Embed Size (px)
Citation preview

Meet HBase 2.0 and Phoenix 5.0Enis SoztutarRajeshbabu Chintaguntla
15th June 2017

2 © Hortonworks Inc. 2011 – 2017. All Rights Reserved
About Us
Enis Soztutar– Apache HBase PMC from 2012
– Release Manager for 1.0
– HBase dev @ Hortonworks
– @enissoz
Rajeshbabu Chintaguntla– Apache HBase Committer
– Apache Phoenix PMC
– HBase dev @ Hortonworks
– @rajeshhcu32

3 © Hortonworks Inc. 2011 – 2017. All Rights Reserved
AgendaVersioning / Compatibility
Changes in Behavior
Major features in HBase 2.0
Phoenix 5.0
Recent Developments in Phoenix

4 © Hortonworks Inc. 2011 – 2017. All Rights Reserved
GIANT DISCLAIMER!!!
HBase-2.0.0 / Phoenix-5.0.0 is NOT released yet (as of June2017)
Community is working hard on these releases
Expected to arrive before end of year 2017
Keep an eye out for scheduled alpha and beta releases

5 © Hortonworks Inc. 2011 – 2017. All Rights Reserved
AgendaVersioning / Compatibility
Changes in Behavior
Major features in HBase 2.0
Phoenix 5.0
Recent Developments in Phoenix
6 © Hortonworks Inc. 2011 – 2017. All Rights Reserved
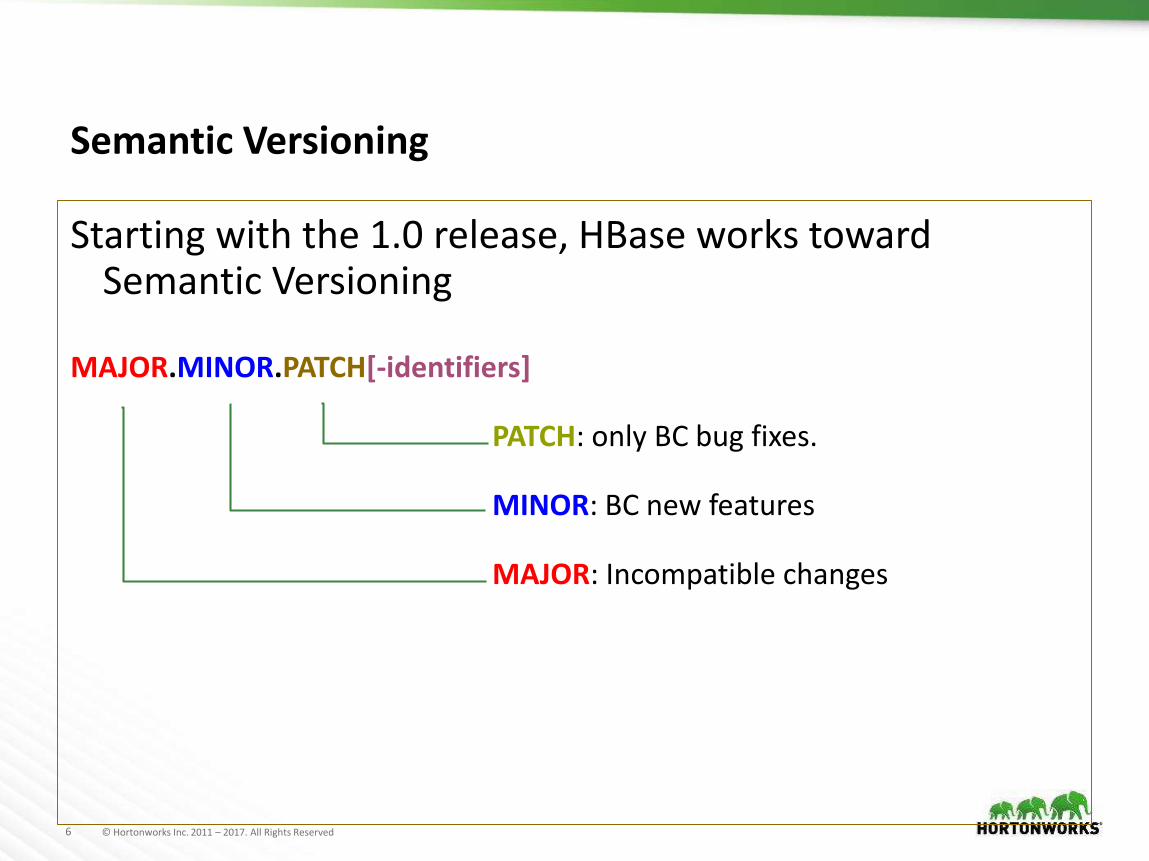
Semantic Versioning
Starting with the 1.0 release, HBase works toward Semantic Versioning
MAJOR.MINOR.PATCH[-identifiers]
PATCH: only BC bug fixes.
MINOR: BC new features
MAJOR: Incompatible changes

7 © Hortonworks Inc. 2011 – 2017. All Rights Reserved
To be, or not to be (Compatible)
Compatibility is NOT a simple yes or noMany dimensionssource, binary, wire, command line,
dependencies etcWhat is client interface?Read
https://hbase.apache.org/book.html#upgrading
7
8 © Hortonworks Inc. 2011 – 2017. All Rights Reserved
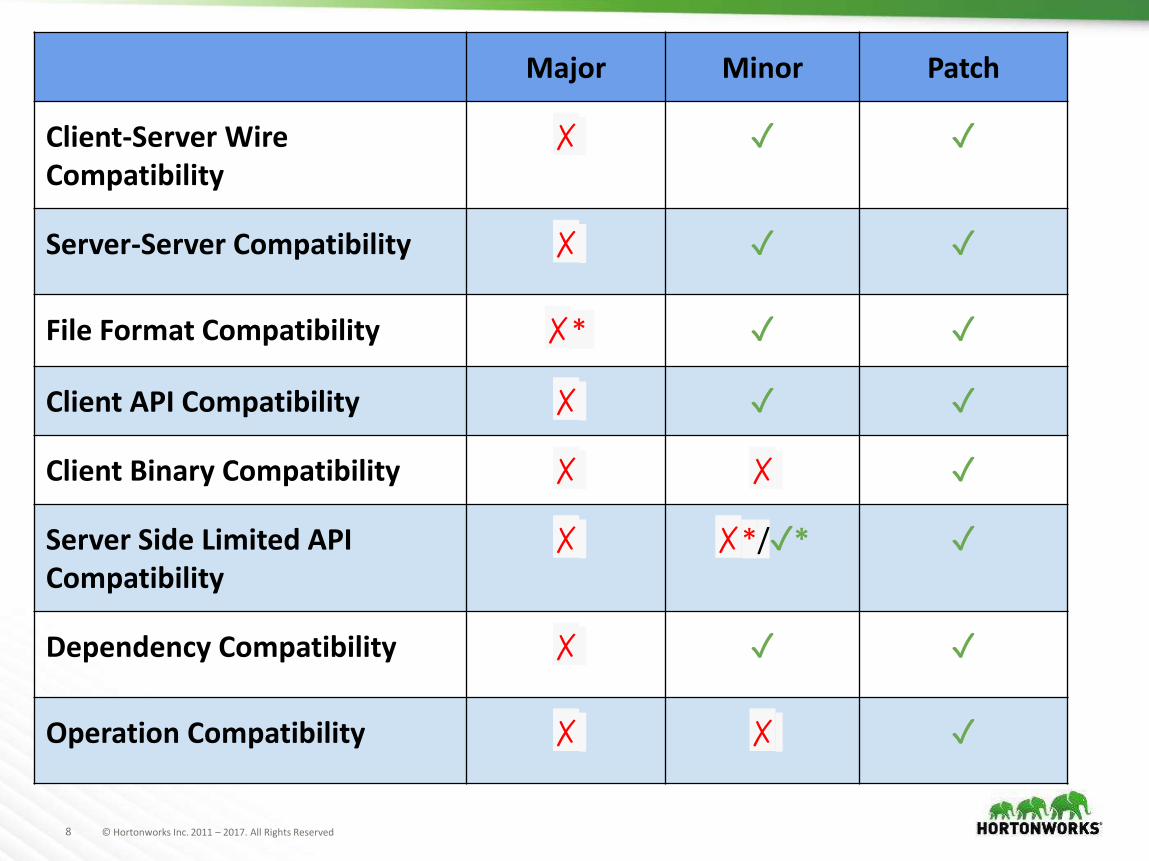
Major Minor Patch
Client-Server Wire Compatibility
✗ ✓ ✓
Server-Server Compatibility ✗ ✓ ✓
File Format Compatibility ✗* ✓ ✓
Client API Compatibility ✗ ✓ ✓
Client Binary Compatibility ✗ ✗ ✓
Server Side Limited API Compatibility
✗ ✗*/✓* ✓
Dependency Compatibility ✗ ✓ ✓
Operation Compatibility ✗ ✗ ✓

