Embed Size (px)
Citation preview

© [email protected] – University of Geneva – Multimedia Retrieval – September 2015 - 1
Multimedia Information Retrieval
Stephane Marchand-Maillet Viper group
University of Geneva Switzerland
http://viper.unige.ch

© [email protected] – University of Geneva – Multimedia Retrieval – September 2015 - 2
• What is your background?
– Computer Science
– Scientific
– Humanities
• This lecture introduces intuition from examples
– More technical details in recommended reading
Quick get-to-know

© [email protected] – University of Geneva – Multimedia Retrieval – September 2015 - 3
• To introduce (recall, rehearse) some key principles and techniques of IR
• To show how these are adapted to Multimedia
• To look at the Multimedia context
• To see how to best face it
Objectives of the lecture

© [email protected] – University of Geneva – Multimedia Retrieval – September 2015 - 4
Outline
• Motivation and context
• Preliminary material on IR
• Audio-visual IR
• Complements
• Evaluation
4
Note: Several illustrations from within these slides have been borrowed from the Web, including Wikipedia or teaching material. Please do not reproduce without permission from the respective authors. When in doubt, don't.

© [email protected] – University of Geneva – Multimedia Retrieval – September 2015 - 5
Data Production
• Growth of Data – 1,250B GB (=1.2EB) of data generated in
2010.
– Data generation growing at a rate of 58% per year • Baraniuk, R., “More is Less: Signal Processing and the
Data Deluge”, Science, V331, 2011.
1 exabyte (EB) = 1,073,741,824 gigabytes
0
2000
4000
6000
8000
10000
2010 2011 2012 2013 2014
Dat
a Si
ze (
EB)
Data Generation Growth
http://www.intel.com/content/www/us/en/communicati
ons/internet-minute-infographic.html
http://www.ritholtz.com/blog/2011/12/financial-industry-
interconnectedness/
Internet
Scientific
Industry
Data
By Sverre Jarp, By Felix'Schürmann
© Copyright attached

© [email protected] – University of Geneva – Multimedia Retrieval – September 2015 - 6
A digital world
[From http://1000memories.com/blog/94-number-of-photos-ever-taken-digital-and-analog-in-shoebox]

© [email protected] – University of Geneva – Multimedia Retrieval – September 2015 - 7
[Picture from: http://www.intel.com/content/www/us/en/communications/internet-minute-infographic.html]
Data communication
© Copyright attached

© [email protected] – University of Geneva – Multimedia Retrieval – September 2015 - 8
User “productivity”
[Picture from: http://www.go-gulf.com/wp-content/themes/go-gulf/blog/online-time.jpg - Feb 2012]
© Copyright attached

© [email protected] – University of Geneva – Multimedia Retrieval – September 2015 - 9
Motivation
• Decision making requires informed choices
• Data production ever easier
• The information is often overwhelming – « Big Data » trend
• The information is often not easy to manage and access
We need to bring a structure to the raw data
• Document (data) representation
• Similarity measurements
• Further analysis: data mining, information retrieval, learning
© Copyright attached

© [email protected] – University of Geneva – Multimedia Retrieval – September 2015 - 10
Components of Data Quality
• Validity
• Integrity
• Completeness
• Consistency
• Relevance
• Accuracy
and…
• Timeliness
• Interpretability
• Reliability
• …
Applies on all media

© [email protected] – University of Geneva – Multimedia Retrieval – September 2015 - 11
• Searching for multimedia – Is it like searching text?
• Information retrieval model
• Representing documents – BoW and TF*IDF
• Indexing model – Inverted files
– hashing
Preliminary

© [email protected] – University of Geneva – Multimedia Retrieval – September 2015 - 12
Searching for multimedia
Basic solution:
• Attach text to multimedia and search for text
– Tags, keywords
– Description
“Multimedia Annotation”
– Domain of “Knowledge Management”
– Requires the definition of Ontologies, Taxonomies,…
Human in the loop
– Not scalable, not feasible

© [email protected] – University of Geneva – Multimedia Retrieval – September 2015 - 13
[Picture from: http://www.intel.com/content/www/us/en/communications/internet-minute-infographic.html]
Per minute rate (some years ago!)
© Copyright attached

© [email protected] – University of Geneva – Multimedia Retrieval – September 2015 - 14
• From the sensing device – Device type, model – Sensing conditions (flash/no flash) – Author (device owner?) – …
• From the environment – Time, date, location – Environment conditions (inside/outside, weather) – Spoken languages – …
• More? From the content? – Later in this lecture
Note: Can never be exhaustive
Auto-annotation

© [email protected] – University of Geneva – Multimedia Retrieval – September 2015 - 15
• “Wasp on a yellow flower” • Specific (latin) name of the flower? Of the insect? • What is the insect exactly doing?
• Weather looks nice: “countryside scene”? • The picture may be arty:
“2015 1st price college photo competition winner”
Inference cannot resolve all • “The wasp who scared my daughter during our holiday in
Gruyere”
Annotation

© [email protected] – University of Geneva – Multimedia Retrieval – September 2015 - 16
• Exif: standard picture annotation container • ID3-tag: standard audio information • NTFS: window-based metadata exchange • JPSearch, MPEG 7: Search-oriented description
standards
• Every format will have a text header to insert “comments” (PNG, GIF, JPG, TIFF,…)
Complementarity text-based / content-based • Other category is recommender-based
– “social” annotation
Annotating mulitmedia

© [email protected] – University of Geneva – Multimedia Retrieval – September 2015 - 17
MPEG-7 Still Image Description

© [email protected] – University of Geneva – Multimedia Retrieval – September 2015 - 18
IBM MPEG-7 Annotation Tool (video/visual stream) [http://www.research.ibm.com/VideoAnnEx/]

© [email protected] – University of Geneva – Multimedia Retrieval – September 2015 - 19
• Given a query (information need) • Given a repository (information source) Infer the most relevant documents from the repository as an answer to the query
The most used query type is Query-by-Example “I want something like this”
• Descriptive query • Free text (Google-like) query • Example document-s (“ ”)
• Relevance is similarity • Similarity is transferred to “closeness”
More like this…
Information Retrieval paradigm

© [email protected] – University of Geneva – Multimedia Retrieval – September 2015 - 20
• IR tells us that we do not (really) need to have a complete absolute understanding of documents to respond queries, we (just) need to be able to compare 2 documents
• We merely need appropriate distance measurements – To infer similarity – Based on document features (space) – and a notion of vicinity (distance)
Everything is about inspecting neighborhoods – Provided the distance is semantically relevant
Information Retrieval

© [email protected] – University of Geneva – Multimedia Retrieval – September 2015 - 21
Information management process
Raw documents
Representation space (visualisation)
Document features
User interaction
Feature extraction
“Appropriate” mapping
“Decision” process
Query

© [email protected] – University of Geneva – Multimedia Retrieval – September 2015 - 22
Distance-based search
Representation space (visualisation)
Query
Relevance list (sorted by distance
to the query)

