Embed Size (px)
Citation preview

From Hadoop to Spark
Introduction Hadoop and Spark Comparison
From Hadoop to Spark

HI, I’m Sujee Maniyam
• Founder / Principal @ ElephantScale • Consulting & Training in Big Data • Spark / Hadoop / NoSQL /
Data Science
• Author – “Hadoop illuminated” open source book – “HBase Design Patterns”
• Open Source contributor: github.com/sujee
• www.ElephantScale.com
(c) ElephantScale.com 2015
Spark Training available!
2

Webinar Audience
u I am already using Hadoop, Should I go to Spark?
u I am thinking about Hadoop, should I skip Hadoop and go to Spark ?
(c) ElephantScale.com 2015 3

Webinar Outline
u Intro: what is Hadoop and what is Spark?
u Capabilities and advantages of Spark & Hadoop u Best use cases for Spark / Hadoop
u From Hadoop to Spark – how to?
Webinar: From Hadoop to Spark (c) ElephantScale.com 2015 4

Introduction
Introduction Hadoop and Spark Comparison
From Hadoop to Spark

Hadoop in 20 Seconds
u ‘The Original’ Big data platform
u Very well field tested
u Scales to peta-bytes of data
u Enables analytics at massive scale
(c) ElephantScale.com 2015 6

Hadoop Eco System
Batch Real Time
(c) ElephantScale.com 2015 7
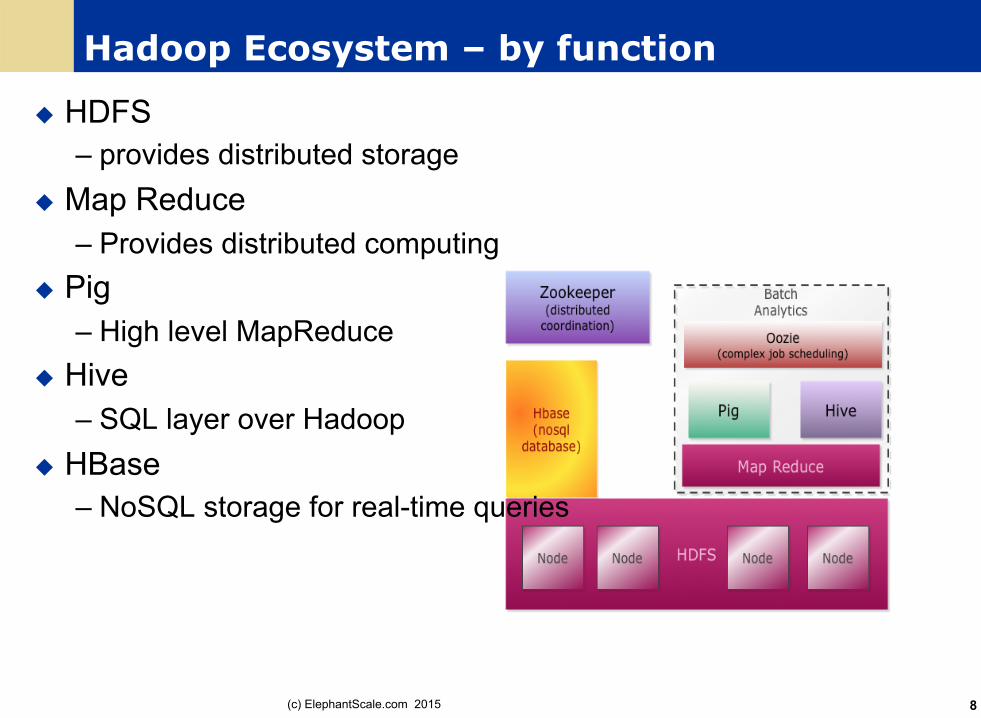
Hadoop Ecosystem – by function
u HDFS – provides distributed storage
u Map Reduce – Provides distributed computing
u Pig – High level MapReduce
u Hive – SQL layer over Hadoop
u HBase – NoSQL storage for real-time queries
(c) ElephantScale.com 2015 8

Hadoop Extended Eco-System
(c) ElephantScale.com 2015
Source : hortonworks
9

Hadoop : Use Cases
u Two modes : Batch & Real Time u Batch use case
– Analytics at large scale (Terra bytes to peta bytes scale) – Analytics times can be minutes / hours.
Depends on • Size of data being analyzed • And type of query
– Examples: • Large ETL work loads • “Analyze clickstream data and calculate top page visits” • “Combine purchase data and click-data and figure out discounts to
apply”
(c) ElephantScale.com 2015 10

