Embed Size (px)
Citation preview

10 More Lessons Learned from building real-life Machine Learning Systems
Xavier Amatriain (@xamat) 10/13/2015

Machine Learning@Quora
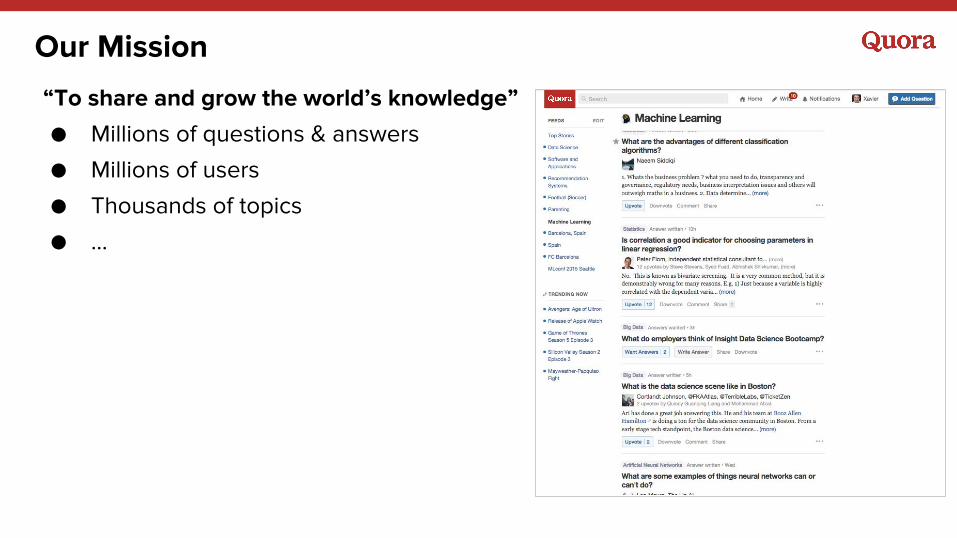
Our Mission
“To share and grow the world’s knowledge”
● Millions of questions & answers
● Millions of users
● Thousands of topics
● ...
Demand
What we care about
Quality
Relevance
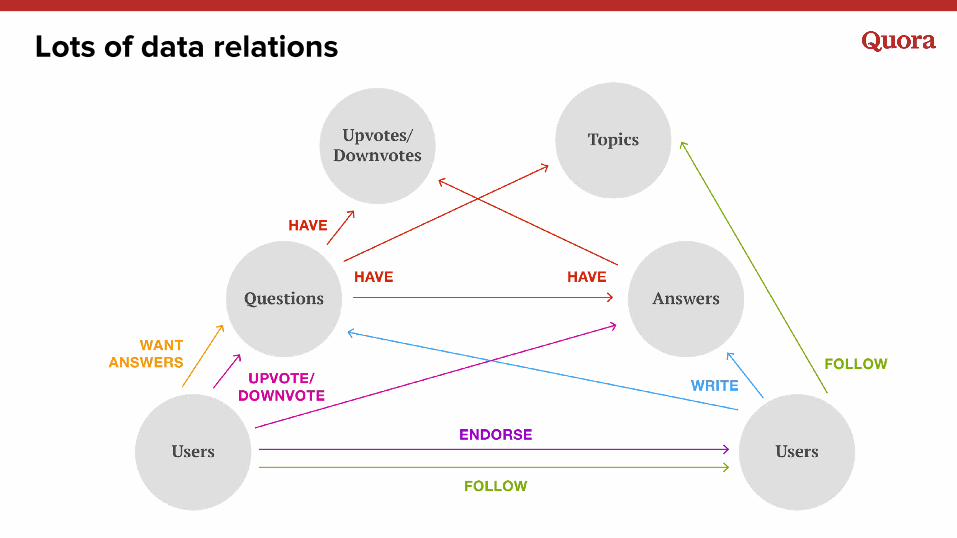
Lots of data relations
ML Applications @ Quora
● Answer ranking
● Feed ranking
● Topic recommendations
● User recommendations
● Email digest
● Ask2Answer
● Duplicate Questions
● Related Questions
● Spam/moderation
● Trending now
● ...
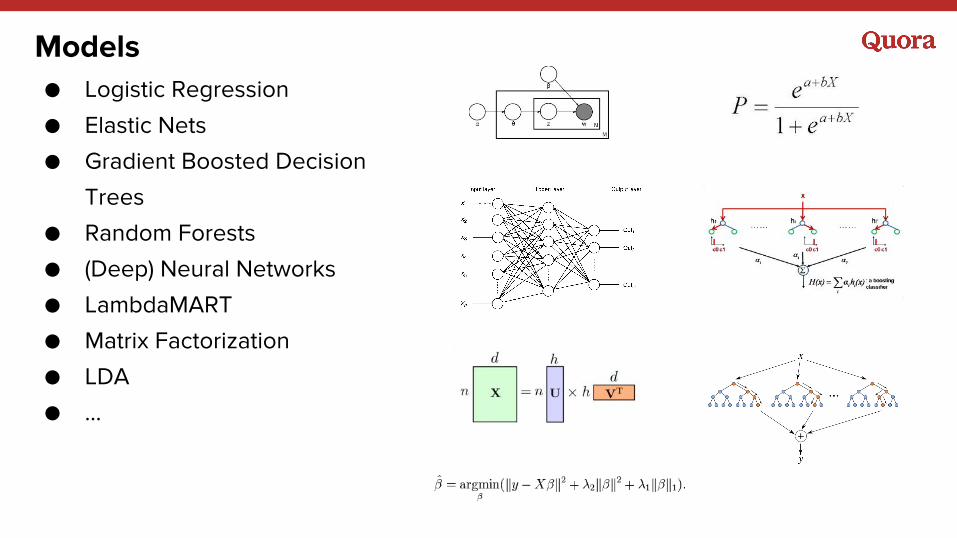
Models● Logistic Regression
● Elastic Nets
● Gradient Boosted Decision
Trees
● Random Forests
● (Deep) Neural Networks
● LambdaMART
● Matrix Factorization
● LDA
● ...