© [email protected] – University of Geneva – Multimedia Retrieval – September 2015 - 23
Example: text
Text documents
Feature extraction
“Appropriate” mapping
User interaction
“Decision” process
“Word” occurrences
Query

© [email protected] – University of Geneva – Multimedia Retrieval – September 2015 - 24
Also...
• Any type of media: webpage, audio, video, data,...
• Objects, based on their characteristics
• People in social networks
• Concepts: processes, states, ... Etc
Anything for which “characteristics” may be measured
This is what this lecture is about

© [email protected] – University of Geneva – Multimedia Retrieval – September 2015 - 25
• Raw data (the documents) carries information + Computers essentially perform additions We need to represent the data somehow to provide the computer with as much as possible faithful information
• The representation is an opportunity for us to
transfer some prior (domain) knowledge as design assumptions
If this (data modelling) step is flawed, the computer will work with random information
Representation spaces (intuition)

© [email protected] – University of Geneva – Multimedia Retrieval – September 2015 - 26
From documents to features
• Features help characterizing 1 document (summary)
• Features help comparing 2 documents (similarity)
• Features help structuring a collection (visualization)

© [email protected] – University of Geneva – Multimedia Retrieval – September 2015 - 27
Comparing two documents (occurrences)
2 1 1 2 1 0 0
1 2 0 1 1 1 2
1 2 0 1 1 1 2
1 1 0 1 1 0 0
“Terms” (Vocabulary)
“Do
cum
en
ts”
(R
epo
sito
ry)

© [email protected] – University of Geneva – Multimedia Retrieval – September 2015 - 28
Comparing two documents (presence)
Y Y Y Y Y N N
Y Y N N Y Y Y
Y Y N N Y Y Y
Y Y N Y Y N N
Similarity: Y+Y=1 Distance: Y+N=1

© [email protected] – University of Geneva – Multimedia Retrieval – September 2015 - 29
Comparing two documents (presence)
Y Y Y Y Y N N
Y Y N Y Y Y Y
1 1 0 1 1 0 0
Similarity = 4 (Distance=3)

© [email protected] – University of Geneva – Multimedia Retrieval – September 2015 - 30
Comparing two documents
6 (0)
3 (4) 3 (4)
4 (1)
3 (2) 3 (2)
S(D)

© [email protected] – University of Geneva – Multimedia Retrieval – September 2015 - 31
“ “
Comparing two documents S(D)
D1 Y Y Y Y Y N N 1(6)
D2 Y Y N N Y Y Y 2(4)
D3 Y Y N N Y Y Y 2(4)
D4 Y Y N Y Y N N 0 (7)
Q N N Y N N Y Y
Nota: The query is seen as a document (Query-by-example)

© [email protected] – University of Geneva – Multimedia Retrieval – September 2015 - 32
Query-based ranking
“ “
• Since similarity is computed only on (Y,Y) pairs, only terms count for computing the similarity
Every document having no common term with the query scores 0
(ie terms not in the query are ignored)
2(4) 2(4) 1(6) 0(7)
D4 D3 D1 D2 Q

© [email protected] – University of Geneva – Multimedia Retrieval – September 2015 - 33
Computing the ranks
Naïve solution (fill the array):
• For every document, for every term, score 1 if the term is both in the query and the document
N (documents) * M (terms) comparisons
Smarter solution
• For every term of the query (few), find documents having this term and work from there (the rest will score 0)

© [email protected] – University of Geneva – Multimedia Retrieval – September 2015 - 34
Information indexing
Goal:
to organize the data so as to
facilitate its access (read or write)
• Fast access for computation
• Fast access with selection criteria
• …
Baseline: exhaustive search, sequential scan (unordered list)
Strategy: enable “direct access”
Simple example:
• Address book: sorted list, with first letter shortcut
– Smith “S” search 19th sublist (ignore 25 other sublists)

© [email protected] – University of Geneva – Multimedia Retrieval – September 2015 - 35
Indexing structures
…+ M-tree Tries Suffix array Suffix Tree Inverted files LSH…
Illustration: Wikipedia

© [email protected] – University of Geneva – Multimedia Retrieval – September 2015 - 36
Term Documents
D1,D2,D3,D4
D1,D2,D3,D4
D1
D1,D4
D1,D2,D3,D4
D2,D3
D2,D3
“find documents having this term”
Arrange documents by the terms they contain
Number of comparisons ~ number of query terms
<< N*M
Inverted file
(D1),(D2,D3),(D2,D3)
D1, D2, D2, D3, D3
D4 is never considered ! (we know already that its score is 0)

© [email protected] – University of Geneva – Multimedia Retrieval – September 2015 - 37
Principles and lessons
• We need to be able to compare 2 documents
• Comparison is based on document features
• Similarity may be based on feature occurrence
• Only occurring features count in building similarity
Feature occurrence allows for the use of inverted files to get independent from the size of the repository
Feature occurrence loses a lot of structure in the document

© [email protected] – University of Geneva – Multimedia Retrieval – September 2015 - 38
In practice (text IR)
• Document features are normalised word (stem) occurrences (Bag of Words model)
– Vocabulary ~ 10’000 stems
– Billions of documents
• Term weighting scheme (TF*IDF) accounts for feature statistics (better than Y/N occurrence)
• Similarity is based on cosine distance
• Inverted files include term statistics

© [email protected] – University of Geneva – Multimedia Retrieval – September 2015 - 39
BoW : Assumptions
• A text is reduced to the base vocabulary it uses • Example:
• Becomes:
The ultimate goal is to define similarity as:
Two documents are similar if they share the same vocabulary
Signals from a particle collider near Geneva suggested in September that scientists might have sighted a long-sought particle thought to be the source of mass itself.
A (x2), be, collide, from, geneva, have, in, itself, long-sought, mass, may, near, of, particle (x2), scientist, see, september, signal, source, suggest, that, the, think, to

© [email protected] – University of Geneva – Multimedia Retrieval – September 2015 - 40
BoW: Limitations • The structure is lost
– Title, sections, paragraphs, sentences, negations
• The representation is incomplete… – If all words appear once only and there is no extra information such as
• Grammatical type
• Priors on terms (recent news, unused terms,…)
– And writing well is often about using a rich vocabulary • Use of synonyms
• …or ambiguous – If a word appears many times but because of polysemy
– Eg: mouse • A part on mouse as a pet
• A part on computer mouse
• A part on Mickey mouse
– Does not make the text about “mouse” but maybe just about “kid amusements”
… still works very well in practice

© [email protected] – University of Geneva – Multimedia Retrieval – September 2015 - 41
A document is represented by the occurrences of the terms of the vocabulary • Earlier example: Y/N occurrence Number of occurrence does not matter
• Counting the term occurrence Favors longer documents (more occurrences) Document length normalization (frequency)
• Not all frequent terms are relevant Balance between representation (TF) and discriminative
power (IDF) How good in my term in my query for this document?
A bit more details

