Embed Size (px)
Citation preview

Hands-on Lab Session 2631 Fast, Scalable, Easy, Machine Learning with OpenPOWER, GPUs and Docker Indrajit Poddar, IBM Systems Michael Gschwind, IBM Systems Introduction:
This exercise shows how to easily get started with open source machine learning and deep learning frameworks such as Caffe, Torch, Tensorflow, DIGITS with pre-trained open source models and data sets on OpenPOWER machines with GPUs. Docker containers are used to easily scale-out the infrastructure as shown in the NIMBIX public cloud.

© Copyright IBM Corporation 2017 IBM, the IBM logo and ibm.com are trademarks of International Business Machines Corp., registered in many jurisdictions worldwide. Other product and service names might be trademarks of IBM or other companies. A current list of IBM trademarks is available on the Web at “Copyright and trademark information” at www.ibm.com/legal/copytrade.shtml. This document is current as of the initial date of publication and may be changed by IBM at any time. The information contained in these materials is provided for informational purposes only, and is provided AS IS without warranty of any kind, express or implied. IBM shall not be responsible for any damages arising out of the use of, or otherwise related to, these materials. Nothing contained in these materials is intended to, nor shall have the effect of, creating any warranties or representations from IBM or its suppliers or licensors, or altering the terms and conditions of the applicable license agreement governing the use of IBM software. References in these materials to IBM products, programs, or services do not imply that they will be available in all countries in which IBM operates. This information is based on current IBM product plans and strategy, which are subject to change by IBM without notice. Product release dates and/or capabilities referenced in these materials may change at any time at IBM’s sole discretion based on market opportunities or other factors, and are not intended to be a commitment to future product or feature availability in any way.

Page 3 of 40 IBM InterConnect IBM InterConnect
Table of Contents 1. Machine and Deep Learning, Docker, OpenPOWER and GPUs 5
2. Connect to the NIMBIX public cloud 6
3. Image Classification with Caffe and a trained model 14
4. Train a model on a small dataset with DIGITS 18
5. Learn the basics of using Torch 31
6. Run a simple Logistic Regression example with Tensorflow 33
7. Image Classify with your own trained model in DIGITS 36
8. Exercise review and wrap-up 40


Session HPZ5313, Fast Scalable Easy Machine Learning on OpenPOWER GPUs and Docker
Page 5 of 40 IBM InterConnect IBM InterConnect
1. Machine and Deep Learning, Docker, OpenPOWER and GPUs
Deep Learning, or the use of multi-layer neural networks, is one of the most promising and fastest growing machine learning techniques for the development of cognitive applications today. Deep Learning has revolutionized speech recognition, natural language processing, and computer vision, and continues to revolutionize IT due to availability of rich data sets, new methods for accelerating neural network training and extremely fast hardware with GPU accelerators. Deep Learning can be used from safety systems to personal assistants to enterprise systems. For example, driver assist technologies rely on machine and deep learning patterns to recognize objects in a rapidly changing environment and personal digital assistant technology is learning to categorize e-mail, text messages, and other content based on context. In the enterprise, machine and deep learning applications can identify high value sales opportunities, enable smart call center automation, detect and react to intrusion or fraud, and suggest solutions to technical or business problems. The emergence of Deep Learning as a revolutionary technology has been catalyzed by the emergence of high-performance numeric accelerators to provide the compute capacity necessary for Deep Learning systems to train with the large data sets necessary to distill large training data sets into actionable insights that can be used to classify and act on new data points. Combining the capabilities of a diverse, innovative OpenPOWER ecosystem is yielding new innovative systems, such as the upcoming “Minsky” system tightly coupling the industry-leading OpenPOWER CPUs and the newest GPU numeric accelerators with a high speed interconnect to yield unprecedented and easy to use computing performance for many application domains, including Machine and Deep learning applications. As evidenced by new deep learning announcements and use cases from IBM Power Systems users like University of Maryland Baltimore County, the University of Illinois, and the STFC-Hartree Centre, OpenPOWER is fast emerging as the premier platform for cognitive computing. OpenPOWER-based cognitive computing solutions benefit from the traditional strengths of a mature enterprise and datacenter RISC architecture combined with the many capabilities of the OpenPOWER partners who collaborate to create new, innovative offerings in the context of the OpenPOWER ecosystem. In this session, we’re using the broad OpenPOWER ecosystem to demonstrate jump starting the use of Deep Learning technologies based on pre-trained models:
• OpenPOWER as the common platform to create innovative solutions • Docker-based containers for virtualization in an efficient scale-out
infrastructure • GPU-based numeric acceleration

