Embed Size (px)
Citation preview

MongoDB for Collaborative Science
Shreyas Cholia, Dan Gunter
LBNL

About Us
We are Computer Scientists and Engineers at Lawrence Berkeley Lab
We work with science teams to help build software and computing infrastructure for doing awesome SCIENCE
1

Talk overview
Background: community science and data
science in general, materials in particular
How (and why) we use MongoDB today
Things we would like to do with MongoDB in the future
Conclusions
2

Science is now a collaborative effortLarge teams of peopleLots of computational power
Science
3

Big Data
Science is increasingly data-driven
Computational cycles are cheap
Take an –omicsapproach to science
Compute all interesting things first, ask questions later
4

The Materials Project
An open science initiative that makes available a huge database of computed materials properties for all materials researchers
5

Why we care about "materials"
solar PVelectric vehicles
other:waste heat recovery (thermoelectrics)hydrogen storagecatalysts/fuel cells
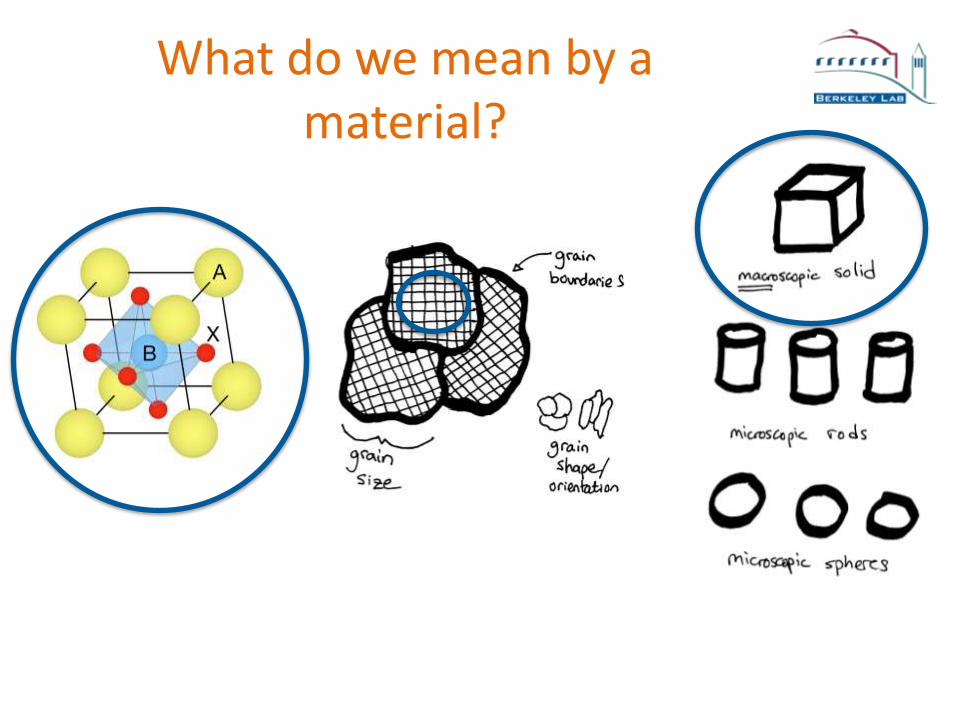
What do we mean by a material?

This is a Material!
https://www.materialsproject.org/materials/24972/{ "created_at": "2012-08-30T02:55:49.139558", "version": { "pymatgen": "2.2.1dev", "db": "2012.07.09", "rest": "1.0" }, "valid_response": true, "copyright": "Copyright 2012, The Materials Project", "response": [ { "formation_energy_per_atom": -1.7873700829440011, "elements": [ "Fe", "O" ], "band_gap": null, "e_above_hull": 0.0460096124999998, "nelements": 2, "pretty_formula": "Fe2O3", "energy": -132.33005625, "is_hubbard": true, "nsites": 20, "material_id": 542309, "unit_cell_formula": { "Fe": 8.0, "O": 12.0 }, ….
8