Hadoop Use Cases
u Real Time Use Cases do not rely on Map Reduce u Instead we use HBase
– A real-time NoSQL datastore built on Hadoop u Example : Tracking Sensor data
– Store data from millions of sensor – Could be billions of data points – “Find latest reading from a sensor” – This query must be done in
real time (in milli-seconds) u “Needle in HayStack” scenarios
– We look for one / few records within billions
(c) ElephantScale.com 2015 11

Hadoop Reference Architecture (Example)
(c) ElephantScale.com 2015 12
Source : hortonworks

Data Spectrum
(c) ElephantScale.com 2015 13

Big Data Analytics Evolution (v1)
u Decision times : batch ( hours / days) u Use cases:
– Modeling – ETL – Reporting
(c) ElephantScale.com 2015 14

Moving Towards Fast Data (v2)
u Decision time : (near) real time – seconds (or milli seconds)
u Use Cases – Alerts (medical / security) – Fraud detection
(c) ElephantScale.com 2015 15

Current Big Data Processing Challenges u Processing needs outpacing 1st generation tools u Beyond Batch
– Not every one has terra-bytes of data to process – Small – Medium data sets (few hundred gigs) are more prevalent – Data may not be on disk
• In memory • Coming via streaming channels
u MapReduce (MR)’s limitations – Batch processing doesn't fit all needs – Not effective for ‘iterative programming’ (machine learning
algorithms ..etc) – High latency for streaming needs
u Spark is a 2nd generation tool addressing these needs 16 (c) ElephantScale.com 2015

What is Spark?
u Open source cluster computing engine – Very fast: In-memory ops 100x faster than MR
• On-disk ops 10x faster than MR – General purpose: MR, SQL, streaming, machine learning,
analytics – Compatible: Runs over Hadoop, Mesos, Yarn, standalone
• Works with HDFS, S3, Cassandra, HBase, … – Easier to code: Word count in 2 lines
u Spark's roots: – Came out of Berkeley AMP Lab – Now top-level Apache project
– Version 1.5 released in Sept 2015
“First Big Data platform to integrate batch, streaming and interactive computations in a unified framework” – stratio.com
(c) ElephantScale.com 2015 17

Spark Illustrated
Spark Core
Spark SQL
Spark Streaming ML lib
Schema / sql Real Time
Machine Learning
Standalone YARN MESOS Cluster
managers
GraphX
Graph processing
HDFS S3 Cassandra ??? Data
Storage
(c) ElephantScale.com 2015 18

Spark Core
u Basic building blocks for distributed compute engine – Task schedulers and memory management – Fault recovery (recovers missing pieces on node failure) – Storage system interfaces
u Defines Spark API and data model
u Data Model: RDD (Resilient Distributed Dataset) – Distributed collection of items – Can be worked on in parallel – Easily created from many data sources (Any HDFS InputSource)
u Spark API: Scala, Python, and Java – Compact API for working with RDD and interacting with Spark – Much easier to use than MapReduce API
Session 2: Introduction to Spark
(c) ElephantScale.com 2015 19

Spark Components
u Spark SQL: Structured data – Supports SQL and HQL (Hive Query Language) – Data sources include Hive tables, JSON, CSV, Parquet (1)
u Spark Streaming: Live streams of data in real-time – Low latency, high throughput (1000s events / sec) – Log files, stock ticks, sensor data / IOT (Internet of Things) …
u ML Lib: Machine Learning at scale – Classification/regression, collaborative filtering … – Model evaluation and data import
u GraphX: Graph manipulation, graph-parallel computation – Social network friendships, link data, … – Graph manipulation and operations and common algorithms
Session 2: Introduction to Spark
(c) ElephantScale.com 2015 20

Spark : 'Unified' Stack
u Spark components support multiple programming models – Map reduce style batch processing – Streaming / real time processing – Querying via SQL – Machine learning
u All modules are tightly integrated – Facilitates rich applications
u Spark can be the only stack you need ! – No need to run multiple clusters (Hadoop cluster, Storm cluster,
etc.)
Session 2: Introduction to Spark
(c) ElephantScale.com 2015 21

