Embed Size (px)
Citation preview

S
Apache HBase: Introduction & Use Cases
Subash D’Souza

What is HBase?
HBase is an open source, distributed, sorted map modeled after Google’s Big Table
NoSQL solution built atop Apache Hadoop
Top level Apache Project

CAP Theorem
Consistency (all nodes see the same data at the same time)
Availability (a guarantee that every request receives a response about whether it was successful or failed)
Partition tolerance (the system continues to operate despite arbitrary message loss or failure of part of the system)
According to the theorem, a distributed system can satisfy any two of these guarantees at the same time, but not all three.
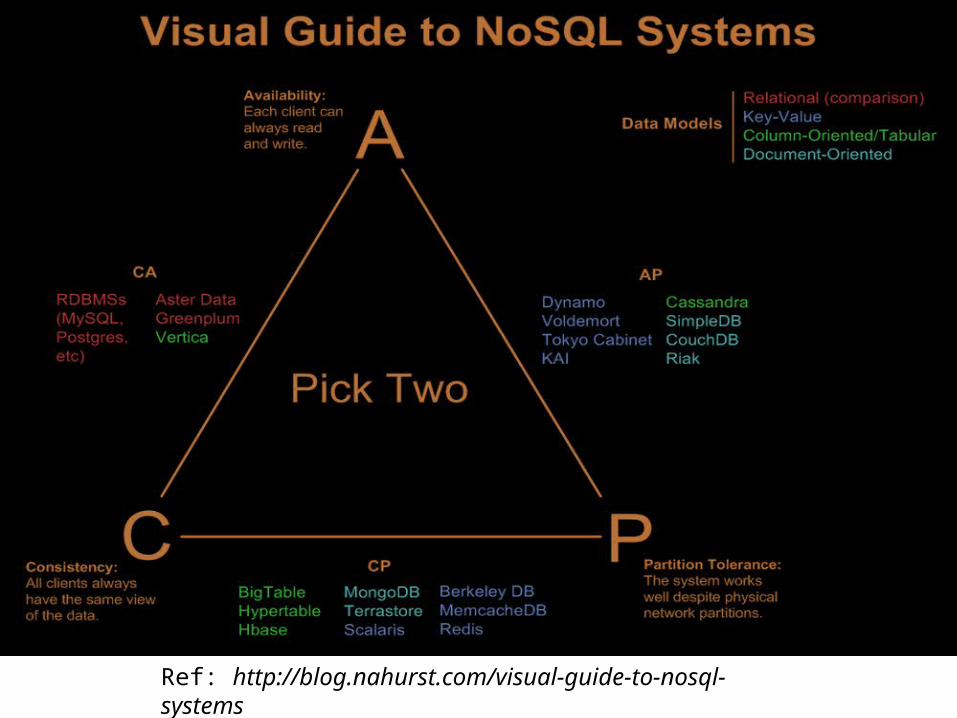
Ref: http://blog.nahurst.com/visual-guide-to-nosql-systems

Usage Scenarios
Lots of Data - 100s of Gigs to Petabytes
High Throughput – 1000’s of records/sec
Scalable cache capacity – Adding several nodes adds to available cache
Data Layout – Excels at key lookup and no penalty for sparse columns

Column Oriented Databases
HBase belongs to family of databases called as Column-oriented
Column-oriented databases save their data grouped by columns.
The reason to store values on a per-column basis instead is based on the assumption that, for specific queries, not all of the values are needed.
Reduced I/O is one of the primary reasons for this new layout
Specialized algorithms—for example, delta and/or prefix compression—selected based on the type of the column (i.e., on the data stored) can yield huge improvements in compression ratios. Better ratios result in more efficient bandwidth usage.

HBase as a Column Oriented Database
HBase is not a column-oriented database in the typical RDBMS sense, but utilizes an on-disk column storage format.
This is also where the majority of similarities end, because although HBase stores data on disk in a column-oriented format, it is distinctly different from traditional columnar databases.
Whereas columnar databases excel at providing real-time analytical access to data, HBase excels at providing key-based access to a specific cell of data, or a sequential range of cells.