Business as usual:“find the needle in a haystack”

hours

The Materials Project is likehaving an army to search
through the haystack
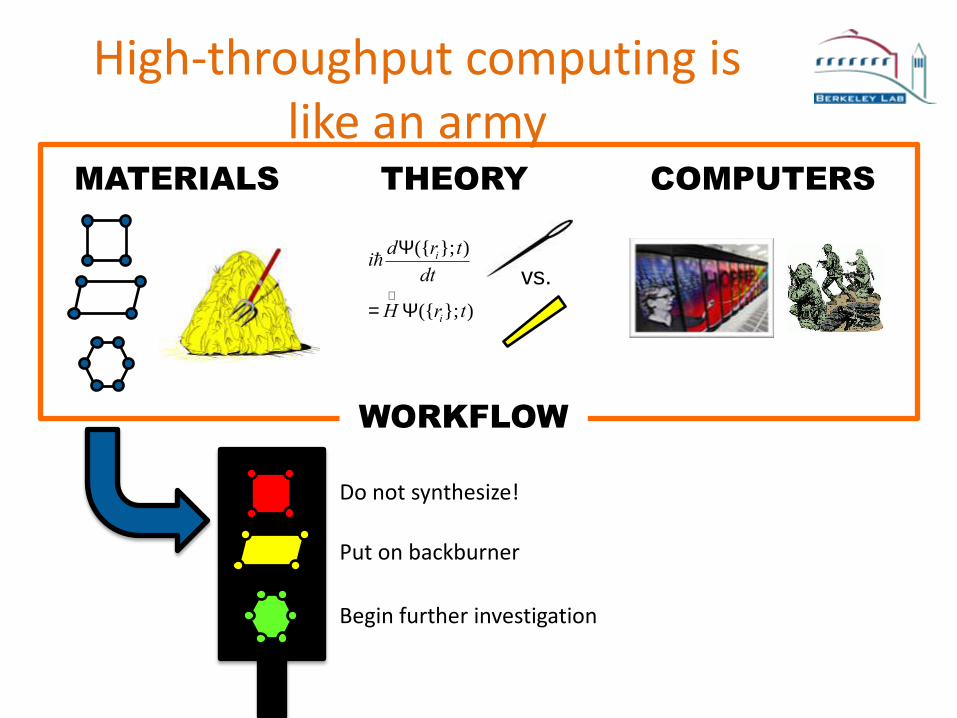
High-throughput computing is like an army
MATERIALS THEORY COMPUTERS
WORKFLOW
vs.idY({ri};t)
dt
= HÙ
Y({ri};t)
Do not synthesize!
Put on backburner
Begin further investigation
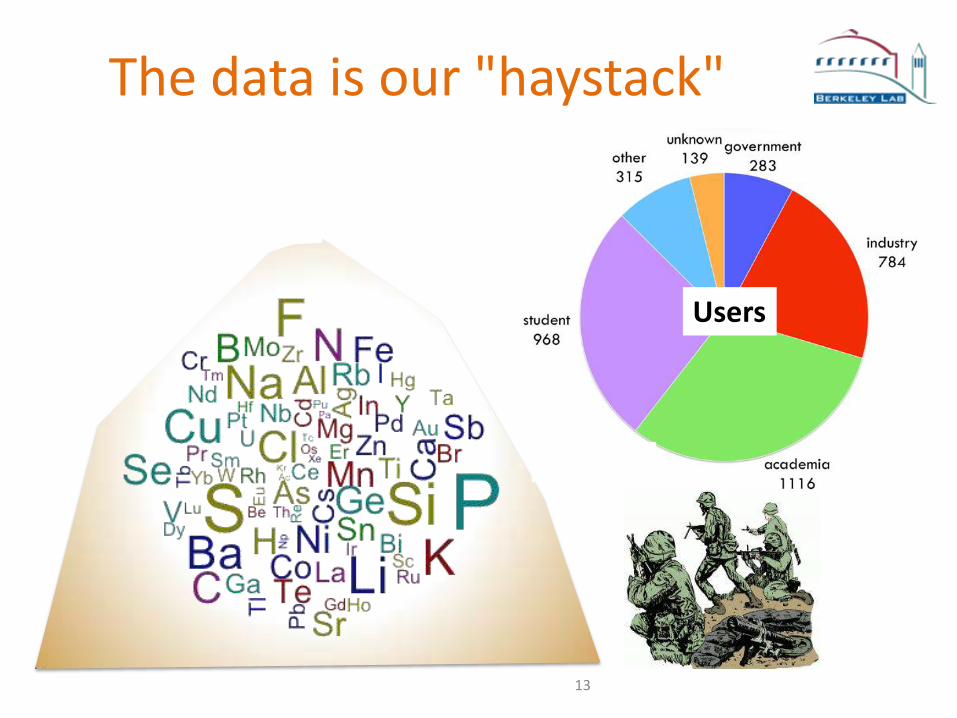
The data is our "haystack"
13
Users

