Embed Size (px)
Citation preview

The inherent complexity of stream processing

Easy problem
i want this talk to be interactive...going deep into technical detailsplease do not hesitate to jump in with any questions

struct PageView { UserID id, String url, Timestamp timestamp }

Implement:
function NumUniqueVisitors( String url, int startHour, int endHour)

Unique visitors over a range
ABCA
BCDE
CDE
1 2 3 4Hours
Pageviews
uniques for just hour 1 = 3uniques for hours 1 and 2 = 3uniques for 1 to 3 = 5uniques for 2-4 = 4

Notes:
• Not limiting ourselves to current tooling
• Reasonable variations of existing tooling are acceptable
• Interested in what’s fundamentally possible
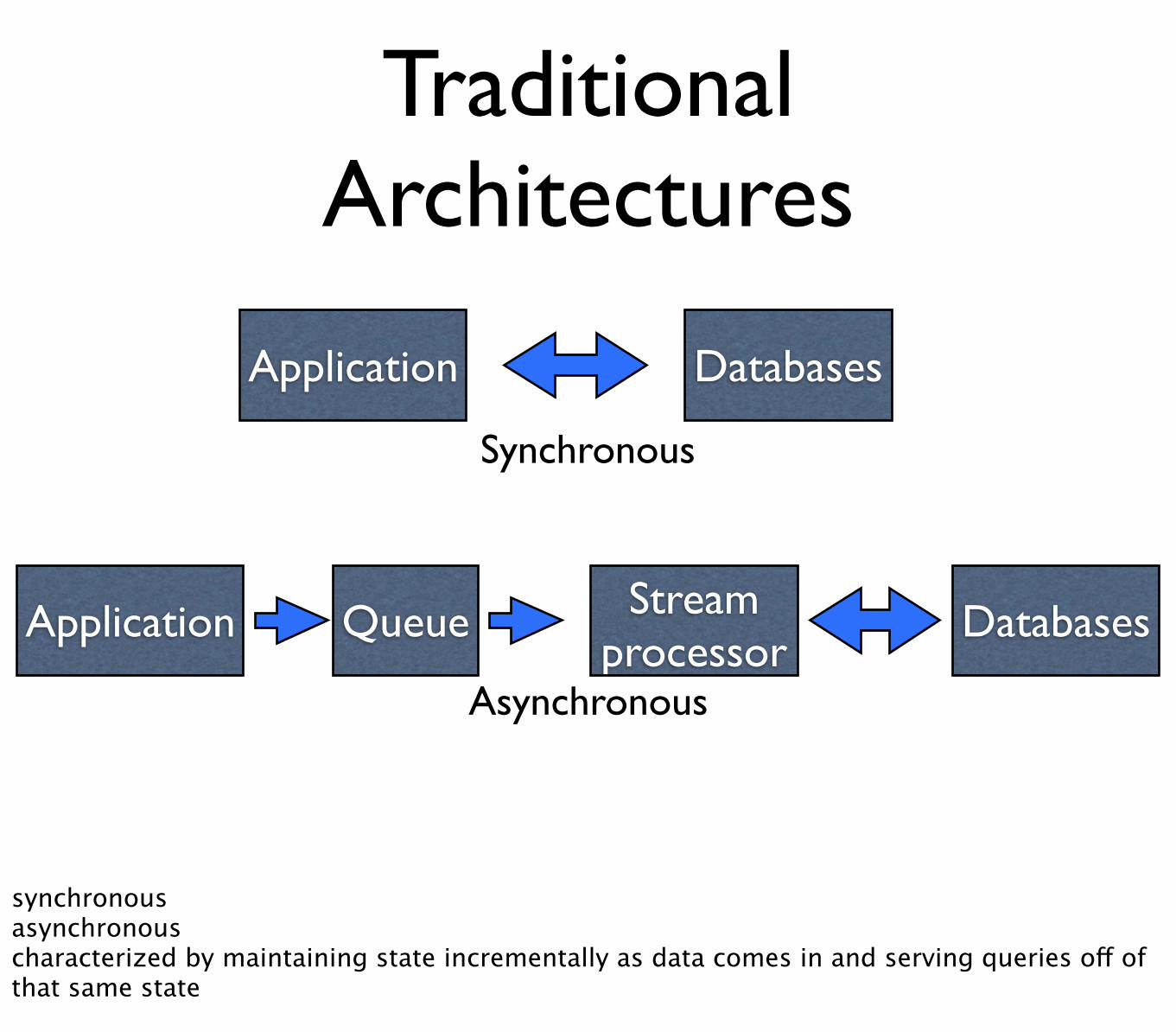
Traditional Architectures
Application Databases
Application DatabasesStream processor
Queue
Synchronous
Asynchronous
synchronousasynchronouscharacterized by maintaining state incrementally as data comes in and serving queries off of that same state

Approach #1
• Use Key->Set database
• Key = [URL, hour bucket]
• Value = Set of UserIDs

Approach #1
• Queries:
• Get all sets for all hours in range of query
• Union sets together
• Compute count of merged set

Approach #1
• Lot of database lookups for large ranges
• Potentially a lot of items in sets, so lots of work to merge/count
• Database will use a lot of space

Approach #2
Use HyperLogLog

interface HyperLogLog { boolean add(Object o); long size(); HyperLogLog merge(HyperLogLog... otherSets);}
1 KB to estimate size up to 1B with only 2% error

Approach #2
• Use Key->HyperLogLog database
• Key = [URL, hour bucket]
• Value = HyperLogLog structure
it’s not a stretch to imagine a database that can do hyperloglog natively, so updates don’t require fetching the entire set

Approach #2
• Queries:
• Get all HyperLogLog structures for all hours in range of query
• Merge structures together
• Retrieve count from merged structure

Approach #2
• Much more efficient use of storage
• Less work at query time
• Mild accuracy tradeoff

Approach #2
• Large ranges still require lots of database lookups / work

Approach #3
• Use Key->HyperLogLog database
• Key = [URL, bucket, granularity]
• Value = HyperLogLog structure
it’s not a stretch to imagine a database that can do hyperloglog natively, so updates don’t require fetching the entire set

Approach #3
• Queries:
• Compute minimal number of database lookups to satisfy range
• Get all HyperLogLog structures in range
• Merge structures together
• Retrieve count from merged structure

Approach #3
• All benefits of #2
• Minimal number of lookups for any range, so less variation in latency
• Minimal increase in storage
• Requires more work at write time
example: 1 month there are ~720 hours, 30 days, 4 weeks, 1 month... adding all granularities makes 755 stored values total instead of 720 values, only a 4.8% increase in storage

Hard problem

struct Equiv { UserID id1, UserID id2}
struct PageView { UserID id, String url, Timestamp timestamp }


Person A Person B

Implement:
function NumUniqueVisitors( String url, int startHour, int endHour)
except now userids should be normalized, so if there’s equiv that user only appears once even if under multiple ids
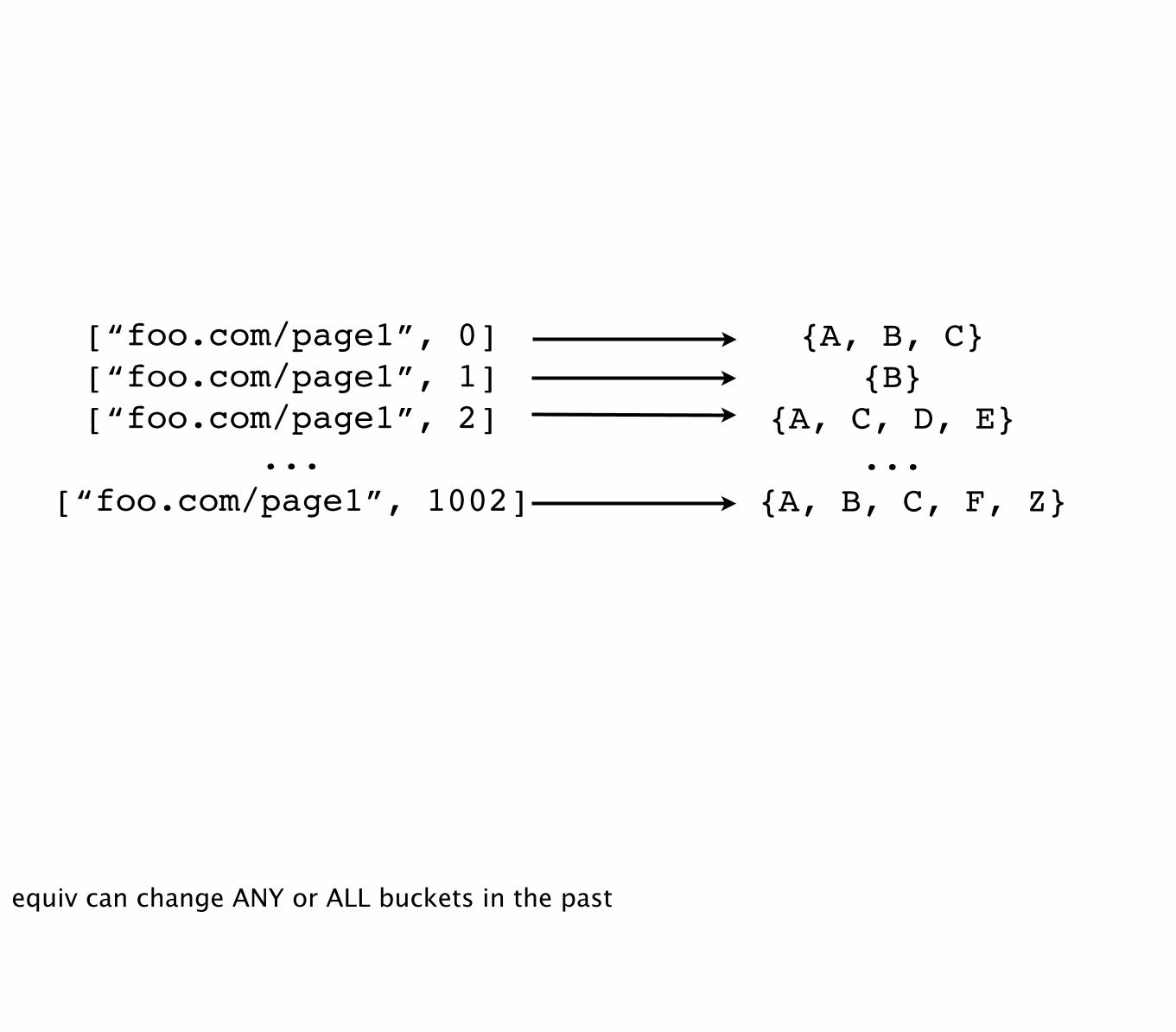
[“foo.com/page1”, 0][“foo.com/page1”, 1] [“foo.com/page1”, 2]
...[“foo.com/page1”, 1002]
{A, B, C}{B}
{A, C, D, E}...
{A, B, C, F, Z}
equiv can change ANY or ALL buckets in the past
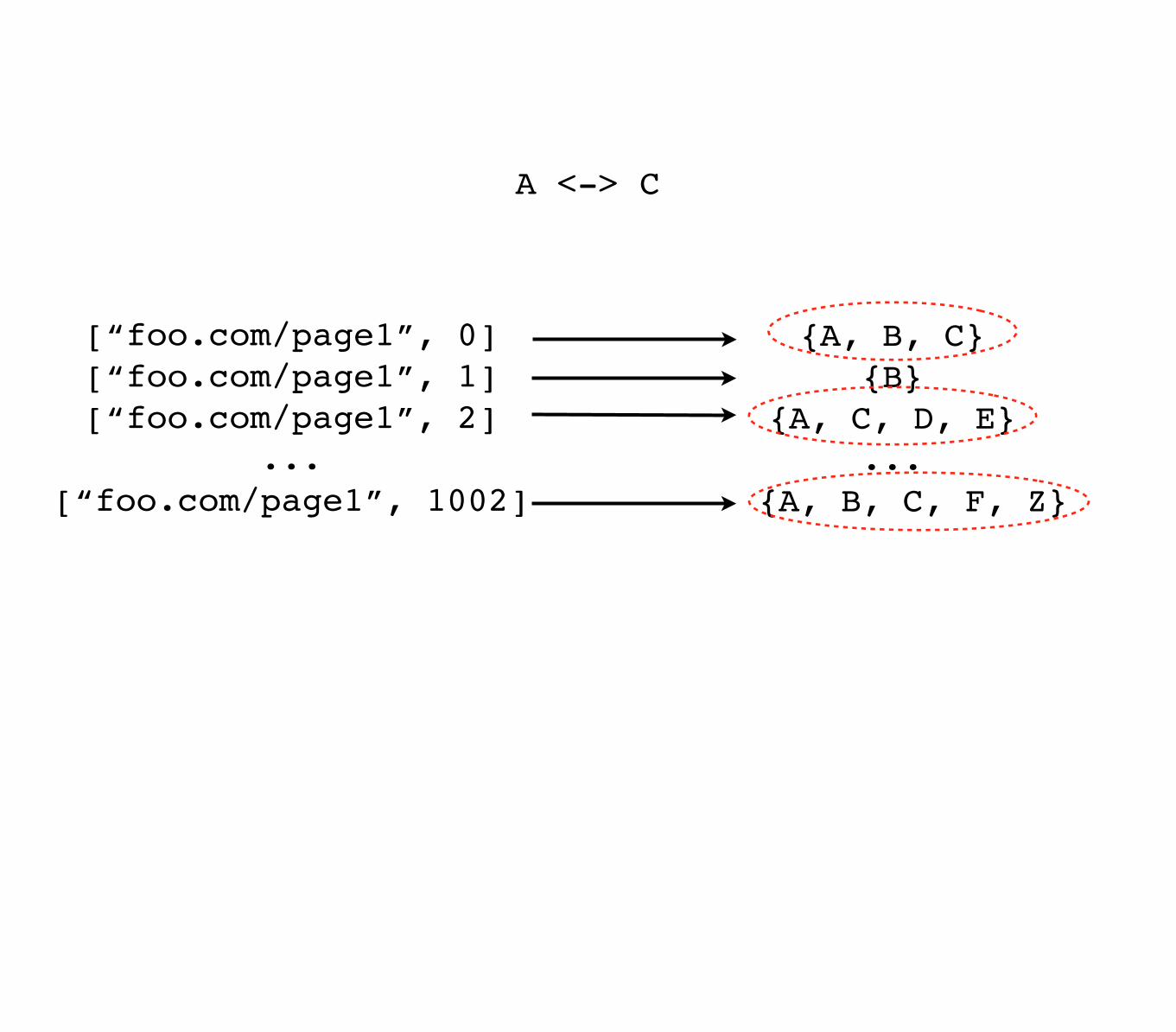
[“foo.com/page1”, 0][“foo.com/page1”, 1] [“foo.com/page1”, 2]
...[“foo.com/page1”, 1002]
{A, B, C}{B}
{A, C, D, E}...
{A, B, C, F, Z}
A <-> C

