Embed Size (px)
Citation preview

Big Data & Machine Learning MindsLab Co., Ltd.
i-VOC 제품소개서
2015. 06
www.mindsinsight.co.kr
2
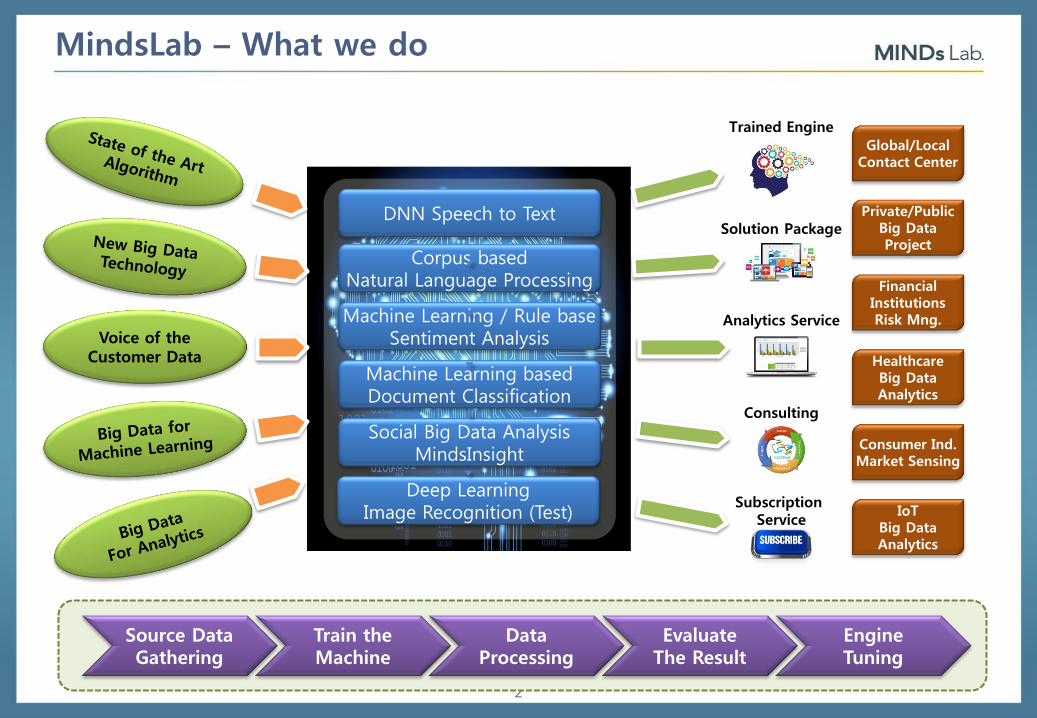
MindsLab – What we do
DNN Speech to Text
Corpus based Natural Language Processing
Machine Learning / Rule base Sentiment Analysis
Machine Learning based Document Classification
Social Big Data Analysis MindsInsight
Deep Learning Image Recognition (Test)
Voice of the Customer Data
Source Data Gathering
Train the Machine
Data Processing
Evaluate The Result
Engine Tuning
Trained Engine
Solution Package
Analytics Service
Consulting
Subscription Service
Global/Local Contact Center
Private/Public Big Data Project
Financial Institutions Risk Mng.
Healthcare Big Data Analytics
Consumer Ind. Market Sensing
IoT Big Data Analytics

3
i-VOC Application Architecture
원천 데이터 수집 음성인식/ 텍스트 분석/ 소셜분석 모델링 / 활용 결과데이터 구조화 시각화
내부 VOC 분석 기업내부
기업외부
인터넷 상담
상담 메모
서신 민원
…
금감원/ 소비자원 민원
뉴스
블로그
트위터
페이스북
…
언어분석 텍스트마이닝
문장분리
형태소분석
개체명인식
구문분석
문서 자동요약/군집
문서 자동 분류
패턴 / 통계 분석
키워드/연관어 분석
감성/고불만 분석
고객이탈 방지
리스크 관리
고객 Segmentation
서비스 개선
신규고객 발굴
잠재VIP 고객 발굴
신상품 개발
…
Document
Sentiment
Keyword
Taxonomy
Analyzed VOC Data
관리도구
페이스북 리포팅
전화 상담
언어분석 텍스트마이닝
문장분리
형태소분석
개체명인식
구문분석
감성 분석
이슈 군집분석
어휘 중요도 분석
연관어 분석
외부 VOC 분석
Market Intelligence
활용 목적 정의
분석 관점/키워드 정의
데이터 수집/검증
사전 관리 Taxonomy 관리 운영 관리
Fan Post Interaction ER …
Power User
활용 목적 정의
End User
관점/키워드 검토
시각화 요소 검토
시각화 구현
대시보드 구성
모니터링
예측
경보
…
Document
Sentiment
Keyword
Taxonomy
Analysis Model
Internal Structured Data
활용목적 別 정제 VOC
Data Analyzed
Data Feeding
Raw Data Feeding
이벤트/리스크 분석
음성인식 학습데이터 준비
음성/언어모델 학습
Full-text Dictation
Keyword Spotting
음성인식
Real-time Recognition
Batch Recognition

4
i-VOC – Module 구성
MODULE A 음성분석 (Voice
Analytics)
MODULE B 텍스트분석
(Text Analytics)
MODULE E 결과데이터
구조화 (Result Data
Set)
MODULE C
소셜분석 (MINDs Insight)
MODULE D
산업별분석 (Market Insight)
MODULE X (관리도구)
MODULE F 데이터 시각화
(Data Visualization)
어휘중요도분석 / 이슈 군집분석 뺀다
Customer Intelligence
Market Intelligence
원천 데이터 수집
음성인식/ 텍스트 분석/ 소셜분석 모델링 / 활용 결과데이터
구조화 시각화
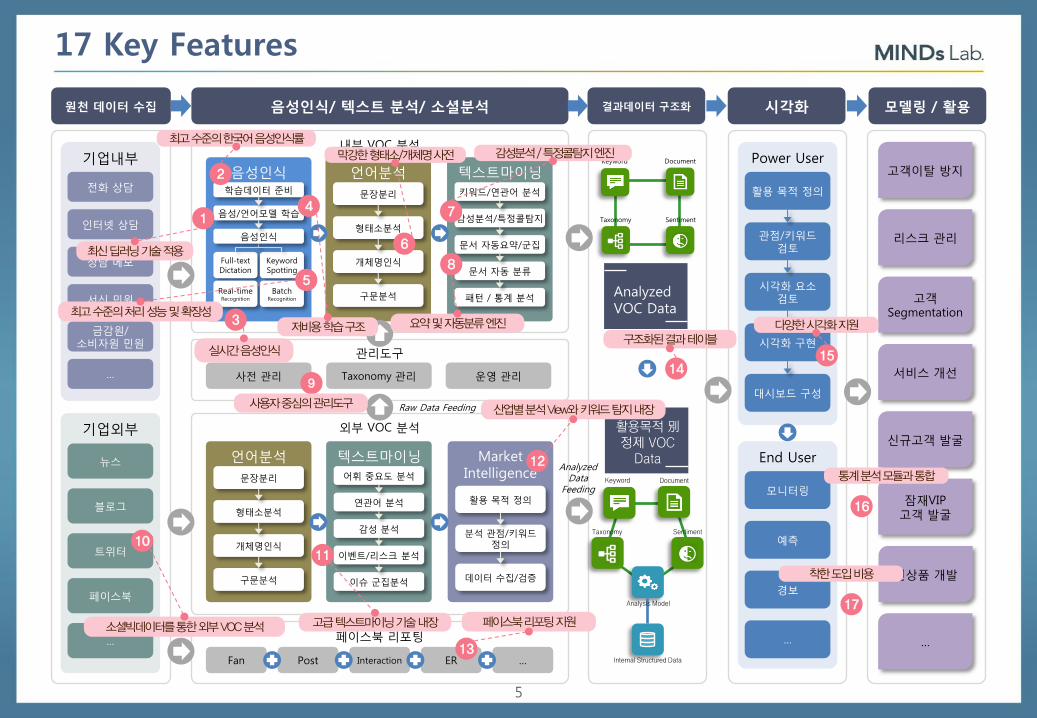
5
17 Key Features
원천 데이터 수집 음성인식/ 텍스트 분석/ 소셜분석 모델링 / 활용 결과데이터 구조화 시각화
내부 VOC 분석 기업내부
기업외부
인터넷 상담
상담 메모
서신 민원
…
금감원/ 소비자원 민원
뉴스
블로그
트위터
페이스북
…
언어분석 텍스트마이닝
문장분리
형태소분석
개체명인식
구문분석
문서 자동요약/군집
문서 자동 분류
패턴 / 통계 분석
키워드/연관어 분석
감성분석/특정콜탐지
고객이탈 방지
리스크 관리
고객 Segmentation
서비스 개선
신규고객 발굴
잠재VIP 고객 발굴
신상품 개발
…
Document
Sentiment
Keyword
Taxonomy
Analyzed VOC Data
관리도구
페이스북 리포팅
전화 상담
언어분석 텍스트마이닝
문장분리
형태소분석
개체명인식
구문분석
감성 분석
이슈 군집분석
어휘 중요도 분석
연관어 분석
외부 VOC 분석
Market Intelligence
활용 목적 정의
분석 관점/키워드 정의
데이터 수집/검증
사전 관리 Taxonomy 관리 운영 관리
Fan Post Interaction ER …
Power User
활용 목적 정의
End User
관점/키워드 검토
시각화 요소 검토
시각화 구현
대시보드 구성
모니터링
예측
경보
…
Document
Sentiment
Keyword
Taxonomy
Analysis Model
Internal Structured Data
활용목적 別 정제 VOC
Data Analyzed
Data Feeding
Raw Data Feeding
이벤트/리스크 분석
음성인식 학습데이터 준비
음성/언어모델 학습
Full-text Dictation
Keyword Spotting
음성인식
Real-time Recognition
Batch Recognition
1
2
3
4
5
6
7
8
9
12
10 11
13
14 15
16
17

Module A 음성인식엔진
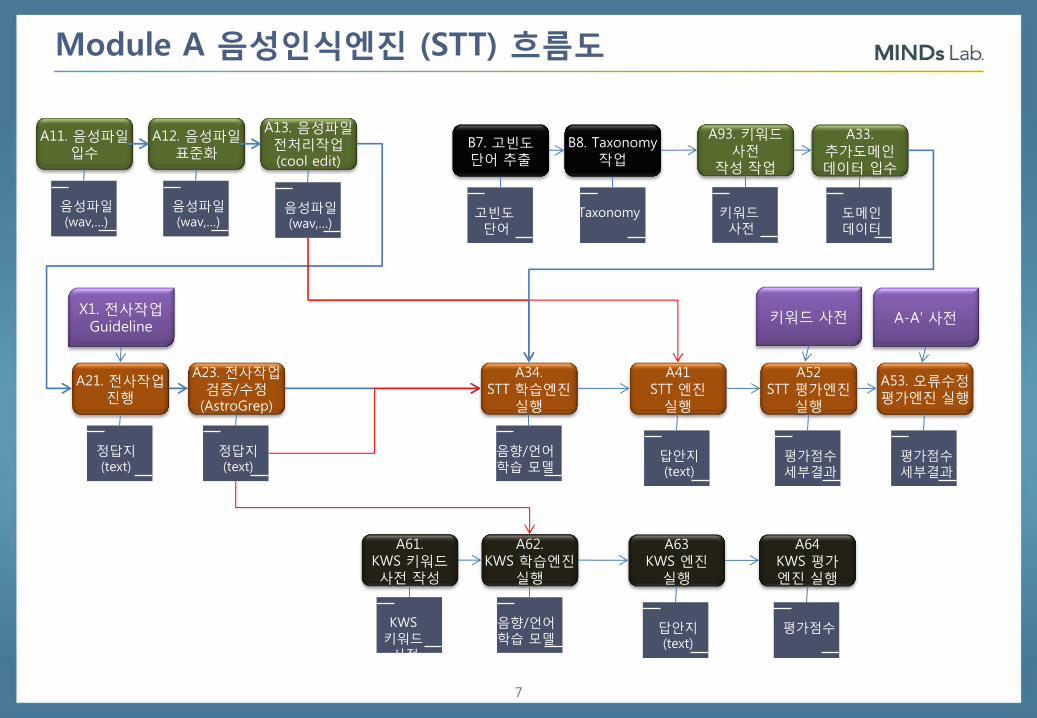
7
Module A 음성인식엔진 (STT) 흐름도
음성파일 (wav,…)
A11. 음성파일 입수
음성파일 (wav,…)
A12. 음성파일 표준화
음성파일 (wav,…)
A13. 음성파일 전처리작업 (cool edit)
정답지 (text)
A21. 전사작업 진행
X1. 전사작업 Guideline
정답지 (text)
A23. 전사작업 검증/수정
(AstroGrep)
음향/언어 학습 모델
A34. STT 학습엔진
실행
답안지 (text)
A41 STT 엔진
실행
평가점수 세부결과
A52 STT 평가엔진
실행
A-A’ 사전 키워드 사전
평가점수 세부결과
A53. 오류수정 평가엔진 실행
도메인 데이터
A33. 추가도메인 데이터 입수
키워드 사전
A93. 키워드 사전
작성 작업
고빈도 단어
B7. 고빈도 단어 추출
Taxonomy
B8. Taxonomy 작업
KWS 키워드 사전
A61. KWS 키워드 사전 작성
음향/언어 학습 모델
A62. KWS 학습엔진
실행
답안지 (text)
A63 KWS 엔진
실행
평가점수
A64 KWS 평가 엔진 실행
8
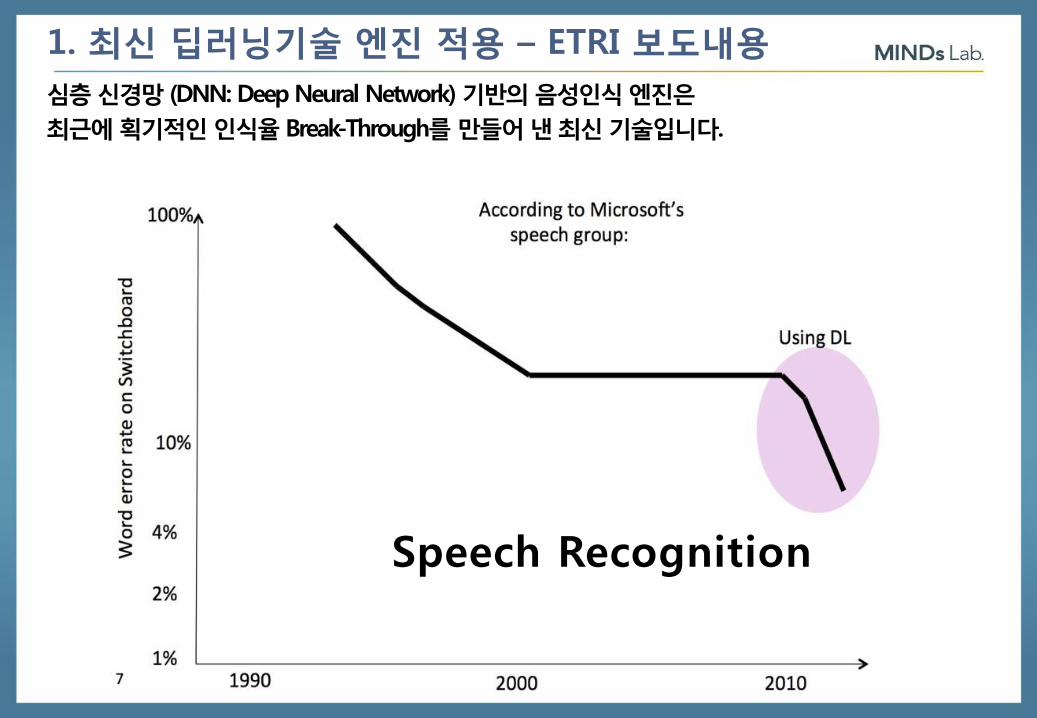
1. 최신 딥러닝기술 엔진 적용 – ETRI 보도내용
심층 신경망 (DNN: Deep Neural Network) 기반의 음성인식 엔진은
최근에 획기적인 인식율 Break-Through를 만들어 낸 최신 기술입니다.
Speech Recognition

9
1. 최신 딥러닝기술 엔진 적용 – 참고
Deep Learning 기술은 인간의 뇌 구조와 유사한 형태의 학습을 통해 인공지능을 구축하는 기술
Deep Learning 기술은 Gartner 2014년 세계 IT 시장 10대 주요 예측 기술
국내외 주요 음성 인식 엔진에 Deep Learning 기반 엔진 채택
• Google 안드로이드 OS 4.1인 Jelly Bean의 음성검색 서비스에 DNN을 적용
• Microsoft Bing 음성검색에 DNN 적용
• Naver는 네이버 Deep Learning 랩을 통해 음성 인식을 테스트하는 한편 뉴스 요
약 서비스, 이미지 분석 등에 Deep Learning 알고리즘을 적용
• 국내 K카드사는 최근 ETRI 음성인식 엔진을 도입하여 콜센터 상담업무 관련 시스
템 오픈

10
1. 최신 딥러닝기술 엔진 적용 – ETRI 보도내용
심층 신경망 (DNN: Deep Neural Network) 및 고속잡음처리 기술 등이 적용된 Deep Learning 기반
한국전자통신연구원(ETRI) 음성인식 엔진이 콜센터 녹취 환경에 최적화되어 개발됨
콜센터 녹취 환경에 최적화된 음성인식 성능 제공…
미국 및 이스라엘의 외산 기술과의 비교 테스트에서 10% 이상 우수한 성능을 나타내…
확실한 기술 우위를 확보하기 위해 심층 신경망 및 고성능 잡음처리기술 등을 지속적..

11
1. 최신 딥러닝기술 엔진 적용 – 엔진 인식률 ( 국산 vs 외산 )
한국어 인식률은 국산 엔진이 약 8% 정도 높고 유지보수도 용이
구 분 국산 엔진
(ETRI) 외산 엔진
한국어 인식률
84.7% 76.8%
유지보수 비용
정기 엔진 업데이트
(국책사업 지원)
라이선스료 고가
(다국어 지원)
개인정보 보안
• 정보통신망법 준수
• 개인정보보호법 준수
• 정보암호화 별도 필요
• Upgrade시 정보 유출
기술 지원속도
• 기술진 국내 거주
• 빠른 지원과 협의 원활
• 기술진 해외본사 거주
• 문제 발생시 해결 지연
적용 사례
지니톡
(국산 자동통역 앱)
SIRI
(휴대폰 음성 개인 도우미)
(기준 : 2014.12, 음절 인식률 , 제3의 평가기관)
자연어 음성인식 성능평가 결과
12
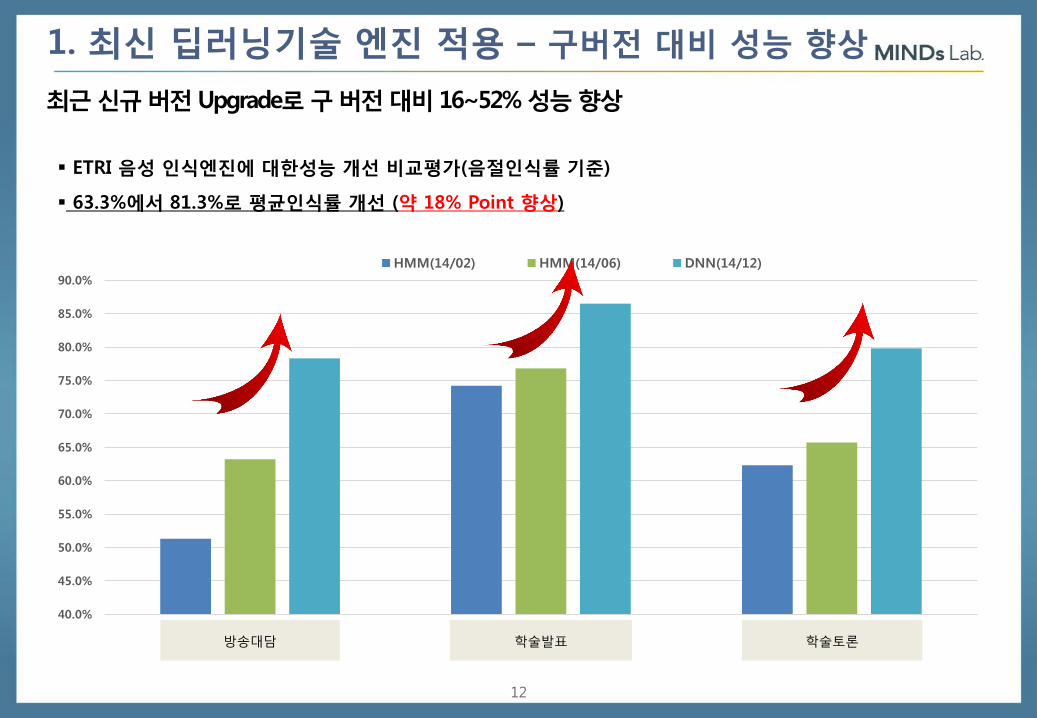
1. 최신 딥러닝기술 엔진 적용 – 구버전 대비 성능 향상
최근 신규 버전 Upgrade로 구 버전 대비 16~52% 성능 향상
40.0%
45.0%
50.0%
55.0%
60.0%
65.0%
70.0%
75.0%
80.0%
85.0%
90.0%
SponBroadCast SponPresentation SponDebate
HMM(14/02) HMM(14/06) DNN(14/12)
방송대담 학술발표 학술토론
ETRI 음성 인식엔진에 대한성능 개선 비교평가(음절인식률 기준)
63.3%에서 81.3%로 평균인식률 개선 (약 18% Point 향상)

