发有哪 4 个步骤?分别利用什么程序完成、产生什么输出文件? 5.2 在汇编语言程序中,如何对内存区进行分段使用? 5.3 表示源程序结束的伪指令是什么?在其后所编写的指令会被汇编吗? 5.4 汇编语言程序一定会从代码段的第一条指令开始执行吗?如果不是,如何指定程序
的入源地址? 5.5 什么是指令助记符?什么是符号地址?符号地址具有哪些属性? 5.6 什么是伪指令?它有什么用途? 5.7 画图说明下列数据定义伪指令所分配的存储空间和初始内容。 (1) Byte_Var DB 'BYTE', 12, -12h, 3DUP(0, ?, 2DUP(1, 2), ?) (2) Word_Var DW 5DUP(0, 1, 2), ?, -5, 256h 5.8 某数据段有如下数据定义,请画图说明该数据段数据的存储空间分配情况。 DEMODATA SEGMENT A1 DW 41h, B0A1h A2 DB '50#', 2 DUP (50. ?) A3 DW $-A2 A4 DD A1+4, $-A1 DEMODATA ENDS 5.9 定义一个 DSEG 数据段,在此段定义以下变量: (1) Str 是一个字符串变量,初始内容为 13,10,'Input a number:$'。 (2) V1 是字节变量,初始内容为 41h。 (3) V2 是字变量,初始内容为 2008h。 (4) V3 是 8 字节变量,初始内容为 15.125。

第 5章 汇编语言程序设计初步
·125·
5.10 有数据段如下: DATA SEGMENT ORG 10h Lab1 LABEL THIS Byte V1 DW 203h, 0C1A0h Lab2 LABEL THIS Word CNT1 DW (Lab2-V1)/2 Lab3 EQU THIS Word V2 DB 'ABCDEFGH' CNT2 DB $-Lab3 DATA ENDS 问:V1, V2, Lab1, Lab2, Lab3, Cnt1, Cnt2 的偏移地址是多少,对应的内容各是什么?
Lab1+2, Lab3+2 的偏移地址是多少,对应的内容是什么? 5.11 实现满足下列要求的宏定义: (1) 对任一寄存器或内存单元中的内容实现任意次数的左移操作。 (2) 任意两个内存单元中的数据相加存入第三个单元中。 (3) 对任意寄存器或内存单元中的补码求绝对值。 (4) 对任意 8 位寄存器中的数据转换为 ASCII 码,并在屏幕上显示。 5.12 现有一宏定义: Input MACRO Num, Addr MOV AH, 01h INT 21h SUB AL, 30h IF Num MOV BL, AL MOV AH, 01h INT 21h SUB AL, 30h MOV CL, 04h SHL BL, CL OR AL, BL ENDIF MOV ADDR, AL ENDM 试说明下述两个宏调用的功能。 Input 10, Da_By1 Input 0, Da_By2 5.13 宏指令 STORE 定义如下: STORE MACRO x, n MOV x+i, i i=i+1 IF i>n STORE x, n ENDIF ENDM

汇编语言程序设计
·126·
试展开下列宏调用: I=0 STORE TAB, 3 5.14 下面的宏指令 CNT 和 INC 完成相继字存储: CNT MACRO A, B A&B DW ? ENDM INCE MACRO A, B CNT A, %B B=B+1 ENDM 请展开下列宏调用,并说明宏指令 INCE 和机器指令 INC 的差别。 C=0 INCE DATA, C INCE DATA, C 5.15 把下列 C 语言的结构或结构变量的定义改写为与之等价的汇编语言定义形式。 (1) struct ScreenBuffer { char c1; //字符 char attr; //字符属性 } Buffer[2000]; (2) struct FILE { int level, flags; char fd, hold; int bsize, istemp, token; }; (3) struct CELLREC { char attrib; union { char text[201]; long value; struct { long fvalue; char formula[201]; } f; } v; }cell[100]; 5.16 把下列 C 语言程序中的说明性语句改写成等价的汇编语言定义形式。 #define N 200 struct buffer {char len1, len2, buff[N];} buff; int Data[N]; 5.17 按下列要求分别写出汇编语言的记录定义。 (1) 定义标志寄存器低 8 位标志位,其相应位用其标志位的符号来命名,未用部分的命名
自行确定。

第 5章 汇编语言程序设计初步
·127·
(2) 定义一个压缩型的 BCD 码类型。
(3) 把一个字节分成三部分:0~2 位、3~5 位和 6~7 位,每部分可独立存取,它们的初
值分别为 4,5 和 2。
(4) 定义一个表示学生情况的记录类型:年龄占 6 位,性别占 1 位(0 女,1 男),健康状
况占 1 位(0 健康,1 不健康)。
5.18 阅读下面的程序,回答问题。 _STACK SEGMENT STACK DB 1000h DUP (?) TOS DW ? _STACK ENDS _DATA SEGMENT Buf DB '123456' N=$-Buf BCD DB N DUP(?) _DATA ENDS _TEXT SEGMENT ASSUME CS: _TEXT, DS: _DATA Start: MOV AX, _DATA MOV DS, AX CLI MOV AX, _STACK MOV SS, AX MOV SP, Offset TOS STI MOV SI, Offset Buf MOV CX, N MOV DI, Offset BCD+N-1 Loop1: MOV AL, [SI] SUB AL, 30h MOV [DI], AL INC SI DEC DI LOOP Loop1 MOV AX, 4C00h INT 21H _TEXT ENDS END Start (1) 画出内存分配图。
(2) 说明程序功能。程序执行后从 BCD 开始的 N 个字节单元中的内容是什么?
(3) 若将指令 MOV DI,Offset BCD+N-1 改成 MOV DI,Offset BCD,将指令 DEC DI 改成
INC DI,其他指令不变,程序执行后,从 BCD 开始的 N 个字节单元中的内容是什么?
(4) 若取消数据段的 BCD 存储区,将处理后的数据放回原处,应如何修改程序?
5.19 下列程序功能:从 Buf 开始的 11 个单元中存放着 n 个整数,找出这 n 个数中的正
数并是偶数的个数,存入 R 中。根据功能要求,将程序填写完整。

汇编语言程序设计
·128·
_STACK SEGMENT DB 1000h DUP (?) TopOfStack DW? _STACK ENDS _DATA SEGMENT R DW ? Buf DW –2, 54, -3, 6, 101, 0, -20, -91, 8, -410, 21 N= ① _DATA ENDS _TEXT SEGMENT ② Begin: MOV AX, _DATA ③ CLI MOV AX, _STACK MOV SS, AX ④ STI MOV BX, Offset Buf MOV CX, N ⑤ Loc1: CMP [BX], Word Ptr 0 ⑥ TEST [BX], Word Ptr 1 ⑦ INC AX Next: INC BX DEC CX ⑧ MOV R, AX ⑨ INT 21h _TEXT ENDS END ⑩ 5.20 编制程序完成两个已知 64 位数 A 和 B 相加,并将结果存入 64 位变量 SUM 中(不考
虑溢出)。 5.21 试编写一程序计算表达式 w=(v-(x×y+z-540))÷x 的值,其中 x, y, z, v 均为有符号数,
存放在 16 位变量 X, Y, Z, V 中,计算的结果存放在 32 位变量 W 之中。

第 6 章 结构化程序设计方法
本章主要讲汇编语言结构化程序设计方法,包括: • 顺序结构程序设计。 • 分支结构的构造及程序设计。 • 循环结构的构造及程序设计。
6.1 概 述
当我们用计算机解决一个实际问题时,我们首先要针对问题进行需求分析,在明确任务
要求的基础上,编写出完整的计算机程序,从而产生一系列的指令告诉计算机如何去完成任
务。可见在程序设计中,代码的编写也是非常重要的部分。这一章主要是介绍汇编语言的程
序设计方法:按照给定的任务要求,使用汇编语言的指令和规则,描述问题的解决方法,即
编写出完整的计算机程序。 所以,简单地说程序设计就是编制计算机程序,包括两方面主要内容:指令代码,用来
告诉计算机如何去执行任务;数据,用来表示计算机所处理的对象。例如,计算机三角形面
积公式为: ( )( )( )( ) / 4S a b c a b c a b c a b c= + + − + + − + + −△ ,若用汇编语言编写求面积程序,
那么首先将公式的计算机过程转换为汇编指令序列,其次三角形必须用 3 条边边长表示,这
便是数据。 但是,也不能单纯地将程序设计理解为代码的编写过程。要使计算机帮助人们解决某一
问题,首先人们自己必须要有对这一问题的解决方法,这便是通常所说的找解决问题的算法,
其次再将算法转换为适合计算机执行的代码,这便是通常所说的编码。仍以求三角形面积为
例,有多种计算面积的方法:0.5×底×高;三边长求面积等。如果选用三边长求面积的方法,
则可以在此基础上编写程序代码,用 C 语言实现,就是 C 语言程序设计;用汇编语言实现,
则是汇编语言程序设计。 在实际应用中,面临的问题并不是这里所说的这么简单,所要找的算法也并不是这么容
易,那么如何进行程序设计呢?一个简单的程序设计一般包含以下 4 个步骤。 (1) 分析问题。对问题进行充分的分析,确定问题是什么,解决问题的步骤又是什么。 (2) 确定算法和数据结构。根据问题的分析结果,选择合适的解决方案即算法。 (3) 编制程序。将算法和数据结构等转换成某种计算机语言的程序代码。 (4) 调试程序。在计算机上实际运行,进行程序的测试和调整,直至获得预期的结果。 由此可见,一个完整的程序要涉及 4 个方面的问题:数据结构、算法、编程语言和程序
设计方法。这 4 个方面的知识都是程序设计人员所必须具备的。 在程序设计中,一般遵循结构化程序设计原则。所谓结构化程序设计是指程序的设计、
编写和测试都采用一种规定的组织形式进行,而不是想怎么写就怎么写。这样,可使编制的
程序结构清晰,易于读懂,易于调试和修改,充分显示出模块化程序设计的优点。

第 6章 结构化程序设计方法
·129·
在 20 世纪 70 年代初,由 Boehm 和 Jacobi 提出并证明的结构定理:即任何程序都可以由
3 种基本结构程序构成,这 3 种结构是:顺序结构、分支(条件选择)结构和循环结构。每一个
结构只有一个入口和一个出口,3 种结构的组合和嵌套就构成了结构化的程序。 3 种结构中,顺序结构最简单,选择和循环结构须通过控制结构来实现。在诸如 C 语言
等高级语言中,选择和循环结构可通过控制语句来实现,而在汇编语言中,选择和循环结构
必须通过比较指令、算术逻辑运算指令、条件转移指令等来完成,其实现代码相对烦琐。 本章主要内容是在已学过了汇编指令系统及汇编语言程序基本知识的基础上,介绍如何
利用汇编语言指令进行结构化程序设计的方法。
6.2 顺序结构程序设计
顺序程序完全按指令书写的前后顺序执行每一条指令,它没有分支、循环和转移等,是
最基本、最常见的程序结构。 例 6.1 编写程序,把(X-Y+24)/Z 的商赋给 A,把(X-Y+24)/Z 的余数赋给 B。其中,变量
X 和 Y 是 32 位有符号数,变量 A, B 和 Z 是 16 位有符号数。(不考虑除法溢出) _STACK SEGMENT STACK 'STACK' DB 1000h DUP (?) TOS DW ? _STACK ENDS _DATA SEGMENT 'DATA' X DD 12345678h Y DD 4A4BEF06h Z DW 7F01h A DW ? B DW ? _DATA ENDS _TEXT SEGMENT 'CODE' ASSUME CS: _TEXT, DS: _DATA Start: MOV AX, _DATA MOV DS, AX CLI MOV AX, _STACK MOV SS, AX MOV SP, Offset TOS STI MOV AX, Word Ptr X MOV DX, Word Ptr X+2 ;用 DX:AX来保存 32位变量 X的数值 SUB AX, Word Ptr Y SBB DX, Word Ptr Y+2 ;DX:AX-Y+2:Y ADD AX, 24 ADC DX, 0 ;DX:AX+24TDS:AX IDIV Z MOV A, AX MOV B, DX MOV AX, 4C00h INT 21H

汇编语言程序设计
·130·
_TEXT ENDS END Start 例 6.2 将一个字节压缩 BCD 码转换为两个 ASCII 码。 分析:一个字节的压缩 BCD 码就是用一个字节的二进制数表示两位十进制数,如十进制
数 96 表示成压缩 BCD 码就是 96h,转换成 ASCII 码就是把压缩 BCD 码表示的十进制数的高
位和低位分开,并转换成 39h 和 36h。(省略了堆栈段) _DATA SEGMENT 'DATA' BCDBUF DB 96h ; 定义 1个字节的压缩 BCD码 ASCBUF DB ?, ? ; 定义 2个字节单元,用来存放结果 _DATA ENDS _TEXT SEGMENT 'CODE' ASSUME CS: _TEXT, DS: _DATA Start: MOV AX, _DATA MOV DS, AX MOV AL, BCDBUF ; 取出 BCD码 MOV AH, AL ; 送 BL暂存 MOV CL, 4 SHR AH, CL ; 高4位移至低4位,高4位补0(96h变为09h) AND AL, 0Fh ; 屏蔽掉高 4位,只保留低 4位(96h变为 06h) ADD AX, 3030h ; 变成 ASCII码(0906h变为 3936h) MOV Word Ptr ASCBUF, AX ; 存储 2个 ASCII码 MOV AX, 4C00h INT 21h _TEXT ENDS END Start 例 6.3 利用直接查表法完成将键盘输入的一位十进制数字字符('0'~'9')转换成对应的立
方值并存放在 CubeBuf 单元中。 分析:0~9 的立方值分别为 0, 1, 8, 27, 64, 125, 216, 343, 512, 729,将它们按顺序放在一
起,形成一个表。若输入数字为 n,则对应的立方数存放在第 n 位置,所在单元地址为:表
首地址+2×n。据此编写的汇编语言程序如下: _DATA SEGMENT 'DATA' CubeTab DW 0, 1, 8, 27, 64, 125, 216, 343, 512, 729 CubeBuf DW ? _DATA ENDS _TEXT SEGMENT 'CODE' ASSUME CS: _TEXT, DS: _DATA Start: MOV AX, _DATA MOV DS, AX MOV AH, 1 INT 21h ; 输入—个数, 得到其 ASCII码 MOV SI, AX AND SI, 0Fh ; 由 ASCII码得到相应的数 n ADD SI, SI ; 2×n⇒SI MOV AX, CubeTab[SI] ; 查表 MOV CubeBuf, AX ; 存储结果 MOV AX, 4C00h

第 6章 结构化程序设计方法
·131·
INT 21h _TEXT ENDS END Start
6.3 分支结构程序设计
分支结构是一种非常重要的程序结构,也是实现程序功能选择所必要的程序结构。分支
结构的特点是:在某一确定的条件下,只执行二分支或多分支中的一个分支。因此一般将分
支结构分为两种形式:二分支结构和多分支结构。
6.3.1 二分支结构程序设计
二分支结构有两种情况:根据条件,在两个分支中选择一个执行,如图 6.1(a)所示;或者
当条件成立时执行指定的指令序列,条件不成立时直接跳过,如图 6.1(b)所示。
(a) 在两个分支中选择一个执行 (b) 当条件成立时执行指定的指令序列
图 6.1 二分支结构的两种情况
在高级语句中,二分支结构一般用 if 语句来实现。在汇编语言中,通过无条件转移指令
和条件转移指令等来构造分支结构,其中条件判断及转移操作通常是由比较、算术逻辑运算
指令和条件转移指令等实现的。通过执行比较、算术逻辑运算指令来设置结果标志位,条件
转移指令再根据标志位的状态决定转到某一分支去执行。 二分支结构程序设计的关键是如何用汇编指令构造分支结构的控制部分。由于控制部分
中的转移指令肯定会破坏程序的结构,所以,编写清晰的分支结构是掌握该结构的重点。 一般而言,在汇编语言程序中可按“模板”来构造分支结构的控制部分,如图 6.2 所示。
; <<<二分支结构开始>>> 用比较、算术、逻辑运算等指令构造控制转移,一个分支是
Then_loc,一个分支是 Else_loc Then_loc: 条件成立指令序列块 JMP Endif_loc Else_loc: 条件不成立指令序列块 Endif_loc: ; <<<二分支结构结束>>>
图 6.2 汇编语言程序中的二分支结构模板示意图
模板的关键之处在于条件转移指令序列的构造。当条件成立时,转移到标号 Then_loc 处;
当条件不成立时,转移到标号 Else_loc 处,两个分支最后汇总到标号 Endif_loc 处。
汇编语言程序设计
·132·
对于单个条件测试,一般简单地使用一条比较指令或算术逻辑运算指令,再加上一条条
件转移指令即可。下面用具体实例说明。 例 6.4 编写程序,将键盘上输入的一个字符的 ASCII 码,以十六进制数形式显示出来。 分析:在计算机内部是用一个字节来存放一个字符(ASCII 码)。一个字节是两个十六进制
位,所以,可以先将高 4 位取出来,转换成 ASCII 字符,然后输出;再将低位取出,转换成
ASCII 字符再输出。若 4 位二进制数对应的数 n 是 0~9,则对应的字符是'0'~'9'(ASCII 码是
30h~39h),所以 n+'0'(30h)即是其对应字符的 ASCII 码;若 n 是 10~15,则对应的字符是'A'~'F'(ASCII 码是 41h~46h),所以其对应字符的 ASCII 码是 n-10+'A'。 这实际上是一个二分支
结构。程序流程如图 6.3 所示。
图 6.3 例 6.4 的流程图
程序中用 DOS 的 01 号功能调用来实现字符的输入,用 DOS 的 02 功能调用实现字符的
输出。源程序如下:(省略了堆栈段) .386 _DATA SEGMENT 'DATA' USE16 Chr DB ? _DATA ENDS _TEXT SEGMENT 'CODE' USE16 ASSUME CS: _TEXT, DS: _DATA Start: MOV AX, _DATA MOV DS, AX MOV AH, 01h INT 21h MOV Chr, AL ROL Chr, 4 MOV DL, Chr AND DL, 0Fh ;构造条件测试 CMP DL, 9 JG Else_1 Then_1: ADD DL, '0' ;Then分支 JMP Endif_1 Else_1:

第 6章 结构化程序设计方法
·133·
ADD DL, -10+'A' ;Else分支 Endif_1: MOV AH, 02h INT 21h ROL Chr, 4 MOV DL, Chr AND DL, 0Fh ;构造条件测试 CMP DL, 9 JG Else_2 Then_2: ADD DL, '0' ;Then分支 JMP Endif_2 Else_2: ADD DL, -10+'A' ;Else分支 Endif_2: MOV AH, 02h INT 21h MOV AX, 4C00h INT 21h _TEXT ENDS END Start 不难发现,程序中两处代码除了标号不同外,其结构完全相同,对这样的代码,可以用
循环结构减少代码的冗长。读者在学习后面的循环结构后,可仿照这个例子,编写习题 6.5的程序。
例 6.5 有两个有符号数 x 和 y,分别存放在 X 单元和 Y 单元中。编写程序求|x-y|,结果
存放在 Z 单元。 分析:若 x>y,则|x-y|=x-y,否则|x-y|=y-x,流程图如图 6.4 所示。
图 6.4 例 6.5 的流程图
据此编写的汇编源程序如下:(省略了堆栈段) _DATA SEGMENT 'DATA' X DW 0FF8Dh Y DW 0E859h Z DW ? _DATA ENDS
汇编语言程序设计
·134·
_TEXT SEGMENT 'CODE' ASSUME CS: _TEXT, DS: _DATA Start: MOV AX, _DATA MOV DS, AX MOV AX, X ;构造条件测试 SUB AX, Y JNS Else_1 Then_1: NEG AX ;Then分支 JMP Endif_1 ;跳转分支结束处 Else_1: ;Else分支,此处为空 Endif_1:MOV Z, AX MOV AX, 4C00h INT 21h _TEXT ENDS END Start 由于程序中 Else 分支为空,所以 JMP Endif_1 不是一条必要的指令,此处为了便于读者
对照模板,特地保留。 通过例 6.4 和例 6.5,使用模板可使分支结构的构造过程“标准化”。 例 6.6 编写程序,将首地址为 B1、长度为 n 的数据块内容传到首地址为 B2 数据块中。 分析:用串处理指令实现数据块传送。假设传送"abcdef"六个字节数据,针对源、目的数
据块重叠与否分三种情况:两数据块地址不重叠,正向传送和反向传送均正确;若两数据块
有部分地址重叠,且 B1<B2,如分别为 100 和 102,则只能反向传送,若正向传送,则目的
块内容为"ababab",其原因是在传送过程中覆盖了源块的重叠部分;若两数据块有部分地址重
叠,且 B1>B2,如分别为 102 和 100,则只能正向传送,若反向传送,则目的块内容为"defdef",原因也是源块的重叠部分被覆盖。所以,若 B1>B2 时,采用正向传送方式;若 B1<B2 时,
采用反向传送方式。程序流程如图 6.5 所示。
图 6.5 例 6.6 程序流程图
据此编写的汇编语言程序如下:

第 6章 结构化程序设计方法
·135·
_DATA SEGMENT 'DATA' ORG 100h s1 DB 10 DUP ('0123456789ABCDEF') ; 共计 160个字节数据 DB 100 DUP (?) B1 DW s1 B2 DW s1+50 Count DW 160 _DATA ENDS _TEXT SEGMENT 'CODE' ASSUME CS:_TEXT, DS:_DATA Start: MOV AX, _DATA MOV DS, AX MOV ES, AX MOV CX, Count MOV SI, B1 MOV DI, B2 CMP SI, DI JNA Else_1 Then_1: CLD JMP Endif_1 Else_1: STD ADD SI, CX ADD DI, CX DEC SI DEC DI Endif_1:REP MOVSB MOV AX, 4C00h INT 21h _TEXT ENDS END Start
对于复杂的条件测试,其对应的控制转移代码比较烦琐。可用逻辑运算中的两条定律:
¬(P∧Q)=¬P∨¬Q,¬(P∨Q)=¬P∧¬Q,将多个条件组合而成的条件测试,转换仅由∧和∨组合
而成的条件测试,在此基础上构造出它对应的控制转移代码。
1. 形如 P1∧P2∧ … ∧Pn的条件测试
对于这种全部由“逻辑与”组合而成的条件测试,可按顺序测试 P1,P2,…,Pn,只要有一个
Pi 为假,则转至标号 Else_loc 处,只有当所有的 Pi 为真时,才转至 Then_loc 处。 例 6.7 编写汇编指令序列,实现下列功能:如果 x1>0,x2为偶数,并且 x3+x4<100,则
置 Sample 为 100,否则置 Sample 为 200。 分析:题中的 3 个条件是与关系:(x1>0)∧x2 为偶数∧(x3+x4<100)。编写的代码序列如下: … CMP X1, 0 JNG Else_1 TEST X2, 1 JNZ Else_1 MOV AX, X3 ADD AX, X4 CMP AX, 100

汇编语言程序设计
·136·
JNL Else_1 Then_1: MOV Sample, 100 JMP Endif_1 Else_1: MOV Sample, 200 Endif_1:…
2. 形如 P1∨P2∨…∨Pn的条件测试
对于这种全部由“逻辑或”组合而成的条件测试,可按顺序测试 P1,P2,…,Pn,只要有一个
Pi 为真,则转至标号 Then_loc 处,只有当所有的 Pi 为假时,才转至 Else_loc 处。 例 6.8 编写汇编指令序列,实现下列功能:如果 x1>0 或者 x2 为偶数,或者 x3+x4<100,
则置 Sample 为 100,否则置 Sample 为 200。 分析:题中的 3 个条件是或关系:x1>0∨x2 为偶数∨ x3+x4<100。编写的代码序列如下: … CMP X1, 0 JG Then_1 TEST X2, 1 JZ Then_1 MOV AX, X3 ADD AX, X4 CMP AX, 100 JNL Else_1 Then_1: MOV Sample, 100 JMP Endif_1 Else_1: MOV Sample, 200 Endif_1:…
3. 由∧和∨组合的条件测试
在 P1∧P2∧…∧Pn 或 P1∨P2∨…∨Pn 的组合条件中,某一项 Pi 又可以是 Q1∧Q2∧…∧Qn 或
Q1∨Q2∨…∨Qn 的形式,这样可以形成非常复杂的条件测试。我们仍然可以用上述的方法构造
出条件转移指令序列。 在形如 P1∧P2∧…∧Pn 的组合条件中,若 Pi 为 Q1∨Q2∨…∨Qn 的形式,则可按顺序测试 Qj,
只要有一个 Qj 为真,则转去测试下一个 Pi+1,当所有的 Qj 为假时,则直接转至 Else_loc。 在形如 P1∨P2∨…∨Pn 的组合条件中,若 Pi 为 Q1∧Q2∧…∧Qn 的形式,则可按顺序测试 Qj,
只要有一个 Qj 为假,则转去测试下一个 Pi+1,当所有的 Qj 为真时,则直接转至 Then_loc。 例 6.9 把下列 C 语言的语句改写成等价的汇编语言指令序列。 if (x1+x2>0&&(x3%2 == 0||x4<'a')&&(x5+x6<0||x7>100)&&x8<'z') a=65;else a=97; 其中:变量 x1, x2, x3, x4, x5, x6, x7 和 x8 都是 16 位有符号的整型变量。 分析:此处的条件测试是:x1+x2>0∧(x3%2==0∨x4<'a')∧(x5-x6<0∨x7>100)∧x8<'z',因此,
可用如下的汇编语言指令序列实现与 C 语言语句等价的功能。 … MOV AX, x1 ADD AX, x2 JNG Else_1 TEST x3, 1

第 6章 结构化程序设计方法
·137·
JZ If_1_1 CMP x4, 'a' JNL Else_1 If_1_1: MOV AX, x5 SUB AX, x6 JL If_1_2 CMP x7, 100 JNG Else_1 If_1_2: CMP x8, 'z' JNL Else_1 Then_1: MOV a, 65 JMP Endif_1 Else_1: MOV a, 97 Endif_1:…
例 6.10 如果 year 不是闰年,则置 days 为 365;否则,置 days 为 366。 分析:此处条件测试为:year÷4 余数不为 0∨(year÷100 余数为 0∧year÷400 余数不为 0)
∨year÷3200 余数为 0。当测试为真时,不是闰年,否则是闰年。指令序列如下: … MOV AX, Year TEST AX, 3 JNE Then_1 MOV BX, 100 CWD DIV BX OR DX, DX JNE If_1_1 TEST AX, 3 JNE Then_1 If_1_1: MOV AX, Year MOV BX, 3200 CWD DIV BX OR DX, DX JNE Else_1 Then_1: MOV Days, 365 JMP Endif_1 Else_1: MOV Days, 366 Endif_1:…
4. 分支结构的嵌套
在汇编语言中编写嵌套的分支结构没有高级语言那样直观,这是因为:一方面汇编语言
本身不是结构化语言;另一方面,在构造分支结构时,多处使用转移指令,因而会有很多标
号,在整个程序范围内取不重名的标号要花费一番工夫。 为提高嵌套分支结构汇编代码的清晰度,我们在使用分支结构的模板构造程序代码的基
础上,以类似 E-mail 地址方式为标号命名,即@前是本层的标号,@后是嵌套层的标号。这
种方式构造的标号名能反映出嵌套关系。下面通过具体例子来说明。 例 6.11 把下列 C 语言的语句改写成等价的汇编语言指令序列。
汇编语言程序设计
·138·
if (x1>0){if (x2>0) x=10; else y=20;}else{if (x3>0) u=30; else v=40;}
其中:变量 x1, x2, x3, x, y, u 和 v 都是 16 位有符号的整型变量。 … CMP x1, 0 JNG Eles1 Then1: CMP x2, 0 JNG Else1@Then1 Then1@Then1: MOV x, 10 JMP Endif1@Then1 Else1@Then1: MOV y, 20 Endif1@Then1: JMP Endif1 Else1: CMP x3, 0 JNG Else1@Else1 Then1@Else1: MOV u, 30 JMP Endif1@Else1 Else1@Else1: MOV v, 40 Endif1: …
6.3.2 多分支结构程序设计
当要根据某个变量的值,进行多种不同处理时,就产生多分支。如图 6.6 所示。在高级
语言中,有专门语句来实现多分支结构,如 C 语言使用的是 switch 语句。但在汇编语言中,
必须通过一系列汇编指令来构造这种结构。
图 6.6 多分支结构示意图
在汇编语言中可以有多种方法来构造多分支结构,以下通过具体实例来说明。
1. 通过直接测试来构造多分支结构
例 6.12 编写多分支结构程序,实现:输入'1', '2', '3',输出"one", "two", "three";输入'0',中止运行;输入其他,输出"error!"。
分析:多分支中的每一个分支条件对应一个条件判断,哪个条件成立,就转入相应分支
体执行。所以此例中的多分支可以化解为二分支和单分支结构的组合。程序如下: _DATA SEGMENT 'DATA' Msg DB 13, 10, "Please input a number: ", 13, 10, "$" s1 DB 9, "one", 13, 10, '$' s2 DB 9, "two", 13, 10, '$' s3 DB 9, "three", 13, 10, '$' err DB 9, "error!", 13, 10, '$' _DATA ENDS _TEXT SEGMENT 'CODE' ASSUME CS: _TEXT, DS: _DATA

第 6章 结构化程序设计方法
·139·
Start: MOV AX, _DATA MOV DS, AX Again: MOV AH, 9 MOV DX, Offset Msg INT 21h MOV AH, 1 INT 21h CMP AL, '0' JE Case0 CMP AL, '1' JE Case1 CMP AL, '2' JE Case2 CMP AL, '3' JE Case3 Default: MOV DX, Offset err JMP EndSwitch Case0: MOV AX, 4C00h INT 21h Case1: MOV DX, Offset s1 JMP EndSwitch Case2: MOV DX, Offset s2 JMP EndSwitch Case3: MOV DX, Offset s3 JMP EndSwitch EndSwitch: MOV AH, 9 INT 21h JMP Again _TEXT ENDS END Start
2. 通过直接地址表来构造多分支结构
使用例 6.12 中的方法构造多分支结构,比较直观自然,但是当分支较多时,如有 100 个
分支,若每一个分支对应一条件检测,那么它对应的控制转移代码非常冗长。所以,当多分
支结构中的分支较多时,适合使用地址表来实现。 在多分支结构中,如果测试的值是连续的,宜用直接地址表来构造。 例 6.13 编写多分支结构程序,实现:输入'4', '5', '6',输出"four", "five", "six";输入'7',
中止运行;输入其他,输出"error!"。 分析:各分支的条件测试为'4', '5', '6', '7',是连续的,可用直接地址表来构造多分支结构。
将输入码减'4',以此直接寻址转移地址表。程序如下: _DATA SEGMENT 'DATA' Msg DB 13, 10, "Please input a number: ", 13, 10, "$" s1 DB 9, "four", 13, 10, '$' s2 DB 9, "five", 13, 10, '$' s3 DB 9, "six", 13, 10, '$' err DB 9, "error!", 13, 10, '$' _DATA ENDS _TEXT SEGMENT 'CODE' ASSUME CS: _TEXT, DS: _DATA Start: MOV AX, _DATA

汇编语言程序设计
·140·
MOV DS, AX Again: MOV AH, 9 MOV DX, Offset Msg INT 21h MOV AH, 1 INT 21h SUB AL, '4' JL Error ; 输入字符小于'4'的情况 CMP AL, 3 JLE Loc1 Error: MOV AL, 4 Loc1: MOV AH, 0 ADD AX, AX ;AX×2⇒AX MOV BX, AX JMP Word Ptr CS: CaseTab [BX] CaseTab DW Case1, Case2, Case3, Case4, Default Default: MOV DX, Offset err JMP EndSwitch Case1: MOV DX, Offset s1 JMP EndSwitch Case2: MOV DX, Offset s2 JMP EndSwitch Case3: MOV DX, Offset s3 JMP EndSwitch Case4: MOV AX, 4C00h INT 21h EndSwitch: MOV AH, 9 INT 21h JMP Again _TEXT ENDS END Start 程序中,CaseTab 是转移地址表,存放各分支的入口地址。如果输入'4'~'7'的字符,转换
(减'4')成数字 n 的范围是 0~3,输入其他字符,则置 n 为 4,也就是说 n 的范围是 0~4。由 n可找到对应的分支入口地址存放单元:CaseTab+2×n,这样,通过执行一条间接近转移指令
(JMP Word Ptr CS: CaseTab [BX])就可转到相应的分支去。 这里的转移地址表是定义在代码段中的,这是因为:一方面,这个地址表属于多分支结
构的一部分,一般情况下仅在转移到分支时使用;另一方面,地址表放在转移指令附近,为
阅读程序和调试程序提供方便,所以这样的地址表作为多分支结构的一部分,放在代码段中
是合适的。需要注意的是,在寻址地址表时,必须明确指出使用段寄存器 CS,否则就会使用
默认的段寄存器 DS。例如,在上述源程序中,如果使用 JMP Word Ptr CaseTab [BX],那么
CPU 就会使用 DS 寻址内容操作数,因而程序就不能正确转到相应分支去。
3. 通过查找地址表构造多分支结构
将各分支的测试条件作为关键字存放在转移地址表中,通过查找关键字得到目标地址,
从而转移到相应的分支去,用这种方法也可以实现多分支结构。 例 6.14 编写多分支结构程序,实现:输入'F', 'E', 'V',输出"File", "Edit", "View";输入'X',
中止运行;输入其他,输出"Error!"。 _DATA SEGMENT 'DATA'
第 6章 结构化程序设计方法
·141·
Msg DB 13, 10, "Please input a character: ", 13, 10, "$" s1 DB 9, "File", 13, 10, '$' s2 DB 9, "Edit", 13, 10, '$' s3 DB 9, "View", 13, 10, '$' err DB 9, "Error!", 13, 10, '$' _DATA ENDS _TEXT SEGMENT 'CODE' ASSUME CS: _TEXT, DS: _DATA Start: MOV AX, _DATA MOV DS, AX Again: MOV AH, 9 MOV DX, Offset Msg INT 21h MOV AH, 1 INT 21h MOV CX, CS: TabItems MOV BX, Offset CaseTab Next_I: CMP Byte Ptr CS: [BX], AL JE ToCase ADD BX, 4 LOOP Next_I ToCase: JMP Word Ptr CS: [BX+2] TabItems DW 8 CaseTab DW 'F',Case1, 'E',Case2, 'V',Case3, 'X',Case4 DW 'f', Case1, 'e', Case2, 'v', Case3, 'x',Case4, 0, Default Default: MOV DX, Offset err JMP EndSwitch Case1: MOV DX, Offset s1 JMP EndSwitch Case2: MOV DX, Offset s2 JMP EndSwitch Case3: MOV DX, Offset s3 JMP EndSwitch Case4: MOV AX, 4C00h INT 21h EndSwitch: MOV AH, 9 INT 21h JMP Again _TEXT ENDS END Start 使用查找转移地址表法可以构造出各种类型的多分支结构,但是地址表中必须包括关键
字和分支入口地址,当然,根据具体情况还可存放其他一些信息。在例 6.14 中,转移地址表
包括所有的正常项和一个例外项(放在最后),正常项的数目存放在 TabItems 中,这样在地址
表中查找输入关键字时,无论找到与否,BX 总能指向一个分支入口。
6.4 循环结构程序设计
循环结构也是一个重要的程序结构,它具有重复执行某段指令序列的功能。重复次数是

汇编语言程序设计
·142·
有限的称做有限循环;重复次数是无限的,则是无限循环,俗称死循环。在实际应用中使用
的循环结构基本上都是有限循环结构,一般根据某一条件成立与否来确定是否重复执行指令
序列。在循环结构中重复执行的指令序列称做循环体。 循环结构分为两种形式:一种是 repeat 结构,先执行循环体,再进行条件测试,根据循
环条件成立与否,决定是否结束循环,如图 6.7(a)所示;另一种是 while 结构,先进行条件测
试,根据条件成立与否来决定是否执行循环,如图 6.7(b)所示。
图 6.7 常用的循环结构示意图
在程序设计中,通常将循环结构分为以下 4 个组成部分。 (1) 循环初始化部分——初始化循环控制变量、循环体所用到的变量。 (2) 循环体部分——循环结构的主体。 (3) 循环调整部分——循环控制变量的修改,或循环终止条件的检查。 (4) 循环控制部分——程序执行的控制转移。 以上四部分在程序中可以以各种不同的形式体现出来,有时也并非清晰地表达出来。
1. 循环结构的构造
构造循环结构的关键是如何用汇编指令构造循环结构中的控制转移代码。在汇编语言中,
循环结构中的控制转移代码是通过无条件转移指令和条件转移指令等来构造出来的,所用方
法与构造二分支结构类似:通过执行比较、算术逻辑运算指令来设置结果标志位,条件转移
指令再根据标志位的状态来决定是否重复执行循环体。 一般而言,使用汇编语言编程时可按“模板”来构造循环结构,如图 6.8 所示。
; <<<循环结构开始>>> 设置循环的初始状态 JMP Rep_loc_? ;repeat 结构不要此指令,while 结构需要此指令 Rep_loc_b: 指令序列(循环体) Rep_loc_?: 用比较、算术运算、逻辑运算等指令构造条件转移指令序列 EndRep_loc: ; <<<循环结构结束>>>
图 6.8 汇编语言程序中的循环结构模板示意图
下面通过具体实例说明循环结构的设计方法。 例 6.15 用 repeat 循环结构编写程序,计算 1+2+3+…+n,其中 n 存放在 16 位变量 N 中,
运算结果存于 16 位变量 Sum 中。(假设结果不会溢出) 这是一个非常简单的循环结构程序,流程如图 6.9 所示。

第 6章 结构化程序设计方法
·143·
图 6.9 例 6.15 的流程图
据此编写的汇编语言程序如下:
_DATA SEGMENT 'DATA'
N DW 131 Sum DW ?
_DATA ENDS
_TEXT SEGMENT 'CODE' ASSUME CS: _TEXT, DS: _DATA
Start: MOV AX, _DATA
MOV DS, AX MOV CX, 1 MOV Sum, 0 ; 设置循环的初始状态 Rep1b:
ADD Sum, CX ; 循环体
INC CX Rep1?:
CMP CX, N ; 循环条件测试及转移 JLE Rep1b EndRep1: MOV AX, 4C00h
INT 21h
_TEXT ENDS END Start
例 6.16 用 while 循环结构编写程序,计算 s=12+22+32+…+n2+…,直到 n>65 000 或
s≥7FF0000h 为止,运算结果存于 32 位变量 Sum 中。 分析:这是一个无符号数的计算。循环控制条件是:n≤65 000∧ s 的高 16 位<7FFh,当
条件成立时继续循环,否则停止循环。程序流程如图 6.10 所示。 据此编写的程序代码如下。注意,Sum 小于 7FF0000h 可简化为 Sum 的高 16 位小于 7FFh。
_DATA SEGMENT 'DATA' Sum DD ? _DATA ENDS _TEXT SEGMENT 'CODE' ASSUME CS: _TEXT, DS: _DATA
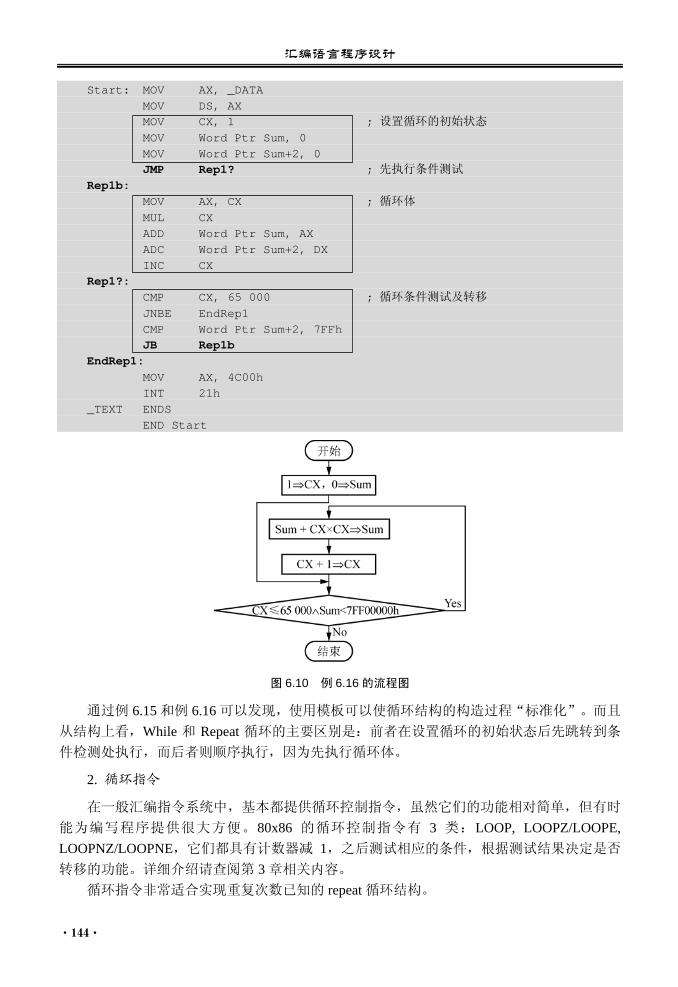
汇编语言程序设计
·144·
Start: MOV AX, _DATA MOV DS, AX MOV CX, 1 ; 设置循环的初始状态 MOV Word Ptr Sum, 0 MOV Word Ptr Sum+2, 0 JMP Rep1? ; 先执行条件测试 Rep1b: MOV AX, CX ; 循环体 MUL CX ADD Word Ptr Sum, AX ADC Word Ptr Sum+2, DX INC CX Rep1?: CMP CX, 65 000 ; 循环条件测试及转移 JNBE EndRep1 CMP Word Ptr Sum+2, 7FFh JB Rep1b EndRep1: MOV AX, 4C00h INT 21h _TEXT ENDS END Start
图 6.10 例 6.16 的流程图
通过例 6.15 和例 6.16 可以发现,使用模板可以使循环结构的构造过程“标准化”。而且
从结构上看,While 和 Repeat 循环的主要区别是:前者在设置循环的初始状态后先跳转到条
件检测处执行,而后者则顺序执行,因为先执行循环体。
2. 循环指令
在一般汇编指令系统中,基本都提供循环控制指令,虽然它们的功能相对简单,但有时
能为编写程序提供很大方便。80x86 的循环控制指令有 3 类:LOOP, LOOPZ/LOOPE, LOOPNZ/LOOPNE,它们都具有计数器减 1,之后测试相应的条件,根据测试结果决定是否
转移的功能。详细介绍请查阅第 3 章相关内容。 循环指令非常适合实现重复次数已知的 repeat 循环结构。

