Embed Size (px)
Citation preview

Meta Learning with Memory-Augmented
Neural Networks
ICML 2016, citation: 10Katy@DataLab
2016.12.30

Background
• Memory Augmented Neural Network(MANN) refers to the class of eternal memory-equipped network instead of those internal memory based architecture(such as LSTMs)

Motivation
• Some problem of interest(ex: motor control) require rapid inference from small quantities of data.
• This kind of flexible adaption is a celebrated aspect of human learning.

Related Work• Graves, Alex, Greg Wayne, and Ivo Danihelka.
"Neural turing machines." arXiv preprint arXiv:1410.5401 (2014).

Related Work• Lake, Brenden M., Ruslan Salakhutdinov, and Joshua B. Tenenbaum.
"Human-level concept learning through probabilistic program induction." Science 350.6266 (2015): 1332-1338.

Main Idea
• Learn to do classification on unseen class
• Learn the sample-class binding on memory instead of weights
• Let the weights learn higher level knowledge

Model• yt (label) is present in a temporally offset manner
• Labels are shuffled from dataset-to-dataset. This prevent the network from slowly learning sample-class binding.

• It must learn to hold data samples in memory until the appropriate labels are presented at the next time- step, after which sample-class information can be bound and stored for later use

ModelBasically the same as neural turing machine(NTM)

• Read from memory using the same content-based approach in NTM
• Write to memory using Least Recent Used Access(LRUA)
• Least: Do you use this knowledge often?
• Recent: Do you just learn it?
Model

LRUA
• Usage weights wut keep track of the locations most recently read or written to
• gamma is the decay parameter

• least-used weights wlut
• m(wut, m) denotes the n smallest element of the vector wu
t
• here we set n equals to the number of read
• write weights wwt
• alpha is a learnable parameter
• prior to writing to memory, the least used memory location is set to zero

Experiments• dataset: Omniglot
• 1643 classes with only a few example per class(the transpose of MNIST)
• 1200 training classes
• 443 test classes

Experiments• train for 100,000
episodes, each episodes with five randomly chosen classes with five randomly chosen labels
• test on never-seen classes

Machine v.s. Human

Class Representation• Since learning the weights of a classifier using large one-
hot vectors becomes increasingly difficult with more classes on one episode, a different approach for labeling classes was employed so that the number of classes presented in a given episode could be arbitrarily increased.
• Characters for each label were uniformly sampled from the set {‘a’, ‘b’, ‘c’, ‘d’, ‘e’}, producing random strings such as ‘ecdba’

Class Representation
• This combinatorial approach allows for 3125 possible labels, which is nearly twice the number of classes in the dataset.