13
ETRI는 6개월에 한번씩 정기 Upgrade (年 2회)를 통해서 State of the Art를 지켜가고 있습니다.
ETRI 음성처리연구실의 음성인식엔진 개발 Roadmap에 따라 年 2회 정기적 업그레이드가 이루어짐
2015년에 추가적인 학습 및 인식 최적화,
잡음처리 개선 진행 예정
2014.06 2014.12 2015.06 2015.12
안정화/최적화 안정화/최적화 안정화/최적화
정기 업그레이드 (HMM)
정기 업그레이드 (DNN)
정기 업그레이드 정기 업그레이드
정기 업그레이드 (HMM) 버전 배포
정기 업그레이드 (DNN) 버전 배포
정기 업그레이드 버전 배포
정기 업그레이드 버전 배포
안정화/최적화
1. 최신 딥러닝기술 엔진 적용 – 정기 업그레이드

14
2. 음성인식율
최신버전 엔진으로 H생명에서 테스트한 결과, Full Text Dictation STT 인식율은 키워드 기준 89.5%, Key Word Spotting 인식율은 92.1%를 기록.
舊버전 100시간 학습
인식률
新버전 100시간 학습
70.9%
76.7%
STT 新버전(DNN)
STT 어휘기준
STT 음절기준
STT 키워드기준
STT 舊버전
300시간 학습 2채널 분리
Live System
95%
2015년 9월 또 다른 버전 업그레이드 예정
(매 6개월 주기)
80.81%
89.5%
77.3%
KWS 92.1%

15
택소노미 작업 결과를 키워드 목록에 반영
분류체계 (Taxonomy)
키워드 목록
Call #0001
…
성별 남
연령 40대
직업 자영업
…
대분류 포인트
중분류 포인트미적립
소분류 …
…
대분류 포인트
중분류 포인트적립
소분류 포인트적립 불만
…
상품 마이신한카드
서비스 포인트적립
불만유형 포인트미적립
…
Taxonomy
…
상품명 대한변액종신
보종 건강, 교육, 실손
상품속성 갱신, 공제, 담보
…
불만원인 병원비, 보장
고불만감성 실망, 화남
감정표현 진짜, 시발
…
사고유형 교통사고, 재해
신체부위 경추, 심장, 혈관
질병증상 골절, 결석, 고열
…
치료법 고주파, 확장술
경제상황 대출, 이자율
대외기관 금융감독원
… a1
a2
a3
b3
b1
b2 c1
c3
c2
음성인식 엔진
키워드 인식률
89.5 %
2. 음성인식율 – 키워드 인식율

16
2. 음성인식율 - 오인식/미인식 유형분석
오인식/미인식 항목 분석 결과
동시 발화로 분별 불가능
너무 작게 중얼거리며 말하거나 심한 사투리
탄식, 감탄사, 추임새 등 한글 철자로 옮기기 어려운 잘 못된 발화 인식불가
인식가능
10~12%
전사한 사람의 오류 (기계가 맞는 경우)
인식 불가로 처리하기에 애매한 정도의 불분명한 음성
동시 발화의 경우 사람과 기계가 다르게 반응한 경우
기계성능으로 인한 미인식 / 오인식 (조사, 간투사 등이 많음)
12~14%
* 참고로 Closed Test (기학습 파일로 테스트)의 경우 88~90%의 인식율 보임
17
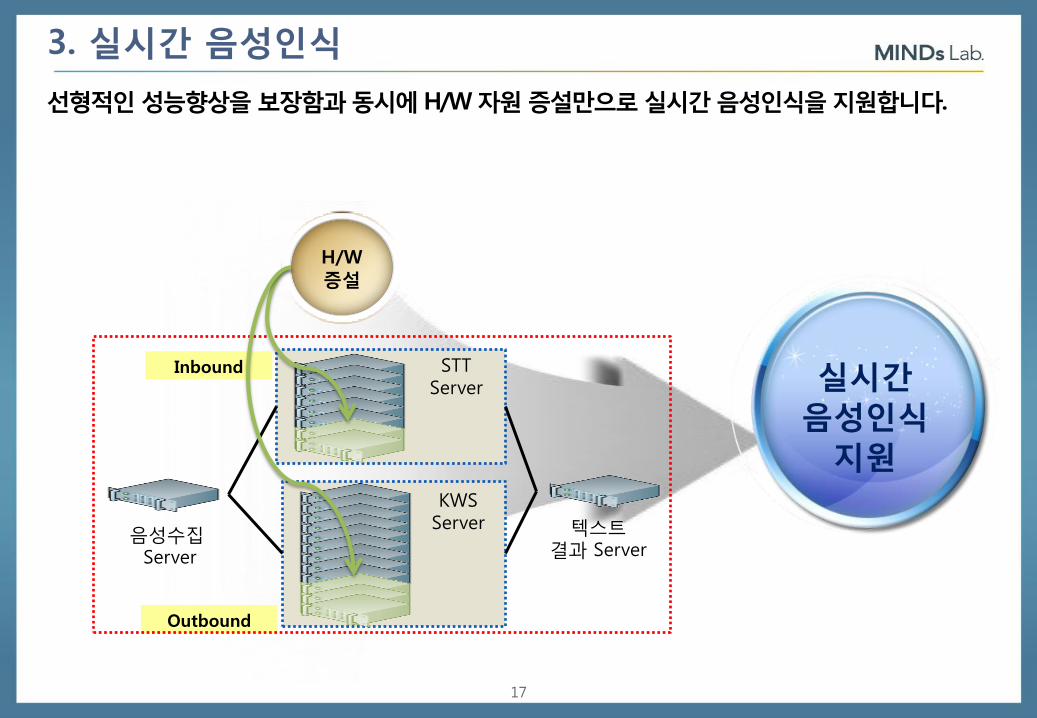
3. 실시간 음성인식
선형적인 성능향상을 보장함과 동시에 H/W 자원 증설만으로 실시간 음성인식을 지원합니다.
Inbound
Outbound
STT Server
KWS Server
음성수집 Server
텍스트 결과 Server
H/W 증설
실시간
음성인식
지원

18
4. 엔진 학습 비용
음성학습 및 기계학습을 위한 도구가 내장되어 효율적인 저비용 학습구조 지원
증강학습 (Incremental Training)
Baseline + Domain Common + Domain
Specific의 Flexible 학습구조를 통한 최적 모델
구축
기본 모델에 세부 영역 모델을 추가함으로써
세부 영역별 최적의 인식성능 보장
효율적인 학습 체계
학습 데이터 구축방식 용이성 및 효율성 제공
음향모델 학습을 위한 텍스트(형태소)분석 및
발음변환(G2P:Grapheme to Phoneme) 자동화
학습작업을 고객사 내부에서 해결 (내부 데이터
외부 유출 필요 없음)
i-VOC 특징 도메인별 효율적이고 최적화된 학습을 통해 최고의 음성인식 품질 제공
학습 작업의 많은 부분을 자동화 제공하고, 데이터 유출 없는 학습작업 제공
i-VOC 음성인식 개념 증강학습 개념
Baseline Model
산업/기업 Model Domain Common Model …
계약 지급 대출 … BD1 BD2 BDn …

19
5. 처리 성능과 확장성
서버당 동시 45채널 보장
용량 산정 사례
IN – 35,400 상담 OUT – 65,000 상담
1일 처리 데이터 IN – 106,200 (분) OUT – 162,500 (분)
작업시간 8시간 30분 주기 처리
30분 주기 처리 데이터 IN – 6,637 (분) OUT – 10,156 (분)
산정 결과
구분 일 평균 통화량 (Call)
평균 통화 (분)
1일 총 통화량
(시간)
서버당 처리용량(Call) (45CH X 8H)
필요 서버수 (식)
30% 여유율 (식)
최종 산정 서버 수
(식)
Inbound 35,400 3 1770.0 360 4.9 6.4 7
Outbound 65,000 2.5 2708.3 360 7.5 9.8 10

20
5. 처리 성능과 확장성 - In/Outbound 유연한 대응
STT모듈과 KWS모듈이 동일한 음성인식 Core 모듈을 공유하여 자유롭게 변경 가능
전처리
특징벡터
탐색 엔진
단어 모델 생성
발성모델 P
음향모델 C
발음사전 L
문법모델 G
음성 DB 텍스트 DB
언어 모델 생성
MINDsSTT
문법모델 G
언어 모델 생성
핵심어 키워드 List
MINDsKWS
Core Module KWS Sub Module STT Sub Module
인바운드 영역 아웃바운드 영역
음성 TEXT

21
5. 처리 성능과 확장성 - 시스템 확장 시 모델
인/아웃바운드 비율 변경 시 설정 변경만으로 가능하며, H/W 자원 증설 만으로 선형적인 확장 및
온라인 방식 전환 가능
Inbound
Outbound
STT Server
KWS Server
상담 좌석 수 변동 時 상담 좌석 수 증가 時
STT Server
KWS Server
Inbound
Outbound
22
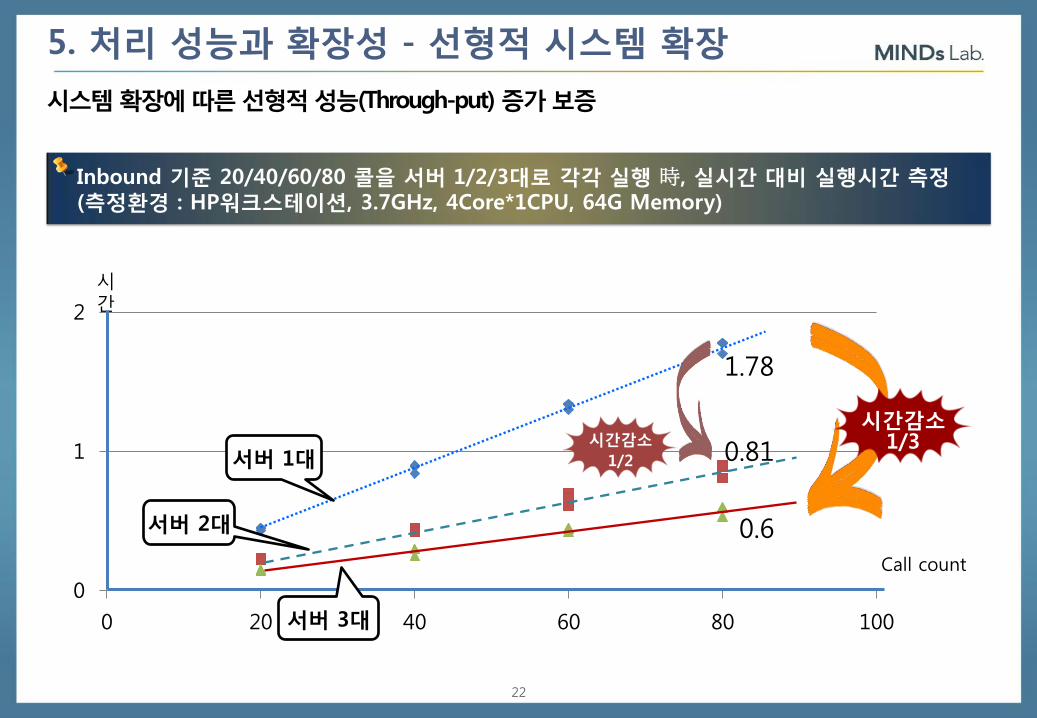
5. 처리 성능과 확장성 - 선형적 시스템 확장
시스템 확장에 따른 선형적 성능(Through-put) 증가 보증
0
1
2
0 20 40 60 80 100
시간
1.78
0.81
0.6 Call count
Inbound 기준 20/40/60/80 콜을 서버 1/2/3대로 각각 실행 時, 실시간 대비 실행시간 측정 (측정환경 : HP워크스테이션, 3.7GHz, 4Core*1CPU, 64G Memory)
시간감소
1/2
시간감소 1/3
서버 1대
서버 2대
서버 3대

Module B 텍스트분석 엔진

24
원천 데이터 텍스트 분석 데이터 모델링
기업내부
인터넷 상담
상담 메모
서신 민원
금감원/ 소비자원 민원
기본 텍스트마이닝 (Basic Text Mining)
자연어처리 (Natural Language
Processing)
고급 텍스트마이닝
(Advanced Text Mining)
문장 분리
형태소 분석
개체명 인식 Named Entity
구문 분석
빈도 분석 Frequency
연관어 분석 Related Words
급상승 키워드
감성 분석 Sentiment
문서 요약 Summarization
문서 분류 Classification
군집 분석 Clustering
개체명 사전
사용자 형태소 사전
형태소 기본 사전
Taxonomy
L1 상품명
L2 불만내용
키워드
유사 키워드
감성사전 문서#1
음성인식 학습데이터 준비
음성/언어모델 학습
Full-text Dictation
Keyword Spotting
음성인식
Real-time Recognition
Batch Recognition
텍스트 전환
실시간 문서 요약 Summarization
요약 키워드 사전
고빈도 추출 (High frequency)
고빈도 단어
요약 키워드 사전
Risk Category
L1 리스크유형
L2 리스크명
시각화/활용
고객이탈 방지
리스크 관리
통합 모니터링
Sentiment
High Risk
Churn
데이터 마이닝 (Data Mining)
정형 데이터
딥러닝 학습 (Deep Learning)
비정형 데이터
데이터 결합 Data Association
키워드 빈도 (n-gram)
키워드 연관어 감성 및 지수
택소노미 리스크
고객 기준정보 계약 원장
거래 데이터
Output 자동분류, 감성
Feature Extractor
Classifier
Input Data, Label
Module B 텍스트분석엔진 (TA)

25
6. 막강한 형태소/개체명 인식성능 – 사전의 종류
기계학습 기반, 방대한 한국어 처리사전 내재화, 강력한 한국어 분석 엔진
분석모델
…
분석모델
Up/Cross Sell
Taxonomy
…
Taxonomy
불만유형
Taxonomy
해지원인
분석모델
고객 Seg.
분석모델ㅂ
민원 예측
TA (Text Analytics) 문서#1 (Call #1)
문서#1
NLP(자연어처리) 텍스트마이닝
문장분리
형태소분석
개체명인식
구문분석
감성 분석
내용기반 자동분류
이슈 군집분석
어휘 중요도 분석
연관어 분석 비정형
Data 분석
Taxonomy
상품분류
…
거래DB
상품DB
고객DB
분석모델
해지예측
활용 고객이탈 방지 대외민원 방지 고객 Segmentation 신규고객 발굴 …
분석결과
사용자사전
개체명사전
복합어사전
기본사전
감성사전
어휘통계모델
내부VOC
외부VOC
전화상담, 상담메모, 상담게시판, …
뉴스, 블로그, 트위터, 커뮤니티, …
26 26
Ⅲ. 제안 내용
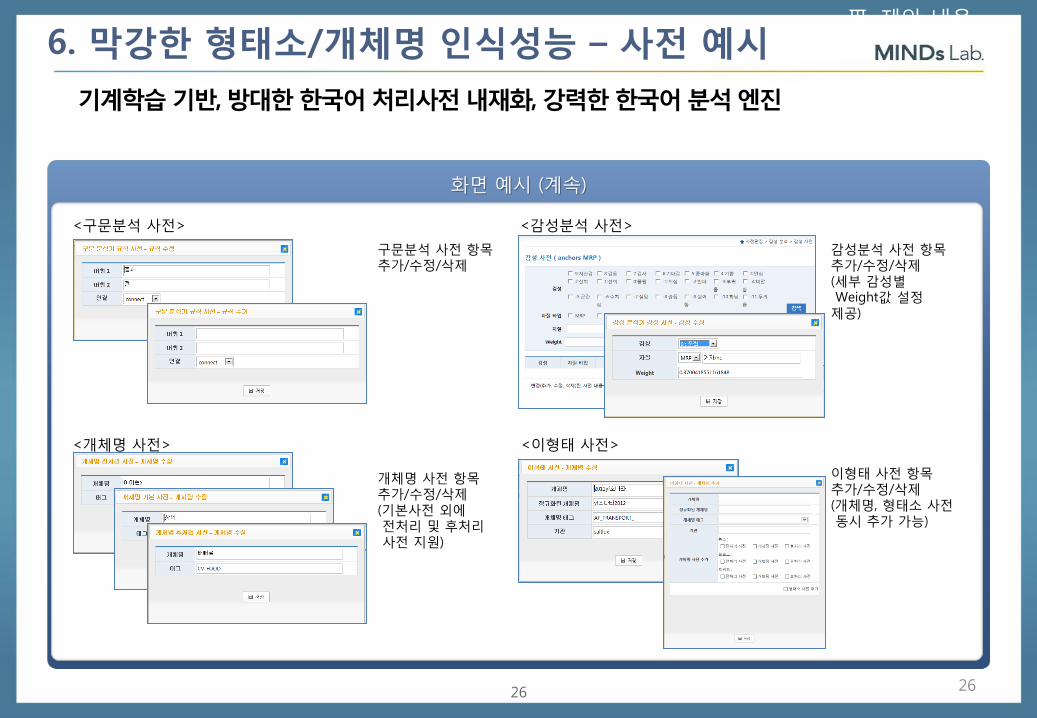
화면 예시 (계속)
<구문분석 사전>
구문분석 사전 항목 추가/수정/삭제
개체명 사전 항목 추가/수정/삭제 (기본사전 외에 전처리 및 후처리 사전 지원)
<개체명 사전>
<감성분석 사전>
감성분석 사전 항목 추가/수정/삭제 (세부 감성별 Weight값 설정 제공)
<이형태 사전>
이형태 사전 항목 추가/수정/삭제 (개체명, 형태소 사전 동시 추가 가능)
6. 막강한 형태소/개체명 인식성능 – 사전 예시
기계학습 기반, 방대한 한국어 처리사전 내재화, 강력한 한국어 분석 엔진

27
6. 막강한 형태소/개체명 인식성능 – NLP가 중요한 이유
기계학습 기반, 방대한 한국어 처리사전 내재화, 강력한 한국어 분석 엔진
대구에 가서 대구탕을 먹었다. {"category" : "", "sentence" : [ { "id" : 0, "text" : "대구에 가서 대구탕을 먹었다 . ", "morp" : [ {"id" : 0, "lemma" : "대구", "type" : "nc", "position" : 0}, {"id" : 1, "lemma" : "에", "type" : "jc", "position" : 4}, {"id" : 2, "lemma" : "가", "type" : "pv", "position" : 7}, {"id" : 3, "lemma" : "어서", "type" : "ec", "position" : 9}, {"id" : 4, "lemma" : "대구", "type" : "nc", "position" : 12}, {"id" : 5, "lemma" : "탕", "type" : "xsn", "position" : 16}, {"id" : 6, "lemma" : "을", "type" : "jc", "position" : 18}, {"id" : 7, "lemma" : "먹", "type" : "pv", "position" : 21}, {"id" : 8, "lemma" : "었", "type" : "ep", "position" : 23}, {"id" : 9, "lemma" : "다", "type" : "ef", "position" : 25}, {"id" : 10, "lemma" : ".", "type" : "s", "position" : 27} ], "NE" : [
{"id" : 0, "text" : "대구", "type" : "LCP_CITY", "begin" : 0, "end" : 0, "weight" : 0.750116, "common_noun" : 2},
{"id" : 1, "text" : "대구탕", "type" : "CV_FOOD", "begin" : 4, "end" : 5, "weight" : 1, "common_noun" : 1}
],
28
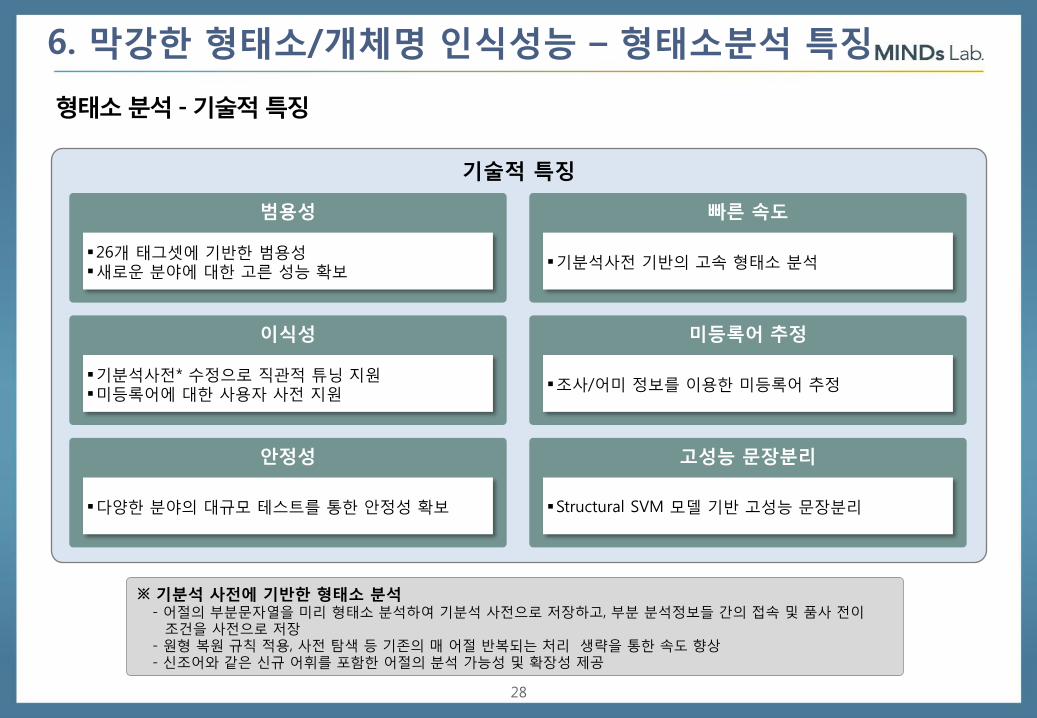
6. 막강한 형태소/개체명 인식성능 – 형태소분석 특징
형태소 분석 - 기술적 특징
기술적 특징
범용성
26개 태그셋에 기반한 범용성 새로운 분야에 대한 고른 성능 확보
이식성
기분석사전* 수정으로 직관적 튜닝 지원 미등록어에 대한 사용자 사전 지원
안정성
다양한 분야의 대규모 테스트를 통한 안정성 확보
빠른 속도
기분석사전 기반의 고속 형태소 분석
미등록어 추정
조사/어미 정보를 이용한 미등록어 추정
고성능 문장분리
Structural SVM 모델 기반 고성능 문장분리
※ 기분석 사전에 기반한 형태소 분석 - 어절의 부분문자열을 미리 형태소 분석하여 기분석 사전으로 저장하고, 부분 분석정보들 간의 접속 및 품사 전이
조건을 사전으로 저장 - 원형 복원 규칙 적용, 사전 탐색 등 기존의 매 어절 반복되는 처리 생략을 통한 속도 향상 - 신조어와 같은 신규 어휘를 포함한 어절의 분석 가능성 및 확장성 제공
29
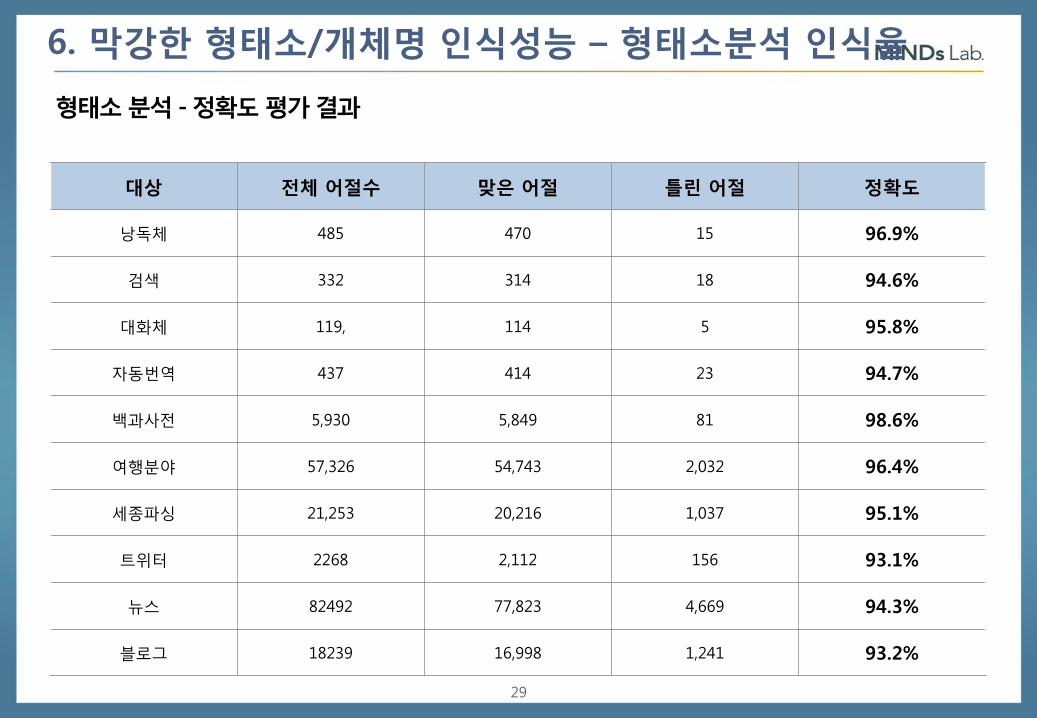
6. 막강한 형태소/개체명 인식성능 – 형태소분석 인식율
형태소 분석 - 정확도 평가 결과
대상 전체 어절수 맞은 어절 틀린 어절 정확도
낭독체 485 470 15 96.9%
검색 332 314 18 94.6%
대화체 119, 114 5 95.8%
자동번역 437 414 23 94.7%
백과사전 5,930 5,849 81 98.6%
여행분야 57,326 54,743 2,032 96.4%
세종파싱 21,253 20,216 1,037 95.1%
트위터 2268 2,112 156 93.1%
뉴스 82492 77,823 4,669 94.3%
블로그 18239 16,998 1,241 93.2%