Any single equiv could change any bucket

No way to take advantage of HyperLogLog

Approach #1
• [URL, hour] -> Set of PersonIDs
• PersonID -> Set of buckets
• Indexes to incrementally normalize UserIDs into PersonIDs
will get back to incrementally updating userids

Approach #1
• Getting complicated
• Large indexes
• Operations require a lot of work
will get back to incrementally updating userids

Approach #2
• [URL, bucket] -> Set of UserIDs
• Like Approach 1, incrementally normalize UserId’s
• UserID -> PersonID
offload a lot of the work to read time

Approach #2
• Query:
• Retrieve all UserID sets for range
• Merge sets together
• Convert UserIDs -> PersonIDs to produce new set
• Get count of new set
this is still an insane amount of work at read timeoverall

Approach #3
• [URL, bucket] -> Set of sampled UserIDs
• Like Approaches 1 & 2, incrementally normalize UserId’s
• UserID -> PersonID
offload a lot of the work to read time

Approach #3• Query:
• Retrieve all UserID sets for range
• Merge sets together
• Convert UserIDs -> PersonIDs to produce new set
• Get count of new set
• Divide count by sample rate
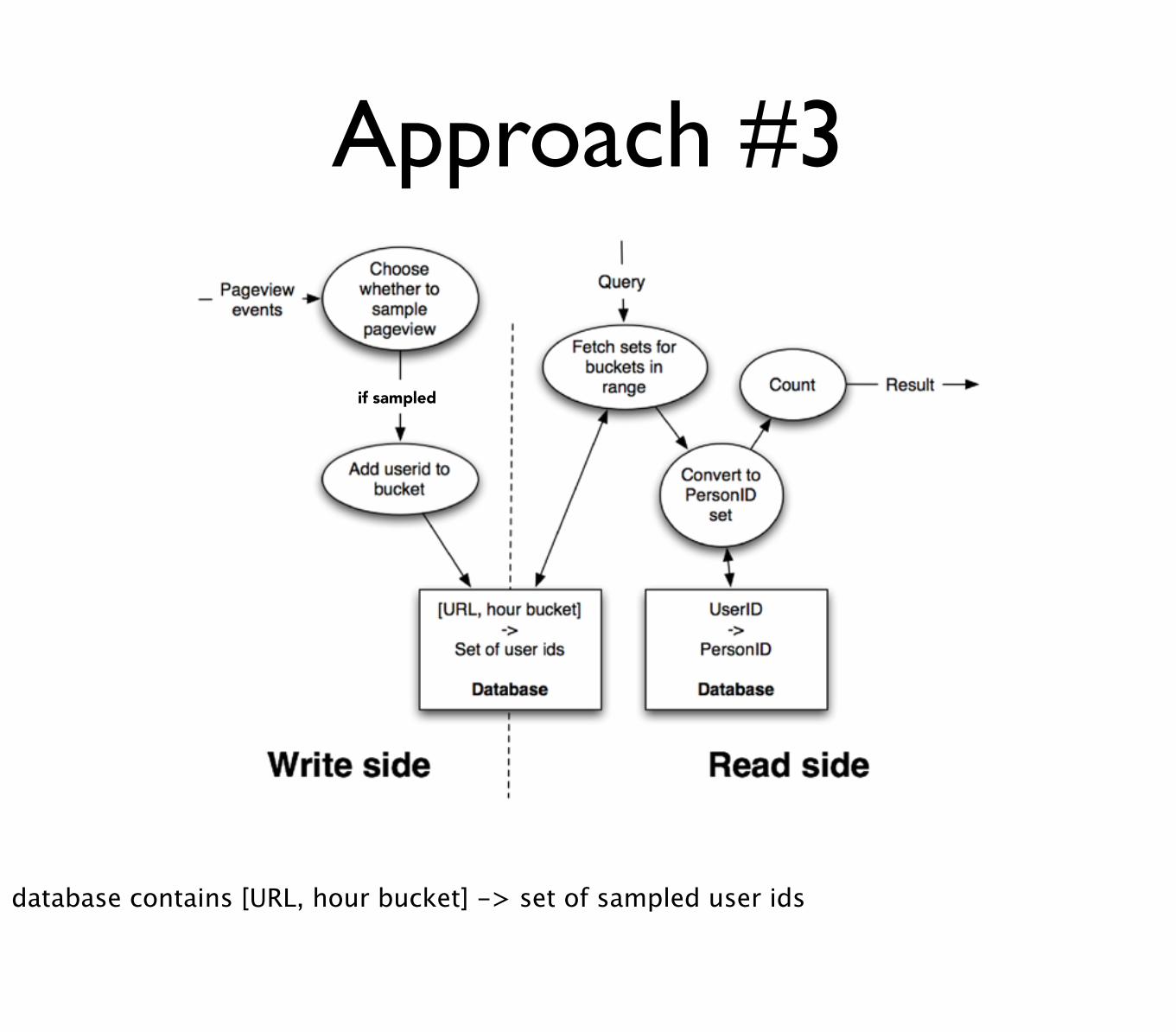
Approach #3
if sampled
database contains [URL, hour bucket] -> set of sampled user ids

Approach #3
• Sample the user ids using hash sampling
• Divide by the sample rate at end to approximate the unique count
can’t just do straight random sampling (imagine if only have 4 user ids that visit thousands of times... a sample rate of 50% will have all user ids, and you’ll end up giving the answer of 8)

Approach #3
• Still need complete UserID -> PersonID index
• Still requires about 100 lookups into UserID -> PersonID index to resolve queries
• Error rate 3-5x worse than HyperLogLog for same space usage
• Requires SSD’s for reasonable throughput

Incremental UserID normalization

Attempt 1:
• Maintain index from UserID -> PersonID
• When receive A <-> B:
• Find what they’re each normalized to, and transitively normalize all reachable IDs to “smallest” val

1 <-> 4 1 -> 14 -> 1
2 <-> 55 -> 22 -> 2
5 <-> 3 3 -> 2
4 <-> 55 -> 12 -> 1
3 -> 1 never gets produced!

Attempt 2:
• UserID -> PersonID
• PersonID -> Set of UserIDs
• When receive A <-> B
• Find what they’re each normalized to, and choose one for both to be normalized to
• Update all UserID’s in both normalized sets

1 <-> 41 -> 14 -> 1
1 -> {1, 4}
2 <-> 55 -> 22 -> 2
2 -> {2, 5}
5 <-> 3 3 -> 22 -> {2, 3, 5}
4 <-> 55 -> 12 -> 13 -> 1
1 -> {1, 2, 3, 4, 5}

Challenges
• Fault-tolerance / ensuring consistency between indexes
• Concurrency challenges
if using distributed database to store indexes and computing everything concurrentlywhen receive equivs for 4<->3 and 3<->1 at same time, will need some sort of locking so they don’t step on each other

General challenges with traditional architectures
• Redundant storage of information (“denormalization”)
• Brittle to human error
• Operational challenges of enormous installations of very complex databases
e.g. granularities, the 2 indexes for user id normalization... we know it’s a bad idea to store the same thing in multiple places... opens up possibility of them getting out of sync if you don’t handle every case perfectlyIf you have a bug that accidentally sets the second value of all equivs to 1, you’re in troubleeven the version without equivs suffers from these problems
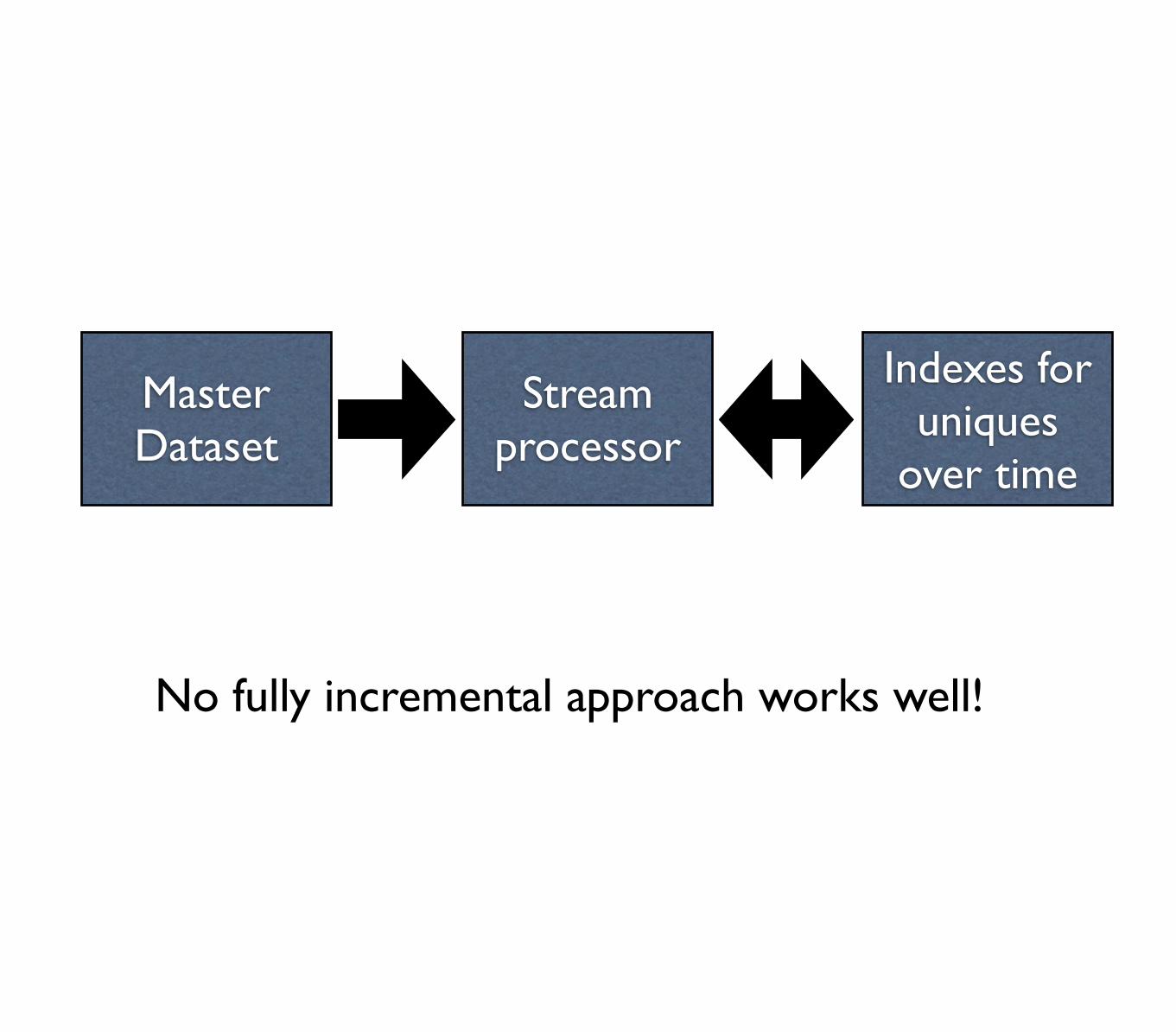
Master Dataset
Indexes for uniques
over time
Stream processor
No fully incremental approach works well!

Let’s take a completely different approach!

Some Rough Definitions
Complicated: lots of parts

Some Rough Definitions
Complex: intertwinement between separate functions

Some Rough Definitions
Simple: the opposite of complex

Real World Example
2 functions: produce water of a certain strength, and produce water of a certain temperaturefaucet on left gives you “hot” and “cold” inputs which each affect BOTH outputs - complex to usefaucet on right gives you independent “heat” and “strength” inputs, so SIMPLE to useneither is very complicated

