Embed Size (px)
Citation preview

AUTOMATED DETECTION OF MOVIE SCRIPT GENRES
Machine Learning Presentation – May 19, 2014
Graham [email protected]
Michael [email protected]
Katherine [email protected]

Contents
Introduction
Genre Association
TFIDF and Modified TFIDF
Topic Modeling

Objective
Given a movie script, predict what genre it is (e.g., Drama, Comedy, Sci-Fi, Horror, etc.)

Corpus
Built a web-scraper to collect screenplays from internet sources
Collected 962 screenplays
Each screenplay has: Full text Multiple genre
labels
ActionHorrorSci-FiThriller
RomanceComedy

Scene Headings: generally identifiable as text starting with “INT.” or “EXT.” and/or text that is formatted in all caps and is left justified (for example. “INT. MORGAN'S HOUSE - DAY.”) facilitate feature extraction. From headings it is possible to extract data indicating whether the scene is interior vs. exterior, where the scene is located, and the time when it occurs. Scene headings may also contain tags indicating whether the scene is a “FLASHBACK.”
Scene Content: Identifiable as text located in between scene headings
Action: Identifiable as non-caps text with narrow margins. Actions may also contain the names of non-speaking characters, which are usually indicated in all caps.
Speaking Character: Identifiable as text all-caps text that is located by itself and center-justified. Character tags also contain extractable information about whether the character is speaking in voiceover
Dialogue: Identifiable as regular-caps text that is located by itself and center-justified with wide margins (in between margin width of action and margin with of characters). Dialogue typically follows the name of the speaking character, enabling matching of speaker and dialogue.
Interlocutor: Characters that speak back-to-back in scenes can be assumed to be interlocutors engaged in a dialogue
Scene Length:Number of lines or quantity of page space devoted to scene. Can be used to estimate the running time of the scene (e.g., assume that 1 page = 1 minute of screen time)
Example: Screenplay Text

Character Attributes: When a major character is introduced, screenplays frequently specify key attributes such the character’s age, physical features, and basic personality. These attributes can be automatically identified and extracted as part of a character profile.
Scene Transitions: Primary identifier is text in all-caps that is right-justified. Secondary identifier is text that matches a limited library of common phrases that are used to indicate transition (e.g., “CUT,” “MATCH CUT,” “FADE OUT”, etc.)
Non-Speaking Characters: Primary identifier is proper names, professional designations, etc. appearing in all caps in action paragraphs.
Shots: Primary identifier is text that matches a limited library of common phrases that are used to indicate shots (e.g., “PAN,” “CLOSE UP,” etc.)
Voice-over: Identifiable as “(V.O.)”
Key Objects: Primary identifier is nouns appearing in all caps in action paragraphs. These objects generally play a key role in the scene.
Example: Screenplay Text

Text Pre-Processing
Remove standard stop-words: Prepositions: “of” “in” “to” “at”, etc. Pronouns: “he” “she” “it” “they” “me” “my”, etc. Helper verbs: “are”, “have,” “had”, etc.
Remove common film terms: Camera / editing: “cut” “close” “shot” “pan” “fade”
“angle” Scene headings: “INT.” “EXT.” “day” “night” “later” Dialogue instructions: “cont’d” “V.O.” “O.S.”
“omit”

Contents
Introduction
Genre Association
TFIDF and Modified TFIDF
Topic Modeling

Genre Distribution
Drama 504 Musical 18 Comedy 299 Crime 173 Sci-Fi 142 Mystery 87 Adventure
143
Fantasy 98 Romance 168 Thriller 322 Sport 2 Action 253 Family 36 War 23 Horror 131
Animation 29 Biography 3 Music 4 Western 10 History 3 Film-Noir 4 Short 2
Total # of Scripts with Full Text: 962 Genre Labels are NOT mutually exclusive

