Embed Size (px)
Citation preview

Site Reliability Engineering©2015 LinkedIn Corporation. All Rights Reserved.
SaltStack at Web Scale…Better, Stronger, Faster
Site Reliability Engineering©2015 LinkedIn Corporation. All Rights Reserved.
Who’s this guy?
2

Site Reliability Engineering©2015 LinkedIn Corporation. All Rights Reserved.
What is SRE?
Hybrid of operations and engineering
Heavily involved in architecture and design
Application support ninjas
Masters of automation
3

Site Reliability Engineering©2015 LinkedIn Corporation. All Rights Reserved.
So, what do I do with salt?
Heavy user
Active developer
Administrator (less so)
4

Site Reliability Engineering©2015 LinkedIn Corporation. All Rights Reserved.
What’s LinkedIn?
Professional social network
You probably all have an account
You probably all get email from us too
5

Site Reliability Engineering©2015 LinkedIn Corporation. All Rights Reserved.
Salt @ LinkedIn
When LinkedIn started
– Aug 2011: Salt 0.8.9
– ~5k minions
When I got involved
– May 2012: Salt 0.9.9
– ~10k minions
Last SaltConf
– Now: 2014.01
– ~30k minions
Now
– 2014.7 (starting 2015.2)
– ~70k minions
6

Site Reliability Engineering©2015 LinkedIn Corporation. All Rights Reserved. 7

Site Reliability Engineering©2015 LinkedIn Corporation. All Rights Reserved.
How to scale 101
We can rebuild it
We have the technology
Better Reliability
Stronger Availability
Faster Performance
8

Site Reliability Engineering©2015 LinkedIn Corporation. All Rights Reserved.
Building it Better: What is Reliability?
Being reliable! ( not helpful)
Maintainability
Debuggability
Not breaking
9

Site Reliability Engineering©2015 LinkedIn Corporation. All Rights Reserved.
Building it Better: Maintainability
Encapsulation/Generalization
– Make systems that are responsible for their own things
– Reuse code as much as possible
Documentation
Examples:
– States: each state module only knows how to interact with its own stuff
– Channels: don’t have to use SREQ directly (handle all the auth, retries, etc.)
– Job cache: single place where all of the returners (master and minion) live
10

Site Reliability Engineering©2015 LinkedIn Corporation. All Rights Reserved.
Building it Better: Maintainability
Tests!
– Write them!
– Write the negative ones
– Keep them up to date with your changes
Don’t’ be that guy
11

Site Reliability Engineering©2015 LinkedIn Corporation. All Rights Reserved.
Building it Better: Debuggability
Logs
– Logging on useful events (such as AES key rotation)
– Debug messages
– Tuning log level on your install
Fire events
– Filesystem update
– AES key rotation
– Etc.
Setproctitle: setting useful process titles for ps output
12

Site Reliability Engineering©2015 LinkedIn Corporation. All Rights Reserved.
Building it Better: Debugability
Useful error messages
13

Site Reliability Engineering©2015 LinkedIn Corporation. All Rights Reserved.
Building it Better: Debugging state output
SLS
foo:
cmd.run:
- name: 'date'
- prereq:
- cmd: fail_one
# anything that will
# fail test=True
bar:
cmd.run:
- name: 'exit 0'
- cwd: 1 # bad value
14
Output
ID: foo
Function: cmd.run
Name: date
Result: False
Comment: One or more requisite failed
----------
ID: bar
Function: cmd.run
Name: exit 0
Result: False
Comment: One or more requisite failed

Site Reliability Engineering©2015 LinkedIn Corporation. All Rights Reserved.
Building it Better: Debugging state output
New Output
ID: foo
Function: cmd.run
Name: date
Result: False
Comment: One or more requisite failed: {'test.fail_one': 'An exception occurred in this state: Traceback (most recent call last):\n <INSERT TRACEBACK>'}
----------
ID: bar
Function: cmd.run
Name: exit 0
Result: False
Comment: An exception occurred in this state: Traceback (most recent call last): <INSERT TRACEBACK>
15