30
6. 막강한 형태소/개체명 인식성능 – 개체명인식 특징
개체명 인식 - 기술적 특징
기술적 특징
세분화된 개체명 체게
15개 대분류 및 180개 세부분류* 개체명 태그
최신 기계학습 모델 사용
통계 기반의 기계학습 방법ㅇ니 Conditional Random Fields, Structural Support Vector Machine 모델 사용
개체명 경계 인식 및 개체명 세부분류 결정을 위해 활용
※ 1. 세계 최고의 상세화된 개체명 분류체계 적용 2. 국내 시장 <국내_시장:TMI_MARKET> 3. <경기도:LCP_PROVINCE> <평택시:LCP_CITY> <팽성읍:LCP_COUNTY> <경기도 평택시 팽성읍:LCP_OTHERS>
사용자 사전
사용자 사전을 통해 개체명 인식 오류 및 미인식을 사용자 관점에서 수정 가능
패턴 기반 규칙 제공
Lexico-Semantic Pattern 기반 규칙 활용
새로운 영역으로의 확장성 제공**
개채명 태그셋 수정 기능 제공***
31
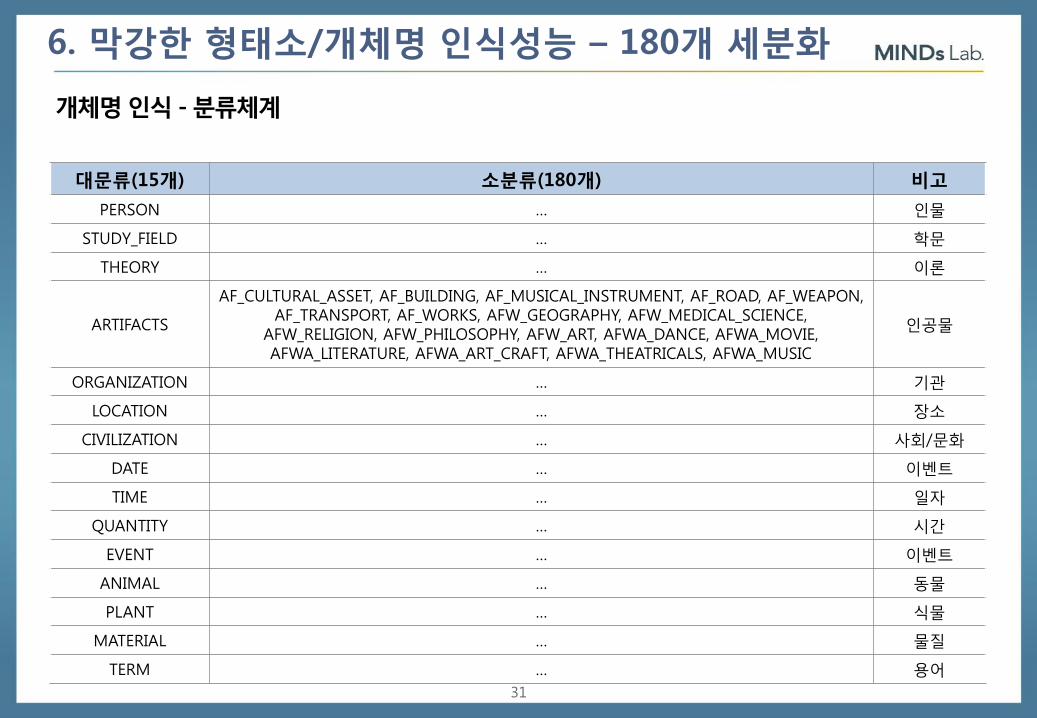
6. 막강한 형태소/개체명 인식성능 – 180개 세분화
개체명 인식 - 분류체계
대문류(15개) 소분류(180개) 비고
PERSON … 인물
STUDY_FIELD … 학문
THEORY … 이론
ARTIFACTS
AF_CULTURAL_ASSET, AF_BUILDING, AF_MUSICAL_INSTRUMENT, AF_ROAD, AF_WEAPON, AF_TRANSPORT, AF_WORKS, AFW_GEOGRAPHY, AFW_MEDICAL_SCIENCE,
AFW_RELIGION, AFW_PHILOSOPHY, AFW_ART, AFWA_DANCE, AFWA_MOVIE, AFWA_LITERATURE, AFWA_ART_CRAFT, AFWA_THEATRICALS, AFWA_MUSIC
인공물
ORGANIZATION … 기관
LOCATION … 장소
CIVILIZATION … 사회/문화
DATE … 이벤트
TIME … 일자
QUANTITY … 시간
EVENT … 이벤트
ANIMAL … 동물
PLANT … 식물
MATERIAL … 물질
TERM … 용어

32
6. 막강한 형태소/개체명 인식성능 – 하이브리드 방식
개체명 인식 - 기계학습과 규칙기반의 장점 활용
기계학습 기반 방식
장점
- 전반적으로 높은 분석 성능
- 타 도메인으로의 용이한 확장성
단점
- 많은 분량의 학습 데이터 필요
- 결과물에 대한 빠른 수정 어려움
규칙기반 방식
장점
- 정해진 규칙(패턴)에 대한 정확한 분석
단점
- 모든 경우의 수를 규칙(패턴)으로 관리
- 타 도메인으로의 확장을 위한 규칙(패턴)관리 어려움
MINDs Lab. 개체명 인식
기계학습 기반 방식과 규칙 기반 방식 혼합
- 기계학습 기반 방식을 기본 채택
- 규칙을 이용하여 결과물의 빠른 수정 가능
- 사용자 사전을 통한 오류 및 미인식 수정 가능
33
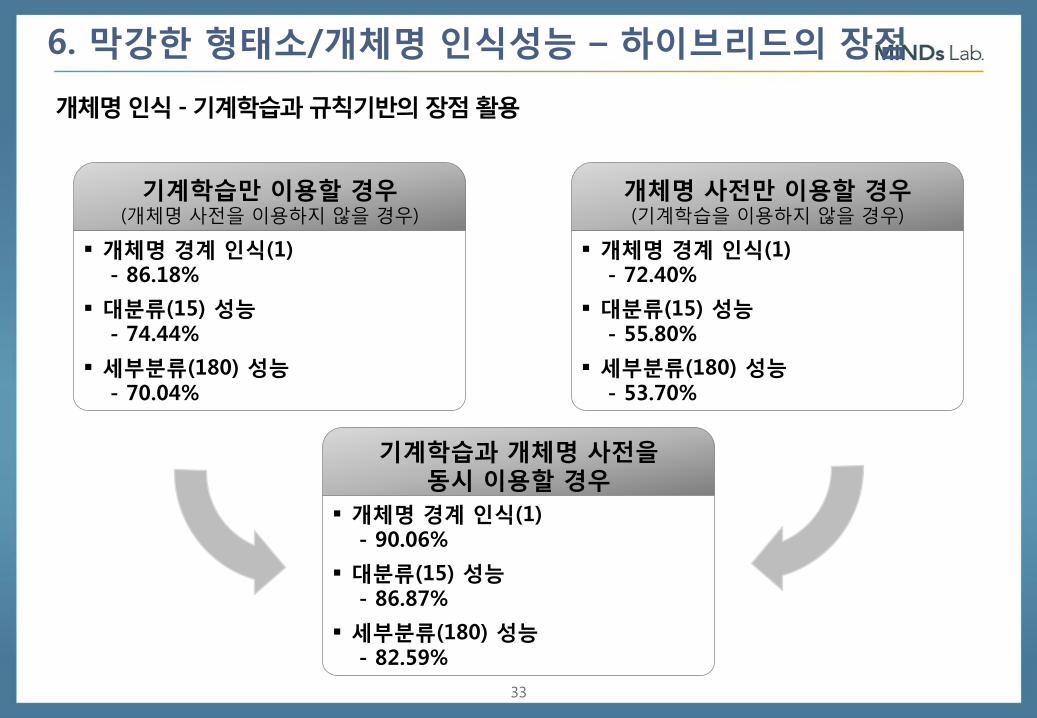
6. 막강한 형태소/개체명 인식성능 – 하이브리드의 장점
개체명 인식 - 기계학습과 규칙기반의 장점 활용
기계학습만 이용할 경우 (개체명 사전을 이용하지 않을 경우)
개체명 경계 인식(1) - 86.18%
대분류(15) 성능 - 74.44%
세부분류(180) 성능 - 70.04%
개체명 사전만 이용할 경우 (기계학습을 이용하지 않을 경우)
개체명 경계 인식(1) - 72.40%
대분류(15) 성능 - 55.80%
세부분류(180) 성능 - 53.70%
기계학습과 개체명 사전을 동시 이용할 경우
개체명 경계 인식(1) - 90.06%
대분류(15) 성능 - 86.87%
세부분류(180) 성능 - 82.59%

34
6. 막강한 형태소/개체명 인식성능 – 최신 기계학습 모델
개체명 인식 - 기계학습 모델
기계학습 모델
현재 가장 활발히 연구되고 있는 최신 기계 학습 모델 개체명 인식 분야에서 가장 높은 성능을 보임 기존의 HMM*** 등에 비해 높은 성능을 보임
x (단어 열), y (개체명 열), c (개체명 클래스), b (개체명 경계) Boundary Detection : Conditional Random Fields 이용
NE Classification : Maximum Entropy 이용
Structural SVM for Boundary Detection and NE classification
CRF*, Structural SVM** 개체명 인식 알고리즘
※ 1. CRF : Conditional Random Fields 2. Structural SVM : Structural Support Vector Machine 3. HMM : Hidden Markov Model

35
6. 막강한 형태소/개체명 인식 성능
개체명 인식 - 성능(정확도)
90.06
86.87
82.5984
68.1
88.8
72.4
50
60
70
80
90
100
1 4 15 180
A. M.-CRF-영어
A. M.-CRF-독일어
IBM-영어
IBM-독일어
MINDs Lab.(ETRI)-한국어
Andrew McCallum – CRF IBM MINDs Lab.(ETRI)
CoNLL-2003 (4개 분류: PLO + Misc)
English: 정확도=84.5, 재현률=83.6, F1=84.0
German: 정확도=76.0, 재현률=61.7, F1=68.1
CoNLL-2003 Best (4개 분류: PLO + Misc)
English: 정확도= 89.0%, 재현률= 88.5%, F1=88.8
German: 정확도= 83.9%, 재현률= 63.7%, F1=72.4
개체명 경계 인식(1) : 정확도=94.0% 재현률=86.4% F1=90.06
대분류(15) : 정확도=90.7% 재현률=83.4% F1=86.87
세부분류(180) : 정확도=85.9% 재현률=79.5% F1=82.59

36
6. 막강한 형태소/개체명 인식성능
개체명 인식 - 성능(속도)
병렬 프로그래밍
OpenMP를 이용한 병렬 프로그래밍 지원
기존 개체명 인식기 대비 3-4배 속도 향상 - i5 quadcore CPU 3배 속도 향상 - i7 quadcore CPU 4배 속도 향상
처리 속도 (형태소분석+개체명인식) - 47KB/sec (i5 quadcore CPU) - 1문서당 1KB 가정 時 1초당 47문서 처리
태그셋 크기에 반비례 - 대분류 기준 약 2배 성능 향상
분산 처리
Haddop 지원 - 리눅스 기반 클러스터 활용 - 선형적 속도 향상 제공

37
Category Sentiment Code
긍정감정
감동 (Impression) 3
만족 (Satisfaction) 2
안심 (Relieved) 1
중립 중립 (Neutral) 0
부정감정
의심 (Doubt) -1
불만 (Complaint) -2
화남 (Anger) -3
VOC분석에 적합한 7단계 감성 분석 (고객 감성 중심, 상담원 감성 중립 처리)
7. 감성분석/특정콜 탐지 - 7단계 감성분석
38
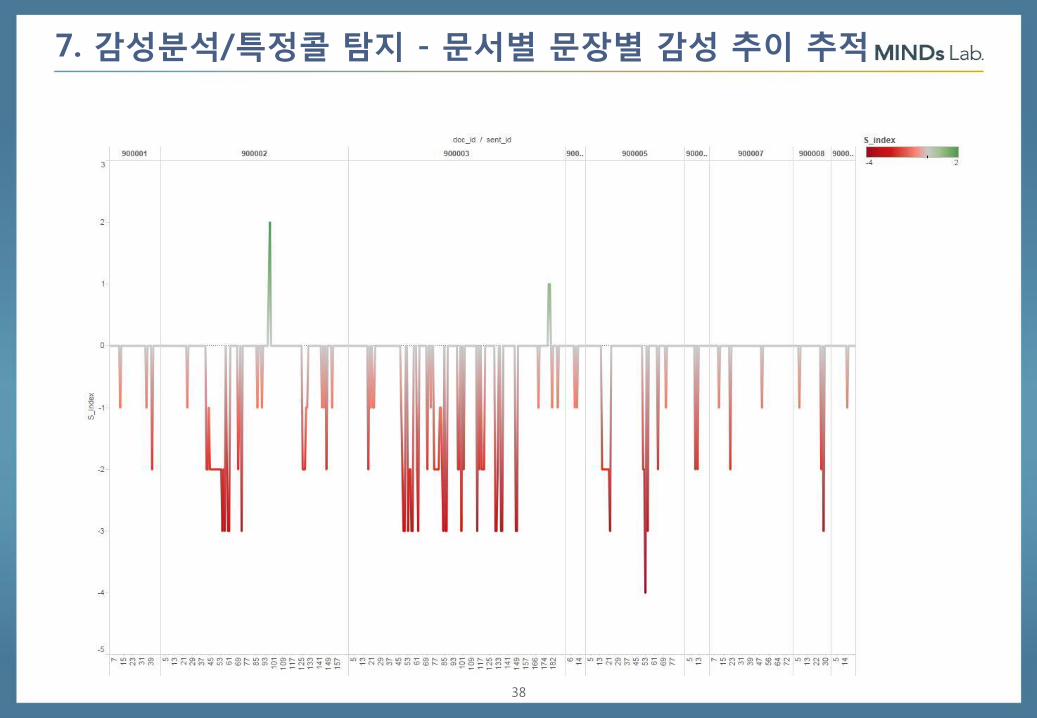
7. 감성분석/특정콜 탐지 - 문서별 문장별 감성 추이 추적

39
7. 감성분석/특정콜 탐지 – Pitch 분석
Raw Data (pcm)
Pitch 산정 위한 가공데이터
Spectrum Analyzer (저/중/고음)
Volume
최종판정
Pitch & Volume Data by Time

40
7. 감성분석/특정콜 탐지 - 원인분석체계
A. 불만고객 유형
B. 불만원인
C. 불만영역
D. 불만행동 표출방법
E. 불만상품
F. 경제상황
극단형(N3) : 화남 적극형(N2) : 실망 소극형(N1) : 의심 중립형(N0) 불완전판매 : 사전
설명부실 FC에 대한 불만 상품 불만 서비스 불만
병원비 보장 지급 수술 시술 입원 진료 처방 초진 치료 통원 퇴원
항의전화 민원:금감원 보건복지부 소비자보호원 언론, 인터넷 고소고발
계약대출 대출횟수차감 대출가능여부 대출문의 대출원리금 대출이자 대출한도 중도인출 지연이자 추가대출
불만고객유형별 텍소노미 불만원인 불만영역 불만행동표출방법 상품 경제상황
병원비
극단형 (N3) :화남 불완전판매:사전설명부실 보장 항의전화 스마트변액CI통합보험 계약대출
적극형 (N2) :실망 FC에 대한 불만 지급 민원 :금감원 스마트변액통합보험 대추횟수차감
소극형(N1) :의심 상품 불만 수술 보건복지부 변액통합종신보험 대출가능여부
중립형(N0) 서비스 불만 시술 보험감독원 무배당마치라이프한안름종합보험 대출문의
입원 소비자보호원 한화손해 비갱신암보험 대출원리금
진료 언론, 인터넷 변액유니버셜CI통합보험 대출이자
처방 고소고발 어린이 변액연금보험 대출한도
초진 무배당 사랑&스마트변액통합보험 중도인출
치료 월지급변액CI통합보험 지연이자
통원 변액CI통합보험 추가대출
퇴원 플러스UP변액연금보험
Start변액연금보험
파워변액연금보험
V플러스변액연금보험
V-Dex변액연금보험
파워플랜변액적립보험
변액유니버셜적립보험
프리미엄변액유니버셜보험

41
7. 감성분석/특정콜 탐지 - 딥러닝 감성인식 엔진
• 기존 기계학습 방법론 – Handcrafting features time-consuming
• Deep Neural Network: Feature Extractor + Classifier