© [email protected] – University of Geneva – Multimedia Retrieval – September 2015 - 42
• Term frequency (TF) – Percentage of space taken by each term in the document: “how much this term represents the document” High TF frequent term in the document potential representative term (keyword)
• Inverse document frequency (IDF)
– Inverse of the percentage of space taken by each term in the collection:
“how much this term discriminates documents” High DF low IDF term frequent in all documents not discriminant (all documents are relevant) Eg: the, at, and, she, he, her… + thematic (patient, disease,…) Good terms are terms with high TF and high IDF
TF*IDF model: intuition

© [email protected] – University of Geneva – Multimedia Retrieval – September 2015 - 43
High TF (frequent in document)
Potential keyword
Low TF (infrequent in document)
High IDF (infrequent in collection)
“Keyword” Good representative
Verb, noun,..
Low representation
(automatically ignored)
Low IDF (frequent in collection)
“Stop word” Does not carry meaning
“structural” The, at, and, she,…
(removed from voc / ignored)
Rare term
(automatically ignored)
TF*IDF term weight
When computing the difference between documents, terms are weighted by their TF*IDF factor

© [email protected] – University of Geneva – Multimedia Retrieval – September 2015 - 44
Inverted file construction
Docs
extraction sorting compaction
Term Doc ID
“blah” N
“new” 1
“the” 1
“tool” N-1
… ...
“tool” 1
“blah” N
“blah” 1
Term Doc ID
“the” 1
“new” 1
“tool” 1
“blah” N
… ...
“tool” N-1
“blah” N
“blah” 1
Term Doc ID
“blah” 1
“new” 1
“the” 1
“tool” N-1
… ...
“tool” 1
“blah” N
Freq
1
1
1
1
...
1
2
Term Tot. F.
“blah” 3
“the” 1
… ...
“tool” 2
“new” 1
...
Doc ID
1
1
1
N-1
1
N
Freq
1
1
1
1
...
1
2
factorisation Misc
operations
Eg: posting file compression
Dictionary Collection information
« idf » Postings
Document information « tf »

© [email protected] – University of Geneva – Multimedia Retrieval – September 2015 - 45
Value Key
1
2
…
20
…
33
…
Hashing / fingerprinting (intuition only)
=1
=2
=3
=4
=5
=6
=7
=1+1+2+3+4+4+5 = 20
=1+2+2+4+5+6+7+7 = 33
Hash Table
Query Immediate access
=1+2+2+4+5+6+7+7 = 33
• Associate a key (hash, fingerprint) to each value
• Insert the (key, value) into a hash table
Immediate retrieval of the query
Difficult constraint (Perceptual hashing) : The key does not vary if the value changes a bit (eg due to noise)
Hash function

© [email protected] – University of Geneva – Multimedia Retrieval – September 2015 - 46
What is multimedia?
Basically our digital life
• Text – Plain text (any language) – Structured text (XML-like, code,…)
• Visual – Images (Photo) – Sketches (drawing, map,..)
• Audio – Music – Speech – Sound
• Misc – 3D object – Video – … (software, playlist,…)
+ Any combination – PDF, Web pages and alike

© [email protected] – University of Geneva – Multimedia Retrieval – September 2015 - 47
Multimedia IR: Use Cases
• Image – Find look-alike pictures, recognize landmark
• Video – Find specific actions
• Music – Find inspirational music, recognize music extract
• Medical – Find similar cases
• Patent – Find similar proposals, plagiarism
Not always doable with text
47
© [email protected] – University of Geneva – Multimedia Retrieval – September 2015 - 48
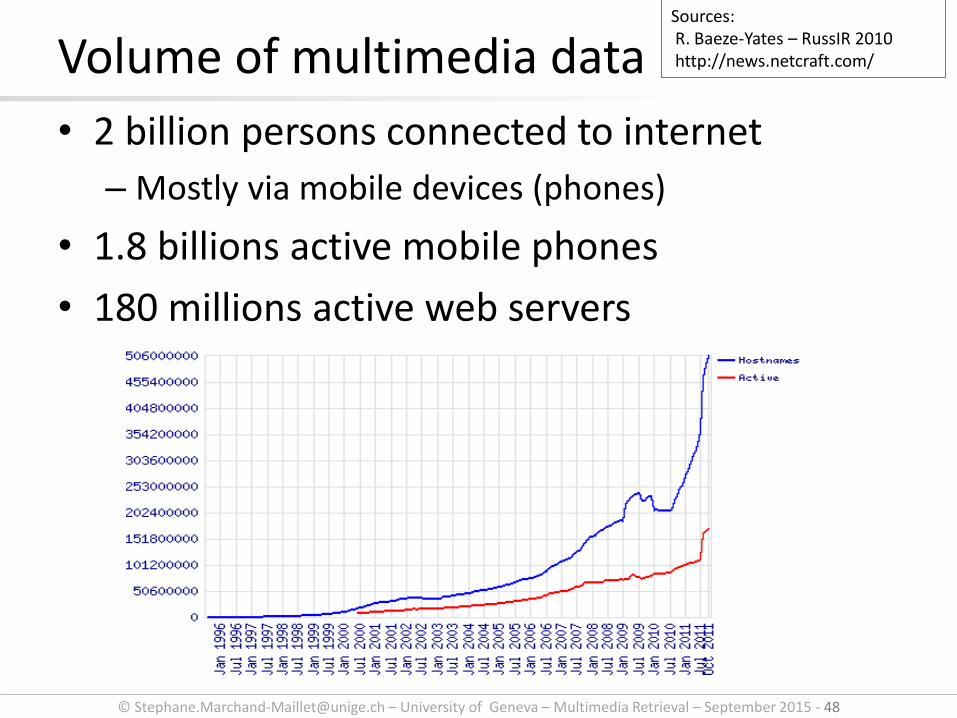
Volume of multimedia data
• 2 billion persons connected to internet
– Mostly via mobile devices (phones)
• 1.8 billions active mobile phones
• 180 millions active web servers
Sources: R. Baeze-Yates – RussIR 2010 http://news.netcraft.com/

© [email protected] – University of Geneva – Multimedia Retrieval – September 2015 - 49
Volume of multimedia data
• Web scale: – Google:
• Early 2004: 4.3 billions indexed pages • Early 2005: 8 billions indexed pages • Today: XX billion indexed pages?
– http://www.archive.org • Growth: 20 Tb/month
• Multimedia collection:
– Facebook: 140 billions photos 180 years at 25 fps
– YouTube (2008): 83.4 million videos
• Curated collections: – AOL Video library
• 410 millions views in October 2011
– Institut National de l'Audiovisuel (INA-France): • 700’000h audio (radio) • 400’000h video (television) • 2 millions documents

© [email protected] – University of Geneva – Multimedia Retrieval – September 2015 - 50
The new wave
[From http://1000memories.com/blog/94-number-of-photos-ever-taken-digital-and-analog-in-shoebox]

