Embed Size (px)
Citation preview

SDx 2016.3のプラグマによるハードウェアと性能
marseeこと小野 雅晃

ソフトウェアとハードウェアのインターフェース
● Vivado HLSは明示的にハードウェアのインターフェースをINTERFACE指示子で定義
● SDSoCはソフトウェアなので、指示子は本来無いのだが、インターフェースを指示子で指定する
● SDSoCの指示子とハードウェアとの関係、性能との関係を調べた– SDSoCは内部でVivado HLSを使っているが、Vivado
HLSで性能が良かったコードはSDSoCでも性能が良いのか?

今回やったこと● SDx(SDSoC) 2016.3を使用
● お馴染みのラプラシアンフィルタを使用した
● ハードウェア化ラプラシアンフィルタ関数 vs ソフトウェア・ラプラシアンフィルタ関数の速度比較– 比較用ソフトウェア・ラプラシアンフィルタ関数は固定
– ハードウェア化ラプラシアンフィルタ関数のデータ転送の指定用プラグマを変更
● ハードウェアの違い(Vivado、Vivado HLS)● 性能の違い
– ハードウェア化ラプラシアンフィルタ関数の記述を変更● 性能の違い
● 最高性能の組み合わせの条件は?

今回使用したデータ転送にかかわるプラグマ
● #pragma SDS data zero_copy(cam_fb[0:ALL_PIXEL_VALUE])● #pragma SDS data zero_copy(lap_fb[0:ALL_PIXEL_VALUE])● #pragma SDS data copy(cam_fb[0:ALL_PIXEL_VALUE])● #pragma SDS data copy(lap_fb[0:ALL_PIXEL_VALUE])● #pragma SDS data access_pattern(cam_fb:RANDOM, lap_fb:RANDOM)● #pragma SDS data access_pattern(cam_fb:SEQUENTIAL, lap_fb:SEQUENTIAL)● #pragma SDS data sys_port(cam_fb:AFI, lap_fb:AFI)
● int lap_filter_axim(int cam_fb[ALL_PIXEL_VALUE], int lap_fb[ALL_PIXEL_VALUE])
● {– ハードウェア関数の引数が配列(要素数をどこかで明示しておかないとエラー)
– 配列がメモリの領域を示している

プラグマによる外部メモリとの転送方法(copy, zero_copy)
● #pragma SDS data copy(<ポート名>…)– データはブロックRAMに一時コピーされる?
– 呼び出し側関数からはmalloc()で取得したメモリの先頭アドレスを配列のアドレスとして渡される
– スキャッタ・ギャザー用DMA● 4kバイトごとにアドレスが不連続の可能性
● #pragma SDS data zero_copy(<ポート名>…)– データはDDRから転送されたそのままを使用
– 呼び出し側関数からはsds_alloc()で取得した連続領域のメモリを配列のアドレスとして渡される
– シンプルDMAでもOK

プラグマによる外部メモリとの転送方法(data access_pattern)
● #pragma SDS data access_pattern(cam_fb:RANDOM, lap_fb:RANDOM)– RANDOM ー RAMインターフェースが生成される
– デフォルトのアクセスパターン
● #pragma SDS data access_pattern(cam_fb:SEQUENTIAL, lap_fb:SEQUENTIAL)– SEQUNTIAL ー ストリーミング・インターフェースが生成される
– 配列のエレメントの順番は守る必要がある(ストリーミングだから)
● zero_copyプラグマが無い引数にのみ適用できる

使用するPSのポートの指定(data sys_port)
● #pragma SDS data sys_port(cam_fb:AFI, lap_fb:AFI)– portはACP、AFI(HP)、MIGのいずれか
– sds_alloc_non_cacheable()かsds_register_dmabuf()でメモリをアロケートした場合はAFI(HP)ポートを使ったほうが良い
– SDSoCでは自動的にデータ・ムーバーが適切なポートに接続する
– ラプラシアンフィルタではデフォルトではACPポートが使われる(malloc(), sds_alloc()使用)