9 © Hortonworks Inc. 2011 – 2017. All Rights Reserved
AgendaVersioning / Compatibility
Changes in Behavior
Major features in HBase 2.0
Phoenix 5.0
Recent Developments in Phoenix

10 © Hortonworks Inc. 2011 – 2017. All Rights Reserved
Changes in behavior – HBase-2.0
JDK-8+ onlyLikely Hadoop-2.7+ and Hadoop-3 supportFilter and Coprocessor changes Managed connections are gone.Deprecated client interfaces are goneTarget is “Rolling upgradable” from 1.xUpdated dependencies
10

11 © Hortonworks Inc. 2011 – 2017. All Rights Reserved
How to prepare for HBase-2.0
2.0 contains more API clean upCleanup PB and guava “leaks” into the APISome deprecated APIs (HConnection, HTable,
HBaseAdmin, etc) going awayStart using JDK-8 (and G1). You will like it.1.x client should be able to do read / write /
scan against 2.0 clustersSome DDL / Admin operations may not work
11

12 © Hortonworks Inc. 2011 – 2017. All Rights Reserved
AgendaVersioning / Compatibility
Changes in Behavior
Major features in HBase 2.0
Phoenix 5.0
Recent Developments in Phoenix

13 © Hortonworks Inc. 2011 – 2017. All Rights Reserved
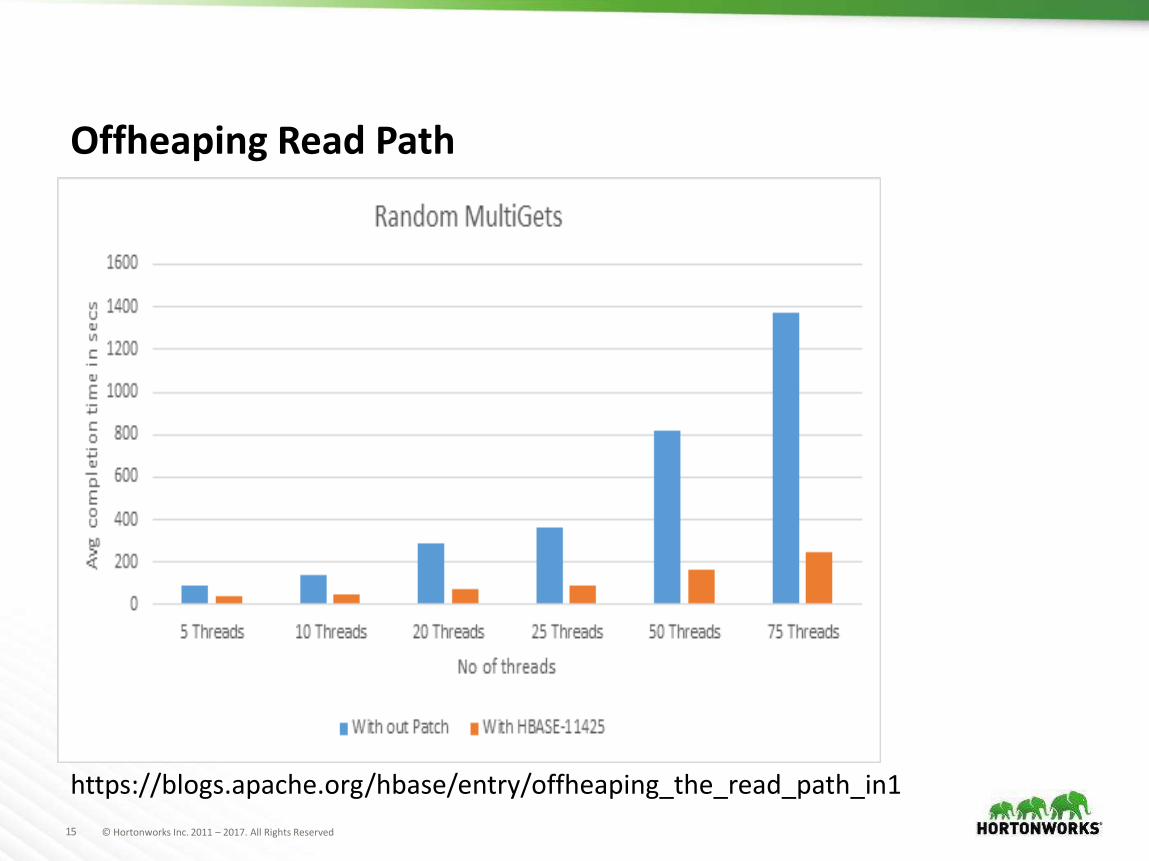
Offheaping Read Path
Goals–Make use of all available RAM–Reduce temporary garbage for reading–Make bucket cache as fast as LRU cache
HBase block cache can be configured as L1 / L2“Bucket cache” can be backed by onheap, off-
heap or SSDDifferent sized buckets in 4MB slicesHFile blocks placed in different bucketsCell comparison only used to deal with byte[]Copy the whole block to heap
13

14 © Hortonworks Inc. 2011 – 2017. All Rights Reserved
https://www.slideshare.net/HBaseCon/offheaping-the-apache-hbase-read-path
15 © Hortonworks Inc. 2011 – 2017. All Rights Reserved
Offheaping Read Path
https://blogs.apache.org/hbase/entry/offheaping_the_read_path_in1
16 © Hortonworks Inc. 2011 – 2017. All Rights Reserved
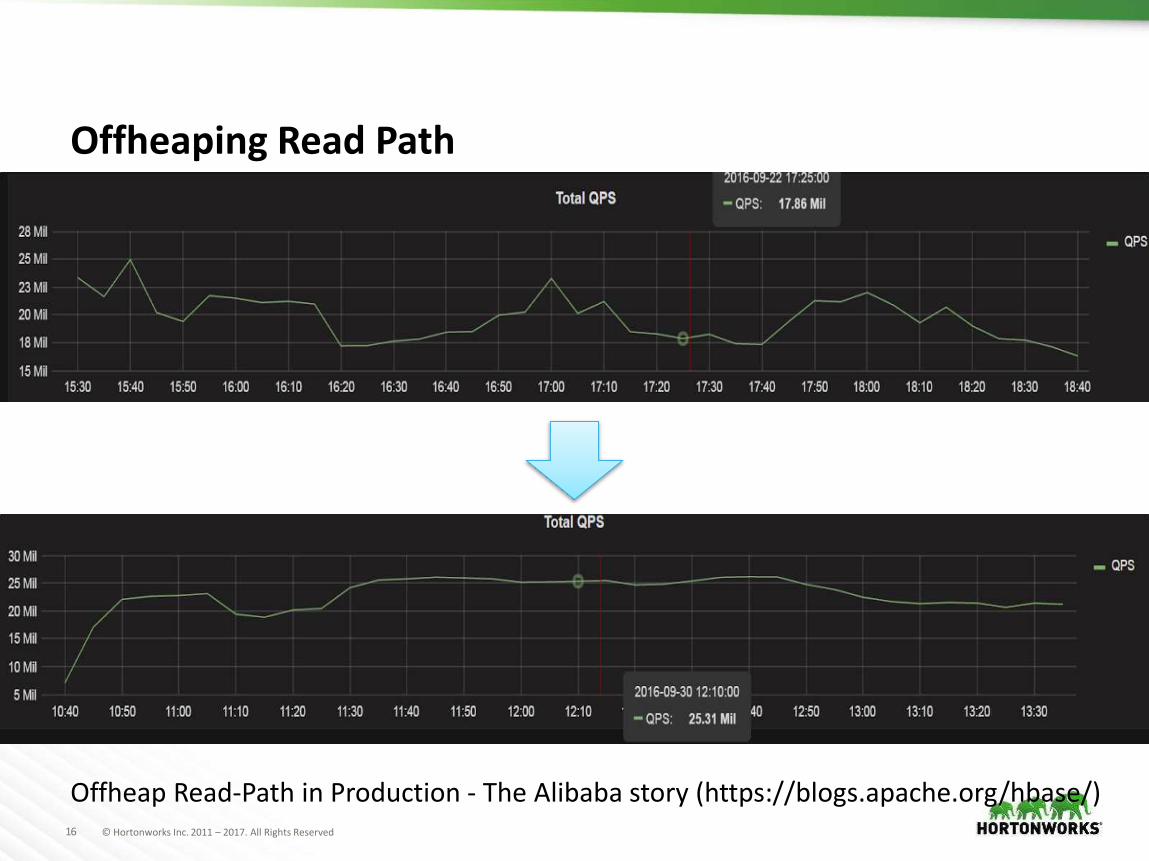
Offheaping Read Path
Offheap Read-Path in Production - The Alibaba story (https://blogs.apache.org/hbase/)