Genre Association Rules
Rule Confidence Support
Drama --> Comedy
0.230158730159
0.125813449024
Comedy --> Drama
0.387959866221
0.125813449024
Drama --> Crime
0.214285714286
0.117136659436
Crime --> Drama
0.624277456647
0.117136659436
Drama --> Romance
0.236111111111
0.129067245119
Romance --> Drama
0.708333333333
0.129067245119
Drama --> Thriller
0.313492063492
0.17136659436
Thriller --> Drama
0.490683229814
0.17136659436
Crime --> Thriller
0.589595375723
0.110629067245
Thriller --> Crime
0.316770186335
0.110629067245
Thriller --> Action
0.400621118012
0.139913232104
Action --> Thriller
0.509881422925
0.139913232104
Most of the screenplays have multiple genre labels. This allows us to analyze the association between genres: Which genre labels tend to be
related to another? What rules could we generate
from them?
Can adapt metrics from Association Rules: Support Confidence Interest

Genre Association Rules
Pr(G1, G2)
Pr(G1)*Pr(G2)Interest(G1, G2) =
> 1 (positively dependent)= 1 (independent)< 1 (negatively dependent)

Genre Association Rules

Genre Association Rules Example
Big genres like Drama, Comedy are more “mixable” / adaptive to other genres, which means the interest is mostly clustered around 1
However, niche genres like Family show extremes of interest: Lots of very low interest (near 0) ‘Family’ is
incompatible with some genres (like Mystery, Horror, and War)
Lots of very high interest (>>1) ‘Family’ is highly compatible with others (like Comedy, Animation, and Musical)

Contents
Introduction
Genre Association
TFIDF and Modified TFIDF
Topic Modeling

TF-IDF
In total, 95341 unlemmatized word types (features) which is too many for processing
Basic idea: extract 10 keywords for each movie and combine together as a keyword list (library), which is later used as the feature list. For example, the keywords for BraveHeart is:
{broadsword, william, barn, knights, king, …} In total, after TFIDF, only 4498 word types
For new incoming movies, the counts of keywords would then be the feature vector
Bag of words assumption