第1段階のラプラシアンフィルタ
● 性能の低いラプラシアンフィルタ– 1ピクセルずつRead– ラプラシアンフィルタ処理
– 1ピクセルずつWrite
● プラグマ– 無し(copy, data access_pattern(RANDOM))
– data access_pattern(SEQUENTIAL)
– zero_copy(sds_alloc())
● 最初にプラグマ無しをやってみよう
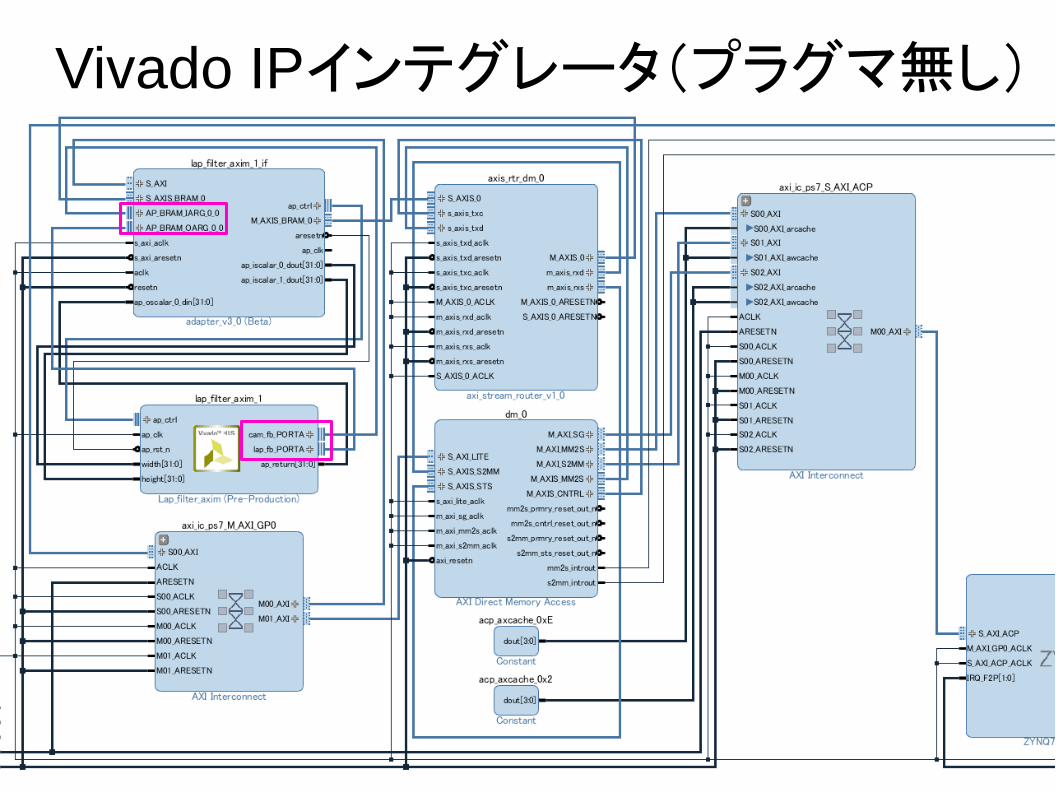