42
7. 감성분석/특정콜 탐지 - 딥러닝 기반 감성인식 엔진
Unsupervised Feature Learning
• 기계학습에 많은 학습 데이터 필요 – 소량의 학습 데이터
• 학습 데이터 구축 비용/시간
– 대량의 원시 코퍼스 (unlabeled data) • Semi-supervised, Unsupervised …
• Deep Neural Network
– Pre-training 방법을 통해 대량의 원시 코퍼스에서 자질 학습
– Restricted Boltzmann Machines (RBM)
– Stacked Autoencoder, Stacked Denosing Autoencoder
– Word Embedding (for NLP)
4
43
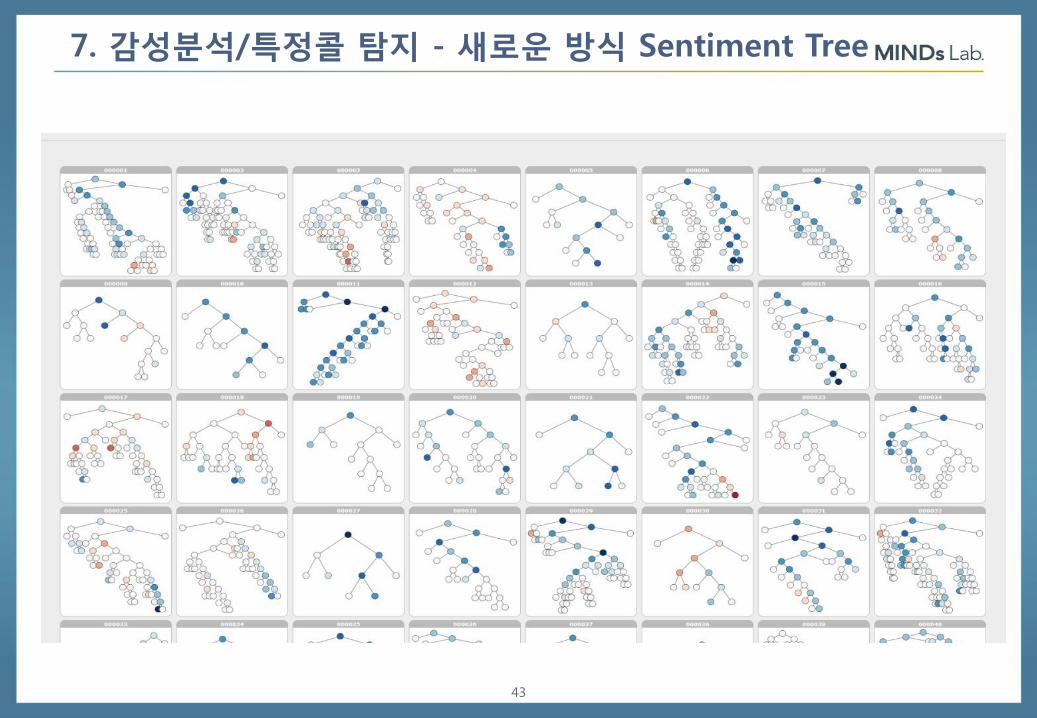
7. 감성분석/특정콜 탐지 - 새로운 방식 Sentiment Tree

44
7. 감성분석/특정콜 탐지 - 새로운 방식 Sentiment Tree
45
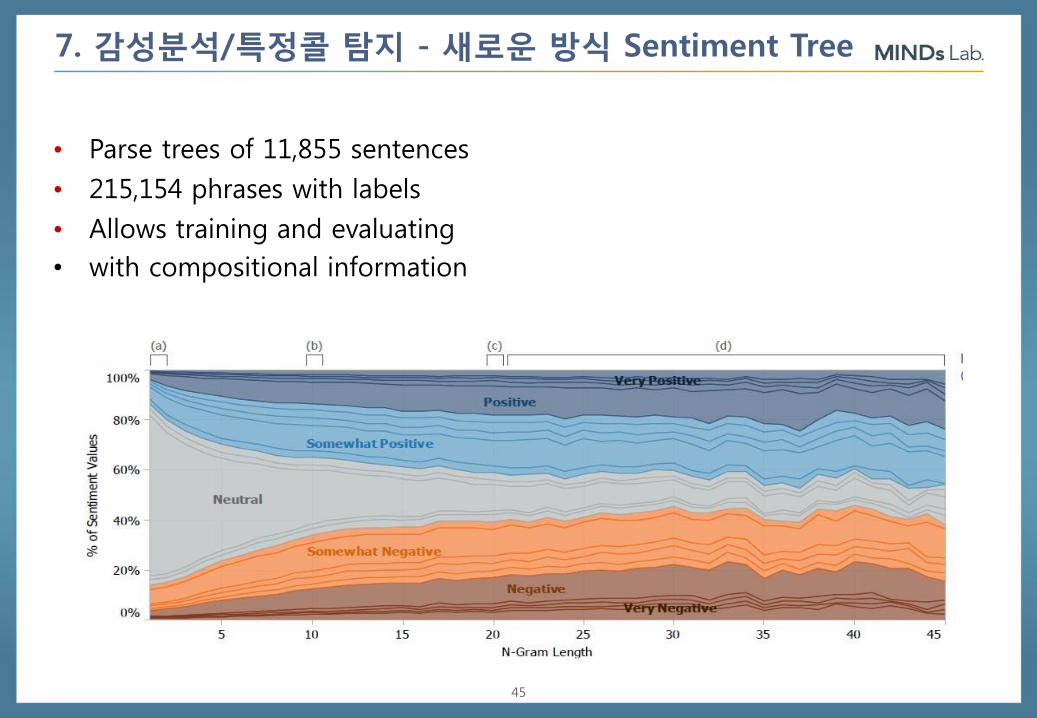
7. 감성분석/특정콜 탐지 - 새로운 방식 Sentiment Tree
• Parse trees of 11,855 sentences
• 215,154 phrases with labels
• Allows training and evaluating
• with compositional information

46
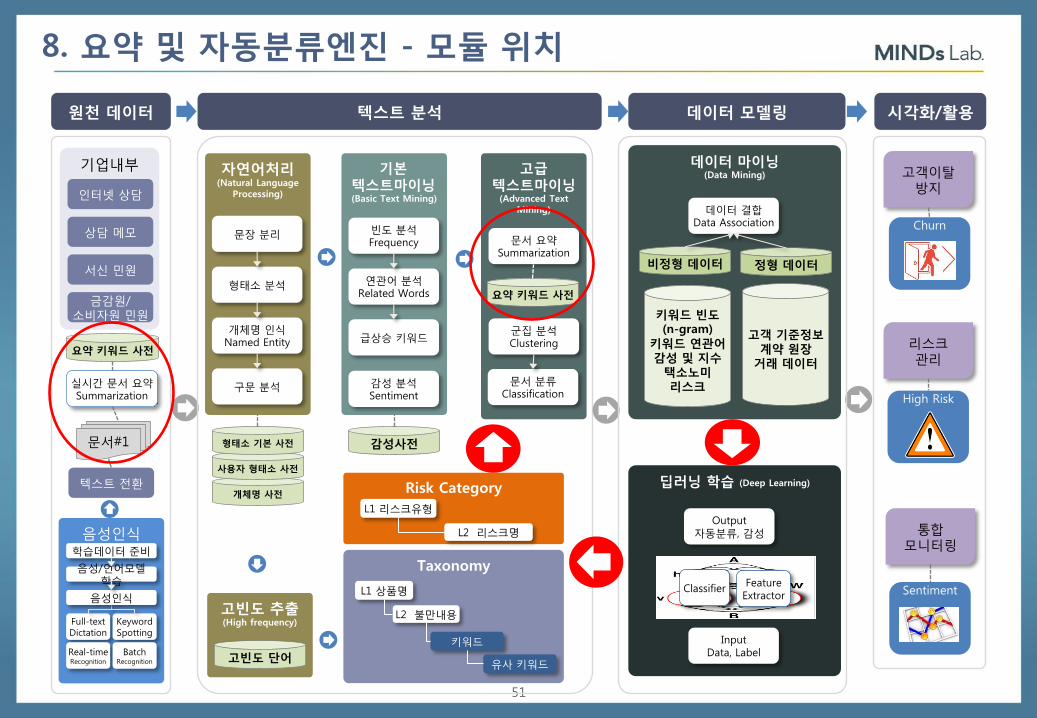
원천 데이터 텍스트 분석 데이터 모델링
기업내부
인터넷 상담
상담 메모
서신 민원
금감원/ 소비자원 민원
기본 텍스트마이닝 (Basic Text Mining)
자연어처리 (Natural Language
Processing)
고급 텍스트마이닝
(Advanced Text Mining)
문장 분리
형태소 분석
개체명 인식 Named Entity
구문 분석
빈도 분석 Frequency
연관어 분석 Related Words
급상승 키워드
감성 분석 Sentiment
문서 요약 Summarization
문서 분류 Classification
군집 분석 Clustering
개체명 사전
사용자 형태소 사전
형태소 기본 사전
Taxonomy
L1 상품명
L2 불만내용
키워드
유사 키워드
감성사전 문서#1
음성인식 학습데이터 준비
음성/언어모델 학습
Full-text Dictation
Keyword Spotting
음성인식
Real-time Recognition
Batch Recognition
텍스트 전환
실시간 문서 요약 Summarization
요약 키워드 사전
고빈도 추출 (High frequency)
고빈도 단어
요약 키워드 사전
Risk Category
L1 리스크유형
L2 리스크명
시각화/활용
고객이탈 방지
리스크 관리
통합 모니터링
Sentiment
High Risk
Churn
데이터 마이닝 (Data Mining)
정형 데이터
딥러닝 학습 (Deep Learning)
비정형 데이터
데이터 결합 Data Association
키워드 빈도 (n-gram)
키워드 연관어 감성 및 지수
택소노미 리스크
고객 기준정보 계약 원장
거래 데이터
Output 자동분류, 감성
Feature Extractor
Classifier
Input Data, Label
7. 감성분석/특정콜 탐지 - 탐지어 추천

47
CTI에 직접 Interface해서 실시간 음성인식과 함께 사용
상담사의 메모 작성 작업을 획기적으로 단축. 콜센터 효율화
TA엔진 실행 후 텍스트파일을 요약
- 원문 Tracking時 전체 원문과 함께 요약 원문을 보여줌 조회 효율화
- 요약 원문을 n-gram화하여 문서자동분류(Document Classification)에 활용
키워드 사전 Update 자동화
- Machine Learning에 의한 Taxonomy Keyword 사전 제안
8. 요약 및 자동분류엔진 - 활용방안

48
신용 카드 신청하시는 건으로 연락 주신 거죠 네 저희가 전화상으로 신용 카드 진행하는 거라 몇가지 소득 정보가 될 건데 통화 괜찮으시구요 네 말씀 하세요 본인 확인차 주민 번호 뒤의 일곱 자리로 확인 부탁 드리겠습니다 네 확인 감사합니다 신용 카드는 지금 현재 소득 정보 확인해봤는데요 네 근데 고객님 직장을 다니시거나 또는 개인 사업을 하시는 거 있으신가요 직장 다니고 있습니다 네 직장에서 직장 의료 보험 결제시구요 네 그렇습니다 아니 직장명은 어떻게 되십니까 마인즈 랩 아 그 카드 연회비가 국내용으로만 하면 팔천원 해외에서 만원 있는데 어떤 카드 어떤 걸로 해드릴까요 국내기 국내용으로 해주세요 네 국내용으로 해서 카드가 버스나 카드 기능 너 드릴까요 예 예 그럼요 화이트 러브 카드로 국내용으로 후불 교통 카드 기능 너 드릴 거 발급 받은 다음달에 카드 연회비 팔 천원 청구될 거구요 네 네 회사 주소랑 전화 번호 필요한데요 전화 번호 먼저 부탁드리겠습니다 전화 번호가요 공삼일 예 공삼일 육이오에 육백이십오에 사삼 사공 주소 부탁 드리겠습니다 카드는 고객님 본인 수령하세요 네 어디에서 수령하시겠습니까 직장이요 대왕 판교로 육백 육십 비동 십이 층으로요 예 이런 서비스내용과심 사항은 카드 나갈 때는 약관 안내장 설명서를 꼭 읽어 주시고 카드가 가게 되면 직장으로 발송되니까요 께서 수령하시고 서명 후 이용 부탁 드리구요 네
신용 카드 신청하시는 건으로 연락 주신 거죠 연회비가 국내용으로만 하면 팔천원 해외에서 만원 있는데 후불 교통 카드 기능 너 드릴 거 발급 받은 다음달에 카드 본인 수령하세요 약관 안내장 설명서를 꼭 읽어 주시고 카드가 가게 되면 서명 후 이용 부탁 드리구요
Summery목적 새로운 상품 구매시 상담원대응의 적절성 평가 신용카드 신청 시 상담원이 금감원 규정 고객고지 의무사항을 잘 지켰는지 점검가능
8. 요약 및 자동분류엔진 - 예시

49
8. 요약 및 자동분류엔진 - 문서 요약 흐름도
문서#1 (Call #1)
NLP(자연어처리)
문장분리
형태소분석
개체명인식
구문분석
개체명사전
형태소사전
사용자사전
음성 인식 결과
Text문서
문서 요약
문서 자질 패턴 추출
요약 패턴 매칭
요약 문장 정규화
요약패턴사전
요약 결과
요약정규화 사전
50
문서번호 #1
문장번호 #1
문장번호 #2
원문
원문 문서번호 #1
문장번호 #1
문장번호 #2
Summary 1,2,3,4,5
날짜
날짜
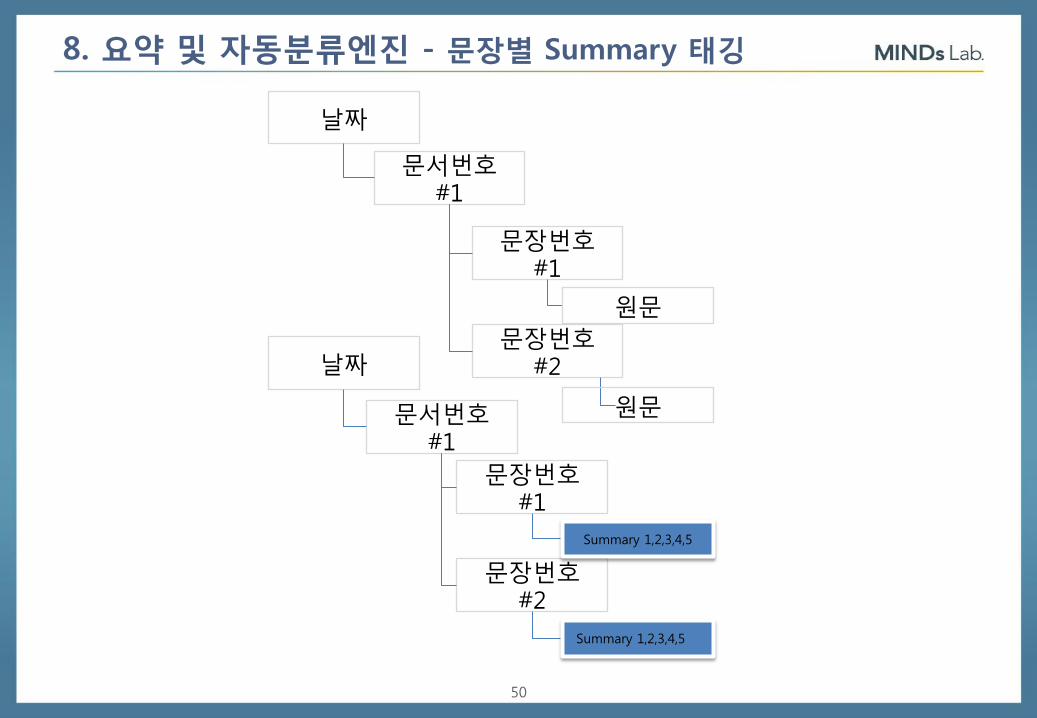
8. 요약 및 자동분류엔진 - 문장별 Summary 태깅
Summary 1,2,3,4,5
51
원천 데이터 텍스트 분석 데이터 모델링
기업내부
인터넷 상담
상담 메모
서신 민원
금감원/ 소비자원 민원
기본 텍스트마이닝 (Basic Text Mining)
자연어처리 (Natural Language
Processing)
고급 텍스트마이닝
(Advanced Text Mining)
문장 분리
형태소 분석
개체명 인식 Named Entity
구문 분석
빈도 분석 Frequency
연관어 분석 Related Words
급상승 키워드
감성 분석 Sentiment
문서 요약 Summarization
문서 분류 Classification
군집 분석 Clustering
개체명 사전
사용자 형태소 사전
형태소 기본 사전
Taxonomy
L1 상품명
L2 불만내용
키워드
유사 키워드
감성사전 문서#1
음성인식 학습데이터 준비
음성/언어모델 학습
Full-text Dictation
Keyword Spotting
음성인식
Real-time Recognition
Batch Recognition
텍스트 전환
실시간 문서 요약 Summarization
요약 키워드 사전
고빈도 추출 (High frequency)
고빈도 단어
요약 키워드 사전
Risk Category
L1 리스크유형
L2 리스크명
시각화/활용
고객이탈 방지
리스크 관리
통합 모니터링
Sentiment
High Risk
Churn
데이터 마이닝 (Data Mining)
정형 데이터
딥러닝 학습 (Deep Learning)
비정형 데이터
데이터 결합 Data Association
키워드 빈도 (n-gram)
키워드 연관어 감성 및 지수
택소노미 리스크
고객 기준정보 계약 원장
거래 데이터
Output 자동분류, 감성
Feature Extractor
8. 요약 및 자동분류엔진 - 모듈 위치
Classifier
Input Data, Label

52
8. 요약 및 자동분류엔진 – 상담분류체계에 활용
a1
a2
a3
b3
b1
b2 c1
c3
c2
a b c
<발급> <이용> <해지>
a11 a12 …
MINDs Classifier
NLP 학습기 분류기
… … <법인> <개인>
기계학습 모델 적용
단일 분류 및 다중 분류
제공
STT 결과
자동분류 결과

53
8. 요약 및 자동분류엔진 - 기계학습 기반 콜 분류기 구조

54
8. 요약 및 자동분류엔진 - 기계학습 기반 콜 분류기 예시

55
8. 요약 및 자동분류엔진 – 택소노미 기반 분류
기계학습 방식에 의한 자동분류 엔진 내장.
중략... 그리고 펌업후에 베터리 소모가 너무 심해 열이 많이나고 동영상 1시간 짜리만 봐도 100%에서 60%로 되요... 아오... 게다가 요즘에 생긴 문젠데... 이거 뭐...... 홈딜도 진짜 밀리고, 화면도 버벅거리고, 어플 로딩시간들도 길어지고, 베터리도 동영상만 보면 갑자기 1%로 떨어지고... 왜이러죠?ㅠㅠ 심지어 램정리 다 하고도 터치믹스가 렉이걸려요!!!!! 나참...할말이 없군요
VOC 1
중략.. 이상하게 어플 설치하고 나서 벨소리 를 내가 원하는 데로 설정후 재부팅을 하고 전화가 왔는데 소리가 안나더라구요…도대체..왜 이러는지.. 갑갑합니다.
원인 품질 불량 결과
VOC 분석
VOC 2
펌웨어 업그레이드
어플 설치 •무음 수신
인과관계
• 배터리 소모 많음, • 홈 복귀시 딜레이 어플 로딩 딜레이 • 터치믹스 렉
Text 분석을 통해 사전에 정의된 원인과 결과로 유형을 자동 분류 ① VOC Taxonomy ② VoC 자동 분류

56
8. 요약 및 자동분류엔진 - 딥러닝 기반 clustering & classification
202: 옵니아보다 빠른 촬영속 도 캠코더 기능으로 동영상 촬 영 만족스러움 238: 카메라화질도 깔끔하고 기능도 다 잘갖춘것같애요
275: 정말 좋은 제품을 싸게 구 입했어요 288: 빠른속도도 마음에들고
388: 디자인 좋고 기능 어플로 다해결 됩니다 454: 디자인 완전 대박입니다
403: 깔끔하네요 487: 너무 귀엽고 쉽고 좋아요
278: 반응속도가 정말 빠르군 요 292: 확실히 2.2가 빠릅니다
한국어 Paragraph Vector