Site Reliability Engineering©2015 LinkedIn Corporation. All Rights Reserved. 16

Site Reliability Engineering©2015 LinkedIn Corporation. All Rights Reserved.
Building it Better: Debugging state output
SLS
foo:
cmd.run:
- name: 'date'
- prereq:
- foo: fail_one
- cmd: work
fail_one:
foo.run:
- name: 'exit 1’
work:
cmd.run:
- name: 'date'
17
Output
ID: foo
Function: cmd.run
Name: date
Result: False
Comment: One or more requisite failed
----------
ID: work
Function: cmd.run
Name: date
Result: False
Comment: One or more requisite failed

Site Reliability Engineering©2015 LinkedIn Corporation. All Rights Reserved.
Building it Better: Debugging state output
New OutputID: foo
Function: cmd.run
Name: date
Result: False
Comment: One or more requisite failed: {'test.fail_one': "State 'foo.run' was not found in SLS 'test'\n"}
----------
ID: work
Function: cmd.run
Name: date
Result: None
Comment: Command "date" would have been executed
18

Site Reliability Engineering©2015 LinkedIn Corporation. All Rights Reserved. 19

Site Reliability Engineering©2015 LinkedIn Corporation. All Rights Reserved.
Building it Better: Not-breaking…ability
Expect failure and code defensively, things fail
– Hardware
– Network
Modules can be… problematic
20

Site Reliability Engineering©2015 LinkedIn Corporation. All Rights Reserved. 21

Site Reliability Engineering©2015 LinkedIn Corporation. All Rights Reserved.
Building it Better: Not-breaking…ability
Some are obvious:
exit(0)
def test():
return True
22

Site Reliability Engineering©2015 LinkedIn Corporation. All Rights Reserved.
Building it Better: Not-breaking…ability
Some less so
import requests
ret = requests.get(‘http://fileserver.corp/somefile’)
def test():
return True
23

Site Reliability Engineering©2015 LinkedIn Corporation. All Rights Reserved.
Building it Better: Not-breaking…ability
Some are very hard to find
WARNING: Mixing fork() and threads detected; memory leaked.
24

Site Reliability Engineering©2015 LinkedIn Corporation. All Rights Reserved.
Building it Better: Not-breaking…ability
Jira
import gevent.monkey
gevent.monkey.patch_all()
<the rest of the library>
25
That’s not good!

Site Reliability Engineering©2015 LinkedIn Corporation. All Rights Reserved.
Building it Better: LazyLoader
Major overhaul of Salt’s loader system
Only load modules when you are going to use them
– This means that bad/malicious modules will only affect their own uses
In addition fixes a few other things
– __context__ is now actually global for a given module dict (e.g. __salt__)
– Submodules work (and reload correctly)
New in 2015.2
26

Site Reliability Engineering©2015 LinkedIn Corporation. All Rights Reserved. 27

Site Reliability Engineering©2015 LinkedIn Corporation. All Rights Reserved.
Building it Stronger: What is Availability?
Being available?
Uptime
Lots of 9’s!
Things to consider:
– What has to work to be “available”? Minions working?
Reactor working?
Pillars working?
Job cache?
– How do you do maintenance? Scheduled downtime?
HA system you can work on live?
How do you measure it?
28

Site Reliability Engineering©2015 LinkedIn Corporation. All Rights Reserved.
Building it Stronger: Availability of minions
Availability for a platform doesn’t just mean “it’s not broken”
Almost always a perception problem
Some examples:
– Can’t run “salt” on my box (not on the master)
– The CLI return didn’t have all of my hosts! (your box is dead…)
– I re-imaged by box and its not getting jobs anymore (key pair changed)
– “Salt isn’t working” – usually not “salt”
29