Hypo-meter J
(c) ElephantScale.com 2015 22

Spark Job Trends
(c) ElephantScale.com 2015 23

Hadoop and Spark Comparison
Introduction Hadoop and Spark Comparison
Going from Hadoop to Spark
Session 2: Introduction to Spark

Spark Benchmarks
Source : stratio.com
(c) ElephantScale.com 2015 25

Spark Code / Activity
(c) ElephantScale.com
2015
Source : stratio.com
26

Timeline : Hadoop & Spark
(c) ElephantScale.com 2015 27

Hadoop Vs. Spark
Hadoop Spark
Source : http://www.kwigger.com/mit-skifte-til-mac/
(c) ElephantScale.com 2015 28

Comparison With Hadoop
Hadoop Spark Distributed Storage + Distributed Compute
Distributed Compute Only
MapReduce framework Generalized computation Usually data on disk (HDFS) On disk / in memory Not ideal for iterative work Great at Iterative workloads
(machine learning ..etc) Batch process - Up 10x faster for data on disk
- Up to 100x faster for data in memory
Mostly Java Compact code Java, Python, Scala supported
No unified shell Shell for ad-hoc exploration
(c) ElephantScale.com 2015 29

Spark Is Better Fit for Iterative Workloads
(c) ElephantScale.com 2015 30

Spark Programming Model
u More generic than MapReduce
(c) ElephantScale.com 2015 31

Is Spark Replacing Hadoop?
u Spark runs on Hadoop / YARN
u Can access data in HDFS
u Use YARN for clustering
u Spark programming model is more flexible than MapReduce
u Spark is really great if data fits in memory (few hundred gigs),
u Spark is ‘storage agnostic’ (see next slide)
(c) ElephantScale.com 2015 32

Spark & Pluggable Storage
Spark (compute engine)
HDFS Amazon S3 Cassandra ???
(c) ElephantScale.com 2015 33

Spark & Hadoop
Use Case Hadoop Spark
Batch processing Hadoop’s MapReduce (Java, Pig, Hive)
Spark RDDs (java / scala / python)
SQL querying Hadoop : Hive Spark SQL
Stream Processing / Real Time processing
Storm Kafka
Spark Streaming
Machine Learning Mahout Spark ML Lib
Real time lookups HBase (NoSQL) No native Spark component. But Spark can query data in NoSQL stores
(c) ElephantScale.com 2015 34

Hadoop + Yarn : OS for Distributed Compute
HDFS
YARN
Batch (mapreduce)
Streaming (storm, S4)
In-memory (spark)
Storage
Cluster Management
Applications
(or at least, that’s the idea)
(c) ElephantScale.com 2015 35

Hadoop & Spark Future ???
(c) ElephantScale.com 2015 36

Going from Hadoop to Spark
Introduction Hadoop and Spark Comparison Going from Hadoop to Spark
Session 2: Introduction to Spark

Why Move From Hadoop to Spark?
u Spark is ‘easier’ than Hadoop
u ‘friendlier’ for data scientists / analysts
– Interactive shell
• fast development cycles
• adhoc exploration
u API supports multiple languages
– Java, Scala, Python
u Great for small (Gigs) to medium (100s of Gigs) data
(c) ElephantScale.com 2015 38

Spark : ‘Unified’ Stack
u Spark supports multiple programming models – Map reduce style batch processing – Streaming / real time processing – Querying via SQL – Machine learning
u All modules are tightly integrated – Facilitates rich applications
u Spark can be the only stack you need ! – No need to run multiple clusters
(Hadoop cluster, Storm cluster, … etc.)
Image: buymeposters.com
(c) ElephantScale.com 2015 39

Migrating From Hadoop à Spark Functionality Hadoop Spark Distributed Storage - HDFS
- Cloud storage (Amazon S3)
- HDFS - Cloud storage
(Amazon S3) - Distributed File
system (NFS / Ceph)
- Distributed NoSQL (Cassandra)
- Tachyon (in memory)
SQL querying Hive Spark SQL (Data frames)
ETL work flow Pig - Spork : Pig on Spark
- Mix of Spark SQL + RDD programming
Machine Learning Mahout ML Lib NoSQL DB HBase ???
(c) ElephantScale.com 2015 40