© [email protected] – University of Geneva – Multimedia Retrieval – September 2015 - 51
Example: Information « loss »
• Annotation – " Wasp on a yellow flower "
• Text search:
– « insect feeding This document will be missed
• The user must know what is the annotation limitation
• The goal is to represent the document – Exhaustively: no specific interpretation context – Automatically: no human intervention

© [email protected] – University of Geneva – Multimedia Retrieval – September 2015 - 52
• Image formation model
• Image features
• Indexing visual content
Visual Information Retrieval

© [email protected] – University of Geneva – Multimedia Retrieval – September 2015 - 53
Visual content has specific types
• Photo
• Medical image, satellite image
• Document: fax, scanned text…
• Drawing: sketch, blueprint, cartoon,…
• 3D, shape
Visual content

© [email protected] – University of Geneva – Multimedia Retrieval – September 2015 - 54
Example: Images
Images
Feature extraction
“Appropriate” mapping
“Decision” process
Search Photo collage Filtering
Color histogram
User interaction
Query

© [email protected] – University of Geneva – Multimedia Retrieval – September 2015 - 55
Pixels
RGB Sensor RGB Color model
Any color = combination of RGB values Image = 3 Arrays (RGB) of values between 0 and 255 Pixel = RGB values (color) at a position in the image

© [email protected] – University of Geneva – Multimedia Retrieval – September 2015 - 56
Image processing / Analysis
RGB Histograms
Gray scale (intensity) Edge image

© [email protected] – University of Geneva – Multimedia Retrieval – September 2015 - 57
Low-level image representation
Global Color Histogram data in color spaces:
Global Texture data from Gabor filter banks:

© [email protected] – University of Geneva – Multimedia Retrieval – September 2015 - 58
Corner detection / keypoints

© [email protected] – University of Geneva – Multimedia Retrieval – September 2015 - 59
Local features: SIFT[Lowe 1999] and SURF[Bay et al 2006]

© [email protected] – University of Geneva – Multimedia Retrieval – September 2015 - 60
From data to information
Interpreting the content
• Data is physically measured
• Information is interpreted semantically Semantic gap
• Fusion is a way to reduce the semantic gap
• Examples – Looking at a movie w/o audio
– Listening to a story w/o visual
– Voice conversation vs video conversation
– Disambiguation (eg „jaguar“)

© [email protected] – University of Geneva – Multimedia Retrieval – September 2015 - 61
From data to information
Semantic gap: “Discrepancy between the level of analysis of a computer and the level of
perception of the same data by a human user.”
Level Text Visual
Interpretation Story “Action”
Semantic segmentation
Paragraph Scene
Group Sentence Object
Physical segmentation
Word Homogeneous region
Physical inspection
Character Color, texture
Le
ve
l o
f in
terp
reta
tion
Re
leva
nce
fo
r in
de
xin
g
Com
pu
ter p
recis
ion
Semantic Gap

© [email protected] – University of Geneva – Multimedia Retrieval – September 2015 - 62
Semantic gap
• Exploited by Captchas

© [email protected] – University of Geneva – Multimedia Retrieval – September 2015 - 63
Region-based image understanding
Images are compared w.r.t the regions (hopefully objects/concepts) they contain
Object detection eg, Face detection

© [email protected] – University of Geneva – Multimedia Retrieval – September 2015 - 64
Object detection / recognition
• Train the machine to recognize specific groups of patterns
Faces [Viola, Jones, 2001]
Objects
Automated image tagging Text search

© [email protected] – University of Geneva – Multimedia Retrieval – September 2015 - 65
Naming faces : Image to text
Specific characteristics of a face are extracted (eg eigenfaces)

© [email protected] – University of Geneva – Multimedia Retrieval – September 2015 - 66
Deep Learning
[http://www.slideshare.net/NVIDIA/visual-computing-the-road-ahead-an-nvidia-ces-2015-presentation-deck]

© [email protected] – University of Geneva – Multimedia Retrieval – September 2015 - 67
Bag of Visual Words
• Once basic visual features are extracted, – Eg: the description of the surrounding of each corner point
(eg SIFT)
• Basic features are grouped – Eg corner of an object
• And “quantified” – Many examples are gathered into one instance
• To create a “visual dictionary” of visual words
• An image is a composition (occurrences) of these visual words (“terms”)
We can use of the machinery related to text - Inverted files, etc

© [email protected] – University of Geneva – Multimedia Retrieval – September 2015 - 68
Comparing two documents (occurrences)
2 1 1 2 1 0 0
1 2 0 1 1 1 2
1 2 0 1 1 1 2
1 1 0 1 1 0 0
“Terms” (Vocabulary)
“Do
cum
en
ts”
(R
epo
sito
ry)

© [email protected] – University of Geneva – Multimedia Retrieval – September 2015 - 69
Hyperbrowser [S. Craver, 1999]

© [email protected] – University of Geneva – Multimedia Retrieval – September 2015 - 70
Hyperbrowser [S. Craver, 1999]

© [email protected] – University of Geneva – Multimedia Retrieval – September 2015 - 71
Digital shoebox

© [email protected] – University of Geneva – Multimedia Retrieval – September 2015 - 72
Digital shoebox

© [email protected] – University of Geneva – Multimedia Retrieval – September 2015 - 73
Collection mining

© [email protected] – University of Geneva – Multimedia Retrieval – September 2015 - 74
• Modeling sound
• Audio information
– Speech, music, sound
• Searching for audio
Audio IR

© [email protected] – University of Geneva – Multimedia Retrieval – September 2015 - 75
Example: Audio
Audio
Feature extraction
“Appropriate” mapping
“Decision” process
Playlist Filtering
User interaction
Query

© [email protected] – University of Geneva – Multimedia Retrieval – September 2015 - 76
Sound characteristics Sound corresponds to waves perturbing the environment Wave characteristics
– Frequency/Period 1 Hertz (Hz) = 1 vibration/second Related notion of pitch
– Intensity
• Human ear has logarithmic scale Decibel (dB) scale 0dB = 10-12 W/m2 (Threshold of hearing) 10dB = 10-11 W/m2 … x*10dB= 10-(12-x) W/m2
2m
Watt
Area
Power
Time
Energy
Area
1I

© [email protected] – University of Geneva – Multimedia Retrieval – September 2015 - 77
Sound perception
Airwave collection Mapping to mechanical waves
Mapping to compressional waves
Mapping to electrical signal
0dB = 10-12 W/m2 : Threshold of hearing 160 dB = 10-4 W/m2 : Instant perforation of eardrum

© [email protected] – University of Geneva – Multimedia Retrieval – September 2015 - 78
200k 100k
Sound perception
0
Frequency f (Hz)
Human (20-20k)
Dog (50-45k)
Cat (50-85k)
50 100 500 1k 5k 10k 50k
Bats (50-85k)
Dolphins (-200k)
Bats (-120k)
Elephant (5-)
Infrasound Audible sound Ultrasound