Site Reliability Engineering©2015 LinkedIn Corporation. All Rights Reserved.
Building it Stronger: Availability of minions
We have to be proactive:
Documentation/training
Monitoring: Minion metrics– Module sync time
– Connectivity to master
– Uptime
Auto-remediation:– Re-imaged boxes: keys are regenerated
We have an internal tool which keep track of hosts
Use internal tool for determining if the host is the same
Simple reactor SLS to run custom runner on auth failure
– SaltGuard Mismatched minion_id and hostname
Detects and reports when master public key changed
And much more!
30

Site Reliability Engineering©2015 LinkedIn Corporation. All Rights Reserved.
Building it Stronger: Availability of Master
Master Metrics
– Collect metrics about how you use salt
– The Reactor is great for generating such metrics
How many jobs published
What jobs where published
Number of worker processes (and stats per process)
Number of auths
Things we noticed
– Reactor doesn’t seem to run on all events??
– Mworkers going defunct
– Publisher process dies every day, requiring a bounce of the master
31

Site Reliability Engineering©2015 LinkedIn Corporation. All Rights Reserved. 32

Site Reliability Engineering©2015 LinkedIn Corporation. All Rights Reserved.
Building it Stronger: Availability of Master
Reactor missing events
– Runner had condition which called exit()– which killed the reactor
Mworkers going defunct
– When the minion didn’t call recv() the socket on the master side would break
– Handle case– and reset socket on master
Publisher dying
– Found zmq pub socket memory leak (grows to ~48gb of memory in 1 day)
– Some work with zmq community– but slow going
Process Manager
– I originally wrote this for netapi, but I generalized it for arbitrary use
– Now the master’s parent process is simply a process manager
– Then we noticed the master restarted every 24h on some (not all) masters
Re-found bug in python subprocess (http://bugs.python.org/issue1731717)
33

Site Reliability Engineering©2015 LinkedIn Corporation. All Rights Reserved.
Building it Stronger: High Availability master
Today: Active/Passive master pair
Problems moving to Active/Active
– Job returns (cache)
Where do they go?
How do people retrieve them?
Retention policy?
– Load distribution
How to get the minions to connect evenly
Redistribute for maintenance
– Clients (people running commands)
Which one do they connect to?
How do they find their job returns later?
34

