Embed Size (px)
Citation preview

1
担当: Takeshi Yamamuro
SIGMOD’17 Session 20: Op4miza4on and performance
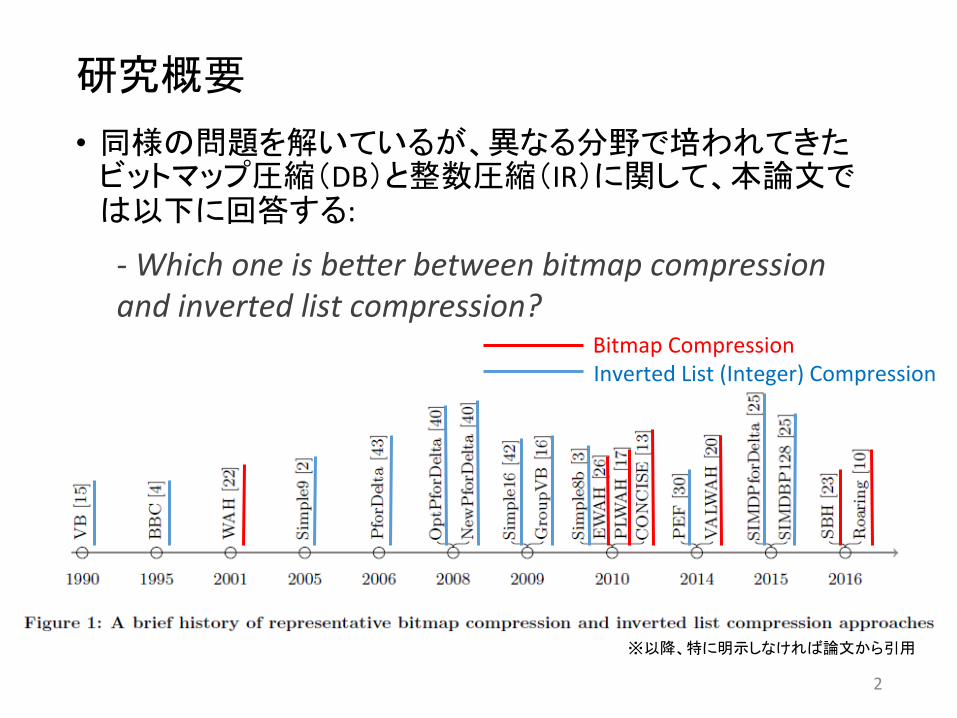
2
研究概要
• 同様の問題を解いているが、異なる分野で培われてきたビットマップ圧縮(DB)と整数圧縮(IR)に関して、本論文では以下に回答する:
※以降、特に明示しなければ論文から引用
Inverted List (Integer) Compression Bitmap Compression
-‐ Which one is be,er between bitmap compression and inverted list compression?
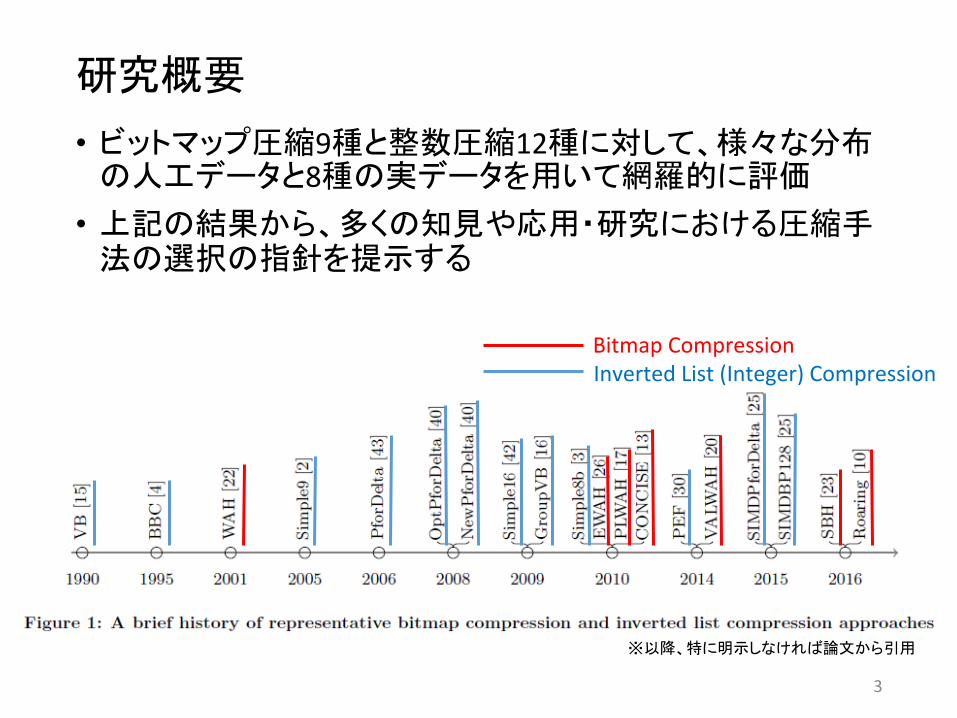
3
研究概要
• ビットマップ圧縮9種と整数圧縮12種に対して、様々な分布の人工データと8種の実データを用いて網羅的に評価 • 上記の結果から、多くの知見や応用・研究における圧縮手
法の選択の指針を提示する
※以降、特に明示しなければ論文から引用
Inverted List (Integer) Compression Bitmap Compression

4
実験結果から得られた知見
• Intersec4on(A∩B)の速度が重要ならビットマップ圧縮、それ以外の指標(圧縮率、復元速度、Union(A∪B))が重要であれば整数圧縮を選択
• ビットマップ圧縮はRLEベースの手法ではないRoaringがどの指標においても性能が良い、RLEベースの他の手法(WAHやEWAHなど)は検討しなくて良い • 他の手法は 悪ケースで無圧縮よりサイズ大
• 整数圧縮はベクトル命令に対応しているSIMDPforDeltaかSIMDBP128が性能が良い、特にSIMDPforDeltaは圧縮率、SIMDBP128は復元速度が良い
• SIMDPforDelta/SIMDBP128は実装が複雑であるため、20行以下で記述できるVBも選択としては有り • 条件によってVBがPForDeltaに比べ性能が良くなるケースも存在