17 © Hortonworks Inc. 2011 – 2017. All Rights Reserved
Offheaping Write Path
Reduce GC, improve throughput predictability Use off-heap buffer pools to read RPC requestsRemove garbage created in Codec parsing, MSLAB
copying, etcMSLAB is used for heap fragmentationNow MSLAB can allocate offheap pooled buffers
[2MB]
17

18 © Hortonworks Inc. 2011 – 2017. All Rights Reserved
Offheaping Write Path
Allows bigger total memstore spaceCell data goes off-heapCell metadata (and CSLM#Entry, etc) is on-heap
(~100 byte overhead)Async WAL is used to avoid copying Cells into
heapWorks with new “Compacting Memstore”
18

19 © Hortonworks Inc. 2011 – 2017. All Rights Reserved
Compacting Memstore
In memory compaction–Eliminate duplicates–Gains are proportional to duplicates
In memory index reduction–Reduce index overhead per cell–Gains proportional to cell size
Reduce flushes to disk–Reduce file creation–Reduce write amplification

20 © Hortonworks Inc. 2011 – 2017. All Rights Reserved
Region Assignment
Region assignment is one of the pain pointsComplete overhaul of region assignmentBased on the internal “Procedure V2” frameworkSeries of operations are broken down into states
in State MachineState’s are serialized to durable storageUses a WAL on HDFSBackup master can recover the state from where
left off
20

21 © Hortonworks Inc. 2011 – 2017. All Rights Reserved
Async Client
A complete new client maintained in HBaseDifferent than OpenTSDB/asynchbaseFully async end to end Based on Netty and JDK-8 CompletableFuturesIncludes most critical functionality including
Admin / DDLSome advanced functionality (read replicas, etc)
are not done yetHave both sync and async client.
21

22 © Hortonworks Inc. 2011 – 2017. All Rights Reserved
Async Client

23 © Hortonworks Inc. 2011 – 2017. All Rights Reserved
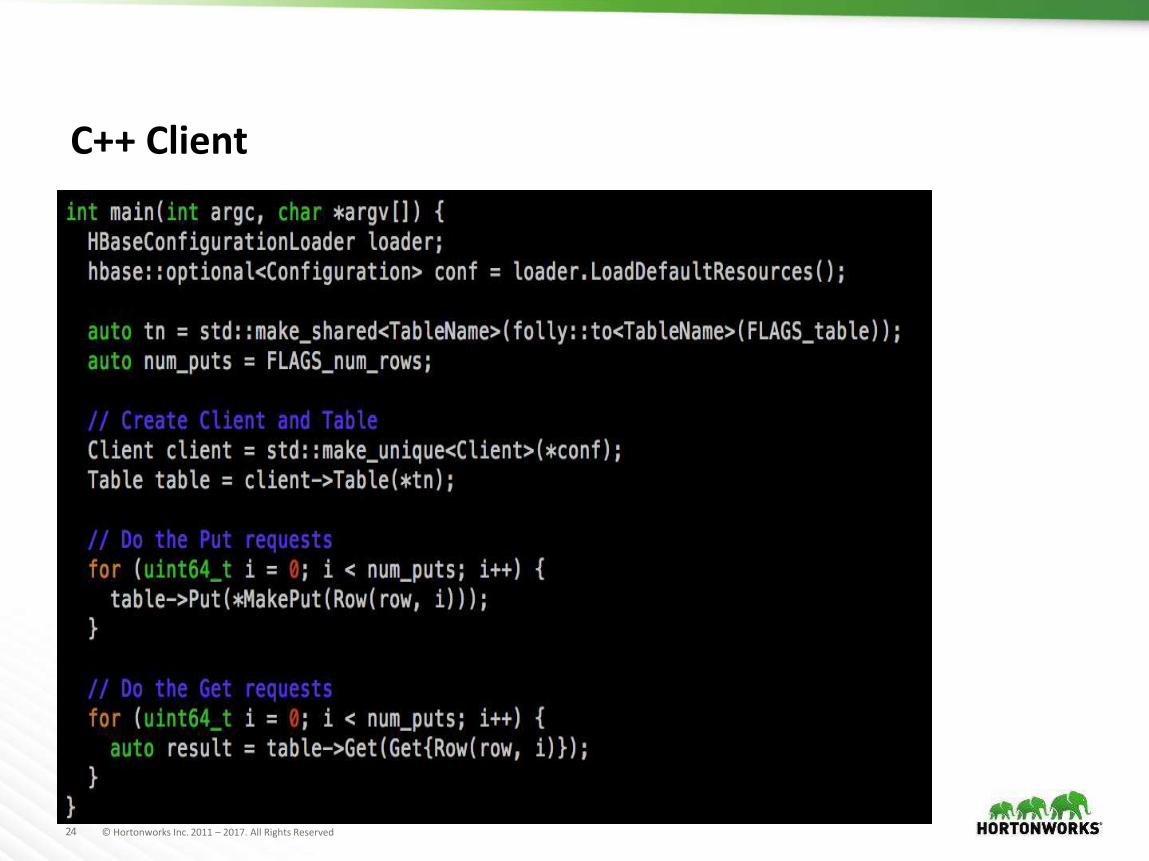
C++ Client
-std=c++14
Synchronous client built fully on async clientUses folly and wangle from FB (like Netty, JDK-8
Futures)Follow the same architecture as the async clientGets / Puts / Multi-Gets are working. Scan next
23
24 © Hortonworks Inc. 2011 – 2017. All Rights Reserved
C++ Client

25 © Hortonworks Inc. 2011 – 2017. All Rights Reserved
Backup / Restore
HBase needs a reliable backup / restore mechanism
Full backups and Incremental backupsBackup destination to a remote FSHDFS, S3, ADLS, WASB, and any Hadoop-
compatible FSFull backup based on “snapshots”Incremental backup ships Write-Ahead-LogsBackup + Replication are complimentary (for a full
DR solution)
25

26 © Hortonworks Inc. 2011 – 2017. All Rights Reserved
FileSystem Quotas
HBase supports quotasRequest count or size per sec,min,hour,day (per
server)Num tables / num regions in namespaceNew work enables quotas for disk space usageMaster periodically gathers info about disk space
usageRegionservers enforce limit when notified from
masterLimits per table or per namespace (not per user)Violation policy: {DISABLE,
NO_WRITES_COMPACTIONS, NO_WRITES, NO_INSERTS}
26

27 © Hortonworks Inc. 2011 – 2017. All Rights Reserved
Will be released for the first time
These will be released for the first time in Apache (although other backports exist)
Medium Object SupportRegion Server groups Favored Nodes enhancementsHBase-Spark moduleWAL’s and data files in separate FileSystems

