Embed Size (px)
Citation preview

Exploring Hybrid Memory for GPU Energy Efficiency
through Software-Hardware Co-Design
Bin Wang, Bo Wu, Dong Li, Xipeng Shen, Weikuan Yu,
Yizheng Jiao, Jeffrey S. Vetter
Auburn University, College of William & Mary, Oak Ridge National Lab
PACT’13
20130923 PAPER STUDY

Outline
Motivation
Working sets, Power consumption
Introduction & Backgrounds
DRAM, PCM
Existing Hybrid Approaches for CPUs
Dbuff & RaPP
Observation
Proposed Mechanism
Hardware Design
Compiler Aided Features
Experimental Result
Conclusion

Motivation (1/2)
Why introduce NVM?
DRAM as main memory
Power Consumption: 30%-50% of the system power
Increasing working sets of manythreads
More size, power required
Why not pure NVM system?
Write speed < DRAM
Write energy > DRAM
Possible Solution
DRAM+NVM hybrid system
CPU CPU CPU CPU
L1 L1 L1 L1
LLC
Main Memory SystemNVM + DRAM

Motivation (2/2)
Why to apply hybrid memory system on GPU? GPU has much more concurrent threads
Larger working set
Why this paper should exist? Existing mechanisms for CPUs
don’t work efficiently on GPUs
354% energy efficiency degradation compared to DRAM-only system
Contribution of this paper It identifies the mismatch between
existing hybrid memory designs and GPU’s working behavior, and enhances previous designs
Introduces Placement Cost Graphto efficiently solve the data placement problem
The first NVM + GPU paper
GPU
GPU
GPU
GPU
L1 L1 L1 L1
LLC
NVM + DRAM

Introduction & Backgrounds
DRAM Dynamic energy
activation/precharge, read/write, termination
Static energy
background, peripheral circuitry, refreshing operations transistor leakage.
The size/capacity is an issue for larger working sets
PCM (one of NVM)
Pros: Higher cell density
Extremely low static energy
Comparable read speed
Cons: “Write” is much slower and consumes more energy
Endurance

Introduction & Backgrounds
Existing Hybrid Approaches for CPUs (Dbuff & RaPP)
Dbuff
DRAM as cache to tolerate PCM Rd/Wr latency and Wr bandwidth
PCM as main-memory to provide large capacity at good cost/power
LRU policy
1.5G 6G

Introduction & Backgrounds
RaPP (Rank-based Page Placement)
combines the DRAM and PCM areas in a large flat memory
(1) place performance-critical pages and frequently written pages in DRAM
(2) place non-critical pages and rarely written pages in PCM, and
(3) spread writes to PCM across many physical frames.
Types of pages are judges by their LLC miss counts
Processor
PCM
DRAM
Flash or SSD
1.5G
6G
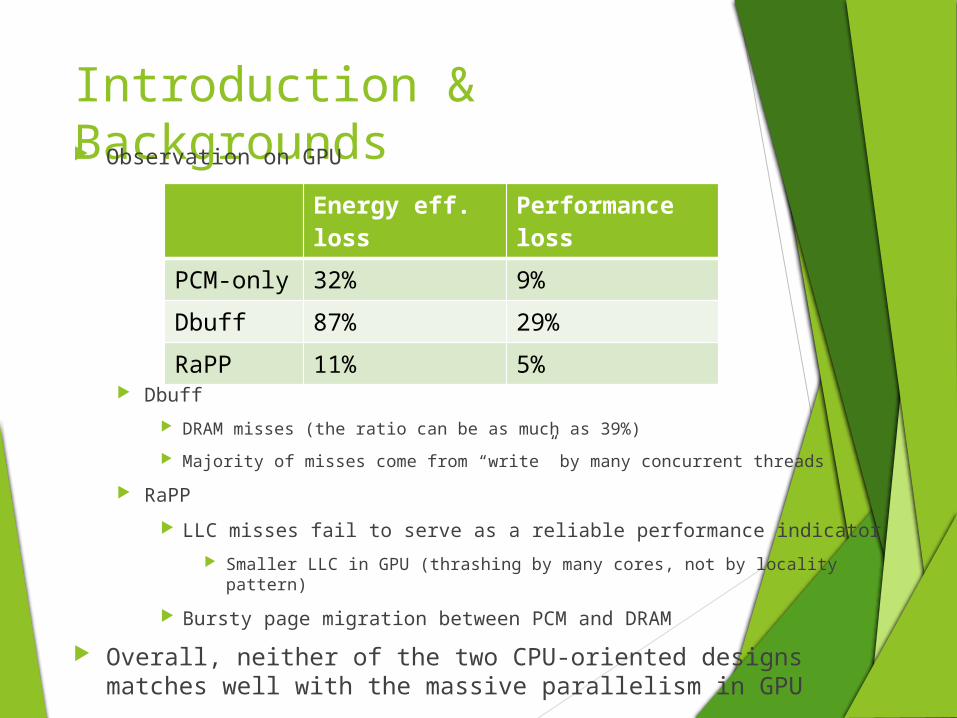
Introduction & Backgrounds Observation on GPU
Dbuff
DRAM misses (the ratio can be as much as 39%)
Majority of misses come from “write” by many concurrent threads
RaPP
LLC misses fail to serve as a reliable performance indicator
Smaller LLC in GPU (thrashing by many cores, not by locality pattern)
Bursty page migration between PCM and DRAM
Overall, neither of the two CPU-oriented designs matches well with the massive parallelism in GPU
Energy eff. loss
Performance loss
PCM-only 32% 9%
Dbuff 87% 29%
RaPP 11% 5%

