Embed Size (px)
Citation preview

Spark-Cassandra Integration DuyHai DOANApache Cassandra Evangelist
@doanduyhai
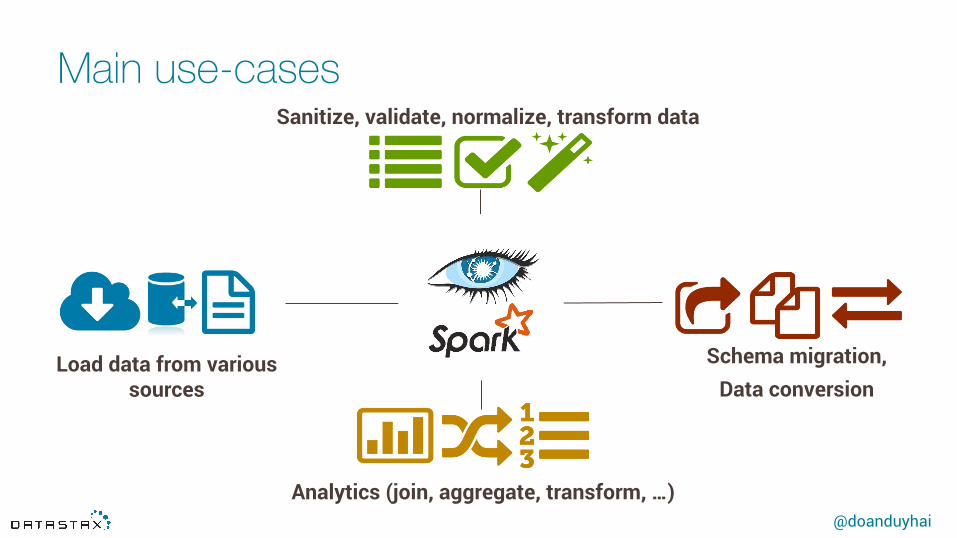
Main use-cases
Load data from various sources
Analytics (join, aggregate, transform, …)
Sanitize, validate, normalize, transform data
Schema migration, Data conversion

@doanduyhai
Data import
3
• Read data from CSV and dump into Cassandra ?
☞ Spark Job to distribute the import !
Load data from various sources

Demo
4
@doanduyhai
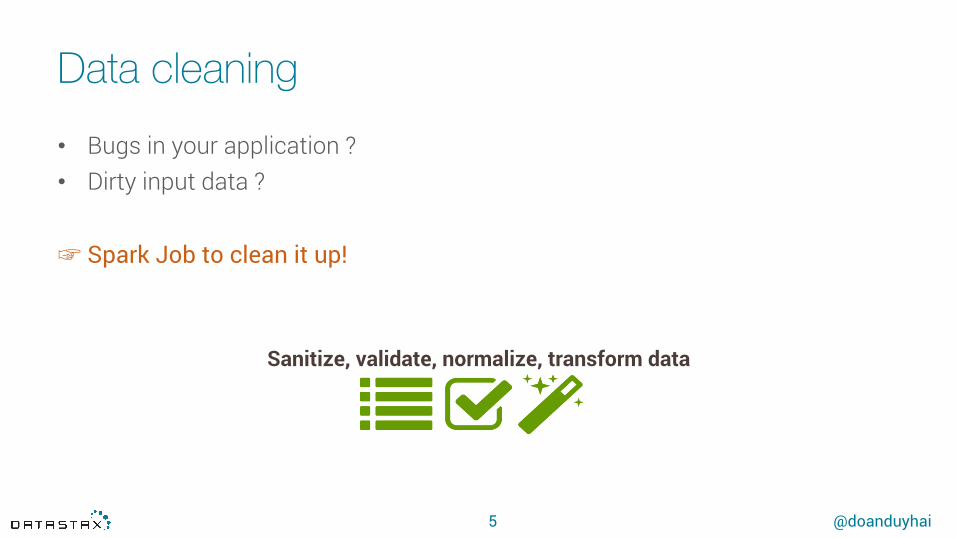
Data cleaning
5
Sanitize, validate, normalize, transform data
• Bugs in your application ?• Dirty input data ?
☞ Spark Job to clean it up!