Naïve Bayes Classifier TFIDF Features
Row Labels TP FP TN FN Accuracy Recall Precision Specificity FDrama 78 48 42 17 0.65 0.82 0.62 0.47 0.71Musical 1 2 179 3 0.97 0.25 0.33 0.99 0.29Comedy 46 39 78 22 0.67 0.68 0.54 0.67 0.6Crime 17 50 111 7 0.69 0.71 0.25 0.69 0.37Scifi 17 19 144 5 0.87 0.77 0.47 0.88 0.59Mystery 10 25 143 7 0.83 0.59 0.29 0.85 0.38Adventure 19 21 138 7 0.85 0.73 0.48 0.87 0.58Fantasy 12 21 144 8 0.84 0.6 0.36 0.87 0.45Romance 28 51 98 8 0.68 0.78 0.35 0.66 0.49Thriller 41 27 96 21 0.74 0.66 0.6 0.78 0.63Sport - - 184 1 0.99 - NaN 1 NaNAction 38 19 121 7 0.86 0.84 0.67 0.86 0.75Family 4 3 176 2 0.97 0.67 0.57 0.98 0.62War 2 8 174 1 0.95 0.67 0.2 0.96 0.31Horror 22 24 128 11 0.81 0.67 0.48 0.84 0.56Animation 6 4 175 - 0.98 1 0.6 0.98 0.75Biography - - 185 - 1 NaN NaN 1 NaNMusic - - 185 - 1 NaN NaN 1 NaNWestern 1 2 182 - 0.99 1 0.33 0.99 0.5History - - 185 - 1 NaN NaN 1 NaNFilm-Noir - - 183 2 0.99 - NaN 1 NaNShort - - 184 1 0.99 - NaN 1 NaNGrand Total 21.4 22.7 147.0 7.6 0.88 0.72 0.45 0.88 0.54
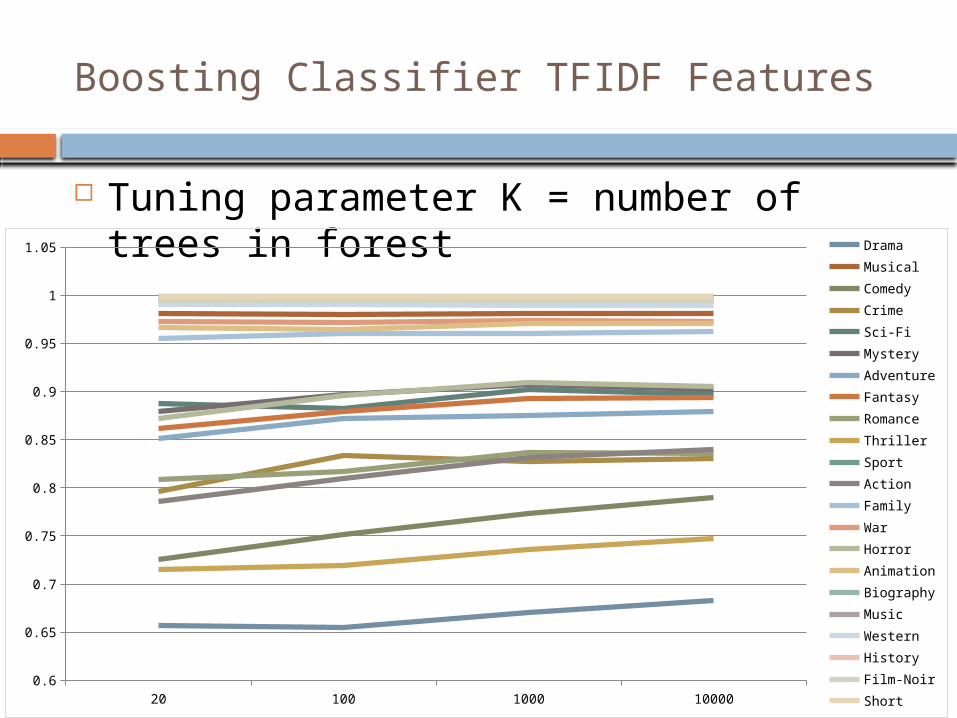
Boosting Classifier TFIDF Features
Tuning parameter K = number of trees in forest
20 100 1000 100000.6
0.65
0.7
0.75
0.8
0.85
0.9
0.95
1
1.05
DramaMusicalComedyCrimeSci-FiMysteryAdventureFantasyRomanceThrillerSportActionFamilyWarHorrorAnimationBiographyMusicWesternHistoryFilm-NoirShort

Boosting Classifier TFIDF Features
20 100 1000 10000 NB
Drama 0.66 0.66 0.67 0.68 0.65 Musical 0.98 0.98 0.98 0.98 0.97 Comedy 0.73 0.75 0.77 0.79 0.67 Crime 0.80 0.83 0.83 0.83 0.69 Sci-Fi 0.89 0.88 0.90 0.90 0.87
Mystery 0.88 0.90 0.91 0.90 0.83 Adventure 0.85 0.87 0.88 0.88 0.85
Fantasy 0.86 0.88 0.89 0.89 0.84 Romance 0.81 0.82 0.84 0.84 0.68 Thriller 0.72 0.72 0.74 0.75 0.74 Sport 1.00 1.00 1.00 1.00 0.99 Action 0.79 0.81 0.83 0.84 0.86 Family 0.96 0.96 0.96 0.96 0.97
War 0.97 0.97 0.97 0.97 0.95 Horror 0.87 0.90 0.91 0.91 0.81
Animation 0.97 0.96 0.97 0.97 0.98 Biography 1.00 1.00 1.00 1.00 1.00
Music 0.99 0.99 0.99 0.99 1.00 Western 0.99 0.99 0.99 0.99 0.99 History 1.00 1.00 1.00 1.00 1.00
Film-Noir 0.99 0.99 0.99 0.99 0.99 Short 1.00 1.00 1.00 1.00 0.99

Modified TFIDF
In normal TFIDF, we penalize the occurrence of number of documents in which a word appears
However, we don’t want to penalize if the document belongs to the same genre of that word, instead, we only penalize on the out-of-genre documents
Modify it as:

Example of Modified TFIDF 5 docs
doc1 = [ ‘man’ ‘star’ ‘ship’ ‘laser’ ‘star’ ‘star’ ‘star’ ‘star’ ‘star’ ‘star’ ‘star’ ‘star’] (Sci-Fi)
doc2 = [‘man’ ‘steve ‘ship’ ‘water water water water water water water ] (Sci-Fi)
doc3 = [‘man’ ‘john’ ‘ship’ ‘diamond diamond diamond diamond diamond diamond] (Sci-Fi)
doc4 = [‘man’ ‘john’ ‘ship’ ‘diamond diamond diamond diamond diamond diamond] (Sci-Fi)
doc5 = [‘man’ ‘john’ ‘ship’ ‘diamond diamond diamond diamond diamond diamond] (Sci-Fi)
doc6 = [‘man’ ‘man’ ‘man’ ‘man’ ‘man’ ‘man’ ‘man’ ‘man’ ‘man’ ‘bed ‘chair ‘lamp] (Family)
When we extract keywords for doc1: Normal TFIDF:
Score(star) = 9/1=9 Score(ship) = 1/5=0.2
Modified TFIDF: Score(star) = log2(9+1) * 1/(0+1)=3.3 Score(ship) = log2(5+1) * 5/(0+1)=12.9

Contents
Introduction
Genre Association
TFIDF and Modified TFIDF
Topic Modeling

Topic Modeling
Idea: Use topics for dimension reduction of raw word frequencies Instead of tens of thousands of word
frequencies, cluster words into a few hundred topics
Topic prevalence becomes features for learning algorithms
Two phases of Machine Learning:1. Unsupervised learning to cluster words into
topics2. Supervised learning of models relating topic
distributions to genre labels

Topic Modeling with LDA
Source: David Blei, “Probabilistic Topic Modeling” (ACM, 2012)

Implementation Details
Extensive Text Pre-Processing: Remove stop-words and film terms Remove character names (more on this…) Convert files to word-count vectors
Used Gensim implementation of Latent Dirichlet Allocation to extract topics Varied num_topics = 32, 64, 128, 256, 512 Which is best? Looked at…
Change in model performance (accuracy, F-measure) as number of topics increased
Manually inspected topics to see if they were crystallizing into a intelligible themes 128 or 256 seem best and roughly equivalent
Several different supervised learning algorithms: Logistic regression Naïve bayes SVM RBF

Example: Interpretable Topics
Topic #100 Topic #126 Topic # 212
Ships & SailingSports Space Travel
Num_Topics = 256
Weight
Word
0.005 shore 0.005 swim 0.005 beat 0.004 just 0.004 move 0.004 way 0.004 room 0.004 along 0.004 bow 0.004 port 0.004 open 0.004 take 0.004 warrior 0.004 harbor 0.004 arctic 0.004 another 0.004 sub 0.004 end 0.004 hull 0.004 like 0.004 forward 0.004 line 0.003 toward
0.003swimmi
ng 0.003 sailor
Weight
Word
0.037 boat 0.035 water 0.019 deck 0.017 ship 0.014 island 0.013 sea 0.011 ocean 0.011 back 0.01 look
0.009 beach 0.008 hold 0.008 come 0.008 see 0.007 radio 0.007 light 0.007 chimera 0.007 dock 0.007 crew 0.006 cabin
0.006continuo
us 0.006 one 0.006 surface 0.006 raft 0.005 foot
0.005underw
ater
Weight
Word
0.005 mcginty 0.005 throw 0.005 two 0.005 take 0.005 gon 0.005 five 0.005 left 0.005 second 0.005 end 0.005 see 0.005 score 0.005 win 0.004 pitch 0.004 head 0.004 hand 0.004 pas 0.004 come 0.004 point 0.004 time 0.004 just 0.004 good 0.004 pull 0.004 dallas 0.004 year 0.004 mike
Weight
Word
0.039 game 0.027 ball 0.02 player
0.017 field 0.016 team 0.012 play 0.011 coach 0.01 football 0.01 guy
0.009 one 0.009 locker 0.009 hit 0.009 run 0.009 look 0.009 big 0.008 back 0.008 line 0.008 got 0.007 first 0.007 get 0.006 right 0.006 three 0.006 like 0.006 walk 0.006 stadium
Weight
Word
0.017 ship 0.011 control 0.009 space 0.007 cockpit 0.007 one 0.006 light 0.006 see 0.006 move 0.006 two 0.005 begin 0.005 turn 0.005 robot 0.005 get 0.005 back 0.004 corridor 0.004 bay 0.004 bridge 0.004 horizon 0.004 around 0.004 look 0.004 pilot 0.004 planet 0.004 right 0.004 going 0.004 just
Weight
Word
0.004 panel 0.004 head 0.004 lewis 0.004 come 0.004 system 0.004 like 0.004 radio 0.004 base 0.004 away 0.004 giant 0.003 cloud 0.003 air 0.003 event 0.003 laser 0.003 power 0.003 know 0.003 toward 0.003 main 0.003 star 0.003 huge 0.003 door 0.003 suddenly 0.003 will 0.003 falcon 0.003 hit