第 6章 结构化程序设计方法
·145·
例 6.17 用循环指令编写程序,计算 1+2+3+…+n,其中 n 存放在 16 位变量 N 中,运算
结果存于 16 位变量 Sum 中(假设结果不会溢出)。源程序如下: _DATA SEGMENT 'DATA' N DW 131 Sum DW ? _DATA ENDS _TEXT SEGMENT 'CODE' ASSUME CS: _TEXT, DS: _DATA Start: MOV AX, _DATA MOV DS, AX MOV CX, N MOV Sum, 0 Rep1b: ADD Sum, CX Rep1?: LOOP Rep1b EndRep1:MOV AX, 4C00h INT 21h _TEXT ENDS END Start 例 6.18 在以 Block 为首地址、长度为 n 的内存块中,存放的是 ASCII 字符,编写程序
找出空格首次出现的位置,若找到,则将位置存于 16 位变量 Pos 中;未找到,则 Pos 置-1。源程序如下:
_DATA SEGMENT 'DATA' Pos DW ? Block DB 'Loops repeatedly to a specified label.LOOP decrements CX (without' DB 'changing any flags) and,if the result is not 0, transfers execution to the' DB 'address specified by the operand.', 13, 10, '$' N DW $-Block _DATA ENDS _TEXT SEGMENT 'CODE' ASSUME CS: _TEXT, DS: _DATA Start: MOV AX, _DATA MOV DS, AX MOV CX, N MOV AL, 20h MOV SI, -1 MOV Pos, -1 Rep1b: INC SI CMP AL, Block [SI] Rep1?: LOOPNE Rep1b EndRep1:JNE Endif1 MOV Pos, SI Endif1: MOV AX, 4C00h INT 21h _TEXT ENDS END Start

汇编语言程序设计
·146·
6.5 MASM 的高级控制流伪指令
前面所介绍的分支结构和循环结构的程序设计方法中,其控制转移代码主要是通过比较、
测试和转移等控制流指令(Control-Flow Instructions)来实现的,但是当测试的条件较多时,其
构造过程相当烦琐,而且代码冗长。为方便程序设计,MASM 6.x 引入了控制流伪指令
(Control-Flow Directives),用来指示汇编程序生成分支结构和循环结构中的控制转移代码。注
意,控制流伪指令并不是普通意义下的伪指令,在它指示下,汇编程序可生成一条或多条指
令代码,而普通伪指令在汇编过程中是不产生运行指令的。 控制流伪指令包括:条件测试、条件伪指令和循环控制伪指令等。
6.5.1 条件测试
条件测试是控制流伪指令的必要组成部分,其基本的表达式形式是: 寄存器或内存操作数 运算符 操作数
两个或多个条件表达式可以用逻辑运算符连接: (表达式 1)逻辑运算符(表达式 2)逻辑运算符(表达式 3)…
可用于条件测试的运算符有:==(等于)、!=(不等于)、>(大于)、>=(大于等于)、<(小于)、<=(小于等于)、&(位与)、!(逻辑非)、&&(逻辑与)、||(逻辑或)等。
注意,条件测试中的运算符和前面介绍的操作数表达式中的运算符几乎完全一样,但两
者功能完全不同。在汇编条件测试时,会生成一系列比较、测试和转移指令,即它对应的是
若干条指令;在汇编操作数表达式时,则直接计算表达式,得到一个常数值。 MASM 的条件测试的语法结构与 C 语言很相似,也可用括号来组成复杂的条件测试;对
于单个变量或寄存器,其内容若是非 0 值,则看做“真”;是 0 值,则看做“假”。 条件测试中的表达式有几个限制:左边不能为常数,两边不能同时为内存操作数。这是
因为汇编程序只是简单地将条件测试翻译成 CMP 或 TEST 指令,而指令中的目的操作数不能
是常数(立即数),且也不允许两个操作数同时是内存操作数。 条件测试仅仅是“测试”,不改变被测试的变量或寄存器的内容,但影响标志位。 对于 80x86 各标志位的测试,汇编程序用专门的符号来表示:CARRY?(相当于 CF==1)、
OVERFLOW?(OF==1)、PARITY?(PF==1)、SIGN?(SF==1)和 ZERO?(ZF==1)等。 注意,这些符号应当放在条件测试的最左边,以免受到比较、测试指令的影响,例如:
CARRY? && (EAX==EBX)。
6.5.2 条件控制伪指令
条件控制伪指令用来指示汇编指令生成分支结构中的控制转移指令代码,格式如下: .IF条件测试 1 测试 1为“真”时执行的指令序列 [.ELSEIF条件测试 2 测试 2为“真”时执行的指令序列] … [.ELSE 所有测试为“假”时执行的指令序列]

第 6章 结构化程序设计方法
·147·
.ENDIF
.ELSEIF 和.ELSE 部分是可选的。前面的点号不能少,否则就是条件汇编伪指令了。 功能:汇编程序根据此伪指令指示,生成相应的分支结构的控制部分所需要的比较、条
件转移等指令代码。 程序员可以使用条件控制伪指令,编写具有清晰的分支结构的源程序。例如,对于例 6.7
的要求,若用条件控制伪指令,那么相应的代码可编写成如下形式: … MOV AX, X3 ADD AX, X4 .IF (X1>0)&& (!(X2&1))&&(AX<100) MOV Sample, 100 .ELSE MOV Sample, 200 .ENDIF …
又如,若用条件控制伪指令,那么例 6.11 的相应代码可写成如下形式: … .IF x1>0 .IF x2>0 MOV x, 10 .ELSE MOV y, 20 .ENDIF .ELSE .IF x3>0 MOV u, 30 .ELSE MOV v, 40 .ENDIF .ENDIF …
6.5.3 循环控制伪指令
在 MASM 6.x 中,可以用循环控制伪指令指示汇编程序,生成循环结构中控制部分的汇
编指令代码。对于两种循环结构,其控制伪指令的格式如下: While 型控制伪指令: .WHILE 条件测试 代码序列 .ENDW Repeat 型控制伪指令:.REPEAT 或 .REPEAT 代码序列 代码序列 .UNTIL 条件测试 .UNTILCXZ [条件测试] 汇编程序根据此伪指令的指示,生成相应的循环结构的控制部分所需要的比较、条件转
移等指令代码。其中,while 型结构实现的循环结构是:当条件测试为真时,重复执行循环体,

汇编语言程序设计
·148·
否则结束循环;repeat 型结构实现的是:重复执行循环体,直到测试条件为真时终止循环。 需要特别说明的是,如果.UNTILCXZ 后面没有测试条件,那么所构造的循环与用 LOOP
指令所构成的循环是一致的,它们都是以“CX=0”为循环终止条件;如果.UNTILCXZ 后面
有测试条件,那么该测试条件只能是“exp1==exp2”或“exp1!=exp2”形式。此时所构造的
循环与用 LOOPNE 或 LOOPE 指令所构成的循环是一致的,它们都是以“测试条件||CX=0”为循环终止条件。
在.WHILE-.ENDW 和.REPEAT-.UNTIL 的循环体内,还可使用.BREAK 和.CONTINUE这两条循环控制伪指令,其格式与功能如下。
.BREAK [.IF 条件测试] 功能:终止当前循环。若后面有条件测试,只有当条件测试为真时,才终止循环,否则
无条件终止循环。 .CONTINUE [.IF 条件测试] 直接转移到当前循环的循环条件测试的代码处。若后面有条件测试,则仅当条件测试为
真时才转移,否则无条件转移到循环条件测试表达式的代码处。 程序员可以使用循环控制伪指令,编写具有清晰的循环结构的源程序。例如,对于例 6.16,
若用循环控制伪指令实现循环结构,那么相关的代码如下: … .WHILE CX<=65000&&(Word Ptr Sum+2)<7FFh MOV AX, CX MUL CX ADD Word Ptr Sum, AX ADC Word Ptr Sum+2, DX INC CX .ENDW …
又如,若用循环控制伪指令,那么例 6.15 的循环结构代码如下: … .REPEAT ADD Sum, CX INC CX .UNTIL CX<=N …
再如,若用条件控制伪指令,那么例 6.15 的循环结构的代码如下: … .REPEAT INC SI UNTILCXZ AL==Block [SI] … 需要说明的是,对于简单条件测试的分支结构和循环结构,特别适合用控制流伪指令来
实现,但是对于复杂的条件测试,如条件测试中含有大量的算术运算,用控制流控制伪指令
来实现反倒不方便。

第 6章 结构化程序设计方法
·149·
6.6 综 合 示 例
本节我们通过具体示例介绍结构化程序的设计方法。在阅读这些示例时,读者也可以掌
握一些用汇编语言编写程序的习惯与技巧,以及熟悉一些常见问题的程序设计方法。当然,
也可以进一步理解和熟悉前面所学的汇编指令。 例 6.19 n1与 n2 是两个 128 位整数,分别存放在首地址为 N1 与 N2 的连续 16 字节单元
中,编写程序计算 n1+n2,并将结果存于 N3 连续 16 字节单元中。(不考虑溢出) 分析:对于通用计算机而言,需执行若干次加法指令,才能完成两个 128 位整数加法运
算。例如,可以通过执行 8 次 16 位加法运算来完成这样的计算。而且在每做一次加法运算时,
必须考虑从低位传递的进位。据此编写的程序如下: _DATA SEGMENT 'DATA' X1 DB 55h, 8Bh, 0ECh, 83h, 0ECh, 0Eh, 57h, 56h, 8Bh, 76h, 04h, 8Bh, 7Eh, 06h, 8Ah, 05h X2 DB 21h, 0E4h, 89h, 46h, 0FCh, 8Ah, 0Ch, 2Ah, 0EDh, 89h, 4Eh, 0FEh, 3Bh, 0C8h, 7Dh, 89h
X3 DB 16 DUP (?) _DATA ENDS _TEXT SEGMENT 'CODE' ASSUME CS: _TEXT, DS: _DATA Start: MOV AX, _DATA MOV DS, AX SUB SI, SI ; 该指令可以:0⇒SI,且 0⇒CF MOV CX, 8 Rep1b: MOV AX, Word Ptr X1 [SI] ADC AX, Word Ptr X2 [SI] ; 若产生进位,则 CF为 1,否则 CF为 0 MOV Word Ptr X3 [SI], AX LEA SI, [SI+2] ; 该指令完成:SI+2⇒SI,但不影响标志位 CF LOOP Rep1b MOV AX, 4C00h INT 21h _TEXT ENDS END Start 例 6.20 现有一个以$结尾的字符串,编写程序,剔除其中的空格。
_DATA SEGMENT 'DATA' String DB ' address specified by the operand.', 13, 10, '$' _DATA ENDS _TEXT SEGMENT 'CODE' ASSUME CS: _TEXT, DS: _DATA Start: MOV AX, _DATA MOV DS, AX MOV ES, AX MOV SI, Offset String MOV DI, SI CLD Rep1b: LODSB CMP AL, 20h ;检测是否是空格 JE Endif1 ;是空格则剔除
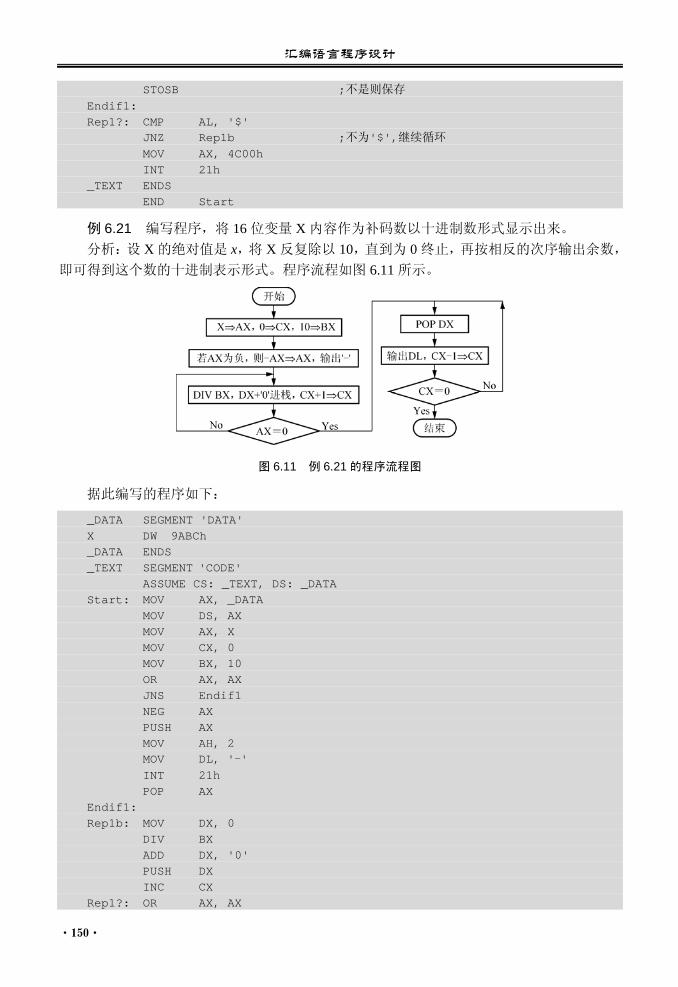
汇编语言程序设计
·150·
STOSB ;不是则保存 Endif1: Rep1?: CMP AL, '$' JNZ Rep1b ;不为'$',继续循环 MOV AX, 4C00h INT 21h _TEXT ENDS END Start 例 6.21 编写程序,将 16 位变量 X 内容作为补码数以十进制数形式显示出来。 分析:设 X 的绝对值是 x,将 X 反复除以 10,直到为 0 终止,再按相反的次序输出余数,
即可得到这个数的十进制表示形式。程序流程如图 6.11 所示。
图 6.11 例 6.21 的程序流程图
据此编写的程序如下: _DATA SEGMENT 'DATA' X DW 9ABCh _DATA ENDS _TEXT SEGMENT 'CODE' ASSUME CS: _TEXT, DS: _DATA Start: MOV AX, _DATA MOV DS, AX MOV AX, X MOV CX, 0 MOV BX, 10 OR AX, AX JNS Endif1 NEG AX PUSH AX MOV AH, 2 MOV DL, '-' INT 21h POP AX Endif1: Rep1b: MOV DX, 0 DIV BX ADD DX, '0' PUSH DX INC CX Rep1?: OR AX, AX
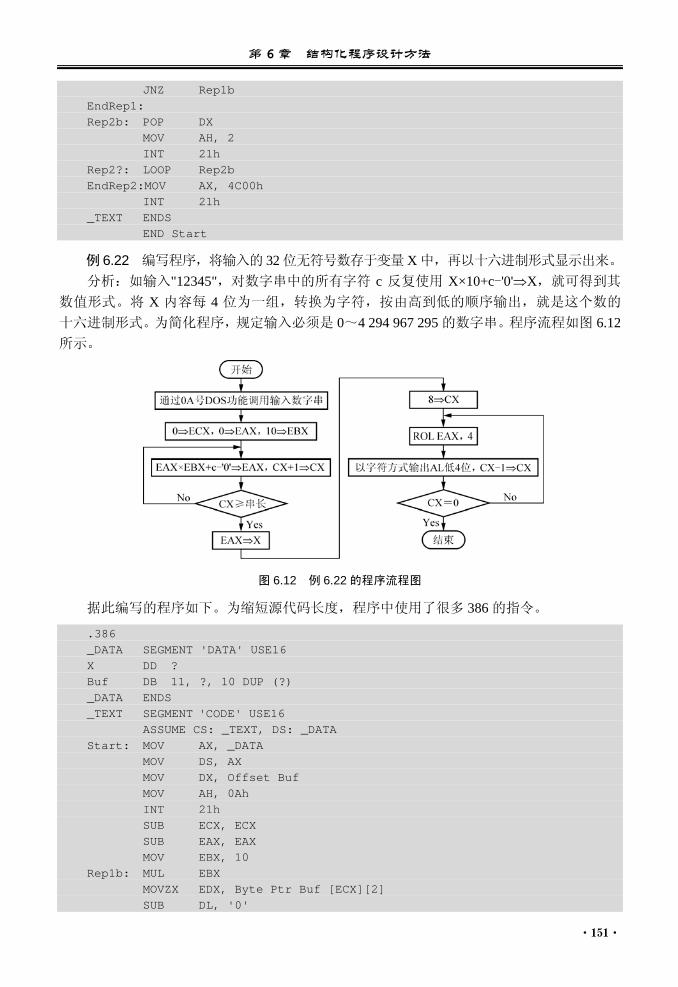
第 6章 结构化程序设计方法
·151·
JNZ Rep1b EndRep1: Rep2b: POP DX MOV AH, 2 INT 21h Rep2?: LOOP Rep2b EndRep2:MOV AX, 4C00h INT 21h _TEXT ENDS END Start 例 6.22 编写程序,将输入的 32 位无符号数存于变量 X 中,再以十六进制形式显示出来。 分析:如输入"12345",对数字串中的所有字符 c 反复使用 X×10+c-'0'⇒X,就可得到其
数值形式。将 X 内容每 4 位为一组,转换为字符,按由高到低的顺序输出,就是这个数的
十六进制形式。为简化程序,规定输入必须是 0~4 294 967 295 的数字串。程序流程如图 6.12所示。
图 6.12 例 6.22 的程序流程图
据此编写的程序如下。为缩短源代码长度,程序中使用了很多 386 的指令。 .386 _DATA SEGMENT 'DATA' USE16 X DD ? Buf DB 11, ?, 10 DUP (?) _DATA ENDS _TEXT SEGMENT 'CODE' USE16 ASSUME CS: _TEXT, DS: _DATA Start: MOV AX, _DATA MOV DS, AX MOV DX, Offset Buf MOV AH, 0Ah INT 21h SUB ECX, ECX SUB EAX, EAX MOV EBX, 10 Rep1b: MUL EBX MOVZX EDX, Byte Ptr Buf [ECX][2] SUB DL, '0'
汇编语言程序设计
·152·
ADD EAX, EDX INC CX Rep1?: CMP CL, Buf [1] JNGE Rep1b EndRep1:MOV X, EAX MOV DL, 10 ; 换行字符 MOV AH, 2 INT 21h MOV CX, 8 Rep2b: ROL X, 4 MOV EDX, X AND DL, 0Fh CMP DL, 9 JG Else1 Then1: ADD DL, '0' JMP Endif1 Else1: ADD DL, 'A'-10 Endif1: MOV AH, 2 INT 21h Rep2?: LOOP Rep2b EndRep2:MOV AX, 4C00h INT 21h _TEXT ENDS END Start
例 6.23 有一个首地址为 A、长度为 N 的 16 位有符号数的数组,编制程序使该数组中
的数按照从大到小的次序排列。 分析:这里采用起泡排序算法。从第一个数开始依次对相邻两个数进行比较,若次序对,
则不做任何操作;否则,使两个数交换位置。表 6.1 是执行这个算法的一个示例。从中可以
看出,在做了第 1 遍的 N-1 次比较后,最小的数已经放到了最后,所以第 2 遍只需要考虑 N-1个数,即只需要比较 N-2 次,依次类推,第 i 遍则只需要做 N-i 次比较,直至 i 为 N-1,即总
共通过 N-1 遍比较,就可以完成排序,如图 6.13 所示。
表 6.1 起泡法排序算法示例
数的排列 比较遍数
63 41 42 51 81 32 7 48 66 15
第 1 遍 63 42 51 81 41 32 48 66 15 7
第 2 遍 63 51 81 42 41 48 66 32 15 7
第 3 遍 63 81 51 42 48 41 66 32 15 7
… …
第 9 遍 81 66 63 51 48 42 41 32 15 7 根据流程图编写的完整段定义的汇编语言程序,以及简化段定义的汇编语言程序如下。 COMMENT /* 例 6.23的程序一:完整段定义的源程序*/ _DATA SEGMENT 'DATA' A DW 63, 41, 42, 51, 81, 32, 7, 48, 66, 15 N DW ($-A)/2

第 6章 结构化程序设计方法
·153·
_DATA ENDS _TEXT SEGMENT 'CODE' ASSUME CS: _TEXT, DS: _DATA Start: MOV AX, _DATA MOV DS, AX MOV CX, N ;数组元素个数⇒CX DEC CX ;元素个数减 1为外循环次数 Rep1b: SUB SI, SI ;0⇒SI,即第一个元素下标 Rep1b@Rep1b: MOV BX, SI ADD BX, BX ;2×SI⇒BX,即 Ai所在的地址 MOV AX, A [BX] CMP AX, A [BX+2] ;Ai与 Ai+1比较 JNL Endif1@Rep1b@Rep1b ;次序对则跳过 XCHG AX, A [BX+2] ; Ai⇔Ai+1 MOV A [BX], AX Endif1@Rep1b@Rep1b: INC SI ;下一个元素的下标 Rep1?@Rep1b: CMP SI, CX JNGE Rep1b@Rep1b EndRep1@Rep1b: Rep1?: LOOP Rep1b EndRep1:MOV AX, 4C00h INT 21h _TEXT ENDS END Start COMMENT /* 例 6.23的程序二:简化段定义的源程序 用控制流伪指令实现分支结构和循环结构 */ .MODEL Small .DATA A DW 63, 41, 42, 51, 81, 32, 7, 48, 66, 15 N DW ($-A)/2 .CODE .STARTUP MOV CX, N ;数组元素个数⇒CX DEC CX ;元素个数减 1为外循环次数 .REPEAT SUB SI, SI ;0⇒SI,即第一个元素下标 .REPEAT MOV BX, SI ADD BX, BX ;2×SI⇒BX,即 Ai所在的地址 MOV AX, A [BX] ;Ai与 Ai+1比较 .IF AX<A [BX+2] XCHG AX, A [BX+2] ;Ai⇔Ai+1 MOV A [BX], AX .ENDIF INC SI ;下一个元素的下标 .UNTIL SI>=CX .UNTILCXZ .EXIT ( 0 ) END
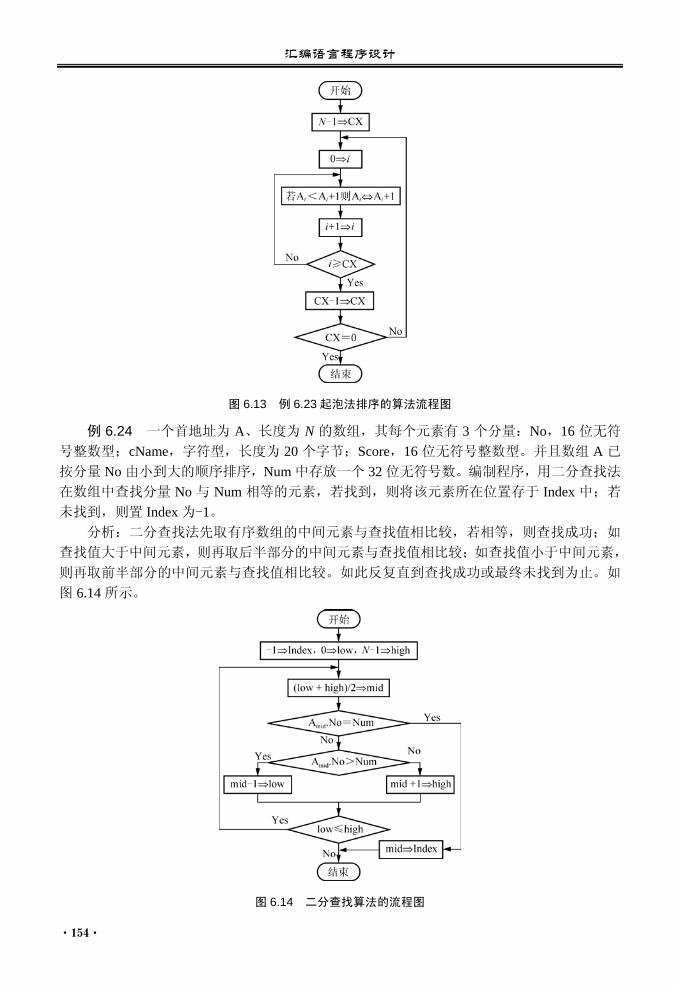
汇编语言程序设计
·154·
图 6.13 例 6.23 起泡法排序的算法流程图
例 6.24 一个首地址为 A、长度为 N 的数组,其每个元素有 3 个分量:No,16 位无符
号整数型;cName,字符型,长度为 20 个字节;Score,16 位无符号整数型。并且数组 A 已
按分量 No 由小到大的顺序排序,Num 中存放一个 32 位无符号数。编制程序,用二分查找法
在数组中查找分量 No 与 Num 相等的元素,若找到,则将该元素所在位置存于 Index 中;若
未找到,则置 Index 为-1。 分析:二分查找法先取有序数组的中间元素与查找值相比较,若相等,则查找成功;如
查找值大于中间元素,则再取后半部分的中间元素与查找值相比较;如查找值小于中间元素,
则再取前半部分的中间元素与查找值相比较。如此反复直到查找成功或最终未找到为止。如
图 6.14 所示。
图 6.14 二分查找算法的流程图

第 6章 结构化程序设计方法
·155·
据此编写的程序如下: STU STRUC No DW ? cName DB 20 DUP(?) Score DW ? STU ENDS _DATA SEGMENT 'DATA' Num DW 135 A STU <101,'Zhang',63>,<102,'Li',72>,<105,'Wang',81>,<132,'Ma',77> STU <134,'Zhao',66>,<135,'Cao',87>,<137,'Gao',90>,<156,'Yao',75> N DW ($-A)/TYPE(STU) Index DW ? _DATA ENDS _TEXT SEGMENT 'CODE' ASSUME CS: _TEXT, DS: _DATA Start: MOV AX, _DATA MOV DS, AX MOV Index, -1 SUB SI, SI MOV BX, N DEC BX Rep1b: LEA BP, [SI+BX] SHR BP, 1 MOV AX, TYPE (STU) MUL BP MOV DI, AX MOV AX, A [DI]. No CMP AX, Num JNZ Endif1@Rep1b MOV Index, BP JMP EndRep1 Endif1@Rep1b: JNG Else2@Rep1b LEA BX, [BP-1] JMP Endif2@Rep1b Else2@Rep1b:LEA SI, [BP+1] Endif2@Rep1b: CMP SI, BX JLE Rep1b EndRep1: MOV AX, 4C00h INT 21h _TEXT ENDS END Start 例 6.25 在 32 位地址模式下,用汇编语言编写程序,实现从键盘上以十六进制形式输入
一个 32 位有符号数,存于变量 X 中,再以十六进制形式显示出来。 程序流程可以参照例 6.22,此处不再赘述。但是这里将不使用 DOS 功能调用,而是改调
用 Win32 的 API。有关 Win32 编程练习环境说明参见附录 B。 .386 Includelib Kernel32.LIB

汇编语言程序设计
·156·
Extrn _GetStdHandle@4:Near,_ReadConsoleA@20:Near,_WriteConsoleA@20:Near Extrn _ExitProcess@4:Near _DATA SEGMENT 'DATA' USE32 X DD ? Buf DB 12 DUP ('*') Handle DD ? Num DD ? _DATA ENDS _TEXT SEGMENT 'CODE' USE32 ASSUME CS: _TEXT, DS: _DATA _main: PUSH -10 CALL _GetStdHandle@4 MOV Handle, EAX PUSH 0 PUSH Offset Num PUSH 12 PUSH Offset Buf PUSH Handle CALL _ReadConsoleA@20 SUB ECX, ECX SUB EAX, EAX MOV EBX, 10 CMP Buf, '-' JNE Rep1b INC ECX Rep1b: MUL EBX MOVZX EDX, Byte Ptr Buf [ECX] SUB DL, '0' ADD EAX, EDX INC ECX Rep1?: CMP Buf[ECX], '0' JB EndRep1 CMP Buf[ECX], '9' JA EndRep1 CMP ECX, Num JNGE Rep1b EndRep1: CMP Buf, '-' JNE Endif1 NEG EAX Endif1: MOV X, EAX MOV Word Ptr Buf, 0A0Dh ; 回车换行字符 SUB ECX, ECX Rep2b: ROL X, 4 MOV EDX, X AND DL, 0Fh CMP DL, 9 JG Else2 Then2: ADD DL, '0' JMP Endif2 Else2: ADD DL, -10+'A' Endif2: MOV Buf[2][ECX], DL INC ECX

第 6章 结构化程序设计方法
·157·
CMP CL, 8 Rep2?: JB Rep2b EndRep2: PUSH -11 CALL _GetStdHandle@4 MOV Handle, EAX PUSH 0 PUSH Offset Num PUSH 10 PUSH Offset Buf PUSH Handle CALL _WriteConsoleA@20 PUSH 0 CALL _ExitProcess@4 _TEXT ENDS END _main
本 章 小 结
本章介绍结构化程序设计中的 3 种结构,包括:顺序结构、分支结构、循环结构。 在汇编语言中,结构化程序设计的关键是如何使用比较、测试和转移等控制流指令及算
术逻辑运算指令,设计出清晰的控制流结构。在实际编程中,可参考本章提供的分支结构“模
板”和循环结构“模板”来编写控制流中的控制转移代码。 程序员也可使用控制流伪指令来指示汇编程序自动生成控制流的控制转移代码。 通过本章学习,读者应当熟悉常见问题的程序设计方法:字母的大小写转换,数据的键
盘输入和显示输出,多精度运算,数据串传送、比较等处理操作,数据求和、平均值、最大
值、最小值及数据统计,数据的排序和查找算法等。
习 题 6
6.1 编写程序,从键盘输入 1 个小写字母,然后找出它的前导字符和后续字符,再按顺
序用大写字母显示这 3 个字符。
6.2 已知 f(x)=2 ( )
2 ( 0)x x
x x⎧⎪⎨⎪⎩
<0≥
。下面的小程序用于计算 f(x),其中 x 存放在 16 位变量 X 中,
计算的结果存放在 16 位变量 R 中。根据功能要求,将程序填写完整。 _TEXT SEGMENT ASSUME CS:_TEXT, DS:_TEXT Start: PUSH CS POP DS MOV AX, X OR AX, AX ① Loc1: IMUL AX ② Loc2: SHL AX, 1 Loc3: MOV R, AX

汇编语言程序设计
·158·
MOV AX, 4C00h INT 21h X DW 100 R DW ? _TEXT ENDS END Start
6.3 已知下列两条 C 语句(各变量均为 16 位) if (x*x>255 && x>=y && r!=0) x=10; else y =20; if (x+y<497 || x*y>32000 || y>z) y=100; else x=200; 分别用汇编语言指令序列 1 和指令序列 2 实现。根据功能要求,将它们填写完整。 (1)指令序列 1 … MOV AX, X ① CMP AX, 255 ② MOV AX, X CMP AX, Y ③ CMP R, 0 ④ LOC1: MOV X, 10 ⑤ LOC2: MOV Y, 20 LOC3: …
(2)指令序列 2 … MOV AX, X ① CMP AX, 497 ② ③ MUL Y CMP AX, 3200 ④ ⑤ CMP AX, Z ⑥ LOC1: MOV Y, 100 ⑦ LOC2: MOV X, 200 LOC3: …
6.4 已知 F1=F2=1,Fn=Fn-1+Fn-2(n>2)。下列小程序将该数列中的前 20 项按从小到大
的顺序存入数组 Fib 中。根据功能要求,将程序填写完整。 _TEXT SEGMENT ASSUME CS:_TEXT, DS:_TEXT Start: PUSH CS POP DS MOV AX, 1 MOV BX, 1 ① ② Loc1: MOV [SI], AX ADD AX, BX XCHG AX, BX ADD SI, 2 ③ CMP CX, 20 ④ MOV AX, 4C00h INT 21h Fib DW 100 DUP(?)

第 6章 结构化程序设计方法
·159·
_TEXT ENDS END Start 6.5 编写程序,将 AX 寄存器中的内容以十六进制数形式显示出来。 6.6 编写程序,比较两个长度均为 n 的字符串 String1 和 String2 所含字符是否相同,若相
同,则显示 Match;若不相同,则显示 No match。 6.7 编制程序,完成对 12h, 45h, 0F3h, 6Ah, 20h, 0FEh, 90h, 0C8h, 57h 和 34h 这 10 个字节
数据求和,并将结果存入 2 字节变量 Sum 中(须考虑溢出)。 6.8 编写程序,将一个包含有 20 个数据的数组 M 分成两个数组:正数数组 P 和负数数组
N,并分别把这两个数组中数据的个数显示出来。 6.9 编写程序,要求:从键盘接收一个 8 位的十六进制数,将其数值存放到 32 位变量 Num
中,并以十进制数形式显示出来。 6.10 设有一段英文,存放在以首地址为 Eng 的内存区,并以'$'字符结束。编写汇编语言
程序,查实单词 Sun 在该文中的出现次数,并以格式“SUN ####”显示出次数。 6.11 有一个首地址为 Mem 的长度为 100 的 16 位数组,编制程序删除数组中所有为 0 的
项,并将后续项向前挪动,最后将数组的剩余部分补上 0。 6.12 在 String 到 String+99 字节单元中存放着一个字符串,编制程序测试该字符串中是否
存在数字字符。若有,则把 CL 的第 5 位置 1,否则将该位置 0。 6.13 在首地址为 wArray 的字数组中,存放了 100h 个 16 位补码数。试编写程序,计算
出它们的平均值,存放到 Average 字单元中,并求出数组中有多少个数小于此平均值,将结
果放在 Count 字单元中。 6.14 n1与 n2是两个 1 024 位整数,分别存放在首地址为 N1 与 N2 的连续 128 字节单元中,
编写程序计算 n1-n2,并将结果存于 N3 连续 128 字节单元中。(不考虑溢出) 6.15 编写程序实现:输入'1', '2', '3', '4', '5', '6', '7',输出'Monday', 'Tuesday', 'Wednesday',
'Thursday', 'Friday', 'Saturday', 'Sunday';输入'0',运行中止;输入其他字符,输出'Error!'。 6.16 已知数组 A1 包含 15 个互不相等的整数,数组 A2 包含 20 个互不相等的整数。试编
制一程序,把既在 A1 中又在 A2 中出现的整数存放于数组 A3 中。 6.17 设在 V1, V2 和 V3 单元中分别存放着 3 个数。若 3 个数都不是 0,则求出 3 数之和,
并存放于 V4 单元中;若其中有一个数为 0,则把其他两个单元也清 0。请编写此程序。 6.18 编写汇编语言程序,实现:输入一个整数 n(1~100),计算 s=13+23+33+…+n3,然
后将 s 的值以十进制形式显示输出。 6.19 编写汇编语言程序,实现:输入一个奇数 n,若 n 是合数,则显示出它的所有素因
子;若 n 是素数,则显示 Prime。例如,输入 123,它的所有因子是 3, 41;输入 113,则没有
素因子。 6.20 下列小程序执行完毕后,s2 中的内容是什么? _TEXT SEGMENT ASSUME CS:_TEXT, DS:_TEXT Start: MOV AX, CS MOV DS, AX MOV ES, AX MOV BX, Offset Tab CLD

汇编语言程序设计
·160·
MOV SI, Offset s1 MOV DI, Offset s2 Loc1: LODSB MOV CL, 4 MOV AH, AL SHR AL, CL XLAT STOSB MOV AL, AH AND AL, 15 XLAT STOSB MOV AL, ',' STOSB CMP SI, Offset s2 JB Loc1 MOV AX, 4C00h INT 21h Tab DB '0123456789ABCDEF' s1 DB 'Assembly', 0 s2 DB 3*(s2-s1) DUP (0) _TEXT ENDS END Start

第 7 章 模块化程序设计方法
本章介绍基于子程序的模块化程序设计方法,主要包括: • 子程序的定义、调用与返回。 • 子程序的参数传递。 • 多模块程序设计。 • 子程序库的建立与使用。
7.1 子程序的设计方法
在程序设计中,经常有这样的一些程序段,它们的功能和结构形式相同,只是某些参数
的值不同,此时,这样的程序段就可以编写成子程序的形式,以便在需要的时候调用它们。
例如,在编写程序时,经常将数据的输入和输出、数组的排序算法等功能相对独立的程序段
编写成子程序。 为便于程序维护与使用,在设计子程序的同时就应当建立相应的说明文档,清楚地描述
子程序的功能和调用方法。通常子程序说明文档应包括:子程序名称、子程序功能、入口参
数、出口参数、工作寄存器、工作单元及 后修改日期等。 在规模稍大的程序中,子程序往往放在一个单独的模块中,这便是程序设计的模块化。 本节先介绍子程序的设计方法,在下一节中我们再介绍模块化程序设计方法。
7.1.1 子程序的定义、调用与返回
子程序的定义由过程定义伪指令 PROC 与 ENDP 来完成的,其格式如下: 过程名 PROC [NEAR/FAR] … ; 子程序代码 过程名 ENDP
其中,PROC 表示过程定义开始,其后的 NEAR/FAR 是可选项,表示该过程的类型属性,一
般情况下默认为 NEAR;ENDP 表示过程定义结束;而过程名是一个标识符,表示过程的入
口地址,也就是说同标号一样,子程序名也是一个符号地址。 对于一个已定义的子程序,可以通过 CALL 指令来调用它,在子程序中用 RET 指令返回
到调用程序继续执行。关于 CALL 指令与 RET 指令的详细介绍参见第 4 章相关内容。 对于直接使用“CALL 子程序名”形式的调用,汇编程序根据子程序定义时的 Near 或
Far 属性,生成相应的直接近调用或直接远调用指令格式。同样,对于子程序中的 RET 指令,
汇编程序也会根据 Near 或 Far 属性,生成相应的 RETN 或 RETF 指令。 也可用 CALL reg/mem 来间接调用子程序,此时需要程序员明确指出近/远调用类型。 例 7.1 在下面程序中定义了两个子程序:DisplayString 和 CRLF,分别是显示字符串和
回车换行,并调用它们。

汇编语言程序设计
·162·
COMMENT /* 子程序定义与调用示例程序 */ _DATA SEGMENT 'DATA' P1 DW DisplayString ;定义近指针,指向子程序 DisplayString的入口地址 P2 DD CRLF ;定义远指针,指向子程序 CRLF的入口地址 Msg1 DB 'this is the first message$' Msg2 DB 'this is the second message$' _DATA ENDS _TEXT SEGMENT 'CODE' ASSUME CS: _TEXT, DS: _DATA DisplayString PROC Near ;子程序定义开始,属性类型为 Near MOV AH, 9 INT 21h RET ;返回到调用程序(近返回指令,由汇编程序确定) DisplayString ENDP ;子程序定义结束 CRLF PROC Far ;子程序定义开始,属性类型为 Far MOV AH, 2 MOV DL, 13 INT 21h MOV DL, 10 INT 21h RET ;返回调用程序(远返回指令,由汇编程序确定) CRLF ENDP ;子程序定义结束 start: MOV AX, _DATA MOV DS, AX MOV DX, Offset Msg1 CALL DisplayString ;调用子程序(直接近调用,由汇编程序确定) CALL CRLF ;子程序调用(直接远调用,由汇编程序确定) MOV DX, Offset Msg2 CALL P1 ;调用子程序(间接近调用,须由程序员确定) CALL P2 ;调用子程序(间接远调用,须由程序员确定) MOV AX, 4C00h INT 21h _TEXT ENDS END Start 由例 7.1 可知,如果子程序定义成 Near 属性,那么汇编程序将 RET 指令翻译成近返回指
令(RETN),将“CALL 子程序名”形式的调用翻译成直接近调用指令;如果子程序定义成 Far属性,那么汇编程序将 RET 指令翻译成远返回指令(RETF),将“CALL 子程序名”形式的调
用翻译成直接远调用指令。但是如果用间接方式调用子程序时,那么必须由程序员明确指出
使用的是近调用还是远调用。 子程序属性的确定原则很简单,即 ① 如调用程序和子程序在同一个代码段中,则使用 Near 属性。 ② 如调用程序和子程序不在同一个代码段中,则使用 Far 属性。 直接调用的 CALL 指令后也可以是标号。例如,下列代码与例 7.1 是相同的。 _DATA SEGMENT 'DATA' P1 DW DisplayString P2 DD CRLF Msg1 DB 'this is the first message$' Msg2 DB 'this is the second message$'