Real World Example #2
recipe... heat it up then cool it down

Real World Example #2
I have to use two devices for the same task!!! temperature control!wouldn’t it be SIMPLER if I had just one device that could regulate temperature from 0 degrees to 500 degrees?then i could have more features, like “450 for 20 minutes then refrigerate”who objects to this?... talk about how mixing them can create REAL COMPLEXITY...- sometimes you need MORE PIECES to AVOID COMPLEXITY and CREATE SIMPLICITY- we’ll come back to this... this same situation happens in software all the time- people want one tool with a million features... but it turns out these features interact with each other and create COMPLEXITY
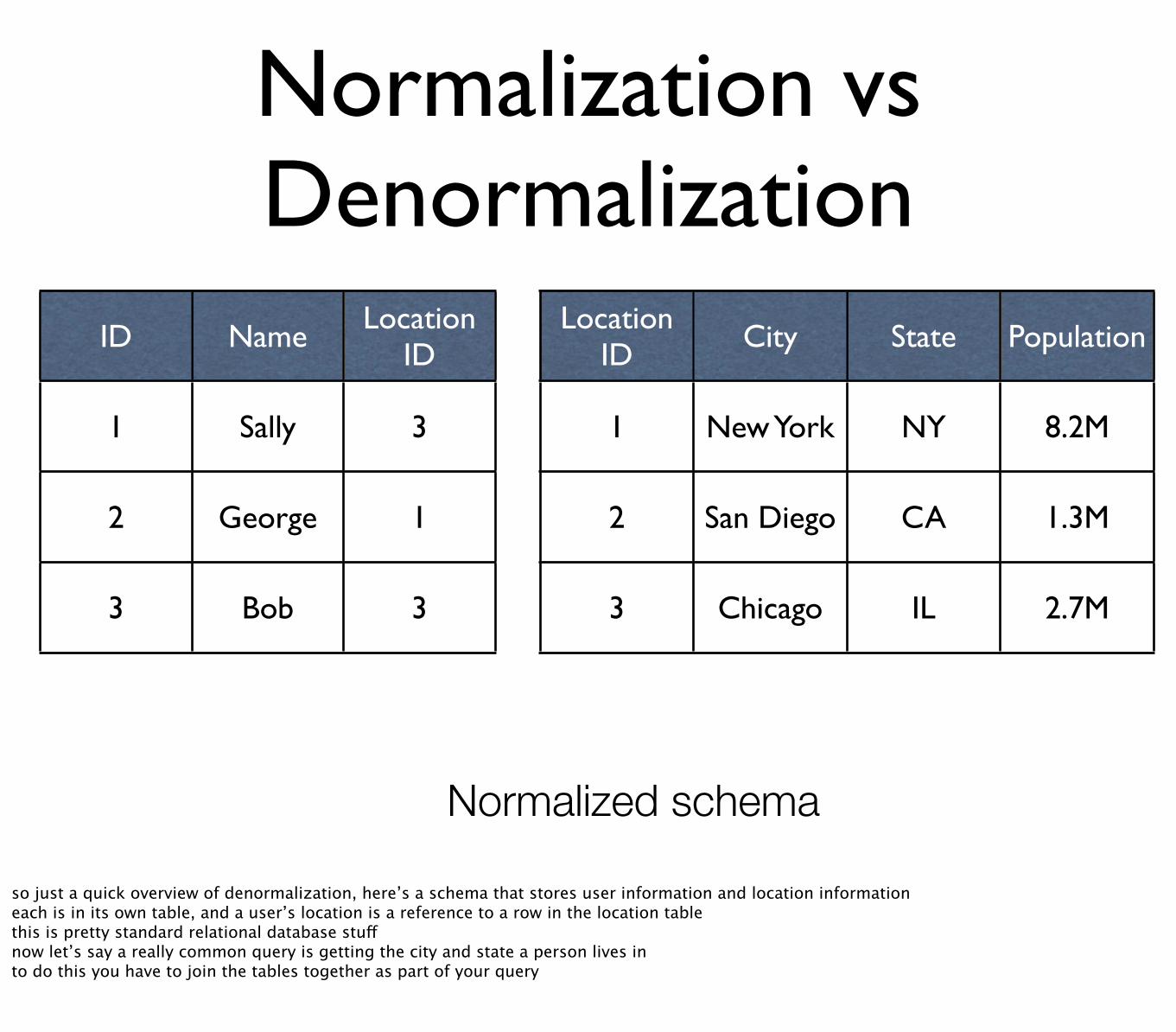
ID Name Location ID
1 Sally 3
2 George 1
3 Bob 3
Location ID City State Population
1 New York NY 8.2M
2 San Diego CA 1.3M
3 Chicago IL 2.7M
Normalized schema
Normalization vs Denormalization
so just a quick overview of denormalization, here’s a schema that stores user information and location informationeach is in its own table, and a user’s location is a reference to a row in the location tablethis is pretty standard relational database stuffnow let’s say a really common query is getting the city and state a person lives into do this you have to join the tables together as part of your query

Join is too expensive, so denormalize...
you might find joins are too expensive, they use too many resources
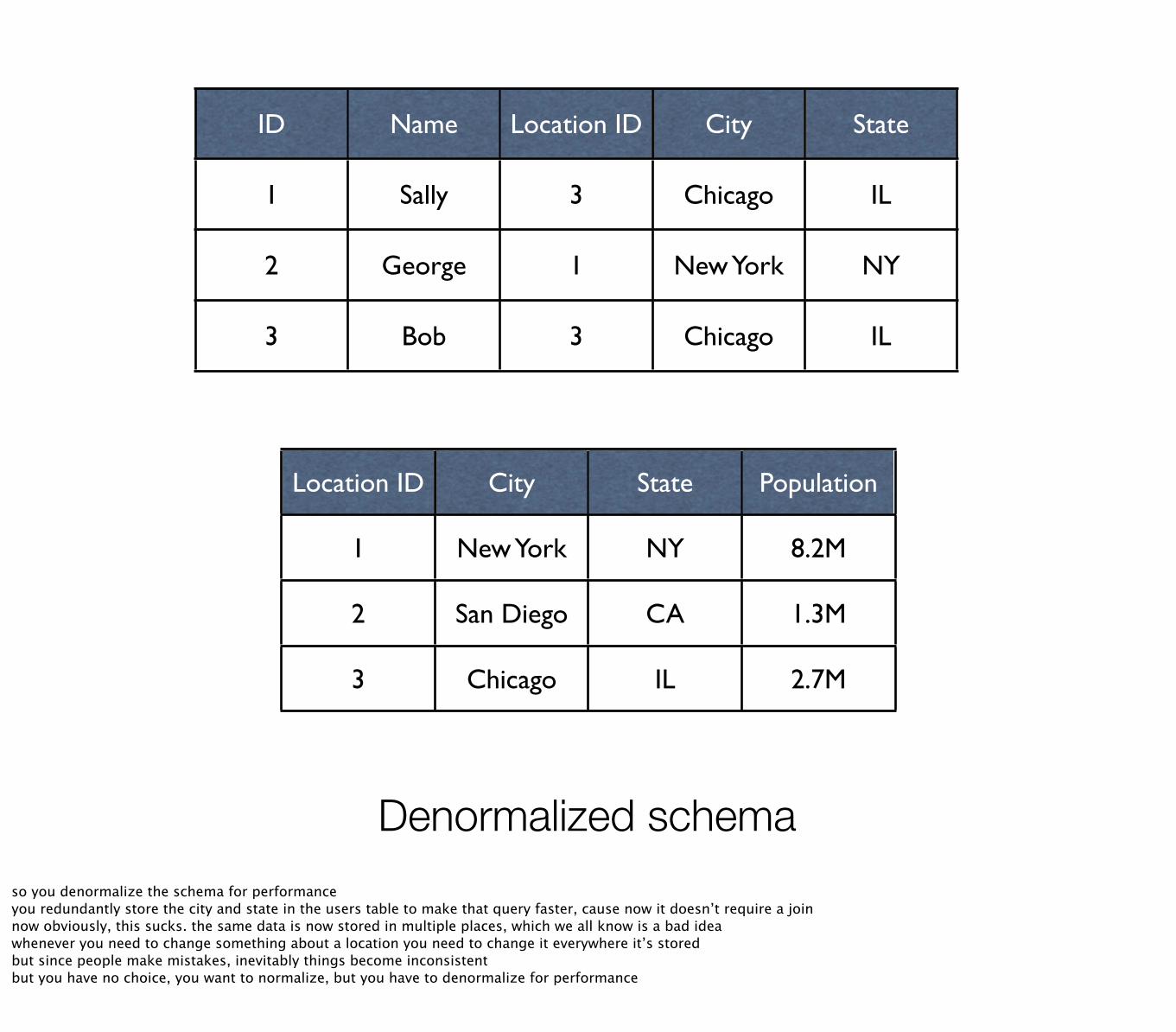
ID Name Location ID City State
1 Sally 3 Chicago IL
2 George 1 New York NY
3 Bob 3 Chicago IL
Location ID City State Population
1 New York NY 8.2M
2 San Diego CA 1.3M
3 Chicago IL 2.7M
Denormalized schemaso you denormalize the schema for performanceyou redundantly store the city and state in the users table to make that query faster, cause now it doesn’t require a joinnow obviously, this sucks. the same data is now stored in multiple places, which we all know is a bad ideawhenever you need to change something about a location you need to change it everywhere it’s storedbut since people make mistakes, inevitably things become inconsistentbut you have no choice, you want to normalize, but you have to denormalize for performance

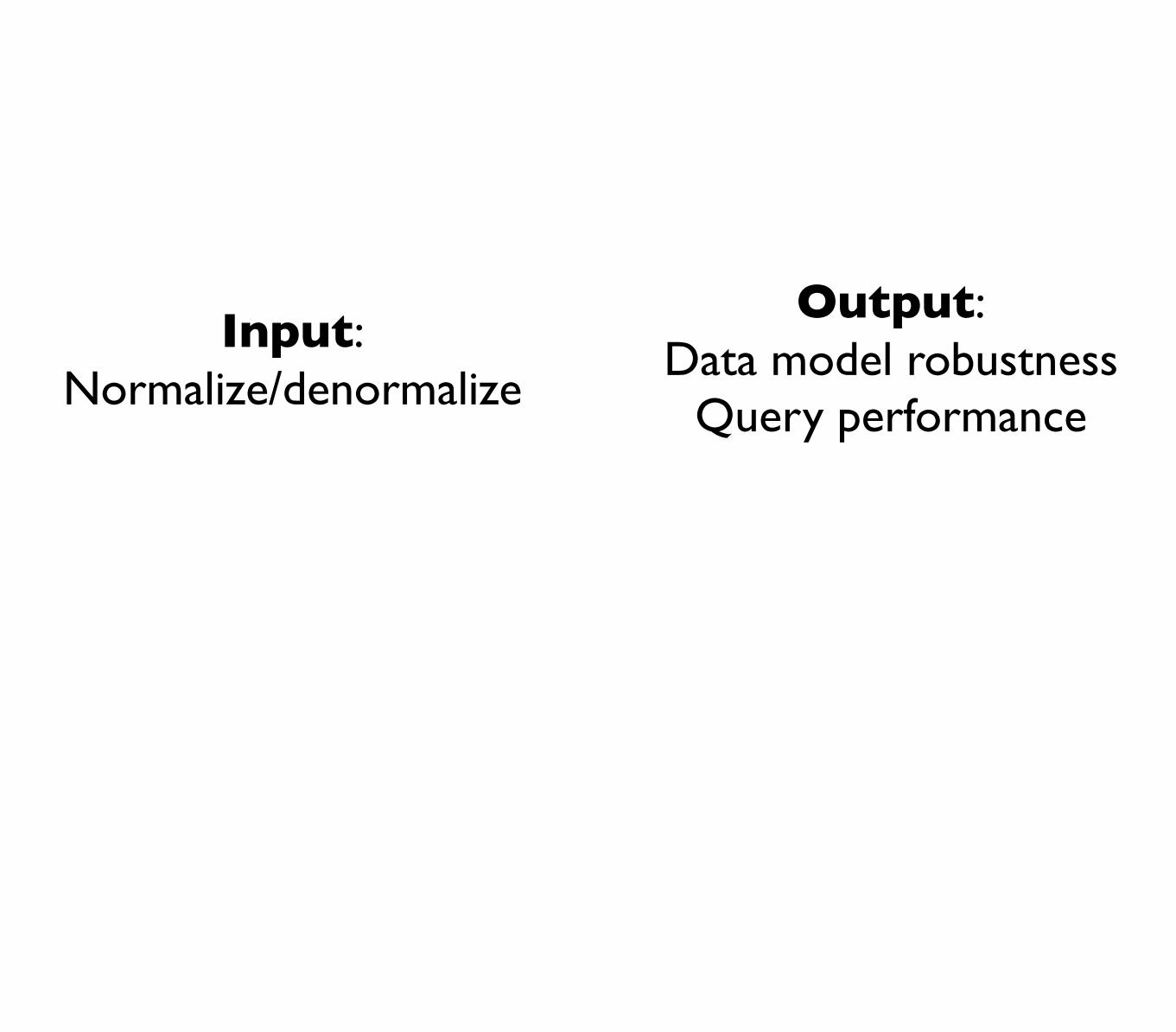
Complexity between robust data modeland query performance
you have to choose which one you’re going to suck at

Allow queries to be out of date by hours

Store every Equiv and PageView
Master Dataset

Master Dataset
Continuously recompute indexes
Indexes for uniques
over time

Indexes = function(all data)

