Embed Size (px)
Citation preview

Jak zacząć przetwarzanie małych i dużych danych
tekstowych?
Łukasz Kobyliński i Jakub NowackiConfitura 2016

PrelegenciŁukasz Kobyliński (@lkobylinski)
● Chief Science Officer w Sages (@sagespl)● Adiunkt w Instytucie Podstaw Informatyki
PAN - Zespół Inżynierii Lingwistycznej● #MachineLearning, #NLProc
Jakub Nowacki
● Trener @sagespl● Senior Software Engineer w nowym
ekscytującym startupie :)● #BigData, #MachineLearning
Jesteś studentem lub doktorantem i chcesz wziąć udział w ciekawych projektach badawczych w zakresie NLP w IPI PAN? Napisz do mnie: lkobylinski_AT_ipipan.waw.pl

Na czym polega problem?● Tekst w języku naturalnym to typowy przykład danych nieustrukturyzowanych
○ nie ma narzuconej organizacji informacji (jak np. tabela),
○ potrzebne jest (najczęściej wieloetapowe) przetwarzanie wstępne, aby możliwe było analizowanie i wnioskowanie na podstawie tego typu danych.
● Wieloznaczość występuje na wszystkich poziomach analizy lingwistycznej, przykład: I made her duck
○ I cooked waterfowl for her.○ I cooked waterfowl belonging to her.○ I created the (plaster?) duck she owns.○ I caused her to quickly lower her head or body.○ I waved my magic wand and turned her into waterfowl.

O czym będziemy mówić dzisiaj1. Podstawowy ciąg przetwarzania tekstu dla języka polskiego.
a. Segmentacja - tokenizacja i podział na zdania.b. Analiza morfosyntaktyczna.c. Tagowanie.d. Analiza składniowa.e. Dalsze etapy przetwarzania.
2. Narzędzia i zasoby dla języka angielskiego.3. Przetwarzanie tekstu w dużej skali - Apache Spark.4. Dyskusja i pytania.

Tokenizacja i podział na zdaniaJak podzielić tekst na poszczególne tokeny (~słowa) i zdania?
● “Trzeba to skonfigurować w XML-u. W wierszach 10. i 15.”○ |'Trzeba'(newline),'to'(space),'skonfigurować'(space),'w'(space),'XML-u'(space),'.'(none)○ |'W'(space),'wierszach'(space),'10'(space),'.'(none),'i'(space),'15'(space),'.'(none)
● "At eight o'clock on Thursday morning Arthur didn't feel very good."○ ['At', 'eight', "o'clock", 'on', 'Thursday', 'morning', 'Arthur', 'did', "n't", 'feel', 'very', 'good', '.']
● Problemy:○ spacja - najczęściej rozdziela tokeny, ale np.: 25 000 000 (25 milionów)?○ przecinek - podobnie, czasem stosowany do rozdzielania cyfr○ myślnik/dywiz - najczęściej rozdziela tokeny, ale por. XML-u powyżej?○ apostrof - rozdziela w przypadku he’s, ale nie rozdziela dla don’t, didn’t, itp.○ kropka - czy rozdziela zdania? co ze skrótami, np. dr hab.○ wielka litera - czy rozpoczyna zdanie?

Jak to zrobić w praktyce?● Segment - segmentacja na podstawie reguł SRX (Java)● Toki - tokenizator regułowy (C++)
echo "Holding Alphabet zaprezentował wyniki spółki Google za III kwartał 2015 roku. Zysk netto Google wyniósł w III kwartale 2015 roku 3,98 miliarda dolarów." | toki-app -q -f "\$bs|'\$orth', "
|'Holding', 'Alphabet', 'zaprezentował', 'wyniki', 'spółki', 'Google', 'za', 'III', 'kwartał', '2015', 'roku', '.', |'Zysk', 'netto', 'Google', 'wyniósł', 'w', 'III', 'kwartale', '2015', 'roku', '3,98', 'miliarda', 'dolarów', '.'

