Embed Size (px)
Citation preview

Apache Hive

Agenda
• What is Apache Hive • How to Setup• Tutorial Examples
Hive
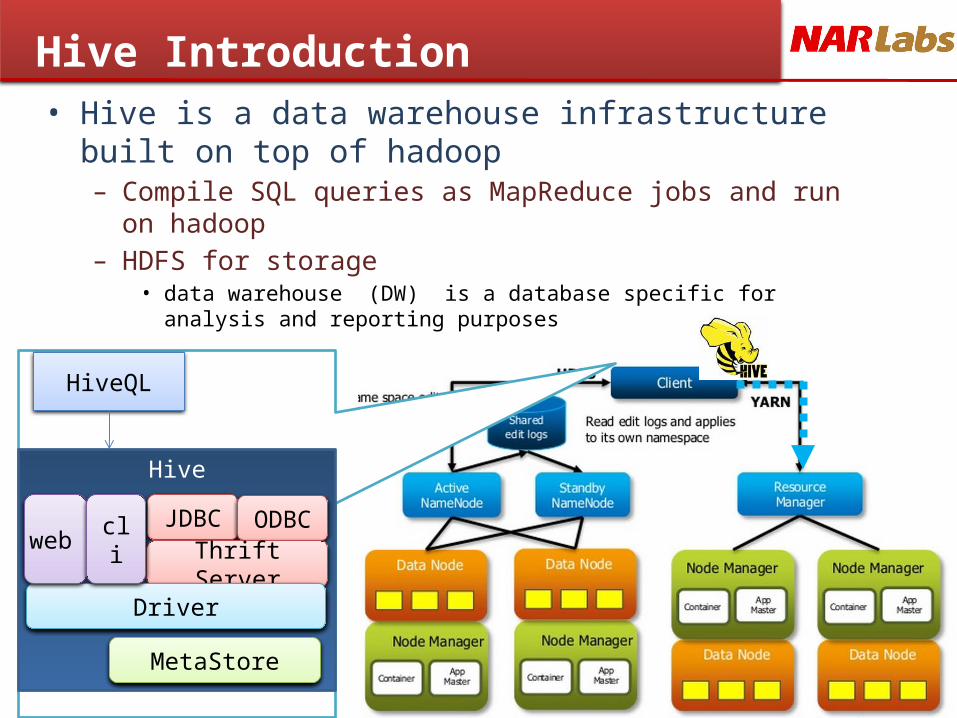
Hive Introduction• Hive is a data warehouse infrastructure built on
top of hadoop– Compile SQL queries as MapReduce jobs and run on
hadoop– HDFS for storage
• data warehouse (DW) is a database specific for analysis and reporting purposes
HiveQL
JDBC ODBC
Thrift Server
Driver
MetaStore
web cli