Site Reliability Engineering©2015 LinkedIn Corporation. All Rights Reserved.
Building it Stronger: High Availability master
Tools we have:
– Failover Minion
Minion with N masters configured– will find one that’s available
Tradeoff: eventually available (in failover)
– Multi-minion
Listen to N masters and do all of their jobs
Tradeoff: nothing for the minion
– Syndic
Allow a master to “proxy” jobs from a higher level master
Tradeoff: Another master to maintain, still single point of failure
– Multi-Syndic
Allow a single syndic to “proxy” multiple masters,
syndic_mode to control forwarding
Tradeoff: Another master to maintain, (potentially) complicated forwarding
35
Site Reliability Engineering©2015 LinkedIn Corporation. All Rights Reserved.
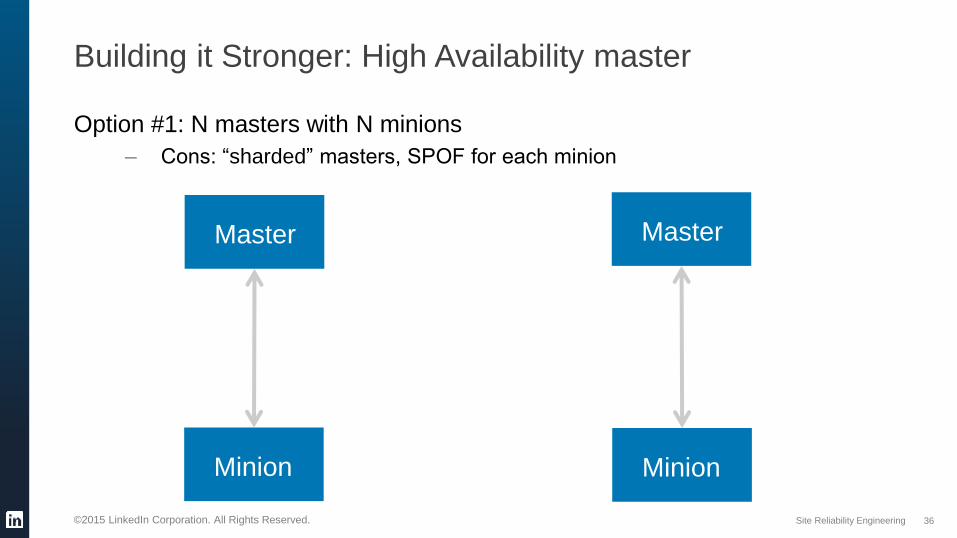
Building it Stronger: High Availability master