Tokenizacja i podział na zdania (cd.)Dla języka polskiego jest to jeszcze trudniejsze…
● Dlaczegoś to zrobił?Dlaczego / ś / to / zrobił / ?
● Pojechałbym tam.Pojechał / by / m / tam / .
Okazuje się, że:
● do przeprowadzenia poprawnej tokenizacji potrzebne są dane słownikowe,● segmentacji mogą podlegać ciągi znaków nierozdzielone spacją.

Analiza morfosyntaktycznaPozwala opisać tokeny w tekście częściami mowy (czasownik, rzeczownik), wraz z ich kategoriami gramatycznymi (liczba, rodzaj, przypadek).
● Ile jest części mowy?○ po szkolnemu: 10?
○ w Narodowym Korpusie Języka Polskiego: ponad 30 różnych fleksemów, np. liczebnik główny (sześć, dużo), liczebnik zbiorowy (sześcioro, trojga)
● Ile jest rodzajów?○ po szkolnemu: męski, żeński, nijaki, męskoosobowy, niemęskoosobowy
○ w Narodowym Korpusie Języka Polskiego: męski osobowy (facet), męski zwierzęcy (koń), męski rzeczowy (stół), …
● Tagset (zbiór tagów opisujących części mowy tokenów) dla polskiego ○ np.: subst:sg:nom:m1○ zawiera ponad 1000 możliwych tagów.

Jak to zrobić w praktyce?● Tokenizacja i analiza morfologiczna
○ Morfeusz - analiza morfologiczna (C++, binding Python i Java),○ Maca - biblioteka opakowująca Toki i Morfeusza (C++, binding Python).
Morfeusz morfeusz = Morfeusz.createInstance();String s = "Holding Alphabet zaprezentował wyniki spółki Google za III kwartał 2015 roku. "
+ "Zysk netto Google wyniósł w III kwartale 2015 roku 3,98 miliarda dolarów.";
ResultsIterator it = morfeusz.analyseAsIterator(s);while (it.hasNext()) {
MorphInterpretation mi = it.next();System.out.println(MorfeuszUtils.getInterpretationString(mi, morfeusz));
}
0 1 Holding holding subst:sg:acc:m3 nazwa pospolita0 1 Holding holding subst:sg:nom:m3 nazwa pospolita1 2 Alphabet Alphabet ign 2 3 zaprezentował zaprezentować praet:sg:m1.m2.m3:perf
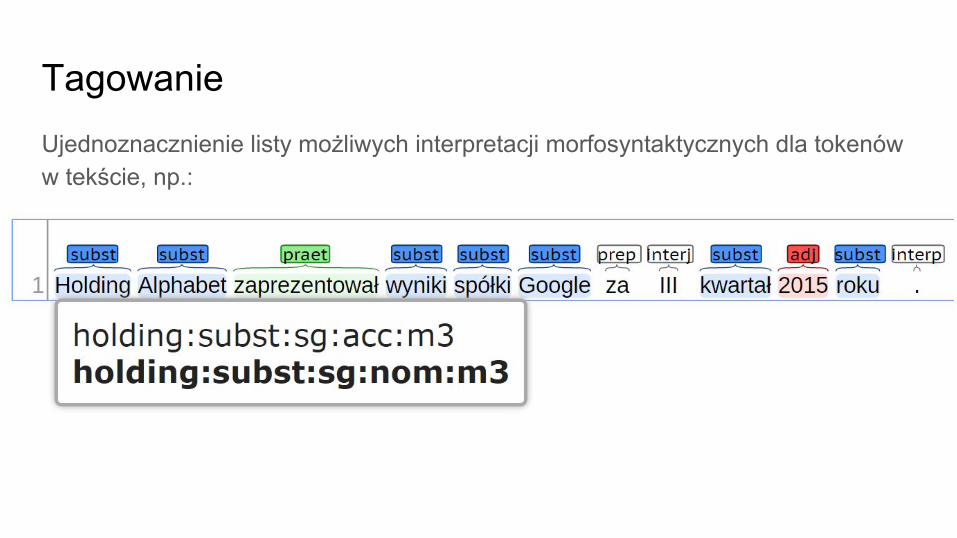
TagowanieUjednoznacznienie listy możliwych interpretacji morfosyntaktycznych dla tokenów w tekście, np.:
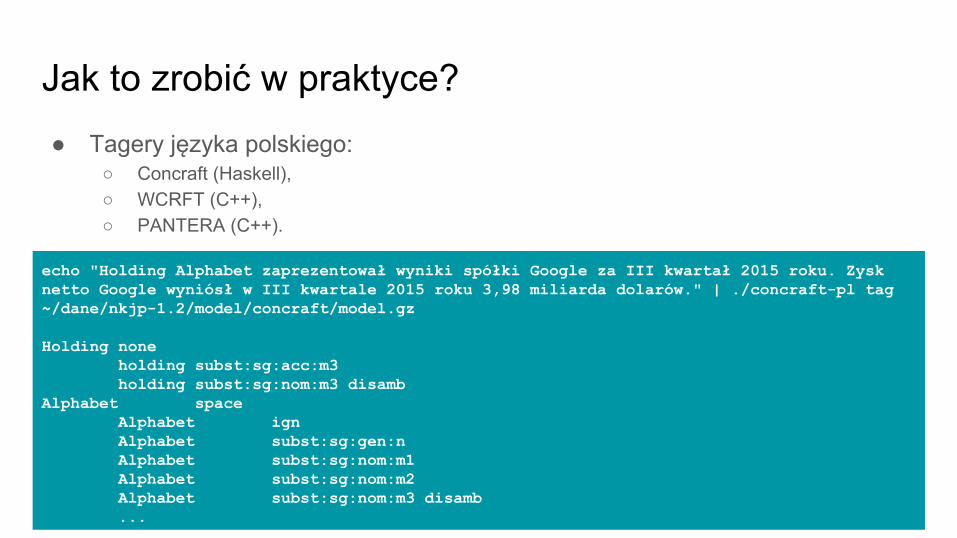
Jak to zrobić w praktyce?● Tagery języka polskiego:
○ Concraft (Haskell), ○ WCRFT (C++),○ PANTERA (C++).
echo "Holding Alphabet zaprezentował wyniki spółki Google za III kwartał 2015 roku. Zysk netto Google wyniósł w III kwartale 2015 roku 3,98 miliarda dolarów." | ./concraft-pl tag ~/dane/nkjp-1.2/model/concraft/model.gz
Holding none holding subst:sg:acc:m3 holding subst:sg:nom:m3 disambAlphabet space Alphabet ign Alphabet subst:sg:gen:n Alphabet subst:sg:nom:m1 Alphabet subst:sg:nom:m2 Alphabet subst:sg:nom:m3 disamb
...

