Embed Size (px)
Citation preview

Link Prediction & Content
Class Data Mining Technology for Business and SocietyProgram M. Sc. Data ScienceUniversity Sapienza University of RomeSemester Spring 2016Lecturer Carlos Castillo http://chato.cl/
Sources:● Lilian Weng, Jacob Ratkiewicz, Nicola Perra, Bruno Gonçalves, Carlos
Castillo, Francesco Bonchi, Rossano Schifanella, Filippo Menczer, Alessandro Flammini: The Role of Information Diffusion in the Evolution of Social Networks. In KDD 2013 [doi]
● Nicola Barbieri, Francesco Bonchi, and Giuseppe Manco. 2014. Who to follow and why: link prediction with explanations. In KDD 2014 [doi]
● Seth A. Myers and Jure Leskovec. 2014. The bursty dynamics of the Twitter information network. In WWW 2014 [doi]

Extension: links and traces, with data from Y! Meme (2009-2010)
Lilian Weng, Jacob Ratkiewicz, Nicola Perra, Bruno Gonçalves, Carlos Castillo, Francesco Bonchi, Rossano Schifanella, Filippo Menczer, Alessandro Flammini: The Role of Information Diffusion in the Evolution of Social Networks. In KDD 2013
http://videolectures.net/kdd2013_menczer_information_diffusion/

Y! Meme Dataset
Lilian Weng, Jacob Ratkiewicz, Nicola Perra, Bruno Gonçalves, Carlos Castillo, Francesco Bonchi, Rossano Schifanella, Filippo Menczer, Alessandro Flammini: The Role of Information Diffusion in the Evolution of Social Networks. In KDD 2013
~128k users
~3.5M links
~7M posts
Entire history available!

Most slides on this section from talk by F. Menczer:http://videolectures.net/kdd2013_menczer_information_diffusion/

Triadic closure with grandparent
Triadic closure with original poster
Triadic closure with someone else


Many traffic shortcuts …can this happen by chance?
● Let's take for instance grandparent links G● Links labeled in creation order● Probability of link being a “grandparent” link by
chance:
● Where NG is the number of grandparents of the link at
creation time, φ(.) the set of people followed by the
creator of the link at link creation time

Expected and actual number of links
● Expected number of links and variance if process is random
● Actual number of grandparent links SG● By central limit theorem, the following should be
normally distributed with mean 0 and variance 1:

z computed for different degrees
Notice z is in general a large number, very unlikely to come from a normal with mean 0 and variance 1. Observe also that at about 75 links, triadic closure starts taking a secondary role.

● The more posts we see from someone, the more likely we are of following her/him next
Effect of repeated exposure
● This is consistent with previous observations regarding repeated exposure to online content

Average number of posts seen through that link per unit of time after the link is created
Link efficiency(Usage of link after creation)
Each box shows data within lower and upper quartile. Whiskers represent the 99th percentile. The triangle and
line in a box represent the median and mean, respectively. Note that the mean can fall outside the shown quantiles for
skewed distributions. The gray area and the black line across the entire figure mark the interquartile range and the median of the measure across all links, respectively.

Link creations might happen by a mixture of reasons
● How do we determine the relative weights of each element in the mixture? E.g. grandparent vs. random
● Likelihood of link being created if we're using strategy Ψ and the state of the graph is Θ
● Combined strategy: link to grandparent with probability p, random with probability (1-p):

Log likelihood
● For numerical stability, the log likelihood is computed
● For instance for grandparent links, it is:
● To plot the log likelihood as a function of p, we
exhaustively use several values of p and
calculate this numerically

Link creations happen through a mixture of reasons

Assume all users create links using a mix of triadic closure and G+O, max likelihood estimate of params

Per-user assignments
● Assume you have p = <ptraffic, pstructure, prandom> (traffic=G+O, structure=Δ)
● Assume you have p' = <p'traffic, p'structure, p'random>
● Could you determine if a particular user is more likely to be using strategy p than p'?

Behavioral clusters
● Expectation-Maximization algorithm for clustering:– Assume there are k centroids
– Each centroid is a vector of three probabilities: <ptraffic, pstructure, prandom> (traffic=G+O, structure=Δ)
– Repeat:● Assign person to most likely centroid● Recompute centroids
● Number k can be determined by cross-validation

Clusters found>0.50 >0.05
● Info: preference for traffic-related linking● Cfrd: preference for friends but also random● Random: preference for random

Clusters of users bymost likely link creation strategy
Random
Mixture
Information oriented
Casual friendship
Friendship


In general ...
In general, active, popular, influential users make an information network more efficient by creating
“shortcuts” for information diffusion.

Link prediction with explanations

Link prediction with explanations
Nicola Barbieri, Francesco Bonchi, and Giuseppe Manco. 2014. Who to follow and why: link prediction with explanations. In Proceedings of the 20th ACM SIGKDD international conference on Knowledge discovery and data mining (KDD '14)

Key idea
● Common identity and common bond theory:– Identity-based attachment holds when people join a
community based on their interest in a well-defined common topic;
– Bond-based attachment is driven by personal social relations with other specific individuals.

Example network
● Sets next to nodes indicate interests (products purchased, hashtags used, keywords, etc.)
Which links are identity-based and which ones are bond-based?