第 7章 模块化程序设计方法
·163·
_DATA ENDS _TEXT SEGMENT 'CODE' ASSUME CS: _TEXT, DS: _DATA DisplayString: MOV AH, 9 INT 21h RET CRLF Label Far MOV AH, 2 MOV DL, 13 INT 21h MOV DL, 10 INT 21h RET start: MOV AX, _DATA MOV DS, AX MOV DX, Offset Msg1 CALL DisplayString CALL CRLF MOV DX, Offset Msg2 CALL P1 CALL P2 MOV AX, 4C00h INT 21h _TEXT ENDS END Start
7.1.2 寄存器的寄护与寄寄
主程序和子程序通常是分别编制的,所以它们所使用的寄存器往往会发生冲突。如果主
程序在调用子程序之前的某个寄存器内容在从子程序返回后还有用,而子程序又恰好使用了
同一个寄存器,这就破坏了该寄存器的原有内容,因而造成程序运行错误,这是不允许的。
为避免这种错误的发生,在一进入子程序后,就应该把子程序所需要使用的寄存器内容寄存
在堆栈中,此过程称做现场寄护。在退出子程序前把寄存器内容寄寄原状,此过程称做现场
寄寄。现场寄护与现场寄寄分别使用压栈和出栈指令实现。 为此,在编写子程序时,除了能对作为入口和出口参数的寄存器进行修改外,对其他寄
存器的修改对调用程序来说都要是透明的,也就是说,在调用子程序指令的前后,除了作为
入口和出口参数的寄存器内容可以不同外,其他寄存器的内容要寄持不变。有时,也要求作
为入口参数的寄存器内容寄持不变。 在子程序中,寄存和寄寄寄存器内容的主要方法是:在子程序的开始把它所用到的寄存
器压进栈,在返回前,再把它们弹出栈。这样编写的好处是该子程序可以被任何其他程序来
调用。在调用指令前,不需要寄存寄存器,在调用指令后,也无须寄寄寄存器。 例如,在例 7.1 中,子程序 CRLF 使用了寄存器 AX, DX。我们可以将 CRLF 改写成如下
形式,使它能够对 AX, DX 寄存器的内容进行寄护和寄寄。 CRLF PROC Far ;子程序定义开始,属性类型为 Far PUSH AX ;AX寄存器内容的寄护 PUSH DX ;DX寄存器内容的寄护 MOV AH, 2

汇编语言程序设计
·164·
MOV DL, 13 INT 21h MOV DL, 10 INT 21h POP DX ;AX寄存器内容的寄寄 POP AX ;DX寄存器内容的寄寄 RET ;返回调用程序(远返回指令,由汇编程序确定) CRLF ENDP ;子程序定义结束 使用堆栈来实现寄存器的寄护与寄寄这项功能时,应注意以下事项。 (1) 对寄存器内容寄护和寄寄所进行进栈和出栈的操作次序刚好相反。 (2) 通常不寄护入口参数寄存器的内容,当然也可根据事先的约定而对它们加以寄护。 (3) 如果用寄存器传递子程序的处理结果,那么这些寄存器就一定不能加以寄护。 (4) 根据需要,可用 PUSHF 和 POPF 来寄护和寄寄标志位。
7.1.3 子程序的参数传递
主程序在调用子程序时,经常要向子程序传递一些参数或控制信息,子程序执行后,也
常需要把运行的结果返回调用程序。这种信息传递称为参数传递,常用的方法有:约定寄存
器传递参数、约定内存单元传递参数、堆栈传递参数,而且这些方法经常同时使用。 需要说明的是,当调用一个带有参数的子程序时,不再是简单地执行一条 CALL 指令就
行,在调用之前,应当将子程序需要的参数放到约定的地方(寄存器、内存单元和堆栈等),然
后再使用 CALL 指令调用子程序。
1. 约定寄存器传递参数
一方面,由于 CPU 中的寄存器在任何程序中都是“可见”的,一个程序对某寄存器赋值
后,在另一个程序中就能直接使用,所以,用寄存器来传递参数 直接、简便,也是 常用
的参数传递方式。但另一方面,CPU 中寄存器的个数和容量都是非常有限,所以,该方法适
用于传递较少的参数信息。 通过寄存器传递参数的实现方法是:调用程序将要传递的参数预先放入事先约定的寄存
器中,转入子程序后再取出进行处理;同样,子程序也可将处理结果放入事先约定的寄存器
中,传递给调用程序。下面通过具体实例进行说明。 例 7.2 编写程序,输入一个 16 位无符号数,再以十六进制形式显示出来。 本例与例 6.21 相同。这里使用了 3 个子程序:Readui16,以十进制数形式输入一个 16 位
无符号数,约定将输入的数存放在 AX 中;Disph16ByDX,以十六进制形式显示一个 16 位数,
约定调用程序将需要显示的数放在 DX 中;CRLF,显示回车和换行。 ; =========================== ; 例 7.2约定寄存器传递参数的示例一 ; =========================== .386 _STACK SEGMENT STACK USE16 DB 3FFEh DUP(?) TOS DW ? _STACK ENDS _DATA SEGMENT 'DATA'

第 7章 模块化程序设计方法
·165·
_DATA ENDS _TEXT SEGMENT 'CODE' USE16 ASSUME CS: _TEXT, DS: _DATA Comment/**************************** 功能:以十进制形式输入无符号数 入口参数:无 出口参数:AX,存放已输入的整数 描述:输入数字串,以非数字结束***/ Readui16 PROC Near PUSH EDX SUB EDX, EDX JMP Rep1?@Readui16 Rep1b@Readui16: IMUL EDX, 10 MOVZX EAX, AL ADD EDX, EAX Rep1?@Readui16: MOV AH, 1 INT 21h SUB AL, '0' JNGE EndRep1@Readui16 CMP AL, 9 JLE Rep1b@Readui16 EndRep1@Readui16: MOV AX, DX POP EDX RET Readui16 ENDP Comment/************************ 功能:以十六进制形式显示整数 入口参数:DX,待显示的数 出口参数:无 描述:通过 4次循环移位*****/ Disph16ByDX PROC Near PUSH AX MOV CX, 4 Rep1b@Disph16ByDX: ROL DX, 4 PUSH DX AND DL, 0Fh CMP DL, 9 JG Else1@Disph16ByDX ADD DL, '0' JMP Endif1@Disph16ByDX Else1@Disph16ByDX: ADD DL, 'A'-10 Endif1@Disph16ByDX: MOV AH, 2 INT 21h POP DX LOOP Rep1b@Disph16ByDX POP AX

汇编语言程序设计
·166·
RET Disph16ByDX ENDP Comment/********************** 功能:执行回车换行 入口参数:无 出口参数:无 描述:修改 AX, DX的内容****/ CRLF PROC NEAR MOV AH, 2 MOV DL, 13 INT 21h MOV DL, 10 INT 21h RET CRLF ENDP ; 主控程序 Start: MOV AX, _DATA MOV DS, AX CLI MOV AX, _STACK MOV SS, AX MOV SP, Offset TOS STI CALL Readui16 PUSH AX CALL CRLF ;回车换行 POP DX CALL Disph16ByDX MOV AX,4C00h INT 21h _TEXT ENDS END Start 例 7.3 编写程序,求 n 个 16 位补码数的累加和,并以十进制形式显示出来。 程序中有 3 个子程序:TotalByReg,计算数组的累加和,约定数组首地址存放在 SI,长
度存放在 CX 中,计算结果通过 AX 返回给调用程序;Dispsi16ByDX,以十进制形式输出一
个 16 位补码数,约定调用程序用 DX 向子程序传递补码数;CRLF,执行回车换行。 ; =========================== ; 例 7.3约定寄存器传递参数的示例二 ; =========================== _STACK SEGMENT STACK USE16 DB 3FFEh DUP(?) TOS DW ? _STACK ENDS _DATA SEGMENT 'DATA' USE16 A1 DW 65, -22, 3, 26, 37, 49 N1 DW ($-A1)/2 A2 DW 1, -3, 5, -7, 9, -11, 13 N2 DW ($-A2)/2 _DATA ENDS _TEXT SEGMENT 'CODE' USE16

第 7章 模块化程序设计方法
·167·
ASSUME CS: _TEXT, DS: _DATA Start: MOV AX, _DATA MOV DS, AX CLI MOV AX, _STACK MOV SS, AX MOV SP, Offset TOS STI MOV SI, Offset A1 MOV CX, N1 CALL TotalByReg MOV DX, AX CALL Dispsi16ByDX CALL CRLF ;回车换行 MOV SI, Offset A2 MOV CX, N2 CALL TotalByReg MOV DX, AX CALL Dispsi16ByDX MOV AX, 4C00h INT 21h Comment/**************************** 功能:计算数组的累加和 入口参数: SI,数组首地址 CX,数组长度 出口参数:AX,存放计算结果 描述:计算累加和时不考虑溢出***/ TotalByReg PROC NEAR SUB AX, AX Rep1b@TotalByReg: ADD AX, [SI] ;不考虑溢出 ADD SI, 2 ;下一个元素 LOOP Rep1b@TotalByReg RET TotalByReg ENDP Comment/************************ 功能:以十进制形式显示补码数 入口参数:DX,待显示的数 出口参数:无 描述:除 10取余法*****/ Dispsi16ByDX PROC Near PUSH AX PUSH BX PUSH CX MOV AX, DX MOV CX, 0 MOV BX, 10 OR AX, AX JNS Rep1b@Dispsi16ByDX NEG AX PUSH AX MOV AH, 2

汇编语言程序设计
·168·
MOV DL, '-' INT 21h POP AX Rep1b@DispSI16ByDX: MOV DX, 0 DIV BX ADD DX, '0' PUSH DX INC CX OR AX, AX JNZ Rep1b@Dispsi16ByDX Rep2b@DispSI16ByDX: POP DX MOV AH, 2 INT 21h LOOP Rep2b@DispSI16ByDX POP CX POP BX POP AX RET Dispsi16ByDX ENDP CRLF PROC NEAR MOV AH, 2 MOV DL, 13 INT 21h MOV DL, 10 INT 21h RET CRLF ENDP _TEXT ENDS END Start
2. 约定内存单元传递参数
这种方法是事先约定一块内存区用于传递参数,调用程序和子程序都按事先的约定,在
指定的内存单元中进行数据交换。调用程序在调用子程序前,把要传送给子程序的参数都存
放在约定的内存区中,再调用子程序,子程序从约定的单元中取出所需参数;子程序的处理
结果也可存入约定的内存单元中去,传递给调用程序。 和使用约定寄存器传递参数方法相比,这种方法的优点是可以传递大量的数据,但是这
种方法需要占用一定数量的内存单元,尤其是开发大规模程序时,为约定的内存单元取不重
寄的名字是非常麻烦的事。 例 7.4 使用约定内存单元传递参数,重新编写例 7.3 的程序。对于求累加和的子程序,
在这里改为用约定内存单元传递参数,并命名为 TotalByMem,约定数组首地址存放在 PA,
长度存放在 Count 中,计算结果存入 Result。其他子程序不变。 ; =========================== ; 例 7.4约定内存单元传递参数的示例 ; =========================== _STACK SEGMENT STACK USE16 DB 3FFEh DUP(?)

第 7章 模块化程序设计方法
·169·
TOS DW ? _STACK ENDS _DATA SEGMENT 'DATA' USE16 Count DW ? PA DW ? Result DW ? A1 DW 65, -22, 3, 26, 37, 49 N1 DW ($-A1)/2 A2 DW 1, -3, 5, -7, 9, -11, 13 N2 DW ($-A2)/2 _DATA ENDS _TEXT SEGMENT 'CODE' USE16 ASSUME CS: _TEXT, DS: _DATA Start: MOV AX, _DATA MOV DS, AX CLI MOV AX, _STACK MOV SS, AX MOV SP, Offset TOS STI MOV PA, Offset A1 MOV CX, N1 MOV Count, CX CALL TotalByMem MOV DX, Result CALL Dispsi16ByDX CALL CRLF ;回车换行 MOV PA, Offset A2 MOV CX, N2 MOV Count, CX CALL TotalByMem MOV DX, Result CALL Dispsi16ByDX MOV AX, 4C00h INT 21h Comment/********************** 功能:计算数组的累加和 入口参数: PA,数组首地址 Count,数组长度 出口参数:Result,存放计算结果*/ TotalByMem PROC NEAR PUSH AX PUSH CX PUSH SI MOV SI, PA MOV CX, Count SUB AX, AX Rep1b@TotalByMem: ADD AX, [SI] ;不考虑溢出 ADD SI, 2 ;下一个元素 LOOP Rep1b@TotalByMem MOV Result, AX

汇编语言程序设计
·170·
POP SI POP CX POP AX RET TotalByMem ENDP Dispsi16ByDX PROC Near ;和例 7.3相同 Dispsi16ByDX ENDP CRLF PROC NEAR ;和例 7.3相同 CRLF ENDP _TEXT ENDS END Start
3. 通过堆栈传递参数
一般在程序中,参数的传递是通过堆栈进行的:调用程序按事先约定的次序,把要传递
的参数压入堆栈,然后调用子程序;子程序按相同的次序,从堆栈中取出相应的参数来使用。
在通常情况下,约定用堆栈传递入口参数,用寄存器传递出口参数。 和前面介绍的方法相比,通过堆栈传递参数不占用寄存器,也无须使用额外的内存单元,
而且也便于子程序的递归调用。所以,在一般程序设计语言中,参数的传递主要是通过堆栈
来进行的。 必须注意,使用堆栈传递参数时,当子程序执行结束返回后,先前压入堆栈的参数不再
有用,应当丢弃。这时调用程序或者子程序必须有一方把堆栈指针调整到调用前的状态。如
果是调用程序来调整,则在 CALL 指令后,加上一条形如“ADD SP, n”(16 位地址模式)或“ADD ESP, n”(32 位地址模式)的指令;如果是子程序来调整,那么须在 RET 指令后带有一个立即
数,即执行形如“RET n”的指令返回到调用程序。 例 7.5 使用堆栈传递参数,重新编写例 7.3 的程序。3 个子程序:Total,求数组的累加
和,用堆栈来传递参数,进栈次序约定为:先压入数组首地址,再压入数组长度,计算结果
约定存入 AX 中;Dispsi16,以十进制形式显示一个 16 位补码数,也是用堆栈传递一个补码
数;CRLF 执行回车换行。 此例也演示了调整堆栈指针的两种方法:调用 Total 时,SP 是由调用程序执行“ADD
SP, 4”指令来调整;调用 Dispsi16 时,SP 则由子程序执行“RET 2”指令来调整。 ; =========================== ; 例 7.5使用堆栈传递参数的示例 ; =========================== _STACK SEGMENT STACK USE16 DB 3FFEh DUP(?) TOS DW ? _STACK ENDS _DATA SEGMENT 'DATA' USE16 A1 DW 65, -22, 3, 26, 37, 49 N1 DW ($-A1)/2 A2 DW 1, -3, 5, -7, 9, -11, 13 N2 DW ($-A2)/2 _DATA ENDS

第 7章 模块化程序设计方法
·171·
_TEXT SEGMENT 'CODE' USE16 ASSUME CS: _TEXT, DS: _DATA Start: MOV AX, _DATA MOV DS, AX CLI MOV AX, _STACK MOV SS, AX MOV SP, Offset TOS STI MOV AX, Offset A1 PUSH AX ;参数 1进栈 PUSH N1 ;参数 2进栈 CALL Total ADD SP, 4 ;调整堆栈指针 PUSH AX CALL Dispsi16 CALL CRLF ;回车换行 MOV AX, Offset A2 PUSH AX PUSH N2 CALL Total ADD SP, 4 PUSH AX CALL Dispsi16 MOV AX, 4C00h INT 21h Comment/**************************** 功能:计算数组的累加和 入口参数: SI,数组首地址 CX,数组长度 出口参数:AX,存放计算结果 ***/ Total PROC NEAR PUSH BP ;寄护基址指针 MOV BP, SP ;设置新栈帧 PUSH SI MOV SI, [BP+6] ;取参数 1 SUB AX, AX Rep1b@Total: ADD AX, [SI] ;不考虑溢出 ADD SI, 2 ;下一个元素 DEC word ptr [BP+4];取参数 2 JNZ Rep1b@Total POP SI MOV SP, BP ;还原堆栈指针 POP BP ;寄寄基址指针 RET Total ENDP Comment/************************ 功能:以十进制形式显示补码数 入口参数:DX,待显示的数 出口参数:无 */ Dispsi16 PROC Near

汇编语言程序设计
·172·
PUSH BP ;寄护基址指针 MOV BP, SP ;设置新栈帧 PUSH AX PUSH BX PUSH CX PUSH DX MOV AX, [BP+4] ;取参数 MOV CX, 0 MOV BX, 10 OR AX, AX JNS Rep1b@Dispsi16 MOV AH, 2 MOV DL, '-' INT 21h MOV AX, [BP+4] NEG AX Rep1b@Dispsi16: MOV DX, 0 DIV BX ADD DX, '0' PUSH DX INC CX OR AX, AX JNZ Rep1b@Dispsi16 Rep2b@Dispsi16: POP DX MOV AH, 2 INT 21h LOOP Rep2b@Dispsi16 POP DX POP CX POP BX POP AX MOV SP, BP ;还原堆栈指针 POP BP ;寄寄基址指针 RET 2 ;返回并调整栈指针 Dispsi16 ENDP CRLF PROC NEAR MOV AH, 2 MOV DL, 13 INT 21h MOV DL, 10 INT 21h RET CRLF ENDP _TEXT ENDS END Start 子程序 Total 和 Dispsi16 中,都是用 BP 作为基址来访问放在堆栈中的参数。实际上,在
一般程序中,子程序普遍使用基址指针(E)BP 来访问堆栈里的参数。 在调用程序中,每次调用 Total 前都向堆栈压入两个参数,再执行 CALL Total。而在子

第 7章 模块化程序设计方法
·173·
程序中,先寄存 BP 原内容,再将 BP 指向当前的 SP 位置,这样就可以 BP 为基址,以不同
位移量来访问堆栈中的不同参数,如图 7.1 所示。我们将这种以(E)BP 作为基址,用不同的位
移量来表示堆栈中的不同参数的布局,称为堆栈帧(Stack Fram)。
SP→ SI SI SI BP→ BP BP BP
SP→ 返回偏移地址 BP+2→ 返回偏移地址 返回偏移地址 返回偏移地址 数组长度 BP+4→ 数组长度 SP→ 数组长度 数组长度 数组首地址 BP+6→ 数组首地址 数组首地址 数组首地址
SP→
(a) 进入 Total 时 (b) 寄存器寄护后 (c) 执行 RET 后 (d) 执行ADD SP,4 后
图 7.1 调用 Total 及返回的堆栈状态变化及使用 BP 访问参数示意图
一般而言,用堆栈传递入口参数的子程序调用形式如下:(假设参数都是 16 位类型) PUSH Para1 PUSH Para2 … PUSH Paran
; n个 16位参数压入堆栈
CALL SubPro ; 调用子程序 SubPro 如果 SubPro 属性是段内近调用,那么在子程序中采用如下形式访问入口参数,相应的堆
栈情况如图 7.2 所示。
SubPro PROC Near PUSH BP ;寄护基址指针 MOV BP, SP ;设置新堆栈帧 SUB SP, m ;分配临时的动态内存单元空间 … ;寄护其他寄存器的指令 MOV Vi, [BP+4+2×(n-i)] ;访问第 i个参数的寻址形式 … MOV SP, BP ;寄寄 SP POP BP ;寄寄基址指针 RET SubPro ENDP
SP→ 其他寄护信息 动态内存单元 BP→ BP
SP→ 返回偏移地址 BP+2→ 返回偏移地址 Paran BP+4→ Paran
… … … Para1 BP+4+2×(n-1)→ Para1
(a) 进入子程序时 (b) 子程序寄存器寄护后
图 7.2 近调用的堆栈及堆栈帧布局示意图
如果 SubPro 属性是远调用,那么在执行 CALL SubPro 指令时,CPU 把返回地址的 IP 和
段寄存器 CS 的内容都压栈,如图 7.3(a)所示。在进入子程序后,因为堆栈中多一个返回段地

汇编语言程序设计
·174·
址,所以,访问第 i 个参数的寻址形式是:[BP+6+2×(n-i)],如图 7.3(b)所示。
SP→ 其他寄护信息 动态内存单元 BP→ BP
SP→ 返回偏移地址 BP+2→ 返回偏移地址 返回段地址 BP+4→ 返回段地址
Paran BP+6→ Paran … … …
Para1 BP+6+2×(n-1)→ Para1
(a) 进入子程序时 (b) 子程序寄存器寄护后
图 7.3 远调用的堆栈及堆栈帧布局示意图
以上介绍的是 16 位地址模式下用堆栈传递参数的规则,所使用的方法也适用于 32 位地
址模式,只不过此时偏移地址是 32 位,基址变址和堆栈指针分别是 EBP 和 ESP,而且返回
地址的 EIP 是 32 位。在近调用情况下,访问第 n 个参数的寻址形式是:[EBP+8];在远调用
的情况下,则第 n 个参数的寻址形式是:[EBP+10]。
7.1.4 静态变量与动态变量
在汇编语言程序中,可以在堆栈上分配一定数量的存储空间作为临时变量来使用:进入
子程序时,才为它分配空间;返回到调用程序时,释放它所占用的存储空间,所以,用这种
方式分配的临时变量,又称为动态变量。 和动态变量不同的是,在某段(一般是数据段)中定义并分配的变量,在程序执行之前和执
行期间始终存在,所以这种类型变量是静态变量。 静态变量主要是通过 DW 这样的数据定义伪指令定义并分配存储空间,并可用变量名来
访问相应的内存单元;而动态变量则由程序员通过调整堆栈指针来分配存储空间,以基址指
针寄存器(E)BP 为基址,使用不同的位移量来访问相应的临时变量。 下面用具体例子说明动态变量的创建和使用的方法。 例 7.6 编写程序计算(x % m + y % m + z % m) % m 的值,其中 x, y, z 为 32 位无符号数,
m 是 16 位无符号数。假设计算过程中不会发生除法溢出。 这里将算式的计算编写成子程序 foo,用堆栈来传递入口参数,进栈次序为:x, y, z 和 m,
计算结果存放在寄存器 AX 中。 在子程序 foo 中,共创建了 6 字节的临时空间,并以 BP 作为基址,以偏移量-2, -4, -6
将它分为 3 个字单元,其中,[BP-2]用来临时存放 x % m 的结果,[BP-4]用来临时存放 y % m的结果,[BP-6]用来临时存放 z % m 的结果。
; 例 7.6使用动态变量的程序示例 _DATA SEGMENT 'DATA' USE16 X DD 81666351h Y DD 53656172h Z DD 715011ABh M DW 65501 _DATA ENDS _TEXT SEGMENT 'CODE' USE16

第 7章 模块化程序设计方法
·175·
ASSUME CS: _TEXT, DS: _DATA foo PROC FAR PUSH BP ;寄护基址指针 MOV BP,SP ;设置新栈帧 SUB SP,6 ;分配临时空间 PUSH DX MOV AX,[BP+16] ;取 x的低 16位 MOV DX,[BP+18] ;取 x的高 16位 DIV Word Ptr[BP+6] ;计算 x % m MOV [BP-2],DX ;寄存余数 MOV AX,[BP+12] ;取 y的低 16位 MOV DX,[BP+14] ;取 y的高 16位 DIV Word Ptr[BP+6] ;计算 y % m MOV [BP-4],DX ;寄存余数 MOV AX,[BP+8] ;取 z的低 16位 MOV DX,[BP+10] ;取 z的高 16位 DIV Word Ptr[BP+6] ;计算 x % m MOV [BP-6],DX ;寄存余数 SUB DX,DX MOV AX,[BP-2] ADD AX,[BP-4] ADC DX,0 ADD AX, [BP-6] ADC DX, 0 DIV Word Ptr[BP+6] MOV AX, DX POP DX MOV SP, BP ;还原堆栈指针 POP BP ;寄寄基址指针 RET foo ENDP Dispsi16 PROC NEAR … ;与例 7.5相同 Dispsi16 ENDP Start: MOV AX, _DATA MOV DS, AX PUSH Word Ptr X+2 ;X高 16位 PUSH Word Ptr X ;X低 16位 PUSH Word Ptr Y+2 ;Y高 16位 PUSH Word Ptr Y ;Y低 16位 PUSH Word Ptr Z+2 ;Z高 16位 PUSH Word Ptr Z ;Z低 16位 PUSH M CALL foo ADD SP, 14 ;调整堆栈指针 PUSH AX CALL Dispsi16 ADD SP, 2 MOV AX, 4C00h INT 21h _TEXT ENDS END Start

汇编语言程序设计
·176·
如图 7.4 所示是调用 foo 的堆栈状态变化情况。需要注意的是,foo 是远调用(Far)类型的
子程序,所以此图实际上是图 7.3 的具体实例。读者可仿照此例,根据程序运行的地址模式
(16/32 位地址模式),以及子程序的调用属性(Near/Far),构造出适合的堆栈帧。
SP→ DX BP-6→ 临时变量 3 BP-4→ 临时变量 2 BP-2→ 临时变量 1 BP→ BP
SP→ 返回偏移地址 BP+2→ 返回偏移地址 返回段地址 BP+4→ 返回段地址 M BP+6→ M Z 低 16 位 BP+8→ Z 低 16 位 Z 高 16 位 BP+10→ Z 高 16 位 Y 低 16 位 BP+12→ Y 低 16 位 Y 高 16 位 BP+14→ Y 高 16 位 X 低 16 位 BP+16→ X 低 16 位 X 高 16 位 BP+18→ X 高 16 位 (a) 进入 foo 时 (b) 子程序寄存器寄护后
图 7.4 例 7.6 子程序 foo 的堆栈及堆栈帧布局示意图
一般而言,在使用汇编语言编程时,建立当前子程序的堆栈帧指令形式如下: 16位地址模式: PUSH BP MOV BP,SP SUB SP,m
32位地址模式: PUSH EBP MOV EBP, ESP SUB ESP, m
撤销当前子程序堆栈帧的指令形式如下:
16位地址模式: MOV SP, BP POP BP
32位地址模式: MOV ESP, EBP POP EBP
实际上在 80x86 汇编指令中,专门有两条指令用来建立堆栈帧和撤销堆栈帧,那就是
ENTER 指令和 LEAVE 指令。上述建立堆栈帧的指令序列等价于 ENTER m, 0,撤销堆栈帧
的指令等价于 LEAVE。 完整的 ENTER 指令格式是:ENTER imm16, imm8,其中 imm16 是分配动态内存区的字
节数,imm8 是过程嵌套级数(0~31),相当执行如下指令序列:(16 位地址模式) PUSH BP MOV BP, SP 依次将第 1层、第 2层、…堆栈帧指针压入堆栈 SUB SP, imm16 ENTER 设计的 初目的是用于支持高级语言的过程的,但实际上这是一条非常寄杂的指
令,它要耗用近 50 个指令周期,结果根本就没有什么应用,即使使用,也是以 ENTERm, 0这样的形式出现。
因为 LEAVE 指令相对比较简单,所以经常在子程序中使用该指令来撤销堆栈帧。

第 7章 模块化程序设计方法
·177·
7.1.5 子程序的嵌套与递归调用
一个子程序包含有子程序的调用,这便是子程序的嵌套调用。如果一个程序直接或间接
地调用自身就是子程序的递归调用,含有递归调用的子程序称为递归子程序。 汇编语言中子程序的嵌套深度受堆栈空间限制,不能无限嵌套下去,否则就会产生堆栈
溢出错误。所以在设计堆栈长度时,就应考虑子程序的 大嵌套层次,必要时在程序中检查
堆栈是否溢出。 需要特别说明的是,由于递归调用子程序会多次调用自身,所以在设计递归子程序时,
必须寄证每次调用都不破坏以前调用时所用的参数和中间结果。为寄证每次调用的正确,一
般把每次调用的参数、中间结果等进栈或寄存在临时的动态变量中。
例 7.7 编写求阶乘( 1)!, 1
!1, 1n n n
nn
× −⎧= ⎨ =⎩
>的递归调用子程序。
;例 7.7递归子程序设计示例 _STACK SEGMENT STACK DB 7FFEh DUP(0) TOS DW 0 _STACK ENDS _DATA SEGMENT 'DATA' USE16 N DW 3 _DATA ENDS _TEXT SEGMENT 'CODE' USE16 ASSUME CS:_TEXT,DS:_DATA,SS:_STACK Start: MOV AX, _DATA MOV DS, AX CLI MOV AX, _STACK MOV SS, AX MOV SP, Offset TOS STI PUSH N ;入口参数 n CALL f ;调用递归子程序 ADD SP, 2 ;调整堆栈指针 PUSH AX ;AX是返回结果 CALL Dispsi16 ADD SP, 2 MOV AX, 4C00h INT 21h ;阶乘子程序,计算结果存于 AX中 f PROC NEAR PUSH BP ;寄护基址指针 MOV BP, SP ;设置新栈帧 SUB SP, 2 ;分配临时空间 MOV AX, [BP+4] ;取 n MOV [BP-2], AX CMP AX, 1 JE L10 DEC AX

汇编语言程序设计
·178·
PUSH AX CALL f ;调用递归子程序 ADD SP, 2 PUSH DX MUL Word Ptr [BP-2] ;n×(n-1) POP DX L10:MOV SP, BP POP BP RET f ENDP Dispsi16 PROC NEAR … ;与例 7.5相同 Dispsi16 ENDP _TEXT ENDS END Start 执行过程中,递归调用的堆栈内容变化如图 7.5 所示。
BP-2→ 1 BP→ 原 BP BP+2→ 返回 IP BP+4→ 1 BP-2→ 2 2 BP→ 原 BP 原 BP BP+2→ 返回 IP 返回 IP BP+4→ 2 2
BP-2→ 3 3 3 BP→ 原 BP 原 BP 原 BP
BP+2→ 返回 IP 返回 IP 返回 IP BP+4→ 3 3 3
(a) 第 1 次调用 (b) 第 2 次调用 (c) 第 3 次调用
1 1 1 原 BP 原 BP 原 BP 返回 IP 返回 IP 返回 IP 1 1 1
BP-2→ 2 2 2 BP→ 原 BP 原 BP 原 BP
BP+2→ 返回 IP 返回 IP 返回 IP BP+4→ 2 2 2
3 BP-2→ 3 3 原 BP BP→ 原 BP 原 BP 返回 IP BP+2→ 返回 IP 返回 IP 3 BP+4→ 3 3
AX=1 AX=2 AX=6
(d) 第 3 次调用返回时 (e) 第 2 次调用返回时 (f) 第 1 次调用返回时
图 7.5 递归调用的堆栈内容变化示意图

第 7章 模块化程序设计方法
·179·
7.2 多模块程序设计
实际上在开发规模稍大的程序时,经常将子程序放在一个单独的模块中,这便是程序设
计的模块化。也就是说,模块化程序设计方法是按各部分程序所实现的不同功能,将程序划
分成若干个模块,并约定相互间数据交换方式等。每个模块的功能相对独立,可以单独编写、
汇编和调试, 后再将它们连接起来,形成一个完整的用户程序。 一个汇编语言程序可以划分成主模块和多级、多个子模块(如果有必要的话),每个模块的
源程序都是以 END 伪指令来结束,但是只有主模块中的 END 后可以接标号,以表示程序的
入口地址,其他模块中的 END 后不能有标号。 采用模块化程序设计需要解决模块间的数据共享和数据交换,以及多模块连接等问题。
7.2.1 全局符号与外部符号
在多模块程序中,模块间的数据共享和数据交换是以全局符号为基础来实现的。
1. 全局符号名说明伪指令 PUBLIC
格式:PUBLIC 符号名 1[, 符号名 2, …]。 功能:将一个或多个符号名说明为全局符号,以便在其他模块中可以引用该符号。符号
名可以是变量、标号或子程序名等,也可以是表示常数的符号。
2. 外部符号名说明伪指令 EXTRN
格式:EXTRN 符号名 1:类型[, 符号名 2:类型, …]。 功能:说明一个或多个符号名为外部符号。当本模块要引用其他模块定义的符号时,则
必须将它们说明为外部符号,其类型应与原模块定义的类型一致,对于符号地址,其类型可
以是:Byte, Word, DWord, FWord, QWord, TByte, Near, Far;对于常数则是:ABS。 通常,PUBLIC 伪指令与 EXTRN 伪指令配套使用。 由于符号地址都是在某段中定义,所以,必须将各模块中的段指定为 PUBLIC 属性,这
样,连接程序将不同模块中的同名段放在一起,从而为各全局符号分配正确的偏移地址。 例 7.8 模块 M1.ASM 实现的是输入字符串子程序 Sub1;模块 M2.ASM 实现的是输出字
符串子程序 Sub2;主模块 M0.ASM 调用 Sub1 和 Sub2,输入字符串后再将它显示出来。 模块 M0.ASM 源程序如下: Comment/************************** M0.ASM 主模块源程序。 说明了全局符号 Buf和 DOSFUN 说明了外部符号 Sub1和 Sub2 ***************************/ PUBLIC Buf, DOSFUN EXTRN Sub1: Near, Sub2: Far DOSFUN = 21h _STACK SEGMENT STACK USE16 DB 3FFEh DUP (?) TOS DW ? _STACK ENDS

汇编语言程序设计
·180·
_DATA SEGMENT 'DATA' USE16 PUBLIC CRLF DB 13, 10, '$' Buf DB 20, 20 DUP (32), 13, 10, '$' _DATA ENDS _TEXT SEGMENT 'CODE' USE16 PUBLIC ASSUME CS: _TEXT, DS: _DATA Start: MOV AX, _DATA MOV DS, AX CLI MOV AX, _STACK MOV SS, AX MOV SP, Offset TOS STI CALL Sub1 MOV AX, Offset CRLF PUSH AX CALL Sub2 POP AX MOV AX, Offset Buf+2 PUSH AX CALL Sub2 POP AX MOV AX, 4C00h INT DOSFUN _TEXT ENDS END Start 模块 M1.ASM 源程序如下: Comment/************************** M1.ASM 输入字符子程序源程序。 说明了全局符号 Sub1 说明了外部符号 DOSFUN ***************************/ EXTRN DOSFUN: Abs, EXTRN Buf: Byte PUBLIC Sub1 _TEXT SEGMENT 'CODE' USE16 PUBLIC ASSUME CS: _TEXT ;子程序 Sub1约定输入缓冲区为 Buf Sub1 PROC NEAR LEA DX, Buf MOV AH, 0Ah INT DOSFUN SUB BX, BX MOV BL, Buf [1] MOV Buf[BX+2],20h RET Sub1 ENDP _TEXT ENDS END ;模块至此结束

第 7章 模块化程序设计方法
·181·
模块 M2.ASM 源程序如下: Comment/************************** M2.ASM 显示字符子程序源程序。 说明了全局符号 Sub2 说明了外部符号 DOSFUN ***************************/ EXTRN DOSFUN: Abs PUBLIC Sub2 _TEXT SEGMENT 'CODE' USE16 PUBLIC ASSUME CS: _TEXT ;子程序 Sub2,约定堆栈传递参数 Sub2 PROC FAR PUSH BP MOV BP, SP MOV DX, [BP+6] MOV AH, 9 INT DOSFUN POP BP RET Sub2 ENDP _TEXT ENDS END ;模块至此结束
7.2.2 多模块程序文多的连接
一个规模稍大的程序一般由几个.ASM 源程序组成,此时对各个.ASM 源程序需要分别汇
编生成各自的.OBJ 模块,然后再用连接程序 LINK 将这些.OBJ 模块装配在一起,形成一个可
执行文多.EXE。 例如,按下述操作可将例 7.8 中各模块汇编、连接生成一个可执行文多 M.EXE。
1. 分别汇编各源程序
可用 MASM.EXE 或 ML.EXE /c 汇编源程序,如下所示: MASM M0.ASM ↵ 或 ML /c M0.ASM ↵ ;生成 M0.OBJ MASM M1.ASM ↵ 或 ML /c M1.ASM ↵ ;生成 M1.OBJ MASM M2.ASM ↵ 或 ML /c M2.ASM ↵ ;生成 M2.OBJ
2. 连接目标文件
此处须用 16 位连接程序 LINK.EXE,操作如下所示: LINK M0+M1+M2, M;↵ ;生成可运行文多 M.EXE
3. 运行可执行文件
M↵
1234567890ABCDE↵ ;输入字符串 1234567890ABCDE ;显示字符串 实际上,可直接进行如下操作即可完成汇编、连接两个过程, 后生成 M.EXE。

汇编语言程序设计
·182·
ML /FeM.EXE M0.ASM M1.ASM M2.ASM↵
为什么将源程序转换为运行程序需要编译(汇编)和连接这两个过程,相信通过上面多模块
的操作,读者应该有所领会。
7.2.3 子程序库
在实际编程中,为方便编程,把常用子程序写成独立的源文多,单独汇编形成 OBJ 文多
后,放到一个专门的文多中,形成子程序库.LIB。在连接时,调入子程序库中的子程序模块,
生成 终的可执行文多。 微软的 MASM 6.x 软多包中所带的命令文多 LIB.EXE,就专门用于建立和修改子程序库,
它通常是在命令行环境(MS DOS 方式)下使用的。LIB 使用格式: LIB 库名 [选项] [命令项] [,列表文多 [,新库名]] 选项的解释如下: 选项 含义 /?、/HELP 显示 LIB命令的用法,描述各命令行参数的含义 /IGNORECASE 忽略子程序名中的大小写 /NOIGNORECASE 不忽略子程序名中的大小写 /NOEXTDICTIONARY 不建立扩展的目录 /Nologo 不显示版本号和版权信息 /PAGESIZE:n 设置库文多的每页字节数为 n 命令项的解释如下: 选项 含义 +name 向子程序库中加一个新的目标文多 -name 从子程序库中删除一个指定的目标文多 -+name 用新的目标文多替换掉子程序库中原有的目标文多 *name 从子程序库中寄制一个指定的目标文多 -*name 从子程序库中移出一个指定的目标文多 下面举例说明 LIB 的使用方法。 例 7.8 中经汇编后的目标文多 M1.OBJ 和 M2.OBJ,将它们放到子程序 MYLIB.LIB 中的
操作如下: LIB MYLIB + M1; ↵ LIB MYLIB + M2; ↵ 当然也可一次性加入到子程序库,操作如下: LIB MYLIB + M1 + M2; ↵ 如果 M1.ASM 已有修改,并重新汇编生成 M1.OBJ,这时,就需要把子程序库 MYLIB.LIB
中的 M1.OBJ 替换成新的目标文多。可用下面命令来实现替换: LIB MYLIB -+ M1; ↵ 子程序库文多中的目标文多可直接用于 LINK 操作中。例如,假设 M1.OB 和 M2.OBJ 已
经放到 MYLIB.LIB,那么例 7.8 的程序在连接时可用如下操作: LINK ↵

第 7章 模块化程序设计方法
·183·
Object Modules [.obj]: M0 ↵ Run File [M0.exe]: M ↵ List File [nul.map]: ↵ Libraries [.lib]: MYLIB ↵ Definitions File [nul.def]: ↵
7.2.4 汇编语言与高级语言程序的连接
对于编译型的高级程序设计语言来说,其源程序转换成可运行文多也要经历两个过程:
编译源程序,形成.OBJ 文多;将.OBJ 文多连接生成可运行文多.EXE。所以说,汇编语言与
高级语言程序的连接是属于多模块文多的连接。 各种语言的源程序分别编写,在各自的开发环境中编译成目标模块文多.OBJ,再将各个
目标模块连接在一起,生成一个可执行文多。这是多种语言混合编程常用的方法。 为能正确地进行连接,各个模块编写时都必须遵守以下共同的约定规则。 (1) 汇编模块必须使用高级语言的标识符命名约定。 (2) 在汇编语言源程序中,如果使用定义在高级语言的符号,必须用 EXTRN 来说明它,
如果让高级语言使用在本模块中定义的符号,则必须用 PUBLIC 来说明它;同理,在高级语
言源程序中,也须用相应的说明语句来说明全局符号与外部符号。 (3) 调用子程序时的参数传递规则主要有:PASCAL 规则(参数自左向右压栈),C 规则(参
数自右向左压栈),以及返回值的传递规则。 (4) 在子程序返回时的堆栈调整规则:由调用程序调整,还是由子程序调整。 (5) 其他诸如寄存器寄护原则、数据类型的对应等问题。 下面以标准 C 语言源程序为具体例子来说明汇编语言模块和高级语言模块的连接方法。 一般 C 语言编译程序在处理 C 源程序时主要使用如下的约定。 (1) 全局符号名(变量名或函数名)前加“_”(下划线)。 (2) 调用子程序时,使用 C 规则传递参数;在 16 位模式下,用 AX 传递 8, 16 位返回结
果,用 DX:AX 传递 32 位返回结果,在 32 位模式下,用 EAX 传递 8, 16 和 32 返回结果,用
EDX:EAX 传递 64 位返回结果。 (3) 由调用程序来调整堆栈指针。 (4) 一般情况下,不寄护 AX, BX, CX, DX(16 位地址模式),或 EAX, EBX, ECX, EDX(32
位地址模式)。 例 7.9 F0.C 是主模块,用 C 语言编写;F1.C 是用 C 语言编写的子函数 Sub1 的源码模
块,F2.ASM 是用汇编语言编写的子程序_Sub2 的源码模块。在这个演示程序中,在 main 函
数中调用汇编语言编写的子程序_Sub2,而在_Sub2 又调用 C 语言编写的子函数 Sub1。 F0.C 源码清单 extern long Sub2(short, long); extern char StringInASM[]; main() { printf ("Link C module and %s together\n%ld\n", StringInASM, Sub2(50,31)); } F1.C 源码清单 long Sub1(short x, long y) /* 不能说明成 static sub1(long x, long y); */ { return (long)(x*y); }