Session HPZ5313, Fast Scalable Easy Machine Learning on OpenPOWER GPUs and Docker
Page 6 of 40 IBM InterConnect IBM InterConnect
• Pre-built and pre-optimized integrated Deep Learning software stacks for Power that create an easy on-ramp to cognitive applications for enterprise users.
2. Connect to the NIMBIX public cloud We will conduct this lab session on the NIMBIX cloud which provides Docker containers with GPUs attached on OpenPOWER S822LC-hpc “Minsky” boxes.
1. Login to your local workstation with user id: localuser and password: passw0rd
2. Launch the Firefox browser and go to https://mc.jarvice.com/

Session HPZ5313, Fast Scalable Easy Machine Learning on OpenPOWER GPUs and Docker
Page 7 of 40 IBM InterConnect IBM InterConnect
3. In the NIMBIX website, click on the Login link. Login with your user id:
4. Go to the Compute tab and find the PowerAI-Example-Notebooks app in the
IBM POWER category:
5. Examine the Dockerfile used to build the sample application. The DockerFile is available here: https://github.com/ibmsoe/Dockerfiles/blob/master/powerai-examples/Dockerfile and the image here: https://hub.docker.com/r/ipoddaribm/powerai-examples/

Session HPZ5313, Fast Scalable Easy Machine Learning on OpenPOWER GPUs and Docker
Page 8 of 40 IBM InterConnect IBM InterConnect
6. This Dockerfile example extends this base Docker image (jarvice/ubuntu-ibm-
mldl-ppc64le) published by Nimbix built from this Dockerfile. The base Docker image includes the IBM PowerAI software distribution. This Dockerfile example adds Jupyter notebook with the iTorch kernel and a few Tensorflow examples. Upon running the docker image, three Jupyter notebook server processes and a NVidia DIGITS server process are automatically started using supervisord. This Dockerfile can be built on any POWER LE Linux VM or bare metal where Docker engine is installed using the standard “docker build .” command. You can request a free VM from the Oregon State University Open Source Lab. Building and uploading this Docker image to DockerHub is a time consuming task (about 20 minutes), which we will not perform in this lab.
FROM jarvice/ubuntu-ibm-mldl-ppc64le
#add Jupyter
RUN pip install notebook pyyaml
#add startupscripts
RUN apt-get install -y supervisor
WORKDIR /root
ADD startjupyter.sh /root/
ADD startdigits.sh /root/
ADD conf.d/* /etc/supervisor/conf.d/
ADD rc.local /etc/rc.local
#add iTorch kernel
WORKDIR /opt/DL/torch/examples
RUN git clone https://github.com/facebook/iTorch.git
WORKDIR iTorch
RUN /bin/bash -c "source /opt/DL/torch/bin/torch-activate && luarocks make"
#add tensorflow examples
WORKDIR /opt/DL/tensorflow
RUN git clone https://github.com/aymericdamien/TensorFlow-Examples.git

Session HPZ5313, Fast Scalable Easy Machine Learning on OpenPOWER GPUs and Docker
Page 9 of 40 IBM InterConnect IBM InterConnect
7. Launch a container for the PowerAI app in the Server mode:
8. Click on Server and then Submit

Session HPZ5313, Fast Scalable Easy Machine Learning on OpenPOWER GPUs and Docker
Page 10 of 40 IBM InterConnect
9. Get the IP address and password of your launched container from the NIMBIX UI.
10. Launch a terminal in your workstation and ssh to your container: ssh nimbix@<host name>.jarvice.com

Session HPZ5313, Fast Scalable Easy Machine Learning on OpenPOWER GPUs and Docker
Page 11 of 40 IBM InterConnect
11. Run “sudo su” and /usr/lib/nvidia-361/bin/nvidia-smi to check the GPU
attached to the container
12. Try out Ubuntu Linux on OpenPOWER, look at the processor architecture by
running “uname –m”