Analiza składniowaIstnieją zjawiska, których opis możliwy jest na poziomie większych jednostek, niż pojedyncze segmenty
● formy analityczne czasowników, np. będzie śpiewał;● opisowe formy stopnia wyższego przymiotników, np. bardziej pracowity;● czasowniki zwrotne, np. opalać się;● jednostki wielowyrazowe, np. kopnąć w kalendarz.
Spejd - płytki parser składniowy
Rule "Adj: opisowy stopień wyższy"
Match: [orth~"[Bb]ardziej"] [pos~"adj"];Eval: word(2, Adj:com, 2.base);

Dalsze etapy przetwarzania● Rozpoznawanie jednostek nazewnicznych

Jak to zrobić w praktyce?● Rozpoznawanie jednostek nazewniczych
○ Liner2 (C++)○ NERF (Haskell)
● Podejścia najczęsciej oparte na paradygmacie uczenia maszynowego (np. CRF - Conditional Random Fields)
○ uczymy model na podstawie przykładów - tekstu oznaczonego wcześniej ręcznie odpowiednimi znacznikami (np. nam_org_company - nazwa firmy),
○ model uczy się jakie segmenty i w jakim kontekście należy oznaczać odpowiednim znacznikiem,
○ tekst reprezentowany jest przez cechy - formy ortograficzne segmentów, ich lematy, tagi morfosyntaktyczne i inne,
○ wyuczony model można zastosować na nowych danych.