汇编语言程序设计
·184·
如果使用 VC 来编译上述 C 语言源代码(假定 VC 环境已经设置好),那么 F2.ASM 应该是
32 位地址模式下的汇编代码,源程序(F2-32.ASM)清单如下:(Flat 模式下代码) .386 EXTRN _Sub1: NEAR PUBLIC _StringInASM, _Sub2 _DATA SEGMENT 'DATA' PUBLIC USE32 _StringInASM DB 'ASM ( USE32 ) MODULE', 0 _DATA ENDS _TEXT SEGMENT 'CODE' PUBLIC USE32 ASSUME CS: _TEXT, DS:_DATA _Sub2 PROC NEAR PUSH EBP MOV EBP, ESP PUSH DWord Ptr [EBP+12] ;this is y PUSH DWord Ptr [EBP+8] ;this is x CALL _Sub1 ADD ESP, 8 SUB EAX, [EBP+8] SUB EAX, [EBP+12] POP EBP RET _Sub2 ENDP _TEXT ENDS END 上面各模块汇编、编译、连接的过程如下, 后生成可执行文多 F.EXE。 ML /c /coff F2-32.ASM ↵ ;生成 F2.OBJ CL /c F0.C F1.C ↵ ;生成 F0.OBJ F1.OBJ LINK /out:F.EXE f0.obj f1.obj f2.obj ↵ ;生成 F.EXE 如果用 TC 编译上述 C 语言源代码(假定 TC 环境已设置好),那么 F2.ASM 应编写成 16
位地址模式下的汇编代码,源程序(F2-16.ASM)清单如下:(Small 模式下的代码) EXTRN _Sub1:NEAR PUBLIC _StringInASM, _Sub2 _DATA SEGMENT 'DATA' PUBLIC USE16 _StringInASM DB 'ASM ( USE16 ) MODULE', 0 _DATA ENDS _TEXT SEGMENT 'CODE' PUBLIC USE16 ASSUME CS: _TEXT, DS:_DATA _Sub2 PROC NEAR PUSH BP MOV BP, SP PUSH Word Ptr [BP+8] ;this is y (high 16bits) PUSH Word Ptr [BP+6] ;this is y (low 16 bits) PUSH Word Ptr [BP+4] ;this is x CALL _Sub1 ADD SP, 6 SUB AX, [BP+4] SBB DX, 0

第 7章 模块化程序设计方法
·185·
SUB AX, [BP+6] SBB DX, [BP+8] POP BP RET _Sub2 ENDP _TEXT ENDS END 上述各模块汇编、编译、连接的过程如下, 后生成可执行文多 F.EXE。 ML /c /omf F2.ASM ↵ ;生成 F2.OBJ TCC -eF.EXE f0.c f1.c f2.obj ↵ ;生成 F.EXE
7.3 子程序控制伪指令
MASM 6.x 引入了若干条与子程序定义与调用相关的子程序控制伪指令,用来指示汇编
程序生成相应的子程序定义格式和调用代码。它们主要有:PROC, PROTO 和 INVOKE 等。
虽然它们使用起来稍微寄杂,但是它们为子程序的调用带来了方便。 首先,在使用 PROC 定义子程序时,提供了增强型的定义方式,如下所示: 子程序名 PROC [距离][语言类型][可视区域][USES 寄存器列表][,参数:类型]...[VarArg] LOCAL 局部变量列表 指令序列 子程序名 ENDP 距离——可以是 Near 和 Far。未指定类型,当内存模型为 Tiny, Small, Compact 和 Flat 时
为 Near;当内存模型为 Medium, Large 和 Huge 时为 Far;若未定内存模型,则为 Near。 语言类型——表示子程序的调用规则和返回约定,以及全局标识符的命名规定。如果没
有指定,则使用程序头部.Model 所指定的语言类型。各种语言中调用子程序的约定是不同的,
见表 7.1。只有在确定了语言类型后,汇编程序才能正确地翻译 Invoke 伪指令。
表 7.1 语言类型及标识符书写规则
C SysCall StdCall Basic Fortran Pascal
先入栈参数 右 右 右 左 左 左
调整栈指针 子程序 子程序* 子程序 调用程序 调用程序 调用程序
使用可变参数 是 是 是 否 否 否
*若使用可变参数,则调用程序调整堆栈指针。 可视区域——可以是 Private, Public 和 Export。如果指定为 Private,则表示子程序名只在
本模块内可见;如果是 Public,则表示该子程序名是全局符号名,允许其他模块使用它;如
果指定为 Export,则表示子程序是导出的函数。默认的设置是 Public。 USES 寄存器列表——指定需要寄护的寄存器列表。汇编程序在子程序指令开始前用
PUSH 指令将这些寄存器内容压栈,在子程序返回前用 POP 指令寄寄先前寄护的寄存器。 参数和类型——子程序所用的参数。格式为:“标识符:类型[,标识符:类型…]”。汇编程
序将这些参数转换成[BP+4]、[BP+6]或者[EBP+8]、[EBP+10]等形式。在定义参数名的时候,

汇编语言程序设计
·186·
不能跟全局变量和该子程序中的局部变量重名,若 后还有 VarArg,表示在已确定的参数后
还可以有数量不定的参数,类似于 C 语言中的 printf 函数的参数。 完成定义之后,可以用 INVOKE 伪指令来调用子程序。其格式如下: INVOKE 地址表达式[,参数表]
其中,地址表达式通常为子程序名,也可以标号等;参数表是调用子程序所需的参数,各参
数之间用逗号“,”分开,参数可以是寄存器、常数表达式或符号地址等。如果传递的是内存
操作数的内存地址,则参数形式是:Addr mem。注意,汇编程序在翻译此形式的参数时,需
要使用累加器 EAX。 汇编程序是这样处理该伪指令的:按语言类型所约定的调用规则,把所有参数压栈,再
调用子程序;子程序结束时,若需要调用程序调整堆栈指针,则生成调整堆栈指针指令。 在参数传递时,汇编程序将根据子程序的原型(Proc 定义或 Proto 说明)进行数据类型检查。
若需要进行参数类型转换的话,汇编程序则会生成相关代码以实现类型转换。 当 Invoke 伪指令位于子程序代码之前的时候,汇编程序在处理到 Invoke 时,由于不能得
知子程序的定义情况而不知如何处理。在这种情况下,须用 Proto 伪指令说明子程序的相关信
息,以“提前”告诉 Invoke 伪指令关于子程序的信息。其格式如下: 子程序名 PROTO [距离] [语言类型] [,参数类型表] 该伪指令告诉汇编程序该子程序的若干属性,如:类型属性(Near/FAR)、语言类型、参
数个数及各参数类型等。这样方便 Invoke 来调用子程序。 在子程序内部可用 Local 伪指令定义局部变量并分配空间(位于堆栈中),其格式如下: LOCAL 变量定义 1[,变量定义 2…] Local 伪指令必须在伪指令 Proc 后、其他指令开始前。汇编程序将用 Local 定义的局部变
量转换成[BP-2]或[EBP-2]等形式,所以局部变量是动态变量,只在子程序范围内有效。 局部变量定义的形式有三种形式,如下所示: LOCAL loc1 ;loc1为默认类型 Word/DWord(16/32位地址模式) LOCAL loc2:Word ;loc2类型为 Word LOCAL loc3[100]:Byte ;loc3为长度为 100的 Byte类型数组 下面通过具体的例子来说明子程序控制伪指令的使用方法。 例 7.10 用子程序控制伪指令编写例 7.9 的 32 位地址模式下的汇编程序 F2-32.ASM。 .386 Sub1 PROTO NEAR C, x: DWord, y: DWord PUBLIC _StringInASM _DATA SEGMENT 'DATA' PUBLIC USE32 _StringInASM DB 'ASM ( USE32 ) MODULE', 0 _DATA ENDS _TEXT SEGMENT 'CODE' PUBLIC USE32 ASSUME CS: _TEXT, DS:_DATA Sub2 PROC NEAR C Public, x: DWord, y: DWord Invoke Sub1, x, y SUB EAX, x SUB EAX, y RET

第 7章 模块化程序设计方法
·187·
Sub2 ENDP _TEXT ENDS END 例 7.11 用子程序控制伪指令编写例 7.5 的汇编程序。代码如下: _STACK SEGMENT STACK USE16 DB 3FFEh DUP(?) TOS DW ? _STACK ENDS _DATA SEGMENT 'DATA' USE16 A1 DW 65, -22, 3, 26, 37, 49 N1 DW ($-A1)/2 A2 DW 1, -3, 5, -7, 9, -11, 13 N2 DW ($-A2)/2 _DATA ENDS Total Proto Near C,:Word,:Word Dispsi16 Proto Near Pascal,:Word _TEXT SEGMENT 'CODE' USE16 ASSUME CS:_TEXT, DS:_DATA Start: MOV AX, _DATA MOV DS, AX CLI MOV AX, _STACK MOV SS, AX MOV SP, Offset TOS STI INVOKE Total, N1, Offset A1 INVOKE Dispsi16, AX CALL CRLF ;回车换行 INVOKE Total, N2, Offset A2 INVOKE Dispsi16, AX MOV AX, 4C00h INT 21h Total Proc Near C uses SI, N:word,A:word MOV SI, a ;取参数 1 SUB AX, AX Rep1b@Total: ADD AX, [SI] ;不考虑溢出 ADD SI, 2 ;下一个元素 DEC n ;取参数 2 JNZ Rep1b@Total RET Total ENDP Dispsi16 Proc Pascal uses ax bx cx dx, n:word MOV AX, n ;取参数 MOV CX, 0 … ;此代码相同 LOOP Rep2b@Dispsi16 RET Dispsi16 ENDP CRLF PROC NEAR

汇编语言程序设计
·188·
MOV AH, 2 MOV DL, 13 INT 21h MOV DL, 10 INT 21h RET CRLF ENDP _TEXT ENDS END Start 例 7.12 用子程序控制伪指令编写例 7.6 的汇编程序。源程序如下: _DATA SEGMENT 'DATA' USE16 X DD 81666351h Y DD 53656172h Z DD 715011ABh M DW 65501 _DATA ENDS _TEXT SEGMENT 'CODE' USE16 ASSUME CS: _TEXT, DS: _DATA foo Proc Far C uses dx, n:word,w:dword, v:dword,u:dword Local t1:word,t2:word,t3:word MOV AX,word ptr u ;取 x的低 16位 MOV DX,word ptr u+2 ;取 x的高 16位 DIV n ;计算 x % m MOV t1,DX ;寄存余数 MOV AX,word ptr v ;取 y的低 16位 MOV DX,word ptr v+2 ;取 y的高 16位 DIV n ;计算 y % m MOV t2, DX ;寄存余数 MOV AX,word ptr w ;取 z的低 16位 MOV DX,word ptr w+2 ;取 z的高 16位 DIV n ;计算 x % m MOV t3, DX ;寄存余数 SUB DX, DX MOV AX, t1 ADD AX, t2 ADC DX, 0 ADD AX, t3 ADC DX, 0 DIV n MOV AX, DX RET foo ENDP Dispsi16 PROC NEAR … … ;与例 7.11相同 Dispsi16 ENDP Start:MOV AX, _DATA MOV DS, AX Invoke foo,m,z,y,x Invoke Dispsi16,AX

第 7章 模块化程序设计方法
·189·
MOV AX, 4C00h INT 21h _TEXT ENDS END Start
7.4 综 合 示 例
例 7.13 编写 32 位模式的查找子程序:在以 A 为首地址、长度为 n 的、按照从大到小
的顺序排序的 16 位有符号数数组中,查找关键字 k,若找到则返回其位置号,否则返回-1。 分析:A 是一个有序数组,故可用二分法来完成关键字 k 的查找,其算法流程框图参照
图 6.13。这里按 C 语言类型设计查找子程序:short BSearch(short *a, int n, int k); .386 _TEXT SEGMENT 'CODE' USE32 PUBLIC ASSUME CS: _TEXT _BSearch PROC Near Public _BSearch PUSH EBP ;寄护基址指针 MOV EBP,ESP ;设置新栈帧 SUB ESP,8 ;分配动态变量空间 PUSH EBX PUSH ESI MOV DWord Ptr [EBP-4],0 MOV EAX,[EBP+12] ;取 n DEC EAX MOV [EBP-8],EAX MOV EBX,[EBP+8] ;取数组首地址 L1: MOV ESI,[EBP-4] ;low⇒SI ADD ESI,[EBP-8] ;low+high⇒SI AND SI,0FFFEh ;2*(SI/2)⇒SI MOV AX,[EBX+ESI] SHR ESI,1 ;SI/2⇒SI,还形成下标 mid CMP AX,[EBP+16] ;与 k比较 JNZ L2 MOV EAX,ESI ;找到,mid⇒AX JMP L5 L2: JNG L3 INC ESI MOV [EBP-4],ESI ;mid-1⇒low JMP L4 L3: DEC ESI MOV [EBP-8],ESI ;mid+1⇒high L4: MOV EAX,[EBP-4] CMP EAX,[EBP-8] JLE L1 MOV EAX,-1 ;未找到,-1⇒AX L5: POP ESI POP EBX MOV ESP,EBP ;还原堆栈 POP EBP ;寄寄基址指针

汇编语言程序设计
·190·
RET _BSearch ENDP _TEXT ENDS END 在子程序_BSearch 中共分配 8 字节的临时空间,作为临时变量,指定 low 对应[BP-4]的
4 字节单元,high 对应[BP-8]的字节单元。 例 7.14 在 DOS 系统下编写简单的计算器程序,实现整数的加、减、乘、除四则运算。
为简单起见,程序功能设计为:输入正确的表达式,则计算结果;输入字符串第一个字符为'#',则退出;其他,则提示出错。程序忽略空格与制表符,即 1 2+34 5 与 12+345 等同。
程序采用模块化结构,虽然简单,但基本包括了程序设计的一些典型方法。整个程序分
为 5 个部分 6 个文多。为缩短代码长度,源程序中使用了一些子程序控制伪指令。 Ex14.INC 程序中所用的说明性信息 Ex14-0.ASM 主控程序模块 Ex14-1.ASM 输入字符串子程序 Ex14-2.ASM 表达式分析子程序 Ex14-3.ASM 整数的四则运算子程序 Ex14-4.ASM 以十进制形式显示 32位补码数 Ex14-5.ASM 显示字符串、字符及回车换行子程序 (1) Ex14.INC。将子程序的原型说明、外部符号的说明等集中放在此文多。 Puts PROTO Near StdCall, : Word Putc PROTO Near StdCall, : Word EXTRN f_add: Near, f_sub: Near, f_mul: Near, f_div: Near EXTRN _InputStr@2: Near, Analyze: Near, Dispsi32: Near, _CRLF@0: Near (2) Ex14-0.ASM。主控模块:输入表达式字符串,分析表达式,根据分析结果,或执行
四则运算,或显示提示错误,或退出程序运行。 Include Ex14.INC _STACK SEGMENT STACK USE16 DB 7FFEh DUP (0) TOS DW 0 _STACK ENDS _DATA SEGMENT 'DATA' USE16 Prompt DB 13,10,'Expression: ', 0 Buffer DB 200h DUP (0) ErrMsg DB 'Error in expression!',13,10,0 _DATA ENDS _TEXT SEGMENT 'CODE' Public USE16 Assume CS:_TEXT,DS:_DATA,SS:_STACK .386 Start: MOV AX, _DATA MOV DS, AX CLI MOV AX, _STACK MOV SS, AX MOV SP, Offset TOS STI Redo: Invoke Puts, Offset Prompt

第 7章 模块化程序设计方法
·191·
PUSH Word Ptr Offset Buffer CALL _InputStr@2 CALL _CRLF@0 PUSH Word Ptr Offset Buffer CALL Analyze MOVZX EAX, AL CALL CS: Tab [EAX*2] JMP Redo Tab DW c0,f_add,f_sub,f_mul,f_div,c5 c5: Invoke Puts, Offset ErrMsg RET c0: MOV AX, 4C00h INT 21h _TEXT ENDS END Start (3) Ex14-1.ASM。输入字符串子程序的实现模块。子程序原型是:stdcall InputStr(char *s);
输入字符串放在 s 中,以 0 作为结束标志。Stdcall 规则:参数采用从右到左的压栈方式,子
程序在退出时调整堆栈指针;源程序经汇编或编译后,会在子程序名前面加上下划线'_',在
函数名后加上'@'和参数的字节数。源程序中的子程序按此规则编写的。 .386 _TEXT Segment 'CODE' Use16 Public ASSUME CS: _TEXT _InputStr@2 PROC Near Public _InputStr@2 Enter 200h, 0 PUSHA PUSH DS PUSH ES MOV [BP-200h], Byte Ptr 255 PUSH DS POP ES PUSH SS POP DS LEA DX, [BP-200h] MOV AH, 0Ah INT 21h LEA SI, [BP-1FFh][1] MOV DI, [BP+4] MOVZX CX, Byte Ptr [BP-1FFh] CLD REP MOVSB POP ES POP DS MOV [DI], Byte Ptr 0 POPA LEAVE RET 2 _InputStr@2 ENDP _TEXT ENDS END

汇编语言程序设计
·192·
(4) Ex14-2.ASM。表达式分析子程序。子程序名 Analyze,表达式字符的首地址通过堆栈
传递进来,分析得到的两个操作数存入 ECX 和 EDX 传递给调用程序,AL 存放的是操作方法
代码:1, 2, 3, 4 分别表示字符串是加、减、乘、除表达式;0 表示程序要终止运行;5 表示字
符串中的表达式不正确。表达式中只允许有:数字字符、空格、制表符及'+', '-', '*', '/',并且
忽略空格和制表符,即:1 2+34 5 与 12+345 等同。 程序通过 REP SCASB 来扫描表达式中的字符,若 AL 是空格或制表符,则 CL 是 15 或
14;若是'+', '-', '*', '/',则对应 10, 11, 12, 13;若是'0'~'9',则对应 0~9。若是其他字符,则
CL 为 0,且 ZF 为 0。 .386 _TEXT Segment 'CODE' Use16 Public ASSUME CS: _TEXT tab DB 32,9,'/*-+9876543210' Bytes EQU $-tab Analyze PROC Near Public Analyze Enter 20h, 0 PUSH SI PUSH DI PUSH ES PUSH CS POP ES MOV SI, [BP+4] SUB EDX, EDX SUB EAX, EAX CMP [SI], Byte Ptr '#' JZ L90 CLD L10: LODSB MOV DI, Offset tab MOV ECX, Bytes REPNE SCASB JE L20 OR AL,AL ;是结束标志符0吗 JNZ L70 ;不是则提示错 CMP AH,11B ;是完整表达式吗 JNE L70 ;不是则提示错 MOV ECX, [BP-4] ;第 1个数值 MOV AL, [BP-8] JMP L90 L20: CMP CL, 13 ;是空格、制表符吗 JG L10 ;是则忽略 CMP CL, 9 JNLE L30 LEA ECX, [EDX*2+ECX] ;d*10+c LEA EDX, [EDX*8+ECX] ;⇒d OR AH, 1 ;操作数已有值 JMP L10 ;取下一个字符 L30: CMP AH, 1 ;只有一个数值?

第 7章 模块化程序设计方法
·193·
JNE L70 ;不是则提示错 SHL AH, 1 ;操作数未有值 MOV [BP-4],EDX ;寄存数值 SUB CL, 9 ;得到操作代码 MOV [BP-8], CL SUB EDX, EDX ;初始值为 0 JMP L10 L70: MOV AL, 5 L90: POP ES POP DI POP SI LEAVE RET 2 Analyze ENDP _TEXT ENDS END (5) Ex14-3.ASM。四则运算子程序,完成运算并显示结果。这里直接用标号作为子程序
的入口,用 RETN 返回,是近调用类型。参加运算的两个数存放在 ECX 和 EDX 中。 Putc PROTO Near StdCall, :Word EXTRN Dispsi32: NEAR Public f_add, f_sub, f_mul, f_div _TEXT Segment 'CODE' Public Use16 ASSUME CS: _TEXT .386 f_div: MOV EAX, ECX MOV ECX, EDX SUB EDX, EDX DIV ECX PUSH EAX CALL Dispsi32 Invoke Putc, ',' PUSH EDX CALL Dispsi32 RETN f_mul: MOV EAX, ECX MUL EDX PUSH EAX CALL Dispsi32 RETN f_sub: SUB ECX, EDX PUSH ECX CALL Dispsi32 RETN f_add: ADD ECX, EDX PUSH ECX CALL Dispsi32 RETN _TEXT ENDS END

汇编语言程序设计
·194·
(6) Ex14-4.ASM。32 位有符号数显示模块。子程序名:Dispsi32,近调用属性,通过堆
栈传递参数,子程序自己调整堆栈指针,没有返回结果。 _TEXT SEGMENT 'CODE' Use16 Public ASSUME CS: _TEXT .386 Dispsi32 PROC Near Public Dispsi32 Enter 0, 0 PUSHAD MOV EAX, [BP+4] MOV EBX, 10 MOV CX, 0 OR EAX, EAX JNS L10 MOV AH, 2 MOV DL, '-' INT 21h MOV EAX, [BP+4] NEG EAX L10: SUB EDX, EDX DIV EBX ADD DL, '0' PUSH DX INC CX OR EAX, EAX JNZ L10 L20: POP DX MOV AH, 2 INT 21h LOOP L20 POPAD LEAVE RET 4 Dispsi32 ENDP _TEXT ENDS END (7) Ex14-5.ASM。3 个子程序:stdcall Puts(char *s);、stdcall Putc(char c);和 stdcall CRLF();,
分别用来显示字符串、字符及回车换行。 .386 PUBLIC Puts, Putc _TEXT SEGMENT 'CODE' Use16 Public ASSUME CS: _TEXT Puts Proc Near StdCall, String: Word PUSHA MOV SI, string L10: MOV DL, [SI] OR DL, DL JZ L20 MOV AH, 2

第 7章 模块化程序设计方法
·195·
INT 21h INC SI JMP L10 L20: POPA RET Puts ENDP Putc PROC Near StdCall, Char: Byte PUSHA MOV DL, Char MOV AH, 2 INT 21h POPA RET Putc ENDP CRLF PROC Near StdCall MOV AH, 2 MOV DL, 13 INT 21h MOV DL, 10 INT 21h RET CRLF ENDP _TEXT ENDS END 以上源程序汇编、连接过程如下: ml /Bllink16.exe ex14-0.asm ex14-1.asm ex14-2.asm ex14-3.asm ex14-4.asm
ex14-5.asm 例 7.15 在 Win32 环境下编写简单的计算器程序,功能同例 7.14。 在 Win32 环境下所有 DOS 功能调用不再有效,为此改用 Win32 的 API 来调用系统功能,
对应的模块分别是:Ex15.INC, Ex15-0.ASM, Ex15-1.ASM, Ex15-2.ASM, Ex15-3.ASM, Ex15-4.ASM, Ex15-5.ASM。
我们知道,DOS 应用程序是运行于 16 位地址模式,而 Win32 的应用程序是运行于 32 位
地址模式。16 位程序与 32 位程序的不同主要体现在两个方面:指令方面,前者偏移地址是
16 位,故内存操作数的偏移量不能超过 64KB,串处理等指令默认使用寄存器 SI, DI 和 CX,
后者用 32 位来表示偏移地址,所以内存操作数的偏移量 大可达到 4GB,串处理等指令默认
使用的寄存器是 ESI, EDI 和 ECX;系统支持方面:DOS 运行于实模式下,应用程序可使用计
算机所有资源,通过 INT 指令调用系统功能(DOS, BIOS),而 Win32 是运行在 32 位寄护模式
下,对危及操作系统安全的一些资源进行了寄护,应用程序不能直接访问 I/O 等资源,也不
能直接设置数据段、堆栈段等,应用程序须通过 Win32 的 API 来调用系统所提供的功能。 下面列出相应的源程序。读者通过比较例 7.14 和例 7.14 相应的源程序可以发现,在 16
位地址模式下和在 32 位地址模式下编程,除了偏移地址一个是 16 位而另一个是 32 位,由此
引起访问放在堆栈中的参数的位移量不同,以及在串处理中默认的寄存器位数等少数方面不
同外,在指令的使用方面没有什么本质上的区别。 (1) Ex15.INC。将子程序的原型说明、外部符号的说明等集中放在此文多。 ExitProcess PROTO Near StdCall, :DWord

汇编语言程序设计
·196·
WriteConsoleA PROTO Near StdCall, :DWord,:DWord,:DWord,:DWord,:DWord ReadConsoleA PROTO Near StdCall, :DWord,:DWord,:DWord,:DWord,:DWord GetStdHandle PROTO Near StdCall, :DWord InputStr PROTO Near StdCall, :DWord Puts PROTO Near StdCall, :DWord Putc PROTO Near StdCall, :DWord EXTRN Analyze:Near, _CRLF@0:Near EXTRN f_add:Near, f_sub:Near, f_mul:Near, f_div:Near (2) Ex15-0.ASM。源码中没有堆栈段及相应的段设置代码,直接使用系统提供的设置。 .386 Include Ex15.INC Includelib KERNEL32.LIB _DATA Segment 'DATA' USE32 Prompt DB 13, 10, 'Expression: ', 0 Buffer DB 200h DUP (0) ErrMsg DB 'Error in expression!',13,10,0 _DATA ENDS _TEXT SEGMENT 'CODE' Public USE32 Assume CS:_TEXT, DS:_DATA _main: Invoke Puts, Offset Prompt Invoke InputStr, Addr Buffer CALL _CRLF@0 PUSH DWord Ptr Offset Buffer CALL Analyze MOVZX EAX, AL CALL CS: Tab [EAX*4] JMP _main Tab DD c0, f_add, f_sub, f_mul, f_div, c5 c5: Invoke Puts, Offset ErrMsg RET c0: Invoke ExitProcess, 0 _TEXT ENDS END _main (3) Ex15-1.ASM。和 Ex14-1 相比,用 Win32 的 API 中的 GetStdHandle 和 ReadConsoleA
实现字符的输入,除此之外其余部分结构相同。 .386 Extrn _GetStdHandle@4 :Near Extrn _ReadConsoleA@20 :Near _TEXT Segment 'CODE' Use32 Public ASSUME CS: _TEXT _InputStr@4 PROC Near Enter 200h, 0 PUSHAD PUSH DWord Ptr -10 CALL _GetStdHandle@4 PUSH DWord ptr 0 LEA EDX, [EBP-200h] PUSH EDX PUSH DWord Ptr 255

第 7章 模块化程序设计方法
·197·
LEA EDX, [EBP-1FCh] PUSH EDX PUSH EAX CALL _ReadConsoleA@20 LEA ESI, [EBP-1FCh] MOV EDI, [EBP+8] MOV ECX, [EBP-200H] CLD REP MOVSB MOV [EDI-2], Byte Ptr 0 POPAD LEAVE RET _InputStr@4 ENDP _TEXT ENDS END (4) Ex15-2.ASM。和 Ex14-2 相比,除了将 SI, DI, BP 相应地改为 ESI, EDI, EBP,以及
因为返回的偏移地址是 32 而对个别处作相应的调整外,其余的完全相同。 .386 _TEXT Segment 'CODE' Use32 Public ASSUME CS: _TEXT Tab DB 32, 9,'/*-+9876543210' Bytes EQU $-tab Analyze PROC Near Public Analyze Enter 20h, 0 PUSH ESI PUSH EDI PUSH ES PUSH CS POP ES MOV ESI, [EBP+8] SUB EDX, EDX SUB EAX, EAX CMP [ESI], Byte Ptr '#' JZ L90 CLD L10:LODSB MOV EDI, Offset tab MOV ECX, Bytes REPNE SCASB JE L20 OR AL, AL ;是结束标志符 0? JNZ L70 ;不是则提示错 CMP AH, 11B ;是完整表达式? JNE L70 ;不是则提示错 MOV ECX, [EBP-4] ;第 1个数值 MOV AL, [EBP-8] JMP L90 L20:CMP CL, 13 ;是空格、制表符?

汇编语言程序设计
·198·
JG L10 ;是则忽略 CMP CL, 9 JNLE L30 LEA ECX, [EDX*2+ECX] ;d*10+c LEA EDX, [EDX*8+ECX] ;⇒d OR AH, 1 ;操作数已有值 JMP L10 ;取下一个字符 L30:CMP AH, 1 ;只有一个数值? JNE L70 ;不是则提示错 SHL AH, 1 ;操作数未有值 MOV [EBP-4], EDX ;寄存数值 SUB CL, 9 ;得到操作代码 MOV [EBP-8], CL SUB EDX, EDX ;初始值为 0 JMP L10 L70:MOV AL, 5 L90:POP ES POP EDI POP ESI LEAVE RET 4 Analyze ENDP _TEXT ENDS END (5) Ex15-3.ASM。除个别地址不同外,几乎与 Ex14-3.ASM 完全相同。 .386 Putc PROTO Near StdCall, : DWord Extrn Dispsi32: Near Public f_add, f_sub, f_mul, f_div _TEXT Segment 'CODE' Public Use32 ASSUME CS: _TEXT f_div: MOV EAX, ECX MOV ECX, EDX SUB EDX, EDX DIV ECX PUSH EDX PUSH EAX CALL Dispsi32 Invoke Putc, ',' CALL Dispsi32 RETN f_mul: MOV EAX, ECX MUL EDX PUSH EAX CALL Dispsi32 RETN f_sub: SUB ECX, EDX PUSH ECX CALL Dispsi32 RETN

第 7章 模块化程序设计方法
·199·
f_add: ADD ECX, EDX PUSH ECX CALL Dispsi32 RETN _TEXT ENDS END (6) Ex15-4.ASM。除调用 GetStdHandle 与 WriteConsoleA 实现输出外,结构与 Ex15-4
相同。 .386 Include Ex15.INC _TEXT SEGMENT 'CODE' Use32 Public ASSUME CS: _TEXT Dispsi32 PROC Near Public Enter 200h, 0 PUSHAD MOV [EBP-200h], Byte Ptr '-' Invoke GetStdHandle, -11 MOV [EBP-1FCh], EAX MOV EAX, [EBP+8] OR EAX, EAX JNS L05 Invoke WriteConsoleA,[EBP-1FCh],\ Addr[EBP-200h], 1, Addr[EBP-1F8h], 0 MOV EAX, [EBP+8] NEG EAX L05: MOV EBX, 10 MOV ECX, 0 L10: SUB EDX, EDX DIV EBX ADD DL, '0' PUSH EDX INC ECX OR EAX, EAX JNZ L10 L20: POP DWord ptr [EBP-1F4h] PUSH ECX Invoke WriteConsoleA,[EBP-1FCh],\ Addr[EBP-1F4h], 1, Addr[EBP-1F8h], 0 POP ECX LOOP L20 POPAD LEAVE RET 4 Dispsi32 ENDP _TEXT ENDS END (7) Ex15-5.ASM。用 GetStdHandle 和 WriteConsoleA 输出字符,实现各子程序。 .386 Include Ex15.INC

汇编语言程序设计
·200·
PUBLIC Puts, Putc, CRLF _TEXT SEGMENT 'CODE' Use32 Public ASSUME CS: _TEXT Puts Proc Near StdCall, String: DWord Local n:DWord PUSHAD Invoke GetStdHandle, -11 MOV EDI, EAX MOV ESI, String L10: CMP [ESI], Byte Ptr Ptr 0 JZ L20 Invoke WriteConsoleA, EDI, ESI, \1,Addr n, 0 INC ESI JMP L10 L20: POPAD RET Puts ENDP Putc PROC Near StdCall, Char: DWord Local n:DWord PUSHAD Invoke GetStdHandle, -11 MOV EDI, EAX Invoke WriteConsoleA, EDI, Addr Char, \1,Addr n, 0 POPAD RET Putc ENDP CRLF PROC Near StdCall Local n, t:DWord PUSHAD MOV t, 0D0Ah Invoke GetStdHandle, -11 MOV EDI, EAX Invoke WriteConsoleA, EDI, Addr t, \2,Addr n, 0 POPAD RET CRLF ENDP _TEXT ENDS END 以上源程序汇编、连接过程如下: ml /coff /Bllink32.exe ex15-0.asm ex15-1.asm ex15-2.asm ex15-3.asm ex15-4.asm
ex15-5.asm 实际上,Win32 环境中的 API 是以动态链接库(DLL)形式存放的,应用程序在使用的时候,
由 Windows 自动装入 DLL 程序,并调用相应的函数。Win32 API 的核心由 3 个 DLL 提供。 ① KERNEL32.DLL——系统服务功能。包括内存管理、任务管理和动态链接等。 ② GDI32.DLL——图形设备接口。 ③ USER32.DLL——用户接口服务。建立窗口和传送消息等。 当然,Win32 API 还包括其他很多函数,这些也是由 DLL 提供的,不同的 DLL 提供了不
同的系统功能。例如,使用 TCP/IP 协议进行网络通信的 DLL 是 Wsock32.dll,它所提供的

第 7章 模块化程序设计方法
·201·
API 称为 Socket API;专用于电话服务方面的 API 称为 TAPI(Telephony API),包含在 Tapi32.dll中。所有的这些 DLL 提供的函数组成了现在所用的 Win32 编程环境。
例 7.16 将下列 C 语言程序转换为汇编语言程序。C 程序所实现的功能是:文多中读入
学生成绩表,再按成绩由高到低排序, 后显示输出。 #include "stdio.h" struct tagSCORE{long No; char cN[20];long m;}; int GetScore( struct tagSCORE *Score, int *pCount, char *name) { FILE *fp; int i, r; if((fp=fopen("score.txt","r"))==NULL) r=0; else{ fscanf(fp,"%d%s\t",pCount,name); for (i=0; i<*pCount; i++) fscanf(fp,"%ld%s%ld", &Score[i].No, Score[i].cN, &Score[i].m); r=1;} return r;} void Sort(struct tagSCORE*Score, int count) { int i; struct tagSCORE t; for (count--; count>0; count--) for(i=0;i<count; i++) if(Score[i].m<Score[i+1].m){t=Score[i];Score[i]=Score[i+1] ;Score[i+1]=t;}} void OutScore(struct tagSCORE *Score, int count) { int i; for (i=0; i<count; i++) printf("%ld\t%s\t%d\n",Score[i].No,Score[i].cN,Score[i].m);} void main(int argc, char* argv[]) { struct tagSCORE Score[200]; char s[100]; int n; GetScore(Score,&n,s); Sort(Score,n); OutScore(Score,n);} 学生成绩文多中第一行是学生数 课程名,从第二行开始存放的是成绩表,格式为:学号
姓名 成绩,如下所示。注意,姓名中不允许出现空格、制表符等空白符。 100 Assembler 30001 Zhang 78 30002 Li 63 … (1) 若 C 编译器是 VC(32 位),那么 C 源码可改写成如下汇编语言程序(32.ASM): .686P includelib MSVCRT.lib Extrn _fopen: Near, _fclose: Near Extrn _fscanf: Near, _printf: Near tagSCORE STRUC No DD ? cN DB 20 dup(0) m DD ? tagSCORE ENDS _DATA SEGMENT 'DATA' PUBLIC @s DB 'r',0,'score.txt',0,'%d%s',0

汇编语言程序设计
·202·
DB '%ld%s%ld',0,'%ld',9,'%s',9,'%d',10,0 _DATA ENDS _TEXT SEGMENT 'CODE' Use32 Public ASSUME CS:_TEXT, DS:_DATA _GetScore PROC Near Enter 4, 0 PUSH ESI PUSH EDI PUSH DWord Ptr Offset @s+0 PUSH DWord Ptr Offset @s+2 CALL _fopen ADD ESP, 8 MOV [EBP-4], EAX OR EAX, EAX JZ G50 PUSH DWord Ptr[EBP+16] PUSH DWord Ptr[EBP+12] PUSH DWord Ptr Offset @s+12 PUSH DWord Ptr [EBP-4] CALL _fscanf ADD ESP, 16 MOV EAX, [EBP+12] MOV EDI, [EAX] SUB ESI, ESI JMP G30 G20: IMUL EDX, ESI, TYPE tagSCORE ADD EDX, [EBP+8] LEA EAX, [EDX+tagSCORE.m] PUSH EAX LEA EAX, [EDX+tagSCORE.cN] PUSH EAX LEA EAX, [EDX+tagSCORE.No] PUSH EAX PUSH DWord Ptr Offset @s+17 PUSH DWord Ptr [EBP-4] CALL _fscanf ADD ESP, 20 INC ESI G30: CMP ESI, EDI JL G20 PUSH DWord Ptr [EBP-4] CALL _fclose ADD ESP, 4 MOV EAX, 1 POP EDI POP ESI G50: LEAVE RET _GetScore ENDP _Sort PROC Near Enter TYPE tagSCORE, 0 PUSH ESI

第 7章 模块化程序设计方法
·203·
PUSH EDI PUSH ES PUSH SS POP ES JMP S60 S10: SUB EBX, EBX JMP S50 S20: IMUL ESI,EBX,type tagSCORE ADD ESI, [EBP+8] MOV EAX, [esi+tagSCORE.m] CMP eax,[esi+tagSCORE.m+type tagSCORE] JNL S30 LEA EDI,[ebp-type tagSCORE] MOV ECX, TYPE tagSCORE REP MOVSB LEA EDI,[esi-type tagSCORE] MOV ECX, TYPE tagSCORE REP MOVSB LEA ESI, [ebp-type tagSCORE] MOV ECX, TYPE tagSCORE REP MOVSB [EDI], SS:[ESI] S30: INC EBX S50: CMP EBX, [EBP+12] JL S20 S60: DEC DWord Ptr[EBP+12] JG S10 POP ES POP EDI POP ESI LEAVE RET _Sort ENDP _OutScore PROC Near Enter 0, 0 PUSH ESI SUB ESI, ESI JMP L50 L10: IMUL EDX,ESI,type tagSCORE ADD EDX, [EBP+8] PUSH [EDX+tagSCORE.m] LEA EAX,[EDX+tagSCORE.cN] PUSH EAX PUSH [EDX+tagSCORE.No] PUSH DWord Ptr Offset @s+26 CALL _printf ADD ESP, 16 INC ESI L50: CMP ESI, [EBP+12] JL L10 POP ESI LEAVE RET

汇编语言程序设计
·204·
_OutScore ENDP _main: Enter 5704, 0 LEA EAX, [EBP-5700] PUSH EAX LEA EAX, [EBP-5704] PUSH EAX LEA EAX, [EBP-5600] PUSH EAX CALL _GetScore ADD ESP, 12 PUSH DWord Ptr[ebp-5704] LEA EAX, [EBP-5600] PUSH EAX CALL _Sort ADD ESP, 8 LEA EAX, [EBP-5600] PUSH EAX CALL _OutScore ADD ESP, 8 LEAVE RET _TEXT ENDS END _main (2) 若 C 编译器是 TC(16 位),那么 C 源码可改写成如下汇编语言程序(16.ASM): Extrn _fopen: Near, _fclose: Near Extrn _fscanf: Near, _printf: Near tagSCORE STRUC No DD ? cN DB 20 dup(0) m DD ? tagSCORE ENDS _DATA SEGMENT 'DATA' PUBLIC @s DB 'r',0,'score.txt',0,'%d%s',0 DB '%ld%s%ld',0,'%ld',9,'%s',9,'%d',10,0 _DATA ENDS _TEXT SEGMENT 'CODE' Use16 Public ASSUME CS:_TEXT, DS:_DATA .586 _GetScore PROC Near Enter 2, 0 PUSH DI PUSH SI PUSH Word Ptr Offset @s+0 PUSH Word Ptr Offset @s+2 CALL _fopen ADD SP, 4 MOV [BP-2], AX OR AX, AX JZ G50 PUSH Word Ptr[BP+8] PUSH Word Ptr[BP+6]

第 7章 模块化程序设计方法
·205·
PUSH Word Ptr Offset @s+12 PUSH Word Ptr [BP-2] CALL _fscanf ADD SP, 8 MOVZX EAX, Word Ptr[BP+6] MOV DI, [EAX] SUB SI, SI JMP G30 G20: IMUL BX, SI, TYPE tagSCORE ADD BX, [BP+4] LEA EAX, [BX+tagSCORE.m] PUSH AX LEA AX, [BX+tagSCORE.cN] PUSH AX LEA AX, [BX+tagSCORE.No] PUSH AX PUSH Word Ptr Offset @s+17 PUSH Word Ptr [BP-2] CALL _fscanf ADD SP, 10 INC SI G30: CMP SI, DI JL G20 PUSH Word Ptr [BP-2] CALL _fclose ADD SP, 2 MOV EAX, 1 POP DI POP SI G50: LEAVE RET _GetScore ENDP _Sort PROC Near Enter TYPE tagSCORE, 0 PUSH SI PUSH DI PUSH ES PUSH SS POP ES JMP S60 S10: SUB BX, BX JMP S50 S20: IMUL SI,BX,type tagSCORE ADD SI, [BP+4] MOV EAX, [si+tagSCORE.m] CMP eax,[si+tagSCORE.m+type tagSCORE] JNL S30 LEA DI,[bp-type tagSCORE] MOV CX, TYPE tagSCORE REP MOVSB LEA DI,[si-type tagSCORE] MOV CX, TYPE tagSCORE REP MOVSB

汇编语言程序设计
·206·
LEA SI, [bp-type tagSCORE] MOV CX, TYPE tagSCORE REP MOVS byte ptr [DI], SS:[SI] S30: INC BX S50: CMP BX, [BP+6] JL S20 S60: DEC Word Ptr[BP+6] JG S10 POP ES POP DI POP SI LEAVE RET _Sort ENDP _OutScore PROCNear Enter 0, 0 PUSH SI SUB SI, SI JMP L50 L10: IMUL BX,SI,type tagSCORE ADD BX, [BP+4] PUSH [BX+tagSCORE.m] LEA AX,[BX+tagSCORE.cN] PUSH AX PUSH DWord Ptr[BX+tagSCORE.No] PUSH Word Ptr Offset @s+26 CALL _printf ADD SP, 8 INC SI L50: CMP SI, [BP+6] JL L10 POP SI LEAVE RET _OutScore ENDP Public _main _main: Enter 5702, 0 LEA AX, [BP-5700] PUSH AX LEA AX, [BP-5702] PUSH AX LEA AX, [BP-5600] PUSH AX CALL _GetScore ADD SP, 6 PUSH Word Ptr[bp-5702] LEA AX, [BP-5600] PUSH AX CALL _Sort ADD SP, 4 PUSH Word Ptr [BP-5702] LEA AX, [BP-5600] PUSH AX