Materials Project websitehttp://materialsproject.org/
14
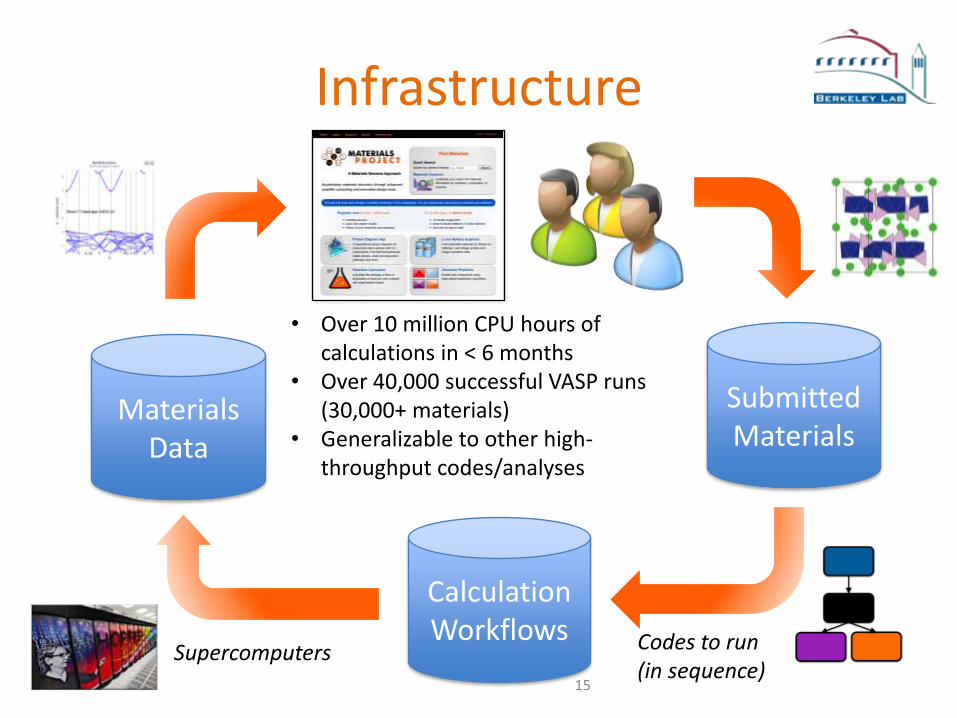
Infrastructure
SubmittedMaterials
MaterialsData
Materials Properties
Supercomputers
• Over 10 million CPU hours of calculations in < 6 months
• Over 40,000 successful VASP runs(30,000+ materials)
• Generalizable to other high-throughput codes/analyses
Calculation Workflows
Supercomputers Codes to run(in sequence)
Atomic positions
15

The Materials Project + MongoDB
We use MongoDB to store data, provenance, and state
16

Application Stack
Python Django Web Service
Pymatgen and other scientific Python libraries
Fireworks + VASP
pymongo
MongoDB under all these layers
Currently at Mongo 2.2
17

Powered by MongoDB
Materials Project data stored in a MongoDB
Core materials properties
User generated data
Workflow and Job data
18

Scalability
We use replica sets in a master/slave configNo sharding (yet)But we are doing pretty well with a small MongoDB cluster so far4 nodes (2 prod, 2 dev)128 GB, 24 cores per node
Current Data volume30000 compounds – 250 GB
Eventuallymillions of compounds, big experimental data
19

Why we like MongoDB
Flexibility
Developer-friendliness
JSON
Great for read-heavy patterns
20

Flexibility
Our data changes frequently
it's research
This was a major pain point for the old SQL schema
The flip side, chaos, has not been a big problem
in reality, all access is programmatic so the code implies the schema
21