Czy dla języka angielskiego jest łatwiej?● Biblioteki realizujące podstawowy ciąg przetwarzania tekstu
○ Stanford CoreNLP (Java)○ Apache OpenNLP (Java)○ GATE (Java)○ NLTK (Python)
<dependency><groupId>edu.stanford.nlp</groupId><artifactId>stanford-corenlp</artifactId><version>3.6.0</version>
</dependency>[...] <classifier>models</classifier> [...]
Document doc = new Document("At eight o'clock on Thursday morning Arthur didn't feel very good. " + "It was raining.");
for (Sentence sent : doc.sentences()) { System.out.println(sent.text()); // At eight o'clock on Thursday morning Arthur ... System.out.println(sent.lemmas()); // [at, eight, o'clock, on, Thursday, morning, Arthur System.out.println(sent.nerTags()); // [O, TIME, TIME, O, DATE, TIME, PERSON, ...}
Przetwarzanie tekstu w dużej skali● Sporo problemów wymaga skali
wykraczającej poza możliwości pojedynczej maszyny (Big Data?)
● Wiele algorytmów nie koniecznie przystosowanych jest do wykorzystania w systemach Big Data
● Ze względu na popularność Spark powstało wiele narzędzi wspomagających NLP
● Pozostaje jednak problem wielu języków
Źródło: http://www.business2community.com

Machine Learning w SparkW Spark można wyróżnić trzy podejścia do ML:
● Przeprowadzić kroswalidację tradycyjnego modelu na klastrze
● Użyć tradycyjnego modelu uczonego na małych danych
● Użyć biblioteki Spark Machine Learning

Machine Learning w SparkDwa warianty do wyboru:
● Spark MLlib - wykorzystuje RDDs
● Spark ML - wykorzystuje DataFrames
Spark ML i DataFrames są zalecaną metodą pracy obecnie gdyż są one najbardziej rozwijane.
Źródło: https://www.coursera.org/learn/machine-learning
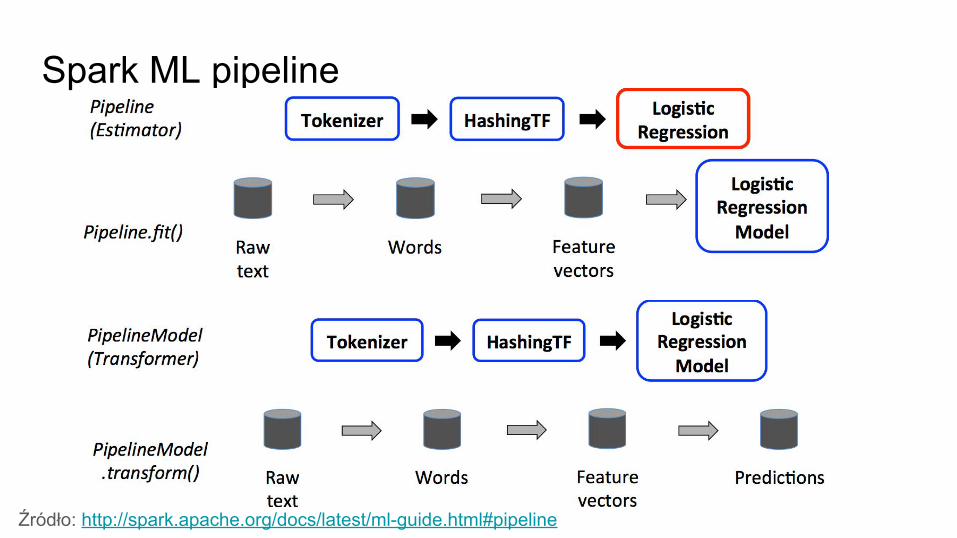
Spark ML pipeline
Źródło: http://spark.apache.org/docs/latest/ml-guide.html#pipeline