第 7章 模块化程序设计方法
·207·
CALL _OutScore ADD SP, 4 LEAVE RET _TEXT ENDS END _main
本 章 小 结
本章通过大量的例子,介绍了汇编语言程序的模块化设计方法。 首先,介绍了简单的、基本的子程序定义、调用与返回方法,在此基础上讲述了子程序
中寄存器的寄护与寄寄,子程序的参数传递方法,动态的局部变量创建方法,子程序的嵌套
与递归调用等内容。在约定寄存器、约定内存单元及通过堆栈这 3 种参数传递方法中,使用
堆栈传递参数是 重要、使用 普遍的方法。 其次,在子程序设计的基础上,介绍了模块化程序设计方法:将程序划分成若干个功能
相对独立的模块,单独编写、汇编和调试,再将它们连接起来,形成一个完整的用户程序。
模块化程序设计主要解决:不同模块间的符号名约定及符号共享,子程序的调用约定规则。 后,简单介绍了 MASM 的子程序控制伪指令内容,用它可定义寄杂格式的子程序,并
且提供简捷的子程序调用方式,给使用汇编语言编程带来了极大的方便。 本章也通过实例介绍了汇编语言与高级语言程序模块的连接方法,DOS 系统下的多模块
程序设计方法,以及 Win32 环境下汇编语言程序设计方法。
习 题 7
7.1 下列程序的子程序 int fun(int x, int y)的功能是计算 x-y,并约定通过 AX 传递结果;
主程序调用 fun 计算 a-b,并将结果存放在 R 中。调用程序与子程序使用堆栈,按 C 规则传
递参数。根据功能要求,将程序填写完整。 _TEXT SEGMENT 'CODE' ASSUME CS:_TEXT, DS:_TEXT _fun Proc Near (1) (2) MOV DX, [BP+4] SUB DX, [ (3) ] (4) (5) (6) RET _fun ENDP _main: MOV AX, CS MOV DS, AX (7) (8) CALL _fun (9)

汇编语言程序设计
·208·
(10) MOV AX, 4C00h INT 21H A DW 300 B DW 200 R DW ? _TEXT ENDS END _main 7.2 下列程序的子程序 void fun(int x, int y, int *q, int *r)的功能是计算 x÷y 的商和余数,并
约定通过 q 与 r 传递给调用程序;主程序调用 fun 计算 a÷b 的商及余数,并将结果分别存放
在 R1 和 R2 中。调用程序与子程序使用堆栈,按 STDCALL 规则传递参数。根据功能要求,
将程序填写完整。 _TEXT SEGMENT 'CODE' ASSUME CS:_TEXT, DS:_TEXT _fun Proc Near (1) (2) MOV DX, [BP+4] SUB DX, DX DIV Word Ptr [ (3) ] (4) MOV [BX], AX (5) MOV [BX], DX MOV SP, BP POP BP (6) _fun ENDP _main: MOV AX, CS MOV DS, AX (7) PUSH AX (8) PUSH AX (9) (10) CALL _fun MOV AX, 4C00h INT 21H A DW 300 B DW 200 R1 DW ? R2 DW ? _TEXT ENDS END _main 7.3 子程序定义的一般格式是怎样的?子程序入口为什么常有 PUSH 指令,返回时为什
么有 POP 指令? 7.4 子程序返回指令 RET 的功能能否用 JMP 指令来模拟,若可以,请用段内子程序的返

第 7章 模块化程序设计方法
·209·
回加以说明,否则,说明理由。 7.5 子程序返回指令“RET 4”的功能是返回数值“4”给调用程序吗?若不是,那么它
的作用是什么? 7.6 编写子程序实现下列功能,参数的传递方式可自行决定(变量都是 16 位类型)。 (1) ABS(x)=| x |; (2) f(x)=3x2 + 5x – 8; (3) 判断三条边 x、y 和 z 能否构成三角形,若能,CF 为 1,否则,CF 为 0。 7.7 子程序的参数传递有传值和传地址之分,在汇编语言中,如何实现传地址?参照
例 7.16 给予说明。 7.8 在高级语言中,子程序可定义其局部变量,在汇编语言中,能创建其局部变量吗?
若能,参照例 7.16 和例 7.12 给予说明。 7.9 用汇编语言程序实现 C 语言的字符串处理函数。 (1) int strlen(const char *s); 返回 s 的长度。 (2) char*strcpy(char *s1, const char *s2); 将 s2 寄制到 s1。 (3) char*strcat(char *s1,const char *s2); 将 s 2 连接到 s 1 的末尾,返回 s1 的首地址。 (4) int strcmp(char *s1,char *s2);当 s1 大于、等于、小于 s2 时,分别返回正数、0、负数。 (5) char*strchr(char *s, char ch); 返回 ch 在 s 中的位置指针,未找到则返回空指针(0)。 (6) char*strlwr(char *s);字符串 s 中大写字母转换成小写字母,返回 s 的首地址。 7.10 一个学习小组有 n 个人,每个人有 3 门课的考试成绩(如下所示)。编写汇编语言程
序,求全组分科的平均成绩和各科总平均成绩。 Zhang 87 65 92 Wang 71 75 67 … 7.11 什么是子程序的嵌套调用?什么递归子程序,设计递归子程序应注意什么? 7.12 已知数列 F0=F1=1,Fn=Fn-1+Fn-2,用汇编语言设计递归子程序计算 Fn,并用调用
程序调用它来验证它是否正确。 7.13 在以 Array 为首地址的数组中,存放 n 个 16 位有符号数,分别按下列约定: (1) 约定寄存器来传递入口参数,返回结果约定存放在 AX 中。 (2) 约定内存单元来传递入口参数,返回结果约定存放在 AX 中。 (3) 通过堆栈来传递入口参数及返回结果。提示:参照例 7.16 传递变量地址。 7.14 在程序模块中,伪指令 PUBLIC 和 EXTRN 的作用是什么? 7.15 在 C 语言程序中,关键字 EXTERN 与汇编语言中 EXTRN 的作用相似吗? 7.16 调用子程序指令 CALL 和调用伪指令 INVOKE 的主要区别是什么? 7.17 设有 n 个学生的成绩。试编制一个子程序统计 60~69 分、70~79 分、80~89 分、
90~99 分和 100 分的人数,并分别存放到 S6, S7, S8, S9 和 S10 单元中。 7.18 编写一多模块汇编语言程序,分别从键盘输入 n 个姓名和 8 个字符的电话号码,并
以一定的格式显示出来。要求: (1) 主程序模块用于:调用输入子程序,输入姓名、电话号码;调用显示子程序显示姓名
及电话号码。 (2) 输入子程序模块用于:输入的姓名和电话号码。 (3) 显示子程序模块用于:显示姓名及电话号码。

汇编语言程序设计
·210·
模块名、子程序名、子程序调用规则和参数传递方式,以及运行环境自行确定。

第 8 章 输入/输出接口程序设计
本章介绍输入/输出(I/O)接口程序设计的知识与方法,包括: • 输入/输出的基本概念与 I/O 指令。 • 程序直接控制的 I/O 方式。 • 中断传送方式。 • I/O 中断服务子程序设计方法。
8.1 概 述
在 80x86 系统中,外部设备与 CPU 连接需要一个接口电路,称为 I/O 接口,CPU 使用 输入/输出指令 IN/OUT 与外部设备交换信息。这些信息包括控制、状态和数据 3 种不同性质
的信息,如图 8.1 所示。这 3 种信息都是通过 I/O 端口与外部设备交换的。
图 8.1 CPU 与 I/O 间传送的信息
控制信息输出到 I/O 接口,通知接口和设备要执行什么动作。例如,CPU 向 I/O 接口发
出启动信号或停止信号,以控制外设的启动与停止。 状态信息从 I/O 接口输入到 CPU,表示 I/O 设备当前所处的状态。对于输入设备,通常
用准备好(READY)信号来表示外设已将输入数据准备好;对于输出设备,通常用忙(BUSY)信号来表示设备是否处于空闲状态,若为空闲状态,则外设可以接收 CPU 送来的数据,否则
CPU 要等待。 数据信息用于 I/O 设备与 CPU 信息内容的传输。 I/O 接口部件中一般有 3 种寄存器:一是用作数据缓冲的数据寄存器;二是用作保存设备
和接口的状态信息,供 CPU 对外设进行测试的状态寄存器;三是用来保存 CPU 发出的命令,
以控制接口和设备操作的命令寄存器。 在 80x86 系统中,这些 I/O 接口寄存器就是 I/O 端口(Port)。I/O 端口独立编址,允许有
64K(65 536)个 8 位端口,或 32K(32 768)个 16 位端口,或 16K(16 384)个 32 位端口。 通常,CPU 与 I/O 设备间可用的数据传送方式概括起来分为 3 种:程序直接控制 I/O 方
式、中断传送方式和直接内存存取(DMA)。根据外围设备的特点,CPU 对输入/输出的控制可
采用不同的方式。

第 8 章 输入/输出接口程序设计
·211·
8.2 程序直接控制 I/O 方式
程序直接控制 I/O 方式是指,CPU 与外设之间的数据传送完全是在用户程序的控制下实
现的,是由 CPU 主动与外设传送数据。此方式又可分为立即传送和程序查询传送。
8.2.1 立即传送方式
立即传送方式又称为无条件传送方式,它是 简单的一种输入/输出传送方式。使用此方
式传送数据时,认为外设肯定是处于准备就绪状态,所以能够直接执行输入、输出指令来完
成数据的传送。 例 8.1 设计一个发声程序。通过 PB 口的 b1 位输出一串 500 个周期方波,使扬声器发声。 分析:在基于 80x86 的 PC 系统中,有一个可编程的接口芯片 8255A,其内部有 3 个 8
位的数据端口:PA, PB 和 PC,对应的端口地址分别为 60h, 61h 和 62h。其中 PB 口的 b0(PB0)和 b1(PB1)用于扬声器控制,如图 8.2 所示。其中 PB0 与定时器门控连接,当 PB0 清 0 时,定
时器固定输出高电平;当 PB0 置为 1 时,可以由定时器输出一个方波。
图 8.2 扬声器控制示意图
程序通过 I/O 指令将 PB0 清 0,并且使 PB1 交替为 0 和 1,即 PB1 由 0 变为 1,延迟一
段时间再由 1 变为 0,如此反复,便产生一个脉冲电流,经放大器放大后,便可驱动扬声器
发出声音。其汇编源代码如下。(省略了数据段与堆栈段) _TEXT SEGMENT 'CODE' ASSUME CS:_TEXT .386 Start: MOV ECX, 1000 ;交替输出 0和 1,500个周期须循环 1000次 IN AL, 61h ;直接读入 PB口数据 AND AL, 0FEh ;PB0清 0 Loc1: XOR AL, 10b ;PB1变反 OUT 61h, AL ;直接向 PB口输出数据 PUSH ECX MOV ECX, 2000h ;延时的循环次数 Delay: LOOPD Delay ;通过循环产生延时 POP ECX LOOPD Loc1 MOV AX, 4C00h INT 21h _TEXT ENDS END Start 程序中的两条指令: MOV ECX, 2000h Delay: LOOPD Delay

汇编语言程序设计
·212·
用来控制脉冲门的开关时间,实际上是扬声器声音的频率。这个频率与计算机的主频密切相
关,主频越快,声音的频率越高,如果保持声音频率不变,则必须增加循环次数。 无条件传送方式又称同步方式,它要求 CPU 的动作必须与外设同步,否则,传送数据出
错,所以一般能够使用的场合较少。
8.2.2 查询传送方式
由于外设和 CPU 的工作速度差别很大,所以大多数情况采用的是程序查询传送方式。程
序查询方式是指:在数据传送之前,CPU 要先查询外设的当前状态,只有当外设数据端口处
于准备就绪或空闲状态时,才执行输入/输出指令,进行数据传送。否则,CPU 循环查询,直
到外设准备就绪。因此,I/O 接口除了要有传送数据的端口外,还要有传送状态的端口。查询
传送方式的流程如图 8.3 所示。
图 8.3 查询传送方式流程图
例 8.2 编写两台计算机采用程序查询方式进行串口通信的程序。 分析:若串行通信使用的串行口是 COM1,对应的数据端口号是 3F8h,状态寄存器地址
是 3FDh。在状态端口 3FDh 中,b0 位是输入状态位,为 1 则表明输入数据已准备好,否则数
据未准备好;b5 位是输出状态位,为 1 表明输出端口为空闲,可以发送数据,否则端口不空
闲,不能发送数据。程序如下,注意,程序前面部分是接口电路初始化部分。 (1) 发送端程序:反复查询输出端口状态,直到输出状态位为 1,之后向端口输出一个字
节数据。程序中从键盘读入字符,再向输出端口发送,当输入 Esc(ASCII 码为 27)时,中止运行。 _TEXT SEGMENT ASSUME CS:_TEXT Start: MOV DX,3FBh MOV AL,80h ;设置数据率 OUT DX,AL MOV DX,3F8h MOV AX,000Ch ;数据率 9600 OUT DX,AX MOV DX,3FBh MOV AL,3 ;8位数据位,1个停止位 OUT DX,AL Check1: MOV DX,3FDh IN AL,DX ;读状态端口 TEST AL,00100000b ;检查输出数据端口是否空闲(b5=1?) JZ Check1 ;忙,再读状态端口 MOV AH,0Bh ;键盘 DOS 0B号功能,检查有无键输入
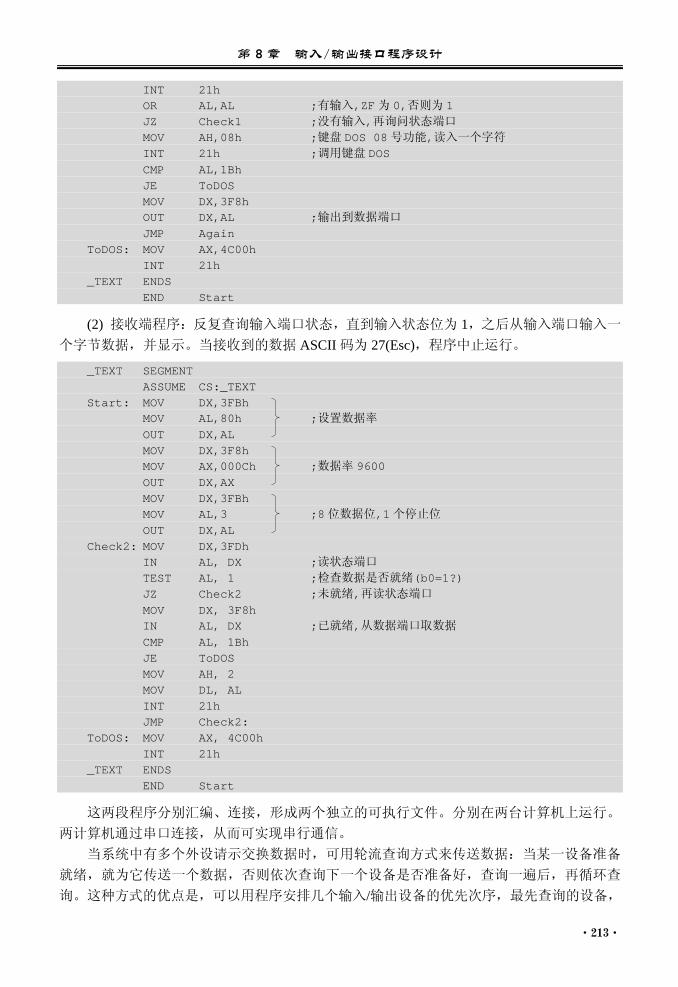
第 8 章 输入/输出接口程序设计
·213·
INT 21h OR AL,AL ;有输入,ZF为 0,否则为 1 JZ Check1 ;没有输入,再询问状态端口 MOV AH,08h ;键盘 DOS 08号功能,读入一个字符 INT 21h ;调用键盘 DOS CMP AL,1Bh JE ToDOS MOV DX,3F8h OUT DX,AL ;输出到数据端口 JMP Again ToDOS: MOV AX,4C00h INT 21h _TEXT ENDS END Start (2) 接收端程序:反复查询输入端口状态,直到输入状态位为 1,之后从输入端口输入一
个字节数据,并显示。当接收到的数据 ASCII 码为 27(Esc),程序中止运行。 _TEXT SEGMENT ASSUME CS:_TEXT Start: MOV DX,3FBh MOV AL,80h ;设置数据率 OUT DX,AL MOV DX,3F8h MOV AX,000Ch ;数据率 9600 OUT DX,AX MOV DX,3FBh MOV AL,3 ;8位数据位,1个停止位 OUT DX,AL Check2: MOV DX,3FDh IN AL, DX ;读状态端口 TEST AL, 1 ;检查数据是否就绪(b0=1?) JZ Check2 ;未就绪,再读状态端口 MOV DX, 3F8h IN AL, DX ;已就绪,从数据端口取数据 CMP AL, 1Bh JE ToDOS MOV AH, 2 MOV DL, AL INT 21h JMP Check2: ToDOS: MOV AX, 4C00h INT 21h _TEXT ENDS END Start 这两段程序分别汇编、连接,形成两个独立的可执行文件。分别在两台计算机上运行。
两计算机通过串口连接,从而可实现串行通信。
当系统中有多个外设请示交换数据时,可用轮流查询方式来传送数据:当某一设备准备
就绪,就为它传送一个数据,否则依次查询下一个设备是否准备好,查询一遍后,再循环查
询。这种方式的优点是,可以用程序安排几个输入/输出设备的优先次序, 先查询的设备,

汇编语言程序设计
·214·
其工作的优先级也 高。其缺点是,CPU 使用效率较低,尤其在设备比较多的情况下,CPU浪费的时间就更多。
8.3 中断传送方式
采用中断方式传送数据时,CPU 不主动与外设交换数据。外部设备将数据准备好,可以
让 CPU 来取数据,或者处于空闲、需要从主机取一个数据时,就向 CPU 发送一个“请求”(中断请求),CPU 在接收到请求后,临时“中断”正在执行的任务,转去处理数据传送(中断处
理),处理完毕,再返回到刚才中断所在处继续执行。 一般来说,计算机系统中必须有一个专门的硬件电路,用来处理外设向 CPU 发出的中断
请求,如图 8.4 所示。其处理过程简单介绍如下。
图 8.4 中断处理方式示意图
(1) 外部设备通过 IRi向中断接口电路发送中断请求信号。 (2) 中断接口电路将外设的中断请求信号通过 INTR 发送给 CPU。 (3) CPU 向中断接口电路回送中断允许的响应信号。 (4) 中断接口电路使用数据总线 D7~D0 向 CPU 发送中断类型码;根据类型码,CPU 确
定对应的中断服务程序入口地址。 (5) CPU 暂停正在执行的程序,转去执行中断服务程序;通过中断服务程序,CPU 与外
设之间进行数据传送。 (6) CPU 执行完中断服务程序,返回原程序继续执行。 以上主要讲述了用中断方式传送数据的基本工作原理。关于中断技术还有许多内容,在
微机原理等课程中有专门的介绍。
8.3.1 中断概述
当一个特殊的事件发生时,CPU 暂停正在运行的程序,而转去执行该事件的处理程序,
处理完该事件后,再返回到原程序继续执行,这一过程就是中断。引起中断的事件就是中断
源。中断源可以来源于外设的输入/输出请求,也可以来自计算机内部,如异常故障或执行中
断指令等。 根据造成中断的原因不同,可将中断分为硬件中断和软件中断两大类,如图 8.5 所示。

第 8 章 输入/输出接口程序设计
·215·
图 8.5 8086 的中断源示意图
1. 硬件中断
硬件中断来自 CPU 的外部条件,如 I/O 设备或其他处理机等,以完全随机的方式中断当
前正在执行的程序而转向中断处理程序。硬件中断又称为外中断。 在 80x86 的 PC 系统中,硬件中断主要有两种来源:非屏蔽中断 NMI 和可屏蔽中断 INTR。 来自外设的中断请求(IR0~IR7),经可编程中断控制器(PIC)8259A 处理,由 INTR 传递给
CPU,如图 8.5 所示,这便是可屏蔽中断。80286 以后,PC 系统中使用两片 8259A,以级联
方式管理 15 个中断源。 标志寄存器中的 IF 位决定 CPU 是否响应 INTR 的中断请求:若 IF=0,那么 CPU 禁止
响应 INTR 的中断请求;若 IF=1,则 CPU 响应 INTR 的中断请求。在 80x86 指令中,CLI指令专门用于将 IF 清 0,STI 指令专门用于将 IF 置 1。
硬件中断的另一个来源是 NMI。CPU 不能禁止 NMI 线上的中断请求,也就是说,如果
系统中发生了非屏蔽中断,CPU 必须做出响应。NMI 中断主要用于一些紧急的故障处理,如
电源掉电等。标志寄存器中的 IF 位不能禁止 CPU 响应 NMI 的中断请求。
2. 软件中断
软件中断是由 CPU 在执行指令时产生的。由于中断源来自 CPU 内部,故又称为内中断。
它通常由三种情况引起:(1)执行 INT 指令引起的中断;(2)处理 CPU 某些错误的中断;(3)为调试程序而设置的单步中断。
软件中断不是随机发生的。例如,执行 INT 10h 指令,必然产生一个类型号为 10h 的中
断;执行 DIV BX 指令,若 BX 为 0,则必然产生一个除法溢出中断;若 TF 位为 1 时,那么
CPU 每执行一条指令,必然会产生一个类型号为 01 的中断。 80386~Pentium 在上述内中断的基础上,把许多执行指令过程中产生的错误也纳入了中
断范围,这类中断称为异常中断。保护模式下,异常中断处理比较复杂,读者若有兴趣,可
以参阅相关资料手册。
3. 中断优先级
当多个中断源同时申请中断时,CPU 按优先级从高到低的次序依次处理各中断源的请求。
其优先级从高到低的次序为: 软件中断(INT n、除法溢出、INTO 等) 优先级高 非屏蔽中断(NMI) 可屏蔽中断(INTR) 单步中断 优先级低
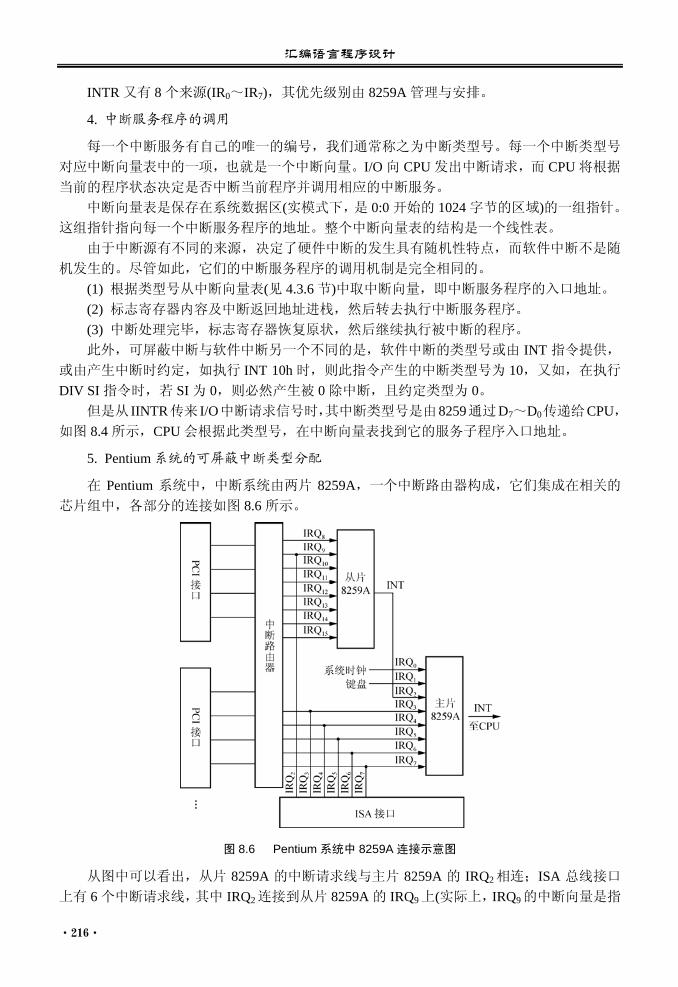
汇编语言程序设计
·216·
INTR 又有 8 个来源(IR0~IR7),其优先级别由 8259A 管理与安排。
4. 中断服务程序的调用
每一个中断服务有自己的唯一的编号,我们通常称之为中断类型号。每一个中断类型号
对应中断向量表中的一项,也就是一个中断向量。I/O 向 CPU 发出中断请求,而 CPU 将根据
当前的程序状态决定是否中断当前程序并调用相应的中断服务。 中断向量表是保存在系统数据区(实模式下,是 0:0 开始的 1024 字节的区域)的一组指针。
这组指针指向每一个中断服务程序的地址。整个中断向量表的结构是一个线性表。 由于中断源有不同的来源,决定了硬件中断的发生具有随机性特点,而软件中断不是随
机发生的。尽管如此,它们的中断服务程序的调用机制是完全相同的。 (1) 根据类型号从中断向量表(见 4.3.6 节)中取中断向量,即中断服务程序的入口地址。 (2) 标志寄存器内容及中断返回地址进栈,然后转去执行中断服务程序。 (3) 中断处理完毕,标志寄存器恢复原状,然后继续执行被中断的程序。 此外,可屏蔽中断与软件中断另一个不同的是,软件中断的类型号或由 INT 指令提供,
或由产生中断时约定,如执行 INT 10h 时,则此指令产生的中断类型号为 10,又如,在执行
DIV SI 指令时,若 SI 为 0,则必然产生被 0 除中断,且约定类型为 0。 但是从 IINTR传来 I/O中断请求信号时,其中断类型号是由8259通过D7~D0传递给CPU,
如图 8.4 所示,CPU 会根据此类型号,在中断向量表找到它的服务子程序入口地址。
5. Pentium 系统的可屏蔽中断类型分配
在 Pentium 系统中,中断系统由两片 8259A,一个中断路由器构成,它们集成在相关的
芯片组中,各部分的连接如图 8.6 所示。
图 8.6 Pentium 系统中 8259A 连接示意图
从图中可以看出,从片 8259A 的中断请求线与主片 8259A 的 IRQ2 相连;ISA 总线接口
上有 6 个中断请求线,其中 IRQ2 连接到从片 8259A 的 IRQ9 上(实际上,IRQ9 的中断向量是指
第 8 章 输入/输出接口程序设计
·217·
向 IRQ2 的中断向量,它们是同一个中断服务程序);PCI 总线接口上的中断请求,由中断路由
器动态分配到 8259A 中未用的中断请求线上。 一般系统中,主片 8259A 的端口地址为 20h 和 21h,从片 8259A 的端口地址为 A0h 和
A1h。IRQ0~IRQ15 中断类型分配见表 8.1。
表 8.1 80x86 的中断类型分配表
中断请求线 中断类型号 中 断 服 务
IRQ0 08h 系统时钟(8254)
IRQ1 09h 键盘
IRQ2 0Ah 连接从 8259
IRQ3 0Bh COM2 串口 2
IRQ4 0Ch COM1 串口 1
IRQ5 0Dh 保留
IRQ6 0Eh 软盘控制器
IRQ7 0Fh LPT1 并口
IRQ8 70h 实时时钟(RTC)
IRQ9 71h 保留(软件指向 0Ah 类型)
IRQ10 72h 保留
IRQ11 73h 显卡
IRQ12 74h 鼠标
IRQ13 75h 数值协处理器
IRQ14 76h 硬盘控制器
IRQ15 77h 保留
8.3.2 中断处理程序的设计
中断服务程序调用过程与子程序调用过程非常类似,但有两方面不同。首先,在保护中
断现场时,需要保存标志寄存器、CS 和 IP,这是因为标志寄存器中记录的是中断发生时指令
运行的状态,当 CPU 处理完中断请求返回原程序时,需要保证原程序工作的连续性和正确性,
须将标志寄存器恢复为中断发生时的状态。其次,中断发生时,CPU 将 IF 和 TF 标志位清 0,其目的是使 CPU 转入中断处理程序后,不允许再产生新的中断。如果在执行中断处理程序时,
还允许外部的 I/O 中断,可以通过 STI 指令将 IF 置 1。 编写中断处理程序和编写子程序一样,所使用的汇编语言指令没有特殊限制,只是中断
处理程序返回时使用 IRET 指令。这条指令的工作步骤和中断发生的工作步骤正好相反。它首
先从堆栈中弹出返回的 IP、CS 和标志寄存器等内容,然后返回被中断程序继续执行。 对于 I/O 外设中断,需要特别说明的是:其中断是随机发生的,所以在进入中断服务程
序时,各寄存器值一般不能预先确定,对于这一点,程序员在编写中断处理程序时必须留意。
此外,在一次中断处理结束之前,还必须给 8259A 的中断命令寄存器发出中断结束(EOI)命令,
即在 80x86 的 PC 中,一般情况下向 20h 端口(主 8259A)或 A0h 端口(从 8259A)发 20h。 中断处理程序的主要步骤如下。 (1) 保存寄存器的内容。

汇编语言程序设计
·218·
(2) 若允许 CPU 响应外设中断,则开中断(STI)。 (3) 处理中断。 (4) 关中断(CLI)。 (5) 若是 I/O 中断服务程序,则送中断结束命令(EOI)给中断命令寄存器。 (6) 恢复寄存器的内容。 (7) 返回被中断的程序(IRET)。 中断服务程序的入口地址只有放到中断向量表中,才能在中断发生时被调用到。除此之
外,对于 I/O 设备的中断处理程序,还必须进行相应的硬件接口初始化,以及相应的中断允
许设置。只有如此,CPU 才能响应外设提交的中断请求。 所以,除了中断处理程序,还有相应设置中断向量及相应的硬件初始化工作,这些工作
一般放在主程序中。 例 8.3 编写串行口通信程序,要求以中断接收、查询发送方式实现。 为便于理解 I/O 中断处理程序的设计,将程序分为两部分:中断服务程序和主程序。此
程序中接收缓冲区是使用循环队列方式进行管理的。 中断发生时,该部分程序从数据端口取数据放到接收缓冲区中。注意,因为处理的是 I/O
中断,所以在中断处理结束前,必须向 8259 送 EOI(此处是向端口 20h 送命令字 20h)。中断
服务程序(Rec.ASM)如下: _TEXT SEGMENT PUBLIC 'CODE' ASSUME CS:_TEXT .386 PUBLIC Rec,RxBuf,BufSize,i1,i2 Rec: STI ;开中断 PUSHA ;保护寄存器内容 MOV DX, 3F8h ;从数据端口取数据 IN AL, DX MOV BX, CS:i2 MOV CS:RxBuf[BX], AL INC BX CMP BX, BufSize JNE Loc1 ;放入接收缓冲区 MOV BX, 0 Loc1: CMP BX, CS:i1 JE Loc2 MOV CS:i2, BX Loc2: CLI ;关中断 MOV AL, 20h OUT 20h, AL POPA ;恢复寄存器内容 IRET ;中断返回 RxBuf DB 400h DUP(0) ;接收缓冲区 BufSize EQU $-RxBuf ;缓冲区大小 i1 DW 0 ;队首 i2 DW 0 ;队尾 _TEXT ENDS END 这个中断服务程序的入口地址 Rec 必须放到中断向量表中,它才能被执行到。这一工作
;送 EOI
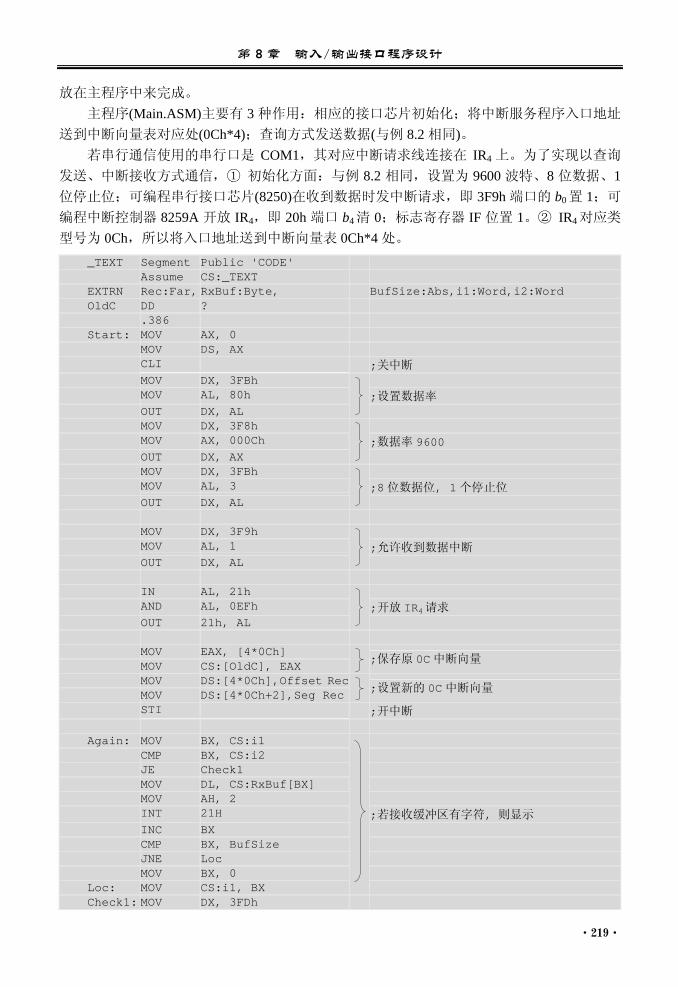
第 8 章 输入/输出接口程序设计
·219·
放在主程序中来完成。 主程序(Main.ASM)主要有 3 种作用:相应的接口芯片初始化;将中断服务程序入口地址
送到中断向量表对应处(0Ch*4);查询方式发送数据(与例 8.2 相同)。 若串行通信使用的串行口是 COM1,其对应中断请求线连接在 IR4 上。为了实现以查询
发送、中断接收方式通信,① 初始化方面:与例 8.2 相同,设置为 9600 波特、8 位数据、1位停止位;可编程串行接口芯片(8250)在收到数据时发中断请求,即 3F9h 端口的 b0置 1;可
编程中断控制器 8259A 开放 IR4,即 20h 端口 b4 清 0;标志寄存器 IF 位置 1。② IR4对应类
型号为 0Ch,所以将入口地址送到中断向量表 0Ch*4 处。 _TEXT Segment Public 'CODE' Assume CS:_TEXT EXTRN Rec:Far, RxBuf:Byte, BufSize:Abs,i1:Word,i2:Word OldC DD ? .386 Start: MOV AX, 0 MOV DS, AX CLI ;关中断 MOV DX, 3FBh MOV AL, 80h ;设置数据率 OUT DX, AL
MOV DX, 3F8h MOV AX, 000Ch ;数据率 9600 OUT DX, AX
MOV DX, 3FBh MOV AL, 3 ;8位数据位, 1个停止位 OUT DX, AL
MOV DX, 3F9h MOV AL, 1 ;允许收到数据中断 OUT DX, AL
IN AL, 21h AND AL, 0EFh ;开放 IR4请求 OUT 21h, AL
MOV EAX, [4*0Ch] MOV CS:[OldC], EAX
;保存原 0C中断向量
MOV DS:[4*0Ch],Offset Rec MOV DS:[4*0Ch+2],Seg Rec
;设置新的 0C中断向量
STI ;开中断 Again: MOV BX, CS:i1 CMP BX, CS:i2 JE Check1 MOV DL, CS:RxBuf[BX] MOV AH, 2 INT 21H ;若接收缓冲区有字符, 则显示 INC BX CMP BX, BufSize JNE Loc MOV BX, 0 Loc: MOV CS:i1, BX
Check1: MOV DX, 3FDh