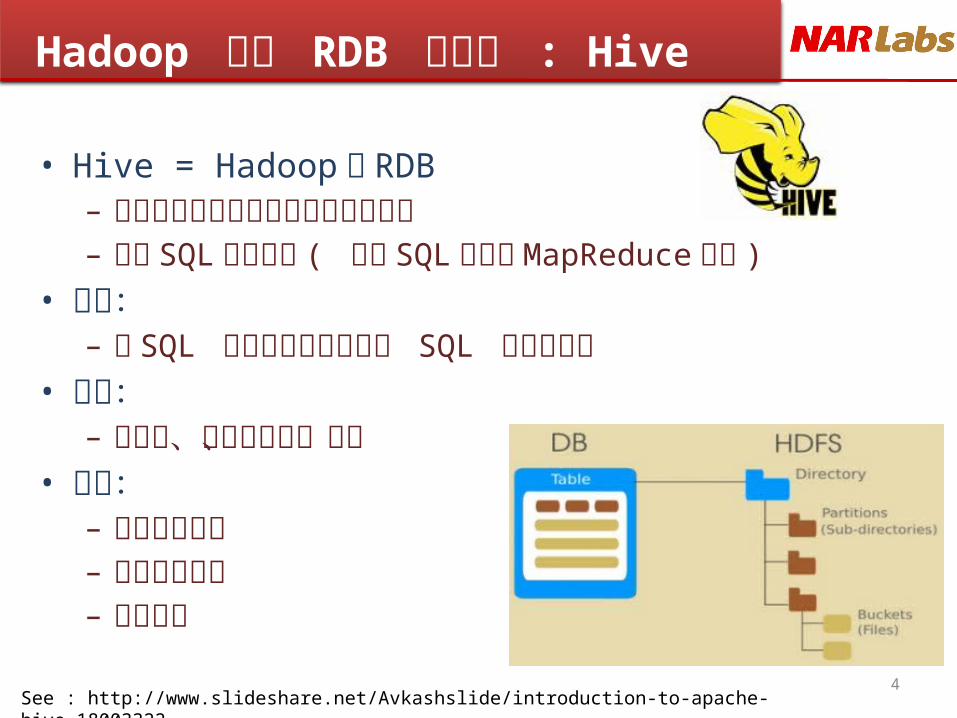
Hadoop 也有 RDB 可以用 : Hive
• Hive = Hadoop 的 RDB– 將結構化的資料檔案映射為資料庫表– 提供 SQL 查詢功能 ( 轉譯 SQL 語法成
MapReduce 程式 ) • 適合:
– 有 SQL 基礎的使用者且基本 SQL 能運算的事• 特色:
– 可擴展、可自訂函數、容錯• 限制:
– 執行時間較久– 資料結構固定– 無法修改
4See : http://www.slideshare.net/Avkashslide/introduction-to-apache-hive-18003322
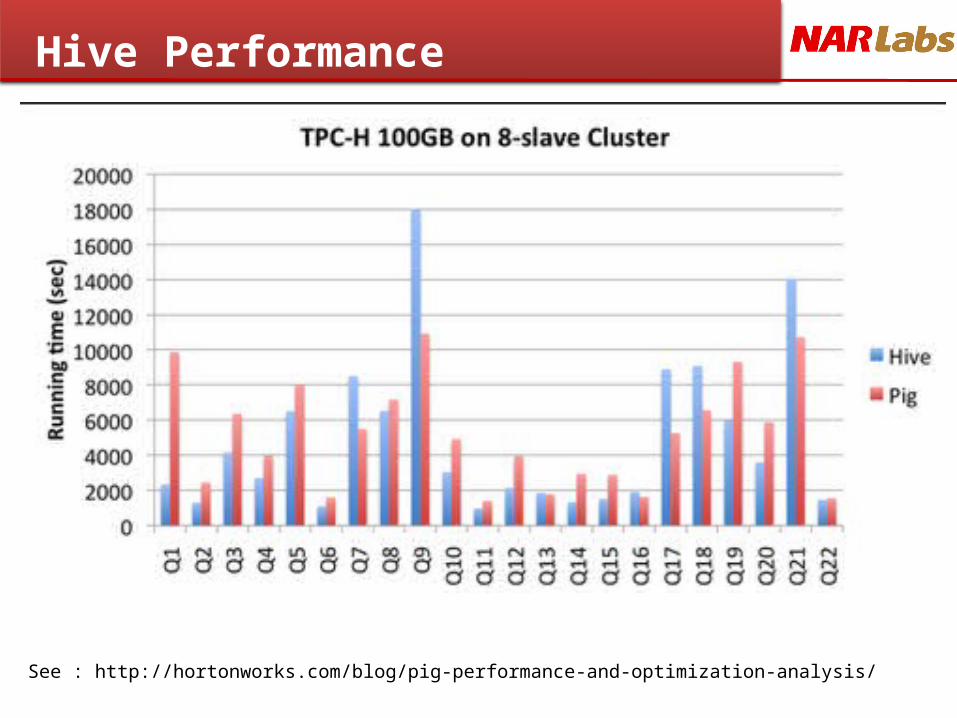
Hive Performance
See : http://hortonworks.com/blog/pig-performance-and-optimization-analysis/

Hive 架構提供了 ..
