Embed Size (px)
Citation preview

第二回IoT関連技術勉強会ログ収集編
田実 誠

• ログ収集に関する知識• なぜログデータを収集するのか?• リアルタイム vs バッチ• ログ収集に関する課題
• Fluentd• Embulk• まとめ
アジェンダ

なぜログデータを収集するのか?• Webサービスにおける各イベント(アクセスした、ログインした、APIを叩いた、ページを離脱した、、、等)の情報が集められている• アクセスログ(Google Analytics、Apache/Nginx)• 購買履歴• アクティビティログ(ユーザの行動履歴)• クリックレート、コンバージョンレート
• 各イベント情報が入っているログを分析して新しい知見を得たい• サービス内容の改善(UI/UX、コンテンツのニーズ、仮説検証)• パフォーマンスの改善(レスポンス時間)
• アクセスのリアルタイムなモニタリング• システム障害の改善(障害検知、死活監視)• 不正なアクセスのブロック(Firewall的な役割)

リアルタイム vs バッチ
リアルタイム(ストリーム)• 少量データを逐次転送
※ストリーミング処理とか聞いたときは、リアルタイムにデータを処理している、と理解すればOK
バッチ• 任意の時間に起動• 大量データを一括転送

ログ収集に関する一般的な課題
• データの入力/出力方式がシステムによって様々• データフォーマット• 通信プロトコル
• ネットワーク/サーバ等の障害発生時のリカバリーの検討(リトライ処理等)
• データ量が増えた場合のスケーラビリティの検討(システムの柔軟性)
• リアルタイムで分析したい

Fluentd• ストリーム(リアルタイム)なログコレクタ(転送・集約)※ログ用のETL• C+RubyなOSS• Pluggable• シンプルな設定ファイル(Apacheに似ている)• Bufferingによる信頼性、Retry処理• 柔軟なシステム構成• TreasureDataが担っているOSS
出典: http://www.fluentd.org/architecture

Pluggable• プラグインをインストールするだけで、任意のプロトコル/ソフトウェアに対して入出力可能になる。• プラグイン自体もOSSなので、自由に利用・公開できる。→最近良く聞くエコシステムってやつ ※ちなみにSalesforceのpluginもあるよ
出典: http://www.fluentd.org/architecture

柔軟なシステム構成Aggregatorを介した多段構成(出力先を柔軟に変更可能)
キューを介したスケールするシステム構成
出典: http://repeatedly.github.io/ja/2014/07/fluentd-and-log-forwarding-patterns/
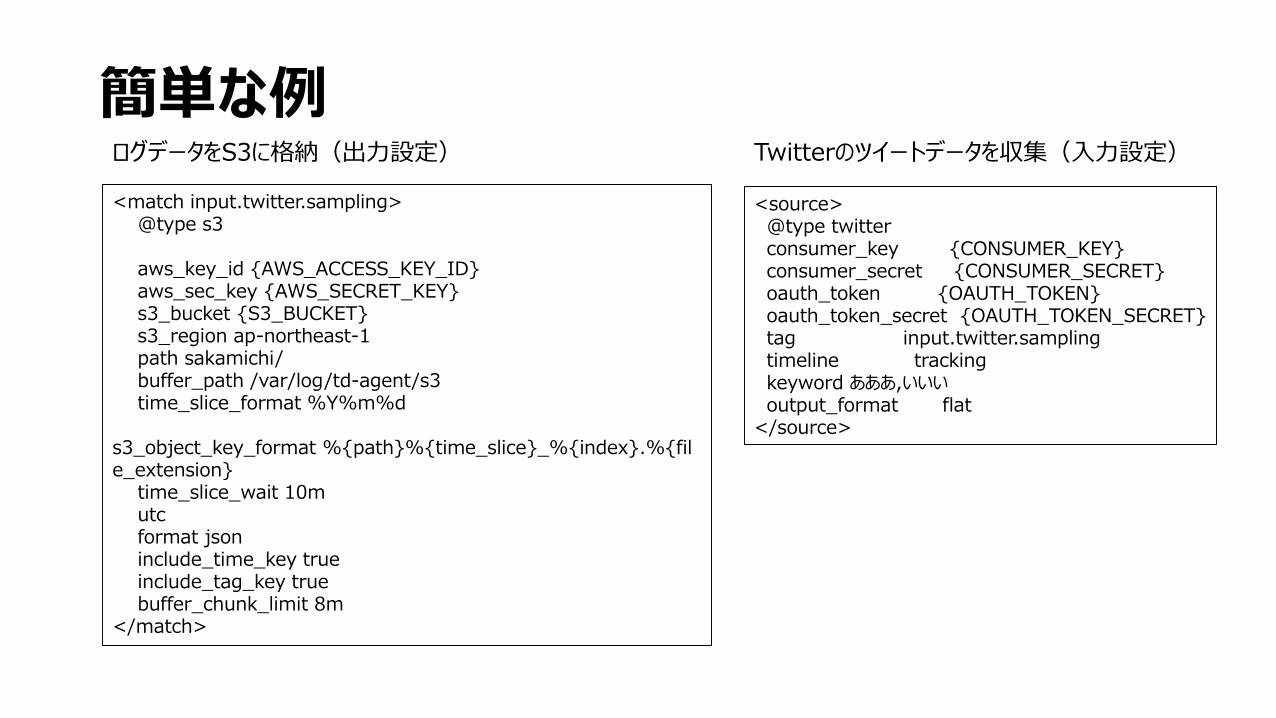
簡単な例ログデータをS3に格納(出力設定) Twitterのツイートデータを収集(入力設定)
<source>@type twitterconsumer_key {CONSUMER_KEY}consumer_secret {CONSUMER_SECRET}oauth_token {OAUTH_TOKEN}oauth_token_secret {OAUTH_TOKEN_SECRET}tag input.twitter.samplingtimeline trackingkeyword あああ,いいいoutput_format flat
</source>
<match input.twitter.sampling>@type s3
aws_key_id {AWS_ACCESS_KEY_ID}aws_sec_key {AWS_SECRET_KEY}s3_bucket {S3_BUCKET}s3_region ap-northeast-1path sakamichi/buffer_path /var/log/td-agent/s3time_slice_format %Y%m%d
s3_object_key_format %{path}%{time_slice}_%{index}.%{file_extension}
time_slice_wait 10mutcformat jsoninclude_time_key trueinclude_tag_key truebuffer_chunk_limit 8m
</match>