28 © Hortonworks Inc. 2011 – 2017. All Rights Reserved
Misc
NettyRpcClientNettyRpcServerAPI CleanupReplication V2New metrics APIMetrics API for CoprocessorsTons of other improvements

29 © Hortonworks Inc. 2011 – 2017. All Rights Reserved
AgendaVersioning / Compatibility
Changes in Behavior
Major features in HBase 2.0
Phoenix 5.0
Recent Developments in Phoenix

30 © Hortonworks Inc. 2011 – 2017. All Rights Reserved
Apache Phoenix-5.0
Phoenix + Calcite introduction
Examples of How Calcite helps to optimize the queries.
Development is happening in a branch for more than a year
31 © Hortonworks Inc. 2011 – 2017. All Rights Reserved
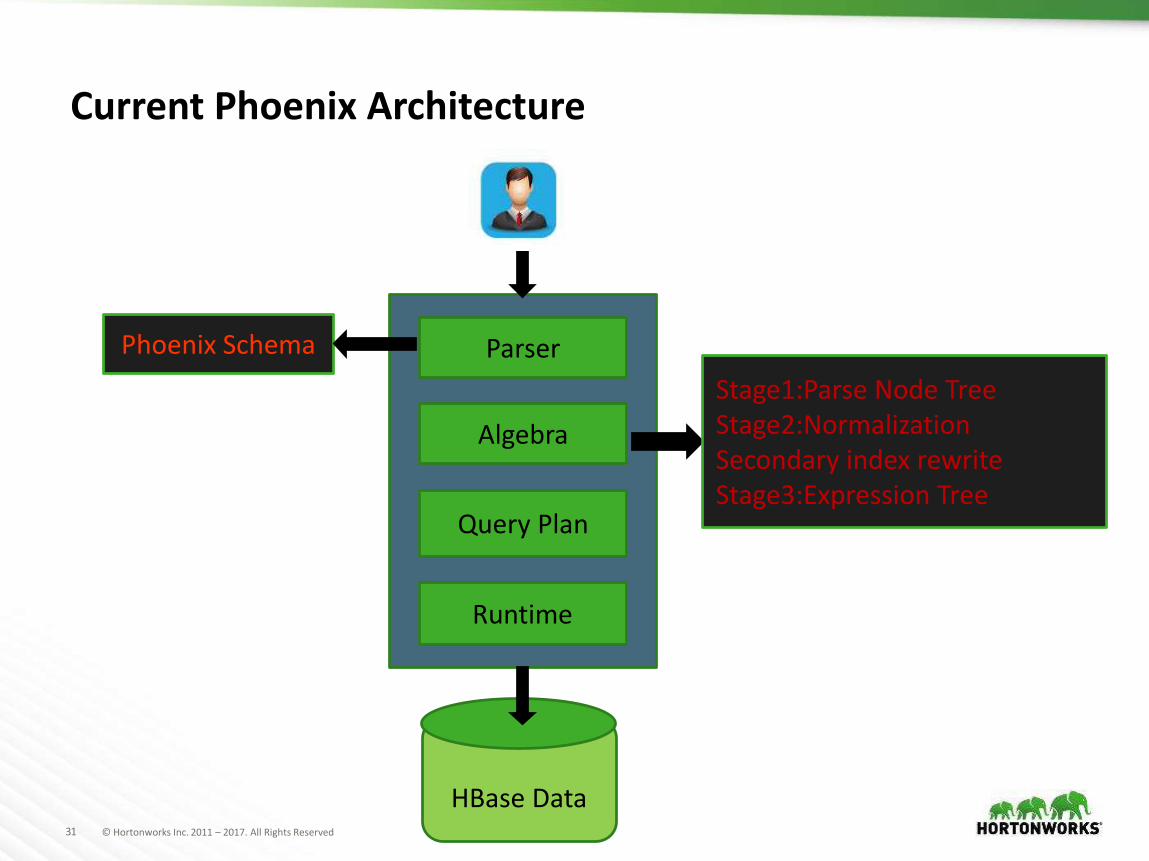
Current Phoenix Architecture
Parser
Algebra
Query Plan
Runtime
HBase Data
Stage1:Parse Node TreeStage2:Normalization Secondary index rewriteStage3:Expression Tree
Phoenix Schema
32 © Hortonworks Inc. 2011 – 2017. All Rights Reserved
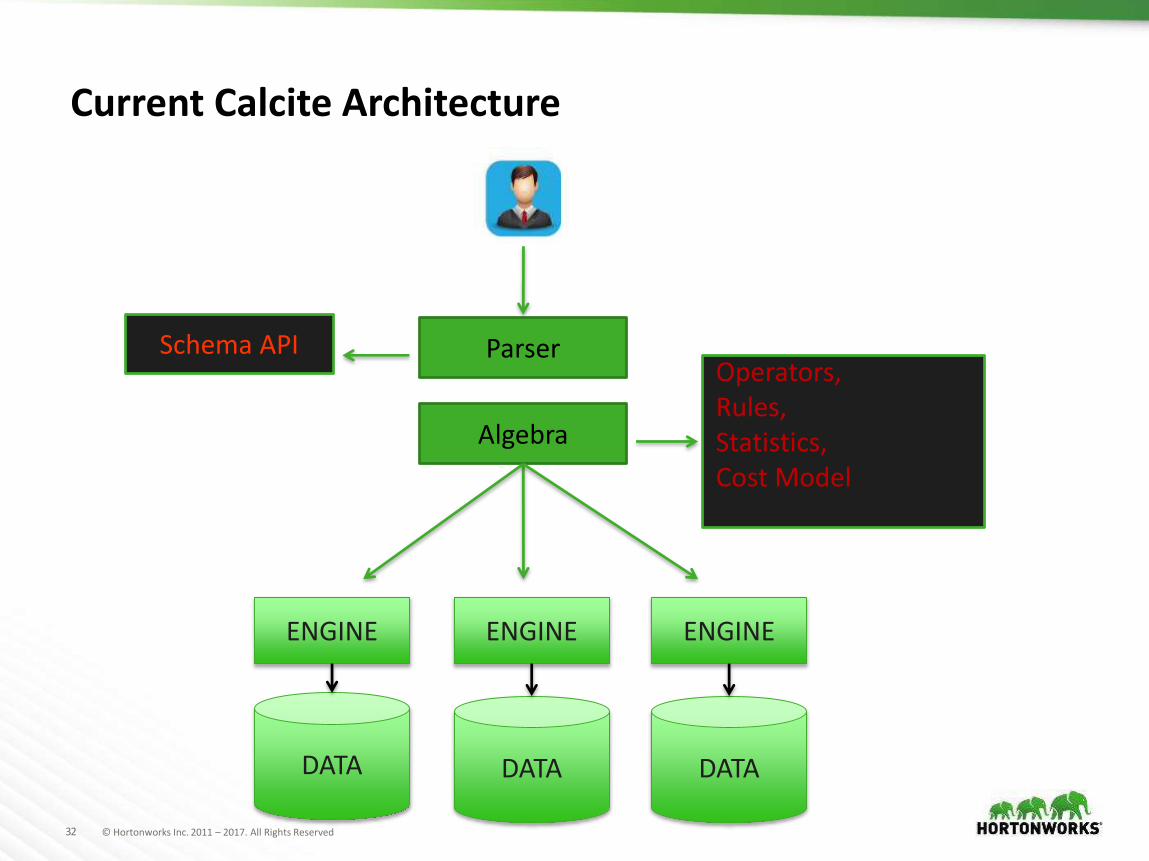
Current Calcite Architecture
Parser
Algebra
Operators,Rules,Statistics,Cost Model
Schema API
ENGINE
DATA
ENGINE
DATA
ENGINE
DATA