Option #1: N masters with N minions
– Cons: “sharded” masters, SPOF for each minion
36
Master Master
Minion Minion
Site Reliability Engineering©2015 LinkedIn Corporation. All Rights Reserved.
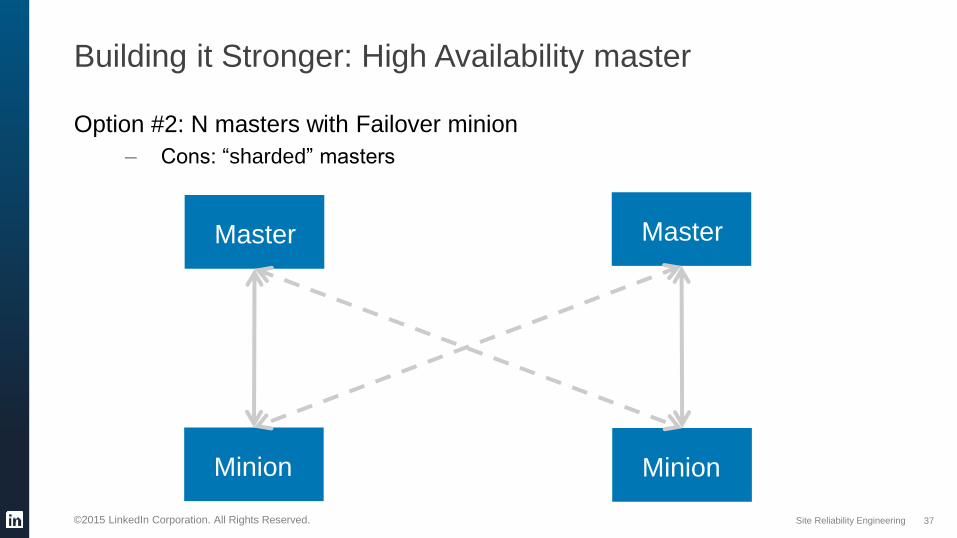
Building it Stronger: High Availability master
Option #2: N masters with Failover minion
– Cons: “sharded” masters
37
Master Master
Minion Minion
Site Reliability Engineering©2015 LinkedIn Corporation. All Rights Reserved.
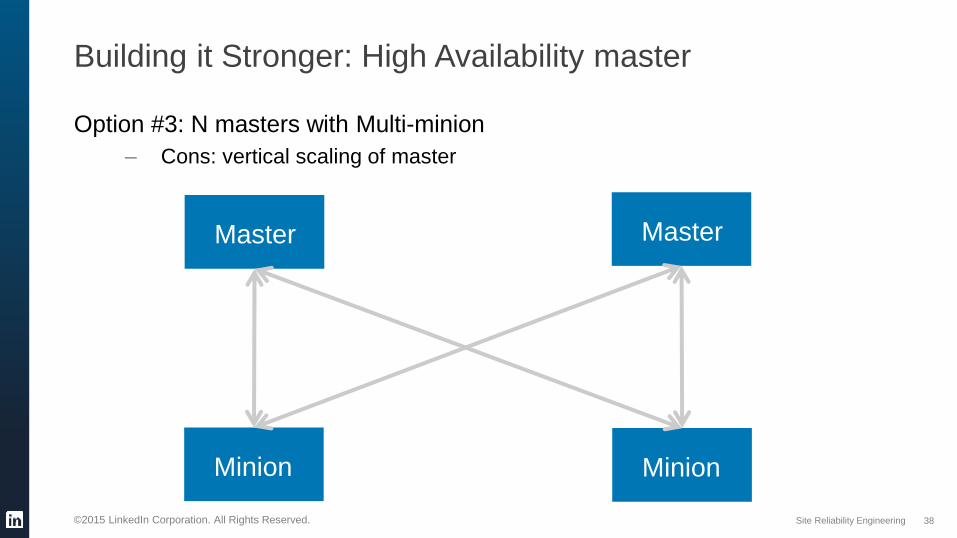
Building it Stronger: High Availability master
Option #3: N masters with Multi-minion
– Cons: vertical scaling of master
38
Master Master
Minion Minion
Site Reliability Engineering©2015 LinkedIn Corporation. All Rights Reserved.
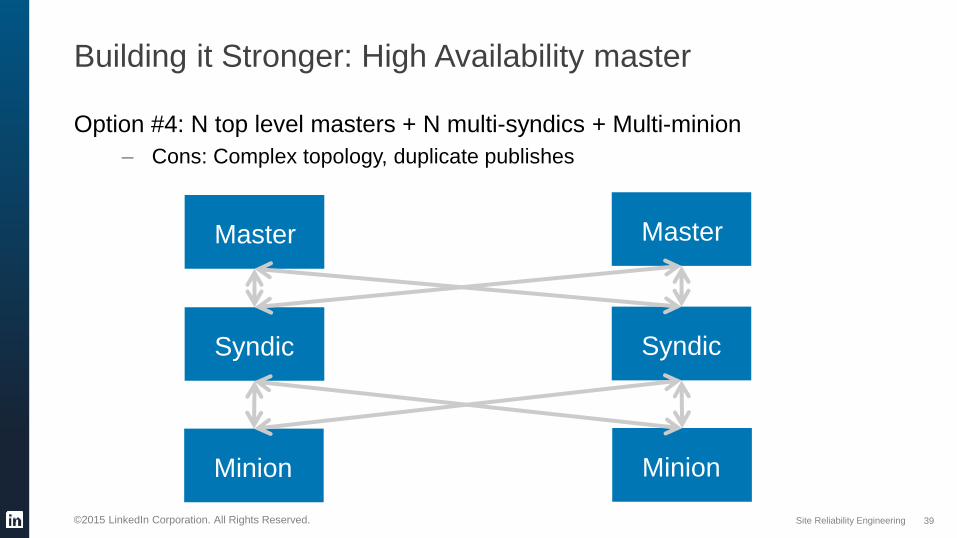
Building it Stronger: High Availability master