• 介面– CLI– WebUI– API
• JDBC and ODBC
• Thrift Server (hiveserver)– 使遠端 Client 可用 API
執行 HiveQL • Metastore
– DB, table, partition…
6figure Source : http://blog.cloudera.com/blog/2013/07/how-hiveserver2-brings-security-and-concurrency-to-apache-hive

大象遇到蜂 ( setup )
• 解壓縮 http://archive.cloudera.com/cdh5/cdh/5/hive-0.13.1-cdh5.3.2.tar.gz
• 修改~/.bashrc
• 修改 conf/hive-env.sh
• 設定 metastoreon hdfs
• 啟動 pig shell
export JAVA_HOME=/usr/lib/jvm/java-7-oracleexport HADOOP_HOME=/home/hadoop/hadoopexport HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoopexport HIVE_HOME=/home/hadoop/hiveexport PATH=$PATH:$HIVE_HOME/bin
$ hivehive>
export HADOOP_HOME=/home/hadoop/hadoopexport HIVE_CONF_DIR=/home/hadoop/hive/conf
hadoop fs -mkdir -p /user/hive/warehousehadoop fs -chmod g+w /tmphadoop fs -chmod g+w /user/hive/warehouse
Ps : 若沒有要用 mysql 當 metastore_db ,可以不用改 hive-site.xml

蜂 也會的程式設計
8
$ hivehive> create table A(x int, y int, z int)hive> load data local inpath ‘file1 ’ into table A;hive> select * from A where y>10000
蜂BigDataSQL 語法
hive> insert table B select * from A where y>10000
