Embed Size (px)
Citation preview

James SnapeApplication Development ConsultingMicrosoft Limited
Microsoft Analysis Services Physical Design

The Kimball Process

Agenda
Hardware
Dimensions
Facts
Relational stuff
Performance tuning next steps
NB: Relational design not complete –logging, auditing etc discussed in next session

Prime Directive:
Sequential IO Good,
Random IO Bad

Hardware
SQL Server Fast Track Data Warehousewww.microsoft.com/sqlserver/2008/en/us/fasttrack.aspx
Pre-tested hardware configurations
Specific disk, filegroup, layouts
Minimal indexing
To feed CPU at maximum capacity

Dimensions vs Facts
Dimension
Small (relatively)
Repeating data
Fact
Large
Numeric data + keys
Treat them differently

Dimensions in Relational Terms
Table structure
Keys
Indexes
Null handling
Managing change
Processing
CustomerFull Name
Post Code
City
State
Country
Gender
Occupation
Marital Status
Email Address
Customer
Geography1. Country
2. State
3. City
4. Post Code
5. Full Name

Star vs. Snowflake Schemas
dbo.CustomerCustomerKey
FullName
PostCode
City
State
Country
Gender
Occupation
MaritalStatus
EmailAddress
dbo.CustomerCustomerKey
GeographyKey
FullName
Gender
Occupation
MaritalStatus
EmailAddress
dbo.GeographyGeographyKey
PostCode
City
State
Country
OR
NB: both are denormalized, one more than the other

Primary Keys
Use smallest possible integer as surrogate primary key
Primary key is a “row identifier”
Multiple row “versions” are possible
“None” and “Unknown” special values are useful
Do NOT use business/source system keys
Clustered primary key is OK for dimensions

Dimension Indexes
Dimension processing queries of the form:
SELECT DISTINCT .... FROM ....
WHERE (filter) clauses never used
WHERE (join) clauses are used in snowflake dimensions
Non-processing queries may end up in SQL
ROLAP dimensions
Direct to SQL queries

Null Handling in Dimensions
By default NULL converts to 0 or an empty string
NULL attribute keys can invoke special “Unknown Member” handling
Prefer to create a specific “Unknown” row
CustomerKey FullName City Country
-1 Unknown Unknown Unknown
-2 None None None
1243 John Smith London United Kingdom
1244 Mary Jones Glasgow United Kingdom

Dimension Attributes
Attributes have keys, names (and values)
Integer attribute keys are smaller and faster
Keys must be unique
SELECT [Month] as [Month],
[Month] + „ „ + [Year] as [Month of Year]
FROM dbo.Time
Attribute Key Name (Value)
Year 2009 CY 2009 2009
Month 4 April 4
Month of Year 20090400 April 2009 4

Slowly Changing Dimensions
PK = row identifier
Multiple rows = multiple versions
Add effective dating columns
Which can be exposed as new dimensional attributes
dbo.CustomerCustomerKey
FullName
PostCode
City
State
Country
Gender
Occupation
MaritalStatus
EmailAddress
EffectiveFrom (smalldatetime)
EffectiveTo (smalldatetime)
CurrentFlag (tinyint)

Facts in Relational Terms
Keys
Indexing
Partitioning
Processing
Consider Row and Page compression
Internet SalesSales Amount
Order Quantity
Tax Amount
Unit Price
Transaction Count

Fact Keys and Indexes
Is a surrogate/primary key required?
Beware the clustered index/primary key
Prefer the date FK as the clustered index
Add NO CHECK to foreign keys
Indexes are usually not useful
Unless processing degenerate dimensions
Or servicing ROLAP/direct to SQL queries

Fact Partitioning – Why?
Parallel processing
Only process most recent data
Multiple storage engine threads during query
Archive off data
Multiple aggregation strategies
NB: Partitions require Enterprise Edition