Vivado IPインテグレータ(プラグマ無し)
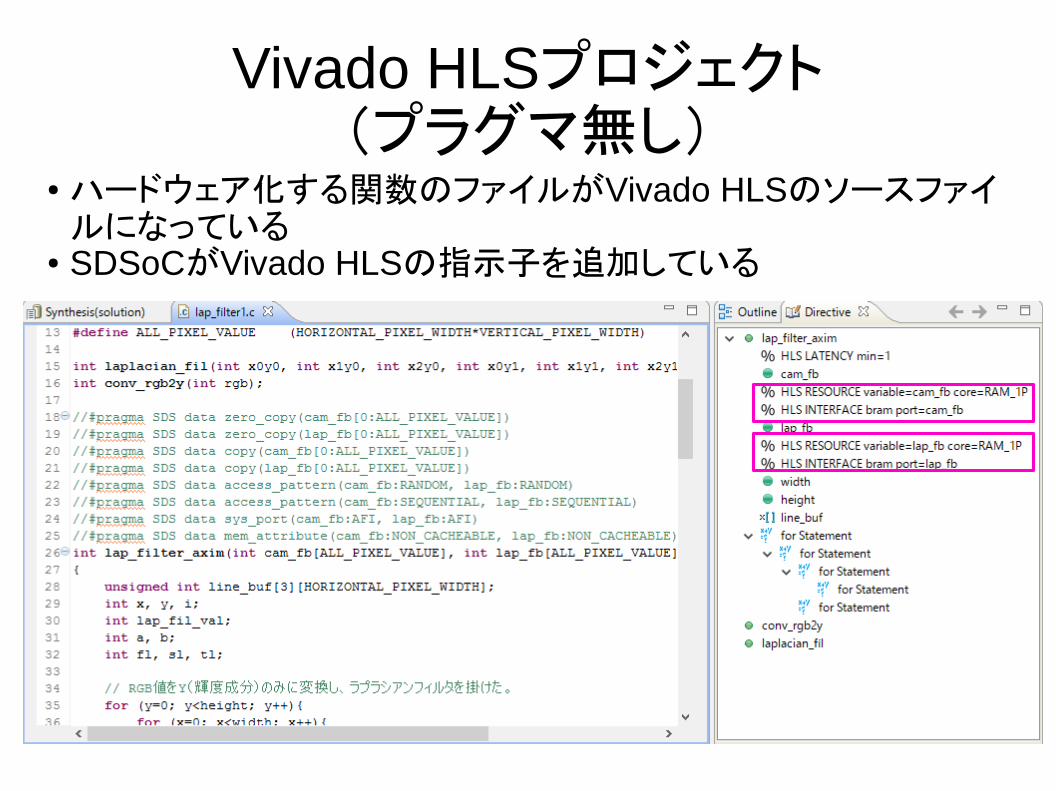
Vivado HLSプロジェクト(プラグマ無し)
● ハードウェア化する関数のファイルがVivado HLSのソースファイルになっている
● SDSoCがVivado HLSの指示子を追加している
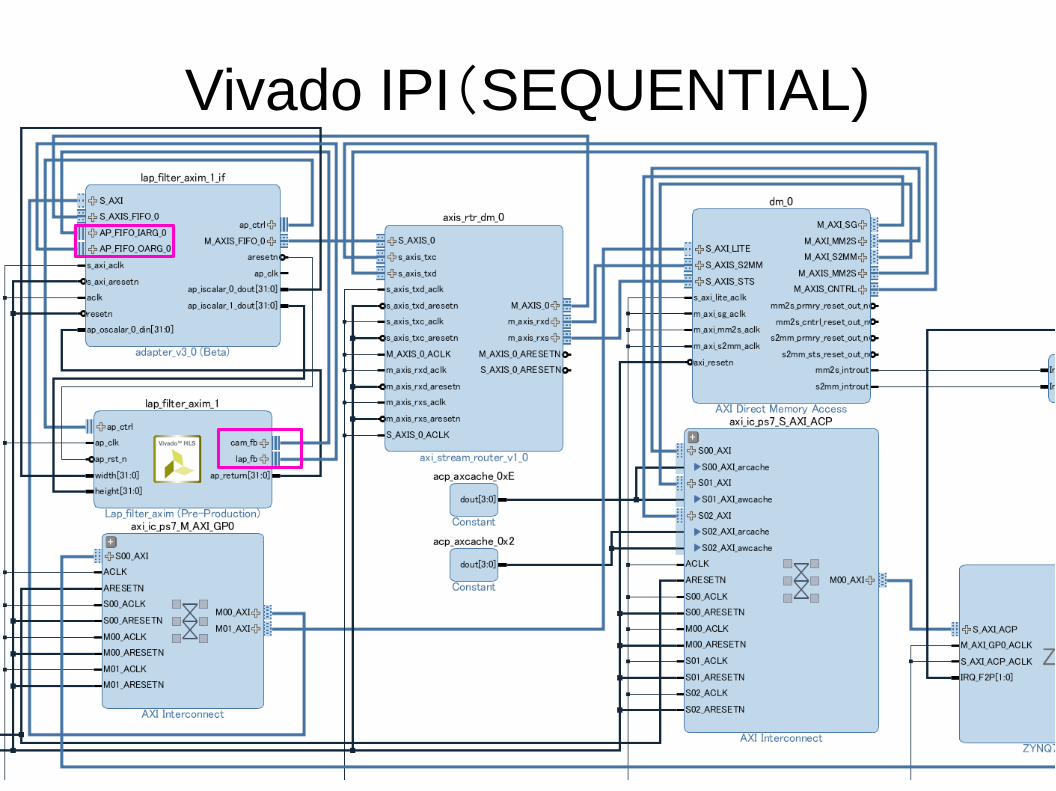
Vivado IPI(SEQUENTIAL)