Things to Consider When Moving From Hadoop to Spark
1. Data size
2. File System
3. Analytics
A. SQL
B. ETL
C. Machine Learning
(c) ElephantScale.com 2015 41

Data Size : “You Don’t Have Big Data”
(c) ElephantScale.com 2015 42

Data Size (T-shirt sizing)
Image credit : blog.trumpi.co.za
10 G + 100 G +
1 TB + 100 TB + PB +
< few G
Hadoop / Spark
Spark
(c) ElephantScale.com 2015 43

Data Size
u Lot of Spark adoption at SMALL – MEDIUM scale
– Good fit
– Data might fit in memory !!
u Applications
– Iterative workloads (Machine learning, etc.)
– Streaming
(c) ElephantScale.com 2015 44

Decision : Data Size
(c) ElephantScale.com 2015 45
Data Size
< 1 TB (Spark)
> 1 TB (Hadoop /
Spark)

Decision : File System
(c) ElephantScale.com 2015 46
“What kind of file system do I need for Spark”

File System u Hadoop = Storage + Compute u Spark = Compute only u Spark needs a distributed FS
u File system choices for Spark – HDFS - Hadoop File System
• Reliable • Good performance (data locality) • Field tested for PB of data
– S3 : Amazon • Reliable cloud storage • Huge scale
– NFS : Network File System (‘shared FS across machines)
– Tachyon (in memory - experimental)
(c) ElephantScale.com 2015 47

Spark File Systems
(c) ElephantScale.com 2015 48

File Systems For Spark
HDFS NFS Amazon S3
Data locality High (best)
Local enough None (ok)
Throughput High (best)
Medium (good)
Low (ok)
Latency Low (best)
Low High
Reliability Very High (replicated)
Low Very High
Cost Varies Varies $30 / TB / Month
(c) ElephantScale.com 2015 49

File Systems Throughput Comparison
u Data : 10G + (11.3 G)
u Each file : ~1+ G ( x 10)
u 400 million records total
u Partition size : 128 M
u On HDFS & S3
u Cluster :
– 8 Nodes on Amazon m3.xlarge (4 cpu , 15 G Mem, 40G SSD )
– Hadoop cluster , Horton Works HDP v2.2
– Spark : on same 8 nodes, stand-alone, v 1.2
(c) ElephantScale.com 2015 50

HDFS Vs. S3 (lower is better)
(c) ElephantScale.com
2015 51

HDFS Vs. S3 (lower is better)
(c) ElephantScale.com
2015 52

HDFS Vs. S3 Conclusions
HDFS S3
Data locality à much higher throughput
Data is streamed à lower throughput
Need to maintain an Hadoop cluster No Hadoop cluster to maintain à convenient
Large data sets (TB + ) Good use case: - Smallish data sets (few gigs) - Load once and cache and re-use
(c) ElephantScale.com 2015 53

Decision : File Systems
(c) ElephantScale.com 2015 54
Already have Hadoop?
NO
HDFS
S3 NFS (Ceph)
Cassandra (real time)
YES use HDFS

Next Decision : SQL
(c) ElephantScale.com 2015 55
“We use SQL heavily for data mining. We are using Hive / Impala on Hadoop. Is Spark right for us?”

SQL in Hadoop / Spark Hadoop Spark
Engine - Hive (on Map Reduce or Tez on Hortonworks)
- Impala (Cloudera)
- Spark SQL using Dataframes
- Hive context
Language HiveQL - HiveQL - RDD programming in Java / Python / Scala
Scale Terabytes / Petabytes Gigabytes / Terabytes / Petabytes
Inter operability Data stored in HDFS - Hive tables
- File system
Formats CSV, JSON, Parquet CSV, JSON, Parquet
(c) ElephantScale.com 2015 56

Dataframes Vs. RDDs
u RDDs have data u DataFrames also have schema u Dataframes Used to be called ‘schemaRDD’ u Unified way to load / save data in multiple formats u Provides high level operations
– Count / sum / average – Select columns & filter them
57
(c) ElephantScale.com 2015
// load json data df = sqlContext.read .format(“json”) .load(“/data/data.json”) // save as parquet (faster queries) df.write .format(“parquet”) .saveAsTable(“/data/datap/”)