Option #4: N top level masters + N multi-syndics + Multi-minion
– Cons: Complex topology, duplicate publishes
39
Master Master
Minion Minion
SyndicSyndic
Site Reliability Engineering©2015 LinkedIn Corporation. All Rights Reserved.
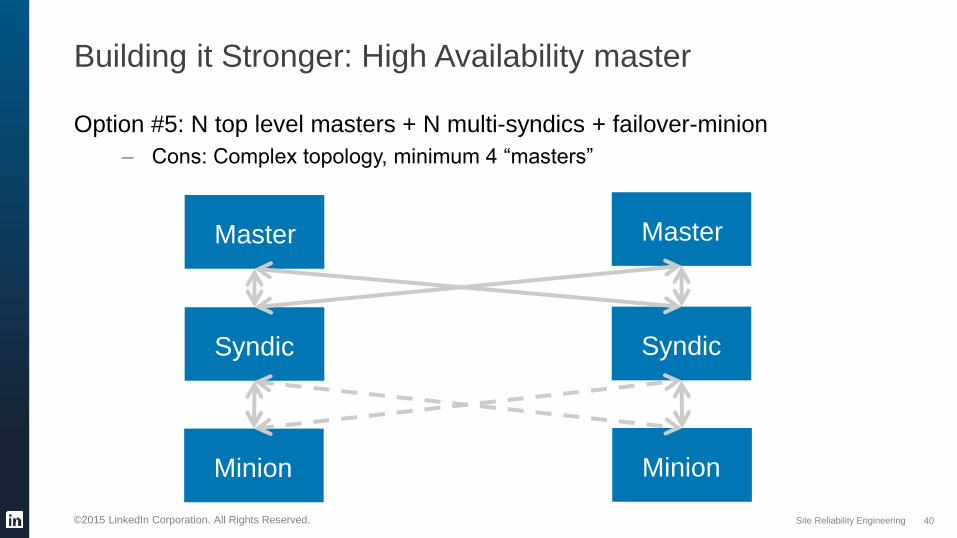
Building it Stronger: High Availability master
Option #5: N top level masters + N multi-syndics + failover-minion
– Cons: Complex topology, minimum 4 “masters”
40
Minion
Master Master
Minion Minion
SyndicSyndic
Site Reliability Engineering©2015 LinkedIn Corporation. All Rights Reserved.
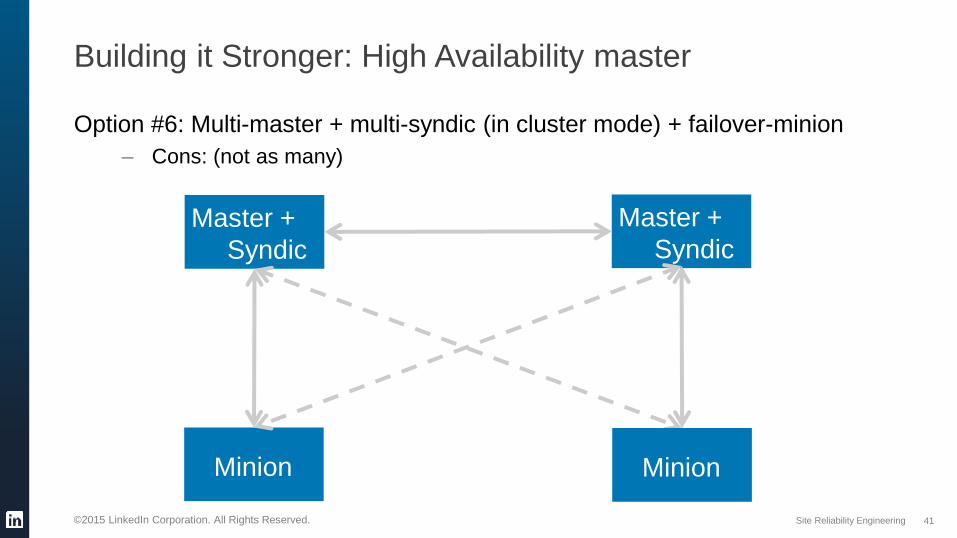
Building it Stronger: High Availability master
Option #6: Multi-master + multi-syndic (in cluster mode) + failover-minion
– Cons: (not as many)
41
Master +
Syndic
Minion
Master +
Syndic
Minion