汇编语言程序设计
·220·
IN AL, DX ;读状态端口 TEST AL, 00100000b ;检查输出数据端口是否空闲(b5=1?) JZ Again ;忙,再读状态端口 MOV AH, 0Bh ;DOS 0B号功能,检查有无字符输入 INT 21h ;有输入, ZF为 0,否则为 1 OR AL, AL JZ Again ;没有输入,再读状态端口 MOV AH, 08h ;DOS 08号功能,读入一个字符 INT 21h ;调用 DOS CMP AL, 1Bh JE ToDOS MOV DX, 3F8h OUT DX, AL ;输出到数据端口 JMP Again ToDOS: CLI ;关中断 IN AL, 21h OR AL, 10h ;屏蔽 IR4请求 OUT 21h, AL
MOV EAX, CS:[OldC] MOV DS:[0Ch*4], EAX
;恢复原 0C中断向量
STI ;开中断 MOV AX, 4C00h INT 21h _TEXT ENDS END Start
8.4 直接内存存取
直接内存存取(Direct Memory Access,DMA)方式,也称为成组数据传送方式,是指不通
过 CPU 而直接对内存进行访问,使外设直接和内存(也可外设与外设,内存与内存之间)进行成
批数据的传送。每个数据一到达端口,就直接从接口送到内存,同样,接口和它的 DMA 控制
器也能直接从内存取出数据,并传送给 I/O 设备。由于不经过 CPU 而直接进行传送,从而大大
提高了传送效率。DMA 方式主要用于一些高速的 I/O 设备,如磁盘、模数转换器(A/D)等设备。 控制 DMA 数据传送的硬件称为 DMA 控制器(DMAC),一般包括 4 个寄存器:控制寄存
器、状态寄存器、地址寄存器和字节计数器。在开始传送数据之前,应对这些寄存器进行初
始化:将传送的数据块的首地址放入地址寄存器中,将传送的数据长度(字节数)放入字节寄存
器中,在状态控制寄存器中设置控制字,指出数据是输入还是输出,并启动 DMA 操作。每
个字节传送后,地址寄存器增 1,字节计数器减 1。 以上只是简单地介绍 DMA 方式的工作原理,有关 DMA 方式的具体操作过程在微机接口
等相关课程中详细介绍。
8.5 乐 曲 程 序
作为综合示例,这里介绍使用扬声器播放乐曲的程序。例 8.1 所产生的声音是一个固定
频率的纯音,在此基础上,通过软件延时的方法,可以设计一个播放不同频率(音符),并且持
续一定的时间(节拍)的程序,从而实现乐曲播放。但是这种方式实现的乐曲程序和计算机的主
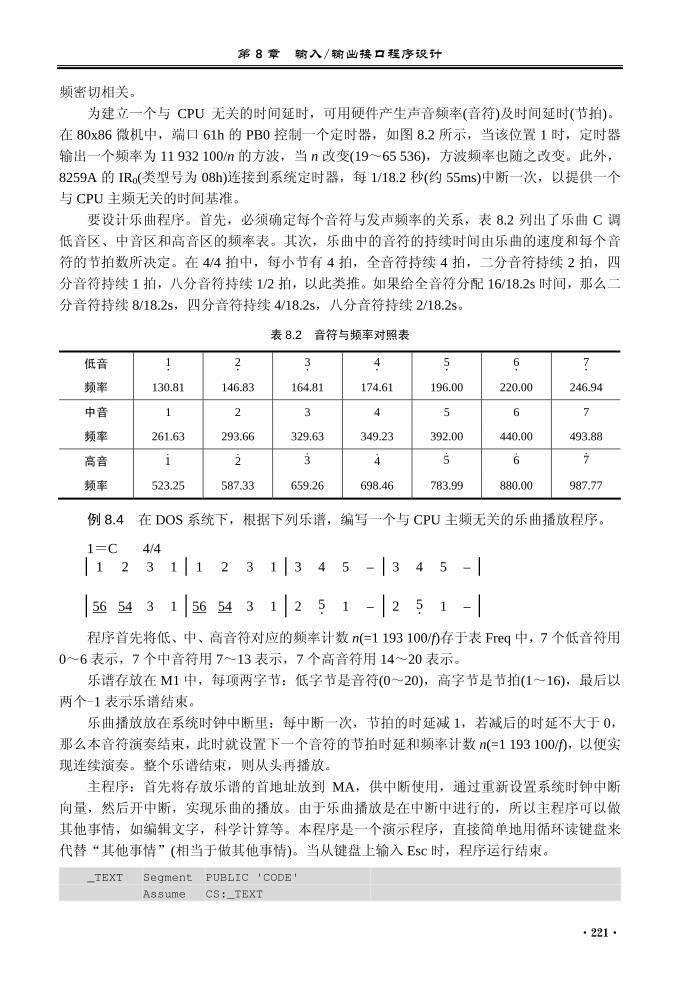
第 8 章 输入/输出接口程序设计
·221·
频密切相关。 为建立一个与 CPU 无关的时间延时,可用硬件产生声音频率(音符)及时间延时(节拍)。
在 80x86 微机中,端口 61h 的 PB0 控制一个定时器,如图 8.2 所示,当该位置 1 时,定时器
输出一个频率为 11 932 100/n 的方波,当 n 改变(19~65 536),方波频率也随之改变。此外,
8259A 的 IR0(类型号为 08h)连接到系统定时器,每 1/18.2 秒(约 55ms)中断一次,以提供一个
与 CPU 主频无关的时间基准。 要设计乐曲程序。首先,必须确定每个音符与发声频率的关系,表 8.2 列出了乐曲 C 调
低音区、中音区和高音区的频率表。其次,乐曲中的音符的持续时间由乐曲的速度和每个音
符的节拍数所决定。在 4/4 拍中,每小节有 4 拍,全音符持续 4 拍,二分音符持续 2 拍,四
分音符持续 1 拍,八分音符持续 1/2 拍,以此类推。如果给全音符分配 16/18.2s 时间,那么二
分音符持续 8/18.2s,四分音符持续 4/18.2s,八分音符持续 2/18.2s。
表 8.2 音符与频率对照表
低音 1. 2. 3. 4. 5. 6. 7.
频率 130.81 146.83 164.81 174.61 196.00 220.00 246.94
中音 1 2 3 4 5 6 7
频率 261.63 293.66 329.63 349.23 392.00 440.00 493.88
高音 1 2 3 4 5 6 7
频率 523.25 587.33 659.26 698.46 783.99 880.00 987.77 例 8.4 在 DOS 系统下,根据下列乐谱,编写一个与 CPU 主频无关的乐曲播放程序。 1=C 4/4
1 2 3 1 1 2 3 1 3 4 5 – 3 4 5 –
56 54 3 1 56 54 3 1 2 5. 1 – 2 5. 1 – 程序首先将低、中、高音符对应的频率计数 n(=1 193 100/f)存于表 Freq 中,7 个低音符用
0~6 表示,7 个中音符用 7~13 表示,7 个高音符用 14~20 表示。 乐谱存放在 M1 中,每项两字节:低字节是音符(0~20),高字节是节拍(1~16), 后以
两个-1 表示乐谱结束。 乐曲播放放在系统时钟中断里:每中断一次,节拍的时延减 1,若减后的时延不大于 0,
那么本音符演奏结束,此时就设置下一个音符的节拍时延和频率计数 n(=1 193 100/f),以便实
现连续演奏。整个乐谱结束,则从头再播放。 主程序:首先将存放乐谱的首地址放到 MA,供中断使用,通过重新设置系统时钟中断
向量,然后开中断,实现乐曲的播放。由于乐曲播放是在中断中进行的,所以主程序可以做
其他事情,如编辑文字,科学计算等。本程序是一个演示程序,直接简单地用循环读键盘来
代替“其他事情”(相当于做其他事情)。当从键盘上输入 Esc 时,程序运行结束。 _TEXT Segment PUBLIC 'CODE' Assume CS:_TEXT
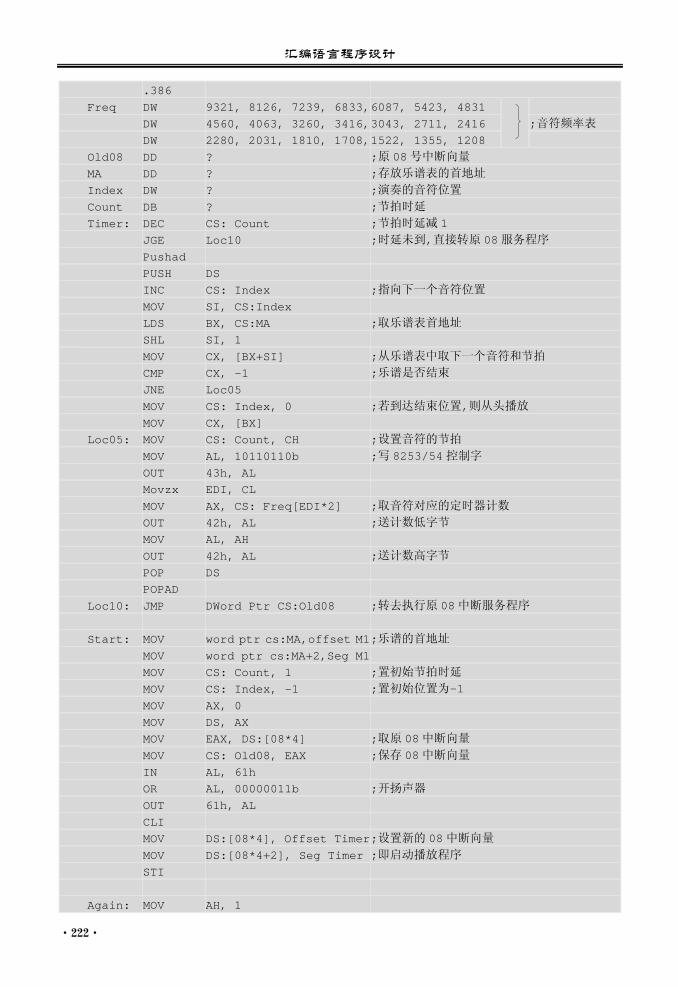
汇编语言程序设计
·222·
.386 Freq DW 9321, 8126, 7239, 6833,6087, 5423, 4831 DW 4560, 4063, 3260, 3416,3043, 2711, 2416 ;音符频率表 DW 2280, 2031, 1810, 1708,1522, 1355, 1208
Old08 DD ? ;原 08号中断向量 MA DD ? ;存放乐谱表的首地址 Index DW ? ;演奏的音符位置 Count DB ? ;节拍时延 Timer: DEC CS: Count ;节拍时延减 1 JGE Loc10 ;时延未到,直接转原 08服务程序 Pushad PUSH DS INC CS: Index ;指向下一个音符位置 MOV SI, CS:Index LDS BX, CS:MA ;取乐谱表首地址 SHL SI, 1 MOV CX, [BX+SI] ;从乐谱表中取下一个音符和节拍 CMP CX, -1 ;乐谱是否结束 JNE Loc05 MOV CS: Index, 0 ;若到达结束位置,则从头播放 MOV CX, [BX] Loc05: MOV CS: Count, CH ;设置音符的节拍 MOV AL, 10110110b ;写 8253/54控制字 OUT 43h, AL Movzx EDI, CL MOV AX, CS: Freq[EDI*2] ;取音符对应的定时器计数 OUT 42h, AL ;送计数低字节 MOV AL, AH OUT 42h, AL ;送计数高字节 POP DS POPAD Loc10: JMP DWord Ptr CS:Old08 ;转去执行原 08中断服务程序
Start: MOV word ptr cs:MA,offset M1;乐谱的首地址 MOV word ptr cs:MA+2,Seg M1 MOV CS: Count, 1 ;置初始节拍时延 MOV CS: Index, -1 ;置初始位置为-1 MOV AX, 0 MOV DS, AX MOV EAX, DS:[08*4] ;取原 08中断向量 MOV CS: Old08, EAX ;保存 08中断向量 IN AL, 61h OR AL, 00000011b ;开扬声器 OUT 61h, AL CLI MOV DS:[08*4], Offset Timer;设置新的 08中断向量 MOV DS:[08*4+2], Seg Timer ;即启动播放程序 STI
Again: MOV AH, 1

第 8 章 输入/输出接口程序设计
·223·
INT 21h CMP AL, 1Bh JNE Again
MOV EAX, CS: Old08 ;恢复原 08中断向量 MOV DS: [08*4], EAX IN AL, 61h AND AL, 11111100b OUT 61h, AL MOV AX, 4C00h INT 21h
M1 DB 7,4, 8,4, 9,4, 7,4, 7, 4, 8, 4, 9, 4, 7, 4 DB 9,4, 10,4, 11, 8, 9, 4, 10, 4, 11, 8 DB 11,2, 12,2, 11,2, 10,2, 9,4, 7,4, 11,2, 12,2, 11,2, 10,2, 9,4 DB 8,4, 4,4, 7,8, 8,4, 4,4, 7,8 DB -1, -1 ;结束标志 _TEXT ENDS END Start
本 章 小 结
在汇编语言源程序中,可以直接使用输入/输出指令与 I/O 设备交换数据。一般来说,CPU与 I/O 设备之间的数据交换方式分为三种:程序直接控制方式、中断传送方式和直接内存存
取(DMA)。本章重点介绍查询方式和中断方式传送数据的程序设计。 使用程序查询方式传送数据时,在数据传送之前,CPU 要先查询外设的 I/O 端口状态,
只有当外设数据端口处于准备就绪时,才执行输入/输出指令,进行数据传送,否则 CPU 循环
查询。 采用中断方式传送数据时,当外部设备将数据准备好,或者处于空闲、需要从主机取一
个数据时,就向 CPU 发送中断请求,让 CPU 临时“中断”正在执行的任务,转去执行中断
处理程序,处理完毕,继续执行被中断的程序。 在 80x86 系统中,I/O 属于可屏蔽的硬件中断。一方面,它具有随机发生的特点;另一方
面,它又受 8259A 管理及 CPU 标志寄存器 IF 的控制。这两点在编写中断服务程序及使用中
断传送数据时应特别注意。 对于直接内存存取的传送方式,则主要适用于高速 I/O 设备(如磁盘),CPU 向 I/O 接口提
供控制信息(如数据块的首地址及字节数),I/O 设备直接和存储器进行成批数据的快速传送。 作为综合例子及趣味性程序,在本章 后设计了一个使用定时芯片及中断方式实现的乐
曲播放程序。
习 题 8
8.1 对程序直接控制方式、中断传送方式、DMA 方式进行比较。 8.2 什么是中断、中断源?80x86 系统中,中断分为哪两大类,它们各有什么区别?

汇编语言程序设计
·224·
8.3 简要叙述在实模式下 I/O 外设中断的相应过程。 8.4 简要叙述在实模式下使用中断方式传送数据的程序设计方法。 8.5 一个中断类型号为 01CH 的中断服务程序存放在 0100H:3800H 开始的内存中,中断
向量存储在地址为_______到________的________个字节单元中。 8.6 某中断程序入口地址为 23456H,放置在中断向量表中的位置为 0020H,问中断向量
号为多少?入口地址在向量表中如何存放? 8.7 在 DOS 系统下,利用系统时钟中断写一个与 CPU 主频无关的时间延迟子程序。 8.8 在例 8.3 的中断服务程序中有一条指令:MOV CS:RxBuf[BX], AL,问:目的操作数
前的 CS 是否可以不要? 8.9 假设有 n(<10)首乐曲,分别编号为 1~n。在例 8.4 的基础上,编写乐曲点播程序:输
入乐曲号,则播放其对应的乐曲。所需要的乐曲乐谱自己准备。 8.10 指出下列程序所完成的功能。 _TEXT SEGMENT 'CODE' ASSUME CS:_TEXT _main: SUB AX, AX MOV ES, AX MOV AH, 1 PUSHF CALL DWord Ptr ES:[0084h] CMP AL, 'a' JB Loc CMP AL, 'z' JA Loc SUB AL, 20H Loc: MOV AH, 2 MOV DL, AL PUSHF CALL DWord Ptr ES:[0084h] MOV AX, 4C00h PUSHF CALL DWord Ptr ES:[0084h] _TEXT ENDS END _main

第 9 章 浮点运算与 SIMD 指令集
本章主要介绍 80x86 系统中有关浮点运算方面的内容,包括: • 浮点运算单元的组织结构。 • 80x87 的浮点运算指令。 • 使用浮点指令的程序示例。 • 简单介绍 3DNow!, MMX, SSE, SSE2 和 SSE3 指令集及程序示例。
9.1 概 述
Intel 8086 初的应用是为整数运算而设计的,但是在实际应用中,往往需要进行大量的
浮点运算,为此 Intel 专门推出浮点协处理器,其主要用来提高进行数学和超越函数计算的速
度。早期协处理器作为单独芯片而存在的,如 8087、80287 及 80387,从 80486DX 开始,浮
点处理硬件便集成进了主 CPU,称为浮点单元(Floating Point Unit, FPU)。 随着图像处理技术和多媒体技术的发展和应用,80x86 的指令集也相应地有了扩充,先
后有 AMD 公司推出的 3Dnow!指令集,Intel 公司推出的 MMX, SSE, SSE2 和 SSE3 等。 目前 新的 Intel 的 CPU 可以支持 MMX, SSE, SSE2, SSE3 指令集。早期的 AMD 的 CPU
仅支持 3DNow!指令集,随着 Intel 的逐步授权,从 Venice 核心的 Athlon64 开始,AMD 的 CPU不仅进一步发展了 3DNow!指令集,并且可以支持 Intel 的 SSE, SSE2, SSE3 指令集。不过目
前业界接受比较广泛的还是 Intel 的 SSE 系列指令集,AMD 的 3DNow!指令集应用比较少。 但是由于受到 IA-32 体系的限制,80x86 系统结构基本上不会再有革命性意义的指令集
出现,所以现在的市场已经把重心转向了 64 位体系架构的处理器指令集开发上,由此出现了
IA-32E,即在兼容 IA-32 的前提下,提出了 64 位内存扩展技术(Extended Memory 64 Technology, EM64T)。
目前 64位主要有EM64T和 IA-64,前者是兼容 IA-32基础发展起来的,而后者是与 IA-32不兼容的全新的体系结构。
9.2 浮点运算指令程序设计
早期 Intel 专门推出一个协处理器来提供浮点运算指令,从 80486DX 开始,FPU 就集成
在主 CPU,所以浮点运算指令也成了 80x86 的基本的常规指令了。
9.2.1 浮点单元的结构
尽管 FPU 已经集成在主 CPU 中,但仍然保持作为一个独立处理器的一些特征,也就是
说 FPU 由两个主要部分组成:控制部件(CU)和数值执行部件(NEU),分别执行处理器的控制
功能和运算功能。

汇编语言程序设计
·226·
FPU 在执行指令过程中需要访问内存单元时,CPU 会为其形成内存地址。FPU 在 FPU 指
令期间内利用数据总线来传递数据。80287 协处理器利用 I/O 地址 00FAh~00FFh 来实现其与
CPU 之间的数据交换,而 80387~Pentium 系列芯片是利用 I/O 地址 800000FAh~800000FFh来实现这两者之间的数据交换。
作为独立的处理单元,FPU 不使用通用寄存器(EAX, EBX 等),它有自己的一套寄存器,
称为寄存器栈,以及相应的控制寄存器和状态寄存器,如图 9.1 所示。在浮点指令执行时,
FPU 将数据存放到寄存器栈,执行运算,然后再将栈上的数值存放到内存中。
图 9.1 浮点单元中的寄存器示意图
1. 浮点数据寄存器栈
FPU 寄存器栈包括 8 个可独立寻址的 80 位的寄存器,分别为 R0, R1, …, R7,以堆栈形
式组织在一起,用于以扩展精度的浮点数据格式来存放操作数和运算结果。栈顶由 FPU 状态
寄存器中的 Top 域(占三个二进制位)来标识,对寄存器的引用是相对于栈顶而言的,栈顶用
ST 或用 ST(0)表示,ST(i)表示栈顶加 i 的寄存器。例如在图 9.2(a)中,Top=011b,说明 R3 是
栈顶。ST(0)(或 ST)对应 R3,ST(1)对应 R4,…,ST(7)(栈底)对应 R2。 8 个寄存器按堆栈方式使用,执行进栈操作时,Top 减 1,其状态相应发生变化,如图 9.2(b)
所示;执行出栈操作时,Top 加 1,如图 9.2(c)所示。
R7 ST(4) R7 ST(5) R7 ST(3) R6 ST(3) R6 ST(4) R6 ST(2) R5 ST(2) R5 ST(3) R5 ST(1) R4 ST(1) R4 ST(2) R4 ST(0)←Top=100 R3 ST(0)←Top=011 R3 ST(1) R3 ST(7) R2 ST(7) R2 ST(0)←Top=010 R2 ST(6) R1 ST(6) R1 ST(7) R1 ST(5) R0 ST(5) R0 ST(6) R0 ST(4)
(a) 栈初始状态 (b) 执行一次进栈操作后 (c) 执行一次出栈操作后
图 9.2 寄存器堆栈操作示意图
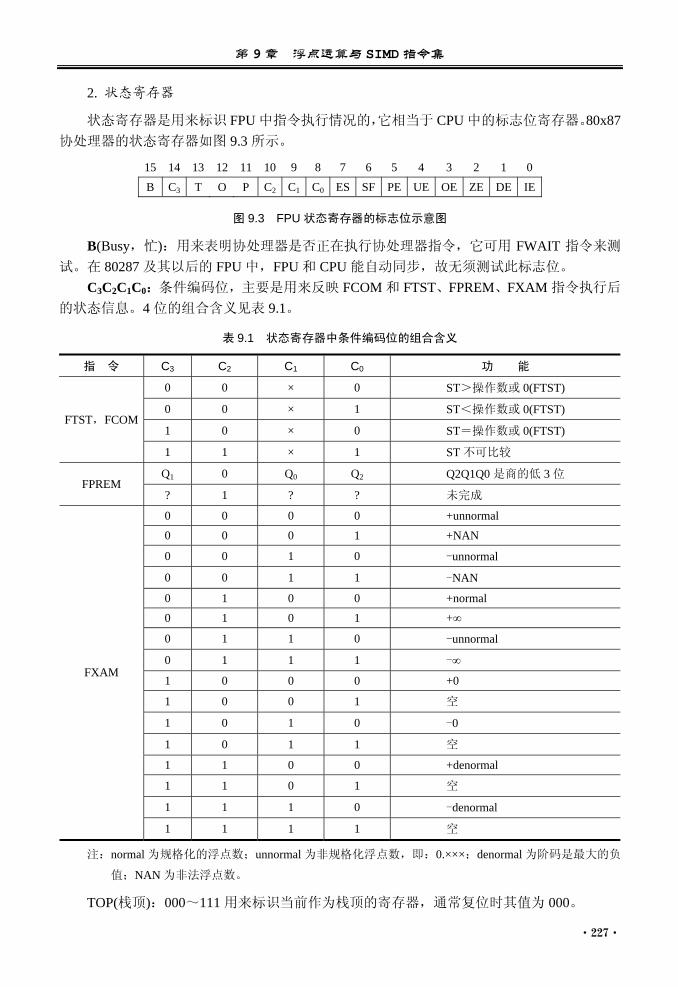
第 9 章 浮点运算与 SIMD 指令集
·227·
2. 状态寄存器
状态寄存器是用来标识 FPU 中指令执行情况的,它相当于 CPU 中的标志位寄存器。80x87协处理器的状态寄存器如图 9.3 所示。
15 14 13 12 11 10 9 8 7 6 5 4 3 2 1 0
B C3 T O P C2 C1 C0 ES SF PE UE OE ZE DE IE
图 9.3 FPU 状态寄存器的标志位示意图
B(Busy,忙):用来表明协处理器是否正在执行协处理器指令,它可用 FWAIT 指令来测
试。在 80287 及其以后的 FPU 中,FPU 和 CPU 能自动同步,故无须测试此标志位。 C3C2C1C0:条件编码位,主要是用来反映 FCOM 和 FTST、FPREM、FXAM 指令执行后
的状态信息。4 位的组合含义见表 9.1。
表 9.1 状态寄存器中条件编码位的组合含义
指 令 C3 C2 C1 C0 功 能
0 0 × 0 ST>操作数或 0(FTST)
0 0 × 1 ST<操作数或 0(FTST)
1 0 × 0 ST=操作数或 0(FTST) FTST,FCOM
1 1 × 1 ST 不可比较
Q1 0 Q0 Q2 Q2Q1Q0 是商的低 3 位 FPREM
? 1 ? ? 未完成
0 0 0 0 +unnormal
0 0 0 1 +NAN
0 0 1 0 -unnormal
0 0 1 1 -NAN
0 1 0 0 +normal
0 1 0 1 +∞
0 1 1 0 -unnormal
0 1 1 1 -∞
1 0 0 0 +0
1 0 0 1 空
1 0 1 0 -0
1 0 1 1 空
1 1 0 0 +denormal
1 1 0 1 空
1 1 1 0 -denormal
FXAM
1 1 1 1 空
注:normal 为规格化的浮点数;unnormal 为非规格化浮点数,即:0.×××;denormal 为阶码是 大的负
值;NAN 为非法浮点数。 TOP(栈顶):000~111 用来标识当前作为栈顶的寄存器,通常复位时其值为 000。

汇编语言程序设计
·228·
ES(错误汇总):ES=PE∧+UE∧OE∧ZE∧DE∧IE,在 8087 协处理器中,当 ES 为 1 时,发
出一个协处理器中断请求,但在其后的协处理器中,不再产生这样的中断申请。 SF(堆栈溢出错误):该状态位用来表明 FPU 内部的堆栈是否有上溢或下溢错误。 PE(精度错误):该状态位用来表明运算结果或操作数是否超过先前设定的精度。 UE(下溢错误):该状态位用来表明一个非 0 的结果太小,不能用控制字节所选定的当前
精度来表示。 OE(上溢错误):该状态位用来表明一个非 0 的结果太大,不能用控制字节所选定的当前
精度来表示,即超过了当前精度所能表示的数据范围。 如果在控制寄存器中屏蔽该错误标志,那么,FPU 把上溢结果定义为无穷大。 ZE(除法错误):该状态位用来表明当前执行了“0 作除数”的除法运算。 DE(非规格化错误):该状态位用来表明当前参与运算的操作数中至少有一个操作数是没
有规格化的。 IE(非法错误):该状态位用来表明执行了一个错误的操作,如:求负数的平方根,也可用
来表明堆栈的溢出错误,不确定的格式(0/0, ±∞等)错误,或用 NAN 作为操作数。 对于 FPU 中状态寄存器的内容,可用指令 FSTSW 把其值送到内存单元中。如果使用的
是 80287 及其以后的 FPU,那么,可用指令“FSTSW AX”把该状态寄存器的值传送给通用
寄存器 AX。一旦状态寄存器的值复制到内存或 AX 中,那么,就可对其各位进行分析,并可
检测出当前 FPU 的工作状态。
3. 控制寄存器
控制寄存器主要用于浮点数精度选择的控制、四舍五入的控制和无穷大的控制等,其低
6 位还可用来决定是否屏蔽 FPU 的异常。指令 FLDCW 可用来设置控制寄存器的值。控制寄
存器中控制位的分布如图 9.4 所示。
15 14 13 12 11 10 9 8 7 6 5 4 3 2 1 0 IC R C P C PM UM OM ZM DM IM
图 9.4 FPU 控制寄存器的控制位分布示意图
IC(无穷大控制):0——投影,假定是无符号无穷;1——仿射,允许正、负无穷。 RC(舍入控制):00——近似到 接近的偶数(默认);01——向下近似趋向于 −∞; 11——向上近似趋向于 +∞;10——近似趋向于 0(截断)。 PC(精度控制):00——单精度;01——保留;11——双精度;10——扩展精度。 PM(精度错误屏蔽位):该位为 1,则状态寄存器的 PE 位被屏蔽。 UM(下溢出屏蔽位):该位为 1,则状态寄存器的 UE 位被屏蔽。 OM(上溢出屏蔽位):该位为 1,则状态寄存器的 OE 位被屏蔽。 ZM(除数为0屏蔽位):该位为 1,则状态寄存器的 ZE 位被屏蔽。 DM(非规格化操作数屏蔽位):该位为 1,则状态寄存器的 DE 位被屏蔽。 IM(非法操作屏蔽位):该位为 1,则状态寄存器的 IE 位被屏蔽。
4. 标记寄存器
标记寄存器用来表明 FPU 堆栈中各寄存器内容的状态,也就是说,该寄存器可表明堆栈
中的数据是合法的,还是非法的,是无穷,还是 0 或空等。

第 9 章 浮点运算与 SIMD 指令集
·229·
堆栈中每个数据寄存器对应两位,如图 9.1 所示,其表示意义为:00 表示合法;01 表示 0;10 表示非法或无穷;11 表示空。
在 FPU 中,查看标记寄存器的方法是使用指令 FSTENV、FSAVE 或 FRSTOR。
9.2.2 浮点单元的指令简介
FPU 的指令分为以下几类:数据传送指令、基本的算术运算指令、比较指令、超越指令、
常量装入指令(预定义常量),以及 FPU 控制指令等。 为了与于整数处理指令,FPU 指令助记符总是以 F 开头,并遵循下列规则: (1) 后面有 P 的指令执行完后,进行一次出栈操作。如 FADD 和 FADDP 等。后面有 R
的指令表示的是反模式操作,仅限于减法、除法指令。如 FSUB 和 FSUBR 等。正模式—栈顶
单元=栈顶数据 op 操作数;反模式—栈顶单元=操作数 op 栈顶数据。 (2) 第 2 个字母是 I 的指令表示内存中数据是整数,它对加、减、乘、除指令都有效,如
FADD 和 FIADD 等;第 2 字母是 B,则表示内存数据是 BCD 数据,如 FBLD;未指定的就
表示操作数是浮点格式。 浮点指令可以有一个或两个操作数,也可没有操作数。如果有两个操作数,其中一个必
须是浮点寄存器。没有立即操作数,但可以装入预定义的值(如 0.0, π , log210 等)。通用寄存
器 EAX, EBX 等不能用作操作数,也不允许两个操作数都是内存操作数。
1. 数据传送指令
该组指令主要是指内存单元和 FPU 之间进行数据传送的指令。 1) 数据装入指令 FLD mem 内存中的浮点数进栈,可以是 real32/real64/real80。 FLD st(i) 浮点寄存器的值进栈。 FILD mem 内存中的整数进栈,可以是 int16/int32/int64。 FBLD mem80 内存中的 18 位 BCD 码进栈。 2) 装入常数指令 FLDZ 0.0 进栈。 FLD1 1.0 进栈。 FLDPI π进栈。 FLDL2E log2e 进栈。 FLDL2T log210 进栈。 FLDLG2 log102 进栈。 FLDLN2 loge10 进栈。 3) 栈顶数据存入指令 FST mem 存入内存,mem 可以是 real32/real64。 FSTP mem 存入内存并出栈,mem 可以是 real32/real64/real80。 FST st(i) 存入 st(i)。 FSTP st(i) 存入 st(i)并出栈。 FIST mem 有符号整数存入内存,mem 可以是 int16/int32。 FISTP mem 有符号整数存入内存并出栈,mem 可以是 int16/int32/int64。

汇编语言程序设计
·230·
FBSTP mem80 有符号整数以 18 位 BCD 形式存入内存并出栈。 4) 其他指令 FXCH st 与 st(1)内容交换。 FXCH ST(i) st 与 st(i)内容交换。 FCMOVcc st, st(i) 测试 EFLAGS 状态位,若条件成立则传送。 其中 cc:B(Below), E(Equal), BE, U(unordered), NB, NE, NBE, NU。
2. 数学运算指令
在 FPU 的指令系统中,有关数学运算指令有:加法指令、减法指令、乘法指令、除法指
令和求平方根指令等。涉及数学运算的指令有比例运算、舍入运算、求绝对值运算和改变数
值符号运算等指令。 1) 加法指令 FADD st+st(1)⇒st(1),再执行出栈。 FADD mem st+mem⇒st,mem 可以是 real32/real64。 FADD st, st(i) st+st(i)⇒st。 FADD st(i), st st+st(i)⇒st(i)。 FADDP st(i), st st+st(i)⇒st(i),再执行出栈。 FIADD mem st+mem⇒st,mem 可以是 int32/int64 2) 减法指令 FSUB st(1)-st⇒st(1),再执行出栈。 FSUB mem st-mem⇒st,mem 可以是 real32/real64。 FSUB st, st(i) st-st(i)⇒st。 FSUB st(i), st st(i)-st⇒st(i)。 FSUBP st(i), st st(i)-st⇒st(i) ,再执行出栈。 FSUBR st-st(1)⇒st(1),再执行出栈。 FSUBR mem mem-st⇒st,mem 可以是 real32/real64。 FSUBR st, st(i) st(i)-st⇒st。 FSUBR st(i), st st-st(i)⇒st(i)。 FSUBRP st(i), st st-st(i)⇒st(i) ,再执行出栈。 FISUB mem st-mem⇒st,mem 可以是 int16/int32。 FISUBR mem mem-st⇒st,mem 可以是 int16/int32。 3) 乘法指令 FMUL st×st(1)⇒st(1),再执行出栈。 FMUL mem st×mem⇒st,mem 可以是 real32/real64。 FMUL st, st(i) st×st(i)⇒st。 FMUL st(i), st st×st(i)⇒st(i)。 FMULP st(i), st st×st(i)⇒st(i),再执行出栈。 FIMUL mem st×mem⇒st,mem 可以是 int16/int32。 4) 除法指令 FDIV st(1)÷st⇒st(1),再执行出栈。

第 9 章 浮点运算与 SIMD 指令集
·231·
FDIV mem st(1)÷mem⇒st,mem 可以是 real32/real64。 FDIV st, st(i) st÷st(i)⇒st。 FDIV st(i), st st(i)÷st⇒st(i)。 FDIVP st(i), st st(i)÷st⇒st(i),再执行出栈。 FDIVR st÷st(1)⇒st(1),再执行出栈。 FDIVR mem mem÷st⇒st,mem 可以是 real32/real64。 FDIVR st, st(i) st(i)÷st⇒st。 FDIVR st(i), st st÷st(i)⇒st(i)。 FDIVRP st(i), st st÷st(i)⇒st(i),再执行出栈。 FIDIV mem st÷mem⇒st,mem 可以是 int16/int32。 FIDIVR mem mem÷st⇒st,mem 可以是 int16/int32。 5) 其他数学运算指令 FSQRT st ⇒st,即求栈顶数的平方根。 FSCALE st(1)转换成整数 n,再 st×2n⇒st。 FPREM st÷st(1)得余数⇒st。 FPREM1 st÷st(1)得 IEEE 格式余数⇒st。 FRNDINT 对栈顶数进行舍入运算,使之转换成整数。 FXTRACT 将栈顶数分成指数和尾数,指数⇒st,尾数再进栈。 FABS |st|⇒st,即求栈顶数的绝对值。 FCHS -st⇒st,即 st 符号取反。
3. 比较运算指令
比较指令是将 st 中的数与指定操作数进行比较,比较结果存于状态寄存器的条件编码位
C3C2C1C0(参见表 9.1)。 FCOM st 与 st(1)比较。 FCOM st(i) st 与 st(i)比较。 FCOM mem st 与 mem 比较,mem 是 real32/real64。 FCOMP st 与 st(1)比较,再执行出栈。 FCOMP st(i) st 与 st(i)比较,再执行出栈。 FCOMP mem st 与 mem 比较,再执行出栈。mem 是 real32/real64。 FCOMPP st 与 st(1)比较,再执行两次出栈。 FUCOM st 与 st(1)无序比较。 FUCOM st(i) st 与 st(i)无序比较。 FUCOMP st 与 st(1)无序比较,再执行出栈。 FUCOMP st(i) st 与 st(i)无序比较,再执行出栈。 FUCOMPP st 与 st(1)无序比较,再执行两次出栈。 FICOM mem st 与 mem 比较,mem 可以是 int16/int32。 FICOMP mem st 与 mem 无序比较,mem 可以是 int16/int32。 FCOMI st, st(i) st 与 st(i)比较,并置 EFLAGS 的 ZF, PF, CF(对应 C3C2C0)。 FCOMIP st, st(i) st 与 st(i)比较,并置 EFLAGS 相应位,再执行出栈。

汇编语言程序设计
·232·
FUCOMI st, st(i) st 与 st(i)无序比较,并置 EFLAGS 相应位。 FUCOMIP st, st(i) st 与 st(i)无序比较,并置 EFLAGS 相应位,再执行出栈。 FTST st 与 0.0 比较。 FXAM 检查 st 中的数是正数、负数、规格化数等。
4. 超越函数运算指令
FSIN sin(st)⇒st,即计算 st(弧度)的正弦值⇒st。 FCOS cos(st)⇒st,即计算 st(弧度)的余弦值⇒st。 FSINCOS 计算 st(弧度)的正弦、余弦值,前者⇒st,后者进栈。 FPTAN tan(st)⇒st,即计算 st(弧度)的部分正切⇒st,然后 1.0 进栈。
8087~80287 的角度范围是:0~4π;以后 FPU 的角度范围是:0~263。
FPATAN 求部分反正切,即 arctan(1)st
st⎛ ⎞⎜ ⎟⎝ ⎠
⇒st(1),并执行出栈。
F2XM1 2st-1⇒st,st 中数的范围是:-1~1。 FYL2X st(1)×log2(st)⇒st(1),再执行出栈。 FYL2XP1 st(1)×log2(st+1)⇒st(1),再执行出栈。
5. FPU 控制指令
FPU 控制指令是用来控制 FPU 状态而设置的,它包括 FPU 的初始化,状态寄存器内容
的存取,异常处理和任务切换等操作。 FINIT 初始化 FPU:控制置 037Fh,状态清 0,标记置空。 FNINIT 与 FINIT 相同,但不检查未决的未屏蔽异常。 FLDCW mem16 将指定的 16 位内存单元内容传送给 FPU 控制寄存器中。 FSTCW mem16 将 FPU 控制字传送到指定的 16 位内存单元。 FNSTCW mem16 与 FSTCW 相同,但不检查未决的未屏蔽异常。 FSTSW mem16 将 FPU 状态字传送到指定的 16 位内存单元。 FSTSW AX 将 FPU 状态字传送到 AX 寄存器。 FNSTSW mem16/AX 与 FSTSW 相同,但不检查未决的未屏蔽异常。 FCLEX 清除状态寄存器中的“错误”和“忙”标志。 FNCLEX 与 FCLEX 相同,但不检查未决的未屏蔽异常。 FSAVE mem FPU 全部状态传送到 94/108 字节内存区,然后重新初始化。 FNSAVE mem 与 FSAVE 相同,但不检查未决的未屏蔽异常。 FRSTOR mem 用 94/108 字节内存内容恢复 FPU 全部状态。 FSTENV mem 存 FPU 环境到 14/28 字节(实模式/保护模式)内存区。 FNSTENV mem 与 FSTENV 相同,但不检查未决的未屏蔽异常。 FLDENV mem 重新装入由指令 FSTENV/FNSTENV 存储的 FPU 环境。 FINCSTP FPU 状态字的 Top 域(堆栈指针)加 1。 FDECSTP FPU 状态字的 Top 域(堆栈指针)减 1。 FFREE st(i) 释放堆栈寄存器 st(i),即使其标记为空。 FNOP FPU 空操作。 FWAIT 等待处理所有未决浮点异常处理程序处理完毕。

第 9 章 浮点运算与 SIMD 指令集
·233·
FXSAVE 保存 FPU, MMX, SSE, SSE2 状态到 512 字节内存区。 FXRSTOR 在 512 字节内存区内容必得 FPU, MMX, SSE, SSE2 状态。
9.2.3 浮点运算的编程示例
在浮点运算程序中常用 3 种类型数:整型数据、BCD 数和浮点数。以下例子用以说明在
汇编语言环境下,这些类型数的定义形式。 i16 DW 213, -340 ;定义并分配空间以存储 16 位整数 i32 DD -321, 320 ;定义并分配空间以存储 32 位整数 i64 DQ -1230, 9034 ;定义并分配空间以存储 64 位整数 bcd18 DT 1234, -567890123 ;定义并分配空间以存储 18 位 BCD 数 f32 DD 3.345E+2 ;定义并分配空间以存储单精度浮点数 f64 DQ -321.545, 1.414 ;定义并分配空间以存储双精度浮点数 f80 DT 254.555E-10 ;定义并分配空间以存储扩展精度浮点数 需要说明的是,一个 BCD 码数据在内存中占 80 位,按低位存放在低字节,高位存放在
高字节约定存放。其 高位字节用来表示正负号(正数和负数分别用 00h 和 80h 表示),其余 9个字节表示 18 个 BCD 编码。例如定义 BCD 码的数据的存储格式为
9 8 7 6 5 4 3 2 1 0 9 8 7 6 5 4 3 2 1 0 00 00 00 00 00 00 00 00 12 34 80 00 00 00 00 05 67 89 01 23
使用浮点指令时,须指定.8087, .287 或.387 指令集。从 486 开始,CPU 指令集包括了浮
点指令。 例 9.1 编写 C 函数 GetDouble(Double*f)实现从键盘上读入一个形如±xxx.xxx 带小数点
的数字字符串,然后把它转换成双精度浮点数,并存入双精度浮点指针所指的变量中。该函
数设计成 16bit C 子函数。 _TEXT SEGMENT PUBLIC 'CODE' ASSUME CS:_TEXT PUBLIC _GetDouble _GetDouble Proc Near .486 Enter 100, 0 MOV DWord Ptr[BP-4], 10 FLDZ ;ST=0.0 MOV AH, 1 INT 21h CMP AL, '-' ;判定是否输入负号 JNE @F NEG Word Ptr[BP-4] ;若是负数,置-10 JMP Rep1B_i @@: CMP AL, '+' ;判定是否输入正号 JE Rep1B_i JNE Rep1? Rep1B: SUB AL, '0' ;整数部分处理循环 MOV [BP-2],AL FIMUL Word Ptr [BP-4] FIADD Word Ptr [BP-2] ;部分数×10.0+(数字符-'0')

汇编语言程序设计
·234·
Rep1B_i:MOV AH, 1 INT 21h Rep1?: CMP AL, '0' JL EndRep1 CMP AL, '9' JLE Rep1B EndRep1:CMP AL, '.' JNE Return FLD1 ;ST=1.0,开始处理小数部分 JMP Rep2B_i Rep2B: FIDIV Word Ptr [BP-4] ;形成 1÷10i SUB AL, '0' MOV [BP-2], AL FILD Word Ptr [BP-2] FMUL ST, ST(1) FADDP ST(2), ST Rep2B_i:MOV AH, 1 INT 21h CMP AL, '0' JL EndRep2 CMP AL, '9' JLE Rep2B EndRep2:FCOMP ;去除浮点栈顶元素 Return: MOV BX, [BP+4] FSTP QWord Ptr [BX] ;保存转换结果到内存 Leave RET _GetDouble ENDP _TEXT ENDS END 例 9.2 编写一个子程序,求解一元二次方程的根 ax2 + bx + c = 0 的根。 编写成 C 子函数:int Quadratic(double a, double b, double c, double r1, double r2),a, b 和 c
是方程系数,r1 和 r2 是指向存放根的指针;返回值:0 表示无实根,1 表示有一个根 r1,2表示有两个实根。代码设计成 VC 的 C 子函数(32 位地址模式)。
.686 _TEXT SEGMENT PUBLIC 'CODE' USE32 ASSUME CS:_TEXT e DQ 1.0E-15 PUBLIC _Quadratic _Quadratic PROC Near Enter 0, 0 MOV EBX, [EBP+32] MOV EDX, [EBP+36] FLD1 ;ST=1.0 FADD ST, ST ;ST=2.0 FLD ST ;把数值 2复制一份到新栈顶 FMUL QWord Ptr[EBP+8] ;ST=2a FMUL ST(1), ST ;ST(1)=4a FXCH ST(1) ;ST和 ST(1)内容互换 FMUL QWord Ptr[EBP+24] ;ST=4ac

第 9 章 浮点运算与 SIMD 指令集
·235·
FLD QWord Ptr[EBP+16] ;ST=b FMUL ST, ST ;ST=b2 FSUBRP ST(1), ST ;ST=b2-4ac FLD CS:e ;取足够小 e FCOMI ST, ST(1) ;e和 b2-4ac比较,即 e-(b2-4ac) JB Else1 ;若 b2-4ac>e,即 b2-4ac>0转去求两根 FCHS ;得到-e FCOMP ST(1) ;比较并出栈(清除浮点栈多余数据) FSTSW AX SAHF MOV EAX, 0 JA Return ;b2-4ac<-e,即 b2-4ac <0则转无根处理 INC EAX ;此时| b2-4ac |≤e,则作为 b2-4ac =0处理 FLD QWord Ptr[EBP+16] ;ST=b FCHS ;得到-b FDIV ST, ST(2) ;ST=-b÷(2a) FST QWord Ptr[EBX] ;存入 x1 FSTP QWord Ptr[EDX] ;存入 x2 JMP Return Else1: MOV EAX, 2 FCOMP ;清除浮点栈多余数据
FSQRT ;ST= −2b 4ac FLD QWord Ptr[EBP+16] FCHS ;得到-b FLD ST ;再复制一份-b
FADD ST, ST(2) ;ST=-b+ −2b 4ac
FDIV ST, ST(3) ;ST=(-b+ −2b 4ac )÷(2a) FSTP QWord Ptr[EBX]
FSUB ST, ST(1) ;ST=-b- −2b 4ac
FDIV ST, ST(2) ;ST=(-b- −2b 4ac )÷(2a) FSTP QWord Ptr[EDX] Return: FCOMPP ;清除浮点栈多余数据 LEAVE RET _Quadratic ENDP _TEXT ENDS END 在浮点运算程序中,一般不要轻易比较两个浮点是否相等,这是由于 FPU 在计算过程中
的近似可能导致本来相等却不相等。例如: 2.0 2.0× -2.0,从数学上讲其结果应该是 0,但在实际计算时,它的结果却不是 0,大约是 4.44×10-16。
比较浮点 x 和 y 是否相等推荐的方法是:取足够小的数ε (如程序中取 2-45),若|x-y|≤ε ,则认为 x 和 y 相等。
9.3 SIMD 指令集
为适应图像处理技术和多媒体技术的发展与应用,80x86 指令集也相应地进行了扩展,
先后出现了 AMD 公司的 3DNow!指令集,Intel 的 MMX、SSE、SSE2 和 SSE3 指令集。这些
指令集都是一种单指令多数据流(Single Instruction Multiple Data, SIMD)体系的指令集,也就是