Demo
6

@doanduyhai
Schema migration
7
• Business requirements change with time ?• Current data model no longer relevant ?
☞ Spark Job to migrate data !
Schema migration, Data conversion

Demo
8

@doanduyhai
Analytics
9
Given existing tables of performers and albums, I want:
① top 10 most common music styles (pop,rock, RnB, …) ?
② performer productivity(albums count) by origin country and by decade ?
☞ Spark Job to compute analytics !
Analytics (join, aggregate, transform, …)

Connector Architecture• Cluster Deployment • Data Locality • Failure Handling • Cross DC/cluster operations

@doanduyhai
Cluster Deployment
11
• Stand-alone cluster
C* SparkM SparkW
C* SparkW
C* SparkW
C* SparkW
C* SparkW

@doanduyhai
Data Locality – remember token ranges ?
12
A : −x,−3x4
⎤
⎦
⎥⎥
⎤
⎦
⎥⎥
B : −3x4
,− 2x4
⎤
⎦
⎥⎥
⎤
⎦
⎥⎥
C : −2x4
,− x4
⎤
⎦
⎥⎥
⎤
⎦
⎥⎥
D : − x4
,0⎤
⎦
⎥⎥
⎤
⎦
⎥⎥
E : 0, x4
⎤
⎦
⎥⎥
⎤
⎦
⎥⎥
F : x4
,2x4
⎤
⎦
⎥⎥
⎤
⎦
⎥⎥
G : 2x4
,3x4
⎤
⎦
⎥⎥
⎤
⎦
⎥⎥
H : 3x4
,x⎤
⎦
⎥⎥
⎤
⎦
⎥⎥
C*
C*
C*
C*
C* C*
C* C*
@doanduyhai
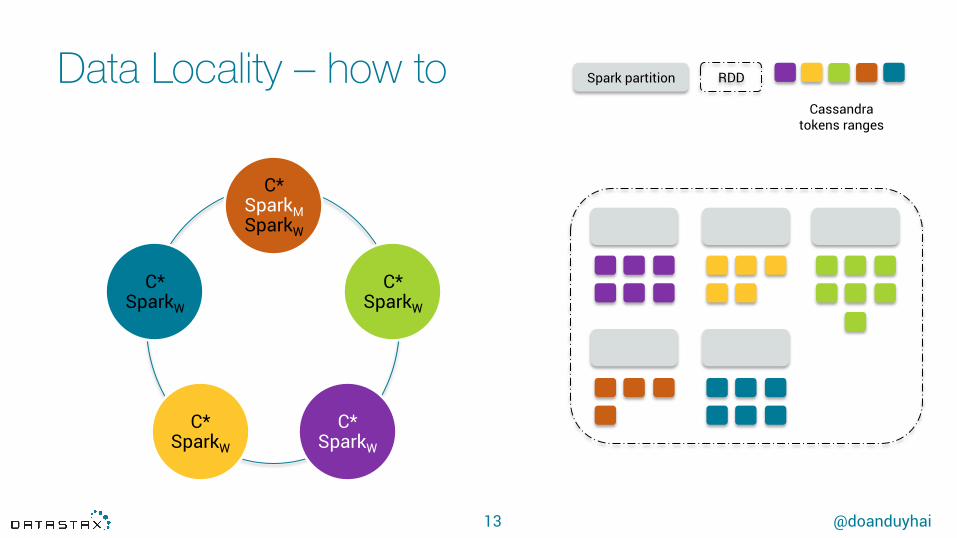
Data Locality – how to
13
Spark partition RDD
Cassandra tokens ranges
C* SparkM SparkW
C* SparkW
C* SparkW
C* SparkW
C* SparkW

@doanduyhai
Data Locality – how to
14
C* SparkM SparkW
C* SparkW
C* SparkW
C* SparkW
C* SparkW

@doanduyhai
Perfect data locality scenario• read localy from Cassandra• use operations that do not require shuffle in Spark (map, filter, …)• repartitionbyCassandraReplica()à to a table having same partition key as original table• save back into this Cassandra table
Sanitize, validate, normalize, transform data USE CASE
15
@doanduyhai
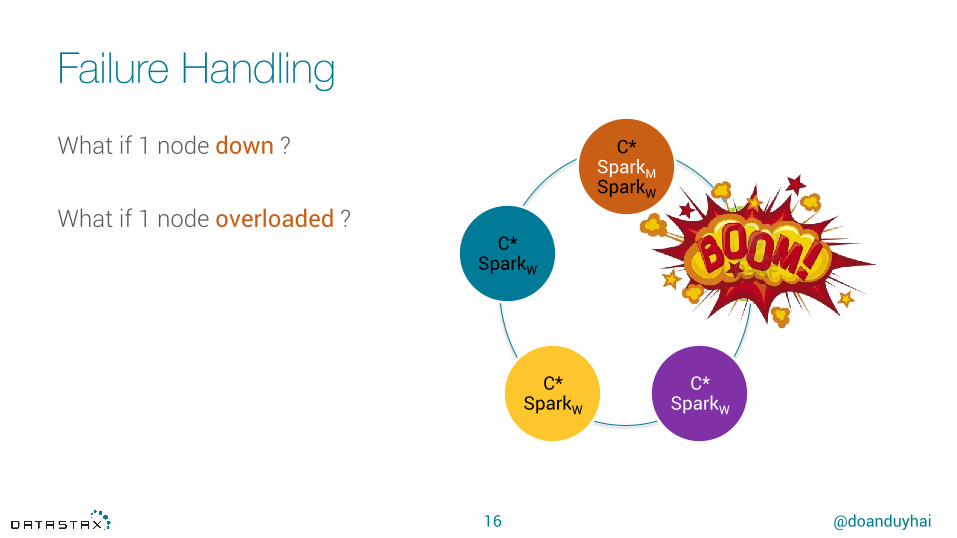
Failure Handling
16
C* SparkM SparkW
C* SparkW
C* SparkW
C* SparkW
C* SparkW
What if 1 node down ?
What if 1 node overloaded ?