57 57
Ⅲ. 제안 내용
목적에 맞는 활용을 위한
정밀하고 편리한 관리기능 제공
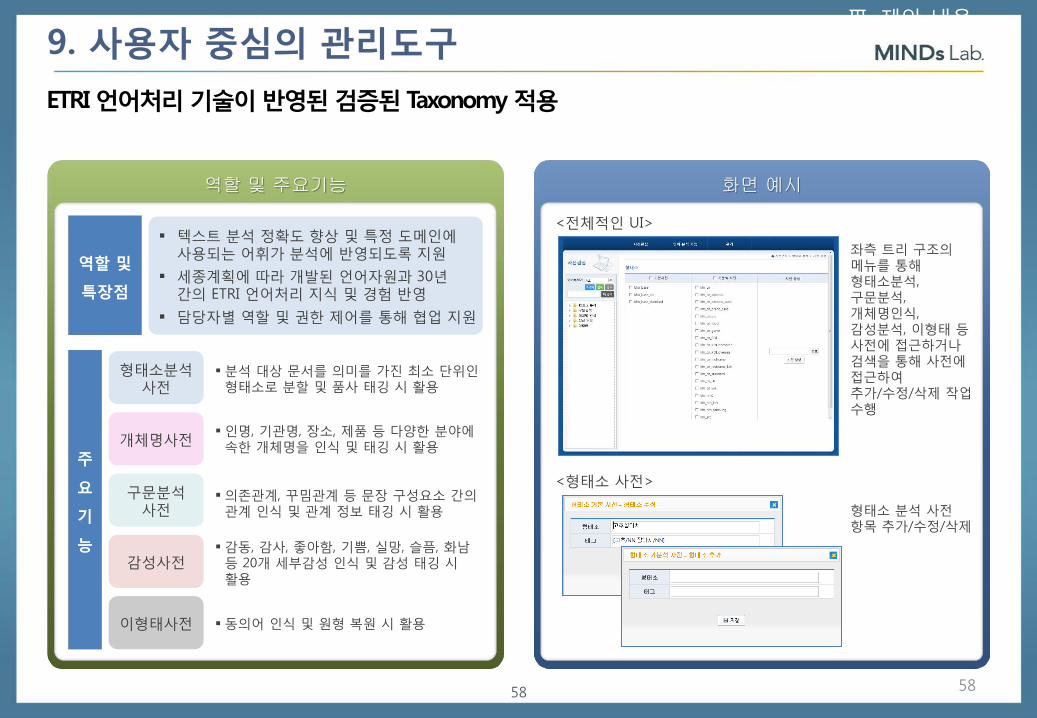
사전 관리
형태소, 개체명, 구문분석, 감성, 이형태 사정 관리기능 제공
텍스트 분석 정확도 향상 및 특정 도메인에 사용되는 어휘가 분석에 반영되도록 지원
세종계획에 따라 개발된 20년 간의 ETRI 언어처리 지식 및 경험 반영
담당자별 역할 및 권한 제어를 통해 협업 지원
운영 관리
텍스트 분석 과정 모니터링 기능 제공
분석 배제를 위한 스팸 키워드 관리 기능 제공
개인정보보호를 위한 개인정보 패턴 관리기능 제공
Taxonomy 관리
VOC 분석 목적을 위한 키워드 및 키워드집합에 대한 분류 기준 역할
계층적 Taxonomy 관리, 데이터 일괄 생성 및 다운로드 기능 제공
사용자 추가/수정/삭제 기능 제공
9. 사용자 중심의 관리도구
사용자 중심의 사전 및 운영관리 도구
58 58
Ⅲ. 제안 내용
역할 및 주요기능 화면 예시
역할 및
특장점
주
요
기
능
텍스트 분석 정확도 향상 및 특정 도메인에 사용되는 어휘가 분석에 반영되도록 지원
세종계획에 따라 개발된 언어자원과 30년 간의 ETRI 언어처리 지식 및 경험 반영
담당자별 역할 및 권한 제어를 통해 협업 지원
형태소분석사전
분석 대상 문서를 의미를 가진 최소 단위인 형태소로 분할 및 품사 태깅 시 활용
개체명사전 인명, 기관명, 장소, 제품 등 다양한 분야에
속한 개체명을 인식 및 태깅 시 활용
구문분석 사전
의존관계, 꾸밈관계 등 문장 구성요소 간의 관계 인식 및 관계 정보 태깅 시 활용
감성사전 감동, 감사, 좋아함, 기쁨, 실망, 슬픔, 화남
등 20개 세부감성 인식 및 감성 태깅 시 활용
이형태사전 동의어 인식 및 원형 복원 시 활용
<전체적인 UI>
좌측 트리 구조의 메뉴를 통해 형태소분석, 구문분석, 개체명인식, 감성분석, 이형태 등 사전에 접근하거나 검색을 통해 사전에 접근하여 추가/수정/삭제 작업 수행
<형태소 사전>
형태소 분석 사전 항목 추가/수정/삭제
ETRI 언어처리 기술이 반영된 검증된 Taxonomy 적용
9. 사용자 중심의 관리도구
59 59
Ⅲ. 제안 내용
역할 및 주요기능 화면 예시
역할 및
특장점
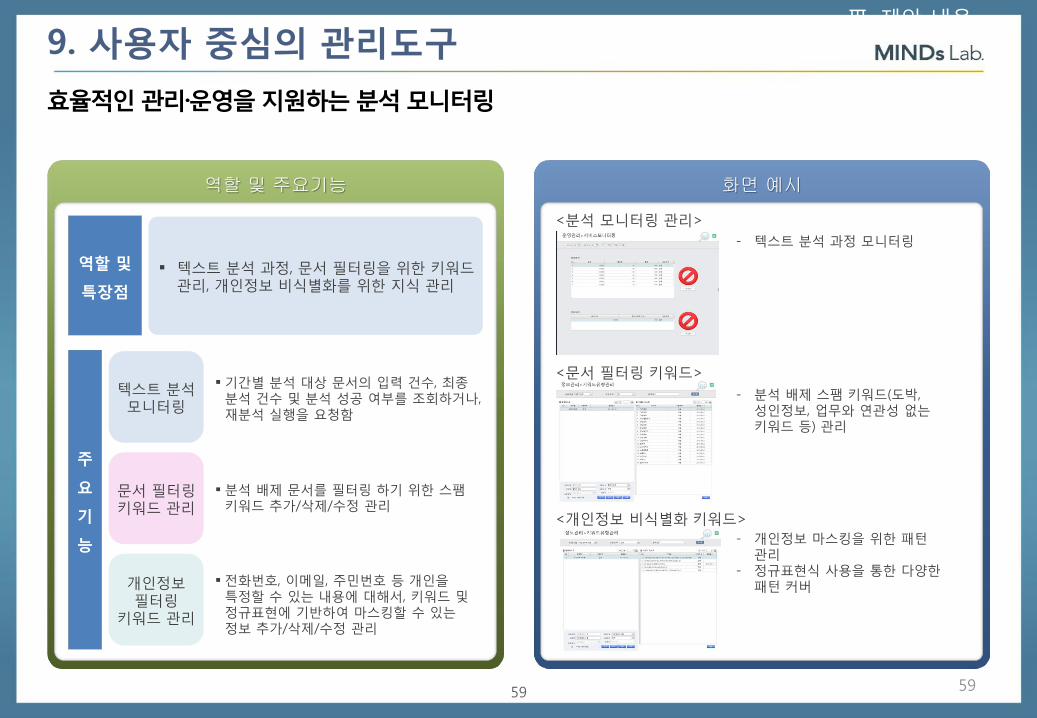
텍스트 분석 과정, 문서 필터링을 위한 키워드 관리, 개인정보 비식별화를 위한 지식 관리
주
요
기
능
텍스트 분석 모니터링
기간별 분석 대상 문서의 입력 건수, 최종 분석 건수 및 분석 성공 여부를 조회하거나, 재분석 실행을 요청함
문서 필터링 키워드 관리
분석 배제 문서를 필터링 하기 위한 스팸 키워드 추가/삭제/수정 관리
개인정보 필터링
키워드 관리
전화번호, 이메일, 주민번호 등 개인을 특정할 수 있는 내용에 대해서, 키워드 및 정규표현에 기반하여 마스킹할 수 있는 정보 추가/삭제/수정 관리
<분석 모니터링 관리>
<문서 필터링 키워드>
<개인정보 비식별화 키워드>
- 텍스트 분석 과정 모니터링
- 분석 배제 스팸 키워드(도박, 성인정보, 업무와 연관성 없는 키워드 등) 관리
- 개인정보 마스킹을 위한 패턴 관리
- 정규표현식 사용을 통한 다양한 패턴 커버
효율적인 관리·운영을 지원하는 분석 모니터링
9. 사용자 중심의 관리도구

60 60
Ⅲ. 제안 내용
효율적인 관리·운영을 지원하는 분석 모니터링
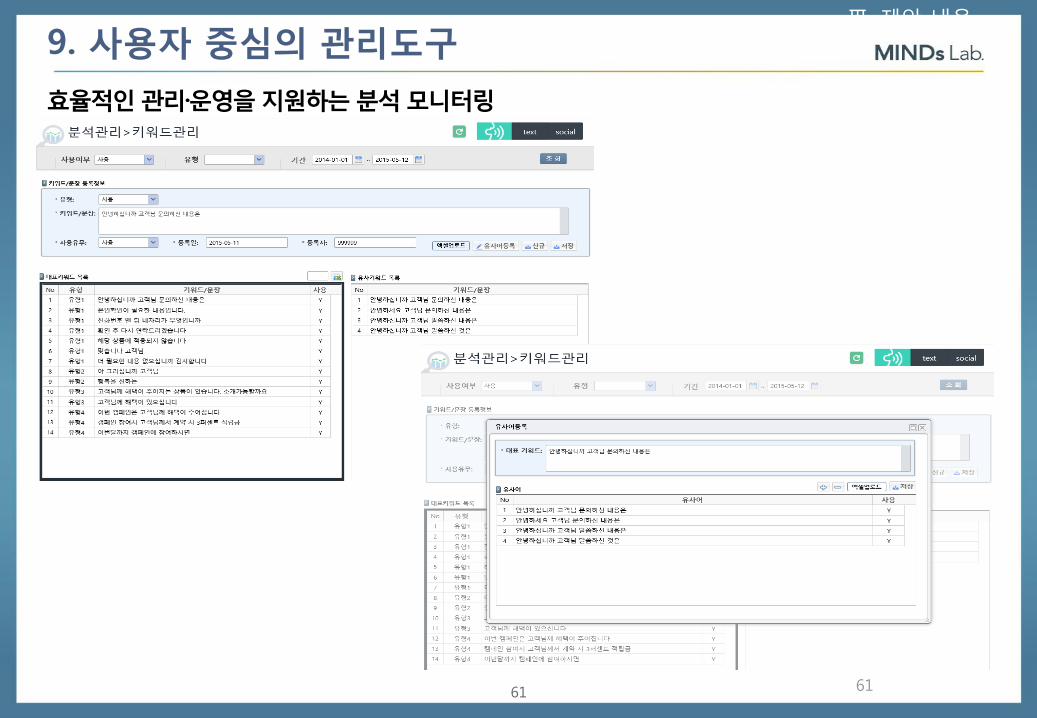
9. 사용자 중심의 관리도구
고빈도 키워드 추출 Taxonomy 정의
키워드 빈도
확인 4753
보험 4752
번호 2914
말씀 2801
감사 2490
상담 2244
전화 2177
해약 2134
금액 1779
대출 1749
가능 1718
연락 1650
계약 1593
… …
분류 키워드
불만원인 지급, 입원, 치료, 약, 통원, 진료, …
사고유형 사망, 상해, 재해, 교통, 자살, …
상품명 변액CI보험, 트리플케어통합종신보험, …
상품유형 대출, 연금, CI, 변액, 종신, 저축, 실손, …
상품속성 납입, 보험료, 환급, 보장, 이자, 보험금, 증권, …
신체부위 위, 간, 뇌, 맹장, 머리, 피부, 눈, 대장, 심장, 혈관, …
질병/증상 암, 장애, 골절, 신경, 성인병, 정신질환, 맹장, …
치료기관 병원, 내과, 한방병원, 안과, 정신병원, 치과, 신경외과, …
치료법 수술, 시술, 처방, 삽입술, 절제술, 조형술,
해지 관련 VOC Sampling
VOC 데이터
음성 VOC 녹취
VOC 텍스트 언어분석
61 61
Ⅲ. 제안 내용
효율적인 관리·운영을 지원하는 분석 모니터링
9. 사용자 중심의 관리도구
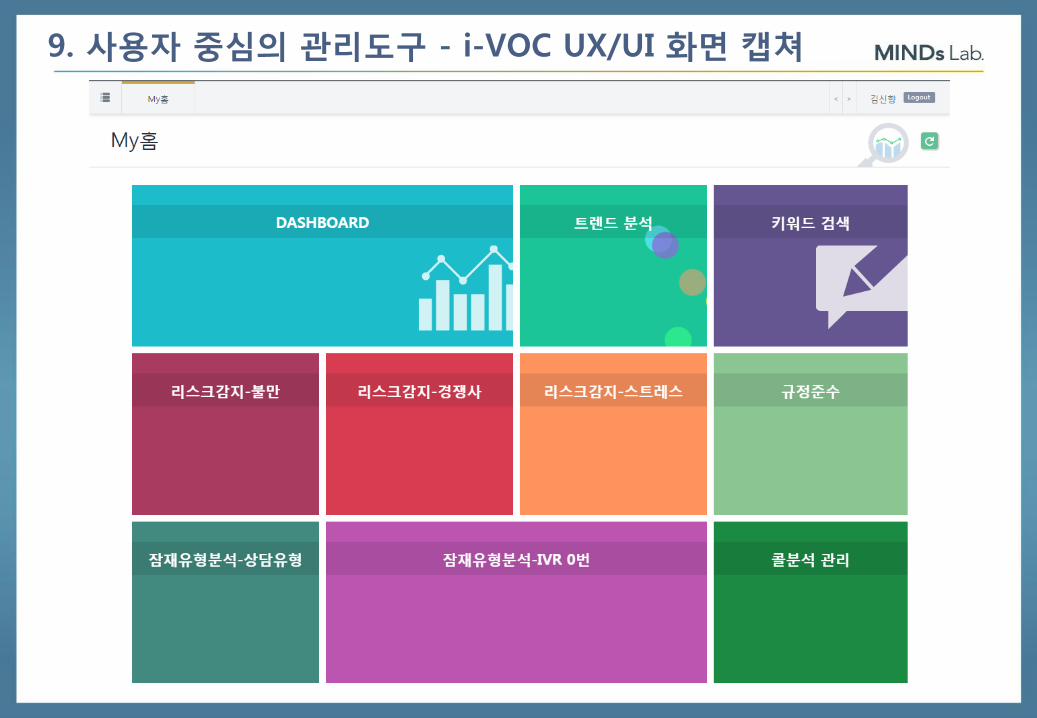
62
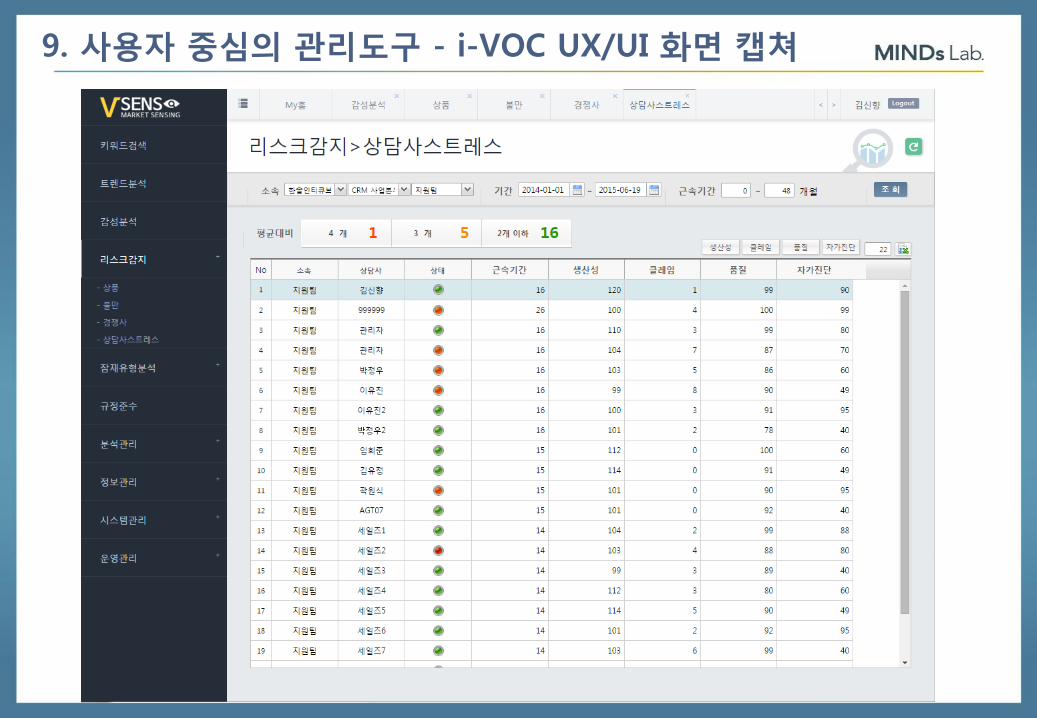
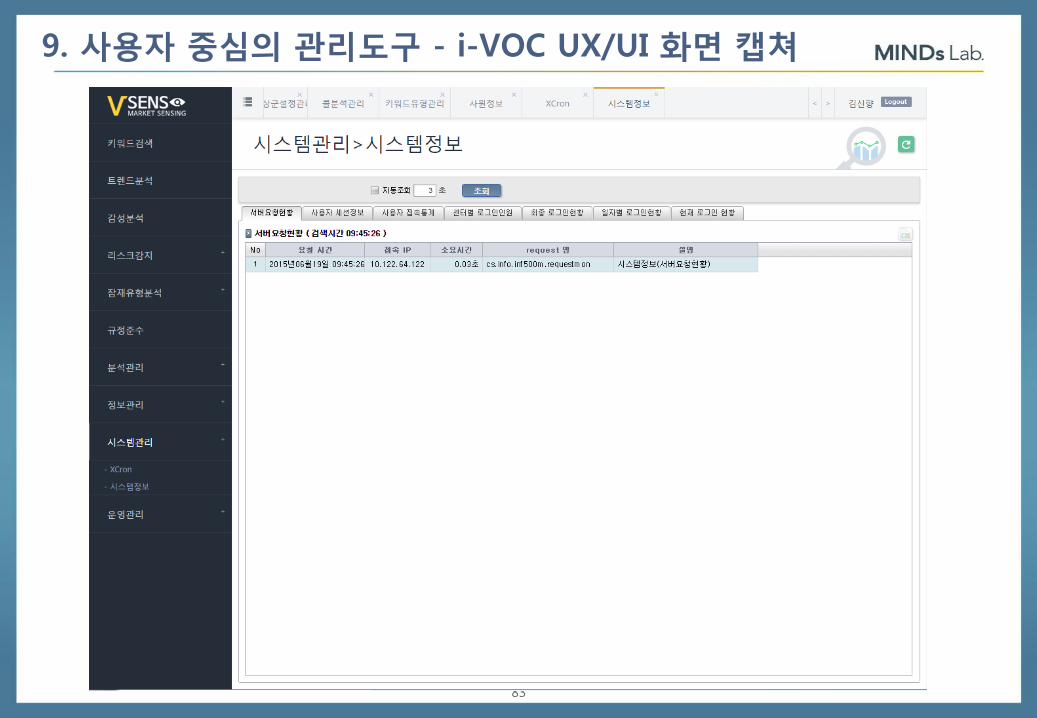
9. 사용자 중심의 관리도구 - i-VOC UX/UI 화면 캡쳐

63
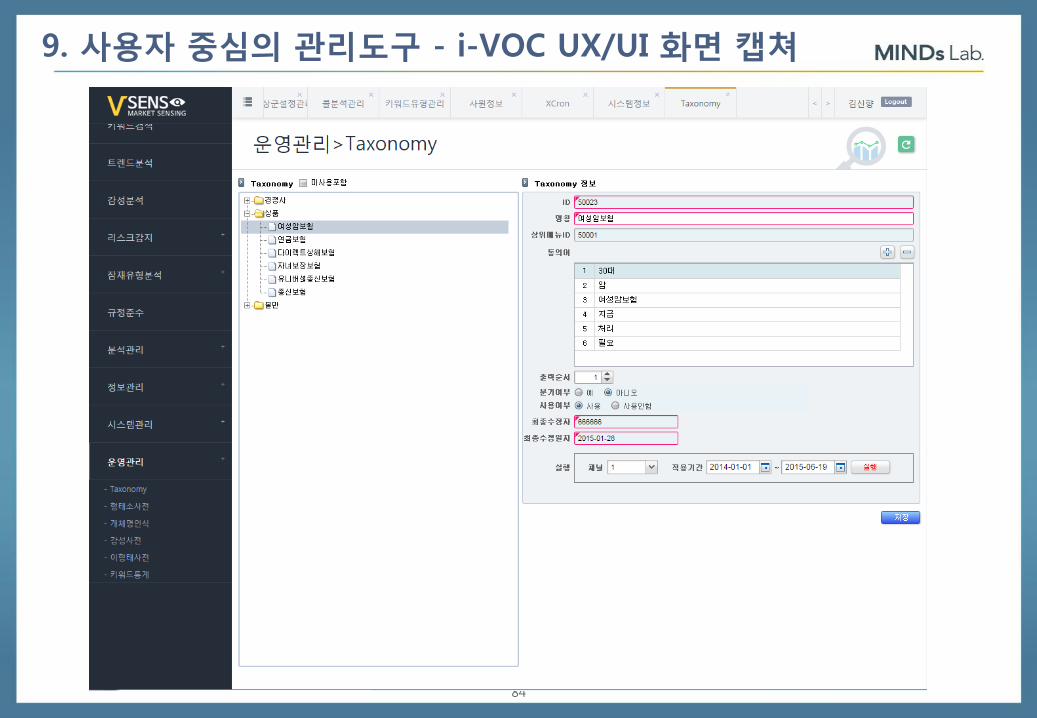
9. 사용자 중심의 관리도구 - i-VOC UX/UI 화면 캡쳐
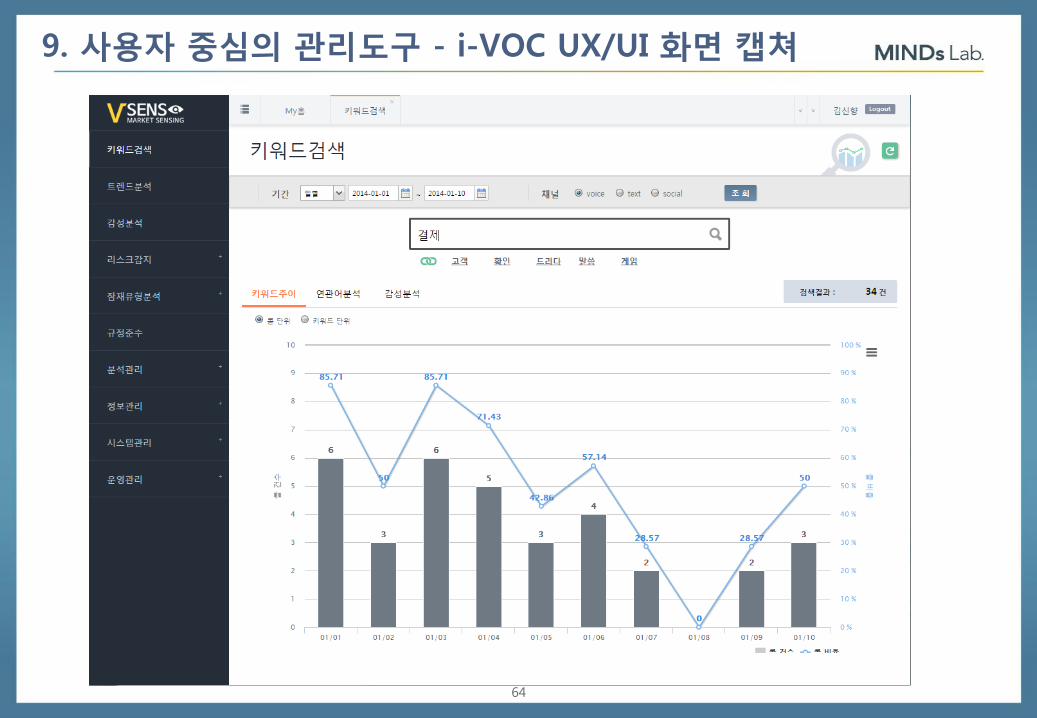
64
9. 사용자 중심의 관리도구 - i-VOC UX/UI 화면 캡쳐
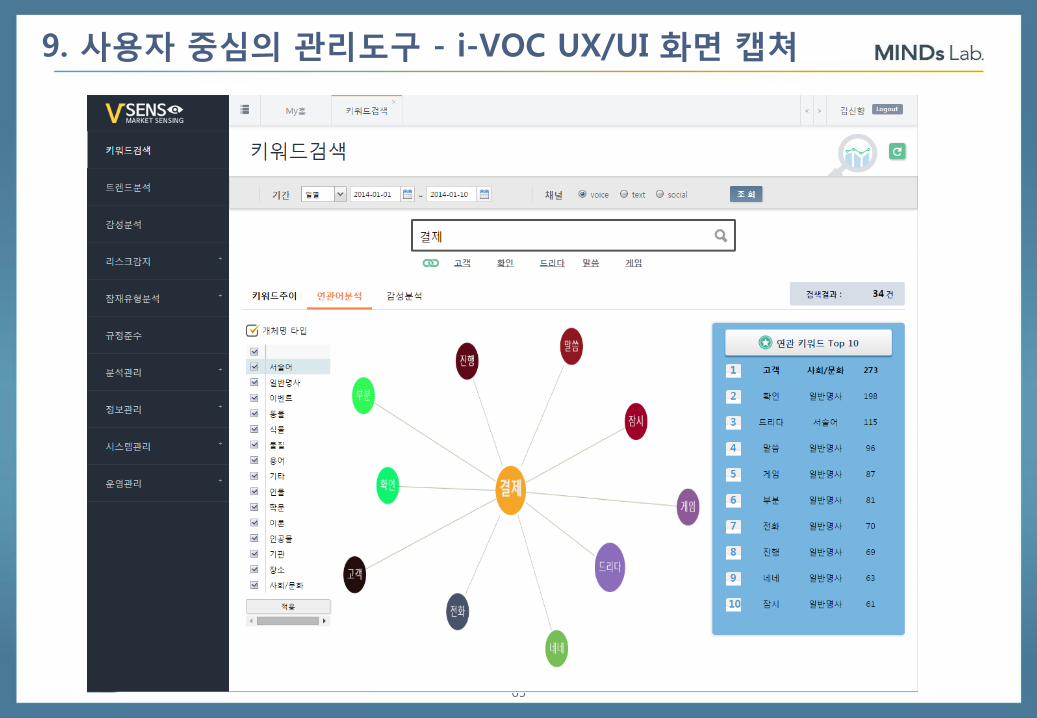
65
9. 사용자 중심의 관리도구 - i-VOC UX/UI 화면 캡쳐