Highest Prevalence of Topic #126
Film
Topic Prevale
nceReplacements, The 0.63
Program, The 0.19 Moneyball 0.16
Major League 0.16 Blind Side, The 0.14
Love and Basketball 0.14 Bull Durham 0.14
Sugar 0.12 Forrest Gump 0.11
Semi-Pro 0.10 Two For The Money 0.10
Damned United, The 0.09 Sandlot Kids, The 0.09 Field of Dreams 0.08
Tin Cup 0.08 Invictus 0.07 eXistenZ 0.06
Buffy the Vampire Slayer 0.05
The Rage: Carrie 2 0.05 Game 6 0.05
Cincinnati Kid, The 0.05

Highest Prevalence of Topic #212
Film
Topic Prevalen
ceStar Wars: The Empire Strikes
Back 0.85 Event Horizon 0.59
Star Wars: A New Hope 0.47 Dark Star 0.32
Alien 0.25 Lost in Space 0.21
Jason X 0.21 TRON 0.19
Star Wars: The Phantom Menace 0.19 Dune 0.16
Independence Day 0.16 Pandorum 0.16
Wall-E 0.16 Mission to Mars 0.15
Airplane 2: The Sequel 0.14 Leviathan 0.13 Abyss, The 0.13 Prometheus 0.12 Pitch Black 0.11
Aliens 0.11 Sphere 0.11 Oblivion 0.11
Heavy Metal 0.10 Thor 0.09
Star Wars: Return of the Jedi 0.09 Moon 0.09

Highest Prevalence of Topic #100
Film
Topic Prevalen
ceGhost Ship 0.70 Life of Pi 0.17
Hard Rain 0.13 Jaws 2 0.13 Jaws 0.12
Master and Commander 0.11 Titanic 0.11
Deep Rising 0.11 Big Blue, The 0.10 Abyss, The 0.10 Cast Away 0.10
Pirates of the Caribbean 0.10 King Kong 0.09
Pearl Harbor 0.09 Lake Placid 0.09
Friday the 13th: Jason Takes Manhattan 0.09
Mud 0.08 Commando 0.06
G.I. Jane 0.06 Jurassic Park III 0.06
Sphere 0.05 Apocalypse Now 0.05 Blood and Wine 0.04
Leviathan 0.04 I Still Know What You Did Last
Summer 0.04 Beasts of the Southern Wild 0.04