Supported Formats
58
(c) ElephantScale.com 2015

Creating a DataFrame From JSON {"name": "John", "age": 35 } {"name": "Jane", "age": 40 } {"name": "Mike", "age": 20 } {"name": "Sue", "age": 52 }
(c) ElephantScale.com 2015 59 Session 6: Spark SQL
scala> val peopleDF = sqlContext.read.json("people.json") peopleDF: org.apache.spark.sql.DataFrame = [age: bigint, name: string] scala> peopleDF.printSchema() root |-- age: long(nullable = true) |-- name: string (nullable = true) scala> peopleDF.show() +---+----+ |age|name| +---+----+ | 35|John| | 40|Jane| | 20|Mike| | 52| Sue| +---+----+

Querying Using SQL
u A DataFrame can be registered as a temporary table – You can then use SQL to query it, as shown below – This is handled similarly to DSL queries - building up an AST and
sending it to Catalyst
(c) ElephantScale.com 2015 60 Session 6: Spark SQL
scala> df.registerTempTable("people") scala> sqlContext.sql("select * from people").show() name age John 35 Jane 40 Mike 20 Sue 52 scala> sqlContext.sql("select * from people where age > 35").show() name age Jane 40 Sue 52

Going From Hive à Spark
u Spark natively supports querying data stored in Hive tables! u Handy to use in an existing Hadoop cluster !!
61 Session 6: Spark SQL
HIVE Hive> select customer_id, SUM(cost) as total from billing group by customer_id order by total DESC LIMIT 10;
SPARK val hiveCtx = new org.apache.spark.sql.hive.HiveContext(sc) val top10 = hiveCtx.sql( "select customer_id, SUM(cost) as total from billing group by customer_id order by total DESC LIMIT 10") top10.collect()
(c) ElephantScale.com 2015

Spark SQL Vs. Hive
(c) ElephantScale.com
2015
Fast on same HDFS data !
62

Spark SQL Vs. Hive
(c) ElephantScale.com
2015
Fast on same data on HDFS
63

Decision : SQL
Using Hive?
Yes Spark Using HiveContext
NO Spark SQL with
Dataframes (c) ElephantScale.com 2015 64

Next Decision : ETL
(c) ElephantScale.com 2015 65
“we do lot of ETL work on our Hadoop cluster. Using tools like Pig / Cascading Can we use Spark? “

ETL on Hadoop / Spark
ETL Hadoop Spark
ETL Tools Pig, Cascading, Oozie - Native RDD programming (Scala, Java, Python)
- Cascading?
Pig High level ETL workflow Spork : Pig on Spark
Cascading High level Spark-scalding
Cask Works Works
(c) ElephantScale.com 2015 66

Data Transformation on Spark
u Dataframes are great for high level manipulation of data – High level operations : Join / Union …etc – Joining / Merging disparate data sets – Can read and understand multitude of data formats (JSON /
Parquet ..etc) – Very easy to program
u RDD APIs allow low level programming – Complex manipulations – Lookups – Supports multiple lanaguages (Java / Scala / Python)
u High level libraries are emerging – Tresata – CASK
(c) ElephantScale.com 2015 67

Decisions : ETL
Current ETL
Pig
Spork RDD API
Dataframes
Cascading
Cascading on Spark
RDD
Data frames
Java MapReduce
/ Custom
RDD
Dataframes
(c) ElephantScale.com 2015 68

Decision : Machine Learning
(c) ElephantScale.com 2015 69
Can we use Spark for Machine Learning?
YES

Machine Learning : Hadoop / Spark
Hadoop Spark
Tool Mahout MLLib
API Java Java / Scala / Python
Iterative Algorithms Slower Very fast (in memory)
In Memory processing No YES
Mahout runs on Hadoop or on Spark
New and young lib
Latest news! Mahout only accepts new code that runs on Spark
Mahout & MLLib on Spark Future? Many opinions
(c) ElephantScale.com 2015 70

Decision : In Memory Process
(c) ElephantScale.com 2015 71
How can we do in-memory processing using Spark?