33 © Hortonworks Inc. 2011 – 2017. All Rights Reserved
Why calcite integration?
Phoenix query optimizer applies minimal static rules to decide the query plan and for selecting the tables to be used in the query.
But with calcite all query optimization decisions will be based on cost and query optimizations are modeled as pluggable rules
– Filter push down; range scan vs. skip scan– Hash aggregate vs. stream aggregate vs. partial stream aggregate– Sort optimized out; sort/limit push through; fwd/rev/unordered
scan– Hash join vs. merge join; join ordering– Use of data table vs. index table– All above (and many others) COMBINED
Can make use of Phoenix Statistics for cost based decisions
34 © Hortonworks Inc. 2011 – 2017. All Rights Reserved
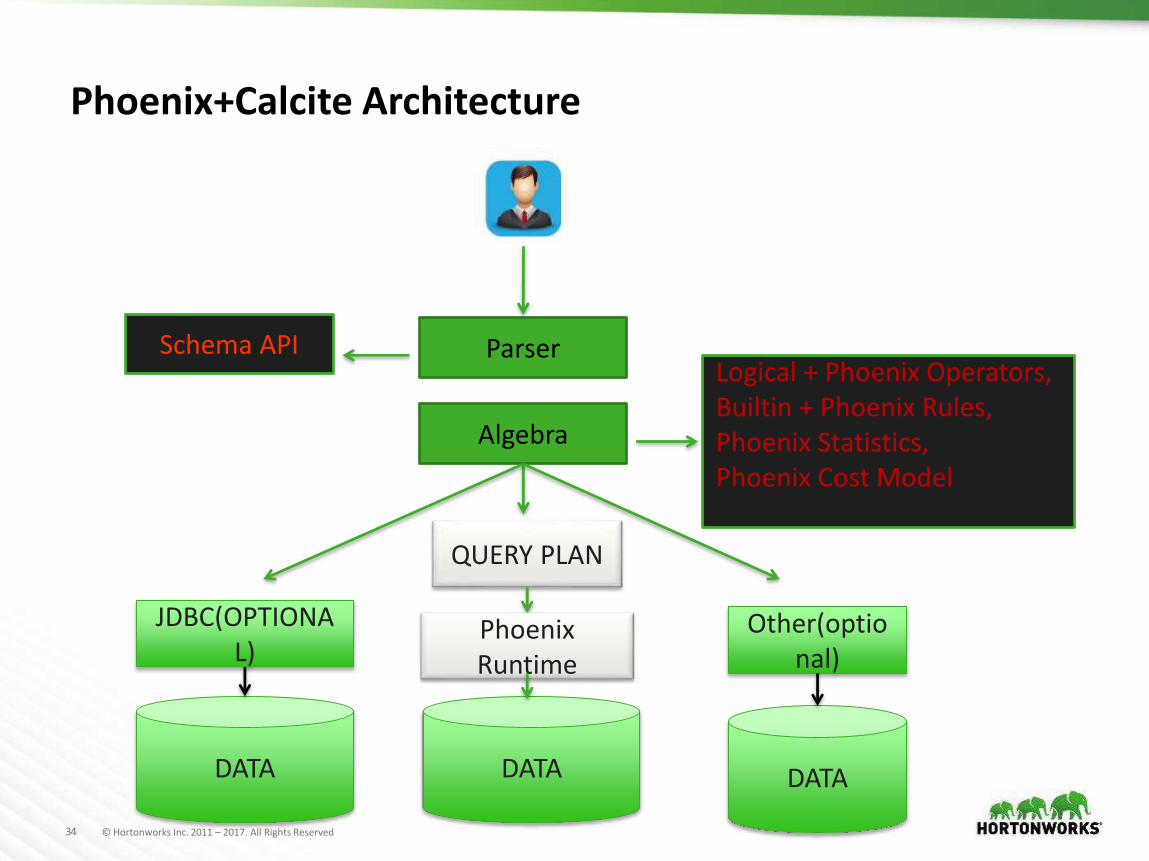
Phoenix+Calcite Architecture
Parser
Algebra
Logical + Phoenix Operators,Builtin + Phoenix Rules,Phoenix Statistics,Phoenix Cost Model
Schema API
JDBC(OPTIONAL)
DATA
QUERY PLAN
Other(optional)
DATADATA
Phoenix Runtime
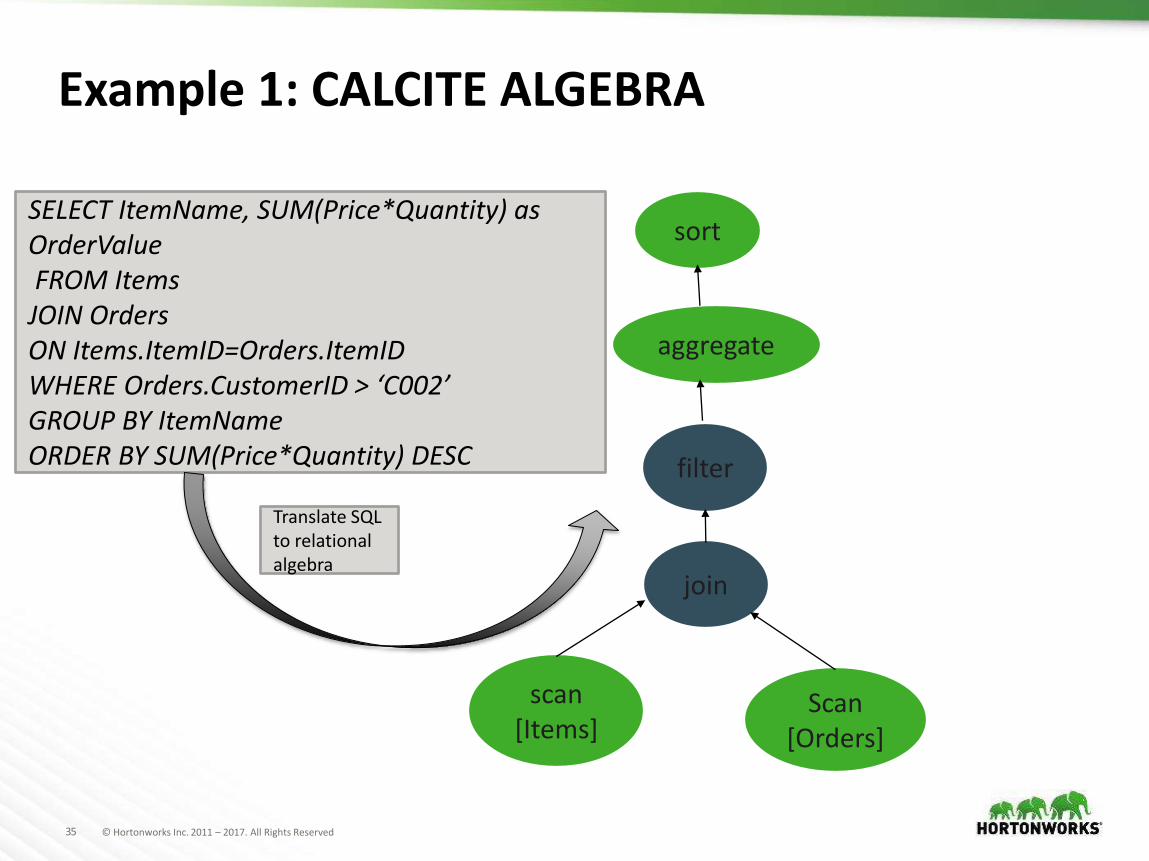
35 © Hortonworks Inc. 2011 – 2017. All Rights Reserved
SELECT ItemName, SUM(Price*Quantity) as OrderValueFROM Items
JOIN Orders ON Items.ItemID=Orders.ItemIDWHERE Orders.CustomerID > ‘C002’GROUP BY ItemNameORDER BY SUM(Price*Quantity) DESC
sort
aggregate
filter
join
scan[Items]
Scan[Orders]
Translate SQL to relational algebra
Example 1: CALCITE ALGEBRA