Example network (3 communities)
● Blue links are bond-based– Bond-based communities
tend to have high density and reciprocal links
● Green and orange links are identity-based– Identity-based
communities tend to exhibit a clear directionality (leaders and followers)

Factors governing link behavior
● Authority (influence held)● Susceptibility (influence received)● Social attitude (propensity to reciprocate links)● Features adopted

Factors governing link behavior

Inference of generative model● Gray circles are observed (u,v) links, (u,f) features● Dirichlet distributions are used for sparsity

Parameters

Once a model has been fitted ...
● Recommend social link (u,v) if both are members of the same social community
● Recommend topical link (u,v) if u is interested in the topic and v is an authority in the topic

Experimental results: baselines
● JSVD (joint-SVD): approx. matrix X'≈X=[E F]– E contains (user, user) pairs for links
– F contains (user, feature) pairs for interests
● CNF (common neighbors and features)
● Adamic/Adar

Results (two datasets)
Twitter (n=81K, m=1.7M) Flickr (n=80K, m=14M)

Temporal dimension

Temporal dimension
● “Bursty” dynamic in which cascades of information create new links– Communities become more dense
– Communities become more topically cohesive
Myers & Leskovec: The bursty dynamics of the Twitter information network. WWW 2014

● Followers gained, followers lost, number of retweets, and number of tweets all scale with the indegree (number of followers) of a user.
● E.g.: in a given month a user of degree 100 tends to gain 10 and lose 3 followers.
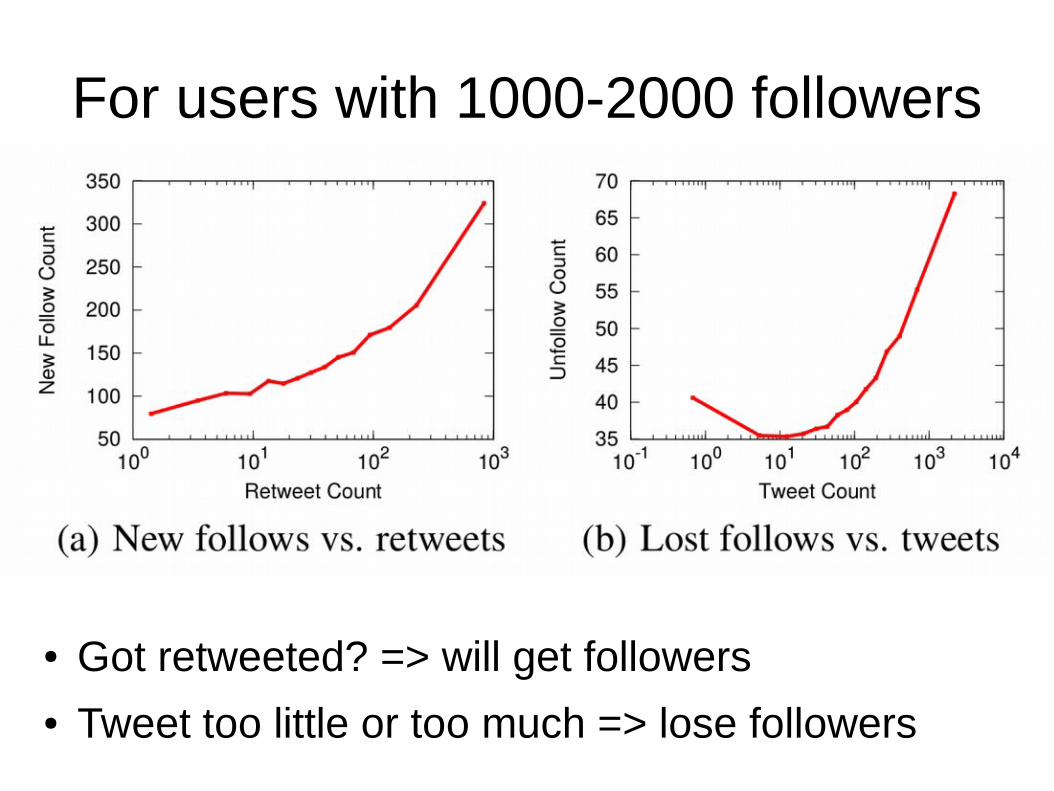
For users with 1000-2000 followers
● Got retweeted? => will get followers● Tweet too little or too much => lose followers

Three case studies
a)266K followers: burst in retweets => burst in followers
b)218K followers: burst in retweets => nothing
c)112K followers: no tweets, but followed/unfollowed

Observations of ego-networks
● Users with 2K or more followers● Instances in which a retweet burst was followed
by a follow burst (or unfollow burst)● Measure properties in their ego network:
– Tweet similarity: average content similarity of (v,u) for all v such that follows(v,u)
– Tweet coherence: average content similarity across all (v,w) pairs such that follows(v,u) and follows(w,u)
– Connected components
– Edge density

Results in ego-nets
Content similarity (to leader) and coherence (among followers) increases.
Weakly connected components increase; edge density increases slightly.

What causes a large follower burst?
The perfect scenario for a large follower burst is that a person's content reaches a large, new, and compatible audience

What does it mean a compatible audience? What is the scale?
● Different users have different characteristic scales● sim(v,u) is lognormal-distributed for follows(v,u)
# Followers
Pro
bab i
lity

Normalized similarityof v as a potential follower of u

Yuv helps predict followersP
roba
b ilit
y th
at v
fol
low
s u
Probability increases exponentially with normalized similarity

Building a predictor
Basic building block, estimates prob. of following given similarity
Set of nodes who have seen content by u
Set of nodes that are followers of followers of u

Experimental results
Method AUC
Myers & Leskovec 2014 0.52
Number of retweet exposures 0.38
Number of retweets 0.33
Number of followers 0.22
Random 0.21
● Task: given a retweet burst (cascade)● Predict whether there will be a follower burst

Conclusions
● Link formation is a complex process● Driven by triadic closure● Driven by shortcut formation● Driven by topical communities● Tends to occur in bursts