Study Details
5

6
共通する解いている問題
• 昇順に並び替えられた整数を少ないbitで表現しつつ、高速な問い合わせ(e.g., A∩B)を実現
ビットマップ圧縮 -‐ ビットが立っている位置は昇順の整数: 011001 -‐> 1,2,5 -‐ 適用例: PostgreSQL/OracleなどのRDBMSやApache Spark/Hiveなど
整数圧縮 -‐ 転置インデックスのドキュメントID、昇順に並び替えて保存 -‐ 主な適用例: Apache Lucene/Solr、Elas4csearchなど(近年では DBMS内部の要素技術としてもよく利用される)
A = 1, 4, 8, 10, 19, … B = 4, 14, 18, 19, 22, … A ∩ B = 4, 19, …
特定の問い合わせを高速に処理できる効率的なコンピュータ上の表現(符号化)方法を模索

7
Apache Sparkにおける適用例
• Spark SQLでcacheしたデータはカラム構造(型毎の配列)としてメモリ上に配置され、整数配列はVBで表現
• SparkのSchedulerが各Task(実行 小単位)の出力サイズを追跡、出力が無いTaskをRoaring Bitmapsで管理 • h`p://roaringbitmap.org • Lemire先生が書いた RoaringのOSS実装
・・・

8
圧縮アルゴリズム紹介(抜粋)
• ビットマップ圧縮 • RLEベースの手法: WAH, EWAH, PLWAH, CONCISE, VALWAH, SBH, BBC
• Hybridな手法: Roaring
• 整数圧縮 • VB, PforDelta, [New|Opt|SIMD]PforDelta, Simple16, GroupVB, Simple8b, PEF, SIMDBP128

9
ビットマップ圧縮: WAH
• RLEベースの古典的なビットマップ圧縮手法 • ビット列を31bitずつのgroupsに分割 • グループを2種類に分類: fill groups or literal groups fill groups: ビットが全て同じグループ(0-‐fill groups or 1-‐fill groups) literal groups: 上記以外のグループ • fill groupsのみをRLEで圧縮、分割したgroupsの先頭に1bitのgroups判定フラグ1bitを付与(1の場合fill groups)
• fill groupsの場合、2bit目でfill groupsの種類(0 or 1)を表し、残りの30bitでrunの長さを表現
具体例) 入力ビット列: 1020 13 0111 125 (160bit)
G1(1020 13 07) G2(031) G3(031) G4(031) G5(011120) G6(02615)
010201307 10027011 0011120 002615

10
ビットマップ圧縮: SBH
• WAHの改良版の手法 • ビット列を7bitずつのgroupsに分割 • 連続するfill-‐groupsの数k(k <= 4093)で表現方法を変える 63 >= k: 1byteでfill-‐groupsを表現 63 < k <= 4093: 2byteでfill-‐groupsを表現
• 具体例) 入力ビット列: 1020130501160(532bit)
G1(106) G2(07) G3(07) G4(1304)G5(07)...G76(07)G78(160) 0106 10000010 (k = 2) 01304 01304 1031031061 (k = 72)