Developer-friendly
We work in small groupsmix of scientists, programmers
need something easy to learn, easy to use
Structuring the data is intuitive
Querying the data is intuitive
Querying the data is easy to map to web interfacesDeveloped a special language "Moogle" that translates pretty cleanly to MongoDB filters
22
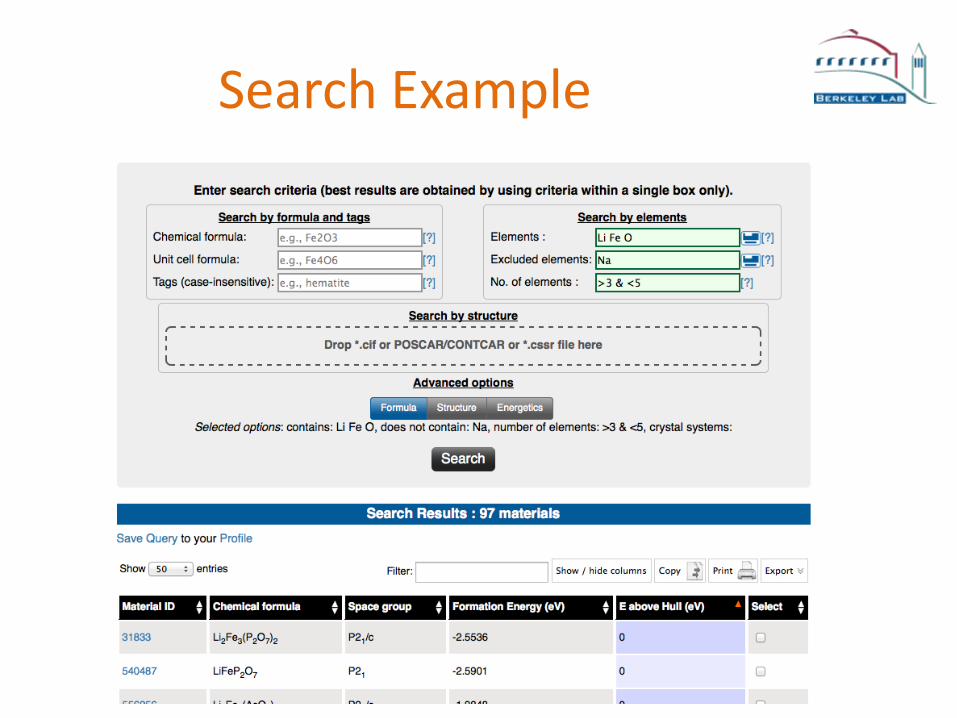
Search Example
23

Search as JSON
{
"nelements": {"$gt": 3, "$lt": 5},
"elements": {
"$all": ["Li", "Fe", "O"],
"$nin": ["Na"]
}
}
24

JSON
JSON is easy (enough) for scientists to read and understandDirect translation between JSON and the database saves lots of timealso nearly-direct mapping to Python dict
For example: Structured Notation Languagethe format for describing the inputs of our computational jobs
Makes it very easy to build an HTTP API on our data Materials API
25

Read/Write Patterns
Scientific data usually generated in large runs
Must go through validation first
Core data only updated in bulk during controlled releases
Core data is essentially read-only
User-generated data is r/w but writes need not complete immediately
Workflow data is r/w and has some write issues, since timing matters
26

Our use of MongoDB
Use it directly, no mongomapper or other ORM-like layer
Did write a "QueryEngine" class
specific to our data, not a general ORM
27

Sample collections in DB
28
Collection Record size Count
diffraction_patterns 450KB 38621
materials 400KB 30758
tasks 150KB 71463
crystals 40KB 125966

Building materials from tasks
if ndocs == 1:
blessed_doc = docs[0]
# Add ntasks_id
# Add task_ids
blessed_doc['task_ids'] = [blessed_doc['task_id']]
blessed_doc['ntask_ids'] = 1
# only one successful result
# could be GGA or GGA+U
elif ndocs >= 2:
# multiple GGA and GGA+U runs
# select the GGA+U run if it exists
# else sort by free_energy_per_atom
....
29
Select the "blessed"
material based on domain
criteria