10 More LessonsLearned from implementing real-life ML systems

1. Implicit signals beat explicit ones
(almost always)
Implicit vs. Explicit
● Many have acknowledged
that implicit feedback is more useful
● Is implicit feedback really always
more useful?
● If so, why?

● Implicit data is (usually):
○ More dense, and available for all users
○ Better representative of user behavior vs.
user reflection
○ More related to final objective function
○ Better correlated with AB test results
● E.g. Rating vs watching
Implicit vs. Explicit

● However
○ It is not always the case that
direct implicit feedback correlates
well with long-term retention
○ E.g. clickbait
● Solution:
○ Combine different forms of
implicit + explicit to better represent
long-term goal
Implicit vs. Explicit

2. Your Model will learn what you teach it to learn

Training a model
● Model will learn according to:
○ Training data (e.g. implicit and explicit)
○ Target function (e.g. probability of user reading an answer)
○ Metric (e.g. precision vs. recall)
● Example 1 (made up):
○ Optimize probability of a user going to the cinema to
watch a movie and rate it “highly” by using purchase history
and previous ratings. Use NDCG of the ranking as final
metric using only movies rated 4 or higher as positives.

Example 2 - Quora’s feed
● Training data = implicit + explicit
● Target function: Value of showing a story to a
user ~ weighted sum of actions: v = ∑a va 1{ya = 1}
○ predict probabilities for each action, then compute expected
value: v_pred = E[ V | x ] = ∑a va p(a | x)
● Metric: any ranking metric

3. Supervised vs. plus Unsupervised Learning

Supervised/Unsupervised Learning
● Unsupervised learning as dimensionality reduction
● Unsupervised learning as feature engineering
● The “magic” behind combining
unsupervised/supervised learning
○ E.g.1 clustering + knn
○ E.g.2 Matrix Factorization■ MF can be interpreted as
● Unsupervised:
○ Dimensionality Reduction a la PCA
○ Clustering (e.g. NMF)
● Supervised
○ Labeled targets ~ regression

Supervised/Unsupervised Learning
● One of the “tricks” in Deep Learning is how it
combines unsupervised/supervised learning
○ E.g. Stacked Autoencoders
○ E.g. training of convolutional nets

4. Everything is an ensemble

Ensembles
● Netflix Prize was won by an ensemble
○ Initially Bellkor was using GDBTs
○ BigChaos introduced ANN-based ensemble
● Most practical applications of ML run an ensemble
○ Why wouldn’t you?
○ At least as good as the best of your methods
○ Can add completely different approaches (e.
g. CF and content-based)
○ You can use many different models at the
ensemble layer: LR, GDBTs, RFs, ANNs...

Ensembles & Feature Engineering
● Ensembles are the way to turn any model into a feature!
● E.g. Don’t know if the way to go is to use Factorization
Machines, Tensor Factorization, or RNNs?
○ Treat each model as a “feature”
○ Feed them into an ensemble

The Master Algorithm?
It definitely is an ensemble!