Spark ML pipelineTransformer:
● Implementuje metodę transform() ● Bierze wejściowy DataFrame i produkuje
nowy przez dodanie odpowiednich kolumn
Estymator:
● Implementuje metodę fit()● Bierze wejściowy DataFrame i trenuje
model● Wytrenowany estymator staje się
modelem● Metoda transform() wykonuje predykcję
import org.apache.spark.ml.feature.Word2Vec
val documentDF = sqlContext.createDataFrame(Seq( "Hi I heard about Spark".split(" "), "I wish Java could use case classes".split(" "), "Logistic regression models are neat".split(" ")).map(Tuple1.apply)).toDF("text")
val word2Vec = new Word2Vec() .setInputCol("text") .setOutputCol("result") .setVectorSize(3) .setMinCount(0)val model = word2Vec.fit(documentDF)val result = model.transform(documentDF)result.select("result").take(3).foreach(println)
Źródło: https://spark.apache.org/docs/latest/ml-features.html#word2vec
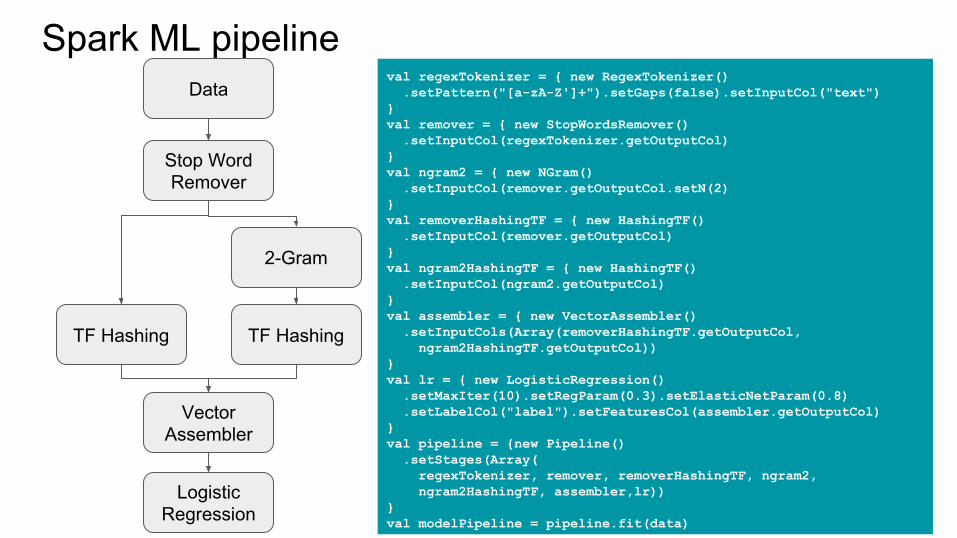
Spark ML pipelineval regexTokenizer = { new RegexTokenizer() .setPattern("[a-zA-Z']+").setGaps(false).setInputCol("text")}val remover = { new StopWordsRemover() .setInputCol(regexTokenizer.getOutputCol)}val ngram2 = { new NGram() .setInputCol(remover.getOutputCol.setN(2)}val removerHashingTF = { new HashingTF() .setInputCol(remover.getOutputCol)}val ngram2HashingTF = { new HashingTF() .setInputCol(ngram2.getOutputCol)}val assembler = { new VectorAssembler() .setInputCols(Array(removerHashingTF.getOutputCol, ngram2HashingTF.getOutputCol))}val lr = { new LogisticRegression() .setMaxIter(10).setRegParam(0.3).setElasticNetParam(0.8) .setLabelCol("label").setFeaturesCol(assembler.getOutputCol)}val pipeline = {new Pipeline() .setStages(Array( regexTokenizer, remover, removerHashingTF, ngram2, ngram2HashingTF, assembler,lr))}val modelPipeline = pipeline.fit(data)
Data
Stop Word Remover
TF Hashing TF Hashing
2-Gram
Vector Assembler
LogisticRegression