Vivado HLS(SEQUENTIAL)

Vivado IPI(zero_copy)
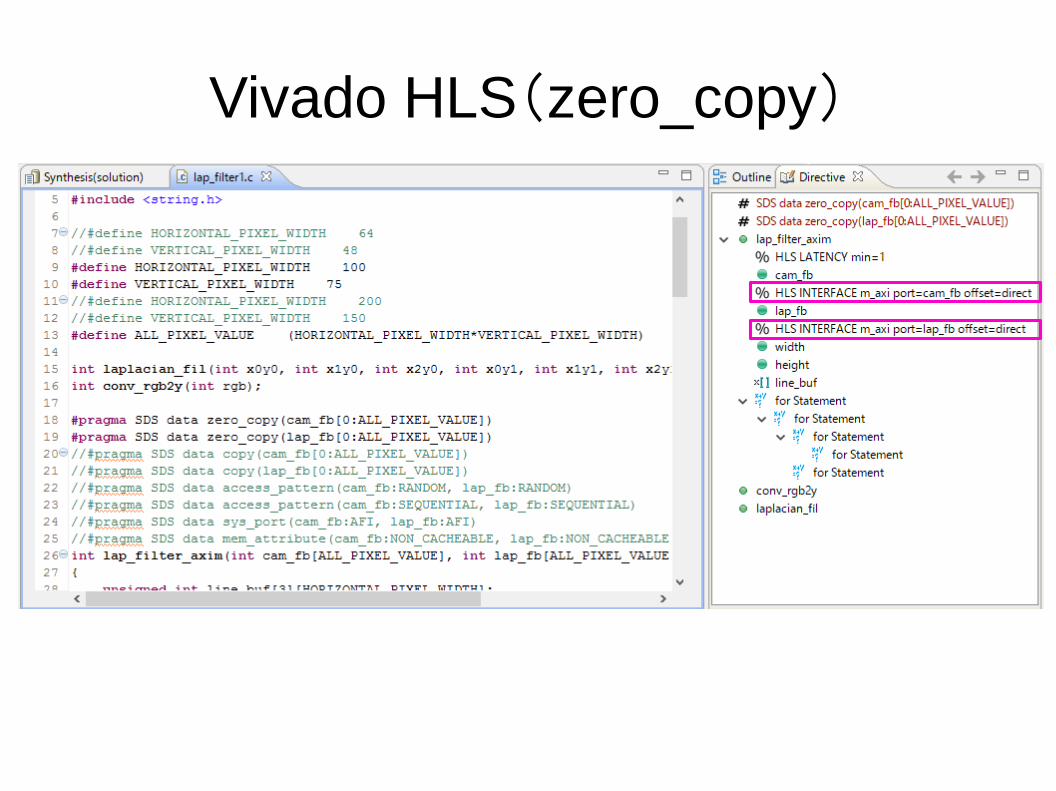
Vivado HLS(zero_copy)

プラグマによるVivado HLSが生成するインターフェース
● 無し(copy, data access_pattern(RANDOM))– ブロックRAMインターフェース
● data access_pattern(SEQUENTIAL)– ストリーミング・インターフェース(FIFO)
● zero_copy– AXI4 Masterインターフェース

第1段階のラプラシアンフィルタのリソース使用量プラグマ無し SEQUENTIAL ZERO_COPY
LUT 46 46 21
LUTRAM 13 12 7
FF 35 35 15
BRAM 53 33 18
DSP 20 13 16
BUFG 3 3 3
(注:単位はパーセンテージ)
画像の大きさは100x75 ピクセル

第1段階のラプラシアンフィルタのリソース使用量(グラフ)
LUT LUTRAM FF BRAM DSP BUFG0
10
20
30
40
50
60
プラグマ無し
SEQUENTIAL
ZERO_COPY

性能比較
● プラグマ無しとSEQUENTIALのハードウエア実行時間は不安定。やるたびに変わる(SDSoC勉強会でmalloc()を使っているためとの指摘あり)
● この状態では性能比較は無理だった
プラグマ無し SEQUENTIAL ZERO_COPY
ハードウェア実行時間
4.32 ~ 10.6 5.8 ~ 10.7 0.943
ソフトウェア実行時間
0.922 0.906 0.824
単位は ms 画像の大きさは100x75 ピクセル

FPGAの部屋のブログの関連記事
● http://marsee101.blog19.fc2.com/blog-entry-3682.html
● http://marsee101.blog19.fc2.com/blog-entry-3684.html
● http://marsee101.blog19.fc2.com/blog-entry-3685.html
● http://marsee101.blog19.fc2.com/blog-entry-3687.html

memcpy()を使用した第2段階のCソースコード
● memcpy()を使ったのCソースコード(PIPELINEも)
● Vivado HLSのプラグマだけでSDSoCで動作
– ハードウェア化関数の引数のvolatileを外した
– INTERFACE指示子のbundleオプションを外した
– malloc()をsds_alloc()に変更、free()も変更
● つまりSDSoCのzero_copyと等価
● ハードウエアの実行時間55.7ms、ソフトウェアの実行時間 51.7ms、SW/HW 0.928≒ 倍(800x600ピクセル)
● http://marsee101.blog19.fc2.com/blog-entry-3688.html