66
9. 사용자 중심의 관리도구 - i-VOC UX/UI 화면 캡쳐

67
9. 사용자 중심의 관리도구 - i-VOC UX/UI 화면 캡쳐

68
9. 사용자 중심의 관리도구 - i-VOC UX/UI 화면 캡쳐
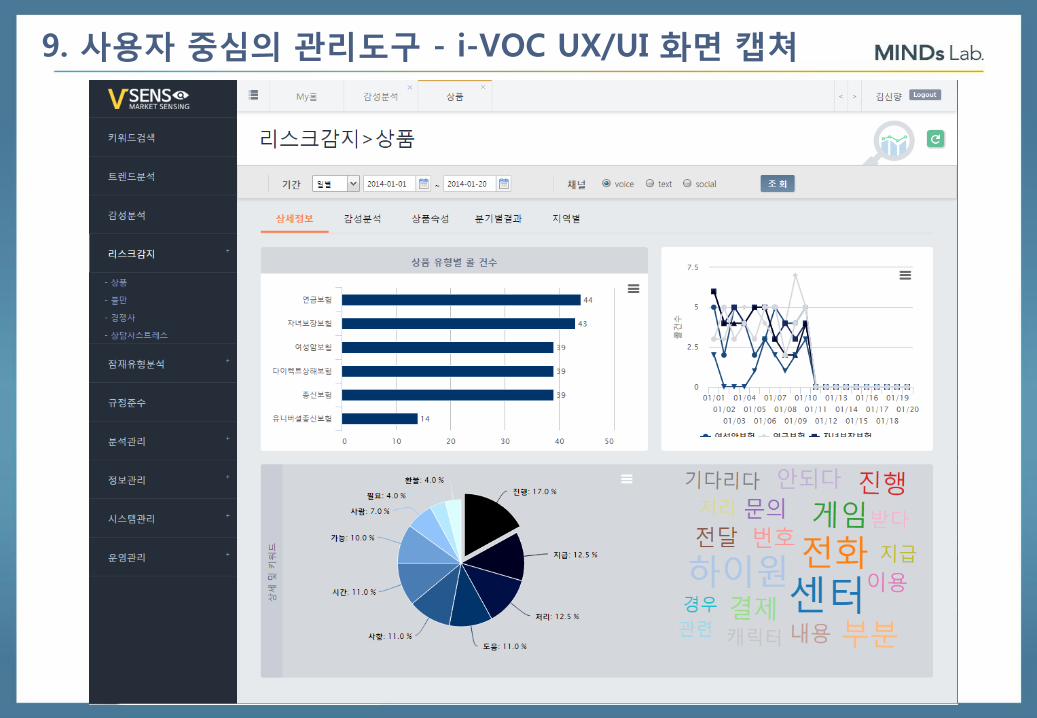
69
9. 사용자 중심의 관리도구 - i-VOC UX/UI 화면 캡쳐

70
9. 사용자 중심의 관리도구 - i-VOC UX/UI 화면 캡쳐

71
9. 사용자 중심의 관리도구 - i-VOC UX/UI 화면 캡쳐
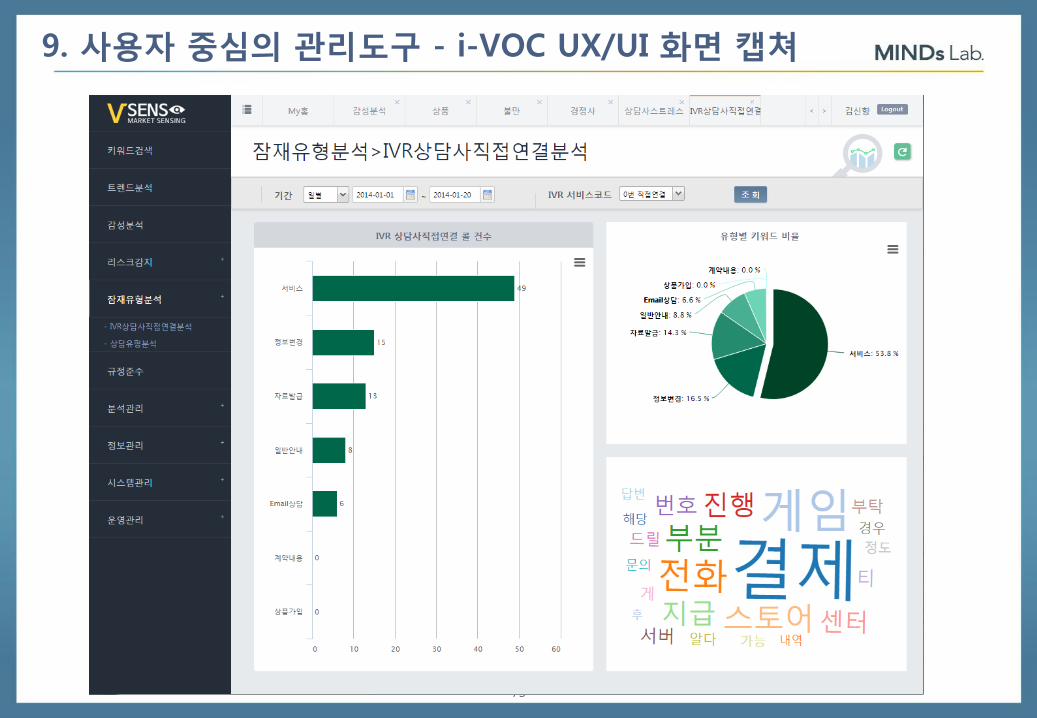
72
9. 사용자 중심의 관리도구 - i-VOC UX/UI 화면 캡쳐
73
9. 사용자 중심의 관리도구 - i-VOC UX/UI 화면 캡쳐

74
9. 사용자 중심의 관리도구 - i-VOC UX/UI 화면 캡쳐
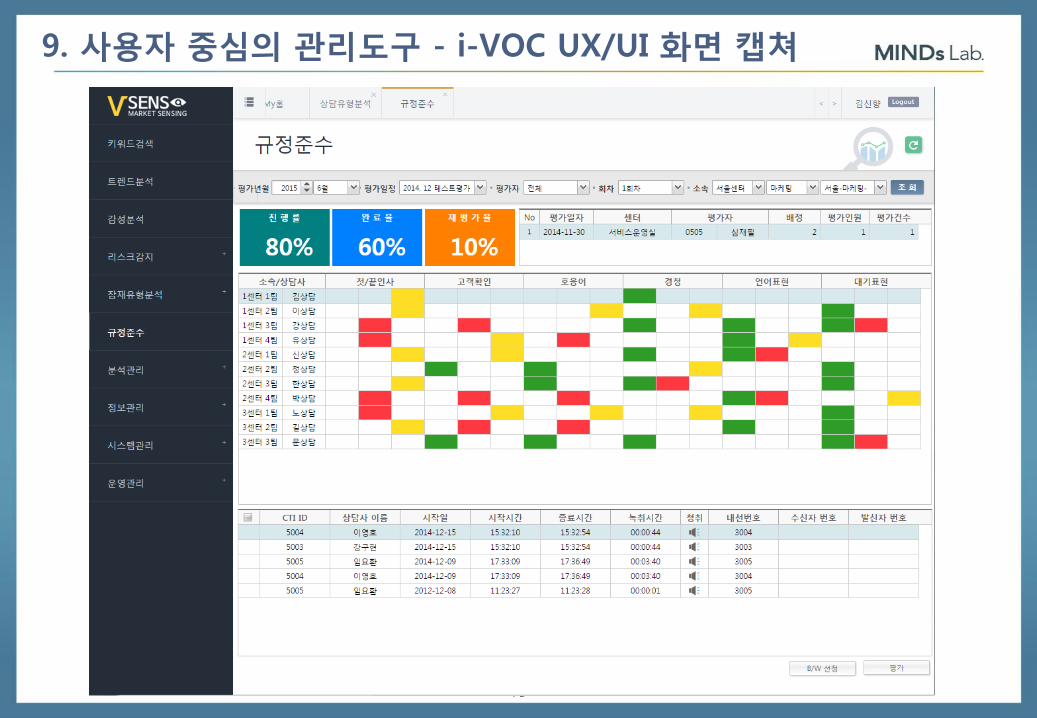
75
9. 사용자 중심의 관리도구 - i-VOC UX/UI 화면 캡쳐
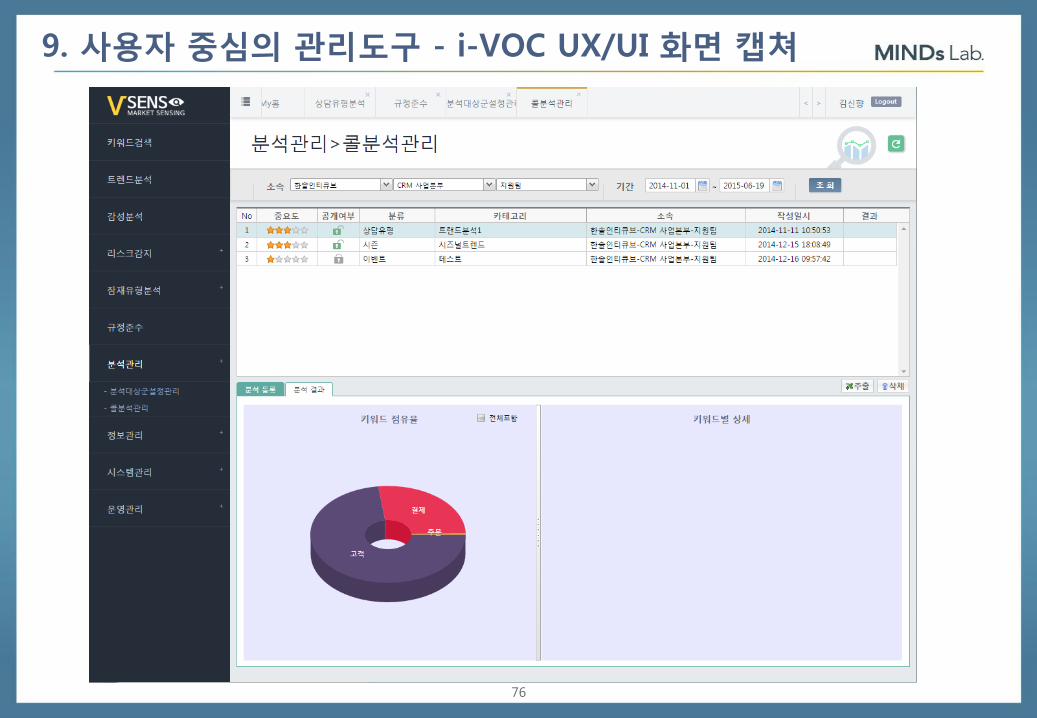
76
9. 사용자 중심의 관리도구 - i-VOC UX/UI 화면 캡쳐
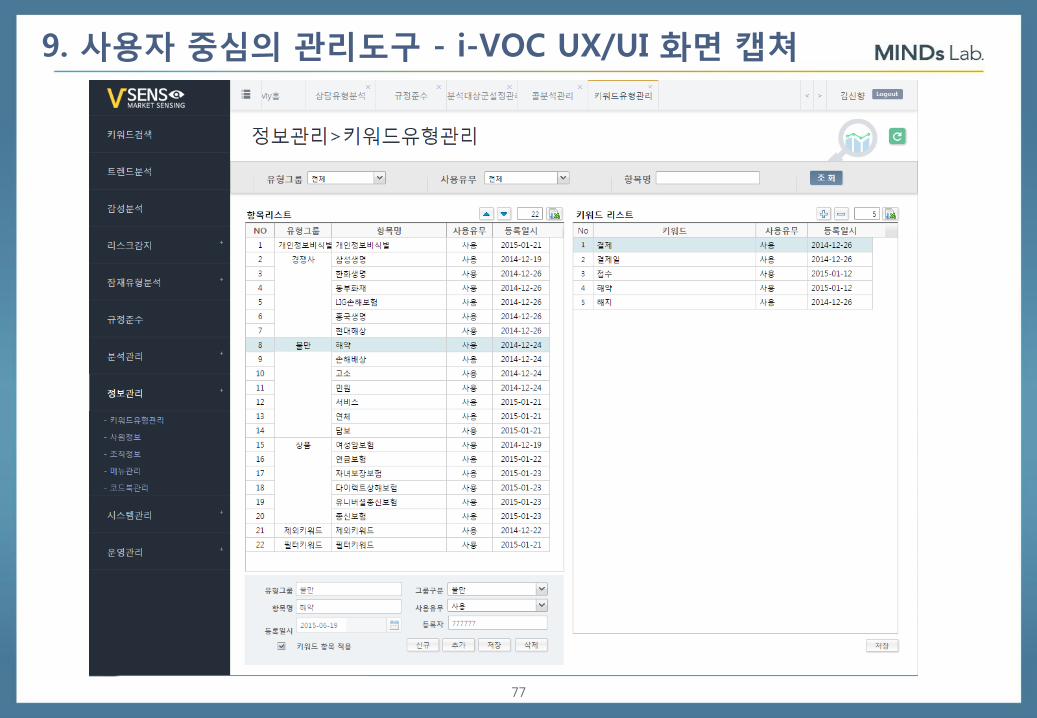
77
9. 사용자 중심의 관리도구 - i-VOC UX/UI 화면 캡쳐

78
9. 사용자 중심의 관리도구 - i-VOC UX/UI 화면 캡쳐
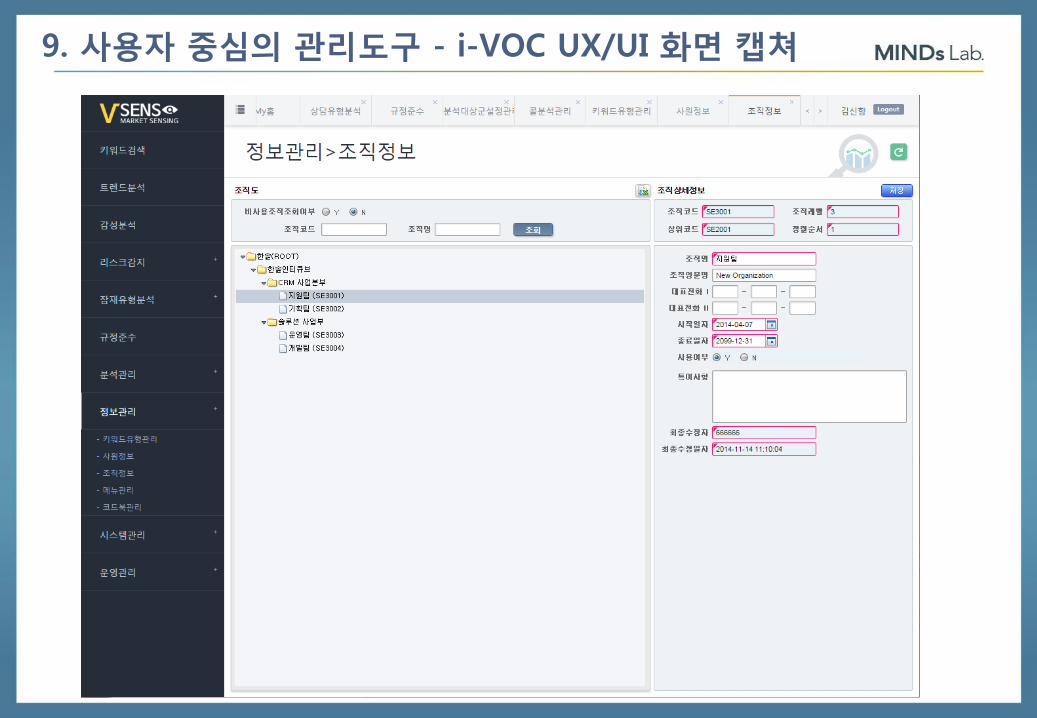
79
9. 사용자 중심의 관리도구 - i-VOC UX/UI 화면 캡쳐
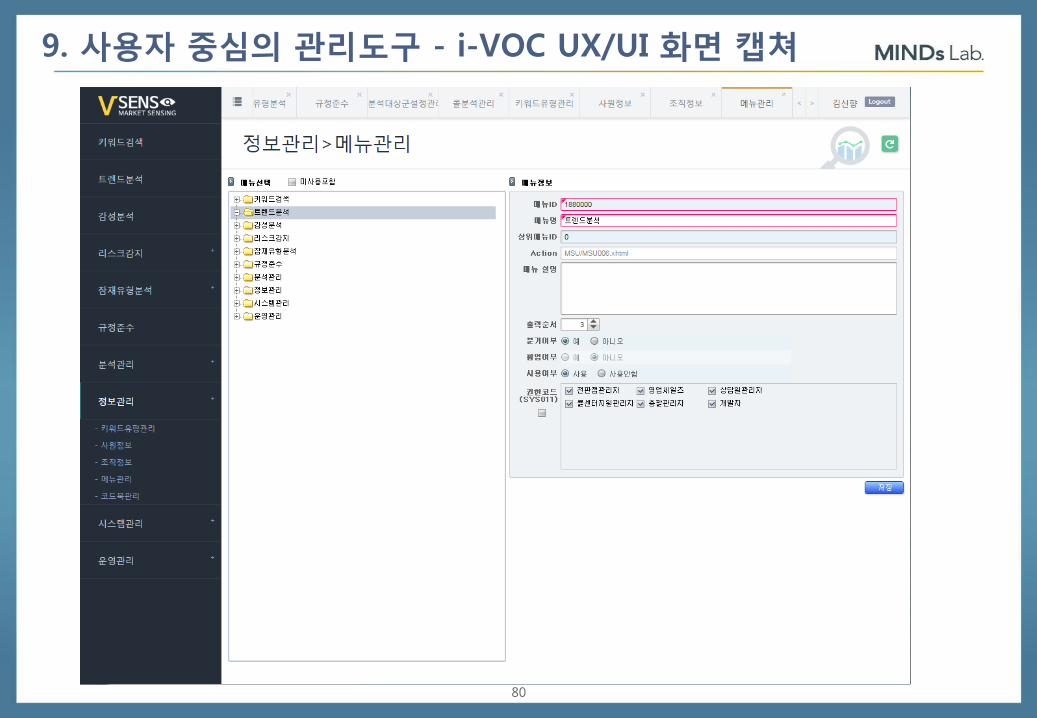
80
9. 사용자 중심의 관리도구 - i-VOC UX/UI 화면 캡쳐
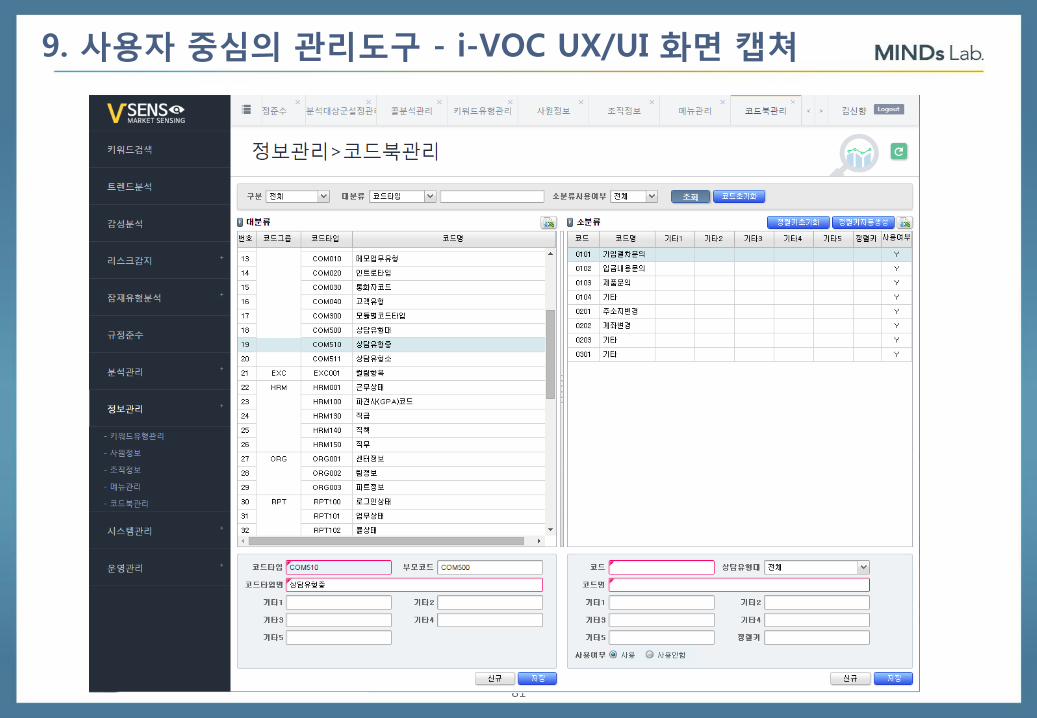
81
9. 사용자 중심의 관리도구 - i-VOC UX/UI 화면 캡쳐