Character Names!
0.038*kirk + 0.032*decker + 0.019*bridge + 0.019*spock + 0.015*captain + 0.013*mccoy + 0.012*viewer + 0.012*enterprise + 0.011*ilia + 0.010*now + 0.009*console + 0.009*sir + 0.009*scott + 0.008*crew + 0.007*shuttle + 0.007*vulcan + 0.007*space + 0.007*cloud + 0.006*intercom + 0.006*starfleet + 0.006*ship + 0.006*station + 0.005*sulu + 0.005*warp + 0.005*klingon + 0.005*control + 0.005*toward + 0.005*energy + 0.005*chekov + 0.004*moment + 0.004*main + 0.004*another + 0.004*science + 0.004*vessel + 0.004*chamber + 0.004*power + 0.004*transporter + 0.003*pod + 0.003*uhura + 0.003*alien + 0.003*engineering + 0.003*voice + 0.003*deck + 0.003*continues + 0.003*move + 0.003*ahead + 0.003*camera + 0.003*see + 0.003*one + 0.003*computer
Topic #203 (of 256) Infuriating problem!
Character names spoil otherwise good topics Character names are
some of the most frequent words in screenplays and therefore dominate topics
But! They don’t have predictive value, since they are highly unlikely to appear to other screenplays in the same genre
Need to eliminate them!

Strategies for Removing Character Names
1. Document-Level: Identify using formatting information: names tend to
appear in all caps in the center of a line Remove all cases in all caps (‘STEVE”) or title case
(‘Steve’)
2. Corpus-Level: Names tend to be very frequent within a single document,
but do not recur across documents Remove all words that occur in ≤ 3 documents. This also
helps to eliminate other noise (e.g., typos, “aaaargh”, etc.) Problem:
Franchise films with many sequels (e.g., Star Wars) Very common names (John, Sue, David, etc.)
Note: In retrospect, it would have been wiser to extract
only verbs and nouns using a POS-tagger…

Scene Headings: generally identifiable as text starting with “INT.” or “EXT.” and/or text that is formatted in all caps and is left justified (for example. “INT. MORGAN'S HOUSE - DAY.”) facilitate feature extraction. From headings it is possible to extract data indicating whether the scene is interior vs. exterior, where the scene is located, and the time when it occurs. Scene headings may also contain tags indicating whether the scene is a “FLASHBACK.”
Scene Content: Identifiable as text located in between scene headings
Action: Identifiable as non-caps text with narrow margins. Actions may also contain the names of non-speaking characters, which are usually indicated in all caps.
Speaking Character: Identifiable as text all-caps text that is located by itself and center-justified. Character tags also contain extractable information about whether the character is speaking in voiceover
Dialogue: Identifiable as regular-caps text that is located by itself and center-justified with wide margins (in between margin width of action and margin with of characters). Dialogue typically follows the name of the speaking character, enabling matching of speaker and dialogue.
Interlocutor: Characters that speak back-to-back in scenes can be assumed to be interlocutors engaged in a dialogue
Scene Length:Number of lines or quantity of page space devoted to scene. Can be used to estimate the running time of the scene (e.g., assume that 1 page = 1 minute of screen time)
Example: Screenplay Text

Results: LR vs. NB vs. SVMSV
M R
BF
NA
ÏVE
BAYES
LOG
ISTIC
R
EG
TRAINING / IN-SAMPLE (800 Scripts)
TESTING / OUT-OF-SAMPLE (156 Scripts)
Num_Topics = 256

Results: Number of Topics3
2 T
opic
s6
4 T
opic
s
TRAINING (IN-SAMPLE) TESTING (OUT-OF-SAMPLE)
SVM_RBF (C=100, GAMMA=1.0)

TRAINING (IN-SAMPLE) TESTING (OUT-OF-SAMPLE)
12
8 T
opic
s2
56
Topic
s5
12
Topic
s
Results: Number of TopicsSVM_RBF (C=100, GAMMA=1.0)

Results: Predictability by Genre
SVM_RBF (C=100, GAMMA=1.0) TOPICS=128 TESTING
Highly Predictability (F > 0.7):• Sci-Fi• Action• Thriller• Western
Low Predictability (F < 0.4):• Crime• Fantasy• Romance

Some Visualization (Forest Gump)

Some Visualization (Jurassic Park)

Some Visualization (Les Miserable)

Screenplay
Title
Text
Genres
Word Freq
Topics
Attributes
Screenplay Class
Program Architecture
Methods
Getter and Setter
Functions
TextCleaner Class
ScriptDatabase Class
ScriptScraper Class
Website





