Data Examples – Fe2O3
https://www.materialsproject.org/materials/24972/{ "created_at": "2012-08-30T02:55:49.139558", "version": { "pymatgen": "2.2.1dev", "db": "2012.07.09", "rest": "1.0" }, "valid_response": true, "copyright": "Copyright 2012, The Materials Project", "response": [ { "formation_energy_per_atom": -1.7873700829440011, "elements": [ "Fe", "O" ], "band_gap": null, "e_above_hull": 0.0460096124999998, "nelements": 2, "pretty_formula": "Fe2O3", "energy": -132.33005625, "is_hubbard": true, "nsites": 20, "material_id": 542309, "unit_cell_formula": { "Fe": 8.0, "O": 12.0 }, ….
30

Mongo works for us
Adding new properties is commonneed flexible schema
Data is nested and structuredmore objects-like, less relational
Need a flexible query mechanism to be able to pull out relevant objects
Read-heavy, few writesCore data only updated in bulk during releases
User writes less critical, so we can survive hiccups
31

Schema-Last
Mongo provides flexible schemas
But web code expects data in a certain structure
M/R methodology allows us to distill the data into the schema expected by the code
Allows us to evolve schema while maintaining a more rigorous structure frontend
32

Fireworks - workflows
Keep all our state in MongoDBraw inputs (crystals) for the calculations
job specifications, ready and running
output of finished runs
Outputs are loaded in batches back to MongoDB
Real-time updates for workflow statusMongoDB "write concerns" are important here
33

Lots of stuff needs to be validated
Atomic compound is stable
Volume of lattice is positive
Time to compute was greater than some minimum
"Phase diagram" correct
Rough agreement across calculation types
Energies agree with experimental results
.....
34

Validation requirements
Fast enough to use in real-time
But not full MongoDB query syntax
too finicky, tricky esp. for "or" type of queries
Want other people to be able to use this
We don't want to become a "mongodb tutor"
Also is nice to be general to any document-oriented datastore
35
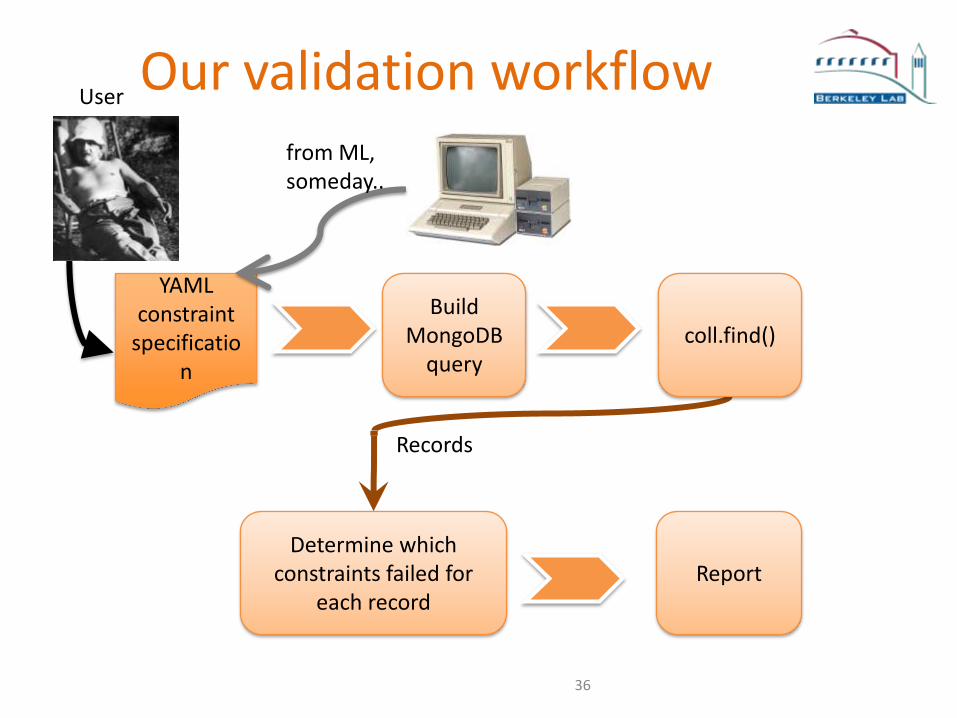
Our validation workflow
YAML constraint
specification
Build MongoDB
query
Determine which constraints failed for
each recordReport
coll.find()
Records
User
from ML,someday..
36