figure Source : http://hortonworks.com/blog/stinger-phase-2-the-journey-to-100x-faster-hive/

Hive 和 SQL 比較
Hive RDMS
查詢語法 HQL SQL
儲存體 HDFS Raw Device or Local FS
運算方法 MapReduce Excutor
延遲 非常高 低
處理數據規模 大 小
修改資料 NO YES
索引 Index, Bigmap index…
複雜健全的索引機制
9Source : http://sishuok.com/forum/blogPost/list/6220.html
練習一 :
• 場景 :– 組織內有統一格式的出勤紀錄資料表,分散在全台各
縣市的各個部門的資料庫中。老闆要我蒐集全台的資料統計所有員工的平均工時。 DB 內的 table 都轉成csv 檔,並且餵進去 Hadoop 的 HDFS 了 , ..
• 問題 :– 雖然我知道 PIG 可以降低 MapReduce 的門檻,但我
還是習慣 SQL 語法來實作,如果有一台超大又免費的 DB 就好了…
• 解法 :
10
編列經費買台高效伺服器再裝個大容量的 sql server 使用 Hive

用 Hive 整形後
11
北 A1 劉 12.5
HiveQL> create table A (nm String, dp String, id String);> create table B (id String, dt Date, hr int);> create table final (dp String, id String , nm String, avg float);> load data inpath ‘file1’ into table A;> load data inpath ‘file2’ into table B;> Insert table final select a.id, collect_set(a.dp), collect_set(a.nm), avg(b.hr) from a,b where b.hr > 8 and b.id = a.id group by a.id;
nm dp Id id dt hr
劉 北 A1 A1 7/7 13
李 中 B1 A1 7/8 12
王 中 B2 A1 7/9 4
Tips : • 沒有 local 模式;• hive load 資料完後會將 input file 刪掉;• 資料格式須嚴格檢查;• 分欄位元僅 1 byte ;• create table & load data 建議用 tool 匯入
資料較不會錯