Numbers Every One Should Know by Jeff Dean, Fellow @ Google
Operation Cost (in nano seconds)
L1 cache reference 0.5
Branch mispredict (cpu) 5
L2 cache reference 7
Mutex lock/unlock 100
Main memory reference 100
Compress 1K bytes with Zippy 10,000
Send 2K bytes over 1 Gbps network 20,000
Read 1 MB sequentially from memory 250,000 0.25 ms
Round trip within same datacenter 500,000 0.5 ms
Disk seek 10,000,000 10 ms
Read 1 MB sequentially from network 10,000,000 10 ms
Read 1 MB sequentially from disk 30,000,000 30 ms
Send packet CA->Netherlands->CA 150,000,000 150 ms
(c) ElephantScale.com 2015 72

Spark Caching
u Caching is pretty effective (small / medium data sets) u Cached data can not be shared across applications
(each application executes in its own sandbox)
(c) ElephantScale.com 2015 73

Caching Results
Cached!
(c) ElephantScale.com 2015 74

Caching Results
Cached!
(c) ElephantScale.com 2015 75

Sharing Cached Data
u By default Spark applications can not share cached data – Running in isolation
u 1) ‘spark job server’ – Multiplexer – All requests are executed through same ‘context’ – Provides web-service interface
u 2) Tachyon – Distributed In-memory file system – Memory is the new disk! – Out of AMP lab , Berkeley – Early stages (very promising)
(c) ElephantScale.com 2015 76

Spark Job Server
(c) ElephantScale.com 2015 77

Spark Job Server
u Open sourced from Ooyala u ‘Spark as a Service’ – simple REST interface to launch jobs u Sub-second latency ! u Pre-load jars for even faster spinup u Share cached RDDs across requests (NamedRDD) u https://github.com/spark-jobserver/spark-jobserver
(c) ElephantScale.com 2015 78
App1 : sharedCtx.saveRDD(“my cached rdd”, rdd1) App2: RDD rdd2 = sharedCtx.loadRDD (“my cached rdd”)

Tachyon + Spark
(c) ElephantScale.com 2015 79

How to Get Spark?
Session 2: Introduction to Spark

Getting Spark
(c) ElephantScale.com 2015 81
Running Hadoop?
NO Need HDFS?
YES Install HDFS + YARN + Spark
NO Environment ?
Production Spark + Mesos +
S3
Testing Spark (standalone)
+ NFS or S3
YES Install Spark on Hadoop cluster

Spark Cluster Setup 1 : Simple
u Great for POCs / experimentation u No dependencies u Using Spark’s ‘stand alone’ manager
(c) ElephantScale.com 2015 82

Spark Cluster Setup 2 : Production
u Works well with Hadoop eco system (HDFS / Hive ..etc) u Best way to adopt Spark on Hadoop u Uses YARN as cluster manager
(c) ElephantScale.com 2015 83

Spark Cluster Setup 3 : Production
u Uses Mesos as cluster manager
(c) ElephantScale.com 2015 84

Hadoop -> Spark Case Study
Session 2: Introduction to Spark

Use Case 1 : Moving to Cloud
(c) ElephantScale.com 2015 86

Use Case 1 : Lessons Learned
u Size – Small Hadoop cluster (8 nodes) – Smallish data : 50G – 300G – Data for processing : few Gigs per query
u Good ! – Only one moving part 'spark' – No Hadoop cluster to maintain – S3 was a dependable storage (passive) – Query response time gone from minutes to seconds (b/c we went
from MR à Spark)
u Not so good – We lost data locality of HDFS
(ok for small/medium data sets) (c) ElephantScale.com 2015 87

Use Case 2 : Persistent Caching in Spark
u Can we improve latency in this setup? u Caching will help u How ever, in Spark cached data can not be shared across
applications L
(c) ElephantScale.com 2015 88

Use Case 2 : Persistent Caching in Spark
u Spark Job Server to rescue !
(c) ElephantScale.com 2015 89

Final Thoughts
u Already on Hadoop? – Try Spark side-by-side – Process some data in HDFS – Try Spark SQL for Hive tables
u Contemplating Hadoop? – Try Spark (standalone) – Choose NFS or S3 file system
u Take advantage of caching – Iterative loads – Spark Job server – Tachyon
(c) ElephantScale.com 2015 90

Thanks and questions?
Sujee Maniyam Founder / Principal @ ElephantScale
Expert Consulting + Training in Big Data technologies [email protected]
Elephantscale.com Sign up for upcoming trainings : ElephantScale.com/training
(c) ElephantScale.com 2015 91





