Proposed Mechanism Observation on GPU (for HW design)
Lessons learned from RaPP
LLC misses fail to serve as a reliable performance indicator
Use ref. count & row-buffer-misses
Bursty page migration between PCM and DRAM
Use finer grain for migration (avoid unnecessary migration)
(1) finer granularity for data migration (256B)
(2) Use ref. count & row-buffer misses as the performance indicator
(3) Batch migration (raise row-buffer hit rate by data remapping)
(4) Bandwidth pressure-aware migration mechanism
(5) Conservative approach for space-efficient access monitoring
Overhead
Larger remapping table (due to finer migration unit and more info.)

Proposed Mechanism
Hardware Design
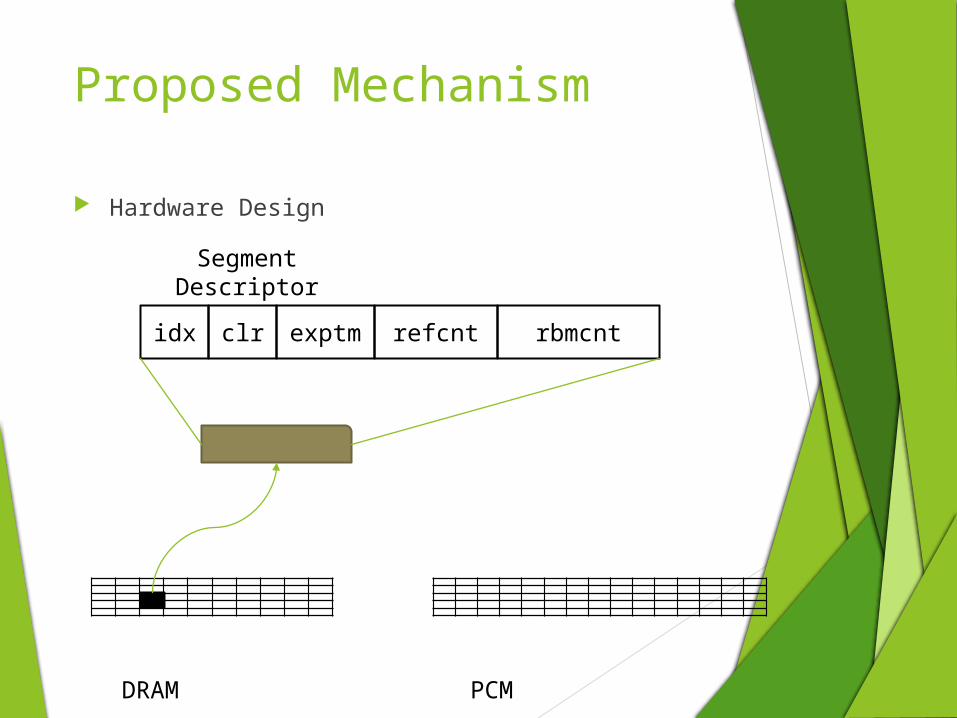
Proposed Mechanism
Hardware Design
DRAM PCM
idx
Segment Descriptor
clr exptm refcnt rbmcnt