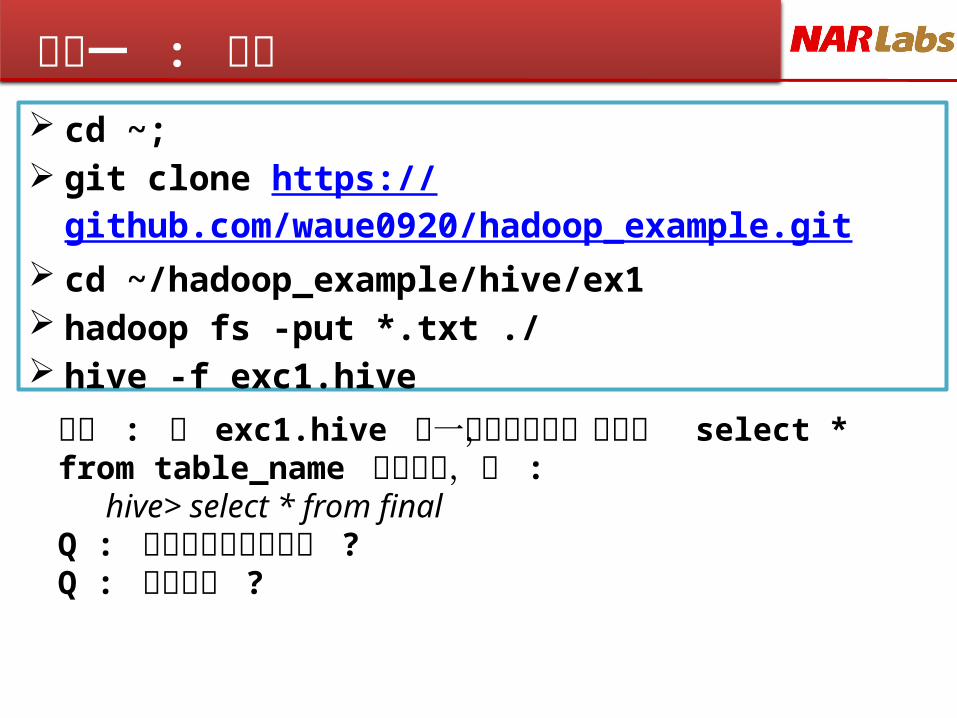
練習一 : 實作 cd ~; git clone https://
github.com/waue0920/hadoop_example.git cd ~/hadoop_example/hive/ex1 hadoop fs -put *.txt ./ hive -f exc1.hive
練習 : 將 exc1.hive 每一行單獨執行,並搭配 select * from table_name 來看結果,如 :
hive> select * from finalQ : 資料是否有改進空間 ? Q : 如何改進 ?
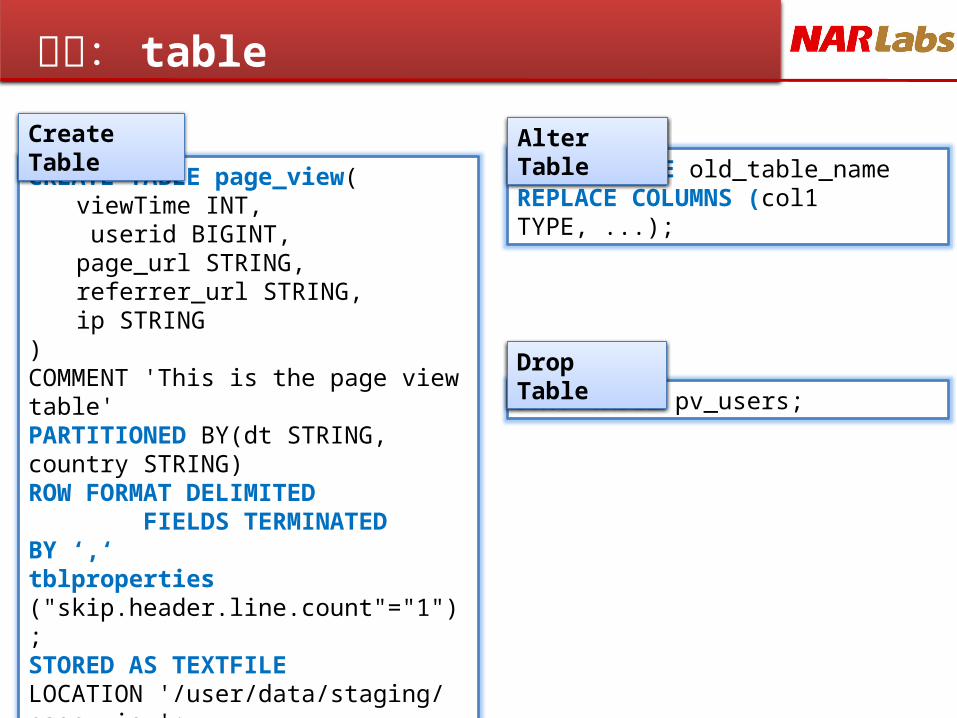
更多: table
CREATE TABLE page_view(viewTime INT, userid BIGINT,page_url STRING, referrer_url STRING,ip STRING
)COMMENT 'This is the page view table'PARTITIONED BY(dt STRING, country STRING)ROW FORMAT DELIMITED FIELDS TERMINATED BY ‘,‘tblproperties ("skip.header.line.count"="1");STORED AS TEXTFILELOCATION '/user/data/staging/page_view';
DROP TABLE pv_users;
ALTER TABLE old_table_name REPLACE COLUMNS (col1 TYPE, ...);
Create Table Alter Table
Drop Table
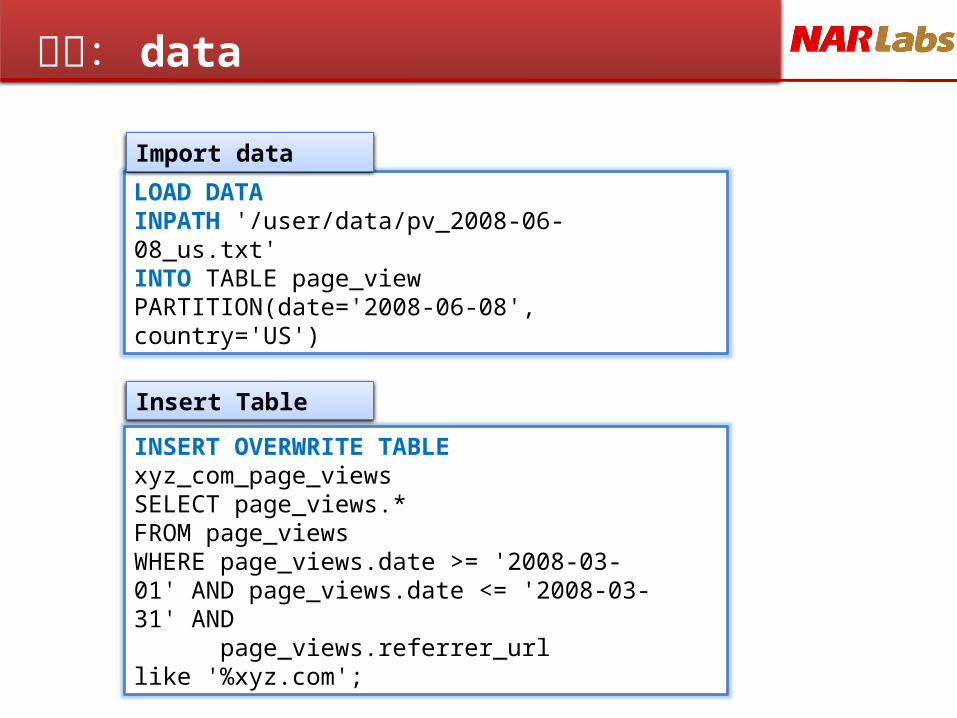
更多: data
LOAD DATA INPATH '/user/data/pv_2008-06-08_us.txt' INTO TABLE page_view PARTITION(date='2008-06-08', country='US')
INSERT OVERWRITE TABLE xyz_com_page_viewsSELECT page_views.*FROM page_viewsWHERE page_views.date >= '2008-03-01' AND page_views.date <= '2008-03-31' AND page_views.referrer_url like '%xyz.com';