Session HPZ5313, Fast Scalable Easy Machine Learning on OpenPOWER GPUs and Docker
Page 12 of 40 IBM InterConnect
13. Run “jupyter notebook list” to find the tokens associated with jupyter
notebook servers that are automatically launched for the remainder of this lab:
Session HPZ5313, Fast Scalable Easy Machine Learning on OpenPOWER GPUs and Docker
Page 13 of 40 IBM InterConnect
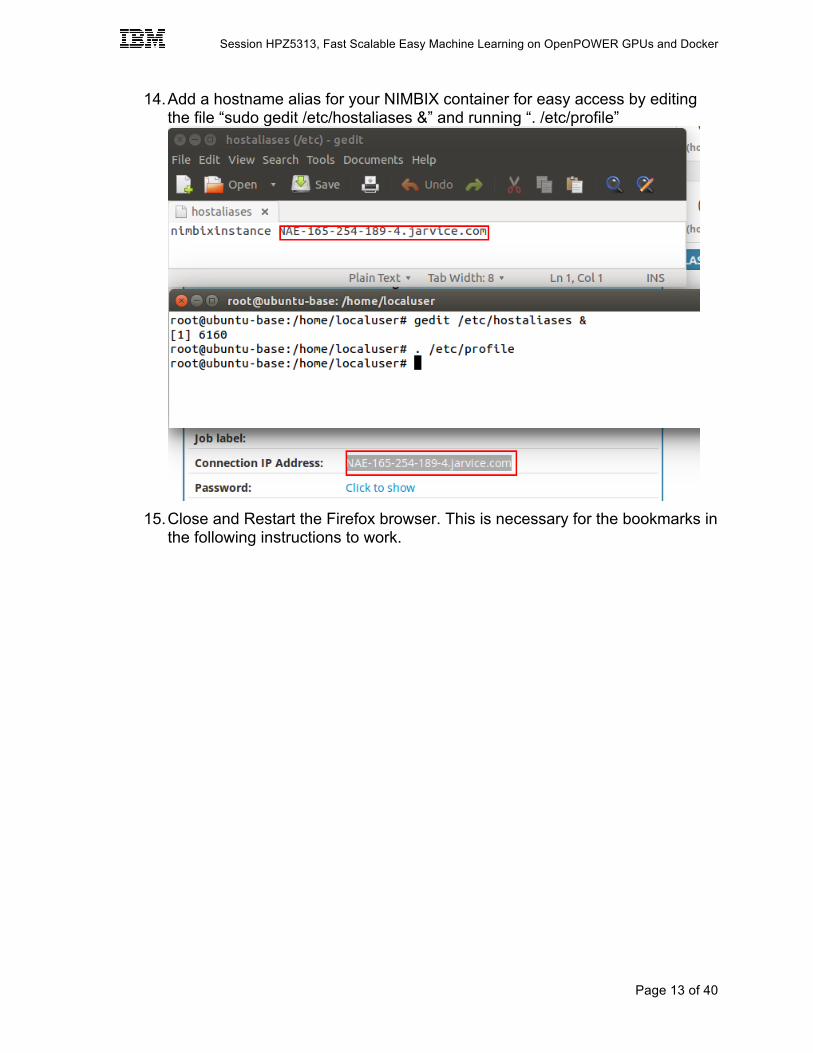
14. Add a hostname alias for your NIMBIX container for easy access by editing the file “sudo gedit /etc/hostaliases &” and running “. /etc/profile”
15. Close and Restart the Firefox browser. This is necessary for the bookmarks in
the following instructions to work.

Session HPZ5313, Fast Scalable Easy Machine Learning on OpenPOWER GPUs and Docker
Page 14 of 40 IBM InterConnect
3. Image Classification with Caffe and a trained model
Caffe is an open source deep learning framework from the Berkeley Vision and Learning Center. In this section we will walk through a deep learning example code using an open source model already trained on images from the ImageNet public dataset. More open source pre-trained models can be found at the Caffe Model Zoo. More open source example code can be found at Github. 1. Click on the Caffe bookmark in the Firefox browser or click the link below:
http://nimbixinstance:8888/notebooks/examples/00-classification.ipynb
2. Copy the token from the Terminal window output for the command “jupyter
notebook list” for the Jupyter Notebook server listening on port 8888 and paste in the browser and click on the Log In button:

Session HPZ5313, Fast Scalable Easy Machine Learning on OpenPOWER GPUs and Docker
Page 15 of 40 IBM InterConnect