11
ビットマップ圧縮: Roaring
• 2016年に提案された 新のビットマップ圧縮手法
• RLEベースではなく、ビット密度(Cardinality)に応じて表現方法を変えるハイブリッドな手法 • ビット列を上位16bitが共通しているbucketに分割 • 各bucket内のビット数kで表現を変更 4096 > k, dense: 65536-‐bit uncompressed bitmap 4096 <= k sparse: sorted 16bit ints.
• 実装の詳細は以下のスライドが理解しやすい • h`ps://spark-‐summit.org/east-‐2017/speakers/daniel-‐lemire/
12
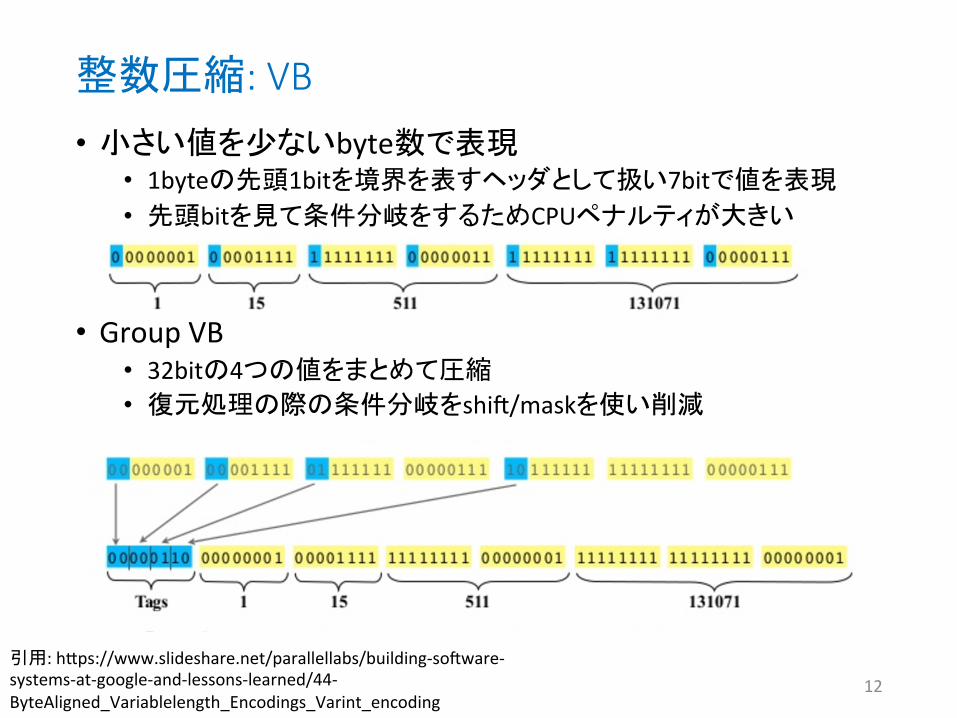
整数圧縮: VB
• 小さい値を少ないbyte数で表現 • 1byteの先頭1bitを境界を表すヘッダとして扱い7bitで値を表現 • 先頭bitを見て条件分岐をするためCPUペナルティが大きい
• Group VB • 32bitの4つの値をまとめて圧縮 • 復元処理の際の条件分岐をshii/maskを使い削減
引用: h`ps://www.slideshare.net/parallellabs/building-‐soiware-‐systems-‐at-‐google-‐and-‐lessons-‐learned/44-‐ByteAligned_Variablelength_Encodings_Varint_encoding
13
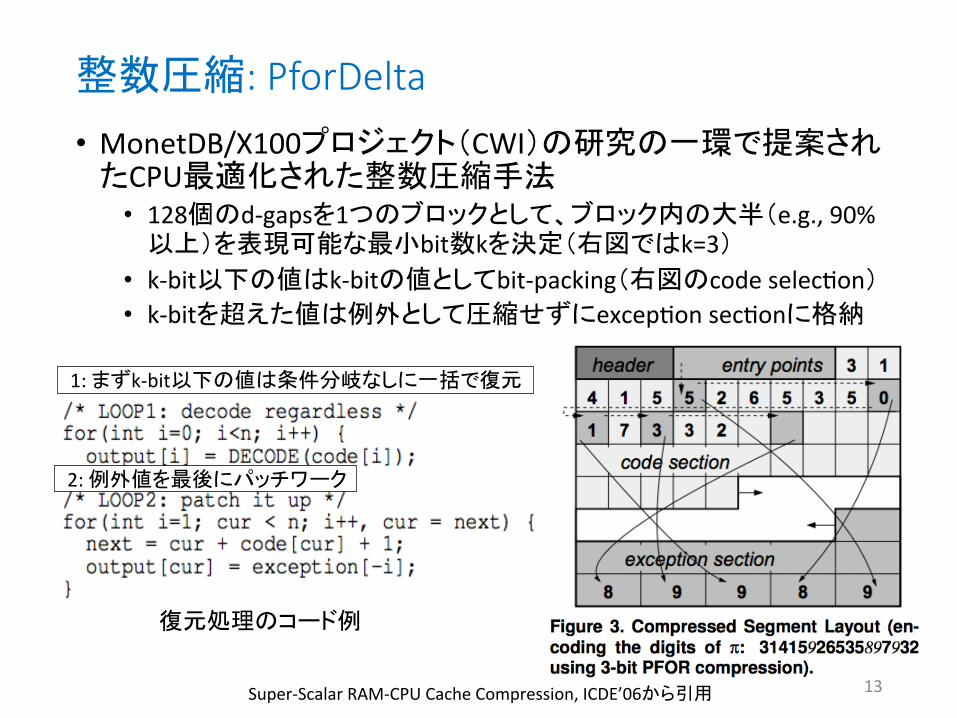
整数圧縮: PforDelta
Super-‐Scalar RAM-‐CPU Cache Compression, ICDE’06から引用
復元処理のコード例
• MonetDB/X100プロジェクト(CWI)の研究の一環で提案されたCPU 適化された整数圧縮手法 • 128個のd-‐gapsを1つのブロックとして、ブロック内の大半(e.g., 90%
以上)を表現可能な 小bit数kを決定(右図ではk=3) • k-‐bit以下の値はk-‐bitの値としてbit-‐packing(右図のcode selec4on) • k-‐bitを超えた値は例外として圧縮せずにexcep4on sec4onに格納
1: まずk-‐bit以下の値は条件分岐なしに一括で復元
2: 例外値を 後にパッチワーク
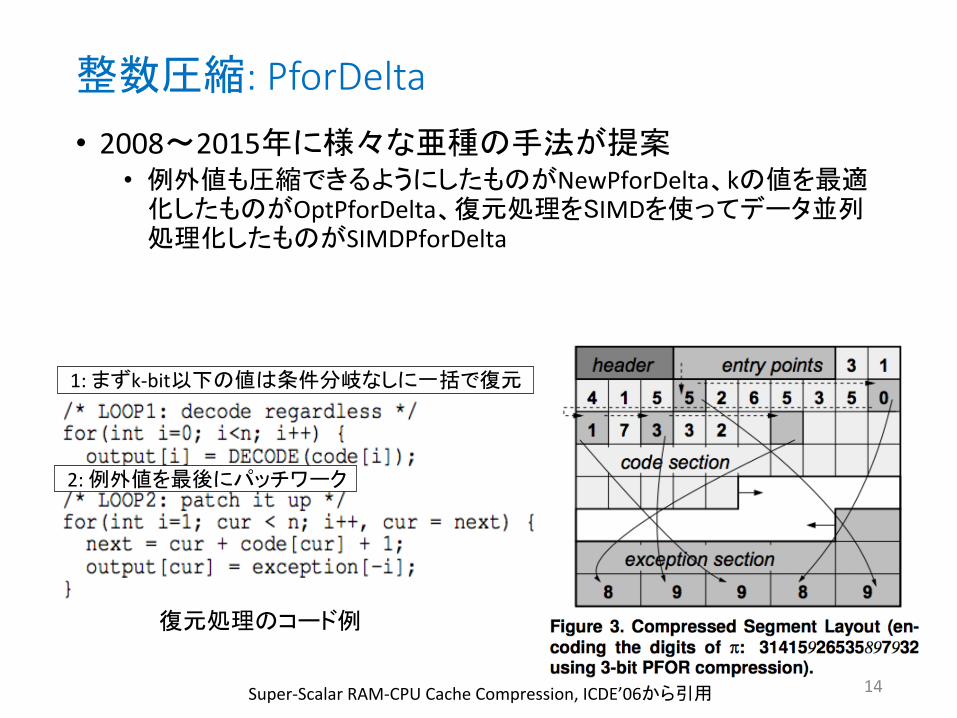
14
整数圧縮: PforDelta
Super-‐Scalar RAM-‐CPU Cache Compression, ICDE’06から引用
復元処理のコード例
• 2008〜2015年に様々な亜種の手法が提案 • 例外値も圧縮できるようにしたものがNewPforDelta、kの値を 適
化したものがOptPforDelta、復元処理をSIMDを使ってデータ並列処理化したものがSIMDPforDelta
1: まずk-‐bit以下の値は条件分岐なしに一括で復元
2: 例外値を 後にパッチワーク