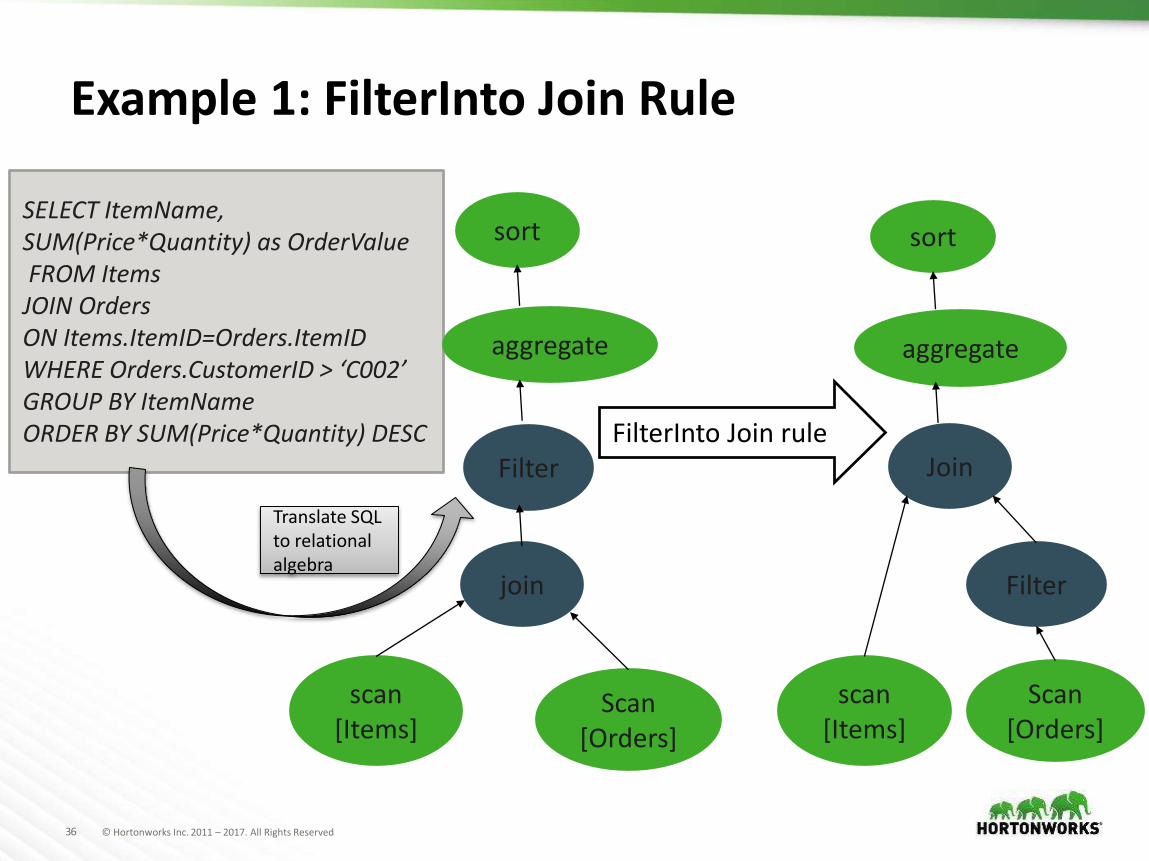
36 © Hortonworks Inc. 2011 – 2017. All Rights Reserved
Example 1: FilterInto Join Rule
SELECT ItemName, SUM(Price*Quantity) as OrderValueFROM ItemsJOIN Orders ON Items.ItemID=Orders.ItemIDWHERE Orders.CustomerID > ‘C002’GROUP BY ItemNameORDER BY SUM(Price*Quantity) DESC
sort sort
aggregate aggregate
Filter
Filterjoin
Join
scan[Items]
Scan[Orders]
scan[Items]
Scan[Orders]
FilterInto Join rule
Translate SQL to relational algebra
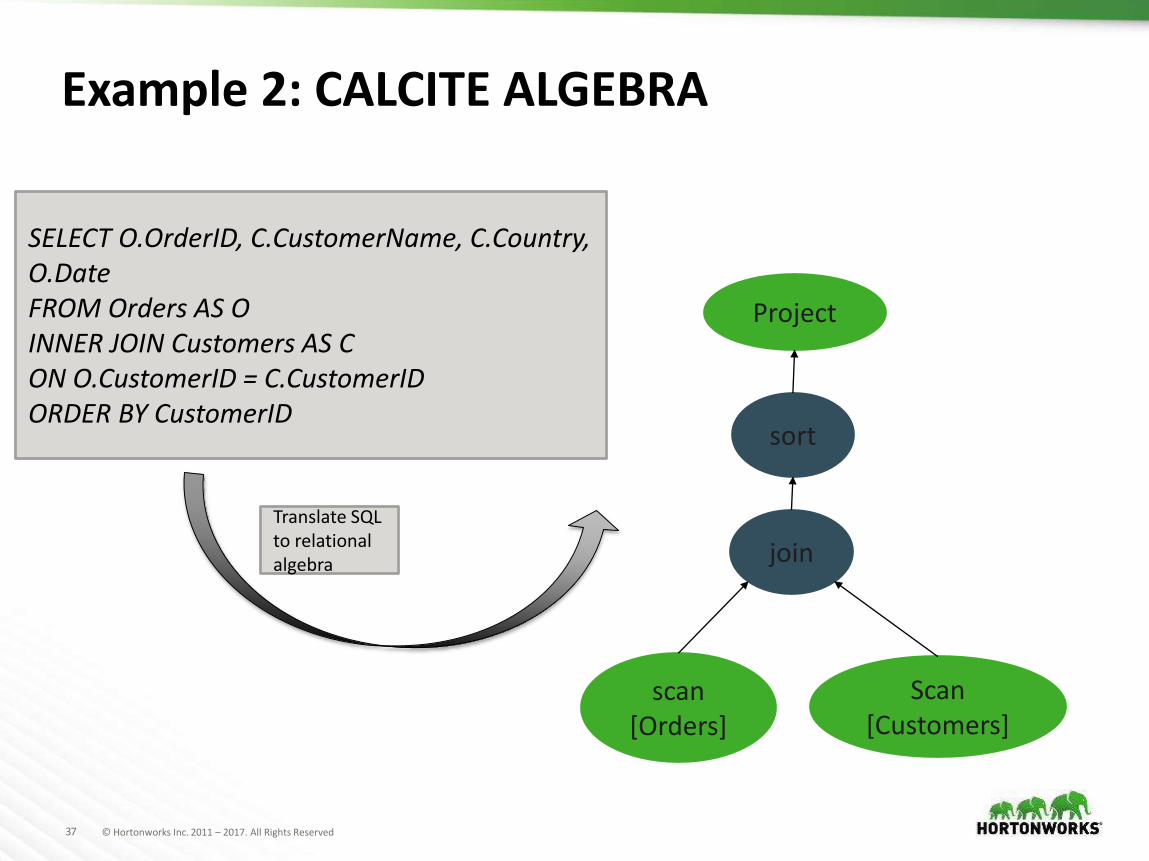
37 © Hortonworks Inc. 2011 – 2017. All Rights Reserved
SELECT O.OrderID, C.CustomerName, C.Country, O.DateFROM Orders AS OINNER JOIN Customers AS CON O.CustomerID = C.CustomerIDORDER BY CustomerID
Project
sort
join
scan[Orders]
Scan[Customers]
Translate SQL to relational algebra
Example 2: CALCITE ALGEBRA
38 © Hortonworks Inc. 2011 – 2017. All Rights Reserved
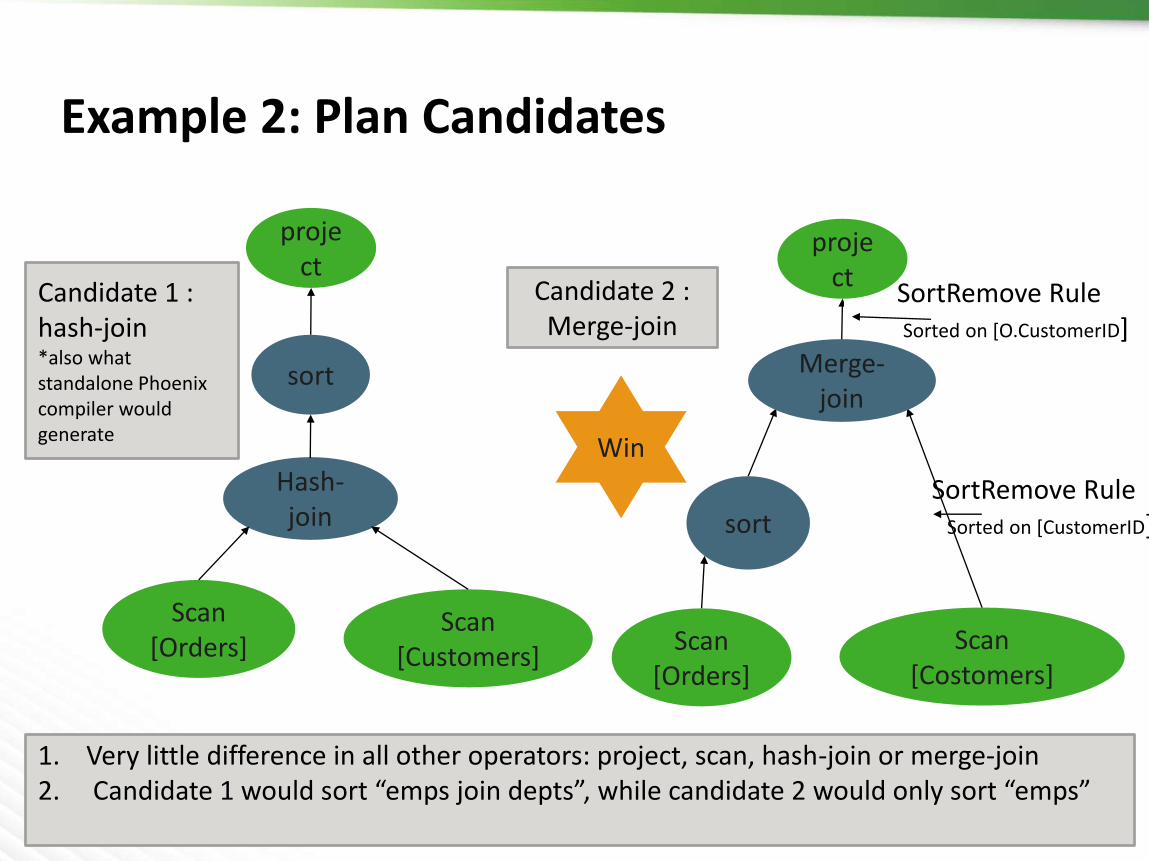
Example 2: Plan Candidates
project
sort
Hash-join
Scan[Orders]
Scan[Customers]
Candidate 1 : hash-join *also what standalone Phoenix compiler would generate
Candidate 2 :Merge-join
Win
sort
Scan[Orders]
Scan[Costomers]
SortRemove RuleSorted on [CustomerID]
SortRemove RuleSorted on [O.CustomerID]
1. Very little difference in all other operators: project, scan, hash-join or merge-join 2. Candidate 1 would sort “emps join depts”, while candidate 2 would only sort “emps”
project
Merge-join

