Embed Size (px)
Citation preview
Big Data In Action
Ilya Buzytsky

Big Data: not all things to all people
• Different Business Verticals have different uses for Big
Data problems
• Specifically, Web Analytics yields itself very nicely to
Big Data Solutions: scales well with Big Data
distributed approach, for both storage and processing
• Other Business Verticals are not as lucky: harder to
parallelize where more complex computations are
required

Big Data for Web Analytics: where to start?
So we got us a “Big Data” system somewhere in the
cloud. Now what?
We can start with asking 3 basic questions:
1. Can this system do what our legacy software stack
cannot do?
2. Even if we got a working legacy solution, can it be
done better with the “Big Data” solution?
3. Can it integrate into what we got already?
We will learn how to address these questions.

Big Data Solutions: Context is everything!
Most businesses have a working BI Solution (or many)
There comes a time when source data grows so much
that it becomes “unwieldy”
Choice is:
1. Scale out the legacy systems’ hardware to try and
accommodate the growth
OR
2. Use a Big Data solution to help with scaling in a new
and exciting ways

Big Data for Web Analytics: Common Pitfalls?
Common Pitfalls
• Pitfall 1: Just storing a bunch of information forever
does not make a real or useful Big Data Solution
• Pitfall 2: Big Data IS big. There is no good way to simply
pull a bunch of it onto your computer and “play with it”
(a very common analyst ask)

Solving the Big Data problem: A Structured Approach
Avoiding the pitfalls requires a structured approach to
figuring out how to make Big Data useful
1. Define business requirements
2. Understand the target audience. Who is the
consumer of the findings from your Big Data
solution? Solution targeting top level executive often
looks different from the one targeting “in the
trenches” analysts
3. Understand your data sources
4. Understand your business analytical pain points well

Building a Big Data Pipeline
• A “data pipeline” is a well defined process that allows sequential
transformation of often unstructured and otherwise
unmanageable data into structured sets that can be used by the
Business for BI and other purposes
• Building pipelines allows to establish clearly defined data flows
within parameterized guidelines
• Big Data Pipelines often leverage existing software stacks to
create or augment BI Solutions already in place
• Sometimes pipelines are required as intermediary mechanism to
communicate needed data from one external source to another,
for purposes of improved BI capabilities

BI Pipelines: Examples
Pipeline Example 1: Unstructured data to the in-house Data
Warehouse
Addresses the how we can augment existing BI solution with a Big
Data capability
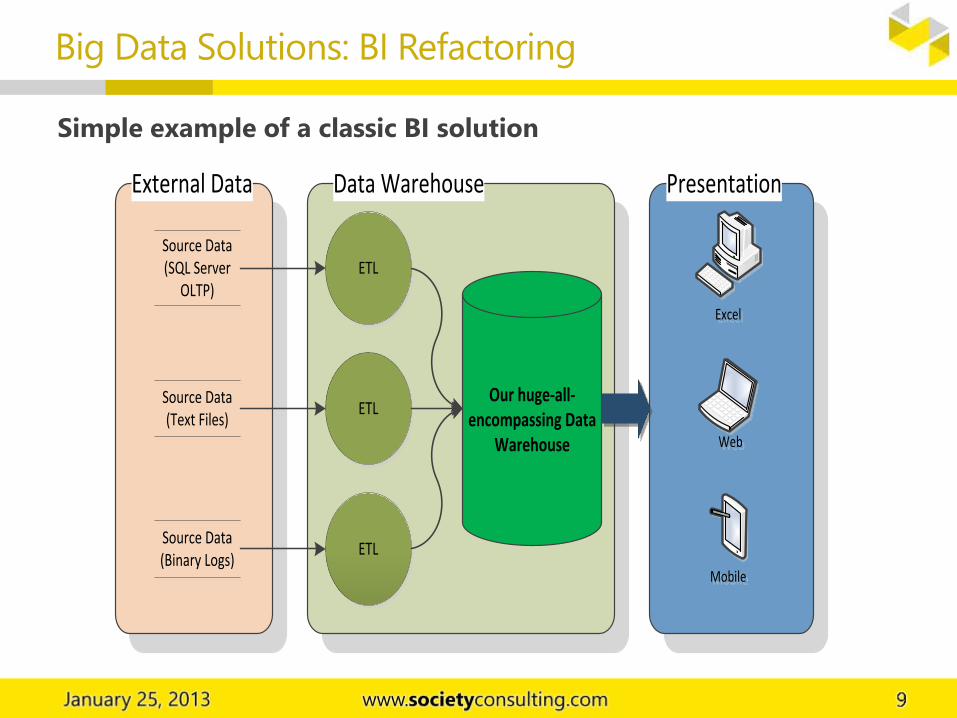
Big Data Solutions: BI Refactoring
Simple example of a classic BI solution
Data WarehouseExternal Data
Source Data (SQL Server
OLTP)
Source Data (Text Files)
Source Data (Binary Logs)
ETL
ETL
ETL
Our huge-all-encompassing Data
Warehouse
Presentation
MobileMobile
ExcelExcel
WebWeb