Insert Table
Import data
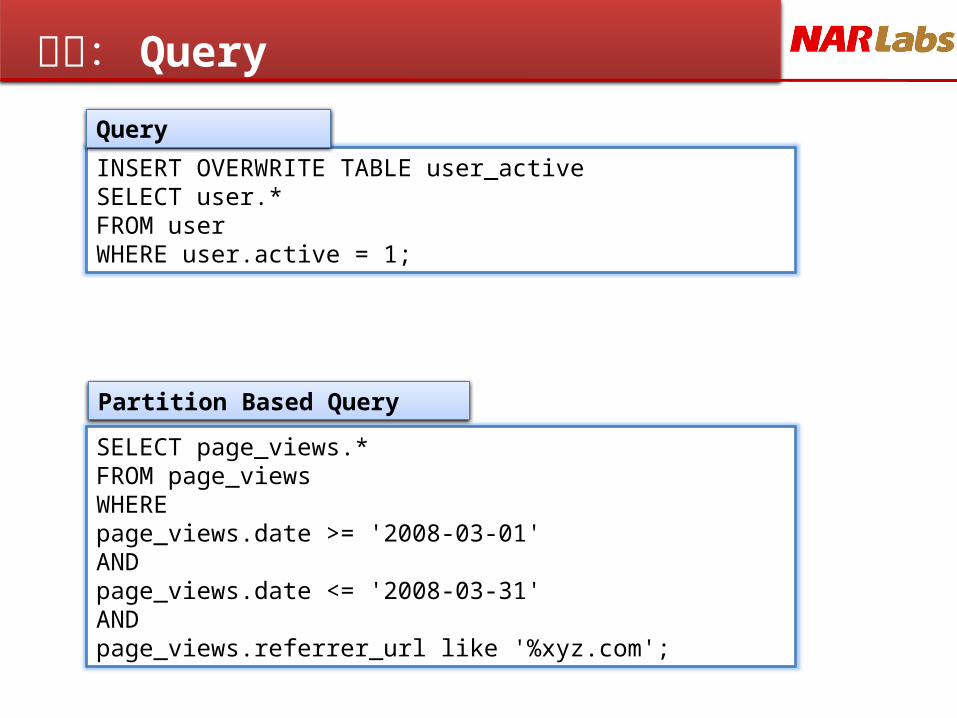
更多: Query
INSERT OVERWRITE TABLE user_activeSELECT user.*FROM userWHERE user.active = 1;
SELECT page_views.*FROM page_viewsWHERE page_views.date >= '2008-03-01' AND page_views.date <= '2008-03-31' AND page_views.referrer_url like '%xyz.com';
Query
Partition Based Query

更多: aggregate
INSERT OVERWRITE TABLE pv_usersSELECT pv.*, u.gender, u.ageFROM user u JOIN page_view pv ON (pv.userid = u.id)WHERE pv.date = '2008-03-03';
INSERT OVERWRITE TABLE pv_gender_sumSELECT pv_users.gender, count (DISTINCT pv_users.userid),collect_set (pv_users.name)FROM pv_usersGROUP BY pv_users.gender;
Joins
Aggregations

更多: union
• Tips: – UNION : 兩個 SQL 語句所產生的欄位需要是同樣的資料種類– JOIN : 透過相同鍵值將兩 table 合併成大的
INSERT OVERWRITE TABLE actions_usersSELECT u.id, actions.dateFROM ( SELECT av.uid AS uid FROM action_video av WHERE av.date = '2008-06-03' UNION ALL SELECT ac.uid AS uid FROM action_comment ac WHERE ac.date = '2008-06-03' ) actions JOIN users u ON(u.id = actions.uid);
UNION ALL

更多:動動腦name sex age
michael male 30will male 35shelley female 27lucy female 57steven male 30
