Embed Size (px)
Citation preview

Agenda
• Spark on Yarn• Autoscaling Spark Apps and Cluster
management• Hive Integration with Spark• Persistent History Server

Spark on Yarn

Hadoop1

Disadvantages of hadoop1
• Limited to only MR• Separate Map and Reduce slots =>
underutilization • JT is heavily loaded for job scheduling,
monitoring and resource allocation.
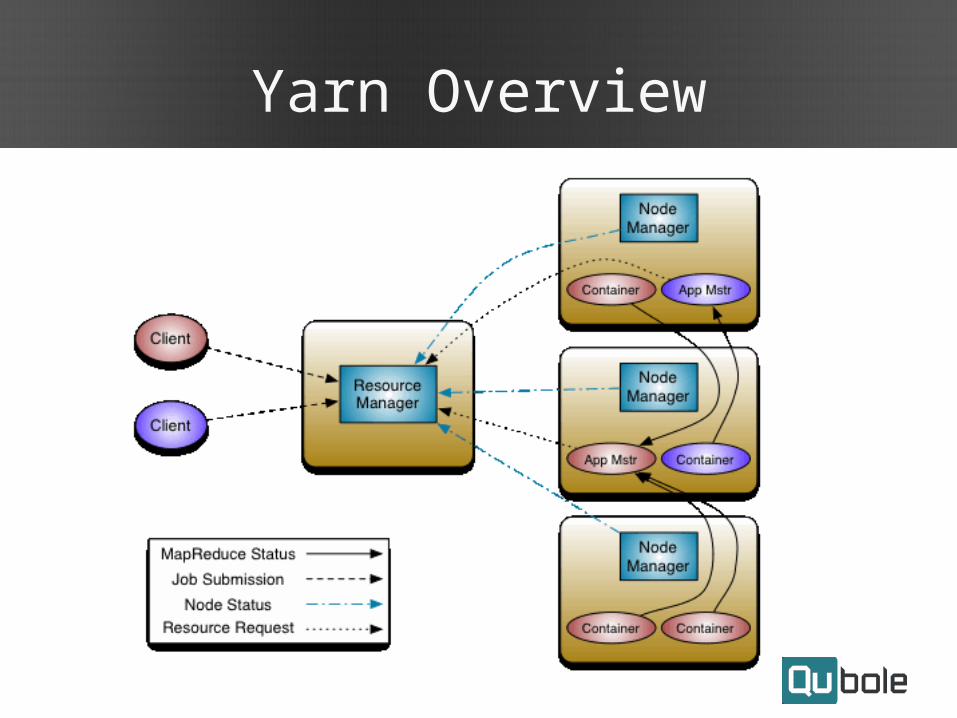
Yarn Overview

Advantages of Spark on Yarn
• General cluster for running multiple workflows. AM can have custom logic for scheduling
• AM can ask for more containers when required and give up containers when free
• This become even better when yarn clusters can autoscale
• Get features like spot nodes etc which brings additional challenges

Advantages of Spark on Yarn
• Qubole Yarn clusters can upscale and downscale based on load and support spot instances.

Autoscaling Spark Applications

Spark Provisioning: Problems
• Spark Application starts with fixed number of resources and hold on to them till its alive
• Sometimes its difficult to estimate resources required by a job since AM is long running
• It becomes limiting spl when Yarn clusters can autoscale.

Dynamic Provisioning
• Speed up spark commands by using free resources in yarn cluster and also by releasing resources when free to RM.

Spark on Yarn basics
DriverAM
Executor-1 Executor-n
• Cluster Mode: Driver and AM run in same JVM in a yarn Executor
• Client Mode: Driver and AM run in separate JVM
• Driver and AM talk using Actors to handle both cases
Driver AM Executor-1 Executor-n

Dynamic Provisioning: Problem Statement
• Two parts: – Spark AM has no way to ask for additional
containers and give up free containers– Automating the process of requesting containers
and releasing containers. Cached data in containers make this difficult

Dynamic Provisioning: Part1

Dynamic Provisioning: Part1
• Implementation of 2 new apis:// Request 5 extra executorssc.requestExecutors(5)// Kill executors with IDs 1, 15, and
16sc.killExecutors(Seq("1", "15",
"16"))

requestExecutors
AMReporter Thread
E1 E2 En
• AM has reporter thread that has count of number of executors
• Reporter thread was used to restart died executors
• Driver increments count of number of executors when sc.requestExecutors is called.
Driver

removeExecutors
• To kill executors, one must precisely tell which executors need to be killed
• Driver maintains list of all executors and can be obtained by:sc.executorStorageStatuses.foreach(x => println(x.blockManagerId.executorId))
• Whats cached in each executor is also available using:sc.executorStorageStatuses.foreach(x => println(s”memUsed = ${x.memUsed} diskUsed=${x.diskUsed)”))

Removing Executors Tradeoffs
• BlockManager in each executor can have cached RDDs, shuffle and broadcast data
• Killing an executor with shuffle data will require the stage to rerun.
• To avoid this use external shuffle service introduced in spark-1.2

Dynamic Provisioning: Part2

Upscaling Heuristics
• Request Executors as many pending tasks• Request Executors in rounds if there are
pending tasks, doubling number of executors added in each round bounded by some upper limit
• Request executors by estimating workload• Introduced –max-executors as extra param