15
整数圧縮: SIMDBP128
• 復元処理をSIMD命令を使い 適化した手法 • 入力列を128個ずつの整数ブロックに分割、16個のブロッ
ク毎に16byteのメタデータを付与 • 各ブロックをk-‐bit(表現可能な 小のbit数)でm個ずつbit-‐packing • kとmの値をメタデータ記録
• 復元処理はメタデータから必要な関数(SIMDunpackk_m)を判断して呼び出す
5bitで表現された値8個をSIMD命令で復元するコード([25]から引用)
16
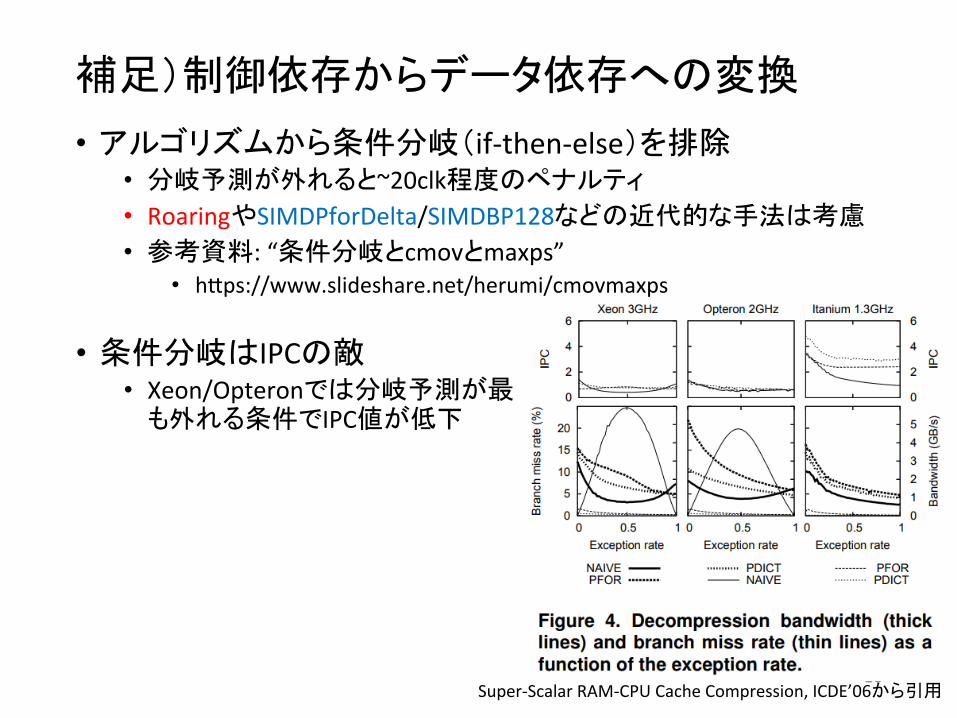
補足)制御依存からデータ依存への変換
• アルゴリズムから条件分岐(if-‐then-‐else)を排除 • 分岐予測が外れると~20clk程度のペナルティ • RoaringやSIMDPforDelta/SIMDBP128などの近代的な手法は考慮 • 参考資料: “条件分岐とcmovとmaxps”
• h`ps://www.slideshare.net/herumi/cmovmaxps
Super-‐Scalar RAM-‐CPU Cache Compression, ICDE’06から引用
• 条件分岐はIPCの敵 • Xeon/Opteronでは分岐予測が
も外れる条件でIPC値が低下

17
補足)制御依存からデータ依存への変換
• 簡単な例)2分探索
1 2 3 4 5 6 7 探索値:
引用: h`ps://ja.wikipedia.org/wiki/%E4%BA%8C%E5%88%86%E6%8E%A2%E7%B4%A2
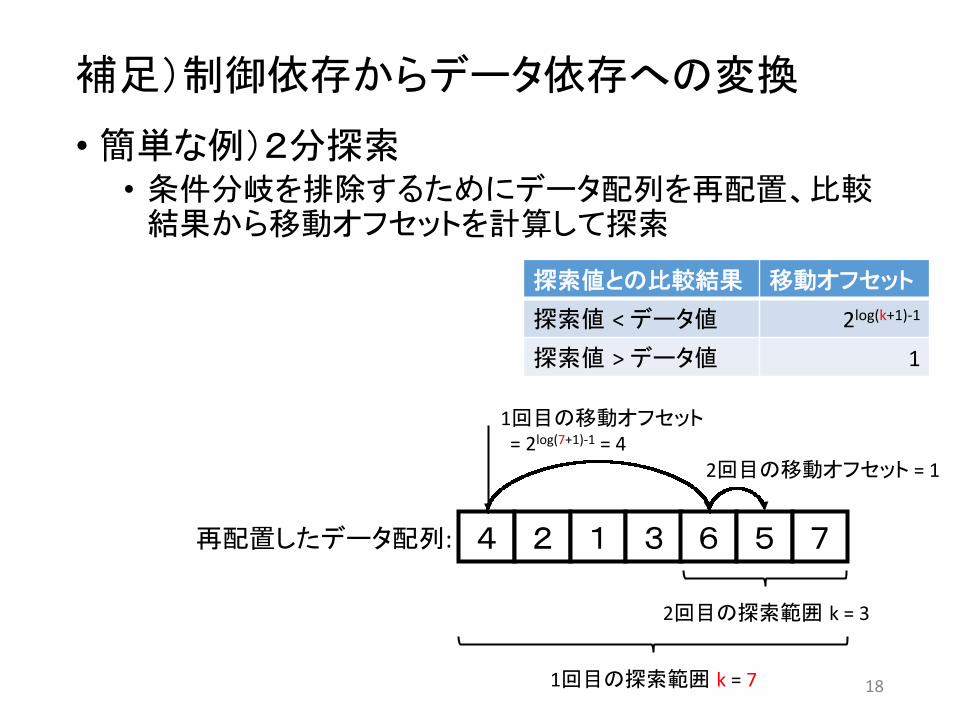
18
補足)制御依存からデータ依存への変換
• 簡単な例)2分探索 • 条件分岐を排除するためにデータ配列を再配置、比較
結果から移動オフセットを計算して探索
探索値との比較結果 移動オフセット
探索値 < データ値 2log(k+1)-‐1
探索値 > データ値 1
4 2 1 3 6 5 7
1回目の探索範囲 k = 7
2回目の探索範囲 k = 3
再配置したデータ配列:
1回目の移動オフセット = 2log(7+1)-‐1 = 4
2回目の移動オフセット = 1