Session HPZ5313, Fast Scalable Easy Machine Learning on OpenPOWER GPUs and Docker
Page 16 of 40 IBM InterConnect
3. Execute the python code cells in order from top to bottom by pressing shift enter (or click a cell and click on the play button on top)
4. Observe the classification result:

Session HPZ5313, Fast Scalable Easy Machine Learning on OpenPOWER GPUs and Docker
Page 17 of 40 IBM InterConnect
5. Observe the difference with acceleration with GPUs on OpenPOWER
6. Shutdown the kernel to release GPU memory:
http://nimbixinstance:8888/tree#running
Session HPZ5313, Fast Scalable Easy Machine Learning on OpenPOWER GPUs and Docker
Page 18 of 40 IBM InterConnect
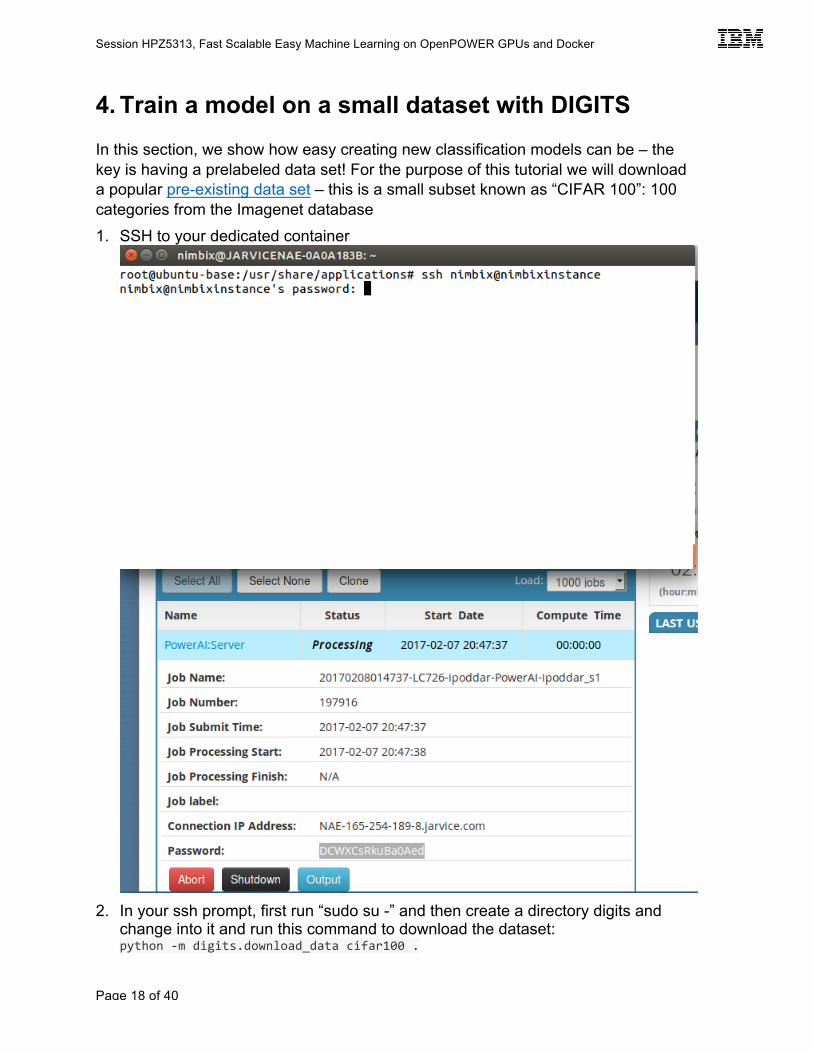
4. Train a model on a small dataset with DIGITS In this section, we show how easy creating new classification models can be – the key is having a prelabeled data set! For the purpose of this tutorial we will download a popular pre-existing data set – this is a small subset known as “CIFAR 100”: 100 categories from the Imagenet database 1. SSH to your dedicated container
2. In your ssh prompt, first run “sudo su -” and then create a directory digits and
change into it and run this command to download the dataset: python -m digits.download_data cifar100 .

