Embed Size (px)
Citation preview

1
Apache Cassandra

2
…

3

4

5

6

7

8
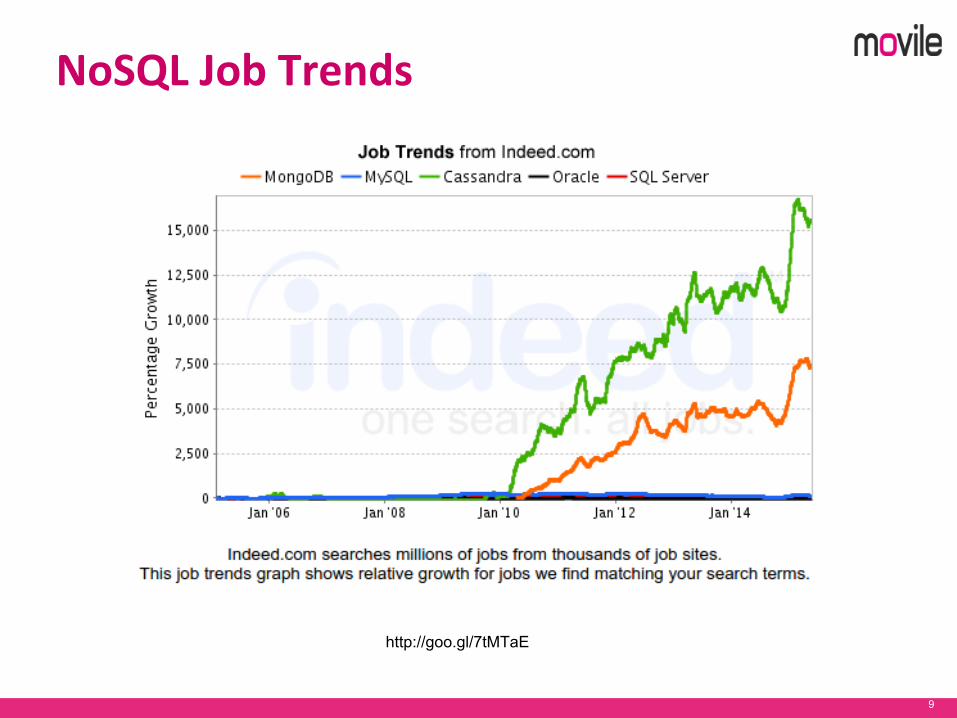
9
http://goo.gl/7tMTaE

10

11
Tolerante a falhas, sem ponto único central de controle, não existe um nó “master”
Utiliza o Protocolo Peer-to-Peer (ao invés do modelo master/slave)

12
A taxa de transferência (throughput) de operações de leitura e escrita aumenta linearmente a medida que novas máquinas são adicionadas

13
Cassandra não usa transações ACID com nos RDBMS com rollback ou mecanismos de lock.
Oference controle de atomicidade e isolamento no contexto de linha (row-level)

14
Escrita é atômica no contexto da partição (row). Atualização ou Inserção de colunas são tratadas como uma operação de write.
Utiliza timestamps para determinar o valor mais atualizado de uma coluna (Last Wins)

15
A consistência e disponibilidade podem ser ajustadas (tunable).
Não há lock ou consistência transacional quando múltiplas linhas ou tabelas são alteradas concorrentemente.
Cassandra >= 2.0, micro transações (lighweight transactions) use em menos de 1% de suas transações

16
Full row-level isolation: Escrita a uma linha é totalmente isolada ao cliente que está executando a escrita e não é visível a nenhum outro cliente até que a operação complete (version >= 1.1)
UPDATE Users SET login='scott' AND password='tiger' WHERE key='550e8400';
SELECT login, password FROM Users WHERE key='550e8400';

17
As escritas são duráveis: Todas as escritas aos nós são registrados em memória e em disco antes de retornar como uma operação completa (acknowledge)