Equivs
PageViews
Compute UserID -> PersonID
Convert PageView UserIDs to PersonIDs
Compute[URL, bucket, granularity] -> HyperLogLog
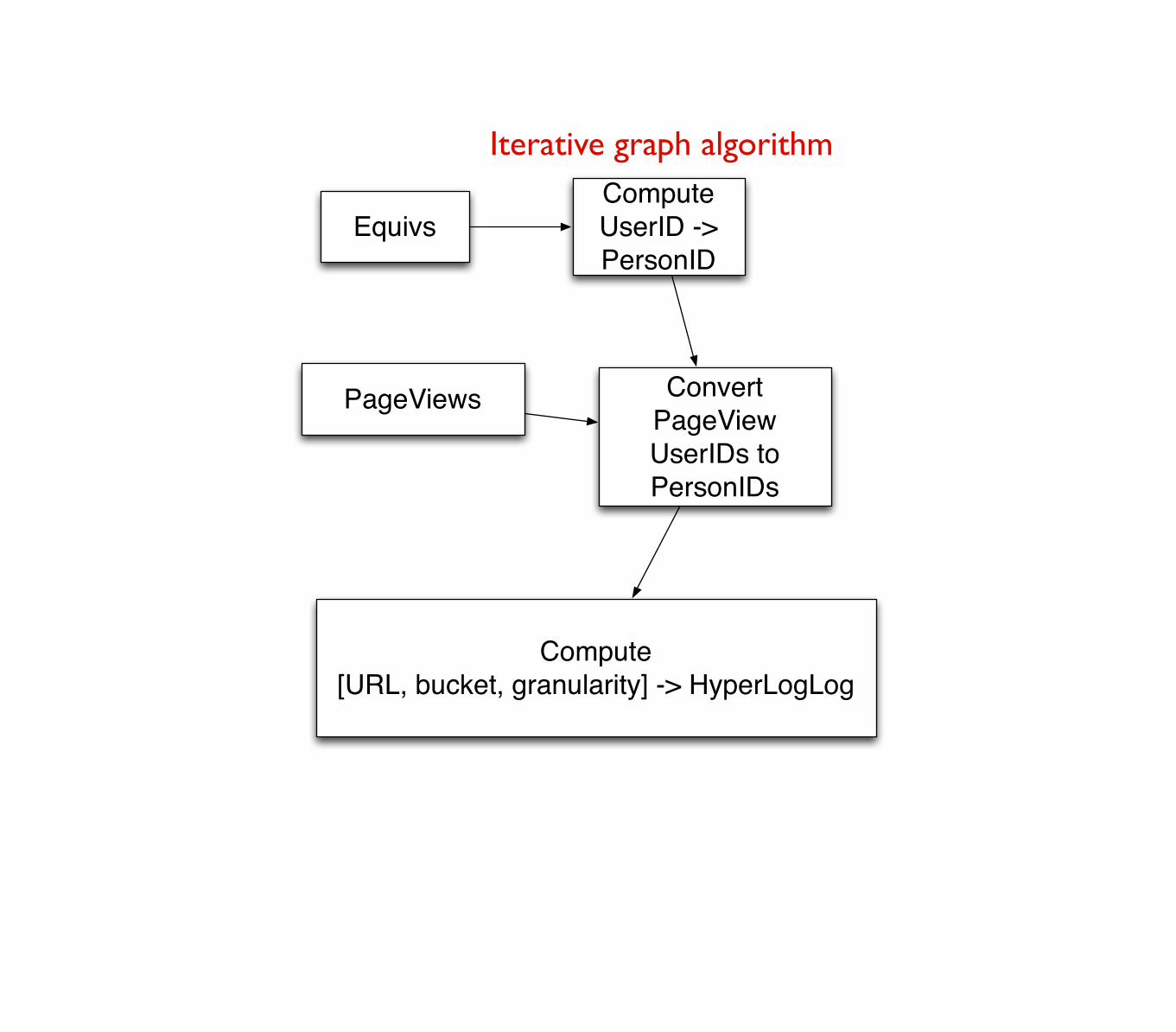
Equivs
PageViews
Compute UserID -> PersonID
Convert PageView UserIDs to PersonIDs
Compute[URL, bucket, granularity] -> HyperLogLog
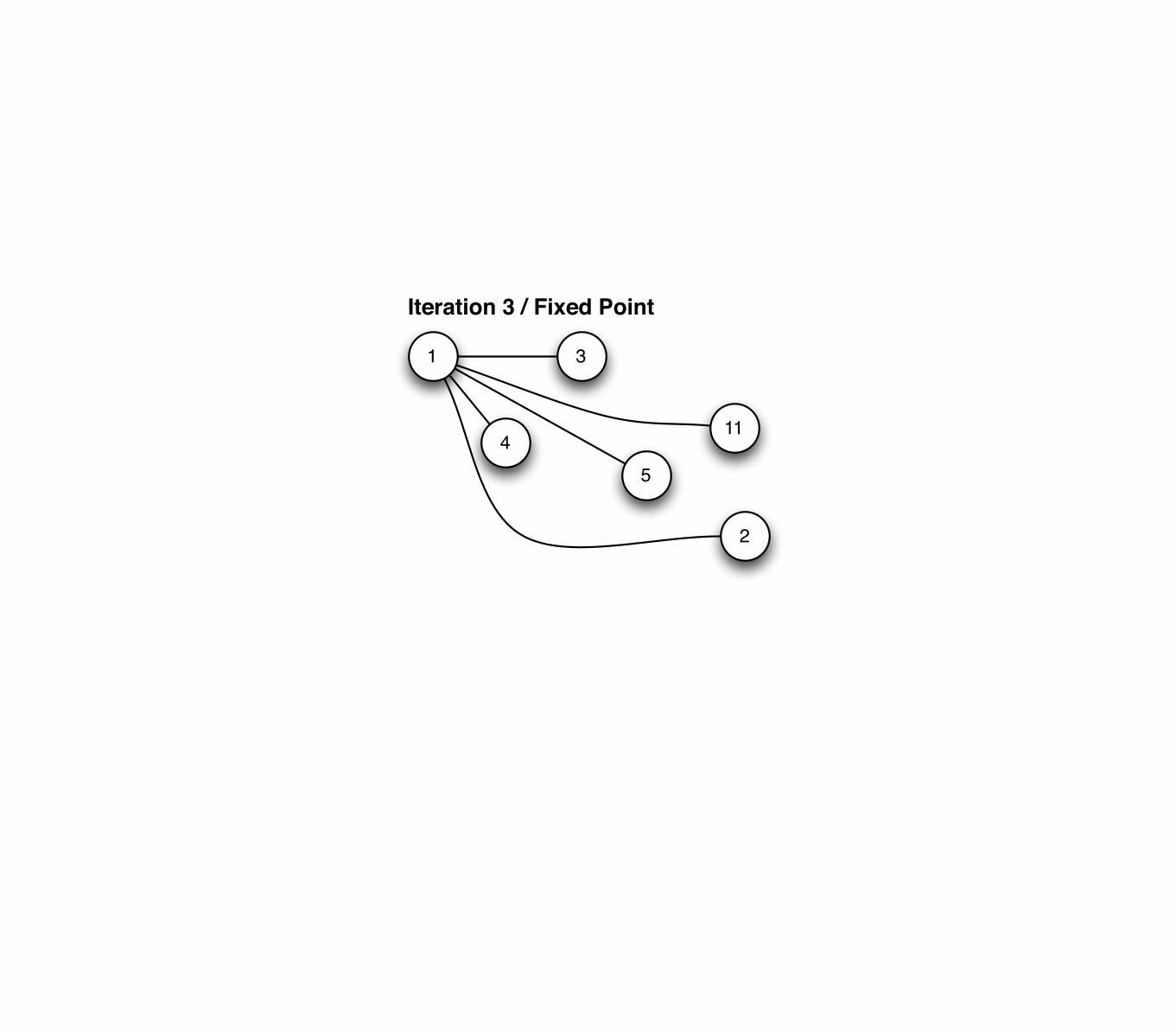
Iterative graph algorithm

Equivs
PageViews
Compute UserID -> PersonID
Convert PageView UserIDs to PersonIDs
Compute[URL, bucket, granularity] -> HyperLogLog
Join
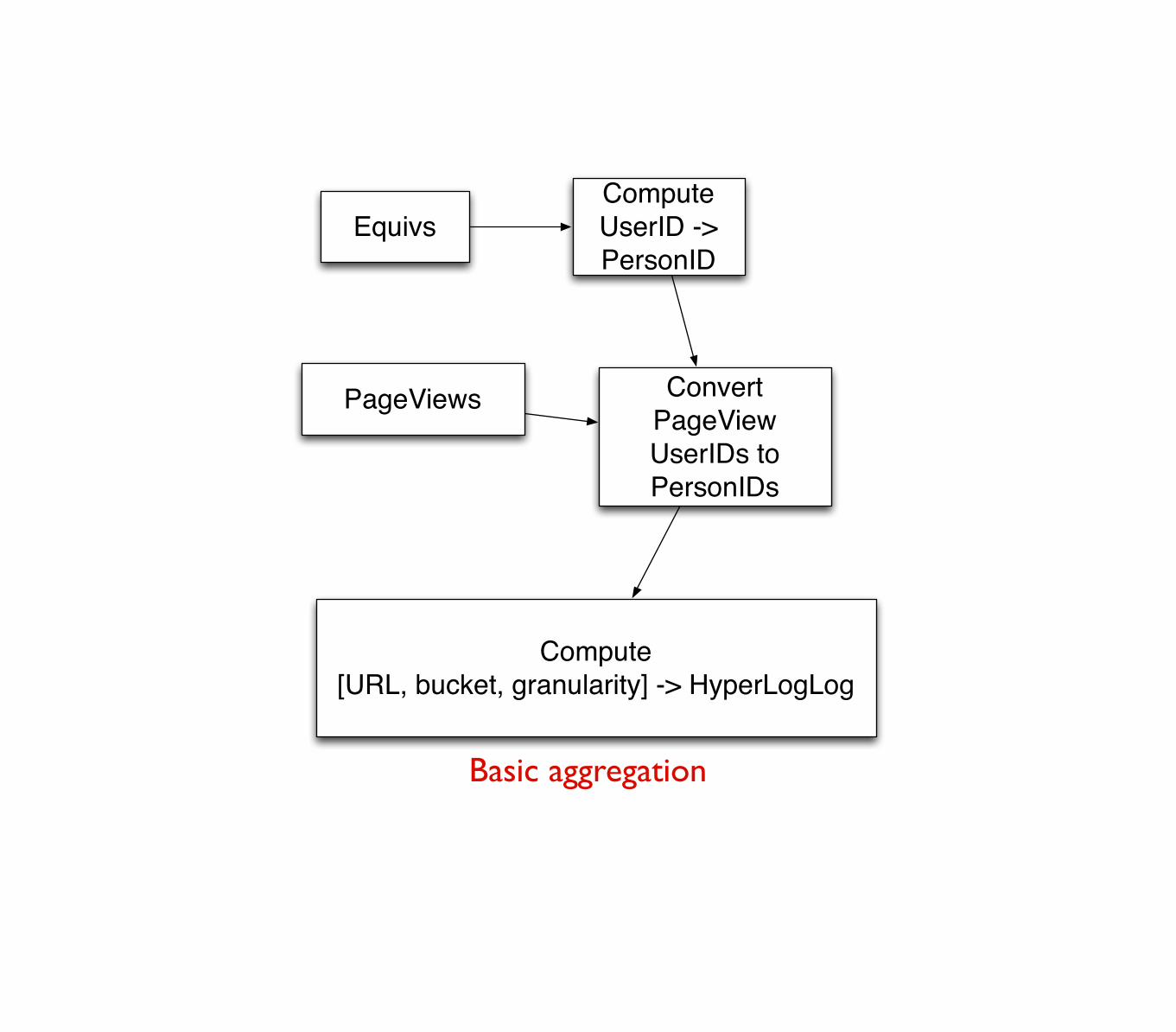
Equivs
PageViews
Compute UserID -> PersonID
Convert PageView UserIDs to PersonIDs
Compute[URL, bucket, granularity] -> HyperLogLog
Basic aggregation

Sidenote on tooling
• Batch processing systems are tools to implement function(all data) scalably
• Implementing this is easy