Fact Partitioning – Guidelines
Partition when fact tables are 50-100GB+
Ideal partition size 2M-20M rows
Less than 1000 partitions per measure group
This wins over partition size
Prefer to partition over time
Can not aggregate higher than partition grain
Align AS and SQL partitions!
Calculated time keys become very useful
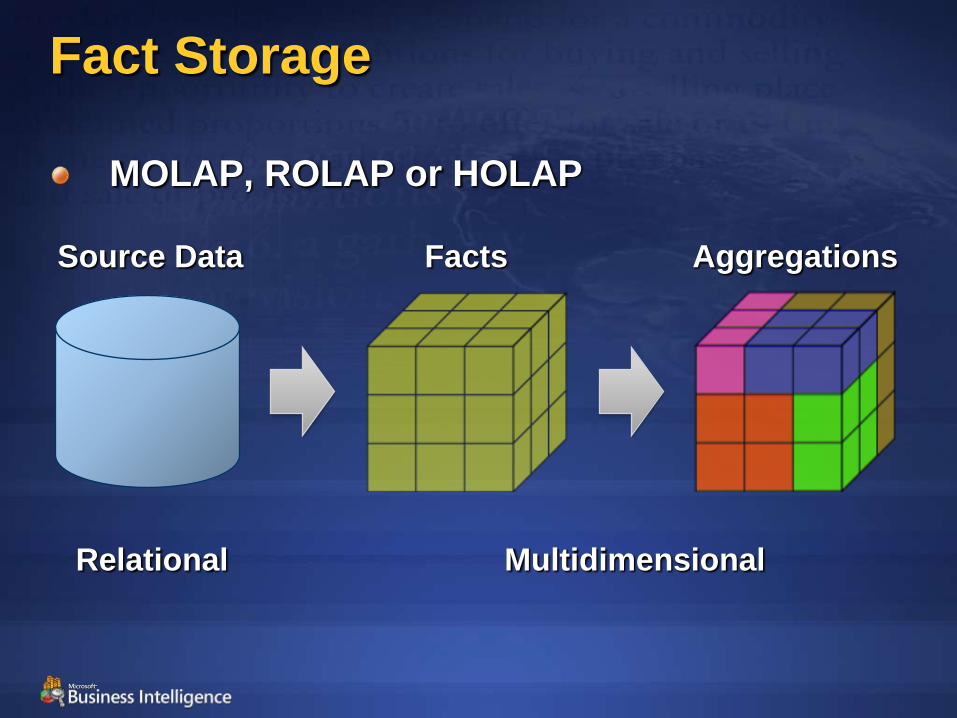
Fact Storage
MOLAP, ROLAP or HOLAP
Source Data Facts Aggregations
Relational Multidimensional

Proactive Caching
Cube = “Cache”
Automatic invalidation of cube
Automatic rebuild of cube
Valid?Valid?
Query
SQL Query

Quick Storage Engine Tuning
Ensure attribute relations are implemented
Turn on query log
Run Usage Based Optimisation (UBO) wizard

© 2007 Microsoft Corporation. All rights reserved. Microsoft, Windows, Windows Vista and other product names are or may be registered trademarks and/or trademarks in the U.S. and/or other
countries.
The information herein is for informational purposes only and represents the current view of Microsoft Corporation as of the date of this presentation. Because Microsoft must respond to
changing market conditions, it should not be interpreted to be a commitment on the part of Microsoft, and Microsoft cannot guarantee the accuracy of any information provided after the date of
this presentation.
MICROSOFT MAKES NO WARRANTIES, EXPRESS, IMPLIED OR STATUTORY, AS TO THE INFORMATION IN THIS PRESENTATION.


![OSI Physical Layer - · PDF fileCisco Public 3. Physical Layer Protocols & Services ... Microsoft PowerPoint - Exploration_Network_Chapter8.ppt [Compatibility Mode] Author:](https://img.dokumen.tips/doc/110x75/5aa424f47f8b9ae7438ba04f/osi-physical-layer-public-3-physical-layer-protocols-services-microsoft-powerpoint.jpg)


