19
補足)制御依存からデータ依存への変換
• 条件分岐除去に着眼した 近の論文(VLDB’17)
• FSMに基づいたパーサは条件分岐によるペナルティが大きい • SIMD命令を活用して条件分岐を除去、またFilter/ProjectのPush-‐downをサポートすることでより効率化
• Apache Sparkを用いて性能比較、デフォルトで利用しているJSON Parser(Jackson)と比べて条件によって10~20倍の性能差

20
実験条件
• CPU: Intel i7-‐4770 w/AVX2を利用 • 全てメモリ上で性能を比較 • 全ての手法をC++で実装して、gcc-‐4.4.7の-‐O3でコンパイル • 比較する4つの指標(圧縮時間に関する言及はなし)
• Space overhead • Decompression 4me • Intersec4on 4me • Union 4me
• 使用するデータセット • 人工的に生成したデータ: Uniform, Zipf, Markov process • 実データ: DBMS(Star Schema Benchmark、TPC-‐H)、Web(clueweb12)、グラフ(twi`er)、KDDCup99、温度(Berkeleyearch)、信号(Higgs)、ゲノム(Kegg)
21
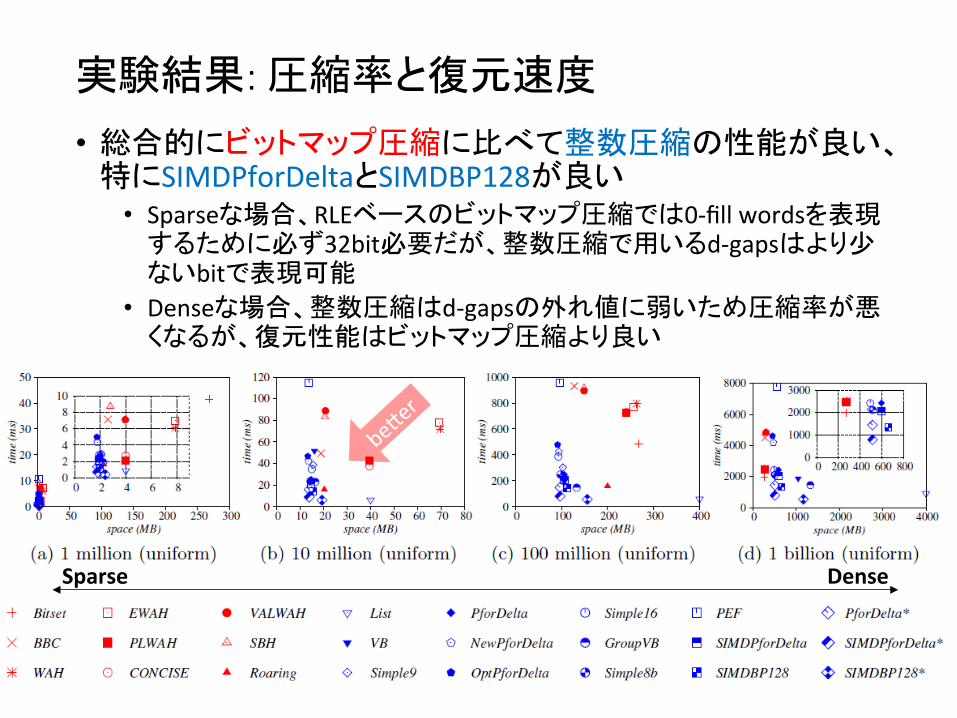
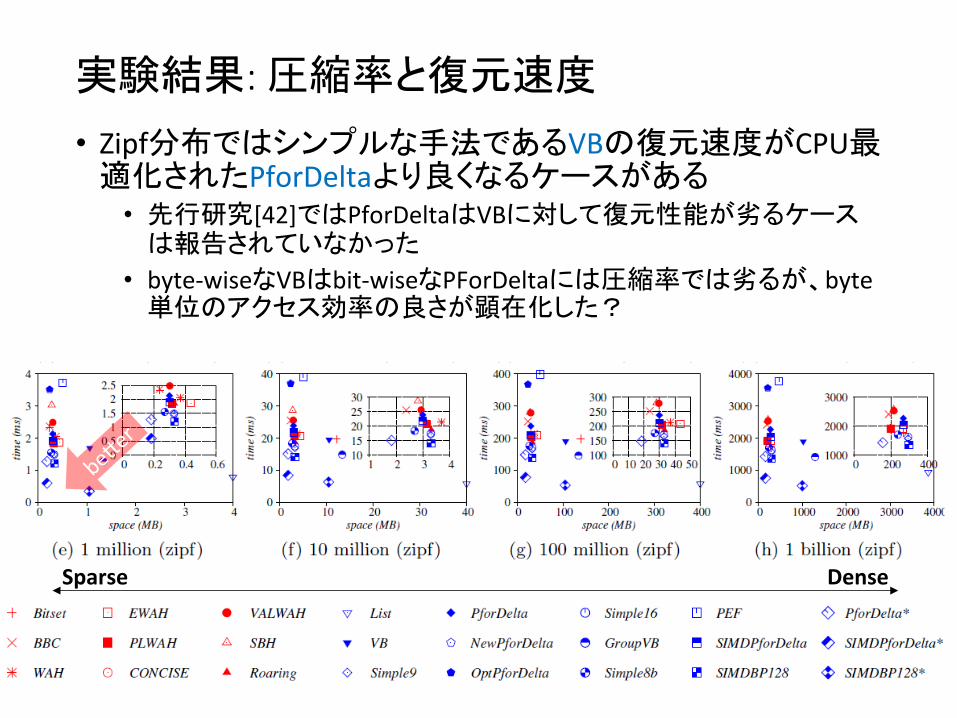
実験結果: 圧縮率と復元速度
• 総合的にビットマップ圧縮に比べて整数圧縮の性能が良い、特にSIMDPforDeltaとSIMDBP128が良い • Sparseな場合、RLEベースのビットマップ圧縮では0-‐fill wordsを表現
するために必ず32bit必要だが、整数圧縮で用いるd-‐gapsはより少ないbitで表現可能
• Denseな場合、整数圧縮はd-‐gapsの外れ値に弱いため圧縮率が悪くなるが、復元性能はビットマップ圧縮より良い
Sparse Dense