39 © Hortonworks Inc. 2011 – 2017. All Rights Reserved
Advantages with Phoenix-Calcite integration
Strong SQL standard compliance Can make use of Calcite features like Window
functions, scalar subquery, FILTER etc.Interop with other Calcite adapters–Already used by Drill, Hive, Kylin, Samza, etc..–Supports any JDBC source
39

40 © Hortonworks Inc. 2011 – 2017. All Rights Reserved
Phoenix – Calcite Integration work status
We are working separate phoenix branch “calcite” for calcite integration work.
Making changes in calcite to support missing features like dynamic columns, ordered-set and hypothetical set aggregation functions etc.
Need to fix some issues in Phoenix Calcite integration as well
~70% test cases are passing.

41 © Hortonworks Inc. 2011 – 2017. All Rights Reserved
AgendaVersioning / Compatibility
Changes in Behavior
Major features in HBase 2.0
Phoenix 5.0
Recent Developments in Phoenix
42 © Hortonworks Inc. 2011 – 2017. All Rights Reserved
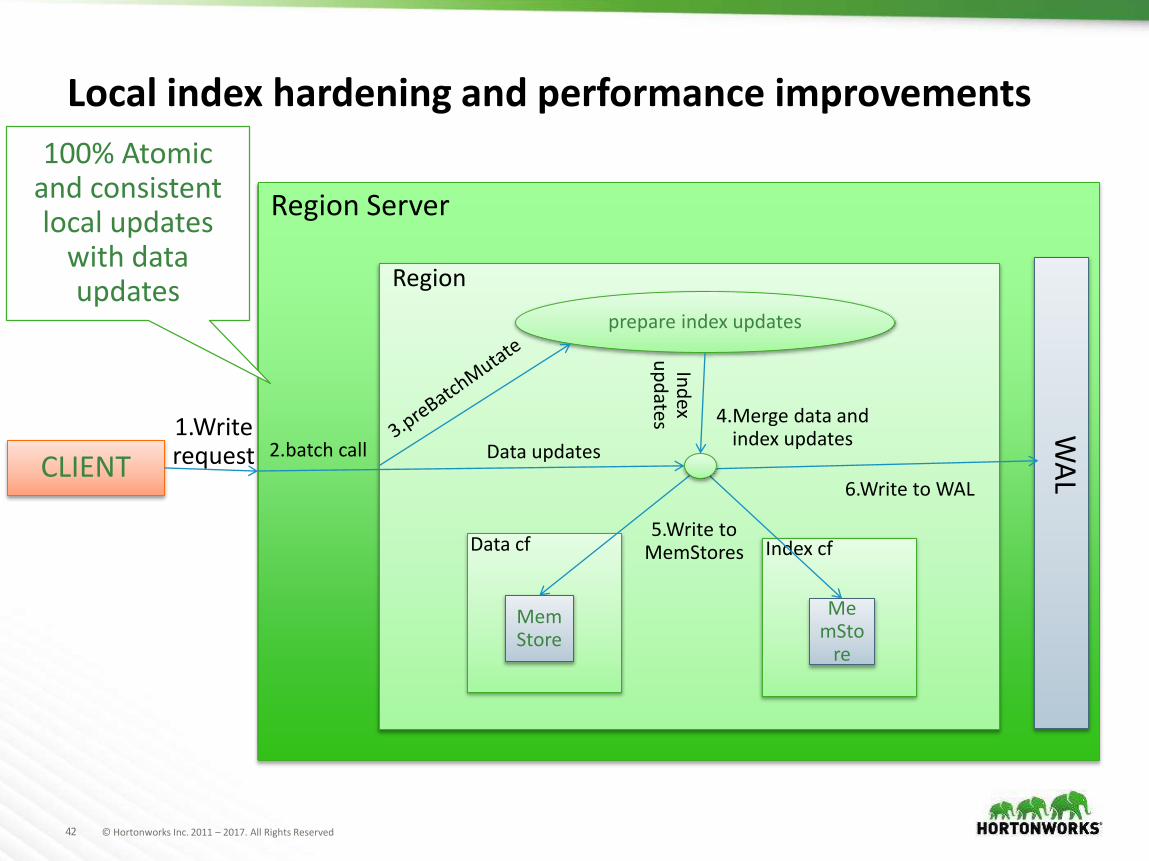
Local index hardening and performance improvements
Region Server
Region
CLIENT
1.Write request
prepare index updates
Data cf Index cf
2.batch call
MemStore
MemSto
re
Ind
ex u
pd
ates
Data updates
4.Merge data and index updates
5.Write to MemStores
WA
L
6.Write to WAL
100% Atomic and consistent local updates
with data updates
43 © Hortonworks Inc. 2011 – 2017. All Rights Reserved
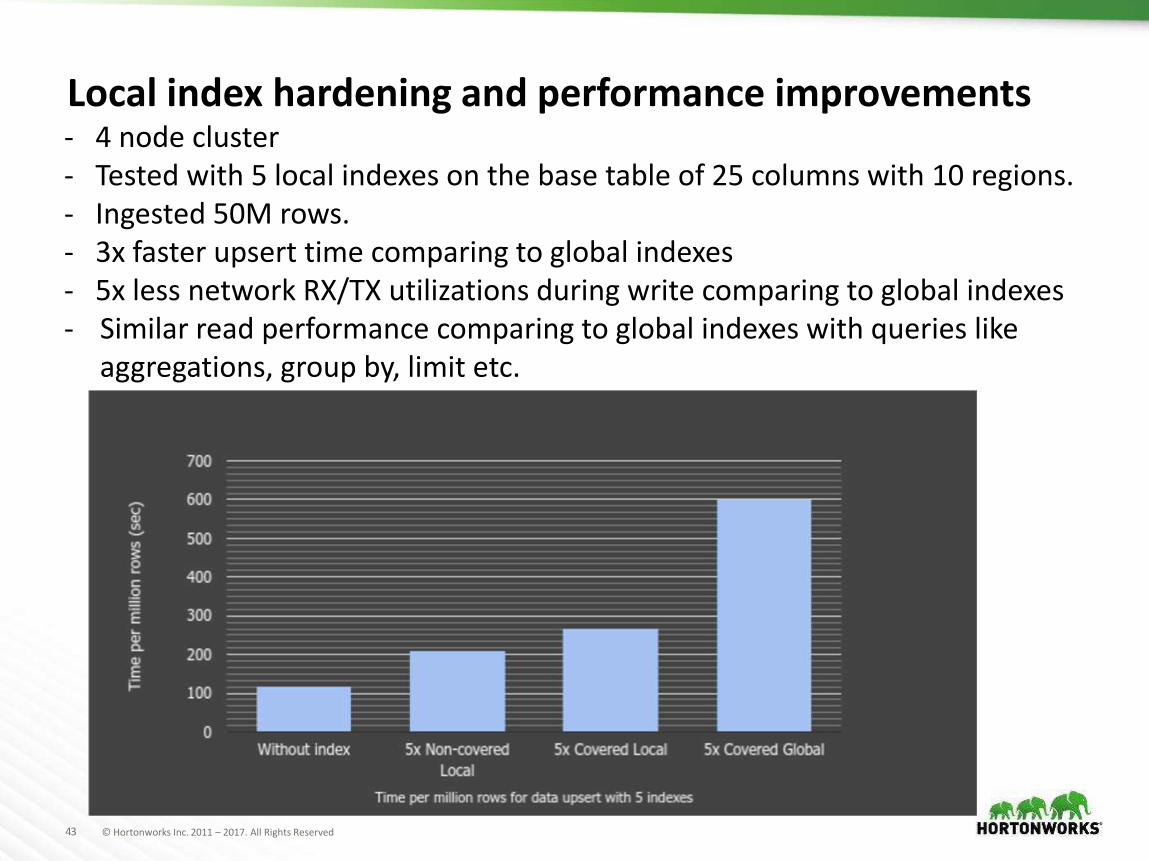
Local index hardening and performance improvements- 4 node cluster- Tested with 5 local indexes on the base table of 25 columns with 10 regions.- Ingested 50M rows.- 3x faster upsert time comparing to global indexes- 5x less network RX/TX utilizations during write comparing to global indexes- Similar read performance comparing to global indexes with queries like
aggregations, group by, limit etc.