HBase and Hadoop
Hadoop excels at storing data of arbitrary, semi-, or even unstructured formats, since it lets you decide how to interpret the data at analysis time, allowing you to change the way you classify the data at any time: once you have updated the algorithms, you simply run the analysis again.
HBase sits atop Hadoop using all the best features of HDFS such as scalability and data replication

HBase UnUsage
When data access patterns are unknown – HBase follows a data centric model rather than relationship centric, Hence it does not make sense doing an ERD model for HBase
Small amounts of data – Just use an RDBMS
Limited/No random reads and writes – Just use HDFS directly

HBase Use Cases - Facebook
One of the earliest and largest users of HBase
Facebook messaging platform built atop HBase in 2010
Chosen because of the high write throughput and low latency random reads
Other features such as Horizontal Scalability, Strong Consistency and High Availability via Automatic Failover.

HBase Use Cases - Facebook
In addition to online transaction processing workloads like messages, it is also used for online analytic processing workloads where large data scans are prevalent.
Also used in production by other Facebook services, including the internal monitoring system, the recently launched Nearby Friends feature, search indexing, streaming data analysis, and data scraping for their internal data warehouses.

Seek vs. Transfer
One of the fundamental differences between typical RDBMS and nosql ones is the use of B or B+ trees and Log Structured Merge Trees(LSM) which was the basis of Google’s BigTable

B+ Trees
B+ Trees allow for efficient insertion, lookup and deletion of records that are identified by keys.
Represent dynamic, multilevel indexes with lower and upper bounds per segment or page
This allows for higher fanout compared to binary trees resulting in lower number of I/O operations
Range scans are also very efficient

LSM Trees
Incoming data first stored in logfile, completely sequentially
Once the log has modification saved, updates an in-memory store.
Once enough updates are accrued in the in-memory store, it flushes a sorted list of key->record pairs to disks creating store files.
At this point all updates to log can be deleted since modifications have been persisted.

Fundamental Difference
Disk Drives
Too Many Modifications force costly optimizations.
More Data at random locations cause faster fragmentation
Updates and deletes are done at disk seek rates rather than disk transfer rates

Fundamental Difference(Contd)
Works at disk transfer rates
Scales better to handle large amounts of data.
Guarantees consistent insert rate
Transform random writes into sequential writes using logfiles plus in-memory store
Reads independent from writes so no contention between the two

HBase Basics
When data is added to HBase, it is first written to the WAL(Write ahead log) called HLog.
Once the write is done, it is then written to an in memory called MemStore
Once the memory exceeds a certain threshold, it flushes to disk as an HFile
Over time HBase merges smaller HFiles into larger ones. This process is called compaction
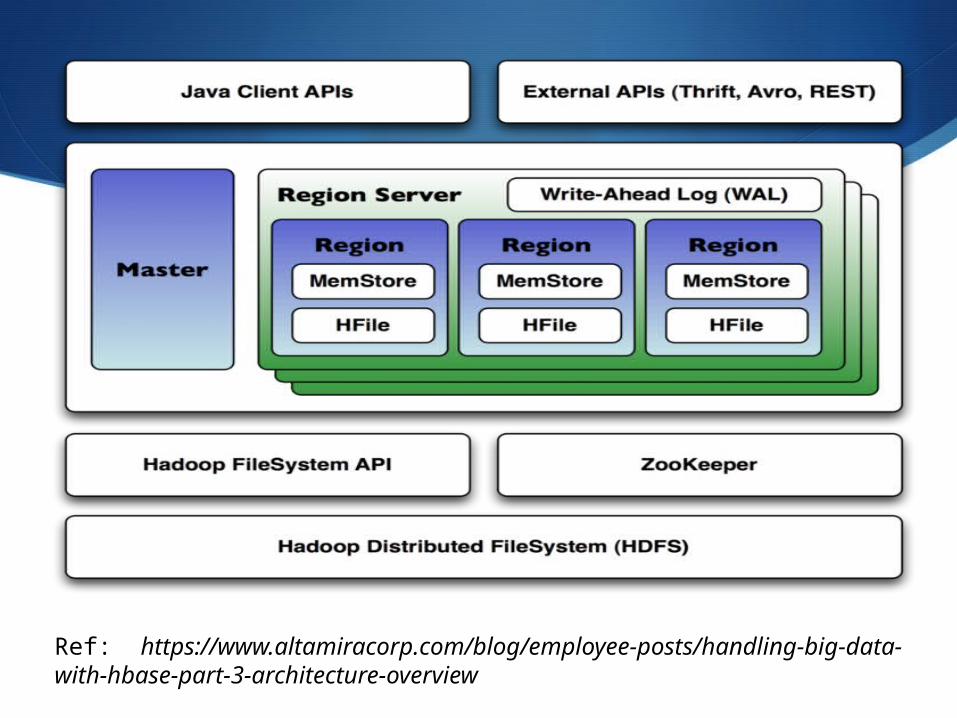
Ref: https://www.altamiracorp.com/blog/employee-posts/handling-big-data-with-hbase-part-3-architecture-overview