Spark CoreNLP Databricks przygotowało Spark CoreNLP - zestaw funkcji do pracy z danymi tekstowymi w oparciu o Stanford CoreNLP Simple API.
Można zarówno używać funkcji na kolumnach jak i używać w transformatorach pipelinach.
Obsługuje wiele języków z angielskim na czele, ale nie ma polskiego bezpośrednio.
Stanford CoreNLP jest na licencji GPL 3.
Źródło: https://github.com/databricks/spark-corenlp
df.withColumn("tokens", tokenize('text)).withColumn("lemma", lemma('text)).show()
+------------+------------------+------------------+| text| tokens| lemma|+------------+------------------+------------------+|Ala ma kota.|[Ala, ma, kota, .]|[Ala, ma, kota, .]|+------------+------------------+------------------+

Co z językiem polskim?Obecnie nie ma wiele dedykowanych narzędzi do NLP w języku polskim dla Spark.
Można używać korpusów do trenowania np Word2Vec i innych algorytmów dostępnych w Spark ML.
Można opakować istniejące narzędzia w User Defined Functions (UDF), które są podstawą transformatorów.
// Prostydef simpleAddOne = sqlContext.udf.register(“simpleAddOne”, (s: String) => s + “one”)// df - DataFrame z textem “Ala ma kota.”df.select(simpleAddOne(‘text).show()// +-------------+// | UDF(text)|// +-------------+// |Ala ma kota.1|// +-------------+
// Złożonydef myTokenize = sqlContext.udf.register("myTokenize", (s: String) => { val sentence = new Sentence(s) sentence.words().asScala })df.select(myTokenize(‘text).show()// +------------------+// | UDF(text)|// +------------------+// |[Ala, ma, kota, .]|// +------------------+

Stworzenie własnego transformera
class MyTokenizer( override val uid: String ) extends UnaryTransformer[String, Seq[String], MyTokenizer] {
def this() = this( s"stok_${UUID.randomUUID().toString.takeRight(12)}" )
override protected def createTransformFunc: String => Seq[String] = { (s: String) => { val sentence = new Sentence(s) sentence.words().asScala } }
override protected def validateInputType( inputType: DataType ): Unit = { require(inputType == StringType, s"Input type must be string type but got $inputType.") } override protected def outputDataType: DataType = new ArrayType(StringType, false)}

Stworzenie własnego transformera
val myTokenizer = { new MyTokenizer() .setInputCol("text") .setOutputCol("my_tokenizer_out") } myTokenizer.transform(df).show()
+------------+------------------+| text| my_tokenizer_out|+------------+------------------+|Ala ma kota.|[Ala, ma, kota, .]|+------------+------------------+

Dzięki za uwagę!
Pytania?

Odnośniki do oprogramowania i zasobów1. Segmentacja
○ Segment: https://github.com/loomchild/segment○ Toki: http://nlp.pwr.wroc.pl/redmine/projects/toki/wiki
2. Analiza morfologiczna○ Morfeusz: http://sgjp.pl/morfeusz/○ Maca: http://nlp.pwr.wroc.pl/redmine/projects/libpltagger/wiki
3. Tagowanie○ Concraft: http://zil.ipipan.waw.pl/Concraft○ WCRFT: http://nlp.pwr.wroc.pl/redmine/projects/wcrft/wiki○ Pantera: http://zil.ipipan.waw.pl/PANTERA
4. Płytkie parsowanie○ Spejd: http://zil.ipipan.waw.pl/Spejd

Odnośniki do oprogramowania i zasobów (cd.)1. Rozpoznawanie jednostek identyfikacyjnych
○ Liner2: http://www.nlp.pwr.wroc.pl/narzedzia-i-zasoby/narzedzia/liner2○ NERF: http://zil.ipipan.waw.pl/Nerf
2. Narzędzia i zasoby w postaci webserwisów○ Clarin2: http://clarin-pl.eu/pl/uslugi/○ Multiserwis: http://multiservice.nlp.ipipan.waw.pl/pl/
3. Inne odnośniki○ CLIP: http://clip.ipipan.waw.pl/LRT

Odnośniki do oprogramowania i zasobów (język angielski)1. Biblioteki
○ Stanford CoreNLP: http://stanfordnlp.github.io/CoreNLP/○ Apache OpenNLP: https://opennlp.apache.org/○ GATE: https://gate.ac.uk/





