Site Reliability Engineering©2015 LinkedIn Corporation. All Rights Reserved. 42

Site Reliability Engineering©2015 LinkedIn Corporation. All Rights Reserved.
Building it Faster: Performance
What drives performance?
– Throughput problems (need to run more jobs!)
– Latency problems (need those runs faster!)
– Capacity problems (need to use fewer boxes!)
43

Site Reliability Engineering©2015 LinkedIn Corporation. All Rights Reserved. 44

Site Reliability Engineering©2015 LinkedIn Corporation. All Rights Reserved.
Building it Faster: How to Performance?
Do less
Do less faster
Do less faster better
Things to watch out for:
– Concurrency is hard (deadlocks, infinite spinning)
– If making it faster is making it more confusing, its probably not the right way
– Prioritize your optimizations
45

Site Reliability Engineering©2015 LinkedIn Corporation. All Rights Reserved.
Building it Faster: Small optimizations
Use libraries as recommended
– disable GC during msgpack (read the docs)
– Runner/Wheel client used to spin while waiting for returns (instead of calling get_event with a timeout)
Sometimes slower is faster
– compiled regex is slower to create, but faster to execute
Disk is SLOOOOW
– Make AES key not hit disk (Mworker had to stat a file on every iteration)
– Removed “verify” from all CLI scripts (except the daemons)
Use the language!
– Built-ins where possible
– Care about your memory (iterate, not copy)
46

Site Reliability Engineering©2015 LinkedIn Corporation. All Rights Reserved.
Python copy vs. iterate
47
Copy Iterate
for k in _dict.values(): for k in _dict.itervalues():
for k in _dict.keys(): for k in _dict:
k = _dict.keys()[0] k = _dict.iterkeys().next()
v = _dict.values()[0] v = _dict.itervalues().next()

Site Reliability Engineering©2015 LinkedIn Corporation. All Rights Reserved.
Building it Faster: Reactor
In addition to the reactor dying, we noticed significant event loss
Turns out the reactor was creating all of the clients (runner, wheel,
LocalClient) on each reaction execution!
– Created cachedict to cache these for a configurable amount of time
Then the reactor was consuming the entire box!
– Found that the reactor fired events for runner starts– which could then be
reacted on– causing infinite recursion in certain cases
– Made the reactor not fire start events for runners (CHECK: user?)
Then we found that on master startup the Master host would be out of PIDs
– Reactor would daemonize a process for each event it reacted to
– Switched reactor to a threadpool (to limit concurrency and CPU usage)
48

Site Reliability Engineering©2015 LinkedIn Corporation. All Rights Reserved.
Building it Faster: LazyLoader
In addition to sandboxing, the LazyLoader is much faster
Instead of loading all incase you might use one, we just-in-time load
In local testing (salt-call) this cuts ~50% off of the time for a local test.ping
49
Old
$ time salt-call --local test.ping
local:
True
real 0m2.908s
user 0m1.976s
sys 0m0.906s
New
$ time salt-call --local test.ping
local:
True
real 0m1.562s
user 0m0.920s
sys 0m0.631s

Site Reliability Engineering©2015 LinkedIn Corporation. All Rights Reserved.
Building it Faster: Auth
Biggest problem (today) with performance/scale for salt is the auth storm
What causes it?
– Salt zmq uses AES crypto– mostly with a shared symmetric key
– When the key rotates, the next job sent to a minion will trigger a re-auth
– ZMQ pub/sub sockets by default send all messages everywhere
Which means if the key rotates and someone pings a minion, all minons will auth
– Bounce of all (or a lot of) minions causes this as well
50

Site Reliability Engineering©2015 LinkedIn Corporation. All Rights Reserved. 51

Site Reliability Engineering©2015 LinkedIn Corporation. All Rights Reserved. 52

Site Reliability Engineering©2015 LinkedIn Corporation. All Rights Reserved.
Building it Faster: Auth
This “storm” state doesn’t always clear up on its own
– ZMQ doesn’t tell you if the client for a message is connected
– If a client has left, we don’t know– so we have to execute the job
Well, that seems bad…
53

Site Reliability Engineering©2015 LinkedIn Corporation. All Rights Reserved. 54

Site Reliability Engineering©2015 LinkedIn Corporation. All Rights Reserved.
Building it Faster: Auth
How can we fix it?
– Only send the publish job to the minions that need it (zmq_filtering)
Meaning all minions won’t re-auth at the same time
Not a “fix”, but avoids the storm if we don’t need it
Useful for large publish jobs (since you have to send it to your targets, not everyone)
– Make the minions back off when the auth times out
acceptance wait time: how long to wait after a failure
acceptance_wait_time_max: if multiple failures, increase backoff up to this
Great, all good right?
55