© [email protected] – University of Geneva – Multimedia Retrieval – September 2015 - 79
Audio and Sound
50 100
80
20
500 1k 5k 10k 20k
40
60
0
120
100
Non-audible
Painful
Audible sounds
Speech
Frequency f (Hz)
Intensity I (dB) Partly adapted from [Schäuble,1997]
Quiet library,
soft whisper
Quiet office,
living room,
Light traffic at a distance,
gentle breeze
Conversation,
Sewing machine
Busy traffic,
noisy restaurant
Subway, heavy city traffic,
alarm clock at 2 feet,
factory noise
Truck traffic, noisy home
appliances, shop tools,
lawnmower
Chain saw,
pneumatic drill
Rock concert in front of
speakers, thunderclap
(180) Rocket launching pad
(140) Gunshot blast, jet plane

© [email protected] – University of Geneva – Multimedia Retrieval – September 2015 - 80
Audio information
• Speech – Male, female speech Signal-based speech characterisation – Automatic speech recognition (ASR) ASR (text) retrieval
• Music
Genre recognition (Jazz, classic,…) Excerpt retrieval Query by humming …
• Sound
– Car, water, people, animals,… – Often useful in relation to visual (video)

© [email protected] – University of Geneva – Multimedia Retrieval – September 2015 - 81
Audio information
high
low
natural man-made
Info
rmat
ion
co
nte
nt
Origin
Animal sounds
Wind Water
Speech Music
Urban noise Machines, engines

© [email protected] – University of Geneva – Multimedia Retrieval – September 2015 - 82
Audio features
• Low-level-audio representation – Spectrogram
– MFCC
• Mid-level representations – MIDI strings
– LPC
• High-level representation – Automatic speech recognition (ASR)

© [email protected] – University of Geneva – Multimedia Retrieval – September 2015 - 83
Translation
Signal- based
Audio information indexing
Audio
Sound Music Speech
ASR
Wordspotting
Translation
Piece/Genre recognition Classification
Visual
A/V Processing
Transcripts, Speaker info
Score, MIDI

© [email protected] – University of Geneva – Multimedia Retrieval – September 2015 - 84
Speech
Speech production model
Speech perception model
Note: In vision, mostly only perception models
Speech

© [email protected] – University of Geneva – Multimedia Retrieval – September 2015 - 85
Speech production
Human apparatus Speech production scenarios
1. Voiced sound (vocal tract) 2. Fricative sound (‘S’) 3. Plosive sound (‘P’)

© [email protected] – University of Geneva – Multimedia Retrieval – September 2015 - 86
Speech production modeling
Mechanical model Human apparatus
Multistage process 1. Build up
pressure 2. Release 3. Return to first
state

© [email protected] – University of Geneva – Multimedia Retrieval – September 2015 - 87
Speech signal modeling
Given w(t) as a speech signal where S(w) is the STFT of w. The model assume H(w) as the vocal tract transfert function and E(w) is the excitation
222)()()( wEwHwS

© [email protected] – University of Geneva – Multimedia Retrieval – September 2015 - 88
Note: MP3 coding
Advanced coding model
MP3 = MPEG 1 Audio layer 3
See previous slides

© [email protected] – University of Geneva – Multimedia Retrieval – September 2015 - 89
Sony music browser

© [email protected] – University of Geneva – Multimedia Retrieval – September 2015 - 90
Islands of music [http://www.oefai.at/~elias/music]
Organisation d'archives musicales
• Basée sur des cartes auto-organisées de Kohonen (Self organising maps – SOM)

© [email protected] – University of Geneva – Multimedia Retrieval – September 2015 - 91
ThemeFinder [http://www.themefinder.org/]

© [email protected] – University of Geneva – Multimedia Retrieval – September 2015 - 92
• Design a nice perceptual hash function for audio (based on perceptual features)
• Slice an audio document (music piece) into small chunks (large enough to be “unique”)
• For each chunk compute a key through the hash function and store as value the music piece ID (title)
Music query by example
Retrieval by noisy chunk
Audio fingerprinting

© [email protected] – University of Geneva – Multimedia Retrieval – September 2015 - 93
• Video type
– Movies
– Amateur souvenir film
– Lectures
– Youtube (short, static)
• Combining individual media (fusion)
– each brings some information…
• Going further: social multimedia…
Multimedia IR

© [email protected] – University of Geneva – Multimedia Retrieval – September 2015 - 94
From data to information
Interpreting the content
• Data is physically measured
• Information is interpreted semantically Semantic gap
• Fusion is a way to reduce the semantic gap
• Examples – Looking at a movie w/o audio
– Listening to a story w/o visual
– Voice conversation vs video conversation
– Disambiguation (eg „jaguar“)

© [email protected] – University of Geneva – Multimedia Retrieval – September 2015 - 95
Multimodal video features
Over temporal modalities:
• Segmentation (boundary) cues
• Categorization (region) cues
Word relatedness measure
Visual syntactic homogeneity
Multimodal boundary-based cues
Semantic region- based cues
Audio
Visual
Text

© [email protected] – University of Geneva – Multimedia Retrieval – September 2015 - 96
Adding context to interpretation
Video Story Segmentation:
Using fusion between the visual and audio modalities, high-level segmentation may be achieved
“shot” keyframe
Audio transcript

© [email protected] – University of Geneva – Multimedia Retrieval – September 2015 - 97
Main goals of fusion
Multimodal information fusion aims at interpreting jointly multiple sources of information representing the same underlying „concept“
The main goal is the extraction of information
By fusing information, one aims at: • Being more accurate in the discovery of the
„concept“ – Each individual stream may be incomplete
• Being more robust in the discovery of the „concept“ – Each individual stream may be distorted (eg, noisy)

© [email protected] – University of Geneva – Multimedia Retrieval – September 2015 - 98
Multimodal fusion
• From many sources of information and context, how to make our best to “interpret” the data
representation
color
texture
shape
face
local features
vector space model
Port;;Naval and River;;For Transportation;;Structure;;Architecture;;Vegetable Garden;;Landscape Farmland - Countryside);;Landscape;;Landscape (Seascape);;Landscape;;Panorama;;View of the City;;View 98
data
Interpretation

© [email protected] – University of Geneva – Multimedia Retrieval – September 2015 - 99
Levels of fusion
How to organise fusion from classical „unimodal“ interpretation?
Feature extraction
Recognizer Raw data
„Knowledge“
Output
Unique source

© [email protected] – University of Geneva – Multimedia Retrieval – September 2015 - 100
Levels of fusion
Raw data
Output
Raw data
Multiple sources
One unique output
Recognizer Decision

© [email protected] – University of Geneva – Multimedia Retrieval – September 2015 - 101
Early fusion strategy
• Acts over features
• All modalities are „concatenated into one“
• Only one decision is taken over the concatenated input
Raw data
Output
Raw data
Multiple Sources
Fusion
One unique output
Recognizer Decision
Example: multimodal medical image analysis • Sources: modalities (XRay, PET,…)