Session HPZ5313, Fast Scalable Easy Machine Learning on OpenPOWER GPUs and Docker
Page 19 of 40 IBM InterConnect
3. Examine the downloaded dataset.
The CIFAR-100 dataset comes in two versions. We’ll be exploring the “fine” version. A dataset consists of multiple components:
• labels.txt A list of “labels”, textual descriptions of each of the categories (or classes) in the training data set.
• train A directory containing the images used for training.
• train.txt A list of mapping each training file to one of the categories. The labels are positional, that is the first label from the labels.txt file is represented by the number 0, the second by number 1, and so forth.
• test A directory containing the images used for testing the training quality.
• test.txt A list of mapping each test file to one of the categories. The labels are positional, that is the first label from the labels.txt file is represented by the number 0, the second by number 1, and so forth.

Session HPZ5313, Fast Scalable Easy Machine Learning on OpenPOWER GPUs and Docker
Page 20 of 40 IBM InterConnect
root@JARVICENAE-0A0A183B:~/digits$ ls fine/train | head apple aquarium_fish baby bear beaver bed bee beetle bicycle bottle root@JARVICENAE-0A0A183B:~/digits$ ls fine/train/apple | head apple_s_000027.png apple_s_000028.png apple_s_000049.png apple_s_000050.png apple_s_000057.png apple_s_000058.png apple_s_000145.png apple_s_000301.png apple_s_000307.png apple_s_000339.png
root@JARVICENAE-0A0A183B:~/digits$ head fine/train.txt ./fine/train/cattle/bos_taurus_s_000507.png 19 ./fine/train/dinosaur/stegosaurus_s_000125.png 29 ./fine/train/apple/mcintosh_s_000643.png 0 ./fine/train/boy/altar_boy_s_001435.png 11 ./fine/train/aquarium_fish/cichlid_s_000031.png 1 ./fine/train/telephone/phone_s_002161.png 86 ./fine/train/train/car_train_s_000043.png 90 ./fine/train/cup/beaker_s_000604.png 28 ./fine/train/cloud/fog_s_000397.png 23 ./fine/train/elephant/rogue_elephant_s_000421.png 31 root@JARVICENAE-0A0A183B:~/digits$ head fine/labels.txt apple aquarium_fish baby bear beaver bed bee beetle bicycle bottle

Session HPZ5313, Fast Scalable Easy Machine Learning on OpenPOWER GPUs and Docker
Page 21 of 40 IBM InterConnect
4. Connect with your browser to the NVIDIA DIGITS application already running in your container to train with our downloaded dataset: http://nimbixinstance:5000
5. We want to create a new dataset for training to classify image, so activate the images pulldown in the Datasets section and select “Classification”:

Session HPZ5313, Fast Scalable Easy Machine Learning on OpenPOWER GPUs and Docker
Page 22 of 40 IBM InterConnect
6. We’re prompted to access jobs associated with a user name – we create a new user name by simply entering it. Here the username will be “user”:
7. We’re prompted to create a new Dataset to train a classification engine:

Session HPZ5313, Fast Scalable Easy Machine Learning on OpenPOWER GPUs and Docker
Page 23 of 40 IBM InterConnect
8. Initialize the screen as follows, provide the path to the downloaded dataset: /root/digits/fine/train in the “Training Images” field. Click on the “Separate test images folder” checkbox and specify this folder: /root/digits/fine/test. Specify cifar100 as the Dataset Name:
9. And select the “Create” button to create the database.
This initializes a job to create a database for training. Job information is shown

Session HPZ5313, Fast Scalable Easy Machine Learning on OpenPOWER GPUs and Docker
Page 24 of 40 IBM InterConnect
on the next screen:

Session HPZ5313, Fast Scalable Easy Machine Learning on OpenPOWER GPUs and Docker
Page 25 of 40 IBM InterConnect
10. The job status is shown on the right hand side and we wait until the training, validation, and test databases have been created.
11. We return to the DIGITS home screen by selecting the DIGITS menu. The
home screen now shows that a Dataset called cifar100 is available

Session HPZ5313, Fast Scalable Easy Machine Learning on OpenPOWER GPUs and Docker
Page 26 of 40 IBM InterConnect
12. Next, we want to create an Image classification model, so we select
“Classification” from the Image pull down of the Models tab:

Session HPZ5313, Fast Scalable Easy Machine Learning on OpenPOWER GPUs and Docker
Page 27 of 40 IBM InterConnect
13. The Entry screen for creating a model:

Session HPZ5313, Fast Scalable Easy Machine Learning on OpenPOWER GPUs and Docker
Page 28 of 40 IBM InterConnect
14. We select the cifar100 dataset we just created, with the “AlexNet” Neural
Network architecture and give the model we’re about to create the name “classify-images”:

Session HPZ5313, Fast Scalable Easy Machine Learning on OpenPOWER GPUs and Docker
Page 29 of 40 IBM InterConnect
15. Select create to create a training job, it shows a job description for a training job.
16. As the Neural Network is being trained, the job statistics are being updated with
training progress and achieved accuracy:

Session HPZ5313, Fast Scalable Easy Machine Learning on OpenPOWER GPUs and Docker
Page 30 of 40 IBM InterConnect
17. At this point, we’ll switch to the next module and come back when the network
has been fully trained.