22
実験結果: 圧縮率と復元速度
• ビットマップ圧縮の中では断然Roaringの性能が良い • 意外だが結果からRLEはビットマップの圧縮には向いていないとい
う結論、RLEに頼らないRoaringが性能的に優位 • ビット密度に応じて表現方法(16bit ints or bitmap)を切り替えるハ
イブリッドな手法が性能に寄与
Sparse Dense
23
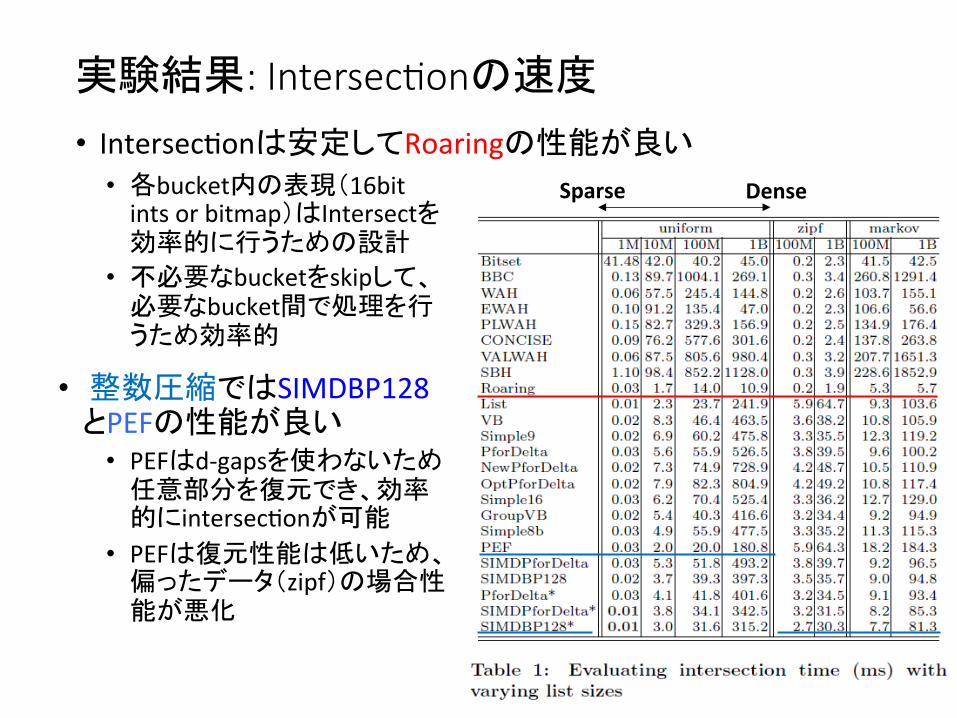
実験結果: 圧縮率と復元速度
• Zipf分布ではシンプルな手法であるVBの復元速度がCPU適化されたPforDeltaより良くなるケースがある • 先行研究[42]ではPforDeltaはVBに対して復元性能が劣るケース
は報告されていなかった • byte-‐wiseなVBはbit-‐wiseなPForDeltaには圧縮率では劣るが、byte
単位のアクセス効率の良さが顕在化した?
Sparse Dense
24
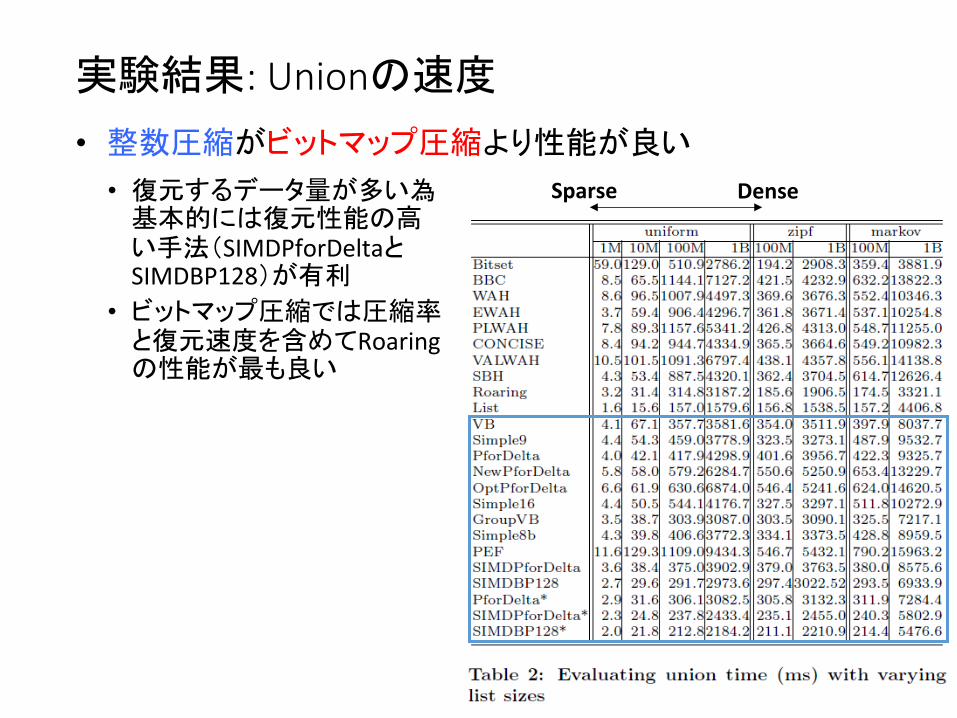
実験結果: IntersecGonの速度
• Intersec4onは安定してRoaringの性能が良い Sparse Dense • 各bucket内の表現(16bit
ints or bitmap)はIntersectを効率的に行うための設計
• 不必要なbucketをskipして、必要なbucket間で処理を行うため効率的
• 整数圧縮ではSIMDBP128とPEFの性能が良い • PEFはd-‐gapsを使わないため