LSTM MANN
5 classes / episode
15 classes / episode
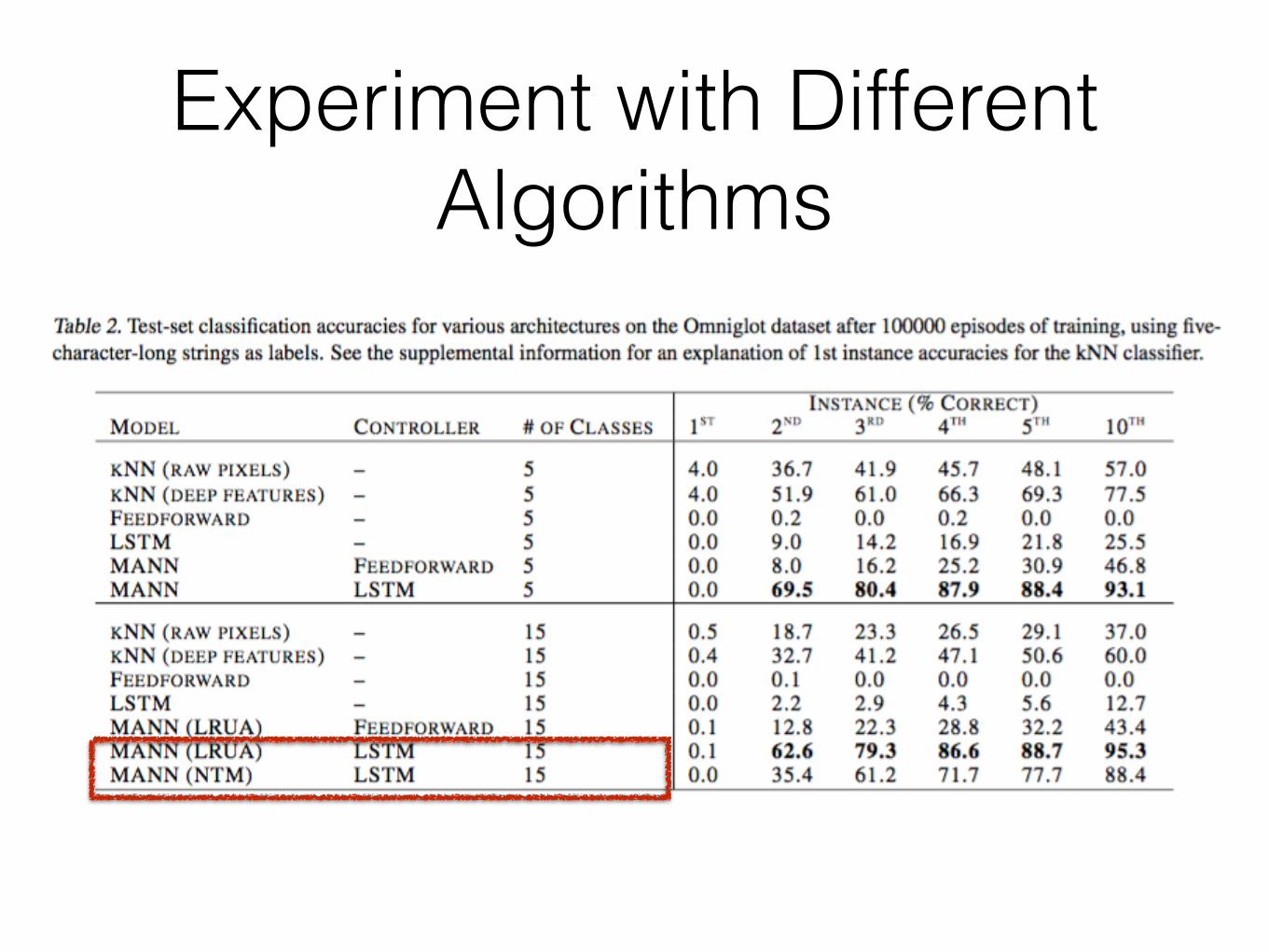
Experiment with Different Algorithms

Experiment with Different Algorithms
• kNN(single nearest neighbour) has an unlimited amount of memory, and could automatically store and retrieve all previously seen examples.
• MANN outperforms kNN
• using LSTM as controller is better than using feedforward NN

Experiment on Memory Wiping
• A good strategy is to wipe the external memory from episode to episode, since each episode contains unique classes with unique labels.

w/o wipping
with wipping

Experiment on Curriculum Training
• gradually increase the classes per episode

Experiment on Curriculum Training

Conclusion• Gradual, incremental learning encodes
background knowledge that spans tasks, while a more flexible memory resource binds information particular to newly encountered tasks. (We wipe out the external memory between episode in this experiment)
• Demonstrate the ability of a memory-augmented neural network to do meta-learning
• Introduce a new method a access external memory

Conclusion• The controller is like the CPU/hippocampus(海⾺馬體), in charges of the long term memory
• The external memory is like the RAM/neocortical(新⽪皮層), in charges of the short term memory and the new coming information

Conclusion
• As machine learning researchers, the lesson we can glean from this is that it is acceptable for our learning algorithms to suffer from forgetting, but they may need complementary algorithms to reduce the information loss.
Goodfellow, Ian J., et al. "An empirical investigation of catastrophic forgetting in gradient-based neural networks." arXiv preprint arXiv:1312.6211 (2013).

Why Memory Augmented Neural Network in general work well?
1. Information must be stored in memory in a representation that is both stable (so that it can be reliably accessed when needed) and element-wise addressable (so that relevant pieces of infor- mation can be accessed selectively).
2. The number of parameters should not be tied to the size of the memory(LSTM doesn’t fulfil this).