Person 1 Person 6
UserID normalization

UserID normalization
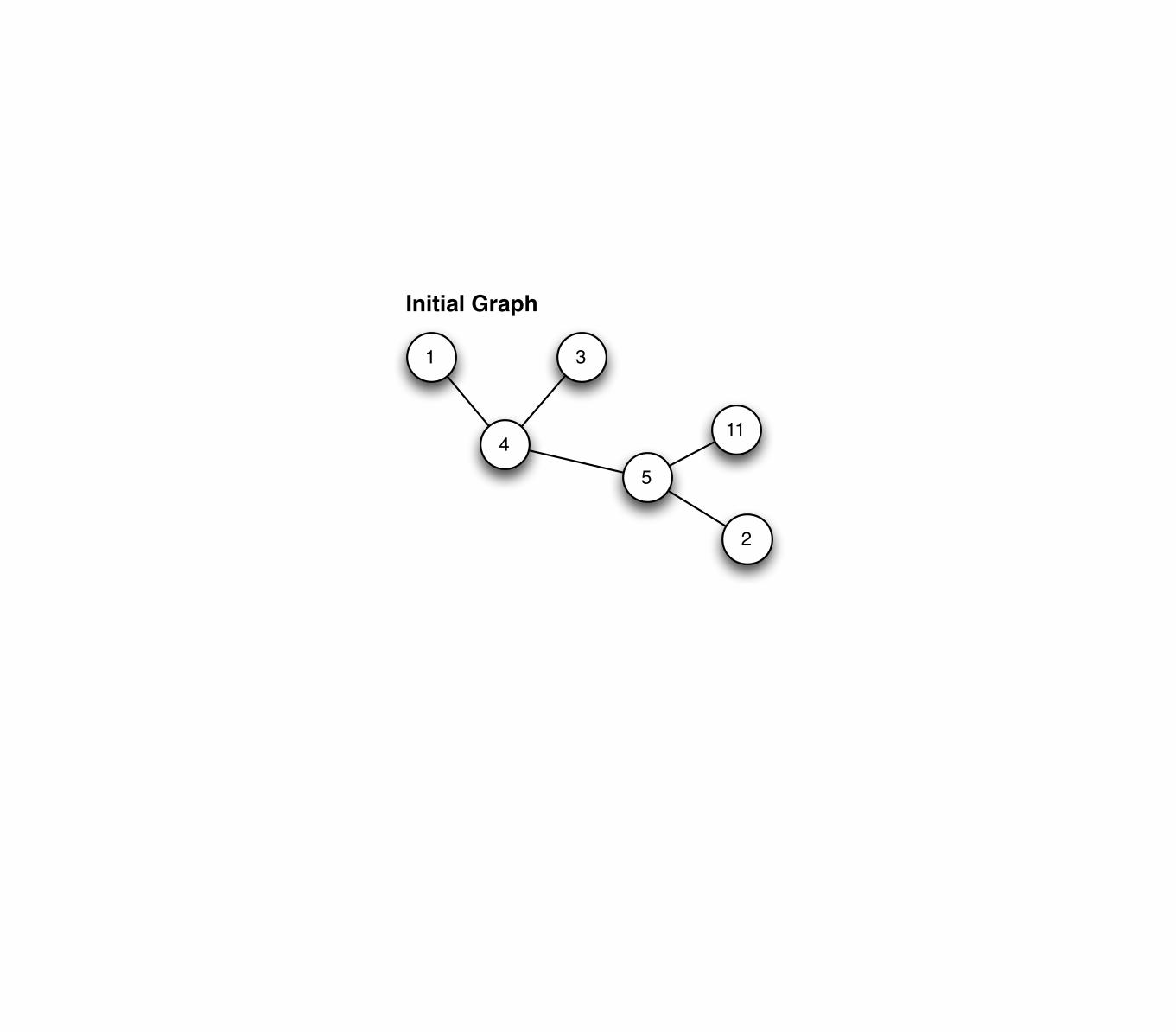
1 3
4
5
11
2
Initial Graph
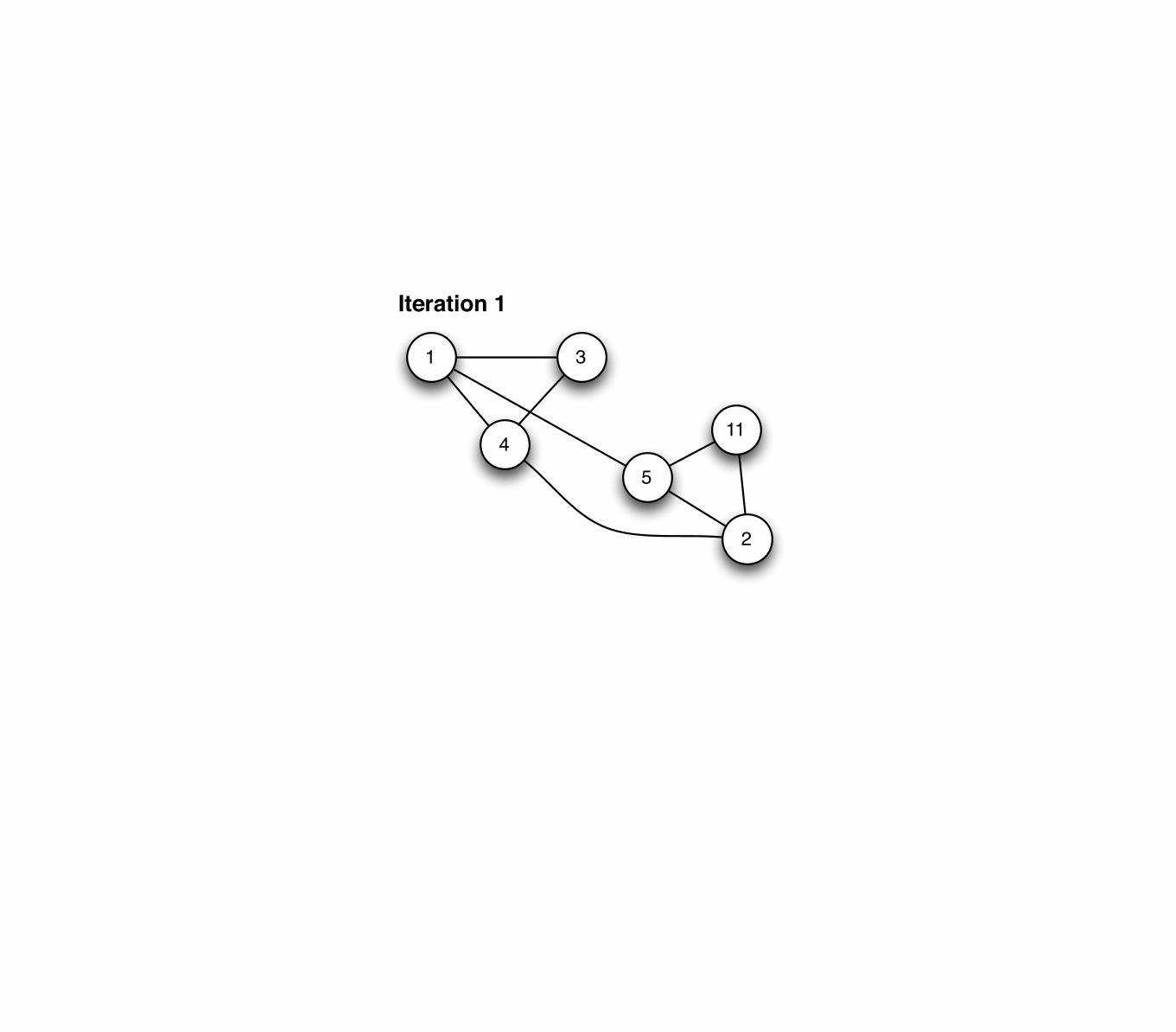
1 3
4
5
11
2
Iteration 1
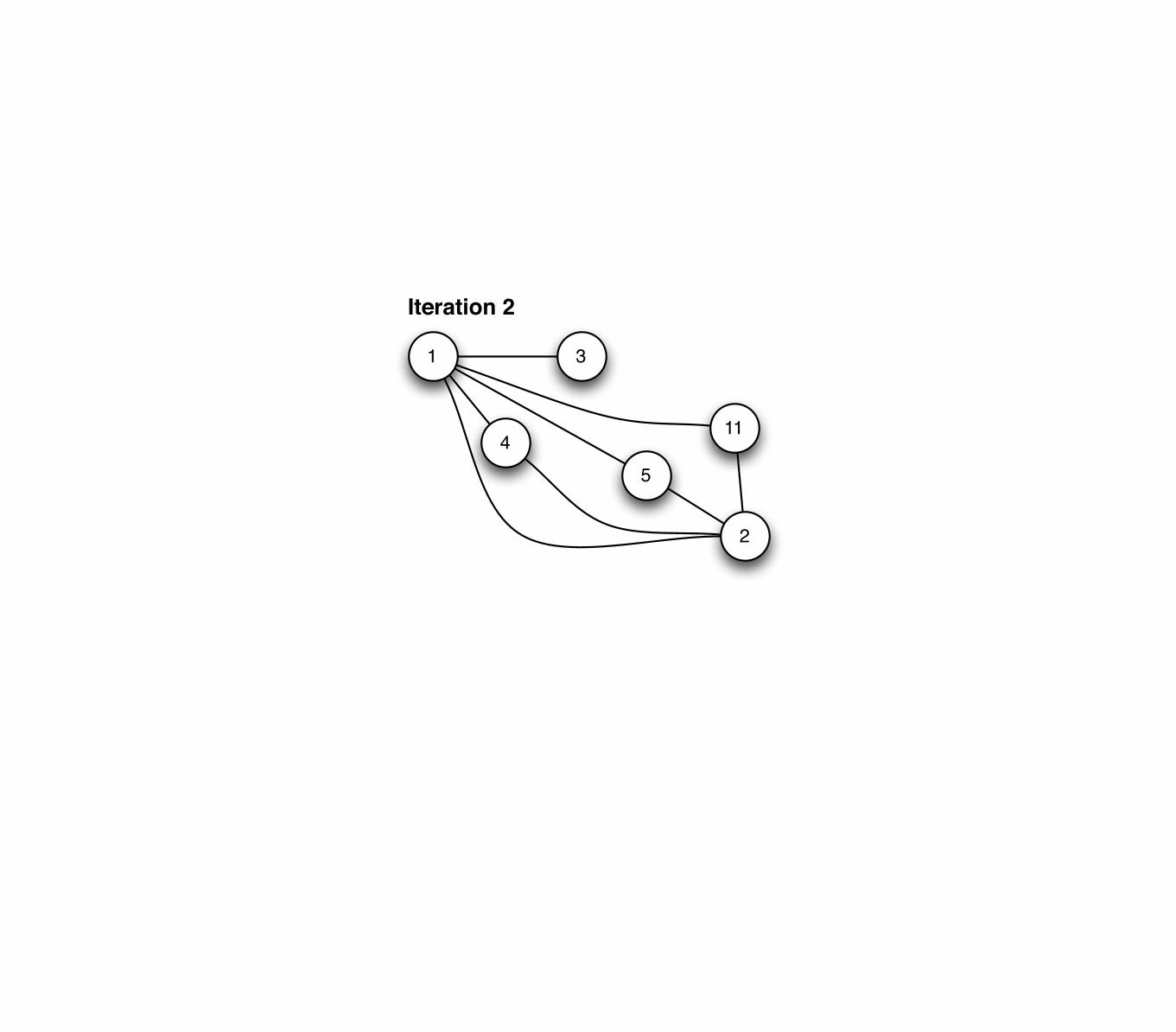
1 3
4
5
11
2
Iteration 2
1 3
4
5
11
2
Iteration 3 / Fixed Point

Conclusions
• Easy to understand and implement
• Scalable
• Concurrency / fault-tolerance easily abstracted away from you
• Great query performance

Conclusions
• But... always out of date
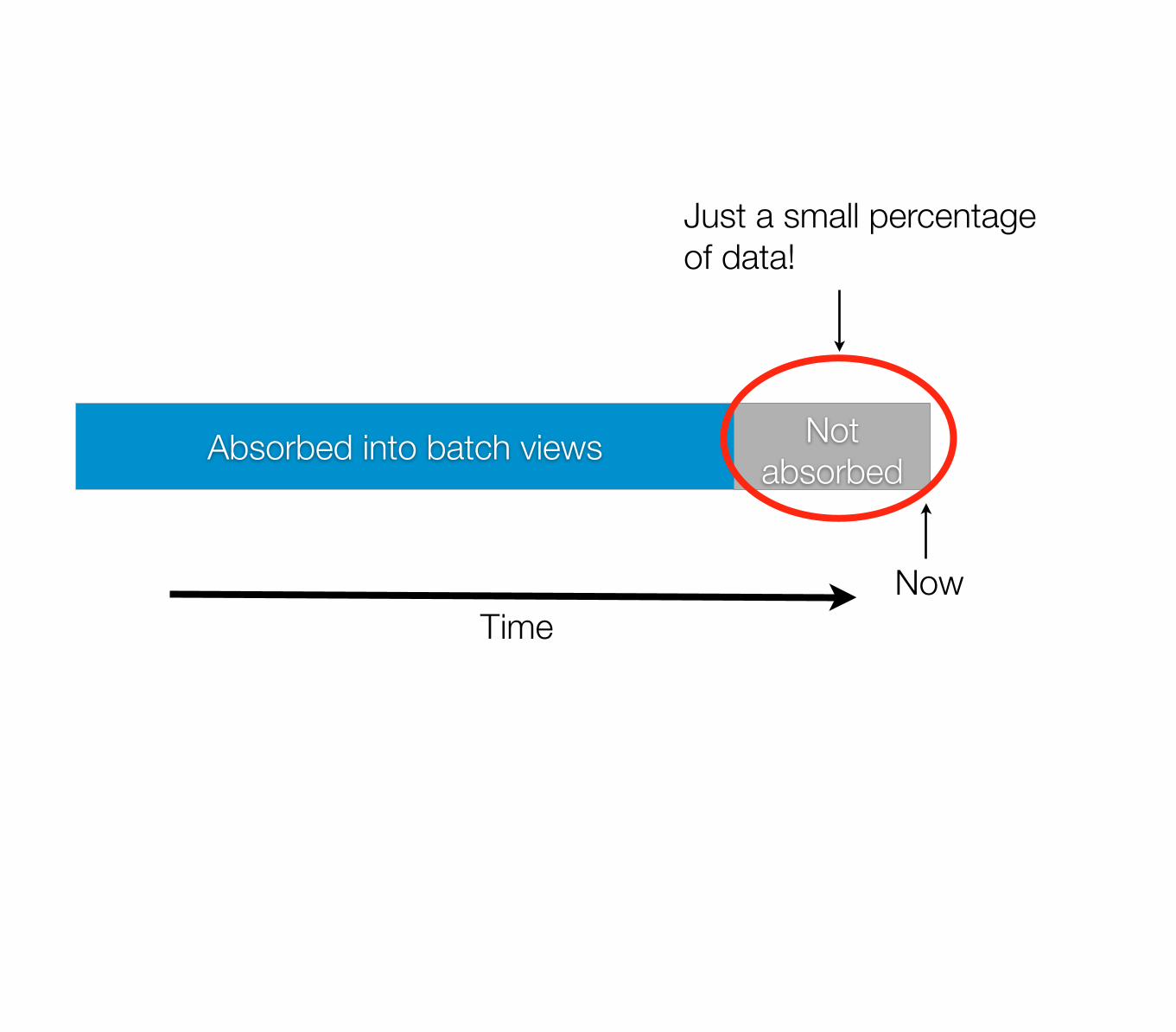
Absorbed into batch views Not absorbed
NowTime
Just a small percentageof data!
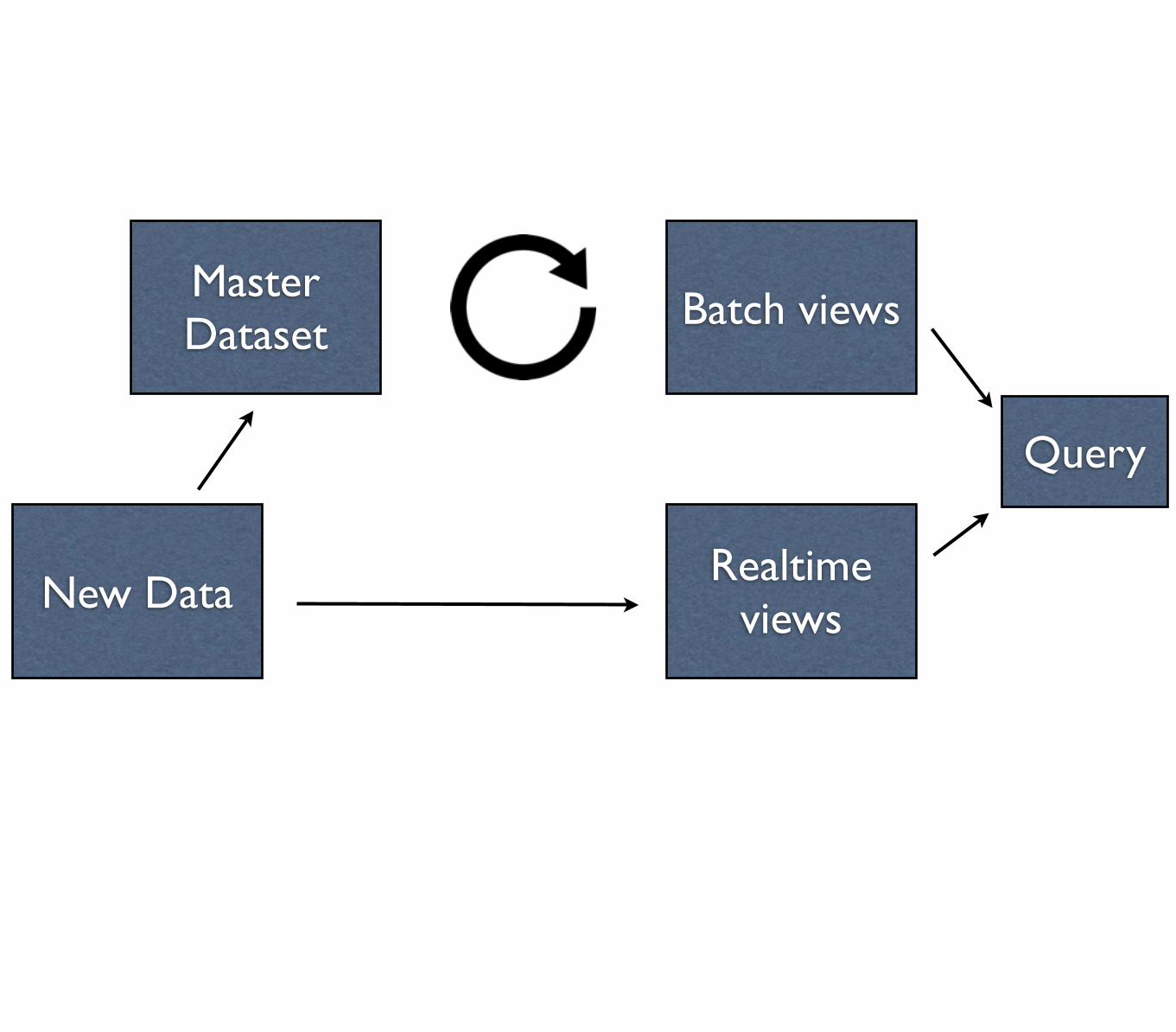
Master Dataset Batch views
New DataRealtime
views
Query

Get historical buckets from batch viewsand recent buckets from realtime views

Implementing realtime layer
• Isn’t this the exact same problem we faced before we went down the path of batch computation?
i hope you are looking at this and asking the question...still have to compute uniques over time and deal with the equivs problemhow are we better off than before?