© [email protected] – University of Geneva – Multimedia Retrieval – September 2015 - 102
Intermediate fusion strategy
• Each source acts as an input for a specific decision
• All recognizers are coupled in some way to form a meta-recognizer
• One decision is taken
Fusion
Raw data
Output
Raw data
Multiple sources
One unique output
Recognizer
Meta- Recognizer
Recognizer
Decision
Example: Video analysis • Source: A/V streams

© [email protected] – University of Geneva – Multimedia Retrieval – September 2015 - 103
Late fusion strategy
• Each source is processed individually by a specific recognizer
• Multiple independent initial decisions are taken, possibly associated with confidence scores
• A final decision is taken based on this output
Final decision
Fusion
Raw data
Output
Raw data
Multiple sources
One unique output
Recognizer
Recognizer
Decision
Decision
Decision Example: Object recognition • Source: image regions

© [email protected] – University of Geneva – Multimedia Retrieval – September 2015 - 104
Prototype-based fusion
,,,, SIFT)( xxx p72π
query
document x
,,7,2, SIFT)( xxx pπ

© [email protected] – University of Geneva – Multimedia Retrieval – September 2015 - 105
Concept “Mona Lisa”
Multimedia is complex data
1503-1506 by L. Da Vinci EN: Mona Lisa IT: La Gioconda FR: La Joconde
Visible in Le Louvre, Paris 48° 51′ 34″ N 2° 19′ 54″ E
Type: Oil on poplar Dimensions: 77 cm × 53 cm (30 in × 21 in)
Photo by Mr. X Date, context Reason of trip
Variations from artists
Embedding into prints
Chocolate piece
URLs about Mona Lisa
Books about Mona Lisa
Videos about Mona Lisa
Audio about Mona Lisa
“official picture”
Texts about Mona Lisa
“Factual” data
“Faithful” data “Related” data

© [email protected] – University of Geneva – Multimedia Retrieval – September 2015 - 106
Networked multimodal data
Data
Tags
Users
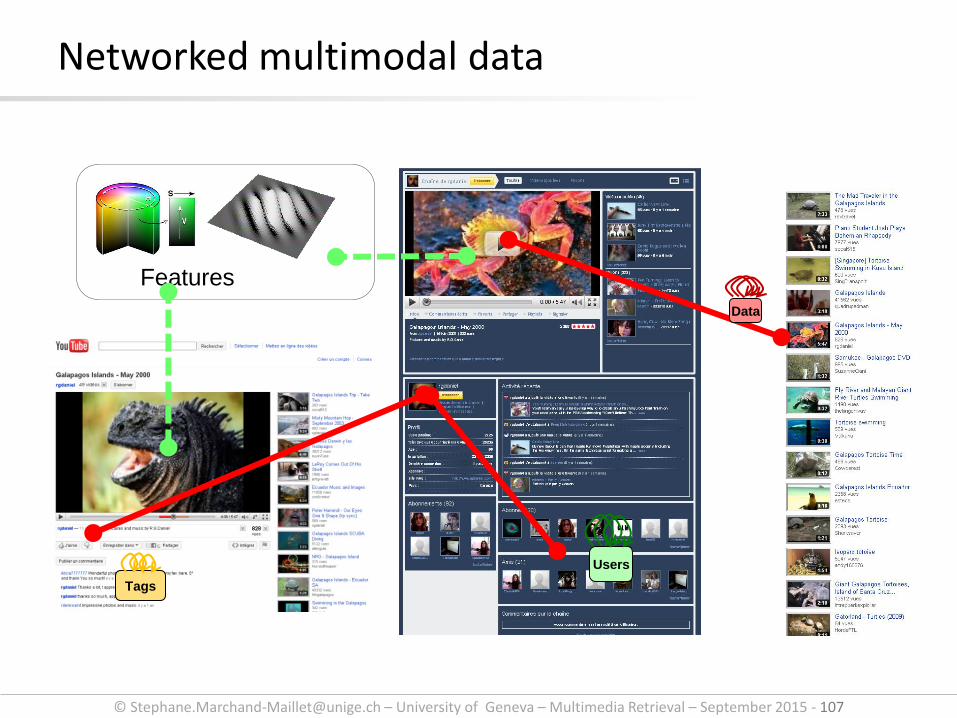
© [email protected] – University of Geneva – Multimedia Retrieval – September 2015 - 107
Features
Networked multimodal data
Data
Tags
Users

© [email protected] – University of Geneva – Multimedia Retrieval – September 2015 - 108
• Curse of dimensionality
– Sparsity
– Dimension reduction/visualisation
• Big data
– Indexing
– Visual Analytics
Complements

© [email protected] – University of Geneva – Multimedia Retrieval – September 2015 - 109
Statistics tell us that the more data we have, the better we get
Simulation: exponential distribution
n=10 n=100 n=1’000 n=3’000
n=10’000 Mean Standard deviation

© [email protected] – University of Geneva – Multimedia Retrieval – September 2015 - 110
Imagine I want to know the age spread of a population • I create 10 intervals (0-10, 10-20,…) and I want to know the proportion of
people in each interval • To have a reliable estimate I want 100 persons per interval in average With 10*100=1000 persons, I get my estimates
Now, imagine I want to estimate the height against age (I add one dimension to my measure) • I create 10 height interval and question, “how many people with height X
that are aged Y?” • I have 10*10=100 such (X,Y) pairs • To get 100 persons for each pair in average I need 100*100 = 10’000
persons
And so on… The size of the data needed for a reliable estimate grows with the
exponential of the dimension (huge!!!) In practice our data size is limited Our only choice to preserve reliability is to reduce the dimension
High dimensionality

© [email protected] – University of Geneva – Multimedia Retrieval – September 2015 - 111
Dimension reduction: principle
• Given a set of data in a M-dimensional space, we seek an equivalent representation of lower dimension – For better statistics – For visualization (2D, 3D,..)
• Dimension reduction induces a loss. What to sacrifice? What to preserve? – Preserve local: neighbourhood, distances – Preserve global: distribution of data, variance – Sacrifice local: noise – Sacrifice global: large distances – Map linearly – Unfold data

© [email protected] – University of Geneva – Multimedia Retrieval – September 2015 - 112
Some example techniques:
• SFC: preserve neighbourhoods
• PCA: preserve global linear structures
• MDS: preserve linear neighbourhoods
• IsoMAP: Unfold neighbourhoods
• SNE family: unfold statistically
Dimension reduction

© [email protected] – University of Geneva – Multimedia Retrieval – September 2015 - 113
Non-recursive Space Filling Curves
Z-Scan Curve Snake Scan Curve
[Illustrations from the lecture “SFC in Info Viz”, Jiwen Huo, Uni Waterloo, CA]

© [email protected] – University of Geneva – Multimedia Retrieval – September 2015 - 114
Recursive Space Filling Curves
Hilbert Curve
Gray Code Curve
Peano Curve
[Illustrations from the lecture “SFC in Info Viz”, Jiwen Huo, Uni Waterloo, CA]