5. The output of your modelwill be the input of another one
(and other design problems)

Outputs will be inputs
● Ensembles turn any model into a feature
○ That’s great!
○ That can be a mess!
● Make sure the output of your model is ready to
accept data dependencies
○ E.g. can you easily change the distribution of the
value without affecting all other models
depending on it?
● Avoid feedback loops
● Can you treat your ML infrastructure as you would
your software one?

ML vs Software
● Can you treat your ML infrastructure as you would
your software one?
○ Yes and No
● You should apply best Software Engineering
practices (e.g. encapsulation, abstraction, cohesion,
low coupling…)
● However, Design Patterns for Machine Learning
software are not well known/documented

6. The pains & gains of Feature Engineering

Feature Engineering
● Main properties of a well-behaved ML feature
○ Reusable
○ Transformable
○ Interpretable
○ Reliable
● Reusability: You should be able to reuse features in different
models, applications, and teams
● Transformability: Besides directly reusing a feature, it
should be easy to use a transformation of it (e.g. log(f), max(f),
∑ft over a time window…)

Feature Engineering
● Main properties of a well-behaved ML feature
○ Reusable
○ Transformable
○ Interpretable
○ Reliable
● Interpretability: In order to do any of the previous, you
need to be able to understand the meaning of features and
interpret their values.
● Reliability: It should be easy to monitor and detect bugs/issues
in features

Feature Engineering Example - Quora Answer Ranking
What is a good Quora answer?
• truthful
• reusable
• provides explanation
• well formatted
• ...

Feature Engineering Example - Quora Answer Ranking
How are those dimensions translated
into features?
• Features that relate to the answer
quality itself
• Interaction features
(upvotes/downvotes, clicks,
comments…)
• User features (e.g. expertise in topic)

7. The two faces of yourML infrastructure

Machine Learning Infrastructure
● Whenever you develop any ML infrastructure, you need to
target two different modes:
○ Mode 1: ML experimentation
■ Flexibility
■ Easy-to-use
■ Reusability
○ Mode 2: ML production
■ All of the above + performance & scalability
● Ideally you want the two modes to be as similar as possible
● How to combine them?

Machine Learning Infrastructure: Experimentation & Production
● Option 1:
○ Favor experimentation and only invest in productionizing
once something shows results
○ E.g. Have ML researchers use R and then ask Engineers
to implement things in production when they work
● Option 2:
○ Favor production and have “researchers” struggle to figure
out how to run experiments
○ E.g. Implement highly optimized C++ code and have ML
researchers experiment only through data available in logs/DB

Machine Learning Infrastructure: Experimentation & Production
● Option 1:
○ Favor experimentation and only invest in productionazing once
something shows results
○ E.g. Have ML researchers use R and then ask Engineers to
implement things in production when they work
● Option 2:
○ Favor production and have “researchers” struggle to figure out
how to run experiments
○ E.g. Implement highly optimized C++ code and have ML
researchers experiment only through data available in logs/DB

● Good intermediate options:
○ Have ML “researchers” experiment on iPython Notebooks using
Python tools (scikit-learn, Theano…). Use same tools in
production whenever possible, implement optimized versions
only when needed.
○ Implement abstraction layers on top of optimized
implementations so they can be accessed from regular/friendly
experimentation tools
Machine Learning Infrastructure: Experimentation & Production

8. Why you should care about answering questions (about your model)

Model debuggability
● Value of a model = value it brings to the product
● Product owners/stakeholders have expectations on
the product
● It is important to answer questions to why did
something fail
● Bridge gap between product design and ML algos
● Model debuggability is so important it can
determine:
○ Particular model to use
○ Features to rely on
○ Implementation of tools
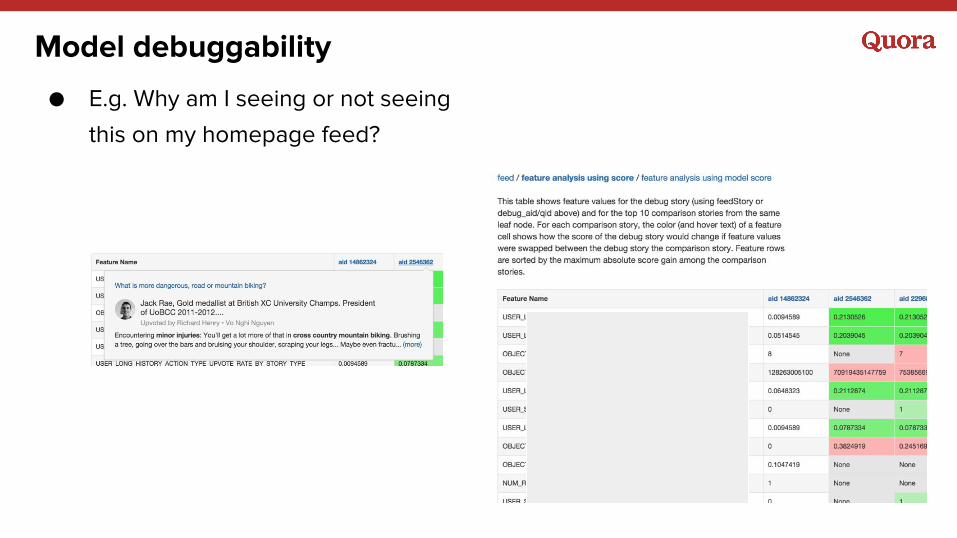
Model debuggability
● E.g. Why am I seeing or not seeing
this on my homepage feed?