Approach #1
• Use the exact same approach as we did in fully incremental implementation
• Query performance only degraded for recent buckets
• e.g., “last month” range computes vast majority of query from efficient batch indexes

Approach #1
• Relatively small number of buckets in realtime layer
• So not that much effect on storage costs

Approach #1
• Complexity of realtime layer is softened by existence of batch layer
• Batch layer continuously overrides realtime layer, so mistakes are auto-fixed

Approach #1
• Still going to be a lot of work to implement this realtime layer
• Recent buckets with lots of uniques will still cause bad query performance
• No way to apply recent equivs to batch views without restructuring batch views

Approach #2
• Approximate!
• Ignore realtime equivs
options for taking different approaches to problem without having to sacrifice too much
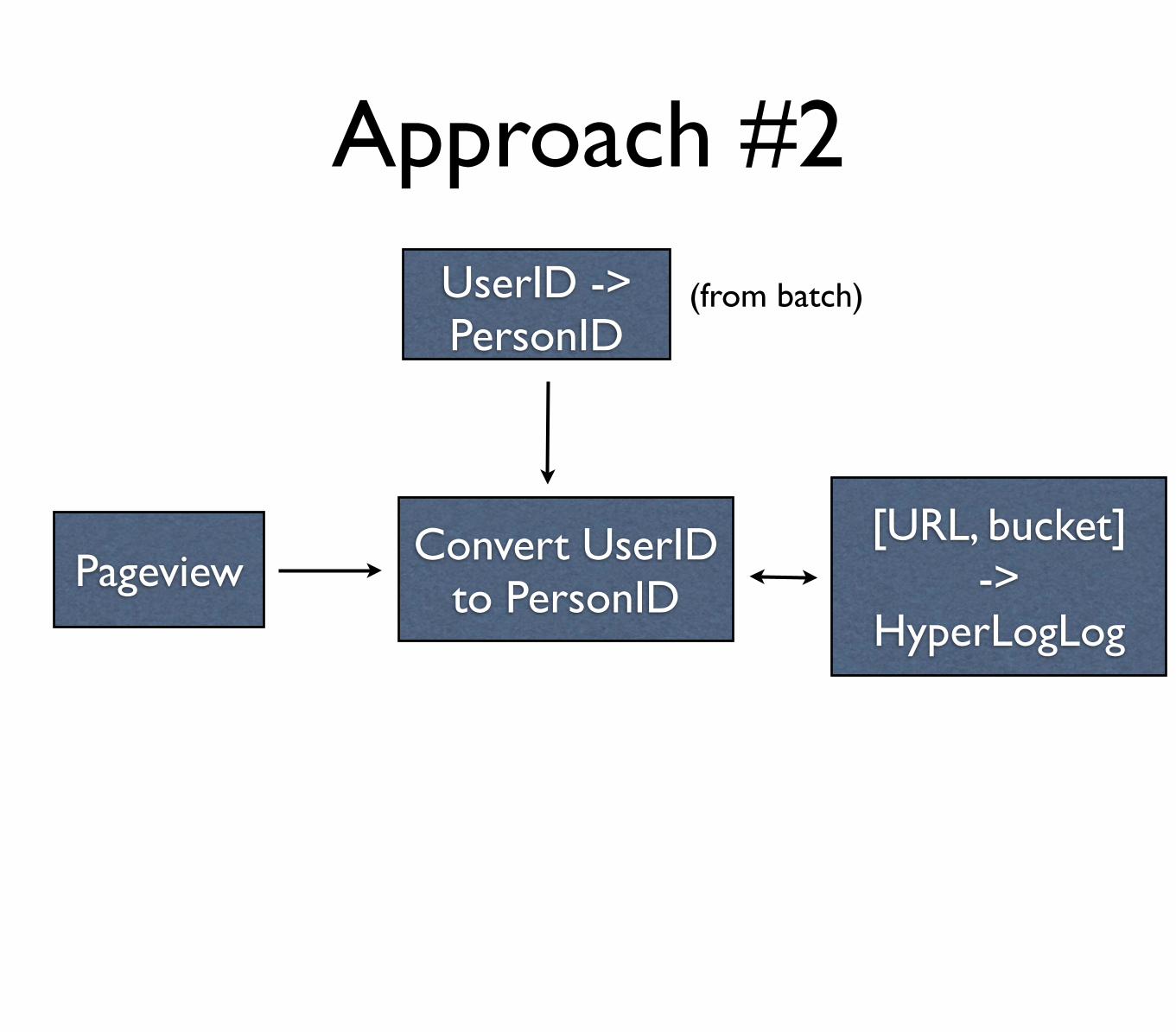
UserID -> PersonID
(from batch)
Approach #2
Pageview Convert UserID to PersonID
[URL, bucket]->
HyperLogLog

Approach #2
• Highly efficient
• Great performance
• Easy to implement

Approach #2
• Only inaccurate for recent equivs
• Intuitively, shouldn’t be that much inaccuracy
• Should quantify additional error

Approach #2
• Extra inaccuracy is automatically weeded out over time
• “Eventual accuracy”

Simplicity
Input:Normalize/denormalize
Output:Data model robustness
Query performance

Master Dataset Batch views
NormalizedRobust data model
DenormalizedOptimized for queries

Normalization problem solved
• Maintaining consistency in views easy because defined as function(all data)
• Can recompute if anything ever goes wrong

Human fault-tolerance

Complexity of Read/Write Databases

Black box fallacy
people say it does “key/value”, so I can use it when I need key/value operations... and they stop therecan’t treat it as a black box, that doesn’t tell the full story

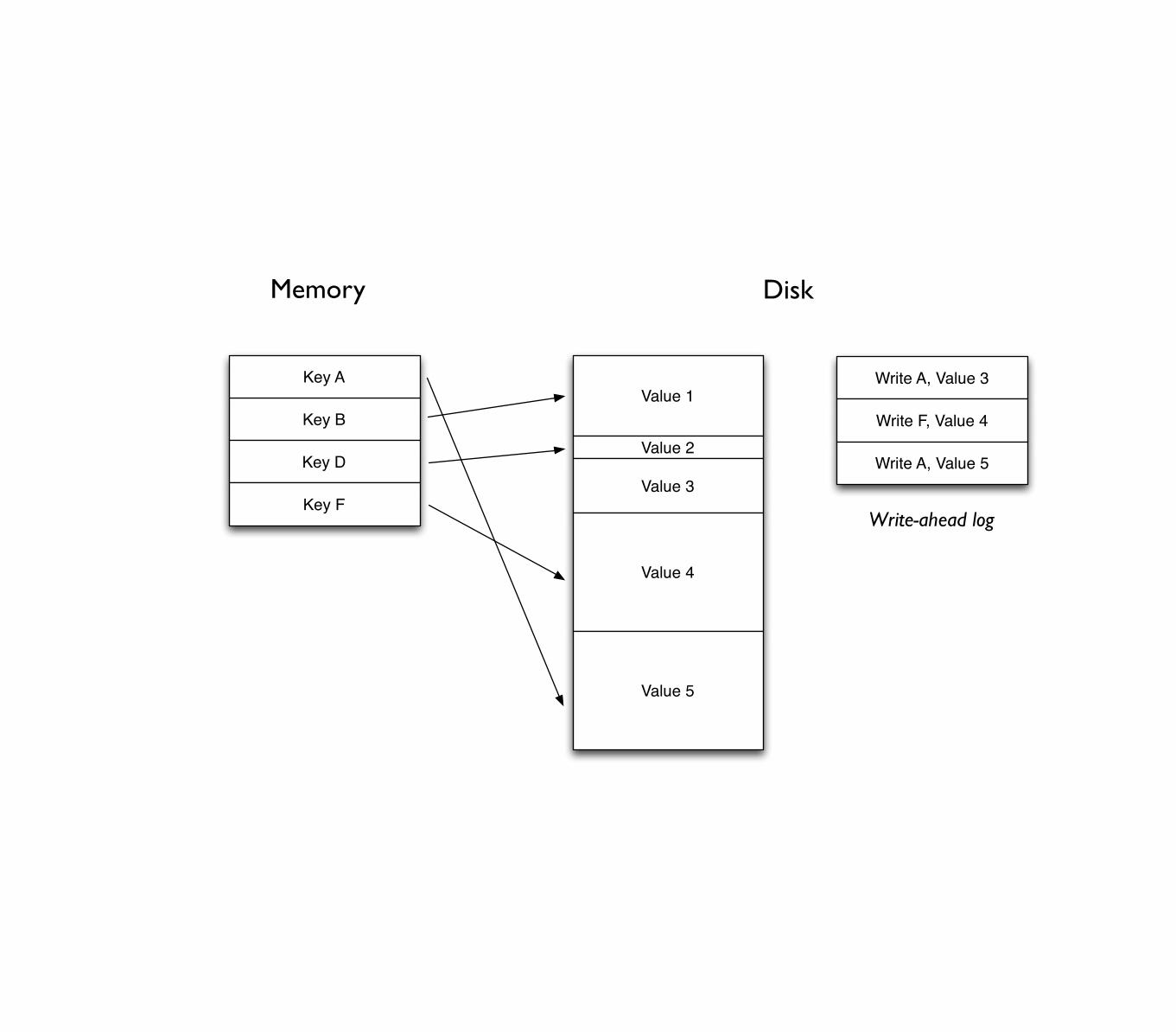
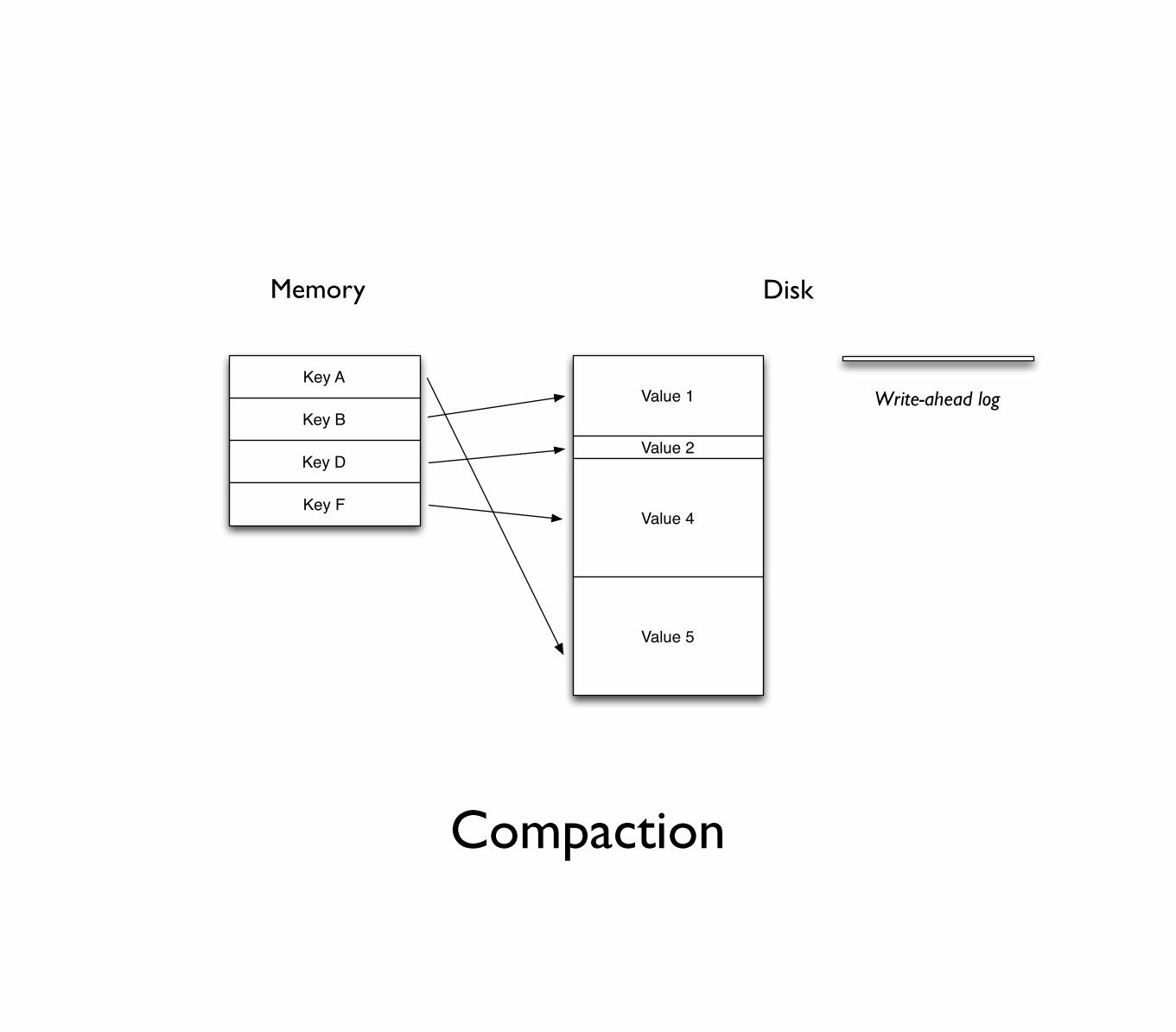
Online compaction
• Databases write to write-ahead log before modifying disk and memory indexes
• Need to occasionally compact the log and indexes

Memory Disk
Key B
Key D
Key F
Value 1
Value 2
Value 3
Value 4
Key A Write A, Value 3
Write F, Value 4
Write-ahead log
Memory Disk
Write-ahead log
Key B
Key D
Key F
Value 1
Value 2
Value 3
Value 4
Key A
Value 5
Write A, Value 3
Write F, Value 4
Write A, Value 5
Memory Disk
Write-ahead logKey B
Key D
Key F
Value 1
Value 2
Value 4
Key A
Value 5
Compaction

