Embed Size (px)
Citation preview

© 2015, Amazon Web Services, Inc. or its Affiliates. All rights reserved.
John Loughlin, Solution Architect
Eric Ferreira, Principal Database Engineer
July 22, 2015
Best Practices: Amazon RedshiftMigration and Loading Data

Amazon Redshift – Resources
Getting Started – June Webinar Series: https://www.youtube.com/watch?v=biqBjWqJi-Q
Best Practices – July Webinar Series:
Optimizing Performance – July 21, 2015
Migration and Data Loading – July 22,2015
Reporting and Advanced Analytics – July 23, 2015

Agenda
Common Migration Patterns
Copy Command
Automation Options
Near real time loading
ETL Options with Partners

Common Migration Patterns

Common Migration Patterns
Data from a variety of relational OLTP systems
structure lends itself to SQL schemas
Data from logs, devices, sensors…
data is less structured

Structured Data Loading
Data is often being loaded into another warehouse
existing ETL process
Temptation is to ‘lift & shift’ workload.
Resist temptation. Instead consider:
What do I really want to do?
What do I need?

Ingesting Less Structured Data
Some data does not lend itself to a relational schema
Common pattern is to use EMR:
impose structure
import into Redshift
Other solutions are often home grown scripting applications.

Loading Data
Load to an empty Redshift database.
Load changes captured in the source system to Redshift

Truncate and Load
This is by far the easiest option:
Move the data to Amazon Simple Storage Service
multi-part upload
import/export service
direct connect
COPY the data into Redshift, a table at a time.

Load Changes
Identify changes in source systems
Move data to Amazon S3
Load changes
‘Upsert process’
Partner ETL tools

Partner ETL
Amazon Redshift is supported by a variety of ETL vendors
Many simplify the process of data loading
Visit http://aws.amazon.com/redshift/partners
There are a variety of vendors offering a free trial of their products, allowing you to evaluate and choose the one that suits your needs.

Upsert
The goal is to insert new rows and update changed rows in Redshift.
Load data into a temporary staging table
Join the staging with production and delete the common rows.
Copy the new data into the production table.
See Updating and Inserting New Data in the developer’s guide

Checkpoint
We’ve talked about common migration patterns
Sources of data and data structure
Methods of getting data to AWS
Options for loading data

COPY

Amazon Redshift Architecture
Leader Node• SQL endpoint, JDBC/ODBC
• Stores metadata
• Coordinates query execution
Compute Nodes• Local, columnar storage
• Execute queries in parallel
• Load, backup, restore via Amazon S3
• Load from Amazon DynamoDB or SSH
Two hardware platforms• Optimized for data processing
• DS2: HDD; scale from 2TB to 2PB
• DC1: SSD; scale from 160GB to 326TB
10 GigE(HPC)
IngestionBackupRestore
SQL Clients/BI Tools
128GB RAM
16TB disk
16 cores
Amazon S3 / DynamoDB / SSH
JDBC/ODBC
128GB RAM
16TB disk
16 coresCompute Node
128GB RAM
16TB disk
16 coresCompute Node
128GB RAM
16TB disk
16 coresCompute Node
LeaderNode
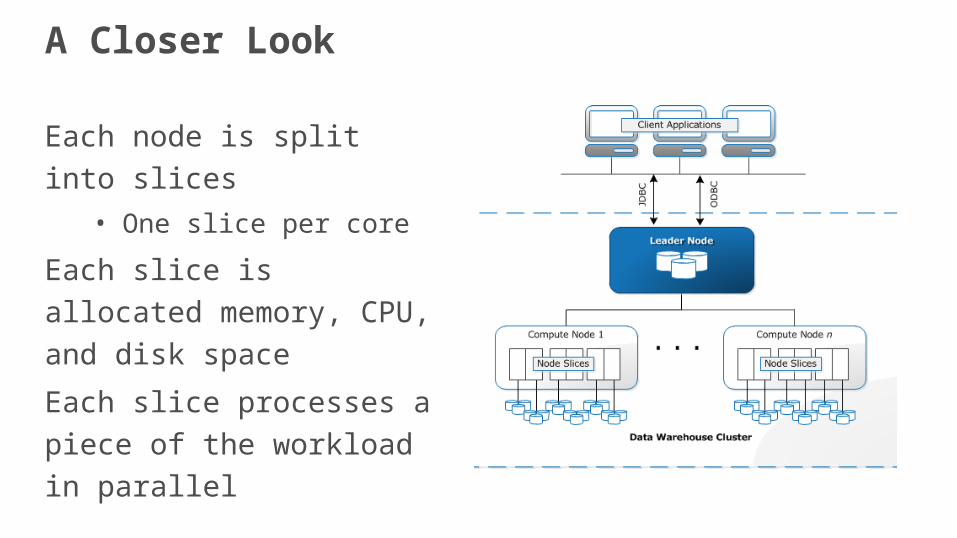
A Closer Look
Each node is split into slices
• One slice per core
Each slice is allocated
memory, CPU, and disk space
Each slice processes a piece
of the workload in parallel

COPY command
COMPUPDATE ON when running on an empty table
Use the COPY command.
Each slice can load one file at a time.
Partition input files so every slice can load in parallel.
Use a Manifest file.

