Embed Size (px)
Citation preview

HDFS Hadoop Distributed File SystemIntroduction
Johan Louwers – Lead Architect Oracle Technology

2Copyright © 2014 Capgemini. All rights reserved.
Hadoop HDFS introduction
HDFS – Hadoop Distributed File System
The Hadoop Distributed File System (HDFS) is a distributed file system designed to run on commodity
hardware. It has many similarities with existing distributed file systems. However, the differences from
other distributed file systems are significant. HDFS is highly fault-tolerant and is designed to be deployed
on low-cost hardware. HDFS provides high throughput access to application data and is suitable for
applications that have large data sets. HDFS relaxes a few POSIX requirements to enable streaming
access to file system data. HDFS was originally built as infrastructure for the Apache Nutch web search
engine project. HDFS is now an Apache Hadoop subproject. The project URL
is http://hadoop.apache.org/hdfs/.

3Copyright © 2014 Capgemini. All rights reserved.
Hadoop HDFS introduction
HDFS – Simple Cluster Setup
Simple HDFS Cluster Setup
A) HDFS cluster consisting out of a number of
commodity servers.
B) A single server containing both a “name
node” and a “data node”
C) Multiple servers containing a “data node”
B
C
A

4Copyright © 2014 Capgemini. All rights reserved.
Hadoop HDFS introduction
HDFS – introduction
HDFS Name Node
• Primary index of where data is stored within
the cluster.
• Primary entry point for all (applications)
clients who request access to HDFS.
• Advisable to size the Name Node bigger then
the Data Node server.
• Option to run a Data Node instance on the
same server as the Name Node.
• Hadoop 2.0.0 and higher provide the option to
have high available Name Node setup. Prior to
2.0.0 the name Node was a single point of
Failure.
A

5Copyright © 2014 Capgemini. All rights reserved.
Hadoop HDFS introduction
HDFS – introduction
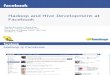
HDFS Storage
• A (large) file is “chopped” into blocks.
• Blocks are written to the different data nodes
in the cluster.
• The name node keeps track of which block is
written to which node.
6Copyright © 2014 Capgemini. All rights reserved.
Hadoop HDFS introduction
HDFS – introduction
On startup, the NameNode enters a special state
called Safemode. Replication of data blocks does
not occur when the NameNode is in the Safemode
state.
HDFS Storage
• Data blocks are replicated over different nodes
in the cluster to ensure availability when a node
fails.
• Level of replication is by default 3. Configured
with the dfs.replication variable in the HDFS
configuration

7Copyright © 2014 Capgemini. All rights reserved.
Hadoop HDFS introduction
HDFS – introduction
HDFS Storage
• When operating a large cluster ensure that
you have enabled the rack aware option.
•Refer to the HADOOP-692 improvement for
more details: http://goo.gl/dQ012n
Thanks to ChrisDag for the image
Typically large Hadoop clusters are arranged in racks
and network traffic between different nodes with in the
same rack is much more desirable than network traffic
across the racks. In addition NameNode tries to place
replicas of block on multiple racks for improved fault
tolerance.

8Copyright © 2014 Capgemini. All rights reserved.
Hadoop HDFS introduction
HDFS – Oracle & Big Data
Oracle Big Data Appliance Introduction
• Oracle Big Data Appliance is a high-
performance, secure platform for running
diverse workloads on Hadoop and NoSQL
systems.