Example query
_aliases:
- energy = final_energy_per_atom
materials_dbv2:
-
filter:
- nelements = 4
constraints:
- energy > 0
- spacegroup.number > 0
- elements size$ nelements
37
{'nelements': 4, '$or': [
{'spacegroup.number': {'$lte': 0}},{'final_energy_per_atom': {'$lte': 0}},{'$where': 'this.elements.length != this.nelements'}
]}
$ mgvv -f mgvv-ex.yaml
MongoDB Query

Example result
38
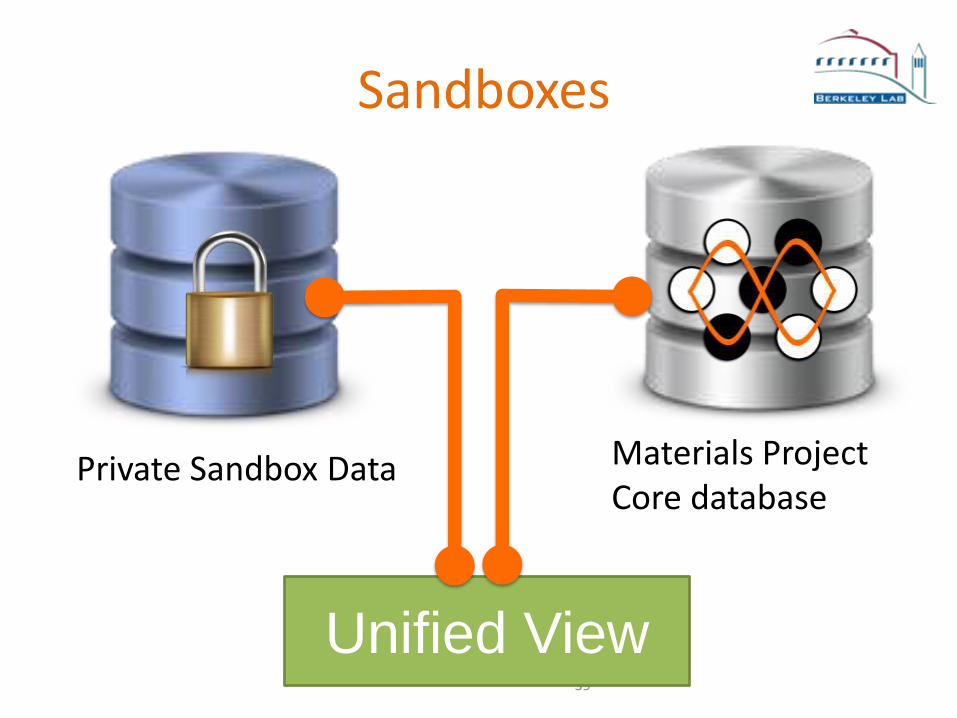
Sandboxes
39
Unified View
Materials ProjectCore database
Private Sandbox Data

Sandbox implementation
We pre-build the sandboxes the same way we pre-build all the other derived collections
We are using collections with "." to separate componentscore.<collection>, sandbox.<name>.<collection>
All access is mediated by our Django serverpermissions stored in Django, map users and groups to access to the sandboxes
No cross-collection querying is needed
40

Where we (and science) are going with all this..
41

Analytics: Smarter, better data mining
42

Share data across disciplines
43
Use MongoDB as a flexible metadata store that connects data/metadata
Store and search user-generated ontologies

Organize and search PBs of data files
Currently store in file hierarchies
/projectX/experimentA/tuesday/run99/foobar.hdf5
Move the metadata to MongoDB
{'project':'X', 'experiment':'A', 'run':99,
'date':'2013-05-10T12:31:56', 'user':'joe', ....
'path':'/projectX/d67001A3.hdf5'}
Already doing this for some projects
one-offs: general layer possible?
44

Thank you
Contact info
Shreyas Cholia [email protected]
Dan Gunter [email protected]
Thanks to these people for slide material
Anubhav Jain, Kristin Persson, David Skinner (LBNL)
Thanks to Materials Project contributors
http://materialsproject.org/contributors
45





