18
●
●
eventually -> after some timeeventualmente -> talvez, possivelmente

19

20
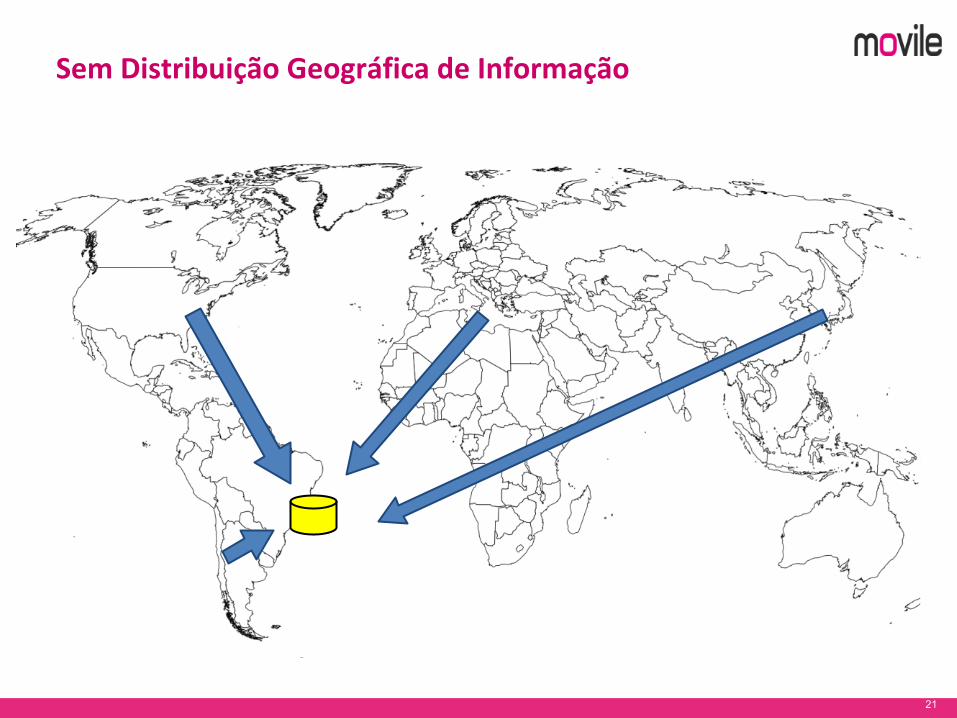
21

22

23

24
Dados MODELOS DADOSAPLICAÇÃO

25

26
●
●
●

27

28
●
●
●
○
○
○
●

29
cd $CASSANDRA_HOME/bin ./cqlsh
Connected to cassandra-cluster at localhost:9160.[cqlsh 3.1.8 | Cassandra 2.1.2 | CQL spec 3.0.5 | Thrift protocol 19.36.2]Use HELP for help.
cqlsh> _

30
# ccm create -v 2.0.14 --nodes 3 --start clusterName
# ccm statusCluster: 'clusterName'--------------node1: UPnode3: UPnode2: UP
# ccm node1 status# ccm node1 stop# ccm node2 start
#ccm stop#ccm start

31
-- multinode keyspace configuration (cluster)
CREATE KEYSPACE music
WITH REPLICATION = { 'class' :
'NetworkTopologyStrategy', 'datacenter1' : 3 };

32
cqlsh> use music;
cqlsh:music>
CREATE TABLE songs ( id varchar PRIMARY KEY, title text, album text, artist text, data blob);
$CASSANDRA_HOME/logs/system.log INFO 14:23:58,307 Initializing music.songs

33
INSERT INTO songs (id, title, artist, album)
VALUES ('song-1','Ojo Rojo', 'Fu Manchu', 'No One Rides');
INSERT INTO songs (id, title, artist, album)
VALUES ('song-2','Enter Sandman', 'Metallica', 'Black');
INSERT INTO songs (id, title, artist, album)
VALUES ('song-3','The Unforgiven', 'Metallica', 'Black');
INSERT INTO songs (id, title, artist, album)
VALUES ('song-4','Run to the hills', 'Iron Maiden',
'Collections');

34
cqlsh:music> select * from songs;

35
id int PRIMARY KEY / PRIMARY KEY (id)
PRIMARY KEY (PARTITION_KEY, CLUSTERING_KEY, CLUSTERING_KEY… );

36
CREATE TABLE playlists ( id varchar, song_order int, song_id varchar, title text, album text, artist text, PRIMARY KEY (id, song_order));
●
●

37
cqlsh:music> delete from songs where id = 'song-4';
cqlsh:music> delete from songs where id = 'song-3';
cqlsh:music> delete from songs where id = 'song-2';
cqlsh:music> select * from songs;

38

39

40
http://www.datastax.com/download-drivers

41
public void connect(String node) {
cluster = Cluster.builder().addContactPoint(node).build();
// get some cluster meta data
Metadata metadata = cluster.getMetadata();
for (Host host : metadata.getAllHosts()) {
System.out.printf("Datatacenter: %s; Host: %s; Rack: %s\n",
host.getDatacenter(), host.getAddress(),
host.getRack());
}
// retrieve a connected session
session = cluster.connect();
}

42
SimpleClient client = new SimpleClient();
client.connect("127.0.0.1");
Session session = client.getSession();
ResultSet results =
session.execute("SELECT * FROM music.playlists");
for (Row row : results.all()) {
print(row);
}
client.close();

43
Caso de Uso Movile

44

45
★★★

46

47
●
●

48
●
●
●
●

49
C*

50

51
cqlsh:music> tracing on;Now Tracing is enabled
cqlsh:music> INSERT INTO songs (id, title, artist, album)VALUES ('song-4','Run to the hills', 'Iron Maiden', 'Collections');

52
CREATE TABLE queues ( id text, created_at timeuuid, value blob, PRIMARY KEY (id, created_at));
SELECT * FROM queues WHERE id = 'myqueue' ORDER BY created_at LIMIT 1;

53
VMs

54
Node 1 - : 200.xxx.xxx.71load_avg: 0.39write_latency(us): 900.8read_latency(us): 894.6
Node 2 - : 200.xxx.xxx.72load_avg: 0.51write_latency(us): 874.1read_latency(us): 1062.5
Node 3 - : 200.xxx.xxx.73load_avg: 0.35write_latency(us): 900.87read_latency(us): 887.6
Node 1 - : 200.xxx.xxx.71load_avg: 0.63write_latency(us): 1037read_latency(us): 1749
Node 2 - : 200.xxx.xxx.72load_avg: 0.37write_latency(us): 819.8read_latency(us): 909.0
Node 3 - : 200.xxx.xxx.74load_avg: 0.62write_latency(us): 1006read_latency(us): 1056.43
DATACENTER 1DATACENTER 2
Now: 2015-07-22 13:11:00Total Reads/second: 12441Total Writes/second: 8883

55
tempo
num
. ope
raçõ
es

56
Dica 1#: usar quando a disponibilidade é um fator importante, onde exista um alto volume de dados, com número grande de operações de escrita.
Dica 2#: entenda os requisitos da aplicação, identifique os padrões de acesso a informação.
Dica #3: pense em desnormalização de dados, mas com cuidado…
Dica #4: usar quando desempenho é um fator importante para a aplicação

57
@eitikimura
facebook.com/eiti.kimura
[email protected]://www.movile.com/pt/carreiras
eiti-kimura-movile
eitikimura





