9Copyright © 2014 Capgemini. All rights reserved.
Hadoop HDFS introduction
HDFS – Oracle & Big Data
Oracle Big Data Appliance Introduction
• Oracle Big Data Appliance includes (almost
without the need to say it) a HDFS storage
component for storing data.
10Copyright © 2014 Capgemini. All rights reserved.
Hadoop HDFS introduction
HDFS – Oracle & Big Data
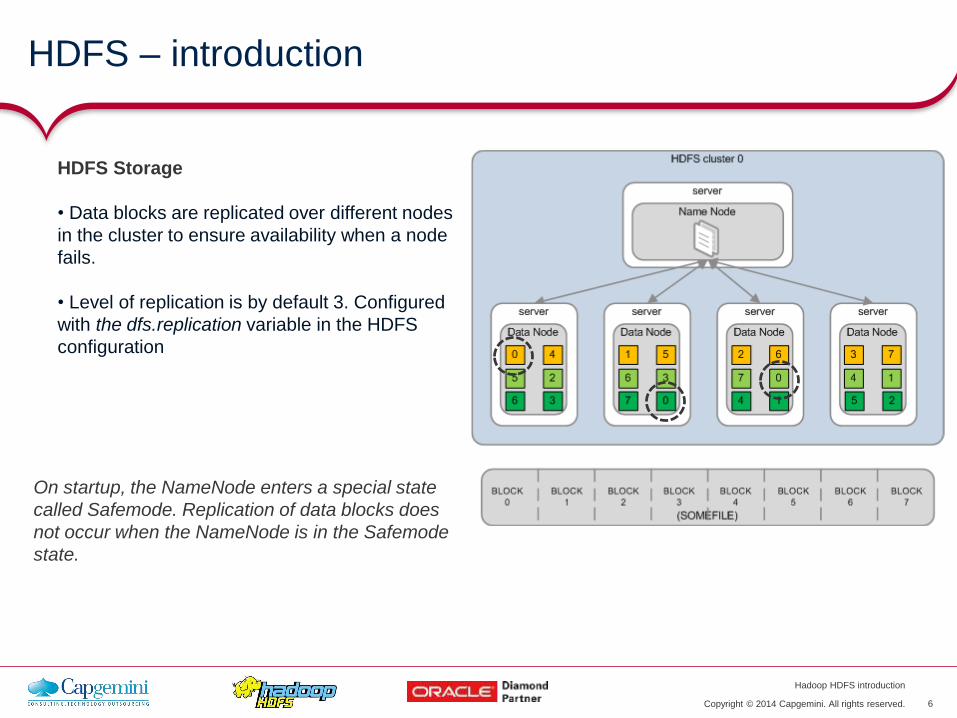
Oracle & Hadoop
• Oracle XQuery for Hadoop
11Copyright © 2014 Capgemini. All rights reserved.
Hadoop HDFS introduction
HDFS – Oracle & Big Data
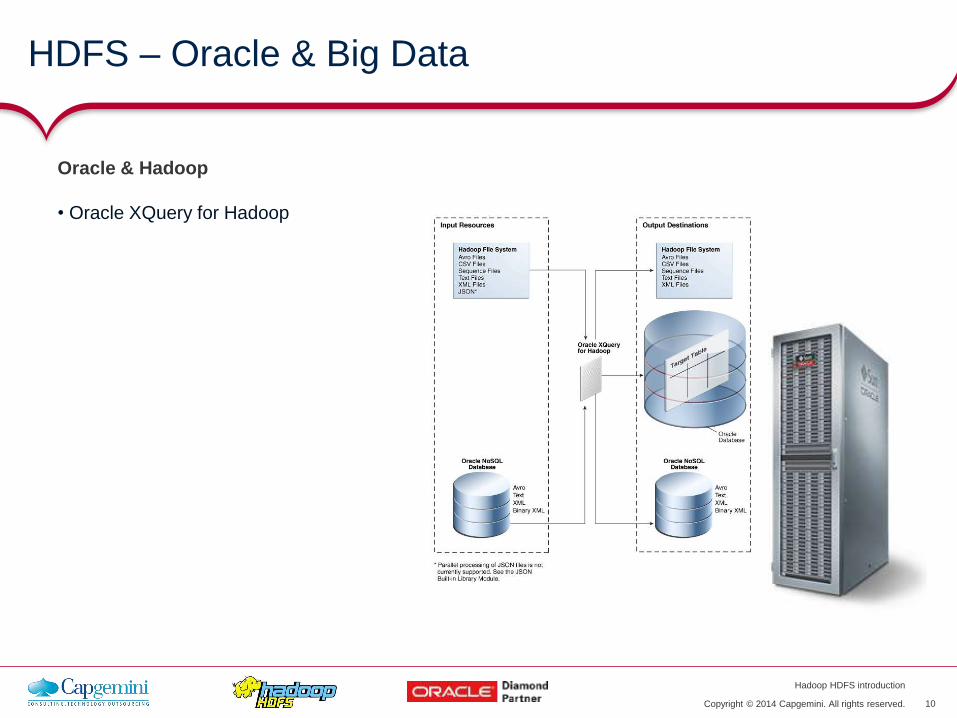
Oracle & Hadoop
• Oracle SQL connector for HDFS
12Copyright © 2014 Capgemini. All rights reserved.
Hadoop HDFS introduction
HDFS – Oracle & Big Data
Oracle & Hadoop
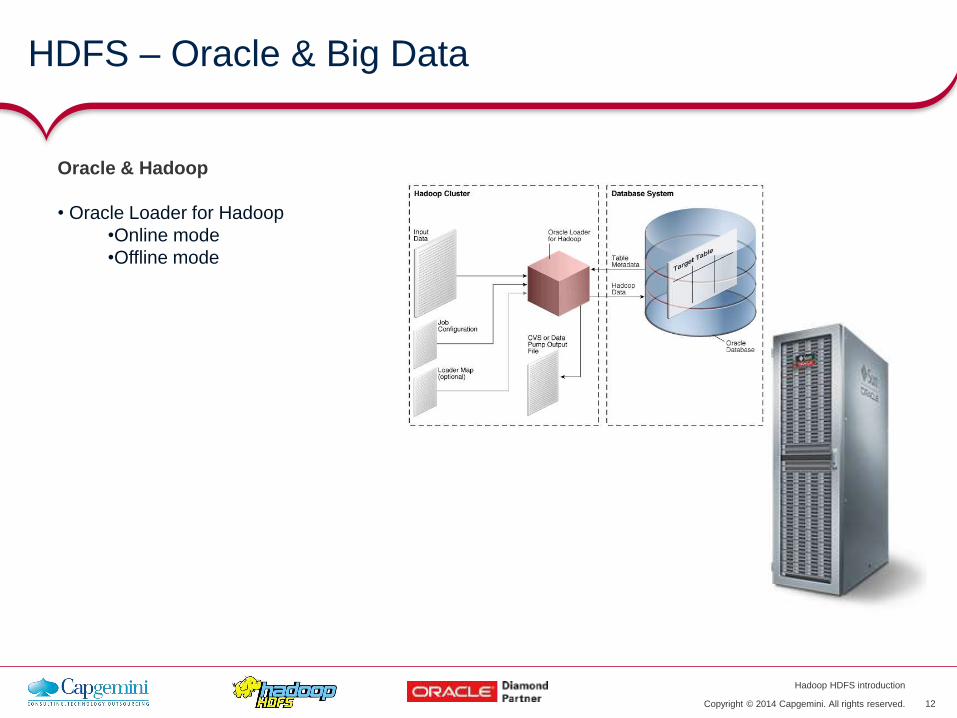
• Oracle Loader for Hadoop
•Online mode
•Offline mode