Facebook-Hydrabase
In HBase, when a regionserver fails, all regions hosted by that regionserver are moved to another regionserver.
Depending on HBase has been setup, this typically entails splitting and replaying the WAL files which could take time and lengthens the failover
Hydrabase differs from HBase in this. Instead of having a region by a single region server, it is hosted by a set of regionservers.
When a regionserver fails, there are standby regionservers ready to take over

Facebook-Hydrabase
The standby region servers can be spread across different racks or even data centers, providing availability.
The set of region servers serving each region form a quorum. Each quorum has a leader that services read and write requests from the client.
HydraBase uses the RAFT consensus protocol to ensure consistency across the quorum.
With a quorum of 2F+1, HydraBase can tolerate up to F failures.
Increases reliability from 99.99% to 99.999% ~ 5 mins downtime/year.

HBase Users - Flurry
Mobile analytics, monetization and advertising company founded in 2005
Recently acquired by Yahoo
2 data centers with 2 clusters each, bi directional replication
1000 slave nodes per cluster – 32 GB RAM, 4 drives(1 or 2 TB), 1 Gig E, Dual Quad Core processors *2 HT = 16 procs
~30 tables, 250k regions, 430TB(after LZO compression)
2 big tables are approx 90% of that, 1 wide table with 3 CF, 4 billion rows with 1 MM cells per row. The other tall table with 1 CF, 1 trillion rows and 1 cell per row

HBase Security – 0.98
Cell Tags – All values in HBase are now written in cells, can also carry arbitrary no. of tags such as metadata
Cell ACLs – enables the checking of (R)ead, (W)rite, E(X)excute, (A)dmin & (C)reate
Cell Labels – Visibility expression support via new security coprocessor
Transparent Encryption – data is encrypted on disk – HFiles are encrypted when written and decrypted when read
RBAC – Uses Hadoop Group Mapping Service and ACL’s to implement

Apache Phoenix
SQL layer atop HBase – Has a query engine, metadata repository & embedded JDBC driver, top level apache project, currently only for HBase
Fastest way to access HBase data – HBase specific push down, compiles queries into native, direct HBase calls(no map-reduce), executes scans in parallel
Integrates with Pig, Flume & Sqoop
Phoenix maps HBase data model to relational world

Ref: Taming HBase with Apache Phoenix and SQL, HBaseCon 2014

Open TSDB 2.0
Distributed, Scalable Time Series Database on top of HBase
Time Series – data points for identity over time.
Stores trillions of data points, never loses precision, scales using HBase
Good for system monitoring & measurement – servers & networks, Sensor data – The internet of things, SCADA, Financial data, Results of Scientific experiments, etc.

Open TSDB 2.0
Users – OVH(3rd largest cloud/hosting provider) to monitor everything from networking, temperature, voltage to resource utilization, etc.
Yahoo uses it to monitor application performance & statistics
Arista networking uses it for high performance networking
Other users such as Pinterest, Ebay, Box, etc.

Apache Slider(Incubator)
YARN application to deploy existing distributed applications on YARN, monitor them and make them larger or smaller as desired -even while the application is running.
Incubator Apache Project; Similar to Tez for Hive/Pig
Applications can be stopped, "frozen" and restarted, "thawed" later; It allows users to create and run multiple instances of applications, even with different application versions if needed
Applications such as HBase, Accumulo & Storm can run atop it

Thanks!!
Credits – Apache, Cloudera, Hortonworks, MapR, Facebook, Flurry & HBaseCon
@sawjd22
www.linkedin.com/in/sawjd/
Q & A

![Otimização do HBase para dados estruturados · 2020-05-13 · 3 2.1 Apache HBase Apache HBase[13] é uma base de dados não-relacional, distribuída e escalá-vel. Inspirada na](https://img.dokumen.tips/doc/110x75/5ec5c12975eb2b22f126d65c/otimizao-do-hbase-para-dados-estruturados-2020-05-13-3-21-apache-hbase-apache.jpg)



