© [email protected] – University of Geneva – Multimedia Retrieval – September 2015 - 115
3D SFC
Z Curve Peano Curve Hilbert Curve
N-dimensional algorithm: A.R. Butz (April 1971). "Alternative algorithm for Hilbert’s space filling curve.". IEEE Trans. On Computers, 20: 424–42.
[Illustrations from the lecture “SFC in Info Viz”, Jiwen Huo, Uni Waterloo, CA]

© [email protected] – University of Geneva – Multimedia Retrieval – September 2015 - 116
PCA
[Illustration Wikipedia]
© [email protected] – University of Geneva – Multimedia Retrieval – September 2015 - 117
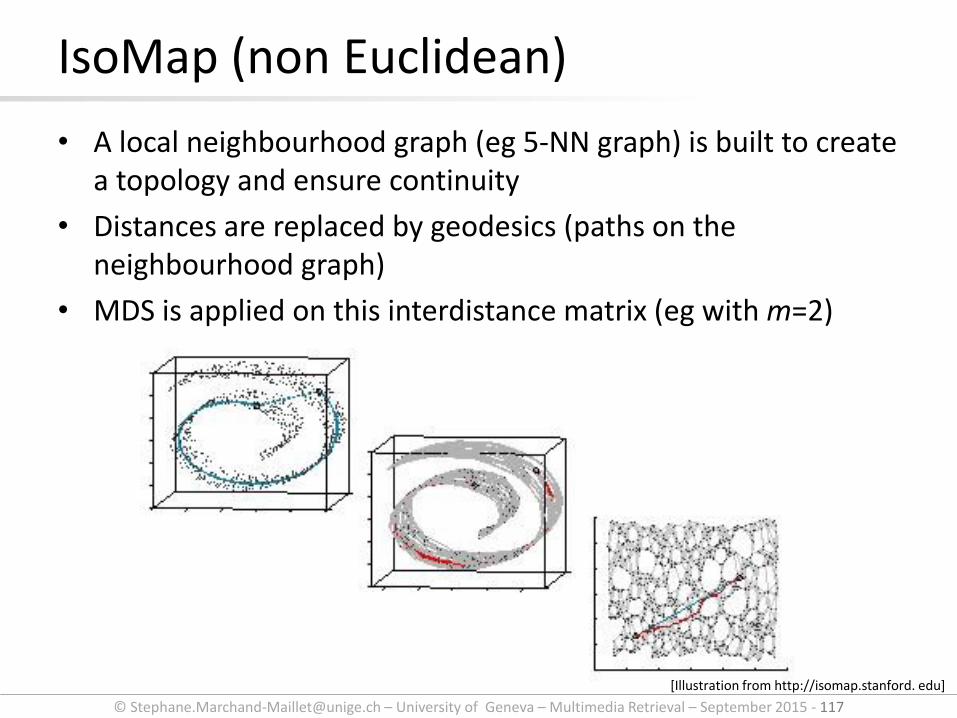
• A local neighbourhood graph (eg 5-NN graph) is built to create a topology and ensure continuity
• Distances are replaced by geodesics (paths on the neighbourhood graph)
• MDS is applied on this interdistance matrix (eg with m=2)
IsoMap (non Euclidean)
[Illustration from http://isomap.stanford. edu]

© [email protected] – University of Geneva – Multimedia Retrieval – September 2015 - 118
• MNIST dataset
t-SNE example
[Illustration from L. van der Maaten’s website]

© [email protected] – University of Geneva – Multimedia Retrieval – September 2015 - 119
Traces of our everyday activities can be:
• Captured, exchanged (production, communication)
• Aggregated, Stored
• Filtered, Mined (Processing)
The “V”’s of Big Data:
• Volume, Variety, Velocity (technical)
• and hopefully... Value
Raw data is almost worthless, the added value is in juicing the data into information (and knowledge)
Big Data

© [email protected] – University of Geneva – Multimedia Retrieval – September 2015 - 120

© [email protected] – University of Geneva – Multimedia Retrieval – September 2015 - 121
Large-scale: Massive data volume, too large to perform sequential scan of a small portion Aim: From a query, “filtering” by (fast) approximate search) a tiny (fixed-size) portion of the data as candidate answers. And then perform (slow) exact search in that tiny-scale sample Method: Assuming the features group the document coherently, approximately identify the vicinity of the query and search within that neighborhood
Tools for Large Scale indexing

© [email protected] – University of Geneva – Multimedia Retrieval – September 2015 - 122
Approximate search
Fast approximate filtering border (exact search zone)
Actual slow border
Final results Never considered

© [email protected] – University of Geneva – Multimedia Retrieval – September 2015 - 123
Idea: reference-based indexing “If I am close to you, I see the same thing as you”
I am close to Geneva, Montreux and Evian, anything also close to these places is close to me • Fix few reference documents (landmarks) • For each document, measure the distance to each
reference document – Eg: define the set of the 5 closest landmarks
• For a query
– Find its 5 closest landmarks – Find all documents whose 5 closest landmarks are the same – Actually (slow distance) compare to these
Fast approximate filtering

© [email protected] – University of Geneva – Multimedia Retrieval – September 2015 - 124
• Fix few reference documents (landmarks) Can be done offline
• For each document, measure the distance to each reference document – Eg: define the set of the 5 closest landmarks Also done offline
• For a query – Find its 5 closest landmarks
Fast since few landmarks
– Find all documents whose 5 closest landmarks are the same Can be made fast (eg Inverted File)
– Actually (slow distance) compare to these Fast since tiny sample
Fast approximate filtering

© [email protected] – University of Geneva – Multimedia Retrieval – September 2015 - 125
Permutation-based Indexing
L(x1, R)= (𝑟1, 𝑟2, 𝑟3, 𝑟4, 𝑟5) L(x2, R)=(𝑟1, 𝑟2, 𝑟3, 𝑟4, 𝑟5) L(x3, R)= (𝑟5, 𝑟3, 𝑟2, 𝑟4, 𝑟1)
n=5:
D={x1, . . . , x𝑁}, N objects,
R = {𝑟1, . . . , 𝑟𝑛} ⊂ D, n references
Each 𝑜𝑖 is identified by an ordered list: L(x𝑖, R)= {𝑟𝑖1, . . . , 𝑟𝑖𝑛} such that d(x𝑖, 𝑟𝑖𝑗) ≤ d(x𝑖, 𝑟𝑖𝑗+1 ) ∀j = 1, . . . , n − 1
x
y
z
1x2x
3x
4x
5x
r1
r2
r3r4
r5
j
ririSFD
rank
i jjRxLRqLxqdxqd || ),(),(),(),(

© [email protected] – University of Geneva – Multimedia Retrieval – September 2015 - 126
• Assess system performance on standard challenges
– Data collection
– Annotation / groud-truth collection
– Query formulation
– Performance measures ( precision, recall,…)
Yearly event / related to scientific conference
In general, participants are academic teams
Evaluation