Session HPZ5313, Fast Scalable Easy Machine Learning on OpenPOWER GPUs and Docker
Page 31 of 40 IBM InterConnect
5. Learn the basics of using Torch Torch is an open source scientific computing framework originally from Facebook using the Lua Just-In-Time (JIT) compiled programming language (based on the c language). In this section, we will walk through an introductory example of using Torch downloaded from Github. 1. Open the Jupyter iTorch example in your browser by clicking on the Torch
bookmark or on this link:http://nimbixinstance:8889/notebooks/examples/01-iTorch_Demo.ipynb . When prompted for a password, switch to the ssh login window and run “jupyter notebook list” as the root user and copy the token for the notebook server running on port 8889.

Session HPZ5313, Fast Scalable Easy Machine Learning on OpenPOWER GPUs and Docker
Page 32 of 40 IBM InterConnect
2. Execute example Lua code in each cell by pressing shift+enter or the play button at the top.
3. Shutdown the kernel to release memory:
http://nimbixinstance:8889/tree#running

Session HPZ5313, Fast Scalable Easy Machine Learning on OpenPOWER GPUs and Docker
Page 33 of 40 IBM InterConnect
6. Run a simple Logistic Regression example with Tensorflow
TensorFlow is an open source software library for numerical computation from Google. TensorFlow has python bindings. Logistic Regression is a technique often used in machine learning to classify an input into different categories with probabilities. For example, classify whether a medical scan image (input) shows a tumor or not (2 categories). In this section, we will walk through example code from a tutorial from github for Logistic Regression using Tensorflow. We will use as input the MNIST database of handwritten digits. 1. Open the Jupyter TensorFlow example in your browser, by clicking on the
Tensorflow bookmark or by clicking on the following link: http://nimbixinstance:8890/notebooks/TensorFlow-Examples/notebooks/2_Basic_Models/logistic_regression.ipynb
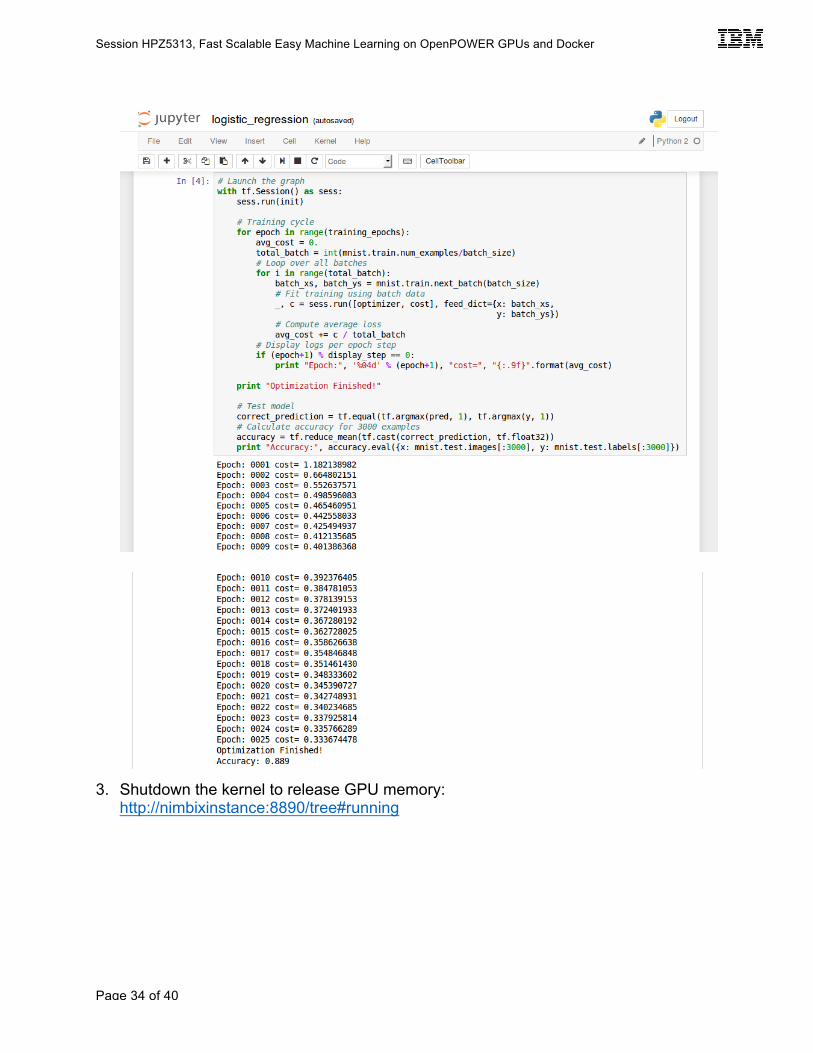
2. Execute example Tensorflow python code in each cell by pressing shift+enter or the play button at the top. The last cell shows training of the logistic regression model on the input dataset and shows the accuracy of classification (~89%).
Session HPZ5313, Fast Scalable Easy Machine Learning on OpenPOWER GPUs and Docker
Page 34 of 40 IBM InterConnect
3. Shutdown the kernel to release GPU memory: http://nimbixinstance:8890/tree#running