性能向上を図った第3段階のCソースコード
● array_partition、3x3レジスタ実装
● 前段階と同様の措置(volatile, bundle, sds_alloc)
● SDSoCのzero_copyと等価
● ハードウエアの実行時間14.9ms、ソフトウェアの実行時間 51.8ms、SW/HW 3.48≒ 倍(800x600ピクセル)
● http://marsee101.blog19.fc2.com/blog-entry-3689.html

Vivado HLSのAXI4-Streamのコード
● Vivado HLSのAXI4-Streamのコードは果たして動くのか?
● @ryosさんの記事を参考にSDSoC 2016.3でサイドチャネル付きAXI4-Streamを実装しようとしたが失敗
● でも、今までもストリームにしてきた
● data access_pattern(SEQUENTIAL)のプラグマを付けて、シーケンシャルに実行するコードだったらOKでは?(AXI4-Streamではないけど)
● AXI4-Streamのコードでやってみたらどうなんだろう?

AXI4-Stream向きのコード1
● AXI4-Streamのコードを使用した– サイドチャネルを使っているので、それを外した
● SDSoCで使うので、Xilinxのビデオ用IPのことは考えない
– 入力のストリームと出力のストリームにはif文がない
– data access_pattern(SEQUENTIAL)プラグマ
● 結果– ソフトウェアの実行時間は、約 47.7 ms– ハードウエアの実行時間は、約 5.54 ms– SW実行時間/HW実行時間≒8.61倍
● 驚異的。。。ハードウエアの実行時間はReadもWriteも重なり合ったフルバーストしないと実現できない
● なぜならば、800ピクセルx600行x10 ns(クロック周期)= 4.8 ms– 1ピクセルは1クロックで転送(1ピクセルはint型、クロック周波数は100MHz)
● http://marsee101.blog19.fc2.com/blog-entry-3690.html

AXI4-Stream向きのコード2
● AXI4-Stream向きのコード1と同様
● ただし、data access_pattern(SEQUENTIAL)プラグマの代わりにdata zero_copyプラグマ
● つまり、Vivado HLSでのメモリ・アクセスをAXI4 Masterに● 結果
– ソフトウェアの実行時間は、約 47.7 ms– ハードウエアの実行時間は、約 6.04 ms– SW実行時間/HW実行時間≒7.90倍
● AXI4-Stream向きのコード1よりも少し遅くなっているが、ReadとWriteが重なり合ってDMAされているはず
● http://marsee101.blog19.fc2.com/blog-entry-3691.html

Vivado HLSで最速コードを確かめる
● 最速の結果が出たSDSoCのコードをVivado HLSでINTERFACE m_axi指示子を入れて確かめた(つまり、AXI4 Master )
● 確かに16バーストのReadとWriteが重なり合ったDMA(見事なものだった。。。)
● if文無しでReadし、if文無しでWriteすれば最高性能(来たままの順番でフィルタして出力)
● http://marsee101.blog19.fc2.com/blog-entry-3692.html● http://marsee101.blog19.fc2.com/blog-entry-3694.html● http://marsee101.blog19.fc2.com/blog-entry-3695.html

ACPポートとAFI(HP)ポートの性能差
● AXI4-Stream向きのコードではACPポートを使用してDMA● それではHPポートを使ったらもっと性能が出るのではないだろ
うか?
● #pragma SDS data sys_port(cam_fb:AFI, lap_fb:AFI)– やってみたところ遅くなった
● 結果– ソフトウェアの実行時間は、約 47.4 ms– ハードウエアの実行時間は、約 16.0 ms– SW実行時間/HW実行時間≒2.96倍
– ACPポートよりもHPポートを使用したほうが遅くなった
– キャッシュのコヒーレンシを保つため?なぜ?
● http://marsee101.blog19.fc2.com/blog-entry-3690.html

まとめ
● SDSoCでプラグマやCソースコードの違いによるハードウェアの違いや性能を検証した
● シンプルなCソースコードが最速だということが分かった
● ACPポートをDMAに使用するよりもHPポートのほうが速度的に遅かった





























