Embed Size (px)
DESCRIPTION
An introductory presentation about table partitioning in PostgreSQL and how to integrate it in your Rails application. Given at the Cambridge Ruby User Group meetup Mar 27th 2014.
Citation preview

Table PartitioningPostgreSQL + Rails
Agnieszka Figiel, Cambridge Ruby User Group Mar 2014

What is table partitioning in PostgreSQL?
1 logical table = n smaller physical tables

What are the benefits?
improved query performance for big tables *
* works best when results are coming from single partition

When to consider partitioning?
Big table that cannot be queried efficiently, as the index is enormous as well.
Rule of thumb: table does not fit into memory

How is data split?
By ranges:year > 2010 AND year <= 2012
By lists of key values:company_id = 5

How does it work?
At the heart of it lie 2 mechanisms:
➔ table inheritance➔ table CHECK constraints

Table inheritance: schemaCREATE TABLE A (value INT);CREATE TABLE B () INHERITS (A);
Table "public.a" Column | Type | Modifiers--------+---------+----------- value | integer |
Table "public.b" Column | Type | Modifiers--------+---------+----------- value | integer |Inherits: a

Table inheritance: schema
CREATE TABLE C (extra_field TEXT) INHERITS (A);
Table "public.c" Column | Type | Modifiers-------------+---------+----------- value | integer | extra_field | text |Inherits: a
NB: may inherit from multiple tables

Table inheritance: querying
INSERT INTO A VALUES (0);INSERT INTO B VALUES (10);INSERT INTO C VALUES (20, 'zonk');
SELECT * FROM A WHERE value < 20; value ------- 0 10
SELECT * FROM ONLY A WHERE value < 20; value ------- 0

What happened?
EXPLAIN ANALYZE SELECT * FROM A WHERE value < 20; QUERY PLAN ---------------------------------------------------------------------------------------------------- Append (cost=0.00..69.38 rows=1290 width=4) (actual time=0.020..0.033 rows=2 loops=1) -> Seq Scan on a (cost=0.00..4.00 rows=80 width=4) (actual time=0.019..0.021 rows=1 loops=1) Filter: (value < 20) -> Seq Scan on b (cost=0.00..40.00 rows=800 width=4) (actual time=0.005..0.006 rows=1 loops=1) Filter: (value < 20) -> Seq Scan on c (cost=0.00..25.38 rows=410 width=4) (actual time=0.005..0.005 rows=0 loops=1) Filter: (value < 20) Rows Removed by Filter: 1

Table CHECK constraint
CREATE TABLE A (value INT);CREATE TABLE B (CHECK (value < 20)) INHERITS (A);CREATE TABLE C (CHECK (value >= 20)) INHERITS (A);
INSERT INTO B VALUES (10);INSERT INTO C VALUES (20);
INSERT INTO C VALUES(5);
ERROR: new row for relation "c" violates check constraint "c_value_check"DETAIL: Failing row contains (5).

Ta da!
EXPLAIN ANALYZE SELECT * FROM A WHERE value < 20; QUERY PLAN ---------------------------------------------------------------------------------------------------- Append (cost=0.00..40.00 rows=801 width=4) (actual time=0.015..0.017 rows=1 loops=1) -> Seq Scan on a (cost=0.00..0.00 rows=1 width=4) (actual time=0.002..0.002 rows=0 loops=1) Filter: (value < 20) -> Seq Scan on b (cost=0.00..40.00 rows=800 width=4) (actual time=0.012..0.013 rows=1 loops=1) Filter: (value < 20)

Gotcha #1
Make sure that:
SET constraint_exclusion = on;

Gotcha #2
All check constraints and not-null constraints on a parent table are automatically inherited by its children.
Other types of constraints (unique, primary key, and foreign key constraints) are not inherited.