汇编语言程序设计
·236·
说一条指令可同时处理多条数据,而传统的 80x86 CPU 是单指令单数据流(Single Instruction Single Data, SISD)体系架构,即一条指令一次只能处理一条数据,所以,SIMD 体系的指令集
较以往的 SISD 体系可大幅度提高运算的效率,特别适合图像处理和多媒体处理所需要的运算。 这一节只对一些 SIMD 指令集作一些简单介绍,并通过例子说明这类指令在程序中的使
用方法。具体指令的详细介绍等参见相关的技术资料。
9.3.1 指令集简介
1. MMX 指令集
MMX(MultiMedia Extension,多媒体扩展指令集)指令集是 Intel 公司于 1996 年推出的一
项多媒体指令增强技术。MMX 指令集中包括 57 条多媒体指令,通过这些指令可以一次处理
多个数据,在处理结果超过实际处理能力的时候,也能进行正常处理,这样在软件的配合下,
就可以得到更高的性能。MMX 的益处在于,当时存在的操作系统不必为此而做出任何修改
便可以轻松地执行 MMX 程序。但是,问题也比较明显,那就是 MMX 指令集与 80x87 浮点
运算指令不能够同时执行,必须做密集式的交错切换,才可以正常执行,这种情况势必造成
整个系统运行质量的下降。
2. SSE 指令集
SSE(Streaming SIMD Extensions,单指令多数据流扩展)指令集是 Intel 在 Pentium III 处理
器中率先推出的。SSE 指令集包括了 70 条指令,其中包含提高 3D 图形运算效率的 50 条
SIMD(单指令多数据技术)浮点运算指令,12 条 MMX 整数运算增强指令,8 条优化内存中连
续数据块传输指令。理论上这些指令对目前流行的图像处理、浮点运算、3D 运算、视频处理、
音频处理等诸多多媒体应用起到全面强化的作用。SSE 指令与 3DNow!指令彼此互不兼容,但
SSE 包含了 3DNow!技术的绝大部分功能,只是实现的方法不同。SSE 兼容 MMX 指令,它可
以通过 SIMD 和单时钟周期并行处理多个浮点数据来有效提高浮点运算速度。
3. SSE2 指令集
SSE2(Streaming SIMD Extensions 2,Intel 官方称为 SIMD 流技术扩展 2 或数据流单指令
多数据扩展指令集2)指令集是 Intel公司在SSE指令集的基础上发展起来的。相比于SSE,SSE2使用了 144 个新增指令,扩展了 MMX 技术和 SSE 技术,这些指令提高了广大应用程序的运
行性能。随 MMX 技术引进的 SIMD 整数指令从 64 位扩展到了 128 位,使 SIMD 整数类型操
作的有效执行率成倍提高。双倍精度浮点 SIMD 指令允许以 SIMD 格式同时执行两个浮点操
作,提供双倍精度操作支持有助于加速内容创建、财务、工程和科学应用。除 SSE2 指令之外,
初的 SSE 指令也得到增强,通过支持多种数据类型(如双字和四字)的算术运算,支持灵活
并且动态范围更广的计算功能。SSE2 指令可让软件开发员极其灵活地实施算法,并在运行诸
如 MPEG-2、MP3、3D 图形等之类的软件时增强性能。Intel 是从 Willamette 核心的 Pentium 4开始支持 SSE2 指令集的,而 AMD 从 K8 架构的 SledgeHammer 核心的 Opteron 开始支持 SSE2指令集。
4. SSE3 指令集
SSE3(Streaming SIMD Extensions 3,Intel 官方称为 SIMD 流技术扩展 3 或数据流单指令

第 9 章 浮点运算与 SIMD 指令集
·237·
多数据扩展指令集 3)指令集是 Intel 公司在 SSE2 指令集的基础上发展起来的。相比于 SSE2,SSE3 在 SSE2 的基础上又增加了 13 个额外的 SIMD 指令。SSE3 中 13 个新指令的主要目的是
改进线程同步和特定应用程序领域,如多媒体和游戏。这些新增指令强化了处理器在浮点转
换至整数、复杂算法、视频编码、SIMD 浮点寄存器操作,以及线程同步等 5 个方面的表现,
终达到提升多媒体和游戏性能的目的。Intel 是从 Prescott 核心的 Pentium 4 开始支持 SSE3指令集的,而 AMD 从 2005 年下半年 Troy 核心的 Opteron 开始支持 SSE3。但需要注意的是,
AMD 所支持的 SSE3 与 Intel 的 SSE3 并不完全相同,主要是删除了针对 Intel 超线程技术优化
的部分指令。
5. 3DNow!指令集
由 AMD 公司提出的 3DNow!指令集应该说出现在 SSE 指令集之前,并被 AMD 广泛应用
于其 K6-2, K6-3 及 Athlon(K7)处理器上。3DNow!指令集技术其实就是 21 条机器码的扩展指
令集。 与 Intel 公司的 MMX 技术侧重于整数运算有所不同,3DNow!指令集主要针对三维建模、
坐标变换和效果渲染等三维应用场合,在软件的配合下,可以大幅度提高 3D 处理性能。后来
在 Athlon 上开发了 Enhanced 3DNow!。这些 AMD 标准的 SIMD 指令和 Intel 的 SSE 具有相同
效能。因为受到 Intel 在商业上 Pentium Ⅲ的成功影响,软件在支持 SSE 上比起 3DNow!更为
普遍。AMD 公司继续为 Enhanced 3DNow!增加至 52 个指令,包含了一些 SSE 码,因而在针
对 SSE 做 佳化的软件中能获得更好的效能。
9.3.2 SIMD 指令集的程序设计示例
SIMD 体系指令集的特点是:在一条指令中,一次可以处理多条数据,因而特别适合图
像处理和多媒体处理所需要的运算。下面通过具体例子来说明它的特点。 例 9.3 已知单精度浮点数组 fa 与 fb,编写子函数 fun(float*fa, float*fb, float*fr, int n)计
算: 2 2l i ir a b= + ,其中,ai, bi 取自 fa[i], fb[i],计算结果 ri 存于 fr[i],n 是数组元素的个数
(4 的倍数)。为便于调试,子程序是在 32 位地址模式下设计的。 (1) 我们先用 FPU 指令来实现,源程序如下: .686 PUBLIC _fun1 _TEXT SEGMENT PUBLIC 'CODE' ASSUME CS: _TEXT PUBLIC _fun1 _fun1 PROC NEAR PUSH EBP MOV EBP, ESP MOV EAX, [EBP+8] MOV EBX, [EBP+12] MOV EDX, [EBP+16] MOV ECX, [EBP+20] A1: FLD DWord Ptr [EAX] FMUL ST, ST FLD DWord Ptr [EBX] FMUL ST, ST

汇编语言程序设计
·238·
FADD FSQRT FSTP DWord Ptr [EDX] ADD EAX, 4 ADD EBX, 4 ADD EDX, 4 LOOP A1 MOV ESP, EBP POP EBP RET _fun1 ENDP _TEXT ENDS END (2) 使用 SSE 指令集实现。支持 SSE 指令集的 CPU 具有 8 个 128 位的寄存器 XMM0~
XMM7,每一个寄存器可以存放 4 个单精度的浮点数,所以一条 SSE 指令一次可以处理 4 个
单精度浮点数据。 .686 .XMM PUBLIC _fun2 _TEXT SEGMENT PUBLIC 'CODE' _fun2 PROC NEAR PUSH EBP MOV EBP, ESP MOV EAX, [EBP+8] MOV EBX, [EBP+12] MOV EDX, [EBP+16] MOV ECX, [EBP+20] SHR ECX, 2 A2: MOVAPS XMM0, [EAX] ; [EAX]⇒XMM0 MULPS XMM0, XMM0 ; XMM0 × XMM0⇒XMM0 MOVAPS XMM1, [EBX] ; [EBX]⇒XMM1 MULPS XMM1, XMM1 ; XMM1 × XMM1⇒XXM1 ADDPS XMM0, XMM1 ; XMM0 + XMM1⇒XMM0 SQRTPS XMM0, XMM0 ; √XMM0⇒XMM0 MOVAPS [EDX], XMM0 ; XMM0⇒[EDX] ADD EAX, 16 ; 指向下一组浮点数 ADD EBX, 16 ; 指向下一组浮点数 ADD EDX, 16 ; 指向下一组浮点数存储单元 LOOP A2 MOV ESP, EBP POP EBP RET _fun2 ENDP _TEXT ENDS END 比较上面两个程序,可以发现:在使用 SSE 指令编写的函数中,每循环一次可以处理 4
个单粒度数据,而使用 FPU 指令,每循环一次只能处理一个单精度数。 例9.4 已知单精度浮点数组 fa,编写子函数 fun(float*fa,float*fr,int n,float*fmin,float*fmax)

第 9 章 浮点运算与 SIMD 指令集
·239·
计算:ri= ia ,其中,ai 取自 fa[i],计算结果 ri 存于 fr[i],n 是数组元素的个数(4 的倍数)。
并且求出数组 fa 元素中的 小值和 大值,分别存放于 fmin 和 fmax。同样,为便于调试,
子程序是在 32 位地址模式下设计的。 .686 .XMM _TEXT SEGMENT USE32 PUBLIC 'CODE' ASSUME CS:_TEXT PUBLIC _fun _fun PROC NEAR PUSH EBP MOV EBP, ESP MOV EAX, [EBP+8] MOV EBX, [EBP+12] MOV ECX, [EBP+16] SHR ECX, 2 MOVAPS XMM1, [EAX] ; 初始的 4个 小值 MOVAPS XMM2, XMM1 ; 初始的 4个 大值 A: MOVAPS XMM0, [EAX] ; [EAX]⇒XMM0 MINPS XMM1, XMM0 ; 重求 4个 小值 MAXPS XMM2, XMM0 ; 重求 4个 大值 SQRTPS XMM0, XMM0 ; √XMM0⇒XMM0 MOVAPS [EBX], XMM0 ; XMM0⇒[EBX] ADD EAX, 16 ADD EBX, 16 LOOP A SHUFPS XMM0, XMM1, 11100000B SHUFPS XMM0, XMM0, 11101110B MINPS XMM1, XMM0 ; 4个值中求出 2个 小值 SHUFPS XMM0, XMM1, 00010000B SHUFPS XMM0, XMM0, 11101110B MINPS XMM1, XMM0 ; 2个值中求出 1个 小值 MOV EAX, [EBP+20] MOVSS [EAX], XMM1 ; XMM1[0] ⇒[EAX] SHUFPS XMM0, XMM2, 11100000B SHUFPS XMM0, XMM0, 11101110B MAXPS XMM2, XMM0 ; 4个值中求出 2个 大值 SHUFPS XMM0, XMM2, 00010000B SHUFPS XMM0, XMM0, 11101110B MAXPS XMM2, XMM0 ; 2个值中求出 1个 小值 MOV EAX, [EBP+24] MOVSS [EAX], XMM2 ; XMM2[0] ⇒[EAX] MOV ESP, EBP POP EBP RET _fun ENDP _TEXT ENDS END

汇编语言程序设计
·240·
本 章 小 结
FPU 有 8 个可独立寻址的 80 位寄存器:R0~R7,是以寄存器堆栈的形式组织的。在计
算时,浮点数以扩展精度的浮点格式存放于 FPU 寄存器栈中,内存操作数可以用于浮点运算。
FPU 可将结果以:16/32/64 整数、单元精度/双精度/扩展精度浮点数及 18 位 BCD 码形式存放
在内存单元中。 FPU 的指令分为以下几类:数据传送指令、基本的算术运算指令、比较指令、超越指令,
以及 FPU 控制指令等。 通过具体示例演示了浮点运算指令的程序设计方法。在实际应用中,对于两个浮点数 x
和 y 不宜直接比较它们相等,而是使用|x-y|≤ ε的方法来比较它们是否相等。 本章也概要介绍了 80x86 的一些 SIMD 指令集,包括 3DNow!, MMX, SSE, SSE2, SSE3
等,并通过例子简单演示了 SIMD 指令的特点及程序设计的基本方法。
习 题 9
9.1 简述 FPU 可以处理的 3 种整型数据格式、3 种浮点数据格式及其表示范围。 9.2 简述 BCD 码数据在内存中所占的位数和存储的形式。 9.3 在 MASM V6.1x 中,如何定义 3 种不同精度的浮点数?试举例说明。 9.4 什么是+0, -0 和 NAN? 9.5 FPU 的状态寄存器中,C3, C2, C1和 C0 的作用是什么?在程序中如何使用它们? 9.6 FPU 指令的一般命名规则有哪些?FDIV 与 FDIVR 有何不同? 9.7 在例 9.2 源程序中,可以用 FCOMIP 替代下列的 3 条指令吗? FCOMP ST(1) ;比较并出栈(清除浮点栈多余数据) FSTSW AX SAHF
9.8 根据公式 log10x= 2
2
loglog 10
x,编写子程序求 log10st,结果仍存入 ST。

第 10 章 汇编语言编程和调试工具
学习汇编语言的目的就是要用汇编语言程序来解决实际问题,下面以 Microsoft 的
MASM 6.15 为基础来介绍汇编语言程序的开发过程,以及汇编语言程序的调试工具。
10.1 汇编语言的开发环境
10.1.1 开发过程
在此先介绍在 DOS 环境下的汇编语言程序开发过程,再介绍 Windows 下 32 位汇编语言
程序的汇编、连接方法。实验环境中,MASM 安装在 D:\MASM 目录下。
1. 编写源程序
可用计算机系统中各种能编辑文本文件的编辑器来编辑汇编源程序。常用的编辑器有:
EDIT、记事本、写字板、Word 和 WPS 等。源文件的类型为:.ASM。
2. 汇编程序
当源程序编写好后,可用 MASM 命令来汇编该源程序。如果源程序没有语法错误,那么,
将生成目标文件(类型为.OBJ),为最终生成可执行文件作准备;如果源程序有错误,汇编程序
将显示出错误位置和原因,也可用列表文件(类型为.LST)来查看出错位置和原因。 下面给出一些使用该命令的实例。(用户输入的命令用“下划线”来标识) 例 10.1 查看 MASM 命令的功能。 MASM /? … /Zi Generate symbolic information for CodeView /Zd Generate line-number information 其中:选项/Zi 和/Zd 与符号跟踪有关,所以在调试程序中经常使用这两个选项。 例 10.2 用 MASM 命令汇编源程序。 MASM Exam.ASM … Invoking: ML.EXE /I. /Zm /c Exam.ASM … Assembling: Exam.ASM 如果 MASM 命令显示了类似如上的处理结果,那么表示源文件 Exam.ASM 已成功汇编,
并已生成了其目标文件 Exam.OBJ。 例 10.3 用 MASM 命令汇编源程序。 MASM Exam.ASM …

汇编语言程序设计
·242·
Invoking: ML.EXE /I. /Zm /c Exam.asm … Assembling: Exam.ASM Exam.ASM(5): error A2070: invalid instruction operands 如果 MASM 命令显示了类似如上的处理结果,那么,表示源文件有错,没有生成其目标
文件。在本例中,显示第 5 行有语法错:非法的指令操作数。这时,要检查源程序的第 5 行,
看看输入指令时是否有误。 假如源程序有许多错误,很难记住全部出错位置,那么,可借助列表文件来排错。 例 10.4 在汇编源程序的同时,生成其列表文件。 MASM Exam.ASM, ,Exam … Assembling: Exam.ASM Exam.ASM(5): error A2070: invalid instruction operands 列表文件 Exam.1st 是一个文本文件,可用编辑器直接阅读,并可看出其错误的位置和原
因。下面是一个列表文件的实例。 EDIT Exam.1st Microsoft (R) Macro Assembler Version 6.15.8803 09/28/08 12:35:48 Exam.ASM Page 1 - 1 0000 _TEXT SEGMENT ASSUME CS:_TEXT 0000 B4 01 Start: MOV AH, 1 0002 CD 21 INT 21h MOV DL, AX Exam.ASM(5) : error A2070: invalid instruction operands 0004 80 EA 20 SUB DL, 32 0007 B4 02 MOV AH, 2 0009 CD 21 INT 21h 000B B8 4C00 MOV AX, 4C00h 000E CD 21 INT 21h 0010 _TEXT ENDS END Start Microsoft (R) Macro Assembler Version 6.15.8803 09/28/08 12:35:48 Exam.ASM Symbols 2 - 1 Segments and Groups: Name Size Length Align Combine Class _TEXT............. 16 Bit 0010 Para Private Symbols: N a m e Type Value Attr Start............. L Near 0000 _TEXT 0 Warnings 1 Errors
3. 连接程序
当源文件汇编成功后,即可用连接程序(LINK.EXE)生成可执行文件。 例 10.5 查看连接程序(LINK.EXE)的具体选项。

第 10 章 汇编语言编程和调试工具
·243·
LINK /? LINK <objs>,<exefile>,<mapfile>,<libs>,<deffile> Valid options are: /? /ALIGNMENT /BATCH /CODEVIEW /CPARMAXALLOC /DOSSEG /DSALLOCATE /DYNAMIC /EXEPACK /FARCALLTRANSLATION /HELP /HIGH /INFORMATION /LINENUMBERS /MAP /NODEFAULTLIBRARYSEARCH /NOEXTDICTIONARY /NOFARCALLTRANSLATION /NOGROUPASSOCIATION /NOIGNORECASE /NOLOGO /NONULLSDOSSEG /NOPACKCODE /NOPACKFUNCTIONS /NOFREEMEM /OLDOVERLAY /ONERROR /OVERLAYINTERRUPT /PACKCODE /PACKDATA /PACKFUNCTIONS /PAUSE /PCODE /PMTYPE /QUICKLIBRARY /SEGMENTS /STACK /TINY /WARNFIXUP 例 10.6 用连接程序生成执行文件。 方法 1: link Exam.ASM … Run File [Exam.exe]: List File [nul.map]: Libraries [.lib]: Definitions File [nul.def]: LINK : warning L4021: no stack segment 这种方法需要确认连接过程中的各种文件名,如果使用文件名的默认值,那么直接按“回
车”键即可。在上面四个文件名中,最重要的两个文件名是:可执行文件名和库文件名。一
般情况下,无须更换最终生成的执行文件名;如果在连接过程中需要其他的库文件,则在显
示第三行提示时,输入所需要的库文件名。 最后一行显示的警告信息:没有堆栈段,这是因为源程序中没有定义堆栈段。一般情况
下,该警告信息可以不必理会,因为操作系统在装入运行程序时会为其安排堆栈段。 方法 2:在文件名后面加上分号“;”,使用各类文件的默认名。 LINK Exam; … LINK : warning L4021: no stack segment
4. 运行程序
当要运行生成的可执行文件时,可直接输入其文件名即可。 Exam

汇编语言程序设计
·244·
5. 符号调试程序
当程序的运行结果不是预期结果时,就需要调试程序,找出错误的语句或逻辑关系。
MASM 系统提供了可用于源程序一级的调试工具 CV(CodeView)。有关 CV 的使用参见“调
试工具”中的介绍。 例 10.7 若 Exam.ASM 汇编通过,可用如下命令生成含有 CV 调试信息的执行文件。 MASM /Zi /Zd Exam; LINK /Co Exam CV Exam.exe 在 MASM 6.15 中,MASM 和 LINK 已整合在一起,即 ML.EXE,也就是说可以用 ML
来汇编源程序和连接目标程序。ML 命令的格式如下: ML [ /options ] filelist [ /link linkoptions ] ML 的选项较多,这里只列出几个常用的选项。 /c 仅汇编不连接; /Zi 目标文件调试用的源程序行号; /Zd 目标文件含有调试信息; /omf 生成 OMF 格式的目标文件; /coff 生成 COFF 格式文件; /Bl<linker> 指定连接程序。 例 10.8 用 ML 汇编、连接源程序。 ML Exam.ASM 先汇编源程序,生成 Exam.OBJ,再连接(调用 LINK.EXE),生成 Exam.EXE。 以上介绍的是汇编语言程序汇编、连接的一般方法。 ML.EXE 也可以用来汇编和连接 Win32 的源程序,此时需注意以下几个方面。 (1) 用/coff 选项,以便生成 COFF 格式的目标码,没有此选项,则默认为/omf。 (2) 用 Win32 的连接程序(MASM 6.15 软件包中的 Link.EXE 用来连接 16 位程序),以及
相应的连接设置。例如,使用 VC 中的 Link.EXE(改名为 Link32.EXE 以便区别),以及连接选
项/subsystem:console 或/subsystem:windows。 (3) 在 Win32 中不提供 DOS 系统功能调用及 BIOS 功能调用,只能使用 Win32 的 API,
所以在连接时要给出包含 API 相应的函数库(如 User32.LIB, Kernel32.EXE 等)。在实验环境中,
将 Win32 的相应的函数库放在 Lib32 目录中。 例 10.9 用 ML 汇编、连接源程序 E32.ASM,生成 Win32 格式的运行程序。 ML /c /coff e32.ASM LINK32 /subsystem:console /libpath:d:\masm\lib32 32.OBJ 或者用 ML 汇编并连接: ML /coff /BlLink32.EXE e32.ASM /link /libpath:d:\masm\lib32 /subsystem:console 先汇编生成 COFF 格式的 e32.OBJ,再调用 Link32.EXE 生成 e32.EXE。
10.1.2 VC 中汇编中成环境的设置
通过如下设置(以 VC 6.0 为例),可用 VC 中成环境来开发 Win32 的汇编语言程序。 (1) 创建一个空 Project,根据需要选一个类型,如图 10.1 所示,选 Win32 Application 类
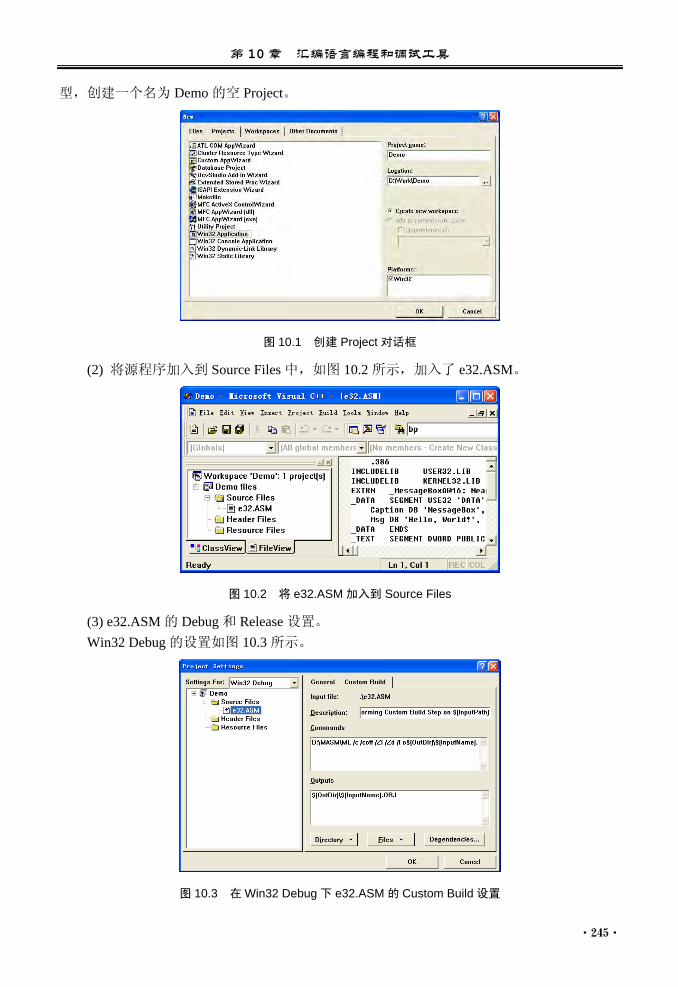
第 10 章 汇编语言编程和调试工具
·245·
型,创建一个名为 Demo 的空 Project。
图 10.1 创建 Project 对话框
(2) 将源程序加入到 Source Files 中,如图 10.2 所示,加入了 e32.ASM。
图 10.2 将 e32.ASM 加入到 Source Files
(3) e32.ASM 的 Debug 和 Release 设置。 Win32 Debug 的设置如图 10.3 所示。
图 10.3 在 Win32 Debug 下 e32.ASM 的 Custom Build 设置
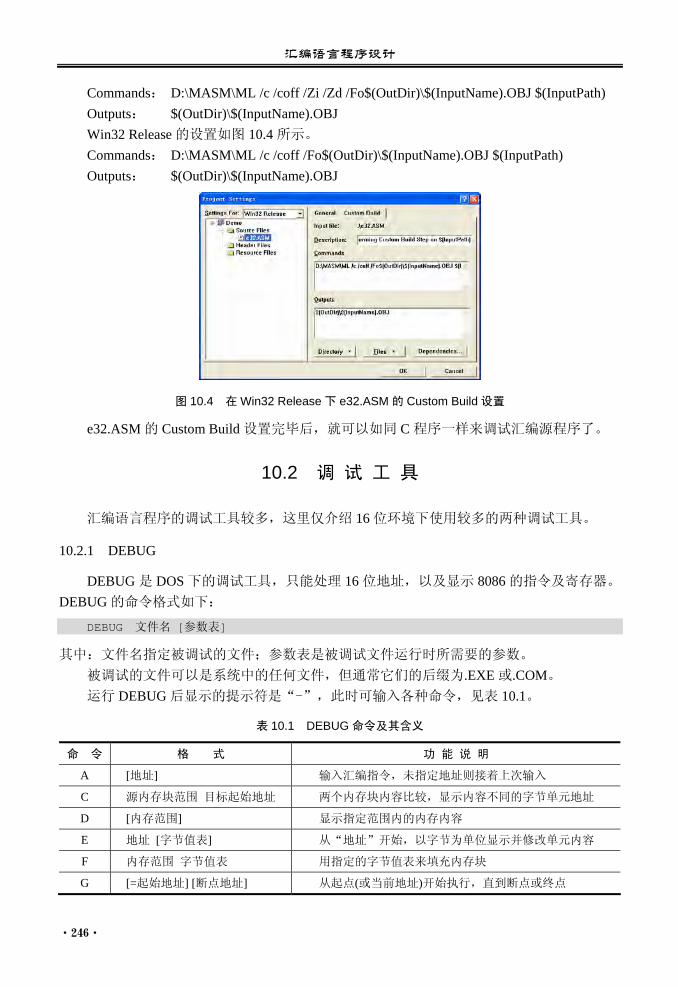
汇编语言程序设计
·246·
Commands: D:\MASM\ML /c /coff /Zi /Zd /Fo$(OutDir)\$(InputName).OBJ $(InputPath) Outputs: $(OutDir)\$(InputName).OBJ Win32 Release 的设置如图 10.4 所示。 Commands: D:\MASM\ML /c /coff /Fo$(OutDir)\$(InputName).OBJ $(InputPath) Outputs: $(OutDir)\$(InputName).OBJ
图 10.4 在 Win32 Release 下 e32.ASM 的 Custom Build 设置
e32.ASM 的 Custom Build 设置完毕后,就可以如同 C 程序一样来调试汇编源程序了。
10.2 调 试 工 具
汇编语言程序的调试工具较多,这里仅介绍 16 位环境下使用较多的两种调试工具。
10.2.1 DEBUG
DEBUG 是 DOS 下的调试工具,只能处理 16 位地址,以及显示 8086 的指令及寄存器。
DEBUG 的命令格式如下: DEBUG 文件名 [参数表]
其中:文件名指定被调试的文件;参数表是被调试文件运行时所需要的参数。 被调试的文件可以是系统中的任何文件,但通常它们的后缀为.EXE 或.COM。 运行 DEBUG 后显示的提示符是“-”,此时可输入各种命令,见表 10.1。
表 10.1 DEBUG 命令及其含义
命 令 格 式 功 能 说 明
A [地址] 输入汇编指令,未指定地址则接着上次输入
C 源内存块范围 目标起始地址 两个内存块内容比较,显示内容不同的字节单元地址
D [内存范围] 显示指定范围内的内存内容
E 地址 [字节值表] 从“地址”开始,以字节为单位显示并修改单元内容
F 内存范围 字节值表 用指定的字节值表来填充内存块
G [=起始地址] [断点地址] 从起点(或当前地址)开始执行,直到断点或终点

第 10 章 汇编语言编程和调试工具
·247·
续表
命 令 格 式 功 能 说 明
H 数值 1 数值 2 显示两个十六进制数值之和、差
I 端口地址 从端口输入
L [地址 [驱动器号 扇区 扇区数]] 从磁盘读
M 源块范围 目标起始地址 源内存块内容传送到目标内存块
N 文件标识符 [文件标识符…] 指定文件名,为读/写文件做准备
O 端口地址 字节值 向端口输出
P [=地址] [指令数] 按执行过程,但不进入子程序调用或软中断
Q 退出 DEBUG
R [寄存器名] 显示和修改寄存器内容
S 内存块范围 字节值表 在内存块内搜索指定的字节值表
T [=地址] [指令数] 跟踪执行,从起点(或当前地点)执行若干条指令
U [范围] 反汇编,显示机器码所对应的汇编指令
W [地址 [驱动器号 扇区 扇区数]] 向磁盘写内容,BX:CX 为写入的字节数
关于参数的几点说明: ① 进制:在 DEBUG 中输入或显示的数据都是十六进制形式。 ② 分隔:命令和参数、参数和参数之间要用空格、逗号或制表符等分隔。 ③ 地址:用“段:偏移”表示,如 1A00:0,或“段寄存器:偏移”表示,如 DS:0。 ④ 范围:有两种表示方式。
• 起始地址 结束地址,例如,10:0 100,表示 10:0~100 共 101 字节的内存块。 • 起始地址 L 长度,例如,10:0 L100,表示 10:0~FF 共 100 字节的内存块。
⑤ 字节值表:由若干个字节值组成,也可以是用'或者"括起来的字符串。 ⑥ 驱动器号:0——驱动器 A、1——驱动器 B、2——驱动器 C、3——驱动器 D 等。 例 10.10 启动 DEBUG,并装入 Test.exe 文件(假设该文件已存在)。 方法 1: 方法 2: DEBUG Test.exe DEBUG - -N test.exe -L 例 10.11 用 A 命令输入汇编指令。 -A 100 0AE1:0100 MOV CX, 100 0AE1:0103 ADD AX, CX 0AE1:0105 LOOP 103 0AE1:0107 (直接按回车结束输入) 例 10.12 比较 DS:0~10 的内存块与从 100:20 开始的内存块内容。 -C DS:0 10 100:20 或 -C DS:0 L11 100:20
汇编语言程序设计
·248·
例 10.13 检查 1000:0 开始的 3 字节内容,并置 41, 42, 43。 -E 1000:0 1000:0000 CD.41 20.42 FF.43 (每个字节以空格结束,最后以回车键结束) 注:每个字节用空格键结束,再移至后一个字节;或'-'结束,再移至前一个字节。 例 10.14 显示以 2000:0~F 内存块内容,再用'abc'来填充它。 -D 2000:0 L10
2000:00008A 04 0E 02 FF 03 0E 02 - 76 09 0E 02 B1 98 00 C0 … v… -F 2000:0 F 'abc' 或 -F 2000:0 F 61 62 63 例 10.15 将 SS:0~40 内存块内容传送到 ES:10 开始的内存块中。 -M SS:0 40 ES:10 例 10.16 R 命令的使用示例,参见表 10.2。 -R 显示所有 16 寄存器内容 AX=00CD BX=0000 CX=0000 DX=0000 SP=FFEE BP=0000 SI=0000 DI=0000 DS=0AE1 ES=0AE1 SS=0AE1 CS=0AE1 IP=0102① NV UP EI NG NZ NA PO NC② 0AE1:0102 0101 ADD [BX+DI],AX DS:0000=4241 注①:指示正准备执行的指令的存放地址。 ②:Flags 只显示 OF,DF,IF,SF,ZF,AF,PF,CF 的状态,所用的符号列示在表 10.2 中。
-R AX 显示 AX 寄存器内容,并修改为 1234。(直接输入回车则不修改) AX 00CD : 1234 -R F 显示 FLAGS 内容,并将 ZF,CF 置 1。(直接输入回车则不修改) NV UP EI NG NZ NA PO NC – CY ZR
表 10.2 DEBUG 中标志位的符号表示
标 志 位 OF DF IF SF ZF AF PF CF
置 1 OV DN EI NG ZR AC PE CY
清 0 NV UP DI PL NZ NA PO NC 例 10.17 反汇编 CS:100~10A 的内容。 -U CS:100 10A (显示的格式:左列地址,中间列是机器代码,右列是汇编指令) 0AE1:0100 B90001 MOV CX,0100 0AE1:0103 01C8 ADD AX,CX 0AE1:0105 E2F9 LOOP 0103 0AE1:0107 A30010 MOV [1000],AX 0AE1:010A CC INT 3

第 10 章 汇编语言编程和调试工具
·249·
例 10.18 执行指令的演示示例。 -G 0AE1:100 从 0AE1:100 开始执行,直到程序终止 -G 0AE1:100 107 从 0AE1:100 开始执行,直到 107 处停止,或程序终止 -T 0AE1:100 从 0AE1:100 开始单步执行 1 条指令
-T 0AE1:100 8 从 0AE1:100 开始单步执行 8 条指令
-T 从当前地址开始单步执行 1 条指令
-P 0AE1:100 8 从 0AE1:100 开始单步执行 8 条指令,不进入子程序/中断内部
10.2.2 CodeView
CodeView 是一个多窗口的全屏幕调试工具,其功能比 DEBUG 强大得多。可调试多种语
言的源程序,支持 16 位地址模式下的各种指令。允许用户运行程序或单步执行,可以设置断
点,在程序运行期间查看并修改内存或寄存器内容。DEBUG 中的大部分命令均可在 CodeView的 Command 窗口内执行。
1. CodeView 的启动和退出
DOS 环境中输入 CV Exam.EXE 即可进入 CodeView 环境,其界面布局如图 10.5 所示。
退出 CodeView 可以选择 File 选单中的 Exit 选项,或在 Command 窗口中输入 Q 命令,此时,
系统返回到 DOS 提示符。
图 10.5 CodeView 界面布局
2. CodeView 工具的各窗格
图 10.5 显示了 4 个窗格,其中左上侧 source1 是主窗格,显示被调试的源程序;左侧中
部的 memory1 窗格用于显示内存单元的内容;左下侧的 command 窗格中可以输入前面介绍
的 Debug 调试命令;右侧的 register 窗格显示寄存器的内容。 除了这 4 个窗格,CodeView 中还有其他窗格,分别有各自不同的作用和功能。在 Windows
选单中可以看到 CodeView 中的窗格列表,0~9 共 10 个,对应的快捷方式为 Alt+数字。 0. Help 提供 CodeView、汇编语言等有关帮助信息。 1. Local 列出当前所有的局部变量。可通过 Option 选单改变当前范围。 2. Watch 查看执行期间变量或表达式的值。可通过 Data 选单添加/删除。 3. Source1 可显示源程序及对应的机器代码。可由 Option 选单设置。 4. Source2 同 Source1。主要用于查看程序的不同部分。