82
9. 사용자 중심의 관리도구 - i-VOC UX/UI 화면 캡쳐
83
9. 사용자 중심의 관리도구 - i-VOC UX/UI 화면 캡쳐
84
9. 사용자 중심의 관리도구 - i-VOC UX/UI 화면 캡쳐

85
9. 사용자 중심의 관리도구 - i-VOC UX/UI 화면 캡쳐

86
9. 사용자 중심의 관리도구 - i-VOC UX/UI 화면 캡쳐

87
9. 사용자 중심의 관리도구 - i-VOC UX/UI 화면 캡쳐

88
9. 사용자 중심의 관리도구 - i-VOC UX/UI 화면 캡쳐
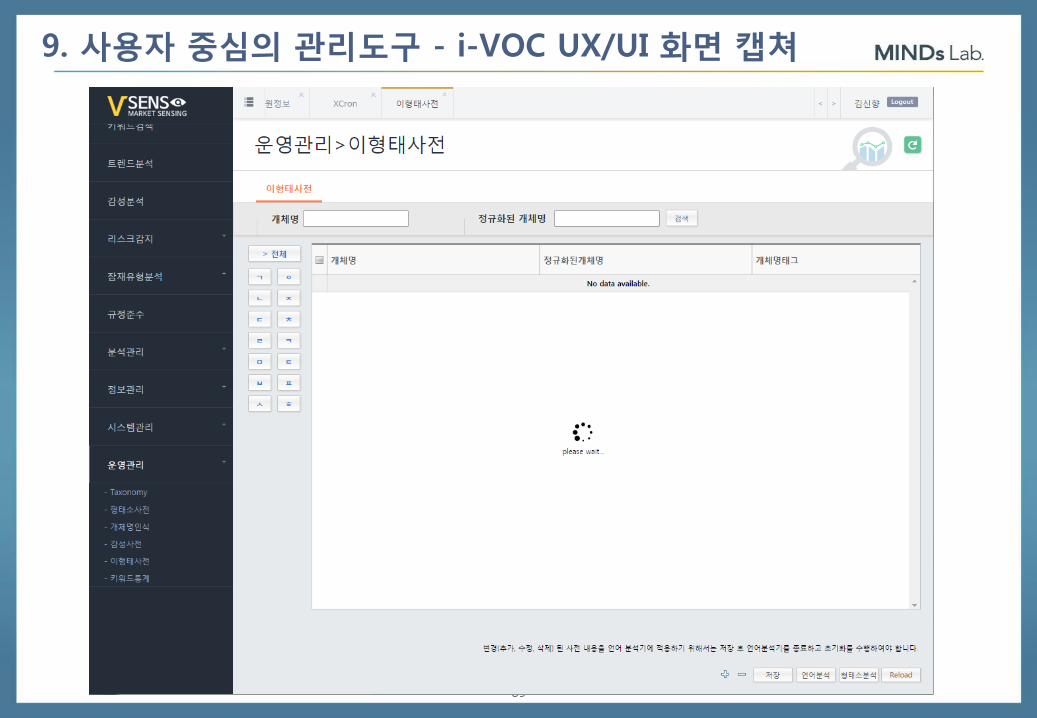
89
9. 사용자 중심의 관리도구 - i-VOC UX/UI 화면 캡쳐
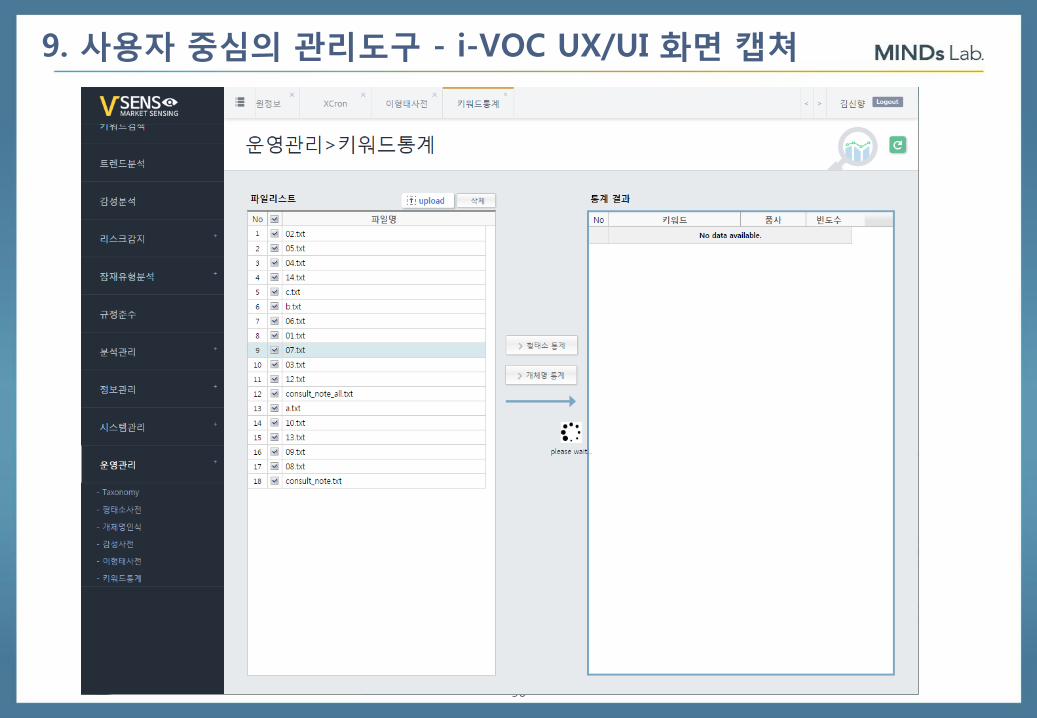
90
9. 사용자 중심의 관리도구 - i-VOC UX/UI 화면 캡쳐
Module C 소셜 빅데이터
92 92
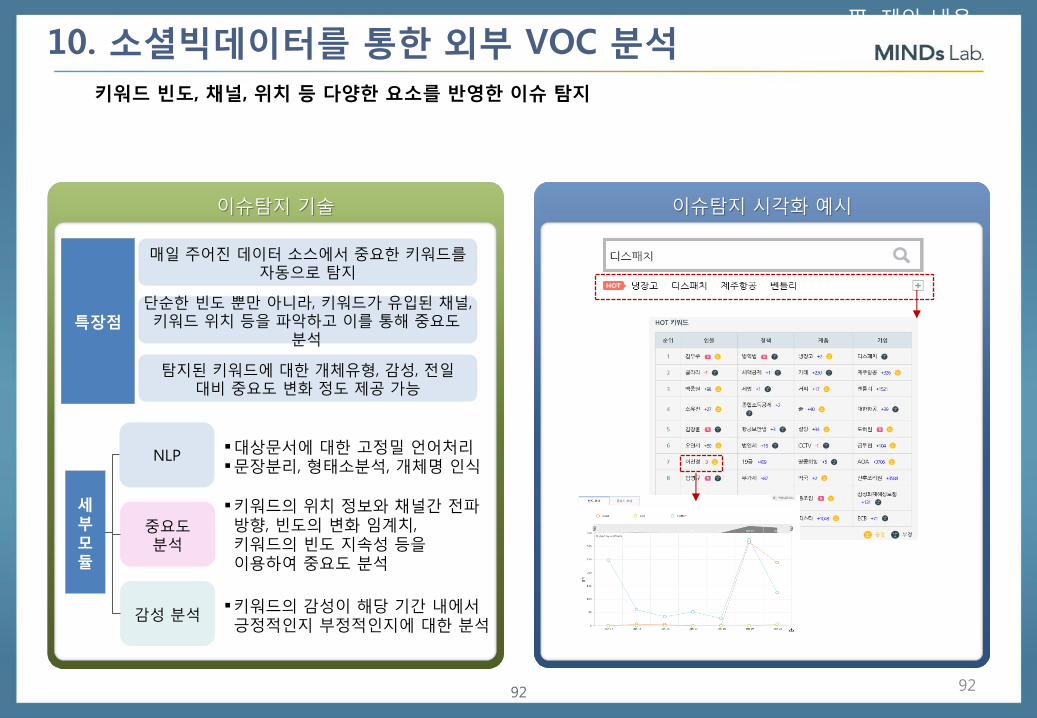
키워드 빈도, 채널, 위치 등 다양한 요소를 반영한 이슈 탐지
Ⅲ. 제안 내용
이슈탐지 기술 이슈탐지 시각화 예시
세부 모듈
NLP
중요도 분석
감성 분석
특장점
대상문서에 대한 고정밀 언어처리 문장분리, 형태소분석, 개체명 인식
키워드의 위치 정보와 채널간 전파 방향, 빈도의 변화 임계치, 키워드의 빈도 지속성 등을 이용하여 중요도 분석
키워드의 감성이 해당 기간 내에서 긍정적인지 부정적인지에 대한 분석
매일 주어진 데이터 소스에서 중요한 키워드를 자동으로 탐지
단순한 빈도 뿐만 아니라, 키워드가 유입된 채널, 키워드 위치 등을 파악하고 이를 통해 중요도
분석
탐지된 키워드에 대한 개체유형, 감성, 전일 대비 중요도 변화 정도 제공 가능
10. 소셜빅데이터를 통한 외부 VOC 분석

93 93
고객 관심사의 시각적 파악을 지원하는 연관어 분석
Ⅲ. 제안 내용
연관어 분석 기술 연관어 시각화 예시
특장점
동시에 한 문장 또는 한 문서에 출현한 키워드 집합을 추출하고, 이에 대한 개체 유형에 따라
연관어를 선택할 수 있음
2차 연관어 정보를 저장하며, 용언에 대한 연관 정보도 활용할 수 있도록 관리함
형태소 분석 개체명 인식
문장 단위 연관어 추출
문서 단위 연관어 추출
2차 연관어 추출
10. 소셜빅데이터를 통한 외부 VOC 분석
94
94
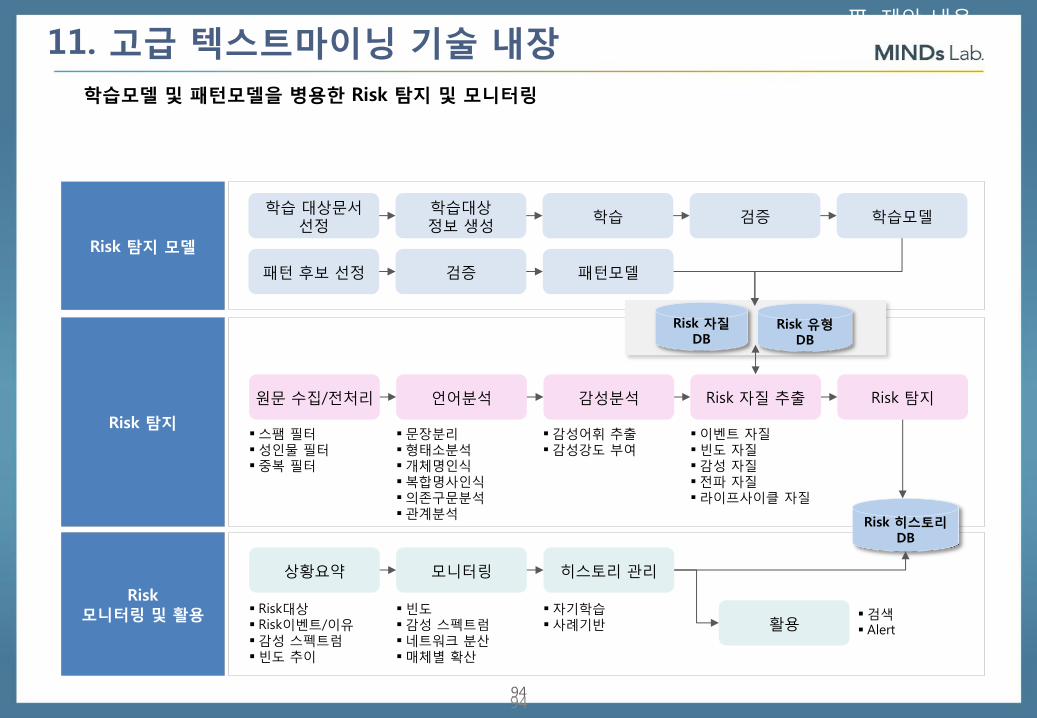
학습모델 및 패턴모델을 병용한 Risk 탐지 및 모니터링
Ⅲ. 제안 내용
Risk 탐지 모델
Risk 탐지
Risk 모니터링 및 활용
학습 대상문서 선정
학습대상 정보 생성
학습 검증
패턴 후보 선정 검증 패턴모델
원문 수집/전처리 언어분석 감성분석 Risk 자질 추출 Risk 탐지
Risk 자질 DB
Risk 유형 DB
Risk 히스토리 DB
이벤트 자질 빈도 자질 감성 자질 전파 자질 라이프사이클 자질
문장분리 형태소분석 개체명인식 복합명사인식 의존구문분석 관계분석
스팸 필터 성인물 필터 중복 필터
감성어휘 추출 감성강도 부여
상황요약 모니터링 히스토리 관리
활용 Risk대상 Risk이벤트/이유 감성 스펙트럼 빈도 추이
빈도 감성 스펙트럼 네트워크 분산 매체별 확산
자기학습 사례기반
검색 Alert
학습모델
94
11. 고급 텍스트마이닝 기술 내장

95
도메인별 Risk 탐지
공공기관 갈등, 경쟁, 법적조치, 법정판결, 부정여론, 소송, 시위, 위법행위, 정보유출, 제재, 조사 등
인물 갈등, 건강악화, 경쟁, 법적조치, 법정판결, 부정여론, 사퇴요구, 소송, 시위, 위법행위, 정보유출, 조사, 징계
스마트기기 가격하락, 결함, 경쟁, 부정여론, 위법행위, 정보유출, 제재, 판매감소 등
먹거리 가격상승, 가격하락, 리콜, 부정여론, 불매운동, 위법행위, 유해식품, 제재, 판매감소 등
자동차 가격하락, 결함, 경쟁, 리콜, 부정여론, 판매감소 등 IT기업 갈등, 경영위기, 경쟁, 법정판결, 부정여론, 불매운동, 사업종료, 소송, 위법행위, 정보유출, 조사, 제재 등
▶ Risk 도메인 및 Risk 예시
▶ Risk 탐지 예시
원문
삼성전자가 지난해 4분기 영업이익이 직전 분기보다 18.31%나 감소한 8조3000억원으로 `어닝쇼크`를 기록했다.
추출된 Risk 자질
[삼성전자]-[영업이익-감소]-[경영위기] [삼성전자]-[어닝쇼크]-[경영위기]
글로벌 신용평가사 무디스가 LG전자의 신용등급을 하향 조정했다.
[LG전자]-[신용등급-하락]-[경영위기]
지난달 현대차는 작년 1월보다 0.3% 감소한 411만508대를, 기아차는 1.3% 줄어든 25만7천331대를 해외 시장에서 판매했다.
[현대자동차]-[판매-감소]-[판매감소] [기아자동차]-[판매-감소]-[판매감소]
질병 사망, 질병발생 등 … …
95
11. 고급 텍스트마이닝 기술 내장
96 96
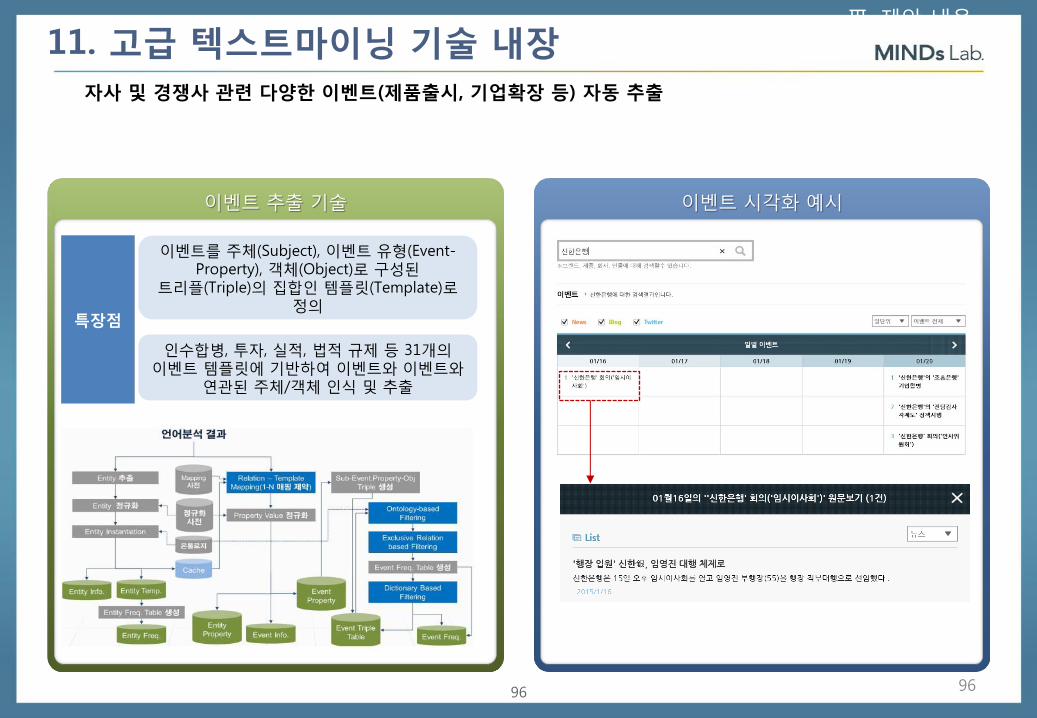
자사 및 경쟁사 관련 다양한 이벤트(제품출시, 기업확장 등) 자동 추출
Ⅲ. 제안 내용
이벤트 추출 기술 이벤트 시각화 예시
특장점
이벤트를 주체(Subject), 이벤트 유형(Event-Property), 객체(Object)로 구성된
트리플(Triple)의 집합인 템플릿(Template)로 정의
인수합병, 투자, 실적, 법적 규제 등 31개의 이벤트 템플릿에 기반하여 이벤트와 이벤트와
연관된 주체/객체 인식 및 추출
11. 고급 텍스트마이닝 기술 내장

97 97
강력한 자동탐지 및 풍부한 감성을 지원하는 텍스트분석 엔진 제공 – 기계학습 모델을 적용 및 분석목적을 반영한 내용 기반 자동분류
Ⅲ. 제안 내용
내용 기반 자동분류 기술 내용 기반 자동분류 예시
a1
a2
a3
b3
b1
b2 c1
c3
c2
a1 b2 b3
<예금> <대출> <외환>
a11 a12 …
MINDs Classifier
NLP 학습기 분류기
… … <단순문의> <정보변경> <이자불만>
분류 대상 문서
세부 모듈
NLP
분류 학습
분류
특장점
분류 대상문서에 대한 고정밀 언어처리 문장분리, 형태소분석, 개체명 인식, 구문 분석
최신 기계학습 모델 적용 CRF(Conditional Random Fields), SVM(Support Vector Machine)
평면적 계층 구조 분류 및 다중 범주 자동분류 수행
고성능 언어분석 기술을 통한 문맥 파악
VOC와 같이 특정 영역의 전문 컨텐츠에 대한 높은 수준의 분석 정확도 제공
다양한 영역(VOC, 뉴스, 블로그, 트위터 등)의 특징에 적합한 자질을 선정 및 활용하여 확장
가능
11. 고급 텍스트마이닝 기술 내장
Module D 산업별 분석

99 99
경영이슈 해결을 위한 체계적인 Insight 도출
Ⅲ. 제안 내용
C. Keyword 정제
E. Visualization 및 수정/보완 D. Data 수집 및 MI 작성
A. 활용목적 정의 B. 분석 View 및 Keyword 선정
P. 검증
12. 산업별 분석 View와 키워드 탐지 내장

100
Ⅲ. 제안 내용
경영이슈 해결을 위한 체계적 Insight 도출 - 시각화 예시
M.I. (Market Intelligence): 경쟁 관계 분석
■해당 산업군/업종에 대한 시장 경쟁 구도 분석
■일자별, 시간별 경쟁 구도 현황 및 빈도별 추이 정보 제공
■뉴스, 블로그, 트위터 별 분류 분석 가능
■경쟁 기업/브랜드 별 소비자 인식 분석 통한 마케팅 전략 활
용
■해당 분석 정보 엑셀 다운로드 제공
사람들이 말하는 기업/브랜드 경쟁구도
경쟁 빈도
■기업/브랜드 간 경쟁빈도가 강할수록 붉은 색으로 표시되며,
사람들이 실제적으로 가장 활발하게 언급하는 경쟁 구도를 보여줌
100
12. 산업별 분석 View와 키워드 탐지 내장