13Copyright © 2014 Capgemini. All rights reserved.
Hadoop HDFS introduction
HDFS – Oracle & Big Data
Oracle & Hadoop
• Oracle Loader for Hadoop
•Online mode
•Offline mode

14Copyright © 2014 Capgemini. All rights reserved.
Hadoop HDFS introduction
HDFS – Oracle & Big Data
Oracle & Hadoop
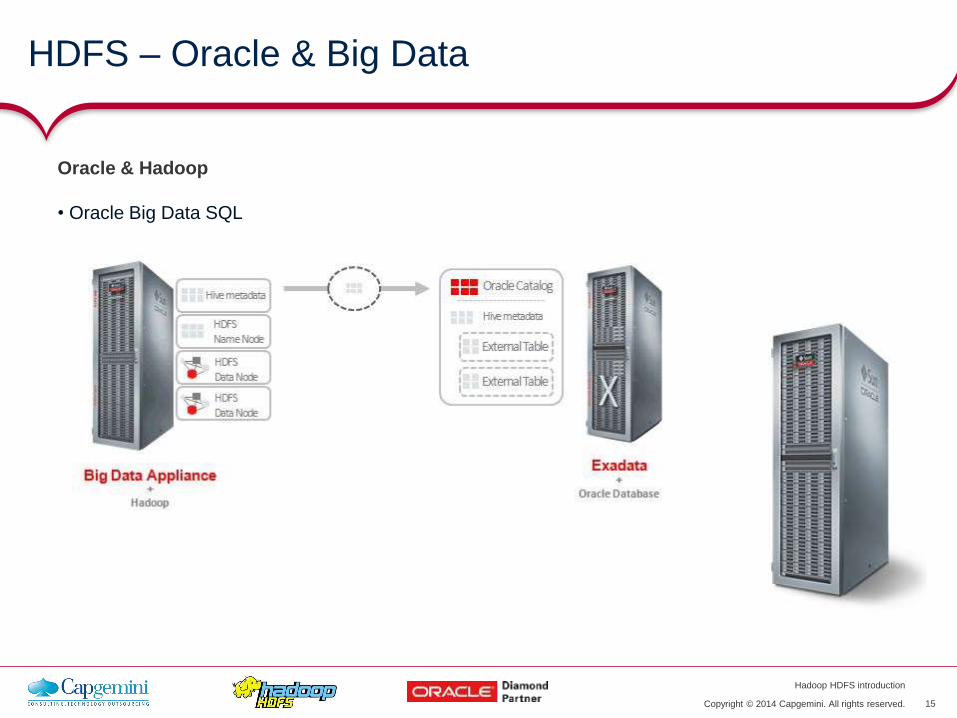
• Oracle Big Data SQL
15Copyright © 2014 Capgemini. All rights reserved.
Hadoop HDFS introduction
HDFS – Oracle & Big Data
Oracle & Hadoop
• Oracle Big Data SQL

16Copyright © 2014 Capgemini. All rights reserved.
Hadoop HDFS introduction
Contact me
Johan Louwers
Capgemini Lead Architect Oracle Technology
• Mail : [email protected]
• Twitter : @johanlouwers
• Blog 1 : http://www.capgemini.com/blog/capgemini-oracle-blog
• Blog 2 : http://johanlouwers.blogspot.com

The information contained in this presentation is proprietary.
© 2014 Capgemini. All rights reserved.
Rightshore® is a trademark belonging to Capgemini.
www.capgemini.com
About Capgemini
With almost 140,000 people in over 40 countries, Capgemini is
one of the world's foremost providers of consulting, technology
and outsourcing services. The Group reported 2013 global
revenues of EUR 10.1 billion.
Together with its clients, Capgemini creates and delivers
business and technology solutions that fit their needs and drive
the results they want. A deeply multicultural organization,
Capgemini has developed its own way of working, the
Collaborative Business Experience™, and draws on
Rightshore®, its worldwide delivery model.
Learn more about us at www.capgemini.com.