44 © Hortonworks Inc. 2011 – 2017. All Rights Reserved
Column mapping and data encoding
Maps columns with numbers of variable size based on number of columns.
It helps to reduce disk space utilization ,makes easy alteration of column names and improve the performance.
Supporting a new encoding scheme for immutable tables that packs all the values into a single cell for column family.
Supported from Phoenix 4.10.0+
CREATE TABLE T( a_string varchar not null, col1 integer CONSTRAINT pk PRIMARY KEY (a_string) ) COLUMN_ENCODED_BYTES = 1;

45 © Hortonworks Inc. 2011 – 2017. All Rights Reserved
Apache Hive integration
Apache Phoenix supports Hive integration to access Phoenix Table data from HiveQL using Phoenix Storage Handler.
create <external> table phoenix_table (s1 string,i1 int,
)STORED BY
'org.apache.phoenix.hive.PhoenixStorageHandler'TBLPROPERTIES (
"phoenix.table.name" = "phoenix_table","phoenix.zookeeper.quorum" = "localhost","phoenix.zookeeper.znode.parent" = "/hbase","phoenix.zookeeper.client.port" = "2181","phoenix.rowkeys" = "s1","phoenix.column.mapping" = "s1:s1, i1:i1",
);
46 © Hortonworks Inc. 2011 – 2017. All Rights Reserved
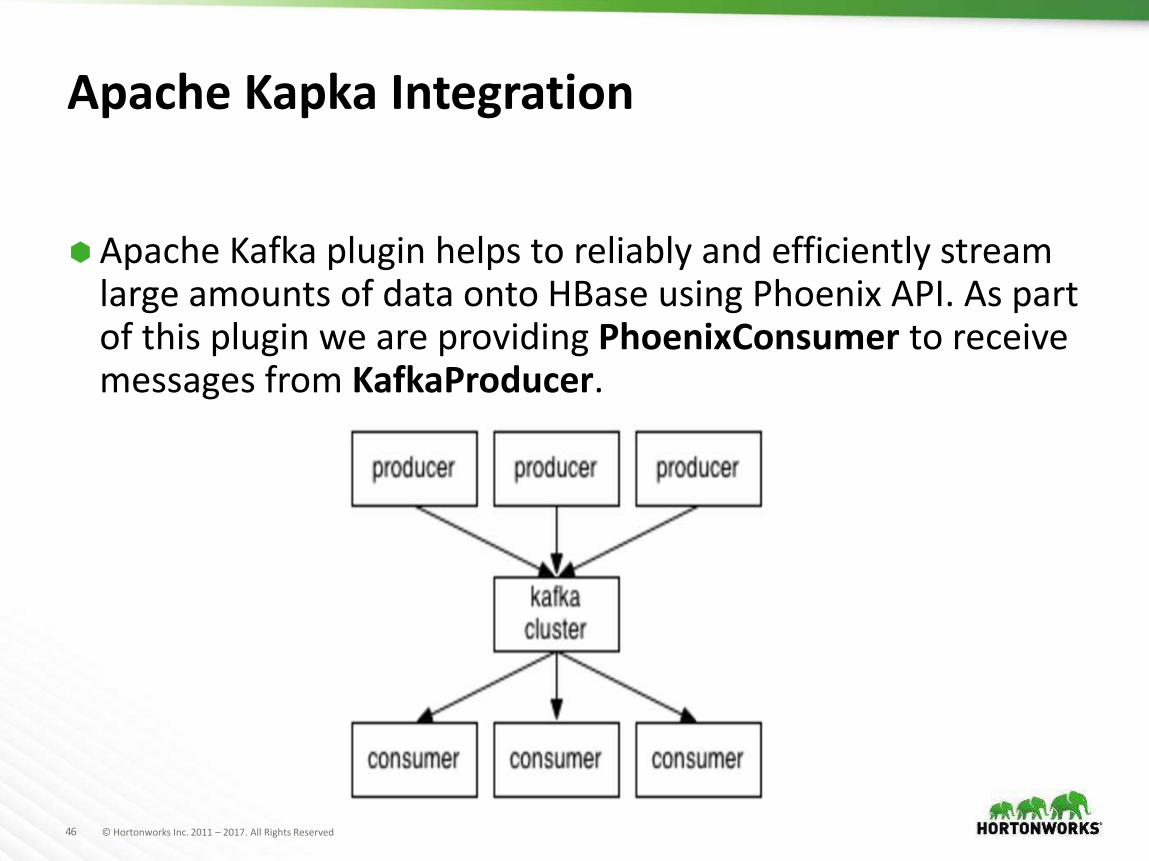
Apache Kapka Integration
Apache Kafka plugin helps to reliably and efficiently stream large amounts of data onto HBase using Phoenix API. As part of this plugin we are providing PhoenixConsumer to receive messages from KafkaProducer.

47 © Hortonworks Inc. 2011 – 2017. All Rights Reserved
Misc
Use Hbase snapshorts for MR Based queries and async index building – 4.11.0
Support for forward-only cursors – 4.11.0
Integration with spark 2.0 – 4.10.0
Support for HBase 1.3.1+ - 4.11.0
Server side upsert select – 4.10.0
Omid transactions Integration – IN PROGRESS

48 © Hortonworks Inc. 2011 – 2017. All Rights Reserved
Thank You
Q & A?




