Big Data Solutions: BI Refactoring
Too much data results in SLAs being missed and too little data
getting to the Data Warehouse layer.
Data WarehouseExternal Data
Source Data (SQL Server
OLTP)
Source Data (Text Files)
Source Data (Binary Logs)
ETL
ETL
ETL
Our huge-all-encompassing Data
Warehouse
Presentation
MobileMobile
ExcelExcel
WebWebS
Scalability Fault Line
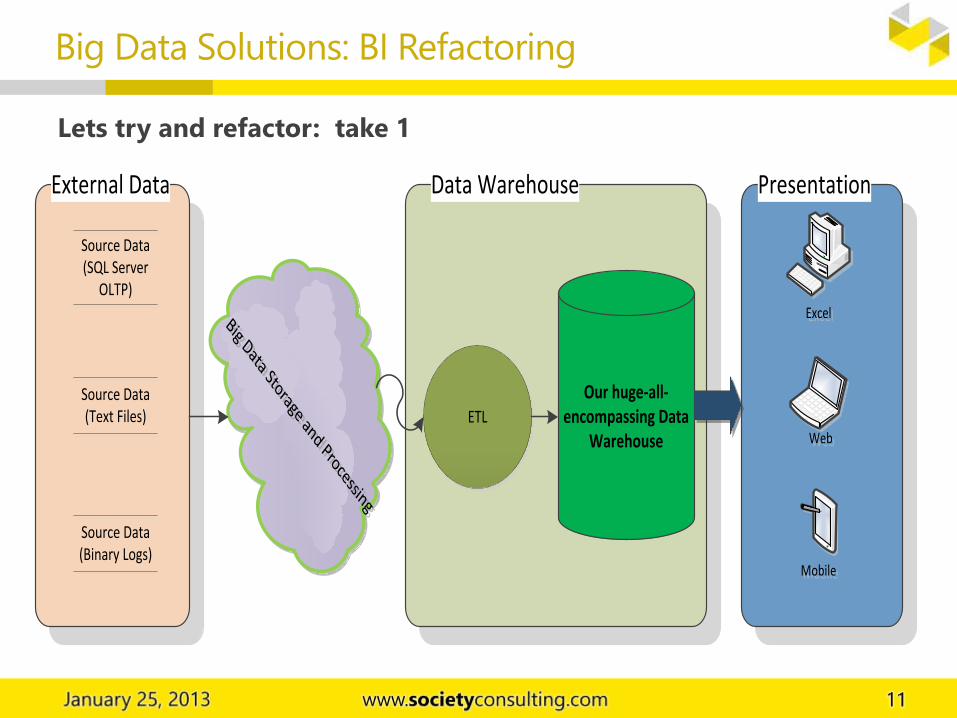
Big Data Solutions: BI Refactoring
Lets try and refactor: take 1
Big Data Storage and Processing
Big Data Storage and Processing
Data WarehouseExternal Data
Source Data (SQL Server
OLTP)
Source Data (Text Files)
Source Data (Binary Logs)
ETL
Our huge-all-encompassing Data
Warehouse
Presentation
MobileMobile
ExcelExcel
WebWeb

BI Pipelines: Example Diagrams (cont.)
Pipeline Example 2: Unstructured data, enriched and cleaned, to the
3rd party Analytics Solution
Sometimes we are just an intermediary, making data better but not
passing it on

2 (sometimes more) large systems, need to scale data enrichment
when moving large volumes across quickly and efficiently
Big Data Solutions: 3rd party integration
Big Data Storage and Enrichment
Big Data Storage and Enrichment
Source System
Source Data (SQL Server
OLTP)
Source Data (Text Files)
Source Data (Binary Logs)
Destination System
Enrichment Metadata
Feed Out (FTP)
Feed Out (Share)

• Raw level data is giant: 10 Billion entries per month
• It makes no sense to look at every event
• KPIs require data to be aggregate (in a meaningful
way)
Enter Distributed Storage and Processing
• Now we can aggregate using the pre-defined KPI
requirements and using the Big Data engine to slim
down the result set to a BI Data Warehouse
manageable size
Case Study 1: Web Logs Processing to identify Market Segmentation

Raw Log Storage
Log Files (Text)
10 Bln.
Filter
Clean
Aggregate
DW (SQL)
Big Data Engine
Enrich
100 Mln.
Case Study 1: Web Logs Processing to identify Market Segmentation

• Current generation of technologies is usually
complementary
• Emphasis on a specific technology depends on the
specific business requirements: real-time analysis vs.
reporting vs. data mining
• Mix of technologies is good
• Pick your tools wisely
Using Specific Big Data Technologies

• Prioritize your needs
• Identify failing links
• Plan for rapid growth
• Plan for a relatively steep learning curve for your
Engineering
• In-house IP (co-)ownership is a good thing
• Scalability != unlimited resources
In Summary





