@doanduyhai
Failure Handling
17
C* SparkM SparkW
C* SparkW
C* SparkW
C* SparkW
C* SparkW
What if 1 node down ?
What if 1 node overloaded ?
☞ Spark master will re-assign the job to another worker

@doanduyhai
Failure Handling
18
Oh no, my data locality !!!

@doanduyhai
Failure Handling
19

@doanduyhai
Data Locality Impl
20
abstract'class'RDD[T](…)'{'' @DeveloperApi'' def'compute(split:'Partition,'context:'TaskContext):'Iterator[T]''' protected'def'getPartitions:'Array[Partition]'' '' protected'def'getPreferredLocations(split:'Partition):'Seq[String]'='Nil'''''''''''''''}'

@doanduyhai
CassandraRDD
21
def getPreferredLocations(split: Partition): Cassandra replicas IP address corresponding to this Spark partition

@doanduyhai
Failure Handling
22
If RF > 1 the Spark master chosesthe next preferred location, whichis a replica 😎
Tune parameters:• spark.locality.wait • spark.locality.wait.process • spark.locality.wait.node

@doanduyhai
Failure Handling
23
If RF > 1 the Spark master chosesthe next preferred location, whichis a replica 😎
Tune parameters:• spark.locality.wait • spark.locality.wait.process • spark.locality.wait.node
Only work for f
ixed
token rang
es (vnodes)

@doanduyhai
Cross cluster/DC operations
24

Tales from the field, SASI index benchmark• Deployment automation • Parallel ingestion • Migrating data • Spark + Cassandra 3.4 SASI index for topK query

@doanduyhai
Deployment Automation
26
Use Ansible to bootstrap a cluster• role tools (install vim, htop, dstat, fio, jmxterm..)• role Cassandra. Do not put all nodes as seeds …. • role Spark (vanilla Spark). Slave on all nodes, master on a random node
DO NOT START ALL CASSANDRA NODES AT THE SAME TIME !!!! • bootstrap first seeds nodes • give ≥ 30secs between 2 node bootstrap for token range agreement• watch -n 5 nodetool status

@doanduyhai
Parallel ingestion for SASI index benchmark
27
Hardware specs• 13 nodes• 6 cores CPU (HT) • 4 SSD in RAID 0 😎 • 64 Gb of RAM
Cassandra conf:• G1GC 32Gb JVM Heap• compaction throughput in MB = 256• concurrent compactor = 2

@doanduyhai
Parallel ingestion for SASI index benchmark
28

@doanduyhai
Parallel ingestion for SASI index benchmark
29
3.2 billions
row in 17h
(compaction disable
d)
RF = 2
☞ ≈ 8000 ips
I/O idle, hi
gh CPU

@doanduyhai
Migrating Data
30

@doanduyhai
Migrating Data
31

@doanduyhai
TopK query
32
Pass 1, for each music provider• sum albums sales count by title• take top N, associate weight from descending order (1st = 1000, 2nd = 999 …)
Retrieve all albums from pass 1• re-sum the sum(sales count) and weight group by title• order again by sum(sales count) in descending order• take top N

@doanduyhai
TopK query
33
Target data set = 3.2 billions rows• minimum filter = 1 month (period_end_month = 201404 for ex)• worst filter = 3 months range• +8 other dynamic filters (music provider, distribution type …)
☞ SASI indices for filtering☞ Spark for aggregation

@doanduyhai
TopK query results
34
3.2 billions rows in total• random distribution over 3 years (36 months) à 88 millions rows/month
Filters #rows Duration #rows/sec
3 months 376 947 612 14 mins (840 secs) 448 747
1 month 94 239 127 6.1 mins (366 secs) 257 483
1 month + 1 provider 7 267 983 2.1 mins (126 secs) 57 682
1 month + 1 provider + 1 country 2 737 178 1.5 mins (90 secs) 30 413

35
Q & A
! "






