Site Reliability Engineering©2015 LinkedIn Corporation. All Rights Reserved. 56

Site Reliability Engineering©2015 LinkedIn Corporation. All Rights Reserved.
Building it Faster: Auth
It turns out each minion actually auth’s 3 times during startup (mine, req
channel, pillar fetch)
Well, just pass it around then!
– Actually, not that simple.
– Some of these can share, but others don’t have access to the main daemon
Solution? Singleton Auth
– Whats a Singleton? Single instance of a class– so you don’t have to pass it
around, the class will just only return one instance to you
– This means everyone can just “create” Auth() and it will take care of just
making one
57

Site Reliability Engineering©2015 LinkedIn Corporation. All Rights Reserved. 58

Site Reliability Engineering©2015 LinkedIn Corporation. All Rights Reserved.
Building it Faster: salt-api
What is salt-api?
– Netapi modules: generic network interfaces to salt
– Only ones today are rest modules
Why? It allows for easy integration with salt
– Deployment
– Auto Remediation
– GUI
– Anything else!
59

Site Reliability Engineering©2015 LinkedIn Corporation. All Rights Reserved.
Building it Faster: salt-api
Problems with the current implementations (wsgi and cherrypy)
– …
– Concurrency limitations
Cherrypy/wsgi are threaded servers
– Request comes in, gets picked up by a thread
– That thread will handle the job and then wait on the response
The wait on the return event can take a significant amount of time, all the
while the thread is blocked waiting on the response– we can do better!
60

Site Reliability Engineering©2015 LinkedIn Corporation. All Rights Reserved.
Building it Faster: Saltnado!
Tornado implementation of Salt-api
What is tornado?
– Network server library
– IOLoop
– Coroutines and Futures (probably do a quick explanation of what that is)
61

Site Reliability Engineering©2015 LinkedIn Corporation. All Rights Reserved.
Building it Faster: Saltnado!
Tornado hello world:
class HelloWorldHandler(RequestHandler):
def get(self):
self.write(“hello world”)
62

Site Reliability Engineering©2015 LinkedIn Corporation. All Rights Reserved.
Building it Faster: Saltnado!
Tornado with callbacks:
class AsyncHandler(RequestHandler):
@tornado.gen.asynchronous
def get(self):
http_client = AsyncHTTPClient()
http_client.fetch("http://example.com",
callback=self.on_fetch)
def on_fetch(self, response):
do_something_with_response(response)
self.render("template.html")
63

Site Reliability Engineering©2015 LinkedIn Corporation. All Rights Reserved.
Building it Faster: Saltnado!
Tornado with coroutines:
class GenAsyncHandler(RequestHandler):
@tornado.gen.coroutine
def get(self):
http_client = AsyncHTTPClient()
response = yield http_client.fetch("http://example.com")
do_something_with_response(response)
self.render("template.html")
64

Site Reliability Engineering©2015 LinkedIn Corporation. All Rights Reserved.
Building it Faster: Saltnado!
What does this all mean for salt?
– Event driven API
– No concurrency limitations–long running jobs are now just as expensive as
short running jobs to the API
– Test coverage
65

Site Reliability Engineering©2015 LinkedIn Corporation. All Rights Reserved.
Takeaways
Better Reliability
– Write maintainable, debuggable, working code
– Write tests and keep them up-to-date
Stronger Availability
– Determine what availability means to your use
– Proactive measuring, monitoring, and remediating
Faster Performance
– Do less faster better
– Use the language effectively
– Prioritize your performance improvements
66
Site Reliability Engineering©2015 LinkedIn Corporation. All Rights Reserved.
Got more questions about Salt @ LinkedIn
Got questions?
– Drop by our SaltConf booth! (do we have one?)
– Connect with me on LinkedIn www.linkedin.com/in/jacksontj
– Jacksontj on #salt on freenode
67






