© [email protected] – University of Geneva – Multimedia Retrieval – September 2015 - 127
ImageCLEF
http://www.imageclef.org/
CLEF= Cross Lingual Evaluation Forum

© [email protected] – University of Geneva – Multimedia Retrieval – September 2015 - 128
ImageCLEF Wikipedia
Images + text (Overall: 237,434)
• English only: 70,127
• German only: 50,291
• French only: 28,461
• English and German: 26,880
• English and French: 20,747 • German and French: 9,646 • English, German and French: 22,899 • Language undetermined: 8,144 • No textual annotation: 239

© [email protected] – University of Geneva – Multimedia Retrieval – September 2015 - 129
TRECVid
The goal of the conference series is to encourage research in information retrieval by providing a large test collection, uniform scoring procedures, and a forum for organizations interested in comparing their results.
http://trecvid.nist.gov/

© [email protected] – University of Geneva – Multimedia Retrieval – September 2015 - 130
MIREX
http://www.music-ir.org
• The Music Information Retrieval Evaluation eXchange (MIREX) is an annual evaluation campaign for Music Information Retrieval (MIR) algorithms, coupled to the International Society (and Conference) for Music Information Retrieval (ISMIR)

© [email protected] – University of Geneva – Multimedia Retrieval – September 2015 - 131
Other
• 3D Retrieval – SHREC: Shape Retrieval Contest
– http://www.aimatshape.net/event/SHREC
• XML retrieval – INitiative for the Evaluation of XML retrieval
– https://inex.mmci.uni-saarland.de/
• Many dedicated corpora for specific tasks – Generic (Image-Net)
– Medical (ImageCLEF)
– Satellite imagery
– …

© [email protected] – University of Geneva – Multimedia Retrieval – September 2015 - 132
Conclusions
• Multimedia Information Retrieval extends classical IR – Word occurrence model is preserved
• Text IR is not always sufficient / feasible
– Completeness – Scalability
• Multimedia IR requires accurate interpretation of multimodal
data
• Fusion is required for reaching such an accurate level
• Multimedia IR still faces many challenges – Accuracy, interactivity, scalability

© [email protected] – University of Geneva – Multimedia Retrieval – September 2015 - 133
Challenges
• Speed and accuracy of response are the major challenges
• IR tends to be mobile
– Low computational power, connection, memory,…
• Large scale
– Big data
• Partial search
– Searching for a part of a document
• Semantic search
– Searching with high-level description

© [email protected] – University of Geneva – Multimedia Retrieval – September 2015 - 134
• Baeza-Yates R. and Ribeiro-Neto B. (1999): Modern Information Retrieval. Addison-Wesley. http://people.ischool.berkeley.edu/~hearst/irbook
• Baeza-Yates R. and Ribeiro-Neto B. (2011): Modern Information Retrieval. Addison-Wesley, Second Edition http://www.mir2ed.org/
Recommended reading

© [email protected] – University of Geneva – Multimedia Retrieval – September 2015 - 135
Thank you!
Questions?

© [email protected] – University of Geneva – Multimedia Retrieval – September 2015 - 136
Big Data and Large-scale data – Mohammed, H., & Marchand-Maillet, S. (2015). Scalable Indexing for
Big Data Processing. Chapman & Hall. – Marchand-Maillet, S., & Hofreiter, B. (2014). Big Data Management
and Analysis for Business Informatics. Enterprise Modelling and Information Systems Architectures (EMISA), 9.
– M. von Wyl, H. Mohamed, E. Bruno, S. Marchand-Maillet, “A parallel cross-modal search engine over large-scale multimedia collections with interactive relevance feedback” in ICMR 2011 - ACM International Conference on Multimedia Retrieval.
– H. Mohamed, M. von Wyl, E. Bruno and S. Marchand-Maillet, “Learning-based interactive retrieval in large-scale multimedia collections” in AMR 2011 - 9th International Workshop on Adaptive Multimedia Retrieval.
– von Wyl, M., Hofreiter, B., & Marchand-Maillet, S. (2012). Serendipitous Exploration of Large-scale Product Catalogs. In 14th IEEE International Conference on Commerce and Enterprise Computing (CEC 2012), Hangzhou, CN.
More at http://viper.unige.ch/publications
References

© [email protected] – University of Geneva – Multimedia Retrieval – September 2015 - 137
References Large-scale Indexing
– Mohamed, H., & Marchand-Maillet, S. (2015). Quantized Ranking for Permutation-Based Indexing. Information Systems.
– Mohamed, H., Osipyan, H., & Marchand-Maillet, S. (2014). Multi-Core (CPU and GPU) For Permutation-Based Indexing. In Proceedings of the 7th Internation Conference on Similarity Search and Applications (SISAP2014), Los Cabos, Mexico.
– H. Mohamed and S. Marchand-Maillet “Parallel Approaches to Permutation-Based Indexing using Inverted Files” in SISAP 2012 - 5th International Conference on Similarity Search and Applications .
– H. Mohamed and S. Marchand-Maillet “Distributed Media indexing based on MPI and MapReduce” in CBMI 2012 - 10th Workshop on Content-Based Multimedia Indexing.
– H. Mohamed and S. Marchand-Maillet “Enhancing MapReduce using MPI and an optimized data exchange policy”, P2S2 2012 - Fifth International Workshop onParallel Programming Models and Systems Software for High-End Computing.
– Mohamed, H., & Marchand-Maillet, S. (2014). Distributed media indexing based on MPI and MapReduce. Multimedia Tools and Applications, 69(2).
– Mohamed, H., & Marchand-Maillet, S. (2013). Permutation-Based Pruning for Approximate K-NN Search. In DEXA, Prague, CZ.
More at http://viper.unige.ch/publications

© [email protected] – University of Geneva – Multimedia Retrieval – September 2015 - 138
References Large data analysis – Manifold learning – Sun, K., Morrison, D., Bruno, E., & Marchand-Maillet, S. (2013).
Learning Representative Nodes in Social Networks. In 17th Pacific-Asia Conference on Knowledge Discovery and Data Mining, Gold Coast, AU.
– Sun, K., Bruno, E., & Marchand-Maillet, S. (2012). Unsupervised Skeleton Learning for Manifold Denoising and Outlier Detection. In International Conference on Pattern Recognition (ICPR'2012), Tsukuba, JP.
– Sun, K., & Marchand-Maillet, S. (2014). An Information Geometry of Statistical Manifold Learning. In Proceedings of the International Conference on Machine Learning (ICML 2014), Beijing, China.
– Wang, J., Sun, K., Sha, F., Marchand-Maillet, S., & Kalousis, A. (2014). Two-Stage Metric Learning. In Proceedings of the International Conference on Machine Learning (ICML 2014), Beijing, China.
– Sun, K., Bruno, E., & Marchand-Maillet, S. (2012). Stochastic Unfolding. In IEEE Machine Learning for Signal Processing Workshop (MLSP'2012), Santander, Spain.
More at http://viper.unige.ch/publications





