Solution #2: create constraints or indexes in all partitionsCREATE TABLE A (id serial NOT NULL, value INT NOT NULL);
CREATE TABLE B ( CONSTRAINT B_pkey PRIMARY KEY (id), CHECK (value < 20)) INHERITS (A);
CREATE TABLE C ( CONSTRAINT C_pkey PRIMARY KEY (id), CHECK (value >= 20)) INHERITS (A);

Gotcha #3There is no practical way to enforce uniqueness of a SERIAL id across partitions.
INSERT INTO B (value) VALUES (10);INSERT INTO C (value) VALUES (20);INSERT INTO C VALUES (1, 30);
SELECT * FROM A; id | value ----+------- 1 | 10 2 | 20 1 | 30

Solution #3
➔ carry on and always filter by partitioning key➔ use UUID (uuid-ossp)

Gotcha #4
Specifying that another table's column REFERENCES a(value) would allow the other table to contain “a values”, but not “b or c values”. There is no good workaround for this case.

How to insert / update rows?
➔ PostgreSQL docs recommend using triggers➔ also possible to do it using rules (overhead, bulk)

Trigger exampleCREATE OR REPLACE FUNCTION a_insert_trigger()RETURNS TRIGGER AS $$BEGIN IF NEW.value < 20 THEN INSERT INTO b VALUES (NEW.*); ELSE INSERT INTO c VALUES (NEW.*); END IF; RETURN NULL;END;$$LANGUAGE plpgsql;
CREATE TRIGGER insert_a_trigger BEFORE INSERT ON a FOR EACH ROW EXECUTE PROCEDURE a_insert_trigger();
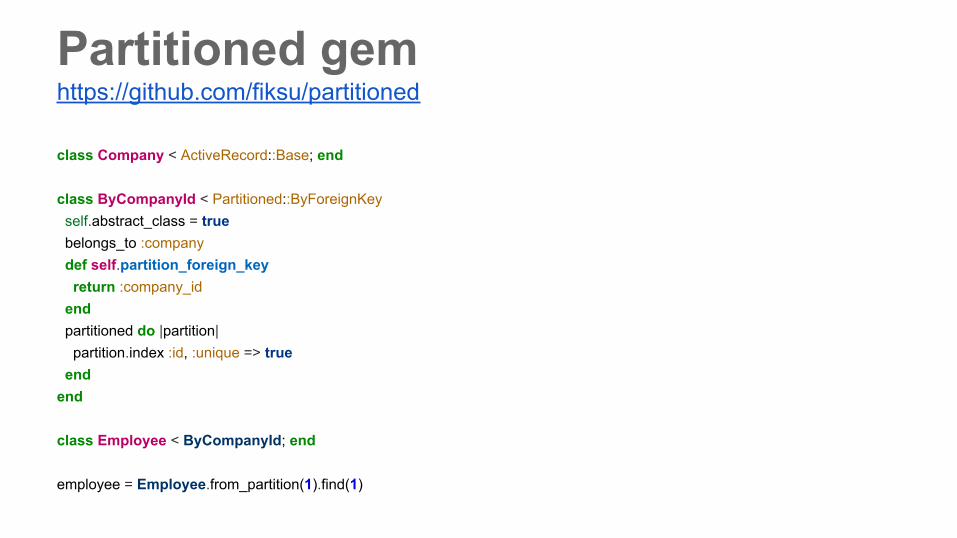
Partitioned gemhttps://github.com/fiksu/partitioned
class Company < ActiveRecord::Base; end
class ByCompanyId < Partitioned::ByForeignKey self.abstract_class = true belongs_to :company def self.partition_foreign_key return :company_id end partitioned do |partition| partition.index :id, :unique => true endend
class Employee < ByCompanyId; end
employee = Employee.from_partition(1).find(1)

UUID in Rails
Rails 4:enable_extension 'uuid-ossp'create_table :documents, id: :uuid do |t| t.string :title t.string :author t.timestampsend
Rails 3:gem postgres_ext https://github.com/dockyard/postgres_ext

Actual performance improvements?
➔ table with ~13 mln rows➔ partitioned by date into 8 partitions➔ complex, long-running query➔ baseline: 0.07 tps➔ when results in single partition: 0.15 tps➔ when results in 2 partitions: like baseline

References➔ http://www.postgresql.org/docs/9.3/static/ddl-
partitioning.html➔ PostgreSQL 9.0 High Performance Gregory Smith





