Proposed Mechanism
FLRB for HW (frequency, locality, recency, bandwidth utilization)
How to determine if the data unit is “hot”
Promotion:
seg. descriptor
Reti
rem
ent
List
1 (1~2)
2 (2~4)
3 (4~8)
4 (8~16)
5 (16~32)
6 (32~64)
8 (128~256
)7 (64~128
)
seg. descriptor
seg. descriptor
seg. descriptor
cold
Hot
ref. count weight
Write: +3Other: +1

Proposed Mechanism
FLRB for HW (frequency, locality, recency, bandwidth utilization)
How to determine if the data unit is “hot”
Expiration:
seg. descriptor
Reti
rem
ent
List
1 (1~2)
2 (2~4)
3 (4~8)
4 (8~16)
5 (16~32)
6 (32~64)
8 (128~256
)7 (64~128
)
seg. descriptor
seg. descriptor
seg. descriptor
cold
Hot
ref. count weight
exptm = last accessed time + 150

Proposed Mechanism
FLRB for HW (frequency, locality, recency, bandwidth utilization)
How to determine whether the data should be moved to DRAM?
PCMDRAM:
seg. descriptor
Reti
rem
ent
List
1 (1~2)
2 (2~4)
3 (4~8)
4 (8~16)
5 (16~32)
6 (32~64)
8 (128~256
)7 (64~128
)
seg. descriptor
seg. descriptor
seg. descriptor
cold
Hot
ref. count weight
candidate: m>=3 & rbmcnt >= 2

Proposed Mechanism
FLRB for HW (frequency, locality, recency, bandwidth utilization)
How to improve row buffer spatial locality?
Batch migration:
candidates at same row, same queue will be migrated to the same row in DRAM
How to implement a bandwidth-aware migration mechanism?
epoch length = 1000 cycle

Proposed Mechanism
Software Design
Why software design?
Data are placed in PCM by default
High compulsory misses
High migration overhead
Software design is to determine the initial position of data with the aid of compiler
This work target input data in arrays of all kernels
DualLayer Compiler
Placement Engine

Proposed Mechanism
DualLayer Compiler
LLVM-based analyzer
Derive kernel memory access patterns
number of reads and writes to each input array in all kernels
number of coalesced and uncoalesced memory transactions with each memory access instruction
PTX code analyzer
Numbers of total instructions and synchronizations for energy estimation
Placement Engine
Determine a proper data placement and migration plan

Proposed Mechanism
Definition of Optimal Placement Problem
K1 K2 K3
…
DRAM
PCM
setup costaccess cost
v
v
v
Kx
(not used by kernel k)
Kk
A1 A2 Aa
…

Proposed Mechanism
Definition of Optimal Placement Problem
A1 A2 Aa
PCM capacityDRAM capacity
Si(Vi): cost for the kernelSi(Vi-1, Vi): migration cost (EDP)

Proposed Mechanism
Definition of Optimal Placement Problem
Placement Cost Graph
Simplify a Optimal Placement Problem into a Shortest Path Problem

Proposed Mechanism
Definition of Optimal Placement Problem
Benchmark Characteristics

Experimental Result

Experimental Result Row Buffer Miss Rates

Experimental Result Data Migration Rate
pc-hw has the highest migration rate for its smaller granularity
However, pc-hw has better energy efficiency than RaPP
Compiler aided design could reduce migration overhead significantly

Conclusion
This paper explored the use of hybrid memory as the GPU global memory
Overall, by exploiting the synergism of compiler and hardware, the proposed architecture leads to an average energy efficiency improvement of 6% and 49% respectively, compared to pure DRAM and pure PCM.
Performance loss is less than 2%





