Online compaction
• Notorious for causing huge, sudden changes in performance
• Machines can seem locked up
• Necessitated by random writes
• Extremely complex to deal with
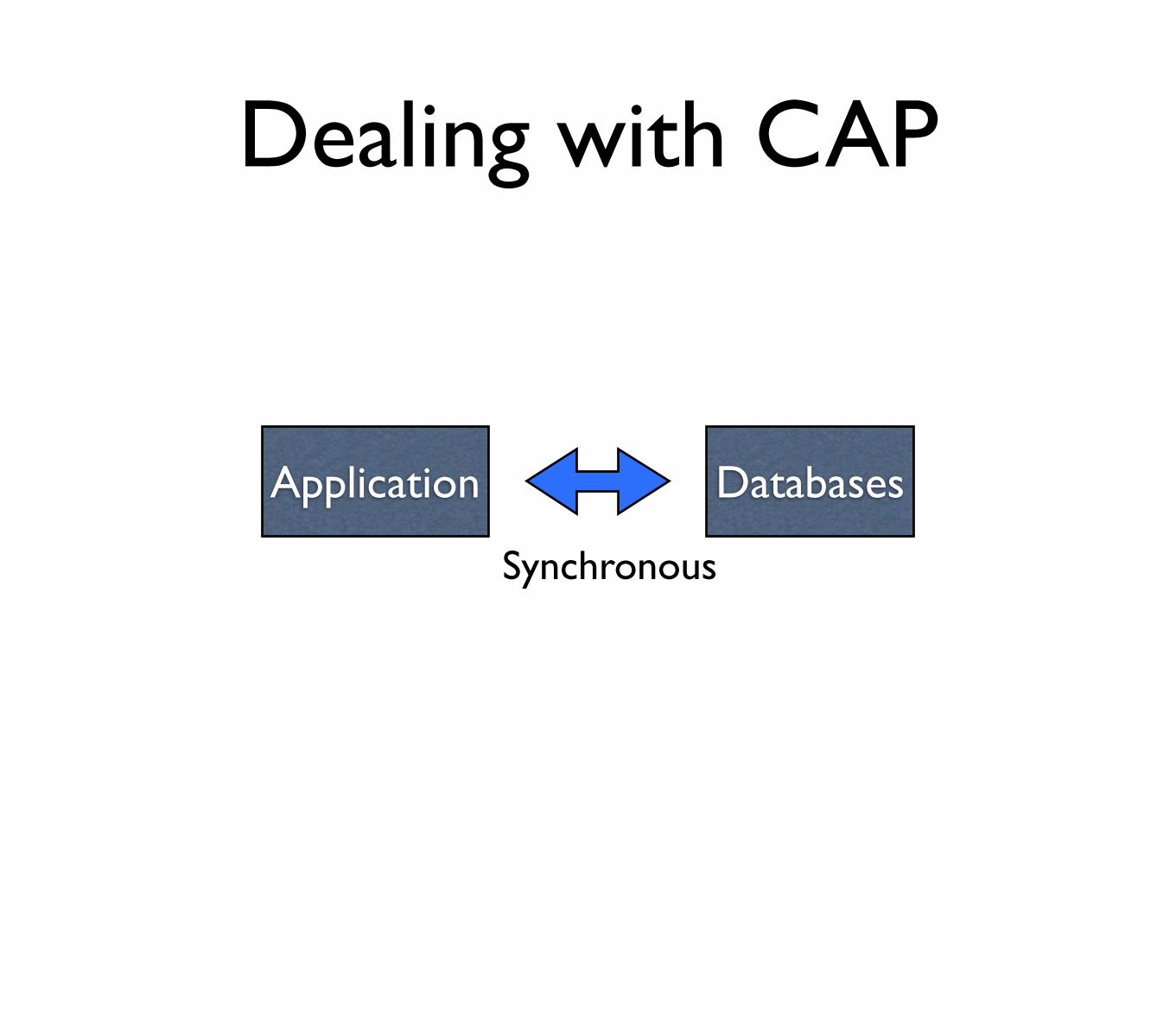
Dealing with CAP
Application Databases
Synchronous
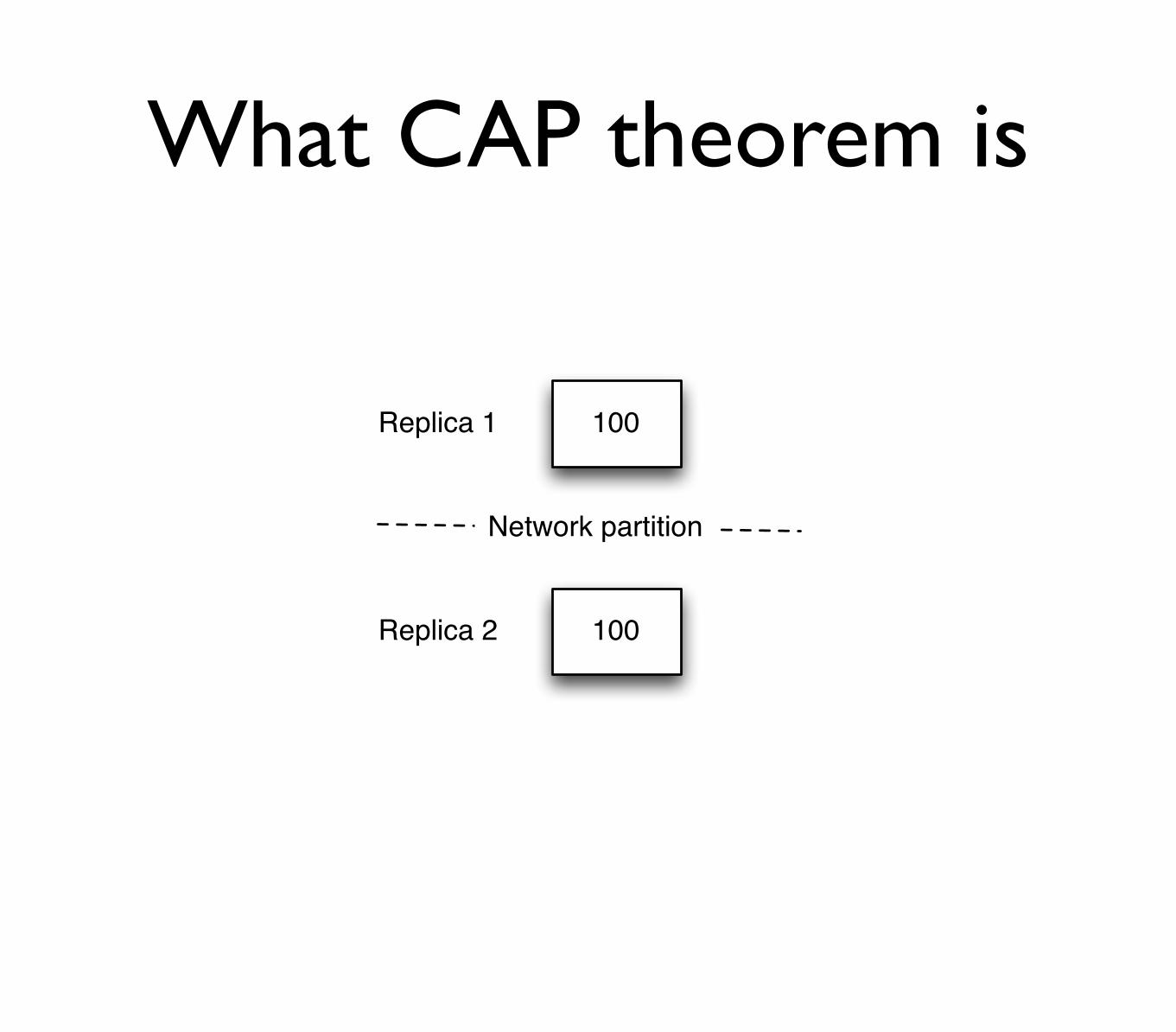
100Replica 1
100Replica 2
Network partition
What CAP theorem is
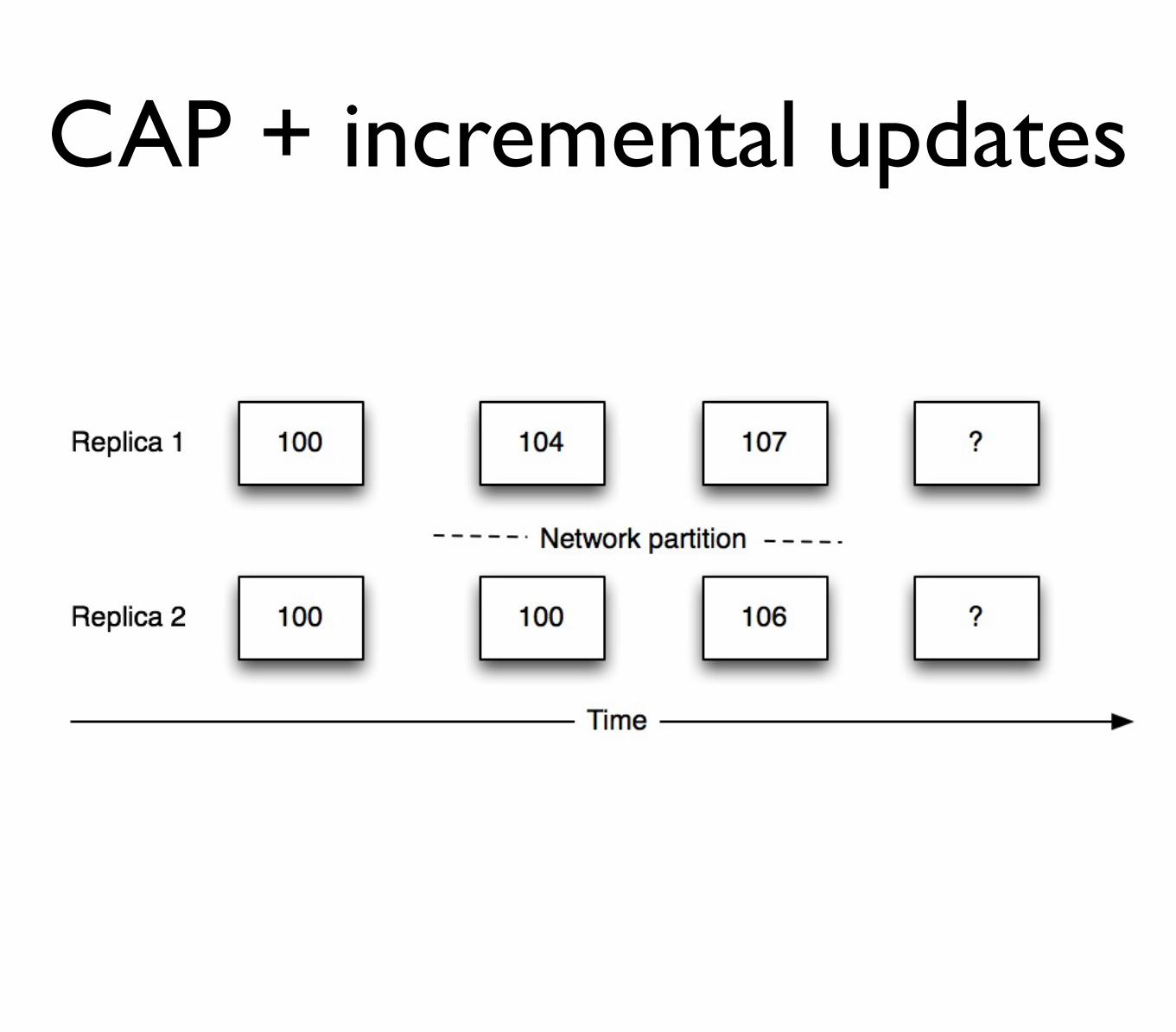
CAP + incremental updates
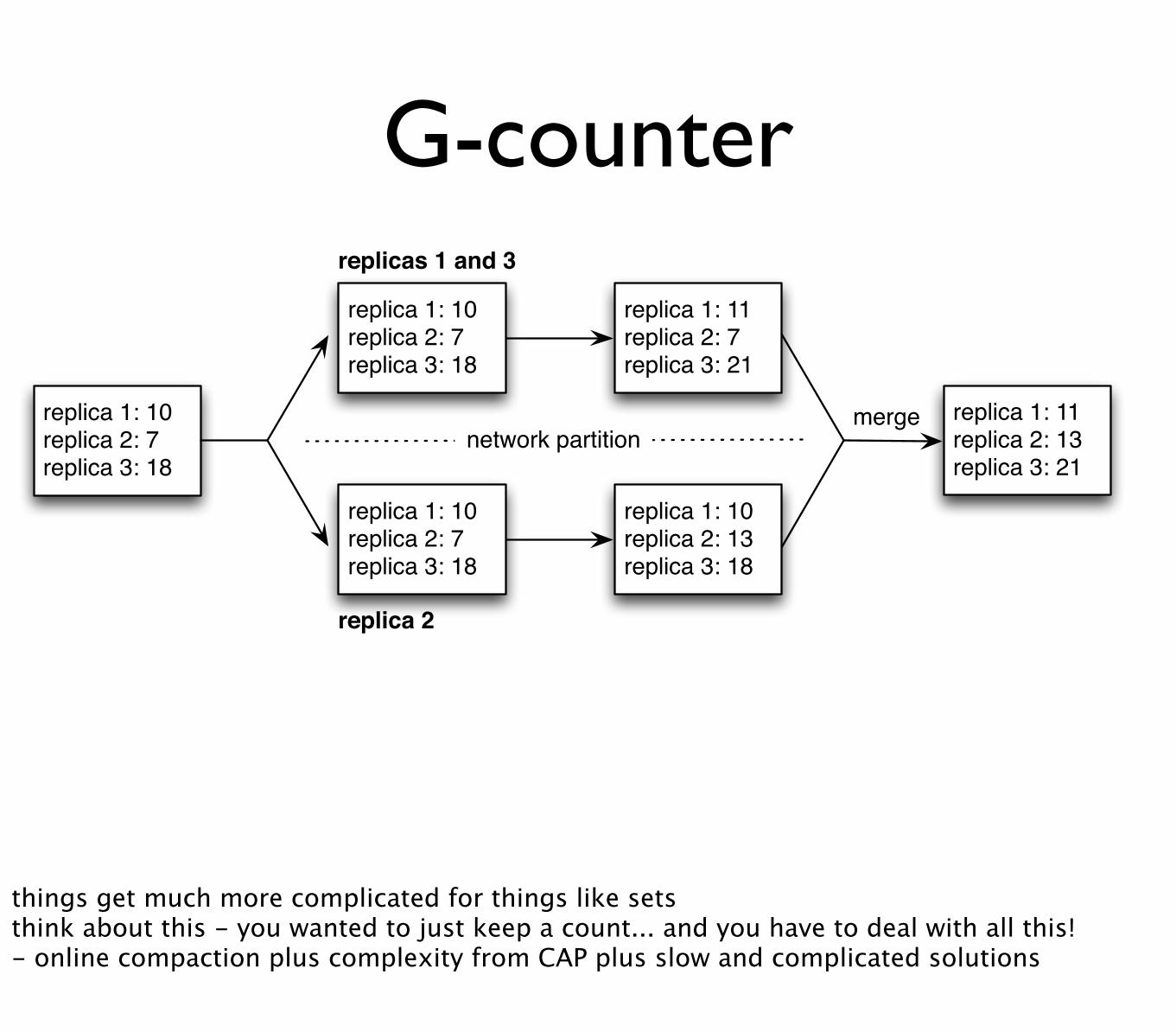
replica 1: 10replica 2: 7replica 3: 18
replica 1: 10replica 2: 7replica 3: 18
replica 1: 10replica 2: 7replica 3: 18
replicas 1 and 3
replica 1: 11replica 2: 7replica 3: 21
replica 1: 10replica 2: 13replica 3: 18
network partition
replica 2
merge replica 1: 11replica 2: 13replica 3: 21
G-counter
things get much more complicated for things like setsthink about this - you wanted to just keep a count... and you have to deal with all this!- online compaction plus complexity from CAP plus slow and complicated solutions