Downscaling Heuristics
• Remove Executors when they are idle• Remove Executors if then are idle for X secs• Cant downscale executors with shuffle data or
broadcast data.• --num-executors act as minimum executors

Scope
• Kill executors on spot nodes first• Flag for not killing up executors if they have
shuffle data

Where is the code?
• https://github.com/apache/spark/pull/2840• https://github.com/apache/spark/pull/2746

Spark Hive Integration

What is involved?
• Spark programs should be able to access hive metastore
• Other Qubole services can be producers or consumers of data and metadata(hive, presto, pig etc)

Using SparkSQL - Command UI
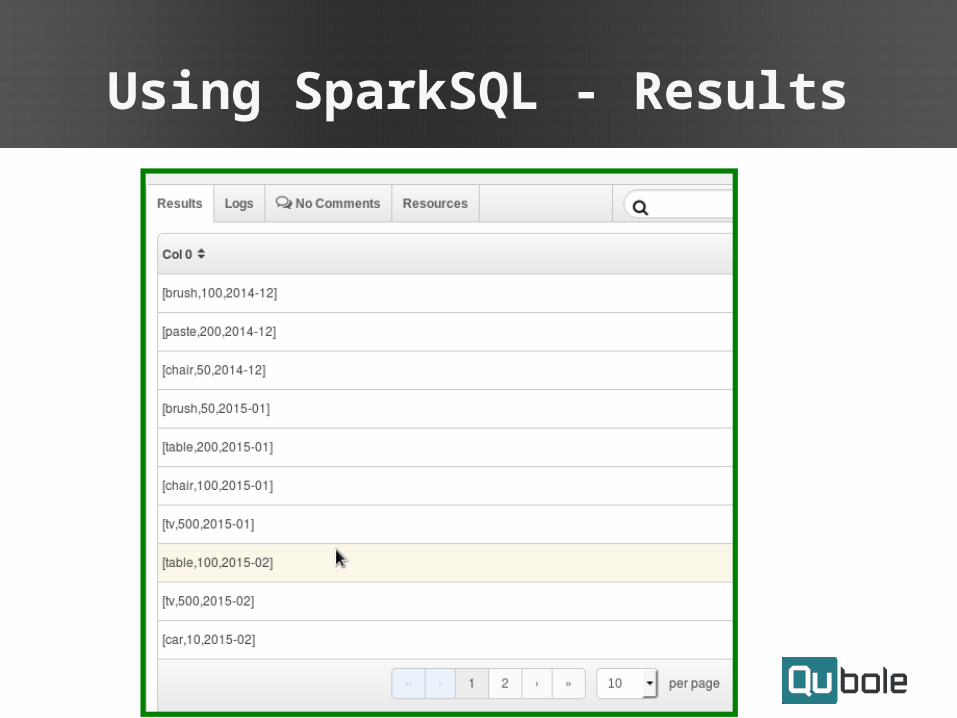
Using SparkSQL - Results

Using SparkSQL - Notebook
• SQL, Python, Scala code can be input

Using SparkSQL - REST api - scalacurl --silent -X POST \ -H "X-AUTH-TOKEN: $AUTH_TOKEN" \ -H "Content-Type: application/json" \ -H "Accept: application/json" \ -d '{ "program" : "val s = new org.apache.spark.sql.hive.HiveContext(sc); s.sql(\"show tables\").collect.foreach(println)", "language" : "scala", "command_type" : "SparkCommand" }' \ https://api.qubole.net/api/latest/commands

Using SparkSQL - REST api - sql
curl --silent -X POST \ -H "X-AUTH-TOKEN: $AUTH_TOKEN" \ -H "Content-Type: application/json" \ -H "Accept: application/json" \ -d '{ "program" : "show tables", "language" : "sql", "command_type" : "SparkCommand" }' \ https://api.qubole.net/api/latest/commands
NOT RELEASE YET

Using SparkSQL - qds-sdk-py / java
from qds_sdk.commands import SparkCommand
with open(“test_spark.py”) as f: code = f.read()cmd = SparkCommand.run(language="python", label="spark", program=code)results = cmd.get_results()

Using SparkSQL - Cluster config

Spark UI container info

Basic cluster organization
• DB instance in Qubole account• ssh tunnel from master to metastore DB• Metastore server running on master on port
10000• On master and slave nodes, hive-site.xml:-
hive.metastore.uris=thrift://master_ip:10000

Hosted metastore

Problems
• yarn overhead should be 20% (TPC-H)• Parquet needs higher PermGen• cached tables use actual table• alter table recover partitions not supported• VPC cluster has slow access to metastore• SchemaRDD gone - old jars dont run• hive jars needed on system classpath

Future/Near future
• Run with Qubole’s hive codebase• Metastore caching• Benchmarking

Future/Near future
• Persistent History Server• Fast access to spark AM running in customer
cluster

Thank You







![Free Spark Cloud Offering - Packt Publishing · [1 ] Free Spark Cloud Offering So far, we have worked with Spark on your machine only. Since Spark was designed with a build locally](https://img.dokumen.tips/doc/110x75/5b80fbb57f8b9a466b8b4cc5/free-spark-cloud-offering-packt-publishing-1-free-spark-cloud-offering.jpg)