9. You don’t need to distribute your ML algorithm

Distributing ML
● Most of what people do in practice can fit into a multi-
core machine
○ Smart data sampling
○ Offline schemes
○ Efficient parallel code
● Dangers of “easy” distributed approaches such
as Hadoop/Spark
● Do you care about costs? How about latencies?

Distributing ML
● Example of optimizing computations to fit them into
one machine
○ Spark implementation: 6 hours, 15 machines
○ Developer time: 4 days
○ C++ implementation: 10 minutes, 1 machine
● Most practical applications of Big Data can fit into
a (multicore) implementation

10. The untold story of Data Science and vs. ML engineering

Data Scientists and ML Engineers
● We all know the definition of a Data Scientist
● Where do Data Scientists fit in an organization?
○ Many companies struggling with this
● Valuable to have strong DS who can bring value
from the data
● Strong DS with solid engineering skills are
unicorns and finding them is not scalable○ DS need engineers to bring things to production
○ Engineers have enough on their plate to be willing to
“productionize” cool DS projects
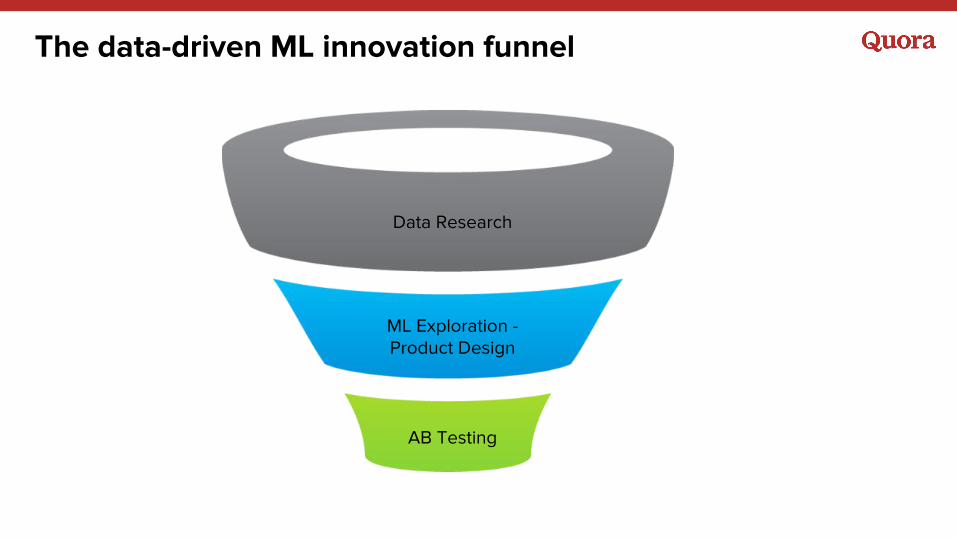
The data-driven ML innovation funnel
Data Research
ML Exploration - Product Design
AB Testing

Data Scientists and ML Engineers
● Solution:
○ (1) Define different parts of the innovation funnel
■ Part 1. Data research & hypothesis
building -> Data Science
■ Part 2. ML solution building &
implementation -> ML Engineering
■ Part 3. Online experimentation, AB
Testing analysis-> Data Science
○ (2) Broaden the definition of ML Engineers
to include from coding experts with high-level
ML knowledge to ML experts with good
software skills
Data Research
ML Solution
AB Testing
Data
ScienceD
ata Science
ML
Engineering

Conclusions

● Make sure you teach your model what you
want it to learn
● Ensembles and the combination of
supervised/unsupervised techniques are key
in many ML applications
● Important to focus on feature engineering
● Be thoughtful about
○ your ML infrastructure/tools
○ about organizing your teams






