Complexity leads to bugs
• “Call Me Maybe” blog posts found data loss problems in many popular databases
• Redis
• Cassandra
• ElasticSearch
some of his tests was seeing over 30% data loss during partitions

Master Dataset Batch views
New DataRealtime
views
Query
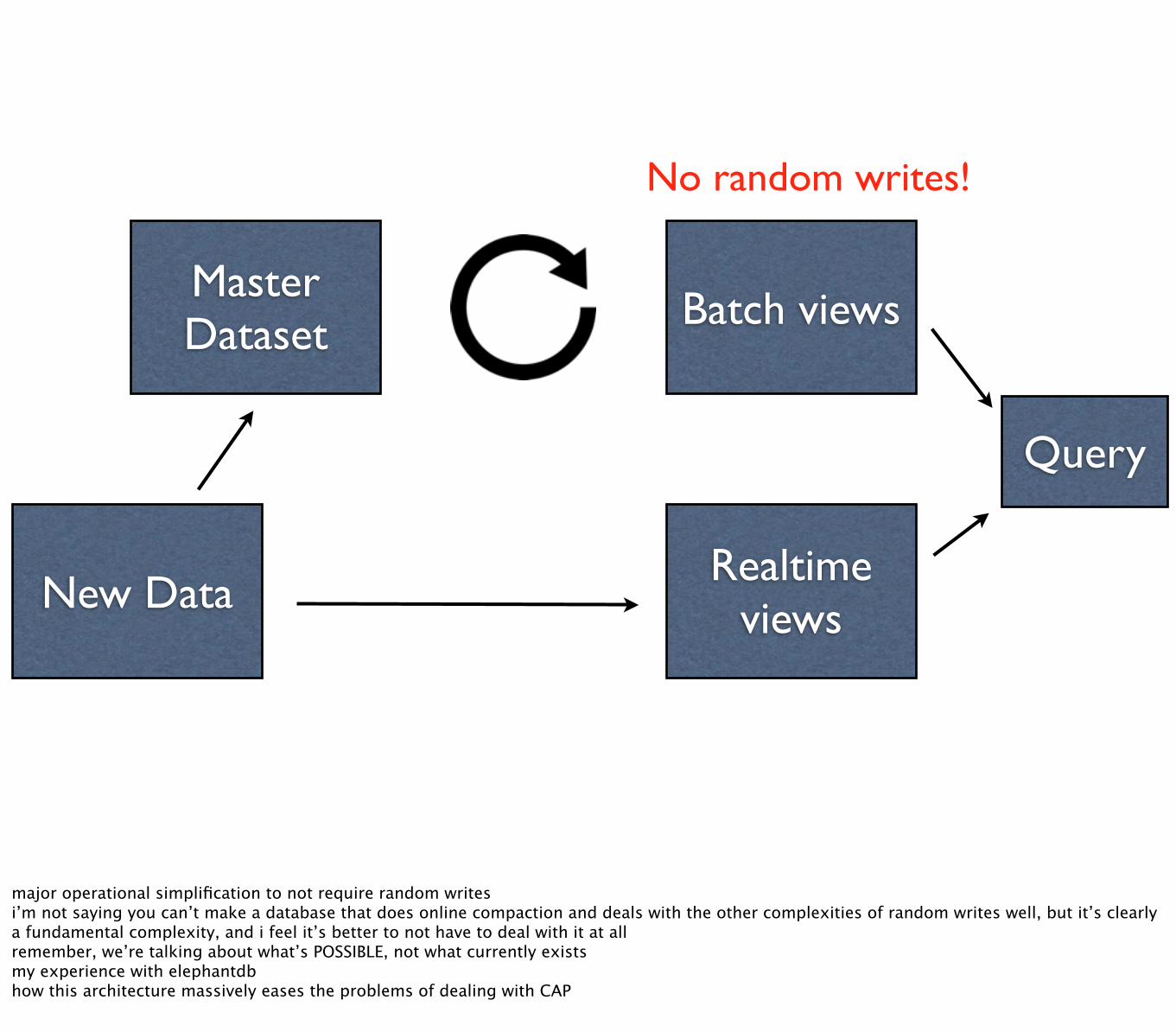
Master Dataset Batch views
New DataRealtime
views
Query
No random writes!
major operational simplification to not require random writesi’m not saying you can’t make a database that does online compaction and deals with the other complexities of random writes well, but it’s clearly a fundamental complexity, and i feel it’s better to not have to deal with it at allremember, we’re talking about what’s POSSIBLE, not what currently existsmy experience with elephantdbhow this architecture massively eases the problems of dealing with CAP

Master Dataset
R/W databases
Stream processor
Does not avoid any of the complexities of massive distributed r/w databases
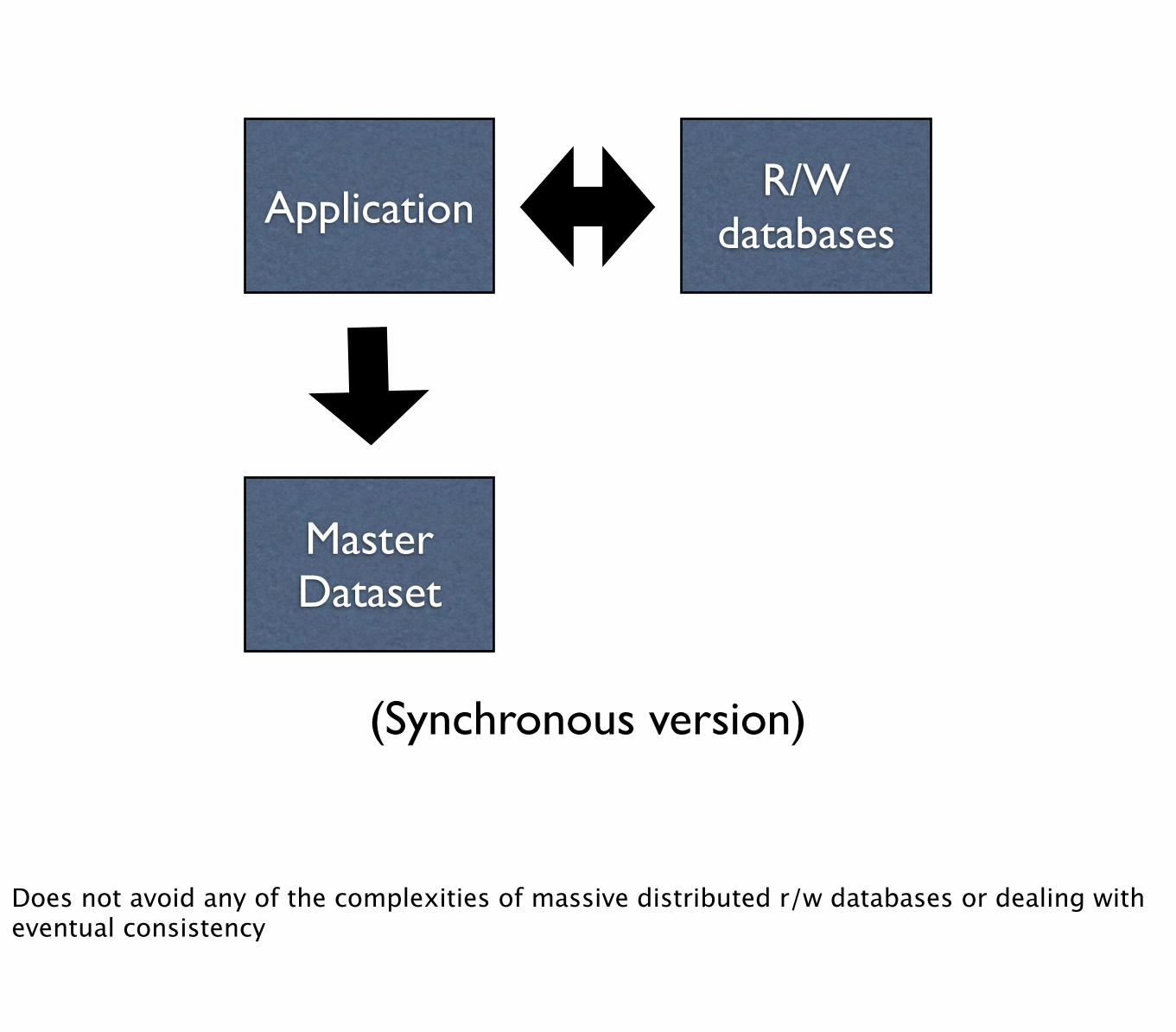
Master Dataset
ApplicationR/W
databases
(Synchronous version)
Does not avoid any of the complexities of massive distributed r/w databases or dealing with eventual consistency
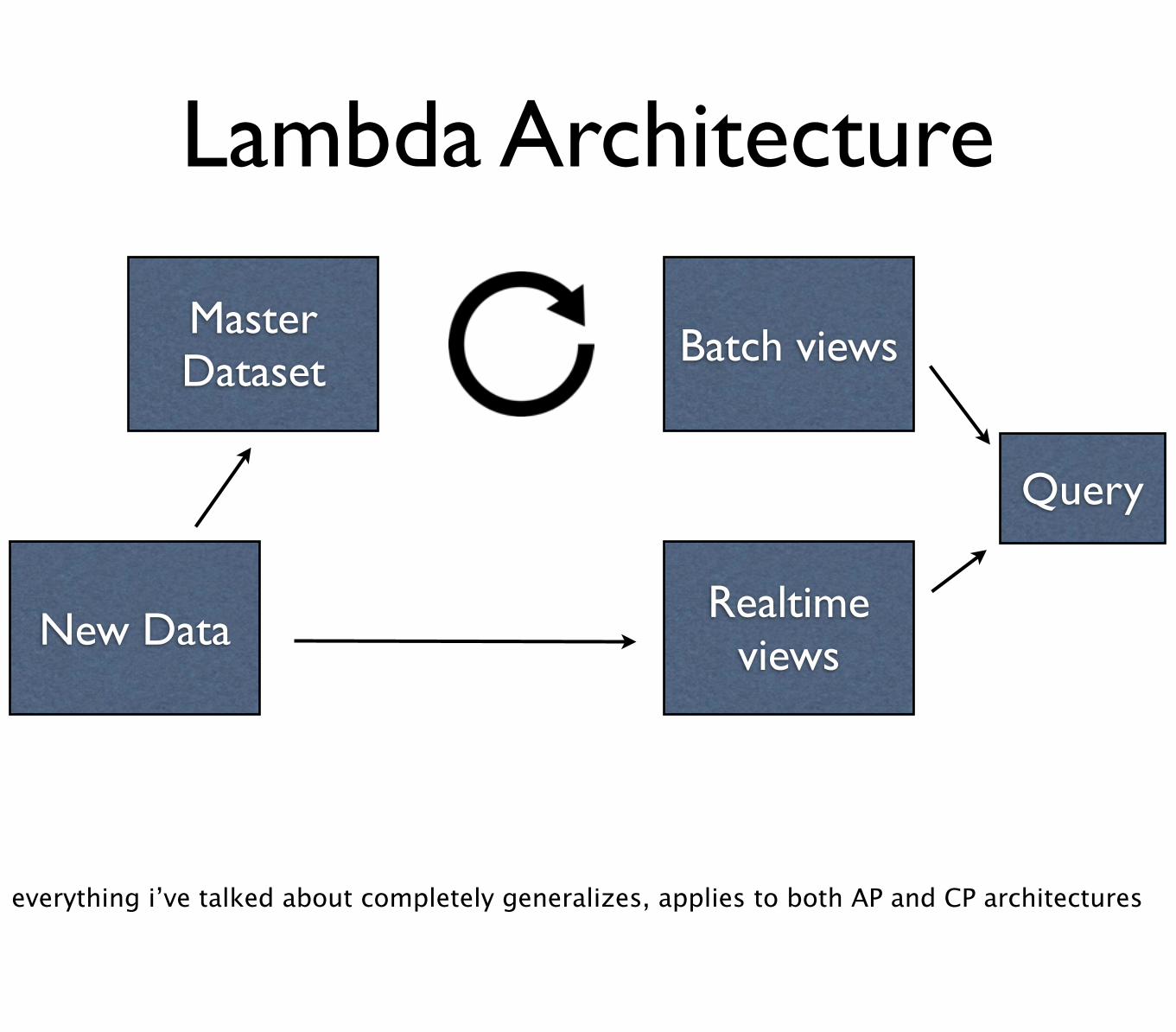
Master Dataset Batch views
New DataRealtime
views
Query
Lambda Architecture
everything i’ve talked about completely generalizes, applies to both AP and CP architectures

Lambda = Function
Query = Function(All Data)

Lambda Architecture
• This is most basic form of it
• Many variants of it incorporating more and/or different kinds of layers

if you actually want to learn lambda architecture, read my book. people on the internet present it so poorly that you’re going to get confused





















![Dependable Systems Software Dependability · Dependable Systems Course PT 2014 Software Dependability • Four inherent properties that make software hard [Brooks 87] • Complexity](https://img.dokumen.tips/doc/110x75/5e08d780496b3921261359f5/dependable-systems-software-dependability-dependable-systems-course-pt-2014-software.jpg)