sex_age.sex
age name
female 57 lucymale 35 will
See : http://willddy.github.io/2014/12/23/Hive-Get-MAX-MIN-Value-Rows.html
SELECT employee.sex_age.sex, employee.sex_age.age, name FROMemployee JOIN (
SELECT max(sex_age.age) as max_age, sex_age.sex as sex FROM employeeGROUP BY sex_age.sex
) maxageON employee.sex_age.age = maxage.max_ageAND employee.sex_age.sex = maxage.sex;
Solution
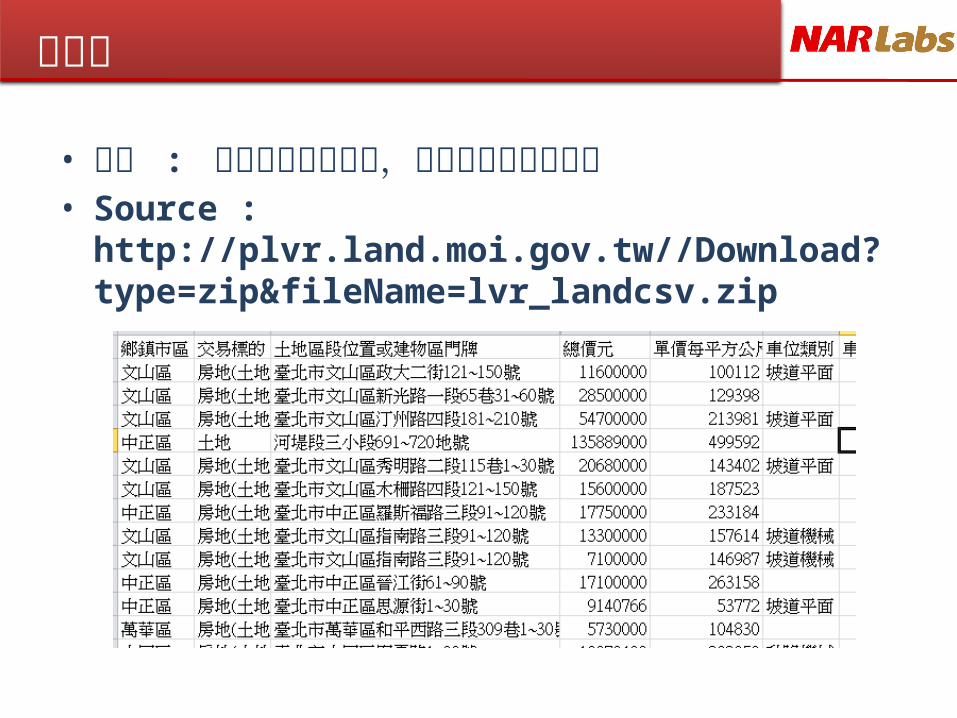
練習二
• 說明 : 使用實價登錄資訊,算出最高與最低房價• Source :
http://plvr.land.moi.gov.tw//Download?type=zip&fileName=lvr_landcsv.zip
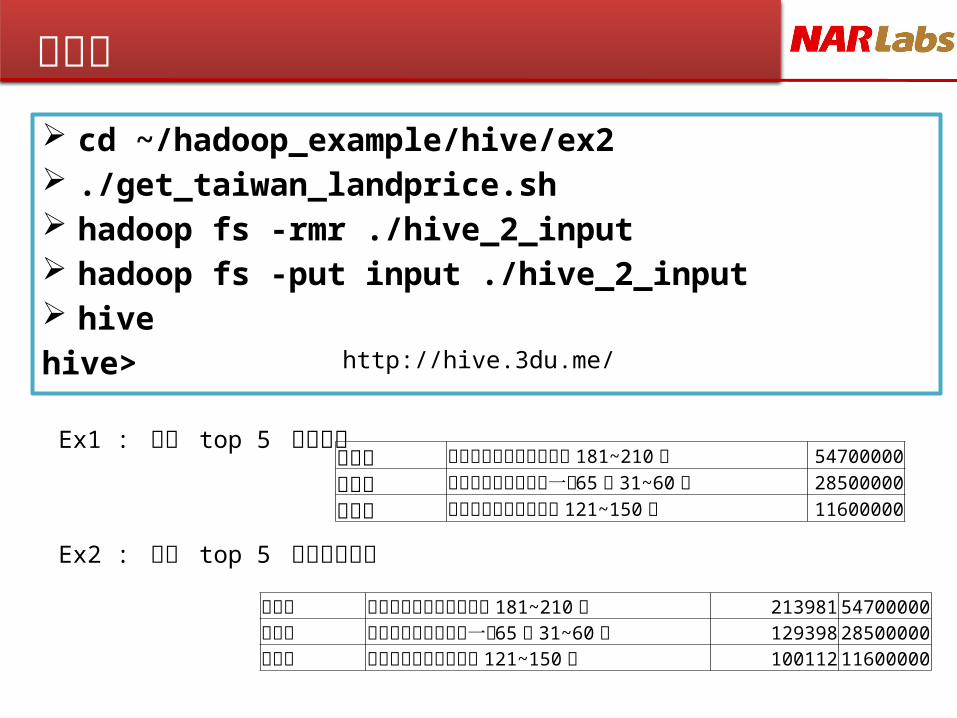
練習二
cd ~/hadoop_example/hive/ex2 ./get_taiwan_landprice.sh hadoop fs -rmr ./hive_2_input hadoop fs -put input ./hive_2_input hive hive>
Ex1 : 算出 top 5 最高房價
Ex2 : 算出 top 5 最高每坪價格
文山區 臺北市文山區汀州路四段 181~210 號 54700000
文山區 臺北市文山區新光路一段 65 巷 31~60 號
28500000
文山區 臺北市文山區政大二街 121~150 號 11600000
文山區 臺北市文山區汀州路四段 181~210 號 2139815470000
0
文山區 臺北市文山區新光路一段 65 巷 31~60
號 129398
28500000
文山區 臺北市文山區政大二街 121~150 號 1001121160000
0
http://hive.3du.me/

Reference
• Hive 官方範例說明– https://
cwiki.apache.org/confluence/display/Hive/Tutorial
• Hive 練習– http://hive.3du.me/