Use multiple input files to maximize throughput
Use the COPY command
Each slice can load one file at a time
A single input file means only one slice is ingesting data
Instead of 100MB/s, you’re only getting 6.25MB/s
DW1.8XL Compute Node
Single Input File

Use multiple input files to maximize throughput
Use the COPY command
You need at least as many input files as you have slices
With 16 input files, all slices are working so you maximize throughput
Get 100MB/s per node; scale linearly as you add nodes
16 Input Files
DW1.8XL Compute Node

Primary keys and manifest files
Amazon Redshift doesn’t enforce primary key constraints• If you load data multiple times, Amazon Redshift won’t complain• If you declare primary keys in your DML, the optimizer will
expect the data to be unique
Use manifest files to control exactly what is loaded and how to respond if input files are missing
• Define a JSON manifest on Amazon S3• Ensures the cluster loads exactly what you want

Analyze sort/dist key columns after every load
Amazon Redshift’s query optimizer relies on up-to-date statistics
Maximize performance by updating stats on sort/dist key columns after every load

Automatic compression
Better performance, lower costs
COPY samples data automatically when loading into an empty table
• Samples up to 100,000 rows and picks optimal encoding
If you have a regular ETL process and you use temp tables or staging tables, turn off automatic compression
• Use analyze compression to determine the right encodings
• Bake those encodings into your DML

Checking STL_LOAD_COMMITS
SELECT query, trim(filename) as filename, curtime, status FROM stl_load_commits WHERE filename LIKE ’%table name%' ORDER BY query;
After the load operation is complete, query the STL_LOAD_COMMITS system table to verify that the expected files were loaded.

COPY and 18 inserts
COPY country FROM 's3://…country.txt' CREDENTIALS … 1.57s then
.
insert into country (country_name) values ('Slovakia'),('Slovenia'),('South Africa'),('South Korea'),('Spain'); 5.44s
‘
Insert vs Copy
Commit info

COPY best practice
Use it.Avoid inserts, which will not run in parallel.If you are moving data from table to another, use the deep copy features:1. Use the original CREATE TABLE ddl and then
INSERT INTO … SELECT2. CREATE TABLE AS3. CREATE TABLE LIKE4. Create a temporary table and truncate the
original.

Automation Options

Automating Data Ingestion
Many customers run custom scripts on EC2 instances to load data into Redshift.
Another option is to use the Amazon Data Pipeline automation tool.
AWS Lambda-based Amazon Redshift Loader

Create a Data Pipeline

Create a Data Pipeline

Review Results

Execution Details

Using the Lambda based Redshift Loader
Offers the ability to drop files into S3 and load them into any number of database tables in multiple Amazon Redshift clusters automatically, with no servers to maintain.

Configure the sample loader
johnlou$ ./configureSample.sh more.ohno.us-east-1.redshift.amazonaws.com 8192 mydb johnlou us-east-1Password for user johnlou: create user test_lambda_load_user password 'Change-me1!';CREATE USERcreate table lambda_redshift_sample(column_a int,column_b int,column_c int);CREATE TABLEEnter the Region for the Redshift Load Configuration > us-east-1Enter the S3 Bucket to use for the Sample Input > johnlou-ohno/loader-demo-dataEnter the Access Key used by Redshift to get data from S3 > nopeEnter the Secret Key used by Redshift to get data from S3 > nopeCreating Tables in Dynamo DB if RequiredConfiguration for johnlou-ohno/loader-demo-data/input successfully written in us-east-1

View Logs

Near Real Time Loading

Micro-batch loading
Ideal for time series data
Balance input files
Pre-configure column encoding
Reduce frequency of statistics calculation
Load in sort key order
Use SSD instances
Consider using the ‘Load Stream’ architecture HasOffers developed.

ETL Options with Partners

Data Loading Options
Parallel upload to Amazon S3
AWS Direct Connect
AWS Import/Export
Amazon Kinesis
Systems integrators
Data Integration Systems Integrators

Resources on the AWS Big Data Blog
Best Practices for Micro-Batch Loading on Amazon Redshift
Using Attunity Cloudbeam at UMUC to Replicate Data to Amazon RDS and Amazon Redshift
A Zero-Administration Amazon Redshift Database Loader

Best Practices References
Best Practices for Designing Tables
Best Practices for Designing Queries
Best Practices for Loading Data

Thank you!



![[AWS Black Belt Online Seminar] Amazon Redshift€¦ · クエリの実行(3/4) Amazon Redshift JDBC/ODBC 広帯域ネットワーキング Redshift フォーマットファイル](https://img.dokumen.tips/doc/110x75/5ec5b91526ea6d3c9424f600/aws-black-belt-online-seminar-amazon-redshift-feoei34i-amazon.jpg)

