• プラガブルなので、さまざまなソースからのイベントをさまざまな媒体に出力できる
• ログの内容がJSON(MessagePack)形式で扱いやすい
fluentd vs syslogd
syslog(rsyslog)• サービスがログを記録するための規格、プログラム• ログの入出力を制御可能(Facility/Severity)• ネットワーク転送して別のサーバにログを集約可能

• Exactly Onceなデータ転送• 欠損も重複も一切ダメ→ストリーム処理でExactly Onceを保証するのは難しい(らしい)
ただし、大抵はExactly Onceでなくても上手くいく(らしい)↓http://docs.fluentd.org/articles/high-availability
• 負荷のかかるフィルタリング(fluentd自体がマルチプロセス対応しそうなので、それを待てば良い?)
• モニタリング(死活監視)→プラグインにZabbix, Nagios, Norikra等あるので、そちらに流し込んでモニタリングする。fluentdはデータのハブとして利用する。
Fluentdが適していないもの

• Fluentdのバッチ版
• 並列処理をすることで高速なアップロードを実現
• Fluentd同様プラガブルなアーキテクチャ→Salesforceのプラグインもあるよ
• リトライ/エラーハンドリング→利用するプラグインに依存するけど…
• 設定ファイルをある程度自動的に作成してくれる仕組み(guess)
• TreasureDataが担っているOSS
Embulk
バッチ実行は $ embulk run config.yml を叩くだけ!

Embulkの設定例in:
type: s3bucket: {backet_name}path_prefix: sakamichi/2016/05/01endpoint: s3-ap-northeast-1.amazonaws.comaccess_key_id:{AWS_ACCESS_KEY_ID}secret_access_key: {AWS_SECRET_ACCESS_KEY}decoders:- {type: gzip}parser:
type: jsonlcharset: UTF-8newline: CRLFcolumns:- {name: id_str, type: string}- {name: text, type: string- {name: favorited, type: boolean}
filters:- type: typecast
columns:- {name: timestamp_ms, type: long}
out:type: tdapikey: {TREASURE_DATA_API_KEY}endpoint: api.treasuredata.comdatabase: test_sakamichitable: testtime_column: timestamp_msunix_timestamp_unit: milli

• Fluentd/Embulkはログデータのデータ転送/集約系のOSSである
• Fluentdはリアルタイム、Embulkはバッチ
• どちらもプラガブルなアーキテクチャでエコシステムを形成→開発者はプラグインを作る or エンハンスしていきましょう!
まとめ

• Fluentの概要http://www.slideshare.net/treasure-data/the-basics-of-fluentd-35681111
• Fluentdのデザインパターンhttp://www.slideshare.net/y-ken/fluentd-system-design-patternhttp://repeatedly.github.io/ja/2014/07/fluentd-and-log-forwarding-patterns/
• AWS Summit 2016で登壇されていたcookpadさんの資料https://speakerdeck.com/kanny/miao-jian-shu-mo-falseroguwoiigan-zinisuruakitekutiya
• Embulkの概要http://www.slideshare.net/frsyuki/embuk-making-data-integration-works-relaxed
参考URL

























![[Black Belt Online Seminar] AWS上でのログ管理](https://img.dokumen.tips/doc/110x75/586fd3f61a28ab18428b46c1/black-belt-online-seminar-aws-5925463aa589a.jpg)