汇编语言程序设计
·250·
5. Memory1 用于显示内存单元内容。可通过 Option 选单进行设置。 6. Memory2 同 Memory1。 7. Register 显示寄存器组的内容。可通过 Option 选单设置 16/32 寄存器。 8. 8087 显示 FPU 的浮点寄存器组的内容。 9. Command 可输入 DEBUG 命令。
3. 功能键
F1 获得帮助信息。 F2 显示/隐含寄存器组窗口。 F3 Source 窗口中代码的三种显示方式的切换。 F4 显示程序的输出屏幕。 F5 相当于 DEBUG 的 G 命令,执行到下一个逻辑断点,或到程序终止。 F6 依次进入当前屏幕所显示的窗口。 F7 与 F5 功能相同。 F8 相当于 DEBUG 的 T 命令,单步执行指令。 F9 设置/取消断点,用鼠标左键双击之也可。 F10 相当于 DEBUG 的 P 命令,单步执行指令,不进入的子程序内部。
附 录
附录 A 常用 80x86 指令速查表
指令按助记符字母顺序排列,缩写、符号约定如下: (1) 指令中,dst, src 表示目的操作数和源操作数。仅一个操作数时,个别处也表示为 opr。 (2) imm 表示立即数,8/16/32 位立即数记作:imm8/imm16/imm32。 (3) reg 表示通用寄存器,8/16/32 位通用寄存器记作:reg8/reg16/reg32。 (4) mem 表示内存操作数,8/16/32 等内存操作数记作:mem8/mem16/mem32 等。 (5) seg 表示段寄存器,CS, DS, SS, ES, FS, GS。 (6) acc 表示累加器,8/16/32 累加器对应 AL/AX/EAX。 (7) OF, SF, ZF, AF, PF, CF 分别表示为 O, S, Z, A, P, C,相应位置为:字母,根据结果状
态设置;?,状态不确定;-,状态不变;1,置 1;0,清 0;例如:0 S Z ? P -表示:OF 清 0,AF 不确定,CF 不变,其他根据结果设置。若该栏空白,则表示无关。
(8) 寄存器符号诸如(E)CX, (E)SI, (E)DI, (E)SP, (E)BP 和(E)IP 等,表示在 16 地址模式下
使用 16 位寄存器(如 CX),或在 32 地址模式下使用 32 位寄存器(如 ECX)。 (9) 周期数表示指令执行所需的 CPU 时钟周期个数,即执行时间:周期数/主频(s)。 (10) 诸如(386+)是表示该指令只能用于 80386 及以后微处理器上。 指 令 功 能 指 令 形 式 周期数 影响标志位
AAA 非压缩BCD加法调整,AH+进位 AAA 3 ? ? ? A ? C AAD AH×10+AL⇒AL,之后AH清0 AAD 10 O S Z A P CAAM AL÷10的商⇒AH,余数⇒AL AAM 18 O S Z A P CAAS 非压缩BCD减法调整,AH-借位 AAS 3 ? S Z ? P C ADC dst, src 带进位加法:dst+src+CF⇒dst ADC reg, reg 1 O S Z A P C ADC reg, mem 2 ADC reg, imm 1 ADC acc, imm 1 ADC mem, reg 3 ADC mem, imm 3 ADD dst, src 加法:dst+src⇒dst ADD reg, reg 1 O S Z A P C ADD reg, mem 2 ADD reg, imm 1 ADD acc, imm 1 ADD mem, reg 3 ADD mem, imm 3 AND dst, src 逻辑与:dst∧src⇒dst AND reg, reg 1 0 S Z ? P 0 AND reg, mem 2 AND reg, imm 1 AND acc, imm 1
汇编语言程序设计
·252·
续表 指 令 功 能 指 令 形 式 周期数 影响标志位
AND mem, reg 3 AND mem, imm 3 ARPL dst, src 调整选择器的RPL域 ARPL reg/mem16, reg16 7 - - z - - - BOUND reg, mem 越界检查:(80188+) BOUND reg16, mem32 INT+32 若reg值超出mem,则产生INT 5 BOUND reg32, mem64 BSF reg, src 从低到高扫描src,16/32位 (386+) BSF reg, reg 6~35 ? ? Z ? ? ? 若src=0,ZF清0,否则置1,位置⇒reg BSF reg, mem 6~43 BSR reg, src 从高到低扫描src, 16/32位 (386+) BSR reg, reg 6~35 ? ? Z ? ? ? 若src=0,ZF清0,否则置1,位置⇒reg BSR reg, mem 6~43 BSWAP reg32 反转reg32字节顺序 (486+) BSWAP reg32 1 BT dst, src 位测试 (386+) BT reg, reg 4 ? ? ? ? ? C 由dst指定的位⇒CF (16/32位) BT reg, imm 4 BT mem, reg 9 BT mem, imm 4 BTC dst, src 位测试并变反 (386+) BTC reg, reg 7 ? ? ? ? ? C dst的指定位⇒CF, 然后该位变反, BTC reg, imm 7 (16/32位) BTC mem, reg 13 BTC mem, imm 8 BTR dst, src 位测试并清0 (386+) BTR reg, reg 7 ? ? ? ? ? C dst的指定位⇒CF, 然后该位清0, BTR reg, imm 7 (16/32位) BTR mem, reg 13 BTR mem, imm 8 BTS dst, src 位测试并置1 (386+) BTS reg, reg 7 ? ? ? ? ? C dst的指定位⇒CF, 然后该位置1, BTS reg, imm 7 (16/32位) BTS mem, reg 13 BTS mem, imm 8 CALL dst 子程序调用 CALL label (near) 1 近调用:返回的偏移地址进栈, CALL reg (near) 2 然后转至dst处执行; CALL mem (near) 2 远调用:返回的段和偏移地址进栈, CALL label (far) 4 然后转至dst处执行 CALL mem (far) 5 CBW AL符号扩展成AX CBW 3 CDQ EAX符号扩展成EDX:EAX CDQ 2 CLC CF清0 CLC 2 - - - - - 0 CLD DF清0 CLD 2 CLI IF清0,即关中断 CLI 7 CLTS 清除CR0中任务切换标志 (386+) CLTS 10 CMC CF取反,即¬CF⇒CF CMC 2 - - - - - C CMOVcc reg, src 条件成立src⇒reg, 16/32位 (586+) CMOVcc reg, reg 4~9 cc: 参见Jcc指令 CMOVcc reg, mem CMP dst, src 比较:dst-src,据此设置标志位 CMP reg, reg 1 O S Z A P C CMP reg, mem 2
附 录
·253·
续表 指 令 功 能 指 令 形 式 周期数 影响标志位
CMP reg, imm 1 CMP acc, imm 1 CMP mem, reg 2 CMP mem, imm 2 CMPSx 串比较:[(E)SI]-ES:[(E)DI], CMPSB 5 O S Z A P C 然后(E)SI, (E)DI增或减Δ(1/2/4) CMPSW
x: B, W, D 对应字节(1)、字(2)、双字(4)。DF=0 增,否则减
CMPSD
CMPXCHG dst, reg acc-dst, 等reg⇒dst,否则 dst⇒acc (486+)
CMPXCHG reg/mem,reg 5,6 O S Z A P C
CMPXCHG8B dst EDX:EAX-dst, 等 ECX:EBX⇒dst, 否则
EDX:EAX⇒dst (486+) CMPXCHG8B mem64 10 - - Z - - -
CPUID CPU标识⇒EAX,EBX,ECX,EDX CPUID 14 CWD AX符号扩展成DX:AX CWD 2 CWDE AX符号扩展成EAX CWDE 3 DAA 加法后的十进制调整 AL DAA 3 ? S Z A P CDAS 减法后的十进制调整 AL DAS 3 ? S Z A P CDEC opr opr 自减 1,即 opr-1⇒opr DEC reg 1 O S Z A P - DEC mem 3 DIV src 无符号除法 DIV reg 17~41 ? ? ? ? ? ? DIV mem
8 位:AX÷src,商⇒AL, 余数⇒AH 16 位:DX:AX÷src,商⇒AX, 余数
⇒DX 32 位 :EDX:EAX÷src, 商⇒EAX, 余数
⇒EDX
ENTER m, n 建 m 字节局部空间,n 级的栈帧 (286+) ENTER imm16, imm8 11+ HLT 暂停 CPU,直到 I/O 中断发生 HLT IDIV src 有符号除 IDIV reg 22~46 ? ? ? ? ? ? IDIV mem
8 位:AX÷src,商⇒AL, 余数⇒AH 16 位:DX:AX÷src,商⇒AX, 余数
⇒DX 32 位 :EDX:EAX÷src, 商⇒EAX, 余数
⇒EDX
IMUL src 有符号乘法 IMUL reg 10~11 O ? ? ? ? C 8 位:AL×src⇒AX IMUL mem 16 位:AX×src⇒DX:AX 32 位:EAX×src⇒EDX:EAX IMUL reg, src 有符号乘法 reg×src⇒reg (286+) IMUL reg, reg/mem 10 O ? ? ? ? C IMUL reg, src,imm 有符号乘法 src×imm⇒reg (286+) IMUL reg, reg/mem,imm 10 O ? ? ? ? C IN acc, src 端口数据⇒acc IN acc, imm8 7 IN acc, DX 7 INC opr opr 自加 1,即 opr+1⇒opr INC reg 1 O S Z A P - INC mem 3 INSx 端口 DX 数据⇒ES:[(E)DI], INSB 9
汇编语言程序设计
·254·
续表 指 令 功 能 指 令 形 式 周期数 影响标志位
然后(E)DI 增或减 Δ(1/2/4) INSW
x: B,W, D 对应字节(1)、字(2)、双字(4);若 DF=0 增,否则减
INSD
INT n FLAGS进栈,IF,TF置0,从[4n]双字单元
取 INT 3 INT+5
段和偏移地址,并转去执行 (实地址模
式) INT imm8 INT+6
INTO 若 OF=1,则执行 INT 4 INTO 4,INT+5 INVD 使 Cache 无效 INVD 15 INVLPG 使 TLB 入口无效 INVLPG 29 IRET 中断返回:从堆栈弹出返回的偏移 IRET 7 和段地址,再弹出标志寄存器内容 Jcc opr 条件满足,则转移至 opr Jcc label 1 JA/JNBE opr 高于(CF=0∧ZF=0) JA/JNBE label JAE/JNB/JNC opr 高于等于(CF=0) JAE/JNB/JNC label JB/JC/JNAE opr 低于(CF=1) JB/JC/JNAE label JBE/JNA opr 低于等于(CF=1∨ZF=1) JBE/JNA label JE/JZ opr 等于(ZF=1) JE/JZ label JG/JNLE opr 大于(ZF=0∧SF=OF) JG/JNLE label JGE/JNL opr 大于等于(SF=OF) JGE/JNL label JL/JNGE opr 小于(SF≠OF) JL/JNGE label JLE/JNG opr 小于等于(ZF=1∨SF≠OF) JLE/JNG label JNE/JNZ opr 不等于(ZF=0) JNE/JNZ label JNO opr 无溢出(OF=0) JNO label JNS opr 非负数(SF=0) JNS label JO opr 溢出(OF=1) JO label JP/JPE opr 有偶数个 1(PF=1) JP/JPE label JPO/JNP opr 有奇数个 1(PF=0) JPO/JNP label JS opr 负数(SF=1) JS label JCXZ opr 若 CX=0,则转移至 opr JCXZ label 6/5 JECXZ opr 若 ECX=0,则转移至 opr JECXZ label 6/5 JMP opr 转移至 opr JMP label (near) 1 近:转移后仅可改变(E)IP JMP reg (near) 2 远:转移后可改变(E)IP 和 CS JMP mem (near) 2 JMP label (far) 3 JMP mem (far) 4 LAHF 标志寄存器低字节⇒AH LAHF 2 - - - - - - LAR reg, dst 将 dst 指定的选择器访问权⇒reg LAR reg, reg/mem 8 - - Z - - - LDS reg, mem 将 mem 内容⇒DS : reg LDS reg, mem 4 LEA reg, mem 将 mem 的偏移地址⇒reg LEA reg, mem 1
LEAVE 释放栈帧,即: (E)BP⇒(E)SP,POP (E)BP LEAVE 3
附 录
·255·
续表 指 令 功 能 指 令 形 式 周期数 影响标志位
LES reg, mem 将 mem 内容⇒ES : reg LES reg, mem 4 LFS reg, mem 将 mem 内容⇒FS : reg (386+) LFS reg, mem 4 LGDT mem 将 mem 内容⇒GDTR (286+) LGDT mem 6 LGS reg, mem 将 mem 内容⇒GS : reg (386+) LGS reg, mem 4 LIDT mem 将 mem 内容⇒IDTR (286+) LIDT mem 6 LLDT src src⇒LDTR (286+) LLDT reg/mem 8 LMSW src src⇒机器状态字(CR0低 16 位) (286+) LMSW reg/mem 8 LOCK 总线锁 (以便其他处理器处理指令) LOCK 1 LODSx 从串取:[(E)SI]⇒acc, LODSB 2 然后(E)SI 增或减 Δ(1/2/4) LODSW
x: B, W, D 对应字节(1)、字(2)、双字(4);若 DF=0 增,否则减
LODSD
LOOP opr (E)CX 自减 1, 若(E)CX≠0 则转移 LOOP label 5/6
LOOPE/LOOPZ opr (E)CX自减 1, 若ZF=1∧(E)CX≠0则转
移 LOOPE/LOOPZ label 7/8
LOOPNE/LOOPNZ opr
(E)CX自减 1, 若ZF=0∧(E)CX≠0则转
移 LOOPNE/LOOPNZ label 7/8
LSL reg, src src 选择器确定的段界⇒reg (286+) LSL reg, reg/mem 8 - - Z - - - LSS reg, mem 将 mem 内容⇒SS : reg (386+) LSS reg, mem 4 LTR src src⇒任务寄存器 TR (286+) LTR reg16/mem16 10 MOV dst, src 数据传送:src⇒dst MOV reg, reg 1 MOV reg, mem 1 MOV reg, imm 1 MOV mem, reg 1 MOV mem, imm 1 MOV acc, mem 1 MOV mem, acc 1 MOV dst, src 控制寄存器内容传送 (386+) MOV reg32, CRi 4 CRi⇒reg32, reg32⇒CRi (i=0,2,3,4) MOV CRi, reg32 12~22 MOV dst, src 调试寄存器内容传送 (386+) MOV reg32, DRi 2~12 DRi⇒reg32, reg32⇒DRi (i=0~7) MOV DRi, reg32 11~12 MOV dst, src 段寄存器内容传送 MOV reg/mem, seg 1 seg⇒dst, src⇒seg(CS 除外) MOV seg, reg/mem 2~12 MOVSx 串传送: [(E)SI]⇒ES:[(E)DI], 然 MOVSB 4 后(E)SI、(E)DI 增或减 Δ(1/2/4) MOVSW
x: B, W, D 对应字节(1)、字(2)、双字(4);若 DF=0 增,否则减
MOVSD
MOVSX reg, src src 经符号扩展后⇒reg (386+) MOVSX reg, reg/mem 3 MOVZX reg, src src 经 0 扩展后⇒reg (386+) MOVZX reg, reg/mem 3 MUL src 无符号乘法 MUL reg 10~11 O ? ? ? ? C 8 位:AL×src⇒AX MUL mem 16 位:AX×src⇒DX:AX 32 位:EAX×src⇒EDX:EAX
汇编语言程序设计
·256·
续表 指 令 功 能 指 令 形 式 周期数 影响标志位
NEG opr opr 求补(负),即-opr⇒opr NEG reg 1 O S Z A P C NEG mem 3 NOP 空操作 NOP 1 NOT opr opr 按位取反,即:¬opr⇒opr NOT reg 1 O S Z A P C NOT mem 3 OR dst, src 逻辑或,dst∨src⇒dst OR reg, reg 1 0 S Z ? P 0 OR reg, mem 2 OR reg, imm 1 OR mem, reg 3 OR mem, imm 3 OR acc, imm 1 OUT dst, acc acc 内容⇒端口 dst OUT imm8, acc 12 OUT DX, acc 12 OUTSx [(E)SI]内容⇒DX 端口, (386+) OUTSB 13 然后(E)SI 增或减 Δ(1/2/4) OUTSW
x: B, W, D 对应字节(1)、字(2)、双字(4);若 DF=0 增,否则减
OUTSD
POP dst 从堆栈弹出数据⇒dst POP reg 1 ((E)SP 增 2 或 4, seg 不能为 CS) POP mem 3 POP seg 3~12 POPA 数据出栈⇒DI, SI, BP, BX, DX, CX,
AX (SP 增 2×8) (286+)
POPA 5
POPAD 堆 栈 弹 出 数 据 ⇒EDI,ESI,EBP,EBX,EDX, ECX,EAX ((E)SP 增 4×8) (386+)
POPAD 5
POPF 数 据 出 栈 ⇒FLAGS ((E)SP 增 2) (286+) POPF 4 O S Z A P C
POPFD 数 据 出 栈⇒EFLAGS ((E)SP 增 4) (386+) POPFD 4 O S Z A P C
PUSH src src 数据进栈 ((E)SP 减 2/4) PUSH reg 1 (reg32,mem32,imm, 386+) PUSH mem 2 PUSH imm 1 PUSH seg 1 PUSHA AX,CX,DX,BX,SP,BP,SI,DI 进栈,
(SP 减 2×8) (286+) PUSHA 5
PUSHAD EAX,ECX,EDX,EBX,ESP,EBP,ESI,EDI进 栈, ((E)SP 减 4×8) (386+)
PUSHAD 5
PUSHF FLAGS 进栈 ((E)SP 减 2) (286+) PUSHF 3 PUSHFD EFLAGS 进栈 ((E)SP 减 4) (386+) PUSHFD 3 RCL dst, n dst 带进位循环左移 n 位 RCL reg, 1 1 O … C RCL mem, 1 3 RCL reg, CL 7~24
dst CF RCL mem, CL 9~26
附 录
·257·
续表 指 令 功 能 指 令 形 式 周期数 影响标志位
注:n 为 imm8 是 386+支持 RCL reg, imm8 8~25 RCL mem, imm8 10~27 RCR dst, n dst 带进位循环右移 n 位 RCR reg, 1 1 O - - - - C RCR mem, 1 3 RCR reg, CL 7~24 RCR mem, CL 9~26 注:n 为 imm8 时,386+支持 RCR reg, imm8 8~25 RCR mem, imm8 10~27 RDMSR MSR[ECX] ⇒EDX:EAX (586+) RDMSR 20~24 REP 串指令 当(E)CX≠0 重复{(E)CX 自减 1, REP INSx 11+3n 再执行其后的串指令} REP LODSx 7+3n REP MOVSx 6,13n REP OUTSx 13+4n REP STOSx 6,9+3n REPE/REPZ 串指令 当(E)CX≠0∧ZF=1 重复{(E)CX 自 REPE/REPZ CMPSx 7,8+4n O S Z A P C 减 1,再执行其后的串指令} REPE/REPZ SCASx 7,8+4n
REPNE/REPNZ CMPSx 7,8+4n O S Z A P CREPNE/REPNZ 串指令
当(E)CX≠0∧ZF=0 重复{(E)CX 自减 1,再执行其后的串指令} REPNE/REPNZ SCASx 7,8+4n
RET [n] 子程序返回:从堆栈弹出返回地 RETN 2 址,若有 n 则返回后(E)SP 再增 n RETF 4 近返回 RETN:只弹出偏移地址 RETN imm16 3 远返回 RETF:弹出偏移和段地址 RETF imm16 4 ROL dst, n dst 循环左移 n 位 ROL reg, 1 1 O … C ROL mem, 1 3 ROL reg, CL 4 ROL mem, CL 4
注:n 为 imm8 是 386+支持 ROL reg, imm8 1 ROL mem, imm8 3 ROR dst, n dst 循环右移 n 位 ROR reg, 1 1 O … C ROR mem, 1 3 ROR reg, CL 4 ROR mem, CL 4
注:n 为 imm8 是 386+支持 ROR reg, imm8 1 ROR mem, imm8 3 RSM 从系统管理方式恢复 RSM O S Z A P CSAHF AH⇒标志寄存器的低 8 位 SAHF 1 - S Z A P C SAL dst, n dst 算术左移 n 位,即 dst×2n⇒dst SAL reg, 1 1 O … C SAL mem, 1 3 SAL reg, CL 4 SAL mem, CL 4 注:n 为 imm8 时,386+支持 SAL reg, imm8 1
汇编语言程序设计
·258·
续表
指 令 功 能 指 令 形 式 周期数 影响标志位
SAL mem, imm8 3
SAR dst, n dst 算术右移 n 位,即 dst÷2n⇒dst SAR reg, 1 1 O … C
SAR mem, 1 3
SAR reg, CL 4
SAR mem, CL 4
注:n 为 imm8 是 386+支持 SAR reg, imm8 1
SAR mem, imm8 3
SBB dst, src 带借位减法:dst-src-CF⇒dst SBB reg, reg 1 O S Z A P C
SBB reg, mem 2
SBB reg, imm 1
SBB acc, imm 1
SBB mem, reg 3
SBB mem, imm 3
SCASx 串扫描:acc-ES:[(E)DI], SCASB 4 O S Z A P C
然后(E)DI 增或减 Δ(1/2/4) SCASW
x: B, W, D 对应字节(1)、字(2)、双字
(4);若 DF=0 增,否则减 SCASD
SETcc dst 条件真,1⇒dst,否则 0⇒dst, cc 见 Jcc(386+) SETcc reg8/mem8 3~8
SGDT mem GDTR⇒mem (286+) SGDT mem 4
SHL dst, n dst 逻辑左移 n 位,与 SAL 相同 SHL/SAL 是一条指令
SHLD dst, reg, n 双精度左移 (操作数:16/32 位)(386+) SHLD reg/mem, reg, imm8 4 ? S Z ? P C
SHLD reg/mem, reg, CL
SHR dst, n dst 逻辑右移 n 位 SAR reg, 1 1 O … C
SAR mem, 1 3
SAR reg, CL 4
SAR mem, CL 4
注:n 为 imm8 时,386+支持 SAR reg, imm8 1
SAR mem, imm8 3
SHRD dst, reg, n 双精度右移 (操作数:16/32 位)(386+) SHLD reg/mem, reg, imm8 4 ? S Z ? P C
SHLD reg/mem, reg, CL
SIDT mem IDTR⇒mem SIDT mem 4
SLDT dst LDTR⇒dst SLDT reg/mem 2
SMSW dst 机器状态字(CR0低16位)⇒dst (286+) SMSW reg/mem 4
STC CF 置 1 STC 2 - - - - - 1
STD DF 置 1 STD 2
附 录
·259·
续表
指 令 功 能 指 令 形 式 周期数 影响标志位
STI IF 置 1,即开中断 STI 7
STOSx 串存入:acc⇒ES:[(E)DI], STOSB 3
然后(E)DI 增或减 Δ(1/2/4) STOSW
x: B, W, D 对应字节(1)、字(2)、双字(4);若 DF=0 增,否则减
STOSD
STR dst 任务寄存器 TR⇒dst STR reg/mem16 2
SUB dst, src 减法:dst-src⇒dst SUB reg, reg 1 O S Z A P C
SUB reg, mem 2
SUB reg, imm 1
SUB acc, imm 1
SUB mem, reg 3
SUB mem, imm 3
TEST dst, src 与测试,dst∧src 据此设置标志位 TEST reg, reg 2 0 S Z ? P 0
TEST reg, mem 1
TEST reg, imm 1
TEST acc, imm 1
TEST mem, imm 2
VERR src 若 src 确定的段可读,1⇒ZF,否则
0⇒ZF VERR reg/mem16 7 …Z…
VERW src 若 src 确定的段可写,1⇒ZF,否则
0⇒ZF VERW reg/mem16 7 …Z…
WAIT 等待,检查挂起未屏蔽的浮点异常 WAIT 1
WBINVD 写回 Cache,并使之无效 (486+) WBINVD 2000+
WRMSR EDX:EAX⇒MSR[ECX] (586+) WRMSR 30~35
XADD dst, src dst⇔src,再 dst+src⇒dst (486+) XADD reg/mem, reg 3,4 O S Z A P C
XCHG dst, src dst, src 内容交换,即 dst⇔src XCHG reg/mem, reg 3
XCHG acc, reg 2
XLAT/XLATB 查表换码:(E)BX+AL 确定的单元值
⇒AL XLAT 4
XOR dst, src 逻辑异或,dst⊕src⇒dst XOR reg, reg 1 0 S Z ? P 0
XOR reg, mem 2
XOR reg, imm 1
XOR acc, imm 1
XOR mem, reg 3
XOR mem, imm 3

汇编语言程序设计
·260·
附录 B 编程练习环境说明
1. 编程练习软件包
附带软件包 x86ASM 是在 Microsoft 的 MASM 6.15 软件包的基础上,加入 CodeView、
Win32 的开发工具及 Turbo C 2.0 等,进行简单整理而成的,以便初学者编程练习使用。 软件包中的基本文件有: MASM.EXE 汇编程序 LINK.EXE 连接程序 ML.EXE 汇编连接程序(自动调用 LINK.EXE) ML.ERR 汇编错误信息文件 LIB.EXE 子程序库管理程序 LIB16.EXE 16 位子程序管理程序 LINK16.EXE 生成 DOS 程序的连接程序 LIB32.EXE Win32 的库管理程序 LINK32.EXE 生成 Win32 程序的连接程序 CV 目录 CodeView 调试程序 CV.EXE 及相应的环境 INC32 目录 Win32 的 API 的函数库声明文件 LIB32 目录 Win32 的 API 的函数库 TC 目录 Turbo C 2.0 命令行环境和集成环境 SET2ML16.BAT ML 默认使用 LINK16.EXE 连接程序 SET2ML32.BAT ML 默认使用 LINK32.EXE 连接程序 使用这个软件包既可以用来练习编写 DOS 环境下的应用程序,也可以用来练习编写
Win32 环境下的应用程序。 提供 TC 的目的是用它来练习 16 位环境下汇编语言程序模块和 C 程序模块的连接。
2. DOS 系统下的编程练习环境
真正的 DOS 是运行在实模式下的一个操作系统,所以 DOS 程序是运行在 16 位地址模式
下的。这种模式下的程序具有这样的特点: (1) 偏移地址是 16 位,所表示的偏移地址只能是 0~64K-1。在默认情况下,指令处理
的数据类型是 16 位的,但也可以处理 32 位数据。 (2) 应用程序可以访问所有的计算机系统资源,可以使用 I/O 指令直接与外设交换数据,
也可以用 INT 指令调用 DOS 环境下的系统功能(DOS 和 BIOS)。 在 DOS 系统下有很多系统功能调用可用,但是这里仅将 DOS 环境作为编程练习的平台,
所以只须如下所述的很少几个系统功能就足够了,主要解决字符的输入、输出,以及应用程
序退出返回。如果读者需要开发 DOS 系统下的应用程序,则必须另外参阅相关的系统资料
手册。 1) 编程练习所用的 DOS 系统调用 (1) 功能 01h。从标准输入设备输入一个字符,并回显。

附 录
·261·
入口:AH=01h 出口:AL=输入字符的 ASCII 码 (2) 功能 02h。向标准输出设备输出一个字符。 入口:AH=02h DL=待输出字符的 ASCII 码 出口:无 (3) 功能 08h。从标准输入设备输入一个字符,无回显。 入口:AH=08h 出口:AL=输入字符的 ASCII 码 (4) 功能 09h。输出一个字符串到标准输出设备上。 入口:AH=09h DS:DX=待输出字符串的地址(字符串须以'$'作为其结束标志) 出口:无 (5) 功能 0Ah。从标准输入设备上读入字符串(以回车结束,有回显)。 入口:AH=0Ah DS:DX=输入缓冲区地址(字节 0 须填入允许输入字符数)。 出口:输入缓冲区字节 1 存放输入的字符数,字节 2 起存放输入的字符串 (6) 功能 0Bh。检查标准输入设备上是否有字符可读。 入口:AH=0Bh 出口:AL=00h——无字符可读;FFh——有字符可读 (7) 功能 4Ch。终止程序的执行,并可返回一个代码。 入口:AH=4Ch AL=返回的代码 出口:无 2) 示例程序 Demo16.ASM 编写程序 Demo16.ASM,输入一个字符和一个字符串,并显示。 _STACK SEGMENT STACK 'STACK' USE16 ; 定义堆栈段 DB 2046 DUP(0) ; 堆栈区长度:2KB TOS DW 0 ; 初始堆栈栈顶 _STACK ENDS ; 堆栈段定义结束 _DATA SEGMENT 'DATA' USE16 ; 定义数据段 Msg DB 13, 10, 'Hello, World!', 13,10,'$' C1 DB 13, 10, 'Character is: *', 13, 10, '$' S2 DB 13, 10, 'Buffer content is: ' Buffer DB 9, 0, 10 DUP('*'), 13, 10, '$' _DATA ENDS ; 数据段定义结束 _TEXT SEGMENT 'CODE' USE16 ; 定义代码段 ASSUME CS: _TEXT, DS:_DATA, SS:_STACK Start: MOV AX, _DATA ; 取数据内存区段地址 MOV DS, AX ; 设置数据段寄存器 CLI ; 设置堆栈期间禁止响应中断 MOV AX, _STACK ; 取堆栈内存区段地址 MOV SS, AX ; 设置堆栈段寄存器

汇编语言程序设计
·262·
MOV SP, Offset TOS ; 设置初始状态时的堆栈指针 STI ; 堆栈设置完毕,允许中断 MOV DX, Offset Msg MOV AH, 9 INT 21h ; 中断 21h的 9号功能,显示字符串 MOV AH, 1 INT 21h MOV S2-4, AL MOV DX, Offset C1 MOV AH, 9 INT 21H MOV DX, Offset Buffer MOV AH, 0Ah INT 21h MOV BL, Buffer[1] MOV BH, 0 MOV Buffer[BX+2], '#' ADD Buffer[0], '0' ADD Buffer[1], '0' MOV DX, Offset S2 MOV AH, 9 INT 21H MOV AX, 4C00h INT 21h ; 运行结束,返回 DOS _TEXT ENDS ; 代码段定义结束 END Start ; 源程序到此为止 3) 汇编连接 须汇编成 OMF 格式的目标代码(.OBJ),使用 LINK16.EXE 连接程序。如果 ML 默认使用
的是 LINK32.EXE,那么可执行 SET2ML16,(用 LINK16.EXE 和 LIB16.EXE 覆盖原来的
LINK.EXE 和 LIB.EXE)将 LINK16.EXE 设置成为 ML 默认调用的连接程序。 ML 的 /omf 选项是生成 OMF 格式的目标码,未指定则默认使用 /omf。 汇编:ML /c Demo16.ASM; 连接:LINK Demo16.OBJ; 或汇编、连接:ML Demo16.ASM。
3. Win32 的编程练习环境
Win32 的应用程序使用 32 位地址模式,所以一般应用程序具有以下特点: (1) 偏移地址是 32 位,所表示的偏移地址是 0~4G-1。在默认情况下,指令处理的数据
类型是 32 位的。 (2) 操作系统对应用程序访问的计算机系统资源有所限制,所有危及系统安全的行为均被
禁止。不允许应用程序使用指令直接访问 I/O 接口等,也不能够简单地使用 INT 指令,与外
设交换数据的操作调用系统内部功能必须通过系统的 API 进行。用户也不能够为应用程序设
置数据段、堆栈段及代码段,所有的内存段安排均由操作系统在运行时自动安排。 Win32 的应用程序分为 Console 和 Windows 两种类型,而且系统提供的 API 数目很多,
作为编程练习我们选用 Console 类型,仅用几个 API。如果读者需要用汇编语言开发 Win32的应用程序,则查阅相关的系统资料手册。

附 录
·263·
1) 编程练习用的 API 说明 Win32 的 API 使用 STDCALL 调用类型,在汇编源程序中必须按照此规则来调用。下面
按照 VC 中的说明规则来介绍它们。这些函数的可通过 Kernel32.LIB 导入。 (1) _stdcall HANDLE GetStdHandle( DWORD nStdHandle ); 根据标准设备号得到对应的句柄号。返回值存放在 EAX 中。 nStdHandle 标准设备号。在 Win32 中,标准输入、输出号定义为-10, -11。 (2) _stdcall bool ReadConsoleA( HANDLE hConsoleInput, //输入设备句柄 LPVOID lpBuffer, //输入缓冲区 DWORD nNumberOfCharsToRead, //允许输入的字符数 LPDWORD lpNumberOfCharsRead, //存放实际输入的字符数 LPVOID lpReserved //保留,一般置 0 ); 从标准输入设备输入若干字符,字符数由 nNumberOfCharsToRead 指定,输入以回车(实
际上是回车、换行两个字符)结束。当返回值为 true 时,lpNumberOfCharsRead 中存放的是实
际输入的字符数,若返回值为 false,则表明输入过程中发生了错误。 (3) _stdcall bool WriteConsoleA( HANDLE hConsoleOutput, //输出设备句柄 LPVOID lpBuffer, //输出缓冲区 DWORD nNumberOfCharsToWrite, //需要输出的字符数 LPDWORD lpNumberOfCharsWritten, //存放实际输出的字符数 LPVOID lpReserved //保留,一般置 0 ); 向标准输出设备输出若干字符,字符数由 nNumberOfCharsToWrite 指定。当返回值为 true
时,lpNumberOfCharsWritten 中存放的是实际输出的字符数,若返回值为 false,则表明在输
出过程中发生了错误。 (4) _stdcall void ExitProcess( UINT uExitCode ); 终止程序执行返回操作系统。uExitCode 是返回码。 2) 示例程序 Demo32.ASM 编写程序 Demo32.ASM,输入一个字符和一个字符串,并显示。作为 Console 类型的 Win32
程序,为方便连接程序正确选择模式,入口标号必须用_main。 .386 INCLUDELIB KERNEL32.LIB Extrn_ExitProcess@4:Near,_GetStdHandle@4:Near,_ReadConsoleA@20:Near, _WriteConsoleA@20:Near _DATA SEGMENT 'DATA' USE32 ; 定义数据段 Msg DB 13, 10, 'Hello, World!', 13,10 S2 DB 13, 10, 'Buffer content is: ' Buffer DB 10 DUP('*'), 13, 10 Num DD ? Handle DD ?, ? _DATA ENDS ; 数据段定义结束

汇编语言程序设计
·264·
_TEXT SEGMENT USE32 'CODE' ; 定义代码段 ASSUME CS: _TEXT, DS:_DATA _main: PUSH -10 CALL _GetStdHandle@4 MOV Handle, EAX PUSH -11 CALL _GetStdHandle@4 MOV Handle+4, EAX PUSH 0 PUSH Offset Num PUSH 10 PUSH Offset Buffer PUSH Handle CALL _ReadConsoleA@20 PUSH 0 PUSH Offset Num PUSH Num-Msg PUSH Offset Msg PUSH Handle+4 CALL _WriteConsoleA@20 PUSH 0 CALL _ExitProcess@4 ; 运行结束,返回系统 _TEXT ENDS ; 代码段定义结束 END _main ; 源程序到此为止 3) 汇编连接 Win32 源程序 必须汇编成 COFF 格式的目标代码(.OBJ),使用 LINK32.EXE 连接程序。如果 ML 默认
使用的是 LINK16.EXE,那么可执行 SET2ML32,(用 LINK32.EXE 和 LIB32.EXE 覆盖原来的
LINK.EXE 和 LIB.EXE)将 LINK32.EXE 设置成为 ML 默认调用的连接程序。 必须指定 ML 的 /coff 选项,否则生成的是 OMF 格式的目标码。 汇编:ML /c /coff Demo32.ASM; 连接:LINK Demo32.OBJ; 或汇编、连接:ML /coff Demo32.ASM。

附录 B 编程练习环境说明
1. 编程练习软件包
附带软件包 x86ASM 是在 Microsoft 的 MASM 6.15 软件包的基础上,加入 CodeView、
Win32 的开发工具及 Turbo C 2.0 等,进行简单整理而成的,以便初学者编程练习使用。 软件包中的基本文件有: MASM.EXE 汇编程序 LINK.EXE 连接程序 ML.EXE 汇编连接程序(自动调用 LINK.EXE) ML.ERR 汇编错误信息文件 LIB.EXE 子程序库管理程序 LIB16.EXE 16 位子程序管理程序 LINK16.EXE 生成 DOS 程序的连接程序 LIB32.EXE Win32 的库管理程序 LINK32.EXE 生成 Win32 程序的连接程序 CV 目录 CodeView 调试程序 CV.EXE 及相应的环境 INC32 目录 Win32 的 API 的函数库声明文件 LIB32 目录 Win32 的 API 的函数库 TC 目录 Turbo C 2.0 命令行环境和集成环境 SET2ML16.BAT ML 默认使用 LINK16.EXE 连接程序 SET2ML32.BAT ML 默认使用 LINK32.EXE 连接程序 使用这个软件包既可以用来练习编写 DOS 环境下的应用程序,也可以用来练习编写
Win32 环境下的应用程序。 提供 TC 的目的是用它来练习 16 位环境下汇编语言程序模块和 C 程序模块的连接。
2. DOS 系统下的编程练习环境
真正的 DOS 是运行在实模式下的一个操作系统,所以 DOS 程序是运行在 16 位地址模式
下的。这种模式下的程序具有以下特点。 (1) 偏移地址是 16 位,所表示的偏移地址只能是 0~64K-1。在默认情况下,指令处理的
数据类型是 16 位的,但也可以处理 32 位数据。 (2) 应用程序可以访问所有的计算机系统资源,可以使用 I/O 指令直接与外设交换数据,
也可以用 INT 指令调用 DOS 环境下的系统功能(DOS 和 BIOS)。 在 DOS 系统下有很多系统功能调用可用,但是这里仅将 DOS 环境作为编程练习的平台,
所以只须如下所述的很少几个系统功能就足够了,主要解决字符的输入、输出,以及应用程序
退出返回。如果读者需要开发 DOS 系统下的应用程序,则必须另外参阅相关的系统资料手册。 1) 编程练习所用的 DOS 系统调用 (1) 功能 01h。从标准输入设备输入一个字符,并回显。

汇编语言程序设计
·262·
入口:AH=01h 出口:AL=输入字符的 ASCII 码 (2) 功能 02h。向标准输出设备输出一个字符。 入口:AH=02h DL=待输出字符的 ASCII 码 出口:无 (3) 功能 08h。从标准输入设备输入一个字符,无回显。 入口:AH=08h 出口:AL=输入字符的 ASCII 码 (4) 功能 09h。输出一个字符串到标准输出设备上。 入口:AH=09h DS:DX=待输出字符串的地址(字符串须以'$'作为其结束标志) 出口:无 (5) 功能 0Ah。从标准输入设备上读入字符串(以回车结束,有回显)。 入口:AH=0Ah DS:DX=输入缓冲区地址(字节 0 须填入允许输入字符数)。 出口:输入缓冲区字节 1 存放输入的字符数,字节 2 起存放输入的字符串 (6) 功能 0Bh。检查标准输入设备上是否有字符可读。 入口:AH=0Bh 出口:AL=00h——无字符可读;FFh——有字符可读 (7) 功能 4Ch。终止程序的执行,并可返回一个代码。 入口:AH=4Ch AL=返回的代码 出口:无 2) 示例程序 Demo16.ASM 编写程序 Demo16.ASM,输入一个字符和一个字符串,并显示。 _STACK SEGMENT STACK 'STACK' USE16 ; 定义堆栈段 DB 2046 DUP(0) ; 堆栈区长度:2KB TOS DW 0 ; 初始堆栈栈顶 _STACK ENDS ; 堆栈段定义结束 _DATA SEGMENT 'DATA' USE16 ; 定义数据段 Msg DB 13, 10, 'Hello, World!', 13,10,'$' C1 DB 13, 10, 'Character is: *', 13, 10, '$' S2 DB 13, 10, 'Buffer content is: ' Buffer DB 9, 0, 10 DUP('*'), 13, 10, '$' _DATA ENDS ; 数据段定义结束 _TEXT SEGMENT 'CODE' USE16 ; 定义代码段 ASSUME CS: _TEXT, DS:_DATA, SS:_STACK Start: MOV AX, _DATA ; 取数据内存区段地址 MOV DS, AX ; 设置数据段寄存器 CLI ; 设置堆栈期间禁止响应中断 MOV AX, _STACK ; 取堆栈内存区段地址 MOV SS, AX ; 设置堆栈段寄存器

附录 B 编程练习环境说明
·263·
MOV SP, Offset TOS ; 设置初始状态时的堆栈指针 STI ; 堆栈设置完毕,允许中断 MOV DX, Offset Msg MOV AH, 9 INT 21h ; 中断 21h的 9号功能,显示字符串 MOV AH, 1 INT 21h MOV S2-4, AL MOV DX, Offset C1 MOV AH, 9 INT 21H MOV DX, Offset Buffer MOV AH, 0Ah INT 21h MOV BL, Buffer[1] MOV BH, 0 MOV Buffer[BX+2], '#' ADD Buffer[0], '0' ADD Buffer[1], '0' MOV DX, Offset S2 MOV AH, 9 INT 21H MOV AX, 4C00h INT 21h ; 运行结束,返回 DOS _TEXT ENDS ; 代码段定义结束 END Start ; 源程序到此为止 3) 汇编连接 须汇编成 OMF 格式的目标代码(.OBJ),使用 LINK16.EXE 连接程序。如果 ML 默认使用
的是 LINK32.EXE,那么可执行 SET2ML16,(用 LINK16.EXE 和 LIB16.EXE 覆盖原来的
LINK.EXE 和 LIB.EXE)将 LINK16.EXE 设置成为 ML 默认调用的连接程序。 ML 的 /omf 选项是生成 OMF 格式的目标码,未指定则默认使用 /omf。 汇编:ML /c Demo16.ASM; 连接:LINK Demo16.OBJ; 或汇编、连接:ML Demo16.ASM。
3. Win32 的编程练习环境
Win32 的应用程序使用 32 位地址模式,所以一般应用程序具有以下特点。 (1) 偏移地址是 32 位,所表示的偏移地址是 0~4G-1。在默认情况下,指令处理的数据
类型是 32 位的。 (2) 操作系统对应用程序访问的计算机系统资源有所限制,所有危及系统安全的行为均被
禁止。不允许应用程序使用指令直接访问 I/O 接口等,也不能够简单地使用 INT 指令,与外
设交换数据的操作调用系统内部功能必须通过系统的 API 进行。用户也不能够为应用程序设
置数据段、堆栈段及代码段,所有的内存段安排均由操作系统在运行时自动安排。 Win32 的应用程序分为 Console 和 Windows 两种类型,而且系统提供的 API 数目很多,
作为编程练习我们选用 Console 类型,仅用几个 API。如果读者需要用汇编语言开发 Win32的应用程序,则查阅相关的系统资料手册。

汇编语言程序设计
·264·
1) 编程练习用的 API 说明 Win32 的 API 使用 STDCALL 调用类型,在汇编源程序中必须按照此规则来调用。下面
按照 VC 中的说明规则来介绍它们。这些函数的可通过 Kernel32.LIB 导入。 (1) _stdcall HANDLE GetStdHandle( DWORD nStdHandle ); 根据标准设备号得到对应的句柄号。返回值存放在 EAX 中。 nStdHandle 标准设备号。在 Win32 中,标准输入、输出号定义为-10,-11。 (2) _stdcall bool ReadConsoleA( HANDLE hConsoleInput, //输入设备句柄 LPVOID lpBuffer, //输入缓冲区 DWORD nNumberOfCharsToRead, //允许输入的字符数 LPDWORD lpNumberOfCharsRead, //存放实际输入的字符数 LPVOID lpReserved //保留,一般置 0 ); 从标准输入设备输入若干字符,字符数由 nNumberOfCharsToRead 指定,输入以回车(实
际上是回车、换行两个字符)结束。当返回值为 true 时,lpNumberOfCharsRead 中存放的是实
际输入的字符数,若返回值为 false,则表明输入过程中发生了错误。 (3) _stdcall bool WriteConsoleA( HANDLE hConsoleOutput, //输出设备句柄 LPVOID lpBuffer, //输出缓冲区 DWORD nNumberOfCharsToWrite, //需要输出的字符数 LPDWORD lpNumberOfCharsWritten, //存放实际输出的字符数 LPVOID lpReserved //保留,一般置 0 ); 向标准输出设备输出若干字符,字符数由 nNumberOfCharsToWrite 指定。当返回值为 true
时,lpNumberOfCharsWritten 中存放的是实际输出的字符数,若返回值为 false,则表明在输
出过程中发生了错误。 (4) _stdcall void ExitProcess( UINT uExitCode ); 终止程序执行返回操作系统。uExitCode 是返回码。 2) 示例程序 Demo32.ASM 编写程序 Demo32.ASM,输入一个字符和一个字符串,并显示。作为 Console 类型的 Win32
程序,为方便连接程序正确选择模式,入口标号必须用_main。 .386 INCLUDELIB KERNEL32.LIB Extrn_ExitProcess@4:Near,_GetStdHandle@4:Near,_ReadConsoleA@20:Near, _WriteConsoleA@20:Near _DATA SEGMENT 'DATA' USE32 ; 定义数据段 Msg DB 13, 10, 'Hello, World!', 13,10 S2 DB 13, 10, 'Buffer content is: ' Buffer DB 10 DUP('*'), 13, 10 Num DD ? Handle DD ?, ? _DATA ENDS ; 数据段定义结束

附录 B 编程练习环境说明
·265·
_TEXT SEGMENT USE32 'CODE' ; 定义代码段 ASSUME CS: _TEXT, DS:_DATA _main: PUSH -10 CALL _GetStdHandle@4 MOV Handle, EAX PUSH -11 CALL _GetStdHandle@4 MOV Handle+4, EAX PUSH 0 PUSH Offset Num PUSH 10 PUSH Offset Buffer PUSH Handle CALL _ReadConsoleA@20 PUSH 0 PUSH Offset Num PUSH Num-Msg PUSH Offset Msg PUSH Handle+4 CALL _WriteConsoleA@20 PUSH 0 CALL _ExitProcess@4 ; 运行结束,返回系统 _TEXT ENDS ; 代码段定义结束 END _main ; 源程序到此为止 3) 汇编连接 Win32 源程序 必须汇编成 COFF 格式的目标代码(.OBJ),使用 LINK32.EXE 连接程序。如果 ML 默认
使用的是 LINK16.EXE,那么可执行 SET2ML32,(用 LINK32.EXE 和 LIB32.EXE 覆盖原来的
LINK.EXE 和 LIB.EXE)将 LINK32.EXE 设置成为 ML 默认调用的连接程序。 必须指定 ML 的 /coff 选项,否则生成的是 OMF 格式的目标码。 汇编:ML /c /coff Demo32.ASM; 连接:LINK Demo32.OBJ; 或汇编、连接:ML /coff Demo32.ASM。

参 考 文 献
[1] 沈美明,温冬婵. IBM-PC 汇编语言程序设计[M]. 2 版. 北京:清华大学出版社,2001.
[2] 马力妮. 80x86 汇编语言程序设计[M]. 北京:机械工业出版社,2004.
[3] 徐建民,王东,邵艳华. 汇编语言程序设计[M]. 2 版. 北京:电子工业出版社,2005.
[4] 葛建梅. 汇编语言程序设计[M]. 北京:中国水利水电出版社,2005.
[5] 蒋本珊. 计算机组成原理[M]. 北京:清华大学出版社,2004.
[6] 王诚,刘卫东,宋佳兴. 计算机组成与体系结构[M]. 北京:清华大学出版社,2004.
[7] 穆玲玲,钱晓捷. 32 位汇编语言程序设计[M]. 北京:电子工业出版社,2007.
[8] 李浪,熊江,睦仁武. 汇编语言程序设计[M]. 武汉:武汉大学出版社,2007.
[9] 赵树升,杨建军. DOS/Windows 汇编语言程序设计教程[M]. 北京:清华大学出版社,2005.
[10] 谭毓安,张雪兰. Windows 汇编语言程序设计教程[M]. 北京:电子工业出版社,2005.
[11] 葛洪伟. Intel 汇编语言程序设计[M]. 北京:中国电力出版社,2007.
[12] 王正智. 8086/8088 宏汇编语言程序设计教程[M]. 2 版. 北京:电子工业出版社,2002.
[13] 曹加恒. 80386/80486 高级汇编设计与技术[M]. 武汉:武汉大学出版社,1996.
[14] 艾德才. Pentium/80486 实用汇编语言程序设计[M]. 北京:清华大学出版社,1997.
[15] [美]Kip R. Irvine. Assembly Language for Intel-Based Computers[M]. 4 版. 北京:清华大学出版社,2005.
[16] http://www.intel.com/products/processor/manuals/.


















![黄金真题53篇 文勇的iBT阅读[必读]5.4版](https://img.dokumen.tips/doc/110x75/63572d31dffe30f4b50c78c8/53-ibt54.jpg)