Session HPZ5313, Fast Scalable Easy Machine Learning on OpenPOWER GPUs and Docker
Page 35 of 40 IBM InterConnect

Session HPZ5313, Fast Scalable Easy Machine Learning on OpenPOWER GPUs and Docker
Page 36 of 40 IBM InterConnect
7. Image Classify with your own trained model in DIGITS Now we will go back to our model training step in Section 4 Train a model on a small dataset with DIGITS, to continue to the next step of classifying an input image with the trained model.
1. The training of the image classification network in DIGITS should have finished by now. If it is still running, that’s fine, we will use the model from the most recently completed training epoch:

Session HPZ5313, Fast Scalable Easy Machine Learning on OpenPOWER GPUs and Docker
Page 37 of 40 IBM InterConnect
2. In the middle section of the screen, we can see the learning progress over time,

Session HPZ5313, Fast Scalable Easy Machine Learning on OpenPOWER GPUs and Docker
Page 38 of 40 IBM InterConnect
3. In the bottom portion of the screen we can classify images, by uploading an image file or by entering an image URL e.g. http://efresh.com/sites/default/files/Green-Apple_1.jpg :

Session HPZ5313, Fast Scalable Easy Machine Learning on OpenPOWER GPUs and Docker
Page 39 of 40 IBM InterConnect
4. When you select “Classify One”, the neural network will classify the image based on the 100 categories that have been trained, with the training corpus. Please bear in mind that the CIFAR-100 database is a small database to complete training within the hour, so the accuracy is not the same as might be obtained with a much more complete training data set:
5. We can also download the model and use it to classify images, e.g., in the contexts that we had used classification models earlier.
End of exercise

Session HPZ5313, Fast Scalable Easy Machine Learning on OpenPOWER GPUs and Docker
Page 40 of 40 IBM InterConnect
8. Exercise review and wrap-up We used Deep Neural Networks for classifying information on Power. Deep Learning is the most exciting machine learning and artificial technology in use today, with incredible momentum in adoption across the IT industry. There is some more background info on Deep Learning in the Appendix. We've used the NIMBIX Power container cloud running Docker containers with GPUs. We reviewed how to build new Docker containers, and the install the Power MLDL distro on Ubuntu. We used the major Deep Learning frameworks on Power to classify images in conjunction with Jupyter iPython notebooks: * Caffe * Torch * TensorFlow We learned about Model Zoo, a repository for pre-trained models available freely from the Berkeley Vision Group We trained our own Alexnet network, the winner of an Imagenet competition, with the CIFAR-100 dataset. We used the DIGITS GUI as a user friendly interface for neural network training with Caffe. We performed classification with Power, which offers the best of breed CPU classification performance today for advanced neural networks such as Alexnet, with the free open-source OpenBLAS linear algebra package. We accelerated classification with GPUs attached to Power, and used GPU accelerated training with Caffe.





