101
Ⅲ. 제안 내용
경영이슈 해결을 위한 체계적 Insight 도출 - 시각화 예시
M.I. (Market Intelligence): 산업 동향 분석
■가입 고객사 정보를 기반으로 해당 산업군/업종에서의
해당 기업/브랜드별 실질적 소비자 인식 위치 파악이 가능
■산업 연관어 분석, 구매 채널별 비중 분석, 구매 채널 언급량 추
이,
구매 채널 언급비중 추이 분석, 브랜드별 감성 분석,
산업 이슈 제품군 언급량&언급비중 변화 추이 분석 제공
■해당 산업군/업종에서의 핵심 키워드별 분류/선별 분석이
가능해, 자사 브랜드의 업종 특징별 동향을 쉽게 파악
■뉴스, 블로그, 트위터 별 분류 분석 가능
■일자별, 시간별 경쟁 구도 현황 및 빈도별 추이 정보 제공
■경쟁 기업/브랜드 별 소비자 인식 분석 통한 마케팅 전략 활용
■해당 기업/브랜드 언급 분석 매체별 원문 보기 제공
■해당 분석 정보 엑셀 다운로드 제공
<산업 이슈 변화 추이 – 제품군 언급량>
해당 산업군/업종에서 우리의 위치는?
101
12. 산업별 분석 View와 키워드 탐지 내장

102
경영이슈 해결을 위한 체계적 Insight 도출 - 시각화 예시
Ⅲ. 제안 내용
<연관어> <소비 채널 언급비중 추이> <소비 채널 언급량 추이>
<소비 채널 비중> <브랜드별 감성> <제품군 언급비중>
102
12. 산업별 분석 View와 키워드 탐지 내장
103
Ⅲ. 제안 내용
경영이슈 해결을 위한 체계적 Insight 도출 - 시각화 예시
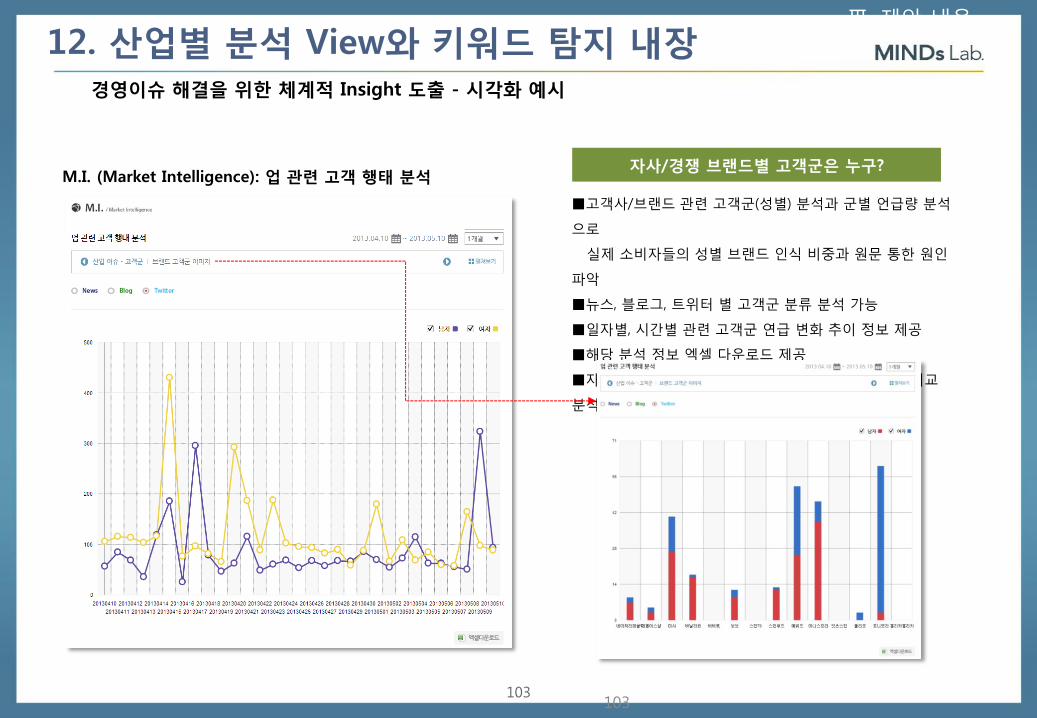
M.I. (Market Intelligence): 업 관련 고객 행태 분석 자사/경쟁 브랜드별 고객군은 누구?
■고객사/브랜드 관련 고객군(성별) 분석과 군별 언급량 분석
으로
실제 소비자들의 성별 브랜드 인식 비중과 원문 통한 원인
파악
■뉴스, 블로그, 트위터 별 고객군 분류 분석 가능
■일자별, 시간별 관련 고객군 연급 변화 추이 정보 제공
■해당 분석 정보 엑셀 다운로드 제공
■자사 및 경쟁 기업/브랜드 제품별 고객군 언급 분포 비교
분석
103
12. 산업별 분석 View와 키워드 탐지 내장

104
Ⅲ. 제안 내용
경영이슈 해결을 위한 체계적 Insight 도출 - 시각화 예시
M.I. (Market Intelligence): 자사 평판 분석 고객이 바라보는 장단점과 이미지는?
■고객사/브랜드 관련 산출된 효과성 연관 핵심 키워드별
자사제품과 경쟁사 제품의 비교 분석 지표를 파악, 약점 보완 및
강점 강화의 제품 경쟁력 및 효과적 마케팅 전략 구축 활용
■브랜드 효과성, 브랜드 신뢰성, 브랜드 세부 제품군 이미지의
다각적 평판 분석과 분석 방법별 관련 핵심 키워드별 추이 제공
■해당 분석 정보 엑셀 다운로드 제공
■뉴스/블로그/트위터별, 일자별 분류 분석 제공
<브랜드 신뢰성 분석> 신뢰성 연관 핵심 키워드별 자사/경쟁사 제품 소비자 인식 분석
<브랜드 세부 제품군 이미지 분석> 제품군 연관 핵심 키워드별
소비자 인식 분석
104
12. 산업별 분석 View와 키워드 탐지 내장
105
Ⅲ. 제안 내용
105
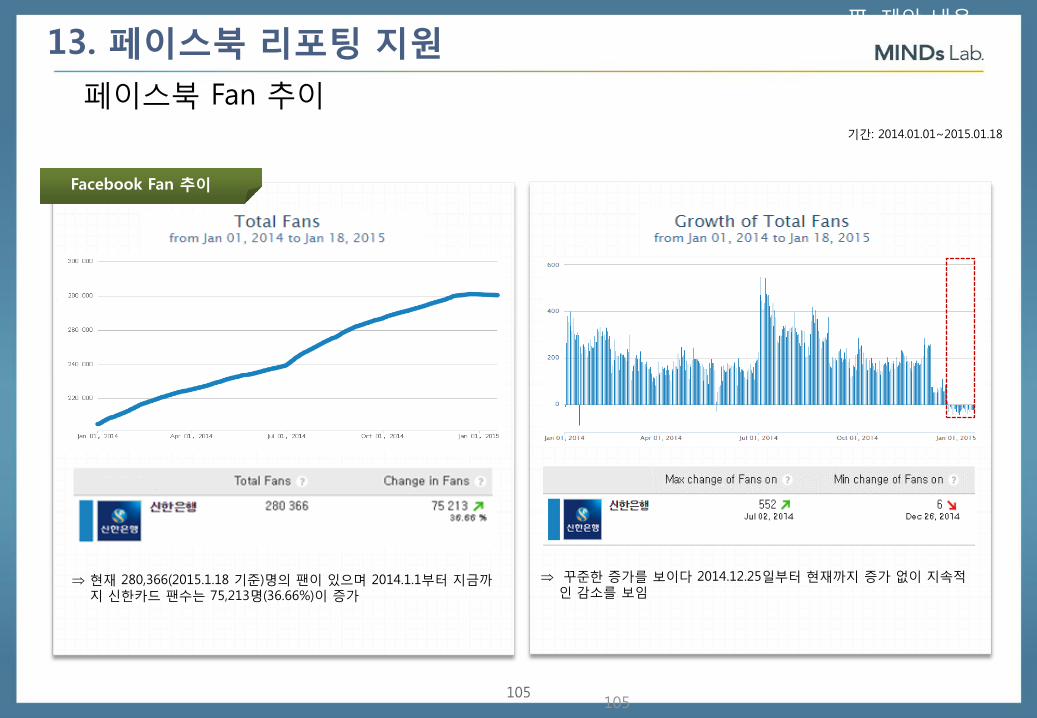
기간: 2014.01.01~2015.01.18
Facebook Fan 추이
현재 280,366(2015.1.18 기준)명의 팬이 있으며 2014.1.1부터 지금까지 신한카드 팬수는 75,213명(36.66%)이 증가
꾸준한 증가를 보이다 2014.12.25일부터 현재까지 증가 없이 지속적인 감소를 보임
13. 페이스북 리포팅 지원
페이스북 Fan 추이

Module E 결과 데이터 구조화
107
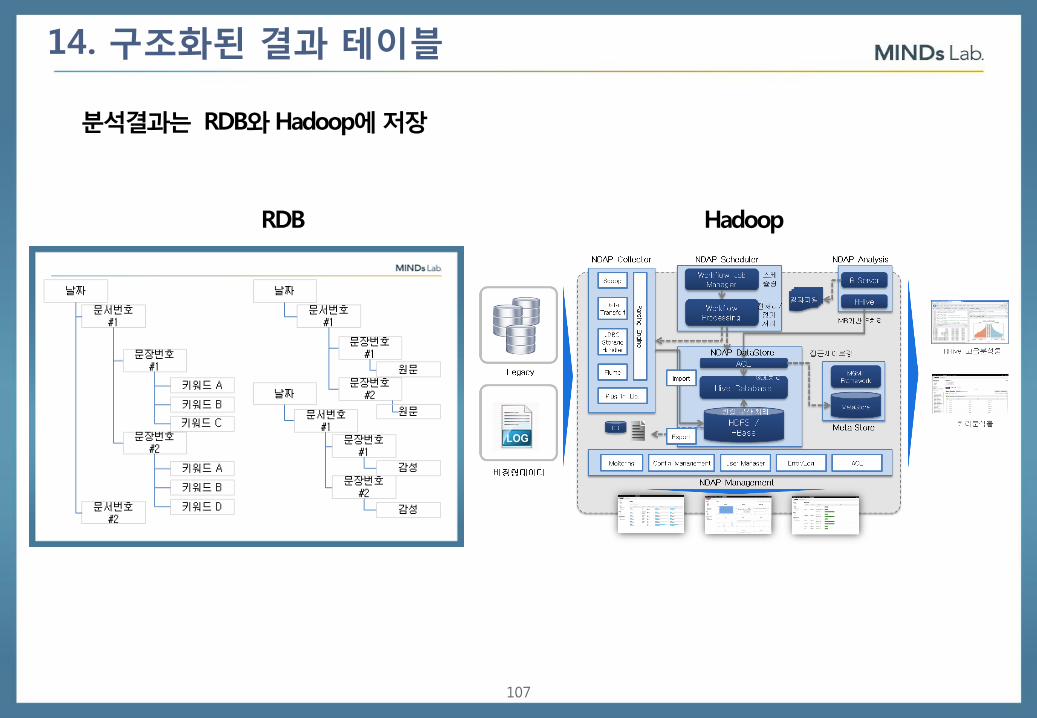
14. 구조화된 결과 테이블
분석결과는 RDB와 Hadoop에 저장
RDB Hadoop

108
POS/Log/교통/위치/결제/통신 데이터 분석
소스 데이터 데이터 처리 활용
Beacong 등 로그데이터
위치 정보 (3G/4G/Wi-Fi)
교통/위치 분석
결제/통신 분석
유동인구 흐름
상범 및 상권 변동
교통 흐름
관광 인구 변동
가족소비정보 처리
기상정보 분석
카드결제 정보처리
통신사 이용
Brand & Competitive
Analysis
Market Research
Customer Segmentation
Marketing Measurement
Influencer Marketing
Customer Support
New Product Development
…
14. 구조화된 결과 테이블 -Big Data Architecture 예시
Analyzed Big Data
관리도구
페이스북/인스타그램 리포팅
POS
음성분석 텍스트분석
감성 분석
이슈 군집분석
어휘 중요도 분석
연관어 분석
Social Big Data Analysis
소셜분석
경쟁환경 / 브랜드 이미지
업의 이슈 흐름
마켓 /소비자 트렌드
기준정보 관리 원천데이터 관리 운영 관리
Fan Post Interaction ER …
결과 구조화
Power User
시각화
활용 목적 정의
End User
관점/키워드 검토
시각화 요소 검토
시각화 구현
대시보드 구성
모니터링
예측
경보
…
Analysis Model
Internal Structured Data
활용목적 別 정제 Data
이벤트/리스크 분석
POS/Log분석 웹 로그 분석
모바일 로그 분석
ERP 분석 BI 분석
비콘 로그 분석 결제 정보
(내국인/외국인)
상점 정보 (전화번호/위치)
이용정보 (TV/Navi)
기상 정보
교통 정보
관광 정보
가족소비 정보
고객 정보
상품/서비스 정보
거래 정보
…ㅋ
뉴스
블로그
트위터
…
이용행태 정보
상권분석 정보
유동인구 정보
내부
외부 통신사
외부 공공
외부 통신사
외부 소셜
학습데이터 준비
음성/언어모델 학습
Full-text Dictation
Keyword Spotting
음성인식
Real-time Recognition
Batch Recognition
POS 데이터 분석

Module F 분석 및 데이터 시각화

110
15. 다양한 시각화 지원
BI Tool을 활용한 시각화

111
15. 다양한 시각화 지원 _ 웹분석화면

112
Pre-made 표준리포트 및 차트
유형별 빈도 및 추이 유형별 통게 보고서
15. 다양한 시각화 지원 _ 빅데이터 분석

113
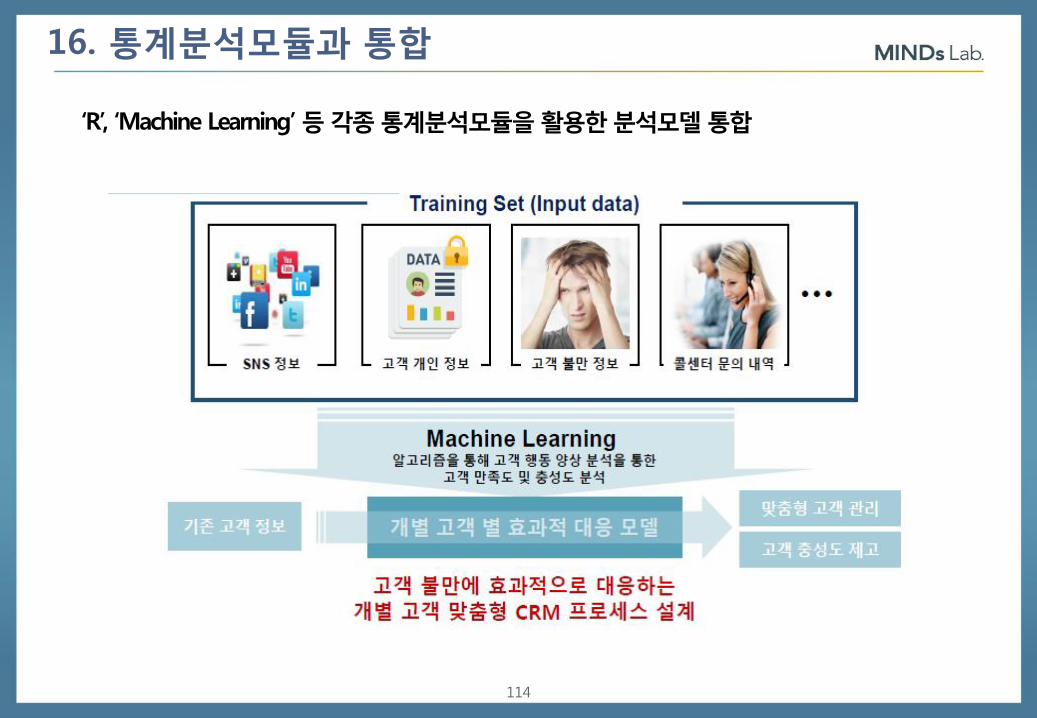
16. 통계분석모듈과 통합
‘R’, ‘Machine Learning’ 등 각종 통계분석모듈을 활용한 분석모델 통합
114
16. 통계분석모듈과 통합
‘R’, ‘Machine Learning’ 등 각종 통계분석모듈을 활용한 분석모델 통합

115
17. 착한 도입비용
비용 효과성
도입 비용 (Acquisition Costs)
효율적인 학습체계를 통한 비용 절감
학습 데이터 구축방식 용이성 및 효율성
음향모델 학습을 위한 텍스트(형태소)분석 및 발음변환(G2P:Grapheme to Phoneme) 자동화
외산 엔진 대비 저렴한 도입 비용
유지관리 비용 (Maintenance Costs)
음성인식 성능 유지
새로운 상품/어휘 발생시 빠른 유지보수
신조어 학습 시 비용효과성
텍스트 분석 전문 도구 지원
새로운 언어현상 조기탐지 및 언어모델 구축 피드백
외산 엔진 대비 저렴한 유지보수 비용
다양한 도입 프로그램 제공
고객 상황 및 요구에 따라 구매, 리스, 임대 등 다양한 도입 프로그램 제공
다양한 검토를 통해 도입 필요성을 인지하고 및 명확한 목표(기대효과)를 설정한 후, 충분한 예산을 확보한 고객의 경우 구매를 통한 도입 추천
다양한 검토를 거쳐 필요성 및 목표를 명확히 했으나 충분한 예산을 확보하지 못한 고객의 경우 리스를 통한 도입 추천
충분한 검토가 미흡하거나 예산확보가 여의치 않은 고객의 경우 임대를 통한 도입 추천
i-VOC 특징
최고의 가격 대비 성능
고객 상황에 따른 다양한 도입 프로그램 제공
116
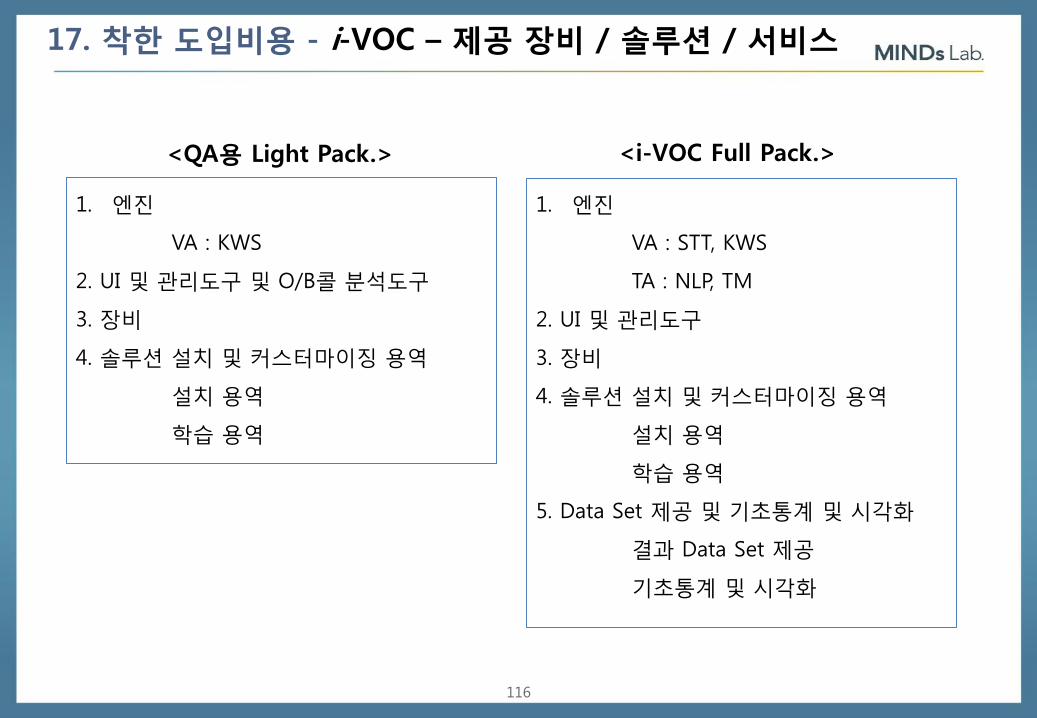
17. 착한 도입비용 - i-VOC – 제공 장비 / 솔루션 / 서비스
1. 엔진
VA : KWS
2. UI 및 관리도구 및 O/B콜 분석도구
3. 장비
4. 솔루션 설치 및 커스터마이징 용역
설치 용역
학습 용역
<QA용 Light Pack.>
1. 엔진
VA : STT, KWS
TA : NLP, TM
2. UI 및 관리도구
3. 장비
4. 솔루션 설치 및 커스터마이징 용역
설치 용역
학습 용역
5. Data Set 제공 및 기초통계 및 시각화
결과 Data Set 제공
기초통계 및 시각화
<i-VOC Full Pack.>

Copyright © 2015 Minds Lab. All rights reserved
463-100, 12F, U-Space 1-B, 660, Daewangpangyo-ro, Bundang-gu, Seongnam-si, Gyeonggi-do, Korea T.031-625-4340 F.031-625-4119 | www.mindslab.co.kr www.mindsinsight.co.kr
No part of this publication may be circulated, quoted, or reproduced for distribution outside the client organization without prior written approval.
Big Data and Machine Learning
The next frontier for innovation, competition, and productivity





