任意部分を復元でき、効率的にintersec4onが可能
• PEFは復元性能は低いため、偏ったデータ(zipf)の場合性能が悪化
25
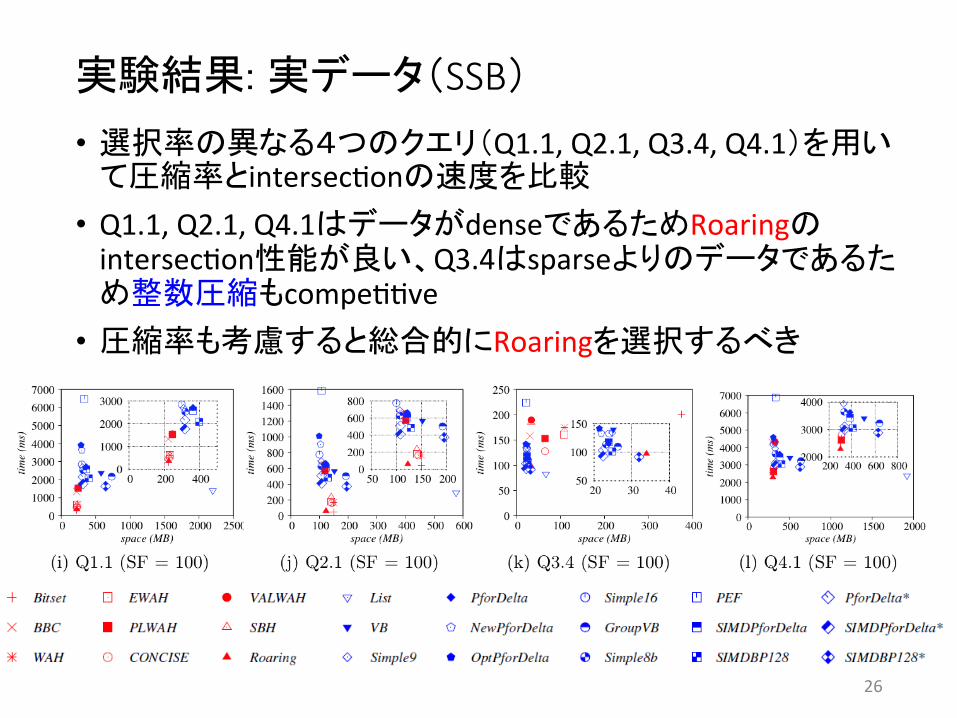
実験結果: Unionの速度
• 整数圧縮がビットマップ圧縮より性能が良い Sparse Dense • 復元するデータ量が多い為
基本的には復元性能の高い手法(SIMDPforDeltaとSIMDBP128)が有利
• ビットマップ圧縮では圧縮率 と復元速度を含めてRoaringの性能が も良い
26
実験結果: 実データ(SSB)
• 選択率の異なる4つのクエリ(Q1.1, Q2.1, Q3.4, Q4.1)を用いて圧縮率とintersec4onの速度を比較
• Q1.1, Q2.1, Q4.1はデータがdenseであるためRoaringのintersec4on性能が良い、Q3.4はsparseよりのデータであるため整数圧縮もcompe44ve
• 圧縮率も考慮すると総合的にRoaringを選択するべき
27
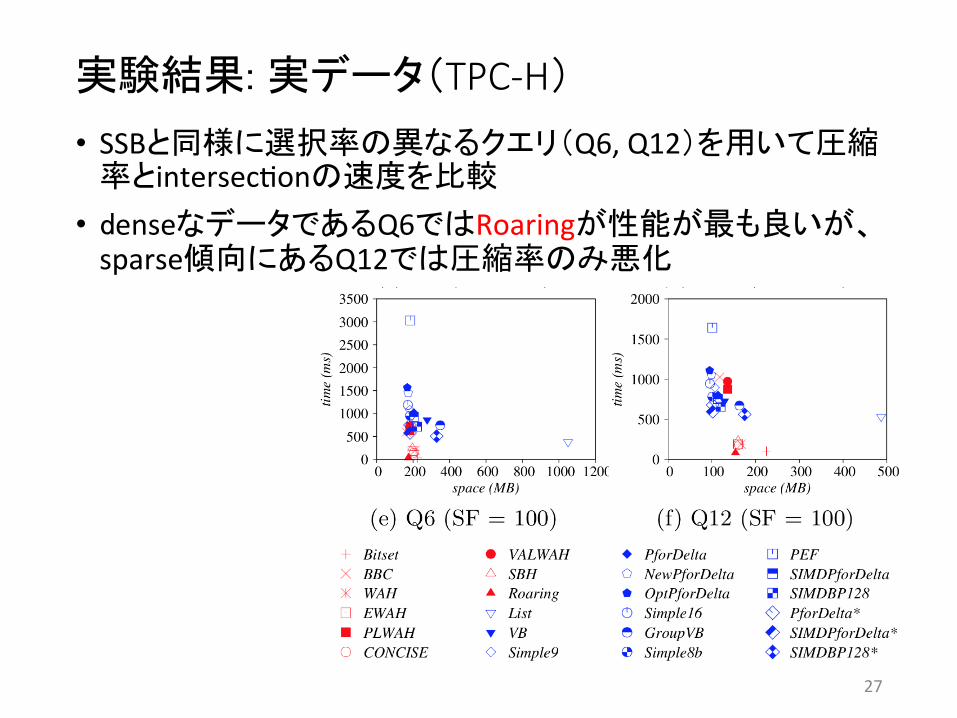
実験結果: 実データ(TPC-‐H)
• SSBと同様に選択率の異なるクエリ(Q6, Q12)を用いて圧縮率とintersec4onの速度を比較 • denseなデータであるQ6ではRoaringが性能が も良いが、sparse傾向にあるQ12では圧縮率のみ悪化
28
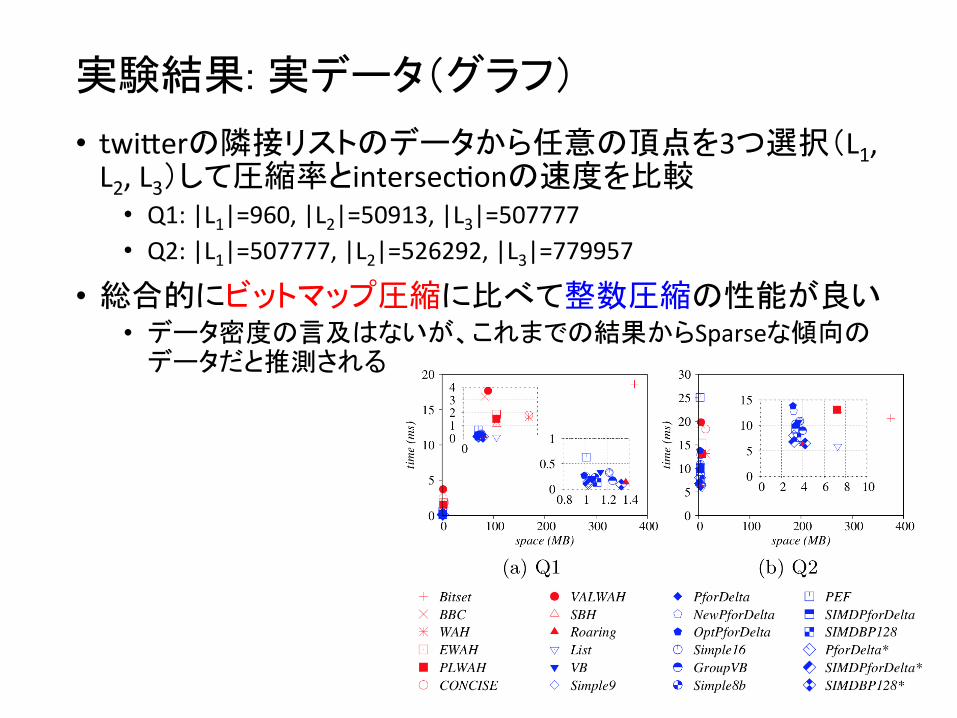
実験結果: 実データ(グラフ)
• twi`erの隣接リストのデータから任意の頂点を3つ選択(L1, L2, L3)して圧縮率とintersec4onの速度を比較 • Q1: |L1|=960, |L2|=50913, |L3|=507777 • Q2: |L1|=507777, |L2|=526292, |L3|=779957
• 総合的にビットマップ圧縮に比べて整数圧縮の性能が良い • データ密度の言及はないが、これまでの結果からSparseな傾向の
データだと推測される
29
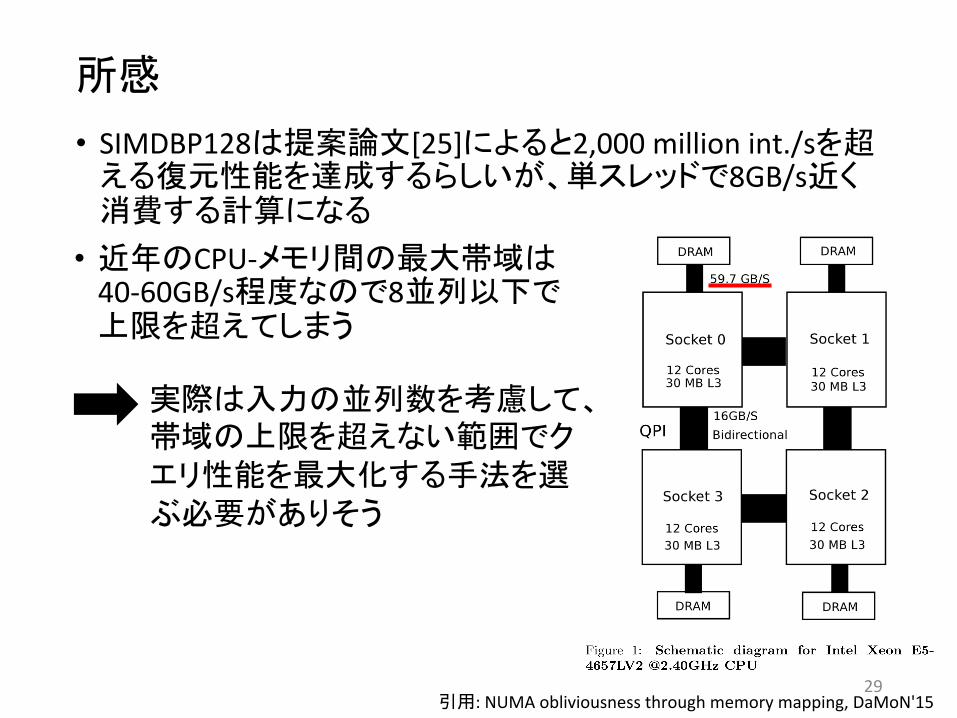
所感
引用: NUMA obliviousness through memory mapping, DaMoN'15
• SIMDBP128は提案論文[25]によると2,000 million int./sを超える復元性能を達成するらしいが、単スレッドで8GB/s近く消費する計算になる
• 近年のCPU-‐メモリ間の 大帯域は40-‐60GB/s程度なので8並列以下で上限を超えてしまう
実際は入力の並列数を考慮して、帯域の上限を超えない範囲でクエリ性能を 大化する手法を選ぶ必要がありそう

30
補足)併せて読みたい論文
• 同著者のVLDB’17論文 • 圧縮率とクエリ性能の両立す
る整数圧縮MILCを提案 • 性能の観点でd-‐gapsではなくoffsetを使用
• 圧縮率の観点でブロック長を固定ではなく、長さを 適化(VSEncoding-‐like)
• キャッシュ考慮&SIMD並列




























